-
 (1)在hive配置中查到元数据密码,但是是加密状态的,请问怎么获取或者解密密码?(2)元数据库显示的连接地址是浮动IP,想在本地用客户端的方式连接数据库可不可行?(3)如果找不到解密的方法,能不能通过授权的方式创建新的连接账号连接数据库?
(1)在hive配置中查到元数据密码,但是是加密状态的,请问怎么获取或者解密密码?(2)元数据库显示的连接地址是浮动IP,想在本地用客户端的方式连接数据库可不可行?(3)如果找不到解密的方法,能不能通过授权的方式创建新的连接账号连接数据库? -
hive元数据内置到DBService,如何通过sql获取对应的元数据信息
-
hive元数据库Guassdb如何获取元数据信息
-
本文为您介绍如何通过CDM数据同步功能,迁移MRS Hive数据至DLI。其他MRS Hadoop组件数据,均可以通过CDM与DLI进行双向同步。前提条件已创建DLI的SQL队列。创建DLI队列的操作可以参考创建DLI队列。注意:创建DLI队列时队列类型需要选择为“SQL队列”。已创建包含Hive组件的MRS安全集群。创建MRS集群的操作详细可以参考创建MRS集群。本示例创建的MRS集群和各组件版本如下:MRS集群版本:MRS 3.1.0Hive版本:3.1.0Hadoop版本:3.1.1本示例创建MRS集群时开启了Kerberos认证。已创建CDM迁移集群。创建CDM集群的操作可以参考创建CDM集群。说明:如果目标数据源为云下的数据库,则需要通过公网或者专线打通网络。通过公网互通时,需确保CDM集群已绑定EIP、CDM云上安全组出方向放通云下数据源所在的主机、数据源所在的主机可以访问公网且防火墙规则已开放连接端口。数据源为云上的MRS、DWS等服务时,网络互通需满足如下条件:i. CDM集群与云上服务处于不同区域的情况下,需要通过公网或者专线打通网络。通过公网互通时,需确保CDM集群已绑定EIP,数据源所在的主机可以访问公网且防火墙规则已开放连接端口。ii. CDM集群与云上服务同区域情况下,同虚拟私有云、同子网、同安全组的不同实例默认网络互通;如果同虚拟私有云但是子网或安全组不同,还需配置路由规则及安全组规则。配置路由规则请参见如何配置路由规则章节,配置安全组规则请参见如何配置安全组规则章节。iii. 此外,您还必须确保该云服务的实例与CDM集群所属的企业项目必须相同,如果不同,需要修改工作空间的企业项目。本示例CDM集群的虚拟私有云、子网以及安全组和MRS集群保持一致。步骤一:数据准备MRS集群上创建Hive表和插入表数据。参考访问MRS Manager登录MRS Manager。在MRS Manager上,选择“系统 > 权限 > 角色”,单击添加“角色”,在添加角色页面分别配置参数。角色名称:输入自定义的“角色名称”,例如当前输入为:hivetestrole。配置资源权限:选择“当前MRS集群的名称 > hive”,勾选“Hive管理员权限”。图1 Manager创建Hive的角色更多MRS创建角色的操作说明可以参考:创建Hive管理员角色。在MRS Manager上,选择“系统 > 权限 > 用户”,单击“添加用户”,在添加用户页面分别配置如下参数。用户名:自定义的用户名。当前示例输入为:hivetestusr。用户类型:当前选择为“人机”。密码和确认密码:输入当前用户名对应的密码。用户组和主组:选择supergroup角色:同时选择2中创建的角色和Manager_viewer角色。图2 MRS Manager上创建Hive用户参考安装MRS客户端下载并安装Hive客户端。例如,当前Hive客户端安装在MRS主机节点的“/opt/hiveclient”目录上。以root用户进入客户端安装目录下。例如:cd /opt/hiveclient执行以下命令配置环境变量。source bigdata_env因为当前集群启用了Kerberos认证,则需要执行以下命令进行安全认证。认证用户为3中创建的用户。kinit 3中创建的用户名例如,kinit hivetestusr执行以下命令连接Hive。beeline创建表和插入表数据。创建表:create table user_info(id string,name string,gender string,age int,addr string);插入表数据:insert into table user_info(id,name,gender,age,addr) values("12005000201","A","男",19,"A城市"); insert into table user_info(id,name,gender,age,addr) values("12005000202","B","男",20,"B城市"); insert into table user_info(id,name,gender,age,addr) values("12005000202","B","男",20,"B城市");说明:上述示例是通过创建表和插入表数据构造迁移示例数据。如果是迁移已有的Hive数据库和表数据,则可以通过以下命令获取Hive的数据库和表信息。在Hive客户端执行如下命令获取数据库信息show databases切换到对应的数据库下use Hive数据库名显示当前数据库下所有的表信息show tables查询Hive表的建表语句show create table Hive表名查询出来的建表语句需要做一些处理,再到具体的DLI上执行。在DLI上创建数据库和表。登录DLI管理控制台,选择“SQL编辑器”,在SQL编辑器中“执行引擎”选择“spark”,“队列”选择已创建的SQL队列。在编辑器中输入以下语句创建数据库,例如当前创建迁移后的DLI数据库testdb。详细的DLI创建数据库的语法可以参考创建DLI数据库。create database testdb;创建数据库下的表。create table user_info(id string,name string,gender string,age int,addr string);说明:如果是通过在MRS Hive中的“show create table hive表名”获取的建表语句,则需要修改该建表语句以符合DLI的建表语法。具体DLI的建表语法可以参考创建DLI表。步骤二:数据迁移配置CDM数据源连接。配置源端MRS Hive的数据源连接。登录CDM控制台,选择“集群管理”,选择已创建的CDM集群,在操作列选择“作业管理”。在作业管理界面,选择“连接管理”,单击“新建连接”,连接器类型选择“MRS Hive”,单击“下一步”。图3 创建MRS Hive数据源连接配置源端MRS Hive的数据源连接,具体参数配置如下。表1 MRS Hive数据源配置参数值名称自定义MRS Hive数据源名称。例如当前配置为:source_hiveManager IP单击输入框旁边的“选择”按钮,选择当前MRS Hive集群即可自动关联出来Manager IP。认证类型如果当前MRS集群为普通集群则选择为SIMPLE,如果是MRS集群启用了Kerberos安全认证则选择为KERBEROS。本示例选择为:KERBEROS。Hive版本根据当前创建MRS集群时候的Hive版本确定。当前Hive版本为3.1.0,则选择为:HIVE_3_X。用户名在3中创建的MRS Hive用户名。密码对应的MRS Hive用户名的密码。其他参数保持默认即可。更多参数的详细说明可以参考CDM上配置Hive连接。图4 CDM配置MRS Hive数据源单击“保存”完成MRS Hive数据源配置。