-
 大家好!我是酷哥,数据库资讯,带您速览,欢迎大家阅读。 ------------------------------------------------ **本期精选** ------------------------------------------------ - 2022大数据十大关键词,重磅发布! - 新数据库时代,不要只学 Oracle、MySQL - IDC:2021H2中国关系型数据库软件市场规模同比增长34.9% - 可信隐私计算:破 解数据密态时代技术困局 - 华为云GaussDB助力“2号人事部”打造高品质HR效率软件 - 数据目录——企业数据资产的一个有序清单 - 数据湖治理:优势、挑战和入门 ------------------------------------------------ **资讯摘要** ------------------------------------------------ - 2022大数据十大关键词,重磅发布! **摘要:** 近日,为进一步加速推动我国数据智能转型进程,推动“十四五”期间数据智能产业交流与合作,由中国信息通信研究院、中国通信标准化协会指导,中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)主办的2022大数据产业峰会在京召开。在峰会主论坛上,中国信通院云大所所长何宝宏发布了《2022大数据十大关键词》: 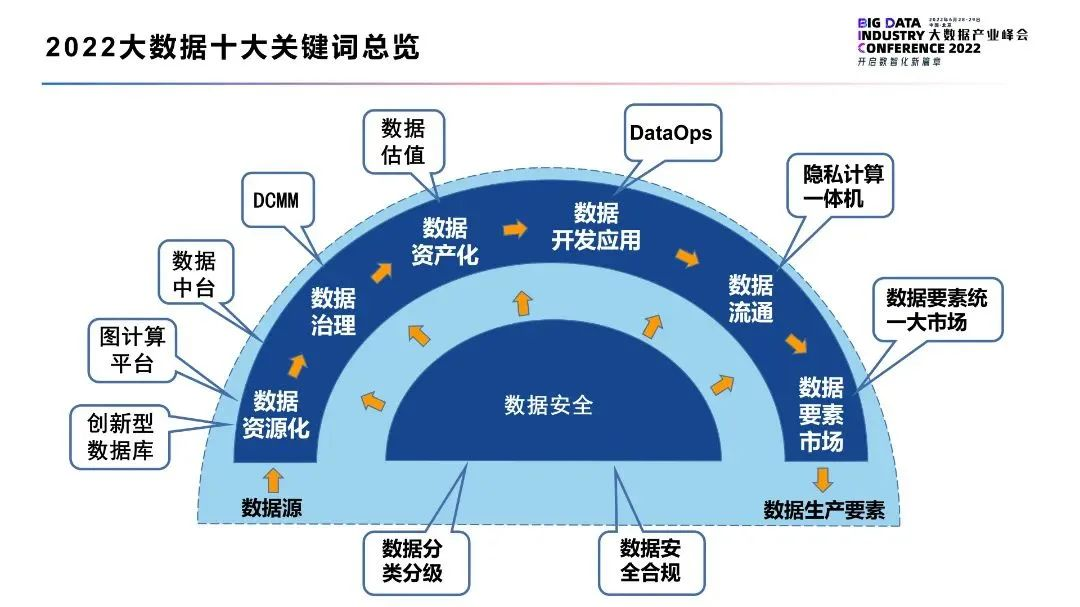 关键词1:创新型数据库优化数据资源化过程 关键词2:图计算平台助力大规模图数据资源化 关键词3:数据中 台成为企业挖掘数据要素价值的核心引擎 关键词4:DCMM贯标引领行业数据治理 关键词5:数据估值成为数据资产化切入点 关键词6:DataOps定义数据开发应用新模式 关键词7:隐私计算一体机助力数据要素流通破 局 关键词8:数据要素政策从宏观到落地 关键词9:数据安全合规整体迈入新阶段 关键词10:数据分类分级在数据安全治理中率先落地 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193543](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193543) - 新数据库时代,不要只学 Oracle、MySQL **摘要:** 目前,中国已经进入“人人都是开发者,家家都是数据公司”的新数据库时代。 近日,CSDN 创始人&董事长、极客帮创投创始合伙人蒋涛发表了《新数据库时代》主题演讲分享。他指出,在开源吞噬世界的背景下,数据库也在大力拥抱开源。不同于传统关系型数据库,新型数据库已成为行业风口,急需大量相关人才汇入,青年才俊应当抓住机遇,迎接挑战。  在此背景下,中国想要构建自己的核心技术生态,数据库是其中关键。今天我将围绕三个部分分享《新数据库时代》: 第一是揭示「我们正在进入的数据大时代」现状; 第二是了解「开源正在吞噬数据库」的改变; 第三是把握「新型的数据库人才特别抢手」的趋势。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193539](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193539) - IDC:2021H2中国关系型数据库软件市场规模同比增长34.9% **摘要:** 2022年6月21日,IDC发布的《2021年下半年中国关系型数据库软件市场跟踪报告》显示:2021下半年中国关系型数据库软件市场规模为15.8亿美元(105.6亿人民币),同比增长34.9%。其中,公有云关系型数据库规模8.7亿美元,同比增长48.7%;本地部署关系型数据库规模7.1亿美元,同比增长21.1%。 IDC预测, 到2026年,中国关系型数据库软件市场规模将达到95.5亿美元,未来5年市场年复合增长率(CAGR)为28.1%。  IDC中国企业软件市场分析师王楠表示:在新兴数据库技术层面,中国本土数据库厂商与国际厂商的差距不大,部分领域还处于领先地位,产品性价比更有优势。在宏观层面,政策极大利好本土厂商,本土厂商的市场机会将会高于国际厂商。在数据库技术发展和宏观政策驱动的双重因素影响下,中国关系型数据库市场过去的格局正在被打破,变革即将到来。