-
 华为云开发者插件英文名是 Huawei Cloud Toolkit,作为华为云围绕其产品能力向开发者桌面上的延伸,帮助开发者快速在本地连接华为云,打通华为云到开发者的最后一公里;支持VS Code、IntelliJ IDEA等主流IDE平台、以及华为云自研 CodeArts IDE ,帮助开发者更高效、便捷的搭建应用。致力于为开发者提供更稳定、快速、安全的编程体验。产品页地址:https://developer.huaweicloud.com/develop/toolkit.html产品页二维码:
华为云开发者插件英文名是 Huawei Cloud Toolkit,作为华为云围绕其产品能力向开发者桌面上的延伸,帮助开发者快速在本地连接华为云,打通华为云到开发者的最后一公里;支持VS Code、IntelliJ IDEA等主流IDE平台、以及华为云自研 CodeArts IDE ,帮助开发者更高效、便捷的搭建应用。致力于为开发者提供更稳定、快速、安全的编程体验。产品页地址:https://developer.huaweicloud.com/develop/toolkit.html产品页二维码: -
 以下 star数截止2023年6月份 1.Gin(69.1K) 项目简介:Gin 是一个用 Go (Golang) 编写的 HTTP Web 框架。 它具有类似 Martini 的 API,但性能比 Martini 快 40 倍。 仓库地址: https://github.com/gin-gonic/gin https://github.com/gin-gonic/gin 官方文档地址: 文档 | Gin Web Framework Gin 是什么?Gin 是一个用 Go (Golang) 编写的 HTTP Web 框架。 它具有类似 Martini 的 API,但性能比 Martini 快 40 倍。如果你需要极好的性能,使用 Gin 吧。如何使用 Gin?我们提供了一些 API … https://gin-gonic.com/zh-cn/docs/ 2.Beego(29.8K) 项目简介:Beego用于在Go中快速开发企业应用程序,包括RESTful API、web应用程序和后端服务。它的灵感来源于Tornado, Sinatra and Flask。beego有一些特定于Go的特性,如接口和结构嵌入。 仓库地址: GitHub - beego/beego: beego is an open-source, high-performance web framework for the Go programming language. beego is an open-source, high-performance web framework for the Go programming language. - GitHub - beego/beego: beego is an open-source, high-performance web framework for the Go programming language. https://github.com/beego/beego 官方文档地址: Welcome to Beego | Beego The most easy use framework https://beego.gocn.vip/beego/zh/developing/ 3.Fiber(26.5K) 项目简介:Fiber是一个Go web框架,构建在Go最快的HTTP引擎Fasthttp之上。它的设计目的是为了在零内存分配和性能的情况下简化快速开发。 仓库地址: https://github.com/gofiber/fiber https://github.com/gofiber/fiber 官方文档地址: Welcome - Fiber https://docs.gofiber.io/ 4.Echo(25.8K) 项目简介:高性能、极简Go web框架 仓库地址: GitHub - labstack/echo: High performance, minimalist Go web framework High performance, minimalist Go web framework. Contribute to labstack/echo development by creating an account on GitHub. https://github.com/labstack/echo 官方文档地址: Echo - High performance, minimalist Go web framework Echo is a high performance, extensible, minimalist web framework for Go (Golang). https://echo.labstack.com/ 5.Iris(24K) 项目简介:Iris是一个高效且设计良好的跨平台web框架,具有强大的功能集。构建具有无限潜力和可移植性的高性能web应用程序和API。 仓库地址: GitHub - kataras/iris: The fastest HTTP/2 Go Web Framework. New, modern, easy to learn. Fast development with Code you control. Unbeatable cost-performance ratio | 谢谢 | #golang The fastest HTTP/2 Go Web Framework. New, modern, easy to learn. Fast development with Code you control. Unbeatable cost-performance ratio :leaves: :rocket: | 谢谢 | #golang - GitHub - kataras/iris: The fastest HTTP/2 Go Web Framework. New, modern, easy to learn. Fast development with Code you control. Unbeatable cost-performance ratio | 谢谢 | #golang https://github.com/kataras/iris 官方文档地址: Iris Docs The fastest HTTP/2 Go Web Framework. Iris provides a beautifully expressive and easy to use foundation for your next website, API, or distributed app. https://www.iris-go.com/docs/#/ ———————————————— 版权声明:本文为CSDN博主「深漂小码哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq2942713658/article/details/127720799
以下 star数截止2023年6月份 1.Gin(69.1K) 项目简介:Gin 是一个用 Go (Golang) 编写的 HTTP Web 框架。 它具有类似 Martini 的 API,但性能比 Martini 快 40 倍。 仓库地址: https://github.com/gin-gonic/gin https://github.com/gin-gonic/gin 官方文档地址: 文档 | Gin Web Framework Gin 是什么?Gin 是一个用 Go (Golang) 编写的 HTTP Web 框架。 它具有类似 Martini 的 API,但性能比 Martini 快 40 倍。如果你需要极好的性能,使用 Gin 吧。如何使用 Gin?我们提供了一些 API … https://gin-gonic.com/zh-cn/docs/ 2.Beego(29.8K) 项目简介:Beego用于在Go中快速开发企业应用程序,包括RESTful API、web应用程序和后端服务。它的灵感来源于Tornado, Sinatra and Flask。beego有一些特定于Go的特性,如接口和结构嵌入。 仓库地址: GitHub - beego/beego: beego is an open-source, high-performance web framework for the Go programming language. beego is an open-source, high-performance web framework for the Go programming language. - GitHub - beego/beego: beego is an open-source, high-performance web framework for the Go programming language. https://github.com/beego/beego 官方文档地址: Welcome to Beego | Beego The most easy use framework https://beego.gocn.vip/beego/zh/developing/ 3.Fiber(26.5K) 项目简介:Fiber是一个Go web框架,构建在Go最快的HTTP引擎Fasthttp之上。它的设计目的是为了在零内存分配和性能的情况下简化快速开发。 仓库地址: https://github.com/gofiber/fiber https://github.com/gofiber/fiber 官方文档地址: Welcome - Fiber https://docs.gofiber.io/ 4.Echo(25.8K) 项目简介:高性能、极简Go web框架 仓库地址: GitHub - labstack/echo: High performance, minimalist Go web framework High performance, minimalist Go web framework. Contribute to labstack/echo development by creating an account on GitHub. https://github.com/labstack/echo 官方文档地址: Echo - High performance, minimalist Go web framework Echo is a high performance, extensible, minimalist web framework for Go (Golang). https://echo.labstack.com/ 5.Iris(24K) 项目简介:Iris是一个高效且设计良好的跨平台web框架,具有强大的功能集。构建具有无限潜力和可移植性的高性能web应用程序和API。 仓库地址: GitHub - kataras/iris: The fastest HTTP/2 Go Web Framework. New, modern, easy to learn. Fast development with Code you control. Unbeatable cost-performance ratio | 谢谢 | #golang The fastest HTTP/2 Go Web Framework. New, modern, easy to learn. Fast development with Code you control. Unbeatable cost-performance ratio :leaves: :rocket: | 谢谢 | #golang - GitHub - kataras/iris: The fastest HTTP/2 Go Web Framework. New, modern, easy to learn. Fast development with Code you control. Unbeatable cost-performance ratio | 谢谢 | #golang https://github.com/kataras/iris 官方文档地址: Iris Docs The fastest HTTP/2 Go Web Framework. Iris provides a beautifully expressive and easy to use foundation for your next website, API, or distributed app. https://www.iris-go.com/docs/#/ ———————————————— 版权声明:本文为CSDN博主「深漂小码哥」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/qq2942713658/article/details/127720799 -
 如题,运行环境支持Golang 吗?
如题,运行环境支持Golang 吗? -
 1. strcpy的基本用法详解 1.1 问题的提出 例如 我们要把字符串"hello"复制到数组arr[20]中去时,你会怎么操作; 首先 arr = "hello";//是错误的 arr数组名是首元素的地址,是个地址常量,是个编号;难道把hello放到这个编号上? 答案应该是放到编号所指向的空间中去; 其中 destination是目标空间的地址,source是源空间的地址 1.2 strcpy的基本原理: 把源指针指向的空间的数据拷贝到目的地指针指向的空间中去; char* p = "hello";//把首字符的地址放到p中,p就指向了这个字符串; strcpy(arr,"hello"); "hello"传参的时候传过去的是首字符'h'的地址,传给了source;其中destination指向了arr[20]整个数组,source指向了hello中'h'的地址;然后把source指向的hello拷贝放到destination指向的arr[20]中去; 1.3使用 strcpy的注意事项: 1.源字符串必须以 '\0' 结束 当拷贝"hello"时字符串的结束标志'\0'也会被拷贝过去,'\0'也是strcpy终止拷贝的一个条件; 2.会将源字符串中的 '\0' 拷贝到目标空间 3.目标空间必须足够大,以确保能存放源字符串 例如 arr[5]=0; strcpy(arr,"hello world");这是错误的 4.目标空间必须可变 例如 char* str = "123456789000"; char* p = "hello world"; strcpy(str,p);//这也是错误的 因为该目标空间是常量字符串,不可修改; 2. 模拟实现strcpy char *my_strcpy(char *destination, const char*source) { char *ret = destination; assert(destination != NULL); assert(source != NULL); while((*destination++ = *source++)) { ; } return ret; } ———————————————— 版权声明:本文为CSDN博主「记忆&碎片」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/YLG_lin/article/details/126690885
1. strcpy的基本用法详解 1.1 问题的提出 例如 我们要把字符串"hello"复制到数组arr[20]中去时,你会怎么操作; 首先 arr = "hello";//是错误的 arr数组名是首元素的地址,是个地址常量,是个编号;难道把hello放到这个编号上? 答案应该是放到编号所指向的空间中去; 其中 destination是目标空间的地址,source是源空间的地址 1.2 strcpy的基本原理: 把源指针指向的空间的数据拷贝到目的地指针指向的空间中去; char* p = "hello";//把首字符的地址放到p中,p就指向了这个字符串; strcpy(arr,"hello"); "hello"传参的时候传过去的是首字符'h'的地址,传给了source;其中destination指向了arr[20]整个数组,source指向了hello中'h'的地址;然后把source指向的hello拷贝放到destination指向的arr[20]中去; 1.3使用 strcpy的注意事项: 1.源字符串必须以 '\0' 结束 当拷贝"hello"时字符串的结束标志'\0'也会被拷贝过去,'\0'也是strcpy终止拷贝的一个条件; 2.会将源字符串中的 '\0' 拷贝到目标空间 3.目标空间必须足够大,以确保能存放源字符串 例如 arr[5]=0; strcpy(arr,"hello world");这是错误的 4.目标空间必须可变 例如 char* str = "123456789000"; char* p = "hello world"; strcpy(str,p);//这也是错误的 因为该目标空间是常量字符串,不可修改; 2. 模拟实现strcpy char *my_strcpy(char *destination, const char*source) { char *ret = destination; assert(destination != NULL); assert(source != NULL); while((*destination++ = *source++)) { ; } return ret; } ———————————————— 版权声明:本文为CSDN博主「记忆&碎片」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/YLG_lin/article/details/126690885 -