配置目的端DLI的数据源连接。登录CDM控制台,选择“集群管理”,选择已创建的CDM集群,在操作列选择“作业管理”。在作业管理界面,选择“连接管理”,单击“新建连接”,连接器类型选择“数据湖探索(DLI)”,单击“下一步”。图5 创建DLI数据源连接配置目的端DLI数据源连接连接参数。具体参数配置可以参考在CDM上配置DLI连接。图6 配置DLI数据源连接参数配置完成后,单击“保存”完成DLI数据源配置。创建CDM迁移作业。登录CDM控制台,选择“集群管理”,选择已创建的CDM集群,在操作列选择“作业管理”。在“作业管理”界面,选择“表/文件迁移”,单击“新建作业”。在新建作业界面,配置当前作业配置信息,具体参数参考如下:图7 新建CDM作业作业配置作业名称:自定义数据迁移的作业名称。例如,当前定义为:hive_to_dli。源端作业配置,具体参考如下:表2 源端作业配置参数名参数值源连接名称选择1.a中已创建的数据源名称。数据库名称选择MRS Hive待迁移的数据库名称。例如当前待迁移的表数据数据库为“default”。表名待建议Hive数据表名。当前示例为在DLI上创建数据库和表中的“user_info”表。读取方式当前示例选择为:HDFS。具体参数含义如下:包括HDFS和JDBC两种读取方式。默认为HDFS方式,如果没有使用WHERE条件做数据过滤及在字段映射页面添加新字段的需求,选择HDFS方式即可。HDFS文件方式读取数据时,性能较好,但不支持使用WHERE条件做数据过滤及在字段映射页面添加新字段。JDBC方式读取数据时,支持使用WHERE条件做数据过滤及在字段映射页面添加新字段。更多参数的详细配置可以参考:CDM配置Hive源端参数。目的端作业配置,具体参考如下:表3 目的端作业配置参数名参数值目的连接名称选择1.b已创建的DLI数据源连接。资源队列选择已创建的DLI SQL类型的队列。数据库名称选择DLI下已创建的数据库。当前示例为在DLI上创建数据库和表中创建的数据库名,即为“testdb”。表名选择DLI下已创建的表名。当前示例为在DLI上创建数据库和表中创建的表名,即为“user_info”。导入前清空数据选择导入前是否清空目的表的数据。当前示例选择为“否”。如果设置为是,任务启动前会清除目标表中数据。更多参数的详细配置可以参考:CDM配置DLI目的端参数。单击“下一步”,进入到字段映射界面,CDM会自动匹配源和目的字段。如果字段映射顺序不匹配,可通过拖拽字段调整。如果选择在目的端自动创建类型,这里还需要配置每个类型的字段类型、字段名称。CDM支持迁移过程中转换字段内容,详细请参见字段转换。图8 字段映射单击“下一步”配置任务参数,一般情况下全部保持默认即可。该步骤用户可以配置如下可选功能:作业失败重试:如果作业执行失败,可选择是否自动重试,这里保持默认值“不重试”。作业分组:选择作业所属的分组,默认分组为“DEFAULT”。在CDM“作业管理”界面,支持作业分组显示、按组批量启动作业、按分组导出作业等操作。是否定时执行:如果需要配置作业定时自动执行,请参见配置定时任务。这里保持默认值“否”。抽取并发数:设置同时执行的抽取任务数。这里保持默认值“1”。是否写入脏数据:如果需要将作业执行过程中处理失败的数据、或者被清洗过滤掉的数据写入OBS中,以便后面查看,可通过该参数配置,写入脏数据前需要先配置好OBS连接。这里保持默认值“否”即可,不记录脏数据。单击“保存并运行”,回到作业管理界面,在作业管理界面可查看作业执行进度和结果。图9 迁移作业进度和结果查询步骤三:结果查询CDM迁移作业运行完成后,再登录到DLI管理控制台,选择“SQL编辑器”,在SQL编辑器中“执行引擎”选择“spark”,“队列”选择已创建的SQL队列,数据库选择已1已创建的数据库,执行DLI表查询语句,查询Hive表数据是否已成功迁移到DLI的“user_info”表中。select * from user_info;图10 迁移后查询DLI的表数据
-
首先:集群规模是健康的。连接的点是集群外。使用hive的beeline和spark的spark-beeline都能正常连接,和操作。但是用IDEA spark开发就出现问题了代码如下:报错如下:2022-05-27 23:29:21,610 [main] ERROR [org.apache.thrift.transport.TSaslTransport] - SASL negotiation failurejavax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)] at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211) at org.apache.thrift.transport.TSaslClientTransport.handleSaslStartMessage(TSaslClientTransport.java:94)。。。Caused by: GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt) at sun.security.jgss.krb5.Krb5InitCredential.getInstance(Krb5InitCredential.java:147)。。。2022-05-27 23:29:21,631 [main] ERROR [org.apache.thrift.transport.TSaslTransport] - SASL negotiation failurejavax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)] at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211) at org.apache.thrift.transport.TSaslClientTransport.handleSaslStartMessage(TSaslClientTransport.java:94)。。。Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient; at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:107) at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:215)。。。Caused by: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522) at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:185)。。Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1523) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:86)。。。Caused by: java.lang.reflect.InvocationTargetException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)。。。Caused by: MetaException(message:Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException: GSS initiate failed at org.apache.thrift.transport.TSaslTransport.sendAndThrowMessage(TSaslTransport.java:232) at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:316) at org.apache.thrift.transport.TSaslClientTransport.open(TSaslClientTransport.java:37)。。。。