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193678](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193678) - 可信隐私计算:破 解数据密态时代技术困局 **摘要:** 数据流通对于国家信息化进程、产业数字化转型是必不可缺的。以前,为了便利数据生产加工和导入导出,许多应用系统常常直接基于明文数据进行开发和流通。在这个过程中,数据流过的每一家机构都有可能会拷贝一份明文数据。随着传播路径的扩散,拥有这份数据的机构越来越多。任何一个机构出现数据滥用或者泄露,都会产生严重影响。可见,明文流通有着显著危害。 《中华人民共和国网络安全法》(简称《网络安全法》)、《中华人民共和国数据安全法》(简称《数据安全法》)、《中华人民共和国个人信息保护法》(简称《个人信息保护法》)须要确保所持有的数据安全,并且对数据的使用进行了严格的限制。在大部分场景下,除了匿名化之后的数据或者已经取得用户授权的数据,数据是不允许任意流通的。在这种情况下,密态流通无疑是最好的选择,能够更好地控制数据的使用和流通范围。  (可信密态计算示例图) **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193755](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193755) - 华为云GaussDB助力“2号人事部”打造高品质HR效率软件 **摘要:** 人才是社会和企业最重要的资产之一。为实现有效管理人才,企业需要一款灵活高效的HR效率软件。“2号人事部”是深圳市点米二号科技有限公司出品的中国第一款即租即用的HR效率软件,为10000家客户、1500万人提供员工管理、招聘管理、考勤打卡、薪酬计算、社保管理等服务,促进企业管理效率提升。 人才是企业的重要资产,高效管理人才是企业成功的重要因素。“2号人事部”全场景数字化平台极大提升了企业组织效率和员工满意度,让人才与企业价值实现共赢。华为云GaussDB数据库愿凭借技术力量,助力万千企业一同推动企业人力资源管理的创新升级,为HR带来工作效能提升和价值重塑。  **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193672](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193672) - 数据目录——企业数据资产的一个有序清单 **摘要:** 数据目录就是关于企业数据资产的一个有序清单。它可以使用元数据来帮助企业管理数据,帮助数据专业人员收集、组织、访问和充实元数据,从而为数据发现和治理提供支持。  与过去相比,想从如今前所未有的数据海洋中找到正确的数据更加困难。同时,关于数据的监管条例和法规(例如 GDPR)也比过去更多、更严格。在这一背景下,除了数据访问之外,数据治理也成为了一个严峻的挑战。您不仅要了解当前您所拥有数据的类型、哪些人在移动数据、数据的用途以及如何保护数据,还必须避免过多的数据层和封装,避免数据因太难使用而毫无用处。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193395](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193395) - 数据湖治理:优势、挑战和入门 **摘要:** 成功的数据治理计划会利用政策、标准和流程来创建高质量数据,并确保在整个组织中正确利用这些数据。数据治理最初侧重于关系数据库和传统数据仓库中的结构化数据,但后来情况发生变化。如果你的企业拥有数据湖环境,并希望从中获得准确的分析结果,那么你还需要部署适当的数据湖治理,作为整体治理计划的一部分。  但数据湖对企业数据管理的所有领域(包括数据治理)带来各种挑战。下面我们将探讨一些主要的治理挑战,以及有效治理数据湖的好处。不过,首先让我们定义什么是数据湖:这是指一个拥有大量原始数据的数据平台,通常包括各种结构化、非结构化和半结构化数据类型。它通常建立在Hadoop、Spark和其他大数据技术之上。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193577](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193577) *声明:文章源于第三方公开的信息,如果存在侵权或信息不实时,请及时联系处理。* 整理者:酷哥
