-
 摘要:KubeEdge设备管理架构的设计实现,有效帮助用户处理设备数字孪生进程中遇到的场景。本文分享自华为云社区《KubeEdge:下一代云原生边缘设备管理标准DMI的设计与实现》。随着5G、AI、分布式云等技术的成熟发展,万物互联、数字孪生、算力泛在等理念不断推进,带来了很多行业业务的创新,越来越多的设备、应用运行在端侧,并产生大量的数据。如何更好地解耦业务应用开发和设备数据访问,为设备提供完整的生命周期数据管理,释放设备数据的价值?如何在保证集群可用性的同时,高效管理和传输设备数据,获得更为方便、灵活的数据访问方式?云原生边缘计算的方案选择可以帮助用户更好地应对这类问题。一、KubeEdge设备管理框架KubeEdge设备管理架构的设计实现,有效帮助用户处理设备数字孪生进程中遇到的场景。用户可以通过KubeEdge,将物理设备抽象成数字孪生,用云原生的方式对设备和数据进行管理。一、KubeEdge设备管理框架 图 1 KubeEdge设备管理架构设计KubeEdge设备管理架构设计如图1所示,具体流程如下:1. 用户调用Kubernetes API接口,创建Device CRD实例到KubeEdge2. KubeEdge云上组件CloudCore watch到Kubernetes中Device CRD实例创建消息3. 此时CloudCore会做两件事情,一方面CloudCore通过云边websocket通道下发Device Twin信息到EdgeCore,另一方面CloudCore会生成一份包含Device Profile信息的Configmap,该Configmap是以Node名称为索引,挂载到对应Mapper的Pod中的4. Mapper通过读取挂载的Configmap中的Device Profile信息,更新本地维护的Device list列表5. EdgeCore把接收到的Device Twin信息发送到指定的mqtt topic6. 该节点上的所有Mapper都会收到该Device Twin消息,并根据Device名称来匹配是否是自己维护的list中的Device7. Mapper根据Device Profile信息,通过对应的协议与设备建立连接8. Mapper通过mqtt topic上报设备状态和采集的数据Device Twin到EdgeCore9. EdgeCore通过云边websocket通道上报Device Twin数据到CloudCore10. CloudCore更新设备Device Twin数据到Kubernetes二、DMI框架设计 在此基础上,KubeEdge团队也对框架不断更新迭代。为帮助用户应对未来更大规模设备场景、更高的可用性需求、更灵活的功能支持以及更优的用户体验,KubeEdge 设计了更优化的设备管理框架——DMI。DMI整合设备管理接口,优化边缘计算场景下的设备管理能力,打造基于云原生技术的,覆盖设备管理、设备数据的设备数字孪生管理平台;同时定义了EdgeCore与Mapper之间统一的连接入口,并分别由EdgeCore和Mapper实现上行数据流和下行数据流的服务端和客户端,承载DMI具体功能。DMI框架设计中解耦了设备管理面与设备业务面数据,让Device CRD只承载设备本身的生命周期管理,而设备业务面数据则直接通过微服务的方式为数据消费者应用提供出来。在这样的架构下,设备就不再是单纯的数据源,而是一种云原生的设备微服务,设备数据消费应用的开发者就可以不再关心如何获取设备数据,而是以更云原生的方式来聚焦应用本身的业务逻辑开发。DMI框架还提供多种数据推送方式,让数据消费者可以更灵活地获取设备数据,用户体验更优。由于DMI的设备管理面与业务面数据分离的特点,业务面数据可以通过业务面通道更灵活地在云端或边端被处理,而管理面的云边通道中只会传输少量管理面信息,大大降低了云边通道拥塞的可能,提高了KubeEdge系统的可用性。另外,DMI提供了统一的设备管理相关接口,无论是设备应用开发者还是设备应用的使用者,都可以以更统一、更灵活、更标准化的方式来开展设备相关工作,不拘泥于具体形式,只要能够实现DMI接口,就能够享受KubeEdge边缘计算平台带来的云原生设备管理体验。▍2.1 DMI框架定位图 2 DMI 在 KubeEdge 架构中的定位DMI在KubeEdge架构中的定位如图2所示。DMI类似Kubernetes的CNI、CSI、CRI等接口,定义了一组EdgeCore与Mapper之间的内部API接口以及外部应用访问Mapper的统一的API接口。其中内部接口底层由gRPC结合UDS的方式来实现,外部API接口支持mqtt和REST两种接入方式。Mapper不论是何种承载、实现方式,只要实现了DMI中所定义的上行、下行数据接口,即可接入KubeEdge云原生边缘计算平台,使用云原生的方式对设备进行管理。▍2.2 DMI设备管理与数据管理DMI框架架构设计如图3所示,其中黄色线条为设备管理面数据流管理,蓝色部分为业务面数据流管理。在DMI的架构设计中,将设备的管理面数据与业务面数据进行分离。其中管理面数据主要包括设备的元数据、设备属性、配置、状态、生命周期等,其特点是相对比较稳定,创建后除状态上报外的信息更新较少,更贴近Pod类型资源所产生的数据,在保证用户可以通过云端Kubernetes API像访问Pod一样维护Device的生命周期的同时,尽量减少设备管理产生的额外数据传输开销。图 3 DMI设备管理与数据管理架构在DMI框架设计下,设备不再是单纯的数据源,而是被抽象为微服务,以云原生的方式为设备数据消费者提供数据服务。DMI框架下的设备数据访问支持多种场景,更加灵活。图3中列出了几种主要的数据访问方式,包括推数据和拉数据等,具体情况如下:1. 边缘侧应用通过REST Service访问设备数据2. 云侧应用通过REST Service访问设备数据3. Mapper通过配置REST目的地址,将数据推送到边缘侧应用4. Mapper通过配置REST目的地址,将数据推送到云侧应用5. Mapper通过配置目的地址,将数据推送到边缘侧数据库6. Mapper通过配置目的地址,将数据推送到mqtt broker7. 边缘侧应用通过mqtt broker topic订阅设备数据8. 云侧应用通过mqtt broker topic 订阅设备数据9. 边缘侧应用处理数据后将处理结果传上云▍2.3 DMI工作流程图 4 DMI设备管理工作流程示例在DMI框架下,设备管理工作的流程有一定的变化。如图4所示,在安装KubeEdge的时候,云端CloudCore会注册DeviceController组件用于监听Device和DeviceModel的CRD资源。DeviceController中存在两个模块,Downstream Controller和Upstream Controller,其中Downstream Controller用于监听云端的Device、DeviceModel事件,并通过Cloudhub下发至边缘,Upstream Controller用于接收从Cloudhub转发来的EdgeHub上报的Device状态和消息,并更新Kubernetes中的Device状态。在边缘侧,Mapper初始化的时候,需要调用DMI中的Mapper注册接口,将Mapper的相关信息注册至Device Manager,并接收接口返回的已下发至该节点的且协议匹配的设备信息。EdgeHub在接收到云端下发的设备消息时,会将其转发到DeviceManager组件,DeviceManager会根据该设备的协议选择对应的Mapper驱动程序,发送创建设备的请求,并且本地数据库也会存储该设备的信息,后续Mapper会将设备孪生消息转化为设备协议格式,跟实际的物理设备进行通信。三、DMI接口定义▍3.1 DMI 接口分类DMI接口实现了EdgeCore与Mapper之间的通信,支持REST和mqtt的通信方式,并以标准化的形式呈现,降低了Mapper开发、适配难度。在数据访问方面,DMI可以实现边缘侧和云侧的应用都可以通过REST Service的方式访问设备数据。图 5 DMI接口定义如图5所示,DMI有六类接口,Mapper管理是针对边缘侧各类设备协议驱动程序,Device管理和Device数据管理对管理面和业务面进行了数据拆分,Device升级管理和Device命令管理为具有升级和命令执行功能的设备提供相关的接口,Device事件管理可以监控Mapper及其纳管的各个设备的运行状态。▍3.2 DMI 接口定义示例图 6 DMI设备管理部分接口定义示例如图6所示,为DMI设备管理部分接口定义,v1版本以gRPC proto的方式定义,可使用make dmi命令创建对应的gRPC-go代码。 ▍3.3 DMI 设备相关 CRD 定义如图7所示,是DMI设备相关CRD定义,主要分为Device和DeviceModel。其中DeviceModel与设备型号是一一对应的关系,代表同一类设备型号的共有属性,主要包含设备产生数据属性Properties和设备支持命令属性Commands。Device为设备实例,与真实的物理设备为一对一的关系,每个DeviceModel可以对应统一型号的多个Device实例。Device类型资源主要包含设备型号对应关系信息、设备协议配置信息、设备部署节点信息、设备状态信息以及设备数据Property采集配置信息。图 7 DMI 设备相关 CRD 定义 四、发布计划 四、发布计划DMI发布计划分为三个版本,Alpha版本提供设备管理相关功能实现,以及提供一个支持DMI接口的Mapper Demo。Beta版本支持设备命令管理、设备升级管理以及设备数据管理的能力,此外还会对接第三方平台,并提供相关对接Demo。GA版本会对多平台、多协议进行对接支持,另外会把设备安全以及事件管理的功能补全。图 8 DMI发布计划目前 KubeEdge Device IoT SIG 专注于第一阶段的设备管理和 Mapper Demo 的开发工作。欢迎大家通过下方联系方式联系我们,一起参与到方案设计和特性开发的工作当中本文作者:华为云 赵然 ;DaoCloud 道客 王梓龙附:KubeEdge社区贡献和技术交流地址网站: https://kubeedge.ioGithub地址: cid:link_1地址: https://kubeedge.slack.com邮件列表: https://groups.google.com/forum/#!forum/kubeedge每周社区例会: https://zoom.us/j/4167237304Twitter: https://twitter.com/KubeEdge文档地址: https://docs.kubeedge.io/en/latest/
摘要:KubeEdge设备管理架构的设计实现,有效帮助用户处理设备数字孪生进程中遇到的场景。本文分享自华为云社区《KubeEdge:下一代云原生边缘设备管理标准DMI的设计与实现》。随着5G、AI、分布式云等技术的成熟发展,万物互联、数字孪生、算力泛在等理念不断推进,带来了很多行业业务的创新,越来越多的设备、应用运行在端侧,并产生大量的数据。如何更好地解耦业务应用开发和设备数据访问,为设备提供完整的生命周期数据管理,释放设备数据的价值?如何在保证集群可用性的同时,高效管理和传输设备数据,获得更为方便、灵活的数据访问方式?云原生边缘计算的方案选择可以帮助用户更好地应对这类问题。一、KubeEdge设备管理框架KubeEdge设备管理架构的设计实现,有效帮助用户处理设备数字孪生进程中遇到的场景。用户可以通过KubeEdge,将物理设备抽象成数字孪生,用云原生的方式对设备和数据进行管理。一、KubeEdge设备管理框架 图 1 KubeEdge设备管理架构设计KubeEdge设备管理架构设计如图1所示,具体流程如下:1. 用户调用Kubernetes API接口,创建Device CRD实例到KubeEdge2. KubeEdge云上组件CloudCore watch到Kubernetes中Device CRD实例创建消息3. 此时CloudCore会做两件事情,一方面CloudCore通过云边websocket通道下发Device Twin信息到EdgeCore,另一方面CloudCore会生成一份包含Device Profile信息的Configmap,该Configmap是以Node名称为索引,挂载到对应Mapper的Pod中的4. Mapper通过读取挂载的Configmap中的Device Profile信息,更新本地维护的Device list列表5. EdgeCore把接收到的Device Twin信息发送到指定的mqtt topic6. 该节点上的所有Mapper都会收到该Device Twin消息,并根据Device名称来匹配是否是自己维护的list中的Device7. Mapper根据Device Profile信息,通过对应的协议与设备建立连接8. Mapper通过mqtt topic上报设备状态和采集的数据Device Twin到EdgeCore9. EdgeCore通过云边websocket通道上报Device Twin数据到CloudCore10. CloudCore更新设备Device Twin数据到Kubernetes二、DMI框架设计 在此基础上,KubeEdge团队也对框架不断更新迭代。为帮助用户应对未来更大规模设备场景、更高的可用性需求、更灵活的功能支持以及更优的用户体验,KubeEdge 设计了更优化的设备管理框架——DMI。DMI整合设备管理接口,优化边缘计算场景下的设备管理能力,打造基于云原生技术的,覆盖设备管理、设备数据的设备数字孪生管理平台;同时定义了EdgeCore与Mapper之间统一的连接入口,并分别由EdgeCore和Mapper实现上行数据流和下行数据流的服务端和客户端,承载DMI具体功能。DMI框架设计中解耦了设备管理面与设备业务面数据,让Device CRD只承载设备本身的生命周期管理,而设备业务面数据则直接通过微服务的方式为数据消费者应用提供出来。在这样的架构下,设备就不再是单纯的数据源,而是一种云原生的设备微服务,设备数据消费应用的开发者就可以不再关心如何获取设备数据,而是以更云原生的方式来聚焦应用本身的业务逻辑开发。DMI框架还提供多种数据推送方式,让数据消费者可以更灵活地获取设备数据,用户体验更优。由于DMI的设备管理面与业务面数据分离的特点,业务面数据可以通过业务面通道更灵活地在云端或边端被处理,而管理面的云边通道中只会传输少量管理面信息,大大降低了云边通道拥塞的可能,提高了KubeEdge系统的可用性。另外,DMI提供了统一的设备管理相关接口,无论是设备应用开发者还是设备应用的使用者,都可以以更统一、更灵活、更标准化的方式来开展设备相关工作,不拘泥于具体形式,只要能够实现DMI接口,就能够享受KubeEdge边缘计算平台带来的云原生设备管理体验。▍2.1 DMI框架定位图 2 DMI 在 KubeEdge 架构中的定位DMI在KubeEdge架构中的定位如图2所示。DMI类似Kubernetes的CNI、CSI、CRI等接口,定义了一组EdgeCore与Mapper之间的内部API接口以及外部应用访问Mapper的统一的API接口。其中内部接口底层由gRPC结合UDS的方式来实现,外部API接口支持mqtt和REST两种接入方式。Mapper不论是何种承载、实现方式,只要实现了DMI中所定义的上行、下行数据接口,即可接入KubeEdge云原生边缘计算平台,使用云原生的方式对设备进行管理。▍2.2 DMI设备管理与数据管理DMI框架架构设计如图3所示,其中黄色线条为设备管理面数据流管理,蓝色部分为业务面数据流管理。在DMI的架构设计中,将设备的管理面数据与业务面数据进行分离。其中管理面数据主要包括设备的元数据、设备属性、配置、状态、生命周期等,其特点是相对比较稳定,创建后除状态上报外的信息更新较少,更贴近Pod类型资源所产生的数据,在保证用户可以通过云端Kubernetes API像访问Pod一样维护Device的生命周期的同时,尽量减少设备管理产生的额外数据传输开销。图 3 DMI设备管理与数据管理架构在DMI框架设计下,设备不再是单纯的数据源,而是被抽象为微服务,以云原生的方式为设备数据消费者提供数据服务。DMI框架下的设备数据访问支持多种场景,更加灵活。图3中列出了几种主要的数据访问方式,包括推数据和拉数据等,具体情况如下:1. 边缘侧应用通过REST Service访问设备数据2. 云侧应用通过REST Service访问设备数据3. Mapper通过配置REST目的地址,将数据推送到边缘侧应用4. Mapper通过配置REST目的地址,将数据推送到云侧应用5. Mapper通过配置目的地址,将数据推送到边缘侧数据库6. Mapper通过配置目的地址,将数据推送到mqtt broker7. 边缘侧应用通过mqtt broker topic订阅设备数据8. 云侧应用通过mqtt broker topic 订阅设备数据9. 边缘侧应用处理数据后将处理结果传上云▍2.3 DMI工作流程图 4 DMI设备管理工作流程示例在DMI框架下,设备管理工作的流程有一定的变化。如图4所示,在安装KubeEdge的时候,云端CloudCore会注册DeviceController组件用于监听Device和DeviceModel的CRD资源。DeviceController中存在两个模块,Downstream Controller和Upstream Controller,其中Downstream Controller用于监听云端的Device、DeviceModel事件,并通过Cloudhub下发至边缘,Upstream Controller用于接收从Cloudhub转发来的EdgeHub上报的Device状态和消息,并更新Kubernetes中的Device状态。在边缘侧,Mapper初始化的时候,需要调用DMI中的Mapper注册接口,将Mapper的相关信息注册至Device Manager,并接收接口返回的已下发至该节点的且协议匹配的设备信息。EdgeHub在接收到云端下发的设备消息时,会将其转发到DeviceManager组件,DeviceManager会根据该设备的协议选择对应的Mapper驱动程序,发送创建设备的请求,并且本地数据库也会存储该设备的信息,后续Mapper会将设备孪生消息转化为设备协议格式,跟实际的物理设备进行通信。三、DMI接口定义▍3.1 DMI 接口分类DMI接口实现了EdgeCore与Mapper之间的通信,支持REST和mqtt的通信方式,并以标准化的形式呈现,降低了Mapper开发、适配难度。在数据访问方面,DMI可以实现边缘侧和云侧的应用都可以通过REST Service的方式访问设备数据。图 5 DMI接口定义如图5所示,DMI有六类接口,Mapper管理是针对边缘侧各类设备协议驱动程序,Device管理和Device数据管理对管理面和业务面进行了数据拆分,Device升级管理和Device命令管理为具有升级和命令执行功能的设备提供相关的接口,Device事件管理可以监控Mapper及其纳管的各个设备的运行状态。▍3.2 DMI 接口定义示例图 6 DMI设备管理部分接口定义示例如图6所示,为DMI设备管理部分接口定义,v1版本以gRPC proto的方式定义,可使用make dmi命令创建对应的gRPC-go代码。 ▍3.3 DMI 设备相关 CRD 定义如图7所示,是DMI设备相关CRD定义,主要分为Device和DeviceModel。其中DeviceModel与设备型号是一一对应的关系,代表同一类设备型号的共有属性,主要包含设备产生数据属性Properties和设备支持命令属性Commands。Device为设备实例,与真实的物理设备为一对一的关系,每个DeviceModel可以对应统一型号的多个Device实例。Device类型资源主要包含设备型号对应关系信息、设备协议配置信息、设备部署节点信息、设备状态信息以及设备数据Property采集配置信息。图 7 DMI 设备相关 CRD 定义 四、发布计划 四、发布计划DMI发布计划分为三个版本,Alpha版本提供设备管理相关功能实现,以及提供一个支持DMI接口的Mapper Demo。Beta版本支持设备命令管理、设备升级管理以及设备数据管理的能力,此外还会对接第三方平台,并提供相关对接Demo。GA版本会对多平台、多协议进行对接支持,另外会把设备安全以及事件管理的功能补全。图 8 DMI发布计划目前 KubeEdge Device IoT SIG 专注于第一阶段的设备管理和 Mapper Demo 的开发工作。欢迎大家通过下方联系方式联系我们,一起参与到方案设计和特性开发的工作当中本文作者:华为云 赵然 ;DaoCloud 道客 王梓龙附:KubeEdge社区贡献和技术交流地址网站: https://kubeedge.ioGithub地址: cid:link_1地址: https://kubeedge.slack.com邮件列表: https://groups.google.com/forum/#!forum/kubeedge每周社区例会: https://zoom.us/j/4167237304Twitter: https://twitter.com/KubeEdge文档地址: https://docs.kubeedge.io/en/latest/ -
使用Kubesphere 安装kubernetes集群【摘要】 设置环境变量 [root@master01 ~]# export KKZONE=cn 下载kubeKey [root@master01 ~]# curl -sfL https://get-kk.kubesphere.io | VERSION=v1.2.1 sh - kk赋权 [root@master01 ~]# chmod ...设置环境变量[root@master01 ~]# export KKZONE=cn下载kubeKey[root@master01 ~]# curl -sfL https://get-kk.kubesphere.io | VERSION=v1.2.1 sh -kk赋权[root@master01 ~]# chmod +x kk生成config[root@master01 ~]# ./kk create config --with-kubernetes v1.21.5安装kubernetes[root@master01 ~]# ./kk create cluster -f config-sample.yaml+----------+------+------+---------+----------+-------+-------+-----------+----------+------------+-------------+------------------+--------------+| name | sudo | curl | openssl | ebtables | socat | ipset | conntrack | docker | nfs client | ceph client | glusterfs client | time |+----------+------+------+---------+----------+-------+-------+-----------+----------+------------+-------------+------------------+文章来源: blog.csdn.net,作者:隔壁老瓦,版权归原作者所有,如需转载,请联系作者。原文链接:blog.csdn.net/wxb880114/article/details/123303525
-
一.存储容器化存储作为基础组件,直接和本地盘打交道,所以我们一个要解决的事情就是如果Kubernetes 管理本地盘。kubernetes管理本地盘通过官方提供的local-static-provisioner自动生成LocalPersistentVolume管理磁盘。LocalPersistentVolume是Kubernetes提供的一种管理本地盘的资源。5.1 使用Statefulset管理存储容器通过statefulset 管理有状态的存储服务, 为每个pod分配一个单独的磁盘可以使用volumeClaimTemplates给每个pod生成唯一的pvc,具体规则{podName},事先准备好PVC 和 PV,通过Statefulset 我们就可以把我们的存储托管到云上了。另外借助daemonset,可以把我们gateway模块部署到每一个node上面。处理云存储的请求。5.2 存储容器化的收益1)降低运维成本基于Kubernetes和statfulset获得了滚动更新,灰度更新,健康检查,快速扩容等功能,只需要一组yaml文件就可以快速搭建一个集群,相比于传统写ansible脚本部署的方式复杂度大大降低。2)降低开发运维成本由于Kubernetes把存储抽象成StorageClass PersistentVolume PersistentVolumeClaim。我们可以通过他们管理我们的存储资源,基于Kubernetes lable的过滤功能,可以实现简单的关系查询,通过PVC与PV管理存储资源,减少管理端的开发。定位问题也能通过POD信息快速定位到问题机器和问题云盘。而且接入Kubernetes生态上的prometheus后,监控告警也能快速开发。3)隔离性增强docker限制cpu memory使用,减少进程之间资源互相干扰,进一步提升资源利用率。在做流媒体容器化过程中,各个系统 Portal 平台、中间件、ops 基础设施、监控等都做了相应的适配改造,改造后的架构矩阵如下图所示。1. Portal:流媒体 的 PaaS 平台入口,提供 CI/CD 能力、资源管理、自助运维、应用画像、应用授权(db 授权、支付授权、应用间授权)等功能。2.运维工具:提供应用的可观测性工具, 包括 watcher(监控和报警)、bistoury (Java 应用在线 Debug)、qtrace(tracing 系统)、loki/elk(提供实时日志/离线日志查看)。中间件:应用用到的所有中间件,mq、配置中心、分布式调度系统 qschedule、dubbo 、mysql sdk 等。3.虚拟化集群:底层的 K8s 和 OpenStack 集群。4.Noah:测试环境管理平台,支持应用 KVM/容器混合部署。一.CI/CD 流程改造主要改造点:应用画像: 把应用相关的运行时配置、白名单配置、发布参数等收敛到一起,为容器发布提供统一的声明式配置。授权系统: 应用所有的授权操作都通过一个入口进行,并实现自动化的授权。K8s 多集群方案: 通过调研对比,KubeSphere 对运维优化、压测评估后也满足我们对性能的要求,最终我们选取了 KubeSphere 作为多集群方案。二.中间件适配改造改造关注点:由于容器化后,IP 经常变化是常态,所以各个公共组件和中间件要适配和接受这种变化。Qmq组件改造点:Broker端加快过期数据的处理速度。原因:由于IP变化频繁,对于一个主题有几百个甚至上千个的IP订阅,会产生很多文件Qconfig/Qschedule组件改造点:按实例级别的推送、任务执行在容器场景下不建议使用 。原因:因为IP经常变化,在容器化场景下发布、pod驱逐等都会导致IP变化,按实例维度推送没有意义Dubbo组件改造点:更改上线下线逻辑,下线记录由永久节点改为临时节点。 原因:上下线机制加上频繁的IP变更会导致zookeeper上产生大量的过期数据Openresty改造点:监听多K8s集群的endpoint变更,并更新到upstream; KVM、容器server地址共存,支持KVM和容器混合部署;三应用平滑迁移方案设计为了帮助业务快速平滑地迁移到容器,制定了一些规范和自动化测试验证等操作来实现这个目标。1.容器化的前置条件: 应用无状态、不存在 post_offline hook(服务下线后执行的脚本)、check_url 中不存在预热操作。2.测试环境验证: 自动升级 SDK、自动迁移。我们会在编译阶段帮助业务自动升级和更改 pom 文件来完成 SDK 的升级,并在测试环境部署和验证,如果升级失败会通知用户并提示。3.线上验证: 第一步线上发布,但不接线上流量,然后通过自动化测试验证,验证通过后接入线上流量。4.线上 KVM 与容器混部署:保险起见,线上的容器和 KVM 会同时在线一段时间,等验证期过后再逐步下线 KVM。5.线上全量发布: 确认服务没问题后,下线 KVM。6.观察: 观察一段时间,如果没有问题则回收 KVM。
-
