-
 在大数据背景下,数据库安全保障体系的构建对于有效防范信息安全事件发生具有重要意义。该文首先分析了大 数据背景下数据库系统的安全威胁问题,然后介绍了几种网络安全的新技术,包括身份认证技术、访问控制技术等,最后 阐述了数据库安全保障体系的构建路径,希望为进一步解决大数据背景下的数据库安全问题提供支持。 现阶段大数据产业的快速发展创造了极大的经济效益,大数据的出现推动了社会经济发展,但是随之而来的数据库安全问题也引起了学者对大数据信息安全问题的反思。大数据时代下的信息与隐私安全问题已经成为全球性重点关注的问题,为了能够更有效地避免数据安全问题发生,需要相关人员积极构建数据库安全保障体系。1 数据库的安全威胁问题研究 数据库的信息安全问题得到了社会的普遍关注,从现有的数据库网络安全事件来看,其信息安全问题的风险具有范围广、影响大、突发性强等特征,并且可能产生严重的损失。与传统的攻击行为相比,数据库的网络安全问题呈现出以下特征:(1)高技术性与高智能性特征。例如部分不法分子为了能够盗取数据库中的资料,会采用各种手段穿越防火墙,通过不断地攻击数据库的安全防护体系或注入SQL等方法篡改数据,导致数据大量流失。(2)作案手段日益多样化。在大数据技术的支持下,不法分子威胁数据库的手段也呈现出了多样化的趋势,例如部分人员会运用程序的漏洞进行作案,甚至通过非法用户向管理人员非法授予操作权限的方法进行授权。(3)网络安全问题不受地域与时间因素的显示,不法分子可以随时远程攻击数据库。(4)数据库攻击的隐蔽性较强,收集证据的难度较大。文献认为,数据库作为一种特殊的信息存储结构,在大数据环境下所面临的信息安全隐患问题更加突出,表现为:(1)在网络方面,大部分数据库采用了TCP/IP 的协议通信方式,而该协议本身存在弊端,难以有效鉴别通信双方的身份,导致数据库无法正确识别攻击者的身份而遭到严重破坏。(2)在数据库管理系统上,大部分数据采用了DB2、SQL Server等商用数据库系统,这些数据库系统的技术条件成熟,但是在应用过程中,一些数据库的安全问题发生,例如关于SQL Server数据库的SQL 注入等。虽然现阶段各个厂商都在不断完善数据库等更新补丁包,但是大部分出于对数据库稳定性的考虑,通常会延后补丁的更新速度,最终导致数据库的漏洞难以第一时间被处理,最终成为安全隐患。2 大数据背景下数据库安全技术分析2.1 身份认证技术分析为实现数据库安全对用户的身份进行认证是其中的重点。现阶段常用的数据库普遍采用“ID+密码”的方式进行身份核实,即将用户的账号信息存储在数据字典等当用户产生连接需求之后,系统能够查询数据字典,并对用户的合法性进行判断。但是在大数据背景下,各种解密技术得到了快速的发展,导致 ID 认证方式面临挑战,因此鉴定人体信息的生物认证安全技术出现,通过语言识别、指纹识别的方法,对用户的身份进行判断。但从现有技术发展情况来看,身份认证技术尚未在数据库安全管理中得到运用,但是鉴于大数据的强大数据处理能力,可预见该技术在未来会具有广阔的发展前景。2.2 访问控制技术访问控制是数据库安全管理的核心内容,能够对规定主体的访问行为进行限制,避免出现任何不满足数据库安全的访问行为发生。2.2.1 自主访问控制目前自主访问控制是数据库信息安全中一种常见的访问控制技术,用户可结合自己的需求对系统的数据进行调整并判断哪些用户能够访问数据库。在此基础上,通过构建自主访问控制模型,能够对访问客体的权限做进一步界定,这样当用户的身份被系统识别后,则可以对客体访问数据库的行为进行监控,用户只能在系统允许的范围内完成操作。作为一种灵活的控制策略,自主访问控制能够保障用户自主地将自己所拥有的权限赋予其他用户,操作过程灵活简单,因此大部分的商业数据库都会采用这种访问控制技术。2.2.2 基于角色的访问控制在数据库安全管理中,基于角色的访问控制作为一种新的控制方法,其主要特征为:在该技术中权限并不是直接赋予指定用户的。所以当用户与特定角色绑定之后,则可以通过将基于角色的访问控制过程进行划分,实现对权限的分配。 2.3 数据加密技术数据加密技术主要包括库内加密与库外加密的方法,其中库内加密是在数据库内部设置加密模块,例如对数据内的相关列表进行加密,而库外加密则是通过特定的加密服务器完成加密与解密操作。在大数据环境下,大部分的数据库都能够提供数据加密功能,例如SQL Server数据库构建的多维度密钥保护与备份信息加密等。但是考虑到数据的特殊性,数据库所存储的信息量较大,在这种情况下可能对数据库的加密与加密的稳定性产生影响,因此用户可根据安全管理要求对数据库中的高度机密的数据做加密处理。3 大数据背景下的数据库安全保障策略分析在大数据背景下,应该围绕信息安全问题落实数据库安全管理方案,以大数据强大的数据处理能力结合数据库的功能诉求对数据库的安全保障方案进行改进。 3.1 角色访问控制策略分析受大数据的影响,数据库的访问人数会快速增加,导致数据库所面临的安全风险更高。因此为了能够进一步保障数据库安全,则需要基于角色访问模型的数据库访问控制,为用户分配数据库角色,最终使用户在数据库上获得相应的权限,进一步提高数据库安全质量。本文基于大数据的技术要求,在数据库安全保障体系的设置上提出了一种新的集中管理模式——基于应用的角色访问模型,该模型能够对数据库的信息安全问题进行有效识别,通过对应用数据库、安全中心的功能进行界定,进而明确数据库安全管理的角色与权限。在实施阶段,其中的重点内容包括: (1)应用方案。在大数据系统中的应用系统中往往会存在大量的账户与用户群,所以在数据库安全保障体系建设中能够将任意一个用户的信息注册到安全中心中,这样数据库可以收录用户权限的有用信息,包括名称、属性、创建时间、应用用途等。 (2)子应用。数据安全管理应用方案需要根据环境进行分类,将数据库中的自应用作为特定类用户的集合,可用于实现数据库的安全管理。例如在数据库安全的子应用中,将DBA作为数据库管理员集合。(3)数据库。这里所提到的数据库为特定数据库,为达到安全管理要求,将数据库注册到系统中并与相关安全软件相绑定,或者在特定的数据库环境下将对应的子应用创设到数据库中。(4)用户。用户的数据安全需要与数据库的账户相连接,在数据库安全管理制定用户所属的子应用,并划分相应的权限即可。 3.2 攻击检测大数据背景下的数据库安全形势严峻,数据库所承受的攻击数量巨大,通过开展攻击检测的方法能够发现滥用与异常的攻击行为。现阶段的大部分数据库都不具有攻击检测功能,所以在安全保障体系的构建中,本文根据技术数据挖掘与数据采集的要求,构建基于攻击检测的数据保全保障体系,通过该方法能够记录数据库被攻击情况,为实现数据库安全奠定基础。实时检测主要是针对各种已知的攻击方式,并将这种攻击以代码的形式存储在数据库中,按照数据库中所记录的数据判断系统是否遭受到攻击。该技术的具有较高的检测精度,但由于该技术无法对内部人员与未知攻击行为进行检测,所以本文在实时检测的基础上进一步完善了其中的功能,包括:(1)登录失败检测。当系统检测到在特定时间段内频繁地出现登录失败的情况,则需要对该IP的用户登录情况进行检测。(2)登录检测。若登录数据库的IP地址与以前登录过的地址不同,则需要警惕数据库安全问题。(3)操作失败检测。针对特定时间内检测到的操作失败次数,检测无访问权限对象的登录行为。(4)用户权限变更检测。其主要功能是检测用户的权限是否在满足规定的情况下进行变更。在该系统中,通过将关于系统安全的规则上传到数据库的审计中心中,再同步到各个数据中,由此实现对滥用规则的统一控制。在实时检测过程中,可在数据库添加两个触发器来完成对攻击的检测,包括:(1)通过DDL触发器来抓取数据库的事物,并检测用户权限变更等情况,作为SQLServer数据库中的一种特有触发器,当数据库发生安全事件的同时能够做出响应,在各种数据库安全事件发生之后快速地捕捉信息并分析安全攻击行为的发生间隔,判断攻击事件是否有效。(2)DML触发器具有跟踪审计信息的功能,针对数据库操作过程中的各种常见问题进行安全评估,包括操作失败事件、登录失败情况以及敏感用户对系统的访问等。当DML 检测到数据库遭受到攻击,则会退出攻击账户,保证数据库的安全。 3.3 数据库的安全防护机制在数据库的安全防护中,可利用虚拟化平台来实现数据库的安全管理,为能够达到有效的安全防护目的,可采用以下措施进行数据库安全管理。 3.3.1 数据库的安全备份数据备份的目的就是要为数据安全增添“第二把锁”,当前数据库的数据备份主要采用物理备份与逻辑备份相结合的方法,按照既定的时间要求对数据库中的数据进行存储。此时假设数据遭到攻击或者出现损害时,可以在原数据库的基础上调度备份数据,达到数据快速复原的目的。为实现该目的,可通过MySQL恢复工具、导出数据等方法并引入数据信息的变化,最终有助于实现二进制文件保存,避免备份数据的滥用。 3.3.2 数据库的防火墙设置防火墙是维护数据安全的关键,所以在设置防火墙期间,利用SQL数据库检测到的攻击痕迹将数据与数据库SQL语句运用到应用程序中,利用数据库防火墙的名单检测对任意一个针对数据库的操作行为进行检测,避免系统遭受注入攻击而造成数据损失。4 结束语在大数据背景下,数据库的安全保障管理更加复杂,为了能够更好地适应数据库管理要求,相关人员要充分发挥大数据技术优势,结合各种常见的数据库安全问题进行处置,这样才能有效降低数据库安全事件发生率,最终适应数据安全管理要求。来自:今日头条
在大数据背景下,数据库安全保障体系的构建对于有效防范信息安全事件发生具有重要意义。该文首先分析了大 数据背景下数据库系统的安全威胁问题,然后介绍了几种网络安全的新技术,包括身份认证技术、访问控制技术等,最后 阐述了数据库安全保障体系的构建路径,希望为进一步解决大数据背景下的数据库安全问题提供支持。 现阶段大数据产业的快速发展创造了极大的经济效益,大数据的出现推动了社会经济发展,但是随之而来的数据库安全问题也引起了学者对大数据信息安全问题的反思。大数据时代下的信息与隐私安全问题已经成为全球性重点关注的问题,为了能够更有效地避免数据安全问题发生,需要相关人员积极构建数据库安全保障体系。1 数据库的安全威胁问题研究 数据库的信息安全问题得到了社会的普遍关注,从现有的数据库网络安全事件来看,其信息安全问题的风险具有范围广、影响大、突发性强等特征,并且可能产生严重的损失。与传统的攻击行为相比,数据库的网络安全问题呈现出以下特征:(1)高技术性与高智能性特征。例如部分不法分子为了能够盗取数据库中的资料,会采用各种手段穿越防火墙,通过不断地攻击数据库的安全防护体系或注入SQL等方法篡改数据,导致数据大量流失。(2)作案手段日益多样化。在大数据技术的支持下,不法分子威胁数据库的手段也呈现出了多样化的趋势,例如部分人员会运用程序的漏洞进行作案,甚至通过非法用户向管理人员非法授予操作权限的方法进行授权。(3)网络安全问题不受地域与时间因素的显示,不法分子可以随时远程攻击数据库。(4)数据库攻击的隐蔽性较强,收集证据的难度较大。文献认为,数据库作为一种特殊的信息存储结构,在大数据环境下所面临的信息安全隐患问题更加突出,表现为:(1)在网络方面,大部分数据库采用了TCP/IP 的协议通信方式,而该协议本身存在弊端,难以有效鉴别通信双方的身份,导致数据库无法正确识别攻击者的身份而遭到严重破坏。(2)在数据库管理系统上,大部分数据采用了DB2、SQL Server等商用数据库系统,这些数据库系统的技术条件成熟,但是在应用过程中,一些数据库的安全问题发生,例如关于SQL Server数据库的SQL 注入等。虽然现阶段各个厂商都在不断完善数据库等更新补丁包,但是大部分出于对数据库稳定性的考虑,通常会延后补丁的更新速度,最终导致数据库的漏洞难以第一时间被处理,最终成为安全隐患。2 大数据背景下数据库安全技术分析2.1 身份认证技术分析为实现数据库安全对用户的身份进行认证是其中的重点。现阶段常用的数据库普遍采用“ID+密码”的方式进行身份核实,即将用户的账号信息存储在数据字典等当用户产生连接需求之后,系统能够查询数据字典,并对用户的合法性进行判断。但是在大数据背景下,各种解密技术得到了快速的发展,导致 ID 认证方式面临挑战,因此鉴定人体信息的生物认证安全技术出现,通过语言识别、指纹识别的方法,对用户的身份进行判断。但从现有技术发展情况来看,身份认证技术尚未在数据库安全管理中得到运用,但是鉴于大数据的强大数据处理能力,可预见该技术在未来会具有广阔的发展前景。2.2 访问控制技术访问控制是数据库安全管理的核心内容,能够对规定主体的访问行为进行限制,避免出现任何不满足数据库安全的访问行为发生。2.2.1 自主访问控制目前自主访问控制是数据库信息安全中一种常见的访问控制技术,用户可结合自己的需求对系统的数据进行调整并判断哪些用户能够访问数据库。在此基础上,通过构建自主访问控制模型,能够对访问客体的权限做进一步界定,这样当用户的身份被系统识别后,则可以对客体访问数据库的行为进行监控,用户只能在系统允许的范围内完成操作。作为一种灵活的控制策略,自主访问控制能够保障用户自主地将自己所拥有的权限赋予其他用户,操作过程灵活简单,因此大部分的商业数据库都会采用这种访问控制技术。2.2.2 基于角色的访问控制在数据库安全管理中,基于角色的访问控制作为一种新的控制方法,其主要特征为:在该技术中权限并不是直接赋予指定用户的。所以当用户与特定角色绑定之后,则可以通过将基于角色的访问控制过程进行划分,实现对权限的分配。 2.3 数据加密技术数据加密技术主要包括库内加密与库外加密的方法,其中库内加密是在数据库内部设置加密模块,例如对数据内的相关列表进行加密,而库外加密则是通过特定的加密服务器完成加密与解密操作。在大数据环境下,大部分的数据库都能够提供数据加密功能,例如SQL Server数据库构建的多维度密钥保护与备份信息加密等。但是考虑到数据的特殊性,数据库所存储的信息量较大,在这种情况下可能对数据库的加密与加密的稳定性产生影响,因此用户可根据安全管理要求对数据库中的高度机密的数据做加密处理。3 大数据背景下的数据库安全保障策略分析在大数据背景下,应该围绕信息安全问题落实数据库安全管理方案,以大数据强大的数据处理能力结合数据库的功能诉求对数据库的安全保障方案进行改进。 3.1 角色访问控制策略分析受大数据的影响,数据库的访问人数会快速增加,导致数据库所面临的安全风险更高。因此为了能够进一步保障数据库安全,则需要基于角色访问模型的数据库访问控制,为用户分配数据库角色,最终使用户在数据库上获得相应的权限,进一步提高数据库安全质量。本文基于大数据的技术要求,在数据库安全保障体系的设置上提出了一种新的集中管理模式——基于应用的角色访问模型,该模型能够对数据库的信息安全问题进行有效识别,通过对应用数据库、安全中心的功能进行界定,进而明确数据库安全管理的角色与权限。在实施阶段,其中的重点内容包括: (1)应用方案。在大数据系统中的应用系统中往往会存在大量的账户与用户群,所以在数据库安全保障体系建设中能够将任意一个用户的信息注册到安全中心中,这样数据库可以收录用户权限的有用信息,包括名称、属性、创建时间、应用用途等。 (2)子应用。数据安全管理应用方案需要根据环境进行分类,将数据库中的自应用作为特定类用户的集合,可用于实现数据库的安全管理。例如在数据库安全的子应用中,将DBA作为数据库管理员集合。(3)数据库。这里所提到的数据库为特定数据库,为达到安全管理要求,将数据库注册到系统中并与相关安全软件相绑定,或者在特定的数据库环境下将对应的子应用创设到数据库中。(4)用户。用户的数据安全需要与数据库的账户相连接,在数据库安全管理制定用户所属的子应用,并划分相应的权限即可。 3.2 攻击检测大数据背景下的数据库安全形势严峻,数据库所承受的攻击数量巨大,通过开展攻击检测的方法能够发现滥用与异常的攻击行为。现阶段的大部分数据库都不具有攻击检测功能,所以在安全保障体系的构建中,本文根据技术数据挖掘与数据采集的要求,构建基于攻击检测的数据保全保障体系,通过该方法能够记录数据库被攻击情况,为实现数据库安全奠定基础。实时检测主要是针对各种已知的攻击方式,并将这种攻击以代码的形式存储在数据库中,按照数据库中所记录的数据判断系统是否遭受到攻击。该技术的具有较高的检测精度,但由于该技术无法对内部人员与未知攻击行为进行检测,所以本文在实时检测的基础上进一步完善了其中的功能,包括:(1)登录失败检测。当系统检测到在特定时间段内频繁地出现登录失败的情况,则需要对该IP的用户登录情况进行检测。(2)登录检测。若登录数据库的IP地址与以前登录过的地址不同,则需要警惕数据库安全问题。(3)操作失败检测。针对特定时间内检测到的操作失败次数,检测无访问权限对象的登录行为。(4)用户权限变更检测。其主要功能是检测用户的权限是否在满足规定的情况下进行变更。在该系统中,通过将关于系统安全的规则上传到数据库的审计中心中,再同步到各个数据中,由此实现对滥用规则的统一控制。在实时检测过程中,可在数据库添加两个触发器来完成对攻击的检测,包括:(1)通过DDL触发器来抓取数据库的事物,并检测用户权限变更等情况,作为SQLServer数据库中的一种特有触发器,当数据库发生安全事件的同时能够做出响应,在各种数据库安全事件发生之后快速地捕捉信息并分析安全攻击行为的发生间隔,判断攻击事件是否有效。(2)DML触发器具有跟踪审计信息的功能,针对数据库操作过程中的各种常见问题进行安全评估,包括操作失败事件、登录失败情况以及敏感用户对系统的访问等。当DML 检测到数据库遭受到攻击,则会退出攻击账户,保证数据库的安全。 3.3 数据库的安全防护机制在数据库的安全防护中,可利用虚拟化平台来实现数据库的安全管理,为能够达到有效的安全防护目的,可采用以下措施进行数据库安全管理。 3.3.1 数据库的安全备份数据备份的目的就是要为数据安全增添“第二把锁”,当前数据库的数据备份主要采用物理备份与逻辑备份相结合的方法,按照既定的时间要求对数据库中的数据进行存储。此时假设数据遭到攻击或者出现损害时,可以在原数据库的基础上调度备份数据,达到数据快速复原的目的。为实现该目的,可通过MySQL恢复工具、导出数据等方法并引入数据信息的变化,最终有助于实现二进制文件保存,避免备份数据的滥用。 3.3.2 数据库的防火墙设置防火墙是维护数据安全的关键,所以在设置防火墙期间,利用SQL数据库检测到的攻击痕迹将数据与数据库SQL语句运用到应用程序中,利用数据库防火墙的名单检测对任意一个针对数据库的操作行为进行检测,避免系统遭受注入攻击而造成数据损失。4 结束语在大数据背景下,数据库的安全保障管理更加复杂,为了能够更好地适应数据库管理要求,相关人员要充分发挥大数据技术优势,结合各种常见的数据库安全问题进行处置,这样才能有效降低数据库安全事件发生率,最终适应数据安全管理要求。来自:今日头条 -
