- 广义的数据分析包括狭义数据分析和数据挖掘。狭义的数据分析是指根据分析目的,采用对比分析、分组分析、交叉分析和回归分析等分析方法,对收集来的数据进行处理与分析,提取有价值的信息,发挥数据的作用,得到一个特征统计量结果的过程。数据挖掘则是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,通过应用聚类、分类、回归和关联规则等技术,挖掘潜在价值的过程。 广义的数据分析包括狭义数据分析和数据挖掘。狭义的数据分析是指根据分析目的,采用对比分析、分组分析、交叉分析和回归分析等分析方法,对收集来的数据进行处理与分析,提取有价值的信息,发挥数据的作用,得到一个特征统计量结果的过程。数据挖掘则是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,通过应用聚类、分类、回归和关联规则等技术,挖掘潜在价值的过程。
- 1.scrapy安装pip isntall scrapy 2.新建项目scrapy startproject mySpider(p2) PS C:\Users\livingbody\Desktop> scrapy startproject mySpiderNew Scrapy project 'mySpider', using template directory 'C:\minicond... 1.scrapy安装pip isntall scrapy 2.新建项目scrapy startproject mySpider(p2) PS C:\Users\livingbody\Desktop> scrapy startproject mySpiderNew Scrapy project 'mySpider', using template directory 'C:\minicond...
- FineBI学习笔记 FineBI学习笔记
- 在随机信号中经常存在信号幅度变化大小交替出现的情况,幅度变化较大的时段称之为能量包,在信号中寻找能量包发生时段的起止时间称之为能量包检测。在生物医学信号处理中能量包的检测时常遇到,如心电、脉搏波、呼吸波等信号中就存在这样的能量包检测普遍性问题。在其他信号处理中也有可能遇到类似情况。在给定能量包宽度范围、包峰间最小距离以及幅度门限的基础上,以通用方法实现能量包检测具有普遍的实际意义。 在随机信号中经常存在信号幅度变化大小交替出现的情况,幅度变化较大的时段称之为能量包,在信号中寻找能量包发生时段的起止时间称之为能量包检测。在生物医学信号处理中能量包的检测时常遇到,如心电、脉搏波、呼吸波等信号中就存在这样的能量包检测普遍性问题。在其他信号处理中也有可能遇到类似情况。在给定能量包宽度范围、包峰间最小距离以及幅度门限的基础上,以通用方法实现能量包检测具有普遍的实际意义。
- 留存分析模型为什么要做留存分析,直接看活跃用户百分比不行吗?答案是不行,如果产品目前处于快速增长阶段,很有可能新用户中的活跃用户数增长掩盖老用户活跃度的变化,按初始行为时间分组的留存分析可以消除用户增长对用户参与数据带来的影响。 什么是留存分析模型?用户在某段时间内开始使用应用,经过一段时间后,仍然继续使用该应用的用户,被认作是留存用户。顾名思义,留存分析模型就是分析这些留存用户的模型,即留... 留存分析模型为什么要做留存分析,直接看活跃用户百分比不行吗?答案是不行,如果产品目前处于快速增长阶段,很有可能新用户中的活跃用户数增长掩盖老用户活跃度的变化,按初始行为时间分组的留存分析可以消除用户增长对用户参与数据带来的影响。 什么是留存分析模型?用户在某段时间内开始使用应用,经过一段时间后,仍然继续使用该应用的用户,被认作是留存用户。顾名思义,留存分析模型就是分析这些留存用户的模型,即留...
- 1、目标 介绍将从PostgreSQL(RDBMS)导出的数据导入Neo4j(GraphDB),即将关系数据库模式建模,使之形成图。 预备知识:熟悉图模型并安装neo4j服务2、导RDBMS数据到Neo4j2.1、RDBMS数据集 用到的数据集是NorthWind dataset(点击下载),该数据库的E-R图如下:2.2、构建图模型 当将E-R模型转换成图模型时,需要遵守如下规则:... 1、目标 介绍将从PostgreSQL(RDBMS)导出的数据导入Neo4j(GraphDB),即将关系数据库模式建模,使之形成图。 预备知识:熟悉图模型并安装neo4j服务2、导RDBMS数据到Neo4j2.1、RDBMS数据集 用到的数据集是NorthWind dataset(点击下载),该数据库的E-R图如下:2.2、构建图模型 当将E-R模型转换成图模型时,需要遵守如下规则:...
