-
 # Kubernetes 使用secret和--device > > k8s 的版本 v1.17 ; docker 版本 18.09.0 ### 1. 创建secret 用于存放预共享秘钥 - 参考文档:[Kubernetes /中文文档 /Secret](https://kubernetes.io/zh/docs/concepts/configuration/secret/) https://kubernetes.io/zh/docs/concepts/configuration/secret/ - 我这儿给出 通过yaml 文件创建 Opaque 类型的 Secret 的实例参考 ```yaml apiVersion: v1 kind: Secret metadata: name: mysecret # 创建secret的名字 namespace: ming-feng # 根据自己的需要设置使用哪个命名空间, 可以不用设置 type: Opaque data: pwd: MTIzNDU2Cg== # value 秘钥:123456 转 base64 的值 ``` - 创建secret ```sh root@ubuntu:~/mingfeng/secret# kubectl apply -f sercet.yaml secret/mysecret created root@ubuntu:~/mingfeng/secret# kubectl get secret -n ming-feng NAME TYPE DATA AGE default-token-lng4k kubernetes.io/service-account-token 3 2m33s mysecret Opaque 1 27s ``` ### 2. Kubernetes 使用 --device - Kubernetes支持`--device`问题在社区上讨论了很久,当前的解决方案有两种 - 1、通过加上 **privileged: true** 是容器拥有物理机上所有设备的使用权限 - 但是从安全角度考虑,使用 privileged:true 可能并不理想 - 2、**device plugins机制来注册要访问的设备,典型的如GPU** - 以下我通过 device plugins 方式来进行演示 #### 2.1 device plugins 的使用 - device plugins 接口的介绍 以下给出k8s 设备插件的接口信息和原理介绍 感兴趣的朋友可以仔细研读一下,自己制作插件 - 参考文档 [Kubernetes 文档/设备插件](https://kubernetes.io/zh/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/) https://kubernetes.io/zh/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/ - 原理介绍 [Kubernetes|中文社区](https://www.kubernetes.org.cn/4391.html) https://www.kubernetes.org.cn/4391.html - 插件介绍 - /dev下有很多的设备,每个设备都写一个插件会很麻烦,有大佬开源了个k8s-hostdev-plugin,可以解决大部分插件问题 - github地址:**[k8s-hostdev-plugin](https://github.com/bluebeach/k8s-hostdev-plugin)** - 码云地址:**[k8s-hostdev-plugin](https://gitee.com/leexiali/k8s-hostdev-plugin)** - 编译 k8s-hostdev-plugin 插件 (之前没用过 go 纯小白 踩了很多坑, 所以以下安装步骤仅供参考) > > linux ubuntu 环境上安装 - 直接基于插件的 README.md Build 说明 编译出现了些问题, 所以我采用了 手动编译的方式 - 1,插件是基于go 语言编译的所以需要安装go环境 - 设置代理 - go env -w GOPROXY=https://goproxy.cn,direct - 2,通过 go env 找到 GOPATH 然后在 GOPATH 新建src目录,将git 下载下来的代码放到该目录下 - 编译 - 第一步 go mod init 初始化后会在当前目录下生成 go.mod 文件 ```sh root@ubuntu:~/go/src/k8s-hostdev-plugin-master# go mod init go: creating new go.mod: module k8s.io/k8s-hostdev-plugin go: converting vendor/vendor.json: stat golang.org/x/tools/go/loader@: golang.org/x/tools/go/loader@: ... 【下载中。。。 耗时很长 耐心等待】 go: copying requirements from vendor/vendor.json go: to add module requirements and sums: go mod tidy ``` - 第二步 go mod tidy - 第一次报错 以及解决方案 ```sh root@ubuntu:~/go/src/k8s-hostdev-plugin-master# go mod tidy go: finding module for package github.com/Sirupsen/logrus go: finding module for package github.com/fsnotify/fsnotify go: finding module for package github.com/pmezard/go-difflib/difflib ... go: k8s.io/k8s-hostdev-plugin imports github.com/Sirupsen/logrus: github.com/Sirupsen/logrus@v1.8.1: parsing go.mod: module declares its path as: github.com/sirupsen/logrus but was required as: github.com/Sirupsen/logrus 原因是因为 模块的 首字母发生了变化 ``` - 解决 go.mod 文件后面加上 一个 replace ```sh root@ubuntu:~/go/src/k8s-hostdev-plugin-master# echo "replace github.com/Sirupsen/logrus v1.4.1 => github.com/sirupsen/logrus v1.4.1" >> go.mod root@ubuntu:~/go/src/k8s-hostdev-plugin-master# cat go.mod module k8s.io/k8s-hostdev-plugin go 1.17 require ( github.com/davecgh/go-spew v1.1.1 github.com/golang/protobuf v1.2.1-0.20180917234931-6e3d092c77c3 golang.org/x/crypto v0.0.0-20181015023909-0c41d7ab0a0e golang.org/x/net v0.0.0-20180911220305-26e67e76b6c3 golang.org/x/sys v0.0.0-20181023152157-44b849a8bc13 google.golang.org/genproto v0.0.0-20180912233945-5a2fd4cab2d6 ) replace github.com/Sirupsen/logrus v1.4.1 => github.com/sirupsen/logrus v1.4.1 ``` - 第二次 运行报错 ```shell root@ubuntu:~/go/src/k8s-hostdev-plugin-master# go mod tidy ... k8s.io/k8s-hostdev-plugin imports k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1: module k8s.io/kubernetes@latest found (v1.23.1), but does not contain package k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1 原因是 $GOPATH/pkg/mod/k8s.io/kubernetes@v1.23.1 下面没有 deviceplugin/v1beta1 ``` - 解决 查了很多资料没有找到合适的办法, 就尝试 将vendor目录下的文件复制到 $GOPATH 下面 ```shell root@ubuntu:~/go/src/k8s-hostdev-plugin-master# cp -rf vendor/k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin /root/go/pkg/mod/k8s.io/kubernetes@v1.23.1/pkg/kubelet/apis /root/go 是 $GOPATH 路径 ``` - 第三次 运行报错 ```sh root@ubuntu:~/go/src/k8s-hostdev-plugin-master# go mod tidy go: finding module for package google.golang.org/grpc go: finding module for package github.com/fsnotify/fsnotify go: finding module for package github.com/pmezard/go-difflib/difflib go: finding module for package k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1 go: found github.com/Sirupsen/logrus in github.com/Sirupsen/logrus v1.4.1 go: found github.com/fsnotify/fsnotify in github.com/fsnotify/fsnotify v1.5.1 go: found google.golang.org/grpc in google.golang.org/grpc v1.43.0 go: found k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1 in k8s.io/kubernetes v1.23.1 go: found github.com/pmezard/go-difflib/difflib in github.com/pmezard/go-difflib v1.0.0 go: k8s.io/kubernetes@v1.23.1 requires k8s.io/api@v0.0.0: reading k8s.io/api/go.mod at revision v0.0.0: unknown revision v0.0.0 ``` - 解决 - 原因 :在Kubernetes主仓中,也使用了公共库,不过`go.mod`文件中所有公共库版本都指定为了**v0.0.0(显然这个版本不存在)**,然后通过**Go Module的replace**机制,将版本替换为子目录 - 资料参考 [Kubernetes平台开发者小技巧](http://dockone.io/article/2434308) http://dockone.io/article/2434308 ```sh 参考资料,编写脚本 root@ubuntu:~/go/src/k8s-hostdev-plugin-master# cat get_k8s_v.sh #!/bin/sh set -euo pipefail VERSION=${1#"v"} if [ -z "$VERSION" ]; then echo "Must specify version!" exit 1 fi MODS=($( curl -sS https://raw.githubusercontent.com/kubernetes/kubernetes/v${VERSION}/go.mod | sed -n 's|.*k8s.io/\(.*\) => ./staging/src/k8s.io/.*|k8s.io/\1|p' )) for MOD in "${MODS[@]}"; do V=$( go mod download -json "${MOD}@kubernetes-${VERSION}" | sed -n 's|.*"Version": "\(.*\)".*|\1|p' ) go mod edit "-replace=${MOD}=${MOD}@${V}" done go get "k8s.io/kubernetes@v${VERSION}" # v1.23.1 可以根据 上面报错的版本填写 root@ubuntu:~/go/src/k8s-hostdev-plugin-master# /bin/bash get_k8s_v.sh v1.23.1 go get: upgraded github.com/golang/protobuf v1.2.1-0.20180917234931-6e3d092c77c3 => v1.5.2 go get: upgraded github.com/stretchr/testify v1.2.3-0.20181115233458-8019298d9fa5 => v1.7.0 go get: upgraded golang.org/x/crypto v0.0.0-20181015023909-0c41d7ab0a0e => v0.0.0-20210817164053-32db794688a5 go get: upgraded golang.org/x/net v0.0.0-20180911220305-26e67e76b6c3 => v0.0.0-20211209124913-491a49abca63 go get: upgraded golang.org/x/sys v0.0.0-20181023152157-44b849a8bc13 => v0.0.0-20210831042530-f4d43177bf5e go get: upgraded google.golang.org/genproto v0.0.0-20180912233945-5a2fd4cab2d6 => v0.0.0-20210831024726-fe130286e0e2 go get: added k8s.io/kubernetes v1.23.1 ``` - 第三步 go mod vendor - 第四步 go build -o k8s-hostdev-plugin - 生成 执行文件 k8s-hostdev-plugin - 本地测试插件是否运行正常 ```sh root@ubuntu:~/mingfeng# ./k8s-hostdev-plugin FATA[0000] Must have arg --devs , for example, --devs /dev/mem:rwm root@ubuntu:~/mingfeng# ./k8s-hostdev-plugin --devs /dev/mem:rwm config: main.HostDevicePluginConfig{DevList:[]*main.DevConfig{(*main.DevConfig)(0xc0000e4500)}} INFO[0000] Starting FS watcher. INFO[0000] Starting OS watcher. INFO[0005] Register /dev/mem success <*>{/dev/mem rwm dev_mem hostdev.k8s.io/dev_mem /var/lib/kubelet/device-plugins/dev_mem <*>{<*>{<max>} /var/lib/kubelet/device-plugins/dev_mem true {<max>}} <*>{{<max>} {<max>} map[<max>] map[<max>] true false <*>{<max>} map[<max>] <nil> <*>{<max>} <*>{<max>} {<max>} {<max>} 0 <*>{<max>} <nil>} [<*>&Device{ID:/dev/mem,Health:Healthy,}] true 0xc00011e000} ``` ### 3. 以 使用设备 /dev/fuse 为例 注册插件 - 注册插件 - 修改 k8s-hostdev-plugin 插件 提供的Dockerfile 构建镜像 ```dockerfile FROM ubuntu:18.04 # 我这儿使用了 下载好的ubuntu的镜像 COPY k8s-hostdev-plugin /usr/bin/k8s-hostdev-plugin CMD ["k8s-hostdev-plugin"] ``` - 修改注册插件 hostdev-plugin-ds.yaml 进行修改 ```yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: hostdev-device-plugin namespace: ming-feng spec: selector: matchLabels: name: hostdev-device-plugin-ds template: metadata: annotations: scheduler.alpha.kubernetes.io/critical-pod: "" labels: name: hostdev-device-plugin-ds spec: tolerations: - key: CriticalAddonsOnly operator: Exists hostNetwork: true containers: - name: hostdev image: hostdev:v1 command: [ "k8s-hostdev-plugin"] args: ["--devs", "/dev/mem:r,/dev/fuse:rwm"] # 在这儿添加用于注册的设备以及权限 # 原来的 yaml 文件中 这儿使用了 securityContext: privileged: true 特权容器 # 但经过我的验证 在挂载 /dev/fuse 时 并不需要 指定 privileged: true 特权参数 volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins - name: dev mountPath: /dev volumes: - name: device-plugin hostPath: path: /var/lib/kubelet/device-plugins - name: dev hostPath: path: /dev ``` - 运行插件 ```shell # 创建 插件容器 root@ubuntu:~/mingfeng# kubectl create -f hostdev-plugin-ds.yaml daemonset.apps/hostdev-device-plugin created # 查看 运行情况 root@ubuntu:~/mingfeng# kubectl get all -n ming-feng NAME READY STATUS RESTARTS AGE pod/hostdev-device-plugin-v6znd 1/1 Running 0 26s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/hostdev-device-plugin 1 1 1 1 1 <none> 26s # 删除 插件容器 root@ubuntu:~/mingfeng# kubectl delete daemonset hostdev-device-plugin -n ming-feng daemonset.apps "hostdev-device-plugin" deleted root@ubuntu:~/mingfeng# ``` ### 4. k8s 使用secret和 --device 下发容器 - 编辑 yaml 文件 ```yaml apiVersion: v1 kind: Pod metadata: name: sznp-pod namespace: ming-feng annotations: # 对应 docker run --security-opt apparmor=profile 参数 container.apparmor.security.beta.kubernetes.io/sznp-con: localhost/profile # docker run -security-opt seccomp=mount.json 参数 container.seccomp.security.alpha.kubernetes.io/sznp-con: localhost/profiles/mount.json spec: hostNetwork: true # 如果要将 secret 挂载到 /run/secret 目录下面 则 需要 设置 ServiceAccount 为false # 挂载到其他的目录则不需要, 原因是因为 ServiceAccount 会默认挂载到 /run/secret/kubernetes.io 下面 automountServiceAccountToken: false containers: - name: sznp-con image: sznp-k8s-demo:v1 securityContext: capabilities: # 对应 docker run --cap-add SYS_ADMIN add: ["SYS_ADMIN"] resources: limits: hostdev.k8s.io/dev_fuse: 1 imagePullPolicy: Never command: [ "/bin/bash", "-c"] args: [ "sleep 3600" ] volumeMounts: - name: secrets mountPath: /run/secrets volumes: - name: secrets secret: secretName: mysecret items: - key: pwd path: pwd ``` - 参数 说明 - capabilities 对应的是 --cap-add SYS_ADMIN - `--device`挂载的设备,容器内的进程通常没有权限操作,需要使用`--cap-add`开放相应的权限 - apparmor - 用于限制容器对资源的访问 - 具体的配置 参考资料 [Kubernetes文档/AppArmor](https://kubernetes.io/zh/docs/tutorials/clusters/apparmor/) https://kubernetes.io/zh/docs/tutorials/clusters/apparmor/ - seccomp - 用于限制容器的系统调用 - 具体的配置 参考资料 [Kubernetes文档/Seccomp ](https://kubernetes.io/zh/docs/tutorials/clusters/seccomp/) https://kubernetes.io/zh/docs/tutorials/clusters/seccomp/ - 运行k8s 下发容器的命名 ```sh 先运行设备插件 root@ubuntu:~/mingfeng# kubectl create -f hostdev-plugin-ds.yaml daemonset.apps/hostdev-device-plugin created 运行使用设备和secret的容器 root@ubuntu:~/mingfeng# kubectl create -f device_secret.yaml pod/sznp-pod created 查看运行情况 root@ubuntu:~/mingfeng# kubectl get all -n ming-feng NAME READY STATUS RESTARTS AGE pod/hostdev-device-plugin-5gfds 1/1 Running 0 22s pod/sznp-pod 1/1 Running 0 10s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/hostdev-device-plugin 1 1 1 1 1 22s ``` - 进入容器里面查看 设备和secret ```sh 进入容器 root@ubuntu:~/mingfeng# kubectl exec -it sznp-pod bash -n ming-feng 查看secret root@ubuntu:/home/mf# cat /run/secrets/pwd 123456 查看 设备挂载情况 root@ubuntu:/home/mf# ll /dev/ total 4 ... crw-rw-rw- 1 root root 1, 7 Dec 29 10:45 full crw-rw-rw- 1 root root 10, 229 Dec 29 10:45 fuse drwxrwxrwt 2 root root 40 Dec 29 10:45 mqueue/ ... root@ubuntu:/home/mf# cat /sys/devices/virtual/misc/fuse/dev 10:229 # 退出容器 root@ubuntu:/home/mf# exit exit ``` - 删除下发的pod和容器 ```sh root@ubuntu:~/mingfeng# kubectl delete pod sznp-pod -n ming-feng pod "sznp-pod" deleted root@ubuntu:~/mingfeng# kubectl delete daemonset hostdev-device-plugin -n ming-feng daemonset.apps "hostdev-device-plugin" deleted root@ubuntu:~/mingfeng# ``` ### 5. 参考文档 []: https://www.cnblogs.com/dream397/p/14034632.html "Docker及Kubernetes下device使用和分析" []: https://kubernetes.io/zh/docs/home/ "Kubernetes 文档" []: http://dockone.io/article/2434308 "Kubernetes平台开发者小技巧"
# Kubernetes 使用secret和--device > > k8s 的版本 v1.17 ; docker 版本 18.09.0 ### 1. 创建secret 用于存放预共享秘钥 - 参考文档:[Kubernetes /中文文档 /Secret](https://kubernetes.io/zh/docs/concepts/configuration/secret/) https://kubernetes.io/zh/docs/concepts/configuration/secret/ - 我这儿给出 通过yaml 文件创建 Opaque 类型的 Secret 的实例参考 ```yaml apiVersion: v1 kind: Secret metadata: name: mysecret # 创建secret的名字 namespace: ming-feng # 根据自己的需要设置使用哪个命名空间, 可以不用设置 type: Opaque data: pwd: MTIzNDU2Cg== # value 秘钥:123456 转 base64 的值 ``` - 创建secret ```sh root@ubuntu:~/mingfeng/secret# kubectl apply -f sercet.yaml secret/mysecret created root@ubuntu:~/mingfeng/secret# kubectl get secret -n ming-feng NAME TYPE DATA AGE default-token-lng4k kubernetes.io/service-account-token 3 2m33s mysecret Opaque 1 27s ``` ### 2. Kubernetes 使用 --device - Kubernetes支持`--device`问题在社区上讨论了很久,当前的解决方案有两种 - 1、通过加上 **privileged: true** 是容器拥有物理机上所有设备的使用权限 - 但是从安全角度考虑,使用 privileged:true 可能并不理想 - 2、**device plugins机制来注册要访问的设备,典型的如GPU** - 以下我通过 device plugins 方式来进行演示 #### 2.1 device plugins 的使用 - device plugins 接口的介绍 以下给出k8s 设备插件的接口信息和原理介绍 感兴趣的朋友可以仔细研读一下,自己制作插件 - 参考文档 [Kubernetes 文档/设备插件](https://kubernetes.io/zh/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/) https://kubernetes.io/zh/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/ - 原理介绍 [Kubernetes|中文社区](https://www.kubernetes.org.cn/4391.html) https://www.kubernetes.org.cn/4391.html - 插件介绍 - /dev下有很多的设备,每个设备都写一个插件会很麻烦,有大佬开源了个k8s-hostdev-plugin,可以解决大部分插件问题 - github地址:**[k8s-hostdev-plugin](https://github.com/bluebeach/k8s-hostdev-plugin)** - 码云地址:**[k8s-hostdev-plugin](https://gitee.com/leexiali/k8s-hostdev-plugin)** - 编译 k8s-hostdev-plugin 插件 (之前没用过 go 纯小白 踩了很多坑, 所以以下安装步骤仅供参考) > > linux ubuntu 环境上安装 - 直接基于插件的 README.md Build 说明 编译出现了些问题, 所以我采用了 手动编译的方式 - 1,插件是基于go 语言编译的所以需要安装go环境 - 设置代理 - go env -w GOPROXY=https://goproxy.cn,direct - 2,通过 go env 找到 GOPATH 然后在 GOPATH 新建src目录,将git 下载下来的代码放到该目录下 - 编译 - 第一步 go mod init 初始化后会在当前目录下生成 go.mod 文件 ```sh root@ubuntu:~/go/src/k8s-hostdev-plugin-master# go mod init go: creating new go.mod: module k8s.io/k8s-hostdev-plugin go: converting vendor/vendor.json: stat golang.org/x/tools/go/loader@: golang.org/x/tools/go/loader@: ... 【下载中。。。 耗时很长 耐心等待】 go: copying requirements from vendor/vendor.json go: to add module requirements and sums: go mod tidy ``` - 第二步 go mod tidy - 第一次报错 以及解决方案 ```sh root@ubuntu:~/go/src/k8s-hostdev-plugin-master# go mod tidy go: finding module for package github.com/Sirupsen/logrus go: finding module for package github.com/fsnotify/fsnotify go: finding module for package github.com/pmezard/go-difflib/difflib ... go: k8s.io/k8s-hostdev-plugin imports github.com/Sirupsen/logrus: github.com/Sirupsen/logrus@v1.8.1: parsing go.mod: module declares its path as: github.com/sirupsen/logrus but was required as: github.com/Sirupsen/logrus 原因是因为 模块的 首字母发生了变化 ``` - 解决 go.mod 文件后面加上 一个 replace ```sh root@ubuntu:~/go/src/k8s-hostdev-plugin-master# echo "replace github.com/Sirupsen/logrus v1.4.1 => github.com/sirupsen/logrus v1.4.1" >> go.mod root@ubuntu:~/go/src/k8s-hostdev-plugin-master# cat go.mod module k8s.io/k8s-hostdev-plugin go 1.17 require ( github.com/davecgh/go-spew v1.1.1 github.com/golang/protobuf v1.2.1-0.20180917234931-6e3d092c77c3 golang.org/x/crypto v0.0.0-20181015023909-0c41d7ab0a0e golang.org/x/net v0.0.0-20180911220305-26e67e76b6c3 golang.org/x/sys v0.0.0-20181023152157-44b849a8bc13 google.golang.org/genproto v0.0.0-20180912233945-5a2fd4cab2d6 ) replace github.com/Sirupsen/logrus v1.4.1 => github.com/sirupsen/logrus v1.4.1 ``` - 第二次 运行报错 ```shell root@ubuntu:~/go/src/k8s-hostdev-plugin-master# go mod tidy ... k8s.io/k8s-hostdev-plugin imports k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1: module k8s.io/kubernetes@latest found (v1.23.1), but does not contain package k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1 原因是 $GOPATH/pkg/mod/k8s.io/kubernetes@v1.23.1 下面没有 deviceplugin/v1beta1 ``` - 解决 查了很多资料没有找到合适的办法, 就尝试 将vendor目录下的文件复制到 $GOPATH 下面 ```shell root@ubuntu:~/go/src/k8s-hostdev-plugin-master# cp -rf vendor/k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin /root/go/pkg/mod/k8s.io/kubernetes@v1.23.1/pkg/kubelet/apis /root/go 是 $GOPATH 路径 ``` - 第三次 运行报错 ```sh root@ubuntu:~/go/src/k8s-hostdev-plugin-master# go mod tidy go: finding module for package google.golang.org/grpc go: finding module for package github.com/fsnotify/fsnotify go: finding module for package github.com/pmezard/go-difflib/difflib go: finding module for package k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1 go: found github.com/Sirupsen/logrus in github.com/Sirupsen/logrus v1.4.1 go: found github.com/fsnotify/fsnotify in github.com/fsnotify/fsnotify v1.5.1 go: found google.golang.org/grpc in google.golang.org/grpc v1.43.0 go: found k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1 in k8s.io/kubernetes v1.23.1 go: found github.com/pmezard/go-difflib/difflib in github.com/pmezard/go-difflib v1.0.0 go: k8s.io/kubernetes@v1.23.1 requires k8s.io/api@v0.0.0: reading k8s.io/api/go.mod at revision v0.0.0: unknown revision v0.0.0 ``` - 解决 - 原因 :在Kubernetes主仓中,也使用了公共库,不过`go.mod`文件中所有公共库版本都指定为了**v0.0.0(显然这个版本不存在)**,然后通过**Go Module的replace**机制,将版本替换为子目录 - 资料参考 [Kubernetes平台开发者小技巧](http://dockone.io/article/2434308) http://dockone.io/article/2434308 ```sh 参考资料,编写脚本 root@ubuntu:~/go/src/k8s-hostdev-plugin-master# cat get_k8s_v.sh #!/bin/sh set -euo pipefail VERSION=${1#"v"} if [ -z "$VERSION" ]; then echo "Must specify version!" exit 1 fi MODS=($( curl -sS https://raw.githubusercontent.com/kubernetes/kubernetes/v${VERSION}/go.mod | sed -n 's|.*k8s.io/\(.*\) => ./staging/src/k8s.io/.*|k8s.io/\1|p' )) for MOD in "${MODS[@]}"; do V=$( go mod download -json "${MOD}@kubernetes-${VERSION}" | sed -n 's|.*"Version": "\(.*\)".*|\1|p' ) go mod edit "-replace=${MOD}=${MOD}@${V}" done go get "k8s.io/kubernetes@v${VERSION}" # v1.23.1 可以根据 上面报错的版本填写 root@ubuntu:~/go/src/k8s-hostdev-plugin-master# /bin/bash get_k8s_v.sh v1.23.1 go get: upgraded github.com/golang/protobuf v1.2.1-0.20180917234931-6e3d092c77c3 => v1.5.2 go get: upgraded github.com/stretchr/testify v1.2.3-0.20181115233458-8019298d9fa5 => v1.7.0 go get: upgraded golang.org/x/crypto v0.0.0-20181015023909-0c41d7ab0a0e => v0.0.0-20210817164053-32db794688a5 go get: upgraded golang.org/x/net v0.0.0-20180911220305-26e67e76b6c3 => v0.0.0-20211209124913-491a49abca63 go get: upgraded golang.org/x/sys v0.0.0-20181023152157-44b849a8bc13 => v0.0.0-20210831042530-f4d43177bf5e go get: upgraded google.golang.org/genproto v0.0.0-20180912233945-5a2fd4cab2d6 => v0.0.0-20210831024726-fe130286e0e2 go get: added k8s.io/kubernetes v1.23.1 ``` - 第三步 go mod vendor - 第四步 go build -o k8s-hostdev-plugin - 生成 执行文件 k8s-hostdev-plugin - 本地测试插件是否运行正常 ```sh root@ubuntu:~/mingfeng# ./k8s-hostdev-plugin FATA[0000] Must have arg --devs , for example, --devs /dev/mem:rwm root@ubuntu:~/mingfeng# ./k8s-hostdev-plugin --devs /dev/mem:rwm config: main.HostDevicePluginConfig{DevList:[]*main.DevConfig{(*main.DevConfig)(0xc0000e4500)}} INFO[0000] Starting FS watcher. INFO[0000] Starting OS watcher. INFO[0005] Register /dev/mem success <*>{/dev/mem rwm dev_mem hostdev.k8s.io/dev_mem /var/lib/kubelet/device-plugins/dev_mem <*>{<*>{<max>} /var/lib/kubelet/device-plugins/dev_mem true {<max>}} <*>{{<max>} {<max>} map[<max>] map[<max>] true false <*>{<max>} map[<max>] <nil> <*>{<max>} <*>{<max>} {<max>} {<max>} 0 <*>{<max>} <nil>} [<*>&Device{ID:/dev/mem,Health:Healthy,}] true 0xc00011e000} ``` ### 3. 