 【摘要】 Karmada已经实现了多集群场景下的Kubernetes资源(包括CRD)的分发以及管理。但当前多集群应用往往不是单一的资源形式,使用Helm对应用进行打包的使用场景也非常常见。借助Karmada原生API的支持能力,Karmada可以借助Flux轻松实现Helm应用的跨集群部署。本文分享自华为云社区《 使用Karmada实现Helm应用的跨集群部署【云原生开源】》,作者:华为云云原生开源团队。背景通过使用 Kubernetes 原生 API 并提供高级调度功能,Karmada已经实现了多集群场景下的Kubernetes资源(包括CRD)的分发以及管理。但当前多集群应用往往不是单一的资源形式,使用Helm对应用进行打包的使用场景也非常常见。借助Karmada原生API的支持能力,Karmada可以借助Flux轻松实现Helm应用的跨集群部署。部署Karmada要部署Karmada,你可以参考社区的安装文档(https://github.com/karmada-io/karmada/blob/master/docs/installation/installation.md)。如果想快速体验Karmada,我们建议通过hack/local-up-karmada.sh构建一个Karmada的开发环境。部署Flux在Karmada控制面中,你需要安装Flux的CRD,但不需要安装Flux控制器来调和基于CRD创建的CR对象,它们被视为资源模板,而不是特定的资源实例。基于Karmada的work API,它们将被封装为一个work对象下发给成员集群,最终由成员集群中的Flux控制器进行调和。kubectl apply -k github.com/fluxcd/flux2/manifests/crds?ref=main --kubeconfig ~/.kube/karmada.config在成员集群中,你可以基于以下命令安装完整的Flux组件。flux install --kubeconfig ~/.kube/members.config --context member1 flux install --kubeconfig ~/.kube/members.config --context member2你可以参考此处的文档(https://fluxcd.io/docs/installation/)来获得更详细的安装Flux的细节。提示:如果你想在你所有的集群上管理基于HelmRelease的应用,你需要在你的所有成员集群中安装Flux。Helm release分发准备工作就绪,下面将以一个podinfo的简单应用为例演示如何完成Helm chart分发。1.在 Karmada 控制平面中定义一个 Flux 的HelmRepository CR对象和一个 HelmRelease CR对象。它们将视作资源模板。apiVersion: source.toolkit.fluxcd.io/v1beta2 kind: HelmRepository metadata: name: podinfo spec: interval: 1m url: https://stefanprodan.github.io/podinfo---apiVersion: helm.toolkit.fluxcd.io/v2beta1 kind: HelmRelease metadata: name: podinfo spec: interval: 5m chart: spec: chart: podinfo version: 5.0.3 sourceRef: kind: HelmRepository name: podinfo2. 定义一个 Karmada的PropagationPolicy 对象将它们的资源实例下发到成员集群:apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: helm-repo spec: resourceSelectors: - apiVersion: source.toolkit.fluxcd.io/v1beta2 kind: HelmRepository name: podinfo placement: clusterAffinity: clusterNames: - member1 - member2---apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: helm-release spec: resourceSelectors: - apiVersion: helm.toolkit.fluxcd.io/v2beta1 kind: HelmRelease name: podinfo placement: clusterAffinity: clusterNames: - member1 - member2上述配置将会把Flux的资源对象下发到成员集群member1和member2中。3. 将上述对象提交给Karmada-apiserver:kubectl apply -f ../helm/ --kubeconfig ~/.kube/karmada.config你将会得到以下的输出结果:helmrelease.helm.toolkit.fluxcd.io/podinfo created helmrepository.source.toolkit.fluxcd.io/podinfo created propagationpolicy.policy.karmada.io/helm-release created propagationpolicy.policy.karmada.io/helm-repo created4. 切换至成员集群验证应用是否成功下发helm --kubeconfig ~/.kube/members.config --kube-context member1 list你将会得到以下的输出结果:基于 Karmada 的 PropagationPolicy,你可以灵活地将 Helm应用发布到你期望的集群。为特定集群定制 Helm 应用上述的示例显示了如何将同一个Helm应用分发到 Karmada 中的多个集群。此外,你还可以使用 Karmada 的 OverridePolicy 为特定集群定制Helm应用。例如,上述应用包括了一个Pod副本,如果你只想更改 member1集群中的应用所包含的Pod副本数,你可以参考以下的 OverridePolicy策略。1.定义一个Karmada的OverridePolicy对象。apiVersion: policy.karmada.io/v1alpha1 kind: OverridePolicy metadata: name: example-override namespace: default spec: resourceSelectors: - apiVersion: helm.toolkit.fluxcd.io/v2beta1 kind: HelmRelease name: podinfo overrideRules: - targetCluster: clusterNames: - member1 overriders: plaintext: - path: "/spec/values" operator: add value: replicaCount: 22. 将上述对象提交给Karmada-apiserver:kubectl apply -f example-override.yaml --kubeconfig ~/.kube/karmada.config你将会得到以下的输出结果:overridepolicy.policy.karmada.io/example-override created3. 在 Karmada 控制平面中应用上述策略后,你会发现 member1成员集群中的Pod实例数已变更为 2,但 member2 集群中的那些保持不变。kubectl --kubeconfig ~/.kube/members.config --context member1 get po你将会得到以下的输出结果:NAME READY STATUS RESTARTS AGE podinfo-68979685bc-6wz6s 1/1 Running 0 6m28s podinfo-68979685bc-dz9f6 1/1 Running 0 7m42s参考文档:https://github.com/karmada-io/karmada/blob/master/docs/working-with-flux.md附:Karmada社区技术交流地址添加Karmada社区助手微信k8s2222进入社区交流群,和Maintainer零距离。项目地址https://github.com/karmada-io/karmadaSlack地址:https://slack.cncf.io/
【摘要】 Karmada已经实现了多集群场景下的Kubernetes资源(包括CRD)的分发以及管理。但当前多集群应用往往不是单一的资源形式,使用Helm对应用进行打包的使用场景也非常常见。借助Karmada原生API的支持能力,Karmada可以借助Flux轻松实现Helm应用的跨集群部署。本文分享自华为云社区《 使用Karmada实现Helm应用的跨集群部署【云原生开源】》,作者:华为云云原生开源团队。背景通过使用 Kubernetes 原生 API 并提供高级调度功能,Karmada已经实现了多集群场景下的Kubernetes资源(包括CRD)的分发以及管理。但当前多集群应用往往不是单一的资源形式,使用Helm对应用进行打包的使用场景也非常常见。借助Karmada原生API的支持能力,Karmada可以借助Flux轻松实现Helm应用的跨集群部署。部署Karmada要部署Karmada,你可以参考社区的安装文档(https://github.com/karmada-io/karmada/blob/master/docs/installation/installation.md)。如果想快速体验Karmada,我们建议通过hack/local-up-karmada.sh构建一个Karmada的开发环境。部署Flux在Karmada控制面中,你需要安装Flux的CRD,但不需要安装Flux控制器来调和基于CRD创建的CR对象,它们被视为资源模板,而不是特定的资源实例。基于Karmada的work API,它们将被封装为一个work对象下发给成员集群,最终由成员集群中的Flux控制器进行调和。kubectl apply -k github.com/fluxcd/flux2/manifests/crds?ref=main --kubeconfig ~/.kube/karmada.config在成员集群中,你可以基于以下命令安装完整的Flux组件。flux install --kubeconfig ~/.kube/members.config --context member1 flux install --kubeconfig ~/.kube/members.config --context member2你可以参考此处的文档(https://fluxcd.io/docs/installation/)来获得更详细的安装Flux的细节。提示:如果你想在你所有的集群上管理基于HelmRelease的应用,你需要在你的所有成员集群中安装Flux。Helm release分发准备工作就绪,下面将以一个podinfo的简单应用为例演示如何完成Helm chart分发。1.在 Karmada 控制平面中定义一个 Flux 的HelmRepository CR对象和一个 HelmRelease CR对象。它们将视作资源模板。apiVersion: source.toolkit.fluxcd.io/v1beta2 kind: HelmRepository metadata: name: podinfo spec: interval: 1m url: https://stefanprodan.github.io/podinfo---apiVersion: helm.toolkit.fluxcd.io/v2beta1 kind: HelmRelease metadata: name: podinfo spec: interval: 5m chart: spec: chart: podinfo version: 5.0.3 sourceRef: kind: HelmRepository name: podinfo2. 定义一个 Karmada的PropagationPolicy 对象将它们的资源实例下发到成员集群:apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: helm-repo spec: resourceSelectors: - apiVersion: source.toolkit.fluxcd.io/v1beta2 kind: HelmRepository name: podinfo placement: clusterAffinity: clusterNames: - member1 - member2---apiVersion: policy.karmada.io/v1alpha1 kind: PropagationPolicy metadata: name: helm-release spec: resourceSelectors: - apiVersion: helm.toolkit.fluxcd.io/v2beta1 kind: HelmRelease name: podinfo placement: clusterAffinity: clusterNames: - member1 - member2上述配置将会把Flux的资源对象下发到成员集群member1和member2中。3. 将上述对象提交给Karmada-apiserver:kubectl apply -f ../helm/ --kubeconfig ~/.kube/karmada.config你将会得到以下的输出结果:helmrelease.helm.toolkit.fluxcd.io/podinfo created helmrepository.source.toolkit.fluxcd.io/podinfo created propagationpolicy.policy.karmada.io/helm-release created propagationpolicy.policy.karmada.io/helm-repo created4. 切换至成员集群验证应用是否成功下发helm --kubeconfig ~/.kube/members.config --kube-context member1 list你将会得到以下的输出结果:基于 Karmada 的 PropagationPolicy,你可以灵活地将 Helm应用发布到你期望的集群。为特定集群定制 Helm 应用上述的示例显示了如何将同一个Helm应用分发到 Karmada 中的多个集群。此外,你还可以使用 Karmada 的 OverridePolicy 为特定集群定制Helm应用。例如,上述应用包括了一个Pod副本,如果你只想更改 member1集群中的应用所包含的Pod副本数,你可以参考以下的 OverridePolicy策略。1.定义一个Karmada的OverridePolicy对象。apiVersion: policy.karmada.io/v1alpha1 kind: OverridePolicy metadata: name: example-override namespace: default spec: resourceSelectors: - apiVersion: helm.toolkit.fluxcd.io/v2beta1 kind: HelmRelease name: podinfo overrideRules: - targetCluster: clusterNames: - member1 overriders: plaintext: - path: "/spec/values" operator: add value: replicaCount: 22. 将上述对象提交给Karmada-apiserver:kubectl apply -f example-override.yaml --kubeconfig ~/.kube/karmada.config你将会得到以下的输出结果:overridepolicy.policy.karmada.io/example-override created3. 在 Karmada 控制平面中应用上述策略后,你会发现 member1成员集群中的Pod实例数已变更为 2,但 member2 集群中的那些保持不变。kubectl --kubeconfig ~/.kube/members.config --context member1 get po你将会得到以下的输出结果:NAME READY STATUS RESTARTS AGE podinfo-68979685bc-6wz6s 1/1 Running 0 6m28s podinfo-68979685bc-dz9f6 1/1 Running 0 7m42s参考文档:https://github.com/karmada-io/karmada/blob/master/docs/working-with-flux.md附:Karmada社区技术交流地址添加Karmada社区助手微信k8s2222进入社区交流群,和Maintainer零距离。项目地址https://github.com/karmada-io/karmadaSlack地址:https://slack.cncf.io/ -
 本文来自微信公共号:分布式实验室。文章观点独特,比喻形象,分享给大家~本文论述了 Kubernetes 的核心价值是其通用、跨厂商和平台、可灵活扩展的声明式 API 框架, 而不是容器(虽然容器是它成功的基础);然后手动创建一个 API Extension(CRD), 通过测试和类比来对这一论述有一个更直观的理解。例子及测试基于 Kubernetes v1.21.0。— 1 —Kubernetes 的核心是其 API 框架而非容器 容器是基础时间回到 2013 年。当一条简单的 docker run postgre 命令就能运行起 Postgre 这样复杂的传统服务时,开发者在震惊之余犹如受到天启;以 Docker 为代表的实用容器技术的横空出世,也预示着一扇通往敏捷基础设施的大门即将打开。此后,一切都在往好的方向迅速发展:越来越多的开发者开始采用容器作为一种标准构建和运行方式。业界也意识到,很容易将这种封装方式引入计算集群,通过 Kubernetes 或 Mesos 这样的编排器来调度计算任务 —— 自此,容器便成为这些调度器最重要的 Workload 类型。但本文将要说明,容器并非 Kubernetes 最重要、最有价值的地方,Kubernetes 也并非仅仅是一个更广泛意义上的 Workload 调度器 —— 高效地调度不同类型的 Workload 只是 Kubernetes 提供的一种重要价值,但并不是它成功的原因。API 才是核心“等等 —— Kubernetes 只是一堆 API?”“不好意思,一直都是!”Kubernetes 的成功和价值在于,提供了一种标准的编程接口(API),可以用来编写和使用软件定义的基础设施服务(本文所说的“基础设施”,范围要大于 IaaS):Specification + Implementation 构成一个完整的 API 框架 —— 用于设计、实现和使用各种类型和规模的基础设施服务;这些 API 都基于相同的核心结构和语义:typed resources watched and reconciled by controllers (资源按类型划分,控制器**相应类型的资源,并将其实际 status 校准到 spec 里期望的状态)。为了进一步解释这一点,考虑下 Kubernetes 出现之前的场景。Kubernetes 之前:各自造轮子,封装厂商 API 差异Kubernetes 之前,基础设施基本上是各种不同 API、格式和语义的“云”服务组成的大杂烩:云厂商只提供了计算实例、块存储、虚拟网络和对象存储等基础构建模块,开发者需要像拼图一样将它们拼出一个相对完整的基础设施方案;对于其他云厂商,重复过程 1,因为各家的 API、结构和语义并不相同,甚至差异很大。虽然 Terraform 等工具的出现,提供了一种跨厂商的通用格式,但原始的结构和语义仍然是五花八门的,—— 针对 AWS 编写的 Terraform descriptor 是无法用到 Azure 的。Kubernetes 面世:标准化、跨厂商的 API、结构和语义现在再来看 Kubernetes 从一开始就提供的东西:描述各种资源需求的标准 API。例如:描述 Pod、Container 等计算需求的 API;描述 Service、Ingress 等虚拟网络功能的 API;描述 Volumes 之类的持久存储的 API;甚至还包括 Service Account 之类的服务身份的 API 等等。这些 API 是跨公有云/私有云和各家云厂商的,各云厂商会将 Kubernetes 结构和语义对接到它们各自的原生 API。因此我们可以说,Kubernetes 提供了一种管理软件定义基础设施(也就是云)的标准接口。或者说,Kubernetes 是一个针对云服务(Cloud Services)的标准 API 框架。Kubernetes API 扩展:CRD提供一套跨厂商的标准结构和语义来声明核心基础设施(Pod/Service/Volume/ServiceAccount/……), 是 Kubernetes 成功的基础。在此基础上,它又通过 CRD(Custom Resource Definition), 将这个结构扩展到任何/所有基础设施资源。CRD 在 1.7 引入,允许云厂商和开发者自己的服务复用 Kubernetes 的 spec/impl 编程框架。有了 CRD,用户不仅能声明 Kubernetes API 预定义的计算、存储、网络服务,还能声明数据库、task runner、消息总线、数字证书……任何云厂商能想到的东西!Operator Framework 以及 SIG API Machinery 等项目的出现,提供了方便地创建和管理这些 CRD 的工具,最小化用户工作量,最大程度实现标准化。例如,Crossplane 之类的项目,将厂商资源 RDS 数据库、SQS queue 资源映射到 Kubernetes API,就像核心 Kubernetes controller 一样用自己的 controller 来管理网卡、磁盘等自定义资源。Google、RedHat 等 Kubernetes 发行商也在它们的基础 Kubernetes 发行版中包含越来越多的自定义资源类型。小结我们说 Kubernetes 的核心是其 API 框架,但并不是说这套 API 框架就是完美的。事实上,后一点并不(非常)重要,因为 Kubernetes 模型已经成为一个事实标准:开发者理解它、大量工具主动与它对接、主流厂商也都已经原生支持它。用户认可度、互操作性 经常比其他方面更能决定一个产品能否成功。随着 Kubernetes 资源模型越来越广泛的传播,现在已经能够 用一组 Kubernetes 资源来描述一整个软件定义计算环境。就像用 docker run 可以启动单个程序一样,用 kubectl apply -f 就能部署和运行一个分布式应用, 而无需关心是在私有云还是公有云以及具体哪家云厂商上,Kubernetes 的 API 框架已经屏蔽了这些细节。因此,Kubernetes 并不是关于容器的,而是关于 API。— 2 —Kubernetes 的 API 类型 可以通过 GET/LIST/PUT/POST/DELETE 等 API 操作,来创建、查询、修改或删除集群中的资源。各 controller **到资源变化时,就会执行相应的 reconcile 逻辑,来使 status 与 spec 描述相符。标准 API(针对内置资源类型)Namespaced 类型,这种类型的资源是区分 namespace,也就是可以用 namespace 来隔离。大部分内置资源都是这种类型,包括:podsservicesnetworkpoliciesAPI 格式:格式:/api/{version}/namespaces/{namespace}/{resource}举例:/api/v1/namespaces/default/podsUn-namespaced 类型,这种类型的资源是全局的,不能用 namespace 隔离,例如:nodesclusterroles(clusterxxx 一般都是,表示它是 cluster-scoped 的资源)API 格式:格式:/api/{version}/{resource}举例:/api/v1/nodes扩展 API(apiextension)1、Namespaced 类型API 格式:格式:/apis/{apiGroup}/{apiVersion}/namespaces/{namespace}/{resource}举例:/apis/cilium.io/v2/namespaces/kube-system/ciliumnetworkpolicies2、Un-namespaced 类型CRD用户发现了 Kubernetes 的强大之后,希望将越来越多的东西(数据)放到 Kubernetes 里面, 像内置的 Pod、Service、NetworkPolicy 一样来管理,因此出现了两个东西:CRD:用来声明用户的自定义资源,例如它是 namespace-scope 还是 cluster-scope 的资源、有哪些字段等等,Kubernetes 会自动根据这个定义生成相应的 API;官方文档的例子[1], 后文也将给出一个更简单和具体的例子。CRD 是资源类型定义,具体的资源叫 CR。Operator 框架:“Operator” 在这里的字面意思是“承担运维任务的程序”, 它们的基本逻辑都是一样的:时刻盯着资源状态,一有变化马上作出反应(也就是 reconcile 逻辑)。这就是扩展 API 的(最主要)声明和使用方式。至此,我们讨论的都是一些比较抽象的东西,接下来通过一些例子和类比来更直观地理解一下。— 3 —直观类比:Kubernetes 是个数据库,CRD 是一张表,API 是 SQL 在本节中,我们将创建一个名为 fruit 的 CRD,它有 name/sweet/weight 三个字段, 完整 CRD 如下:apiVersion: apiextensions.k8s.io/v1kind: CustomResourceDefinitionmetadata: name: fruits.example.org # CRD 名字spec: conversion: strategy: None group: example.org # REST API: /apis/<group>/<version> names: kind: Fruit listKind: FruitList plural: fruits singular: fruit scope: Namespaced # Fruit 资源是区分 namespace 的 versions: - name: v1 # REST API: /apis/<group>/<version> schema: openAPIV3Schema: properties: spec: properties: comment: # 字段 1,表示备注 type: string sweet: # 字段 2,表示甜否 type: boolean weight: # 字段 3,表示重量 type: integer type: object type: object served: true # 启用这个版本的 API(v1) storage: true additionalPrinterColumns: # 可选项,配置了这些 printer columns 之后, - jsonPath: .spec.sweet # 命令行 k get <crd> <cr> 时,能够打印出下面这些字段, name: sweet # 否则,k8s 默认只打印 CRD 的 NAME 和 AGE type: boolean - jsonPath: .spec.weight name: weight type: integer - jsonPath: .spec.comment name: comment type: string后面会解释每个 section 都是什么意思。在此之前,先来做几个(直观而粗糙的)类比。Kubernetes 是个数据库像其他数据库技术一样,它有自己的持久存储引擎(etcd),以及构建在存储引擎之上的 一套 API 和语义。这些语义允许用户创建、读取、更新和删除(CURD)数据库中的数据。下面是一些概念对应关系:关系型数据库Kubernetes(as a database)说明DATABASEcluster一套 Kubernetes 集群就是一个 database 【注 1】TABLEKind每种资源类型对应一个表;分为内置类型和扩展类型 【注 2】COLUMNproperty表里面的列,可以是 string、boolean 等类型rowsresources表中的一个具体 record表中的一个具体 record【注 1】 如果只考虑 namespaced 资源的话,也可以说一个 namespace 对应一个 database。【注 2】 前面已经介绍过,内置 Kind:Job、Service、Deployment、Event、NetworkPolicy、Secret、ConfigMap 等等;扩展 Kind:各种 CRD,例如 CiliumNetworkPolicy。所以,和其他数据库一样,本质上 Kubernetes 所做的不过是以 schema 规定的格式来处理 records。