-
 紧接MA3E:面向遥感场景的角度感知的掩码自编码器(一),我们继续分享MA3E的实验与分析。实验与分析MA3E模型首先在无标签的MillionAID数据集~\cite{long2021creating}上自监督预训练,然后迁移MA3E的编码器至下游的场景分类、旋转目标检测和语义分割任务上微调。所有报告的结果中,†\dag†表示使用其官方代码在MillionAID数据集上预训练的复现版本,⋆\star⋆表示直接加载开源预训练权重进行端到端微调或线性探测。预训练设置表1. MA3E的预训练和下游分类设置场景分类所有微调和线性探测实验均在NWPU-RESISC45(NU45)、AID和UC Merced(UCM)数据集上进行。对于NU45,随机选取每个类别20%的图像作为训练集,剩余80%作为测试集。对于AID和UCM,这两个比例均为50%。微调和线性探测的设置如表1所示。数据集缩写:IN1k为ImageNet-1k,MA为MillionAID,S-2为Sentinel-2,$\sim$2M为约两百万张图像,G.I.为GeoPile和ImageNet-22k,f-S为fMoW-Sentinel,f-R为fMoW-RGB。表2. 不同方法在三个场景分类数据集上的微调结果对比表3. 不同方法在三个场景分类数据集上的线性探测结果对比表2和表3分别展示了在三个数据集上的微调和线性探测结果。预训练300 epochsepochsepochs的MA3E取得了有竞争力的结果。尽管在UCM数据集上的微调精度低于 ViT+RVSA,但MA3E仅需后者52%的FLOPs。随着预训练的进行,三个数据集上的微调和线性探测结果持续提升。经过1600 epochsepochsepochs预训练后,MA3E在各项指标上全面领先,这证明了MA3E能够有效学习对角度多样的遥感目标判别的旋转不变性表征。此外,表中统计了单张GPU所需的每epochsepochsepochs的训练时间。与MAE相比,MA3E仅增加约0.2小时的训练时间,却显著提升了准确率。旋转目标检测与语义分割我们在DOTA1.0和DIOR-R数据集上进行的旋转目标检测实验,并使用Oriented R-CNN作为检测器。对于语义分割任务,我们采用UperNet框架,在Potsdam和iSAID数据集上进行端到端的有监督微调。其设置如表4所示。表4. 旋转目标检测和语义分割的端到端微调设置表5. 不同方法在多个数据集上的检测和分割结果对比表5展示了不同方法在DOTA1.0和DIOR-R上的微调结果,其中MA3E仅使用朴素的主干网络就取得了优越的检测性能。预训练300 epochsepochsepochs的版本超越了同样预训练300 epochsepochsepochs的其他方法,而训练1600 epochsepochsepochs的MA3E全面领先。相较于微调主干网络为ViTAE+RVSA的MAE,MA3E在DOTA1.0和DIOR-R上的mAP分别提升了0.51和0.87。这种检测性能的显著提升说明了MA3E在预训练期间感知角度信息的有效性。对于分割结果,在预训练较少epochsepochsepochs下,MA3E便展现出有竞争力的性能,在Potsdam数据集上的mF1仅比CMID低0.04。当预训练1600 epochsepochsepochs时,MA3E再次取得最佳结果,在iSAID和Potsdam数据集上分别比次优方法提高了0.3 mIoU和0.28 mF1。这说明MA3E学到的旋转不变性表征在在语义分割中仍然发挥着重要的作用。可视化分析图1. MillionAID训练图像的重建效果示例。对每一组图像来说,从左至右依次展示原始图像、包含旋转区域的复合图像、掩码图像和MA3E重建图像。为了便于观察,旋转区域都用红框标出。与MAE~\cite{he2022masked}一样,模型在可视图像块上的输出也展示出来以全面展现MA3E的重建质量。图1定量地可视化了MA3E在遥感图像上的重建效果。所有示例图像都随机采样自包含一万张图像的MillionAID训练集。每张图像调整为224×224224 \times 224224×224像素(196个图像块,p=16p=16p=16),并设置旋转区域为96×9696 \times 9696×96(36个图像块)进行重建。旋转区域和背景的掩码比例为75%,分别对应9个和40个可视图像块。从图中可以看到,MA3E在重建原始像素时有效地恢复了旋转区域上预设的角度变化。此外,重建的旋转区域可能会出现一些不均匀色块,例如图1中的水面和操场。这种现象的出现主要是因为本章所提出的最优传输损失函数计算了每个旋转区域的预测图像块与多个作为目标的原始图像块之间的均方误差。小结我们提出了一种面向遥感图像的掩码图像建模方法——角度感知的掩码自编码器MA3E。通过设计了放缩中心裁剪操作构造旋转区域,为每张原始图像引入显式的角度变化。MA3E以创建的复合图像作为输入,旨在同时实现原始像素重建和角度恢复。其中,旋转区域的重建被视为一个最优传输问题,MA3E从而能够有效感知角度并学习判别的旋转不变性表征,并在多种下游任务中均取得了优越的表现。本文已发表在European Conference on Computer Vision 2024(ECCV 2024)会议中,我们希望MA3E能促进遥感领域基础模型的发展。尽管MA3E展现了角度感知的能力,但在大多遥感场景中,只有人造目标的角度信息需要被更加重视。对于广阔的土地覆盖,模型可能无法从角度信息中获得显著收益。在未来的工作中,将考虑所有遥感场景中都普遍存在的尺度信息,进一步探索人造目标的角度感知与土地覆盖的尺度建模的有机结合道路。
紧接MA3E:面向遥感场景的角度感知的掩码自编码器(一),我们继续分享MA3E的实验与分析。实验与分析MA3E模型首先在无标签的MillionAID数据集~\cite{long2021creating}上自监督预训练,然后迁移MA3E的编码器至下游的场景分类、旋转目标检测和语义分割任务上微调。所有报告的结果中,†\dag†表示使用其官方代码在MillionAID数据集上预训练的复现版本,⋆\star⋆表示直接加载开源预训练权重进行端到端微调或线性探测。预训练设置表1. MA3E的预训练和下游分类设置场景分类所有微调和线性探测实验均在NWPU-RESISC45(NU45)、AID和UC Merced(UCM)数据集上进行。对于NU45,随机选取每个类别20%的图像作为训练集,剩余80%作为测试集。对于AID和UCM,这两个比例均为50%。微调和线性探测的设置如表1所示。数据集缩写:IN1k为ImageNet-1k,MA为MillionAID,S-2为Sentinel-2,$\sim$2M为约两百万张图像,G.I.为GeoPile和ImageNet-22k,f-S为fMoW-Sentinel,f-R为fMoW-RGB。表2. 不同方法在三个场景分类数据集上的微调结果对比表3. 不同方法在三个场景分类数据集上的线性探测结果对比表2和表3分别展示了在三个数据集上的微调和线性探测结果。预训练300 epochsepochsepochs的MA3E取得了有竞争力的结果。尽管在UCM数据集上的微调精度低于 ViT+RVSA,但MA3E仅需后者52%的FLOPs。随着预训练的进行,三个数据集上的微调和线性探测结果持续提升。经过1600 epochsepochsepochs预训练后,MA3E在各项指标上全面领先,这证明了MA3E能够有效学习对角度多样的遥感目标判别的旋转不变性表征。此外,表中统计了单张GPU所需的每epochsepochsepochs的训练时间。与MAE相比,MA3E仅增加约0.2小时的训练时间,却显著提升了准确率。旋转目标检测与语义分割我们在DOTA1.0和DIOR-R数据集上进行的旋转目标检测实验,并使用Oriented R-CNN作为检测器。对于语义分割任务,我们采用UperNet框架,在Potsdam和iSAID数据集上进行端到端的有监督微调。其设置如表4所示。表4. 旋转目标检测和语义分割的端到端微调设置表5. 不同方法在多个数据集上的检测和分割结果对比表5展示了不同方法在DOTA1.0和DIOR-R上的微调结果,其中MA3E仅使用朴素的主干网络就取得了优越的检测性能。预训练300 epochsepochsepochs的版本超越了同样预训练300 epochsepochsepochs的其他方法,而训练1600 epochsepochsepochs的MA3E全面领先。相较于微调主干网络为ViTAE+RVSA的MAE,MA3E在DOTA1.0和DIOR-R上的mAP分别提升了0.51和0.87。这种检测性能的显著提升说明了MA3E在预训练期间感知角度信息的有效性。对于分割结果,在预训练较少epochsepochsepochs下,MA3E便展现出有竞争力的性能,在Potsdam数据集上的mF1仅比CMID低0.04。当预训练1600 epochsepochsepochs时,MA3E再次取得最佳结果,在iSAID和Potsdam数据集上分别比次优方法提高了0.3 mIoU和0.28 mF1。这说明MA3E学到的旋转不变性表征在在语义分割中仍然发挥着重要的作用。可视化分析图1. MillionAID训练图像的重建效果示例。对每一组图像来说,从左至右依次展示原始图像、包含旋转区域的复合图像、掩码图像和MA3E重建图像。为了便于观察,旋转区域都用红框标出。与MAE~\cite{he2022masked}一样,模型在可视图像块上的输出也展示出来以全面展现MA3E的重建质量。图1定量地可视化了MA3E在遥感图像上的重建效果。所有示例图像都随机采样自包含一万张图像的MillionAID训练集。每张图像调整为224×224224 \times 224224×224像素(196个图像块,p=16p=16p=16),并设置旋转区域为96×9696 \times 9696×96(36个图像块)进行重建。旋转区域和背景的掩码比例为75%,分别对应9个和40个可视图像块。从图中可以看到,MA3E在重建原始像素时有效地恢复了旋转区域上预设的角度变化。此外,重建的旋转区域可能会出现一些不均匀色块,例如图1中的水面和操场。这种现象的出现主要是因为本章所提出的最优传输损失函数计算了每个旋转区域的预测图像块与多个作为目标的原始图像块之间的均方误差。小结我们提出了一种面向遥感图像的掩码图像建模方法——角度感知的掩码自编码器MA3E。通过设计了放缩中心裁剪操作构造旋转区域,为每张原始图像引入显式的角度变化。MA3E以创建的复合图像作为输入,旨在同时实现原始像素重建和角度恢复。其中,旋转区域的重建被视为一个最优传输问题,MA3E从而能够有效感知角度并学习判别的旋转不变性表征,并在多种下游任务中均取得了优越的表现。本文已发表在European Conference on Computer Vision 2024(ECCV 2024)会议中,我们希望MA3E能促进遥感领域基础模型的发展。尽管MA3E展现了角度感知的能力,但在大多遥感场景中,只有人造目标的角度信息需要被更加重视。对于广阔的土地覆盖,模型可能无法从角度信息中获得显著收益。在未来的工作中,将考虑所有遥感场景中都普遍存在的尺度信息,进一步探索人造目标的角度感知与土地覆盖的尺度建模的有机结合道路。 -
在之前的研究中,我们分别从多尺度难特征和MLP引导两个角度探索了基于对比学习的遥感图像表征学习方法。随着掩码图像建模逐渐成为计算机视觉领域中自监督表征学习的主流范式,我们将研究重点转向遥感场景下的MIM方法。与自然图像不同,遥感图像中的目标具有多样化的角度分布,这一特性在现有MIM方法中未得到充分考虑。针对这一问题,我们提出了一种新的角度感知的掩码自编码器,通过在像素重建时同时恢复角度变化,引导模型学习更判别的旋转不变性表征,为遥感图像解译任务提供更有效的通用预训练模型。引言在自然图像领域,无需标签的自监督表征学习如SimCLR、MoCo、BEiT和DINO等方法已经成为在大规模数据集上预训练模型的新范式。其中,掩码图像建模(Masked Image Modeling,MIM)通过重建被掩码的部分输入来学习视觉表征,凭借简洁的架构和在下游任务上出色的性能受到了研究者的广泛关注。最近,遥感图像领域出现了一些有趣的MIM工作如SatMAE、ScaleMAE等,它们为视觉Transformer提供了良好的初始化并在一系列下游任务中取得了优越表现,这证明了MIM在遥感图像上的表征学习具有极大潜力。尽管现有针对遥感图像定制的MIM方法考虑了诸多因素,如不同分辨率、蕴含多尺度目标及复杂背景、成像自多光谱波段等,但它们在面对遥感目标多样的角度时并不是一个有效的学习者。自然图像中的目标在重力作用下具有固定的朝向,而通过鸟瞰视角捕获的遥感图像中目标往往具有较大的角度分布范围。同一遥感目标在不同角度下会呈现出不同的形状和外观。正确感知并考虑角度信息符合遥感技术研究中如何捕获目标的本质,有助于更准确的遥感图像解译。然而上述方法仅关注遥感目标的原始像素值重建,对角度信息的学习往往只隐式地伴随在重建过程中。因此,我们提出一种角度感知的掩码自编码器(Masked Angle-Aware Auto Encoder,MA3E),通过在原始像素重建过程中恢复预设的角度变化来感知并学习角度信息。此处提供一个说明性的例子,在旋转目标检测任务中微调预训练模型时,统计了DOTA1.0数据集中所有被正确检测到的目标的角度,并在图1中报告了不同角度范围内目标的AP50^{50}50指标。现有方法RVSA仅在接近水平角度(如0∘^\circ∘或90∘^\circ∘)的目标上获得较高的AP50^{50}50,而MA3E则显著提升了对大倾角目标的AP50^{50}50,这充分说明MA3E有效地感知到目标的多样角度并学到鲁棒的旋转不变性表征。图1. 加载MA3E和MAE预训练模型的检测器对不同角度范围的遥感目标的检测结果,MA3E模型经300 epochsepochsepochs和1600 epochsepochsepochs预训练后,显著提升了对10∘^\circ∘至80∘^\circ∘目标的AP50^{50}50,证明了在预训练期间感知角度信息是有效的。MA3E图2. (a)MA3E的工作流程。通过设计的放缩中心裁剪操作,在原始图像中创建旋转区域以引入显式的角度变化。旋转区域在添加一个角度嵌入向量后,MA3E分别对旋转区域和剩余背景进行随机掩码。之后,所有可视图像块经过顺序编码和解码,最终重建原始图像并恢复旋转区域上预设的角度变化。(b)MA3E将旋转区域的重建视为一个最优运输(OT)问题。基于Sinkhorn-Knopp快速迭代算法求解的运输计划Ω\OmegaΩ,提出了一个OT损失函数来自动为解码器预测的每个旋转区域的图像块分配相似的原始图像块为重建目标。MA3E旨在感知不同的角度并学习旋转不变性视觉表征,其工作流程如图2(a)所示。MA3E在每张遥感图像任意位置上使用放缩中心裁剪操作构建旋转区域来提供显式的角度变化,这些旋转区域具有随机的角度,并替换其原来位置上的场景。MA3E为每个旋转区域上添加一个额外的角度嵌入向量,并分别掩码旋转区域和剩余背景。对于旋转区域的重建,MA3E基于Sinkhorn-Knopp算法求解的传输计划,自动为每个旋转区域的图像块分配多个相似的原始图像块作为重建目标,以避免直接重建引入的偏差。构造旋转区域图3. (a)我们提出的放缩中心裁剪操作在原始图像的任意位置构造具有随机角度的旋转区域,从而引入显式的角度变化。(b)在左列和中列,简单的随机旋转操作导致:i)出现无意义的零值背景;ii)丢失部分场景;iii)场景尺度发生变化。而右列固定角度(如90°、180°、270°)的旋转则限制了场景的多样性。使用简单的随机旋转操作在每张遥感图像中构造边长为aaa的旋转区域会出现如图3(b)所示的不良结果。模型难以从这些区域学习到高质量的表征,从而造成计算资源的浪费。因此,本章提出了一种放缩中心裁剪操作来创建多样化且主要场景得到极大程度保留的旋转区域,如图3(a)所示。对于图像上任意位置的边长为hhh的正方形区域(蓝色),以任何角度旋转该区域均会损失边缘场景(灰色),但该区域内最大内切圆(红色)中的场景能得到完整保留。因此,利用中心裁剪,从红色圆内提取边长为a=22ha = \frac{\sqrt 2}{2}ha=22h的最大内切正方形区域作为最终的旋转区域。该区域场景有任意朝向,它将替换原始场景从而为复合图像引入显式的角度变化。为了确保每个旋转区域能够被完整地划分为图像块,其边长aaa需能被图像块大小ppp整除,并且起始位置为ppp的倍数。角度嵌入除了为复合图像中分离的图像块嵌入向量添加位置嵌入向量外,MA3E还为旋转区域添加了一个额外的角度嵌入向量。每个角度嵌入是一个可学习的向量,并在同一个旋转区域的所有图像块嵌入向量之间共享。角度嵌入能作为一种隐式的提示引导模型感知旋转区域的角度变化,同时将其与剩余背景区分开来。随机掩码策略给定来自旋转区域的Nr=a2/p2N_r = {a^2}/{p^2}Nr=a2/p2个图像块(表示为r={ri∣i=1,2,...,Nr}r = \{{r_i}|i = 1,2,...,{N_r}\}r={ri∣i=1,2,...,Nr})以及来自背景的Nb=N−NrN_b = N - {N_r}Nb=N−Nr个图像块(表示为b={bi∣i=1,2,...,Nb}b = \{{b_i}|i = 1,2,...,{N_b}\}b={bi∣i=1,2,...,Nb}),为了避免随机掩码策略移除旋转区域中过多或全部的图像块,按照一定比例分别掩码rrr和bbb,例如75%。因此,来自背景的可视图像块和被掩码图像块分别表示为bv={biv∣i=1,2,...,Nbv}{b^v} = \{b_i^v|i = 1,2,...,N_b^v\}bv={biv∣i=1,2,...,Nbv}和bm={bim∣i=1,2,...,Nbm}{b^m} = \{b_i^m|i=1,2,...,N_b^m\}bm={bim∣i=1,2,...,Nbm}。对于旋转区域的图像块rrr,同样有着类似的定义,即rvr^vrv和rmr^mrm。像素重建MA3E使用均方误差损失函数来预测背景中被掩码图像块的像素值。对于旋转区域,则提出了一种OT损失函数LOT{\cal L}_{OT}LOT,以最小化每个图像块与其匹配的原始图像块在像素空间中的距离。整体损失函数可表示为:Lrec=LMSE(bm,b^m)+LOT(r,r^),{\cal L}_{rec} = {\cal L}_{MSE}(b^m,\hat b^m) + {\cal L}_{OT}(r,\hat r), Lrec=LMSE(bm,b^m)+LOT(r,r^),其中,b^m∈RNbm×p2C{\hat b^m} \in {\mathbb R}^{N_b^m \times {p^2}C}b^m∈RNbm×p2C表示解码器输出的对背景中被掩码图像块的预测值,而r^∈RNr×p2C\hat r \in {\mathbb R}^{{N_r} \times {p^2}C}r^∈RNr×p2C表示旋转区域中所有的预测图像块。旋转区域的重建经放缩中心裁剪后,旋转区域的每个图像块与原始图像中相同位置上的图像块相比产生内容和角度上的场景偏移。此时直接计算被掩码图像块与原始图像块之间的均方误差不仅会引入不可避免的偏差,还会忽略可视图像块上的场景变化。我们将旋转区域的重建视作一个最优传输问题,使每个预测图像块能够自动匹配相似的原始图像块进行重建。最优传输假设有MMM个供给方和NNN个需求方,其中第iii个供给方拥有uiu_iui单位的货物,第jjj个需求方需要vjv_jvj单位的货物。第iii个供给方给第jjj个需求方运输一单位货物的成本记作cijc_{ij}cij。最优传输问题的目标是找到一个传输方案,记作Ω={ωi,j∣i=1,2,...,M,j=1,2,...,N}\Omega = \{\omega _{i,j}|i = 1,2,...,M,j = 1,2,...,N\}Ω={ωi,j∣i=1,2,...,M,j=1,2,...,N},它能以最小的总传输成本确保所有货物都能从供给方运送至需求方,即:minω∑i=1M∑j=1Ncijωij.s.t.∑i=1Mωij=vj,∑j=1Nωij=ui,∑i=1Mui=∑j=1Nvj,ωij≥0,i=1,2,…,M,j=1,2,…,N.\begin{aligned} \min _\omega & \sum_{i=1}^M \sum_{j=1}^N c_{i j} \omega_{i j} . \\ \text {s.t.} & \sum_{i=1}^M \omega_{i j}=v_j, \sum_{j=1}^N \omega_{i j}=u_i, \\ & \sum_{i=1}^M u_i=\sum_{j=1}^N v_j, \\ & \omega_{i j} \geq 0, i=1,2, \ldots, M, j=1,2, \ldots, N . \end{aligned} ωmins.t.i=1∑Mj=1∑Ncijωij.i=1∑Mωij=vj,j=1∑Nωij=ui,i=1∑Mui=j=1∑Nvj,ωij≥0,i=1,2,…,M,j=1,2,…,N.基于最优传输的重建重建旋转区域的情景如图2(b)所示,考虑有NrN_rNr个原始图像块和NrN_rNr个旋转区域的预测图像块,每个原始图像块可视为供给方,持有p2C{p^2}Cp2C单位的像素值(即ui=p2C,i=1,2,...,Nru_i = {p^2}C, i = 1,2,...,{N_r}ui=p2C,i=1,2,...,Nr),每个预测图像块则视为需求方,它的p2C{p^2}Cp2C单位的通道(即vj=p2C,j=1,2,...,Nrv_j = {p^2}C, j = 1,2,...,{N_r}vj=p2C,j=1,2,...,Nr)需要p2C{p^2}Cp2C单位的像素值进行重建。原始图像块中每一单元的像素值与预测图像块中每一单元的通道间的相似度表示传输成本cijc_{ij}cij。这一过程可扩展为矩阵级的MSE计算以便于GPU加速计算。因此,从第iii个原始图像块到第jjj个预测图像块的传输成本为:cij=∥ri−r^j∥22,{c_{ij}} = \left\| {{r_i} - {{\hat r}_j}} \right\|_2^2, cij=∥ri−r^j∥22,其中,L2距离较近的原始图像块与预测图像块具有更高的相似度,从而倾向于产生更低的传输成本。一种快速迭代算法Sinkhorn-Knopp被用来计算总体传输方案Ω\OmegaΩ。根据求解得到的Ω={ωi,j}\Omega = \{\omega_{i,j}\}Ω={ωi,j},如图2(b)所示,OT损失会自动为第jjj个预测图像块分配多个相似的原始图像块作为重建目标,即:LOT(r,r^)=∑i=1Nr∑j=1Nr∥ri−r^j∥22ωij.\mathcal{L}_{OT}(r, \hat{r})=\sum_{i=1}^{N_r} \sum_{j=1}^{N_r}\left\|r_i-\hat{r}_j\right\|_2^2 \omega_{i j}. LOT(r,r^)=i=1∑Nrj=1∑Nr∥ri−r^j∥22ωij.LOT{\cal L}_{OT}LOT在像素重建和角度恢复过程中,能引导模型感知旋转区域的角度变化。随着训练的进行,MA3E可以有效地学习旋转不变性视觉表征。传输方案分析在旋转区域重建过程中,定义原始图像块为供给方,对旋转区域的预测图像块为需求方,每对图像块间的L2相似度为传输成本。这个OT问题的传输方案Ω\OmegaΩ通过Sinkhorn-Knopp迭代法来快速求解,该算法通过在目标函数上加入熵正则化项,将复杂的边际线性规划问题转化为在平滑可行域上的求解过程。需要注意的是,这个经典算法属于教材教授的知识,并非我们的贡献。图4. 在MillionAID训练图像的示例场景下求解的传输方案Ω\OmegaΩ的热力图可视化。对于每一组,实际求解过程中预测图像块都是从解码器输出的,此处展示被掩码图像块只是为了便于读者观察。图像经分块处理后,按照从左到右、从上到下的顺序为每个目标图像块和预测图像块分配索引。热力图展示了计算索引为iii的目标图像块和索引为jjj的预测图像块之间的MSE权重。每一列的权重和为1/361/361/36,整个热力图的权重和为1。MA3E利用传输方案Ω={ωi,j}\Omega = \{\omega_{i,j}\}Ω={ωi,j}为每个预测图像块分配多个相似的原始图像块作为像素重建目标。图4可视化了部分求解的传输方案的热力图。本质上,ωi,j\omega_{i,j}ωi,j可以看作使用LOT{\cal L}_{OT}LOT计算第iii个目标图像块与第jjj个预测图像块间均方误差时的权重,其中更高的权重赋给了更相似的目标-预测对。在重建第jjj个预测图像块时,模型计算它与多个目标图像块之间的加权MSE和(见图4中热力图第jjj列)。显然,每个预测图像块与分布在多个不同位置的相似目标图像块相匹配,而非仅仅与相同位置(即主对角线上)的目标图像块匹配。这充分证明了MA3E以求解OT问题的方式来重建旋转区域是有效的。实验与分析篇幅所限,请读者移步MA3E:面向遥感场景的角度感知的掩码自编码器(二)
