-
 >摘要:我是一个Redis服务,最引以为傲的就是我的速度,我的 QPS 能达到10万级别。本文分享自华为云社区《[Redis:我是如何与客户端进行通信的](https://bbs.huaweicloud.com/blogs/327076?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 码农参上 。 江湖上说,**天下武功,无坚不摧,唯快不破**,这句话简直是为我量身定制。 我是一个Redis服务,最引以为傲的就是我的速度,我的 QPS 能达到10万级别。 在我的手下有数不清的小弟,他们会时不时到我这来存放或者取走一些数据,我管他们叫做客户端,还给他们起了英文名叫 Redis-client。 有时候一个小弟会来的非常频繁,有时候一堆小弟会同时过来,但是,即使再多的小弟我也能管理的井井有条。 有一天,小弟们问我。 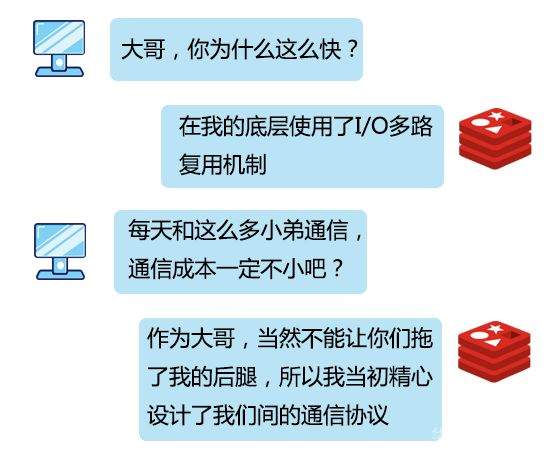 想当年,为了不让小弟们拖垮我傲人的速度,在设计和他们的通信协议时,我绞尽脑汁,制定了下面的三条原则: - 实现简单 - 针对计算机来说,解析速度快 - 针对人类来说,可读性强 为什么这么设计呢?先来看看一条指令发出的过程,首先在客户端需要对指令操作进行封装,使用网络进行传输,最后在服务端进行相应的解析、执行。 这一过程如果设计成一种非常复杂的协议,那么封装、解析、传输的过程都将非常耗时,无疑会降低我的速度。什么,你问我为什么要遵循最后一条规则?算是对于程序员们的馈赠吧,我真是太善良了。 我把创造出来的这种协议称为 RESP (REdis Serialization Protocol)协议,它工作在 TCP 协议的上层,作为我和客户端之间进行通讯的标准形式。 说到这,我已经有点迫不及待想让你们看看我设计出来的杰作了,但我好歹也是个大哥,得摆点架子,不能我主动拿来给你们看。 所以我建议你直接使用客户端发出一条向服务器的命令,然后取出这条命令对应的报文来直观的看一下。话虽如此,不过我已经被封装的很严实了,正常情况下你是看不到我内部进行通讯的具体报文的,所以,你可以伪装成一个Redis的服务端,来截获小弟们发给我的消息。 实现起来也很简单,我和小弟之间是基于 Socket 进行通讯,所以在本地先启动一个ServerSocket,用来监听Redis服务的6379端口: public static void server() throws IOException { ServerSocket serverSocket = new ServerSocket(6379); Socket socket = serverSocket.accept(); byte[] bytes = new byte[1024]; InputStream input = socket.getInputStream(); while(input.read(bytes)!=0){ System.out.println(new String(bytes)); } } 然后启动redis-cli客户端,发送一条命令: `set key1 value1` 这时,伪装的服务端就会收到报文了,在控制台打印了: *3 $3 set $4 key1 $6 value1 看到这里,隐隐约约看到了刚才输入的几个关键字,但是还有一些其他的字符,要怎么解释呢,是时候让我对协议报文中的格式进行一下揭秘了。 我对小弟们说了,对大哥说话的时候得按规矩来,这样吧,你们在请求的时候要遵循下面的规则: *参数数量> CRLF $参数1的字节长度> CRLF 参数1的数据> CRLF $参数2的字节长度> CRLF 参数2的数据> CRLF ... $参数N的字节长度> CRLF 参数N的数据> CRLF 首先解释一下每行末尾的CRLF,转换成程序语言就是\r\n,也就是回车加换行。看到这里,你也就能够明白为什么控制台打印出的指令是竖向排列了吧。 在命令的解析过程中,set、key1、value1会被认为是3个参数,因此参数数量为3,对应第一行的*3。 第一个参数set,长度为3对应$3;第二个参数key1,长度为4对应$4;第三个参数value1,长度为6对应$6。在每个参数长度的下一行对应真正的参数数据。 看到这,一条指令被转换为协议报文的过程是不是就很好理解了?  当小弟对我发送完请求后,作为大哥,我就要对小弟的请求进行**指令回复**了,而且我得根据回复内容进行一下分类,要不然小弟该搞不清我的指示了。 # 简单字符串 简单字符串回复只有一行回复,回复的内容以+作为开头,不允许换行,并以\r\n结束。有很多指令在执行成功后只会回复一个OK,使用的就是这种格式,能够有效的将传输、解析的开销降到最低。 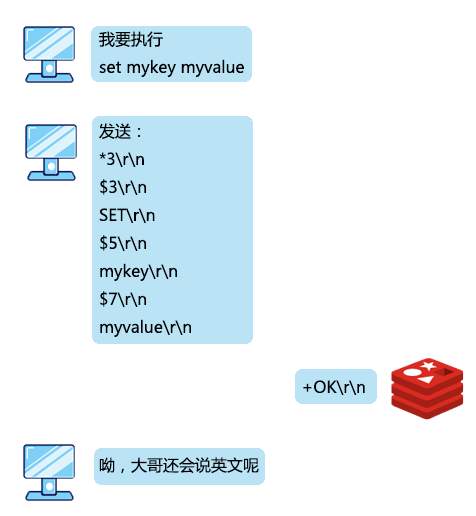 # 错误回复 在RESP协议中,错误回复可以当做简单字符串回复的变种形式,它们之间的格式也非常类似,区别只有第一个字符是以-作为开头,错误回复的内容通常是错误类型及对错误描述的字符串。 错误回复出现在一些异常的场景,例如当发送了错误的指令、操作数的数量不对时,都会进行错误回复。在客户端收到错误回复后,会将它与简单字符串回复进行区分,视为异常。 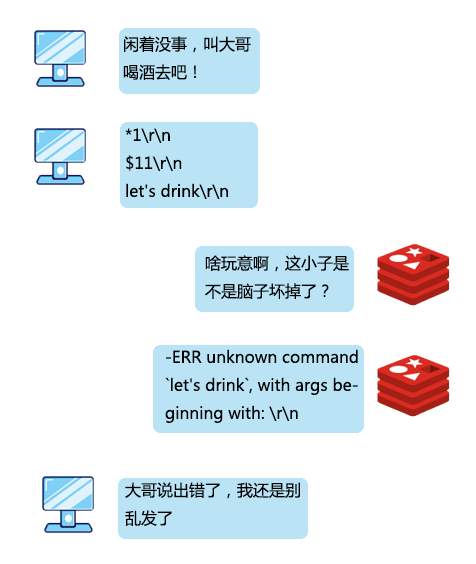 # 整数回复 整数回复的应用也非常广泛,它以:作为开头,以\r\n结束,用于返回一个整数。例如当执行incr后返回自增后的值,执行llen返回数组的长度,或者使用exists命令返回的0或1作为判断一个key是否存在的依据,这些都使用了整数回复。 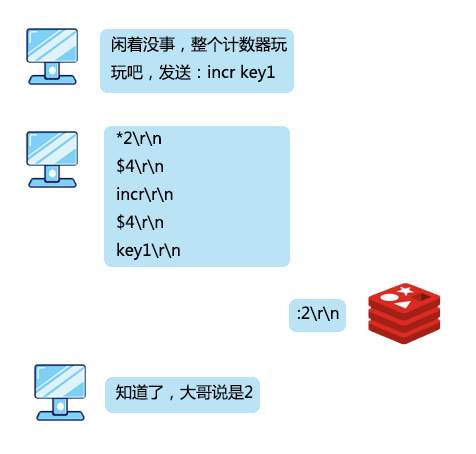 # 批量回复 批量回复,就是多行字符串的回复。它以$作为开头,后面是发送的字节长度,然后是\r\n,然后发送实际的数据,最终以\r\n结束。如果要回复的数据不存在,那么回复长度为-1。 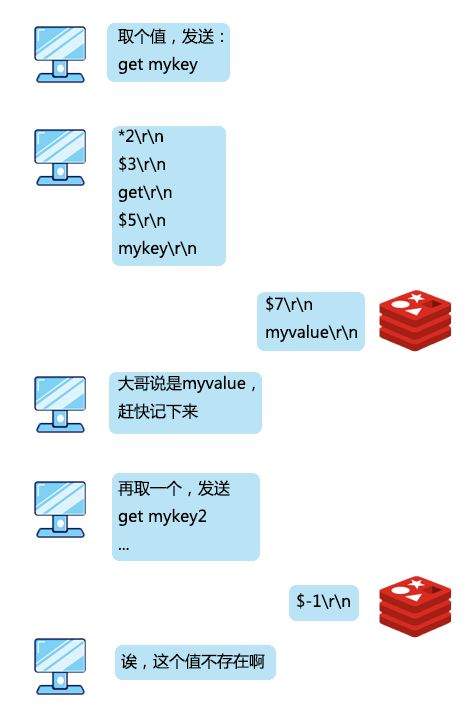 # 多条批量回复 当服务端要返回多个值时,例如返回一些元素的集合时,就会使用多条批量回复。它以*作为开头,后面是返回元素的个数,之后再跟随多个上面讲到过的批量回复。 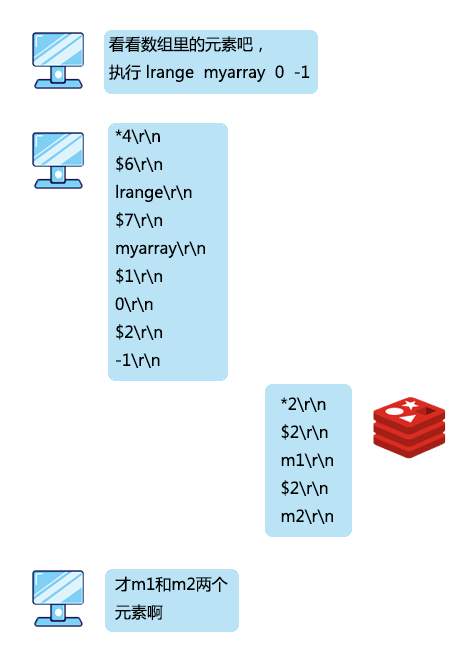 到这里,基本上我和小弟之间的通讯协议就介绍完了。刚才你尝试了伪装成一个服务端,这会再来试一试直接写一个客户端来直接和我进行交互吧。 private static void client() throws IOException { String CRLF="\r\n"; Socket socket=new Socket("localhost", 6379); try (OutputStream out = socket.getOutputStream()) { StringBuffer sb=new StringBuffer(); sb.append("*3").append(CRLF) .append("$3").append(CRLF).append("set").append(CRLF) .append("$4").append(CRLF).append("key1").append(CRLF) .append("$6").append(CRLF).append("value1").append(CRLF); out.write(sb.toString().getBytes()); out.flush(); try (InputStream inputStream = socket.getInputStream()) { byte[] buff = new byte[1024]; int len = inputStream.read(buff); if (len > 0) { String ret = new String(buff, 0, len); System.out.println("Recv:" + ret); } } } } 运行上面的代码,控制台输出: `Recv:+OK` 上面模仿了客户端发出set命令的过程,并收到了回复。依此类推,你也可以自己封装其他的命令,来实现一个自己的Redis客户端来和我进行通信。
>摘要:我是一个Redis服务,最引以为傲的就是我的速度,我的 QPS 能达到10万级别。本文分享自华为云社区《[Redis:我是如何与客户端进行通信的](https://bbs.huaweicloud.com/blogs/327076?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 码农参上 。 江湖上说,**天下武功,无坚不摧,唯快不破**,这句话简直是为我量身定制。 我是一个Redis服务,最引以为傲的就是我的速度,我的 QPS 能达到10万级别。 在我的手下有数不清的小弟,他们会时不时到我这来存放或者取走一些数据,我管他们叫做客户端,还给他们起了英文名叫 Redis-client。 有时候一个小弟会来的非常频繁,有时候一堆小弟会同时过来,但是,即使再多的小弟我也能管理的井井有条。 有一天,小弟们问我。  想当年,为了不让小弟们拖垮我傲人的速度,在设计和他们的通信协议时,我绞尽脑汁,制定了下面的三条原则: - 实现简单 - 针对计算机来说,解析速度快 - 针对人类来说,可读性强 为什么这么设计呢?先来看看一条指令发出的过程,首先在客户端需要对指令操作进行封装,使用网络进行传输,最后在服务端进行相应的解析、执行。 这一过程如果设计成一种非常复杂的协议,那么封装、解析、传输的过程都将非常耗时,无疑会降低我的速度。什么,你问我为什么要遵循最后一条规则?算是对于程序员们的馈赠吧,我真是太善良了。 我把创造出来的这种协议称为 RESP (REdis Serialization Protocol)协议,它工作在 TCP 协议的上层,作为我和客户端之间进行通讯的标准形式。 说到这,我已经有点迫不及待想让你们看看我设计出来的杰作了,但我好歹也是个大哥,得摆点架子,不能我主动拿来给你们看。 所以我建议你直接使用客户端发出一条向服务器的命令,然后取出这条命令对应的报文来直观的看一下。话虽如此,不过我已经被封装的很严实了,正常情况下你是看不到我内部进行通讯的具体报文的,所以,你可以伪装成一个Redis的服务端,来截获小弟们发给我的消息。 实现起来也很简单,我和小弟之间是基于 Socket 进行通讯,所以在本地先启动一个ServerSocket,用来监听Redis服务的6379端口: public static void server() throws IOException { ServerSocket serverSocket = new ServerSocket(6379); Socket socket = serverSocket.accept(); byte[] bytes = new byte[1024]; InputStream input = socket.getInputStream(); while(input.read(bytes)!=0){ System.out.println(new String(bytes)); } } 然后启动redis-cli客户端,发送一条命令: `set key1 value1` 这时,伪装的服务端就会收到报文了,在控制台打印了: *3 $3 set $4 key1 $6 value1 看到这里,隐隐约约看到了刚才输入的几个关键字,但是还有一些其他的字符,要怎么解释呢,是时候让我对协议报文中的格式进行一下揭秘了。 我对小弟们说了,对大哥说话的时候得按规矩来,这样吧,你们在请求的时候要遵循下面的规则: *参数数量> CRLF $参数1的字节长度> CRLF 参数1的数据> CRLF $参数2的字节长度> CRLF 参数2的数据> CRLF ... $参数N的字节长度> CRLF 参数N的数据> CRLF 首先解释一下每行末尾的CRLF,转换成程序语言就是\r\n,也就是回车加换行。看到这里,你也就能够明白为什么控制台打印出的指令是竖向排列了吧。 在命令的解析过程中,set、key1、value1会被认为是3个参数,因此参数数量为3,对应第一行的*3。 第一个参数set,长度为3对应$3;第二个参数key1,长度为4对应$4;第三个参数value1,长度为6对应$6。在每个参数长度的下一行对应真正的参数数据。 看到这,一条指令被转换为协议报文的过程是不是就很好理解了?  当小弟对我发送完请求后,作为大哥,我就要对小弟的请求进行**指令回复**了,而且我得根据回复内容进行一下分类,要不然小弟该搞不清我的指示了。 # 简单字符串 简单字符串回复只有一行回复,回复的内容以+作为开头,不允许换行,并以\r\n结束。有很多指令在执行成功后只会回复一个OK,使用的就是这种格式,能够有效的将传输、解析的开销降到最低。  # 错误回复 在RESP协议中,错误回复可以当做简单字符串回复的变种形式,它们之间的格式也非常类似,区别只有第一个字符是以-作为开头,错误回复的内容通常是错误类型及对错误描述的字符串。 错误回复出现在一些异常的场景,例如当发送了错误的指令、操作数的数量不对时,都会进行错误回复。在客户端收到错误回复后,会将它与简单字符串回复进行区分,视为异常。  # 整数回复 整数回复的应用也非常广泛,它以:作为开头,以\r\n结束,用于返回一个整数。例如当执行incr后返回自增后的值,执行llen返回数组的长度,或者使用exists命令返回的0或1作为判断一个key是否存在的依据,这些都使用了整数回复。  # 批量回复 批量回复,就是多行字符串的回复。它以$作为开头,后面是发送的字节长度,然后是\r\n,然后发送实际的数据,最终以\r\n结束。如果要回复的数据不存在,那么回复长度为-1。  # 多条批量回复 当服务端要返回多个值时,例如返回一些元素的集合时,就会使用多条批量回复。它以*作为开头,后面是返回元素的个数,之后再跟随多个上面讲到过的批量回复。  到这里,基本上我和小弟之间的通讯协议就介绍完了。刚才你尝试了伪装成一个服务端,这会再来试一试直接写一个客户端来直接和我进行交互吧。 private static void client() throws IOException { String CRLF="\r\n"; Socket socket=new Socket("localhost", 6379); try (OutputStream out = socket.getOutputStream()) { StringBuffer sb=new StringBuffer(); sb.append("*3").append(CRLF) .append("$3").append(CRLF).append("set").append(CRLF) .append("$4").append(CRLF).append("key1").append(CRLF) .append("$6").append(CRLF).append("value1").append(CRLF); out.write(sb.toString().getBytes()); out.flush(); try (InputStream inputStream = socket.getInputStream()) { byte[] buff = new byte[1024]; int len = inputStream.read(buff); if (len > 0) { String ret = new String(buff, 0, len); System.out.println("Recv:" + ret); } } } } 运行上面的代码,控制台输出: `Recv:+OK` 上面模仿了客户端发出set命令的过程,并收到了回复。依此类推,你也可以自己封装其他的命令,来实现一个自己的Redis客户端来和我进行通信。 -
 DWS工作负载管理概述 在实际的业务场景中,使用DWS的客户可能会同时使用多个用户同时运行查询作业,这其中有些查询可能会非常复杂,此时如果对数据库资源未做控制,这些复杂作业的查询容易占用大部分的集群资源并长时间运行,从而影响其他查询的性能,使其不得不等待哪些复杂作业执行完成。 其实在上述场景中,我们完全可以对这些执行复杂作业的用户进行分组,对这些用户进行合理的资源限制,使在可接受的执行时间范围内使用一定的资源执行这些复杂查询,同时划分出部分资源给那些查询消耗没那么大的用户,这样在部分用户执行复杂作业的同时,另一部分用户的作业也不会受到太大影响。 这就是DWS工作负载管理多队列资源管控的思想模型,客户可以根据自己的业务特点预先创建好多个工作负载队列,对每个队列配置好可以使用的资源上限,然后为每种业务创建好数据库用户并添加到对应的队列中,这样每次这些不同的用户在提交作业的时候都会被分配到对应的队列中,只能使用该队列中拥有的资源执行作业,队列资源不足时,该查询将在该队列中排队等待执行,各个队列之间资源个各自隔离,各不冲突,这样当一些数据库用户在自己队列中执行一些非常耗时的查询作业时,其他用户在各自的队列同时在执行一些简单或者有自己业务特点的作业,这些作业互不干扰。 工作负载管理功能以队列为资源承载点,目前可以配置队列的CPU时间片占比、内存占比、并发(复杂查询并发数)以及磁盘空间大小(永久表空间)等资源。 CPU资源配比为队列可使用的最小时间片占比,当某个队列A的CPU负载超限并且有某个队列B恰好空闲时,队列A可以暂时使用空闲队列B的CPU资源,但是一旦空闲队列B开始对CPU资源有诉求时,将会收回“出借”给队列A的CPU资源。这种CPU控制方式我们称之为CPU配额控制,即可以保证至少有配比的资源可用。 DWS在创建集群时会根据集群中的节点规格为每个DN计算好可用的内存大小max_process_memory,DN在启动时会一次性申请max_process_memory大小的内存,DWS会在此基础上,根据每个队列的内存配比,对作业使用的内存进行限制。队列中所有数据库用户共享队列内存,并且执行作业可消耗的内存资源不超过队列的内存配比。 DWS目前只支持永久表空间的存储资源限制,队列中所有数据库用户共享队列的存储资源,并且可使用的永久表空间大小不超过队列配置的存储资源大小。 队列的并发数指的是队列内多有数据库用户可同时执行的作业数,作业数达到并发数限制之后,再提交的作业会在队列中排队等待执行。DWS负载管理页面介绍页面概览 DWS负载管理页面主要包括工作负载管理配置区域、工作负载队列列表区域以及工作负载队列详情展示区域,工作负载管理配置用来管理工作负载功能的全局配置,包括工作负载开关和全局最大并发数的配置(每个CN的最大并发数);工作负载队列列表区域显示所有已创建的工作队列,可以在这里添加队列;队列详情区域包括队列的短查询配置、资源配置、异常规则配置以及队列中数据库用户的管理。添加队列 添加一个工作负载队列并配置相应的资源 修改队列 修改一个队列资源配比 向队列中添加数据库用户 向队列中添加数据库用户,以限制该用户执行作业时消耗的资源占比 从队列中移除数据库用户 从队列中将已添加的某个数据库用户移除,每个数据库用户只能添加到一个队列中,从队列中移除之后可再添加至其他队列中 作为工作负载管理系列的开端,以上就是DWS工作负载管理的基本使用场景介绍以及基础功能概览,后续我们会陆续推出对CPU、内存、并发、磁盘等单项资源管控机制深度解密的系列博文,敬请关注。
DWS工作负载管理概述 在实际的业务场景中,使用DWS的客户可能会同时使用多个用户同时运行查询作业,这其中有些查询可能会非常复杂,此时如果对数据库资源未做控制,这些复杂作业的查询容易占用大部分的集群资源并长时间运行,从而影响其他查询的性能,使其不得不等待哪些复杂作业执行完成。 其实在上述场景中,我们完全可以对这些执行复杂作业的用户进行分组,对这些用户进行合理的资源限制,使在可接受的执行时间范围内使用一定的资源执行这些复杂查询,同时划分出部分资源给那些查询消耗没那么大的用户,这样在部分用户执行复杂作业的同时,另一部分用户的作业也不会受到太大影响。 这就是DWS工作负载管理多队列资源管控的思想模型,客户可以根据自己的业务特点预先创建好多个工作负载队列,对每个队列配置好可以使用的资源上限,然后为每种业务创建好数据库用户并添加到对应的队列中,这样每次这些不同的用户在提交作业的时候都会被分配到对应的队列中,只能使用该队列中拥有的资源执行作业,队列资源不足时,该查询将在该队列中排队等待执行,各个队列之间资源个各自隔离,各不冲突,这样当一些数据库用户在自己队列中执行一些非常耗时的查询作业时,其他用户在各自的队列同时在执行一些简单或者有自己业务特点的作业,这些作业互不干扰。 工作负载管理功能以队列为资源承载点,目前可以配置队列的CPU时间片占比、内存占比、并发(复杂查询并发数)以及磁盘空间大小(永久表空间)等资源。 CPU资源配比为队列可使用的最小时间片占比,当某个队列A的CPU负载超限并且有某个队列B恰好空闲时,队列A可以暂时使用空闲队列B的CPU资源,但是一旦空闲队列B开始对CPU资源有诉求时,将会收回“出借”给队列A的CPU资源。这种CPU控制方式我们称之为CPU配额控制,即可以保证至少有配比的资源可用。 DWS在创建集群时会根据集群中的节点规格为每个DN计算好可用的内存大小max_process_memory,DN在启动时会一次性申请max_process_memory大小的内存,DWS会在此基础上,根据每个队列的内存配比,对作业使用的内存进行限制。队列中所有数据库用户共享队列内存,并且执行作业可消耗的内存资源不超过队列的内存配比。 DWS目前只支持永久表空间的存储资源限制,队列中所有数据库用户共享队列的存储资源,并且可使用的永久表空间大小不超过队列配置的存储资源大小。 队列的并发数指的是队列内多有数据库用户可同时执行的作业数,作业数达到并发数限制之后,再提交的作业会在队列中排队等待执行。DWS负载管理页面介绍页面概览 DWS负载管理页面主要包括工作负载管理配置区域、工作负载队列列表区域以及工作负载队列详情展示区域,工作负载管理配置用来管理工作负载功能的全局配置,包括工作负载开关和全局最大并发数的配置(每个CN的最大并发数);工作负载队列列表区域显示所有已创建的工作队列,可以在这里添加队列;队列详情区域包括队列的短查询配置、资源配置、异常规则配置以及队列中数据库用户的管理。添加队列 添加一个工作负载队列并配置相应的资源 修改队列 修改一个队列资源配比 向队列中添加数据库用户 向队列中添加数据库用户,以限制该用户执行作业时消耗的资源占比 从队列中移除数据库用户 从队列中将已添加的某个数据库用户移除,每个数据库用户只能添加到一个队列中,从队列中移除之后可再添加至其他队列中 作为工作负载管理系列的开端,以上就是DWS工作负载管理的基本使用场景介绍以及基础功能概览,后续我们会陆续推出对CPU、内存、并发、磁盘等单项资源管控机制深度解密的系列博文,敬请关注。 -
 当某一地区故障而导致业务不可用,可以使用数据复制服务DRS推出的灾备场景,为业务连续性提供数据库的同步保障。本节小课为您介绍RDS for MySQL实例通过DRS服务搭建异地单主灾备的过程。实现原理RDS跨Region容灾实现原理说明:在两个数据中心独立部署RDS for MySQL实例,通过DRS服务将生产中心MySQL库中的数据同步到灾备中心MySQL库中,实现RDS for MySQL主实例和跨Region灾备实例之间的实时同步。更多关于MySQL实例灾备须知请单击这里了解。一、生产中心RDS for MySQL实例准备创建MySQL业务实例,选择已规划的业务实例所属VPC,并为实例绑定EIP。1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华北-北京一”。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。4. 单击“购买数据库实例”。5. 填选实例信息后,单击“立即购买”。 选择引擎版本信息。选择规格信息。选择已规划的网络信息。设置管理员密码。6. 为创建的RDS实例绑定弹性公网IP。二、灾备中心RDS for MySQL实例准备创建MySQL灾备实例,选择已规划的灾备实例所属VPC。1. 单击管理控制台左上角的,选择区域“华北-北京四”。2. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。3. 单击“购买数据库实例”。4. 填选实例信息后,单击“立即购买”。选择灾备实例引擎版本信息选择灾备实例规格信息选择灾备实例已规划的网络信息设置灾备实例管理员密码三、搭建容灾关系创建DRS灾备实例,创建时选择灾备中心创建的RDS for MySQL实例。1. 在“华北-北京四”区域,单击左侧的服务列表图标,选择“数据库 > 数据复制服务 DRS”。2. 选择左侧“实时灾备管理”,单击右上角“创建灾备任务”。3. 灾备类型选择“单主灾备”,灾备关系选择“本云为备”,灾备数据库实例选择在“华北-北京四”新创建的MySQL灾备实例,单击“下一步”,开始创建灾备实例。设置基本信息设置灾备实例信息4. 返回“实时灾备管理”页面,可以看到新创建的灾备实例。创建完成5. 在灾备实例上,单击“编辑”。6. 根据界面提示,将灾备实例的弹性公网IP加入生产中心MySQL实例所属安全组的入方向规则,选择TCP协议,端口为生产中心MySQL实例的端口号。添加安全组规则 源库信息中的“IP地址或域名”填写生产中心MySQL实例绑定的EIP,“端口”填写生产中心MySQL实例的端口号。测试通过后,单击“下一步”,直到任务启动,任务状态为“灾备中”。编辑灾备任务灾备中四、容灾切换生产中心数据库故障时,需要手动将灾备数据库实例切换为可读写状态。切换后,将通过灾备实例写入数据,并同步到源库。1. 生产中心源库发生故障,例如:源库无法连接、源库执行缓慢、CPU占比高。2. 收到SMN邮件通知。邮件通知3. 查看灾备任务时延异常。时延异常4. 用户自行判断业务已经停止。具体请参考如何确保业务数据库的全部业务已经停止。5. 选择“批量操作 > 主备倒换”,将灾备实例由只读状态更改为读写状态。主备倒换倒换完成6. 在应用端修改数据库连接地址后,可正常连接数据库,进行数据读写。
当某一地区故障而导致业务不可用,可以使用数据复制服务DRS推出的灾备场景,为业务连续性提供数据库的同步保障。本节小课为您介绍RDS for MySQL实例通过DRS服务搭建异地单主灾备的过程。实现原理RDS跨Region容灾实现原理说明:在两个数据中心独立部署RDS for MySQL实例,通过DRS服务将生产中心MySQL库中的数据同步到灾备中心MySQL库中,实现RDS for MySQL主实例和跨Region灾备实例之间的实时同步。更多关于MySQL实例灾备须知请单击这里了解。一、生产中心RDS for MySQL实例准备创建MySQL业务实例,选择已规划的业务实例所属VPC,并为实例绑定EIP。1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华北-北京一”。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。4. 单击“购买数据库实例”。5. 填选实例信息后,单击“立即购买”。 选择引擎版本信息。选择规格信息。选择已规划的网络信息。设置管理员密码。6. 为创建的RDS实例绑定弹性公网IP。二、灾备中心RDS for MySQL实例准备创建MySQL灾备实例,选择已规划的灾备实例所属VPC。1. 单击管理控制台左上角的,选择区域“华北-北京四”。2. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。3. 单击“购买数据库实例”。4. 填选实例信息后,单击“立即购买”。选择灾备实例引擎版本信息选择灾备实例规格信息选择灾备实例已规划的网络信息设置灾备实例管理员密码三、搭建容灾关系创建DRS灾备实例,创建时选择灾备中心创建的RDS for MySQL实例。1. 在“华北-北京四”区域,单击左侧的服务列表图标,选择“数据库 > 数据复制服务 DRS”。2. 选择左侧“实时灾备管理”,单击右上角“创建灾备任务”。3. 灾备类型选择“单主灾备”,灾备关系选择“本云为备”,灾备数据库实例选择在“华北-北京四”新创建的MySQL灾备实例,单击“下一步”,开始创建灾备实例。设置基本信息设置灾备实例信息4. 返回“实时灾备管理”页面,可以看到新创建的灾备实例。创建完成5. 在灾备实例上,单击“编辑”。6. 根据界面提示,将灾备实例的弹性公网IP加入生产中心MySQL实例所属安全组的入方向规则,选择TCP协议,端口为生产中心MySQL实例的端口号。添加安全组规则 源库信息中的“IP地址或域名”填写生产中心MySQL实例绑定的EIP,“端口”填写生产中心MySQL实例的端口号。测试通过后,单击“下一步”,直到任务启动,任务状态为“灾备中”。编辑灾备任务灾备中四、容灾切换生产中心数据库故障时,需要手动将灾备数据库实例切换为可读写状态。切换后,将通过灾备实例写入数据,并同步到源库。1. 生产中心源库发生故障,例如:源库无法连接、源库执行缓慢、CPU占比高。2. 收到SMN邮件通知。邮件通知3. 查看灾备任务时延异常。时延异常4. 用户自行判断业务已经停止。具体请参考如何确保业务数据库的全部业务已经停止。5. 选择“批量操作 > 主备倒换”,将灾备实例由只读状态更改为读写状态。主备倒换倒换完成6. 在应用端修改数据库连接地址后,可正常连接数据库,进行数据读写。 -
数据复制服务(Data Replication Service,简称DRS)支持将其他云MySQL数据库的数据迁移到本云云数据库MySQL。通过DRS提供的实时迁移任务,实现在数据库迁移过程中业务和数据库不停机,业务中断时间最小化。本节小课为您介绍将其他云MySQL迁移到RDS for MySQL实例。部署架构更多关于MySQL数据迁移须知请单击这里了解。一. 创建RDS for MySQL实例创建MySQL业务实例,选择已规划的业务实例所属VPC和安全组。1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。4. 单击“购买数据库实例”。5. 配置实例名称和实例基本信息。 6. 选择实例规格。 7. 选择实例所属的VPC和安全组、配置数据库端口。 8. 配置实例密码。 9. 单击“立即购买”。10. 返回云数据库实例列表。当RDS实例运行状态为“正常”时,表示实例创建完成。二、其他云MySQL实例准备帐号权限要求当使用DRS将其他云MySQL数据库的数据迁移到本云云数据库MySQL实例时,帐号权限要求如下表所示,授权的具体操作请参考授权操作。迁移帐号权限迁移类型全量迁移全量+增量迁移源数据库(MySQL)SELECT、SHOW VIEW、EVENT。SELECT、SHOW VIEW、EVENT、LOCK TABLES、REPLICATION SLAVE、REPLICATION CLIENT。网络设置源数据库MySQL实例需要开放外网域名的访问。白名单设置其他云MySQL实例需要将目标端DRS迁移实例的弹性公网IP添加到其网络白名单中,目标端DRS迁移实例的弹性公网IP在创建完DRS迁移实例后可以获取到,确保源数据库可以与DRS实例互通,各厂商云数据库添加白名单的方法不同,请参考各厂商云数据库官方文档进行操作。三、创建DRS迁移任务1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域,即为目标实例所在的区域。3. 单击左侧的服务列表图标,选择“数据库 > 数据复制服务 DRS”。4. 单击“创建迁移任务”。5. 填写迁移任务参数。 配置迁移任务名称。 填写迁移数据并选择模板库。这里的目标库选择创建的RDS实例。 6. 单击“下一步”。 迁移实例创建中,大约需要5-10分钟。迁移实例创建完成后可获取弹性公网IP信息。 7. 配置源库信息和目标库数据库密码。 8. 单击“下一步”。9. 在“迁移设置”页面,设置流速模式、迁移用户和迁移对象。流速模式:不限速迁移对象:全部迁移10. 单击“下一步”,在“预检查”页面,进行迁移任务预校验,校验是否可进行任务迁移。查看检查结果,如有不通过的检查项,需要修复不通过项后,单击“重新校验”按钮重新进行迁移任务预校验。预检查完成后,且所有检查项结果均成功时,单击“下一步”。11. 参数对比。若您选择不进行参数对比,可跳过该步骤,单击页面右下角“下一步”按钮,继续执行后续操作。若您选择进行参数对比,对于常规参数,如果源库和目标库存在不一致的情况,建议将目标数据库的参数值通过“一键修改”按钮修改为和源库对应参数相同的值。12. 单击“提交任务”。 返回DRS实时迁移管理,查看迁移任务状态。 启动中状态一般需要几分钟,请耐心等待。 当状态变更为“已结束”,表示迁移任务完成。四、确认迁移结果确认迁移结果可参考如下两种方式:DRS会针对迁移对象、用户、数据等维度进行对比,从而给出迁移结果,详情参见在DRS管理控制台查看迁移结果。直接登录数据库查看库、表、数据是否迁移完成。手工确认数据迁移情况,详情参见在RDS管理控制台查看迁移结果。在DRS管理控制台查看迁移结果1. 登录华为云控制台。2. 单击管理控制台左上角的,选择目标区域。3. 单击左侧的服务列表图标,选择“数据库 > 数据复制服务 DRS”。4. 单击DRS实例名称。5. 单击“迁移对比”,选择“对象级对比”,单击“开始对比”,校验数据库对象是否缺失。6. 选择“数据级对比”,单击“创建对比任务”,查看迁移的数据库和表内容是否一致。7. 选择“用户对比”,查看迁移的源库和目标库的账号和权限是否一致。在RDS管理控制台查看迁移结果1. 登录华为云控制台。2. 单击管理控制台左上角的,选择目标区域。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。4. 单击迁移的目标实例的操作列的“更多 > 登录”。 5. 在弹出的对话框中输入密码单击“测试连接”检查。6. 连接成功后单击“登录”。7. 输入实例密码,登录RDS实例。8. 查看并确认目标库名和表名等。确认相关数据是否迁移完成。
