-
 1 介绍简要介绍大数据组件flink-shaded-netty module。2 环境要求硬件要求仅在线下的物理服务器时涉及,需要写作此章节。没有内容时请删除。硬件要求如表2-1所示。表2-1 硬件要求项目说明服务器Taishan服务器CPU鲲鹏920处理器 或 鲲鹏916处理器磁盘分区对磁盘分区无要求网络可访问外网 软件要求表2-2 软件要求项目说明CentOS7.6OS Kernel4.14.0GCC4.8.5Openjdk1.8.0_252Maven3.5.4Protobuf2.5.0netty-all4.1.39.Final 3 配置编译环境提供编译安装该软件所需的环境的安装方法,例如编译器、第三方库、JDK、OS的yum源、防火墙、用户帐号(如要安装前需要单独创建用户或用户组)、环境变量等。多个任务时原则上建议采用Section进行区分,任务操作步骤较多时可以灵活处理为子章节。任务之间的依赖关系需要在各自的任务中明确。写作注意点:l 执行的操作和命令必须用正文,不能用带灰色底纹的回显。l 命令执行后的回显,必须用文本(带灰色底纹的回显样式),不要用截图。示例:3.1 安装基础库 步骤 1 安装gcc等相关软件。确保有外网环境后,执行yum -y install gcc.aarch64 gcc-c++.aarch64 gcc-gfortran.aarch64 libgcc.aarch64XXXX 步骤 2 解决-fsigned-char问题(修改gcc)a、寻找gcc所在路径(一般位于“/usr/bin/gcc”)。command -v gcc b、更改gcc的名字(例如改成gcc-impl)。mv /usr/bin/gcc /usr/bin/gcc-impl c、新建gcc文件。vi /usr/bin/gcc d、填入如下内容保存。#! /bin/sh/usr/bin/gcc-impl -fsigned-char "$@" e、给脚本添加执行权限。chmod +x /usr/bin/gcc f、确认命令是否可用。gcc --version 步骤 3 解决-fsigned-char问题(修改g++)a、寻找gcc所在路径(一般位于“/usr/bin/g++”)。command -v g++ b、更改g++的名字(例如改成g++-impl)。mv /usr/bin/gcc /usr/bin/g++-impl c、新建g++文件。vi /usr/bin/g++ d、填入如下内容保存。#! /bin/sh/usr/bin/g++-impl -fsigned-char "$@" e、给脚本添加执行权限。chmod +x /usr/bin/g++ f、确认命令是否可用。g++ --version 步骤 4 安装依赖 yum安装依赖的相关软件。yum install -y wget vim openssl-devel zlib-devel automake libtool make libstdc++-static glibc-static git snappy snappy-devel fuse fuse-devel ----结束 3.2 安装OpenJDK 步骤 1 下载并解压安装到指定目录(此处以指定“/opt/tools/installed”目录为例)wget https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u252-b09/OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gztar -zxf OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gzmkdir -p /opt/tools/installed/mv jdk8u252-b09 /opt/tools/installed/ 步骤 2 配置Java环境变量vim /etc/profile在文件末尾添加如下代码。export JAVA_HOME=/opt/tools/installed/jdk8u252-b09export PATH=$JAVA_HOME/bin:$PATH 步骤 3 使修改的环境变量生效source /etc/profile 步骤 4 查看配置是否生效 3.3 安装Maven 步骤 1 下载并安装到指定目录(此处以指定“/opt/tools/installed”目录为例)wget https://archive.apache.org/dist/maven/maven-3/3.5.4/binaries/apache-maven-3.5.4-bin.tar.gztar -zxf apache-maven-3.5.4-bin.tar.gzmv apache-maven-3.5.4 /opt/tools/installed/ 步骤 2 修改Maven环境变量vim /etc/profile在“/etc/profile”文件末尾增加下面代码。export MAVEN_HOME=/opt/tools/installed/apache-maven-3.5.4export PATH=$MAVEN_HOME/bin:$PATH 步骤 3 使修改的环境变量生效source /etc/profile 步骤 4 查看配置是否生效。mvn -v 步骤 5 查看配置是否生效。修改Maven配置文件中的:本地仓路径、远程仓等。配置文件路径:“/opt/tools/installed/apache-maven-3.5.4/conf/settings.xml”远程仓库配置(修改成自己搭建的Maven仓库,如果没有,可以按照下面示例配置),在<mirrors>标签内添加以下内容: <mirror> <id>huaweimaven</id> <name>huawei maven</name> <url>https://mirrors.huaweicloud.com/repository/maven/</url> <mirrorOf>central</mirrorOf></mirror> 若编译环境需要代理才能访问外网,需要在settings.xml配置文件中添加代理配置,具体内容如下:<proxies> <proxy> <id>optional</id> <active>true</active> <protocol>http</protocol> <username>用户名</username> <password>密码</password> <host>代理服务器网址</host> <port>代理服务器端口</port> <nonProxyHosts>local.net|some.host.com</nonProxyHosts> </proxy></proxies> 3.4 安装Protobuf 步骤 1 查看配置是否生效。yum install -y protobuf protobuf-devel 步骤 2 通过执行以下命令,指定安装的Protoc可执行文件mvn install:install-file -DgroupId=com.google.protobuf -DartifactId=protoc -Dversion=2.5.0 -Dclassifier=linux-aarch_64 -Dpackaging=exe -Dfile=/usr/bin/protoc 4 编译4.1 编译netty-all-4.1.39.Final 步骤 1 按xxx指导编译netty-all-4.1.39.Final4.2 编译flink-shaded-netty 步骤 1 下载flink-shaded-11.0安装包。wget https://github.com/apache/flink-shaded/archive/release-11.0.tar.gz 步骤 2 解压安装包。tar -zxf release-11.0.tar.gz 步骤 3 进入解压后目录cd flink-shaded-release-11.0 步骤 4 执行编译编译打成jar包,flink-shaded-netty-4.1.39.Final-11.0.jar放置于“flink-shaded-netty-4/target”目录。mvn clean install -pl flink-shaded-netty-4 步骤 5 使用鲲鹏分析扫描工具扫描编译生成的jar包,确保没有包含有x86的so和jar包。----结束A 修订记录写作说明:仅在第一次发布时,明确第一次正式发布。后续的刷新记录,不需要写作是第几次发布,只需要提供发布日期和修订说明即可。发布日期修订记录2021-01-05第一次正式发布
1 介绍简要介绍大数据组件flink-shaded-netty module。2 环境要求硬件要求仅在线下的物理服务器时涉及,需要写作此章节。没有内容时请删除。硬件要求如表2-1所示。表2-1 硬件要求项目说明服务器Taishan服务器CPU鲲鹏920处理器 或 鲲鹏916处理器磁盘分区对磁盘分区无要求网络可访问外网 软件要求表2-2 软件要求项目说明CentOS7.6OS Kernel4.14.0GCC4.8.5Openjdk1.8.0_252Maven3.5.4Protobuf2.5.0netty-all4.1.39.Final 3 配置编译环境提供编译安装该软件所需的环境的安装方法,例如编译器、第三方库、JDK、OS的yum源、防火墙、用户帐号(如要安装前需要单独创建用户或用户组)、环境变量等。多个任务时原则上建议采用Section进行区分,任务操作步骤较多时可以灵活处理为子章节。任务之间的依赖关系需要在各自的任务中明确。写作注意点:l 执行的操作和命令必须用正文,不能用带灰色底纹的回显。l 命令执行后的回显,必须用文本(带灰色底纹的回显样式),不要用截图。示例:3.1 安装基础库 步骤 1 安装gcc等相关软件。确保有外网环境后,执行yum -y install gcc.aarch64 gcc-c++.aarch64 gcc-gfortran.aarch64 libgcc.aarch64XXXX 步骤 2 解决-fsigned-char问题(修改gcc)a、寻找gcc所在路径(一般位于“/usr/bin/gcc”)。command -v gcc b、更改gcc的名字(例如改成gcc-impl)。mv /usr/bin/gcc /usr/bin/gcc-impl c、新建gcc文件。vi /usr/bin/gcc d、填入如下内容保存。#! /bin/sh/usr/bin/gcc-impl -fsigned-char "$@" e、给脚本添加执行权限。chmod +x /usr/bin/gcc f、确认命令是否可用。gcc --version 步骤 3 解决-fsigned-char问题(修改g++)a、寻找gcc所在路径(一般位于“/usr/bin/g++”)。command -v g++ b、更改g++的名字(例如改成g++-impl)。mv /usr/bin/gcc /usr/bin/g++-impl c、新建g++文件。vi /usr/bin/g++ d、填入如下内容保存。#! /bin/sh/usr/bin/g++-impl -fsigned-char "$@" e、给脚本添加执行权限。chmod +x /usr/bin/g++ f、确认命令是否可用。g++ --version 步骤 4 安装依赖 yum安装依赖的相关软件。yum install -y wget vim openssl-devel zlib-devel automake libtool make libstdc++-static glibc-static git snappy snappy-devel fuse fuse-devel ----结束 3.2 安装OpenJDK 步骤 1 下载并解压安装到指定目录(此处以指定“/opt/tools/installed”目录为例)wget https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u252-b09/OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gztar -zxf OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gzmkdir -p /opt/tools/installed/mv jdk8u252-b09 /opt/tools/installed/ 步骤 2 配置Java环境变量vim /etc/profile在文件末尾添加如下代码。export JAVA_HOME=/opt/tools/installed/jdk8u252-b09export PATH=$JAVA_HOME/bin:$PATH 步骤 3 使修改的环境变量生效source /etc/profile 步骤 4 查看配置是否生效 3.3 安装Maven 步骤 1 下载并安装到指定目录(此处以指定“/opt/tools/installed”目录为例)wget https://archive.apache.org/dist/maven/maven-3/3.5.4/binaries/apache-maven-3.5.4-bin.tar.gztar -zxf apache-maven-3.5.4-bin.tar.gzmv apache-maven-3.5.4 /opt/tools/installed/ 步骤 2 修改Maven环境变量vim /etc/profile在“/etc/profile”文件末尾增加下面代码。export MAVEN_HOME=/opt/tools/installed/apache-maven-3.5.4export PATH=$MAVEN_HOME/bin:$PATH 步骤 3 使修改的环境变量生效source /etc/profile 步骤 4 查看配置是否生效。mvn -v 步骤 5 查看配置是否生效。修改Maven配置文件中的:本地仓路径、远程仓等。配置文件路径:“/opt/tools/installed/apache-maven-3.5.4/conf/settings.xml”远程仓库配置(修改成自己搭建的Maven仓库,如果没有,可以按照下面示例配置),在<mirrors>标签内添加以下内容: <mirror> <id>huaweimaven</id> <name>huawei maven</name> <url>https://mirrors.huaweicloud.com/repository/maven/</url> <mirrorOf>central</mirrorOf></mirror> 若编译环境需要代理才能访问外网,需要在settings.xml配置文件中添加代理配置,具体内容如下:<proxies> <proxy> <id>optional</id> <active>true</active> <protocol>http</protocol> <username>用户名</username> <password>密码</password> <host>代理服务器网址</host> <port>代理服务器端口</port> <nonProxyHosts>local.net|some.host.com</nonProxyHosts> </proxy></proxies> 3.4 安装Protobuf 步骤 1 查看配置是否生效。yum install -y protobuf protobuf-devel 步骤 2 通过执行以下命令,指定安装的Protoc可执行文件mvn install:install-file -DgroupId=com.google.protobuf -DartifactId=protoc -Dversion=2.5.0 -Dclassifier=linux-aarch_64 -Dpackaging=exe -Dfile=/usr/bin/protoc 4 编译4.1 编译netty-all-4.1.39.Final 步骤 1 按xxx指导编译netty-all-4.1.39.Final4.2 编译flink-shaded-netty 步骤 1 下载flink-shaded-11.0安装包。wget https://github.com/apache/flink-shaded/archive/release-11.0.tar.gz 步骤 2 解压安装包。tar -zxf release-11.0.tar.gz 步骤 3 进入解压后目录cd flink-shaded-release-11.0 步骤 4 执行编译编译打成jar包,flink-shaded-netty-4.1.39.Final-11.0.jar放置于“flink-shaded-netty-4/target”目录。mvn clean install -pl flink-shaded-netty-4 步骤 5 使用鲲鹏分析扫描工具扫描编译生成的jar包,确保没有包含有x86的so和jar包。----结束A 修订记录写作说明:仅在第一次发布时,明确第一次正式发布。后续的刷新记录,不需要写作是第几次发布,只需要提供发布日期和修订说明即可。发布日期修订记录2021-01-05第一次正式发布 -
