-
 # 华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习 ## 背景说明 随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。 SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎自1.7.2版本开始引入Flink SQL的特性,并不断发展。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。 但是真正的要将Flink SQL开发工作投入到实际的生产场景中,如果使用原生的API接口进行作业的开发还是存在门槛较高,易用性低,SQL代码可维护性差的问题。新需求由业务人员提交给IT人员,IT人员排期开发。从需求到上线,周期长,导致错失新业务最佳市场时间窗口。同时,IT人员工作繁重,大量相似Flink作业,成就感低。 ## 华为Flink可视化开发平台FlinkServer优势: - 提供基于Web的可视化开发平台,只需要写SQL即可开发作业,极大降低作业开发门槛。 - 通过作业平台能力开放,支持业务人员自行编写SQL开发作业,快速应对需求,并将IT人员从繁琐的Flink作业开发工作中解放出来; - 同时支持流作业和批作业; - 支持常见的Connector,包括Kafka、Redis、HDFS等 下面将以kafka为例分别使用原生API接口以及FlinkServer进行作业开发,对比突出FlinkServer的优势 ## 场景说明 参考已发论坛帖 [《华为FusionInsight MRS FlinkSQL 复杂嵌套Json解析最佳实践》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=153494) 需要使用FlinkSQL从一个源kafka topic接收cdl复杂嵌套json数据并进行解析,将解析后的数据发送到另一个kafka topic里 ## 使用原生API接口方案开发flink sql操作步骤 ### 前提条件 - 完成MRS Flink客户端的安装以及配置 - 完成Flink SQL原生接口相关配置 ### 操作步骤 - 使用如下命令首先启动Flink集群 ``` source /opt/hadoopclient/bigdata_env kinit developuser cd /opt/hadoopclient/Flink/flink ./bin/yarn-session.sh -t ssl/ ```  - 使用如下命令启动Flink SQL Client ``` cd /opt/hadoopclient/Flink/flink/bin ./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml ```  - 使用如下flink sql创建源端kafka表,并提取需要的信息: ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); ``` 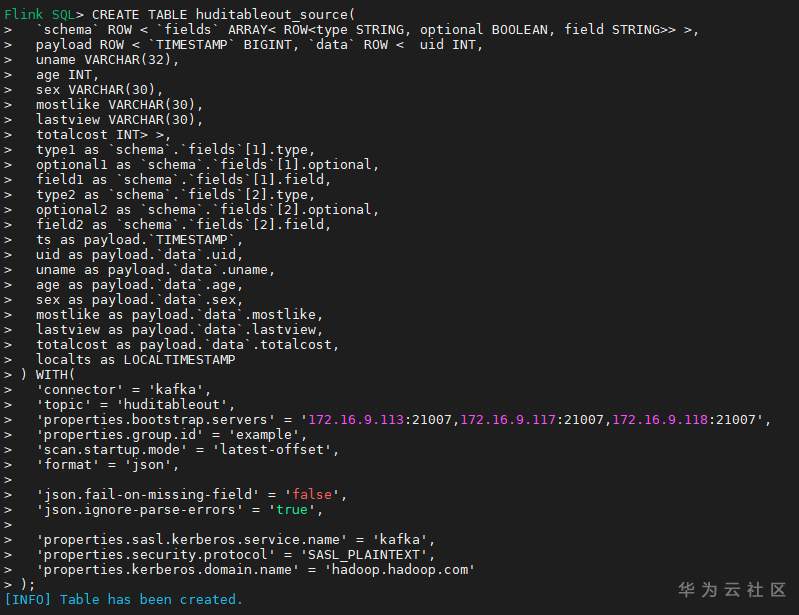 - 使用如下flink sql创建目标端kafka表: ``` CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); ``` 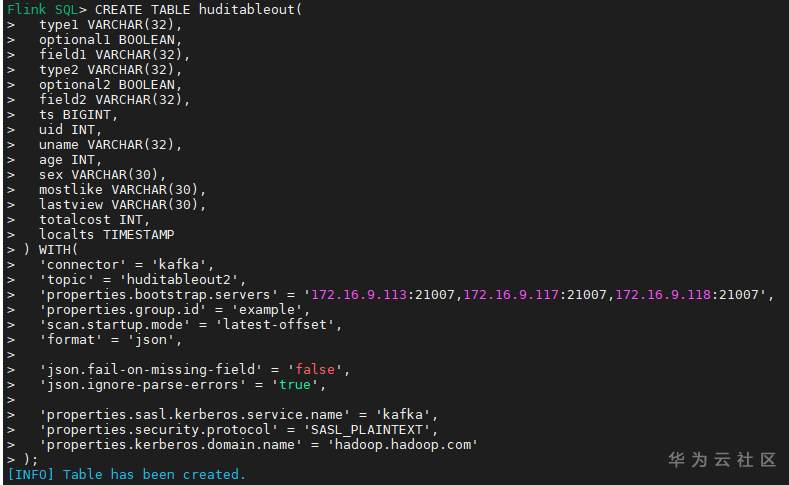 - 使用如下flink sql将源端kafka流表写入到目标端kafka流表中 ``` insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ``` 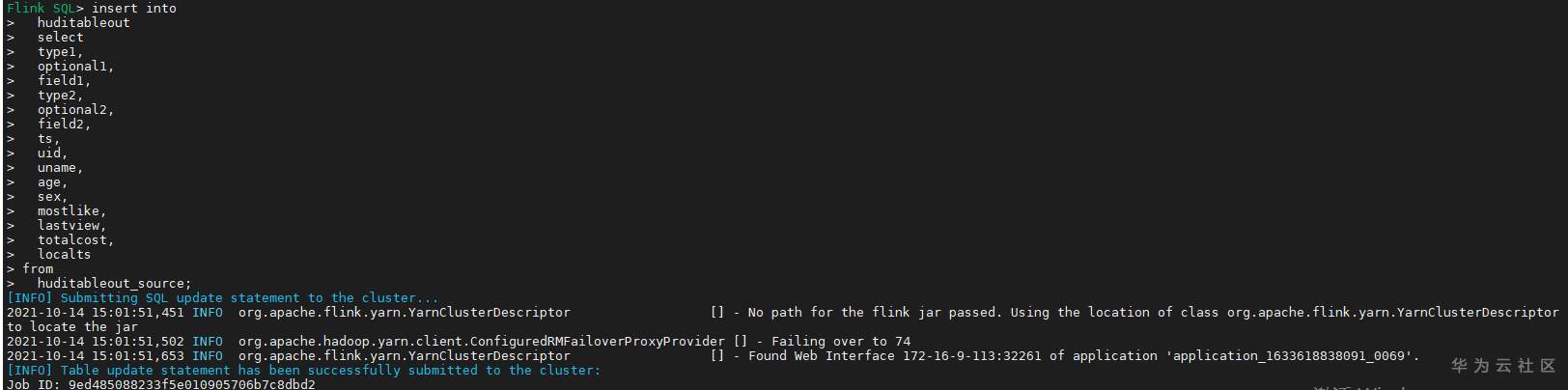 - 检查测试结果 消费生产源kafka topic的数据(由cdl生成)  消费目标端kafka topic解析后的数据(flink sql任务生成的结果)  可以登录flink原生界面查看任务 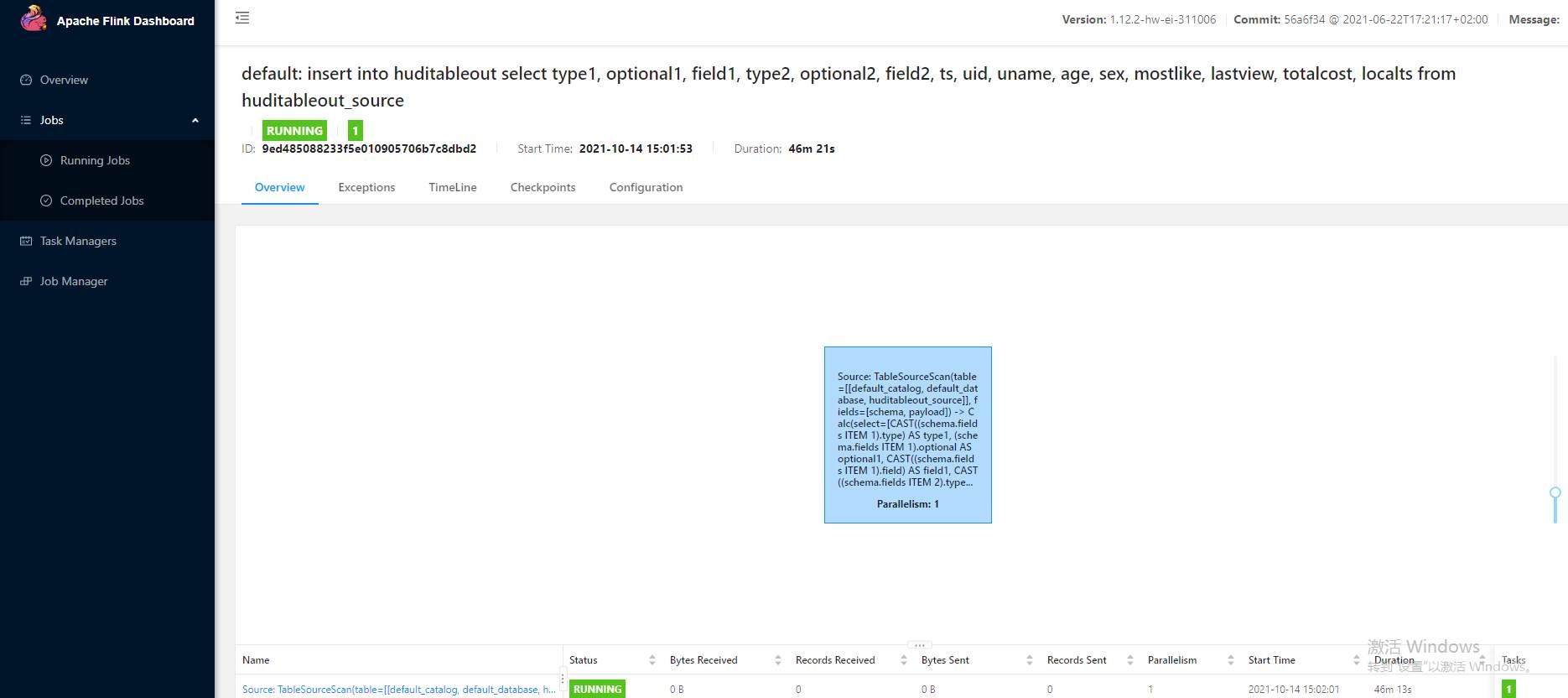 - 使用flink sql client方式查看结果 首先使用命令`set execution.result-mode=tableau;` 可以让查询结果直接输出到终端  使用flink sql查询上面已创建好的流表 `select * from huditableout`  注意:因为是kafka流表,所以查询结果只会显示select任务启动之后写进该topic的数据 ## 使用FlinkServer可视化开发平台方案开发flink sql操作步骤 ### 前提条件 - 参考产品文档 《基于用户和角色的鉴权》章节创建一个具有“FlinkServer管理操作权限”的用户,使用该用户访问Flink Server ### 操作步骤 - 登录FlinkServer选择作业管理 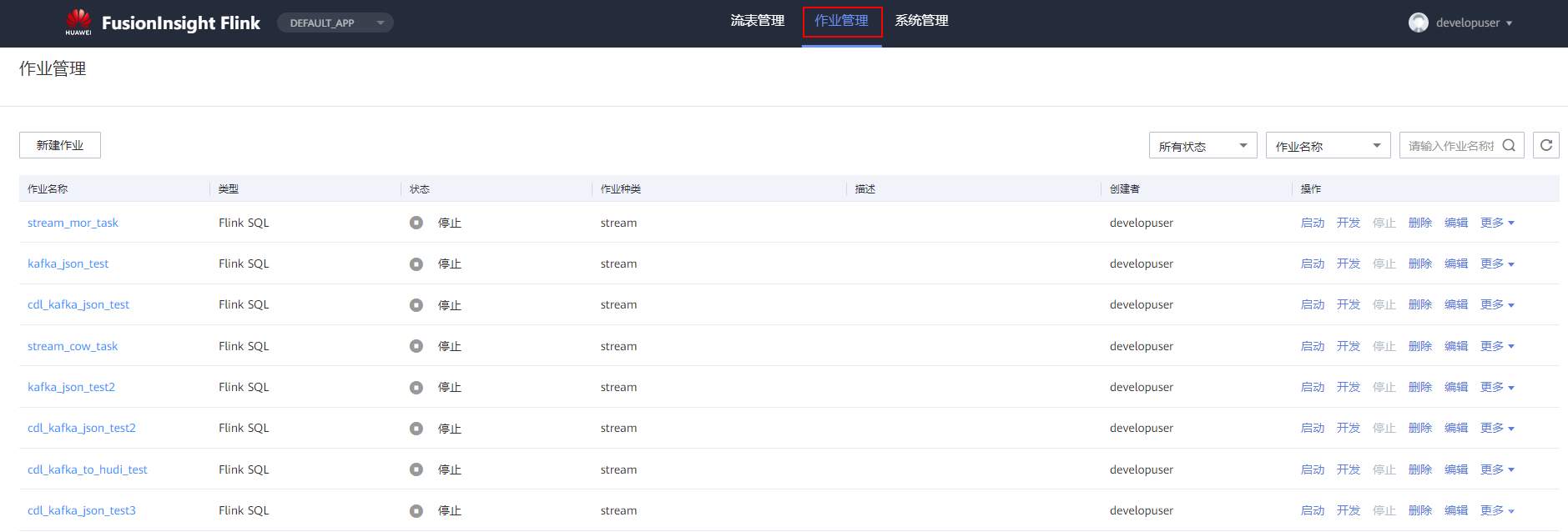 - 创建任务cdl_kafka_json_test3并输入flink sql 说明: 可以看到开发flink sql任务时在FlinkServer界面可以自行设置flink集群规模 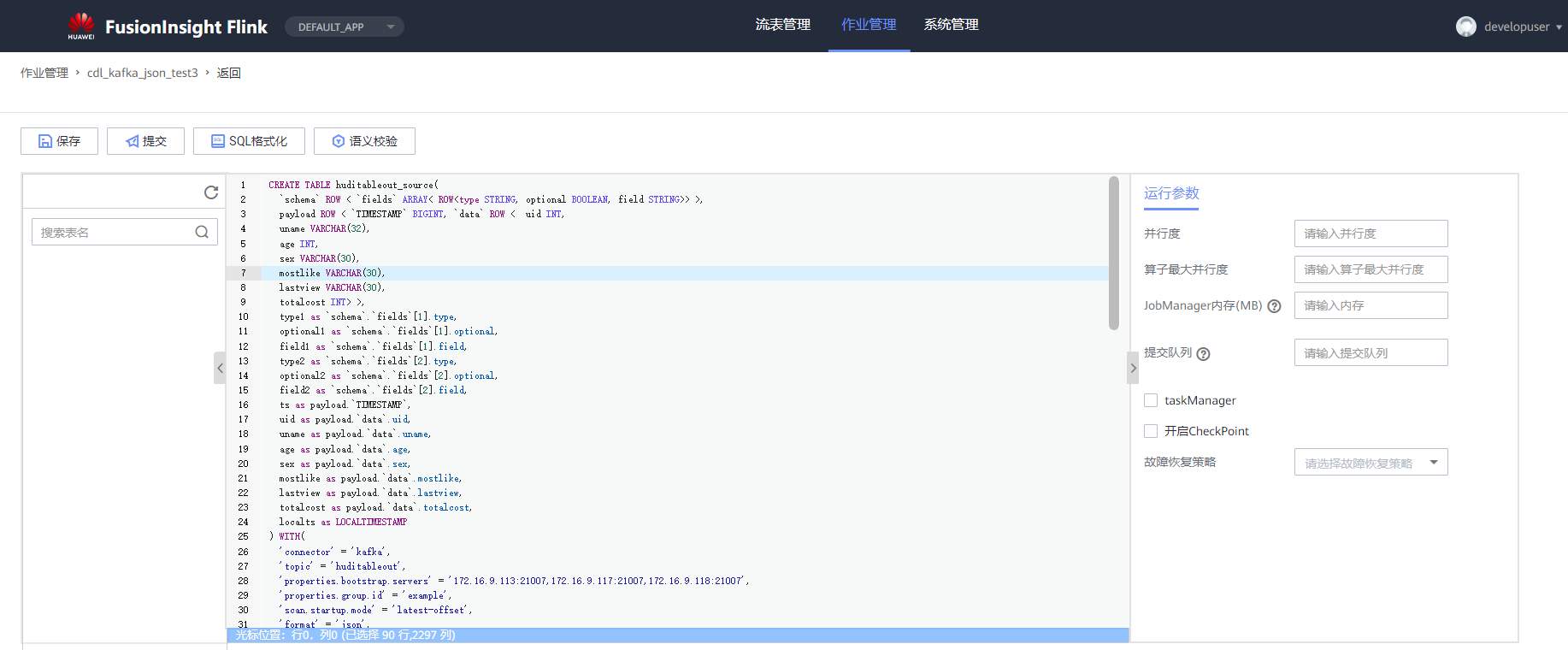 ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ``` - 点击语义校验,确保语义校验通过 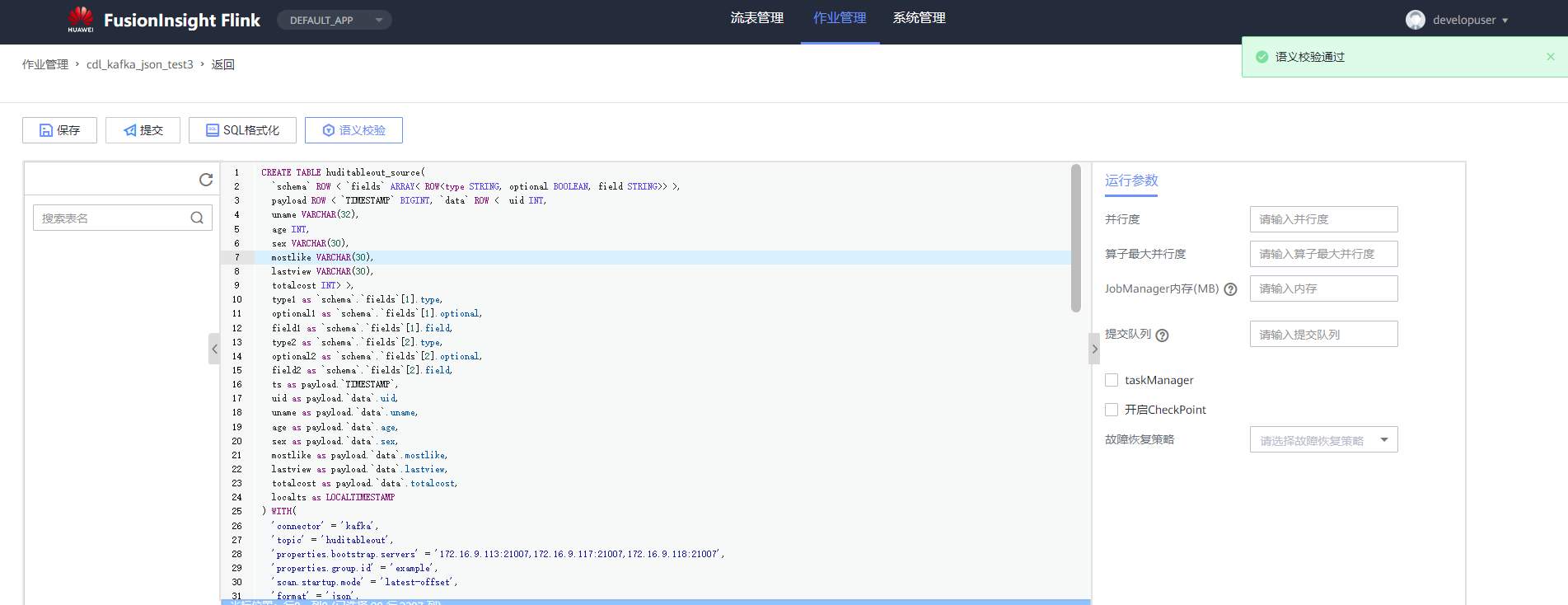 - 点击提交并启动任务 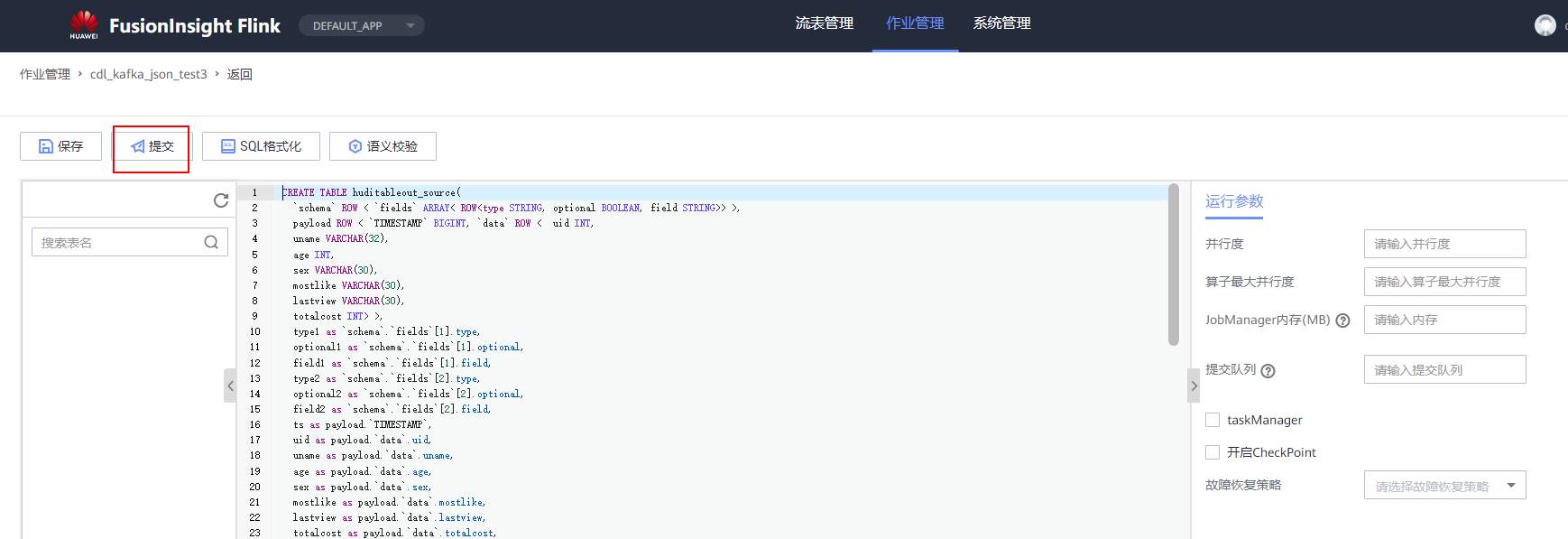 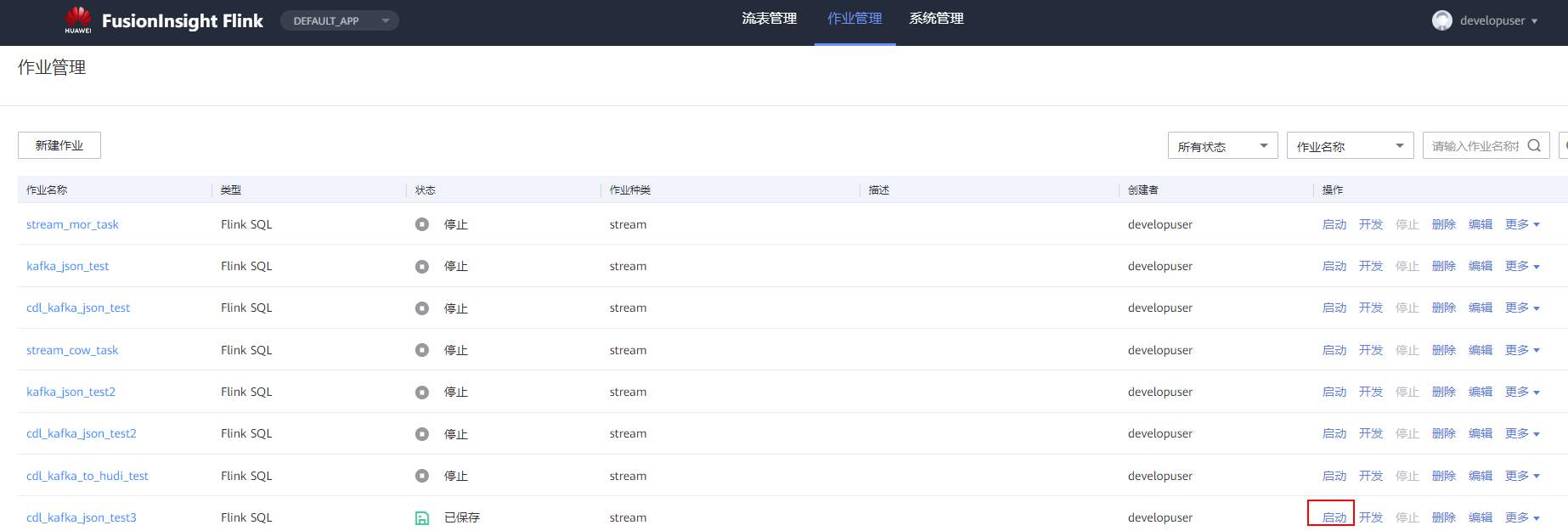 - 检查测试结果 消费生产源kafka topic的数据(由cdl生成)  消费目标端kafka topic解析后的数据(flink sql任务生成的结果) 
# 华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习 ## 背景说明 随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。 SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎自1.7.2版本开始引入Flink SQL的特性,并不断发展。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。 但是真正的要将Flink SQL开发工作投入到实际的生产场景中,如果使用原生的API接口进行作业的开发还是存在门槛较高,易用性低,SQL代码可维护性差的问题。新需求由业务人员提交给IT人员,IT人员排期开发。从需求到上线,周期长,导致错失新业务最佳市场时间窗口。同时,IT人员工作繁重,大量相似Flink作业,成就感低。 ## 华为Flink可视化开发平台FlinkServer优势: - 提供基于Web的可视化开发平台,只需要写SQL即可开发作业,极大降低作业开发门槛。 - 通过作业平台能力开放,支持业务人员自行编写SQL开发作业,快速应对需求,并将IT人员从繁琐的Flink作业开发工作中解放出来; - 同时支持流作业和批作业; - 支持常见的Connector,包括Kafka、Redis、HDFS等 下面将以kafka为例分别使用原生API接口以及FlinkServer进行作业开发,对比突出FlinkServer的优势 ## 场景说明 参考已发论坛帖 [《华为FusionInsight MRS FlinkSQL 复杂嵌套Json解析最佳实践》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=153494) 需要使用FlinkSQL从一个源kafka topic接收cdl复杂嵌套json数据并进行解析,将解析后的数据发送到另一个kafka topic里 ## 使用原生API接口方案开发flink sql操作步骤 ### 前提条件 - 完成MRS Flink客户端的安装以及配置 - 完成Flink SQL原生接口相关配置 ### 操作步骤 - 使用如下命令首先启动Flink集群 ``` source /opt/hadoopclient/bigdata_env kinit developuser cd /opt/hadoopclient/Flink/flink ./bin/yarn-session.sh -t ssl/ ```  - 使用如下命令启动Flink SQL Client ``` cd /opt/hadoopclient/Flink/flink/bin ./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml ```  - 使用如下flink sql创建源端kafka表,并提取需要的信息: ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); ```  - 使用如下flink sql创建目标端kafka表: ``` CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); ```  - 使用如下flink sql将源端kafka流表写入到目标端kafka流表中 ``` insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ```  - 检查测试结果 消费生产源kafka topic的数据(由cdl生成)  消费目标端kafka topic解析后的数据(flink sql任务生成的结果)  可以登录flink原生界面查看任务  - 使用flink sql client方式查看结果 首先使用命令`set execution.result-mode=tableau;` 可以让查询结果直接输出到终端  使用flink sql查询上面已创建好的流表 `select * from huditableout`  注意:因为是kafka流表,所以查询结果只会显示select任务启动之后写进该topic的数据 ## 使用FlinkServer可视化开发平台方案开发flink sql操作步骤 ### 前提条件 - 参考产品文档 《基于用户和角色的鉴权》章节创建一个具有“FlinkServer管理操作权限”的用户,使用该用户访问Flink Server ### 操作步骤 - 登录FlinkServer选择作业管理  - 创建任务cdl_kafka_json_test3并输入flink sql 说明: 可以看到开发flink sql任务时在FlinkServer界面可以自行设置flink集群规模  ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ``` - 点击语义校验,确保语义校验通过  - 点击提交并启动任务   - 检查测试结果 消费生产源kafka topic的数据(由cdl生成)  消费目标端kafka topic解析后的数据(flink sql任务生成的结果)  -

-