-
执行 insert into table2 select * from table1报错。表是parquet格式,lzo压缩。
-
 本文分享自华为云社区《从零开发大数据SQL引擎》,作者:JavaEdge 。 学习大数据技术的核心原理,掌握一些高效的思考和思维方式,构建自己的技术知识体系。 明白了原理,有时甚至不需要学习,顺着原理就可以推导出各种实现细节。 各种知识表象看杂乱无章,若只是学习繁杂知识点,固然自己的知识面是有限的,并且遇到问题的应变能力也很难提高。所以有些高手看起来似乎无所不知,不论谈论起什么技术,都能头头是道,其实并不是他们学习、掌握了所有技术,而是他们是在谈到这个问题时,才开始进行推导,并迅速得出结论。 高手不一定要很资深、经验丰富,把握住技术的核心本质,掌握快速分析推导的能力,能迅速将自己的知识技能推到陌生领域,就是高手。 本系列专注大数据开发需要关注的问题及解决方案。跳出繁杂知识表象,掌握核心原理和思维方式,进而融会贯通各种技术,再通过各种实践训练,成为终极高手。 # 大数据仓库Hive 作为一个成功的大数据仓库,它将SQL语句转换成MapReduce执行过程,并把大数据应用的门槛下降到普通数据分析师和工程师就可以很快上手的地步。 但Hive也有问题,由于它使用自定义Hive QL,对熟悉Oracle等传统数据仓库的分析师有上手难度。特别是很多企业使用传统数据仓库进行数据分析已久,沉淀大量SQL语句,非常庞大也非常复杂。某银行的一条统计报表SQL足足两张A4纸,光是完全理解可能就要花很长时间,再转化成Hive QL更费力,还不说可能引入bug。 开发一款能支持标准数据库SQL的大数据仓库引擎,让那些在Oracle上运行良好的SQL可以直接运行在Hadoop上,而不需要重写成Hive QL。 # Hive处理过程 1. 将输入的Hive QL经过语法解析器转换成Hive抽象语法树(Hive AST) 2. 将Hive AST经过语义分析器转换成MapReduce执行计划 3. 将生成的MapReduce执行计划和Hive执行函数代码提交到Hadoop执行 可见,最简单的,对第一步改造即可。考虑替换Hive语法解析器:能将标准SQL转换成Hive语义分析器能处理的Hive抽象语法树,即红框代替黑框 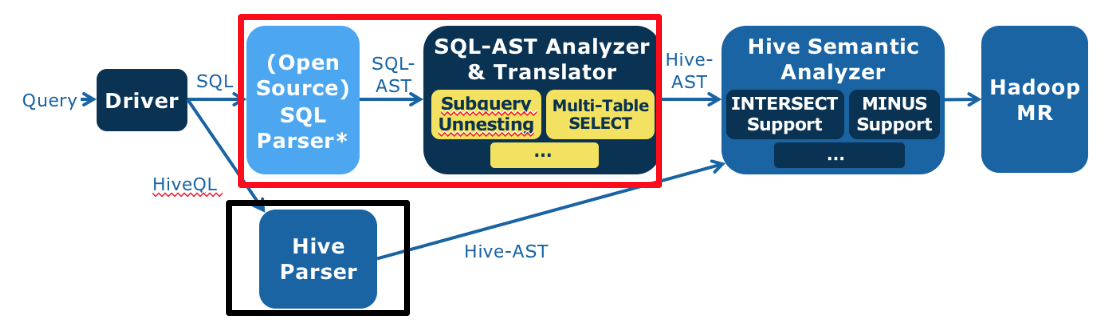 红框内:浅蓝色是个开源的SQL语法解析器,将标准SQL解析成标准SQL抽象语法树(SQL AST),后面深蓝色定制开发的SQL抽象语法树分析与转换器,将SQL AST转换成Hive AST。 那么关键问题就来了: # 标准SQL V.S Hive QL - 语法表达方式,Hive QL语法和标准SQL语法略有不同 - Hive QL支持的语法元素比标准SQL要少很多,比如,数据仓库领域主要的测试集TPC-H所有的SQL语句,Hive都不支持。尤其是Hive不支持复杂嵌套子查询,而数据仓库分析中嵌套子查询几乎无处不在。如下SQL,where条件existes里包含了另一条SQL: ```mysql select o_orderpriority, count(*) as order_count from orders where o_orderdate >= date '[DATE]' and o_orderdate date '[DATE]' + interval '3' month and exists (select * from lineitem where l_orderkey = o_orderkey and l_commitdate l_receiptdate) group by o_orderpriority order by o_orderpriority; ``` 开发支持标准SQL语法的SQL引擎难点,就是**消除复杂嵌套子查询掉**,即让where里不包含select。 SQL理论基础是关系代数,主要操作仅包括:并、差、积、选择、投影。而一个嵌套子查询可等价转换成一个连接(join)操作,如: ```mysql select s_grade from staff where s_city not in ( select p_city from proj where s_empname = p_pname ) ``` 这是个在where条件里嵌套了not in子查询的SQL语句,它可以用left outer join和left semi join进行等价转换,示例如下,这是Panthera自动转换完成得到的等价SQL。这条SQL语句不再包含嵌套子查询, ```mysql select panthera_10.panthera_1 as s_grade from (select panthera_1, panthera_4, panthera_6, s_empname, s_city from (select s_grade as panthera_1, s_city as panthera_4, s_empname as panthera_6, s_empname as s_empname, s_city as s_city from staff) panthera_14 left outer join (select panthera_16.panthera_7 as panthera_7, panthera_16.panthera_8 as panthera_8, panthera_16.panthera_9 as panthera_9, panthera_16.panthera_12 as panthera_12, panthera_16.panthera_13 as panthera_13 from (select panthera_0.panthera_1 as panthera_7, panthera_0.panthera_4 as panthera_8, panthera_0.panthera_6 as panthera_9, panthera_0.s_empname as panthera_12, panthera_0.s_city as panthera_13 from (select s_grade as panthera_1, s_city as panthera_4, s_empname as panthera_6, s_empname, s_city from staff) panthera_0 left semi join (select p_city as panthera_3, p_pname as panthera_5 from proj) panthera_2 on (panthera_0.panthera_4 = panthera_2.panthera_3) and (panthera_0.panthera_6 = panthera_2.panthera_5) where