-
 feifei_active
发表于2021-12-11 13:10:05
2021-12-11 13:10:05
最后回复
feifei_active
2021-12-11 13:10:05
3222 0
feifei_active
发表于2021-12-11 13:10:05
2021-12-11 13:10:05
最后回复
feifei_active
2021-12-11 13:10:05
3222 0 -
转载来源:中华网https://tech.china.com/article/20211105/112021_917283.html中小微企业为申请银行贷款跑断腿?税务、人社、住建、水、电……为了给企业有更好的信用建模,需要向不同的机构申请不同维度的数据,流程冗长复杂,让人望而生畏。探索和发现新的药物,需要结合多家医疗和科研机构的基因、临床、药物数据,可是这些样本数据散落在不同医疗和科研机构手中,有的数据不能共享,有的不愿意共享。货物运输,由于苏伊士运河堵塞,需要快速为公司梳理出受到影响的货物和客户,以及快速给出备份方案,可是合同、研发、供应链、部件等数据位于企业内外不同的系统中,想要短时间盘点出来简直困难重重。……数据要素的重要性已毋庸置疑,但是如果无法流通起来,就像上面例子所示,就会大大制约经济社会的数字化发展进程,难以充分开发出数据价值。政企数据可信流通存难题当前,在政府和企业的信息化系统中,普遍存在着应用“烟囱”和数据孤岛现象。在政府,委办局之间、甚至委办局内部不同科室都可能存在数据割裂现象;在企业,不同职能部门、分支机构、投资公司,都可能有着自己的应用系统、数据库和大数据平台。究其原因,政企或是出于对数据保护的考虑,亦或是组织管理机制的问题,信息系统设计的限制,导致不同部门之间的数据共享和流通存在巨大障碍。各类机构对于数据流通顾虑重重,就容易造成数据的重复采集、冗余开发和信息不完整,带来决策分析不准确、甚至决策失误等问题。数据即资产,既希望实现数据的高安全可信,也希望通过数据流通创造要素价值,二者要兼得。那么,能否构建可信的数据流通价值链,让各方可以把自己的数据在自己的信任域中进行可信计算,再将结果加密汇聚起来进行整合计算,实现“数据可用不可见,可控可计量”?华为云TICS让“鱼”与“熊掌”兼得在这样的大背景下,华为云在今年推出FusionInsight可信智能计算服务TICS,目标实现数据的可信流通和计算。比如将原始明细数据控制在所属方的信任域,同时又通过互信联盟实现了多方数据的联邦计算,从而将散落在不同机构的数据联合起来,转换成有价值的信息或模型,实现数据流通。华为云FusionInsight可信智能计算服务TICS框架该服务基于华为可信流程打造,通过了信通院和人民银行金标委等权威机构在联邦学习、安全多方计算、可信执行环境等方向的认证,作为中立第三方,旨在为政府、金融、消费、医疗、工业等领域提供可信智能计算平台。华为云FusionInsight可信智能计算服务TICS并不是一项单一的技术,而是一套理论框架和技术体系,是大数据、密码学、人工智能、区块链、可信硬件、安全容器等领域的交叉和融合。在多方数据库联合查询场景中,平台既要做到保护敏感明细数据,又要实现多方数据库的联邦统计分析。在多方样本或特征的联合建模场景中,平台既要对敏感ID和特征进行保护,又要把多方样本或特征联合起来训练出更好的模型。这个过程中华为云FusionInsight可信智能计算服务TICS会为各参与方提供全生命周期的监控和管理,TICS和华为云区块链服务紧密配合,进行数据管理和计算过程的确权和存证,做到整个计算过程可追踪可审计。华为云FusionInsight可信智能计算服务TICS极具开放性。囊括行业主流算法,支持3大任务场景、7大类可信技术、60+原子化算子,根据最佳实践,会为计算任务匹配选择最优协议组合;具有丰富的集成对接能力,开放了80+北向接口,支持与伙伴一起打造联合解决方案;支持丰富的部署形态,包括华为公有云、混合云、智能边缘、华为云金融专区等,满足不同行业和组织的合规需求。华为云FusionInsight可信智能计算服务TICS还提供多种专利技术,保障数据安全,提升计算效率。例如,将联邦SQL与多方安全计算技术深度融合,实现SQL执行前、执行中、执行结果的全流程安全保护;再如,TICS具备多层级自适应的ID求交能力,能够满足数十亿量级ID的求交,从7小时提升到30 分钟。2021年,《数据安全法》和《个人信息保护法》相继生效,为数据的开发利用和安全保护提供了规范和指引。为充分发挥数据价值,实现可持续发展,政企等组织在保护数据安全和个人信息的前提下实现数据要素流通就显得至关重要。尤其是关系到国计民生的重要领域,迫切需要破解数据孤岛难题,实现数据可信流通。华为云FusionInsight可信智能计算服务TICS的推出,让“鱼”和“熊掌”兼得成为可能。
feifei_active
发表于2021-12-11 12:18:38
2021-12-11 12:18:38
最后回复
feifei_active
2021-12-11 12:18:38
3576 0
-
 Spark的小文件合并是否走merge,如果不走merge的话,Spark是否有自动合并小文件的方法?
Spark的小文件合并是否走merge,如果不走merge的话,Spark是否有自动合并小文件的方法? -
当前通过Rest API端口调用删除GrapHbase的一个边,发现该删除操作提交的是一个MR任务,使用的是default队列,但是default队列没有资源,导致该任务一直处于挂起状态,当前想知道如何在代码中修改调用的这个默认队列为指定队列。删除边代码调用如下:客户用户进行的任务提交打印:yarn原生界面上显示的该任务是graphbase用户提交的,使用的default队列:针对yarn上的提交任务,当前有如下问题:1. 为什么rest调用 登录用户与yarn界面任务提交用户不一样?2. 针对使用的default默认队列在代码中该如何配置为指定队列?