 【功能模块】DLI 模块【操作步骤&问题现象】1、创建新的flink作业 无法提交运行【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】DLI 模块【操作步骤&问题现象】1、创建新的flink作业 无法提交运行【截图信息】【日志信息】(可选,上传日志内容或者附件) -
【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】按照官方的代码,提交flink消费kafka任务后,出现错误。在flink客户端使用的命令为bin/flink run -yt conf/ssl/ -ys 2 -m yarn-cluster -yjm 1024 -ytm 1024 -c org.mytest.stream.ReadFromKafka /opt/flink/flink.jar --topic topictest --bootstrap.servers $bs --security.protocol SASL_PLAINTEXT --sasl.kerberos.service.name kafka【截图信息】【日志信息】(可选,上传日志内容或者附件)[root@node3 flink]# bin/flink run -yt conf/ssl/ -ys 2 -m yarn-cluster -yjm 1024 -ytm 1024 -c org.mytest.stream.ReadFromKafka /opt/flink/flink.jar --topic topictest --bootstrap.servers $bs --security.protocol SASL_PLAINTEXT --sasl.kerberos.service.name kafkaSLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/hadoopclient/Flink/flink/lib/logback-classic-1.2.3.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/opt/hadoopclient/HDFS/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.30.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [ch.qos.logback.classic.util.ContextSelectorStaticBinder]Cluster started: Yarn cluster with application id application_1625541283910_0063Job has been submitted with JobID f50af8c85ed9c74e813f52c71231674fjava.util.concurrent.ExecutionException: org.apache.flink.client.program.ProgramInvocationException: Job failed (JobID: f50af8c85ed9c74e813f52c71231674f) at java.util.concurrent.CompletableFuture.reportGet(CompletableFuture.java:357) at java.util.concurrent.CompletableFuture.get(CompletableFuture.java:1908) at org.apache.flink.streaming.api.environment.StreamContextEnvironment.execute(StreamContextEnvironment.java:83) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1651) at org.apache.flink.streaming.api.environment.StreamExecutionEnvironment.execute(StreamExecutionEnvironment.java:1633) at org.mytest.stream.ReadFromKafka.main(ReadFromKafka.java:21) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:321) at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:205) at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:138) at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:700) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:219) at org.apache.flink.client.cli.CliFrontend.parseParameters(CliFrontend.java:932) at