如果您是 Go 新手,那么您一定遇到过方法和函数的概念。让我们找出两者之间的区别-通过指定参数的类型、返回值和函数体来声明函数。type Person struct { Name string Age int }func NewPerson(name string, age int) *Person { return &Person{ Name: name, Age: age, } }方法只是一个带有接收器参数的函数。它使用相同的语法声明,并添加了接收者。func (p *Person) isAdult bool { return p.Age > 18 }在上面的方法声明中,我们在类型上声明了isAdult方法。*Person现在我们将看到值接收器和指针接收器之间的区别。值接收者复制类型并将其传递给函数。函数堆栈现在拥有一个相等的对象,但在内存上的不同位置。这意味着对传递的对象所做的任何更改都将保留在该方法的本地。原始对象将保持不变。指针接收器将类型的地址传递给函数。函数堆栈具有对原始对象的引用。因此对传递对象的任何修改都会修改原始对象。让我们通过示例来理解这一点-package mainimport ( "fmt")type Person struct { Name string Age int}func ValueReceiver(p Person) { p.Name = "John" fmt.Println("Inside ValueReceiver : ", p.Name)}func PointerReceiver(p *Person) { p.Age = 24 fmt.Println("Inside PointerReceiver model: ", p.Age)}func main() { p := Person{"Tom", 28} p1:= &Person{"Patric", 68} ValueReceiver(p)fmt.Println("Inside Main after value receiver : ", p.Name) PointerReceiver(p1)fmt.Println("Inside Main after value receiver : ", p1.Age)} ------------Inside ValueReceiver : JohnInside Main after value receiver : TomInside PointerReceiver : 24Inside Main after pointer receiver : 24这表明具有值接收者的方法修改了对象的副本,而原始对象保持不变。Like- 通过 ValueReceiver 方法将一个人的姓名从 Tom 更改为 John,但这种更改并未反映在 main 方法中。另一方面,带有指针接收器的方法会修改实际对象。Like- 通过 PointerReceiver 方法将人的年龄从 68 岁更改为 24 岁,同样的变化反映在 main 方法中。您可以通过在指针或值接收器操作之前和之后打印出对象的地址来检查事实。那么如何在 Pointer 和 Value 接收器之间进行选择呢?如果要更改方法中接收器的状态,操作它的值,请使用指针接收器。使用按值复制的值接收器是不可能的。对值接收器的任何修改对于该副本都是本地的。如果您不需要操作接收器值,请使用值接收器。指针接收器避免在每个方法调用上复制值。如果接收器是一个大型结构,这可能会更有效,值接收器是并发安全的,而指针接收器不是并发安全的。因此,程序员需要照顾它。汇总:如果接收者是 map、func 或 chan,不要使用指向它的指针。尽量对所有方法使用相同的接收器类型。如果接收者是一个切片并且该方法没有重新切片或重新分配切片,则不要使用指向它的指针。如果方法需要改变接收者,接收者必须是一个指针。如果接收者是包含sync.Mutex或类似同步字段的结构,则接收者必须是指针以避免复制。如果接收器是大型结构或数组,则指针接收器效率更高。大有多大?假设它相当于将其所有元素作为参数传递给方法。如果感觉太大,那么对于接收器来说也太大了。函数或方法是否可以同时或在从此方法调用时改变接收者?调用方法时,值类型会创建接收器的副本,因此外部更新不会应用于此接收器。如果更改必须在原始接收器中可见,则接收器必须是指针。如果接收器是结构体、数组或切片,并且它的任何元素都是指向可能发生变化的东西的指针,则更喜欢指针接收器,因为它会使读者更清楚意图。如果接收者是一个小数组或结构,它自然是一个值类型(例如,类似time.Time类型),没有可变字段和指针,或者只是一个简单的基本类型,如 int 或 string,则值接收器更好。值接收器可以减少可以生成的垃圾量;如果将值传递给值方法,则可以使用堆栈上的副本而不是在堆上分配。(编译器试图巧妙地避免这种分配,但它并不总是成功。)不要在没有首先进行分析的情况下选择值接收器类型。最后,当有疑问时,使用指针接收器。————————————————版权声明:本文为CSDN博主「hebiwen95」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/hebiwen95/article/details/126124140
-
 【摘要】 在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。 为什么需要分布式链路追踪系统 微服务架构给运维、排障带来新挑战在分布式架构...本文分享自华为云社区《一文详解|Go 分布式链路追踪实现原理》,作者:开源小E。在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。为什么需要分布式链路追踪系统微服务架构给运维、排障带来新挑战在分布式架构下,当用户从浏览器客户端发起一个请求时,后端处理逻辑往往贯穿多个分布式服务,这时会浮现很多问题,比如:请求整体耗时较长,具体慢在哪个服务?请求过程中出错了,具体是哪个服务报错?某个服务的请求量如何,接口成功率如何?回答这些问题变得不是那么简单,我们不仅仅需要知道某一个服务的接口处理统计数据,还需要了解两个服务之间的接口调用依赖关系,只有建立起整个请求在多个服务间的时空顺序,才能更好的帮助我们理解和定位问题,而这,正是分布式链路追踪系统可以解决的。分布式链路追踪系统如何帮助我们分布式链路追踪技术的核心思想:在用户一次分布式请求服务的调⽤过程中,将请求在所有子系统间的调用过程和时空关系追踪记录下来,还原成调用链路集中展示,信息包括各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。如上图所示,通过分布式链路追踪构建出完整的请求链路后,可以很直观地看到请求耗时主要耗费在哪个服务环节,帮助我们更快速聚焦问题。同时,还可以对采集的链路数据做进一步的分析,从而可以建立整个系统各服务间的依赖关系、以及流量情况,帮助我们更好地排查系统的循环依赖、热点服务等问题。分布式链路追踪系统架构概览核心概念在分布式链路追踪系统中,最核心的概念,便是链路追踪的数据模型定义,主要包括 Trace 和 Span。其中,Trace 是一个逻辑概念,表示一次(分布式)请求经过的所有局部操作(Span)构成的一条完整的有向无环图,其中所有的 Span 的 TraceId 相同。Span 则是真实的数据实体模型,表示一次(分布式)请求过程的一个步骤或操作,代表系统中一个逻辑运行单元,Span 之间通过嵌套或者顺序排列建立因果关系。Span 数据在采集端生成,之后上报到服务端,做进一步的处理。其包含如下关键属性:Name:操作名称,如一个 RPC 方法的名称,一个函数名StartTime/EndTime:起始时间和结束时间,操作的生命周期ParentSpanId:父级 Span 的 IDAttributes:属性,一组 <K,V> 键值对构成的集合Event:操作期间发生的事件SpanContext:Span 上下文内容,通常用于在 Span 间传播,其核心字段包括 TraceId、SpanId一般架构分布式链路追踪系统的核心任务是:围绕 Span 的生成、传播、采集、处理、存储、可视化、分析,构建分布式链路追踪系统。其一般的架构如下如所示:我们看到,在应用端需要通过侵入或者非侵入的方式,注入 Tracing Sdk,以跟踪、生成、传播和上报请求调用链路数据;Collect agent 一般是在靠近应用侧的一个边缘计算层,主要用于提高 Tracing Sdk 的写性能,和减少 back-end 的计算压力;采集的链路跟踪数据上报到后端时,首先经过 Gateway 做一个鉴权,之后进入 kafka 这样的 MQ 进行消息的缓冲存储;在数据写入存储层之前,我们可能需要对消息队列中的数据做一些清洗和分析的操作,清洗是为了规范和适配不同的数据源上报的数据,分析通常是为了支持更高级的业务功能,比如流量统计、错误分析等,这部分通常采用flink这类的流处理框架来完成;存储层会是服务端设计选型的一个重点,要考虑数据量级和查询场景的特点来设计选型,通常的选择包括使用 Elasticsearch、Cassandra、或 Clickhouse 这类开源产品;流处理分析后的结果,一方面作为存储持久化下来,另一方面也会进入告警系统,以主动发现问题来通知用户,如错误率超过指定阈值发出告警通知这样的需求等。刚才讲的,是一个通用的架构,我们并没有涉及每个模块的细节,尤其是服务端,每个模块细讲起来都要很花些功夫,受篇幅所限,我们把注意力集中到靠近应用侧的 Tracing Sdk,重点看看在应用侧具体是如何实现链路数据的跟踪和采集的。协议标准和开源实现刚才我们提到 Tracing Sdk,其实这只是一个概念,具体到实现,选择可能会非常多,这其中的原因,主要是因为:不同的编程语言的应用,可能采用不同技术原理来实现对调用链的跟踪不同的链路追踪后端,可能采用不同的数据传输协议当前,流行的链路追踪后端,比如 Zipin、Jaeger、PinPoint、Skywalking、Erda,都有供应用集成的 sdk,导致我们在切换后端时应用侧可能也需要做较大的调整。社区也出现过不同的协议,试图解决采集侧的这种乱象,比如 OpenTracing、OpenCensus 协议,这两个协议也分别有一些大厂跟进支持,但最近几年,这两者已经走向了融合统一,产生了一个新的标准 OpenTelemetry,这两年发展迅猛,已经逐渐成为行业标准。OpenTelemetry 定义了数据采集的标准 api,并提供了一组针对多语言的开箱即用的 sdk 实现工具,这样,应用只需要与 OpenTelemetry 核心 api 包强耦合,不需要与特定的实现强耦合。应用侧调用链跟踪实现方案概览应用侧核心任务应用侧围绕 Span,有三个核心任务要完成:生成 Span:操作开始构建 Span 并填充 StartTime,操作完成时填充 EndTime 信息,期间可追加 Attributes、Event 等传播 Span:进程内通过 context.Context、进程间通过请求的 header 作为 SpanContext 的载体,传播的核心信息是 TraceId 和 ParentSpanId上报 Span:生成的 Span 通过 tracing exporter 发送给 collect agent / back-end server要实现 Span 的生成和传播,要求我们能够拦截应用的关键操作(函数)过程,并添加 Span 相关的逻辑。实现这个目的会有很多方法,不过,在罗列这些方法之前,我们先看看在 OpenTelemetry 提供的 go sdk 中是如何做的。基于 OTEL 库实现调用拦截OpenTelemetry 的 go sdk 实现调用链拦截的基本思路是:基于 AOP 的思想,采用装饰器模式,通过包装替换目标包(如 net/http)的核心接口或组件,实现在核心调用过程前后添加 Span 相关逻辑。当然,这样的做法是有一定的侵入性的,需要手动替换使用原接口实现的代码调用改为包装接口实现。我们以一个 http server 的例子来说明,在 go 语言中,具体是如何做的:假设有两个服务 serverA 和 serverB,其中 serverA 的接口收到请求后,内部会通过 httpclient 进一步发起到 serverB 的请求,那么 serverA 的核心代码可能如下图所示:以 serverA 节点为例,在 serverA 节点应该产生至少两个 Span:Span1,记录 httpServer 收到一个请求后内部整体处理过程的一个耗时情况Span2,记录 httpServer 处理请求过程中,发起的另一个到 serverB 的 http 请求的耗时情况并且 Span1 应该是 Span2 的 ParentSpan我们可以借助 OpenTelemetry 提供的 sdk 来实现 Span 的生成、传播和上报,上报的逻辑受篇幅所限我们不再详述,重点来看看如何生成这两个 Span,并使这两个 Span 之间建立关联,即 Span 的生成和传播 。HttpServer Handler 生成 Span 过程对于 httpserver 来讲,我们知道其核心就是 http.Handler 这个接口。因此,可以通过实现一个针对 http.Handler 接口的拦截器,来负责 Span 的生成和传播。package http type Handler interface { ServeHTTP(ResponseWriter, *Request) } http.ListenAndServe(":8090", http.DefaultServeMux)要使用 OpenTelemetry Sdk 提供的 http.Handler 装饰器,需要如下调整 http.ListenAndServe 方法:import ( "net/http" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/sdk/trace" "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" ) wrappedHttpHandler := otelhttp.NewHandler(http.DefaultServeMux, ...) http.ListenAndServe(":8090", wrappedHttpHandler)如图所示,wrppedHttpHandler 中将主要实现如下逻辑(精简考虑,此处部分为伪代码):① ctx := tracer.Extract(r.ctx, r.Header):从请求的 header 中提取 traceparent header 并解析,提取 TraceId和 SpanId,进而构建 SpanContext 对象,并最终存储在 ctx 中;② ctx, span := tracer.Start(ctx, genOperation(r)):生成跟踪当前请求处理过程的 Span(即前文所述的Span1),并记录开始时间,这时会从 ctx 中读取 SpanContext,将 SpanContext.TraceId 作为当前 Span 的TraceId,将 SpanContext.SpanId 作为当前 Span的ParentSpanId,然后将自己作为新的 SpanContext 写入返回的 ctx 中;③ r.WithContext(ctx):将新生成的 SpanContext 添加到请求 r 的 context 中,以便被拦截的 handler 内部在处理过程中,可以从 r.ctx 中拿到 Span1 的 SpanId 作为其 ParentSpanId 属性,从而建立 Span 之间的父子关系;④ span.End():当 innerHttpHandler.ServeHTTP(w,r) 执行完成后,就需要对 Span1 记录一下处理完成的时间,然后将它发送给 exporter 上报到服务端。HttpClient 请求生成 Span 过程我们再接着看 serverA 内部去请求 serverB 时的 httpclient 请求是如何生成 Span 的(即前文说的 Span2)。我们知道,httpclient 发送请求的关键操作是 http.RoundTriper 接口:package http type RoundTripper interface { RoundTrip(*Request) (*Response, error) }OpenTelemetry 提供了基于这个接口的一个拦截器实现,我们需要使用这个实现包装一下 httpclient 原来使用的 RoundTripper 实现,代码调整如下:import ( "net/http" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/sdk/trace" "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" ) wrappedTransport := otelhttp.NewTransport(http.DefaultTransport) client := http.Client{Transport: wrappedTransport}如图所示,wrappedTransport 将主要完成以下任务(精简考虑,此处部分为伪代码):① req, _ := http.NewRequestWithContext(r.ctx, “GET”,url, nil) :这里我们将上一步 http.Handler 的请求的 ctx,传递到 httpclient 要发出的 request 中,这样在之后我们就可以从 request.Context() 中提取出 Span1 的信息,来建立 Span 之间的关联;② ctx, span := tracer.Start(r.Context(), url):执行 client.Do() 之后,将首先进入 WrappedTransport.RoundTrip() 方法,这里生成新的 Span(Span2),开始记录 httpclient 请求的耗时情况,与前文一样,Start 方法内部会从 r.Context() 中提取出 Span1 的 SpanContext,并将其 SpanId 作为当前 Span(Span2)的 ParentSpanId,从而建立了 Span 之间的嵌套关系,同时返回的 ctx 中保存的 SpanContext 将是新生成的 Span(Span2)的信息;③ tracer.Inject(ctx, r.Header):这一步的目的是将当前 SpanContext 中的 TraceId 和 SpanId 等信息写入到 r.Header 中,以便能够随着 http 请求发送到 serverB,之后在 serverB 中与当前 Span 建立关联;④ span.End():等待 httpclient 请求发送到 serverB 并收到响应以后,标记当前 Span 跟踪结束,设置 EndTime 并提交给 exporter 以上报到服务端。基于 OTEL 库实现调用链跟踪总结我们比较详细的介绍了使用 OpenTelemetry 库,是如何实现链路的关键信息(TraceId、SpanId)是如何在进程间和进程内传播的,我们对这种跟踪实现方式做个小的总结:如上分析所展示的,使用这种方式的话,对代码还是有一定的侵入性,并且对代码有另一个要求,就是保持 context.Context 对象在各操作间的传递,比如,刚才我们在 serverA 中创建 httpclient 请求时,使用的是http.NewRequestWithContext(r.ctx, ...) 而非http.NewRequest(...)方法,另外开启 goroutine 的异步场景也需要注意 ctx 的传递。非侵入调用链跟踪实现思路我们刚才详细展示了基于常规的一种具有一定侵入性的实现,其侵入性主要表现在:我们需要显式的手动添加代码使用具有跟踪功能的组件包装原代码,这进一步会导致应用代码需要显式的引用具体版本的 OpenTelemetry instrumentation 包,这不利于可观测代码的独立维护和升级。那我们有没有可以实现非侵入跟踪调用链的方案可选?所谓无侵入,其实也只是集成的方式不同,集成的目标其实是差不多的,最终都是要通过某种方式,实现对关键调用函数的拦截,并加入特殊逻辑,无侵入重点在于代码无需修改或极少修改。上图列出了现在可能的一些无侵入集成的实现思路,与 .net、java 这类有 IL 语言的编程语言不同,go 直接编译为机器码,导致无侵入的方案实现起来相对比较麻烦,具体有如下几种思路:编译阶段注入:可以扩展编译器,修改编译过程中的ast,插入跟踪代码,需要适配不同编译器版本。启动阶段注入:修改编译后的机器码,插入跟踪代码,需要适配不同 CPU 架构。如 monkey, gohook。运行阶段注入:通过内核提供的 eBPF 能力,监听程序关键函数执行,插入跟踪代码,前景光明!如,tcpdump,bpftrace。Go 非侵入链路追踪实现原理Erda 项目的核心代码主要是基于 golang 编写的,我们基于前文所述的 OpenTelemetry sdk,采用基于修改机器码的的方式,实现了一种无侵入的链路追踪方式。前文提到,使用 OpenTelemetry sdk 需要代码做一些调整,我们看看这些调整如何以非侵入的方式自动的完成:我们以 httpclient 为例,做简要的解释。gohook 框架提供的 hook 接口的签名如下:// target 要hook的目标函数 // replacement 要替换为的函数 // trampoline 将源函数入口拷贝到的位置,可用于从replcement跳转回原target func Hook(target, replacement, trampoline interface{}) error对于 http.Client,我们可以选择 hook DefaultTransport.RoundTrip() 方法,当该方法执行时,我们通过 otelhttp.NewTransport() 包装起原 DefaultTransport 对象,但需要注意的是,我们不能将 DefaultTransport 直接作为 otelhttp.NewTransport() 的参数,因为其 RoundTrip() 方法已经被我们替换了,而其原来真正的方法被写到了 trampoline 中,所以这里我们需要一个中间层,来连接 DefaultTransport 与其原来的 RoundTrip 方法。