-
 HSV色彩空间RGB是从硬件的角度提出的颜色模型,在与人眼匹配的过程中可能存在一定的差异。而HSV色彩空间是一种面向视觉感知的颜色模型。HSV色彩空间是从心理学和视觉的角度出发,指出人眼色彩知觉主要包含3个要素:色调,饱和度,亮度。说到这里,相信用过PS的都应该清楚HSV到底能干什么了吧?不过,我们还是介绍一些这3个要素,毕竟本篇博文就是专门将色彩空间理论知识的,不能有空缺。色调(H):指光的颜色,色调与混合光谱中的主要光波长相关,例如“赤橙黄绿青蓝紫”分别表示不同的色调。如果从波长的角度考虑,不同的波长的光表现为不同的颜色,实际上它们体现的是色调的差异。饱和度(S):指色彩的深浅层度,相对于纯净度,或一种颜色混合白光的数量。纯谱色是全饱和的,像深红色(红加白)和淡紫色(紫加白)这样的彩色是欠饱和的,饱和度与所加白光的数量成反比。亮度(V):反映的是人眼感受到的光的明暗程度,该指标与物体的反射度有关。对于色彩来讲,如果在其中掺入的白色越多,则其亮度越高;如果在其掺入的黑色越多,则亮度越低。在具体的实现上,我们将物理空间的颜色分布在圆周上,不同的角度代表不同的颜色。因此,通过调整色调值,我们就能选取不同的颜色,色调的取值范围为[0,360]。色调取值不同,颜色也不同,具体如下表所示:色调值(度)颜色0红色60黄色120绿色180青色240蓝色300品红色饱和度的值为[0,1],饱和度的值为0时,只有灰度,饱和度越大,颜色值越丰富。至于亮度,其取值范围也是[0,1]。例如,博主现在取色调=0,饱和度=1,亮度=1,就可以提取色彩深红色。介绍完理论知识,HSV与上面的色彩空间一样,也需要与RGB进行转换,不过,我们这里转换之前,需要先将RGB色彩空间的值转换到[0,1]之间,然后在进行处理。具体处理如下:V=max(R,G,B) 亮度 这里,H的计算结果可能小于0,如果出现这种情况,则需要对H进一步的处理计算。如下所示: 上述公式计算的结果肯定与前面说的色调,亮度,饱和度的范围一致。至于HSV转RGB,感兴趣的可以参考开发文档。HLS色彩空间HLS与HSV色彩空间类似,都具有3要素。只是HLS色彩空间就L与V不同,其中HLS色彩空间的L(光亮度/明度)替换了亮度。那么什么是光亮度/明度呢?其实,光亮度/明度是用来控制色彩的明暗变换,它的取值范围同样也是[0,1]。我们在程序中,可以通过光亮度/明度的大小来衡量有多少光线从物体表面反射出来。光亮度/明度对于眼睛感知颜色很重要,因为当一个具有色彩的物体处于光线太强或者太暗的地方时,眼睛是无法准确获取物体颜色的。说实话,编辑公式有点费劲,感兴趣的自己查询开发文档,后续在python中开发,我们都是使用cv2.cvtColor()进行转换的。使用起来,你只需要了解其到底做什么的,并不需要知道其内部如何实现,但内部实现,就是上面的这些数学公式。CIELab*色彩空间CIELab*色彩空间是均匀色彩空间模型,它是面向视觉感知的颜色模型。从视觉感知均匀的角度来讲,人所感知到的两种颜色的区别程度,应该与这两种颜色在色彩空间中的距离成正比。在某个色彩空间中如果人所观察的两种颜色的区别程度,与这两种颜色在该色彩空间中对应的点之间的欧式距离成正比,则称该色彩空间为均匀色彩空间。CIELab色彩空间中的L分量用于表示像素的亮度,取值范围为[0,100],表示从纯黑到纯白;a分量表示从红色到绿色的范围,取值范围为[-127,127];b*分量表示从黄色到蓝色的范围,取值范围为[-127.127]。由于CIELab是在CIE的XYZ色彩空间上发展起来的,所以转换的时候,需要先将RGB转换为XYZ色彩空间,然后在转换为CIELab。具体的数学公式感兴趣的查询开发文档。CIELuv*色彩空间CIELuv色彩空间同CIELab色彩空间一样,是均匀的颜色模型。CIELuv*色彩空间与设备无关,适用于显示器显示和根据加色原理进行组合的场合,该模型中比较强调对红色的表示,即对红色的变化比较敏感,但对蓝色的变化不太敏感。同样的,CIELuv色彩空间也需要先将RGB转换为XYZ色彩空间,然后在转换为CIELuv,具体公式感兴趣的可以查询开发文档。Bayer色彩空间Bayer色彩空间被广泛的应用在CCD和CMOS相机中。色彩空间的理论知识,到这里基本就讲解完成了,感兴趣的可以自己扩展最后几个数学公式。作者:极客学编程链接:https://juejin.cn/post/6983234024609169421来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
HSV色彩空间RGB是从硬件的角度提出的颜色模型,在与人眼匹配的过程中可能存在一定的差异。而HSV色彩空间是一种面向视觉感知的颜色模型。HSV色彩空间是从心理学和视觉的角度出发,指出人眼色彩知觉主要包含3个要素:色调,饱和度,亮度。说到这里,相信用过PS的都应该清楚HSV到底能干什么了吧?不过,我们还是介绍一些这3个要素,毕竟本篇博文就是专门将色彩空间理论知识的,不能有空缺。色调(H):指光的颜色,色调与混合光谱中的主要光波长相关,例如“赤橙黄绿青蓝紫”分别表示不同的色调。如果从波长的角度考虑,不同的波长的光表现为不同的颜色,实际上它们体现的是色调的差异。饱和度(S):指色彩的深浅层度,相对于纯净度,或一种颜色混合白光的数量。纯谱色是全饱和的,像深红色(红加白)和淡紫色(紫加白)这样的彩色是欠饱和的,饱和度与所加白光的数量成反比。亮度(V):反映的是人眼感受到的光的明暗程度,该指标与物体的反射度有关。对于色彩来讲,如果在其中掺入的白色越多,则其亮度越高;如果在其掺入的黑色越多,则亮度越低。在具体的实现上,我们将物理空间的颜色分布在圆周上,不同的角度代表不同的颜色。因此,通过调整色调值,我们就能选取不同的颜色,色调的取值范围为[0,360]。色调取值不同,颜色也不同,具体如下表所示:色调值(度)颜色0红色60黄色120绿色180青色240蓝色300品红色饱和度的值为[0,1],饱和度的值为0时,只有灰度,饱和度越大,颜色值越丰富。至于亮度,其取值范围也是[0,1]。例如,博主现在取色调=0,饱和度=1,亮度=1,就可以提取色彩深红色。介绍完理论知识,HSV与上面的色彩空间一样,也需要与RGB进行转换,不过,我们这里转换之前,需要先将RGB色彩空间的值转换到[0,1]之间,然后在进行处理。具体处理如下:V=max(R,G,B) 亮度 这里,H的计算结果可能小于0,如果出现这种情况,则需要对H进一步的处理计算。如下所示: 上述公式计算的结果肯定与前面说的色调,亮度,饱和度的范围一致。至于HSV转RGB,感兴趣的可以参考开发文档。HLS色彩空间HLS与HSV色彩空间类似,都具有3要素。只是HLS色彩空间就L与V不同,其中HLS色彩空间的L(光亮度/明度)替换了亮度。那么什么是光亮度/明度呢?其实,光亮度/明度是用来控制色彩的明暗变换,它的取值范围同样也是[0,1]。我们在程序中,可以通过光亮度/明度的大小来衡量有多少光线从物体表面反射出来。光亮度/明度对于眼睛感知颜色很重要,因为当一个具有色彩的物体处于光线太强或者太暗的地方时,眼睛是无法准确获取物体颜色的。说实话,编辑公式有点费劲,感兴趣的自己查询开发文档,后续在python中开发,我们都是使用cv2.cvtColor()进行转换的。使用起来,你只需要了解其到底做什么的,并不需要知道其内部如何实现,但内部实现,就是上面的这些数学公式。CIELab*色彩空间CIELab*色彩空间是均匀色彩空间模型,它是面向视觉感知的颜色模型。从视觉感知均匀的角度来讲,人所感知到的两种颜色的区别程度,应该与这两种颜色在色彩空间中的距离成正比。在某个色彩空间中如果人所观察的两种颜色的区别程度,与这两种颜色在该色彩空间中对应的点之间的欧式距离成正比,则称该色彩空间为均匀色彩空间。CIELab色彩空间中的L分量用于表示像素的亮度,取值范围为[0,100],表示从纯黑到纯白;a分量表示从红色到绿色的范围,取值范围为[-127,127];b*分量表示从黄色到蓝色的范围,取值范围为[-127.127]。由于CIELab是在CIE的XYZ色彩空间上发展起来的,所以转换的时候,需要先将RGB转换为XYZ色彩空间,然后在转换为CIELab。具体的数学公式感兴趣的查询开发文档。CIELuv*色彩空间CIELuv色彩空间同CIELab色彩空间一样,是均匀的颜色模型。CIELuv*色彩空间与设备无关,适用于显示器显示和根据加色原理进行组合的场合,该模型中比较强调对红色的表示,即对红色的变化比较敏感,但对蓝色的变化不太敏感。同样的,CIELuv色彩空间也需要先将RGB转换为XYZ色彩空间,然后在转换为CIELuv,具体公式感兴趣的可以查询开发文档。Bayer色彩空间Bayer色彩空间被广泛的应用在CCD和CMOS相机中。色彩空间的理论知识,到这里基本就讲解完成了,感兴趣的可以自己扩展最后几个数学公式。作者:极客学编程链接:https://juejin.cn/post/6983234024609169421来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 -