大家好!我是酷哥,数据库资讯,带您速览,欢迎大家阅读。 ------------------------------------------------ **本期精选** ------------------------------------------------ - 2022大数据十大关键词,重磅发布! - 新数据库时代,不要只学 Oracle、MySQL - IDC:2021H2中国关系型数据库软件市场规模同比增长34.9% - 可信隐私计算:破 解数据密态时代技术困局 - 华为云GaussDB助力“2号人事部”打造高品质HR效率软件 - 数据目录——企业数据资产的一个有序清单 - 数据湖治理:优势、挑战和入门 ------------------------------------------------ **资讯摘要** ------------------------------------------------ - 2022大数据十大关键词,重磅发布! **摘要:** 近日,为进一步加速推动我国数据智能转型进程,推动“十四五”期间数据智能产业交流与合作,由中国信息通信研究院、中国通信标准化协会指导,中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)主办的2022大数据产业峰会在京召开。在峰会主论坛上,中国信通院云大所所长何宝宏发布了《2022大数据十大关键词》:  关键词1:创新型数据库优化数据资源化过程 关键词2:图计算平台助力大规模图数据资源化 关键词3:数据中 台成为企业挖掘数据要素价值的核心引擎 关键词4:DCMM贯标引领行业数据治理 关键词5:数据估值成为数据资产化切入点 关键词6:DataOps定义数据开发应用新模式 关键词7:隐私计算一体机助力数据要素流通破 局 关键词8:数据要素政策从宏观到落地 关键词9:数据安全合规整体迈入新阶段 关键词10:数据分类分级在数据安全治理中率先落地 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193543](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193543) - 新数据库时代,不要只学 Oracle、MySQL **摘要:** 目前,中国已经进入“人人都是开发者,家家都是数据公司”的新数据库时代。 近日,CSDN 创始人&董事长、极客帮创投创始合伙人蒋涛发表了《新数据库时代》主题演讲分享。他指出,在开源吞噬世界的背景下,数据库也在大力拥抱开源。不同于传统关系型数据库,新型数据库已成为行业风口,急需大量相关人才汇入,青年才俊应当抓住机遇,迎接挑战。  在此背景下,中国想要构建自己的核心技术生态,数据库是其中关键。今天我将围绕三个部分分享《新数据库时代》: 第一是揭示「我们正在进入的数据大时代」现状; 第二是了解「开源正在吞噬数据库」的改变; 第三是把握「新型的数据库人才特别抢手」的趋势。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193539](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193539) - IDC:2021H2中国关系型数据库软件市场规模同比增长34.9% **摘要:** 2022年6月21日,IDC发布的《2021年下半年中国关系型数据库软件市场跟踪报告》显示:2021下半年中国关系型数据库软件市场规模为15.8亿美元(105.6亿人民币),同比增长34.9%。其中,公有云关系型数据库规模8.7亿美元,同比增长48.7%;本地部署关系型数据库规模7.1亿美元,同比增长21.1%。 IDC预测, 到2026年,中国关系型数据库软件市场规模将达到95.5亿美元,未来5年市场年复合增长率(CAGR)为28.1%。  IDC中国企业软件市场分析师王楠表示:在新兴数据库技术层面,中国本土数据库厂商与国际厂商的差距不大,部分领域还处于领先地位,产品性价比更有优势。