-
 1环境说明: python 3.6+ java 1.8.0.402前置安装: 安装python第三方库jaydebeapi、jpype1。 1)安装jpype : pip3 install jpype1 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com 2)安装JayDeBeApi : pip3 install JayDeBeApi -i http://pypi.douban.com/simple --trusted-host pypi.douban.com 3) 安装java yum install java3下载DWS JDBC包: 登录华为云->DWS-->连接管理:下载JDBC驱动包4 配置测试案例:vi test1.py 贴入内容import jaydebeapiurl = '通过华为云---DWS---连接管理---JDBC连接字符串(公网)'user = '账号'password = '密码'dirver = 'com.huawei.gauss200.jdbc.Driver'jarFile = '/root/jdbc/gsjdbc200.jar' #下载的DWS JDBC包sqlStr ='select 1' #测试的sqlconn = jaydebeapi.connect(dirver,url,[user,password],jarFile)curs=conn.cursor()curs.execute(sqlStr)result=curs.fetchall()print(result)curs.close()conn.close() 执行:python3 test1.py
1环境说明: python 3.6+ java 1.8.0.402前置安装: 安装python第三方库jaydebeapi、jpype1。 1)安装jpype : pip3 install jpype1 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com 2)安装JayDeBeApi : pip3 install JayDeBeApi -i http://pypi.douban.com/simple --trusted-host pypi.douban.com 3) 安装java yum install java3下载DWS JDBC包: 登录华为云->DWS-->连接管理:下载JDBC驱动包4 配置测试案例:vi test1.py 贴入内容import jaydebeapiurl = '通过华为云---DWS---连接管理---JDBC连接字符串(公网)'user = '账号'password = '密码'dirver = 'com.huawei.gauss200.jdbc.Driver'jarFile = '/root/jdbc/gsjdbc200.jar' #下载的DWS JDBC包sqlStr ='select 1' #测试的sqlconn = jaydebeapi.connect(dirver,url,[user,password],jarFile)curs=conn.cursor()curs.execute(sqlStr)result=curs.fetchall()print(result)curs.close()conn.close() 执行:python3 test1.py -
【功能模块】【操作步骤&问题现象】1、用JAVA编写JDBC连接hive元数据,但是无法登录【截图信息】连接信息如下报错信息如下我尝试修改/srv/BigData/dbdata_service/data/pg_hba.conf,然后重启DBService之后,这个文件的变动又被改回去了【日志信息】(可选,上传日志内容或者附件)
-
 Java数据库连接(JDBC)API是一系列能够让Java编程人员访问数据库的接口,各个开发商的接口并不完全相同。在使用多年的Oracle公司的JDBC后,我积累了许多技巧,这些技巧能够使我们更好地发挥系统的性能和实现更多的功能。 1、在客户端软件开发中使用Thin驱动程序 在开发Java软件方面,Oracle的数据库提供了四种类型的驱动程序,二种用于应用软件、applets、servlets等客户端软件,另外二种用于数据库中的Java存储过程等服务器端软件。在客户机端软件的开发中,我们可以选择OCI驱动程序或Thin驱动程序。OCI驱动程序利用Java本地化接口(JNI),通过Oracle客户端软件与数据库进行通讯。Thin驱动程序是纯Java驱动程序,它直接与数据库进行通讯。为了获得最高的性能,Oracle建议在客户端软件的开发中使用OCI驱动程序,这似乎是正确的。但我建议使用Thin驱动程序,因为通过多次测试发现,在通常情况下,Thin驱动程序的性能都超过了OCI驱动程序。 2、关闭自动提交功能,提高系统性能 在第一次建立与数据库的连接时,在缺省情况下,连接是在自动提交模式下的。为了获得更好的性能,可以通过调用带布尔值false参数的Connection类的setAutoCommit()方法关闭自动提交功能,如下所示: conn.setAutoCommit(false);值得注意的是,一旦关闭了自动提交功能,我们就需要通过调用Connection类的commit()和rollback()方法来人工的方式对事务进行管理。 3、在动态SQL或有时间限制的命令中使用Statement对象 在执行SQL命令时,我们有二种选择:可以使用PreparedStatement对象,也可以使用Statement对象。无论多少次地使用同一个SQL命令,PreparedStatement都只对它解析和编译一次。当使用Statement对象时,每次执行一个SQL命令时,都会对它进行解析和编译。这可能会使你认为,使用PreparedStatement对象比使用Statement对象的速度更快。然而,我进行的测试表明,在客户端软件中,情况并非如此。因此,在有时间限制的SQL操作中,除非成批地处理SQL命令,我们应当考虑使用Statement对象。 此外,使用Statement对象也使得编写动态SQL命令更加简单,因为我们可以将字符串连接在一起,建立一个有效的SQL命令。因此,我认为,Statement对象可以使动态SQL命令的创建和执行变得更加简单。 4、利用helper函数对动态SQL命令进行格式化 在创建使用Statement对象执行的动态SQL命令时,我们需要处理一些格式化方面的问题。例如,如果我们想创建一个将名字O'Reilly插入表中的SQL命令,则必须使用二个相连的“''”号替换O'Reilly中的“'”号。完成这些工作的最好的方法是创建一个完成替换操作的helper方法,然后在连接字符串心服用公式表达一个SQL命令时,使用创建的helper方法。