-
 CodeArts快捷键在编码过程中经常使用,能够极大提升编码效率。键盘快捷键编辑器CodeArts使用键盘快捷键编辑器提供丰富且简单的键盘快捷键编辑体验。您可以通过快捷键Ctrl+K Ctrl+S或点击左下角的Manage > Keyboard Shortcuts来打开快捷键编辑器。它列出了所有绑定及未绑定的可用命令,您可以通过使用右键菜单轻松更改/删除/重置其键绑定。顶部搜索框可帮助您查找命令或键绑定。 键盘快捷键编辑器主要包含Command、Keybinding、When、Source,其中您可以通过When值来查看何种条件下使用快捷键,如果您的快捷键没有when值,则键绑定为全局可用。检测键绑定冲突如果您自定义了键盘快捷键,有时可能会遇到键绑定冲突,即相同的键盘快捷键映射到多个命令。这可能会让您感到混乱,特别是当您在编辑器中操作快捷键,相同的快捷键绑定不同的When值时。 键盘快捷键编辑器有一个上下文菜单命令Show Same Keybindings,该命令将根据键盘快捷键过滤键绑定以显示冲突。选择一个您认为重复的快捷键,您可以查看是否定义了多个命令、键绑定的来源及触发条件。录制按键功能录制按键功能可以帮助您快速找到键绑定及命令,按快捷键Alt+K或点击Record Keys,在键盘敲快捷键,即可成功查找到该快捷键绑定的所有命令。默认已绑定快捷键基本的编辑功能命令快捷键功能剪切Ctrl+X/Shift+Delete剪切当前行或选定的内容到剪切板复制Ctrl+C/Ctrl+Insert复制当前行或选定的内容到剪切板粘贴Ctrl+V/Shift+Insert从剪切板粘贴删除行Ctrl+Shift+K删除当前行在下面插入行Ctrl+Shift+Enter/Shift+Enter在光标下方开始新的一行在上面插入行Ctrl+Alt+ Enter在光标上方开始新的一行向下移动行Ctrl+Shift+DownArrow/Shift+Alt+DownArrow将当前行向下移动向上移动行Ctrl+Shift+UpArrow/Shift+Alt+UpArrow将当前行向上移动向下复制行Ctrl+D将当前行向下复制撤消Ctrl+Z返回上一次操作恢复Ctrl+Y恢复上一次操作选择全部Ctrl+A全选内容光标撤消Shift+AIt+J撤消最后一次光标操作在行尾添加光标Shift+AIt+I在选定的每一行的末尾插入光标选择所有找到的查找匹配项Ctrl+Shift+Alt+J选择当前选择的所有匹配项更改所有匹配项Shift+F6选择当前单词的所有匹配项在下面添加光标Ctrl+Alt+DownArrow在下方插入光标在上面添加光标Ctrl+Alt+UpArrow在上方插入光标转到括号Ctrl+Shift+\跳转到匹配的括号行缩进Ctrl+]缩进代码行减少缩进Ctri+[反缩进代码转到行首Home转到当前行的顶部转到行尾End转到当前行的尾部转到文件末尾Ctrl+End转到文件末尾转到文件开头Ctrl+Home转到文件开头向下滚动行Ctrl+DownArrow向下滚动行向上滚动行Ctrl+UpArrow向上滚动行向下滚动页面Alt+PageDown向下滚动页面向上滚动页面Alt+PageUp向上滚动页面折叠Ctrl+-折叠所有代码块展开Ctrl++/Ctrl+=展开所有代码块添加行注释Ctrl+K Ctrl+C添加行注释删除行注释Ctrl+K Ctrl+U删除行注释切换行注释Ctrl+/注释/取消行注释切换块注释Ctrl+Shift+/注释/取消块注释查找Ctrl+F文件内查找替换Ctrl+R文件内替换查找下一个F3/Enter查找模式下,向下查找查找上一个Shift+F3查找模式下,向上查找切换Tab键移动焦点 Ctrl+M使用 Tab 键设置焦点查看: 切换自动换行Alt+Z显示/隐藏自动换行丰富的语言编辑命令快捷键功能触发建议Ctrl+Shift+Space触发代码推荐格式化文档Shift+Alt+F格式化文件格式化选定内容Ctrl+K Ctrl+F格式化选择的文件内容转到声明Ctrl+B/Ctrl+Enter跳转到光标所在的方法、类的声明位置显示悬停Ctrl+Q显示鼠标所在位置的代码的简要信息查看声明Alt+F11快速打开光标所在方法、类的声明打开侧边的定义Ctrl+K F12分屏展示代码的定义快速修复Alt+Enter代码报错,提供修复方案转到引用Shift+F12跳转到引用重命名符号Shift+F6重命名符号展开选择Shift+Alt+RightArrow展开选择收起选择Shift+Alt+LeftArrow收起选择裁剪尾随空格Ctrl+K Ctrl+X去掉行末尾没用的空格Show Call HierarchyShift+Alt+H调用层次结构代码重构命令快捷键功能Introduce VariableCtrl+Alt+V引入变量Introduce FieldCtrl+Alt+Shift+F引入字段Introduce ConstantCtrl+Alt+C引入常数Introduce ParameterCtrl+Alt+Shift+P引入参数Extract MethodCtrl+Alt+Shift+M提取方法Copy classShift+F5复制类Change Class SignatureCtrl+F6更改类签名Change Method SignatureCtrl+F6更改方法签名Inline ParameterCtrl+Alt+Shift+P内联参数Inline MethodCtrl+Alt+Shift+L内联方法Safe DeleteAlt+Del安全删除导航命令快捷键功能后退Ctrl+Alt+LeftArrow退回到上一个操作的地方前进Ctrl+Alt+RightArrow前进到上一个操作的地方转到上一编辑位置Ctrl+Shift+Backspace光标跳转到上一次编辑位置转到编辑器中的符号Ctrl+F12/Ctrl+Shift+Alt+N转到编辑器中的符号转到文件…Ctrl+Shift+N打开文件搜索面板转到行/列Ctrl+G当前文件跳转到行视图: 快速打开组中上一个最近使用过的编辑器Ctrl+Tab快速打开组中上一个最近使用过的编辑器编辑器/窗口管理命令快捷键功能关闭窗口Ctrl+W/Ctrl+Shift+W关闭CodeArts窗口视图: 拆分编辑器Ctrl+\拆分编辑器视图: 关闭编辑器Ctrl+F4关闭编辑器视图: 关闭组中的所有编辑器Ctrl+K W关闭组中的所有编辑器视图: 关闭所有编辑器Ctrl+K Ctrl+W关闭所有编辑器视图: 重新打开已关闭的编辑器Ctrl+Shift+T重新打开已关闭的编辑器视图: 聚焦于第一个编辑器组Ctrl+1聚焦于第一个编辑器组视图: 聚焦于第二个编辑器组Ctrl+2聚焦于第二个编辑器组视图: 聚焦于第三个编辑器组Ctrl+3聚焦于第三个编辑器组视图: 聚焦到上一组编辑器Shift+Alt+Tab聚焦到上一组编辑器视图: 聚焦到下一组编辑器Alt+Tab聚焦到下一组编辑器视图: 向左移动编辑器Ctrl+Shift+PageUp向左移动编辑器视图: 向右移动编辑器Ctrl+Shift+PageDown向右移动编辑器视图: 向左移动编辑器组Ctrl+K LeftArrow向左移动编辑器组视图: 向右移动编辑器组Ctrl+K RightArrow向右移动编辑器组文件/工程管理命令快捷键功能工程: 打开工程Ctrl+O打开工程工程: 打开工程属性Shift+Alt+F9打开工程属性工程: 打开文件夹...Ctrl+Shift+O打开文件夹…工程: 导入工程Ctrl+Shift+I弹出导入工程窗口工程: 关闭文件夹/工程Ctrl+K F关闭文件夹/工程工程: 新建工程Alt+P弹出新建工程窗口文件: 新建文件Ctrl+Alt+N弹出新建文件窗口文件: 保存Ctrl+S保存所有文件: 另存为...Ctrl+Shift+S另存为文件: 打开最近的文件…Ctrl+E打开最近的文件文件: 复制活动文件的路径Ctrl+Shift+C复制绝对路径文件: 复制活动文件的相对路径Ctrl+K Ctrl+Shift+C复制相对路径显示命令快捷键功能视图: 切换全屏Ctrl+Alt+F切换全屏切换禅模式Ctrl+K Z切换禅模式退出禅模式Escape Escape退出禅模式显示快速修复Ctrl+.显示问题的修复方案显示所有命令Ctrl+Shift+A打开命令面板视图: 显示资源管理器Alt+1显示/隐藏资源管理器视图视图: 显示搜索Alt+3打开文本搜索视图: 显示源代码管理Alt+9显示/隐藏源代码管理视图视图: 显示运行和调试Alt+5/Ctrl+Shift+F8显示/隐藏运行视图视图: 切换输出Ctrl+Shift+U显示/隐藏输出视图视图: 切换集成终端Alt+F12显示/隐藏终端视图Markdown: 打开预览Ctrl+Shift+V打开Markdown预览Markdown: 打开侧边预览Ctrl+K V在侧边打开Markdown预览搜索命令快捷键功能智能搜索Ctrl Ctrl/Ctrl+N/Ctrl+Shift+L打开智能搜索面板视图: 显示搜索Alt+3打开文本搜索面板搜索: 在文件中查找Ctrl+Shift+F在文件中查找搜索: 在文件中替换Ctrl+Shift+R在文件中替换显示下一个搜索词DownArrow/Alt+DownArrow显示下一个搜索词显示上一个搜索词UpArrow/Alt+UpArrow显示上一个搜索词设置命令快捷键功能首选项: 打开设置Ctrl+,打开设置首选项: 打开Java SmartAssist开发套件设置Ctrl+Alt+P打开Java SmartAssist开发套件设置首选项: 打开键盘快捷方式Ctrl+K Ctrl+S打开键盘快捷方式首选项: 颜色主题Ctrl+`切换颜色主题运行/调试/构建命令快捷键功能运行: 开始执行(不调试)Shift+F10运行,不进入断点开始调试项目Ctrl+Alt+D调试Project调试: 开始调试Shift+F9调试Debug: 单步调试F7单步执行,进入函数内部Debug: 单步跳出Shift+F8单步执行,进出函数内部Debug: 单步跳过F8从断点处开始,执行单步语句Debug: 继续F9执行至下一个断点Debug: 停止Ctrl+F2停止调试构建工程Ctrl+Alt+U构建工程重新构建工程Ctrl+Alt+I重新构建工程
CodeArts快捷键在编码过程中经常使用,能够极大提升编码效率。键盘快捷键编辑器CodeArts使用键盘快捷键编辑器提供丰富且简单的键盘快捷键编辑体验。您可以通过快捷键Ctrl+K Ctrl+S或点击左下角的Manage > Keyboard Shortcuts来打开快捷键编辑器。它列出了所有绑定及未绑定的可用命令,您可以通过使用右键菜单轻松更改/删除/重置其键绑定。顶部搜索框可帮助您查找命令或键绑定。 键盘快捷键编辑器主要包含Command、Keybinding、When、Source,其中您可以通过When值来查看何种条件下使用快捷键,如果您的快捷键没有when值,则键绑定为全局可用。检测键绑定冲突如果您自定义了键盘快捷键,有时可能会遇到键绑定冲突,即相同的键盘快捷键映射到多个命令。这可能会让您感到混乱,特别是当您在编辑器中操作快捷键,相同的快捷键绑定不同的When值时。 键盘快捷键编辑器有一个上下文菜单命令Show Same Keybindings,该命令将根据键盘快捷键过滤键绑定以显示冲突。选择一个您认为重复的快捷键,您可以查看是否定义了多个命令、键绑定的来源及触发条件。录制按键功能录制按键功能可以帮助您快速找到键绑定及命令,按快捷键Alt+K或点击Record Keys,在键盘敲快捷键,即可成功查找到该快捷键绑定的所有命令。默认已绑定快捷键基本的编辑功能命令快捷键功能剪切Ctrl+X/Shift+Delete剪切当前行或选定的内容到剪切板复制Ctrl+C/Ctrl+Insert复制当前行或选定的内容到剪切板粘贴Ctrl+V/Shift+Insert从剪切板粘贴删除行Ctrl+Shift+K删除当前行在下面插入行Ctrl+Shift+Enter/Shift+Enter在光标下方开始新的一行在上面插入行Ctrl+Alt+ Enter在光标上方开始新的一行向下移动行Ctrl+Shift+DownArrow/Shift+Alt+DownArrow将当前行向下移动向上移动行Ctrl+Shift+UpArrow/Shift+Alt+UpArrow将当前行向上移动向下复制行Ctrl+D将当前行向下复制撤消Ctrl+Z返回上一次操作恢复Ctrl+Y恢复上一次操作选择全部Ctrl+A全选内容光标撤消Shift+AIt+J撤消最后一次光标操作在行尾添加光标Shift+AIt+I在选定的每一行的末尾插入光标选择所有找到的查找匹配项Ctrl+Shift+Alt+J选择当前选择的所有匹配项更改所有匹配项Shift+F6选择当前单词的所有匹配项在下面添加光标Ctrl+Alt+DownArrow在下方插入光标在上面添加光标Ctrl+Alt+UpArrow在上方插入光标转到括号Ctrl+Shift+\跳转到匹配的括号行缩进Ctrl+]缩进代码行减少缩进Ctri+[反缩进代码转到行首Home转到当前行的顶部转到行尾End转到当前行的尾部转到文件末尾Ctrl+End转到文件末尾转到文件开头Ctrl+Home转到文件开头向下滚动行Ctrl+DownArrow向下滚动行向上滚动行Ctrl+UpArrow向上滚动行向下滚动页面Alt+PageDown向下滚动页面向上滚动页面Alt+PageUp向上滚动页面折叠Ctrl+-折叠所有代码块展开Ctrl++/Ctrl+=展开所有代码块添加行注释Ctrl+K Ctrl+C添加行注释删除行注释Ctrl+K Ctrl+U删除行注释切换行注释Ctrl+/注释/取消行注释切换块注释Ctrl+Shift+/注释/取消块注释查找Ctrl+F文件内查找替换Ctrl+R文件内替换查找下一个F3/Enter查找模式下,向下查找查找上一个Shift+F3查找模式下,向上查找切换Tab键移动焦点 Ctrl+M使用 Tab 键设置焦点查看: 切换自动换行Alt+Z显示/隐藏自动换行丰富的语言编辑命令快捷键功能触发建议Ctrl+Shift+Space触发代码推荐格式化文档Shift+Alt+F格式化文件格式化选定内容Ctrl+K Ctrl+F格式化选择的文件内容转到声明Ctrl+B/Ctrl+Enter跳转到光标所在的方法、类的声明位置显示悬停Ctrl+Q显示鼠标所在位置的代码的简要信息查看声明Alt+F11快速打开光标所在方法、类的声明打开侧边的定义Ctrl+K F12分屏展示代码的定义快速修复Alt+Enter代码报错,提供修复方案转到引用Shift+F12跳转到引用重命名符号Shift+F6重命名符号展开选择Shift+Alt+RightArrow展开选择收起选择Shift+Alt+LeftArrow收起选择裁剪尾随空格Ctrl+K Ctrl+X去掉行末尾没用的空格Show Call HierarchyShift+Alt+H调用层次结构代码重构命令快捷键功能Introduce VariableCtrl+Alt+V引入变量Introduce FieldCtrl+Alt+Shift+F引入字段Introduce ConstantCtrl+Alt+C引入常数Introduce ParameterCtrl+Alt+Shift+P引入参数Extract MethodCtrl+Alt+Shift+M提取方法Copy classShift+F5复制类Change Class SignatureCtrl+F6更改类签名Change Method SignatureCtrl+F6更改方法签名Inline ParameterCtrl+Alt+Shift+P内联参数Inline MethodCtrl+Alt+Shift+L内联方法Safe DeleteAlt+Del安全删除导航命令快捷键功能后退Ctrl+Alt+LeftArrow退回到上一个操作的地方前进Ctrl+Alt+RightArrow前进到上一个操作的地方转到上一编辑位置Ctrl+Shift+Backspace光标跳转到上一次编辑位置转到编辑器中的符号Ctrl+F12/Ctrl+Shift+Alt+N转到编辑器中的符号转到文件…Ctrl+Shift+N打开文件搜索面板转到行/列Ctrl+G当前文件跳转到行视图: 快速打开组中上一个最近使用过的编辑器Ctrl+Tab快速打开组中上一个最近使用过的编辑器编辑器/窗口管理命令快捷键功能关闭窗口Ctrl+W/Ctrl+Shift+W关闭CodeArts窗口视图: 拆分编辑器Ctrl+\拆分编辑器视图: 关闭编辑器Ctrl+F4关闭编辑器视图: 关闭组中的所有编辑器Ctrl+K W关闭组中的所有编辑器视图: 关闭所有编辑器Ctrl+K Ctrl+W关闭所有编辑器视图: 重新打开已关闭的编辑器Ctrl+Shift+T重新打开已关闭的编辑器视图: 聚焦于第一个编辑器组Ctrl+1聚焦于第一个编辑器组视图: 聚焦于第二个编辑器组Ctrl+2聚焦于第二个编辑器组视图: 聚焦于第三个编辑器组Ctrl+3聚焦于第三个编辑器组视图: 聚焦到上一组编辑器Shift+Alt+Tab聚焦到上一组编辑器视图: 聚焦到下一组编辑器Alt+Tab聚焦到下一组编辑器视图: 向左移动编辑器Ctrl+Shift+PageUp向左移动编辑器视图: 向右移动编辑器Ctrl+Shift+PageDown向右移动编辑器视图: 向左移动编辑器组Ctrl+K LeftArrow向左移动编辑器组视图: 向右移动编辑器组Ctrl+K RightArrow向右移动编辑器组文件/工程管理命令快捷键功能工程: 打开工程Ctrl+O打开工程工程: 打开工程属性Shift+Alt+F9打开工程属性工程: 打开文件夹...Ctrl+Shift+O打开文件夹…工程: 导入工程Ctrl+Shift+I弹出导入工程窗口工程: 关闭文件夹/工程Ctrl+K F关闭文件夹/工程工程: 新建工程Alt+P弹出新建工程窗口文件: 新建文件Ctrl+Alt+N弹出新建文件窗口文件: 保存Ctrl+S保存所有文件: 另存为...Ctrl+Shift+S另存为文件: 打开最近的文件…Ctrl+E打开最近的文件文件: 复制活动文件的路径Ctrl+Shift+C复制绝对路径文件: 复制活动文件的相对路径Ctrl+K Ctrl+Shift+C复制相对路径显示命令快捷键功能视图: 切换全屏Ctrl+Alt+F切换全屏切换禅模式Ctrl+K Z切换禅模式退出禅模式Escape Escape退出禅模式显示快速修复Ctrl+.显示问题的修复方案显示所有命令Ctrl+Shift+A打开命令面板视图: 显示资源管理器Alt+1显示/隐藏资源管理器视图视图: 显示搜索Alt+3打开文本搜索视图: 显示源代码管理Alt+9显示/隐藏源代码管理视图视图: 显示运行和调试Alt+5/Ctrl+Shift+F8显示/隐藏运行视图视图: 切换输出Ctrl+Shift+U显示/隐藏输出视图视图: 切换集成终端Alt+F12显示/隐藏终端视图Markdown: 打开预览Ctrl+Shift+V打开Markdown预览Markdown: 打开侧边预览Ctrl+K V在侧边打开Markdown预览搜索命令快捷键功能智能搜索Ctrl Ctrl/Ctrl+N/Ctrl+Shift+L打开智能搜索面板视图: 显示搜索Alt+3打开文本搜索面板搜索: 在文件中查找Ctrl+Shift+F在文件中查找搜索: 在文件中替换Ctrl+Shift+R在文件中替换显示下一个搜索词DownArrow/Alt+DownArrow显示下一个搜索词显示上一个搜索词UpArrow/Alt+UpArrow显示上一个搜索词设置命令快捷键功能首选项: 打开设置Ctrl+,打开设置首选项: 打开Java SmartAssist开发套件设置Ctrl+Alt+P打开Java SmartAssist开发套件设置首选项: 打开键盘快捷方式Ctrl+K Ctrl+S打开键盘快捷方式首选项: 颜色主题Ctrl+`切换颜色主题运行/调试/构建命令快捷键功能运行: 开始执行(不调试)Shift+F10运行,不进入断点开始调试项目Ctrl+Alt+D调试Project调试: 开始调试Shift+F9调试Debug: 单步调试F7单步执行,进入函数内部Debug: 单步跳出Shift+F8单步执行,进出函数内部Debug: 单步跳过F8从断点处开始,执行单步语句Debug: 继续F9执行至下一个断点Debug: 停止Ctrl+F2停止调试构建工程Ctrl+Alt+U构建工程重新构建工程Ctrl+Alt+I重新构建工程 -