另外,Kubernetes 的表都有自带文档:$ k explain fruitsKIND: FruitVERSION: example.org/v1DESCRIPTION: <empty>FIELDS: apiVersion <string> APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources kind <string> Kind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds metadata <Object> Standard object's metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata spec <Object>另外,Kubernetes API 还有两大特色:极其可扩展:声明 CRD 就会自动创建 API;支持事件驱动。CRD 是一张表CRD 和内置的 Pod、Service、NetworkPolicy 一样,不过是数据库的一张表。例如,前面给出的 fruit CRD,有 name/sweet/weight 列,以及 “apple”、“banana” 等 entry。用户发现了 Kubernetes 的强大,希望将越来越多的东西(数据)放到 Kubernetes 里面来管理。数据类 型显然多种多样的,不可能全部内置到 Kubernetes 里。因此,一种方式就是允许用户创建自己的 “表”,设置自己的“列” —— 这正是 CRD 的由来。1、定义表结构(CRD spec)CRD(及 CR)描述格式可以是 YAML 或 JSON。CRD 的内容可以简单分为三部分:常规 Kubernetes metadata:每种 Kubernetes 资源都需要声明的字段,包括 apiVersion、kind、metadata.name 等。 apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: name: fruits.example.org # CRD 名字Table-level 信息:例如表的名字,最好用小写,方便以后命令行操作; spec: conversion: strategy: None group: example.org # REST API: /apis/<group>/<version> names: kind: Fruit listKind: FruitList plural: fruits singular: fruit scope: Namespaced # Fruit 资源是区分 namespace 的Column-level 信息:列名及类型等等,遵循 OpenAPISpecification v3 规范。 versions: - name: v1 # REST API: /apis/<group>/<version> schema: openAPIV3Schema: properties: spec: properties: comment: # 字段 1,表示备注 type: string sweet: # 字段 2,表示甜否 type: boolean weight: # 字段 3,表示重量 type: integer type: object type: object served: true # 启用这个版本的 API(v1) storage: true additionalPrinterColumns: # 可选项,配置了这些 printer columns 之后, - jsonPath: .spec.sweet # 命令行 k get <crd> <cr> 时,能够打印出下面这些字段, name: sweet # 否则,k8s 默认只打印 CRD 的 NAME 和 AGE type: boolean - jsonPath: .spec.weight name: weight type: integer - jsonPath: .spec.comment name: comment type: string2、测试:CR 增删查改 vs. 数据库 SQL创建 CRD:这一步相当于 CREATE TABLE fruits ...;。 $ kubectl create -f fruits-crd.yaml customresourcedefinition.apiextensions.k8s.io/fruits.example.org created创建 CR:相当于 INSERT INTO fruits values(...);。apple-cr.yaml: apiVersion: example.org/v1 kind: Fruit metadata: name: apple spec: sweet: false weight: 100 comment: little bit rottenbanana-cr.yaml: apiVersion: example.org/v1 kind: Fruit metadata: name: banana spec: sweet: true weight: 80 comment: just bought创建: $ kubectl create -f apple-cr.yaml fruit.example.org/apple created $ kubectl create -f banana-cr.yaml fruit.example.org/banana created查询 CR:相当于 SELECT * FROM fruits ... ; 或 SELECT * FROM fruits WHERE name='apple';。 $ k get fruits.example.org # or kubectl get fruits NAME SWEET WEIGHT COMMENT apple false 100 little bit rotten banana true 80 just bought $ kubectl get fruits apple NAME SWEET WEIGHT COMMENT apple false 100 little bit rotten删除 CR:相当于 DELETE FROM fruits WHERE name='apple';。 $ kubectl delete fruit apple可以看到,CRD/CR 的操作都能对应到常规的数据库操作。API 是 SQL上一节我们是通过 kubectl 命令行来执行 CR 的增删查改,它其实只是一个外壳,内部 调用的是 Kubernetes 为这个 CRD 自动生成的 API —— 所以又回到了本文第一节论述的内容:Kubernetes 的核心是其 API 框架。只要在执行 kubectl 命令时指定一个足够大的 loglevel,就能看到背后的具体 API 请求。例如:$ kubectl create -v 10 -f apple-cr.yaml ... Request Body: {"apiVersion":"example.org/v1","kind":"Fruit",\"spec\":{\"comment\":\"little bit rotten\",\"sweet\":false,\"weight\":100}}\n"},"name":"apple","namespace":"default"},"spec":{"comment":"little bit rotten","sweet":false,"weight":100}} curl -k -v -XPOST 'https://127.0.0.1:6443/apis/example.org/v1/namespaces/default/fruits?fieldManager=kubectl-client-side-apply' POST https://127.0.0.1:6443/apis/example.org/v1/namespaces/default/fruits?fieldManager=kubectl-client-side-apply 201 Created in 25 milliseconds ...— 4 —其他 给 CR 打标签(label),根据 label 过滤和内置资源类型一样,Kubernetes 支持对 CR 打标签,然后根据标签做过滤:# 查看所有 frutis$ k get fruitsNAME SWEET WEIGHT COMMENTapple false 100 little bit rottenbanana true 80 just bought# 给 banana 打上一个特殊新标签$ k label fruits banana tastes-good=truefruit.example.org/banana labeled# 按标签筛选 CR$ k get fruits -l tastes-good=trueNAME SWEET WEIGHT COMMENTbanana true 80 just bought# 删除 label$ k label fruits banana tastes-good-fruit.example.org/banana labeledKubernetes API 与鉴权控制(RBAC)不管是内置 API,还是扩展 API,都能用 Kubernetes 强大的 RBAC 来做鉴权控制。关于如何使用 RBAC 网上已经有大量文档;但如果想了解其设计,可参考 Cracking Kubernetes RBAC Authorization Model[2], 它展示了如何从零开始设计出一个 RBAC 鉴权模型(假设 Kubernetes 里还没有)。相关链接:https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/#create-a-customresourcedefinitionhttps://arthurchiao.art/blog/cracking-k8s-authz-rbac/参考链接:https://blog.joshgav.com/2021/12/16/kubernetes-isnt-about-containers.htmlhttps://github.com/gotopple/k8s-for-users-intro/blob/master/database.mdhttps://itnext.io/crd-is-just-a-table-in-kubernetes-13e15367bbe4原文阅读:https://mp.weixin.qq.com/s/MEhDJYg_lmjbPEdFFLdedg
本文来自微信公共号:分布式实验室。文章观点独特,比喻形象,分享给大家~本文论述了 Kubernetes 的核心价值是其通用、跨厂商和平台、可灵活扩展的声明式 API 框架, 而不是容器(虽然容器是它成功的基础);然后手动创建一个 API Extension(CRD), 通过测试和类比来对这一论述有一个更直观的理解。例子及测试基于 Kubernetes v1.21.0。— 1 —Kubernetes 的核心是其 API 框架而非容器 容器是基础时间回到 2013 年。当一条简单的 docker run postgre 命令就能运行起 Postgre 这样复杂的传统服务时,开发者在震惊之余犹如受到天启;以 Docker 为代表的实用容器技术的横空出世,也预示着一扇通往敏捷基础设施的大门即将打开。此后,一切都在往好的方向迅速发展:越来越多的开发者开始采用容器作为一种标准构建和运行方式。业界也意识到,很容易将这种封装方式引入计算集群,通过 Kubernetes 或 Mesos 这样的编排器来调度计算任务 —— 自此,容器便成为这些调度器最重要的 Workload 类型。但本文将要说明,容器并非 Kubernetes 最重要、最有价值的地方,Kubernetes 也并非仅仅是一个更广泛意义上的 Workload 调度器 —— 高效地调度不同类型的 Workload 只是 Kubernetes 提供的一种重要价值,但并不是它成功的原因。API 才是核心“等等 —— Kubernetes 只是一堆 API?”“不好意思,一直都是!”Kubernetes 的成功和价值在于,提供了一种标准的编程接口(API),可以用来编写和使用软件定义的基础设施服务(本文所说的“基础设施”,范围要大于 IaaS):Specification + Implementation 构成一个完整的 API 框架 —— 用于设计、实现和使用各种类型和规模的基础设施服务;这些 API 都基于相同的核心结构和语义:typed resources watched and reconciled by controllers (资源按类型划分,控制器**相应类型的资源,并将其实际 status 校准到 spec 里期望的状态)。为了进一步解释这一点,考虑下 Kubernetes 出现之前的场景。Kubernetes 之前:各自造轮子,封装厂商 API 差异Kubernetes 之前,基础设施基本上是各种不同 API、格式和语义的“云”服务组成的大杂烩:云厂商只提供了计算实例、块存储、虚拟网络和对象存储等基础构建模块,开发者需要像拼图一样将它们拼出一个相对完整的基础设施方案;对于其他云厂商,重复过程 1,因为各家的 API、结构和语义并不相同,甚至差异很大。虽然 Terraform 等工具的出现,提供了一种跨厂商的通用格式,但原始的结构和语义仍然是五花八门的,—— 针对 AWS 编写的 Terraform descriptor 是无法用到 Azure 的。Kubernetes 面世:标准化、跨厂商的 API、结构和语义现在再来看 Kubernetes 从一开始就提供的东西:描述各种资源需求的标准 API。例如:描述 Pod、Container 等计算需求的 API;描述 Service、Ingress 等虚拟网络功能的 API;描述 Volumes 之类的持久存储的 API;甚至还包括 Service Account 之类的服务身份的 API 等等。这些 API 是跨公有云/私有云和各家云厂商的,各云厂商会将 Kubernetes 结构和语义对接到它们各自的原生 API。因此我们可以说,Kubernetes 提供了一种管理软件定义基础设施(也就是云)的标准接口。或者说,Kubernetes 是一个针对云服务(Cloud Services)的标准 API 框架。Kubernetes API 扩展:CRD提供一套跨厂商的标准结构和语义来声明核心基础设施(Pod/Service/Volume/ServiceAccount/……), 是 Kubernetes 成功的基础。在此基础上,它又通过 CRD(Custom Resource Definition), 将这个结构扩展到任何/所有基础设施资源。CRD 在 1.7 引入,允许云厂商和开发者自己的服务复用 Kubernetes 的 spec/impl 编程框架。有了 CRD,用户不仅能声明 Kubernetes API 预定义的计算、存储、网络服务,还能声明数据库、task runner、消息总线、数字证书……任何云厂商能想到的东西!Operator Framework 以及 SIG API Machinery 等项目的出现,提供了方便地创建和管理这些 CRD 的工具,最小化用户工作量,最大程度实现标准化。例如,Crossplane 之类的项目,将厂商资源 RDS 数据库、SQS queue 资源映射到 Kubernetes API,就像核心 Kubernetes controller 一样用自己的 controller 来管理网卡、磁盘等自定义资源。Google、RedHat 等 Kubernetes 发行商也在它们的基础 Kubernetes 发行版中包含越来越多的自定义资源类型。小结我们说 Kubernetes 的核心是其 API 框架,但并不是说这套 API 框架就是完美的。事实上,后一点并不(非常)重要,因为 Kubernetes 模型已经成为一个事实标准:开发者理解它、大量工具主动与它对接、主流厂商也都已经原生支持它。用户认可度、互操作性 经常比其他方面更能决定一个产品能否成功。随着 Kubernetes 资源模型越来越广泛的传播,现在已经能够 用一组 Kubernetes 资源来描述一整个软件定义计算环境。就像用 docker run 可以启动单个程序一样,用 kubectl apply -f 就能部署和运行一个分布式应用, 而无需关心是在私有云还是公有云以及具体哪家云厂商上,Kubernetes 的 API 框架已经屏蔽了这些细节。因此,Kubernetes 并不是关于容器的,而是关于 API。— 2 —Kubernetes 的 API 类型 可以通过 GET/LIST/PUT/POST/DELETE 等 API 操作,来创建、查询、修改或删除集群中的资源。各 controller **到资源变化时,就会执行相应的 reconcile 逻辑,来使 status 与 spec 描述相符。标准 API(针对内置资源类型)Namespaced 类型,这种类型的资源是区分 namespace,也就是可以用 namespace 来隔离。大部分内置资源都是这种类型,包括:podsservicesnetworkpoliciesAPI 格式:格式:/api/{version}/namespaces/{namespace}/{resource}举例:/api/v1/namespaces/default/podsUn-namespaced 类型,这种类型的资源是全局的,不能用 namespace 隔离,例如:nodesclusterroles(clusterxxx 一般都是,表示它是 cluster-scoped 的资源)API 格式:格式:/api/{version}/{resource}举例:/api/v1/nodes扩展 API(apiextension)1、Namespaced 类型API 格式:格式:/apis/{apiGroup}/{apiVersion}/namespaces/{namespace}/{resource}举例:/apis/cilium.io/v2/namespaces/kube-system/ciliumnetworkpolicies2、Un-namespaced 类型CRD用户发现了 Kubernetes 的强大之后,希望将越来越多的东西(数据)放到 Kubernetes 里面, 像内置的 Pod、Service、NetworkPolicy 一样来管理,因此出现了两个东西:CRD:用来声明用户的自定义资源,例如它是 namespace-scope 还是 cluster-scope 的资源、有哪些字段等等,Kubernetes 会自动根据这个定义生成相应的 API;官方文档的例子[1], 后文也将给出一个更简单和具体的例子。CRD 是资源类型定义,具体的资源叫 CR。Operator 框架:“Operator” 在这里的字面意思是“承担运维任务的程序”, 它们的基本逻辑都是一样的:时刻盯着资源状态,一有变化马上作出反应(也就是 reconcile 逻辑)。这就是扩展 API 的(最主要)声明和使用方式。至此,我们讨论的都是一些比较抽象的东西,接下来通过一些例子和类比来更直观地理解一下。— 3 —直观类比:Kubernetes 是个数据库,CRD 是一张表,API 是 SQL 在本节中,我们将创建一个名为 fruit 的 CRD,它有 name/sweet/weight 三个字段, 完整 CRD 如下:apiVersion: apiextensions.k8s.io/v1kind: CustomResourceDefinitionmetadata: name: fruits.example.org # CRD 名字spec: conversion: strategy: None group: example.org # REST API: /apis/<group>/<version> names: kind: Fruit listKind: FruitList plural: fruits singular: fruit scope: Namespaced # Fruit 资源是区分 namespace 的 versions: - name: v1 # REST API: /apis/<group>/<version> schema: openAPIV3Schema: properties: spec: properties: comment: # 字段 1,表示备注 type: string sweet: # 字段 2,表示甜否 type: boolean weight: # 字段 3,表示重量 type: integer type: object type: object served: true # 启用这个版本的 API(v1) storage: true additionalPrinterColumns: # 可选项,配置了这些 printer columns 之后, - jsonPath: .spec.sweet # 命令行 k get <crd> <cr> 时,能够打印出下面这些字段, name: sweet # 否则,k8s 默认只打印 CRD 的 NAME 和 AGE type: boolean - jsonPath: .spec.weight name: weight type: integer - jsonPath: .spec.comment name: comment type: string后面会解释每个 section 都是什么意思。在此之前,先来做几个(直观而粗糙的)类比。Kubernetes 是个数据库像其他数据库技术一样,它有自己的持久存储引擎(etcd),以及构建在存储引擎之上的 一套 API 和语义。这些语义允许用户创建、读取、更新和删除(CURD)数据库中的数据。下面是一些概念对应关系:关系型数据库Kubernetes(as a database)说明DATABASEcluster一套 Kubernetes 集群就是一个 database 【注 1】TABLEKind每种资源类型对应一个表;分为内置类型和扩展类型 【注 2】COLUMNproperty表里面的列,可以是 string、boolean 等类型rowsresources表中的一个具体 record表中的一个具体 record【注 1】 如果只考虑 namespaced 资源的话,也可以说一个 namespace 对应一个 database。【注 2】 前面已经介绍过,内置 Kind:Job、Service、Deployment、Event、NetworkPolicy、Secret、ConfigMap 等等;扩展 Kind:各种 CRD,例如 CiliumNetworkPolicy。所以,和其他数据库一样,本质上 Kubernetes 所做的不过是以 schema 规定的格式来处理 records。另外,Kubernetes 的表都有自带文档:$ k explain fruitsKIND: FruitVERSION: example.org/v1DESCRIPTION: <empty>FIELDS: apiVersion <string> APIVersion defines the versioned schema of this representation of an object. Servers should convert recognized schemas to the latest internal value, and may reject unrecognized values. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#resources kind <string> Kind is a string value representing the REST resource this object represents. Servers may infer this from the endpoint the client submits requests to. Cannot be updated. In CamelCase. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#types-kinds metadata <Object> Standard object's metadata. More info: https://git.k8s.io/community/contributors/devel/sig-architecture/api-conventions.md#metadata spec <Object>另外,Kubernetes API 还有两大特色:极其可扩展:声明 CRD 就会自动创建 API;支持事件驱动。CRD 是一张表CRD 和内置的 Pod、Service、NetworkPolicy 一样,不过是数据库的一张表。例如,前面给出的 fruit CRD,有 name/sweet/weight 列,以及 “apple”、“banana” 等 entry。用户发现了 Kubernetes 的强大,希望将越来越多的东西(数据)放到 Kubernetes 里面来管理。数据类 型显然多种多样的,不可能全部内置到 Kubernetes 里。因此,一种方式就是允许用户创建自己的 “表”,设置自己的“列” —— 这正是 CRD 的由来。1、定义表结构(CRD spec)CRD(及 CR)描述格式可以是 YAML 或 JSON。CRD 的内容可以简单分为三部分:常规 Kubernetes metadata:每种 Kubernetes 资源都需要声明的字段,包括 apiVersion、kind、metadata.name 等。 apiVersion: apiextensions.k8s.io/v1 kind: CustomResourceDefinition metadata: name: fruits.example.org # CRD 名字Table-level 信息:例如表的名字,最好用小写,方便以后命令行操作; spec: conversion: strategy: None group: example.org # REST API: /apis/<group>/<version> names: kind: Fruit listKind: FruitList plural: fruits singular: fruit scope: Namespaced # Fruit 资源是区分 namespace 的Column-level 信息:列名及类型等等,遵循 OpenAPISpecification v3 规范。 versions: - name: v1 # REST API: /apis/<group>/<version> schema: openAPIV3Schema: properties: spec: properties: comment: # 字段 1,表示备注 type: string sweet: # 字段 2,表示甜否 type: boolean weight: # 字段 3,表示重量 type: integer type: object type: object served: true # 启用这个版本的 API(v1) storage: true additionalPrinterColumns: # 可选项,配置了这些 printer columns 之后, - jsonPath: .spec.sweet # 命令行 k get <crd> <cr> 时,能够打印出下面这些字段, name: sweet # 否则,k8s 默认只打印 CRD 的 NAME 和 AGE type: boolean - jsonPath: .spec.weight name: weight type: integer - jsonPath: .spec.comment name: comment type: string2、测试:CR 增删查改 vs. 数据库 SQL创建 CRD:这一步相当于 CREATE TABLE fruits ...;。 $ kubectl create -f fruits-crd.yaml customresourcedefinition.apiextensions.k8s.io/fruits.example.org created创建 CR:相当于 INSERT INTO fruits values(...);。apple-cr.yaml: apiVersion: example.org/v1 kind: Fruit metadata: name: apple spec: sweet: false weight: 100 comment: little bit rottenbanana-cr.yaml: apiVersion: example.org/v1 kind: Fruit metadata: name: banana spec: sweet: true weight: 80 comment: just bought创建: $ kubectl create -f apple-cr.yaml fruit.example.org/apple created $ kubectl create -f banana-cr.yaml fruit.example.org/banana created查询 CR:相当于 SELECT * FROM fruits ... ; 或 SELECT * FROM fruits WHERE name='apple';。 $ k get fruits.example.org # or kubectl get fruits NAME SWEET WEIGHT COMMENT apple false 100 little bit rotten banana true 80 just bought $ kubectl get fruits apple NAME SWEET WEIGHT COMMENT apple false 100 little bit rotten删除 CR:相当于 DELETE FROM fruits WHERE name='apple';。 $ kubectl delete fruit apple可以看到,CRD/CR 的操作都能对应到常规的数据库操作。API 是 SQL上一节我们是通过 kubectl 命令行来执行 CR 的增删查改,它其实只是一个外壳,内部 调用的是 Kubernetes 为这个 CRD 自动生成的 API —— 所以又回到了本文第一节论述的内容:Kubernetes 的核心是其 API 框架。只要在执行 kubectl 命令时指定一个足够大的 loglevel,就能看到背后的具体 API 请求。例如:$ kubectl create -v 10 -f apple-cr.yaml ... Request Body: {"apiVersion":"example.org/v1","kind":"Fruit",\"spec\":{\"comment\":\"little bit rotten\",\"sweet\":false,\"weight\":100}}\n"},"name":"apple","namespace":"default"},"spec":{"comment":"little bit rotten","sweet":false,"weight":100}} curl -k -v -XPOST 'https://127.0.0.1:6443/apis/example.org/v1/namespaces/default/fruits?fieldManager=kubectl-client-side-apply' POST https://127.0.0.1:6443/apis/example.org/v1/namespaces/default/fruits?fieldManager=kubectl-client-side-apply 201 Created in 25 milliseconds ...— 4 —其他 给 CR 打标签(label),根据 label 过滤和内置资源类型一样,Kubernetes 支持对 CR 打标签,然后根据标签做过滤:# 查看所有 frutis$ k get fruitsNAME SWEET WEIGHT COMMENTapple false 100 little bit rottenbanana true 80 just bought# 给 banana 打上一个特殊新标签$ k label fruits banana tastes-good=truefruit.example.org/banana labeled# 按标签筛选 CR$ k get fruits -l tastes-good=trueNAME SWEET WEIGHT COMMENTbanana true 80 just bought# 删除 label$ k label fruits banana tastes-good-fruit.example.org/banana labeledKubernetes API 与鉴权控制(RBAC)不管是内置 API,还是扩展 API,都能用 Kubernetes 强大的 RBAC 来做鉴权控制。关于如何使用 RBAC 网上已经有大量文档;但如果想了解其设计,可参考 Cracking Kubernetes RBAC Authorization Model[2], 它展示了如何从零开始设计出一个 RBAC 鉴权模型(假设 Kubernetes 里还没有)。相关链接:https://kubernetes.io/docs/tasks/extend-kubernetes/custom-resources/custom-resource-definitions/#create-a-customresourcedefinitionhttps://arthurchiao.art/blog/cracking-k8s-authz-rbac/参考链接:https://blog.joshgav.com/2021/12/16/kubernetes-isnt-about-containers.htmlhttps://github.com/gotopple/k8s-for-users-intro/blob/master/database.mdhttps://itnext.io/crd-is-just-a-table-in-kubernetes-13e15367bbe4原文阅读:https://mp.weixin.qq.com/s/MEhDJYg_lmjbPEdFFLdedg -
本文分享自华为云社区《[解构HE2E中的Kubernetes技术应用](https://bbs.huaweicloud.com/blogs/352564?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=paas&utm_content=content)》,作者: 敏捷小智 。 在《[解构HE2E中的容器技术应用](https://bbs.huaweicloud.com/blogs/345979)》 一文当中,为大家分析了HE2E项目的代码仓库、编译构建、部署等各环节中对于容器技术的应用。今天,我们将从Kubernetes技术应用的角度解构[华为云 DevCloud HE2E DevOps实践](https://support.huaweicloud.com/bestpractice-devcloud/devcloud_practice_2000.html) 。 # 什么是Kubernetes? Kubernetes (也称K8S)是用于自动部署,扩展和管理容器化应用程序的开源系统。 # K8S与CCE 在上一篇文章中,大家已经了解了HE2E项目中通过Docker实现容器化部署,在该实践中通过此方式部署至ECS弹性云服务器中,并称之为ECS部署。在该实践中,提供了另外一套部署方式,将应用部署至CCE集群当中,即CCE部署,使用的工具即K8S。 总之,根据部署目标的不同,HE2E实践中分别介绍了ECS部署与CCE部署。根据部署采用的技术工具不同,也可以将这两种方式称为Docker部署与K8S部署。 # 为什么选择K8S 在正式的生产环境中,企业和团队往往会需要将应用部署至多个服务器主机,而CCE集群和K8S则共同为应用的部署、运行及管理提供了保障。相较而言,HE2E实践中介绍的ECS部署方式更倾向于开发、测试等环境下的单机部署。 # K8S的代码配置 回到项目本身,代码仓库中的./kompose/文件夹下有多个yaml文件。可以看出,每个服务都有两个配置文件(*-deployment.yaml与*-service.yaml)共同进行配置。 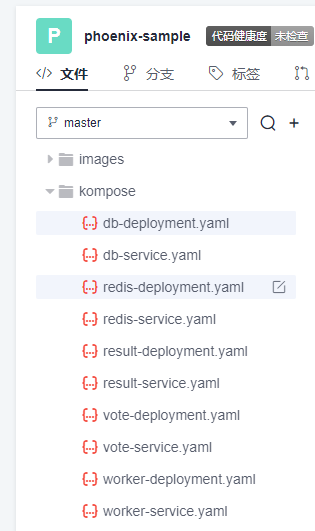 此处以db-deployment.yaml为例,对yaml配置仅作简短的介绍,帮助大家理解配置内容。随着集群版本和产品能力的更迭,也有很多配置信息将发生变化。所以在实践当中,需要调整 yaml 文件配置 。 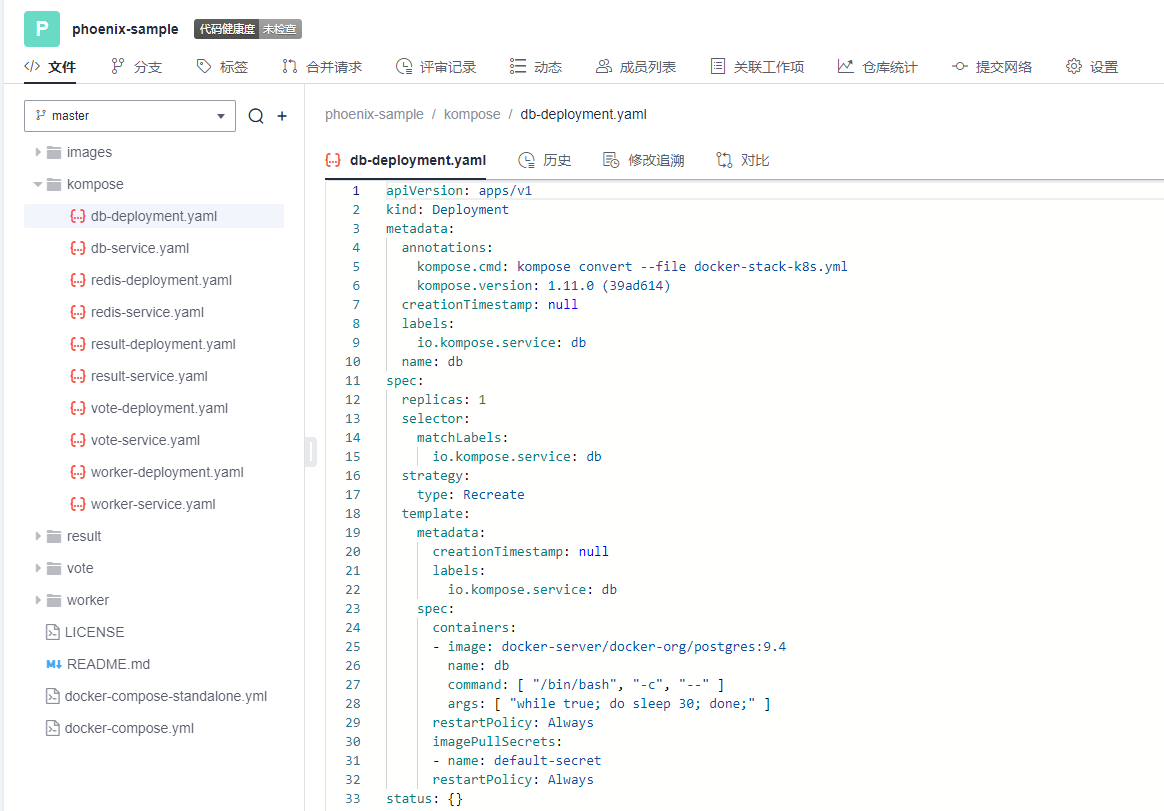 • apiVersion:此处值为apps/v1,这个版本号需要根据安装的K8S版本和资源类型进行变化。目前实践中对应v1.19版本的K8S集群。 • kind:此处创建的是Deployment,根据实际情况,此处资源类型可以是Pod、Job、Ingress、Service等。如:在*-service.yaml文件中,创建的资源类型则是Service。 • metadata:包含Deployment的一些meta信息。其中,annotations的含义是注解。 • spec:你所期望的该对象的状态。包括replicas、selector、containers等Kubernetes需要的参数。其中,containers定义了该deployment使用的镜像:docker-server/docker-org/postgres:9.4。在上篇文章中提到过,这里的docker-server、docker-org都会在构建任务中替换为实际镜像对应的镜像地址和组织。strategy、restartPolicy等字段共同构成了容器失败时重启的策略。 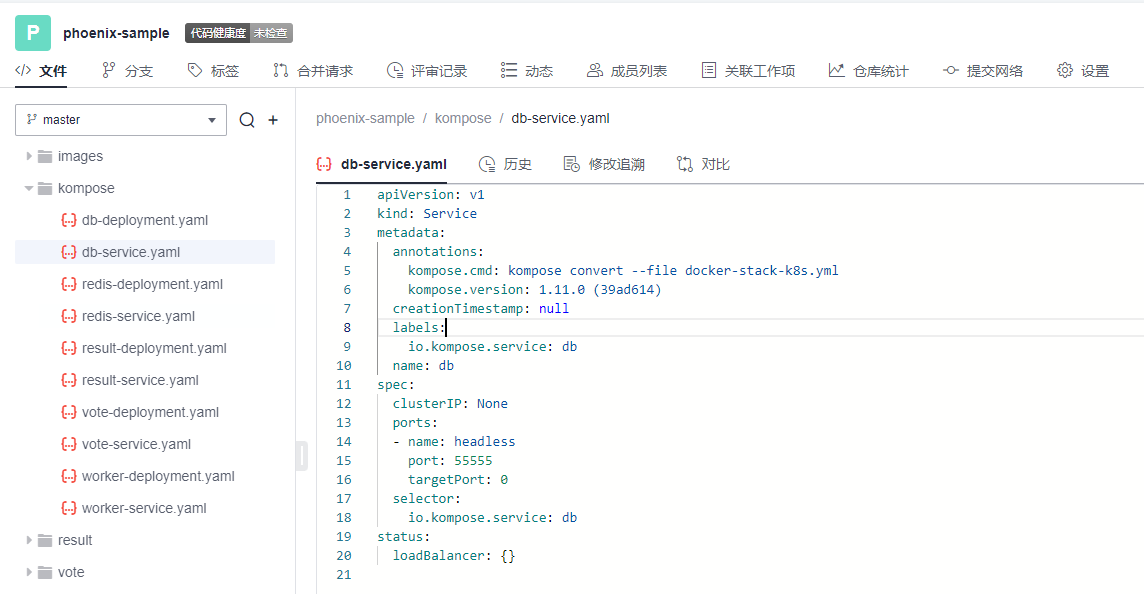 在*-service.yaml当中,主体内容与*-deployment.yaml相差也不算大,主要差异集中于spec这部分。*-service.yaml对应的spec主要是定义了集群内访问的方式,使各个服务之间可以互相访问。 可以看出,*-deployment.yaml 与*-service.yaml共同定义了一个服务*。*-deployment.yaml主要定义了该服务的镜像源,或者说工作负载是什么。而*-service.yaml则定义了该服务访问方式。 # K8S的部署配置 在编译构建环节,主体还是制作镜像上传到SWR镜像仓库,与上篇文章的没有区别。相关的配置文件也通过构建任务上传到软件发布库了,所以这里就不赘述了。 镜像、配置和集群资源都准备妥当以后,就是使用K8S部署的环节了。 # - 代理机配置 我们在HE2E实践中采用的是代理机的部署方式,将集群中的一个节点作为代理机进行授信、部署。所以在实践中我们从集群下载Kubectl配置文件并配置到节点主机当中(见《配置 Kubectl 》)。通过配置Kubectl的操作,我们就可以在节点主机上执行命令进而影响整个CCE集群。 # - CCE部署任务 HE2E实践中,phoenix-cd-cce是我们所需执行的部署任务。该任务将配置文件传输到目标主机,即代理机、集群节点。 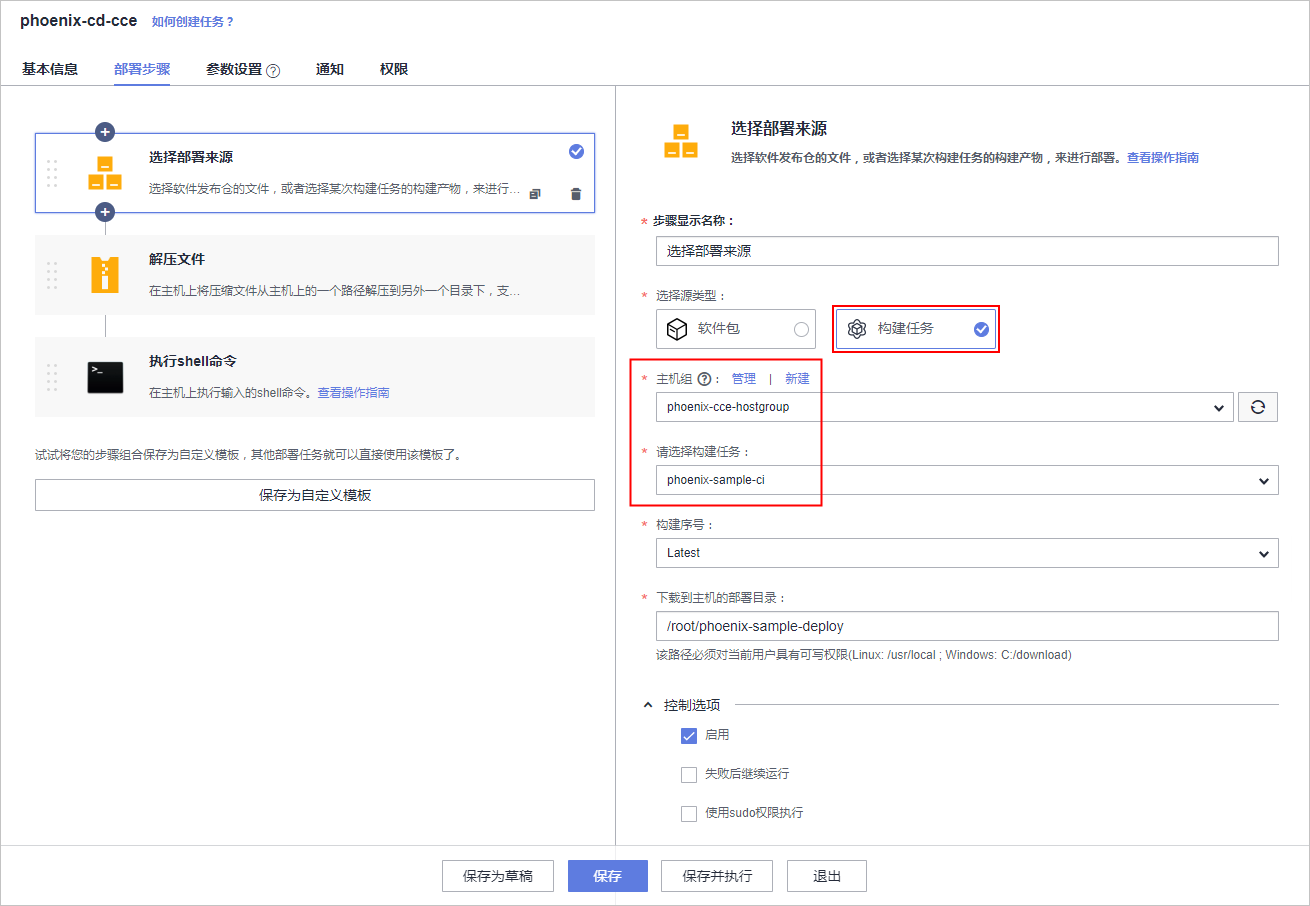 而后,通过执行shell命令启动Kubenetes。 kubectl delete secret regcred kubectl create secret docker-registry regcred --docker-server=${docker-server} --docker-username=${docker-username} --docker-password=${docker-password} --docker-email=***@***.cn kubectl delete -f /root/phoenix-sample-deploy/kompose/ kubectl apply -f /root/phoenix-sample-deploy/kompose/ • 这里先是删除原有的secret,这一步主要是为了防止由于使用临时登录命令变化而导致secret错误引发的任务执行失败。 • 接着,创建新的secret。包含docker-server、docker-username、docker-password等信息。 • 按配置文件(/root/phoenix-sample-deploy/kompose/)删除资源。 • 按配置文件(/root/phoenix-sample-deploy/kompose/)对资源进行配置。 成功执行该部署任务后,可以在CCE集群中看到五个工作负载已经处于“运行中”的状态。 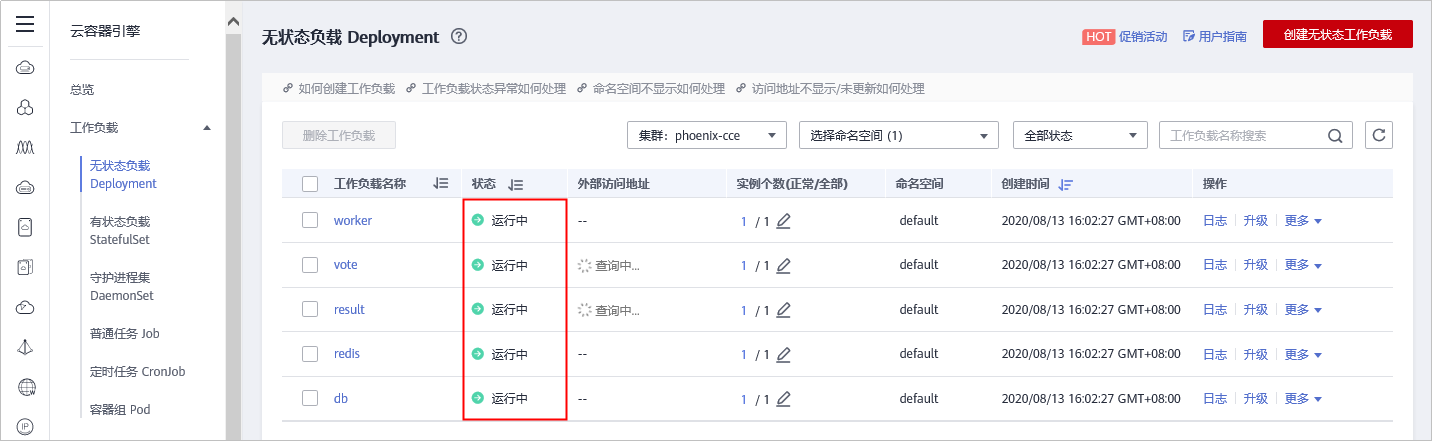 不过目前还需要设置“节点访问”才能正常访问。所以在后续实践中对工作负载vote和result手动添加访问方式。 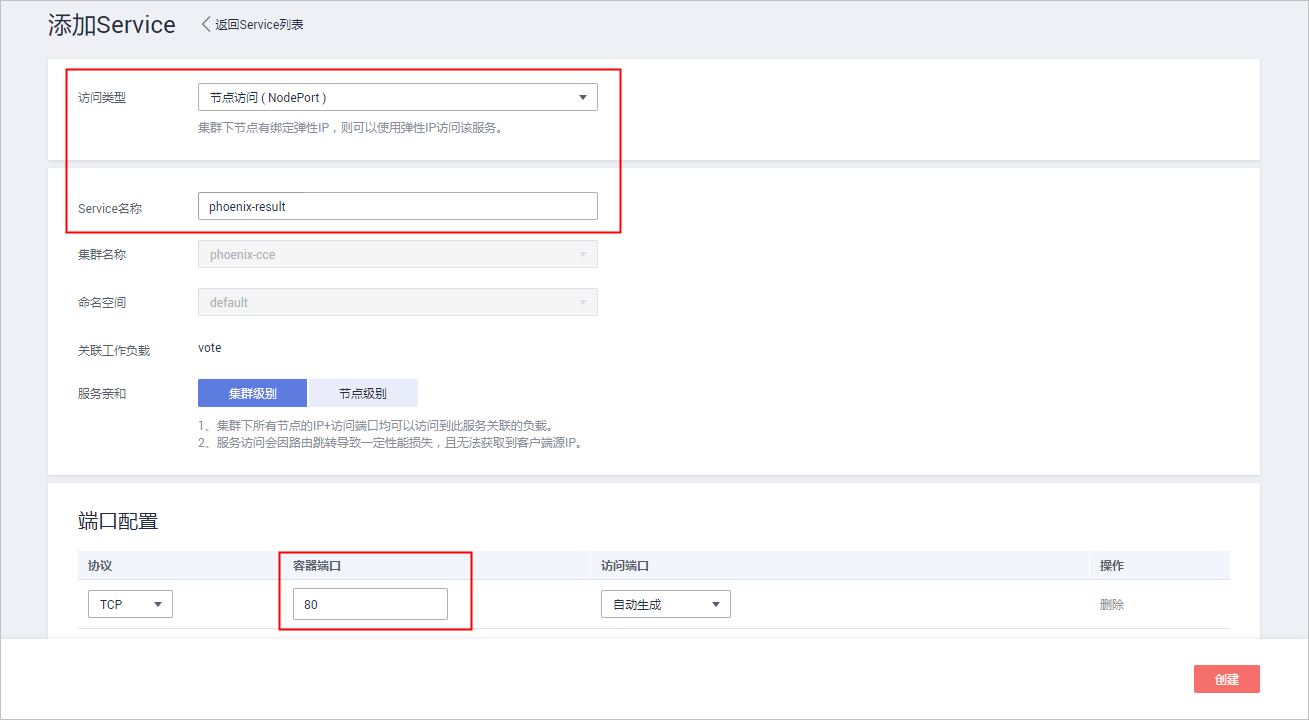 节点访问设置完毕后,即可访问项目的用户端与管理端了。   # K8S的模板部署方式 理论上,讲到现在,HE2E实践中的K8S部署就已经讲完了。但是,笔者猜到,肯定有很多人不喜欢这种通过代理机部署集群的方式。不过没关系,下面我就来介绍DevCloud当中的Kubernetes模板部署。 新建模板时,现在可以选择模板:Kubernetes部署。 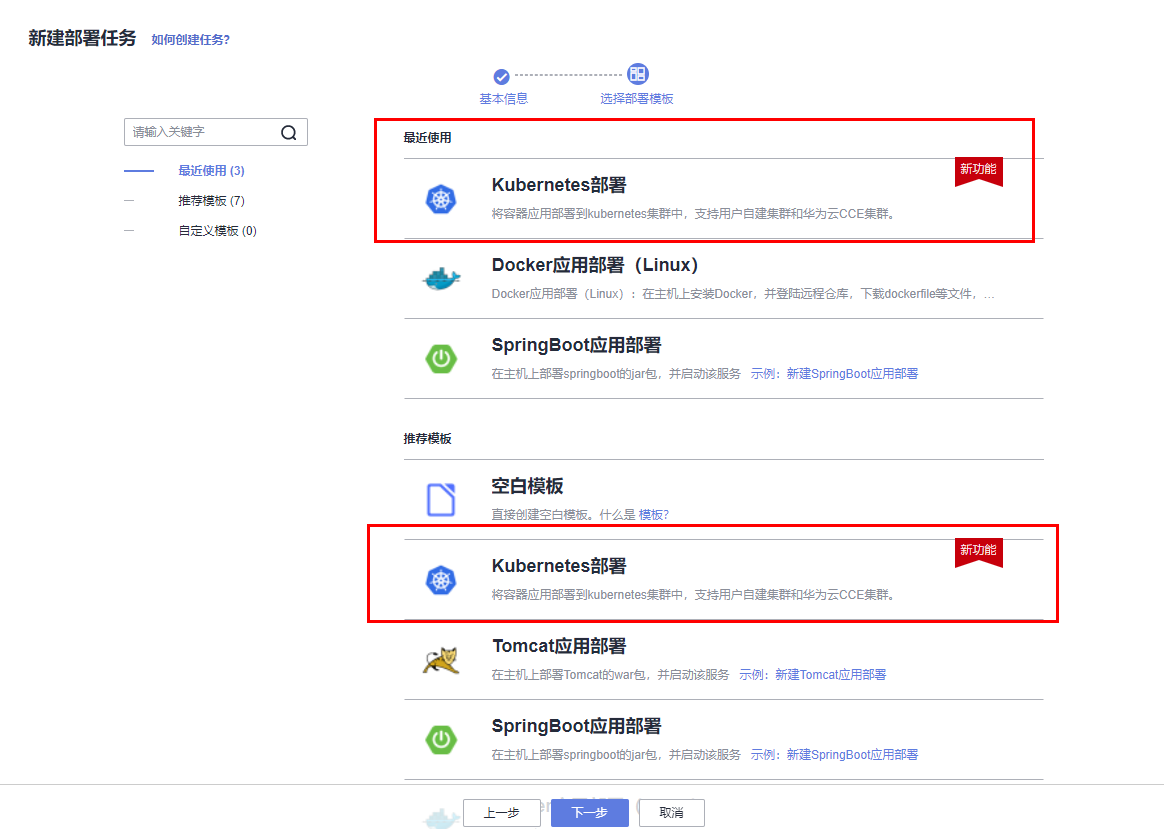 进入模板以后,可以选择集群类型、区域、命名空间、部署方式等信息。 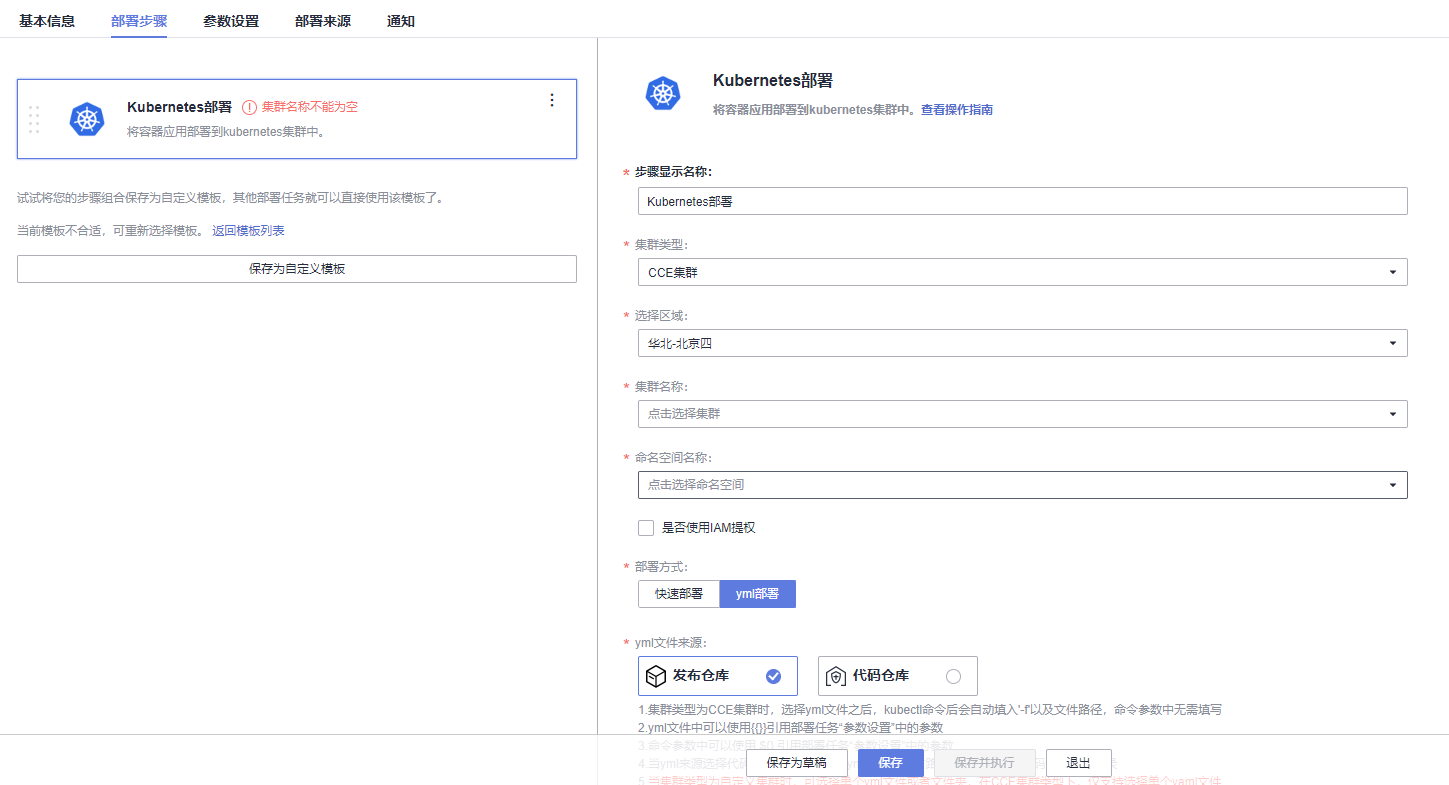 由于本项目通过10个yaml文件共同配置,所以需要添加相同的“Kubernetes部署”步骤共计10个,每个步骤都对应一个yaml文件。 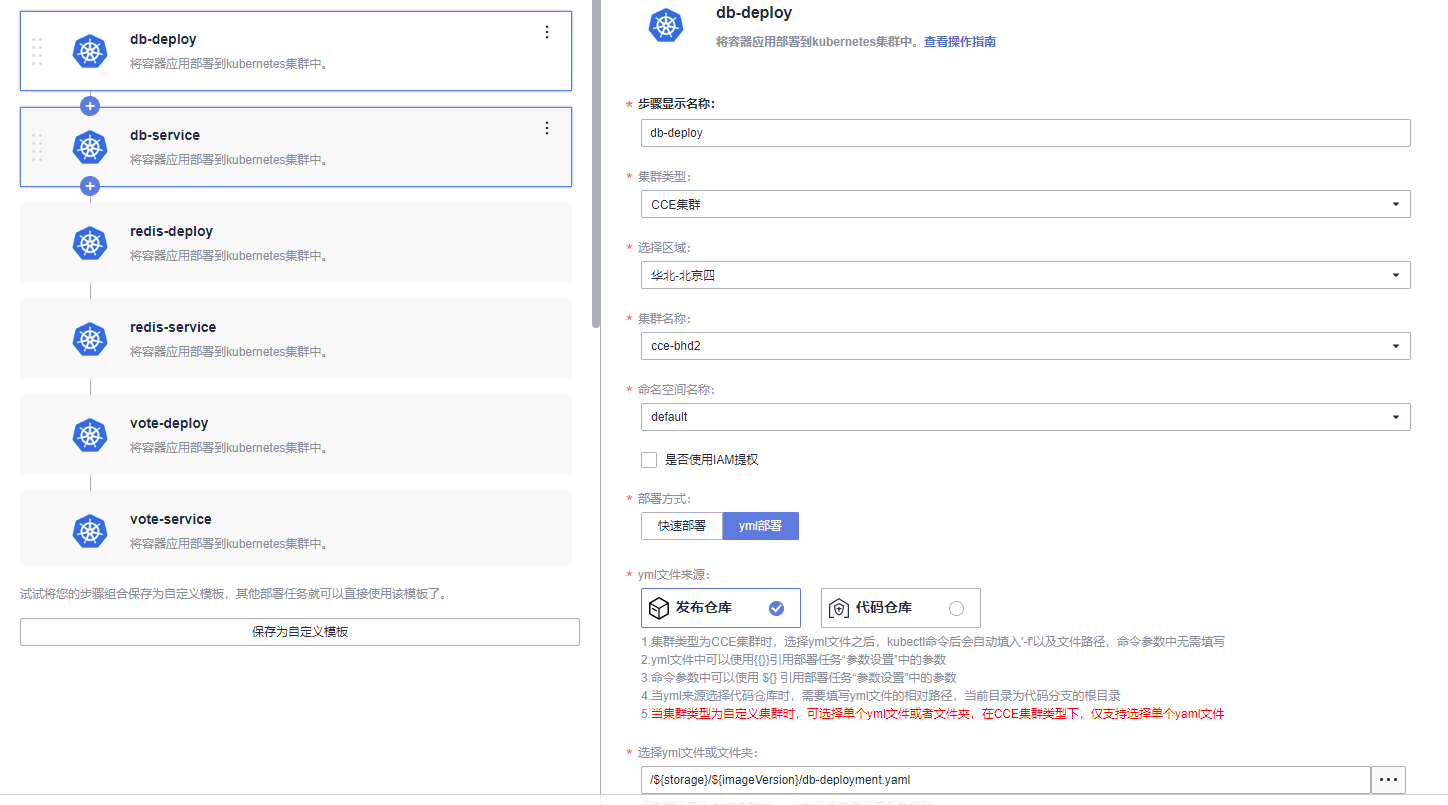 而由于我们在代码仓库中的配置并非我们最终部署时所需的配置(经过编译构建修改docker-server等参数),所以我们需要每个步骤都设置软件发布库中对应的yaml文件。此时,我们会发现,我们原本的构建任务是将所有yaml文件进行了打包压缩后才上传的,没有办法直接选中。所以,我们可以再次创建一个构建任务或者在原有构建任务上进行修改,以使软件发布库中存放有所有的yaml文件。 构建任务上传步骤的配置参考:(上传所有yaml文件而非打包后上传) 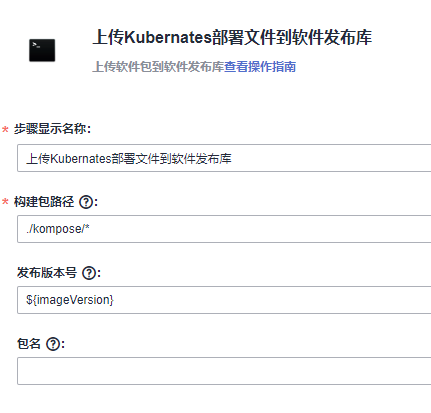 完成以上配置以后,执行Kubernetes部署模板任务,即可将服务部署至选定的CCE集群当中。此时再添加节点访问方式即可访问用户端与管理端。 当然,我们也可以将节点访问也写入yaml文件中,实现进一步的一键部署。这里就暂且留作一个小思考题,感兴趣的小伙伴可以自己尝试一下,将节点访问写入yaml当中。 # 结语 本篇文章一面介绍了HE2E实践中的CCE部署方式,一面又介绍了该实践中未提到的Kubernetes模板部署。两者的主要区别是“CCE部署”是通过代理机控制集群进行K8S部署;Kubernetes模板部署则是直接在集群中部署。此外,本文也对项目中关于K8S的配置进行了一定程度的解析。
-
第三章:云原生基础设施之Kubernetes学习笔记容器集群管理概述• 容器编排指自动化容器的部署、管理、扩展和联网,其价值: 灵活的资源管理及调度; 自动化部署及服务发现; 高效的监控及运维; 弹性扩展及高可用。• 从Borg到Kubernetes:起源于google内部Borg项目,于2015年7月22日迭代到v1.0并正式对外公布。• 2017年10月17日Docker宣布支持Kubernetes。Kubernetes核心架构与理念• 下图展现K8S的架构和工作流程• 基础的K8s集群通常包含一个Master节点和多个Node节点,每个节点可以是物理机也可以是虚拟机。• Master节点:提供的集群控制,对集群做出全局性决策Kube-apiserver:对外暴露K8s API,接收外部请求,写入etcd,可水平扩展;etcd:分布式数据存储组件,存储集群配置数据,提供数据备份Kube-controller-manager:控制器,执行集群级功能,例如复制组件,跟踪Node节点,处理节点故障等Kube-scheduler:负责任务调度,根据各种条件(如可用的资源、节点的亲和性等)将容器调度到Node上运行• Node节点:运行容器应用,根据Master的要求管理容器的生命周期Kubelet:接受Master指令,负责管理容器(Pod)Kube-proxy:应用组件间的访问代理,解决节点上应用的访问问题 Add-ons:插件,用于扩展K8s的功能Container runtime:容器运行时,如Docker,最主要的功能是下载镜像和运行容器。• 开放接口CRI、CNI、CSICRI:容器运行时的接口,提供计算能力CNI:容器网络接口,提供网络能力CSI:容器存储接口,提供存储能力• K8s工作流程• K8s核心概念:Pod:最小工作单元,每一个Pod包含一个或多个相关容器,K8s将其视为一个整体进行调度。引入Pod目的:扩展和实现生命周期管理。相同POD内的容器:使用相同的namespace空间,即有相同的IP地址和port,使用同一个localhost,volume可挂载到所有pod内的容器实现共享。但pod中每个容器的cpu和memory等资源通过其自身cgroup来做限制。Label:为资源打上标签,方便分类管理Namespace:在集群中对资源进行组织上的隔离。四个默认namespace:default、kube-public(公共访问区)、kube-system(系统资源区,如kubelet、kubeproxy等)、kube-node-lease。每个资源仅属于一个namespace,不同namespace中的资源命名可以相同;通过ResouceQuota做资源限制;全局资源不属于某一个namespaceConroller:控制器,K8S通过控制器管理PodService:定义Pod逻辑集合及访问策略,为Pod提供了负载均衡,通过label来选择Pod。Volume:管理Kubernetes存储,声明Pod中容器可以访问的文件目录,需挂载。Kubernetes应用编排与管理• Kubectl:K8s的命令行工具;指令式:kubectl [command] [TYPE] [NAME] [flags]声明式:kubectl apply –f [yaml文件名] .yaml文件的必选配置字段:apiVersion,kind,metadata,spec• YAML的语法规则Label的形式为key-value形式大小写敏感使用缩进表示层级关系,缩进使用空格而非tab,相同层级的元素左侧对齐在同一个yaml配置文件内可以同时定义多个资源• Kubernetes管理的对象类型总览:• 状态工作负载:Deployment、ReplicaSet• Deployment控制器下的每个Pod除了名称和IP地址不同,其余完全相同。Deployment可以根据需要同故宫Pod模板创建Pod或者删除任意一个Pod。• ReplicaSet,确定Deployment中Pod的副本数量• 从大到小的管理逻辑为:Deployment>ReplicaSet>Pod>容器• 创建Deployment指令式:kubectl create deployment deployment_name --image=image_name –replicas=number声明式:vi filename.yaml [注意,此处 kind: Deployment] Kubectl apply –f filename.yaml• 查看deployment创建情况:kubectl get deployment• 滚动更新:使用新的实例逐步更新Pod实例,零停机进行工作负载的更新。更新Deployement:kubectl edit deploy nginxkubectl set image deploy nginx nginx=nginx:1.9.1 kubectl apply -f nginx.yaml • 查看Deployment滚动更新情况/历史:kubectl rollout status deploy nginxkubectl rollout history deploy nginx• 回滚:kubectl rollout pause deploy nginxkubectl rollout resume deploy nginx• 有状态工作负载:StatefulSet:StatefulSet给每个Pod提供固定名称,Pod名称增加从0-N的固定后缀,Pod重新调度后Pod名称和HostName不变。StatefulSet通过Headless Service给每个Pod提供固定的访问域名。每个Pod有单独存储,StatefulSet通过创建固定标识的PVC保证Pod重新调度后还是能访问到相同的持久化数据。创建StatefulSet,yaml文件指定kind为StatefulSet,并指定volumeMounts• 守护进程工作负载:DaemonSetDaemonSet(守护进程集)在集群的每个节点上运行一个Pod,且保证只有一个Pod,适合系统层面的应用,例如日志收集、资源监控等Yaml文件创建DaemonSet时,kind选择DaemonSet,不需要规定replicas项。• Jobs:主要处理短暂的一次性任务,Job管理的Pod根据用户的设置把任务成功完成就自动退出(Pod自动删除),Jobs特点:保证指定数量Pod成功运行结束。支持并发执行。支持错误自动重试。支持暂停/恢复Jobs。• 创建JobsKind选择Job。Completions当前的任务需要执行的Pod数量。Parallelism表示最多有多少个并发执行的任务。RestartPolicy只能选择Never或OnFailure。BackoffLimit参数指定job失败后进行重试的次数。• CronJob:处理周期性或者重复性的任务,可使用Cron格式快速指定任务的调度时间,在yaml文件中kind选择CronJob,spec中的schedule: "* * * * *" 用来进行配置┌───────────── minute (0 - 59)│ ┌───────────── hour (0 - 23)│ │ ┌───────────── day of the month (1 - 31)│ │ │ ┌───────────── month (1 - 12)│ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday;│ │ │ │ │ 7 is also Sunday on some systems)│ │ │ │ ││ │ │ │ │* * * * * 如果您想要每个月的第一天里面每半个小时执行一次,那就可以设置为" 0,30 * 1 * * " 如果您想每个星期天的3am执行一次任务,那就可以设置为 "0 3 * * 0"。Kubernetes服务发布• Pod特征:有独立IP、扩缩容时数量会变更、故障时ReplicaSet会创建新的Pod• Service定义了访问逻辑上一组Pod的策略,有如下如所示3种类型• ClusterIP:提供一个集群内部的虚拟IP地址以供Pod访问(默认模式)• NodePort:在Node上打开一个端口以供外部访问• LoadBalance:通过外部的负载均衡器来访问。如果创建一个LoadBalancer,系统则会创建一个NodePort,NodePort则会创建ClusterIP。• Ingress:七层负载均衡,基于七层的HTTP和HTTPS协议进行转发Ingress资源:一组基于域名或URL把请求转发到指定Service实例的访问规则,是Kubernetes的一种资源对象,通过接口服务实现增、删、改、查的操作。Ingress Controller:请求转发的执行器,用以实时监控资源对象Ingress、Service、End-point、Secret(主要是TLS证书和Key)、Node、ConfigMap的变化,解析Ingress定义的规则并负责将请求转发到相应的后端Service。Ingress Controller在不同厂商之间的实现方式不同,根据负载均衡器种类的不同,可以将其分成ELB型和Nginx型。Kubernetes存储管理• Volume的核心是一个目录,用于Pod中的容器共享文件,与挂在它的Pod的生命周期相同。Pod不存在时,临时卷类型(emptyDir、ConfigMap、Secret等)中的数据会被销毁,持久化存储的卷(hostPath、PVC等)中的数据会保存。Volume不能独立创建,只能在Pod中定义。• emptyDir:一种简单的空目录,主要用于临时存储,适用于缓存空间,日志采集等场景。• ConfigMap:用于存储应用所需配置信息(key-value 形式)的资源类型,在被Pod引用前需单独定义。在Volume中引用ConfigMap:就是通过文件的方式直接将ConfigMap的每条数据填入Volume,每条数据是一个文件,键就是文件名,键值就是文件内容。• Secret:与ConfigMap类似,都是key-value键值对形式,使用方式也相同;Secret会加密存储,所以适用于存储敏感信息。只有Pod请求的Secret在其容器中才是可见的,一个Pod不能访问另一个Pod的Secret。• hostPath:能将主机节点文件系统上的文件或目录挂载到Pod中。适用于读取主机上的数据。永远不要使用HostPath存储跨Pod的数据。• PersistentVolume:PV描述的是持久化存储卷,主要定义的是一个持久化存储在宿主机上的目录,比如一个NFS的挂载目录。• PersistentVolumeClaim:PVC描述的是Pod所希望使用的持久化存储的属性,比如,Volume存储的大小、可读写权限等等。• StorageClass:存储类,简称SC,为管理员提供了描述存储 “类” 的方法,通过相应的存储插件(CSI)实现,可根据用户提出的PVC动态提供不同性质的PV。
-
 链接:https://bbs.huaweicloud.com/blogs/352564在《解构 H E2E 中的容器技术应用》 一文当中,为大家分析了HE2E项目的代码仓库、编译构建、部署等各环节中对于容器技术的应用。今天,我们将从Kubernetes技术应用的角度解构华为云 DevCloud HE2E D evOps 实践 。什么是Kubernetes?Kubernetes (也称K8S)是用于自动部署,扩展和管理容器化应用程序的开源系统。K8S与CCE在上一篇文章中,大家已经了解了HE2E项目中通过Docker实现容器化部署,在该实践中通过此方式部署至ECS弹性云服务器中,并称之为ECS部署。在该实践中,提供了另外一套部署方式,将应用部署至CCE集群当中,即CCE部署,使用的工具即K8S。总之,根据部署目标的不同,HE2E实践中分别介绍了ECS部署与CCE部署。根据部署采用的技术工具不同,也可以将这两种方式称为Docker部署与K8S部署。为什么选择K8S在正式的生产环境中,企业和团队往往会需要将应用部署至多个服务器主机,而CCE集群和K8S则共同为应用的部署、运行及管理提供了保障。相较而言,HE2E实践中介绍的ECS部署方式更倾向于开发、测试等环境下的单机部署。K8S的代码配置回到项目本身,代码仓库中的./kompose/文件夹下有多个yaml文件。可以看出,每个服务都有两个配置文件(*-deployment.yaml与*-service.yaml)共同进行配置。此处以db-deployment.yaml为例,对yaml配置仅作简短的介绍,帮助大家理解配置内容。随着集群版本和产品能力的更迭,也有很多配置信息将发生变化。所以在实践当中,需要调整 yaml 文件配置 。• apiVersion:此处值为apps/v1,这个版本号需要根据安装的K8S版本和资源类型进行变化。目前实践中对应v1.19版本的K8S集群。• kind:此处创建的是Deployment,根据实际情况,此处资源类型可以是Pod、Job、Ingress、Service等。如:在*-service.yaml文件中,创建的资源类型则是Service。• metadata:包含Deployment的一些meta信息。其中,annotations的含义是注解。• spec:你所期望的该对象的状态。包括replicas、selector、containers等Kubernetes需要的参数。其中,containers定义了该deployment使用的镜像:docker-server/docker-org/postgres:9.4。在上篇文章中提到过,这里的docker-server、docker-org都会在构建任务中替换为实际镜像对应的镜像地址和组织。strategy、restartPolicy等字段共同构成了容器失败时重启的策略。在*-service.yaml当中,主体内容与*-deployment.yaml相差也不算大,主要差异集中于spec这部分。*-service.yaml对应的spec主要是定义了集群内访问的方式,使各个服务之间可以互相访问。可以看出,*-deployment.yaml 与*-service.yaml共同定义了一个服务*。*-deployment.yaml主要定义了该服务的镜像源,或者说工作负载是什么。而*-service.yaml则定义了该服务访问方式。K8S的部署配置在编译构建环节,主体还是制作镜像上传到SWR镜像仓库,与上篇文章的没有区别。相关的配置文件也通过构建任务上传到软件发布库了,所以这里就不赘述了。镜像、配置和集群资源都准备妥当以后,就是使用K8S部署的环节了。代理机配置我们在HE2E实践中采用的是代理机的部署方式,将集群中的一个节点作为代理机进行授信、部署。所以在实践中我们从集群下载Kubectl配置文件并配置到节点主机当中(见《配置 Kubectl 》)。通过配置Kubectl的操作,我们就可以在节点主机上执行命令进而影响整个CCE集群。CCE部署任务HE2E实践中,phoenix-cd-cce是我们所需执行的部署任务。该任务将配置文件传输到目标主机,即代理机、集群节点。而后,通过执行shell命令启动Kubenetes。kubectl delete secret regcredkubectl create secret docker-registry regcred --docker-server=${docker-server} --docker-username=${docker-username} --docker-password=${docker-password} --docker-email=***@***.cn kubectl delete -f /root/phoenix-sample-deploy/kompose/kubectl apply -f /root/phoenix-sample-deploy/kompose/• 这里先是删除原有的secret,这一步主要是为了防止由于使用临时登录命令变化而导致secret错误引发的任务执行失败。• 接着,创建新的secret。包含docker-server、docker-username、docker-password等信息。• 按配置文件(/root/phoenix-sample-deploy/kompose/)删除资源。• 按配置文件(/root/phoenix-sample-deploy/kompose/)对资源进行配置。成功执行该部署任务后,可以在CCE集群中看到五个工作负载已经处于“运行中”的状态。不过目前还需要设置“节点访问”才能正常访问。所以在后续实践中对工作负载vote和result手动添加访问方式。节点访问设置完毕后,即可访问项目的用户端与管理端了。K8S的模板部署方式理论上,讲到现在,HE2E实践中的K8S部署就已经讲完了。但是,笔者猜到,肯定有很多人不喜欢这种通过代理机部署集群的方式。不过没关系,下面我就来介绍DevCloud当中的Kubernetes模板部署。新建模板时,现在可以选择模板:Kubernetes部署。进入模板以后,可以选择集群类型、区域、命名空间、部署方式等信息。由于本项目通过10个yaml文件共同配置,所以需要添加相同的“Kubernetes部署”步骤共计10个,每个步骤都对应一个yaml文件。而由于我们在代码仓库中的配置并非我们最终部署时所需的配置(经过编译构建修改docker-server等参数),所以我们需要每个步骤都设置软件发布库中对应的yaml文件。此时,我们会发现,我们原本的构建任务是将所有yaml文件进行了打包压缩后才上传的,没有办法直接选中。所以,我们可以再次创建一个构建任务或者在原有构建任务上进行修改,以使软件发布库中存放有所有的yaml文件。构建任务上传步骤的配置参考:(上传所有yaml文件而非打包后上传)完成以上配置以后,执行Kubernetes部署模板任务,即可将服务部署至选定的CCE集群当中。此时再添加节点访问方式即可访问用户端与管理端。当然,我们也可以将节点访问也写入yaml文件中,实现进一步的一键部署。这里就暂且留作一个小思考题,感兴趣的小伙伴可以自己尝试一下,将节点访问写入yaml当中。结语本篇文章一面介绍了HE2E实践中的CCE部署方式,一面又介绍了该实践中未提到的Kubernetes模板部署。两者的主要区别是“CCE部署”是通过代理机控制集群进行K8S部署;Kubernetes模板部署则是直接在集群中部署。此外,本文也对项目中关于K8S的配置进行了一定程度的解析。希望可以帮助小伙伴们理解K8S、HE2E,祝大家在技术成长的道路上越走越远。感谢小伙伴们的阅读。如果觉得还不错,不妨点个赞再走~此文由DevSecOps专家服务团队出品,前往 专家服务 ,获取更多DevSecOps工程方法、工具平台、最佳实践等干货。
