-
 想做一个系统生成器,需要一款相对成熟的AI代码生成器,求推荐
想做一个系统生成器,需要一款相对成熟的AI代码生成器,求推荐 -
 编译优化编译器已经发展优化很多年了,一些关于指令重排,精简操作指令,尽量去满足cpu的流水操作,对程序分支进行预测,重新调整代码执行顺序,对简单的程序,使用循环展开等等这些优化代码的操作,大部分的编译器就可以完成。因此本文并不会着重介绍这些性能优化方法,尤其是指令重排和精简指令操作这两种。这些优化,可以通过一些优化选项来让编译器帮我们完成。1.1 Gcc的四级优化-O0:不做任何优化,这是默认的编译选项。 -O1:对程序做部分编译优化,对于大函数,优化编译占用稍微多的时间和相当大的内存。使用本项优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。 它主要对代码的分支,常量以及表达式等进行优化。 -O2:会尝试更多的寄存器级的优化以及指令级的优化,它会在编译期间占用更多的内存和编译时间。Gcc将执行几乎所有不包含时间和空间折中的优化。当设置O2选项时,编译器并不进行循环展开以及函数内联。与O1比较而言,O2优化增加了编译时间的基础上,提高了生成代码的执行效率。 -O3:在O2的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。-Os:主要是对程序的尺寸进行优化。打开了大部分O2优化中不会增加程序大小的优化选项,并对程序代码的大小做更深层的优化。(通常我们不需要这种优化)1.2 编译优化可能带来的问题调试问题:任何级别的优化都将带来代码结构的改变。例如:对分支的合并和消除,对公用子表达式的消除,对循环内load/store操作的替换和更改等,都将会使目标代码的执行顺序变得面目全非,导致调试信息严重不足。 内存操作顺序改变所带来的问题:在O2优化后,编译器会对影响内存操作的执行顺序。例如:-fschedule-insns允许数据处理时先完成其他的指令;-fforce-mem有可能导致内存与寄存器之间的数据产生类似脏数据的不一致等。对于某些依赖内存操作顺序而进行的逻辑,需要做严格的处理后才能进行优化。例如,采用volatile关键字限制变量的操作方式,或者利用barrier迫使cpu严格按照指令序执行的。精简指令操作带来的精度问题:编译优化,会精简指令操作,将某两条指令合并成一条指令等。在数学计算中,先后计算会带来精度不一致的问题。比如计算公式A*B-C*D,我们希望先计算C*D,再计算A*B,最后计算减法,于是代码中用两个乘法和一个减法指令实现此功能,然而编译器会将此三条指令优化成两个指令,即一个乘法指令和一个乘减指令。从而会先计算A*B =X,再计算X-C*D,此类问题在双精度的浮点计算时,会有较大的精度差异。1.3 常用解决方法对于上述编译优化可能引入的一些问题,一般常用的解决方法是用内联汇编的方式重新封装需要的指令。一般在一个工程中,不同代码段,被优化引入的问题是不同的,我们可能无法去修改编译选项。比如上述例子中,因为精简指令带来的精度问题,如果在编译选项中关闭精简指令,势必会影响整个工程的性能。如果在相关函数中告诉编译器禁止优化,那么其他优化方法,此函数也享受不到了。但是如果使用内联汇编的方式,此部分代码编译后,会按照内联的汇编中的指令以及指令顺序执行,这样我们就可以控制问题代码的逻辑同时其他部分继续享受编译器的优化。下面用一个简单例子来说明://下列代码为了计算A*B+E*F以及G*H-C*D float64x2_t X = vmulq_f64(A, B);//乘法指令,计算X=A*B float64x2_t Y = vmulq_f64(C, D);//乘法指令,计算Y=C*D Y = vnegq_f64(Y);//取反,即Y=-Y float64x2_t RST1 = vmlaq_f64(X, E, F);//乘加指令,计算X+E*F float64x2_t RST2= vmlaq_f64(Y, G, H);//乘加指令,计算Y+G*H代码中的实现顺序为先计算A*B=X,再计算X+E*F,先计算Y=C*D,再计算-Y+G*H。假设这是我们希望的逻辑计算顺序。开了编译优化以后,上面指令会被精简优化,取反指令会和乘加指令合并成乘减指令。优化后的公式就变成了A*B+E*F以及G*H-C*D,先计算A*B和G*H,再分别用一条乘加指令和乘减指令完成计算。此与我们希望的运算顺序不同,上述优化是因为优化了乘加指令导致的,因此,我们只用重新封装乘加指令就可以了。当程序到乘加指令的时候,走的是内联汇编版本,按照写的代码执行。如封装的内联汇编如下:FORCE_INLINE float64x2_t vmlaq_f64_ext(float64x2_t a, float64x2_t b, float64x2_t c){ float64x2_t result; __asm__ __volatile__ ( "fmla %0.2d, %2.2d, %3.2d" : "=w"(result) : "0"(a), "w"(b), "w"(c) : /* No clobbers */ ); return result;}
编译优化编译器已经发展优化很多年了,一些关于指令重排,精简操作指令,尽量去满足cpu的流水操作,对程序分支进行预测,重新调整代码执行顺序,对简单的程序,使用循环展开等等这些优化代码的操作,大部分的编译器就可以完成。因此本文并不会着重介绍这些性能优化方法,尤其是指令重排和精简指令操作这两种。这些优化,可以通过一些优化选项来让编译器帮我们完成。1.1 Gcc的四级优化-O0:不做任何优化,这是默认的编译选项。 -O1:对程序做部分编译优化,对于大函数,优化编译占用稍微多的时间和相当大的内存。使用本项优化,编译器会尝试减小生成代码的尺寸,以及缩短执行时间,但并不执行需要占用大量编译时间的优化。 它主要对代码的分支,常量以及表达式等进行优化。 -O2:会尝试更多的寄存器级的优化以及指令级的优化,它会在编译期间占用更多的内存和编译时间。Gcc将执行几乎所有不包含时间和空间折中的优化。当设置O2选项时,编译器并不进行循环展开以及函数内联。与O1比较而言,O2优化增加了编译时间的基础上,提高了生成代码的执行效率。 -O3:在O2的基础上进行更多的优化,例如使用伪寄存器网络,普通函数的内联,以及针对循环的更多优化。-Os:主要是对程序的尺寸进行优化。打开了大部分O2优化中不会增加程序大小的优化选项,并对程序代码的大小做更深层的优化。(通常我们不需要这种优化)1.2 编译优化可能带来的问题调试问题:任何级别的优化都将带来代码结构的改变。例如:对分支的合并和消除,对公用子表达式的消除,对循环内load/store操作的替换和更改等,都将会使目标代码的执行顺序变得面目全非,导致调试信息严重不足。 内存操作顺序改变所带来的问题:在O2优化后,编译器会对影响内存操作的执行顺序。例如:-fschedule-insns允许数据处理时先完成其他的指令;-fforce-mem有可能导致内存与寄存器之间的数据产生类似脏数据的不一致等。对于某些依赖内存操作顺序而进行的逻辑,需要做严格的处理后才能进行优化。例如,采用volatile关键字限制变量的操作方式,或者利用barrier迫使cpu严格按照指令序执行的。精简指令操作带来的精度问题:编译优化,会精简指令操作,将某两条指令合并成一条指令等。在数学计算中,先后计算会带来精度不一致的问题。比如计算公式A*B-C*D,我们希望先计算C*D,再计算A*B,最后计算减法,于是代码中用两个乘法和一个减法指令实现此功能,然而编译器会将此三条指令优化成两个指令,即一个乘法指令和一个乘减指令。从而会先计算A*B =X,再计算X-C*D,此类问题在双精度的浮点计算时,会有较大的精度差异。1.3 常用解决方法对于上述编译优化可能引入的一些问题,一般常用的解决方法是用内联汇编的方式重新封装需要的指令。一般在一个工程中,不同代码段,被优化引入的问题是不同的,我们可能无法去修改编译选项。比如上述例子中,因为精简指令带来的精度问题,如果在编译选项中关闭精简指令,势必会影响整个工程的性能。如果在相关函数中告诉编译器禁止优化,那么其他优化方法,此函数也享受不到了。但是如果使用内联汇编的方式,此部分代码编译后,会按照内联的汇编中的指令以及指令顺序执行,这样我们就可以控制问题代码的逻辑同时其他部分继续享受编译器的优化。下面用一个简单例子来说明://下列代码为了计算A*B+E*F以及G*H-C*D float64x2_t X = vmulq_f64(A, B);//乘法指令,计算X=A*B float64x2_t Y = vmulq_f64(C, D);//乘法指令,计算Y=C*D Y = vnegq_f64(Y);//取反,即Y=-Y float64x2_t RST1 = vmlaq_f64(X, E, F);//乘加指令,计算X+E*F float64x2_t RST2= vmlaq_f64(Y, G, H);//乘加指令,计算Y+G*H代码中的实现顺序为先计算A*B=X,再计算X+E*F,先计算Y=C*D,再计算-Y+G*H。假设这是我们希望的逻辑计算顺序。开了编译优化以后,上面指令会被精简优化,取反指令会和乘加指令合并成乘减指令。优化后的公式就变成了A*B+E*F以及G*H-C*D,先计算A*B和G*H,再分别用一条乘加指令和乘减指令完成计算。此与我们希望的运算顺序不同,上述优化是因为优化了乘加指令导致的,因此,我们只用重新封装乘加指令就可以了。当程序到乘加指令的时候,走的是内联汇编版本,按照写的代码执行。如封装的内联汇编如下:FORCE_INLINE float64x2_t vmlaq_f64_ext(float64x2_t a, float64x2_t b, float64x2_t c){ float64x2_t result; __asm__ __volatile__ ( "fmla %0.2d, %2.2d, %3.2d" : "=w"(result) : "0"(a), "w"(b), "w"(c) : /* No clobbers */ ); return result;} -
# GCC for openEuler -mcmodel选项详解 ## 导语 GCC for openEuler是基于开源GCC开发的编译器工具链(包含编译器,汇编器,链接器),在openEuler社区开源发布,并通过鲲鹏社区免费提供二进制包,支持包含ARM、x86在内的多种处理器架构。 本文将向大家详细介绍-mcmodel选项的作用以及GCC for openEuler 在-mcmodel选项上做的新功能支持[1]。 ## 背景 编译的过程中,编译器是不知道要操作的数据在哪里的,计算数据地址的工作是在链接阶段实现的。也就是说,编译器需要先把拿取数据的汇编指令定下来,在编译结束之后,链接器进行重定位计算时再填上指令的操作数是多少。那就有一个问题,编译器如何选择一个合适的指令拿取数据? **PC相对寻址** 在考虑这个问题前,我们先了解一下PC相对地址。PC(Program Count)特指PC寄存器(以下都用PC表示),是计算机处理器内部的一个专用寄存器,用来表示下一个将被执行的指令的地址。在我们的程序中,如果某一条指令访问的符号(变量,函数等)是基于当前指令的相对地址,我们就称这是**PC相对寻址**。 例如跳转指令`b, <label>`中的 `<lable>` 就是**偏移量**,并不是绝对地址。在链接阶段,链接器会根据符号出现的位置计算出正确的偏移,编码到指令中去。程序执行时到这条指令时,就会把`<lable>`所代表的偏移量与当前PC值相加,得到要跳转的指令地址。 类似的还有ADR,ADRP指令。ADR/ADRP分别是获取某个符号的地址/页面地址,并把它们存放到指定的寄存器中。它们的格式是这样的:`ADR Rd, <label>`, `ADRP Rd, <label>`, 这里的`<label>`都是代表当前指令位置的偏移量。 `<label>`受到指令位域的限制,所以偏移量都是有限制的。比如说`b, <label>` 可以基于当前PC有±128MB的寻址范围,`ADR Rd, <label>`有±1MB的寻址范围,`ADRP Rd, <label>`有±4GB的寻址范围。 链接器在链接时会把各个目标文件进行合理布局,使得跳转、函数调用、变量访问等操作都不会离当前指令特别远。通常情况下,使用前面提到的指令能满足绝大多数的情景,但是如果指令要访问的符号超出了4GB(32位)的范围,这时用默认的符号取值方式就会出错。 ## 案例 比如说在AArch64后端如果待链接符号的距离超过4GB(如图1),编译的时候又决定使用ADRP指令(32bit寻址范围,如图2)。此时如果使用这种方式去链接,则会报relocation truncated to fit这样的错(如图3)。 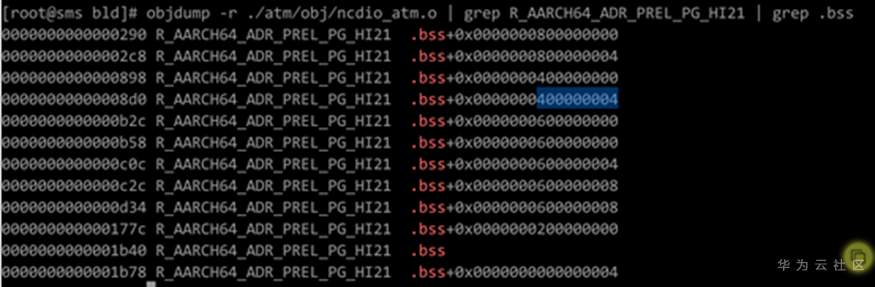 图1:符号相对于.bss段的偏移大于4GB  图2:指令集中对于ADRP指令的描述,可见其寻址范围只在±4GB  图3:CESM代码中出问题的字段描述,`R_AARCH64_ ADR_PREL_PG_HI21`对应ADRP指令进行相对PC寻址 那么怎么解决这个问题?在这种情况下需要指导编译器:符号可能特别远(超过4GB),需要生成恰当的指令来获取符号地址。那么编译器就不会再用传统的ADRP这样的指令,而是采用其他的办法。 对此,GCC提供了`-mcmodel`参数,用于指导编译器应该使用哪种模型来生成指令。 下面是GCC的`-mcmodel`对AArch64架构的的官方说明: > -mcmodel=tiny\ > Generate code for the tiny code model. The program and its statically defined symbols must be within 1MB of each other. Programs can be statically or dynamically linked.\ > -mcmodel=small\ > Generate code for the small code model. The program and its statically defined symbols must be within 4GB of each other. Programs can be statically or dynamically linked. This is the default code model.