 >摘要: J.U.C是Java并发编程中非常重要的工具包,今天,我们就来着重讲讲J.U.C里面的FutureTask、Fork/Join框架和BlockingQueue。 本文分享自华为云社区《[【高并发】J.U.C组件扩展](https://bbs.huaweicloud.com/blogs/353871?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 冰 河 。 # FutureTask FutureTask是J.U.C(java.util.concurrent)下的,但不是AQS(AbstractQueuedSynchronizer)的子类。其对线程结果的处理值得借鉴和在项目中使用。 Thread和Runnable执行完任务无法获取执行结果。Java1.5开始提供了Callable和Future,通过它们可以在任务执行完毕之后,得到任务执行的结果。 # Callable与Runnable接口对比 Callable:泛型接口,提供一个call()方法,支持抛出异常,并且执行后有返回值 Runnable:接口,提供一个run()方法,不支持抛出异常,执行后无返回值 # Future接口 对于具体的Callable和Runnable任务,可以进行取消,查询任务是否被取消,查询是否完成以及获取结果等。 Future可以监视目标线程调用call()的情况,当调用Future的get()方法时,就可以获得结果。此时,执行任务的线程可能不会直接完成,当前线程就开始阻塞,直到call()方法结束返回结果,当前线程才会继续执行。总之,Future可以得到别的线程任务方法的返回值。 # FutureTask类 实现的接口为RunnableFuture,而RunnableFuture接口继承了Runnable和Future两个接口,所以FutureTask类最终也是执行Callable类型的任务。如果FutureTask类的构造方法参数是Runnable的话,会转换成Callable类型。 类实现了两个接口:Runnable和Future。所以,它即可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值,这样设计的好处如下: 假设有一个很费时的逻辑,需要计算并且返回这个值,同时,这个值又不是马上需要,则可以使用Runnable和Future的组合,用另外一个线程去计算返回值,而当前线程在使用这个返回值之前,可以做其他的操作,等到需要这个返回值时,再通过Future得到。 Future示例代码如下: ``` package io.binghe.concurrency.example.aqs; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Future; @Slf4j public class FutureExample { static class MyCallable implements Callable{ @Override public String call() throws Exception { log.info("do something in callable"); Thread.sleep(5000); return "Done"; } } public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); Future future = executorService.submit(new MyCallable()); log.info("do something in main"); Thread.sleep(1000); String result = future.get(); log.info("result: {}", result); executorService.shutdown(); } } ``` FutureTask示例代码如下: ``` package io.binghe.concurrency.example.aqs; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; @Slf4j public class FutureTaskExample { public static void main(String[] args) throws Exception{ FutureTask futureTask = new FutureTask(new Callable() { @Override public String call() throws Exception { log.info("do something in callable"); Thread.sleep(5000); return "Done"; } }); new Thread(futureTask).start(); log.info("do something in main"); Thread.sleep(1000); String result = futureTask.get(); log.info("result: {}", result); } } ``` # Fork/Join框架 位于J.U.C(java.util.concurrent)中,是Java7中提供的用于执行并行任务的框架,其可以将大任务分割成若干个小任务,最终汇总每个小任务的结果后得到最终结果。基本思想和Hadoop的MapReduce思想类似。 主要采用的是工作窃取算法(某个线程从其他队列里窃取任务来执行),并行分治计算中的一种Work-stealing策略 ## 为什么需要使用工作窃取算法呢? 假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。 ## 工作窃取算法的优点: 充分利用线程进行并行计算,并减少了线程间的竞争 ## 工作窃取算法的缺点: 在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。 对于Fork/Join框架而言,当一个任务正在等待它使用Join操作创建的子任务结束时,执行这个任务的工作线程查找其他未被执行的任务,并开始执行这些未被执行的任务,通过这种方式,线程充分利用它们的运行时间来提高应用程序的性能。为了实现这个目标,Fork/Join框架执行的任务有一些局限性。 ## Fork/Join框架局限性: (1)任务只能使用Fork和Join操作来进行同步机制,如果使用了其他同步机制,则在同步操作时,工作线程就不能执行其他任务了。比如,在Fork/Join框架中,使任务进行了睡眠,那么,在睡眠期间内,正在执行这个任务的工作线程将不会执行其他任务了。 (2)在Fork/Join框架中,所拆分的任务不应该去执行IO操作,比如:读写数据文件 (3)任务不能抛出检查异常,必须通过必要的代码来出来这些异常 Fork/Join框架的核心类 Fork/Join框架的核心是两个类:ForkJoinPool和ForkJoinTask。ForkJoinPool负责实现工作窃取算法、管理工作线程、提供关于任务的状态以及执行信息。ForkJoinTask主要提供在任务中执行Fork和Join操作的机制。 示例代码如下: ``` package io.binghe.concurrency.example.aqs; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.Future; import java.util.concurrent.RecursiveTask; @Slf4j public class ForkJoinTaskExample extends RecursiveTask { public static final int threshold = 2; private int start; private int end; public ForkJoinTaskExample(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; //如果任务足够小就计算任务 boolean canCompute = (end - start) = threshold; if (canCompute) { for (int i = start; i = end; i++) { sum += i; } } else { // 如果任务大于阈值,就分裂成两个子任务计算 int middle = (start + end) / 2; ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle); ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end); // 执行子任务 leftTask.fork(); rightTask.fork(); // 等待任务执行结束合并其结果 int leftResult = leftTask.join(); int rightResult = rightTask.join(); // 合并子任务 sum = leftResult + rightResult; } return sum; } public static void main(String[] args) { ForkJoinPool forkjoinPool = new ForkJoinPool(); //生成一个计算任务,计算1+2+3+4 ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100); //执行一个任务 Future result = forkjoinPool.submit(task); try { log.info("result:{}", result.get()); } catch (Exception e) { log.error("exception", e); } } } ``` # BlockingQueue 阻塞队列,是线程安全的。 ## 被阻塞的情况如下: (1)当队列满时,进行入队列操作 (2)当队列空时,进行出队列操作 ## 使用场景如下: 主要在生产者和消费者场景 ## BlockingQueue的方法 BlockingQueue 具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:  四组不同的行为方式解释: - 抛出异常 如果试图的操作无法立即执行,抛一个异常。 - 特殊值 如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。 - 阻塞 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。 - 超时 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。 ## BlockingQueue的实现类如下: - ArrayBlockingQueue:有界的阻塞队列(容量有限,必须在初始化的时候指定容量大小,容量大小指定后就不能再变化),内部实现是一个数组,以FIFO的方式存储数据,最新插入的对象是尾部,最新移除的对象是头部。 - DelayQueue:阻塞的是内部元素,DelayQueue中的元素必须实现一个接口——Delayed(存在于J.U.C下)。Delayed接口继承了Comparable接口,这是因为Delayed接口中的元素需要进行排序,一般情况下,都是按照Delayed接口中的元素过期时间的优先级进行排序。应用场景主要有:定时关闭连接、缓存对象、超时处理等。内部实现使用PriorityQueue和ReentrantLock。 - LinkedBlockingQueue:大小配置是可选的,如果初始化时指定了大小,则是有边界的;如果初始化时未指定大小,则是无边界的(其实默认大小是Integer类型的最大值)。内部实现时一个链表,以FIFO的方式存储数据,最新插入的对象是尾部,最新移除的对象是头部。 - PriorityBlockingQueue:带优先级的阻塞队列,无边界,但是有排序规则,允许插入空对象(也就是null)。所有插入的对象必须实现Comparable接口,队列优先级的排序规则就是按照对Comparable接口的实现来定义的。可以从PriorityBlockingQueue中获得一个迭代器Iterator,但这个迭代器并不保证按照优先级的顺序进行迭代。 - SynchronousQueue:队列内部仅允许容纳一个元素,当一个线程插入一个元素后,就会被阻塞,除非这个元素被另一个线程消费。因此,也称SynchronousQueue为同步队列。SynchronousQueue是一个无界非缓存的队列。准确的说,它不存储元素,放入元素只有等待取走元素之后,才能再次放入元素
>摘要: J.U.C是Java并发编程中非常重要的工具包,今天,我们就来着重讲讲J.U.C里面的FutureTask、Fork/Join框架和BlockingQueue。 本文分享自华为云社区《[【高并发】J.U.C组件扩展](https://bbs.huaweicloud.com/blogs/353871?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 冰 河 。 # FutureTask FutureTask是J.U.C(java.util.concurrent)下的,但不是AQS(AbstractQueuedSynchronizer)的子类。其对线程结果的处理值得借鉴和在项目中使用。 Thread和Runnable执行完任务无法获取执行结果。Java1.5开始提供了Callable和Future,通过它们可以在任务执行完毕之后,得到任务执行的结果。 # Callable与Runnable接口对比 Callable:泛型接口,提供一个call()方法,支持抛出异常,并且执行后有返回值 Runnable:接口,提供一个run()方法,不支持抛出异常,执行后无返回值 # Future接口 对于具体的Callable和Runnable任务,可以进行取消,查询任务是否被取消,查询是否完成以及获取结果等。 Future可以监视目标线程调用call()的情况,当调用Future的get()方法时,就可以获得结果。此时,执行任务的线程可能不会直接完成,当前线程就开始阻塞,直到call()方法结束返回结果,当前线程才会继续执行。总之,Future可以得到别的线程任务方法的返回值。 # FutureTask类 实现的接口为RunnableFuture,而RunnableFuture接口继承了Runnable和Future两个接口,所以FutureTask类最终也是执行Callable类型的任务。如果FutureTask类的构造方法参数是Runnable的话,会转换成Callable类型。 类实现了两个接口:Runnable和Future。所以,它即可以作为Runnable被线程执行,又可以作为Future得到Callable的返回值,这样设计的好处如下: 假设有一个很费时的逻辑,需要计算并且返回这个值,同时,这个值又不是马上需要,则可以使用Runnable和Future的组合,用另外一个线程去计算返回值,而当前线程在使用这个返回值之前,可以做其他的操作,等到需要这个返回值时,再通过Future得到。 Future示例代码如下: ``` package io.binghe.concurrency.example.aqs; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Future; @Slf4j public class FutureExample { static class MyCallable implements Callable{ @Override public String call() throws Exception { log.info("do something in callable"); Thread.sleep(5000); return "Done"; } } public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); Future future = executorService.submit(new MyCallable()); log.info("do something in main"); Thread.sleep(1000); String result = future.get(); log.info("result: {}", result); executorService.shutdown(); } } ``` FutureTask示例代码如下: ``` package io.binghe.concurrency.example.aqs; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.Callable; import java.util.concurrent.FutureTask; @Slf4j public class FutureTaskExample { public static void main(String[] args) throws Exception{ FutureTask futureTask = new FutureTask(new Callable() { @Override public String call() throws Exception { log.info("do something in callable"); Thread.sleep(5000); return "Done"; } }); new Thread(futureTask).start(); log.info("do something in main"); Thread.sleep(1000); String result = futureTask.get(); log.info("result: {}", result); } } ``` # Fork/Join框架 位于J.U.C(java.util.concurrent)中,是Java7中提供的用于执行并行任务的框架,其可以将大任务分割成若干个小任务,最终汇总每个小任务的结果后得到最终结果。基本思想和Hadoop的MapReduce思想类似。 主要采用的是工作窃取算法(某个线程从其他队列里窃取任务来执行),并行分治计算中的一种Work-stealing策略 ## 为什么需要使用工作窃取算法呢? 假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。 ## 工作窃取算法的优点: 充分利用线程进行并行计算,并减少了线程间的竞争 ## 工作窃取算法的缺点: 在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。 对于Fork/Join框架而言,当一个任务正在等待它使用Join操作创建的子任务结束时,执行这个任务的工作线程查找其他未被执行的任务,并开始执行这些未被执行的任务,通过这种方式,线程充分利用它们的运行时间来提高应用程序的性能。为了实现这个目标,Fork/Join框架执行的任务有一些局限性。 ## Fork/Join框架局限性: (1)任务只能使用Fork和Join操作来进行同步机制,如果使用了其他同步机制,则在同步操作时,工作线程就不能执行其他任务了。比如,在Fork/Join框架中,使任务进行了睡眠,那么,在睡眠期间内,正在执行这个任务的工作线程将不会执行其他任务了。 (2)在Fork/Join框架中,所拆分的任务不应该去执行IO操作,比如:读写数据文件 (3)任务不能抛出检查异常,必须通过必要的代码来出来这些异常 Fork/Join框架的核心类 Fork/Join框架的核心是两个类:ForkJoinPool和ForkJoinTask。ForkJoinPool负责实现工作窃取算法、管理工作线程、提供关于任务的状态以及执行信息。ForkJoinTask主要提供在任务中执行Fork和Join操作的机制。 示例代码如下: ``` package io.binghe.concurrency.example.aqs; import lombok.extern.slf4j.Slf4j; import java.util.concurrent.ForkJoinPool; import java.util.concurrent.Future; import java.util.concurrent.RecursiveTask; @Slf4j public class ForkJoinTaskExample extends RecursiveTask { public static final int threshold = 2; private int start; private int end; public ForkJoinTaskExample(int start, int end) { this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; //如果任务足够小就计算任务 boolean canCompute = (end - start) = threshold; if (canCompute) { for (int i = start; i = end; i++) { sum += i; } } else { // 如果任务大于阈值,就分裂成两个子任务计算 int middle = (start + end) / 2; ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle); ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end); // 执行子任务 leftTask.fork(); rightTask.fork(); // 等待任务执行结束合并其结果 int leftResult = leftTask.join(); int rightResult = rightTask.join(); // 合并子任务 sum = leftResult + rightResult; } return sum; } public static void main(String[] args) { ForkJoinPool forkjoinPool = new ForkJoinPool(); //生成一个计算任务,计算1+2+3+4 ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100); //执行一个任务 Future result = forkjoinPool.submit(task); try { log.info("result:{}", result.get()); } catch (Exception e) { log.error("exception", e); } } } ``` # BlockingQueue 阻塞队列,是线程安全的。 ## 被阻塞的情况如下: (1)当队列满时,进行入队列操作 (2)当队列空时,进行出队列操作 ## 使用场景如下: 主要在生产者和消费者场景 ## BlockingQueue的方法 BlockingQueue 具有 4 组不同的方法用于插入、移除以及对队列中的元素进行检查。如果请求的操作不能得到立即执行的话,每个方法的表现也不同。这些方法如下:  四组不同的行为方式解释: - 抛出异常 如果试图的操作无法立即执行,抛一个异常。 - 特殊值 如果试图的操作无法立即执行,返回一个特定的值(常常是 true / false)。 - 阻塞 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行。 - 超时 如果试图的操作无法立即执行,该方法调用将会发生阻塞,直到能够执行,但等待时间不会超过给定值。返回一个特定值以告知该操作是否成功(典型的是 true / false)。 ## BlockingQueue的实现类如下: - ArrayBlockingQueue:有界的阻塞队列(容量有限,必须在初始化的时候指定容量大小,容量大小指定后就不能再变化),内部实现是一个数组,以FIFO的方式存储数据,最新插入的对象是尾部,最新移除的对象是头部。 - DelayQueue:阻塞的是内部元素,DelayQueue中的元素必须实现一个接口——Delayed(存在于J.U.C下)。Delayed接口继承了Comparable接口,这是因为Delayed接口中的元素需要进行排序,一般情况下,都是按照Delayed接口中的元素过期时间的优先级进行排序。应用场景主要有:定时关闭连接、缓存对象、超时处理等。内部实现使用PriorityQueue和ReentrantLock。 - LinkedBlockingQueue:大小配置是可选的,如果初始化时指定了大小,则是有边界的;如果初始化时未指定大小,则是无边界的(其实默认大小是Integer类型的最大值)。内部实现时一个链表,以FIFO的方式存储数据,最新插入的对象是尾部,最新移除的对象是头部。 - PriorityBlockingQueue:带优先级的阻塞队列,无边界,但是有排序规则,允许插入空对象(也就是null)。所有插入的对象必须实现Comparable接口,队列优先级的排序规则就是按照对Comparable接口的实现来定义的。可以从PriorityBlockingQueue中获得一个迭代器Iterator,但这个迭代器并不保证按照优先级的顺序进行迭代。 - SynchronousQueue:队列内部仅允许容纳一个元素,当一个线程插入一个元素后,就会被阻塞,除非这个元素被另一个线程消费。因此,也称SynchronousQueue为同步队列。SynchronousQueue是一个无界非缓存的队列。准确的说,它不存储元素,放入元素只有等待取走元素之后,才能再次放入元素 -
