-
 摘要 因果特征选择算法(也称为马尔科夫边界发现)学习目标变量的马尔科夫边界,选择与目标存在因果关系的特征,具有比传统方法更好的可解释性和鲁棒性.文中对现有因果特征选择算法进行全面综述,分为单重马尔科夫边界发现算法和多重马尔科夫边界发现算法.基于每类算法的发展历程,详细介绍每类的经典算法和研究进展,对比它们在准确性、效率、数据依赖性等方面的优劣.此外,进一步总结因果特征选择在特殊数据(半监督数据、多标签数据、多源数据、流数据等)中的改进和应用.最后,分析该领域的当前研究热点和未来发展趋势,并建立因果特征选择资料库(http://home.ustc.edu.cn/~xingyuwu/MB.html),汇总该领域常用的算法包和数据集. 高维数据为真实世界的机器学习任务带来诸多挑战, 如计算资源和存储资源的消耗、数据的过拟合, 学习算法的性能退化[1], 而最具判别性的信息仅被一部分相关特征携带[2].为了降低数据维度, 避免维度灾难, 特征选择研究受到广泛关注.大量的实证研究[3, 4, 5]表明, 对于多数涉及数据拟合或统计分类的机器学习算法, 在去除不相关特征和冗余特征的特征子集上, 通常能获得比在原始特征集合上更好的拟合度或分类精度.此外, 选择更小的特征子集有助于更好地理解底层的数据生成流程[6]. 传统的特征选择算法主要分为封装法、过滤法和嵌入法三类[7].封装法[8]为不同的特征子集训练一个学习器, 评估其在该特征子集上的表现, 决定所选特征子集.过滤法[9]使用一个评估函数, 为特征评分并选择分数较高的特征, 因此不依赖额外的分类器, 更高效.嵌入法[10]将特征选择过程嵌入学习过程中, 同时搜索特征选择空间和学习器参数空间, 获得特征子集. 传统的特征选择算法根据特征和目标变量之间的相关性寻找相关特征子集[11].然而, 相关关系只能反映目标变量和特征之间的共存关系, 而无法解释决定目标变量取值的潜在机制[12, 13].一些研究表明[12, 13], 因果关系具有更好的可解释性和鲁棒性.例如, 将吸烟与肺癌患者数据集上“ 肺癌” (例子中变量取值均为“ 是” 、“ 否” )作为目标变量, “ 黄手指” 和“ 吸烟” 作为特征变量.由于“ 吸烟” 可用来解释“ 肺癌” , 而长期吸烟手指会受到焦油的污染, 因此“ 黄手指” 和“ 吸烟” 与“ 肺癌” 之间存在相关关系, 而只有“ 吸烟” 与“ 肺癌” 之间存在因果关系.当一些吸烟者为了隐藏吸烟习惯而去除手指上的黄渍时, 基于“ 黄手指” 的预测模型将失效, 而基于“ 吸烟” 的预测模型更鲁棒. 为了寻找更鲁棒的因果特征, 近年来, 因果特征选择算法被广泛研究.该类算法通过学习目标变量的马尔科夫边界(Markov Boundary, MB)[14]以寻找关键特征, 因此又被称为MB发现算法.具体地, MB的概念来源于因果贝叶斯网络, 在满足忠实性假设的贝叶斯网络中, 一个变量的MB集合是唯一的, 包含该目标变量的父节点、子节点及配偶节点(子节点的其它父节点)[14].因此, MB反映目标变量周围的局部因果关系, 给定目标变量的MB作为条件集合, 其它特征条件独立于目标变量[14].基于此属性:Tsamardinos等[15]证明在分类问题中, 类别变量的MB是具有最大预测性的最小特征子集; Pellet等[16]证明类别变量的MB集合是特征选择的最优解.因此, 因果特征选择算法通常具有可靠的理论保证.作为一种算法思路, 基于因果关系的特征选择算法促进特征选择的可解释性和鲁棒性.近年来, 因果特征选择算法不断发展, 不仅提升单/多重马尔科夫边界发现算法的搜索精度和计算效率, 在半监督数据、流数据、多源数据、多标签数据等特殊场景下也不断发展.这些算法无需学习包含所有特征的完整贝叶斯网络结构, 即可挖掘目标变量周围的因果特征.本文对现有因果特征选择方法进行较全面的研究和综述.基于原理与现有方法分类1.问题定义与基础理论本节介绍MB相关的基本定义和基础理论.本文使用U表示特征集合, T表示目标变量(标签).MB的概念来源于人工智能基础模型之一的贝叶斯网络.定义 1 贝叶斯网络[14] 对于三元组< U, G, P> , U表示变量集合, G表示U上的有向无环图(Directed Acyclic Graph, DAG), P表示U上的概率分布.对于∀ X∈ U, 将X在G中的父变量作为条件集合, 如果任意X的非后代变量在P中都条件独立于X, 那么< U, G, P> 为贝叶斯网络.贝叶斯网络表征一个变量集合中的因果关系.在有向无环图中, 对于一对直接相连的父子变量, 父变量是子变量的直接原因, 子变量是父变量的直接结果[14].忠实性是贝叶斯网络的基础假设之一, 定义如下.定义 2 忠实性[14] 给定贝叶斯网络< U, G, P> , G忠实于P当且仅当P中的每个条件独立性关系都是由G和马尔科夫条件决定的.P忠实于G当且仅当存在一个G的子图忠实于P.MB的概念是基于忠实的贝叶斯网络而提出的, 定义如下.定义 3 马尔科夫边界[14] 在满足忠实性的贝叶斯网络中, 一个节点的马尔科夫边界包含该节点的父节点、子节点和配偶节点(子节点的其它父节点)[14].根据定义3, 一个节点的MB可直接从忠实的贝叶斯网络中“ 读” 出来.如图1所示, 节点T的MB为{A, B, G, H, F}, 包含父节点A、B, 子节点G、H, 配偶节点F.从因果图的角度分析, MB提供变量周围的局部因果结构, 父节点、子节点、配偶节点分别对应目标变量的直接原因、直接结果、直接结果的其它原因.MB发现算法通过挖掘变量的局部因果结构, 无需学习完整的贝叶斯网络即可找到变量的MB.而变量的MB集合有一个特殊的统计特性, 见定理1.图1 马尔科夫边界的例子Fig.1 An example of Markov boundary定理 1 对于变量X∈ U, X的马尔科夫边界MB⊆U, 满足:∀ Y∈ U-MB-{X}, X⊥Y| MB, 且MB为满足该统计特性的最小变量集.定理1 中阐述MB的最小性, MB的超集通常称为马尔科夫毯(Markov Blanket).根据定理1, 以MB集合为条件, 目标变量会条件独立于其它特征.因此, MB中的特征携带所有关于目标变量的预测信息, 并且其“ 最小性” 保证MB可作为特征选择问题的最优解, 见定理2.定理 2 在满足忠实性假设的数据中, 目标变量的MB是唯一的, 并且为特征选择的最优解[15, 16].定理2 为MB发现算法解决特征选择问题提供理论保证, 由于MB发现算法根据数据中的因果关系选择特征, 并且特征包含目标变量的因果信息, 因此使用MB发现算法选择特征的过程称为因果特征选择.2.现有马尔科夫边界学习方法分类及其基本原理图2给出本文对现有MB发现算法的分类.常规数据中的MB发现算法主要分为单重MB发现算法和多重MB发现算法, 这两类算法的应用场景取决于训练数据是否满足忠实性假设.根据定理2, 在满足忠实性的条件下, 目标变量的MB是唯一的, 当真实数据并不完全满足忠实性条件时, 目标变量可能存在多个等价的MB.因此, 一部分现有算法假设数据满足忠实性, 并且试图寻找目标变量的唯一MB, 该类算法称为单重MB发现算法.另一部分算法考虑忠实性假设被违反的情况, 这些算法可挖掘目标变量的多个等价MB, 该类算法称为多重MB发现算法.特殊数据中的MB发现算法作为一类单独介绍, 其中包括半监督数据MB发现算法、流数据MB发现算法、多源数据MB发现算法、多标签数据MB发现算法.本文按照上述分类介绍现有算法的特点. 图2 现有MB发现算法的分类Fig.2 Categories of existing MB discovery algorithms单重MB发现算法假设目标变量有唯一的MB, 输出的MB集合可直接作为特征选择的结果.该类算法主要分为两类:直接的MB发现算法(直接法)和分治的MB发现算法(分治法).主要区别是:直接法根据MB的性质(定理1)直接学习MB变量, 而分治法分别学习父子变量和配偶变量.主要理论依据为定理3和定理4.定理 3 在U上的贝叶斯网络中, 如果节点X和Y满足:任意变量子集Z⊆U-{X, Y}, X⊥Y|Z不成立, 那么X和Y是一对父子变量[17].定理 4 在U上的贝叶斯网络中, 如果不相连的节点X和Y均与T相连, 如果存在变量子集Z⊆U-{X, Y, T}, 使得X⊥Y|Z成立但X⊥Y|Z∪ {T}不成立, 那么X和Y是一对配偶变量[17].定理3和定理4分别给出父子变量和配偶变量的判别条件, 基于上述定理, 分治的MB发现算法可通过条件独立性测试分别搜索父子和配偶变量.如图3所示, 单重MB发现算法通常使用增长阶段和收缩阶段搜索MB变量或父子变量.增长阶段用于识别并添加可能的真变量, 而收缩阶段检测并删除增长步骤中找到的假变量.基于这一框架, 分治法需要进一步搜索配偶变量.直接法通常在时间效率上更优.但由于分治法在条件独立性测试中使用规模更小的条件集合, 因此通常分治法可达到比直接法更高的准确性.图3 直接法和分治法的区别Fig.3 Difference between direct methods and divide-and-conquer methods 可用于MB发现算法的通用条件独立性测试方法有5种:1)λ 2测试、G2测试、互信息计算, 可用于离散数据[18]; 2)菲尔逊Z检验[19], 可用于带有高斯误差的线性关系的连续数据; 3)基于核的条件独立性测试方法[20], 可用于非线性、非高斯噪声的连续数据.多重MB发现算法研究忠实性假设被违反的情况下一个变量的多个等价MB.理论上来说, 目标变量的多重MB携带等价的信息且具有相似的预测能力[21], 该类算法存在的意义是:1)由于实际应用中多个等价的MB适应的特定学习模型是不同的, 多重MB可用于解释学习模型的多样性现象; 2)实际应用中可能存在多个等价的MB, 但并非所有MB都适合作为特征子集建立学习模型.例如, 当不同变量的获取成本可能不同时, 多重MB算法可用于探索较低获取成本但具有相似预测性的替代解决方案(特征子集).根据Statnikov等[21]的研究, 多重MB的本质原因是等价信息现象, 定义4和定理5如下.定义 4 等价信息[21] 对变量集合X⊆U, Y⊆U及目标变量T∈ U, X和Y包含T的等价信息当且仅当X和Y与T相关且满足X⊥T|Y, Y⊥T|X.定理 5 当且仅当没有发生信息等价时, 目标变量有一个唯一的MB集合[21].根据定理5, 多重MB与等价信息现象是共存的, 因此寻找多个MB的过程也就是识别等价信息的过程[21].现有的多重MB发现算法通常遵循如下步骤:1)使用单重MB发现算法找到一个初始的MB; 2)在当前MB中选择特征子集, 将其从源数据分布中移除, 再在新的数据分布中找到新的MB; 3)测试新MB是否正确.特殊数据的MB发现算法主要是面向近年来逐渐流行的一些特殊学习场景, 根据本文的调研, 目前主要包括但不限于:半监督数据MB发现算法、多标签数据MB发现算法、多源数据MB发现算法和流数据MB发现算法.这些算法大多对应某个单重MB发现算法, 考虑对应场景的特点, 将单重MB算法扩展应用到特殊数据中.