以 使用设备 /dev/fuse 为例 注册插件 - 注册插件 - 修改 k8s-hostdev-plugin 插件 提供的Dockerfile 构建镜像 ```dockerfile FROM ubuntu:18.04 # 我这儿使用了 下载好的ubuntu的镜像 COPY k8s-hostdev-plugin /usr/bin/k8s-hostdev-plugin CMD ["k8s-hostdev-plugin"] ``` - 修改注册插件 hostdev-plugin-ds.yaml 进行修改 ```yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: hostdev-device-plugin namespace: ming-feng spec: selector: matchLabels: name: hostdev-device-plugin-ds template: metadata: annotations: scheduler.alpha.kubernetes.io/critical-pod: "" labels: name: hostdev-device-plugin-ds spec: tolerations: - key: CriticalAddonsOnly operator: Exists hostNetwork: true containers: - name: hostdev image: hostdev:v1 command: [ "k8s-hostdev-plugin"] args: ["--devs", "/dev/mem:r,/dev/fuse:rwm"] # 在这儿添加用于注册的设备以及权限 # 原来的 yaml 文件中 这儿使用了 securityContext: privileged: true 特权容器 # 但经过我的验证 在挂载 /dev/fuse 时 并不需要 指定 privileged: true 特权参数 volumeMounts: - name: device-plugin mountPath: /var/lib/kubelet/device-plugins - name: dev mountPath: /dev volumes: - name: device-plugin hostPath: path: /var/lib/kubelet/device-plugins - name: dev hostPath: path: /dev ``` - 运行插件 ```shell # 创建 插件容器 root@ubuntu:~/mingfeng# kubectl create -f hostdev-plugin-ds.yaml daemonset.apps/hostdev-device-plugin created # 查看 运行情况 root@ubuntu:~/mingfeng# kubectl get all -n ming-feng NAME READY STATUS RESTARTS AGE pod/hostdev-device-plugin-v6znd 1/1 Running 0 26s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/hostdev-device-plugin 1 1 1 1 1 <none> 26s # 删除 插件容器 root@ubuntu:~/mingfeng# kubectl delete daemonset hostdev-device-plugin -n ming-feng daemonset.apps "hostdev-device-plugin" deleted root@ubuntu:~/mingfeng# ``` ### 4. k8s 使用secret和 --device 下发容器 - 编辑 yaml 文件 ```yaml apiVersion: v1 kind: Pod metadata: name: sznp-pod namespace: ming-feng annotations: # 对应 docker run --security-opt apparmor=profile 参数 container.apparmor.security.beta.kubernetes.io/sznp-con: localhost/profile # docker run -security-opt seccomp=mount.json 参数 container.seccomp.security.alpha.kubernetes.io/sznp-con: localhost/profiles/mount.json spec: hostNetwork: true # 如果要将 secret 挂载到 /run/secret 目录下面 则 需要 设置 ServiceAccount 为false # 挂载到其他的目录则不需要, 原因是因为 ServiceAccount 会默认挂载到 /run/secret/kubernetes.io 下面 automountServiceAccountToken: false containers: - name: sznp-con image: sznp-k8s-demo:v1 securityContext: capabilities: # 对应 docker run --cap-add SYS_ADMIN add: ["SYS_ADMIN"] resources: limits: hostdev.k8s.io/dev_fuse: 1 imagePullPolicy: Never command: [ "/bin/bash", "-c"] args: [ "sleep 3600" ] volumeMounts: - name: secrets mountPath: /run/secrets volumes: - name: secrets secret: secretName: mysecret items: - key: pwd path: pwd ``` - 参数 说明 - capabilities 对应的是 --cap-add SYS_ADMIN - `--device`挂载的设备,容器内的进程通常没有权限操作,需要使用`--cap-add`开放相应的权限 - apparmor - 用于限制容器对资源的访问 - 具体的配置 参考资料 [Kubernetes文档/AppArmor](https://kubernetes.io/zh/docs/tutorials/clusters/apparmor/) https://kubernetes.io/zh/docs/tutorials/clusters/apparmor/ - seccomp - 用于限制容器的系统调用 - 具体的配置 参考资料 [Kubernetes文档/Seccomp ](https://kubernetes.io/zh/docs/tutorials/clusters/seccomp/) https://kubernetes.io/zh/docs/tutorials/clusters/seccomp/ - 运行k8s 下发容器的命名 ```sh 先运行设备插件 root@ubuntu:~/mingfeng# kubectl create -f hostdev-plugin-ds.yaml daemonset.apps/hostdev-device-plugin created 运行使用设备和secret的容器 root@ubuntu:~/mingfeng# kubectl create -f device_secret.yaml pod/sznp-pod created 查看运行情况 root@ubuntu:~/mingfeng# kubectl get all -n ming-feng NAME READY STATUS RESTARTS AGE pod/hostdev-device-plugin-5gfds 1/1 Running 0 22s pod/sznp-pod 1/1 Running 0 10s NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE daemonset.apps/hostdev-device-plugin 1 1 1 1 1 22s ``` - 进入容器里面查看 设备和secret ```sh 进入容器 root@ubuntu:~/mingfeng# kubectl exec -it sznp-pod bash -n ming-feng 查看secret root@ubuntu:/home/mf# cat /run/secrets/pwd 123456 查看 设备挂载情况 root@ubuntu:/home/mf# ll /dev/ total 4 ... crw-rw-rw- 1 root root 1, 7 Dec 29 10:45 full crw-rw-rw- 1 root root 10, 229 Dec 29 10:45 fuse drwxrwxrwt 2 root root 40 Dec 29 10:45 mqueue/ ... root@ubuntu:/home/mf# cat /sys/devices/virtual/misc/fuse/dev 10:229 # 退出容器 root@ubuntu:/home/mf# exit exit ``` - 删除下发的pod和容器 ```sh root@ubuntu:~/mingfeng# kubectl delete pod sznp-pod -n ming-feng pod "sznp-pod" deleted root@ubuntu:~/mingfeng# kubectl delete daemonset hostdev-device-plugin -n ming-feng daemonset.apps "hostdev-device-plugin" deleted root@ubuntu:~/mingfeng# ``` ### 5. 参考文档 []: https://www.cnblogs.com/dream397/p/14034632.html "Docker及Kubernetes下device使用和分析" []: https://kubernetes.io/zh/docs/home/ "Kubernetes 文档" []: http://dockone.io/article/2434308 "Kubernetes平台开发者小技巧" -
 MindSpore官方资料GitHub : https://github.com/mindspore-ai/mindsporeGitee : https : //gitee.com/mindspore/mindspore官方QQ群 : 486831414
MindSpore官方资料GitHub : https://github.com/mindspore-ai/mindsporeGitee : https : //gitee.com/mindspore/mindspore官方QQ群 : 486831414 -
 >摘要:CNCF(云原生计算基金会)正式接纳由华为云贡献的多云容器编排项目Karmada,迎来CNCF首个多云容器编排项目。 本文分享自华为云社区[《华为云开源的Karmada正式成为CNCF首个多云容器编排项目》](https://blog.csdn.net/devcloud/article/details/120566049?spm=1001.2014.3001.5501),作者:华为云开发者社区 北京时间9月15日,CNCF(云原生计算基金会)正式接纳由华为云贡献的多云容器编排项目Karmada(https://github.com/karmada-io/karmada),迎来CNCF首个多云容器编排项目。Karmada 项目的加入,将CNCF的云原生版图进一步扩展至分布式云领域。 华为云在技术上一直积极回馈社区,已开源了以智能边缘项目KubeEdge和批量计算项目Volcano为代表的一系列云原生项目。Karmada项目由华为云、工商银行、小红书、中国一汽等8家企业联合发起,沉淀了各企业在多云管理领域的丰富积累,为开发者提供详实有效的实践指导与帮助,使用Karmada,可以构建无极可扩展的容器资源池,让开发者像使用单个Kubernetes集群一样使用多云集群。 # Karmada介绍 随着企业业务的快速发展,多云也逐步成为数据中心建设的基础架构,多区域容灾与多活、大规模多集群管理、跨云弹性与迁移等场景推动云原生多云相关技术的快速发展。 然而,在实际的生产落地过程中,云原生的多云仍面临如下挑战: - 集群繁多的重复劳动:运维工程师需要应对繁琐的集群配置、不同云厂商集群间的管理差异以及碎片化的API访问入口等问题; - 业务过度分散的维护难题:应用在各集群的差异化配置繁琐;业务跨云访问以及集群间的应用同步难以管理; - 集群的边界限制:应用的可用性受限于集群;资源调度、弹性伸缩受限于集群; - 厂商绑定:业务部署的黏性问题,缺少自动化故障迁移;缺少中立的开源多云容器编排项目。 Karmada结合了华为云多云容器平台MCP以及Kubernetes Federation核心实践,并融入了众多新技术:包括Kubernetes原生API支持、多层级高可用部署、多集群自动故障迁移、多集群应用自动伸缩、多集群服务发现等,并且提供原生Kubernetes平滑演进路径,让基于Karmada的多云方案无缝融入云原生技术生态,为企业提供从单集群到多云架构的平滑演进方案。  Karmada项目全景 # 生态合作 Karmada项目由华为云、工商银行、浦发银行、小红书、VIPKID、趣头条、中国一汽和T3出行联合发起,于2021年4月25日在华为开发者大会(HDC.Cloud)2021上正式宣布开源。Karmada自开源以来受到了广泛的关注和支持,目前已有30+大型企业/机构/高校参与社区开发及贡献。 >Karmada项目源自华为云多云容器平台MCP,同时融入了工商银行、小红书、中国一汽等不同行业客户在多云管理方面的经验,可以为各企业提供详实有效的落地指导与帮助,企业通过Karmada构建跨云、跨数据中心的无极可扩展的应用资源池,可以像管理单个Kubernetes集群一样简单、便捷的管理不同云、不同数据中心里的集群与应用。——华为云CTO 张宇昕>在社区贡献方面,工商银行作为 Karmada项目的头部参与单位,结合工行多年来多容器集群管理的经验,已在集群生命周期管理、核心调度控制器等核心模块进行深度定制化的开发。后续,工行将持续参与Karmada 社区的开发和管理工作,计划在多集群自动调度、多集群自动伸缩等模块继续深入研究及贡献,反哺开源社区,持续扩大业界影响力。——工商银行软件开发中心专家 鲁金彪>集团型企业同时存在多个混合容器的复杂场景,跨多云技术架构的运维难题日益突出。华为Karmada作为多集群、多云及混合云的集中化、兼容原生Kubernetes API接口的管理架构,有效解决目前容器编排多集群、多环境无法集中式管理、安全隔离机制不健全等痛点。希望Karmada在加入CNCF后,通过社区的共同维护与贡献,不断壮大其功能。期待Karmada早日从CNCF毕业,反哺云原生生态。——一汽体系数字化部技术运营主任 王广>Karmada原生兼容Kubernetes API的能力,可以不加改造地对接现有Kubernetes生态。在落地实践过程中,我们使用Karmada对接了现有的GitOps生态,极大提高了应用跨集群部署的效率。 ——VIPKID运维总监 谷玉虎>Karmada提供丰富的多集群调度策略以及开箱即用的内置策略集,可以极大的简化两地三中心、异地容灾和同城双活架构下的系统复杂性,这对于金融行业至关重要。 ——浦发银行云转型处处长 吕炳刚 # 未来可期 目前,Karmada已在华为云多云容器平台(Multi-Cloud Container Platform,MCP)商用,提供分布式云解决方案,提供跨云的多集群统一管理、应用统一部署及流量分发等关键能力。 除MCP以外,Karmada已在数十家来自金融、互联网、教育等企业中落地。 此次CNCF正式将Karmada接纳为云原生领域首个多云容器编排项目,将极大促进Karmada上下游社区生态构建及合作,吸引广大云原生企业用户深度参与,Karmada将在多集群应用管理、服务治理、高可用部署等领域发挥越来越重要的作用,华为云也将在云原生领域持续耕耘、持续引领创新、繁荣生态,助力各行业走向快速智能发展之路。
>摘要:CNCF(云原生计算基金会)正式接纳由华为云贡献的多云容器编排项目Karmada,迎来CNCF首个多云容器编排项目。 本文分享自华为云社区[《华为云开源的Karmada正式成为CNCF首个多云容器编排项目》](https://blog.csdn.net/devcloud/article/details/120566049?spm=1001.2014.3001.5501),作者:华为云开发者社区 北京时间9月15日,CNCF(云原生计算基金会)正式接纳由华为云贡献的多云容器编排项目Karmada(https://github.com/karmada-io/karmada),迎来CNCF首个多云容器编排项目。Karmada 项目的加入,将CNCF的云原生版图进一步扩展至分布式云领域。 华为云在技术上一直积极回馈社区,已开源了以智能边缘项目KubeEdge和批量计算项目Volcano为代表的一系列云原生项目。Karmada项目由华为云、工商银行、小红书、中国一汽等8家企业联合发起,沉淀了各企业在多云管理领域的丰富积累,为开发者提供详实有效的实践指导与帮助,使用Karmada,可以构建无极可扩展的容器资源池,让开发者像使用单个Kubernetes集群一样使用多云集群。 # Karmada介绍 随着企业业务的快速发展,多云也逐步成为数据中心建设的基础架构,多区域容灾与多活、大规模多集群管理、跨云弹性与迁移等场景推动云原生多云相关技术的快速发展。 然而,在实际的生产落地过程中,云原生的多云仍面临如下挑战: - 集群繁多的重复劳动:运维工程师需要应对繁琐的集群配置、不同云厂商集群间的管理差异以及碎片化的API访问入口等问题; - 业务过度分散的维护难题:应用在各集群的差异化配置繁琐;业务跨云访问以及集群间的应用同步难以管理; - 集群的边界限制:应用的可用性受限于集群;资源调度、弹性伸缩受限于集群; - 厂商绑定:业务部署的黏性问题,缺少自动化故障迁移;缺少中立的开源多云容器编排项目。 Karmada结合了华为云多云容器平台MCP以及Kubernetes Federation核心实践,并融入了众多新技术:包括Kubernetes原生API支持、多层级高可用部署、多集群自动故障迁移、多集群应用自动伸缩、多集群服务发现等,并且提供原生Kubernetes平滑演进路径,让基于Karmada的多云方案无缝融入云原生技术生态,为企业提供从单集群到多云架构的平滑演进方案。  Karmada项目全景 # 生态合作 Karmada项目由华为云、工商银行、浦发银行、小红书、VIPKID、趣头条、中国一汽和T3出行联合发起,于2021年4月25日在华为开发者大会(HDC.Cloud)2021上正式宣布开源。Karmada自开源以来受到了广泛的关注和支持,目前已有30+大型企业/机构/高校参与社区开发及贡献。 >Karmada项目源自华为云多云容器平台MCP,同时融入了工商银行、小红书、中国一汽等不同行业客户在多云管理方面的经验,可以为各企业提供详实有效的落地指导与帮助,企业通过Karmada构建跨云、跨数据中心的无极可扩展的应用资源池,可以像管理单个Kubernetes集群一样简单、便捷的管理不同云、不同数据中心里的集群与应用。——华为云CTO 张宇昕>在社区贡献方面,工商银行作为 Karmada项目的头部参与单位,结合工行多年来多容器集群管理的经验,已在集群生命周期管理、核心调度控制器等核心模块进行深度定制化的开发。后续,工行将持续参与Karmada 社区的开发和管理工作,计划在多集群自动调度、多集群自动伸缩等模块继续深入研究及贡献,反哺开源社区,持续扩大业界影响力。——工商银行软件开发中心专家 鲁金彪>集团型企业同时存在多个混合容器的复杂场景,跨多云技术架构的运维难题日益突出。华为Karmada作为多集群、多云及混合云的集中化、兼容原生Kubernetes API接口的管理架构,有效解决目前容器编排多集群、多环境无法集中式管理、安全隔离机制不健全等痛点。希望Karmada在加入CNCF后,通过社区的共同维护与贡献,不断壮大其功能。期待Karmada早日从CNCF毕业,反哺云原生生态。——一汽体系数字化部技术运营主任 王广>Karmada原生兼容Kubernetes API的能力,可以不加改造地对接现有Kubernetes生态。在落地实践过程中,我们使用Karmada对接了现有的GitOps生态,极大提高了应用跨集群部署的效率。 ——VIPKID运维总监 谷玉虎>Karmada提供丰富的多集群调度策略以及开箱即用的内置策略集,可以极大的简化两地三中心、异地容灾和同城双活架构下的系统复杂性,这对于金融行业至关重要。 ——浦发银行云转型处处长 吕炳刚 # 未来可期 目前,Karmada已在华为云多云容器平台(Multi-Cloud Container Platform,MCP)商用,提供分布式云解决方案,提供跨云的多集群统一管理、应用统一部署及流量分发等关键能力。 除MCP以外,Karmada已在数十家来自金融、互联网、教育等企业中落地。 此次CNCF正式将Karmada接纳为云原生领域首个多云容器编排项目,将极大促进Karmada上下游社区生态构建及合作,吸引广大云原生企业用户深度参与,Karmada将在多集群应用管理、服务治理、高可用部署等领域发挥越来越重要的作用,华为云也将在云原生领域持续耕耘、持续引领创新、繁荣生态,助力各行业走向快速智能发展之路。 -