org.apache.flink.client.cli.CliFrontend.lambda$main$10(CliFrontend.java:1005) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1737) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1005)Caused by: org.apache.flink.client.program.ProgramInvocationException: Job failed (JobID: f50af8c85ed9c74e813f52c71231674f) at org.apache.flink.client.deployment.ClusterClientJobClientAdapter.lambda$null$6(ClusterClientJobClientAdapter.java:112) at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:616) at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:591) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488) at java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975) at org.apache.flink.client.program.rest.RestClusterClient.lambda$pollResourceAsync$21(RestClusterClient.java:565) at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774) at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488) at java.util.concurrent.CompletableFuture.complete(CompletableFuture.java:1975) at org.apache.flink.runtime.concurrent.FutureUtils.lambda$retryOperationWithDelay$8(FutureUtils.java:291) at java.util.concurrent.CompletableFuture.uniWhenComplete(CompletableFuture.java:774) at java.util.concurrent.CompletableFuture$UniWhenComplete.tryFire(CompletableFuture.java:750) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:488) at java.util.concurrent.CompletableFuture.postFire(CompletableFuture.java:575) at java.util.concurrent.CompletableFuture$UniCompose.tryFire(CompletableFuture.java:943) at java.util.concurrent.CompletableFuture$Completion.run(CompletableFuture.java:456) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748)Caused by: org.apache.flink.runtime.client.JobExecutionException: Job execution failed. at org.apache.flink.runtime.jobmaster.JobResult.toJobExecutionResult(JobResult.java:147) at org.apache.flink.client.deployment.ClusterClientJobClientAdapter.lambda$null$6(ClusterClientJobClientAdapter.java:110) ... 19 moreCaused by: org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:110) at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:76) at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:192) at org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:186) at org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:180) at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:484) at