-
 9月23日至25日,华为全联接2021以“深耕数字化”为主题,各行业领军人物分享最新成果与实践。在“华为云FusionInsight智能数据湖打造千行百业数据底座”专题演讲中,北京东华博泰科技有限公司(以下简称“东华博泰”)副总经理任东岩,发表“东华博泰携手华为云FusionInsight打造能源大数据解决方案”演讲。随着我国提出“2030年前碳达峰,2060年前实现碳中和”的国家级战略目标,到2030年,中国单位国内生产总值(GDP)二氧化碳排放将比2005年下降65%以上,非化石能源占一次能源消费比重将达到25%左右。这意味我国未来非化石能源发电量占全部发电量的比重将大幅增加,非化石能源的装机量要大幅提升。电力作为我国高碳排放的行业,在产业供给侧的优化势在必行,未来能源是数字技术驱动的、以可再生能源为主体的智慧能源系统。在这种大趋势下,东华博泰携手华为云FusionInsight在华为全联接2021上宣布共同打造能源大数据解决方案。本次东华携手华为云FusionInsight发布的能源大数据联合解决方案,其核心目标是建设新型电力工业互联网能源大数据体系。任东岩副总经理表示,未来的能源生产将从现有电力系统自顶向下的发电-输电-配电-用电的结构,走向扁平化、分布式的能源自治、单元对等的互联结构。这种能源互联结构,将实现可再生能源的分层接入与消纳,并且能源大数据平台将成为以可再生能源为主体的新型电力系统核心平台。从能源大数据平台的技术作用看,通过物联、数采,联接各种与发电、用电相关的设备,通过对设备数据的采集、清洗、治理、建模、分析等环节,综合运用电力行业知识沉淀、大数据分析、AI等技术手段,以数据贯穿业务、用数据驱动业务,激发数据要素价值,实现能源产业链的协同与延伸,实现纵向专业领域的贯穿,为能源行业用户、为用能端用户提供技术服务。从平台的技术结构看,数据底座+业务知识沉淀,支撑以设备为核心的能源大数据平台。以华为云FusionInsight强大的智能数据湖解决方案研发团队与技术实力为支撑,东华博泰阿凡达平台实现海量能源数据的编码,设备对象的构建,丰富能源算子算法库,加强海量能源数据探索能力。能源大数据联合解决方案构建能源大数据平台、生态运营管理、智慧能源生态圈三层结构,已在电力领域多次应用,通过大数据应用实现电、热、冷等形式互联互通,风光水火储多能互补。 2021年,东华博泰将携手华为云FusionInsight,实现以数据为源力核,平台为运力核,应用为创力核,体系为内力核,生态为汇力核,打造“五核聚一”的数字化运营架构,为能源行业提供大数据创新解决方案,共建智慧能源生态圈。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
9月23日至25日,华为全联接2021以“深耕数字化”为主题,各行业领军人物分享最新成果与实践。在“华为云FusionInsight智能数据湖打造千行百业数据底座”专题演讲中,北京东华博泰科技有限公司(以下简称“东华博泰”)副总经理任东岩,发表“东华博泰携手华为云FusionInsight打造能源大数据解决方案”演讲。随着我国提出“2030年前碳达峰,2060年前实现碳中和”的国家级战略目标,到2030年,中国单位国内生产总值(GDP)二氧化碳排放将比2005年下降65%以上,非化石能源占一次能源消费比重将达到25%左右。这意味我国未来非化石能源发电量占全部发电量的比重将大幅增加,非化石能源的装机量要大幅提升。电力作为我国高碳排放的行业,在产业供给侧的优化势在必行,未来能源是数字技术驱动的、以可再生能源为主体的智慧能源系统。在这种大趋势下,东华博泰携手华为云FusionInsight在华为全联接2021上宣布共同打造能源大数据解决方案。本次东华携手华为云FusionInsight发布的能源大数据联合解决方案,其核心目标是建设新型电力工业互联网能源大数据体系。任东岩副总经理表示,未来的能源生产将从现有电力系统自顶向下的发电-输电-配电-用电的结构,走向扁平化、分布式的能源自治、单元对等的互联结构。这种能源互联结构,将实现可再生能源的分层接入与消纳,并且能源大数据平台将成为以可再生能源为主体的新型电力系统核心平台。从能源大数据平台的技术作用看,通过物联、数采,联接各种与发电、用电相关的设备,通过对设备数据的采集、清洗、治理、建模、分析等环节,综合运用电力行业知识沉淀、大数据分析、AI等技术手段,以数据贯穿业务、用数据驱动业务,激发数据要素价值,实现能源产业链的协同与延伸,实现纵向专业领域的贯穿,为能源行业用户、为用能端用户提供技术服务。从平台的技术结构看,数据底座+业务知识沉淀,支撑以设备为核心的能源大数据平台。以华为云FusionInsight强大的智能数据湖解决方案研发团队与技术实力为支撑,东华博泰阿凡达平台实现海量能源数据的编码,设备对象的构建,丰富能源算子算法库,加强海量能源数据探索能力。能源大数据联合解决方案构建能源大数据平台、生态运营管理、智慧能源生态圈三层结构,已在电力领域多次应用,通过大数据应用实现电、热、冷等形式互联互通,风光水火储多能互补。 2021年,东华博泰将携手华为云FusionInsight,实现以数据为源力核,平台为运力核,应用为创力核,体系为内力核,生态为汇力核,打造“五核聚一”的数字化运营架构,为能源行业提供大数据创新解决方案,共建智慧能源生态圈。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html -
9月23日至25日,华为全联接2021以“深耕数字化”为主题,各行业领军人物分享最新成果与实践。在“华为云FusionInsight智能数据湖打造千行百业数据底座”专题演讲中,深圳市华傲数据技术有限公司(以下简称“华傲数据”)CEO贾西贝博士,发表“华傲数据携手华为云FusionInsight构建政务三算一景,释放数字红利”演讲。“三算”鼎“一景”自1993年以来,电子政务历经共享交换、整合共享和数据要素市场化三大阶段,从以共享交换为标志的建设方式,演进为强调系统之间的互联互通,数据之间的整合共享,最终走向数据要素化,要素市场化的潮流当中。高质量算料,保障业务服务精度众所周知,中国是世界第一人口大国,也是世界第一数据资源大国,面对不断产生的数据,如何破解政务数据横向碎片化,纵向烟囱林立难题?如何保障数据质量?华傲数据携手FusionInsight智能数据湖团队,以GLDM方法论为核心,专注数据治理,解决数据的重复性、完整性、混乱性、冲突性和时序性,保障数据不多、不少、不乱、不错、不旧,让海量数据要素结构化、标准化、精确化。数据是生产要素,是数字城市建设的基础。同时,人们通过实践,也逐步意识到,再好的算法,再好的应用场景,如果数据错了,将会导致通过数据的决策也产生错误。我们要利用云计算、数据湖、人工智能等技术,在符合数据安全法律法规的前提下,统一规划,统一标准,最终实现统一供数,以高质量的数据,保障业务决策准确性。高效能算力,使能业务响应速度在工业时代,电力是机械文明的基石,而迈入数字时代的今天,算力正在成为驱动数字世界的发动机。华傲数据携手FusionInsight打造了数据治理总体架构,可概括为“三算一景”。FusionInsight智能数据湖提供完整的大数据云服务产品组合,包括MRS云原生数据湖、DWS云数据仓库、DGC数据湖治理、GES图计算、TICS隐私计算云服务,其基于华为云,提供海量数据所需的“算力”;基于各委办局的海量数据资源,即“算料”,通过数据治理的模型、工具,不断打磨数据 “算法”,提升算料质量,进而准确、高效为业务场景服务;“应用场景”则包括一网统管、一网通办、一屏尽览等重要政务业务场景。高智能算法,赋能业务覆盖广度华傲数据携手FusionInsight团队联合打造政务大数据治理解决方案,将政策事项化、事项算法化,让智能算法贯穿政务服务、治理、决策全流程,实现事前防范、事中控制、事后治理。其中“一秒七办”,以自动匹配、自动填表、自动证明、自动核对、自动审批、自动评审、自动响应,实现业务场景纵向高效畅通;结合大数据、区块链、AI技术,横向扩宽业务范围,实现跨部门、跨层级的互联互通。基于大量算料,持续对算法进行训练,使业务场景在不再局限于政务应用,而是拓宽至交通、能源、教育、医疗、农业等行业;同时,不再局限于单个部门,以智能算法打通多部门数据,实现数据共享、业务互通,提升业务覆盖广度。 形象来讲,算料是原料、算法是工匠、算力是平台,如同工匠通过平台工具加工原材料打造“利器”一样,算料、算法、算力三者相辅相成,在数字城市建设中赋能各应用场景。“一景”领“三算”泛政务场景包含政府、交通、能源、教育、医疗、农业等行业,如若针对每个场景定制建设其特有的数据中心、算法平台、技术底座,不仅开发周期长、成本高,且难以批量复制。因此,提取出多场景的最大公约数,形成标准且统一的中枢和底座是必要的。围绕最大公约数“一景”,布局其所需的算料、算力、算法(“三算”),才能真正的发挥数据价值。无论是一网通办、秒批秒办等政府服务型业务场景,还是一网统管、数字战疫等政府治理型应用场景,亦或是城市大脑IOC、城市运营中心等政府决策型应用场景,是打开数字城市大门的“钥匙”,让数字化技术不是为了技术而技术,让算料、算法、算力为服务业务场景而生,从而能为政府、百姓、企业乃至整个社会带来“数字红利”。释放“数字红利” 华傲数据基于华为云FusionInsight智能数据湖解决方案,已服务于全国几十个城市上百个客户,打造了多个城市IOC标杆项目。例如于2018年启动建设的某市政务管理服务指挥中心(城市IOC)项目,包括人口、教育服务、卫生健康、就业等14个专题。其中教育服务专题应用,通过信息化等手段汇聚和分析各方数据,对现有学校、在建学校、规划未建成教育用地、新增规划教育用地、适龄人口及未来布局调整等方面情况,进行立体化、可视化、动态化综合展示,对公办学位缺口、教育资源优化配置、政策制定等进行综合分析和辅助决策,高质量实现“幼有善育、学有优教”。通过建设数字龙华智慧企业服务平台,实现了该区营商环境改革大提速,用数据赋能企业服务,为政策安上算法“大脑”,从“人找政策”变为“政策找人”,让资金不再沉睡,保障政策落地执行。秒审秒批服务,让规则显性化,避免人为干预,让规则暴露在阳光下,让企业公平公正的享受政策红利。未来,华傲携手华为云FusionInsight团队,将持续完善政务“三算一景”方案,赋能数字城市建设,助力数字经济发展,让城市站在数据之巅。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
