-
 作者:荀礼勇(华为云开天aPaaS专家) 众所周知,企业内部存在很多支撑运营的应用,包括:HR类应用、差旅类应用、财务类应用、业务相关类应用如CRM,这些应用都有自己的账号体系,自己的部门管理,这就导致用户很难以一个账号使用多个应用,也无法基于统一的账号来梳理企业内部的信息流,这不仅影响用户的使用体验,也大大降低了工作效率。 怎么解决呢?最好的办法就是进行账号管理的统一,这也是大多数企业数字化转型的第一步。 像华为云云商店已经有超过700+个SaaS软件,但是当前用户没有使用统一的ID服务,而是分散在每个SaaS软件独立的ID体系内,用户使用每个SaaS时都需要重新登录,使用体验很不好。 并且,由于每个SaaS之间用户体系不通,各SaaS之间如果需要数据和信息互通,就需要专门的集成开发,例如:用户想把会议系统上的会议信息同步到自己的日历上,但如果没有打通用户ID,这么简单的需求就无法完成。 为了解决上述问题,开天aPaaS企业工作台提出了“四统一”规范,即:统一账号:提供账号注册,账号同步管理能力,实现全应用账号的统一;统一组织:提供组织管理(包括部门新增、修改、删除和查看),通讯录管理及成员管理(添加成员、修改、删除、成员邀请)能力;统一登录:实现应用一次登录,其他应用无须二次登录,包括Web单点登录能力、APP单点登录登录能力;统一授权:实现SaaS应用进行组织的统一授权,授权方式包括:用户授权、组织授权、用户组授权、管理员授权。 企业工作台提出“四统一”规范,目的就是要实现账号的统一,信息的协同。这就要求必须要对用户、部门统一进行集中管理。这也是“四统一”规范主要包括的两部分内容:账号管理统一:涉及到用户管理(通过用户生成应用账号)统一、部门管理统一、授权管理统一。先将登录的相关用户信息同步到ISV服务商,ISV再根据同步过来的信息入库,并初始化用户的权限等相关内容。认证协议规范:账号如何应用到SaaS应用系统中,这就需要SaaS应用基于标准的认证协议进行改造,其认证源指向企业工作台。用户登录应用时,应用根据标准协议获取用户信息,之后与账号管理同步过来的信息进行比对,如果存在相应的角色赋权,就展示页面并显示可访问页面菜单。 这就是企业工作台统一账号、统一组织、统一登录、统一授权的“四统一”规范,如果你对“四统一”规范感兴趣,可点击以下链接,了解规范详细内容:https://support.huaweicloud.com/accessg-marketplace/zh-cn_topic_0070649109.html
作者:荀礼勇(华为云开天aPaaS专家) 众所周知,企业内部存在很多支撑运营的应用,包括:HR类应用、差旅类应用、财务类应用、业务相关类应用如CRM,这些应用都有自己的账号体系,自己的部门管理,这就导致用户很难以一个账号使用多个应用,也无法基于统一的账号来梳理企业内部的信息流,这不仅影响用户的使用体验,也大大降低了工作效率。 怎么解决呢?最好的办法就是进行账号管理的统一,这也是大多数企业数字化转型的第一步。 像华为云云商店已经有超过700+个SaaS软件,但是当前用户没有使用统一的ID服务,而是分散在每个SaaS软件独立的ID体系内,用户使用每个SaaS时都需要重新登录,使用体验很不好。 并且,由于每个SaaS之间用户体系不通,各SaaS之间如果需要数据和信息互通,就需要专门的集成开发,例如:用户想把会议系统上的会议信息同步到自己的日历上,但如果没有打通用户ID,这么简单的需求就无法完成。 为了解决上述问题,开天aPaaS企业工作台提出了“四统一”规范,即:统一账号:提供账号注册,账号同步管理能力,实现全应用账号的统一;统一组织:提供组织管理(包括部门新增、修改、删除和查看),通讯录管理及成员管理(添加成员、修改、删除、成员邀请)能力;统一登录:实现应用一次登录,其他应用无须二次登录,包括Web单点登录能力、APP单点登录登录能力;统一授权:实现SaaS应用进行组织的统一授权,授权方式包括:用户授权、组织授权、用户组授权、管理员授权。 企业工作台提出“四统一”规范,目的就是要实现账号的统一,信息的协同。这就要求必须要对用户、部门统一进行集中管理。这也是“四统一”规范主要包括的两部分内容:账号管理统一:涉及到用户管理(通过用户生成应用账号)统一、部门管理统一、授权管理统一。先将登录的相关用户信息同步到ISV服务商,ISV再根据同步过来的信息入库,并初始化用户的权限等相关内容。认证协议规范:账号如何应用到SaaS应用系统中,这就需要SaaS应用基于标准的认证协议进行改造,其认证源指向企业工作台。用户登录应用时,应用根据标准协议获取用户信息,之后与账号管理同步过来的信息进行比对,如果存在相应的角色赋权,就展示页面并显示可访问页面菜单。 这就是企业工作台统一账号、统一组织、统一登录、统一授权的“四统一”规范,如果你对“四统一”规范感兴趣,可点击以下链接,了解规范详细内容:https://support.huaweicloud.com/accessg-marketplace/zh-cn_topic_0070649109.html -
 感谢大家对本次活动的支持与参与,恭喜以下获奖的童鞋,获奖码豆将于10月31日前发放至您的获奖账号,请注意查收。为保证您顺利领取奖品,请您及时查看活动信息并最迟于12月9日前前往码豆中心>礼品专区<兑换领取实物奖品,过期兑换入口将关闭。如对获奖结果或礼品兑换有疑问,请联系版主反馈。奖励新论坛旧论坛说明回复内容逢“88”楼层,奖励20000码豆yzq18941596181ziyuw1301.本活动期间正值论坛搬迁,根据活动规则,分别统计了新旧论坛回帖楼层;2.符合回帖楼层但由于内容不符合要求的楼层已删除且不顺延。3.如有疑问,请联系版主反馈。回复内容逢“8”楼层,奖励3000码豆huaweiqiujieyd_220556499yd_246534115hwqiujie马影guguanggongmayingjdzxwuxiaomenghwdandongjkzxyd_228857742zhengyong134ziyuweiws15041591187zhengguixiangguoky1894159zyw13019809851wyz13694166286td13009201335⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐【活动时间】2022年7月11日-2022年10月8日【活动参与方式】步骤① 报名华为开发者大赛任意赛道云应用创新赛道 无人车赛道 代码上太空赛道 世界难题赛道 乾坤云服务赛道步骤②与直播专家进行互动【互动方式】直播后您可以针对专家提出的技术性问题在活动帖发表您的答案或看法【获奖规则】回复内容逢“8”楼层,奖励3000码豆回复内容逢“88”楼层,奖励20000码豆(码豆可在>礼品专区<兑换实物奖品) ⭐ 直播列表 ⭐ 日期直播主题 直播简介 观看链接专家问题回答格式7月11日19:00-21:00崇本英才·智汇吴江 无人车挑战赛赛题解读赛题讲解、baseline操作演示、常见问题答疑点击回顾如何确认自己的模型包,可以顺利进行判分?直接在本活动帖下方回复内容:直播主题+专家问题+针对专家问题发表您的答案或看法7月13日19:00-21:00云应用创新赛道·IoT领域赛题解读1.华为云IoT构筑全场景物联网云服务2.IoT设备接入/IoT边缘/IoT数据分析3.华为云IoT生态,打造万物互联黑土地点击回顾你对物联网行业、技术有何看法?7月14日19:00-21:00云应用创新赛道·媒体领域赛题解读1.华为云云视频技术实践、RTC技术要点、RTC应用场景2.Meeting服务技术点讲解、赛题讲解、问题答疑3.华为云数字人整体能力介绍、大赛数字人服务提供的能力介绍、大赛数字人服务相关材料获取方式介绍点击回顾华为云提供3D建模能力服务的服务名称是什么?7月15日19:00-21:00代码上太空 · 赛题解读赛题讲解、KubeEdge&Sedna核心功能介绍、ModelArts核心功能介绍、常见问题答疑点击回顾请问卫星发射计划是怎样的?7月18日19:00-21:00云创新应用赛道 · AI领域赛题解读赛题讲解、baseline操作演示、常见问题答疑点击回顾华为云EI有哪些产品服务?7月19日19:00-21:00云应用创新赛 · 数据库领域赛题解读1.大赛攻略之:GaussDB(openGauss)产品特性与开放能力2.大赛攻略之:数据库迁移工具UGO、DRS,智能管理工具的特性与开放能力3.成功案例构建分享、与专家线上趣聊GaussDB解决方案构建之道点击回顾华为云数据库是如何保障迁移过程数据不丢失?7月20日19:00-21:00乾坤云服务赛道 · 赛题解读1.华为乾坤赛道说明2.赛题说明-安全云服务+云管理网络3.线上专家答疑互动点击回顾请问通常在做无线网规时需要考虑哪些因素?7月21日19:00-21:00云应用创新赛道 · PaaS领域赛题解读1.数字资产背景2.华为云区块链实践案例3.华为云区块链产品栈介绍点击回顾华为云提供了哪些区块链产品和服务?7月22日9:00-12:00华为开发者大赛·中国区北部赛区开幕式本次直播主要为华为开发者大赛·中国区北部赛区开幕式点击回顾7月25日15:00-17:10华为开发者大赛·中国区东部赛区开幕式本次直播主要为华为开发者大赛·中国区东部赛区开幕式点击回顾8月11日15:00-17:10华为开发者大赛·中国区南部赛区开幕式本次直播主要为华为开发者大赛·中国区南部赛区开幕式点击回顾8月12日19:00-21:00崇本英才·智汇吴江·无人车挑战赛决赛赛前培训本次直播主要包括初赛总结&开发者认证宣讲、决赛赛题介绍&决赛赛前备赛培训、往届优胜队伍经验分享点击观看使用ModelArts,如果模型想部署在使用无人小车上,需要经过哪一个步骤?8月15日19:00-21:00如何基于华为云开天aPaaS实现积木式应用创新本次直播将解读aPaaS赛题,演示API->连接器->自动化流的过程和两个工业应用间的数据集成操作点击回顾华为云开天aPaaS集成工作台的开发理念是什么? ⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐温馨提示1、奖项公布时间10月21日(由于开发者大赛云应用创新赛道报名延长至10月14日,本活动奖项公布变化请理解),为保证您顺利领取奖品,请于10月31日前填写收货信息并完成实名认证,否则视为放弃奖励。2、用户回复的内容,必须与主题相关,回复其他内容均视为无效内容,取消该用户获奖资格。3、用户回复内容的字数需≥30字,禁止复制其他楼层内容或改编自其它楼层内容(包括本人发布在其他楼层的内容),如经发现,取消该用户获奖资格。4、本次活动不限用户的总回复数,但不得连续回复超过3层,如获奖楼层前后连续4层及以上为同一用户所发,则该楼层奖项直接作废、不做顺延。5、如用户发布的内容经华为云社区工作人员认定为无效内容,亦取消该用户获奖资格。6、本活动最终解释权归华为云所有,其他事宜请参考【华为云社区常规活动规则】。