 package base;public class demo02 { public static void main(String[] args) { //八大基本数据类型 //整型 int num1 = 10; //最常用 //范围在100多// byte num2 = 200; //short short num3 = 20; //long long num4 = 40L; //Long类型在数字后面加个L表示是long类型 //float 浮点数:小数 float num5 = 12.3F; //float类型加F,否则就报错 double num6 = 3.14159; //字符 char name1 = 'a';// char name2 = 'as'; //字符是一个 //字符串 //String 不是关键字,是一个类 String num7 = "asd"; //布尔值 boolean flag = true; //真 boolean fla = false; //假 }}
package base;public class demo02 { public static void main(String[] args) { //八大基本数据类型 //整型 int num1 = 10; //最常用 //范围在100多// byte num2 = 200; //short short num3 = 20; //long long num4 = 40L; //Long类型在数字后面加个L表示是long类型 //float 浮点数:小数 float num5 = 12.3F; //float类型加F,否则就报错 double num6 = 3.14159; //字符 char name1 = 'a';// char name2 = 'as'; //字符是一个 //字符串 //String 不是关键字,是一个类 String num7 = "asd"; //布尔值 boolean flag = true; //真 boolean fla = false; //假 }} -
 ## 前言 Postman和Apifox有什么区别?他们之间分别有什么优势,感兴趣的同学可以继续往下看。 不吹不黑,只列功能,纯客观比对。 ## 一.功能列表对比 ### (一)接口设计与文档管理功能  1.导入功能对比 Apifox的导入功能除了支持OpenApi之外,还支持yapi,RAP2,postman等国内用得比较多的接口文档导入,而Postman支持的格式相对较少。   2.在线分享功能对比 Postman的在线分享功能,付费版支持“只读”功能,Apifox分享功能支持选择过期日期、设置密码,选择分享内容的范围,选择环境等功能。   3.编辑接口文档对比 接口文档既可以纯粹的MD格式文档对接口做整体说明,也可以在单个接口内部对单个接口进行说明注释。Apifox会增加创建时间、负责人、所属业务分组等业务和协同层面的注释信息。     4.生成代码功能对比 Postman支持将接口生成代码,postman支持的接口和框架为4种,Apifox支持130多种语言和框架 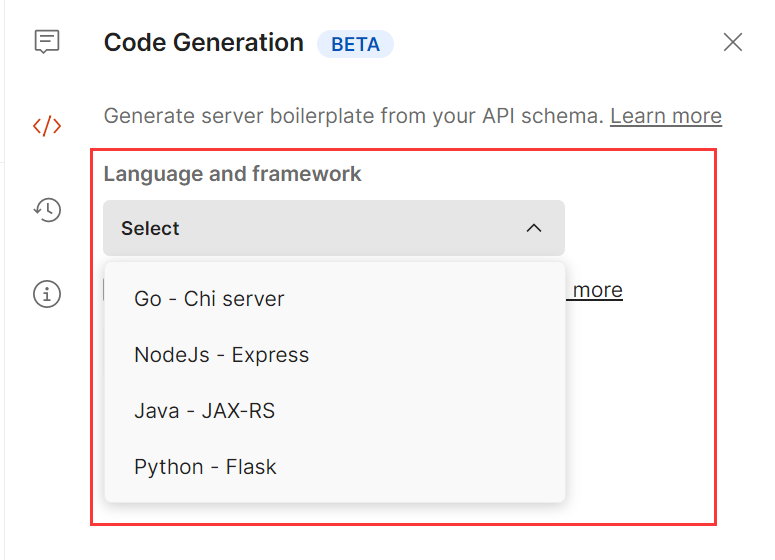  5.数据模型功能对比 在postman中没有这个功能,在Apifox中,由于本身具备接口设计的功能,因此会将实体类的相关参数封装成一个数据模型,供不同的接口调用,提高数据复用的效率,提高接口封装的程度,减少重复的工作。  ### (二)接口调试功能对比  对比了下,Postman基本依赖于JS脚本,通过编写脚本对接口进行调试。 Apifox则是可视化调试界面为主,自定义脚本编辑为辅。     两者对比,在postman中需要写脚本才能实现的接口断言和提取变量、等待时间,在这里都能直接通过填写参数来完成、不需要写脚本。 而操作数据库这个功能postman则不支持。postman只支持js脚本,Apifox目前支持调用其他语言的外部函数和脚本,不过需要先安装相关的Python、java等环境。 ### (三)接口mock功能  Postman也有mock功能,但它的mock服务需要自己搭建而且mock功能并不强。 在Postman上执行API mock 需要经过3步: 第一步:创建 mock服务器,获得mock url 第二步:逐个编写并添加 mock 示例,供执行mock时返回对应的接口响应  也就是说接口mock 出来的响应来源于先前调试已经有的,或者直接自己编辑一个响应进去,才能得到一个返回。 mock server 只能返回自己手动添加进去的几条响应,而无法自己无限制创建出mock 数据。 第三步: 将mock url 复制到接口里进行调试。 而想要在 Apifox 内做接口 mock 只需要在`环境`中选择mock服务 在响应参数中选择mock规则,点击发送请求,则mock服务会返回与实际业务返回高度相似的接口响应。    ### (四)接口测试功能  在Postman里写测试脚本,使用动态参数,接口响应断言,参数传递都通过写脚本来实现。 如果要作业务接口测试,需要写各种场景下的用例,同样是通过写脚本来修改参数用例的执行顺序和设置循环次数的。使用postman至少需要掌握基础的js语言。 Apifox里面做自动化测试可视化程度相对较高一些,创建用例的时候可以在接口设计面板修改参数然后保存,场景用例可以添加不同的参数用例作为步骤,通过拖曳来选择用例的执行顺序。 右侧的面板可以填写循环次数,接口间的参数传递和断言也可以在可视化面板提取出来。完成单个接口测试或者场景测试,都不需要写代码。  ## 二.团队协作功能  Postman的团队协作功能是付费的,3人以下团队可使用免费版协作,3人以上根据可用功能和人数有不同的价格版本。 但通常一个团队不可能只有3个人,也就是说,有限开放的那点协同功能是无法支持正常的团队协作需求的。  Apifox的协同功能是免费的,团队成员的权限管理,接口数据同步、在线分享都没有障碍。 本身Apifox的定位和Postman就不一样,它一出生就是定位在API管理和协作上。 所以除了协作功能必须的权限管理和数据同步上,它也最大程度地做数据复用,尽量减少不必要的工作量。 比如说接口调试的参数用例可以直接导入来做自动化测试,一个数据模型可以给多个接口使用,一套接口数据可以给后端做调试、前端做mock、测试做自动化。  ## 三.Apifox 没有的功能 Postman支持fork GitHub上的代码,以及API 网关。这两块在Apifox上均没有相关的功能。 两个工具的功能有相同的地方,但本质上各自的市场定位还是不同的,Postman打通了接口调试、测试、到线上监测,代码生成。 而Apifox始终立身于前端、后端测试间基于接口的设计、调试、测试、文档管理等一系列接口的生命周期管理来发力。 在相同的功能点上,Apifox基于本土互联网团队的协作模式和痛点,基本做到了人无我有,人有我优 的程度。 因此如果基于各种原因,寻找Postman替代的开发们,不妨体验一下Apifox。 ## 四.产品价格 从收费模式上看,postman是基础功能不收费,协作功能收费;Apifox是公网版本不收费,私有化部署收费。 Apifox的SaaS版本也没有什么功能和团队人数的限制,对于我们常规的项目开发来说,免费版本就够用了。 公网的SaaS版本,数据的确是放在他们服务器上的,但这点Postman其实也一样,而且postman的服务器可是放在国外的。 如果大家的项目安全保密级别较高,想要做私有化部署,可以去他们官网咨询,这方面我没咨询过就不对比了。  ### 下载地址 **Apifox官网**:[www.apifox.cn](https://www.apifox.cn/?utm_source=liam)
## 前言 Postman和Apifox有什么区别?他们之间分别有什么优势,感兴趣的同学可以继续往下看。 不吹不黑,只列功能,纯客观比对。 ## 一.功能列表对比 ### (一)接口设计与文档管理功能  1.导入功能对比 Apifox的导入功能除了支持OpenApi之外,还支持yapi,RAP2,postman等国内用得比较多的接口文档导入,而Postman支持的格式相对较少。   2.在线分享功能对比 Postman的在线分享功能,付费版支持“只读”功能,Apifox分享功能支持选择过期日期、设置密码,选择分享内容的范围,选择环境等功能。   3.编辑接口文档对比 接口文档既可以纯粹的MD格式文档对接口做整体说明,也可以在单个接口内部对单个接口进行说明注释。Apifox会增加创建时间、负责人、所属业务分组等业务和协同层面的注释信息。     4.生成代码功能对比 Postman支持将接口生成代码,postman支持的接口和框架为4种,Apifox支持130多种语言和框架   5.数据模型功能对比 在postman中没有这个功能,在Apifox中,由于本身具备接口设计的功能,因此会将实体类的相关参数封装成一个数据模型,供不同的接口调用,提高数据复用的效率,提高接口封装的程度,减少重复的工作。  ### (二)接口调试功能对比  对比了下,Postman基本依赖于JS脚本,通过编写脚本对接口进行调试。 Apifox则是可视化调试界面为主,自定义脚本编辑为辅。     两者对比,在postman中需要写脚本才能实现的接口断言和提取变量、等待时间,在这里都能直接通过填写参数来完成、不需要写脚本。 而操作数据库这个功能postman则不支持。postman只支持js脚本,Apifox目前支持调用其他语言的外部函数和脚本,不过需要先安装相关的Python、java等环境。 ### (三)接口mock功能  Postman也有mock功能,但它的mock服务需要自己搭建而且mock功能并不强。 在Postman上执行API mock 需要经过3步: 第一步:创建 mock服务器,获得mock url 第二步:逐个编写并添加 mock 示例,供执行mock时返回对应的接口响应  也就是说接口mock 出来的响应来源于先前调试已经有的,或者直接自己编辑一个响应进去,才能得到一个返回。 mock server 只能返回自己手动添加进去的几条响应,而无法自己无限制创建出mock 数据。 第三步: 将mock url 复制到接口里进行调试。 而想要在 Apifox 内做接口 mock 只需要在`环境`中选择mock服务 在响应参数中选择mock规则,点击发送请求,则mock服务会返回与实际业务返回高度相似的接口响应。    ### (四)接口测试功能  在Postman里写测试脚本,使用动态参数,接口响应断言,参数传递都通过写脚本来实现。 如果要作业务接口测试,需要写各种场景下的用例,同样是通过写脚本来修改参数用例的执行顺序和设置循环次数的。使用postman至少需要掌握基础的js语言。 Apifox里面做自动化测试可视化程度相对较高一些,创建用例的时候可以在接口设计面板修改参数然后保存,场景用例可以添加不同的参数用例作为步骤,通过拖曳来选择用例的执行顺序。 右侧的面板可以填写循环次数,接口间的参数传递和断言也可以在可视化面板提取出来。完成单个接口测试或者场景测试,都不需要写代码。  ## 二.团队协作功能  Postman的团队协作功能是付费的,3人以下团队可使用免费版协作,3人以上根据可用功能和人数有不同的价格版本。 但通常一个团队不可能只有3个人,也就是说,有限开放的那点协同功能是无法支持正常的团队协作需求的。  Apifox的协同功能是免费的,团队成员的权限管理,接口数据同步、在线分享都没有障碍。 本身Apifox的定位和Postman就不一样,它一出生就是定位在API管理和协作上。 所以除了协作功能必须的权限管理和数据同步上,它也最大程度地做数据复用,尽量减少不必要的工作量。 比如说接口调试的参数用例可以直接导入来做自动化测试,一个数据模型可以给多个接口使用,一套接口数据可以给后端做调试、前端做mock、测试做自动化。  ## 三.Apifox 没有的功能 Postman支持fork GitHub上的代码,以及API 网关。这两块在Apifox上均没有相关的功能。 两个工具的功能有相同的地方,但本质上各自的市场定位还是不同的,Postman打通了接口调试、测试、到线上监测,代码生成。 而Apifox始终立身于前端、后端测试间基于接口的设计、调试、测试、文档管理等一系列接口的生命周期管理来发力。 在相同的功能点上,Apifox基于本土互联网团队的协作模式和痛点,基本做到了人无我有,人有我优 的程度。 因此如果基于各种原因,寻找Postman替代的开发们,不妨体验一下Apifox。 ## 四.产品价格 从收费模式上看,postman是基础功能不收费,协作功能收费;Apifox是公网版本不收费,私有化部署收费。 Apifox的SaaS版本也没有什么功能和团队人数的限制,对于我们常规的项目开发来说,免费版本就够用了。 公网的SaaS版本,数据的确是放在他们服务器上的,但这点Postman其实也一样,而且postman的服务器可是放在国外的。 如果大家的项目安全保密级别较高,想要做私有化部署,可以去他们官网咨询,这方面我没咨询过就不对比了。  ### 下载地址 **Apifox官网**:[www.apifox.cn](https://www.apifox.cn/?utm_source=liam) -
操作场景DLI支持用户编写代码创建Spark作业来创建数据库、创建DLI表或OBS表和插入表数据等操作。本示例完整的演示通过编写java代码、使用Spark作业创建数据库、创建表和插入表数据的详细操作,帮助您在DLI上进行作业开发。约束限制不支持的场景:在SQL作业中创建了数据库(database),编写程序代码指定在该数据库下创建表。例如在DLI的SQL编辑器中的某SQL队列下,创建了数据库testdb。后续通过编写程序代码在testdb下创建表testTable,编译打包后提交的Spark Jar作业则会运行失败。不支持创建加密的DLI表,即不支持创建DLI表时设置encryption=true。例如,如下建表语句不支持:CREATE TABLE tb1(id int) using parquet options(encryption=true)支持的场景在SQL作业中创建数据库(database),表(table) , 通过SQL或Spark程序作业读取插入数据。在Spark程序作业中创建数据库(database),表(table), 通过SQL或Spark程序作业读取插入数据。环境准备在进行Spark 作业访问DLI元数据开发前,请准备以下开发环境。表1 Spark Jar作业开发环境准备项说明操作系统Windows系统,支持Windows7以上版本。安装JDKJDK使用1.8版本。安装和配置IntelliJ IDEAIntelliJ IDEA为进行应用开发的工具,版本要求使用2019.1或其他兼容版本。安装Maven开发环境的基本配置。用于项目管理,贯穿软件开发生命周期。开发流程DLI进行Spark作业访问DLI元数据开发流程参考如下:图1 Spark作业访问DLI元数据开发流程表2 开发流程说明序号阶段操作界面说明1创建DLI通用队列DLI控制台创建作业运行的DLI队列。2OBS桶文件配置OBS控制台如果是创建OBS表,则需要上传文件数据到OBS桶下。配置Spark创建表的元数据信息“spark.sql.warehouse.dir”的存储路径。3新建Maven工程,配置pom文件IntelliJ IDEA参考样例代码说明,编写程序代码创建DLI表或OBS表。4编写程序代码5调试,编译代码并导出Jar包6上传Jar包到OBS和DLIOBS控制台将生成的Spark Jar包文件上传到OBS目录下和DLI程序包中。7创建Spark Jar作业DLI控制台在DLI控制台创建Spark Jar作业并提交运行作业。8查看作业运行结果DLI控制台查看作业运行状态和作业运行日志。步骤1:创建DLI通用队列第一次提交Spark作业,需要先创建队列,例如创建名为“sparktest”的队列,队列类型选择为“通用队列”。在DLI管理控制台的左侧导航栏中,选择“队列管理”。单击“队列管理”页面右上角“购买队列”进行创建队列。创建名为“sparktest”的队列,队列类型选择为“通用队列”。创建队列详细介绍请参考创建队列。单击“立即购买”,确认配置。配置确认无误,单击“提交”完成队列创建。步骤2:OBS桶文件配置如果需要创建OBS表,则需要先上传数据到OBS桶目录下。本次演示的样例代码创建了OBS表,测试数据内容参考如下示例,创建名为的testdata.csv文件。12,Michael 27,Andy 30,Justin进入OBS管理控制台,在“桶列表”下,单击已创建的OBS桶名称,本示例桶名为“dli-test-obs01”,进入“概览”页面。单击左侧列表中的“对象”,选择“上传对象”,将testdata.csv文件上传到OBS桶根目录下。在OBS桶根目录下,单击“新建文件夹”,创建名为“warehousepath”的文件夹。该文件夹路径用来存储Spark创建表的元数据信息“spark.sql.warehouse.dir”。步骤3:新建Maven工程,配置pom依赖以下通过IntelliJ IDEA 2020.2工具操作演示。打开IntelliJ IDEA,选择“File > New > Project”。图2 新建Project选择Maven,Project SDK选择1.8,单击“Next”。定义样例工程名和配置样例工程存储路径,单击“Finish”完成工程创建。如上图所示,本示例创建Maven工程名为:SparkJarMetadata,Maven工程路径为:“D:\DLITest\SparkJarMetadata”。在pom.xml文件中添加如下配置。<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.3.2</version> </dependency> </dependencies>图3 修改pom.xml文件在工程路径的“src > main > java”文件夹上鼠标右键,选择“New > Package”,新建Package和类文件。Package根据需要定义,本示例定义为:“com.huawei.dli.demo”,完成后回车。在包路径下新建Java Class文件,本示例定义为:DliCatalogTest。步骤4:编写代码编写DliCatalogTest程序创建数据库、DLI表和OBS表。完整的样例请参考Java样例代码,样例代码分段说明如下:导入依赖的包。import org.apache.spark.sql.SparkSession;创建SparkSession会话。创建SparkSession会话时需要指定Spark参数:"spark.sql.session.state.builder"、"spark.sql.catalog.class"和"spark.sql.extensions",按照样例配置即可。SparkSession spark = SparkSession .builder() .config("spark.sql.session.state.builder", "org.apache.spark.sql.hive.UQueryHiveACLSessionStateBuilder") .config("spark.sql.catalog.class", "org.apache.spark.sql.hive.UQueryHiveACLExternalCatalog") .config("spark.sql.extensions","org.apache.spark.sql.CarbonInternalExtensions"+","+"org.apache.spark.sql.DliSparkExtension") .appName("java_spark_demo") .getOrCreate();创建数据库。如下样例代码演示,创建名为test_sparkapp的数据库。spark.sql("create database if not exists test_sparkapp").collect();创建DLI表并插入测试数据。spark.sql("drop table if exists test_sparkapp.dli_testtable").collect(); spark.sql("create table test_sparkapp.dli_testtable(id INT, name STRING)").collect(); spark.sql("insert into test_sparkapp.dli_testtable VALUES (123,'jason')").collect(); spark.sql("insert into test_sparkapp.dli_testtable VALUES (456,'merry')").collect();创建OBS表。