与此类似的是,我们可以让helper方法接受一个Date型的值,然后让它输出基于Oracle的to_date()函数的字符串表达式。 5、利用PreparedStatement对象提高数据库的总体效率 在使用PreparedStatement对象执行SQL命令时,命令被数据库进行解析和编译,然后被放到命令缓冲区。然后,每当执行同一个PreparedStatement对象时,它就会被再解析一次,但不会被再次编译。在缓冲区中可以发现预编译的命令,并且可以重新使用。在有大量用户的企业级应用软件中,经常会重复执行相同的SQL命令,使用PreparedStatement对象带来的编译次数的减少能够提高数据库的总体性能。如果不是在客户端创建、预备、执行PreparedStatement任务需要的时间长于Statement任务,我会建议在除动态SQL命令之外的所有情况下使用PreparedStatement对象。 6、在成批处理重复的插入或更新操作中使用PreparedStatement对象 如果成批地处理插入和更新操作,就能够显著地减少它们所需要的时间。Oracle提供的Statement和 CallableStatement并不真正地支持批处理,只有PreparedStatement对象才真正地支持批处理。我们可以使用addBatch()和executeBatch()方法选择标准的JDBC批处理,或者通过利用PreparedStatement对象的setExecuteBatch()方法和标准的executeUpdate()方法选择速度更快的Oracle专有的方法。要使用Oracle专有的批处理机制,可以以如下所示的方式调用setExecuteBatch():
Java数据库连接(JDBC)API是一系列能够让Java编程人员访问数据库的接口,各个开发商的接口并不完全相同。在使用多年的Oracle公司的JDBC后,我积累了许多技巧,这些技巧能够使我们更好地发挥系统的性能和实现更多的功能。 1、在客户端软件开发中使用Thin驱动程序 在开发Java软件方面,Oracle的数据库提供了四种类型的驱动程序,二种用于应用软件、applets、servlets等客户端软件,另外二种用于数据库中的Java存储过程等服务器端软件。在客户机端软件的开发中,我们可以选择OCI驱动程序或Thin驱动程序。OCI驱动程序利用Java本地化接口(JNI),通过Oracle客户端软件与数据库进行通讯。Thin驱动程序是纯Java驱动程序,它直接与数据库进行通讯。为了获得最高的性能,Oracle建议在客户端软件的开发中使用OCI驱动程序,这似乎是正确的。但我建议使用Thin驱动程序,因为通过多次测试发现,在通常情况下,Thin驱动程序的性能都超过了OCI驱动程序。 2、关闭自动提交功能,提高系统性能 在第一次建立与数据库的连接时,在缺省情况下,连接是在自动提交模式下的。为了获得更好的性能,可以通过调用带布尔值false参数的Connection类的setAutoCommit()方法关闭自动提交功能,如下所示: conn.setAutoCommit(false);值得注意的是,一旦关闭了自动提交功能,我们就需要通过调用Connection类的commit()和rollback()方法来人工的方式对事务进行管理。 3、在动态SQL或有时间限制的命令中使用Statement对象 在执行SQL命令时,我们有二种选择:可以使用PreparedStatement对象,也可以使用Statement对象。无论多少次地使用同一个SQL命令,PreparedStatement都只对它解析和编译一次。当使用Statement对象时,每次执行一个SQL命令时,都会对它进行解析和编译。这可能会使你认为,使用PreparedStatement对象比使用Statement对象的速度更快。然而,我进行的测试表明,在客户端软件中,情况并非如此。因此,在有时间限制的SQL操作中,除非成批地处理SQL命令,我们应当考虑使用Statement对象。 此外,使用Statement对象也使得编写动态SQL命令更加简单,因为我们可以将字符串连接在一起,建立一个有效的SQL命令。因此,我认为,Statement对象可以使动态SQL命令的创建和执行变得更加简单。 4、利用helper函数对动态SQL命令进行格式化 在创建使用Statement对象执行的动态SQL命令时,我们需要处理一些格式化方面的问题。例如,如果我们想创建一个将名字O'Reilly插入表中的SQL命令,则必须使用二个相连的“''”号替换O'Reilly中的“'”号。完成这些工作的最好的方法是创建一个完成替换操作的helper方法,然后在连接字符串心服用公式表达一个SQL命令时,使用创建的helper方法。与此类似的是,我们可以让helper方法接受一个Date型的值,然后让它输出基于Oracle的to_date()函数的字符串表达式。 5、利用PreparedStatement对象提高数据库的总体效率 在使用PreparedStatement对象执行SQL命令时,命令被数据库进行解析和编译,然后被放到命令缓冲区。然后,每当执行同一个PreparedStatement对象时,它就会被再解析一次,但不会被再次编译。在缓冲区中可以发现预编译的命令,并且可以重新使用。在有大量用户的企业级应用软件中,经常会重复执行相同的SQL命令,使用PreparedStatement对象带来的编译次数的减少能够提高数据库的总体性能。如果不是在客户端创建、预备、执行PreparedStatement任务需要的时间长于Statement任务,我会建议在除动态SQL命令之外的所有情况下使用PreparedStatement对象。 6、在成批处理重复的插入或更新操作中使用PreparedStatement对象 如果成批地处理插入和更新操作,就能够显著地减少它们所需要的时间。Oracle提供的Statement和 CallableStatement并不真正地支持批处理,只有PreparedStatement对象才真正地支持批处理。我们可以使用addBatch()和executeBatch()方法选择标准的JDBC批处理,或者通过利用PreparedStatement对象的setExecuteBatch()方法和标准的executeUpdate()方法选择速度更快的Oracle专有的方法。要使用Oracle专有的批处理机制,可以以如下所示的方式调用setExecuteBatch(): -