在宏观层面,政策极大利好本土厂商,本土厂商的市场机会将会高于国际厂商。在数据库技术发展和宏观政策驱动的双重因素影响下,中国关系型数据库市场过去的格局正在被打破,变革即将到来。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193678](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193678) - 可信隐私计算:破 解数据密态时代技术困局 **摘要:** 数据流通对于国家信息化进程、产业数字化转型是必不可缺的。以前,为了便利数据生产加工和导入导出,许多应用系统常常直接基于明文数据进行开发和流通。在这个过程中,数据流过的每一家机构都有可能会拷贝一份明文数据。随着传播路径的扩散,拥有这份数据的机构越来越多。任何一个机构出现数据滥用或者泄露,都会产生严重影响。可见,明文流通有着显著危害。 《中华人民共和国网络安全法》(简称《网络安全法》)、《中华人民共和国数据安全法》(简称《数据安全法》)、《中华人民共和国个人信息保护法》(简称《个人信息保护法》)须要确保所持有的数据安全,并且对数据的使用进行了严格的限制。在大部分场景下,除了匿名化之后的数据或者已经取得用户授权的数据,数据是不允许任意流通的。在这种情况下,密态流通无疑是最好的选择,能够更好地控制数据的使用和流通范围。  (可信密态计算示例图) **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193755](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193755) - 华为云GaussDB助力“2号人事部”打造高品质HR效率软件 **摘要:** 人才是社会和企业最重要的资产之一。为实现有效管理人才,企业需要一款灵活高效的HR效率软件。“2号人事部”是深圳市点米二号科技有限公司出品的中国第一款即租即用的HR效率软件,为10000家客户、1500万人提供员工管理、招聘管理、考勤打卡、薪酬计算、社保管理等服务,促进企业管理效率提升。 人才是企业的重要资产,高效管理人才是企业成功的重要因素。“2号人事部”全场景数字化平台极大提升了企业组织效率和员工满意度,让人才与企业价值实现共赢。华为云GaussDB数据库愿凭借技术力量,助力万千企业一同推动企业人力资源管理的创新升级,为HR带来工作效能提升和价值重塑。  **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193672](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193672) - 数据目录——企业数据资产的一个有序清单 **摘要:** 数据目录就是关于企业数据资产的一个有序清单。它可以使用元数据来帮助企业管理数据,帮助数据专业人员收集、组织、访问和充实元数据,从而为数据发现和治理提供支持。  与过去相比,想从如今前所未有的数据海洋中找到正确的数据更加困难。同时,关于数据的监管条例和法规(例如 GDPR)也比过去更多、更严格。在这一背景下,除了数据访问之外,数据治理也成为了一个严峻的挑战。您不仅要了解当前您所拥有数据的类型、哪些人在移动数据、数据的用途以及如何保护数据,还必须避免过多的数据层和封装,避免数据因太难使用而毫无用处。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193395](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193395) - 数据湖治理:优势、挑战和入门 **摘要:** 成功的数据治理计划会利用政策、标准和流程来创建高质量数据,并确保在整个组织中正确利用这些数据。数据治理最初侧重于关系数据库和传统数据仓库中的结构化数据,但后来情况发生变化。如果你的企业拥有数据湖环境,并希望从中获得准确的分析结果,那么你还需要部署适当的数据湖治理,作为整体治理计划的一部分。  但数据湖对企业数据管理的所有领域(包括数据治理)带来各种挑战。下面我们将探讨一些主要的治理挑战,以及有效治理数据湖的好处。不过,首先让我们定义什么是数据湖:这是指一个拥有大量原始数据的数据平台,通常包括各种结构化、非结构化和半结构化数据类型。它通常建立在Hadoop、Spark和其他大数据技术之上。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193577](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193577) *声明:文章源于第三方公开的信息,如果存在侵权或信息不实时,请及时联系处理。* 整理者:酷哥 -