-
9月23日至25日,华为全联接2021以“深耕数字化”为主题,各行业领军人物分享最新成果与实践。其中在“华为云FusionInsight智能数据湖打造千行百业数据底座”专题演讲中,华为云FusionInsight技术专家陈祥,发表“华为云FusionInsight智能数据湖版本新能力解读”演讲。进入智能数据时代,业界建设数据湖的十大共识 经过数十年的快速发展,大数据处理技术已日渐成熟,围绕数据湖衍生技术多如繁星,业界在多年的探索之中,也对未来数据湖形态有了十个重要共识,如充分利用云技术实现云原生的数据分析,支持混合云及多云部署,各种类型的数据、支持更多的数据用户类型,提供不同的数据引擎、不同的数据处理能力等,这些需求对大数据技术创新提出了诸多挑战。面对这些挑战,华为云FusionInsight发布智能数据湖最新版本8.1.0去应对新时代对大数据的这些技术诉求。华为云FusionInsight提供湖仓一体的解决方案,兼顾历史与未来华为云FusionInisght智能数据湖为企业客户提供完整的大数据云服务产品组合,有单集群最大支持5W节点的云原生数据湖MRS服务和全球最大的商用部署的云数据仓库DWS服务,MRS和DWS既可以灵活按需部署,也可以融合演进到湖仓一体的架构;同时面向不断增长的数据探索分析、新型的图分析、可信计算等诉求,提供了完全托管式的DLI数据湖探索服务,完全自研的高性能一体化的GES图计算服务、创新的可信智能计算服务TICS,并提供源自华为自身数字化转型经验沉淀的DGC数据湖治理中心服务,用于海量数据的数据治理、离线分析、实时分析、数仓集市、多模分析等场景,帮助客户构建一站式的大数据分析平台,释放企业数据价值。MRS云原生数据湖提供三湖一集市能力,让数据分析更敏捷MRS云原生数据湖作为FusionInsight主打的云服务,是一款Lakehouse架构的云原生数据湖服务,解决传统大数据平台零散式建设、供数链路长、人工搬迁慢等问题,一个架构实现离线、实时、逻辑三种数据湖:离线数据湖:提供交互式、BI、AI等多个计算引擎,基于云原生存储实现存算分离架构,使得云原生数据湖的架构更灵活,业务更敏捷。同时还支持单集群5万(通过集群联邦,支持10万+规模)节点的超大规模,支持集群滚动升级,保障关键业务升级不中断。实时数据湖:提供生成数据CDL实时捕获入湖、Hudi数据湖存储引擎、ClickHouse毫秒级OLAP分析等构建实时更新处理能力,使得供数时效从T+1到T+0。逻辑数据湖:HetuEngine提供跨湖、跨仓、跨云的协同分析,实现湖仓一体,减少80%数据搬迁,协同分析提效50倍。MRS云原生数据湖实现数据全链路实时分析,价值兑现从T+1走向T+0在华为云FusionInsight 8.1.0 新版本中,MRS云原生数据湖实现了数据全链路实时分析,让价值兑现从T+1走向T+0。传统方案从数据接入、数据入湖到数据入湖,不支持增量数据更新,数据处理采用离线批处理方式,数据分析则需提前制定各种CUBE,预聚合的方式费时费力,导致数据分析时效性T+1,无法满足新时代的业务诉求。为解决上述问题,MRS云原生数据湖通过创新的CDL组件支持直接读取Binlog日志实时入湖,结合Flink/Spark实现数据实时合并、实时加工,打通信息生产到分析平台的最后一公里;通过引入Hudi,支持数据更新、数据删除,还有ACID能力,保证数据实时入湖更新操作;通过引入ClickHouse,可以把数据拉到一个大宽表内去做分析,只需要对接后端的BI工具,就可以自助式的完成报表开发。同时,ClickHouse支持实时OLAP,可实现毫秒级实时分析,且ClickHouse不需要建Cube,只要对接BI工具就能轻松完成新业务的开发。MRS云原生数据湖通过CDL+Hudi+Clickhouse的新方案,实现全链路实时分析,快速构筑实时数据湖能力。IoTDB工业物联网时序数据库,云边端协同轻松构建时序数据集市MRS云原生数据湖提供一架构三湖能力的同时,还支持构建多模态数据集市,在新版本中引入了MRS IoTDB工业物联网时序数据库,实现云边端协同轻松构建时序数据集市。MRS IoTDB是由华为云FusionInsight团队与是清华大学共同开发,聚焦工业物联网领域的工业复杂时序数据的处理,如千万级超大规模测点处理、乱序处理、多序列对齐、序列分割、子序列匹配、旋转门压缩、降采样存储等专业时序需求,解决通用数据库在超大规模复杂时序场景的功能短板和性能瓶颈,高效管理海量工业物联网数据,形成跨越端、边、云的工业物联网大数据的利器,在海量时序数据处理场景发挥其“专、快、稳、省、易”能力。在实际应用落地中,一台IoTDB实例就能替代13台传统时序数据库,性能优势明显。灾备:两地三中心高可用,确保业务连续性,SLA 99.999%在增强数据湖平台全链路实时分析与工业物联网数据库能力的基础上,MRS云原生数据湖在数据可靠性上再次进行增强,提供了三个容灾方案:提供原有的数据备份能力,支持将关键数据备份到异地中,一旦出现集群故障导致数据丢失,则可以将备份数据恢复回来。新增了单集群跨AZ高可用方案:支持将一个集群部署在多个机房中,通过副本放置策略确保数据副本存放在不同的机房,通过YARN的任务调度机制的优化确保任务优先访问任务所在机房的数据副本,当一个机房出现故障后,任务会自动切换到其他机房的机器上,从而确保单AZ故障时数据不丢失,关键业务不中断。同时,还新增了异地主备容灾方案:也就是分别建设主、备两个MRS集群,主集群数据会周期或实时自动同步到备集群上。当主集群故障时,将业务倒换到备集群上,确保业务快速恢复。通过以上三种方案,MRS云原生数据湖可以实现从简单的数据备份到跨AZ高可用,到异地容灾的完整场景覆盖,业务可以根据自身业务特点以及需要应对的故障场景,灵活选择适合自己的方案。DWS:新一代全场景云数据仓库 华为云FusionInsight智能数据湖另一主打云服务为DWS云数据仓库,它是一款具备分析及混合负载能力的云数据仓库服务,具有高性能、高扩展、高可用等特点,广泛应用于汽车、制造、零售、互联网、金融、政府、电信等行业的核心分析决策系统。它不仅仅是把数仓搬上云这么简单,而是真正面向未来的云原生架构的数仓服务。作为全球最大的金融数仓,DWS通过了信通院单集群2048节点的规模认证,当前已经商用的最大集群有480个节点。DWS通过一套内核一套架构同时支持标准数仓、实时数仓和云数仓,匹配了用户全场景需求。DGC:一站式数据开发与治理,让开发者轻松驾驭数据华为云FusionInsight智能数据湖不仅为政企客户提供湖仓一体的架构,还有DGC数据湖治理中心服务,提供一站式数据开发集成管理平台,提供统一的数据治理工具,加速数据资产沉淀。DGC的特性主要集中在平台能力和生态两个方面:在平台能力方面:DGC提供一站式数据开发集成管理平台,支持40多种异构数据源、全拖拽式开发、多维实时搜索、0代码API开发等能力;并提供基于华为10多年数据治理经验沉淀出的数据架构、标准规范、数据开发、数据质量等数据治理能力;在生态建设方面:DGC通过开放API,使能行业 ISV 快速集成开发;通过合作伙伴提供数据标准、模型、指标、接口等行业数据模型,帮助企业快速构筑数据治理能力。华为云FusionInsight深耕大数据10年+,持续创新引领大数据技术发展华为云FusionInsight持续投入10年+,坚持开放路线,在扎根社区的同时,也积极回馈社区,为行业新技术发展贡献力量;同时,华为云FusionInsight智能数据湖将持续贯彻“平台+生态”战略,携手800+合作伙伴,服务于全球60+国家和地区3000+政企客户,已广泛应用于政府、金融、运营商、大企业等行业。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
-
9月23日至25日,华为全联接2021以“深耕数字化”为主题,各行业领军人物分享最新成果与实践。在“华为云FusionInsight智能数据湖打造千行百业数据底座”专题演讲中,中国工商银行(以下简称“工行”)大数据平台产品经理袁一,发表“工商银行携手华为云FusionInsight共建大数据体系”演讲。随着金融业的快速发展和大数据技术生态的不断完善,近年来工行与华为持续联合创新,通过引入FusionInsight智能数据湖,工行大数据技术从仅对大数据批量加工,已延展到大数据实时计算、联机查询、数据可视化、安全管控等金融应用场景,不断提升工行服务实体经济的能力,倾力打造服务于经济高质量发展的数字工行。目前工行已建成同业最大的单集群,已部署上线的FusionInsight MRS云原生数据湖和DWS云数据仓库集群规模达2000+节点,支撑了300+总行应用、分行及集团子公司的平台化大数据应用开发,日均承载批量计算作业数达20万+,强力支撑了行内、行外的金融数据服务。传统的大数据平台主要以支撑增值类业务为主,但随着大数据技术的发展,诸如像风险控制、损益预查询、监管报送、交互查询(如交易明细查询)等关键业务也开始接入到大数据平台:在风险控制场景,工行通过FusionInsight MRS构建实时数据湖的能力,结合工行专家规则的风险防控系统能力,实现毫秒级交易风险控制,让风控从事后处理,向事中控制快速转变,已为工行客户挽回资金损失数10亿元;在损益预查询场景,传统方案采用批量作业,不仅存在业务时效性差的问题,同时也需消耗大量的主机资源,为此工行基于FusionInsight MRS和DWS开展了架构转型,通过准实时数据复制技术,将主机上产生的数据,准实时地同步到大数据平台,使原先每天只能跑10轮的批量作业,提升到每天30轮,让之前每轮批量作业耗时30分钟耗时缩减了2倍,不仅大幅提升分析时效性,同时也减少了主机的资源开销;在监管报送场景,伴随工行业务的不断增长,数据的体量也越来越大,传统一体机架构的建设成本越来越高,报送时效性也越来越难以满足业务发展现状。