摘要 因果特征选择算法(也称为马尔科夫边界发现)学习目标变量的马尔科夫边界,选择与目标存在因果关系的特征,具有比传统方法更好的可解释性和鲁棒性.文中对现有因果特征选择算法进行全面综述,分为单重马尔科夫边界发现算法和多重马尔科夫边界发现算法.基于每类算法的发展历程,详细介绍每类的经典算法和研究进展,对比它们在准确性、效率、数据依赖性等方面的优劣.此外,进一步总结因果特征选择在特殊数据(半监督数据、多标签数据、多源数据、流数据等)中的改进和应用.最后,分析该领域的当前研究热点和未来发展趋势,并建立因果特征选择资料库(http://home.ustc.edu.cn/~xingyuwu/MB.html),汇总该领域常用的算法包和数据集. 高维数据为真实世界的机器学习任务带来诸多挑战, 如计算资源和存储资源的消耗、数据的过拟合, 学习算法的性能退化[1], 而最具判别性的信息仅被一部分相关特征携带[2].为了降低数据维度, 避免维度灾难, 特征选择研究受到广泛关注.大量的实证研究[3, 4, 5]表明, 对于多数涉及数据拟合或统计分类的机器学习算法, 在去除不相关特征和冗余特征的特征子集上, 通常能获得比在原始特征集合上更好的拟合度或分类精度.此外, 选择更小的特征子集有助于更好地理解底层的数据生成流程[6]. 传统的特征选择算法主要分为封装法、过滤法和嵌入法三类[7].封装法[8]为不同的特征子集训练一个学习器, 评估其在该特征子集上的表现, 决定所选特征子集.过滤法[9]使用一个评估函数, 为特征评分并选择分数较高的特征, 因此不依赖额外的分类器, 更高效.嵌入法[10]将特征选择过程嵌入学习过程中, 同时搜索特征选择空间和学习器参数空间, 获得特征子集. 传统的特征选择算法根据特征和目标变量之间的相关性寻找相关特征子集[11].然而, 相关关系只能反映目标变量和特征之间的共存关系, 而无法解释决定目标变量取值的潜在机制[12, 13].一些研究表明[12, 13], 因果关系具有更好的可解释性和鲁棒性.例如, 将吸烟与肺癌患者数据集上“ 肺癌” (例子中变量取值均为“ 是” 、“ 否” )作为目标变量, “ 黄手指” 和“ 吸烟” 作为特征变量.由于“ 吸烟” 可用来解释“ 肺癌” , 而长期吸烟手指会受到焦油的污染, 因此“ 黄手指” 和“ 吸烟” 与“ 肺癌” 之间存在相关关系, 而只有“ 吸烟” 与“ 肺癌” 之间存在因果关系.当一些吸烟者为了隐藏吸烟习惯而去除手指上的黄渍时, 基于“ 黄手指” 的预测模型将失效, 而基于“ 吸烟” 的预测模型更鲁棒. 为了寻找更鲁棒的因果特征, 近年来, 因果特征选择算法被广泛研究.该类算法通过学习目标变量的马尔科夫边界(Markov Boundary, MB)[14]以寻找关键特征, 因此又被称为MB发现算法.具体地, MB的概念来源于因果贝叶斯网络, 在满足忠实性假设的贝叶斯网络中, 一个变量的MB集合是唯一的, 包含该目标变量的父节点、子节点及配偶节点(子节点的其它父节点)[14].因此, MB反映目标变量周围的局部因果关系, 给定目标变量的MB作为条件集合, 其它特征条件独立于目标变量[14].基于此属性:Tsamardinos等[15]证明在分类问题中, 类别变量的MB是具有最大预测性的最小特征子集; Pellet等[16]证明类别变量的MB集合是特征选择的最优解.因此, 因果特征选择算法通常具有可靠的理论保证.作为一种算法思路, 基于因果关系的特征选择算法促进特征选择的可解释性和鲁棒性.近年来, 因果特征选择算法不断发展, 不仅提升单/多重马尔科夫边界发现算法的搜索精度和计算效率, 在半监督数据、流数据、多源数据、多标签数据等特殊场景下也不断发展.这些算法无需学习包含所有特征的完整贝叶斯网络结构, 即可挖掘目标变量周围的因果特征.本文对现有因果特征选择方法进行较全面的研究和综述.基于原理与现有方法分类1.问题定义与基础理论本节介绍MB相关的基本定义和基础理论.本文使用U表示特征集合, T表示目标变量(标签).MB的概念来源于人工智能基础模型之一的贝叶斯网络.定义 1 贝叶斯网络[14] 对于三元组< U, G, P> , U表示变量集合, G表示U上的有向无环图(Directed Acyclic Graph, DAG), P表示U上的概率分布.对于∀ X∈ U, 将X在G中的父变量作为条件集合, 如果任意X的非后代变量在P中都条件独立于X, 那么< U, G, P> 为贝叶斯网络.贝叶斯网络表征一个变量集合中的因果关系.在有向无环图中, 对于一对直接相连的父子变量, 父变量是子变量的直接原因, 子变量是父变量的直接结果[14].忠实性是贝叶斯网络的基础假设之一, 定义如下.定义 2 忠实性[14] 给定贝叶斯网络< U, G, P> , G忠实于P当且仅当P中的每个条件独立性关系都是由G和马尔科夫条件决定的.P忠实于G当且仅当存在一个G的子图忠实于P.MB的概念是基于忠实的贝叶斯网络而提出的, 定义如下.定义 3 马尔科夫边界[14] 在满足忠实性的贝叶斯网络中, 一个节点的马尔科夫边界包含该节点的父节点、子节点和配偶节点(子节点的其它父节点)[14].根据定义3, 一个节点的MB可直接从忠实的贝叶斯网络中“ 读” 出来.如图1所示, 节点T的MB为{A, B, G, H, F}, 包含父节点A、B, 子节点G、H, 配偶节点F.从因果图的角度分析, MB提供变量周围的局部因果结构, 父节点、子节点、配偶节点分别对应目标变量的直接原因、直接结果、直接结果的其它原因.MB发现算法通过挖掘变量的局部因果结构, 无需学习完整的贝叶斯网络即可找到变量的MB.而变量的MB集合有一个特殊的统计特性, 见定理1.图1 马尔科夫边界的例子Fig.1 An example of Markov boundary定理 1 对于变量X∈ U, X的马尔科夫边界MB⊆U, 满足:∀ Y∈ U-MB-{X}, X⊥Y| MB, 且MB为满足该统计特性的最小变量集.定理1 中阐述MB的最小性, MB的超集通常称为马尔科夫毯(Markov Blanket).根据定理1, 以MB集合为条件, 目标变量会条件独立于其它特征.因此, MB中的特征携带所有关于目标变量的预测信息, 并且其“ 最小性” 保证MB可作为特征选择问题的最优解, 见定理2.定理 2 在满足忠实性假设的数据中, 目标变量的MB是唯一的, 并且为特征选择的最优解[15, 16].定理2 为MB发现算法解决特征选择问题提供理论保证, 由于MB发现算法根据数据中的因果关系选择特征, 并且特征包含目标变量的因果信息, 因此使用MB发现算法选择特征的过程称为因果特征选择.2.现有马尔科夫边界学习方法分类及其基本原理图2给出本文对现有MB发现算法的分类.常规数据中的MB发现算法主要分为单重MB发现算法和多重MB发现算法, 这两类算法的应用场景取决于训练数据是否满足忠实性假设.根据定理2, 在满足忠实性的条件下, 目标变量的MB是唯一的, 当真实数据并不完全满足忠实性条件时, 目标变量可能存在多个等价的MB.因此, 一部分现有算法假设数据满足忠实性, 并且试图寻找目标变量的唯一MB, 该类算法称为单重MB发现算法.另一部分算法考虑忠实性假设被违反的情况, 这些算法可挖掘目标变量的多个等价MB, 该类算法称为多重MB发现算法.特殊数据中的MB发现算法作为一类单独介绍, 其中包括半监督数据MB发现算法、流数据MB发现算法、多源数据MB发现算法、多标签数据MB发现算法.本文按照上述分类介绍现有算法的特点. 图2 现有MB发现算法的分类Fig.2 Categories of existing MB discovery algorithms单重MB发现算法假设目标变量有唯一的MB, 输出的MB集合可直接作为特征选择的结果.该类算法主要分为两类:直接的MB发现算法(直接法)和分治的MB发现算法(分治法).主要区别是:直接法根据MB的性质(定理1)直接学习MB变量, 而分治法分别学习父子变量和配偶变量.主要理论依据为定理3和定理4.定理 3 在U上的贝叶斯网络中, 如果节点X和Y满足:任意变量子集Z⊆U-{X, Y}, X⊥Y|Z不成立, 那么X和Y是一对父子变量[17].定理 4 在U上的贝叶斯网络中, 如果不相连的节点X和Y均与T相连, 如果存在变量子集Z⊆U-{X, Y, T}, 使得X⊥Y|Z成立但X⊥Y|Z∪ {T}不成立, 那么X和Y是一对配偶变量[17].定理3和定理4分别给出父子变量和配偶变量的判别条件, 基于上述定理, 分治的MB发现算法可通过条件独立性测试分别搜索父子和配偶变量.如图3所示, 单重MB发现算法通常使用增长阶段和收缩阶段搜索MB变量或父子变量.增长阶段用于识别并添加可能的真变量, 而收缩阶段检测并删除增长步骤中找到的假变量.基于这一框架, 分治法需要进一步搜索配偶变量.直接法通常在时间效率上更优.但由于分治法在条件独立性测试中使用规模更小的条件集合, 因此通常分治法可达到比直接法更高的准确性.图3 直接法和分治法的区别Fig.3 Difference between direct methods and divide-and-conquer methods 可用于MB发现算法的通用条件独立性测试方法有5种:1)λ 2测试、G2测试、互信息计算, 可用于离散数据[18]; 2)菲尔逊Z检验[19], 可用于带有高斯误差的线性关系的连续数据; 3)基于核的条件独立性测试方法[20], 可用于非线性、非高斯噪声的连续数据.多重MB发现算法研究忠实性假设被违反的情况下一个变量的多个等价MB.理论上来说, 目标变量的多重MB携带等价的信息且具有相似的预测能力[21], 该类算法存在的意义是:1)由于实际应用中多个等价的MB适应的特定学习模型是不同的, 多重MB可用于解释学习模型的多样性现象; 2)实际应用中可能存在多个等价的MB, 但并非所有MB都适合作为特征子集建立学习模型.例如, 当不同变量的获取成本可能不同时, 多重MB算法可用于探索较低获取成本但具有相似预测性的替代解决方案(特征子集).根据Statnikov等[21]的研究, 多重MB的本质原因是等价信息现象, 定义4和定理5如下.定义 4 等价信息[21] 对变量集合X⊆U, Y⊆U及目标变量T∈ U, X和Y包含T的等价信息当且仅当X和Y与T相关且满足X⊥T|Y, Y⊥T|X.定理 5 当且仅当没有发生信息等价时, 目标变量有一个唯一的MB集合[21].根据定理5, 多重MB与等价信息现象是共存的, 因此寻找多个MB的过程也就是识别等价信息的过程[21].现有的多重MB发现算法通常遵循如下步骤:1)使用单重MB发现算法找到一个初始的MB; 2)在当前MB中选择特征子集, 将其从源数据分布中移除, 再在新的数据分布中找到新的MB; 3)测试新MB是否正确.特殊数据的MB发现算法主要是面向近年来逐渐流行的一些特殊学习场景, 根据本文的调研, 目前主要包括但不限于:半监督数据MB发现算法、多标签数据MB发现算法、多源数据MB发现算法和流数据MB发现算法.这些算法大多对应某个单重MB发现算法, 考虑对应场景的特点, 将单重MB算法扩展应用到特殊数据中. -
 【版本信息】 docker镜像:版本:22.0.RC1。地址:https://ascendhub.huawei.com/#/detail/infer-modelzoo【操作步骤&问题现象】1.昇腾社区链接:https://www.hiascend.com/zh/software/modelzoo/models/detail/C/ea8c34895d1b4697b3f1e940da1e97d22、按照readme指导进行分布式训练,epoch:90训练中没有报错。后面进行验证。bash run_eval.sh [MODEL_TYPE] [DATASET_TYPE] [DATASET_PATH] [CHECKPOINT_PATH]指令:bash run_eval.sh resnet50 imagenet2012 /home/yyj/data/Imagenet_val/ /home/yyj/ResNet50_for_MindSpore_1.4_code/train/resnet-50_2502.ckpt【截图信息】【日志信息】(可选,上传日志内容或者附件)
【版本信息】 docker镜像:版本:22.0.RC1。地址:https://ascendhub.huawei.com/#/detail/infer-modelzoo【操作步骤&问题现象】1.昇腾社区链接:https://www.hiascend.com/zh/software/modelzoo/models/detail/C/ea8c34895d1b4697b3f1e940da1e97d22、按照readme指导进行分布式训练,epoch:90训练中没有报错。后面进行验证。bash run_eval.sh [MODEL_TYPE] [DATASET_TYPE] [DATASET_PATH] [CHECKPOINT_PATH]指令:bash run_eval.sh resnet50 imagenet2012 /home/yyj/data/Imagenet_val/ /home/yyj/ResNet50_for_MindSpore_1.4_code/train/resnet-50_2502.ckpt【截图信息】【日志信息】(可选,上传日志内容或者附件) -
 本文时间:2022年7月基于当前v1.8版本官网地址:https://mindspore.cn/ 大家好,本篇是官网使用指南系列的第3篇啦,本次我们分享的是资源和基础模型板块,往期篇章请看这里:https://bbs.huaweicloud.com/forum/thread-192262-1-1.htmlhttps://bbs.huaweicloud.com/forum/thread-193766-1-1.html对于文中有需要补充说明的部分,您也可以在下方留言哦~~资源本版块主要是提供工具、课程、书籍、视频等资源供大家开始MindSpore学习。特别要提一下的是,v1.8版本新增了拓展工具MindSpore Dev Toolkit,它是一个面向MindSpore开发者的开发套件。提供包括工程管理、安装环境、智能代码补全、智能知识搜索、算子互搜等一系列全方位辅助功能。全面提升MindSpore框架的易用性。还有其他工具如算子对照表和Mindconverter。其中算子对照表当前提供PyTorch、TensorFlow与MindSpore算子的API对照信息。方便您快速找到已有网络算子的替代方案快速将网络迁移到我们的MindSpore上。而MindConverter是一款模型迁移工具,可将PyTorch(ONNX)或Tensorflow(PB)模型快速迁移到MindSpore框架下使用。模型文件(ONNX/PB)包含网络模型结构(network)与权重信息(weights),迁移后将生成MindSpore框架下的模型定义脚本(model.py)与权重文件(ckpt)。提供的模型与样例包含Model Zoo和预训练模型(Hub)Model Zoo其中为您提供可直接调用的昇思MindSpore支持的网络,包括LeNet、LSTM、BERT、ResNet等,避免您重复进行定义,提升开发效率。可以通过import mindspore.model_zoo.xxx等直接调用典型的神经网络。而MindSpore Hub中,官方对于典型的大型网络提供已训练好的网络模型文件,用户可以用来进行模型推理、微调、迁移学习等,避免花费大量算力和时间重头训练。课程认证中,包含了初中高级课程资料,视频,PDF等形式方便您的学习!无论您是哪个级别的开发者,都能从中有所收获。还提供不同级别工程师职业认证,通过考试获得证书,让自己脱颖而出。应用案例提供企业、高校和开发者的众多开发案例。您可以借此了解企业、高校、开发者如何使用升思MindSpore解决问题、技术研究、开发应用等。其中小编比较印象深刻的、也是之前推过一个有趣的开发者案例,对于小白来说非常友好的《AI诗人》https://zhuanlan.zhihu.com/p/254937902。大家可以闲暇的时候体验一下。当然,顶流的学术论文我们也是有整理和汇总的,均发布在资源->学术论文板块中,想要充电请访问https://www.mindspore.cn/resources/papers。最后!超丰富奖金来啦!虽说搞深度学习是一门艺术,但艺术家也是要吃饭的哈哈。金钱的滋味真的不亚于寒冬腊月风雪夜归后的一碗热馄饨汤。我们也提供了丰富的竞赛活动,当前有很多也在进行中!了解了MindSpore之后,不妨加入其中挑战一下自己吧!基础模型当前的基础模型我们上线了两个,分别是大名鼎鼎的鹏城实验室的——鹏程.盘古和中科院自动化研究所的——紫东.太初。偷个懒贴个简介给大家看看:鹏程.盘古:业界首个千亿级参数中文自然语言处理大模型,可支持知识问答、知识检索、知识推理、阅读理解等丰富的下游应用。「鹏城.盘古」由以鹏城实验室为首的技术团队联合攻关,首次基于“鹏城云脑Ⅱ”和国产MindSpore框架的自动混合并行模式实现在2048卡算力集群上的大规模分布式训练,训练出业界首个2000亿参数以中文为核心的预训练生成语言模型。鹏程·盘古α预训练模型支持丰富的场景应用,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出,具备很强的小样本学习能力。紫东.太初:业界首个三模态千亿参数大模型,支持文本、视觉、语音不同模态间的高效协同,可支撑影视创作、工业质检、智能驾驶等产业应用。我们的初心是原生支持基础创新模型,加速科研创新与行业应用落地。 本月昇思MindSpore又又又又又更新啦!已经是V1.8版本了,大家快来体验一下!欢迎友友们补充和建议,直接评论在下方,系列还没结束,我们下期再会。See you ~~~~