\ > -mcmodel=large\ > Generate code for the large code model. This makes no assumptions about addresses and sizes of sections. Programs can be statically linked only. The -mcmodel=large option is incompatible with -mabi=ilp32, -fpic and -fPIC. `-mcmodel`选项指导编译器做出这样一种假设:代码里所有符号的位置都在某个位宽范围之内。比如`-mcmodel=small`,就是假设所有符号都在4GB范围内,32bit的位宽就可以找到符号的位置,那我们使用ADRP指令就可以了。 但是假设不成立的时候,比如上面的情况,ADRP指令不再适用,需要用位宽更大的指令。这个时候就需要增大`-mcmodel`的预设,使用`-mcmodel=large`,变更寻址方式为LDR指令。LDR指令只能绝对寻址,但是有更大的寻址范围。如果你的应用可以非地址无关编译的话,那么`-mcmodel=large`理论上可以解决所有的问题。 而例如HPC场景中的CESM应用在符号超过4GB寻址范围的时候,作为一些共享库,仍然需要按照地址无关代码(position-independent code,PIC) 的方式编译(-fPIC / -fpic地址无关功能),可以说地址无关代码是动态共享库必须的。这时LDR指令也不再适用,因为GCC对于AArch64的支持非常有限,它仅支持非地址无关代码。这是AArch64独有的一类问题。 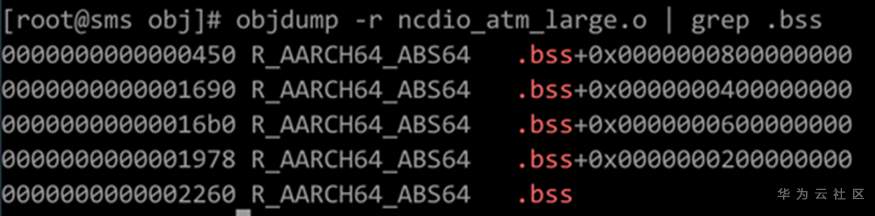 图4:aarch64 `-mcmodle=large`时的寻址方式 在x86上有可以大位宽操作的`mov`指令,它可以实现4GB以上的地址无关寻址。根据与x86后端对比可以发现,x86后端在`-mcmodel=medium`的时候之所以还可以生成地址无关代码,主要原因是其寻址方式还是相对PC寻址。与`-mcmodel=small`相比唯一的变动是相对寻址的指令由`mov`变成了`movabs`,可以进行更大范围的寻址(64bit)。  图5:x86 ABI 中对于`-mcmodle=medium`、`-mcmodle=large`的描述 反观AArch64后端,其实相对PC寻址的指令和64bit的加法指令都是有的,甚至是64位的相对PC寻址方式在ABI中都是有的(如图6),缺少的是这种重定位方式。 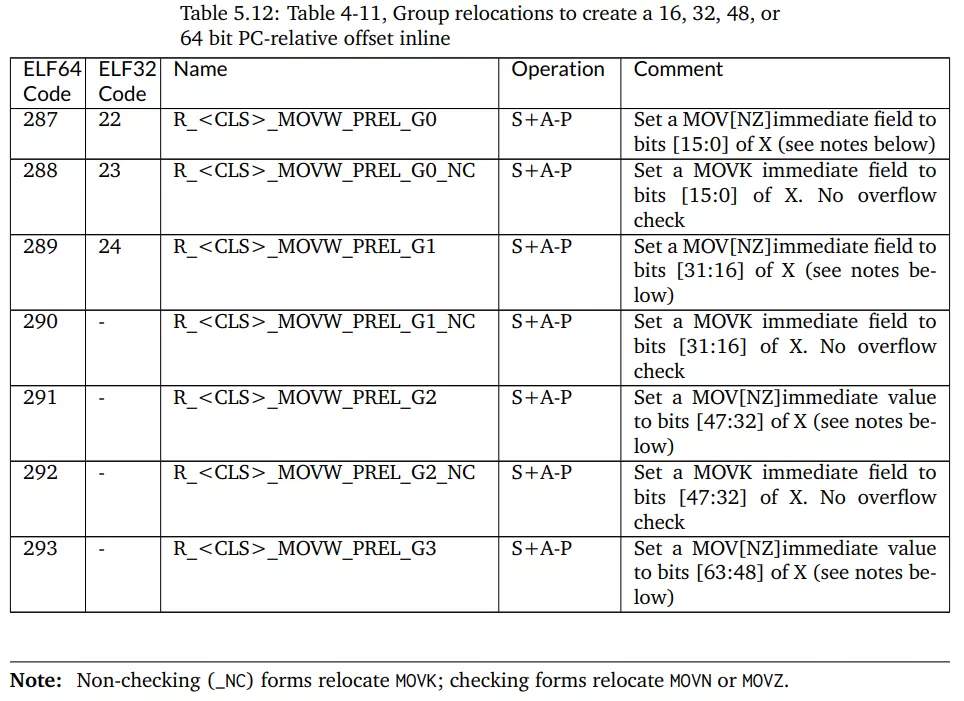 图6: AArch64 ABI 中关于64位相对PC寻址的描述 ## -mcmodel=medium, -mlarge-data-threshold=n GCC for openEuler根据上述问题的痛点,新开发了`-mcmodel=medium`, `-mlarge-data-threshold=n`两个选项。此选项使能了32bit之外的动态取址操作。在使用`-mcmodel=medium`时,对于符号size大于`aarch64_data_threshold`的符号使用**通过mov序列来获取PC值的offset,再与PC值相加**的方式实现64bit的相对PC寻址,在地址无关选项打开时,可以实现64bit相对PC寻址,获取GOT表入口,并且通过mov序列+LDR方式获取符号。 说明:`aarch64_data_threshold`的默认值为2^16 = 65536,用户可以使用`-mlarge-data-threshold=n`选项指定大符号的阈值为n。 ### 举例 如图7所示,假设`foovar`的符号距离寻址指令的距离大于4GB,`-mcmodel=small`会使用ADRP+ADD指令进行符号拿取,而`foovar`在链接时计算距离的方式是如**使用方法**中的.bss+size方式,在链接时会报`relocation truncated to fit`错误。在此使用图8中的mov序列+PC寻址方式可将寻址范围扩大至64位,解决由于地址溢出导致的报错。 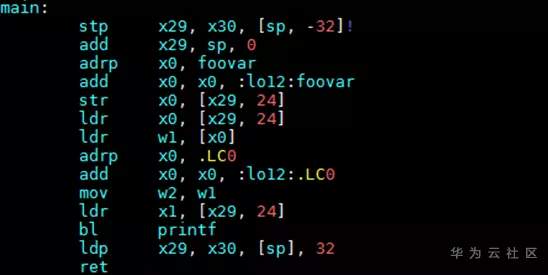 图7:smallcode model寻址方式 在这种模式下,通过`adrp`和`add`指令获取`foovar`的地址。`adrp`是PC相对寻址,它会把`foovar`的页地址偏移量与当前PC值相加,并存储到`x0`寄存器,下一条指令`add`把页内地址(低12位)再加到`x0`寄存器上,这样就得到了`foovar`的地址。 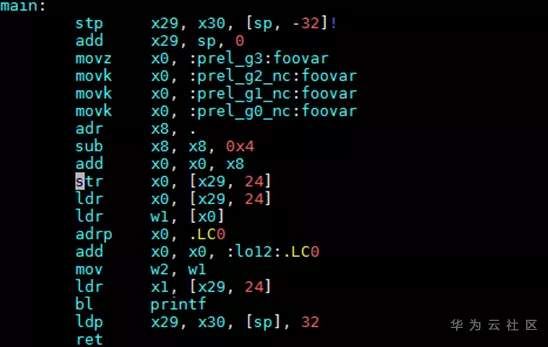 图8:mov序列+PC寻址方式 可以看出这里使用了`movz`, `movk`, `adr`, `sub`, `add`这样一系列的指令最终得到了`foovar`的地址。`movz`和3条`movk`指令的作用是把`foovar`的64位的偏移量分4次,每次转存16位,依次存放到了x0寄存器,`adr x8, .`的作用是获取当前的PC值,`sub`是对PC值做一些修正,然后`add`是把64位偏移量与修正后的PC值相加。这样就得到具有64位PC相对地址的`foovar`地址了。 ### 使用方法 用例: libdemo.cpp ```cpp libdemo.cpp #include <iostream> char arr[10][1*1024*1024*1024]; void set_and_print(){ arr[8][0]='A'; std::cout << arr[8][0] << std::endl; } ``` 上述代码定义了一个二维数组`arr`,第一维有10个元素,每一个元素又是一个总大小为1GB的字符数组。在访问`arr[8][0]`时需要偏移8GB,已经超过了`ADR`, `ADRP`这样的取值范围。 main.cpp ```cpp extern char arr[10][1*1024*1024*1024]; void set_and_print(); int main(){ set_and_print(); return 0; } ``` 主程序会使用共享库中的`set_and_print`函数。 现在我们来编译上面的代码。如下图所示,如果不指定`-mcmodel`参数就会报`relocation truncated to fit`错误;当程序指定`-mcmodel=large`时,又与-fpic冲突,无法生成动态共享库。 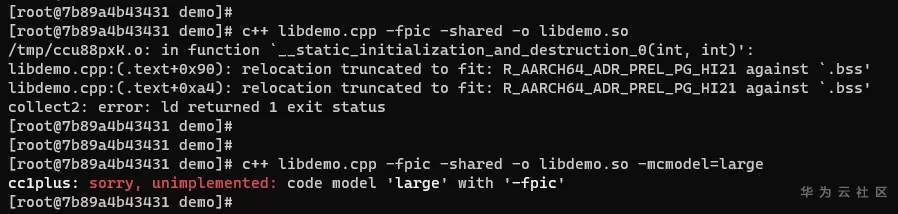 图9:不指定`-mcmodel`,或者指定`-mcmodel=large`进行编译,编译失败 当我们使用GCC for openEuler开发的`-mcmodel=medium`和`-mlarge-data-threshold=1`后,动态共享库被成功创建了,主程序也能正常调用它,并且得到正确的结果。 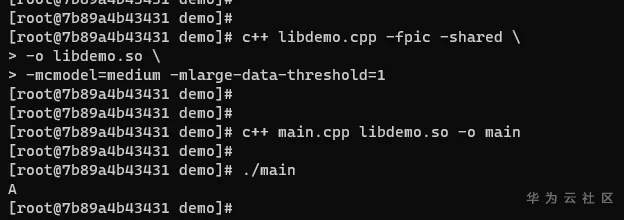 图10:指定-mcmodel=medium -mlarge-data-threshold=1 进行编译,编译成功 我们对共享库进行反编译查看汇编代码就会看到,取址指令已经是movz, movk这样的序列了。 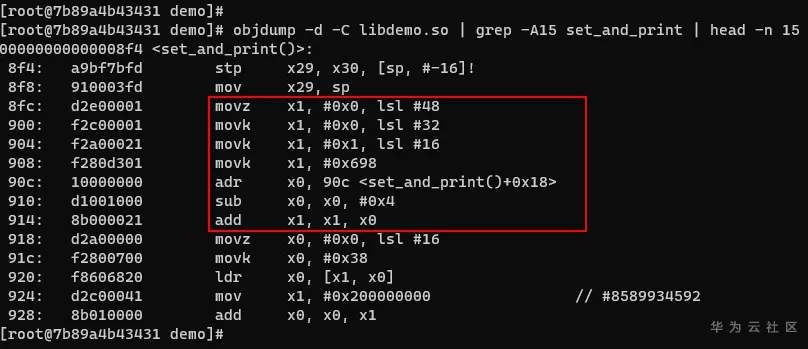 编译命令: ```bash c++ libdemo.cpp -fpic -shared -o libdemo.so -mcmodel=medium -mlarge-data-threshold=1 c++ main.cpp libdemo.so -o main ``` 运行主程序: ```bash ./main ``` ## 总结 该选项通过软件模拟的方式,使用多条指令去模拟`movabs`指令,使得在HPC领域一些需要大范围地址无关寻址的应用能够平滑地从其他平台迁移到鲲鹏平台中来。 所以在GCC for openEuler使用过程中,若出现`relocation truncated to fit`错误,可以尝试添加编译选项`-mcmodel=medium -mlarge-data-threshold=1`解决。 时间问题暂时写到此处,后续会继续更新一些GCC for openEuler或者毕昇编译器相关优化选项的介绍,感兴趣的朋友敬请博客留言,也可以点击文末**阅读原文**进入GCC for openEuler网页下载使用GCC for openEuler。 ## 参考 [1] https://bbs.huaweicloud.com/blogs/272527 [2] https://www.hikunpeng.com/developer/devkit/compiler/gcc [3] https://gcc.gnu.org/onlinedocs/gcc/AArch64-Options.html ## 后记 欢迎加入Compiler SIG交流群与大家共同交流学习编译技术相关内容,扫码添加小助手微信邀请你进入Compiler SIG交流群。  ------ 原文转载自[毕昇编译-GCC for openEuler -mcmodel选项详解](https://mp.weixin.qq.com/s/9OXRMg6xCTSdlhx_44BCvA)  访问GCC for openEuler网页:https://www.hikunpeng.com/developer/devkit/compiler/gcc
-
HPC( High Performance Computing,高性能计算)领域主要是解决计算密集型、海量数据处理等业务的计算需求,如科学研究、气象预报、计算模拟等。如何提高计算能力、极致化应用性能成为当前 HPC 领域各大平台最关键的课题之一,编译器在其中发挥着至关重要的作用。毕昇编译器作为一款基于鲲鹏平台的高性能编译器,在编译算法、加速指令集、 Autotuner 等方面对应用场景进行了深度的优化,为开发者提供高效的性能加持。本期由毕昇编译器工程师卜乐为你介绍鲲鹏的性能优化利器——毕昇编译器如何释放鲲鹏的强劲算力。了解毕昇编译器毕昇编译器是基于 LLVM,针对鲲鹏平台进行了深度优化的高性能编译器。除支持 LLVM 通用功能之外,对以下三个方面进行了增强,使得鲲鹏平台的强劲算力能够最大限度地得到释放。高性能编译算法:编译深度优化,内存优化增强,自动矢量化等,大幅提升指令和数据呑吐量。加速指令集:结合 NEON/SVE 等内嵌指令技术,深度优化指令编译和运行时库,发挥鲲鹏架构极致算力。AI 迭代调优:内置 AI 自学习模型,自动优化编译配置,迭代提升程序性能,完成最优编译。毕昇编译器特性架构图当前毕昇编译器已广泛应用于多种 HPC 典型场景,如气象、安防、流体力学等,性能优势已初步体现。其中,SPEC CPU 2017 benchmark 跑分平均优于 GCC 20%以上,HPC 典型气象应用 WRF 优于 GCC 10%。毕昇编译器与开源编译器SPEC CPU 2017 跑分对比毕昇编译器典型优化场景及其优化原理1 结构体内存布局优化—大幅提升缓存命中率,突破访存瓶颈SPEC CPU 2017 benchmark 中的 mcf 子项是对内存要求极高的应用,它是一款叫做MCF的大规模交通规划软件的核心代码。其瓶颈代码如下图左边所示。结构体优化原理示意图可见在 struct 中,data1 的使用率极高,而 data2 是不使用的。然而由于源代码中,数据的排布是以结构体数组的形式排布。按照一般编译器的编译方式,拿数据时每次都会将整个结构体放到 cache 里面,导致大量不参与计算的 data2 也被加载到了 cache 中,造成高速内存空间的浪费和性能的损耗。毕昇编译器会通过用户标记的结构体声明,或者通过自动检查循环中适合优化的内存场景,确认优化点。然后通过将结构体数组变为数组结构体的方式(如上图右),将有效数据紧凑排布,从而提高 cache 命中率和应用性能。经测试,此优化可以对 mcf 子项带来50%的性能提升。2 自动矢量化—计算效率提升的秘诀鲲鹏平台支持 Armv8 NEON 矢量化指令集。当前支持32个128位的矢量寄存器,指令可以同时操作4*32或2*64的数据。毕昇编译器依托这种硬件优势做了大量优化,包括 SLP(superword-level parallelism) 矢量化和循环自动矢量化。例如在 SPEC CPU 2017 benchmark 中处理视频流格式转换的x264子项中,毕昇编译器会自动识别并使用 uabd 和 udot 这类高效向量指令完成计算来替换标量指令,增大单时钟周期的数据处理量, 从而大幅提升计算效率。对于 x264 子项,这项优化可有效提升其30%的计算效率。 矢量化优化示例 3 Autotuner—基于机器学习快速获取最优编译配置如何获取性能最优编译选项是编译器使用中常见的问题,往往需要长时间的手动选项调优。为了减少这其中的工作量,使得用户能快速找到最优的优化选项,毕昇编译器自研了基于 ML 的自动搜索技术(ML-based Search) 的 Autotuner 工具。Autotuner 的调优流程由两个阶段组成:初始编译阶段(initial compilation)和调优阶段(tuning process),如下图所示:Autotuner 使用流程简单来说,在初始编译阶段,编译器会通过用户指定的调优方向,对可调优的代码区间进行标记。在随后的调优阶段,Autotuner 会根据搜索算法对不同的优化区间生成不同的编译配置。然后使用此配置编译运行,并根据运行性能的反馈来迭代优化配置参数。最后经过给定迭代次数后找出最优配置供用户使用。在实践过程中,通过 Autotuner 对 Coremark Benchmark 进行调优可以获取5%以上的收益。 以上介绍的三个优化特性分别是毕昇编译器在中前端算法优化、后端指令优化、迭代调优中最具代表性、在各自领域对性能提升表现最佳的三个特性。除以上介绍的三个优化特性之外,毕昇编译器在软件预取、循环优化、分支预测、指针压缩等编译优化技术均有探索且取得了显著的收益,详情可点击官网获取毕昇编译器详细信息,快来试试吧! 原文转载自 华为计算-【鲲鹏DevKit黑科技揭秘】┃ 毕昇编译器,让你的代码快到飞起!