-
紧接MGC:面向遥感场景的MLP引导CNN预训练的对比学习(一),我们继续分享MGC的实验部分。实验预训练设置表1. Fusion数据集包含的类别我们使用三个场景分类数据集MLRSNet, NWPU-RESISC45(NU45)和Aerial Image Dataset (AID)构造预训练数据集Fusion。MLRSNet和NU45数据集中的每个类的样本都随机划分为40%用于训练或微调,60%用于测试。对于AID数据集,划分比例为50%和50%。这三个训练集中相同类别将被合并以构建一个Fusion数据集,该数据集包含61,272张图像,涵盖60个类别,如表1所示,用于MGC预训练。随机采样确保了预训练数据的合理和平衡分布,MGC只专注于探索高效的预训练范式本身而不受不均衡数据分布的影响。我们训练了两个具有不同步长的模型,即MGC-Base和MGC-Large。场景分类对于下游场景分类任务,除了上述三个数据集,我们还在EuroSAT数据集上进行了对比实验,结果如表2所示,表2. 场景分类结果对比可以看到,MGC-B在所有数据集上均取得最佳准确率,但MGC-L在MLRSNet上的表现不及SwAV和CARE,在NU45上的表现也不及CARE。这是由于较大的步长sss使得E:mE_:^mE:m聚合更大范围的空间上下文信息从而增强E:cE_:^cE:c在大规模场景中的定位能力。而相比定位能力,图像级分类任务更依赖于E:cE_:^cE:c本身的局部识别能力。而在MGC-B中,E:cE_:^cE:c学习到的小尺度场景信息提高了其局部识别能力。旋转目标检测我们使用3种检测器Oriented-RCNN、RoI Transformer和S2ANet,在DOTA1.0和HRSC2016数据集上进行实验。篇幅所限,我们只展示部分实验结果。DOTA1.0是一个大规模的旋转目标检测数据集。它包含2,806张图像,尺寸从800×800800 \times 800800×800到4,000×4,0004,000 \times 4,0004,000×4,000像素不等,并且包含188,282个实例,所有实例都有旋转边界框标注,属于15个目标类别,即桥梁(BR)、港口(HA)、船只(SH)、飞机(PL)、直升机(HC)、小型车辆(SV)、大型车辆(LV)、棒球场(BD)、田径场(GTF)、网球场(TC)、篮球场(BC)、足球场(SBF)、环形交叉口(RA)、游泳池(SP)和储油罐(ST)。在实验中,每张图像都被裁剪成1,024×1,0241,024 \times 1,0241,024×1,024的图像块,步幅为824,训练集和验证集都用于训练。HRSC2016是一个广泛用于检测旋转舰船的热门数据集。它只有船一个类别,包含1,061张图像,图像大小从300×300300 \times 300300×300到1,500×9001,500 \times 9001,500×900像素不等。训练集包含436张图像,验证集包含181张图像,其余144张图像用于测试。通过固定图像的长宽比,将图像的较短边调整为800像素,较长边不超过1,333像素。表2-1. 双阶段检测器Oriented R-CNN加载不同预训练模型在DOTA1.0上的旋转目标检测结果对比表2-2. 单阶段检测器S2ANet加载不同预训练模型在DOTA1.0上的旋转目标检测结果对比表2-3. 不同检测器加载多种预训练模型在HRSC2016的检测结果对比从表2-1和表2-2可以看出,MGC-B在预测包含大尺寸目标的类别(如GTF、TC和RA)时表现更好。使用单阶段检测器时,除了在TC和RA上取得相同的高性能外,MGC-L还对小尺寸甚至稠密目标(如BR、LV和SH)有着很好的预测能力。MGC预训练模型的准确率均达到了先进水平,且超越了INP。尽管与监督学习的RSP相比还存在一定的性能差距,但MGC仅依靠前者使用预训练数据集7%左右规模的小规模数据集预训练就取得了极具竞争力的结果。表2-3显示了所有方法在HRSC2016上的检测结果,MGC-B和MGC-L超越了所有其他基于对比学习的预训练方法,并且与监督学习的INP相当。有趣的是,MGC-B在双阶段检测器Oriented R-CNN中总是优于MGC-L。而在单阶段检测器S2ANet中,MGC-L的表现则优于MGC-B。这可能是因为MGC-L中大范围的上下文信息抑制了双阶段检测器对区域候选框的提取,而MGC-B更适合后续区域候选框的分类。语义分割我们使用3种分割框架UperNet、DeeplabV3+和PSPNet,在iSAID和Potsdam数据集上进行实验。iSAID是一个大规模的实例分割数据集。需要注意的是,该数据集与DOTA1.0共享相同的场景,不同之处只在于iSAID 采用语义掩码标签,包括一个背景类和15个前景类别:船舶(Ship)、储油罐(ST)、棒球场(BD)、网球场(TC)、篮球场(BC)、田径场(GTF)、桥梁(Bridge)、大型车辆(LV)、小型车辆(SV)、直升机(HC)、游泳池(SP)、环岛(RA)、足球场(SBF)、飞机(Plane)和港口(Harbor)。该数据集包含2,806张高分辨率图像,像素尺寸范围从800×800800 \times 800800×800到4,000×13,0004,000 \times 13,0004,000×13,000像素。其中训练集、验证集和测试集分别包含1,411、458和937张图像。以512的步长将所有图像裁剪为896×896896 \times 896896×896的小块,并仅使用验证集进行评估,这是因为测试集标签不可用。Potsdam数据集由ISPRS委员会WG II/4发布,包含38幅平均尺寸为6,000×6,0006,000 \times 6,0006,000×6,000像素的图像。这些图像覆盖了德国波茨坦市3.42平方千米的区域,并包含六类场景,即:不透水表面(IS)、建筑物(BD)、低矮植被(LV)、树木(Tree)、汽车(Car)和杂物(Clutter)。其中训练集和测试集分别包含24张和14张图像,以384的步长将所有图像裁剪为512×512512 \times 512512×512的小块。在计算评估指标时,从数据集中排除了杂物(Clutter)类别。表3-1. 不同预训练模型使用UperNet框架在iSAID上的分割结果对比表3-2. 不同预训练模型使用DeeplabV3+框架在iSAID上的分割结果对比表3-3. 不同预训练模型使用UperNet框架在Potsdam上的分割结果对比表3-4. 不同预训练模型使用DeeplabV3+框架在Potsdam上的分割结果对比在iSAID数据集上,MGC模型表现优异,其中MGC-L在UperNet和DeeplabV3+框架下的mIoU分别比RSP高出0.37和0.87。具体而言,表3-1展示了UperNet的结果,MGC-L在BD、HC和RA类别上取得最佳性能。对于DeeplabV3+,MGC模型整体表现优秀,如表3-2所示,在GTF、LV、SV和Bridge类别上达到了最高的IoU。在Potsdam数据集的结果分别展示在表3-3和表3-4中。MGC模型的表现优于所有其他对比学习方法,但整体上仍不及两种监督预训练模型INP和RSP。变化检测我们选择BIT作为统一的变化检测框架,在CDD和LEVIR数据集上进行评估。CDD是一个反映真实季节变化的基准数据集,包括7对4,725×2,2004,725 \times 2,2004,725×2,200和4对1,900×1,0001,900 \times 1,0001,900×1,000像素的多源RGB图像。这些图像均来自Google Earth,分辨率范围从0.03m到1m不等。遵循\parencite{ji2018fully}的方式,图像被裁剪为256×256256 \times 256256×256的小块。最终训练集、验证集和测试集分别包含10,000、3,000和3,000个小图像块。LEVIR数据集包含637对1,024×1,0241,024 \times 1,0241,024×1,024像素的图像,这些图像同样采集自Google Earth,覆盖了美国德克萨斯州2002年到2018年间20个不同的地区。数据集中包含31,333个独立的建筑变化目标,如别墅、公寓、车库和仓库。训练集、验证集和测试集分别包含445、64和128对图像。LEVIR数据集的大图被裁剪为256×256256 \times 256256×256的无重叠小图像块。表4-1. 不同预训练模型使用BIT框架在CDD和LEVIR上的变化检测结果对比所有方法在两个数据集上微调的F1分数如表4-1所示。变化检测任务旨在匹配一对双时相图像中同位置的像素,因此局部识别能力得到加强的MGC-B模型取得了比MGC-L模型更好的效果。遗憾的是,由于Fusion数据集中缺乏对变化检测友好的双时相信息,MGC模型的F1分数均低于INP模型。但是,MGC仍然比所有对比学习方法的效果好,甚至在CDD数据集上MGC-B模型超越了RSP模型。与视觉Transformer比较凭借全局注意力机制,ViT能够捕捉图像中前景与全局场景之间的空间关系。MGC旨在通过MLP分支引导CNN分支关注正确的前景区域。因此,本节对比了自然图像领域基于\textbf{ViT-B}ase的三种最新的预训练方法以进一步验证MGC的有效性,即对比学习方法MoCo v3和DINO,以及掩码图像建模方法MAE。MGC分别与使用这三种方法的默认设置在Fusion数据集上预训练的模型和官方预训练权重进行比较。此外,还将基于时间和光谱图像重建的SatMAE(在约71.2万张遥感图像上预训练)的开源预训练权重用于对比实验。表5. 与基于视觉Transformer的不同预训练方法的综合性能比较当使用小规模的Fusion数据集预训练模型时,MGC在稠密预测任务上的检测和分割表现全部优于三种对比方法,如表5第2、4和6行所示,这也进一步证明MGC能充分学习前景区域的有效判别表征。与在ImageNet-1k上预训练的官方模型相比,除了在DOTA1.0上的检测精度比MAE低0.64的mAP外,MGC仅从有限数据中学习充分的高质量表征,就能与利用大规模数据预训练的模型相媲美。使用大规模遥感图像预训练与RSP方法类似,我们采用大规模公开的场景分类数据集MillionAID进行预训练。由于MillionAID数据集未公开训练集标签,因此全部图像均用于预训练。MillionAID是一个大规模的遥感场景数据集,包含1,000,848张从Google Earth收集的RGB图像。训练集由10,000张图像组成,分为51个类别,而测试集包含其余990,848张未标注的图像。这些图像由不同的传感器拍摄,因此具有从0.5m至153m不等的空间成像分辨率,图像大小从110×110110 \times 110110×110到31,672×31,67231,672 \times 31,67231,672×31,672像素不等。表6. 不同预训练模型在来自多种传感器源图像上的分割性能比较各种下游任务的结果如表6所示。在大规模数据集上预训练的MGC模型的分类性能得到显著提升。此外,它在DOTA1.0和iSAID上超越了INP和RSP方法。在HRSC2016和Potsdam上,MGC模型的性能几乎与INP相当。MillionAID中的多样化场景有助于MGC学习更全面的视觉表征,从而获得更优的结果。然而,这些进步往往需要较高的训练成本(训练200 epochsepochsepochs,约148小时)。相比之下,尽管使用小规模Fusion数据集的MGC方法在旋转目标检测任务中的表现相对较差,但对于大多数任务,小规模预训练的MGC能够在约49小时的时间训练800 epochsepochsepochs,提高获得通用预训练模型的效率。可视化结果图1. 不同模型在多种场景下的注意力图。(a)原始图像;(b)INP;(c)MoCo v2;(d)MGC-B的CNN分支;(e)MGC-B的MLP分支;(f)MGC-L的CNN分支;(g)MGC-L的MLP分支。MGC的MLP分支(绿框)有效地引导CNN分支(红框)关注正确的前景区域。图1展示了使用GradCAM++技术可视化的不同模型在多样场景中的注意力图。可以看到,无论面对稠密目标还是稀疏目标,CNN主干网络(红框)在MLP分支(绿框)的引导下,都能将注意力集中在正确的前景区域。与MGC-B相比,MGC-L的注意力更加判别,这也解释了为什么MGC-L预训练的CNN主干模型有着更强的定位能力。例如,MGC-L减少了在纯纹理场景(如沙漠)中的冗余注意力;MGC-L的CNN主干从小规模区域中学到的纹理信息具有高判别性。相比之下,MoCo v2预训练模型对有着大纵横比的目标(如桥梁、机场)或区域目标(如教堂、湖泊)的注意力不完全,而对于稠密目标(如密集住宅区)则表现出冗余的注意力。INP由于域差异出现了错误的关注。小结我们提出了一种基于MLP引导的CNN预训练的对比学习方法——MGC。通过独特设计的的MLP分支,MGC能有效引导传统的CNN分支克服浅层的局部性问题,从而将注意力集中在正确的前景区域上并提取高质量判别表征。MGC预训练的模型不仅拥有着最佳的场景分类性精度,而且在旋转目标检测、语义分割和变化检测任务上也表现出极具竞争力的性能。MGC为遥感图像领域提供了一种有效且通用的预训练方法,对其他特殊类型的图像(如高光谱或合成孔径雷达图像)的预训练同样具有一定的参考价值。本文已发表在2024年的IEEE Transactions on Geoscience and Remote Sensing(TGRS)期刊上。
-
引言现有一些工作已经充分探讨了专门针对遥感图像的预训练,但它们通常需要多样化的遥感图像数据源,此外,在大规模数据集上进行预训练需要大量的计算资源,这使得只有少数研究机构能够实施。我们的目标是在随机采样得到的小规模遥感图像数据集上仅使用有限的计算资源(例如,四块NVIDIA V100 GPU)就训练出具有竞争力的通用预训练模型。我们采用了一种基于对比学习的CNN预训练范式。CNNs依靠局部性建模强大的判别特征有助于对比模型挖掘成对样本间的一致性,促进了对比学习在自然场景下取得进步。局部性即卷积层的局部感知性,通过卷积操作将卷积核与场景中相应位置的局部区域相乘,从而捕获当前位置的空间结构和局部模式。经过卷积操作,特征图的高和宽变小,固定大小的卷积核会带给深层卷积层更大的感受野。换句话说,局部性使CNNs的浅层关注局部区域而深层关注全局。但这一特点适用于自然场景而非遥感场景,我们利用Grad-CAM++可视化不同方法预训练的CNNs每一层的注意力图并排除域差异的影响来更好的说明。图1. 不同预训练模型各层的注意力图(a)MoCo v2在ImageNet-1k上预训练的ResNet-50(b)MoCo v2在小规模遥感图像数据集上预训练的ResNet-50(c)MGC在小规模遥感图像数据集上预训练的ResNet-50(d)MGC在小规模遥感图像数据集上预训练的MLP分支对于图1(a)的自然场景,由于前景目标单一且尺寸较大,与背景间差异明显,CNN的layer1layer1layer1和layer2layer2layer2从不同位置的局部场景中有极大概率捕获到前景狗和背景的差异。感受野较大的layer3layer3layer3能逐渐从更大区域中定位部分狗的判别区域。到layer4layer4layer4阶段,CNN的关注域能覆盖正确前景区域并从中提取强大的判别表征。相反,遥感场景通常覆盖广阔而复杂的地形,卫星传感器质量的变化可能导致遥感图像模糊或失真。此外,图像中的前景目标、感兴趣区域和土地覆盖等主要判别要素在尺度和分布上也不均匀。在图1(b)的遥感场景中,预训练CNN的layer1layer1layer1和layer2layer2layer2只能从有限的局部区域中学习前景桥梁和背景之间的差异信息,限制了layer3layer3layer3建立对更大区域内正确前景的认识。进一步地,这导致layer4layer4layer4对海面等背景的冗余关注和对前景桥梁的不充分关注,并认为该处判别。遥感场景下浅层的局部性导致CNN不完全定位正确前景,提取的低质量表征不利于对比模型学习一致性,这也造成了对数据的浪费。为此,我们提出一种用于遥感图像的MLP指导CNN预训练的对比学习方法(MLP-Guided CNN Pre-training,MGC)。MGC在CNN分支之外额外引入了MLP分支,以克服浅层的局部性问题,并引导CNN分支关注正确的前景区域。MLP分支由三层卷积层和多个MLP组成,能够从特征图中的不同位置聚合空间上下文信息。在图1(c)和(d)的遥感场景中,尽管layer3layer3layer3仍错误地关注了桥梁右下角的土地覆盖区域,但MLP分支的各层通过聚合来自不同区域的特征逐步定位到了完整的桥梁,成功引导CNN关注正确的前景区域。MGC模型架构MGC采用经典的孪生编码器架构进行对比预训练。其中,编码器kkk的参数通过动量更新机制平滑的从编码器qqq获得,即:θk←α⋅θk+(1−α)⋅θq\theta_k \leftarrow \alpha \cdot \theta_k+(1-\alpha) \cdot \theta_qθk←α⋅θk+(1−α)⋅θq,其中θq\theta_qθq和θk\theta_kθk表示编码器的参数。如图~\ref{mgc-fig2}(a)所示,每个编码器由一个普通CNN分支(EqcE_q^cEqc / EkcE_k^cEkc)和一个对前景敏感的MLP分支(EqmE_q^mEqm / EkmE_k^mEkm)组成。与SimCLR方法相同,输入遥感图像xxx通过随机数据增强创建两个视图vqv_qvq和vkv_kvk,然后分别输入到两个编码器的各个分支中来提取多种形式的表征。在图2(a)中,灰色的ck−c_{k^-}ck−和mk−m_{k^-}mk−表示来自除xxx以外其他图像的特征。图2. MGC的完整架构CNN分支CNN分支E:cE_:^cE:c包括来自编码器qqq的EqcE_q^cEqc和来自动量编码器kkk的EkcE_k^cEkc,它们均由ResNet-50主干网络链接着一个投影头组成,EqcE_q^cEqc连接着一个额外的预测头,投影头与预测头结构相同,均由通道全连接层(Channel FC layer,即线性层)、BN层、ReLU激活函数和另一个通道全连接层组成。MLP分支图3. MLP分支结构MLP分支E:mE_:^mE:m与E:cE_:^cE:c唯一区别在于主干结构上的差异。E:mE_:^mE:m的主干网络中仅保留ResNet-50的前三层,之后与一个单独设计的MLP网络相连,其结构如图3所示由两个普通的MLP和nnn个CycleMLP组成。CycleMLP中的Cycle FC层可以沿着特征图的通道维度进行循环偏移和采样,从而在不同的高度和宽度维度上聚合空间上下文信息,具体计算方式如下:Mh,w,:cycleFC=∑c=0cinWc⋅Fh+Δh,w+Δw,c+b,M_{h, w,:}^{\text {cycleFC}}=\sum_{c=0}^{c_{in}} W_c \cdot F_{h+\Delta h, w+\Delta w, c}+b, Mh,w,:cycleFC=c=0∑cinWc⋅Fh+Δh,w+Δw,c+b,其中Fh+Δh,w+Δw,cF_{h+\Delta h, w+\Delta w, c}Fh+Δh,w+Δw,c表示在动态循环位置(h+Δh,w+Δw)(h + \Delta h, w + \Delta w)(h+Δh,w+Δw)处第ccc通道的值。Wc∈RCin×CoutW_c \in {\mathbb R}^{C_{in} \times C_{out}}Wc∈RCin×Cout和b∈RCoutb \in {\mathbb R}^{C_{out}}b∈RCout分别是Cycle FC中可学习的权重和偏置。在第ccc通道上高度和宽度两个方向上的偏移量通过计算Δh=(c mod s)−1\Delta h = (c \bmod s) - 1Δh=(cmods)−1和Δw=(⌊c/s⌋ mod s)−1\Delta w = (\left\lfloor {c/s} \right\rfloor \bmod s) - 1Δw=(⌊c/s⌋mods)−1来获得,其中sss是可调节步长。较大的步长sss意味着E:mE_:^mE:m能聚合更多空间上下文信息。随着训练的进行,E:mE_:^mE:m能够挖掘与前景区域相关的判别表征。随着sss的增加,E:mE_:^mE:m关注更大且更具判别性的前景区域。