前言在前面,我们只介绍了三种图像的类型,分别位二值图像、灰度图像以及RGB图像。但我们现在常用的图像肯定是RGB图像,不过它只是色彩空间的一种类型,在实际的图像中,还有许多其他的色彩空间,对于会PS的读者来说肯定不会陌生。比如GRAY色彩空间(灰度图像),XYZ色彩空间,YCrCb色彩空间,HSV色彩空间,HLS色彩空间,CIELab色彩空间,CIELuv色彩空间,Bayer色彩空间等。每个图像都有其擅长处理的内容,因此我们要掌握这些色彩空间图像的转换,以便后续更方便的处理图像的问题。GRAY色彩空间GRAY就是我们前面介绍的灰度图像,通常指8位灰度图像,其具有256个灰度级,像素值范围位[0,255]。RGB转换位GRAY的数学公式如下:Gray=0.229R+0.587G+0.114*B而图像有GRAY色彩空间转换为RGB色彩空间时,最终所有通道的值都是相同的,其处理方式如下:R=GrayG=GrayB=GrayXYZ色彩空间XYZ色彩空间是由CIE(International Commission on Illumination)定义的,是一种更便于计算的色彩空间,它不像RGB转换位GRAY,只能单向转换,XYZ色彩空间与RGB转换不会丢失任何值。将RGB色彩空间转换为XYZ色彩空间,其转换公式为:将XYZ色彩空间转换为RGB色彩空间,其转换公式为:YCrCb色彩空间人眼视觉系统对颜色的敏感度要低于对亮度的敏感度。在传统的RGB色彩空间内,RGB三原色具有相同的重要性,但是忽略了亮度的信息。所以,才有了YCrCb色彩空间。在YCrCb色彩空间中,Y代表光源的亮度,色度信息保存在Cr和Cb中,其中,Cr表示红色分量信息,Cb表示蓝色分量信息。亮度给出了颜色亮或暗的程度信息,该信息可以通过照明中强度成分的加权和来计算。在RGB光源中,绿色分量的影响最大,蓝色分量的影响最小。从RGB色彩空间转换YCrCb色彩空间的数学公式如下:Y=0.229R+0.587G+0.114*BCr=(R-Y)*0.713+deltaCb=(B-Y)*0.564+delta其中delta的值为: 从YCrCb色彩空间转RGB数学公式如下:R=Y+1.403*(Cr-delta)G=Y-0.714*(Cr-delta)-0.344*(Cb-delta)B=Y+1.773*(Cb-delta)
-
前言在前面博文讲解位平面分解的时候,我们就提到过可以通过位平面分解的方式给图像添加水印。而数值水印是图片版权用到最多的加密方式。通过在最低有效位的位平面分解图中隐藏二值图像信息,具有极高的隐蔽性。所以,友情提示各位程序员,不要以为网上的图像可以随便用,现在的加密方式真是让你防不胜防。就算你知道了添加数值谁水印的原理,恐怕也无法找到其哪个是秘密的信息。(尊重版权,不要存在侥幸心理)数字水印的处理过程从位平面来看,数字水印的处理过程分为如下几步:(1)嵌入过程:将载体图像的第0个位平面替换为数字水印信息。(2)提取过程:将载体图像的最低有效位平面提取出来,得到数字水印信息。代码实现嵌入与提取数字水印原理我们都清楚之后,我们可以直接开始编写代码:import cv2 import numpy as np img = cv2.imread("4.jpg", 0) watermark = cv2.imread("watermark.jpg", 0) #因为水印图像就是让人不易察觉也不影响原图像,所以要将水印非0位全部替换位最小值1 w = watermark[:, :] > 0 watermark[w] = 1 #嵌入水印 r, c = img.shape #生成元素都是254的数组 img254=np.ones((r,c),dtype=np.uint8)*254 #获取高7位平面 imgH7=cv2.bitwise_and(img,img254) #将水印嵌入即可 water_img=cv2.bitwise_or(imgH7,watermark) cv2.imshow("1",img) cv2.imshow("2",watermark*255) cv2.imshow("3",water_img) #生成都是1的数组 img1=np.ones((r,c),dtype=np.uint8) #提取水印 water_extract=cv2.bitwise_and(water_img,img1) #将水印里面的1还原成255 w=water_extract[:,:]>0 water_extract[w]=255 cv2.imshow("4",water_extract) cv2.waitKey() cv2.destroyAllWindows() 复制代码前面我们介绍过,图像的最低位平面就是00000001,而其他7个位平面合并就是11111110,也就是254,所以我们创建了一个全部为254的数组。通过它获取高7个位平面,然后与数字水印图合并即可。同样的,提取图像中数字水印,我们只需要获取最低有效位平面,然后将其1值,全部换成255,就可以显示出原水印图。运行之后,显示的效果如下图所示:作者:极客学编程链接:https://juejin.cn/post/6983234006359752711来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
按位异或要实现图像的加密与解密,我们首先需要掌握数学中的按位异或计算方式。异或运算也叫半加运算,其运算法则与不带进位的二进制加法类似。在python中,通过“^”符号进行异或计算。下面,博主专门列出一个表格详解按位异或运算:算数1算数2结果python代码0000^00110^11011^01101^1简单的概括按位异或运算的规则是:相同的两个数运算为0,不同两个数运算为1。按位异或不仅仅用于图像的加密与解密,而且可以通过它统计不相同的数。什么是图像的加密与解密图像的加密定义:通过对原始图像与密钥图像进行按位异或运算。图像的解密定义:将加密后的图像与密钥图像在次进行按位异或运算。从图像的加密与解密可以看出来,它们都是同一种运算。我们现在规定异或的文字符号为xor,根据上述按位异或运算,我们假设:xor(a,b)=c则可以得到:xor(c,b)=a亦或者:xor(c,a)=b综上所述,我们假设a为原始的图像数据,b为密钥,那么通过xor(a,c)计算出来的c就是加密后的密文。简单的概括加密与解密。加密过程:将图像a与密钥b进行按位异或运算,完成加密,得到密文c。解密过程:将密文c与密钥b进行按位异或运算,完成解密,得到图像a。将图像加密既然我们完全掌握了图像加密与解密的原理,下面我们通过代码来实现一个图像的加密。同样的,这里我们先获取一个灰度图像。import cv2 import numpy as np img = cv2.imread("4.jpg", 0) r, c = img.shape key = np.random.randint(0, 256, size=[r, c], dtype=np.uint8) encryption = cv2.bitwise_xor(img, key) cv2.imshow("111", encryption) cv2.waitKey() cv2.destroyAllWindows() 复制代码运行之后,我们会得到乱码图像:将图像解密将图像解密通过是通过按位异或运算,这里我们只需要用加密后的图像与key进行按位异或即可,完整代码如下所示:import cv2 import numpy as np img = cv2.imread("4.jpg", 0) r, c = img.shape key = np.random.randint(0, 256, size=[r, c], dtype=np.uint8) encryption = cv2.bitwise_xor(img, key) decryption = cv2.bitwise_xor(encryption, key) cv2.imshow("111", encryption) cv2.imshow("222", decryption ) cv2.waitKey() cv2.destroyAllWindows() 复制代码运行之后,我们即可得到原图与加密图像:作者:极客学编程链接:https://juejin.cn/post/6982874209147944974来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