感谢大家对本次活动的支持与参与,恭喜以下获奖的童鞋,获奖码豆将于10月31日前发放至您的获奖账号,请注意查收。为保证您顺利领取奖品,请您及时查看活动信息并最迟于12月9日前前往码豆中心>礼品专区<兑换领取实物奖品,过期兑换入口将关闭。如对获奖结果或礼品兑换有疑问,请联系版主反馈。奖励新论坛旧论坛说明回复内容逢“88”楼层,奖励20000码豆yzq18941596181ziyuw1301.本活动期间正值论坛搬迁,根据活动规则,分别统计了新旧论坛回帖楼层;2.符合回帖楼层但由于内容不符合要求的楼层已删除且不顺延。3.如有疑问,请联系版主反馈。回复内容逢“8”楼层,奖励3000码豆huaweiqiujieyd_220556499yd_246534115hwqiujie马影guguanggongmayingjdzxwuxiaomenghwdandongjkzxyd_228857742zhengyong134ziyuweiws15041591187zhengguixiangguoky1894159zyw13019809851wyz13694166286td13009201335⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐【活动时间】2022年7月11日-2022年10月8日【活动参与方式】步骤① 报名华为开发者大赛任意赛道云应用创新赛道 无人车赛道 代码上太空赛道 世界难题赛道 乾坤云服务赛道步骤②与直播专家进行互动【互动方式】直播后您可以针对专家提出的技术性问题在活动帖发表您的答案或看法【获奖规则】回复内容逢“8”楼层,奖励3000码豆回复内容逢“88”楼层,奖励20000码豆(码豆可在>礼品专区<兑换实物奖品) ⭐ 直播列表 ⭐ 日期直播主题 直播简介 观看链接专家问题回答格式7月11日19:00-21:00崇本英才·智汇吴江 无人车挑战赛赛题解读赛题讲解、baseline操作演示、常见问题答疑点击回顾如何确认自己的模型包,可以顺利进行判分?直接在本活动帖下方回复内容:直播主题+专家问题+针对专家问题发表您的答案或看法7月13日19:00-21:00云应用创新赛道·IoT领域赛题解读1.华为云IoT构筑全场景物联网云服务2.IoT设备接入/IoT边缘/IoT数据分析3.华为云IoT生态,打造万物互联黑土地点击回顾你对物联网行业、技术有何看法?7月14日19:00-21:00云应用创新赛道·媒体领域赛题解读1.华为云云视频技术实践、RTC技术要点、RTC应用场景2.Meeting服务技术点讲解、赛题讲解、问题答疑3.华为云数字人整体能力介绍、大赛数字人服务提供的能力介绍、大赛数字人服务相关材料获取方式介绍点击回顾华为云提供3D建模能力服务的服务名称是什么?7月15日19:00-21:00代码上太空 · 赛题解读赛题讲解、KubeEdge&Sedna核心功能介绍、ModelArts核心功能介绍、常见问题答疑点击回顾请问卫星发射计划是怎样的?7月18日19:00-21:00云创新应用赛道 · AI领域赛题解读赛题讲解、baseline操作演示、常见问题答疑点击回顾华为云EI有哪些产品服务?7月19日19:00-21:00云应用创新赛 · 数据库领域赛题解读1.大赛攻略之:GaussDB(openGauss)产品特性与开放能力2.大赛攻略之:数据库迁移工具UGO、DRS,智能管理工具的特性与开放能力3.成功案例构建分享、与专家线上趣聊GaussDB解决方案构建之道点击回顾华为云数据库是如何保障迁移过程数据不丢失?7月20日19:00-21:00乾坤云服务赛道 · 赛题解读1.华为乾坤赛道说明2.赛题说明-安全云服务+云管理网络3.线上专家答疑互动点击回顾请问通常在做无线网规时需要考虑哪些因素?7月21日19:00-21:00云应用创新赛道 · PaaS领域赛题解读1.数字资产背景2.华为云区块链实践案例3.华为云区块链产品栈介绍点击回顾华为云提供了哪些区块链产品和服务?7月22日9:00-12:00华为开发者大赛·中国区北部赛区开幕式本次直播主要为华为开发者大赛·中国区北部赛区开幕式点击回顾7月25日15:00-17:10华为开发者大赛·中国区东部赛区开幕式本次直播主要为华为开发者大赛·中国区东部赛区开幕式点击回顾8月11日15:00-17:10华为开发者大赛·中国区南部赛区开幕式本次直播主要为华为开发者大赛·中国区南部赛区开幕式点击回顾8月12日19:00-21:00崇本英才·智汇吴江·无人车挑战赛决赛赛前培训本次直播主要包括初赛总结&开发者认证宣讲、决赛赛题介绍&决赛赛前备赛培训、往届优胜队伍经验分享点击观看使用ModelArts,如果模型想部署在使用无人小车上,需要经过哪一个步骤?8月15日19:00-21:00如何基于华为云开天aPaaS实现积木式应用创新本次直播将解读aPaaS赛题,演示API->连接器->自动化流的过程和两个工业应用间的数据集成操作点击回顾华为云开天aPaaS集成工作台的开发理念是什么? ⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐⭐温馨提示1、奖项公布时间10月21日(由于开发者大赛云应用创新赛道报名延长至10月14日,本活动奖项公布变化请理解),为保证您顺利领取奖品,请于10月31日前填写收货信息并完成实名认证,否则视为放弃奖励。2、用户回复的内容,必须与主题相关,回复其他内容均视为无效内容,取消该用户获奖资格。3、用户回复内容的字数需≥30字,禁止复制其他楼层内容或改编自其它楼层内容(包括本人发布在其他楼层的内容),如经发现,取消该用户获奖资格。4、本次活动不限用户的总回复数,但不得连续回复超过3层,如获奖楼层前后连续4层及以上为同一用户所发,则该楼层奖项直接作废、不做顺延。5、如用户发布的内容经华为云社区工作人员认定为无效内容,亦取消该用户获奖资格。6、本活动最终解释权归华为云所有,其他事宜请参考【华为云社区常规活动规则】。 -
 感谢大家对本次直播的支持与参与,恭喜以下获奖的童鞋,请于7月19日前私信云小宅反馈邮寄信息,以便准时收到奖品,逾期未反馈信息则视为自动放弃获奖资格,请知悉。直播后期论坛优质提问有礼公示:用户1:高级云网管用户2:问道直播期间优质问题公示:用户1:165***4 问题:用户2:165***6问题:用户3:165***7问题:直播简介【专家简介】程泽 华为云SaaS专家【直播简介】SaaS作为一种有效的软件交付形式,让企业IT团队可以将工作的重心从部署和业务系统定制转移到管理业务系统所提供的服务上来;但多租户开发、技术选型等问题会给SaaS应用开发带来挑战;本次系列直播将助力您解决这些难题,轻松构建云原生SaaS化应用。【直播时间】2022年7月7日 19:00-20:30直播链接:https://bbs.huaweicloud.com/live/DTT_live/202207071900.html活动介绍【互动方式】直播前您可以在本帖留下您感兴趣的问题,专家会在直播时为您解答。直播后您可以继续在本帖留言,与专家互动交流。我们会在全部活动结束后对参与互动的用户进行评选。【活动时间】6月30日—7月12日【奖励说明】活动1:优质提问有礼评奖规则:在本帖提出与直播相关的问题,由专家在所有互动贴中选出2名最优问题贴的开发者进行奖励。奖品:华为AI音箱2e 1个 活动2:热门提问有礼评奖规则:在本帖提出与直播相关的问题,TOP 3热门问题的开发者进行奖励。奖品:华为定制文化衫1件【活动奖品】【注意事项】1、为保证您顺利领取活动奖品,请您在活动公示奖项后3个工作日内私信提前填写奖品收货信息,如您没有填写,视为自动放弃奖励。2、活动奖项公示时间截止2022年7月15日,如未填写视为弃奖。本次活动奖品将于奖项公示后15个工作日内统一发出,请您耐心等待。3、活动期间每个ID(同一姓名/电话/收货地址)只能获奖一次,若重复则中奖资格顺延至下一位合格开发者,仅一次顺延。4、如活动奖品出现没有库存的情况,华为云工作人员将会替换等价值的奖品,获奖者不同意此规则视为放弃奖品。5、其他事宜请参考【华为云社区常规活动规则】。
感谢大家对本次直播的支持与参与,恭喜以下获奖的童鞋,请于7月19日前私信云小宅反馈邮寄信息,以便准时收到奖品,逾期未反馈信息则视为自动放弃获奖资格,请知悉。直播后期论坛优质提问有礼公示:用户1:高级云网管用户2:问道直播期间优质问题公示:用户1:165***4 问题:用户2:165***6问题:用户3:165***7问题:直播简介【专家简介】程泽 华为云SaaS专家【直播简介】SaaS作为一种有效的软件交付形式,让企业IT团队可以将工作的重心从部署和业务系统定制转移到管理业务系统所提供的服务上来;但多租户开发、技术选型等问题会给SaaS应用开发带来挑战;本次系列直播将助力您解决这些难题,轻松构建云原生SaaS化应用。【直播时间】2022年7月7日 19:00-20:30直播链接:https://bbs.huaweicloud.com/live/DTT_live/202207071900.html活动介绍【互动方式】直播前您可以在本帖留下您感兴趣的问题,专家会在直播时为您解答。直播后您可以继续在本帖留言,与专家互动交流。我们会在全部活动结束后对参与互动的用户进行评选。【活动时间】6月30日—7月12日【奖励说明】活动1:优质提问有礼评奖规则:在本帖提出与直播相关的问题,由专家在所有互动贴中选出2名最优问题贴的开发者进行奖励。奖品:华为AI音箱2e 1个 活动2:热门提问有礼评奖规则:在本帖提出与直播相关的问题,TOP 3热门问题的开发者进行奖励。奖品:华为定制文化衫1件【活动奖品】【注意事项】1、为保证您顺利领取活动奖品,请您在活动公示奖项后3个工作日内私信提前填写奖品收货信息,如您没有填写,视为自动放弃奖励。2、活动奖项公示时间截止2022年7月15日,如未填写视为弃奖。本次活动奖品将于奖项公示后15个工作日内统一发出,请您耐心等待。3、活动期间每个ID(同一姓名/电话/收货地址)只能获奖一次,若重复则中奖资格顺延至下一位合格开发者,仅一次顺延。4、如活动奖品出现没有库存的情况,华为云工作人员将会替换等价值的奖品,获奖者不同意此规则视为放弃奖品。5、其他事宜请参考【华为云社区常规活动规则】。 -
 作者:Byron Reese术语AI的另一个用途是描述我们所谓的通用AI,或通常称为AGI。除了在科幻小说中,它还不存在,而且没有人知道如何制造它。关注人工智能领域发展新闻的挑战之一是,“人工智能”一词经常被不加区别地用来表示两个不相关的事物。术语 AI 的第一次使用更准确地称为狭义 AI。它是一项强大的技术,但也非常简单明了:您获取一堆关于过去的数据,使用计算机对其进行分析并找到模式,然后使用该分析来预测未来。这种类型的人工智能每天都会多次触及我们的生活,因为它会从我们的电子邮件中过滤垃圾邮件并通过流量引导我们。但是因为它是用过去的数据训练的,所以它只适用于未来与过去相似的地方。这就是它可以识别猫和下棋的原因,因为它们在基本层面上不会每天发生变化。术语AI的另一个用途是描述我们所谓的通用AI,或通常称为AGI。除了在科幻小说中,它还不存在,而且没有人知道如何制造它。通用人工智能是一种像人类一样智能多样的计算机程序。它可以自学之前从未接受过训练的全新事物。狭义AI和通用AI的区别在电影中,AGI 是《星际迷航》中的数据、《星球大战》中的 C-3PO 和《银翼杀手》中的复制人。虽然从直觉上看,狭义 AI 与一般 AI 是同一类东西,只是一种不太成熟和复杂的实现,但事实并非如此。通用 AI 有所不同。例如,识别垃圾邮件在计算上并不等同于真正的创造性,而通用智能则可以做到这一点。我曾经主持过一个关于人工智能的播客,叫做“人工智能中的声音”。这很有趣,因为大多数伟大的科学实践者都是平易近人的,也愿意上播客。因此,我最终得到了超过100位伟大的AI思考者对这个话题的深入讨论。有两个问题我会问大多数客人。第一个问题是,“通用人工智能可能吗?”几乎所有人——只有四个例外——都说有可能。然后我会问他们我们什么时候能造出来。这些答案五花八门,有的五年就有了,有的长达500年。为什么会这样?为什么几乎所有的客人都说通用人工智能是可能的,但却提供了如此广泛的估计,我们将何时实现?这个问题的答案要回到我之前说过的一句话:我们不知道如何构建通用智能,所以你的猜测和其他人的一样好。“但等等!你可能会这么说。“如果我们不知道如何制造,为什么专家们压倒性地同意这是可能的?”我也会问他们这个问题,而我通常得到的是相同答案的不同版本。他们相信我们会造出真正智能的机器,这是基于一个核心信念:人是智能机器。因为我们是机器,推理是这样的,并且拥有通用的智能,制造具有通用智能的机器一定是可能的。人与机器可以肯定的是,如果人是机器,那么那些专家是对的:通用智能不仅是可能的,而且是不可避免的。然而,如果事实证明人不仅仅是机器,那么人的某些东西可能无法在硅中复制。有趣的是,这数百名 AI 专家与其他所有人之间的脱节。当我就这个话题向普通观众发表演讲并问他们谁认为自己是机器时,大约之后 15% 的人举手,而 AI 专家却高达96%。在我的播客上,当我反驳这种关于人类智能本质的假设时,我的客人通常会指责我——当然是非常礼貌的——沉迷于某种以反科学为核心的神奇思维。“如果不是生物机器,我们还能成为什么?”这是一个公平且重要的问题。我们只知道宇宙中具有一般智力的一件事,那就是我们。我们怎么会碰巧拥有如此强大的创造力?我们真的不知道。智慧是一种超级力量试着回忆你第一辆自行车的颜色或者你一年级老师的名字。也许你已经多年没有想过这两件事了,但你的大脑可能不费什么力气就能把它们找回来,当你考虑到“数据”不像存储在硬盘上那样存储在你的大脑里时,这就更令人印象深刻了。事实上,我们不知道它是如何储存的。我们可能会发现,你大脑中的一千亿个神经元中的每一个都像我们最先进的超级计算机一样复杂。但这正是我们智慧的奥秘所在。从那以后就变得更棘手了。事实证明,我们有一种叫做心灵的东西,它与大脑不同。头脑是你脑子里的三磅粘稠物能做的一切,就像拥有幽默感或坠入爱河,这似乎是它不应该做的。你的心脏不会,肝脏也不会。但不知怎么的,你做到了。我们甚至不确定心智只是大脑的产物。很多人在出生时就失去了高达 95% 的大脑,但仍然拥有正常的智力,而且往往直到晚年进行诊断检查时才知道自己的状况。此外,我们似乎有很多智能没有储存在我们的大脑中,而是分布在我们的全身。通用人工智能:意识的复杂性尽管我们不了解大脑或思想,但实际上从那里开始就变得更加困难:一般的智力很可能需要意识。意识是你对世界的体验。温度计可以准确地告诉你温度,但它感觉不到温暖。知道和体验的区别,就是意识,我们几乎没有理由相信电脑能像椅子一样体验世界。所以现在我们有了我们无法理解的大脑,无法解释的心灵,至于意识,我们甚至没有一个好的理论来解释仅仅是物质如何可能有一种体验。然而,尽管如此,相信通用人工智能的人工智能人士相信,我们可以在计算机中复制人类的所有能力。在我看来,这似乎是一种魔幻思维。我这样说并不是轻视任何人的信仰。他们很可能是正确的。我只是认为通用人工智能的想法是一个未经证实的假设,而不是一个明显的科学真理。建造这样一个生物,然后控制它的欲望,是人类古老的梦想。在现代,它已经有几个世纪的历史了,也许始于玛丽·雪莱的《弗兰肯斯坦》,然后体现在后来的1000个故事中。但实际上它比那要古老得多。早在我们有文字的时候,我们就有这样的想象,比如塔洛斯的故事,一个由希腊科技之神赫菲斯托斯创造的机器人,以保卫克里特岛。我们内心深处的某个地方渴望创造这种生物并控制其强大的力量,但到目前为止,还没有任何迹象表明我们确实可以。责任编辑:姜华 来源: 千家网