在新一轮IT架构转型中,工行携手FusionInsight构建监管报送系统,实现从数据加工、脱敏、校验,到最终的报送环节,充分利用了大数据平台分布式数据处理的能力,使报送频度从季度提升到月度;在交互查询场景,工行通过MRS HetuEngine数据虚拟化引擎,使得耗时从小时级降至秒级,提效50倍,提升工行13000名分析师即时BI体验,面向全行推广。以上仅是工行联合FusionInsight团队在金融大数据技术创新及应用落地的冰山一角,未来双方还将从以下几个方面持续创新:大集群跨机房部署:随着金融机构业务量的极速增长,底层的大数据基础设施也越来越庞大,如何对物理分散的基础设施进行有效管理,成为各金融机构最为关注问题之一。工行将通过FusionInsight MRS联邦集群管理能力,将同一个数据中心内多个机房的集群进行联合管控,形成一个资源可统一调度的大集群,为用户提供服务。大数据云原生:工行将建设具备固定资源池和弹性资源池混合部署的大集群,通过高性能固定资源池,满足日常相对固定的资源需求;通过存算分离的弹性资源池,灵活扩缩容,轻松应对特殊时间节点上的资源需求高峰。高可用能力提升:随着越来越多的关键业务逐步接入到大数据平台,业务对平台的可靠性和服务连续性,提出了更高要求。为此工行在同城两个数据中心内,建设了主备双活集群,提升关键业务场景的可靠性和服务连续性。数据入湖时效性提升:传统的数据交换时效一般为T+1,即使通过CDC等技术实现流式数据入湖,但最快也只能达到15-30分钟才能完成一个批次,造成业务感知慢。随着大数据生态中诸如Hudi实时增量更新技术的成熟,有望将数据入湖时效控制在5分钟以内,进一步提升数据处理时效性。 工行将不断加强与FusionInsight团队的合作,通过云计算、数据湖、人工智能、IoT等创新技术,更好地利用数据生产要素,从社会的痛点、难点入手,做好金融大数据平台的建设工作,提升工行服务实体经济的能力。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
-
9月23日至25日,华为全联接2021在线上正式开幕,在“华为云FusionInsight智能数据湖打造千行百业数据底座”专题演讲中,华为云FusionInsight技术专家陈祥发表了“华为云FusionInsight智能数据湖版本新能力解读”演讲。华为云FusionInsight发布智能数据湖8.1.0新版本,提供湖仓一体的解决方案,兼顾历史与未来。在新版本中:MRS云原生数据湖提供三湖一集市能力,提供数据全链路实时分析,让供数时效从T+1走向T+0;通过IoTDB工业物联网数据库,云边端协同轻松构建时序数据集市;在新版本中,更是提供两地三中心等三种高可用容灾方案,确保关键业务的连续性。DWS云数据仓库推出高性能、高扩展、高可用特点的新一代全场景云数据仓库,一套内核一套架构同时支持标准数仓、实时数仓和云数仓。DGC数据湖治理中心提供一站式数据开发与治理工具,还增强了其一键数据服务和数据分层分级安全功能。华为云FusionInsight深耕大数据10年+,持续创新引领大数据技术发展,把复杂留给自己,把简单留给伙伴,携手800+合作伙伴,服务于全球60+国家和地区3000+政企客户,已广泛应用于政府、金融、运营商、大企业等行业。线上观看链接:https://live.huawei.com/huaweiconnect/meeting/cn/9404.html 。
-
2021年9月23-25日,华为全联接2021以“深耕数字化”为主题,在线上隆重举办。当前,数据已是第5种生产要素,如何发挥数据要素价值已是共同话题。本次将由华为云FusionInsight携手客户和伙伴,率先揭秘FusionInsight 8.1.0版本的实时数据湖、容灾、时序数据库新能力,工商银行讲述携手FusionInsight共建大数据体系;更有中国顶级高校-清华大学,携手顶级大数据厂商-华为云,共同打造全球大数据社区顶级项目-时序数据库IoTDB的创新故事,分享基于IoTDB成果的中国软件创新体系实践经验。数据要素价值和产业生态离不开众多伙伴,本次还邀请到华傲数据、东华博泰、永洪BI各行业伙伴,共同分享各行业的大数据联合解决方案,更多精彩请关注华为云全连接2021官网和FusionInsight专题演讲,地址:https://live.huawei.com/huaweiconnect/meeting/cn/9404.html 。
-
 # 华为FusionInsight MRS实战 - 使用FlinkSQL处理数据并使用redis做实时展示 ## 场景说明 【需求】计算最近1小时各个账户交易总金额。 【分析】将账户交易数据接入Kafka中,通过Flink计算过去1小时各个账户的交易总金额,将计算结果写入Redis中。做实时大屏展示。 【实现】通过FlinkSQL的滚动窗口计算 数据流图 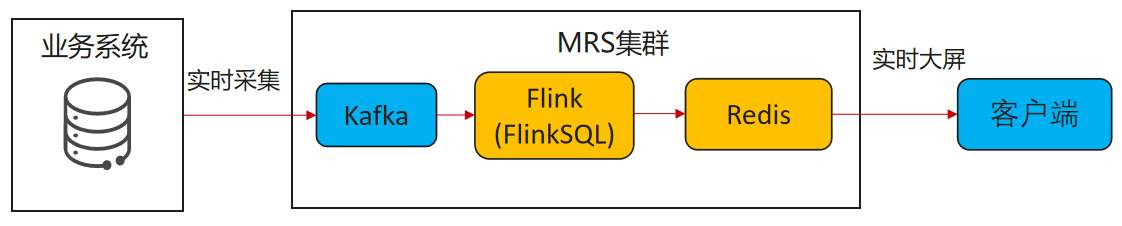 ## 操作步骤 - 登录华为FusionInisght MRS Flink WebUI  - 在作业管理选择新建作业创建一个FlinkSQL任务 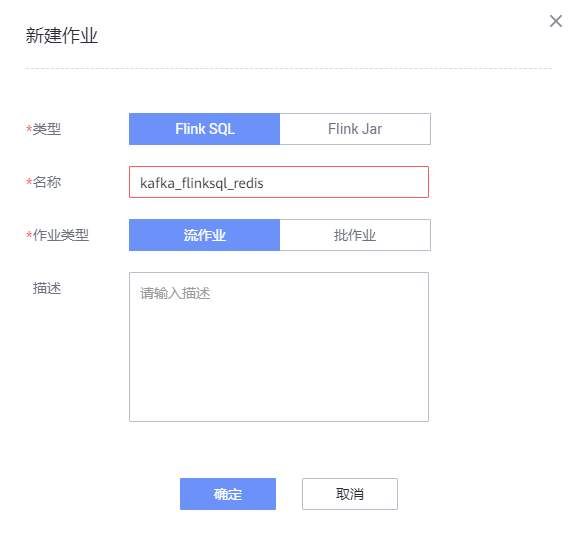 - 编辑如下Flink SQL语句 ``` CREATE TABLE kafka_source ( account varchar(10), cost int, ts AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'redisdemo', 'properties.bootstrap.servers' = '172.16.9.117:21005', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ); CREATE SINK STREAM redis_sink( account varchar, costs int, PRIMARY KEY(account) ) WITH ( 'isSafeMode' = 'true', 'clusterAddress' = '172.16.9.117:22404,172.16.9.118:22404,172.16.9.113:22404', 'redistype' = 'String', 'type' = 'Redis', 'isSSLMode' = 'false' ); INSERT INTO redis_sink SELECT account, SUM(cost) FROM kafka_source GROUP BY TUMBLE(ts, INTERVAL '10' SECOND), --为了快算看到计算结果使用10s窗口 account; ``` - 点击语义校验,确保语义校验通过 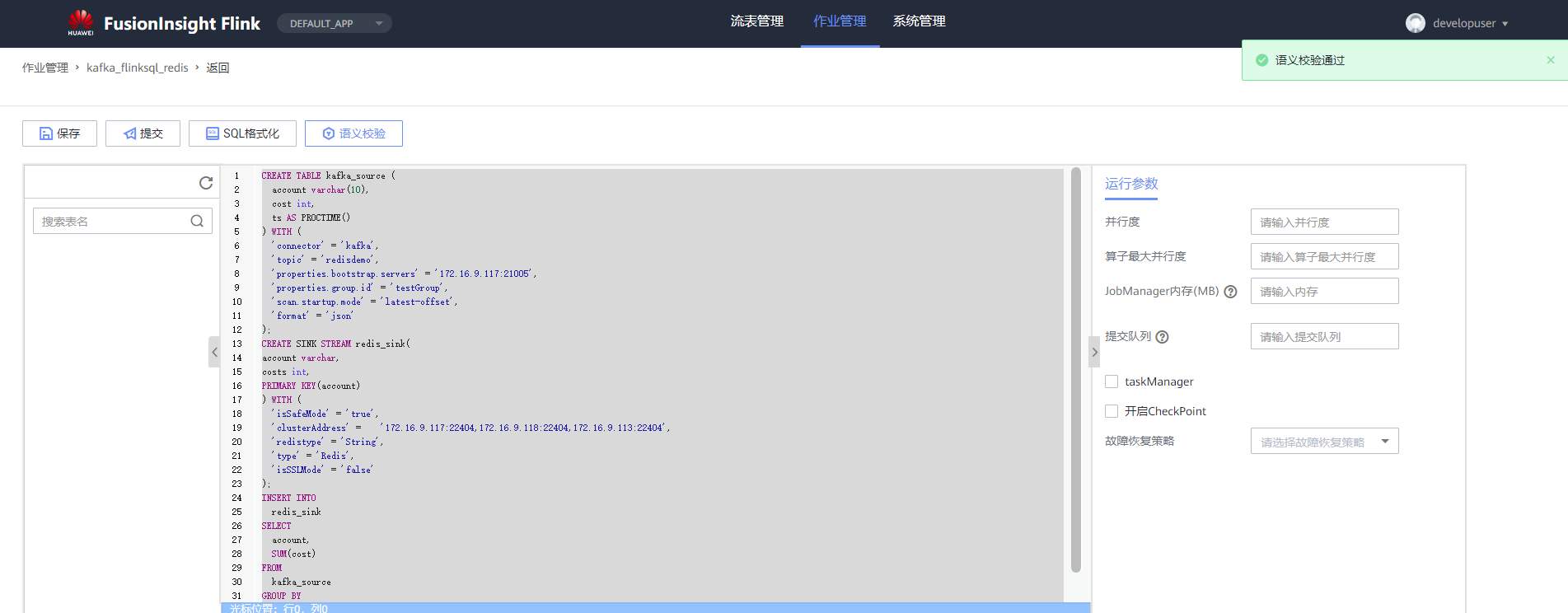 - 启动该Flink SQL任务 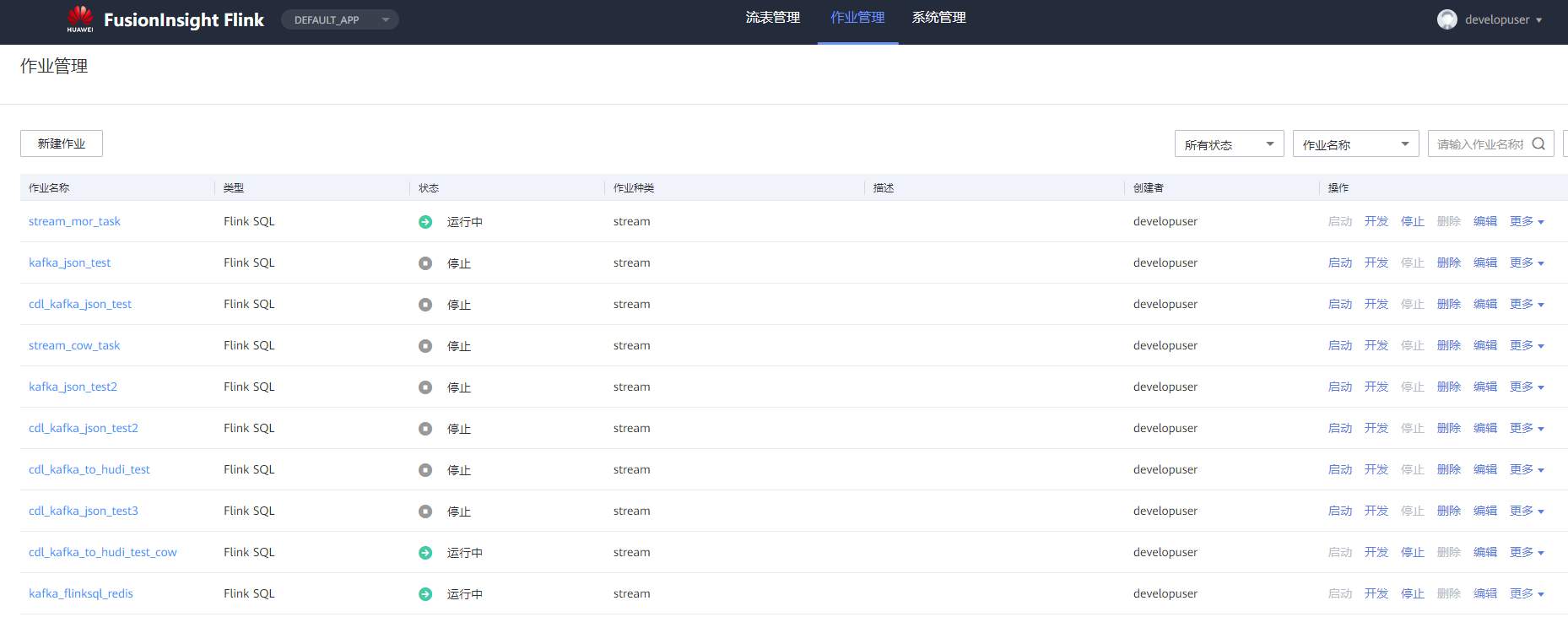 - 使用kafka客户端插入测试数据 ``` {"account": "A1","cost":"11"} {"account": "A1","cost":"22"} {"account": "A2","cost":"33"} {"account": "A3","cost":"44"} ```  注意: 因为flink窗口时间为10秒,并且redis是key value数据库,数据会根据主键覆盖,所以需要在10s内将数据全部输入 - 登录redis客户端查看结果: `redis-cli -c -h 172.16.9.117 -p 22404` 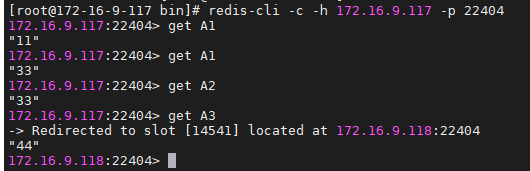
# 华为FusionInsight MRS实战 - 使用FlinkSQL处理数据并使用redis做实时展示 ## 场景说明 【需求】计算最近1小时各个账户交易总金额。 【分析】将账户交易数据接入Kafka中,通过Flink计算过去1小时各个账户的交易总金额,将计算结果写入Redis中。做实时大屏展示。 【实现】通过FlinkSQL的滚动窗口计算 数据流图  ## 操作步骤 - 登录华为FusionInisght MRS Flink WebUI  - 在作业管理选择新建作业创建一个FlinkSQL任务  - 编辑如下Flink SQL语句 ``` CREATE TABLE kafka_source ( account varchar(10), cost int, ts AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'redisdemo', 'properties.bootstrap.servers' = '172.16.9.117:21005', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ); CREATE SINK STREAM redis_sink( account varchar, costs int, PRIMARY KEY(account) ) WITH ( 'isSafeMode' = 'true', 'clusterAddress' = '172.16.9.117:22404,172.16.9.118:22404,172.16.9.113:22404', 'redistype' = 'String', 'type' = 'Redis', 'isSSLMode' = 'false' ); INSERT INTO redis_sink SELECT account, SUM(cost) FROM kafka_source GROUP BY TUMBLE(ts, INTERVAL '10' SECOND), --为了快算看到计算结果使用10s窗口 account; ``` - 点击语义校验,确保语义校验通过  - 启动该Flink SQL任务  - 使用kafka客户端插入测试数据 ``` {"account": "A1","cost":"11"} {"account": "A1","cost":"22"} {"account": "A2","cost":"33"} {"account": "A3","cost":"44"} ```  注意: 因为flink窗口时间为10秒,并且redis是key value数据库,数据会根据主键覆盖,所以需要在10s内将数据全部输入 - 登录redis客户端查看结果: `redis-cli -c -h 172.16.9.117 -p 22404`  -
## 背景 Apache Hudi 是目前最流行的实时数据湖解决方案之一,能够使大数据平台支持数据事务性,解决了数据从外部数据源实时入湖的痛点问题。 