-
 【功能模块】【操作步骤&问题现象】1、能连接,也能够查询单张表的数据,只有在使用bi的数据库管理功能的时候会报错,这个功能就是查询某个schema下的所有表名,都是通过jdbc方式查询的2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】【操作步骤&问题现象】1、能连接,也能够查询单张表的数据,只有在使用bi的数据库管理功能的时候会报错,这个功能就是查询某个schema下的所有表名,都是通过jdbc方式查询的2、【截图信息】【日志信息】(可选,上传日志内容或者附件) -
 一、无权限创建Topic会报错“ERROR kafka.admin.AdminOperationException: Error while deleting topic topicName解决办法是使用具有kafkaadmin权限的用户。二、“topic.enable”配置为falseFusionInsight Manager页面“集群->Kafka->配置->全部配置”查看Kafka服务端delete.topic.enable参数配置。如果参数设置为false,改为true后保存并重启kafka服务。三、节点异常或节点磁盘下线或数据目录异常1. 节点异常FusionInsight Manager页面“集群->Kafka->实例”查看各个实例状态是否是良好。2. 磁盘下线FusionInsight Manager有没有“数据目录状态异常”的告警。Topic副本所在节点server.log日志中搜“offline”关键字和“checkpoint file”关键字查看磁盘是否下线或因checkpoint文件问题没有上线。搜“cannot allocate memory”关键字查看是否内存不足导致。搜“No space left”关键字查看是否磁盘写满。注意:出现“数据目录状态异常”的告警后,只有重启告警节点才可以使磁盘重新上线。3. 数据目录权限异常节点上Kafka数据目录(一般是“/srv/BigData/kafka/dataX/kafka-logs”)目录权限是否正常。四、删除后又自动创建TopicFusionInsight Manager页面“集群->Kafka”查看controller所在主机节点,此节点上Kafka日志目录中查看controller.log,如果日志中有“Deletion of topic topicName successfully completed”和“New topics: [Set(topicName)]”说明topic又被自动创建。五、Controller未执行删除如果controller.log日志中只有“Starting topic deletion”日志而未打印具体的执行成功或失败的日志,可尝试切controller,步骤如下:1. 进FI客户端(例如/opt/hadoopclient)2. 执行zkCli.sh -server zk业务IP:24002/kafka3. 执行get /controller4. 若获取到controller信息,执行deleteall /controller和get /controller。
一、无权限创建Topic会报错“ERROR kafka.admin.AdminOperationException: Error while deleting topic topicName解决办法是使用具有kafkaadmin权限的用户。二、“topic.enable”配置为falseFusionInsight Manager页面“集群->Kafka->配置->全部配置”查看Kafka服务端delete.topic.enable参数配置。如果参数设置为false,改为true后保存并重启kafka服务。三、节点异常或节点磁盘下线或数据目录异常1. 节点异常FusionInsight Manager页面“集群->Kafka->实例”查看各个实例状态是否是良好。2. 磁盘下线FusionInsight Manager有没有“数据目录状态异常”的告警。Topic副本所在节点server.log日志中搜“offline”关键字和“checkpoint file”关键字查看磁盘是否下线或因checkpoint文件问题没有上线。搜“cannot allocate memory”关键字查看是否内存不足导致。搜“No space left”关键字查看是否磁盘写满。注意:出现“数据目录状态异常”的告警后,只有重启告警节点才可以使磁盘重新上线。3. 数据目录权限异常节点上Kafka数据目录(一般是“/srv/BigData/kafka/dataX/kafka-logs”)目录权限是否正常。四、删除后又自动创建TopicFusionInsight Manager页面“集群->Kafka”查看controller所在主机节点,此节点上Kafka日志目录中查看controller.log,如果日志中有“Deletion of topic topicName successfully completed”和“New topics: [Set(topicName)]”说明topic又被自动创建。五、Controller未执行删除如果controller.log日志中只有“Starting topic deletion”日志而未打印具体的执行成功或失败的日志,可尝试切controller,步骤如下:1. 进FI客户端(例如/opt/hadoopclient)2. 执行zkCli.sh -server zk业务IP:24002/kafka3. 执行get /controller4. 若获取到controller信息,执行deleteall /controller和get /controller。 -
如题,寻求smartbi v95对接FusionInsight Hetu的操作步骤。
-
 未来4年随着5G、AI、IoT等发展,数据量将激增4倍,到35年呈50倍增长,数据已成为世界各国关键的战略资源,跨境数据流通成为多边贸易重要议题,中国也从数据大国迈向数据强国,数据已作为继土地、资本、技术、劳动力的第5种生产要素,其重要性越来越凸显。各企业若想要在数字化转型过程中乘风破浪,搭上通往“数字经济“的快艇,选择具有竞争力的数字底座至关重要。近日, Frost&Sullivan弗若斯特沙利文发布了《2020年中国数据管理解决方案市场报告》,从产品创新能力、成长能力、基础能力三个维度对主流大数据厂商进行全面评估,报告显示华为云位居“领导者”位置,在中国大数据厂商中全面领先。报告解读本次报告从创新能力、成长能力、基础能力三方面对产品进行全面评估,其中横坐标代表创新指数,重点关注湖仓一体能力、海量数据事务支持能力,以及数据虚拟化能力;纵坐标代表成长指数,关注包含可扩展性、生态对接等能力;圆环中的色深代表产品的基础指数,关注支持的部署形态、数据类型等能力。从Frost Radar(弗若斯特雷达)中不难看出,活跃在中国市场的大数据厂商均已进入报告,产品表现上华为云最为抢眼,在上述三方面的表现都处于中国领先位置。华为云FusionInsight智能数据湖为政企客户提供湖仓一体的解决方案,包含MRS云原生数据湖、GaussDB(DWS)云数据仓库、DGC数据湖治理中心、GES图引擎、DLI数据湖探索等云服务,用于离线分析、实时分析、数仓集市、交互查询、实时检索、多模分析、数据接入治理、图计算等海量数据分析场景。本次报告中,华为云FusionInsight智能数据湖解决方案能位居“领导者”位置,有哪些过人之处呢?下面将从创新能力、成长能力及基础能力三方面进行解读:创新能力-湖仓一体打通数据壁垒,跨湖跨仓协同分析高效用数华为云FusionInsight解决方案中的MRS云原生数据湖产品,通过创新的HetuEngine数据虚拟化引擎,可以帮助客户构建逻辑数据湖,提供跨湖、跨仓、跨云的协同分析,实现湖仓一体,减少80%数据搬迁。同时,MRS云原生数据湖还可构建实时数据湖,提供Hudi ACID数据实时增量入湖、ClickHouse毫秒级OLAP分析、Flink批流合一等实时处理能力,支撑全自助实时分析处理等场景,使得数据时效从T+1到T+0。成长能力-一个可持续演进的数字底座至关重要华为云FusionInsight MRS云原生数据湖作为企业级平台,支持2万+超大规模集群,通过集群联邦可达10万节点,助力客户一个平台持续演进。通过创新的超级调度器Superior,任务调度性能相比传统方案提升20+倍。华为云FusionInsight MRS云原生数据湖不仅在规模上满足企业持续高速发展的需求,同时还提供滚动升级能力,使得升级过程业务不中断,保障业务连续性。基础能力-数据不出湖,分析性能提升50%+华为云FusionInsight MRS云原生数据湖可构建离线数据湖,实现湖内建仓,数据不出湖,缩短数据分析链路,让分析性能提升50%+;离线数据湖拥有交互式、BI、AI等多个计算引擎,一个平台实现海量数据多场景分析;采用OBS实现存算分离,计算与存储按需扩容,其企业级EC能力替代了传统3副本方案,统一数据存储有效提升存储周期2倍+,使得云原生数据湖架构更灵活。同时,华为云FusionInsight智能数据湖解决方案,不仅包含有MRS云原生数据湖,可以使政企客户一个架构构建离线、实时、逻辑3种数据湖,还提供GaussDB(DWS)云数据仓库、DGC数据湖治理中心、GES图引擎、DLI数据湖探索等云服务,助力政企客户实现一企一湖、一城一湖,业务洞见更准,价值兑现更快!。GaussDB(DWS)云数据仓库:是一款具备分析及混合负载能力的云数据仓库,具有高性能、高扩展、高可用等特点,广泛应用于汽车、制造、零售、互联网、金融、政府、电信等行业核心分析决策系统。DGC数据湖治理中心:一站式数据开发集成管理平台,包含数据架构、标准规范、数据开发、数据质量等功能,统一数据标准,加速数据资产沉淀。GES图引擎:是中国首个商用的、拥有自主知识产权的原生图产品,具备多项自主专利。针对以关系为基础的图结构数据,应用于社交APP、关系分析、物流配送、知识图谱等场景。DLI数据湖探索:提供一站式Serverless的融合处理分析服务。企业使用标准SQL、Spark、Flink就可轻松完成多数据源的联合计算分析,挖掘和探索数据价值。通过以上 “硬核”能力加持,华为云FusionInsight位居 “领导者”位置和国内领先的大数据厂商,可谓实至名归。 