-
 一、C++概念C++是一种面向对象的计算机程序设计语言,由美国AT&T贝尔实验室的本贾尼·斯特劳斯特卢普博士在20世纪80年代初期发明并实现,最初它被称作“C with Classes”(包含类的C语言)。C++它是一种静态数据类型检查的、支持多重编程范式的通用程序设计语言,支持过程化程序设计、数据抽象、面向对象程序设计、泛型程序设计等多种程序设计风格。C++是C语言的继承,进一步扩充和完善了C语言,成为一种面向对象的程序设计语言二、C++关键字C++中总共63个关键字,包括了C语言中32个关键字三、C++命名空间在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。1.命名空间的定义定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。2.命名空间的使用C++为了防止命名冲突,把自己库里面的东西都定义在一个std的命名空间中要使用标准库里面的东西,有三种方式指定命名空间–麻烦,每个地方都要指定,但也是最规范的方式代码如下:int c = 100;namespace N{ int a = 10; int b = 20; int Add(int left, int right) { return left + right; } int Sub(int left, int right) { return left - right; }}把std整个展开,相当于库里面的东西全部到全局域里面去了,使用起来方便但是可能会有与自己命名空间定义的冲突,规范工程中不推荐这种,日常练习可以用这种。代码如下:using namespace std;对部分常用的库里面的东西展开->针对1和2的折中方案,项目中也经常使用代码如下:using std::cout;using std::endl;int main(){ printf("%d\n", N::a); printf("%d\n", N::b); printf("%d\n", N::Add(1, 2)); printf("%d\n", N::Sub(1, 2)); int c = 10; printf("%d\n", c); //局部变量优先,所以c为10 printf("%d\n", ::c); //指定访问左边域,空白表示全局域}四、C++输入&&输出使用cout标准输出(控制台)和cin标准输入(键盘)时,必须包含< iostream >头文件以及std标准命名空间。注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此推荐使用+std的方式。使用C++输入输出更方便,不需增加数据格式控制,比如:整形–%d,字符–%costream 类型全局对象,istream 类型全局对象 ,endl全局的换行符号代码如下:struct Person{ char name[10]; int age;};int main(){ std::cout << "bit education "; std::cout << "bit education" << std::endl; //cout与cin对比C语言printf\scanf 来说可以自动识别类型(函数重载+运算符重载) int a = 10; int* p = &a; printf("%d,%p\n", a, p); std::cout << a << "," << p << std::endl; std::cin >> a; printf("%d\n", a); char str[100]; std::cin >> str; //cin不用&,因为引用 std::cout << str << std::endl; struct Person P = { "uzi", 23 }; //格式化输出printf比cout好 printf("name:%s age:%d\n", P.name, P.age); std::cout << "name:" << P.name<<" age:"<< P.age << "\n";}五、C++缺省参数1.缺省参数的概念1.缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参代码如下:void TestFunc(int a = 0){ cout << a << endl;}int main(){ TestFunc(); // 没有传参时,使用参数的默认值 TestFunc(10); // 传参时,使用指定的实参}2.缺省参数的分类半缺省参数代码如下:void testFunc3(int a, int b = 10, int c = 20){ cout << "a = " << a << endl; cout << "b = " << b << endl; cout << "c = " << c << endl;}全缺省参数代码如下:void testFunc2(int a = 10, int b = 20, int c = 30){ cout << "a = " << a << endl; cout << "b = " << b << endl; cout << "c = " << c << endl;}正常参数代码如下:void testFunc1(int a = 0){ std::cout << a << std::endl;}int main(){ testFunc1(10); testFunc2(); testFunc3(1); return 0;}注意:半缺省参数必须从右往左依次来给出,不能间隔着给缺省参数不能在函数声明和定义中同时出现缺省值必须是常量或者全局变量C语言不支持(编译器不支持)六、C++函数重载1.函数重载概念函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,常用来处理实现功能类似数据类型不同的问题。2.函数重载实现代码如下:int Add(int left, int right){ return left + right;}double Add(double left, double right){ return left + right;}int main(){ cout << Add(10, 20) << endl; cout << Add(10.5, 20.0) << endl; //fun(); return 0;}注意(特别重要): 缺省参数缺省参数符合重载的定义,但如果调用的时候编译器不识别函数重载调用哪个函数,所以分情况讨论。代码如下:void fun(int a, int b, int c = 10){}void fun(int a, int b){}3.函数命名规则–>C++支持重载,C不支持为什么C++支持函数重载,而C语言不支持函数重载呢?在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)。每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程 序员个人的程序库,将其需要的函数也链接到程序中。其中编译和链接也分为几个步骤:其中分为更细的话:在C++调用Add函数在C下调用Add函数通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。4.extern "C"的作用有时候在C++工程中可能需要将某些函数按照C的风格来编译,在函数前加extern “C”,意思是告诉编译器,将该函数按照C语言规则来编译,所以这个函数不能进行重载。代码如下:extern "C" int Add(int left, int right);int main(){ Add(1, 2); return 0;}七、C++引用1.引用的概念引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间代码如下:int main(){ int x = 10; int &y = x; y = 20; std::cout << "y=" << y << std::endl; int &z = y; z = 30; std::cout << "z=" << z << std::endl;}2.引用的特性引用在定义时必须初始化一个变量可以有多个引用引用一旦引用一个实体,再不能引用其他实体3.常引用代码如下:void TestConstRef(){ //常引用是创建一个临时变量,引用名是临时变量的引用 const int a = 10; //int& ra = a; // 该语句编译时会出错,a为常量,而且a为不可以修改 const int& ra = a; // int& b = 10; // 该语句编译时会出错,b为常量 const int& b = 10; double d = 12.34; //int& rd = d; // 该语句编译时会出错,类型不同 const int& rd = d;}rc是临时空间的别名代码如下:int c=10;double d=1.11;const double& rc=c;4.引用的使用场景1.做参数代码如下:void Swap2(int& a, int& b) //通过引用来交换{ int tmp = a; a = b; b = tmp;}void Swap1(int* a, int *b) //通过指针来交换{ int tmp = *a; *a = *b; *b = tmp;}2.做返回值代码如下:int& Add(int a, int b){ int c = a + b; return c;}int main(){ int& ret = Add(1, 2); Add(3, 4); cout << "Add(1, 2) is :" << ret << endl; return 0;}如果函数返回时,出了函数作用域,如果返回对象还未还给系统,则可以使用引用返回,如果已经还给系统了,则必须使用传值返回5.传值、传引用效率比较以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。6.引用和指针的区别在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间,在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。八、C++内联函数1.内联函数概念以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数压栈的开销,内联函数提升程序运行的效率。2.内联函数特性代码如下:#define _CRT_SECURE_NO_WARNINGS 1#include<iostream>int Add2(int left, int right){ return left + right;}inline int Add1(int left, int right){ return left + right;}int main(){ int ret1, ret2; ret1 = Add1(1, 2); ret2 = Add1(1, 2); std::cout << ret1 << std::endl; std::cout << ret2 << std::endl; return 0;}inline是一种以空间换时间的做法,省去调用函数额开销。所以代码很长或者有循环/递归的函数不适宜使用作为内联函数。inline对于编译器而言只是一个建议,编译器会自动优化,如果定义为inline的函数体内有循环/递归等等,编译器优化时会忽略掉内联。inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。九、C++auto关键字1.auto关键字概念在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可思考下为什么?C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。2.auto关键字的使用代码如下:int main(){ int x = 10; auto a = &x; // int* auto* b = &x; // int* int& y = x; // y的类型是什么?int auto c = y; // int auto& d = x; // d的类型是int, 但是这里指定了d是x的引用 // 打印变量的类型 cout << typeid(x).name() << endl; cout << typeid(y).name() << endl; cout << typeid(a).name() << endl; cout << typeid(b).name() << endl; cout << typeid(c).name() << endl; cout << typeid(d).name() << endl; return 0;}auto与指针和引用结合起来使用,用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&在同一行定义多个变量当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。3.auto关键字不能使用场景auto不能作为函数的参数代码如下:// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导void TestAuto(auto a){}auto不能直接用来声明数组代码如下:void TestAuto(){ int a[] = {1,2,3}; auto b[] = {4,5,6};}为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有lambda表达式等进行配合使用。十、基于范围的for循环(C++11)1.范围for的语法在C++98中如果要遍历一个数组,可以按照以下方式进行:代码如下:int main(){ int array[] = { 1, 2, 3, 4, 5 }; for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i) { cout << array[i] << " "; } cout << endl;} return 0;}对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。代码如下:int main(){ // 范围for C++11新语法遍历,更简单,数组都可以 // 自动遍历,依次取出array中的元素,赋值给e,直到结束 for (auto& e : array) { e *= 2; } for (auto ee : array) { cout << ee << " "; } cout << endl;}2.范围for的使用条件for循环迭代的范围必须是确定的,对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。迭代的对象要实现++和==的操作。(关于迭代器这个问题,以后会讲,现在大家了解一下就可以了)十一、指针空值nullptr(C++11)1.程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。2.在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下3.将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0。在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。总结以上就是今天要讲的内容,本文仅仅简单介绍了C++入门的简单知识,虽然这么知识范围很大,但也为我们以后学习C++有更好的了解,我们务必掌握。另外如果上述有任何问题,请懂哥指教,不过没关系,主要是自己能坚持,更希望有一起学习的同学可以帮我指正,但是如果可以请温柔一点跟我讲,爱与和平是永远的主题,爱各位了。