【功能模块】GaussDB(DWS)驱动在SparkApp中使用问题【操作步骤&问题现象】1、在同一个DWS库及模式下,现有两张结构相同的表,分别称为表A、表B。其中表A有大约160万行数据2、编写简单的SparkApp,依赖 gsjdbc200.jar(driverClass=com.huawei.gauss200.jdbc.Driver)和 gsjdbc4.jar(driverClass=org.postgresql.Driver)首先使用gsjdbc200.jar作为驱动读取A表数据,得到Dataset实例Dataset ds = sparkSession.read().format("jdbc") .option("url", "jdbc:gaussdb://xx.xxx.xx.xx:8000/dwhm") .option("driver", "com.huawei.gauss200.jdbc.Driver") .option("user", "******") .option("password", "**********") .option("dbtable", "表A") .option("numPartitions", 6) .option("lowerBound", 0) .option("upperBound", 1728454) .option("partitionColumn", "id_column") .option("fetchsize", 1024) .load();然后立即再使用gsjdbc200.jar(driverClass=com.huawei.gauss200.jdbc.Driver)作为驱动,尝试将A表数据写入B表ds.write().format("jdbc") .option("dbtable", "表B") .mode(SaveMode.Overwrite) .option("url", "jdbc:gaussdb://10.2.121.11:8000/dwhm") .option("driver", "com.huawei.gauss200.jdbc.Driver") .option("user", "xxxxxx") .option("password", "**************") .option("truncate", true) .option("batchsize", 500) .save();读取到数据后,在开始执行数据写入task时很快就报出如下异常而失败。java.sql.BatchUpdateException: Batch entry 0 INSERT INTO 表B名称 ("po_process_action_id","tenant_id","po_header_id","po_line_id","po_line_location_id","display_line_num","display_line_location_num","version_num","process_type_code","process_remark","processed_date","process_user_id","process_user_name","object_version_number","creation_date","created_by","last_updated_by","last_update_date","storage_time") VALUES ('1155064','20453','194759',NULL,NULL,NULL,NULL,'1','UPDATE',NULL,'2021-07-11 01:14:21+08','859953','华为接口账号','1','2021-07-11 01:14:21+08','859953','859953','2021-07-11 01:14:21+08','2021-09-27 13:47:06+08') was aborted: ERROR: invalid input syntax for type oid: "" Call getNextException to see other errors in the batch. at com.huawei.gauss200.jdbc.jdbc.BatchResultHandler.handleError(BatchResultHandler.java:152) at com.huawei.gauss200.jdbc.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2584) at com.huawei.gauss200.jdbc.core.v3.QueryExecutorImpl.executeBatch(QueryExecutorImpl.java:575) at com.huawei.gauss200.jdbc.jdbc.PgStatement.executeBatch(PgStatement.java:879) at com.huawei.gauss200.jdbc.jdbc.PgPreparedStatement.executeBatch(PgPreparedStatement.java:1580) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$.savePartition(JdbcUtils.scala:654) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:821) at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$saveTable$1.apply(JdbcUtils.scala:821) at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:935) at org.apache.spark.rdd.RDD$$anonfun$foreachPartition$1$$anonfun$apply$29.apply(RDD.scala:935) at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2074) at org.apache.spark.SparkContext$$anonfun$runJob$5.apply(SparkContext.scala:2074) at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:87) at org.apache.spark.scheduler.Task.run(Task.scala:109) at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:345) at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149) at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624) at java.lang.Thread.run(Thread.java:748) Caused by: com.huawei.gauss200.jdbc.util.PSQLException: ERROR: invalid input syntax for type oid: "" at com.huawei.gauss200.jdbc.