华为云 FusionInsight 智能数据湖深入各行业客户需求,已经规模商用湖仓一体创新技术方案,以数据驱动各行业业务增长。据了解,华为云 FusionInsight 客户覆盖全球 60 多个国家 3000 多家客户,覆盖政府、金融、运营商、电力、传媒、医疗、教育、交通、油气、物流、零售、制造等行业。 在政务领域,在政务数字化参与部委、各省市智慧城市、数字城市建设。在某市,华为云 FusionInsight 联合伙伴建成“一云二网三平台”,针对民生、产业、政府的“痛点”和“难点”,从构建城市数据资源库为开端,以大数据分析支撑政府智慧决策,在 “数聚惠民”、“数聚兴业”、“数聚善政”三大方面,支撑 “一号、一窗、一网” 政务服务,让简政放权、百姓办业务“最多跑一次”成为现实。 在金融领域,华为云 FusionInsight在工商银行、建设银行、招商银行等银行、证券、保险行业广泛应用。其中工商银行与华为开展联创工作,引入了华为云 FusionInsight 智能数据湖解决方案,搭建了自主可控的大数据云平台,解决了大数据全场景生态化应用的存储、算力和算法挑战,支撑了企业级数据湖、数据仓库、集团信息库的建设,通过HetuEngine提升了全行13000+分析师的即时BI体验,智能服务演进由事后快速演进到事前、事中的阶段。 在运营商领域,已覆盖国内三大运营商以及海外运营商客户。其中广东移动基于华为云 FusionInsight,联合政企客户共同打造智慧电网、智慧港口、高清视频等系列标杆应用,打通数据全生命周期链路,实现对内业务支撑、对外应用赋能,全面支撑了各类政务、民生等大数据应用服务。 面向大企业客户,覆盖能源、交通、制造等行业客户大数据平台建设。其中深圳地铁采用华为城轨云解决方案,利用云计算、大数据、5G、人工智能等技术核心,建立了统一、开放、智能的城轨数字平台,利用华为云 FusionInsight MRS 云原生数据湖能力构建深圳地铁大数据分析平台,在智慧车站、智慧运维方面,对新技术与地铁场景进行创新融合,推进了车站业务全日自动运行、线上线下一体化客服、设备主动检测、健康管理等应用,探索数字化、高效化的新业务模式,为城市提供更优质的公共交通服务。 华为云FusionInsight持续投入10年+,坚持与世界同行,在开源社区先后开放CarbonData和openLooKeng等组件,携手800+合作伙伴,服务于全球60+国家和地区3000+政企客户,已广泛应用于政府、金融、运营商、大企业等行业。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
未来4年随着5G、AI、IoT等发展,数据量将激增4倍,到35年呈50倍增长,数据已成为世界各国关键的战略资源,跨境数据流通成为多边贸易重要议题,中国也从数据大国迈向数据强国,数据已作为继土地、资本、技术、劳动力的第5种生产要素,其重要性越来越凸显。各企业若想要在数字化转型过程中乘风破浪,搭上通往“数字经济“的快艇,选择具有竞争力的数字底座至关重要。近日, Frost&Sullivan弗若斯特沙利文发布了《2020年中国数据管理解决方案市场报告》,从产品创新能力、成长能力、基础能力三个维度对主流大数据厂商进行全面评估,报告显示华为云位居“领导者”位置,在中国大数据厂商中全面领先。报告解读本次报告从创新能力、成长能力、基础能力三方面对产品进行全面评估,其中横坐标代表创新指数,重点关注湖仓一体能力、海量数据事务支持能力,以及数据虚拟化能力;纵坐标代表成长指数,关注包含可扩展性、生态对接等能力;圆环中的色深代表产品的基础指数,关注支持的部署形态、数据类型等能力。从Frost Radar(弗若斯特雷达)中不难看出,活跃在中国市场的大数据厂商均已进入报告,产品表现上华为云最为抢眼,在上述三方面的表现都处于中国领先位置。华为云FusionInsight智能数据湖为政企客户提供湖仓一体的解决方案,包含MRS云原生数据湖、GaussDB(DWS)云数据仓库、DGC数据湖治理中心、GES图引擎、DLI数据湖探索等云服务,用于离线分析、实时分析、数仓集市、交互查询、实时检索、多模分析、数据接入治理、图计算等海量数据分析场景。本次报告中,华为云FusionInsight智能数据湖解决方案能位居“领导者”位置,有哪些过人之处呢?下面将从创新能力、成长能力及基础能力三方面进行解读:创新能力-湖仓一体打通数据壁垒,跨湖跨仓协同分析高效用数华为云FusionInsight解决方案中的MRS云原生数据湖产品,通过创新的HetuEngine数据虚拟化引擎,可以帮助客户构建逻辑数据湖,提供跨湖、跨仓、跨云的协同分析,实现湖仓一体,减少80%数据搬迁。同时,MRS云原生数据湖还可构建实时数据湖,提供Hudi ACID数据实时增量入湖、ClickHouse毫秒级OLAP分析、Flink批流合一等实时处理能力,支撑全自助实时分析处理等场景,使得数据时效从T+1到T+0。成长能力-一个可持续演进的数字底座至关重要华为云FusionInsight MRS云原生数据湖作为企业级平台,支持2万+超大规模集群,通过集群联邦可达10万节点,助力客户一个平台持续演进。通过创新的超级调度器Superior,任务调度性能相比传统方案提升20+倍。华为云FusionInsight MRS云原生数据湖不仅在规模上满足企业持续高速发展的需求,同时还提供滚动升级能力,使得升级过程业务不中断,保障业务连续性。基础能力-数据不出湖,分析性能提升50%+华为云FusionInsight MRS云原生数据湖可构建离线数据湖,实现湖内建仓,数据不出湖,缩短数据分析链路,让分析性能提升50%+;离线数据湖拥有交互式、BI、AI等多个计算引擎,一个平台实现海量数据多场景分析;采用OBS实现存算分离,计算与存储按需扩容,其企业级EC能力替代了传统3副本方案,统一数据存储有效提升存储周期2倍+,使得云原生数据湖架构更灵活。同时,华为云FusionInsight智能数据湖解决方案,不仅包含有MRS云原生数据湖,可以使政企客户一个架构构建离线、实时、逻辑3种数据湖,还提供GaussDB(DWS)云数据仓库、DGC数据湖治理中心、GES图引擎、DLI数据湖探索等云服务,助力政企客户实现一企一湖、一城一湖,业务洞见更准,价值兑现更快!。GaussDB(DWS)云数据仓库:是一款具备分析及混合负载能力的云数据仓库,具有高性能、高扩展、高可用等特点,广泛应用于汽车、制造、零售、互联网、金融、政府、电信等行业核心分析决策系统。DGC数据湖治理中心:一站式数据开发集成管理平台,包含数据架构、标准规范、数据开发、数据质量等功能,统一数据标准,加速数据资产沉淀。GES图引擎:是中国首个商用的、拥有自主知识产权的原生图产品,具备多项自主专利。针对以关系为基础的图结构数据,应用于社交APP、关系分析、物流配送、知识图谱等场景。DLI数据湖探索:提供一站式Serverless的融合处理分析服务。企业使用标准SQL、Spark、Flink就可轻松完成多数据源的联合计算分析,挖掘和探索数据价值。通过以上 “硬核”能力加持,华为云FusionInsight位居 “领导者”位置和国内领先的大数据厂商,可谓实至名归。 华为云 FusionInsight 智能数据湖深入各行业客户需求,已经规模商用湖仓一体创新技术方案,以数据驱动各行业业务增长。据了解,华为云 FusionInsight 客户覆盖全球 60 多个国家 3000 多家客户,覆盖政府、金融、运营商、电力、传媒、医疗、教育、交通、油气、物流、零售、制造等行业。 在政务领域,在政务数字化参与部委、各省市智慧城市、数字城市建设。在某市,华为云 FusionInsight 联合伙伴建成“一云二网三平台”,针对民生、产业、政府的“痛点”和“难点”,从构建城市数据资源库为开端,以大数据分析支撑政府智慧决策,在 “数聚惠民”、“数聚兴业”、“数聚善政”三大方面,支撑 “一号、一窗、一网” 政务服务,让简政放权、百姓办业务“最多跑一次”成为现实。 在金融领域,华为云 FusionInsight在工商银行、建设银行、招商银行等银行、证券、保险行业广泛应用。其中工商银行与华为开展联创工作,引入了华为云 FusionInsight 智能数据湖解决方案,搭建了自主可控的大数据云平台,解决了大数据全场景生态化应用的存储、算力和算法挑战,支撑了企业级数据湖、数据仓库、集团信息库的建设,通过HetuEngine提升了全行13000+分析师的即时BI体验,智能服务演进由事后快速演进到事前、事中的阶段。 在运营商领域,已覆盖国内三大运营商以及海外运营商客户。其中广东移动基于华为云 FusionInsight,联合政企客户共同打造智慧电网、智慧港口、高清视频等系列标杆应用,打通数据全生命周期链路,实现对内业务支撑、对外应用赋能,全面支撑了各类政务、民生等大数据应用服务。 面向大企业客户,覆盖能源、交通、制造等行业客户大数据平台建设。其中深圳地铁采用华为城轨云解决方案,利用云计算、大数据、5G、人工智能等技术核心,建立了统一、开放、智能的城轨数字平台,利用华为云 FusionInsight MRS 云原生数据湖能力构建深圳地铁大数据分析平台,在智慧车站、智慧运维方面,对新技术与地铁场景进行创新融合,推进了车站业务全日自动运行、线上线下一体化客服、设备主动检测、健康管理等应用,探索数字化、高效化的新业务模式,为城市提供更优质的公共交通服务。 华为云FusionInsight持续投入10年+,坚持与世界同行,在开源社区先后开放CarbonData和openLooKeng等组件,携手800+合作伙伴,服务于全球60+国家和地区3000+政企客户,已广泛应用于政府、金融、运营商、大企业等行业。更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html -