-
数据复制服务DRS支持将本地MySQL数据库的数据迁移至RDS for MySQL。通过DRS提供的实时迁移任务,实现在数据库迁移过程中业务和数据库不停机,业务中断时间最小化。本节小课为您介绍将自建MySQL迁移到RDS for MySQL的过程。部署架构本示例中,数据库源端为ECS自建MySQL,目的端为RDS实例,同时假设ECS和RDS实例在同一个VPC中。更多关于MySQL数据迁移须知请单击这里了解。一. 创建ECS(MySQL服务器)并安装MySQL社区版购买并登录弹性云服务器,用于安装MySQL社区版。1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华东-上海一”。3. 单击左侧的服务列表图标,选择“计算 > 弹性云服务器 ECS”。4. 单击“购买云服务器”。5. 配置弹性云服务器参数,填选信息后,单击“立即购买”。 选择镜像和磁盘规格。 6. 在创建的ECS上单击“远程登录”。选择“CloudShell登录”。7. 输入root用户密码,完成登录。8. 执行如下命令,创建mysql文件夹。 mkdir /mysql9. 执行如下命令,查看数据盘信息。 fdisk -l10. 执行如下命令,初始化数据盘。 mkfs.ext4 /dev/vdb11. 执行如下命令,挂载磁盘。 mount /dev/vdb /mysql12. 执行如下命令,查看磁盘是否挂在成功。 df -h 当回显出现 /dev/vdb的数据时,表示挂载成功。13. 依次执行如下命令,创建文件夹并切换至install文件夹。 mkdir -p /mysql/install/data mkdir -p /mysql/install/tmp mkdir -p /mysql/install/file mkdir -p /mysql/install/log cd /mysql/install14. 下载依赖包并上传到/mysql/install/file命令。15. 下载并安装社区版MySQL。二. 创建ECS并安装MySQL客户端1. 创建MySQL客户端的弹性云服务器。确保和MySQL服务器所在ECS配置成相同Region、相同可用区、相同VPC、相同安全组。不用购买数据盘。云服务器名配置为:ecs-client。其他参数同MySQL服务器的ECS配置。2. 下载并安装MySQL客户,请参考安装MySQL客户端。三. 创建RDS实例本章节介绍创建RDS实例,该实例选择和自建MySQL服务器相同的VPC和安全组。1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华东-上海一”。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。4. 填选信息后,单击“购买数据库实例”。 选择实例规格。 选择实例所属的VPC和安全组、配置数据库端口。 配置实例密码。 四. 创建DRS迁移任务介绍自建MySQL服务器上的loadtest数据库迁移到RDS MySQL实例的详细操作过程。1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华东-上海一”。3. 单击左侧的服务列表图标,选择“数据库 > 数据复制服务 DRS”。4. 单击“创建迁移任务”。5. 填写迁移任务参数,直到任务创建完成。 配置迁移任务名称。 填写迁移数据并选择模板库。这里的目标库选择创建的RDS实例。 6. 配置源库信息和目标库数据库密码。 7. 单击“下一步”,直到迁移任务提交成功,数据迁移完成。
-
 文章摘要:随着企业数字化转型深化,数据在企业中扮演着愈发重要的作用。数据无论从存储规模、还是计算要求都有着较之以往更高的需求。金融行业,作为数据应用的“高地”,这一点表现尤为突出。如何在新时期,满足对数据基础设施更高的要求,成为各金融机构首要面对的问题。分布式数据库,作为一种新的数据库架构,经过近十余年的高速发展,已逐步成熟,并开始在一些金融机构中投产使用。但这种新的架构,较之以往的传统架构有着诸多不同。本文尝试从建设背景、技术趋势、落地实践、典型产品等多角度,分析当前分布式数据库与金融行业背景想结合,如何实现更好的落地实践。1. 金融业分布式数据库建设背景1) 多元素驱动数据库架构升级数字化转型随着全行业数字化转型深化,金融业作为数据应用“高地”,走在这一趋势的前沿。一方面,金融业企业的业绩水平与数字化能力是直接挂钩的,从今年数据来看,转型较快的金融机构业绩提速明显快于较慢的;另一方面,来自宏观经济发展压力,导致规模盈利减低,进而导致业务转型加速。在数字化转型加剧的大背景下,金融 企业对数据使用呈现多样化特点且针对特性能力提出更高要求。相应的也对数据底层基础设施之一的数据库提出要求。金融业 业务驱动如上面所谈,金融业在数字化转型中,面临业务转型问题。当前金融业整体处于信息化末期、移动化成熟期、开放化成长期、智能化探索期。其典型特点是,金融行业的数据急剧增长,对数据存储和管理提出了更高要求;在高并发业务和大用户量带来的系统压力的同时,也要求移动应用响应速度更快。国家 政策指导在政策层面,国家很早就将新型数据库作为重要基础设施来看待并给出指导性原则。在《金融科技( FinTech)发展规划(2019-2021)》中明确指出:“加强分布式数据库的研发应用。做好分布式数据库金融应用的长期规划,加大研发与应用投入力度。有计划、分步骤稳妥推动分布式数据产品先行先试,形成可借鉴、能推广的典型案例和解决方案,为分布式数据库在金融领域的全面应用探明路径。建立健全产学结合、校企协同的人才培养机制,持续加强分布式数据库底层和前沿技术研究,制定分布式数据库金融应用标准规范,从技术架构、安全防护、灾难恢复等方面明确管理要求,确保分布式数据库在金融领域的稳妥应用。”2) 金融业对数据库转型诉求在上述大背景情况下,金融业对数据库支持能力呈现如下特点:实时性在数字化趋势下,数据会更多参与到企业决策、业务调整甚至驱动业务变化。数据的鲜活性,对企业价值意义完全不同。实时的交易处理、实时的反馈、实时的汇聚、实时的洞察成为全场景数字化的必备。例如在金融场景中,金融需求与生活场景相融合,实时风控的复杂度以及时效性要求随场景服务的发展不断增长,通常需要秒级完成业务流程。翻译成技术语言,即要求支持对数据高频实时多点写入、对多类信息实时汇聚分析处理。于是近些年来,在数据流式处理、 HTAP、高性能计算等领域的发展,正是为迎合这一诉求。敏捷性数字化转型下,各种业务形态不断涌现且单业务内变化也很大,这对底层基础设施提出了敏捷性要求。即具备快速响应能力,满足各类业务应用需求。作为传统的以静态、固定资源供给方式,过渡到以动态、可调节的资源供给方式。这其中以云、容器化、 Serverless、存算分离为代表的技术能力,正是为满足这类需求而诞生。即使是以较为传统架构的资源供给方式,也更为强调弹性、可定制能力,满足客户此方面需求。安全性数据安全,是近些年来的热门话题。从监管方的频频出台各项政策,可见一斑。作为承载数据的主体,数据库首当其冲需要将更为重视安全问题。从数据存储、数据访问、数据传输、数据应用等多角度解决数据安全问题。特别是过去一二十年开源数据库蓬勃发展,但开源数据库自身在安全方面是否能达到商用标准,值得关注。此外,考虑到复杂的国际产业环境,开源协议本身的合法合规性也值得关注。可用性可用性要求,一直是数据库提供的基本能力之一。随着数字化深入,越来越多的数据参与到企业经营管理之中,这些对于可用性要求提出了更高的要求。从数据库的角度来看,之前单机架构或集中式架构,一般是通过高可用硬件 +软件来解决;对于新兴的分布式架构来说,其组件更多也更为复杂,且对于硬件也无较多要求,这就要求软件本身提供更高要求。经济性随着数据存储规模越来越大,对数据计算要求越来越高,整体数据存储和计算的成本也整体提高。如何提供更具经济性的方案,对客户能否大规模使用意义很大。这其中云数据库、存算分离、数据分层等技术,正是为了应对这一诉求。云作为一种新的资源供给方式,可以带来更为切合需求的资源消耗。存算分离,则提供一种按计算和存储独立扩展能力,避免冗余浪费。数据分层,则可根据数据热度等因素提供不同的能力,满足个性化需求。智能化由上述变化可见,对于数据库而言,无论从使用规模、复杂程度都会带来很大调整。针对这一问题,一方面可以通过工具化、平台化的方式来满足管理问题;而更为优雅的方式是在数据库端提供内置的智能管理能力,例如智能调优、索引推荐、自我诊断、故障自愈等,可协助 DBA降低运维难度,大幅提升管理效率。海量并发这是两个需求,一个是数据规模问题,提供海量数据支撑能力;一个是数据计算问题,提供高并发访问支持。这些都是数字化会带来业务变化的必然。对应于技术而言,分布式数据库无疑是一种很好的方式,也是其主要面对解决的场景之一。统一管理随着数字化深入,对数据库的种类与数量、企业的 IT体系等都发生了不少变化。这些变化冲击了传统的数据库生态,第一数据库选型自身呈现多元化趋势;第二随着分布式、存算分离等新兴架构,对管理也带来了管理难题;第三随着对安全性、可靠性等方面的更高要求,也带来了不少难点。面对上述问题,为数据库提供统一管理和运维的平台型工具也逐渐走向台前,变得越来越重要。自主可控对基础软件来说,自主可控非常关键。作为数字化的载体,数据库的自主可控能力尤为重要。近些年国产化诉求日益高涨,也有着这方面的考虑。这其中值得关注的一点是关于开源的使用。根据近期的调研,开源数据库份额已经超越商业数据库;但对于开源数据库的把控能力,却有着较大差异。特别是某些商业数据库,底层也是基于开源产品的,尤其值得关注。开放生态数字化深入,带来的更多的场景、更多的方案、更多的产品。如何能做到产品之间的很好的融合,发挥最大的作用,开放生态非常重要。对于数据库而言,过去数十年来以国外商用数据库产品为主,已经培育自己的生态圈;而对于国内产品而言,还需要走过这一过程。比较可喜的是,开源软件的使用可大大加速这一过程。以 MySQL、PG为代表的开源软件,具有较为完备的生态,国内产品可通过兼容开源产品,复用其生态,大大加速这一进程。简化融合如之前所说,数字化深化带来的技术需求的多元化,与之对应的产品方案也呈现同样的态势。虽然可以通过统一管理角度去简化管理,但对于用户而言仍然不得不去面对复杂的管理和使用问题。如果能通过单一平台提供所需能力,无疑对用户非常有吸引力。这就是简化融合的诉求的来源。近些年来,包括混合事务与分析处理( HTAP)、湖仓一体、流批一体等,都是代表着用户追求 “简化、融合”技术栈的需求。此外,云也是一种简化融合的体现,通过一站式的产品+方案,解决用户复杂管理和使用问题。消费创新数据在未来扮演着愈发重要的角色,人们对数据的消费使用习惯也发生了很多变化。从使用角度来看,普惠性得以强调。数据的使用消费者,从传统的分析师、 BI工程师向普通的数据消费者转移。越来越多的用户能够触达数据,享受数据结果。当然,这也得对数据提供方式带来新的挑战,自助式、对话式、自动化甚至智能化的数据计算展现方式得到更多的使用,进一步减低人们使用数据的门槛。这对于底层数据库带来包括适配能力、实时计算、多模计算、智能分析等诸多要求。3) 分布式数据库在金融业使用痛点如之前所说,金融业一方面面临诸多转型压力,对底层数据库提出了更多要求;另一方面原有数据库技术已不适应当前业务特点,继续升级换代。面对底层基础设施的转型问题,分布式数据库作为解决上述方案的唯一选型。但在这一选择过程中,往往存在较多的痛点和难点。这主要是因为金融行业的特殊性所造成的。基础功能待完善对标传统集中式数据库,现有的分布式数据库在功能上仍然有待完善。这一方面是因为分布式架构所造成的功能 tradeoff,另一方面是在产品化能力完整性上的欠缺。前者是我们在使用分布式数据库产品时,需要在架构、设计层面需要在关注的,在项目初期都需要解决掉的。而后者厂商产品经过多年发展在内核能力上已趋于完善,但在周边配套的管理、设计、优化工具上,仍需进一步完善。毕竟最终为用户呈现的,是一套完整的数据库解决方案。运行稳定待验证对于金融行业而言,稳定性是第一位的。虽然分布式数据库在设计之初,就将稳定性设计放在优先位置,其天然的分布式架构也有利于提供更高的可用性保证。但一方面分布式架构天然由多组件组成,其复杂程度较集中式更高;另一方面其对底层基础环境的要求也更高。此外,产品的稳定性是要在长期实践中不断打磨、持续改进的。分布式数据库作为后来者,也需要经历这一过程。迁移改造任务重选择使用分布式数据库产品,对应用侧来说,需要有大量的应用迁移工作。一方面是由于分布式数据库较集中式数据库功能上有所削弱,另一方面更换数据库天然所需要的移植工作。虽然目前各分布式数据库也推出 兼容能力,但从实际效果来看仅能减少部分移植工作,整体迁移任务量仍然很高。且迁移采用所谓的兼容模式,也不利于后期平滑更换,这点后面会讲到。风险巨大需并行对底层数据库的更换,是存在较大技术风险的。一是由于新产品、新架构所带来的风险;二是应用迁移改造带来的不确定性;三是产品本身的稳定性的潜在风险。为应对这种情况,最为稳妥的方式是采取应用双发并行的方式解决。这种方式可在最大程度上减少可能初期的风险,可做到数据冗余、无缝切换、灵活可控等,但其花费的代价也是非常高的。需要从应用端做大量双发改造,如果更换系统很多,这方面代价是比较大的。生态环境需培育虽然发展多年,但国产分布式数据库在整体市场上仍然属于小众选择。之前国外厂商产品占据市场领导地位,经过多年发展已形成了较为完善的生态。随着近些年来, MySQL、PG开源数据库在互联网行业得到大量应用,积累大量用户,建立其不错的生态。很多国产分布式数据库采用迂回策略,通过兼容上述数据库标准,来享受开源生态红利。此外,近期国产数据库如TiDB、OceanBase、PorlaDB、openGuass等,也纷纷开源建设自有生态。信创要求时间紧作为国家安全的重要举措之一,安全可控成为基础要求,信创因而诞生。为保证上述政策执行到位,国家也设定实施计划。作为基础软件的数据库,也是信创工作的重点。如何在规定的时间内完成,也为各企业带来的很大压力。场景多元难选择与互联网企业不同,金融行业对数据的使用场景更加多元化,这也对数据库提出了较高的要求。仅选择单一数据库满足全场景需求,几乎是不可能的。在传统集中式数据库上,这一问题还不明显,因为这些数据库往往是多面手,各方面功能较为均衡;而分布式数据库则不然,其往往有明确的适用场景范围。而作为企业用户,是需要对自己场景有个清晰的认识,然后按图索骥找到适合自己的产品。厂商绑定风险高选择某厂商产品,也就意味着选择某一技术路线,如果深度依赖厂商产品的特有能力,无疑存在绑定风险问题。这点对于分布式数据库来说,表现尤甚。各厂商产品实现差异很大,没有通用的使用标准。如何规避这一风险,带来最大的自由度选择?后文会展开说明。2. 分布式数据库技术发展趋势1) 数据库技术发展整体趋势数据库技术 ,最早源自上世纪70年代,从IBM著名的论文开始,后面诞生了Oracle、DB2为代表的优秀商业产品以及PostgreSQL、MySQL为代表的开源产品。这些产品很好的满足了对数据存储和计算的需求。随着21世纪初期,互联网浪潮的来临,数据规模呈爆炸式增长,单机数据库越来越难以满足用户需求。这也催生了分布式数据库的到来。到了2006年之后,出现以HBase/Cassadra/MongoDB为代表的NoSQL类产品。这些产品实现了分布式架构,可以实现容量的水平扩展,但也牺牲了诸如事务、SQL访问接口等能力。存储模型的简化为存储系统的开发带来了便利,但是降低了对业务的支撑。在这一阶段,很多企业为了解决大规模数据存储与访问的问题,也研发了很多中间件产品。其原理是通过将数据分片存储到单机库,上层对SQL解析实现对语句的路由。这种方式有一定的难点,例如对分布式事务的处理及规模扩大下的管理问题。到了2012年,Google的论文为关系模型的分布式架构,提供了新型分布式数据库理论基础。在此之后,诞生了一系列新型分布式数据库产品。其原理是通过分布式一致性算法协议完成底层数据多副本存储,上层则实现了标准SQL支持能力。数据库架构演进,从整体来看,走过了大致三个阶段。第一阶段,是以单节点为主要特征,通过单机能力来承载数据计算和存储的能力。这一架构的优势在于架构简单、维护成本低,随着单机能力的提升可满足大部分业务场景需求。缺点是数据库节点(包括内置存储)容易出现单点故障,且计算和存储能力受限于硬件性能,无法扩展。第二阶段,是以共享存储为主要特征,通过多台主机来承载数据计算能力,数据存储则集中于集中式共享存储之中。这一架构的优势在于解决了前一阶段数据计算部分的单点故障,结构仍较简单,易于实现事务一致性等问题。缺点在于数据计算部分扩展能力有限,底层数据存储部分依赖于高端共享存储且扩展能力也有限。第三阶段,是以分布式为主要特征,通过多台主机来承担数据计算与存储能力。这一架构优点在于良好地水平扩展能力,数据多副本存储,无需依赖共享存储。缺点在于,计算与存储能力需同步扩展,灵活度稍差,此外存在分布式查询、分布式事务的处理开销问题。2) 主流的分布式数据库技术分布式中间件这种架构是从之前谈到的中间件路线演进而来 ,是一种典型的“ Share Nothing”架构。通过上层无状态的计算节点提供弹性可扩展的计算能力,下层通过增强单机数据库提供基础存储能力及本地算力。这一架构通过硬件堆叠,可近似线性地提供计算性能和存储容量,具有可支持超大规模集群的能力。这种架构在分布式事务、全局MVCC等方面,往往存在一定难点,各厂商也有各自解决之道。这一架构产品优势在于功能丰富、可按业务做定制;稳定性较高,基于成熟稳定的单机引擎。在面对超大规模数据存储,通过灵活的分片配置策略,支持高灵活度数据打散技术,并可贴近场景需求定制分片。相对不足在于全局事务能力、全局 MVCC、副本控制、高可用等方面存在先天短板,需要有针对性增强。例如引入全局事务管理器组件,突破单机限制,实现分布式事务的实时一致性及全局MVCC能力,对应用透明的分布式事务处理,应用无需改造。通过一阶段提交+自动补偿机制,提升分布式事务处理性能。针对数据强一致性的要求,在单机库同步技术基础上,通过内核级的增强优化实现更高级别的复制保证数据不丢失。此外,由于需维护多节点一致性而带来的在跨分片DDL、分片节点扩容、跨节点复杂查询、全局一致的备份恢复等方面问题值得关注。这种架构产品较为适用于数据规模巨大、对延迟要求很高的在线交易场景。在数据库设计时,需要特别注意分区键和分区策略的选择,合理布局数据,尽量避免跨节点的分布式事务处理,以提高数据库的效率。分布式事务这 种架构正是受到Google论文影响演进而来 ,采用“ Share Nothing”架构。其采用存储与计算分离架构,底层多采用自研或裸存储引擎,数据按规则打散并存储多个副本,通过paoxs/raft等分布式协议保证多个副本间数据一致。上层实现数据库基础的优化器、执行器等组件,对分布式事务、全局MVCC等支持更为彻底。此外,由于其底层的存储引擎不是依赖某一产品,可根据需要组织数据,因此在适配场景上 更有优势,例如在某些分析类场景可选择列存。原生分布式实现,工程上不依赖其他产品,可控程度更高。面对很多新的需求,可从底层加以实现支持,不受限于第三方。在副本控制、数据一致性、容灾、弹性能力等方面更具有优势。此外,场景方面有更为灵活的选择及未来可扩展的空间。 但这一方式在产品成熟度,仍需较长时间沉淀。特别是使用在核心业务场景,仍然需要较长时间的锤炼。此外,其内置的分片规则,对于某些需贴合业务的架构设计不太友好。对于高并发、低延迟的极端场景仍然有一定局限。分布式存储在某种程度上讲,云原生数据库也是一种分布式,但与前两者区别是非 Share Nothing架构,而是Share Everything模式。其底层是与分布式云存储,本质上来说仍然是一种集中式架构。上层的计算部分,是无状态的一组结点组成。针对这种架构不足展开说明,原因是这种方式是需要对底座有比较重的依赖,无法在金融行业相对要求独立环境中部署,除非整个底层都更换。因此,使用选择上存在一定困难。3. 分布式数据库金融业实践1) 金融业数据库选型难点金融业在分布式数据库选型存在若干难点:复杂业务逻辑问题,包括数据库技术基因匹配性(如:数据库本身锁机制、隔离级别问题),包括技术兼任性(如存储过程、视图兼容性);应用的适配度问题,银行应用大部分都是基于单机关系型数据库机制设计的,例如大部分场景都是串行机制,发挥不出来分布式数据库的强大并发处理技术,反而分布式数据库本身的二阶段提交机制,对简单事务的延时增加问题,造成串行事务执行性能低下;人员能力的匹配性,需要根据人员技术能力进行选型考虑,例如基于 Spanner体系,基于Aurora体系,基于国内互联网公司自研的产品等,要考虑现有人员对数据库技术的了解程度,更要关注数据库技术本身的开放度和社区热度,让人员可以很快的学习和提升数据库技术能力;数据库自身能力问题,包括在分布式事务、数据一致性、高可用容灾等,相较于传统集中式数据库还是存在一些不足;此外金融业在联机交易的低延迟要求、跑批类的高吞吐要求也对分布式数据库提出了很高的要求;数据库运营维护问题,包括是否具备足够能力维护分布式数据库?是否能够接受数据库转型期间的业务中断时间?是否具备迁移(甚至在线)迁移能力?是否具有应用级双发能力,规避可能出现的风险等。2) 金融业数据库选型策略通过数据库的技术标准化和轻量化工作,形成统一的数据库使用规范,解耦应用和底层数据库技术架构,在标准数据库协议及语义下,可以很轻松的更换数据库架构。通过构建异构间数据同步、流量接入控制(限流、灰度等)、全局数据服务(如事务、快照等),实现业务的无感切换和迁移回退,保证最大的灵活可控。针对上述诸多难点、痛点,作为金融行业如何选择分布式数据库呢?可遵从以下几个方面:尊重路线之争,无关技术领先如前面所述,分布式数据库的发展有着不同的技术路线。曾有种观点认为,“分布式数据库的发展方向代表着未来,分布式中间件方向没有前途”。针对这一问题,我的观点是采用不同技术路线的产品有自己的适用场景,与技术领先性无关。某种技术通过提出理论、工程化实现、产品能力输出,可解决某方面需求、甚至带来巨大产品能力的提升;但希望以此通过大一统的产品解决所有问题是不现实的,未来仍然是多种技术路线并存的情况。成熟度有待完善,但时不我待提前规划分布式数据库作为一种新兴技术产品,其成熟度尚需锤炼,但不能基于此就选择观望态度。产品成熟的提高,一方面来自厂商对产品的不断迭代优化;另一方面也来自使用者的不断打磨。企业内对数据库的落地使用,也需要较为长期的过程。此外,外部驱动也对这一选择起到加速推动作用。作为企业来讲,根据自身情况可以选择不同策略(引领、跟随);但无论那种都需要提前规划,有明确方向和实施路径。国产数据库百花齐放,机会无限近些年来,国产数据库发展迅猛,呈现百花齐放态势。针对这一现状,一方面要持续关注这些产品,给予这些产品充分施展机会;另一方面制定准入标准严格把关,让真正有实力的厂商能够进入,得到充分锻炼、打磨的机会。慎重技术选型,不迷信宣传技术选型是个很严谨的过程,需要慎重对待。有很多第三方的评测和厂商宣传结论,但这些只能做参考,决策层面的依据还是需依靠自己。一方面宣传内容一般都会所选择有利于自己,这会带来一定误导性;另一方面对同一概念的理解是有偏差的,很难仅仅通过一段文字描述就能完全说清楚。这些问题只有在真实环境,叠加上自身需求,测试出的结果才具说服力。结合场景需求,没有最好只有最适合业务场景千差万别,其对数据库能力要求和侧重点也有所不同。很难选择一款通用型产品满足全场景,那就需要根据实际情况做有针对性的选择。此外,不同产品各有强点和局限之处,选择最适合你的产品就好。例如上文谈到的分布式中间件产品,在超大规模、自定义分片、超高性能、业务控制等方面往往更有优势;而分布式数据库产品,则在分布式事务、数据强一致、混合负载等方面有所擅长。不选产品选兼容性,保持最大自由度当前分布式数据库,仍然处于快速发展期,很难确定未来的主流选择。为了规避路线选择、厂商绑定的风险,比较现实的方法是选择一款兼容通用性协议的产品,并且在使用中仅使用标准数据库的用法。举个例子,选择一款兼容 MySQL的产品并且安装标准MySQL的用法使用;当出现风险时完全可选择另外一款同样兼容MySQL的产品来替代。目前MySQL生态在国内最为成熟,很多厂商产品也选择了兼容它,因此选择兼容性产品在未来的自由度最大。保持技术敏感度,紧跟时代发展步伐面对技术发展多变、应用特点多变、外部需求紧迫的现状,时刻关注分布式数据库发展,保持足够的技术敏感度,紧跟技术发展趋势。采取架构前置、谨慎选型、局部试点、多线布局、掌握主动、自建增强等策略,保持主动。3) 金融业数据库场景梳理金融企业对数据库使用场景众多,而对应分布式数据库产品功能各异且特点鲜明。如何为不同场景选择最为适合的分布式数据库产品,成为分布式数据库落地前提。下表结合金融行业特点,抽象出若干数据应用场景,形成以事务类、分析类、混合类为代表的三大类五种典型场景。从适用场景、技术架构特征、关键指标、功能维度等多方面对场景进行梳理。一句话总结:“没有最好的产品,只有最合适的产品!”。4) 金融业分布式数据库选型技术要素技术为业务服务的,不能为了使用技术而使用,需要综合考虑成本和收益的平衡。分布式数据库使用场景,应当在数据大规模、高并发、高可用性等场景下有其特有优势。一般的业务场景如果能用单机数据库支撑的尽量用单机库。选择一款分布式数据库,会带来一系列的成本,如应用适配成本、运维成本、硬件成本,这方面后面会赘述。此外,在做上述判断时,还需考虑业务的发展,最好是能判断三年的数据量和交易量的增长变化。在进行分布式选型时,可重点考察下列几个方面:分布式事务分布式架构,自然会带来分布式事务的问题。由于需要跨节点的网络交互,因此较单机事务会有很多损耗。随之带来的是事务处理时间较长、事务期间的锁持有时间也会增加,数据库的并发性和扩展性也会很差。针对单笔事务来说,分布式事务执行效率是肯定会有降低的,分布式带来的更多是整体处理能力的提升。但在设计之初,就应尽量做到业务单元化,将事务控制为本地事务,这可大大提升执行效率。性能由于二阶段提交和各节点之间的网络交互会有性能影响,分布式数据库优势不是单个简单 SQL的性能,但是大数据量的SQL查询,每个节点会将过滤之后的数据集进行反馈,会提升性能,并且分布式数据库的优势是并发,大量的SQL并发也会比单机数据库强大,应用需要做分布式架构的适配,将串行执行机制尽量都改造成并发处理。对于含有需要节点间数据流动的SQL语句的事务,OLTP类的分布式数据库处理效率一般较差,事务处理时间会较长,事务期间的锁持有时间也会增加,数据库的并发性和扩展性也会很差。建议尽量改造存在跨节点数据流动的SQL语句 (主要是多表关联)的事务。 分布式数据库性能是软硬整体架构的保障,不仅在软件、S QL 语句方面做优化,硬件方面也需要重视,包括处理器、内存、网络、磁盘等等,尤其在支撑交易类业务系统时重视对基础设施选型和优化。数据备份分布式数据库一致性保证通过内部时钟机制,所有节点都会遵循一致的时钟,所以备份恢复的增量也是基于时钟,相当于单机数据,但是分布式数据库的备份解决方案最重要标志是否支持物理级的备份,物理级的备份会比逻辑的备份性能吞吐会大很多,还有就是是否支持一些分布式备份方案,比如 S3协议接口,是否支持压缩等功能。分布式数据库基本都具备备份和恢复方案,通常从备节点进行连续备份(全量+日志),恢复的时候制定节点进行恢复到指定时间点,整个过程可配置自动任务自动执行。高可用分布式数据库大多都是基于多数派协议,同城双中心不适合多数派的要求,同城数据级多活建议采用三中心部署,如果同城主备可以采用集群级的异步复制。异地建议采用集群级的 binlog异步复制。建议实例的主备节点设置在同城两个双活数据中心,仲裁节点三机房部署;异地灾备单独启实例与本地实例进行数据库间同步,也可以将本地备份文件T+1恢复到异地灾备。数据一致性NewSQL分布式数据库基本都是通过获取全局时钟时间戳,采用二阶段提交实现一致性,可以实现一致性的保证,分库分表架构对于事务的一致性,需要应用层考虑,比如通过合理的分区键设计来规避。分布式数据库对于跨节点事务目前还是实现的最终一致,对于全局一致性读,一般通过引入类似全局时间戳的组件统一管理全局事务,在数据库选型时可以重点关注厂商对这一块的实现。如果目前暂时无法提供全局一致性读的分布式数据库,对于要依赖分布式事务“中间状态”的业务,优先进行业务改造进行规避,其次通过合理的数据分片设计让其在单节点内完成。其他因素金融行业在数据库选型中,除了需要考虑上述外,还有其他一些因素的考虑。如原有系统的承载能力、是否必须进行选择等。5) 金融业分布式数据库选型非技术要素金融业分布式数据库选型,除了上述技术要素外,还包含如下非技术要素,主要是在成本投入方面:硬件成本一般采用 x86服务器,存储多为本地存储,推荐使用SSD甚至是NVMe SSD,网络一般 采用 万兆网络。在这部分主要成本是取决于集群规模、数据量及数据库自身架构。此外,如果涉及到灾备方案,还需要考虑灾备环境的硬件投入及主备间的专线费用。 此外,考虑很多金融单位现在机房建设空间和能耗有限,可采用配置较高的硬件设备,如基于英特尔 ®至强® 金牌处理器内核的x 86 物理机、配置 英特尔®傲腾™固态盘 等,减少服务器数量、降低耗电量。软件成本主要来自分布式数据库本身的软件采购成本,成本取决于各厂商的内部商业策略。但这部分总体来讲,是较传统数据库产品还是有优势的。此外,这部分还涉及到维保费用,针对分布式数据库来说,相对较新,企业自有能力尚不具备,还是建议购买原厂服务或其他三方公司的服务,降低风险。开发测试成本这部分是指针对数据库更换后,应用需要需要完成的必要的开发测试成本。这部分成本差异很大,跟原有系统实现有较大关系。如果原有系统重度依赖数据库(大量功能是基于数据库自身功能实现的),那么存在的改造量较大。新型分布式数据库的功能,不能与传统数据库做一一对应,很多能力是需要在应用层重构完成。针对这种情况,是建议应用开发遵循数据库标准方式进行(如采用 MySQL作为标准)开发,这样如有改型也很简单。此外,还有一类隐形成本包含在这部分,如果业务比较重要,是需要考虑双发支持或灰度迁移的方式,这会带来一部分工作量。总体来说, 这部分成本是比较高的,可能占整体成本的大部分。运营维护成本这部分成本,包括了为满足更换数据库所带来的数据迁移成本和上线后的日常维护成本。针对前者,可以在应用侧解决或者外采商业软件解决;后者更多是人员管理成本。针对这部分成本,是有个相对较长的投入,且整体成本不少。6) 金融业分布式数据库运维要点分布式数据库,作为较为新兴的基础架构产品,在运维层面有其独有特点。下面结合之前的实践,将运维要点整理如下:软件规划和部署方案分布式数据库组件众多,而且每个组件都有高可用备份,所以在有限数量的服务器下进行组件的分配要尽量考虑达到各个服务器负载的均衡, GTM作为分布式数据库的瓶颈尽量和他们组件分开部署。监控方案监控一般可以采用开源的 zabbix进行定制化开发,当然也可以基grafana+prometheus的方案做监控。但一般大中型金融企业都有一套自己的监控系统,这里需要有个对接适配的过程。此外,由于分布式的多组件特点,在监控指标数量及指标间关联上,与传统数据库差异巨大,是需要监控摸索过程。语句调优因为不同厂商研发的数据库 SQL优化器及执行计划都有所不同,所以要根据不同产品进行学习。天然由于分布式架构带来的复杂度,也会影响到语句的执行效率。比较常见的如数据库访问链路长所带来的的问题、数据分布不均带来的问题及分布式优化器的问题等。备份方案分布式数据库如何做到多节点全局一致性备份也是难点,要做到真正意义上的基于时点恢复,就需要做到分布式环境下每个全局事务的可追溯操作。应急方案因为分布式数据库还处于发展阶段,还不成熟,技术比较复杂,所以生产环境下要制定详细的应急方案,让不了解分布式数据库的同事也能够在出现问题时按照手册操作。DDL变更在分布式架构下, DDL变更是个难点。如果做到全局一致,做到业务无感知,是核心点。不同厂商产品实现能力层次不齐,介于此安排在低峰期操作并做好必要的监控回退。水平扩容分布式架构下,都是支持水平扩容的。一般来说,非数据节点的扩容是相对容易的,对业务也是无感的,但涉及到数据节点的扩容,势必会遇到数据 reshard的问题。建议选择在低峰期,同时控制好扩容粒度。即便如此,仍然建议提前做好容量规划,避免扩容。跨片计算分布式架构下,数据是分布在多个节点中。如果数据计算是可以在本地计算完成,无疑是效率最高的,但完全避免跨片计算是不太现实的。如果发生跨片计算,则不可避免地对上层节点带来压力,要做好相应监控,并争取在根本上避免跨片类计算。5. 总结分布式数据库 ,作为 一种新型数据库 产品架构,正处于蓬勃发展阶段。其 具备 的 数据分片管理、分布式事务、读写分离等关键分布式能力, 能够很好地满足企业在 高性能、大数据量 等多种 业务 场景 。近年来,各国产厂商都在积极推进分布式数据库产品的研发,技术已经逐步成熟 。金融行业,作为数字化转型的先导性行业,对数据基础设施有着更高的要求。分布式数据库的出现,恰好可以满足金融企业迫切需求。随着近些年来,分布式数据库的成熟,并在 金融行业已有成功案例投入生产系统使用。 相信,两者的结合,必定在未来能擦出更多火花,促进金融行业在新时代转型发展。文章来源:https://www.talkwithtrend.com/Article/259665 纯属学习、分享,如有涉及版权,请联系处理。