true) panthera_16 group by panthera_16.panthera_7, panthera_16.panthera_8, panthera_16.panthera_9, panthera_16.panthera_12, panthera_16.panthera_13) panthera_15 on ((((panthera_14.panthera_1 => panthera_15.panthera_7) and (panthera_14.panthera_4 => panthera_15.panthera_8)) and (panthera_14.panthera_6 => panthera_15.panthera_9)) and (panthera_14.s_empname => panthera_15.panthera_12)) and (panthera_14.s_city => panthera_15.panthera_13) where ((((panthera_15.panthera_7 is null) and (panthera_15.panthera_8 is null)) and (panthera_15.panthera_9 is null)) and (panthera_15.panthera_12 is null)) and (panthera_15.panthera_13 is null)) panthera_10 ; ``` 通过可视化工具将上面两条SQL的语法树展示出来,是这样的。  这是原始的SQL抽象语法树。  这是等价转换后的抽象语法树,内容太多被压缩的无法看清,不过你可以感受一下(笑)。 那么,在程序设计上如何实现这样复杂的语法转换呢?当时Panthera项目组合使用了几种经典的设计模式,每个语法点被封装到一个类里去处理,每个类通常不过几十行代码,这样整个程序非常简单、清爽。如果在测试过程中遇到不支持的语法点,只需为这个语法点新增加一个类即可,团队协作与代码维护非常容易。 使用装饰模式的语法等价转换类的构造,Panthera每增加一种新的语法转换能力,只需要开发一个新的Transformer类,然后添加到下面的构造函数代码里即可。 private static SqlASTTransformer tf = new RedundantSelectGroupItemTransformer( new DistinctTransformer( new GroupElementNormalizeTransformer( new PrepareQueryInfoTransformer( new OrderByTransformer( new OrderByFunctionTransformer( new MinusIntersectTransformer( new PrepareQueryInfoTransformer( new UnionTransformer( new Leftsemi2LeftJoinTransformer( new CountAsteriskPositionTransformer( new FilterInwardTransformer( //use leftJoin method to handle not exists for correlated new CrossJoinTransformer( new PrepareQueryInfoTransformer( new SubQUnnestTransformer( new PrepareFilterBlockTransformer( new PrepareQueryInfoTransformer( new TopLevelUnionTransformer( new FilterBlockAdjustTransformer( new PrepareFilterBlockTransformer( new ExpandAsteriskTransformer( new PrepareQueryInfoTransformer( new CrossJoinTransformer( new PrepareQueryInfoTransformer( new ConditionStructTransformer( new MultipleTableSelectTransformer( new WhereConditionOptimizationTransformer( new PrepareQueryInfoTransformer( new InTransformer( new TopLevelUnionTransformer( new MinusIntersectTransformer( new NaturalJoinTransformer( new OrderByNotInSelectListTransformer( new RowNumTransformer( new BetweenTransformer( new UsingTransformer( new SchemaDotTableTransformer( new NothingTransformer()))))))))))))))))))))))))))))))))))))); 而在具体的Transformer类中,则使用组合模式对抽象语法树AST进行遍历,以下为Between语法节点的遍历。我们看到使用组合模式进行树的遍历不需要用递归算法,因为递归的特性已经隐藏在树的结构里面了。 @Override protected void transform(CommonTree tree, TranslateContext context) throws SqlXlateException { tf.transformAST(tree, context); trans(tree, context); } void trans(CommonTree tree, TranslateContext context) { // deep firstly for (int i = 0; i tree.getChildCount(); i++) { trans((CommonTree) (tree.getChild(i)), context); } if (tree.getType() == PantheraExpParser.SQL92_RESERVED_BETWEEN) { transBetween(false, tree, context); } if (tree.getType() == PantheraExpParser.NOT_BETWEEN) { transBetween(true, tree, context); } } 将等价转换后的抽象语法树AST再进一步转换成Hive格式的抽象语法树,就可以交给Hive的语义分析器去处理了,从而也就实现了对标准SQL的支持。 当时Facebook为证明Hive对数据仓库的支持,手工将TPC-H的测试SQL转换成Hive QL,将这些手工Hive QL和Panthera进行对比测试,两者性能各有所长,总体上不相上下,说明Panthera自动进行语法分析和转换的效率还行。 Panthera(ASE)和Facebook手工Hive QL对比测试:  标准SQL语法集的语法点很多,007进行各种关系代数等价变形,也不可能适配所有标准SQL语法。 # SQL注入 常见的Web攻击手段,如下图所示,攻击者在HTTP请求中注入恶意SQL命令(drop table users;),服务器用请求参数构造数据库SQL命令时,恶意SQL被一起构造,并在数据库中执行。  但JDBC的PrepareStatement可阻止SQL注入攻击,MyBatis之类的ORM框架也可以阻止SQL注入,请从数据库引擎的工作机制解释PrepareStatement和MyBatis的防注入攻击的原理。