- 编辑Python可视化数据分析07、Pandas_CSV文件读写📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Python初始环境地址:【Python可视化数据分析01、python环境搭建】💝 环境需求环境:win10开发工... 编辑Python可视化数据分析07、Pandas_CSV文件读写📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Python初始环境地址:【Python可视化数据分析01、python环境搭建】💝 环境需求环境:win10开发工...
- 编辑Python可视化数据分析05、Pandas数据分析📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Python初始环境地址:【Python可视化数据分析01、python环境搭建】💝 环境需求环境:win10开发工具:P... 编辑Python可视化数据分析05、Pandas数据分析📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Python初始环境地址:【Python可视化数据分析01、python环境搭建】💝 环境需求环境:win10开发工具:P...
- 编辑Spark高效数据分析03、Spack SQL📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Spark初始环境地址:【Spark高效数据分析01、idea开发环境搭建】💝环境需求环境:win10开发工具:IntelliJ ID... 编辑Spark高效数据分析03、Spack SQL📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Spark初始环境地址:【Spark高效数据分析01、idea开发环境搭建】💝环境需求环境:win10开发工具:IntelliJ ID...
- 编辑Spark高效数据分析01、idea开发环境搭建📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Spark初始环境地址:【Spark高效数据分析01、idea开发环境搭建】💝环境需求环境:win10开发工具:IntelliJ... 编辑Spark高效数据分析01、idea开发环境搭建📋前言📋💝博客:【红目香薰的博客_CSDN博客-计算机理论,2022年蓝桥杯,MySQL领域博主】💝✍本文由在下【红目香薰】原创,首发于CSDN✍🤗2022年最大愿望:【服务百万技术人次】🤗💝Spark初始环境地址:【Spark高效数据分析01、idea开发环境搭建】💝环境需求环境:win10开发工具:IntelliJ...
- 1. 聚类分析简介我们知道,机器学习本质上是一类优化问题——获取数据样本和目标函数,并尝试优化目标函数。在监督学习中,目标函数基于数据数据样本的标签,我们的目标是最小化模型预测和实际标签之间的差异,但在无监督学习中,我们并没有数据样本的标签。本文主要介绍无监督学习中最重要的分枝之一——聚类 (Clustering)。 当我们需要为在不带有标签的数据中挖掘所需的潜在信息时,聚类通常是我们的首选... 1. 聚类分析简介我们知道,机器学习本质上是一类优化问题——获取数据样本和目标函数,并尝试优化目标函数。在监督学习中,目标函数基于数据数据样本的标签,我们的目标是最小化模型预测和实际标签之间的差异,但在无监督学习中,我们并没有数据样本的标签。本文主要介绍无监督学习中最重要的分枝之一——聚类 (Clustering)。 当我们需要为在不带有标签的数据中挖掘所需的潜在信息时,聚类通常是我们的首选...
- Python数据分析之时间序列1. 时间序列的基本操作1.1创建时间序列1.2 通过时间戳索引选取子集2. 固定频率的时间序列2.1 创建固定频率的时间序列2.2 时间序列的频率、偏移量2.3 时间序列的移动3. 时间周期及计算3.1 创建时期对象3.2 时期的频率转换4. 重采样4.1 重采样方法(resample)4.2 降采样4.3 升采样5. 数据统计—滑动窗口5.1 什么是滑动窗口... Python数据分析之时间序列1. 时间序列的基本操作1.1创建时间序列1.2 通过时间戳索引选取子集2. 固定频率的时间序列2.1 创建固定频率的时间序列2.2 时间序列的频率、偏移量2.3 时间序列的移动3. 时间周期及计算3.1 创建时期对象3.2 时期的频率转换4. 重采样4.1 重采样方法(resample)4.2 降采样4.3 升采样5. 数据统计—滑动窗口5.1 什么是滑动窗口...