本文时间:2022年7月基于当前v1.8版本官网地址:https://mindspore.cn/ 大家好,本篇是官网使用指南系列的第3篇啦,本次我们分享的是资源和基础模型板块,往期篇章请看这里:https://bbs.huaweicloud.com/forum/thread-192262-1-1.htmlhttps://bbs.huaweicloud.com/forum/thread-193766-1-1.html对于文中有需要补充说明的部分,您也可以在下方留言哦~~资源本版块主要是提供工具、课程、书籍、视频等资源供大家开始MindSpore学习。特别要提一下的是,v1.8版本新增了拓展工具MindSpore Dev Toolkit,它是一个面向MindSpore开发者的开发套件。提供包括工程管理、安装环境、智能代码补全、智能知识搜索、算子互搜等一系列全方位辅助功能。全面提升MindSpore框架的易用性。还有其他工具如算子对照表和Mindconverter。其中算子对照表当前提供PyTorch、TensorFlow与MindSpore算子的API对照信息。方便您快速找到已有网络算子的替代方案快速将网络迁移到我们的MindSpore上。而MindConverter是一款模型迁移工具,可将PyTorch(ONNX)或Tensorflow(PB)模型快速迁移到MindSpore框架下使用。模型文件(ONNX/PB)包含网络模型结构(network)与权重信息(weights),迁移后将生成MindSpore框架下的模型定义脚本(model.py)与权重文件(ckpt)。提供的模型与样例包含Model Zoo和预训练模型(Hub)Model Zoo其中为您提供可直接调用的昇思MindSpore支持的网络,包括LeNet、LSTM、BERT、ResNet等,避免您重复进行定义,提升开发效率。可以通过import mindspore.model_zoo.xxx等直接调用典型的神经网络。而MindSpore Hub中,官方对于典型的大型网络提供已训练好的网络模型文件,用户可以用来进行模型推理、微调、迁移学习等,避免花费大量算力和时间重头训练。课程认证中,包含了初中高级课程资料,视频,PDF等形式方便您的学习!无论您是哪个级别的开发者,都能从中有所收获。还提供不同级别工程师职业认证,通过考试获得证书,让自己脱颖而出。应用案例提供企业、高校和开发者的众多开发案例。您可以借此了解企业、高校、开发者如何使用升思MindSpore解决问题、技术研究、开发应用等。其中小编比较印象深刻的、也是之前推过一个有趣的开发者案例,对于小白来说非常友好的《AI诗人》https://zhuanlan.zhihu.com/p/254937902。大家可以闲暇的时候体验一下。当然,顶流的学术论文我们也是有整理和汇总的,均发布在资源->学术论文板块中,想要充电请访问https://www.mindspore.cn/resources/papers。最后!超丰富奖金来啦!虽说搞深度学习是一门艺术,但艺术家也是要吃饭的哈哈。金钱的滋味真的不亚于寒冬腊月风雪夜归后的一碗热馄饨汤。我们也提供了丰富的竞赛活动,当前有很多也在进行中!了解了MindSpore之后,不妨加入其中挑战一下自己吧!基础模型当前的基础模型我们上线了两个,分别是大名鼎鼎的鹏城实验室的——鹏程.盘古和中科院自动化研究所的——紫东.太初。偷个懒贴个简介给大家看看:鹏程.盘古:业界首个千亿级参数中文自然语言处理大模型,可支持知识问答、知识检索、知识推理、阅读理解等丰富的下游应用。「鹏城.盘古」由以鹏城实验室为首的技术团队联合攻关,首次基于“鹏城云脑Ⅱ”和国产MindSpore框架的自动混合并行模式实现在2048卡算力集群上的大规模分布式训练,训练出业界首个2000亿参数以中文为核心的预训练生成语言模型。鹏程·盘古α预训练模型支持丰富的场景应用,在知识问答、知识检索、知识推理、阅读理解等文本生成领域表现突出,具备很强的小样本学习能力。紫东.太初:业界首个三模态千亿参数大模型,支持文本、视觉、语音不同模态间的高效协同,可支撑影视创作、工业质检、智能驾驶等产业应用。我们的初心是原生支持基础创新模型,加速科研创新与行业应用落地。 本月昇思MindSpore又又又又又更新啦!已经是V1.8版本了,大家快来体验一下!欢迎友友们补充和建议,直接评论在下方,系列还没结束,我们下期再会。See you ~~~~ -
# 1. 关于Softmax 机器学习中有一个经典的方法:逻辑回归(Logistic Regression)。它属于一种有监督学习(Supervised Learning)方法。 逻辑回归输出的范围为0-1的值,表示概率,并依据概率的大小将样本归类,其中包括二分类问题与多分类问题。二分类逻辑回归模型输出一个值,该值用于表示样本属于其中一类的概率,多分类逻辑回归模型的输出结果为所有类别的概率分布。 在多分类深度神经网络中,在输出层加上Softmax,使得输出结果为0~1的向量,合为1,表示一种概率分布。此时概率最大的项作为分类预测的类别。Softmax便是沿用了逻辑回归的方法。  详细内容可参考:[二分类逻辑回归与多分类逻辑回归的公式推导](https://zhuanlan.zhihu.com/p/97915473)。 # 2. 交叉熵 交叉熵(Cross Entropy) 本质上是用来衡量两个概率分布的相似性: *"… the cross entropy is the average number of bits needed to encode data coming from a source with distribution p when we use model q …"* — Page 57, [Machine Learning: A Probabilistic Perspective](https://amzn.to/2xKSTCP), 2012. 交叉熵可以用来评估两个概率事件P和Q的相似性计算,公式如下 $$ H(P,Q) = – \sum_x^X P(x) * log(Q(x)) $$ # 3. 分类任务损失函数 分类任务的损失函数,就是计算输出结果的预测分类与给定标签的误差,该误差越小越好。简单来说,对于二分类任务,如果给定的标签是1,则模型的输出值越接近1越好;若标签为0,则模型输出值越接近于0越好。换句话说,若标签为1,则最大化概率$P(y_i =1)$。 交叉熵(Cross Entropy)可以衡量两个概率分布之间的距离的,Softmax能把一切转换成概率分布。那么自然二者一起使用可以用于分类任务的损失函数。 根据交叉熵的定义,由于一个样本只有一个标签,即给定标签只存在一个$P(x)=1$,其他值为0,不难得出交叉熵损失函数计算公式: $$ loss(x, c) = -log(\frac{e^{x_c}}{\sum_j^ne^{x_j}}) = -x_c + log({\sum_j^ne^{x_j}}) $$ 其中,n表示分类标签的个数,x为长度n的向量,表示预测每个标签的概率值,c是真实标签对应的编号位置,取值范围[0,n-1]。 # 4. nn.SoftmaxCrossEntropyWithLogits的使用 SoftmaxCrossEntropyWithLogits接口就是分类任务的交叉熵损失函数实现,接口参数说明见[官方文档](https://www.mindspore.cn/docs/zh-CN/r1.7/api_python/nn/mindspore.nn.SoftmaxCrossEntropyWithLogits.html)。 下面介绍如何使用SoftmaxCrossEntropyWithLogits。 - sparse=Fasle,表示输入参数labels与输入参数shape相同,给出了每个label对应的值。 ``` from mindspore import Tensor, nn import numpy as np import mindspore x = Tensor(np.array([[1, 2, 3]]),mindspore.float32) y1 = Tensor(np.array([[0, 1, 0]]), mindspore.float32) loss_false = nn.SoftmaxCrossEntropyWithLogits(sparse=False) print("x shape:", x.shape) print("y1 shape:", y1.shape) out1 = loss_false(x, y1) print("sparse false:", out1) def softmax_cross_entropy(x, c): exps = np.exp(x) return -x[c] + np.log(np.sum(exps)) x = np.array([1,2,3]) c = 1 out3 = softmax_cross_entropy(x, c) print("numpy:", out3) ``` 输出结果如下 ``` x shape: (1, 3) y1 shape: (1, 3) sparse false: [1.4076059] numpy: 1.4076059644443801 ``` - sparse=true时,输入y是一维,表示真标签对应的位置 ``` from mindspore import Tensor, nn import numpy as np import mindspore x = Tensor(np.array([[1, 2, 3]]),mindspore.float32) y2 = Tensor(np.array([1]), mindspore.int32) # 编号1标签为真 loss_true = nn.SoftmaxCrossEntropyWithLogits(sparse=True) print("x shape:", x.shape) print("y2 shape:", y2.shape) out2 = loss_true(x, y2) print("sparse true:", out2) ``` 输出结果: ``` x shape: (1, 3) y2 shape: (1,) sparse true: [1.4076059] ``` **总结**: 1、由于数据批处理的原因,接口参数logits只支持二维输入,第一维度表示的是batch size; 2、sparse 参数取不同的值,对输入labels的shape和type有不同的要求; 3、reduction 参数可以指定应用于输出结果的计算方式,例如求均值、求和等。
-
基于MindStudio的BiT模型离线推理全流程本文是基于 MindStudio 的 big_transfer 模型的 ONNX 推理说明。本实验对应的 CANN 版本为 5.0.3,请先按照官网教程,配置好 MindStudio 与其所需依赖。本文使用 MindStudio 中的 ATC 工具,对 Big_transfer 的 pytorch 模型转换成适配昇腾 AI 处理器的离线模型。 一、 模型介绍在训练视觉的深度神经网络时,预训练表征的转移提高了采样频率并简化了超参数的调整。该模型重新审视了在大型数据集上进行预训练并在目标任务上对模型进行微调的范式,称之为 Big Transfer(BiT)。该模型在多个数据集上实现理强大的性能,在 CIFAR-10 上达到了 97%,在其他数据集上的性能也达到了最优的性能。 论文地址:https://arxiv.org/abs/1912.11370 代码地址:https://github.com/google-research/big_transfer二、 推理环境准备1. 安装 MindStudio 安装教程在该网址中,按流程安装 MindStudio 和依赖https://www.hiascend.com/document/detail/zh/mindstudio/50RC1/instg 2. 安装 conda 环境 配置自己的环境,安装如下软件包及对应版本: ONNX 1.7.0 onnxruntime 1.11.0 Torch 1.11.0 Numpy 1.22.3 opencv-python 4.5.5.64 三、推理过程3.1 推理工程创建打开 MindStudio 界面,点击 File->New->Project: 进入以下界面: 在界面左侧选择 Ascend Training,右侧 Name 为自己的项目名称,CANN Version 为本机 MindStudio 所对应的 CANN 版本,Project Location 为项目地址,读者根据自己实际情况进行填写。 在此处选择PyTorch Project,然后单击Finish,完成项目创建。3.2 获取源码、预训练模型、数据集和模型参数1. 在终端输入如下命令,获取 GitHub 代码。 1. git clone https://github.com/google-research/big_transfer 2. 终端进入 big_transfer 文件夹后,输入以下指令,以安装所需依赖(注意: 此处必须安装最新版本的 pytorch,否则后续转 onnx 模型时会出现问题): 1. pip install -r bit_pytorch/requirements.txt3. 在终端输入如下命令,下载所需要的预训练模型。 1. wget https://storage.googleapis.com/bit_models/BiT-M-R50x1.npz4. 由于后续需要.bin的文件,故需下载数据集,下载网址为: C I F A R - 1 0 a n d C I FA R - 10 0 d at a s et s ( t o ro n t o . e d u ) 5.获取已训练好的预训练模型,下载连接如下:bit.pth_ ,access code "3jnx"3.3 数据集预处理下载好 CIFAR10 数据集后,需要将数据集进行预处理,转换成 bin 格式,以送入 om 模型进行推理。 代码如下: 1. def preprocess(dataset_path, data_bin_path, batch_size): 2. 