文章摘要:随着企业数字化转型深化,数据在企业中扮演着愈发重要的作用。数据无论从存储规模、还是计算要求都有着较之以往更高的需求。金融行业,作为数据应用的“高地”,这一点表现尤为突出。如何在新时期,满足对数据基础设施更高的要求,成为各金融机构首要面对的问题。分布式数据库,作为一种新的数据库架构,经过近十余年的高速发展,已逐步成熟,并开始在一些金融机构中投产使用。但这种新的架构,较之以往的传统架构有着诸多不同。本文尝试从建设背景、技术趋势、落地实践、典型产品等多角度,分析当前分布式数据库与金融行业背景想结合,如何实现更好的落地实践。1. 金融业分布式数据库建设背景1) 多元素驱动数据库架构升级数字化转型随着全行业数字化转型深化,金融业作为数据应用“高地”,走在这一趋势的前沿。一方面,金融业企业的业绩水平与数字化能力是直接挂钩的,从今年数据来看,转型较快的金融机构业绩提速明显快于较慢的;另一方面,来自宏观经济发展压力,导致规模盈利减低,进而导致业务转型加速。在数字化转型加剧的大背景下,金融 企业对数据使用呈现多样化特点且针对特性能力提出更高要求。相应的也对数据底层基础设施之一的数据库提出要求。金融业 业务驱动如上面所谈,金融业在数字化转型中,面临业务转型问题。当前金融业整体处于信息化末期、移动化成熟期、开放化成长期、智能化探索期。其典型特点是,金融行业的数据急剧增长,对数据存储和管理提出了更高要求;在高并发业务和大用户量带来的系统压力的同时,也要求移动应用响应速度更快。国家 政策指导在政策层面,国家很早就将新型数据库作为重要基础设施来看待并给出指导性原则。在《金融科技( FinTech)发展规划(2019-2021)》中明确指出:“加强分布式数据库的研发应用。做好分布式数据库金融应用的长期规划,加大研发与应用投入力度。有计划、分步骤稳妥推动分布式数据产品先行先试,形成可借鉴、能推广的典型案例和解决方案,为分布式数据库在金融领域的全面应用探明路径。建立健全产学结合、校企协同的人才培养机制,持续加强分布式数据库底层和前沿技术研究,制定分布式数据库金融应用标准规范,从技术架构、安全防护、灾难恢复等方面明确管理要求,确保分布式数据库在金融领域的稳妥应用。”2) 金融业对数据库转型诉求在上述大背景情况下,金融业对数据库支持能力呈现如下特点:实时性在数字化趋势下,数据会更多参与到企业决策、业务调整甚至驱动业务变化。数据的鲜活性,对企业价值意义完全不同。实时的交易处理、实时的反馈、实时的汇聚、实时的洞察成为全场景数字化的必备。例如在金融场景中,金融需求与生活场景相融合,实时风控的复杂度以及时效性要求随场景服务的发展不断增长,通常需要秒级完成业务流程。翻译成技术语言,即要求支持对数据高频实时多点写入、对多类信息实时汇聚分析处理。于是近些年来,在数据流式处理、 HTAP、高性能计算等领域的发展,正是为迎合这一诉求。敏捷性数字化转型下,各种业务形态不断涌现且单业务内变化也很大,这对底层基础设施提出了敏捷性要求。即具备快速响应能力,满足各类业务应用需求。作为传统的以静态、固定资源供给方式,过渡到以动态、可调节的资源供给方式。这其中以云、容器化、 Serverless、存算分离为代表的技术能力,正是为满足这类需求而诞生。即使是以较为传统架构的资源供给方式,也更为强调弹性、可定制能力,满足客户此方面需求。安全性数据安全,是近些年来的热门话题。从监管方的频频出台各项政策,可见一斑。作为承载数据的主体,数据库首当其冲需要将更为重视安全问题。从数据存储、数据访问、数据传输、数据应用等多角度解决数据安全问题。特别是过去一二十年开源数据库蓬勃发展,但开源数据库自身在安全方面是否能达到商用标准,值得关注。此外,考虑到复杂的国际产业环境,开源协议本身的合法合规性也值得关注。可用性可用性要求,一直是数据库提供的基本能力之一。随着数字化深入,越来越多的数据参与到企业经营管理之中,这些对于可用性要求提出了更高的要求。从数据库的角度来看,之前单机架构或集中式架构,一般是通过高可用硬件 +软件来解决;对于新兴的分布式架构来说,其组件更多也更为复杂,且对于硬件也无较多要求,这就要求软件本身提供更高要求。经济性随着数据存储规模越来越大,对数据计算要求越来越高,整体数据存储和计算的成本也整体提高。如何提供更具经济性的方案,对客户能否大规模使用意义很大。这其中云数据库、存算分离、数据分层等技术,正是为了应对这一诉求。云作为一种新的资源供给方式,可以带来更为切合需求的资源消耗。存算分离,则提供一种按计算和存储独立扩展能力,避免冗余浪费。数据分层,则可根据数据热度等因素提供不同的能力,满足个性化需求。智能化由上述变化可见,对于数据库而言,无论从使用规模、复杂程度都会带来很大调整。针对这一问题,一方面可以通过工具化、平台化的方式来满足管理问题;而更为优雅的方式是在数据库端提供内置的智能管理能力,例如智能调优、索引推荐、自我诊断、故障自愈等,可协助 DBA降低运维难度,大幅提升管理效率。海量并发这是两个需求,一个是数据规模问题,提供海量数据支撑能力;一个是数据计算问题,提供高并发访问支持。这些都是数字化会带来业务变化的必然。对应于技术而言,分布式数据库无疑是一种很好的方式,也是其主要面对解决的场景之一。统一管理随着数字化深入,对数据库的种类与数量、企业的 IT体系等都发生了不少变化。这些变化冲击了传统的数据库生态,第一数据库选型自身呈现多元化趋势;第二随着分布式、存算分离等新兴架构,对管理也带来了管理难题;第三随着对安全性、可靠性等方面的更高要求,也带来了不少难点。面对上述问题,为数据库提供统一管理和运维的平台型工具也逐渐走向台前,变得越来越重要。自主可控对基础软件来说,自主可控非常关键。作为数字化的载体,数据库的自主可控能力尤为重要。近些年国产化诉求日益高涨,也有着这方面的考虑。这其中值得关注的一点是关于开源的使用。根据近期的调研,开源数据库份额已经超越商业数据库;但对于开源数据库的把控能力,却有着较大差异。特别是某些商业数据库,底层也是基于开源产品的,尤其值得关注。开放生态数字化深入,带来的更多的场景、更多的方案、更多的产品。如何能做到产品之间的很好的融合,发挥最大的作用,开放生态非常重要。对于数据库而言,过去数十年来以国外商用数据库产品为主,已经培育自己的生态圈;而对于国内产品而言,还需要走过这一过程。比较可喜的是,开源软件的使用可大大加速这一过程。以 MySQL、PG为代表的开源软件,具有较为完备的生态,国内产品可通过兼容开源产品,复用其生态,大大加速这一进程。简化融合如之前所说,数字化深化带来的技术需求的多元化,与之对应的产品方案也呈现同样的态势。虽然可以通过统一管理角度去简化管理,但对于用户而言仍然不得不去面对复杂的管理和使用问题。如果能通过单一平台提供所需能力,无疑对用户非常有吸引力。这就是简化融合的诉求的来源。近些年来,包括混合事务与分析处理( HTAP)、湖仓一体、流批一体等,都是代表着用户追求 “简化、融合”技术栈的需求。此外,云也是一种简化融合的体现,通过一站式的产品+方案,解决用户复杂管理和使用问题。消费创新数据在未来扮演着愈发重要的角色,人们对数据的消费使用习惯也发生了很多变化。从使用角度来看,普惠性得以强调。数据的使用消费者,从传统的分析师、 BI工程师向普通的数据消费者转移。越来越多的用户能够触达数据,享受数据结果。当然,这也得对数据提供方式带来新的挑战,自助式、对话式、自动化甚至智能化的数据计算展现方式得到更多的使用,进一步减低人们使用数据的门槛。这对于底层数据库带来包括适配能力、实时计算、多模计算、智能分析等诸多要求。3) 分布式数据库在金融业使用痛点如之前所说,金融业一方面面临诸多转型压力,对底层数据库提出了更多要求;另一方面原有数据库技术已不适应当前业务特点,继续升级换代。面对底层基础设施的转型问题,分布式数据库作为解决上述方案的唯一选型。但在这一选择过程中,往往存在较多的痛点和难点。这主要是因为金融行业的特殊性所造成的。基础功能待完善对标传统集中式数据库,现有的分布式数据库在功能上仍然有待完善。这一方面是因为分布式架构所造成的功能 tradeoff,另一方面是在产品化能力完整性上的欠缺。前者是我们在使用分布式数据库产品时,需要在架构、设计层面需要在关注的,在项目初期都需要解决掉的。而后者厂商产品经过多年发展在内核能力上已趋于完善,但在周边配套的管理、设计、优化工具上,仍需进一步完善。毕竟最终为用户呈现的,是一套完整的数据库解决方案。运行稳定待验证对于金融行业而言,稳定性是第一位的。虽然分布式数据库在设计之初,就将稳定性设计放在优先位置,其天然的分布式架构也有利于提供更高的可用性保证。但一方面分布式架构天然由多组件组成,其复杂程度较集中式更高;另一方面其对底层基础环境的要求也更高。此外,产品的稳定性是要在长期实践中不断打磨、持续改进的。分布式数据库作为后来者,也需要经历这一过程。迁移改造任务重选择使用分布式数据库产品,对应用侧来说,需要有大量的应用迁移工作。一方面是由于分布式数据库较集中式数据库功能上有所削弱,另一方面更换数据库天然所需要的移植工作。虽然目前各分布式数据库也推出 兼容能力,但从实际效果来看仅能减少部分移植工作,整体迁移任务量仍然很高。且迁移采用所谓的兼容模式,也不利于后期平滑更换,这点后面会讲到。风险巨大需并行对底层数据库的更换,是存在较大技术风险的。一是由于新产品、新架构所带来的风险;二是应用迁移改造带来的不确定性;三是产品本身的稳定性的潜在风险。为应对这种情况,最为稳妥的方式是采取应用双发并行的方式解决。这种方式可在最大程度上减少可能初期的风险,可做到数据冗余、无缝切换、灵活可控等,但其花费的代价也是非常高的。需要从应用端做大量双发改造,如果更换系统很多,这方面代价是比较大的。生态环境需培育虽然发展多年,但国产分布式数据库在整体市场上仍然属于小众选择。之前国外厂商产品占据市场领导地位,经过多年发展已形成了较为完善的生态。随着近些年来, MySQL、PG开源数据库在互联网行业得到大量应用,积累大量用户,建立其不错的生态。很多国产分布式数据库采用迂回策略,通过兼容上述数据库标准,来享受开源生态红利。此外,近期国产数据库如TiDB、OceanBase、PorlaDB、openGuass等,也纷纷开源建设自有生态。信创要求时间紧作为国家安全的重要举措之一,安全可控成为基础要求,信创因而诞生。为保证上述政策执行到位,国家也设定实施计划。作为基础软件的数据库,也是信创工作的重点。如何在规定的时间内完成,也为各企业带来的很大压力。场景多元难选择与互联网企业不同,金融行业对数据的使用场景更加多元化,这也对数据库提出了较高的要求。仅选择单一数据库满足全场景需求,几乎是不可能的。在传统集中式数据库上,这一问题还不明显,因为这些数据库往往是多面手,各方面功能较为均衡;而分布式数据库则不然,其往往有明确的适用场景范围。而作为企业用户,是需要对自己场景有个清晰的认识,然后按图索骥找到适合自己的产品。厂商绑定风险高选择某厂商产品,也就意味着选择某一技术路线,如果深度依赖厂商产品的特有能力,无疑存在绑定风险问题。这点对于分布式数据库来说,表现尤甚。各厂商产品实现差异很大,没有通用的使用标准。如何规避这一风险,带来最大的自由度选择?后文会展开说明。2. 分布式数据库技术发展趋势1) 数据库技术发展整体趋势数据库技术 ,最早源自上世纪70年代,从IBM著名的论文开始,后面诞生了Oracle、DB2为代表的优秀商业产品以及PostgreSQL、MySQL为代表的开源产品。这些产品很好的满足了对数据存储和计算的需求。随着21世纪初期,互联网浪潮的来临,数据规模呈爆炸式增长,单机数据库越来越难以满足用户需求。这也催生了分布式数据库的到来。到了2006年之后,出现以HBase/Cassadra/MongoDB为代表的NoSQL类产品。这些产品实现了分布式架构,可以实现容量的水平扩展,但也牺牲了诸如事务、SQL访问接口等能力。存储模型的简化为存储系统的开发带来了便利,但是降低了对业务的支撑。在这一阶段,很多企业为了解决大规模数据存储与访问的问题,也研发了很多中间件产品。其原理是通过将数据分片存储到单机库,上层对SQL解析实现对语句的路由。这种方式有一定的难点,例如对分布式事务的处理及规模扩大下的管理问题。到了2012年,Google的论文为关系模型的分布式架构,提供了新型分布式数据库理论基础。在此之后,诞生了一系列新型分布式数据库产品。其原理是通过分布式一致性算法协议完成底层数据多副本存储,上层则实现了标准SQL支持能力。数据库架构演进,从整体来看,走过了大致三个阶段。第一阶段,是以单节点为主要特征,通过单机能力来承载数据计算和存储的能力。这一架构的优势在于架构简单、维护成本低,随着单机能力的提升可满足大部分业务场景需求。缺点是数据库节点(包括内置存储)容易出现单点故障,且计算和存储能力受限于硬件性能,无法扩展。第二阶段,是以共享存储为主要特征,通过多台主机来承载数据计算能力,数据存储则集中于集中式共享存储之中。这一架构的优势在于解决了前一阶段数据计算部分的单点故障,结构仍较简单,易于实现事务一致性等问题。缺点在于数据计算部分扩展能力有限,底层数据存储部分依赖于高端共享存储且扩展能力也有限。第三阶段,是以分布式为主要特征,通过多台主机来承担数据计算与存储能力。这一架构优点在于良好地水平扩展能力,数据多副本存储,无需依赖共享存储。缺点在于,计算与存储能力需同步扩展,灵活度稍差,此外存在分布式查询、分布式事务的处理开销问题。2) 主流的分布式数据库技术分布式中间件这种架构是从之前谈到的中间件路线演进而来 ,是一种典型的“ Share Nothing”架构。通过上层无状态的计算节点提供弹性可扩展的计算能力,下层通过增强单机数据库提供基础存储能力及本地算力。这一架构通过硬件堆叠,可近似线性地提供计算性能和存储容量,具有可支持超大规模集群的能力。这种架构在分布式事务、全局MVCC等方面,往往存在一定难点,各厂商也有各自解决之道。这一架构产品优势在于功能丰富、可按业务做定制;稳定性较高,基于成熟稳定的单机引擎。在面对超大规模数据存储,通过灵活的分片配置策略,支持高灵活度数据打散技术,并可贴近场景需求定制分片。相对不足在于全局事务能力、全局 MVCC、副本控制、高可用等方面存在先天短板,需要有针对性增强。例如引入全局事务管理器组件,突破单机限制,实现分布式事务的实时一致性及全局MVCC能力,对应用透明的分布式事务处理,应用无需改造。通过一阶段提交+自动补偿机制,提升分布式事务处理性能。针对数据强一致性的要求,在单机库同步技术基础上,通过内核级的增强优化实现更高级别的复制保证数据不丢失。此外,由于需维护多节点一致性而带来的在跨分片DDL、分片节点扩容、跨节点复杂查询、全局一致的备份恢复等方面问题值得关注。这种架构产品较为适用于数据规模巨大、对延迟要求很高的在线交易场景。在数据库设计时,需要特别注意分区键和分区策略的选择,合理布局数据,尽量避免跨节点的分布式事务处理,以提高数据库的效率。分布式事务这 种架构正是受到Google论文影响演进而来 ,采用“ Share Nothing”架构。其采用存储与计算分离架构,底层多采用自研或裸存储引擎,数据按规则打散并存储多个副本,通过paoxs/raft等分布式协议保证多个副本间数据一致。上层实现数据库基础的优化器、执行器等组件,对分布式事务、全局MVCC等支持更为彻底。此外,由于其底层的存储引擎不是依赖某一产品,可根据需要组织数据,因此在适配场景上 更有优势,例如在某些分析类场景可选择列存。原生分布式实现,工程上不依赖其他产品,可控程度更高。面对很多新的需求,可从底层加以实现支持,不受限于第三方。在副本控制、数据一致性、容灾、弹性能力等方面更具有优势。此外,场景方面有更为灵活的选择及未来可扩展的空间。 但这一方式在产品成熟度,仍需较长时间沉淀。特别是使用在核心业务场景,仍然需要较长时间的锤炼。此外,其内置的分片规则,对于某些需贴合业务的架构设计不太友好。对于高并发、低延迟的极端场景仍然有一定局限。分布式存储在某种程度上讲,云原生数据库也是一种分布式,但与前两者区别是非 Share Nothing架构,而是Share Everything模式。其底层是与分布式云存储,本质上来说仍然是一种集中式架构。上层的计算部分,是无状态的一组结点组成。针对这种架构不足展开说明,原因是这种方式是需要对底座有比较重的依赖,无法在金融行业相对要求独立环境中部署,除非整个底层都更换。因此,使用选择上存在一定困难。3. 分布式数据库金融业实践1) 金融业数据库选型难点金融业在分布式数据库选型存在若干难点:复杂业务逻辑问题,包括数据库技术基因匹配性(如:数据库本身锁机制、隔离级别问题),包括技术兼任性(如存储过程、视图兼容性);应用的适配度问题,银行应用大部分都是基于单机关系型数据库机制设计的,例如大部分场景都是串行机制,发挥不出来分布式数据库的强大并发处理技术,反而分布式数据库本身的二阶段提交机制,对简单事务的延时增加问题,造成串行事务执行性能低下;人员能力的匹配性,需要根据人员技术能力进行选型考虑,例如基于 Spanner体系,基于Aurora体系,基于国内互联网公司自研的产品等,要考虑现有人员对数据库技术的了解程度,更要关注数据库技术本身的开放度和社区热度,让人员可以很快的学习和提升数据库技术能力;数据库自身能力问题,包括在分布式事务、数据一致性、高可用容灾等,相较于传统集中式数据库还是存在一些不足;此外金融业在联机交易的低延迟要求、跑批类的高吞吐要求也对分布式数据库提出了很高的要求;数据库运营维护问题,包括是否具备足够能力维护分布式数据库?是否能够接受数据库转型期间的业务中断时间?是否具备迁移(甚至在线)迁移能力?是否具有应用级双发能力,规避可能出现的风险等。2) 金融业数据库选型策略通过数据库的技术标准化和轻量化工作,形成统一的数据库使用规范,解耦应用和底层数据库技术架构,在标准数据库协议及语义下,可以很轻松的更换数据库架构。通过构建异构间数据同步、流量接入控制(限流、灰度等)、全局数据服务(如事务、快照等),实现业务的无感切换和迁移回退,保证最大的灵活可控。针对上述诸多难点、痛点,作为金融行业如何选择分布式数据库呢?可遵从以下几个方面:尊重路线之争,无关技术领先如前面所述,分布式数据库的发展有着不同的技术路线。曾有种观点认为,“分布式数据库的发展方向代表着未来,分布式中间件方向没有前途”。针对这一问题,我的观点是采用不同技术路线的产品有自己的适用场景,与技术领先性无关。某种技术通过提出理论、工程化实现、产品能力输出,可解决某方面需求、甚至带来巨大产品能力的提升;但希望以此通过大一统的产品解决所有问题是不现实的,未来仍然是多种技术路线并存的情况。成熟度有待完善,但时不我待提前规划分布式数据库作为一种新兴技术产品,其成熟度尚需锤炼,但不能基于此就选择观望态度。产品成熟的提高,一方面来自厂商对产品的不断迭代优化;另一方面也来自使用者的不断打磨。企业内对数据库的落地使用,也需要较为长期的过程。此外,外部驱动也对这一选择起到加速推动作用。作为企业来讲,根据自身情况可以选择不同策略(引领、跟随);但无论那种都需要提前规划,有明确方向和实施路径。国产数据库百花齐放,机会无限近些年来,国产数据库发展迅猛,呈现百花齐放态势。针对这一现状,一方面要持续关注这些产品,给予这些产品充分施展机会;另一方面制定准入标准严格把关,让真正有实力的厂商能够进入,得到充分锻炼、打磨的机会。慎重技术选型,不迷信宣传技术选型是个很严谨的过程,需要慎重对待。有很多第三方的评测和厂商宣传结论,但这些只能做参考,决策层面的依据还是需依靠自己。一方面宣传内容一般都会所选择有利于自己,这会带来一定误导性;另一方面对同一概念的理解是有偏差的,很难仅仅通过一段文字描述就能完全说清楚。这些问题只有在真实环境,叠加上自身需求,测试出的结果才具说服力。结合场景需求,没有最好只有最适合业务场景千差万别,其对数据库能力要求和侧重点也有所不同。很难选择一款通用型产品满足全场景,那就需要根据实际情况做有针对性的选择。此外,不同产品各有强点和局限之处,选择最适合你的产品就好。例如上文谈到的分布式中间件产品,在超大规模、自定义分片、超高性能、业务控制等方面往往更有优势;而分布式数据库产品,则在分布式事务、数据强一致、混合负载等方面有所擅长。不选产品选兼容性,保持最大自由度当前分布式数据库,仍然处于快速发展期,很难确定未来的主流选择。为了规避路线选择、厂商绑定的风险,比较现实的方法是选择一款兼容通用性协议的产品,并且在使用中仅使用标准数据库的用法。举个例子,选择一款兼容 MySQL的产品并且安装标准MySQL的用法使用;当出现风险时完全可选择另外一款同样兼容MySQL的产品来替代。目前MySQL生态在国内最为成熟,很多厂商产品也选择了兼容它,因此选择兼容性产品在未来的自由度最大。保持技术敏感度,紧跟时代发展步伐面对技术发展多变、应用特点多变、外部需求紧迫的现状,时刻关注分布式数据库发展,保持足够的技术敏感度,紧跟技术发展趋势。采取架构前置、谨慎选型、局部试点、多线布局、掌握主动、自建增强等策略,保持主动。3) 金融业数据库场景梳理金融企业对数据库使用场景众多,而对应分布式数据库产品功能各异且特点鲜明。如何为不同场景选择最为适合的分布式数据库产品,成为分布式数据库落地前提。下表结合金融行业特点,抽象出若干数据应用场景,形成以事务类、分析类、混合类为代表的三大类五种典型场景。从适用场景、技术架构特征、关键指标、功能维度等多方面对场景进行梳理。一句话总结:“没有最好的产品,只有最合适的产品!”。4) 金融业分布式数据库选型技术要素技术为业务服务的,不能为了使用技术而使用,需要综合考虑成本和收益的平衡。分布式数据库使用场景,应当在数据大规模、高并发、高可用性等场景下有其特有优势。一般的业务场景如果能用单机数据库支撑的尽量用单机库。选择一款分布式数据库,会带来一系列的成本,如应用适配成本、运维成本、硬件成本,这方面后面会赘述。此外,在做上述判断时,还需考虑业务的发展,最好是能判断三年的数据量和交易量的增长变化。在进行分布式选型时,可重点考察下列几个方面:分布式事务分布式架构,自然会带来分布式事务的问题。由于需要跨节点的网络交互,因此较单机事务会有很多损耗。随之带来的是事务处理时间较长、事务期间的锁持有时间也会增加,数据库的并发性和扩展性也会很差。针对单笔事务来说,分布式事务执行效率是肯定会有降低的,分布式带来的更多是整体处理能力的提升。但在设计之初,就应尽量做到业务单元化,将事务控制为本地事务,这可大大提升执行效率。性能由于二阶段提交和各节点之间的网络交互会有性能影响,分布式数据库优势不是单个简单 SQL的性能,但是大数据量的SQL查询,每个节点会将过滤之后的数据集进行反馈,会提升性能,并且分布式数据库的优势是并发,大量的SQL并发也会比单机数据库强大,应用需要做分布式架构的适配,将串行执行机制尽量都改造成并发处理。对于含有需要节点间数据流动的SQL语句的事务,OLTP类的分布式数据库处理效率一般较差,事务处理时间会较长,事务期间的锁持有时间也会增加,数据库的并发性和扩展性也会很差。建议尽量改造存在跨节点数据流动的SQL语句 (主要是多表关联)的事务。 分布式数据库性能是软硬整体架构的保障,不仅在软件、S QL 语句方面做优化,硬件方面也需要重视,包括处理器、内存、网络、磁盘等等,尤其在支撑交易类业务系统时重视对基础设施选型和优化。数据备份分布式数据库一致性保证通过内部时钟机制,所有节点都会遵循一致的时钟,所以备份恢复的增量也是基于时钟,相当于单机数据,但是分布式数据库的备份解决方案最重要标志是否支持物理级的备份,物理级的备份会比逻辑的备份性能吞吐会大很多,还有就是是否支持一些分布式备份方案,比如 S3协议接口,是否支持压缩等功能。分布式数据库基本都具备备份和恢复方案,通常从备节点进行连续备份(全量+日志),恢复的时候制定节点进行恢复到指定时间点,整个过程可配置自动任务自动执行。高可用分布式数据库大多都是基于多数派协议,同城双中心不适合多数派的要求,同城数据级多活建议采用三中心部署,如果同城主备可以采用集群级的异步复制。异地建议采用集群级的 binlog异步复制。建议实例的主备节点设置在同城两个双活数据中心,仲裁节点三机房部署;异地灾备单独启实例与本地实例进行数据库间同步,也可以将本地备份文件T+1恢复到异地灾备。数据一致性NewSQL分布式数据库基本都是通过获取全局时钟时间戳,采用二阶段提交实现一致性,可以实现一致性的保证,分库分表架构对于事务的一致性,需要应用层考虑,比如通过合理的分区键设计来规避。分布式数据库对于跨节点事务目前还是实现的最终一致,对于全局一致性读,一般通过引入类似全局时间戳的组件统一管理全局事务,在数据库选型时可以重点关注厂商对这一块的实现。如果目前暂时无法提供全局一致性读的分布式数据库,对于要依赖分布式事务“中间状态”的业务,优先进行业务改造进行规避,其次通过合理的数据分片设计让其在单节点内完成。其他因素金融行业在数据库选型中,除了需要考虑上述外,还有其他一些因素的考虑。如原有系统的承载能力、是否必须进行选择等。5) 金融业分布式数据库选型非技术要素金融业分布式数据库选型,除了上述技术要素外,还包含如下非技术要素,主要是在成本投入方面:硬件成本一般采用 x86服务器,存储多为本地存储,推荐使用SSD甚至是NVMe SSD,网络一般 采用 万兆网络。在这部分主要成本是取决于集群规模、数据量及数据库自身架构。此外,如果涉及到灾备方案,还需要考虑灾备环境的硬件投入及主备间的专线费用。 此外,考虑很多金融单位现在机房建设空间和能耗有限,可采用配置较高的硬件设备,如基于英特尔 ®至强® 金牌处理器内核的x 86 物理机、配置 英特尔®傲腾™固态盘 等,减少服务器数量、降低耗电量。软件成本主要来自分布式数据库本身的软件采购成本,成本取决于各厂商的内部商业策略。但这部分总体来讲,是较传统数据库产品还是有优势的。此外,这部分还涉及到维保费用,针对分布式数据库来说,相对较新,企业自有能力尚不具备,还是建议购买原厂服务或其他三方公司的服务,降低风险。开发测试成本这部分是指针对数据库更换后,应用需要需要完成的必要的开发测试成本。这部分成本差异很大,跟原有系统实现有较大关系。如果原有系统重度依赖数据库(大量功能是基于数据库自身功能实现的),那么存在的改造量较大。新型分布式数据库的功能,不能与传统数据库做一一对应,很多能力是需要在应用层重构完成。针对这种情况,是建议应用开发遵循数据库标准方式进行(如采用 MySQL作为标准)开发,这样如有改型也很简单。此外,还有一类隐形成本包含在这部分,如果业务比较重要,是需要考虑双发支持或灰度迁移的方式,这会带来一部分工作量。总体来说, 这部分成本是比较高的,可能占整体成本的大部分。运营维护成本这部分成本,包括了为满足更换数据库所带来的数据迁移成本和上线后的日常维护成本。针对前者,可以在应用侧解决或者外采商业软件解决;后者更多是人员管理成本。针对这部分成本,是有个相对较长的投入,且整体成本不少。6) 金融业分布式数据库运维要点分布式数据库,作为较为新兴的基础架构产品,在运维层面有其独有特点。下面结合之前的实践,将运维要点整理如下:软件规划和部署方案分布式数据库组件众多,而且每个组件都有高可用备份,所以在有限数量的服务器下进行组件的分配要尽量考虑达到各个服务器负载的均衡, GTM作为分布式数据库的瓶颈尽量和他们组件分开部署。监控方案监控一般可以采用开源的 zabbix进行定制化开发,当然也可以基grafana+prometheus的方案做监控。但一般大中型金融企业都有一套自己的监控系统,这里需要有个对接适配的过程。此外,由于分布式的多组件特点,在监控指标数量及指标间关联上,与传统数据库差异巨大,是需要监控摸索过程。语句调优因为不同厂商研发的数据库 SQL优化器及执行计划都有所不同,所以要根据不同产品进行学习。天然由于分布式架构带来的复杂度,也会影响到语句的执行效率。比较常见的如数据库访问链路长所带来的的问题、数据分布不均带来的问题及分布式优化器的问题等。备份方案分布式数据库如何做到多节点全局一致性备份也是难点,要做到真正意义上的基于时点恢复,就需要做到分布式环境下每个全局事务的可追溯操作。应急方案因为分布式数据库还处于发展阶段,还不成熟,技术比较复杂,所以生产环境下要制定详细的应急方案,让不了解分布式数据库的同事也能够在出现问题时按照手册操作。DDL变更在分布式架构下, DDL变更是个难点。如果做到全局一致,做到业务无感知,是核心点。不同厂商产品实现能力层次不齐,介于此安排在低峰期操作并做好必要的监控回退。水平扩容分布式架构下,都是支持水平扩容的。一般来说,非数据节点的扩容是相对容易的,对业务也是无感的,但涉及到数据节点的扩容,势必会遇到数据 reshard的问题。建议选择在低峰期,同时控制好扩容粒度。即便如此,仍然建议提前做好容量规划,避免扩容。跨片计算分布式架构下,数据是分布在多个节点中。如果数据计算是可以在本地计算完成,无疑是效率最高的,但完全避免跨片计算是不太现实的。如果发生跨片计算,则不可避免地对上层节点带来压力,要做好相应监控,并争取在根本上避免跨片类计算。5. 总结分布式数据库 ,作为 一种新型数据库 产品架构,正处于蓬勃发展阶段。其 具备 的 数据分片管理、分布式事务、读写分离等关键分布式能力, 能够很好地满足企业在 高性能、大数据量 等多种 业务 场景 。近年来,各国产厂商都在积极推进分布式数据库产品的研发,技术已经逐步成熟 。金融行业,作为数字化转型的先导性行业,对数据基础设施有着更高的要求。分布式数据库的出现,恰好可以满足金融企业迫切需求。随着近些年来,分布式数据库的成熟,并在 金融行业已有成功案例投入生产系统使用。 相信,两者的结合,必定在未来能擦出更多火花,促进金融行业在新时代转型发展。文章来源:https://www.talkwithtrend.com/Article/259665 纯属学习、分享,如有涉及版权,请联系处理。 -