-
针对当前金融各局点安全扫描排查出来的sudo提取问题,想知道集群上哪些操作涉及到了sudo提权,需要举例说明(涉及的操作场景以及执行命令),可以的话请提供资料支持。
-
转载来源:凤凰网https://tech.ifeng.com/c/8Au4D82w9la解读华为云FusionInsight可信智能计算服务TICS中小微企业为申请银行贷款跑断腿?税务、人社、住建、水、电……为了给企业有更好的信用建模,需要向不同的机构申请不同维度的数据,流程冗长复杂,让人望而生畏。探索和发现新的药物,需要结合多家医疗和科研机构的基因、临床、药物数据,可是这些样本数据散落在不同医疗和科研机构手中,有的数据不能共享,有的不愿意共享。货物运输,由于苏伊士运河堵塞,需要快速为公司梳理出受到影响的货物和客户,以及快速给出备份方案,可是合同、研发、供应链、部件等数据位于企业内外不同的系统中,想要短时间盘点出来简直困难重重。……数据要素的重要性已毋庸置疑,但是如果无法流通起来,就像上面例子所示,就会大大制约经济社会的数字化发展进程,难以充分开发出数据价值。政企数据可信流通存难题当前,在政府和企业的信息化系统中,普遍存在着应用“烟囱”和数据孤岛现象。在政府,委办局之间、甚至委办局内部不同科室都可能存在数据割裂现象;在企业,不同职能部门、分支机构、投资公司,都可能有着自己的应用系统、数据库和大数据平台。究其原因,政企或是出于对数据保护的考虑,亦或是组织管理机制的问题,信息系统设计的限制,导致不同部门之间的数据共享和流通存在巨大障碍。各类机构对于数据流通顾虑重重,就容易造成数据的重复采集、冗余开发和信息不完整,带来决策分析不准确、甚至决策失误等问题。数据即资产,既希望实现数据的高安全可信,也希望通过数据流通创造要素价值,二者要兼得。那么,能否构建可信的数据流通价值链,让各方可以把自己的数据在自己的信任域中进行可信计算,再将结果加密汇聚起来进行整合计算,实现“数据可用不可见,可控可计量”?华为云TICS让“鱼”与“熊掌”兼得在这样的大背景下,华为云在今年推出FusionInsight可信智能计算服务TICS,目标实现数据的可信流通和计算。比如将原始明细数据控制在所属方的信任域,同时又通过互信联盟实现了多方数据的联邦计算,从而将散落在不同机构的数据联合起来,转换成有价值的信息或模型,实现数据流通。华为云FusionInsight可信智能计算服务TICS框架该服务基于华为可信流程打造,通过了信通院和人民银行金标委等权威机构在联邦学习、安全多方计算、可信执行环境等方向的认证,作为中立第三方,旨在为政府、金融、消费、医疗、工业等领域提供可信智能计算平台。华为云FusionInsight可信智能计算服务TICS并不是一项单一的技术,而是一套理论框架和技术体系,是大数据、密码学、人工智能、区块链、可信硬件、安全容器等领域的交叉和融合。在多方数据库联合查询场景中,平台既要做到保护敏感明细数据,又要实现多方数据库的联邦统计分析。在多方样本或特征的联合建模场景中,平台既要对敏感ID和特征进行保护,又要把多方样本或特征联合起来训练出更好的模型。这个过程中华为云FusionInsight可信智能计算服务TICS会为各参与方提供全生命周期的监控和管理,TICS和华为云区块链服务紧密配合,进行数据管理和计算过程的确权和存证,做到整个计算过程可追踪可审计。华为云FusionInsight可信智能计算服务TICS极具开放性。囊括行业主流算法,支持3大任务场景、7大类可信技术、60+原子化算子,根据最佳实践,会为计算任务匹配选择最优协议组合;具有丰富的集成对接能力,开放了80+北向接口,支持与伙伴一起打造联合解决方案;支持丰富的部署形态,包括华为公有云、混合云、智能边缘、华为云金融专区等,满足不同行业和组织的合规需求。华为云FusionInsight可信智能计算服务TICS还提供多种专利技术,保障数据安全,提升计算效率。例如,将联邦SQL与多方安全计算技术深度融合,实现SQL执行前、执行中、执行结果的全流程安全保护;再如,TICS具备多层级自适应的ID求交能力,能够满足数十亿量级ID的求交,从7小时提升到30 分钟。2021年,《数据安全法》和《个人信息保护法》相继生效,为数据的开发利用和安全保护提供了规范和指引。为充分发挥数据价值,实现可持续发展,政企等组织在保护数据安全和个人信息的前提下实现数据要素流通就显得至关重要。尤其是关系到国计民生的重要领域,迫切需要破解数据孤岛难题,实现数据可信流通。华为云FusionInsight可信智能计算服务TICS的推出,让“鱼”和“熊掌”兼得成为可能。
-