摘要:可信智能计算服务TICS,使能数据可信流通,安全释放数据价值。商业开发者可以通过TICS,为多个参与方快速构建互信联盟,将可开发的数据资源范围从企业扩张到海量的社会数据,通过数据流通创造更大价值。在华为开发者大会2021(Cloud)期间,余承东重磅发布了6大创新产品及服务,包括华为云CCE Turbo容器集群、CloudIDE智能编程助手、GaussDB(for openGauss)数据库、可信智能计算服务TICS、华为云盘古系列大模型(包含全球最大规模的中文NLP大模型及CV大模型等)、多样性计算基础软件,为开发者提供技术支持,并使能开发者提升开发效率和质量。为了帮助开发者抓住智能升级的黄金机会,华为带来6大创新技术发布:数据使能——TICS可信智能计算服务数据作为关键生产要素,一定要流动才能发挥更大的价值。释放数据价值的关键是可信安全流通,但开放难、共享难、流通难是亟需解决的三大挑战。 今天,我们发布TICS可信智能计算服务,使能数据可信流通,安全释放数据价值。它具有以下三大特性: 基于多方数据联邦探查和建模,让隐私数据不出域,可用不可见。通过联邦AI算法和同态加密算法协同,实现模型批量计算,训练性能提升10倍,无须加速卡,也能大幅提升计算性能。支持主流大数据源,无须转换即可适配。原文地址: https://mp.weixin.qq.com/s/cl0RtAShnmXk3GQThNEDxQ
-
华为开发者大会2021(Cloud)于2021年4月24日-26日在深圳成功举行。本届大会以#每一个开发者都了不起#为主题,为众多开发者带来一场ICT方面的技术盛宴。 大会期间,由华为技术专家天团打造的《名师大讲堂》系列专题演讲,围绕云原生、大数据、人工智能等话题,探讨技术创新带来的价值,分享创新实践。其中,华为云FusionInsight MRS云原生数据湖HetuEngine架构师武文博,分享了“跨湖跨仓场景下如何实现海量数据分钟级分析”主题。华为云FusionInsight MRS云原生数据湖HetuEngine架构师武文博演讲传统大数据平台融合分析存在数据墙、数据难打通、数据协同慢三大问题 随着大数据技术的应用和发展,数据种类越来越多,分布越来越广,查询场景也越来越复杂,尤其在新兴业务中,需要在一个平台上使用离线分析、实时分析、图分析、文本分析、交互式查询等多种引擎,多元异构的数据融合才能盘活数据,通过数据挖掘开发数据价值,发挥数据作为生产要素的作用。而传统大数据平台在应对数据融合分析时逐渐显露疲态,存在如下问题: 多数据源间存在数据墙:Hive、HBase、MPPDB、Oracle….数据组件众多,组件间形成“数据墙”;为了应对不同场景的需求,数据重复存储到多个数据组件:Hive(历史数据),HBase(原始数据),MPPDB(专题数据),管理复杂,耗费存储空间; 多中心数据难以打通:各类分析应用只能基于本地数据;用外中心数据做碰撞分析需要先搬迁到本地,操作复杂,效率低;异地数据加工需要在当地部署和维护加工平台,架构复杂; 多数据中心难以形成合力:数据集中在主中心,造成主中心负载畸高,分中心却空闲严重;紧急任务需要迅速处理,却因为分中心数据还未同步,无法分析;多数据中心和多集群的计算和扩展能力远远强于单个中心,但由于跨数据中心访问技术基本处于空白状态,业务只能依靠单中心支撑。简化用数,HetuEngine统一接口,跨湖跨仓跨云协同分析从数天降至分钟级 为了让数据使用更简单,跨湖协同更容易,解决上述三大问题,华为推出了“HetuEngine”,于2019年11月发布,2020年6月正式开源(开源名称openLooKeng)。HetuEngine是统一高效的数据虚拟化引擎,与大数据生态无缝融合,实现海量数据秒级查询;业界首创多源异构协同,实现一站式SQL融合分析。HetuEngine具备如下特性:高性能交互式查询:传统大数据通过Hive引擎构建即席查询任务,查询时间长, HetuEngine通过启发式索引和执行计划Cache,实现秒级查询响应;跨湖跨仓跨云融合:传统数据分析需先统一数据格式,HetuEngine可实现不同数据格式间的join,减少数据搬迁,较传统方案提效30%;传统DC分析要建手工摆渡数据,HetuEngine可通过DC Connector进行连接,数据全局可视,协同耗时从数天缩短至分钟级;多引擎融合:传统大数据在进行多引擎组件开发时,需涉及多组件定制开发,HetuEngine可统一SQL接口访问大数据,降低用数门槛,开发提效2-10倍。 目前,华为云FusionInsight MRS云原生数据湖为政企提供湖仓一体的解决方案,一个架构可构建三种数据湖:离线数据湖、实时数据湖、逻辑数据湖。其中逻辑数据湖通过HetuEngine提供跨湖、跨仓、跨云统一访问,减少数据搬迁,数据高效流动,全域数据分钟级协同分析,业务上线效率提升10倍,由周级缩短至天级。 HetuEngine已在各行各业大规模使用,下面一起来看HetuEngine在金融领域的典型场景实践。工商银行基于HetuEngine实现即时BI,加速金融数据湖的灵活数据探索 工行金融数据湖承载总行及分行全量原始数据,供全行数据分析师进行数据探索分析。目前日查询量5000条,查询数据平均10亿行,最大可达百亿行,伴随数字化转型进入深水区,多样性业务诉求对数据融合分析提出了更高的要求。 在某些场景中,金融业务需要在数据湖内先使用批处理技术对原始数据加工成专题数据,然后跨集群搬移数据集市,再从数据集市上做BI分析。传统大数据平台中,SAS等工具通过Hive SQL访问数据湖数据性能差,平均响应时间5分钟~2小时,并发能力不足10,且湖仓数据割裂,将数据加工后加载到OLAP集市,数据链路长,分析效率和开发效率都很低。 该行通过华为云FusionInsight MRS云原生数据湖提供的HetuEngine,解决了数据湖与数仓间的数据协同分析问题,避免了不必要的ETL。通过HetuEngine数据虚拟化实现湖仓互联互通协同分析;避免不必要的ETL流程,减少数据搬迁。 通过引入HetuEngine数据虚拟化引擎,在数据湖查询分析方面该行提升了并发能力,仅1/5的资源即可支持45并发,峰值并发最大达200QPS,平均时延优化到8秒;在湖仓协同分析方面,通过HetuEngine打通数据湖与数仓间的数据壁垒,湖仓协同分析性能从分钟级提升至秒级,同时减少80%的系统间数据搬迁同步,大大提升数据治理效率。结语 HetuEngine作为统一高效的数据虚拟化引擎,打通了多数据源间的数据墙,实现高性能跨湖跨仓跨云数据融合分析,同时,HetuEngine提供统一访问入口,屏蔽了传统复杂的访问接口,并统一使用 SQL 接口,降低大数据使用门槛,简化用数! 华为云FusionInsight MRS云原生数据湖还将持续创新,做大数字世界黑土地,携手800+ISV为客户提供持续演进的湖仓一体解决方案,可以在一个架构上实现离线数据湖、实时数据湖、逻辑数据湖,在千行百业构筑“一企一湖,一城一湖”。原文链接:https://bbs.huaweicloud.com/blogs/262885更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
-
华为开发者大会2021(Cloud)于2021年4月24日-26日在深圳成功举行。本届大会以#每一个开发者都了不起#为主题,为众多开发者带来一场ICT方面的技术盛宴。 大会期间,由华为技术专家天团打造的《名师大讲堂》系列专题演讲,围绕云原生、大数据、人工智能等话题,探讨技术创新带来的价值,分享创新实践。其中,华为云FusionInsight解决方案架构师许田立,分享了“千级节点的大数据集群如何无业务中断升级”主题。华为云FusionInsight解决方案架构师许田立演讲照片数据量激增,可持续发展的数据底座尤为重要 随着5G、IoT技术的飞速发展,数据已成为重要的战略资源。据预测未来4年数据量将激增4倍+,达180ZB,到35年呈50倍增长。同时,数据作为继土地、资本、技术、劳动力的第5种生产要素,已是数字经济发展的重要要素。但相关调查结果显示,企业运营中仅56%的数据被存储,仅32%的数据被利用。为应对呈指数级增长的数据资产,挖掘海量数据价值,政企客户采用大规模数据底座的需求越来越迫切。 众所周知,企业早期业务较小,各业务从数据集成到数据应用,系统自建,烟囱林立,伴随业务飞速发展,数据不统一、数据融合分析难、开发维护成本高等问题日益凸显,烟囱式的数据体系演进达到瓶颈。 为突破以上瓶颈,挖掘数据价值,驱动业务增长,传统烟囱式数据体系向统一数据湖架构演进,实现一致的数据清洁,做到同名同义,统一数据标准;通过一套技术架构减少维护成本;采用乐高积木式的指标体系,提升开发效率;拉通数据实现跨域融合分析,带来更多的业务创新。 立足于长远,大集群的数据湖架构不仅需满足当下,更应具备可持续演进的能力。 从技术角度来看,大数据开源、开放技术仍在蓬勃发展,以前,驾驭大数据“三驾马车”可转遍大数据的池塘,现如今,大数据技术已发展成一片海洋,社区已具有100+开源项目,大数据技术创新进入深水区。现在大数据不仅限于Hadoop生态,已是多种主流数据处理技术的集合,在不同场景有着丰富的组件进行支撑。华为云大数据技术与世界同步,积极拥抱开源,汲取全球顶尖大数据实践经验。 从业务角度来看,大数据平台承载了海量数据各业务分析场景,其中更涉及多个关键业务,如运营商的对内收入稽核、对外广告精准投放,金融领域的反欺诈、精准营销等场景,服务连续性要求高,7*24小时不中断;如何让大数据平台软件保持最新保本,实现最优的平台参数,达到最快的问题解决速度?这些都对平台运维部门提出了极高的要求。 为了保持业务的连续性和技术引领,一个超大规模、高效率、可持续发展的数据底座显得尤为重要,而不中断业务的滚动升级能力则成为其中的必备能力。滚动升级实现架构平滑演进,业务无中断 华为云FusionInsight MRS云原生数据湖提供超大规模集群,支持单集群2万+节点规模,并可联邦无限扩容,同时,从500+节点集群的标配开始,华为云FusionInsight MRS云原生数据湖已提供滚动升级能力,截止目前升级成功率为100%。 当然,滚动升级的成功并不是一蹴而就的,在其升级过程中也将面临如下挑战:无处不在的兼容性:HDFS作为一个分布式架构组件,涉及的跨进程的接口众多,在中间状态,涉及到新老版本交互的场景众多,每一种组合都存在兼容性问题;可靠性:集群规模达到一定数量后,集群升级历时需数天,升级过程中需要应对各种突发事件,例如硬件的磁盘故障、网络拥塞等各种异常场景,面临这些挑战需要确保升级进度不受影响;业务无中断:大数据平台承载企业多场景应用,升级过程中,关键业务不允许中断。 为了保障大集群升级过程的平滑,华为云FusionInsight MRS云原生数据湖团队提供了升级管理可视化服务工具,可以端到端分步骤的完成滚动升级,实现升级过程中的可视化控制和管理,并应对上述挑战,主要做了如下处理:在接口中增加版本号,新版本客户端带上版本号标识;服务端提供两种RPC实现入口,在入口处进行消息格式不兼容的预处理,解决接口兼容性问题;面对社区大版本变更导致的不兼容问题,通过多版本并存的方式,解决滚动升级对业务的影响;为快速处理升级过程中出现的硬件故障,提供了故障节点隔离能力,在故障发生时,可以跳过该节点的升级动作,使得故障处理和升级可以有序进行;为降低在升级过程中对关键任务SLA的影响,提供了滚动升级暂停的能力,关键作业或者作业高峰时段,无论是同一批次内还是多批次间,都可暂停升级动作,保障关键任务平稳执行。 