1 介绍简要介绍大数据组件flink-shaded-netty module。2 环境要求表2-1 硬件要求项目说明服务器Taishan服务器CPU鲲鹏920处理器 或 鲲鹏916处理器磁盘分区对磁盘分区无要求网络可访问外网 软件要求表2-2 软件要求项目说明CentOS7.6OS Kernel4.14.0GCC4.8.5Openjdk1.8.0_252Maven3.5.4Protobuf2.5.0netty-all4.1.49.Final 3 配置编译环境提供编译安装该软件所需的环境的安装方法,例如编译器、第三方库、JDK、OS的yum源、防火墙、用户帐号(如要安装前需要单独创建用户或用户组)、环境变量等。多个任务时原则上建议采用Section进行区分,任务操作步骤较多时可以灵活处理为子章节。任务之间的依赖关系需要在各自的任务中明确。写作注意点:l 执行的操作和命令必须用正文,不能用带灰色底纹的回显。l 命令执行后的回显,必须用文本(带灰色底纹的回显样式),不要用截图。示例:3.1 安装基础库 步骤 1 安装gcc等相关软件。确保有外网环境后,执行yum -y install gcc.aarch64 gcc-c++.aarch64 gcc-gfortran.aarch64 libgcc.aarch64XXXX 步骤 2 解决-fsigned-char问题(修改gcc)a、寻找gcc所在路径(一般位于“/usr/bin/gcc”)。command -v gcc b、更改gcc的名字(例如改成gcc-impl)。mv /usr/bin/gcc /usr/bin/gcc-impl c、新建gcc文件。vi /usr/bin/gcc d、填入如下内容保存。#! /bin/sh/usr/bin/gcc-impl -fsigned-char "$@" e、给脚本添加执行权限。chmod +x /usr/bin/gcc f、确认命令是否可用。gcc --version 步骤 3 解决-fsigned-char问题(修改g++)a、寻找gcc所在路径(一般位于“/usr/bin/g++”)。command -v g++ b、更改g++的名字(例如改成g++-impl)。mv /usr/bin/gcc /usr/bin/g++-impl c、新建g++文件。vi /usr/bin/g++ d、填入如下内容保存。#! /bin/sh/usr/bin/g++-impl -fsigned-char "$@" e、给脚本添加执行权限。chmod +x /usr/bin/g++ f、确认命令是否可用。g++ --version 步骤 4 安装依赖 yum安装依赖的相关软件。yum install -y wget vim openssl-devel zlib-devel automake libtool make libstdc++-static glibc-static git snappy snappy-devel fuse fuse-devel ----结束 3.2 安装OpenJDK 步骤 1 下载并解压安装到指定目录(此处以指定“/opt/tools/installed”目录为例)wget https://github.com/AdoptOpenJDK/openjdk8-binaries/releases/download/jdk8u252-b09/OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gztar -zxf OpenJDK8U-jdk_aarch64_linux_hotspot_8u252b09.tar.gzmkdir -p /opt/tools/installed/mv jdk8u252-b09 /opt/tools/installed/ 步骤 2 配置Java环境变量vim /etc/profile在文件末尾添加如下代码。export JAVA_HOME=/opt/tools/installed/jdk8u252-b09export PATH=$JAVA_HOME/bin:$PATH 步骤 3 使修改的环境变量生效source /etc/profile 步骤 4 查看配置是否生效 3.3 安装Maven 步骤 1 下载并安装到指定目录(此处以指定“/opt/tools/installed”目录为例)wget https://archive.apache.org/dist/maven/maven-3/3.5.4/binaries/apache-maven-3.5.4-bin.tar.gztar -zxf apache-maven-3.5.4-bin.tar.gzmv apache-maven-3.5.4 /opt/tools/installed/ 步骤 2 修改Maven环境变量vim /etc/profile在“/etc/profile”文件末尾增加下面代码。export MAVEN_HOME=/opt/tools/installed/apache-maven-3.5.4export PATH=$MAVEN_HOME/bin:$PATH 步骤 3 使修改的环境变量生效source /etc/profile 步骤 4 查看配置是否生效。mvn -v 步骤 5 查看配置是否生效。修改Maven配置文件中的:本地仓路径、远程仓等。配置文件路径:“/opt/tools/installed/apache-maven-3.5.4/conf/settings.xml”远程仓库配置(修改成自己搭建的Maven仓库,如果没有,可以按照下面示例配置),在<mirrors>标签内添加以下内容: <mirror> <id>huaweimaven</id> <name>huawei maven</name> <url>https://mirrors.huaweicloud.com/repository/maven/</url> <mirrorOf>central</mirrorOf></mirror> 若编译环境需要代理才能访问外网,需要在settings.xml配置文件中添加代理配置,具体内容如下:<proxies> <proxy> <id>optional</id> <active>true</active> <protocol>http</protocol> <username>用户名</username> <password>密码</password> <host>代理服务器网址</host> <port>代理服务器端口</port> <nonProxyHosts>local.net|some.host.com</nonProxyHosts> </proxy></proxies> 3.4 安装Protobuf 步骤 1 查看配置是否生效。yum install -y protobuf protobuf-devel 步骤 2 通过执行以下命令,指定安装的Protoc可执行文件mvn install:install-file -DgroupId=com.google.protobuf -DartifactId=protoc -Dversion=2.5.0 -Dclassifier=linux-aarch_64 -Dpackaging=exe -Dfile=/usr/bin/protoc 4 编译4.1 编译netty-all-4.1.49.Final 步骤 1 按xxx指导编译netty-all-4.1.49.Final4.2 编译flink-shaded-netty 步骤 1 下载flink-shaded-12.0安装包。wget https://github.com/apache/flink-shaded/archive/release-1.12.tar.gz 步骤 2 解压安装包。tar -zxf release-1.12.tar.gz 步骤 3 进入解压后目录cd flink-shaded-release-1.12 步骤 4 执行编译编译打成jar包,flink-shaded-netty-4.1.49.Final-12.0.jar放置于“flink-shaded-netty-4/target”目录。mvn clean install -pl flink-shaded-netty-4 步骤 5 使用鲲鹏分析扫描工具扫描编译生成的jar包,确保没有包含有x86的so和jar包。----结束
-
 >摘要:Apache Flink是为分布式、高性能的流处理应用程序打造的开源流处理框架。本文分享自华为云社区《[【云驻共创】手把手教你玩转Flink流批一体分布式实时处理引擎](https://bbs.huaweicloud.com/blogs/317816?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 萌兔之约。 Apache Flink是为分布式、高性能的流处理应用程序打造的开源流处理框架。Flink不仅能提供同时支持高吞吐和exactly-once语义的实时计算,还能提供批量数据处理。相较于市面上的其他数据处理引擎,它采用的是基于流计算来模拟批处理。 # 一、Flink原理及架构 ## Flink简介 Apache Flink是为分布式、高性能的流处理应用程序打造的开源流处理框架。Flink不仅能提供同时支持高吞吐和exactly-once语义的实时计算,还能提供批量数据处理。主要由Java代码实现,支持实时流处理和批处理,批数据只是流数据的一个极限案例。支持了迭代计算,内存管理和程序优化。  相较于市面上的其他数据处理引擎,Flink和Spark都可以同时支持流处理和批处理。但是,Spark的技术理念是基于批处理来模拟流的计算;而Flink则完全相反,它采用的是基于流计算来模拟批处理。 ## Flink关键机制 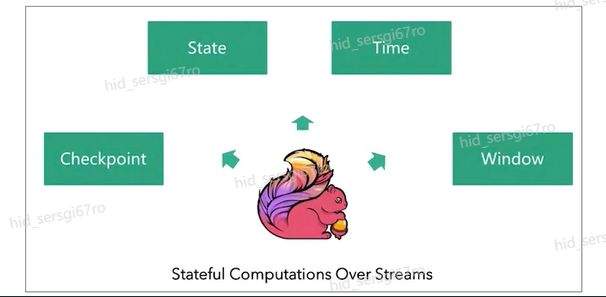 四个机制:状态、时间、检查点、窗口 Flink中有四种最重要的关键机制,这些关键机制在后面我们也会来进行详细的介绍,这里我们主要介绍它的基本概念以及主要用途。首先Flink中最重要的一个机制是状态机制(State),Flink是一种有状态的流计算引擎。状态的作用主要是我们Flink是一种流计算,它需要存储节点的中间计算结果。另外状态的保存还有利于Flink进行容错恢复。状态有密切关系的是Flink的Checkpoint,也就是检查点的机制,Checkpoint能够去把Flink的状态进行存储,相当于是做一次快照,方便Flink进行容错恢复。另外因为Flink它是一种流计算引擎,它的数据是不间断产生的,是没有界限的,因此我们需要有一种机制能够对数据进行切分,我们会采用的时间(Time)作为切分点,另外Flink进行容错性的恢复,它也需要知道从哪个时间点来进行恢复。所以说时间也是Flink中一种很重要的机制。最后是窗口window,在Flink中需要使用的窗口对数据进行切分,也方便对数据进行聚合计算。 ## Flink核心理念 Flink与其他流计算引擎的最大区别,就是状态管理。 Flink提供了内置的状态管理,可以把工作时状态存储在Flink内部,而不需要把它存储在外部系统。这样做的好处: - 降低了计算引擎对外部系统的依赖,使得部署、运维更加简单; - 对性能带来了极大的提升。 ## Flink Runtime整体架构 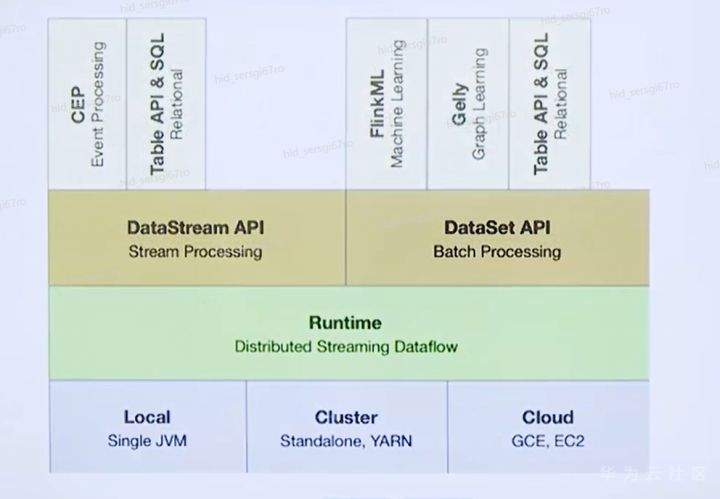 Flink运行时架构从下至上可以分为了三层,在最下层是Flink的一些配置方式,Flink可以采用单机的方式安装,也可以采用的集群的方式安装,另外也可以采用云的方式部署。在大多数情况下,Flink都是采用的集群的方式进行配置和安装的。其中呢它支持了两种集群模式,一种是Standalon,这种方式是采用了Flink自身提供的资源调度管理器。另外一种方式是基于YARN的方式进行了配置安装。 YARN提供了专用的资源管理器。在中间层次是Flink的计算引擎,这个计算引擎它同时能够支持流处理和批处理,可以接收了上层的api提交给它做作业 。Runtime这个引擎上面可以分为了两个模块,一个模块是DataStream api,一个是DataSet api。Flink向dataset和datastream,也就是批数据集以及流数据集是分开处理的,但是都是公用下面的计算引擎。基于两种类型的api,Flink又提供了更多的上层的抽象的api,API越抽象,它的表达能力越弱,但是它对数据的处理能力、抽象性也越强。在针对于上层Table api和SQL,它是主要是针对关系运算的,那针对关系数据的查询,Flink提供了统一的接口,基于流数据api,同时提供了复杂事件处理api。复杂事件指的就是说对不能够用时间去表示事件的开始、次序以及结束这样的事件进行处理的api接口。另外针对于数据及api,它提供了机器学习api以及图计算的api。 ## Flink核心概念- DataStream  DataStream: Flink用类DataStream来表示程序中的流式数据。用户可以认为它们是含有重复数据的不可修改的集合(collection),DataStream中元素的数量是无限的。 从图中我们可以发现,对DataStream可以使用一些算子,例如KeyBy这样的算子,对它进行处理转换之后,它会转换成另外一种数据流,也称为keyedstream。那么基于keyedstream,我们进一步可以使用窗口算子,这主要是Flink程序设计中对数据流的一些处理方式。 ## Flink核心概念- DataSet DataSet : Flink系统可对数据集进行转换(例如,过滤,映射,联接,分组),数据集可从读取文件或从本地集合创建。结果通过接收器( Sink)返回,接收器可以将数据写入(分布式)文件或标准输出(例如命令行终端) ## Flink程序 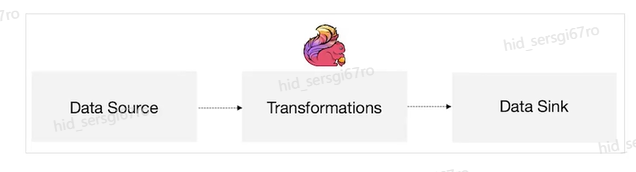 Flink程序由Source、Transformation和Sink三部分组成,其中Source主要负责数据的读取,支持HDFS、kafka和文本等;Transformation主要负责对数据的转换操作; Sink负责最终数据的输出,支持HDFS、kafka和文本输出等。在各部分之间流转的数据称为流( stream ) 。 ## Flink数据源 批处理: Files:HDFS,Local file system,MapR file system;Text,CSV,Avro,Hadoop input formats JDBC、HBase和 Collections 流处理: Files、Socket streams、Kafka、RabbitMQ、Flume、Collections、 Implement your own和SourceFunction.collecto # Flink程序运行图 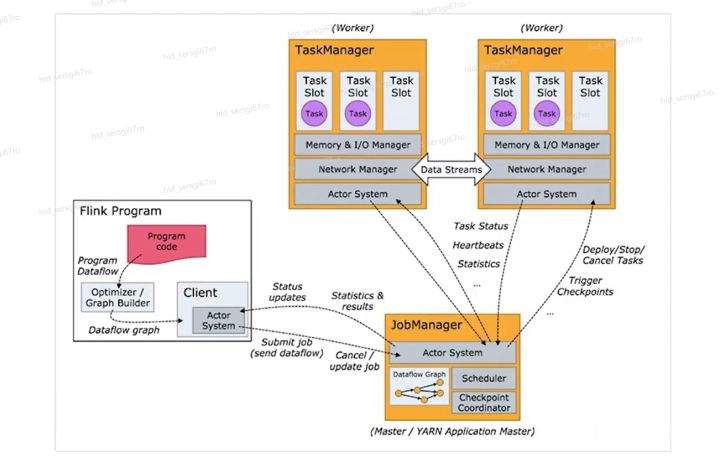 Flink是一种master-Slave架构,它在启动的时候就会产生了JobManger以及TaskManager。事实上在Flink程序中还包含两个组件,这两个组件一个叫resource manager,主要负责了资源的调度与管理,另外一个称为Dispatcher。主要是用来进行client,要把JobManager进行分发公布。我们来看一看具体的运行流程。 首先是用户提交Flink程序,这个Flink程序就会转换成逻辑数据流图。客户端接收到逻辑数据流图之后,然后连同jar包以及一些依赖包就会提交给了JobManger,JobManger接收到逻辑数据流图之后会转成物理数据流图,这个物理数据流图是真实的可执行的,能够具体的将任务放置在TaskManager上,在TaskManager中会将它所拥有的资源划分成一个一个的TaskSlot。每个TaskSlot实际上就相当于是jvm,它的一个具体的线程。每个TaskSlot占用了TaskManager的一部分资源,这里的资源主要是以内存进行划分的,TaskSlot不对cpu的资源进行划分,因此没有对cpu的资源进行隔离。 ## Flink作业运行流程(一) 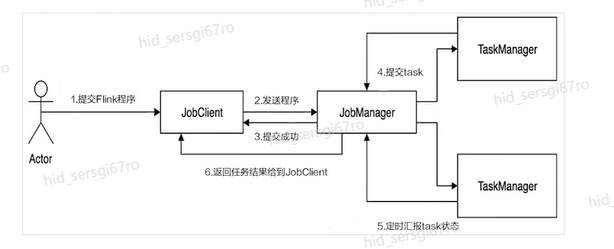 用户首先提交Flink程序到JobClient,经过JobClient的处理、解析、优化提交到JobManager,最后由TaskManager运行task。 在Flink中它通过了JobClient提交了任务,做过JobClient提交的任务进一步的进行优化、解析以及处理,提交给了JobManager。JobManager会将jobClient提交了逻辑数据流图转换成物理数据流图,然后将这些任务分配给taskmanager。taskmanager接受到任务之后就相应地进行处理,并且汇报了task的状态给JobManager,JobManager最后就把结果反馈给jobClient。 JobClient是Flink程序和JobManager交互的桥梁。主要负责接收程序、解析程序的执行计划、优化程序的执行计划,然后提交执行计划到JobManager。在Flink中主要有三类Operator。 Source Operator:数据源操作,比如文件、socket、Kafka等。 Transformation Operator:数据转换操作,比如map,flatMap,reduce等算子。 Sink Operator:数据存储操作。比如数据存储到HDFS、Mysql、Kafka等等。 ## 一个完整的Flink程序---java   ## Flink的数据处理 Apache Flink它同时支持批处理和流处理,也能用来做一些基于事件的应用。 首先Flink是一个纯流式的计算引擎,它的基本数据模型是数据流。流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,就是批处理。因此Flink用一套架构同时支持了流处理和批处理。 其次,Flink的一个优势是支持有状态的计算。如果处理一个事件(或一条数据)的结果只跟事6件本身的内容有关,称为无状态处理;反之结果还和之前处理过的事件有关,称为有状态处理。 ## 有界流与无界流 无界流:有定义流的开始,但没有定义流的结束。数据源会无休止地产生数据。无界流的数据必须持续处理,即数据被读取后需要立刻处理。不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。 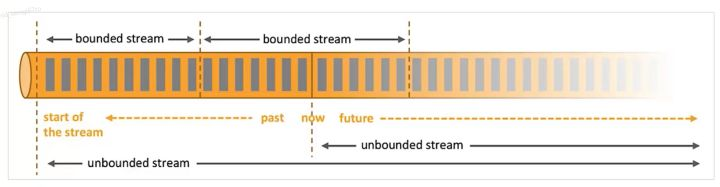 有界流:有定义流的开始,也有定义流的结束。有界流可以在读取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。 ## 批处理示例  批处理是流处理的一种非常特殊的情况。在流处理中,我们为数据定义滑动窗口或滚动窗口,并且在每次窗口滑动或滚动时生成结果。批处理则不同,我们定义一个全局窗口,所有的记录都属于同一个窗口。举例来说,以下代码表示一个简单的Flink程序,它负责每小时对某网站的访问者计数,并按照地区分组。 如果知道输入数据是有限的,则可以通过以下代码实现批处理。  如果输入数据是有限的,那么下面代码与上面代码的运行结果相同。  ## Flink批处理模型 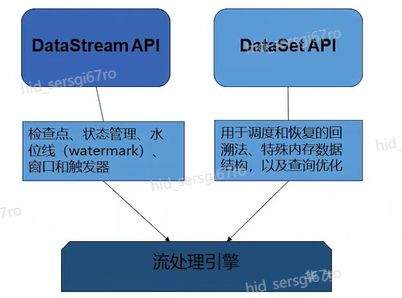 Flink通过一个底层引擎同时支持流处理和批处理。 在流处理引擎之上,Flink 有以下机制: - 检查点机制和状态机制:用于实现容错、有状态的处理; - 水印机制:用于实现事件时钟; - 窗口和触发器:用于限制计算范围,并定义呈现结果的时间。 在同一个流处理引擎之上,Flink 还存在另一套机制,用于实现高效的批处理。 - 用于调度和恢复的回溯法:由 Microsoft Dryad 引入,现在几乎用于所有批处理器; - 用于散列和排序的特殊内存数据结构:可以在需要时,将一部分数据从内存溢出到硬盘上; - 优化器:尽可能地缩短生成结果的时间。 流与批处理机制 两套机制分别对应各自的API(DataStream API 和 DataSet API);在创建 Flink 作业时,并不能通过将两者混合在一起来同时 利用 Flink 的所有功能。 Flink支持两种关系型的API,Table APl和sQL。这两个API都是批处理和流处理统一的APl,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型API会以相同的语义执行查询,并产生相同的结果。 - **Table API / SQL** 正在以流批统一的方式成为分析型用例的主要 API。 - **DataStream API** 是数据驱动应用程序和数据管道的主要API。 # 二、Flink的Time与Window ## 时间背景 在流处理器编程中,对于时间的处理是非常关键的。比如计数的例子,事件流数据(例如服务器日志数据、网页点击数据和交易数据)不断产生,我们需要用key将事件分组,并且每隔一段时间就针对每一个key对应的事件计数。这就是我们熟知的“大数据”应流处理中的时间分类 在数据流处理过程中,我们经常使用系统处理时间即: processing time作为某个事件的时间,而实际上系统时间processing time是我们强加给事件的时间,由于网络延迟等原因并不能较好的反应事件之间发生的先后顺序。 