>摘要:遥感影像,作为地球自拍照,能够从更广阔的视角,为人们提供更多维度的辅助信息,来帮助人类感知自然资源、农林水利、交通灾害等多领域信息。本文分享自华为云社区[《AI+云原生,把卫星遥感虐的死去活来》](https://bbs.huaweicloud.com/blogs/296183?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content),作者:tsjsdbd。 # AI牛啊,云原生牛啊,所以1+1>2? 遥感影像,作为地球自拍照,能够从更广阔的视角,为人们提供更多维度的辅助信息,来帮助人类感知自然资源、农林水利、交通灾害等多领域信息。 AI技术,可以在很多领域超过人类,关键是它是自动的,省时又省力。可显著提升遥感影像解译的工作效率,对各类地物元素进行自动化的检测,例如建筑物,河道,道路,农作物等。能为智慧城市发展&治理提供决策依据。  云原生技术,近年来可谓是一片火热。易构建,可重复,无依赖等优势,无论从哪个角度看都与AI算法天生一对。所以大家也可以看到,各领域的AI场景,大都是将AI推理算法运行在Docker容器里面的。 AI+云原生这么6,那么强强联手后,地物分类、目标提取、变化检测等高性能AI解译不就手到擒来?我们也是这么认为的,所以基于AI+Kubernetes云原生,构建了支持遥感影像AI处理的空天地平台。 不过理想是好的,过程却跟西天取经一般,九九八十一难,最终修成正果。 # 业务场景介绍 遇到问题的业务场景叫影像融合(Pansharpen),也就是对地球自拍照进行“多镜头合作美颜”功能。(可以理解成:手机的多个摄像头,同时拍照,合并成一张高清彩色大图)。  所以业务简单总结就是:读取2张图片,生成1张新的图片。该功能我们放在一个容器里面执行,每张融合后的结果图片大约5GB。 问题的关键是,一个批次业务量需要处理的是3000多张卫星影像,所以每批任务只需要同时运行完成3000多个容器就OK啦。云原生YYDS! # 业务架构图示 为了帮助理解,这里分解使用云原生架构实现该业务场景的逻辑图如下: 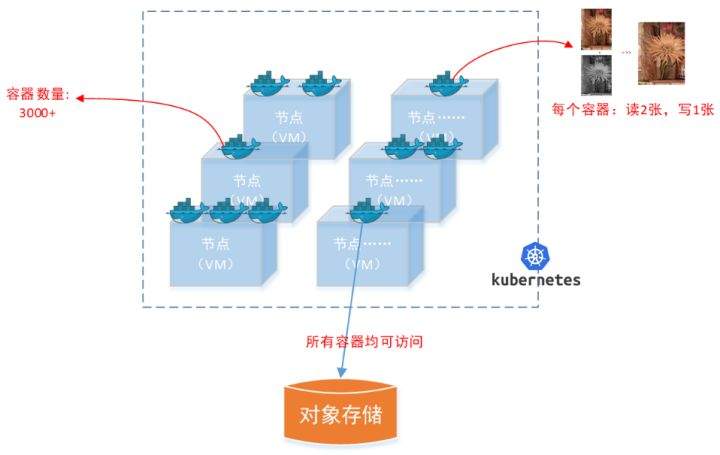 在云上,原始数据,以及结果数据,一定是要存放在对象存储桶里面的。因为这个数据量,只有对象存储的价格是合适的。(对象存储,1毛钱/GB。文件存储则需要3毛钱/GB) 因为容器之间是互相独立无影响的,每个容器只需要处理自己的那幅影像就行。例如1号容器处理 1.tif影像;2号容器处理2.tif影像;一次类推。 所以管理程序,只需要投递对应数量的容器(3000+),并监控每个容器是否成功执行完毕就行(此处为简化说明,实际业务场景是一个pipeline处理流程)。那么,需求已经按照云原生理想的状态分解,咱们开始起(tang)飞(keng)吧~ 注:以下描述的问题,是经过梳理后呈现的,实际问题出现时是互相穿插错综复杂的。 # K8s死掉了 当作业投递后,不多久系统就显示作业纷纷失败。查看日志报调用K8s接口失败,再一看,K8s的Master都已经挂了。。。 K8s-Master处理过程,总结版: 1. 发现Master挂是因为CPU爆了 2. 所以扩容Master节点(此次重复N次); 3. 性能优化:扩容集群节点数量; 4. 性能优化:容器分批投放; 5. 性能优化:查询容器执行进度,少用ListPod接口; 详细版: 看监控Master节点的CPU已经爆掉了,所以最简单粗暴的想法就是给Master扩容呀,嘎嘎的扩。于是从4U8G * 3 一路扩容一路测试一路失败,扩到了32U64G * 3。可以发现CPU还是爆满。看来简单的扩容是行不通了。 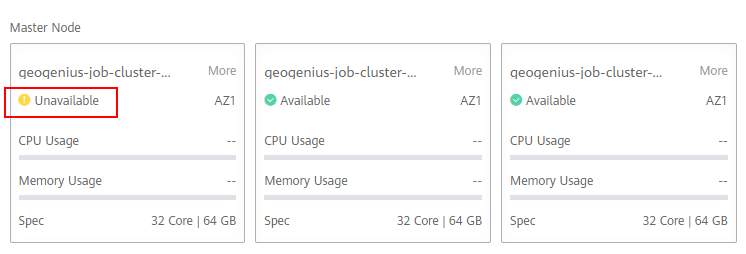 3000多个容器,投给K8s后,大量的容器都处于Pending状态(集群整体资源不够,所以容器都在排队呢)。而正在Pending的Pod,K8s的Scheduler会不停的轮训,去判断能否有资源可以给它安排上。所以这也会给Scheduler巨大的CPU压力。扩容集群节点数量,可以减少排队的Pod数量。 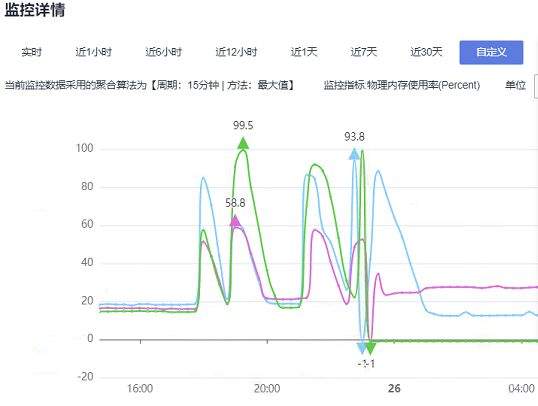 另外,既然排队的太多,不如就把容器分批投递给K8s吧。于是开始分批次投递任务,想着别一次把K8s压垮了。每次投递数量,减少到1千,然后到500,再到100。 同时,查询Pod进度的时候,避免使用ListPod接口,改为直接查询具体的Pod信息。因为List接口,在K8s内部的处理会列出所有Pod信息,处理压力也很大。 这一套组合拳下来,Master节点终于不挂了。不过,一头问题按下去了,另一头问题就冒出来了。 # 容器跑一半,挂了 虽然Master不挂了,但是当投递1~2批次作业后,容器又纷纷失败。 容器挂掉的处理过程,总结版: 1. 发现容器挂掉是被eviction驱逐了; 2. Eviction驱逐,发现原因是节点报Disk Pressure(存储容量满了); 3. 于是扩容节点存储容量; 4. 延长驱逐容器(主动kill容器)前的容忍时间; 详细版: (注:以下问题是定位梳理后,按顺序呈现给大家。但其实出问题的时候,顺序没有这么友好) 容器执行失败,首先想到的是先看看容器里面脚本执行的日志呗:结果报日志找不到~  于是查询Pod信息,从event事件中发现有些容器是被Eviction驱逐干掉了。同时也可以看到,驱逐的原因是 DiskPressure(即节点的存储满了)。 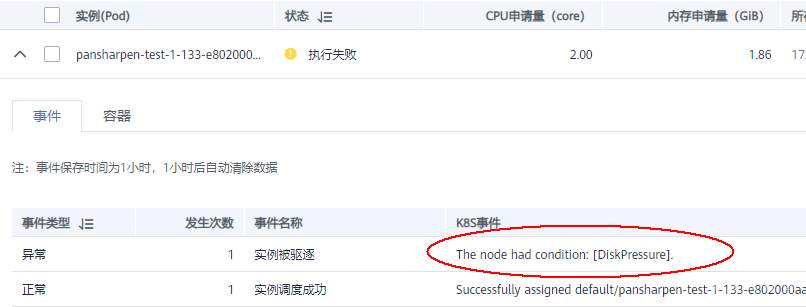 当Disk Pressure发生后,节点被打上了驱逐标签,随后启动主动驱逐容器的逻辑: 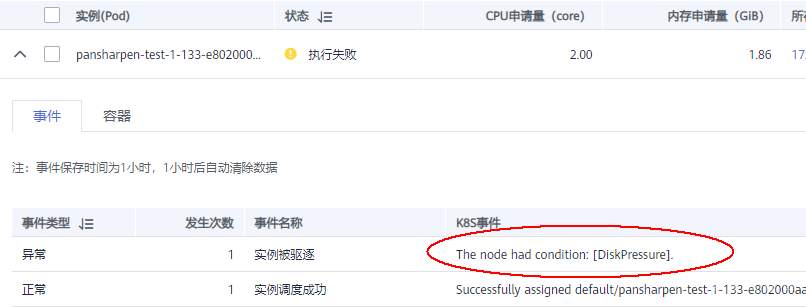 由于节点进入Eviction驱逐状态,节点上面的容器,如果在5分钟后,还没有运行完,就被Kubelet主动杀死了。(因为K8s想通过干掉容器来腾出更多资源,从而尽快退出Eviction状态)。 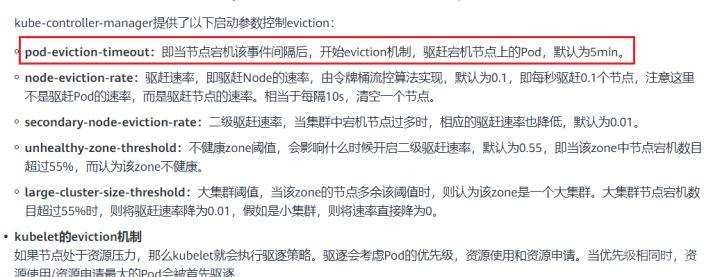 这里我们假设每个容器的正常运行时间为1~2个小时,那么不应该一发生驱动就马上杀死容器(因为已经执行到一半的容器,杀掉重新执行是有成本浪费的)。我们期望应该尽量等待所有容器都运行结束才动手。所以这个 pod-eviction-timeout 容忍时间,应该设置为24小时(大于每个容器的平均执行时间)。 Disk Pressure的直接原因就是本地盘容量不够了。所以得进行节点存储扩容,有2个选择:1)使用云存储EVS(给节点挂载云存储)。 2)扩容本地盘(节点自带本地存储的VM)。 由于云存储(EVS)的带宽实在太低了,350MB/s。一个节点咱们能同时跑30多个容器,带宽完全满足不了。最终选择使用 i3类型的VM。这种VM自带本地存储。并且将8块NVMe盘,组成Raid0,带宽还能x8。 # 对象存储写入失败 容器执行继续纷纷失败。 容器往对象存储写入失败处理过程,总结版: 1. 不直接写入,而是先写到本地,然后cp过去。 2. 将普通对象桶,改为支持文件语义的并行文件桶。 详细版: 查看日志发现,脚本在生成新的影像时,往存储中写入时出错: 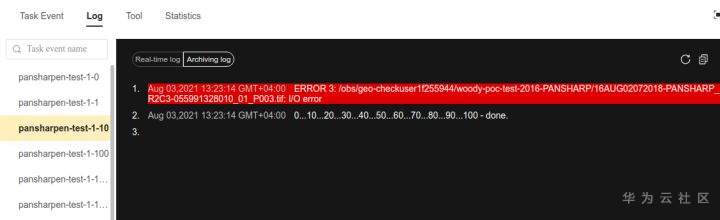 我们整集群是500核的规模,同时运行的容器数量大概在250个(每个2u2g)。这么多的容器同时往1个对象存储桶里面并发追加写入。这个应该是导致该IO问题的原因。 对象存储协议s3fs,本身并不适合大文件的追加写入。因为它对文件的操作都是整体的,即使你往一个文件追加写入1字节,也会导致整个文件重新写一遍。 最终这里改为:先往本地生成目标影像文件,然后脚本的最后,再拷贝到对象存储上。相当于增加一个临时存储中转一下。 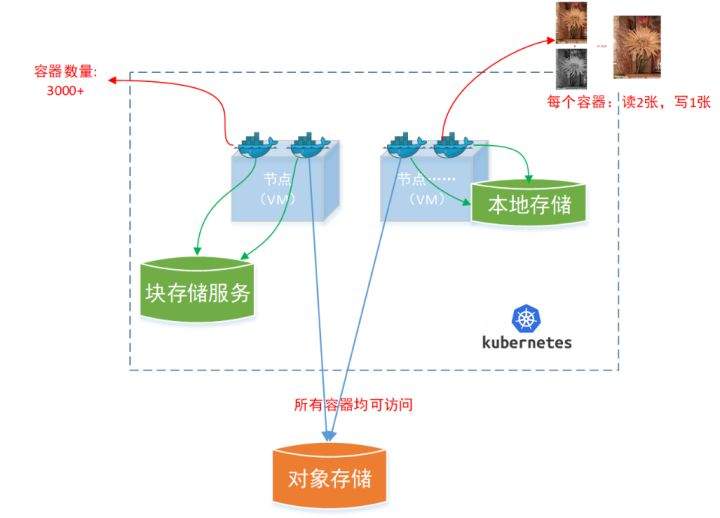 在临时中转存储选择中,2种本地存储都试过: 1)块存储带宽太低,350MB/s影响整体作业速度。2)可以选择带本地存储的VM,多块本地存储组成Raid阵列,带宽速度都杠杠滴。 同时,华为云在对象存储协议上也有一个扩展,使其支持追加写入这种的POSIX语义,称为并行文件桶。后续将普通的对象桶,都改为了文件语义桶。以此来支撑大规模的并发追加写入文件的操作。 # K8s计算节点挂了 So,继续跑任务。但是这容器作业,执行又纷纷失败鸟~ 计算节点挂掉,定位梳理后,总结版: 1. 计算节点挂掉,是因为好久没上报K8s心跳了。 2. 没上报心跳,是因为kubelet(K8s节点的agent)过得不太好(死掉了)。 3. 是因为Kubelet的资源被容器抢光了(由于不想容器经常oom kill,并未设置limit限制) 4. 为了保护kubelet,所有容器全都设置好limit。 详细版,直接从各类奇葩乱象等问题入手: - 容器启动失败,报超时错误。 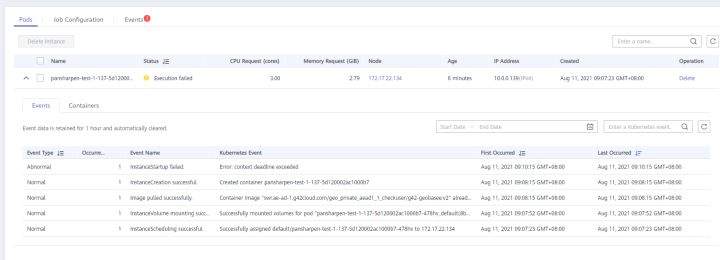 - 然后,什么PVC共享存储挂载失败:  - 或者,又有些容器无法正常结束(删不掉)。  - 查询节点Kubelet日志,可以看到充满了各种超时错误: 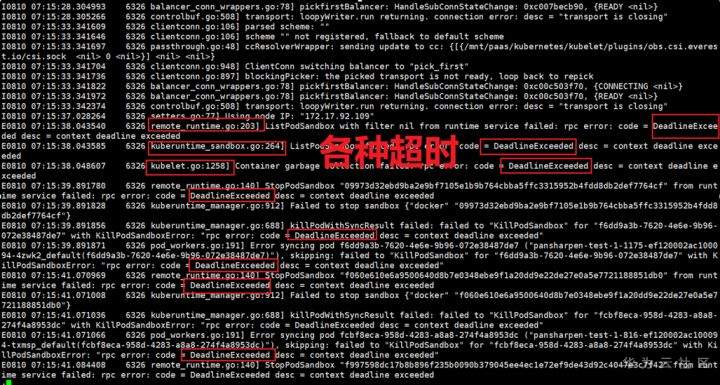 啊,这么多的底层容器超时,一开始感觉的Docker的Daemon进程挂了,通过重启Docker服务来试图修复问题。 后面继续定位发现,K8s集群显示,好多计算节点Unavailable了(节点都死掉啦)。 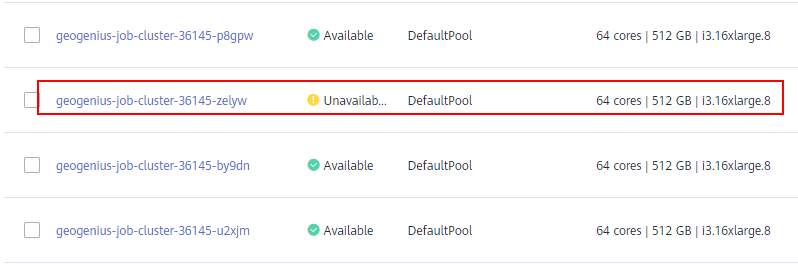 继续分析节点不可用(Unavailable),可以发现是Kubelet好久没有给Master上报心跳了,所以Master认为节点挂了。说明不仅仅是Docker的Daemon受影响,节点的Kubelet也有受影响。 那什么情况会导致Kubelet,Docker这些主机进程都不正常呢?这个就要提到Kubernetes在调度容器时,所设计的Request和Limit这2个概念了。 Request是K8s用来调度容器到空闲计算节点上的。而Limit则会传递给Docker用于限制容器资源上限(触发上限容易被oom killer 杀掉)。前期我们为了防止作业被杀死,仅为容器设置了Request,没有设置Limit。也就是每个容器实际可以超出请求的资源量,去抢占额外的主机资源。大量容器并发时,主机资源会受影响。 考虑到虽然不杀死作业,对用户挺友好,但是平台自己受不了也不是个事。于是给所有的容器都加上了Limit限制,防止容器超限使用资源,强制用户进程运行在容器Limit资源之内,超过就Kill它。以此来确保主机进程(如Docker,Kubelet等),一定是有足够的运行资源的。 # K8s计算节点,又挂了 于是,继续跑任务。不少作业执行又双叒失败鸟~ 节点又挂了,总结版: 1. 分析日志,这次挂是因为PLEG(Pod Lifecycle Event Generator)失败。 2. PLEG异常是因为节点上面存留的历史容器太多(>500个),查询用时太久超时了。 3. 及时清理已经运行结束的容器(即使跑完的容器,还是会占用节点存储资源)。 4. 容器接口各种超时(cpu+memory是有limit保护,但是io还是会被抢占)。 5. 提升系统磁盘的io性能,防止Docker容器接口(如list等)超时。 详细版: 现象还是节点Unavailable了,查看Kubelet日志搜索心跳情况,发现有PLEG is not healthy 的错误:  于是搜索PLEG相关的Kubelet日志,发现该错误还挺多:  这个错误,是因为kubelet去list当前节点所有容器(包括已经运行结束的容器)时,超时了。看了代码:https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L203 kubelet判断超时的时间,3分钟的长度是写死的。所以当pod数量越多,这个超时概率越大。很多场景案例表明,节点上的累计容器数量到达500以上,容易出现PLEG问题。(此处也说明K8s可以更加Flexible一点,超时时长应该动态调整)。 缓解措施就是及时的清理已经运行完毕的容器。但是运行结束的容器一旦清理,容器记录以及容器日志也会被清理,所以需要有相应的功能来弥补这些问题(比如日志采集系统等)。 List所有容器接口,除了容器数量多,IO慢的话,也会导致超时。 这时,从后台可以看到,在投递作业期间,大量并发容器同时运行时,云硬盘的写入带宽被大量占用: 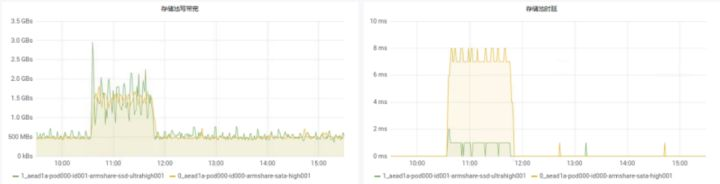 对存储池的冲击也很大: 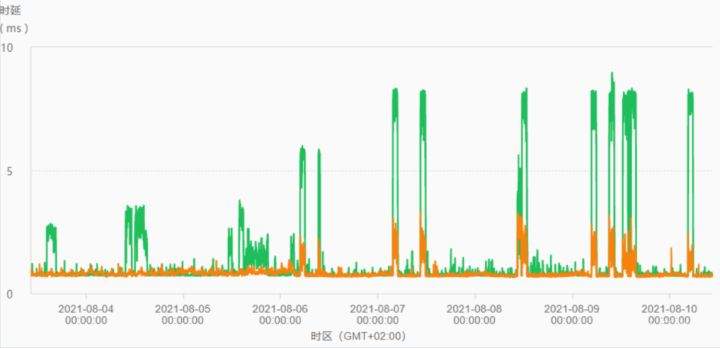 这也导致了IO性能变很差,也会一定程度影响list容器接口超时,从而导致PLEG错误。 该问题的解决措施:尽量使用的带本地高速盘的VM,并且将多块数据盘组成Raid阵列,提高读写带宽。 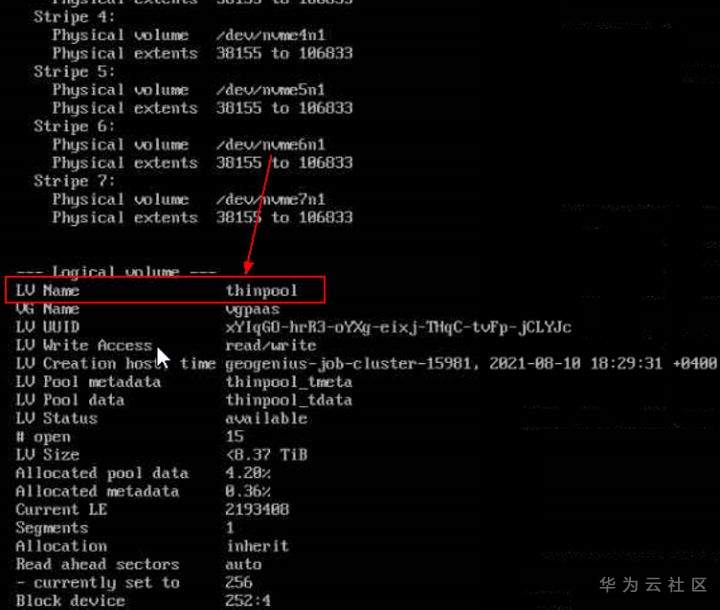 这样,该VM作为K8s的节点,节点上的容器都直接读写本地盘,io性能较好。(跟大数据集群的节点用法一样了,强依赖本地shuffle~)。 在这多条措施实施后,后续多批次的作业都可以平稳的运行完。
-
## 一、K8S是什么? ### 1.1 概述 K8S全名Kubernetes。因k与s之间有8个字符,故缩写为K8S。 K8S是一个可自动实施 Linux 容器管理的可移植、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 ## 二、为什么需要K8S? 要了解这个问题,需要回顾一下应用程序的部署方式。 ### 2.1 传统部署 传统部署直接在物理服务器上运行应用程序。存在缺陷: + 无法为服务器中的应用程序定义资源边界,导致资源分配出现问题(一个程序占用大部分资源,其它程序性能下降)。 + 若将应用程序运行在不同物理服务器上,一方面导致资源浪费,另一方面提高成本。 ### 2.2 虚拟化部署 虚拟化技术允许我们在单个的物理服务器上运行多个虚拟机(VM),应用程序在VM之间完全隔离。 每个VM是一个完整的计算机,在虚拟化硬件上运行包括自己的操作系统在内的所有组件。VM共享主机硬件资源。 但因为VM需要运行硬件虚拟副本和完整的操作系统副本,会占用大量的系统资源。 ### 2.3 容器部署 容器将应用程序软件代码和所需的所有组件打包在一起,使得容器内的用意可以在任何基础架构上一致的运行。 + **隔离性**:容器同样可以虚拟化基础计算机,应用程序可在不同容器间实现进程级隔离。 + **轻量性**:每个容器共享物理服务器的OS内核,二进制文件和库,但具有自己的文件系统、CPU、内存、进程空间等。这样的共享可以大大减少重现操作系统代码的需求。因此容器非常轻量,容量小且启动快。 + **可移植**:容器与基础架构分离,可以实现跨云和OS发行版本进行移植。 **K8S**即是在大规模服务器环境中,负责部署和管理容器组,用于解决容器的复制,扩展,健康,启动,负载均衡等问题。只需告诉 Kubernetes 您希望在哪里运行软件,该平台就会负责执行部署和管理容器所需的几乎一切工作。 ## 三、K8S有哪些组件? 我们会在一组用于**运行容器化应用**的节点计算机(Node)的上部署K8S,这一组节点计算机即称为K8S集群。正常运行的K8S集群包含以下组件。 ### 3.1 集群相关术语 + **控制平面(Control Plane):**控制 Kubernetes 节点的进程的集合。所有任务分配都来自于此。 + **节点(Node):**这些机器负责执行由控制平面分配的请求任务。 + **容器集(Pod):**部署到单个节点上且包含一个或多个容器的容器组。容器集是最小、最简单的 Kubernetes 对象。 + **服务(Service):**一种将运行于一组容器集上的应用开放为网络服务的方法。它将工作定义与容器集分离。 + **卷(Volume):**一个包含数据的目录,可供容器集内的容器访问。Kubernetes 卷与所在的容器集具有相同的生命周期。卷的生命周期要长于容器集内运行的所有容器的生命周期,并且在容器重新启动时会保留相应的数据。 + **命名空间(Namespace):**一个虚拟集群。命名空间允许 Kubernetes 管理同一物理集群中的多个集群(针对多个团队或项目)。 ### 3.2 控制平面组件 控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件。控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会**在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器**。 + **kube-apiserver**:该组件开放 Kubernetes API。API服务器是K8S控制平面的前端。 + **etcd**:etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库 + **kube-scheduler**:该组件负责监视新创建的、为指定运行节点(node)的Pods,并选择节点让Pod在上面运行。 + **kube-controller-manager**:运行控制器进程的控制平面组件。多中控制器被编译到一个可执行文件,并在一个进程中进行运行。 + **cloud-controller-manager**:云控制器管理器是指嵌入特定云的控制逻辑的 [控制平面](https://kubernetes.io/zh/docs/reference/glossary/?all=true#term-control-plane)组件。 云控制器管理器使得你可以将你的集群连接到云提供商的 API 之上, 并将与该云平台交互的组件同与你的集群交互的组件分离开来。 ### 3.3 Node组件 节点组件在每个节点上运行,维护运行的Pod并提供Kubernetes 运行环境。 + **Kubelet**:每个节点上运行的代理。它保证容器都运行在Pod中。 + **kube-proxy**:kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes [服务(Service)](https://kubernetes.io/zh/docs/concepts/services-networking/service/) 概念的一部分。它维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。 ### 3.4 容器运行时 容器运行环境是负责运行容器的软件。支持包括像Docker,iSula以及任何实现k8s CRI的容器运行环境。 ### 3.5 其它可用插件 插件并非严格意义上的必须组件。仅列举以下常用的两种。 + **DNS:**几乎所有 Kubernetes 集群都应该有集群DNS。 + **Web界面**:Dashboard 是 Kubernetes 集群的通用的、基于 Web 的用户界面。
-