org.apache.flink.runtime.jobmaster.JobMaster.updateTaskExecutionState(JobMaster.java:380) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:279) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:194) at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:152) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21) at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123) at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at akka.actor.Actor$class.aroundReceive(Actor.scala:517) at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592) at akka.actor.ActorCell.invoke(ActorCell.scala:561) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258) at akka.dispatch.Mailbox.run(Mailbox.scala:225) at akka.dispatch.Mailbox.exec(Mailbox.scala:235) at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)Caused by: java.lang.NoSuchMethodError: org.apache.flink.streaming.connectors.kafka.internal.KafkaConsumerThread.<init>(Lorg/slf4j/Logger;Lorg/apache/flink/streaming/connectors/kafka/internal/Handover;Ljava/util/Properties;Lorg/apache/flink/streaming/connectors/kafka/internals/ClosableBlockingQueue;Ljava/lang/String;JZLorg/apache/flink/metrics/MetricGroup;Lorg/apache/flink/metrics/MetricGroup;)V at org.apache.flink.streaming.connectors.kafka.internal.KafkaFetcher.<init>(KafkaFetcher.java:109) at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer.createFetcher(FlinkKafkaConsumer.java:237) at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:695) at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:100) at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:63) at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:196)[root@node3 flink]# MRS版本:3.0.2flink版本:1.10.0
-
【功能模块】在将flink任务提交到集群时,如果指定-yn参数,任务提交失败。【操作步骤&问题现象】1、使用Flink客户端提交flink任务,按照产品文档中提供的参数提交,任务失败。2、去掉-yn参数重新提交,提交成功。【截图信息】1,失败截图2,成功截图MRS版本:3.0.1flink版本:1.10.0
-
【功能模块】使用flink run命令提交任务报错【操作步骤&问题现象】1、在idea中编写程序,打包,部署到集群中。2、使用flink run提交任务,语句如下:./bin/flink run -yt conf/ssl/ -ys 4 -m yarn-cluster -c org.mytest.stream.StreamTest /opt/flink/flink.jar --host 10.10.10.10 --port 77773,查看yarn中,任务已经提交成功【截图信息】1,提交后报错截2、测试程序主要功能截图
-
【功能模块】mrs-flink【操作步骤&问题现象】1、使用per-job模式上传样例代码到集群上运行,执行FemaleInfoCollectionFromKafka这个样例;2、flink任务创建成功,但是任务执行时报错,显示KafkaConsumer的一个方法不存在。【截图信息】报错信息:客户端lib里已补充相关jar包,不知道具体缺少哪个?