链接:https://bbs.huaweicloud.com/blogs/352564在《解构 H E2E 中的容器技术应用》 一文当中,为大家分析了HE2E项目的代码仓库、编译构建、部署等各环节中对于容器技术的应用。今天,我们将从Kubernetes技术应用的角度解构华为云 DevCloud HE2E D evOps 实践 。什么是Kubernetes?Kubernetes (也称K8S)是用于自动部署,扩展和管理容器化应用程序的开源系统。K8S与CCE在上一篇文章中,大家已经了解了HE2E项目中通过Docker实现容器化部署,在该实践中通过此方式部署至ECS弹性云服务器中,并称之为ECS部署。在该实践中,提供了另外一套部署方式,将应用部署至CCE集群当中,即CCE部署,使用的工具即K8S。总之,根据部署目标的不同,HE2E实践中分别介绍了ECS部署与CCE部署。根据部署采用的技术工具不同,也可以将这两种方式称为Docker部署与K8S部署。为什么选择K8S在正式的生产环境中,企业和团队往往会需要将应用部署至多个服务器主机,而CCE集群和K8S则共同为应用的部署、运行及管理提供了保障。相较而言,HE2E实践中介绍的ECS部署方式更倾向于开发、测试等环境下的单机部署。K8S的代码配置回到项目本身,代码仓库中的./kompose/文件夹下有多个yaml文件。可以看出,每个服务都有两个配置文件(*-deployment.yaml与*-service.yaml)共同进行配置。此处以db-deployment.yaml为例,对yaml配置仅作简短的介绍,帮助大家理解配置内容。随着集群版本和产品能力的更迭,也有很多配置信息将发生变化。所以在实践当中,需要调整 yaml 文件配置 。• apiVersion:此处值为apps/v1,这个版本号需要根据安装的K8S版本和资源类型进行变化。目前实践中对应v1.19版本的K8S集群。• kind:此处创建的是Deployment,根据实际情况,此处资源类型可以是Pod、Job、Ingress、Service等。如:在*-service.yaml文件中,创建的资源类型则是Service。• metadata:包含Deployment的一些meta信息。其中,annotations的含义是注解。• spec:你所期望的该对象的状态。包括replicas、selector、containers等Kubernetes需要的参数。其中,containers定义了该deployment使用的镜像:docker-server/docker-org/postgres:9.4。在上篇文章中提到过,这里的docker-server、docker-org都会在构建任务中替换为实际镜像对应的镜像地址和组织。strategy、restartPolicy等字段共同构成了容器失败时重启的策略。在*-service.yaml当中,主体内容与*-deployment.yaml相差也不算大,主要差异集中于spec这部分。*-service.yaml对应的spec主要是定义了集群内访问的方式,使各个服务之间可以互相访问。可以看出,*-deployment.yaml 与*-service.yaml共同定义了一个服务*。*-deployment.yaml主要定义了该服务的镜像源,或者说工作负载是什么。而*-service.yaml则定义了该服务访问方式。K8S的部署配置在编译构建环节,主体还是制作镜像上传到SWR镜像仓库,与上篇文章的没有区别。相关的配置文件也通过构建任务上传到软件发布库了,所以这里就不赘述了。镜像、配置和集群资源都准备妥当以后,就是使用K8S部署的环节了。代理机配置我们在HE2E实践中采用的是代理机的部署方式,将集群中的一个节点作为代理机进行授信、部署。所以在实践中我们从集群下载Kubectl配置文件并配置到节点主机当中(见《配置 Kubectl 》)。通过配置Kubectl的操作,我们就可以在节点主机上执行命令进而影响整个CCE集群。CCE部署任务HE2E实践中,phoenix-cd-cce是我们所需执行的部署任务。该任务将配置文件传输到目标主机,即代理机、集群节点。而后,通过执行shell命令启动Kubenetes。kubectl delete secret regcredkubectl create secret docker-registry regcred --docker-server=${docker-server} --docker-username=${docker-username} --docker-password=${docker-password} --docker-email=***@***.cn kubectl delete -f /root/phoenix-sample-deploy/kompose/kubectl apply -f /root/phoenix-sample-deploy/kompose/• 这里先是删除原有的secret,这一步主要是为了防止由于使用临时登录命令变化而导致secret错误引发的任务执行失败。• 接着,创建新的secret。包含docker-server、docker-username、docker-password等信息。• 按配置文件(/root/phoenix-sample-deploy/kompose/)删除资源。• 按配置文件(/root/phoenix-sample-deploy/kompose/)对资源进行配置。成功执行该部署任务后,可以在CCE集群中看到五个工作负载已经处于“运行中”的状态。不过目前还需要设置“节点访问”才能正常访问。所以在后续实践中对工作负载vote和result手动添加访问方式。节点访问设置完毕后,即可访问项目的用户端与管理端了。K8S的模板部署方式理论上,讲到现在,HE2E实践中的K8S部署就已经讲完了。但是,笔者猜到,肯定有很多人不喜欢这种通过代理机部署集群的方式。不过没关系,下面我就来介绍DevCloud当中的Kubernetes模板部署。新建模板时,现在可以选择模板:Kubernetes部署。进入模板以后,可以选择集群类型、区域、命名空间、部署方式等信息。由于本项目通过10个yaml文件共同配置,所以需要添加相同的“Kubernetes部署”步骤共计10个,每个步骤都对应一个yaml文件。而由于我们在代码仓库中的配置并非我们最终部署时所需的配置(经过编译构建修改docker-server等参数),所以我们需要每个步骤都设置软件发布库中对应的yaml文件。此时,我们会发现,我们原本的构建任务是将所有yaml文件进行了打包压缩后才上传的,没有办法直接选中。所以,我们可以再次创建一个构建任务或者在原有构建任务上进行修改,以使软件发布库中存放有所有的yaml文件。构建任务上传步骤的配置参考:(上传所有yaml文件而非打包后上传)完成以上配置以后,执行Kubernetes部署模板任务,即可将服务部署至选定的CCE集群当中。此时再添加节点访问方式即可访问用户端与管理端。当然,我们也可以将节点访问也写入yaml文件中,实现进一步的一键部署。这里就暂且留作一个小思考题,感兴趣的小伙伴可以自己尝试一下,将节点访问写入yaml当中。结语本篇文章一面介绍了HE2E实践中的CCE部署方式,一面又介绍了该实践中未提到的Kubernetes模板部署。两者的主要区别是“CCE部署”是通过代理机控制集群进行K8S部署;Kubernetes模板部署则是直接在集群中部署。此外,本文也对项目中关于K8S的配置进行了一定程度的解析。希望可以帮助小伙伴们理解K8S、HE2E,祝大家在技术成长的道路上越走越远。感谢小伙伴们的阅读。如果觉得还不错,不妨点个赞再走~此文由DevSecOps专家服务团队出品,前往 专家服务 ,获取更多DevSecOps工程方法、工具平台、最佳实践等干货。 -
一、创建Kubernetes集群1、创建集群1.1、登录CCE控制台https://console.huaweicloud.com/cce/1.2、创建CCE集群登录CCE控制台后会看见一个引导页面,请在CCE集群下单击“创建”按钮。1.3、配置集群参数参数说明如下:参数参数说明集群名称新建集群的名称。集群名称长度范围为4-128个字符,以小写字母开头,由小写字母、数字、中划线(-)组成,且不能以中划线(-)结尾。集群版本集群版本。建议选择最新的版本,对应Kubernetes社区基线版本。集群规模当前集群可以管理的最大Node节点规模。若选择50节点,表示当前集群最多可管理50个Node节点。高可用默认选择“是”。网络模型默认即可。虚拟私有云新建集群所在的虚拟私有云。若没有可选虚拟私有云,单击“新建虚拟私有云”进行创建,完成创建后单击刷新按钮。容器网段按默认配置即可。服务网段按默认配置即可。1.4、提交在右侧界面中会显示集群的资源清单,选择计费模式后,单击“提交”按钮,等待集群创建成功。创建成功后在集群管理下会显示一个运行中的集群,且集群节点数量为0。2、创建节点集群创建成功后,您还需要在集群中创建运行工作负载的节点。2.1、参数配置登录CCE控制台,单击创建的集群,进入集群控制台,在左侧菜单栏选择节点管理,单击右上角“创建节点”,在弹出的页面中配置节点的参数。参数说明如下:参数参数说明计算配置可用区默认即可。节点类型选择“虚拟机节点”。节点规格根据业务需求选择相应的节点规格。操作系统请选择节点对应的操作系统。节点名称自定义节点名称。登录方式支持密码和密钥对两种方式“密码”方式:用户名默认为“root”,请输入登录节点的密码,并确认密码。“密钥对”方式:在选项框中选择用于登录本节点的密钥对,并单击勾选确认信息。密钥对用于远程登录节点时的身份认证。若没有密钥对,可单击选项框右侧的“创建密钥对”来新建。存储配置系统盘按您的业务需求选择,缺省值为50GB。数据盘按您的业务需求选择,缺省值为100GB。网络配置虚拟私有云使用默认,即创建集群时选择的子网。节点子网选择节点所在的子网。2.2、规格确认在页面最下方选择节点的数量和计费模式,单击“下一步: 规格确认”。2.3、提交查看节点规格无误后,阅读页面上的使用说明,勾选“我已阅读并知晓上述使用说明”,单击“提交”按钮,等待节点创建成功,创建成功后在节点管理下会显示一个运行中的节点。二、镜像创建无状态工作负载(Nginx)1、前提条件您需要创建一个至少包含一个节点的集群,且该节点已绑定弹性公网IP,集群是运行工作负载的逻辑分组,包含一组云服务器资源,每台云服务器即集群中的一个节点。2、Nginx应用概述Nginx是一款轻量级的Web服务器,您可通过CCE快速搭建nginx web服务器。博主这里以选择“开源镜像中心”的方式创建应用为例,来创建一个Nginx工作负载。3、操作步骤3.1、镜像创建登录CCE控制台,单击集群进入集群控制台,在左侧菜单栏选择“工作负载”,单击右上角“镜像创建”。3.2、参数配置填写以下参数,其它保持默认。(1)基本参数配置参数参数说明负载类型选择无状态负载。负载名称nginx。实例数量设置为1。容器配置在基本信息中单击“选择镜像”,在弹出的窗口中选择“镜像中心”,并搜索“nginx”,选择nginx镜像。(2)服务配置单击服务配置下的加号,创建服务(Service),用于从外部访问负载,配置参数如下:参数参数说明Service名称输入应用发布的可被外部访问的名称,设置为:nginx。访问类型选择“负载均衡 ( LoadBalancer )”。服务亲和保持默认。负载均衡器如果已有负载均衡(ELB)实例,可以选择已有ELB,如果没有可单击“创建负载均衡器”,在ELB控制台创建一个公网类型负载均衡器。端口配置对外协议:TCP。服务端口:设置为8080,该端口号将映射到容器端口。容器端口:容器中应用启动监听的端口,nginx镜像请设置为80,其他应用容器端口和应用本身的端口一致。3.3、创建工作负载单击右下角“创建工作负载”,等待工作负载创建成功。创建成功后在无状态负载下会显示一个运行中的工作负载。4、访问Nginx(1)获取Nginx的外部访问地址单击Nginx工作负载名称,进入工作负载详情页。在访问方式页签下可以看到nginx的IP地址,其中负载均衡IP就是外部访问地址,如图所示:(2)在浏览器中输入“外部访问地址”,即可成功访问应用,如下图所示:【与云原生的故事】有奖征文火热进行中:https://bbs.huaweicloud.com/blogs/345260链接:https://bbs.huaweicloud.com/blogs/351622
-
 前文: Kubernetes的主要功能是容器编排,是指确保所有容器都按照计划运行在物理机或虚拟机上。这些容器在部署环境和集群配置的约束下被打包执行大量工作负载。此外,Kubernetes必须密切关注所有运行中的容器,替换运行中止,无响应或其他非正常状态的容器。 软件开发平台(DevCloud)是面向开发者提供的一站式云端DevOps平台,即开即用,随时随地在云端交付软件全生命周期,覆盖需求下发、代码提交、代码检查、代码编译、验证、部署、发布,打通软件交付的完整路径,提供软件研发流程的端到端支持,全面支撑落地DevOps。 本文着重介绍各位技术大咖在进行devcloud->部署->Kubernetes部署时,如何高效正确打通全流程参数化~ 废话不多说,下面开始手把手教学(*^▽^*)!! 首先我们介绍一下为什么要参数化~ 在敏捷开发,小步快跑的过程中,我们通过提交代码,执行各种各样的构建任务,编译打包镜像并上传到我们的华为云容器镜像服务SWR中,那么我们如何方便的管理我们的镜像呢?如果把镜像名称写成固定值,那么每次上传都会把旧版本覆盖掉,不利于我们的回滚和版本管理;而且我们的Kubernetes部署需要识别到yml文件的内容变动,部署后才会触发镜像更新!基于以上几点,参数化这个功能真是显得格外重要~ 下面我们开始图文并茂,直接上干货!持续集成嘛,提交代码的目的是为了打包编译,然后部署到目标集群,我们通过编译构建任务,新建步骤“制作镜像并推送到SWR仓库”,实现这个目的:我们试着构建一下~ 构建成功后,可以去容器镜像服务SWR里确认一下成果~!然后我们去部署服务里,新建kubernetes部署,按下图进行配置~同样~:我们在部署任务的参数设置中,也像构建那样,新建参数。接下来这步是重点哦,我们去代码仓库中的yml文件里,通过{{}}引用我们部署任务里的参数“version”下图是样例:接下来,我们通过流水线服务,把上述任务串起来~ 然后我们把流水线中的这个参数类型改为自增长,勾选"运行时设置",这样我们只需要首次执行流水线任务的时候给它赋予一个初始值,以后就会根据这个初始值进行自增长接下来,我们保存并执行一下这个流水线任务~(可以手动执行,也可以通过提交代码触发执行),然后静静的等待任务结束哎呦,部署成功了~我们看下执行参数是否成功取到了自增长的参数值。看起来没什么问题~ 因为我太菜~已经测试了4次OK!大功告成,最后我们去CCE集群的工作负载里检验一下最终成果!怎么样大咖们? 大家都学废,啊呸,大家都学会了嘛~ 请奔走相告~~
前文: Kubernetes的主要功能是容器编排,是指确保所有容器都按照计划运行在物理机或虚拟机上。这些容器在部署环境和集群配置的约束下被打包执行大量工作负载。此外,Kubernetes必须密切关注所有运行中的容器,替换运行中止,无响应或其他非正常状态的容器。 软件开发平台(DevCloud)是面向开发者提供的一站式云端DevOps平台,即开即用,随时随地在云端交付软件全生命周期,覆盖需求下发、代码提交、代码检查、代码编译、验证、部署、发布,打通软件交付的完整路径,提供软件研发流程的端到端支持,全面支撑落地DevOps。 本文着重介绍各位技术大咖在进行devcloud->部署->Kubernetes部署时,如何高效正确打通全流程参数化~ 废话不多说,下面开始手把手教学(*^▽^*)!! 首先我们介绍一下为什么要参数化~ 在敏捷开发,小步快跑的过程中,我们通过提交代码,执行各种各样的构建任务,编译打包镜像并上传到我们的华为云容器镜像服务SWR中,那么我们如何方便的管理我们的镜像呢?如果把镜像名称写成固定值,那么每次上传都会把旧版本覆盖掉,不利于我们的回滚和版本管理;而且我们的Kubernetes部署需要识别到yml文件的内容变动,部署后才会触发镜像更新!基于以上几点,参数化这个功能真是显得格外重要~ 下面我们开始图文并茂,直接上干货!持续集成嘛,提交代码的目的是为了打包编译,然后部署到目标集群,我们通过编译构建任务,新建步骤“制作镜像并推送到SWR仓库”,实现这个目的:我们试着构建一下~ 构建成功后,可以去容器镜像服务SWR里确认一下成果~!然后我们去部署服务里,新建kubernetes部署,按下图进行配置~同样~:我们在部署任务的参数设置中,也像构建那样,新建参数。接下来这步是重点哦,我们去代码仓库中的yml文件里,通过{{}}引用我们部署任务里的参数“version”下图是样例:接下来,我们通过流水线服务,把上述任务串起来~ 然后我们把流水线中的这个参数类型改为自增长,勾选"运行时设置",这样我们只需要首次执行流水线任务的时候给它赋予一个初始值,以后就会根据这个初始值进行自增长接下来,我们保存并执行一下这个流水线任务~(可以手动执行,也可以通过提交代码触发执行),然后静静的等待任务结束哎呦,部署成功了~我们看下执行参数是否成功取到了自增长的参数值。看起来没什么问题~ 因为我太菜~已经测试了4次OK!大功告成,最后我们去CCE集群的工作负载里检验一下最终成果!怎么样大咖们? 大家都学废,啊呸,大家都学会了嘛~ 请奔走相告~~ -
>摘要:为保证高速公路上门架系统的落地项目的成功落地,选择K8s和KubeEdge来进行整体的应用和边缘节点管理。本文分享自华为云社区《[如何使用Kubernetes管理中国高速公路上的10万边缘节点?](https://huaweicloud.blog.csdn.net/article/details/113683195)》,原文作者:技术火炬手。 # 一、项目背景 本项目是在高速公路ETC联网和推动取消省界收费站的大前提下,门架系统的落地,也就是要把门架部署在覆盖全国范围的高速公路上,收集车辆通行的牌示信息,以及相应的交易信息。 整体的情况是在边缘侧,即高速公路上会部署大量的门架和相应的控制器,相应的边缘终端,这些终端大概10万台,其上部署了相关的应用以收集相关信息。超过50万个应用部署到边缘节点,收集到信息后,通过收费专网向省中心以及路网中心上传对应的数据。 **本次项目的工作挑战主要有两个方面:** 将近10万台异构设备的管理,包括arm,x86等异构设备。 50余万个应用的生命周期管理 **为保证项目的成功落地,我们对整体架构做了选型,最终选择了K8s和KubeEdge来进行整体的应用和边缘节点管理。** # 二、为什么选择Kubernetes 在项目里,虽然说是部署在边缘侧的应用,但它的复杂程度已经和云上是类似的了,在边缘侧部署的应用已经是由很多个微服务组成的。所以Kubernetes对于支撑这种微服务化的、云原生化的应用部署和大规模管理的能力,同样也适用于这个项目在边缘侧的使用。 **具体来说,有一些典型的部署需求:** - 双机热备 - 多机多活互备 - 有关联的应用同节点部署以提升应用间交互效率 - 同一应用的不同实例跨节点部署以提升可用性 - 依据边缘节点的不同属性将应用部署于不同分组中 - 定义独立于节点的应用部署以及实现满足条件的新边缘节点上线后自动安装应用 **这些需求,用K8s的这些Deployment、Pod、ReplicaSet、DaemonSet等核心对象来表示,是非常适合的。所以我们就选择了Kubernetes。** 当然,还有一些重要的边缘侧特有的需求是原生的Kubernetes不具备的,但Kubernetes的架构是非常好的,易于扩展,灵活性很高,可以基于原生Kubernetes架构基础,根据边缘管理的特殊需求进行扩展。 # 三、为什么选择KubeEdge **一是业务自身的特点来决定的。** 这个业务的量非常大,涉及的边缘节点分布在全国各地,所以它的边缘侧是多硬件架构、多厂家的,我们需要异构的支持; 边缘工控机低至4核ARM SOC、1G可用内存,我们需要低资源占用的方案来管理边缘侧的节点;管理运维复杂,从路网中心到最终路段,分为6级管理层次,管理成本高,我们需要高集成度边缘的方案,让边缘足够简单,把出问题的概率降到最低,降低运维成本。 **二是从边缘环境的特点来看的。** 从网络的角度来看,网络分为部省、省站两层,多次转发,我们需要边缘接入具有高灵活性,可支持专线、代理、公网、有线和无线接入等多种方式;各地基础设施的建设不同,有些省份的网络带宽低至3M,我们需要边缘和云之间的管理带宽占用降到最低;有些高速公路上的网络条件是非常差的,经常出现断网的情况。我们需要边缘方案有离线自治的能力。 # 四、整体方案 接下来我会把整体方案打开成几层来分别介绍。 **应用部署** 首先是应用部署,就像我刚才说的,在边缘侧要部署的业务非常复杂,它是由多个微服务所构成的云原生化的架构。所以我们这些微服务以及中间件都容器化之后可以非常好的适应各种不同的异构操作系统,方便统一管理。 如下图所示,微服务架构分成前端和后端,前端主要把业务通过Deployment的方式部署到门架上,与后端之间是通过EdgeMesh实现的。通过这种服务发现的方式,实现微服务前后端业务的通信。而后端业务容器本身是无状态的,可以通过Deployment来部署。 后面的Redis包括MySql就可以通过Statefulset的方式来进行部署。通过这样的部署模型,我们可以很完美的进行封装和自动化管理高可用的边缘侧的整套业务系统。  但如果仅仅是用原生的K8s部署方式,并不能完全满足我们的需求,因为在项目里要部署的量非常大,左图的环境只是应用于一个收费站,而一个路段要管理几百上千个收费站,逐个部署成本过高。所以我们基于K8s之上又构建了一个任务工作流的引擎系统,把每一个部署微服务的步骤定义为一个job。用批量的方式大量、快速部署成百上千个同样的微服务系统和环境。  **大规模节点接入** 除了上面提到的挑战,在应对大规模节点接入的情况下也遇见过一些问题: 每个省有自己的管理权限,我们按K8s集群的配置配了多个K8s集群来进行管理,一个省对应一个K8s集群,然后在K8s之上通过统一的管理层处理复杂跨集群数据统计等操作,从中心侧管理每个省的边缘侧,这就是多集群的管理手段。 我们曾遇见一种现象,路网中心或省中心做网络升级等动作之后,网络有时候会出现问题,所有省的边缘节点,失去与K8s的连接,等网络恢复之后,又会发生所有节点同时连接中心侧的K8s集群,引起大量的并发连接,对中心侧的系统造成冲击,导致应用异常。为了应对这种情况,我们通过动态退避算法缓解节点同时接入所形成的流量冲击。 需要精简NodeStatus和PodStatus上报的信息。就前文所提到的,各地基础设施的建设不同,有些省份的网络带宽低至3M,所以我们需要减小状态信息的大小,降低上报流量的冲击,降低对网络的影响。 镜像仓库Mirror分级加速,有效降低了对网络的冲击,提高大批量部署的部署效率。 **边缘业务高可用** 接下来的是边缘业务高可用,按照原生K8s的升级状态,它会先删除旧版本Pod,再创建新Pod并在这个过程中去拉取新版本镜像。这种操作在公有云网络条件较好的情况下,是没太大问题的。但在边缘侧,这样就会造成业务长时间的中断,收费数据缺失。所以针对这一个流程,我们也是做了相应的升级和优化。 我们先把升级下载镜像的通知下发做预下载,下载成功之后再删除已有的旧Pod,启动新应用,优化了应用升级对服务中断的时间的影响,将业务升级时整体业务中断的时间从分钟级缩减到了10s内。 同时,考虑到边缘设备有主备部署的情况,而边缘侧又不像云上有ELB服务。我们又在边缘节点中容器化部署了Keepalived,通过VIP,为门架的摄像头等设备提供对应的K8s集群内的容器服务。 # 五、总结 当前基于KubeEdge的边缘管理系统管理着全国29个省、市 、自治区的将近100,000个边缘节点,超过500,000边缘应用的部署。支撑了高速公路门架业务的不断调整、更新,满足了每日3亿条以上的信息采集。 为日后车路协同、自动驾驶等创新业务的发展提供了良好的平台支撑。 K8s提供的通用部署和调度模型很适合部署大规模边缘应用。 单纯原生K8s不能满足边缘侧业务的所有需求,KubeEdge集成K8s云原生管理能力,同时对边缘业务部署和管理提供了很好的支持。
-