在实际场景中,每个事件的时间可以分为三种: - event time,即事件发生时的时间; - ingestion time,即事件到达流处理系统的时间; - processing time,即事件被系统处理的时间。 ## 三种时间示例 例如,一条日志进入Flink的时间为2019-11-1210:00:00.123,到达window的系统时间为2019-11-1210:00:01.234,日志的内容如下: 2019-11-0218:37:15.624 INFO Fail over to rm2 2019-11-0218:37:15.624是Event Time; 2019-11-1210:00:00.123是Ingestion Time; 2019-11-1210:00:01.234是Processing Time; ## 三种时间的区别 实际情况中事件真正发生的先后顺序与系统处理时间存在一定的差异,这些差异主要由网络延迟、处理时间的长短等造成。如图所示: 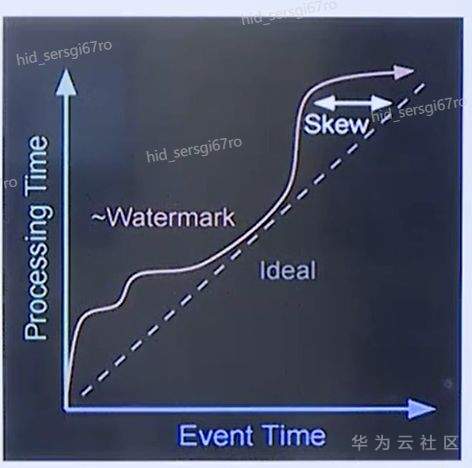 横坐标代表Event time,纵坐标代表processing time。理想情况下,eventtime和processing time构成的坐标应该形成一条倾斜角为45度的线。但实际应用过程中,processing time要落后与eventtime,造成事件到来的先后顺序不一致。 ## Flink支持的时间语义 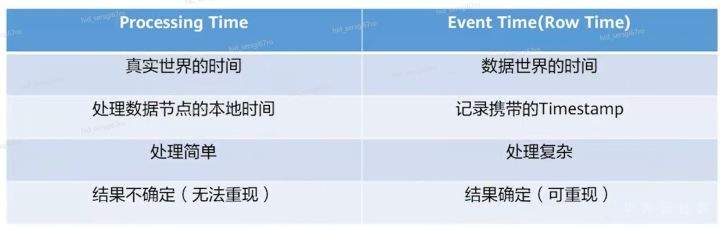 Processing Time是指事件数据被Operator处理时所在机器的系统时间,它提供了最好的性能和最低的延迟。 Event Time是指在数据产生时该设备上对应的时间,这个时间在进入Flink之前已经存在于数据记录中了。 Ingestion Time指的是事件数据进入到Flink的时间。 ## Window概述 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而Window是一种切割无限数据为有限块进行处理的手段。Window是无限数据流处理的核心,它将一个无限的stream拆分成有限大小的"buckets"桶,我们可以在这些桶上做计算操作。 ## Window类型 Window根据应用类型可以分成两类: - CountWindow:数据驱动,按照指定的数据条数生成一个Window,与时间无关。 - TimeWindow:时间驱动,按照时间生成Window。 Apache Flink是一个天然支持无限流数据处理的分布式计算框架,在Flink中 Window可以将无限流切分成有限流。Flink中 Window可以是Time Window,也可以是Count Window。 # TimeWindow分类 TimeWindow可以根据窗口实现原理的不同分成三类:滚动窗口(Tumbling Window ) .滑动窗口( Sliding Window)和会话窗口( Session Window)。 ## 滚动窗口 将数据依据固定的窗口长度对数据进行切片。特点:时间对齐,窗口长度固定,没有重叠。 适用场景:适合做Bl统计等(做每个时间段的聚合计算)。 举一个例子,假设要对传感器输出的数值求和。一分钟滚动窗口收集最近一分钟的数值,并在一分钟结束时输出总和,如下图所示。 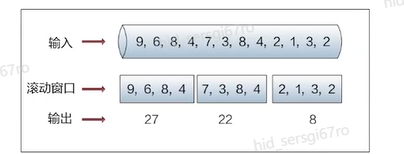 ## 滑动窗口 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。特点∶时间对齐,窗口长度固定,有重叠。 适用场景:对最近一个时间段内的统计(求某接口最近5min的失败率来决定是否要报警)。 示例:一分钟滑动窗口计算最近一分钟的数值总和,但每半分钟滑动一次并输出结果,如下图所示。 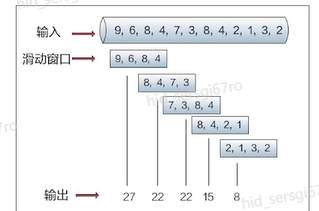 ## 会话窗口 会话窗口由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。特点:时间无对齐。 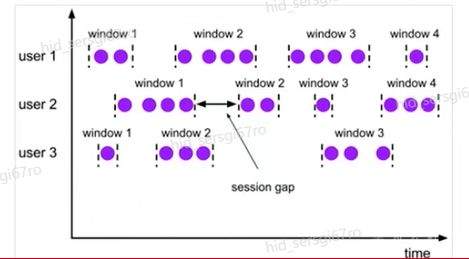 ## 代码定义 在Flink中,一分钟滚动窗口的定义如下: `stream.timeWindow(Time.minutes(1));` 在Flink中,每半分钟(即30秒)滑动一次的一分钟滑动窗口,如下所示: `stream.timeWindow(Time.minutes(1),Time.seconds(30));` # 三、Flink的Watermark ## 乱序问题 流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。  此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。 ## 乱序示例 例子:某App会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。A用户在11:02对App进行操作,B用户在11:03对App进行操作,但是A用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到B用户11:03的消息,然后再接受到A用户11:02的消息,消息乱序了。 # 水位线(Watermark) 对于无穷数据集,我们缺乏一种有效的方式来判断数据完整性,因此就有了Watermark,它是建立在事件时间上的一个概念,用来刻画数据流的完整性。如果按照处理时间来衡量事件,一切都是有序的、完美的,自然而然也就不需要Watermark了。换句话说事件时间带来了乱序的问题,而Watermark就是用来解决乱序问题。所谓的乱序,其实就是有事件延迟了,对于延迟的元素,我们不可能无限期的等下去,必须要有一种机制来保证一个特定的时间后,必须触发Window进行计算。这个特别的机制,就是Watermark,它告诉了算子延迟到达的消息不应该再被接收。 - Watermark是一种衡量Event Time进展的机制。 - Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。 - 数据流中的Watermark用于表示timestamp小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的。 - Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。 - watermark 用来让程序自己平衡延迟和结果正确性 # Watermark的原理 Flink怎么保证基于event-time的窗口在销毁的时候,已经处理完了所有的数据呢? 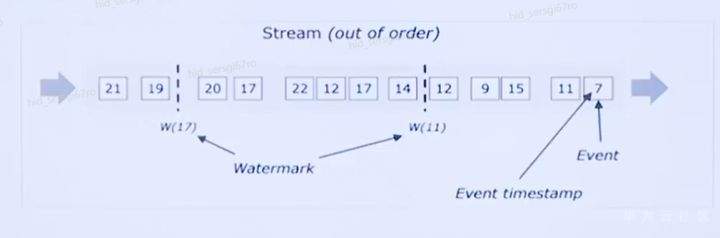 这就是watermark的功能所在。watermark会携带一个单调递增的时间戳t,Watermark(t)表示所有时间戳不大于t的数据都已经到来了,未来小于等于t的数据不会再来,因此可以放心地触发和销毁窗口了。 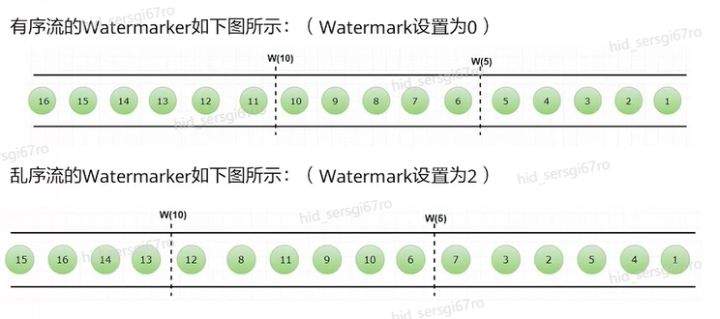 当Flink,接收到数据时,会按照一定的规则去生成Watermark,这条Watermark就等于当前所有到达数据中的maExertT me"-延N时长,也就定说,Watermark是基于数据携带的时间戳生成的,一旦Watermark比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于eventtime是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。 上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的Watermark 是 5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口是1s-5s,窗口2是6s~-10s,那么时间戳为7s的事件到达时的Matermarker.恰好触发窗口1,时间戳为 12s的事件到达时的Watermark恰好触发窗口2。 Watermark就是触发前一窗口的“关窗时间”,一旦触发关门那么以当前时刻为准在窗口范围内的所有所有数据都会收入窗中。只要没有达到水位那么不管现实中的时间推进了多久都不会触发关窗。 ## 延迟的数据 Watermark能够应对乱序的数据,但是真实世界中没法得到一个完美的 Watermark数值。要么没法获取到,要么耗费太大,因此实际工作中会近似 Watermark(t)之后,还有较小的概率接受到时间戳t之前的数据,在Flink中将这些数据定义为“late elements”,同样可以在Window中指定允许延迟的最大时间(默认为О),可以使用下面的代码进行设置:  ## 延迟数据处理机制 延迟事件是乱序事件的特例,和一般乱序事件不同的是它们的乱序程度超出了水位线( Watermark)的预计,导致窗口在它们到达之前已经关闭。 延迟事件出现时窗口已经关闭并产出了计算结果,对于此种情况处理的方法有3种: - 重新激活已经关闭的窗口并重新计算以修正结果。 - 将延迟事件收集起来另外处理。 - 将延迟事件视为错误消息并丢弃。 Flink默认的处理方式是第3种直接丢弃,其他两种方式分别使用Side Output和AllowedLateness。 ## Side Output机制 Side Output机制可以将延迟事件单独放入一个数据流分支,这会作为Window计算结果的副产品,以便用户获取并对其进行特殊处理。 side Output获取延迟数据: 设置allowedLateness之后,迟来的数据同样可以触发窗口,进行输出,利用Flink的sideoutput机制,可以获取到这些延迟的数据,使用方式如下:  ## Allowed Lateness机制 Allowed Lateness机制允许用户设置一个允许的最大延迟时长。Flink会在窗口关闭后一直保存窗口的状态直至超过允许延迟时长,这期间的延迟事件不会被丢弃,而是默认会触发窗口重新计算。因为保存窗口状态需要额外内存,并且如果窗口计算使用了ProcessWindowFunction APl还可能使得每个延迟事件触发一次窗口的全量计算,代价比较大,所以允许延迟时长不宜设得太长,延迟事件也不宜过多。 # 四、Flink的容错 ## Flink容错机制 为了保证程序的容错恢复以及程序启动时其状态恢复,Flink任务都会开启Checkpoint或者触发Savepoint进行状态保存。 - Checkpoint机制。这种机制保证了实时程序运行时,即使突然遇到异常也能够进行自我恢复。Checkpoint对于用户层面,是透明的,用户会感觉不到Checkpoint过程的存在。 - Savepoint机制。是在某个时间点程序状态全局镜像,以后程序在进行升级,或者修改并发度等情况,还能从保存的状态位继续启动恢复。Savepoint可以看做是Checkpoint在特定时期的一个状态快照。 ## Checkpoint Flink 如何保证exactly-once呢?它使用一种被称为“检查点( Checkpoint )”的特性,在出现故障时将系统重置回正确状态。Flink状态保存主要依靠Checkpoint机制,Checkpoint会定时制作分布式快照,对程序中的状态进行备份。 ## Checkpoint检查点机制 Flink中基于异步轻量级的分布式快照技术提供了Checkpoints容错机制,分布式快照可以将同一时间点Task/Operator的状态数据全局统一快照处理。Flink会在输入的数据集上间隔性地生成checkpoint barrier,通过棚栏( barrier)将间隔时间段内的数据划分到相应的checkpoint中。当应用出现异常时,Operator就能够从上一次快照中恢复所有算子之前的状态,从而保证数据的一致性。 对于状态占用空间比较小的应用,快照产生过程非常轻量,高频率创建且对Flink任务性能影响相对较小。Checkpoint过程中状态数据一般被保存在一个可配置的环境中,通常是在JobManager节点或HDFS上。 ## Checkpoint配置  默认情况下Flink不开启检查点,用户需要在程序中通过调用enableCheckpointing(n)方法配置和开启检查点,其中n为检查点执行的时间间隔,单位为毫秒。 **exactly-once和at-least-once语义选择** exactly-once:保证端到端数据一致性,数据要求高,不允许出现数据丢失和数据重复,Flink的性能也相对较弱; at-least-once:时延和吞吐量要求非常高但对数据的一致性要求不高的场景。 Flink默认使用exactly-once模式,可以通过setCheckpointingMode()方法来设定语义模式。 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) **Checkpoint超时时间** 指定每次Checkpoint执行过程中的上限时间范围,一旦Checkpoint执行时间超过该阈值,Flink将会中断Checkpoint过程,并按照超时处理。 该指标可以通过setCheckpointTimeout方法设定,默认10分钟。 env.getCheckpointConfig().setCheckpointingTimeout(60000) **检查点之间最小时间间隔** 设定两个Checkpoint之间的最小时间间隔,防止出现状态数据过大而导致Checkpoint执行时间过长,从而导致Checkpoint积压过多,最终Flink应用密集地触发Checkpoint操作,会占用大量计算资源而影响到整个应用的性能。 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500) **最大并行执行的检查点数量** 设定能够同时执行的Checkpoint数量。在默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时触发多个Checkpoint,从而提升Checkpoint整体的效率。 env.getCheckpointConfig().setMaxConcurrentCheckpoints(500) **外部检查点** 设定周期性的外部检查点,然后将状态数据持久化到外部系统中,使用这种方式不会在任务停止的过程中清理掉检查点数据,而是一直保存在外部系统介质中,也可以通过从外部检查点中对任务就行恢复。 env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) # 作业如何恢复数据? Flink在Cancel时允许在外部介质保留Checkpoint;另一方面,Flink还有另外一个机制是SavePoint. Savepoints是检查点的一种特殊实现,底层其实是使用Checkpoints的机制。Savepoints是用户以手工命令的方式触发,并将结果持久化到指定的存储路径中,目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况,从而无法实现端到端的Exactly-Once语义保证。 ## Savepoint与Checkpoint 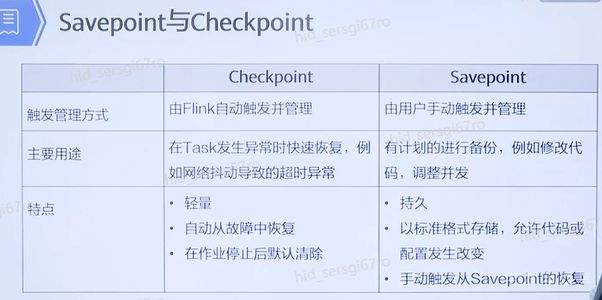 checkpoint的侧重点是“容错”,即Flink作业意外失败并重启之后,能够直接从早先打下的checkpoint恢复运行,且不影响作业逻辑的准确性。而savepoint的侧重点是“维护”,即Flink作业需要在人工干预下手动重启、升级、迁移或A/B测试时,先将状态整体写入可靠存储,维护完毕之后再从savepoint恢复现场。 savepoint是“通过checkpoint机制”创建的,所以savepoint本质上是特殊的checkpoint。 checkpoint面向Flink Runtime本身,由Flink的各个TaskManager定时触发快照并自动清理,一般不需要用户干预;savepoint面向用户,完全根据用户的需要触发与清理。 - 触发管理方式上,Checkpoint是由Flink自动触发并管理;Savepoint由用户手动触发并管理 - 主要用途上,Checkpoint在Task发生异常时快速恢复,例如网络抖动导致的超时异常;Savepoint有计划的进行备份,例如修改代码,调整并发 - 从特点上看,Checkpoint轻量,自动从故障中恢复,在作业停止后默认清除;Savepoint持久,以标准格式存储,允许代码或配置发生改变,手动触发从Savepoint的恢复。 ## 状态的存储方式-MemoryStateBackend 构造方式: MemoryStateBackend(int maxStateSize, boolean asynchronousSnapshots) 存储方式: - State: TaskManager内存;Checkpoint: JobManager内存。 容量限制: 单个state maxStateSize默认5M; maxStateSize=akka.framesize ,默认10 M。·总大小不超过JobManager的内存 推荐使用的场景:本地测试;几乎无状态的作业,比如ETL。 ## 状态的存储方式- FsStateBackend 构造方式: FsStateBackend(URI checkpointDataUri ,boolean asynchronousSnapshots) 存储方式: State: TaskManager内存; CHeckpoint:外部文件存储系统(本地或HDFS)。 容量限制: ·单TaskManager 上state总量不超过它的内存; ·总大小不超过配置的文件系统容量。 推荐使用的场景:常规使用状态的作业,例如分钟级别窗口聚合、Join;需要开启HA的作业;可以在生产场景使用。 ## 状态的存储方式- RocksDBStateBackend 构造方式: RocksDBStateBackend(URI checkpointDataUri ,boolean enableIncrementalCheckpointing) 存储方式: State: TaskManager上的KV数据库(实际使用内存+磁盘); CHeckpoint:外部文件存储系统(本地或HDFS)。 容量限制: 单TaskManager 上State总量不超过它的内存+磁盘; 单Key最大2G; 总大小不超过配置的文件系统容量。 推荐使用的场景:超大状态的作业,例如天级别窗口聚合;需要开启HA的作业;要求不高的作业;可以在生产场景使用。 # 总结 本章主要讲述了Flink的架构及技术原理,以及Flink程序的运行过程。重点在于Flink流处理与批处理的不同方式,从长远来看,DataStream API应该通过有界数据流完全包含DataSet APl。