 金融领域的反欺诈、精准营销等大量的业务场景对服务连续性要求高,7*24小时不能中断,为了保持业务的连续性和技术引领,一个超大规模、高效率、可持续发展的数据底座显得尤为重要,而不中断业务的滚动升级能力则成为最硬核的衡量指标,中国最佳零售银行,金融数据湖上千节点滚动升级,2万多个业务正常运行,这背后的奥秘究竟是什么?今天让我们深入了解一下……作为“中国最佳零售银行”,某股份制银行一直将客户体验放在首位。近年来,该行以轻型银行为战略目标,打造以数据作为关键战略资产的未来银行,通过引入华为云FusionInsight建设全行统一的金融数据湖,汇聚各渠道业务数据,实现全行数据资源共享,用于探索新的客户体验和商业模式。当前,该行金融数据湖规模达到千余节点,承载了行内上万应用,支撑反欺诈、智慧营销等重要业务场景,日均处理数万大数据作业。随着该行不断深入使用大数据技术,逐步支撑行内关键金融业务,对于整个数据湖平台的服务连续性要求也越来越高,一方面行内金融数据湖要紧跟技术潮流不断升级革新,一方面要求支撑行内外业务的数据湖能够7*24小时不中断服务。然而传统的方案需要断电重启,显然不能满足行内业务连续性保障的要求;同时在金融数据湖升级过程中,对于数据湖这种复杂系统来讲,传统升级方案如果碰到突发的故障,容易导致整个升级动作中断重来,为平稳升级带来极大地挑战。近期,该行采用FusionInsight MRS云原生数据湖滚动升级能力,实现行内大数据平台的成功滚动升级,升级过程中金融数据湖承载的行内2万+应用正常运行,实现两个“不中断”:业务不中断数据湖承载了成千上万的任务作业,在升级过程中,关键的数据分析服务要能够不间断地支撑上层业务,这就导致升级和使用存在着矛盾冲突;MRS具有循环滚动升级能力,一次升级少量节点,循环滚动,直至整个集群的所有节点升级到新版本;同时,为了降低升级对关键任务SLA的影响,MRS还提供滚动升级暂停能力,在任务高峰时段或关键任务执行时,可以保障关键任务正常平稳运行。分批次升级示意图进度不中断数据湖是一个复杂系统,由服务器、存储、网络、软件等组成,在升级时经常会碰到突发事件,如磁盘故障、网络拥塞问题。在大数据平台升级过程中,部署人员需要应对各种突发事件,如磁盘故障、网络拥塞等多种异常场景,客户要求不中断升级。MRS提供故障节点隔离能力,在故障发生时,可以跳过该节点的升级动作,让故障处理和集群升级有序进行。滚动升级不仅是一个升级动作,更是一个系统工程。该行携手华为云FusionInsight MRS云原生数据湖,从兼容性、可靠性、工具自动化、保障团队等多方面入手,注重细节,实现了行内大数据平台架构的平滑演进,升级过程行内用户无感知,保障上层业务平稳运行。MRS目前已通过中国信通院3万+大集群评测,还可以通过集群联邦扩展到10万+大集群。除此之外,还为大规模集群提供超级调度器Superior,资源调度效率是开源大数据的30倍+,能够让整个集群的资源利用率最高达到90%+。截止目前,华为云FusionInsight已先后帮助国有大行、股份制银行、城商农信行,运营商如广东移动、浙江移动等客户实现平滑升级,顺利完成累计60000多节点的无风险升级,让3000+政企客户技术永新,业务永远在线。在本次升级过程中,某股份制银行成功上线了最新版本的华为云FusionInsight MRS云原生数据湖,并在新集群上提供如HetuEngine、 ClickHouse、Hudi等新组件,为项目管理、反欺诈、BI报表等业务创新提供有力技术支撑。在整个升级期间,行内数万名数据分析师毫无感觉,同事模型平台、先机平台、反欺诈平台等关键业务应用平滑运行无中断,为进一步行内实现湖仓一体目标,深度使用FusionInsight奠定良好基础。