- 本文将会讲解Pandas对excel文件的处理;讲解内容如下:Python数据分析之Excel文件1.Pandas安装2.文件的读取及其写入3.数据的操作4.数据的筛选5.数据的删除思考:在python中,读写excel数据方法很多,比如xlrd、xlwt和openpyxl,实际上限制比较多,不是很方便。比如openpyxl也不支持csv格式。有没有更好的方法?答:更好的方法可以使用pand... 本文将会讲解Pandas对excel文件的处理;讲解内容如下:Python数据分析之Excel文件1.Pandas安装2.文件的读取及其写入3.数据的操作4.数据的筛选5.数据的删除思考:在python中,读写excel数据方法很多,比如xlrd、xlwt和openpyxl,实际上限制比较多,不是很方便。比如openpyxl也不支持csv格式。有没有更好的方法?答:更好的方法可以使用pand...
- Python数据分析之csv文件1. csv文本概述2. 操作CSV文件2.1 describe()方法数据统计2.2 读取文件前几行数据2.3 读取某一行所有数据2.4 读取某几行的数据2.5 读取所有行和列数据2.6 读取某一列的所有行数据2.7 读取某几列的某几行2.8 读取某一行和某一列对应的数据3. CSV数据的导入导出(复制CSV文件)4. 实例演示1. csv文本概述CSV文件... Python数据分析之csv文件1. csv文本概述2. 操作CSV文件2.1 describe()方法数据统计2.2 读取文件前几行数据2.3 读取某一行所有数据2.4 读取某几行的数据2.5 读取所有行和列数据2.6 读取某一列的所有行数据2.7 读取某几列的某几行2.8 读取某一行和某一列对应的数据3. CSV数据的导入导出(复制CSV文件)4. 实例演示1. csv文本概述CSV文件...
- # Logistics_Day10:主题及指标开发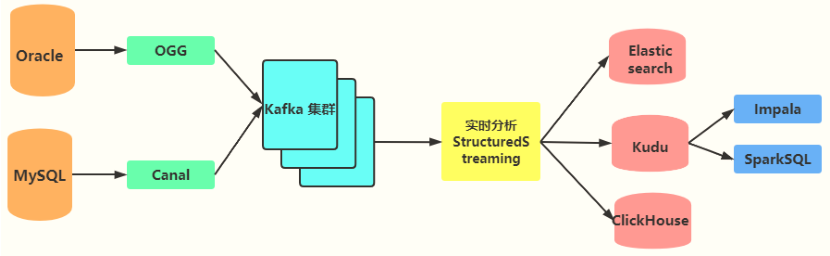## 01-[复习]-上次课程内容回顾 > 主要讲解:实时ETL转换... # Logistics_Day10:主题及指标开发## 01-[复习]-上次课程内容回顾 > 主要讲解:实时ETL转换...








上滑加载中
推荐直播
-
 华为云码道 × 仓颉编程:工程化AI编码探索
华为云码道 × 仓颉编程:工程化AI编码探索2026/05/27 周三 19:00-21:00
刘俊杰-华为云仓颉语言专家/李炎-华为云码道技术专家/王智鹏-OpenCangjie开源社区发起人
本场直播围绕华为云仓颉语言与华为云码道的深度结合,展示华为云智能编程从零基础到高效落地的完整生态能力。以华为云码道为引擎,仓颉语言为载体,带给大家日常提效、趣味创新到极速量产的开发体验。
回顾中 -
 一个AI团队帮你写代码:华为云码道Agent Space实战
一个AI团队帮你写代码:华为云码道Agent Space实战2026/06/25 周四 19:00-21:00
张翰文-华为云码道工程师/郭英旭-青软创新科技集团股份有限公司 软件架构师
本场直播聚焦华为云码道Agent Space两大模式:研发办公、代码开发,亲身体验从需求到代码的AI自动化能力。实操演示基于华为 CodeArts CLI,依托 OpenSpec 规格体系从零搭建业务项目。
回顾中
热门标签