本文分享自华为云社区《从零开发大数据SQL引擎》,作者:JavaEdge 。 学习大数据技术的核心原理,掌握一些高效的思考和思维方式,构建自己的技术知识体系。 明白了原理,有时甚至不需要学习,顺着原理就可以推导出各种实现细节。 各种知识表象看杂乱无章,若只是学习繁杂知识点,固然自己的知识面是有限的,并且遇到问题的应变能力也很难提高。所以有些高手看起来似乎无所不知,不论谈论起什么技术,都能头头是道,其实并不是他们学习、掌握了所有技术,而是他们是在谈到这个问题时,才开始进行推导,并迅速得出结论。 高手不一定要很资深、经验丰富,把握住技术的核心本质,掌握快速分析推导的能力,能迅速将自己的知识技能推到陌生领域,就是高手。 本系列专注大数据开发需要关注的问题及解决方案。跳出繁杂知识表象,掌握核心原理和思维方式,进而融会贯通各种技术,再通过各种实践训练,成为终极高手。 # 大数据仓库Hive 作为一个成功的大数据仓库,它将SQL语句转换成MapReduce执行过程,并把大数据应用的门槛下降到普通数据分析师和工程师就可以很快上手的地步。 但Hive也有问题,由于它使用自定义Hive QL,对熟悉Oracle等传统数据仓库的分析师有上手难度。特别是很多企业使用传统数据仓库进行数据分析已久,沉淀大量SQL语句,非常庞大也非常复杂。某银行的一条统计报表SQL足足两张A4纸,光是完全理解可能就要花很长时间,再转化成Hive QL更费力,还不说可能引入bug。 开发一款能支持标准数据库SQL的大数据仓库引擎,让那些在Oracle上运行良好的SQL可以直接运行在Hadoop上,而不需要重写成Hive QL。 # Hive处理过程 1. 将输入的Hive QL经过语法解析器转换成Hive抽象语法树(Hive AST) 2. 将Hive AST经过语义分析器转换成MapReduce执行计划 3. 将生成的MapReduce执行计划和Hive执行函数代码提交到Hadoop执行 可见,最简单的,对第一步改造即可。考虑替换Hive语法解析器:能将标准SQL转换成Hive语义分析器能处理的Hive抽象语法树,即红框代替黑框  红框内:浅蓝色是个开源的SQL语法解析器,将标准SQL解析成标准SQL抽象语法树(SQL AST),后面深蓝色定制开发的SQL抽象语法树分析与转换器,将SQL AST转换成Hive AST。 那么关键问题就来了: # 标准SQL V.S Hive QL - 语法表达方式,Hive QL语法和标准SQL语法略有不同 - Hive QL支持的语法元素比标准SQL要少很多,比如,数据仓库领域主要的测试集TPC-H所有的SQL语句,Hive都不支持。尤其是Hive不支持复杂嵌套子查询,而数据仓库分析中嵌套子查询几乎无处不在。如下SQL,where条件existes里包含了另一条SQL: ```mysql select o_orderpriority, count(*) as order_count from orders where o_orderdate >= date '[DATE]' and o_orderdate date '[DATE]' + interval '3' month and exists (select * from lineitem where l_orderkey = o_orderkey and l_commitdate l_receiptdate) group by o_orderpriority order by o_orderpriority; ``` 开发支持标准SQL语法的SQL引擎难点,就是**消除复杂嵌套子查询掉**,即让where里不包含select。 SQL理论基础是关系代数,主要操作仅包括:并、差、积、选择、投影。而一个嵌套子查询可等价转换成一个连接(join)操作,如: ```mysql select s_grade from staff where s_city not in ( select p_city from proj where s_empname = p_pname ) ``` 这是个在where条件里嵌套了not in子查询的SQL语句,它可以用left outer join和left semi join进行等价转换,示例如下,这是Panthera自动转换完成得到的等价SQL。这条SQL语句不再包含嵌套子查询, ```mysql select panthera_10.panthera_1 as s_grade from (select panthera_1, panthera_4, panthera_6, s_empname, s_city from (select s_grade as panthera_1, s_city as panthera_4, s_empname as panthera_6, s_empname as s_empname, s_city as s_city from staff) panthera_14 left outer join (select panthera_16.panthera_7 as panthera_7, panthera_16.panthera_8 as panthera_8, panthera_16.panthera_9 as panthera_9, panthera_16.panthera_12 as panthera_12, panthera_16.panthera_13 as panthera_13 from (select panthera_0.panthera_1 as panthera_7, panthera_0.panthera_4 as panthera_8, panthera_0.panthera_6 as panthera_9, panthera_0.s_empname as panthera_12, panthera_0.s_city as panthera_13 from (select s_grade as panthera_1, s_city as panthera_4, s_empname as panthera_6, s_empname, s_city from staff) panthera_0 left semi join (select p_city as panthera_3, p_pname as panthera_5 from proj) panthera_2 on (panthera_0.panthera_4 = panthera_2.panthera_3) and (panthera_0.panthera_6 = panthera_2.panthera_5) where true) panthera_16 group by panthera_16.panthera_7, panthera_16.panthera_8, panthera_16.panthera_9, panthera_16.panthera_12, panthera_16.panthera_13) panthera_15 on ((((panthera_14.panthera_1 => panthera_15.panthera_7) and (panthera_14.panthera_4 => panthera_15.panthera_8)) and (panthera_14.panthera_6 => panthera_15.panthera_9)) and (panthera_14.s_empname => panthera_15.panthera_12)) and (panthera_14.s_city => panthera_15.panthera_13) where ((((panthera_15.panthera_7 is null) and (panthera_15.panthera_8 is null)) and (panthera_15.panthera_9 is null)) and (panthera_15.panthera_12 is null)) and (panthera_15.panthera_13 is null)) panthera_10 ; ``` 通过可视化工具将上面两条SQL的语法树展示出来,是这样的。  