7 月 8 日,由中国信息通信研究院(以下简称中国信通院)、中国通信标准化协会指导,中国通信标准化协会大数据技术标准推进委员会主办的“ 2022 可信数据库峰会”在京召开。SphereEx创始人兼CEO 张亮受邀参会,并于现场进行了《数据库增强引擎 ShardingSphere 实践》的主题演讲。会上,张亮重点强调了未来 ShardingSphere将在Database Plus 理念的指导下,针对不同的场景需求,为数据库全域带来最大限度的复用数据库原生存算能力,为广大用户提供基于数据库上层生态相关的全局扩展、叠加计算等方面的性能。在当前普遍追求技术可信的大背景下,围绕理念、性能与场景这三方面,张亮全面介绍了 ShardingSphere 在数据底座层面的可信能力。理念可信:ShardingSphere 的设计哲学 DatabasePlus Database Plus 是一种分布式数据库系统的设计理念,旨在碎片化的异构数据库上层构建生态,在最大限度的复用数据库原生存算能力的前提下,进一步提供面向全局的扩展和叠加计算能力。使应用和数据库间的交互面向 Database Plus 构建的标准,从而屏蔽数据库碎片化对上层业务带来的差异化影响。其中,『连接、增强、可插拔』是定义 Database Plus 核心价值的三个关键词。1.连接:打造数据库上层标准相对于提供一个全新的标准,Database Plus更倾向于提供一个可以适配于各种数据库 SQL方言和访问协议的中间层,用于便捷地连接碎片化的数据库。通过提供开放的接口用于对接各种数据库,因此在使用体验上与数据库并无二致,同时支持任意的开发语言和数据库访问客户端。此外,Database Plus 能够最大限度支持 SQL 方言间的相互转换,打通了连接异构数据库之间相互访问的通道。目前 ShardingSphere 已支持 MySQL、PostgreSQL、openGauss等数据库协议,以及 MySQL、PostgreSQL、openGauss、SQLServer、Oracle和所有支持SQL92标准的SQL方言。连接层抽象的顶层接口可供其他数据库开放对接,包括:数据库协议、SQL解析和数据库访问等。2.增强:数据库计算增强引擎分布式和云原生时代的到来,将数据库原有的计算和存储能力全部打散,并植入分布式和云原生级别的全新能力,会不可避免出现“重复造轮”。但 Database Plus既重视传统数据库的实践经验,又适配于新一代分布式数据库的设计理念。无论是集中式还是分布式的数据库,Database Plus都能复用数据库的存储和原生计算能力,并在其基础之上提供全局化的能力增强,主要体现在:分布式、数据控制、流量控制三个方面。Database Plus 将支持的数据库种类和增强功能相叠加,以排列组合的方式提供给用户使用。ShardingSphere将功能增强划层面划分为内核层和可选功能层。其中内核层包含查询优化器、分布式事务、执行引擎、权限引擎等与数据库内核强相关的功能,以及调度引擎、分布式治理等与分布式强相关的功能;可选功能层的功能模块由开源社区沉淀而形成,除最具代表性的数据分片和读写分离之外,高可用、弹性伸缩、数据加密、影子库等功能模块也都在逐步的完善之中。3.可插拔:构建数据库功能生态连接和增强的可插拔化,既是Database Plus通用层维持小而美的基石,也是扩展生态无限化的有效保障。通过可插拔体系,Database Plus 将能够真正构建面向数据库的功能生态,将异构数据库的全局能力统一纳管。它不仅面向集中式数据库的分布式化,也同时面向分布式数据库的竖井功能一体化。ShardingSphere 的可插拔架构更像是一个平台,并不会关注具体某一个功能或数据库,而是将所有的功能和连接都插件化,能够在 ShardingSphere生态中实现快速融合与脱离。目前,从最初的 MySQL+数据分片为核心的架构模型,到如今的微内核+可插拔架构,ShardingSphere已进行了彻底的改造。从提供连接的数据库种类和增强功能到内核能力,ShardingSphere已全部面向可插拔。ShardingSphere 的架构核心到外围,由微内核、可插拔接口、插件实现的三层模型组成,层次之间单项依赖,微内核对插件功能完全无需感知,插件之间也无需相互依赖。对于一个拥有200+模块的大型项目来说,架构的解耦和隔离,是社区开放协作,并且将错误影响范围降低至最小的有效保障。性能可信:使用ShardingSphere的核心优势 目前数据库市场碎片化程度日益加重,不同数据库在各领域细分场景下得以充分展现自身优势的同时,也为企业带来了较为复杂的选型问题。而ShardingSphere凭借强劲且可信度较高的性能,天然支持多数据库用户生态,能够为用户有效控制选型及迁移成本。一方面,ShardingSphere能够做到让企业级用户在不变更数据库底层配置的基础上,实现数据库上层的增量加强服务。另一方面,如果用户想要变更数据库底层环境及相关配置,使用ShardingSphere也可以实现无感知的“无缝迁移”。1.ShardingSphere 的极致性能根据上图,可以看到非常明显的差异。毫无疑问,ShardingSphere-JDBC 的性能最为突出。当然,ShardingSphere 作为一款为底层数据库提供增量服务的平台,与底层数据库对接后双方的『适配』情况也关系到在真实生产环境中的性能。而自身高度灵活的可扩展性以及强兼容性,使得 ShardingSphere 具备了面向多种底层数据库的强大兼容能力。此前在ShardingSphere与openGauss的合作中,双方使用16台服务器在超过1小时的测试中,得到了超过1000万tpmC的结果,在极大提升数据库性能极限的同时,ShardingSphere更是满足了 openGauss在海量数据场景下关于可用性以及运维成本等多方面的诉求。Apache ShardingSphere凭借本身强大的兼容性,向下支持多种数据存储引擎,使其可以存在于各类数据库之上,形成一套特有的数据库上层服务生态。而这种能力,恰好能够与国产老牌数据库之间产生明显的互补作用。Apache ShardingSphere愿意同国产数据库共同成长,充分利用现有国产数据库的计算与存储能力,通过插件化方式增强自身核心能力,共同构建健壮的国产数字化基础设施。2.ShardingSphere的易用性在使用层面,用户操作ShardingSphere和操作数据库是没有任何区别的。当然ShardingSphere提供了很多额外的能力,包括数据分片、数据加密、流量治理、读写分离等等。但这些能力在原生数据库上并不具备,因此用户无法通过操作标准SQL来实现这些能力。在考虑到这些后,ShardingSphere提供了DistSQL能力,凭借其『动态生效、无需重启』的特性,开发者和运维人员可以通过 DistSQL来操作管理ShardingSphere,不需要增加更多的学习成本,为ShardingSphere生态带来了强大的动态管理能力。通过DistSQL,用户可以实现在线创建逻辑库、动态配置规则、实时调整存储资源、即时切换事物类型、随时开关SQL日志、预览 SQL路由结果等能力,极大提升了产品的易用性。3.ShardingSphere 的可插拔内核架构上图为 ShardingSphere 微内核架构的组合,可以分成大致的三层。中心部分是微内核,设置了ShardingSphere核心流程,由计算下推引擎和联邦查询组成。计算下推引擎主要负责SQL改写。联邦查询帮助ShardingSphere提升了SQL兼容能力,实现了跨库关联查询及跨库子查询的能力。紫色部分是ShardingSphere所定义的可插拔接口,当开发者想提供新的基于ShardingSphere的能力时,无论是对接新的数据库还是开发多租户的功能,都可以通过可插拔接口直接将该功能植入到 ShardingSphere体系中。最外侧绿色部分是开发者基于ShardingSphere所实现的具体内容,包括根据自身业务场景和商业诉求进行适配后所实现的具体能力,这部分并不强迫进行开源。此外这部分的能力也能够以系统级别植入到公司自己的ShardingSphere内核层面,进而实现完全自主可控的数据库平台。场景可信:ShardingSphere适用场景 此外,针对不同的用户需求ShardingSphere能够在多元化的应用场景下实现完美适配。前面提到,ShardingSphere能够复用数据库的存储和原生计算能力,并在其基础之上提供全局化的能力增强,主要体现在分布式、数据控制、流量控制三个方面。1.分布式数据库为解决原有方案的技术瓶颈,降低更换架构带来的复杂性风险,在不更换原有架构前提下,ShardingSphere能够实现数据库同步、管理多个异构数据库集群、线性提升数据存储容量及并发吞吐。进而为用户提供基于数据分片,分布式事务、弹性伸缩的分布式数据库解决方案,使用户的数据库兼具单机交易型数据库稳定性和分布式数据库的扩展能力。2.面向数据控制用户可以通过ShardingSphere对数据本身实现控制,如数据加解密、SQL审计等。此外为防止数据泄露,用户可以使用 ShardingSphere 在基于产品的数据加密和数据脱敏功能之上升级为数据安全解决方案,进而能够在不改动原有代码的前提下,为企业提供跨平台、异构环境的数据安全解决方案。3.面向流量控制基于本身内核的SQL解析能力以及可插拔平台架构,ShardingSphere能够实现压测数据与生产数据的隔离,帮助应用自动路由,同时支持全链路压测,进而帮助用户实现在生产环境下获得较为准确地反应系统真实容量水平和性能的测试结果。作为数据库相关领域的强劲引擎,ShardingSphere 将以其极致性能处理、高易用、可插拔内核架构的核心特点,切实帮助各企业级用户解决其业务场景中的痛点问题,从而充分释放数据潜能,加速自身业务增长。来源:大数据技术标准推进委员会
-
 2022年上半年,Gauss松鼠会联合合作伙伴(openGauss社区、CCF数据库专委会、鲲鹏论坛、墨天轮等)、技术专家、热心会员,通过大咖讲堂、论文分享、高校课堂、技术群英会、活动竞赛、技术宣传等栏目的运作,共开展直播19期,技术群答疑1200+,openGauss训练营、知识问答等各项活动参与人次2500+,CSDN、知乎、B站、鲲鹏论坛、墨天轮等各平台松鼠会相关专栏阅读/播放量110W+。 目前,Gauss松鼠会关注者已超过3.2万人,由Gauss松鼠会主办或合办的各项活动中,关注者们积极参与、贡献、宣传推广,为Gauss松鼠会技术圈的建设及openGauss、GaussDB生态的发展注入了源源不断的活力,促进了Gauss数据库的推广和发展。在墨天轮国产数据库流行度排名中,openGauss最高排名第1,GaussDB排名第4。 为感谢广大Gauss数据库关注者的积极奉献、推广,Gauss松鼠会将启动2022半年度优秀会员评选。现发出诚挚邀请,欢迎在本帖下方留言“参评人姓名+推选理由” 提名推荐或自荐。 活动参与奖说明在本贴下方进行推荐/自荐留言的小伙伴们,均有机会中奖(一等奖定制保温杯,二等奖为定制鼠标垫或晴雨伞一件)。获奖规则为:一等奖:每个统计周期第一位有效留言的楼层(按照活动要求回复“参评人姓名+推选理由”的)。二等奖:获奖楼层=单周期总楼层*中奖百分比,如出现小数点,则按四舍五入的规则计算。注:1、周期计算(提名推荐/自荐 2022.8.5——2022.8.14):第一周期:活动起始——8月8日20时第二周期:8月8日20时——8月11日20时第三周期:8月11日20时——8月14日24时以每三天为一个周期,直至推荐/自荐流程的截止日期的晚12点。每个周期结束后统计对应的总楼层。2、中奖百分比:第一周期取第5%、25%、45%、65%、85%楼层的10名用户;第二周期取第10%、30%、50%、70%、90%楼层的5名用户;第三周期取第20%、40%、60%、80%、100%楼层的5名用户。例如:第二周期总楼层为20,第2、6、10、14、18楼获奖。获奖楼层必须为有效楼层(按照活动要求回复“参评人姓名+推选理由”的);无效楼层不参与中奖,作顺延处理,如下一楼层仍不符合中奖条件,则视为该楼层无人获奖;同一周期内同一用户只能获奖一次,重复的获奖楼层资格将顺延至下一楼层。3、奖品数量有限,先到先得哦。4、其他事宜请参考【鲲鹏论坛活动规则】。 FAQ Q1:评选活动实时更新信息查看? A1:鲲鹏论坛/CSDN/墨天轮/知乎的“Gauss松鼠会”、“Gauss松鼠会”微信公众号均会及时更新,敬请关注~ Q2:评选过程中咨询方式?A2:扫描“Gauss松鼠会优秀会员评选交流群”二维码,加入群聊,进行咨询。注:如果微信群无法扫码加入,请务必添加Gauss松鼠会小助手微信(ID:Gauss_Asst),发送暗号“Gauss松鼠会优秀会员评选”,小助手将拉您进群。 一路走来,感谢大家对Gauss松鼠会的支持。希望越来越多的数据库人员和专家加入Gauss松鼠会技术交流圈,一起学习、探索、成长,为国产数据库的发展贡献力量。
2022年上半年,Gauss松鼠会联合合作伙伴(openGauss社区、CCF数据库专委会、鲲鹏论坛、墨天轮等)、技术专家、热心会员,通过大咖讲堂、论文分享、高校课堂、技术群英会、活动竞赛、技术宣传等栏目的运作,共开展直播19期,技术群答疑1200+,openGauss训练营、知识问答等各项活动参与人次2500+,CSDN、知乎、B站、鲲鹏论坛、墨天轮等各平台松鼠会相关专栏阅读/播放量110W+。 目前,Gauss松鼠会关注者已超过3.2万人,由Gauss松鼠会主办或合办的各项活动中,关注者们积极参与、贡献、宣传推广,为Gauss松鼠会技术圈的建设及openGauss、GaussDB生态的发展注入了源源不断的活力,促进了Gauss数据库的推广和发展。在墨天轮国产数据库流行度排名中,openGauss最高排名第1,GaussDB排名第4。 为感谢广大Gauss数据库关注者的积极奉献、推广,Gauss松鼠会将启动2022半年度优秀会员评选。现发出诚挚邀请,欢迎在本帖下方留言“参评人姓名+推选理由” 提名推荐或自荐。 活动参与奖说明在本贴下方进行推荐/自荐留言的小伙伴们,均有机会中奖(一等奖定制保温杯,二等奖为定制鼠标垫或晴雨伞一件)。获奖规则为:一等奖:每个统计周期第一位有效留言的楼层(按照活动要求回复“参评人姓名+推选理由”的)。二等奖:获奖楼层=单周期总楼层*中奖百分比,如出现小数点,则按四舍五入的规则计算。注:1、周期计算(提名推荐/自荐 2022.8.5——2022.8.14):第一周期:活动起始——8月8日20时第二周期:8月8日20时——8月11日20时第三周期:8月11日20时——8月14日24时以每三天为一个周期,直至推荐/自荐流程的截止日期的晚12点。每个周期结束后统计对应的总楼层。2、中奖百分比:第一周期取第5%、25%、45%、65%、85%楼层的10名用户;第二周期取第10%、30%、50%、70%、90%楼层的5名用户;第三周期取第20%、40%、60%、80%、100%楼层的5名用户。例如:第二周期总楼层为20,第2、6、10、14、18楼获奖。获奖楼层必须为有效楼层(按照活动要求回复“参评人姓名+推选理由”的);无效楼层不参与中奖,作顺延处理,如下一楼层仍不符合中奖条件,则视为该楼层无人获奖;同一周期内同一用户只能获奖一次,重复的获奖楼层资格将顺延至下一楼层。3、奖品数量有限,先到先得哦。4、其他事宜请参考【鲲鹏论坛活动规则】。 FAQ Q1:评选活动实时更新信息查看? A1:鲲鹏论坛/CSDN/墨天轮/知乎的“Gauss松鼠会”、“Gauss松鼠会”微信公众号均会及时更新,敬请关注~ Q2:评选过程中咨询方式?A2:扫描“Gauss松鼠会优秀会员评选交流群”二维码,加入群聊,进行咨询。注:如果微信群无法扫码加入,请务必添加Gauss松鼠会小助手微信(ID:Gauss_Asst),发送暗号“Gauss松鼠会优秀会员评选”,小助手将拉您进群。 一路走来,感谢大家对Gauss松鼠会的支持。希望越来越多的数据库人员和专家加入Gauss松鼠会技术交流圈,一起学习、探索、成长,为国产数据库的发展贡献力量。 -
 >摘要:GaussDB(DWS)使用DMS来承载数据库的智能运维体系,提供了数据库运维过程中的监控,分析,处理三大核心处理过程。 本文分享自华为云社区《[GaussDB(DWS) 数据库智能监控运维服务-性能监控指标](https://bbs.huaweicloud.com/blogs/367270?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者:power_gouge 。 GaussDB(DWS)使用DMS来承载数据库的智能运维体系,提供了数据库运维过程中的监控,分析,处理三大核心处理过程。 # 节点监控指标 在GaussDB(DWS) 产品中完成集群创建后,即可在集群管理页面看到创建的集群信息,选择集群操作选项中的监控面板功能,即可进入 DMS服务中。  DMS提供了多项关于数据库相关的监控与工具功能,本文中我们主要关注监控功能中对于节点监控指标。 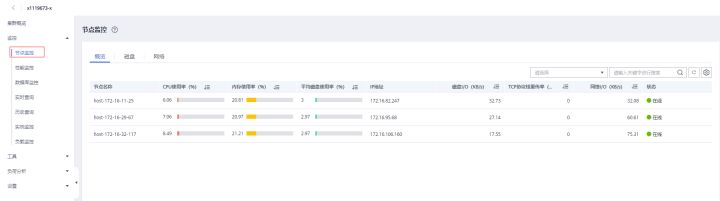 对于数据库集群中节点监控主要在于CPU 内存 磁盘 网络四个方面,从当前这个概览界面可以看主机当前的一些状态指标 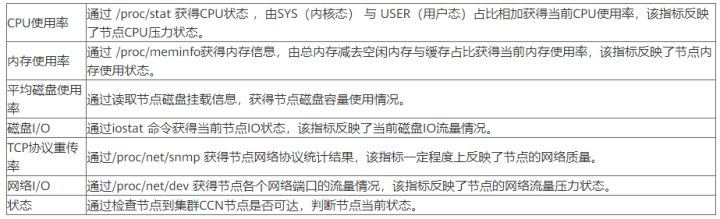 将鼠标移动至某个指标,还可以查看更详细的一些监控值例如CPU,可以查看用户态 系统态 IDLE IO等待消耗的CPU占比。 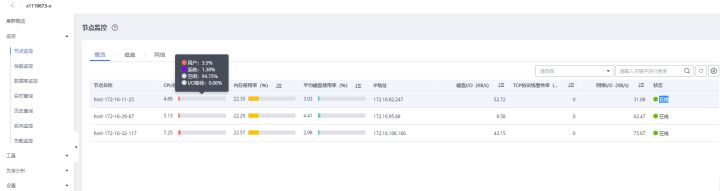 节点监控页面上还可以针对磁盘和网络活动更加详细的信息,例如磁盘功能将对每个节点各个磁盘的IO状态指标进行采集与展示。 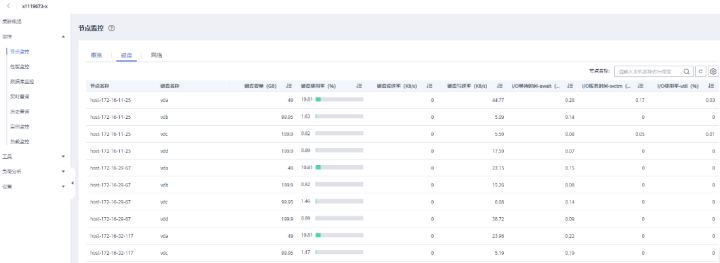 DMS服务从CPU 内存 磁盘 网络四个方面对数据库节点展开监控,那么这些监控指标如何体现了数据库当前的状态,从这些指标又怎么发现数据库当前可能存在的问题 CPU指标:CPU使用率反映了集群当前运行业务情况,业务数量越多计算量越多,节点的CPU使用率越高,当在集群业务高峰期观察时将可以看到CPU使用率是处在高位。对于CPU指标举例两类场景问题:  内存指标:内存使用率反映当前集群运行时消耗内存情况,业务涉及的数据量越多,节点的内存消耗越多。举例内存指标相关问题:  磁盘指标:磁盘指标反映了当前集群运行时集群数据对于磁盘占用情况, 举例磁盘指标相关问题:  网络指标:网络指标反映了当前集群运行时各个节点网络流量状态,举例网络问题:  # 性能监控指标 在GaussDB(DWS) 产品中完成集群创建后,即可在集群管理页面看到创建的集群信息,选择集群操作选项中的监控面板功能,即可进入 DMS服务中。MS提供了多项关于数据库相关的监控与工具功能,接下来我们主要关注监控功能中对于集群整体的性能监控。  在性能监控页面上,我们首先关注功能区域:   当前的版本中支持哪些监控指标呢? 可以参考下表 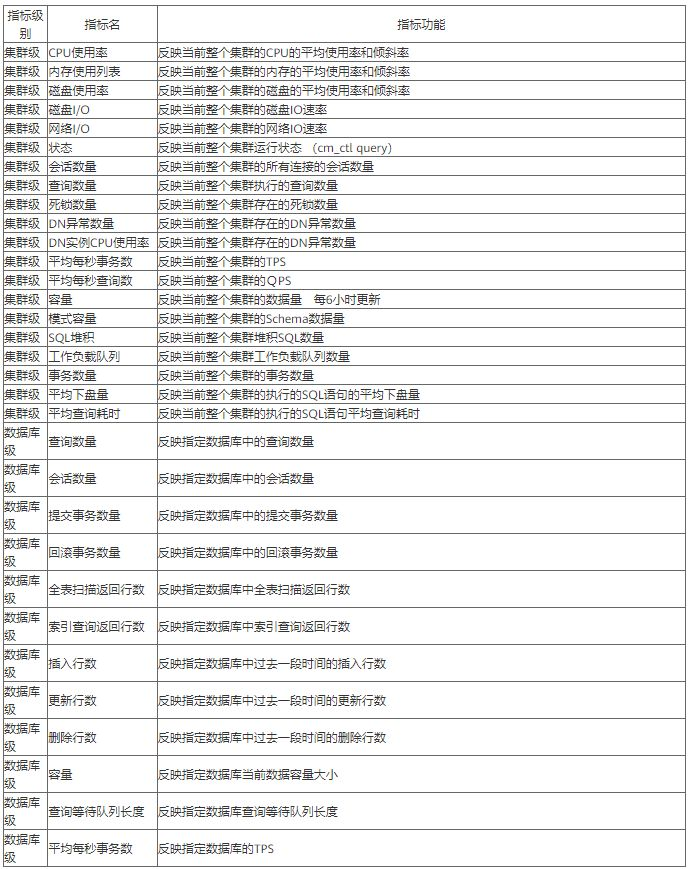
>摘要:GaussDB(DWS)使用DMS来承载数据库的智能运维体系,提供了数据库运维过程中的监控,分析,处理三大核心处理过程。 本文分享自华为云社区《[GaussDB(DWS) 数据库智能监控运维服务-性能监控指标](https://bbs.huaweicloud.com/blogs/367270?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者:power_gouge 。 GaussDB(DWS)使用DMS来承载数据库的智能运维体系,提供了数据库运维过程中的监控,分析,处理三大核心处理过程。 # 节点监控指标 在GaussDB(DWS) 产品中完成集群创建后,即可在集群管理页面看到创建的集群信息,选择集群操作选项中的监控面板功能,即可进入 DMS服务中。  DMS提供了多项关于数据库相关的监控与工具功能,本文中我们主要关注监控功能中对于节点监控指标。  对于数据库集群中节点监控主要在于CPU 内存 磁盘 网络四个方面,从当前这个概览界面可以看主机当前的一些状态指标  将鼠标移动至某个指标,还可以查看更详细的一些监控值例如CPU,可以查看用户态 系统态 IDLE IO等待消耗的CPU占比。  节点监控页面上还可以针对磁盘和网络活动更加详细的信息,例如磁盘功能将对每个节点各个磁盘的IO状态指标进行采集与展示。  DMS服务从CPU 内存 磁盘 网络四个方面对数据库节点展开监控,那么这些监控指标如何体现了数据库当前的状态,从这些指标又怎么发现数据库当前可能存在的问题 CPU指标:CPU使用率反映了集群当前运行业务情况,业务数量越多计算量越多,节点的CPU使用率越高,当在集群业务高峰期观察时将可以看到CPU使用率是处在高位。对于CPU指标举例两类场景问题:  内存指标:内存使用率反映当前集群运行时消耗内存情况,业务涉及的数据量越多,节点的内存消耗越多。举例内存指标相关问题:  磁盘指标:磁盘指标反映了当前集群运行时集群数据对于磁盘占用情况, 举例磁盘指标相关问题:  网络指标:网络指标反映了当前集群运行时各个节点网络流量状态,举例网络问题:  # 性能监控指标 在GaussDB(DWS) 产品中完成集群创建后,即可在集群管理页面看到创建的集群信息,选择集群操作选项中的监控面板功能,即可进入 DMS服务中。MS提供了多项关于数据库相关的监控与工具功能,接下来我们主要关注监控功能中对于集群整体的性能监控。  在性能监控页面上,我们首先关注功能区域:   当前的版本中支持哪些监控指标呢? 可以参考下表  -