3. val_tx = tv.transforms.Compose([ 4. tv.transforms.Resize((128, 128)), 5. tv.transforms.ToTensor(), 6. tv.transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)), 7. ]) 8. 9. valid_set = tv.datasets.CIFAR10(dataset_path, transform=val_tx, train=False, download=True) 10. 11. valid_loader = torch.utils.data.DataLoader( 12. valid_set, batch_size=batch_size, shuffle=False, 13. pin_memory=True, drop_last=False) 14. 15. if not os.path.isdir(data_bin_path): 16. os.mkdir(data_bin_path) 17. 18. with open('label1.txt', 'w+') as f: 19. for i, (images, target) in enumerate(valid_loader): 20. label = ' '.join((str(i) for i in target.tolist())) 21. f.write(label+'\n') 22. save_file_name = "%d.bin" % i 23. save_path = "%s/%s" % (data_bin_path, save_file_name) 24. if images.shape[0] != batch_size: 25. images = F.pad(input=images, pad=(0, 0, 0, 0, 0, 0, 0, batch_size-images.shape[0]), mode='constant', value=0) 26. images.numpy().tofile(save_path) 27. 28. if __name__ == "__main__": 29. 30. parser = argparse.ArgumentParser(description='EfficientNet preprocess') 31. parser.add_argument('--dataset_path', type=str, help='dataset path', required=True) 32. parser.add_argument('--save_path', type=str, help='bin file save path', required=True) 33. parser.add_argument('--batch_size', type=int, default=1, help='om batch size') 34. args = parser.parse_args() 35. 36. preprocess(args.dataset_path, args.save_path, args.batch_size) 该脚本按照模型的方式读入测试集并进行相应的处理,然后将原来的图片数据转为 bin 格式。把数据集解压到 DATADIR 文件夹下,然后输入如下命令,即可将生成 bin 格式文件存入 val_bin 文件夹下: 此处 dataset_path 表示数据路径,save_path 表示输出文件路径 3.4 编写info文件由于数据集已经是.bin 格式的了因此直接执行 dataset_info.py 脚本即可。输入参数:bin ./val_bin/ ./val_data.info 128 128 分别代表:数据格式、数据路径、需要得到的文件名、图像宽度、图像高度3.5 ONNX 模型转换编写如下 python 文件,使用 PyTorch 将模型权重文件.pth 转换为.onnx 文件。 1. import torch 2. import sys 3. 4. def pth2onnx(input_file, output_file): 5. model = torch.load(input_file, map_location = torch.device('cpu')) # map_location为转换设备 6. model.eval() 7. print(model) 8. input_names = ["image"] 9. output_names = ["class"] 10. dynamic_axes = {'image': {0: '-1'}, 'class': {0: '-1'}} 11. dummy_input = torch.randn(1, 3, 128, 128) # 模型输入的shape 12. torch.onnx.export(model.module, dummy_input, output_file, 13. input_names=input_names,dynamic_axes = dynamic_axes, 14. output_names=output_names, opset_version=13, verbose=True) # opset是可视化用的,verbose输出进度条显示 15. 16. def main(): 17. input_file = sys.argv[1] # 脚本的第一个参数 18. output_file = sys.argv[2] 19. pth2onnx(input_file, output_file) 20. 21. if __name__ == '__main__': 22. main() 运行: 输入 model.pth 参数模型,输出 model.onnx 参数模型然后在 File Transfer 处会执行上传文件的操作等待一段时间后会完成输出.onnx的模型参数文件3.6 OM 模型转换此处使用 MindStudio 提供的 ATC 转换工具在此处点击:Ascend->Model Converte出现以下界面: 此处 CANN Machine 无需配置。Model File 点击文件夹图标,然后选择自己所需转换的模型。Model Name 自行输入需要输出的模型名称。Target SoC Version 为需要转换成适配的芯片类型Input Format 为输入模型的四维。分别代表的含义,默认为 NCHWimage 为输入图片的 batch_size。Dynamic Batch 可以自行选择 Batch Size 的大小,此处不作改变,如下图所示:然后点击 Model File 右侧的眼睛图标,就可以生成模型的可视化框架。 点击 next,即可进行模型转换出现上图后确认无误,点击Finish,完成模型转换,然后去output中找到对应生成的模型即可。3.7离线推理此处和前面的 python 脚本不同,它在 MindStudio 中属于 ACL 应用,可以如图所示创建应用:单击 run->run configuration 然后进行配置。此处:Executable:Benchmark 工具包地址路径,这个包可以进入昇腾社区的 model zoo中选择任意一个模型进行下载。Command Arguments: -model_type=vision -device_id=0 -batch_size=1 - om_path=model.om -input_text_path=./data.info -input_width=128 - input_height=128 -output_binary=True -useDvpp=False注:此处 om_path 为转换的 om 模型文件名,input_text_path 为之前生成的.info文件,input_width 和 input_height 分别为输入文件的宽和长,其余可不做修改。Environment Variables: 所需要的环境变量,读者可直接复制以下内容。LD_LIBRARY_PATH=/usr/local/Ascend/ascend- toolkit/latest/lib64:/usr/local/Ascend/ascend- toolkit/latest/lib64/plugin/opskernel:/usr/local/Ascend/ascend- toolkit/latest/lib64/plugin/nnengine:$LD_LIBRARY_PATH;PYTHONPATH=/usr/local/Ascend/ascend-toolkit/latest/python/site- packages:/usr/local/Ascend/ascend-toolkit/latest/opp/op_impl/built- in/ai_core/tbe:$PYTHONPATH;PATH=/usr/local/Ascend/ascend-toolkit/latest/bin:/usr/local/Ascend/ascend- toolkit/latest/compiler/ccec_compiler/bin:$PATH;ASCEND_AICPU_PATH=/us r/local/Ascend/ascend- toolkit/latest;ASCEND_OPP_PATH=/usr/local/Ascend/ascend- toolkit/latest/opp;TOOLCHAIN_HOME=/usr/local/Ascend/ascend- toolkit/latest/toolkit;ASCEND_HOME_PATH=/usr/local/Ascend/ascend- toolkit/latest完成配置后运行,会得到以下结果: 输出了吞吐率等性能参数,用户可以根据自己的需求进行性能计算。 3.8 精度检测按照图示修改参数:其中,output_dir result/dumpOutput_device0/ 即上一步得到的结果所存放的文件夹 --label_path label.txt 为标签路径得到如下结果: 即模型的 top1 正确率为 97.68%,论文要求的准确率为 97%,符合论文要求。 F&Q1. 在执行数据预处理时报错: 这是因为默认安装的 Numpy 版本不适合当前代码,存在安全漏洞。可以将 Numpy卸载后重新安装。2. 运行出错:error while loading shared libraries: libascendcl.so: cannot open shared object file: No such file or directory 这个错误是因为没有配置好环境变量。因为我们在终端运行它时,一般要先执行一下:source /usr/local/Ascend/ascend-toolkit/set_env.sh,这一步操作在MindStudio 中可以通过如图所示的方法配置环境变量解决: 所 需 要 的 环 境 变 量 , 读 者 可 直 接 复 制 以 下 内 容 。LD_LIBRARY_PATH=/usr/local/Ascend/ascend-toolkit/latest/lib64:/usr/local/Ascend/ascend- toolkit/latest/lib64/plugin/opskernel:/usr/local/Ascend/ascend- toolkit/latest/lib64/plugin/nnengine:$LD_LIBRARY_PATH;PYTHONPATH=/usr/local/Ascend/ascend-toolkit/latest/python/site- packages:/usr/local/Ascend/ascend-toolkit/latest/opp/op_impl/built- in/ai_core/tbe:$PYTHONPATH;PATH=/usr/local/Ascend/ascend- toolkit/latest/bin:/usr/local/Ascend/ascend- toolkit/latest/compiler/ccec_compiler/bin:$PATH;ASCEND_AICPU_PATH=/us r/local/Ascend/ascend- toolkit/latest;ASCEND_OPP_PATH=/usr/local/Ascend/ascend- toolkit/latest/opp;TOOLCHAIN_HOME=/usr/local/Ascend/ascend- toolkit/latest/toolkit;ASCEND_HOME_PATH=/usr/local/Ascend/ascend- toolkit/latest 3. 转换模型时出错:Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU- only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU. 这是因为该设备上只有 CPU,按照提示改为 map_location=torch.device('cpu')即可如果遇到其他问题,也可以在昇腾社区中的昇腾论坛(https://www.huaweicloud.com/s/JU1pbmRTdHVkaW_mkK3lu7ol/t_60_p_1)里进行 查询或者提问,会有华为内部技术人员对其进行解答,帮助你更好使用MindStudio。
-
 嗨咯,宝子们,每周一见!今天给大家带来一些优化算法。优化算法,顾名思义,小编猜应该是帮忙我们训练模型优化,提高训练速度的方法。废话不多说,今天就给大家科普一下Mini-batch梯度下降法~如何使用在我们之前的介绍中,m个样本其实是看作向量方便大家较快处理计算的,因此,我们把训练样本放到矩阵X中进行处理:X=[x(1) x(2) x(3) ……x(m) ],同理,Y也是如此,Y=[y(1) y(2) y(3)……y(m) ],X的维数是(nx,m),Y的维数是(1,m)。当然,这里有个前提,就是m的数值不会很大,否则依然处理速度缓慢。那么这个时候,我们就可以借助梯度下降法提前处理一部分数据。可以把训练集分割为小一点的子集训练,这些子集我们可以称之为mini-batch。假设每一个子集中只有1000个样本,那么把其中的x(1)——x(1000))提取出来,将其称为第一个子训练集,也叫做mini-batch,然后再取出x(1000)——x(2000),以此类推。这里为了方便更好地统计,X{1}=x(1)——x(1000)),X{2}=x(1000)——x(2000)X^({2}),假设训练样本m=500w,每个mini-batch都有1000个样本,也就是说,这个训练集一共有5000个mini-batch。对于Y的处理也是同样的,拆分Y的训练集,对应地,Y{1}=y(1001)——y(2000),Y{2},...,Y{5000}。mini-batch的数量t组成了X{t}和Y{t},包含相应的输入和输出,这里的t就表示不同的mini-batch。X{t}和Y{t}的维数:X{t}所有维数都是(nx,1000),而Y{t}的维数都是(1,1000)。那么mini-batch梯度下降法的原理是什么样的呢?在训练集上运行mini-batch梯度下降法,运行:for t=1……5000,在for循环里对X{t}和Y{t}执行一步梯度下降法。假设有一个拥有1000个样本的训练集,要用向量化去几乎同时处理1000个样本。首先对输入X{t},执行前向传播,然后执行z[1]=W[1]X+b[1],而处理第一个mini-batch时就全部转成X{t},即z[1]=W[1] X{t}+b[1],然后执行A[1]k=g[1](Z[1]),以此类推,直到A[L]k=g[L](ZL]),也就是我们的预测值。这样一个向量化的执行命令一次性处理1000个而不是500万个样本。接下来就是执行反向传播来计算J{t}的梯度,更新加权值,W[l]:=W[l]-adW[l],b[l]:=b[l]-adb[l],这是使用mini-batch梯度下降法训练样本的一步,也可被称为进行“一代”(1 epoch)的训练。