一、C++概念C++是一种面向对象的计算机程序设计语言,由美国AT&T贝尔实验室的本贾尼·斯特劳斯特卢普博士在20世纪80年代初期发明并实现,最初它被称作“C with Classes”(包含类的C语言)。C++它是一种静态数据类型检查的、支持多重编程范式的通用程序设计语言,支持过程化程序设计、数据抽象、面向对象程序设计、泛型程序设计等多种程序设计风格。C++是C语言的继承,进一步扩充和完善了C语言,成为一种面向对象的程序设计语言二、C++关键字C++中总共63个关键字,包括了C语言中32个关键字三、C++命名空间在C/C++中,变量、函数和后面要学到的类都是大量存在的,这些变量、函数和类的名称将都存在于全局作用域中,可能会导致很多冲突。使用命名空间的目的是对标识符的名称进行本地化,以避免命名冲突或名字污染,namespace关键字的出现就是针对这种问题的。1.命名空间的定义定义命名空间,需要使用到namespace关键字,后面跟命名空间的名字,然后接一对{}即可,{}中即为命名空间的成员。2.命名空间的使用C++为了防止命名冲突,把自己库里面的东西都定义在一个std的命名空间中要使用标准库里面的东西,有三种方式指定命名空间–麻烦,每个地方都要指定,但也是最规范的方式代码如下:int c = 100;namespace N{ int a = 10; int b = 20; int Add(int left, int right) { return left + right; } int Sub(int left, int right) { return left - right; }}把std整个展开,相当于库里面的东西全部到全局域里面去了,使用起来方便但是可能会有与自己命名空间定义的冲突,规范工程中不推荐这种,日常练习可以用这种。代码如下:using namespace std;对部分常用的库里面的东西展开->针对1和2的折中方案,项目中也经常使用代码如下:using std::cout;using std::endl;int main(){ printf("%d\n", N::a); printf("%d\n", N::b); printf("%d\n", N::Add(1, 2)); printf("%d\n", N::Sub(1, 2)); int c = 10; printf("%d\n", c); //局部变量优先,所以c为10 printf("%d\n", ::c); //指定访问左边域,空白表示全局域}四、C++输入&&输出使用cout标准输出(控制台)和cin标准输入(键盘)时,必须包含< iostream >头文件以及std标准命名空间。注意:早期标准库将所有功能在全局域中实现,声明在.h后缀的头文件中,使用时只需包含对应头文件即可,后来将其实现在std命名空间下,为了和C头文件区分,也为了正确使用命名空间,规定C++头文件不带.h;旧编译器(vc 6.0)中还支持<iostream.h>格式,后续编译器已不支持,因此推荐使用+std的方式。使用C++输入输出更方便,不需增加数据格式控制,比如:整形–%d,字符–%costream 类型全局对象,istream 类型全局对象 ,endl全局的换行符号代码如下:struct Person{ char name[10]; int age;};int main(){ std::cout << "bit education "; std::cout << "bit education" << std::endl; //cout与cin对比C语言printf\scanf 来说可以自动识别类型(函数重载+运算符重载) int a = 10; int* p = &a; printf("%d,%p\n", a, p); std::cout << a << "," << p << std::endl; std::cin >> a; printf("%d\n", a); char str[100]; std::cin >> str; //cin不用&,因为引用 std::cout << str << std::endl; struct Person P = { "uzi", 23 }; //格式化输出printf比cout好 printf("name:%s age:%d\n", P.name, P.age); std::cout << "name:" << P.name<<" age:"<< P.age << "\n";}五、C++缺省参数1.缺省参数的概念1.缺省参数是声明或定义函数时为函数的参数指定一个默认值。在调用该函数时,如果没有指定实参则采用该默认值,否则使用指定的实参代码如下:void TestFunc(int a = 0){ cout << a << endl;}int main(){ TestFunc(); // 没有传参时,使用参数的默认值 TestFunc(10); // 传参时,使用指定的实参}2.缺省参数的分类半缺省参数代码如下:void testFunc3(int a, int b = 10, int c = 20){ cout << "a = " << a << endl; cout << "b = " << b << endl; cout << "c = " << c << endl;}全缺省参数代码如下:void testFunc2(int a = 10, int b = 20, int c = 30){ cout << "a = " << a << endl; cout << "b = " << b << endl; cout << "c = " << c << endl;}正常参数代码如下:void testFunc1(int a = 0){ std::cout << a << std::endl;}int main(){ testFunc1(10); testFunc2(); testFunc3(1); return 0;}注意:半缺省参数必须从右往左依次来给出,不能间隔着给缺省参数不能在函数声明和定义中同时出现缺省值必须是常量或者全局变量C语言不支持(编译器不支持)六、C++函数重载1.函数重载概念函数重载:是函数的一种特殊情况,C++允许在同一作用域中声明几个功能类似的同名函数,这些同名函数的形参列表(参数个数 或 类型 或 顺序)必须不同,常用来处理实现功能类似数据类型不同的问题。2.函数重载实现代码如下:int Add(int left, int right){ return left + right;}double Add(double left, double right){ return left + right;}int main(){ cout << Add(10, 20) << endl; cout << Add(10.5, 20.0) << endl; //fun(); return 0;}注意(特别重要): 缺省参数缺省参数符合重载的定义,但如果调用的时候编译器不识别函数重载调用哪个函数,所以分情况讨论。代码如下:void fun(int a, int b, int c = 10){}void fun(int a, int b){}3.函数命名规则–>C++支持重载,C不支持为什么C++支持函数重载,而C语言不支持函数重载呢?在C/C++中,一个程序要运行起来,需要经历以下几个阶段:预处理、编译、汇编、链接。组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)。每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程 序员个人的程序库,将其需要的函数也链接到程序中。其中编译和链接也分为几个步骤:其中分为更细的话:在C++调用Add函数在C下调用Add函数通过这里就理解了C语言没办法支持重载,因为同名函数没办法区分。而C++是通过函数修饰规则来区分,只要参数不同,修饰出来的名字就不一样,就支持了重载。4.extern "C"的作用有时候在C++工程中可能需要将某些函数按照C的风格来编译,在函数前加extern “C”,意思是告诉编译器,将该函数按照C语言规则来编译,所以这个函数不能进行重载。代码如下:extern "C" int Add(int left, int right);int main(){ Add(1, 2); return 0;}七、C++引用1.引用的概念引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间代码如下:int main(){ int x = 10; int &y = x; y = 20; std::cout << "y=" << y << std::endl; int &z = y; z = 30; std::cout << "z=" << z << std::endl;}2.引用的特性引用在定义时必须初始化一个变量可以有多个引用引用一旦引用一个实体,再不能引用其他实体3.常引用代码如下:void TestConstRef(){ //常引用是创建一个临时变量,引用名是临时变量的引用 const int a = 10; //int& ra = a; // 该语句编译时会出错,a为常量,而且a为不可以修改 const int& ra = a; // int& b = 10; // 该语句编译时会出错,b为常量 const int& b = 10; double d = 12.34; //int& rd = d; // 该语句编译时会出错,类型不同 const int& rd = d;}rc是临时空间的别名代码如下:int c=10;double d=1.11;const double& rc=c;4.引用的使用场景1.做参数代码如下:void Swap2(int& a, int& b) //通过引用来交换{ int tmp = a; a = b; b = tmp;}void Swap1(int* a, int *b) //通过指针来交换{ int tmp = *a; *a = *b; *b = tmp;}2.做返回值代码如下:int& Add(int a, int b){ int c = a + b; return c;}int main(){ int& ret = Add(1, 2); Add(3, 4); cout << "Add(1, 2) is :" << ret << endl; return 0;}如果函数返回时,出了函数作用域,如果返回对象还未还给系统,则可以使用引用返回,如果已经还给系统了,则必须使用传值返回5.传值、传引用效率比较以值作为参数或者返回值类型,在传参和返回期间,函数不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时的拷贝,因此用值作为参数或者返回值类型,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。6.引用和指针的区别在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间,在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。八、C++内联函数1.内联函数概念以inline修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,没有函数压栈的开销,内联函数提升程序运行的效率。2.内联函数特性代码如下:#define _CRT_SECURE_NO_WARNINGS 1#include<iostream>int Add2(int left, int right){ return left + right;}inline int Add1(int left, int right){ return left + right;}int main(){ int ret1, ret2; ret1 = Add1(1, 2); ret2 = Add1(1, 2); std::cout << ret1 << std::endl; std::cout << ret2 << std::endl; return 0;}inline是一种以空间换时间的做法,省去调用函数额开销。所以代码很长或者有循环/递归的函数不适宜使用作为内联函数。inline对于编译器而言只是一个建议,编译器会自动优化,如果定义为inline的函数体内有循环/递归等等,编译器优化时会忽略掉内联。inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,就没有函数地址了,链接就会找不到。九、C++auto关键字1.auto关键字概念在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,但遗憾的是一直没有人去使用它,大家可思考下为什么?C++11中,标准委员会赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。2.auto关键字的使用代码如下:int main(){ int x = 10; auto a = &x; // int* auto* b = &x; // int* int& y = x; // y的类型是什么?int auto c = y; // int auto& d = x; // d的类型是int, 但是这里指定了d是x的引用 // 打印变量的类型 cout << typeid(x).name() << endl; cout << typeid(y).name() << endl; cout << typeid(a).name() << endl; cout << typeid(b).name() << endl; cout << typeid(c).name() << endl; cout << typeid(d).name() << endl; return 0;}auto与指针和引用结合起来使用,用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&在同一行定义多个变量当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。3.auto关键字不能使用场景auto不能作为函数的参数代码如下:// 此处代码编译失败,auto不能作为形参类型,因为编译器无法对a的实际类型进行推导void TestAuto(auto a){}auto不能直接用来声明数组代码如下:void TestAuto(){ int a[] = {1,2,3}; auto b[] = {4,5,6};}为了避免与C++98中的auto发生混淆,C++11只保留了auto作为类型指示符的用法auto在实际中最常见的优势用法就是跟以后会讲到的C++11提供的新式for循环,还有lambda表达式等进行配合使用。