模型训练MGC中每个提出的组件的工作流程如图2所示。首先,同分支对比学习利用从编码器qqq的CNN分支EqcE_q^cEqc提取的特征cqc_qcq和来自动量编码器kkk的EkcE_k^cEkc的特征ckc_kck,或由MLP分支 E:mE_:^mE:m提供的特征mqm_qmq和mkm_kmk,构建正负样本对,通过典型的对比学习来探索一致性。同时,正样本对引导策略推动cqc_qcq (mqm_qmq)从其正样本ck+c_{k^+}ck+(mk+m_{k^+}mk+)中学习信息,从而促进同分支对比学习。之后,跨分支对比学习从EqcE_q^cEqc选择cqc_qcq和来自EkmE_k^mEkm的mk+m_{k^+}mk+与mk−m_{k^-}mk−,构建成对样本;类似地,mqm_qmq也被用来与ck+c_{k^+}ck+和ck−c_{k^-}ck−创建正负对,进一步丰富模型学到的一致性。最终,注意力引导策略被提出用以拟合同一编码器中E:cE_:^cE:c和E:mE_:^mE:m提取的特征的分布,从而驱使E:mE_:^mE:m引导E:cE_:^cE:c逐渐关注前景区域并学习判别表征,最终克服E:cE_:^cE:c浅层的局部性问题。经过充分的训练,编码器qqq的CNN分支EqcE_q^cEqc作为通用预训练模型微调一系列下游遥感任务。同分支对比学习同分支对比学习的目标是为“查询向量”检索与之相关的“键向量”,并使它们在嵌入空间中彼此接近,这通过最小化infoNCE损失函数来实现。因此,在获得由E:cE_:^cE:c编码的cqc_qcq和ckc_kck后,损失计算如下:Lc↔c(cq,ck)=−logexp(cq⋅ck+/τ)exp(cq⋅ck+/τ)+∑k−exp(cq⋅ck−/τ),\mathcal{L}_{c \leftrightarrow c}(c_q,c_k){\rm{ = }} - \log \frac{\exp (c_q \cdot {c_{k^+}} /\tau )}{\exp (c_q \cdot {c_{k^+}}/\tau ) + \sum\nolimits_{k_{\rm{ - }}} {\exp (c_q \cdot {c_{k^-}}/\tau )} }, Lc↔c(cq,ck)=−logexp(cq⋅ck+/τ)+∑k−exp(cq⋅ck−/τ)exp(cq⋅ck+/τ),其中τ\tauτ是用于控制相似度计算尺度的温度系数,ck+c_{k^+}ck+和cqc_qcq来自同一图像的不同视图,即一个正样本对。ck−c_{k^-}ck−是从其他图像中提取的,通常被视为cqc_qcq的负样本。当然,遵循相同的设置再次计算来自MLP分支E:mE_:^mE:m的mqm_qmq与mkm_kmk间的infoNCE损失。模型通过同分支对比学习来挖掘基本的一致性信息,其完整的损失函数写为:Lconsame=Lc↔c(cq,ck)+Lm↔m(mq,mk).\mathcal{L}_{con}^{\rm{same}} = {\mathcal{L}_{{\rm{c}} \leftrightarrow c}}(c_q,c_k) + {\mathcal{L}_{m \leftrightarrow m}}(m_q,m_k). Lconsame=Lc↔c(cq,ck)+Lm↔m(mq,mk).跨分支对比学习E:cE_:^cE:c能从场景中的任何区域提取局部特征。而聚合较大尺度场景内空间上下文的特性使得E:mE_:^mE:m能够专注于前景区域,从而学到对前景敏感的区域辨别表征。因此,跨分支对比学习被提出来充分挖掘这两种不同偏好表征之间的互信息,进一步提升模型学到的一致性。对于一个随机输入图像,可将EqcE_q^cEqc提取的cqc_qcq视为“查询向量”,EkmE_k^mEkm编码的数据增强视图的mk+m_{k^+}mk+作为cqc_qcq的正样本,来自其他图像的表征作为cqc_qcq的负样本mk−m_{k^-}mk−。同样,当mqm_qmq作为“查询向量”时,用于构造正负样本对的样本都来自EkcE_k^cEkc。投影头和预测头确保了所有分支提取的特征向量维度相同。通过跨分支的构建正负样本对,本章最小化如式~\ref{mgc-eq2}所定义的infoNCE损失。因此,跨分支对比学习的完整损失函数可以写为:Lconcross=Lc↔m(cq,mk)+Lm↔c(mq,ck).\mathcal{L}_{con}^{\rm{cross}} = {\mathcal{L}_{{\rm{c}} \leftrightarrow m}}(c_q,m_k) + {\mathcal{L}_{m \leftrightarrow c}}(m_q,c_k). Lconcross=Lc↔m(cq,mk)+Lm↔c(mq,ck).正样本对引导策略一般的,典型对比范式通常设置较大的动量更新系数α\alphaα来保证两个编码器的网络参数近似。动量编码器kkk提取的特征中包含的判别信息在每次迭代中都得到了充分保留,这使得特征具有很高的稳定性。因此当对比一个由“查询向量”cqc_qcq 和稳定特征ck+c_{k^+}ck+构建的正样本对时,模型就会全神贯注的探索一致性。否则,模型可能会在cqc_qcq和不稳定的ck+c_{k^+}ck+之间学习到一些噪声。因此,基于动量更新机制带来的优势,设计了一种正样本对引导策略,以增强同分支对比学习的效果。如图~\ref{mgc-fig2}(d)所示,对于E:cE_:^cE:c,最小化cqc_qcq和ck+c_{k^+}ck+分布之间的KL散度:Lk+→qc(cq,ck+)=−ck+logck+cq,\mathcal{L}_{k^{+} \rightarrow q}^c\left(c_q, c_{k^{+}}\right)=-c_{k^{+}} \log \frac{c_{k^{+}}}{c_q}, Lk+→qc(cq,ck+)=−ck+logcqck+,上式迫使ck+c_{k^+}ck+和cqc_qcq特征分布一致,进一步促进了同一类型分支内的对比学习。随着动量更新的进行,EkcE_k^cEkc会逐渐具备相同的特征提取能力。在E:mE_:^mE:m中,同样的策略应用于从E:mE_:^mE:m提取的mqm_qmq和mk+m_{k^+}mk+,完整的正样本对引导策略的损失函数可定义为:LklPG=Lk+→qc(cq,ck+)+Lk+→qm(mq,mk+).\mathcal{L}_{kl}^{{\rm{PG}}} = \mathcal{L}_{{k^ + } \to q}^c(c_q,c_{k^+}) + \mathcal{L}_{{k^ + } \to q}^m(m_q,m_{k^ + }). LklPG=Lk+→qc(cq,ck+)+Lk+→qm(mq,mk+).注意力引导策略CNN中浅层的局部性问题导致E:cE_:^cE:c不可避免关注到冗余的背景信息,并忽略部分前景区域。与此相反,E:mE_:^mE:m从不同区域聚合空间上下文信息,驱使注意力覆盖正确的前景区域,这使得E:mE_:^mE:m挖掘的表征在前景目标或区域的位置上有着足够的判别性。基于上述发现,提出注意力引导策略帮助CNN分支关注正确前景区域,这通过最小化mqm_qmq和cqc_qcq的分布之间的KL散度来实现的。Lm→cq(cq,mq)=−mqlogmqcq,\mathcal{L}_{m \rightarrow c}^q\left(c_q, m_q\right)=-m_q \log \frac{m_q}{c_q}, Lm→cq(cq,mq)=−mqlogcqmq,其中,区域判别表征mqm_qmq将作为监督信号,迫使EqcE_q^cEqc关注相同场景中的前景区域。同时,EkcE_k^cEkc也被引导在另一视图中定位相同的前景。最终的损失函数可以写为:LklAG=Lm→cq(cq,mq)+Lm→ck+(ck+,mk+).\mathcal{L}_{k l}^{\mathrm{AG}}=\mathcal{L}_{m \rightarrow c}^q\left(c_q, m_q\right)+\mathcal{L}_{m \rightarrow c}^{k^{+}}\left(c_{k^{+}}, m_{k^{+}}\right) . LklAG=Lm→cq(cq,mq)+Lm→ck+(ck+,mk+).在图1中,CNN分支的注意力覆盖了正确的前景区域,证明了注意力引导策略的有效性。LossMGC通过联合优化EqcE_q^cEqc, EqmE_q^mEqm, EkcE_k^cEkc和EkmE_k^mEkm来进行高质量的表征学习,即:Ltotal =Lcon same +λC⋅Lcon cross +λP⋅LklPG+λA⋅LklAG,\mathcal{L}_{\text {total }}=\mathcal{L}_{\text {con }}^{\text {same }}+\lambda_C \cdot \mathcal{L}_{\text {con }}^{\text {cross }}+\lambda_P \cdot \mathcal{L}_{k l}^{\mathrm{PG}}+\lambda_A \cdot \mathcal{L}_{k l}^{\mathrm{AG}}, Ltotal =Lcon same +λC⋅Lcon cross +λP⋅LklPG+λA⋅LklAG,其中权重λC\lambda_CλC平衡模型优化期间的跨分支对比学习,合适的正样本对引导损失的权重λP\lambda_PλP能促进同分支对比学习的质量,改变权重λA\lambda_AλA能控制MLP分支E:mE_:^mE:m引导CNN分支E:cE_:^cE:c注意力的强度。实验篇幅所限,请读者移步MGC:面向遥感场景的MLP引导CNN预训练的对比学习(二)
-
引言遥感图像场景分类作为遥感技术中一种基础的应用手段,在现代化的地质勘探、道路规划、精准农业、灾害监测、病媒传播监测和应对气候变化等涉及国防和民生的领域中起着举足轻重的作用。传统分类模型通常采用在ImageNet等通用自然图像数据集上预训练的权重进行初始化。然而,自然图像与遥感图像在数据类型、成像机制及空间特征等方面存在显著差异,导致此类预训练模型在遥感场景下泛化能力受限,难以充分发挥性能潜力。近年来,遥感技术迅猛发展,推动了空间分辨率与光谱分辨率更高、图像质量更优的遥感数据的持续产出。然而,对这些高分辨率图像进行精细化标注,往往依赖专家经验或昂贵的地面传感器,成本高昂且效率低下。与此同时,随着在轨观测卫星数量的激增,每日产生的遥感图像数据量呈指数级增长。在这一背景下,如何高效、智能地解析和理解海量遥感数据,已成为民用与军事应用领域共同面临的紧迫挑战。因此,发展高效、鲁棒的自监督表征学习方法,实现对海量未标注遥感数据的自动表征提取与语义理解,正日益成为推动遥感智能分析迈向新阶段的核心技术路径。对比学习对比学习作为自监督表征学习中的主流范式之一,通过将嵌入空间中正样本对(即同一图像的不同视图)的表征拉近,同时推远负样本对(即不同图像的视图),能从无标注图像中学习充分的一致性视觉表征。我们借助图1简要介绍对比学习的学习过程:图1. 对比学习范式每张无标签图像xxx经两种独立的数据增强操作创建出两个不同的视图,即查询视图vqv_qvq和键视图vkv_kvk。之后,它们分别输入到具有相同结构的孪生编码器中提取特征。经编码器提取的查询向量为qqq,存储在记忆库中的一组已编码的键向量为{k0,k1,k2,...}\{k^0, k^1, k^2, ...\}{k0,k1,k2,...},这其中一定存在一个唯一的正键向量k+k_+k+与查询向量qqq匹配,因为该正键向量和查询向量来自同一图像的不同视图。因此,qqq和k+k_+k+构成正样本对,对比学习往往采用典型的infoNCE损失函数来拉近正样本对,同时增加查询与所有其他负键向量k−k_-k−之间的距离,其公式如下:Lc(q,k)=−logexp(q⋅k+/τ)exp(q⋅k+/τ)+∑k−exp(q⋅k−/τ),{{\cal L}_c}(q,k){\rm{ = }} - \log \frac{{\exp (q \cdot {k_ + }/\tau )}}{{\exp (q \cdot {k_ + }/\tau ) + \sum\nolimits_{{k_ - }} {\exp (q \cdot {k_ - }/\tau )} }}, Lc(q,k)=−logexp(q⋅k+/τ)+∑k−exp(q⋅k−/τ)exp(q⋅k+/τ),其中τ\tauτ为用于控制特征分布平缓程度的温度系数。基于多尺度难特征的对比学习与自然图像相比,遥感图像涵盖的场景中背景复杂,其中作为判别依据的前景目标的尺度和分布不均匀,且不同卫星的成像质量差异也造成了视觉模糊和图像畸变等负面因素,因此,我们提出了一种基于多尺度难特征的对比学习方法(Multi-scale Hard Contrastive Learning, MHCL)。MHCL利用我们设计的难特征转换方法从小规模遥感图像数据中创建更判别的多尺度难特征,从而鼓励模型从复杂遥感场景中学习丰富的一致性视觉表征,其结构如图2所示。图2. MHCL架构我们以经典方法MoCo v2作为baseline,收集编码器ResNet-50的layer2layer2layer2、layer3layer3layer3、layer4layer4layer4和layer5layer5layer5输出的浅层纹理特征和深层语义特征,分别送入四个具有不同输入维度的投影头来生成简单的多层级特征和对应的记忆队列。难特征转换所有提取的特征kik^iki和qiq^iqi在L2归一化后,都会映射到一个统一的单位球面空间中。为充分挖掘和利用每张遥感图像所含场景信息,我们对每一组特征向量均采用难特征转换方法HFT,包括难正特征离心化和难负特征向心化操作。通过HFT,直接编码得到的简单查询向量和简单键向量彼此融合,从而转换为难样本。这些生成的难特征所包含的合成场景信息会突破数据集中固有场景的限制,帮助模型探索更判别的一致性信息从而提升表征学习的质量。图3. 难特征转换难正特征离心化从最大化利用图像信息的角度出发,最直接的思路是挖掘更多包含场景语义的特征。通常,在标准单位球面空间中,从球心指向球面的两个归一化特征之间的夹角越大,它们的相似性就越低,即夹角较大的两个特征可被视为彼此的难样本。因此,通过离心化操作来增大每对查询特征向量与其正键特征向量之间的夹角来获取难正特征。具体而言,如图3(a)所示,使用加权减法运算外推qiq^iqi来生成离心的难特征。同理也可以得到k+ik_+^ik+i的难样本,该过程可以表示为:{q^i=(1+λ)⋅qi−λ⋅k+ik^+i=(1+λ)⋅k+i−λ⋅qi,\left\{ \begin{array}{l} {{\hat q}^i} = (1 + \lambda ) \cdot {q^i} - \lambda \cdot k_ + ^i\\ \hat k_ + ^i = (1 + \lambda ) \cdot k_ + ^i - \lambda \cdot {q^i} \end{array} \right., {q^i=(1+λ)⋅qi−λ⋅k+ik^+i=(1+λ)⋅k+i−λ⋅qi,其中,权重λ\lambdaλ服从Beta分布,即λ∼Beta(α,β)\lambda \sim Beta(\alpha, \beta)λ∼Beta(α,β),且λ∈(0,1)\lambda \in (0,1)λ∈(0,1)。更小的λ\lambdaλ能生成更难的样本。由于场景分类数据集的规模远小于ImageNet等大型自然图像基准,过难的特征可能会破坏图像中的独特场景,不利于模型的学习和训练的收敛。因此,我们一般选择较大的λ\lambdaλ以避免生成的难正特征过度偏离原始场景。难负特征向心化在模型迭代训练时,baseline模型的记忆队列仅更新最前面一个batchsizebatchsizebatchsize大小的负键向量,这会导致模型反复计算那些没有得到及时更新的剩余负样本的损失。因此,增加不同负特征之间的相似性来生成更多样化的难负样本,能帮助MHCL降低重复计算的代价。具体的,每一组相同尺度的负键向量都存储在一个单独的记忆队列中,即{k−i}={k1,k2,...,kQ}−i\{k_-^i\} = {\{k_1},{k_2},...,{k_Q}\}_-^i{k−i}={k1,k2,...,kQ}−i,其中QQQ是每个队列的大小,定义{k−i}rand\{k_-^i\}_{rand}{k−i}rand为队列{k−i}\{k_-^i\}{k−i}的随机重排列版本。如图3(b)所示,难负特征向心化操作通过使用加权加法来减少{k−i}\{k_-^i\}{k−i}中的负样本与{k−i}rand\{k_-^i\}_{rand}{k−i}rand中的随机排列的负样本之间的角度,即:{k^−i}=λ⋅{k−i}+(1−λ)⋅{k−i}rand,\{\hat k_-^i\} = \lambda \cdot \{k_-^i\} + (1 - \lambda) \cdot {\{k_-^i\}_{rand}}, {k^−i}=λ⋅{k−i}+(1−λ)⋅{k−i}rand,其中,λ\lambdaλ与难正特征离心化中的λ\lambdaλ作用一致。本章同样赋予λ\lambdaλ一个较大的值,以避免生成如上述描述的造成信息崩塌的难负样本。向心化的队列{k^−i}\{\hat k_-^i\}{k^−i}可以提供多样化的负样本特征,从而进一步促进多层级中间特征对比学习。最终Loss在离心化简单正特征生成难正特征q^i\hat q^iq^i和k^+i\hat k_+^ik^+i,并创建包含难负特征的记忆队列{k^−i}\{\hat k_-^i\}{k^−i}之后,MHCL利用多尺度难特征联合对比损失函数,在每个尺度上推远难负样本对并拉近难正样本对,从而引导模型学习更具一致性的判别表征,即:Lmhc(q,k)=Lmlc(qi,ki)+ωh⋅Lmlc(q^i,k^i),{{\cal L}_{mhc}}(q,k) = {{\cal L}_{mlc}}({q^i},{k^i}) + {\omega _h} \cdot {{\cal L}_{mlc}}({\hat q^i},{\hat k^i}), Lmhc(q,k)=Lmlc(qi,ki)+ωh⋅Lmlc(q^i,k^i),其中,ωh\omega_hωh是一个超参数,控制难特征参与模型优化的强度。在将模型迁移到下游场景分类任务时,转换的难特征包含的部分合成场景信息会在一定程度上混淆模型的判别能力。这种情况在小规模数据集上尤为明显。因此,不同规模的数据集设置不同的ωh\omega_hωh,从而在最大化利用这些难特征挖掘模型潜能的同时降低错误预测的风险。实验数据集MHCL的一系列实验均在三个常见的遥感图像场景分类数据集UC Merced、NWPU-RESISC45和MLRSNet上进行:UC Merced包含21个土地利用类别,每个类别有100张尺寸为256×256256 \times 256256×256像素的图像,这2,100张RGB图像收集自美国地质调查局(USGS)发布的国家地图集。NWPU-RESISC45是由西北工业大学从Google Earth收集的一个常用遥感图像场景分类基准数据集。它包含31,500张RGB彩色空间的图像,平均分为45类,每类包括700张图像。这些图像的空间分辨率范围从0.2米到30米不等,所有图像的大小均为256×256256 \times 256256×256像素。MLRSNet是一个大规模的多标签遥感图像数据集,包含109,161张从 Google Earth收集的图像。这些图像的空间分辨率范围为0.1米到10米,图像大小为256×256256 \times 256256×256像素。所有图像被分配到46个大类,每个大类包含1,500到3,000张图像不等。同时,每张图像都有着从1到13个数量不等的子标签。全部实验仅使用大类标签。在实验中,所有数据集中每个类别的图像都被随机分成两部分。一部分用于训练,包括自监督预训练和在场景分类任务上微调;另一部分用于测试模型性能。UC Merced(UCM)数据集被随机划分为60%的训练集和40%的测试集。对于NWPU-RESISC45数据集,随机选择20%和80%的图像用于训练,其余20%和80%的图像用于测试。这两个划分的数据集分别称为NU45 2-8和NU45 8-2。同样,MLRSNet数据集将40%作为训练集,60%作为测试集,并且在测试阶段仅使用广义类别标签。主要结果表1. 主要结果对比我们选取自然图像领域的11种优秀的对比学习方法进行比较,在表1可以看到,MHCL在三个数据集上均取得了卓越的性能,尤其是在小规模的UCM上。除了BYOL之外,所有对比方法均在MLRSNet上取得最佳结果,这表明数据集中包含的场景信息越丰富,由对比机制引导的模型所学习的一致性表征就越具判别力。然而,这些方法在其他三个小型和中型数据集上的Top-1准确率表现均不理想,只有MHCL在所有数据集上均保持了全面的竞争力。尽管训练样本有限,但通过利用主干网络中间层的多尺度难特征挖掘一致性视觉表征,MHCL仍然能为场景分类任务提供有效的预训练模型。表2. 不同预训练方法对比许多对比学习方法都是基于自然图像数据集(如包含约128万张图像的 ImageNet-1k)逐步发展而来的。这些方法在自监督生成的预训练模型在许多下游任务中表现出良好的微调性能。为了探究所提出的MHCL方法在遥感图像数据集上的优势,我们进行了以下实验:不加载任何预训练权重,从头开始训练一个ResNet-50网络用作分类。表2第一行的分类结果表明,随机初始化对分类任务产生了不利影响。直接将传统ImageNet-1k预训练模型迁移到场景分类任务。表2第二行的结果显示,仅使用简单的微调策略即可取得良好性能,并在NU45 2-8和UCM数据集上实现最佳分类结果,相比之下MHCL略显逊色。然而,在规模相对较大的NU45 8-2和MLRSNet数据集上,ImageNet预训练模型的准确率低于MHCL方法。尽管自然图像与遥感图像之间存在明显差异,但ImageNet-1k大量的图像数据仍然能够提供丰富的判别信息。采用标准的监督预训练方式,在每个场景分类数据集上训练一个监督预训练模型,并将其迁移到场景分类任务。实验结果如表2第三行所示,在相同数量级的训练图像基础上,MHCL通常明显优于监督预训练方法,尤其是在较小的NU45 2-8和UCM数据集上。小结MHCL仅通过有限的遥感图像数据就能学习到丰富的一致性视觉表征,我们希望MHCL能够加速遥感社区的预训练算法研究。本文已发表在2023年的IEEE Transactions on Geoscience and Remote Sensing(TGRS)期刊上。在下一节中,将继续探索对比学习在遥感领域中的应用潜力,届时不仅仅局限于场景分类任务,还将为其他重要的遥感图像任务,如旋转目标检测、变化检测和语义分割,贡献一种更通用的上游预训练模型。