图数据库像新一代的关系型数据库,取代传统关系型数据库在诸多领域大展拳脚、高歌猛进。图数据库较传统关系型数据库有何优势?适用于哪些技术领域?未来是何态势,有何机遇?《新程序员002》特邀Neo4j亚太地区售前和技术总监俞方桦为大家解读图数据库。随着大数据时代的到来,传统的关系型数据库由于其在数据建模和存储方面的限制,变得越来越难以满足大量频繁变化的需求。关系型数据库,尽管其名称中有“关系”这个词,却并不擅长处理复杂关系的查询和分析。另外,关系型数据库也缺乏在多服务器之上进行水平扩展的能力。基于此,一类非关系型数据库,统称“NoSQL”存储应运而生,并且很快得到广泛研究和应用。NoSQL(Not Only SQL,非关系型数据库)是一类范围广泛、类型多样的数据持久化解决方案。它们不遵循关系型数据库模型,也不使用SQL作为查询语言。其数据存储不需要固定的表格模式,也经常会避免使用SQL的JOIN操作,一般都有水平可扩展的特征。简言之,NoSQL数据库可以按照它们的数据存储模型分4类:键值存储库(Key-Value-stores)列存储 (Column-based-stores) 文档库(Document-stores)图数据库(Graph Database)从DB-Engines发布的数据库技术类别变化趋势图(见图1)中,不难看出图数据库在近十年受到广泛关注、是发展趋势最迅猛的数据库类型。那么,到底什么是“图数据库”?相比关系型数据库,图数据库又有哪些优势呢?1、图数据库与关系型数据库的比较图数据库(Graph Database)是指以图表示、存储和查询数据的一类数据库。这里的“图”,与图片、图形、图表等没有关系,而是基于数学领域的“图论”概念,通常用来描述某些事物之间的某种特定关系。比如在我们的日常生活中:社交网络是图。每个社交网络的参与者是节点,我们在社交网络中的交互,例如“加好友”“点赞”就是连接节点的边。城市交通是图。每个路口、门牌号、公交站点等都是节点,街道或者公交线路是边,将可以到达的地方连接起来。知识也是图。每个名称、概念、人物、事件等都是节点,而类属关系、分类关系、因果关系等是边,将节点连接起来,形成庞大、丰富并且随时在演变的知识图谱。可以说,“图无处不在”(Graphs are everywhere),也正因如此,传统关系型数据库不擅长处理关系的问题,能够被图数据库很好地解决,图数据库正是为解决这一问题而生。其实,在某些方面,图数据库就像新一代的关系数据库,区别在于图数据库不仅存储实体,还存储实体之间的关系。关系型数据库通过“主键-外键”表示隐含的“关系”连接,但实际上这里的“关系”是关系代数中的概念,与我们现实世界中的“关系”不同。通过将关系预先物理存储在数据库中(我们称之为“原生”),图数据库将查询性能由原先的数分钟提高到数毫秒,特别是对于JOIN频繁查询,这种优势更加明显。图2中比较了在社交网络数据集上搜索朋友圈的查询,在原生的图数据库和关系数据库的查询执行效率。显然,使用图数据库比使用传统关系数据库效率有极大提升。作为NoSQL数据库的一种,图数据库通常不需要先定义严格的数据模式,以及强制的字段类型,这使其在处理结构化和半结构化的数据时同样得心应手。除了存储和查询效率方面的优势,图数据库也拥有更加丰富的分析能力,我们通过比较这四类主要的非关系型数据库特点(见表1),就可以得知。2、图数据库的主要技术领域既然图数据库有诸多优势且发展迅速,那它主要涉及哪些技术领域呢?我们用图3来描述。具体来讲,图数据库的主要技术领域包括存储模式、图模型、图查询语言、图分析以及图可视化。存储模式原生图vs非原生图图数据库以节点和边来对现实世界进行数据建模。对于实际的底层物理存储技术,目前主流有两大类方法:原生(Native),即按照节点、边和属性组织数据存储。典型代表有Neo4j、JanusGraph、TigerGraph等。非原生,使用其他存储类型。例如基于列式存储的DataStax、基于键值对的OrientDB以及基于文档的MongoDB。部分关系型数据库也在关系存储之上提供类似图的操作。有的图计算平台底层支持各类存储技术,包括图存储,称作“多模式”,例如百度HugeGraph。原生的图存储由于针对图数据和图操作的特点进行了优化,并且从物理存储到内存中的图处理,都采用一致的模型而无需进行“模式转换”,在大数据量、深度复杂查询以及高并发情况下,性能普遍优于非原生的图存储。图的分布式存储为了支持大规模的图存储和查询,需要对图进行分布式存储。这里有两类分布式的实现方法:1、分片(Sharding)。分片就是根据某一原则(例如根据节点的ID随机分布)将数据分布存储在多个存储实例中。根据切分规则,又可以分为:按点切分。每条边只保存一次,并且出现在同一个分区上。如果处于不同分区的两条边有共同的点,那么点会在各自的分区中复制。这样,邻居多的点(繁忙节点)会被分发到多个分区上,增加了存储空间,并且有可能产生同步问题。这种方法的好处是减少了网络通信。按边切分。通过边切分之后,顶点只保存一次,切断的边会打断保存在不同分区上。在基于边的操作时,对于两个顶点分到两个不同分区的边来说,需要通过网络传输数据。这增加了网络传输的数据量,但好处是节约了存储空间。出于优化性能的考虑,目前按点切分的分布式图更加常见。2、分库(Partitioning)。由于现实世界中的图往往遵循“幂律分布”,即少数节点拥有大量的边,而多数节点拥有很少的边。分片存储不可避免地会造成大量数据冗余复制,或增加分区间网络通信的负担。因此,另外一种分布式的方法是分库。这是借助图建模的方法,将节点按照业务需求、根据查询类型分布在不同库中,是最小化跨库的网络传输。不同库中的数据则通过联邦式查询(Federated Query)实现。图模型在基于图的数据模型中,最常见的两种方法是资源描述框架(Resource Description Framework,RDF)和标签属性图(Labelled Property Graph,LPG)。RDFRDF是W3C组织指定的标准,它使用Web标识符(URI)来标识事物,并通过属性和属性值来描述资源。根据RDF的定义:资源是可拥有URI的任何事物,比如 "http://www.w3school.com.cn/rdf";属性是拥有名称的资源,比如"author"或"homepage";属性值是某个属性的值,比如"David"或"http://www.w3school.com.cn"(请注意一个属性值可以是另外一个资源)。我们来看看RDF是怎样描述 “西湖是位于杭州的一个旅游景点”这个事实的(见图4)。RDF图的查询语言是SPARQL。如果要询问“位于杭州的旅游节点有哪些?”,使用SPARQL的查询如下:PREFIX ns: <http://kg.com/ns/travel#> SELECT ?place WHERE { ?place ns:地理位置 ns:杭州 . ?place ns:实例 ns:旅游景点 . }LPG在LPG属性图模型中,数据对象被表示成节点(拥有一个或多个标签)、关系和属性。我们用下面的例子来说明(见图5)。在图5中:节点/顶点是事物(Object)或者实体(Entity)的抽象,可以是“人”“导演”“电影”“演员”等抽象。节点可以拥有一个或多个标签,例如代表“张艺谋”的节点可以有“个人”“导演”“演员”等标签。节点的属性。节点的属性为节点提供丰富的语义,根据顶点代表的类型不同,每个顶点可以有不同的属性,比如以“人”作为顶点,属性可以是“姓名”“性别”等。边/关系。边连接两个节点或同一个节点(指向自己的边),边可以有向或无向。边可以有类型,比如连接“李连杰”和“英雄”的边的类型是“主演”。边的属性。和顶点的属性类似,每条边上也可以有属性。比如连接“李连杰”和“英雄”的边有属性“角色”,其值是“无名”。相比RDF,LPG由于可以在节点和边上定义丰富的属性,更加易于我们理解,建模也更加灵活。图查询语言应该说,关系型数据库在过去半个世纪的成功离不开SQL查询语言标准化。目前,图查询语言的标准化(GQL)工作还在进行当中,其核心语法和特性基于Neo4j的Cypher、Oracle的PGQL和GCORE框架。从查询语言本身来说,主要有两类:声明型(Declarative)。声明型查询语言只要求使用者描述要实现的目标,由查询引擎分析查询语句、生成查询计划然后执行。SQL是声明型查询语言。在图数据库领域,Cypher是最流行的声明型查询语言。命令型(Imperative)。命令型查询语言要求使用者描述具体执行的操作步骤,然后由数据库执行。在图数据库领域,Gremlin是最流行的(近似)命令型的查询语言。从未来的发展趋势来看,声明型查询语言由于其易于理解、学习门槛低、便于推广等特性,将成为主流的图查询语言。智能、优化的查询执行引擎将成为衡量图数据库技术优势的关键。图分析在计算机科学领域,图算法是一个重要的算法类别,经常用于解决复杂的问题。大家应该还能记得在《数据结构》或者软件开发相关课程中都会学到的“树的遍历”(前序、中序、后序等),这就是典型的图算法。部分成熟的图数据库内置了这些图算法,以提供对图数据的高级分析功能。最短路径搜索最短路径是图计算中一类最常见的问题,通常见于解决下面的应用场景:在两个地理位置之间寻找导航路径;在社交网络分析中,计算人们之间相隔的距离,“最短”则基于路径上边的距离和成本,例如:最少跳转次数;Dijkstra算法:边带权重的最短路径;A*算法:基于启发式规则的最短路径;k条最短路径。计算范围则包括:节点对之间;单一起点到图中其他所有节点;全图中所有节点对之间。除此之外,最小生成树、随机游走等图遍历算法也属于这一类。社团检测“物以类聚,人以群分”,这句话非常形象地描述了网络的一个重要特征:聚集成群。群也称作“社区”“团体”“群组”。社区的形成和演变是图分析和研究的又一个重要领域,因为它帮助我们理解和评估群体行为、研究新兴现象。社区检测算法就是在图中对节点进行分组和集合(见图6):在同一集合中的节点之间的边(代表交互/连接)比分属不同集合的节点之间更多。从这一意义上,我们认为它们有更多共同点。社区检测可以揭示节点集群、隔离的群组和网络结构。在社交网络分析中,这种信息有助于推断拥有共同兴趣的人群。在产品推荐中,可以用来发现相似产品。在自然语言处理/理解中(NLP/NLU),可以用来对文本内容自动分类。社区检测算法还用于生成网络的可视化展现。有助于推断拥有共同兴趣的人群。在产品推荐中,可以用来发现相似产品。在自然语言处理/理解中(NLP/NLU),可以用来对文本内容自动分类。社区检测算法还用于生成网络的可视化展现。中心性算法在图论和网络分析中,中心性指标识别图中最重要的顶点。其应用广泛,包括识别社交网络中最有影响力的人、互联网或城市网络中的关键基础设施节点,以及疾病的超级传播者。最成功的中心度算法当属“页面排行”(PageRank)。这是谷歌搜索引擎背后的网页排序算法的核心。页面排行除了计算页面本身的连接,同时评估链接到它的其他页面的影响力。页面的重要性越高,信息来源的可靠度也越高。应用到社交网络中,这一方法可以简单地解释成“认识我的人越重要,我也越重要”。是不是挺有道理?相似度算法相似度描述两个节点以及更加复杂的子图结构是否在何等程度上属于同一类别,或者有多相似。图/网络相似性度量有三种基本方法:结构等价(Structural Equivalence);自同构等价(Automorphic Equivalence); 正则等价(Regular Equivalence)。还有一类是先将节点转换成N维向量(x 1,x 2,…x n)并“投射”到一个N维空间中,然后计算节点之间的夹角或者距离来衡量相似度。这个转换的方法叫作“嵌入”(Embedding),转换的过程叫作“图的表示”,如果是由算法自动得到最佳的转换结果,那么该过程叫作“图的表示学习”。基于图的学习是近年来在人工智能领域非常热门的一个方向,被广泛应用到欺诈检测、智能推荐、自然语言处理等多个领域。图可视化“一图胜万言”这句话是对图可视化最恰当的描述。图可视化直观、智能地展现数据之间的结构和关联,能看到从前在表格或者图表中看不到的内容。2019年,当新冠病毒开始在全球肆虐时,来自Neo4j图数据库社区的一群成员集成了多个异构生物医学和环境数据集(https://github.com/covid-19-net/covid-19-community),建立了关于新冠病毒的知识图谱,以帮助研究人员分析宿主、病原体、环境和病毒之间的相互作用。图7是该知识图谱的部分可视化结果,图中最左边的部分是病毒暴发的地理位置子图,包含国家、地区、城市;中间绿色的部分是流行病学子图,包括有关病毒株、病原体和宿主生物的信息,病例和菌株分别与报告和发现它们的位置相关联;右边紫色的部分是生物学子图,代表生物体、基因组、染色体、变异体等等。图数据的可视化建立了关于事物之间关联的最直观的展现,并且使得原本并不明显、甚至于淹没在数据汪洋中的重要特征得以显现出来,成为新的认知。3、图数据库的未来展望在图数据库出现并兴起的十余年间,它在各个领域都得到了成功的应用,并且产生了众多创新性的解决方案。在社交平台的“网络水军”识别方面,通过分析用户的关系图特征、结合传统的基于用户行为和用户内容的发现方法,可以有效提高预测的准确性和鲁棒性。在金融领域,图和图分析帮助机构更高效地发现异常的关联交易,以赢得反洗钱战争。在电力、电信行业,图数据库帮助管理复杂庞大的设备和线路网络,并及时为故障分析根源、估算影响。在制造、科研、医药等领域,图数据库广泛用于存储和查询知识图谱,成为大数据管理、数据分析和价值挖掘乃至人工智能技术领域的重要支撑。在可预见的未来内,图数据库与人工智能技术的结合应用将会带来更多创新和飞跃。图数据库至少能在以下四个领域帮助提升AI能力。第一,知识图谱,它为决策支持提供领域相关知识/上下文,并且帮助确保答适合于该特定情况。第二,图提供更高的处理效率,因此借助图来优化模型并加速学习过程,可以有效地增强机器学习的效率。第三,基于数据关系的特征提取分析可以识别数据中最具预测性的元素。基于数据中发现的强特征所建立的预测模型拥有更高的准确性。第四,图提供了一种保证AI决策透明度的方法,这使得通过AI得到的结论更加具有可解释性。AI和机器学习具有很大的应用潜力,而图解锁了这种潜力。这是因为图数据库技术支持领域相关知识和关联数据,使AI变得更广泛适用。除此以外,近年来,云端部署的图数据库(SaaS/DaaS)成为了又一个发展趋势。国内的众多大厂纷纷推出自研的云端图数据库产品,例如百度的HugeGraph、阿里的GDB、腾讯的TGDB、华为的GES图计算引擎。就总体趋势而言,我们能够预见,大数据时代,数据缺失不再是最大的挑战,我们渴求的是挖掘数据价值的能力,而数据的价值很大一部分在于数据之间的关联。图数据库和图分析作为处理关联数据最有效的技术和方法,一定会继续大放异彩,书写数据库应用的新篇章。来源:CSDN
-
Oracle 较上月减少了 19.50 分,是本月分数下降最多的数据库,并且连续两个月出现了下滑。分数上涨较多的则是 MySQL 和 MongoDB,两者分别增加了 7.98 和 4.68 分。DB-Engines 数据库流行度排行榜发布了 8 月份的更新。可以看到,Oracle 较上月减少了 19.50 分,是本月分数下降最多的数据库,并且连续两个月出现了下滑。分数上涨较多的则是 MySQL 和 MongoDB,两者分别增加了 7.98 和 4.68 分。不过和去年同期相比,三巨头(Oracle、MySQL 和 SQL Server)和 MongoDB 的分数均下降了不少。与之形成对比的 PostgreSQL 则保持着稳定的上升趋势,其每月流行度分数跟去年同期相比都有不少的上涨。下表是 TOP 10 数据库的最新分数和变化情况。继续看看主流数据库的分数趋势变化:最后看看各类型数据库的排名情况。关系数据库前 10 名Key-Value 数据库前 10 名文档数据库前 10 名时序数据库前 10 名图数据库前 10 名DB-Engines 根据流行度对数据库管理系统进行排名,排名每月更新一次。排名的数据依据 5 个不同的指标:Google 以及 Bing 搜索引擎的关键字搜索数量Google Trends 的搜索数量Indeed 网站中的职位搜索量LinkedIn 中提到关键字的个人资料数Stackoverflow 上相关的问题和关注者数量这份榜单分析旨在为数据库相关从业人员提供一个技术方向的参考,其中涉及到的排名情况并非基于产品的技术先进程度或市场占有率等因素。无论排名先后,选择适合与企业业务需求相比配的技术才是最重要的。来源:OSCHINA
-