【功能模块】FusionInsight HD 6.5.1.7 hive【操作步骤&问题现象】1、select from a where id = '123456' ,实际查出来的id为1237892、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】FusionInsight C70 集群,使用默认的 Hive 配置(MR引擎)客户有许多hive表,然后在上面创建视图,对外使用的时候通过视图来访问,这样底层改变的话,不影响上层应用。【操作步骤&问题现象】因为使用视图,所以发现一些查询条件无法被利用到做分区过滤,导致 hive 启动大量的 task (可能上万);而其实很多文件/目录下没有合适的数据,所以许多任务执行时间很短;但是启动这么多 task 的资源浪费是比较严重的,导致许多的调度开销和任务等待。受环境管控,无法提供日志或截图。【问题】FI 是否支持和建议使用 Tez 引擎?什么情况下建议开启?除了使用 Tez 引擎,是否有其它优化手段?是否 view 支持分区列声明和查询条件下压?希望能得到指导,感谢!
-
我配置了一个24小时更新一次MetaData元数据信息的操作,当前在查看更新成功的元数据信息文件时发现一个问题:更新配置如下:NN原生界面上MetaData元数据更新文件时间:HUE原生界面查看Metadata元数据更新文件时间:想知道这个是更新元数据执行了12个小时,还是说hue上时间显示有问题?
-
我配置了一个24小时更新一次MetaData元数据信息的操作,当前在查看更新成功的元数据信息文件时发现一个问题:更新配置如下:NN原生界面上MetaData元数据更新文件时间:HUE原生界面查看Metadata元数据更新文件时间:想知道这个是更新元数据执行了12个小时,还是说hue上时间显示有问题?
-
求助,Fusioninsight6.5.1集群如何升级。背景:xEngine产品团队监测到apache官方发布HTTP Server安全更新,FI集群使用到Apache HTTP Server2.4.39,需要升级到2.4.48需求:想要寻求FI集群升级的方法,或者单独升级Apache HTTP Server的方法。
-
 # 华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习 ## 背景说明 随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。 SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎自1.7.2版本开始引入Flink SQL的特性,并不断发展。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。 但是真正的要将Flink SQL开发工作投入到实际的生产场景中,如果使用原生的API接口进行作业的开发还是存在门槛较高,易用性低,SQL代码可维护性差的问题。新需求由业务人员提交给IT人员,IT人员排期开发。从需求到上线,周期长,导致错失新业务最佳市场时间窗口。同时,IT人员工作繁重,大量相似Flink作业,成就感低。 ## 华为Flink可视化开发平台FlinkServer优势: - 提供基于Web的可视化开发平台,只需要写SQL即可开发作业,极大降低作业开发门槛。 - 通过作业平台能力开放,支持业务人员自行编写SQL开发作业,快速应对需求,并将IT人员从繁琐的Flink作业开发工作中解放出来; - 同时支持流作业和批作业; - 支持常见的Connector,包括Kafka、Redis、HDFS等 下面将以kafka为例分别使用原生API接口以及FlinkServer进行作业开发,对比突出FlinkServer的优势 ## 场景说明 参考已发论坛帖 [《华为FusionInsight MRS FlinkSQL 复杂嵌套Json解析最佳实践》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=153494) 需要使用FlinkSQL从一个源kafka topic接收cdl复杂嵌套json数据并进行解析,将解析后的数据发送到另一个kafka topic里 ## 使用原生API接口方案开发flink sql操作步骤 ### 前提条件 - 完成MRS Flink客户端的安装以及配置 - 完成Flink SQL原生接口相关配置 ### 操作步骤 - 使用如下命令首先启动Flink集群 ``` source /opt/hadoopclient/bigdata_env kinit developuser cd /opt/hadoopclient/Flink/flink ./bin/yarn-session.sh -t ssl/ ```  - 使用如下命令启动Flink SQL Client ``` cd /opt/hadoopclient/Flink/flink/bin ./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml ```  - 使用如下flink