如下示例中的OBS路径需要根据步骤2:OBS桶文件配置中的实际数据路径修改。spark.sql("drop table if exists test_sparkapp.dli_testobstable").collect(); spark.sql("create table test_sparkapp.dli_testobstable(age INT, name STRING) using csv options (path 'obs://dli-test-obs01/testdata.csv')").collect();关闭SparkSession会话spark。spark.stop();步骤5:调试、编译代码并导出Jar包单击IntelliJ IDEA工具右侧的“Maven”,参考下图分别单击“clean”、“compile”对代码进行编译。编译成功后,单击“package”对代码进行打包。打包成功后,生成的Jar包会放到target目录下,以备后用。本示例将会生成到:“D:\DLITest\SparkJarMetadata\target”下名为“SparkJarMetadata-1.0-SNAPSHOT.jar”。步骤6:上传Jar包到OBS和DLI下登录OBS控制台,将生成的“SparkJarMetadata-1.0-SNAPSHOT.jar”Jar包文件上传到OBS路径下。将Jar包文件上传到DLI的程序包管理中,方便后续统一管理。登录DLI管理控制台,单击“数据管理 > 程序包管理”。在“程序包管理”页面,单击右上角的“创建”创建程序包。在“创建程序包”对话框,配置以下参数。包类型:选择“JAR”。OBS路径:程序包所在的OBS路径。分组设置和组名称根据情况选择设置,方便后续识别和管理程序包。图4 创建程序包单击“确定”,完成创建程序包。步骤7:创建Spark Jar作业登录DLI控制台,单击“作业管理 > Spark作业”。在“Spark作业”管理界面,单击“创建作业”。在作业创建界面,配置对应作业运行参数。具体说明如下:表3 Spark Jar作业参数填写参数名参数值所属队列选择已创建的DLI通用队列。例如当前选择步骤1:创建DLI通用队列创建的通用队列“sparktest”。作业名称(--name)自定义Spark Jar作业运行的名称。当前定义为:SparkTestMeta。应用程序选择步骤6:上传Jar包到OBS和DLI下中上传到DLI程序包。例如当前选择为:“SparkJarObs-1.0-SNAPSHOT.jar”。主类格式为:程序包名+类名。例如当前为:com.huawei.dli.demo.DliCatalogTest。Spark参数(--conf)spark.dli.metaAccess.enable=truespark.sql.warehouse.dir=obs://dli-test-obs01/warehousepath说明:spark.sql.warehouse.dir参数的OBS路径为步骤2:OBS桶文件配置中配置创建。访问元数据选择:是其他参数保持默认值即可。图5 创建Spark Jar作业单击“执行”,提交该Spark Jar作业。在Spark作业管理界面显示已提交的作业运行状态。查看作业运行结果在Spark作业管理界面显示已提交的作业运行状态。初始状态显示为“启动中”。如果作业运行成功则作业状态显示为“已成功”,通过以下操作查看创建的数据库和表。可以在DLI控制台,左侧导航栏,单击“SQL编辑器”。在“数据库”中已显示创建的数据库“test_sparkapp”。图6 查看创建的数据库双击数据库名,可以在数据库下查看已创建成功的DLI和OBS表。图7 查看表双击DLI表名dli_testtable,单击“执行”查询DLI表数据。图8 查询DLI表数据注释掉DLI表查询语句,双击OBS表名dli_testobstable,单击“执行”查询OBS表数据。图9 查询OBS表数据如果作业运行失败则作业状态显示为“已失败”,单击“操作”列“更多”下的“Driver日志”,显示当前作业运行的日志,分析报错原因。图10 查看Driver日志原因定位解决后,可以在作业“操作”列,单击“编辑”,修改作业相关参数后,单击“执行”重新运行该作业即可。后续指引如果您想通过Spark Jar作业访问其他数据源,请参考《使用Spark作业跨源访问数据源》。创建DLI表的语法请参考创建DLI表,创建OBS表的语法请参考创建OBS表。如果是通过API接口调用提交该作业请参考以下操作说明:调用创建批处理作业接口,参考以下请求参数说明。详细的API参数说明请参考《数据湖探索API参考》>《创建批处理作业》。将请求参数中的“catalog_name”参数设置为“dli”。conf 中需要增加"spark.dli.metaAccess.enable":"true"。如果需要执行DDL,则还要在conf中配置"spark.sql.warehouse.dir": "obs://bucket/warehousepath"。完整的API请求参数可以参考如下示例说明。{ "queue":"citest", "file":"SparkJarMetadata-1.0-SNAPSHOT.jar", "className":"DliCatalogTest", "conf":{"spark.sql.warehouse.dir": "obs://bucket/warehousepath", "spark.dli.metaAccess.enable":"true"}, "sc_type":"A", "executorCores":1, "numExecutors":6, "executorMemory":"4G", "driverCores":2, "driverMemory":"7G", "catalog_name": "dli" }Java样例代码本示例操作步骤采用Java进行编码,具体完整的样例代码参考如下:package com.huawei.dli.demo; import org.apache.spark.sql.SparkSession; public class DliCatalogTest { public static void main(String[] args) { SparkSession spark = SparkSession .builder() .config("spark.sql.session.state.builder", "org.apache.spark.sql.hive.UQueryHiveACLSessionStateBuilder") .config("spark.sql.catalog.class", "org.apache.spark.sql.hive.UQueryHiveACLExternalCatalog") .config("spark.sql.extensions","org.apache.spark.sql.CarbonInternalExtensions"+","+"org.apache.spark.sql.DliSparkExtension") .appName("java_spark_demo") .getOrCreate(); spark.sql("create database if not exists test_sparkapp").collect(); spark.sql("drop table if exists test_sparkapp.dli_testtable").collect(); spark.sql("create table test_sparkapp.dli_testtable(id INT, name STRING)").collect(); spark.sql("insert into test_sparkapp.dli_testtable VALUES (123,'jason')").collect(); spark.sql("insert into test_sparkapp.dli_testtable VALUES (456,'merry')").collect(); spark.sql("drop table if exists test_sparkapp.dli_testobstable").collect(); spark.sql("create table test_sparkapp.dli_testobstable(age INT, name STRING) using csv options (path 'obs://dli-test-obs01/testdata.csv')").collect(); spark.stop(); } }scala样例代码scala样例代码object DliCatalogTest { def main(args:Array[String]): Unit = { val sql = args(0) val runDdl = Try(args(1).toBoolean).getOrElse(true) System.out.println(s"sql is $sql runDdl is $runDdl") val sparkConf = new SparkConf(true) sparkConf .set("spark.sql.session.state.builder", "org.apache.spark.sql.hive.UQueryHiveACLSessionStateBuilder") .set("spark.sql.catalog.class", "org.apache.spark.sql.hive.UQueryHiveACLExternalCatalog") sparkConf.setAppName("dlicatalogtester") val spark = SparkSession.builder .config(sparkConf) .enableHiveSupport() .config("spark.sql.extensions", Seq("org.apache.spark.sql.CarbonInternalExtensions", "org.apache.spark.sql.DliSparkExtension").mkString(",")) .appName("SparkTest") .getOrCreate() System.out.println("catalog is " + spark.sessionState.catalog.toString) if (runDdl) { val df = spark.sql(sql).collect() } else { spark.sql(sql).show() } spark.close() } }Python样例代码Python样例代码#!/usr/bin/python # -*- coding: UTF-8 -*- from __future__ import print_function import sys from pyspark.sql import SparkSession if __name__ == "__main__": url = sys.argv[1] creatTbl = "CREATE TABLE test_sparkapp.dli_rds USING JDBC OPTIONS ('url'='jdbc:mysql://%s'," \ "'driver'='com.mysql.jdbc.Driver','dbtable'='test.test'," \ " 'passwdauth' = 'DatasourceRDSTest_pwd','encryption' = 'true')" % url spark = SparkSession \ .builder \ .enableHiveSupport() \ .config("spark.sql.session.state.builder","org.apache.spark.sql.hive.UQueryHiveACLSessionStateBuilder") \ .config("spark.sql.catalog.class", "org.apache.spark.sql.hive.UQueryHiveACLExternalCatalog") \ .config("spark.sql.extensions",','.join(["org.apache.spark.sql.CarbonInternalExtensions","org.apache.spark.sql.DliSparkExtension"])) \ .appName("python Spark test catalog") \ .getOrCreate() spark.sql("CREATE database if not exists test_sparkapp").collect() spark.sql("drop table if exists test_sparkapp.dli_rds").collect() spark.sql(creatTbl).collect() spark.sql("select * from test_sparkapp.dli_rds").show() spark.sql("insert into table test_sparkapp.dli_rds select 12,'aaa'").collect() spark.sql("select * from test_sparkapp.dli_rds").show() spark.sql("insert overwrite table test_sparkapp.dli_rds select 1111,'asasasa'").collect() spark.sql("select * from test_sparkapp.dli_rds").show() spark.sql("drop table test_sparkapp.dli_rds").collect() spark.stop()
-
操作场景DLI支持用户使用Hive UDTF(User-Defined Table-Generating Functions)自定义表值函数,UDTF用于解决一进多出业务场景,即其输入与输出是一对多的关系,读入一行数据,输出多个值。约束限制在DLI Console上执行UDTF相关操作时,需要使用自建的SQL队列。跨账号使用UDTF时,除了创建UDTF函数的用户,其他用户如果需要使用时,需要先进行授权才可使用对应的UDTF函数。授权操作参考如下:登录DLI管理控制台,选择“ 数据管理 > 程序包管理”页面,选择对应的UDTF Jar包,单击“操作”列中的“权限管理”,进入权限管理页面,单击右上角“授权”,勾选对应权限。自定义函数中引用static类或接口时,必须要加上“try catch”异常捕获,否则可能会造成包冲突,导致函数功能异常。环境准备在进行UDTF开发前,请准备以下开发环境。表1 UDTF开发环境准备项说明操作系统Windows系统,支持Windows7以上版本。安装JDKJDK使用1.8版本。安装和配置IntelliJ IDEAIntelliJ IDEA为进行应用开发的工具,版本要求使用2019.1或其他兼容版本。安装Maven开发环境的基本配置。用于项目管理,贯穿软件开发生命周期。开发流程DLI下UDTF函数开发流程参考如下:图1 UDTF开发流程表2 开发流程说明序号阶段操作界面说明1新建Maven工程,配置pom文件IntelliJ IDEA参考操作步骤说明,编写UDTF函数代码。2编写UDTF函数代码3调试,编译代码并导出Jar包4上传Jar包到OBSOBS控制台将生成的UDTF函数Jar包文件上传到OBS目录下。5创建DLI的UDTF函数DLI控制台在DLI控制台的SQL作业管理界面创建使用的UDTF函数。6验证和使用DLI的UDTF函数DLI控制台在DLI作业中使用创建的UDTF函数。操作步骤新建Maven工程,配置pom文件。以下通过IntelliJ IDEA 2020.2工具操作演示。打开IntelliJ IDEA,选择“File > New > Project”。图2 新建Project选择Maven,Project SDK选择1.8,单击“Next”。定义样例工程名和配置样例工程存储路径,单击“Finish”完成工程创建。在pom.xml文件中添加如下配置。<dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency> </dependencies>图3 pom文件中添加配置在工程路径的“src > main > java”文件夹上鼠标右键,选择“New > Package”,新建Package和类文件。Package根据需要定义,本示例定义为:“com.huawei.demo”,完成后回车。在包路径下新建Java Class文件,本示例定义为:UDTFSplit。编写UDTF函数代码。完整样例代码请参考样例代码。UDTF的类需要继承“org.apache.hadoop.hive.ql.udf.generic.GenericUDTF”,实现initialize,process,close三个方法。UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息,如,返回个数,类型等。初始化完成后,会调用process方法,真正处理在process函数中,在process中,每一次forward()调用产生一行。如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。public void process(Object[] args) throws HiveException { // TODO Auto-generated method stub if(args.length == 0){ return; } String input = args[0].toString(); if(StringUtils.isEmpty(input)){ return; } String[] test = input.split(";"); for (int i = 0; i < test.length; i++) { try { String[] result = test[i].split(":"); forward(result); } catch (Exception e) { continue; } } }最后调用close方法,对需要清理的方法进行清理。编写调试完成代码后,通过IntelliJ IDEA工具编译代码并导出Jar包。单击工具右侧的“Maven”,参考下图分别单击“clean”、“compile”对代码进行编译。编译成功后,单击“package”对代码进行打包。图4 编译打包打包成功后,生成的Jar包会放到target目录下,以备后用。本示例将会生成到:“D:\MyUDTF\target”下名为“MyUDTF-1.0-SNAPSHOT.jar”。登录OBS控制台,将生成的Jar包文件上传到OBS路径下。说明:Jar包文件上传的OBS桶所在的区域需与DLI的队列区域相同,不可跨区域执行操作。(可选)可以将Jar包文件上传到DLI的程序包管理中,方便后续统一管理。登录DLI管理控制台,单击“数据管理 > 程序包管理”。在“程序包管理”页面,单击右上角的“创建”创建程序包。在“创建程序包”对话框,配置以下参数。包类型:选择“JAR”。OBS路径:程序包所在的OBS路径。分组设置和组名称根据情况选择设置,方便后续识别和管理程序包。单击“确定”,完成创建程序包。创建DLI的UDTF函数。登录DLI管理控制台,单击“SQL编辑器”,执行引擎选择“spark”,选择已创建的SQL队列和数据库。图5 选择队列和数据库在SQL编辑区域输入下列命令创建UDTF函数,单击“执行”提交创建。CREATE FUNCTION mytestsplit AS 'com.huawei.demo.UDTFSplit' using jar 'obs://dli-test-obs01/MyUDTF-1.0-SNAPSHOT.jar';重启原有SQL队列,使得创建的UDTF函数生效。登录数据湖探索管理控制台,选择“队列管理”,在对应“SQL队列”类型作业的“操作”列,单击“重启”。在“重启队列”界面,选择“确定”完成队列重启。验证和使用创建的UDTF函数。在查询语句中使用6中创建的UDTF函数,如:select mytestsplit('abc:123\;efd:567\;utf:890');图6 执行结果(可选)删除UDTF函数。如果不再使用该Function,可执行以下语句删除UDTF函数:Drop FUNCTION mytestsplit;样例代码UDTFSplit.java完整的样例代码参考如下所示:package com.huawei.demo; import java.util.ArrayList; import org.apache.commons.lang.StringUtils; import org.apache.hadoop.hive.ql.exec.UDFArgumentException; import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException; import org.apache.hadoop.hive.ql.metadata.HiveException; import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory; import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector; import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory; public class UDTFSplit extends GenericUDTF { @Override public void close() throws HiveException { // TODO Auto-generated method stub } @Override public void process(Object[] args) throws HiveException { // TODO Auto-generated method stub if(args.length == 0){ return; } String input = args[0].toString(); if(StringUtils.isEmpty(input)){ return; } String[] test = input.split(";"); for (int i = 0; i < test.length; i++) { try { String[] result = test[i].split(":"); forward(result); } catch (Exception e) { continue; } } } @Override public StructObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException { if (args.length != 1) { throw new UDFArgumentLengthException("ExplodeMap takes only one argument"); } if (args[0].getCategory() != ObjectInspector.Category.PRIMITIVE) { throw new UDFArgumentException("ExplodeMap takes string as a parameter"); } ArrayList<String> fieldNames = new ArrayList<String>(); ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>(); fieldNames.add("col1"); fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); fieldNames.add("col2"); fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector); return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNames, fieldOIs); } }