Oracle数据库经过40多年的发展,已经发展了丰富多样和成熟的能力。Oracle也没有故步自封,一直在根据行业的发展趋势和基于用户的业务需求来探索和发展新的能力,如融合化,自治化等。Oracle数据库的核心能力就体现在接下来要介绍的解决方案当中,而这些方案也是支持前述用户关系的数字化转型,数据底座等方案的重要基础。这些方案涉及到数据的方方面面,包括数据管理,数据分析,数据安全,数据保护,数据集成等。熟悉Oracle的朋友,一定对MAA不会陌生。MAA表示Oracle 最高可用性体系结构,是建设用户业务连续性的蓝图和最佳实践。MAA可以最大程度提高系统可用性,并在系统可用性、服务质量和数据保护方面达到最严苛的服务级别协议 (SLA) 要求。MAA涉及的领域非常广泛,但最核心的3个方面包括备份,高可用(HA)和灾难恢复(DR)。备份是业务连续性保护的起点和底线,业务也许可以停,但数据一定不能丢。Oracle 零数据丢失恢复一体机(简称为ZDLRA或RA)是一款集成式数据保护解决方案,有助于消除整个企业中所有 Oracle 数据库的数据丢失风险。利用实时Redo传输技术,所有数据更改都会立刻记录到恢复一体机中,一旦发生故障或勒索软件攻击时,数据库可以恢复到故障发生时刻的前一秒内。恢复一体机提供基于验证的自动化的永远增备方法,这消除了对耗时的全量备份的需求,并可将数据库服务器和管理资源释放出来用于生产负载。此外,恢复自动化、备份不可更改和高可用性架构可帮助企业满足政府对于保护和快速恢复关键数据的要求。备份的下一阶段是高可用。数据库高可用在硬件层面通过冗余部件实现,在软件层面则是通过RAC,即真正应用集群。Oracle RAC允许客户在多个服务器上运行单个 Oracle 数据库,以最大限度地提高可用性并在访问共享存储时实现水平可扩展性。连接到 Oracle RAC 实例的用户会话可以在中断期间进行故障转移并安全地重放更改,而无需对最终用户应用程序进行任何更改,从而隐藏了中断的影响并提升了用户体验。为防止整个站点失效,还可以进一步实施灾难恢复或灾备方案。Oracle数据库标准的灾备组件为ADG,即活动数据卫士。ADG支持丰富的Redo传输模式(同步,异步,Far Sync),数据保护模式(最大性能,最大可用和最大保护),备库模式(物理备库,快照备库和逻辑备库)和拓扑结构(一对一,一对多,级联),可实现深度的Oracle数据库保护。同时,ADG管理运维简单,可实现一键式数据库切换和回切。由于备库可读,因此可以将查询,分析,备份等负载在备库运行,减轻生产端数据库的负担,提升灾备的投资回报率。Oracle GoldenGate(OGG)本质上属于数据集成产品,当与其他 Oracle MAA 技术结合使用时,OGG 消除了日常数据库维护和升级、操作系统补丁、应用程序升级和平台迁移期间的停机时间。所有操作都受到故障恢复功能的保护,消除了丢失数据的风险。OGG 可以部署在双活或多活配置中,以实现数据库可扩展性或分布式同步。OGG的多活特性和ADG配合,可以构成Oracle数据库最高级别的业务连续性保障方案。如果说软件是思想,硬件则是身体,两者不可偏废。Exadata作为承载Oracle数据库的首选平台,本身也结合了MAA最佳实践,并且提供私有云,专有云和公有云多种部署方式。在经历了存储整合、服务器整合、桌面整合后,企业逐渐将重点转向数据层面的整合。Oracle相应推出了数据库整合解决方案,即DBaaS(数据库即服务)。组织之所以被 DBaaS 所吸引,是因为它可以简化 IT 基础架构,从而可以方便地从同一个硬件和软件基础架构为许多用户和多个部门提供数据库功能,同时还能使手工供应流程实现自动化。在传统环境中供应新数据库可能需要数天甚至数周时间。而 DBaaS 可以使这个时间缩短为寥寥数分钟。更简单的 IT 基础架构可确保更大的业务敏捷性和更低的风险及成本。DBaaS 最吸引人的另一个方面是,整合能带来更小的硬件空间占用,这会降低成本。此外,许多用户和部门在为自己的数据库服务付费的同时共享基础架构,这会降低这些服务的单价。Oracle DBaaS解决方案的三个技术核心组件为数据库软件层面的多租户选件(Multitenant),数据库硬件层面的Exadata,以及数据库运维管理层面的Oracle企业管理器(Enterprise Manager)。Oracle Multitenant 可将 Oracle 数据库“转变”为容器数据库 (CDB),一个 CDB 可整合多个可插拔数据库 (PDB),从而提高资源利用率、优化管理和增强整体安全性。Multitenant的多合一管理可以简化运维,PDB的克隆,快照和增量可刷新功能可快速提供生产数据库最新副本,支持多样化的开发和测试需求。Oracle 企业管理器是Oracle数据库首选运维管理解决方案,专为监控和管理本地部署和云环境中的Oracle 数据库和集成系统而设计。Oracle 企业管理器针对数据库的主要功能包括:- 数据库性能管理,帮助 DBA 快速发现和修复性能问题。- 数据库运营自动化,包括大规模自动化运营、自动化供应和克隆、配置管理、安全性和合规性实施等。- 针对Oracle数据库和Exadata的企业级监控和一体化管理。Oracle Exadata是理想的数据库整合平台。由于 Exadata 数据库云平台可提供超强性能、大存储容量和独有的压缩功能,因此,原本需要超大型传统硬件系统的负载现在可以在小得多的 Exadata 系统上运行。在选型方面,与传统系统相比,Exadata 系统规模通常要小 2-4 倍。数据库整合除了以上三大技术支柱外,ZDLRA可实现数据库备份的整合,Oracle的融合数据库特性可实现非结构化数据,JSON,Spatial和Graph等多数据类型的整合。Database In-Memory数据库选件可实现极限分析工作负载的整合。总之,对于数据库整合场景,无论是多租户,多工作负载,还是多数据类型,Oracle都可以提供全面的支持。没有仪表盘的汽车很难驾驶,同样,没有Oracle Enterprise Manager的数据库也很难管理。Oracle Enterprise Manager(简称EM)是Oracle数据库运维管理的首选工具,可以集中统一的管理Oracle,MySQL,TimesTen等数据库,Exadata和ZDLRA工程化系统,Oracle中间件和Oracle应用。通过插件,EM还可以管理Microsoft SQL Server,IBM DB2,Sybase ASE数据库。通过连接器,EM可以与BMC Remedy,CA Service Desk,HP Operations/Service Manager,IBM Tivoli,Microsoft Systems Center,PagerDuty和ServiceNow等管理框架集成。对于数据库的管理,如上图所示,EM提供了5个管理包(Management Pack)。其中诊断包和调优包通常是用户最基础的选择,也是DBA的最佳搭档。AWR,ASH和ADDM等常用工具均包含在诊断包中。调优包中则包括了各式各样的调优顾问和自动调优工具,如SQL Access Advisor、SQL Tuning Advisor和Automatic SQL Tuning。数据脱敏与子集包可提取所有或部分生产数据,脱敏后交付给开发和测试环境,自动化的过程和丰富的脱敏选项大幅降低了DBA的运维负担,同时保证了数据隐私和安全合规性。数据库生命周期管理包是一个全面的解决方案,可帮助数据库、系统和应用程序管理员自动执行管理 Oracle 数据库生命周期所需的流程。此外,数据库生命周期管理包还提供了用于行业和法规遵从性标准报告和管理的合规框架。Oracle数据库云管理包可用来建立数据库云或DBaaS服务。Oracle关于架构的三字经,除了之前介绍的MAA,还有一个MSA,就是最高安全架构。Oracle最高安全架构提供加密、密钥管理、数据脱敏、特权用户访问控制、活动监视和审计等功能,可帮助您降低数据泄露风险并简化合规性流程。Oracle数据安全秉承两大原则,即深度防御和最小权限原则。深度防御也称为纵深防御或多层防御,类似于洋葱,外层攻破了还有内层的保护。从应用整体来看,从外到内包括网络,硬件,操作系统,应用软件,数据库;从Oracle数据库角度看,则包括风险评估、防止未经授权的数据泄露、检测和报告数据库活动以及通过数据驱动的安全性在数据库中实施数据访问控制。Oracle数据库安全性的优势包括:- 利用机器学习防范威胁:自动化保障数据库安全,包括应用关键补丁,从而节省时间,最大限度避免人为错误。 - 集成的解决方案,提供更高性能:Oracle 透明数据加密(TDE)和 Oracle Database Vault 直接在数据库内核中运行,更快捷,更易于维护。 - 降低用户、数据和配置风险:Oracle Data Safe云服务或DBSAT(数据库安全评估工具)通过安全性评估、活动审计、敏感数据发现以及数据屏蔽为您降低风险。 - 自动化且始终启用的内置安全性:Oracle 自治数据库提供多项功能,例如始终加密、自动打补丁以及预配置职责分离,从而增强了安全性并降低了人为错误的风险。 在上述优势中,特别强调两点。一是Oracle可以为用户或协助用户利用DBSAT对数据库进行评估。二是,Oracle透明数据加密可在数据库层面直接启用表空间或列级加密,无需改变应用。从开销考虑,列加密要大于表空间加密。 Oracle MSA架构中,有几个产品也支持非Oracle数据库,他们是:- Enterprise Manager中的数据脱敏和子集包 - Oracle AVDF(审计保险箱和数据库防火墙) - Oracle Key Vault (秘钥保险箱),建议配合TDE使用 最后,Oracle数据库19c版本于2020年4月10日高分通过公安部“信息安全技术网络安全等级保护基本要求”(即等保2.0)第四级要求中数据库系统的安全防护要求能力测评,建议您在新系统中采用19c或尽快将数据库迁移至19c。 提到内存,大家都会想到和性能相关。但考虑到Oracle内存计算技术的多样性,最终还是决定单独来写,而没有放入后续的高性能和可扩展性解决方案。Oracle内存计算家族的第一个成员是TimesTen。TimesTen最初来自于惠普实验室的内存驻留数据库项目Smallbase。1996年,TimesTen从惠普分拆并在加州成立独立公司。1998年,TimesTen发布业界第一个商用的内存关系型数据库。2005年6月,TimesTen被Oracle正式收购。TimesTen有两种用法,一种是作为Oracle数据库的读写缓存。读缓存用于加速热点数据的访问,写缓存适用于物联网应用的高速数据摄入。这种缓存方式除了提升数据存取性能外,还可以减轻后端数据库压力,并提升整体的高可用性。另一种是作为独立数据库使用,支持传统和分布式两种模式。除了性能,TimesTen的主要特点,第一个是关系型。毕竟对于数据库而言,支持SQL和ACID都是非常重要的特性。第二个是和Oracle数据库和Oracle GoldenGate的紧密集成。在作为Oracle数据库缓存时,TimesTen只需配置而无需编程。TimesTen也高度兼容Oracle的数据类型,SQL和PL/SQL语法。第三个则是分布式,对性能有极致需求的应用可以考虑使用。Oracle内存计算家族的第二个成员是Oracle Database In-Memory,简称DBIM。有人说,DBIM的推出是为了应对SAP HANA,对此我无法确定。但不可否认,两者的应用场景高度重叠,技术实现上也有诸多类似之处。和TimesTen不同,DBIM是Oracle数据库的一个选件。其用途只针对有分析型负载的应用,如纯用于分析的数据仓库和数据集市,或ERP,CRM,财务,人力资源等混合负载应用。由于DBIM是数据库内核的一部分,因此其可以就地加速分析,这对于实时分析或运营分析的场景是非常重要的。Oracle Database In-Memory对于应用的加速是透明的,无需修改应用,可以减少或消除对分析型索引的依赖,由此也可以提升OLTP负载的性能。在技术实现上,DBIM 提供了一种独特的双格式架构,可以同时使用传统的行格式和新的内存中列格式在内存中表示表。Oracle SQL 优化器自动将分析查询路由到列格式,将 OLTP 查询路由到行格式,从而透明地提供两全其美的性能优势。Oracle 数据库自动维护行格式和列格式之间的事务一致性,就像维护表和索引之间的一致性那样。新的列格式是纯内存中格式,不会在磁盘上持久保留,因此不存在额外的存储成本或存储同步问题。关于DBIM的介绍,可参见之前文章“加速度:走进Oracle Database In-Memory”和“海信Oracle Database In-Memory案例分享”。其实Oracle内存计算家族还有另一重要成员Oracle Coherence,技术上属于内存网格。本解决方案主要谈内存数据库,因此这里就不涉及了。Oracle的高性能保证来自于软件,硬件,管理多个层面。在软件方面,Oracle数据库有RAC,Partitioning、高级压缩和Database In-Memory共4个选件。Oracle RAC是一个共享缓存的集群数据库架构,它突破了传统的无共享和共享磁盘架构的限制,从而能够提供无与伦比的数据库性能、可伸缩性和可靠性,而且无需对现有的 Oracle 数据库应用程序进行修改。所以你会看到RAC是一个比较全面的数据库选件,对性能,高可用和可扩展性都有贡献。说到压缩,大家通常想到的都是节省空间,包括数据库本身,以及相应的备份,开发测试环境,网络传输等。除了节省成本,Oracle高级压缩还可以提升查询的性能,这是由于压缩导致内存中可以缓存更多的数据,从而减少了物理I/O请求。和Oracle RAC一样,Oracle Partitioning也是一个综合型的选件,可以提升数据库的性能,可用性和可管理性。技术上,Oracle Partitioning可以将表和索引细分为更小、更易于管理的单元,这样数据库管理员便可采用一种“分而治之”的方法来管理数据。如果需要极速实时分析,可以使用Database In-Memory来应对,这在上一个方案中已有介绍。再来谈一下Oracle数据库的可扩展性。有些人认为Oracle数据库是单体架构,扩展起来可能会有问题。有时也会碰到用户,担心未来业务增长太快,所以一开始就要求分布式架构,要求分库分表。实际上,Oracle也支持原生分片(Sharding)技术,只是Oracle不主张在没有对应用负载有清晰的了解和估算的情况下,一开始就谈分布式和分库分表。大家可能只看到了分布式无限扩展性的一面,往往忽视了分布式在开发,运维,变更和集成等方面的复杂性,以及为保证一致性、高可用性和跨片查询的高技术门槛。所以,我个人的观点是非必要不分布。而且,就我所了解的业务系统中,很多都是用单体Oracle来支持,并没有用到分布式架构。对于分库分表,Oracle Partitioning强大的能力和丰富的分区类型使得分库分表在绝大多数情况下没有必要。Oracle数据库没有单表行数的限制,Oracle的用户中,单表数十亿条记录的情形并不少见。不必分库分表实际上简化了架构,简化了集成,简化了开发和运维。Oracle用于可扩展性的第一个技术是RAC,可以将更多的计算资源聚合在一起,并通过服务实现负载分布和负载均衡。第二个可扩展技术是数据复制。当源数据库负载不堪重负时,可以利用Oracle GoldenGate和Active Data Guard生成一个或多个数据副本,然后转移部分负载在这些数据副本上进行处理。最后,如果有必要可以使用应用定制的分库分表或Oracle原生的Sharding技术。为了保障Oracle数据库的性能,硬件的支持也非常重要。需要保证有足够的内存,高性能的CPU,高I/O能力的存储系统。Exadata可以为Oracle数据库提供坚实的性能保障。性能管理方面,Oracle提供EM诊断包和调优包。EM可以查看非常全面和细致的数据库指标,为数据库性能诊断和调优提供可信的依据,强力辅助应用开发端完善应用架构,优化应用代码。这种看似非常基础的能力,实际上并不容易做到,需要长期的积淀,需要在大量用户应用基础上经验和教训的总结归纳。在Oracle数据库中运行的应用代码,就如同放置于显微镜下,纤毫毕现,可以清楚的知道其来龙去脉。又如同CT扫描,可以清楚知道其健康状况,从而快速准确的定位和解决问题。前面提到,很多用户可能对自己的应用负载没有清晰的认识,此时可以借助Oracle真正应用测试(Real Application Testing,简称RAT)数据库选件,用户不必费时费力编写负载模拟代码来对应用进行测试。RAT包括2个组件,即Database Replay和SQL Performance Analyzer(SPA)。Database Replay可以抓取生产数据库的工作负载并在测试数据库中存放,SPA则通过识别每个 SQL 语句的性能差异来自动化评估系统变化(数据库升级,索引变更,参数调整等)对整个 SQL 工作负载的总体影响的过程。Oracle真正应用测试使新系统规划更准确,系统迁移更有信心,同时简化了DBA的工作任务。总之,通过Oracle全面深入的性能管理工具和性能测试工具,您可以消除当前的性能问题,准确预估未来负载对可扩展性的要求;通过Oracle的性能组件,可以使用简洁的单体架构承载大型应用负载,避免分布式架构,分库分表在开发,运维,扩展,集成,安全管理,高可用等方面带来的复杂性。最后,如果必要,也利用数据库复制和应用定制或原生的分片技术来实现Oracle数据库的可扩展性。Oracle商务智能与数据仓库解决方案,或称为BIDW解决方案,从数据流动的方向,包括数据集成,数据存储与处理,数据分析和展现几个阶段。BIDW方案中,数据源支持结构化的关系型数据库,也支持半结构化和非结构化的JSON,文本,图形图像等。集成方式包括属于CDC(变化数据捕获)支持实时集成的Oracle GoldenGate以及属于ELT的Oracle Data Integrator。Oracle GoldenGate的特点包括实时非侵入式数据集成,以及对于异构的支持,包括不同的数据库产品,相同数据库不同的版本,不同的硬件平台,不同的操作系统。Oracle Data Integrator也称为ODI,ODI的特点是支持丰富的转换转换,以及提供丰富的知识模块,从而简化集成任务,免除或减少用户端代码开发。另外需要强调的一点是,ODI和OGG都支持大数据体系,特别是OGG与Kafka的集成,在用户处得到了广泛采用。数据的存储和处理自然是使用Oracle数据库。Oracle数据库企业版还提供两个重要的选件来简化和加速数据分析。Oracle Partitioning可以将表和索引细分为更小、更易于管理的单元,提高数据库的可管理性、性能和可用性。为加速分析,Oracle数据库可使用索引,物化视图,立方体等手段,而Oracle Database In-Memory可以减少和避免对这些手段的使用,从而简化了分析架构,并且应用无需修改。关于Database In-Memory的介绍可参见前面的方案5:Oracle内存计算解决方案。Oracle Exadata 是一款经过高度优化的Oracle 数据库硬件平台。Exadata 为数据仓库应用提供了杰出的 I/O 和 SQL 处理性能,利用高度并行的架构实现动态存储网格以用于 Oracle数据库部署。Exadata 是用于存储和访问 Oracle 数据库的软件和硬件的组合。它提供数据库感知的存储服务,例如,能够将数据库处理从数据库服务器分流到存储,同时保持对 SQL 处理和数据库应用透明。Exadata 存储大幅提升了性能,具有无限的 I/O 可扩展性,同时易于使用和管理。对于分析和展现,Oracle的解决方案是Oracle 分析平台。Oracle 分析平台提供两种部署选项,即支持云部署的 Oracle 分析云 (OAC) 和支持本地部署的 Oracle 分析服务器 (OAS)。企业在混合部署中可同时采用这两种选项。Oracle 分析平台可连接到许多企业数据源,包括第三方数据源。互联数据源可以是云端、本地部署或自助数据集。同时,您也可以开发和交付经治理的企业级语义模型,以获得一致的业务关键数据视图。Oracle和大数据的关系,可以从数据库内外两个层面来看。从内部来说,Oracle数据库本身就是融合数据库,可以支持非结构化或半结构化类型数据的处理,如文本,图形图像,JSON等。从外部来看,开源大数据体系已相对成熟,Oracle也没必要重新搞一遍。因此Oracle除了自己有一个NoSQL数据库外,其余就将重点放在了和大数据体系的融合上面。在此基础上,可以衍生出湖仓一体,数据平台,数据中台,数据底座之类的解决方案。第一个大数据融合技术是Oracle Big Data SQL。Oracle Big Data SQL 让您可以利用 Oracle SQL 的全部功能无缝访问和集成跨 Oracle 数据库、Hadoop、Kafka、对象存储和NoSQL 存储的数据。它将 Oracle 数据库安全性扩展到所有数据。其独特的智能扫描利用集群来解析、智能过滤和聚合其所在位置的数据。通过分布式处理和最小化数据移动,Smart Scan 最大限度地提高了查询性能。这里有几点需要强调一下,一是跨多个数据源统一查询的能力,二是使用了数据库开发者早已熟悉的SQL语言,现有基于 SQL 的应用程序可以无缝集成新数据。这些都简化了开发任务,并降低了开发的难度。技术实现上,Oracle Big Data SQL通过访问驱动将外部大数据源映射为外部表,从而可以充分利用Oracle数据库强大的SQL功能;同时可以在一个统一系统中,使用标准 Oracle 数据库角色和权限管理对跨平台数据的访问,从而简化安全性设置。大数据融合的第二项技术是Oracle GoldenGate for Big Data和。Oracle GoldenGate for Big Data 将事务数据实时流式传输到大数据和云系统,而不会影响源系统的性能。