Apache Flink 作为目前最流行的流计算框架,在流式计算场景有天然的优势,当前,Flink 社区也在积极拥抱 Hudi 社区 Hudi 和 Fink 在 0.8.0 版本做了大量的集成工作[1]。核心的工作包括: - 实现了新的 Flink Streaming Writer - 支持 Flink SQL API - 支持 batch 和 streaming 的模式 Reader 本文介绍如何使用华为自研CDC工具CDL,结合自研的可视化开发平台Flink WebUI, 使用Flink SQL API 的方式实现数据的实时入湖。 数据流向图: 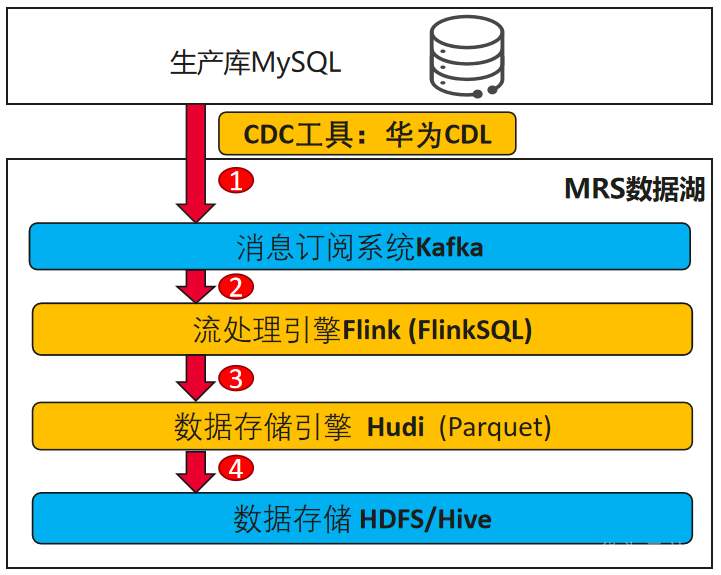 ## 前提条件 根据之前学习材料已掌握 - CDL已完成同步任务的设计,并运行 - 华为Flink WebUI的使用 - Flink SQL解析嵌套Json的方法 ## 操作步骤 - 登录华为FusionInisght MRS Flink WebUI  - 在作业管理选择新建作业创建一个FlinkSQL任务  - 编辑如下Flink SQL语句 注意check point必须打开 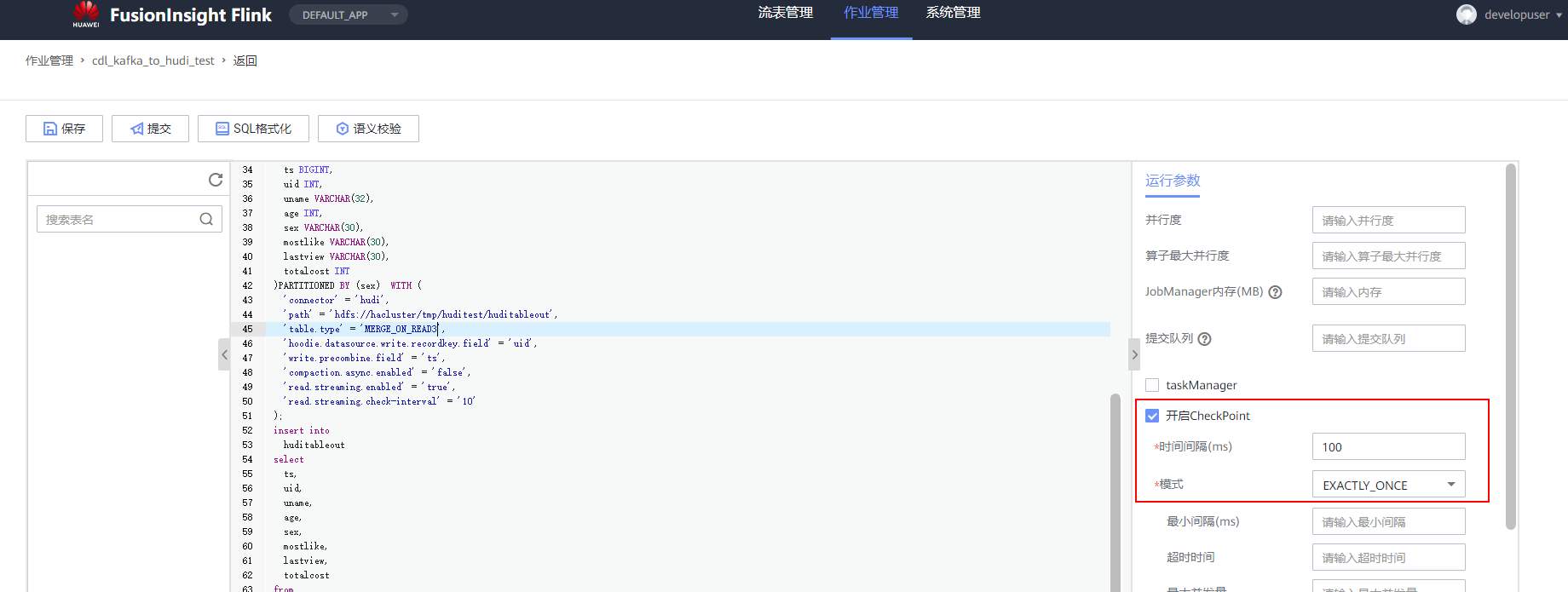 ``` CREATE TABLE huditableout_source( payload ROW < `TIMESTAMP` BIGINT, `data` ROW < uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE TABLE huditableout( ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT )PARTITIONED BY (sex) WITH ( 'connector' = 'hudi', 'path' = 'hdfs://hacluster/tmp/huditest/huditableout', 'table.type' = 'MERGE_ON_READ', 'hoodie.datasource.write.recordkey.field' = 'uid', 'write.precombine.field' = 'ts', 'compaction.async.enabled' = 'false', 'read.streaming.enabled' = 'true', 'read.streaming.check-interval' = '10' ); insert into huditableout select ts, uid, uname, age, sex, mostlike, lastview, totalcost from huditableout_source; ``` 说明:hudi表创建时将 read.streaming.enabled 设置为 true,表明通过 streaming 的方式读取表数据, read.streaming.check-interval 指定了 source 监控新的 commits 的间隔为 10s, table.type 设置表类型为 MERGE_ON_READ,目前只有 MERGE_ON_READ 表支持 streaming 读。 - 点击语义校验,确保语义校验通过 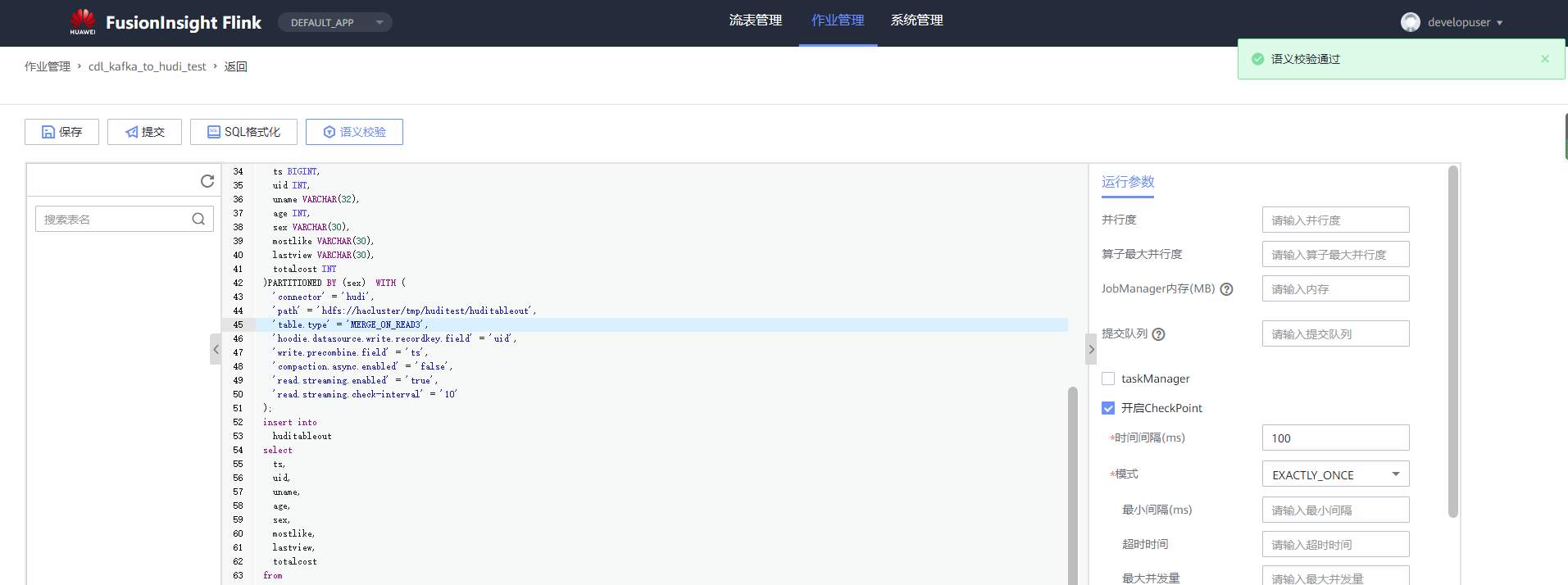 - 启动该Flink SQL任务 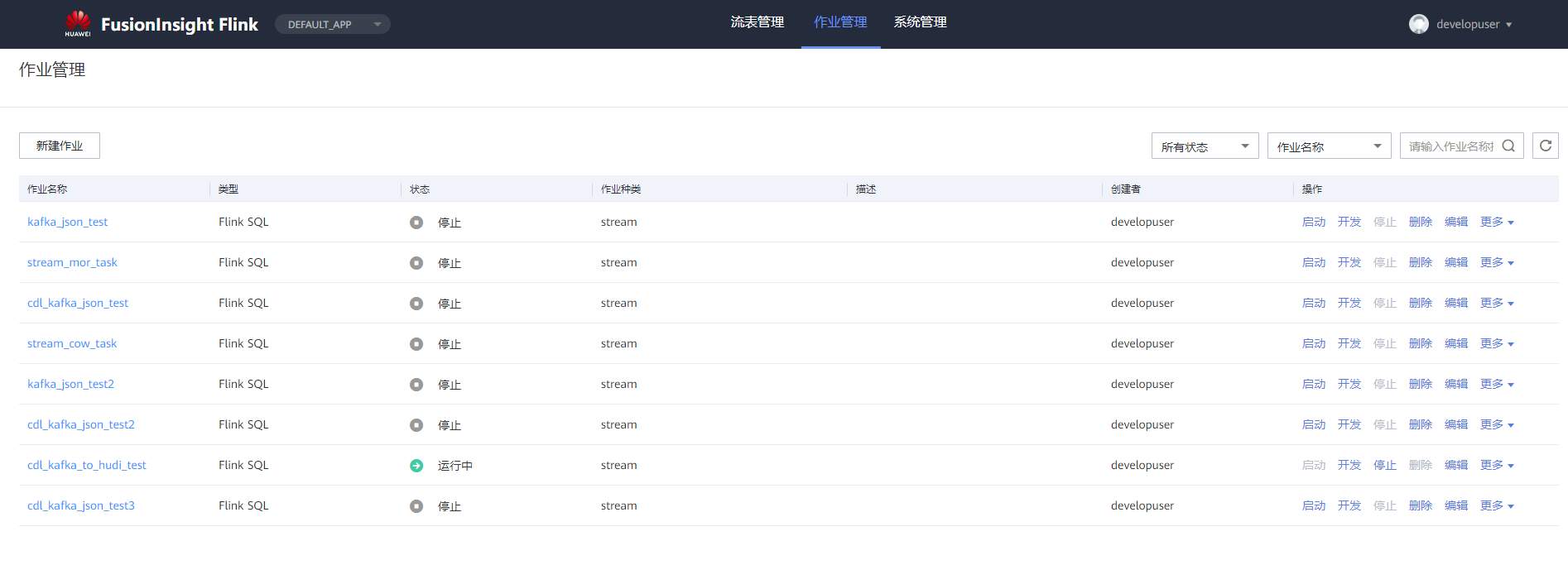 - 在源MySQL库插入数据 ``` insert into hudi.hudisource values (1,"韦浩",52,"女","加减法","漫画",23142); insert into hudi.hudisource values (2,"汪烨霖",67,"男","手游","联盟",27211); insert into hudi.hudisource values (3,"谭昊焱",26,"女","查询网","全集观看",6280); insert into hudi.hudisource values (4,"顾明",34,"男","地图","模板",16771); insert into hudi.hudisource values (5,"白修杰",61,"女","快递单号","手游",24577); insert into hudi.hudisource values (6,"郑雨泽",50,"男","板","植物",5988); insert into hudi.hudisource values (7,"戴鹤轩",37,"女","网站大全","模板",30925); insert into hudi.hudisource values (8,"邹鸿煊",69,"男","官网","阅读网",14020); insert into hudi.hudisource values (9,"沈烨霖",67,"女","客户端","图",34704); insert into hudi.hudisource values (10,"丁彬",55,"男","百度","网站大全",30885); ``` - 检查hdfs路径是否有文件写入 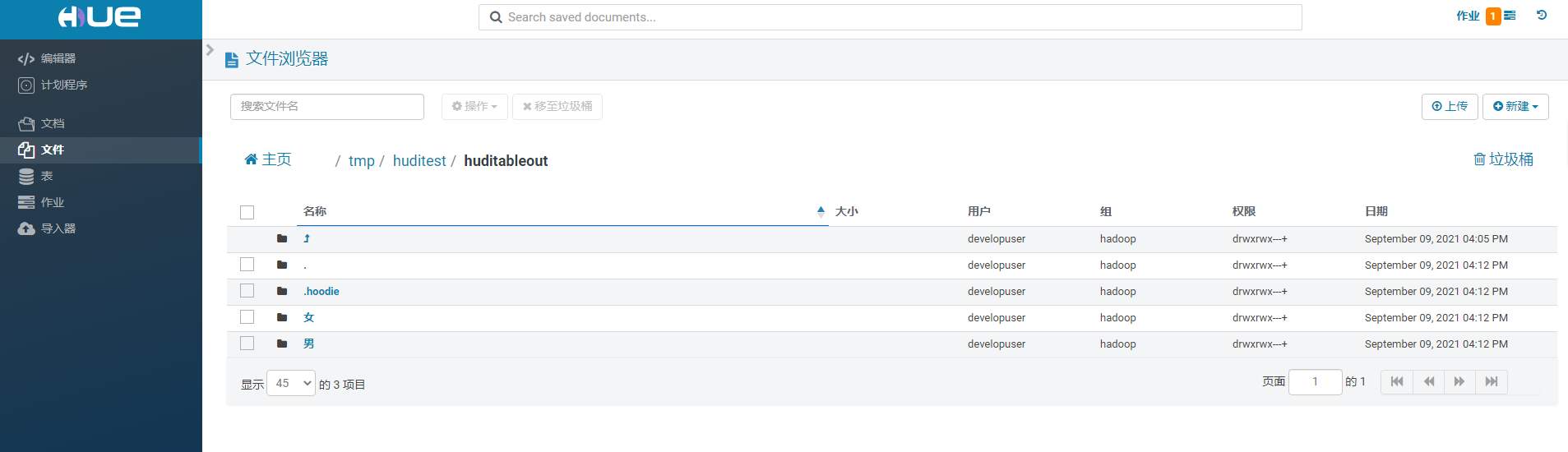 - 参考如下命令在客户端将hdfs对应路径的hudi表写入hive `run_hive_sync_tool.sh --partitioned-by sex --base-path hdfs://hacluster//tmp/huditest/huditableout/ --table huditableout --partition-value-extractor org.apache.hudi.hive.MultiPartKeysValueExtractor --support-timestamp `  - 登录hive客户端检查hive表 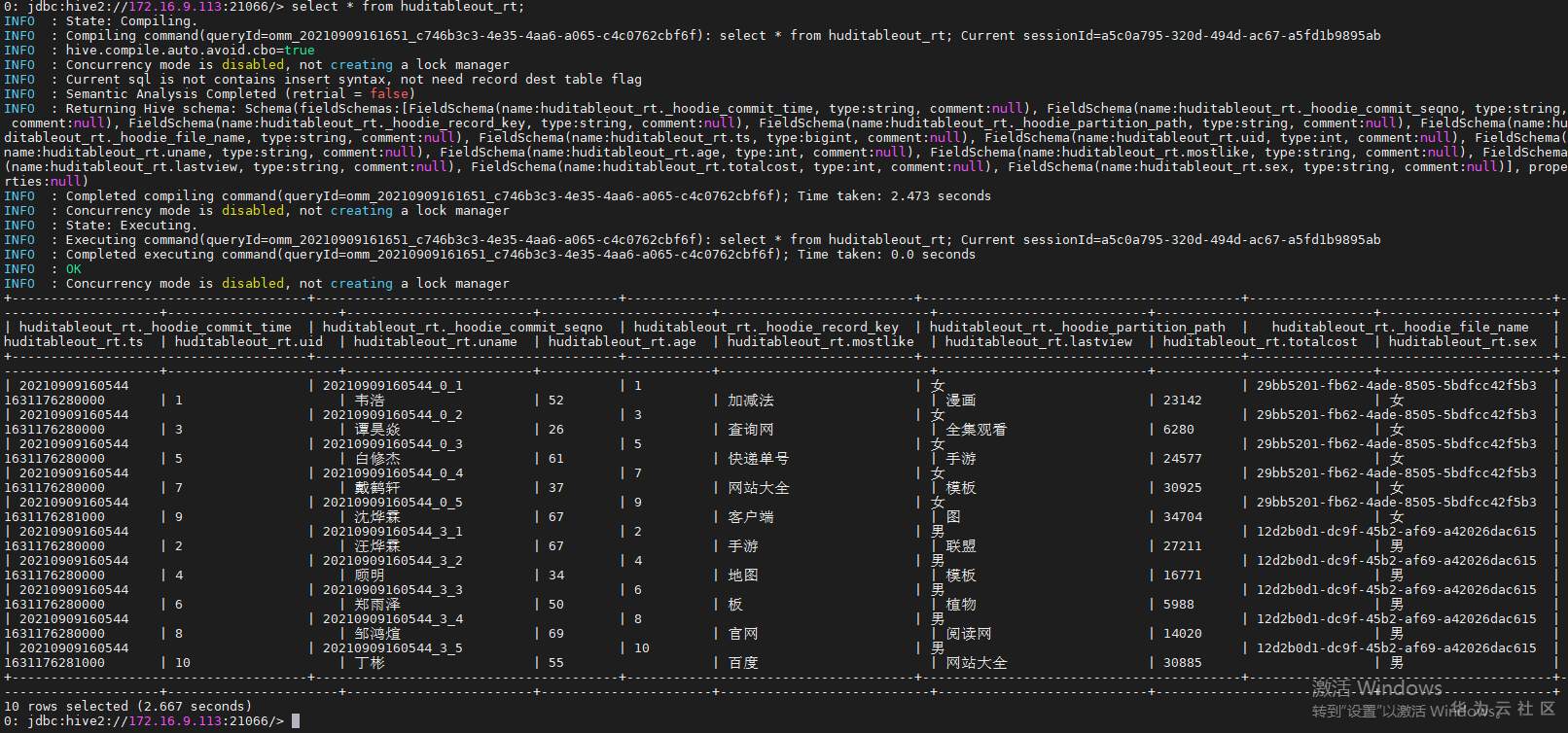 - 下面检查数据新增以及更新的同步情况 在源MySQL库插入数据 insert into hudi.hudisource values (11,"蒋语堂",38,"女","图","播放器",28732); 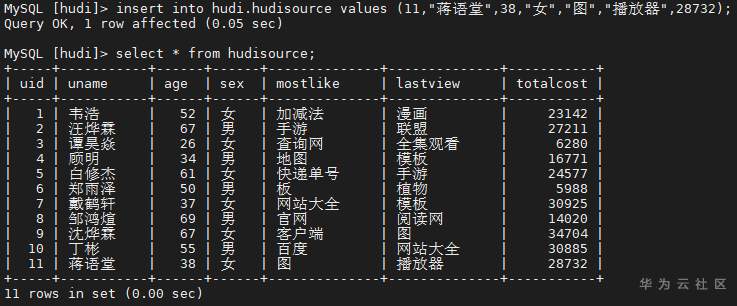 对应hive表同步情况 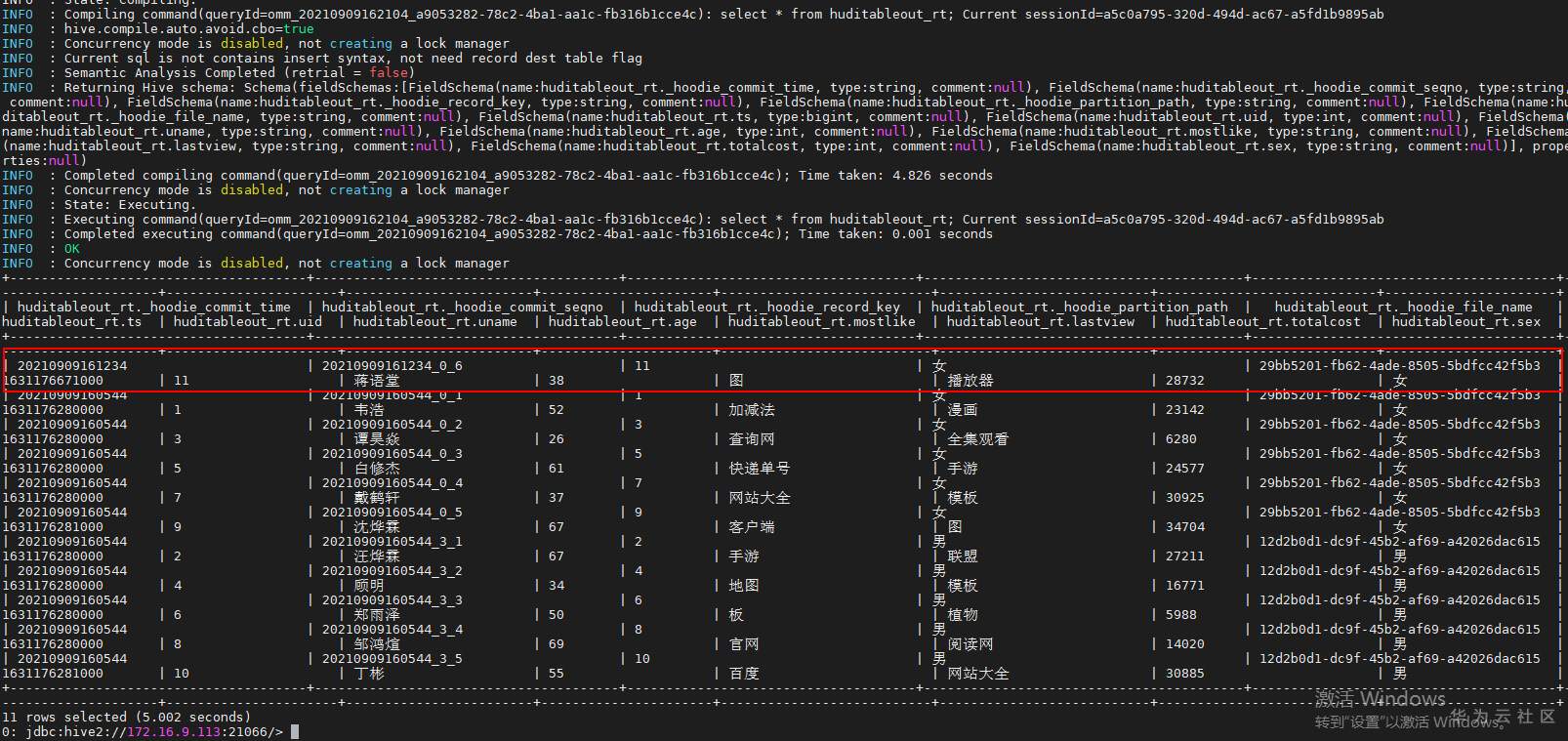 在源MySQL库对数据进行更改: UPDATE hudi.hudisource SET uname='Anne Marie333' WHERE uid=11; 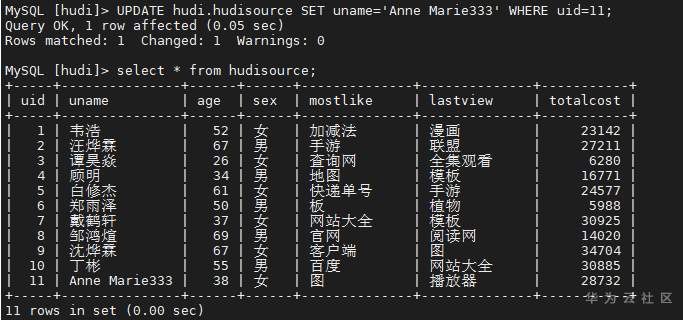 对应hive表同步情况 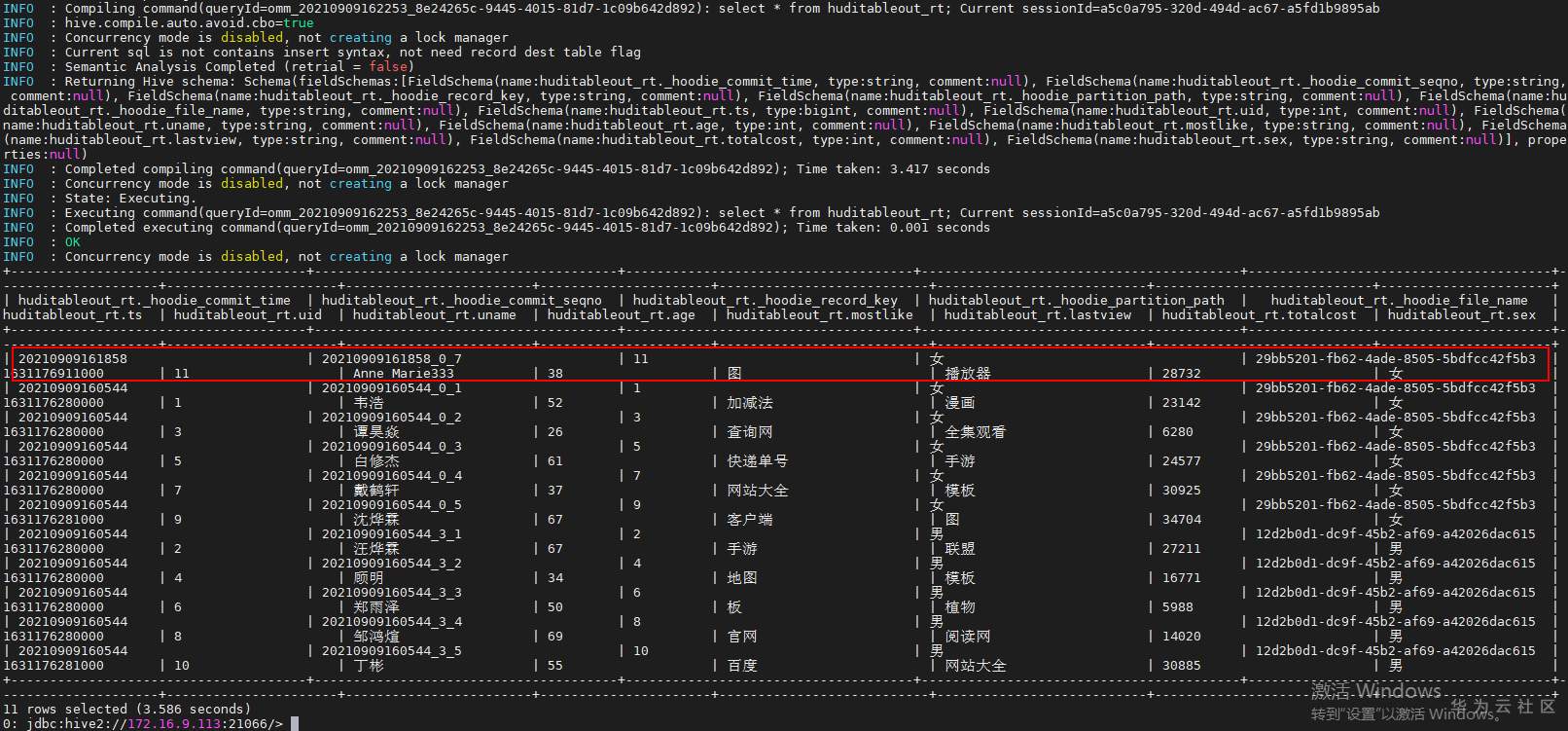 引用链接 [1] 集成工作: https://issues.apache.org/jira/browse/HUDI-1521
-
# 华为FusionInsight MRS FlinkSQL 复杂嵌套Json解析最佳实践 ## 背景说明 随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂,开发者可能是资深的大数据从业者、初学 Java 的爱好者,或是不懂代码的数据分析者。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。 SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎,致力于提供一套 SQL 支持全部应用场景,Flink SQL 的实现也完全遵循 ANSI SQL 标准。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。 