什么是位平面分解将灰度图像中处于统一比特位上的二进制像素值进行组合,得到一副二进制图像,该图像被称为灰度图像的一个位平面,这个过程被称为位平面分解。例如,将一副灰度图像内所有像素点上处于二进制位内的最低位上的值进行组合,可以构成“最低有效位”位平面。在8位灰度图像中,每一个像素使用8位二进制来表示,其值的范围在[0,255]之间,从低到高的分别位:00000001 00000010 00000100 00001000 00010000 00100000 01000000 10000000取这些值之后,我们通过按位与运算,就可以得到所有位平面分解图。至于有什么用呢?聪明的小伙伴肯定知道。比如,我们需要给一个图像添加水印,是在高位平面添加好,还是最低有效位平面添加好呢?当然是低位平面,因为它的信息最少,添加水印后,去除水印也比较容易。灰度图位平面分解既然,我们了解了灰度位平面分解以及它的所有知识。下面,我们就来获取一张绘图图像,提取它的所有位平面图。具体代码如下所示:import cv2 import numpy as np a = cv2.imread("4.jpg", 0) r, c = a.shape b = np.zeros((r, c, 8), dtype=np.uint8) for i in range(8): b[:, :, i] = 2 ** i for i in range(8): temp = cv2.bitwise_and(a, b[:, :, i]) cv2.imshow(str(i),temp) cv2.waitKey() cv2.destroyAllWindows() 复制代码运行之后,我们得到灰度图像的8个位平面图: 而原图是这样的:彩色图位平面分解既然灰度图像有其位平面,那么彩色图像同样也可以提取出来。但是因为彩色图像的矩阵为3维矩阵,所以我们需要给RGB的每个颜色值进行按位与运算。具体代码如下所示:import cv2 import numpy as np a = cv2.imread("4.jpg", -1) x, y, z = a.shape b = np.zeros((x, y, 8), dtype=np.uint8) for i in range(8): b[:, :, i] = 2 ** i temp = np.zeros((x, y, 3), dtype=np.uint8) for i in range(8): temp[:, :, 0] = cv2.bitwise_and(a[:, :, 0], b[:, :, i]) temp[:, :, 1] = cv2.bitwise_and(a[:, :, 1], b[:, :, i]) temp[:, :, 2] = cv2.bitwise_and(a[:, :, 2], b[:, :, i]) cv2.imshow(str(i), temp) cv2.waitKey() cv2.destroyAllWindows() 复制代码运行之后,我们会得到下面8张位平面图:阈值不知道,读者注意到了没有,不管是灰度图像还是彩色图像,其0-4位图的细节几乎看不到,都是黑色的。这个时候如何让其细节更加凸显呢?答案是改变其阈值,它们数值肯定非常小,我们直接把其更改为255,除0之外都可以凸显其细节出来。现在我们把彩色位图提取的代码更改一下,代码如下:import cv2 import numpy as np a = cv2.imread("4.jpg", -1) x, y, z = a.shape b = np.zeros((x, y, 8), dtype=np.uint8) for i in range(8): b[:, :, i] = 2 ** i temp = np.zeros((x, y, 3), dtype=np.uint8) for i in range(8): temp[:, :, 0] = cv2.bitwise_and(a[:, :, 0], b[:, :, i]) temp[:, :, 1] = cv2.bitwise_and(a[:, :, 1], b[:, :, i]) temp[:, :, 2] = cv2.bitwise_and(a[:, :, 2], b[:, :, i]) m = temp[:, :] > 0 temp[m] = 255 cv2.imshow(str(i), temp) cv2.waitKey() cv2.destroyAllWindows() 复制代码运行之后,效果如下所示:彩色位平面图合成既然有分解,那么肯定有合成。所以我们也需要掌握如何将所有位平面合成为一张图。代码如下:import cv2 import numpy as np a = cv2.imread("4.jpg", -1) x, y, z = a.shape b = np.zeros((x, y, 8), dtype=np.uint8) for i in range(8): b[:, :, i] = 2 ** i bit_img = np.zeros((x, y, 3), dtype=np.uint8) temp = np.zeros((x, y, 3), 'uint8') for i in range(8): bit_img[:, :, 0] = cv2.bitwise_and(a[:, :, 0], b[:, :, i]) bit_img[:, :, 1] = cv2.bitwise_and(a[:, :, 1], b[:, :, i]) bit_img[:, :, 2] = cv2.bitwise_and(a[:, :, 2], b[:, :, i]) temp[:, :, 0] = cv2.bitwise_or(temp[:, :, 0], bit_img[:, :, 0]) temp[:, :, 1] = cv2.bitwise_or(temp[:, :, 1], bit_img[:, :, 1]) temp[:, :, 2] = cv2.bitwise_or(temp[:, :, 2], bit_img[:, :, 2]) m = bit_img[:, :] > 0 bit_img[m] = 255 #cv2.imshow(str(i)+".bmp",bit_img) cv2.imshow('00000000', temp) cv2.waitKey() cv2.destroyAllWindows() 复制代码这里,我们通过按位或bitwise_or函数合并为位平面图。运行之后,temp就是原图,而bit_img就是位平面图。这样我们在实际处理的时候,能在中间对位平面图bit_img进行操作后,在合并为一张图。灰度位平面图合成彩色比灰度要复杂的多,灰度位平面图合并就相对较为简单。话不多说,我们直接上代码:import cv2 import numpy as np a = cv2.imread("4.jpg", 0) r, c = a.shape b = np.zeros((r, c, 8), dtype=np.uint8) for i in range(8): b[:, :, i] = 2 ** i c=np.zeros((r,c),dtype=np.uint8) for i in range(8): temp = cv2.bitwise_and(a, b[:, :, i]) c=cv2.bitwise_or(c,temp) cv2.imshow("111",c) cv2.waitKey() cv2.destroyAllWindows()作者:极客学编程链接:https://juejin.cn/post/6982863982402994190来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