它可以实时将数据交付到流行的大数据目标,包括Apache Hadoop、Apache HBase、Apache Hive、Confluent Kafka、NoSQL数据库、Elasticsearch、JDBC、公有云(Oracle OCI,AWS,Azure,GCP)和数据仓库,以促进企业改进洞察力和及时行动。Oracle Data Integrator for Big Data是一种基于开放轻量级 ELT 架构的透明异构大数据集成技术。他还可以为多种语言生成代码以允许各种工作负载,这包括 HiveQL、Pig Latin、Spark RDD 和 Spark DataFrames。以上两项数据集成技术,可以极大缩短大数据项目的价值实现时间,同时简化和缩短了大数据集成项目的开发实施过程。Oracle Big Data Connectors 是一个软件套件,它将 Apache Hadoop 中的处理与 Oracle 数据库中的操作集成在一起。它支持使用 Hadoop 处理和分析大量数据,并将其与数据库数据一起使用,以获得新的和关键的业务洞察力。该套件中的工具包括 Oracle SQL Connector for HDFS、Oracle Loader for Hadoop、Oracle XQuery for Hadoop、Oracle R Advanced Analytics for Hadoop 和 Oracle Datasource for Apache Hadoop。以上组件部分已在图中说明,此外,Oracle XQuery for Hadoop 可以将 XQuery 语言表达的转换翻译为一系列 MapReduce 作业,然后在 Hadoop 集群上并行执行。输入可以位于HDFS或Oracle NoSQL,输出可以写到HDFS、Oracle NoSQL、Apache Solr 或 Oracle 数据库。Oracle R Advanced Analytics for Hadoop 提供了一个通用计算框架,您可以在其中使用 R 语言将自定义逻辑编写为mapper或reducer。R 包集合中提供了作为 MapReduce 作业运行的预测分析技术。 而代码则使用 Hadoop 集群上的计算和存储资源以分布式并行方式执行。Oracle R Advanced Analytics for Hadoop 包括了连接Apache Hive 表、Apache Hadoop 计算基础架构、本地 R 环境和 Oracle 数据库表的接口。Oracle的公有云,简称为OCI,即Oracle 云基础设施。OCI是首款从零开始打造的公有云,旨在成为更适合每种应用的云。OCI提供了迁移、构建和运行 IT 所需的全部服务,包括从现有企业负载到新的云原生应用和数据平台的服务。目前,OCI在全球已建立32个商业云区域,其中在美国,加拿大,英国,法国,阿联酋,巴西,澳大利亚,印度,日本和韩国均具有至少2个云区域。OCI虽然起步相对较晚,但一直在坚定不移地贯彻云战略并稳步前进,并展现出强劲的增长势头。在2021 年 Gartner 集成基础设施即服务 (IaaS) 和平台即服务 (PaaS) 解决方案记分卡中,OCI的总体得分为 78%,位列AWS,Azure和阿里云之后。同时,OCI也是进步最快的云,其在 2020 年的得分为 62%。另外,Oracle 在必需标准方面的得分从 74% 提高到 90%,其中计算、存储、网络和软件基础架构(例如数据库即服务和函数)的得分为 100%。越来越多的用户选择将其工作负载迁移到OCI,其主要原因包括:轻松迁移关键企业应用所有服务开发人员都需要构建云原生应用通过自治服务轻松管理安全性、性能和可扩展性全面支持混合云策略默认启用内置的安全功能,且无需额外付费卓越的性价比2022年7月20日,Oracle和微软联合宣布了适用于 Microsoft Azure 的 Oracle 数据库服务(ODSA:Oracle Database Service for Azure),从而可以更好地支持用户的多云战略。Azure 客户可以轻松地为他们的 Azure 应用程序配置和管理在 OCI 上运行的 Oracle 数据库,享受 Oracle 数据库服务的所有好处,同时使用类似于 Azure 的门户来配置数据库——并使用 Azure 来处理其他一切。 与其他 Azure 资源一样,该数据库在 Azure 门户中可用。结语:通过这9个解决方案,相信您已经对Oracle的核心数据能力有了基本的了解。实际上,这些解决方案是通过Oracle数据库企业版及选件,数据库管理包,工程化数据基础设施,数据集成和数据分析等产品组合而成。这些解决方案并非固定不变,您也可以根据自己的理解或实际项目的需要对这些组件进行调整,形成更适合和贴切的解决方案。文章来源:甲骨文云技术
-
近日,IDC发布了最新的《2021年下半年中国关系型数据库软件市场跟踪报告》。报告显示,在本地部署模式市场中,华为云GaussDB以12%的市场份额排名国内第一,这也是自2020H1至今,GaussDB连续四次斩获第一。IDC在报告中预测,“到2026年,中国关系型数据库软件市场规模将达到95.5亿美元,未来5年市场年复合增长率(CAGR)为28.1%。” 中国关系型数据库市场欣欣向荣的背后,是企业数字化转型的深入,以及数据库厂商的持续创新。 IDC在报告中提到,“关系型数据库正向着分布式、云原生、AI使能、HTAP(混合事务与分析型数据库)、多模等方向发展。”华为云GaussDB不仅立于时代浪潮之巅,而且在实际应用中锤炼出更多贴合客户业务场景的功能特性,为客户提供更专业、贴心、高效的服务。 在技术创新方面,华为云GaussDB深化云原生能力,优化云原生GaussDB架构,更好解决热点数据问题、故障秒恢复等难题;同时结合Serverless和华为云数据库提供的应用无损透明倒换技术 (ALT),实现规格灵活变更,对应用基本无感;还深度融合OLTP和OLAP两者优势,推出云原生HTAP重大特性,提升数据处理的准确性,为企业提供实时精准的决策支持。目前该特性已正式商用。针对金融行业,华为云GaussDB重磅推出了Ustore存储引擎、基于Paxos协议的DCF高可用组件、同城双集群高可用等多个重大内核新特性,为企业级用户打造强稳定、高性能、高可用的内核能力,进一步推动企业智能升级。 在行业应用方面,华为云GaussDB目前已服务了2500+中大型企业,广泛应用于金融、政企、电商、制造业、交通、泛互联网等领域,历经关键行业的锤炼,并取得重大实践成果。 在邮储银行新一代个人业务分布式核心系统建设中,华为云GaussDB可容纳500TB以上数据,完美解决了海量数据存储容量和性能瓶颈问题,并实现毫秒级查询响应,稳定服务6亿多用户日均20亿笔交易。 在甘肃医保信息平台建设中,华为云GaussDB承载甘肃医保数十个业务系统的数字底座,门诊结算响应速度从5秒降低到0.9秒,入院办理响应时间从3秒降低到0.4秒,住院结算响应时间从10秒降低到 1.9秒,大幅度减少了群众就医结算的等待时间。 在助力中国一汽数字化升级中,华为云GaussDB提供海量数据存储、数据实时同步的商业数据智能分析,极大缩短复杂报表作业执行时间,从天到分钟,数据实时汇聚。助力一汽红旗ERP系统重构,高效支撑海量订单需求,可靠性达99.99%。 此外,华为云GaussDB广受业界认可,荣获众多荣誉奖项。比如在2022中国国际大数据产业博览会,华为云GaussDB荣获最高奖项“领先科技成果新产品奖”;第四届云原生产业大会,荣获“云原生技术创新领航者-云原生技术创新案例”大奖。在Gartner报告中,华为云GaussDB连续两年入选云数据库管理系统魔力象限,目前营收排名全球第9。 数据库作为企业数字化转型的坚实数据底座,肩负着守护企业核心数据资产的重任,华为云GaussDB必将利剑出鞘,携手千行百业客户,共同迈向数字化转型的最深处,共建智能美好的数字世界。 正如IDC中国企业软件市场分析师王楠所说:“在新兴数据库技术层面,中国本土数据库厂商与国际厂商的差距不大,部分领域还处于领先地位,产品性价比更有优势。在宏观层面,政策极大利好本土厂商,本土厂商的市场机会将会高于国际厂商。在数据库技术发展和宏观政策驱动的双重因素影响下,中国关系型数据库市场过去的格局正在被打破,变革即将到来。”面对变革,华为云GaussDB已做好准备。
-
 MongoDB是NoSQL数据库的典型代表,支持文档结构的存储方式数据存储和使用更为便捷,数据存取效率也很高,但计算能力较弱,实际使用中涉及MongoDB的计算尤其是复杂计算会很麻烦,这就需要具备强计算能力的数据处理引擎与其配合。开源集算器SPL是一款专业结构化数据计算引擎,拥有丰富的计算类库和完备、不依赖数据库的计算能力。SPL提供了独立的过程计算语法,尤其擅长复杂计算,可以增强MongoDB的计算能力,完成分组汇总、关联计算、子查询等通通不在话下。常规查询MongoDB不容易搞定的连接JOIN运算,用SPL很容易搞定:A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") /连接MongDB2 =mongo_shell(A1,"c1.find()").fetch() /获取数据3 =mongo_shell(A1,"c2.find()").fetch() 4 =A2.join(user1:user2,A3:user1:user2,output) /关联计算5 >A1.close() /关闭连接 单表多次参与运算,复用计算结果:A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 2 =mongo_shell(A1,“course.find(,{_id:0})”).fetch() /获取数据3 =A2.group(Sno).((avg = ~.avg(Grade), ~.select(Grade>avg))).conj() /计算成绩大于平均值4 >A1.close() IN计算:A B1 =mongo_open("mongodb://localhost:27017/test") 2 =mongo_shell(A1,"orders.find(,{_id:0})") /获取数据3 =mongo_shell(A1,"employee.find({STATE:'California'},{_id:0})").fetch() /过滤employee数据4 =A3.(EID).sort() /取出EID并排序5 =A2.select(A4.pos@b(SELLERID)).fetch() /二分法查找6 >A1.close() 外键对象化,外键指针不仅方便,效率也高:A B1 =mongo_open("mongodb://localhost:27017/local") 2 =mongo_shell(A1,"Progress.find({}, {_id:0})").fetch() /获取Progress数据3 =A2.groups(courseid; count(userId):popularityCount) /按课程分组计数4 =mongo_shell(A1,"Course.find(,{title:1})").fetch() /获取Course数据5 =A3.switch(courseid,A4:_id) /外键连接6 =A5.new(popularityCount,courseid.title) /创建结果集7 =A1.close() APPLY算法的简单实现:A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 2 =mongo_shell(A1,"users.find()").fetch() /获取users数据3 =mongo_shell(A1,"workouts.find()").fetch() /获取workouts数据4 =A2.conj(A3.select(A2.workouts.pos(_id)).derive(A2.name)) /查询_id 值workouts 序列的记录5 >A1.close() 集合运算,合并交差:A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 2 =mongo_shell(A1,"emp1.find()").fetch() 3 =mongo_shell(A1,"emp2.find()").fetch() 4 =[A2,A3].conj() /多序列合集5 =[A2,A3].merge@ou() /全行对比求并集6 =[A2,A3].merge@ou(_id, NAME) /键值对比求并集7 =[A2,A3].merge@oi() /全行对比求交集8 =[A2,A3].merge@oi(_id, NAME) /键值对比求交集9 =[A2,A3].merge@od() /全行对比求差集10 =[A2,A3].merge@od(_id, NAME) /键值对比求差集11 >A1.close() 在序列中查找成员序号:A B1 =mongo_open("mongodb://localhost:27017/local) 2 =mongo_shell(A1,"users.find({name:'jim'},{name:1,friends:1,_id:0})") .fetch() 3 =A2.friends.pos("luke") /从friends序列中获取成员序号4 =A1.close() 多成员集合的交集:A B1 [Chemical, Biology, Math] /课程2 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 3 =mongo_shell(A2,"student.find()").fetch() /获取student数据4 =A3.select(Lesson^A1!=[]) /查询选修至少一门的记录5 =A4.new(_id, Name, ~.Lesson^A1:Lession) /计算出结果6 >A2.close() 复杂计算TOPN运算:A B 1 =mongo_open("mongodb://127.0.0.1:27017/test") 2 =mongo_shell(A1,"last3.find(,{_id:0};{variable:1})") /获取last3数据,并按variable排序 3 for A2;variable =A3.top(3;-timestamp) /选出timestamp最晚的3个4 =@|B3 /将选出文档追加到B4中5 =B4.minp(~.timestamp) /选出timstamp最早的文档 6 >mongo_close(A1) 嵌套结构的聚合:A1 =mongo_open("mongodb://127.0.0.1:27017/raqdb")2 =mongo_shell(A1,"computer.find()").fetch()3 =A2.new(_id:ID,income.array().sum():INCOME,output.array().sum():OUTPUT)4 >A1.close() 合并多属性子文档:A B C1 =mongo_open("mongodb://localhost:27017/local") 2 =mongo_shell(A1,"c1.find(,{_id:0};{name:1})") 3 =create(_id, readUsers) /创建结果序表4 for A2;name =A4.conj(acls.read.users|acls.append.users|acls.edit.users|acls.fullControl.users).id() /取出所有users字段5 >A3.insert(0, A4.name, B4) /插入本组数据6 =A1.close() 嵌套List子文档的查询A B1 =mongo_open("mongodb://localhost:27017/local") 2 =mongo_shell(A1,"Cbettwen.find(,{_id:0})").fetch() 3 =A2.conj((t=~.objList.data.dataList, t.select((s=float(~.split@c1()(1)), s>6154 && s<=6155)))) /找到符合条件的字符串4 =A1.close() 交叉汇总:A1 =mongo_open("mongodb://localhost:27017/local")2 =mongo_shell(A1,"student.find()").fetch()3 =A2.group(school)4 =A3.new(school:school,~.align@a(5,sub1).(~.len()):sub1,~.align@a(5,sub2).(~.len()):sub2)5 =A4.new(school,sub1(5):sub1-5,sub1(4):sub1-4,sub1(3):sub1-3,sub1(2):sub1-2,sub1(1):sub1-1,sub2(5):sub2-5,sub2(4):sub2-4,sub2(3):sub2-3,sub2(2):sub2-2,sub2(1):sub2-1)6 =A1.close() 分段分组A B1 [3000,5000,7500,10000,15000] /Sales分段区间2 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 3 =mongo_shell(A2,"sales.find()").fetch() 4 =A3.groups(A1.pseg(~.SALES):Segment;count(1): number) /根据 SALES 区间分组统计员工数5 >A2.close() 分类分组A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 2 =mongo_shell(A1,"books.find()") 3 =A2.groups(addr,book;count(book): Count) /分组计数4 =A3.groups(addr;sum(Count):Total) /分组统计5 =A3.join(addr,A4:addr,Total) /关联计算6 >A1.close() 数据写入导出成CSV:A B1 =mongo_open("mongodb://localhost:27017/raqdb") 2 =mongo_shell(A1,"carInfo.find(,{_id:0})") 3 =A2.conj((t=~,cars.car.new(t.id:id, t.cars.name, ~:car))) /对car字段进行拆分成行4 =file("D:\\data.csv").export@tc(A3) /导出生成csv文件5 >A1.close() 更新数据库(MongoDB到MySQL):A B1 =mongo_open("mongodb://localhost:27017/raqdb") /连接MongDB2 =mongo_shell(A1,"course.find(,{_id:0})").fetch() 3 =connect("myDB1") /连接mysql4 =A3.query@x("select * from course2").keys(Sno, Cno) 5 >A3.update(A2:A4, course2, Sno, Cno, Grade; Sno,Cno) /向mysql更新数据6 >A1.close() 更新数据库(MySQL到MongoDB):A B1 =connect("mysql") /连接mysql2 =A1.query@x("select * from course2") /获取表course2数据3 =mongo_open("mongodb://localhost:27017/raqdb") /连接MongDB4 =mongo_insert(A3, "course",A2) /将MySQL表course2导入MongoDB集合course5 >A3.close() 混合计算借助SPL还很容易实现MongoDB与其他数据源进行混合计算:A B1 =mongo_open("mongodb://localhost:27017/test") /连接MongDB2 =mongo_shell(A1,"emp.find({'$and':[{'Birthday':{'$gte':'"+string(begin)+"'}},{'Birthday':{'$lte':'"+string(end)+"'}}]},{_id:0})").fetch() /查询某时间段的记录3 =A1.close() /关闭MongoDB4 =myDB1.query("select * from cities") /获取mysql中表cities数据5 =A2.switch(CityID,A4: CityID) /外键关联6 =A5.new(EID,Dept,CityID.CityName:CityName,Name,Gender) /创建结果集7 return A6 /返回SQL支持SPL除了原生语法,还提供了相当于SQL92标准的SQL支持,可以使用SQL查询MongoDB了,比如前面的关联计算:A1 =mongo_open("mongodb://127.0.0.1:27017/test")2 =mongo_shell(A1,"c1.find()").fetch()3 =mongo_shell@x(A1,"c2.find()").fetch()4 $select s.