一代表示一次遍历了训练集。使用batch梯度下降法,一次遍历训练集只能做一个梯度下降,而使用mini-batch梯度下降法,一次遍历训练集,能做5000个梯度下降,因此,mini-batch梯度下降法比batch梯度下降法运行地更快。当然也可以一直处理遍历训练集,直到最后能收敛到一个合适的精度。进一步理解使用batch梯度下降法时,每次迭代都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数J是迭代次数的一个函数,它应该会随着每次迭代而减少,如果J在某次迭代中增加了,那肯定出了问题,也许学习率太大。使用mini-batch梯度下降法,我们会发现成本函数并不是每次迭代都是下降的,特别是在每次迭代中,我们要处理X{t}和Y{t},成本函数J{t}的只和X{t}、Y{t}有关,最终我们会发现,图像整体走向朝下,但是有更多的噪声,我们需要决定的变量之一是mini-batch的大小,m指训练集的大小,其实如果mini-batch的大小等于m,就是batch梯度下降法,这样的话我们就有了mini-batchX{1}和Y{1},并且该mini-batch等于整个训练集。当然还可以假设mini-batch大小为1,这样就变成了随机梯度下降法,每个样本都是独立的mini-batch,第一个mini-batch就是第一个训练样本,接着是第二个mini-batch,也就是第二个训练样本,以此类推,一次只处理一个。从上图中我们可以发现,在两种极端下成本函数的优化情况:1、batch梯度下降法从某处开始,相对噪声低些,幅度也大一些,但可以继续找最小值;2、而在随机梯度下降法中,从某一点开始,每次迭代只对一个样本进行梯度下降,大部分时候会向着全局最小值靠近,因此随机梯度下降法是有很多噪声的,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动。实际上我们选择的mini-batch大小应该在在1和m之间,如果使用batch梯度下降法,mini-batch的大小为m,每个迭代需要处理大量训练样本,该算法的主要弊端在于训练样本数量巨大的时候,单次迭代耗时太长;相反,如果使用随机梯度下降法,通过减小学习率,噪声会被改善或有所减小,但随机梯度下降法的一大缺点是,会失去所有向量化带来的加速,因为一次性只处理了一个训练样本。所以实际上一些位于中间的mini-batch大小效果最好,这里有个小技巧可以无偿赠送给大家!1、如果训练集较小,直接使用batch梯度下降法(小于2000个样本)2、样本数目较大的话,一般的mini-batch大小为64到512(设成2的次方)3、需要确保X{t}和Y{t}和CPU/GPU内存相匹配当然啦,优化算法肯定不止这一个,我们后续会给大家继续带来讲解!再见不送~
嗨咯,宝子们,每周一见!今天给大家带来一些优化算法。优化算法,顾名思义,小编猜应该是帮忙我们训练模型优化,提高训练速度的方法。废话不多说,今天就给大家科普一下Mini-batch梯度下降法~如何使用在我们之前的介绍中,m个样本其实是看作向量方便大家较快处理计算的,因此,我们把训练样本放到矩阵X中进行处理:X=[x(1) x(2) x(3) ……x(m) ],同理,Y也是如此,Y=[y(1) y(2) y(3)……y(m) ],X的维数是(nx,m),Y的维数是(1,m)。当然,这里有个前提,就是m的数值不会很大,否则依然处理速度缓慢。那么这个时候,我们就可以借助梯度下降法提前处理一部分数据。可以把训练集分割为小一点的子集训练,这些子集我们可以称之为mini-batch。假设每一个子集中只有1000个样本,那么把其中的x(1)——x(1000))提取出来,将其称为第一个子训练集,也叫做mini-batch,然后再取出x(1000)——x(2000),以此类推。这里为了方便更好地统计,X{1}=x(1)——x(1000)),X{2}=x(1000)——x(2000)X^({2}),假设训练样本m=500w,每个mini-batch都有1000个样本,也就是说,这个训练集一共有5000个mini-batch。对于Y的处理也是同样的,拆分Y的训练集,对应地,Y{1}=y(1001)——y(2000),Y{2},...,Y{5000}。mini-batch的数量t组成了X{t}和Y{t},包含相应的输入和输出,这里的t就表示不同的mini-batch。X{t}和Y{t}的维数:X{t}所有维数都是(nx,1000),而Y{t}的维数都是(1,1000)。那么mini-batch梯度下降法的原理是什么样的呢?在训练集上运行mini-batch梯度下降法,运行:for t=1……5000,在for循环里对X{t}和Y{t}执行一步梯度下降法。假设有一个拥有1000个样本的训练集,要用向量化去几乎同时处理1000个样本。首先对输入X{t},执行前向传播,然后执行z[1]=W[1]X+b[1],而处理第一个mini-batch时就全部转成X{t},即z[1]=W[1] X{t}+b[1],然后执行A[1]k=g[1](Z[1]),以此类推,直到A[L]k=g[L](ZL]),也就是我们的预测值。这样一个向量化的执行命令一次性处理1000个而不是500万个样本。接下来就是执行反向传播来计算J{t}的梯度,更新加权值,W[l]:=W[l]-adW[l],b[l]:=b[l]-adb[l],这是使用mini-batch梯度下降法训练样本的一步,也可被称为进行“一代”(1 epoch)的训练。一代表示一次遍历了训练集。使用batch梯度下降法,一次遍历训练集只能做一个梯度下降,而使用mini-batch梯度下降法,一次遍历训练集,能做5000个梯度下降,因此,mini-batch梯度下降法比batch梯度下降法运行地更快。当然也可以一直处理遍历训练集,直到最后能收敛到一个合适的精度。进一步理解使用batch梯度下降法时,每次迭代都需要历遍整个训练集,可以预期每次迭代成本都会下降,所以如果成本函数J是迭代次数的一个函数,它应该会随着每次迭代而减少,如果J在某次迭代中增加了,那肯定出了问题,也许学习率太大。使用mini-batch梯度下降法,我们会发现成本函数并不是每次迭代都是下降的,特别是在每次迭代中,我们要处理X{t}和Y{t},成本函数J{t}的只和X{t}、Y{t}有关,最终我们会发现,图像整体走向朝下,但是有更多的噪声,我们需要决定的变量之一是mini-batch的大小,m指训练集的大小,其实如果mini-batch的大小等于m,就是batch梯度下降法,这样的话我们就有了mini-batchX{1}和Y{1},并且该mini-batch等于整个训练集。当然还可以假设mini-batch大小为1,这样就变成了随机梯度下降法,每个样本都是独立的mini-batch,第一个mini-batch就是第一个训练样本,接着是第二个mini-batch,也就是第二个训练样本,以此类推,一次只处理一个。从上图中我们可以发现,在两种极端下成本函数的优化情况:1、batch梯度下降法从某处开始,相对噪声低些,幅度也大一些,但可以继续找最小值;2、而在随机梯度下降法中,从某一点开始,每次迭代只对一个样本进行梯度下降,大部分时候会向着全局最小值靠近,因此随机梯度下降法是有很多噪声的,它最终会靠近最小值,不过有时候也会方向错误,因为随机梯度下降法永远不会收敛,而是会一直在最小值附近波动。实际上我们选择的mini-batch大小应该在在1和m之间,如果使用batch梯度下降法,mini-batch的大小为m,每个迭代需要处理大量训练样本,该算法的主要弊端在于训练样本数量巨大的时候,单次迭代耗时太长;相反,如果使用随机梯度下降法,通过减小学习率,噪声会被改善或有所减小,但随机梯度下降法的一大缺点是,会失去所有向量化带来的加速,因为一次性只处理了一个训练样本。所以实际上一些位于中间的mini-batch大小效果最好,这里有个小技巧可以无偿赠送给大家!1、如果训练集较小,直接使用batch梯度下降法(小于2000个样本)2、样本数目较大的话,一般的mini-batch大小为64到512(设成2的次方)3、需要确保X{t}和Y{t}和CPU/GPU内存相匹配当然啦,优化算法肯定不止这一个,我们后续会给大家继续带来讲解!再见不送~ -
# 基于MIndSpore框架的道路场景语义分割方法研究 ## 概述 本文以华为最新国产深度学习框架Mindspore为基础,将城市道路下的实况图片解析作为任务背景,以复杂城市道路进行高精度的语义分割为任务目标,对上述难处进行探究并提出相应方案,成功地在Cityscapes数据集上完成了语义分割任务。 整体的技术方案见图: 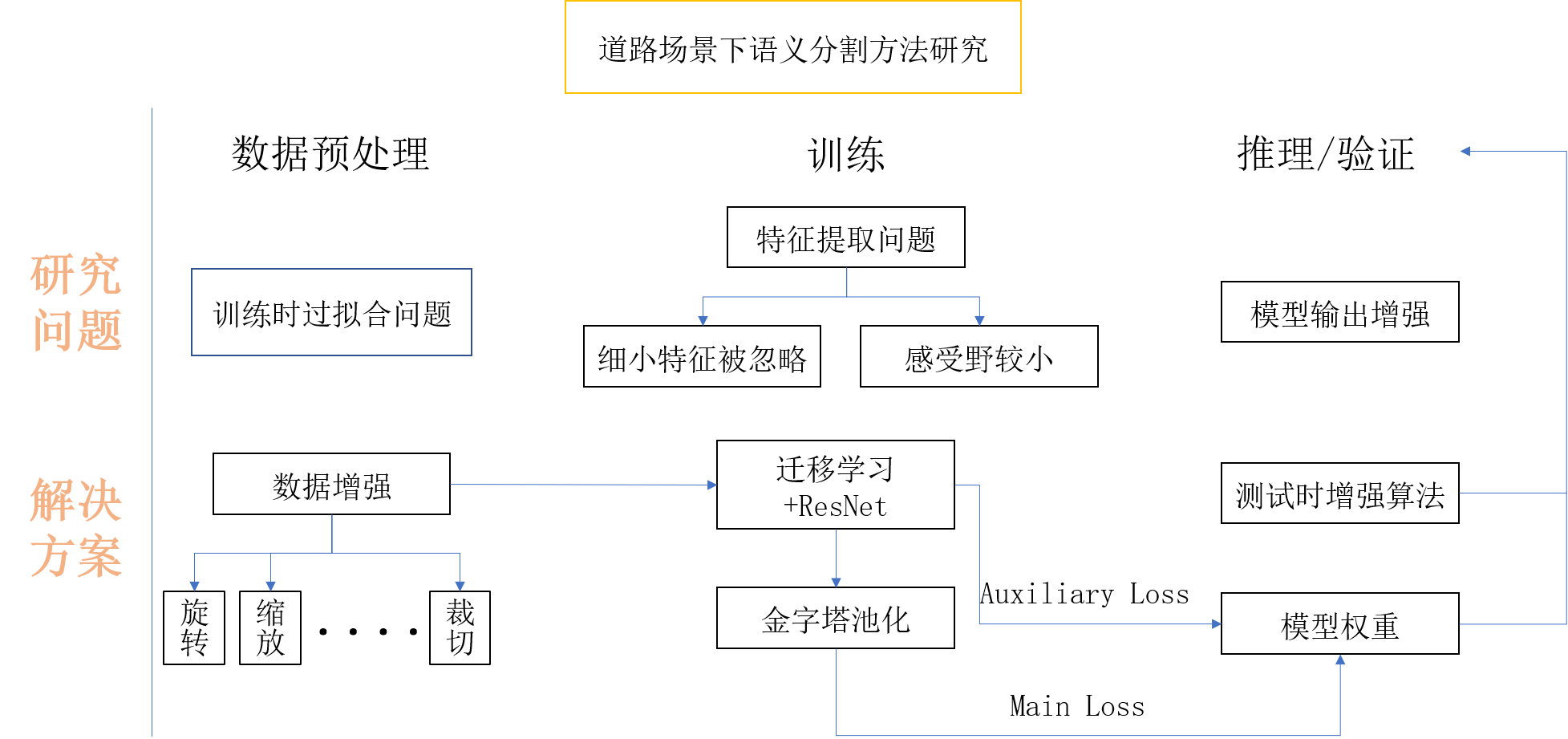 本帖仅对代码上的更改以及项目进行介绍。 ## 项目地址 https://gitee.com/xujinminghahaha/mindspore_model ## 相关配置 ### 硬件配置 | 操作系统 |Ubuntu 18.04| 硬件架构 | X86_64 | |:--:|:--:|:--:|:--:| | CPU | Intel(R) Xeon(R) Gold 6154 CPU @ 3.00GHz | GPU | NVIDIA-A100(40G) | | 深度学习框架 | Mindspore 1.6.0 | Batch_sizes | 7 | ### Cityscapes数据集: Cityscapes数据集提供了3475张细粒度分割标签图,以及20 000张粗略分割的图像,本文使用了细粒度标注的train/val集进行训练和验证,此数据集与之前的CamVid,Leuven,Daimler 城市数据集不同,Cityscapes更多的捕捉到了真实世界的城市道路场景的多样性与复杂性,尤其是为城市环境中的自动驾驶量身定制,涉及范围更广的高度复杂的市中心街道场景,并且这些场景分别在50个不同城市采集。  数据集下载地址:https://www.cityscapes-dataset.com/ ## 实现流程记录 1、 参考华为官方gitee仓库的modelzoo克隆至本地,找到research/cv/PSPNet目录,在此代码基础上进行修改。  本项目基于GPU平台,对modelzoo中原有的昇腾文件已清除。代码中shell_command提供了训练脚本和验证脚本的启动命令,同时附带linux服务器一键下载Cityscapes下载方式。 2、由于选题是道路场景,所以需要更改数据集为Cityscapes,由于modelzoo上的数据集仅支持VOC2012和ADE20K,所以需要增加对数据集的适配和标签信息转换。 在代码中已经添加了对于cityscapes的像素点和label的转换代码,可以直接使用,其中颜色和类别的映射关系请见:config/cityscapes_colors.txt以及config/cityscapes_names.txt 3、网络架构选用可插拔的残差网络,以及金字塔池化模块解码。相关代码实现在src/model目录下。 ResNet论文地址:https://arxiv.org/abs/1512.03385 PSPNet论文地址:https://arxiv.org/abs/1612.01105 网络结构图: 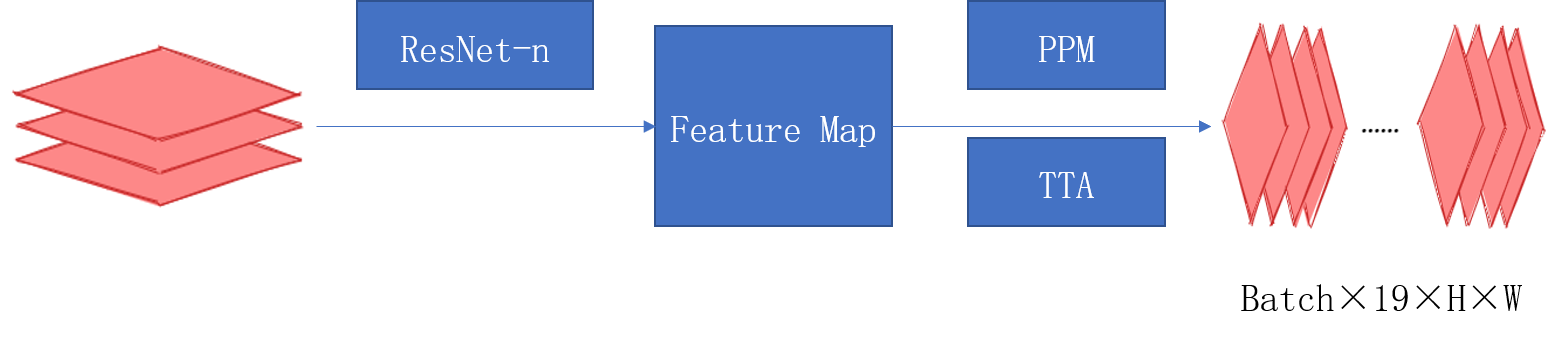 金字塔池化模块: 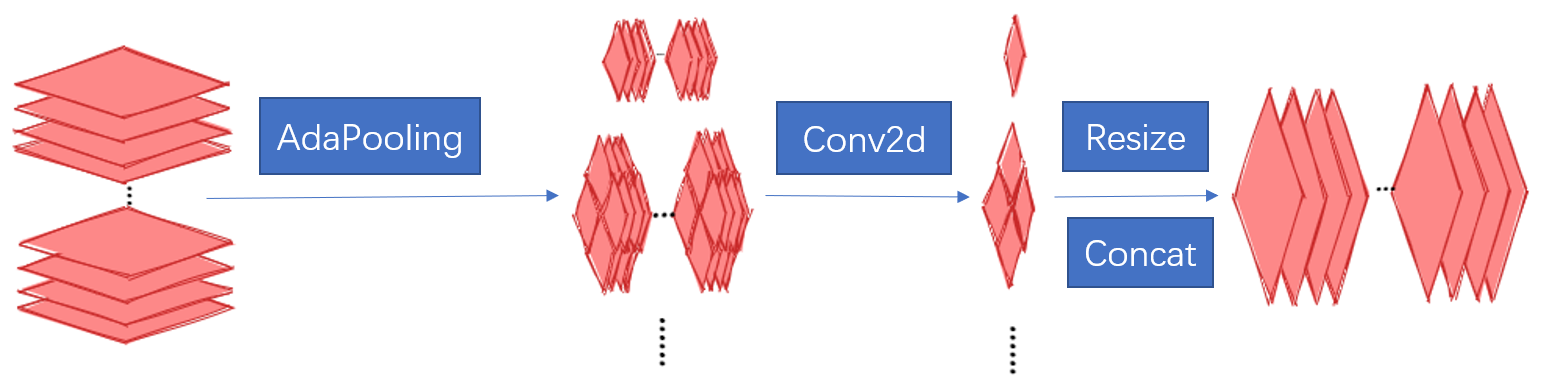 loss函数的设计: 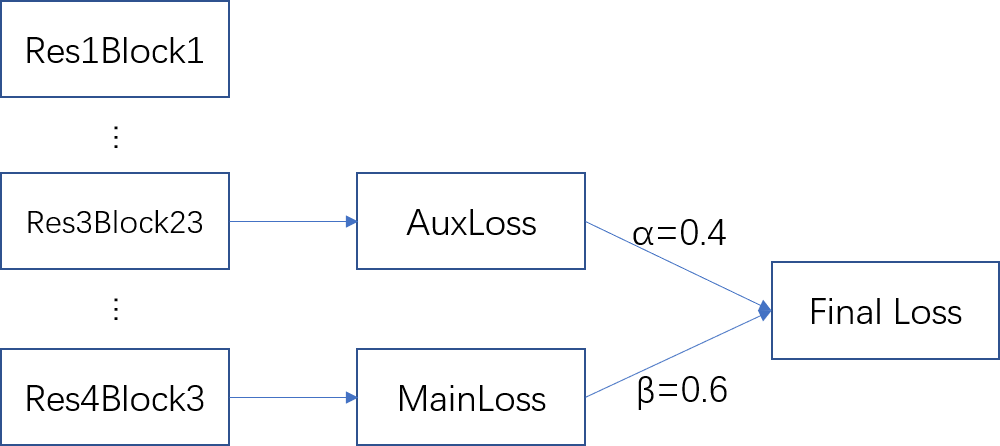 实际训练时的loss值变化趋势: 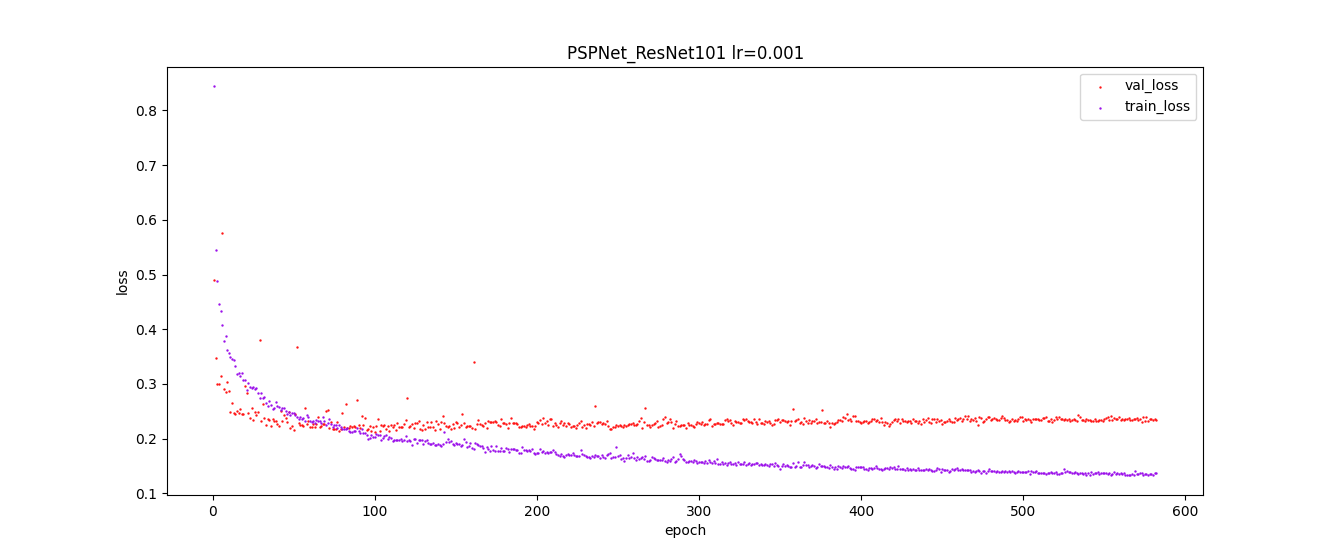 #### 特色功能 4、测试时增强(TTA, Test Time Augmentation),通过多尺度推理最后取平均的方法获得更好的效果: 以下给出方法伪码,供大家参考,具体实现请结合代码仓库查阅。 ``` # Algorithm 1: TTA(Test Time Augmentation) # Input:Image,Scales,Crop_size,Net # OutPut:Image with Label batch, _,ori_height, ori_width = image.shape #获取图像shape stride_h ,stride_w = crop_size #步长,cropsize为训练时设置的crop参数 final_pred = Tensor(np.zeros([1, dataset.num_classes, ori_height, ori_width])) #初始化结果 for scales: image = dataset.multi_scale_aug(image,scale) height, width = image.shape[:-1] new_h, new_w = image.shape[:-1] rows, cols = GetParam(new_h, new_w) #一张图片分为row行和col列分块推理 preds = np.zeros([1, dataset.num_classes, new_h, new_w]).astype(np.float32)#初始化 count = np.zeros([1, 1, new_h, new_w]).astype(np.float32)#记录像素点推理次数 for rows,cols: h0 , w0, h1, w1 = GetIndex(rows,cols,stride_h,strid_w) #获得格点坐标 crop_img = new_img[h0:h1, w0:w1, :] crop_img = crop_img.transpose((2, 0, 1)) crop_img = np.expand_dims(crop_img, axis=0) pred = dataset.inference(model, crop_img, flip) preds[:, :, h0:h1, w0:w1] += pred.asnumpy()[:, :, 0:h1 - h0, 0:w1 - w0] count[:, :, h0:h1, w0:w1] += 1 #将推理矩阵相加,再把标记矩阵相加 preds = preds / count #求得平均推理像素值 preds = preds[:, :, :height, :width] preds = P.ResizeBilinear((ori_height, ori_width))(preds) #恢复原始大小 final_pred = P.Add()(final_pred, preds) return final_pred ``` 在config/pspnet_resnet_cityscapes_gpu.yaml下scales那一行,可以输入一个数组,该数组中每一个Value对应一个Scale,inference将会在此scale下输出一次。 5、 结果展示: | road | traffic light | rider | bicycle | sidewalk | traffic sign | car |pole | |:--:|:--:|:--:|:--:|:--:|:--:|:--:|:--:| | 97.81% | 63.08% | 56.61% | 74.33% |83.69% | 69.24% | 92.79% | 45.66% | |**building** | **vegetation** | **truck** | **person** | **fence** | **sky** | **train** |**mIoU** | | 90.71% | 90.43% | 71.73% | 75.35% | 55.50% | 92.89% | 43.63% | **74.874%** | 
-