滚动升级不仅是一个升级动作,更是一个系统工程,华为云FusionInsight MRS云原生数据湖从兼容性、可靠性、工具自动化、保障团队等多方面入手,注重细节,通过滚动升级助力政企客户平台架构平滑演进。工商银行实现首个金融行业1000+大集群滚动升级成功 工行大数据平台的Hadoop批量集群已超过1000节点,日均处理作业10万+,数据存储数十PB,承载了全行重点批量作业,其中包括反欺诈、精准营销等多个重要业务场景,服务连续性需求较高。而大数据技术迭代快,传统升级方式需断电、重启等操作,升级操作复杂,影响现网业务运行,且大集群升级耗时长,突发故障易中断升级动作。 大数据技术快速发展,为满足业务变化发展需求,工行采用了华为云FusionInsight MRS 滚动升级方案,借助于大数据核心组件的高可用机制, MRS按照依赖层次,多层次并行,在不影响集群整体业务的情况下,一次升级/重启少量节点,依据组件和实例的依赖关系,自动编排升级批次。升级过程中,隔离故障节点,待升级完成后,再进行故障处理。循环滚动,直至集群所有节点升级到新版本。 通过华为云FusionInsight滚动升级能力,实现大集群分批次滚动升级,业务0中断;故障节点隔离功能确保升级动作的稳定运行,实现7*24小时不间断服务;1000+精细化运维指标及可视化操作简化运维,实现一个架构持续演进。结语 滚动升级作为大集群数据底座的必备能力,完美解决了传统大数据平台操作繁琐、业务停机、升级成本高等问题,实现一个架构的持续演进,业务无中断。同时,华为云FusionInsight MRS云原生数据湖还将持续创新,做大数字世界黑土地,携手800+ISV为客户提供持续演进的湖仓一体解决方案,可以在一个架构上实现离线数据湖、实时数据湖、逻辑数据湖,在千行百业构筑“一企一湖,一城一湖”。原文链接:https://bbs.huaweicloud.com/blogs/262883更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
-
2021年4月26日,HDC.Cloud2021(华为开发者大会2021)成功落下帷幕。本次大会,华为云FusionInsight MRS云原生数据湖带着“一架构三湖”的愿景与使命来到现场,与众多行业客户、合作伙伴、开发者一起,就如何在5G、AI、IoT高速发展的当下,用更好的技术创新,赋能千行百业等议题进行深入的探讨。下面,让我们一起再次重温本次活动的精彩瞬间。数据使能展区华为云FusionInsight MRS云原生数据湖绽放光彩华为云FusionInsight MRS一架“构”三湖在数据使能展区,华为云FusionInsight MRS云原生数据湖带来最懂行的大数据解决方案,为政企客户提供湖仓一体、云原生的大数据解决方案,一个架构可构建3种数据湖:离线数据湖、实时数据湖、逻辑数据湖,支撑政企客户全量数据的实时分析、离线分析、交互查询、实时检索、多模分析、数据仓库、数据接入和治理等大数据应用场景,使政企客户高效用数、简化用数,助力政企客户实现一企一湖、一城一湖,业务洞见更准,价值兑现更快。离线数据湖:HetuEngine提供秒级交互式查询能力,数据不出湖,分析链路短,性能比Impala快30%+,分析提效10倍+;DLC提供统一的元数据,数据全局可视;HetuEngine提供湖内统一SQL接口:HDFS、Hive、HBase、ES等,简化用数。实时数据湖:流处理 + Hudi实现数据更新入湖,从T+1到T+0;ClickHouse提供毫秒级实时OLAP分析能力;Flink提供FlinkSQL能力,批流SQL接口统一,实现流批一体。逻辑数据湖:HetuEngine提供跨湖、跨仓、跨云统一访问,减少数据搬迁,数据高效流动,全域数据秒级协同分析秒级响应,业务上线效率提升10倍,由周级缩短至天级。 华为云FusionInsight MRS践行产学研合作,全面推进大数据开源技术发展,联合清华大学发布了IoTDB时序引擎版本。目前华为云FusionInsight MRS已应用于60多个国家3000+客户,助力政企客户实现一企一湖、一城一湖,业务洞见更准,价值兑现更快!华为云FusionInsight技术生态工程师黄昊兮讲解实验在华为云FusionInsight MRS云原生数据湖展台的一侧,设有开发者实操的沙箱实验室,华为云FusionInsight技术生态资深工程师黄昊兮,在现场为大家现身授教,讲述“使用MRS Hudi体验实时入湖、使用MRS Clickhouse体验实时OLAP、使用MRS HetuEngine体验跨源跨域分析能力”三个实验,通过上手实操体验加深了解各组件的特性,Hudi能够支持数据增量更新,从传统Append 到 Upsert,实现数据实时更新,数据价值释放从T+1转变为T+0;Clickhouse具备毫秒级的OLAP分析能力,实现数据分析不出湖,解决了传统数据冗余、来回搬迁的问题;HetuEngine提供统一标准SQL对分布于多个地域(或数据中心)的多种数据源实现高效访问,屏蔽数据在结构、存储及地域上的差异,实现数据与应用的解耦。华为云FusionInsight MRS云原生数据湖展区 展区不仅拥有华为云FusionInsight MRS云原生数据湖一架“构”三湖的特性,更有落地实际应用的沙箱体验,让观展嘉宾在获得大数据前沿技术的同时,收获一份上手操作的亲身体验。名师大讲堂:畅谈新技术、新价值、新趋势 大会期间,由华为技术专家天团打造的《名师大讲堂》系列专题演讲,围绕云原生、大数据、人工智能等话题,探讨技术创新带来的价值,分享创新实践。其中,华为云FusionInsight MRS云原生数据湖带来两场专家演讲,由华为云FusionInsight解决方案架构师许田立,分享“千级节点的大数据集群如何无业务中断升级”主题,由HetuEngine架构师武文博,分享“跨源、跨域场景下如何实现海量数据分钟级分析”主题。千级节点的大数据集群滚动升级,业务无中断华为云FusionInsight解决方案架构师许田立演讲随着政企数字化发展,数据湖在政府、金融、运营商、大型企业等中承载越来越多的关键数据分析、处理的业务,在日常升级和维护过程中,对于业务连续性保障的要求也越来越高。而大数据技术迭代快,传统大数据平台采用离线升级方式,需断电、重启等操作,升级操作复杂,运维繁琐,影响现网业务运行,且大集群升级耗时长,突发故障易中断升级动作,为保持业务的连续性和技术引领,急需业务不中断的滚动升级能力,确保大集群数据底座的持续演进。华为云FusionInsight MRS云原生数据湖提供超大规模集群,支持单集群2万+节点规模,并可联邦无限扩容,同时,从500+节点集群的标配开始,华为云FusionInsight MRS云原生数据湖已提供滚动升级能力,截止目前升级成功率为100%。 通过华为云FusionInsight MRS云原生数据湖滚动升级能力,助力政企客户实现大集群分批次、循环滚动升级,业务0中断;故障节点隔离功能确保升级动作的稳定运行,实现7*24小时不间断服务;1000+精细化运维指标及可视化操作简化运维,实现一个架构持续演进。海量数据跨湖跨仓分钟级分析HetuEngine架构师武文博演讲HetuEngine是统一高效的数据虚拟化分析引擎,与大数据生态无缝融合,实现海量数据秒级查询;业界首创多源异构协同,实现一站式SQL融合分析,海量数据协同分析分钟级。高性能交互式查询:传统大数据通过Hive引擎构建即席查询任务,查询时间长, HetuEngine通过启发式索引和执行计划Cache,实现秒级查询响应;跨湖跨仓跨云融合:传统数据分析需先统一数据格式,HetuEngine可实现不同数据格式间的join,减少数据搬迁,较传统方案提效30%;传统DC分析要建手工摆渡数据,HetuEngine可通过DC Connector进行连接,数据全局可视,协同耗时从数天缩短至分钟级;多引擎融合:传统大数据在进行多引擎组件开发时,需涉及多组件定制开发,HetuEngine可统一SQL接口访问大数据,降低用数门槛,开发提效2-10倍。结语大幕拉下,并不是终点,而是新一段征程的起点。华为云FusionInsight MRS云原生数据湖将不忘初心,砥砺前行,保持技术创新源动力,做大数字世界黑土地,携手800+ISV为客户提供持续演进的湖仓一体解决方案,可以在一个架构上实现离线数据湖、实时数据湖、逻辑数据湖,在千行百业构筑“一企一湖,一城一湖”。文章来源:https://bbs.huaweicloud.com/blogs/262882 更多精彩文章:https://bbs.huaweicloud.com/forum/thread-66105-1-1.html
-