常见的按位逻辑运算在OpenCV内,常见的按位运算函数如下表所示:函数名含义bitwise_and()按位与bitwise_or()按位或bitwise_xor()按位异或bitwise_not()按位取反按位与运算数学中按位与运算,简单概括就是只有对应的两个二进位都为1时,结果位才为1。在python中,通过“&”符号进行按位与运算,具体运算结果如下标:算1算2结果对应python代码0000&00100&11001&01111&1按位与运算是将数值转换为二进制后,对应位置进行运算。例如博主这里随便取两个数据,计算结果如下表:|数值|十进制 |二进制结果 | |--|--|--|--| | 数值1| 165 | 10100101 | | 数值2| 122| 01111010 | | 结果 |32 | 00100000 |掩模图像要获取掩模图像,我们需要先介绍OpenCV中的按位与函数:cv2.bitwise_and()。其具体的语法为:dst=cv2.bitwise_and(src1,src2[,mask])dst:表示输入值具有同样大小的array输出值。 src1:表示第一个array或scalar类型的输入值 src2:表示第二个array或scalar类型的输入值 mask:表示可选操作掩码,8位单通道array通过上面的按位与计算,我们知道,任何图像只要不是黑色,都不是0。所以,我们将黑色0与任何数字按位与计算都会得到1。这样,我们可以将不想显示的部分去掉。首先,我们需要构建一个掩模图像,具体代码如下:a = cv2.imread("2_2.png", 1) b=np.zeros(a.shape,dtype=np.uint8) b[100:400,200:400]=255 复制代码这里的b就是掩模图像,白色显示的部分就是我们需要截取的图像部分。这里[100:400,200:400],你可以把图像想象成一个坐标系,左上角(100,200),右下角(200,400)。运行之后,掩模图像b与原图a如下所示:通过掩模图像,保留需要的图像既然我们已经获取了掩模图像,下面我们可以直接通过OpenCV提供的函数进行运算得到,具体代码如下所示:import cv2 import numpy as np a = cv2.imread("2_2.png", 1) b=np.zeros(a.shape,dtype=np.uint8) b[100:400,200:400]=255 c=cv2.bitwise_and(a,b) cv2.imshow("a", a) cv2.imshow("b", b) cv2.imshow("c", c) cv2.waitKey() cv2.destroyAllWindows() 复制代码运行之后,显示效果如下所示:作者:极客学编程链接:https://juejin.cn/post/6982494321035444237来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
什么是图像加权和所谓图像加权和,就是计算两幅图像的像素值之和时,将两幅图像的权重考虑进来,数据公式表示为如下:dst=saturate(src1a+src2b+y)OpenCV中提供cv2.addWeighted()函数,来实现图像的加权和,该函数的定义为:addWeighted(src1, alpha, src2, beta, gamma, dst=None, dtype=None)其中,参数alpha和beta是src1和src2所对应的系数,它们的和可以等于1,也可以不等于1。分别对应数学公式a,b。而gamma对应数学公司y。需要注意的是gamma的值可以是0,但不能省略,是必选参数。简单的理解就是“图像1系数1+图像2系统2+亮度调节参数”。玻璃上出现人头在各大灵异的网站,我们都会见到各种的拍摄图像中出现各种鬼影。当然,博主并不是要说这完全不存在,至于存不存在不在这里的讨论范畴,但是我们可以通过图像加权和给某个图片嵌入人头,造成有鬼影的样子。上面是两张原始的图像,分别对应上面的src1,src2。叠加实现鬼影效果的具体代码如下所示:import cv2 img = cv2.imread("2_2.png", 1) head = cv2.imread("2_1.png", 1) print(img.shape, head.shape) head = cv2.addWeighted(img, 1, head, 0.3, 0) cv2.imshow("123", head) cv2.waitKey() cv2.destroyAllWindows() 复制代码运行之后,效果如下所示:作者:极客学编程链接:https://juejin.cn/post/6982421319329513479来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
图像的两种加法运算对于图像的处理来说,加法运算都是比较基础的运算。而复杂的图像处理,都是通过这些基础的知识来完成的。所以,对于OpenCV的开篇,我们要详细介绍它的加法运算。在图像的处理过程中,OpenCV给我们提供了两种对图像的加法运算。一种是通过“+”号直接处理,一种是通过add函数进行处理。“+”与add函数在认识“+”运算符之前,我们需要了解一下RGB图像颜色的组成。众所周知,不管是红色,蓝色还是绿色,通过程序设置的最大值就是255。那么现在就有一个棘手的问题,假如加法运算之后,大于255怎么办?对于“+”运算符来说,如果大于了255,就需要取余数。比如绿色值为222,现在要加55,那么最后值不是277,而是21。而add函数并不是这样,通过add实现图像的加法运算,没有取余数的说法,凡是加法之后大于255的,统一都设置为255。了解了这些,我们就可以非常灵活的使用加法运算。获取一个图像既然了解了图像的加法运算,下面我们就来获取一个图像进行操作,代码如下所示:import cv2 img = cv2.imread("1.jpg", 1) 这里,我们通过import cv2导入OpenCV库,然后获取图像,这里需要注意第2个参数。博主这里专门列出一个表格方便大家认识第2个参数意义。数值含义-1保持原格式不变 (也就是如果是灰度图像那么就是灰度图像,如果是彩色图像,那么就是彩色)0将图像调整为单通道灰度图像1将图像调整为3通道BGR图像,这个是more五年值2当载入图像深度为16位或者32位时,就返回其对应的深度图像;否则,将其转换为8位图像4以任何可能的颜色格式读取图像8使用gdal驱动程序加载图像以上是我们常用到的参数值,当然不仅仅只有这些参数,还有一大堆获取图像后缩小图像大小的参数,感兴趣的可以查询开发文档。接着,我们将获取的图像显示出来,具体代码如下所示:import cv2 img = cv2.imread("1.jpg", -1) cv2.imshow("图片", img)#显示图像,参数1为窗口标题,2为获取的图像,中文乱码后续讲解 cv2.waitKey()#等待用户按下 cv2.destroyAllWindows()#释放所有窗口 复上面的注释够详细,这里就不在赘述。运行之后,显示的效果如下所示:调整图像亮度调整图像亮度我们一般使用add函数,但是为了区分两种加法的区别,我们同时计算并同时显示其图像,具体代码如下所示:import cv2 img = cv2.imread("1.jpg", -1) symbol_img=img+img add_img=cv2.add(img,img) cv2.imshow("图片1", symbol_img) cv2.imshow("图片2", add_img) cv2.waitKey() cv2.destroyAllWindows() 运行之后,显示的效果如下图所示(左“+”,右add):其中左边图像大于255的全部取余数,导致本来亮的像素变得更暗了。而右边图像因为使用add函数不用取模,大于255统一赋值为255,所以每个细节都只会比原图更亮。来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