 本篇文章来自《华为云云原生王者之路训练营》黄金系列课程第6课,由华为云容器技术专家Jabin主讲,详细介绍有状态应用StagefulSet,PersistentVolume,PersistentVolumeClaim及StorageClass的概念及使用。主要内容包含4个部分:有状态应用(StatefulSet)介绍 PV/PVC/SC介绍 华为云CCE存储管理功能使用介绍 实验:基于CCE集群快速部署web系统的有状态应用DB数据库 从上节课程(云原生第5课:Kubernetes工作负载管理)我们已经了解无状态应用了。应用是为了某项特殊的任务而编写的程序。程序是由算法和数据组成的。在生产环境中,除了一些无状态应用外,还有一部分应用需要将结果数据(也即:状态)缓存下来,并永久的记录在存储中,以供后续使用。这类应用就是我们将要讨论的“有状态应用”,与“无状态应用”相比,我们期望“有状态应用” 具有哪些能力呢?1)计算维度: 每个pod的名字需要是稳定的,不会发生变化的;pods之间的启动、升级、退出可以按照某种顺序控制的;2)存储维度: 存储是持久的,拥有独立于pod的生命周期,不会随着pod的生命周期结束而销毁;每个pod与其使用的存储关系是稳定的,不会因升级等因素而发生变化;3)网络维度: 每个pod的有独立、稳定的网络标识;01有状态应用(StatefulSet)介绍 有状态应用(StatefulSet)概念介绍基于社区对有状态应用的通用需求,K8S设计了一种有状态应用对象,也即:StatefulSet。它可以为用户提供一组具有稳定、有序、唯一特性的应用实例集合。如右图所示:1)稳定:稳定的podName:{stsName}-{序号[0-n]}稳定的网络标识:{podName}. {headless-svcName}.{namespace}.svc.cluster.local稳定的存储关系:{volumeClaimTemplatesName}-{podName}2)有序:按照编号从小到大顺序的部署:0 ~ n按照编号从大到小进行删除:n ~ 0支持有序的扩缩容和升级策略3)唯一:每个pod拥有一个唯一的网络标识:{podName}. {headless-svcName}.{namespace}.svc.cluster.local从下图可以看出,与Deployment通过ReplicaSet来管理pod生命周期不同,StatefulSet是直接管理pod的。常用操作小结# kubectl create -f mysql-adv-sts.yaml# kubectl -n default get stsNAME READY AGEmysql-adv 3/3 17m# kubectl -n default get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEmysql-adv ClusterIP 10.247.168.413306/TCP 17mmysql-adv-headless ClusterIP None3306/TCP 17m# kubectl -n default get podNAME READY STATUS RESTARTS AGEmysql-adv-0 1/1 Running 0 17mmysql-adv-1 1/1 Running 0 17mmysql-adv-2 1/1 Running 0 17m# kubectl -n default scale statefulset mysql-adv --replicas=1# kubectl -n default scale statefulset mysql-adv --replicas=3# kubectl patch statefulset mysql-adv --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"mysql:5.7"}]‘# kubectl -n default get podNAME READY STATUS RESTARTS AGEmysql-adv-0 1/1 Running 0 20mmysql-adv-1 1/1 Running 0 12smysql-adv-2 1/1 Running 0 12s# kubectl get pods -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESmysql-adv-0 1/1 Running 0 47m 172.16.1.111 10.1.20.7mysql-adv-1 1/1 Running 0 26m 172.16.0.107 10.1.19.71mysql-adv-2 0/1 ContainerCreating 0 11s10.1.23.66# kubectl delete sts mysql-adv02 PV/PVC/SC介绍 PV/PVC/SC概念介绍PersistentVolume:简称pv,持久化存储,是k8s为云原生应用提供一种拥有独立生命周期的、用户可管理的存储的抽象设计。PersistentVolumeClaim:简称pvc,持久化存储声明,是k8s为解耦云原生应用和数据存储而设计的,通过pvc可以让资源管控更细更灵活、应用模板更通用。StorageClass:简称sc,存储类,是k8s平台为存储提供商提供存储接入的一种声明。通过sc和相应的存储插件(csi)为容器应用提供持久存储卷的能力。 PVC样例模板详解PVC中定义应用所需的规格等配置:apiVersion: v1kind: PersistentVolumeClaimmetadata:annotations:everest.io/disk-volume-type: satavolume.beta.kubernetes.io/storage-provisioner: everest-csi-provisionerlabels:app: mysql-adv-mgmdrelease: mysql-advname: mysql-data-mysql-adv-mgmd-0namespace: defaultspec:accessModes:- ReadWriteOnceresources:requests:storage: 10GistorageClassName: csi-diskvolumeMode: Filesystem1)accessModes: ReadWriteOnce:允许以读写能力挂载到一个host上,如:云盘ReadOnlyMany:允许以只读能力挂到多个host上,如:文件存储ReadWriteMany:允许以读写能力挂载到多个host上,如:文件存储 2)volumeMode: Filesystem:将云盘挂载为文件系统Block:将云盘挂载为块设备3)Resources: Requests:最小容量Limites:最大容量4)storageClassName:sc名字 5)mountOptions:mount指令中的options SC样例模板详解apiVersion: storage.k8s.io/v1kind: StorageClassmetadata:name: csi-disk-ssdparameters:csi.storage.k8s.io/csi-driver-name: disk.csi.everest.iocsi.storage.k8s.io/fstype: ext4everest.io/disk-volume-type: SSDeverest.io/passthrough: "true"provisioner: everest-csi-provisionerreclaimPolicy: DeletevolumeBindingMode: ImmediateallowVolumeExpansion: trueSC中定义存储类型和驱动等配置:1)Parameters:插件驱动定义的参数2)Provisioner:指定存储卷的供应者3)reclaimPolicy:Retain:保留Delete:删除4)volumeBindingMode:Immediate:立即绑定WaitForFirstConsumer:延迟绑定5)allowVolumeExpansion:True:允许扩容False:不允许扩容PV样例模板详解apiVersion: v1kind: PersistentVolumemetadata:name: static-volumespec:accessModes:- ReadWriteOncecapacity:storage: 10Gicsi:driver: disk.csi.everest.iofsType: ext4volumeAttributes:everest.io/disk-mode: SCSIeverest.io/disk-volume-type: SATAstorage.kubernetes.io/csiProvisionerIdentity: everest-csi-provisionervolumeHandle: 9a074a5b-a67e-4fae-860e-07c5307594eapersistentVolumeReclaimPolicy: DeletestorageClassName: csi-diskvolumeMode: FilesystemPV中定义应用所需的规格等配置:1)accessModes:ReadWriteOnce:允许以读写能力挂载到一个host上,如:云盘ReadOnlyMany:允许以只读能力挂到多个host上,如:文件存储ReadWriteMany:允许以读写能力挂载到多个host上,如:文件存储2)capacitystorage:容量大小3)csi:out-tree驱动类型Driver:驱动名字fstType:磁盘文件类型volumeAttributes:存储驱动定义的参数volumeHandle:存储volume的唯一ID4)persistentVolumeReclaimPolicy:Retain:保留Delete:删除5)storageClassName:sc名字6)volumeMode:Filesystem:将云盘挂载为文件系统Block:将云盘挂载为块设备有状态应用&持久化存储的最佳实践apiVersion: apps/v1kind: StatefulSetmetadata: name: mysql-adv namespace: defaultspec: podManagementPolicy: Parallel replicas: 3 serviceName: mysql-adv-headless template: spec: containers: image: mysql:latest imagePullPolicy: Always name: container-0 volumeMounts: - mountPath: /var/lib/mysql name: mysql-data dnsPolicy: ClusterFirst restartPolicy: Always terminationGracePeriodSeconds: 30 updateStrategy: rollingUpdate: partition: 2 type: RollingUpdate volumeClaimTemplates: - metadata: annotations: everest.io/disk-volume-type: SATA name: mysql-data spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: csi-disk volumeMode: Filesystem# kubectl get pvcNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEmysql-data-mysql-adv-0 Bound pvc-b4d21c69-9101-4721-bc97-8d319a5f961e 1Gi RWO csi-disk 10hmysql-data-mysql-adv-1 Bound pvc-d7387797-8ff5-457a-a2b9-2fb22d5d4e11 1Gi RWO csi-disk 10hmysql-data-mysql-adv-2 Bound pvc-85fb7ffc-8ca4-4381-8b23-9156dd929fea 1Gi RWO csi-disk 10h# kubectl get pvNAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGEpvc-85fb7ffc-8ca4-4381-8b23-9156dd929fea 1Gi RWO Delete Bound default/mysql-data-mysql-adv-2 csi-disk 10hpvc-b4d21c69-9101-4721-bc97-8d319a5f961e 1Gi RWO Delete Bound default/mysql-data-mysql-adv-0 csi-disk 10hpvc-d7387797-8ff5-457a-a2b9-2fb22d5d4e11 1Gi RWO Delete Bound default/mysql-data-mysql-adv-1 csi-disk 10h常用操作小结# kubectl create -f pv.yaml# kubectl get pv | grep static-volumestatic-volume 10Gi RWO Delete Available csi-disk 3s# kubectl create -f pvc.yaml# kubectl get pvc,pv -A | grep mysql-data-mysql-advNAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGEdefault persistentvolumeclaim/mysql-data-mysql-adv-0 Bound static-volume 10Gi RWO csi-disk 2m44spersistentvolume/static-volume 10Gi RWO Delete Bound default/mysql-data-mysql-adv-0 csi-disk 18m# kubectl create -f sc.yaml# kubectl get sc csi-disk-ssdcsi-disk-ssd everest-csi-provisioner Delete Immediate true 9s# kubectl delete pvc mysql-data-mysql-adv-0# kubectl delete pv static-volume# kubectl delete sc csi-disk-ssd03 华为云CCE存储管理功能使用介绍 华为云CCE存储管理功能使用介绍:静态卷CCE提供多种存储:云硬盘存储卷文件存储卷极速文件系统存储卷对象存储卷CCE提供两种静态卷的创建方式:通过购买新的存储创建PVC;通过导入已有的存储创建PVC;
本篇文章来自《华为云云原生王者之路训练营》黄金系列课程第6课,由华为云容器技术专家Jabin主讲,详细介绍有状态应用StagefulSet,PersistentVolume,PersistentVolumeClaim及StorageClass的概念及使用。主要内容包含4个部分:有状态应用(StatefulSet)介绍 PV/PVC/SC介绍 华为云CCE存储管理功能使用介绍 实验:基于CCE集群快速部署web系统的有状态应用DB数据库 从上节课程(云原生第5课:Kubernetes工作负载管理)我们已经了解无状态应用了。应用是为了某项特殊的任务而编写的程序。程序是由算法和数据组成的。在生产环境中,除了一些无状态应用外,还有一部分应用需要将结果数据(也即:状态)缓存下来,并永久的记录在存储中,以供后续使用。这类应用就是我们将要讨论的“有状态应用”,与“无状态应用”相比,我们期望“有状态应用” 具有哪些能力呢?1)计算维度: 每个pod的名字需要是稳定的,不会发生变化的;pods之间的启动、升级、退出可以按照某种顺序控制的;2)存储维度: 存储是持久的,拥有独立于pod的生命周期,不会随着pod的生命周期结束而销毁;每个pod与其使用的存储关系是稳定的,不会因升级等因素而发生变化;3)网络维度: 每个pod的有独立、稳定的网络标识;01有状态应用(StatefulSet)介绍 有状态应用(StatefulSet)概念介绍基于社区对有状态应用的通用需求,K8S设计了一种有状态应用对象,也即:StatefulSet。它可以为用户提供一组具有稳定、有序、唯一特性的应用实例集合。如右图所示:1)稳定:稳定的podName:{stsName}-{序号[0-n]}稳定的网络标识:{podName}. {headless-svcName}.{namespace}.svc.cluster.local稳定的存储关系:{volumeClaimTemplatesName}-{podName}2)有序:按照编号从小到大顺序的部署:0 ~ n按照编号从大到小进行删除:n ~ 0支持有序的扩缩容和升级策略3)唯一:每个pod拥有一个唯一的网络标识:{podName}. {headless-svcName}.{namespace}.svc.cluster.local从下图可以看出,与Deployment通过ReplicaSet来管理pod生命周期不同,StatefulSet是直接管理pod的。常用操作小结# kubectl create -f mysql-adv-sts.yaml# kubectl -n default get stsNAME READY AGEmysql-adv 3/3 17m# kubectl -n default get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEmysql-adv ClusterIP 10.247.168.413306/TCP 17mmysql-adv-headless ClusterIP None3306/TCP 17m# kubectl -n default get podNAME READY STATUS RESTARTS AGEmysql-adv-0 1/1 Running 0 17mmysql-adv-1 1/1 Running 0 17mmysql-adv-2 1/1 Running 0 17m# kubectl -n default scale statefulset mysql-adv --replicas=1# kubectl -n default scale statefulset mysql-adv --replicas=3# kubectl patch statefulset mysql-adv --type='json' -p='[{"op": "replace", "path": "/spec/template/spec/containers/0/image", "value":"mysql:5.7"}]‘# kubectl -n default get podNAME READY STATUS RESTARTS AGEmysql-adv-0 1/1 Running 0 20mmysql-adv-1 1/1 Running 0 12smysql-adv-2 1/1 Running 0 12s# kubectl get pods -o wideNAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATESmysql-adv-0 1/1 Running 0 47m 172.16.1.111 10.1.20.7mysql-adv-1 1/1 Running 0 26m 172.16.0.107 10.1.19.71mysql-adv-2 0/1 ContainerCreating 0 11s10.1.23.66# kubectl delete sts mysql-adv02 PV/PVC/SC介绍 PV/PVC/SC概念介绍PersistentVolume:简称pv,持久化存储,是k8s为云原生应用提供一种拥有独立生命周期的、用户可管理的存储的抽象设计。PersistentVolumeClaim:简称pvc,持久化存储声明,是k8s为解耦云原生应用和数据存储而设计的,通过pvc可以让资源管控更细更灵活、应用模板更通用。StorageClass:简称sc,存储类,是k8s平台为存储提供商提供存储接入的一种声明。通过sc和相应的存储插件(csi)为容器应用提供持久存储卷的能力。 