具体代码如下://go:linkname RoundTrip net/http.(*Transport).RoundTrip //go:noinline // RoundTrip . func RoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) //go:noinline func originalRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) { return RoundTrip(t, req) } type wrappedTransport struct { t *http.Transport } //go:noinline func (t *wrappedTransport) RoundTrip(req *http.Request) (*http.Response, error) { return originalRoundTrip(t.t, req) } //go:noinline func tracedRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) { req = contextWithSpan(req) return otelhttp.NewTransport(&wrappedTransport{t: t}).RoundTrip(req) } //go:noinline func contextWithSpan(req *http.Request) *http.Request { ctx := req.Context() if span := trace.SpanFromContext(ctx); !span.SpanContext().IsValid() { pctx := injectcontext.GetContext() if pctx != nil { if span := trace.SpanFromContext(pctx); span.SpanContext().IsValid() { ctx = trace.ContextWithSpan(ctx, span) req = req.WithContext(ctx) } } } return req } func init() { gohook.Hook(RoundTrip, tracedRoundTrip, originalRoundTrip) }我们使用 init() 函数实现了自动添加 hook,因此用户程序里只需要在 main 文件中 import 该包,即可实现无侵入的集成。值得一提的是 req = contextWithSpan(req) 函数,内部会依次尝试从 req.Context() 和 我们保存的 goroutineContext map 中检查是否包含 SpanContext,并将其赋值给 req,这样便可以解除了必须使用 http.NewRequestWithContext(...) 写法的要求。详细的代码可以查看 Erda 仓库:https://github.com/erda-project/erda-infra/tree/master/pkg/trace参考链接https://opentelemetry.io/registry/https://opentelemetry.io/docs/instrumentation/go/getting-started/https://www.ipeapea.cn/post/go-asm/https://github.com/brahma-adshonor/gohookhttps://www.jianshu.com/p/7b3638b47845https://paper.seebug.org/1749/
【摘要】 在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。 为什么需要分布式链路追踪系统 微服务架构给运维、排障带来新挑战在分布式架构...本文分享自华为云社区《一文详解|Go 分布式链路追踪实现原理》,作者:开源小E。在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。为什么需要分布式链路追踪系统微服务架构给运维、排障带来新挑战在分布式架构下,当用户从浏览器客户端发起一个请求时,后端处理逻辑往往贯穿多个分布式服务,这时会浮现很多问题,比如:请求整体耗时较长,具体慢在哪个服务?请求过程中出错了,具体是哪个服务报错?某个服务的请求量如何,接口成功率如何?回答这些问题变得不是那么简单,我们不仅仅需要知道某一个服务的接口处理统计数据,还需要了解两个服务之间的接口调用依赖关系,只有建立起整个请求在多个服务间的时空顺序,才能更好的帮助我们理解和定位问题,而这,正是分布式链路追踪系统可以解决的。分布式链路追踪系统如何帮助我们分布式链路追踪技术的核心思想:在用户一次分布式请求服务的调⽤过程中,将请求在所有子系统间的调用过程和时空关系追踪记录下来,还原成调用链路集中展示,信息包括各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。如上图所示,通过分布式链路追踪构建出完整的请求链路后,可以很直观地看到请求耗时主要耗费在哪个服务环节,帮助我们更快速聚焦问题。同时,还可以对采集的链路数据做进一步的分析,从而可以建立整个系统各服务间的依赖关系、以及流量情况,帮助我们更好地排查系统的循环依赖、热点服务等问题。分布式链路追踪系统架构概览核心概念在分布式链路追踪系统中,最核心的概念,便是链路追踪的数据模型定义,主要包括 Trace 和 Span。其中,Trace 是一个逻辑概念,表示一次(分布式)请求经过的所有局部操作(Span)构成的一条完整的有向无环图,其中所有的 Span 的 TraceId 相同。Span 则是真实的数据实体模型,表示一次(分布式)请求过程的一个步骤或操作,代表系统中一个逻辑运行单元,Span 之间通过嵌套或者顺序排列建立因果关系。Span 数据在采集端生成,之后上报到服务端,做进一步的处理。其包含如下关键属性:Name:操作名称,如一个 RPC 方法的名称,一个函数名StartTime/EndTime:起始时间和结束时间,操作的生命周期ParentSpanId:父级 Span 的 IDAttributes:属性,一组 <K,V> 键值对构成的集合Event:操作期间发生的事件SpanContext:Span 上下文内容,通常用于在 Span 间传播,其核心字段包括 TraceId、SpanId一般架构分布式链路追踪系统的核心任务是:围绕 Span 的生成、传播、采集、处理、存储、可视化、分析,构建分布式链路追踪系统。其一般的架构如下如所示:我们看到,在应用端需要通过侵入或者非侵入的方式,注入 Tracing Sdk,以跟踪、生成、传播和上报请求调用链路数据;Collect agent 一般是在靠近应用侧的一个边缘计算层,主要用于提高 Tracing Sdk 的写性能,和减少 back-end 的计算压力;采集的链路跟踪数据上报到后端时,首先经过 Gateway 做一个鉴权,之后进入 kafka 这样的 MQ 进行消息的缓冲存储;在数据写入存储层之前,我们可能需要对消息队列中的数据做一些清洗和分析的操作,清洗是为了规范和适配不同的数据源上报的数据,分析通常是为了支持更高级的业务功能,比如流量统计、错误分析等,这部分通常采用flink这类的流处理框架来完成;存储层会是服务端设计选型的一个重点,要考虑数据量级和查询场景的特点来设计选型,通常的选择包括使用 Elasticsearch、Cassandra、或 Clickhouse 这类开源产品;流处理分析后的结果,一方面作为存储持久化下来,另一方面也会进入告警系统,以主动发现问题来通知用户,如错误率超过指定阈值发出告警通知这样的需求等。刚才讲的,是一个通用的架构,我们并没有涉及每个模块的细节,尤其是服务端,每个模块细讲起来都要很花些功夫,受篇幅所限,我们把注意力集中到靠近应用侧的 Tracing Sdk,重点看看在应用侧具体是如何实现链路数据的跟踪和采集的。协议标准和开源实现刚才我们提到 Tracing Sdk,其实这只是一个概念,具体到实现,选择可能会非常多,这其中的原因,主要是因为:不同的编程语言的应用,可能采用不同技术原理来实现对调用链的跟踪不同的链路追踪后端,可能采用不同的数据传输协议当前,流行的链路追踪后端,比如 Zipin、Jaeger、PinPoint、Skywalking、Erda,都有供应用集成的 sdk,导致我们在切换后端时应用侧可能也需要做较大的调整。社区也出现过不同的协议,试图解决采集侧的这种乱象,比如 OpenTracing、OpenCensus 协议,这两个协议也分别有一些大厂跟进支持,但最近几年,这两者已经走向了融合统一,产生了一个新的标准 OpenTelemetry,这两年发展迅猛,已经逐渐成为行业标准。OpenTelemetry 定义了数据采集的标准 api,并提供了一组针对多语言的开箱即用的 sdk 实现工具,这样,应用只需要与 OpenTelemetry 核心 api 包强耦合,不需要与特定的实现强耦合。应用侧调用链跟踪实现方案概览应用侧核心任务应用侧围绕 Span,有三个核心任务要完成:生成 Span:操作开始构建 Span 并填充 StartTime,操作完成时填充 EndTime 信息,期间可追加 Attributes、Event 等传播 Span:进程内通过 context.Context、进程间通过请求的 header 作为 SpanContext 的载体,传播的核心信息是 TraceId 和 ParentSpanId上报 Span:生成的 Span 通过 tracing exporter 发送给 collect agent / back-end server要实现 Span 的生成和传播,要求我们能够拦截应用的关键操作(函数)过程,并添加 Span 相关的逻辑。实现这个目的会有很多方法,不过,在罗列这些方法之前,我们先看看在 OpenTelemetry 提供的 go sdk 中是如何做的。基于 OTEL 库实现调用拦截OpenTelemetry 的 go sdk 实现调用链拦截的基本思路是:基于 AOP 的思想,采用装饰器模式,通过包装替换目标包(如 net/http)的核心接口或组件,实现在核心调用过程前后添加 Span 相关逻辑。当然,这样的做法是有一定的侵入性的,需要手动替换使用原接口实现的代码调用改为包装接口实现。我们以一个 http server 的例子来说明,在 go 语言中,具体是如何做的:假设有两个服务 serverA 和 serverB,其中 serverA 的接口收到请求后,内部会通过 httpclient 进一步发起到 serverB 的请求,那么 serverA 的核心代码可能如下图所示:以 serverA 节点为例,在 serverA 节点应该产生至少两个 Span:Span1,记录 httpServer 收到一个请求后内部整体处理过程的一个耗时情况Span2,记录 httpServer 处理请求过程中,发起的另一个到 serverB 的 http 请求的耗时情况并且 Span1 应该是 Span2 的 ParentSpan我们可以借助 OpenTelemetry 提供的 sdk 来实现 Span 的生成、传播和上报,上报的逻辑受篇幅所限我们不再详述,重点来看看如何生成这两个 Span,并使这两个 Span 之间建立关联,即 Span 的生成和传播 。HttpServer Handler 生成 Span 过程对于 httpserver 来讲,我们知道其核心就是 http.Handler 这个接口。因此,可以通过实现一个针对 http.Handler 接口的拦截器,来负责 Span 的生成和传播。package http type Handler interface { ServeHTTP(ResponseWriter, *Request) } http.ListenAndServe(":8090", http.DefaultServeMux)要使用 OpenTelemetry Sdk 提供的 http.Handler 装饰器,需要如下调整 http.ListenAndServe 方法:import ( "net/http" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/sdk/trace" "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" ) wrappedHttpHandler := otelhttp.NewHandler(http.DefaultServeMux, ...) http.ListenAndServe(":8090", wrappedHttpHandler)如图所示,wrppedHttpHandler 中将主要实现如下逻辑(精简考虑,此处部分为伪代码):① ctx := tracer.Extract(r.ctx, r.Header):从请求的 header 中提取 traceparent header 并解析,提取 TraceId和 SpanId,进而构建 SpanContext 对象,并最终存储在 ctx 中;② ctx, span := tracer.Start(ctx, genOperation(r)):生成跟踪当前请求处理过程的 Span(即前文所述的Span1),并记录开始时间,这时会从 ctx 中读取 SpanContext,将 SpanContext.TraceId 作为当前 Span 的TraceId,将 SpanContext.SpanId 作为当前 Span的ParentSpanId,然后将自己作为新的 SpanContext 写入返回的 ctx 中;③ r.WithContext(ctx):将新生成的 SpanContext 添加到请求 r 的 context 中,以便被拦截的 handler 内部在处理过程中,可以从 r.ctx 中拿到 Span1 的 SpanId 作为其 ParentSpanId 属性,从而建立 Span 之间的父子关系;④ span.End():当 innerHttpHandler.ServeHTTP(w,r) 执行完成后,就需要对 Span1 记录一下处理完成的时间,然后将它发送给 exporter 上报到服务端。HttpClient 请求生成 Span 过程我们再接着看 serverA 内部去请求 serverB 时的 httpclient 请求是如何生成 Span 的(即前文说的 Span2)。我们知道,httpclient 发送请求的关键操作是 http.RoundTriper 接口:package http type RoundTripper interface { RoundTrip(*Request) (*Response, error) }OpenTelemetry 提供了基于这个接口的一个拦截器实现,我们需要使用这个实现包装一下 httpclient 原来使用的 RoundTripper 实现,代码调整如下:import ( "net/http" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/sdk/trace" "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" ) wrappedTransport := otelhttp.NewTransport(http.DefaultTransport) client := http.Client{Transport: wrappedTransport}如图所示,wrappedTransport 将主要完成以下任务(精简考虑,此处部分为伪代码):① req, _ := http.NewRequestWithContext(r.ctx, “GET”,url, nil) :这里我们将上一步 http.Handler 的请求的 ctx,传递到 httpclient 要发出的 request 中,这样在之后我们就可以从 request.Context() 中提取出 Span1 的信息,来建立 Span 之间的关联;② ctx, span := tracer.Start(r.Context(), url):执行 client.Do() 之后,将首先进入 WrappedTransport.RoundTrip() 方法,这里生成新的 Span(Span2),开始记录 httpclient 请求的耗时情况,与前文一样,Start 方法内部会从 r.Context() 中提取出 Span1 的 SpanContext,并将其 SpanId 作为当前 Span(Span2)的 ParentSpanId,从而建立了 Span 之间的嵌套关系,同时返回的 ctx 中保存的 SpanContext 将是新生成的 Span(Span2)的信息;③ tracer.Inject(ctx, r.Header):这一步的目的是将当前 SpanContext 中的 TraceId 和 SpanId 等信息写入到 r.Header 中,以便能够随着 http 请求发送到 serverB,之后在 serverB 中与当前 Span 建立关联;④ span.End():等待 httpclient 请求发送到 serverB 并收到响应以后,标记当前 Span 跟踪结束,设置 EndTime 并提交给 exporter 以上报到服务端。基于 OTEL 库实现调用链跟踪总结我们比较详细的介绍了使用 OpenTelemetry 库,是如何实现链路的关键信息(TraceId、SpanId)是如何在进程间和进程内传播的,我们对这种跟踪实现方式做个小的总结:如上分析所展示的,使用这种方式的话,对代码还是有一定的侵入性,并且对代码有另一个要求,就是保持 context.Context 对象在各操作间的传递,比如,刚才我们在 serverA 中创建 httpclient 请求时,使用的是http.NewRequestWithContext(r.ctx, ...) 而非http.NewRequest(...)方法,另外开启 goroutine 的异步场景也需要注意 ctx 的传递。非侵入调用链跟踪实现思路我们刚才详细展示了基于常规的一种具有一定侵入性的实现,其侵入性主要表现在:我们需要显式的手动添加代码使用具有跟踪功能的组件包装原代码,这进一步会导致应用代码需要显式的引用具体版本的 OpenTelemetry instrumentation 包,这不利于可观测代码的独立维护和升级。那我们有没有可以实现非侵入跟踪调用链的方案可选?所谓无侵入,其实也只是集成的方式不同,集成的目标其实是差不多的,最终都是要通过某种方式,实现对关键调用函数的拦截,并加入特殊逻辑,无侵入重点在于代码无需修改或极少修改。上图列出了现在可能的一些无侵入集成的实现思路,与 .net、java 这类有 IL 语言的编程语言不同,go 直接编译为机器码,导致无侵入的方案实现起来相对比较麻烦,具体有如下几种思路:编译阶段注入:可以扩展编译器,修改编译过程中的ast,插入跟踪代码,需要适配不同编译器版本。启动阶段注入:修改编译后的机器码,插入跟踪代码,需要适配不同 CPU 架构。如 monkey, gohook。运行阶段注入:通过内核提供的 eBPF 能力,监听程序关键函数执行,插入跟踪代码,前景光明!如,tcpdump,bpftrace。Go 非侵入链路追踪实现原理Erda 项目的核心代码主要是基于 golang 编写的,我们基于前文所述的 OpenTelemetry sdk,采用基于修改机器码的的方式,实现了一种无侵入的链路追踪方式。前文提到,使用 OpenTelemetry sdk 需要代码做一些调整,我们看看这些调整如何以非侵入的方式自动的完成:我们以 httpclient 为例,做简要的解释。