图像的基本表示方法在实现图像如何变亮之前,我们需要认识一下图像的基本表示方法。在电脑中,图像被分为3种:二值图像,灰度图像以及彩色图像。其中二值图像是指仅仅包含黑色和白色两种颜色的图像,比如在程序中,为了表示数字A,我们可以通过如下栅格状排列的数据集来表示,如下图所示:其中0代表黑色,1代表白色,这样我们可以确定我们要显示的内容,不过其没有颜色,也没有深浅,只能显示形状。第2个种图像就是灰度图像,它可以通过深浅绘制出大致的人物形状,内容样式等等,但其没有颜色。效果与上面一样,只是每一个方块的数值不在是0和1,而是[0,255]。最后一种是彩色图像,它就是在灰度图像上添加了颜色,虽然也可以用上面的二值图像来表示,但其中的一个方块不是0和1,也不是[0,255],而是[[0,255],[0,255],[0,255]]。这样也就是变成了一个三维的矩阵。来源:掘金著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
-
 # opencv编译指导 此指导可以将MindX SDK中的opencv增加FFmpeg视频解码和图像显示功能。需要按如下指导编译opencv之后将生成的libopencv_world.so替换SDK本身的so。 ## 1. 标准形态软件依赖 以安装包Ascend-mindxsdk-mxvision_2.0.2.b011_linux-aarch64.run为例,其中的opencv版本为4.3.0 | 依赖软件 | 版本 | 下载地址 | 说明 | | -------- | ----- | ------------------------------------------------------------ | ------------------------------------ | | opencv | 4.3.0 | [link](https://github.com/opencv/opencv/releases) | opencv的基本组件,用于图像的基本处理 | | ffmpeg | 4.2.1 | [link](https://github.com/FFmpeg/FFmpeg/archive/n4.2.1.tar.gz) | 视频转码解码组件 | | 注意: - 其中opencv的版本需要和SDK动态链接库的opencv版本一致 - 设备区别(x86 和 arm 等) ### 1.1 FFmpeg 下载完解压,进入解压后的目录,按以下命令编译即可 **注意** 其中的${路径} 为自己指定的FFmpeg安装路径需要替换成实际路径 ``` ./configure --prefix=${路径}/ffmpeg --enable-shared make -j make install ``` ffmpeg 编译完成请设置环境变量,${路径}需替换成实际的安装路径 ``` export LD_LIBRARY_PATH=${路径}/ffmpeg/lib:$LD_LIBRARY_PATH ``` ## 2 编译opencv ### 2.1 安装gtk 可视化需要 [参考链接](https://stackoverflow.com/questions/58370077/how-can-i-enable-gtk-for-opencv-in-cmake) ``` sudo apt-get install libgtk2.0-dev libgtk-3-dev ``` ### 2.1 准备脚本 **步骤1** 将脚本放到和opencv源码包同级的路径下 eg: 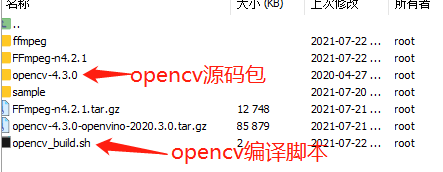 **步骤2** 修改opencv编译脚本中的路径需要将脚本中的${路径}替换为实际的FFmpeg安装路径 ``` PKG_CONFIG_PATH=$PKG_CONFIG_PATH:${路径}/ffmpeg/lib/pkgconfig \ ``` **步骤3** 运行脚本 bash opencv_build.sh 将在opencv_build.sh同级的目录中生成一个tmp路径 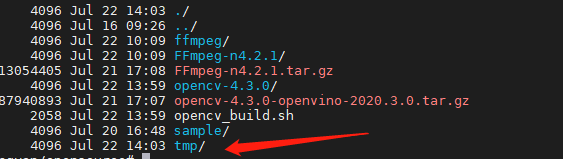 **步骤4** 进入tmp -> opencv -> lib 执行 ldd -r libopencv_world.so.4.3.0 | grep av 查看是否和FFmpeg的库链接成功  ## 3 替换SDK中的opencv链接库 1 进入${SDK安装路径}/opensource/lib,将其中libopencv_world.so.4.3.0移入其他路径备份 2 将编译opencv的路径下tmp/opencv/lib 路径下的libopencv_world.so.4.3.0复制到当前路径,配置好软链接。 3 测试是否成功 **注意** 编译的opencv库和SDK是否兼容。比如SDK是aarch64但是编译的opencv是x86的。 ### 4 验证 指导后面有两个样例,一个是图像显示imshow,另一个是视频显示videosample。 1 调整CMakeLists.txt 配置的路径 include_directories和link_directories需要配置为自己的SDK安装路径。 ``` include_directories(${SDK安装路径}/opensource/include/opencv4) link_directories(${SDK安装路径}/opensource/lib) ``` 2 编译运行 新建目录build -> 进入build目录 -> 执行编译指令 操作如下 ``` mkdir build cd build cmake .. make -j ``` 运行可执行文件DisplayImage ### 5 对可视化的推理结果进行弹窗 之前有很多样例是将结果可视化写入结果图片,可以在其基础上对可视化结果进行弹窗展示。 比如修改前:直接将结果写入result.jpg。  修改为: ``` // 把Mat类型的图像矩阵保存为图像到指定位置。 cv::imwrite("./result.jpg", imgBgr); cv::Mat result_image; result_image = cv::imread("result.jpg"); if ( !result_image.data ) { printf("No image data \n"); return -1; } namedWindow("Display Image", cv::WINDOW_AUTOSIZE ); imshow("Display Image", result_image); cv::waitKey(0); return APP_ERR_OK; ``` 修改后效果,弹框出现如下图: 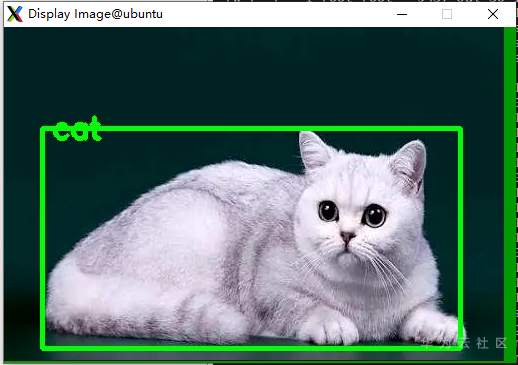 ## 常见问题 执行图形化界面显示的时候可能会遇到报错  解决: 1.先确认服务器端配置文件/etc/ssh/sshd_config中包含ForwardX11 yes 2.修改环境变量 DISPLAY export DISPLAY=本机IP:0.0 ## opencv_build.sh 脚本 其中fileName为opencv源码包文件夹名,编译生成的文件会生成在和opencv源码包同级的tmp路径下。 PKG_CONFIG_PATH需要配置为自己编译的FFmpeg路径下的pkgconfig。 ``` #!