* from {A2} as s left join {A3} as r on s.user1=r.user1 and s.user2=r.user2 where r.income>0.3应用集成不仅如此,SPL提供了标准JDBC/ODBC等应用程序接口,集成调用很方便。如JDBC的使用:…Class.forName("com.esproc.jdbc.InternalDriver");Connection conn = DriverManager.getConnection("jdbc:esproc:local://");PrepareStatement st=con.prepareStatement("call splScript(?)"); // splScript为spl脚本文件名st.setObject(1,"California");st.execute();ResultSet rs = st.getResultSet();…有了这些功能,增强MongoDB的计算能力可不是说说而已,要不要下载试试?————————————————版权声明:本文为CSDN博主「石臻臻的杂货铺」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/u010634066/article/details/125854301
MongoDB是NoSQL数据库的典型代表,支持文档结构的存储方式数据存储和使用更为便捷,数据存取效率也很高,但计算能力较弱,实际使用中涉及MongoDB的计算尤其是复杂计算会很麻烦,这就需要具备强计算能力的数据处理引擎与其配合。开源集算器SPL是一款专业结构化数据计算引擎,拥有丰富的计算类库和完备、不依赖数据库的计算能力。SPL提供了独立的过程计算语法,尤其擅长复杂计算,可以增强MongoDB的计算能力,完成分组汇总、关联计算、子查询等通通不在话下。常规查询MongoDB不容易搞定的连接JOIN运算,用SPL很容易搞定:A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") /连接MongDB2 =mongo_shell(A1,"c1.find()").fetch() /获取数据3 =mongo_shell(A1,"c2.find()").fetch() 4 =A2.join(user1:user2,A3:user1:user2,output) /关联计算5 >A1.close() /关闭连接 单表多次参与运算,复用计算结果:A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 2 =mongo_shell(A1,“course.find(,{_id:0})”).fetch() /获取数据3 =A2.group(Sno).((avg = ~.avg(Grade), ~.select(Grade>avg))).conj() /计算成绩大于平均值4 >A1.close() IN计算:A B1 =mongo_open("mongodb://localhost:27017/test") 2 =mongo_shell(A1,"orders.find(,{_id:0})") /获取数据3 =mongo_shell(A1,"employee.find({STATE:'California'},{_id:0})").fetch() /过滤employee数据4 =A3.(EID).sort() /取出EID并排序5 =A2.select(A4.pos@b(SELLERID)).fetch() /二分法查找6 >A1.close() 外键对象化,外键指针不仅方便,效率也高:A B1 =mongo_open("mongodb://localhost:27017/local") 2 =mongo_shell(A1,"Progress.find({}, {_id:0})").fetch() /获取Progress数据3 =A2.groups(courseid; count(userId):popularityCount) /按课程分组计数4 =mongo_shell(A1,"Course.find(,{title:1})").fetch() /获取Course数据5 =A3.switch(courseid,A4:_id) /外键连接6 =A5.new(popularityCount,courseid.title) /创建结果集7 =A1.close() APPLY算法的简单实现:A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 2 =mongo_shell(A1,"users.find()").fetch() /获取users数据3 =mongo_shell(A1,"workouts.find()").fetch() /获取workouts数据4 =A2.conj(A3.select(A2.workouts.pos(_id)).derive(A2.name)) /查询_id 值workouts 序列的记录5 >A1.close() 集合运算,合并交差:A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 2 =mongo_shell(A1,"emp1.find()").fetch() 3 =mongo_shell(A1,"emp2.find()").fetch() 4 =[A2,A3].conj() /多序列合集5 =[A2,A3].merge@ou() /全行对比求并集6 =[A2,A3].merge@ou(_id, NAME) /键值对比求并集7 =[A2,A3].merge@oi() /全行对比求交集8 =[A2,A3].merge@oi(_id, NAME) /键值对比求交集9 =[A2,A3].merge@od() /全行对比求差集10 =[A2,A3].merge@od(_id, NAME) /键值对比求差集11 >A1.close() 在序列中查找成员序号:A B1 =mongo_open("mongodb://localhost:27017/local) 2 =mongo_shell(A1,"users.find({name:'jim'},{name:1,friends:1,_id:0})") .fetch() 3 =A2.friends.pos("luke") /从friends序列中获取成员序号4 =A1.close() 多成员集合的交集:A B1 [Chemical, Biology, Math] /课程2 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 3 =mongo_shell(A2,"student.find()").fetch() /获取student数据4 =A3.select(Lesson^A1!=[]) /查询选修至少一门的记录5 =A4.new(_id, Name, ~.Lesson^A1:Lession) /计算出结果6 >A2.close() 复杂计算TOPN运算:A B 1 =mongo_open("mongodb://127.0.0.1:27017/test") 2 =mongo_shell(A1,"last3.find(,{_id:0};{variable:1})") /获取last3数据,并按variable排序 3 for A2;variable =A3.top(3;-timestamp) /选出timestamp最晚的3个4 =@|B3 /将选出文档追加到B4中5 =B4.minp(~.timestamp) /选出timstamp最早的文档 6 >mongo_close(A1) 嵌套结构的聚合:A1 =mongo_open("mongodb://127.0.0.1:27017/raqdb")2 =mongo_shell(A1,"computer.find()").fetch()3 =A2.new(_id:ID,income.array().sum():INCOME,output.array().sum():OUTPUT)4 >A1.close() 合并多属性子文档:A B C1 =mongo_open("mongodb://localhost:27017/local") 2 =mongo_shell(A1,"c1.find(,{_id:0};{name:1})") 3 =create(_id, readUsers) /创建结果序表4 for A2;name =A4.conj(acls.read.users|acls.append.users|acls.edit.users|acls.fullControl.users).id() /取出所有users字段5 >A3.insert(0, A4.name, B4) /插入本组数据6 =A1.close() 嵌套List子文档的查询A B1 =mongo_open("mongodb://localhost:27017/local") 2 =mongo_shell(A1,"Cbettwen.find(,{_id:0})").fetch() 3 =A2.conj((t=~.objList.data.dataList, t.select((s=float(~.split@c1()(1)), s>6154 && s<=6155)))) /找到符合条件的字符串4 =A1.close() 交叉汇总:A1 =mongo_open("mongodb://localhost:27017/local")2 =mongo_shell(A1,"student.find()").fetch()3 =A2.group(school)4 =A3.new(school:school,~.align@a(5,sub1).(~.len()):sub1,~.align@a(5,sub2).(~.len()):sub2)5 =A4.new(school,sub1(5):sub1-5,sub1(4):sub1-4,sub1(3):sub1-3,sub1(2):sub1-2,sub1(1):sub1-1,sub2(5):sub2-5,sub2(4):sub2-4,sub2(3):sub2-3,sub2(2):sub2-2,sub2(1):sub2-1)6 =A1.close() 分段分组A B1 [3000,5000,7500,10000,15000] /Sales分段区间2 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 3 =mongo_shell(A2,"sales.find()").fetch() 4 =A3.groups(A1.pseg(~.SALES):Segment;count(1): number) /根据 SALES 区间分组统计员工数5 >A2.close() 分类分组A B1 =mongo_open("mongodb://127.0.0.1:27017/raqdb") 2 =mongo_shell(A1,"books.find()") 3 =A2.groups(addr,book;count(book): Count) /分组计数4 =A3.groups(addr;sum(Count):Total) /分组统计5 =A3.join(addr,A4:addr,Total) /关联计算6 >A1.close() 数据写入导出成CSV:A B1 =mongo_open("mongodb://localhost:27017/raqdb") 2 =mongo_shell(A1,"carInfo.find(,{_id:0})") 3 =A2.conj((t=~,cars.car.new(t.id:id, t.cars.name, ~:car))) /对car字段进行拆分成行4 =file("D:\\data.csv").export@tc(A3) /导出生成csv文件5 >A1.close() 更新数据库(MongoDB到MySQL):A B1 =mongo_open("mongodb://localhost:27017/raqdb") /连接MongDB2 =mongo_shell(A1,"course.find(,{_id:0})").fetch() 3 =connect("myDB1") /连接mysql4 =A3.query@x("select * from course2").keys(Sno, Cno) 5 >A3.update(A2:A4, course2, Sno, Cno, Grade; Sno,Cno) /向mysql更新数据6 >A1.close() 更新数据库(MySQL到MongoDB):A B1 =connect("mysql") /连接mysql2 =A1.query@x("select * from course2") /获取表course2数据3 =mongo_open("mongodb://localhost:27017/raqdb") /连接MongDB4 =mongo_insert(A3, "course",A2) /将MySQL表course2导入MongoDB集合course5 >A3.close() 混合计算借助SPL还很容易实现MongoDB与其他数据源进行混合计算:A B1 =mongo_open("mongodb://localhost:27017/test") /连接MongDB2 =mongo_shell(A1,"emp.find({'$and':[{'Birthday':{'$gte':'"+string(begin)+"'}},{'Birthday':{'$lte':'"+string(end)+"'}}]},{_id:0})").fetch() /查询某时间段的记录3 =A1.close() /关闭MongoDB4 =myDB1.query("select * from cities") /获取mysql中表cities数据5 =A2.switch(CityID,A4: CityID) /外键关联6 =A5.new(EID,Dept,CityID.CityName:CityName,Name,Gender) /创建结果集7 return A6 /返回SQL支持SPL除了原生语法,还提供了相当于SQL92标准的SQL支持,可以使用SQL查询MongoDB了,比如前面的关联计算:A1 =mongo_open("mongodb://127.0.0.1:27017/test")2 =mongo_shell(A1,"c1.find()").fetch()3 =mongo_shell@x(A1,"c2.find()").fetch()4 $select s.* from {A2} as s left join {A3} as r on s.user1=r.user1 and s.user2=r.user2 where r.income>0.3应用集成不仅如此,SPL提供了标准JDBC/ODBC等应用程序接口,集成调用很方便。如JDBC的使用:…Class.forName("com.esproc.jdbc.InternalDriver");Connection conn = DriverManager.getConnection("jdbc:esproc:local://");PrepareStatement st=con.prepareStatement("call splScript(?)"); // splScript为spl脚本文件名st.setObject(1,"California");st.execute();ResultSet rs = st.getResultSet();…有了这些功能,增强MongoDB的计算能力可不是说说而已,要不要下载试试?————————————————版权声明:本文为CSDN博主「石臻臻的杂货铺」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/u010634066/article/details/125854301 -