1. 购买ECS云服务器2. 通过MobaXterm访问购买的云服务器3. 切换到HwHiAiUser用户4. 获取源码:命令行运行:git clone https://gitee.com/ascend/samples.git 可以看到目录中有samples文件夹5. 进行模型下载并转换(1)进入samples/cplusplus/level2_simple_inference/6_other/animeGAN_picture/model目录(2)下载三种shape的模型256*256:wget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/animeGAN_picture/AnimeGAN_256_256.pbwget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/animeGAN_picture/aipp_256_256.cfg512*512:wget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/animeGAN_picture/AnimeGAN_512_512.pbwget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/animeGAN_picture/aipp_512_512.cfg 1024*1024:wget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/animeGAN_picture/AnimeGAN_1024_1024.pbwget https://c7xcode.obs.cn-north-4.myhuaweicloud.com/models/animeGAN_picture/aipp_1024_1024.cfg (3)模型转换atc --model="./AnimeGAN_256_256.pb" --output_type=FP32 --input_shape="test:1,256,256,3" --input_format=NHWC --output="AnimeGANv2_256" --soc_version=Ascend310 --framework=3 --precision_mode=allow_fp32_to_fp16 --insert_op_conf=aipp_256_256.cfgatc --model="./AnimeGAN_512_512.pb" --output_type=FP32 --input_shape="test:1,512,512,3" --input_format=NHWC --output="AnimeGANv2_512" --soc_version=Ascend310 --framework=3 --precision_mode=allow_fp32_to_fp16 --insert_op_conf=aipp_512_512.cfgatc --model="./AnimeGAN_1024_1024.pb" --output_type=FP32 --input_shape="test:1,1024,1024,3" --input_format=NHWC --output="AnimeGANv2_1024" --soc_version=Ascend310 --framework=3 --precision_mode=allow_fp32_to_fp16 --insert_op_conf=aipp_1024_1024.cfg6. 样例部署, 执行编译脚本,进行样例编译进入/animeGAN_picture/scripts目录,运行samples_build.sh,同时测试图片mountain.jpg已下载到/animeGAN_picture/data目录下原图如下:7.样例运行进入/animeGAN_picture/scripts目录,运行samples_run.sh,需要输入shape大小,即 bash sample_run.sh 256。输出的图片在/animeGAN_picture/out/output目录下输出效果如下:
-
 深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。自下上升的非监督学习就是从底层开始,一层一层地往顶层训练。采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,这也是和传统神经网络区别最大的部分,可以看作是特征学习过程。具体的,先用无标定数据训练第一层,训练时先学习第一层的参数,这层可以看作是得到一个使得输出和输入差别最小的三层神经网络的隐层,由于模型容量的限制以及稀疏性约束,使得得到的模型能够学习到数据本身的结构,从而得到比输入更具有表示能力的特征;在学习得到n-l层后,将n-l层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数。自顶向下的监督学习就是通过带标签的数据去训练,误差自顶向下传输,对网络进行微调。基于第一步得到的各层参数进一步优调整个多层模型的参数,这一步是一个有监督训练过程。第一步类似神经网络的随机初始化初值过程,由于第一步不是随机初始化,而是通过学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果。所以深度学习的良好效果在很大程度上归功于第一步的特征学习的过程。
深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。自下上升的非监督学习就是从底层开始,一层一层地往顶层训练。采用无标定数据(有标定数据也可)分层训练各层参数,这一步可以看作是一个无监督训练过程,这也是和传统神经网络区别最大的部分,可以看作是特征学习过程。具体的,先用无标定数据训练第一层,训练时先学习第一层的参数,这层可以看作是得到一个使得输出和输入差别最小的三层神经网络的隐层,由于模型容量的限制以及稀疏性约束,使得得到的模型能够学习到数据本身的结构,从而得到比输入更具有表示能力的特征;在学习得到n-l层后,将n-l层的输出作为第n层的输入,训练第n层,由此分别得到各层的参数。自顶向下的监督学习就是通过带标签的数据去训练,误差自顶向下传输,对网络进行微调。基于第一步得到的各层参数进一步优调整个多层模型的参数,这一步是一个有监督训练过程。第一步类似神经网络的随机初始化初值过程,由于第一步不是随机初始化,而是通过学习输入数据的结构得到的,因而这个初值更接近全局最优,从而能够取得更好的效果。所以深度学习的良好效果在很大程度上归功于第一步的特征学习的过程。 -
【功能模块】【操作步骤&问题现象】1、训练生成caffemodel文件及其prototxt文件2、ATC转化为om模型其中步骤2失败【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
 船海数据智能应用创新大赛/选手对话/为了促进现代信息技术和新一代人工智能技术与船舶技术融合发展,深海技术科学太湖实验室(以下简称太湖实验室)联合无锡市委人才工作领导小组办公室、无锡市科学技术局、华为技术有限公司共同主办了首届“船海数据智能应用创新大赛”。在初赛第一赛道“水面/水下典型目标识别”中,来自华中科技大学张钧杰团队、南京理工大学沈飞团队、浙江大学许可团队获得了前三名。比赛地址:https://competition.huaweicloud.com/information/1000041661/introduction赛题解读提高典型目标检测识别能力面向日益增长的智能化水上交通、海洋环境探测、水下探测等场景需求,提高水面/水下针对船只、渔网、浮标、漂浮物、礁石、水生物等典型目标的检测识别能力成为船舶领域人工智能应用亟需解决的难题。科研的道路上永远不会一帆风顺,在提交解决方案的过程中,三组参赛选手都或多或少的遇到了一些难题;而通过专业资料检索、选手平台交流,以及赛事主办方专业指引,最终都迎刃而解。张钧杰华中科技大学张钧杰是华中科技大学研一学生,曾参加过目标检测相关的赛事,如城市红绿灯视觉检测与识别比赛、雨雪雾行驶场景下交通参与者视觉检测与识别以及阿里天池的小样本商标检测挑战赛。对于初赛提交的方案,张钧杰用中规中矩来形容。训练阶段用的都是一些常见的数据增强手段,然后对学习率、优化器等参数进行精细调整。谈到比赛过程中的难点,他表示:“赛题中对于FPS的要求是一个比较难的点,这要求我们在精度与速度之间进行平衡。如何保证速度达标的情况下仍然能够展现出良好的性能是这个比赛的关键所在。”沈飞南京理工大学沈飞主攻人工智能目标检测方向。在比赛过程中,他们遇到了两个比较大的挑战:第一个挑战是来自数据,如:背景复杂导致的目标物体虚化、光照和角度变化、样本稀少不均衡、样本标注误差较大等问题。针对数据问题,团队使用了丰富的数据增强技术、中值滤波进行噪声抑制、mixup混合图像增加抗拟合性以及图卷积来增强局部特征提取能力。第二个挑战是来自比赛限时30FPS,让他们面临速度和精度的平衡挑战。初赛的模型暂时能满足要求,后续会考虑使用知识蒸馏、模型剪枝量化、TensorRT等技术进行模型加速。许可浙江大学在初赛中,许可介绍说,团队主要用的都是很成熟的技术,其中有4点提分比较高。一是多尺度训练和测试时增强(tta),多尺度训练能让模型适应不同尺寸的目标,而tta对于一张测试图像,将不同尺度下所得到的bbox放在一起做nms,能够有效提高mAP。二是multi-lable,因为他们观察到很多船只十分的模糊,人眼都无法分辩。三是merge-nms,对于置信度比较低的bbox,不直接删除,而是通过iou对最终的bbox坐标进行加权,这是针对数据集中bbox的标注不够精确,并且计算量也不大。四是Swa(模型参数平均), 能让模型更具泛化性,有着ensemble的效果但不增加计算量。硬核创新赛事排行榜实时刷新 公开透明张钧杰对此次参赛感受比较深刻的有两点:一是排行榜实时刷新,比赛更透明,也让选手更有冲劲;二是这次比赛因为对速度有要求,所以对于显卡的要求不是很高,用的baseline也是比较熟悉的yolov5,三是智慧船海的应用背景,使这个比赛也非常具有实际意义。科研立项是比赛最大的奖励比赛很透明,公平性好,而且影响力大。此外,这个比赛最特殊、也是吸引沈飞的地方就是“科研立项”——太湖实验室给出了按照国家自然科学基金重大项目立项标准,为获奖团队在赛题方向提供不少于100万元科研立项支持!促进传统方法到深度学习的跨越初赛第三名来自浙江大学的许可曾参加过诸如图像分析类竞赛,但是目标检测类的还是首次。作为人工智能专业日常主要学习传统视觉优化。此次参赛,团队不仅冲着大赛诱人的奖金,也是想借着比赛实现从传统方法到深度学习的跨越,达到以赛促学的目的。营造创新生态 带动产业发展“未来我们将致力于营造船海和数字化结合的创新生态环境、搭建鼓励更多科技人才参与交流的平台,并带动上下游产业链的协同发展。”本次赛事不仅吸引了众多科技人才的参与、带动相关产业发展,太湖实验室也希望以此为起点,营造创新生态环境、孵化更多智能应用项目,进一步促进我国船海探索软硬件的不断升级。太湖实验室与华为在各自专业领域的“强强联手”,也将推动更多科技研究成果转化为船海中的实际应用,为走向深远海、建设海洋强国的国家战略需求进一步助力。本文转自:https://mp.weixin.qq.com/s/SfbI5n18m_U-lxQcUT5mCQ
船海数据智能应用创新大赛/选手对话/为了促进现代信息技术和新一代人工智能技术与船舶技术融合发展,深海技术科学太湖实验室(以下简称太湖实验室)联合无锡市委人才工作领导小组办公室、无锡市科学技术局、华为技术有限公司共同主办了首届“船海数据智能应用创新大赛”。在初赛第一赛道“水面/水下典型目标识别”中,来自华中科技大学张钧杰团队、南京理工大学沈飞团队、浙江大学许可团队获得了前三名。比赛地址:https://competition.huaweicloud.com/information/1000041661/introduction赛题解读提高典型目标检测识别能力面向日益增长的智能化水上交通、海洋环境探测、水下探测等场景需求,提高水面/水下针对船只、渔网、浮标、漂浮物、礁石、水生物等典型目标的检测识别能力成为船舶领域人工智能应用亟需解决的难题。科研的道路上永远不会一帆风顺,在提交解决方案的过程中,三组参赛选手都或多或少的遇到了一些难题;而通过专业资料检索、选手平台交流,以及赛事主办方专业指引,最终都迎刃而解。张钧杰华中科技大学张钧杰是华中科技大学研一学生,曾参加过目标检测相关的赛事,如城市红绿灯视觉检测与识别比赛、雨雪雾行驶场景下交通参与者视觉检测与识别以及阿里天池的小样本商标检测挑战赛。对于初赛提交的方案,张钧杰用中规中矩来形容。训练阶段用的都是一些常见的数据增强手段,然后对学习率、优化器等参数进行精细调整。谈到比赛过程中的难点,他表示:“赛题中对于FPS的要求是一个比较难的点,这要求我们在精度与速度之间进行平衡。如何保证速度达标的情况下仍然能够展现出良好的性能是这个比赛的关键所在。”沈飞南京理工大学沈飞主攻人工智能目标检测方向。在比赛过程中,他们遇到了两个比较大的挑战:第一个挑战是来自数据,如:背景复杂导致的目标物体虚化、光照和角度变化、样本稀少不均衡、样本标注误差较大等问题。针对数据问题,团队使用了丰富的数据增强技术、中值滤波进行噪声抑制、mixup混合图像增加抗拟合性以及图卷积来增强局部特征提取能力。第二个挑战是来自比赛限时30FPS,让他们面临速度和精度的平衡挑战。初赛的模型暂时能满足要求,后续会考虑使用知识蒸馏、模型剪枝量化、TensorRT等技术进行模型加速。许可浙江大学在初赛中,许可介绍说,团队主要用的都是很成熟的技术,其中有4点提分比较高。一是多尺度训练和测试时增强(tta),多尺度训练能让模型适应不同尺寸的目标,而tta对于一张测试图像,将不同尺度下所得到的bbox放在一起做nms,能够有效提高mAP。二是multi-lable,因为他们观察到很多船只十分的模糊,人眼都无法分辩。三是merge-nms,对于置信度比较低的bbox,不直接删除,而是通过iou对最终的bbox坐标进行加权,这是针对数据集中bbox的标注不够精确,并且计算量也不大。四是Swa(模型参数平均), 能让模型更具泛化性,有着ensemble的效果但不增加计算量。硬核创新赛事排行榜实时刷新 公开透明张钧杰对此次参赛感受比较深刻的有两点:一是排行榜实时刷新,比赛更透明,也让选手更有冲劲;二是这次比赛因为对速度有要求,所以对于显卡的要求不是很高,用的baseline也是比较熟悉的yolov5,三是智慧船海的应用背景,使这个比赛也非常具有实际意义。科研立项是比赛最大的奖励比赛很透明,公平性好,而且影响力大。此外,这个比赛最特殊、也是吸引沈飞的地方就是“科研立项”——太湖实验室给出了按照国家自然科学基金重大项目立项标准,为获奖团队在赛题方向提供不少于100万元科研立项支持!促进传统方法到深度学习的跨越初赛第三名来自浙江大学的许可曾参加过诸如图像分析类竞赛,但是目标检测类的还是首次。作为人工智能专业日常主要学习传统视觉优化。此次参赛,团队不仅冲着大赛诱人的奖金,也是想借着比赛实现从传统方法到深度学习的跨越,达到以赛促学的目的。营造创新生态 带动产业发展“未来我们将致力于营造船海和数字化结合的创新生态环境、搭建鼓励更多科技人才参与交流的平台,并带动上下游产业链的协同发展。”本次赛事不仅吸引了众多科技人才的参与、带动相关产业发展,太湖实验室也希望以此为起点,营造创新生态环境、孵化更多智能应用项目,进一步促进我国船海探索软硬件的不断升级。太湖实验室与华为在各自专业领域的“强强联手”,也将推动更多科技研究成果转化为船海中的实际应用,为走向深远海、建设海洋强国的国家战略需求进一步助力。本文转自:https://mp.weixin.qq.com/s/SfbI5n18m_U-lxQcUT5mCQ -