HDC.Cloud2021 作为华为ICT基础设施业务面向全球开发者的年度盛会,华为开发者大会2021(Cloud)将于2021年4月24日-26日在深圳举行。本届大会以#每一个开发者都了不起#为主题,将汇聚业界大咖、华为科学家、顶级技术专家、天才少年和众多开发者,共同探讨和分享云、计算、人工智能等最新ICT技术在行业的深度创新和应用。智能时代,每一个开发者都在创造一往无前的奔腾时代。世界有你,了不起!华为云FusionInsight MRS云原生数据湖作为大数据行业的佼佼者,携最新硬核能力亮相。华为云FusionInsight MRS云原生数据湖一个架构实现三种数据湖:逻辑数据湖、实时数据湖、离线数据湖,助力政企客户实现一企一湖、一城一湖,业务洞见更准,价值兑现更快!逻辑数据湖:HetuEngine提供跨湖、跨仓、跨云统一访问,减少数据搬迁,数据高效流动,全域数据秒级协同分析秒级响应,业务上线效率提升10倍,由周级缩短至天级。实时数据湖:流处理 + Hudi实现数据更新入湖,从T+1到T+0; ClickHouse提供毫秒级实时OLAP分析能力;Flink提供FlinkSQL能力,批流SQL接口统一,实现流批一体。 离线数据湖:HetuEngine提供秒级交互式查询能力,数据不出湖,分析链路短,性能比Impala快30%+,分析提效10倍+;DLC提供统一的元数据,数据全局可视; HetuEngine提供湖内统一SQL接口:HDFS、Hive、HBase、ES等,简化用数。 在华为云FuisonInsight MRS云原生数据湖展台,您不仅能感受到数据湖前沿科技的魅力,更能参与问卷抽奖活动,精美好礼送不停! 问卷链接: https://devcloud.huaweicloud.com/expert/open-assessment/qtn?id=86a27a8138c34a4eb63ce04b07e2fd0d 华为云FusionInsight MRS云原生数据湖宣传海报活动步骤通过活动指引中的链接或展台扫码二维码进入调查问卷页面;登录华为云账号进入问卷填写;填写问卷获取抽奖资格;问卷提交后进行抽奖;中奖者现场领取奖品并拍照留念。活动奖品 系统随机抽取幸运用户,获奖奖品有华为手环4及三合一数据线。注意事项 中奖兑换时间:2021年4月24日-2021年4月26日; 中奖兑换地点:深圳大学城(西丽)HDC展区,华为云FusionInsight展台。 请中奖者凭中奖记录截图在指定时间内到指定地点兑换奖品。 FusionInsight在4月26号的名师大讲堂中, 1.将由许田立在15:30宣讲“千级节点的大数据集群如何无业务中断升级?” 2.由武文博14:30宣讲“跨源、跨域场景下如何实现海量数据分钟级分析?” 如有兴趣可以点击预约问卷链接: https://devcloud.huaweicloud.com/expert/open-assessment/qtn?id=86a27a8138c34a4eb63ce04b07e2fd0d
-
 ## 背景说明 本文是参考开源Hudi的快速开始指导操作,链接为 https://hudi.apache.org/cn/docs/spark_quick-start-guide.html FusionInsight HD版本 8.1.0,下载链接 https://support.huawei.com/enterprise/zh/cloud-computing/mapreduce-service-pid-22396131/software/252491775?idAbsPath=fixnode01%7C22658044%7C22662728%7C22666212%7C22396131 集群安装模式:安全模式 必选安装服务:Spark2X 、Hive ## 操作步骤 1、集群安装(略) 2、集群客户端安装 参考产品文档,本示例中客户端默认安装到了/opt/client目录 3、创建安全认证用户 参考产品文档,例如用户名 developuser 密码 Haosuwei123 4、ssh登录客户端 (1)安全认证 ``` source /opt/client/bigdata_env echo Haosuwei123 | kinit developuser ``` (2)进入spark-shell 注意这里和开源指导文档不一样,这里将所有的依赖包通过--jars导入,各个jar包之间使用逗号隔开 ``` spark-shell --jars /opt/client/Hudi/hudi/lib/hudi-spark-common-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-spark2_2.11-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-client-common-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-common-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-spark-client-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-hive-sync-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-sync-common-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-spark_2.11-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/parquet-avro-1.12.0-hw-ei-1.0.jar,/opt/client/Hudi/hudi/lib/hudi-hadoop-mr-0.7.0-hw-ei-310003.jar --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' ``` (3)从第三步开始所有命令在spark-shell中执行 ### Hudi样例 #### 准备 设置表名、基本路径和数据生成器来为本示例生成记录。 ``` import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ import org.apache.spark.sql.SaveMode._ import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._ val tableName = "hudi_cow_table" val basePath = "hdfs:///tmp/hudi_cow_table" val dataGen = new DataGenerator ``` #### 插入数据 生成一些新的行程样本,将其加载到DataFrame中,然后将DataFrame写入Hudi数据集中,如下所示。 ``` val inserts = convertToStringList(dataGen.generateInserts(10)) val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2)) df.write.format("org.apache.hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Overwrite). save(basePath); ``` #### 查询数据 将数据文件加载到DataFrame中,通过spark-sql查询 ``` val roViewDF = spark. read. format("org.apache.hudi"). load(basePath + "/*/*/*/*") roViewDF.registerTempTable("hudi_ro_table") spark.sql("select fare, begin_lon, begin_lat, ts from hudi_ro_table where fare > 20.0").show() spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_ro_table").show() ``` 执行结果示例 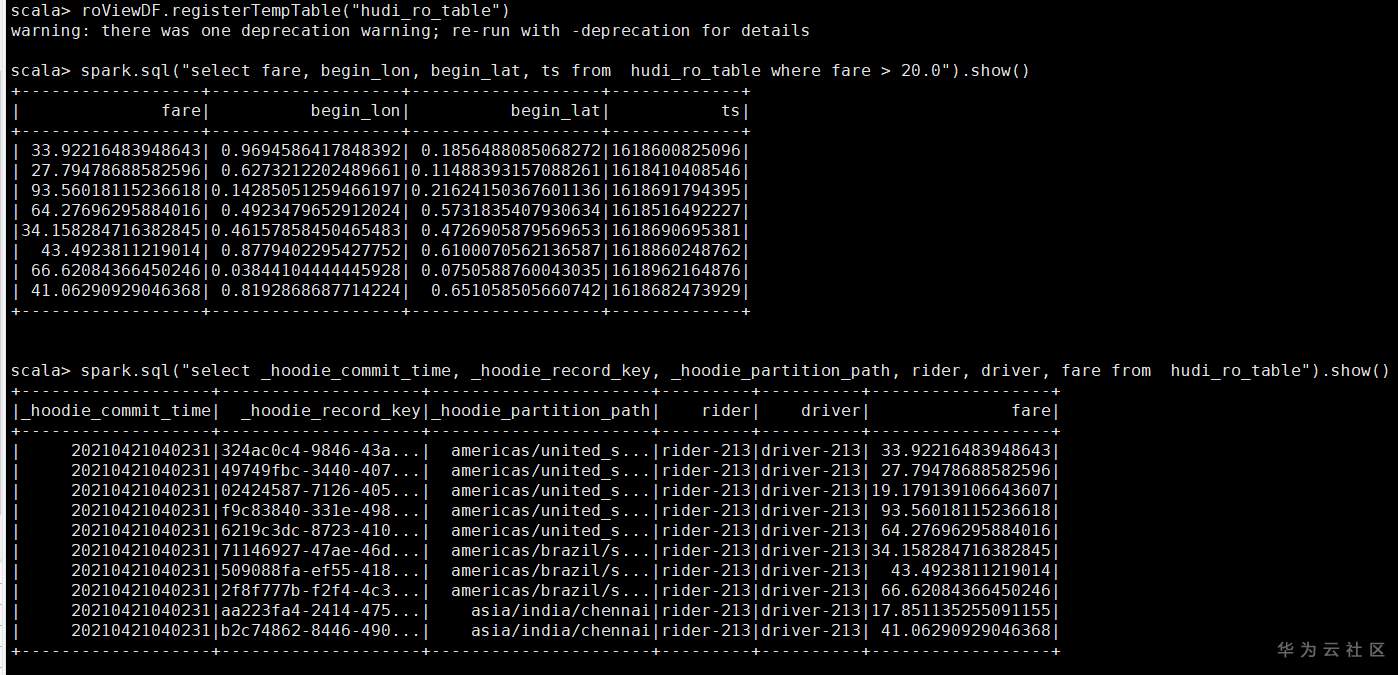 #### 更新数据 这类似于插入新数据。使用数据生成器生成对现有行程的更新,加载到DataFrame中并将DataFrame写入hudi数据集。 ``` val updates = convertToStringList(dataGen.generateUpdates(10)) val df = spark.read.json(spark.sparkContext.parallelize(updates, 2)); df.write.format("org.apache.hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath); ``` 注意,保存模式现在为追加。通常,除非您是第一次尝试创建数据集,否则请始终使用追加模式。 查询现在再次查询数据将显示更新的行程。每个写操作都会生成一个新的由时间戳表示的commit 。在之前提交的相同的_hoodie_record_key中寻找_hoodie_commit_time, rider, driver字段变更。 #### 增量查询 Hudi还提供了获取给定提交时间戳以来已更改的记录流的功能。 这可以通过使用Hudi的增量视图并提供所需更改的开始时间来实现。 如果我们需要给定提交之后的所有更改(这是常见的情况),则无需指定结束时间。 ``` spark. read. format("org.apache.hudi"). load(basePath + "/*/*/*/*"). createOrReplaceTempView("hudi_ro_table") val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_ro_table order by commitTime").map(k => k.getString(0)).take(50) val beginTime = commits(commits.length - 2) // commit time we are interested in // 增量查询数据 val incViewDF = spark. read. format("org.apache.hudi"). option(VIEW_TYPE_OPT_KEY, VIEW_TYPE_INCREMENTAL_OPT_VAL). option(BEGIN_INSTANTTIME_OPT_KEY, beginTime). load(basePath); incViewDF.registerTempTable("hudi_incr_table") spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_incr_table where fare > 20.0").show() ``` 结果示例  #### 特定时间点查询 让我们看一下如何查询特定时间的数据。可以通过将结束时间指向特定的提交时间,将开始时间指向”000”(表示最早的提交时间)来表示特定时间。 ``` val beginTime = "000" // Represents all commits > this time. val endTime = commits(commits.length - 2) // commit time we are interested in // 增量查询数据 val incViewDF = spark.read.format("org.apache.hudi"). option(VIEW_TYPE_OPT_KEY, VIEW_TYPE_INCREMENTAL_OPT_VAL). option(BEGIN_INSTANTTIME_OPT_KEY, beginTime). option(END_INSTANTTIME_OPT_KEY, endTime). load(basePath); incViewDF.registerTempTable("hudi_incr_table") spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_incr_table where fare > 20.0").show() ``` 结果示例 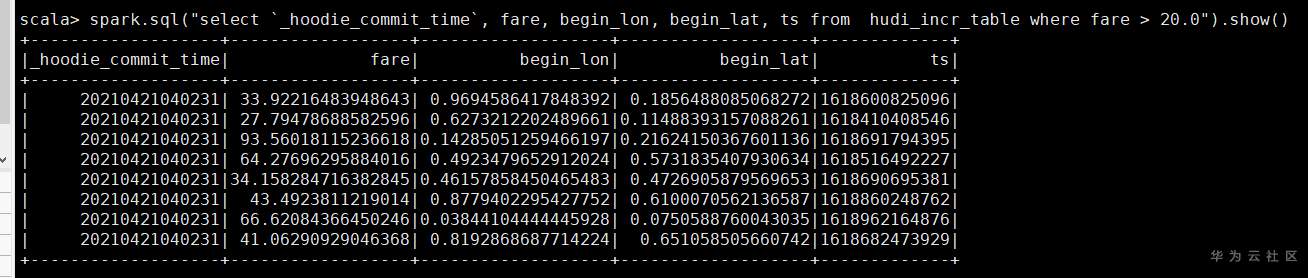 #### 删除数据 删除传入的 HoodieKeys 的记录。 ``` // 查询当前的记录 val roAfterDeleteViewDF = spark. read. format("hudi"). load(basePath + "/*/*/*/*") roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot") // 如下返回10条记录 spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count() ``` 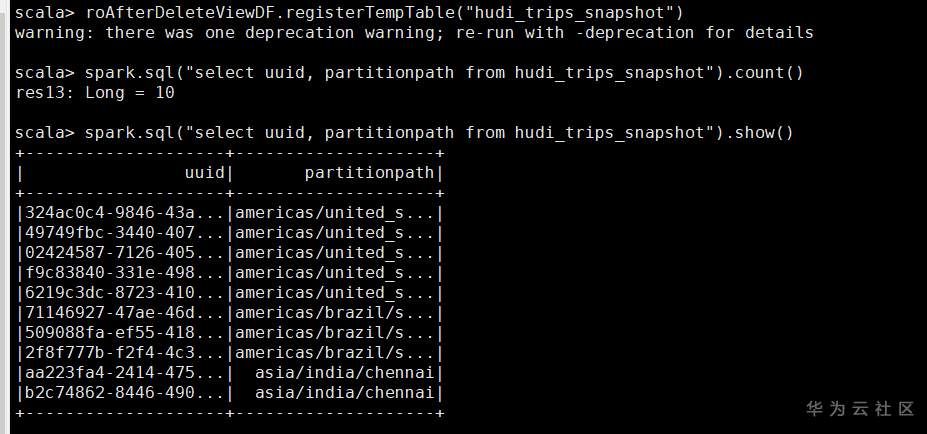 选出2条数据删除后查询 ``` // 拿到两条将要删除的数据 val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2) // 执行删除 val deletes = dataGen.generateDeletes(ds.collectAsList()) val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2)) df.write.format("hudi"). options(getQuickstartWriteConfigs). option(OPERATION_OPT_KEY,"delete"). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath) // 像之前一样运行查询 val roAfterDeleteViewDF = spark. read. format("hudi"). load(basePath + "/*/*/*/*") roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot") // 应返回 (total - 2) 条记录 spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count() ``` 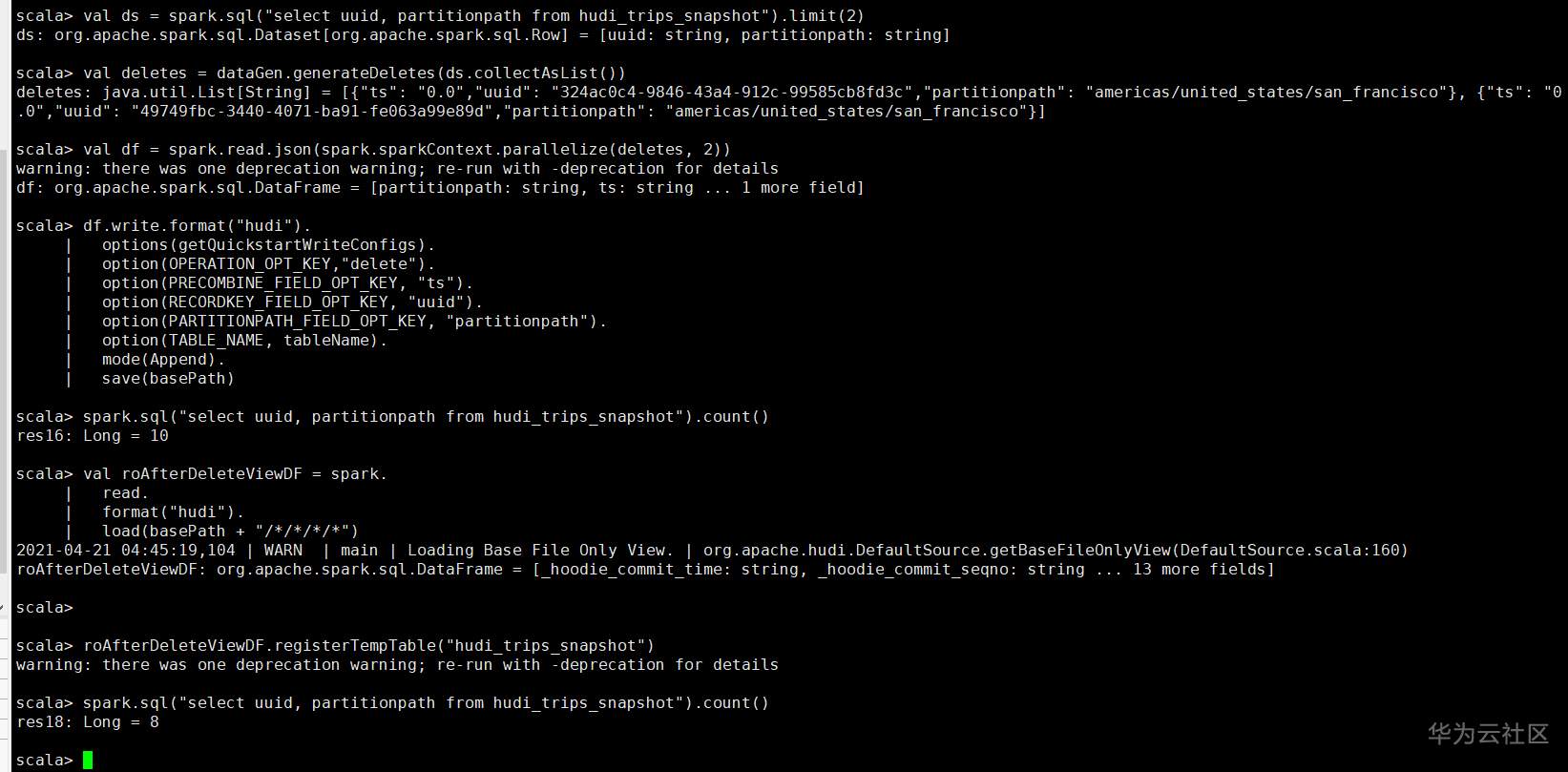
## 背景说明 本文是参考开源Hudi的快速开始指导操作,链接为 https://hudi.apache.org/cn/docs/spark_quick-start-guide.html FusionInsight HD版本 8.1.0,下载链接 https://support.huawei.com/enterprise/zh/cloud-computing/mapreduce-service-pid-22396131/software/252491775?idAbsPath=fixnode01%7C22658044%7C22662728%7C22666212%7C22396131 集群安装模式:安全模式 必选安装服务:Spark2X 、Hive ## 操作步骤 1、集群安装(略) 2、集群客户端安装 参考产品文档,本示例中客户端默认安装到了/opt/client目录 3、创建安全认证用户 参考产品文档,例如用户名 developuser 密码 Haosuwei123 4、ssh登录客户端 (1)安全认证 ``` source /opt/client/bigdata_env echo Haosuwei123 | kinit developuser ``` (2)进入spark-shell 注意这里和开源指导文档不一样,这里将所有的依赖包通过--jars导入,各个jar包之间使用逗号隔开 ``` spark-shell --jars /opt/client/Hudi/hudi/lib/hudi-spark-common-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-spark2_2.11-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-client-common-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-common-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-spark-client-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-hive-sync-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-sync-common-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/hudi-spark_2.11-0.7.0-hw-ei-310003.jar,/opt/client/Hudi/hudi/lib/parquet-avro-1.12.0-hw-ei-1.0.jar,/opt/client/Hudi/hudi/lib/hudi-hadoop-mr-0.7.0-hw-ei-310003.jar --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' ``` (3)从第三步开始所有命令在spark-shell中执行 ### Hudi样例 #### 准备 设置表名、基本路径和数据生成器来为本示例生成记录。 ``` import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ import org.apache.spark.sql.SaveMode._ import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._ val tableName = "hudi_cow_table" val basePath = "hdfs:///tmp/hudi_cow_table" val dataGen = new DataGenerator ``` #### 插入数据 生成一些新的行程样本,将其加载到DataFrame中,然后将DataFrame写入Hudi数据集中,如下所示。 ``` val inserts = convertToStringList(dataGen.generateInserts(10)) val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2)) df.write.format("org.apache.hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Overwrite). save(basePath); ``` #### 查询数据 将数据文件加载到DataFrame中,通过spark-sql查询 ``` val roViewDF = spark. read. format("org.apache.hudi"). load(basePath + "/*/*/*/*") roViewDF.registerTempTable("hudi_ro_table") spark.sql("select fare, begin_lon, begin_lat, ts from hudi_ro_table where fare > 20.0").show() spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_ro_table").show() ``` 执行结果示例  #### 更新数据 这类似于插入新数据。使用数据生成器生成对现有行程的更新,加载到DataFrame中并将DataFrame写入hudi数据集。 ``` val updates = convertToStringList(dataGen.generateUpdates(10)) val df = spark.read.json(spark.sparkContext.parallelize(updates, 2)); df.write.format("org.apache.hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath); ``` 注意,保存模式现在为追加。通常,除非您是第一次尝试创建数据集,否则请始终使用追加模式。 查询现在再次查询数据将显示更新的行程。每个写操作都会生成一个新的由时间戳表示的commit 。在之前提交的相同的_hoodie_record_key中寻找_hoodie_commit_time, rider, driver字段变更。 #### 增量查询 Hudi还提供了获取给定提交时间戳以来已更改的记录流的功能。 这可以通过使用Hudi的增量视图并提供所需更改的开始时间来实现。 如果我们需要给定提交之后的所有更改(这是常见的情况),则无需指定结束时间。 ``` spark. read. format("org.apache.hudi"). load(basePath + "/*/*/*/*"). createOrReplaceTempView("hudi_ro_table") val commits = spark.sql("select distinct(_hoodie_commit_time) as commitTime from hudi_ro_table order by commitTime").map(k => k.getString(0)).take(50) val beginTime = commits(commits.length - 2) // commit time we are interested in // 增量查询数据 val incViewDF = spark. read. format("org.apache.hudi"). option(VIEW_TYPE_OPT_KEY, VIEW_TYPE_INCREMENTAL_OPT_VAL). option(BEGIN_INSTANTTIME_OPT_KEY, beginTime). load(basePath); incViewDF.registerTempTable("hudi_incr_table") spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_incr_table where fare > 20.0").show() ``` 结果示例  #### 特定时间点查询 让我们看一下如何查询特定时间的数据。可以通过将结束时间指向特定的提交时间,将开始时间指向”000”(表示最早的提交时间)来表示特定时间。 ``` val beginTime = "000" // Represents all commits > this time. val endTime = commits(commits.length - 2) // commit time we are interested in // 增量查询数据 val incViewDF = spark.read.format("org.apache.hudi"). option(VIEW_TYPE_OPT_KEY, VIEW_TYPE_INCREMENTAL_OPT_VAL). option(BEGIN_INSTANTTIME_OPT_KEY, beginTime). option(END_INSTANTTIME_OPT_KEY, endTime). load(basePath); incViewDF.registerTempTable("hudi_incr_table") spark.sql("select `_hoodie_commit_time`, fare, begin_lon, begin_lat, ts from hudi_incr_table where fare > 20.0").show() ``` 结果示例  #### 删除数据 删除传入的 HoodieKeys 的记录。 ``` // 查询当前的记录 val roAfterDeleteViewDF = spark. read. format("hudi"). load(basePath + "/*/*/*/*") roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot") // 如下返回10条记录 spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count() ```  选出2条数据删除后查询 ``` // 拿到两条将要删除的数据 val ds = spark.sql("select uuid, partitionpath from hudi_trips_snapshot").limit(2) // 执行删除 val deletes = dataGen.generateDeletes(ds.collectAsList()) val df = spark.read.json(spark.sparkContext.parallelize(deletes, 2)) df.write.format("hudi"). options(getQuickstartWriteConfigs). option(OPERATION_OPT_KEY,"delete"). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Append). save(basePath) // 像之前一样运行查询 val roAfterDeleteViewDF = spark. read. format("hudi"). load(basePath + "/*/*/*/*") roAfterDeleteViewDF.registerTempTable("hudi_trips_snapshot") // 应返回 (total - 2) 条记录 spark.sql("select uuid, partitionpath from hudi_trips_snapshot").count() ```  -
请大佬答疑一下……active NameNode和standby NameNode在进行fsimage checkpoint同步的过程中为什么使用HTTP而不是RPC?
-
 ## Manager简介 FusionInsight Manager是集群的运维管理系统,为部署在集群内的服务提供统一的集群管理能力。 Manager支持大规模集群的安装部署性能监控、告警、用户管理、权限管理、审计、服务管理、健康检查、日志采集等功能。 FusionInsight Manager Rest API需要受限通过HTTP基本认证(Basic Authentication)后才能使用 ## REST API REST API是访问Web服务器的一套API,REST API接口的执行方式是通过HTTP请求进行的,接收GET、PUT、POST、DELETE等请求并使用JSON数据进行响应。 HTTP请求的格式为:http://:/。 其中Process_IP是指进程所在服务器节点的IP地址,Process_Port是指进程的监听端口,Path为具体路径。 例如:http://10.162.181.57:32261/config ## 基本认证(Basic Authentication) 在HTTP中,基本认证是一种用来允许Web浏览器或其他客户端程序在请求时提供用户名和口令形式的身份凭证的一种登录验证方式。 在请求发送之前,以用户名追加一个冒号然后串接上口令,再将此字符串用Base64算法编码。 例如: 用户名是admin、口令是xxx,则拼接后的字符串就是admin:xxx,然后进行Base64编码,得到QWxhZGRpbjpvcGVuIHNlc2FtZQ==,最终将编码后的字符串发送出去,由接收者解码得到一个由冒号分隔的用户名和口令的字符串。 ## 场景说明 使用curl命令直接访问FusionInsight Manager的Rest接口,导出所有用户列表。 命令如下: ``` curl -k -i --basic -u : -c /tmp/jsessionid.txt 'https://x.x.x.x:28443/web/api/v2/permission/users?limit=10&offset=0&filter=&order=ASC&order_by=userName' ```
## Manager简介 FusionInsight Manager是集群的运维管理系统,为部署在集群内的服务提供统一的集群管理能力。 Manager支持大规模集群的安装部署性能监控、告警、用户管理、权限管理、审计、服务管理、健康检查、日志采集等功能。 FusionInsight Manager Rest API需要受限通过HTTP基本认证(Basic Authentication)后才能使用 ## REST API REST API是访问Web服务器的一套API,REST API接口的执行方式是通过HTTP请求进行的,接收GET、PUT、POST、DELETE等请求并使用JSON数据进行响应。 HTTP请求的格式为:http://:/。 其中Process_IP是指进程所在服务器节点的IP地址,Process_Port是指进程的监听端口,Path为具体路径。 例如:http://10.162.181.57:32261/config ## 基本认证(Basic Authentication) 在HTTP中,基本认证是一种用来允许Web浏览器或其他客户端程序在请求时提供用户名和口令形式的身份凭证的一种登录验证方式。 在请求发送之前,以用户名追加一个冒号然后串接上口令,再将此字符串用Base64算法编码。 例如: 用户名是admin、口令是xxx,则拼接后的字符串就是admin:xxx,然后进行Base64编码,得到QWxhZGRpbjpvcGVuIHNlc2FtZQ==,最终将编码后的字符串发送出去,由接收者解码得到一个由冒号分隔的用户名和口令的字符串。 ## 场景说明 使用curl命令直接访问FusionInsight Manager的Rest接口,导出所有用户列表。 命令如下: ``` curl -k -i --basic -u : -c /tmp/jsessionid.txt 'https://x.x.x.x:28443/web/api/v2/permission/users?limit=10&offset=0&filter=&order=ASC&order_by=userName' ``` -
【功能模块】集群安装redis服务【操作步骤&问题现象】1、安装redis服务的时候初始化实例个数比服务器的CPU核数多,导致安装失败,请问如何修改redis安装时的初始化实例个数2、集群版本为 FusionInsight 8.0.2【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