>摘要:Apache Flink是为分布式、高性能的流处理应用程序打造的开源流处理框架。本文分享自华为云社区《[【云驻共创】手把手教你玩转Flink流批一体分布式实时处理引擎](https://bbs.huaweicloud.com/blogs/317816?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 萌兔之约。 Apache Flink是为分布式、高性能的流处理应用程序打造的开源流处理框架。Flink不仅能提供同时支持高吞吐和exactly-once语义的实时计算,还能提供批量数据处理。相较于市面上的其他数据处理引擎,它采用的是基于流计算来模拟批处理。 # 一、Flink原理及架构 ## Flink简介 Apache Flink是为分布式、高性能的流处理应用程序打造的开源流处理框架。Flink不仅能提供同时支持高吞吐和exactly-once语义的实时计算,还能提供批量数据处理。主要由Java代码实现,支持实时流处理和批处理,批数据只是流数据的一个极限案例。支持了迭代计算,内存管理和程序优化。  相较于市面上的其他数据处理引擎,Flink和Spark都可以同时支持流处理和批处理。但是,Spark的技术理念是基于批处理来模拟流的计算;而Flink则完全相反,它采用的是基于流计算来模拟批处理。 ## Flink关键机制  四个机制:状态、时间、检查点、窗口 Flink中有四种最重要的关键机制,这些关键机制在后面我们也会来进行详细的介绍,这里我们主要介绍它的基本概念以及主要用途。首先Flink中最重要的一个机制是状态机制(State),Flink是一种有状态的流计算引擎。状态的作用主要是我们Flink是一种流计算,它需要存储节点的中间计算结果。另外状态的保存还有利于Flink进行容错恢复。状态有密切关系的是Flink的Checkpoint,也就是检查点的机制,Checkpoint能够去把Flink的状态进行存储,相当于是做一次快照,方便Flink进行容错恢复。另外因为Flink它是一种流计算引擎,它的数据是不间断产生的,是没有界限的,因此我们需要有一种机制能够对数据进行切分,我们会采用的时间(Time)作为切分点,另外Flink进行容错性的恢复,它也需要知道从哪个时间点来进行恢复。所以说时间也是Flink中一种很重要的机制。最后是窗口window,在Flink中需要使用的窗口对数据进行切分,也方便对数据进行聚合计算。 ## Flink核心理念 Flink与其他流计算引擎的最大区别,就是状态管理。 Flink提供了内置的状态管理,可以把工作时状态存储在Flink内部,而不需要把它存储在外部系统。这样做的好处: - 降低了计算引擎对外部系统的依赖,使得部署、运维更加简单; - 对性能带来了极大的提升。 ## Flink Runtime整体架构  Flink运行时架构从下至上可以分为了三层,在最下层是Flink的一些配置方式,Flink可以采用单机的方式安装,也可以采用的集群的方式安装,另外也可以采用云的方式部署。在大多数情况下,Flink都是采用的集群的方式进行配置和安装的。其中呢它支持了两种集群模式,一种是Standalon,这种方式是采用了Flink自身提供的资源调度管理器。另外一种方式是基于YARN的方式进行了配置安装。 YARN提供了专用的资源管理器。在中间层次是Flink的计算引擎,这个计算引擎它同时能够支持流处理和批处理,可以接收了上层的api提交给它做作业 。Runtime这个引擎上面可以分为了两个模块,一个模块是DataStream api,一个是DataSet api。Flink向dataset和datastream,也就是批数据集以及流数据集是分开处理的,但是都是公用下面的计算引擎。基于两种类型的api,Flink又提供了更多的上层的抽象的api,API越抽象,它的表达能力越弱,但是它对数据的处理能力、抽象性也越强。在针对于上层Table api和SQL,它是主要是针对关系运算的,那针对关系数据的查询,Flink提供了统一的接口,基于流数据api,同时提供了复杂事件处理api。复杂事件指的就是说对不能够用时间去表示事件的开始、次序以及结束这样的事件进行处理的api接口。另外针对于数据及api,它提供了机器学习api以及图计算的api。 ## Flink核心概念- DataStream  DataStream: Flink用类DataStream来表示程序中的流式数据。用户可以认为它们是含有重复数据的不可修改的集合(collection),DataStream中元素的数量是无限的。 从图中我们可以发现,对DataStream可以使用一些算子,例如KeyBy这样的算子,对它进行处理转换之后,它会转换成另外一种数据流,也称为keyedstream。那么基于keyedstream,我们进一步可以使用窗口算子,这主要是Flink程序设计中对数据流的一些处理方式。 ## Flink核心概念- DataSet DataSet : Flink系统可对数据集进行转换(例如,过滤,映射,联接,分组),数据集可从读取文件或从本地集合创建。结果通过接收器( Sink)返回,接收器可以将数据写入(分布式)文件或标准输出(例如命令行终端) ## Flink程序  Flink程序由Source、Transformation和Sink三部分组成,其中Source主要负责数据的读取,支持HDFS、kafka和文本等;Transformation主要负责对数据的转换操作; Sink负责最终数据的输出,支持HDFS、kafka和文本输出等。在各部分之间流转的数据称为流( stream ) 。 ## Flink数据源 批处理: Files:HDFS,Local file system,MapR file system;Text,CSV,Avro,Hadoop input formats JDBC、HBase和 Collections 流处理: Files、Socket streams、Kafka、RabbitMQ、Flume、Collections、 Implement your own和SourceFunction.collecto # Flink程序运行图  Flink是一种master-Slave架构,它在启动的时候就会产生了JobManger以及TaskManager。事实上在Flink程序中还包含两个组件,这两个组件一个叫resource manager,主要负责了资源的调度与管理,另外一个称为Dispatcher。主要是用来进行client,要把JobManager进行分发公布。我们来看一看具体的运行流程。 首先是用户提交Flink程序,这个Flink程序就会转换成逻辑数据流图。客户端接收到逻辑数据流图之后,然后连同jar包以及一些依赖包就会提交给了JobManger,JobManger接收到逻辑数据流图之后会转成物理数据流图,这个物理数据流图是真实的可执行的,能够具体的将任务放置在TaskManager上,在TaskManager中会将它所拥有的资源划分成一个一个的TaskSlot。每个TaskSlot实际上就相当于是jvm,它的一个具体的线程。每个TaskSlot占用了TaskManager的一部分资源,这里的资源主要是以内存进行划分的,TaskSlot不对cpu的资源进行划分,因此没有对cpu的资源进行隔离。 ## Flink作业运行流程(一)  用户首先提交Flink程序到JobClient,经过JobClient的处理、解析、优化提交到JobManager,最后由TaskManager运行task。 在Flink中它通过了JobClient提交了任务,做过JobClient提交的任务进一步的进行优化、解析以及处理,提交给了JobManager。JobManager会将jobClient提交了逻辑数据流图转换成物理数据流图,然后将这些任务分配给taskmanager。taskmanager接受到任务之后就相应地进行处理,并且汇报了task的状态给JobManager,JobManager最后就把结果反馈给jobClient。 JobClient是Flink程序和JobManager交互的桥梁。主要负责接收程序、解析程序的执行计划、优化程序的执行计划,然后提交执行计划到JobManager。在Flink中主要有三类Operator。 Source Operator:数据源操作,比如文件、socket、Kafka等。 Transformation Operator:数据转换操作,比如map,flatMap,reduce等算子。 Sink Operator:数据存储操作。比如数据存储到HDFS、Mysql、Kafka等等。 ## 一个完整的Flink程序---java   ## Flink的数据处理 Apache Flink它同时支持批处理和流处理,也能用来做一些基于事件的应用。 首先Flink是一个纯流式的计算引擎,它的基本数据模型是数据流。流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,就是批处理。因此Flink用一套架构同时支持了流处理和批处理。 其次,Flink的一个优势是支持有状态的计算。如果处理一个事件(或一条数据)的结果只跟事6件本身的内容有关,称为无状态处理;反之结果还和之前处理过的事件有关,称为有状态处理。 ## 有界流与无界流 无界流:有定义流的开始,但没有定义流的结束。数据源会无休止地产生数据。无界流的数据必须持续处理,即数据被读取后需要立刻处理。不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。  有界流:有定义流的开始,也有定义流的结束。有界流可以在读取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。 ## 批处理示例  批处理是流处理的一种非常特殊的情况。在流处理中,我们为数据定义滑动窗口或滚动窗口,并且在每次窗口滑动或滚动时生成结果。批处理则不同,我们定义一个全局窗口,所有的记录都属于同一个窗口。举例来说,以下代码表示一个简单的Flink程序,它负责每小时对某网站的访问者计数,并按照地区分组。 如果知道输入数据是有限的,则可以通过以下代码实现批处理。  如果输入数据是有限的,那么下面代码与上面代码的运行结果相同。  ## Flink批处理模型  Flink通过一个底层引擎同时支持流处理和批处理。 在流处理引擎之上,Flink 有以下机制: - 检查点机制和状态机制:用于实现容错、有状态的处理; - 水印机制:用于实现事件时钟; - 窗口和触发器:用于限制计算范围,并定义呈现结果的时间。 在同一个流处理引擎之上,Flink 还存在另一套机制,用于实现高效的批处理。 - 用于调度和恢复的回溯法:由 Microsoft Dryad 引入,现在几乎用于所有批处理器; - 用于散列和排序的特殊内存数据结构:可以在需要时,将一部分数据从内存溢出到硬盘上; - 优化器:尽可能地缩短生成结果的时间。 流与批处理机制 两套机制分别对应各自的API(DataStream API 和 DataSet API);在创建 Flink 作业时,并不能通过将两者混合在一起来同时 利用 Flink 的所有功能。 Flink支持两种关系型的API,Table APl和sQL。这两个API都是批处理和流处理统一的APl,这意味着在无边界的实时数据流和有边界的历史记录数据流上,关系型API会以相同的语义执行查询,并产生相同的结果。 - **Table API / SQL** 正在以流批统一的方式成为分析型用例的主要 API。 - **DataStream API** 是数据驱动应用程序和数据管道的主要API。 # 二、Flink的Time与Window ## 时间背景 在流处理器编程中,对于时间的处理是非常关键的。比如计数的例子,事件流数据(例如服务器日志数据、网页点击数据和交易数据)不断产生,我们需要用key将事件分组,并且每隔一段时间就针对每一个key对应的事件计数。这就是我们熟知的“大数据”应流处理中的时间分类 在数据流处理过程中,我们经常使用系统处理时间即: processing time作为某个事件的时间,而实际上系统时间processing time是我们强加给事件的时间,由于网络延迟等原因并不能较好的反应事件之间发生的先后顺序。 在实际场景中,每个事件的时间可以分为三种: - event time,即事件发生时的时间; - ingestion time,即事件到达流处理系统的时间; - processing time,即事件被系统处理的时间。 ## 三种时间示例 例如,一条日志进入Flink的时间为2019-11-1210:00:00.123,到达window的系统时间为2019-11-1210:00:01.234,日志的内容如下: 2019-11-0218:37:15.624 INFO Fail over to rm2 2019-11-0218:37:15.624是Event Time; 2019-11-1210:00:00.123是Ingestion Time; 2019-11-1210:00:01.234是Processing Time; ## 三种时间的区别 实际情况中事件真正发生的先后顺序与系统处理时间存在一定的差异,这些差异主要由网络延迟、处理时间的长短等造成。如图所示:  横坐标代表Event time,纵坐标代表processing time。理想情况下,eventtime和processing time构成的坐标应该形成一条倾斜角为45度的线。但实际应用过程中,processing time要落后与eventtime,造成事件到来的先后顺序不一致。 ## Flink支持的时间语义  Processing Time是指事件数据被Operator处理时所在机器的系统时间,它提供了最好的性能和最低的延迟。 Event Time是指在数据产生时该设备上对应的时间,这个时间在进入Flink之前已经存在于数据记录中了。 Ingestion Time指的是事件数据进入到Flink的时间。 ## Window概述 流式计算是一种被设计用于处理无限数据集的数据处理引擎,而无限数据集是指一种不断增长的本质上无限的数据集,而Window是一种切割无限数据为有限块进行处理的手段。Window是无限数据流处理的核心,它将一个无限的stream拆分成有限大小的"buckets"桶,我们可以在这些桶上做计算操作。 ## Window类型 Window根据应用类型可以分成两类: - CountWindow:数据驱动,按照指定的数据条数生成一个Window,与时间无关。 - TimeWindow:时间驱动,按照时间生成Window。 Apache Flink是一个天然支持无限流数据处理的分布式计算框架,在Flink中 Window可以将无限流切分成有限流。Flink中 Window可以是Time Window,也可以是Count Window。 # TimeWindow分类 TimeWindow可以根据窗口实现原理的不同分成三类:滚动窗口(Tumbling Window ) .滑动窗口( Sliding Window)和会话窗口( Session Window)。 ## 滚动窗口 将数据依据固定的窗口长度对数据进行切片。特点:时间对齐,窗口长度固定,没有重叠。 适用场景:适合做Bl统计等(做每个时间段的聚合计算)。 举一个例子,假设要对传感器输出的数值求和。一分钟滚动窗口收集最近一分钟的数值,并在一分钟结束时输出总和,如下图所示。  ## 滑动窗口 滑动窗口是固定窗口的更广义的一种形式,滑动窗口由固定的窗口长度和滑动间隔组成。特点∶时间对齐,窗口长度固定,有重叠。 适用场景:对最近一个时间段内的统计(求某接口最近5min的失败率来决定是否要报警)。 示例:一分钟滑动窗口计算最近一分钟的数值总和,但每半分钟滑动一次并输出结果,如下图所示。  ## 会话窗口 会话窗口由一系列事件组合一个指定时间长度的timeout间隙组成,类似于web应用的session,也就是一段时间没有接收到新数据就会生成新的窗口。特点:时间无对齐。  ## 代码定义 在Flink中,一分钟滚动窗口的定义如下: `stream.timeWindow(Time.minutes(1));` 在Flink中,每半分钟(即30秒)滑动一次的一分钟滑动窗口,如下所示: `stream.timeWindow(Time.minutes(1),Time.seconds(30));` # 三、Flink的Watermark ## 乱序问题 流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。  此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。 ## 乱序示例 例子:某App会记录用户的所有点击行为,并回传日志(在网络不好的情况下,先保存在本地,延后回传)。A用户在11:02对App进行操作,B用户在11:03对App进行操作,但是A用户的网络不太稳定,回传日志延迟了,导致我们在服务端先接受到B用户11:03的消息,然后再接受到A用户11:02的消息,消息乱序了。 # 水位线(Watermark) 对于无穷数据集,我们缺乏一种有效的方式来判断数据完整性,因此就有了Watermark,它是建立在事件时间上的一个概念,用来刻画数据流的完整性。如果按照处理时间来衡量事件,一切都是有序的、完美的,自然而然也就不需要Watermark了。换句话说事件时间带来了乱序的问题,而Watermark就是用来解决乱序问题。所谓的乱序,其实就是有事件延迟了,对于延迟的元素,我们不可能无限期的等下去,必须要有一种机制来保证一个特定的时间后,必须触发Window进行计算。这个特别的机制,就是Watermark,它告诉了算子延迟到达的消息不应该再被接收。 - Watermark是一种衡量Event Time进展的机制。 - Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。 - 数据流中的Watermark用于表示timestamp小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的。 - Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。 - watermark 用来让程序自己平衡延迟和结果正确性 # Watermark的原理 Flink怎么保证基于event-time的窗口在销毁的时候,已经处理完了所有的数据呢?  这就是watermark的功能所在。watermark会携带一个单调递增的时间戳t,Watermark(t)表示所有时间戳不大于t的数据都已经到来了,未来小于等于t的数据不会再来,因此可以放心地触发和销毁窗口了。  当Flink,接收到数据时,会按照一定的规则去生成Watermark,这条Watermark就等于当前所有到达数据中的maExertT me"-延N时长,也就定说,Watermark是基于数据携带的时间戳生成的,一旦Watermark比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于eventtime是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。 