/bin/bash # Build # fileName is opencv source code path fileName="opencv-4.3.0" cd "$fileName" || { warn "cd to ./${fileName} failed" exit 254 } # in opencv-4.3.0 if [[ -d "_build" ]];then rm -r _build fi mkdir _build cd _build || { warn "Opencv needs a separate directory for building" exit 253 } # in opencv-4.3.0/_build if [[ $(uname -m) == aarch64 ]]; then opencv_aarch64_cmake_arg="-DCMAKE_CXX_FLAGS="'"'"-march=armv8-a"'"' fi export LDFLAGS="-Wl,-z,relro,-z,now -s -pie" && \ PKG_CONFIG_PATH=$PKG_CONFIG_PATH:${路径}/ffmpeg/lib/pkgconfig \ cmake \ $opencv_aarch64_cmake_arg \ -DCMAKE_BULLD_TYPE=RELEASE \ -Dgoogle=mindxsdk_private \ -DCMAKE_INSTALL_PREFIX="$(pwd)/../../tmp/opencv" \ -DCMAKE_SKIP_RPATH=TRUE \ -DCMAKE_CXX_FLAGS_RELEASE="-O2 -DNDEBUG -std=c++11 -fPIE -fstack-protector-all -fPIC -Wall -D_GLIBCXX_USE_CXX11_ABI=0" \ -DCMAKE_C_FLAGS_RELEASE="-O2 -DNDEBUG1 -fPIE -fstack-protector-all -fPIC -Wall" \ -DBUILD_opencv_world=ON \ -DBUILD_PERE_TESTS=OFF \ -DBUILD_SHARED_LIBS=ON \ -DBUILD_TESTS=OFF \ -DWITH_ADE=OFF \ -DWITH_GSTREAMER=ON \ -DWITH_GTK=ON \ -DWITH_FFMPEG=ON \ -DWITH_IPP=OFF \ -DWITH_LAPACK=OFF \ -DWITH_WEBP=OFF \ -DENABLE_NEON=OFF \ -DCPU_NEON_SUPPORTED=OFF \ -DCPU_BASELINE_REQUIRE=";" \ -G "Unix Makefiles" -j .. || { warn "Building OpenCV failed during cmake" exit 254 } make -j12 || { warn "Building OpenCV failed during cmake" exit 254 } make install -j || { warn "Building OpenCV failed during cmake install" exit 254 } cd ../.. info "Building OpenCV done." ``` ## 测试样例 ### imshow **main.cpp** ``` #include <stdio.h> #include <opencv2/opencv.hpp> using namespace cv; int main(int argc, char** argv) { if ( argc != 2 ) { printf("usage: DisplayImage.out <Image_path>\n"); return -1; } Mat image; image = imread( argv[1], 1 ); if ( !image.data ) { printf("No image data \n"); return -1; } namedWindow("Display Image", WINDOW_AUTOSIZE ); imshow("Display Image", image); waitKey(0); return 0; } ``` **CMakeLists.txt** ``` cmake_minimum_required(VERSION 2.8) project( DisplayImage ) add_compile_options(-std=c++11 -fPIC -fstack-protector-all -g -Wl,-z,relro,-z,now,-z -pie -Wall) add_definitions(-D_GLIBCXX_USE_CXX11_ABI=0 -Dgoogle=mindxsdk_private) include_directories(/home/MindX_SDK/mxVision/opensource/include/opencv4) link_directories(/home/MindX_SDK/mxVision/opensource/lib) add_executable(DisplayImage main.cpp) target_link_libraries(DisplayImage opencv_world) ``` ### video_sample **main.cpp** ``` #include <stdio.h> #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> #include <iostream> using namespace cv; using std::string; int main(int argc, char** argv) { string filename = "test.mp4"; VideoCapture capture(filename); Mat frame; if ( !capture.isOpened() ) throw "Error when reading steam_avi"; namedwindow( "w", 1); for( ; ; ) { capture >> frame; if(frame.empty()) break; waitKey(20); // waits to display frame std::cout << "hello" << std::endl; } waitKey(0); // key press to close window // releases and window destroy are automatic in C++ interfece } ``` **CMakeLists.txt** 和imshow的CMakeLists.txt 相同
# opencv编译指导 此指导可以将MindX SDK中的opencv增加FFmpeg视频解码和图像显示功能。需要按如下指导编译opencv之后将生成的libopencv_world.so替换SDK本身的so。 ## 1. 标准形态软件依赖 以安装包Ascend-mindxsdk-mxvision_2.0.2.b011_linux-aarch64.run为例,其中的opencv版本为4.3.0 | 依赖软件 | 版本 | 下载地址 | 说明 | | -------- | ----- | ------------------------------------------------------------ | ------------------------------------ | | opencv | 4.3.0 | [link](https://github.com/opencv/opencv/releases) | opencv的基本组件,用于图像的基本处理 | | ffmpeg | 4.2.1 | [link](https://github.com/FFmpeg/FFmpeg/archive/n4.2.1.tar.gz) | 视频转码解码组件 | | 注意: - 其中opencv的版本需要和SDK动态链接库的opencv版本一致 - 设备区别(x86 和 arm 等) ### 1.1 FFmpeg 下载完解压,进入解压后的目录,按以下命令编译即可 **注意** 其中的${路径} 为自己指定的FFmpeg安装路径需要替换成实际路径 ``` ./configure --prefix=${路径}/ffmpeg --enable-shared make -j make install ``` ffmpeg 编译完成请设置环境变量,${路径}需替换成实际的安装路径 ``` export LD_LIBRARY_PATH=${路径}/ffmpeg/lib:$LD_LIBRARY_PATH ``` ## 2 编译opencv ### 2.1 安装gtk 可视化需要 [参考链接](https://stackoverflow.com/questions/58370077/how-can-i-enable-gtk-for-opencv-in-cmake) ``` sudo apt-get install libgtk2.0-dev libgtk-3-dev ``` ### 2.1 准备脚本 **步骤1** 将脚本放到和opencv源码包同级的路径下 eg:  **步骤2** 修改opencv编译脚本中的路径需要将脚本中的${路径}替换为实际的FFmpeg安装路径 ``` PKG_CONFIG_PATH=$PKG_CONFIG_PATH:${路径}/ffmpeg/lib/pkgconfig \ ``` **步骤3** 运行脚本 bash opencv_build.sh 将在opencv_build.sh同级的目录中生成一个tmp路径  **步骤4** 进入tmp -> opencv -> lib 执行 ldd -r libopencv_world.so.4.3.0 | grep av 查看是否和FFmpeg的库链接成功  ## 3 替换SDK中的opencv链接库 1 进入${SDK安装路径}/opensource/lib,将其中libopencv_world.so.4.3.0移入其他路径备份 2 将编译opencv的路径下tmp/opencv/lib 路径下的libopencv_world.so.4.3.0复制到当前路径,配置好软链接。 