十、基于范围的for循环(C++11)1.范围for的语法在C++98中如果要遍历一个数组,可以按照以下方式进行:代码如下:int main(){ int array[] = { 1, 2, 3, 4, 5 }; for (int i = 0; i < sizeof(array) / sizeof(array[0]); ++i) { cout << array[i] << " "; } cout << endl;} return 0;}对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。代码如下:int main(){ // 范围for C++11新语法遍历,更简单,数组都可以 // 自动遍历,依次取出array中的元素,赋值给e,直到结束 for (auto& e : array) { e *= 2; } for (auto ee : array) { cout << ee << " "; } cout << endl;}2.范围for的使用条件for循环迭代的范围必须是确定的,对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。迭代的对象要实现++和==的操作。(关于迭代器这个问题,以后会讲,现在大家了解一下就可以了)十一、指针空值nullptr(C++11)1.程序本意是想通过f(NULL)调用指针版本的f(int*)函数,但是由于NULL被定义成0,因此与程序的初衷相悖。2.在C++98中,字面常量0既可以是一个整形数字,也可以是无类型的指针(void*)常量,但是编译器默认情况下3.将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0。在使用nullptr表示指针空值时,不需要包含头文件,因为nullptr是C++11作为新关键字引入的。在C++11中,sizeof(nullptr) 与 sizeof((void*)0)所占的字节数相同。为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。总结以上就是今天要讲的内容,本文仅仅简单介绍了C++入门的简单知识,虽然这么知识范围很大,但也为我们以后学习C++有更好的了解,我们务必掌握。另外如果上述有任何问题,请懂哥指教,不过没关系,主要是自己能坚持,更希望有一起学习的同学可以帮我指正,但是如果可以请温柔一点跟我讲,爱与和平是永远的主题,爱各位了。 -
 摘要:性能优化指在不影响系统运行正确性的前提下,使之运行得更快,完成特定功能所需的时间更短,或拥有更强大的服务能力。#一、思维导图#二、什么是性能优化?性能优化指在不影响系统运行正确性的前提下,使之运行得更快,完成特定功能所需的时间更短,或拥有更强大的服务能力。##关注不同程序有不同的性能关注点,比如科学计算关注运算速度,游戏引擎注重渲染效率,而服务程序追求吞吐能力。服务器一般都是可水平扩展的分布式系统,系统处理能力取决于单机负载能力和水平扩展能力,所以,提升单机性能和提升水平扩展能力是两个主要方向,理论上系统水平方向可以无限扩展,但水平扩展后往往导致通信成本飙升(甚至瓶颈),同时面临单机处理能力下降的问题。##指标衡量单机性能有很多指标,比如:QPS(Query Per Second)、TPS、OPS、IOPS、最大连接数、并发数等评估吞吐的指标。CPU为了提高吞吐,会把指令执行分为多个阶段,会搞指令Pipeline,同样,软件系统为了提升处理能力,往往会引入批处理(攒包),跟CPU流水线会引起指令执行Latency增加一样,伴随着系统负载增加也会导致延迟(Latency)增加,可见,系统吞吐和延迟是两个冲突的目标。显然,过高的延迟是不能接受的,所以,服务器性能优化的目标往往变成:追求可容忍延迟(Latency)下的最大吞吐(Throughput)。延迟(也叫响应时间:RT)不是固定的,通常在一个范围内波动,我们可以用平均时延去评估系统性能,但有时候,平均时延是不够的,这很容易理解,比如80%的请求都在10毫秒以内得到响应,但20%的请求时延超过2秒,而这20%的高延迟可能会引发投诉,同样不可接受。一个改进措施是使用TP90、TP99之类的指标,它不是取平均,而是需确保排序后90%、99%请求满足时延的要求。通常,执行效率(CPU)是我们的重点关注,但有时候,我们也需要关注内存占用、网络带宽、磁盘IO等,影响性能的因素很多,它是一个复杂而有趣的问题。#三、基础知识能编写运行正确的程序不一定能做性能优化,性能优化有更高的要求,这样讲并不是想要吓阻想做性能优化的工程师,而是实事求是讲,性能优化既需要扎实的系统知识,又需要丰富的实践经验,只有这样,你才能具备case by case分析问题解决问题的能力。所以,相比直接给出结论,我更愿意多花些篇幅讲一些基础知识,我坚持认为底层基础是理解并掌握性能优化技能的前提,值得花费一些时间研究并掌握这些根技术。##CPU架构你需要了解CPU架构,理解运算单元、记忆单元、控制单元是如何既各司其职又相互配合完成工作的。你需要了解CPU如何读取数据,CPU如何执行任务。你需要了解数据总线,地址总线和控制总线的区别和作用。你需要了解指令周期:取指、译指、执行、写回。你需要了解CPU Pipeline,超标量流水线,乱序执行。你需要了解多CPU、多核心、逻辑核、超线程、多线程、协程这些概念。##存储金字塔CPU的速度和访存速度相差200倍,高速缓存是跨越这个鸿沟的桥梁,你需要理解存储金字塔,而这个层次结构思维基于着一个称为局部性原理(principle of locality)的思想,它对软硬件系统的设计和性能有着极大的影响。局部性又分为时间局部性和空间局部性。### 缓存现代计算机系统一般有L1-L2-L3三级缓存。比如在我的系统,我通过进入 /sys/devices/system/cpu/cpu0/cache/index0 1 2 3目录下查看。size对应大小、type对应类型、coherency_line_size对应cache line大小。每个CPU核心有独立的L1、L2高速缓存,所以L1和L2是on-chip缓存;L3是多个CPU核心共享的,它是off-chip缓存。L1缓存又分为i-cache(指令缓存)和d-cache(数据缓存),L1缓存通常只有32K/64KB,速度高达4 cycles。L2缓存能到256KB,速度在8 cycles左右。L3则高达30MB,速度32 cycles左右。而内存高达数G,访存时延则在200 cycles左右。所以CPU->寄存器->L1->L2->L3->内存->磁盘构成存储层级结构:越靠近CPU,存储容量越小、速度越快、单位成本越高,越远离CPU,存储容量越大、速度越慢、单位成本越低。### 虚拟存储器(VM)进程和虚拟地址空间是操作系统的2个核心抽象。系统中的所有进程共享CPU和主存资源,虚拟存储是对主存的抽象,它为每个进程提供一个大的、一致的、私有的地址空间,我们gdb调试的时候,打印出来的变量地址是虚拟地址。操作系统+CPU硬件(MMU)紧密合作完成虚拟地址到物理地址的翻译(映射),这个过程总是沉默的自动的进行,不需要应用程序员的任何干预。每个进程有一个单独的页表(Page Table),页表是一个页表条目(PTE)的数组,该表的内容由操作系统管理,虚拟地址空间中的每个页(4K或者8K)通过查找页表找到物理地址,页表往往是层级式的,多级页表减少了页表对存储的需求,命失(Page Fault)将导致页面调度(Swapping或者Paging),这个惩罚很重,所以,我们要改善程序的行为,让它有更好的局部性,如果一段时间内访存的地址过于发散,将导致颠簸(Thrashing),从而严重影响程序性能。为了加速地址翻译,MMU中增加了一个关于PTE的小的缓存,叫翻译后备缓冲器(TLB),地址翻译单元做地址翻译的时候,会先查询TLB,只有TLB命失才会查询高速缓存(L1-2-3)。## 汇编基础虽然写汇编的场景越来越少,但读懂汇编依然很有必要,理解高级语言的程序是怎么转化为汇编语言有助于我们编写高质量高性能的代码。对于汇编,至少需要了解几种寻址模式,了解数据操作、分支、传送、控制跳转指令。理解C语言的if else、while/do while/for、switch case、函数调用是怎么翻译成汇编代码。理解ebp+esp寄存器在函数调用过程中是如何构建和撤销栈帧的。理解函数参数和返回值是怎么传递的。## 异常和系统调用异常会导致控制流突变,异常控制流发生在计算机系统的各个层次,异常可以分为四类:中断(interrupt):中断是异步发生的,来自处理器外部IO设备信号,中断处理程序分上下部。陷阱(trap):陷阱是有意的异常,是执行一条指令的结果,系统调用是通过陷阱实现的,陷阱在用户程序和内核之间提供一个像过程调用一样的接口:系统调用。故障(fault):故障由错误情况引起,它有可能被故障处理程序修复,故障发生,处理器将控制转移到故障处理程序,缺页(Page Fault)是经典的故障实例。终止(abort):终止是不可恢复的致命错误导致的结果,通常是硬件错误,会终止程序的执行。系统调用:## 内核态和用户态你需要了解操作系统的一些概念,比如内核态和用户态,应用程序在用户态运行我们编写的逻辑,一旦调用系统调用,便会通过一个特定的陷阱陷入内核,通过系统调用号标识功能,不同于普通函数调用,陷入内核态和从内核态返回需要做上下文切换,需要做环境变量的保存和恢复工作,它会带来额外的消耗,我们编写的程序应避免频繁做context swap,提升用户态的CPU占比是性能优化的一个目标。
摘要:性能优化指在不影响系统运行正确性的前提下,使之运行得更快,完成特定功能所需的时间更短,或拥有更强大的服务能力。#一、思维导图#二、什么是性能优化?性能优化指在不影响系统运行正确性的前提下,使之运行得更快,完成特定功能所需的时间更短,或拥有更强大的服务能力。##关注不同程序有不同的性能关注点,比如科学计算关注运算速度,游戏引擎注重渲染效率,而服务程序追求吞吐能力。服务器一般都是可水平扩展的分布式系统,系统处理能力取决于单机负载能力和水平扩展能力,所以,提升单机性能和提升水平扩展能力是两个主要方向,理论上系统水平方向可以无限扩展,但水平扩展后往往导致通信成本飙升(甚至瓶颈),同时面临单机处理能力下降的问题。##指标衡量单机性能有很多指标,比如:QPS(Query Per Second)、TPS、OPS、IOPS、最大连接数、并发数等评估吞吐的指标。CPU为了提高吞吐,会把指令执行分为多个阶段,会搞指令Pipeline,同样,软件系统为了提升处理能力,往往会引入批处理(攒包),跟CPU流水线会引起指令执行Latency增加一样,伴随着系统负载增加也会导致延迟(Latency)增加,可见,系统吞吐和延迟是两个冲突的目标。显然,过高的延迟是不能接受的,所以,服务器性能优化的目标往往变成:追求可容忍延迟(Latency)下的最大吞吐(Throughput)。延迟(也叫响应时间:RT)不是固定的,通常在一个范围内波动,我们可以用平均时延去评估系统性能,但有时候,平均时延是不够的,这很容易理解,比如80%的请求都在10毫秒以内得到响应,但20%的请求时延超过2秒,而这20%的高延迟可能会引发投诉,同样不可接受。一个改进措施是使用TP90、TP99之类的指标,它不是取平均,而是需确保排序后90%、99%请求满足时延的要求。通常,执行效率(CPU)是我们的重点关注,但有时候,我们也需要关注内存占用、网络带宽、磁盘IO等,影响性能的因素很多,它是一个复杂而有趣的问题。#三、基础知识能编写运行正确的程序不一定能做性能优化,性能优化有更高的要求,这样讲并不是想要吓阻想做性能优化的工程师,而是实事求是讲,性能优化既需要扎实的系统知识,又需要丰富的实践经验,只有这样,你才能具备case by case分析问题解决问题的能力。所以,相比直接给出结论,我更愿意多花些篇幅讲一些基础知识,我坚持认为底层基础是理解并掌握性能优化技能的前提,值得花费一些时间研究并掌握这些根技术。##CPU架构你需要了解CPU架构,理解运算单元、记忆单元、控制单元是如何既各司其职又相互配合完成工作的。你需要了解CPU如何读取数据,CPU如何执行任务。你需要了解数据总线,地址总线和控制总线的区别和作用。你需要了解指令周期:取指、译指、执行、写回。你需要了解CPU Pipeline,超标量流水线,乱序执行。你需要了解多CPU、多核心、逻辑核、超线程、多线程、协程这些概念。##存储金字塔CPU的速度和访存速度相差200倍,高速缓存是跨越这个鸿沟的桥梁,你需要理解存储金字塔,而这个层次结构思维基于着一个称为局部性原理(principle of locality)的思想,它对软硬件系统的设计和性能有着极大的影响。局部性又分为时间局部性和空间局部性。### 缓存现代计算机系统一般有L1-L2-L3三级缓存。比如在我的系统,我通过进入 /sys/devices/system/cpu/cpu0/cache/index0 1 2 3目录下查看。size对应大小、type对应类型、coherency_line_size对应cache line大小。每个CPU核心有独立的L1、L2高速缓存,所以L1和L2是on-chip缓存;L3是多个CPU核心共享的,它是off-chip缓存。L1缓存又分为i-cache(指令缓存)和d-cache(数据缓存),L1缓存通常只有32K/64KB,速度高达4 cycles。L2缓存能到256KB,速度在8 cycles左右。L3则高达30MB,速度32 cycles左右。而内存高达数G,访存时延则在200 cycles左右。所以CPU->寄存器->L1->L2->L3->内存->磁盘构成存储层级结构:越靠近CPU,存储容量越小、速度越快、单位成本越高,越远离CPU,存储容量越大、速度越慢、单位成本越低。### 虚拟存储器(VM)进程和虚拟地址空间是操作系统的2个核心抽象。系统中的所有进程共享CPU和主存资源,虚拟存储是对主存的抽象,它为每个进程提供一个大的、一致的、私有的地址空间,我们gdb调试的时候,打印出来的变量地址是虚拟地址。操作系统+CPU硬件(MMU)紧密合作完成虚拟地址到物理地址的翻译(映射),这个过程总是沉默的自动的进行,不需要应用程序员的任何干预。每个进程有一个单独的页表(Page Table),页表是一个页表条目(PTE)的数组,该表的内容由操作系统管理,虚拟地址空间中的每个页(4K或者8K)通过查找页表找到物理地址,页表往往是层级式的,多级页表减少了页表对存储的需求,命失(Page Fault)将导致页面调度(Swapping或者Paging),这个惩罚很重,所以,我们要改善程序的行为,让它有更好的局部性,如果一段时间内访存的地址过于发散,将导致颠簸(Thrashing),从而严重影响程序性能。为了加速地址翻译,MMU中增加了一个关于PTE的小的缓存,叫翻译后备缓冲器(TLB),地址翻译单元做地址翻译的时候,会先查询TLB,只有TLB命失才会查询高速缓存(L1-2-3)。## 汇编基础虽然写汇编的场景越来越少,但读懂汇编依然很有必要,理解高级语言的程序是怎么转化为汇编语言有助于我们编写高质量高性能的代码。对于汇编,至少需要了解几种寻址模式,了解数据操作、分支、传送、控制跳转指令。理解C语言的if else、while/do while/for、switch case、函数调用是怎么翻译成汇编代码。理解ebp+esp寄存器在函数调用过程中是如何构建和撤销栈帧的。理解函数参数和返回值是怎么传递的。## 异常和系统调用异常会导致控制流突变,异常控制流发生在计算机系统的各个层次,异常可以分为四类:中断(interrupt):中断是异步发生的,来自处理器外部IO设备信号,中断处理程序分上下部。陷阱(trap):陷阱是有意的异常,是执行一条指令的结果,系统调用是通过陷阱实现的,陷阱在用户程序和内核之间提供一个像过程调用一样的接口:系统调用。故障(fault):故障由错误情况引起,它有可能被故障处理程序修复,故障发生,处理器将控制转移到故障处理程序,缺页(Page Fault)是经典的故障实例。终止(abort):终止是不可恢复的致命错误导致的结果,通常是硬件错误,会终止程序的执行。系统调用:## 内核态和用户态你需要了解操作系统的一些概念,比如内核态和用户态,应用程序在用户态运行我们编写的逻辑,一旦调用系统调用,便会通过一个特定的陷阱陷入内核,通过系统调用号标识功能,不同于普通函数调用,陷入内核态和从内核态返回需要做上下文切换,需要做环境变量的保存和恢复工作,它会带来额外的消耗,我们编写的程序应避免频繁做context swap,提升用户态的CPU占比是性能优化的一个目标。 -