上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的Watermark 是 5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口是1s-5s,窗口2是6s~-10s,那么时间戳为7s的事件到达时的Matermarker.恰好触发窗口1,时间戳为 12s的事件到达时的Watermark恰好触发窗口2。 Watermark就是触发前一窗口的“关窗时间”,一旦触发关门那么以当前时刻为准在窗口范围内的所有所有数据都会收入窗中。只要没有达到水位那么不管现实中的时间推进了多久都不会触发关窗。 ## 延迟的数据 Watermark能够应对乱序的数据,但是真实世界中没法得到一个完美的 Watermark数值。要么没法获取到,要么耗费太大,因此实际工作中会近似 Watermark(t)之后,还有较小的概率接受到时间戳t之前的数据,在Flink中将这些数据定义为“late elements”,同样可以在Window中指定允许延迟的最大时间(默认为О),可以使用下面的代码进行设置:  ## 延迟数据处理机制 延迟事件是乱序事件的特例,和一般乱序事件不同的是它们的乱序程度超出了水位线( Watermark)的预计,导致窗口在它们到达之前已经关闭。 延迟事件出现时窗口已经关闭并产出了计算结果,对于此种情况处理的方法有3种: - 重新激活已经关闭的窗口并重新计算以修正结果。 - 将延迟事件收集起来另外处理。 - 将延迟事件视为错误消息并丢弃。 Flink默认的处理方式是第3种直接丢弃,其他两种方式分别使用Side Output和AllowedLateness。 ## Side Output机制 Side Output机制可以将延迟事件单独放入一个数据流分支,这会作为Window计算结果的副产品,以便用户获取并对其进行特殊处理。 side Output获取延迟数据: 设置allowedLateness之后,迟来的数据同样可以触发窗口,进行输出,利用Flink的sideoutput机制,可以获取到这些延迟的数据,使用方式如下:  ## Allowed Lateness机制 Allowed Lateness机制允许用户设置一个允许的最大延迟时长。Flink会在窗口关闭后一直保存窗口的状态直至超过允许延迟时长,这期间的延迟事件不会被丢弃,而是默认会触发窗口重新计算。因为保存窗口状态需要额外内存,并且如果窗口计算使用了ProcessWindowFunction APl还可能使得每个延迟事件触发一次窗口的全量计算,代价比较大,所以允许延迟时长不宜设得太长,延迟事件也不宜过多。 # 四、Flink的容错 ## Flink容错机制 为了保证程序的容错恢复以及程序启动时其状态恢复,Flink任务都会开启Checkpoint或者触发Savepoint进行状态保存。 - Checkpoint机制。这种机制保证了实时程序运行时,即使突然遇到异常也能够进行自我恢复。Checkpoint对于用户层面,是透明的,用户会感觉不到Checkpoint过程的存在。 - Savepoint机制。是在某个时间点程序状态全局镜像,以后程序在进行升级,或者修改并发度等情况,还能从保存的状态位继续启动恢复。Savepoint可以看做是Checkpoint在特定时期的一个状态快照。 ## Checkpoint Flink 如何保证exactly-once呢?它使用一种被称为“检查点( Checkpoint )”的特性,在出现故障时将系统重置回正确状态。Flink状态保存主要依靠Checkpoint机制,Checkpoint会定时制作分布式快照,对程序中的状态进行备份。 ## Checkpoint检查点机制 Flink中基于异步轻量级的分布式快照技术提供了Checkpoints容错机制,分布式快照可以将同一时间点Task/Operator的状态数据全局统一快照处理。Flink会在输入的数据集上间隔性地生成checkpoint barrier,通过棚栏( barrier)将间隔时间段内的数据划分到相应的checkpoint中。当应用出现异常时,Operator就能够从上一次快照中恢复所有算子之前的状态,从而保证数据的一致性。 对于状态占用空间比较小的应用,快照产生过程非常轻量,高频率创建且对Flink任务性能影响相对较小。Checkpoint过程中状态数据一般被保存在一个可配置的环境中,通常是在JobManager节点或HDFS上。 ## Checkpoint配置  默认情况下Flink不开启检查点,用户需要在程序中通过调用enableCheckpointing(n)方法配置和开启检查点,其中n为检查点执行的时间间隔,单位为毫秒。 **exactly-once和at-least-once语义选择** exactly-once:保证端到端数据一致性,数据要求高,不允许出现数据丢失和数据重复,Flink的性能也相对较弱; at-least-once:时延和吞吐量要求非常高但对数据的一致性要求不高的场景。 Flink默认使用exactly-once模式,可以通过setCheckpointingMode()方法来设定语义模式。 env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE) **Checkpoint超时时间** 指定每次Checkpoint执行过程中的上限时间范围,一旦Checkpoint执行时间超过该阈值,Flink将会中断Checkpoint过程,并按照超时处理。 该指标可以通过setCheckpointTimeout方法设定,默认10分钟。 env.getCheckpointConfig().setCheckpointingTimeout(60000) **检查点之间最小时间间隔** 设定两个Checkpoint之间的最小时间间隔,防止出现状态数据过大而导致Checkpoint执行时间过长,从而导致Checkpoint积压过多,最终Flink应用密集地触发Checkpoint操作,会占用大量计算资源而影响到整个应用的性能。 env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500) **最大并行执行的检查点数量** 设定能够同时执行的Checkpoint数量。在默认情况下只有一个检查点可以运行,根据用户指定的数量可以同时触发多个Checkpoint,从而提升Checkpoint整体的效率。 env.getCheckpointConfig().setMaxConcurrentCheckpoints(500) **外部检查点** 设定周期性的外部检查点,然后将状态数据持久化到外部系统中,使用这种方式不会在任务停止的过程中清理掉检查点数据,而是一直保存在外部系统介质中,也可以通过从外部检查点中对任务就行恢复。 env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION) # 作业如何恢复数据? Flink在Cancel时允许在外部介质保留Checkpoint;另一方面,Flink还有另外一个机制是SavePoint. Savepoints是检查点的一种特殊实现,底层其实是使用Checkpoints的机制。Savepoints是用户以手工命令的方式触发,并将结果持久化到指定的存储路径中,目的是帮助用户在升级和维护集群过程中保存系统中的状态数据,避免因为停机运维或者升级应用等正常终止应用的操作而导致系统无法恢复到原有的计算状态的情况,从而无法实现端到端的Exactly-Once语义保证。 ## Savepoint与Checkpoint  checkpoint的侧重点是“容错”,即Flink作业意外失败并重启之后,能够直接从早先打下的checkpoint恢复运行,且不影响作业逻辑的准确性。而savepoint的侧重点是“维护”,即Flink作业需要在人工干预下手动重启、升级、迁移或A/B测试时,先将状态整体写入可靠存储,维护完毕之后再从savepoint恢复现场。 savepoint是“通过checkpoint机制”创建的,所以savepoint本质上是特殊的checkpoint。 checkpoint面向Flink Runtime本身,由Flink的各个TaskManager定时触发快照并自动清理,一般不需要用户干预;savepoint面向用户,完全根据用户的需要触发与清理。 - 触发管理方式上,Checkpoint是由Flink自动触发并管理;Savepoint由用户手动触发并管理 - 主要用途上,Checkpoint在Task发生异常时快速恢复,例如网络抖动导致的超时异常;Savepoint有计划的进行备份,例如修改代码,调整并发 - 从特点上看,Checkpoint轻量,自动从故障中恢复,在作业停止后默认清除;Savepoint持久,以标准格式存储,允许代码或配置发生改变,手动触发从Savepoint的恢复。 ## 状态的存储方式-MemoryStateBackend 构造方式: MemoryStateBackend(int maxStateSize, boolean asynchronousSnapshots) 存储方式: - State: TaskManager内存;Checkpoint: JobManager内存。 容量限制: 单个state maxStateSize默认5M; maxStateSize=akka.framesize ,默认10 M。·总大小不超过JobManager的内存 推荐使用的场景:本地测试;几乎无状态的作业,比如ETL。 ## 状态的存储方式- FsStateBackend 构造方式: FsStateBackend(URI checkpointDataUri ,boolean asynchronousSnapshots) 存储方式: State: TaskManager内存; CHeckpoint:外部文件存储系统(本地或HDFS)。 容量限制: ·单TaskManager 上state总量不超过它的内存; ·总大小不超过配置的文件系统容量。 推荐使用的场景:常规使用状态的作业,例如分钟级别窗口聚合、Join;需要开启HA的作业;可以在生产场景使用。 ## 状态的存储方式- RocksDBStateBackend 构造方式: RocksDBStateBackend(URI checkpointDataUri ,boolean enableIncrementalCheckpointing) 存储方式: State: TaskManager上的KV数据库(实际使用内存+磁盘); CHeckpoint:外部文件存储系统(本地或HDFS)。 容量限制: 单TaskManager 上State总量不超过它的内存+磁盘; 单Key最大2G; 总大小不超过配置的文件系统容量。 推荐使用的场景:超大状态的作业,例如天级别窗口聚合;需要开启HA的作业;要求不高的作业;可以在生产场景使用。 # 总结 本章主要讲述了Flink的架构及技术原理,以及Flink程序的运行过程。重点在于Flink流处理与批处理的不同方式,从长远来看,DataStream API应该通过有界数据流完全包含DataSet APl。 -
 # 华为FusionInsight MRS实战 - 使用Flink SQL-Client连接hive ## 介绍 在之前的文章我们了解到如何使用华为Flink Server界面通过Flink SQL将数据写入hive。详细内容请参考如下连接。 [《华为FusionInsight MRS实战 - FlinkSQL从kafka写入hive》](https://bbs.huaweicloud.com/forum/thread-173950-1-1.html) 本文介绍如何使用Flink SQL-Client方式连接hive,并写入数据 ## 前提条件 首先需要了解以下三点内容。 1. 如何配置Flink客户端。 参考:[《华为FusionInsight MRS Flink客户端配置》](https://bbs.huaweicloud.com/forum/thread-175741-1-1.html) 2. 如何配置Flink SQL Client。参考:[《华为FusionInsight MRS Flink SQL-Client客户端配置》](https://bbs.huaweicloud.com/forum/thread-176103-1-1.html) 3. 如何使用Flink SQL Client。参考:[《华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=161992) ## 操作步骤 - 因为将写入hive表,需要开启flink的checkpoint功能,需要手动在客户端配置文件`/opt/92_client/hadoopclient/Flink/flink/conf/flink-conf.yaml`添加如下内容 ``` execution.checkpointing.interval: 15000 state.backend: filesystem state.checkpoints.dir: hdfs:///flink/checkpoints ```  - 使用命令启动flink session `./bin/yarn-session.sh -t conf/`  - 使用命令登录flink sql client客户端 `./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml`  - 创建hive目的表 ``` use catalog myhive; SET table.sql-dialect=hive; CREATE TABLE IF NOT EXISTS hive_dialect_tbl ( `id` int , `name` string , `age` int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; ```  - 创建数据源表 ``` SET table.sql-dialect=default; CREATE TABLE datagen ( `id` int , `name` string , `age` int ) WITH ( 'connector' = 'datagen', 'rows-per-second'='1' ); ``` 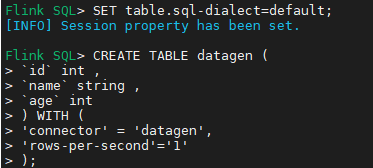 - 在sql client创建数据写入 `INSERT INTO hive_dialect_tbl SELECT * FROM datagen;` - sql client端查看结果 ``` set execution.result-mode=tableau; select * from hive_dialect_tbl; ``` 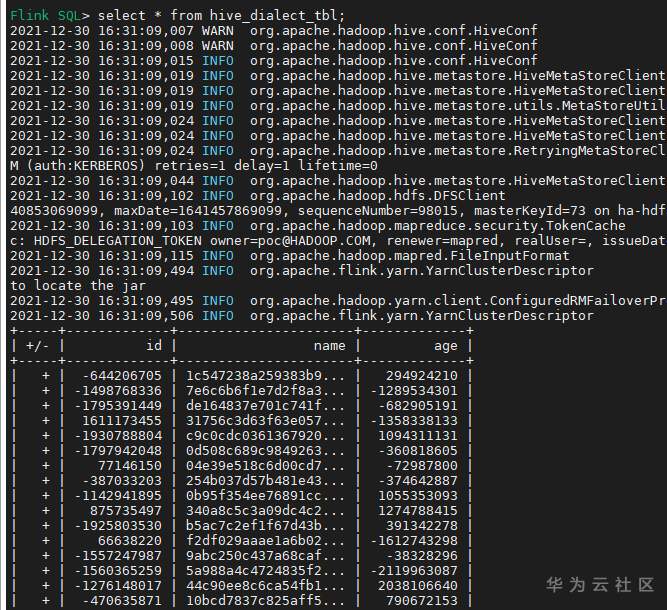 - hive端查看数据 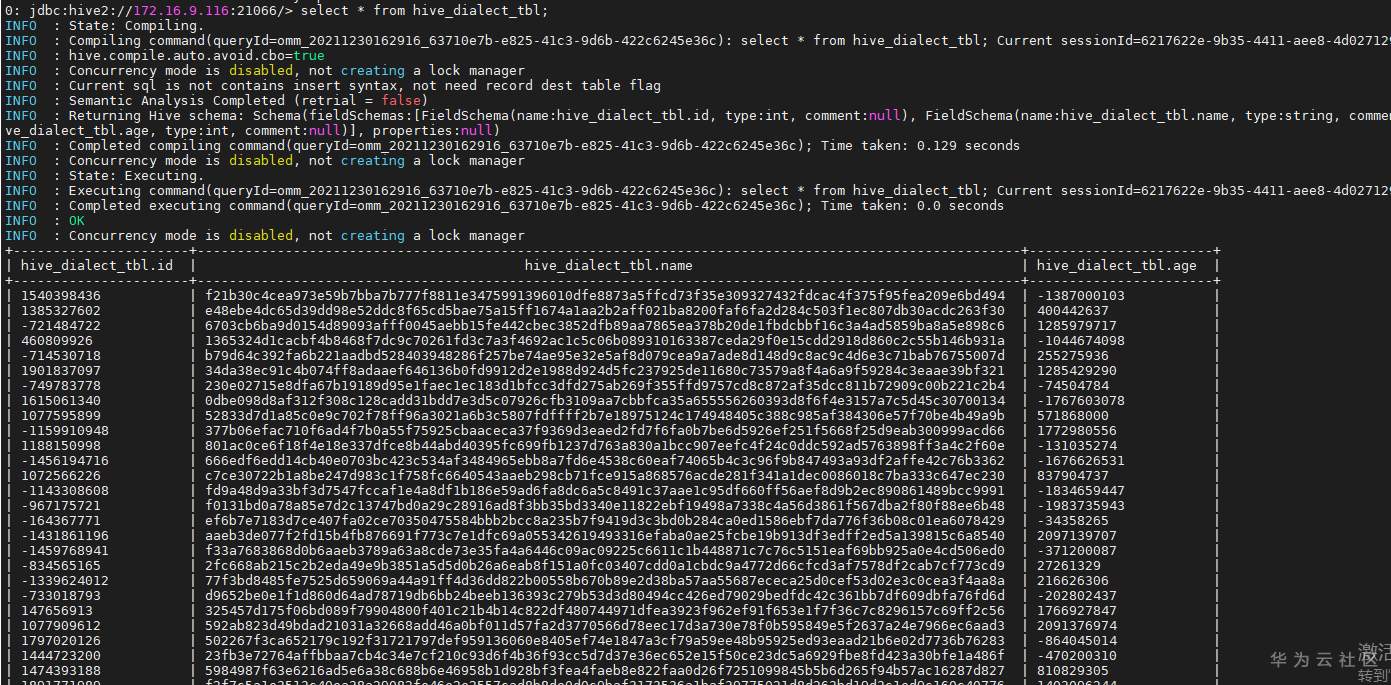
# 华为FusionInsight MRS实战 - 使用Flink SQL-Client连接hive ## 介绍 在之前的文章我们了解到如何使用华为Flink Server界面通过Flink SQL将数据写入hive。详细内容请参考如下连接。 [《华为FusionInsight MRS实战 - FlinkSQL从kafka写入hive》](https://bbs.huaweicloud.com/forum/thread-173950-1-1.html) 本文介绍如何使用Flink SQL-Client方式连接hive,并写入数据 ## 前提条件 首先需要了解以下三点内容。 1. 如何配置Flink客户端。 参考:[《华为FusionInsight MRS Flink客户端配置》](https://bbs.huaweicloud.com/forum/thread-175741-1-1.html) 2. 如何配置Flink SQL Client。参考:[《华为FusionInsight MRS Flink SQL-Client客户端配置》](https://bbs.huaweicloud.com/forum/thread-176103-1-1.html) 3. 如何使用Flink SQL Client。参考:[《华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=161992) ## 操作步骤 - 因为将写入hive表,需要开启flink的checkpoint功能,需要手动在客户端配置文件`/opt/92_client/hadoopclient/Flink/flink/conf/flink-conf.yaml`添加如下内容 ``` execution.checkpointing.interval: 15000 state.backend: filesystem state.checkpoints.dir: hdfs:///flink/checkpoints ```  - 使用命令启动flink session `./bin/yarn-session.sh -t conf/`  - 使用命令登录flink sql client客户端 `./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml`  - 创建hive目的表 ``` use catalog myhive; SET table.sql-dialect=hive; CREATE TABLE IF NOT EXISTS hive_dialect_tbl ( `id` int , `name` string , `age` int ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; ```  - 创建数据源表 ``` SET table.sql-dialect=default; CREATE TABLE datagen ( `id` int , `name` string , `age` int ) WITH ( 'connector' = 'datagen', 'rows-per-second'='1' ); ```  - 在sql client创建数据写入 `INSERT INTO hive_dialect_tbl SELECT * FROM datagen;` - sql client端查看结果 ``` set execution.result-mode=tableau; select * from hive_dialect_tbl; ```  - hive端查看数据  -

-