sql创建源端kafka表,并提取需要的信息: ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); ``` 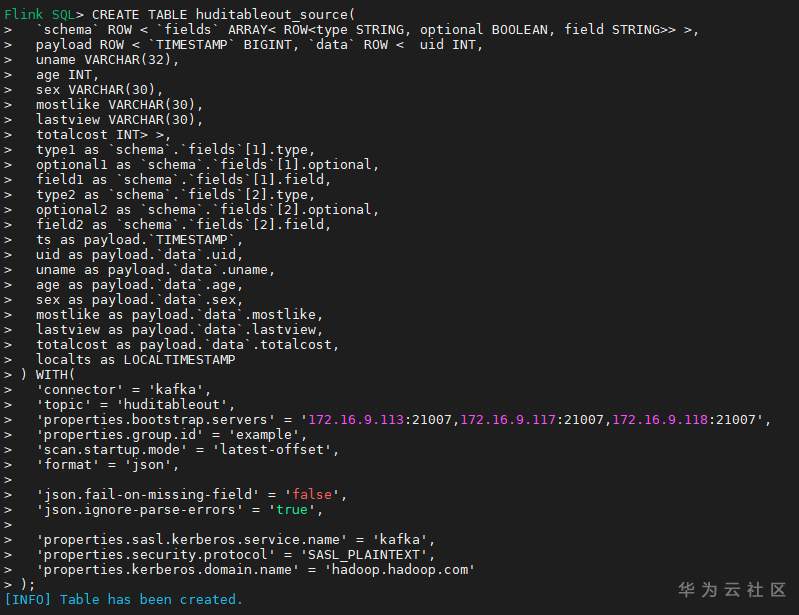 - 使用如下flink sql创建目标端kafka表: ``` CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); ``` 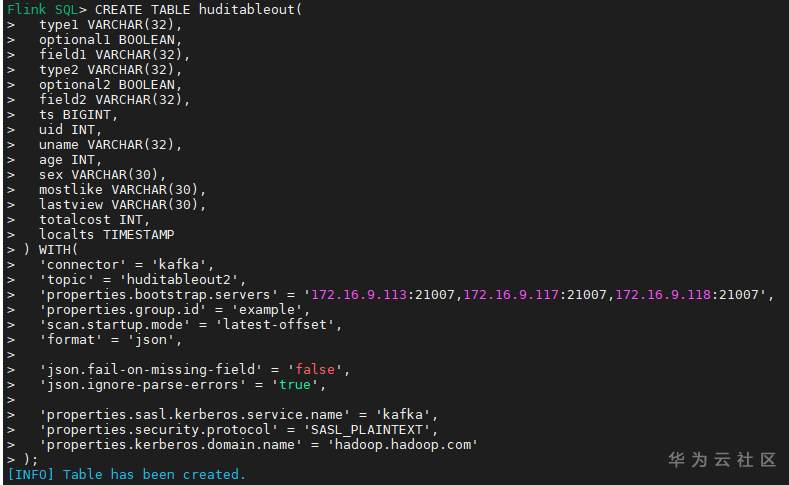 - 使用如下flink sql将源端kafka流表写入到目标端kafka流表中 ``` insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ``` 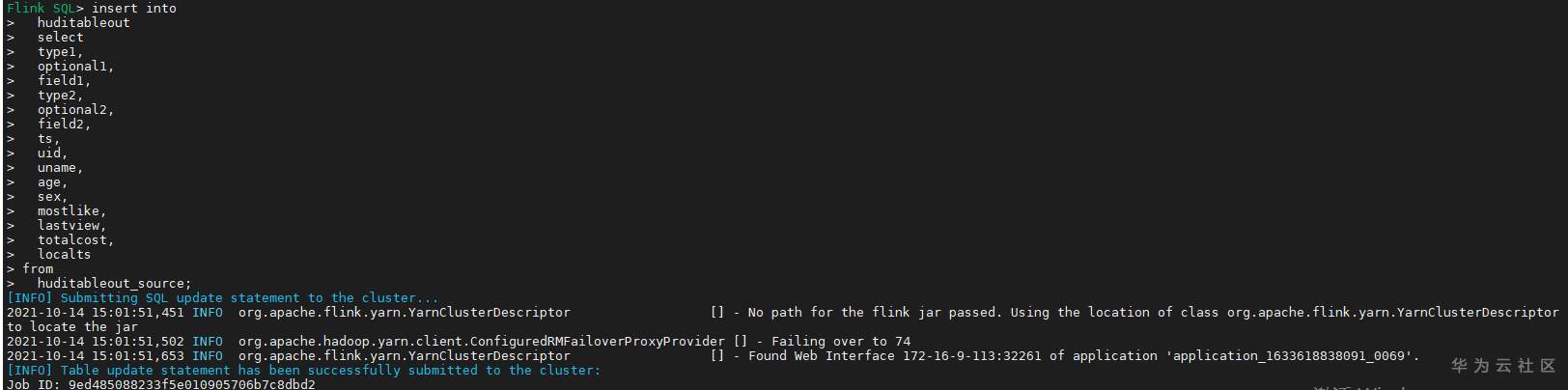 - 检查测试结果 消费生产源kafka topic的数据(由cdl生成)  消费目标端kafka topic解析后的数据(flink sql任务生成的结果)  可以登录flink原生界面查看任务 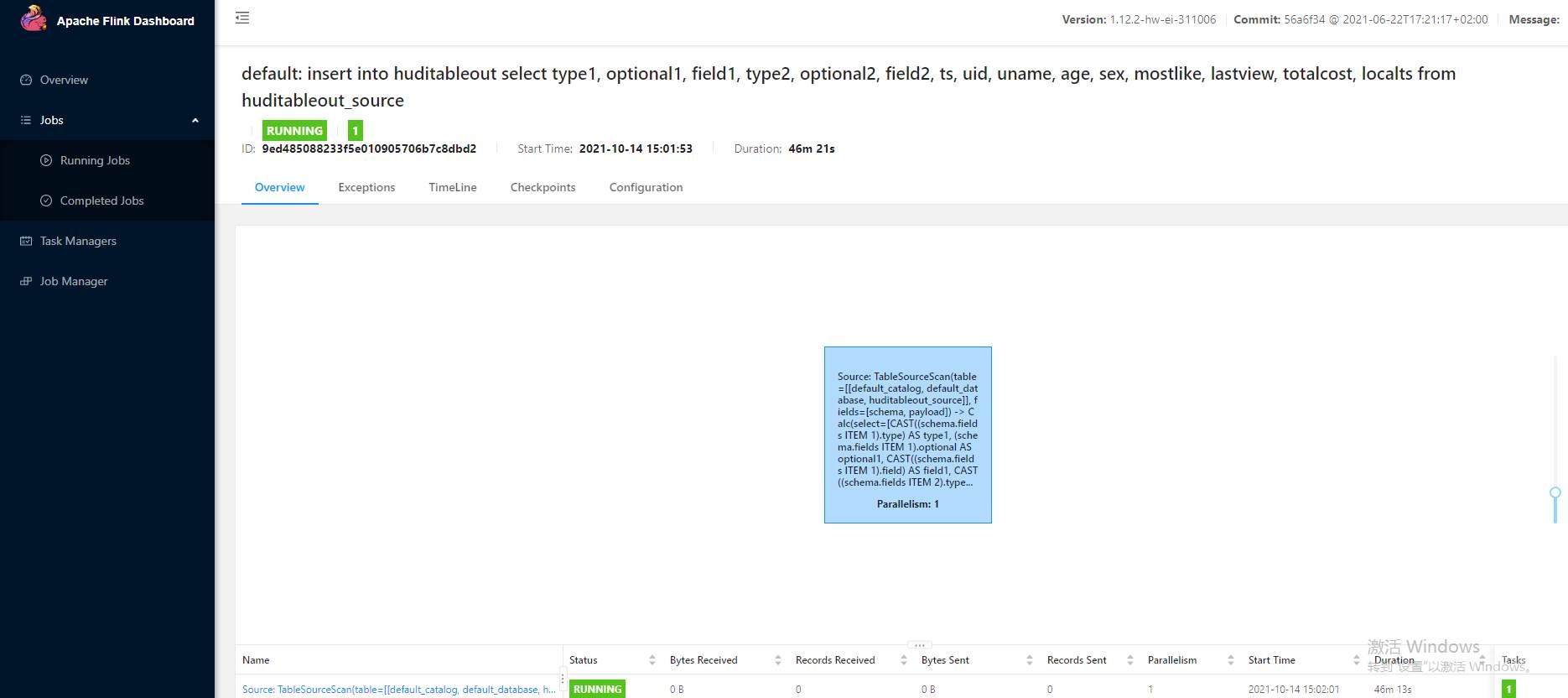 - 使用flink sql client方式查看结果 首先使用命令`set execution.result-mode=tableau;` 可以让查询结果直接输出到终端  使用flink sql查询上面已创建好的流表 `select * from huditableout`  注意:因为是kafka流表,所以查询结果只会显示select任务启动之后写进该topic的数据 ## 使用FlinkServer可视化开发平台方案开发flink sql操作步骤 ### 前提条件 - 参考产品文档 《基于用户和角色的鉴权》章节创建一个具有“FlinkServer管理操作权限”的用户,使用该用户访问Flink Server ### 操作步骤 - 登录FlinkServer选择作业管理 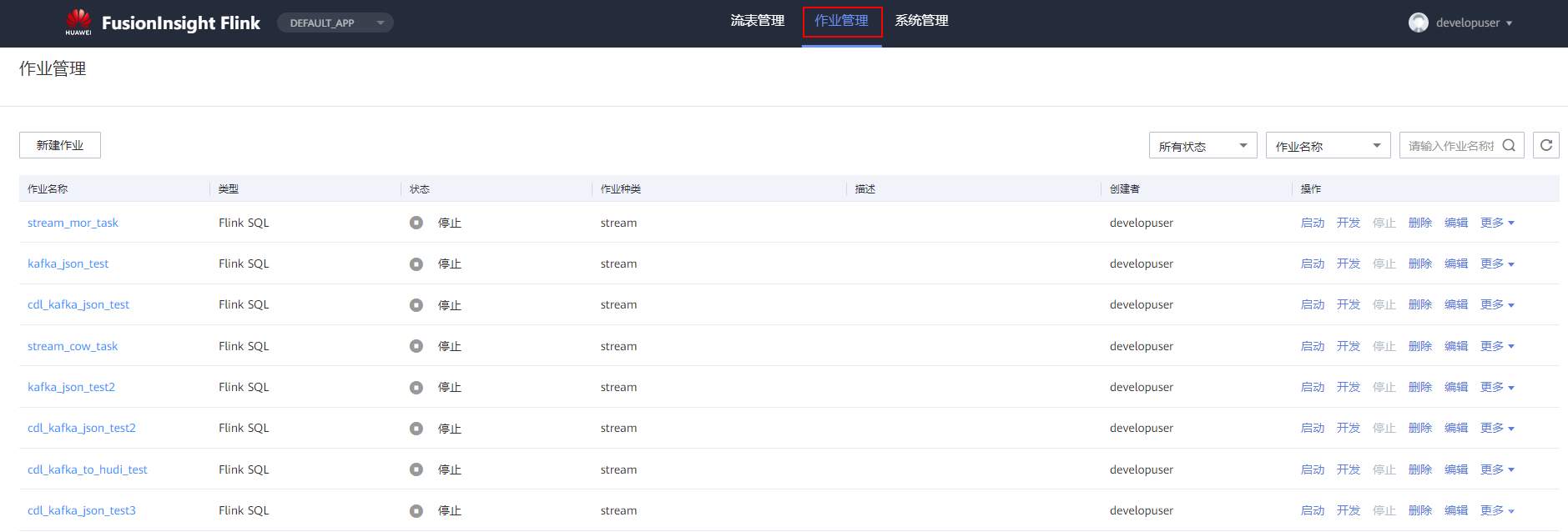 - 创建任务cdl_kafka_json_test3并输入flink sql 说明: 可以看到开发flink sql任务时在FlinkServer界面可以自行设置flink集群规模 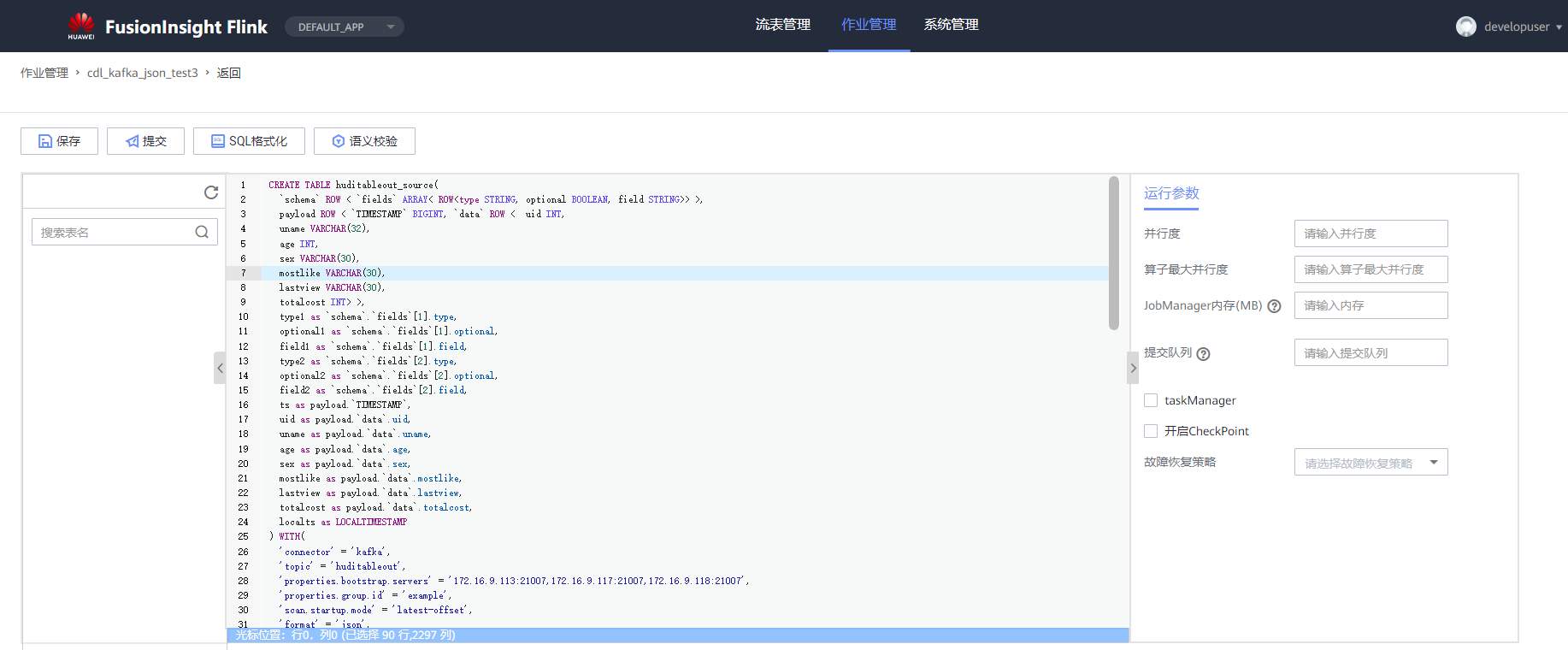 ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ``` - 点击语义校验,确保语义校验通过 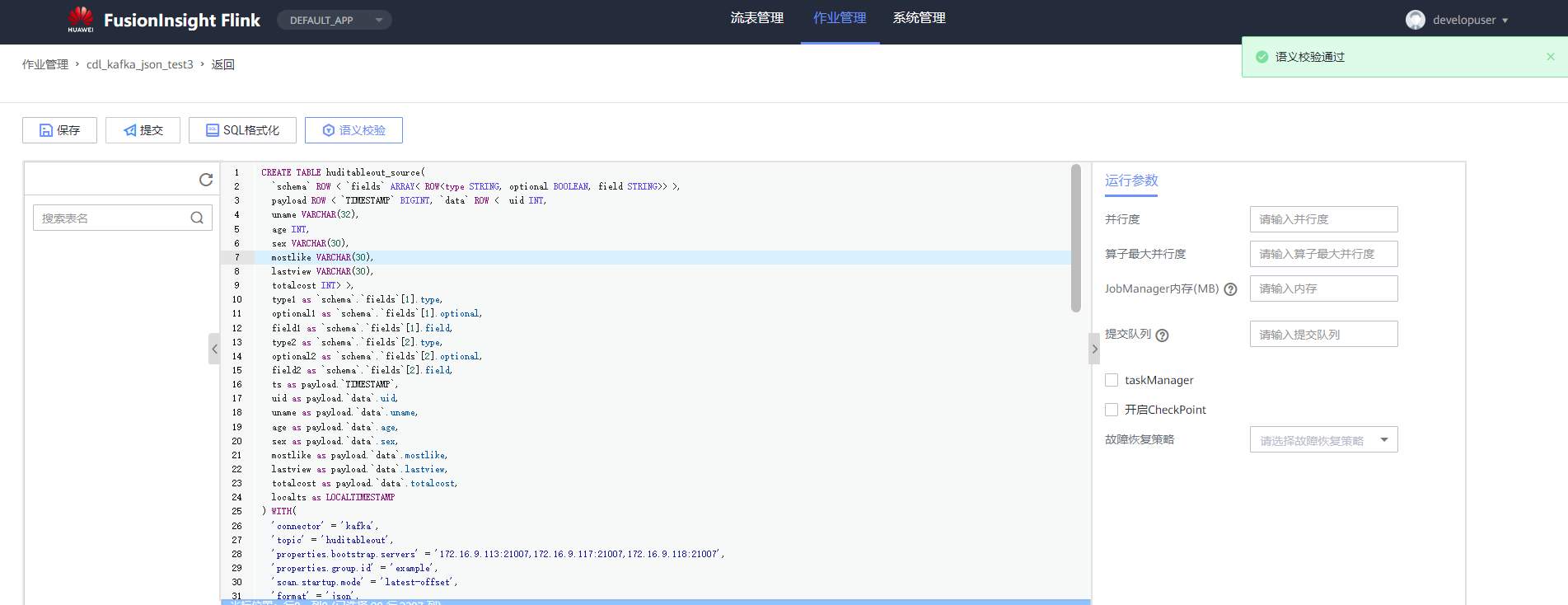 - 点击提交并启动任务 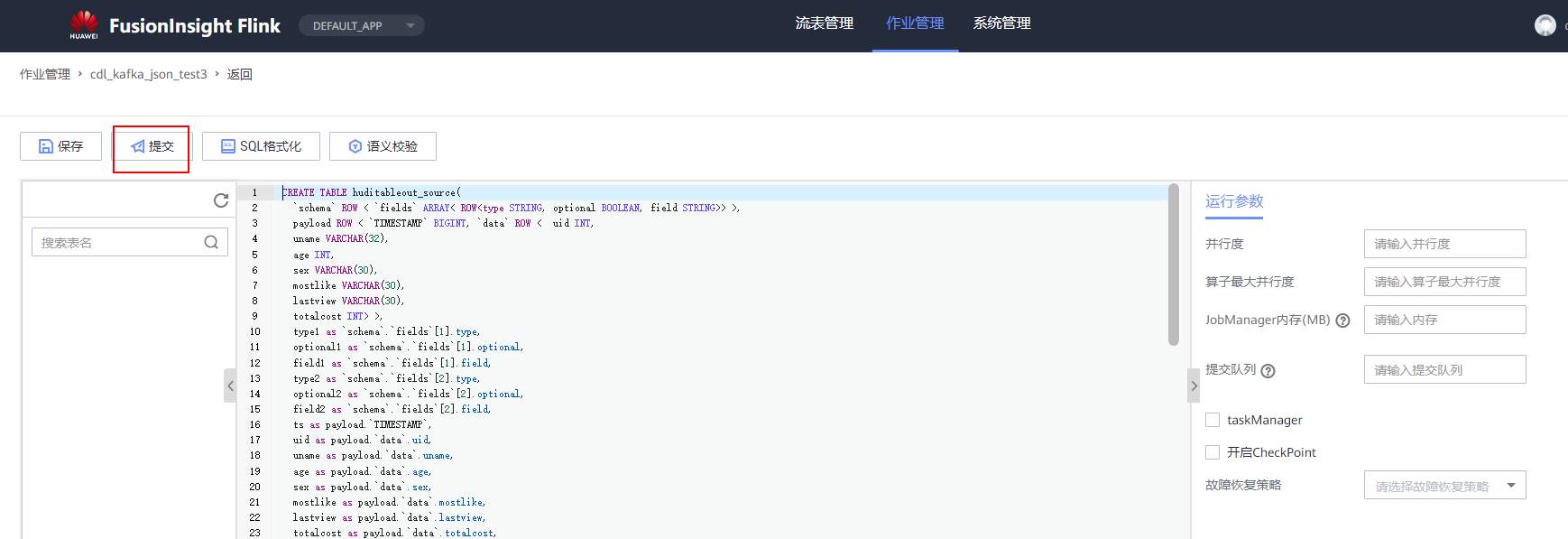 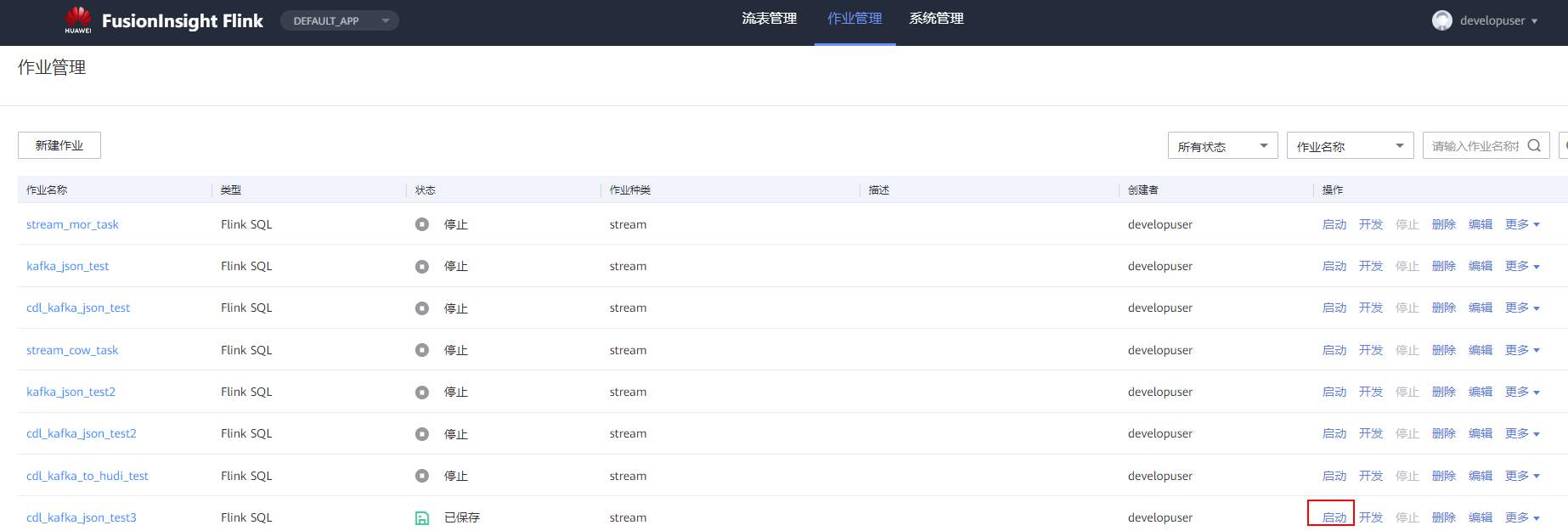 - 检查测试结果 消费生产源kafka topic的数据(由cdl生成)  消费目标端kafka topic解析后的数据(flink sql任务生成的结果) 
# 华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习 ## 背景说明 随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。 SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎自1.7.2版本开始引入Flink SQL的特性,并不断发展。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。 但是真正的要将Flink SQL开发工作投入到实际的生产场景中,如果使用原生的API接口进行作业的开发还是存在门槛较高,易用性低,SQL代码可维护性差的问题。新需求由业务人员提交给IT人员,IT人员排期开发。从需求到上线,周期长,导致错失新业务最佳市场时间窗口。同时,IT人员工作繁重,大量相似Flink作业,成就感低。 ## 华为Flink可视化开发平台FlinkServer优势: - 提供基于Web的可视化开发平台,只需要写SQL即可开发作业,极大降低作业开发门槛。 - 通过作业平台能力开放,支持业务人员自行编写SQL开发作业,快速应对需求,并将IT人员从繁琐的Flink作业开发工作中解放出来; - 同时支持流作业和批作业; - 支持常见的Connector,包括Kafka、Redis、HDFS等 下面将以kafka为例分别使用原生API接口以及FlinkServer进行作业开发,对比突出FlinkServer的优势 ## 场景说明 参考已发论坛帖 [《华为FusionInsight MRS FlinkSQL 复杂嵌套Json解析最佳实践》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=153494) 需要使用FlinkSQL从一个源kafka topic接收cdl复杂嵌套json数据并进行解析,将解析后的数据发送到另一个kafka topic里 ## 使用原生API接口方案开发flink sql操作步骤 ### 前提条件 - 完成MRS Flink客户端的安装以及配置 - 完成Flink SQL原生接口相关配置 ### 操作步骤 - 使用如下命令首先启动Flink集群 ``` source /opt/hadoopclient/bigdata_env kinit developuser cd /opt/hadoopclient/Flink/flink ./bin/yarn-session.sh -t ssl/ ```  - 使用如下命令启动Flink SQL Client ``` cd /opt/hadoopclient/Flink/flink/bin ./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml ```  - 使用如下flink sql创建源端kafka表,并提取需要的信息: ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); ```  - 使用如下flink sql创建目标端kafka表: ``` CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); ```  - 使用如下flink sql将源端kafka流表写入到目标端kafka流表中 ``` insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ```  - 检查测试结果 消费生产源kafka topic的数据(由cdl生成)  消费目标端kafka topic解析后的数据(flink sql任务生成的结果)  可以登录flink原生界面查看任务  - 使用flink sql client方式查看结果 首先使用命令`set execution.result-mode=tableau;` 可以让查询结果直接输出到终端  使用flink sql查询上面已创建好的流表 `select * from huditableout`  注意:因为是kafka流表,所以查询结果只会显示select任务启动之后写进该topic的数据 ## 使用FlinkServer可视化开发平台方案开发flink sql操作步骤 ### 前提条件 - 参考产品文档 《基于用户和角色的鉴权》章节创建一个具有“FlinkServer管理操作权限”的用户,使用该用户访问Flink Server ### 操作步骤 - 登录FlinkServer选择作业管理  - 创建任务cdl_kafka_json_test3并输入flink sql 说明: 可以看到开发flink sql任务时在FlinkServer界面可以自行设置flink集群规模  ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ``` - 点击语义校验,确保语义校验通过  - 点击提交并启动任务   - 检查测试结果 消费生产源kafka topic的数据(由cdl生成)  消费目标端kafka topic解析后的数据(flink sql任务生成的结果)  -
 9月23日至25日,华为全联接2021以“深耕数字化”为主题,各行业领军人物分享最新成果与实践。其中在“华为云Stack构筑繁荣行业生态,让伙伴用好云”专题演讲中,永洪科技副总裁石虎,发表“永洪BI携手华为云FusionInsight,让数据分析更敏捷”演讲。永洪科技大数据BI解决方案以华为云FusionInsight智能数据湖为平台,实现海量数据的多维度、多层级、多粒度的数据分析,帮助政企客户实现从目标结果管理到过程管理,从“能看”向“能管”演进,助力政务、金融、制造、零售、电力、教育等各行业实现数据应用“全行业覆盖,多场景提升”。永洪BI携手FusionInsight已为各行业提供多款大数据BI联合解决方案,依托FusionInsight MRS三湖一集市能力,提供GB~PB级数据的可视化分析、多模分析和实时分析能力,实现PB级数据关联分析秒级响应的极致体验。在某大型国有银行转型大数据云服务的过程中,通过敏捷BI联合解决方案迁移了PB级数据,由传统的一体机模式,转型为开放可扩展的分布式架构。2021年4月,永洪科技携手华为在华为苏州研究所正式发布金融大数据分析平台联合解决方案,为金融行业搭建一个“高扩展性、响应快速、业务全面”的智慧运营分析平台。目前,华为与永洪BI已完成互通测试,在营销、反欺诈等典型场景中完成验证,实现在大型国有银行中的落地应用。