-
 随着人工智能的发展和落地应用,以地理空间大数据为基础,利用人工智能技术对遥感数据智能分析与解译成为未来发展趋势。本文以遥感数据转化过程中对观测对象的整体观测、分析解译与规律挖掘为主线,通过综合国内外文献和相关报道,梳理了该领域在遥感数据精准处理、遥感数据时空处理与分析、遥感目标要素分类识别、遥感数据关联挖掘以及遥感开源数据集和共享平台等方面的研究现状和进展。首先,针对遥感数据精准处理任务,从光学、SAR等遥感数据成像质量提升和低质图像重建两个方面对精细化处理研究进展进行了回顾,并从遥感图像的局部特征匹配和区域特征匹配两个方面对定量化提升研究进展进行了回顾。其次,针对遥感数据时空处理与分析任务,从遥感影像时间序列修复和多源遥感时空融合两个方面对其研究进展进行了回顾。再次,针对遥感目标要素分类识别任务,从典型地物要素提取和多要素并行提取两个方面对其研究进展进行了回顾。最后,针对遥感数据关联挖掘任务,从数据组织关联、专业知识图谱构建两个方面对其研究进展进行了回顾。除此之外,面向大智能分析技术发展需求,本文还对遥感开源数据集和共享平台方面的研究进展进行了回顾。在此基础上,对遥感数据智能分析与解译的研究情况进行梳理、总结,给出了该领域的未来发展趋势与展望。 引言近几年来,国内外人工智能的发展和落地应用如火如荼,促成这种现象的原因可以归纳为两个关键词,即“大数据”与“高算力”。在地理空间数据分析与应用领域,这种变化也正在发生着,比如在国家高分辨率对地观测重大科技专项(简称“高分专项”)等国家重大任务的推动下,我们可获取的地理空间数据越来越多,另外,以“云+端”架构为代表的高性能计算框架也在不断发展,促进了算力的提升。在此背景下,以地理空间大数据为基础,利用人工智能技术挖掘其深层信息、赋予其更多的应用模式,将成为未来地理空间数据分析应用领域发展的长期主题。发展遥感数据智能分析技术的目的是将长期积累的遥感数据转化为对观测对象的整体观测、分析、解译,获取丰富准确的属性信息,挖掘目标区域的演化规律,主要包括遥感数据精准处理、遥感数据时空处理与分析、遥感目标要素分类识别、遥感数据关联挖掘等。此外,面向大智能分析技术发展需求,遥感开源数据集和共享平台方面也取得了显著进展(陈述彭等, 2000; 宫辉力等, 2005)。遥感数据精准处理方面,遥感数据精准处理的目的是对传感器获取的光谱反射或雷达散射数据进行成像处理和定标校正,恢复为与地物观测对象某些信息维度精确关联的图像产品。传统方法需要根据卫星、传感器、传输环境、地形地表等先验模型,以及外场定标试验获取定标参数,建立精确的成像模型将观测数据映射为图像产品。随着传感器新技术的发展和分辨率等性能的提升,先验模型的建立越来越困难,外场定标的难度和消耗也越来越大,并且成像处理和定标校正获取的模型和参数与传感器的耦合,只能以一星一议的方式实现,无法多星一体化实现。如何在传统方法的基础上,构建观测数据到精准图像产品的深度学习网络结构,设置面向不同应用的图像优化指标体系,以大量历史数据和标注结果作为输入,实现网络结构对传感器物理模型和参数的精确重构和逼近,形成基于人工智能技术的多星一体化遥感图像精准处理能力。遥感数据时空处理与分析方面,多时相影像相比单一时相的遥感影像,能够进一步展示地表的动态变化和揭示地物的演化规律。然而,一方面受限于遥感自身的时间分辨率与空间分辨率之间的不可兼得;另一方面受气象、地形等成像条件的影响,光学传感器获取的遥感影像往往被云层及其阴影覆盖(特别是在多云多雨地区,如我国西南地区),而难以获取真实的地面信息。这样的数据缺失,严重限制了遥感影像的应用;特别是对于多时相影像的遥感应用(如森林退化、作物生长、城市扩张和湿地流失等监测),云层及其阴影所导致的数据缺失将延长影像获取的时间间隔、造成时序间隔不规则的问题,加大后续时间序列处理与分析的难度。因此,进行遥感影像的时间与空间维度的处理与分析对提高遥感影像数据的可用性、时间序列分析水平和遥感应用的深度广度具有重要意义。遥感目标要素分类识别方面,遥感数据中一般包含大量噪声,大多数现有的处理分析方法并未充分利用计算机强大的自主学习能力,依赖的信息获取和计算手段较为有限,很难满足准确率、虚警率等性能要求。如何在传统的基于人工数学分析的方法基础上,结合人工智能方法,定量描述并分析遥感数据中目标模型失真和背景噪声干扰对于解译精度的影响机理,是遥感智能分析面临的另一项关键科学问题。通过该问题的分析与发展,有望实现构建一个基于深度学习的多源遥感数据自动化分析框架,在统一框架下有机融合模型、算法和知识,提升遥感数据中目标要素提取和识别的智能化水平。遥感数据关联挖掘方面,随着遥感大数据时代的到来,我们可以更方便地获取高分辨率和高时间采集频率的遥感数据,对于目标信息的需求,也由目标静态解译信息,拓展到全维度的综合认知与预测分析。为了满足上述需求,基于海量多源异构遥感数据,实现时间、空间等多维度的信息快速关联组织与分析,是未来遥感解译技术发展的重要方向。遥感开源数据集和共享平台方面,大多数现有数据集仍然存在数据规模较小、缺乏遥感特性的问题,并且现有深度学习平台难以有效支撑遥感特性及应用,领域内数据集算法模型的准确性、实用性、智能化程度也待进一步提高。如何结合遥感数据特性,建设更具遥感特色的开源数据集和共享平台,是遥感智能生态建设的一项重要研究内容。本文主要围绕上述五个方面的研究,论述遥感智能分析技术的发展现状、前沿动态、热点问题和未来趋势。 01国际研究现状1.1遥感数据精准处理利用智能手段开展数据预处理技术,国外将智能技术用于遥感数据(光学、SAR、光谱)配准、校正等的工作。 1.1.1光学/SAR 精细化处理遥感图像为遥感应用分析提供了数据基础,可广泛应用于农林监测、城市规划、军事侦察等领域,遥感数据质量是决定其应用性能的关键。评价遥感数据质量的指标包括图像时间/空间分辨率、图像幅宽、空间特征、光谱特征、辐射几何精度等。高质量遥感影像具有高分辨率、高信噪比等特点。提升遥感影像质量的方法可大致分为两类,一是改进传统成像算法聚焦得到高质量图像;二是将已有的低质量的图像通过去噪去云以及超分辨率重建等技术得到高分辨率高质量图像。与传统的 SAR成像算法比较,基于深度学习的SAR 成像算法可以简化成像过程。Rittenbach等人(2020)提出 RDAnet 神经网络从原始雷达回波数据训练聚焦得到SAR图像,网络经过训练可以匹配距离多普勒算法的性能,算法将SAR成像问题处理为监督学习问题,RDAnet是第一个基于深度学习的SAR 成像算法。Gao等人(2019)提出了一种基于深度网络的线谱估计方法,并将其应用于三维 SAR成像,大大加快了成像过程。Pu(2021)提出了一种深度 SAR 成像算法,减少了 SAR 的采样量,并且提出了一种基于深度学习的 SAR 运动补偿方法,可以有效地消除运动误差的影响。仅依赖遥感卫星载荷能力推动图像分辨率提升,使得高分辨率图像成本大幅提高,给遥感图像大规模应用力带来困难。以超分辨、图像重构等为代表的图像级和信号级处理方法为遥感图像分辨率和质量提升提供了另一种可行的技术途径。Wei 等人(2021)提出了基于 MC-ADM 和基于 PSRI-Net 的两种参数化超分辨率 SAR 图像重建方法,根据预先设计的损耗,深度网络通过端到端训练来学习,可应用于得到高质量 SAR 超分辨率图像的参数估计。Luo 等人(2019)提出了一种基于卷积神经网络的SAR 图像超分辨率重建的方法,针对浮点图像数据采用深度学习对 SAR 图像进行重建,可以更好地重建SAR图像。针对非生成对抗网络在光学遥感图像超分辨重建以及噪声去除中出现的信息损失和对比度降低的问题,Feng(2020)提出了利用生成对抗网络对小波变换域光学遥感图像进行超分辨重建以及噪声去除的方法。Xiong(2021)提出了一种适应于遥感图像超分辨的改进超分辨率生成对抗网络(Super-resolution GAN, SRGAN),增强了模型在跨区域和传感器的迁移能力。Bai 等人(2021)提出一种改进的密集连接网络遥感图像超分辨重建算法。Dong等(2020)提出了一种改进的反投影网络实现遥感图像的超分辨率重建。Tao(2020)提出了一种以 DPSRResNet 作为其超级解析器的 DPSR 框架的遥感图像超分辨重建算法。Yang 等(2020)提出了一种多尺度深度残差网络(MDRN)用于从遥感图像中去除云。Wang 等(2021)构建了 SAR 辅助下光学图像去云数据库,建立了基于条件生成对抗网络的 SAR 辅助下的光学遥感图像去云模型,实现了SAR辅助下光学图像薄云、雾、厚云等覆盖下地物信息的有效复原与重建。目前,人工智能在遥感数据处理和图像质量提升方面的应用主要得益于机器学习技术的引入。基于GAN 网络的方法试图利用生成器克服原始高分辨率遥感图像难以获取的问题,另一些无监督的学习方法则通过学习图像质量退化前后关系试图获取原始的高分辨率遥感图像。由于迁移学习可以从其它域样本中获得先验信息,并且在目标域中进一步优化,借鉴迁移学习和零样本学习的思路可以尝试解决遥感图像质量提升的问题。由于作用距离远,遥感图像分辨率和清晰度相对于自然图像仍有一定的差距,这导致遥感图像细节丢失相对较为严重。为了从遥感图像中获取更为丰富的信息,需要对遥感图像空间特征进行提取(注意力机制、局部-全局联合特征提取等),需要对遥感图像目视效果进行可视化增强(边缘增强、小波变换等)。此外,面向图像细节特征解译的需求,还需要对遥感图像中的弱小目标和细微结构进行检测、提取和增强(弱小目标检测等),提升遥感图像中细节缺失造成的信息损失。 1.1.2光学/SAR 定量化提升可见光、SAR、高光谱等遥感图像的定量化提升主要体现在几何、辐射、光谱、极化等几个方面,通过寻找稳定点来消除成像过程中产生的畸变,改善图像质量,使数据产品能够定量化反映地物的真实信息,以达到定量化提升的效果。在国际主流研究中,神经网络技术主要被应用在提升图像匹配精度方面,并以此带动几何定位精度定量化提升。得益于机器学习方法的引进,遥感图像匹配技术获得了系统性发展,匹配精度获得了显著进步。典型的两种方法为局部特征点匹配方法和区域匹配方法。与全局特征相比,局部特征点与遥感图像获取的大场景松耦合,对大场景的仿射变化、辐射/亮度变化噪声水平不敏感。目前,基于特征点匹配的遥感图像质量提升技术取得了一系列研究成果。典型的特征点匹配包括关键点检测和描述子提取两个部分。深度学习应用于局部特征点匹配可以分成三个阶段,形成了三类代表性方法。第一类方法重点关注和解决关键点检测问题,即如何检测得到特征点的方向、位置、以及尺度信息。关键点检测中响应图的构建是重点,关键点检测的数量和准确性依赖于特征准确、信息丰富的响应图。Savinov 等人(2017)提出了无监督学习的神经网络训练方法,该方法首先将遥感图像目标像素点映射为实值响应图,进而排列得到响应值序列,响应序列的顶部/底部像素点即可以视为关键点。Ma 等人(2019b)采用由粗到细的策略,先用一个卷积神经网络计算近似空间关系,然后在基于局部特征的匹配方法中引入考虑空间关系的匹配策略,同时保证了精度和鲁棒性。第二类方法重点关注和解决描述子提取问题,即用一组特征向量表示描述子,描述子代表了特征点的信息,可以通过端到端训练获得描述子。描述子训练是获得高精度匹配结果的关键。Simo-Serra 等人(2015)提出了 Deep-Desc 特征点描述子提取方法,该方法中神经网络采用了 Siamese 结构(Chopra等, 2005),构造了一种 128 维的描述子,应用于具有一定差异性的图像对匹配问题,通过比较描述子欧氏距离对图像间描述子的相似性进行衡量。第三类方法关注于联合训练关键点检测模块和描述子提取模块。关键点检测和描述子提取两个模块的协同工作和联合训练是该方法重点解决的难点。Yi 等人(2016)提出了基于 LIFT 网络的联合训练,是最早解决关键点检测和描述子提取的联合训练的网络之一。LIFT 网络的输入是以 SIFT 特征点(Lowe, 2004)所在图像块,LIFT 网络的关键点检测效果也与 SIFT算法类似,鲁棒性较好。Ono 等人(2018)提出的LF-Net,采用 Siamese 结构训练整个网络,通过深层特征提取网络产生特征图。Shen 等人(2019)以LF-Net 为的基础,提出了基于感受野的 RF-Net 匹配网络,该网络实现关键点检测时保留了遥感图像低层特征、部分保留了遥感图像高层特征,在描述子提取中采用了与 Hard-Net(Mishchuk 等, 2017)一致的网络结构。与局部特征点相比,区域特征对整体性表征更加完整,对区域形变、区域变化等的稳定性更好。传统区域特征匹配技术的代表为模板匹配方法。深度学习应用于区域特征匹配形成了两类代表性方法。第一类方法的核心思想是用分类技术解决匹配问题。Han 等人(2015)利用 MatchNet 提取图像区域特征,将三个全连接层得到特征的相似性作为输出,对输出采用概率归一化处理(Softmax)进行分类匹配。Zagoruko 等人(2015)重点解决了对光照变化、观测角度具有很好适应性的区域特征提取问题,提出了基于DeepCompare 网络的区域特征提取方法,该方法的匹配性能对于不同时间空间获取的遥感图像具有极佳的稳定性。第二类方法的核心思想是构建合适的描述子解决区域特征匹配问题。Tian 等人(2017)提出了一种 L2-Net网络的区域匹配方,该网络生成了128 维的描述子,在迭代次数较少的约束下,利用递进采样策略,对百万量级的训练样本进行遍历学习,并通过额外引入监督提高学习效率,该网络泛化能力较好。可见,深度学习网络的引入在特征提取、关键点检测和描述子提取等多方面优化了遥感图像匹配能力。考虑到深度学习网络的持续研究,网络结构、训练方式的更新和进步有望进一步提升遥感图像匹配精度,基于深度学习的遥感图像匹配算法仍然具有相当的研究价值和应用前景。除了几何质量定量化提升外,还有少数研究学者开展了利用神经网络技术在辐射、光谱、极化定量化提升方面的研究工作。杨进涛等人(2019)提出了一种基于海量 SAR 数据进行地物散射稳定特性的分析与挖掘,并成功在普通地物中找到一种统计意义下稳定的散射特征量用作定标参考,从而为SAR 系统的常态化辐射定标奠定初步的技术基础。Jiang 等人(2018)考虑到极化观测过程中会受到多种误差的影响,造成极化测量失真,影响数据的极化应用性能,提出一种利用普遍分布的地物进行串扰和幅相不平衡的定量评价方法,该方法不受时间和空间限制,能够实现大量数据极化校正性能的实时、便捷评估,对极化数据质量进行长期监测。和几何定量化提升不同,神经网络技术在这些领域还没有大量的、深入的应用,为后续进一步进行系统性、规模化研究提供了指导方向。 1.2遥感数据时空处理与分析近年来,陆续开展多源遥感时间与空间协同处理与分析方面开展研究工作,力求实现多源数据间互补协同、融合重建,提高遥感时空分析的能力1.2.1遥感影像时间序列修复研究人员构建了大量的时间序列遥感影像修复和重建的方法。根据修复所用参考数据的不同,这些方法大致可以分为三类:基于影像本身的修补方法(self-complementation-based)、基于参考影像的修补方法(reference-complementation-based)和基于多时相影像的修补方法(multi-temporal-complementation-based)。基于影像本身的修复方法利用同一影像上无云/影覆盖区域的数据来修补被云/影覆盖区域的缺失数据;假设影像中数据缺失区域与剩余区域具有相似或相同的统计与几何纹理结构,通过传播局部或非局部无云区域的几何结构来重建云/影区域的缺失数据。依据空间插值与误差传播理论,缺失像素插值(missingpixel interpolation)、影像修补(image inpainting)和模型拟合(model fitting)等多种方法被广泛应用于云影区域的数据重建。虽然能够重建出貌似真实的影像区域,但这些方法对云/影覆盖下地物的类型非常敏感,其修补数据也不适用于进一步的数据分析;并且由于不确定性和误差随着传播而积累,这些方法很难修复大区域或异质缺失数据。为了克服基于影像本身修补方法的瓶颈,Chen 等人(2016)提出了通过模拟参考影像与云/影覆盖影像之间映射与转换关系的基于参考影像修补方法;这类方法依赖于不同光谱数据之间的强相关性,利用多光谱或高光谱影像中对云不敏感的光谱波段来重建被云/影覆盖区域其他波段的缺失数据。比如利用 MODIS数据的第七波段来修复第六波段的数据缺失、利用Landsat 近红外波段来估算水面区域的可见光波段、利用MODIS数据预测 Landsat 影像的缺失数据和利用不受云雨干扰的合成空间雷达数据来重建被云影覆盖的光学数据等。尽管参考影像能够提供云影覆盖区域的缺失信息,但这类方法仍然受到光谱一致性、空间分辨率和成像时间相关性等限制,而难以重建出高质量的用于模拟地表变化的时间序列数据。前两种方法受限于其对重建影像没有渐进变化的假设,这种平稳性假设将成为土地覆盖变化和作物生长监测等时间序列应用中的明显弱点。遥感卫星以固定的重复周期来观测地表,同一区域又不可能总是被云影覆盖,因此很容易获得同一区域的多时相影像。这些同一区域的多时相影像(有云/影覆盖的和无云/影覆盖的)提供了利用多时相影像修复云/影覆盖区域缺失影像的可能(Chen 等, 2011)。基于多时相影像的修补方法包括两个主要步骤:查找有云/影覆盖区域和无云/影覆盖区域相似的像元(pixel)或区域(patch)和利用相似的像元(区域)预测云/影覆盖区域的缺失数据。在查找相似像元中,Roy 等人(2008)深入研究并集成空间、光谱和时相等信息来度量有云/影覆盖区域和无云/影覆盖区域像元的相似性。在重建云/影覆盖像元中,Gao等(2017)提出和发展了诸如多时相直接替换、基于泊松方程的复制、时空加权插值等方法;同时也吸纳用于修复传感器条带修复的方法,如近邻相似像元插值(neighborhood similar pixel interpolator,NSPI)(Zhu 等, 2011)和加权线性回归(weightedlinear regression,WLR)等。近年来,深度学习方法也被运用于云影覆盖影像的修复和重建;Grohnfeldt 等人(2018)利用生成对抗网络(generative adversarial networks)来融合合成空间雷达数据和光学影像生成无云影像;Malek等人(2017)利用自动编码网络(autoencoder neuralnetwork)来构建有云影覆盖区域和无云影覆盖区域影像的映射函数;Zhang 等人(2018a)利用深度卷积网络(deep convolutional neural networks)集成光谱、空间和时相信息来修复缺失数据。虽然现有研究取得了不错的重建效果,但仍存在一些局限性:(1)相对于光谱和空间相似性,多时相影像中的时间趋势能更详细地反映地表覆盖变化,而以往方法(尤其是传统方法)中的简单线性回归或光谱、空间度量很难捕捉复杂的非线性时间趋势;(2)现有的利用深度学习的重建方法多集中运用空间卷积网络 CNN 获取光谱和空间纹理信息(且需要大量的训练样本),少有研究使用循环神经网络 RNN学习跨影像的时间趋势;(3)由于云/影总在不确定的影像区域和不确定的时间上出现,像元级的时间序列难以保证多时相影像的时间间隔相等与时相对齐,加大了现有方法进行时间序列重建的难度。1.2.2多源遥感时空融合遥感图像融合研究可大致分为两个阶段。第一阶段主要集中于全色增强算法研究,即通过融合来自同一传感器的全色波段和多光谱波段进而生成高分辨率的多光谱图像。这类算法研究较多,已形成较为成熟的系列算法。第二阶段则是多源多分辨的时空融合算法研究,即通过融合高空间分辨率遥感数据的空间分辨率特征和高时间分辨率遥感数据的时间分辨率特征,进而生成兼具高时间和高空间分辨率的遥感数据。这类研究从最近十几年才发展起来,仍处于快速发展阶段,研究成果相对较少,但是对遥感数据的应用具有重要意义。时空融合算法研究最早出现在 2006 年美国农业部 Gao(2006)的研究中。其在 Landsat ETM+和MODIS 数据地表反射率的融合中提出一种时空自适应反射率融合模型(Spatial and Temporal AdaptiveReflectance Fusion Model,STARFM),可融合生成具有和 Landsat ETM+数据一样空间分辨率的逐日(和 MODIS 数据时间分辨率一样)地表反射率数据。此后,系列基于 STARFM 或其他理论框架的融合算法相继被提出。当前的时空融合算法根据其融合原理可大致分为三种:基于解混、基于滤波和基于学习的方法。基于解混的方法,通过光谱替换的方式生成融合图像。基于滤波的方法,待预测像元值通过对其一定邻域内光谱相似像元的加权求和获得。而基于学习的方法(Huang 等, 2012; Song 等,2012),首先通过学习待融合传感器图像之间的映射关系,然后将先验图像的信息融入融合模型最终生成融合图像。基于学习的时空融合研究起初多在 MODIS 和Landsat 这两类遥感图像上。如针对这两类数据的融合,Song 等人(2012)提出基于稀疏表示的时空反射融合模型。该模型在已知两对 MODIS 和 Landsat图像对差分域中学习它们的映射关系,形成字典对信息。而因为两者图像的空间分辨率存在较大差异,作者设计了两层融合框架,使得基于稀疏表示的方法大大提高了融合精度,但字典对中存在扰动的问题一直不可忽视。Wu 等人(2015)通过引入误差边界正则化的方法到字段对学习中解决了扰动问题。近年来,因深度卷积神经网络在各类图像领域表现出良好性能,Song 等人(2018)提出基于卷积神经网络的遥感图像时空融合算法(SpatiotemporalSatellite Image Fusion Using Deep ConvolutionalNeural Networks,STFDCNN)。他们的模型分两阶段进行学习,首先学习降采样 Landsat 图像(lowspatial resolution,LSR)与 MODIS 图像之间的非线性映射关系;其次学习 LSR Landsat 图像与原始Landsat 图像之间的超分辨率映射关系。通过这两阶段学习模型实现对遥感图像中丰富细节信息的利用。尽管 STFDCNN 模型在时空融合性能上大幅度超过其他融合算法,但因其神经网络层数较少(仅有 3 个隐藏层),如此浅层的卷积神经网络对存在较大空间尺度差异的不同卫星传感器数据(MODIS-Landsat)间的非线性映射关系的学习仍是有难度的。因此,当前如何处理两类传感器数据(MODIS-Landsat)之间的空间差异变化,以及如何确定深度卷积网络的最优层数和卷积核数目仍旧是卷积神经网络时空融合算法研究中亟待解决的问题。此外,Kim 等人(2016)在超分辨重建研究中,通过利用残差网络结构得以训练一个深度的卷积神经网络模型,这对后续遥感图像融合研究具有一定启发。 