PVC样例模板详解PVC中定义应用所需的规格等配置:apiVersion: v1kind: PersistentVolumeClaimmetadata:annotations:everest.io/disk-volume-type: satavolume.beta.kubernetes.io/storage-provisioner: everest-csi-provisionerlabels:app: mysql-adv-mgmdrelease: mysql-advname: mysql-data-mysql-adv-mgmd-0namespace: defaultspec:accessModes:- ReadWriteOnceresources:requests:storage: 10GistorageClassName: csi-diskvolumeMode: Filesystem1)accessModes: ReadWriteOnce:允许以读写能力挂载到一个host上,如:云盘ReadOnlyMany:允许以只读能力挂到多个host上,如:文件存储ReadWriteMany:允许以读写能力挂载到多个host上,如:文件存储 2)volumeMode: Filesystem:将云盘挂载为文件系统Block:将云盘挂载为块设备3)Resources: Requests:最小容量Limites:最大容量4)storageClassName:sc名字 5)mountOptions:mount指令中的options SC样例模板详解apiVersion: storage.k8s.io/v1kind: StorageClassmetadata:name: csi-disk-ssdparameters:csi.storage.k8s.io/csi-driver-name: disk.csi.everest.iocsi.storage.k8s.io/fstype: ext4everest.io/disk-volume-type: SSDeverest.io/passthrough: "true"provisioner: everest-csi-provisionerreclaimPolicy: DeletevolumeBindingMode: ImmediateallowVolumeExpansion: trueSC中定义存储类型和驱动等配置:1)Parameters:插件驱动定义的参数2)Provisioner:指定存储卷的供应者3)reclaimPolicy:Retain:保留Delete:删除4)volumeBindingMode:Immediate:立即绑定WaitForFirstConsumer:延迟绑定5)allowVolumeExpansion:True:允许扩容False:不允许扩容PV样例模板详解apiVersion: v1kind: PersistentVolumemetadata:name: static-volumespec:accessModes:- ReadWriteOncecapacity:storage: 10Gicsi:driver: disk.csi.everest.iofsType: ext4volumeAttributes:everest.io/disk-mode: SCSIeverest.io/disk-volume-type: SATAstorage.kubernetes.io/csiProvisionerIdentity: everest-csi-provisionervolumeHandle: 9a074a5b-a67e-4fae-860e-07c5307594eapersistentVolumeReclaimPolicy: DeletestorageClassName: csi-diskvolumeMode: FilesystemPV中定义应用所需的规格等配置:1)accessModes:ReadWriteOnce:允许以读写能力挂载到一个host上,如:云盘ReadOnlyMany:允许以只读能力挂到多个host上,如:文件存储ReadWriteMany:允许以读写能力挂载到多个host上,如:文件存储2)capacitystorage:容量大小3)csi:out-tree驱动类型Driver:驱动名字fstType:磁盘文件类型volumeAttributes:存储驱动定义的参数volumeHandle:存储volume的唯一ID4)persistentVolumeReclaimPolicy:Retain:保留Delete:删除5)storageClassName:sc名字6)volumeMode:Filesystem:将云盘挂载为文件系统Block:将云盘挂载为块设备有状态应用&持久化存储的最佳实践apiVersion: apps/v1kind: StatefulSetmetadata: name: mysql-adv namespace: defaultspec: podManagementPolicy: Parallel replicas: 3 serviceName: mysql-adv-headless template: spec: containers: image: mysql:latest imagePullPolicy: Always name: container-0 volumeMounts: - mountPath: /var/lib/mysql name: mysql-data dnsPolicy: ClusterFirst restartPolicy: Always terminationGracePeriodSeconds: 30 updateStrategy: rollingUpdate: partition: 2 type: RollingUpdate volumeClaimTemplates: - metadata: annotations: everest.io/disk-volume-type: SATA name: mysql-data spec: accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: csi-disk volumeMode: Filesystem# kubectl get pvcNAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGEmysql-data-mysql-adv-0 Bound pvc-b4d21c69-9101-4721-bc97-8d319a5f961e 1Gi RWO csi-disk 10hmysql-data-mysql-adv-1 Bound pvc-d7387797-8ff5-457a-a2b9-2fb22d5d4e11 1Gi RWO csi-disk 10hmysql-data-mysql-adv-2 Bound pvc-85fb7ffc-8ca4-4381-8b23-9156dd929fea 1Gi RWO csi-disk 10h# kubectl get pvNAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGEpvc-85fb7ffc-8ca4-4381-8b23-9156dd929fea 1Gi RWO Delete Bound default/mysql-data-mysql-adv-2 csi-disk 10hpvc-b4d21c69-9101-4721-bc97-8d319a5f961e 1Gi RWO Delete Bound default/mysql-data-mysql-adv-0 csi-disk 10hpvc-d7387797-8ff5-457a-a2b9-2fb22d5d4e11 1Gi RWO Delete Bound default/mysql-data-mysql-adv-1 csi-disk 10h常用操作小结# kubectl create -f pv.yaml# kubectl get pv | grep static-volumestatic-volume 10Gi RWO Delete Available csi-disk 3s# kubectl create -f pvc.yaml# kubectl get pvc,pv -A | grep mysql-data-mysql-advNAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGEdefault persistentvolumeclaim/mysql-data-mysql-adv-0 Bound static-volume 10Gi RWO csi-disk 2m44spersistentvolume/static-volume 10Gi RWO Delete Bound default/mysql-data-mysql-adv-0 csi-disk 18m# kubectl create -f sc.yaml# kubectl get sc csi-disk-ssdcsi-disk-ssd everest-csi-provisioner Delete Immediate true 9s# kubectl delete pvc mysql-data-mysql-adv-0# kubectl delete pv static-volume# kubectl delete sc csi-disk-ssd03 华为云CCE存储管理功能使用介绍 华为云CCE存储管理功能使用介绍:静态卷CCE提供多种存储:云硬盘存储卷文件存储卷极速文件系统存储卷对象存储卷CCE提供两种静态卷的创建方式:通过购买新的存储创建PVC;通过导入已有的存储创建PVC; -
本篇文章来自《华为云云原生王者之路训练营》黄金系列课程第1课,由CNCF大使、Kubernetes社区Maintainer以及CNCF多个项目联合创始人王泽锋老师主讲,帮助大家了解云原生技术的发展历程、云原生的基本概念、核心理念、技术体系等。云原生技术的发展历程 云原生,其实不是一个全新的概念,而是在整个云计算发展历程中的对理念的更新和延伸。站在一个用户的角度,从时间线上看,整个云计算的技术演进是朝着越来越灵活的方向发展:核心单元从早期的物理服务器,变成后来的虚拟机,一直到现在通过Kubernetes编排调度的容器;资源分配颗粒度越来越小,启动速度也越来越快资源重建的代价越来越小,不可变基础设施逐渐成为主流软件栈从传统商业软件走向开源,用户拥有更多的选择“云”的资源,在使用者看来是可以无限扩展的,并且可以“随时获取、按需使用,随时扩展”,并按使用付费。这种特性经常被称为像水电一样使用IT基础设施。而Kubernetes做为当时众多开源平台中的一个,凭借着先进的架构理念和活跃的社区生态,热度持续上升。Kubernetes也是近30年来增长最快的开源项目之一。CNCF (2020年度)最新的调查显示,Kubernetes 已经成为约定俗成的容器编排器,有82% 的单位在生产中使用了 Kubernetes。K8s的出现带动了云原生生态的蓬勃发展,在整个IT技术发展史上也是颇具突破性的。从2015年CNCF只有Kubernetes一个项目,到了到如今80多个官方项目,以及整个云原生生生态内容丰富的宏大版图。底层有众多的容器运行时、容器存储、容器网络以及硬件加速器方案可以选择;而面向用户,K8s的北向可以运行、对接各种业界主流的数据库、中间件等。目前市面上通过认证的K8s的云服务或者发行版已经超过130款,并且有大量的厂商提供丰富的周边软件、服务的配套支持。超过250家认证服务商和培训合作伙伴提供丰富的周边软件:https://twitter.com/_Lebsky/status/1351925956504662018而在中国,云原生的生态也飞速发展,CNCF的会员数量也从2015年的1家初创&白金会员发展到今天60家成员单位。全球1/4认证的K8s服务提供商来自中国;1/3的K8s培训发生在中国;同时中国也是CNCF生态的第3大贡献者,CNCF管理的80多个官方项目中,有11个来自中国。2020年,CNCF在中国主办了首次线上会议“Cloud Native + Open Source Virtual Summit China 2020”,注册参会人数达到 近六千人,超过12万人观看了直播。整个云原生产业的规模也发展十分迅猛:调查显示,2019年中国云原生市场规模已经达到了350.2亿元,并且云原生技术在加速向各个垂直行业渗透。企业在云原生的投入比例持续增高,2019年有接近10%的企业,其云原生相关投入占IT总投入一般以上,而主要的支出是技术研发和运维。云原生技术的采用率也在持续提升以容器为例,目前已有68%的机构在生产过程中使用容器,相比2年前增长了240%。生产中使用 Kubernetes 的比例在过去两年里也有了惊人的增长,从去年的72% 增长到了82% —— Kubernetes 已经无处不在02 云原生核心理念 关于云原生,CNCF给出了如下的定义:“云原生技术有利于各企业在各种云环境中,构建并运行可弹性扩展的应用,云原生的代表技术包括容器、服务网格、微服务、不可变基础设施和声明式API”。在最近的几年里,云原生技术呈现如下几个明显的发展趋势:趋势1 :软硬一体化:传统基础设施的网络、存储、计算能力与云原生技术生态开始深度对接。—— (Forrester2020.7市场调研云原生战略落地聚焦的能力中高居榜首)趋势2 :基于网格的服务治理能力:服务治理与业务逻辑逐步解耦,服务治理能力下沉到基础设施,服务网格以基础设施的方式提供无侵入的连接控制、安全、可监测性、灰度发布等治理能力。趋势3 :有状态应用向云原生迁移:无状态+Job类应用趋于成熟,有状态应用逐步成为云原生市场中新的增长点。Operator 的出现,为有状态应用在云原生基础设施上运行提供一套行之有效的标准规范,降低了使用门槛,使有状态应用得以真正发展。趋势4 :多云统一管理和多云业务流量统一调度:云原生北向API区域稳定,客户更多开始关注跨区域、跨平台、跨云大规模可复制能力云原生这么受欢迎,与它先进的理念是分不开的 ,总得来说有以下几大核心理念:利用容器和服务网格等技术,解耦软件开发,提高了业务开发部署的灵活性和易维护性以Kubernetes为核心的多层次、丰富的开源软件栈,被各大厂商支持,用户选择多,避免厂商绑定以Kubernetes为核心的松耦合平台架构,易扩展,避免侵入式定制 - Kubernetes已被公认是platform for platform 中心式编排,对应用和微服务进行统一的动态管理和调度,提高工作效率和资源利用率云原生代表技术1)Kubernetes的声明式API – 面向开发者提供全新分布式原语针对期望状态(结果)给出声明,而不是针对过程 - 系统自行分析差异并触发动作API对象彼此互补、可组合2)服务网格 – 剥离业务代码和分布式框架服务网格通过非侵入式的方式接管应用的服务通信。对于每个业务单元/模块来说,他们甚至不需要对网络通信、负载均衡等有任何的感知。服务网格提供细粒度流量治理,包括灰度发布、故障注入、可观测性支持等能力,提高了业务应用的易维护性对于企业开发者来说,服务网格可以很好地帮助他们剥离业务代码和分布式框架平台团队聚焦框架层的开发和调优业务团队聚焦业务本身的开发03 云原生技术体系及CNCF核心项目 在奉行事实标准的IT界,云技术发展多年的今天:开源社区已然是云原生技术的关键推动者,同时也是相关技术标准的制定者。我们知道云原生飞速发展的背景,解决应用的标准化问题:下层基础设施不统一,如何构建通用的弹性扩缩容能力,以及分布式监控、日志和追踪等等。开源的好处是可以加快技术普及,汇集业界的力量来促进技术架构和接口的标准化,所以云原生基于开源来发展是必然。—— 可以说云原生是源自开源,而开源促进云原生的发展。华为云坚持构建标准化、开源、开放的云原生技术平台。我们不仅仅深度参与社区内包括K8s、Istio等核心项目,而且将华为云产品的核心能力对外开放。我们分别于2018年、2019年开源了KubeEdge边缘计算项目、Volcano批量计算项目,并捐献给了CNCF基金会,得到了社区的积极响应。这两个项目目前都在国内外多个企业实际生产环境得到了应用。目前KubeEdge也于2020进入了CNCF incubator孵化阶段。今年,我们又联合多家单位共同开源了多云容器编排项目Karmada,与产业伙伴一起共建云原生多云的开源标准。而在基础设施层,我们在运行时、网络、存储、异构设施等方面也都广泛参与或开放了多个开源项目,将华为云在基础设施层的丰富积累与社区共享,共同促进Kubernetes以及CNCF云原生社区的快速创新与发展。应该说云原生已经成为业界公认的主力技术领域,CNCF拥有所有开源基金会中最大的最终用户社区,云原生的企业和开发者在过去几年里增长了近20倍,越来越多的客户将云原生作为企业数字化转型的的关键一步。—21家白金、19家黄金、476家白银,白金会员集齐全球Top5云供应商云原生的技术版图CNCF的项目成熟度模型CNCF当前管理的项目主要有三个等级的划分:最初级的等级Sandbox,关键的一个考虑是帮助许多创新的开源项目去解决厂商中立、知识产权以及license的保障等孵化级:面向早期使用者和保守使用者,其对于项目成熟度的考量,除过项目本身的质量,还包括项目社区的生态以及周边的落地情况毕业级:并不意味着项目的停滞,相反来说项目的成熟度达到了巅峰的水平,业界有非常多的用户在大规模落地和使用,其社区生态也呈现了非常活跃,多元化的态势。对于很多保守的企业或采用者。可以放心的去落地使用或者跟进这个开源项目。CNCF官方项目目前有15个毕业项目,21个孵化项目,46个沙盒项目,值得一提的是,CNCF的Sandbox经过流程优化之后,2020年增长速度明显提升。云原生平台技术架构发展方向:以“应用”为中心的云“OS”从2015年的1.0发布至今,Kubernetes已经有20多个大版本发布,各项功能特性和接口API都已经趋于稳定,K8s已经进入了成熟期。虽然严格意义上的K8s核心项目迭代在逐渐放缓,但是整个云原生技术栈将会进入更高速发展的阶段,围绕K8s的技术栈将会与云计算的应用、平台、设备各层次进行更深入的结合。各类现代化的应用都将会运行在K8s之上,不仅仅是前些年已经备受关注的以互联网App、WebService为代表的无状态应用,而新型的诸如大数据、AI、分布式数据中间件等等有状态应用,以及新型的边缘应用也将会普遍运行在K8s之上,从而K8s将完成对各类现有平台的归一化,成为一个统一的应用运行的分布式云原生平台。而为了更好地支撑现代化应用以及统一的基础技术平台,下层的各类设备包括虚拟化计算/网络/存储、裸金属服务器以及专用芯片如AI、高性能网络、高性能存储等等都会与K8s更紧密的配合,围绕云原生应用,通过软硬一体化的方案来提供更高性能、更稳定可靠、更高效的基础设施。与“应用、平台、设备”三个层面的协同,意味着云原生技平台将真正成为 以“应用”为中心的云“OS”。
-
9月 CNCF(云原生计算基金会)正式接纳由华为云贡献的多云容器编排项目Karmada迎来CNCF首个多云容器编排项目Karmada 项目的加入,将CNCF的云原生版图进一步扩展至分布式云领域。 华为云在技术上一直积极回馈社区,已开源了以智能边缘项目KubeEdge和批量计算项目Volcano为代表的一系列云原生项目。 Karmada项目由华为云、工商银行、小红书、中国一汽等8家企业联合发起,沉淀了各企业在多云管理领域的丰富积累,为开发者提供详实有效的实践指导与帮助,使用Karmada,可以构建无极可扩展的容器资源池,让开发者像使用单个Kubernetes集群一样使用多云集群。Karmada介绍随着企业业务的快速发展,多云也逐步成为数据中心建设的基础架构,多区域容灾与多活、大规模多集群管理、跨云弹性与迁移等场景推动云原生多云相关技术的快速发展。然而,在实际的生产落地过程中,云原生的多云仍面临如下挑战:集群繁多的重复劳动:运维工程师需要应对繁琐的集群配置、不同云厂商集群间的管理差异以及碎片化的API访问入口等问题;业务过度分散的维护难题:应用在各集群的差异化配置繁琐;业务跨云访问以及集群间的应用同步难以管理;集群的边界限制:应用的可用性受限于集群;资源调度、弹性伸缩受限于集群;厂商绑定:业务部署的黏性问题,缺少自动化故障迁移;缺少中立的开源多云容器编排项目。 Karmada结合了华为云多云容器平台MCP以及Kubernetes Federation核心实践,并融入了众多新技术:包括Kubernetes原生API支持、多层级高可用部署、多集群自动故障迁移、多集群应用自动伸缩、多集群服务发现等,并且提供原生Kubernetes平滑演进路径,让基于Karmada的多云方案无缝融入云原生技术生态,为企业提供从单集群到多云架构的平滑演进方案。生态合作Karmada项目由华为云、工商银行、浦发银行、小红书、VIPKID、趣头条、中国一汽和T3出行联合发起,于2021年4月在华为开发者大会2021(Cloud)上正式宣布开源。(延伸阅读:HDC.Cloud 2021 | 华为云发布重磅新品,全栈云原生技术能力持续创新升级)Karmada自开源以来受到了广泛的关注和支持,目前已有30+大型企业/机构/高校参与社区开发及贡献。 Karmada项目源自华为云多云容器平台MCP,同时融入了工商银行、小红书、中国一汽等不同行业客户在多云管理方面的经验,可以为各企业提供详实有效的落地指导与帮助,企业通过Karmada构建跨云、跨数据中心的无极可扩展的应用资源池,可以像管理单个Kubernetes集群一样简单、便捷的管理不同云、不同数据中心里的集群与应用。——华为云CTO 张宇昕在社区贡献方面,工商银行作为 Karmada项目的头部参与单位,结合工行多年来多容器集群管理的经验,已在集群生命周期管理、核心调度控制器等核心模块进行深度定制化的开发。后续,工行将持续参与Karmada 社区的开发和管理工作,计划在多集群自动调度、多集群自动伸缩等模块继续深入研究及贡献,反哺开源社区,持续扩大业界影响力。——工商银行软件开发中心专家 鲁金彪集团型企业同时存在多个混合容器的复杂场景,跨多云技术架构的运维难题日益突出。华为Karmada作为多集群、多云及混合云的集中化、兼容原生Kubernetes API接口的管理架构,有效解决目前容器编排多集群、多环境无法集中式管理、安全隔离机制不健全等痛点。希望Karmada在加入CNCF后,通过社区的共同维护与贡献,不断壮大其功能。期待Karmada早日从CNCF毕业,反哺云原生生态。——汽体系数字化部技术运营主任 王广Karmada原生兼容Kubernetes API的能力,可以不加改造地对接现有Kubernetes生态。在落地实践过程中,我们使用Karmada对接了现有的GitOps生态,极大提高了应用跨集群部署的效率。 ——VIPKID运维总监 谷玉虎Karmada提供丰富的多集群调度策略以及开箱即用的内置策略集,可以极大的简化两地三中心、异地容灾和同城双活架构下的系统复杂性,这对于金融行业至关重要。——浦发银行云转型处处长 吕炳刚 未来可期目前,Karmada已在华为云多云容器平台(Multi-Cloud Container Platform,MCP)商用,提供分布式云解决方案,提供跨云的多集群统一管理、应用统一部署及流量分发等关键能力。除MCP以外,Karmada已在数十家来自金融、互联网、教育等企业中落地。 此次CNCF正式将Karmada接纳为云原生领域首个多云容器编排项目,将极大促进Karmada上下游社区生态构建及合作,吸引广大云原生企业用户深度参与,Karmada将在多集群应用管理、服务治理、高可用部署等领域发挥越来越重要的作用,华为云也将在云原生领域持续耕耘、持续引领创新、繁荣生态,助力各行业走向快速智能发展之路。
-