>摘要:Kubernetes 很多看起来比较“繁琐”的设计的主要目的,都是希望为开发者提供更多的“可扩展性”,给使用者带来更多的“稳定性”和“安全感”。本文分享自华为云社区《[如何在 Kubernetes 集群中搭建一个复杂的 MySQL 数据库?](https://bbs.huaweicloud.com/blogs/302931?utm_source=zhihu&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者:zuozewei 。 # 前言 实际生产环境中,为了稳定和高可用,运维团队一般不会把 MySQL 数据库部署在 Kubernetes 集群中,一般是用云厂商的数据库或者自己在高性能机器(如裸金属服务器)上搭建。 但是,对于测试开发环境,我们完全可以把 MySQL 部署到各自的 Kubernetes 集群中,非常有助于提升运维效率,而且还有助于Kubernetes 使用的经验积累。 # 简易部署 如下所示,我们仅需设置 root 用户密码(环境变量 MYSQL_ROOT_PASSWORD), 便可轻松的使用 MySQL 官方镜像构建一个 MySQL 数据库。 apiVersion: extensions/v1beta1 kind: Deployment metadata: labels: app: mysql-min name: mysql-min spec: replicas: 1 selector: matchLabels: app: mysql-min template: metadata: labels: app: mysql-min spec: containers: - image: centos/mysql-57-centos7:latest name: mysql-min imagePullPolicy: IfNotPresent env: - name: MYSQL_ROOT_PASSWORD value: admin@123 创建一 Service 以便集群内外均可访问数据库,其中集群外需通过 nodePort 设置的 30336 端口访问。 apiVersion: v1 kind: Service metadata: labels: app: mysql-min release: mysql-min name: mysql-min namespace: default spec: ports: - name: mysql port: 3306 protocol: TCP nodePort: 30336 targetPort: mysql selector: app: mysql-min #目前sessionAffinity可以提供"None""ClientIP"两种设定: #None: 以round robin的方式轮询下面的Pods。 #ClientIP: 以client ip的方式固定request到同一台机器。 sessionAffinity: None type: NodePort #status: # loadBalancer: {} 接着,访问数据库并验证其运行正常: # kubectl get pod # 当前Pod名称 NAME READY STATUS RESTARTS AGE mysql-min-5b5668c448-t44ml 1/1 Running 0 3h # 通过本机访问 # kubectl exec -it mysql-min-5b5668c448-t44ml -- mysql -uroot -padmin@123 mysql> select 1; +---+ | 1 | +---+ | 1 | +---+ # 集群内部通过mysql service访问: # kubectl exec -it mysql-min-5b5668c448-t44ml -- mysql -uroot -padmin@123 -hmysql mysql> select now(); +---------------------+ | now() | +---------------------+ | 2021-03-13 07:19:14 | +---------------------+ # 集群外部,可通过任何一个 K8S 节点访问数据库: # mysql -uroot -padmin@123 -hworker-1 -P30336 mysql> show databases; +--------------------+ | Database | +--------------------+ | information_schema | | mysql | | performance_schema | | sys | +--------------------+ # 扩展部署 ## 持久化存储 若要确保 MySQL 重启后数据仍然存在,我们需为其配置可持久化存储,我这里的实验环境使用的是 Local Persistent Volume,也就是说,我希望 Kubernetes 能够直接使用宿主机上的本地磁盘目录,而不依赖于远程存储服务,来提供“持久化”的容器 Volume。这样做的好处很明显,由于这个 Volume 直接使用的是本地磁盘,尤其是 SSD 盘,它的读写性能相比于大多数远程存储来说,要好得多。这个需求对本地物理服务器部署的私有 Kubernetes 集群来说,非常常见。 值得指出的是其次,相比于正常的 PV,一旦这些节点宕机且不能恢复时,本地存储 Volume 的数据就可能丢失。这就要求使用 其的应用必须具备数据备份和恢复的能力,允许你把这些数据定时备份在其他位置。 不难想象, Local Persistent Volume 的设计,主要面临两个难点。 **第一个难点在于:如何把本地磁盘抽象成 PV。** 可能你会说,Local Persistent Volume 不就等同于 hostPath 加 NodeAffinity 吗? 比如,一个 Pod 可以声明使用类型为 Local 的 PV,而这个 PV 其实就是一个 hostPath 类型的 Volume。如果这个 hostPath 对应的目录,已经在节点 A 上被事先创建好了。那么,我只需要再给这个 Pod 加上一个 nodeAffinity=nodeA,不就可以使用这个 Volume 了吗? 事实上,你绝不应该把一个宿主机上的目录当作 PV 使用。这是因为,这种本地目录的存储行为完全不可控,它所在的磁盘随时都可能被应用写满,甚至造成整个宿主机宕机。而且,不同的本地目录之间也缺乏哪怕最基础的 I/O 隔离机制。 所以,一个 本地存储 Volume 对应的存储介质,一定是一块额外挂载在宿主机的磁盘或者块设备(“额外”的意思是,它不应该是宿主机根目录所使用的主硬盘)。这个原则,我们可以称为“**一个 PV 一块盘**”。 **第二个难点在于:调度器如何保证 Pod 始终能被正确地调度到它所请求的本地 Volume 所在的节点上呢?** 造成这个问题的原因在于,对于常规的 PV 来说,Kubernetes 都是先调度 Pod 到某个节点上,然后,再通过“两阶段处理”来“持久化”这台机器上的 Volume 目录,进而完成 Volume 目录与容器的绑定挂载。 可是,对于 Local PV 来说,节点上可供使用的磁盘(或者块设备),必须是运维人员提前准备好的。它们在不同节点上的挂载情况可以完全不同,甚至有的节点可以没这种磁盘。 所以,这时候,调度器就必须能够知道所有节点与 Local Persistent Volume 对应的磁盘的关联关系,然后根据这个信息来调度 Pod。 这个原则,我们可以称为“在调度的时候考虑 Volume 分布”。在 Kubernetes 的调度器里,有一个叫作 VolumeBindingChecker 的过滤条件专门负责这个事情。在 Kubernetes v1.11 中,这个过滤条件已经默认开启了。 基于上述讲述,在开始使用 Local Persistent Volume 之前,你首先需要在集群里配置好磁盘或者块设备。在公有云上,这个操作等同于给虚拟机额外挂载一个磁盘,比如 GCE 的 Local SSD 类型的磁盘就是一个典型例子。 而在我们部署的私有环境中,你有两种办法来完成这个步骤。 - 第一种,当然就是给你的宿主机挂载并格式化一个可用的本地磁盘,这也是最常规的操作; - 第二种,对于实验环境,你其实可以在宿主机上挂载几个 RAM Disk(内存盘)来模拟本地磁盘。 接下来,我会使用第二种方法,在我们之前部署的 Kubernetes 集群上进行实践。首先,在名叫 node-1 的宿主机上创建一个挂载点,比如 /mnt/disks;然后,用几个 RAM Disk 来模拟本地磁盘,如下所示: # 在node-1上执行 $ mkdir /mnt/disks $ for vol in vol1 vol2 vol3; do mkdir /mnt/disks/$vol mount -t tmpfs $vol /mnt/disks/$vol done 需要注意的是,如果你希望其他节点也能支持 Local Persistent Volume 的话,那就需要为它们也执行上述操作,并且确保这些磁盘的名字(vol1、vol2 等)都不重复。接下来,我们就可以为这些本地磁盘定义对应的 PV 了,如下所示: apiVersion: v1 kind: PersistentVolume metadata: name: mysql-min-pv-local namespace: default spec: capacity: storage: 5Gi volumeMode: Filesystem accessModes: - ReadWriteOnce storageClassName: "mysql-min-storageclass-local" persistentVolumeReclaimPolicy: Retain #表示使用本地存储 local: path: /mnt/disks/vol1 #使用local pv时必须定义nodeAffinity,Kubernetes Scheduler需要使用PV的nodeAffinity描述信息来保证Pod能够调度到有对应local volume的Node上。 #创建local PV之前,你需要先保证有对应的storageClass已经创建。 nodeAffinity: required: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: # pod 需要分不到的主机名,这台主机上开启了 local-pv 资源。 - node-1 可以看到,这个 PV 的定义里:local 字段,指定了它是一个 Local Persistent Volume;而 path 字段,指定的正是这个 PV 对应的本地磁盘的路径,即:/mnt/disks/vol1。 当然了,这也就意味着如果 Pod 要想使用这个 PV,那它就必须运行在 node-1 上。所以,在这个 PV 的定义里,需要有一个 nodeAffinity 字段指定 node-1 这个节点的名字。这样,调度器在调度 Pod 的时候,就能够知道一个 PV 与节点的对应关系,从而做出正确的选择。这正是 Kubernetes 实现“在调度的时候就考虑 Volume 分布”的主要方法。 接下来要创建一个 StorageClass 来描述这个 PV,如下所示: kind: StorageClass apiVersion: storage.k8s.io/v1 metadata: name: mysql-min-storageclass-local #指定存储类的供应者,比如aws, nfs等,具体取值参考官方说明。 #存储类有一个供应者的参数域,此参数域决定PV使用什么存储卷插件。参数必需进行设置 #由于demo中使用的是本地存储,所以这里写kubernetes.io/no-provisioner. provisioner: kubernetes.io/no-provisioner #volumeBindingMode 参数将延迟PVC绑定,直到 pod 被调度。 volumeBindingMode: WaitForFirstConsumer 这个 StorageClass 的名字,叫作 local-storage。需要注意的是,在它的 provisioner 字段,我们指定的是 no-provisioner。这是因为 Local Persistent Volume 目前尚不支持 Dynamic Provisioning,所以它没办法在用户创建 PVC 的时候,就自动创建出对应的 PV。也就是说,我们前面创建 PV 的操作,是不可以省略的。 与此同时,这个 StorageClass 还定义了一个 volumeBindingMode=WaitForFirstConsumer 的属性。它是 Local Persistent Volume 里一个非常重要的特性,即:延迟绑定。 >通过这个延迟绑定机制,原本实时发生的 PVC 和 PV 的绑定过程,就被延迟到了 Pod 第一次调度的时候在调度器中进行,从而保证了这个绑定结果不会影响 Pod 的正常调度。 接下来,我们只需要定义一个非常普通的 PVC,就可以让 Pod 使用到上面定义好的 Local Persistent Volume 了,如下所示: apiVersion: v1 items: - apiVersion: v1 kind: PersistentVolumeClaim metadata: #当启用PVC 保护 alpha 功能时,如果用户删除了一个 pod 正在使用的 PVC,则该 PVC 不会被立即删除。PVC 的删除将被推迟,直到 PVC 不再被任何 pod 使用。 #可以看到,当 PVC 的状态为 Teminatiing 时,PVC 受到保护,Finalizers 列表中包含 kubernetes.io/pvc-protection: finalizers: - kubernetes.io/pvc-protection labels: app: mysql-min release: mysql-min name: mysql-min namespace: default spec: #PV 的访问模式(accessModes)有三种: #ReadWriteOnce(RWO):是最基本的方式,可读可写,但只支持被单个 Pod 挂载。 #ReadOnlyMany(ROX):可以以只读的方式被多个 Pod 挂载。 #ReadWriteMany(RWX):这种存储可以以读写的方式被多个 Pod 共享。 accessModes: - ReadWriteOnce resources: requests: storage: 10Gi storageClassName: mysql-min-storageclass-local #表示使用本地磁盘,实际生产中一般都使用nfs。 volumeMode: Filesystem volumeName: mysql-min-pv-local # status: # accessModes: # - ReadWriteOnce # capacity: # storage: 1Gi kind: List 可以看到,这个 PVC 没有任何特别的地方。唯一需要注意的是,它声明的 storageClassName 是 mysql-min-storageclass-local。所以,将来 Kubernetes 的 Volume Controller 看到这个 PVC 的时候,不会为它进行绑定操作。 最后,我们创建 Local Persistent Volume 资源文件: kubectl apply -f mysql-min-pv-local.yaml kubectl apply -f mysql-min-storageclass-local.yaml kubectl apply -f mysql-min-pvc.yaml 而后,调整 Deploy 并挂载卷: spec: containers: - image: centos/mysql-57-centos7:latest ... volumeMounts: - name: data mountPath: /var/lib/mysql volumes: - name: data persistentVolumeClaim: claimName: mysql-min ## 自定义配置文件 通过创建 configmap 并挂载到容器中,我们可自定义 MySQL 配置文件。如下所示,名为 mysql-config 的 cm 包含一个 my.cnf 文件: apiVersion: v1 kind: ConfigMap metadata: name: mysql-config data: my.cnf: | [mysqld] default_storage_engine=innodb skip_external_locking lower_case_table_names=1 skip_host_cache skip_name_resolve max_connections=2000 innodb_buffer_pool_size=8589934592 init_connect='SET collation_connection = utf8_unicode_ci' init_connect='SET NAMES utf8' character-set-server=utf8 collation-server=utf8_unicode_ci skip-character-set-client-handshake query_cache_type=0 innodb_flush_log_at_trx_commit = 0 sync_binlog = 0 query_cache_size = 104857600 slow_query_log =1 slow_query_log_file=/var/lib/mysql/slow-query.log log-error=/var/lib/mysql/mysql.err long_query_time = 0.02 table_open_cache_instances=16 table_open_cache = 6000 skip-grant-tables sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION 将 configmap 挂载到容器内: spec: containers: - image: centos/mysql-57-centos7:latest volumeMounts: - name: mysql-config mountPath: /etc/my.cnf.d/my.cnf subPath: my.cnf volumes: - name: mysql-config - name: mysql-config configMap: name: mysql-config ## 设置容器时区 最傻瓜也最方便的处理方式,设置宿主机时区和时间文件与容器的映射。 spec: containers: - image: centos/mysql-57-centos7:latest volumeMounts: - name: localtime readOnly: true mountPath: /etc/localtime volumes: - name: localtime hostPath: type: File path: /etc/localtime ## 加密敏感数据 用户密码等敏感数据以 Secret 加密保存,而后被 Deployment 通过 volume 挂载或环境变量引用。如本例,我们创建root、user用户,将用户的密码加密保存: apiVersion: v1 data: #将mysql数据库的所有user的password配置到secret,统一管理 mysql-password: YWRtaW4= mysql-root-password: OVplTmswRGdoSA== kind: Secret metadata: labels: app: mysql-min release: mysql-min name: mysql-min namespace: default #Secret有三种类型: #Opaque:base64编码格式的Secret,用来存储密码、密钥等;但数据也通过base64 –decode解码得到原始数据,所有加密性很弱。 #kubernetes.io/dockerconfigjson:用来存储私有docker registry的认证信息。 #kubernetes.io/service-account-token: 用于被serviceaccount引用。serviceaccout创建时Kubernetes会默认创建对应的secret。Pod如果使用了serviceaccount,对应的secret会自动挂载到Pod目录/run/secrets/ kubernetes.io/serviceaccount中。 type: Opaque Secret 创建完成后,我们将用户明文密码从 Deployment 去除,采用环境变量方式引用 Secret 数据,参见如下 Yaml 修改: root 用户及 MYSQL_USER 用户,其密码均通过 secretKeyRef 从 secret 获取。 spec: containers: - image: centos/mysql-57-centos7:latest name: mysql-min imagePullPolicy: IfNotPresent env: #password存储在secret中 - name: MYSQL_ROOT_PASSWORD valueFrom: secretKeyRef: key: mysql-root-password name: mysql-min - name: MYSQL_PASSWORD valueFrom: secretKeyRef: key: mysql-password name: mysql-min - name: MYSQL_USER value: zuozewei ## 容器健康检查 K8S 镜像控制器可通过 livenessProbe 判断容器是否异常,进而决定是否重建容器;而 Service 服务可通过 readinessProbe 判断容器服务是否正常,从而确保服务可用性。 本例配置的 livenessProbe 与 readinessProbe 是一样的,即连续 3 次查询数据库失败,则定义为异常。对 livenessProbe 与readinessProbe 详细用法,不在本文的讨论范围内,可参考 K8S 官方文档: - Configure Liveness and Readiness Probes - Pod Lifecycle spec: containers: image: centos/mysql-57-centos7:latest #kubelet 使用 liveness probe(存活探针)来确定何时重启容器。例如,当应用程序处于运行状态但无法做进一步操作,liveness 探针将捕获到 deadlock,重启处于该状态下的容器,使应用程序在存在 bug 的情况下依然能够继续运行下去 livenessProbe: exec: command: - /bin/sh - "-c" - MYSQL_PWD="${MYSQL_ROOT_PASSWORD}" - mysql -h 127.0.0.1 -u root -e "SELECT 1" failureThreshold: 3 #探测成功后,最少连续探测失败多少次才被认定为失败。默认是 3。最小值是 1。 initialDelaySeconds: 30 #容器启动后第一次执行探测是需要等待多少秒。 periodSeconds: 10 #执行探测的频率。默认是10秒,最小1秒。 successThreshold: 1 #探测失败后,最少连续探测成功多少次才被认定为成功。默认是 1。对于 liveness 必须是 1。最小值是 1。 timeoutSeconds: 5 #探测超时时间。默认1秒,最小1秒。 #Kubelet 使用 readiness probe(就绪探针)来确定容器是否已经就绪可以接受流量。只有当 Pod 中的容器都处于就绪状态时 kubelet 才会认定该 Pod处于就绪状态。该信号的作用是控制哪些 Pod应该作为service的后端。如果 Pod 处于非就绪状态,那么它们将会被从 service 的 load balancer中移除。 readinessProbe: exec: command: - /bin/sh - "-c" - MYSQL_PWD="${MYSQL_ROOT_PASSWORD}" - mysql -h 127.0.0.1 -u root -e "SELECT 1" failureThreshold: 3 initialDelaySeconds: 5 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 ## 容器初始化 容器的一些初始化操作显然适合通过 InitContainer 来完成,这里的 initContainer 是为了保证在 POD 启动前,PV盘 要先行绑定成功,同时为了避免 MySQL 数据库目录内的 lost+found 目录被误认为是数据库,初始化容器中将其删除; #Init 容器支持应用容器的全部字段和特性,包括资源限制、数据卷和安全设置。 然而,Init 容器对资源请求和限制的处理稍有不同,在下面 资源 处有说明。 而且 Init 容器不支持 Readiness Probe,因为它们必须在 Pod 就绪之前运行完成。 #如果为一个 Pod 指定了多个 Init 容器,那些容器会按顺序一次运行一个。 每个 Init 容器必须运行成功,下一个才能够运行。 当所有的 Init 容器运行完成时,Kubernetes 初始化 Pod 并像平常一样运行应用容器。 #mysql这里的initContainer是为了保证在POD启动前,PV盘要先行绑定成功。 initContainers: - command: - rm - -fr - /var/lib/mysql/lost+found image: busybox:1.29.3 imagePullPolicy: IfNotPresent name: remove-lost-found resources: {} terminationMessagePath: /dev/termination-log terminationMessagePolicy: File volumeMounts: - mountPath: /var/lib/mysql name: data restartPolicy: Always #scheduler 是 kubernetes 的调度器,主要的任务是把定义的 pod 分配到集群的节点上。 schedulerName: default-scheduler securityContext: {} #如果您的Pod通常需要超过30秒才能关闭,请确保增加优雅终止宽限期。可以通过在Pod YAML中设置terminationGracePeriodSeconds选项来实现. #如果容器在优雅终止宽限期后仍在运行,则会发送SIGKILL信号并强制删除。与此同时,所有的Kubernetes对象也会被清除。 terminationGracePeriodSeconds: 30 #定义数据卷PVC,与PV匹配。 volumes: - name: data persistentVolumeClaim: claimName: mysql-min - name: mysql-config configMap: name: mysql-config - name: localtime hostPath: type: File path: /etc/localtime **注:文本有限,故删减一部分,具体内容请参考原文。** # 小结 Kubernetes 很多看起来比较“繁琐”的设计的主要目的,都是希望为开发者提供更多的“可扩展性”,给使用者带来更多的“稳定性”和“安全感”。这两个能力的高低,是衡量开源基础设施项目水平的重要标准。 示例中揉合 Kubernetes 多项技术,构建了一个复杂且可做生产使用的单实例数据库。 本文源码: - blog-example/Kubernetes/k8s-mysql-pv-local at master · zuozewei/blog-example · GitHub # 参考资料: [1]:《深入剖析Kubernetes》
-