作者:Byron Reese术语AI的另一个用途是描述我们所谓的通用AI,或通常称为AGI。除了在科幻小说中,它还不存在,而且没有人知道如何制造它。关注人工智能领域发展新闻的挑战之一是,“人工智能”一词经常被不加区别地用来表示两个不相关的事物。术语 AI 的第一次使用更准确地称为狭义 AI。它是一项强大的技术,但也非常简单明了:您获取一堆关于过去的数据,使用计算机对其进行分析并找到模式,然后使用该分析来预测未来。这种类型的人工智能每天都会多次触及我们的生活,因为它会从我们的电子邮件中过滤垃圾邮件并通过流量引导我们。但是因为它是用过去的数据训练的,所以它只适用于未来与过去相似的地方。这就是它可以识别猫和下棋的原因,因为它们在基本层面上不会每天发生变化。术语AI的另一个用途是描述我们所谓的通用AI,或通常称为AGI。除了在科幻小说中,它还不存在,而且没有人知道如何制造它。通用人工智能是一种像人类一样智能多样的计算机程序。它可以自学之前从未接受过训练的全新事物。狭义AI和通用AI的区别在电影中,AGI 是《星际迷航》中的数据、《星球大战》中的 C-3PO 和《银翼杀手》中的复制人。虽然从直觉上看,狭义 AI 与一般 AI 是同一类东西,只是一种不太成熟和复杂的实现,但事实并非如此。通用 AI 有所不同。例如,识别垃圾邮件在计算上并不等同于真正的创造性,而通用智能则可以做到这一点。我曾经主持过一个关于人工智能的播客,叫做“人工智能中的声音”。这很有趣,因为大多数伟大的科学实践者都是平易近人的,也愿意上播客。因此,我最终得到了超过100位伟大的AI思考者对这个话题的深入讨论。有两个问题我会问大多数客人。第一个问题是,“通用人工智能可能吗?”几乎所有人——只有四个例外——都说有可能。然后我会问他们我们什么时候能造出来。这些答案五花八门,有的五年就有了,有的长达500年。为什么会这样?为什么几乎所有的客人都说通用人工智能是可能的,但却提供了如此广泛的估计,我们将何时实现?这个问题的答案要回到我之前说过的一句话:我们不知道如何构建通用智能,所以你的猜测和其他人的一样好。“但等等!你可能会这么说。“如果我们不知道如何制造,为什么专家们压倒性地同意这是可能的?”我也会问他们这个问题,而我通常得到的是相同答案的不同版本。他们相信我们会造出真正智能的机器,这是基于一个核心信念:人是智能机器。因为我们是机器,推理是这样的,并且拥有通用的智能,制造具有通用智能的机器一定是可能的。人与机器可以肯定的是,如果人是机器,那么那些专家是对的:通用智能不仅是可能的,而且是不可避免的。然而,如果事实证明人不仅仅是机器,那么人的某些东西可能无法在硅中复制。有趣的是,这数百名 AI 专家与其他所有人之间的脱节。当我就这个话题向普通观众发表演讲并问他们谁认为自己是机器时,大约之后 15% 的人举手,而 AI 专家却高达96%。在我的播客上,当我反驳这种关于人类智能本质的假设时,我的客人通常会指责我——当然是非常礼貌的——沉迷于某种以反科学为核心的神奇思维。“如果不是生物机器,我们还能成为什么?”这是一个公平且重要的问题。我们只知道宇宙中具有一般智力的一件事,那就是我们。我们怎么会碰巧拥有如此强大的创造力?我们真的不知道。智慧是一种超级力量试着回忆你第一辆自行车的颜色或者你一年级老师的名字。也许你已经多年没有想过这两件事了,但你的大脑可能不费什么力气就能把它们找回来,当你考虑到“数据”不像存储在硬盘上那样存储在你的大脑里时,这就更令人印象深刻了。事实上,我们不知道它是如何储存的。我们可能会发现,你大脑中的一千亿个神经元中的每一个都像我们最先进的超级计算机一样复杂。但这正是我们智慧的奥秘所在。从那以后就变得更棘手了。事实证明,我们有一种叫做心灵的东西,它与大脑不同。头脑是你脑子里的三磅粘稠物能做的一切,就像拥有幽默感或坠入爱河,这似乎是它不应该做的。你的心脏不会,肝脏也不会。但不知怎么的,你做到了。我们甚至不确定心智只是大脑的产物。很多人在出生时就失去了高达 95% 的大脑,但仍然拥有正常的智力,而且往往直到晚年进行诊断检查时才知道自己的状况。此外,我们似乎有很多智能没有储存在我们的大脑中,而是分布在我们的全身。通用人工智能:意识的复杂性尽管我们不了解大脑或思想,但实际上从那里开始就变得更加困难:一般的智力很可能需要意识。意识是你对世界的体验。温度计可以准确地告诉你温度,但它感觉不到温暖。知道和体验的区别,就是意识,我们几乎没有理由相信电脑能像椅子一样体验世界。所以现在我们有了我们无法理解的大脑,无法解释的心灵,至于意识,我们甚至没有一个好的理论来解释仅仅是物质如何可能有一种体验。然而,尽管如此,相信通用人工智能的人工智能人士相信,我们可以在计算机中复制人类的所有能力。在我看来,这似乎是一种魔幻思维。我这样说并不是轻视任何人的信仰。他们很可能是正确的。我只是认为通用人工智能的想法是一个未经证实的假设,而不是一个明显的科学真理。建造这样一个生物,然后控制它的欲望,是人类古老的梦想。在现代,它已经有几个世纪的历史了,也许始于玛丽·雪莱的《弗兰肯斯坦》,然后体现在后来的1000个故事中。但实际上它比那要古老得多。早在我们有文字的时候,我们就有这样的想象,比如塔洛斯的故事,一个由希腊科技之神赫菲斯托斯创造的机器人,以保卫克里特岛。我们内心深处的某个地方渴望创造这种生物并控制其强大的力量,但到目前为止,还没有任何迹象表明我们确实可以。责任编辑:姜华 来源: 千家网 -
 居家健身热潮不仅捧红了刘畊宏、帕梅拉、小马哥Marshall等健身网红达人,也点燃了人们对健身智能终端的购买热情。2020年智能健身镜“横空出世”,不到两年时间,智能健身镜逐渐成为全家老小都适用的智能健身器材,不仅能为年轻健身爱好者提供视频健身操和健身私教服务,还为儿童提供多种少儿体感游戏、为长辈准备了花式广场舞和太极健身功等健身内容……智能健身镜实现强势增长凭借高颜值、定制化健身训练、动作实时捕捉等黑科技,智能健身镜成为健身爱好者的新宠。根据百度联合京东发布的《百度x京东618消费趋势洞察报告》,2022年“运动健身”相关内容搜索环比上涨121%,其中“智能健身镜”搜索上涨225%。根据京东披露的开门红数据,智能健身镜在京东618开启后的十分钟成交额同比增长300%。智研咨询发布的《2022—2028年中国智能运动健身行业市场深度评估及投资机会预测报告》显示,在每月最少进行一次或以上运动健身的人群中,使用过智能健身硬件进行健身的人群占比为78%,其中男性占比61%,女性占比39%。艾瑞咨询数据显示,2021年中国智能运动健身行业市场规模约180亿元,预计2025年中国智能运动健身市场规模将达到820亿元。随着人们越发重视健康生活和身材管理,我国智能运动健身市场将进入高速发展期,智能健身镜市场也有望“乘风”增长。公开数据显示,2020年智能健身镜的市场规模和出货量分别为0.3亿元和0.4万台。艾瑞咨询预测,智能健身镜在2025年有望达到187万台的出货量和112亿元的市场规模,占智能运动健身行业市场总体的13.66%。看好智能健身镜的发展前景,不少企业选择入局这一市场。例如,咕咚、乐刻科技等健身平台,百度、小米、华为等互联网科技公司,FITURE、Mirror等专业初创公司。谈到入局智能健身镜的初衷,百度智能生活事业群总经理、小度科技CEO景鲲在接受记者采访时表示,新冠肺炎疫情让很多原本潜伏的需求变成刚需,关键是通过什么产品能够撬动刚需。在他看来,实现居家运动和健身的健身镜,是符合大趋势的产品。为了突出家庭感,百度健身镜还加入了广场舞、太极等内容,可实现不同年龄段家庭成员共用。价格仍有进一步下探空间智能健身镜在外观上有些许差异,但功能相似度较高。开启智能健身镜,镜面可以显示视频画面,用户可以通过触控的方式操作。关闭之后,智能健身镜还可以当作普通的镜子来用。行业专家表示,智能健身镜可谓一个披着镜子“外衣”的液晶显示器,其显示技术已经十分成熟。赛迪顾问高级分析师刘暾向《中国电子报》记者表示,此类魔镜产品玻璃采用真空磁控溅射工艺进行表明处理,可在玻璃表面形成镜面反射,主要用于汽车智能型后视镜、传媒广告显示器、幻影成像和彩色电视。镜面玻璃在显示设备关闭时形成镜面效果,作为镜子使用;在显示设备打开时,可以透出清淅的画面图像。智能健身镜在国内推出不足两年,市场价格整体呈现出走低趋势。早前,智能健身镜的价格在万元左右,如今入门级智能健身镜价格已低至2500元左右。对此,奥维云网(AVC)消费电子大数据事业部总经理揭美娟在接受《中国电子报》采访时表示,降价取决于目标用户人群的扩大。揭美娟分析称,智能健身镜最初目标用户是健身人群,这部分人群以男性居多,同时大部分是中高收入者,因此智能健身镜最初价格定位较高。但随着疫情影响,越来越多的普通人群加入健身行列,另一方面智能健身镜的品牌参与者也在不断增加,市场竞争下产品价格逐步亲民化。智能健身镜品类的价格变得更加“亲民”,但是相比同品类的液晶产品,还是价格偏高。揭美娟透露,目前智能健身镜产品的主要显示尺寸是43英寸,相同尺寸的液晶电视产品均价大概在1450元。为何面积相同的显示面板,智能健身镜成本更高?刘暾分析认为,尽管与标准电视显示屏的面积相似,但是智能健身镜尺寸更加“细长”和特殊,这会降低面板厂商的切割效率,因此单价要高于相同面积的标准化显示屏。另外,智能健身镜的销售量与电视机产品相比亦相差甚远,“小量的VIP定制化面板”价格自然远高于标准化的显示屏。刘暾判断:“若智能健身镜产品的销售量提升至十万或者几十万级,其专用的显示屏价格仍有进一步下探空间。”有望在全屋智能中扮演重要角色尽管外界看好智能健身镜的未来发展前景,但是作为问世不足两年的年轻消费电子品类,其产品体验和软硬件都有待进一步提升。行业专家建议智能健身镜不应局限于居家健身场景,应增加更多智能控制功能,争取充当全屋智能中的控制器“角色”。目前智能健身镜在软件服务和硬件产品方面都有进一步提升的空间。不少健身镜用户在社交平台反馈,智能健身镜在使用中出现过产品过热、自动关机、动作识别不准确、动作纠正提醒延迟、动作检测范围受限、联网信号卡顿等问题。在内容方面,健身课程服务种类少、内容付费接受度较低也受到部分用户的诟病。对此,行业专家告诉《中国电子报》记者,随着用户群体的不断扩大、硬件和AI技术的不断进步,智能健身镜的用户使用体验将不断提升。“智能健身镜功能聚焦在健身内容和AI健身指导,预计2030年我国健身人群数量将突破5.6亿,因此该品类在健身领域具有较大发展潜力。”揭美娟指出,但是智能健身镜仍不具备刚需产品属性,健身的实现方式是多种多样的,健身镜的替代性较强。尽管智能健身镜与液晶电视的硬件载体相似,但两类产品的内容价值不同,健身镜聚焦健身内容进行差异化竞争。产业界人士指出,若智能健身镜增加更多智能家居的控制功能,成为全屋智能中的“控制器”,有望得到更多发展空间。相比智能健身市场,中国智能家居的市场规模更加广阔。根据国际调研机构IDC发布的《中国智能家居设备市场季度跟踪报告(2021年第四季度)》,2021年中国智能家居设备市场出货量超过2.2亿台,IDC预计2022年该数字将突破2.6亿台,并在2026年突破5亿台大关。早前,京东方曾公开展示过其多种智能功能为一身的魔镜产品,用户可以通过按键、触摸、语音等多种方式与BOE魔镜交流,不仅可以获取日期、天气、交通、新闻资讯、健康状况等信息,还可以成为用户的智能管家,控制窗帘、灯光、智能音箱、扫地机器人等智能设备。多种功能于一身的智能魔镜或许能为智能健身镜的发展提供更宽广的思路原文链接:智能健身镜:“巨型手机”想成全屋智能核心_新闻中心_物联网世界 (iotworld.com.cn)