这是原始的SQL抽象语法树。  这是等价转换后的抽象语法树,内容太多被压缩的无法看清,不过你可以感受一下(笑)。 那么,在程序设计上如何实现这样复杂的语法转换呢?当时Panthera项目组合使用了几种经典的设计模式,每个语法点被封装到一个类里去处理,每个类通常不过几十行代码,这样整个程序非常简单、清爽。如果在测试过程中遇到不支持的语法点,只需为这个语法点新增加一个类即可,团队协作与代码维护非常容易。 使用装饰模式的语法等价转换类的构造,Panthera每增加一种新的语法转换能力,只需要开发一个新的Transformer类,然后添加到下面的构造函数代码里即可。 private static SqlASTTransformer tf = new RedundantSelectGroupItemTransformer( new DistinctTransformer( new GroupElementNormalizeTransformer( new PrepareQueryInfoTransformer( new OrderByTransformer( new OrderByFunctionTransformer( new MinusIntersectTransformer( new PrepareQueryInfoTransformer( new UnionTransformer( new Leftsemi2LeftJoinTransformer( new CountAsteriskPositionTransformer( new FilterInwardTransformer( //use leftJoin method to handle not exists for correlated new CrossJoinTransformer( new PrepareQueryInfoTransformer( new SubQUnnestTransformer( new PrepareFilterBlockTransformer( new PrepareQueryInfoTransformer( new TopLevelUnionTransformer( new FilterBlockAdjustTransformer( new PrepareFilterBlockTransformer( new ExpandAsteriskTransformer( new PrepareQueryInfoTransformer( new CrossJoinTransformer( new PrepareQueryInfoTransformer( new ConditionStructTransformer( new MultipleTableSelectTransformer( new WhereConditionOptimizationTransformer( new PrepareQueryInfoTransformer( new InTransformer( new TopLevelUnionTransformer( new MinusIntersectTransformer( new NaturalJoinTransformer( new OrderByNotInSelectListTransformer( new RowNumTransformer( new BetweenTransformer( new UsingTransformer( new SchemaDotTableTransformer( new NothingTransformer()))))))))))))))))))))))))))))))))))))); 而在具体的Transformer类中,则使用组合模式对抽象语法树AST进行遍历,以下为Between语法节点的遍历。我们看到使用组合模式进行树的遍历不需要用递归算法,因为递归的特性已经隐藏在树的结构里面了。 @Override protected void transform(CommonTree tree, TranslateContext context) throws SqlXlateException { tf.transformAST(tree, context); trans(tree, context); } void trans(CommonTree tree, TranslateContext context) { // deep firstly for (int i = 0; i tree.getChildCount(); i++) { trans((CommonTree) (tree.getChild(i)), context); } if (tree.getType() == PantheraExpParser.SQL92_RESERVED_BETWEEN) { transBetween(false, tree, context); } if (tree.getType() == PantheraExpParser.NOT_BETWEEN) { transBetween(true, tree, context); } } 将等价转换后的抽象语法树AST再进一步转换成Hive格式的抽象语法树,就可以交给Hive的语义分析器去处理了,从而也就实现了对标准SQL的支持。 当时Facebook为证明Hive对数据仓库的支持,手工将TPC-H的测试SQL转换成Hive QL,将这些手工Hive QL和Panthera进行对比测试,两者性能各有所长,总体上不相上下,说明Panthera自动进行语法分析和转换的效率还行。 Panthera(ASE)和Facebook手工Hive QL对比测试:  标准SQL语法集的语法点很多,007进行各种关系代数等价变形,也不可能适配所有标准SQL语法。 # SQL注入 常见的Web攻击手段,如下图所示,攻击者在HTTP请求中注入恶意SQL命令(drop table users;),服务器用请求参数构造数据库SQL命令时,恶意SQL被一起构造,并在数据库中执行。  但JDBC的PrepareStatement可阻止SQL注入攻击,MyBatis之类的ORM框架也可以阻止SQL注入,请从数据库引擎的工作机制解释PrepareStatement和MyBatis的防注入攻击的原理。 -