1.3遥感目标要素分类识别经典遥感要素分类与识别方法一般为“单输入单输出”的模型架构,面向不同目标要素、不同模态数据或不同分类识别任务时,通常设计不同的专用网络模型。而我们实际面临的应用场景中,常会有不同模态的数据供我们使用,并给出多种类型的决策结果,例如,人类的感知系统会结合听、说、看等多种输入,并给出目标的位置、属性等多种信息。而传统的模型架构难以实现这种“多输入多输出”的能力,主要问题在于,一是传统模型对新场景、新任务的适应能力不足;二是模型对各类数据的特征提取过程相对独立,难以实现不同数据的特征共享从而实现性能增益;三是在多输入多输出情况下,传统模型的简单叠加会导致计算和空间复杂度的显著上升,限制其实用能力。为了解决上述问题,当前的主流发展方向是多要素目标信息并行提取,通过在网络模型中探索多模态数据、多任务多要素特征的共享学习,在降低模型复杂度的同时提升其泛化能力。1.3.1典型遥感目标要素提取传统的遥感目标要素提取方法面向不同目标要素时,通常设计不同的专用的方法流程。这种流程设计主要解决两类问题,一是针对遥感数据本身的特征/特性分析,为构建适合数据特征/特性的模型提供依据;二是适合遥感数据特点的专用网络模型构建,即以通用的网络模型为基础,构建符合遥感数据特点的模型,改进通用模型在遥感数据中的应用能力。遥感数据的获取过程中存在诸多与自然场景图像不同的影响因素,如电磁波散射特性、大气辐射特性、目标反射特性等,因此对于数据的上述特性的分析和表达是构建有效模型的基础。Kusk 等人(2016)和 Hansen 等人(2017)通过对 SAR 成像时地形、回波噪声等要素进行建模,实现基于 3DCAD 对不同类型地物要素的 SAR 图像仿真。Yan等(2019)通过对舰船等目标进行三维模型构建,从而生成仿真的目标点云数据。Ma 等(2019a)提出了一种包含生成和判别结构的网络模型,通过对抗学习实现样本表观真实性的增强。Zhan 等(2017)和 Zhu 等(2018)提出了一种针对高光谱影像分类的生成对抗网络模型。Zhang 等(2018b)设计出一种基于条件模型的生成对抗网络,用于遥感图像中飞机目标的精细仿真。Yan 等人(2019)则基于点云数据在三维空间上进行船舶模型构建,并利用正射投影变换将模型从模型空间投影至海岸遥感图像上进行仿真数据生成。为了进一步提升仿真对象和遥感背景间的适配性,Wang 等人(2020b)则进一步提出利用 CycleGAN 对仿真的飞机目标和背景进行自适应调整,设计了一种用于目标检测任务的建模仿真数据生成框架。在地物要素分类任务上,Kong 等人(2020)则利用 CityEngine 仿真平台的批量建模特性,首次探索在广域范围内进行城市级别的场景建模,并发布了一套用于建筑物分割的遥感仿真数据集 Synthinel-1。面向遥感数据特点的专用网络模型设计方面,主要结合遥感图像中目标旋转、多尺度、目标分布特性等特点,针对性设计网络结构来提升专用模型性能。Zhou 等(2018)设计了一种源域到目标域数据共现特征聚焦结构,提升高光谱图像的语义分割效果。Luo 等(2018)针对高光谱图像语义分割中存在的类内特征分布差异,提出了一种均值差异最大化约束模型。Rao 等(2019)设计了一种自适应距离度量模型,提升高光谱图像地物要素的分类精度。Kampffmeyer 等(2016)针对地物要素数量、空间分布差异大的问题,提出了一种结合区域分组与像素分组的模型训练策略,用于国土资源监测任务。Liu 等(2017)针对遥感目标尺度差异大的特点,提出基于沙漏网络的多尺度特征增强模型,提升光学遥感图像的分类精度。Marcos 等人(2018)提出了基于旋转卷积构建的多源数据提取网络,通过编码图像的旋转不变性特征在多个数据集取得了先进的结果。Peng 等人(2020)基于注意机制和密集连接网络有效融合 DSM 数据和光谱图像并获得了更好的分割效果。Hua 等人(2021)提出了特征和空间关系调节网络,利用稀疏注释,基于无监督的学习信号来补充监督任务,显著提升了语义分割的性能。随着遥感图像分辨率的提升、网络深度的增加、参数的堆叠带来性能的提升,与之相伴的是庞大的模型、巨量的参数和缓慢的算法效率。考虑到星上遥感数据实时处理对计算资源、存储资源的限制,一些工作尝试在保留算法高性能前提下,减少模型参数,提高算法运算速度。Valada 等人(2019)利用分组卷积的设计思想提出了一种高效的带孔空间金字塔池化结构,用于高分辨遥感图像地物要素提取。提出的方法能够减少 87.87%的参数量,减少89.88%每秒浮点运算次数(floating-point operationsper second, FLOPS)。Zhang 等人(2019b)基于深度可分卷积设计了一种面向合成孔径雷达图像的船舶检测算法的特征提取网络,大大提升了检测速度,相比于轻量化前的网络检测速度提高了 2.7 倍。Cao等人(2019)利用深度可分卷积设计了一种用于提取数字表面模型数据的结构,该网络结构无需预训练模型仍可以快速收敛,将网络训练时间降低 50%以上。Wang 等人(2019b)提出一种轻量级网络MFNet,实现对高分辨率航拍数据的地物要素分类任务的高效推理,相比于轻量级网络 ResNet-18,提出的网络在分类精度提升的同时,将参数量减少了40%,推理速度提高了 27%。Ma 等人(2020)针对灾后损毁评估任务,以 ShuffleNet v2 模型为基础,设计了一种轻量化建筑物提取模型,相比传统模型,在精度提升 5.24%的同时,速度提高 5.21f/s。上述方法通过结合遥感目标要素特点,通过提出专用网络结构或特征提取方法,提升传统模型针对遥感数据的应用能力。然而,对于不同类型数据、不同特征/特性,仍缺乏统一的网络结构进行表征,因此多要素信息多任务并行网络和模型仍需进一步研究。1.3.2多要素信息并行提取多要素信息并行提取方法的研究,主要集中于探索如何在一个统一模型中实现多类遥感地物要素目标的类别、位置等属性信息的高精度获取。如前所述,针对这种典型的“多输入多输出”场景,现有方法重点针对多模态输入数据的特征表示和多任务输出特征的共享融合两方面问题开展研究。特征共享研究方面,根据模型共享参数实现方式的区别,现有方法可大致分为硬参数共享( hard-parameter sharing ) 和软参数共享(soft-parameter sharing)两种。硬参数共享方法利用同一个模型实现在输入和输出端的多任务分支模型特征共享融合。Liebel 等(2020)面向城市建设状况分析任务,将多个任务共享同一编码器,并分别解码输出,实现同时输出建筑物位置和深度信息。Papadomanolaki 等(2019)将地物要素重建模型融合到分类模型中,并约束分类模型训练,来提升分类效果。Khalel 等(2019)则在同一个网络模型中同时嵌入图像锐化与地物要素分类两类任务的模型。Rosa 等(2020)设计了一种面向农业生产状况监控的多任务全卷积回归网络。软参数共享方法直接将针对不同任务的多个独立网络通过参数加权连接,实现多类任务的共享输出。Volpi 等(2018)将条件随机场拟合结果与图像同时作为数据,构建类内相似度和边界值预测的两个分支模型,改善地物要素分类结果。Zhang 等(2019a)提出了面向极化 SAR 多通道数据的地物要素分类方法,利用独立的特征提取网络对幅值和相位信息分别建模,利用分类器进行联合约束训练,来提升精度。Shi 等(2020)针对高光谱图像的多类要素分类任务,利用多任务集成学习实现通道选择,获取最优通道组合。针对多模态数据的联合特征表示,如图像纹理特征、三维高程特征、目标要素矢量拓扑特征等,能有效提升各类任务的性能。Chen 等(2019)针对洪灾区域检测任务,提出融合多时相的多模态图像的模型,来提升其检测精度。Fernandez 等(2018)将SAR 图像和多光谱图像作为输入,进行无监督的地物要素分类。Benson 等(2017)在森林冠层三维高度估计任务中,提出利用光谱特性数据的方法,能有效改善传统三维估计方法的精度。
随着人工智能的发展和落地应用,以地理空间大数据为基础,利用人工智能技术对遥感数据智能分析与解译成为未来发展趋势。本文以遥感数据转化过程中对观测对象的整体观测、分析解译与规律挖掘为主线,通过综合国内外文献和相关报道,梳理了该领域在遥感数据精准处理、遥感数据时空处理与分析、遥感目标要素分类识别、遥感数据关联挖掘以及遥感开源数据集和共享平台等方面的研究现状和进展。首先,针对遥感数据精准处理任务,从光学、SAR等遥感数据成像质量提升和低质图像重建两个方面对精细化处理研究进展进行了回顾,并从遥感图像的局部特征匹配和区域特征匹配两个方面对定量化提升研究进展进行了回顾。其次,针对遥感数据时空处理与分析任务,从遥感影像时间序列修复和多源遥感时空融合两个方面对其研究进展进行了回顾。再次,针对遥感目标要素分类识别任务,从典型地物要素提取和多要素并行提取两个方面对其研究进展进行了回顾。最后,针对遥感数据关联挖掘任务,从数据组织关联、专业知识图谱构建两个方面对其研究进展进行了回顾。除此之外,面向大智能分析技术发展需求,本文还对遥感开源数据集和共享平台方面的研究进展进行了回顾。在此基础上,对遥感数据智能分析与解译的研究情况进行梳理、总结,给出了该领域的未来发展趋势与展望。 引言近几年来,国内外人工智能的发展和落地应用如火如荼,促成这种现象的原因可以归纳为两个关键词,即“大数据”与“高算力”。在地理空间数据分析与应用领域,这种变化也正在发生着,比如在国家高分辨率对地观测重大科技专项(简称“高分专项”)等国家重大任务的推动下,我们可获取的地理空间数据越来越多,另外,以“云+端”架构为代表的高性能计算框架也在不断发展,促进了算力的提升。在此背景下,以地理空间大数据为基础,利用人工智能技术挖掘其深层信息、赋予其更多的应用模式,将成为未来地理空间数据分析应用领域发展的长期主题。发展遥感数据智能分析技术的目的是将长期积累的遥感数据转化为对观测对象的整体观测、分析、解译,获取丰富准确的属性信息,挖掘目标区域的演化规律,主要包括遥感数据精准处理、遥感数据时空处理与分析、遥感目标要素分类识别、遥感数据关联挖掘等。此外,面向大智能分析技术发展需求,遥感开源数据集和共享平台方面也取得了显著进展(陈述彭等, 2000; 宫辉力等, 2005)。遥感数据精准处理方面,遥感数据精准处理的目的是对传感器获取的光谱反射或雷达散射数据进行成像处理和定标校正,恢复为与地物观测对象某些信息维度精确关联的图像产品。传统方法需要根据卫星、传感器、传输环境、地形地表等先验模型,以及外场定标试验获取定标参数,建立精确的成像模型将观测数据映射为图像产品。随着传感器新技术的发展和分辨率等性能的提升,先验模型的建立越来越困难,外场定标的难度和消耗也越来越大,并且成像处理和定标校正获取的模型和参数与传感器的耦合,只能以一星一议的方式实现,无法多星一体化实现。如何在传统方法的基础上,构建观测数据到精准图像产品的深度学习网络结构,设置面向不同应用的图像优化指标体系,以大量历史数据和标注结果作为输入,实现网络结构对传感器物理模型和参数的精确重构和逼近,形成基于人工智能技术的多星一体化遥感图像精准处理能力。遥感数据时空处理与分析方面,多时相影像相比单一时相的遥感影像,能够进一步展示地表的动态变化和揭示地物的演化规律。然而,一方面受限于遥感自身的时间分辨率与空间分辨率之间的不可兼得;另一方面受气象、地形等成像条件的影响,光学传感器获取的遥感影像往往被云层及其阴影覆盖(特别是在多云多雨地区,如我国西南地区),而难以获取真实的地面信息。这样的数据缺失,严重限制了遥感影像的应用;特别是对于多时相影像的遥感应用(如森林退化、作物生长、城市扩张和湿地流失等监测),云层及其阴影所导致的数据缺失将延长影像获取的时间间隔、造成时序间隔不规则的问题,加大后续时间序列处理与分析的难度。因此,进行遥感影像的时间与空间维度的处理与分析对提高遥感影像数据的可用性、时间序列分析水平和遥感应用的深度广度具有重要意义。遥感目标要素分类识别方面,遥感数据中一般包含大量噪声,大多数现有的处理分析方法并未充分利用计算机强大的自主学习能力,依赖的信息获取和计算手段较为有限,很难满足准确率、虚警率等性能要求。如何在传统的基于人工数学分析的方法基础上,结合人工智能方法,定量描述并分析遥感数据中目标模型失真和背景噪声干扰对于解译精度的影响机理,是遥感智能分析面临的另一项关键科学问题。通过该问题的分析与发展,有望实现构建一个基于深度学习的多源遥感数据自动化分析框架,在统一框架下有机融合模型、算法和知识,提升遥感数据中目标要素提取和识别的智能化水平。遥感数据关联挖掘方面,随着遥感大数据时代的到来,我们可以更方便地获取高分辨率和高时间采集频率的遥感数据,对于目标信息的需求,也由目标静态解译信息,拓展到全维度的综合认知与预测分析。为了满足上述需求,基于海量多源异构遥感数据,实现时间、空间等多维度的信息快速关联组织与分析,是未来遥感解译技术发展的重要方向。遥感开源数据集和共享平台方面,大多数现有数据集仍然存在数据规模较小、缺乏遥感特性的问题,并且现有深度学习平台难以有效支撑遥感特性及应用,领域内数据集算法模型的准确性、实用性、智能化程度也待进一步提高。如何结合遥感数据特性,建设更具遥感特色的开源数据集和共享平台,是遥感智能生态建设的一项重要研究内容。本文主要围绕上述五个方面的研究,论述遥感智能分析技术的发展现状、前沿动态、热点问题和未来趋势。 01国际研究现状1.1遥感数据精准处理利用智能手段开展数据预处理技术,国外将智能技术用于遥感数据(光学、SAR、光谱)配准、校正等的工作。 1.1.1光学/SAR 精细化处理遥感图像为遥感应用分析提供了数据基础,可广泛应用于农林监测、城市规划、军事侦察等领域,遥感数据质量是决定其应用性能的关键。评价遥感数据质量的指标包括图像时间/空间分辨率、图像幅宽、空间特征、光谱特征、辐射几何精度等。高质量遥感影像具有高分辨率、高信噪比等特点。提升遥感影像质量的方法可大致分为两类,一是改进传统成像算法聚焦得到高质量图像;二是将已有的低质量的图像通过去噪去云以及超分辨率重建等技术得到高分辨率高质量图像。与传统的 SAR成像算法比较,基于深度学习的SAR 成像算法可以简化成像过程。Rittenbach等人(2020)提出 RDAnet 神经网络从原始雷达回波数据训练聚焦得到SAR图像,网络经过训练可以匹配距离多普勒算法的性能,算法将SAR成像问题处理为监督学习问题,RDAnet是第一个基于深度学习的SAR 成像算法。Gao等人(2019)提出了一种基于深度网络的线谱估计方法,并将其应用于三维 SAR成像,大大加快了成像过程。Pu(2021)提出了一种深度 SAR 成像算法,减少了 SAR 的采样量,并且提出了一种基于深度学习的 SAR 运动补偿方法,可以有效地消除运动误差的影响。仅依赖遥感卫星载荷能力推动图像分辨率提升,使得高分辨率图像成本大幅提高,给遥感图像大规模应用力带来困难。以超分辨、图像重构等为代表的图像级和信号级处理方法为遥感图像分辨率和质量提升提供了另一种可行的技术途径。Wei 等人(2021)提出了基于 MC-ADM 和基于 PSRI-Net 的两种参数化超分辨率 SAR 图像重建方法,根据预先设计的损耗,深度网络通过端到端训练来学习,可应用于得到高质量 SAR 超分辨率图像的参数估计。Luo 等人(2019)提出了一种基于卷积神经网络的SAR 图像超分辨率重建的方法,针对浮点图像数据采用深度学习对 SAR 图像进行重建,可以更好地重建SAR图像。针对非生成对抗网络在光学遥感图像超分辨重建以及噪声去除中出现的信息损失和对比度降低的问题,Feng(2020)提出了利用生成对抗网络对小波变换域光学遥感图像进行超分辨重建以及噪声去除的方法。Xiong(2021)提出了一种适应于遥感图像超分辨的改进超分辨率生成对抗网络(Super-resolution GAN, SRGAN),增强了模型在跨区域和传感器的迁移能力。Bai 等人(2021)提出一种改进的密集连接网络遥感图像超分辨重建算法。Dong等(2020)提出了一种改进的反投影网络实现遥感图像的超分辨率重建。Tao(2020)提出了一种以 DPSRResNet 作为其超级解析器的 DPSR 框架的遥感图像超分辨重建算法。Yang 等(2020)提出了一种多尺度深度残差网络(MDRN)用于从遥感图像中去除云。Wang 等(2021)构建了 SAR 辅助下光学图像去云数据库,建立了基于条件生成对抗网络的 SAR 辅助下的光学遥感图像去云模型,实现了SAR辅助下光学图像薄云、雾、厚云等覆盖下地物信息的有效复原与重建。目前,人工智能在遥感数据处理和图像质量提升方面的应用主要得益于机器学习技术的引入。基于GAN 网络的方法试图利用生成器克服原始高分辨率遥感图像难以获取的问题,另一些无监督的学习方法则通过学习图像质量退化前后关系试图获取原始的高分辨率遥感图像。由于迁移学习可以从其它域样本中获得先验信息,并且在目标域中进一步优化,借鉴迁移学习和零样本学习的思路可以尝试解决遥感图像质量提升的问题。由于作用距离远,遥感图像分辨率和清晰度相对于自然图像仍有一定的差距,这导致遥感图像细节丢失相对较为严重。为了从遥感图像中获取更为丰富的信息,需要对遥感图像空间特征进行提取(注意力机制、局部-全局联合特征提取等),需要对遥感图像目视效果进行可视化增强(边缘增强、小波变换等)。此外,面向图像细节特征解译的需求,还需要对遥感图像中的弱小目标和细微结构进行检测、提取和增强(弱小目标检测等),提升遥感图像中细节缺失造成的信息损失。 1.1.2光学/SAR 定量化提升可见光、SAR、高光谱等遥感图像的定量化提升主要体现在几何、辐射、光谱、极化等几个方面,通过寻找稳定点来消除成像过程中产生的畸变,改善图像质量,使数据产品能够定量化反映地物的真实信息,以达到定量化提升的效果。在国际主流研究中,神经网络技术主要被应用在提升图像匹配精度方面,并以此带动几何定位精度定量化提升。得益于机器学习方法的引进,遥感图像匹配技术获得了系统性发展,匹配精度获得了显著进步。典型的两种方法为局部特征点匹配方法和区域匹配方法。与全局特征相比,局部特征点与遥感图像获取的大场景松耦合,对大场景的仿射变化、辐射/亮度变化噪声水平不敏感。目前,基于特征点匹配的遥感图像质量提升技术取得了一系列研究成果。典型的特征点匹配包括关键点检测和描述子提取两个部分。深度学习应用于局部特征点匹配可以分成三个阶段,形成了三类代表性方法。第一类方法重点关注和解决关键点检测问题,即如何检测得到特征点的方向、位置、以及尺度信息。关键点检测中响应图的构建是重点,关键点检测的数量和准确性依赖于特征准确、信息丰富的响应图。Savinov 等人(2017)提出了无监督学习的神经网络训练方法,该方法首先将遥感图像目标像素点映射为实值响应图,进而排列得到响应值序列,响应序列的顶部/底部像素点即可以视为关键点。Ma 等人(2019b)采用由粗到细的策略,先用一个卷积神经网络计算近似空间关系,然后在基于局部特征的匹配方法中引入考虑空间关系的匹配策略,同时保证了精度和鲁棒性。第二类方法重点关注和解决描述子提取问题,即用一组特征向量表示描述子,描述子代表了特征点的信息,可以通过端到端训练获得描述子。描述子训练是获得高精度匹配结果的关键。Simo-Serra 等人(2015)提出了 Deep-Desc 特征点描述子提取方法,该方法中神经网络采用了 Siamese 结构(Chopra等, 2005),构造了一种 128 维的描述子,应用于具有一定差异性的图像对匹配问题,通过比较描述子欧氏距离对图像间描述子的相似性进行衡量。第三类方法关注于联合训练关键点检测模块和描述子提取模块。关键点检测和描述子提取两个模块的协同工作和联合训练是该方法重点解决的难点。Yi 等人(2016)提出了基于 LIFT 网络的联合训练,是最早解决关键点检测和描述子提取的联合训练的网络之一。LIFT 网络的输入是以 SIFT 特征点(Lowe, 2004)所在图像块,LIFT 网络的关键点检测效果也与 SIFT算法类似,鲁棒性较好。Ono 等人(2018)提出的LF-Net,采用 Siamese 结构训练整个网络,通过深层特征提取网络产生特征图。Shen 等人(2019)以LF-Net 为的基础,提出了基于感受野的 RF-Net 匹配网络,该网络实现关键点检测时保留了遥感图像低层特征、部分保留了遥感图像高层特征,在描述子提取中采用了与 Hard-Net(Mishchuk 等, 2017)一致的网络结构。与局部特征点相比,区域特征对整体性表征更加完整,对区域形变、区域变化等的稳定性更好。传统区域特征匹配技术的代表为模板匹配方法。深度学习应用于区域特征匹配形成了两类代表性方法。第一类方法的核心思想是用分类技术解决匹配问题。Han 等人(2015)利用 MatchNet 提取图像区域特征,将三个全连接层得到特征的相似性作为输出,对输出采用概率归一化处理(Softmax)进行分类匹配。Zagoruko 等人(2015)重点解决了对光照变化、观测角度具有很好适应性的区域特征提取问题,提出了基于DeepCompare 网络的区域特征提取方法,该方法的匹配性能对于不同时间空间获取的遥感图像具有极佳的稳定性。第二类方法的核心思想是构建合适的描述子解决区域特征匹配问题。Tian 等人(2017)提出了一种 L2-Net网络的区域匹配方,该网络生成了128 维的描述子,在迭代次数较少的约束下,利用递进采样策略,对百万量级的训练样本进行遍历学习,并通过额外引入监督提高学习效率,该网络泛化能力较好。可见,深度学习网络的引入在特征提取、关键点检测和描述子提取等多方面优化了遥感图像匹配能力。考虑到深度学习网络的持续研究,网络结构、训练方式的更新和进步有望进一步提升遥感图像匹配精度,基于深度学习的遥感图像匹配算法仍然具有相当的研究价值和应用前景。除了几何质量定量化提升外,还有少数研究学者开展了利用神经网络技术在辐射、光谱、极化定量化提升方面的研究工作。杨进涛等人(2019)提出了一种基于海量 SAR 数据进行地物散射稳定特性的分析与挖掘,并成功在普通地物中找到一种统计意义下稳定的散射特征量用作定标参考,从而为SAR 系统的常态化辐射定标奠定初步的技术基础。Jiang 等人(2018)考虑到极化观测过程中会受到多种误差的影响,造成极化测量失真,影响数据的极化应用性能,提出一种利用普遍分布的地物进行串扰和幅相不平衡的定量评价方法,该方法不受时间和空间限制,能够实现大量数据极化校正性能的实时、便捷评估,对极化数据质量进行长期监测。和几何定量化提升不同,神经网络技术在这些领域还没有大量的、深入的应用,为后续进一步进行系统性、规模化研究提供了指导方向。 1.2遥感数据时空处理与分析近年来,陆续开展多源遥感时间与空间协同处理与分析方面开展研究工作,力求实现多源数据间互补协同、融合重建,提高遥感时空分析的能力1.2.1遥感影像时间序列修复研究人员构建了大量的时间序列遥感影像修复和重建的方法。