-
操作场景DLI支持用户使用Hive UDF(User Defined Function,用户定义函数)进行数据查询等操作,UDF只对单行数据产生作用,适用于一进一出的场景。约束限制在DLI Console上执行UDF相关操作时,需要使用自建的SQL队列。跨账号使用UDF时,除了创建UDF函数的用户,其他用户如果需要使用时,需要先进行授权才可使用对应的UDF函数。授权操作参考如下:登录DLI管理控制台,选择“ 数据管理 > 程序包管理”页面,选择对应的UDF Jar包,单击“操作”列中的“权限管理”,进入权限管理页面,单击右上角“授权”,勾选对应权限。自定义函数中引用static类或接口时,必须要加上“try catch”异常捕获,否则可能会造成包冲突,导致函数功能异常。环境准备在进行UDF开发前,请准备以下开发环境。表1 UDF开发环境准备项说明操作系统Windows系统,支持Windows7以上版本。安装JDKJDK使用1.8版本。安装和配置IntelliJ IDEAIntelliJ IDEA为进行应用开发的工具,版本要求使用2019.1或其他兼容版本。安装Maven开发环境的基本配置。用于项目管理,贯穿软件开发生命周期。开发流程DLI下UDF函数开发流程参考如下:图1 开发流程表2 开发流程说明序号阶段操作界面说明1新建Maven工程,配置pom文件IntelliJ IDEA参考操作步骤说明,编写UDF函数代码。2编写UDF函数代码3调试,编译代码并导出Jar包4上传Jar包到OBSOBS控制台将生成的UDF函数Jar包文件上传到OBS目录下。5创建DLI的UDF函数DLI控制台在DLI控制台的SQL作业管理界面创建使用的UDF函数。6验证和使用DLI的UDF函数DLI控制台在DLI作业中使用创建的UDF函数。操作步骤新建Maven工程,配置pom文件。以下通过IntelliJ IDEA 2020.2工具操作演示。打开IntelliJ IDEA,选择“File > New > Project”。图2 新建Project选择Maven,Project SDK选择1.8,单击“Next”。定义样例工程名和配置样例工程存储路径,单击“Finish”完成工程创建。在pom.xml文件中添加如下配置。<dependencies> <dependency> <groupId>org.apache.hive</groupId> <artifactId>hive-exec</artifactId> <version>1.2.1</version> </dependency> </dependencies>图3 pom文件中添加配置在工程路径的“src > main > java”文件夹上鼠标右键,选择“New > Package”,新建Package和类文件。Package根据需要定义,本示例定义为:“com.huawei.demo”,完成后回车。在包路径下新建Java Class文件,本示例定义为:SumUdfDemo。编写UDF函数代码。UDF函数实现,主要注意以下几点:自定义UDF需要继承org.apache.hadoop.hive.ql.UDF。需要实现evaluate函数,evaluate函数支持重载。详细UDF函数实现,可以参考如下样例代码:package com.huawei.demo; import org.apache.hadoop.hive.ql.exec.UDF; public class SumUdfDemo extends UDF { public int evaluate(int a, int b) { return a + b; } }编写调试完成代码后,通过IntelliJ IDEA工具编译代码并导出Jar包。单击工具右侧的“Maven”,参考下图分别单击“clean”、“compile”对代码进行编译。编译成功后,单击“package”对代码进行打包。打包成功后,生成的Jar包会放到target目录下,以备后用。本示例将会生成到:“D:\DLITest\MyUDF\target”下名为“MyUDF-1.0-SNAPSHOT.jar”。登录OBS控制台,将生成的Jar包文件上传到OBS路径下。说明:Jar包文件上传的OBS桶所在的区域需与DLI的队列区域相同,不可跨区域执行操作。(可选)可以将Jar包文件上传到DLI的程序包管理中,方便后续统一管理。登录DLI管理控制台,单击“数据管理 > 程序包管理”。在“程序包管理”页面,单击右上角的“创建”创建程序包。在“创建程序包”对话框,配置以下参数。包类型:选择“JAR”。OBS路径:程序包所在的OBS路径。分组设置和组名称根据情况选择设置,方便后续识别和管理程序包。单击“确定”,完成创建程序包。创建UDF函数。登录DLI管理控制台,单击“SQL编辑器”,执行引擎选择“spark”,选择已创建的SQL队列和数据库。图4 选择队列和数据库在SQL编辑区域输入下列命令创建UDF函数,单击“执行”提交创建。CREATE FUNCTION TestSumUDF AS 'com.huawei.demo.SumUdfDemo' using jar 'obs://dli-test-obs01/MyUDF-1.0-SNAPSHOT.jar';重启原有SQL队列,使得创建的Function生效。登录数据湖探索管理控制台,选择“队列管理”,在对应“SQL队列”类型作业的“操作”列,单击“重启”。在“重启队列”界面,选择“确定”完成队列重启。使用UDF函数。在查询语句中使用6中创建的UDF函数:select TestSumUDF(1,2);图5 执行结果(可选)删除UDF函数。如果不再使用UDF函数,可执行以下语句删除该函数:Drop FUNCTION TestSumUDF;
-
 在实际开发中,通过反射可以得到一个类的完整结构,包括类的构造方法、类的属性、类的方法,这就需要使用到java.lang.reflect包中的以下几个类:1、Constructor:表示类中的构造方法2、Field:表示类中的属性3、Method:表示类中的方法目录1、使用反射技术获取构造器对象并使用2、使用反射技术获取成员变量对象并使用3、使用反射技术获取方法对象并使用使用反射技术获取构造器对象并使用实验类:public class 反射机制_2实验类 { private String name; private int age; private 反射机制_2实验类() { System.out.println("无参构造器执行!"); } public 反射机制_2实验类(String name, int age) { System.out.println("有参构造器执行!"); this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "反射机制_2实验类{" + "name='" + name + '\'' + ", age=" + age + '}'; }} 获取构造器对象:import org.junit.Test; import java.lang.reflect.Constructor; public class 反射机制_2构造器获取对象 { //1、getConstructors //获取全部的构造器,只能获取public修饰的构造器 @Test public void getConstructors(){ //获取类对象 Class c=反射机制_2实验类.class; //提取类中的全部的构造器对象(这里只能拿public修饰的构造器) Constructor[] constructors=c.getConstructors(); //遍历构造器 for (Constructor constructor : constructors) { System.out.println(constructor.getName()+"\t构造器参数个数为:"+constructor.getParameterCount()+"个"); } //运行结果:IT2.反射机制_2实验类 构造器参数个数为:2个 } //2、getDeclaredConstructors //获取全部的构造器:只要你敢写,这里就能拿到,无所谓权限是否可及 @Test public void getDeclaredConstructors(){ //获取类对象 Class c=反射机制_2实验类.class; //提取类中的全部的构造器对象 Constructor[] constructors=c.getDeclaredConstructors(); //遍历构造器 for (Constructor constructor : constructors) { System.out.println(constructor.getName()+"\t构造器参数个数为:"+constructor.getParameterCount()+"个"); } //运行结果: // IT2.反射机制_2实验类 构造器参数个数为:0个 // IT2.反射机制_2实验类 构造器参数个数为:2个 } //3、getConstructor //获取某个构造器:只能拿Public修饰的某个构造器 @Test public void getConstructor() throws Exception { //获取类对象 Class c=反射机制_2实验类.class; //定位单个构造器对象(按照参数,这里定位的是有参的构造器) Constructor cons=c.getConstructor(String.class,int.class); // Constructor cons=c.getConstructor();//如果获取无参构造器,但因为我设置的是private私有的,权限不足无法获取,便会报错 System.out.println(cons.getName()+"\t构造器参数个数为:"+cons.getParameterCount()+"个"); //运行结果:IT2.反射机制_2实验类 构造器参数个数为:2个 } //4、getDeclaredConstructor //获取某个构造器:只要你敢写,这里就能拿到,无所谓权限是否可及 //一般是用这个,什么都可以获取,并且是根据自己需要什么而获取 @Test public void getDeclaredConstructor() throws Exception { //获取类对象 Class c=反射机制_2实验类.class; //定位单个构造器对象(按照参数,这里定位的是有参的构造器) Constructor cons=c.getDeclaredConstructor(String.class,int.class); System.out.println(cons.getName()+"\t构造器参数个数为:"+cons.getParameterCount()+"个"); //运行结果:IT2.反射机制_2实验类 构造器参数个数为:2个 //获取类对象 Class c2=反射机制_2实验类.class; //定位单个构造器对象(按照参数定位无参构造器) Constructor cons2=c2.getDeclaredConstructor(); System.out.println(cons2.getName()+"\t构造器参数个数为:"+cons2.getParameterCount()+"个"); //运行结果:IT2.反射机制_2实验类 构造器参数个数为:0个 }}Class在开发中最常见的用法就是将Class类对象实例化为自定义类的对象,即可通过一个给定的字符串(类的全限定类名)实例化一个本类的对象。将Class对象实例化为本类对象时,可以通过无参构造完成,也可以通过有参构造完成。 创建对象:import org.junit.Test;import java.lang.reflect.Constructor; //反射可以破坏封装性,私有的也可以执行了public class 反射机制_2创建对象 { @Test public void getDeclaredConstructor() throws Exception { //获取类对象 Class c=反射机制_2实验类.class; //定位单个构造器对象(按照参数,这里定位的是有参的构造器) Constructor cons=c.getDeclaredConstructor(String.class,int.class); System.out.println(cons.getName()+"\t构造器参数个数为:"+cons.getParameterCount()+"个"); 反射机制_2实验类 s1= (反射机制_2实验类) cons.newInstance("狗蛋",18); System.out.println(s1); System.out.println(); //获取类对象 Class c2=反射机制_2实验类.class; //定位单个构造器对象(按照参数定位无参构造器) Constructor cons2=c2.getDeclaredConstructor(); System.out.println(cons2.getName()+"\t构造器参数个数为:"+cons2.getParameterCount()+"个"); //如果遇到了私有的构造器,可以暴力反射 cons2.setAccessible(true);//权限打开(只是这一次有效,并不是一直打开) 反射机制_2实验类 s2= (反射机制_2实验类) cons2.newInstance(); System.out.println(s2); //运行结果: //IT2.反射机制_2实验类 构造器参数个数为:2个 //有参构造器执行! //反射机制_2实验类{name='狗蛋', age=18} // //IT2.反射机制_2实验类 构造器参数个数为:0个 //无参构造器执行! //反射机制_2实验类{name='null', age=0} }}使用反射技术获取成员变量对象并使用实验类:public class 反射机制_2实验类2 { private String name; private int age; public static String schoolName; public static final String Name="遇安"; public 反射机制_2实验类2() { System.out.println("无参构造器执行!"); } public 反射机制_2实验类2(String name, int age) { System.out.println("有参构造器执行!"); this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public static String getSchoolName() { return schoolName; } public static void setSchoolName(String schoolName) { 反射机制_2实验类2.schoolName = schoolName; } @Override public String toString() { return "反射机制_2实验类2{" + "name='" + name + '\'' + ", age=" + age + '}'; }} 获取成员变量:在反射操作中可以获取一个类中的全部属性,但是类中的属性包括两部分,即从父类继承的属性和本类定义的属性。因此,在获取类的属性时也有以下两种不同的方式:1、获取实现的接口或父类中的公共属性:public Field [] getFields throws SecurityException2、获取本类中的全部属性:public Field [] getDeclaredFields throws Exception上述两种方法返回的都是Field数组,每一个Field对象表示类中的一个属性。如果要获取属性中的详细信息,就需要调用Field类的方法。import org.junit.Test; import java.lang.reflect.Field; public class 反射机制_2获取成员变量 { //1、获取全部的成员变量 // Field[] getDeclaredFields //获得所有的成员变量对应的Field对象,只要申明了就可以得到 @Test public void getDeclaredFields(){ //定位Class对象 Class c=反射机制_2实验类2.class; //定位全部成员变量 Field [] fields=c.getDeclaredFields(); //遍历获取,常量也会被当做成员变量 for (Field field : fields) { System.out.println(field.getName()+"的类型是:"+field.getType()); } } //2、获取某个成员变量对象 //Field getDeclaredField(String name) @Test public void getDeclaredField() throws Exception { //定位Class对象 Class c=反射机制_2实验类2.class; //根据名称定位某个成员变量 Field f=c.getDeclaredField("age"); System.out.println(f); System.out.println(f.getName()+"的类型是:"+f.getType()); }}运行结果:Test1、name的类型是:class java.lang.Stringage的类型是:intschoolName的类型是:class java.lang.StringCOUNTTRY的类型是:class java.lang.String Test2、private int IT2.反射机制_2实验类2.ageage的类型是:int 获取了成员变量有什么用呢?import org.junit.Test; import java.lang.reflect.Field; public class 反射机制_2获取成员变量 { //获取了成员变量有什么用呢? @Test public void demo() throws Exception { //反射第一步获取Class对象 Class c=反射机制_2实验类2.class; //提取某个成员变量 Field f=c.getDeclaredField("age"); f.setAccessible(true);//因为我的age成员变量是用private修饰的,所以需要暴力打开权限 //作用一:赋值 反射机制_2实验类2 s=new 反射机制_2实验类2(); f.set(s,18);//s.setAge(18); System.out.println(s); //运行结果: // 无参构造器执行! //反射机制_2实验类2{name='null', age=18}这里可以看出,成员变量被赋值成功 //作用二:取值 int age = (int) f.get(s); System.out.println(age);//18 }}使用反射技术获取方法对象并使用实验类:public class 反射机制_2实验类3 { private String name; public 反射机制_2实验类3() { } public 反射机制_2实验类3(String name) { this.name = name; } public void run(){ System.out.println("跑起来了。。"); } private void eat(){ System.out.println("累了,该吃饭了。。"); } private String eat(String name){ System.out.println("那就浅吃一下"+name+"吧"); return "针不戳"; } public static void ind(){ System.out.println("欢迎来到遇安的博客!"); } public String getName() { return name; } public void setName(String name) { this.name = name; }} 获取成员方法:import org.junit.Test; import java.lang.reflect.Method; public class 反射机制_2获取成员方法 { //获得类中的所有成员方法对象 @Test public void getDeclaredMethods(){ //获取类对象 Class c=反射机制_2实验类3.class; //提取全部方法,包括私有的 Method [] methods=c.getDeclaredMethods(); //遍历全部方法 for (Method method : methods) { System.out.println(method.getName()+"返回值类型:"+method.getReturnType()+"参数个数:"+method.getParameterCount()); } } //提取某个方法对象 @Test public void getDeclaredMethod() throws Exception { //获取类对象 Class c=反射机制_2实验类3.class; //提取单个方法对象 Method m1=c.getDeclaredMethod("eat"); Method m2=c.getDeclaredMethod("eat",String.class); //暴力打开权限 m1.setAccessible(true); m2.setAccessible(true); //触发方法的执行 反射机制_2实验类3 s=new 反射机制_2实验类3(); //注意:如果方法是没有结果返回的,那么返回的是Null Object result =m1.invoke(s); System.out.println(result); Object result2=m2.invoke(s,"海鲜大餐"); System.out.println(result2); }}运行结果:累了,该吃饭了。。null那就浅吃一下海鲜大餐原文链接:https://blog.csdn.net/qq_62731133/article/details/125089941