居家健身热潮不仅捧红了刘畊宏、帕梅拉、小马哥Marshall等健身网红达人,也点燃了人们对健身智能终端的购买热情。2020年智能健身镜“横空出世”,不到两年时间,智能健身镜逐渐成为全家老小都适用的智能健身器材,不仅能为年轻健身爱好者提供视频健身操和健身私教服务,还为儿童提供多种少儿体感游戏、为长辈准备了花式广场舞和太极健身功等健身内容……智能健身镜实现强势增长凭借高颜值、定制化健身训练、动作实时捕捉等黑科技,智能健身镜成为健身爱好者的新宠。根据百度联合京东发布的《百度x京东618消费趋势洞察报告》,2022年“运动健身”相关内容搜索环比上涨121%,其中“智能健身镜”搜索上涨225%。根据京东披露的开门红数据,智能健身镜在京东618开启后的十分钟成交额同比增长300%。智研咨询发布的《2022—2028年中国智能运动健身行业市场深度评估及投资机会预测报告》显示,在每月最少进行一次或以上运动健身的人群中,使用过智能健身硬件进行健身的人群占比为78%,其中男性占比61%,女性占比39%。艾瑞咨询数据显示,2021年中国智能运动健身行业市场规模约180亿元,预计2025年中国智能运动健身市场规模将达到820亿元。随着人们越发重视健康生活和身材管理,我国智能运动健身市场将进入高速发展期,智能健身镜市场也有望“乘风”增长。公开数据显示,2020年智能健身镜的市场规模和出货量分别为0.3亿元和0.4万台。艾瑞咨询预测,智能健身镜在2025年有望达到187万台的出货量和112亿元的市场规模,占智能运动健身行业市场总体的13.66%。看好智能健身镜的发展前景,不少企业选择入局这一市场。例如,咕咚、乐刻科技等健身平台,百度、小米、华为等互联网科技公司,FITURE、Mirror等专业初创公司。谈到入局智能健身镜的初衷,百度智能生活事业群总经理、小度科技CEO景鲲在接受记者采访时表示,新冠肺炎疫情让很多原本潜伏的需求变成刚需,关键是通过什么产品能够撬动刚需。在他看来,实现居家运动和健身的健身镜,是符合大趋势的产品。为了突出家庭感,百度健身镜还加入了广场舞、太极等内容,可实现不同年龄段家庭成员共用。价格仍有进一步下探空间智能健身镜在外观上有些许差异,但功能相似度较高。开启智能健身镜,镜面可以显示视频画面,用户可以通过触控的方式操作。关闭之后,智能健身镜还可以当作普通的镜子来用。行业专家表示,智能健身镜可谓一个披着镜子“外衣”的液晶显示器,其显示技术已经十分成熟。赛迪顾问高级分析师刘暾向《中国电子报》记者表示,此类魔镜产品玻璃采用真空磁控溅射工艺进行表明处理,可在玻璃表面形成镜面反射,主要用于汽车智能型后视镜、传媒广告显示器、幻影成像和彩色电视。镜面玻璃在显示设备关闭时形成镜面效果,作为镜子使用;在显示设备打开时,可以透出清淅的画面图像。智能健身镜在国内推出不足两年,市场价格整体呈现出走低趋势。早前,智能健身镜的价格在万元左右,如今入门级智能健身镜价格已低至2500元左右。对此,奥维云网(AVC)消费电子大数据事业部总经理揭美娟在接受《中国电子报》采访时表示,降价取决于目标用户人群的扩大。揭美娟分析称,智能健身镜最初目标用户是健身人群,这部分人群以男性居多,同时大部分是中高收入者,因此智能健身镜最初价格定位较高。但随着疫情影响,越来越多的普通人群加入健身行列,另一方面智能健身镜的品牌参与者也在不断增加,市场竞争下产品价格逐步亲民化。智能健身镜品类的价格变得更加“亲民”,但是相比同品类的液晶产品,还是价格偏高。揭美娟透露,目前智能健身镜产品的主要显示尺寸是43英寸,相同尺寸的液晶电视产品均价大概在1450元。为何面积相同的显示面板,智能健身镜成本更高?刘暾分析认为,尽管与标准电视显示屏的面积相似,但是智能健身镜尺寸更加“细长”和特殊,这会降低面板厂商的切割效率,因此单价要高于相同面积的标准化显示屏。另外,智能健身镜的销售量与电视机产品相比亦相差甚远,“小量的VIP定制化面板”价格自然远高于标准化的显示屏。刘暾判断:“若智能健身镜产品的销售量提升至十万或者几十万级,其专用的显示屏价格仍有进一步下探空间。”有望在全屋智能中扮演重要角色尽管外界看好智能健身镜的未来发展前景,但是作为问世不足两年的年轻消费电子品类,其产品体验和软硬件都有待进一步提升。行业专家建议智能健身镜不应局限于居家健身场景,应增加更多智能控制功能,争取充当全屋智能中的控制器“角色”。目前智能健身镜在软件服务和硬件产品方面都有进一步提升的空间。不少健身镜用户在社交平台反馈,智能健身镜在使用中出现过产品过热、自动关机、动作识别不准确、动作纠正提醒延迟、动作检测范围受限、联网信号卡顿等问题。在内容方面,健身课程服务种类少、内容付费接受度较低也受到部分用户的诟病。对此,行业专家告诉《中国电子报》记者,随着用户群体的不断扩大、硬件和AI技术的不断进步,智能健身镜的用户使用体验将不断提升。“智能健身镜功能聚焦在健身内容和AI健身指导,预计2030年我国健身人群数量将突破5.6亿,因此该品类在健身领域具有较大发展潜力。”揭美娟指出,但是智能健身镜仍不具备刚需产品属性,健身的实现方式是多种多样的,健身镜的替代性较强。尽管智能健身镜与液晶电视的硬件载体相似,但两类产品的内容价值不同,健身镜聚焦健身内容进行差异化竞争。产业界人士指出,若智能健身镜增加更多智能家居的控制功能,成为全屋智能中的“控制器”,有望得到更多发展空间。相比智能健身市场,中国智能家居的市场规模更加广阔。根据国际调研机构IDC发布的《中国智能家居设备市场季度跟踪报告(2021年第四季度)》,2021年中国智能家居设备市场出货量超过2.2亿台,IDC预计2022年该数字将突破2.6亿台,并在2026年突破5亿台大关。早前,京东方曾公开展示过其多种智能功能为一身的魔镜产品,用户可以通过按键、触摸、语音等多种方式与BOE魔镜交流,不仅可以获取日期、天气、交通、新闻资讯、健康状况等信息,还可以成为用户的智能管家,控制窗帘、灯光、智能音箱、扫地机器人等智能设备。多种功能于一身的智能魔镜或许能为智能健身镜的发展提供更宽广的思路原文链接:智能健身镜:“巨型手机”想成全屋智能核心_新闻中心_物联网世界 (iotworld.com.cn) -
居家健身热潮不仅捧红了刘畊宏、帕梅拉、小马哥Marshall等健身网红达人,也点燃了人们对健身智能终端的购买热情。2020年智能健身镜“横空出世”,不到两年时间,智能健身镜逐渐成为全家老小都适用的智能健身器材,不仅能为年轻健身爱好者提供视频健身操和健身私教服务,还为儿童提供多种少儿体感游戏、为长辈准备了花式广场舞和太极健身功等健身内容……智能健身镜实现强势增长凭借高颜值、定制化健身训练、动作实时捕捉等黑科技,智能健身镜成为健身爱好者的新宠。根据百度联合京东发布的《百度x京东618消费趋势洞察报告》,2022年“运动健身”相关内容搜索环比上涨121%,其中“智能健身镜”搜索上涨225%。根据京东披露的开门红数据,智能健身镜在京东618开启后的十分钟成交额同比增长300%。智研咨询发布的《2022—2028年中国智能运动健身行业市场深度评估及投资机会预测报告》显示,在每月最少进行一次或以上运动健身的人群中,使用过智能健身硬件进行健身的人群占比为78%,其中男性占比61%,女性占比39%。艾瑞咨询数据显示,2021年中国智能运动健身行业市场规模约180亿元,预计2025年中国智能运动健身市场规模将达到820亿元。随着人们越发重视健康生活和身材管理,我国智能运动健身市场将进入高速发展期,智能健身镜市场也有望“乘风”增长。公开数据显示,2020年智能健身镜的市场规模和出货量分别为0.3亿元和0.4万台。艾瑞咨询预测,智能健身镜在2025年有望达到187万台的出货量和112亿元的市场规模,占智能运动健身行业市场总体的13.66%。看好智能健身镜的发展前景,不少企业选择入局这一市场。例如,咕咚、乐刻科技等健身平台,百度、小米、华为等互联网科技公司,FITURE、Mirror等专业初创公司。谈到入局智能健身镜的初衷,百度智能生活事业群总经理、小度科技CEO景鲲在接受记者采访时表示,新冠肺炎疫情让很多原本潜伏的需求变成刚需,关键是通过什么产品能够撬动刚需。在他看来,实现居家运动和健身的健身镜,是符合大趋势的产品。为了突出家庭感,百度健身镜还加入了广场舞、太极等内容,可实现不同年龄段家庭成员共用。价格仍有进一步下探空间智能健身镜在外观上有些许差异,但功能相似度较高。开启智能健身镜,镜面可以显示视频画面,用户可以通过触控的方式操作。关闭之后,智能健身镜还可以当作普通的镜子来用。行业专家表示,智能健身镜可谓一个披着镜子“外衣”的液晶显示器,其显示技术已经十分成熟。赛迪顾问高级分析师刘暾向《中国电子报》记者表示,此类魔镜产品玻璃采用真空磁控溅射工艺进行表明处理,可在玻璃表面形成镜面反射,主要用于汽车智能型后视镜、传媒广告显示器、幻影成像和彩色电视。镜面玻璃在显示设备关闭时形成镜面效果,作为镜子使用;在显示设备打开时,可以透出清淅的画面图像。智能健身镜在国内推出不足两年,市场价格整体呈现出走低趋势。早前,智能健身镜的价格在万元左右,如今入门级智能健身镜价格已低至2500元左右。对此,奥维云网(AVC)消费电子大数据事业部总经理揭美娟在接受《中国电子报》采访时表示,降价取决于目标用户人群的扩大。揭美娟分析称,智能健身镜最初目标用户是健身人群,这部分人群以男性居多,同时大部分是中高收入者,因此智能健身镜最初价格定位较高。但随着疫情影响,越来越多的普通人群加入健身行列,另一方面智能健身镜的品牌参与者也在不断增加,市场竞争下产品价格逐步亲民化。智能健身镜品类的价格变得更加“亲民”,但是相比同品类的液晶产品,还是价格偏高。揭美娟透露,目前智能健身镜产品的主要显示尺寸是43英寸,相同尺寸的液晶电视产品均价大概在1450元。为何面积相同的显示面板,智能健身镜成本更高?刘暾分析认为,尽管与标准电视显示屏的面积相似,但是智能健身镜尺寸更加“细长”和特殊,这会降低面板厂商的切割效率,因此单价要高于相同面积的标准化显示屏。另外,智能健身镜的销售量与电视机产品相比亦相差甚远,“小量的VIP定制化面板”价格自然远高于标准化的显示屏。刘暾判断:“若智能健身镜产品的销售量提升至十万或者几十万级,其专用的显示屏价格仍有进一步下探空间。”有望在全屋智能中扮演重要角色尽管外界看好智能健身镜的未来发展前景,但是作为问世不足两年的年轻消费电子品类,其产品体验和软硬件都有待进一步提升。行业专家建议智能健身镜不应局限于居家健身场景,应增加更多智能控制功能,争取充当全屋智能中的控制器“角色”。目前智能健身镜在软件服务和硬件产品方面都有进一步提升的空间。不少健身镜用户在社交平台反馈,智能健身镜在使用中出现过产品过热、自动关机、动作识别不准确、动作纠正提醒延迟、动作检测范围受限、联网信号卡顿等问题。在内容方面,健身课程服务种类少、内容付费接受度较低也受到部分用户的诟病。对此,行业专家告诉《中国电子报》记者,随着用户群体的不断扩大、硬件和AI技术的不断进步,智能健身镜的用户使用体验将不断提升。“智能健身镜功能聚焦在健身内容和AI健身指导,预计2030年我国健身人群数量将突破5.6亿,因此该品类在健身领域具有较大发展潜力。”揭美娟指出,但是智能健身镜仍不具备刚需产品属性,健身的实现方式是多种多样的,健身镜的替代性较强。尽管智能健身镜与液晶电视的硬件载体相似,但两类产品的内容价值不同,健身镜聚焦健身内容进行差异化竞争。产业界人士指出,若智能健身镜增加更多智能家居的控制功能,成为全屋智能中的“控制器”,有望得到更多发展空间。相比智能健身市场,中国智能家居的市场规模更加广阔。根据国际调研机构IDC发布的《中国智能家居设备市场季度跟踪报告(2021年第四季度)》,2021年中国智能家居设备市场出货量超过2.2亿台,IDC预计2022年该数字将突破2.6亿台,并在2026年突破5亿台大关。早前,京东方曾公开展示过其多种智能功能为一身的魔镜产品,用户可以通过按键、触摸、语音等多种方式与BOE魔镜交流,不仅可以获取日期、天气、交通、新闻资讯、健康状况等信息,还可以成为用户的智能管家,控制窗帘、灯光、智能音箱、扫地机器人等智能设备。多种功能于一身的智能魔镜或许能为智能健身镜的发展提供更宽广的思路原文链接:智能健身镜:“巨型手机”想成全屋智能核心_新闻中心_物联网世界 (iotworld.com.cn)
-