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2852) at com.huawei.gauss200.jdbc.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:2583) ... 16 more表B只是普通的行存表,其中 po_process_action_id 为主键。表内没有名为“oid”的用户定义列。如果换用 gsjdbc4.jar(driverClass=org.postgresql.Driver)作为 write 时的驱动,只相应改动 url、driver 两项option,其它代码不做任何改变,则数据写入可以成功,没有任何问题。使用Spark版本为 2.3.2,程序运行于本地笔记本,原意为简单试一下Spark读写DWS
-
-
【功能模块】MRS 8.0.2混合云版本 Spark 组件 Spark SQL,通过JDBC方式访问Spark SQL【操作步骤&问题现象】1、调测样例 “SparkThriftServerScalaExample”,修改对应的参数信息,在安装MRS客户端的虚拟机上执行如下命令是可以运行成功的java -cp ${SPARK_HOME}/jars/*:${SPARK_HOME}/conf:/home/openlab/SparkThriftServerExample-1.0.jar com.huawei.bigdata.spark.examples.ThriftServerQueriesTest ${SPARK_HOME}/conf/hive-site.xml ${SPARK_HOME}/conf/spark-defaults.conf2、在本地开发的编译器中,修改对应的参数信息,进行运行程序报如下错误Exception in thread "main" java.lang.IllegalArgumentException: Illegal character in path at index 212: hive2://dummyhost:00000/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=sparkthriftserver2x;saslQop=auth-conf;auth=KERBEROS;principal=spark2x/hadoop.HADOOP.COM@HADOOP.COM;user.principal=wx657505;user.keytab=D:\conf\user.keytab; at java.net.URI.create(URI.java:852) at org.apache.hive.jdbc.Utils.parseURL(Utils.j【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
1. JDBC报错:Invalid username/password, login denied这类问题首先确认用户名和密码正确,确认正确之后请确认所用JDBC驱动版本是否是GaussDB配套的驱动版本,建议更换gauss200的驱动包重新验证。驱动连接串配置参考:https://bbs.huaweicloud.com/forum/thread-59902-1-1.html2. 出现报错:prepared statement '%s' already exists确认没有重复使用prepare语句之后,可尝试设置prepareThreshold=03. 出现报错:portal "%s" does not exist使用setFetchSize分批获取结果集时,需关闭autocommit,如果手动commit后继续获取结果集,会出现该报错,需排查本次获取结果集后,下次获取结果集前,是否有手动commit的操作
-
数据库通过jdbc发送给客户端的数据性能有没有参数控制?比如我查询163万条数据需要2s,全部发送给客户端需要25s,这个性能有没有参数控制?
努力学习ing
发表于2021-08-31 21:41:59
2021-08-31 21:41:59
最后回复
Select*fromMacchiato
2021-08-31 21:57:11
1025 1
-
 数据库通过jdbc发送给客户端的数据性能有没有参数控制?比如我查询163万条数据需要2s,全部发送给客户端需要25s,这个性能有没有参数控制?
数据库通过jdbc发送给客户端的数据性能有没有参数控制?比如我查询163万条数据需要2s,全部发送给客户端需要25s,这个性能有没有参数控制? -
配置了数据源和模式及表名未带出字段属性:
-
【问题来源】【必填】 【武汉农商行】 【问题简要】【必填】 AICC CC-CMS产品中通过jdbc连接华为测试库,返回结果中文乱码。【问题类别】【必填】 【aicc cc-cms】【AICC解决方案版本】【必填】 【AICC可选择版本:AICC 8.13.0 CC-CMS】【期望解决时间】【选填】 尽快【问题现象描述】【必填】 //描述做了什么,期望发生什么,实际发生了什么,发生问题坐席等。如果已经尝试了一些措施但是没有解决问题,也请描述出来。 //请描述环境信息,如:华东,华北等。 1.AICC产品升级后,通过jdbc连接华为数据库,查询结果显示乱码。
-