【功能模块】用spark 读hive 写gaussdb代码如下:取hive一条数据测试【操作步骤&问题现象】提交到yarn上 client模式 但是出现如下问题:、请问如何解决?是配置问题 ,还是其它问题?【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】【操作步骤&问题现象】我用spark读Hive数据 然后写入gaussdb时 出现下述问题为了方便测试,取了hive的一条数据,然后写gaussdb ;submit 提交到yarn集群跑的,client模式。请问是写错了,还是哪里配置的不对?谢谢【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
本文分享自华为云社区《[Hive执行原理](https://bbs.huaweicloud.com/blogs/348195?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: JavaEdge 。 MapReduce简化了大数据编程的难度,使得大数据计算不再是高不可攀的技术圣殿,普通工程师也能使用MapReduce开发大数据程序。但是对于经常需要进行大数据计算的人,比如从事研究商业智能(BI)的数据分析师来说,他们通常使用SQL进行大数据分析和统计,MapReduce编程还是有一定的门槛。而且如果每次统计和分析都开发相应的MapReduce程序,成本也确实太高了。 有没有更简单的办法,可以直接将SQL运行在大数据平台? 先看如何用MapReduce实现SQL数据分析。 # MapReduce实现SQL的原理 常见的一条SQL分析语句,MapReduce如何编程实现? ```mysql ` SELECT pageid, age, count(1) FROM pv_users GROUP BY pageid, age;` ``` 统计分析语句,统计不同年龄用户访问不同网页的兴趣偏好,具体数据输入和执行结果:  - 左边,要分析的数据表 - 右边,分析结果 把左表相同的行求和,即得右表,类似WordCount计算。该SQL的MapReduce的计算过程,按MapReduce编程模型 - map函数的输入K和V,主要看V V就是左表中每行的数据,如1, 25> - map函数的输出就是以输入的V作为K,V统一设为1 比如1, 25>, 1> map函数的输出经shuffle后,相同的K及其对应的V被放在一起组成一个,作为输入交给reduce函数处理。比如2, 25>, 1>被map函数输出两次,那么到了reduce这里,就变成输入2, 25>, 1, 1>>,这里的K是2, 25>,V集合是1, 1>。 在reduce函数内部,V集合里所有的数字被相加,然后输出。所以reduce的输出就是2, 25>, 2>  如此,一条SQL就被MapReduce计算好了。 在数据仓库中,SQL是最常用的分析工具,既然一条SQL可以通过MapReduce程序实现,那有无工具能自动将SQL生成MapReduce代码?这样数据分析师只要输入SQL,即可自动生成MapReduce可执行的代码,然后提交Hadoop执行。这就是Hadoop大数据仓库Hive。 # Hive架构 Hive能直接处理我们输入的SQL(Hive SQL语法和数据库标准SQL略不同),调用MapReduce计算框架完成数据分析操作。  通过Hive Client(Hive的命令行工具,JDBC等)向Hive提交SQL命令: - 若为DDL,Hive会通过执行引擎Driver将数据表的信息记录在Metastore元数据组件,该组件通常用一个关系数据库实现,记录表名、字段名、字段类型、关联HDFS文件路径等这些数据库的元信息 - 若为DQL,Driver就会将该语句提交给自己的编译器Compiler进行语法分析、语法解析、语法优化等一系列操作,最后生成一个MapReduce执行计划。然后根据执行计划生成一个MapReduce的作业,提交给Hadoop MapReduce计算框架处理。 对一个简单的SQL命令: ```mysql SELECT * FROM status_updates WHERE status LIKE ‘michael jackson’; ``` 其对应的Hive执行计划:  Hive内部预置了很多函数,Hive执行计划就是根据SQL语句生成这些函数的DAG(有向无环图),然后封装进MapReduce的map、reduce函数。该案例中的map函数调用了三个Hive内置函数TableScanOperator、FilterOperator、FileOutputOperator,就完成了map计算,而且无需reduce函数。 # Hive如何实现join操作 除了简单的聚合(group by)、过滤(where),Hive还能执行连接(join on)操作。 pv_users表的数据在实际中无法直接得到,因为pageid数据来自用户访问日志,每个用户进行一次页面浏览,就会生成一条访问记录,保存在page_view表中。而age年龄信息则记录在用户表user。  这两张表都有一个相同的字段userid,据该字段可连接两张表,生成前面例子的pv_users表: ```mysql SELECT pv.pageid, u.age FROM page_view pv JOIN user u ON (pv.userid = u.userid); ``` 该SQL命令也能转化为MapReduce计算,连接过程如下:  join的MapReduce计算过程和前面的group by稍有不同,因为join涉及两张表,来自两个文件(夹),所以需要在map输出的时候进行标记,比如来自第一张表的输出Value就记录为1, X>,这里的1表示数据来自第一张表。这样经过shuffle以后,相同的Key被输入到同一个reduce函数,就可以根据表的标记对Value数据求笛卡尔积,用第一张表的每条记录和第二张表的每条记录连接,输出就是join的结果。 所以打开Hive源码,看join相关代码,会看到一个两层for循环,对来自两张表的记录进行连接操作。 # 总结 开发无需经常编写MapReduce程序,因为网站最主要的大数据处理就是SQL分析,因此Hive在大数据应用很重要。 随Hive普及,我们对在Hadoop上执行SQL的需求越强,对大数据SQL的应用场景也多样化起来,于是又开发了各种大数据SQL引擎。 Cloudera开发了Impala,运行在HDFS上的MPP架构的SQL引擎。和MapReduce启动Map和Reduce两种执行进程,将计算过程分成两个阶段进行计算不同,Impala在所有DataNode服务器上部署相同的Impalad进程,多个Impalad进程相互协作,共同完成SQL计算。在一些统计场景中,Impala可做到ms级计算速度。 后来Spark诞生,也推出自己的SQL引擎Shark,即Spark SQL,将SQL语句解析成Spark的执行计划,在Spark上执行。由于Spark比MapReduce快很多,Spark SQL也相应比Hive快很多,并且随着Spark的普及,Spark SQL也逐渐被人们接受。后来Hive推出了Hive on Spark,将Hive的执行计划转换成Spark的计算模型。 我们还希望在NoSQL执行SQL,毕竟SQL发展几十年,积累庞大用户,很多人习惯用SQL解决问题。于是Saleforce推出了Phoenix,一个执行在HBase上的SQL引擎。 这些SQL引擎只支持类SQL语法,并不能像数据库那样支持标准SQL,特别是数据仓库领域几乎必然会用到嵌套查询SQL:在where条件里面嵌套select子查询,但几乎所有的大数据SQL引擎都不支持。然而习惯于传统数据库的使用者希望大数据也能支持标准SQL。 回到Hive。Hive本身的技术架构其实并没有什么创新,数据库相关的技术和架构已经非常成熟,只要将这些技术架构应用到MapReduce上就得到了Hadoop大数据仓库Hive。但是想到将两种技术嫁接到一起,却是极具创新性的,通过嫁接产生出的Hive极大降低大数据的应用门槛,也使Hadoop得到普及。 >参考 - https://learning.oreilly.com/library/view/hadoop-the-definitive/9781491901687/ch17.html#TheMetastore