 ## Mingw MinGW全称Minimalist GNU For Windows,是个精简的Windows平台C/C++、ADA及Fortran编译器,相比Cygwin而言,体积要小很多,使用较为方便。MinGW提供了一套完整的开源编译工具集,以适合Windows平台应用开发,且不依赖任何第三方C运行时库。 MinGW包括: 一套集成编译器,包括C、C++、ADA语言和Fortran语言编译器 用于生成Windows二进制文件的GNU工具的(编译器、链接器和档案管理器) 用于Windows平台安装和部署MinGW和MSYS的命令行安装器(mingw-get) 用于命令行安装器的GUI打包器(mingw-get-inst) ## GCC GCC(GNU Compiler Collection,GNU编译器套件),是由 GNU 开发的编程语言编译器。它是以GPL许可证所发行的自由软件,也是 GNU计划的关键部分。GCC原本作为GNU操作系统的官方编译器,现已被大多数类Unix操作系统(如Linux、BSD、Mac OS X等)采纳为标准的编译器,GCC同样适用于微软的Windows。 GCC是自由软件过程发展中的著名例子,由自由软件基金会以GPL协议发布。 GCC 原名为 GNU C 语言编译器(GNU C Compiler),因为它原本只能处理 C语言。GCC 很快地扩展,变得可处理 C++。后来又扩展能够支持更多编程语言,如Fortran、Pascal、Objective-C、Java、Ada、Go以及各类处理器架构上的汇编语言等,所以改名GNU编译器套件(GNU Compiler Collection)。 ## 总结 mingw可以理解为gcc在windows平台下的实现。但是MinGW使用Windows中的C运行库,因此用MinGW开发的程序不需要额外的第三方DLL支持就可以直接在Windows下运行,而且也不一定必须遵从GPL许可证;这同时造成了MinGW开发的程序只能使用Win32API和跨平台的第三方库,而缺少POSIX支持,大多数GNU软件无法在不修改源代码的情况下用MinGW编译。
## Mingw MinGW全称Minimalist GNU For Windows,是个精简的Windows平台C/C++、ADA及Fortran编译器,相比Cygwin而言,体积要小很多,使用较为方便。MinGW提供了一套完整的开源编译工具集,以适合Windows平台应用开发,且不依赖任何第三方C运行时库。 MinGW包括: 一套集成编译器,包括C、C++、ADA语言和Fortran语言编译器 用于生成Windows二进制文件的GNU工具的(编译器、链接器和档案管理器) 用于Windows平台安装和部署MinGW和MSYS的命令行安装器(mingw-get) 用于命令行安装器的GUI打包器(mingw-get-inst) ## GCC GCC(GNU Compiler Collection,GNU编译器套件),是由 GNU 开发的编程语言编译器。它是以GPL许可证所发行的自由软件,也是 GNU计划的关键部分。GCC原本作为GNU操作系统的官方编译器,现已被大多数类Unix操作系统(如Linux、BSD、Mac OS X等)采纳为标准的编译器,GCC同样适用于微软的Windows。 GCC是自由软件过程发展中的著名例子,由自由软件基金会以GPL协议发布。 GCC 原名为 GNU C 语言编译器(GNU C Compiler),因为它原本只能处理 C语言。GCC 很快地扩展,变得可处理 C++。后来又扩展能够支持更多编程语言,如Fortran、Pascal、Objective-C、Java、Ada、Go以及各类处理器架构上的汇编语言等,所以改名GNU编译器套件(GNU Compiler Collection)。 ## 总结 mingw可以理解为gcc在windows平台下的实现。但是MinGW使用Windows中的C运行库,因此用MinGW开发的程序不需要额外的第三方DLL支持就可以直接在Windows下运行,而且也不一定必须遵从GPL许可证;这同时造成了MinGW开发的程序只能使用Win32API和跨平台的第三方库,而缺少POSIX支持,大多数GNU软件无法在不修改源代码的情况下用MinGW编译。 -
以下为译文:70年代初,贝尔实验室创建了C语言,它是开发UNIX的副产品。很快C就成为了最受欢迎的编程语言之一。但是对于Bjarne Stroustrup来说,C的表达能力还不够。于是,他在1983年的博士论文中扩展了C语言。于是,支持类的C语言诞生了。当时,Bjarne Stroustrup明白编程语言有许多组成部分,除了语言本身,还有编译器、链接器和各种库。提供熟悉的工具有助于语言被广泛接受。在这种历史背景下,在C语言的基础上开发C++也是有道理的。40年后,C和C++都在行业中得到了广泛使用。但是,互联网上的C开发人员认为C++是有史以来最糟糕的人类发明,而许多C++开发人员则希望有朝一日C语言灰飞烟灭。究竟发生了什么事?从表面上看,C和C++都可以满足相同的用例:高性能、确定性、原生但可移植的代码,可用于最广泛的硬件和应用程序。但是,更让C自豪的是它是一门低级语言,更接近汇编。而C++,从诞生第一天开始就充斥了各种奇怪的东西。例如析构函数这个黑魔法。自作主张的编译器。尽管很早C++就有了类型推断功能,但是80年代中期的开发人员还无法接受这个概念,因此Bjarne Stroustrup不得不删除了auto,直到C++ 11又重新添加回来。从那以后,C++就不断加入各种工具来实现抽象。很难说C++是一种低级语言还是高级语言。从设计目的上来说,C++两者都是。但是在不牺牲性能的情况下,建立高级抽象是很困难的。于是C++引入了各种工具来实现constexpr、move语义、模板和不断增长的标准库。从根本上讲,我认为C信任开发人员,而C++信任编译器。这是一个巨大的差异,单凭“两者的原生类型相同”、“while循环的语法相同”等简单一致是无法掩盖的。C++开发人员将有这些问题归咎于C,而C开发人员则认为C++过于疯狂。我觉得站在C的角度看C++,这种说法也很正确。作为C的超集,C++确实很疯狂。一个经验丰富的C开发人员面对C++可能没有熟悉的感觉。C++不是C,这就足以引发互联网上的激烈争论。然而,虽然我不喜欢C,但也没有权利取笑C。尽管我有一定的C++经验,但用C编写过的代码少之又少,而且肯定是很糟糕的代码。好的编程语言包括良好的实践、模式、惯用写法,这些都需要多年的学习。如果你尝试用编写C++的方式写C的代码,或者用C的方式编写C++的代码,那感觉一定很糟糕。即便你懂C,也不一定会C++,反之亦然,懂C++也不一定会用C编程。那么,我们是否应该停止说C/C++,为这两个不幸的命名而感到悲哀吗?也不至于。尽管C++的设计理念与C不一样,但是C++仍然是C的超集。也就是说,你可以在C++转换单元中包含C的头文件,这样依然可以通过编译。而这正是造成混乱的地方。C++不是C的扩展,它是由不同的委员会、不同的人独立设计的标准。从逻辑上讲,喜欢C++理念的人会参与C++社区以及C++标准化的过程,而其他人可能会尝试参与C。无论是C的委员会还是C++委员会,他们表达意图和方向的方式只能通过各自的最终产品:标准;而标准是众多投票的成果。然而,编译器很难知道它正在处理的是C头文件还是C++头文件。extern “C” 标记并没有得到广泛一致的使用,而且它只能影响修饰,而不会影响语法或语义。头文件仅对预处理器有影响,对于C++编译器而言,所有内容都是C++转换单元,因此也就是C++。然而,人们依然会在C++中包含C头文件,并期望它“正常工作”,而大多数时候也确实可以正常工作。那么,我们不禁想问:由不同地方的、不同的人开发的C++代码如何保持C的兼容性?恐怕很难。最近,一位同事让我想起了康威定律:"设计系统的架构受制于产生这些设计的组织的沟通结构。"根据这个逻辑,如果两个委员不互相合作,则他们创造的语言也不会互通。C++维护了一个与C及其标准库的不兼容列表。然而该列表似乎并未反映出许多C11和C18中添加、但在C++中不合法的功能。更清晰的介绍请参见这个维基本科页面(https://en.wikipedia.org/wiki/Compatibility_of_C_and_C%2B%2B)。然而,仅仅列出两种语言之间的不兼容性,并不足以衡量二者的不兼容性。那些存在于C++标准库中但主要声明来自C的函数,很难声明成constexpr,更难声明成noexcept。C的兼容性会导致性能成本,而C函数是优化的障碍。许多C的结构在C++中都是有效的,但无法通过代码审查(如NULL、longjmp、malloc、构造/析构函数、free、C风格的类型强制转换等)。在C看来,这些惯用写法可能问题不大,但在C++中可不行。C++具有更强大的类型系统,不幸的是,C的惯用写法在这个类型系统中凿了一个洞,因此实现C的兼容性需要在安全性方面付出代价。别误会,C++仍然关心C的兼容性,某种程度上。然而,有趣的是C也很关心C++,某种程度上。实话实说,C对C++的关心程度可能高于C++对C的关心。看来,每个委员会还是在乎另一个委员会的工作。但我们很不情愿。C++知道,许多基础库都是用C编写的,不仅包括libc,而且还有zip、png、curl、openssl(!)以及许多其他库,无数的C++项目都在使用这些库。C++不能破坏这些兼容性。但是最近,尤其是在过去的十年中,C++的规模已远远超过C。C++拥有更多的用户,并且社区更加活跃。也许这就是为什么如今C++委员会的规模是C委员会的10倍以上。C++是不可忽视的力量,因此C委员会必须考虑不破坏C++兼容性。如果非要说一个标准追随另一个标准对话,那么如今C++是领头者,而C是追随者。现在,C++处于稳定的三年周期中,无论是风雨还是烈日,抑或是致命的新疫情。而C每十年左右才发布一次主版本。不过这也很合理,因为作为一种较低级的语言,C不需要发展得那么快。C语言的环境也与C++完全不同。C多用于平台,更多地用于编译器。每个人(甚至他们的狗狗)都会编写C编译器,因为该语言的特性集很小,所以任何人都可以编写C编译器。而C++委员会真正考虑的实现只有四种,而且在每次会议上这四种实现都会出现。所以,C语言中的许多功能都是与实现有关的,或者是可选支持的,这样各种编译器不需要做太多努力就可以声称自己遵从了标准,据说这样委员会的人会比较高兴。如今,C++更加侧重于可移植性,而不是实现的自由。这又是一个理念的不同。因此,你的提议破坏了C的兼容性我提议的P2178的一部分理论上会影响与C的兼容性。这样的话所有方案都不会令人满意。有人可能会说,你可以先向C委员会提议你的新特性。这意味着需要召开更多会议。C会议的严格出席规则可能导致你无法参加会议,这就将那些不愿意花上数千美元成为ISO会员的个人拒之门外。这是因为C委员会必须遵守ISO的规则。而且,如果新的标准刚刚发布,那么可能还需要等待十年时间,你的提案才会被考虑。最重要的是,如果C委员不理解或不在乎你正在努力解决的问题,那么你的提案就石沉大海了。或者他们可能没有精力来处理这个问题。而且,可能你也没有精力来处理C。毕竟,你的本意是要改进C++。实际上,哪怕会议上无人反对你的提议(尽管不太可能发生),如果有人让你先去跟C委员会的人讨论,就等于给你的提议判了死刑。另一种可能的情况是,C委员会接受与C++中存在的版本略有不同的版本。true只能做一个宏来实现。char16_t需要通过typedef。char32_t不一定是UTF-32。static_assert对应的是 _Static_assert。这类的情况还有很多,我们应该责备C吗?可能不应该。他们的委员会只是在尽力将C语言做好。反之亦然。在C++20中,指定的初始化器就受到了C的启发,但采取了略微不同的规则,因为如果完全一样的话就不符合C++的初始化规则。对于这个问题,我也有责任。C有VLA。如果当时我在,我一定会反对在标准C++中采用它,因为它导致了太多安全性问题。我也会坚决反对将_Generic添加到C++中的提议。也许_Generic的目的是减少由于缺乏模板或缺乏重载而导致的问题,但是C++有这两个功能,从我的角度来看,_Generic并不适合我想象中的C++。这两个委员会似乎对于对方语言的关心程度也不一样。有时我们会遇到兼容性非常好的情况(std::complex),有时完全不在乎兼容性(静态数组参数)。这没有办法。别忘了每个委员会都是一群人,他们在不同的时间、不同的地点投票,而试图控制结果会导致投票毫无意义。将这些人放在同一个房间也不现实。ISO可能会反对,参与者的不平衡会导致C的人处于极大的劣势。C的兼容性不重要如果你是C开发人员,那么肯定会把C视为一种简洁的编程语言。但对于我们其他人而言,C的印象完全不同。C是通用的、跨语言的胶水,可以将一切紧密地结合在一起。对于C++用户而言,C就是他们的API。从这一点来看,C的价值在于其简单性。请记住,C++关心的那一部分C是出现在接口(头文件)中的C。我们关心的是声明,而不是定义。C++需要调用C库中的函数(Python、Fortran、Rust、D、Java等语言也一样,在所有情况下都可以在接口边界使用C)。因此,C是一种接口定义语言。向C添加的内容越多,定义接口就越困难。这些接口随着时间的推移保持稳定的可能性较小。那么,C++中缺少<threads.h>是否重要?可能并不重要,因为这不太可能出现在公共接口中。如今大家都在谈论C过去,C的兼容性是C++的一大卖点。但如今,每个人(甚至他们的金鱼)都懂C。Rust可以调用C函数,Python、Java、一切语言都可以!甚至怪异的Javascript都可以在WebAssemby中调用C函数。但是在这些语言中,接口是显式的。该语言提供的工具可以公开特定的C声明。当然,这比较麻烦。但这可以让接口非常非常清晰。而且还是有界的。例如,在rust中,调用C函数并不会迫使Rust牺牲某些设计来容纳C子集。实际上C是被包含进去的。mod confinment {use std::os::raw::{c_char};extern "C" {pub fn puts(txt: *const c_char);}}pub fn main() {unsafe {confinment::puts(std::ffi::CString::new("Hello, world!").expect("failed!").as_ptr());}}