3 测试是否成功 **注意** 编译的opencv库和SDK是否兼容。比如SDK是aarch64但是编译的opencv是x86的。 ### 4 验证 指导后面有两个样例,一个是图像显示imshow,另一个是视频显示videosample。 1 调整CMakeLists.txt 配置的路径 include_directories和link_directories需要配置为自己的SDK安装路径。 ``` include_directories(${SDK安装路径}/opensource/include/opencv4) link_directories(${SDK安装路径}/opensource/lib) ``` 2 编译运行 新建目录build -> 进入build目录 -> 执行编译指令 操作如下 ``` mkdir build cd build cmake .. make -j ``` 运行可执行文件DisplayImage ### 5 对可视化的推理结果进行弹窗 之前有很多样例是将结果可视化写入结果图片,可以在其基础上对可视化结果进行弹窗展示。 比如修改前:直接将结果写入result.jpg。  修改为: ``` // 把Mat类型的图像矩阵保存为图像到指定位置。 cv::imwrite("./result.jpg", imgBgr); cv::Mat result_image; result_image = cv::imread("result.jpg"); if ( !result_image.data ) { printf("No image data \n"); return -1; } namedWindow("Display Image", cv::WINDOW_AUTOSIZE ); imshow("Display Image", result_image); cv::waitKey(0); return APP_ERR_OK; ``` 修改后效果,弹框出现如下图:  ## 常见问题 执行图形化界面显示的时候可能会遇到报错  解决: 1.先确认服务器端配置文件/etc/ssh/sshd_config中包含ForwardX11 yes 2.修改环境变量 DISPLAY export DISPLAY=本机IP:0.0 ## opencv_build.sh 脚本 其中fileName为opencv源码包文件夹名,编译生成的文件会生成在和opencv源码包同级的tmp路径下。 PKG_CONFIG_PATH需要配置为自己编译的FFmpeg路径下的pkgconfig。 ``` #!/bin/bash # Build # fileName is opencv source code path fileName="opencv-4.3.0" cd "$fileName" || { warn "cd to ./${fileName} failed" exit 254 } # in opencv-4.3.0 if [[ -d "_build" ]];then rm -r _build fi mkdir _build cd _build || { warn "Opencv needs a separate directory for building" exit 253 } # in opencv-4.3.0/_build if [[ $(uname -m) == aarch64 ]]; then opencv_aarch64_cmake_arg="-DCMAKE_CXX_FLAGS="'"'"-march=armv8-a"'"' fi export LDFLAGS="-Wl,-z,relro,-z,now -s -pie" && \ PKG_CONFIG_PATH=$PKG_CONFIG_PATH:${路径}/ffmpeg/lib/pkgconfig \ cmake \ $opencv_aarch64_cmake_arg \ -DCMAKE_BULLD_TYPE=RELEASE \ -Dgoogle=mindxsdk_private \ -DCMAKE_INSTALL_PREFIX="$(pwd)/../../tmp/opencv" \ -DCMAKE_SKIP_RPATH=TRUE \ -DCMAKE_CXX_FLAGS_RELEASE="-O2 -DNDEBUG -std=c++11 -fPIE -fstack-protector-all -fPIC -Wall -D_GLIBCXX_USE_CXX11_ABI=0" \ -DCMAKE_C_FLAGS_RELEASE="-O2 -DNDEBUG1 -fPIE -fstack-protector-all -fPIC -Wall" \ -DBUILD_opencv_world=ON \ -DBUILD_PERE_TESTS=OFF \ -DBUILD_SHARED_LIBS=ON \ -DBUILD_TESTS=OFF \ -DWITH_ADE=OFF \ -DWITH_GSTREAMER=ON \ -DWITH_GTK=ON \ -DWITH_FFMPEG=ON \ -DWITH_IPP=OFF \ -DWITH_LAPACK=OFF \ -DWITH_WEBP=OFF \ -DENABLE_NEON=OFF \ -DCPU_NEON_SUPPORTED=OFF \ -DCPU_BASELINE_REQUIRE=";" \ -G "Unix Makefiles" -j .. || { warn "Building OpenCV failed during cmake" exit 254 } make -j12 || { warn "Building OpenCV failed during cmake" exit 254 } make install -j || { warn "Building OpenCV failed during cmake install" exit 254 } cd ../.. info "Building OpenCV done." ``` ## 测试样例 ### imshow **main.cpp** ``` #include <stdio.h> #include <opencv2/opencv.hpp> using namespace cv; int main(int argc, char** argv) { if ( argc != 2 ) { printf("usage: DisplayImage.out <Image_path>\n"); return -1; } Mat image; image = imread( argv[1], 1 ); if ( !image.data ) { printf("No image data \n"); return -1; } namedWindow("Display Image", WINDOW_AUTOSIZE ); imshow("Display Image", image); waitKey(0); return 0; } ``` **CMakeLists.txt** ``` cmake_minimum_required(VERSION 2.8) project( DisplayImage ) add_compile_options(-std=c++11 -fPIC -fstack-protector-all -g -Wl,-z,relro,-z,now,-z -pie -Wall) add_definitions(-D_GLIBCXX_USE_CXX11_ABI=0 -Dgoogle=mindxsdk_private) include_directories(/home/MindX_SDK/mxVision/opensource/include/opencv4) link_directories(/home/MindX_SDK/mxVision/opensource/lib) add_executable(DisplayImage main.cpp) target_link_libraries(DisplayImage opencv_world) ``` ### video_sample **main.cpp** ``` #include <stdio.h> #include <opencv2/core/core.hpp> #include <opencv2/highgui/highgui.hpp> #include <iostream> using namespace cv; using std::string; int main(int argc, char** argv) { string filename = "test.mp4"; VideoCapture capture(filename); Mat frame; if ( !capture.isOpened() ) throw "Error when reading steam_avi"; namedwindow( "w", 1); for( ; ; ) { capture >> frame; if(frame.empty()) break; waitKey(20); // waits to display frame std::cout << "hello" << std::endl; } waitKey(0); // key press to close window // releases and window destroy are automatic in C++ interfece } ``` **CMakeLists.txt** 和imshow的CMakeLists.txt 相同 -
【功能模块】 Mindx sdk 基础组件层 DvppWrapper 接口调用【操作步骤&问题现象】1、在自定义插件中按照https://support.huaweicloud.com/ug-vis-mindxsdk201/atlasmx_02_0185.html调用VpcResize接口2、 将resize后的数据通过Opencv转成BGR后,不能正常显示。3、VpcResize改为opencv的resize是正常的。部分代码如下:/// DVPP API 图像缩放DvppDataInfo inputDataInfo;inputDataInfo.width = imageWidth;inputDataInfo.height = imageHeight;inputDataInfo.format = MXBASE_PIXEL_FORMAT_YUV_SEMIPLANAR_420;inputDataInfo.frameId = inputMxpiFrame.frameinfo().frameid();inputDataInfo.channelId = m_channelID;inputDataInfo.dataSize = mxpVisionList->visionvec(0).visiondata().datasize();inputDataInfo.data = (uint8_t *)hostMem.ptrData;inputDataInfo.dataType = 0;DvppDataInfo outputDataInfo;ResizeConfig resizeConfig;resizeConfig.width = 352;resizeConfig.height = 192;//resizeConfig.scale_x = scale_x;//resizeConfig.scale_y = scale_y;LogInfo << "inputDataInfo.dataSize = " << inputDataInfo.dataSize;dvppWrapper.VpcResize(inputDataInfo, outputDataInfo, resizeConfig);LogInfo << "outputDataInfo.dataSize = " << outputDataInfo.dataSize;cv::Mat imgYUV(outputDataInfo.height + outputDataInfo.height / 2, outputDataInfo.width, CV_8UC1, (unsigned char *) outputDataInfo.data);cvtColor(imgYUV, output, cv::COLOR_YUV2BGR_NV12);请问下,DvppDataInfo的dataType默认值是0,是表示默认的是uin8类型的吗?VpcResize的outputDataInfo的data是转换后的数据吗?【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
因为业务需求需要在海思平台运行opencv的图像拼接功能,我将opencv和opencv_contrib下载后进行编译出现fatal error: arm-linux-gnueabi/freetype2/freetype/config/ftheader.h: No such file or director 报错,现在找不到原因,在虚拟机上用g++编译又是正常的,希望有大神指导
-
【功能模块】python版本的公共库atlas_utils中, 读取的图片都是AclImage类型,请问此类型如何保存到本地?此类型如何转换成opencv的OutputArray类型?
-
【功能模块】编译样例yolov3的时候报错,报错如下这是提示我需要下载opencv吗,可是我下载安装完opencv后依旧有这个错误,这是需要下载某个特定版本的opencv吗,异或是存在别的错误在论坛中看到https://bbs.huaweicloud.com/forum/thread-99625-1-1.html这篇帖子有一样的问题,但是该贴并没有解决我的问题,对于该样例我并没有并没有更改任何文件路径
-
【功能模块】Modelart推理作业【操作步骤&问题现象】1、psenet网络推理需要安装C++版本的opencv和编译C++文件,与此同时需要在/etc/ld.so.conf.d目录下创建opencv.conf文件t添加opencv路径2、本人采用操作:os.system('cd /etc/ld.so.conf.d&&sudo echo /usr/local/lib64 > opencv.conf&&ldconfig')【截图信息】【报错信息】(可选,上传日志内容或者附件)sh : opencv.conf: permission denied256
上滑加载中
推荐直播
-
 算子工具性能优化新特性演示——MatMulLeakyRelu性能调优实操
算子工具性能优化新特性演示——MatMulLeakyRelu性能调优实操2025/01/10 周五 15:30-17:30
MindStudio布道师
算子工具性能优化新特性演示——MatMulLeakyRelu性能调优实操
回顾中 -
 用代码全方位驱动 OBS 存储
用代码全方位驱动 OBS 存储2025/01/14 周二 16:30-18:00
阿肯 华为云生态技术讲师
如何用代码驱动OBS?常用的数据管理,对象清理,多版本对象访问等应该如何编码?本期课程一一演示解答。
即将直播 -
 GaussDB数据库开发
GaussDB数据库开发2025/01/15 周三 16:00-17:30
Steven 华为云学堂技术讲师
本期直播将带你了解GaussDB数据库开发相关知识,并通过实验指导大家利用java基于JDBC的方式来完成GaussD数据库基础操作。
去报名
热门标签