【日志信息】(可选,上传日志内容或者附件)org.apache.flink.runtime.JobException: Recovery is suppressed by NoRestartBackoffTimeStrategy at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.handleFailure(ExecutionFailureHandler.java:110) at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler.getFailureHandlingResult(ExecutionFailureHandler.java:76) at org.apache.flink.runtime.scheduler.DefaultScheduler.handleTaskFailure(DefaultScheduler.java:192) at org.apache.flink.runtime.scheduler.DefaultScheduler.maybeHandleTaskFailure(DefaultScheduler.java:186) at org.apache.flink.runtime.scheduler.DefaultScheduler.updateTaskExecutionStateInternal(DefaultScheduler.java:180) at org.apache.flink.runtime.scheduler.SchedulerBase.updateTaskExecutionState(SchedulerBase.java:484) at org.apache.flink.runtime.jobmaster.JobMaster.updateTaskExecutionState(JobMaster.java:380) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:279) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:194) at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:74) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:152) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:26) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:21) at scala.PartialFunction$class.applyOrElse(PartialFunction.scala:123) at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:21) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:170) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:171) at akka.actor.Actor$class.aroundReceive(Actor.scala:517) at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:225) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:592) at akka.actor.ActorCell.invoke(ActorCell.scala:561) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:258) at akka.dispatch.Mailbox.run(Mailbox.scala:225) at akka.dispatch.Mailbox.exec(Mailbox.scala:235) at akka.dispatch.forkjoin.ForkJoinTask.doExec(ForkJoinTask.java:260) at akka.dispatch.forkjoin.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1339) at akka.dispatch.forkjoin.ForkJoinPool.runWorker(ForkJoinPool.java:1979) at akka.dispatch.forkjoin.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:107)Caused by: java.lang.NoSuchMethodError: org.apache.flink.streaming.connectors.kafka.internal.KafkaConsumerThread.(Lorg/slf4j/Logger;Lorg/apache/flink/streaming/connectors/kafka/internal/Handover;Ljava/util/Properties;Lorg/apache/flink/streaming/connectors/kafka/internals/ClosableBlockingQueue;Ljava/lang/String;JZLorg/apache/flink/metrics/MetricGroup;Lorg/apache/flink/metrics/MetricGroup;)V at org.apache.flink.streaming.connectors.kafka.internal.KafkaFetcher.