同时,该解决方案通过引入MRS HetuEngine数据虚拟化引擎进一步提升“交互式查询”性能。在对某集团及分公司上万业务目标的应用中,原Hive查询一张数据表需耗时几分钟,甚至出现“千行数据半小时都不出结果”的问题,通过HetuEngine,将交互式查询从分钟级缩短至秒级,提升业务决策效率。在风险管控领域,双方携手打造的金融大数据联合解决方案,总结某行反欺诈风险领域的防控经验,并结合FusionInsight团队和永洪自身的金融大数据解决方案优势,通过智慧可视化分析平台的建设,实现风险预警自动化,风险处置流程化,帮助该银行完善了事前防控、事中控制和事后分析与处置为一体的风控体系。时至今日,BI可视化数据分析已是数字化转型过程中的刚需,永洪科技和华为云FusionInsight团队,凭借双方团队的技术实力和联合解决方案的不断创新,得到各行业的广泛认可。2020年,IDC MarketScape中国大数据管理平台评估报告中,华为云凭借FusionInsight不断创新,位居“领导者(Leaders)”象限,并在市场份额和技术实力两个维度双领先;2021年,IDC发布的中国大数据平台市场研究报告中,华为云凭借FusionInsight智能数据湖在政企行业的实践积累以及ICT市场的整体生态,位居市场份额第一。而永洪科技也已连续五年被评为敏捷BI领域第一名,在爱分析《2021年中国BI商业智能报告》中显示,永洪BI在Top20银行客户覆盖率达80%,在金融、制造领域的市场占有率第一。永洪科技拥有1000+家合作伙伴,6000+家企业客户,涵盖了金融、制造、零售、能源、政府、教育等近20个中国支柱产业及新经济产业。未来,永洪科技将和华为云FusionInsight将强强联合,进一步深化合作,倾力打造更敏捷、更快速、更强大的大数据BI联合创新解决方案,让数据分析更敏捷,实现“释放数据价值,人人都是数据分析师”的宏大愿景。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
9月23日至25日,华为全联接2021以“深耕数字化”为主题,各行业领军人物分享最新成果与实践。其中在“华为云Stack构筑繁荣行业生态,让伙伴用好云”专题演讲中,永洪科技副总裁石虎,发表“永洪BI携手华为云FusionInsight,让数据分析更敏捷”演讲。永洪科技大数据BI解决方案以华为云FusionInsight智能数据湖为平台,实现海量数据的多维度、多层级、多粒度的数据分析,帮助政企客户实现从目标结果管理到过程管理,从“能看”向“能管”演进,助力政务、金融、制造、零售、电力、教育等各行业实现数据应用“全行业覆盖,多场景提升”。永洪BI携手FusionInsight已为各行业提供多款大数据BI联合解决方案,依托FusionInsight MRS三湖一集市能力,提供GB~PB级数据的可视化分析、多模分析和实时分析能力,实现PB级数据关联分析秒级响应的极致体验。在某大型国有银行转型大数据云服务的过程中,通过敏捷BI联合解决方案迁移了PB级数据,由传统的一体机模式,转型为开放可扩展的分布式架构。2021年4月,永洪科技携手华为在华为苏州研究所正式发布金融大数据分析平台联合解决方案,为金融行业搭建一个“高扩展性、响应快速、业务全面”的智慧运营分析平台。目前,华为与永洪BI已完成互通测试,在营销、反欺诈等典型场景中完成验证,实现在大型国有银行中的落地应用。同时,该解决方案通过引入MRS HetuEngine数据虚拟化引擎进一步提升“交互式查询”性能。在对某集团及分公司上万业务目标的应用中,原Hive查询一张数据表需耗时几分钟,甚至出现“千行数据半小时都不出结果”的问题,通过HetuEngine,将交互式查询从分钟级缩短至秒级,提升业务决策效率。在风险管控领域,双方携手打造的金融大数据联合解决方案,总结某行反欺诈风险领域的防控经验,并结合FusionInsight团队和永洪自身的金融大数据解决方案优势,通过智慧可视化分析平台的建设,实现风险预警自动化,风险处置流程化,帮助该银行完善了事前防控、事中控制和事后分析与处置为一体的风控体系。时至今日,BI可视化数据分析已是数字化转型过程中的刚需,永洪科技和华为云FusionInsight团队,凭借双方团队的技术实力和联合解决方案的不断创新,得到各行业的广泛认可。2020年,IDC MarketScape中国大数据管理平台评估报告中,华为云凭借FusionInsight不断创新,位居“领导者(Leaders)”象限,并在市场份额和技术实力两个维度双领先;2021年,IDC发布的中国大数据平台市场研究报告中,华为云凭借FusionInsight智能数据湖在政企行业的实践积累以及ICT市场的整体生态,位居市场份额第一。而永洪科技也已连续五年被评为敏捷BI领域第一名,在爱分析《2021年中国BI商业智能报告》中显示,永洪BI在Top20银行客户覆盖率达80%,在金融、制造领域的市场占有率第一。永洪科技拥有1000+家合作伙伴,6000+家企业客户,涵盖了金融、制造、零售、能源、政府、教育等近20个中国支柱产业及新经济产业。未来,永洪科技将和华为云FusionInsight将强强联合,进一步深化合作,倾力打造更敏捷、更快速、更强大的大数据BI联合创新解决方案,让数据分析更敏捷,实现“释放数据价值,人人都是数据分析师”的宏大愿景。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html -