2022年1月18日——IDC近日发布了《IDC FutureScape: 全球数据和内容技术2022年预测 – 中国启示》(IDC #CHC48686822, 2022年1月),报告提供了 IDC 对数据和内容技术的 2022 年十大预测,主要关注数据和内容为企业所创造的价值,代表未来几年对数据、内容及分析技术的部署和使用具有最大潜在影响的预期趋势。 本报告基于全球预测提供对中国市场的启示,预测内容的主题分别为:数据运维、实时流式数据、AI增强分析及知识网络、规范事物命名、决策平台、视频内容分析、数据共享、数据文化、智能文档处理和图数据库。IDC 2022年中国数据与内容技术十大预测具体内容如下: 预测一:数据运维(DataOps) 到 2022 年,55% 的中国500强企业将拥有面向最终数据使用者的统一数据应用架构,以支持数据运维(DataOps)、推动基于 ML 的数据工程、降低数据风险并推动数字一代(Gen D)员工的创新。 预测二:实时流式数据 到2026年,50%的数据捕获和移动技术支出将用于实时流式数据管道(streaming data pipeline),从而支持新一代的实时仿真模拟、优化和推荐功能。 预测三:AI增强分析及知识网络 到2024年,基于AI增强分析,15%的 BI 解决方案将融入智能知识网络/知识管理系统,通过实现内外部协作和集体智能(collective intelligence)功能,为用户提供更强大的核心分析能力。 预测四:规范事物命名 到2025年,30%的中国500强企业将开发并发布正式本体(Ontologies),这些本体包含与企业相关性最强的内、外部对象和指标,即规范对这些事物的命名并与企业外部共享。 预测五:决策平台 到2026年,由于缺乏对分析决策过程的统一管理,25%的中国1000强企业将采用具有统一分析、业务规则、工作流程和协作能力的决策平台 预测六:视频内容分析 到2024年,尽管目前早已有三分之二的大型企业使用视频与员工、客户沟通,然而仅有不到15%的企业将视频内容分析应用到决策中。 预测七:数据共享 到2024年,35%的中国500强企业将通过数据洁净室(data clean room)与外部利益相关者建立数据共享伙伴关系, 在保护数据隐私和宝贵的数据资产的同时增加相互依赖。 预测八:数据文化 到2026年,为了提升自身的数据文化,40%的中国1000强企业将制定数据素养计划,包括帮助员工发现错误信息和用数据进行沟通或影响的培训。 预测九:智能文档处理 70%的中国1000强企业将完全实现文档流程的数字化和转型,利用人工智能支持以内容为中心的工作流的编排和决策。 预测十:图数据库 到2024年,55%的中国500强企业将部署图数据库,认识到这项技术适用于越来越多的应用场景,涉及关系、影响、路径和模式分析。 IDC中国高级分析师王丽萌表示:“数据是企业的基础资产之一,围绕数据和内容所开发的应用正在发挥越来越重要的价值,促使企业作出反应。我们预测,在未来几年内,企业将迅速增加对管理、分析数据和内容的技术投资与部署。”文章来源:IDC中国
-
 主要内容为使用gsql数据库开发调试工具连接openGauss数据库。gsql客户端工具gsql是openGauss提供在命令行下运行的数据库连接工具,可以通过此工具连接服务器并对其进行操作和维护,除了具备操作数据库的基本功能,gsql还提供了若干高级特性,便于用户使用。gsql连接数据库gsql是openGauss自带的客户端工具。使用gsql连接数据库,可以交互式地输入、编辑、执行SQL语句。确认连接信息客户端工具通过数据库主节点连接数据库。因此连接前,需获取数据库主节点所在服务器的IP地址及数据库主节点的端口号信息。步骤 1 切换到omm用户,以操作系统用户omm登录数据库主节点。[root@db1 script]# su - omm 步骤 2 使用“gs_om -t status --detail”命令查询openGauss各实例情况。[omm@db1 ~]$ gs_om -t status --detail情况显示如下:[ DBnode State ] node node_ip instance state ------------------------------------------------------------------------------------- 1 db1 192.168.0.58 6001 /gaussdb/data/db1 P Primary Normal如上部署了数据库主节点实例的服务器IP地址为192.168.0.58。数据库主节点数据路径为“/gaussdb/data/db1”。步骤 3 确认数据库主节点的端口号。在步骤2查到的数据库主节点数据路径下的postgresql.conf文件中查看端口号信息。示例如下:port = 26000 # (change requires restart) #ssl_renegotiation_limit = 0 # amount of data between renegotiations, no longer supported #tcp_recv_timeout = 0 # SO_RCVTIMEO, specify the receiving timeouts until reporting an error(change requires restart) #comm_sctp_port = 1024 # Assigned by installation (change requires restart) #comm_control_port = 10001 # Assigned by installation (change requires restart) # supported by the operating system: # The heartbeat thread will not start if not set localheartbeatport and remoteheartbeatport. # e.g. 'localhost=xx.xx.xxx.2 localport=12211 localheartbeatport=12214 remotehost=xx.xx.xxx.3 remoteport=12212 remoteheartbeatport=12215, localhost=xx.xx.xxx.2 localport=12213 remotehost=xx.xx.xxx.3 remoteport=12214' # %r = remote host and port alarm_report_interval = 1026000为数据库主节点的端口号。请在实际操作中记录数据库主节点实例的服务器IP地址,数据路径和端口号,并在之后操作中按照实际情况进行替换。本地连接数据库步骤 1 切换到omm用户,以操作系统用户omm登录数据库主节点。[root@db1 script]# su - omm步骤 2 启动数据库服务。[root@db1 script]# gs_om -t start显示如下,启动成功。Starting cluster. ========================================= ========================================= Successfully started.步骤 3 连接数据库。执行如下命令连接数据库。[omm@db1 ~]$ gsql -d postgres -p 26000 -r 其中postgres为需要连接的数据库名称,26000为数据库主节点的端口号。请根据实际情况替换。连接成功后,系统显示类似如下信息:gsql ((openGauss 1.0.0 build 290d125f) compiled at 2020-05-08 02:59:43 commit 2143 last mr 131 Non-SSL connection (SSL connection is recommended when requiring high-security) Type "help" for help. postgres=# omm用户是管理员用户,因此系统显示“DBNAME=#”。若使用普通用户身份登录和连接数据库,系统显示“DBNAME=>”。“Non-SSL connection”表示未使用SSL方式连接数据库。如果需要高安全性时,请用SSL进行安全的TCP/IP连接。步骤 4 退出数据库。postgres=# \q gsql获取帮助前提条件以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),切换到omm用户。su - omm连接数据库时,可以使用如下命令获取帮助信息gsql --help显示如下帮助信息:...... Usage: gsql [OPTION]... [DBNAME [USERNAME]] General options: -c, --command=COMMAND run only single command (SQL or internal) and exit -d, --dbname=DBNAME database name to connect to (default: "postgres") -f, --file=FILENAME execute commands from file, then exit ......连接到数据库后,可以使用如下命令获取帮助信息步骤 1 使用如下命令连接数据库。gsql -d postgres -p 26000 -r 步骤 2 输入help指令。postgres=#help显示如下帮助信息:You are using gsql, the command-line interface to gaussdb. Type: \copyright for distribution terms \h for help with SQL commands \? for help with gsql commands \g or terminate with semicolon to execute query \q to quit步骤 3 查看版权信息。postgres=#\copyright显示如下版权信息:openGauss Database Management System Copyright (c) Huawei Technologies Co., Ltd. 2020. All rights reserved.步骤 4 查看openGauss支持的所有SQL语句。postgres=#\h显示如下信息:Available help: ABORT ALTER AGGREGATE ALTER APP WORKLOAD GROUP ... ...步骤 5 查看CREATE DATABASE命令的参数可使用下面的命令。postgres=#\help CREATE DATABASE显示如下帮助信息:Command: CREATE DATABASE Description: create a new database Syntax: CREATE DATABASE database_name [ [ WITH ] {[ OWNER [=] user_name ]| [ TEMPLATE [=] template ]| [ ENCODING [=] encoding ]| [ LC_COLLATE [=] lc_collate ]| [ LC_CTYPE [=] lc_ctype ]| [ DBCOMPATIBILITY [=] compatibility_type ]| [ TABLESPACE [=] tablespace_name ]| [ CONNECTION LIMIT [=] connlimit ]}[...] ];步骤 6 查看gsql支持的命令。postgres=# \? 显示如下信息:General \copyright show PostgreSQL usage and distribution terms \g [FILE] or ; execute query (and send results to file or |pipe) \h(\help) [NAME] help on syntax of SQL commands, * for all commands \q quit gsql ... ...步骤 7 退出数据库。postgres=# \qgsql命令使用前提条件以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),切换到omm用户。su - omm执行一条字符串命令gsql命令直接执行一条显示版权信息的字符串命令gsql -d postgres -p 26000 -c "\copyright"显示如下,显示后退出gsql环境:openGauss Database Management System Copyright (c) Huawei Technologies Co., Ltd. 2020. All rights reserved $使用文件作为命令源而不是交互式输入步骤 1 创建文件夹存放相关文档。mkdir /home/omm/openGauss步骤 2 创建文件,例如文件名为“mysql.sql”,并写入可执行sql语句“select * from pg_user;”。vi /home/omm/openGauss/mysql.sql文件打开输入i,进入INSERT模式,输入” select * from pg_user;”。select * from pg_user;然后点击Esc,输入“:wq”保存文档并退出。步骤 3 执行如下命令使用文件作为命令源。gsql -d postgres -p 26000 -f /home/omm/openGauss/mysql.sql 结果如下,并且gsql将在处理完文件后结束:usename | usesysid | usecreatedb | usesuper | usecatupd | userepl | passwd | valbegin | valuntil | respool | parent | spacel imit | useconfig | nodegroup | tempspacelimit | spillspacelimit ---------+----------+-------------+----------+-----------+---------+----------+----------+----------+--------------+--------+------- -----+-----------+-----------+----------------+----------------- omm | 10 | t | t | t | t | ******** | | | default_pool | 0 | | | | | jack | 16385 | f | f | f | f | ******** | | | default_pool | 0 | | | | | (2 rows) total time: 3 ms步骤 4 如果FILENAME是-(连字符),则从标准输入读取。gsql -d postgres -p 26000 -f - postgres=# select * from pg_user; usename | usesysid | usecreatedb | usesuper | usecatupd | userepl | passwd | valbegin | valuntil | respool | parent | spacel imit | useconfig | nodegroup | tempspacelimit | spillspacelimit ---------+----------+-------------+----------+-----------+---------+----------+----------+----------+--------------+--------+------- -----+-----------+-----------+----------------+----------------- omm | 10 | t | t | t | t | ******** | | | default_pool | 0 | | | | | joe | 16385 | f | f | f | f | ******** | | | default_pool | 0 | | | | | (2 rows)步骤 5 退出数据库连接。postgres=# \q total time: 174163 ms列出所有可用的数据库(\l的l表示list)gsql -d postgres -p 26000 -l 结果如下,并且gsql将在显示后结束: List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+-------+-----------+---------+-------+------------------- db_tpcc | joe | SQL_ASCII | C | C | postgres | omm | SQL_ASCII | C | C | template0 | omm | SQL_ASCII | C | C | =c/omm + | | | | | omm=CTc/omm template1 | omm | SQL_ASCII | C | C | =c/omm + | | | | | omm=CTc/omm (4 rows) $设置gsql变量NAME为VALUE步骤 1 设置foo的值为bar。gsql -d postgres -p 26000 -v foo=bar 步骤 2 在数据库能够显示foo的值。postgres=# \echo :foo bar步骤 3 退出数据库连接。postgres=> \q打印gsql版本信息gsql -V结果如下,并且gsql将在显示后结束:gsql (openGauss 1.0.0 build 0bd0ce80) compiled at 2020-06-30 18:19:23 commit 0 last mr 使用文件作为输出源步骤 1 创建文件,例如文件名为“output.txt”。touch /home/omm/openGauss/output.txt步骤 2 执行如下命令,除了正常的输出源之外,把所有查询输出记录到文件中。gsql -d postgres -p 26000 -L /home/omm/openGauss/output.txt进入gsql环境,输入以下语句:postgres=# create table mytable (firstcol int); CREATE TABLE postgres=# insert into mytable values(100); INSERT 0 1 postgres=# select * from mytable ; firstcol ---------- 100 (1 row) postgres=# \q步骤 3 查看“output.txt”文档中的内容如下:cat /home/omm/openGauss/output.txt显示如下:********* QUERY ********** create table mytable (firstcol int); ************************** CREATE TABLE ********* QUERY ********** insert into mytable values(100); ************************** INSERT 0 1 ********* QUERY ********** select * from mytable; ************************** firstcol ---------- 100 (1 row)将所有查询输出重定向到文件FILENAME步骤 1 创建文件,例如文件名为“outputOnly.txt”。touch /home/omm/openGauss/outputOnly.txt步骤 2 执行如下命令。gsql -d postgres -p 26000 -o /home/omm/openGauss/outputOnly.txt 步骤 3 进入gsql环境,输入以下语句:postgres=# drop table mytable; postgres=# create table mytable (firstcol int); postgres=# insert into mytable values(100); postgres=# select * from mytable; postgres=# \q 所有操作都没有回显。步骤 4 查看“outputOnly.txt”文档中的内容如下:cat /home/omm/openGauss/outputOnly.txt显示如下:DROP TABLE CREATE TABLE INSERT 0 1 firstcol ---------- 100 (1 row) "/opt/software/openGauss/output.txt" 8L, 76C 安静模式安静模式:执行时不会打印出额外信息gsql -d postgres -p 26000 -q进入gsql环境,输入以下语句:postgres=# create table t_test (firstcol int); postgres=# insert into t_test values(200); postgres=# select * from t_test; firstcol ---------- 200 (1 row) postgres=# \q连接上数据库,创建数据库和插入数据等都没有回显信息。单行运行模式单行运行模式:这时每个命令都将由换行符结束,像分号那样gsql -d postgres -p 26000 -S进入gsql环境,输入以下语句:postgres^# select * from t_test; firstcol ---------- 200 (1 row) postgres^# select * from t_test firstcol ---------- 200 (1 row) postgres=# \q语句最后结尾有;号和没有;号,效果都一样。编辑模式步骤 1 如下命令连接数据库,开启在客户端操作中可以进行编辑的模式。gsql -d postgres -p 26000 -r步骤 2 进入gsql环境,输入以下语句:步骤 3 写完后不要按回车,光标在最后闪烁。步骤 4 按“向左”键讲光标移动到“*”,将此符号修改为“firstcol”。编辑模式“上下左右键”,“删除键”和“退格键”都可以使用,并且按下“*向上”、“向下”键可以切换输入过的命令。步骤 5 退出数据库连接。postgres=# \q远程使用用户名和密码连接数据库远程使用jack用户连接ip地址为192.168.0.58端口号为26000的数据库。登录客户端主机(192.168.0.58),使用以下命令远程登录数据库。gsql -d postgres -h 192.168.0.58 -U jack -p 26000 -W Bigdata@123;-d参数指定目标数据库名、-U参数指定数据库用户名、-h参数指定主机名、-p参数指定端口号信息,-W参数指定数据库用户密码。进入gsql环境,显示如下:gsql ((openGauss 1.0 build ec0e781b) compiled at 2020-04-27 17:25:57 commit 2144 last mr 131 ) SSL connection (cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256) Type "help" for help. postgres=> gsql元命令使用前提条件以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),使用gsql连接到openGauss数据库。步骤 1 切换到omm用户,以操作系统用户omm登录数据库主节点。su - omm步骤 2 gsql连接数据库。gsql -d postgres -p 26000 -r 打印当前查询缓冲区到标准输出步骤 1 创建“outputSQL.txt”文件。touch /home/omm/openGauss/outputSQL.txt步骤 2 连接数据库。gsql -d postgres -p 26000 -r步骤 3 输入以下语句。postgres=# select * from pg_roles; rolname | rolsuper | rolinherit | rolcreaterole | rolcreatedb | rolcatupdate | rolcanlogin | rolreplication | rolauditadmin | rolsy stemadmin | rolconnlimit | rolpassword | rolvalidbegin | rolvaliduntil | rolrespool | rolparentid | roltabspace | rolconfig | oid | roluseft | rolkind | nodegroup | roltempspace | rolspillspace ---------+----------+------------+---------------+-------------+--------------+-------------+----------------+---------------+------ ----------+--------------+-------------+---------------+---------------+--------------+-------------+-------------+-----------+----- --+----------+---------+-----------+--------------+--------------- omm | t | t | t | t | t | t | t | t | t | -1 | ******** | | | default_pool | 0 | | | 1 0 | t | n | | | joe | f | t | f | f | f | t | f | f | f | -1 | ******** | | | default_pool | 0 | | | 1725 5 | f | n | | | (3 rows) postgres=# \w /home/omm/openGauss/outputSQL.txt postgres=# \q步骤 4 打开文件“outputSQL.txt”文件,查看其中内容。cat /home/omm/openGauss/outputSQL.txt显示如下:select * from pg_roles;导入数据步骤 1 连接数据库。gsql -d postgres -p 26000 -r步骤 2 创建目标表a。postgres=# CREATE TABLE a(a int);步骤 3 导入数据,从stdin拷贝数据到目标表a。postgres=# \copy a from stdin;出现>>符号提示时,输入数据,输入.时结束。Enter data to be copied followed by a newline. End with a backslash and a period on a line by itself. >> 1 >> 2 >> \.步骤 4 查询导入目标表a的数据。postgres=# SELECT * FROM a; a --- 1 2 退出数据库:postgres=# \q步骤 5 从本地文件拷贝数据到目标表a,创建文件/home/omm/openGauss/2.csv。vi /home/omm/openGauss/2.csv步骤 6 输入i,切换到INSERT模式,插入数据如下:3 4 5如果有多个数据,分隔符为‘,’。在导入过程中,若数据源文件比外表定义的列数多,则忽略行尾多出来的列。步骤 7 按下Esc键,输入“:wq”后回车,保存并退出。步骤 8 连接数据库。gsql -d postgres -p 26000 -r步骤 9 如下命令拷贝数据到目标表。postgres=# \copy a FROM '/home/omm//openGauss/2.csv' WITH (delimiter',',IGNORE_EXTRA_DATA 'on');步骤 10 查询导入目标表a的数据。postgres=# SELECT * FROM a; a --- 1 2 3 4 5 (5 rows)查询表空间postgres=# \db 显示如下:postgres=> List of tablespaces Name | Owner | Location ------------+-------+---------- pg_default | omm | pg_global | omm | (2 rows)查询表的属性步骤 1 创建表customer_t1。postgres=# DROP TABLE IF EXISTS customer_t1; postgres=# CREATE TABLE customer_t1 ( c_customer_sk integer, c_customer_id char(5), c_first_name char(6), c_last_name char(8) );步骤 2 查询表的属性。postgres=# \d+;显示如下:Schema | Name | Type | Owner | Size | Storage | Description --------+-------------+-------+-------+------------+----------------------------------+------------- public | customer_t1 | table | omm | 0 bytes | {orientation=row,compression=no} | public | mytable | table | omm | 8192 bytes | {orientation=row,compression=no} | public | t_test | table | omm | 8192 bytes | {orientation=row,compression=no} | public | ta | table | omm | 0 bytes | {orientation=row,compression=no} | (4 rows)步骤 3 查询表customer_t1的属性。postgres=# \d+ customer_t1;显示如下: Table "public.customer_t1" Column | Type | Modifiers | Storage | Stats target | Description ---------------+--------------+-----------+----------+--------------+------------- c_customer_sk | integer | | plain | | c_customer_id | character(5) | | extended | | c_first_name | character(6) | | extended | | c_last_name | character(8) | | extended | | Has OIDs: no Options: orientation=row, compression=no查询索引信息步骤 1 在表customer_t1上创建索引。create index customer_t1_index1 on customer_t1(c_customer_id);步骤 2 查询索引信息。postgres=# \di+;显示如下: List of relations Schema | Name | Type | Owner | Table | Size | Storage | Description --------+--------------------+-------+-------+-------------+------------+---------+------------- public | customer_t1_index1 | index | omm | customer_t1 | 8192 bytes | |步骤 3 查询customer_t1_index1索引的信息。postgres=# \di+ customer_t1_index1显示如下: List of relations Schema | Name | Type | Owner | Table | Size | Storage | Description --------+--------------------+-------+-------+-------------+------------+---------+------------- public | customer_t1_index1 | index | omm | customer_t1 | 8192 bytes | |切换数据库步骤 1 创建数据库。DROP DATABASE IF EXISTS db_tpcc02; CREATE DATABASE db_tpcc02;步骤 2 切换数据库。postgres=# \c db_tpcc02;显示如下:Non-SSL connection (SSL connection is recommended when requiring high-security) You are now connected to database "db_tpcc" as user "omm". db_tpcc=# 步骤 3 退出数据库:postgres=# \q