(KafkaFetcher.java:109) at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer.createFetcher(FlinkKafkaConsumer.java:237) at org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumerBase.run(FlinkKafkaConsumerBase.java:695) at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:100) at org.apache.flink.streaming.api.operators.StreamSource.run(StreamSource.java:63) at org.apache.flink.streaming.runtime.tasks.SourceStreamTask$LegacySourceFunctionThread.run(SourceStreamTask.java:196)
-
【功能模块】mrs的flink【操作步骤&问题现象】1、执行启动flink集群脚本:./bin/yarn-session.sh -t ssl/ -n 22、显示报错:org.apache.flink.client.deployment.ClusterDeploymentException: Couldn't deploy Yarn session cluster at org.apache.flink.yarn.YarnClusterDescriptor.deploySessionCluster(YarnClusterDescriptor.java:380) at org.apache.flink.yarn.cli.FlinkYarnSessionCli.run(FlinkYarnSessionCli.java:551) at org.apache.flink.yarn.cli.FlinkYarnSessionCli.lambda$main$7(FlinkYarnSessionCli.java:789) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1761) at org.apache.flink.runtime.security.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.yarn.cli.FlinkYarnSessionCli.main(FlinkYarnSessionCli.java:789)Caused by: org.apache.flink.yarn.YarnClusterDescriptor$YarnDeploymentException: The YARN application unexpectedly switched to state FAILED during deployment. Diagnostics from YARN: Application application_1624785727989_0098 failed 2 times in previous 10000 milliseconds due to AM Container for appattempt_1624785727989_0098_000002 exited with exitCode: 1Failing this attempt.Diagnostics: [2021-07-09 15:44:51.047]Exception from container-launch.Container id: container_e02_1624785727989_0098_02_000001Exit code: 1Exception message: Launch container failedShell output: main : command provided 13.后台日志显示初始化cluster entrypoint失败: Could not start cluster entrypoint YarnSessionClusterEntrypoint. | org.apache.flink.runtime.entrypoint.ClusterEntrypoint (ClusterEntrypoint.java:520) org.apache.flink.runtime.entrypoint.ClusterEntrypointException: Failed to initialize the cluster entrypoint YarnSessionClusterEntrypoint.【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
pom文件导入的华为依赖包,运行flink java的样例demo或者自己写的wordcount使用本地环境的demo时均报如下错误:Exception in thread "main" com.typesafe.config.ConfigException$UnresolvedSubstitution: reference.conf @ jar:file:/E:/tools/.m2/repository/org/apache/flink/flink-runtime_2.11/1.10.0-hw-ei-302002/flink-runtime_2.11-1.10.0-hw-ei-302002.jar!/reference.conf: 875: Could not resolve substitution to a value: ${akka.stream.materializer}自己单独新建工程使用官方flink依赖跑wordcount样例程序正常。