9月23日至25日,华为全联接2021以“深耕数字化”为主题,各行业领军人物分享最新成果与实践。其中在“华为云Stack,使能政企从业务上云到云上创新”专题演讲中,清华大学软件学院院长、大数据系统软件国家工程实验室执行主任王建民教授,发表“清华大学携手华为云FusionInsight共筑软件创新体系”演讲。 大数据作为一种新型战略资源,在今年来随着其逐步进入生产系统,已改变人们传统认知。同时,大数据的创新模式则离不开开源,近几年人们已不再满足于简单地修改开源大数据软件,在中国,已陆续诞生一批优秀的开源大数据软件项目和商用大数据解决方案,我国已不仅是全球开源软件生态的重要参与方,众多软件创新者在向引领者转变,并成为全球开源生态所不可或缺的贡献力量。 清华大学软件团队在大数据软件技术和应用方面持续创新,积极在开源软件持续贡献;同时,清华大学携手华为云FusionInsight智能数据湖团队,持续探索商业化的软件创新模式。 首先在开源方面,王建民教授认为对高校大数据研究和创新有着三大好处:1)开源是高校对外进行技术输出的一种有效手段。开源可以让新一代软件人接触到来自现实应用中的真实需求,能培养他们在学校里难以学到的大数据软件开发技能。开源也是一种对世界、对人类的一种无私的回馈,也是对高校师生奉献精神的重要培养渠道。2)开源是一个重要的软件工程培训环境。在清华大学软件学院,鼓励学生和教授为开源软件做出贡献。自2018年起,清华大学软件学院在学生奖学金的评定标准当中,不仅强调论文发表,还考察学生对开源项目的贡献。 3)开源是将科研成果溢价的有效手段。在实践方面,清华大学软件学院从2011年开始筹备,2015年正式启动工业物联网时序数据库开发项目。至2019年,该项目正式成为Apache的顶级项目,即IoTDB。今年,在最新的ASF年报上,IoTDB的代码提交活跃度,在Apache基金会351个项目中排名第七。近年来,清华大学和华为云FusionInsight团队以Apache IoTDB开源组件为基础,开始一种新型的、基于开源社区的产、学、研合作模式,正是这种开源与开源的合作、开源和商业的碰撞,以及对工业时序数据库软件的期待,双方最终成功在华为云FusionInsight 8.1.0版本的MRS云原生数据湖服务中完成IoTDB商用版本开发和集成,进一步完善了MRS三湖一集市能力,为工业海量时序数据分析提供企业级的时序数据库。IoTDB时序数据库聚焦海量时序数据的处理,具有“专、快、稳、省、易”五大特点,轻松应对海量时间序列数据的处理,一套引擎打通云边端时序数据分析。专:IoTDB总结了过去十年来在工业应用中遇到的典型需求,解决了传统数据库和列式数据库在超大规模复杂时序场景存在功能短板和性能瓶颈的问题,适用于如千万级超大规模测点处理、乱序处理、多序列对齐、序列分割、子序列匹配、旋转门压缩、降采样存储等专业场景。而且针对工业物联网时序分析场景,设计了TsFile专业时序存储格式和tLSM时序处理算法,弥补了传统方案的功能短板和性能瓶颈;快:时序数据库面临数据采集频率高,每秒上万次采集,数据存储周期长,时间跨度大的现状,IoTDB可实现单台服务器千万级数据秒级写入,十亿量级数据毫秒级聚合检索;稳:工业级的时序数据库,需要具备高可用特征,才能达到商用要求,IoTDB通过创新算法研究,采用对等分布式架构、双层多Raft协议、边云节点同步双活等机制实现高可用,保障工业物联网7*24小时的零故障运行;省:工业海量时序数据库的存储成本往往随数据量指数级增长,IoTDB提供了高压缩比算法,包括有损压缩和无损压缩,针对不同场景可以自动识别,降低海量时序数据的存储成本;易:易用性是成熟的商用软件产品基础特征,IoTDB采用类SQL,降低客户使用门槛,为客户打造集查询、存储、分析为一体的工业时序数据解决方案。目前,IoTDB已在交通、制造等众多工业级时序数据分析应用中落地。在IoTDB商用过程中,清华大学软件学院持续与华为云FusionInsight团队,通过组织与企业,人员与人员,代码和代码的丝丝相扣,实现IoTDB时序数据库在FusionInsight8.1.0新版本中正式商用。正是这种企业和高校,在代码开发中面对面,开发者和研究者深入交流,才会形成软件创新的一个正向循环;通过形成的开源项目,将技术与产品贡献给客户使用,不仅实现技术的应用落地,而且从客户那里不断打磨产品,这将又形成一个正向循环。“独行快,众行远”,正是这种环环相扣的正向循环,促使企业、客户、高校多方共同受益,进一步让清华大学和华为云FusionInsight团队,在中国大数据软件创新之路上越走越远。未来,清华大学大数据软件团队携手华为云FusionInsight,持续聚焦工业大数据软件,在国家特色化、示范性软件学院旗帜的引领下,加强建设中国高校大数据人才高地,让大数据人才“学以致其道”,让华为云大数据“算以致其用”,通过持续技术创新,为大数据软件产业蓬勃发展,贡献源源不断的能量,最终服务于国家大数据战略。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