-
[Thread-44] DEBUG cn.hsa.ims.engine.bo.impl.DataPreprocessionBOImpl2.genFilterCriteriaTmpTableSql(160) - 生成筛选条件临时表SQL:create table TMP_MDTRT_D_15000020220420143641111001 as select xxx [Thread-44] INFO cn.hsa.ims.bigdata.odps.HuaweiJdbcClient.submit(58) - Hive的入参:create table TMP_MDTRT_D_15000020220420143641111001 as select xxx[Thread-44] INFO org.apache.hadoop.hive.conf.HiveConf.findConfigFile(198) - Found configuration file null[Thread-44] WARN org.apache.hadoop.hive.conf.HiveConf.initialize(5430) - HiveConf of name hive.s3a.locals3.jceks does not exist[Thread-44] INFO org.apache.hadoop.hive.conf.HiveConf.initTimeZoneIsLocal(5471) - current conf hive.parquet.time.zone.isLocal=true[Thread-44] ERROR com.alibaba.druid.pool.DruidDataSource.init(973) - {dataSource-4} init error
-
mrs中hive二次开发,怎么使用druid管理hive连接。代码例子core-site.xml和user.hive.jaas.conf没看出有什么用。JDBCExamplePreLogin比JDBCExample 多了login。登录和不登录有什么区别?不需要写LoginUtil.setJaasConf、LoginUtil.setZookeeperServerPrincipal、LoginUtil.login也可以连接hive用spark引擎执行语句吗?
-
1.说明 正常在提交任务时,Hive都是提交在yarn上面。启动local模式的目的就是让hive的任务不运行在yarn上面,直接当前的服务器执行任务。2.优点当我们对Hive的源码进行Debug,且代码需要Debug到每个task内部时,如果任务是执行在yarn模式的话,那么是无法打断点的,需要进入local模式才能打断点3.MR当引擎为MR时,需要修改以下参数,可以修改配置文件hive-site.xml,也可以通过set来生效3.1 hive-site.xml<property> <name>hive.exec.mode.local.auto</name> <value>true</value> </property> <property> <name>hive.exec.mode.local.auto.inputbytes.max</name> <value>134217728</value> </property> <property> <name>hive.exec.mode.local.auto.input.files.max</name> <value>10</value> </property>3.2 set模式# 是否开启local模式 set hive.exec.mode.local.auto=true; # 输入最大数据量,默认128MB set hive.exec.mode.local.auto.inputbytes.max=134217728; # 最大任务数 set hive.exec.mode.local.auto.input.files.max=10;4.Tez当引擎为MR时,需要修改tez的配置文件tez-site.xml,如果通过set来执行将不生效4.1 tez-site.xml<property> <name>tez.local.mode</name> <value>true</value> </property> <property> <name>tez.grouping.split-count</name> <value>1</value> </property>说明:tez.grouping.split-count和上面的hive.exec.mode.local.auto.input.files.max类似
-
数据开发-hive脚本页面如何使用变量RT
-
使用cdm导入10G的数据进入hive,表A,parquest格式,压缩lzo。在hdfs里面生成的是一个10G左右的文件。然后创建格式一模一样的表B,执行语句, insert overwrite table 表B select * from表A,将表A数据插入到表B一份。表B在HDFS的形式是一些256M大小的文件,大约四十多个。现在执行select count(1) from 表A ,结果是:40086390select count(1) from 表B,报错,报错是:Error while processing statement FAILED Execution Error code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask计算引擎是MR。
上滑加载中
推荐直播
-
 GaussDB管理平台TPOPS,DBA高效运维的一站式解决方案
GaussDB管理平台TPOPS,DBA高效运维的一站式解决方案2024/12/24 周二 16:30-18:00
Leo 华为云数据库DTSE技术布道师
数据库的复杂运维,是否让你感到头疼不已?今天,华为云GaussDB管理平台将彻底来改观!本期直播,我们将深入探索GaussDB管理平台的TPOPS功能,带你感受一键式部署安装的便捷,和智能化运维管理的高效,让复杂的运维、管理变得简单,让简单变得可靠。
回顾中 -
 DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新
DTT年度收官盛典:华为开发者空间大咖汇,共探云端开发创新2025/01/08 周三 16:30-18:00
Yawei 华为云开发工具和效率首席专家 Edwin 华为开发者空间产品总监
数字化转型进程持续加速,驱动着技术革新发展,华为开发者空间如何巧妙整合鸿蒙、昇腾、鲲鹏等核心资源,打破平台间的壁垒,实现跨平台协同?在科技迅猛发展的今天,开发者们如何迅速把握机遇,实现高效、创新的技术突破?DTT 年度收官盛典,将与大家共同探索华为开发者空间的创新奥秘。
回顾中
热门标签