gohook 框架提供的 hook 接口的签名如下:// target 要hook的目标函数 // replacement 要替换为的函数 // trampoline 将源函数入口拷贝到的位置,可用于从replcement跳转回原target func Hook(target, replacement, trampoline interface{}) error对于 http.Client,我们可以选择 hook DefaultTransport.RoundTrip() 方法,当该方法执行时,我们通过 otelhttp.NewTransport() 包装起原 DefaultTransport 对象,但需要注意的是,我们不能将 DefaultTransport 直接作为 otelhttp.NewTransport() 的参数,因为其 RoundTrip() 方法已经被我们替换了,而其原来真正的方法被写到了 trampoline 中,所以这里我们需要一个中间层,来连接 DefaultTransport 与其原来的 RoundTrip 方法。具体代码如下://go:linkname RoundTrip net/http.(*Transport).RoundTrip //go:noinline // RoundTrip . func RoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) //go:noinline func originalRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) { return RoundTrip(t, req) } type wrappedTransport struct { t *http.Transport } //go:noinline func (t *wrappedTransport) RoundTrip(req *http.Request) (*http.Response, error) { return originalRoundTrip(t.t, req) } //go:noinline func tracedRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) { req = contextWithSpan(req) return otelhttp.NewTransport(&wrappedTransport{t: t}).RoundTrip(req) } //go:noinline func contextWithSpan(req *http.Request) *http.Request { ctx := req.Context() if span := trace.SpanFromContext(ctx); !span.SpanContext().IsValid() { pctx := injectcontext.GetContext() if pctx != nil { if span := trace.SpanFromContext(pctx); span.SpanContext().IsValid() { ctx = trace.ContextWithSpan(ctx, span) req = req.WithContext(ctx) } } } return req } func init() { gohook.Hook(RoundTrip, tracedRoundTrip, originalRoundTrip) }我们使用 init() 函数实现了自动添加 hook,因此用户程序里只需要在 main 文件中 import 该包,即可实现无侵入的集成。值得一提的是 req = contextWithSpan(req) 函数,内部会依次尝试从 req.Context() 和 我们保存的 goroutineContext map 中检查是否包含 SpanContext,并将其赋值给 req,这样便可以解除了必须使用 http.NewRequestWithContext(...) 写法的要求。详细的代码可以查看 Erda 仓库:https://github.com/erda-project/erda-infra/tree/master/pkg/trace参考链接https://opentelemetry.io/registry/https://opentelemetry.io/docs/instrumentation/go/getting-started/https://www.ipeapea.cn/post/go-asm/https://github.com/brahma-adshonor/gohookhttps://www.jianshu.com/p/7b3638b47845https://paper.seebug.org/1749/ -
>摘要:装饰者模式通过组合的方式,提供了能够动态地给对象/模块扩展新功能的能力。理论上,只要没有限制,它可以一直把功能叠加下去,具有很高的灵活性。 本文分享自华为云社区《[【Go实现】实践GoF的23种设计模式:装饰者模式](https://bbs.huaweicloud.com/blogs/362755?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 元闰子。 # 简介 我们经常会遇到“**给现有对象/模块新增功能**”的场景,比如 http router 的开发场景下,除了最基础的路由功能之外,我们常常还会加上如日志、鉴权、流控等 middleware。如果你查看框架的源码,就会发现 middleware 功能的实现用的就是**装饰者模式**(Decorator Pattern)。 GoF 给装饰者模式的定义如下: >Decorators provide a flexible alternative to subclassing for extending functionality. Attach additional responsibilities to an object dynamically. 简单来说,装饰者模式通过组合的方式,提供了能够动态地给对象/模块扩展新功能的能力。理论上,只要没有限制,它可以一直把功能叠加下去,具有很高的灵活性。 如果写过 Java,那么一定对 I/O Stream 体系不陌生,它是装饰者模式的经典用法,客户端程序可以动态地为原始的输入输出流添加功能,比如按字符串输入输出,加入缓冲等,使得整个 I/O Stream 体系具有很高的可扩展性和灵活性。 # UML 结构 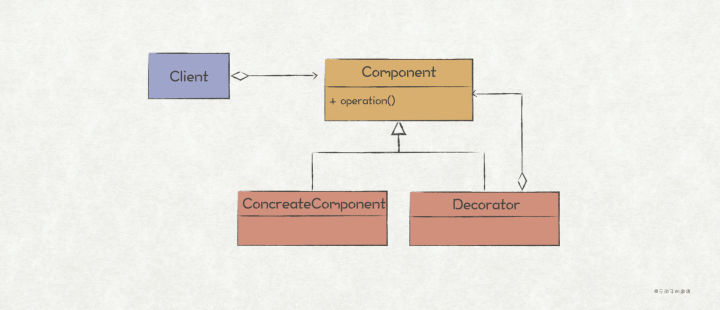 # 场景上下文 在简单的分布式应用系统(示例代码工程)中,我们设计了 Sidecar 边车模块,它的用处主要是为了 1)方便扩展 network.Socket 的功能,如增加日志、流控等非业务功能;2)让这些附加功能对业务程序隐藏起来,也即业务程序只须关心看到 network.Socket 接口即可。 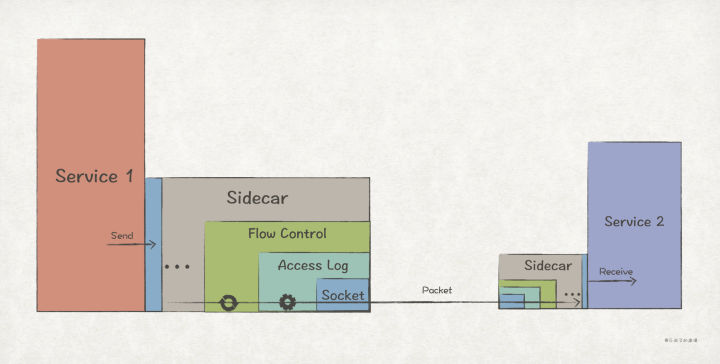 # 代码实现 Sidecar 的这个功能场景,很适合使用装饰者模式来实现,代码如下: ``` // demo/network/socket.go package network // 关键点1: 定义被装饰的抽象接口 // Socket 网络通信Socket接口 type Socket interface { // Listen 在endpoint指向地址上起监听 Listen(endpoint Endpoint) error // Close 关闭监听 Close(endpoint Endpoint) // Send 发送网络报文 Send(packet *Packet) error // Receive 接收网络报文 Receive(packet *Packet) // AddListener 增加网络报文监听者 AddListener(listener SocketListener) } // 关键点2: 提供一个默认的基础实现 type socketImpl struct { listener SocketListener } func DefaultSocket() *socketImpl { return &socketImpl{} } func (s *socketImpl) Listen(endpoint Endpoint) error { return Instance().Listen(endpoint, s) } ... // socketImpl的其他Socket实现方法 // demo/sidecar/flowctrl_sidecar.go package sidecar // 关键点3: 定义装饰器,实现被装饰的接口 // FlowCtrlSidecar HTTP接收端流控功能装饰器,自动拦截Socket接收报文,实现流控功能 type FlowCtrlSidecar struct { // 关键点4: 装饰器持有被装饰的抽象接口作为成员属性 socket network.Socket ctx *flowctrl.Context } // 关键点5: 对于需要扩展功能的方法,新增扩展功能 func (f *FlowCtrlSidecar) Receive(packet *network.Packet) { httpReq, ok := packet.Payload().(*http.Request) // 如果不是HTTP请求,则不做流控处理 if !ok { f.socket.Receive(packet) return } // 流控后返回429 Too Many Request响应 if !f.ctx.TryAccept() { httpResp := http.ResponseOfId(httpReq.ReqId()). AddStatusCode(http.StatusTooManyRequest). AddProblemDetails("enter flow ctrl state") f.socket.Send(network.NewPacket(packet.Dest(), packet.Src(), httpResp)) return } f.socket.Receive(packet) } // 关键点6: 不需要扩展功能的方法,直接调用被装饰接口的原生方法即可 func (f *FlowCtrlSidecar) Close(endpoint network.Endpoint) { f.socket.Close(endpoint) } ... // FlowCtrlSidecar的其他方法 // 关键点7: 定义装饰器的工厂方法,入参为被装饰接口 func NewFlowCtrlSidecar(socket network.Socket) *FlowCtrlSidecar { return &FlowCtrlSidecar{ socket: socket, ctx: flowctrl.NewContext(), } } // demo/sidecar/all_in_one_sidecar_factory.go // 关键点8: 使用时,通过装饰器的工厂方法,把所有装饰器和被装饰者串联起来 func (a AllInOneFactory) Create() network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), a.producer) } ``` 总结实现装饰者模式的几个关键点: 1. 定义需要被装饰的抽象接口,后续的装饰器都是基于该接口进行扩展。 2. 为抽象接口提供一个基础实现。 3. 定义装饰器,并实现被装饰的抽象接口。 4. 装饰器持有被装饰的抽象接口作为成员属性。“装饰”的意思是在原有功能的基础上扩展新功能,因此必须持有原有功能的抽象接口。 5. 在装饰器中,对于需要扩展功能的方法,新增扩展功能。 6. 不需要扩展功能的方法,直接调用被装饰接口的原生方法即可。 7. 为装饰器定义一个工厂方法,入参为被装饰接口。 8. 使用时,通过装饰器的工厂方法,把所有装饰器和被装饰者串联起来。 # 扩展 ## Go 风格的实现 在 Sidecar 的场景上下文中,被装饰的 Socket 是一个相对复杂的接口,装饰器通过实现 Socket 接口来进行功能扩展,是典型的面向对象风格。 如果被装饰者是一个简单的接口/方法/函数,我们可以用更具 Go 风格的实现方式,考虑前文提到的 http router 场景。如果你使用原生的 net/http 进行 http router 开发,通常会这么实现: ``` func main() { // 注册/hello的router http.HandleFunc("/hello", hello) // 启动http服务器 http.ListenAndServe("localhost:8080", nil) } // 具体的请求处理逻辑,类型是 http.HandlerFunc func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello, world")) } ``` 其中,我们通过 http.HandleFunc 来注册具体的 router, hello 是具体的请求处理方法。现在,我们想为该 http 服务器增加日志、鉴权等通用功能,那么可以把 func(w http.ResponseWriter, r *http.Request) 作为被装饰的抽象接口,通过新增日志、鉴权等装饰器完成功能扩展。 ``` // demo/network/http/http_handle_func_decorator.go // 关键点1: 确定被装饰接口,这里为原生的http.HandlerFunc type HandlerFunc func(ResponseWriter, *Request) // 关键点2: 定义装饰器类型,是一个函数类型,入参和返回值都是 http.HandlerFunc 函数 type HttpHandlerFuncDecorator func(http.HandlerFunc) http.HandlerFunc // 关键点3: 定义装饰函数,入参为被装饰的接口和装饰器可变列表 func Decorate(h http.HandlerFunc, decorators ...HttpHandlerFuncDecorator) http.HandlerFunc { // 关键点4: 通过for循环遍历装饰器,完成对被装饰接口的装饰 for _, decorator := range decorators { h = decorator(h) } return h } // 关键点5: 实现具体的装饰器 func WithBasicAuth(h http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { cookie, err := r.Cookie("Auth") if err != nil || cookie.Value != "Pass" { w.WriteHeader(http.StatusForbidden) return } // 关键点6: 完成功能扩展之后,调用被装饰的方法,才能将所有装饰器和被装饰者串起来 h(w, r) } } func WithLogger(h http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { log.Println(r.Form) log.Printf("path %s", r.URL.Path) h(w, r) } } func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello, world")) } func main() { // 关键点7: 通过Decorate函数完成对hello的装饰 http.HandleFunc("/hello", Decorate(hello, WithLogger, WithBasicAuth)) // 启动http服务器 http.ListenAndServe("localhost:8080", nil) } ``` 上述的装饰者模式的实现,用到了类似于 Functional Options 的技巧,也是巧妙利用了 Go 的函数式编程的特点,总结下来有如下几个关键点: 1. 确定被装饰的接口,上述例子为 http.HandlerFunc。 2. 定义装饰器类型,是一个函数类型,入参和返回值都是被装饰接口,上述例子为 func(http.HandlerFunc) http.HandlerFunc。 3. 定义装饰函数,入参为被装饰的接口和装饰器可变列表,上述例子为 Decorate 方法。 4. 在装饰方法中,通过for循环遍历装饰器,完成对被装饰接口的装饰。这里是用来类似 Functional Options 的技巧,一定要注意装饰器的顺序! 5. 实现具体的装饰器,上述例子为 WithBasicAuth 和 WithLogger 函数。 6. 在装饰器中,完成功能扩展之后,记得调用被装饰者的接口,这样才能将所有装饰器和被装饰者串起来。 7. 在使用时,通过装饰函数完成对被装饰者的装饰,上述例子为 Decorate(hello, WithLogger, WithBasicAuth)。 ## Go 标准库中的装饰者模式 在 Go 标准库中,也有一个运用了装饰者模式的模块,就是 context,其中关键的接口如下: ``` package context // 被装饰接口 type Context interface { Deadline() (deadline time.Time, ok bool) Done() -chan struct{} Err() error Value(key any) any } // cancel装饰器 type cancelCtx struct { Context // 被装饰接口 mu sync.Mutex done atomic.Value children map[canceler]struct{}= err error } // cancel装饰器的工厂方法 func WithCancel(parent Context) (ctx Context, cancel CancelFunc) { // ... c := newCancelCtx(parent) propagateCancel(parent, &c) return &c, func() { c.cancel(true, Canceled) } } // timer装饰器 type timerCtx struct { cancelCtx // 被装饰接口 timer *time.Timer deadline time.Time } // timer装饰器的工厂方法 func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) { // ... c := &timerCtx{ cancelCtx: newCancelCtx(parent), deadline: d, } // ... return c, func() { c.cancel(true, Canceled) } } // timer装饰器的工厂方法 func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) { return WithDeadline(parent, time.Now().Add(timeout)) } // value装饰器 type valueCtx struct { Context // 被装饰接口 key, val any } // value装饰器的工厂方法 func WithValue(parent Context, key, val any) Context { if parent == nil { panic("cannot create context from nil parent") } // ... return &valueCtx{parent, key, val} } ``` 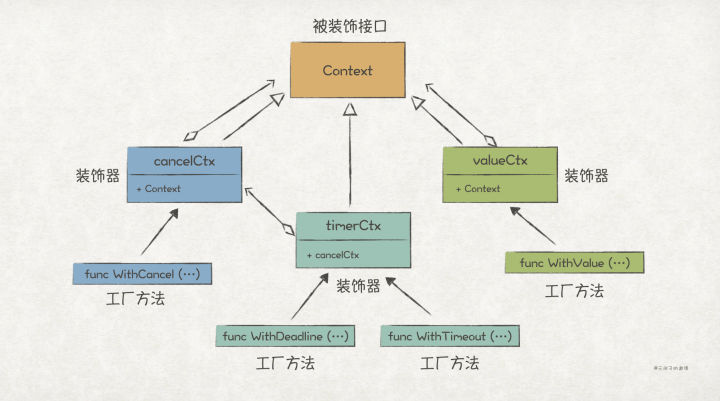 使用时,可以这样: ``` // 使用时,可以这样 func main() { ctx := context.Background() ctx = context.WithValue(ctx, "key1", "value1") ctx, _ = context.WithTimeout(ctx, time.Duration(1)) ctx = context.WithValue(ctx, "key2", "value2") } ``` 不管是 UML 结构,还是使用方法,context 模块都与传统的装饰者模式有一定出入,但也不妨碍 context 是装饰者模式的典型运用。还是那句话,**学习设计模式,不能只记住它的结构,而是学习其中的动机和原理**。 ## 典型使用场景 - I/O 流,比如为原始的 I/O 流增加缓冲、压缩等功能。 - Http Router,比如为基础的 Http Router 能力增加日志、鉴权、Cookie等功能。 - ...... ## 优缺点 **优点** 1. 遵循开闭原则,能够在不修改老代码的情况下扩展新功能。 2. 可以用多个装饰器把多个功能组合起来,理论上可以无限组合。 **缺点** 1. 一定要注意装饰器装饰的顺序,否则容易出现不在预期内的行为。 2. 当装饰器越来越多之后,系统也会变得复杂。 ## 与其他模式的关联 装饰者模式和代理模式具有很高的相似性,但是两种所强调的点不一样。前者强调的是为本体对象添加新的功能;后者强调的是对本体对象的访问控制。 装饰者模式和适配器模式的区别是,前者只会扩展功能而不会修改接口;后者则会修改接口。