 前言安装初始化项目结构三大命令前言本篇文章,阐述一下Flask中数据库的迁移为什么要说数据库迁移呢?比如我们以前有一个数据库,里面的信息有 id, name现在我想再加一个gender属性,应该怎么办呢?不可能直接把数据库删除掉吧。然后重新创建一个,因此本文介绍一种,通过数据库迁移的方法,可以保留原始的数据,并完成添加新的一列的方法。安装直接使用pip install flask-migrate即可初始化项目结构123# exts.pyfrom flask_sqlalchemy import SQLAlchemydb = SQLAlchemy()老样子,我们还是在exts.py中,初始我们的数据库,这里时放Flask扩展的地方。1234567# models.pyfrom exts import dbclass User(db.Model): id = db.Column(db.Integer,primary_key=True) username = db.Column(db.String(80),unique=True) def __repr__(self): return '<User %s>' % self.usernamemodels.py是放模型的地方。1234567891011# app.pyfrom flask import Flaskfrom exts import dbfrom flask_migrate import Migrateapp = Flask(__name__)app.config['SQLALCHEMY_DATABASE_URI'] = "sqlite:///foo.db"# !!!绑定app和数据库db.init_app(app)migrate = Migrate(app,db)if __name__ == '__main__': app.run()主程序,我们在!!!进行初始化数据库迁移的migrate 对象。初始化之后我们可以执行下面的三大命令去创建我们的数据库。就不需要db.create_all()命令啦。三大命令# (1)初始化flask db init# 把当前的模型添加到迁移文件flask db migrate# 将映射文件真正的映射到数据库中flask db upgrade(1)新建一个名字为migrations的文件夹,并且记录一个数据库版本号其他问题:如果报错[flask_migrate] Error: Can‘t locate revision identified by '409392ed6301'答:db revision --rev-id 409392ed6301 409392ed6301是问题的版本号Error: While importing ‘app’, an ImportError was raised.答:请先去运行一下app.py,确保app.py可以运行Error: Could not locate a Flask application. You did not provide the “FLASK_APP” environment variable, and a “wsgi.py” or “app.py” module was not found in the current directory. 答:请确保执行命令时的文件夹中有app.py文件
前言安装初始化项目结构三大命令前言本篇文章,阐述一下Flask中数据库的迁移为什么要说数据库迁移呢?比如我们以前有一个数据库,里面的信息有 id, name现在我想再加一个gender属性,应该怎么办呢?不可能直接把数据库删除掉吧。然后重新创建一个,因此本文介绍一种,通过数据库迁移的方法,可以保留原始的数据,并完成添加新的一列的方法。安装直接使用pip install flask-migrate即可初始化项目结构123# exts.pyfrom flask_sqlalchemy import SQLAlchemydb = SQLAlchemy()老样子,我们还是在exts.py中,初始我们的数据库,这里时放Flask扩展的地方。1234567# models.pyfrom exts import dbclass User(db.Model): id = db.Column(db.Integer,primary_key=True) username = db.Column(db.String(80),unique=True) def __repr__(self): return '<User %s>' % self.usernamemodels.py是放模型的地方。1234567891011# app.pyfrom flask import Flaskfrom exts import dbfrom flask_migrate import Migrateapp = Flask(__name__)app.config['SQLALCHEMY_DATABASE_URI'] = "sqlite:///foo.db"# !!!绑定app和数据库db.init_app(app)migrate = Migrate(app,db)if __name__ == '__main__': app.run()主程序,我们在!!!进行初始化数据库迁移的migrate 对象。初始化之后我们可以执行下面的三大命令去创建我们的数据库。就不需要db.create_all()命令啦。三大命令# (1)初始化flask db init# 把当前的模型添加到迁移文件flask db migrate# 将映射文件真正的映射到数据库中flask db upgrade(1)新建一个名字为migrations的文件夹,并且记录一个数据库版本号其他问题:如果报错[flask_migrate] Error: Can‘t locate revision identified by '409392ed6301'答:db revision --rev-id 409392ed6301 409392ed6301是问题的版本号Error: While importing ‘app’, an ImportError was raised.答:请先去运行一下app.py,确保app.py可以运行Error: Could not locate a Flask application. You did not provide the “FLASK_APP” environment variable, and a “wsgi.py” or “app.py” module was not found in the current directory. 答:请确保执行命令时的文件夹中有app.py文件 -
 灵魂画师再次上线在开饭前我们先了解下两个关键的配置文件数据目录下的postgresql.conf比对一下主备节点的postgresql.conf,应该有以下几个参数不一致listen_addresses 远程客户端连接使用的数据库主节点ip或者主机名 local_bind_address 当前节点连接openGauss其他节点时绑定的本地IP地址 replconninfo1 设置本端侦听和鉴权的第一个节点信息,如果备机有2个,就会有replconninfo2 log_directory 决定存放服务器日志文件的目录,om初始化安装时命名跟实例id相关 audit_directory 审计文件的存储目录,om初始化安装时命名跟实例id相关 application_name 连接请求时所使用的客户端名称,om初始化安装时命名跟实例id相关来自踩坑者的warning:根据某一个节点生成例外一个节点的postgresql.conf文件,俗手请按参数逐个修改,不可全量替换,容易改错ip等$GAUSSHOME/bin/cluster_static_config俗称静态配置文件,OM工具的核心,记录了当前节点和集群的基本信息,二进制结构化文件可以通过gs_om -t view 来查看可以通过gs_om -t generateconf -X XMLFILE --distribute 重新生成有静态配置文件,就有动态配置文件cluster_static_config动态配置文件最大的作用就是记录了当前节点状态,标记节点主备角色,这样重启的时候知道节点的启动方式可以通过gs_om -t refreshconf生成 只有进行过主备切换才有必要执行这个命令开胃菜拼盘之备机的数据目录丢失建立postgresql.conf文件后build即可postgresql.conf可以从主机拷贝后修改,如果日常养成了备份的习惯那就更方便了gs_om -t status --detail scp xb01:/data1/zxbog/openGauss/data/dn1/postgresql.conf ./data1/zxbog/openGauss/data/dn2/ gs_ctl build -D /data1/zxbog/openGauss/data/dn2开胃菜拼盘之主机的数据目录丢失按修复备机的方式肯定是不行滴,需要先备升主,然后按备机方式修复,最后再主备切换主机down的时候,需要在备机failover来实现备升主主机normal的时候,需要在备机switchover来实现备升主gs_ctl failover -D /data1/zxbog/openGauss/data/dn2 gs_ctl switchover -D /data1/zxbog/openGauss/data/dn1开胃菜拼盘之GPHOME/GAUSSHOME目录丢失GPHOME下主要是OM脚本(数据库运维工具),python语言如果丢失,可以从其他节点直接cp(推荐),或者安装包直接解压覆盖,也可以重新执行一遍gs_preinstallGAUSSHOME下主要存放数据库内核可执行文件,C/C++语言编译如果丢失,可以从同集群其他节点cp(推荐)或者解压安装包中的bz压缩包,由于GAUSSHOME/bin目录下存放了各自的静态配置文件,需要修改为啥我都是推荐从其他节点cp呢,通过om安装的数据库会产生证书在每个节点,解压包是不会产生这些的,如果用到了openssl,需要手动生成正菜之节点替换与修复节点替换与修复一般有两种场景机器损坏,需要重新搭建一台,配置比如ip都不变机器被征用,需要换一台新的机器,ip地址也变更了这种情况可以先用gs_dropnode删除老的节点,然后通过gs_expansion扩新的节点这两个命令都是要求在主节点下执行,如果要修改主节点,请先主备切换,并刷新静态/动态配置文件gs_dropnode 需要在普通用户下执行,gs_expansion需要在root用户下执行[xb0608@xb01 ~]$ gs_dropnode -U xb0608 -G xb0608 -h 192.168.0.26 [root@xb01 script]# /opt/software/script/gs_expansion -U xb0608 -G xb0608 -X ../double.xml -h 192.168.0.26在执行扩节点之前,为减少不必要的麻烦,请确保新的节点足够干净,邪 恶代码如下,谨慎使用ps -ef|grep ^xb0608|awk '{print $2}'|xargs kill -9 && userdel -r xb0608 rm -rf /data1/zxbog/openGauss/ groupadd xb0608 && useradd xb0608 -g xb0608 passwd xb0608 传说中的甜点如果整个集群都被 干掉了咋办~~既然有主备节点,就可以有主备集群啦OM重磅功能支持主备集群-流式容灾搭建即将上线,敬请期待
灵魂画师再次上线在开饭前我们先了解下两个关键的配置文件数据目录下的postgresql.conf比对一下主备节点的postgresql.conf,应该有以下几个参数不一致listen_addresses 远程客户端连接使用的数据库主节点ip或者主机名 local_bind_address 当前节点连接openGauss其他节点时绑定的本地IP地址 replconninfo1 设置本端侦听和鉴权的第一个节点信息,如果备机有2个,就会有replconninfo2 log_directory 决定存放服务器日志文件的目录,om初始化安装时命名跟实例id相关 audit_directory 审计文件的存储目录,om初始化安装时命名跟实例id相关 application_name 连接请求时所使用的客户端名称,om初始化安装时命名跟实例id相关来自踩坑者的warning:根据某一个节点生成例外一个节点的postgresql.conf文件,俗手请按参数逐个修改,不可全量替换,容易改错ip等$GAUSSHOME/bin/cluster_static_config俗称静态配置文件,OM工具的核心,记录了当前节点和集群的基本信息,二进制结构化文件可以通过gs_om -t view 来查看可以通过gs_om -t generateconf -X XMLFILE --distribute 重新生成有静态配置文件,就有动态配置文件cluster_static_config动态配置文件最大的作用就是记录了当前节点状态,标记节点主备角色,这样重启的时候知道节点的启动方式可以通过gs_om -t refreshconf生成 只有进行过主备切换才有必要执行这个命令开胃菜拼盘之备机的数据目录丢失建立postgresql.conf文件后build即可postgresql.conf可以从主机拷贝后修改,如果日常养成了备份的习惯那就更方便了gs_om -t status --detail scp xb01:/data1/zxbog/openGauss/data/dn1/postgresql.conf ./data1/zxbog/openGauss/data/dn2/ gs_ctl build -D /data1/zxbog/openGauss/data/dn2开胃菜拼盘之主机的数据目录丢失按修复备机的方式肯定是不行滴,需要先备升主,然后按备机方式修复,最后再主备切换主机down的时候,需要在备机failover来实现备升主主机normal的时候,需要在备机switchover来实现备升主gs_ctl failover -D /data1/zxbog/openGauss/data/dn2 gs_ctl switchover -D /data1/zxbog/openGauss/data/dn1开胃菜拼盘之GPHOME/GAUSSHOME目录丢失GPHOME下主要是OM脚本(数据库运维工具),python语言如果丢失,可以从其他节点直接cp(推荐),或者安装包直接解压覆盖,也可以重新执行一遍gs_preinstallGAUSSHOME下主要存放数据库内核可执行文件,C/C++语言编译如果丢失,可以从同集群其他节点cp(推荐)或者解压安装包中的bz压缩包,由于GAUSSHOME/bin目录下存放了各自的静态配置文件,需要修改为啥我都是推荐从其他节点cp呢,通过om安装的数据库会产生证书在每个节点,解压包是不会产生这些的,如果用到了openssl,需要手动生成正菜之节点替换与修复节点替换与修复一般有两种场景机器损坏,需要重新搭建一台,配置比如ip都不变机器被征用,需要换一台新的机器,ip地址也变更了这种情况可以先用gs_dropnode删除老的节点,然后通过gs_expansion扩新的节点这两个命令都是要求在主节点下执行,如果要修改主节点,请先主备切换,并刷新静态/动态配置文件gs_dropnode 需要在普通用户下执行,gs_expansion需要在root用户下执行[xb0608@xb01 ~]$ gs_dropnode -U xb0608 -G xb0608 -h 192.168.0.26 [root@xb01 script]# /opt/software/script/gs_expansion -U xb0608 -G xb0608 -X ../double.xml -h 192.168.0.26在执行扩节点之前,为减少不必要的麻烦,请确保新的节点足够干净,邪 恶代码如下,谨慎使用ps -ef|grep ^xb0608|awk '{print $2}'|xargs kill -9 && userdel -r xb0608 rm -rf /data1/zxbog/openGauss/ groupadd xb0608 && useradd xb0608 -g xb0608 passwd xb0608 传说中的甜点如果整个集群都被 干掉了咋办~~既然有主备节点,就可以有主备集群啦OM重磅功能支持主备集群-流式容灾搭建即将上线,敬请期待 -
 【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件) -
缺乏自主的关键技术是国产数据库被诟病最多的痛点。众所周之,国产数据库中,绝大多数是基于开源数据库改造的,尤其是基MySQL或 PostgreSQL改造的居多,这本身无可厚非。自研,并非只有从0开始完全自研一条路,基于开源数据库做半自研,然后逐渐深入关键核心模块,直至最终完全掌控开源数据库,也是自研。但是,这绝不是在开源数据库上穿个“衣”带个“帽”。毫无疑问,在数据库市场中,自研、内核创新、核心业务系统等词被滥用了。那么,基于开源数据库的国产数据库中,到底有没有,具有自己的技术创新,甚至内核级创新的产品呢?答案,当然是有的。今天,老鱼就想来聊一聊openGauss的技术创新,为此,老鱼采访了openGauss 技术委员会主席李国良,openGauss开源数据库首席架构师黄凯耀,听他们说一说openGauss内核与架构技术创新的故事。李国良,清华大学计算机系副主任、教授、博士生导师。在数据库会议和期刊上发表论文150余篇,他引10000余次。获得了VLDB 2017 Early Career Research Contributions Award(亚洲首位)、IEEE TCDE Early Career Award(亚洲首位)。SIGMOD 2021大会主席,VLDB 2021 Demo 主席,ICDE 2022 Industry Chair,获国家科技进步二等奖、江苏省科技进步一等奖。黄凯耀,openGauss开源数据库首席架构师,负责openGauss的技术规划与产品设计工作,在数据库高性能架构、高可用架构、OLTP性能优化、OLAP性能优化、一体化架构、软硬协同等领域有丰富的理论、工程与实践经验。什么是数据库内核?学过数据库的都知道,内核通常指数据库最核心的部分,比如:优化器、解析器、执行器、存储引擎等。openGauss对内核如何界定?老鱼找到一张官方图:如上图,粉色的部分就是openGauss界定的内核部分,包括线程管理、通信管理、SQL引擎、存储引擎、安全管理、AI。那么,openGauss在内核上都有哪些创新?其实,上图已经能看出一部分东西。众所周之,openGauss内核早期衍生自PostgreSQL-XC,但如今,openGauss与PostgreSQL-在架构和内核上,已经有了极大的差异。如上图,openGauss执行模型,采用线程池模型。而PostgreSQL是进程模型。这么改有什么好处?进程模型,数据库进程通过共享内存实现通讯和数据共享,每个进程对应一个并发连接,这就存在高并发下,进程切换性能损耗,导致多核扩展性问题。而线程池技术的整体设计思想是线程资源池化、并且在不同连接之间复用,因此,高并发连接切换代价小,内存损耗小,执行效率高。李国良说,openGauss尤其在核心的优化器、执行器、存储引擎方面,做了很多的改进和优化,与传统的关系型数据库,有了本质区别。存储引擎方面,openGauss实现存储引擎融合,即一套架构支持多种存储模式。openGauss支持多引擎(行存储引擎、列存储引擎、内存引擎),而PostgreSQL仅支持行存储引擎。看起来只是多支持了2个引擎,但其中涉及很多关键技术。比如:openGauss行存储引擎采用原地更新(in-place update)设计(又名:Ustore存储引擎),追加写引擎(HEAP),支持MVCC(Multi-Version Concurrency Control,多版本并发控制),同时支持本地存储和存储、计算分离部署方式。原地更新相比非原地更新有什么好处?李国良给老鱼打了个比方,简单的说,非原地更新是一张表一直往上加,有删有增,维护这张表代价非常大。openGauss 内核此前的版本使用的行存储引擎是Append Update(追加更新)模式,追加更新对于业务中的增、删以及HOT(Heap Only Tuple) Update(即同一页面内更新)有很好的表现,但对于跨数据页面的非HOT UPDATE场景,垃圾回收不够高效,因此,Ustore存储引擎应运而生。众所周知,优化器的好坏会直接决定关系型数据库的强弱,优化器一般分为RBO(Rule-Based Optimizer)基于规则的优化器和CBO(Cost-Based Optimizer)基于代价的优化器,PostgreSQL支持CBO,openGauss支持CBO,SQL by pass。