# 华为FusionInsight MRS实战 - Flink CDC特性学习 ## Flink cdc介绍 Flink CDC连接器是Apache Flink新版本特性,是数据源连接器,使用更改数据捕获(CDC)从不同数据库接收更改。Flink CDC连接器集成了Debezium作为引擎来捕获数据更改。所以它可以充分利用Debezium的能力。  华为FusionInsight MRS 812版本,Flink版本1.12为例,介绍Flink CDC对应能力 Flink CDC与Flink版本对应关系 |Flink CDC Connector Version|Flink Version| | ---- | ---- | |1.0.0|1.11.*| |1.1.0|1.11.*| |1.2.0|1.12.*| |1.3.0|1.12.*| |1.4.0|1.13.*| |2.0.*|1.13.*| |2.1.*|1.13.*| 选择使用flink cdc版本1.2.0 Flink CDC支持数据源 |Database|Version| | ---- | ---- | |MySQL|Database: 5.7, 8.0.xJDBC Driver: 8.0.16| |PostgreSQL|Database: 9.6, 10, 11, 12JDBC Driver: 42.2.12 | 可支持的格式 |Format |Supported Connector |Flink Version| | ---- | ---- | ---- | |Changelog Json|Apache Kafka|1.11+| ## Flink cdc 方案优势 同之前的实时同步方案相比,使用flink cdc能够减少cdl工具和kafka的维护成本,链路更短,延迟更低,flink提供了exactly once语义,可以从指定position读取,并且去掉了kafka,减少了消息的存储成本。 ## 场景说明  1. 使用Flink cdc的能力直接从数据源MySQL中获取数据内容并使用Flink SQL处理发送至数据下游 2. 使用Kafka进行数据接收,使用Changelog格式 ## 样例数据简介 生产库MySQL原始数据: 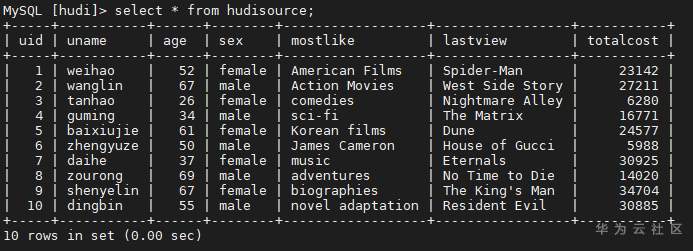 ## 前提条件 该特性目前只支持在Flink Client客户端使用,所以首先需要了解以下三点内容。 1. 如何配置Flink客户端。 参考:[《华为FusionInsight MRS Flink客户端配置》](https://bbs.huaweicloud.com/forum/thread-175741-1-1.html) 2. 如何配置Flink SQL Client。参考:[《华为FusionInsight MRS Flink SQL-Client客户端配置》](https://bbs.huaweicloud.com/forum/thread-176103-1-1.html) 3. 如何使用Flink SQL Client。参考:[《华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=161992) ## 操作步骤 - 准备驱动包 https://github.com/ververica/flink-cdc-connectors/releases 根据上述对应版本,选择flink cdc版本为1.2.0  下载对应的jar包并放置到flink客户端lib目录下,比如 /opt/92_client/hadoopclient/Flink/flink/lib  - 使用命令启动flink session `./bin/yarn-session.sh -t conf/`  - 使用命令登录flink sql client客户端 `./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml`  - 在sql client创建数据源表 ``` CREATE TABLE MYSQL_MATERIAL_INFO( uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'mysql-cdc', 'hostname' = '172.16.2.118', 'port' = '3306', 'username' = 'root', 'password' = 'Huawei@123', 'database-name' = 'hudi', 'table-name' = 'hudisource' ); ``` 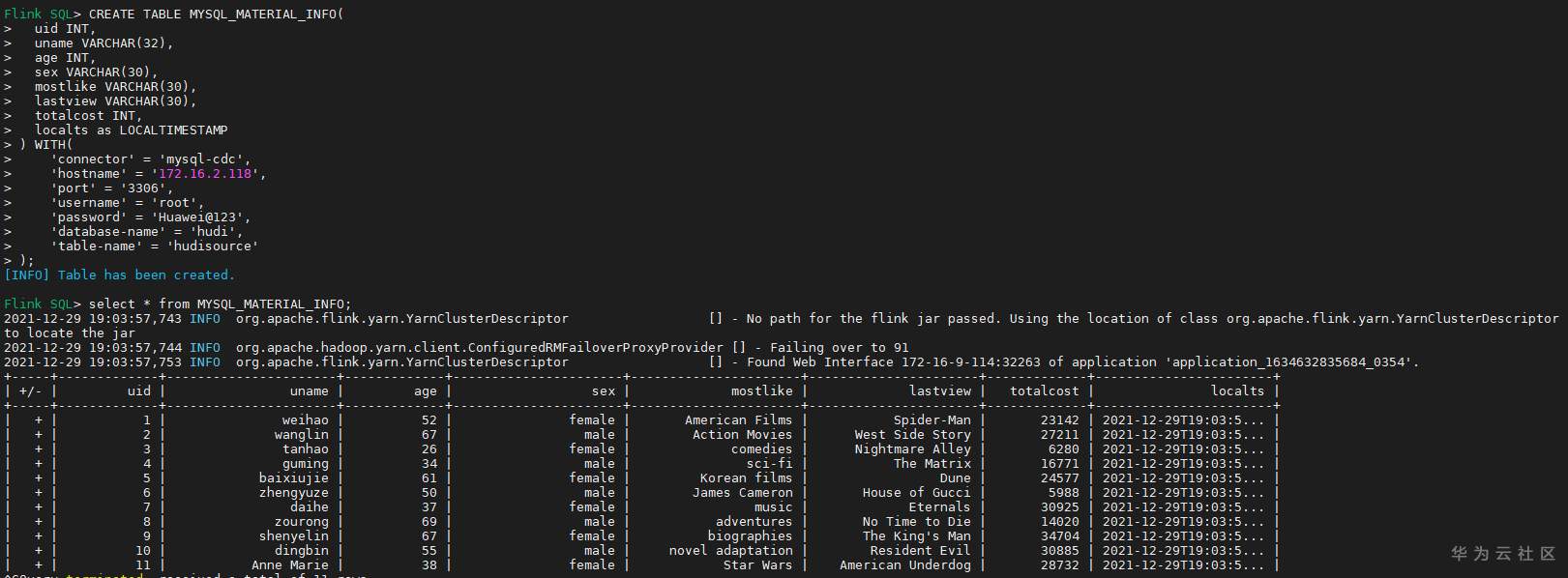 - 在sql client创建kafka目的表 ``` CREATE TABLE huditableout( uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'changelog_json_format_test', 'properties.bootstrap.servers' = '172.16.9.116:21005', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'changelog-json' ); ``` 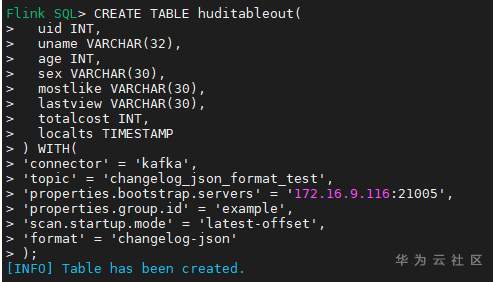 - 在sql client创建数据写入 ``` insert into huditableout select uid, uname, age, sex, mostlike, lastview, totalcost, localts from MYSQL_MATERIAL_INFO; ``` 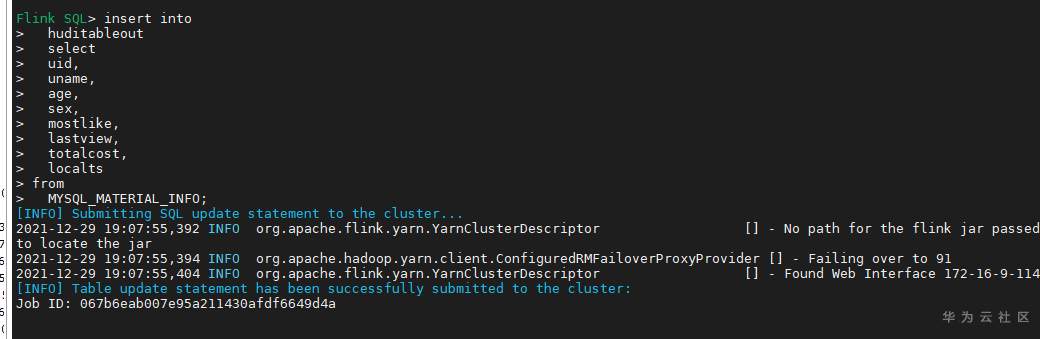 - 在mysql源库中测试数据的增删改查,然后使用kafka消费查看changelog-json格式的结果 
-
1. 根据产品文档安装Flink客户端; 2. 将sql-client-defaults.yaml(见附件)放入/opt/client/Flink/flink/conf中 3. 将jaas.conf 放入/opt/client/Flink/flink/conf中 ``` Client { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=false useTicketCache=true debug=false; }; ``` 4. 添加sql-client.sh中添加在JVM_ARGS参数: JVM_ARGS="-Djava.security.auth.login.config=/opt/client/Flink/flink/conf/jaas.conf $JVM_ARGS" 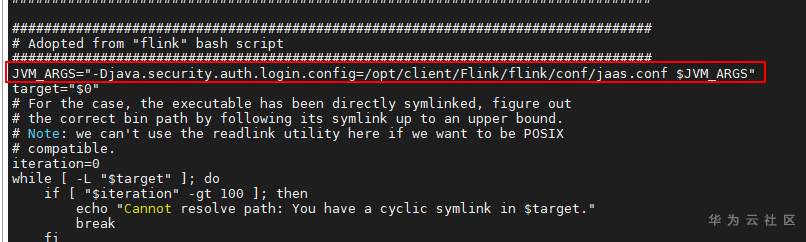
-
# 华为FusionInsight MRS Flink客户端配置 ## 场景说明 使用华为FusionInsight MRS的Flink组件进行开发工作时,需要了解如何配置Flink客户端。本文将介绍如何进行该配置 ## 前提条件 已安装FusionInsight MRS客户端,比如在/opt/hadoopclient路径 ## 操作步骤 - 下载用户认证文件并上传至客户端/opt/hadoopclient/Flink/flink/conf  并配置/opt/hadoopclient/Flink/flink/conf/flink-conf.yaml文件中的认证内容跟上述下载信息匹配  注意:配置的值和冒号之间要有一个空格 - 生成cookie密钥 先加载环境变量: source /opt/hadoopclient/bigdata_env 完成认证: kinit poc 登录客户端路径: /opt/hadoopclient/Flink/flink/bin 执行: sh generate_keystore.sh 密码可填:123456  上述该步骤会在/opt/hadoopclient/Flink/flink/conf路径中生成配置文件flink.keystore以及flink.truststore - 配置/opt/hadoopclient/Flink/flink/conf/flink-conf.yaml文件 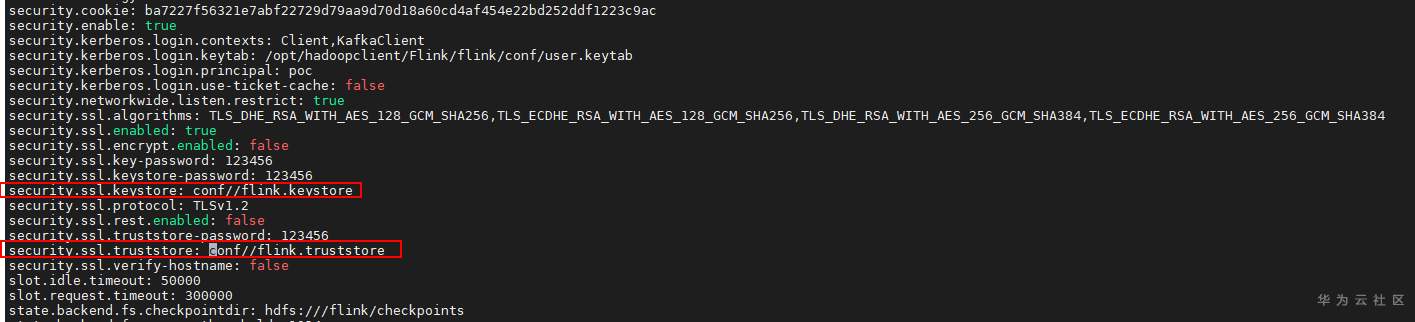 注意:配置flink.keystore以及flink.truststore文件的路径要是相对路径,并且配置的值和冒号之间要有一个空格 - 使用如下命令启动flink session ``` cd /opt/hadoopclient/Flink/flink ./bin/yarn-session.sh -t conf/ ```  
-
 尊敬的微认证客户:您好!为帮助您深入了解华为云产品,探索新的技术场景,我们非常高兴地与您分享一个好消息:由华为资深研发团队精心打磨,潜心研发的新微认证《使用DLI Flink SQL进行电商实时业务数据分析》将于2021年12月31日正式上线!届时请进入华为云培训中心-微认证-大数据 查看产品详情,体验使用,我们非常期待您的宝贵建议。以下为该微认证详情,您可提前了解:产品名称: 《使用DLI Flink SQL进行电商实时业务数据分析开发》适合人群: 向大数据转型的运维软件开发人员和对大数据应用开发感兴趣的社会大众;培训方案: 基于电商实时业务应用场景,完成Flink对实时数据采集及计算的应用开发实践;技术能力: 实时数据采集及计算引擎Flink的应用开发流程;认证价值: 实时数据采集及计算引擎Flink的应用开发,通过实践提升大数据应用开发能力。届时我们还将开展相关微认证上新活动,详情请关注华为云培训中心论坛-热门活动 相关通知。发布日期:2021年12月28日
尊敬的微认证客户:您好!为帮助您深入了解华为云产品,探索新的技术场景,我们非常高兴地与您分享一个好消息:由华为资深研发团队精心打磨,潜心研发的新微认证《使用DLI Flink SQL进行电商实时业务数据分析》将于2021年12月31日正式上线!届时请进入华为云培训中心-微认证-大数据 查看产品详情,体验使用,我们非常期待您的宝贵建议。以下为该微认证详情,您可提前了解:产品名称: 《使用DLI Flink SQL进行电商实时业务数据分析开发》适合人群: 向大数据转型的运维软件开发人员和对大数据应用开发感兴趣的社会大众;培训方案: 基于电商实时业务应用场景,完成Flink对实时数据采集及计算的应用开发实践;技术能力: 实时数据采集及计算引擎Flink的应用开发流程;认证价值: 实时数据采集及计算引擎Flink的应用开发,通过实践提升大数据应用开发能力。届时我们还将开展相关微认证上新活动,详情请关注华为云培训中心论坛-热门活动 相关通知。发布日期:2021年12月28日 -
 前言随着云数仓技术的不断成熟,数据湖俨然已成为当下最热门的技术之一,而 Apache Hudi 是当下最具竞争力的数据湖格式之一:拥有最活跃的开源社区之一,周活跃 PR 一直维持在 50+ 水平;拥有最活跃的国内用户群之一,目前的 Apache Hudi 钉钉群用户已超过 2200+,国内各大厂商都已经布局 Apache Hudi 生态。Apache Hudi 的活跃度得益于其出色的 file format 设计和丰富的事物语义支持:类 LSM 的 file format 布局很好的适配了近实时更新场景,解决了超大数据集更新的痛点;Hudi 的事物层语义在目前的湖存储中是极其成熟和丰富的,基本所有的数据治理都可以自动化完成:compaction、rollback、cleaning、clustering。Flink On HudiApache Hudi 的 table format 对流计算友好的特性使得 Flink On Hudi 成为 Apache Hudi 项目最值得探索和挖掘的方向之一,Flink 不仅为 Hudi 解锁了超大数据流的实时更新能力、更添加了流式消费和计算的能力,让端到端近实时 ETL 得以在低成本的文件存储上轻松实现。Flink On Hudi 项目在 2020 年 11 月立项,至今已迭代了三个版本,从第一个版本开始人气和活跃度就一直高涨。5 月份组建的 Apache Hudi 钉钉群截止目前半年的时间,已经有超过 2200+ 用户,并且活跃度一直排在 Flink 用户群的前列。Flink On Hudi 已成为部署 Apache Hudi 项目的首选方案,国内主要云厂商:阿里云、华为云、腾讯云,国外的 AWS 都已集成 Flink On Hudi;国内的大型互联网公司:头条、快手、B站 以及传统企业:顺丰、海康等均有 Flink On Hudi 的生产实践,具钉钉群的跟踪回访等不完全统计,至少超过 50+ 国内公司在生产上使用 Flink On Hudi,Uber 公司更将 Flink On Hudi 作为 2022 年的重点方向在推进 !Flink On Hudi 的开发者生态也非常活跃,目前国内有阿里云、华为云、头条、B站的同学持续贡献,Uber 公司和 AWS 更专门投入人力来对接 Flink On Hudi。版本 Highlights0.10.0 版本经过社区用户的千锤百炼,贡献了多项重要的 fix,更有核心读写能力的大幅增强,解锁了多个新场景,Flink On Hudi 侧的更新重点梳理如下:Bug 修复修复对象存储上极端 case 流读数据丢失的问题 [HUDI-2548];修复全量+增量同步偶发的数据重复 [HUDI-2686];修复 changelog 模式下无法正确处理 DELETE 消息 [HUDI-2798];修复在线压缩的内存泄漏问题 [HUDI-2715]。新特性支持增量读取;支持 batch 更新;新增 Append 模式写入,同时支持小文件合并;支持 metadata table。功能增强写入性能大幅提升:优化写入内存、优化了小文件策略(更加均衡,无碎片文件)、优化了 write task 和 coordinator 的交互;流读语义增强:新增参数 earliest,提升从最早消费性能、支持参数跳过压缩读取,解决读取重复问题;在线压缩策略增强:新增 eager failover + rollback,压缩顺序改为从最早开始;优化事件顺序语义:支持处理序,支持事件序自动推导。下面挑一些重点内容为大家详细介绍:小文件优化Flink On Hudi 写入流程大致分为以下几个组件:row data to hoodie:负责将 table 的数据结构转成 HoodieRecord;bucket assigner:负责新的文件 bucket (file group) 分配;write task:负责将数据写入文件存储;coordinator:负责写 trasaction 的发起和 commit;cleaner:负责数据清理。其中的 bucket assigner 负责了文件 file group 的分配,也是小文件分配策略的核心组件。0.10.0 版本的每个 bucket assign task 持有一个 bucket assigner,每个 bucket assigner 独立管理自己的一组 file group 分组:在写入 INSERT 数据的时候,bucket assigner 会扫描文件视图,查看当前管理的 file group 中哪些属于小文件范畴,如果 file group 被判定为小文件,则会继续追加写入。比如上图中 task-1 会继续往 FG-1、FG-2 中追加 80MB 和 60MB 的数据。为了避免过度的写放大,当可写入的 buffer 过小时会忽略,比如上图中 FG-3、FG-4、FG-5 虽然是小文件,但是不会往文件中追加写。task-2 会新开一个 file group 写入。全局文件视图0.10.0 版本将原本 write task 端的文件视图统一挪到 JobManager,JobManager 启动之后会使用 Javaline 本地启动一个 web server,提供全局文件视图的访问代理。Write task 通过发送 http 请求和 web server 交互,拿到当前写入的 file group 视图。Web server 避免了重复的文件系统视图加载,极大的节省了内存开销。流读能力增强0.10.0 版本新增了从最早消费数据的参数,通过指定 read.start-commit 为 earliest 即可流读全量 + 增量数据,值得一提的是,当从 earliest 开始消费时,第一次的 file split 抓取会走直接扫描文件视图的方式,在开启 metadata table 功能后,文件的扫描效率会大幅度提升;之后的增量读取部分会扫描增量的 metadata,以便快速轻量地获取增量的文件讯息。新增处理顺序Apache Hudi 的消息合并大体分为两块:增量数据内部合并、历史数据和增量数据合并。消息之间合并通过 write.precombine.field 字段来判断版本新旧,如下图中标注蓝色方块的消息为合并后被选中的消息。0.10.0 版本可以不指定 write.precombine.field 字段,此时使用处理顺序:即后来的消息比较新,对应上图紫色部分被选中的消息。Metadata TableMetadata table 是 0.7.0 Hudi 引入的功能,目的是在查询端减少 DFS 的访问,类似于文件 listings 和 partitions 信息直接通过 metadata table 查询获取。Metadata 在 0.10.0 版本得到大幅加强,Flink 端也支持了 该功能。新版的 metadata table 为同步更新模型,当完成一次成功的数据写入之后,coordinator 会先同步抽取文件列表、partiiton 列表等信息写入 metadata table 然后再写 event log 到 timeline (即 metadata 文件)。Metadata table 的基本文件格式为 avro log,avro log 中的文件编码区别于正常的 MOR data log 文件,是由高效的 HFile data block 构成,这样做的好处是自持更高效率的 kv 查找。同时 metadata table 的 avro log 支持直接压缩成 HFile 文件,进一步优化查询效率。总结和展望在短短的半年时间,Flink On Hudi 至今已积攒了数量庞大的用户群体。积极的用户反馈和丰富的用户场景不断打磨 Flink On Hudi 的易用性和成熟度,使得 Flink On Hudi 项目以非常高效的形式快速迭代。通过和头部公司如头条、B 站等共建的形式,Flink On Hudi 形成了非常良性的开发者用户群。Flink On Hudi 是 Apache Hudi 社区接下来两个大版本主要的发力方向,在未来规划中,主要有三点:完善端到端 streaming ETL 场景 支持原生的 change log、支持维表查询、支持更轻量的去重场景;Streaming 查询优化 record-level 索引,二级索引,独立的文件索引;Batch 查询优化 z-ordering、data skipping。文章转载自Apache Flink公众号 https://mp.weixin.qq.com/s/q_yqa4jTmEHHoItp1V5Vgg免责声明:转载文章版权归原作者所有。如涉及作品内容、版权等问题,请及时联系文章编辑!