根据修复所用参考数据的不同,这些方法大致可以分为三类:基于影像本身的修补方法(self-complementation-based)、基于参考影像的修补方法(reference-complementation-based)和基于多时相影像的修补方法(multi-temporal-complementation-based)。基于影像本身的修复方法利用同一影像上无云/影覆盖区域的数据来修补被云/影覆盖区域的缺失数据;假设影像中数据缺失区域与剩余区域具有相似或相同的统计与几何纹理结构,通过传播局部或非局部无云区域的几何结构来重建云/影区域的缺失数据。依据空间插值与误差传播理论,缺失像素插值(missingpixel interpolation)、影像修补(image inpainting)和模型拟合(model fitting)等多种方法被广泛应用于云影区域的数据重建。虽然能够重建出貌似真实的影像区域,但这些方法对云/影覆盖下地物的类型非常敏感,其修补数据也不适用于进一步的数据分析;并且由于不确定性和误差随着传播而积累,这些方法很难修复大区域或异质缺失数据。为了克服基于影像本身修补方法的瓶颈,Chen 等人(2016)提出了通过模拟参考影像与云/影覆盖影像之间映射与转换关系的基于参考影像修补方法;这类方法依赖于不同光谱数据之间的强相关性,利用多光谱或高光谱影像中对云不敏感的光谱波段来重建被云/影覆盖区域其他波段的缺失数据。比如利用 MODIS数据的第七波段来修复第六波段的数据缺失、利用Landsat 近红外波段来估算水面区域的可见光波段、利用MODIS数据预测 Landsat 影像的缺失数据和利用不受云雨干扰的合成空间雷达数据来重建被云影覆盖的光学数据等。尽管参考影像能够提供云影覆盖区域的缺失信息,但这类方法仍然受到光谱一致性、空间分辨率和成像时间相关性等限制,而难以重建出高质量的用于模拟地表变化的时间序列数据。前两种方法受限于其对重建影像没有渐进变化的假设,这种平稳性假设将成为土地覆盖变化和作物生长监测等时间序列应用中的明显弱点。遥感卫星以固定的重复周期来观测地表,同一区域又不可能总是被云影覆盖,因此很容易获得同一区域的多时相影像。这些同一区域的多时相影像(有云/影覆盖的和无云/影覆盖的)提供了利用多时相影像修复云/影覆盖区域缺失影像的可能(Chen 等, 2011)。基于多时相影像的修补方法包括两个主要步骤:查找有云/影覆盖区域和无云/影覆盖区域相似的像元(pixel)或区域(patch)和利用相似的像元(区域)预测云/影覆盖区域的缺失数据。在查找相似像元中,Roy 等人(2008)深入研究并集成空间、光谱和时相等信息来度量有云/影覆盖区域和无云/影覆盖区域像元的相似性。在重建云/影覆盖像元中,Gao等(2017)提出和发展了诸如多时相直接替换、基于泊松方程的复制、时空加权插值等方法;同时也吸纳用于修复传感器条带修复的方法,如近邻相似像元插值(neighborhood similar pixel interpolator,NSPI)(Zhu 等, 2011)和加权线性回归(weightedlinear regression,WLR)等。近年来,深度学习方法也被运用于云影覆盖影像的修复和重建;Grohnfeldt 等人(2018)利用生成对抗网络(generative adversarial networks)来融合合成空间雷达数据和光学影像生成无云影像;Malek等人(2017)利用自动编码网络(autoencoder neuralnetwork)来构建有云影覆盖区域和无云影覆盖区域影像的映射函数;Zhang 等人(2018a)利用深度卷积网络(deep convolutional neural networks)集成光谱、空间和时相信息来修复缺失数据。虽然现有研究取得了不错的重建效果,但仍存在一些局限性:(1)相对于光谱和空间相似性,多时相影像中的时间趋势能更详细地反映地表覆盖变化,而以往方法(尤其是传统方法)中的简单线性回归或光谱、空间度量很难捕捉复杂的非线性时间趋势;(2)现有的利用深度学习的重建方法多集中运用空间卷积网络 CNN 获取光谱和空间纹理信息(且需要大量的训练样本),少有研究使用循环神经网络 RNN学习跨影像的时间趋势;(3)由于云/影总在不确定的影像区域和不确定的时间上出现,像元级的时间序列难以保证多时相影像的时间间隔相等与时相对齐,加大了现有方法进行时间序列重建的难度。1.2.2多源遥感时空融合遥感图像融合研究可大致分为两个阶段。第一阶段主要集中于全色增强算法研究,即通过融合来自同一传感器的全色波段和多光谱波段进而生成高分辨率的多光谱图像。这类算法研究较多,已形成较为成熟的系列算法。第二阶段则是多源多分辨的时空融合算法研究,即通过融合高空间分辨率遥感数据的空间分辨率特征和高时间分辨率遥感数据的时间分辨率特征,进而生成兼具高时间和高空间分辨率的遥感数据。这类研究从最近十几年才发展起来,仍处于快速发展阶段,研究成果相对较少,但是对遥感数据的应用具有重要意义。时空融合算法研究最早出现在 2006 年美国农业部 Gao(2006)的研究中。其在 Landsat ETM+和MODIS 数据地表反射率的融合中提出一种时空自适应反射率融合模型(Spatial and Temporal AdaptiveReflectance Fusion Model,STARFM),可融合生成具有和 Landsat ETM+数据一样空间分辨率的逐日(和 MODIS 数据时间分辨率一样)地表反射率数据。此后,系列基于 STARFM 或其他理论框架的融合算法相继被提出。当前的时空融合算法根据其融合原理可大致分为三种:基于解混、基于滤波和基于学习的方法。基于解混的方法,通过光谱替换的方式生成融合图像。基于滤波的方法,待预测像元值通过对其一定邻域内光谱相似像元的加权求和获得。而基于学习的方法(Huang 等, 2012; Song 等,2012),首先通过学习待融合传感器图像之间的映射关系,然后将先验图像的信息融入融合模型最终生成融合图像。基于学习的时空融合研究起初多在 MODIS 和Landsat 这两类遥感图像上。如针对这两类数据的融合,Song 等人(2012)提出基于稀疏表示的时空反射融合模型。该模型在已知两对 MODIS 和 Landsat图像对差分域中学习它们的映射关系,形成字典对信息。而因为两者图像的空间分辨率存在较大差异,作者设计了两层融合框架,使得基于稀疏表示的方法大大提高了融合精度,但字典对中存在扰动的问题一直不可忽视。Wu 等人(2015)通过引入误差边界正则化的方法到字段对学习中解决了扰动问题。近年来,因深度卷积神经网络在各类图像领域表现出良好性能,Song 等人(2018)提出基于卷积神经网络的遥感图像时空融合算法(SpatiotemporalSatellite Image Fusion Using Deep ConvolutionalNeural Networks,STFDCNN)。他们的模型分两阶段进行学习,首先学习降采样 Landsat 图像(lowspatial resolution,LSR)与 MODIS 图像之间的非线性映射关系;其次学习 LSR Landsat 图像与原始Landsat 图像之间的超分辨率映射关系。通过这两阶段学习模型实现对遥感图像中丰富细节信息的利用。尽管 STFDCNN 模型在时空融合性能上大幅度超过其他融合算法,但因其神经网络层数较少(仅有 3 个隐藏层),如此浅层的卷积神经网络对存在较大空间尺度差异的不同卫星传感器数据(MODIS-Landsat)间的非线性映射关系的学习仍是有难度的。因此,当前如何处理两类传感器数据(MODIS-Landsat)之间的空间差异变化,以及如何确定深度卷积网络的最优层数和卷积核数目仍旧是卷积神经网络时空融合算法研究中亟待解决的问题。此外,Kim 等人(2016)在超分辨重建研究中,通过利用残差网络结构得以训练一个深度的卷积神经网络模型,这对后续遥感图像融合研究具有一定启发。 1.3遥感目标要素分类识别经典遥感要素分类与识别方法一般为“单输入单输出”的模型架构,面向不同目标要素、不同模态数据或不同分类识别任务时,通常设计不同的专用网络模型。而我们实际面临的应用场景中,常会有不同模态的数据供我们使用,并给出多种类型的决策结果,例如,人类的感知系统会结合听、说、看等多种输入,并给出目标的位置、属性等多种信息。而传统的模型架构难以实现这种“多输入多输出”的能力,主要问题在于,一是传统模型对新场景、新任务的适应能力不足;二是模型对各类数据的特征提取过程相对独立,难以实现不同数据的特征共享从而实现性能增益;三是在多输入多输出情况下,传统模型的简单叠加会导致计算和空间复杂度的显著上升,限制其实用能力。为了解决上述问题,当前的主流发展方向是多要素目标信息并行提取,通过在网络模型中探索多模态数据、多任务多要素特征的共享学习,在降低模型复杂度的同时提升其泛化能力。1.3.1典型遥感目标要素提取传统的遥感目标要素提取方法面向不同目标要素时,通常设计不同的专用的方法流程。这种流程设计主要解决两类问题,一是针对遥感数据本身的特征/特性分析,为构建适合数据特征/特性的模型提供依据;二是适合遥感数据特点的专用网络模型构建,即以通用的网络模型为基础,构建符合遥感数据特点的模型,改进通用模型在遥感数据中的应用能力。遥感数据的获取过程中存在诸多与自然场景图像不同的影响因素,如电磁波散射特性、大气辐射特性、目标反射特性等,因此对于数据的上述特性的分析和表达是构建有效模型的基础。Kusk 等人(2016)和 Hansen 等人(2017)通过对 SAR 成像时地形、回波噪声等要素进行建模,实现基于 3DCAD 对不同类型地物要素的 SAR 图像仿真。Yan等(2019)通过对舰船等目标进行三维模型构建,从而生成仿真的目标点云数据。Ma 等(2019a)提出了一种包含生成和判别结构的网络模型,通过对抗学习实现样本表观真实性的增强。Zhan 等(2017)和 Zhu 等(2018)提出了一种针对高光谱影像分类的生成对抗网络模型。Zhang 等(2018b)设计出一种基于条件模型的生成对抗网络,用于遥感图像中飞机目标的精细仿真。Yan 等人(2019)则基于点云数据在三维空间上进行船舶模型构建,并利用正射投影变换将模型从模型空间投影至海岸遥感图像上进行仿真数据生成。为了进一步提升仿真对象和遥感背景间的适配性,Wang 等人(2020b)则进一步提出利用 CycleGAN 对仿真的飞机目标和背景进行自适应调整,设计了一种用于目标检测任务的建模仿真数据生成框架。在地物要素分类任务上,Kong 等人(2020)则利用 CityEngine 仿真平台的批量建模特性,首次探索在广域范围内进行城市级别的场景建模,并发布了一套用于建筑物分割的遥感仿真数据集 Synthinel-1。面向遥感数据特点的专用网络模型设计方面,主要结合遥感图像中目标旋转、多尺度、目标分布特性等特点,针对性设计网络结构来提升专用模型性能。Zhou 等(2018)设计了一种源域到目标域数据共现特征聚焦结构,提升高光谱图像的语义分割效果。Luo 等(2018)针对高光谱图像语义分割中存在的类内特征分布差异,提出了一种均值差异最大化约束模型。Rao 等(2019)设计了一种自适应距离度量模型,提升高光谱图像地物要素的分类精度。Kampffmeyer 等(2016)针对地物要素数量、空间分布差异大的问题,提出了一种结合区域分组与像素分组的模型训练策略,用于国土资源监测任务。Liu 等(2017)针对遥感目标尺度差异大的特点,提出基于沙漏网络的多尺度特征增强模型,提升光学遥感图像的分类精度。Marcos 等人(2018)提出了基于旋转卷积构建的多源数据提取网络,通过编码图像的旋转不变性特征在多个数据集取得了先进的结果。Peng 等人(2020)基于注意机制和密集连接网络有效融合 DSM 数据和光谱图像并获得了更好的分割效果。Hua 等人(2021)提出了特征和空间关系调节网络,利用稀疏注释,基于无监督的学习信号来补充监督任务,显著提升了语义分割的性能。随着遥感图像分辨率的提升、网络深度的增加、参数的堆叠带来性能的提升,与之相伴的是庞大的模型、巨量的参数和缓慢的算法效率。考虑到星上遥感数据实时处理对计算资源、存储资源的限制,一些工作尝试在保留算法高性能前提下,减少模型参数,提高算法运算速度。Valada 等人(2019)利用分组卷积的设计思想提出了一种高效的带孔空间金字塔池化结构,用于高分辨遥感图像地物要素提取。提出的方法能够减少 87.87%的参数量,减少89.88%每秒浮点运算次数(floating-point operationsper second, FLOPS)。Zhang 等人(2019b)基于深度可分卷积设计了一种面向合成孔径雷达图像的船舶检测算法的特征提取网络,大大提升了检测速度,相比于轻量化前的网络检测速度提高了 2.7 倍。Cao等人(2019)利用深度可分卷积设计了一种用于提取数字表面模型数据的结构,该网络结构无需预训练模型仍可以快速收敛,将网络训练时间降低 50%以上。Wang 等人(2019b)提出一种轻量级网络MFNet,实现对高分辨率航拍数据的地物要素分类任务的高效推理,相比于轻量级网络 ResNet-18,提出的网络在分类精度提升的同时,将参数量减少了40%,推理速度提高了 27%。Ma 等人(2020)针对灾后损毁评估任务,以 ShuffleNet v2 模型为基础,设计了一种轻量化建筑物提取模型,相比传统模型,在精度提升 5.24%的同时,速度提高 5.21f/s。上述方法通过结合遥感目标要素特点,通过提出专用网络结构或特征提取方法,提升传统模型针对遥感数据的应用能力。然而,对于不同类型数据、不同特征/特性,仍缺乏统一的网络结构进行表征,因此多要素信息多任务并行网络和模型仍需进一步研究。1.3.2多要素信息并行提取多要素信息并行提取方法的研究,主要集中于探索如何在一个统一模型中实现多类遥感地物要素目标的类别、位置等属性信息的高精度获取。如前所述,针对这种典型的“多输入多输出”场景,现有方法重点针对多模态输入数据的特征表示和多任务输出特征的共享融合两方面问题开展研究。特征共享研究方面,根据模型共享参数实现方式的区别,现有方法可大致分为硬参数共享( hard-parameter sharing ) 和软参数共享(soft-parameter sharing)两种。硬参数共享方法利用同一个模型实现在输入和输出端的多任务分支模型特征共享融合。Liebel 等(2020)面向城市建设状况分析任务,将多个任务共享同一编码器,并分别解码输出,实现同时输出建筑物位置和深度信息。Papadomanolaki 等(2019)将地物要素重建模型融合到分类模型中,并约束分类模型训练,来提升分类效果。Khalel 等(2019)则在同一个网络模型中同时嵌入图像锐化与地物要素分类两类任务的模型。Rosa 等(2020)设计了一种面向农业生产状况监控的多任务全卷积回归网络。软参数共享方法直接将针对不同任务的多个独立网络通过参数加权连接,实现多类任务的共享输出。Volpi 等(2018)将条件随机场拟合结果与图像同时作为数据,构建类内相似度和边界值预测的两个分支模型,改善地物要素分类结果。Zhang 等(2019a)提出了面向极化 SAR 多通道数据的地物要素分类方法,利用独立的特征提取网络对幅值和相位信息分别建模,利用分类器进行联合约束训练,来提升精度。Shi 等(2020)针对高光谱图像的多类要素分类任务,利用多任务集成学习实现通道选择,获取最优通道组合。针对多模态数据的联合特征表示,如图像纹理特征、三维高程特征、目标要素矢量拓扑特征等,能有效提升各类任务的性能。Chen 等(2019)针对洪灾区域检测任务,提出融合多时相的多模态图像的模型,来提升其检测精度。Fernandez 等(2018)将SAR 图像和多光谱图像作为输入,进行无监督的地物要素分类。Benson 等(2017)在森林冠层三维高度估计任务中,提出利用光谱特性数据的方法,能有效改善传统三维估计方法的精度。 -
 我们是怎央打团队,以下是对本次大赛的一些心得的分享。我们从数据切分方式、网络选择、训练的Tricks、后处理等方面来介绍我们所使用的方法。一、数据切分方式我们本次参赛的训练过程包含两个阶段(后面会详细介绍),每个阶段使用了不同的数据划分方式。训练阶段一将图像划分为大小为1024x1024、重叠率为1/8的图像块(与baseline中的cut_data.py一致)。训练阶段二将图像划分为大小1024x1024且无重叠的图像块。切分结束后,对两个数据集都进行了数据清洗,去掉image图像为全黑(无图像信息)以及label图像为全白(无道路)的图像对。然后将切割代码会产生的个别label错误的图像对手动删除, 这样的问题在切分后的数据集中一般会出现小于十组图像对。二、网络选择本次参赛使用的网络是LinkNet34, 将LinkNet网络自身的backbone由ResNet18替换为ResNet34,使用的Loss是BCE+DICE一比一的直接加和。经过比赛期间的测试我们发现不同的网络对于结果的影响不会到很明显的程度,因此在网络结构本身的选择上其实在比赛早期可以不用花太多功夫。提分重点还是在数据增强、后处理和训练技巧上。三、训练的Tricks数据增强使用了①亮度对比度随机变换(albumentations默认的参数设置);②随机尺度的高斯模糊(尺度3-7随机);③HSV抖动;④物理增强(平移、尺度缩放、旋转±15°、随机水平垂直翻转、随机旋转90°)。数据增强之后将输入网络的图像像素值归一化到±1.6(借鉴自D-LinkNet)。采取了两步训练的方式,第一阶段和第二阶段的训练数据不同,数据准备如第一部分内容中所述。第一阶段使用imagenet预训练的权重做初始化,第二阶段使用第一阶段的训练结果作为初始化。优化器使用Adam,在训练阶段1初始化学习率为2e-4,衰减周期为5个epoch,衰减系数为0.9;在训练阶段2初始化学习率为1e-5,衰减周期为1个epoch,衰减系数为0.9。四、后处理在模型预测阶段使用了8张预测结果来整合最终结果(原图、水平翻转、垂直翻转、水平+垂直翻转,以及上述4张图分别逆时针旋转90°得到的图)。同时采用了膨胀预测的方法。谢谢大家!本文首发 AI Gallery: https://marketplace.huaweicloud.com/markets/aihub/modelhub/detail/?id=2b06e091-140e-4e2e-b39a-8ad9bfa80f16本赛事赛题:https://competition.huaweicloud.com/information/1000041322/circumstance决赛获奖选手分享集锦:https://competition.huaweicloud.com/information/1000041322/share
我们是怎央打团队,以下是对本次大赛的一些心得的分享。我们从数据切分方式、网络选择、训练的Tricks、后处理等方面来介绍我们所使用的方法。一、数据切分方式我们本次参赛的训练过程包含两个阶段(后面会详细介绍),每个阶段使用了不同的数据划分方式。训练阶段一将图像划分为大小为1024x1024、重叠率为1/8的图像块(与baseline中的cut_data.py一致)。训练阶段二将图像划分为大小1024x1024且无重叠的图像块。切分结束后,对两个数据集都进行了数据清洗,去掉image图像为全黑(无图像信息)以及label图像为全白(无道路)的图像对。然后将切割代码会产生的个别label错误的图像对手动删除, 这样的问题在切分后的数据集中一般会出现小于十组图像对。二、网络选择本次参赛使用的网络是LinkNet34, 将LinkNet网络自身的backbone由ResNet18替换为ResNet34,使用的Loss是BCE+DICE一比一的直接加和。经过比赛期间的测试我们发现不同的网络对于结果的影响不会到很明显的程度,因此在网络结构本身的选择上其实在比赛早期可以不用花太多功夫。提分重点还是在数据增强、后处理和训练技巧上。三、训练的Tricks数据增强使用了①亮度对比度随机变换(albumentations默认的参数设置);②随机尺度的高斯模糊(尺度3-7随机);③HSV抖动;④物理增强(平移、尺度缩放、旋转±15°、随机水平垂直翻转、随机旋转90°)。数据增强之后将输入网络的图像像素值归一化到±1.6(借鉴自D-LinkNet)。采取了两步训练的方式,第一阶段和第二阶段的训练数据不同,数据准备如第一部分内容中所述。第一阶段使用imagenet预训练的权重做初始化,第二阶段使用第一阶段的训练结果作为初始化。优化器使用Adam,在训练阶段1初始化学习率为2e-4,衰减周期为5个epoch,衰减系数为0.9;在训练阶段2初始化学习率为1e-5,衰减周期为1个epoch,衰减系数为0.9。四、后处理在模型预测阶段使用了8张预测结果来整合最终结果(原图、水平翻转、垂直翻转、水平+垂直翻转,以及上述4张图分别逆时针旋转90°得到的图)。同时采用了膨胀预测的方法。谢谢大家!本文首发 AI Gallery: https://marketplace.huaweicloud.com/markets/aihub/modelhub/detail/?id=2b06e091-140e-4e2e-b39a-8ad9bfa80f16本赛事赛题:https://competition.huaweicloud.com/information/1000041322/circumstance决赛获奖选手分享集锦:https://competition.huaweicloud.com/information/1000041322/share -
 描述“华为云杯”2020人工智能创新应用大赛赛题任务:基于高分辨可见光遥感卫星影像,提取复杂场景的道路与街道网络信息,将影像的逐个像素进行前、背景分割,检测所有道路像素的对应区域。数据集为data.zip,详细介绍请查看赛题页面说明。
描述“华为云杯”2020人工智能创新应用大赛赛题任务:基于高分辨可见光遥感卫星影像,提取复杂场景的道路与街道网络信息,将影像的逐个像素进行前、背景分割,检测所有道路像素的对应区域。数据集为data.zip,详细介绍请查看赛题页面说明。 -