#### jdbc的参数配置 当我们用jdbc连MySQL的时候,有一个连接串,一般形如 ``` jdbc:mysql://127.0.0.1:3307/test_tb?connectTimeout=5000&serverTimezone=UTC&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF8&useConfigs=fullDebug ``` 还有时候我们会用一个properties对象配置参数,这些参数是怎么发挥作用的,而且有什么约束呢,带着这个问题,我们慢慢研究一下jdbc的源码 ##### 参数传递 1、jdbc中连接数据库的入口在DriverManager的getConnection中,会把user,password放入properties中 ``` //DriverManager.java @CallerSensitive public static Connection getConnection(String url, java.util.Properties info) throws SQLException { return (getConnection(url, info, Reflection.getCallerClass())); } @CallerSensitive public static Connection getConnection(String url, String user, String password) throws SQLException { java.util.Properties info = new java.util.Properties(); if (user != null) { info.put("user", user); } if (password != null) { info.put("password", password); } return (getConnection(url, info, Reflection.getCallerClass())); } @CallerSensitive public static Connection getConnection(String url) throws SQLException { java.util.Properties info = new java.util.Properties(); return (getConnection(url, info, Reflection.getCallerClass())); } ``` 2、MySQL jdbc建立连接的处理在NonRegisteringDriver的connect中,会把连接串拼接成url§{properties}格式,生成ConnectionUrl对象包装起来 ``` //com.mysql.cj.conf.ConnectionUrl#buildConnectionStringCacheKey private static String buildConnectionStringCacheKey(String connString, Properties info) { StringBuilder sbKey = new StringBuilder(connString); sbKey.append("\u00A7"); // Section sign. sbKey.append( info == null ? null : info.stringPropertyNames().stream().map(k -> k + "=" + info.getProperty(k)).collect(Collectors.joining(", ", "{", "}"))); return sbKey.toString(); } ``` 3、然后整个url§{properties}会给ConnectionUrlParser处理,通过CONNECTION_STRING_PTRN正则匹配出scheme(jdbc:mysql), authority(ip:port), path(dbname),query(url中的参数部分),并通过PROPERTIES_PTRN匹配出url中的参数对 ``` Pattern CONNECTION_STRING_PTRN = Pattern.compile("(?[\\w\\+:%]+)\\s*" // scheme: required; alphanumeric, plus, colon or percent + "(?://(?[^/?#]*))?\\s*" // authority: optional; starts with "//" followed by any char except "/", "?" and "#" + "(?:/(?!\\s*/)(?[^?#]*))?" // path: optional; starts with "/" but not followed by "/", and then followed by by any char except "?" and "#" + "(?:\\?(?!\\s*\\?)(?[^#]*))?" // query: optional; starts with "?" but not followed by "?", and then followed by by any char except "#" + "(?:\\s*#(?.*))?"); Pattern PROPERTIES_PTRN = Pattern.compile("[&\\s]*(?[\\w\\.\\-\\s%]*)(?:=(?[^&]*))?"); ``` 4、最后通过ConnectionUrl的collectProperties,把参数放入ConnectionUrl自己的properties里面去。由此可见,通过url配置参数与properties配置参数效果基本是一样的 ``` //com.mysql.cj.conf.ConnectionUrl#collectProperties protected void collectProperties(ConnectionUrlParser connStrParser, Properties info) { // Fill in the properties from the connection string. connStrParser.getProperties().entrySet().stream().forEach(e -> this.properties.put(PropertyKey.normalizeCase(e.getKey()), e.getValue())); // Properties passed in override the ones from the connection string. if (info != null) { info.stringPropertyNames().stream().forEach(k -> this.properties.put(PropertyKey.normalizeCase(k), info.getProperty(k))); } // Collect properties from additional sources. setupPropertiesTransformer(); expandPropertiesFromConfigFiles(this.properties); injectPerTypeProperties(this.properties); } ``` 