前言随着云数仓技术的不断成熟,数据湖俨然已成为当下最热门的技术之一,而 Apache Hudi 是当下最具竞争力的数据湖格式之一:拥有最活跃的开源社区之一,周活跃 PR 一直维持在 50+ 水平;拥有最活跃的国内用户群之一,目前的 Apache Hudi 钉钉群用户已超过 2200+,国内各大厂商都已经布局 Apache Hudi 生态。Apache Hudi 的活跃度得益于其出色的 file format 设计和丰富的事物语义支持:类 LSM 的 file format 布局很好的适配了近实时更新场景,解决了超大数据集更新的痛点;Hudi 的事物层语义在目前的湖存储中是极其成熟和丰富的,基本所有的数据治理都可以自动化完成:compaction、rollback、cleaning、clustering。Flink On HudiApache Hudi 的 table format 对流计算友好的特性使得 Flink On Hudi 成为 Apache Hudi 项目最值得探索和挖掘的方向之一,Flink 不仅为 Hudi 解锁了超大数据流的实时更新能力、更添加了流式消费和计算的能力,让端到端近实时 ETL 得以在低成本的文件存储上轻松实现。Flink On Hudi 项目在 2020 年 11 月立项,至今已迭代了三个版本,从第一个版本开始人气和活跃度就一直高涨。5 月份组建的 Apache Hudi 钉钉群截止目前半年的时间,已经有超过 2200+ 用户,并且活跃度一直排在 Flink 用户群的前列。Flink On Hudi 已成为部署 Apache Hudi 项目的首选方案,国内主要云厂商:阿里云、华为云、腾讯云,国外的 AWS 都已集成 Flink On Hudi;国内的大型互联网公司:头条、快手、B站 以及传统企业:顺丰、海康等均有 Flink On Hudi 的生产实践,具钉钉群的跟踪回访等不完全统计,至少超过 50+ 国内公司在生产上使用 Flink On Hudi,Uber 公司更将 Flink On Hudi 作为 2022 年的重点方向在推进 !Flink On Hudi 的开发者生态也非常活跃,目前国内有阿里云、华为云、头条、B站的同学持续贡献,Uber 公司和 AWS 更专门投入人力来对接 Flink On Hudi。版本 Highlights0.10.0 版本经过社区用户的千锤百炼,贡献了多项重要的 fix,更有核心读写能力的大幅增强,解锁了多个新场景,Flink On Hudi 侧的更新重点梳理如下:Bug 修复修复对象存储上极端 case 流读数据丢失的问题 [HUDI-2548];修复全量+增量同步偶发的数据重复 [HUDI-2686];修复 changelog 模式下无法正确处理 DELETE 消息 [HUDI-2798];修复在线压缩的内存泄漏问题 [HUDI-2715]。新特性支持增量读取;支持 batch 更新;新增 Append 模式写入,同时支持小文件合并;支持 metadata table。功能增强写入性能大幅提升:优化写入内存、优化了小文件策略(更加均衡,无碎片文件)、优化了 write task 和 coordinator 的交互;流读语义增强:新增参数 earliest,提升从最早消费性能、支持参数跳过压缩读取,解决读取重复问题;在线压缩策略增强:新增 eager failover + rollback,压缩顺序改为从最早开始;优化事件顺序语义:支持处理序,支持事件序自动推导。下面挑一些重点内容为大家详细介绍:小文件优化Flink On Hudi 写入流程大致分为以下几个组件:row data to hoodie:负责将 table 的数据结构转成 HoodieRecord;bucket assigner:负责新的文件 bucket (file group) 分配;write task:负责将数据写入文件存储;coordinator:负责写 trasaction 的发起和 commit;cleaner:负责数据清理。其中的 bucket assigner 负责了文件 file group 的分配,也是小文件分配策略的核心组件。0.10.0 版本的每个 bucket assign task 持有一个 bucket assigner,每个 bucket assigner 独立管理自己的一组 file group 分组:在写入 INSERT 数据的时候,bucket assigner 会扫描文件视图,查看当前管理的 file group 中哪些属于小文件范畴,如果 file group 被判定为小文件,则会继续追加写入。比如上图中 task-1 会继续往 FG-1、FG-2 中追加 80MB 和 60MB 的数据。为了避免过度的写放大,当可写入的 buffer 过小时会忽略,比如上图中 FG-3、FG-4、FG-5 虽然是小文件,但是不会往文件中追加写。task-2 会新开一个 file group 写入。全局文件视图0.10.0 版本将原本 write task 端的文件视图统一挪到 JobManager,JobManager 启动之后会使用 Javaline 本地启动一个 web server,提供全局文件视图的访问代理。Write task 通过发送 http 请求和 web server 交互,拿到当前写入的 file group 视图。Web server 避免了重复的文件系统视图加载,极大的节省了内存开销。流读能力增强0.10.0 版本新增了从最早消费数据的参数,通过指定 read.start-commit 为 earliest 即可流读全量 + 增量数据,值得一提的是,当从 earliest 开始消费时,第一次的 file split 抓取会走直接扫描文件视图的方式,在开启 metadata table 功能后,文件的扫描效率会大幅度提升;之后的增量读取部分会扫描增量的 metadata,以便快速轻量地获取增量的文件讯息。新增处理顺序Apache Hudi 的消息合并大体分为两块:增量数据内部合并、历史数据和增量数据合并。消息之间合并通过 write.precombine.field 字段来判断版本新旧,如下图中标注蓝色方块的消息为合并后被选中的消息。0.10.0 版本可以不指定 write.precombine.field 字段,此时使用处理顺序:即后来的消息比较新,对应上图紫色部分被选中的消息。Metadata TableMetadata table 是 0.7.0 Hudi 引入的功能,目的是在查询端减少 DFS 的访问,类似于文件 listings 和 partitions 信息直接通过 metadata table 查询获取。Metadata 在 0.10.0 版本得到大幅加强,Flink 端也支持了 该功能。新版的 metadata table 为同步更新模型,当完成一次成功的数据写入之后,coordinator 会先同步抽取文件列表、partiiton 列表等信息写入 metadata table 然后再写 event log 到 timeline (即 metadata 文件)。Metadata table 的基本文件格式为 avro log,avro log 中的文件编码区别于正常的 MOR data log 文件,是由高效的 HFile data block 构成,这样做的好处是自持更高效率的 kv 查找。同时 metadata table 的 avro log 支持直接压缩成 HFile 文件,进一步优化查询效率。总结和展望在短短的半年时间,Flink On Hudi 至今已积攒了数量庞大的用户群体。积极的用户反馈和丰富的用户场景不断打磨 Flink On Hudi 的易用性和成熟度,使得 Flink On Hudi 项目以非常高效的形式快速迭代。通过和头部公司如头条、B 站等共建的形式,Flink On Hudi 形成了非常良性的开发者用户群。Flink On Hudi 是 Apache Hudi 社区接下来两个大版本主要的发力方向,在未来规划中,主要有三点:完善端到端 streaming ETL 场景 支持原生的 change log、支持维表查询、支持更轻量的去重场景;Streaming 查询优化 record-level 索引,二级索引,独立的文件索引;Batch 查询优化 z-ordering、data skipping。文章转载自Apache Flink公众号 https://mp.weixin.qq.com/s/q_yqa4jTmEHHoItp1V5Vgg免责声明:转载文章版权归原作者所有。如涉及作品内容、版权等问题,请及时联系文章编辑! -
【功能模块】MRS 8.0.2混合云版本 Flink组件【操作步骤&问题现象】1、登录MRS客户端,kinit登录2、执行命令yarn-session.sh -t conf/ -d提示flink任务运行失败,怀疑是MRS环境问题。【截图信息】
-
【功能模块】flink执行yarn-session.sh -t conf/ -d报错【操作步骤&问题现象】1、mrs 3.0.2 线下环境【问题现象】执行 yarn-session.sh -t conf/ -d报 Error while running the Flink session. | org.apache.flink.yarn.cli.FlinkYarnSessionCli (AbstractCustomCommandLine.java:118) org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session cluster【操作步骤】source bigdata_env kinit 用户 密码 在flink目录下执行:yarn-session.sh -t conf/ -d【预期结果】能够成功提交任务,执行通过【实际结果】客户端报: Error while running the Flink session. | org.apache.flink.yarn.cli.FlinkYarnSessionCli (AbstractCustomCommandLine.java:118) org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session cluster 前台页面查看logs日志显示:Exception in thread "main" java.lang.IllegalArgumentException: Can't get Kerberos realm at org.apache.hadoop.security.HadoopKerberosName.setConfiguration(HadoopKerberosName.java:65)【原因定位】提交任务阻塞,最后导致超时,flink on yarn启动时检查虚拟内存,虚拟内存不足导致的 尝试解决的办法:1.关掉ssl 2、注释掉dns、3.将flink访问Zookeeper目录【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
-
摘要:本⽂主要内容为:为什么要做流批一体?当前行业已有的解决方案和现状,优势和劣势探索生产实践场景的经验Shuflle Service 在 Spark 和 Flink 上的对比,以及 Flink 社区后面可以考虑做的工作总结一、为什么要做流批一体做流批一体到底有哪些益处,尤其是在 BI/AI/ETL 的场景下。整体来看,如果能帮助用户做到流批一体,会有以上 4 个比较明显的益处:可以避免代码重复,复用代码核心处理逻辑代码逻辑能完全一致是最好的,但这会有一定的难度。但整体来讲,现在的商业逻辑越来越长,越来越复杂,要求也很多,如果我们使用不同的框架,不同的引擎,用户每次都要重新写一遍逻辑,压力很大并且难以维护。所以整体来讲,尽量避免代码重复,帮助用户复用代码逻辑,就显得尤为重要。流批一体有两个方向这两个方向要考虑的问题很不一样,目前 Flink 做 Streaming、Spark 做 Batch 等等一些框架在批处理或流处理上都比较成熟,都已经产生了很多的单方面用户。当我们想帮助用户移到另外一个方向上时,比如一些商业需求,通常会分成两类,是先从流处理开始到批处理,还是从批处理开始到流处理。之后介绍的两个生产实践场景案例,正好对应这两个方向。减少维护工作量避免维护多套系统,系统之间的差异可能非常大,框架和引擎都不一样,会带来比较多的问题。如果公司内部有多条 pipeline ,一个实时一个离线,会造成数据不一致性,因此会在数据验证、数据准确性查询、数据存储等方面做很多工作,尽量去维护数据的一致性。学习更多框架和引擎很多,商业逻辑既要跑实时,也要跑离线,所以,支持用户时需要学习很多东西。二、当前行业现状Flink 和 Spark 都是同时支持流处理和批处理的引擎。我们一致认为 Flink 的流处理做的比较好,那么它的批处理能做到多好?同时,Spark 的批处理做的比较好,那么它的流处理能不能足够帮助用户解决现有的需求?现在有各种各样的引擎框架,能不能在它们之上有一个统一的框架,类似于联邦处理或者是一些简单的 physical API,比如 Beam API 或者是自定义接口。Beam 方面需要考虑的问题,是它在批处理和流处理上的优化能做到多好?Beam 目前还是偏物理执行,之后的计划是我们需要考究的。LinkedIn,包括其他公司,会考虑做一些自定义接口的解决方案,考虑有一个共通的 SQL 层,通用的 SQL 或 API 层,底下跑不同的框架引擎。这里需要考虑的问题是,像 Spark 、Flink 都是比较成熟的框架了,已经拥有大量的用户群体。当我们提出一个新的 API ,一个新的解决方案,用户的接受度如何? 在公司内部应该如何维护一套新的解决方案?三、生产案例场景后面内容主要聚焦在 Flink 做 batch 的效果,Flink 和 Spark 的简单对比,以及 LinkedIn 内部的一些解决方案。分享两个生产上的实例场景,一个是在机器学习特征工程生成时如何做流批一体,另一个是复杂的 ETL 数据流中如何做流批一体。3.1 案例 A - 机器学习特征工程第一类方向,流处理 -> 批处理,归类为流批一体。 案例 A 的主体逻辑是在机器学习中做特征生成时,如何从流处理到批处理的流批一体。核心的业务逻辑就是特征转换,转化的过程和逻辑比较复杂,用它做一些标准化。比如在 LinkedIn 的页面上输入的一些会员信息背景等,需要将这些信息提取出来标准化掉,才能进行一些推荐,帮你找一些工作等等。当会员的身份信息有更新时,会有过滤、预处理的逻辑、包括读取 Kafka 的过程,做特征转换的过程中,可能会有一些小表查询。这个逻辑是非常直接的,没有复杂的 join 操作及其他的数据处理过程。以前它的 pipeline 是实时的,需要定期从离线 pipeline 中读取补充信息来更新流。这种 backfill 对实时集群的压力是很大的,在 backfill 时,需要等待 backfill 工作起来,需要监控工作流不让实时集群宕掉。所以,用户提出能不能做离线的 backfill,不想通过实时流处理做 backfill。当前我们的用户是使用 Beam on Samza 做流处理,他们非常熟悉 Beam API 和 Spark Dataset API,也会用 Dataset API 去做除了 backfill 之外的一些其他业务处理。需要特别强调的是, Dataset API 很多都是直接对 Object 操作,对 type 安全性要求很高,如果建议这些用户直接改成 SQL 或者 DataFrame 等 workflow 是不切实际的,因为他们已有的业务逻辑都是对 Object 进行直接操作和转化等。在这个案例下,我们能提供给用户一些方案选择,Imperative API 。看下业界提供的方案:第一个选择是即将要统一化的 Flink DataStream API,此前我们在做方案评估时也有调研 Flink DataSet API(deprecated),DataStream API 可以做到统一,并且在流处理和批处理方面的支持都是比较完善的。但缺点是,毕竟是 Imperative API ,可能没有较多的优化,后续应该会持续优化。可以看下 FLIP-131: Consolidate the user-facing Dataflow SDKs/APIs (and deprecate the DataSet API) [1] 和 FLIP-134: Batch execution for the DataStream API [2]。第二个选择是 Spark Dataset ,也是用户一个比较自然的选择。可以用 Dataset API 做 Streaming,区别于 Flink 的 Dataset 、DataStream API 等物理 API,它是基于 Spark Dataframe SQL engine 做一些 type safety,优化程度相对好一些。可以看下文章 Databricks: Introducing Apache Spark Datasets [3] 和 Spark Structured Streaming Programming Guide: Unsupported-operations [4]。第三个选择是 Beam On Spark,它目前主要还是用 RDD runner,目前支持带 optimization 的 runner 还是有一定难度的。之后会详细说下 Beam 在案例 B 中的一些 ongoing 的工作。可以看下 Beam Documentation - Using the Apache Spark Runner [5] 和 BEAM-8470 Create a new Spark runner based on Spark Structured streaming framework [6]。从用户的反馈上来说,Flink 的 DataStream (DataSet) API 和 Spark 的 Dataset API 在用户 interface 上是非常接近的。作为 Infra 工程师来说,想要帮用户解决问题,对 API 的熟悉程度就比较重要了。但是 Beam 和 Flink 、Spark 的 API 是非常不一样的,它是 Google 的一条生态系统,我们之前也帮助用户解决了一些问题,他们的 workflow 是在 Beam on Samza 上,他们用 p collections 或者 p transformation 写了一些业务逻辑,output、input 方法的 signature 都很不一样,我们开发了一些轻量级 converter 帮助用户复用已有的业务逻辑,能够更好的用在重新写的 Flink 或 Spark 作业里。从 DAG 上来看,案例 A 是一个非常简单的业务流程,就是简单直接的对 Object 进行转换。Flink 和 Spark 在这个案例下,性能表现上是非常接近的。通常,我们会用 Flink Dashboard UI 看一些异常、业务流程等,相比 Spark 来说是一个比较明显的优势。Spark 去查询 Driver log,查询异常是比较麻烦的。但是 Flink 依旧有几个需要提升的地方:History Server - 支持更丰富的 Metrics 等Spark History Server UI 呈现的 metrics 比较丰富的,对用户做性能分析的帮助是比较大的。Flink 做批处理的地方是否也能让 Spark 用户能看到同等的 metrics 信息量,来降低用户的开发难度,提高用户的开发效率。更好的批处理运维工具分享一个 LinkedIn 从两三年前就在做的事情。LinkedIn 每天有 200000 的作业跑在集群上,需要更好的工具支持批处理用户运维自己的作业,我们提供了 Dr. Elephant 和 GridBench 来帮助用户调试和运维自己的作业。Dr. Elephant 已开源,能帮助用户更好的调试作业,发现问题并提供建议。另外,从测试集群到生产集群之前,会根据 Dr. Elephant 生成的报告里评估结果的分数来决定是否允许投产。GridBench 主要是做一些数据统计分析,包括 CPU 的方法热点分析等,帮助用户优化提升自己的作业。GridBench 后续也有计划开源,可以支持各种引擎框架,包括可以把 Flink 加进来,Flink job 可以用 GridBench 更好的做评估。GridBench Talk: Project Optimum: Spark Performance at LinkedIn Scale [7]。用户不仅可以看到 GridBench 生成的报告,Dr. Elephant 生成的报告,也可以通过命令行看到 job 的一些最基本信息,应用 CPU 时间、资源消耗等,还可以对不同 Spark job 和 Flink job 之间进行对比分析。以上就是 Flink 批处理需要提升的两块地方。3.2 案例 B - 复杂的 ETL 数据流第二类方向,批处理 -> 流处理,归类为流批一体。ETL 数据流的核心逻辑相对复杂一些,比如包括 session window 聚合窗口,每个小时计算一次页面的用户浏览量,分不同的作业,中间共享 metadata table 中的 page key,第一个作业处理 00 时间点,第二个作业处理 01 时间点,做一些 sessionize 的操作,最后输出结果,分 open session、close session ,以此来做增量处理每个小时的数据。这个 workflow 原先是通过 Spark SQL 做的离线增量处理,是纯离线的增量处理。当用户想把作业移到线上做一些实时处理,需要重新搭建一个比如 Beam On Samza 的实时的 workflow,在搭建过程中我们和用户有非常紧密的联系和沟通,用户是遇到非常多的问题的,包括整个开发逻辑的复用,确保两条业务逻辑产生相同的结果,以及数据最终存储的地方等等,花了很长时间迁移,最终效果是不太好的。另外,用户的作业逻辑里同时用 Hive 和 Spark 写了非常多很大很复杂的 UDF ,这块迁移也是非常大的工作量。用户对 Spark SQL 和 Spark DataFrame API 是比较熟悉的。上图中的黑色实线是实时处理的过程,灰色箭头主要是批处理的过程,相当于是一个Lambda结构。针对案例 B,作业中包括很多 join 和 session window,他们之前也是用 Spark SQL 开发作业的。很明显我 们要从 Declartive API 入手,当前提供了 3 种方案:第一个选择是 Flink Table API/SQL ,流处理批处理都可以做,同样的SQL,功能支持很全面,流处理和批处理也都有优化。可以看下文章 Alibaba Cloud Blog: What's All Involved with Blink Merging with Apache Flink? [8] 和 FLINK-11439 INSERT INTO flink_sql SELECT * FROM blink_sql [9]。第二个选择是 Spark DataFrame API/SQL ,也是可以用相同的 interface 做批处理和流处理,但是 Spark 的流处理支持力度还是不够的。可以看下文章 Databricks Blog: Deep Dive into Spark SQL’s Catalyst Optimizer [10] 和 Databricks Blog: Project Tungsten: Bringing Apache Spark Closer to Bare Metal [11]。第三个选择是 Beam Schema Aware API/SQL ,Beam 更多的是物理的 API ,在 Schema Aware API/SQL 上目前都在开展比较早期的工作,暂不考虑。所以,之后的主要分析结果和经验都是从 Flink Table API/SQL 和 Spark DataFrame API/SQL 的之间的对比得出来的。可以看下文章 Beam Design Document - Schema-Aware PCollections [12] 和 Beam User Guide - Beam SQL overview [13]。从用户的角度来说,Flink Table API/SQL 和 Spark DataFrame API/SQL 是非常接近的,有一些比较小的差别,比如 keywords、rules、 join 具体怎么写等等,也会给用户带来一定的困扰,会怀疑自己是不是用错了。Flink 和 Spark 都很好的集成了 Hive ,比如 HIve UDF 复用等,对案例B中的 UDF 迁移,减轻了一半的迁移压力。Flink 在 pipeline 模式下的性能是明显优于 Spark 的,可想而知,要不要落盘对性能影响肯定是比较大的,如果需要大量落盘,每个 stage 都要把数据落到磁盘上,再重新读出来,肯定是要比不落盘的 pipeline 模式的处理性能要差的。pipeline 比较适合短小的处理,在 20 分钟 40 分钟还是有比较大的优势的,如果再长的 pipeline 的容错性肯定不能和 batch 模式相比。Spark 的 batch 性能还是要比 Flink 好一些的。这一块需要根据自己公司内部的案例进行评估。Flink 对 window 的支持明显比其他引擎要丰富的多,比如 session window,用户用起来非常方便。我们用户为了实现 session window ,特意写了非常多的 UDF ,包括做增量处理,把 session 全部 build 起来,把 record 拿出来做处理等等。现在直接用 session window operator ,省了大量的开发消耗。