 符号主义人工智能的基本观点是:知识和推理是智能的基础。 其代表理论是物理符号系统假说,认为无论是机器智能还是人类智能,其本质都是符号的操作和运算,更具体地强调机器应具有推理能力,并通过推理解决问题。 由于该流派坚持人工智能只能通过符号系统和逻辑实现,所以也被称作逻辑主义人工智能流派。 另外,符号主义人工智能聚焦于人类高级智能行为,例如搜索、推理、规划等。机器定理证明不仅是符号主义人工智能的重大成果,也是人工智能最先取得重大突破的领域之一。事实上,在达特茅斯会议的前一年,即1955年,Allen和Simon就开发了“逻辑理论家"程序,完成了罗素《数学原理》第2章38个定理的证明。进而,1957年,Allen等人提出不依赖特定领域的通用问题求解器。1965年,罗宾逊提出逻辑推理的归结原理,代表着为期10年的人工智能发展第一次高潮的终结。人工智能从高潮进人第一个低谷期,但正是在低谷中孕育出了知识工程。在批判前10年人工智能聚焦于“玩具世界”“闭世界”人工智能系统和强调通用人工智能系统的基础上,1968年,Feigenbaum等人开发了第一个专家系统DENTRAL系统,用于进行基于质谱仪数据的化学结构推理。1975年,Edward等人开发了细菌感染诊断专家系统MYCIN系统,提出了考虑确定性因子的不精确推理。 在强调知识重要性的基础上,Feigenbaum在1977年的国际人工智能联合大会上首次提出“知识工程”的概念,以开发专家系统为主要内容,让机器使用专家知识和推理解决实际问题。专家系统和知识工程掀起了人工智能发展的第二次高潮。由于专家系统定位于专业知识的运用,不可避免会遇到知识获取难题。而且人们很多时候并不一定需要专家知识,更多的是需要常识。常识是人类通过身体与世界直接或间接交互体验认知而得到的经验知识。这类知识无需言明便可被理解或意义自明。 常识和专业知识都不可缺少。美国Douglas等人实施的Cyc项目旨在开发百科全书式的常识知识库。该项目始于1984年,试图将人类的所有常识进行编码而建立知识库,利用人工方法将上百万条人类常识编码成机器可用、可理解的形式,用于与常识相关的智能推理。Cyc也被认为是最早的知识图谱。 对专家系统的批判之一是专家知识实际上是浅层知识,而现实事物的结构、行为、功能等深层知识(第一原理)才是解决专家系统知识获取困难以及知识受限问题所必需的。为此,从20世纪70年代末到80年代初,人工智能領域出现了一个新的研究分支:定性物理或定性推理(也称作基于模型的推理〕。 具体来讲,定性推理通过对物理系统结构的描述和分析推导出系统的状态变化(行为预测),并解释行为之间的因果关系,确定系统功能或作用。1984年和1991年,《人工智能》杂志分别刊出两期定性推理专辑。定性推理发展出定性仿真、定性过程理论、定性因果推理、功能推理、定性空间推理等分支理论。
符号主义人工智能的基本观点是:知识和推理是智能的基础。 其代表理论是物理符号系统假说,认为无论是机器智能还是人类智能,其本质都是符号的操作和运算,更具体地强调机器应具有推理能力,并通过推理解决问题。 由于该流派坚持人工智能只能通过符号系统和逻辑实现,所以也被称作逻辑主义人工智能流派。 另外,符号主义人工智能聚焦于人类高级智能行为,例如搜索、推理、规划等。机器定理证明不仅是符号主义人工智能的重大成果,也是人工智能最先取得重大突破的领域之一。事实上,在达特茅斯会议的前一年,即1955年,Allen和Simon就开发了“逻辑理论家"程序,完成了罗素《数学原理》第2章38个定理的证明。进而,1957年,Allen等人提出不依赖特定领域的通用问题求解器。1965年,罗宾逊提出逻辑推理的归结原理,代表着为期10年的人工智能发展第一次高潮的终结。人工智能从高潮进人第一个低谷期,但正是在低谷中孕育出了知识工程。在批判前10年人工智能聚焦于“玩具世界”“闭世界”人工智能系统和强调通用人工智能系统的基础上,1968年,Feigenbaum等人开发了第一个专家系统DENTRAL系统,用于进行基于质谱仪数据的化学结构推理。1975年,Edward等人开发了细菌感染诊断专家系统MYCIN系统,提出了考虑确定性因子的不精确推理。 在强调知识重要性的基础上,Feigenbaum在1977年的国际人工智能联合大会上首次提出“知识工程”的概念,以开发专家系统为主要内容,让机器使用专家知识和推理解决实际问题。专家系统和知识工程掀起了人工智能发展的第二次高潮。由于专家系统定位于专业知识的运用,不可避免会遇到知识获取难题。而且人们很多时候并不一定需要专家知识,更多的是需要常识。常识是人类通过身体与世界直接或间接交互体验认知而得到的经验知识。这类知识无需言明便可被理解或意义自明。 常识和专业知识都不可缺少。美国Douglas等人实施的Cyc项目旨在开发百科全书式的常识知识库。该项目始于1984年,试图将人类的所有常识进行编码而建立知识库,利用人工方法将上百万条人类常识编码成机器可用、可理解的形式,用于与常识相关的智能推理。Cyc也被认为是最早的知识图谱。 对专家系统的批判之一是专家知识实际上是浅层知识,而现实事物的结构、行为、功能等深层知识(第一原理)才是解决专家系统知识获取困难以及知识受限问题所必需的。为此,从20世纪70年代末到80年代初,人工智能領域出现了一个新的研究分支:定性物理或定性推理(也称作基于模型的推理〕。 具体来讲,定性推理通过对物理系统结构的描述和分析推导出系统的状态变化(行为预测),并解释行为之间的因果关系,确定系统功能或作用。1984年和1991年,《人工智能》杂志分别刊出两期定性推理专辑。定性推理发展出定性仿真、定性过程理论、定性因果推理、功能推理、定性空间推理等分支理论。 -
 限时奖励名单公布昵称考试成绩读书笔记问答官合计排名奖品孙小北12520050+103851富士INSTAX相机 mini7花溪125200503752雷柏机械键盘V700醉卧独钓125200503753雷柏机械键盘V700木斯佳001125200403654雷柏机械键盘V700蛋挞挞挞挞挞115200503655雷柏机械键盘V700HB1688125200303556折叠帆布包Allen2000125200203457折叠帆布包相信光的奥特王小懒115200303458折叠帆布包suifeng1324115200303459折叠帆布包Ania1252001033510折叠帆布包小浪1152001032511 黄生8050013012 yd_2198882131200012013 iolink10021200012014 yd_2767334681200012015 yd_2230554941200012016 自测打卡1150011517 禄仁恝1100011018 hw358243021100011019 yd_2512837441100011020 蓝瘦的蜕变1050010521 逝缘~80008022 莒青芒55005523 沐尘而生25002524 yd_1137946325002525 张辉25002526 高雷啊20002027 lanlingxueyu20002028 依依汉南00101029 yd_232561929500530 如有异议请与课程社群中的小助手联系获奖用户填写以下问卷,问卷填写信息截止 8月8日收货信息填写:cid:link_1雷柏机械键盘V700库存不足,已替换成其他等价值奖品开发者,你好!欢迎来到 华为云 · 云享读书会 第13期本期领读书籍为《FFmpeg从入门到精通》由华为云云享专家,音视频技术架构师,2021年度华为云年度十佳博主华为云享专家—刘振,带你深入浅出讲述FFmpeg音视频技术经过视频领读,如果你有相关知识收获,欢迎在此帖留下你的读书笔记~征集时间即日起 - 2022.07.27- 学习视频:点此学习-学习笔记提交:点击前往-互动问答:点击前往活动规则1)完成自测题:社群内公布自测题答题入口,每题回答正确后,增加5分;回答错误,0分。2)提交读书笔记:读书会进入领读期后,在指定云社区活动帖内,按照示例格式回复笔记内容(字数要求≥300字,内容要求与书籍内容、领读视频内容相关,要求原创不可抄袭),通过审核后,增加50分/篇。本次活动通过提交读书笔记获取积分上限为200分。3)互动问答:学员在结业期可参加互动问答,参与话题讨论或向专家提问、与专家互动。参与即可获得10分,上限50分,优质互动可根据质量额外获得10分或20分。评奖方式1)排行榜前20名;在活动结束后15个工作日内,积分获取方式关闭并停止更新积分榜,按照最终积分榜发放活动奖励,发放标准为:积分排名 第1名 富士INSTAX相机 mini7积分排行 第2-5 名 雷柏机械键盘V700活动积分排行 第6-10 名折叠帆布包2)针对活动时间内提交的有效读书笔记,领读专家将根据内容质量和完成篇数综合评选1位最佳读书笔记获奖者,并奖励提交人 富士INSTAX相机 mini7 1个,每个笔记提交人仅可获得一次最佳读书笔记奖励。活动积分注意事项1) 其他未说明的积分获取方式,请以社群公告为主;2) 活动涉及的所有积分仅在活动周期内生效,过期失效;3) 若积分值相同则以完成学习任务的时间先后排序,其中任务完成时间的判定优先级为:读书笔记>自测题>专家坐堂Q&A>其他;
限时奖励名单公布昵称考试成绩读书笔记问答官合计排名奖品孙小北12520050+103851富士INSTAX相机 mini7花溪125200503752雷柏机械键盘V700醉卧独钓125200503753雷柏机械键盘V700木斯佳001125200403654雷柏机械键盘V700蛋挞挞挞挞挞115200503655雷柏机械键盘V700HB1688125200303556折叠帆布包Allen2000125200203457折叠帆布包相信光的奥特王小懒115200303458折叠帆布包suifeng1324115200303459折叠帆布包Ania1252001033510折叠帆布包小浪1152001032511 黄生8050013012 yd_2198882131200012013 iolink10021200012014 yd_2767334681200012015 yd_2230554941200012016 自测打卡1150011517 禄仁恝1100011018 hw358243021100011019 yd_2512837441100011020 蓝瘦的蜕变1050010521 逝缘~80008022 莒青芒55005523 沐尘而生25002524 yd_1137946325002525 张辉25002526 高雷啊20002027 lanlingxueyu20002028 依依汉南00101029 yd_232561929500530 如有异议请与课程社群中的小助手联系获奖用户填写以下问卷,问卷填写信息截止 8月8日收货信息填写:cid:link_1雷柏机械键盘V700库存不足,已替换成其他等价值奖品开发者,你好!欢迎来到 华为云 · 云享读书会 第13期本期领读书籍为《FFmpeg从入门到精通》由华为云云享专家,音视频技术架构师,2021年度华为云年度十佳博主华为云享专家—刘振,带你深入浅出讲述FFmpeg音视频技术经过视频领读,如果你有相关知识收获,欢迎在此帖留下你的读书笔记~征集时间即日起 - 2022.07.27- 学习视频:点此学习-学习笔记提交:点击前往-互动问答:点击前往活动规则1)完成自测题:社群内公布自测题答题入口,每题回答正确后,增加5分;回答错误,0分。2)提交读书笔记:读书会进入领读期后,在指定云社区活动帖内,按照示例格式回复笔记内容(字数要求≥300字,内容要求与书籍内容、领读视频内容相关,要求原创不可抄袭),通过审核后,增加50分/篇。本次活动通过提交读书笔记获取积分上限为200分。3)互动问答:学员在结业期可参加互动问答,参与话题讨论或向专家提问、与专家互动。参与即可获得10分,上限50分,优质互动可根据质量额外获得10分或20分。评奖方式1)排行榜前20名;在活动结束后15个工作日内,积分获取方式关闭并停止更新积分榜,按照最终积分榜发放活动奖励,发放标准为:积分排名 第1名 富士INSTAX相机 mini7积分排行 第2-5 名 雷柏机械键盘V700活动积分排行 第6-10 名折叠帆布包2)针对活动时间内提交的有效读书笔记,领读专家将根据内容质量和完成篇数综合评选1位最佳读书笔记获奖者,并奖励提交人 富士INSTAX相机 mini7 1个,每个笔记提交人仅可获得一次最佳读书笔记奖励。活动积分注意事项1) 其他未说明的积分获取方式,请以社群公告为主;2) 活动涉及的所有积分仅在活动周期内生效,过期失效;3) 若积分值相同则以完成学习任务的时间先后排序,其中任务完成时间的判定优先级为:读书笔记>自测题>专家坐堂Q&A>其他; -