5、当然参数值,还有其它的设置方式,比如expandPropertiesFromConfigFiles方法里面就是在是预置配置在com/mysql/cj/configurations/xxx.properties里面,例如url中增加&useConfigs=fullDebug,就可以在参数中增加如下四个参数; 还有一些其它的配置,比如dbname,既可以配置在port/后面,也可以以参数的形式配置 ``` profileSQL=true gatherPerfMetrics=true useUsageAdvisor=true logSlowQueries=true explainSlowQueries=true ``` 最终所有这些参数会封装成一个HostInfo对象 ##### 参数名与取值约束 1、建立连接的时候,会创建一个com.mysql.cj.jdbc.ConnectionImpl对象,它有两个属性:HostInfo(hostInfo为我们声明的参数),和PropertySet系统参数 2、所有PropertySet配置的属性名称,都必须是com.mysql.cj.conf.PropertyKey类中定义的名字 3、所有PropertySet配置的属性值的设置规则,都必须是com.mysql.cj.conf.PropertyDefinitions#PROPERTY_KEY_TO_PROPERTY_DEFINITION中定义的规则 值的规则有,boolean, enum, string,int,long等几种PropertyDefinition 4、属性值的用com.mysql.cj.conf.RuntimeProperty保存 其中UML关系如下: 连接与参数属性 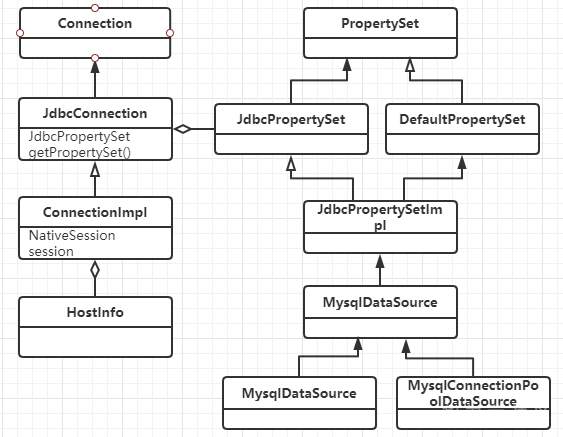 参数属性名与属性值 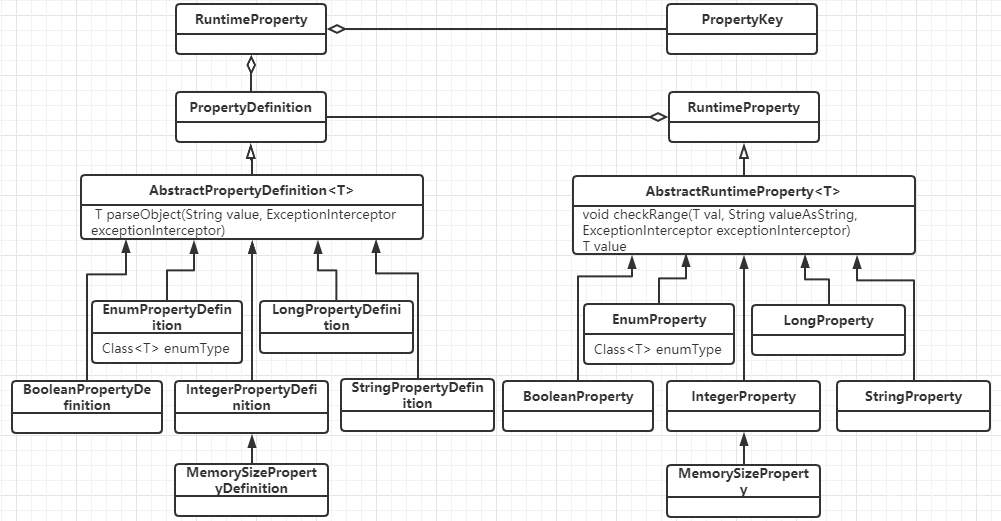 连接相关的对象 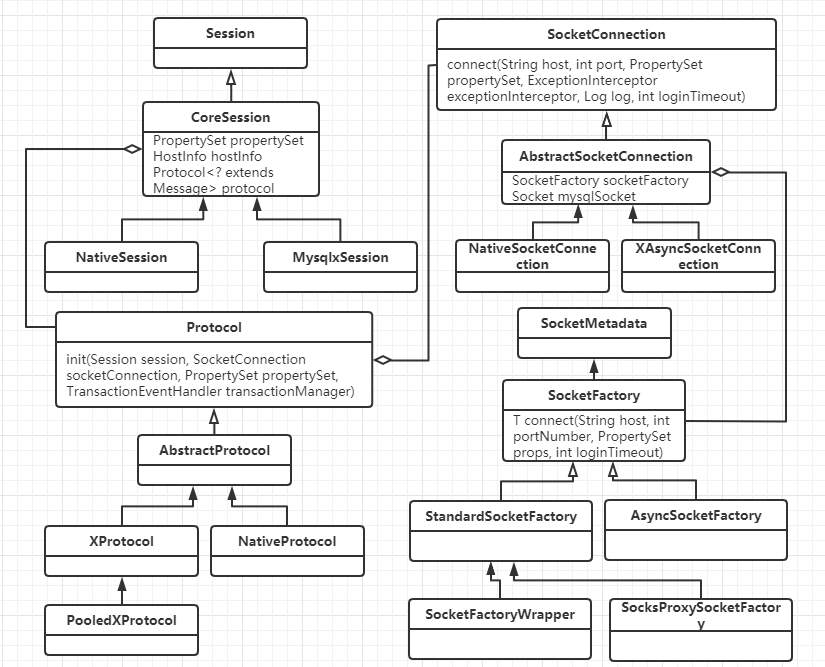 ##### 参数使用 1、TCP连接 创建连接默认是通过com.mysql.cj.protocol.StandardSocketFactory做TCP连接,当然也可以通过socketFactory参数来配置 其中给socket配置的时候,使用到了tcpNoDelay,tcpKeepAlive,tcpRcvBuf,tcpSndBuf,tcpTrafficClass几个参数 连接地址使用到了ip, port参数 连接参数使用了connectTimeout和socketTimeout 可以通过useReadAheadInput,useUnbufferedInput两个bool参数决定使用哪种输入流 如果单次连接失败,还会根据initialTimeout(int),maxReconnects(int)来重试 2、协议连接 协议连接配置是在com.mysql.cj.protocol.a.NativeProtocol里面做的, 其中使用到useNanosForElapsedTime,maintainTimeStats(bool),maxQuerySizeToLog(int),autoSlowLog(bool),,maxAllowedPacket(int),profileSQL(bool),autoGenerateTestcaseScript(bool),useServerPrepStmts(bool), 慢查询相关logSlowQueries(bool),slowQueryThresholdMillis(int),useNanosForElapsedTime(bool),slowQueryThresholdNanos(int) 3、读取服务端参数 首先读取一个服务端发来的数据包,把服务端的参数设置到com.mysql.cj.protocol.a.NativeCapabilities对象里去,包括protocolVersion,serverVersion,threadId,seed,flag,capabilityFalgs,serverDefaultCollationIndex,authPluginDataLength 其中capabilityFalgs为服务端参数集,具体值及其意思,可以从com.mysql.cj.protocol.a.NativeServerSession中的那些值判断看出来 ``` public static final int CLIENT_LONG_PASSWORD = 0x00000001; /* new more secure passwords */ public static final int CLIENT_FOUND_ROWS = 0x00000002; public static final int CLIENT_LONG_FLAG = 0x00000004; /* Get all column flags */ public static final int CLIENT_CONNECT_WITH_DB = 0x00000008; public static final int CLIENT_COMPRESS = 0x00000020; /* Can use compression protcol */ public static final int CLIENT_LOCAL_FILES = 0x00000080; /* Can use LOAD DATA LOCAL */ public static final int CLIENT_PROTOCOL_41 = 0x00000200; // for > 4.1.1 public static final int CLIENT_INTERACTIVE = 0x00000400; public static final int CLIENT_SSL = 0x00000800; public static final int CLIENT_TRANSACTIONS = 0x00002000; // Client knows about transactions public static final int CLIENT_RESERVED = 0x00004000; // for 4.1.0 only public static final int CLIENT_SECURE_CONNECTION = 0x00008000; public static final int CLIENT_MULTI_STATEMENTS = 0x00010000; // Enable/disable multiquery support public static final int CLIENT_MULTI_RESULTS = 0x00020000; // Enable/disable