-
 2020-09-28:内存屏障的汇编指令是啥?#福大大架构师每日一题#
2020-09-28:内存屏障的汇编指令是啥?#福大大架构师每日一题# -
asm volatile ( "neoncopypld: \n\t" "PLD [ %[src] , #0xC0] \n\t" "VLDM %[src]! , {d0 - d7} \n\t" "VSTM %[dst]! , {d0 - d7} \n\t" "SUBS %[sz], %[sz] , #0x40 \n\t" "BGE neoncopypld \n\t" : [dst]"+r"(dst), [src]"+r"(src) : [sz]"r"(sz) :"d0", "d1", "d2", "d3", "d4", "d5", "d6", "d7", "cc","memory");这是在网上找到的neon memcpy加速的代码,我在鲲鹏上用g++编译会报错“Error: unknown mnemonic ",不能识别 pld vldm vstm, 汇编小白求助该怎样修改
-
 华为云鲲鹏云专业工具验证报告背景介绍 为了进一步提高鲲鹏云的软件移植效率与工作量评估以及性能调优能力深化;针对华为云鲲鹏云,鲲鹏软件栈的开发工具中提供的三款分析迁移与性能优化工具进行了研究;并给出了验证报告;具体工具如下: Dependency Advisor一、工具介绍一款可以简化客户应用迁移到TaiShan服务器过程的工具。该工具安装在X86服务器上,当客户有软件需要移植到TaiShan服务器上时,可先用该工具分析可移植性和移植投入。该工具解决了客户软件移植评估分析过程中人工分析投入大、准确率低、整体效率低下的痛点,通过该工具能够自动分析并输出指导报告。工具支持的功能特性如下:检查用户软件资源包(RPM、JAR、TAR、zip、gzip文件)中包含的SO依赖库,并评估SO依赖库的可移植性。检查指定的用户软件安装路径下的SO依赖库,并评估SO依赖库的可移植性。检查用户软件C/C++软件构建工程文件,并评估该文件的可移植性。检查用户软件C/C++源码,并评估软件源文件的可移植性。向用户提供软件移植报告,提供移植工作量评估。支持命令行方式和Web两种工作模式。二、安装按照《华为鲲鹏分析扫描工具 用户指南.pdf》在linux-x86_64安装web模式。三、进行测试案例一以hadoop安装包为例分析发布版本二进制软件包迁移可行性及迁移投入该发布包中部分包含so文件的jar包需要重新编译迁移,hadoop相关的多个二进制文件以及so动态库需要重新编译。分析结果如下:从分析报告可知迁移需要重新编译上述5个库文件,但该库的路径不够明确。案例二以mysql-clustre源码包为例分析源码包迁移可行性及迁移投入该源码包迁移过程中遇到C库不兼容导致的C代码修改40行以及汇编未适配导致的20行左右内嵌汇编需要重写。分析结果如下:从分析报告可知无需代码量修改可直接重新编译进行迁移。四、总结1. 优点1)安装、使用简单,方便,可在迁移前进行分析,工具无需安装到迁移环境上;2)支持RPM、JAR、TAR、zip、gzip文件等文件的分析;3)根据分析报告给出具体的工作量。2. 缺点1)只能分析出so文件是否需要重新编译,并且未给出so所在路径以便查找所属包;2)对C/C++源码分析不够准确,存在遗漏项,导致工作量遗漏;3)工具未评估so的可移植性。4)源码编译时的工作量评估不够准确。3. 预测使用场景1)业务二进制发布包迁移评估工作量时可使用该工具进行评估作为参考,但不可过度依赖该工具评估的工作量。Porting Advisor一、工具介绍该工具是一款可以简化客户应用迁移到TaiShan服务器的过程的工具。当客户有X86平台上源代码的软件要移植到TaiShan服务器上时,可用该工具自动分析出需修改的代码内容,并指导用户如何修改。该工具解决了用户代码兼容性人工排查困难、移植经验欠缺、反复依赖编译调错定位等痛点。支持的功能特性如下:检查用户C/C++软件构建工程文件,并指导用户如何移植该文件。检查用户C/C++软件构建工程文件使用的链接库,并提供可移植性信息。检查用户C/C++软件源码,并指导用户如何移植源文件。检查用户软件中X86汇编代码,并指导用户如何移植。支持命令行方式和Web两种工作模式。二、安装按照《华为鲲鹏代码迁移工具 用户指南.pdf》在linux-x86_64安装web模式。三、进行测试案例一以mysql-clustre源码包为例分析源码包迁移可行性该源码包迁移过程中遇到C库不兼容导致的C代码修改40行以及汇编未适配导致的20行左右内嵌汇编需要增加。分析结果如下:从分析结果看未扫出任何需要修改的代码,与实际不符。四、总结1. 优点1)安装、使用简单,方便,可在迁移前进行分析,工具无需安装到迁移环境上;2. 缺点1)内嵌汇编检查不够完善。2)对库调用检查不完整(如:syscall(__NR_epoll_create, size));3)当工具无法扫描到,实施时人工识别到时,无法从工具页面获取如何修改的案例。4)用户手册中的白名单不知从哪里获取更新,并且其格式是什么,资料中未给出。5)用户对自己识别到的常用迁移问题无法扩展。3. 预测使用场景1)业务代码或开源代码迁移前先用该工具扫描,可以识别到部分迁移过程可能会遇到的问题。Tuning Kit一、工具介绍是针对TaiShan服务器的性能分析和优化工具,能收集服务器的处理器硬件、操作系统、进程/线程、函数等各层次的性能数据,分析出系统性能指标,定位到瓶颈点及热点函数。华为鲲鹏性能优化工具支持的功能特性如下:支持采集整个系统或指定进程(包括运行中的进程或直接启动的进程)的CPU Cycles性能事件,能够快速定位到热点函数,包括应用程序函数、模块函数与内核函数,甚至能够定位到热点指令。支持热点函数按照CPU核/线程/模块进行分组,支持查看热点函数调用栈。支持通过火焰图查看热点函数及其调用栈。支持代码映射功能,即查看函数内的热点指令及该指令对应的高级语言文件及行号。支持显示汇编代码的控制流图。支持分析Java代码的热点函数及热点指令。二、安装按照《华为鲲鹏性能优化工具 用户指南.pdf》在鲲鹏云linux-aarch64实例上进行安装。三、进行测试案例一以ls为例检查工具功能可用性分析结果如下:从分析结果可以看到热点函数、火焰图等信息进行分析系统瓶颈。四、总结1. 存在如下问题1)安装资料2.3章节步骤8安装nginx:./auto/configure文件不存在,需要修改为./configure;2)安装资料2.3章节步骤9安装python3:发布包未包含python3包,需要自行下载,资料未提供下载路径;4)安装资料2.3章节步骤11修改端口号:端口号不可修改为8000端口,该端口为gunicron监听端口。2. 优点:1)安装部署方便、除第三方工具外支持一键部署;2)工具分析比较全面,可分析正在运行以及未运行的C、JAVA进程的热点函数、指令以及调用栈、火焰图;3)可分析整体系统的热点函数、指令以及火焰图。3. 缺点:1)需要部署在待分析环境上进行分析;2)需要安装的第三方软件包python3、nginx、sqlite3需要自行编译安装,比较麻烦。4. 预测使用场景1)有助于开发人员分析客户应用以及开源软件迁移导致的性能变化的原因;2)有助于开发人员进行软件及系统性能的调优;3)由于需要部署到待测环境上,所以在生产环境上可能存在使用限制问题。
华为云鲲鹏云专业工具验证报告背景介绍 为了进一步提高鲲鹏云的软件移植效率与工作量评估以及性能调优能力深化;针对华为云鲲鹏云,鲲鹏软件栈的开发工具中提供的三款分析迁移与性能优化工具进行了研究;并给出了验证报告;具体工具如下: Dependency Advisor一、工具介绍一款可以简化客户应用迁移到TaiShan服务器过程的工具。该工具安装在X86服务器上,当客户有软件需要移植到TaiShan服务器上时,可先用该工具分析可移植性和移植投入。该工具解决了客户软件移植评估分析过程中人工分析投入大、准确率低、整体效率低下的痛点,通过该工具能够自动分析并输出指导报告。工具支持的功能特性如下:检查用户软件资源包(RPM、JAR、TAR、zip、gzip文件)中包含的SO依赖库,并评估SO依赖库的可移植性。检查指定的用户软件安装路径下的SO依赖库,并评估SO依赖库的可移植性。检查用户软件C/C++软件构建工程文件,并评估该文件的可移植性。检查用户软件C/C++源码,并评估软件源文件的可移植性。向用户提供软件移植报告,提供移植工作量评估。支持命令行方式和Web两种工作模式。二、安装按照《华为鲲鹏分析扫描工具 用户指南.pdf》在linux-x86_64安装web模式。三、进行测试案例一以hadoop安装包为例分析发布版本二进制软件包迁移可行性及迁移投入该发布包中部分包含so文件的jar包需要重新编译迁移,hadoop相关的多个二进制文件以及so动态库需要重新编译。分析结果如下:从分析报告可知迁移需要重新编译上述5个库文件,但该库的路径不够明确。案例二以mysql-clustre源码包为例分析源码包迁移可行性及迁移投入该源码包迁移过程中遇到C库不兼容导致的C代码修改40行以及汇编未适配导致的20行左右内嵌汇编需要重写。分析结果如下:从分析报告可知无需代码量修改可直接重新编译进行迁移。四、总结1. 优点1)安装、使用简单,方便,可在迁移前进行分析,工具无需安装到迁移环境上;2)支持RPM、JAR、TAR、zip、gzip文件等文件的分析;3)根据分析报告给出具体的工作量。2. 缺点1)只能分析出so文件是否需要重新编译,并且未给出so所在路径以便查找所属包;2)对C/C++源码分析不够准确,存在遗漏项,导致工作量遗漏;3)工具未评估so的可移植性。4)源码编译时的工作量评估不够准确。3. 预测使用场景1)业务二进制发布包迁移评估工作量时可使用该工具进行评估作为参考,但不可过度依赖该工具评估的工作量。Porting Advisor一、工具介绍该工具是一款可以简化客户应用迁移到TaiShan服务器的过程的工具。当客户有X86平台上源代码的软件要移植到TaiShan服务器上时,可用该工具自动分析出需修改的代码内容,并指导用户如何修改。该工具解决了用户代码兼容性人工排查困难、移植经验欠缺、反复依赖编译调错定位等痛点。支持的功能特性如下:检查用户C/C++软件构建工程文件,并指导用户如何移植该文件。检查用户C/C++软件构建工程文件使用的链接库,并提供可移植性信息。检查用户C/C++软件源码,并指导用户如何移植源文件。检查用户软件中X86汇编代码,并指导用户如何移植。支持命令行方式和Web两种工作模式。二、安装按照《华为鲲鹏代码迁移工具 用户指南.pdf》在linux-x86_64安装web模式。三、进行测试案例一以mysql-clustre源码包为例分析源码包迁移可行性该源码包迁移过程中遇到C库不兼容导致的C代码修改40行以及汇编未适配导致的20行左右内嵌汇编需要增加。分析结果如下:从分析结果看未扫出任何需要修改的代码,与实际不符。四、总结1. 优点1)安装、使用简单,方便,可在迁移前进行分析,工具无需安装到迁移环境上;2. 缺点1)内嵌汇编检查不够完善。2)对库调用检查不完整(如:syscall(__NR_epoll_create, size));3)当工具无法扫描到,实施时人工识别到时,无法从工具页面获取如何修改的案例。4)用户手册中的白名单不知从哪里获取更新,并且其格式是什么,资料中未给出。5)用户对自己识别到的常用迁移问题无法扩展。3. 预测使用场景1)业务代码或开源代码迁移前先用该工具扫描,可以识别到部分迁移过程可能会遇到的问题。Tuning Kit一、工具介绍是针对TaiShan服务器的性能分析和优化工具,能收集服务器的处理器硬件、操作系统、进程/线程、函数等各层次的性能数据,分析出系统性能指标,定位到瓶颈点及热点函数。华为鲲鹏性能优化工具支持的功能特性如下:支持采集整个系统或指定进程(包括运行中的进程或直接启动的进程)的CPU Cycles性能事件,能够快速定位到热点函数,包括应用程序函数、模块函数与内核函数,甚至能够定位到热点指令。支持热点函数按照CPU核/线程/模块进行分组,支持查看热点函数调用栈。支持通过火焰图查看热点函数及其调用栈。支持代码映射功能,即查看函数内的热点指令及该指令对应的高级语言文件及行号。支持显示汇编代码的控制流图。支持分析Java代码的热点函数及热点指令。二、安装按照《华为鲲鹏性能优化工具 用户指南.pdf》在鲲鹏云linux-aarch64实例上进行安装。三、进行测试案例一以ls为例检查工具功能可用性分析结果如下:从分析结果可以看到热点函数、火焰图等信息进行分析系统瓶颈。四、总结1. 存在如下问题1)安装资料2.3章节步骤8安装nginx:./auto/configure文件不存在,需要修改为./configure;2)安装资料2.3章节步骤9安装python3:发布包未包含python3包,需要自行下载,资料未提供下载路径;4)安装资料2.3章节步骤11修改端口号:端口号不可修改为8000端口,该端口为gunicron监听端口。2. 优点:1)安装部署方便、除第三方工具外支持一键部署;2)工具分析比较全面,可分析正在运行以及未运行的C、JAVA进程的热点函数、指令以及调用栈、火焰图;3)可分析整体系统的热点函数、指令以及火焰图。3. 缺点:1)需要部署在待分析环境上进行分析;2)需要安装的第三方软件包python3、nginx、sqlite3需要自行编译安装,比较麻烦。4. 预测使用场景1)有助于开发人员分析客户应用以及开源软件迁移导致的性能变化的原因;2)有助于开发人员进行软件及系统性能的调优;3)由于需要部署到待测环境上,所以在生产环境上可能存在使用限制问题。 -
 化鲲为鹏,我有话说最近在研究视频解码器的代码,他们用的armv7 neon,即32位的neon指令寄存器,如何在鲲鹏arm64位系统运行,进一步的,如何优化重新代码,使用armv8提供的neon指令?先来说,如何做到armv7 32位neon和armv8 64位neon指令兼容性?推荐使用arm-neon.h头文件提供的内联汇编函数,编译器已经做了兼容。如果追求性能,也可以自己再写一套armv8 neon的实现,但这样代码可移植性差。其次,armv8 neon对armv7 neon性能更好吗?未必,原因:1、armv7和armv8都使用了128位的寄存器,只是armv7 128寄存器的个数比armv8少了一半。如果引用的寄存器数量不超过16,不引起寄存器与内存交换数据,那么性能应该持平;2、armv7 neon和armv8 neon指令没有精简,即CPU执行周期是一样的。armv8 neon和armv7 neon有哪些不同呢?1、armv8a have scalar NEON operations;2、armv8a NEON shares status flag with CPU;3、armv8a has wider registers and new instructions;4、it's possible to use chain of one-cycle MACs with fast path;上面的4点来自stackoverflow的讨论以上是个人的理解,欢迎讨论!