 ## HPDC2022 MindStudio模型调优实践 ### 一、环境要求 - **下载[MindStudio](https://www.hiascend.com/software/mindstudio/download)安装包**。 - Windows安装MindStudio指南可参照[**官网安装手册**](https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000018.html),安装操作(Windows)章节。安装完[**python3.7.5**](https://repo.huaweicloud.com/python/3.7.5/python-3.7.5.exe)后,打开cmd命令窗口,使用pip命令安装requests,pillow,pandas和libcst包。 ### 二、启动MindStudio - 进入到安装目录bin下面,双击MindStudio64.exe  - 弹出如下对话框直接点击“OK”  ### 三、连接云服务器和同步CANN - 同步CANN    SSH连接到云端昇腾服务器,认证类型选择Key pair。 *说明:服务器的IP和密钥对可以通过扫描文章后面的图片二维码加入HPDCMindStuio2022微信群,找管理员获取。*   - 其他:MobaXterm登录如下图。 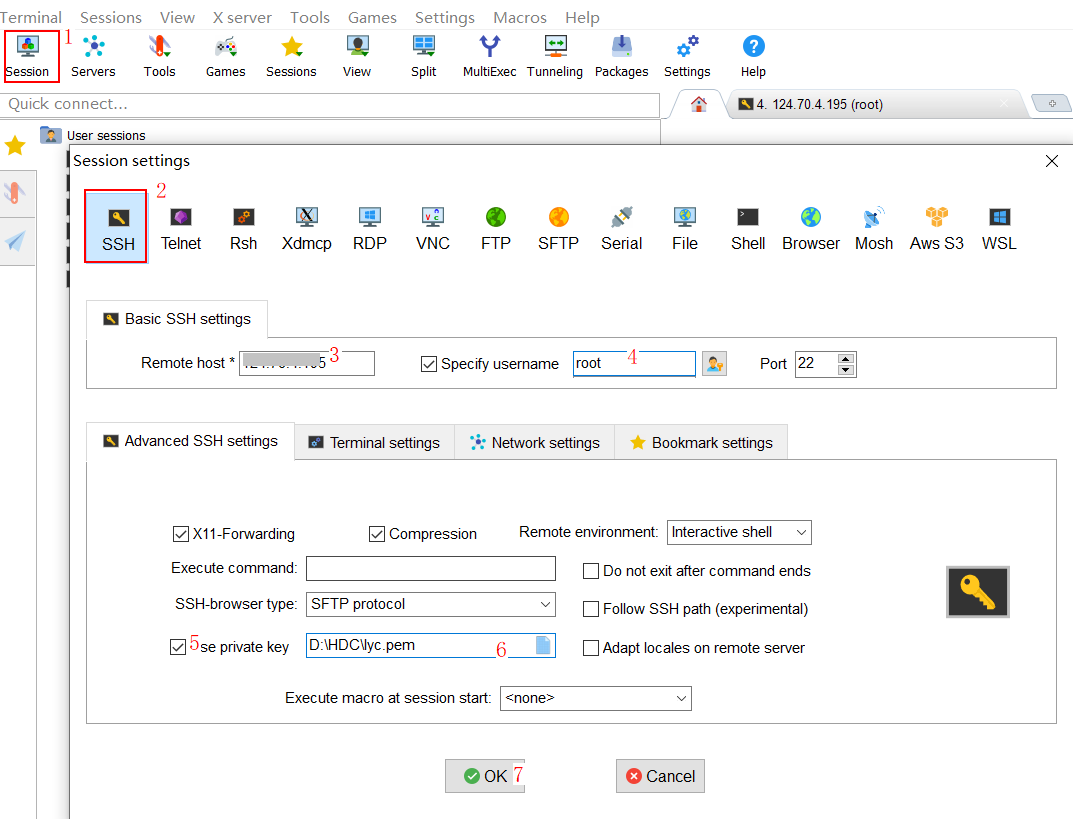 ### 四、实验 ### 实验一:将PyTorch框架训练脚本转换成MindSpore框架训练脚本 ***分析迁移工具集中的X2Mindspore工具可以快速的将PyTorch模型训练脚本转换成MindSpore训练脚本,无需手动修改代码或仅需少量修改代码,方便的让开发者将训练脚本快速迁移到昇腾生态。*** 步骤一:准备原始脚本。 - 准备PyTorch模型训练脚本,这里以pytorch-cifar100为例,[点击这里下载](https://github.com/weiaicunzai/pytorch-cifar100.git)。 步骤二:脚本迁移。 - 创建一个昇腾工程。    - 点击“Ascend --> Framework Trans --> X2MindSpore”,或者点击工具栏图标。 - 参照下图进行配置,点击“Transplant”进行脚本转换。  转换成功后会在Output Path指定路径下生成pytorch-cifar100_x2ms目录,转换生成的脚本会放在该目录下。  *说明:如果报“ModuleNotFoundError: No module named 'XXX'的错误,需要在cmd中执行pip install XXX命令。”* ### **实验二:运行推理应用工程并进行profiling**,找出性能瓶颈 ***Profiling实现了Host+Device侧丰富的性能数据采集能力和全景Timeline交互分析能力,展示Host+Device侧各项性能指标,帮助用户快速发现和定位AI应用、芯片及算子的性能瓶颈。包括资源瓶颈导致的AI算法短板,指导算法性能提升和系统资源利用率的优化。Profiling支持Host+Device侧的资源利用可视化统计分析,具体包括Host侧CPU、Memory、Disk、Network利用率和Device侧APP工程的硬件和软件性能数据。*** 步骤一:新建AscendCL推理应用样例工程。 - 如图所示创建AscendCL样例工程。    步骤二:准备推理数据和模型文件。 - 准备数据。 下载样例图片[图片一](https://ascend-package.obs.cn-north-4.myhuaweicloud.com/hdc/dog1_1024_683.jpg)、[图片二](https://ascend-package.obs.cn-north-4.myhuaweicloud.com/hdc/dog2_1024_683.jpg),将图片拷贝到data目录。打开cmd窗口,切换到工程目录下的data目录,执行如下命令: `python ..\script\transfer_pic.py` 在data目录下生成跟图片同名的bin文件。 *说明:图片也可以自行在网上下载狗的图片,保存为jpg格式。如果使用自定义图片,需要修改如下地方代码为自定义图片bin文件名称,如自定义图片生成的bin文件名称为test_1.bin和test_2.bin,可以参考如下代码修改。*  - 准备模型文件。 查看云服务器的/root/目录是否存在resnet50.prototxt和resnet50.caffemodel文件,如不存在,则下载[.prototxt](https://ascend-package.obs.cn-north-4.myhuaweicloud.com/hdc/resnet50.prototxt)文件和[.caffemodel](https://ascend-package.obs.cn-north-4.myhuaweicloud.com/hdc/resnet50.caffemodel)文件并放到该目录。然后使用MindStudio的Model Converter工具生成om文件,详细操作如下: 点击“Ascend --> Model Converter”,或者点击工具栏图标打开Model Converter界面。 配置好模型文件后一直点“Next”,最后点“Finish”进行模型转换。 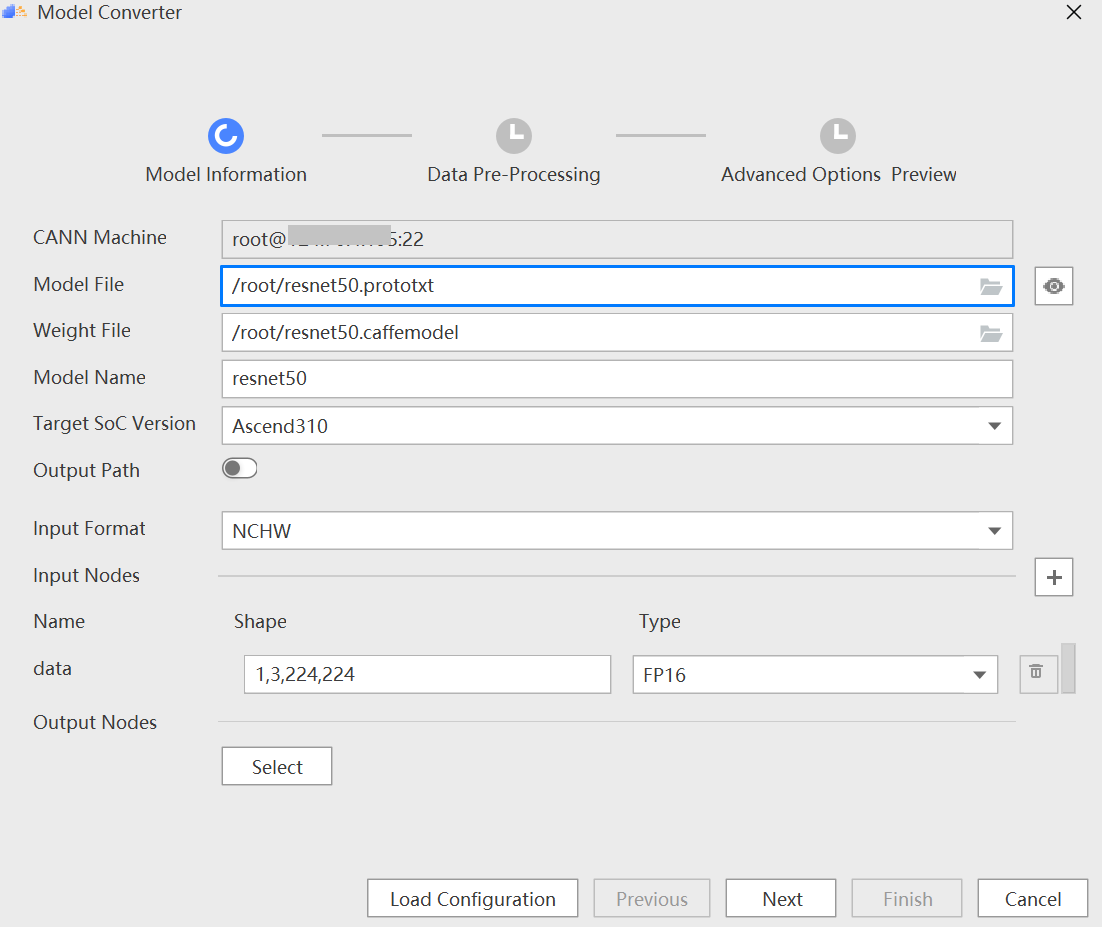  查看输出窗口,如下图表示模型转换成功,生成的om文件在目录/root/modelzoo/resnet50/Ascend310下,手动将om下载到工程model目录下。  步骤三:编译应用工程。 - 点击“Build --> Edit Build Configuration...”打开Build Configuration界面  - 点击上方工具栏图标运行编辑,编辑成功后会在out目录下生成main文件。 步骤四:配置运行参数并运行。 - 点击“Run --> Edit Configuration...”打开Run/Debug Configuration界面。 - 配置Deployment: 点击打开deployment,点击右侧Mappings标签页,把原来的映射路径删掉,点击列表下方+号按钮重新添加一个新的默认映射路径。  - 将编译生成main配置到Executable。 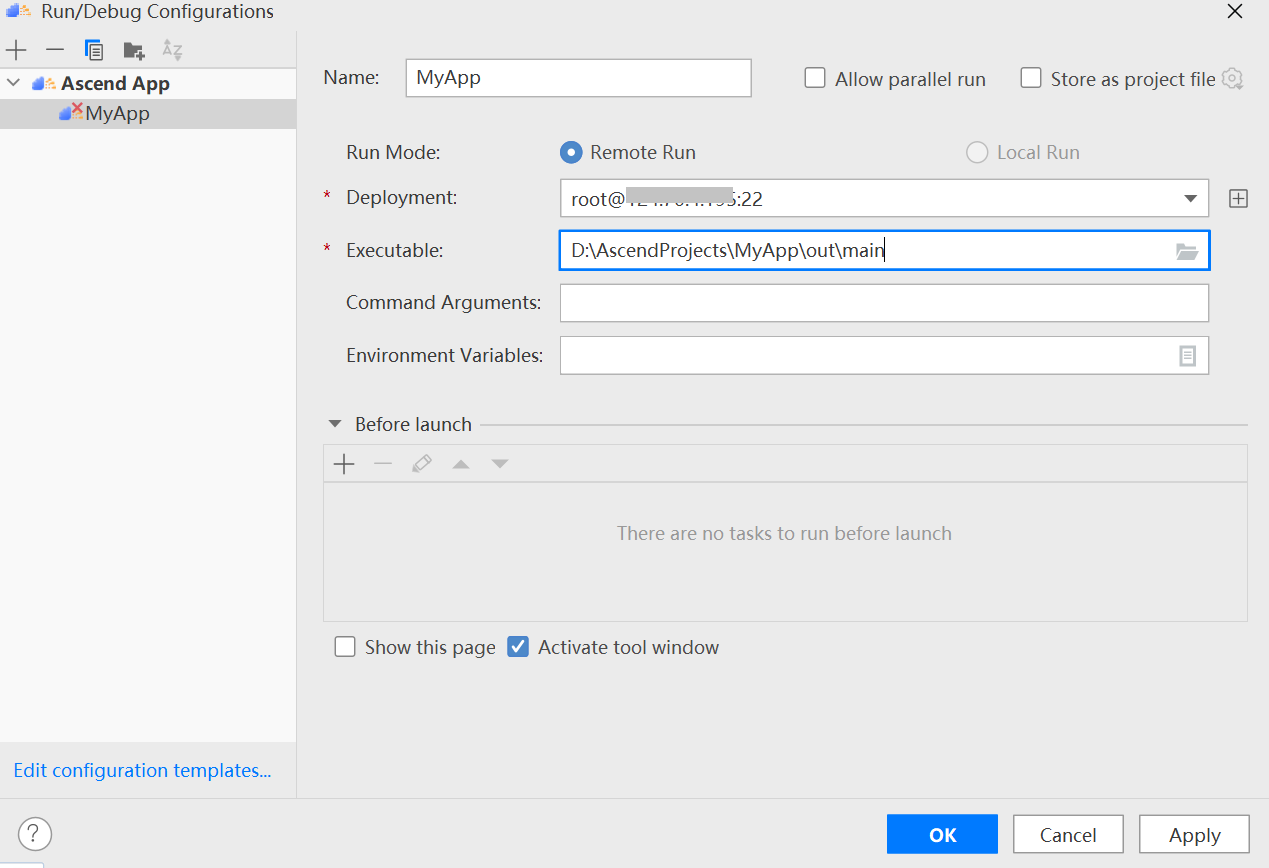 - 点击图标运行推理工程。等待运行结束不报错,output打印类似如下信息表示运行成功:  步骤五:使能profiling工具。 - 点击“Ascend --> System Profiler --> New Project”,打开Profiling Configuration界面。参照如下截图配置并使能Profiling。 环境变量:LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/5.1.RC1/runtime/lib64:$LD_LIBRARY_PATH。  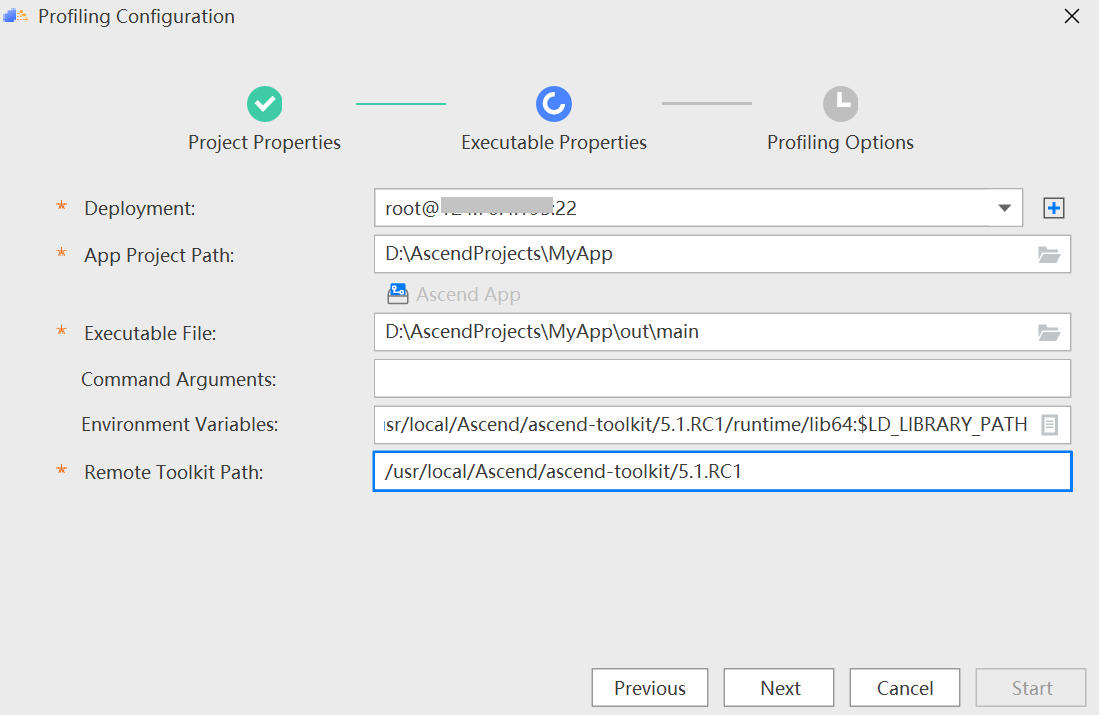 不勾选OS Runtime API,如下图:  - 最后弹出如下界面表示Profiling成功。  上面的profiling结果可视化的视图展示了模型、算子、Runtime API等耗时数据,开发者可以快速找到性能瓶颈,并针对性的进行优化。 Profiling视图的详细介绍可以参考这个[链接](https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/msug/msug_000263.html)。 ### **实验三:使用专家系统功能对推理应用工程进行分析,查看优化建议** ***专家系统(MindStudio Advisor)是用于聚焦模型和算子的性能调优TOP问题,识别性能瓶颈Pattern,重点构建瓶颈分析、优化推荐模型,支撑开发效率提升的工具。当前提供的功能有:基于Roofline模型的算子瓶颈识别与优化建议、基于Timeline的AICPU算子优化和算子融合推荐、算子优化分析。*** - 步骤一:参照实验二的步骤一、二、三准备样例工程。 - 步骤二:点击“Ascend --> Advisor”打开专家系统界面。 - 步骤三:点击图标打开Advisor System Configuration界面。 - 步骤四:配置Advisor,如下图:  运行成功后会弹出如下界面:  专家系统呈现了模型性能评估结果,并给出优化建议。 [点击这里阅读更多专家系统相关内容]("https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/msug/msug_000345.html") ## [欢迎参加MindStudio体验官活动,收获HUAWEI Mate Pad Pro、HUAWEI WATCH 3 等惊喜大礼!](https://bbs.huaweicloud.com/forum/thread-190510-1-1.html)
## HPDC2022 MindStudio模型调优实践 ### 一、环境要求 - **下载[MindStudio](https://www.hiascend.com/software/mindstudio/download)安装包**。 - Windows安装MindStudio指南可参照[**官网安装手册**](https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg/instg_000018.html),安装操作(Windows)章节。安装完[**python3.7.5**](https://repo.huaweicloud.com/python/3.7.5/python-3.7.5.exe)后,打开cmd命令窗口,使用pip命令安装requests,pillow,pandas和libcst包。 ### 二、启动MindStudio - 进入到安装目录bin下面,双击MindStudio64.exe  - 弹出如下对话框直接点击“OK”  ### 三、连接云服务器和同步CANN - 同步CANN    SSH连接到云端昇腾服务器,认证类型选择Key pair。 *说明:服务器的IP和密钥对可以通过扫描文章后面的图片二维码加入HPDCMindStuio2022微信群,找管理员获取。*   - 其他:MobaXterm登录如下图。  ### 四、实验 ### 实验一:将PyTorch框架训练脚本转换成MindSpore框架训练脚本 ***分析迁移工具集中的X2Mindspore工具可以快速的将PyTorch模型训练脚本转换成MindSpore训练脚本,无需手动修改代码或仅需少量修改代码,方便的让开发者将训练脚本快速迁移到昇腾生态。*** 步骤一:准备原始脚本。 - 准备PyTorch模型训练脚本,这里以pytorch-cifar100为例,[点击这里下载](https://github.com/weiaicunzai/pytorch-cifar100.git)。 步骤二:脚本迁移。 - 创建一个昇腾工程。    - 点击“Ascend --> Framework Trans --> X2MindSpore”,或者点击工具栏图标。 - 参照下图进行配置,点击“Transplant”进行脚本转换。  转换成功后会在Output Path指定路径下生成pytorch-cifar100_x2ms目录,转换生成的脚本会放在该目录下。  *说明:如果报“ModuleNotFoundError: No module named 'XXX'的错误,需要在cmd中执行pip install XXX命令。”* ### **实验二:运行推理应用工程并进行profiling**,找出性能瓶颈 ***Profiling实现了Host+Device侧丰富的性能数据采集能力和全景Timeline交互分析能力,展示Host+Device侧各项性能指标,帮助用户快速发现和定位AI应用、芯片及算子的性能瓶颈。包括资源瓶颈导致的AI算法短板,指导算法性能提升和系统资源利用率的优化。Profiling支持Host+Device侧的资源利用可视化统计分析,具体包括Host侧CPU、Memory、Disk、Network利用率和Device侧APP工程的硬件和软件性能数据。*** 步骤一:新建AscendCL推理应用样例工程。 - 如图所示创建AscendCL样例工程。    步骤二:准备推理数据和模型文件。 - 准备数据。 下载样例图片[图片一](https://ascend-package.obs.cn-north-4.myhuaweicloud.com/hdc/dog1_1024_683.jpg)、[图片二](https://ascend-package.obs.cn-north-4.myhuaweicloud.com/hdc/dog2_1024_683.jpg),将图片拷贝到data目录。打开cmd窗口,切换到工程目录下的data目录,执行如下命令: `python ..\script\transfer_pic.py` 在data目录下生成跟图片同名的bin文件。 *说明:图片也可以自行在网上下载狗的图片,保存为jpg格式。如果使用自定义图片,需要修改如下地方代码为自定义图片bin文件名称,如自定义图片生成的bin文件名称为test_1.bin和test_2.bin,可以参考如下代码修改。*  - 准备模型文件。 查看云服务器的/root/目录是否存在resnet50.prototxt和resnet50.caffemodel文件,如不存在,则下载[.prototxt](https://ascend-package.obs.cn-north-4.myhuaweicloud.com/hdc/resnet50.prototxt)文件和[.caffemodel](https://ascend-package.obs.cn-north-4.myhuaweicloud.com/hdc/resnet50.caffemodel)文件并放到该目录。