本文介绍如何使用华为FusionInsight MRS FlinkServer服务进行界面化的FlinkSQL编辑,从而处理复杂的嵌套Json格式 ## Json内容 下面以cdl新增数据的json为例 ``` { "schema":{ "type":"struct", "fields":[ { "type":"string", "optional":false, "field":"DATA_STORE" }, { "type":"string", "optional":false, "field":"SEG_OWNER" }, { "type":"string", "optional":false, "field":"TABLE_NAME" }, { "type":"int64", "optional":false, "name":"org.apache.kafka.connect.data.Timestamp", "version":1, "field":"TIMESTAMP" }, { "type":"string", "optional":false, "field":"OPERATION" }, { "type":"string", "optional":true, "field":"LOB_COLUMNS" }, { "type":"struct", "fields":[ { "type":"array", "items":{ "type":"struct", "fields":[ { "type":"string", "optional":false, "field":"name" }, { "type":"string", "optional":true, "field":"value" } ], "optional":false }, "optional":false, "field":"properties" } ], "optional":false, "name":"transaction", "field":"transaction" }, { "type":"struct", "fields":[ { "type":"int64", "optional":false, "field":"uid" } ], "optional":true, "name":"unique", "field":"unique" }, { "type":"struct", "fields":[ { "type":"int64", "optional":false, "field":"uid" }, { "type":"string", "optional":true, "default":"", "field":"uname" }, { "type":"int64", "optional":true, "field":"age" }, { "type":"string", "optional":true, "field":"sex" }, { "type":"string", "optional":true, "field":"mostlike" }, { "type":"string", "optional":true, "field":"lastview" }, { "type":"int64", "optional":true, "field":"totalcost" } ], "optional":true, "name":"data", "field":"data" }, { "type":"struct", "fields":[ ], "optional":true, "name":"EMPTY", "field":"before" }, { "type":"string", "optional":true, "field":"HEARTBEAT_IDENTIFIER" } ], "optional":false, "name":"hudi.hudisource" }, "payload":{ "DATA_STORE":"MYSQL", "SEG_OWNER":"hudi", "TABLE_NAME":"hudisource", "TIMESTAMP":1631070742000, "OPERATION":"INSERT", "LOB_COLUMNS":"", "transaction":{ "properties":[ { "name":"file", "value":"mysql-bin.000005" }, { "name":"pos", "value":"32307" }, { "name":"gtid", "value":"" } ] }, "unique":{ "uid":11 }, "data":{ "uid":11, "uname":"蒋语堂", "age":38, "sex":"女", "mostlike":"图", "lastview":"播放器", "totalcost":28732 }, "before":null, "HEARTBEAT_IDENTIFIER":"998d66cc-1405-40e2-bbdc-41f2adf40724" } } ``` 上面的数据信息为复杂的json嵌套结构,包含了 Map、Array、Row 等类型, 对于这样的复杂格式需要有一种高效的方式进行解析,下面介绍如何实现。 ## 华为FusionInsight MRS Flink WebUI介绍 Flink WebUI提供基于Web的可视化开发平台,用户只需要编写SQL即可开发作业,极大降低作业开发门槛。同时通过作业平台能力开放,支持业务人员自行编写SQL开发作业来快速应对需求,大大减少Flink作业开发工作量。 Flink WebUI主要有以下特点: - 企业级可视化运维:运维管理界面化、作业监控、作业开发Flink SQL标准化等。 - 快速建立集群连接:通过集群连接功能配置访问一个集群,需要客户端配置、用户认证密钥文件。 - 快速建立数据连接:通过数据连接功能配置访问一个组件。创建“数据连接类型”为“HDFS”类型时需创建集群连接,其他数据连接类型的“认证类型”为“KERBEROS”需创建集群连接,“认证类型”为“SIMPLE”不需创建集群连接。 - 可视化开发平台:支持自定义输入/输出映射表,满足不同输入来源、不同输出目标端的需求。 - 图形化作业管理:简单易用。 下面介绍如何使用Flink WebUI开发FlinkSQL DDL语句解析出有效信息 ### 操作步骤 - 登录华为FusionInisght MRS Flink WebUI  - 在作业管理选择新建作业创建一个FlinkSQL任务  - 编辑Flink SQL语句 SQL说明:创建两张kafka流表,起作用为从kafka源端读取cdl对应topic,解析出需要的字段。并将结果写入另外一个kafka topic 1. Json 中的每个 {} 都需要用 Row 类型来表示 2. Json 中的每个 [] 都需要用 Arrary 类型来表示 3. 数组的下标是从 1 开始的不是 0 如下面 SQL 中的 \`schema\`.\`fields\`[1].type 4. 关键字在任何地方都需要加反引号 如上面 SQL 中的 \`type\` 5. select 语句中的字段类型和顺序一定要和结果表的字段类型和顺序保持一致 6. 可使用flink函数比如LOCALTIMESTAMP为获取flink系统时间  ``` CREATE TABLE huditableout_source( `schema` ROW `fields` ARRAY ROW> >, payload ROW `TIMESTAMP` BIGINT, `data` ROW uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT> >, type1 as `schema`.`fields`[1].type, optional1 as `schema`.`fields`[1].optional, field1 as `schema`.`fields`[1].field, type2 as `schema`.`fields`[2].type, optional2 as `schema`.`fields`[2].optional, field2 as `schema`.`fields`[2].field, ts as payload.`TIMESTAMP`, uid as payload.`data`.uid, uname as payload.`data`.uname, age as payload.`data`.age, sex as payload.`data`.sex, mostlike as payload.`data`.mostlike, lastview as payload.`data`.lastview, totalcost as payload.`data`.totalcost, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE TABLE huditableout( type1 VARCHAR(32), optional1 BOOLEAN, field1 VARCHAR(32), type2 VARCHAR(32), optional2 BOOLEAN, field2 VARCHAR(32), ts BIGINT, uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'huditableout2', 'properties.bootstrap.servers' = '172.16.9.113:21007,172.16.9.117:21007,172.16.9.118:21007', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'json', 'json.fail-on-missing-field' = 'false', 'json.ignore-parse-errors' = 'true', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); insert into huditableout select type1, optional1, field1, type2, optional2, field2, ts, uid, uname, age, sex, mostlike, lastview, totalcost, localts from huditableout_source; ``` - 点击语义校验,确保语义校验通过  - 启动该Flink SQL任务  - 检查结果 源端kafka 数据  目标端kafka 数据 
-