虽然都支持CBO,但对复杂场景的优化能力是完全不同的。李国良说,openGauss在优化器的CBO上做了很多技术创新。首先,openGauss添加了很多查询重写规则,查询重写优化;其次,openGauss做了很多CBO代价的调优模型,适应不同场景;最后,openGauss加了基于机器学习的代价估计方法和优化算法,使得优化器更智能,适用于更多、更全面的复杂场景。Sql-bypass是openGauss针对OLTP场景开发的一个轻量化执行器,它解决的是什么问题?在典型的OLTP场景中,简单SQL查询占了很大部分比例。试想一下,如果一个简单的SQL查询因为复杂的CBO逻辑,而消耗不必要的CPU资源浪费执行时间,那肯定是不行的。SQL by pass就是为了加速这类查询设计的,可以极大地缩短执行器通用框架处理逻辑,极大地提升执行的性能。执行器方面,为了提高SQL的执行速度,解决传统数据处理引擎条件逻辑冗余的问题,openGauss执行器引入了自适应实时编译(Codegen)技术,其核心思想是为具体的查询生成定制化的机器码代替通用的函数实现,并尽可能地将数据存储在CPU寄存器中。总的来说,openGauss内核创新围绕“四高”原则,即:高性能、高可用、高安全、高智能。比如:高性能,openGauss聚焦了很多新型技术,包括NUMA-Aware技术、智能优化技术、内核并行执行的技术,这些都是在内核创新方面引领的一些新型技术。高智能,在数据库内核方面涉及到很多优化技术,包括很多优化NP问题,以及代价估算技术。传统方式都是基于一些独立性假设、均匀分布假设,这导致估算结果非常不准确,而openGauss通过众多智能技术(智能索引技术、智能数据化分析技术、智能优化内核技术)提升准确性、提升数据库内核优化效率,提高可复制性。高安全,是openGauss非常重视的一个特性,openGauss引领了防篡改、全密态数据库发展,也得到了一些POC的测试。此后,openGauss会持续构筑这些能力,打造安全、稳定的数据库密态内核,达到商用产品化标准,保护用户敏感、隐私数据的全生命周期的安全。黄凯耀则给老鱼分享了4个架构创新,工具创新的故事,分别是插件化架构、可观测内核架构、资源池化架构、数据安全架构,而这四个架构创新是基于用户场景驱动的,解决的是易迁移、易运维、易开发、易扩展的刚需问题。篇幅所限,本文只解析插件化架构及可观测内核架构。黄凯耀告诉老鱼,插件化架构的提出,是为了易迁移的目标,也就是为了实现方便简单的把其它数据库往openGauss迁移。为了达成这个目标,openGauss设计了数据库的插件化架构。首先,在计算引擎这一层上面,定义了数据库的扩展点。数据库内核开发者可以基于这些扩展点,去实现其它数据库语法的兼容插件。同时,为了更方便支持应用开发者把原有的数据库迁移到openGauss上,在内核层面,openGauss实现了SQL兼容性评估插件。基于应用提供的SQL语句,去调用相应的数据库插件,基于该插件的能力,对SQL语句进行评估并得出可读性很强的评估报告,为什么说可读性很强?因为,它是从其它数据库迁移到openGauss的迁移建议的中文提示,而非模糊化的英文提示。第二个故事,是可观测架构。可观测与可运维是社区开发者对openGauss提出的另外一项重大诉求,并不亚于迁移方面的呼声。黄凯耀说,解决的问题是怎样对openGauss进行更加全面系统地性能监控和故障诊断。搞过数据库运维的人都知道一个棘手的场景,就是业务部门反馈系统慢,但DBA从有限的数据库监控指标上却看不出任何问题。因此,加强数据库可观测性是降低数据库使用成本一个非常重要的手段。相较而言,要实现全栈的可观测、可跟踪架构,技术难度很高。因为,这不仅涉及到数据库内核,数据库运维,还涉及操作系统内核等,黄凯耀说。openGauss通过资源消耗链的角度,把整个系统的资源消耗分为三类:存储资源消耗链网络资源消耗链CPU内存资源消耗链在每一个资源消耗链上,可以通过上钻下探的方法,去实现系统性能问题的优化或者故障问题的定位。通过这种全面系统的上钻下探,就可以实现一个良好的可观测架构。而这背后,需要对数据库内核代码做更多的增强,并且仅数据库内核增强还不够,还需要借助操作系统最先进的eBPF技术,才可能提供更全面、更丰富的可观测数据。而有了丰富的数据,诊断系统就可以基于这些数据做基于专家模型的推理或AI诊断。通常,从一个业务指标,关联到数据库等待时间指标,再关联到操作系统的资源消耗指标,是目前主流数据库所提供的可观测能力。但openGauss更进了一步,直接把数据库内核中的热点函数也追踪起来,这样,实现了在等待事件之下的进一步的观测与诊断。因此,openGauss可观测架构实现了从观测数据到诊断定位的全链条打通。实际上,openGauss内核与架构技术创新的故事远不止这些,本文也只是管中窥豹,无法一一列举。比如:在Oracle 21c中才出现的区块链表 ,在openGauss 2.0中就已经被实现 。当然,即便如此,openGauss依然还需要持续提升和完善,创新之路上还有很长的路要走。但本文想表达的是,无论是内核创新,还是架构创新,事实上,无论是那种架构的创新,最终都与内核息息相关,只有完全掌握消化内核并在此基础上持续创新,才算是真正的自主可控。数据库发展了半个多世纪,在旧的数据库技术上,中国与西方差距其实不大,大家都知道怎么去做。李国良说,但在软件工程能力上,我们与国外是有差距的,这需要我们努力,而超越机会更大的是创新性,我们要去引领创新,而不是跟随别人创新。文章来源:IT168企业级
-
在帮助企业安全迁移到云端方面,混合云架构发挥着至关重要的作用,并且,对于必须保留在本地的数据,混合云架构提供一种方法来满足数据治理和风险管理要求。但是,将应用程序和支持它们的数据库迁移到混合云也需要大量的规划和测试,以及持续的管理和监控。 在混合云数据库环境中,有些数据在本地存储和管理,有些数据被移动到公共云。因此,在混合云中运行数据库引入新的数据管理注意事项,必须解决这些注意事项以确保数据安全、准确并符合法规,同时确保数据能够得到有效处理。什么是混合云?混合云结合公共云服务与传统企业IT基础设施(通常设置为私有云)。企业 IT 方面可能包含服务器,这些服务器由企业在其自己的设施中直接管理的服务器,或托管在与其他用户共享的第三方数据中心中。有些应用程序使用熟悉的内部IT流程进行管理,而其他应用程序则通过特定于云的流程进行管理。 混合云数据库部署将相同的概念扩展到数据本身。但技术研究咨询公司Everest Group的合伙人Yugal Joshi表示,企业是否需要采用混合云数据库模型,这应该取决于,需要数据库在混合云的应用程序和工作负载需求。如果是这种情况,混合架构可以为底层应用程序提供补充优势-通过简化对所需数据的访问。 尽管它们通常比本地数据库系统提供更低的成本和更大的灵活性,但云服务并不是对每个企业或应用程序都适用。Joshi表示:“随着数据审查的增加、强大的数据引力、对延迟的工作负载要求、许可复杂性和数据分散化,并非所有数据都可以放在一个地方,例如公共云,这是混合模型可以增加价值的地方。” 对于部署数据库 混合云的优势 混合云数据库环境的好处就像针对应用程序的混合云一样:提供对自动化云服务的访问、打开新选项并提高可移植性。 自动化的云服务。咨询公司Nucleus Research的研究分析师Alexander Wurm解释说:“通过使用混合云来部署数据库,企业可以获得现代云的好处,例如定期更新和弹性可扩展性,而不会影响安全性和可靠性-由支持关键任务工作负载的现有本地基础设施提供。” 新选项。企业还可以探索新选项。管理咨询公司Kearney的数字化转型实践合伙人Joshua Swartz表示,如果与安全、性能、质量或成本等关键变量相关的需求随时间发生变化,则可以使用更多选项来重新平衡投资组合。 可移植性。混合云数据库方法还支持跨多个私有云和公共云服务的数据和工作负载可移植性。数据管理和分析平台提供商1010data公司的首席技术官Terry Sage称:“这反过来又允许企业选择跨混合云协调数据和工作负载,从而避免供应商锁定,实现成本和效率优势,以及扩展和缩小环境以满足服务需求的能力。”此外,可移植性可以使恢复和业务连续性规划更容易,并鼓励实验和创新。 在规划混合云数据库策略时应考虑的事项 混合云架构提供的好处可以带来降低成本的新机会;然而,它们也引入新的安全、性能、集成和数据质量挑战,需要首先解决这些挑战,以最大限度地利用混合云数据库战略。 IT 团队、数据经理和数据库管理员在混合云环境中部署数据库之前应考虑以下问题。 1. 数字化转型和应用程序现代化目标 最好的起点之一是确定各种目标,以实现业务流程和为其提供动力的应用程序的现代化和转型。IT管理咨询公司Capgemini多云管理交付架构师Brian Schneider表示:“企业不仅需要了解业务的数字化转型目标,还需要了解他们希望通过对现有应用程序和这些应用程序使用的数据库进行现代化改造所获得的结果。”其结果应该是为业务和终端用户提供最有效和最具效益的数据库选项。 这个过程应该从发现阶段开始,应该涵盖应用程序团队和业务所有者,以确定当前的架构、应用程序体验和最终用户的痛点,然后创建一个转型路线图以进行改进。让利益相关者参与该过程至关重要。数据经理可以帮助利益相关者了解可能影响规划的本地和云数据库技术进步。 2. 应用程序和数据库的适当分组 专注于业务和应用程序目标还有助于确定暂存数据以支持不同应用程序需求的最佳方式。 托管服务提供商Syntax公司首席技术官Colin Dawes指出:“移动应用程序和数据库需要将应用程序和数据库适当地分组为逻辑单元。” 创建这些自然断层线可以帮助数据管理团队将整体系统划分为可管理的块。Dawes警告说,如果弄错这部分流程,可能会出现性能和稳定性问题,从而导致利益相关者全面拒绝流程。 3. 成本效益分析与其他方法 数据经理需要分析对现有本地数据库进行现代化改造、迁移到云端或采用混合方法的相关成本和收益。与纯云或本地方法相比,混合云的部署和管理本质上会更加复杂和昂贵。数据智能平台提供商BigID公司客户服务高级副总裁George Chedzhemov表示:“企业应该计算额外的成本和管理开销,并通过收益和业务需求来证明其合理性。” 增加的费用可能是值得的,但对于部署新的云数据库服务,企业还需要仔细权衡所带来的挑战,毕竟这些服务作为混合战略的一部分会带来额外的困难。Chedzhemov认为,专有方法(例如 AWS DynamoDB或Google Cloud Spanner)可能会限制部署选项。他推荐了基于MySQL、PostgreSQL、MongoDB和Apache Cassandra等开放标准的云服务,以提高跨本地和云服务的兼容性。 4. 数据输出费用 混合云数据库策略应包括数据流。原本使用本地数据库数据传输成本可忽略不计,在迁移到混合环境后,数据传输成本可能会很高。Sage指出:“这些成本可能很高,并且取决于为支持混合云数据库策略而复制的数据量。” 通过适当的架构,可以减轻其中一些成本。尽管如此,如果数据流经昂贵的渠道,则应实施适当的控制。 5. 数据延迟 由于不同云服务提供商之间的数据传输以及物理资源之间的距离,混合云数据库也会引入网络延迟。Sage说,混合方法通常会导致更长的路由和更多的网络跃点,这可能会增加数毫秒甚至数秒的数据传输时间。在规划时,应考虑网络延迟和重新审视所选物理区域的决策。她建议道:“有时将不同的云服务提供商托管在相似的地理区域以降低成本和网络延迟会更有意义。” 在规划云端或本地节点是否具有更主动或被动的角色时,还需要从延迟的角度考虑配置选择。例如,主动-主动集群配置通常在私有云和公共云之间具有较少的竞争延迟,Wurm 说,主动-被动配置可能是拥有大量边缘数据的资产密集型行业的更好选择。 6. 数据安全 区块链数据库平台提供商Fluree公司首席执行官兼联合创始人Brian Platz表示,管理和保护数据必须成为混合云数据库战略的一部分,因为混合云环境的复杂性会增加潜在的攻击面。他解释说:“重要的是,在所有可能的环境中绘制数据的架构流程,以及部署安全和治理措施,并在所有可能的环境中管理、部署、移植和虚拟化数据时,保护数据。” 考虑使用持续集成/持续交付测试和版本控制来降低安全风险。探索以数据为中心的安全治理也是值得的,这可以在数据跨各种网络和云移动时保护数据。 7. 新工具和技能要求 混合云数据库可能会引入需要解决的新数据工作流。Everest Group公司的Joshi表示,公共和本地系统的数据管理工具集可能会有所不同,这可能会增加运营成本。他建议开发标准操作模型和工具策略,用于扩展、跨技能和即插即用操作。 沿着这些思路,不同的技能可能需要支持这些新的工作流程。Joshi承认:“为公共云寻找人才很困难,但对于混合云来说,情况更糟。” 8.平衡稳定性和简单性 任何用于存储和传输数据的新基础设施都有可能产生新的故障点。考虑如何在系统或网络脱机时最大限度地减少对运营的干扰。Kearney公司的Swartz称:“解决这个问题有点像保险单,绝对可以创建冗余和故障安全机制,但成本相当高。”大多数公司遵循的方法是根据业务关键性对数据进行分层,并仅为最关键的数据提供最昂贵的冗余。 同样重要的是,对需要集成多个系统所需的工作做好准备。每个额外的系统或数据库都会带来与核心应用程序和系统集成所需的另一个接口。开发具有较少接口的架构可以降低管理风险。 Swartz说,与纯云或本地方法相比,管理混合云环境可能要复杂得多,成本也会更高。更改、更新、补丁和增强都需要更广泛和更精细的计划、测试和监控,以避免产生兼容性问题的多米诺骨牌效应。来源 :TechTarget
-
本期文章继续为大家解读《数据库服务能力成熟度模型》运维运营能力域的备份恢复与应急方案演练两个能力项。《数据库服务能力成熟度模型》的整体框架如下图所示:《数据库服务能力成熟度模型》按照交付类型总体分为规划设计能力域、实施部署能力域和运维运营能力域,共包含27个能力项。每个能力项均从人员、工具、流程、制度、技术等维度,通过人员访谈、资料审查、工具演示等方式,对企业服务能力的评价从低到高依次划分为初始级、可重复级、稳健级、量化管理级和优化级五个等级。每个能力域的等级评定是由能力域所包含能力项的等级按照一定算法计算得出,每个能力项的等级评定是由该能力项五个等级的符合程度按照一定算法判定所得。简单来说,备份恢复是指数据库服务方根据需求方的需求或规划好的备份策略进行数据库备份和恢复的运维操作,在遭遇数据丢失故障时,能够快速实现数据恢复,满足需求方RTO、RPO的要求。数据库备份别可划分为物理备份和逻辑备份两大类,物理备份可进一步分为冷备和热备。备份恢复的主要过程描述如下:a) 制定备份策略:制定并确认备份策略;b) 备份策略部署:按照备份策略,进行备份策略部署,包括但不限于备份脚本的编写与部署、设置备份任务、备份存放位置、备份文件存储格式、备份文件加密方式、备份方式、备份频度、冗余策略等;c) 备份确认:确认备份的有效性和备份策略的准确性;d) 制定恢复策略和方案:根据故障场景和用户需求,制定恢复策略和方案,应充分考虑业务的特点、投入成本等多方面因素;e) 验证恢复策略:按照恢复方案,进行恢复测试,确认恢复脚本的可行性和完整性;f) 恢复演练:定期执行恢复演练,熟悉恢复过程,确认恢复各步骤的详细时间,为故障发生时快速实现业务恢复奠定基础;g) 实施恢复:根据故障场景,结合恢复策略和恢复工具的特点,选定恢复方案并实现数据快速恢复。按照服务能力成熟度的差异划分,备份恢复能力要求如表1所示:评估要点:◆ 备份恢复策略、手册、方案、报告等;◆ 备份恢复工具/平台功能丰富程度、易用性等;◆ 人员制定备份恢复策略、支持多种主流数据库备份恢复的能力。介绍完备份恢复后,接下来解读运维运营的第八个能力项:应急方案演练。应急方案演练是指数据库服务方为确保核心系统出现故障时,业务能够尽可能不受影响,针对可能出现的紧急情况,如数据库无法启动、数据文件访问报错、访问性能极差、连接数超限等,提前规划应急方案并进行演练。应急方案应考虑全面且经过验证。应急方案应提供标准的判断方法、应急作业规程及善后指导并具备标准化和可操作性。为确保紧急情况出现时应急方案的有效性,应定期组织开展应急方案演练。应急方案演练的主要过程描述如下:a) 调研和需求分析:对需求方的安全审计需求进行调研和分析,了解需求方的管理规范、管理流程和审计需求;b) 制定方案:根据需求分析结果,制定安全审计方案。方案包括但不限于安全审计的配置操作手册、安全审计结果记录、安全审计结果呈现等;c) 安全审计实施:根据制定的安全审计方案,对安全审计进行在线或离线的启用、关闭等,并对相关的审计规则、告警规则等进行配置。如果有安全审计的辅助平台,要一并部署并保证能顺利执行;d) 安全审计验证:根据安全审计方案实施后,形成满足需求方的安全审计环境。与需求方一起选取代表性的业务场景,对安全审计功能进行验证,从而证明安全审计功能满足需求方的要求。e) 应急响应启动:故障发生,启动快速应急响应流程;f) 灾难评估启动:根据灾难的不同等级,结合风险、技术、人员等综合条件,评估已有的灾备手段,选出可行的应急方案;g) 灾难恢复决策启动:根据灾难评估的结果及选出可行的应急方案,进行灾难恢复决策;h) 应急演练启动:相应的应急小组成员、应急厂家人员根据灾难评估和灾难恢复决策,根据应急演练计划及应用演练具体操作步骤,正式启动应急演练,应急演练执行过程包括但不限于:1) IT系统切换;2) 切换后的业务验证;3) 对外提供业务;4) 业务回流开启;5) 切换后业务运行;6) 业务回切;7) 容灾系统恢复;8) 演练结束。i) 应急方案演练总结:根据应急演练执行的具体操作步骤在应急演练的各流程阶段出现的问题与应急小组成员专项讨论及优化改进,更新应急方案。按照服务能力成熟度的差异划分,应急方案演练的等级要求如表2所示:评估要点:◆ 标准化的运维服务体系,实施文档和管理规范;◆ 人员具备制定应急方案演练的能力;◆ 定制化的应急方案演练平台及开发支撑团队技术能力。《数据库服务能力成熟度模型》标准是由中国信息通信研究院依托通信标准化协会大数据技术标准推进委员会(CCSA TC601),联合云和恩墨、腾讯云、星环科技、新炬网络、中兴通讯、爱可生、华为云、华胜信泰、科蓝软件、浪潮云、金山云、迪思杰、万里开源、百度智能云等企业于2020年联合编制而成,标准共包括900多个评估点,成为国内数据库服务领域最权威的行业标准,目前已累计完成3批6家共11次评估工作,包括云和恩墨、星环科技、腾讯云、科蓝软件、中移苏研和京东科技,为行业遴选优质服务商提供有力依据文章来源:大数据技术标准推进委员会 (如有侵权,请联系删除)
推荐直播
-
 华为云码道Skill实战与极速交付,智能开发全链路实战
华为云码道Skill实战与极速交付,智能开发全链路实战2026/07/22 周三 19:00-21:00
王一男-华为云码道产品规划专家;李炎-华为云码道产品专家;姜浩-华为云HCDG核心组成员
直播深度解读华为云码道6月产品新特性,从Skill市场安装专家技能,带你零距离体验从需求,开发,审查,重构全链路闭环的开发过程。从零构建并交付一个完整项目,让您体验从代码提交到服务上线的“极速”之旅。
回顾中 -
 聚开发者之力,创具身新未来
聚开发者之力,创具身新未来2026/07/23 周四 15:00-17:00
张豪杰/程文/王军/刘新春/黄钦开 /张晓天
本次华为云具身智能开发平台CloudRobo培训面向具身智能开发者,带您全流程体验机器人本体R2C小时级接入、环境重建与轨迹生成仿真数据生产、PB级数据管理、数据评测、模型训推、强化学习和Benchmark一键评测等功能,并体验业界主流具身模型应用。
回顾中
热门标签