-
随着交行业务高速发展,其内部大数据集群随着系统的不断建设,数据分析链路变长,准实时应用场景支撑不足,在某些计算量较大的场景,数据处理时效性差,作业高峰期因为资源占用,而发生作业互相影响的情况时有发生。在2021年,交行通过FusionInsight新版本能力,基于实时数据增量更新入湖、实时计算能力、批流融合,实现海量数据T+0实时供数。离线数据湖全面走向实时数据湖,业务创新更加敏捷。交行的智能数据湖构筑了数据从采集,到分析,再到消费的端到端全流程实时化:实时入湖:结合CDC、实时流技术、新一代数据湖框架,实现数据实时T+0入湖,数据在线更新与删除;实时分析:数据实时分析加工,Lakehouse湖内建仓,批流融合分析;实时供数:面向不同的查询场景,提供多种实时OLAP分析能力,毫秒/秒级响应;引入新版本FusionInsight后,交行智能数据湖全面支撑各场景业务分析走向准实时模式:在营销场景,基于用户交易交互行为,深度挖掘用户喜好,针对不同用户,实施实时个性化精准营销。营销效果实时监控,客户转化率提升164%。在风控场景,通过实时流处理技术,实现行为特征实时分析,欺诈行为实时识别。对风险交易及时执行拦截、人工校验、加强验证等干预措施,风险案件降低52%。在运营场景,构筑全行统一数据底座,降低数据获取难度,提供高质量的数据服务能力。供数模式从T+1离线模式,变成T+0实时模式。基于自助式的实时报表查询和分析,快速支撑业务决策。在监管报送场景,海量监管数据搜集、清洗、挖掘、整理、报送,以往需要执行8个小时,资源占用大,耗时长,灵活性差。通过FusionInsight“实时数据湖”能力,构建实时接入、实时更新、实时分析的分钟级全链路实时能力,该业务缩短至仅需2小时,提效4倍;在客户关系管理场景,建立客户流失预警模型,对流失率等级前部的客户及时启动客户关怀。对客户动账实时监测,第一时间进行挽客等活动。交通银行实现数字化平台思维上的重构,以立而不破的理念,实现交行“业务数字化,数据业务化”,实现海量数据的批量服务,提升数据时效,覆盖零售、风险、监管、历史查询、多维分析、预测模型等数据服务支持应用,提供数据治理监控集中化、管理流程化、数据资产全景视图化,加速建设数字化新交行。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
上滑加载中
推荐直播
-
 码道新技能,AI 新生产力——从自动视频生成到开源项目解析
码道新技能,AI 新生产力——从自动视频生成到开源项目解析2026/04/08 周三 19:00-21:00
童得力-华为云开发者生态运营总监/何文强-无人机企业AI提效负责人
本次华为云码道 Skill 实战活动,聚焦两大 AI 开发场景:通过实战教学,带你打造 AI 编程自动生成视频 Skill,并实现对 GitHub 热门开源项目的智能知识抽取,手把手掌握 Skill 开发全流程,用 AI 提升研发效率与内容生产力。
回顾中 -
 华为云码道:零代码股票智能决策平台全功能实战
华为云码道:零代码股票智能决策平台全功能实战2026/04/18 周六 10:00-12:00
秦拳德-中软国际教育卓越研究院研究员、华为云金牌讲师、云原生技术专家
利用Tushare接口获取实时行情数据,采用Transformer算法进行时序预测与涨跌分析,并集成DeepSeek API提供智能解读。同时,项目深度结合华为云CodeArts(码道)的代码智能体能力,实现代码一键推送至云端代码仓库,建立起高效、可协作的团队开发新范式。开发者可快速上手,从零打造功能完整的个股筛选、智能分析与风险管控产品。
回顾中 -
 华为云码道全新升级,多会话并行与多智能体协作
华为云码道全新升级,多会话并行与多智能体协作2026/05/08 周五 19:00-21:00
王一男-华为云码道产品专家;张嘉冉-华为云码道工程师;胡琦-华为云HCDE;程诗杰-华为云HCDG
华为云码道4月份版本全新升级,此次直播深度解读4月份产品特性,通过“特性解读+实操演示+实战案例+设计创新”的组合,全方位展现码道在多会话并行与多智能体协作方面的能力,赋能开发者提升效率
即将直播
热门标签