 1 背景石墨文档全部应用部署在Kubernetes上,每时每刻都会有大量的日志输出,我们之前主要使用SLS和ES作为日志存储。但是我们在使用这些组件的时候,发现了一些问题。成本问题:SLS个人觉得是一个非常优秀的产品,速度快,交互方便,但是SLS索引成本比较贵我们想减少SLS索引成本的时候,发现云厂商并不支持分析单个索引的成本,导致我们无法知道是哪些索引构建的不够合理ES使用的存储非常多,并且耗费大量的内存通用问题:如果业务是混合云架构,或者业务形态有SAAS和私有化两种方式,那么SLS并不能通用日志和链路,需要用两套云产品,不是很方便精确度问题:SLS存储的精度只能到秒,但我们实际日志精度到毫秒,如果日志里面有traceid,SLS中无法通过根据traceid信息,将日志根据毫秒时间做排序,不利于排查错误我们经过一番调研后,发现使用Clickhouse能够很好的解决以上问题,并且Clickhouse省存储空间,非常省钱,所以我们选择了Clickhouse方案存储日志。但当我们深入研究后,Clickhouse作为日志存储有许多落地的细节,但业界并没有很好阐述相关Clickhouse采集日志的整套流程,以及没有一款优秀的Clickhouse日志查询工具帮助分析日志,为此我们写了一套Clickhouse日志系统贡献给开源社区,并将Clickhouse的日志采集架构的经验做了总结。先上个Clickhouse日志查询界面,让大家感受下石墨最懂前端的后端程序员。2 架构原理图我们将日志系统分为四个部分:日志采集、日志传输、日志存储、日志管理。日志采集:LogCollector采用Daemonset方式部署,将宿主机日志目录挂载到LogCollector的容器内,LogCollector通过挂载的目录能够采集到应用日志、系统日志、K8S审计日志等日志传输:通过不同Logstore映射到Kafka中不同的Topic,将不同数据结构的日志做了分离日志存储:使用Clickhouse中的两种引擎数据表和物化视图日志管理:开源的Mogo系统,能够查询日志,设置日志索引,设置LogCollector配置,设置Clickhouse表,设置报警等以下我们按照这四大部分,阐述其中的架构原理3 日志采集3.1 采集方式Kubernetes容器内日志收集的方式通常有以下三种方案DaemonSet方式采集:在每个 node 节点上部署LogCollector,并将宿主机的目录挂载为容器的日志目录,LogCollector读取日志内容,采集到日志中心。网络方式采集:通过应用的日志 SDK,直接将日志内容采集到日志中心 。SideCar方式采集:在每个 pod 内部署LogCollector,LogCollector只读取这个 pod 内的日志内容,采集到日志中心。以下是三种采集方式的优缺点:DaemonSet方式 网络方式 SideCar方式采集日志类型 标准输出+文件 应用日志部署运维 一般,维护DaemonSet 低,维护配置文件日志分类存储 可通过容器/路径等映射 业务独立配置支持集群规模 取决于配置数 无限制适用场景 日志分类明确、功能较单一 性能要求极高的场景资源消耗 中 低我们主要采用DaemonSet方式和网络方式采集日志。DaemonSet方式用于ingress、应用日志的采集,网络方式用于大数据日志的采集。以下我们主要介绍下DeamonSet方式的采集方式。 3.2 日志输出从上面的介绍中可以看到,我们的DaemonSet会有两种方式采集日志类型,一种是标准输出,一种是文件。 引用元乙的描述:虽然使用 Stdout 打印日志是 Docker 官方推荐的方式,但大家需要注意:这个推荐是基于容器只作为简单应用的场景,实际的业务场景中我们还是建议大家尽可能使用文件的方式,主要的原因有以下几点:Stdout 性能问题,从应用输出 stdout 到服务端,中间会经过好几个流程(例如普遍使用的JSON LogDriver):应用 stdout -> DockerEngine -> LogDriver -> 序列化成 JSON -> 保存到文件 -> Agent 采集文件 -> 解析 JSON -> 上传服务端。整个流程相比文件的额外开销要多很多,在压测时,每秒 10 万行日志输出就会额外占用 DockerEngine 1 个 CPU 核;Stdout 不支持分类,即所有的输出都混在一个流中,无法像文件一样分类输出,通常一个应用中有 AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog 等,而这些日志的格式、用途不一,如果混在同一个流中将很难采集和分析;Stdout 只支持容器的主程序输出,如果是 daemon/fork 方式运行的程序将无法使用 stdout;文件的 Dump 方式支持各种策略,例如同步/异步写入、缓存大小、文件轮转策略、压缩策略、清除策略等,相对更加灵活。从这个描述中,我们可以看出在docker中输出文件在采集到日志中心是一个更好的实践。所有日志采集工具都支持采集文件日志方式,但是我们在配置日志采集规则的时候,发现开源的一些日志采集工具,例如fluentbit、filebeat在DaemonSet部署下采集文件日志是不支持追加例如pod、namespace、container_name、container_id等label信息,并且也无法通过这些label做些定制化的日志采集。agent类型 采集方式 daemonset部署 sidecar部署ilogtail 文件日志 能够追加label信息,能够根据label过滤采集 能够追加label信息,能够根据label过滤采集fluentbit 文件日志 无法追加label信息,无法根据label过滤采集 能够追加abel信息,能够根据label过滤采集filebeat 文件日志 无法追加label信息,无法根据label过滤采集 能够追加label信息,能够根据label过滤采集ilogtail 标准输出 能够追加label信息,能够根据label过滤采集 能够追加label信息,能够根据label过滤采集fluentbit 标准输出 能够追加label信息,能够根据label过滤采集 能够追加abel信息,能够根据label过滤采集filebeat 标准输出 能够追加label信息,能够根据label过滤采集 能够追加label信息,能够根据label过滤采集基于无法追加label信息的原因,我们暂时放弃了DeamonSet部署下文件日志采集方式,采用的是基于DeamonSet部署下标准输出的采集方式。 3.3 日志目录以下列举了日志目录的基本情况目录 描述 类型/var/log/containers 存放的是软链接,软链到/var/log/pods里的标准输出日志 标准输出/var/log/pods 存放标准输出日志 标准输出/var/log/kubernetes/ master存放Kubernetes 审计输出日志 标准输出/var/lib/docker/overlay2 存放应用日志文件信息 文件日志/var/run 获取docker.sock,用于docker通信 文件日志/var/lib/docker/containers 用于存储容器信息 两种都需要因为我们采集日志是使用的标准输出模式,所以根据上表我们的LogCollector只需要挂载/var/log,/var/lib/docker/containers两个目录。3.3.1 标准输出日志目录应用的标准输出日志存储在/var/log/containers目录下,文件名是按照K8S日志规范生成的。这里以nginx-ingress的日志作为一个示例。我们通过ls /var/log/containers/ | grep nginx-ingress指令,可以看到nginx-ingress的文件名。 nginx-ingress-controller-mt2wx_kube-system_nginx-ingress-controller-be3741043eca1621ec4415fd87546b1beb29480ac74ab1cdd9f52003cf4abf0a.log 我们参照K8S日志的规范:/var/log/containers/%{DATA:pod_name}_%{DATA:namespace}_%{GREEDYDATA:container_name}-%{DATA:container_id}.log。可以将nginx-ingress日志解析为:pod_name:nginx-ingress-controller-mt2wnamespace:kube-systemcontainer_name:nginx-ingress-controllercontainer_id:be3741043eca1621ec4415fd87546b1beb29480ac74ab1cdd9f52003cf4abf0a通过以上的日志解析信息,我们的LogCollector 就可以很方便的追加pod、namespace、container_name、container_id的信息。 3.3.2 容器信息目录应用的容器信息存储在/var/lib/docker/containers目录下,目录下的每一个文件夹为容器ID,我们可以通过cat config.v2.json获取应用的docker基本信息。3.4 LogCollector采集日志3.4.1 配置我们LogCollector采用的是fluent-bit,该工具是cncf旗下的,能够更好的与云原生相结合。通过Mogo系统可以选择Kubernetes集群,很方便的设置fluent-bit configmap的配置规则。3.4.2 数据结构fluent-bit的默认采集数据结构@timestamp字段:string or float,用于记录采集日志的时间log字段:string,用于记录日志的完整内容Clickhouse如果使用@timestamp的时候,因为里面有@特殊字符,会处理的有问题。所以我们在处理fluent-bit的采集数据结构,会做一些映射关系,并且规定双下划线为Mogo系统日志索引,避免和业务日志的索引冲突。_time_字段:string or float,用于记录采集日志的时间_log_字段:string,用于记录日志的完整内容例如你的日志记录的是{"id":1},那么实际fluent-bit采集的日志会是{"_time_":"2022-01-15...","_log_":"{\"id\":1}" 该日志结构会直接写入到kafka中,Mogo系统会根据这两个字段_time_、_log_设置clickhouse中的数据表。3.4.3 采集如果我们要采集ingress日志,我们需要在input配置里,设置ingress的日志目录,fluent-bit会把ingress日志采集到内存里。然后我们在filter配置里,将log改写为_log_ 然后我们在ouput配置里,将追加的日志采集时间设置为_time_,设置好日志写入的kafka borkers和kafka topics,那么fluent-bit里内存的日志就会写入到kafka中日志写入到Kafka中_log_需要为json,如果你的应用写入的日志不是json,那么你就需要根据fluent-bit的parser文档,调整你的日志写入的数据结构:https://docs.fluentbit.io/manual/pipeline/filters/parser4 日志传输Kafka主要用于日志传输。上文说到我们使用fluent-bit采集日志的默认数据结构,在下图kafka工具中我们可以看到日志采集的内容。 在日志采集过程中,会由于不用业务日志字段不一致,解析方式是不一样的。所以我们在日志传输阶段,需要将不同数据结构的日志,创建不同的Clickhouse表,映射到Kafka不同的Topic。这里以ingress为例,那么我们在Clickhouse中需要创建一个ingress_stdout_stream的Kafka引擎表,然后映射到Kafka的ingress-stdout Topic里。5 日志存储我们会使用三种表,用于存储一种业务类型的日志。Kafka引擎表:将数据从Kafka采集到Clickhouse的ingress_stdout_stream数据表中create table logger.ingress_stdout_stream( _source_ String, _pod_name_ String, _namespace_ String, _node_name_ String, _container_name_ String, _cluster_ String, _log_agent_ String, _node_ip_ String, _time_ Float64, _log_ String)engine = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'ingress-stdout', kafka_group_name = 'logger_ingress_stdout', kafka_format = 'JSONEachRow', kafka_num_consumers = 1;物化视图:将数据从ingress_stdout_stream数据表读取出来,_log_根据Mogo配置的索引,提取字段在写入到ingress_stdout结果表里CREATE MATERIALIZED VIEW logger.ingress_stdout_view TO logger.ingress_stdout ASSELECT toDateTime(toInt64(_time_)) AS _time_second_,fromUnixTimestamp64Nano(toInt64(_time_*1000000000),'Asia/Shanghai') AS _time_nanosecond_, _pod_name_, _namespace_, _node_name_, _container_name_, _cluster_, _log_agent_, _node_ip_, _source_, _log_ AS _raw_log_,JSONExtractInt(_log_, 'status') AS status,JSONExtractString(_log_, 'url') AS url FROM logger.ingress_stdout_stream where 1=1;结果表:存储最终的数据create table logger.ingress_stdout( _time_second_ DateTime, _time_nanosecond_ DateTime64(9, 'Asia/Shanghai'), _source_ String, _cluster_ String, _log_agent_ String, _namespace_ String, _node_name_ String, _node_ip_ String, _container_name_ String, _pod_name_ String, _raw_log_ String, status Nullable(Int64), url Nullable(String),)engine = MergeTree PARTITION BY toYYYYMMDD(_time_second_)ORDER BY _time_second_TTL toDateTime(_time_second_) + INTERVAL 7 DAYSETTINGS index_granularity = 8192;6 总结流程日志会通过fluent-bit的规则采集到kafka,在这里我们会将日志采集到两个字段里_time_字段用于存储fluent-bit采集的时间_log_字段用于存放原始日志通过mogo,在clickhouse里设置了三个表app_stdout_stream: 将数据从Kafka采集到Clickhouse的Kafka引擎表app_stdout_view: 视图表用于存放mogo设置的索引规则app_stdout:根据app_stdout_view索引解析规则,消费app_stdout_stream里的数据,存放于app_stdout结果表中最后mogo的UI界面,根据app_stdout的数据,查询日志信息7 Mogo界面展示查询日志界面 设置日志采集配置界面以上文档描述是针对石墨Kubernetes的日志采集,想了解物理机采集日志方案的,可以在下文中找到《Mogo使用文档》的链接,运行docker-compose体验Mogo 全部流程,查询Clickhouse日志。限于篇幅有限,Mogo的日志报警功能,下次在讲解。
1 背景石墨文档全部应用部署在Kubernetes上,每时每刻都会有大量的日志输出,我们之前主要使用SLS和ES作为日志存储。但是我们在使用这些组件的时候,发现了一些问题。成本问题:SLS个人觉得是一个非常优秀的产品,速度快,交互方便,但是SLS索引成本比较贵我们想减少SLS索引成本的时候,发现云厂商并不支持分析单个索引的成本,导致我们无法知道是哪些索引构建的不够合理ES使用的存储非常多,并且耗费大量的内存通用问题:如果业务是混合云架构,或者业务形态有SAAS和私有化两种方式,那么SLS并不能通用日志和链路,需要用两套云产品,不是很方便精确度问题:SLS存储的精度只能到秒,但我们实际日志精度到毫秒,如果日志里面有traceid,SLS中无法通过根据traceid信息,将日志根据毫秒时间做排序,不利于排查错误我们经过一番调研后,发现使用Clickhouse能够很好的解决以上问题,并且Clickhouse省存储空间,非常省钱,所以我们选择了Clickhouse方案存储日志。但当我们深入研究后,Clickhouse作为日志存储有许多落地的细节,但业界并没有很好阐述相关Clickhouse采集日志的整套流程,以及没有一款优秀的Clickhouse日志查询工具帮助分析日志,为此我们写了一套Clickhouse日志系统贡献给开源社区,并将Clickhouse的日志采集架构的经验做了总结。先上个Clickhouse日志查询界面,让大家感受下石墨最懂前端的后端程序员。2 架构原理图我们将日志系统分为四个部分:日志采集、日志传输、日志存储、日志管理。日志采集:LogCollector采用Daemonset方式部署,将宿主机日志目录挂载到LogCollector的容器内,LogCollector通过挂载的目录能够采集到应用日志、系统日志、K8S审计日志等日志传输:通过不同Logstore映射到Kafka中不同的Topic,将不同数据结构的日志做了分离日志存储:使用Clickhouse中的两种引擎数据表和物化视图日志管理:开源的Mogo系统,能够查询日志,设置日志索引,设置LogCollector配置,设置Clickhouse表,设置报警等以下我们按照这四大部分,阐述其中的架构原理3 日志采集3.1 采集方式Kubernetes容器内日志收集的方式通常有以下三种方案DaemonSet方式采集:在每个 node 节点上部署LogCollector,并将宿主机的目录挂载为容器的日志目录,LogCollector读取日志内容,采集到日志中心。网络方式采集:通过应用的日志 SDK,直接将日志内容采集到日志中心 。SideCar方式采集:在每个 pod 内部署LogCollector,LogCollector只读取这个 pod 内的日志内容,采集到日志中心。以下是三种采集方式的优缺点:DaemonSet方式 网络方式 SideCar方式采集日志类型 标准输出+文件 应用日志部署运维 一般,维护DaemonSet 低,维护配置文件日志分类存储 可通过容器/路径等映射 业务独立配置支持集群规模 取决于配置数 无限制适用场景 日志分类明确、功能较单一 性能要求极高的场景资源消耗 中 低我们主要采用DaemonSet方式和网络方式采集日志。DaemonSet方式用于ingress、应用日志的采集,网络方式用于大数据日志的采集。以下我们主要介绍下DeamonSet方式的采集方式。 3.2 日志输出从上面的介绍中可以看到,我们的DaemonSet会有两种方式采集日志类型,一种是标准输出,一种是文件。 引用元乙的描述:虽然使用 Stdout 打印日志是 Docker 官方推荐的方式,但大家需要注意:这个推荐是基于容器只作为简单应用的场景,实际的业务场景中我们还是建议大家尽可能使用文件的方式,主要的原因有以下几点:Stdout 性能问题,从应用输出 stdout 到服务端,中间会经过好几个流程(例如普遍使用的JSON LogDriver):应用 stdout -> DockerEngine -> LogDriver -> 序列化成 JSON -> 保存到文件 -> Agent 采集文件 -> 解析 JSON -> 上传服务端。整个流程相比文件的额外开销要多很多,在压测时,每秒 10 万行日志输出就会额外占用 DockerEngine 1 个 CPU 核;Stdout 不支持分类,即所有的输出都混在一个流中,无法像文件一样分类输出,通常一个应用中有 AccessLog、ErrorLog、InterfaceLog(调用外部接口的日志)、TraceLog 等,而这些日志的格式、用途不一,如果混在同一个流中将很难采集和分析;Stdout 只支持容器的主程序输出,如果是 daemon/fork 方式运行的程序将无法使用 stdout;文件的 Dump 方式支持各种策略,例如同步/异步写入、缓存大小、文件轮转策略、压缩策略、清除策略等,相对更加灵活。从这个描述中,我们可以看出在docker中输出文件在采集到日志中心是一个更好的实践。所有日志采集工具都支持采集文件日志方式,但是我们在配置日志采集规则的时候,发现开源的一些日志采集工具,例如fluentbit、filebeat在DaemonSet部署下采集文件日志是不支持追加例如pod、namespace、container_name、container_id等label信息,并且也无法通过这些label做些定制化的日志采集。agent类型 采集方式 daemonset部署 sidecar部署ilogtail 文件日志 能够追加label信息,能够根据label过滤采集 能够追加label信息,能够根据label过滤采集fluentbit 文件日志 无法追加label信息,无法根据label过滤采集 能够追加abel信息,能够根据label过滤采集filebeat 文件日志 无法追加label信息,无法根据label过滤采集 能够追加label信息,能够根据label过滤采集ilogtail 标准输出 能够追加label信息,能够根据label过滤采集 能够追加label信息,能够根据label过滤采集fluentbit 标准输出 能够追加label信息,能够根据label过滤采集 能够追加abel信息,能够根据label过滤采集filebeat 标准输出 能够追加label信息,能够根据label过滤采集 能够追加label信息,能够根据label过滤采集基于无法追加label信息的原因,我们暂时放弃了DeamonSet部署下文件日志采集方式,采用的是基于DeamonSet部署下标准输出的采集方式。 3.3 日志目录以下列举了日志目录的基本情况目录 描述 类型/var/log/containers 存放的是软链接,软链到/var/log/pods里的标准输出日志 标准输出/var/log/pods 存放标准输出日志 标准输出/var/log/kubernetes/ master存放Kubernetes 审计输出日志 标准输出/var/lib/docker/overlay2 存放应用日志文件信息 文件日志/var/run 获取docker.sock,用于docker通信 文件日志/var/lib/docker/containers 用于存储容器信息 两种都需要因为我们采集日志是使用的标准输出模式,所以根据上表我们的LogCollector只需要挂载/var/log,/var/lib/docker/containers两个目录。3.3.1 标准输出日志目录应用的标准输出日志存储在/var/log/containers目录下,文件名是按照K8S日志规范生成的。这里以nginx-ingress的日志作为一个示例。我们通过ls /var/log/containers/ | grep nginx-ingress指令,可以看到nginx-ingress的文件名。 nginx-ingress-controller-mt2wx_kube-system_nginx-ingress-controller-be3741043eca1621ec4415fd87546b1beb29480ac74ab1cdd9f52003cf4abf0a.log 我们参照K8S日志的规范:/var/log/containers/%{DATA:pod_name}_%{DATA:namespace}_%{GREEDYDATA:container_name}-%{DATA:container_id}.log。可以将nginx-ingress日志解析为:pod_name:nginx-ingress-controller-mt2wnamespace:kube-systemcontainer_name:nginx-ingress-controllercontainer_id:be3741043eca1621ec4415fd87546b1beb29480ac74ab1cdd9f52003cf4abf0a通过以上的日志解析信息,我们的LogCollector 就可以很方便的追加pod、namespace、container_name、container_id的信息。 3.3.2 容器信息目录应用的容器信息存储在/var/lib/docker/containers目录下,目录下的每一个文件夹为容器ID,我们可以通过cat config.v2.json获取应用的docker基本信息。3.4 LogCollector采集日志3.4.1 配置我们LogCollector采用的是fluent-bit,该工具是cncf旗下的,能够更好的与云原生相结合。通过Mogo系统可以选择Kubernetes集群,很方便的设置fluent-bit configmap的配置规则。3.4.2 数据结构fluent-bit的默认采集数据结构@timestamp字段:string or float,用于记录采集日志的时间log字段:string,用于记录日志的完整内容Clickhouse如果使用@timestamp的时候,因为里面有@特殊字符,会处理的有问题。所以我们在处理fluent-bit的采集数据结构,会做一些映射关系,并且规定双下划线为Mogo系统日志索引,避免和业务日志的索引冲突。_time_字段:string or float,用于记录采集日志的时间_log_字段:string,用于记录日志的完整内容例如你的日志记录的是{"id":1},那么实际fluent-bit采集的日志会是{"_time_":"2022-01-15...","_log_":"{\"id\":1}" 该日志结构会直接写入到kafka中,Mogo系统会根据这两个字段_time_、_log_设置clickhouse中的数据表。3.4.3 采集如果我们要采集ingress日志,我们需要在input配置里,设置ingress的日志目录,fluent-bit会把ingress日志采集到内存里。然后我们在filter配置里,将log改写为_log_ 然后我们在ouput配置里,将追加的日志采集时间设置为_time_,设置好日志写入的kafka borkers和kafka topics,那么fluent-bit里内存的日志就会写入到kafka中日志写入到Kafka中_log_需要为json,如果你的应用写入的日志不是json,那么你就需要根据fluent-bit的parser文档,调整你的日志写入的数据结构:https://docs.fluentbit.io/manual/pipeline/filters/parser4 日志传输Kafka主要用于日志传输。上文说到我们使用fluent-bit采集日志的默认数据结构,在下图kafka工具中我们可以看到日志采集的内容。 在日志采集过程中,会由于不用业务日志字段不一致,解析方式是不一样的。所以我们在日志传输阶段,需要将不同数据结构的日志,创建不同的Clickhouse表,映射到Kafka不同的Topic。这里以ingress为例,那么我们在Clickhouse中需要创建一个ingress_stdout_stream的Kafka引擎表,然后映射到Kafka的ingress-stdout Topic里。5 日志存储我们会使用三种表,用于存储一种业务类型的日志。Kafka引擎表:将数据从Kafka采集到Clickhouse的ingress_stdout_stream数据表中create table logger.ingress_stdout_stream( _source_ String, _pod_name_ String, _namespace_ String, _node_name_ String, _container_name_ String, _cluster_ String, _log_agent_ String, _node_ip_ String, _time_ Float64, _log_ String)engine = Kafka SETTINGS kafka_broker_list = 'kafka:9092', kafka_topic_list = 'ingress-stdout', kafka_group_name = 'logger_ingress_stdout', kafka_format = 'JSONEachRow', kafka_num_consumers = 1;物化视图:将数据从ingress_stdout_stream数据表读取出来,_log_根据Mogo配置的索引,提取字段在写入到ingress_stdout结果表里CREATE MATERIALIZED VIEW logger.ingress_stdout_view TO logger.ingress_stdout ASSELECT toDateTime(toInt64(_time_)) AS _time_second_,fromUnixTimestamp64Nano(toInt64(_time_*1000000000),'Asia/Shanghai') AS _time_nanosecond_, _pod_name_, _namespace_, _node_name_, _container_name_, _cluster_, _log_agent_, _node_ip_, _source_, _log_ AS _raw_log_,JSONExtractInt(_log_, 'status') AS status,JSONExtractString(_log_, 'url') AS url FROM logger.ingress_stdout_stream where 1=1;结果表:存储最终的数据create table logger.ingress_stdout( _time_second_ DateTime, _time_nanosecond_ DateTime64(9, 'Asia/Shanghai'), _source_ String, _cluster_ String, _log_agent_ String, _namespace_ String, _node_name_ String, _node_ip_ String, _container_name_ String, _pod_name_ String, _raw_log_ String, status Nullable(Int64), url Nullable(String),)engine = MergeTree PARTITION BY toYYYYMMDD(_time_second_)ORDER BY _time_second_TTL toDateTime(_time_second_) + INTERVAL 7 DAYSETTINGS index_granularity = 8192;6 总结流程日志会通过fluent-bit的规则采集到kafka,在这里我们会将日志采集到两个字段里_time_字段用于存储fluent-bit采集的时间_log_字段用于存放原始日志通过mogo,在clickhouse里设置了三个表app_stdout_stream: 将数据从Kafka采集到Clickhouse的Kafka引擎表app_stdout_view: 视图表用于存放mogo设置的索引规则app_stdout:根据app_stdout_view索引解析规则,消费app_stdout_stream里的数据,存放于app_stdout结果表中最后mogo的UI界面,根据app_stdout的数据,查询日志信息7 Mogo界面展示查询日志界面 设置日志采集配置界面以上文档描述是针对石墨Kubernetes的日志采集,想了解物理机采集日志方案的,可以在下文中找到《Mogo使用文档》的链接,运行docker-compose体验Mogo 全部流程,查询Clickhouse日志。限于篇幅有限,Mogo的日志报警功能,下次在讲解。 -