【功能模块】源码:https://gitee.com/lljyoyo1995/cswin.git【操作步骤&问题现象】1、train.py拉起训练失败【截图信息】运行平台:在ModelArts镜像:tensorflow1.15-mindspore1.5.1-cann5.0.2-euler2.8-aarch64RuntimeError: ({'errCode': 'E60011', 'range': '[2,4096]', 'attr_name': 'dy_w*stride_w', 'value': 1}, 'In op, the [dy_w*stride_w] must in range [[2,4096]], actual is [1]')【日志信息】(可选,上传日志内容或者附件)Traceback (most recent call last):File "/home/ma-user/modelarts/user-job-dir/cswin/train.py", line 101, inmain()File "/home/ma-user/modelarts/user-job-dir/cswin/train.py", line 92, in maindataset_sink_mode = False)File "/home/ma-user/anaconda/lib/python3.7/site-packages/mindspore/train/model.py", line 726, in trainsink_size=sink_size)File "/home/ma-user/anaconda/lib/python3.7/site-packages/mindspore/train/model.py", line 498, in _trainself._train_process(epoch, train_dataset, list_callback, cb_params)File "/home/ma-user/anaconda/lib/python3.7/site-packages/mindspore/train/model.py", line 626, in _train_processoutputs = self._train_network(*next_element)File "/home/ma-user/anaconda/lib/python3.7/site-packages/mindspore/nn/cell.py", line 404, in callout = self.compile_and_run(*inputs)File "/home/ma-user/anaconda/lib/python3.7/site-packages/mindspore/nn/cell.py", line 682, in compile_and_runself.compile(*inputs)File "/home/ma-user/anaconda/lib/python3.7/site-packages/mindspore/nn/cell.py", line 669, in compile_cell_graph_executor.compile(self, *inputs, phase=self.phase, auto_parallel_mode=self._auto_parallel_mode)File "/home/ma-user/anaconda/lib/python3.7/site-packages/mindspore/common/api.py", line 548, in compileresult = self._graph_executor.compile(obj, args_list, phase, use_vm, self.queue_name)RuntimeError: mindspore/ccsrc/backend/kernel_compiler/tbe/ascend_kernel_compile.cc:384 ParseTargetJobStatus] Single op compile failed, op: depthwise_conv2d_backprop_input_d_4348327921004145570_0except_msg : 2022-07-15 10:30:01.881592: Query except_msg:Traceback (most recent call last):File "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/te_fusion/parallel_compilation.py", line 1471, in runtune_param=self._tune_param)File "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/te_fusion/fusion_manager.py", line 1271, in build_single_opcompile_info = call_op()File "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/te_fusion/fusion_manager.py", line 1259, in call_opopfunc(*inputs, *outputs, *new_attrs, **kwargs)File "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/tbe/common/utils/para_check.py", line 539, in _in_wrapperreturn func(args, **kwargs)File "/usr/local/Ascend/nnae/latest/opp/op_impl/built-in/ai_core/tbe/impl/depthwise_conv2d_backprop_input_d.py", line 380, in depthwise_conv2d_backprop_input_dpara_dict=para_dictFile "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/te/lang/cce/te_compute/conv2d_backprop_input_compute.py", line 65, in conv2d_backprop_input_computereturn conv2d_backprop_input_compute(filters, out_backprop, filter_sizes, input_sizes, para_dict)File "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/tbe/common/utils/para_check.py", line 986, in in_wrapperreturn func(args, **kwargs)File "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/tbe/dsl/compute/conv2d_backprop_input_compute.py", line 735, in conv2d_backprop_input_computeswitch_to_general_scheme=switch_to_general_scheme)File "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/tbe/dsl/compute/conv2d_backprop_input_compute.py", line 594, in _check_input_params_check_dy()File "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/tbe/dsl/compute/conv2d_backprop_input_compute.py", line 417, in _check_dydy_filling_w_maxFile "/usr/local/Ascend/nnae/latest/fwkacllib/python/site-packages/tbe/dsl/compute/conv2d_backprop_input_compute.py", line 149, in _check_variable_rangeerror_manager_util.get_error_message(args_dict))RuntimeError: ({'errCode': 'E60011', 'range': '[2,4096]', 'attr_name': 'dy_wstride_w', 'value': 1}, 'In op, the [dy_wstride_w] must in range [[2,4096]], actual is [1]')
-
 中国自古就有“民以食为天”的说法,甚至在日常交流中,连问候都离不开吃饭这件大事——“吃了吗?您呐。”而肉类是百姓饮食结构中的重要组成部分。当下,随着生活水平逐步提升,人们对肉类的消耗也越来越多,这对畜牧养殖业而言带来了一些挑战。虽然畜牧养殖业在我国已经有上千年的经验积累,但对于养殖户自身来说,一直以来都是一个极耗心力的劳动密集型行业。比如品种识别、数据管理、健康监护等,都需要精细化管理。对于动辄上千头牲畜的养殖场来说,假设需要依靠人工进行全盘管理,养殖场工作效率将难以得到有效提升。早前在诸多中小型养殖场里,要准确无误地统计出有多少头牲畜是一件极其困难的事情。特别是出售装车清点数量的过程中,经常出现农场方和客户统计数量不一致的情况,供需双方纠纷频发。是否有智能化的方式,能帮助养殖户在实现无接触式的智能看护的同时,降低管理成本、提高人工监管的准确率?“边打麻将边在手机APP上看猪圈”,这又是怎样的体验?天视通携手华为云,帮助养殖户开启智慧养殖的全新路径。传统硬件厂商的AI转型只需一套工作流基于摄像头帮助养殖户做好精细化畜牧养殖管理,是非常重要的一环。作为专业的摄像头模组供应商,天视通累计年出货超过1000万台,并在畜牧养殖业沉淀了大量的客户与项目经验。随着数字化在畜牧养殖业的深入,天视通面临着新的挑战。单一的业务模式已经无法适应当下环境。以养牛为例。在牛场里,养殖户需要亲自到牛场里进行观察,现场拿纸记录每一只牛的健康状况、育种条件等等。这导致他们需要无数次往返牛场和家,每天行走10000步以上。此外,由于牛群视人类为捕食者,看见养殖专家时会产生紧张情绪,这加大了牲畜精细化管理的工作难度。面对零散的养殖管理需求,天视通需要借助算法供应商的能力,定制不同的AI技能。但算法供应商常常由于成本、开发周期以及隐私泄漏等问题,无法快速提供解决方案。加上算法定制依赖算法供应商,天视通的研发和试错成本在不断增加,间接地导致了天视通的业务流失情况。为寻求突破,天视通联系到在算法定制领域有合作项目的华为云,希望运用华为云的AI能力满足畜牧养殖户的需求。华为云针对天视通的零散化定制AI需求,基于华为云AI开发生产线ModelArts和端边云统一AI应用开发框架ModelBox,提供了“智能摄像头自定义算法定制部署一体工作流”解决方案,不需要高阶AI能力即可覆盖大部分的零散AI定制需求,并能零代码迭代部署AI算法到端侧设备。以上文提到的牲畜健康监管为例,天视通利用摄像头从养殖场实际采集到的健康牛只和生病牛只的体态及日常行为特征图片数据,通过ModelArts对视频中的牛进行标注,接着再启动模型训练。确认模型的效果后,可将牛只生病行为检测技能一键发布到华为云AI Gallery上,接着部署到天视通技能管理App及牛场的端侧设备里,在家即可实时关注每一头牛的状态。华为云提供的解决方案不仅提高了天视通的算法开发效率,而且帮助养殖畜牧业解决了人力资源短缺和牲畜质量管理的难题。“畜牧业是一个智能化启动较晚的行业,但实际上却非常重要,关系到每个家庭的日常生活。这些年食品安全收到社会的广泛关注,产业的规模化和IT技术的应用让精准管理成为可能,养殖过程自动化管理和全流程溯源就是大家看到的热点应用”,天视通技术负责人分享了AI赋能智慧养殖的趋势与应用效果。 定制化算法+端侧一键部署打通AI全流程 得益于华为云AI技术所积累的场景化行业工作流能力,天视通能够快速完成面向特殊场景的算法开发和一键式远程部署:数据标注:通过收集摄像头场景需求和少量数据,华为云利用ModelArts标注工具完成对图片标注;算法训练:工作流内置行业主流标准算法,一键启动即可进行训练,生成算法并能直接查看模型性能;算法优化:训练完之后在平台上就能生成针对具体摄像头硬件的优化过的高性能算法。针对客户的硬件平台,优化适配模型与技能,实现一键技能发布;算法部署:生成的算法部署到实际应用的摄像头中,再结合ModelBox的端云部署能力,完成对算法授权管理,上架到手机端的算法市场App。 华为云EI工作流,实际上是把共通性的场景单独抽象出来,形成一个相对固定的开发模式,提供给研发团队使用。在这个过程中,华为云降低了对算法工程师的能力要求,只需要让软件开发人员聚焦工程。华为云研发专家表示,作为解决方案的核心,华为云EI工作流以业务场景为中心,以“定义场景→分布实施→持续迭代→形成闭环”的模式,通过聚焦各行业可落地的AI开发方式,为服务客户提供基于场景化的工作流,完成全流程的AI开发及迭代。携手伙伴,谋全局,争当弄潮儿天视通始终专注在图像处理和通讯的技术领域前沿,通过技术和产品的不断创新,为广大客户提供技术更先进、更贴近客户需求的远程视频设备和开发方案,提供高品质的视频产品和专业的图像处理服务。凭借自身的技术优势,天视通的产品已广泛应用到养殖场、鱼塘、餐馆、商店等社会的众多行业。天视通在应用华为云EI工作流之后发现,和传统的线下开发环境相比,华为云平台整合了多种开发工具,同时提供可视化界面、大幅度减少通用环境的配置工作,大大提高用户的使用体验。基于算法后装的方式,很大程度上减轻了天视通对摄像头硬件本身的库存规划,让库存周转变得更加灵活。在算法定制方面,华为云EI工作流为天视通节省30%的支出;算法云端部署方面,节省硬件库存运营成本20%。基于华为云提供的能力,天视通从传统硬件厂商转型成为了具备AI能力的解决方案提供商,实现无缝转型升级;同时提升了产品竞争力和业务定制需求的承接能力,能够向客户提供更多服务。当前,华为云工作流积累了大量的场景化行业工作流,助力客户零代码、高灵活的实现全流程AI开发应用。华为云在AI、音视频、IoT领域方面的技术深耕,也让天视通与华为云未来在不同的领域场景有了更多的合作可能。在智能化发展的道路上,华为云用技术加持、应用赋能的方式,给正在智能化转型的企业猛“踩油门”,降低企业智能化发展门槛,助力前行。