 MindX DL (Deep Learning) MindX DL是支持多款异腾AI服务器,异腾AI加速卡的训练、推理组件,其包含的四个组件和管理的训练、推理任务均运行在Kubernetes(K8s)平台上。MindXDL提供了异腾AI处理器资源管理和监控、任务优化调度、分布式训练集合通信配置生成等基础功能,快速使能合作伙伴进行训练、推理开发以及搭建自己的AI平台。它由四大组件组成:设备的发现:基于Kubernetes设备插件机制,增加异腾处理器的设备发现、设备分配、设备健康状态上报功能,使得Kubernetes可以管理异腾处理器资源。集合通信配置:自动生成训练任务依赖的通信配置。调度优化:基于开源Volcano调度的插件机制,增加异腾处理器的亲和性调度,故障重调度等特性,最大化发挥异腾处理器计算性能。资源监控:提供对异腾处理器的实时监控,可实时获取异腾处理器利用率、频率、温度、电压、内存等信息。MindX DL应用场景: 从图中可以看出:MindX DL架起的桥梁连接了第三方AI平台和异腾设备,其提供的功能可以使客户快速构建AI平台,降低用户在K8s.上使用异腾设备的难度和对接难度。安装MindX DL分以下几个步骤:第一步:获取安装包以及文档可以直接去华为官网下载各个组件软件包和文档:https://www.hiascend.com/software/mindx-dl第二步:安装前准备工作了解环境依赖,硬件、软件环境的典型配置。基础软件环境的搭建。组网方案:(1)逻辑组网方案:单机部署逻辑组网和集群部署逻辑组网;(2)典型物理组网方案:MindX DL一般部署在数据中心内部,在数据中心对外的防火墙上需要开通MindX DL的访问端口制作MindX DL组件镜像:1.准备基础镜像2.获取软件包3.将软件包上传K8s管理节点上并解压4.制作镜像 命令docker build --no-cache -t xxxxx节点必要配置:创建节点标签,创建用户,创建MindX DL日志目录。第三步:安装MindX DL安装 HCCL-Controller :1.以root用户登录K8s管理节点,并执行以下命令:docker images | grep hccl-controller 查看HCCL-Controller镜像和版本号是否正确.2.将HCCL-Controller软件包解压目录(以“/home/ascend-hccl-controller”为例)下的yaml文件拷贝到K8s管理节点上任意目录.3.修改启动配置文件yaml的权限为640:chmod 640 hccl-controller-*.yaml4.修改yaml中HCCL-Controller的启动参数(根据自身的需求修改):vim hccl-controller-*.yaml5.启动HCCL-Controller:kubectl apply -f hccl-controller-*.yaml。安装Volcano:1.以root用户登录K8s管理节点,并执行以下命令:docker images | grep volcanosh,查看Volcano镜像和版本号是否正确。2.修改启动配置文件yaml的权限为640。3.修改yaml中Volcano的启动参数。4.启动Volcano:kubectl apply -f volcano-*.yaml安装Ascend Device Plugin:1.以root用户登录各计算节点,并执行命令vim hccl-controller-*.yaml查看镜像和版本号是否正确。2.将Ascend Device Plugin软件包解压目录。3.以root用户登录K8s管理节点,修改启动配置文件yaml的权限为640。4.修改yaml文件中Ascend Device Plugin的启动参数。5.在K8s管理点上执行以下命令,启动对应服务。安装NPU-Exporter:1.以root用户登录各计算节点,并执行命令docker images | grep npu-exporter,查看NPU-Exporter镜像和版本号是否正确2.将软件包上传到各计算节点任意目录并解压3.设置环境变量4.进行安全加固5.复制任意计算节点解压目录下的yaml文件到K8s管理节点上6.以root用户登录K8s管理节点7.修改yaml文件中NPU-Exporter的启动参数8.启动NPU-Exporter:kubectl apply -f npu-exporter-*.yaml安装后检查:在管理节点上执行命令kubectl get pod --all-namespaces,检查启动的各组件Pod状态执行命令kubectl describe node <node-name>查看节点详情卸载MindX DL只需要三步:以root用户登录管理节点。进入NPU-Exporter配置文件yaml所在目录。执行命令kubectl delete -f npu-exporter-*.yaml,卸载NPU-Exporter单节点和集群部署的差异:单节点部署:●建议开发环境使用●MindX DL组件镜像只需要放到一个节点上●只需要给-一个节点创建标签日志文件只会放到一个节点上●NPU-Exporter需要的证书、私钥等文件只需要放到一个节点●职责不单一,节点既要对任务进行调度和管理,又要执行训练、推理集群部署●生产环境使用:●节点需要放置对应的MindX DL组件镜像●需要给多个节点创建对应标签需要在多个节点存放日志●NPU-Exporter需要的证书、私钥等文件需要放到多个节点●职责单一,管理节点负责调度和管理训练、推理任务;计算节点负责执行训练、推理
MindX DL (Deep Learning) MindX DL是支持多款异腾AI服务器,异腾AI加速卡的训练、推理组件,其包含的四个组件和管理的训练、推理任务均运行在Kubernetes(K8s)平台上。MindXDL提供了异腾AI处理器资源管理和监控、任务优化调度、分布式训练集合通信配置生成等基础功能,快速使能合作伙伴进行训练、推理开发以及搭建自己的AI平台。它由四大组件组成:设备的发现:基于Kubernetes设备插件机制,增加异腾处理器的设备发现、设备分配、设备健康状态上报功能,使得Kubernetes可以管理异腾处理器资源。集合通信配置:自动生成训练任务依赖的通信配置。调度优化:基于开源Volcano调度的插件机制,增加异腾处理器的亲和性调度,故障重调度等特性,最大化发挥异腾处理器计算性能。资源监控:提供对异腾处理器的实时监控,可实时获取异腾处理器利用率、频率、温度、电压、内存等信息。MindX DL应用场景: 从图中可以看出:MindX DL架起的桥梁连接了第三方AI平台和异腾设备,其提供的功能可以使客户快速构建AI平台,降低用户在K8s.上使用异腾设备的难度和对接难度。安装MindX DL分以下几个步骤:第一步:获取安装包以及文档可以直接去华为官网下载各个组件软件包和文档:https://www.hiascend.com/software/mindx-dl第二步:安装前准备工作了解环境依赖,硬件、软件环境的典型配置。基础软件环境的搭建。组网方案:(1)逻辑组网方案:单机部署逻辑组网和集群部署逻辑组网;(2)典型物理组网方案:MindX DL一般部署在数据中心内部,在数据中心对外的防火墙上需要开通MindX DL的访问端口制作MindX DL组件镜像:1.准备基础镜像2.获取软件包3.将软件包上传K8s管理节点上并解压4.制作镜像 命令docker build --no-cache -t xxxxx节点必要配置:创建节点标签,创建用户,创建MindX DL日志目录。第三步:安装MindX DL安装 HCCL-Controller :1.以root用户登录K8s管理节点,并执行以下命令:docker images | grep hccl-controller 查看HCCL-Controller镜像和版本号是否正确.2.将HCCL-Controller软件包解压目录(以“/home/ascend-hccl-controller”为例)下的yaml文件拷贝到K8s管理节点上任意目录.3.修改启动配置文件yaml的权限为640:chmod 640 hccl-controller-*.yaml4.修改yaml中HCCL-Controller的启动参数(根据自身的需求修改):vim hccl-controller-*.yaml5.启动HCCL-Controller:kubectl apply -f hccl-controller-*.yaml。安装Volcano:1.以root用户登录K8s管理节点,并执行以下命令:docker images | grep volcanosh,查看Volcano镜像和版本号是否正确。2.修改启动配置文件yaml的权限为640。3.修改yaml中Volcano的启动参数。4.启动Volcano:kubectl apply -f volcano-*.yaml安装Ascend Device Plugin:1.以root用户登录各计算节点,并执行命令vim hccl-controller-*.yaml查看镜像和版本号是否正确。2.将Ascend Device Plugin软件包解压目录。3.以root用户登录K8s管理节点,修改启动配置文件yaml的权限为640。4.修改yaml文件中Ascend Device Plugin的启动参数。5.在K8s管理点上执行以下命令,启动对应服务。安装NPU-Exporter:1.以root用户登录各计算节点,并执行命令docker images | grep npu-exporter,查看NPU-Exporter镜像和版本号是否正确2.将软件包上传到各计算节点任意目录并解压3.设置环境变量4.进行安全加固5.复制任意计算节点解压目录下的yaml文件到K8s管理节点上6.以root用户登录K8s管理节点7.修改yaml文件中NPU-Exporter的启动参数8.启动NPU-Exporter:kubectl apply -f npu-exporter-*.yaml安装后检查:在管理节点上执行命令kubectl get pod --all-namespaces,检查启动的各组件Pod状态执行命令kubectl describe node <node-name>查看节点详情卸载MindX DL只需要三步:以root用户登录管理节点。进入NPU-Exporter配置文件yaml所在目录。执行命令kubectl delete -f npu-exporter-*.yaml,卸载NPU-Exporter单节点和集群部署的差异:单节点部署:●建议开发环境使用●MindX DL组件镜像只需要放到一个节点上●只需要给-一个节点创建标签日志文件只会放到一个节点上●NPU-Exporter需要的证书、私钥等文件只需要放到一个节点●职责不单一,节点既要对任务进行调度和管理,又要执行训练、推理集群部署●生产环境使用:●节点需要放置对应的MindX DL组件镜像●需要给多个节点创建对应标签需要在多个节点存放日志●NPU-Exporter需要的证书、私钥等文件需要放到多个节点●职责单一,管理节点负责调度和管理训练、推理任务;计算节点负责执行训练、推理 -
 当企业计划在公有云中运行工作负载时,需要选择合适的云计算提供商:必须比较不同云计算提供商提供的各种功能和定价,以确定是否最适合其工作负载。但是,如果采用了混合云解决方案,那么选择公有云平台来推动企业发展战略更具挑战性。这不仅需要比较公有云本身的核心特性,还需要比较它们提供的与混合云相关的服务。以下是企业在构建混合云解决方案策略时如何选择合适的云计算提供商的一些建议。公有云和混合云解决方案混合云的含义有点模糊,这使得在某些情况下很难确定什么是混合云。混合云中工作负载部署、管理和监控的集中程度可能会有所不同。然而,所有的混合云解决方案都有一个共同的核心特性:它们将公有云平台的服务与私有基础设施相结合。因此,公有云是混合云的必要组成部分。为混合云解决方案选择合适的公有云如果企业想构建混合云解决方案,那么第一步是决定使用哪个公有云平台,以交付有助于为混合云提供动力的公有云服务或基础设施。这是一个复杂的决定,因为在功能和定价等方面有许多考虑因素。企业不仅需要考虑云计算提供商的服务如何在其云平台中工作,还需要考虑它们如何与私有基础设施集成作为混合云战略的一部分。当企业选择混合云平台时,需要询问以下这些问题:(1)云计算供应商是否有官方的混合云框架?如今,许多云计算供应商都拥有专门设计用于帮助企业部署和管理混合云环境的框架。例如,亚马逊公司提供AWS Outposts和EKS Anywhere。谷歌公司提供Anthos。微软公司提供Azure Stack和Azure Hub。这些框架通常是构建混合云的最简单方法。但它们不一定是最具成本效益的,而且它们往往会将企业锁定在特定公有云平台的混合环境管理工具中。此外,其中一些框架需要使用特定的硬件,而不是允许企业使用其已经拥有的基础设施来构建混合云。出于这些原因,企业可能还希望查看可用于构建混合云环境的公有云平台,但不一定提供为此用例专门构建的框架。如果采用这种方式,可能最终会使用来自第三方供应商的管理工具,例如ServiceNow或ManageEngine。这些解决方案的集成将更加复杂,但它们更加与云计算无关,它们的成本也可能更低。(2)会使用Kubernetes吗?通过Kubernetes部署应用程序是构建混合云的一种简单方法。它允许企业使用Kubernetes来集中和标准化其部署和管理流程,而不管应用程序是由哪个基础设施(公有或私有)托管的。如果企业采用基于Kubernetes的混合云策略,那么在选择公有云平台时主要考虑该平台的Kubernetes服务提供哪些功能,以及该服务与第三方基础设施的集成程度。像Google Anthos这样的Kubernetes服务,谷歌公司推出的明确目标是允许Kubernetes与任何基础设施一起工作,可以说比AWS EKS等服务更适合混合云策略,后者目前与基础设施无关。(3)云计算支持哪些IaC工具?企业能够在混合云环境中使用与基础架构即代码(IaC)模板相同的基础设施,使得企业部署工作负载比在公有云平台上使用一组IaC模板,而在私有基础设施上使用另一组IaC模板更容易。大多数第三方IaC工具可用于任何公有云或内部部署环境。但是,来自公有云平台的原生IaC服务(如AWS CloudFormation)往往仅适用于公有云本身,如果企业采用混合云策略,这可能是一个限制。(4)云计算的IAM平台对混合云的支持程度如何?一般来说,公有云平台的身份和访问管理(IAM)框架设计为仅管理在这些云平台中运行的工作负载的访问。但有时也可以将IAM角色扩展到混合云环境中,从而简化访问管理。例如,企业可以使用AWS或Azure Active Directory来实现这一点。(5)考虑过出口费用吗?由于出口费用(云计算提供商对某些类型的数据移动收取的费用)可能是企业的云计算账单的主要部分,因此应该仔细评估其正在考虑的公有云平台的出口费用。需要特别注意的是,出口费用如何影响企业计划构建的混合架构。例如,如果使用虚拟私有云(VPC),需要评估将数据移入和移出虚拟私有云(VPC)的成本。(6)提供哪些网络服务?在虚拟私有云(VPC)方面,VPC和其他网络服务通常是将私有基础设施与公有云集成的重要组成部分。网络服务也往往高度复杂和微妙。例如Azure VPN网关和Azure Express Route都允许企业将私有基础设施与Azure公有云连接,但它们的连接方式略有不同。企业应该进行研究以确定每个公有云提供的网络服务类型,以及根据功能和价格最适合其混合云计划。结论任何公有云平台都可以作为混合云架构的一部分。但是,公有云在从出口费用和网络功能到混合云管理和Kubernetes服务等领域存在显著的差异。在企业决定哪种公有云平台最适合其混合云愿景时,需要评估所有这些方面。
当企业计划在公有云中运行工作负载时,需要选择合适的云计算提供商:必须比较不同云计算提供商提供的各种功能和定价,以确定是否最适合其工作负载。但是,如果采用了混合云解决方案,那么选择公有云平台来推动企业发展战略更具挑战性。这不仅需要比较公有云本身的核心特性,还需要比较它们提供的与混合云相关的服务。以下是企业在构建混合云解决方案策略时如何选择合适的云计算提供商的一些建议。公有云和混合云解决方案混合云的含义有点模糊,这使得在某些情况下很难确定什么是混合云。混合云中工作负载部署、管理和监控的集中程度可能会有所不同。然而,所有的混合云解决方案都有一个共同的核心特性:它们将公有云平台的服务与私有基础设施相结合。因此,公有云是混合云的必要组成部分。为混合云解决方案选择合适的公有云如果企业想构建混合云解决方案,那么第一步是决定使用哪个公有云平台,以交付有助于为混合云提供动力的公有云服务或基础设施。这是一个复杂的决定,因为在功能和定价等方面有许多考虑因素。企业不仅需要考虑云计算提供商的服务如何在其云平台中工作,还需要考虑它们如何与私有基础设施集成作为混合云战略的一部分。当企业选择混合云平台时,需要询问以下这些问题:(1)云计算供应商是否有官方的混合云框架?如今,许多云计算供应商都拥有专门设计用于帮助企业部署和管理混合云环境的框架。例如,亚马逊公司提供AWS Outposts和EKS Anywhere。谷歌公司提供Anthos。微软公司提供Azure Stack和Azure Hub。这些框架通常是构建混合云的最简单方法。但它们不一定是最具成本效益的,而且它们往往会将企业锁定在特定公有云平台的混合环境管理工具中。此外,其中一些框架需要使用特定的硬件,而不是允许企业使用其已经拥有的基础设施来构建混合云。出于这些原因,企业可能还希望查看可用于构建混合云环境的公有云平台,但不一定提供为此用例专门构建的框架。如果采用这种方式,可能最终会使用来自第三方供应商的管理工具,例如ServiceNow或ManageEngine。这些解决方案的集成将更加复杂,但它们更加与云计算无关,它们的成本也可能更低。(2)会使用Kubernetes吗?通过Kubernetes部署应用程序是构建混合云的一种简单方法。它允许企业使用Kubernetes来集中和标准化其部署和管理流程,而不管应用程序是由哪个基础设施(公有或私有)托管的。如果企业采用基于Kubernetes的混合云策略,那么在选择公有云平台时主要考虑该平台的Kubernetes服务提供哪些功能,以及该服务与第三方基础设施的集成程度。像Google Anthos这样的Kubernetes服务,谷歌公司推出的明确目标是允许Kubernetes与任何基础设施一起工作,可以说比AWS EKS等服务更适合混合云策略,后者目前与基础设施无关。(3)云计算支持哪些IaC工具?企业能够在混合云环境中使用与基础架构即代码(IaC)模板相同的基础设施,使得企业部署工作负载比在公有云平台上使用一组IaC模板,而在私有基础设施上使用另一组IaC模板更容易。大多数第三方IaC工具可用于任何公有云或内部部署环境。但是,来自公有云平台的原生IaC服务(如AWS CloudFormation)往往仅适用于公有云本身,如果企业采用混合云策略,这可能是一个限制。(4)云计算的IAM平台对混合云的支持程度如何?一般来说,公有云平台的身份和访问管理(IAM)框架设计为仅管理在这些云平台中运行的工作负载的访问。但有时也可以将IAM角色扩展到混合云环境中,从而简化访问管理。例如,企业可以使用AWS或Azure Active Directory来实现这一点。(5)考虑过出口费用吗?由于出口费用(云计算提供商对某些类型的数据移动收取的费用)可能是企业的云计算账单的主要部分,因此应该仔细评估其正在考虑的公有云平台的出口费用。需要特别注意的是,出口费用如何影响企业计划构建的混合架构。例如,如果使用虚拟私有云(VPC),需要评估将数据移入和移出虚拟私有云(VPC)的成本。(6)提供哪些网络服务?在虚拟私有云(VPC)方面,VPC和其他网络服务通常是将私有基础设施与公有云集成的重要组成部分。网络服务也往往高度复杂和微妙。例如Azure VPN网关和Azure Express Route都允许企业将私有基础设施与Azure公有云连接,但它们的连接方式略有不同。企业应该进行研究以确定每个公有云提供的网络服务类型,以及根据功能和价格最适合其混合云计划。结论任何公有云平台都可以作为混合云架构的一部分。但是,公有云在从出口费用和网络功能到混合云管理和Kubernetes服务等领域存在显著的差异。在企业决定哪种公有云平台最适合其混合云愿景时,需要评估所有这些方面。 -
 什么是多云和混合云伴随着Kubernetes和云原生的普及,高可用、高并发以及弹性突发等也成为很多应用程序的必备要求。而要实现这些功能,就需要应用程序不仅可以跨可用区和跨地区部署,还需要在云服务商容量不足或发生故障时自动切换到其他的云服务商或者混合云环境中去。并且,很多人也不希望把自己的所有服务都绑定到某一个云服务商中。多云和混合云就是指应用程序可以跨本地数据中心和多家云服务商混合部署,并可以按需在它们之间进行动态调度。多云和混合云的好处包括:解除云服务商锁定:不再单纯依赖于某一家云服务商或某个地域的数据中心可用性保障:不仅可以跨地区和跨地域,即使某个云服务商出现故障应用程序还可以继续在其他云服务商运行成本优化:可以根据云服务商的价格选择成本较低的方案,甚至是根据友商的成本去议价弹性突发保障:本地数据中心或云服务商容量不足时,还可以扩展到其他云服务商中去但是,多云和混合云的难点也很明显,最突出的结果问题是:跨云网络的打通跨云数据的一致性海量数据的访问延迟多云接口不一致带来的管理复杂度为了解决这些问题,在 Kubernetes 诞生之前,其实就有很多云管理平台专门解决云平台资源异构的问题。这些云管理平台解决了云资源的管理、成本的优化甚至是应用的 Devops 等各种问题,但一般并不负责实际管理应用的编排,所以在很多地方也被称之为多云 1.0。Kubernetes催生了多云2.0在 Kubernetes 和容器技术诞生之前,要实现多云和混合云是相当难的,需要针对每一个云服务商进行定制化开发。由于应用程序跟云服务商的接口绑定,所以也会导致迁移云服务商时需要从基础架构到应用程序都做相应的适配。这是很多人在上云时都会碰到的痛点,这可以通过云管理平台来解决。不过,目前的云管理平台更侧重于云资源的管理。虽然很多云管理平台也会提供应用的Deveops,但实际上只是把应用分发到不同的云平台上,并不负责应用程序的编排。比如,要想实现跨云的高可用和弹性突发,应用程序还是需要去调用不同云服务商的接口。有了Kubernetes 和容器之后,本地数据中心和云服务商的Kubernetes集群可以提供一致的接口,这样应用程序在大部分情况下就不需要跟具体的云服务商直接绑定了。如果只考虑Kubernetes集群,云管理平台也可以进一步简化为多云的Kubernetes集群管理,再借助于Kubernetes Operator模式,很多Kubernetes应用依赖的云资源可以抽象为相同的CRD。这就进一步解耦了应用和云服务商,被很多人称之为多云 2.0。说到Kubernetes的多云,最理想的是同一个Kubernetes集群横跨在多个不同的云平台上,通过同一个Kubernetes API去管理所有的应用。当然,由于云服务商差异、网络延迟、数据存储以及Kubernetes自身的规模限制等等,这种理想情况并不实用。所以,现在主流的方法都是在不同的地区以及不同的云服务商运行多个集群,再在这些集群之上打通多个集群的应用。比如,最简单的是在多个集群中部署服务的副本,再通过 Consul、Linkerd 或者 Global DNS 去为它们做负载均衡。