金融领域的反欺诈、精准营销等大量的业务场景对服务连续性要求高,7*24小时不能中断,为了保持业务的连续性和技术引领,一个超大规模、高效率、可持续发展的数据底座显得尤为重要,而不中断业务的滚动升级能力则成为最硬核的衡量指标,中国最佳零售银行,金融数据湖上千节点滚动升级,2万多个业务正常运行,这背后的奥秘究竟是什么?今天让我们深入了解一下……作为“中国最佳零售银行”,某股份制银行一直将客户体验放在首位。近年来,该行以轻型银行为战略目标,打造以数据作为关键战略资产的未来银行,通过引入华为云FusionInsight建设全行统一的金融数据湖,汇聚各渠道业务数据,实现全行数据资源共享,用于探索新的客户体验和商业模式。当前,该行金融数据湖规模达到千余节点,承载了行内上万应用,支撑反欺诈、智慧营销等重要业务场景,日均处理数万大数据作业。随着该行不断深入使用大数据技术,逐步支撑行内关键金融业务,对于整个数据湖平台的服务连续性要求也越来越高,一方面行内金融数据湖要紧跟技术潮流不断升级革新,一方面要求支撑行内外业务的数据湖能够7*24小时不中断服务。然而传统的方案需要断电重启,显然不能满足行内业务连续性保障的要求;同时在金融数据湖升级过程中,对于数据湖这种复杂系统来讲,传统升级方案如果碰到突发的故障,容易导致整个升级动作中断重来,为平稳升级带来极大地挑战。近期,该行采用FusionInsight MRS云原生数据湖滚动升级能力,实现行内大数据平台的成功滚动升级,升级过程中金融数据湖承载的行内2万+应用正常运行,实现两个“不中断”:业务不中断数据湖承载了成千上万的任务作业,在升级过程中,关键的数据分析服务要能够不间断地支撑上层业务,这就导致升级和使用存在着矛盾冲突;MRS具有循环滚动升级能力,一次升级少量节点,循环滚动,直至整个集群的所有节点升级到新版本;同时,为了降低升级对关键任务SLA的影响,MRS还提供滚动升级暂停能力,在任务高峰时段或关键任务执行时,可以保障关键任务正常平稳运行。分批次升级示意图进度不中断数据湖是一个复杂系统,由服务器、存储、网络、软件等组成,在升级时经常会碰到突发事件,如磁盘故障、网络拥塞问题。在大数据平台升级过程中,部署人员需要应对各种突发事件,如磁盘故障、网络拥塞等多种异常场景,客户要求不中断升级。MRS提供故障节点隔离能力,在故障发生时,可以跳过该节点的升级动作,让故障处理和集群升级有序进行。滚动升级不仅是一个升级动作,更是一个系统工程。该行携手华为云FusionInsight MRS云原生数据湖,从兼容性、可靠性、工具自动化、保障团队等多方面入手,注重细节,实现了行内大数据平台架构的平滑演进,升级过程行内用户无感知,保障上层业务平稳运行。MRS目前已通过中国信通院3万+大集群评测,还可以通过集群联邦扩展到10万+大集群。除此之外,还为大规模集群提供超级调度器Superior,资源调度效率是开源大数据的30倍+,能够让整个集群的资源利用率最高达到90%+。截止目前,华为云FusionInsight已先后帮助国有大行、股份制银行、城商农信行,运营商如广东移动、浙江移动等客户实现平滑升级,顺利完成累计60000多节点的无风险升级,让3000+政企客户技术永新,业务永远在线。在本次升级过程中,某股份制银行成功上线了最新版本的华为云FusionInsight MRS云原生数据湖,并在新集群上提供如HetuEngine、 ClickHouse、Hudi等新组件,为项目管理、反欺诈、BI报表等业务创新提供有力技术支撑。在整个升级期间,行内数万名数据分析师毫无感觉,同事模型平台、先机平台、反欺诈平台等关键业务应用平滑运行无中断,为进一步行内实现湖仓一体目标,深度使用FusionInsight奠定良好基础。 -
 DGC免费实例购买流程1、 账号注册 a) 在免费试用页面cid:link_0 找到数据湖治理中心DGC b) 点击立即购买 c) 输入手机号,验证码及密码,点击注册 d) 在新的窗口中勾选阅读并同意,点击开通 e) 注册成功 2、 实名认证 a) 微信扫描上图中的二维码完成实名认证b) 认证成功截图如下: 3、 购买DGC免费实例 a) 认证成功后,点击立即购买,进入新页面,在弹窗中勾选All b) 创建虚拟私有云 c) 创建虚拟私有云成功 d) 返回刚刚DGC订购页面,点击虚拟私有云旁的刷新按钮 e) 加载成功后效果 f) 点击立即购买 g) 在下一页中点击“去支付” h) 在新页面的折扣中选择“数据库治理中心DGC-初级版-1个月 0折”,并确认付款 i) 支付成功,订单完成 j) 点击左上角菜单,搜索DGC,点击进入DGC首页 k) 刷新页面,直至加载出DGC实例,创建DGC免费实例完成