-
问题描述:请问专家当前FI版本的flink1.10在使用HiveCatlog如何进行zookeeper的鉴权认证?如有示例代码能提供最好,谢谢了。官网的代码如下,但是未发现有鉴权相关的类或者方法:EnvironmentSettings settings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build(); TableEnvironment tableEnv = TableEnvironment.create(settings); String name = "myhive"; String defaultDatabase = "mydatabase"; String hiveConfDir = "/opt/hive-conf"; // a local path String version = "2.3.4"; HiveCatalog hive = new HiveCatalog(name, defaultDatabase, hiveConfDir, version); tableEnv.registerCatalog("myhive", hive); // set the HiveCatalog as the current catalog of the session tableEnv.useCatalog("myhive");在flink集群上面访问zookeeper后面的hive该如何鉴权认证呀?
-
flink提交测试程序wordCount能正常跑,自己写的flink消费kafka写hive的任务打包上去报如下错误:运行脚本如下:flink run --detached -m yarn-cluster \ -ynm test_real_time1 \ -c com.xxxx.xxxxx1.FlinkKafka2Hive \ ./DataCollectorRealTime-1.0-SNAPSHOT.jar config运维跟我说有可能是jar冲突,请问有可能是jar包冲突吗?另外尝试过使用如下参数提交任务,没有效果:-D java.security.auth.login.config "/data01/BigData/data1/FusionInsight/client/Kafka/kafka/config/jaas.conf" \-D zookeeper.server.principal "zookeeper/xxxx.xxxx1" \-D java.security.krb5.conf "/data01/BigData/data1/FusionInsight/keytab/krb5.conf" \求助解决办法
-
【功能模块】【mrs.6.5.1 】【flink 引入第三方jar包 】flink 怎么配置第三方jar包? flink 版本1.7.2 commit id:3ff30be【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】FI集群的flink 是开启的Kerberos认证 再flink-conf.yml中配置过的。现在需要用flink消费另外一个集群中开启Kerberos认证的kafka 拿到了kafka集群的的认证文件 krb5.conf jaas.conf user.keytab。【操作步骤&问题现象】1、整个flink应用是需要自己集群的认证 ,怎么在一个flink程序中认证另外一个kafka ,将其当作该Flink应用的source源,然后处理呢?拜托各位大佬提供一下处理思路!
-
请问MRS8.1.0.1 版本 flink可以读写hudi文件吗?
上滑加载中
推荐直播
-
 华为云码道-玩转OpenClaw,在线养虾
华为云码道-玩转OpenClaw,在线养虾2026/03/11 周三 19:00-21:00
刘昱,华为云高级工程师/谈心,华为云技术专家/李海仑,上海圭卓智能科技有限公司CEO
OpenClaw 火爆开发者圈,华为云码道最新推出 Skill ——开发者只需输入一句口令,即可部署一个功能完整的「小龙虾」智能体。直播带你玩转华为云码道,玩转OpenClaw
回顾中 -
 华为云码道-AI时代应用开发利器
华为云码道-AI时代应用开发利器2026/03/18 周三 19:00-20:00
童得力,华为云开发者生态运营总监/姚圣伟,华为云HCDE开发者专家
本次直播由华为专家带你实战应用开发,看华为云码道(CodeArts)代码智能体如何在AI时代让你的创意应用快速落地。更有华为云HCDE开发者专家带你用码道玩转JiuwenClaw,让小艺成为你的AI助理。
回顾中 -
 Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案
Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案2026/03/25 周三 19:00-20:00
余伟,华为云软件研发工程师/万邵业(万少),华为云HCDE开发者专家
本次直播带来两大实战:华为云码道 Skill-Creator 手把手搭建专属知识库 Skill;如何用码道提效 OpenClaw 小说文本,打造从大纲到成稿的 AI 原创小说全链路。技术干货 + OPC创作思路,一次讲透!
回顾中
热门标签