然后使用MindStudio的Model Converter工具生成om文件,详细操作如下: 点击“Ascend --> Model Converter”,或者点击工具栏图标打开Model Converter界面。 配置好模型文件后一直点“Next”,最后点“Finish”进行模型转换。   查看输出窗口,如下图表示模型转换成功,生成的om文件在目录/root/modelzoo/resnet50/Ascend310下,手动将om下载到工程model目录下。  步骤三:编译应用工程。 - 点击“Build --> Edit Build Configuration...”打开Build Configuration界面  - 点击上方工具栏图标运行编辑,编辑成功后会在out目录下生成main文件。 步骤四:配置运行参数并运行。 - 点击“Run --> Edit Configuration...”打开Run/Debug Configuration界面。 - 配置Deployment: 点击打开deployment,点击右侧Mappings标签页,把原来的映射路径删掉,点击列表下方+号按钮重新添加一个新的默认映射路径。  - 将编译生成main配置到Executable。  - 点击图标运行推理工程。等待运行结束不报错,output打印类似如下信息表示运行成功:  步骤五:使能profiling工具。 - 点击“Ascend --> System Profiler --> New Project”,打开Profiling Configuration界面。参照如下截图配置并使能Profiling。 环境变量:LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/5.1.RC1/runtime/lib64:$LD_LIBRARY_PATH。   不勾选OS Runtime API,如下图:  - 最后弹出如下界面表示Profiling成功。  上面的profiling结果可视化的视图展示了模型、算子、Runtime API等耗时数据,开发者可以快速找到性能瓶颈,并针对性的进行优化。 Profiling视图的详细介绍可以参考这个[链接](https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/msug/msug_000263.html)。 ### **实验三:使用专家系统功能对推理应用工程进行分析,查看优化建议** ***专家系统(MindStudio Advisor)是用于聚焦模型和算子的性能调优TOP问题,识别性能瓶颈Pattern,重点构建瓶颈分析、优化推荐模型,支撑开发效率提升的工具。当前提供的功能有:基于Roofline模型的算子瓶颈识别与优化建议、基于Timeline的AICPU算子优化和算子融合推荐、算子优化分析。*** - 步骤一:参照实验二的步骤一、二、三准备样例工程。 - 步骤二:点击“Ascend --> Advisor”打开专家系统界面。 - 步骤三:点击图标打开Advisor System Configuration界面。 - 步骤四:配置Advisor,如下图:  运行成功后会弹出如下界面:  专家系统呈现了模型性能评估结果,并给出优化建议。 [点击这里阅读更多专家系统相关内容]("https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/msug/msug_000345.html") ## [欢迎参加MindStudio体验官活动,收获HUAWEI Mate Pad Pro、HUAWEI WATCH 3 等惊喜大礼!](https://bbs.huaweicloud.com/forum/thread-190510-1-1.html) -
 问卷有礼,选出top3命题活动获奖名单公布如下:请以下获奖同学在6月23日之前填写收货信息>>>点我填写收货地址信息<<<注意事项:活动奖品颜色随机,且部分奖品数量有限发完将用等值奖品代替,手机支架、冰箱贴、数据线、冰箱贴等等随机发放哟!序号获奖姓名获奖人手机号1*亮153****1963 2*鑫磊156****45213*仰玉151****31724*士尼153****16175*静怡188****21176*鹏178****61587*小北138****32608*旭星139****24579*士奇153****076710*丙坤177****972511*一凡181****053812*思敏136****960913*源毅166****875114*峰135****130515*海天159****050916*子杰158****357317*西提132****916218*宏屹135****028819*彦雄184****131420*博文182****0583【注】1、如未在6月23日前填写视为弃奖。本次活动将尽快发出,请您耐心等待。2、活动期间每个ID(同一姓名/电话/收货地址)只能获奖一次,若重复则中奖资格则往后评选一个问题。3、如活动奖品出现没有库存的情况,华为云工作人员将会替换等价值的奖品,获奖者不同意此规则视为放弃奖品。
问卷有礼,选出top3命题活动获奖名单公布如下:请以下获奖同学在6月23日之前填写收货信息>>>点我填写收货地址信息<<<注意事项:活动奖品颜色随机,且部分奖品数量有限发完将用等值奖品代替,手机支架、冰箱贴、数据线、冰箱贴等等随机发放哟!序号获奖姓名获奖人手机号1*亮153****1963 2*鑫磊156****45213*仰玉151****31724*士尼153****16175*静怡188****21176*鹏178****61587*小北138****32608*旭星139****24579*士奇153****076710*丙坤177****972511*一凡181****053812*思敏136****960913*源毅166****875114*峰135****130515*海天159****050916*子杰158****357317*西提132****916218*宏屹135****028819*彦雄184****131420*博文182****0583【注】1、如未在6月23日前填写视为弃奖。本次活动将尽快发出,请您耐心等待。2、活动期间每个ID(同一姓名/电话/收货地址)只能获奖一次,若重复则中奖资格则往后评选一个问题。3、如活动奖品出现没有库存的情况,华为云工作人员将会替换等价值的奖品,获奖者不同意此规则视为放弃奖品。 -
6月13日19点-21点华为云命题解读直播 回帖有礼活动(已结束)中奖名单如下:请以下获奖同学在6月23日之前填写收货信息>>>点我填写收货地址信息<<<注意事项:活动奖品颜色随机,且部分奖品数量有限发完将用等值奖品代替,手机支架、冰箱贴、数据线、冰箱贴等等随机发放哟!【注意事项】1、为保证您顺利领取活动奖品,请您提前填写奖品收货信息,如您没有填写,视为放弃奖励,后续更新收件地址。2、活动获奖信息已经公布,请获奖人尽快填写获奖地址,收件地址填写时间截止2022年6月23日,如未填写视为弃奖。本次活动奖品将尽快发出,请您耐心等待。3、活动期间每个ID(同一姓名/电话/收货地址)只能获奖一次,若重复则中奖资格则往后评选一个问题。4、如活动奖品出现没有库存的情况,华为云工作人员将会替换等价值的奖品,获奖者不同意此规则视为放弃奖品。
-
参与活动前请先报名活动:https://developer.huaweicloud.com/signup/f76f269a26894924833f7087737ae633 开发者,你好!欢迎来到 华为云 · 云享读书会 第13期本期领读书籍为《FFmpeg从入门到精通》由华为云云享专家,音视频技术架构师,2021年度华为云年度十佳博主华为云享专家—刘振,带你深入浅出讲述FFmpeg音视频技术经过视频领读,如果你有相关知识收获,欢迎在此帖留下你的读书笔记~ 活动时间 即日起-7月27日 回复内容要求1.可以提出您在课程学习中产生的任何疑问或者问题,也可以是您产生的深刻思考,我们统统欢迎;2.禁止抄袭或复制读书笔记帖的任何内容;3.您也可以参考以下互动话题,与领读专家和其他同学互动交流;4.回帖时请务必留下你的微信昵称和华为云账号。 互动话题请说说您在本次课程中的收获。 注意事项1.小助手会在活动结束后按续完成审核,并增加活动积分10活动积分/人,优质回复额外增加10或20活动积分/人;2.本次活动通过参与专家坐堂Q&A,可获得的积分上限为50分;3.请务必按照上述要求提交内容,以免影响积分增加;4.若积分值相同则以完成学习任务的时间先后排序,其中任务完成时间的判定优先级为:读书笔记>自测题>专家Q&A>其他;5.其他积分获取方式请查看活动社群公告;6其他未说明事项请参照:云享读书会 第13期 《FFmpeg从入门到精通》
-
 三秦都市报—三秦网讯(记者 李海涛 李佳)记者6月11日获悉,为认真贯彻落实陕西省《关于进一步提升产业链发展水平的实施意见》要求,凝聚企业共识、形成推进合力,共同促进陕西物联网产业链高质量发展,由陕西省工信厅牵头举办的第一期“陕西物联网产业链提升工作座谈会”6月9日在航天基地圆满落幕。会议由陕西省工信厅信息化产业发展处一级调研员高翔主持。西安市工信局两化融合处副处长董卓例,陕西物联网产业联盟秘书长刘立琦、副秘书长张栋,航天基地物联网产业链专班班长、实业公司董事长叶华中,西北大学信息科学与技术学院院长张志勇,西安邮电大学自动化学院副院长屈军锁,西安电子科技大学计算机学院教授王书振,中星测控、中航电测、大唐电信等14家企业代表,运营商代表、设计公司有关人员参会。为对物联网产业链承载地有更直观的认知,会前与会人员赴秦创原·航天软件科技园、秦创原·航天新能源科技园实地考察,通过看现场、听讲解、问细节,对项目的区位、规划、配套、进度等进行全方位了解。在随后的座谈会上,刘立琦从七个方面对陕西物联网产业链提升发展工作作了全面汇报,展示了工作亮点、明确了工作重点、梳理了工作思路。此外,与会人员通过观看航天基地宣传片,听取园区建设及航天基地物联网产业情况介绍,对在航天基地落位秦创原·陕西物联网产业基地整体规划有了更深入的了解。在交流环节,与会专家及企业代表结合各自工作和企业发展实际,就提升陕西物联网产业链发展水平、建设物联网产业基地和“陕西物联网产业展示中心”等提出了中肯的建议和意见。企业家及专家表示,从产业园区的规划建设、高效推进中看到了机遇,希望在后续交流对接中,能充分发挥各自优势,将多方资源凝聚成推动发展的合力,实现互惠共享、互利共赢。同时,对园区及“展示中心”的规划设计提出几点建议:一是搭建交流平台,增强企业联动,找到彼此的发展契合点;二是增强展厅沉浸式、交互式体验,将物联网实际应用场景进行直观展示;三是可将园区打造成为最富科技感的“网红”打卡地,擦亮名片;四是展示中心的设计要虚实结合,既有硬件产品展示,又要有数字化矩阵。叶华中表示,在省市产业链规划中,物联网承担了很重要的功能。建设秦创原·陕西物联网产业基地对于提升全省物联网产业发展核心竞争力、塑造全省重点产业链发展模式具有重要意义。此次会议,各位专家、企业家为物联网产业发展贡献了诸多智慧,航天基地物联网产业链专班将尽快对现有方案予以改进优化,建设好园区、开展好运营、落实好服务,与在座企业家携手,一起为陕西物联网产业发展作出积极贡献。高翔指出,物联网是一个链广、链长的赋能产业,做大做强需要脚踏实地、高瞻远瞩。一是站高,要格局大、立意高,集聚省市区三方力量,以政策交叉并进为思路,集中力量办大事,力求实现产业链、创新链“两链融合”、物联网与传感器“双链并进”。二是看远,在航天基地构建物联网产业高质量生态圈底气和后劲很足,希望各企业家能站高望远,从思想和行动上入园,充分利用这一富有创新性的集中空间强化交流、扬长补短、共谋发展。三是做实,打造物联网产业基地,集合省市区产业扶持政策促进物联网产业链提升,展现了政府的诚意和决心,希望各企业家也要实心实意出谋划策并带领上下游企业共同入园,以实际行动为陕西物联网产业链高质量发展贡献应尽之力。