在实际开发中,通过反射可以得到一个类的完整结构,包括类的构造方法、类的属性、类的方法,这就需要使用到java.lang.reflect包中的以下几个类:1、Constructor:表示类中的构造方法2、Field:表示类中的属性3、Method:表示类中的方法目录1、使用反射技术获取构造器对象并使用2、使用反射技术获取成员变量对象并使用3、使用反射技术获取方法对象并使用使用反射技术获取构造器对象并使用实验类:public class 反射机制_2实验类 { private String name; private int age; private 反射机制_2实验类() { System.out.println("无参构造器执行!"); } public 反射机制_2实验类(String name, int age) { System.out.println("有参构造器执行!"); this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "反射机制_2实验类{" + "name='" + name + '\'' + ", age=" + age + '}'; }} 获取构造器对象:import org.junit.Test; import java.lang.reflect.Constructor; public class 反射机制_2构造器获取对象 { //1、getConstructors //获取全部的构造器,只能获取public修饰的构造器 @Test public void getConstructors(){ //获取类对象 Class c=反射机制_2实验类.class; //提取类中的全部的构造器对象(这里只能拿public修饰的构造器) Constructor[] constructors=c.getConstructors(); //遍历构造器 for (Constructor constructor : constructors) { System.out.println(constructor.getName()+"\t构造器参数个数为:"+constructor.getParameterCount()+"个"); } //运行结果:IT2.反射机制_2实验类 构造器参数个数为:2个 } //2、getDeclaredConstructors //获取全部的构造器:只要你敢写,这里就能拿到,无所谓权限是否可及 @Test public void getDeclaredConstructors(){ //获取类对象 Class c=反射机制_2实验类.class; //提取类中的全部的构造器对象 Constructor[] constructors=c.getDeclaredConstructors(); //遍历构造器 for (Constructor constructor : constructors) { System.out.println(constructor.getName()+"\t构造器参数个数为:"+constructor.getParameterCount()+"个"); } //运行结果: // IT2.反射机制_2实验类 构造器参数个数为:0个 // IT2.反射机制_2实验类 构造器参数个数为:2个 } //3、getConstructor //获取某个构造器:只能拿Public修饰的某个构造器 @Test public void getConstructor() throws Exception { //获取类对象 Class c=反射机制_2实验类.class; //定位单个构造器对象(按照参数,这里定位的是有参的构造器) Constructor cons=c.getConstructor(String.class,int.class); // Constructor cons=c.getConstructor();//如果获取无参构造器,但因为我设置的是private私有的,权限不足无法获取,便会报错 System.out.println(cons.getName()+"\t构造器参数个数为:"+cons.getParameterCount()+"个"); //运行结果:IT2.反射机制_2实验类 构造器参数个数为:2个 } //4、getDeclaredConstructor //获取某个构造器:只要你敢写,这里就能拿到,无所谓权限是否可及 //一般是用这个,什么都可以获取,并且是根据自己需要什么而获取 @Test public void getDeclaredConstructor() throws Exception { //获取类对象 Class c=反射机制_2实验类.class; //定位单个构造器对象(按照参数,这里定位的是有参的构造器) Constructor cons=c.getDeclaredConstructor(String.class,int.class); System.out.println(cons.getName()+"\t构造器参数个数为:"+cons.getParameterCount()+"个"); //运行结果:IT2.反射机制_2实验类 构造器参数个数为:2个 //获取类对象 Class c2=反射机制_2实验类.class; //定位单个构造器对象(按照参数定位无参构造器) Constructor cons2=c2.getDeclaredConstructor(); System.out.println(cons2.getName()+"\t构造器参数个数为:"+cons2.getParameterCount()+"个"); //运行结果:IT2.反射机制_2实验类 构造器参数个数为:0个 }}Class在开发中最常见的用法就是将Class类对象实例化为自定义类的对象,即可通过一个给定的字符串(类的全限定类名)实例化一个本类的对象。将Class对象实例化为本类对象时,可以通过无参构造完成,也可以通过有参构造完成。 创建对象:import org.junit.Test;import java.lang.reflect.Constructor; //反射可以破坏封装性,私有的也可以执行了public class 反射机制_2创建对象 { @Test public void getDeclaredConstructor() throws Exception { //获取类对象 Class c=反射机制_2实验类.class; //定位单个构造器对象(按照参数,这里定位的是有参的构造器) Constructor cons=c.getDeclaredConstructor(String.class,int.class); System.out.println(cons.getName()+"\t构造器参数个数为:"+cons.getParameterCount()+"个"); 反射机制_2实验类 s1= (反射机制_2实验类) cons.newInstance("狗蛋",18); System.out.println(s1); System.out.println(); //获取类对象 Class c2=反射机制_2实验类.class; //定位单个构造器对象(按照参数定位无参构造器) Constructor cons2=c2.getDeclaredConstructor(); System.out.println(cons2.getName()+"\t构造器参数个数为:"+cons2.getParameterCount()+"个"); //如果遇到了私有的构造器,可以暴力反射 cons2.setAccessible(true);//权限打开(只是这一次有效,并不是一直打开) 反射机制_2实验类 s2= (反射机制_2实验类) cons2.newInstance(); System.out.println(s2); //运行结果: //IT2.反射机制_2实验类 构造器参数个数为:2个 //有参构造器执行! //反射机制_2实验类{name='狗蛋', age=18} // //IT2.反射机制_2实验类 构造器参数个数为:0个 //无参构造器执行! //反射机制_2实验类{name='null', age=0} }}使用反射技术获取成员变量对象并使用实验类:public class 反射机制_2实验类2 { private String name; private int age; public static String schoolName; public static final String Name="遇安"; public 反射机制_2实验类2() { System.out.println("无参构造器执行!"); } public 反射机制_2实验类2(String name, int age) { System.out.println("有参构造器执行!"); this.name = name; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public static String getSchoolName() { return schoolName; } public static void setSchoolName(String schoolName) { 反射机制_2实验类2.schoolName = schoolName; } @Override public String toString() { return "反射机制_2实验类2{" + "name='" + name + '\'' + ", age=" + age + '}'; }} 获取成员变量:在反射操作中可以获取一个类中的全部属性,但是类中的属性包括两部分,即从父类继承的属性和本类定义的属性。因此,在获取类的属性时也有以下两种不同的方式:1、获取实现的接口或父类中的公共属性:public Field [] getFields throws SecurityException2、获取本类中的全部属性:public Field [] getDeclaredFields throws Exception上述两种方法返回的都是Field数组,每一个Field对象表示类中的一个属性。如果要获取属性中的详细信息,就需要调用Field类的方法。import org.junit.Test; import java.lang.reflect.Field; public class 反射机制_2获取成员变量 { //1、获取全部的成员变量 // Field[] getDeclaredFields //获得所有的成员变量对应的Field对象,只要申明了就可以得到 @Test public void getDeclaredFields(){ //定位Class对象 Class c=反射机制_2实验类2.class; //定位全部成员变量 Field [] fields=c.getDeclaredFields(); //遍历获取,常量也会被当做成员变量 for (Field field : fields) { System.out.println(field.getName()+"的类型是:"+field.getType()); } } //2、获取某个成员变量对象 //Field getDeclaredField(String name) @Test public void getDeclaredField() throws Exception { //定位Class对象 Class c=反射机制_2实验类2.class; //根据名称定位某个成员变量 Field f=c.getDeclaredField("age"); System.out.println(f); System.out.println(f.getName()+"的类型是:"+f.getType()); }}运行结果:Test1、name的类型是:class java.lang.Stringage的类型是:intschoolName的类型是:class java.lang.StringCOUNTTRY的类型是:class java.lang.String Test2、private int IT2.反射机制_2实验类2.ageage的类型是:int 获取了成员变量有什么用呢?import org.junit.Test; import java.lang.reflect.Field; public class 反射机制_2获取成员变量 { //获取了成员变量有什么用呢? @Test public void demo() throws Exception { //反射第一步获取Class对象 Class c=反射机制_2实验类2.class; //提取某个成员变量 Field f=c.getDeclaredField("age"); f.setAccessible(true);//因为我的age成员变量是用private修饰的,所以需要暴力打开权限 //作用一:赋值 反射机制_2实验类2 s=new 反射机制_2实验类2(); f.set(s,18);//s.setAge(18); System.out.println(s); //运行结果: // 无参构造器执行! //反射机制_2实验类2{name='null', age=18}这里可以看出,成员变量被赋值成功 //作用二:取值 int age = (int) f.get(s); System.out.println(age);//18 }}使用反射技术获取方法对象并使用实验类:public class 反射机制_2实验类3 { private String name; public 反射机制_2实验类3() { } public 反射机制_2实验类3(String name) { this.name = name; } public void run(){ System.out.println("跑起来了。。"); } private void eat(){ System.out.println("累了,该吃饭了。。"); } private String eat(String name){ System.out.println("那就浅吃一下"+name+"吧"); return "针不戳"; } public static void ind(){ System.out.println("欢迎来到遇安的博客!"); } public String getName() { return name; } public void setName(String name) { this.name = name; }} 获取成员方法:import org.junit.Test; import java.lang.reflect.Method; public class 反射机制_2获取成员方法 { //获得类中的所有成员方法对象 @Test public void getDeclaredMethods(){ //获取类对象 Class c=反射机制_2实验类3.class; //提取全部方法,包括私有的 Method [] methods=c.getDeclaredMethods(); //遍历全部方法 for (Method method : methods) { System.out.println(method.getName()+"返回值类型:"+method.getReturnType()+"参数个数:"+method.getParameterCount()); } } //提取某个方法对象 @Test public void getDeclaredMethod() throws Exception { //获取类对象 Class c=反射机制_2实验类3.class; //提取单个方法对象 Method m1=c.getDeclaredMethod("eat"); Method m2=c.getDeclaredMethod("eat",String.class); //暴力打开权限 m1.setAccessible(true); m2.setAccessible(true); //触发方法的执行 反射机制_2实验类3 s=new 反射机制_2实验类3(); //注意:如果方法是没有结果返回的,那么返回的是Null Object result =m1.invoke(s); System.out.println(result); Object result2=m2.invoke(s,"海鲜大餐"); System.out.println(result2); }}运行结果:累了,该吃饭了。。null那就浅吃一下海鲜大餐原文链接:https://blog.csdn.net/qq_62731133/article/details/125089941 -