 >摘要:遥感影像,作为地球自拍照,能够从更广阔的视角,为人们提供更多维度的辅助信息,来帮助人类感知自然资源、农林水利、交通灾害等多领域信息。本文分享自华为云社区[《AI+云原生,把卫星遥感虐的死去活来》](https://bbs.huaweicloud.com/blogs/296183?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content),作者:tsjsdbd。 # AI牛啊,云原生牛啊,所以1+1>2? 遥感影像,作为地球自拍照,能够从更广阔的视角,为人们提供更多维度的辅助信息,来帮助人类感知自然资源、农林水利、交通灾害等多领域信息。 AI技术,可以在很多领域超过人类,关键是它是自动的,省时又省力。可显著提升遥感影像解译的工作效率,对各类地物元素进行自动化的检测,例如建筑物,河道,道路,农作物等。能为智慧城市发展&治理提供决策依据。  云原生技术,近年来可谓是一片火热。易构建,可重复,无依赖等优势,无论从哪个角度看都与AI算法天生一对。所以大家也可以看到,各领域的AI场景,大都是将AI推理算法运行在Docker容器里面的。 AI+云原生这么6,那么强强联手后,地物分类、目标提取、变化检测等高性能AI解译不就手到擒来?我们也是这么认为的,所以基于AI+Kubernetes云原生,构建了支持遥感影像AI处理的空天地平台。 不过理想是好的,过程却跟西天取经一般,九九八十一难,最终修成正果。 # 业务场景介绍 遇到问题的业务场景叫影像融合(Pansharpen),也就是对地球自拍照进行“多镜头合作美颜”功能。(可以理解成:手机的多个摄像头,同时拍照,合并成一张高清彩色大图)。  所以业务简单总结就是:读取2张图片,生成1张新的图片。该功能我们放在一个容器里面执行,每张融合后的结果图片大约5GB。 问题的关键是,一个批次业务量需要处理的是3000多张卫星影像,所以每批任务只需要同时运行完成3000多个容器就OK啦。云原生YYDS! # 业务架构图示 为了帮助理解,这里分解使用云原生架构实现该业务场景的逻辑图如下: 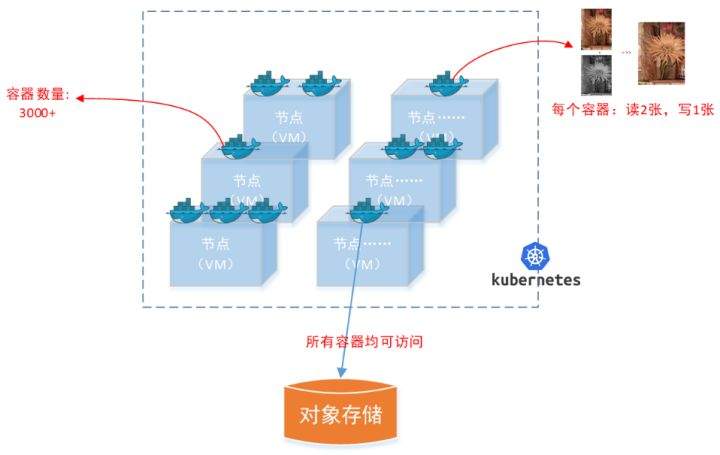 在云上,原始数据,以及结果数据,一定是要存放在对象存储桶里面的。因为这个数据量,只有对象存储的价格是合适的。(对象存储,1毛钱/GB。文件存储则需要3毛钱/GB) 因为容器之间是互相独立无影响的,每个容器只需要处理自己的那幅影像就行。例如1号容器处理 1.tif影像;2号容器处理2.tif影像;一次类推。 所以管理程序,只需要投递对应数量的容器(3000+),并监控每个容器是否成功执行完毕就行(此处为简化说明,实际业务场景是一个pipeline处理流程)。那么,需求已经按照云原生理想的状态分解,咱们开始起(tang)飞(keng)吧~ 注:以下描述的问题,是经过梳理后呈现的,实际问题出现时是互相穿插错综复杂的。 # K8s死掉了 当作业投递后,不多久系统就显示作业纷纷失败。查看日志报调用K8s接口失败,再一看,K8s的Master都已经挂了。。。 K8s-Master处理过程,总结版: 1. 发现Master挂是因为CPU爆了 2. 所以扩容Master节点(此次重复N次); 3. 性能优化:扩容集群节点数量; 4. 性能优化:容器分批投放; 5. 性能优化:查询容器执行进度,少用ListPod接口; 详细版: 看监控Master节点的CPU已经爆掉了,所以最简单粗暴的想法就是给Master扩容呀,嘎嘎的扩。于是从4U8G * 3 一路扩容一路测试一路失败,扩到了32U64G * 3。可以发现CPU还是爆满。看来简单的扩容是行不通了。 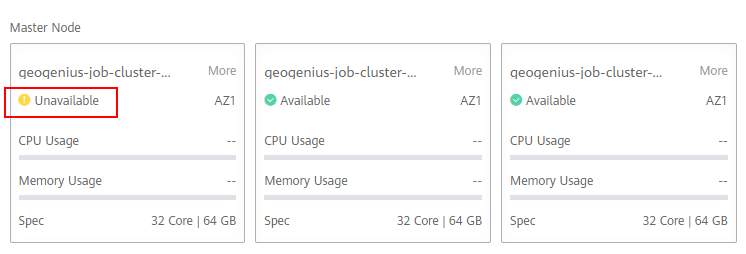 3000多个容器,投给K8s后,大量的容器都处于Pending状态(集群整体资源不够,所以容器都在排队呢)。而正在Pending的Pod,K8s的Scheduler会不停的轮训,去判断能否有资源可以给它安排上。所以这也会给Scheduler巨大的CPU压力。扩容集群节点数量,可以减少排队的Pod数量。  另外,既然排队的太多,不如就把容器分批投递给K8s吧。于是开始分批次投递任务,想着别一次把K8s压垮了。每次投递数量,减少到1千,然后到500,再到100。 同时,查询Pod进度的时候,避免使用ListPod接口,改为直接查询具体的Pod信息。因为List接口,在K8s内部的处理会列出所有Pod信息,处理压力也很大。 这一套组合拳下来,Master节点终于不挂了。不过,一头问题按下去了,另一头问题就冒出来了。 # 容器跑一半,挂了 虽然Master不挂了,但是当投递1~2批次作业后,容器又纷纷失败。 容器挂掉的处理过程,总结版: 1. 发现容器挂掉是被eviction驱逐了; 2. Eviction驱逐,发现原因是节点报Disk Pressure(存储容量满了); 3. 于是扩容节点存储容量; 4. 延长驱逐容器(主动kill容器)前的容忍时间; 详细版: (注:以下问题是定位梳理后,按顺序呈现给大家。但其实出问题的时候,顺序没有这么友好) 容器执行失败,首先想到的是先看看容器里面脚本执行的日志呗:结果报日志找不到~  于是查询Pod信息,从event事件中发现有些容器是被Eviction驱逐干掉了。同时也可以看到,驱逐的原因是 DiskPressure(即节点的存储满了)。 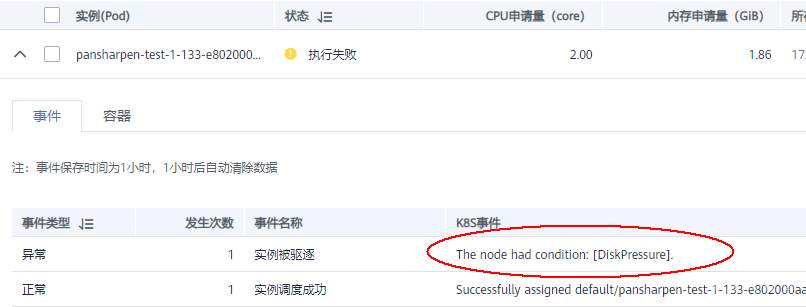 当Disk Pressure发生后,节点被打上了驱逐标签,随后启动主动驱逐容器的逻辑: 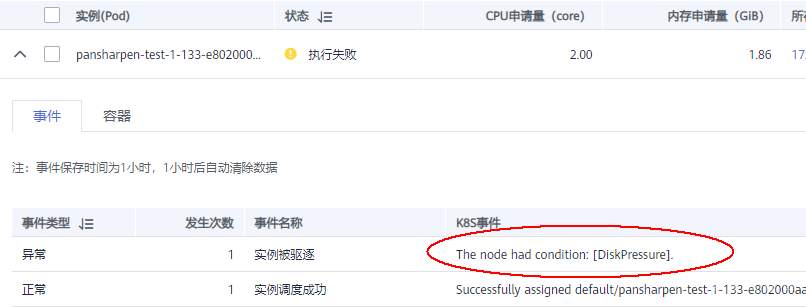 由于节点进入Eviction驱逐状态,节点上面的容器,如果在5分钟后,还没有运行完,就被Kubelet主动杀死了。(因为K8s想通过干掉容器来腾出更多资源,从而尽快退出Eviction状态)。 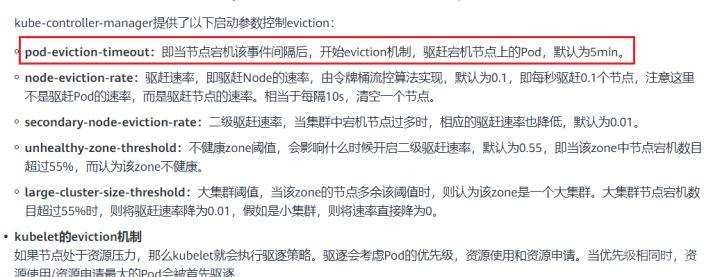 这里我们假设每个容器的正常运行时间为1~2个小时,那么不应该一发生驱动就马上杀死容器(因为已经执行到一半的容器,杀掉重新执行是有成本浪费的)。我们期望应该尽量等待所有容器都运行结束才动手。所以这个 pod-eviction-timeout 容忍时间,应该设置为24小时(大于每个容器的平均执行时间)。 Disk Pressure的直接原因就是本地盘容量不够了。所以得进行节点存储扩容,有2个选择:1)使用云存储EVS(给节点挂载云存储)。 2)扩容本地盘(节点自带本地存储的VM)。 由于云存储(EVS)的带宽实在太低了,350MB/s。一个节点咱们能同时跑30多个容器,带宽完全满足不了。最终选择使用 i3类型的VM。这种VM自带本地存储。并且将8块NVMe盘,组成Raid0,带宽还能x8。 # 对象存储写入失败 容器执行继续纷纷失败。 容器往对象存储写入失败处理过程,总结版: 1. 不直接写入,而是先写到本地,然后cp过去。 2. 将普通对象桶,改为支持文件语义的并行文件桶。 详细版: 查看日志发现,脚本在生成新的影像时,往存储中写入时出错: 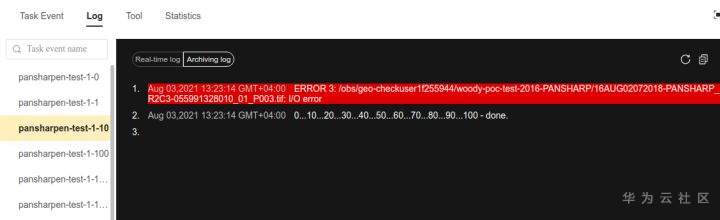 我们整集群是500核的规模,同时运行的容器数量大概在250个(每个2u2g)。这么多的容器同时往1个对象存储桶里面并发追加写入。这个应该是导致该IO问题的原因。 对象存储协议s3fs,本身并不适合大文件的追加写入。因为它对文件的操作都是整体的,即使你往一个文件追加写入1字节,也会导致整个文件重新写一遍。 最终这里改为:先往本地生成目标影像文件,然后脚本的最后,再拷贝到对象存储上。相当于增加一个临时存储中转一下。 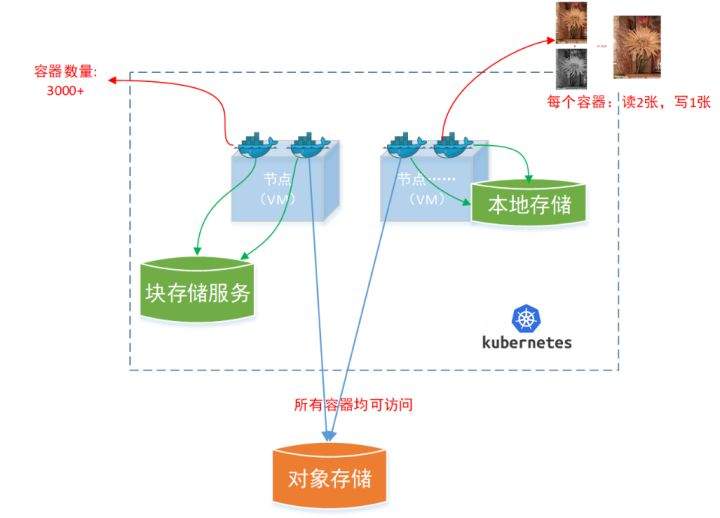 在临时中转存储选择中,2种本地存储都试过: 1)块存储带宽太低,350MB/s影响整体作业速度。2)可以选择带本地存储的VM,多块本地存储组成Raid阵列,带宽速度都杠杠滴。 同时,华为云在对象存储协议上也有一个扩展,使其支持追加写入这种的POSIX语义,称为并行文件桶。后续将普通的对象桶,都改为了文件语义桶。以此来支撑大规模的并发追加写入文件的操作。 # K8s计算节点挂了 So,继续跑任务。但是这容器作业,执行又纷纷失败鸟~ 计算节点挂掉,定位梳理后,总结版: 1. 计算节点挂掉,是因为好久没上报K8s心跳了。 2. 没上报心跳,是因为kubelet(K8s节点的agent)过得不太好(死掉了)。 3. 是因为Kubelet的资源被容器抢光了(由于不想容器经常oom kill,并未设置limit限制) 4. 为了保护kubelet,所有容器全都设置好limit。 详细版,直接从各类奇葩乱象等问题入手: - 容器启动失败,报超时错误。 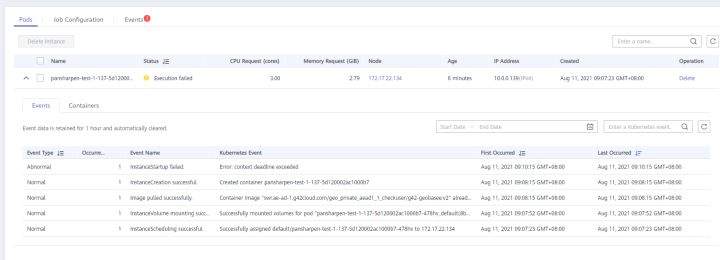 - 然后,什么PVC共享存储挂载失败:  - 或者,又有些容器无法正常结束(删不掉)。  - 查询节点Kubelet日志,可以看到充满了各种超时错误: 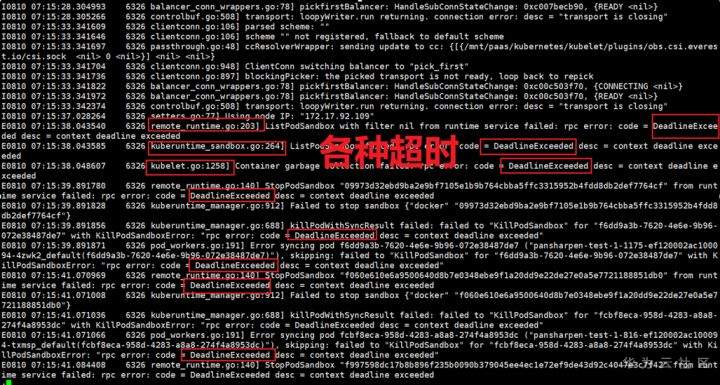 啊,这么多的底层容器超时,一开始感觉的Docker的Daemon进程挂了,通过重启Docker服务来试图修复问题。 后面继续定位发现,K8s集群显示,好多计算节点Unavailable了(节点都死掉啦)。 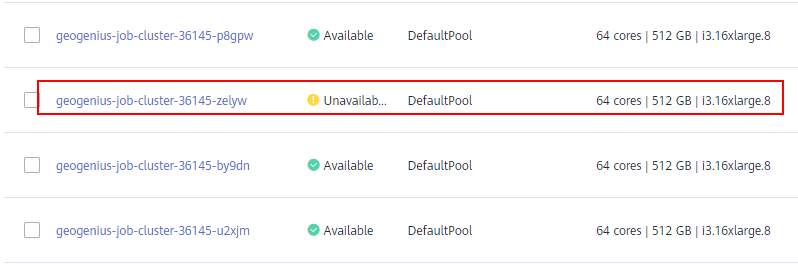 继续分析节点不可用(Unavailable),可以发现是Kubelet好久没有给Master上报心跳了,所以Master认为节点挂了。说明不仅仅是Docker的Daemon受影响,节点的Kubelet也有受影响。 那什么情况会导致Kubelet,Docker这些主机进程都不正常呢?这个就要提到Kubernetes在调度容器时,所设计的Request和Limit这2个概念了。 Request是K8s用来调度容器到空闲计算节点上的。而Limit则会传递给Docker用于限制容器资源上限(触发上限容易被oom killer 杀掉)。前期我们为了防止作业被杀死,仅为容器设置了Request,没有设置Limit。也就是每个容器实际可以超出请求的资源量,去抢占额外的主机资源。大量容器并发时,主机资源会受影响。 考虑到虽然不杀死作业,对用户挺友好,但是平台自己受不了也不是个事。于是给所有的容器都加上了Limit限制,防止容器超限使用资源,强制用户进程运行在容器Limit资源之内,超过就Kill它。以此来确保主机进程(如Docker,Kubelet等),一定是有足够的运行资源的。 # K8s计算节点,又挂了 于是,继续跑任务。不少作业执行又双叒失败鸟~ 节点又挂了,总结版: 1. 分析日志,这次挂是因为PLEG(Pod Lifecycle Event Generator)失败。 2. PLEG异常是因为节点上面存留的历史容器太多(>500个),查询用时太久超时了。 3. 及时清理已经运行结束的容器(即使跑完的容器,还是会占用节点存储资源)。 4. 容器接口各种超时(cpu+memory是有limit保护,但是io还是会被抢占)。 5. 提升系统磁盘的io性能,防止Docker容器接口(如list等)超时。 详细版: 现象还是节点Unavailable了,查看Kubelet日志搜索心跳情况,发现有PLEG is not healthy 的错误:  于是搜索PLEG相关的Kubelet日志,发现该错误还挺多:  这个错误,是因为kubelet去list当前节点所有容器(包括已经运行结束的容器)时,超时了。看了代码:https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L203 kubelet判断超时的时间,3分钟的长度是写死的。所以当pod数量越多,这个超时概率越大。很多场景案例表明,节点上的累计容器数量到达500以上,容易出现PLEG问题。(此处也说明K8s可以更加Flexible一点,超时时长应该动态调整)。 缓解措施就是及时的清理已经运行完毕的容器。但是运行结束的容器一旦清理,容器记录以及容器日志也会被清理,所以需要有相应的功能来弥补这些问题(比如日志采集系统等)。 List所有容器接口,除了容器数量多,IO慢的话,也会导致超时。 这时,从后台可以看到,在投递作业期间,大量并发容器同时运行时,云硬盘的写入带宽被大量占用: 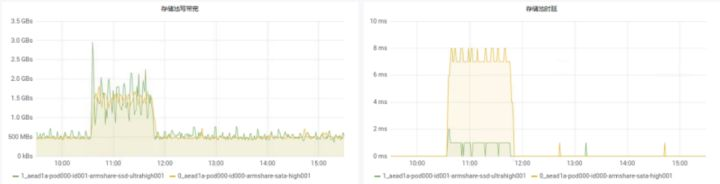 对存储池的冲击也很大: 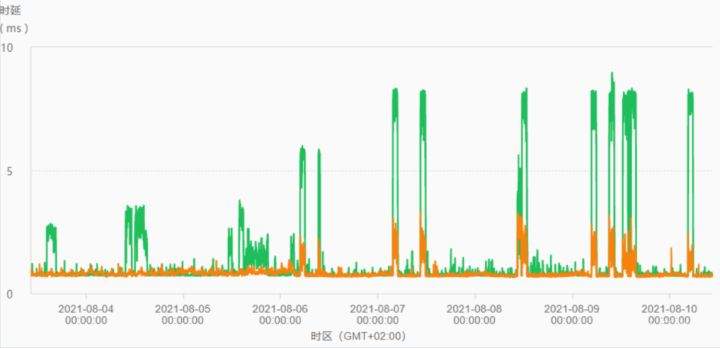 这也导致了IO性能变很差,也会一定程度影响list容器接口超时,从而导致PLEG错误。 该问题的解决措施:尽量使用的带本地高速盘的VM,并且将多块数据盘组成Raid阵列,提高读写带宽。  这样,该VM作为K8s的节点,节点上的容器都直接读写本地盘,io性能较好。(跟大数据集群的节点用法一样了,强依赖本地shuffle~)。 在这多条措施实施后,后续多批次的作业都可以平稳的运行完。
>摘要:遥感影像,作为地球自拍照,能够从更广阔的视角,为人们提供更多维度的辅助信息,来帮助人类感知自然资源、农林水利、交通灾害等多领域信息。本文分享自华为云社区[《AI+云原生,把卫星遥感虐的死去活来》](https://bbs.huaweicloud.com/blogs/296183?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content),作者:tsjsdbd。 # AI牛啊,云原生牛啊,所以1+1>2? 遥感影像,作为地球自拍照,能够从更广阔的视角,为人们提供更多维度的辅助信息,来帮助人类感知自然资源、农林水利、交通灾害等多领域信息。 AI技术,可以在很多领域超过人类,关键是它是自动的,省时又省力。可显著提升遥感影像解译的工作效率,对各类地物元素进行自动化的检测,例如建筑物,河道,道路,农作物等。能为智慧城市发展&治理提供决策依据。  云原生技术,近年来可谓是一片火热。易构建,可重复,无依赖等优势,无论从哪个角度看都与AI算法天生一对。所以大家也可以看到,各领域的AI场景,大都是将AI推理算法运行在Docker容器里面的。 AI+云原生这么6,那么强强联手后,地物分类、目标提取、变化检测等高性能AI解译不就手到擒来?我们也是这么认为的,所以基于AI+Kubernetes云原生,构建了支持遥感影像AI处理的空天地平台。 不过理想是好的,过程却跟西天取经一般,九九八十一难,最终修成正果。 # 业务场景介绍 遇到问题的业务场景叫影像融合(Pansharpen),也就是对地球自拍照进行“多镜头合作美颜”功能。(可以理解成:手机的多个摄像头,同时拍照,合并成一张高清彩色大图)。  所以业务简单总结就是:读取2张图片,生成1张新的图片。该功能我们放在一个容器里面执行,每张融合后的结果图片大约5GB。 问题的关键是,一个批次业务量需要处理的是3000多张卫星影像,所以每批任务只需要同时运行完成3000多个容器就OK啦。云原生YYDS! # 业务架构图示 为了帮助理解,这里分解使用云原生架构实现该业务场景的逻辑图如下:  在云上,原始数据,以及结果数据,一定是要存放在对象存储桶里面的。因为这个数据量,只有对象存储的价格是合适的。(对象存储,1毛钱/GB。文件存储则需要3毛钱/GB) 因为容器之间是互相独立无影响的,每个容器只需要处理自己的那幅影像就行。例如1号容器处理 1.tif影像;2号容器处理2.tif影像;一次类推。 所以管理程序,只需要投递对应数量的容器(3000+),并监控每个容器是否成功执行完毕就行(此处为简化说明,实际业务场景是一个pipeline处理流程)。那么,需求已经按照云原生理想的状态分解,咱们开始起(tang)飞(keng)吧~ 注:以下描述的问题,是经过梳理后呈现的,实际问题出现时是互相穿插错综复杂的。 # K8s死掉了 当作业投递后,不多久系统就显示作业纷纷失败。查看日志报调用K8s接口失败,再一看,K8s的Master都已经挂了。。。 K8s-Master处理过程,总结版: 1. 发现Master挂是因为CPU爆了 2. 所以扩容Master节点(此次重复N次); 3. 性能优化:扩容集群节点数量; 4. 性能优化:容器分批投放; 5. 性能优化:查询容器执行进度,少用ListPod接口; 详细版: 看监控Master节点的CPU已经爆掉了,所以最简单粗暴的想法就是给Master扩容呀,嘎嘎的扩。于是从4U8G * 3 一路扩容一路测试一路失败,扩到了32U64G * 3。可以发现CPU还是爆满。看来简单的扩容是行不通了。  3000多个容器,投给K8s后,大量的容器都处于Pending状态(集群整体资源不够,所以容器都在排队呢)。而正在Pending的Pod,K8s的Scheduler会不停的轮训,去判断能否有资源可以给它安排上。所以这也会给Scheduler巨大的CPU压力。扩容集群节点数量,可以减少排队的Pod数量。  另外,既然排队的太多,不如就把容器分批投递给K8s吧。于是开始分批次投递任务,想着别一次把K8s压垮了。每次投递数量,减少到1千,然后到500,再到100。 同时,查询Pod进度的时候,避免使用ListPod接口,改为直接查询具体的Pod信息。因为List接口,在K8s内部的处理会列出所有Pod信息,处理压力也很大。 这一套组合拳下来,Master节点终于不挂了。不过,一头问题按下去了,另一头问题就冒出来了。 # 容器跑一半,挂了 虽然Master不挂了,但是当投递1~2批次作业后,容器又纷纷失败。 容器挂掉的处理过程,总结版: 1. 发现容器挂掉是被eviction驱逐了; 2. Eviction驱逐,发现原因是节点报Disk Pressure(存储容量满了); 3. 于是扩容节点存储容量; 4. 延长驱逐容器(主动kill容器)前的容忍时间; 详细版: (注:以下问题是定位梳理后,按顺序呈现给大家。但其实出问题的时候,顺序没有这么友好) 容器执行失败,首先想到的是先看看容器里面脚本执行的日志呗:结果报日志找不到~  于是查询Pod信息,从event事件中发现有些容器是被Eviction驱逐干掉了。同时也可以看到,驱逐的原因是 DiskPressure(即节点的存储满了)。  当Disk Pressure发生后,节点被打上了驱逐标签,随后启动主动驱逐容器的逻辑:  由于节点进入Eviction驱逐状态,节点上面的容器,如果在5分钟后,还没有运行完,就被Kubelet主动杀死了。(因为K8s想通过干掉容器来腾出更多资源,从而尽快退出Eviction状态)。  这里我们假设每个容器的正常运行时间为1~2个小时,那么不应该一发生驱动就马上杀死容器(因为已经执行到一半的容器,杀掉重新执行是有成本浪费的)。我们期望应该尽量等待所有容器都运行结束才动手。所以这个 pod-eviction-timeout 容忍时间,应该设置为24小时(大于每个容器的平均执行时间)。 Disk Pressure的直接原因就是本地盘容量不够了。所以得进行节点存储扩容,有2个选择:1)使用云存储EVS(给节点挂载云存储)。 2)扩容本地盘(节点自带本地存储的VM)。 由于云存储(EVS)的带宽实在太低了,350MB/s。一个节点咱们能同时跑30多个容器,带宽完全满足不了。最终选择使用 i3类型的VM。这种VM自带本地存储。并且将8块NVMe盘,组成Raid0,带宽还能x8。 # 对象存储写入失败 容器执行继续纷纷失败。 容器往对象存储写入失败处理过程,总结版: 1. 不直接写入,而是先写到本地,然后cp过去。 2. 将普通对象桶,改为支持文件语义的并行文件桶。 详细版: 查看日志发现,脚本在生成新的影像时,往存储中写入时出错:  我们整集群是500核的规模,同时运行的容器数量大概在250个(每个2u2g)。这么多的容器同时往1个对象存储桶里面并发追加写入。这个应该是导致该IO问题的原因。 对象存储协议s3fs,本身并不适合大文件的追加写入。因为它对文件的操作都是整体的,即使你往一个文件追加写入1字节,也会导致整个文件重新写一遍。 最终这里改为:先往本地生成目标影像文件,然后脚本的最后,再拷贝到对象存储上。相当于增加一个临时存储中转一下。  在临时中转存储选择中,2种本地存储都试过: 1)块存储带宽太低,350MB/s影响整体作业速度。2)可以选择带本地存储的VM,多块本地存储组成Raid阵列,带宽速度都杠杠滴。 同时,华为云在对象存储协议上也有一个扩展,使其支持追加写入这种的POSIX语义,称为并行文件桶。后续将普通的对象桶,都改为了文件语义桶。以此来支撑大规模的并发追加写入文件的操作。 # K8s计算节点挂了 So,继续跑任务。但是这容器作业,执行又纷纷失败鸟~ 计算节点挂掉,定位梳理后,总结版: 1. 计算节点挂掉,是因为好久没上报K8s心跳了。 2. 没上报心跳,是因为kubelet(K8s节点的agent)过得不太好(死掉了)。 3. 是因为Kubelet的资源被容器抢光了(由于不想容器经常oom kill,并未设置limit限制) 4. 为了保护kubelet,所有容器全都设置好limit。 详细版,直接从各类奇葩乱象等问题入手: - 容器启动失败,报超时错误。  - 然后,什么PVC共享存储挂载失败:  - 或者,又有些容器无法正常结束(删不掉)。  - 查询节点Kubelet日志,可以看到充满了各种超时错误:  啊,这么多的底层容器超时,一开始感觉的Docker的Daemon进程挂了,通过重启Docker服务来试图修复问题。 后面继续定位发现,K8s集群显示,好多计算节点Unavailable了(节点都死掉啦)。  继续分析节点不可用(Unavailable),可以发现是Kubelet好久没有给Master上报心跳了,所以Master认为节点挂了。说明不仅仅是Docker的Daemon受影响,节点的Kubelet也有受影响。 那什么情况会导致Kubelet,Docker这些主机进程都不正常呢?这个就要提到Kubernetes在调度容器时,所设计的Request和Limit这2个概念了。 Request是K8s用来调度容器到空闲计算节点上的。而Limit则会传递给Docker用于限制容器资源上限(触发上限容易被oom killer 杀掉)。前期我们为了防止作业被杀死,仅为容器设置了Request,没有设置Limit。也就是每个容器实际可以超出请求的资源量,去抢占额外的主机资源。大量容器并发时,主机资源会受影响。 考虑到虽然不杀死作业,对用户挺友好,但是平台自己受不了也不是个事。于是给所有的容器都加上了Limit限制,防止容器超限使用资源,强制用户进程运行在容器Limit资源之内,超过就Kill它。以此来确保主机进程(如Docker,Kubelet等),一定是有足够的运行资源的。 # K8s计算节点,又挂了 于是,继续跑任务。不少作业执行又双叒失败鸟~ 节点又挂了,总结版: 1. 分析日志,这次挂是因为PLEG(Pod Lifecycle Event Generator)失败。 2. PLEG异常是因为节点上面存留的历史容器太多(>500个),查询用时太久超时了。 3. 及时清理已经运行结束的容器(即使跑完的容器,还是会占用节点存储资源)。 4. 容器接口各种超时(cpu+memory是有limit保护,但是io还是会被抢占)。 5. 提升系统磁盘的io性能,防止Docker容器接口(如list等)超时。 详细版: 现象还是节点Unavailable了,查看Kubelet日志搜索心跳情况,发现有PLEG is not healthy 的错误:  于是搜索PLEG相关的Kubelet日志,发现该错误还挺多:  这个错误,是因为kubelet去list当前节点所有容器(包括已经运行结束的容器)时,超时了。看了代码:https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L203 kubelet判断超时的时间,3分钟的长度是写死的。所以当pod数量越多,这个超时概率越大。很多场景案例表明,节点上的累计容器数量到达500以上,容易出现PLEG问题。(此处也说明K8s可以更加Flexible一点,超时时长应该动态调整)。 缓解措施就是及时的清理已经运行完毕的容器。但是运行结束的容器一旦清理,容器记录以及容器日志也会被清理,所以需要有相应的功能来弥补这些问题(比如日志采集系统等)。 List所有容器接口,除了容器数量多,IO慢的话,也会导致超时。 这时,从后台可以看到,在投递作业期间,大量并发容器同时运行时,云硬盘的写入带宽被大量占用:  对存储池的冲击也很大:  这也导致了IO性能变很差,也会一定程度影响list容器接口超时,从而导致PLEG错误。 该问题的解决措施:尽量使用的带本地高速盘的VM,并且将多块数据盘组成Raid阵列,提高读写带宽。  这样,该VM作为K8s的节点,节点上的容器都直接读写本地盘,io性能较好。(跟大数据集群的节点用法一样了,强依赖本地shuffle~)。 在这多条措施实施后,后续多批次的作业都可以平稳的运行完。 -