主要内容为使用gsql数据库开发调试工具连接openGauss数据库。gsql客户端工具gsql是openGauss提供在命令行下运行的数据库连接工具,可以通过此工具连接服务器并对其进行操作和维护,除了具备操作数据库的基本功能,gsql还提供了若干高级特性,便于用户使用。gsql连接数据库gsql是openGauss自带的客户端工具。使用gsql连接数据库,可以交互式地输入、编辑、执行SQL语句。确认连接信息客户端工具通过数据库主节点连接数据库。因此连接前,需获取数据库主节点所在服务器的IP地址及数据库主节点的端口号信息。步骤 1 切换到omm用户,以操作系统用户omm登录数据库主节点。[root@db1 script]# su - omm 步骤 2 使用“gs_om -t status --detail”命令查询openGauss各实例情况。[omm@db1 ~]$ gs_om -t status --detail情况显示如下:[ DBnode State ] node node_ip instance state ------------------------------------------------------------------------------------- 1 db1 192.168.0.58 6001 /gaussdb/data/db1 P Primary Normal如上部署了数据库主节点实例的服务器IP地址为192.168.0.58。数据库主节点数据路径为“/gaussdb/data/db1”。步骤 3 确认数据库主节点的端口号。在步骤2查到的数据库主节点数据路径下的postgresql.conf文件中查看端口号信息。示例如下:port = 26000 # (change requires restart) #ssl_renegotiation_limit = 0 # amount of data between renegotiations, no longer supported #tcp_recv_timeout = 0 # SO_RCVTIMEO, specify the receiving timeouts until reporting an error(change requires restart) #comm_sctp_port = 1024 # Assigned by installation (change requires restart) #comm_control_port = 10001 # Assigned by installation (change requires restart) # supported by the operating system: # The heartbeat thread will not start if not set localheartbeatport and remoteheartbeatport. # e.g. 'localhost=xx.xx.xxx.2 localport=12211 localheartbeatport=12214 remotehost=xx.xx.xxx.3 remoteport=12212 remoteheartbeatport=12215, localhost=xx.xx.xxx.2 localport=12213 remotehost=xx.xx.xxx.3 remoteport=12214' # %r = remote host and port alarm_report_interval = 1026000为数据库主节点的端口号。请在实际操作中记录数据库主节点实例的服务器IP地址,数据路径和端口号,并在之后操作中按照实际情况进行替换。本地连接数据库步骤 1 切换到omm用户,以操作系统用户omm登录数据库主节点。[root@db1 script]# su - omm步骤 2 启动数据库服务。[root@db1 script]# gs_om -t start显示如下,启动成功。Starting cluster. ========================================= ========================================= Successfully started.步骤 3 连接数据库。执行如下命令连接数据库。[omm@db1 ~]$ gsql -d postgres -p 26000 -r 其中postgres为需要连接的数据库名称,26000为数据库主节点的端口号。请根据实际情况替换。连接成功后,系统显示类似如下信息:gsql ((openGauss 1.0.0 build 290d125f) compiled at 2020-05-08 02:59:43 commit 2143 last mr 131 Non-SSL connection (SSL connection is recommended when requiring high-security) Type "help" for help. postgres=# omm用户是管理员用户,因此系统显示“DBNAME=#”。若使用普通用户身份登录和连接数据库,系统显示“DBNAME=>”。“Non-SSL connection”表示未使用SSL方式连接数据库。如果需要高安全性时,请用SSL进行安全的TCP/IP连接。步骤 4 退出数据库。postgres=# \q gsql获取帮助前提条件以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),切换到omm用户。su - omm连接数据库时,可以使用如下命令获取帮助信息gsql --help显示如下帮助信息:...... Usage: gsql [OPTION]... [DBNAME [USERNAME]] General options: -c, --command=COMMAND run only single command (SQL or internal) and exit -d, --dbname=DBNAME database name to connect to (default: "postgres") -f, --file=FILENAME execute commands from file, then exit ......连接到数据库后,可以使用如下命令获取帮助信息步骤 1 使用如下命令连接数据库。gsql -d postgres -p 26000 -r 步骤 2 输入help指令。postgres=#help显示如下帮助信息:You are using gsql, the command-line interface to gaussdb. Type: \copyright for distribution terms \h for help with SQL commands \? for help with gsql commands \g or terminate with semicolon to execute query \q to quit步骤 3 查看版权信息。postgres=#\copyright显示如下版权信息:openGauss Database Management System Copyright (c) Huawei Technologies Co., Ltd. 2020. All rights reserved.步骤 4 查看openGauss支持的所有SQL语句。postgres=#\h显示如下信息:Available help: ABORT ALTER AGGREGATE ALTER APP WORKLOAD GROUP ... ...步骤 5 查看CREATE DATABASE命令的参数可使用下面的命令。postgres=#\help CREATE DATABASE显示如下帮助信息:Command: CREATE DATABASE Description: create a new database Syntax: CREATE DATABASE database_name [ [ WITH ] {[ OWNER [=] user_name ]| [ TEMPLATE [=] template ]| [ ENCODING [=] encoding ]| [ LC_COLLATE [=] lc_collate ]| [ LC_CTYPE [=] lc_ctype ]| [ DBCOMPATIBILITY [=] compatibility_type ]| [ TABLESPACE [=] tablespace_name ]| [ CONNECTION LIMIT [=] connlimit ]}[...] ];步骤 6 查看gsql支持的命令。postgres=# \? 显示如下信息:General \copyright show PostgreSQL usage and distribution terms \g [FILE] or ; execute query (and send results to file or |pipe) \h(\help) [NAME] help on syntax of SQL commands, * for all commands \q quit gsql ... ...步骤 7 退出数据库。postgres=# \qgsql命令使用前提条件以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),切换到omm用户。su - omm执行一条字符串命令gsql命令直接执行一条显示版权信息的字符串命令gsql -d postgres -p 26000 -c "\copyright"显示如下,显示后退出gsql环境:openGauss Database Management System Copyright (c) Huawei Technologies Co., Ltd. 2020. All rights reserved $使用文件作为命令源而不是交互式输入步骤 1 创建文件夹存放相关文档。mkdir /home/omm/openGauss步骤 2 创建文件,例如文件名为“mysql.sql”,并写入可执行sql语句“select * from pg_user;”。vi /home/omm/openGauss/mysql.sql文件打开输入i,进入INSERT模式,输入” select * from pg_user;”。select * from pg_user;然后点击Esc,输入“:wq”保存文档并退出。步骤 3 执行如下命令使用文件作为命令源。gsql -d postgres -p 26000 -f /home/omm/openGauss/mysql.sql 结果如下,并且gsql将在处理完文件后结束:usename | usesysid | usecreatedb | usesuper | usecatupd | userepl | passwd | valbegin | valuntil | respool | parent | spacel imit | useconfig | nodegroup | tempspacelimit | spillspacelimit ---------+----------+-------------+----------+-----------+---------+----------+----------+----------+--------------+--------+------- -----+-----------+-----------+----------------+----------------- omm | 10 | t | t | t | t | ******** | | | default_pool | 0 | | | | | jack | 16385 | f | f | f | f | ******** | | | default_pool | 0 | | | | | (2 rows) total time: 3 ms步骤 4 如果FILENAME是-(连字符),则从标准输入读取。gsql -d postgres -p 26000 -f - postgres=# select * from pg_user; usename | usesysid | usecreatedb | usesuper | usecatupd | userepl | passwd | valbegin | valuntil | respool | parent | spacel imit | useconfig | nodegroup | tempspacelimit | spillspacelimit ---------+----------+-------------+----------+-----------+---------+----------+----------+----------+--------------+--------+------- -----+-----------+-----------+----------------+----------------- omm | 10 | t | t | t | t | ******** | | | default_pool | 0 | | | | | joe | 16385 | f | f | f | f | ******** | | | default_pool | 0 | | | | | (2 rows)步骤 5 退出数据库连接。postgres=# \q total time: 174163 ms列出所有可用的数据库(\l的l表示list)gsql -d postgres -p 26000 -l 结果如下,并且gsql将在显示后结束: List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+-------+-----------+---------+-------+------------------- db_tpcc | joe | SQL_ASCII | C | C | postgres | omm | SQL_ASCII | C | C | template0 | omm | SQL_ASCII | C | C | =c/omm + | | | | | omm=CTc/omm template1 | omm | SQL_ASCII | C | C | =c/omm + | | | | | omm=CTc/omm (4 rows) $设置gsql变量NAME为VALUE步骤 1 设置foo的值为bar。gsql -d postgres -p 26000 -v foo=bar 步骤 2 在数据库能够显示foo的值。postgres=# \echo :foo bar步骤 3 退出数据库连接。postgres=> \q打印gsql版本信息gsql -V结果如下,并且gsql将在显示后结束:gsql (openGauss 1.0.0 build 0bd0ce80) compiled at 2020-06-30 18:19:23 commit 0 last mr 使用文件作为输出源步骤 1 创建文件,例如文件名为“output.txt”。touch /home/omm/openGauss/output.txt步骤 2 执行如下命令,除了正常的输出源之外,把所有查询输出记录到文件中。gsql -d postgres -p 26000 -L /home/omm/openGauss/output.txt进入gsql环境,输入以下语句:postgres=# create table mytable (firstcol int); CREATE TABLE postgres=# insert into mytable values(100); INSERT 0 1 postgres=# select * from mytable ; firstcol ---------- 100 (1 row) postgres=# \q步骤 3 查看“output.txt”文档中的内容如下:cat /home/omm/openGauss/output.txt显示如下:********* QUERY ********** create table mytable (firstcol int); ************************** CREATE TABLE ********* QUERY ********** insert into mytable values(100); ************************** INSERT 0 1 ********* QUERY ********** select * from mytable; ************************** firstcol ---------- 100 (1 row)将所有查询输出重定向到文件FILENAME步骤 1 创建文件,例如文件名为“outputOnly.txt”。touch /home/omm/openGauss/outputOnly.txt步骤 2 执行如下命令。gsql -d postgres -p 26000 -o /home/omm/openGauss/outputOnly.txt 步骤 3 进入gsql环境,输入以下语句:postgres=# drop table mytable; postgres=# create table mytable (firstcol int); postgres=# insert into mytable values(100); postgres=# select * from mytable; postgres=# \q 所有操作都没有回显。步骤 4 查看“outputOnly.txt”文档中的内容如下:cat /home/omm/openGauss/outputOnly.txt显示如下:DROP TABLE CREATE TABLE INSERT 0 1 firstcol ---------- 100 (1 row) "/opt/software/openGauss/output.txt" 8L, 76C 安静模式安静模式:执行时不会打印出额外信息gsql -d postgres -p 26000 -q进入gsql环境,输入以下语句:postgres=# create table t_test (firstcol int); postgres=# insert into t_test values(200); postgres=# select * from t_test; firstcol ---------- 200 (1 row) postgres=# \q连接上数据库,创建数据库和插入数据等都没有回显信息。单行运行模式单行运行模式:这时每个命令都将由换行符结束,像分号那样gsql -d postgres -p 26000 -S进入gsql环境,输入以下语句:postgres^# select * from t_test; firstcol ---------- 200 (1 row) postgres^# select * from t_test firstcol ---------- 200 (1 row) postgres=# \q语句最后结尾有;号和没有;号,效果都一样。编辑模式步骤 1 如下命令连接数据库,开启在客户端操作中可以进行编辑的模式。gsql -d postgres -p 26000 -r步骤 2 进入gsql环境,输入以下语句:步骤 3 写完后不要按回车,光标在最后闪烁。步骤 4 按“向左”键讲光标移动到“*”,将此符号修改为“firstcol”。编辑模式“上下左右键”,“删除键”和“退格键”都可以使用,并且按下“*向上”、“向下”键可以切换输入过的命令。步骤 5 退出数据库连接。postgres=# \q远程使用用户名和密码连接数据库远程使用jack用户连接ip地址为192.168.0.58端口号为26000的数据库。登录客户端主机(192.168.0.58),使用以下命令远程登录数据库。gsql -d postgres -h 192.168.0.58 -U jack -p 26000 -W Bigdata@123;-d参数指定目标数据库名、-U参数指定数据库用户名、-h参数指定主机名、-p参数指定端口号信息,-W参数指定数据库用户密码。进入gsql环境,显示如下:gsql ((openGauss 1.0 build ec0e781b) compiled at 2020-04-27 17:25:57 commit 2144 last mr 131 ) SSL connection (cipher: DHE-RSA-AES256-GCM-SHA384, bits: 256) Type "help" for help. postgres=> gsql元命令使用前提条件以下操作在openGauss的数据库主节点所在主机上执行(本地连接数据库),使用gsql连接到openGauss数据库。步骤 1 切换到omm用户,以操作系统用户omm登录数据库主节点。su - omm步骤 2 gsql连接数据库。gsql -d postgres -p 26000 -r 打印当前查询缓冲区到标准输出步骤 1 创建“outputSQL.txt”文件。touch /home/omm/openGauss/outputSQL.txt步骤 2 连接数据库。gsql -d postgres -p 26000 -r步骤 3 输入以下语句。postgres=# select * from pg_roles; rolname | rolsuper | rolinherit | rolcreaterole | rolcreatedb | rolcatupdate | rolcanlogin | rolreplication | rolauditadmin | rolsy stemadmin | rolconnlimit | rolpassword | rolvalidbegin | rolvaliduntil | rolrespool | rolparentid | roltabspace | rolconfig | oid | roluseft | rolkind | nodegroup | roltempspace | rolspillspace ---------+----------+------------+---------------+-------------+--------------+-------------+----------------+---------------+------ ----------+--------------+-------------+---------------+---------------+--------------+-------------+-------------+-----------+----- --+----------+---------+-----------+--------------+--------------- omm | t | t | t | t | t | t | t | t | t | -1 | ******** | | | default_pool | 0 | | | 1 0 | t | n | | | joe | f | t | f | f | f | t | f | f | f | -1 | ******** | | | default_pool | 0 | | | 1725 5 | f | n | | | (3 rows) postgres=# \w /home/omm/openGauss/outputSQL.txt postgres=# \q步骤 4 打开文件“outputSQL.txt”文件,查看其中内容。cat /home/omm/openGauss/outputSQL.txt显示如下:select * from pg_roles;导入数据步骤 1 连接数据库。gsql -d postgres -p 26000 -r步骤 2 创建目标表a。postgres=# CREATE TABLE a(a int);步骤 3 导入数据,从stdin拷贝数据到目标表a。postgres=# \copy a from stdin;出现>>符号提示时,输入数据,输入.时结束。Enter data to be copied followed by a newline. End with a backslash and a period on a line by itself. >> 1 >> 2 >> \.步骤 4 查询导入目标表a的数据。postgres=# SELECT * FROM a; a --- 1 2 退出数据库:postgres=# \q步骤 5 从本地文件拷贝数据到目标表a,创建文件/home/omm/openGauss/2.csv。vi /home/omm/openGauss/2.csv步骤 6 输入i,切换到INSERT模式,插入数据如下:3 4 5如果有多个数据,分隔符为‘,’。在导入过程中,若数据源文件比外表定义的列数多,则忽略行尾多出来的列。步骤 7 按下Esc键,输入“:wq”后回车,保存并退出。步骤 8 连接数据库。gsql -d postgres -p 26000 -r步骤 9 如下命令拷贝数据到目标表。postgres=# \copy a FROM '/home/omm//openGauss/2.csv' WITH (delimiter',',IGNORE_EXTRA_DATA 'on');步骤 10 查询导入目标表a的数据。postgres=# SELECT * FROM a; a --- 1 2 3 4 5 (5 rows)查询表空间postgres=# \db 显示如下:postgres=> List of tablespaces Name | Owner | Location ------------+-------+---------- pg_default | omm | pg_global | omm | (2 rows)查询表的属性步骤 1 创建表customer_t1。postgres=# DROP TABLE IF EXISTS customer_t1; postgres=# CREATE TABLE customer_t1 ( c_customer_sk integer, c_customer_id char(5), c_first_name char(6), c_last_name char(8) );步骤 2 查询表的属性。postgres=# \d+;显示如下:Schema | Name | Type | Owner | Size | Storage | Description --------+-------------+-------+-------+------------+----------------------------------+------------- public | customer_t1 | table | omm | 0 bytes | {orientation=row,compression=no} | public | mytable | table | omm | 8192 bytes | {orientation=row,compression=no} | public | t_test | table | omm | 8192 bytes | {orientation=row,compression=no} | public | ta | table | omm | 0 bytes | {orientation=row,compression=no} | (4 rows)步骤 3 查询表customer_t1的属性。postgres=# \d+ customer_t1;显示如下: Table "public.customer_t1" Column | Type | Modifiers | Storage | Stats target | Description ---------------+--------------+-----------+----------+--------------+------------- c_customer_sk | integer | | plain | | c_customer_id | character(5) | | extended | | c_first_name | character(6) | | extended | | c_last_name | character(8) | | extended | | Has OIDs: no Options: orientation=row, compression=no查询索引信息步骤 1 在表customer_t1上创建索引。create index customer_t1_index1 on customer_t1(c_customer_id);步骤 2 查询索引信息。postgres=# \di+;显示如下: List of relations Schema | Name | Type | Owner | Table | Size | Storage | Description --------+--------------------+-------+-------+-------------+------------+---------+------------- public | customer_t1_index1 | index | omm | customer_t1 | 8192 bytes | |步骤 3 查询customer_t1_index1索引的信息。postgres=# \di+ customer_t1_index1显示如下: List of relations Schema | Name | Type | Owner | Table | Size | Storage | Description --------+--------------------+-------+-------+-------------+------------+---------+------------- public | customer_t1_index1 | index | omm | customer_t1 | 8192 bytes | |切换数据库步骤 1 创建数据库。DROP DATABASE IF EXISTS db_tpcc02; CREATE DATABASE db_tpcc02;步骤 2 切换数据库。postgres=# \c db_tpcc02;显示如下:Non-SSL connection (SSL connection is recommended when requiring high-security) You are now connected to database "db_tpcc" as user "omm". db_tpcc=# 步骤 3 退出数据库:postgres=# \q -