-
为什么我们从 Python 切换到 Go原文链接:https://softwareengineeringdaily.com/2021/03/03/why-we-switched-from-python-to-go/转换到一种新的语言总是一个很大的步骤,尤其是当你的团队成员中只有一个人有这种语言的经验时。今年早些时候,我们将 Stream 的主要编程语言从 Python 转换到了 Go。这篇文章将解释为什么我们决定放弃 Python 转而使用 Go 的一些原因。原因 1 – 性能Go 非常快。性能类似于 Java 或 C++。对于我们的用例,Go 通常比 Python 快 40 倍。这是一个比较Go 和 Python的小型基准测试游戏。原因 2 – 语言表现很重要对于许多应用程序来说,编程语言只是应用程序和数据库之间的粘合剂。语言本身的表现通常并不重要。然而,Stream 是一个为700家公司和超过5亿终端用户提供 feed 和聊天平台的 API 提供商。多年来,我们一直在优化 Cassandra、 PostgreSQL、 Redis 等等,但最终,我们达到了所使用语言的极限。Python 是一种很棒的语言,但是对于序列化/反序列化、排序和聚合等用例来说,它的性能相当缓慢。我们经常遇到性能问题,Cassandra 需要1ms 来检索数据,而 Python 需要10ms 来将数据转换为对象。原因 3 – 开发人员的生产力和没有太有创意看看 我如何开始 Go 教程中的一小段 Go 代码。(这是一个很棒的教程,也是学习 Go 的一个很好的起点。)如果您是 Go 新手,那么在阅读那个小代码片段时不会有太多让您感到惊讶的事情。它展示了多个赋值、数据结构、指针、格式和一个内置的 HTTP 库。当我第一次开始编程时,我一直喜欢使用 Python 更高级的功能。Python 允许您在编写代码时获得相当的创意。例如,您可以:Use MetaClasses to self-register classes upon code initialization 在代码初始化时使用元类自寄存器类Swap out True and False 替换掉 True 和 FalseAdd functions to the list of built-in functions 将函数添加到内置函数列表中Overload operators via magic methods 通过魔术方法重载操作符Use functions as properties via the @property decorator 通过@property decorator 将函数用作属性这些功能玩起来很有趣,但是,正如大多数程序员会同意的那样,在阅读别人的作品时,它们通常会使代码更难理解。Go 迫使你坚持基础。这使得阅读任何人的代码并立即了解发生了什么变得非常容易。 注意:当然,它实际上有多“容易”取决于您的用例。如果你想创建一个基本的 CRUD API,我仍然推荐 Django + DRF或 Rails。这些功能玩起来很有趣,但是,正如大多数程序员会同意的那样,在阅读别人的作品时,它们通常会使代码更难理解。Go 迫使你坚持基础。这使得阅读任何人的代码并立即了解发生了什么变得非常容易。 注意:当然,它实际上有多“容易”取决于您的场景。如果你想创建一个基本的 CRUD API,我仍然推荐 Django + DRF或 Rails。原因 4 – 并发和通道作为一门语言,Go 试图让事情变得简单。它没有引入许多新概念。重点是创建一种非常快速且易于使用的简单语言。它唯一具有创新性的领域是 goroutine 和通道。(100% 正确 CSP的概念始于 1977 年,所以这项创新更多是对旧思想的一种新方法。)Goroutines 是 Go 的轻量级线程方法,通道是 goroutines 之间通信的首选方式。Goroutines 的创建非常便宜,并且只需要几 KB 的额外内存。因为 Goroutine 非常轻量,所以有可能同时运行数百甚至数千个。您可以使用通道在 goroutine 之间进行通信。Go 运行时处理所有复杂性。goroutines 和基于通道的并发方法使得使用所有可用的 CPU 内核和处理并发 IO 变得非常容易——所有这些都不会使开发复杂化。与 Python/Java 相比,在 goroutine 上运行函数需要最少的样例代码。您只需在函数调用前加上关键字“go”:https://tour.golang.org/concurrency/1 Go 的并发方法很容易使用。与 Node 相比,这是一种有趣的方法,开发人员必须密切关注异步代码的处理方式。Go 中并发的另一个重要方面是 竞争检测器。这样可以很容易地确定异步代码中是否存在任何竞争条件。以下是开始使用 Go 和频道的一些很好的资源:https://gobyexample.com/channelshttps://tour.golang.org/concurrency/2http://guzalexander.com/2013/12/06/golang-channels-tutorial.htmlhttps://www.golang-book.com/books/intro/10https://www.goinggo.net/2014/02/the-nature-of-channels-in-go.htmlGoroutines vs Green threads原因 5 – 快速编译时间我们目前用 Go 编写的最大的微服务编译需要 4 秒。与以编译速度慢而闻名的 Java 和 C++ 等语言相比,Go 的快速编译时间是一项重大的生产力胜利。我喜欢剑术,但在我还记得代码应该做什么的同时完成事情会更好:理由 6 - 团队建设的能力首先,让我们从显而易见的开始:与 C++ 和 Java 等旧语言相比,Go 开发人员的数量并不多。根据 StackOverflow的数据, 38% 的开发人员知道 Java, 19.3%的 人知道 C++,只有 4.6%的 人知道 Go。 GitHub 数据 显示了 类似的趋势:Go 比 Erlang、Scala 和 Elixir 等语言使用更广泛,但不如 Java 和 C++ 流行。幸运的是,Go 是一种非常简单易学的语言。它提供了您需要的基本功能,仅此而已。它引入的新概念是“延迟”声明和内置的并发管理与“goroutines”和通道。(对于纯粹主义者来说:Go 并不是第一种实现这些概念的语言,只是第一种使它们流行起来的语言。)任何加入团队的 Python、Elixir、C++、Scala 或 Java 开发人员都可以在一个月内在 Go 上上手,因为它的简单性。与许多其他语言相比,我们发现组建 Go 开发人员团队更容易。如果您在生态系统中招聘人员, 这是一项重要的优势。理由 7 – 强大的生态系统对于我们这样规模的团队(大约20人)来说,生态系统很重要。如果你不得不彻底改造每一个小功能,你就不能为你的客户创造价值。Go 对我们使用的工具有很好的支持。实体库已经可用于 Redis、RabbitMQ、PostgreSQL、模板解析、任务调度、表达式解析和 RocksDB。与 Rust 或 Elixir 等其他较新的语言相比,Go 的生态系统是一个重大胜利。它当然不如 Java、Python 或 Node 之类的语言好,但它很可靠,而且对于许多基本需求,你会发现已经有高质量的包可用。原因 8 – Gofmt,强制代码格式化让我们从什么是 Gofmt 开始?不,这不是一个发誓的话。Gofmt 是一个很棒的命令行实用程序,内置在 Go 编译器中,用于格式化代码。就功能而言,它与 Python 的 autopep8 非常相似。尽管《硅谷》的节目以其他方式描绘,但我们大多数人并不真正喜欢争论制表符与空格。格式的一致性很重要,但实际的格式标准并不那么重要。Gofmt 通过使用一种正式的方式来格式化您的代码来避免所有这些讨论。原因 9 – gRPC 和协议缓冲区Go 对 Protocol Buffers 和 gRPC 有一流的支持。这两个工具非常适合构建需要通过 RPC 进行通信的微服务。您需要做的就是编写一个清单,定义可以进行的 RPC 调用以及它们采用的参数。然后从这个清单中自动生成服务器和客户端代码。生成的代码速度快,网络占用空间小,易于使用。从同一个清单中,您甚至可以为许多不同的语言生成客户端代码,例如 C++、Java、Python 和 Ruby。因此,内部流量不再有模棱两可的 REST 端点,而且您每次都必须编写几乎相同的客户端和服务器代码。缺点 1 – 缺乏框架Go 没有像 Rails 用于 Ruby、Django 用于 Python 或 Laravel 用于 PHP 那样的单一主导框架。这是 Go 社区内激烈争论的话题,因为许多人主张你不应该一开始就使用框架。我完全同意这对于某些用例是正确的。但是,如果有人想构建一个简单的 CRUD API,他们将更容易使用 Django/DJRF、Rails Laravel 或 Phoenix。 更新: 正如评论所指出的,有几个项目为 Go 提供了框架。 Revel , Iris , Echo , Macaron 和 Buffalo 似乎是主要的竞争者。对于 Stream 的用例,我们更喜欢不使用框架。然而,对于许多希望提供简单 CRUD API 的新项目来说,缺乏主导框架将是一个严重的劣势。缺点 2 – 错误处理Go 通过简单地从函数返回错误并期望调用代码来处理错误(或将其返回到调用堆栈)来处理错误。虽然这种方法有效,但很容易失去问题的范围,以确保您可以向用户提供有意义的错误。错误包 通过允许您向错误添加上下文和堆栈跟踪来解决此问题。 另一个问题是很容易忘记处理错误。像 errcheck 和 megacheck 这样的静态分析工具可以方便地避免犯这些错误。虽然这些变通办法效果很好,但感觉不太对劲。您希望该语言支持正确的错误处理。劣势3——包管理更新:自写这篇文章以来,Go 的包管理已经取得了长足的进步。 Go 模块 是一个有效的解决方案,我看到的唯一问题是它们破坏了一些静态分析工具,如 errcheck。这是一个使用 Go modules学习使用 Go 的教程 。 Go 的包管理绝不是完美的。默认情况下,它无法指定特定版本的依赖项,也无法创建可重现的构建。Python、Node 和 Ruby 都有更好的包管理系统。但是,使用正确的工具,Go 的包管理工作得很好。您可以使用 Dep 来管理您的依赖项,以允许指定和固定版本。除此之外,我们还贡献了一个名为的开源工具 VirtualGo ,它可以更轻松地处理用 Go 编写的多个项目。结论Go 是一种非常高性能的语言,对并发有很好的支持。它几乎与 C++ 和 Java 等语言一样快。虽然与 Python 或 Ruby 相比,使用 Go 构建东西确实需要更多时间,但您将节省大量用于优化代码的时间。我们在 Stream有一个小型开发团队, 为超过 5 亿最终用户 提供动力和 聊天。Go 结合了 强大的生态系统、 新开发人员的 轻松入门、快速的性能、 对并发的 可靠支持和高效的编程环境 ,使其成为一个不错的选择。 **Stream 仍然在我们的仪表板、站点和机器学习中利用 Python 来提供 个性化的订阅源. 我们不会很快与 Python 说再见,但今后所有性能密集型代码都将使用 Go 编写。我们新的 聊天 API 也完全用 Go 编写。**如果您想了解有关 Go 的更多信息,请查看下面列出的博客文章。原文链接:https://blog.csdn.net/inthat/article/details/124994033
-
>摘要:工厂方法模式(Factory Method Pattern)将对象创建的逻辑封装起来,为使用者提供一个简单易用的对象创建接口,常用于不指定对象具体类型的情况下创建对象的场景。 本文分享自华为云社区《[【Go实现】实践GoF的23种设计模式:工厂方法模式](https://bbs.huaweicloud.com/blogs/353969?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 元闰子。 # 简述 工厂方法模式(Factory Method Pattern)跟上一篇讨论的建造者模式类似,**都是将对象创建的逻辑封装起来,为使用者提供一个简单易用的对象创建接口**。两者在应用场景上稍有区别,建造者模式常用于需要传递多个参数来进行实例化的场景;工厂方法模式常用于**不指定对象具体类型的情况下创建对象**的场景。 # UML 结构 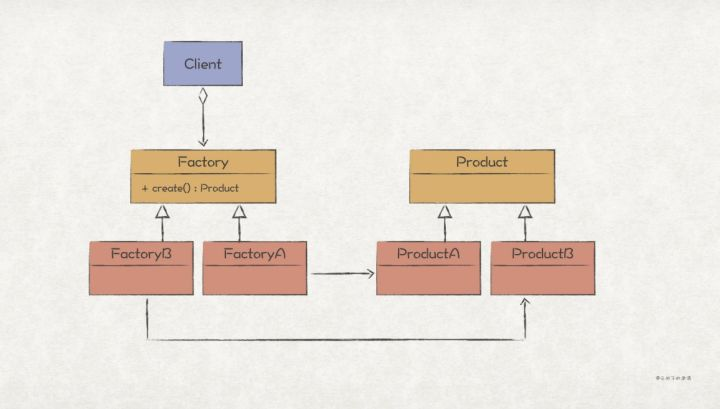 # 代码实现 ## 示例 在简单的分布式应用系统(示例代码工程)中,我们设计了 Sidecar 边车模块, Sidecar 的作用是为了给原生的 Socket 增加额外的功能,比如流控、日志等。 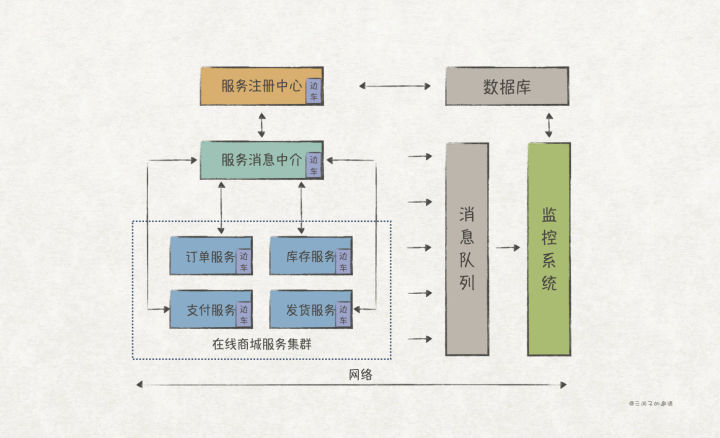 Sidecar 模块的设计运用了**装饰者模式**,修饰的是 Socket 。所以客户端其实是把 Sidecar 当成是 Socket 来使用了,比如: ``` // demo/network/http/http_client.go package http // 创建一个新的HTTP客户端,以Socket接口作为入参 func NewClient(socket network.Socket, ip string) (*Client, error) { ... // 一些初始化逻辑 return client, nil } // 使用NewClient时,我们可以传入Sidecar来给Http客户端附加额外的流控功能 client, err := http.NewClient(sidecar.NewFlowCtrlSidecar(network.DefaultSocket()), "192.168.0.1") ``` 在服务消息中介中,每次收到上游服务的 HTTP 请求,都会调用 http.NewClient 来创建一个 HTTP 客户端,并通过它将请求转发给下游服务: ``` type ServiceMediator struct { ... server *http.Server } // Forward 转发请求,请求URL为 /{serviceType}+ServiceUri 的形式,如/serviceA/api/v1/task func (s *ServiceMediator) Forward(req *http.Request) *http.Response { ... // 发现下游服务的目的IP地址 dest, err := s.discovery(svcType) // 创建HTTP客户端,硬编码sidecar.NewFlowCtrlSidecar(network.DefaultSocket()) client, err := http.NewClient(sidecar.NewFlowCtrlSidecar(network.DefaultSocket()), s.localIp) // 通过HTTP客户端转发请求 resp, err := client.Send(dest, forwardReq) ... } ``` 在上述实现中,我们在调用 http.NewClient 时把 sidecar.NewFlowCtrlSidecar(network.DefaultSocket()) 硬编码进去了,那么如果以后要扩展 Sidecar ,就得修改这段代码逻辑,这违反了开闭原则 OCP。 有经验的同学可能会想到,可以通过让 ServiceMediator 依赖 Socket 接口,在 Forward 方法调用 http.NewClient 时把 Socket 接口作为入参;然后在 ServiceMediator 初始化时,将具体类型的 Sidecar 注入到 ServiceMediator 中: ``` type ServiceMediator struct { ... server *http.Server // 依赖Socket抽象接口 socket network.Socket } // Forward 转发请求,请求URL为 /{serviceType}+ServiceUri 的形式,如/serviceA/api/v1/task func (s *ServiceMediator) Forward(req *http.Request) *http.Response { ... // 发现下游服务的目的IP地址 dest, err := s.discovery(svcType) // 创建HTTP客户端,将s.socket抽象接口作为入参 client, err := http.NewClient(s.socket, s.localIp) // 通过HTTP客户端转发请求 resp, err := client.Send(dest, forwardReq) ... } // 在ServiceMediator初始化时,将具体类型的Sidecar注入到ServiceMediator中 mediator := &ServiceMediator{ socket: sidecar.NewFlowCtrlSidecar(network.DefaultSocket()) } ``` 上述的修改,从原来依赖具体,改成了依赖抽象,符合了开闭原则。 但是, Forward 方法存在并发调用的场景,因此它希望每次被调用时都创建一个新的 Socket/Sidecar 来完成网络通信,否则就需要加锁来保证并发安全。而上述的修改会导致在 ServiceMediator 的生命周期内都使用同一个 Socket/Sidecar,显然不符合要求。 因此,我们需要一个方法,既能够满足开闭原则,而且在每次调用Forward 方法时也能够创建新的 Socket/Sidecar 实例。工厂方法模式恰好就能满足这两点要求,下面我们通过它来完成代码的优化。 # 实现 ``` // demo/sidecar/sidecar_factory.go // 关键点1: 定义一个Sidecar工厂抽象接口 type Factory interface { // 关键点2: 工厂方法返回Socket抽象接口 Create() network.Socket } // 关键点3: 按照需要实现具体的工厂 // demo/sidecar/raw_socket_sidecar_factory.go // RawSocketFactory 只具备原生socket功能的sidecar,实现了Factory接口 type RawSocketFactory struct { } func (r RawSocketFactory) Create() network.Socket { return network.DefaultSocket() } // demo/sidecar/all_in_one_sidecar_factory.go // AllInOneFactory 具备所有功能的sidecar工厂,实现了Factory接口 type AllInOneFactory struct { producer mq.Producible } func (a AllInOneFactory) Create() network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), a.producer) } ``` 上述代码中,我们定义了一个工厂抽象接口 Factory ,并有了 2 个具体的实现 RawSocketFactory 和 AllInOneFactory。