什么是多云和混合云伴随着Kubernetes和云原生的普及,高可用、高并发以及弹性突发等也成为很多应用程序的必备要求。而要实现这些功能,就需要应用程序不仅可以跨可用区和跨地区部署,还需要在云服务商容量不足或发生故障时自动切换到其他的云服务商或者混合云环境中去。并且,很多人也不希望把自己的所有服务都绑定到某一个云服务商中。多云和混合云就是指应用程序可以跨本地数据中心和多家云服务商混合部署,并可以按需在它们之间进行动态调度。多云和混合云的好处包括:解除云服务商锁定:不再单纯依赖于某一家云服务商或某个地域的数据中心可用性保障:不仅可以跨地区和跨地域,即使某个云服务商出现故障应用程序还可以继续在其他云服务商运行成本优化:可以根据云服务商的价格选择成本较低的方案,甚至是根据友商的成本去议价弹性突发保障:本地数据中心或云服务商容量不足时,还可以扩展到其他云服务商中去但是,多云和混合云的难点也很明显,最突出的结果问题是:跨云网络的打通跨云数据的一致性海量数据的访问延迟多云接口不一致带来的管理复杂度为了解决这些问题,在 Kubernetes 诞生之前,其实就有很多云管理平台专门解决云平台资源异构的问题。这些云管理平台解决了云资源的管理、成本的优化甚至是应用的 Devops 等各种问题,但一般并不负责实际管理应用的编排,所以在很多地方也被称之为多云 1.0。Kubernetes催生了多云2.0在 Kubernetes 和容器技术诞生之前,要实现多云和混合云是相当难的,需要针对每一个云服务商进行定制化开发。由于应用程序跟云服务商的接口绑定,所以也会导致迁移云服务商时需要从基础架构到应用程序都做相应的适配。这是很多人在上云时都会碰到的痛点,这可以通过云管理平台来解决。不过,目前的云管理平台更侧重于云资源的管理。虽然很多云管理平台也会提供应用的Deveops,但实际上只是把应用分发到不同的云平台上,并不负责应用程序的编排。比如,要想实现跨云的高可用和弹性突发,应用程序还是需要去调用不同云服务商的接口。有了Kubernetes 和容器之后,本地数据中心和云服务商的Kubernetes集群可以提供一致的接口,这样应用程序在大部分情况下就不需要跟具体的云服务商直接绑定了。如果只考虑Kubernetes集群,云管理平台也可以进一步简化为多云的Kubernetes集群管理,再借助于Kubernetes Operator模式,很多Kubernetes应用依赖的云资源可以抽象为相同的CRD。这就进一步解耦了应用和云服务商,被很多人称之为多云 2.0。说到Kubernetes的多云,最理想的是同一个Kubernetes集群横跨在多个不同的云平台上,通过同一个Kubernetes API去管理所有的应用。当然,由于云服务商差异、网络延迟、数据存储以及Kubernetes自身的规模限制等等,这种理想情况并不实用。所以,现在主流的方法都是在不同的地区以及不同的云服务商运行多个集群,再在这些集群之上打通多个集群的应用。比如,最简单的是在多个集群中部署服务的副本,再通过 Consul、Linkerd 或者 Global DNS 去为它们做负载均衡。 -
 Volcano是一个基于Kubernetes的云原生批量计算平台,也是CNCF的首个批量计算项目。Volcano 主要用于AI、大数据、基因、渲染等诸多高性能计算场景,对主流通用计算框架均有很好的支持。它提供高性能计算任务调度,异构设备管理,任务运行时管理等能力。本篇文章将从Volcano架构、Volcano核心概念及功能、Volcano Code Tour、平台组件安装部署等方面来带大家认识Volcano。 Volcano架构 1、Volcano全景Volcano是基于Kubernetes的高性能批量计算平台,目前支持几乎所有的主流计算框架,包括MindSpore、TensorFlow、Kubeflow、MPI、PyTorch、飞浆、Spark、HOROVOD 等。Volcano支持的部分计算框架 计算框架遇到的问题:1)1:1的operator部署运维复杂2)不同框架对作业管理、并行计算等要求不同3)计算密集高,资源需求波动大,需要高级调度能力 Volcano面向主流计算框架提供:1)统一容器基础设施,提高资源利用率2)通用作业管理、队列Fair-share, Gang, bin-pack等高级调度算法3)简化运维管理 2、Volcano整体架构Volcano利用声明式的CRD定义我们的API,主要有3个核心的API,Volcano Job、PodGroup、Queue。Volcano Job 是对高性能任务的通用定义,PodGroup提供了Job中Task的管理能力,Queue 为任务的分类提供了基础。Volcano的架构 Volcano 核心组件主要包含三个:Admission、ControllerManager、Scheduler 。Admission对Volcano CRD API提供校验能力;ControllerManager负责对Volcano CRD进行资源管理;Scheduler对任务提供丰富的调度能力。 3、Volcano工作流程从零开始运行Volcano作业:1)用户创建一个 Volcano 作业2)Volcano Admission 拦截作业的创建请求,并进行合法性校验3)Kubernetes 持久化存储 Volcano Job 到 ETCD4)ControllerManager 通过 List-Watch 机制观察到Job 资源的创建,创建任务(Pod)5)Scheduler 负责任务的调度,绑定 Node6)Kubelet Watch 到 Pod的创建,接管 Pod 的运行7)ControllerManager 监控所有任务的运行状态,保证所有的任务在期望的状态下运行 Volcano核心概念及功能1、Volcano核心概念1)Queue:Queue的概念源于 Yarn,它是Cluster 级别的资源对象,可为其声明资源配额,也可由多namespace 共享,并且提供 soft isolation2)PodGroup:PodGroup是任务的分组,它与 queue 绑定,占用队列的资源。它与 Volcano Job 是一对一的关系;也可为其声明 Scheduling 条件3)Volcano Job:它是批量计算作业的定义,支持定义作业所属队列、生命周期策略、所包含的任务模板以及持久卷等信息 2、作业管理插件 svc:提供不同类型任务之间互访能力env:任务索引,例如 Tensorflow Worker indexssh:ssh 秘钥对创建及挂载,主要供 MPI 作业使用 3、Scheduler架构Scheduler支持动态配置和加载。 4、核心调度算法1)Gang Scheduling2)Fair Share3)Preempt & Reclaim4)Reserve & Backfill5)Topology Aware Scheduling6)GPU Sharing Volcano Code Tourcmd目录是Volcano所有组件启动的入口;config 是Volcano的配置;defs 是安装时的配置;docs 是Volcano的设计文档;example 提供了简单的例子,hack 提供安装时的脚本;installer 提供安装的模板。 pkg 是最重要的目录,里面包含了 api、controller、scheduler 、webhook 等代码。test 提供了e2e测试用例, vendor是依赖库。 安装部署1、Volcano InstallVolcano安装部署有多种方式:若已存在K8S集群,建议通过 Helm方式安装部署,该方式支持自定义安装配置;开发者建议通过Development Yaml方式部署。 对于开发者,Volcano已内置一键式安装部署脚本,路径为 volcano. sh/volcano/hack/local-up-volcano. sh。运行该脚本时,默认会使用kind创建 Docker in Docker的模拟集群,并安装部署Volcano。 2、Volcano 组件正确安装部署后,将生成4个组件,分别为:Volcano-admission、Volcano-admission-init、Volcano-controllers、 Volcano-scheduler ,其中admission-init以作业的方式生成证书。
Volcano是一个基于Kubernetes的云原生批量计算平台,也是CNCF的首个批量计算项目。Volcano 主要用于AI、大数据、基因、渲染等诸多高性能计算场景,对主流通用计算框架均有很好的支持。它提供高性能计算任务调度,异构设备管理,任务运行时管理等能力。本篇文章将从Volcano架构、Volcano核心概念及功能、Volcano Code Tour、平台组件安装部署等方面来带大家认识Volcano。 Volcano架构 1、Volcano全景Volcano是基于Kubernetes的高性能批量计算平台,目前支持几乎所有的主流计算框架,包括MindSpore、TensorFlow、Kubeflow、MPI、PyTorch、飞浆、Spark、HOROVOD 等。Volcano支持的部分计算框架 计算框架遇到的问题:1)1:1的operator部署运维复杂2)不同框架对作业管理、并行计算等要求不同3)计算密集高,资源需求波动大,需要高级调度能力 Volcano面向主流计算框架提供:1)统一容器基础设施,提高资源利用率2)通用作业管理、队列Fair-share, Gang, bin-pack等高级调度算法3)简化运维管理 2、Volcano整体架构Volcano利用声明式的CRD定义我们的API,主要有3个核心的API,Volcano Job、PodGroup、Queue。Volcano Job 是对高性能任务的通用定义,PodGroup提供了Job中Task的管理能力,Queue 为任务的分类提供了基础。Volcano的架构 Volcano 核心组件主要包含三个:Admission、ControllerManager、Scheduler 。Admission对Volcano CRD API提供校验能力;ControllerManager负责对Volcano CRD进行资源管理;Scheduler对任务提供丰富的调度能力。 3、Volcano工作流程从零开始运行Volcano作业:1)用户创建一个 Volcano 作业2)Volcano Admission 拦截作业的创建请求,并进行合法性校验3)Kubernetes 持久化存储 Volcano Job 到 ETCD4)ControllerManager 通过 List-Watch 机制观察到Job 资源的创建,创建任务(Pod)5)Scheduler 负责任务的调度,绑定 Node6)Kubelet Watch 到 Pod的创建,接管 Pod 的运行7)ControllerManager 监控所有任务的运行状态,保证所有的任务在期望的状态下运行 Volcano核心概念及功能1、Volcano核心概念1)Queue:Queue的概念源于 Yarn,它是Cluster 级别的资源对象,可为其声明资源配额,也可由多namespace 共享,并且提供 soft isolation2)PodGroup:PodGroup是任务的分组,它与 queue 绑定,占用队列的资源。它与 Volcano Job 是一对一的关系;也可为其声明 Scheduling 条件3)Volcano Job:它是批量计算作业的定义,支持定义作业所属队列、生命周期策略、所包含的任务模板以及持久卷等信息 2、作业管理插件 svc:提供不同类型任务之间互访能力env:任务索引,例如 Tensorflow Worker indexssh:ssh 秘钥对创建及挂载,主要供 MPI 作业使用 3、Scheduler架构Scheduler支持动态配置和加载。 4、核心调度算法1)Gang Scheduling2)Fair Share3)Preempt & Reclaim4)Reserve & Backfill5)Topology Aware Scheduling6)GPU Sharing Volcano Code Tourcmd目录是Volcano所有组件启动的入口;config 是Volcano的配置;defs 是安装时的配置;docs 是Volcano的设计文档;example 提供了简单的例子,hack 提供安装时的脚本;installer 提供安装的模板。 pkg 是最重要的目录,里面包含了 api、controller、scheduler 、webhook 等代码。test 提供了e2e测试用例, vendor是依赖库。 安装部署1、Volcano InstallVolcano安装部署有多种方式:若已存在K8S集群,建议通过 Helm方式安装部署,该方式支持自定义安装配置;开发者建议通过Development Yaml方式部署。 对于开发者,Volcano已内置一键式安装部署脚本,路径为 volcano. sh/volcano/hack/local-up-volcano. sh。运行该脚本时,默认会使用kind创建 Docker in Docker的模拟集群,并安装部署Volcano。 2、Volcano 组件正确安装部署后,将生成4个组件,分别为:Volcano-admission、Volcano-admission-init、Volcano-controllers、 Volcano-scheduler ,其中admission-init以作业的方式生成证书。 -
Helm应用包管理器,辅助管理 Kubernetes 应用程序,Helm Charts 定义、安装和升级复杂的 Kubernetes 应用程序。Helm是一个Kubernetes的包管理工具,就像Linux下的包管理器,如yum/apt等,可以很方便的将之前打包好的yaml文件部署到kubernetes上。Helm有两个重要概念:- helm:一个命令行客户端工具,主要用于Kubernetes应用chart的创建、打包、发布和管理。- Chart:应用描述,一系列用于描述 k8s 资源相关文件的集合。- Release:基于Chart的部署实体,一个 chart 被 Helm 运行后将会生成对应的一个 release;将在k8s中创建出真实运行的资源对象。 为什么需要Helm?K8S上的应用对象,都是由特定的资源描述组成,包括deployment、service等。都保存各自文件中或者集中写到一个配置文件。然后统一通过kubectl apply –f 部署。这种命令行部署的方式,只适合应用只由一个或几个这样的服务组成的简单应用,而对于一个复杂的应用,会有很多类似上面的资源描述文件,例如微服务架构应用,组成应用的服务可能多达十个,几十个。如果有更新或回滚应用的需求,可能要修改和维护所涉及的大量资源文件,而这种手动的组织和管理应用的方式就显得不足了。并且由于缺少对发布过的应用版本管理和控制,使Kubernetes上的应用维护和更新等面临诸多的挑战,主要面临以下问题:1. 如何将这些服务作为一个整体管理:如应用的快速迁移2. 这些资源文件如何高效复用:同一个应用稍做改动,部署另外一个应用上去。3. 不支持应用级别的版本管理:微服务面临的灰度发布helm可以很好的解决这些问题。
-
StatefulSet控制器用于部署有状态应用,满足一些有状态应用的需求,主要考虑三个方面问题: 1.Pod有序的部署、扩容、删除和停止 2.Pod分配一个稳定的且唯一的网络标识 3.Pod分配一个独享的存储稳定的网络标识:使用Headless Service(相比普通Service只是将spec.clusterIP定义为None)来维护Pod网络身份,会为每个Pod分配一个数字编号并且按照编号顺序部署。还需要在StatefulSet添加 serviceName: “xxx”字段指定StatefulSet控制器要使用这个Headless Service。稳定的网络标识主要体现在主机名和Pod A记录:主机名:<statefulset名称>-<编号> Pod DNS A记录:<statefulset名称-编号>.<service-name> .<namespace>.svc.cluster.local[root@k8s-node2 ~]# vi headless-service.yamlapiVersion: v1kind: Servicemetadata: name: headless-webspec: clusterIP: None selector: app: nginx type: ClusterIP ports: - protocol: TCP port: 80 targetPort: 9376[root@k8s-node2 ~]# vi head.yamlapiVersion: apps/v1kind: StatefulSetmetadata: name: webspec: serviceName: "headless-web" replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx ports: - containerPort: 80 name: webkubectl apply -f headless-service.yamlkubectl apply -f head.yaml[root@k8s-node2 ~]# kubectl get podNAME READY STATUS RESTARTS AGEdns-test 1/1 Running 0 42mweb-0 1/1 Running 0 10mweb-1 1/1 Running 0 10mweb-2 1/1 Running 0 10m[root@k8s-node2 ~]# kubectl get svcNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEheadless-web ClusterIP None <none> 80/TCP 22mkubernetes ClusterIP 10.96.0.1 <none> 443/TCP 5d3h[root@k8s-node2 ~]# 启用一个dns测试容器:kubectl run -i -t dns-test --image busybox:1.28.4 /bin/sh/ # nslookup headless-webServer: 10.96.0.10Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.localName: headless-webAddress 1: 10.244.169.161 web-1.headless-web.default.svc.cluster.localAddress 2: 10.244.169.160 web-0.headless-web.default.svc.cluster.localAddress 3: 10.244.169.162 web-2.headless-web.default.svc.cluster.local
-
Kubernetes 安全框架主要由下面3个阶段进行控制,每一个阶段都支持插件方式,通过API Server配置来启用插件。1. Authentication(鉴权)2. Authorization(授权)3. Admission Control(准入控制)与通信行业常用的radius3A认证类似,也有鉴权、授权,不同的radius的第三个A是accounting统计。前两个A好理解,后面的准入控制难理解。为什么授权了之后还要有准入控制呢?个人理解,准入控制和授权是不同粒度的控制,授权的粒度更大,准入控制的更精细,就好像门锁和抽屉的锁。Adminssion Control实际上是一个准入控制器插件列表,发送到API Server的请求都需要经过这个列表中的每个准入控制器插件的检查,检查不通过,则拒绝请求。客户端要访问k8s集群API Server,一般需要证书、token或者用户名密码;如果是Pod访问,则需要ServiceAccount。前面是 例如kubectl 对 apiserver 的一个请求过程;后面是 Pod 中的业务逻辑与 apiserver 之间的交互。apiserver 收到访问请求后,就会开启访问控制流程。如果Authentication 认证阶段判定为不合法用户,那 apiserver 会返回一个 401 的状态码,并终止该请求;(跟volte的信令流程类似)如果用户合法的话,进入到访问控制的第二阶段鉴权,判断用户是否有权限进行请求中的操作。这个阶段是粗分类,只判定有权无权。如果无权,apiserver 会返回 403 的状态码,并终止该请求;如果用户有权,访问控制会进入更细化的控制阶段:AdmissionControl。在该阶段中 apiserver 的 admission controller 会判断请求是否是一个安全合规的请求。
推荐直播
-
 鲲鹏开发者创享日·江苏站暨数字技术创新应用峰会
鲲鹏开发者创享日·江苏站暨数字技术创新应用峰会2024/04/25 周四 09:30-16:00
鲲鹏专家团
这是华为推出的旨在和众多技术大牛、行业大咖一同探讨最前沿的技术思考,分享最纯粹的技术经验,进行最真实的动手体验,为开发者提供一个深度探讨与交流的平台。
回顾中 -
 产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》
产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》2024/04/25 周四 16:00-18:00
于晓东 上海杉达学院信息科学与技术学院副院长;崔宝才 天津电子信息职业技术学院电子与通信技术系主任
本期直播将与您一起探讨高校人才培养创新模式经验。
回顾中
热门标签