前提条件:FusionInsight HD 集群安装完毕,集群状态健康已安装最新版本HetuEngine服务已在FusionInsight Hetu集群中创建“人机”用户Windows环境已安装PowerBI 说明:该方法仅适用于2021.3.30版本之后,3.30之前的版本不适用一、获取JDBC jar包 下载HetuEngine客户端。登录FusionInsight Manager。选择“集群 > 待操作的集群名称 > 服务 > HetuEngine > 概览”。在页面右上角,选择“更多 > 下载客户端”,根据界面提示下载“完整客户端”文件到本地。解压HetuEngine客户端压缩包文件“FusionInsight_Cluster_集群ID_Services_Client.tar”获取jdbc文件,并存放在本地,例如D:\test 说明:jdbc文件在压缩包中的路径:FusionInsight_Cluster_集群ID_Services_Client \FusionInsight_Cluster_1_Services_ClientConfig\FusionInsight_Cluster_集群ID_Services_ClientConfig\HetuEngine\ presto-jdbc-316-hw-ei-*-SNAPSHOT二、PowerBI配置步骤1:采用ODBC登录方式访问HetuEngine,首先需要安装ODBC驱动程序。使用默认配置安装“hetu-odbc-win64.msi”驱动程序。下载地址:https://openlookeng.io/download.html。步骤2:配置数据源驱动执行以下命令停止自动启动的odbc服务。 cd C:\Program Files\openLooKeng\openLooKeng ODBC Driver 64-bit\odbc_gateway\mycat\bin mycat.bat stop 2.替换jdbc驱动。 拷贝第一节中获取的jdbc jar包到“C:\Program Files\openLooKeng\openLooKeng ODBC Driver 64-bit\odbc_gateway\mycat\lib”目录下,并删除该目录下原始的“hetu-jdbc-1.0.1.jar”包。 3.编辑odbc的“server.xml”文件的协议前缀 将“C:\Program Files\openLooKeng\openLooKeng ODBC Driver 64-bit\odbc_gateway\mycat\conf”目录中的“server.xml”文件的属性值“<property name="jdbcUrlPrefix">jdbc:lk://</property>”修改为“<property name="jdbcUrlPrefix">jdbc:presto://</property>” 4.配置用户名/密码方式连接。 在自定义路径,如“C:\hetu”中新建“jdbc_param.properties”文件,添加如下内容:user=admintestpassword=admintest@123456 说明: user:已创建的“人机”用户的用户名,如:admintest。 password:已创建的“人机”用户的用户密码,如:admintest@123456。 5.执行以下命令重启odbc服务 cd C:\Program Files\openLooKeng\openLooKeng ODBC Driver 64-bit\odbc_gateway\mycat\bin mycat.bat restart 备注:每次修改配置时都需要停止odbc服务,修改完毕后再重启服务。步骤3:在window系统的控制面板中输入“odbc”搜索odbc的管理程序。步骤4:在应用程序中选择“添加 > openLookeng ODBC 1.1 Driver > 完成”步骤5:参考下图创建数据源名称和描述,单击“Next”步骤6:参考下图完成参数配置。 Connection URL:<HSBrokerIP1:port1>,<HSBrokerIP2:port2>,<HSBrokerIP3:port3>/hive/default?serviceDiscoveryMode=hsbroker;获取HSBroker节点及端口号:a. 登录FusionInsight Managerb. 选择“集群 -> 待操作的集群名称 –> 服务 -> HetuEngine –> 角色 -> HSBroker”获取HSBroker所有实例的业务IP选择“集群 -> 待操作的集群名称 –> 服务 -> HetuEngine -> 配置 -> 全部配置”,右侧搜索“server.port”,获取HSBroker的端口号样例:192.168.8.37:29860,192.168.8.38:29860, 192.168.8.39:29860/hive/default?serviceDiscoveryMode=hsbrokerConnection Config:选择步骤2准备好的“jdbc_param.properties”文件;User Name”是下载凭据的用户名称。步骤7:单击“Test DSN ”测试连接, 显示连接成功且“Catalog”和“Schema”中均有内容表示连接成功,单击“Next”。步骤8:单击“Finish”完成连接。步骤9:使用PowerBI对接,选择“获取数据 > 更多 > ODBC > 连接”。步骤10:选择步骤5中添加的数据源,单击“确定”完成数据源添加。步骤11:(可选)输入下载凭据用户的“用户名”及“密码”,单击“连接”。步骤12:连接成功后,显示所有表信息
-
前提条件:FusionInsight HD 集群安装完毕,集群状态健康已安装最新版本HetuEngine服务已在FusionInsight Hetu集群中创建“人机”用户Windows环境已安装永洪BI 说明:该方法仅适用于2021.3.30版本之后,3.30之前的版本不适用一、获取JDBC jar包 下载HetuEngine客户端。登录FusionInsight Manager。选择“集群 > 待操作的集群名称 > 服务 > HetuEngine > 概览”。在页面右上角,选择“更多 > 下载客户端”,根据界面提示下载“完整客户端”文件到本地。解压HetuEngine客户端压缩包文件“FusionInsight_Cluster_集群ID_Services_Client.tar”获取jdbc文件,并存放在本地,例如D:\test 说明:jdbc文件在压缩包中的路径:FusionInsight_Cluster_集群ID_Services_Client \FusionInsight_Cluster_1_Services_ClientConfig\FusionInsight_Cluster_集群ID_Services_ClientConfig\HetuEngine\ presto-jdbc-316-hw-ei-*-SNAPSHOT二、永洪BI配置步骤1:打开Yonghong Desktop,选择“添加数据源”->“presto”步骤2:在数据源配置页面参考下图完成参数配置,“用户名”和“密码”为已创建的“人机”用户的用户名和用户密码。配置完成后可以单击“测试连接”测试。驱动:选择“自定义 > 选择自定义驱动”,单击,编辑驱动名称,单击“上传文件”上传已获取的JDBC jar包,单击“确定”。URL格式:jdbc:presto://<HSBrokerIP1:port1>:<HSBrokerIP2:port2>:<HSBrokerIP3:port3>/hive/default?serviceDiscoveryMode=hsbroker获取HSBroker节点及端口号:a. 登录FusionInsight Managerb. 选择“集群 -> 待操作的集群名称 –> 服务 -> HetuEngine –> 角色 -> HSBroker”获取HSBroker所有实例的业务IPc. 选择“集群 -> 待操作的集群名称 –> 服务 -> HetuEngine -> 配置 -> 全部配置”,右侧搜索“server.port”,获取HSBroker的端口号样例:jdbc:presto:// 192.168.8.37:29860,192.168.8.38:29860, 192.168.8.39:29860/hive/default?serviceDiscoveryMode=hsbroker服务器登录:选择“用户名和密码”,并填写“人机”用户的用户名和密码。步骤3:单击“新建数据集”,在弹出的页面参考下图修改保存路径,单击“确定”保存路径,最后“测试连接”。步骤4:在数据源选择“hetu > hive > default > 视图”,在右侧“新建数据集”选择“SQL数据集”。步骤5:在“数据源”处选择步骤3新建的数据集,显示所有表信息,选中其中一个表,如“test”表,单击“刷新数据”,可在右侧“数据详情”中显示表的所有信息。
上滑加载中
推荐直播
-
 Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案
Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案2026/03/25 周三 19:00-20:00
余伟,华为云软件研发工程师/万邵业(万少),华为云HCDE开发者专家
本次直播带来两大实战:华为云码道 Skill-Creator 手把手搭建专属知识库 Skill;如何用码道提效 OpenClaw 小说文本,打造从大纲到成稿的 AI 原创小说全链路。技术干货 + OPC创作思路,一次讲透!
回顾中 -
 码道新技能,AI 新生产力——从自动视频生成到开源项目解析
码道新技能,AI 新生产力——从自动视频生成到开源项目解析2026/04/08 周三 19:00-21:00
童得力-华为云开发者生态运营总监/何文强-无人机企业AI提效负责人
本次华为云码道 Skill 实战活动,聚焦两大 AI 开发场景:通过实战教学,带你打造 AI 编程自动生成视频 Skill,并实现对 GitHub 热门开源项目的智能知识抽取,手把手掌握 Skill 开发全流程,用 AI 提升研发效率与内容生产力。
回顾中 -
 华为云码道:零代码股票智能决策平台全功能实战
华为云码道:零代码股票智能决策平台全功能实战2026/04/18 周六 10:00-12:00
秦拳德-中软国际教育卓越研究院研究员、华为云金牌讲师、云原生技术专家
利用Tushare接口获取实时行情数据,采用Transformer算法进行时序预测与涨跌分析,并集成DeepSeek API提供智能解读。同时,项目深度结合华为云CodeArts(码道)的代码智能体能力,实现代码一键推送至云端代码仓库,建立起高效、可协作的团队开发新范式。开发者可快速上手,从零打造功能完整的个股筛选、智能分析与风险管控产品。
回顾中
热门标签