大家好!我是酷哥,一周精选,带您速览,欢迎大家关注。 **本期整理如下:** ------------------------------------------------**本期精选**------------------------------------------------ - 数据库产业发展综述 - IDC:中国关系型数据库软件市场报告 - 墨天轮2021年度中国数据库魔力象限 - 开源、智能化、隐私安全等八大数据库发展趋势 - 原生分布式数据库与分库分表中间件、云原生数据库有何区别 - Neo4j 针对2022图数据平台发展的十大预测 - 云产融合是方向 人才竞争更关键 - 10个大数据挑战以及应对方法 ------------------------------------------------**资讯全文**------------------------------------------------ - 数据库产业发展综述 **摘要:** 本文节选自中国信通院于2021年6月24日在“2021大数据产业峰会”上发布的《数据库发展研究报告(2021年)》全球数据库产业生态成熟壮大,在发展过程中,逐渐细分出数据库产品、数据库服务和数据库支撑体系三个细分产业。 数据库产品主要由关系型数据库、非关系型数据库、混合型数据库及数据库周边工具构成。数据库服务是指围绕数据库的咨询规划、实施部署和运维运营等环节,为数据库系统的正常、高效、持续、安全使用提供信息技术服务工作。数据库支撑体系由从事数据库学术研究、人才培养、开源社区、评测认证等工作的相关主体共同构成。 据中国信通院测算,2020年全球数据库市场规模为671亿美元,其中中国数据库市场规模为35亿美元(约合240.9亿元人民币),占全球5.2%。预计到2025年,全球数据库市场规模将达到798亿美元。中国的IT总支出将占全球12.3%。我们预计,中国数据库市场在全球的占比将在2025年接近中国IT总支出在全球的占比,中国数据库市场总规模将达到688亿元,市场年复合增长率(CAGR)为23.4%。 **文章详情:** https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=178100 - IDC:中国关系型数据库软件市场报告 **摘要:** 1月17日,国际数据公司(IDC)发布的《2021年上半年中国关系型数据库软件市场跟踪报告》显示,2021上半年中国关系型数据库软件市场规模为11.9亿美元,整体市场同比增长37.2%,其中,公有云关系型数据库规模6.7亿美金,同比增长50.1%;本地部署关系型数据库规模5.2亿美金,同比增长23.7%。IDC预测,2021全年中国关系型数据库软件市场规模为27.5亿美元, 到2025年将达到76.7亿美元,未来5年市场年复合增长率(CAGR)为30.4%。 **文章详情:** https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=177976 - 墨天轮2021年度中国数据库魔力象限 **摘要:** 墨天轮2019年6月即推出了中国数据库流行度排行,排行榜中的数量也从50增加到194个,见证着中国数据库近三年的蓬勃发展。 墨天轮参考 Gartner 的魔力象限模型,结合墨天轮数据库流行度排行表现,综合得出了2021年度中国数据库魔力象限(魔力象限、领导者象限、挑战者象限、远见者象限)。 **文章详情:** https://bbs.huaweicloud.com/forum/thread-178379-1-1.html - 开源、智能化、隐私安全等八大数据库发展趋势 **摘要:** 新年换旧年之际,便到了盘点时间。随着数字经济不断发展,数据库的重要性愈发凸显。数据库技术有怎样的发展新趋势? ITPUB&IT168结合一些大会上嘉宾的演讲、采访,以及对市场的观察和理解,梳理出数据库技术八大趋势:开源、智能化、隐私安全、软硬一体、上云、分布式、细分场景、架构融合。 **文章详情:** https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=178306 - 原生分布式数据库与分库分表中间件、云原生数据库有何区别 **摘要:** 如今,我们正处于数据库从互联网基础软件转变为社会数字化基础软件的时代,在传统集中式数据库已不能满足大规模数据承载需求与高并发处理需求的形势下,基于海量数据场景应用而生的分布式数据库迎来应用热潮。据IDC调研,目前约26.8%的企业级市场用户部署了分布式数据库,超过90%的企业认可分布式数据库部署后的效果。 在分布式数据库中,主要有三类解决方案,一类是以中间件+单机数据库为主的分布式数据库,下层的单机数据库提供存储和执行能力,在多个单机数据库上封装一层中间层,以统一分片规则管理及处理分布在不同数据库节点的数据,并提供SQL解析,请求转发和结果合并的能力;第二类是原生分布式数据库,在架构设计之初,便根据分布式一致性协议做底层设计,因此,数据的存储、查询、处理都天然具备分布式特性,各数据节点提供对等的读写服务,组成统一的集群对外提供服务;第三类是通过构建分布式共享存储实现扩展,采用非对称计算节点,大部分公有云数据库都属于此类。在本文中,我们重点说说前两类。 **文章详情:** https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=178099 - Neo4j 针对2022图数据平台发展的十大预测 **摘要:** 数字化经济方兴未艾的浪潮中,中国各类企业乃至政府都面临着数字化转型的挑战。而随着疫情的逐步稳定,是否能成功实现数字化转型成为重要的核心竞争力。作为转型的要素之一,数据日益复杂,且随着世界的连接而愈加密切地相互关联。 以大数据、云计算、人工智能为代表的新一代数字技术日新月异,其中图技术就是数据库产业中增长最快且最具发展前景的领域。根据 Gartner®预测,“到2025年,使用图技术进行数据和分析创新的比例将由2021年的10%提升至80%。”各种类型的数据关联越来越普遍和重要,不同规模价值企业对图技术认知也不断提升。 **文章详情:** https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=177859 - 云产融合是方向 人才竞争更关键 **摘要:** 受疫情影响,全球大多数企业线下活动受到明显冲击,线上服务的需求激增,从而带动了云计算服务市场。赛迪数据显示,2020年,全球云计算市场销售额为2957.6亿美元,增速为9.8%,2021年更是有增无减。在政策推动和市场需求的刺激下,分析者普遍认为,未来几年,云计算市场的强劲发展势头有望保持下去。另外,云计算后半程的竞争,云产融合是发展方向,人才竞争才是关键。 **文章详情:** https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=177920 - 10个大数据挑战以及应对方法 **摘要:** 执行良好的大数据战略可以简化运营成本、缩短上市时间并支持新产品。但是,在将董事会讨论的大数据举措付诸实践的过程中,企业面临着各种大数据挑战。 IT和数据专业人员需要构建物理基础架构,以便在不同来源和多个应用程序之间移动数据。他们还需要满足性能、可扩展性、及时性、安全性和数据治理的要求。此外,企业必须预先考虑部署成本,因为它们可能会迅速失控。 ERP软件提供商VAI的商业智能经理Bill Szybillo说:“大数据项目面临的最大挑战之一是,如何成功应用所获得的见解。”他解释说,很多应用程序和系统都在捕获数据,但企业往往难以理解什么是有价值的数据,而且无法应用这些见解。 **文章详情:** https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=178206 上一期:[【技术之声】第五期(20220117)一周精选](https://bbs.huaweicloud.com/forum/thread-177954-1-1.html) ------------ *声明:文章源于第三方公开的信息,如内容中涉嫌侵权或存在信息不实时,请及时联系删除。* 整理者:酷哥
-
墨天轮2019年6月即推出了中国数据库流行度排行,排行榜中的数量也从50增加到194个,每月一日更新,同时发布上月的大事记以及排行榜解读文章,另外我们举办了各种类型与中国数据库相关的活动,见证了中国数据库近三年的蓬勃发展,也为数据库国产化贡献了一份力量。2021年度中国数据库魔力象限墨天轮参考 Gartner 的魔力象限模型,结合墨天轮数据库流行度排行表现,综合得出了2021年度中国数据库魔力象限。魔力象限(Gartner Magic Quadrant)由Gartner于2006年推出,该模型是对某一特定企业级 IT 技术市场的研究总结。墨天轮选取2021年年度平均分排行前40的数据库产品,通过2021年平均分、最新得分、三方评测(TPC-C、TPC-DS、TPC-H、大数据产品能力以及电信行业能力)、生态(社区平台、高校合作、培训认证、开放文档、代码开源、介质下载)以及论文和专利数量综合评定,同时参考了该数据库在 Gartner 全球云数据库魔力象限的表现以及 IDC 全球数据库市场份额报告。最后将数据汇总到两个维度上 — Ability to Execute(执行层面,即当前产品、服务、销售等表现)和 Completeness of Vision (战略层面,即未来愿景的清晰完整性),根据各家供应商们的表现,将其划分入如下四个象限中,分别为:领导者、远见者、挑战者和特定领域者。领导者象限领导者象限代表当前数据库产品及服务能力强,市场销售表现好,客户满意度较高,同时有清晰完整的未来战略。该象限中有7个数据库:● TiDBTiDB 是 PingCAP 公司研发的开源分布式关系型数据库,是一款同时支持在线事务处理与在线分析处理(HTAP)的融合型分布式数据库产品,具备水平扩容或者缩容、金融级高可用、实时 HTAP、云原生的分布式数据库、兼容 MySQL 5.7 协议和 MySQL 生态等重要特性。TiDB技术创新能力处于世界领先水平,每年会进行超过 40% 的代码更新,在GitHub上获得逾3万颗星,已应用于全球超过 2000 家头部企业。● OceanBase蚂蚁集团 OceanBase 连续 8 年稳定支撑双 11,创新推出“三地五中心”城市级容灾新标准,是全球唯一在 TPC-C 和 TPC-H 测试上都刷新了世界纪录的国产原生分布式数据库,具备高可用、高扩展、高兼容、易管理、部署灵活、高性价比等特点,已助力 200+ 行业客户实现核心系统升级。在区域性的银行、保险、证券及基金公司中,OceanBase市场占比达到行业第一。来自非金融类客户的营收占比已达到OceanBase总营收的35%,且在快速增长中。● PolarDB阿里云 PolarDB 是全球范围内业界首个实现了存储、内存及计算三层解耦的云原生数据库,为用户提供具备极致弹性、海量存储、高性能、低成本的数据库服务。PolarDB目前兼容三种数据库引擎:MySQL、PostgreSQL、高度兼容Oracle语法。计算能力最高可扩展至1000核以上,存储容量最高可达 100T。PolarDB已经全面应用于天猫双11的交易、买家、卖家以及物流等系统,刷新了数据库处理峰值记录,高达1.4亿TPS。● 达梦达梦数据库源代码100%自主研发,特别是 DM8,是国内第一款实现数据共享存储集群的数据库,支持超大规模并发事务处理和事务-分析混合型业务处理,动态分配计算资源,降低成本。达梦数据库系列产品及解决方案现已服务于国内外用户数十万家,装机产品累计近百万套,已在金融、电力、民航、通信、审计、公安、铁路、电子政务、应急救援等50多个关乎国计民生的行业领域取得广泛应用。● GaussDB华为 Gauss 数据库是全球首款企业级 AI-Native 分布式数据库,将AI能力植入到数据库内核的架构和算法中,使其具备一定的自运维、自管理、自调优、故障自诊断和自愈的能力。Gauss 数据库异构计算支持X86、ARM、GPU、NPU,支持行存储和列存储,可增加节点实现存储、查询及加载性能的线性扩展,集群最大可扩展至 2048 个节点,支撑 PB 级数据管理能力。GaussDB已在1500+金融政企与泛互联网大客户取得规模商用。● openGaussopenGauss 是华为推出的一款企业级开源关系型数据库。在主备模式下60%满负载故障切换时间10秒以内;利用 AI 进行智能参数调优和索引推荐,可减少 85% 的传统索引,且索引的推荐准确率达 90%;支持全密态计算;结合鲲鹏硬件优化,1000wh数据量可跑到150万tmpC,相对业界主流产品的性能超过50%。openGauss全球下载量超50万,超过2500名开发者参与技术贡献,诸多合作伙伴基于openGauss打造商业发行版。● TDSQLTDSQL 是腾讯云企业级分布式数据库,旗下涵盖金融级分布式、云原生、分析型等多引擎融合的完整数据库产品体系,提供业界领先的金融级高可用、计算存储分离、数据仓库、企业级安全等能力,同时具备智能运维平台、Serverless版本等完善的产品服务体系 。TDSQL已被3000多家来自金融、公共服务和电信垂直行业的客户采用,中国十大银行中的六家都应用了该产品,在金融行业的核心系统国产化替换场景中表现抢眼。挑战者象限挑战者象限代表产品及服务能力较强,经营状况良好,有一定的市场占有率,拥有强大的企业生存能力和财务稳定性,并表现出强大的客户支持。该象限中有2个数据库:● Gbase南大通用 GBase 系列 主要包括分布式分析型数据库 GBase 8a、交易型数据库 GBase 8s、分布式交易型数据库 GBase 8c,以及目录型数据库 GBase 8d。目前已在金融、电信、政企、安全等关键领域得到规模化应用,服务范围覆盖全国 32 个省级行政区域,建立节点超过 30000 个,管理数据总量超过 300PB。● 人大金仓人大金仓 KingbaseES 搭载高内聚、低耦合的可扩展内核架构,支持大数据分析,单机单表支持140TB级大数据量存储;具备自动发现问题、诊断问题、异常发生的自愈以避免业务中断;具有良好的容灾恢复能力,支持双机热备功能。金仓数据库广泛服务于电子政务、国防军工、能源、金融、电信等千行百业,累计装机部署近100万套。远见者象限远见者象限表示数据库市场有着深刻的市场理解和强大的技术路线图,虽然当前的市场份额相对较少,但是作为长期主义者,他们对未来有十足的把握和信心。该象限中有2个数据库:● AnalyticDBAnalyticDB是阿里云自主研发的云原生数据仓库,采用存储计算分离+多副本架构,支持最大5000节点规模的弹性扩容,对复杂SQL查询速度比传统的关系型数据库快10倍以上。AnalyticDB高度兼容MySQL、PostgreSQL,Oracle应用迁移成本低,可对万亿级别的数据进行实时的多维度分析透视,极大地提升了企业挖掘数据价值效率。● SequoiaDBSequoiaDB (巨杉)作为一款金融级分布式数据库,多数据中心间容灾可做到 RPO = 0,RTO < 15秒。SequoiaDB 基于湖仓一体架构,能支撑联机交易和联机分析的场景,支持ACID事务一致性。在面向在线系统提供业务流程中,提供声纹指纹、人脸识别、音视频交互等联机处理的支持;更可以基于AI及机器学习,对非结构化的数据进行治理,实现与其他重要系统的交互。特定领域者象限特定领域者表示通过提供高度专业化的产品在某些场景下有独特的优势,能够高效解决特定问题,如客户明确产品及功能的使用定位,采用特定领域者产品也是一种好的选择。该象限中有8个数据库:● 神舟通用神通数据库是企业级大规模并行处理分布式关系型数据库,具备高兼容、高可靠、高安全、异地容灾等特点。神通数据库获得公安部国家安全四级的高安全等级认证,在长五火箭发射、“天问一号”探火、“天和”核心舱等任务中都有应用。神通数据库不仅成功应用于国防军工、航天等关键行业,也在政府、金融、电信、网安、能源等领域全面开花。● GoldenDB中兴通讯 GoldenDB 是一款具有银行基因的金融级分布式数据库产品,从架构层面保证事务强一致和数据高可靠,并可根据业务需要实现在线扩容,支持金融行业已有业务升级及创新业务快速部署的需求。GoldenDB 产品已覆盖国有大行、股份制银行、农信联社、城商行及农商行全系列银行。● TcaplusDBTcaplusDB 是腾讯专为游戏设计的分布式 NoSQL 数据库。结合内存和 SSD 高速磁盘,针对游戏业务的开发、运营需求,TcaplusDB 支持全区全服、分区分服的业务模式,为游戏业务爆发增长和长尾运维提供不停服扩缩容、自动合服等功能。TcaplusDB已应用于《王者荣耀》、《天涯明月刀手游》、《QQ飞车》等数百款腾讯游戏。● GoldilocksGoldilocks 是科蓝软件拥有完整自主知识产权的分布式内存数据库,具有极强的高并发、高吞吐量、低延时的性能优势,支持在线横向扩展、收缩的能力,能够满足大数据处理的多样化业务需求,适用于金融、电信等对实时性要求较为严格要求的场景。● UXDBUXDB(优炫数据库)具备支持多种数据类型、在线弹性扩容、高可用性、高性能、高安全性、数据即服务等核心能力;可应用于高频联机系统、地理信息、数据仓库、商业智能等多业务场景;产品已完成与多数芯片、操作系统、应用软件厂家适配,支持众多应用软件的稳健运行;满足我国政府、军工、金融、能源、制造、医疗等各行业产业升级需求。● TDengineTDengine 是涛思数据专为物联网、车联网、工业互联网、IT运维等设计和优化的时序数据库。除核心的快10倍以上的时序数据库功能外,还提供缓存、数据订阅、流式计算等功能,最大程度减少研发和运维的复杂度,且核心代码,包括集群功能全部开源。● MogDBMogDB 是云和恩墨基于基于华为openGauss内核推出的企业发行版。相较于MySQL,MogDB主备之间的数据一致性更容易得到保障。同时,MogDB可以提供SQL兼容性分析、性能压测对比分析、极限数据恢复等管理组件,帮助企业级用户方便高效地使用openGauss,减轻运维压力。目前,MogDB已应用在民生银行、哈尔滨银行、渤海财险、合众人寿等多个金融行业客户的核心或关键业务系统上。● EsgynDBEsgynDB(易鲸捷) 是一款企业级融合型分布式数据库。融合OLTP与OLAP能力,支持结构化与非结构化数据统一存储。相较于传统数据库,EsgynDB 的实时分析特性与分布式架构更能支撑5G时代的物联网、人工智能、智能制造、区块链等新兴技术对于实时海量数据的融合管理需求。以上象限仅供参考,具体市场请根据各自项目需求进行选型及测试验证。中国数据库的黄金年代国产化背景从2019年开始,中美贸易战常态化,华为等多家中国企业列入“实体清单”,同时芯片等多项技术及设备被列上“管制清单”,数据库、中间件、操作系统三大基础软件也在“卡脖子”之列,过去一直被美国巨头占据。结合国内数据产业的迅猛发展,数据库作为与之最紧密的软件成为国内企业争相突破的技术,追求自主创新、安全可控。中国数据库主要分为以下三类:以达梦、人大金仓、南大通用、神舟通用四大传统数据库厂商,在政务、能源等行业保持较高的市场占有率;阿里、华为、腾讯、中兴等头部科技企业,首先自有场景的数据库替换,然后通过公有云对外通过提供服务,近几年又从云上数据库并下沉到私有云平台的市场;最后就是PingCAP、易鲸捷、瀚高、巨杉等独立创业公司,通过分布式等技术在金融行业占据了半壁江山。通过数据库发展源流图发现,当前中国数据库多数是从MySQL以及PostgreSQL演讲而来,然后在兼容性、易用性进行了大量改造,同事通过降低国外商业数据库迁移的成本,使得中国数据库慢慢发展起来,开源数据库已经成为中国数据库突破实现突围、发展自主可控产品的主要途径。从2020年6月,华为建立openGauss开源社区,并于2021年3月发布第一个Release版本;2021年5月,阿里云宣布对外开放关系型数据库PolarDB for PostgreSQL源代码,同年6月,蚂蚁集团宣布开源OceanBase。2022年1月11日中国软件行业协会发布《中国软件根技术发展白皮书(基础软件册)》,表明当前国内已经开始着手构建自己的基础软件根技术。同时,我们注意到2020年我国高校和企业在 VLDB、ICDE 和 SIGMOD 数据库三大顶会上贡献占比为23.81%,也反映出目前中国数据库在技术创新上有了不错的成绩。近三年中国数据库大事记2019年-发展元年2019年8月28日,腾讯云一次推出五大数据库新品,包括数据库智能管家DBBrain、云原生数据库CynosDB正式商业化、数据库TBase启动公测、灾备服务DBS启动邀测、Redis混合存储版启动邀测。2019年10月2日,OceanBase打破数据库基准性能测试(TPC-C)的世界纪录,其tpmC值超过6000万,排名第一。2019年10月27日,采用中兴GoldenDB的中信银行信用卡中心核心业务系统上线运行。2020年-百家争鸣2020年6月30日,华为openGauss终于正式亮相,源代码开放、社区成立。2020年10月19日,易鲸捷数据库4.2亿中标贵阳银行核心业务系统中国数据库应用项目,创造了中国数据库的单一采购项目记录。2020年11月17日,PingCAP 完成 D 轮 2.7 亿美元融资,创造全球数据库历史新的里程碑。2021年-百花齐放2021年2月24日,华为云正式发布云数据库GaussDB(for openGauss)全网商用。2021年6月1日,蚂蚁集团自研数据库OceanBase宣布开源,开放近300万行源代码。2021年12月17日,Gartner 2021 云数据库管理系统魔力象限已经出炉。阿里云再次进入领导者象限,华为云进入特定领域者象限(NICHE PLAYERS),是国内入选的仅有两家企业。资本不断注入2019年开始资本大量进入中国数据库行业,其中2021年更是井喷式爆发,融资次数达到了20多次,融资额度超过30亿人民币。时间公司名称轮次金额2021年12月16日人大金仓战略融资近2亿人民币2021年12月9日智臾科技B轮1亿人民币2021年12月6日创邻科技A++轮过亿人民币2021年11月29日四维纵横A轮1亿元2021年11月19日拜贝思云计算科技天使轮300万美元2021年9月28日聚云位智B轮近亿人民币2021年8月25日偶数科技B+轮2亿人民币2021年7月20日PingCAPE轮数亿美元2021年7月12日睿帆科技A轮5000万人民币2021年7月8日人大金仓战略融资近亿人民币2021年6月22日中科知道天使轮1200万人民币2020年6月17日聚云位智A+轮未披露2021年5月24日涛思数据B轮4700万美元2021年5月9日易鲸捷战略投资5769万人民币2021年3月16日青云科技IPO上市7.644亿人民币2021年2月26日天云融创战略投资未披露2021年2月10日爱可生B轮近亿人民币2021年2月1日创邻科技A+轮数千万人民币2021年1月21日新炬网络IPO上市5.59亿人民币2021年1月18日智臾科技A轮数千万人民币数据库相关的上市公司有:优炫软件、科蓝软件、海量数据、东方国信、创意信息、金山云、青云科技,另外据悉有几家数据库厂商正处于上市前冲刺阶段。基础软件的投入成本和研发周期都非常长,在资本注入后,其中大部分都投入到研发中,只有数据库产品稳定、高效、安全,同时方便迁移和管理,替换原有市场也就变得非常容易,那么国内新增市场也就自然会优先采购中国数据库。政策持续利好当前中国数据库应用主要集中在金融、电信、政务、制造、互联网等行业,这离不开国家各种政策的引导,尤其是金融行业,人民银行等机构多次发文要求核心场景技术和产品自主可控,同时由于金融行业的高要求,也成了中国数据库的试炼场,经过近几年的高速发展和场景磨炼,已经有了非常成熟的金融行业案例。2021年12月12日,为应对新形势新挑战,把握数字化发展新机遇,拓展经济发展新空间,推动我国数字经济健康发展,依据《中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要》,支持具有自主核心技术的开源社区、开源平台、开源项目发展,推动创新资源共建共享,促进创新模式开放化演进。2022年1月16日出版的第2期《求是》杂志发表中共中央总书记的重要文章《不断做强做优做大我国数字经济》。文章指出要全面推进产业化、规模化应用,培育具有国际影响力的大型软件企业,重点突破关键软件,推动软件产业做大做强,提升关键软件技术创新和供给能力。市场足够大据IDC预测,2021全年中国关系型数据库软件市场规模为27.5亿美元,到2025年将达到76.7亿美元,未来5年市场年复合增长率(CAGR)为30.4%。据信通院预测,中国数据库市场总规模将达到688亿元,市场年复合增长率(CAGR)为23.4%,假如出现传统头部企业占据70%的市场,那就是480亿的营收。以上两个预测数据库行业市场规模年复合增长率都超过20%,属于高新赛道,一定会有更多的“玩家”加入,让技术、产品、生态、服务等都会得到快速发展。中国数据库未来发展趋势数据库私有云平台Gartner预测到2023年,全球数据库市场中75%的数据库将完成到云平台的迁移,公有云数据库的增速也将放缓,而下一个争夺的市场主要为数据库私有云平台,以云的方式部署在客户私有环境中,这样既享受了云的便捷,也打消了对公有云数据安全、可靠性等疑虑。开源生态建设2021年1月至今,在 DB-Engines 上开源数据库流行度超过商业数据库,开源生态建设既是帮助企业商业布局的利器,也是促进技术发展和推广的重要手段,国内以PingCAP、openGauss等数据库为例,通过开源生态的建设,大大提升了品牌的影响力,未来阿里、腾讯等越来越多的厂商会加大开源生态的建设。分布式分布式数据库成为解决传统数据库瓶颈的主要手段。分布式数据库可以帮助企业应对海量数据和高增长的问题,在数据增大时可以平滑的水平扩展,解决了过去系统数据增大时需要人工进行分库分表的复杂和高风险的工作。HTAPHTAP数据库即需要同时支持OLTP和OLAP场景,在报表实时性要求不断提升,HTAP数据库通过对计算、存储架构的调整省去数据同步的过程,在同一套数据库中完成交易和报表的请求。AI随着数据量的不断暴增,减轻人力维护成本以及避免故障,通过引入AI,让数据库自动驾驶,如自动调优、自诊断、自愈、自组装等,最终实现对管理员透明,只需提供简单API即可,在保证稳定和性能的情况下,让易用性达到极致。文章来源:https://www.modb.pro/db/240097
-