中国自古就有“民以食为天”的说法,甚至在日常交流中,连问候都离不开吃饭这件大事——“吃了吗?您呐。”而肉类是百姓饮食结构中的重要组成部分。当下,随着生活水平逐步提升,人们对肉类的消耗也越来越多,这对畜牧养殖业而言带来了一些挑战。虽然畜牧养殖业在我国已经有上千年的经验积累,但对于养殖户自身来说,一直以来都是一个极耗心力的劳动密集型行业。比如品种识别、数据管理、健康监护等,都需要精细化管理。对于动辄上千头牲畜的养殖场来说,假设需要依靠人工进行全盘管理,养殖场工作效率将难以得到有效提升。早前在诸多中小型养殖场里,要准确无误地统计出有多少头牲畜是一件极其困难的事情。特别是出售装车清点数量的过程中,经常出现农场方和客户统计数量不一致的情况,供需双方纠纷频发。是否有智能化的方式,能帮助养殖户在实现无接触式的智能看护的同时,降低管理成本、提高人工监管的准确率?“边打麻将边在手机APP上看猪圈”,这又是怎样的体验?天视通携手华为云,帮助养殖户开启智慧养殖的全新路径。传统硬件厂商的AI转型只需一套工作流基于摄像头帮助养殖户做好精细化畜牧养殖管理,是非常重要的一环。作为专业的摄像头模组供应商,天视通累计年出货超过1000万台,并在畜牧养殖业沉淀了大量的客户与项目经验。随着数字化在畜牧养殖业的深入,天视通面临着新的挑战。单一的业务模式已经无法适应当下环境。以养牛为例。在牛场里,养殖户需要亲自到牛场里进行观察,现场拿纸记录每一只牛的健康状况、育种条件等等。这导致他们需要无数次往返牛场和家,每天行走10000步以上。此外,由于牛群视人类为捕食者,看见养殖专家时会产生紧张情绪,这加大了牲畜精细化管理的工作难度。面对零散的养殖管理需求,天视通需要借助算法供应商的能力,定制不同的AI技能。但算法供应商常常由于成本、开发周期以及隐私泄漏等问题,无法快速提供解决方案。加上算法定制依赖算法供应商,天视通的研发和试错成本在不断增加,间接地导致了天视通的业务流失情况。为寻求突破,天视通联系到在算法定制领域有合作项目的华为云,希望运用华为云的AI能力满足畜牧养殖户的需求。华为云针对天视通的零散化定制AI需求,基于华为云AI开发生产线ModelArts和端边云统一AI应用开发框架ModelBox,提供了“智能摄像头自定义算法定制部署一体工作流”解决方案,不需要高阶AI能力即可覆盖大部分的零散AI定制需求,并能零代码迭代部署AI算法到端侧设备。以上文提到的牲畜健康监管为例,天视通利用摄像头从养殖场实际采集到的健康牛只和生病牛只的体态及日常行为特征图片数据,通过ModelArts对视频中的牛进行标注,接着再启动模型训练。确认模型的效果后,可将牛只生病行为检测技能一键发布到华为云AI Gallery上,接着部署到天视通技能管理App及牛场的端侧设备里,在家即可实时关注每一头牛的状态。华为云提供的解决方案不仅提高了天视通的算法开发效率,而且帮助养殖畜牧业解决了人力资源短缺和牲畜质量管理的难题。“畜牧业是一个智能化启动较晚的行业,但实际上却非常重要,关系到每个家庭的日常生活。这些年食品安全收到社会的广泛关注,产业的规模化和IT技术的应用让精准管理成为可能,养殖过程自动化管理和全流程溯源就是大家看到的热点应用”,天视通技术负责人分享了AI赋能智慧养殖的趋势与应用效果。 定制化算法+端侧一键部署打通AI全流程 得益于华为云AI技术所积累的场景化行业工作流能力,天视通能够快速完成面向特殊场景的算法开发和一键式远程部署:数据标注:通过收集摄像头场景需求和少量数据,华为云利用ModelArts标注工具完成对图片标注;算法训练:工作流内置行业主流标准算法,一键启动即可进行训练,生成算法并能直接查看模型性能;算法优化:训练完之后在平台上就能生成针对具体摄像头硬件的优化过的高性能算法。针对客户的硬件平台,优化适配模型与技能,实现一键技能发布;算法部署:生成的算法部署到实际应用的摄像头中,再结合ModelBox的端云部署能力,完成对算法授权管理,上架到手机端的算法市场App。 华为云EI工作流,实际上是把共通性的场景单独抽象出来,形成一个相对固定的开发模式,提供给研发团队使用。在这个过程中,华为云降低了对算法工程师的能力要求,只需要让软件开发人员聚焦工程。华为云研发专家表示,作为解决方案的核心,华为云EI工作流以业务场景为中心,以“定义场景→分布实施→持续迭代→形成闭环”的模式,通过聚焦各行业可落地的AI开发方式,为服务客户提供基于场景化的工作流,完成全流程的AI开发及迭代。携手伙伴,谋全局,争当弄潮儿天视通始终专注在图像处理和通讯的技术领域前沿,通过技术和产品的不断创新,为广大客户提供技术更先进、更贴近客户需求的远程视频设备和开发方案,提供高品质的视频产品和专业的图像处理服务。凭借自身的技术优势,天视通的产品已广泛应用到养殖场、鱼塘、餐馆、商店等社会的众多行业。天视通在应用华为云EI工作流之后发现,和传统的线下开发环境相比,华为云平台整合了多种开发工具,同时提供可视化界面、大幅度减少通用环境的配置工作,大大提高用户的使用体验。基于算法后装的方式,很大程度上减轻了天视通对摄像头硬件本身的库存规划,让库存周转变得更加灵活。在算法定制方面,华为云EI工作流为天视通节省30%的支出;算法云端部署方面,节省硬件库存运营成本20%。基于华为云提供的能力,天视通从传统硬件厂商转型成为了具备AI能力的解决方案提供商,实现无缝转型升级;同时提升了产品竞争力和业务定制需求的承接能力,能够向客户提供更多服务。当前,华为云工作流积累了大量的场景化行业工作流,助力客户零代码、高灵活的实现全流程AI开发应用。华为云在AI、音视频、IoT领域方面的技术深耕,也让天视通与华为云未来在不同的领域场景有了更多的合作可能。在智能化发展的道路上,华为云用技术加持、应用赋能的方式,给正在智能化转型的企业猛“踩油门”,降低企业智能化发展门槛,助力前行。 -
【功能模块】使用码云上的sample样例进行推理自己训练的yolov4模型(sample样例链接如下https://gitee.com/ascend/samples/tree/master/cplusplus/level2_simple_inference/2_object_detection/YOLOV4_coco_detection_picture)无报错现象,但是发现推理输出结果不对。打印boxBuff[0]即模型经过程序推理后最原始的输出以及NMS之后的值发现输出的预测框明显不对【操作步骤&问题现象】1、打印sample原样例输出的boxBuff[0]以及NMS之后的值如下,正常无误2、打印自己训练的yolov4模型输出的NMS后输出的值如下:boxBuff[0]数值如下经过我初步分析。未转换前的.pth模型输出是正确的,将.pth模型转换为.onnx 模型再转换为.om模型输出不正常,具体如截图2,3所示。尤其是定位的预测框很小且有负值。而原sample样例中NMS后的输出是正确的如截图1所示。在替换过自己训练的模型后修改过样例中的类别信息与类别个数,并且运行无报错而且打印的是om模型经过推理最原始输出boxBuff[0]可见不是后处理的问题,也应该不是精读损失的问题,不知道是不是模型转换的配置文件问题,配置文件参考的官方给出的输入数据为JPEG图像时的配置模板,如下所示aipp_op { aipp_mode: static input_format : YUV420SP_U8 csc_switch : true rbuv_swap_switch : false matrix_r0c0 : 256 matrix_r0c1 : 0 matrix_r0c2 : 359 matrix_r1c0 : 256 matrix_r1c1 : -88 matrix_r1c2 : -183 matrix_r2c0 : 256 matrix_r2c1 : 454 matrix_r2c2 : 0 input_bias_0 : 0 input_bias_1 : 128 input_bias_2 : 128 } 实在不知道问题在哪里,项目紧急,特来求助!【日志信息】(可选,上传日志内容或者附件)
-
 大作业(二):将jpeg解码后的数据格式由YUV420SP NV12定制为YUV420SP NV21,并基于YUV420SPNV21打通应用全流程同大作业的第一个任务一样,这个任务也是需要我们修改检测预处理阶段整个样例实现流程:流程图中,经过JpegD解码解码成了YUV420SP_U8,对于YUV420SP_U8,根据UV分量顺序不同,YUV420SP_U8又分为YUV420SP_UV(NV12)和YUV420SP_VU(NV21)我们的图片经过acllite的JpegD接口会转换会YUV420SP NV12数据格式,并且后面对这个数据格式的数据进行了缩放以及抠图操作。所以此任务,我们要把解码为YUV420SP NV12改为解码为YUV420SP NV21,并想要跑通整个流程,我们需要对JpegD以及后面涉及的缩放与抠图都要修改STEP1:修改JpegD解码功能进入目录cd /home/HwHiAiUser/samples/cplusplus/common/acllite/src可以看到该目录下包含了许多代码文件,下面我们需要逐个修改JpegDHelper,ResizeHelper,CropAndPasteHelper,这三个代码文件先修改JpegD解码功能(JpegDHelper.cpp):PIXEL_FORMAT_YUV_SEMIPLANAR_420修改为PIXEL_FORMAT_YVU_SEMIPLANAR_420 STEP2: 修改图片缩放功能(ResizeHelper.cpp)与第一步做同样的修改共三处,分别在55,106,158行STEP3: 修改抠图功能(CropAndPasteHelper.cpp)修改相同,共四处,分别在89,144,220,286行STEP4: 重新编译AclLite库,因为前三步涉及到acllite公共库的修改,需要重新编译库进入acllite目录cd ${HOME}/samples/cplusplus/common/acllite执行编译安装命令make make install然后再回到scripts,进行样例编译cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify/scriptsbash sample_build.sh再回到out目录下,运行main文件cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify/out ./main查看output目录下的结果:我发现识别出来的车颜色出现了错误,识别成了blue,最初我以为可能就是模型出错了(虽然概率很小),但是其他学员好像都是正确的经过询问,我们还漏了一步,我们需要修改模型转换的两个aipp配置文件,并重新转换模型STEP5: 修改配置文件,并重新转换模型我们两个配置文件的rbuv_swap_switch都是false,我们需要修改为true进入文件目录cd /home/HwHiAiUser/samples/cplusplus/level3_application/1_cv/detect_and_classify/model修改aipp_onnx.cfg和aipp.cfg内的rbuv_swap_switch参数重新转换两个模型atc --model=./yolov3_t.onnx --framework=5 --output=yolov3 --input_shape="images:1,3,416,416;img_info:1,4" --soc_version=Ascend310 --input_fp16_nodes="img_info" --insert_op_conf=aipp_onnx.cfgatc --input_shape="input_1:-1,224,224,3" --output=./color_dynamic_batch --soc_version=Ascend310 --framework=3 --model=./color.pb --insert_op_conf=./aipp.cfg --dynamic_batch_size="1,2,4,8"STEP6: 编译运行然后再回到scripts,进行样例编译cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify/scriptsbash sample_build.sh再回到out目录下,运行main文件cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify/out ./main查看output目录下的结果:结果正确!!
大作业(二):将jpeg解码后的数据格式由YUV420SP NV12定制为YUV420SP NV21,并基于YUV420SPNV21打通应用全流程同大作业的第一个任务一样,这个任务也是需要我们修改检测预处理阶段整个样例实现流程:流程图中,经过JpegD解码解码成了YUV420SP_U8,对于YUV420SP_U8,根据UV分量顺序不同,YUV420SP_U8又分为YUV420SP_UV(NV12)和YUV420SP_VU(NV21)我们的图片经过acllite的JpegD接口会转换会YUV420SP NV12数据格式,并且后面对这个数据格式的数据进行了缩放以及抠图操作。所以此任务,我们要把解码为YUV420SP NV12改为解码为YUV420SP NV21,并想要跑通整个流程,我们需要对JpegD以及后面涉及的缩放与抠图都要修改STEP1:修改JpegD解码功能进入目录cd /home/HwHiAiUser/samples/cplusplus/common/acllite/src可以看到该目录下包含了许多代码文件,下面我们需要逐个修改JpegDHelper,ResizeHelper,CropAndPasteHelper,这三个代码文件先修改JpegD解码功能(JpegDHelper.cpp):PIXEL_FORMAT_YUV_SEMIPLANAR_420修改为PIXEL_FORMAT_YVU_SEMIPLANAR_420 STEP2: 修改图片缩放功能(ResizeHelper.cpp)与第一步做同样的修改共三处,分别在55,106,158行STEP3: 修改抠图功能(CropAndPasteHelper.cpp)修改相同,共四处,分别在89,144,220,286行STEP4: 重新编译AclLite库,因为前三步涉及到acllite公共库的修改,需要重新编译库进入acllite目录cd ${HOME}/samples/cplusplus/common/acllite执行编译安装命令make make install然后再回到scripts,进行样例编译cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify/scriptsbash sample_build.sh再回到out目录下,运行main文件cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify/out ./main查看output目录下的结果:我发现识别出来的车颜色出现了错误,识别成了blue,最初我以为可能就是模型出错了(虽然概率很小),但是其他学员好像都是正确的经过询问,我们还漏了一步,我们需要修改模型转换的两个aipp配置文件,并重新转换模型STEP5: 修改配置文件,并重新转换模型我们两个配置文件的rbuv_swap_switch都是false,我们需要修改为true进入文件目录cd /home/HwHiAiUser/samples/cplusplus/level3_application/1_cv/detect_and_classify/model修改aipp_onnx.cfg和aipp.cfg内的rbuv_swap_switch参数重新转换两个模型atc --model=./yolov3_t.onnx --framework=5 --output=yolov3 --input_shape="images:1,3,416,416;img_info:1,4" --soc_version=Ascend310 --input_fp16_nodes="img_info" --insert_op_conf=aipp_onnx.cfgatc --input_shape="input_1:-1,224,224,3" --output=./color_dynamic_batch --soc_version=Ascend310 --framework=3 --model=./color.pb --insert_op_conf=./aipp.cfg --dynamic_batch_size="1,2,4,8"STEP6: 编译运行然后再回到scripts,进行样例编译cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify/scriptsbash sample_build.sh再回到out目录下,运行main文件cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify/out ./main查看output目录下的结果:结果正确!!
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签