第一步:完成界面搭建要求:创建两个窗口:一个客户端,一个服务端,完成代码书写步骤:1.定义JFrame窗体中的组件:文本域,滚动条,面板,文本框,按钮 //属性 //文本域 private JTextArea jta; //滚动条 private JScrollPane jsp; //面板 private JPanel jp; //文本框 private JTextField jtf; //按钮 private JButton jb; 2.在构造方法中初始化窗口的组件: //构造方法 public ServerChatMain(){ //初始化组件 jta = new JTextArea(); //设置文本域默认不可编辑 jta.setEditable(false); //注意:需要将文本域添加到滚动条中,实现滚动效果 jsp =new JScrollPane(jta); //初始化面板 jp = new JPanel(); jtf = new JTextField(10); jb=new JButton("发送"); //注意:需要将文本框与按钮添加到面板中 jp.add(jtf); jp.add(jb); 注意:需要将滚动条与面板全部添加到窗体中,继承了窗体的属性,这里this就是窗体 this.add(jsp, BorderLayout.CENTER);//BorderLayout--边框布局 this.add(jp,BorderLayout.SOUTH);4.设置设置”标题“,大小,位置,关闭,是否可见 //注意:需要设置”标题“,大小,位置,关闭,是否可见 this.setTitle("QQ聊天服务端"); this.setSize(400,300); this.setLocation(700,300); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);//窗体关闭,程序就退出 this.setVisible(true);//设置窗体可见 }这样我们就完成了服务端的QQ聊天界面窗口搭建:注意:JTextArea文本域是不可以书写的客户端与服务端代码类似,这里就不一一展示了书写完毕代码,运行效果如下图:第二步:TPC通信的思路与步骤❄️使用网络编程完成数据点的传输(TCP,UDP协议)TCP协议TCP 是面向连接的运输层协议。应用程序在使用 TCP 协议之前,必须先建立 TCP 连接。在传送数据完毕后,必须释放已经建立的 TCP 连接每一条 TCP 连接只能有两个端点,每一条 TCP 连接只能是点对点的(一对一)TCP 提供可靠交付的服务。通过 TCP 连接传送的数据,无差错、不丢失、不重复,并且按序到达TCP 提供全双工通信。TCP 允许通信双方的应用进程在任何时候都能发送数据。TCP 连接的两端都设有发送缓存和接受缓存,用来临时存放双向通信的数据面向字节流。TCP 中的“流”指的是流入到进程或从进程流出的字节序列TCP 服务端 具体步骤(客户端类似)具体步骤: 1.创建一个服务端的套接字 2.等待客户端连接 3.获取socket通道的输入流(输入六是实现读取数据的,一行一行读取)BufferedReader->readLine(); 4.获取socket 通道的输出流(输出流实现写出数据,也是写一行换一行,刷新)BufferedWriter->newLine(); 5.关闭socket 通道TCP通信步骤代码实现: try { //1.创建一个服务端的套接字 ServerSocket serverSocket = new ServerSocket(8888); //2.等待客户端连接 Socket socket = serverSocket.accept(); //3.获取socket通道的输入流(输入六是实现读取数据的,一行一行读取)BufferedReader->readLine(); //InputStream in = socket.getInputStream(); BufferedReader br=new BufferedReader(new InputStreamReader(socket.getInputStream())); //4.获取socket 通道的输出流(输出流实现写出数据,也是写一行换一行,刷新)BufferedWriter->newLine(); //当用户点击发送按钮的时候写出数据 BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream())); //循环读取数据并拼接到文本域 String line = null; while((line = br.readLine())!=null){ //将读取的数据拼接到文本域中显示 jta.append(line+System.lineSeparator()); } //5.关闭socket 通道 serverSocket.close(); }catch (IOException e) { e.printStackTrace(); } 点击发送按钮实现数据的传输 @Override public void actionPerformed(ActionEvent actionEvent) { System.out.println("发送按钮被点击了"); }步骤:1.获取文本框中发送的内容2.拼接需要发送的数据内容3.自己也要显示4.发送5.清空文本框内容@Override public void actionPerformed(ActionEvent actionEvent) { //System.out.println("发送按钮被点击了"); //1.获取文本框中发送的内容 String text = jtf.getText(); //2.拼接需要发送的数据内容 text = "服务端对客户端说:"+text; //3.自己也要显示 jta.append(text); //4.发送 try { bw.write(text); bw.newLine();//换行刷新 bw.flush(); //5.清空文本框内容 jtf.setText(""); } catch (IOException e) { e.printStackTrace(); } } 第三步:实现回车键发送数据(客户端类似)首先要实现一个接口public class ClientChatMain extends JFrame implements ActionListener, KeyListener {@Override public void keyPressed(KeyEvent e) { //回车键 // System.out.println(e); //发送数据到socket 同道中 if(e.getKeyCode()==KeyEvent.VK_ENTER) { sendDataToSocket(); }全部代码:服务端:package com.ithmm.chat; import javax.swing.*;import java.awt.*;import java.awt.event.ActionEvent;import java.awt.event.ActionListener;import java.awt.event.KeyEvent;import java.awt.event.KeyListener;import java.io.*;import java.net.ServerSocket;import java.net.Socket;import java.util.Properties; //说明:如果一个类,需要有界面的显示,那么这个类就需要继承JFrame,此时,该类可以被成为一个窗体类/*步骤: 1.定义JFrame窗体中的组件 2.在构造方法中初始化窗口的组件 3.使用网络编程完成数据的链接(TPC,UDP 协议) 4.实现"发送”按钮的监听点击事件 5.实现“回车键”发送数据 */public class ServerChatMain extends JFrame implements ActionListener, KeyListener { public static void main(String[] args) { //调用构造方法 new ServerChatMain(); } //属性 //文本域 private JTextArea jta; //滚动条 private JScrollPane jsp; //面板 private JPanel jp; //文本框 private JTextField jtf; //按钮 private JButton jb; //输出流(成员变量) private BufferedWriter bw = null; //服务端的端口号 //private static int serverPort; //使用static静态方法读取外部京台文件 //static代码块特点:1.在类加载的时候自动执行 //特点2:一个类会被加载一次,因此静态代码块在程序中仅会被执行一次 /*static{ Properties prop = new Properties(); try { //加载 prop.load(new FileReader("chat.properties")); //给属性赋值 Integer.parseInt(prop.getProperty("serverPort")); } catch (IOException e) { e.printStackTrace(); } }*/ //构造方法 public ServerChatMain(){ //初始化组件 jta = new JTextArea(); //设置文本域默认不可编辑 jta.setEditable(false); //注意:需要将文本域添加到滚动条中,实现滚动效果 jsp =new JScrollPane(jta); //初始化面板 jp = new JPanel(); jtf = new JTextField(10); jb=new JButton("发送"); //注意:需要将文本框与按钮添加到面板中 jp.add(jtf); jp.add(jb); //注意:需要将滚动条与面板全部添加到窗体中,继承了窗体的属性,这里this就是窗体 this.add(jsp, BorderLayout.CENTER);//BorderLayout--边框布局 this.add(jp,BorderLayout.SOUTH); //注意:需要设置”标题“,大小,位置,关闭,是否可见 this.setTitle("QQ聊天服务端"); this.setSize(400,300); this.setLocation(700,300); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);//窗体关闭,程序就退出 this.setVisible(true);//设置窗体可见 /**************** TCP 服务端 Start *********************/ //给发送按钮绑定一个监听点击事件 jb.addActionListener(this); //给文本框绑定一个键盘点击事件 jtf.addKeyListener(this); try { //1.创建一个服务端的套接字 ServerSocket serverSocket = new ServerSocket(8888); //2.等待客户端连接 Socket socket = serverSocket.accept(); //3.获取socket通道的输入流(输入六是实现读取数据的,一行一行读取)BufferedReader->readLine(); //InputStream in = socket.getInputStream(); BufferedReader br=new BufferedReader(new InputStreamReader(socket.getInputStream())); //4.获取socket 通道的输出流(输出流实现写出数据,也是写一行换一行,刷新)BufferedWriter->newLine(); //当用户点击发送按钮的时候写出数据 bw = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream())); //循环读取数据并拼接到文本域 String line = null; while((line = br.readLine())!=null){ //将读取的数据拼接到文本域中显示 jta.append(line+System.lineSeparator()); } //5.关闭socket 通道 serverSocket.close(); }catch (IOException e) { e.printStackTrace(); } /**************** TCP 服务端 end *********************/ } @Override public void actionPerformed(ActionEvent actionEvent) { //System.out.println("发送按钮被点击了"); sendDataToSocket(); } //行为 @Override public void keyPressed(KeyEvent e) { //回车键 // System.out.println(e); //发送数据到socket 同道中 if(e.getKeyCode()==KeyEvent.VK_ENTER) { sendDataToSocket(); } } //定义一个方法,实现将数据发送到socket通道中 private void sendDataToSocket(){ //1.获取文本框中发送的内容 String text = jtf.getText(); //2.拼接需要发送的数据内容 text = "服务端对客户端说:"+text; //3.自己也要显示 jta.append(text+System.lineSeparator()); //4.发送 try { bw.write(text); bw.newLine();//换行刷新 bw.flush(); //5.清空文本框内容 jtf.setText(""); } catch (IOException e) { e.printStackTrace(); } } @Override public void keyTyped(KeyEvent keyEvent) { } @Override public void keyReleased(KeyEvent keyEvent) { } } 客户端: import javax.swing.JButton;import javax.swing.JFrame;import javax.swing.JPanel;import javax.swing.JScrollPane;import javax.swing.JTextArea;import javax.swing.JTextField;import java.awt.BorderLayout;import java.awt.event.ActionEvent;import java.awt.event.ActionListener;import java.awt.event.KeyEvent;import java.awt.event.KeyListener;import java.io.BufferedReader;import java.io.BufferedWriter;import java.io.IOException;import java.io.InputStreamReader;import java.io.OutputStreamWriter;import java.net.Socket;import java.util.Properties; //说明:如果一个类,需要有界面的显示,那么这个类就需要继承JFrame,此时,该类可以被成为一个窗体类/*步骤: 1.定义JFrame窗体中的组件 2.在构造方法中初始化窗口的组件 */ public class ClientChatMain extends JFrame implements ActionListener, KeyListener { public static void main(String[] args) { //调用构造方法 new ClientChatMain(); } //属性 //文本域 private JTextArea jta; //滚动条 private JScrollPane jsp; //面板 private JPanel jp; //文本框 private JTextField jtf; //按钮 private JButton jb; //s输出流 private BufferedWriter bw =null; //客户端的IP地址 // private static String clientIp; //客户端的port端口号 // private static int clientPort; //静态代码块加载外部配置文件 /* static{ Properties prop = new Properties(); try { prop.load(new FileReader("chat.properties")); clientIp = prop.getProperty("clientIp"); clientPort =Integer.parseInt( prop.getProperty("clientPort")); } catch (IOException e) { e.printStackTrace(); } }*/ //构造方法 public ClientChatMain(){ //初始化组件 jta = new JTextArea(); //设置文本域默认不可编辑 jta.setEditable(false); //注意:需要将文本域添加到滚动条中,实现滚动效果 jsp =new JScrollPane(jta); //初始化面板 jp = new JPanel(); jtf = new JTextField(10); jb=new JButton("发送"); //注意:需要将文本框与按钮添加到面板中 jp.add(jtf); jp.add(jb); //注意:需要将滚动条与面板全部添加到窗体中,继承了窗体的属性,这里this就是窗体 this.add(jsp, BorderLayout.CENTER);//BorderLayout--边框布局 this.add(jp,BorderLayout.SOUTH); //注意:需要设置”标题“,大小,位置,关闭,是否可见 this.setTitle("QQ聊天客户端"); this.setSize(400,300); this.setLocation(700,300); this.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);//窗体关闭,程序就退出 this.setVisible(true);//设置窗体可见 /**************** TCP 客户端 Start *********************/ //给发送按钮绑定一个监听点击事件 jb.addActionListener(this); //给文本框绑定一个键盘键 jtf.addKeyListener(this); try { //1.创建一个客户端的套接字(尝试连接) Socket socket = new Socket("127.0.0.1",8888); //2.获取socket通道的输入流 BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream())); //3.获取socket 通道的输出流 bw = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream())); //循环读取数据,并拼接到文本域 String line = null; while((line = br.readLine())!=null){ jta.append(line + System.lineSeparator()); } //4.关闭socket 通道 socket.close(); }catch (Exception e){ e.printStackTrace(); } /**************** TCP 客户端 end *********************/ } @Override public void actionPerformed(ActionEvent e) { sendDataToSocket(); } //行为 @Override public void keyPressed(KeyEvent e) { //回车键 if(e.getKeyCode() == KeyEvent.VK_ENTER){ //发送数据 sendDataToSocket(); } } private void sendDataToSocket(){ //1.获取文本框需要发送内容 String text = jtf.getText(); //2.拼接内容 text = "客户端对服务端说"+text; //3.自己显示 jta.append(text+System.lineSeparator()); try { //4.发送 bw.write(text); bw.newLine();//换行加刷新 bw.flush(); bw.write(text); //5.清空 jtf.setText(""); } catch (IOException e) { e.printStackTrace(); } } @Override public void keyTyped(KeyEvent e) { } @Override public void keyReleased(KeyEvent e) { } } 接口类:public interface addActistener {}public interface addActionListener {原文链接:https://blog.csdn.net/m0_68089732/article/details/124897209
-
-
首先,介绍一下我自己,从普通二本毕业,到上海工作,不知不觉,已经两年时间了。说实话,自己还是一个菜鸟,总是在迷茫,从未去努力。刚毕业的时候,想着自己还年轻,菜就菜吧,工作一年就好了,毕竟工作的环境几乎都是比自己大,或者和自己同龄的年轻人,说不上当一天和尚撞一天钟吧,偶尔会去学习一些东西,但是努力确实谈不上。很多时候,也能发现自己和同事的差距,但是很少去思考为什么。在此还是要感叹一句C+V大法确实牛逼啊。目前,在这家公司已经呆了两年的时间了,期间也从未想过换工作,因为公司的氛围我还是蛮喜欢的,同事们都很友好,很少加班,即使加班了也可以换调休,在这里确实也学到了很多东西,但是我觉得差的很远。平时的工作怎么说呢,让我写代码还行,但是让我干别的,不不不,我真不会。我真的很害怕经理又让我建表,然后把我怼一顿,建的是个什么玩意(有些夸张,经理还是蛮好的,教了我很多东西);让我写一些项目里没有样例的代码,写完之后,把我叫过去,指着我的代码,删掉,然后敲一遍给我看,简直是折磨我啊(我还是挺佩服经理的,在我和他的多次博弈中,我好像没赢过)。我对我的总结就是,干啥啥不行,CV第一名。其实,公司用的技术还是蛮新的,springboot微服务+hibernate+vue,至少在现在还算是比较新的技术,我也很庆幸用的不是jsp(并没有看不起的意思,谁还没用过jsp是不是,手动狗头),哈哈哈。之前也有想过写博客,也确实写了两篇,但是那时候确实还是很太菜了,所以后来文章被我删掉了,因为当我回头去看的时候,我想说:写的是个什么玩意啊,连si都不如。。。我想可能有很多人和我一样吧,摸鱼的日子确实还是可以的,但是总觉得少了点什么,没有核心竞争力是件可怕的事情,短时间还看不出来,时间长了,你总是要被时代所抛弃的。以后的日子里,争取每周两篇博客,忙的话至少也要一篇,有关于自己的心得和一些技术的(大家千万别喷我)。这篇文章就当成是我csdn的开山之作吧,我并没有想要赞和评论的意思,但是那也算是对我的一种鼓励和认可吧(狗头奉上),谢谢大家原文链接:https://blog.csdn.net/qq_42281590/article/details/106183225
-
课程质量真的是好得没话说,我看过很多前端的课程,但从没有哪家课程能将前端的知识体系划分的如此全面细致,还能保证每一个知识点还都能讲得如此透彻,在讲知识点的基础上还能开篇幅去讲思想,更是难得。比如下面的函数式编程,这种编程范式我之前从来都没使用过,更不知道柯里化、函数组合为何物。直到在拉钩大前端课程中,每一个知识点的学习,都让我有种重获新生的感觉,仿佛以前学习的东西都白学了,只知道简单的用法,不了解核心原理,更不会用高级特性。现在每学习完一个模块,就期待着解锁下一个模块,迫不及待地想去知道下一个模块可以让自己get到哪些技能。