# 华为FusionInsight MRS CDL使用指南 ## 说明 CDL是一种简单、高效的数据实时集成服务,能够从各种OLTP数据库中抓取Data Change事件,然后推送至Kafka中,最后由Sink Connector消费Topic中的数据并导入到大数据生态软件应用中,从而实现数据的实时入湖。 CDL服务包含了两个重要的角色:CDLConnector和CDLService。CDLConnector是具体执行数据抓取任务的实例,CDLService是负责管理和创建任务的实例。 本此实践介绍以mysql作为数据源进行数据抓取 ## 前提条件 - MRS集群已安装CDL服务。 - MySQL数据库需要开启mysql的bin log功能(默认情况下是开启的)。 查看MySQL是否开启bin log: 使用工具或者命令行连接MySQL数据库(本示例使用navicat工具连接),执行show variables like 'log_%'命令查看。 例如在navicat工具选择"File > New Query"新建查询,输入如下SQL命令,单击"Run"在结果中"log_bin"显示为"ON"则表示开启成功。 `show variables like 'log_%'` 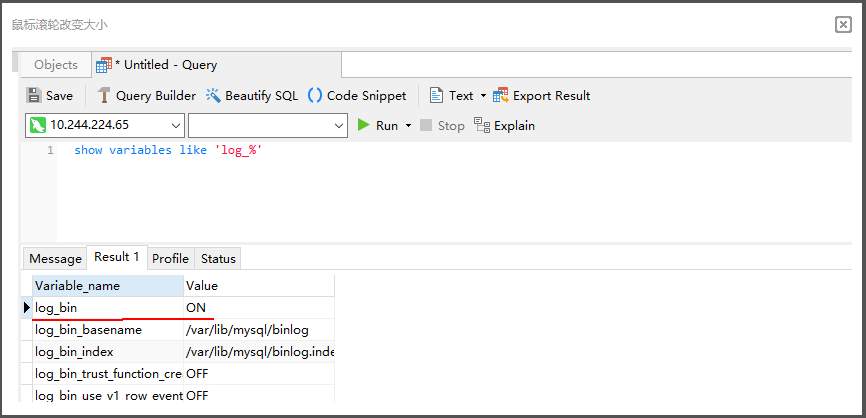 ## 工具准备 现在cdl只能使用rest api的方式进行命令提交,所以需要提前安装工具进行调试。本文使用VSCode工具。  完成之后安装rest client插件:  完成之后创建一个cdl.http的文件进行编辑:  ## 创建CDL任务 CDL任务创建的流程图如下所示: 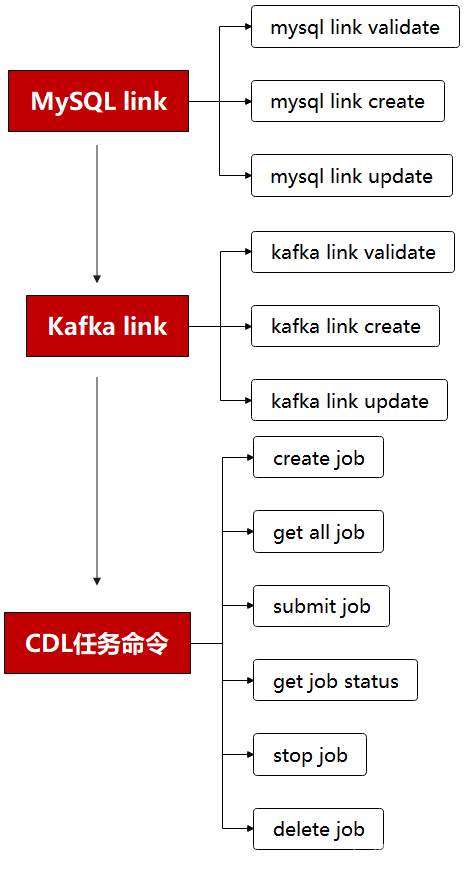 说明:需要先创建一个MySQL link, 在创建一个Kafka link, 然后再创建一个CDL同步任务并启动。 MySQL link部分rest请求代码 ``` @hostname = 172.16.9.113 @port = 21495 @host = {{hostname}}:{{port}} @bootstrap = "172.16.9.113:21007" @bootstrap_normal = "172.16.9.113:21005" @mysql_host = "172.16.2.118" @mysql_port = "3306" @mysql_database = "hudi" @mysql_user = "root" @mysql_password = "Huawei@123" ### get links get https://{{host}}/api/v1/cdl/link ### mysql link validate post https://{{host}}/api/v1/cdl/link?validate=true content-type: application/json { "name": "MySQL_link", //link名,全局唯一,不能重复 "description":"MySQL connection", //link描述 "link-type":"mysql", //link的类型 "enabled":"true", "link-config-values": { "inputs": [ { "name": "host", "value": {{mysql_host}} }, //数据库安装节点的ip { "name": "port", "value": {{mysql_port}} },//数据库监听的端口 { "name": "database.name", "value": {{mysql_database}} }, //连接的数据库名 { "name": "user", "value": {{mysql_user}} }, //用户 { "name": "password","value": {{mysql_password}} } ,//密码 { "name":"schema", "value": {{mysql_database}}}//同数据库名 ] } } ### mysql link create post https://{{host}}/api/v1/cdl/link content-type: application/json { "name": "MySQL_link", //link名,全局唯一,不能重复 "description":"MySQL connection", //link描述 "link-type":"mysql", //link的类型 "enabled":"true", "link-config-values": { "inputs": [ { "name": "host", "value": {{mysql_host}} }, //数据库安装节点的ip { "name": "port", "value": {{mysql_port}} },//数据库监听的端口 { "name": "database.name", "value": {{mysql_database}} }, //连接的数据库名 { "name": "user", "value": {{mysql_user}} }, //用户 { "name": "password","value": {{mysql_password}} } ,//密码 { "name":"schema", "value": {{mysql_database}}}//同数据库名 ] } } ### mysql link update put https://{{host}}/api/v1/cdl/link/MySQL_link content-type: application/json { "name": "MySQL_link", //link名,全局唯一,不能重复 "description":"MySQL connection", //link描述 "link-type":"mysql", //link的类型 "enabled":"true", "link-config-values": { "inputs": [ { "name": "host", "value": {{mysql_host}} }, //数据库安装节点的ip { "name": "port", "value": {{mysql_port}} },//数据库监听的端口 { "name": "database.name", "value": {{mysql_database}} }, //连接的数据库名 { "name": "user", "value": {{mysql_user}} }, //用户 { "name": "password","value": {{mysql_password}} } ,//密码 { "name":"schema", "value": {{mysql_database}}}//同数据库名 ] } } ``` Kafka link部分rest请求代码 ``` ### get links get https://{{host}}/api/v1/cdl/link ### kafka link validate post https://{{host}}/api/v1/cdl/link?validate=true content-type: application/json { "name": "kafka_link", "description":"test kafka link", "link-type":"kafka", "enabled":"true", "link-config-values": { "inputs": [ { "name": "bootstrap.servers", "value": "172.16.9.113:21007" }, { "name": "sasl.kerberos.service.name", "value": "kafka" }, { "name": "security.protocol","value": "SASL_PLAINTEXT" }//安全模式为SASL_PLAINTEXT,普通模式为PLAINTEXT ] } } ### kafka link create post https://{{host}}/api/v1/cdl/link content-type: application/json { "name": "kafka_link", "description":"test kafka link", "link-type":"kafka", "enabled":"true", "link-config-values": { "inputs": [ { "name": "bootstrap.servers", "value": "172.16.9.113:21007" }, { "name": "sasl.kerberos.service.name", "value": "kafka" }, { "name": "security.protocol","value": "SASL_PLAINTEXT" }//安全模式为SASL_PLAINTEXT,普通模式为PLAINTEXT ] } } ### kafka link update put https://{{host}}/api/v1/cdl/link/kafka_link content-type: application/json { "name": "kafka_link", "description":"test kafka link", "link-type":"kafka", "enabled":"true", "link-config-values": { "inputs": [ { "name": "bootstrap.servers", "value": "172.16.9.113:21007" }, { "name": "sasl.kerberos.service.name", "value": "kafka" }, { "name": "security.protocol","value": "SASL_PLAINTEXT" }//安全模式为SASL_PLAINTEXT,普通模式为PLAINTEXT ] } } ``` CDL任务命令部分rest请求代码 ``` @hostname = 172.16.9.113 @port = 21495 @host = {{hostname}}:{{port}} @bootstrap = "172.16.9.113:21007" @bootstrap_normal = "172.16.9.113:21005" @mysql_host = "172.16.2.118" @mysql_port = "3306" @mysql_database = "hudi" @mysql_user = "root" @mysql_password = "Huawei@123" ### create job post https://{{host}}/api/v1/cdl/job content-type: application/json { "job_type": "CDL_JOB", //job类型,目前只支持CDL_JOB这一种 "name": "mysql_to_kafka", //job名称 "description":"mysql_to_kafka", //job描述 "from-link-name": "MySQL_link", //数据源Link "to-link-name": "kafka_link", //目标源Link "from-config-values": { "inputs": [ {"name" : "connector.class", "value" : "com.huawei.cdc.connect.mysql.MysqlSourceConnector"}, {"name" : "schema", "value" : "hudi"}, {"name" : "db.name.alias", "value" : "hudi"}, {"name" : "whitelist", "value" : "hudisource"}, {"name" : "tables", "value" : "hudisource"}, {"name" : "tasks.max", "value" : "10"}, {"name" : "mode", "value" : "insert,update,delete"}, {"name" : "parse.dml.data", "value" : "true"}, {"name" : "schema.auto.creation", "value" : "false"}, {"name" : "errors.tolerance", "value" : "all"}, {"name" : "multiple.topic.partitions.enable", "value" : "false"}, {"name" : "topic.table.mapping", "value" : "[ {\"topicName\":\"huditableout\", \"tableName\":\"hudisource\"} ]" }, {"name" : "producer.override.security.protocol", "value" : "SASL_PLAINTEXT"},//安全模式为SASL_PLAINTEXT,普通模式为PLAINTEXT {"name" : "consumer.override.security.protocol", "value" : "SASL_PLAINTEXT"}//安全模式为SASL_PLAINTEXT,普通模式为PLAINTEXT ] }, "to-config-values": {"inputs": []}, "job-config-values": { "inputs": [ {"name" : "global.topic", "value" : "demo"} ] } } ### get all job get https://{{host}}/api/v1/cdl/job ### submit job put https://{{host}}/api/v1/cdl/job/mysql_to_kafka/start ### get job status get https://{{host}}/api/v1/cdl/submissions?jobName=mysql_to_kafka ### stop job put https://{{host}}/api/v1/cdl/job/mysql_to_kafka/submissions/13/stop ### delete job DELETE https://{{host}}/api/v1/cdl/job/mysql_to_kafka ``` ## 场景验证 生产库MySQL原始数据如下: 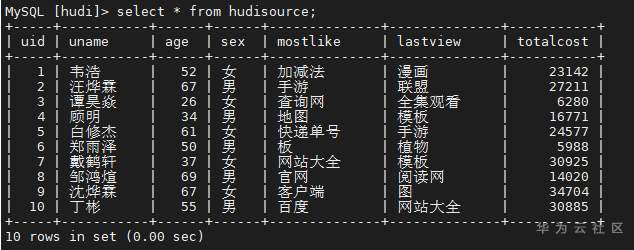 提交CDL任务之后 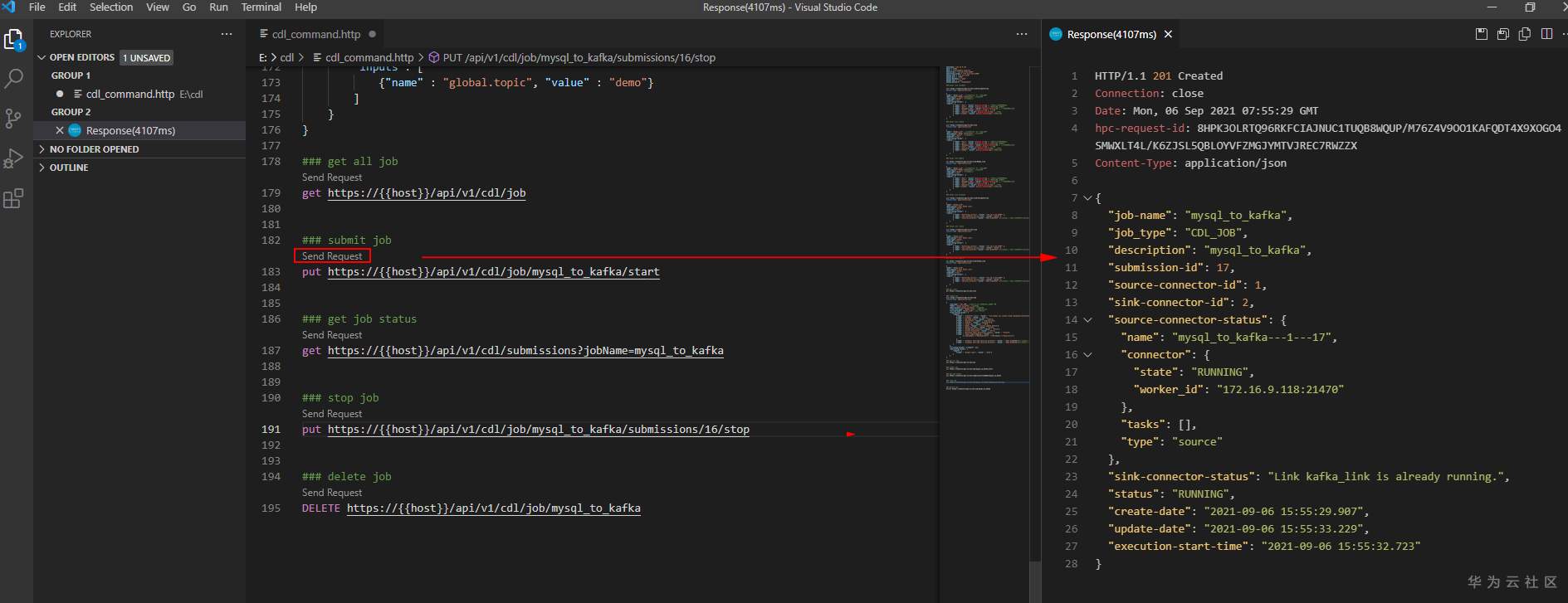 增加操作: insert into hudi.hudisource values (11,"蒋语堂",38,"女","图","播放器",28732); 对应kafka消息体:  更改操作: UPDATE hudi.hudisource SET uname='Anne Marie333' WHERE uid=11; 对应kafka消息体:  删除操作:delete from hudi.hudisource where uid=11; 对应kafka消息体: 
-
 【功能模块】关于kafka节点部署台数规划【操作步骤&问题现象】1、某局点kafka broker节点部署了4个,在开会讨论中,客户领导说kafka节点必须保持奇数,否则有台broker会浪费,而且leader选举时也会有问题2、但实际情况4台broker节点都进行了存储和使用,并没有出现客户说的问题,而且产品文档中也说明了,broker节点最少三台,并没有说必须保持奇数。只是zookeeper需要保持奇数。客户想让说明,问什么开源的需要保持奇数,但FusionInsight HD 没有这个要求,麻烦大佬帮忙解释下。【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】关于kafka节点部署台数规划【操作步骤&问题现象】1、某局点kafka broker节点部署了4个,在开会讨论中,客户领导说kafka节点必须保持奇数,否则有台broker会浪费,而且leader选举时也会有问题2、但实际情况4台broker节点都进行了存储和使用,并没有出现客户说的问题,而且产品文档中也说明了,broker节点最少三台,并没有说必须保持奇数。只是zookeeper需要保持奇数。客户想让说明,问什么开源的需要保持奇数,但FusionInsight HD 没有这个要求,麻烦大佬帮忙解释下。【截图信息】【日志信息】(可选,上传日志内容或者附件) -
1.华为云MRS二次开发介绍二次开发赋能视频汇总:https://bbs.huaweicloud.com/forum/thread-90936-1-1.html学习材料《FusionInsight MRS二次开发样例.pdf》2.华为云MRS技术对接介绍FusionInsight MRS生态地图:https://fusioninsight.github.io/ecosystem/zh-hans/学习材料:《FusionInsight MRS技术生态介绍v3.pdf》3.华为云MRS运维调优介绍运维汇总FusionInsight MRS运维HDFS/Hive问题定位解决https://bbs.huaweicloud.com/videos/103220FusionInsight MRS运维HBase/Spark问题定位解决https://bbs.huaweicloud.com/videos/103222FusionInsight MRS运维ES问题定位解决https://bbs.huaweicloud.com/videos/103221调优汇总FusionInsight MRS Hive调优https://bbs.huaweicloud.com/videos/103825FusionInsight MRS Spark调优https://bbs.huaweicloud.com/videos/103830FusionInsight MRS HBase调优https://bbs.huaweicloud.com/videos/103824FusionInsight MRS ES调优https://bbs.huaweicloud.com/videos/103822FusionInsight MRS Kafka调优https://bbs.huaweicloud.com/videos/103827FusionInsight MRS Solr调优https://bbs.huaweicloud.com/videos/103829
-