multi-results public static final int CLIENT_PS_MULTI_RESULTS = 0x00040000; // Enable/disable multi-results for server prepared statements public static final int CLIENT_PLUGIN_AUTH = 0x00080000; public static final int CLIENT_CONNECT_ATTRS = 0x00100000; public static final int CLIENT_PLUGIN_AUTH_LENENC_CLIENT_DATA = 0x00200000; public static final int CLIENT_CAN_HANDLE_EXPIRED_PASSWORD = 0x00400000; public static final int CLIENT_SESSION_TRACK = 0x00800000; public static final int CLIENT_DEPRECATE_EOF = 0x01000000; ``` 4、配置客户端参数 根据capabilityFalgs及propertySet的值来设置clientParams的值,包括useCompression,createDatabaseIfNotExist,useAffectedRows,allowLoadLocalInfile,interactiveClient,allowMultiQueries,disconnectOnExpiredPasswords,connectionAttributes, 根据capabilityFalgs及propertySet的来useInformationSchema,sslMode做一些校验 还会使用defaultAuthenticationPlugin,disabledAuthenticationPlugins,authenticationPlugins,serverRSAPublicKeyFile,allowPublicKeyRetrieval来做认证插件相关配置 认证阶段,还会使用到user, password, database的信息 认证完之后,还会根据useCompression,traceProtocol,enablePacketDebug,packetDebugBufferSize来配置本地的环境 5、设置session参数可以通过参数sessionVariables来配置 ``` // public void setSessionVariables() { String sessionVariables = getPropertySet().getStringProperty(PropertyKey.sessionVariables).getValue(); if (sessionVariables != null) { List variablesToSet = new ArrayList(); for (String part : StringUtils.split(sessionVariables, ",", "\"'(", "\"')", "\"'", true)) { variablesToSet.addAll(StringUtils.split(part, ";", "\"'(", "\"')", "\"'", true)); } if (!variablesToSet.isEmpty()) { StringBuilder query = new StringBuilder("SET "); String separator = ""; for (String variableToSet : variablesToSet) { if (variableToSet.length() > 0) { query.append(separator); if (!variableToSet.startsWith("@")) { query.append("SESSION "); } query.append(variableToSet); separator = ","; } } sendCommand(this.commandBuilder.buildComQuery(null, query.toString()), false, 0); } } } ``` 6、查询服务端参数 建立连接之后,会在com.mysql.cj.NativeSession里面请求服务端参数,并把参数存储到ServerSession中 ``` //com.mysql.cj.NativeSession#loadServerVariables if (versionMeetsMinimum(5, 1, 0)) { StringBuilder queryBuf = new StringBuilder(versionComment).append("SELECT"); queryBuf.append(" @@session.auto_increment_increment AS auto_increment_increment"); queryBuf.append(", @@character_set_client AS character_set_client"); queryBuf.append(", @@character_set_connection AS character_set_connection"); queryBuf.append(", @@character_set_results AS character_set_results"); queryBuf.append(", @@character_set_server AS character_set_server"); queryBuf.append(", @@collation_server AS collation_server"); queryBuf.append(", @@collation_connection AS collation_connection"); queryBuf.append(", @@init_connect AS init_connect"); queryBuf.append(", @@interactive_timeout AS interactive_timeout"); if (!versionMeetsMinimum(5, 5, 0)) { queryBuf.append(", @@language AS language"); } queryBuf.append(", @@license AS