-

-
>摘要:几乎所有涉及应用数据交互的场景都可以通过DCM来改善应用结构,提升开发与计算效率。 本文分享自华为云社区《[DCM:中间件家族迎来新成员](https://bbs.huaweicloud.com/blogs/354299?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 石臻臻的杂货铺。 # DCM是什么 现代应用无时无刻不在与数据打交道,数据计算无处不在,报表统计、数据分析、业务处理不一而足。当前数据处理的主要手段仍然是以关系数据库为代表的相关技术,虽然使用高级语言(如Java)硬编码也能实现各类计算,但远不如数据库(SQL)方便,数据库在当代数据处理中仍然发挥举足轻重的作用。 不过,随着信息技术的发展,存储与计算分离、微服务、前置计算、边缘计算等架构与概念的兴起,过于沉重、封闭的数据库在应对这些场景时越来越显得捉襟见肘。数据库要求数据入库才能计算,但面对丰富的多样数据源时,数据入库不仅效率低资源消耗大,实时性也无法保障,而有的数据只是临时使用却要入库持久化就更得不偿失了。另外对于微服务、边缘计算等需要将计算能力前置到应用端的场景,数据库也很难嵌入使用。 在这样的背景下,如果有一种不依赖数据库、具备开放计算能力、能够与应用嵌入集成使用的数据计算处理技术,那么这些问题就都能够很好地解决,这就是数据计算中间件(Data Computing Middleware,简称DCM)。DCM的应用场景非常广泛,可以说无处不在,在优化应用开发、微服务实现、存储过程替代、数据库解耦、ETL辅助、多样性数据源计算、BI数据准备等等多方面都能发挥重要的作用,几乎所有涉及应用数据交互的场景都可以通过DCM来改善应用结构,提升开发与计算效率。 # DCM应用场景 ## 优化应用开发 应用中数据处理逻辑只能通过编码实现,使用原生的Java实现由于缺少必要的结构化计算类库往往比较困难,即使用新增加的Stream/Kotlin也并没有明显改善。借助ORM技术可以一定程度缓解开发困境,但仍然缺乏专业的结构化数据类型,集合运算不够方便,同时读写数据库时代码繁琐,复杂计算也难以实现。ORM的这些缺点经常导致业务逻辑的开发效率不仅没有明显提升,甚至还大幅降低。此外,这些实现方式还会导致应用结构问题。Java实现的计算逻辑必须与主应用一起部署导致紧耦合,同时由于不支持热部署开发运维也很麻烦。 如果借助DCM的敏捷计算、易集成、热切换等特性,在应用中替代Java实现数据处理逻辑,就可以很好解决上述问题,不仅开发效率提升,还可以优化应用结构,实现计算模块的解耦,同时支持热部署。  ## 多样性数据源计算 现代应用还经常面临多样性数据源问题,通过数据库处理不仅需要数据入库,效率低下,还无法保障数据的实时性。不同数据源有各自的优势,RDB计算能力较强,但IO吞吐能力弱;NoSQL的IO效率高,但计算能力很弱;而文本等文件数据完全没有计算能力,但使用非常灵活。强迫这些数据入库就会丧失这些原数据源的优势。 通过DCM的多源混算能力,不仅可以直接对RDB、文本、Excel、JSON、XML、NoSQL以及其他网络接口数据进行混合计算,保证数据与计算的实时性,而且还能同时保留各类数据源的优点,充分发挥其效力。  ## 微服务实现 当前微服务实现时仍然大量依赖Java和数据库实施数据处理,Java的缺点在于实现复杂、无法热切换;而数据库由于有“库”的限制,多源数据要入库才能计算,灵活性很低,不仅数据时效性无法保证,也无法充分发挥各类数据源的优势。 将可集成的DCM分别嵌入中台或微服务的各个环节完成数据采集整理、数据处理以及前置的数据计算任务,利用开放的计算体系可以充分发挥多数据源自身的优势,灵活性增强。多源数据处理、实时计算、热部署这些问题均能迎刃而解。  ## 存储过程替代 以往为了实现复杂计算或整理数据常常会使用存储过程,存储过程在库内计算有一定优势,但缺点也很明显。存储过程缺乏可移植性,编辑调试困难,创建和使用存储过程需要较高权限存在安全问题,为前端应用服务的存储过程还会造成数据库与应用紧耦合。 通过DCM将存储过程外置到应用中,可以实现“库外存储过程”,数据库则主要用于存储,将存储过程从数据库中解耦出来就可以很好解决存储过程带来的各类问题。  ## 报表BI数据准备 为报表提供数据准备是DCM的重要场景,以往使用数据库为报表准备数据存在实现难度高、耦合性强等问题,而报表本身计算能力不足又无法完成很多复杂计算。通过DCM的库外强计算能力就可以为报表提供一个专门的数据计算层,不仅可以解耦数据库为数据库减负,还可以弥补报表工具自身的计算能力不足。逻辑上分层后,报表开发维护都很清爽。  ## 中间表消除 有时为了加快查询效率事先将要查询的数据加工成结果表存储在数据库中,这就是中间表。另外,有些复杂计算需要保存中间结果也会存成中间表;多样数据源也要先存成中间表才能在数据库中混合计算。与存储过程类似,中间表一旦建立就可能被多个应用(模块)使用,造成应用与数据库的紧耦合,同时由于中间表无法轻易删除,数量会越积越多。中间表数量过多会引发数据库容量和性能问题,存储中间表需要空间,加工中间表则需要数据库计算资源。 通过DCM可以将中间表外置到文件系统,利用DCM实施计算,解耦数据库减轻数据库存储和计算负担。这里的关键是DCM使得文件也拥有了计算能力,所以才能将库内的中间表置于库外,原来中间表放在库内主要为了获得数据库的计算能力,现在有DCM的计算能力中间表存成什么形式就不重要了,外置到文件系统反而更优。  ## T+0查询 数据量积累到一定程度时基于生产库查询会影响交易,这时就会将大量的历史数据剥离到其他历史数据库中,进行冷热数据分离。这时如果要查询全量数据就要完成跨库查询、冷热数据路由等工作。数据库对于跨库查询尤其是跨异构库存在很多问题,不仅效率低下,还存在数据传输不稳定、可扩展性低等很多不足,无法很好实现T+0全量数据查询。 而这些问题都可以通过DCM来解决,由于具备独立且完善的计算能力,可以分别从不同的数据库取数计算,因此可以很好适应异构数据库的情况,还可以根据数据库的资源状况决定计算是在数据库还是DCM中实施,非常灵活。在计算实现上,DCM的敏捷计算能力还可以简化T+0查询中的复杂计算,提升开发效率。  ## ETL ETL需要对数据清洗转换再加载到目标端,但由于源端数据可能来源多处(文本、数据库、web)加上数据质量参差不齐,因此E和T这两个步骤会涉及大量数据计算。目前除了数据库以外,其他数据源并不太具备这样的计算能力,想要完成这些计算就要先加载到数据库再进行,这就形成了LET。大量无用的数据存储在数据库中会占用大量存储空间,极易引发容量问题。而将清洗和转换的计算工作都压给数据库又会增加数据处理时间,再叠加大量未经清洗转换的原始数据入库时间,有限的ETL时间窗口很可能不够,如果无法在规定时间完成ETL工作就会影响第二天的业务。 在ETL任务中引入DCM就可以按顺序完成清洗E、转换T、加载L,解决LET面临的各种问题。借助DCM的开放计算能力,在库外对多源数据实施清洗转换,DCM拥有强计算能力可以应对各类复杂计算,最后将整理后数据装在到目标端,实现真正的ETL。  # DCM特性 可以看到,DCM的应用场景非常广泛。那么要很好应对这些场景,一个优秀的DCM应该具备哪些特点呢? ## 兼容性(Compatible) 首先DCM需要具备很好的兼容性,可以跨平台使用,各类操作系统、云平台、应用服务器下均可以很好运行,这决定了DCM的使用范围。 此外,兼容性还意味着可以兼容多样性数据源,无论何种数据源都可以直接使用并进行混合计算,这要求DCM拥有足够强的开放性。 ## 热部署(Hot-deploy) 数据处理是一种高频且稳定性较差的场景,在业务开展过程中经常要新增修改计算任务,这就要求DCM应该具备热部署特性,修改数据处理逻辑无需重启应用(服务)就能生效。 ## 高性能(Efficient) 计算性能是数据计算场景重点关注的方面,有时会成为最主要的关注点,所谓天下武功无快不破。DCM应该能够高效处理数据,提供诸如高性能计算库、高性能存方案、并行计算等高性能保障机制。 ## 敏捷性(Agile) 敏捷性要求DCM能够快速实现数据处理逻辑,具备完备的计算能力,尤其面对复杂计算场景通过足够简单的编码就能完成数据处理,同时可以高效运行。这需要DCM提供敏捷编程机制和易于使用的开发环境等支持。 ## 扩展性(Scalable) 当计算容量无法满足需要时,DCM应该具备灵活的横向扩展能力。扩展性对当代应用十分重要,扩展能力的好坏决定了DCM的上限。 ## 集成性(Embeddable) DCM应该能够很好与应用集成嵌入使用,在应用内充当计算引擎,作为应用的一部分随应用一起打包部署。这样应用本身就获得了强计算能力,不再强依赖数据库后,可以很好应对存储与计算分离、微服务和边缘计算等场景。并且,良好的集成性还是敏捷性的另一方面体现,DCM很轻,随时随地都能嵌入与应用结合使用。 如果将DCM这几个特性的首字母组合起来,与CHEESE(奶酪)很接近(CHEASE),而DCM的作用就像夹在汉堡里的奶酪一样,如果缺少,味道和营养都会差很多。  这样能否作为理想的DCM就可以使用CHEASE的标准去考察。这里不妨看一下一些主流技术对DCM的满足情况。 # 现有技术的情况 ## SQL 数据库是使用SQL的主要阵地,数据库通常具备较强的计算能力,一些头部数据库的计算性能也很强,基本可以满足高性能(E)的需要。而且数据库过于封闭,数据要入库才能计算,无法很好满足多样性数据源场景的需要,兼容性(C)较差。 对于集成性(E),由于绝大部分数据库都是独立使用的,极少数(如SQLite)支持嵌入的数据库往往功能和性能都达不到要求,因此数据库几乎不满足集成性的要求。 而SQL作为专用的集合计算语言,实现简单计算很方便,但复杂计算用SQL表达很繁琐,经常要嵌套多层,实际业务中经常能看到几千行的“长”SQL,不仅难写,维护也不方便,所以SQL不太符合敏捷性(A)的要求。 与数据库类似的Hadoop相关技术也存在同样的问题,封闭性导致兼容性差、敏捷性不足、基本不具备集成性等缺点,虽然在扩展性方面表现要优于数据库,但总体并不符合DCM的要求。Spark的表现要略好,但Scala不支持热部署,实现复杂计算也不够方便,而Spark SQL仍然存在SQL的那些问题。这些技术都过于沉重,很难满足DCM在敏捷性、集成性、热部署等方面的需要。 ## Java Java作为原生的编程语言可以很好跨平台运行,也可以通过编码完成多数据源计算任务,因此兼容性(C)很好。而且对于大部分都采用Java开发的应用来说,集成性(E)也不在话下。 但Java的缺点也很明显,作为编译型语言无法实现热部署(H)。由于缺少必要的结构化计算类库完成简单的分组汇总也要几十行代码,就别提复杂计算了。虽然现在微服务架构中也经常使用Java硬编码完成数据处理,但其实计算实现要比SQL复杂得多,没办法,计算前置就不能再用数据库,难写也得挺着,因此敏捷性(A)极其不足。虽然在Java8以后引入了Stream,但计算能力并没有实质改善(Kotlin也存在类似的问题)。 使用Java虽然理论上也能实现各类高性能算法,但是如果只是为某个应用/项目服务,要实现这些高性能算法封装投入就太大了,因此从实际应用角度来看,Java并不具备高性能(E)特性。扩展性(S)也存在同样的问题。因此综合来看,Java很难作为优秀的DCM技术使用。 ## Python Python作为大火的一类计算技术不得不提一下。Python的兼容性(C)较强,无论是跨平台还是对接多数据源都能支持。尤其是丰富的数据处理包让Python的适用范围极广。 Python在结构化数据处理相比于Java等技术有相当的优势,但却难说很完善,尤其在处理有序分组等复杂计算时会很绕,Python在敏捷性(A)上略有所欠缺。 不仅如此,Pandas的性能(E)也往往达不到要求,尤其针对大数据量计算方面,这跟算法的实现效率有很大关系,敏捷语法可以很方便地实现高性能算法,反之就很困难。同样,在扩展性(S)方面,Python也不尽如人意,本质上来讲作为编程语言的Python要拥有良好的扩展性需要投入大量资源开发完成,这点与Java是一样的。 Python最大的问题是集成性(E),很难与现有应用集成在一起使用。虽然可以通过诸如sidecar模式进行服务间调用,但本质上与DCM要求与应用结合嵌入在一起(同一个进程)相去甚远。Python的主要应用场景并非像Java一样做企业级应用开发,各有用途,勉强不来。归根到底,专业的事儿还需要专业的工具来做。 # 专业数据计算中间件SPL 开源集算器SPL是专业的数据计算中间件,具备不依赖数据库的完备计算能力,同时开放的计算能力可以混合计算多样性数据,同时解释执行的SPL天然支持热部署,良好的集成性可以很方便嵌入应用中,让应用拥有强计算能力,充分发挥DCM的效力。 ## 兼容性 SPL采用Java开发,跨平台能力与Java一致,可以很好运行在各类操作系统、云平台下。而在多数据源支持方面,SPL具备开放的计算能力,可以对接多种数据源,RDB、NoSQL、CSV、Excel、JSON/XML、Hadoop、RESTful、Webservice都可以直接对接并进行混合计算,不需要入库,数据实时性和计算实时性都可以很好保障。  多源计算支持很好解决了原来数据库无法跨源计算、无法计算外部数据的问题,再加上SPL完备的计算能力和相对SQL更简洁的语法,对于应用来说就获得了与数据库相当(超过)的计算能力。 除了原生计算语法,SPL还提供了SQL支持(相当SQL92标准),可以使用SQL查询文本、Excel、NoSQL等非RDB数据源,这样就极大方便了熟悉SQL的应用开发人员。  DCM只有在开放计算体系的支持下才能拥有足够强的兼容性,才能适应更多的应用场景。 ## 热部署 SPL采用解释执行机制,天然支持热部署。这样对于一些稳定性差经常需要新增、修改计算逻辑的业务(如报表、微服务)非常友好。  ## 高性能 在性能方面,SPL提供了诸多高性能算法与高性能存储机制。在前面提到的DCM消除中间表和ETL场景中,数据往往要落地成文件存储在数据库外,这时采用SPL的文件格式存储可以获得比文本等开放格式高很多的性能。 SPL提供了两种存储类型:集文件和组表。集文件采用了压缩技术(占用空间更小读取更快),存储了数据类型(无需解析数据类型读取更快),支持可追加数据的倍增分段机制,利用分段策略很容易实现并行计算,保证计算性能。组表支持列式存储,在参与计算的列数(字段)较少时会有巨大优势。组表上还实现了minmax索引,同时支持倍增分段,这样不仅能享受到列存的优势,也更容易并行提升计算性能。 SPL还支持各种高性能算法。比如常见的TopN运算,在SPL中TopN被理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。  这里的语句中没有排序字样,也不会产生大排序的动作,在全集还是分组中计算TopN的语法基本一致,而且都会有较高的性能,类似的算法在SPL中还有很多。 SPL也很容易实施并行计算,发挥多CPU的优势。SPL有很多计算函数都提供并行机制,如文件读取、过滤、排序只要增加一个@m选项就可以自动实施并行计算,简单方便。同时也可以显示编写并行程序,通过多线程并行提升计算性能。  ## 敏捷性 SPL提供了原生的计算语法和简洁易用的IDE环境,在IDE中不仅可以很方便编码调试,过程计算的每步计算结果都可以实时查看,网格式编码代码天然整齐,通过格子名称引用中间计算结果无需定义变量,简单方便。  同时,基于SPL丰富的计算类库实施结构化数据计算更方便,分组汇总、循环、过滤、集合运算、有序计算等应有尽有。  SPL尤其擅长复杂计算,原来SQL要嵌套很多层的计算使用SPL却可以很方便实现。比如根据股票记录计算某只股票最长连续上涨多少天?SPL就比SQL简单很多。  上面SQL嵌套了3层,读起来都很绕就别提写了;下面的SPL完全按照自然思维、简单3行就能实现,高下立判。 良好的敏捷性不仅能提升开发效率,很多高性能算法通过SPL可以很方便实现。算法不仅要能想出来,还要能实现,最好实现还简单,SPL提供了这种可能。 ## 扩展性 对于计算性能要求较高的场景,SPL还可以部署单独的计算服务,同时支持多机分布式集群,支持负载均衡和容错机制,当计算资源达到上限时可以通过横向扩容增加算力,具备良好的扩展性。 在分布式计算中,用户可根据数据和计算任务的特点灵活定制数据分布及冗余方案,有效减少节点间数据传输量,以获得更高性能,实现可控数据分布。 SPL采用无中心集群设计,集群没有永久的中心主控节点,允许程序员用代码控制参与计算的节点,从而有效避免单点失效。同时SPL会根据每个节点空闲程度(线程数量)决定是否分配任务,实现负担和资源的有效平衡。 在容错方面,SPL提供内外存两种数据容错机制,外存冗余式容错和内存备胎式容错。支持计算容错,节点故障时自动将该节点计算任务迁移掉其他节点继续完成。 ## 集成性 作为DCM与应用结合方面,SPL提供了标准JDBC/ODBC/RESTful接口,应用可以像调用存储过程一样请求SPL计算结果。  逻辑上SPL作为DCM介于应用和数据源之间实施数据处理,对上提供计算服务,对下屏蔽多样性数据源差异,充分彰显了DCM的重要作用。 JDBC调用SPL 代码示例: ``` Class.forName("com.esproc.jdbc.InternalDriver"); Connection conn =DriverManager.getConnection("jdbc:esproc:local://"); CallableStatement st = conn.prepareCall("{call splscript(?, ?)}"); st.setObject(1, 3000); st.setObject(2, 5000); ResultSet result=st.execute(); ``` 综合起来,从DCM的6个特性(CHEASE)来看,SPL在各方面能力综合起来十分均衡,整体远优于其他技术,是DCM的理想选择。  # SPL资料 - SPL官网 - SPL下载 - [SPL源代码](https://github.com/SPLWare/esProc)
-
 学习一门新的编程语言当熟练了Java之后,再去学习新的编程语言,比如Python,这个时候不仅能够很快的学习好Python,Java语言能力也在迅速提高因为语言是相通的,当学习Python的时候,会带着和Java相比较的心去学,这个时候,不仅学习了Python,也加深了对Java的理解尝试独立完成一个项目独立完整地完成一个项目,可以更全面的了解项目的构成重温经典书籍意识到操作系统,计算机网络,编译原理,数据结构与算法,数据库知识的重要性动物书:O’Reilly出版的系列书犀牛书蝴蝶书图灵书: 人民邮电大学出版社黑皮书: 机械工业出版社异步图书清华大学出版社《设计模式》认真研读源码查看源码一方面可以了解看的东西是如何实现的,用到的算法,数据结构学习代码的架构使用Google进行搜索使用谷歌可以更加快速的解决开发时遇到的问题还能翻查Github,Stack Overflow上的博客使用英文文档最主流,最新鲜,最正确的技术文章都是英文当开始阅读英文技术文档之后:明显感觉学的东西都是很多书上没有的知识点更加细节也更加系统编程不应该死记硬背,要善于查阅技术文档国外的技术文档写的清晰又详细,都有上手特别容易的QuickStart有最全面的API,而且很多新特性也能先人一步用起来Stack OverflowRedditGithub深入学习技术疯狂追求技术上的细节追求更深处的实现细节,理解语言的思想以及应用场景下的解决方案,并养成对方案问为什么的准备注重培养自己的技术能力,阅读并参与到一些开源项目中,进入自己喜欢的技术细节领域编码时先思考再写:每个需求的思考占据70%编码的时间只要20% - 30%追求问题的完美解决方案,着重培养自己的工程能力,短时间之内理解新技术并投入使用理解语言只是解决问题的工具,思考编程语言对场景的适用性,学习和接纳新的编程语言并投入使用遇到问题,学会分析问题源头并寻找最合适的解决方法,学会阶段性的自我总结注重工程能力的培养,开始注重利用技术开发高稳定可用的完整产品,注重代码的结构,设计和规范链接:https://bbs.huaweicloud.com/blogs/354470
学习一门新的编程语言当熟练了Java之后,再去学习新的编程语言,比如Python,这个时候不仅能够很快的学习好Python,Java语言能力也在迅速提高因为语言是相通的,当学习Python的时候,会带着和Java相比较的心去学,这个时候,不仅学习了Python,也加深了对Java的理解尝试独立完成一个项目独立完整地完成一个项目,可以更全面的了解项目的构成重温经典书籍意识到操作系统,计算机网络,编译原理,数据结构与算法,数据库知识的重要性动物书:O’Reilly出版的系列书犀牛书蝴蝶书图灵书: 人民邮电大学出版社黑皮书: 机械工业出版社异步图书清华大学出版社《设计模式》认真研读源码查看源码一方面可以了解看的东西是如何实现的,用到的算法,数据结构学习代码的架构使用Google进行搜索使用谷歌可以更加快速的解决开发时遇到的问题还能翻查Github,Stack Overflow上的博客使用英文文档最主流,最新鲜,最正确的技术文章都是英文当开始阅读英文技术文档之后:明显感觉学的东西都是很多书上没有的知识点更加细节也更加系统编程不应该死记硬背,要善于查阅技术文档国外的技术文档写的清晰又详细,都有上手特别容易的QuickStart有最全面的API,而且很多新特性也能先人一步用起来Stack OverflowRedditGithub深入学习技术疯狂追求技术上的细节追求更深处的实现细节,理解语言的思想以及应用场景下的解决方案,并养成对方案问为什么的准备注重培养自己的技术能力,阅读并参与到一些开源项目中,进入自己喜欢的技术细节领域编码时先思考再写:每个需求的思考占据70%编码的时间只要20% - 30%追求问题的完美解决方案,着重培养自己的工程能力,短时间之内理解新技术并投入使用理解语言只是解决问题的工具,思考编程语言对场景的适用性,学习和接纳新的编程语言并投入使用遇到问题,学会分析问题源头并寻找最合适的解决方法,学会阶段性的自我总结注重工程能力的培养,开始注重利用技术开发高稳定可用的完整产品,注重代码的结构,设计和规范链接:https://bbs.huaweicloud.com/blogs/354470
上滑加载中
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签