同时 group 聚合等 window 操作也都是流批同时支持的。Session Window:// Session Event-time Window .window(Session withGap 10.minutes on $"rowtime" as $"w") // Session Processing-time Window (assuming a processing-time attribute "proctime") .window(Session withGap 10.minutes on $"proctime" as $"w")Slide Window:// Sliding Event-time Window .window(Slide over 10.minutes every 5.minutes on $"rowtime" as $"w") // Sliding Processing-time Window (assuming a processing-time attribute "proctime") .window(Slide over 10.minutes every 5.minutes on $"proctime" as $"w") // Sliding Row-count Window (assuming a processing-time attribute "proctime") .window(Slide over 10.rows every 5.rows on $"proctime" as $"w")UDF 是在引擎框架之间迁移时最大的障碍。如果 UDF 是用 Hive 写的,那是方便迁移的,因为不管是 Flink 还是 Spark 对 Hive UDF 的支持都是很好的,但如果 UDF 是用 Flink 或者 Spark 写的,迁移到任何一个引擎框架,都会遇到非常大的问题,比如迁移到 Presto 做 OLAP 近实时查询。为了实现 UDF 的复用,我们 LinkedIn 在内部开发了一个 transport 项目,已经开源至 github [14] 上, 可以看下 LinkedIn 发表的博客:Transport: Towards Logical Independence Using Translatable Portable UDFs [15]。transport 给所有引擎框架提供一个面向用户的 User API ,提供通用的函数开发接口,底下自动生成基于不同引擎框架的 UDF ,比如 Presto、Hive、Spark、Flink 等。用一个共通的 UDF API 打通所有的引擎框架,能让用户复用自己的业务逻辑。用户可以很容易的上手使用,比如如下用户开发一个 MapFromTwoArraysFunction:public class MapFromTwoArraysFunction extends StdUDF2<StdArray,StdArray,StdMap>{ private StdType _mapType; @Override public List<String> getInputParameterSignatures(){ return ImmutableList.of( "array[K]", "array[V]" ); } @Override public String getOutputParameterSignature(){ return "map(K,V)"; } } @Override public void init(StdFactory stdFactory){ super.init(stdFactory); } @Override public StdMap eval(StdArray a1, StdArray a2){ if(a1.size() != a2.size()) { return null; } StdMap map = getStdFactory().createMap(_mapType); for(int i = 0; i < a1.size; i++) { map.put(a1.get(i), a2.get(i)); } return map; }处理用户的 SQL 迁移问题 ,用户之前是用 Spark SQL 开发的作业,之后想使用流批一体,改成 Flink SQL 。目前的引擎框架还是比较多的,LinkedIn 开发出一个 coral 的解决方案,已在 github [16] 上开源,在 facebook 上也做了一些 talk ,包括和 transport UDF 一起给用户提供一个隔离层使用户可以更好的做到跨引擎的迁移,复用自己的业务逻辑。看下 coral 的执行流程,首先作业脚本中定义 熟悉的 ASCII SQL 和 table 的属性等,之后会生成一个 Coral IR 树状结构,最后翻译成各个引擎的 physical plan。在案例 B 分析中,流批统一,在集群业务量特别大的情况下,用户对批处理的性能、稳定性、成功率等是非常重视的。其中 Shuffle Service ,对批处理性能影响比较大。四、Shuffle Service 在 Spark 和 Flink 上的对比In-memory Shuffle,Spark 和 Flink 都支持,比较快,但不支持可扩展。Hash-based Shuffle ,Spark 和 Flink 都支持 , 相比 In-memory Shuffle ,容错性支持的更好一些,但同样不支持可扩展。Sort-based Shuffle,对大的 Shuffle 支持可扩展,从磁盘读上来一点一点 Sort match 好再读回去,在 FLIP-148: Introduce Sort-Based Blocking Shuffle to Flink [17] 中也已经支持。External Shuffle Service, 在集群非常繁忙,比如在做动态资源调度时,外挂服务就会非常重要,对 Shuffle 的性能和资源依赖有更好的隔离,隔离之后就可以更好的去调度资源。FLINK-11805 A Common External Shuffle Service Framework [18] 目前处于 reopen 状态。Disaggregate Shuffle,大数据领域都倡导 Cloud Native 云原生,计算存储分离在 Shuffle Service 的设计上也是要考虑的。FLINK-10653 Introduce Pluggable Shuffle Service Architecture [19] 引入了可插拔的 Shuffle Service 架构。Spark 对 Shuffle Service 做了一个比较大的提升,这个工作也是由 LinkedIn 主导的 magnet 项目,形成了一篇名称为 introducing-magnet 的论文 (Magnet: A scalable and performant shuffle architecture for Apache Spark) [20],收录到了 LinkedIn blog 2020 里。magnet 很明显的提升了磁盘读写的效率,从比较小的 random range ,到比较大的顺序读,也会做一些 merging ,而不是随意的随机读取 shuffle data ,避免 random IO 的一些问题。通过 Magent Shuffle Service 缓解了 Shuffle 稳定性和可扩展性方面的问题。在此之前,我们发现了很多 Shuffle 方面的问题,比如 Job failure 等等非常高。如果想用 Flink 做批处理,帮助到以前用 Spark 做批处理的用户,在 Shuffle 上确实要花更大功夫。在 Shuffle 可用性上,会采用 best-effort 方式去推 shuffle blocks,忽略一些大的 block ,保证最终的一致性和准确性; 为 shuffle 临时数据生成一个副本,确保准确性。如果 push 过程特别慢,会有提前终止技术。Magent Shuffle 相比 Vanilla Shuffle ,读取 Shuffle data 的等待时间缩较少了几乎 100%,task 执行时间缩短了几乎 50%,端到端的任务时长也缩短了几乎 30%。五、总结LinkedIn 非常认可和开心看到 Flink 在流处理和批处理上的明显优势,做的更加统一,也在持续优化中。Flink 批处理能力有待提升,如 history server,metrics,调试。用户在开发的时候,需要从用户社区看一些解决方案,整个生态要搭建起来,用户才能方便的用起来。Flink 需要对 shuffle service 和大集群离线工作流投入更多的精力,确保 workflow 的成功率,如果规模大起来之后,如何提供更好的用户支持和对集群进行健康监控等。随着越来越多的框架引擎出现,最好能给到用户一个更加统一的 interface,这一块的挑战是比较大的,包括开发和运维方面,根据 LinkedIn 的经验,还是看到了很多问题的,并不是通过一个单一的解决方案,就能囊括所有的用户使用场景,哪怕是一些 function 或者 expression,也很难完全覆盖到。像 coral、transport UDF。原视频: https://www.bilibili.com/video/BV13a4y1H7XY?p=12参考链接[1] https://cwiki.apache.org/confluence/pages/viewpage.action?pageId=158866741[2] https://cwiki.apache.org/confluence/display/FLINK/FLIP-134%3A+Batch+execution+for+the+DataStream+API[3] https://databricks.com/blog/2016/01/04/introducing-apache-spark-datasets.html[4] https://spark.apache.org/docs/latest/structured-streaming-programming-guide.html#unsupported-operations[5] https://beam.apache.org/documentation/runners/spark/[6] https://issues.apache.org/jira/browse/BEAM-8470[7] https://www.youtube.com/watch?v=D47CSeGpBd0[8] https://www.alibabacloud.com/blog/whats-all-involved-with-blink-merging-with-apache-flink_595401[9] https://issues.apache.org/jira/browse/FLINK-11439[10] https://databricks.com/blog/2015/04/13/deep-dive-into-spark-sqls-catalyst-optimizer.html[11] https://databricks.com/blog/2015/04/28/project-tungsten-bringing-spark-closer-to-bare-metal.html[12] https://docs.google.com/document/d/1tnG2DPHZYbsomvihIpXruUmQ12pHGK0QIvXS1FOTgRc/edit#heading=h.puuotbien1gf[13] https://beam.apache.org/documentation/dsls/sql/overview/[14] https://github.com/linkedin/transport[15] https://engineering.linkedin.com/blog/2018/11/using-translatable-portable-UDFs[16] https://github.com/linkedin/coral[17] https://cwiki.apache.org/confluence/display/FLINK/FLIP-148%3A+Introduce+Sort-Based+Blocking+Shuffle+to+Flink[18] https://issues.apache.org/jira/browse/FLINK-11805[19] https://issues.apache.org/jira/browse/FLINK-10653[20] https://engineering.linkedin.com/blog/2020/introducing-magnet文章转载自过往记忆大数据公众号 https://mp.weixin.qq.com/s/B-xb2rIL07oKuvAKvNa7Fw 免责声明:转载文章版权归原作者所有。如涉及作品内容、版权等问题,请及时联系文章编辑!
-
摘要:本文介绍了顺丰科技数仓的架构,趟过的一些问题、使用 Hudi 来优化整个 job 状态的实践细节,以及未来的一些规划。主要内容为:数仓架构Hudi 代码躺过的坑状态优化未来规划顺丰科技早在 2019 年引入 Hudi ,当时是基于 Spark 批处理,2020 年对数据的实时性要求更高公司对架构进行了升级,在社区 Hudi on Flink 的半成品上持续优化实现Binlog 数据 CDC 入湖。在 Hudi 社区飞速发展的同时公司今年对数仓也提出了新的要求,最终采用 Flink + Hudi 的方式来宽表的实时化。过程中遇到了很多问题主要有两点:Hudi Master 代码当时存在一些漏洞;宽表涉及到多个 Join,Top One 等操作使得状态很大。庆幸的是社区的修复速度很给力加上 Hudi 强大 upsert 能力使这两个问题得到以有效的解决。一、数仓架构感兴趣的同学可以参考之前顺丰分享的《Hudi on Flink 在顺丰的实践应用》二、Hudi 代码趟过的坑在去年我们是基于 Hudi 0.6 左右进行的 Hudi on Flink 的实践,代码较老。为了拥抱社区我们使用最新 master 代码进行实践,在大数据量写入场景中,发现了一个比较隐秘的丢数问题,这个问题花了将近两周的时间才定位到。1. Hudi StreamWriteFunction 算子核心流程梳理算子收数据的时候会先把数据按照 fileld 分组缓存好,数据的持续流会使得缓存数据越来越大,当达到一定阈值时便会执行 flush。阈值由 2 个核心参数控制:, 。当单个分组数据达到 64M 或者总缓存数据达到 800M ~ 1G 就会触发 flush 。flush 会调用 client 的 api 去创建一个 WriteHandle,然后把 WriteHandle 放入 Map 进行缓存,一个 handle 可以理解为对应一个文件的 cow。如果一个 fileld 在同一 checkpoint 期间被多次写入,则后一次是基于前一次的 cow, 它的 handle 是一个,判断一个 fileld 是否之前被写入过就是根据上面 Map 缓存得来的。执行 snapshotState 时会把内存的所有分组数据一次进行 flush, 之后对 client 的 handle 进行清空。2. 场景还原Hudi 本身是具备 upsert 能力的,所以我们开始认为 Hudi Sink 在 At Least Once 模式下是没问题的,并且 At Least Once 模式下 Flink 算子不需要等待 Barrier 对齐,能够处理先到的数据使得处理速度更快,于是我们在 Copy On Write 场景中对 Flink CheckpointingMode 设置了 AT_LEAST_ONCE。writeFunction 的上游是文件 fileld 分配算子,假如有一批 insert 数据 A、B、C、D 属于同一个分区并且分配到同一个的 subtask ,但是 A、B 和 C、D 是相邻两个不同的 checkpoint。当 A 进入时如果发现没有新的小文件可以使用,就会创建一个新的 fileld f0,当 B 流入时也会给他分配到 f0 上。同时因为是 AT_LEAST_ONCE 模式,C、D 数据都有可能被处理到也被分配到了 f0 上。也就是说 在 AT_LEAST_ONCE 模式下由于 C、D 数据被提前处理,导致 A、B、C、D 4 条属于两个 checkpoint 的 insert 数据被分配到了同一个 fileld。writeFunction 有可能当接收到 A、B、C 后这个算子的 barrier 就对齐了,会把 A、B、C 进行 flush,而 D 将被遗留到下一个 checkpoint 才处理。A、B、C 是 insert 数据所以就会直接创建一个文件写入,D 属于下一个 checkpoint ,A、B、C 写入时创建的 handle 已被清理了,等到下一个 checkpoint 执行 flush。因为 D 也是 insert 数据所以也会直接创建一个文件写数据,但是 A、B、C、D 的 fileld 是一样的,导致最终 D 创建的文件覆盖了 A、B、C 写入的文件最终导致 A、B、C 数据丢失。3. 问题定位这个问题之所以难定位是因为具有一定随机性,每次丢失的数据都不太一样,而且小数据量不易出现。最终通过开启 Flink 的 Queryable State 进行查询, 查找丢失数据的定位到 fileld, 发现 ABCD state 的 instant 都是 I,然后解析对应 fileld 的所有版本进行跟踪还原。三、状态优化我们对线上最大的离线宽边进行了实时化的,宽表字段较多,涉及到多个表对主表的 left join 还包括一些 Top One 的计算,这些算子都会占用 state. 而我们的数据周期较长需要保存 180 天数据。估算下来状态大小将会达到上百 T,这无疑会对状态的持久化带来很大的压力。但是这些操作放入 Hudi 来做就显得轻而易举。1. Top One 下沉 Hudi在 Hudi 中有一个配置项用来指定使用某个字段对 flush 的数据去重,当出现多条数据需要去重时就会按照整个字段进行比较,保留最大的那条记录,这其实和 Top One 很像。我们在 SQL 上将 Top One 的排序逻辑组合成了一个字段设置为 Hudi 的,同时把这个字段写入 state,同一 key 的数据多次进来时都会和 state 的 进行比较更新。Flink Top One 的 state 默认是保存整记录的所有字段,但是我们只保存了一个字段,大大节省了 state 的大小。2. 多表 Left Join 下沉 Hudi■ 2.1 Flink SQL join我们把这个场景简化成如下一个案例,假如有宽表 t_p 由三张表组成在 Flink SQL join 算子内部会维护一个左表和右表的 state,这都是每个 table 的全字段,且多一次 join 就会多出一个 state. 最终导致 state 大小膨胀,如果 join 算子上游是一个 append 流,state 大小膨胀的效果更明显。■ 2.2 把 Join 改写成 Union All对于上面案例每次 left join 只是补充了几个字段,我们想到用 union all 的方式进行 SQL 改写,union all 需要补齐所有字段,缺的字段用 null 补。我们认为 null 补充的字段不是有效字段。改成从 union all 之后要求 Hudi 具备局部更新的能力才能达到 join 的效果。当收到的数据是来自 t0 的时候就只更新 id 和 name 字段;同理 ,数据是来自 t1 的时候就只更新 age 字段;t2 只更新 sex 字段。不幸的是 Hudi 的默认实现是全字段覆盖,也就是说当收到 t0 的数据时会把 age sex 覆盖成 null, 收到 t1 数据时会把 name sex 覆盖成 null。这显然是不可接受的。这就要求我们对 Hudi sink 进行改造。■ 2.3 Hudi Union All 实现Hudi 在 cow 模式每条记录的更新写入都是对旧数据进行 copy 覆盖写入,似乎只要知道这条记录来自哪个表,哪几个字段是有效的字段就选择性的对 copy 出来的字段进行覆盖即可。但是在分区变更的场景中就不是那么好使了。在分区变更的场景中,数据从一个分区变到另一个分区的逻辑是把旧分区数据删掉,往新分区新增数据。这可能会把一些之前局部更新的字段信息丢失掉。细聊下来 Hudi on Flink 涉及到由几个核心算子组成 pipeline。RowDataToHoodieFunction:这是对收入的数据进行转化成一个 HudiRecord,收到数据是包含全字段的,我们在转化 HudiRecord 的时候只选择了有效字段进行转化。BoostrapFunction:在任务恢复的时候会读取文件加载索引数据,当任务恢复后次算子不做数据转化处理。BucketAssignFunction:这个算子用来对记录分配 location,loaction 包含两部分信息。一是分区目录,另一个是 fileld。fileld 用来标识记录将写入哪个文件,一旦记录被确定写入哪个文件,就会发记录按照 fileld 分组发送到 StreamWriteFunction,StreamWriteFunction 再按文件进行批量写入。原生的 BucketAssignFunction 的算子逻辑如下图,当收到一条记录时会先从 state 里面进行查找是否之前有写过这条记录,如果有就会找对应的 location。如果分区没有发生变更,就把当前这条记录也分配给这个location,如果在 state 中没有找到 location 就会新创建一个 location,把这个新的location 分配给当前记录,并更新到 state。总之这个 state 存储的 location 就是告诉当前记录应该从哪个文件进行更新或者写入。遇到分区变更的场景会复杂一点。假如一条记录从 2020 分区变更成了 2021,就会创建一条删除的记录,它的 loaction 是 state 中的 location。这条记录让下游进行实际的删除操作,然后再创建一个新的 location (分区是 2021) 发送到下游进行 insert。为了在 Hudi 中实现 top one,我们对 state 信息进行了扩展,用来做 Top One 时间字段。对于 StreamWriteFunction 在 Insert 场景中,假如收到了如下 3 条数据 ,,,在执行 flush 时会创建一个全字段的空记录 ,然后依次和 3 条记录进行合并。注意,这个合并过程只会选择有效字段的合并。如下图:在 Update 场景中的更新逻辑类似 insert 场景,假如老数据是 ,新收到了, 这 2 条数据,就会先从文件中把老的数据读出来,然后依次和新收到的数据进行合并,合并步骤同 insert。如下图:这样通过 union all 的方式达到了 left join 的效果,大大节省了 state 的大小。四、未来规划parquet 元数据信息收集,parquet 文件可以从 footer 里面得到每个行列的最大最小等信息,我们计划在写入文件的后把这些信息收集起来,并且基于上一次的 commit 的元数据信息进行合并,生成一个包含所有文件的元数据文件,这样可以在读取数据时进行谓词下推进行文件的过滤。公司致力于打造基于 Hudi 作为底层存储,Flink 作为流批一体化的 SQL 计算引擎,Flink 的批处理 Hudi 这块还涉足不深,未来可能会计划用 Flink 对 Hudi 实现 clustering 等功能,在 Flink 引擎上完善 Hudi 的批处理功能。文章转载至腾讯新闻,作者西北木土 https://xw.qq.com/amphtml/s/20210929A02O4F00 免责声明:转载文章版权归原作者所有。如涉及作品内容、版权等问题,请及时联系文章编辑!
上滑加载中
推荐直播
-
 华为云码道-玩转OpenClaw,在线养虾
华为云码道-玩转OpenClaw,在线养虾2026/03/11 周三 19:00-21:00
刘昱,华为云高级工程师/谈心,华为云技术专家/李海仑,上海圭卓智能科技有限公司CEO
OpenClaw 火爆开发者圈,华为云码道最新推出 Skill ——开发者只需输入一句口令,即可部署一个功能完整的「小龙虾」智能体。直播带你玩转华为云码道,玩转OpenClaw
回顾中 -
 华为云码道-AI时代应用开发利器
华为云码道-AI时代应用开发利器2026/03/18 周三 19:00-20:00
童得力,华为云开发者生态运营总监/姚圣伟,华为云HCDE开发者专家
本次直播由华为专家带你实战应用开发,看华为云码道(CodeArts)代码智能体如何在AI时代让你的创意应用快速落地。更有华为云HCDE开发者专家带你用码道玩转JiuwenClaw,让小艺成为你的AI助理。
回顾中 -
 Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案
Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案2026/03/25 周三 19:00-20:00
余伟,华为云软件研发工程师/万邵业(万少),华为云HCDE开发者专家
本次直播带来两大实战:华为云码道 Skill-Creator 手把手搭建专属知识库 Skill;如何用码道提效 OpenClaw 小说文本,打造从大纲到成稿的 AI 原创小说全链路。技术干货 + OPC创作思路,一次讲透!
回顾中
热门标签