最后, ServiceMediator 依赖 Factory ,并在 Forward 方法中通过 Factory 来创建新的 Socket/Sidecar : ``` // demo/service/mediator/service_mediator.go type ServiceMediator struct { ... server *http.Server // 关键点4: 客户端依赖Factory抽象接口 sidecarFactory sidecar.Factory } // Forward 转发请求,请求URL为 /{serviceType}+ServiceUri 的形式,如/serviceA/api/v1/task func (s *ServiceMediator) Forward(req *http.Request) *http.Response { ... // 发现下游服务的目的IP地址 dest, err := s.discovery(svcType) // 创建HTTP客户端,调用sidecarFactory.Create()生成Socket作为入参 client, err := http.NewClient(s.sidecarFactory.Create(), s.localIp) // 通过HTTP客户端转发请求 resp, err := client.Send(dest, forwardReq) ... } // 关键点5: 在ServiceMediator初始化时,将具体类型的sidecar.Factory注入到ServiceMediator中 mediator := &ServiceMediator{ sidecarFactory: &AllInOneFactory{} // sidecarFactory: &RawSocketFactory{} } ``` 下面总结实现工厂方法模式的几个关键点: 1. 定义一个工厂方法抽象接口,比如前文中的 sidecar.Factory。 2. 工厂方法中,返回需要创建的对象/接口,比如 network.Socket。其中,工厂方法通常命名为 Create。 3. 按照具体需要,定义工厂方法抽象接口的具体实现对象,比如 RawSocketFactory 和 AllInOneFactory。 4. 客户端使用时,依赖工厂方法抽象接口。 5. 在客户端初始化阶段,完成具体工厂对象的依赖注入。 # 扩展 ## Go 风格的实现 前文的工厂方法模式实现,是非常典型的**面向对象风格**,下面我们给出一个更具 Go 风格的实现。 ``` // demo/sidecar/sidecar_factory_func.go // 关键点1: 定义Sidecar工厂方法类型 type FactoryFunc func() network.Socket // 关键点2: 按需定义具体的工厂方法实现,注意这里定义的是工厂方法的工厂方法,返回的是FactoryFunc工厂方法类型 func RawSocketFactoryFunc() FactoryFunc { return func() network.Socket { return network.DefaultSocket() } } func AllInOneFactoryFunc(producer mq.Producible) FactoryFunc { return func() network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), producer) } } type ServiceMediator struct { ... server *http.Server // 关键点3: 客户端依赖FactoryFunc工厂方法类型 sidecarFactoryFunc FactoryFunc } func (s *ServiceMediator) Forward(req *http.Request) *http.Response { ... dest, err := s.discovery(svcType) // 关键点4: 创建HTTP客户端,调用sidecarFactoryFunc()生成Socket作为入参 client, err := http.NewClient(s.sidecarFactoryFunc(), s.localIp) resp, err := client.Send(dest, forwardReq) ... } // 关键点5: 在ServiceMediator初始化时,将具体类型的FactoryFunc注入到ServiceMediator中 mediator := &ServiceMediator{ sidecarFactoryFunc: RawSocketFactoryFunc() // sidecarFactory: AllInOneFactoryFunc(producer) } ``` 上述的实现,利用了 Go 语言中**函数作为一等公民**的特点,少定义了几个 interface 和 struct,代码更加的简洁。 几个实现的关键点与面向对象风格的实现类似。值得注意的是 关键点2 ,我们相当于定义了一个**工厂方法的工厂方法**,这么做是为了利用函数闭包的特点来**传递参数**。如果直接定义工厂方法,那么 AllInOneFactoryFunc 的实现是下面这样的,无法实现多态: ``` // 并非FactoryFunc类型,无法实现多态 func AllInOneFactoryFunc(producer mq.Producible) network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), producer) } ``` ## 简单工厂 工厂方法模式的另一个变种是**简单工厂**,它并不通过多态,而是通过简单的 switch-case/if-else 条件判断来决定创建哪种产品: ``` // demo/sidecar/sidecar_simple_factory.go // 关键点1: 定义sidecar类型 type Type uint8 // 关键点2: 按照需要定义sidecar具体类型 const ( Raw Type = iota AllInOne ) // 关键点3: 定义简单工厂对象 type SimpleFactory struct { producer mq.Producible } // 关键点4: 定义工厂方法,入参为sidecar类型,根据switch-case或者if-else来创建产品 func (s SimpleFactory) Create(sidecarType Type) network.Socket { switch sidecarType { case Raw: return network.DefaultSocket() case AllInOne: return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), s.producer) default: return nil } } // 关键点5: 创建产品时传入具体的sidecar类型,比如sidecar.AllInOne simpleFactory := &sidecar.SimpleFactory{producer: producer} sidecar := simpleFactory.Create(sidecar.AllInOne) ``` ## 静态工厂方法 静态工厂方法是 Java/C++ 的说法,主要用于替代构造函数来完成对象的实例化,能够让代码的可读性更好,而且起到了与客户端解耦的作用。比如 Java 的静态工厂方法实现如下: ``` public class Packet { private final Endpoint src; private final Endpoint dest; private final Object payload; private Packet(Endpoint src, Endpoint dest, Object payload) { this.src = src; this.dest = dest; this.payload = payload; } // 静态工厂方法 public static Packet of(Endpoint src, Endpoint dest, Object payload) { return new Packet(src, dest, payload); } ... } // 用法 packet = Packet.of(src, dest, payload) ``` Go 中并没有**静态**一说,直接通过普通函数来完成对象的构造即可,比如: ``` // demo/network/packet.go type Packet struct { src Endpoint dest Endpoint payload interface{} } // 工厂方法 func NewPacket(src, dest Endpoint, payload interface{}) *Packet { return &Packet{ src: src, dest: dest, payload: payload, } } // 用法 packet := NewPacket(src, dest, payload) ``` # 典型应用场景 1. **对象实例化逻辑较为复杂**时,可选择使用工厂方法模式/简单工厂/静态工厂方法来进行封装,为客户端提供一个易用的接口。 2. 如果**实例化的对象/接口涉及多种实现**,可以使用工厂方法模式实现多态。 3. **普通对象的创建,推荐使用静态工厂方法**,比直接的实例化(比如 &Packet{src: src, dest: dest, payload: payload})具备更好的可读性和低耦合。 # 优缺点 ## 优点 1. 代码的可读性更好。 2. 与客户端程序解耦,当实例化逻辑变更时,只需改动工厂方法即可,避免了霰弹式修改。 ## 缺点 1. 引入工厂方法模式会新增一些对象/接口的定义,滥用会导致代码更加复杂。 # 与其他模式的关联 很多同学容易将工厂方法模式和**抽象工厂模式**混淆,抽象工厂模式主要运用在实例化“产品族”的场景,可以看成是工厂方法模式的一种演进。 # 参考 [1] [【Go实现】实践GoF的23种设计模式:SOLID原则](https://mp.weixin.qq.com/s/s3aD4mK2Aw4v99tbCIe9HA), 元闰子 [2] Design Patterns, Chapter 3. Creational Patterns, GoF [3] Factory patterns in Go (Golang), Soham Kamani [4] 工厂方法, 维基百科 简单的分布式应用系统(示例代码工程):https://github.com/ruanrunxue/Practice-Design-Pattern–Go-Implementation
-
本文分享自华为云社区《[设备如何使用go sdk轻松连接华为云IoT平台](https://bbs.huaweicloud.com/blogs/349842?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=iot&utm_content=content)》,作者:华为云IoT专家团 。 本文介绍使用[huaweicloud-iot-device-sdk-go](https://github.com/ctlove0523/huaweicloud-iot-device-sdk-go) 连接华为云IoT平台,实现简单的华为云文档介绍的四个功能:设备连接鉴权、设备命令、设备消息和设备属性。huaweicloud-iot-device-sdk-go提供设备接入华为云IoT物联网平台的Go版本的SDK,提供设备和平台之间通讯能力,以及设备服务、网关服务、OTA等高级服务。IoT设备开发者使用SDK可以大大简化开发复杂度,快速的接入平台。 Gihub项目地址:[huaweicloud-iot-device-sdk-go](https://github.com/ctlove0523/huaweicloud-iot-device-sdk-go) # 安装和构建 安装和构建的过程取决于使用go的 modules(推荐) 还是还是GOPATH # Modules 如果你使用 modules 只需要导入包"github.com/ctlove0523/huaweicloud-iot-device-sdk-go"即可使用。当你使用go build命令构建项目时,依赖的包会自动被下载。注意使用go build命令构建时会自动下载最新版本,最新版本还没有达到release的标准可能存在一些尚未修复的bug。如果想使用稳定的发布版本可以从release 获取最新稳定的版本号,并在go.mod文件中指定版本号。 module example go 1.15 require github.com/ctlove0523/huaweicloud-iot-device-sdk-go v0.0.1-alpha # GOPATH 如果你使用GOPATH,下面的一条命令即可实现安装 `go get github.com/ctlove0523/huaweicloud-iot-device-sdk-go` # 使用API # 创建设备并初始化 1、首先,在华为云IoT平台创建一个设备,设备的信息如下: 设备ID:5fdb75cccbfe2f02ce81d4bf_go-mqtt 设备密钥:123456789 2、使用SDK创建一个Device对象,并初始化Device。 // 创建一个设备并初始化 device := iot.CreateIotDevice("5fdb75cccbfe2f02ce81d4bf_go-mqtt", "123456789", "tcp://iot-mqtts.cn-north-4.myhuaweicloud.com:1883") device.Init() # 完整样例 import ( "fmt" "github.com/ctlove0523/huaweicloud-iot-device-sdk-go" "time" ) func main() { // 创建一个设备并初始化 device := iot.CreateIotDevice("5fdb75cccbfe2f02ce81d4bf_go-mqtt", "123456789", "tcp://iot-mqtts.cn-north-4.myhuaweicloud.com:1883") device.Init() if device.IsConnected() { fmt.Println("device connect huawei iot platform success") } else { fmt.Println("device connect huawei iot platform failed") } } >iot-mqtts.cn-north-4.myhuaweicloud.com为华为IoT平台(基础班)在华为云北京四的访问端点,如果你购买了标准版或企业版,请将iot-mqtts.cn-north-4.myhuaweicloud.com更换为对应的MQTT协议接入端点。 # 设备处理平台下发的命令 1、首先,在华为云IoT平台创建一个设备,设备的信息如下: 设备ID:5fdb75cccbfe2f02ce81d4bf_go-mqtt 设备密钥:123456789 2、使用SDK创建一个Device对象,并初始化Device。 // 创建一个设备并初始化 device := iot.CreateIotDevice("5fdb75cccbfe2f02ce81d4bf_go-mqtt", "123456789", "tcp://iot-mqtts.cn-north-4.myhuaweicloud.com:1883") device.Init() if device.IsConnected() { fmt.Println("device connect huawei iot platform success") } else { fmt.Println("device connect huawei iot platform failed") } 3、注册命令处理handler,支持注册多个handler并且按照注册的顺序回调 // 添加用于处理平台下发命令的callback device.AddCommandHandler(func(command iot.Command) bool { fmt.Println("First command handler begin to process command.") return true }) device.AddCommandHandler(func(command iot.Command) bool { fmt.Println("Second command handler begin to process command.") return true }) 4、通过应用侧API向设备下发一个命令,可以看到程序输出如下: device connect huawei iot platform success First command handler begin to process command. Second command handler begin to process command. # 完整样例 import ( "fmt" "github.com/ctlove0523/huaweicloud-iot-device-sdk-go" "time" ) // 处理平台下发的同步命令 func main() { // 创建一个设备并初始化 device := iot.CreateIotDevice("5fdb75cccbfe2f02ce81d4bf_go-mqtt", "123456789", "tcp://iot-mqtts.cn-north-4.myhuaweicloud.com:1883") device.Init() if device.IsConnected() { fmt.Println("device connect huawei iot platform success") } else { fmt.Println("device connect huawei iot platform failed") } // 添加用于处理平台下发命令的callback device.AddCommandHandler(func(command iot.Command) bool { fmt.Println("First command handler begin to process command.") return true }) device.AddCommandHandler(func(command iot.Command) bool { fmt.Println("Second command handler begin to process command.") return true }) time.Sleep(1 * time.Minute) } >设备支持的命令定义在产品中 # 设备消息 1、首先,在华为云IoT平台创建一个设备,设备的信息如下: 设备ID:5fdb75cccbfe2f02ce81d4bf_go-mqtt 设备密钥:123456789 2、使用SDK创建一个Device对象,并初始化Device。 