化鲲为鹏,我有话说最近在研究视频解码器的代码,他们用的armv7 neon,即32位的neon指令寄存器,如何在鲲鹏arm64位系统运行,进一步的,如何优化重新代码,使用armv8提供的neon指令?先来说,如何做到armv7 32位neon和armv8 64位neon指令兼容性?推荐使用arm-neon.h头文件提供的内联汇编函数,编译器已经做了兼容。如果追求性能,也可以自己再写一套armv8 neon的实现,但这样代码可移植性差。其次,armv8 neon对armv7 neon性能更好吗?未必,原因:1、armv7和armv8都使用了128位的寄存器,只是armv7 128寄存器的个数比armv8少了一半。如果引用的寄存器数量不超过16,不引起寄存器与内存交换数据,那么性能应该持平;2、armv7 neon和armv8 neon指令没有精简,即CPU执行周期是一样的。armv8 neon和armv7 neon有哪些不同呢?1、armv8a have scalar NEON operations;2、armv8a NEON shares status flag with CPU;3、armv8a has wider registers and new instructions;4、it's possible to use chain of one-cycle MACs with fast path;上面的4点来自stackoverflow的讨论以上是个人的理解,欢迎讨论! -
 这个帖子我已经写第二遍了,现在都没有写的欲望了,原因是这样的,我在写这篇帖子的时候,写完了准备上传附件,发现不管上传什么附件都提示类型错误,然后我想反正会自动保存到草稿箱(之前有退出过,而且草稿箱里的内容都完好),就刷新一下,然后内容全部没了。然后就提示我华为云账号没登陆,这个设定真的是。。。 不知道你们有没有碰到过,平时在用着华为云的产品,突然就又要重新登陆华为云账号,这可能是华为为了安全性设置的,一段时间不用就会自动退出账号。有时候离开或者转去微信谈工作,很有可能长时间不操作。希望官方能够改进一下。或者给个设置选项,让我们自己选择是否自动退出账号。我相信大部分人工作都是在自己的或公司的电脑上。(其实是有设置选项的,只是当时没找到而已)以下正文1、keil简介Keil C51是美国Keil Software公司出品的51系列兼容单片机C语言软件开发系统,与汇编相比,C语言在功能上、结构性、可读性、可维护性上有明显的优势,因而易学易用。Keil提供了包括C编译器、宏汇编、链接器、库管理和一个功能强大的仿真调试器等在内的完整开发方案,通过一个集成开发环境(μVision)将这些部分组合在一起。运行Keil软件需要WIN98、NT、WIN2000、WINXP等操作系统。如果你使用C语言编程,那么Keil几乎就是你的不二之选,即使不使用C语言而仅用汇编语言编程,其方便易用的集成环境、强大的软件仿真调试工具也会令你事半功倍。--来自百度百科2、软件下载Keil开发环境可以在官网下载:https://www.keil.com/download/product/官网下载需要填写个人信息,非常麻烦,因为附件最多放20M的资料,所以我把 keil 5.28软件安装包、Pack包、常用驱动等放在了百度网盘上,需要的小伙伴可自行下载 链接:https://pan.baidu.com/s/1ZLp4TqbyZiWKgBOO-0zpGg 提取码:re3t(我不太喜欢设回复可见,你们拿了资源能在底下留个言么?感谢也好,吐槽也好,扣1也好,不要做伸手党,最好还能关注一下我哈,谢谢大家)3、软件安装之前我在这个步骤写了一大堆的,现在就放个我之前从导师那拿来的教程吧,这教程不知道是我老师写的还是来自于哪里。安装教程网上一大堆,虽然我之前写的教程丢了,但步骤都差不多。详情看附件:keil5软件安装与工程建立说明文档如果没有购买keil软件也是可以使用的,但是代码的编译量是有限制的。教程里面也有破解教程,但仅供学习交流使用,请24小时内删除,还请大家多多支持正版。
这个帖子我已经写第二遍了,现在都没有写的欲望了,原因是这样的,我在写这篇帖子的时候,写完了准备上传附件,发现不管上传什么附件都提示类型错误,然后我想反正会自动保存到草稿箱(之前有退出过,而且草稿箱里的内容都完好),就刷新一下,然后内容全部没了。然后就提示我华为云账号没登陆,这个设定真的是。。。 不知道你们有没有碰到过,平时在用着华为云的产品,突然就又要重新登陆华为云账号,这可能是华为为了安全性设置的,一段时间不用就会自动退出账号。有时候离开或者转去微信谈工作,很有可能长时间不操作。希望官方能够改进一下。或者给个设置选项,让我们自己选择是否自动退出账号。我相信大部分人工作都是在自己的或公司的电脑上。(其实是有设置选项的,只是当时没找到而已)以下正文1、keil简介Keil C51是美国Keil Software公司出品的51系列兼容单片机C语言软件开发系统,与汇编相比,C语言在功能上、结构性、可读性、可维护性上有明显的优势,因而易学易用。Keil提供了包括C编译器、宏汇编、链接器、库管理和一个功能强大的仿真调试器等在内的完整开发方案,通过一个集成开发环境(μVision)将这些部分组合在一起。运行Keil软件需要WIN98、NT、WIN2000、WINXP等操作系统。如果你使用C语言编程,那么Keil几乎就是你的不二之选,即使不使用C语言而仅用汇编语言编程,其方便易用的集成环境、强大的软件仿真调试工具也会令你事半功倍。--来自百度百科2、软件下载Keil开发环境可以在官网下载:https://www.keil.com/download/product/官网下载需要填写个人信息,非常麻烦,因为附件最多放20M的资料,所以我把 keil 5.28软件安装包、Pack包、常用驱动等放在了百度网盘上,需要的小伙伴可自行下载 链接:https://pan.baidu.com/s/1ZLp4TqbyZiWKgBOO-0zpGg 提取码:re3t(我不太喜欢设回复可见,你们拿了资源能在底下留个言么?感谢也好,吐槽也好,扣1也好,不要做伸手党,最好还能关注一下我哈,谢谢大家)3、软件安装之前我在这个步骤写了一大堆的,现在就放个我之前从导师那拿来的教程吧,这教程不知道是我老师写的还是来自于哪里。安装教程网上一大堆,虽然我之前写的教程丢了,但步骤都差不多。详情看附件:keil5软件安装与工程建立说明文档如果没有购买keil软件也是可以使用的,但是代码的编译量是有限制的。教程里面也有破解教程,但仅供学习交流使用,请24小时内删除,还请大家多多支持正版。 -
 作为一个开发者,每天都离不开IDE的帮助。而一个好用的集成开发环境,能够大大的提高开发效率。今天就要给大家推荐一个简单易用的物联网端侧IDE——华为IoT Studio。1 什么是IoT Studio华为IoT Studio是支持LiteOS嵌入式系统软件开发的工具,支持C、C++、汇编等多种开发语言,为您提供开发、构建、调试的一站式全流程开发体验。2 产品亮点功能丰富的SDK示例工程• IoT Studio提供了丰富的SDK示例工程,用户可基于示例工程快速创建可运行的工程原型。• 集成10分钟快速上云工程,用户可以基于智慧路灯案例体验10分钟快速上云。• 支持ARM Cortex-M、Cortex-A、RISC-V等多种内核芯片。• 兼容多种硬件开发板平台。 基于云端模型构建IoT Studio可根据云端设备模型的Profile文件自动生成C语言代码框架,确保程序能够正常编译调试,提升上云对接效率。支持LWM2M/CoAP等协议。 SDK图形化配置• 图形化配置SDK模块功能• 自动识别并管理模块间依赖关系• 模块配置后一键编译运行 3 产品优势3.1 简单易用IoT Studio支持一键安装,安装步骤简单。安装包小,软件占用资源少,配置也十分简单。支持C&C++、汇编、HTML以及JavaScript等等各种语言,用户能够快速上手操作。3.2 高效的代码调试功能断点控制• 支持普通断点和条件断点• C文件和.s汇编文件均可添加断点• 兼容软件断点反汇编调试• C源码和反汇编自动高亮联动• 支持反汇编断点• 可针对反汇编文件单步、跳入、跳出 3.3 更加智能的编码辅助• 智能提示/自动补齐 符号智能联想,按符号类型快速、准确联想,补齐语法关键字和语法结构• 符号定义引用跳转以及符号列表查看• 函数调用树查看 以图形的方式展示• 强大的搜索功能 帮助开发者快速找到所需要的文件、字符串、函数等• 自动排版/格式对齐 使代码编辑界面干净整洁,目录结构一目了然 4 产品快速定位问题的能力通信模组检测工具IoT Studio在与OC云端连通使用时,用户使用通信模组检测工具可以快速定位模组与云端连通性问题,自动化检测NB-IoT模组硬件与云端通信状态,准确定位问题发生阶段并提供解决建议。提高开发效率。 Watchpoint监视点• 支持添加读、写变量监视• 支持对内存地址读写监视• 监视点触发时自动暂停在对应代码行 查看内存和变量• 查看实时的内存地址数据• 支持导出内存数据(文本和二进制格式)• 支持添加变量和表达式监视• 支持调试过程中修改内存和变量值 系统异常自动捕获• OS异常时自动捕获并展示异常堆栈• 帮助您快速定位问题所在的代码行 好了,看完IoT Studio强大的功能介绍,您是否心动了呢?赶紧戳如下链接下载安装体验吧https://developer.obs.cn-north-4.myhuaweicloud.com/idea/IoT-Studio.zip
作为一个开发者,每天都离不开IDE的帮助。而一个好用的集成开发环境,能够大大的提高开发效率。今天就要给大家推荐一个简单易用的物联网端侧IDE——华为IoT Studio。1 什么是IoT Studio华为IoT Studio是支持LiteOS嵌入式系统软件开发的工具,支持C、C++、汇编等多种开发语言,为您提供开发、构建、调试的一站式全流程开发体验。2 产品亮点功能丰富的SDK示例工程• IoT Studio提供了丰富的SDK示例工程,用户可基于示例工程快速创建可运行的工程原型。• 集成10分钟快速上云工程,用户可以基于智慧路灯案例体验10分钟快速上云。• 支持ARM Cortex-M、Cortex-A、RISC-V等多种内核芯片。• 兼容多种硬件开发板平台。 基于云端模型构建IoT Studio可根据云端设备模型的Profile文件自动生成C语言代码框架,确保程序能够正常编译调试,提升上云对接效率。支持LWM2M/CoAP等协议。 SDK图形化配置• 图形化配置SDK模块功能• 自动识别并管理模块间依赖关系• 模块配置后一键编译运行 3 产品优势3.1 简单易用IoT Studio支持一键安装,安装步骤简单。安装包小,软件占用资源少,配置也十分简单。支持C&C++、汇编、HTML以及JavaScript等等各种语言,用户能够快速上手操作。3.2 高效的代码调试功能断点控制• 支持普通断点和条件断点• C文件和.s汇编文件均可添加断点• 兼容软件断点反汇编调试• C源码和反汇编自动高亮联动• 支持反汇编断点• 可针对反汇编文件单步、跳入、跳出 3.3 更加智能的编码辅助• 智能提示/自动补齐 符号智能联想,按符号类型快速、准确联想,补齐语法关键字和语法结构• 符号定义引用跳转以及符号列表查看• 函数调用树查看 以图形的方式展示• 强大的搜索功能 帮助开发者快速找到所需要的文件、字符串、函数等• 自动排版/格式对齐 使代码编辑界面干净整洁,目录结构一目了然 4 产品快速定位问题的能力通信模组检测工具IoT Studio在与OC云端连通使用时,用户使用通信模组检测工具可以快速定位模组与云端连通性问题,自动化检测NB-IoT模组硬件与云端通信状态,准确定位问题发生阶段并提供解决建议。提高开发效率。 Watchpoint监视点• 支持添加读、写变量监视• 支持对内存地址读写监视• 监视点触发时自动暂停在对应代码行 查看内存和变量• 查看实时的内存地址数据• 支持导出内存数据(文本和二进制格式)• 支持添加变量和表达式监视• 支持调试过程中修改内存和变量值 系统异常自动捕获• OS异常时自动捕获并展示异常堆栈• 帮助您快速定位问题所在的代码行 好了,看完IoT Studio强大的功能介绍,您是否心动了呢?赶紧戳如下链接下载安装体验吧https://developer.obs.cn-north-4.myhuaweicloud.com/idea/IoT-Studio.zip -
gcc 语言编译全过程:预处理->编译->汇编->链接一、GCC快速入门Gcc指令的一般格式为:Gcc [选项] 要编译的文件 [选项] [目标文件]其中,目标文件可缺省,Gcc默认生成可执行的文件名为:a.out我们来看一下经典入门程序"Hello World!"# vi hello.c#include <stdlib.h>#include <stdio.h>void main(void){printf("hello world!\r\n");}用gcc编译成执行程序。#gcc hello.c该命令将hello.c直接生成最终二进制可执行程序a.out这条命令隐含执行了(1)预处理、(2)汇编、(3)编译并(4)链接形成最终的二进制可执行程序。这里未指定输出文件,默认输出为a.out。如何要指定最终二进制可执行程序名,那么用-o选项来指定名称。比如需要生成执行程序hello.exe那么#gcc hello.c -o hello.exe二、GCC的命令剖析--四步走从上面我们知道GCC编译源代码生成最终可执行的二进制程序,GCC后台隐含执行了四个阶段步骤。GCC编译C源码有四个步骤:预处理-----> 编译 ----> 汇编 ----> 链接现在我们就用GCC的命令选项来逐个剖析GCC过程。1)预处理(Pre-processing)在该阶段,编译器将C源代码中的包含的头文件如stdio.h编译进来,用户可以使用gcc的选项”-E”进行查看。用法:#gcc -E hello.c -o hello.i 作用:将hello.c预处理输出hello.i文件。[root]# gcc -E hello.c -o hello.i[root]# lshello.c hello.i[root]# vi hello.i# 1 "hello.c"# 1 "<built-in>"# 1 "<command line>"# 1 "hello.c"# 1 "/usr/include/stdlib.h" 1 3# 25 "/usr/include/stdlib.h" 3# 1 "/usr/include/features.h" 1 3# 291 "/usr/include/features.h" 3# 1 "/usr/include/sys/cdefs.h" 1 3# 292 "/usr/include/features.h" 2 3# 314 "/usr/include/features.h" 3# 1 "/usr/include/gnu/stubs.h" 1 3# 315 "/usr/include/features.h" 2 3# 26 "/usr/include/stdlib.h" 2 3# 3 "hello.c" 2void main(void){printf("hello world!\r\n");}2)编译阶段(Compiling)第二步进行的是编译阶段,在这个阶段中,Gcc首先要检查代码的规范性、是否有语法错误等,以确定代码的实际要做的工作,在检查无误后,Gcc把代码翻译成汇编语言。用户可以使用”-S”选项来进行查看,该选项只进行编译而不进行汇编,生成汇编代码。选项 -S用法:[root]# gcc –S hello.i –o hello.s 作用:将预处理输出文件hello.i汇编成hello.s文件。[root@richard hello-gcc]# lshello.c hello.i hello.s如下为hello.s汇编代码[root@richard hello-gcc]# vi hello.s.file "hello.c".section .rodata.LC0:.string "hello world!\r\n".text.globl main.type main,@functionmain:pushl %ebpmovl %esp, %ebpsubl $8, %espandl $-16, %espmovl $0, %eaxsubl %eax, %espsubl $12, %esppushl $.LC0call printfaddl $16, %espmovl $0, %eaxleaveret.Lfe1:.size main,.Lfe1-main.ident "GCC: (GNU) 3.2.2 20030222 (Red Hat Linux 3.2.2-5)"3)汇编阶段(Assembling)汇编阶段是把编译阶段生成的”.s”文件转成二进制目标代码.选项 -c用法:[root]# gcc –c hello.s –o hello.o 作用:将汇编输出文件test.s编译输出test.o文件。[root]# gcc -c hello.s -o hello.o[root]# lshello.c hello.i hello.o hello.s4)链接阶段(Link)在成功编译之后,就进入了链接阶段。无选项链接用法:[root]# gcc hello.o –o hello.exe 作用:将编译输出文件hello.o链接成最终可执行文件hello.exe。[root]# lshello.c hello.exe hello.i hello.o hello.s运行该可执行文件,出现正确的结果如下。[root@localhost Gcc]# ./helloHello World!在这里涉及到一个重要的概念:函数库。读者可以重新查看这个小程序,在这个程序中并没有定义”printf”的函数实现,且在预编译中包含进的”stdio.h”中也只有该函数的声明,而没有定义函数的实现,那么,是在哪里实现”printf”函数的呢?最后的答案是:系统把这些函数实现都被做到名为libc.so.6的库文件中去了,在没有特别指定时,gcc会到系统默认的搜索路径”/usr/lib”下进行查找,也就是链接到libc.so.6库函数中去,这样就能实现函数”printf” 了,而这也就是链接的作用。你可以用ldd命令查看动态库加载情况:[root]# ldd hello.exelibc.so.6 => /lib/tls/libc.so.6 (0x42000000)/lib/ld-linux.so.2 => /lib/ld-linux.so.2 (0x40000000)函数库一般分为静态库和动态库两种。静态库是指编译链接时,把库文件的代码全部加入到可执行文件中,因此生成的文件比较大,但在运行时也就不再需要库文件了。其后缀名一般为”.a”。动态库与之相反,在编译链接时并没有把库文件的代码加入到可执行文件中,而是在程序执行时由运行时链接文件加载库,这样可以节省系统的开销。动态库一般后缀名为”.so”,如前面所述的libc.so.6就是动态库。gcc在编译时默认使用动态库。
推荐直播
-
 华为云码道Skill实战与极速交付,智能开发全链路实战
华为云码道Skill实战与极速交付,智能开发全链路实战2026/07/22 周三 19:00-21:00
王一男-华为云码道产品规划专家;李炎-华为云码道产品专家;姜浩-华为云HCDG核心组成员
直播深度解读华为云码道6月产品新特性,从Skill市场安装专家技能,带你零距离体验从需求,开发,审查,重构全链路闭环的开发过程。从零构建并交付一个完整项目,让您体验从代码提交到服务上线的“极速”之旅。
回顾中 -
 聚开发者之力,创具身新未来
聚开发者之力,创具身新未来2026/07/23 周四 15:00-17:00
张豪杰/程文/王军/刘新春/黄钦开 /张晓天
本次华为云具身智能开发平台CloudRobo培训面向具身智能开发者,带您全流程体验机器人本体R2C小时级接入、环境重建与轨迹生成仿真数据生产、PB级数据管理、数据评测、模型训推、强化学习和Benchmark一键评测等功能,并体验业界主流具身模型应用。
回顾中
热门标签