license"); queryBuf.append(", @@lower_case_table_names AS lower_case_table_names"); queryBuf.append(", @@max_allowed_packet AS max_allowed_packet"); queryBuf.append(", @@net_write_timeout AS net_write_timeout"); queryBuf.append(", @@performance_schema AS performance_schema"); if (!versionMeetsMinimum(8, 0, 3)) { queryBuf.append(", @@query_cache_size AS query_cache_size"); queryBuf.append(", @@query_cache_type AS query_cache_type"); } queryBuf.append(", @@sql_mode AS sql_mode"); queryBuf.append(", @@system_time_zone AS system_time_zone"); queryBuf.append(", @@time_zone AS time_zone"); if (versionMeetsMinimum(8, 0, 3) || (versionMeetsMinimum(5, 7, 20) && !versionMeetsMinimum(8, 0, 0))) { queryBuf.append(", @@transaction_isolation AS transaction_isolation"); } else { queryBuf.append(", @@tx_isolation AS transaction_isolation"); } queryBuf.append(", @@wait_timeout AS wait_timeout"); NativePacketPayload resultPacket = sendCommand(this.commandBuilder.buildComQuery(null, queryBuf.toString()), false, 0); Resultset rs = ((NativeProtocol) this.protocol).readAllResults(-1, false, resultPacket, false, null, new ResultsetFactory(Type.FORWARD_ONLY, null)); Field[] f = rs.getColumnDefinition().getFields(); if (f.length > 0) { ValueFactory vf = new StringValueFactory(this.propertySet); Row r; if ((r = rs.getRows().next()) != null) { for (int i = 0; i f.length; i++) { this.protocol.getServerSession().getServerVariables().put(f[i].getColumnLabel(), r.getValue(i, vf)); } } } } else { NativePacketPayload resultPacket = sendCommand(this.commandBuilder.buildComQuery(null, versionComment + "SHOW VARIABLES"), false, 0); Resultset rs = ((NativeProtocol) this.protocol).readAllResults(-1, false, resultPacket, false, null, new ResultsetFactory(Type.FORWARD_ONLY, null)); ValueFactory vf = new StringValueFactory(this.propertySet); Row r; while ((r = rs.getRows().next()) != null) { this.protocol.getServerSession().getServerVariables().put(r.getValue(0, vf), r.getValue(1, vf)); } } ``` 查询到这些数据之后,就可以做一些正常查询时候的设置与判断了
-
jdbc执行语句报错:prepared statement "S_x" already exists规避方式:可通过设置preparethreashold=0规避
-
基本功能介绍在客户端执行批量的插入和更新的时候可以使用PEB的批量绑定功能。在服务端通过support_batch_bind参数进行控制。在ODBC端通过配置 odbc.ini文件中 UseBatchProtocol=1来开启这个功能。在JDBC端通过通过调用addBatch和executeBatch接口来使用该功能。代码调用示例(完整代码参考产品手册基于JDBC开发章节):批量插入性能通过执行上面的测试用例,插入3W条语句耗时,20S左右。通过后台日志和元组信息,可以看到该语句的执行过程是做了一次prepare, 一次批量执行完成插入的,对比早期的版本,性能要提升三倍以上。通过观察上面的事务信息,可以发现是在同一个事务中完成的批量插入。对比C80的版本,没有实现批量插入功能,执行3W条语句的插入耗时80s左右。通过分析后台日志和元组信息发现是一条条执行的插入。因此性能要差一些。因此在支持批量绑定的版本上,在执行数据小批量的插入的时候要通过批量绑定的形式进行。这种情况下的执行流程:1次prepare n次bind, 1次execute。当然如果需要大批量的数据导入还是要选用通过GDS导入。
-
RowBounds 表面是在“所有”数据中检索数据,其实并非是一次性查询出所有数据,因为 MyBatis 是对 jdbc 的封装,在 jdbc 驱动中有一个 Fetch Size 的配置,它规定了每次最多从数据库查询多少条数据,假如你要查询更多数据,它会在你执行 next()的时候,去查询更多的数据。就好比你去自动取款机取 10000 元,但取款机每次最多能取 2500 元,所以你要取 4 次才能把钱取完。只是对于 jdbc 来说,当你调用 next()的时候会自动帮你完成查询工作。这样做的好处可以有效的防止内存溢出。
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签