device := iot.CreateIotDevice("5fdb75cccbfe2f02ce81d4bf_go-mqtt", "123456789", "tcp://iot-mqtts.cn-north-4.myhuaweicloud.com:1883") device.Init() # 设备消息上报 message := iot.Message{ ObjectDeviceId: uuid.NewV4().String(), Name: "Fist send message to platform", Id: uuid.NewV4().String(), Content: "Hello Huawei IoT Platform", } device.SendMessage(message) # 平台消息下发 接收平台下发的消息,只需注册消息处理handler,支持注册多个handler并按照注册顺序回调。 // 注册平台下发消息的callback,当收到平台下发的消息时,调用此callback. // 支持注册多个callback,并且按照注册顺序调用 device.AddMessageHandler(func(message iot.Message) bool { fmt.Println("first handler called" + iot.Interface2JsonString(message)) return true }) device.AddMessageHandler(func(message iot.Message) bool { fmt.Println("second handler called" + iot.Interface2JsonString(message)) return true }) # 完整样例 import ( "fmt" iot "github.com/ctlove0523/huaweicloud-iot-device-sdk-go" uuid "github.com/satori/go.uuid" "time" ) func main() { // 创建一个设备并初始化 device := iot.CreateIotDevice("5fdb75cccbfe2f02ce81d4bf_go-mqtt", "123456789", "tcp://iot-mqtts.cn-north-4.myhuaweicloud.com:1883") device.Init() // 注册平台下发消息的callback,当收到平台下发的消息时,调用此callback. // 支持注册多个callback,并且按照注册顺序调用 device.AddMessageHandler(func(message iot.Message) bool { fmt.Println("first handler called" + iot.Interface2JsonString(message)) return true }) device.AddMessageHandler(func(message iot.Message) bool { fmt.Println("second handler called" + iot.Interface2JsonString(message)) return true }) //向平台发送消息 message := iot.Message{ ObjectDeviceId: uuid.NewV4().String(), Name: "Fist send message to platform", Id: uuid.NewV4().String(), Content: "Hello Huawei IoT Platform", } device.SendMessage(message) time.Sleep(2 * time.Minute) } # 设备属性 1、首先,在华为云IoT平台创建一个设备,并在该设备下创建3个子设备,设备及子设备的信息如下: 设备ID:5fdb75cccbfe2f02ce81d4bf_go-mqtt 设备密钥:123456789 子设备ID:5fdb75cccbfe2f02ce81d4bf_sub-device-1 子设备ID:5fdb75cccbfe2f02ce81d4bf_sub-device-2 子设备ID:5fdb75cccbfe2f02ce81d4bf_sub-device-3 2、使用SDK创建一个Device对象,并初始化Device。 // 创建设备并初始化 device := iot.CreateIotDevice("5fdb75cccbfe2f02ce81d4bf_go-mqtt", "123456789", "tcp://iot-mqtts.cn-north-4.myhuaweicloud.com:1883") device.Init() fmt.Printf("device connected: %v\n", device.IsConnected()) # 设备属性上报 使用ReportProperties(properties ServiceProperty) bool 上报设备属性 // 设备上报属性 props := iot.ServicePropertyEntry{ ServiceId: "value", EventTime: iot.DataCollectionTime(), Properties: DemoProperties{ Value: "chen tong", MsgType: "23", }, } var content []iot.ServicePropertyEntry content = append(content, props) services := iot.ServiceProperty{ Services: content, } device.ReportProperties(services) # 网关批量设备属性上报 使用BatchReportSubDevicesProperties(service DevicesService) 实现网关批量设备属性上报 // 批量上报子设备属性 subDevice1 := iot.DeviceService{ DeviceId: "5fdb75cccbfe2f02ce81d4bf_sub-device-1", Services: content, } subDevice2 := iot.DeviceService{ DeviceId: "5fdb75cccbfe2f02ce81d4bf_sub-device-2", Services: content, } subDevice3 := iot.DeviceService{ DeviceId: "5fdb75cccbfe2f02ce81d4bf_sub-device-3", Services: content, } var devices []iot.DeviceService devices = append(devices, subDevice1, subDevice2, subDevice3) device.BatchReportSubDevicesProperties(iot.DevicesService{ Devices: devices, }) # 平台设置设备属性 使用AddPropertiesSetHandler(handler DevicePropertiesSetHandler) 注册平台设置设备属性handler,当接收到平台的命令时SDK回调。 // 注册平台设置属性callback,当应用通过API设置设备属性时,会调用此callback,支持注册多个callback device.AddPropertiesSetHandler(func(propertiesSetRequest iot.DevicePropertyDownRequest) bool { fmt.Println("I get property set command") fmt.Printf("request is %s", iot.Interface2JsonString(propertiesSetRequest)) return true }) # 平台查询设备属性 使用SetPropertyQueryHandler(handler DevicePropertyQueryHandler)注册平台查询设备属性handler,当接收到平台的查询请求时SDK回调。 // 注册平台查询设备属性callback,当平台查询设备属性时此callback被调用,仅支持设置一个callback device.SetPropertyQueryHandler(func(query iot.DevicePropertyQueryRequest) iot.ServicePropertyEntry { return iot.ServicePropertyEntry{ ServiceId: "value", Properties: DemoProperties{ Value: "QUERY RESPONSE", MsgType: "query property", }, EventTime: "2020-12-19 02:23:24", } }) # 设备侧获取平台的设备影子数据 使用QueryDeviceShadow(query DevicePropertyQueryRequest, handler DevicePropertyQueryResponseHandler) 可以查询平台的设备影子数据,当接收到平台的响应后SDK自动回调DevicePropertyQueryResponseHandler。 // 设备查询设备影子数据 device.QueryDeviceShadow(iot.DevicePropertyQueryRequest{ ServiceId: "value", }, func(response iot.DevicePropertyQueryResponse) { fmt.Printf("query device shadow success.\n,device shadow data is %s\n", iot.Interface2JsonString(response)) }) # 完整样例 import ( "fmt" iot "github.com/ctlove0523/huaweicloud-iot-device-sdk-go" "time" ) func main() { // 创建设备并初始化 device := iot.CreateIotDevice("5fdb75cccbfe2f02ce81d4bf_go-mqtt", "123456789", "tcp://iot-mqtts.cn-north-4.myhuaweicloud.com:1883") device.Init() fmt.Printf("device connected: %v\n", device.IsConnected()) // 注册平台设置属性callback,当应用通过API设置设备属性时,会调用此callback,支持注册多个callback device.AddPropertiesSetHandler(func(propertiesSetRequest iot.DevicePropertyDownRequest) bool { fmt.Println("I get property set command") fmt.Printf("request is %s", iot.Interface2JsonString(propertiesSetRequest)) return true }) // 注册平台查询设备属性callback,当平台查询设备属性时此callback被调用,仅支持设置一个callback device.SetPropertyQueryHandler(func(query iot.DevicePropertyQueryRequest) iot.ServicePropertyEntry { return iot.ServicePropertyEntry{ ServiceId: "value", Properties: DemoProperties{ Value: "QUERY RESPONSE", MsgType: "query property", }, EventTime: "2020-12-19 02:23:24", } }) // 设备上报属性 props := iot.ServicePropertyEntry{ ServiceId: "value", EventTime: iot.DataCollectionTime(), Properties: DemoProperties{ Value: "chen tong", MsgType: "23", }, } var content []iot.ServicePropertyEntry content = append(content, props) services := iot.ServiceProperty{ Services: content, } device.ReportProperties(services) // 设备查询设备影子数据 device.QueryDeviceShadow(iot.DevicePropertyQueryRequest{ ServiceId: "value", }, func(response iot.DevicePropertyQueryResponse) { fmt.Printf("query device shadow success.\n,device shadow data is %s\n", iot.Interface2JsonString(response)) }) // 批量上报子设备属性 subDevice1 := iot.DeviceService{ DeviceId: "5fdb75cccbfe2f02ce81d4bf_sub-device-1", Services: content, } subDevice2 := iot.DeviceService{ DeviceId: "5fdb75cccbfe2f02ce81d4bf_sub-device-2", Services: content, } subDevice3 := iot.DeviceService{ DeviceId: "5fdb75cccbfe2f02ce81d4bf_sub-device-3", Services: content, } var devices []iot.DeviceService devices = append(devices, subDevice1, subDevice2, subDevice3) device.BatchReportSubDevicesProperties(iot.DevicesService{ Devices: devices, }) time.Sleep(1 * time.Minute) } type DemoProperties struct { Value string `json:"value"` MsgType string `json:"msgType"` }
-
上一篇:【Go实现】实践GoF的23种设计模式:SOLID原则简单的分布式应用系统(示例代码工程):https://github.com/ruanrunxue/Practice-Design-Pattern–Go-Implementation简述GoF 对单例模式(Singleton)的定义如下:Ensure a class only has one instance, and provide a global point of access to it.也即,保证一个类只有一个实例,并且为它提供一个全局访问点。在程序设计中,有些对象通常只需要一个共享的实例,比如线程池、全局缓存、对象池等。实现共享实例最简单直接的方式就是全局变量。但是,使用全局变量会带来一些问题,比如:客户端程序可以创建同类实例,从而无法保证在整系统上只有一个共享实例。难以控制对象的访问,比如想增加一个“访问次数统计”的功能就很难,可扩展性较低。把实现细节暴露给客户端程序,加深了耦合,容易产生霰弹式修改。对这种全局唯一的场景,更好的是使用单例模式去实现。单例模式能够限制客户端程序创建同类实例,并且可以在全局访问点上扩展或修改功能,而不影响客户端程序。但是,并非所有的全局唯一都适用单例模式。比如下面这种场景:考虑需要统计一个API调用的情况,有两个指标,成功调用次数和失败调用次数。这两个指标都是全局唯一的,所以有人可能会将其建模成两个单例SuccessApiMetric和FailApiMetric。按照这个思路,随着指标数量的增多,你会发现代码里类的定义会越来越多,也越来越臃肿。这也是单例模式最常见的误用场景,更好的方法是将两个指标设计成一个对象ApiMetric下的两个实例ApiMetic success和ApiMetic fail。那么,如何判断一个对象是否应该被建模成单例?通常,被建模成单例的对象都有“中心点”的含义,比如线程池就是管理所有线程的中心。所以,在判断一个对象是否适合单例模式时,先思考下,是一个中心点吗?UML结构代码实现根据单例模式的定义,实现的关键点有两个:限制调用者直接实例化该对象;为该对象的单例提供一个全局唯一的访问方法。对于 C++ / Java 而言,只需把对象的构造函数设计成私有的,并提供一个 static 方法去访问该对象的唯一实例即可。但 Go 语言并没有构造函数的概念,也没有 static 方法,所以需要另寻出路。我们可以利用 Go 语言 package 的访问规则来实现,将单例对象设计成首字母小写,这样就能限定它的访问范围只在当前package下,模拟了 C++ / Java 的私有构造函数;然后,在当前 package 下实现一个首字母大写的访问函数,也就相当于 static 方法的作用了。示例在简单的分布式应用系统(示例代码工程)中,我们定义了一个网络模块 network,模拟实现了网络报文转发功能。network 的设计也很简单,通过一个哈希表维持了 Endpoint 到 Socket 的映射,报文转发时,通过 Endpoint 寻址到 Socket,再调用 Socket 的 Receive 方法完成转发。因为整系统只需一个 network 对象,而且它在领域模型中具有中心点的语义,所以我们很自然地使用单例模式来实现它。单例模式大致可以分成两类,“饿汉模式”和“懒汉模式”。前者是在系统初始化期间就完成了单例对象的实例化;后者则是在调用时才进行延迟实例化,从而一定程度上节省了内存。“饿汉模式”实现// demo/network/network.go package network // 1、设计为小写字母开头,表示只在network包内可见,限制客户端程序的实例化 type network struct { sockets sync.Mapvar instancevar instance } // 2、定义一个包内可见的实例对象,也即单例 var instance = &network{sockets: sync.Map{}} // 3、定义一个全局可见的唯一访问方法 func Instance() *network { return instance } func (n *network) Listen(endpoint Endpoint, socket Socket) error { if _, ok := n.sockets.Load(endpoint); ok { return ErrEndpointAlreadyListened } n.sockets.Store(endpoint, socket) return nil } func (n *network) Send(packet *Packet) error { record, rOk := n.sockets.Load(packet.Dest()) socket, sOk := record.(Socket) if !rOk || !sOk { return ErrConnectionRefuse } go socket.Receive(packet) return nil }那么,客户端就可以通过 network.Instance() 引用该单例了:// demo/sidecar/flowctrl_sidecar.go package sidecar type FlowCtrlSidecar struct {...