大家好,我是鹤轩,上一期我们了解到计算故障注入的背景和现状,应该对故障注入有了一个初步的认识,本期我们一起来学习业界故障注入工具现状和混沌工程,在介绍故障注入工具之前,先一起来了解下什么是故障注入测试吧。一、故障注入测试: 故障注入是一种可靠性验证技术,通过受控实验向系统中刻意引入故障,并观察系统中存在故障时的行为。故障注入技术一般分为:基于硬件的故障注入、基于软件的故障注入以及基于仿真的故障注入。故障注入测试则是结合软件测试的特点,在保证评测准确性的前提下,利用故障注入技术解决容错机制导致的故障需求复杂、故障构造困难等问题,实现理想的故障注入测试方法在软件测试中的应用。 故障注入可分为软件故障注入、硬件故障注入和仿真故障注入。 硬件故障注入:硬件故障注入是模拟硬件在实际运行中发生的故障,例如实时的干扰、硬件芯片的随机失效等,使得计算机的某个硬件信号发生改变。硬件故障具体可分为如下几类:模拟量、离散量、数字量、电源等方面。例如在数字量方面,有存储器故障、通讯器故障等。硬件故障注入就是使用额外的硬件将故障注入到目标系统硬件中。硬件故障注入方式具有破坏性和不可控制性的缺点,因此硬件故障注入没有被广泛的使用。 软件故障注入:软件故障注入技术是根据软件的故障模式,通过改变软件的执行流程,或改变软件的操作数据等,使软件产生错误。软件故障注入包括动态故障注入和静态故障注入,动态故障注入是在运行的过程中进行故障注入的,而静态故障注入则是在运行程序之前将故障注入到程序中,然后再运行程序根据程序的运行结果来判定程序中是否存在故障。软件故障注入不需要昂贵的注入仪器,而且使用起来更为灵活。它的目标系统可能是应用程序,也可以是操作系统。软件注入的目标是在功能级别注入故障,与在物理层、逻辑层的注入达到一致的效果。仿真故障注入:仿真故障注入可以在不修改软件系统情况下,通过使用更加精准的故障模型来进行故障注入。并具有很好的时间粒度、良好的可控性和观察性。 与其它两种方法相比,软件故障注入有实现简单、灵活、花费少、工作量小、评 测范围大、对原系统无损害等特点,有广泛的应用前景。基于软件的故障注入,是通过软件方法,在机器指令可以访问到的范围内,通过修改硬件或软件的状态变量或数据来模拟故障的产生,加速系统的失效,修改内存数据,通过应用软件生成故障或者通过底层软件如操作系统生成故障。二、混沌工程简介: 混沌工程由Netflix提出,它是在分布式系统上进行实验的学科, 目的是建立对系统抵御生产环境中失控条件的能力以及信心。它的应用场景主要是针对云原生 (DevOps+持续交付+微服务+容器)相关的业务,发展史如下所示:混沌工程与传统测试之间的区别:混沌工程和传统测试(故障注入 FIT、故障测 试)在关注点和工具集上都有很大的重叠。比如,在Netflix的很多混沌工程实验研究的对象都是基于故障注入来引入的。混沌工程和这些传统测试方法的主要区别在于:混沌工程是发现新信息的实践过程,而故障注入则是对一个特定的条件、变量的验证方法。 为了更好的理解混沌工程,这里着重介绍一下Chaos Monkey。Chaos Monkey 通过关停一个或多个虚拟机来模拟Service实例的失效。Chaos Monkey的名字来源于其工作的方式:如同一只野生的、武装了的猴子,在数据中心释放后,造成的严重破坏。 Chaos Monkey 的原则:避免大多数失效的主要方式就是经常失效。失效一定会发生,并且无法避免。在大多数情况下,我们的应用设计要保证当服务的某个实例下线时仍能继续工作,但是在那些特殊的场景下,我们需要确保有人在值守,以便解决计算故障注入工具(DemonCAT)技术白书计算全栈故障注入工具(DemonCAT)简介问题,并从问题中进行经验学习。基于这个想法,Chaos Monkey仅会在工作时间内被使用,以保证能发现警告信息,并做出适当的回应。 故障演练也是一项遵循混沌工程实验原理的一项测试活动,提供丰富故障场景, 能够帮助分布式系统提升容错性和可恢复性;此外故障演练还建立了一套标准的演练 流程,包含准备阶段、执行阶段、检查阶段和恢复阶段。通过四阶段的流程,覆盖用户从计划到还原的完整演练过程,并通过可视化的方式清晰的呈现给用户。 三、业界故障注入工具业界内故障注入工具大致分为三类,涵盖了从硬件、OS、容器以及应用各个层级的故障注入能力: 与混沌工程相关的故障注入软件工具:业界内故障注入工具大部分与混沌工程相 结合。它的应用场景主要是针对云原生(DevOps+持续交付+微服务+容器)相关的业务,因此相应的故障注入能力主要集中在OS、容器与应用上面,这类工具通常带有chaos的标识。与硬件可靠性相关的故障注入软件工具:这一类主要硬件厂商通过软件修改硬件 状态,从而达到模拟硬件故障的目的,这类工具主要被用来测试硬件的可靠性,因此大多数不具备通用性,各大厂商也未开源相关工具。非系统性故障注入软件工具:除了上述两种系统性的工具之外,还存在一些开源 且比较优秀的零散工具,这些工具原本目的不是用来进行故障注入的,而是用来对某些特性做数据修改、性能压测等测试,它们在某些方面是可以被用来模拟故障注入的。下一期我们将一起来学习鲲鹏计算注入工具DemonCAT,可能会有小伙伴好奇DemonCAT实现的原则是什么呢,还会介绍故障注入的流程,一起来看看吧。
-
>摘要:云原生浪潮下,容器技术是串联起整个云原生世界的关键一环。本文分享自华为云社区[《左手自研,右手开源,技术揭秘华为云如何领跑容器市场》](https://bbs.huaweicloud.com/blogs/281793?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content),作者:华为云社区精选。  近日,IDC 发布的《PRC SDC Market Overview and Analysis, 2020H2/2020》报告显示,华为云**以24.3%的市场份额,斩获中国容器软件市场第一**。 下面,我们从技术角度分析,华为云为什么能领跑容器软件市场。 # 容器如何成为宠儿? 容器是什么? 从字面上看,这是一个用于盛放某种东西的器具,实际也是如此,容器技术可以将软件的程序代码和依赖项打包起来,让其与实际运行的环境隔离,哪里需要搬哪里,比如在数据中心、个人电脑上部署运行。 这个概念有点像老大哥虚拟机,但是两者的相似点仅仅在于:提供独立的环境运行软件。在[基因、容器和上帝](https://bbs.huaweicloud.com/blogs/114535) 中,作者从哲学化的视角谈了程序员创造的虚拟世界,也点出了两者的异曲同工之妙:Docker容器技术和VM虚拟机从技术原理上看,是完全不同的路线,连实现思路都不一样。但是,它们所达成的效果或者说是目标确是惊人的一致:即模拟一台看着像物理机一样的东西。 虽然如此,但两者内在逻辑差别很大。容器可以在操作系统级别进行虚拟化,一个操作系统内核上可以运行多个容器,而虚拟机只是硬件层面的虚拟化。相比较VM,容器更轻巧、启动速度更快、占用的内存微乎其微,[容器与Docker](https://bbs.huaweicloud.com/blogs/203431)详细对比了虚拟机和容器的优缺点。 随着用户对云端应用开发、部署和运维的效率愈加重视,间接促成了容器的盛行。 不过,容器在云服务领域“发光发热“离不开一个关键技术:**Docker**。  Docker是目前应用最多的容器引擎技术,它的logo是一只蓝色的鲸鱼驮着一堆小方块。开发者通过docker可以为任何应用创建容器:应用的流程、库和依赖,甚至整个操作系统的文件系统能被打包成一个简单的可移植的包,这个包就像是鲸鱼背上蓝色的小方块,它可以在任何运行Docker的机器上使用,从根本上解决了开发运行环境不一致的问题,让容器真正实现了一次构建,随处运行。 当应用程序被分解为多个小组件或服务,每个组件或服务都放置在一个容器中,每个容器可能还运行在不同的计算机中,此时就需要对容器进行有序的编排和管理。就像电脑上的操作系统,它可以管理所有应用程序,并规划哪个应用程序何时使用电脑的CPU和其他硬件资源。 脱胎于Google内部集群管理系统Borg的kubernetes逐渐成为业界标准,它可以通过API的方式将多个不同的计算机作为一个资源池进行管理,类似某种集群操作系统,管理整个集群中的容器化应用程序。[ Docker与Kubernetes的兴起](https://bbs.huaweicloud.com/blogs/138949)这篇文章就具体谈到了kubernetes(k8s)如何从三足鼎立的局面中PK掉其他两个对手,在混战中取得胜利。 至此,属于容器的黄金时代大幕正式拉开。 Gartner预测,到2023年,70%的组织将在生产中运行三个或更多容器化应用程序。容器、Kubernetes和微服务应用模式是企业IT创新和数字化转型的三大驱动力。 华为很早就投入了容器的怀抱中,由于一直使用虚拟机封装应用程序,每次启动虚拟机花费了大量的时间,这给管理及部署基于虚机应用程序的高成本和低效率带来了挑战。所以在2015年的时候,华为决定利用Kubernetes技术对自身IT系统进行容器化改造。华为在通过自身的容器化改造实践受益的同时,又将遇到的实际问题不断贡献给社区,与社区成员一同推动Kubernetes的发展。 2018年4月,华为云获得了CNCF基金会的顶级席位——CNCF技术监督委员会席位,全球共9席,华为是亚洲首家进入者。 同时,随着越来越多的企业业务选择容器化,在集群的规模、性能、实时监控与弹性扩缩容等方面都提出了新的要求,当开源社区方案难以解决这些问题的时候,就非常考验各大云服务供应商的技术能力。 # 万丈高楼平地起,建设好云原生基础设施 在[为什么说容器的崛起预示着云原生时代到来?](https://bbs.huaweicloud.com/blogs/200395)中,华为云云原生团队认为,各类现代化的应用都将会运行在K8s之上,不仅仅是当前以互联网App、WebService为代表的无状态应用,还有新型的诸如大数据、AI、分布式数据中间件等等有状态应用,以及边缘应用也将会普遍运行在K8s之上,K8s将完成对各类现有平台的归一化,成为一个统一的应用运行的基础平台。 华为云最早于2018年洞察到了这一技术趋势,在容器全栈产品中构建了Vessel云原生技术平台,主要包括了以**容器引擎iSula、容器网络Yangtse、容器存储Everest**为代表的面向统一资源层的云原生基础设施组件。  下面,我们将逐一为大家揭开华为云的容器技术面纱。 # 容器引擎iSula 基于docker和kubernetes,首先Docker并不是万能药,它在某些场景下也存在不足,比如: - 在资源敏感环境,或需要部署高密度容器节点时,容器对基础设施的资源占用会急剧升高; - 当大规模应用拉起或遇到突发流量时,并发速度可能成为瓶颈。 当主流的 Docker 等容器引擎在特定用例下力不从心时,一些针对某种用例进行过专门优化的容器引擎技术开始崛起。比如说,以 Kata Container 为代表的专门针对容器隔离性不够严格而设计的安全容器技术;以 iSula 为代表的针对资源受限的边缘计算和 IoT 环境设计的轻量级容器技术。 可以看出,iSula是与Docker相对的一种容器引擎,它一方面完全兼容现有容器生态,另一方面相比Docker内存占用下降68%、启动时间缩短35%。 比如相比Golang编写的Docker,iSula使用C/C++实现,具有轻、灵、巧、快的特点,不受硬件规格和架构的限制,底噪开销更小。在严苛的资源要求环境下,轻量模式下的 iSulad 本身占用资源极低( 15M) 。  2017 年,iSula 技术团队成功将 Kata Containers 集成到 iSula 容器平台,并于 18 年初应用于华为云容器服务,**推出基于iSulad 容器引擎和 Kata Containers 的商用容器服务——华为云容器实例 CCI(Cloud Container Instance),这也是业界首个 Serverless 架构的云容器服务**。 那么,基于iSulad 容器引擎和 Kata Containers 如何打造安全、高性能的CCI?且看 [基于 Kata Containers 与 iSulad 的云容器实践解析](https://bbs.huaweicloud.com/blogs/147030)进一步分析,文中提到真正的 Serverless 容器服务中,集群管理由云服务提供商承担,客户只需要关注每个应用的容器实例即可。在这种情况下,云服务提供商需要考虑如何在统一管理面下保证每个用户的安全。 CCI 服务所属的 Kubernetes 集群直接部署在裸金属服务器之上,底层是 Kata Containers,中间靠 iSula 容器平台连接。其中,依靠 Kata Containers 的强隔离特性,多个租户之间的容器运行环境强隔离,不同租户之间的容器不感知、不可见,做到在同一台裸金属服务器上混合部署而安全无虞。 安全之外,在算力方面,CCI基于iSula提供的GPU直通功能,可以直接在容器中使用各种GPU进行AI计算。再加上CCI无需购买和管理弹性服务器,可直接在华为云上运行容器和pod,也无需创建集群,管理master和work节点,非常适用于批量计算,高性能计算,突发扩容,以及CI/CD测试。 在此,华为云社区推荐一些有趣的案例,可以帮助大家快速上手CCI,比如[云容器实例CCI - 使用Tensorflow训练神经网络](https://support.huaweicloud.com/bestpractice-cci/cci_04_0008.html#toTop) 和[云容器实例CCI – 经典2048数字合成游戏部署指南](https://bbs.huaweicloud.com/forum/thread-17431-1-1.html) ,通过这些简单的实操和小游戏,能够对Serverless 架构的云容器服务有更直观的认识。 # 容器网络Yangtse 大家应该都看过某些明星导致社交媒体平台宕机的新闻,明星事件带来的突发流量触发业务扩容,以前是扩容虚拟机,速度慢还情有可原,现在大部分互联网平台都使用容器了,为什么扩容速度还是跟不上流量增长的节奏呢? 首先,Kubernetes本身并不负责网络通信,它提供了容器网络接口CNI负责具体的网络通信,开源的CNI插件非常多,像Flannel、Calico等。包括华为云容器引擎CCE也专门为Kubernetes定制了CNI插件,使得Kubernetes可以使用华为云VPC网络。 尽管如此,多个容器集群的网络通信(容器连接到其他容器、主机和外部网络的机制)始终是个复杂的问题。比如大规模节点管理场景下网络性能的瓶颈;网口发放速度如何匹配容器扩容速度等等。最终,对对底层虚拟化网络提出了**密度更高,规模更大,发放更快,调整更频繁**的要求。 容器网络Yangtse深度融合华为云虚拟私有云(VPC)原生网络能力,它采用的VPC-Native组网被称作ENI(Elastic Network Interface)模式,容器直接挂载具有VPC子网地址的ENI,具备完全VPC网络互通能力。容器实例可以在集群VPC网络和与之相连的其他VPC网络中进行原生路由,并且直接使用VPC原生的网络能力如 network policy、ELB、EIP、NAT等。换言之,就是容器地址属于VPC子网,容器独占对应的ENI网口,解决了容器的互通性问题。 而且Yangtse基于华为云擎天架构的软硬协同能力,会把治理和转发逻辑下沉到擎天卡上,实现容器网络主机资源0占用。数据显示,通过硬件直通方式及动态网络队列,网络整体性能提升40%,单容器PPS提升2倍;基于warm pool的能力,1-2秒内完成ENI的发放和网络端到端打通。 至于具体如何实现,大体上可以总结为三点: 1、warm pool 机制可以解决网络资源预热的问题。如果不做预热,容器网络端到端打通时间在一分钟以上,分钟级容器启动时间是不可接受的。 Warm pool机制在裸金属节点上预挂载一定数量ENI(用户可根据服务部署并发量自定义配置),容器随时调度到预热节点上都有即时可用的ENI网卡。经过warm pool的优化,容器网络端到端打通时间缩短为1s-2s。 2、得益于擎天架构的优势,裸金属容器还可以向虚拟机容器扩容,而在虚拟机容器上,容器网络Yangtse使用了Trunkport技术,结合ENI的优势,在保障性能的前提下,单台服务器理论上可为千容器同时提供直通网络能力。 3、当应用业务流量增长触发扩容时,如果ELB直接全量发放分摊的流量请求,海量请求会迅速压垮(overload)新扩的容器,造成扩容失败。 所以新扩容的后端实例需要“慢启动”的过程,但一个节点部署多个容器时,节点的二次分发让ELB无法感知到最终的后端容器,进而无法做到容器级别的流控,也难以保证稳态后的负载均衡。容器网络Yangtse实现了与华为云ELB v3独享型负载均衡实例的直通。 具体技术详解,可以阅读[华为云第二代裸金属容器技术系列:应对海量并发的网络黑科技](https://bbs.huaweicloud.com/blogs/194532) 。 目前,Yangtse已经为华为云CCE/CCI/IEF等容器服务提供了统一的容器网络方案,覆盖虚机、裸金属、Serverless和边缘节点等各种容器运行环境。 其中**最值得注意的是CCE,它是一种托管的Kubernetes服务,可进一步简化基于容器的应用程序部署和管理,深度整合华为云的计算、存储、网络和安全等技术构建高可用Kubernetes集群**。 在CCE中,用户可以直接使用华为云高性能的弹性云服务器、裸金属服务器、GPU加速云服务器等多种异构基础设施,也可以根据业务需要在云容器引擎中快速创建CCE集群、鲲鹏集群、CCE Turbo集群,并通过云容器引擎对创建的集群进行统一管理。 以今年在HDC重磅发布的云容器集群CCE Turbo为例,它主要针对企业大规模业务生产中的高性能、低成本诉求,在计算、网络和调度上全方位加速, [新一代容器解决方案:云容器引擎CCE Turbo集群](https://bbs.huaweicloud.com/blogs/198569)就总结了它在这三个方面的新突破。 >在计算加速方面,业界独家实现容器100%卸载,服务器资源和性能双零损耗。 >在网络加速方面,采用独创的容器直通网络,让两层网络变成一层,端到端连通时间缩短一半,有效支撑业务秒级扩容千容器。 >在调度加速方面,通过感知AI、大数据、WEB业务的不同特征,以及应用模型、网络拓扑等,实现业务混合部署、智能调度,还自动优化任务调度策略,实现1万容器/秒的大规模并发调度能力。 再就是容器存储Everest, 每个POD使用独立VF,读写时延降低50%;将Posix组件卸载,单进程节省30M内存;NAS卷直挂POD容器内,提高请求处理效率30%。 # “查漏补缺”Kuberentes,开源技术解决特殊场景难题 基础设施之外,华为云先后将Vessel的核心组件Volcano和KubeEdge开源,并贡献给云原生计算基金会CNCF,成为社区首个容器智能边缘项目和容器批量计算项目。 # Volcano——批量计算 当有更多的用户希望在Kubernetes上运行大数据、 AI和HPC应用,而它默认调度器又无法满足包括公平调度、优先级、队列等高级调度功能时,就需要一些新的技术解决方案登场了。 考虑到AI、大数据等业务的需求,华为云在Kubernetes调度上做了一个感知上层业务的调度——Volavano,它是基于Kubernetes构建的一个通用批量计算系统,[Volcano架构设计与原理解读](https://bbs.huaweicloud.com/blogs/239645)就Volcano产生的背景、架构设计与原理进行深度解读,用数据证明了Volavano为分布式训练、大数据、HPC场景带来了效率的提高。 [Volcano火山:容器与批量计算的碰撞](https://bbs.huaweicloud.com/blogs/205045)则从并行计算开始说起,详细解释了Volcano的调度框架、调度实现原理。作为调度系统,Volcano通过**作业级的调度**和**多种插件机制**来支持多种作业,其中作业级的调度支持以多种类型的作业为目标进行设计,比如基于时间的、跨队列的等等。Volcano的插件机制有效的支撑了针对不同场景算法的落地,从早期的gang-scheduling/co-scheduling,到后来各个级别的公平调度。  图:总体架构 在华为云今年刚推出的CCE Turbo容器集群中,就采取了多项Volcano关键调度技术,如基于共享资源视图的多调度器、决策复用、应用模型感知、数据位置亲和调度、网络拓扑调度等,从而实现1万容器/秒的大规模并发调度能力。 # KubeEdge——边缘计算 容器天然的轻量化和可移植性,非常适合边缘计算的场景。理想情况下,在边缘部署复杂的应用,Kubernetes 是个很好的选择,现实真相是要想在边缘部署 Kubernetes集群,各种问题层出。 比如很多设备边缘的资源规格有限,特别是 CPU 处理能力较弱,因此无法部署完整的 Kubernetes;Kubernetes 依赖 list/watch 机制,不支持离线运行,而边缘节点的离线又是常态,例如:设备休眠重启;边缘业务通常在私有网络中,无公网IP,云边跨越公网导致延迟高。 为了解决这些问题,KubeEdge应运而生。KubeEdge即Kube+Edge,顾名思义就是依托K8S的容器编排和调度能力,实现云边协同、计算下沉、海量设备的平滑接入。 其架构主要包含三部分,分别是云端、边缘侧和终端。云端负责应用和配置的下发,边缘侧则负责运行边缘应用和管理接入设备。 [KubeEdge架构解读:云原生的边缘计算平台](https://bbs.huaweicloud.com/blogs/241350)从KubeEdge架构设计理念、KubeEdge代码目录概览、KubeEdge集群部署三方面带大家认识KubeEdge。  关于KubeEdge和Volcano的更多技术硬实力体现和落地案例,可以阅读专题[【技术补给站】第5期:从架构和实践,剖析KubeEdge+Volcano技术硬实力](https://bbs.huaweicloud.com/blogs/240234),在此不再赘述。 # 解决多云容器集群管理,新秀Karmada崛起 批量计算和边缘计算的问题解决后,伴随云原生技术和市场的不断成熟,很多企业都是多云或者混合云的部署,一方面可以避免被单供应商锁定降低风险,另一方面也可以是出于成本的考量。 但是多集群同时也带来了巨大的复杂性,包括如何让应用面向多集群部署分发,并做到多集群之间灵活切换。在今年的HDC上,华为云宣布了**多云容器编排项目Karmada正式开源**,Karmada项目由华为、工商银行、小红书、中国一汽等8家企业联合发起,它可以构建无极可扩展的容器资源池,让开发者像使用单个K8s集群一样使用多云集群。 Karmada是一个 Kubernetes 管理系统,基于 [Kubernetes Federation v1](https://github.com/kubernetes-retired/federation) 和[ v2](https://github.com/kubernetes-sigs/kubefed) 开发,它可以跨多个 Kubernetes 集群和云运行云原生应用程序,直接使用 Kubernetes 原生 API 并提供高级调度功能,实现真正的开放式多云 Kubernetes。 [华为云MCP多云跨云的容器治理与实践](https://bbs.huaweicloud.com/blogs/281796)为我们梳理了Karmada项目诞生的前因后果,以及整个项目的核心价值,比如对K8s原生API兼容 、丰富的多集群调度支持、开箱即用等等。  Karmada的架构设计图 从架构图可以看到,整个控制面板可以分为四大块:提供原生API入口,存放用户yaml和Karmada资源对象的Karmda API Server,和配套存储ETCD;以及资源控制器Karmda Controller Manager、多集群调度器 Karmda Sheduler。其中,最关键的就是API Server,让用户既有的资源配置(yaml)可以借助K8s原生API进行部署。 综上,Karmada 旨在为多云和混合云场景下的多集群应用程序管理提供 turnkey 自动化,其关键功能包括集中式多云管理、高可用性、故障恢复和流量调度。 今年的HDC期间,在线教育平台VIPKID的后端研发高级专家分享了使用 Karmada实现从天到秒的跨云迁移实践。在剖析VIPKID的多场景云原生落地实践后,他对多集群管理提出了一些思考,如下图所示,理想的多集群管理方式是: - 集中管理,但要原生; - 应用在不同集群的差异化管理; - 集群故障自动转移。  对比了多家方案后,VIPKID选择了开源的方案 Karmada。作者表示Karmada的整个设计结构就是按原生k8s开发标准开发的,唯一差别之处是需要管理多个集群不同的 workload信息,所以改写了调度器和控制器,在它们下面对接了多个集群管理起来。这样最大的好处是看起来在控制一个集群,但最终的效果是在控制多个集群。 具体案例情况参见[Karmada | VIPKID在线教育平台从天到秒的跨云迁移实践](https://bbs.huaweicloud.com/blogs/281788),文章内有现场demo演示用Karmada实现多集群管理。 另一个经典案例是[工商银行多k8s集群管理及容灾实践](https://bbs.huaweicloud.com/blogs/281790)。工商银行的应用平台云容器规模超20万,业务容器占到55,000个左右,整体的一些核心业务都已入容器云内部,包括个人金融体系的账户,快捷支付、线上渠道等。当越来越多的核心业务应用入云之后,最大的挑战是容灾以及高可用。 但既有的运管平台并不能解决这些问题,比如没有整体的跨集群自动伸缩能力、集群对上层用户不透明、没有跨集群的自动调度和迁移等等。对此,他们根据业务场景调研了一些多集群管理平台,最终也选择了社区支持的开源项目Karmada。 Karmada以类k8s的形式部署,对他们来说,改造成本是比较小的,只需在上面部署一个管理集群即可。而且Karmada仅管理资源在集群间的调度,子集群内分配高度自治。在实践中,Karmada的资源调度、容灾、集群管理和资源管理的优势突出。 截止到现在,工行在测试环境中已经用Karmada对存量集群进行一些纳管,未来规划的关键的点是如何和整体云平台进行集成。 项目地址 :GitHub - karmada-io/karmada: Open, Multi-Cloud, Multi-Cluster Kubernetes Orchestration 总结 围绕Docker和kubernetes,华为云在技术层面做了诸多的优化和新的探索尝试,除此之外,华为云还有端到端的容器运维管理体系,涵盖资源编排、容器应用持续交付、应用生命周期管理、镜像安全扫描以及日常运维监控等。 云原生浪潮下,容器技术是串联起整个云原生世界的关键一环,它的市场之争,正是山雨欲来风满楼,想要占得高地,技术实力、开源生态、合作伙伴,缺一不可。
推荐直播
-
 码道新技能,AI 新生产力——从自动视频生成到开源项目解析
码道新技能,AI 新生产力——从自动视频生成到开源项目解析2026/04/08 周三 19:00-21:00
童得力-华为云开发者生态运营总监/何文强-无人机企业AI提效负责人
本次华为云码道 Skill 实战活动,聚焦两大 AI 开发场景:通过实战教学,带你打造 AI 编程自动生成视频 Skill,并实现对 GitHub 热门开源项目的智能知识抽取,手把手掌握 Skill 开发全流程,用 AI 提升研发效率与内容生产力。
回顾中 -
 华为云码道:零代码股票智能决策平台全功能实战
华为云码道:零代码股票智能决策平台全功能实战2026/04/18 周六 10:00-12:00
秦拳德-中软国际教育卓越研究院研究员、华为云金牌讲师、云原生技术专家
利用Tushare接口获取实时行情数据,采用Transformer算法进行时序预测与涨跌分析,并集成DeepSeek API提供智能解读。同时,项目深度结合华为云CodeArts(码道)的代码智能体能力,实现代码一键推送至云端代码仓库,建立起高效、可协作的团队开发新范式。开发者可快速上手,从零打造功能完整的个股筛选、智能分析与风险管控产品。
回顾中 -
 华为云码道全新升级,多会话并行与多智能体协作
华为云码道全新升级,多会话并行与多智能体协作2026/05/08 周五 19:00-21:00
王一男-华为云码道产品专家;张嘉冉-华为云码道工程师;胡琦-华为云HCDE;程诗杰-华为云HCDG
华为云码道4月份版本全新升级,此次直播深度解读4月份产品特性,通过“特性解读+实操演示+实战案例+设计创新”的组合,全方位展现码道在多会话并行与多智能体协作方面的能力,赋能开发者提升效率
正在直播
热门标签