维护宝典汇总贴1:https://bbs.huaweicloud.com/forum/thread-85548-1-1.html维护宝典汇总贴2:https://bbs.huaweicloud.com/forum/thread-98530-1-1.html维护宝典汇总贴3:https://bbs.huaweicloud.com/forum/thread-178341-1-1.htmlSupport上维护宝典链接:https://support.huawei.com/enterprise/zh/doc/EDOC1100160683?idPath=22658044%7C7919788%7C9856606%7C250949677本帖为GaussDB(DWS)维护宝典汇总贴3,欢迎在评论区交流探讨~篇一:【维护宝典汇总】GaussDB(DWS)维护宝典汇总贴1,欢迎大家交流探讨(持续更新中)篇二:【维护宝典汇总】GaussDB(DWS)维护宝典汇总贴2,欢迎大家交流探讨(持续更新中)序号主题分类标题链接272SQL如何pg_terminate_backend多条sqlhttps://bbs.huaweicloud.com/forum/thread-148364-1-1.html273SQL执行sql报错:ERROR:bufferoverflow,limitof20000https://bbs.huaweicloud.com/forum/thread-137344-1-1.html274SQL客户使用JDBC执行sql报错:ERROR:insufficientdataleftinmessagehttps://bbs.huaweicloud.com/forum/thread-119769-1-1.html275SQL报错:thespaceusedonDNhasexceededthesqlusespacelimithttps://bbs.huaweicloud.com/forum/thread-119304-1-1.html276SQL多nodegroup场景sql执行慢,查看等锁的wait-status是nonehttps://bbs.huaweicloud.com/forum/thread-123154-1-1.html277管控面【管控面升级】1859560,参数信息校验失败,措施信息:Failedtologingaussdbhttps://bbs.huaweicloud.com/forum/thread-154096-1-1.html278管控面【HCS管控面升级】ECF-Common/ECF-Cluster用户ecf登录验证失败https://bbs.huaweicloud.com/forum/thread-149808-1-1.html279管控面【DWS管控面升级】802升级803,参数信息校验失败:failedtologinmysqldbhttps://bbs.huaweicloud.com/forum/thread-141530-1-1.html280管控面【8.0.3】【Insight】【日志收集】serviceOM数仓界面收集DWS日志,报错500InternalERRORhttps://bbs.huaweicloud.com/forum/thread-146787-1-1.html281管控面【8.0.3】RdsPingInstanceManageIpTask失败,BMS实例未能正常开机https://bbs.huaweicloud.com/forum/thread-150640-1-1.html282管控面【8.0.3】DWS集群没有内网域名,查明为RdsCreatePrivateZoneTask失败。https://bbs.huaweicloud.com/forum/thread-150643-1-1.html283管控面【8.0.3】DWS安装完成后不显示创建集群按钮https://bbs.huaweicloud.com/forum/thread-150656-1-1.html284管控面DWS安装完成后页面无法显示规格https://bbs.huaweicloud.com/forum/thread-150650-1-1.html285管控面从mananger页面启动MPPDB失败,prestart报错执行kerberosUtility.py脚本报错https://bbs.huaweicloud.com/forum/thread-130127-1-1.html286管控面从mananger页面启动MPPDB失败,prestart报错cannotbindtoldapserverhttps://bbs.huaweicloud.com/forum/thread-130129-1-1.html287管控面登录管控面后台数据库dwscontrollerecfdmshttps://bbs.huaweicloud.com/forum/thread-173822-1-1.html288管控面DWS管控面服务修改参数并让参数立即生效https://bbs.huaweicloud.com/forum/thread-173819-1-1.html289集群【集群发放失败】实例创建到9x%无法创建/RdsActiveClusterTaskFAILhttps://bbs.huaweicloud.com/forum/thread-168394-1-1.html290集群【集群创建失败】64%失败/DWS.6000/RdsIntInstanceTaskFAILhttps://bbs.huaweicloud.com/forum/thread-161238-1-1.html291集群【集群创建失败】创建报错DWS.6000/在64%失败/RdsIntInstanceTask为FAILhttps://bbs.huaweicloud.com/forum/thread-158691-1-1.html292集群【集群创建失败】集群创建失败DWS.6000/进度40%失败/RdsPingInstanceManagerIpTaskhttps://bbs.huaweicloud.com/forum/thread-159358-1-1.html293集群【创建集群失败】DWS.6000/BMS.0047/进度32%https://bbs.huaweicloud.com/forum/thread-159362-1-1.html294集群【创建集群失败】进度到在50%,在RdsCreatePortTask任务FAILhttps://bbs.huaweicloud.com/forum/thread-153161-1-1.html295集群升级集群42%报错,更新系统表cannotchangereturntypeofexistingfunctiohttps://bbs.huaweicloud.com/forum/thread-148604-1-1.html296集群xx局点DWS8.0.1线下集群安装preinstall卡住https://bbs.huaweicloud.com/forum/thread-127017-1-1.html297集群XX局点安装集群时,安装日志提示超时报错https://bbs.huaweicloud.com/forum/thread-127791-1-1.html298集群DWS集群创建,BMS规格不显示https://bbs.huaweicloud.com/forum/thread-124336-1-1.html299集群oms组件iam状态exception,manager无法登录https://bbs.huaweicloud.com/forum/thread-174990-1-1.html300集群GaussDB(DWS)重建实例https://bbs.huaweicloud.com/forum/thread-165194-1-1.html301集群GaussDB(DWS)主备切换分析https://bbs.huaweicloud.com/forum/thread-156025-1-1.html302集群主机故障导致MPPDB集群降级https://bbs.huaweicloud.com/forum/thread-148606-1-1.html303集群新搭建集群,导入lisence文件失败https://bbs.huaweicloud.com/forum/thread-148600-1-1.html304集群DN长时间处于starting状态--(文件系统问题)https://bbs.huaweicloud.com/forum/thread-137897-1-1.html305集群GaussDB(DWS)单节点长时间故障应急https://bbs.huaweicloud.com/forum/thread-136663-1-1.html306集群【集群创建失败】DWS.6000/46%左右失败/RdsDownloadPackageTask失败https://bbs.huaweicloud.com/forum/thread-165795-1-1.html307集群集群更多查看监控指标不显示内容https://bbs.huaweicloud.com/forum/thread-153410-1-1.html308集群Toomanyopenfilesinsystem导致单节点故障,导致集群不可用https://bbs.huaweicloud.com/forum/thread-149144-1-1.html309集群重启集群https://bbs.huaweicloud.com/forum/thread-147701-1-1.html310集群某局点FIM页面有37031告警,CM_AGENT连接数据库失败https://bbs.huaweicloud.com/forum/thread-144626-1-1.html311集群【创建集群失败】ResTenantTask报错https://bbs.huaweicloud.com/forum/thread-160669-1-1.html312集群【8.0.3】创建DWS集群报错,资源租户VPC,后台查错误步骤为CreateResourceTenantVpcFailed,https://bbs.huaweicloud.com/forum/thread-146791-1-1.html313集群集群信息报异常DWS.0005访问资源不存在或状态异常https://bbs.huaweicloud.com/forum/thread-115811-1-1.html314集群【HC/HCS/HCSO】主备均衡https://bbs.huaweicloud.com/forum/thread-150166-1-1.html315集群【HC/HCS/HCSO】清理系统表https://bbs.huaweicloud.com/forum/thread-150164-1-1.html316集群【HC/HCS/HCSO】gs_replace修复实例https://bbs.huaweicloud.com/forum/thread-150101-1-1.html317集群重启集群https://bbs.huaweicloud.com/forum/thread-145772-1-1.html318集群主备均衡https://bbs.huaweicloud.com/forum/thread-145786-1-1.html319集群【gs_diagnose】集群故障诊断&&集群故障时间线梳理工具介绍https://bbs.huaweicloud.com/forum/thread-173152-1-1.html320变更扩容问题定位指南https://bbs.huaweicloud.com/forum/thread-116902-1-1.html321变更上传包报错,时间不同步,fcd的时间和swift时间https://bbs.huaweicloud.com/forum/thread-177763-1-1.html322变更C80SPC80x升级8.0.0.2升级集群42%报错,更新系统表失败updatacatalogfailedhttps://bbs.huaweicloud.com/forum/thread-175029-1-1.html323变更ECF-->Region:初始化Master虚拟机失败https://bbs.huaweicloud.com/forum/thread-168590-1-1.html324变更ECF-->Region:创建EI公共CDK集群安装失败https://bbs.huaweicloud.com/forum/thread-154104-1-1.html325变更老版本巡检工具speed_test残留排查方法https://bbs.huaweicloud.com/forum/thread-139009-1-1.html326变更添加主机第五步添加节点报diskmgt.service无法启动https://bbs.huaweicloud.com/forum/thread-139043-1-1.html327变更GaussDB(DWS)switchover标准步骤https://bbs.huaweicloud.com/forum/thread-140502-1-1.html328变更【8.1.1】某局点升级8.1.1在升级Manager步骤,DeployOMServer报错https://bbs.huaweicloud.com/forum/thread-145499-1-1.html329变更升级数据库报错,在【升级集群】步骤42%报错https://bbs.huaweicloud.com/forum/thread-148602-1-1.html330变更在33%RdsCreateInstance步骤失败https://bbs.huaweicloud.com/forum/thread-132763-1-1.html331变更租户面升级UpdatePreinstallTask失败https://bbs.huaweicloud.com/forum/thread-132748-1-1.html332变更报DWS.6004,BMS.0010,到30%失败,子任务执行到RdsCreateInstanceTaskhttps://bbs.huaweicloud.com/forum/thread-130122-1-1.html333变更报DWS.6000,到15%时创建失败,执行到RdsCreateResourceTenantVpcTaskhttps://bbs.huaweicloud.com/forum/thread-128955-1-1.html334变更升级数据库只读,DDL报错cannotexecutexinaread-onlytransactionhttps://bbs.huaweicloud.com/forum/thread-121738-1-1.html335变更升级停老集群阶段一个dn进程一直停不掉https://bbs.huaweicloud.com/forum/thread-121526-1-1.html336变更在升级集群前准备失败,升级日志报获取环境变量失败问题https://bbs.huaweicloud.com/forum/thread-120685-1-1.html337变更数据重分布重入时deletepgxc_redistb操作耗时长,3小时以上无法完成https://bbs.huaweicloud.com/forum/thread-116906-1-1.html338变更扩容问题定位方法解析https://bbs.huaweicloud.com/forum/thread-116903-1-1.html339变更重装主机FAQhttps://bbs.huaweicloud.com/forum/thread-116846-1-1.html340变更数据重分布报错pmk在个别dn上不存在https://bbs.huaweicloud.com/forum/thread-115557-1-1.html341变更【8.0.0.1】报错Failedtocheckusedspaceofthedatabaseusershttps://bbs.huaweicloud.com/forum/thread-115556-1-1.html342变更添加主机在初始化服务和实例失败,还原元数据报错optionfoldername存在非法字符https://bbs.huaweicloud.com/forum/thread-115555-1-1.html343标准方案更换ntp服务器https://bbs.huaweicloud.com/forum/thread-147725-1-1.html344标准方案修改iphttps://bbs.huaweicloud.com/forum/thread-145809-1-1.html345标准方案安装LVShttps://bbs.huaweicloud.com/forum/thread-145807-1-1.html346标准方案重装主机https://bbs.huaweicloud.com/forum/thread-145803-1-1.html347标准方案清理系统表https://bbs.huaweicloud.com/forum/thread-145800-1-1.html348标准方案gs_replace修复实例https://bbs.huaweicloud.com/forum/thread-145788-1-1.html349标准方案增加CNhttps://bbs.huaweicloud.com/forum/thread-145792-1-1.html350标准方案删除CNhttps://bbs.huaweicloud.com/forum/thread-145796-1-1.html351存储存储过程执行慢问题https://bbs.huaweicloud.com/forum/thread-153297-1-1.html352工具gsar网络监测工具使用及含义说明https://bbs.huaweicloud.com/forum/thread-121639-1-1.html353工具DWS监控脚本https://bbs.huaweicloud.com/forum/thread-135778-1-1.html354工具GaussDB(DWS)pg_xlogdump pagehack工具https://bbs.huaweicloud.com/forum/thread-142380-1-1.html355工具GaussDB(DWS)如何安装gdb/gstack/iotop工具https://bbs.huaweicloud.com/forum/thread-143096-1-1.html356工具GaussDB(DWS)calxid工具https://bbs.huaweicloud.com/forum/thread-147126-1-1.html357工具根据relfilenode查找Schema、表名,判断是表文件还是索引文件https://bbs.huaweicloud.com/forum/thread-173239-1-1.html358工具排查系统表索引、元组后置问题https://bbs.huaweicloud.com/forum/thread-171819-1-1.html359性能劣化DWS单点性能案例集锦https://bbs.huaweicloud.com/forum/thread-90331-1-1.html360性能劣化外表导入40G数据耗时1小时https://bbs.huaweicloud.com/forum/thread-177546-1-1.html361性能劣化常见GATHER慢问题集锦https://bbs.huaweicloud.com/forum/thread-161503-1-1.html362性能劣化DDL慢之系统表索引后置问题https://bbs.huaweicloud.com/forum/thread-161454-1-1.html363性能劣化列存小CU多导致的性能慢问题https://bbs.huaweicloud.com/forum/thread-161327-1-1.html364性能劣化GaussDB(DWS)为什么会出现普通用户比dbadmin用户执行的慢https://bbs.huaweicloud.com/forum/thread-116830-1-1.html365性能劣化GaussDB(DWS)第一次查询慢https://bbs.huaweicloud.com/forum/thread-116834-1-1.html366性能劣化批量绑定执行PBE形式语句性能分析https://bbs.huaweicloud.com/forum/thread-132681-1-1.html367性能劣化客户简单groupby查询慢,等待视图中有streamgetconnhttps://bbs.huaweicloud.com/forum/thread-136091-1-1.html368性能劣化性能问题之CN(Coordinator协调节点)hang问题汇总https://bbs.huaweicloud.com/forum/thread-136283-1-1.html369性能劣化explainperformance显示的执行时间短gsql返回的时间长https://bbs.huaweicloud.com/forum/thread-144153-1-1.html370性能劣化查询information_schema模式下的tables系统视图性能差https://bbs.huaweicloud.com/forum/thread-143470-1-1.html371性能劣化单点性能问题基础篇&实战篇&案例篇汇总https://bbs.huaweicloud.com/forum/thread-150120-1-1.html372性能劣化DWS系统级性能问题处理套路https://bbs.huaweicloud.com/forum/thread-150310-1-1.html373性能劣化未对ELK组件做操作,执行性能突然下降https://bbs.huaweicloud.com/forum/thread-146945-1-1.html374性能劣化短查询高并发导致性能下降https://bbs.huaweicloud.com/forum/thread-146934-1-1.html375性能劣化DWS性能问题之单节点IO高https://bbs.huaweicloud.com/forum/thread-152917-1-1.html376业务报错连接DWS集群报错theauthenticationtype5isnotsupportedhttps://bbs.huaweicloud.com/forum/thread-177553-1-1.html377业务报错随机DN频繁corehttps://bbs.huaweicloud.com/forum/thread-177550-1-1.html378业务报错gds报错unexpectedEOFonGDSconnection"gsfs://10.100.19.187:/500https://bbs.huaweicloud.com/forum/thread-177545-1-1.html379业务报错配置elb添加CN后,远程连接新CN执行DDL慢https://bbs.huaweicloud.com/forum/thread-177544-1-1.html380业务报错过多Savepoint导致查询慢https://bbs.huaweicloud.com/forum/thread-177388-1-1.html381业务报错表删除报错:relationdoesnotexistonDNhttps://bbs.huaweicloud.com/forum/thread-177376-1-1.html382业务报错作业报错:multipleupdatestoarowbyasinglequeryforcolumnstorhttps://bbs.huaweicloud.com/forum/thread-177250-1-1.html383业务报错DWS-10000告警https://bbs.huaweicloud.com/forum/thread-173717-1-1.html384业务报错部分监控面板没有信息https://bbs.huaweicloud.com/forum/thread-173708-1-1.html385业务报错SSH命令报错:"packet_write_wait:connectiontoport22:Brokenpipe"https://bbs.huaweicloud.com/forum/thread-169934-1-1.html386业务报错ECF-->Region:初始化Master虚拟机失败https://bbs.huaweicloud.com/forum/thread-168388-1-1.html387业务报错工作负载队列关联用户报错dnxxxx_xxxxpermspacepermspacelimithttps://bbs.huaweicloud.com/forum/thread-167044-1-1.html388业务报错工作负载队列接口异常https://bbs.huaweicloud.com/forum/thread-165343-1-1.html389业务报错集群ntp配置异常,节点时间有差异https://bbs.huaweicloud.com/forum/thread-164998-1-1.html390业务报错关于SmartRaid驱动问题导致DWS发放BMS集群失败的处理办法https://bbs.huaweicloud.com/forum/thread-162631-1-1.html391业务报错FI界面告警:gtm主备不同步或者断连https://bbs.huaweicloud.com/forum/thread-153822-1-1.html392业务报错使用mergeinto时,结果集不满足预期怎么办https://bbs.huaweicloud.com/forum/thread-153783-1-1.html393业务报错JDBC使用过程中的常见报错及处理方法https://bbs.huaweicloud.com/forum/thread-153750-1-1.html394业务报错数据库服务端编码是latin1,存入的字符格式是gbk,如何导出utf8格式的字符https://bbs.huaweicloud.com/forum/thread-153728-1-1.html395业务报错日志目录cm_agent/pg_log目录下javaudf函数打印大量日志https://bbs.huaweicloud.com/forum/thread-145332-1-1.html396业务报错GaussDB(DWS)pg_class中relpages页面估算严重不准https://bbs.huaweicloud.com/forum/thread-147133-1-1.html397业务报错【8.0.3】【DWS】【弹性EIP】解绑弹性IP报错,IP找不到,但EIP资源中该IP已处于解绑状态https://bbs.huaweicloud.com/forum/thread-147351-1-1.html398业务报错【8.0.3】【DWS】【连接实例】使用运维容器的connectTool连接实例,报错DecryptFailedhttps://bbs.huaweicloud.com/forum/thread-147084-1-1.html399业务报错copy入库失败,报错detail:1054SCTPconnectfailedhttps://bbs.huaweicloud.com/forum/thread-148605-1-1.html400业务报错update语句报错:multipleupdatestoarowbyasinglequeryforcolumhttps://bbs.huaweicloud.com/forum/thread-145415-1-1.html401业务报错spark连接dws报Theauthenticationtype5isnotsupporthttps://bbs.huaweicloud.com/forum/thread-140422-1-1.html402业务报错查询pg_rules系统表报错:unrecognizedquerycommandtype:7https://bbs.huaweicloud.com/forum/thread-141390-1-1.html403业务报错GaussDB(DWS)查询报错临时空间不足temporaryfilesizeexceedshttps://bbs.huaweicloud.com/forum/thread-140484-1-1.html404业务报错jdbc执行语句报错:preparedstatement"S_x"alreadyexistshttps://bbs.huaweicloud.com/forum/thread-132864-1-1.html405业务报错FusionInsightManager系统报错连接数据库失败,failedtoreadthedatabasehttps://bbs.huaweicloud.com/forum/thread-133442-1-1.html406业务报错内部连接场景一:pooler:Thenodedn_xx[xx]hasnoavailableslothttps://bbs.huaweicloud.com/forum/thread-125510-1-1.html407业务报错停止定时任务报错Cannotoperatethisjobduetorunningstatushttps://bbs.huaweicloud.com/forum/thread-119719-1-1.html408业务报错执行业务报错:Can'tfitxidintopagehttps://bbs.huaweicloud.com/forum/thread-116810-1-1.html409业务应急向elb监听器中增加后台云服务器组时报错ipaddressxxxisnotvalidIPforthespecihttps://bbs.huaweicloud.com/forum/thread-175760-1-1.html410业务应急通过容器登录DN失败报错:Load-Key“xxxxxxx”:Invalidformat;Mike@“ip”:Permishttps://bbs.huaweicloud.com/forum/thread-174755-1-1.html411业务应急HCS/HCSO形态DWS管控面故障案例总结https://bbs.huaweicloud.com/forum/thread-173841-1-1.html412业务应急DWSHCS场景netcardmonitor.sh脚本产生大量软终端,导致OS定期重启https://bbs.huaweicloud.com/forum/thread-173389-1-1.html413业务应急审计日志转储失败https://bbs.huaweicloud.com/forum/thread-171110-1-1.html414业务应急Dmsagent进程在长时间运行(4-5个月后)占用内存过多,导致内核无法分配内存,进程异常https://bbs.huaweicloud.com/forum/thread-168527-1-1.html415业务应急connectTool.sh连接cn节点超时port22:Connectiontimedouthttps://bbs.huaweicloud.com/forum/thread-155037-1-1.html416业务应急根目录满排查方法https://bbs.huaweicloud.com/forum/thread-154290-1-1.html417业务应急单实例重启或隔离https://bbs.huaweicloud.com/forum/thread-147713-1-1.html418业务应急单节点重启或隔离https://bbs.huaweicloud.com/forum/thread-147714-1-1.html419业务应急多个CN节点隔离https://bbs.huaweicloud.com/forum/thread-147718-1-1.html420业务应急升级数据库报错,You(omm)arenotallowedtousethisprogram(crontab)https://bbs.huaweicloud.com/forum/thread-144953-1-1.html421业务应急句柄不回收,空间不释放https://bbs.huaweicloud.com/forum/thread-145138-1-1.html422业务应急【HC/HCS/HCSO】查杀语句https://bbs.huaweicloud.com/forum/thread-150168-1-1.html423业务应急【HC/HCS/HCSO】单实例重启或隔离https://bbs.huaweicloud.com/forum/thread-150170-1-1.html424业务应急【HC/HCS/HCSO】单节点重启或隔离https://bbs.huaweicloud.com/forum/thread-150171-1-1.html425业务应急【HC/HCS/HCSO】重启集群https://bbs.huaweicloud.com/forum/thread-150174-1-1.html426业务应急【HC/HCS/HCSO】多个CN节点隔离https://bbs.huaweicloud.com/forum/thread-150172-1-1.html427业务应急如何查询残留线程https://bbs.huaweicloud.com/forum/thread-150382-1-1.html428业务应急某局点一个dn的pg_xlog一直增长https://bbs.huaweicloud.com/forum/thread-140434-1-1.html429业务应急DN线程残留导致表drop不掉的问题https://bbs.huaweicloud.com/forum/thread-143379-1-1.html430业务应急GaussDB(DWS)OMS节点上单机库的statscollector进程IO高https://bbs.huaweicloud.com/forum/thread-143389-1-1.html431应急系列【应急标准操作】【线下】查杀语句https://bbs.huaweicloud.com/forum/thread-147712-1-1.html432运维技巧【总结】GaussDB(DWS)现网运维常用命令,掌握这些就够了https://bbs.huaweicloud.com/forum/thread-140018-1-1.html【最新活动汇总】DWS活动火热进行中,互动好礼送不停(持续更新中) HOT 【推荐阅读】【博文汇总】GaussDB(DWS)博文汇总1,欢迎大家交流探讨~(持续更新中)【维护宝典汇总】GaussDB(DWS)维护宝典汇总贴1,欢迎大家交流探讨(持续更新中)【项目实践汇总】GaussDB(DWS)项目实践汇总贴,欢迎大家交流探讨(持续更新中)【DevRun直播汇总】GaussDB(DWS)黑科技直播汇总,欢迎大家交流学习(持续更新中)【培训视频汇总】GaussDB(DWS) 培训视频汇总,欢迎大家交流学习(持续更新中)扫码关注我哦,我在这
-