} // 通过 network.Instance() 直接引用单例 func (f *FlowCtrlSidecar) Listen(endpoint network.Endpoint) error { return network.Instance().Listen(endpoint, f) } ...“懒汉模式”实现众所周知,“懒汉模式”会带来线程安全问题,可以通过普通加锁,或者更高效的双重检验加锁来优化。不管是哪种方法,都是为了保证单例只会被初始化一次。type network struct {...} // 单例 var instance *network // 定义互斥锁 var mutex = sync.Mutex{} // 普通加锁,缺点是每次调用 Instance() 都需要加锁 func Instance() *network { mutex.Lock() if instance == nil { instance = &network{sockets: sync.Map{}} } mutex.Unlock() return instance } // 双重检验后加锁,实例化后无需加锁 func Instance() *network { if instance == nil { mutex.Lock() if instance == nil { instance = &network{sockets: sync.Map{}} } mutex.Unlock() } return instance }对于“懒汉模式”,Go 语言还有一个更优雅的实现方式,那就是利用 sync.Once。它有一个 Do 方法,方法声明为 func (o *Once) Do(f func()),其中入参是 func() 的方法类型,Go 会保证该方法仅会被调用一次。利用这个特性,我们就能够实现单例只被初始化一次了。type network struct {...} // 单例 var instance *network // 定义 once 对象 var once = sync.Once{} // 通过once对象确保instance只被初始化一次 func Instance() *network { once.Do(func() { // 只会被调用一次 instance = &network{sockets: sync.Map{}} }) return instance }扩展提供多个实例虽然单例模式从定义上表示每个对象只能有一个实例,但是我们不应该被该定义限制住,还得从模式本身的动机来去理解它。单例模式的一大动机是限制客户端程序对对象进行实例化,至于实例有多少个其实并不重要,根据具体场景来进行建模、设计即可。比如在前面的 network 模块中,现在新增一个这样的需求,将网络拆分为互联网和局域网。那么,我们可以这么设计:type network struct {...} // 定义互联网单例 var inetInstance = &network{sockets: sync.Map{}} // 定义局域网单例 var lanInstance = &network{sockets: sync.Map{}} // 定义互联网全局可见的唯一访问方法 func Internet() *network { return inetInstance } // 定义局域网全局可见的唯一访问方法 func Lan() *network { return lanInstance }虽然上述例子中,network 结构有两个实例,但是本质上还是单例模式,因为它做到了限制客户端实例化,以及为每个单例提供了全局唯一的访问方法。提供多种实现单例模式也可以实现多态,如果你预测该单例未来可能会扩展,那么就可以将它设计成抽象的接口,让客户端依赖抽象,这样,未来扩展时就无需改动客户端程序了。比如,我们可以 network 设计为一个抽象接口:// network 抽象接口 type network interface { Listen(endpoint Endpoint, socket Socket) error Send(packet *Packet) error } // network 的实现1 type networkImpl1 struct { sockets sync.Map } func (n *networkImpl1) Listen(endpoint Endpoint, socket Socket) error {...} func (n *networkImpl1) Send(packet *Packet) error {...} // networkImpl1 实现的单例 var instance = &networkImpl1{sockets: sync.Map{}} // 定义全局可见的唯一访问方法,注意返回值时network抽象接口! func Instance() network { return instance } // 客户端使用示例 func client() { packet := network.NewPacket(srcEndpoint, destEndpoint, payload) network.Instance().Send(packet) }如果未来需要新增一种 networkImpl2 实现,那么我们只需修改 instance 的初始化逻辑即可,客户端程序无需改动:// 新增network 的实现2 type networkImpl2 struct {...} func (n *networkImpl2) Listen(endpoint Endpoint, socket Socket) error {...} func (n *networkImpl2) Send(packet *Packet) error {...} // 将单例 instance 修改为 networkImpl2 实现 var instance = &networkImpl2{...} // 单例全局访问方法无需改动 func Instance() network { return instance } // 客户端使用也无需改动 func client() { packet := network.NewPacket(srcEndpoint, destEndpoint, payload) network.Instance().Send(packet) }有时候,我们还可能需要通过读取配置来决定使用哪种单例实现,那么,我们可以通过 map 来维护所有的实现,然后根据具体配置来选取对应的实现:// network 抽象接口 type network interface { Listen(endpoint Endpoint, socket Socket) error Send(packet *Packet) error } // network 具体实现 type networkImpl1 struct {...} type networkImpl2 struct {...} type networkImpl3 struct {...} type networkImpl4 struct {...} // 单例 map var instances = make(map[string]network) // 初始化所有的单例 func init() { instances["impl1"] = &networkImpl1{...} instances["impl2"] = &networkImpl2{...} instances["impl3"] = &networkImpl3{...} instances["impl4"] = &networkImpl4{...} } // 全局单例访问方法,通过读取配置决定使用哪种实现 func Instance() network { impl := readConf() instance, ok := instances[impl] if !ok { panic("instance not found") } return instance }典型应用场景日志。每个服务通常都会需要一个全局的日志对象来记录本服务产生的日志。全局配置。对于一些全局的配置,可以通过定义一个单例来供客户端使用。唯一序列号生成。唯一序列号生成必然要求整系统只能有一个生成实例,非常合适使用单例模式。线程池、对象池、连接池等。xxx池的本质就是共享,也是单例模式的常见场景。全局缓存…优缺点优点在合适的场景,使用单例模式有如下的优点:整系统只有一个或几个实例,有效节省了内存和对象创建的开销。通过全局访问点,可以方便地扩展功能,比如新增加访问次数的统计。对客户端隐藏实现细节,可避免霰弹式修改。缺点虽然单例模式相比全局变量有诸多的优点,但它本质上还是一个“全局变量”,还是避免不了全局变量的一些缺点:函数调用的隐式耦合。通常我们都期望从函数的声明中就能知道该函数做了什么、依赖了什么、返回了什么。使用使用单例模式就意味着,无需通过函数传参,就能够在函数中使用该实例。也即将依赖/耦合隐式化了,不利于更好地理解代码。对测试不友好。通常对一个方法/函数进行测试,我们并不需要知道它的具体实现。但如果方法/函数中有使用单例对象,我们就不得不考虑单例状态的变化了,也即需要考虑方法/函数的具体实现了。并发问题。共享就意味着可能存在并发问题,我们不仅需要在初始化阶段考虑并发问题,在初始化后更是要时刻注意。因此,在高并发的场景,单例模式也可能存在锁冲突问题。单例模式虽然简单易用,但也是最容易被滥用的设计模式。它并不是“银弹”,在实际使用时,还需根据具体的业务场景谨慎使用。与其他模式的关联工厂方法模式、抽象工厂模式很多时候都会以单例模式来实现,因为工厂类通常是无状态的,而且全局只需一个实例即可,能够有效避免对象的频繁创建和销毁。
-
 【欢喜闹元宵专题活动】元宵圆圆,福利连连,游戏go~go~go~的奖品没收到。。
【欢喜闹元宵专题活动】元宵圆圆,福利连连,游戏go~go~go~的奖品没收到。。 -

-
如题
-
 论文题目:OntoProtein: Protein Pretraining With Gene Ontology Embedding本文作者:张宁豫(浙江大学)、毕祯(浙江大学)、梁孝转(浙江大学)、程思源(浙江大学)、洪浩森(浙江大学)、邓淑敏(浙江大学)、连佳长(浙江大学)、张强(浙江大学)、陈华钧(浙江大学)发表会议:ICLR 2022论文链接:https://www.zhuanzhi.ai/paper/6e757d23f8b6b16cb91cdcad6f124b3c代码链接:https://github.com/zjunlp/OntoProtein欢迎转载,转载请注明出处一、引言近年来,预训练模型以强大的算法效果,席卷了自然语言处理为代表的各大AI榜单与测试数据集。与自然语言类似,蛋白质的一级结构具有序列特性,这为将语言预训练模型引入蛋白质表示提供了有利条件。然而,蛋白质本质上不同于自然语言文本,其包含了大量预训练目标较难习得的生物学知识。事实上,人类科学家已经积累了海量的关于蛋白质结构功能的生物学知识。那么如何利用这些知识促进蛋白质预训练呢?本文将介绍被ICLR2022录用的新工作:OntoProtein,其提出一种新颖的融入知识图谱的蛋白质预训练方法。 二、蛋白质预训练 蛋白质是控制生物和生命本身的基本大分子,对蛋白质的研究有助于理解人类健康和发展疾病疗法。蛋白质包含一级结构,二级结构和三级结构,其中一级结构与语言具有相似的序列特性。受到自然语言处理预训练模型的启发,诸多蛋白质预训练模型和工具被提出,包括MSA Transformer[1]、ProtTrans[2]、悟道 · 文溯[3]、百度的PaddleHelix等。大规模无监督蛋白质预训练甚至可以从训练语料中习得一定程度的蛋白质结构和功能。然而,蛋白质本质上不同于自然语言文本,其包含了诸多生物学特有的知识,较难直接通过预训练目标习得,且会受到数据分布影响低频长尾的蛋白质表示。为了解决这些问题,我们利用人类科学家积累的关于蛋白质结构功能的海量生物知识,首次提出融合知识图谱的蛋白质预训练方法。下面首先介绍知识图谱构建的方法。三、基因知识图谱我们通过访问公开的基因本体知识图谱“Gene Ontology(简称Go)”,并将其和来自Swiss-Prot数据库的蛋白质序列对齐,来构建用于预训练的知识图谱ProteinKG25,该知识图谱包含4,990,097个三元组, 其中4,879,951个蛋白质-Go的三元组,110,146 个Go-Go三元组,并已全部开放供社区使用。如下图所示,基于“结构决定功能”的思想,如果在蛋白质预训练过程中显式地告诉模型什么样的结构具备什么样的功能,显然能够促进如蛋白质功能预测、蛋白质交互预测等任务的效果。四、融入基因知识图谱的蛋白质预训练:OntoProtein基于构建好的知识图谱,我们设计了一个特殊的蛋白质预训练模型OntoProtein。注意到在预训练输入中包含两种不同的序列:蛋白质序列和描述蛋白质功能、生物过程等的文本描述信息。因此,我们采取两路不同的编码器。对蛋白质序列我们采用已有的蛋白质预训练模型ProtBert进行编码,对文本序列我们采用BERT进行编码。为了更好地进行预训练和融合三元组知识信息,我们采用了两个优化目标。首先是传统的掩码语言模型目标,我们通过随机Mask序列中的一个Token并预测该Token。其次是三元组知识增强目标,我们通过类似知识图谱嵌入学习的方式来植入生物学三元组知识,如下公式所示:注意到这里的事实知识分为两类不同的三元组,分别是Go-Go和蛋白质-Go,因此我们提出一种知识增强的负采样方法,以获得更有代表性的负样本提升预训练效果,采样方式如下 :五、实验分析我们在蛋白质测试基准TAPE,以及蛋白质蛋白质交互、蛋白质功能预测(我们参考CAFA竞赛构建了一个新的蛋白质功能预测数据集)上进行了实验。如下表所示,可以发现融合知识图谱的蛋白质预训练方法在一定程度上取得了较好或可比的性能。特别地,我们的方法没有使用同源序列比对(MSA),因此较难超越基于MSA Transformer的方法。详细的实验结果请参见论文,我们会在近期将预训练模型整理并发布到Huggingface上供社区使用。六、小结与展望当下蓬勃兴起的 AI for Science 正在促使以数据驱动的开普勒范式和以第一性原理驱动的牛顿范式的深度融合。基于“数据与知识双轮驱动”的学术思想,我们在本文中首次提出了融合知识图谱的蛋白质预训练方法OntoProtein,并在多个下游任务中验证了模型的效果。在未来,我们将维护好OntoProtein以供更多学者使用,并计划探索融合同源序列比对的知识图谱增强预训练方法以实现更优性能。[1] MSA Transformer ICML2021 [2] ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Learning TPAMI2021 [3] Modeling Protein Using Large-scale Pretrain Language Model 2021
论文题目:OntoProtein: Protein Pretraining With Gene Ontology Embedding本文作者:张宁豫(浙江大学)、毕祯(浙江大学)、梁孝转(浙江大学)、程思源(浙江大学)、洪浩森(浙江大学)、邓淑敏(浙江大学)、连佳长(浙江大学)、张强(浙江大学)、陈华钧(浙江大学)发表会议:ICLR 2022论文链接:https://www.zhuanzhi.ai/paper/6e757d23f8b6b16cb91cdcad6f124b3c代码链接:https://github.com/zjunlp/OntoProtein欢迎转载,转载请注明出处一、引言近年来,预训练模型以强大的算法效果,席卷了自然语言处理为代表的各大AI榜单与测试数据集。与自然语言类似,蛋白质的一级结构具有序列特性,这为将语言预训练模型引入蛋白质表示提供了有利条件。然而,蛋白质本质上不同于自然语言文本,其包含了大量预训练目标较难习得的生物学知识。事实上,人类科学家已经积累了海量的关于蛋白质结构功能的生物学知识。那么如何利用这些知识促进蛋白质预训练呢?本文将介绍被ICLR2022录用的新工作:OntoProtein,其提出一种新颖的融入知识图谱的蛋白质预训练方法。 二、蛋白质预训练 蛋白质是控制生物和生命本身的基本大分子,对蛋白质的研究有助于理解人类健康和发展疾病疗法。蛋白质包含一级结构,二级结构和三级结构,其中一级结构与语言具有相似的序列特性。受到自然语言处理预训练模型的启发,诸多蛋白质预训练模型和工具被提出,包括MSA Transformer[1]、ProtTrans[2]、悟道 · 文溯[3]、百度的PaddleHelix等。大规模无监督蛋白质预训练甚至可以从训练语料中习得一定程度的蛋白质结构和功能。然而,蛋白质本质上不同于自然语言文本,其包含了诸多生物学特有的知识,较难直接通过预训练目标习得,且会受到数据分布影响低频长尾的蛋白质表示。为了解决这些问题,我们利用人类科学家积累的关于蛋白质结构功能的海量生物知识,首次提出融合知识图谱的蛋白质预训练方法。下面首先介绍知识图谱构建的方法。三、基因知识图谱我们通过访问公开的基因本体知识图谱“Gene Ontology(简称Go)”,并将其和来自Swiss-Prot数据库的蛋白质序列对齐,来构建用于预训练的知识图谱ProteinKG25,该知识图谱包含4,990,097个三元组, 其中4,879,951个蛋白质-Go的三元组,110,146 个Go-Go三元组,并已全部开放供社区使用。如下图所示,基于“结构决定功能”的思想,如果在蛋白质预训练过程中显式地告诉模型什么样的结构具备什么样的功能,显然能够促进如蛋白质功能预测、蛋白质交互预测等任务的效果。四、融入基因知识图谱的蛋白质预训练:OntoProtein基于构建好的知识图谱,我们设计了一个特殊的蛋白质预训练模型OntoProtein。注意到在预训练输入中包含两种不同的序列:蛋白质序列和描述蛋白质功能、生物过程等的文本描述信息。因此,我们采取两路不同的编码器。对蛋白质序列我们采用已有的蛋白质预训练模型ProtBert进行编码,对文本序列我们采用BERT进行编码。为了更好地进行预训练和融合三元组知识信息,我们采用了两个优化目标。首先是传统的掩码语言模型目标,我们通过随机Mask序列中的一个Token并预测该Token。其次是三元组知识增强目标,我们通过类似知识图谱嵌入学习的方式来植入生物学三元组知识,如下公式所示:注意到这里的事实知识分为两类不同的三元组,分别是Go-Go和蛋白质-Go,因此我们提出一种知识增强的负采样方法,以获得更有代表性的负样本提升预训练效果,采样方式如下 :五、实验分析我们在蛋白质测试基准TAPE,以及蛋白质蛋白质交互、蛋白质功能预测(我们参考CAFA竞赛构建了一个新的蛋白质功能预测数据集)上进行了实验。如下表所示,可以发现融合知识图谱的蛋白质预训练方法在一定程度上取得了较好或可比的性能。特别地,我们的方法没有使用同源序列比对(MSA),因此较难超越基于MSA Transformer的方法。详细的实验结果请参见论文,我们会在近期将预训练模型整理并发布到Huggingface上供社区使用。六、小结与展望当下蓬勃兴起的 AI for Science 正在促使以数据驱动的开普勒范式和以第一性原理驱动的牛顿范式的深度融合。基于“数据与知识双轮驱动”的学术思想,我们在本文中首次提出了融合知识图谱的蛋白质预训练方法OntoProtein,并在多个下游任务中验证了模型的效果。在未来,我们将维护好OntoProtein以供更多学者使用,并计划探索融合同源序列比对的知识图谱增强预训练方法以实现更优性能。[1] MSA Transformer ICML2021 [2] ProtTrans: Towards Cracking the Language of Life’s Code Through Self-Supervised Learning TPAMI2021 [3] Modeling Protein Using Large-scale Pretrain Language Model 2021
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签