1. 华为云原生数据湖MRS基线方案介绍学习材料《FusionInsight MRS云原生数据湖基线方案--离线数据湖.pdf》《FusionInsight MRS云原生数据湖基线方案--实时数据湖.pdf》《FusionInsight MRS云原生数据湖基线方案--逻辑数据湖.pdf》《FusionInsight MRS云原生数据湖基线方案--专题集市.pdf》2. FusionInsight MRS Hudi最佳实践视频介绍参考博文Hudi最佳实践材料材料链接华为MRS基于Hudi和HetuEngine构建实时数据湖最佳实践https://bbs.huaweicloud.com/blogs/290858华为FusionInsight MRS实战 - Hudi实时入湖之DeltaStreamer工具最佳实践https://bbs.huaweicloud.com/blogs/2893153. FusionInisght MRS CDL最佳实践CDL最佳实践材料材料链接华为FusionInsight MRS CDL使用指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=152937华为FusionInsight MRS CDL最新版本使用指南https://bbs.huaweicloud.com/forum/thread-167340-1-1.html华为MRS CDL最新版本使用指南 - hudi实时入湖实战https://bbs.huaweicloud.com/forum/thread-167671-1-1.html4. FusionInisght MRS Flink最佳实践Flink最佳实践材料材料链接华为FusionInsight MRS Flink客户端配置https://bbs.huaweicloud.com/forum/thread-175741-1-1.html华为FusionInsight MRS Flink SQL-Client客户端配置https://bbs.huaweicloud.com/forum/thread-176103-1-1.html华为FusionInsight MRS FlinkSQL 复杂嵌套Json解析最佳实践https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=153494华为FusionInsight MRS实战 - 使用CDL, FlinkSQL以及Hudi实时入湖https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=153823华为FusionInsight MRS实战 - 使用FlinkSQL处理数据并使用redis做实时展示https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=154299华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=161992华为FusionInsight MRS实战 - FlinkSQL从kafka写入hivehttps://bbs.huaweicloud.com/forum/thread-173950-1-1.html华为FusionInsight MRS实战 - 使用Flink SQL-Client连接hivehttps://bbs.huaweicloud.com/forum/thread-176154-1-1.html华为FusionInsight MRS实战 - Flink CDC特性学习https://bbs.huaweicloud.com/forum/thread-176113-1-1.html5. FusionInsight MRS HetuEngine介绍及最佳实践HetuEngine专场学习直播回放:https://www.huaweicloud.com/about/live/HetuEngine.html视频介绍HetuEngine动手实践材料材料链接HetuEngine学习1-创建HBase数据源并且构建样例表 https://bbs.huaweicloud.com/forum/thread-147626-1-1.htmlHetuEngine学习2-创建hive样例数据并且和hbase做跨源融合分析https://bbs.huaweicloud.com/forum/thread-147719-1-1.htmlHetuEngine学习3-创建dws数据源并和hive做跨仓融合分析https://bbs.huaweicloud.com/forum/thread-147732-1-1.htmlHetuEngine学习4-Jmeter压测工具使用之HetuEngine压力测试https://bbs.huaweicloud.com/forum/thread-141244-1-1.html6. FusionInsight MRS ClickHouse动手实践视频介绍ClickHouse动手实践材料材料链接MRS Clickhouse 学习01-如何创建复制表以及分布式表并导入数据https://bbs.huaweicloud.com/forum/thread-148243-1-1.html7. FusionInsight MRS Manager Rest接口学习华为FusionInsight MRS实战 - Manager rest接口基础学习https://bbs.huaweicloud.com/forum/thread-175716-1-1.html华为FusionInsight MRS实战 - Manager rest接口进阶学习https://bbs.huaweicloud.com/forum/thread-175718-1-1.html8. 常见问题答疑openlookeng官网:https://openlookeng.io/
-
【功能模块】【操作步骤&问题现象】 500节点的HD 集群,各种GC参数设置多大合适?主要涉及Namenode、DataNode、MetaStore、Spark2x等等【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
1.华为云原生数据湖MRS关键技术介绍材料:《华为云Stack 8.0.3 FusionInsight MRS云原生数据湖 技术主打.pdf》课程视频: 2.优势poc用例最佳实践2.1. MRS多租户介绍及操作实践多租户特性介绍:多租户实操材料材料连接MRS多租户学习1-资源共享和抢占https://bbs.huaweicloud.com/forum/thread-147066-1-1.htmlMRS多租户学习2-用户权重配置以及资源抢占https://bbs.huaweicloud.com/forum/thread-147420-1-1.htmlMRS多租户学习3-资源池配置及使用https://bbs.huaweicloud.com/forum/thread-147441-1-1.html2.2 MRS TPC-DS 测试工具操作实践MRS TPC-DS 测试工具学习材料:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=146814&page=1&authorid=&replytype=&extra=#pid1286986 2.3 MRS Ranger介绍及操作实践Ranger特性学习材料:Ranger动手操作视频MRS ranger操作视频 ElasticSearchhttps://v.qq.com/x/page/m3259j8lzqe.htmlMRS Ranger操作视频 HetuEnginehttps://v.qq.com/x/page/s3259i43cs7.htmlMRS Ranger操作视频 Hivehttps://v.qq.com/x/page/g3259fwpihf.htmlMRS Ranger操作视频 Kafkahttps://v.qq.com/x/page/g3259dahl8q.htmlMRS Ranger操作视频 Spark2xhttps://v.qq.com/x/page/h3259de5aul.htmlMRS Ranger操作视频 Yarnhttps://v.qq.com/x/page/j3259jt9q0m.htmlMRS Ranger操作视频 HDFShttps://v.qq.com/x/page/c3261lhxugz.html3.常见问题答疑安装问题答疑:安装问题论坛帖:https://bbs.huaweicloud.com/forum/thread-146731-1-1.html https://bbs.huaweicloud.com/forum/thread-146999-1-1.html HetuEngine相比Hive查询加速问题HetuEngine使用如下特点保证计算查询的快速1. MPP架构2. 计算下推3. 预先启动4. 资源自己管理(spark是交给yarn管理)5. 动态过滤6. 小表广播
上滑加载中
推荐直播
-
 码道新技能,AI 新生产力——从自动视频生成到开源项目解析
码道新技能,AI 新生产力——从自动视频生成到开源项目解析2026/04/08 周三 19:00-21:00
童得力-华为云开发者生态运营总监/何文强-无人机企业AI提效负责人
本次华为云码道 Skill 实战活动,聚焦两大 AI 开发场景:通过实战教学,带你打造 AI 编程自动生成视频 Skill,并实现对 GitHub 热门开源项目的智能知识抽取,手把手掌握 Skill 开发全流程,用 AI 提升研发效率与内容生产力。
回顾中 -
 华为云码道:零代码股票智能决策平台全功能实战
华为云码道:零代码股票智能决策平台全功能实战2026/04/18 周六 10:00-12:00
秦拳德-中软国际教育卓越研究院研究员、华为云金牌讲师、云原生技术专家
利用Tushare接口获取实时行情数据,采用Transformer算法进行时序预测与涨跌分析,并集成DeepSeek API提供智能解读。同时,项目深度结合华为云CodeArts(码道)的代码智能体能力,实现代码一键推送至云端代码仓库,建立起高效、可协作的团队开发新范式。开发者可快速上手,从零打造功能完整的个股筛选、智能分析与风险管控产品。
回顾中 -
 华为云码道全新升级,多会话并行与多智能体协作
华为云码道全新升级,多会话并行与多智能体协作2026/05/08 周五 19:00-21:00
王一男-华为云码道产品专家;张嘉冉-华为云码道工程师;胡琦-华为云HCDE;程诗杰-华为云HCDG
华为云码道4月份版本全新升级,此次直播深度解读4月份产品特性,通过“特性解读+实操演示+实战案例+设计创新”的组合,全方位展现码道在多会话并行与多智能体协作方面的能力,赋能开发者提升效率
即将直播
热门标签