新年换旧年之际,便到了盘点时间。随着数字经济不断发展,数据库的重要性愈发凸显。数据库技术有怎样的发展新趋势?ITPUB&IT168结合一些大会上嘉宾的演讲、采访,以及对市场的观察和理解,梳理出数据库技术八大趋势:开源、智能化、隐私安全、软硬一体、上云、分布式、细分场景、架构融合。01、开源:开源上升为国策联合创新发力生态在《开源的诱惑——数据库篇》中,我写道:开源如一个意气风发的少年,在数据库领域大展拳脚。2021年初,根据DB-Engines的数据,开源数据库license数量首次超过商业数据库,这是开源数据库的里程碑,近两年开源数据库厂商融资屡创新高,不断刷新数据库单笔最高融资纪录。Gartner预计,到2025年,与目前的IT支出相比,超过70%的企业将增加开源软件方面的IT支出。开源社区被誉为当今科技领域最具创新的一种组织方式,专家强调数据库作为公认最为复杂跨技术领域最多的基础软件,也要充分利用开源和发展开源,广泛吸纳全产业力量。尤其国内,一系列政策利好开源发展,开源纳入“十四五”规划,成为国家战略,去年11月底,工信部印发《“十四五”信息化和工业化深度融合发展规划》指出,开源软件已经成为软件产业创新源泉和“标准件库”。同时,开源开辟了产业竞争新赛道,基于全球开发者众研众用众创的开源生态正加速形成。近年来,越来越多主流数据库产品选择开源来完善生态,打磨产品。比如,openGauss、PolarDB、OceanBase、浪潮云溪等选择开源……业内人士指出开源发展的需要在开放源码与商业发展之间找到平衡,而当前目国内开源生态还面临发展基础较弱、底层技术掌控不足、开源文化氛围不浓、政策支持有待加强等制约因素。02、智能化:AI与数据库结合智能化发展北航计算机学院童咏昕教授在openGauss Summit2021峰会上指出,从学术研究角度,AI与数据库结合的智能化成为最近几年数据库顶级会议里非常热门的研究主题之一。智能化分为两个方面,AI for DB,运用AI技术优化经典数据库算法。DB for AI,运用数据库技术提升人工智能性能。AI for DB方面,童咏昕介绍,传统的经典数据库优化算法称为理性主义,是问题导向,针对问题直接设计算法策略,不需要依赖数据库可以直接求解,在 最坏情况下算法性能具有理论保证。最近几年尤其是2018年之后学习型算法开始流行,可以称之为经验主义,数据导向。通过学习数据分布指导模型设计,在数据服从给定分布时能够取得更优效果,可以使数据库优化算法更快,但并不是有了学习算法就无敌了,更重要的是如何把经典的理性主义和数据驱动经验主义做有机融合,这是未来非常火的方向。DB for AI方面,近两年数据库顶级学术研究尤其在产业研究中多篇论文都共识了一个问题,机器学习的实战性能问题,很大一部分原因是来自数据库问题,数据库经典技术优化不好导致机器学习性能不好。数据库如何协助机器学习的技术也是最近几年非常热门的研究主题。03、隐私安全:法律法规监管加强以技术解决合规问题在数据库研究领域,隐私安全是数据库长期关注的主题。童咏昕指出,隐私和安全是两件事,安全关心计算过程的安全,隐私所强调的是拿出结果不能反推回原始数据。上世纪80年代已经开始提出了安全计算,而隐私计算从最简单的脱敏,到匿名化隐私,再到现在相关法律法规下如何合规处理数据,带来了挑战。2021年数据库顶级会议提出把数据库隐私研究和法律合规嫁接在一起。目前有很多合规要求,在不同隐私和安全约束下,如何自动用基础算子高效集成是最近几年在数据库研究中隐私安全的热点。此外,多实体间如何进行安全高效的数据共享也是数据库技术热点。传统大数据计算是计算不动数据动的架构,在传统架构下需要数据离开本地,但是法律法规要求数据不能离开本地,需要数据不动计算动。数据不动计算动的联邦计算框架区别于传统集中式共享,保护各方数据隐私安全。海量移动设备的端侧拥有大量隐私数据,通过联邦学习,保证个人敏感数据不离开端侧设备本地。最近几年可信执行环境(TEE)是非常火热的话题,比如,软硬结合的高效密态数据库系统,基于TEE的有限内存约束,设计高效的密态数据库框架。利用TEE提升设备的安全计算性能,构建面向海量设备的数据联邦等。如何真正执行安全多方计算,如何高效执行同态加密,这些都是未来数据库发展中安全可信技术的基石,软硬协同也非常重要。04、软硬一体:新硬件带来的机遇和挑战软硬一体化是当下数据库研究热点之一,主要因为新硬件技术为数据库领域带来机遇与挑战。有专家曾经指出,数据库首先是一个系统,而系统就需要能够安全高效地使用有限的硬件资源。所以数据库系统的设计和发展和硬件的发展紧密相关,数据库系统设计需要考虑新硬件所带来的变化。童咏昕在演讲中指出,在存储、网络、计算层面,新硬件都发挥着软硬结合的威力。比如在计算层面,新硬件如何优化数据库中的智能计算,如何支撑数据的隐私安全需求成为热点研究主题。面向数据处理的专用硬件不断产生,近年来除了CPU、GPU外,TPU、NPU等各式各样面向人工智能专用型芯片在不断产生,可以利用专用芯片优化数据库中的智能计算,而CPU与GPU合理协同也是当下研究热点,CPU与GPU混合的数据库查询处理,结合不同计算内核特点进行协同异构计算。05、上云:云原生到DBaaS上云是大势所趋,Gartner预计,到2022年,所有数据库中的75%将被部署或迁移到云平台,只有5%被考虑遣返到本地环境。到2023年,云数据库收入将占数据库市场收入总额的50%。根据日前IDC发布的《2021年上半年中国关系型数据库软件市场跟踪报告》显示,2021上半年中国关系型数据库软件市场公有云关系型数据库规模6.7亿美金,同比增长50.1%。IDC发现,云数据库厂商寻求在私有云、行业客户等传统数据库市场发展,本地部署数据库市场竞争加剧。由于利用了云资源的优势,云数据库具备弹性好、计费模式便捷、套件生态好等特点。不过上云并一定能够节省成本,中小企业成本会降低,大型企业可能会不降反升。在云时代,数据库的演化经历了从采购License自建到云上托管数据库,再到云原生数据库的转变。在OLAP场景下,Snowflake为云原生数据库的发展做出了很好的表率。云原生最大的特点是计算存储分离,有业内专家指出,计算存储分离还不够,未来计算、存储、网络、内存等都要分离解耦,随着未来企业逐步上云,底层基础设施云化,数据库不用关注底层的硬件CPU、磁盘、网络等,而是直接面向各类云服务,资源池化、容器化,真正实现多租户应用架构,订阅收费。如此才能更好发挥云的弹性、扩展、高可用等能力。云时代一切皆向服务化发展,DBaaS(数据库即服务)的时代将要到来。06、分布式:从预演到大规模落地随着摩尔定律的失效,当数据量达到一定量级时,单体集中式架构的瓶颈愈发明显,采用分布式数据库往往是必经之路。总体来看,由于国内企业组织有更大的规模和数据量,对于应用分布式数据库更为迫切。国产数据库寄希望于通过分布式数据库实现变道超车,近几年国产数据库不断成长,在一些难点如分布式事务性、一致性,以及数据容错、灾备等高可用能力方面取得了突破,分布式数据库进入到落地阶段。这一变化可以在DTCC大会上有直观的感受,一位专家在参加完DTCC2021大会后指出,几年前分布式、一致性与CAP/BASE等话题等相关技术细节话题是DTCC大会热点,近两年在DTCC已经没有嘉宾专门演讲相关主题,说明分布式与分布式事务、一致性等这些东西在技术界已经达成共识,在这几年也已经纷纷落地为产品。在政策层面分布式数据库迎来利好,2021年11月底,工信部印发的《“十四五”信息化和工业化深度融合发展规划》明确,加速分布式数据库等产品研发和应用推广。近几年分布式数据库投产金融核心系统的消息不断出现,经过前期大量的预演和准备工作,2022年分布式数据库在国内的落地值得期待。07、细分场景:图数据库、时序数据库细分场景应用成为数据库的一大趋势。图数据库以及时序数据库的发展是细分场景应用的代表,根据DB-Engines,从2013年图数据库流行度趋势一骑绝尘,DB-Engines 从 2014 年起也把时序数据库作为独立的目录进行分类统计,如上图,其流行度发展势头仅次于当红炸子鸡图数据库。2019年开始,DTCC大会设置了图数据库专场,在DTCC2021数据库技术大会,图数据库专场比较火爆受到广泛关注,时序数据库相关的演讲主题也多了起来,通过梳理发现,2021年不少时序数据库创业公司获得了融资。图数据库是一个使用图结构进行语义查询的数据库。图是天生为相关性而生,典型的应用场景如欺诈检测,通过将问题解构为图,更容易在现有数据中获得重要的见解。有国外图数据库专家指出,图数据库方面中外基本处在同一起跑线,甚至在新软硬件协同方面走在前面。有专家指出,目前,图数据库还存在许多挑战需要解决,比如数据的完备性、一致性,对分布式事务的支持以及与OLAP 和 OLTP 融合等。当前,万亿大图、大规模处理以及与新硬件的融合是图数据库的热点话题。时序数据库全称为时间序列数据库,时序数据库指主要用于处理带时间标签(按照时间的顺序变化,即时间序列化)的数据,随着5G商用启动,IoT不断发展,进入到万物互联时代,时序数据作为大数据、机器学习、实时预测、预警的基础数据的作用更加显著,堪称万物互联时代的基石,时序数据库将迎来重大发展机遇。08、架构融合:HTAP、湖仓一体、多模、集中式与分布式一体化架构融合的趋势之一是HTAP混合负载场景的发展,产业界当前正基于创新的计算存储框架研发HTAP数据库,其能够基于同一套引擎同时支撑业务系统运行和分析决策场景,避免在传统架构中,在线与离线数据库之间大量的数据交互。在数据驱动决策的大势所趋下,HTAP在实时数据分析处理方面的优势愈发明显。湖仓一体(Lakehouse)也是目前架构融合的一大趋势,Snowflake、Databricks是其中的代表。湖仓一体解决了传统数据库仓库在数据类型支持上的局限性,可以支持结构化、非结构化、半结构化多种数据类型。湖仓一体(Lakehouse)需要打通数据仓库和数据湖两套体系,让数据和计算在湖和仓之间自由流动。架构融合的另一大趋势是多模(Multi-Model),Gartner 曾在 2017 年预测多模数据管理将成为未来的主要趋势,多模架构逐渐成为主流数据库的选择。2010 年以来,随着移动化的发展以及数字化转型的逐步深化,快速变化的业务场景越来越复杂多元,半结构化、非结构化数据海量增长,单模型数据库虽然优化了数据存储和处理,却难以满足日趋增长的多样化业务场景需求。复杂多元的业务场景往往需要使用多种数据模型,以及数据模型间的融合。从单一数据管理系统到融合型、多模型数据管理系统成为数据库发展趋势。集中式与分布式一体化融合,OceanBase提出的第三代企业级分布式数据库所拥有的一体化架构特性,集中式与分布式一体化融合是一个比较新的概念,数据库系统同时具备分布式与集中式系统的技术优势,即使使用一台机器不用分布式时性能、功能不损失,而且能够随时进行分布式扩展。业务初期一台机器就可以先用起来,随着业务增长系统能力遇到瓶颈再做扩展。回看数据库发展趋势,我们可以看到天下大势分久必合合久必分,业务场景复杂多元化需求催生了图数据库、时序数据库等满足细分场景的数据库发展,而多个单模数据库所带来的管理复杂度等因素又促进多模融合架构发展。世上没有完美的数据库,也从来没有一款数据库可以包打天下,只有适合自己业务的数据库。面对百花齐放的数据库,如何进行数据库选型?ITPUB&IT168将在2022年推出数据库选型相关选题,敬请关注。文章来源:http://blog.itpub.net/69925873/viewspace-2853329/
-
>摘要:本文来自华为云MySQL研发团队,主要分享了MySQL备份工具Xtrabackup的备份过程、华为云数据库团队对其做的优化改进,以及在使用中可能遇到的问题与解决方法。本文分享自华为云社区[《华为云带你探秘Xtrabackup备份原理和常见问题分析》](https://bbs.huaweicloud.com/blogs/302682?utm_source=zhihu&utm_medium=bbs-ex&utm_campaign=database&utm_content=content),作者:GaussDB 数据库 。 本文来自华为云MySQL研发团队,主要分享了MySQL备份工具Xtrabackup的备份过程、华为云数据库团队对其做的优化改进,以及在使用中可能遇到的问题与解决方法。文章讨论的内容主要是针对华为云RDS for MySQL, 以及用户自建的社区版MySQL数据库,希望有助于大家理解和使用Xtrabackup,以后面对Xtrabackup问题也更加从容。 # 一、Xtrabackup简介 Xtrabackup是Percona团队开发的用于MySQL数据库物理热备份的开源备份工具,具有**备份速度快、支持备份数据压缩、自动校验备份数据、支持流式输出、备份过程中几乎不影响业务**等特点,是目前各个云厂商普遍使用的MySQL备份工具。 当前Xtrabackup存在两个版本:Xtrabackup 2.4.x与8.0.x,分别用于备份MySQL 5.x与MySQL 8.0.x 版本。下面我们分别介绍 Xtrabackup如何备份MySQL社区版以及华为云上的Xtrabackup的备份原理 # 二、社区版MySQL的Xtrabackup备份 Xtrabackup是为Percona MySQL设计的,同时也支持对官方社区版本MySQL进行备份,过程如下图所示:  图1:Xtrabackup备份官方MySQL流程示意 1. **兼容性检查**:Xtrabackup社区版本只支持 MyISAM , InnoDB , CSV , MRG_MYISAM 四种存储引擎的表,其他存储引擎的表不会备份;在这一步中,通过查询tables,若发现存在表的存储引擎不是上述四种引擎之一,会打印warning, 表明Xtrabackup不会备份该表。 2. **启动redo后台备份线程**:启动redo后台备份线程,从备份实例的最近一次checkpoint LSN的位置开始备份所有增量的redo log,一直持续到备份任务结束。 3. **加载所有的innodb表空间**:打开并扫描所有innodb表的数据文件,检查所有表空间的第一个页面,初始化所有表的内存结构。 4. **备份innodb表**:遍历步骤3所构建的表的内存结构,备份每一个innodb表的数据文件,备份的过程中会检查每个页面的数据是否正确。 5. **加备份锁 FLUSH TABLES WITH READ LOCK (FTWRL)**:FTWRL锁是MySQL实例级的读锁,加锁过程复杂,且加锁之后,所有表的所有更新操作以及DDL都会堵塞。 6. **备份非innodb表**:因为在步骤5我们已经对实例加了读锁,因此,此时备份非innodb表是安全的,此时一定没有写业务。 7. **记录binlog当前的GTID信息**:请注意,此时我们仍持有全局读锁。这一步主要是方便我们使用该备份集快速地创建出备机。 8. **停止redo备份线程**。 9. **释放锁资源,备份结束**。 需要注意的是,Xtrabackup 2.4.x与8.0.x在第7、8这两个步骤存在差异,这个差异有MySQL 8.0.x的原因,详情我们在下文介绍。 # 三、华为云RDS for MySQL备份 在备份社区版MySQL实例时,Xtrabackup会对实例加全局读锁(FTWRL),该锁对数据库的业务影响很大,严重时甚至会导致数据库“挂起”,这对客户来说是不可接受的。因此华为云MySQL团队对这个过程进行了优化,主要有两点: 1. 对MySQL 5.x以及0.x增加了备份锁:LOCK TABLES FOR BACKUP 2. 对MySQL 5.x新增了binlog锁:LOCK BINLOG FOR BACKUP 优化之后,华为云Xtrabackup对MySQL的备份过程如下:  图2 Xtrabackup备份华为云MySQL流程示意 与FTWRL锁相比,**备份锁 LOCK TABLES FOR BACKUP对客户实例影响很小,其加锁过程简单,加锁期间innodb表的DML操作不受影响**,但是非innodb表的所有的更新操作以及DDL操作仍然是不允许的。 备份完所有的表文件后,Xtrabackup需要获取binlog GTID信息。 - 对于MySQL 5.x版本,Xtrabackup 2.4.x会执行 LOCK BINLOG FOR BACKUP 操作,对binlog加锁,然后获取GTID信息。 - 对于MySQL 8.0.x版本,华为云Xtrabackup 8.0.x沿用官方的一致性备份点查询方法。Xtrabackup查询log_status 时,MySQL服务器会分别对redo log, binlog等加轻量级锁,获取一致性备份点,这个过程是非常短暂的,对实例的运行几乎没有影响。MySQL 8.0.x的备份一致性点,会告诉我们一致性的redo log LSN以及binlog的GTID;查询完备份一致点后,Xtrabackup会备份最后一个binlog文件,用于恢复时仲裁事务是否需要回滚;最后,redo log备份线程任务会在其读取到的redo log的LSN大于查询到的备份一致性点的redo log LSN处停止。 由于Xtrabackup 2.4.x与8.0.x在处理binlog时存在差异,恢复过程也存在差异,我们会在后续文章中详细阐述。 # 四、常见问题与解决方法 华为云已经使用Xtrabackup为公司几乎所有的MySQL实例提供备份服务,在使用过程中,我们积极与社区保持联系,向Percona社区报告使用过程中的一些问题,帮助Xtrabackup向更好的方向演进。此外,对于发现的一些致命问题,若社区未能及时修复,华为云数据库团队会进行及时修复以保证备份数据的正确性。 下面是我们总结在使用Xtrabackup备份过程各个阶段可能遇到的问题,分析其原因以及对应的解决方法, ## 1. 兼容性检查阶段 - **问题现象**:Xtrabackup启动后,立即长时间“挂起”,查看日志发现redo log备份线程也没有启动。 **原因**:Xtrabackup兼容性检查时无法获取MDL锁。Xtrabackup兼容性检查是通过查询 imformation_schema.tables这个插件表实现: “SELECT CONCAT(table_schema, '/', table_name), engine FROM information_schema.tables WHERE engine NOT IN ('MyISAM', 'InnoDB', 'CSV', 'MRG_MYISAM') AND table_schema NOT IN ('performance_schema', 'information_schema', 'mysql')” 在查询每张表时,需要获取对应表的MDL锁,如果此时MySQL实例中存在长时间的DML或者DDL 语句,或者更严重者出现了MDL死锁,上面的查询会一直堵塞在等待MDL锁阶段,此时 Xtrabackup会长时间“挂起”。 **解决办法**:若等待锁的原因只是因为其他SQL语句的堵塞,等待其他SQL执行完成即可;若是发生了死锁,此时需要分析出死锁原因,将死锁解除;华为云RDS for MySQL提供了MDL锁视图功能,可以很好地帮助用户分析业务的MDL死锁。 ## 2.redo log备份阶段 - **问题现象1**:redo log回卷,备份失败,Xtrabackup报如下错误信息: “xtrabackup: error:it looks like InnoDB log has wrapped around before xtrabackup could process all records due to either log copying being too slow, or log files being too small.\n");” **原因**:在备份的过程中,如果主机业务负载很高,导致redo log写入的速度很快,会发生Xtrabackup的redo log备份线程的备份速度小于redo log的写入速度,因为MySQL redo log文件写入使用了 round-robin的方式,使得新写入的日志覆盖了之前写入却还未备份的日志,因此备份失败。 **解决办法**:推荐在业务低峰期进行备份,或者增大redo log的文件大小。 - **问题现象2**:备份因DDL操作失败,错误信息如下: “An optimized (without redo logging) DDLoperation has been performed. All modified pages may not have been flushed to the disk yet. PXB will not be able take a consistent backup. Retry the backup operation” **原因**: 备份过程中MySQL实例发生了创建索引的DDL操作,因为创建索引不会写redo,若继续备份会引起数据不一致问题,所以Xtrabackup在这种场景中备份失败是预期行为。 **解决办法**:不要在备份过程中创建索引,如果确实需要,建议在建表语句中直接带上索引,或者使用 lock-ddl 参数进行备份(阻塞实例上新的DDL操作)。 - **问题现象3**:undo truncate导致备份失败,Xtrabackup错误信息如下: “An undo ddl truncation (could be automatic) operation has been performed.” **原因**:在Xtrabackup备份期间,如果MySQL实例发生undo truncate时,有可能会出现写入新 undo文件(space id不同)的undo日志丢失导致恢复出来的数据存在问题。官方在Xtrabackup 8.0.14版本(基于MySQL 8.0.21)对该问题进行了修复,修复方法是redo备份线程,解析redo log时若发现该操作是undo log的truncate操作,则会备份失败。遗憾的是,该修复并没有完全解决问题,在以下两种场景中,社区版本的Xtrabackup仍可能会发生恢复出来的数据存在不一致的现象: 1. MySQL版本低于MySQL 8.0.21; 2. 用户在备份过程中,自己创建了新的undo tablespace。 **解决办法**:在备份期间关闭undo tablespace的truncate操作,并禁止用户创建undo tablespace, 能够有效地防止备份数据恢复出来不一致的问题;另外华为云Xtrabackup对这个问题进行了进一步的修复,可以有效地防止此类现象发生。 ## 3.加载表空间阶段 - **问题现象1**:Xtrabackup报错:Too many open files **原因**:操作系统允许同时打开的文件数量是有限的,Xtrabackup在load tablespace阶段会同时打开所有的表文件,如果Xtrabackup打开的表的个数超过了该限制,则会备份失败。 **解决办法**:调大操作系统,允许同时打开最大文件数的配置,或者使用 lock-ddl 参数(阻塞实例上新的DDL操作)。 - **问题现象2**:rename table导致备份失败,错误信息如下: “Trying to add tablespace 'xxxx' with id xxx to the tablespace memory cache, but tablespace xxxx already exists in the cache!;” **原因**:在Xtrabackup打开表空间的全过程是没有加锁的,如果发生了rename table有概率会发生重复加载相同的表空间,此时Xtrabackup会检测到重复的tablespace id,因此备份失败。 **解决办法**:一般来说,加载表空间是一个很快的操作,rename table并不是一个很频繁的操作,这种情况重试即可(Percona Xtrabackup 2.4.x仅支持单线程加载表空间,华为云Xtrabackup支持多线程加载表空间)。 ## 4.备份innodb表阶段 - **问题现象**:innodb表数据文件损坏,备份失败,错误信息如下: “xtrabackup: Database page corruption detected at page xxxx, retrying.” **原因**:Xtrabackup在备份innodb表数据文件时,会检查每个页面的checksum,如果发现checksum不对,则备份失败,这时说明MySQL实例的数据已经发生了损坏(例如磁盘静默错误)。 **解决办法**:需要通过恢复前一次的备份数据或者其他的办法将数据进行修复之后,备份才能成功,在后续的文章中,我们也会详细介绍数据修复办法。 # 五、结语 本文主要对比介绍了Xtrabackup备份原理,备份社区版MySQL以及华为云对其的改进,并分享了Xtrabackup常见问题的排查与解决,后续我们也会为大家带来更深入的分析,更实用的使用技巧,希望对大家理解和使用Xtrabackup有帮助。我们也将持续为客户提供更好的数据库服务,并时刻守护客户的数据安全。
-
>摘要:告警功能是各大云平台必不可少的模块,个性化的告警配置,为帮助用户和运维人员及时发现问题发挥着重要作用。本文分享自华为云社区[《GaussDB(DWS) 数据库智能监控系统告警框架上线啦!》](https://bbs.huaweicloud.com/blogs/304824?utm_source=zhihu&utm_medium=bbs-ex&utm_campaign=ei&utm_content=content),作者:codefulture。 本文将从一下几个方面介绍DMS告警框架: - 数据库智能监控系统告警框架的来源 - 告警框架的实现 - 告警框架的不足和期望 # 一、数据库智能监控系统告警框架的简介 告警功能是各大云平台必不可少的模块,包括阿里云、腾讯云,乃至华为云本身都提供了十分丰富的告警功能。个性化的告警配置,为帮助用户和运维人员及时发现问题发挥着重要作用。 数据库智能监控系统(简称DMS)告警框架(以下简称告警框架)用于监控数据仓库的集群信息,且基于8.1.1以上版本的集群进行开发,如果您的集群版本低于8.1.1或没有安装DMS,则不能适用次告警功能。 告警功能是结合产品自身需求、业务需求、客户需求独立进行设计与开发,为了能够让用户更快速的熟悉和使用次功能,告警功能在设计之处也参照了其他平台的使用方式、相关概念,并结合自身情况进行调整,完成了初版的设计与开发。 # 二、告警框架的实现与使用 ## 1. 告警框架的实现 在说具体实现之前,先了解下告警框架中涉及的相关概念。 - 告警指标:告警指标是实际监控的内容,如:CPU使用率、磁盘使用率、IO等。 - 告警策略:告警策略是触发告警的最小单元,每一条策略针对一种告警指标。告警策略分为阈值策略、状态策略等。 - 告警规则:告警规则是实际监测(任务调度)的最小单元,是告警策略的集合。告警规则包含自默认规则和自定义规则。 - 默认告警规则:默认规则是系统提供的基础告警项,用户只需根据业务简单的配置,即可收到告警信息。 - 义告警规则:当默认告警规则不能满足实际需求时,用户可根据自己的实际需求创建自定义告警规则。 - 规则、告警策略、告警指标三者关系:一个告警规则(默认/自定义)可包含多个告警策略,并且规则中的策略存在不同关系,当前已知策略关系如下: 1. 相互独立(或):策略之间并无实际联系,只要一个策略满足条件则发送告警; 2. 优先级:一般指同一规则下,所有策略监控的指标项相同,但触发的阈值不同,按照阈值递减顺序判断是否发送告警; 3. 与:所有策略都满足条件则发送告警。 了解了以上概念,再来说下告警框架的组成,告警框架主要分为三大部分,监控指标采集、告警策略定制、告警任务调度。 ### 1-1. 监控指标采集 监控数据库,必须要对数据库各指标数据进行采集,通过合理的统计查询,获得实时或周期性的数据库和集群的状态,结合告警策略触发告警。 ### 1-2. 告警策略定制 下图所示是告警策略的组成,通过各配置项的不同组合,达成多样化的配置,后续版本的迭代中,会加入更多的可配置项,以支持更多的业务场景。  ### 1-3. 告警任务调度 监控指标是周而复始的过程,需要一个稳定的调度器支撑告警框架的任务调度,目前采用的是分布式调度框架Quartz。下图所示是调度任务的执行逻辑。  ## 2. 告警框架的使用 DMS告警框架位于【数据仓库服务】中的【告警管理】菜单中。  首页提供了告警统计功能,包含了一周内发生的告警,用户可查看统计数字和告警详细信息。 点击【查看告警规则】查看告警规则列表。  告警框架提供了自定义告警规则和默认告警规则,默认告警规则未系统内置,用户可根绝自身需求添加自定义告警。 点击【创建规则】或【修改】按钮进入配置页面。  目前可修改的内容只有“绑定集群”、“阈值”、“持续周期”、“抑制条件”、“告警级别”,其他选项,将在后续的版本中放开为用户提供更丰富的配置选择。 ### 2-1. 各修改项说明 1. 修改绑定集群可以设置次告警规则适用的集群范围,默认为全部,可多选; 2. 修改阈值可以调整触发告警的上限或下限,每种指标默认提供了阈值范围,可按照页面提示和实际情况进行合理修改。 3. 修改持续周期,可以拉长或缩短指标数据的查询范围,检测的是长周期的指标变化趋势,还是某时刻的指标异常变化。 4. 修改抑制条件可以控制告警的发送频率,处于抑制期的告警不会重复发送。 告警框架的不足与期望 DMS告警框架还在建设当中,存在诸多不足,譬如:还需提供更多的监控指标,支持多种策略配置方式,告警项的拓展不够便捷等。 除了解决上述的痛点,更多的希望告警框架能够和系统的功能模块联动起来,让监控系统更“智能”。
-
在上一篇中,我们介绍到使用虚拟机在CentOS上安装部署附录一Linux操作系统相关命令,本文会介绍附录二:openGauss数据库基本操作。4.1 查看数据库对象查看帮助信息:postgres=# \?切换数据库:postgres=# \c dbname列举数据库: 使用\l元命令查看数据库系统的数据库列表。postgres=# \l 使用如下命令通过系统表pg_database查询数据库列表。postgres=# SELECT datname FROM pg_database;列举表:postgres=# \dt列举所有表、视图和索引:postgres=# \d+ 使用gsql的\d+命令查询表的属性。postgres=# \d+ tablename查看表结构:postgres=# \d tablename列举schema:postgres=# \dn查看索引:postgres=# \di查询表空间: 使用gsql程序的元命令查询表空间。postgres=# \db 检查pg_tablespace系统表。如下命令可查到系统和用户定义的全部表空间。postgres=# SELECT spcname FROM pg_tablespace;要查看用户属性:postgres=# SELECT * FROM pg_authid;查看所有角色:postgres=# SELECT * FROM PG_ROLES;4.2 其他操作切换数据库:postgres=# \c dbname切换用户:postgres=# \c – username退出数据库:postgres=# \q随着本篇结束,《数据库》在虚拟机在CentOS上安装部署openGauss数据库指导手册就已全部更新完结。
推荐直播
-
 华为云码道-玩转OpenClaw,在线养虾
华为云码道-玩转OpenClaw,在线养虾2026/03/11 周三 19:00-21:00
刘昱,华为云高级工程师/谈心,华为云技术专家/李海仑,上海圭卓智能科技有限公司CEO
OpenClaw 火爆开发者圈,华为云码道最新推出 Skill ——开发者只需输入一句口令,即可部署一个功能完整的「小龙虾」智能体。直播带你玩转华为云码道,玩转OpenClaw
回顾中 -
 华为云码道-AI时代应用开发利器
华为云码道-AI时代应用开发利器2026/03/18 周三 19:00-20:00
童得力,华为云开发者生态运营总监/姚圣伟,华为云HCDE开发者专家
本次直播由华为专家带你实战应用开发,看华为云码道(CodeArts)代码智能体如何在AI时代让你的创意应用快速落地。更有华为云HCDE开发者专家带你用码道玩转JiuwenClaw,让小艺成为你的AI助理。
回顾中 -
 Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案
Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案2026/03/25 周三 19:00-20:00
余伟,华为云软件研发工程师/万邵业(万少),华为云HCDE开发者专家
本次直播带来两大实战:华为云码道 Skill-Creator 手把手搭建专属知识库 Skill;如何用码道提效 OpenClaw 小说文本,打造从大纲到成稿的 AI 原创小说全链路。技术干货 + OPC创作思路,一次讲透!
回顾中
热门标签