三秦都市报—三秦网讯(记者 李海涛 李佳)记者6月11日获悉,为认真贯彻落实陕西省《关于进一步提升产业链发展水平的实施意见》要求,凝聚企业共识、形成推进合力,共同促进陕西物联网产业链高质量发展,由陕西省工信厅牵头举办的第一期“陕西物联网产业链提升工作座谈会”6月9日在航天基地圆满落幕。会议由陕西省工信厅信息化产业发展处一级调研员高翔主持。西安市工信局两化融合处副处长董卓例,陕西物联网产业联盟秘书长刘立琦、副秘书长张栋,航天基地物联网产业链专班班长、实业公司董事长叶华中,西北大学信息科学与技术学院院长张志勇,西安邮电大学自动化学院副院长屈军锁,西安电子科技大学计算机学院教授王书振,中星测控、中航电测、大唐电信等14家企业代表,运营商代表、设计公司有关人员参会。为对物联网产业链承载地有更直观的认知,会前与会人员赴秦创原·航天软件科技园、秦创原·航天新能源科技园实地考察,通过看现场、听讲解、问细节,对项目的区位、规划、配套、进度等进行全方位了解。在随后的座谈会上,刘立琦从七个方面对陕西物联网产业链提升发展工作作了全面汇报,展示了工作亮点、明确了工作重点、梳理了工作思路。此外,与会人员通过观看航天基地宣传片,听取园区建设及航天基地物联网产业情况介绍,对在航天基地落位秦创原·陕西物联网产业基地整体规划有了更深入的了解。在交流环节,与会专家及企业代表结合各自工作和企业发展实际,就提升陕西物联网产业链发展水平、建设物联网产业基地和“陕西物联网产业展示中心”等提出了中肯的建议和意见。企业家及专家表示,从产业园区的规划建设、高效推进中看到了机遇,希望在后续交流对接中,能充分发挥各自优势,将多方资源凝聚成推动发展的合力,实现互惠共享、互利共赢。同时,对园区及“展示中心”的规划设计提出几点建议:一是搭建交流平台,增强企业联动,找到彼此的发展契合点;二是增强展厅沉浸式、交互式体验,将物联网实际应用场景进行直观展示;三是可将园区打造成为最富科技感的“网红”打卡地,擦亮名片;四是展示中心的设计要虚实结合,既有硬件产品展示,又要有数字化矩阵。叶华中表示,在省市产业链规划中,物联网承担了很重要的功能。建设秦创原·陕西物联网产业基地对于提升全省物联网产业发展核心竞争力、塑造全省重点产业链发展模式具有重要意义。此次会议,各位专家、企业家为物联网产业发展贡献了诸多智慧,航天基地物联网产业链专班将尽快对现有方案予以改进优化,建设好园区、开展好运营、落实好服务,与在座企业家携手,一起为陕西物联网产业发展作出积极贡献。高翔指出,物联网是一个链广、链长的赋能产业,做大做强需要脚踏实地、高瞻远瞩。一是站高,要格局大、立意高,集聚省市区三方力量,以政策交叉并进为思路,集中力量办大事,力求实现产业链、创新链“两链融合”、物联网与传感器“双链并进”。二是看远,在航天基地构建物联网产业高质量生态圈底气和后劲很足,希望各企业家能站高望远,从思想和行动上入园,充分利用这一富有创新性的集中空间强化交流、扬长补短、共谋发展。三是做实,打造物联网产业基地,集合省市区产业扶持政策促进物联网产业链提升,展现了政府的诚意和决心,希望各企业家也要实心实意出谋划策并带领上下游企业共同入园,以实际行动为陕西物联网产业链高质量发展贡献应尽之力。 -
三秦都市报—三秦网讯(记者 李海涛 李佳)记者6月11日获悉,为认真贯彻落实陕西省《关于进一步提升产业链发展水平的实施意见》要求,凝聚企业共识、形成推进合力,共同促进陕西物联网产业链高质量发展,由陕西省工信厅牵头举办的第一期“陕西物联网产业链提升工作座谈会”6月7日在航天基地圆满落幕。会议由陕西省工信厅信息化产业发展处一级调研员高翔主持。西安市工信局两化融合处副处长董卓例,陕西物联网产业联盟秘书长刘立琦、副秘书长张栋,航天基地物联网产业链专班班长、实业公司董事长叶华中,西北大学信息科学与技术学院院长张志勇,西安邮电大学自动化学院副院长屈军锁,西安电子科技大学计算机学院教授王书振,中星测控、中航电测、大唐电信等14家企业代表,运营商代表、设计公司有关人员参会。为对物联网产业链承载地有更直观的认知,会前与会人员赴秦创原·航天软件科技园、秦创原·航天新能源科技园实地考察,通过看现场、听讲解、问细节,对项目的区位、规划、配套、进度等进行全方位了解。在随后的座谈会上,刘立琦从七个方面对陕西物联网产业链提升发展工作作了全面汇报,展示了工作亮点、明确了工作重点、梳理了工作思路。此外,与会人员通过观看航天基地宣传片,听取园区建设及航天基地物联网产业情况介绍,对在航天基地落位秦创原·陕西物联网产业基地整体规划有了更深入的了解。在交流环节,与会专家及企业代表结合各自工作和企业发展实际,就提升陕西物联网产业链发展水平、建设物联网产业基地和“陕西物联网产业展示中心”等提出了中肯的建议和意见。企业家及专家表示,从产业园区的规划建设、高效推进中看到了机遇,希望在后续交流对接中,能充分发挥各自优势,将多方资源凝聚成推动发展的合力,实现互惠共享、互利共赢。同时,对园区及“展示中心”的规划设计提出几点建议:一是搭建交流平台,增强企业联动,找到彼此的发展契合点;二是增强展厅沉浸式、交互式体验,将物联网实际应用场景进行直观展示;三是可将园区打造成为最富科技感的“网红”打卡地,擦亮名片;四是展示中心的设计要虚实结合,既有硬件产品展示,又要有数字化矩阵。叶华中表示,在省市产业链规划中,物联网承担了很重要的功能。建设秦创原·陕西物联网产业基地对于提升全省物联网产业发展核心竞争力、塑造全省重点产业链发展模式具有重要意义。此次会议,各位专家、企业家为物联网产业发展贡献了诸多智慧,航天基地物联网产业链专班将尽快对现有方案予以改进优化,建设好园区、开展好运营、落实好服务,与在座企业家携手,一起为陕西物联网产业发展作出积极贡献。高翔指出,物联网是一个链广、链长的赋能产业,做大做强需要脚踏实地、高瞻远瞩。一是站高,要格局大、立意高,集聚省市区三方力量,以政策交叉并进为思路,集中力量办大事,力求实现产业链、创新链“两链融合”、物联网与传感器“双链并进”。二是看远,在航天基地构建物联网产业高质量生态圈底气和后劲很足,希望各企业家能站高望远,从思想和行动上入园,充分利用这一富有创新性的集中空间强化交流、扬长补短、共谋发展。三是做实,打造物联网产业基地,集合省市区产业扶持政策促进物联网产业链提升,展现了政府的诚意和决心,希望各企业家也要实心实意出谋划策并带领上下游企业共同入园,以实际行动为陕西物联网产业链高质量发展贡献应尽之力。
-
 各位开发者:因回帖人数不足50人未能达到互动奖开奖条件本活动仅抽取报名抽奖抽奖过程可查看本帖附件奖品将在7月31日邮寄如遇其他情况延迟发货将在本帖进行说明没有填写奖品邮寄信息表的用户请抓紧填写兑奖截止日期:2022年7月20日23:59逾期视为弃奖,不补发【华为伙伴暨开发者大会社区活动获奖信息收集表】抽奖资格用户:报名观看直播的用户奖励:无线鼠标1个获奖用户名单公示yd_211703867yd_260205259yd_263630217yd_274911067yd_235608551yd_278600528yd_211451365yd_296963602欣然21yd_238832873清雨小竹爱的华尔兹yd_256139377Richieryd_278800950(活动已结束)【报名奖励】活动结束后,我们会在所有报名直播的开发者中抽取幸运奖,奖品为华为云开发者定制礼品,数量有限,快快报名吧>>点击报名观看<<无线鼠标定制polo衫活动时间06月8日—06月30日互动方式您可以在本帖留言,与专家互动交流,我们会在全部活动结束后对参与互动的用户进行抽奖。 活动规则和奖励说明1.本次活动结束后,将由华为云工作人员将符合抽奖条件的用户名单导入至巨公摇号平台(https://www.jugong.wang/random-portal/)内,抽取各奖项,并截屏公示抽奖过程。如您不同意此抽奖规则,请勿参加本次活动。2.奖励数量互动量(重复回帖不算)礼品数量回帖150人及以上HUAWEI FreeBuds 4i 无线耳机(碳晶黑)1回帖100人及以上无线鼠标20回帖50人及以上文件收纳包30 注意事项1、为保证您顺利领取活动奖品,请您提前填写奖品收货信息【点击此处填写 】,如您没有填写,视为放弃奖励。2、活动获奖信息填写时间截止至大会结束,如未填写视为弃奖。3、本次活动幸运奖将采用巨公摇号平台(https://www.jugong.wang/random-portal/)进行抽取,话题质量相关奖项将由华为云社区工作人员进行评选,如您对评奖方式有异议,请勿参加本次活动。本活动最终解释权归华为云所有。4、如出现活动奖品出现没有库存的情况,华为云工作人员将会替换等价值的奖品,获奖者不同意此规则视为放弃奖品。5、其他事宜请参考【华为云社区常规活动规则】 温馨提示 请您认真填写收货地址信息【点击此处填写 】,在“华为伙伴暨开发者大会社区活动”系列活动中完成一次填写即可。我们最终将会按照您最后一次填写的信息发放奖励。请务必使用个人账号参与活动(IAM、企业账号等账号参与无效)。所有获得华为电子产品奖项的获奖用户,请于获奖后3日内完成实名认证,否则视为放弃奖励。本次活动如一个实名认证对应多个账号,只有一个账号可领取奖励。本次活动一个实名认证账号只能对应一个收件人,如同一账号填写多个不同收件人或不同账号填写同一收件人,均不予发放奖励。
各位开发者:因回帖人数不足50人未能达到互动奖开奖条件本活动仅抽取报名抽奖抽奖过程可查看本帖附件奖品将在7月31日邮寄如遇其他情况延迟发货将在本帖进行说明没有填写奖品邮寄信息表的用户请抓紧填写兑奖截止日期:2022年7月20日23:59逾期视为弃奖,不补发【华为伙伴暨开发者大会社区活动获奖信息收集表】抽奖资格用户:报名观看直播的用户奖励:无线鼠标1个获奖用户名单公示yd_211703867yd_260205259yd_263630217yd_274911067yd_235608551yd_278600528yd_211451365yd_296963602欣然21yd_238832873清雨小竹爱的华尔兹yd_256139377Richieryd_278800950(活动已结束)【报名奖励】活动结束后,我们会在所有报名直播的开发者中抽取幸运奖,奖品为华为云开发者定制礼品,数量有限,快快报名吧>>点击报名观看<<无线鼠标定制polo衫活动时间06月8日—06月30日互动方式您可以在本帖留言,与专家互动交流,我们会在全部活动结束后对参与互动的用户进行抽奖。 活动规则和奖励说明1.本次活动结束后,将由华为云工作人员将符合抽奖条件的用户名单导入至巨公摇号平台(https://www.jugong.wang/random-portal/)内,抽取各奖项,并截屏公示抽奖过程。如您不同意此抽奖规则,请勿参加本次活动。2.奖励数量互动量(重复回帖不算)礼品数量回帖150人及以上HUAWEI FreeBuds 4i 无线耳机(碳晶黑)1回帖100人及以上无线鼠标20回帖50人及以上文件收纳包30 注意事项1、为保证您顺利领取活动奖品,请您提前填写奖品收货信息【点击此处填写 】,如您没有填写,视为放弃奖励。2、活动获奖信息填写时间截止至大会结束,如未填写视为弃奖。3、本次活动幸运奖将采用巨公摇号平台(https://www.jugong.wang/random-portal/)进行抽取,话题质量相关奖项将由华为云社区工作人员进行评选,如您对评奖方式有异议,请勿参加本次活动。本活动最终解释权归华为云所有。4、如出现活动奖品出现没有库存的情况,华为云工作人员将会替换等价值的奖品,获奖者不同意此规则视为放弃奖品。5、其他事宜请参考【华为云社区常规活动规则】 温馨提示 请您认真填写收货地址信息【点击此处填写 】,在“华为伙伴暨开发者大会社区活动”系列活动中完成一次填写即可。我们最终将会按照您最后一次填写的信息发放奖励。请务必使用个人账号参与活动(IAM、企业账号等账号参与无效)。所有获得华为电子产品奖项的获奖用户,请于获奖后3日内完成实名认证,否则视为放弃奖励。本次活动如一个实名认证对应多个账号,只有一个账号可领取奖励。本次活动一个实名认证账号只能对应一个收件人,如同一账号填写多个不同收件人或不同账号填写同一收件人,均不予发放奖励。
推荐直播
-
 通用人工智能(AGI)到来前夕如何实现企业降本增效和应用现代化
通用人工智能(AGI)到来前夕如何实现企业降本增效和应用现代化2024/04/19 周五 14:00-16:00
李京峰 T3出行VP/CTO
李京峰是T3出行CTO,本次他将分享通用人工智能(AGI)到来前夕,如何实现企业降本增效和应用现代化。
回顾中 -
 华为云云原生FinOps解决方案,为您释放云原生最大价值
华为云云原生FinOps解决方案,为您释放云原生最大价值2024/04/24 周三 16:30-18:00
Roc 华为云云原生DTSE技术布道师
还在对CCE集群成本评估感到束手无策?还在担心不合理的K8s集群资源申请和过度浪费?华为云容器服务CCE全新上线云原生FinOps中心,为用户提供多维度集群成本可视化,结合智能规格推荐、混部、超卖等成本优化手段,助力客户降本增效,释放云原生最大价值。
去报名 -
 产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》
产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》2024/04/25 周四 16:00-18:00
于晓东 上海杉达学院信息科学与技术学院副院长;崔宝才 天津电子信息职业技术学院电子与通信技术系主任
本期直播将与您一起探讨高校人才培养创新模式经验。
去报名
热门标签