-
 全球遥感产业发展正迎来爆发期。遥感,就算你不了解它,但也不代表你不会用到它。无论是在天气、环境保护、经济、保险等行业,还是日常生活中的导航、遥控无人机,实际上都离不开遥感技术的广泛支持。诞生于20世纪60年代的遥感技术,经过几十年的迅速发展,目前已被广泛应用于各行各业,为人类带来巨大的价值。随着云计算、人工智能、5G等技术的飞速融合发展,遥感产业的发展进入了智能化时代。遥感产业的挑战和智能化机遇当前,全球遥感产业发展正迎来爆发期。据中国四维测绘技术有限公司总经理徐文透露,遥感卫星市场目前已是通、导、遥三大细分市场中发展最快的一个,2010年至2018年,全球遥感卫星服务收入年复合增长8.3%。有统计数据显示,在过去5年,每年平均有12颗遥感卫星发射,未来5年,每年平均将有25颗遥感卫星发射。随着发射数量的激增,遥感卫星占在轨卫星比例也在迅速上升,已从2012年的10%,迅速攀升至2018年的27%。与此同时,产业应用增长速度也较快。徐文表示,自2013年以来,应用领域年复合增长率达92%,近三年更是保持15%的增速。实际上,在过去20年来,中国遥感卫星技术已经实现了从无到有,自主可控的大踏步发展。据悉,光是2020-2023年间中国将陆续发射15颗遥感卫星,预计2020年在轨遥感卫星将有200颗。尽管如此,遥感产业的发展仍然面临诸多制约和挑战。如今随着遥感卫星的增多、高分辨率趋势明显,遥感数据量激增,用于处理这些数据的算力明显不足。此外,用户获取数据的流程较长、数据更新速度慢、遥感数据加工工序多难度大,导致数据获取效率低、成本高的问题日益突出,行业急需一种全新、高效、智能、便捷的技术手段来弥补这些缺陷。在云+AI+5G时代,遥感行业尽管面对着很大的挑战,但也同时面临着很大的机遇,人工智能与大数据技术激发遥感应用创新,智能化升级已成大势所趋。利用云计算强大的算力和可靠的存储,可以助力遥感数据加工处理更高效、成本更低;利用云端人工智能可以自动实现遥感行业的增值服务,例如变化检测服务的人工智能自动识别,相比传统模式依赖遥感行业专家人工效率得到极大提升;而5G的普及必将使得从云端获取遥感数据及服务就如同在本地读取数据一样流畅。中国四维测绘技术有限公司董事长、中国资源卫星应用中心主任徐文表示,目前欧美等国家在遥感行业智能升级上处于领先地位。早在2017年,美国商业遥感卫星代表企业MAXAR公司就开始“All-in on AWS”,目前已实现全部遥感卫星数据云上运维。同时,它还投资配套建设了AI智能应用系统和云上卫星接收站,实现了从太空到用户的云际联接。此外,欧盟在2018年就建成并启动了“哥白尼”云平台, 平台成为“海量卫星数据应用的最佳土壤”。预计将带动下游产业价值超200亿欧元,欧洲遥感卫星产业链与产业模式将发生重大变革。可以看到,在云+AI+5G技术的共同赋能下,遥感产业犹如坐上了“火箭”,正迅速迎来新的爆发期。华为云如何使能中国遥感产业?如今,“上云”已是大势所趋,也逐渐成为各行各业的共识,今天我国的遥感产业也正在迅速迎头赶上。伴随着云计算、人工智能和5G技术的蓬勃发展和广泛应用,越来越多的中国高科技公司已着手尝试利用新型技术来解决遥感产业遇到的问题,并取得了阶段性的进展。在1月8日举行的华为云遥感产业高峰论坛上,从华为云带来的解决方案“GeoGenius-遥感智能体”,就可以一窥中国云计算企业在赋能遥感产业方面到底有哪些技术突破和积累。据介绍,“GeoGenius-遥感智能体”可提供包括数据管理平台和智能计算平台在内的一站式全流程遥感智能开发云平台,帮助用户聚焦挖掘时空数据核心价值。其中,数据管理平台可实现多场景多类型的海量时空数据,智能数据湖统一管理;智能计算平台可提供全流程的AI开发服务。此外,智能计算平台从AI训练到推理再到验证分析的流水线式的拖拉拽任务编排,模型开发甚至可缩短到“天”,相比传统线下AI开发需5-6天,效率提升了5-6倍。据介绍,“GeoGenius-遥感智能体”在这方面的技术优势十分明显。如其在EB级的分布式储存能力,EB级可伸缩储存,同时具有高可靠性;数据冷热分离存储,成本降低50%,访问性能能提升30%。作为高性能AI一站式开发平台,其可适配多种深度学习训练引擎、知识模型快速训练成型、观察结果快速呈现,可实现模型开发周期缩短到“天”。依靠其提供的统一的分布式并行计算引擎、Self-Driving业务驱动、自适应的大数据+AI双引擎和弹性调度、计算弹性无限扩展的能力可提供超大规模的并行算力。此外,在昇腾AI处理器、华为云鲲鹏云服务等全栈AI技术的加持下,可提供超高性价比的计算能力。据华为云中国区总裁洪方明介绍,该技术目前已被应用至两期影像全要素变化监测、影像全要素地物提取分类、无人机影像车辆识别、近海岸线水质趋势分析、高分影像水指数提取,以及一带一路地区历年干旱指数提取等案例实践中去。华为云还携手生态伙伴正共建从数据接收处理,到数据预处理、数据增值加工和应用服务开发的全行业链全栈解决方案。在数据接收处理上,卫星制造商、地面接收站通过“传感器+AI”、专线直通上云,可实现卫星即服务。在数据预处理上,卫星中心和自然资源分中心通过微服务化和容器化,可实现预处理软件系统云化集成。在数据增值加工阶段,遥感应用中心、信息中心,可通过云山工作站,实现加工软件云化、自动化。最后,在应用服务开发阶段,遥感应用中心、应用服务提供商,可通过基于遥感智能云平台,实现数据、算法、软件集成和二次开发,整个流程方便了不少,大大提升了效率。可以看到,“GeoGenius-遥感智能体”通过将人工智能、云计算等技术赋能遥感产业,贯穿从数据存储、到分析处理再到应用开发的全链路以来,大大促进了遥感产业的加速变革。遥感产业上云正当时实际上,在GeoGenius-遥感智能体推出之前,华为云就有着丰富的使能中国遥感产业的成功先例可循。去年11月6日,在澳大利亚举行的GEO 2019年会议周上,中国国家航天局推出了“中国国家航天局高分卫星16米数据共享服务平台”,宣布将中国高分16米数据对外开放共享。此次共享将让95%的没有卫星发射能力的国家享受到中国高分卫星数据对外开放共享的红利。这一决策的背后是中国国家航天局基于华为云的跨区域部署,利用华为云的全球布局的优势,为全球用户提供服务。该平台应用主要由中科星图、航天宏图、中国资源卫星应用中心等多家单位共同研制创建。据洪方明介绍,华为云此前还与中国资源卫星应用中心合作,双方共同发布了四维地球遥感解决方案。该方案可提供包括基础影像底图、每日新图在内的通用遥感产品服务,大幅降低遥感数据使用门槛,实现按需、准实时云端提供高质量遥感数据。还能提供包括目标识别、变化检测在内的智能信息产品服务,大幅降低人工判图时间,实现利用人工智能快速准确识别地物、检测变化等信息。此外,还包括网络地图服务、网络地图切片服务在内的应用开发服务及标准国际开放地理组织接口和表述性状态传递接口,可直接支持智慧城市平台、业务系统、手机APP以及各行业应用软件调用,实现联接政府、企业、公众等海量用户应用。这正是综合运用大数据、云计算、人工智能、5G等技术构建的业界典型案例之一。此外,华为云还与中科天塔合作,其航天器测控管理与空间信息应用服务平台-航天云立方目前已经在华为云稳定运行。据介绍,航天云立方平台完全基于华为云公有云架构进行了全新设计构建,将为各类用户提供在轨航天器与地面测运控资源的访问、控制和管理服务,通过标准化的信息接口向行业用户提供随时随地的航天资源访问能力,实现了信息透明、状态共享与并发操作。航天云立方的所有底层框架服务和上层应用全部基于华为公司国产鲲鹏服务器构建,具有自主、安全、可靠的特点。如利用最新Docker容器技术所研发的轨道与控制计算微服务架构,在国内首次实现支持高并发访问的轨道控制计算接口和多语言版本的SDK开发包,能够为行业用户提供随时可用的高精度的计算与分析服务。实际上,上述案例仅是遥感行业智能化升级的开始,未来十年,中国的遥感行业想要有更加长足的发展,其关键点就在于抓住智能化升级的大潮。在华为云等平台的共同使能下,中国遥感产业智能化升级正步入快车道。
全球遥感产业发展正迎来爆发期。遥感,就算你不了解它,但也不代表你不会用到它。无论是在天气、环境保护、经济、保险等行业,还是日常生活中的导航、遥控无人机,实际上都离不开遥感技术的广泛支持。诞生于20世纪60年代的遥感技术,经过几十年的迅速发展,目前已被广泛应用于各行各业,为人类带来巨大的价值。随着云计算、人工智能、5G等技术的飞速融合发展,遥感产业的发展进入了智能化时代。遥感产业的挑战和智能化机遇当前,全球遥感产业发展正迎来爆发期。据中国四维测绘技术有限公司总经理徐文透露,遥感卫星市场目前已是通、导、遥三大细分市场中发展最快的一个,2010年至2018年,全球遥感卫星服务收入年复合增长8.3%。有统计数据显示,在过去5年,每年平均有12颗遥感卫星发射,未来5年,每年平均将有25颗遥感卫星发射。随着发射数量的激增,遥感卫星占在轨卫星比例也在迅速上升,已从2012年的10%,迅速攀升至2018年的27%。与此同时,产业应用增长速度也较快。徐文表示,自2013年以来,应用领域年复合增长率达92%,近三年更是保持15%的增速。实际上,在过去20年来,中国遥感卫星技术已经实现了从无到有,自主可控的大踏步发展。据悉,光是2020-2023年间中国将陆续发射15颗遥感卫星,预计2020年在轨遥感卫星将有200颗。尽管如此,遥感产业的发展仍然面临诸多制约和挑战。如今随着遥感卫星的增多、高分辨率趋势明显,遥感数据量激增,用于处理这些数据的算力明显不足。此外,用户获取数据的流程较长、数据更新速度慢、遥感数据加工工序多难度大,导致数据获取效率低、成本高的问题日益突出,行业急需一种全新、高效、智能、便捷的技术手段来弥补这些缺陷。在云+AI+5G时代,遥感行业尽管面对着很大的挑战,但也同时面临着很大的机遇,人工智能与大数据技术激发遥感应用创新,智能化升级已成大势所趋。利用云计算强大的算力和可靠的存储,可以助力遥感数据加工处理更高效、成本更低;利用云端人工智能可以自动实现遥感行业的增值服务,例如变化检测服务的人工智能自动识别,相比传统模式依赖遥感行业专家人工效率得到极大提升;而5G的普及必将使得从云端获取遥感数据及服务就如同在本地读取数据一样流畅。中国四维测绘技术有限公司董事长、中国资源卫星应用中心主任徐文表示,目前欧美等国家在遥感行业智能升级上处于领先地位。早在2017年,美国商业遥感卫星代表企业MAXAR公司就开始“All-in on AWS”,目前已实现全部遥感卫星数据云上运维。同时,它还投资配套建设了AI智能应用系统和云上卫星接收站,实现了从太空到用户的云际联接。此外,欧盟在2018年就建成并启动了“哥白尼”云平台, 平台成为“海量卫星数据应用的最佳土壤”。预计将带动下游产业价值超200亿欧元,欧洲遥感卫星产业链与产业模式将发生重大变革。可以看到,在云+AI+5G技术的共同赋能下,遥感产业犹如坐上了“火箭”,正迅速迎来新的爆发期。华为云如何使能中国遥感产业?如今,“上云”已是大势所趋,也逐渐成为各行各业的共识,今天我国的遥感产业也正在迅速迎头赶上。伴随着云计算、人工智能和5G技术的蓬勃发展和广泛应用,越来越多的中国高科技公司已着手尝试利用新型技术来解决遥感产业遇到的问题,并取得了阶段性的进展。在1月8日举行的华为云遥感产业高峰论坛上,从华为云带来的解决方案“GeoGenius-遥感智能体”,就可以一窥中国云计算企业在赋能遥感产业方面到底有哪些技术突破和积累。据介绍,“GeoGenius-遥感智能体”可提供包括数据管理平台和智能计算平台在内的一站式全流程遥感智能开发云平台,帮助用户聚焦挖掘时空数据核心价值。其中,数据管理平台可实现多场景多类型的海量时空数据,智能数据湖统一管理;智能计算平台可提供全流程的AI开发服务。此外,智能计算平台从AI训练到推理再到验证分析的流水线式的拖拉拽任务编排,模型开发甚至可缩短到“天”,相比传统线下AI开发需5-6天,效率提升了5-6倍。据介绍,“GeoGenius-遥感智能体”在这方面的技术优势十分明显。如其在EB级的分布式储存能力,EB级可伸缩储存,同时具有高可靠性;数据冷热分离存储,成本降低50%,访问性能能提升30%。作为高性能AI一站式开发平台,其可适配多种深度学习训练引擎、知识模型快速训练成型、观察结果快速呈现,可实现模型开发周期缩短到“天”。依靠其提供的统一的分布式并行计算引擎、Self-Driving业务驱动、自适应的大数据+AI双引擎和弹性调度、计算弹性无限扩展的能力可提供超大规模的并行算力。此外,在昇腾AI处理器、华为云鲲鹏云服务等全栈AI技术的加持下,可提供超高性价比的计算能力。据华为云中国区总裁洪方明介绍,该技术目前已被应用至两期影像全要素变化监测、影像全要素地物提取分类、无人机影像车辆识别、近海岸线水质趋势分析、高分影像水指数提取,以及一带一路地区历年干旱指数提取等案例实践中去。华为云还携手生态伙伴正共建从数据接收处理,到数据预处理、数据增值加工和应用服务开发的全行业链全栈解决方案。在数据接收处理上,卫星制造商、地面接收站通过“传感器+AI”、专线直通上云,可实现卫星即服务。在数据预处理上,卫星中心和自然资源分中心通过微服务化和容器化,可实现预处理软件系统云化集成。在数据增值加工阶段,遥感应用中心、信息中心,可通过云山工作站,实现加工软件云化、自动化。最后,在应用服务开发阶段,遥感应用中心、应用服务提供商,可通过基于遥感智能云平台,实现数据、算法、软件集成和二次开发,整个流程方便了不少,大大提升了效率。可以看到,“GeoGenius-遥感智能体”通过将人工智能、云计算等技术赋能遥感产业,贯穿从数据存储、到分析处理再到应用开发的全链路以来,大大促进了遥感产业的加速变革。遥感产业上云正当时实际上,在GeoGenius-遥感智能体推出之前,华为云就有着丰富的使能中国遥感产业的成功先例可循。去年11月6日,在澳大利亚举行的GEO 2019年会议周上,中国国家航天局推出了“中国国家航天局高分卫星16米数据共享服务平台”,宣布将中国高分16米数据对外开放共享。此次共享将让95%的没有卫星发射能力的国家享受到中国高分卫星数据对外开放共享的红利。这一决策的背后是中国国家航天局基于华为云的跨区域部署,利用华为云的全球布局的优势,为全球用户提供服务。该平台应用主要由中科星图、航天宏图、中国资源卫星应用中心等多家单位共同研制创建。据洪方明介绍,华为云此前还与中国资源卫星应用中心合作,双方共同发布了四维地球遥感解决方案。该方案可提供包括基础影像底图、每日新图在内的通用遥感产品服务,大幅降低遥感数据使用门槛,实现按需、准实时云端提供高质量遥感数据。还能提供包括目标识别、变化检测在内的智能信息产品服务,大幅降低人工判图时间,实现利用人工智能快速准确识别地物、检测变化等信息。此外,还包括网络地图服务、网络地图切片服务在内的应用开发服务及标准国际开放地理组织接口和表述性状态传递接口,可直接支持智慧城市平台、业务系统、手机APP以及各行业应用软件调用,实现联接政府、企业、公众等海量用户应用。这正是综合运用大数据、云计算、人工智能、5G等技术构建的业界典型案例之一。此外,华为云还与中科天塔合作,其航天器测控管理与空间信息应用服务平台-航天云立方目前已经在华为云稳定运行。据介绍,航天云立方平台完全基于华为云公有云架构进行了全新设计构建,将为各类用户提供在轨航天器与地面测运控资源的访问、控制和管理服务,通过标准化的信息接口向行业用户提供随时随地的航天资源访问能力,实现了信息透明、状态共享与并发操作。航天云立方的所有底层框架服务和上层应用全部基于华为公司国产鲲鹏服务器构建,具有自主、安全、可靠的特点。如利用最新Docker容器技术所研发的轨道与控制计算微服务架构,在国内首次实现支持高并发访问的轨道控制计算接口和多语言版本的SDK开发包,能够为行业用户提供随时可用的高精度的计算与分析服务。实际上,上述案例仅是遥感行业智能化升级的开始,未来十年,中国的遥感行业想要有更加长足的发展,其关键点就在于抓住智能化升级的大潮。在华为云等平台的共同使能下,中国遥感产业智能化升级正步入快车道。 -
 关键字:遥感图像处理、人工智能、软件开发云教育解决方案介绍:大连海事大学(原大连海运学院)是交通运输部所属的全国重点大学,是国家“211工程”重点建设高校、国家“双一流”建设高校。学校素有“航海家的摇篮”之称,是中国著名的高等航海学府,是被国际海事组织认定的世界上少数几所“享有国际盛誉”的海事院校之一。遥感图像处理(processing of remote sensing image data)是对遥感图像进行辐射校正和几何纠正、图像整饰、投影变换、镶嵌、特征提取、分类以及各种专题处理等一系列操作,以求达到预期目的的技术。解决方案:人工智能涵盖的深度学习技术具有特征学习和深层结构两个特点,有利于遥感图像分类精度的提升。特征学习能够根据不同的应用自动从海量数据中学习到所需的高级特征表示,更能表达数据的内在信息。因此,AI已经逐步成为遥感图像处理研究中的热点与趋势。借于当前人工智能,机器学习技术在大数据图像处理,图像分析领域中的突破与成果,大连海事大学将传统遥感图像处理课程结合华为软件开发云教育解决方案,引入华为云Classroom智能教学平台与《人工智能:算法与实践》课程,为该专业课程学生提供优秀的理论+动手实践环境外,更赋予前沿技术,热门知识等(人工智能,机器学习算法)的学习。新课程大大提升了学生对遥感图像处理的多方面理论,Python语言编程能力和人工智能相关算法应用能力,同时平台自动判题功能更减轻了老师批改代码习题的工作量。课程目的:了解遥感图像的基本原理 ( 成像机理、图像特征)学习遥感图像的校正恢复以及分析处理的基本算法了解遥感图像处理的前沿知识通过习题实践掌握遥感影像处理的基本方法课程大纲:AI基础习题示例:学生作业与老师批改界面:专家现场培训:
关键字:遥感图像处理、人工智能、软件开发云教育解决方案介绍:大连海事大学(原大连海运学院)是交通运输部所属的全国重点大学,是国家“211工程”重点建设高校、国家“双一流”建设高校。学校素有“航海家的摇篮”之称,是中国著名的高等航海学府,是被国际海事组织认定的世界上少数几所“享有国际盛誉”的海事院校之一。遥感图像处理(processing of remote sensing image data)是对遥感图像进行辐射校正和几何纠正、图像整饰、投影变换、镶嵌、特征提取、分类以及各种专题处理等一系列操作,以求达到预期目的的技术。解决方案:人工智能涵盖的深度学习技术具有特征学习和深层结构两个特点,有利于遥感图像分类精度的提升。特征学习能够根据不同的应用自动从海量数据中学习到所需的高级特征表示,更能表达数据的内在信息。因此,AI已经逐步成为遥感图像处理研究中的热点与趋势。借于当前人工智能,机器学习技术在大数据图像处理,图像分析领域中的突破与成果,大连海事大学将传统遥感图像处理课程结合华为软件开发云教育解决方案,引入华为云Classroom智能教学平台与《人工智能:算法与实践》课程,为该专业课程学生提供优秀的理论+动手实践环境外,更赋予前沿技术,热门知识等(人工智能,机器学习算法)的学习。新课程大大提升了学生对遥感图像处理的多方面理论,Python语言编程能力和人工智能相关算法应用能力,同时平台自动判题功能更减轻了老师批改代码习题的工作量。课程目的:了解遥感图像的基本原理 ( 成像机理、图像特征)学习遥感图像的校正恢复以及分析处理的基本算法了解遥感图像处理的前沿知识通过习题实践掌握遥感影像处理的基本方法课程大纲:AI基础习题示例:学生作业与老师批改界面:专家现场培训: -
中国人自己的遥感系列处理软件正式入驻华为云市场,开启遥感服务新模式!PIE(Pixel Information Expert)系列产品是北京航天宏图信息技术股份有限公司自主研发的一款专业的遥感影像处理软件,提供面向航天、航空等多源异构遥感图像的处理、辅助解译、信息提取及专题制图能力,特别是在国产卫星数据的支持和处理方面独具优势,是一套高度自动化、简单易用的遥感工程化应用平台,已广泛应用于气象、海洋、水利、农业、林业、国土、减灾、环保等多个领域。PIE致力于打造中国人自己的遥感软件,经过多年发展,PIE总体水平已比肩国外主流遥感软件,成为入围中央国家机关软件协议供货清单的唯一遥感类产品。1、产品特色2、产品体系3、行业应用方向
推荐直播
-
 华为云码道Skill实战与极速交付,智能开发全链路实战
华为云码道Skill实战与极速交付,智能开发全链路实战2026/07/22 周三 19:00-21:00
王一男-华为云码道产品规划专家;李炎-华为云码道产品专家;姜浩-华为云HCDG核心组成员
直播深度解读华为云码道6月产品新特性,从Skill市场安装专家技能,带你零距离体验从需求,开发,审查,重构全链路闭环的开发过程。从零构建并交付一个完整项目,让您体验从代码提交到服务上线的“极速”之旅。
回顾中 -
 聚开发者之力,创具身新未来
聚开发者之力,创具身新未来2026/07/23 周四 15:00-17:00
张豪杰/程文/王军/刘新春/黄钦开 /张晓天
本次华为云具身智能开发平台CloudRobo培训面向具身智能开发者,带您全流程体验机器人本体R2C小时级接入、环境重建与轨迹生成仿真数据生产、PB级数据管理、数据评测、模型训推、强化学习和Benchmark一键评测等功能,并体验业界主流具身模型应用。
回顾中
热门标签