DGC免费实例购买流程1、 账号注册 a) 在免费试用页面cid:link_0 找到数据湖治理中心DGC b) 点击立即购买 c) 输入手机号,验证码及密码,点击注册 d) 在新的窗口中勾选阅读并同意,点击开通 e) 注册成功 2、 实名认证 a) 微信扫描上图中的二维码完成实名认证b) 认证成功截图如下: 3、 购买DGC免费实例 a) 认证成功后,点击立即购买,进入新页面,在弹窗中勾选All b) 创建虚拟私有云 c) 创建虚拟私有云成功 d) 返回刚刚DGC订购页面,点击虚拟私有云旁的刷新按钮 e) 加载成功后效果 f) 点击立即购买 g) 在下一页中点击“去支付” h) 在新页面的折扣中选择“数据库治理中心DGC-初级版-1个月 0折”,并确认付款 i) 支付成功,订单完成 j) 点击左上角菜单,搜索DGC,点击进入DGC首页 k) 刷新页面,直至加载出DGC实例,创建DGC免费实例完成 -
 先说观点:因为还没找到更好的。接下来说原因,首先来看看大数据平台都在干什么。原因结构化数据计算仍是重中之重大数据平台主要是为了应对海量数据存储和分析的需求,海量数据存储的确不假,除了生产经营产生的结构化数据,还有大量音视频等非结构化数据,这部分数据很大,占用的空间也很多,有时大数据平台80%以上都存储着非结构化数据。不过,数据光存储还不行,只有利用起来才能产生价值,这就要进行分析了。大数据分析要分结构化和非机构化数据两部分讨论。结构化数据主要是企业生产经营过程中产生的业务数据,可以说是企业的核心,以往在没有大数据平台的时候企业主要或全部在使用的就是这部分数据。随着业务的不断积累,这部分数据也越来越大,传统数据库方案面临很大挑战,建设大数据平台自然要解决这部分核心数据分析问题。有了大数据平台,给大家的想象空间也大了起来,以往无法利用的日志、图片、音视频等非结构化数据也要产生价值,这就涉及到非结构化数据分析了。相对核心业务数据分析,非结构化数据分析看起来更像是锦上添花。即使如此,非结构化数据分析并不是孤立存在,也还会伴随大量结构化数据处理。采集非结构化数据的同时,常常会伴随着采集许多相关的结构化数据,比如音视频的制作人、制作时间、所属类别、时长、…;有些非结构化数据经过处理后也会转变成结构化数据,比如网页日志中拆解出访问人 IP、访问时刻、关键搜索词等。所谓的非结构化数据分析,经常实际上是针对这些伴生而出的结构化数据。结构化数据分析仍然是大数据平台的重中之重。而结构化数据处理技术就比较成熟了,比如我们常用的基于关系数据模型的关系数据库(SQL)。SQL仍是目前最广泛的结构化数据计算技术回归 SQL 却是当前大数据计算语法的一个发展倾向。在 Hadoop 体系中,早期的 PIG Latin 已经被淘汰,而 Hive 却一直坚挺;Spark 上也在更多地使用 Spark SQL,而 Scala 反而少很多(Scala易学难精,作为编译型语言不支持热部署也有很多不方便之处)。其它一些新的大数据计算体系一般也将 SQL 作为首选的计算语法,经过几年时间的混战,现在 SQL 又逐步拿回了主动权。这个现象,大概有这么两个原因:1. 实在没什么别的好用关系数据库过于普及,程序员对 SQL 相当熟悉,甚至思维习惯都是 SQL 式的。SQL 用来做一些常规查询也比较简单,虽然用于处理复杂的过程计算或有序运算并不方便,但其它那些替代技术也好不到哪里去,碰到 SQL 难写的运算一样要写和 UDF 相当的复杂代码,反正都是麻烦,还不如继续用 SQL。2. 大数据厂商的鼎力支持大数据的技术本质是高性能,而 SQL 是性能比拼的关键阵地。比性能要面对同样的运算才有意义,过于专门和复杂的运算涉及的影响因素太多,不容易评估出大数据平台本身的能力。而 SQL 有国际标准的 TPC 系列,所有用户都看得懂,这样就有明确的可比性,厂商也会把性能优化的重点放在 SQL 上。兼容SQL更利于移植大数据平台兼容 SQL 的好处是很明显的,SQL 的应用非常广泛,会 SQL 的程序员很多,如果继续采用 SQL 则可以避免许多学习成本。支持 SQL 的前端软件也很多,使用 SQL 的大数据平台很容易融入这个现成的生态圈中。大数据平台打算替代的传统数据库也是 SQL 语法的,这样兼容性会很好,移植成本相对较低。好了,我们说完大数据平台为什么会回归关系数据模型了。那么继续使用关系数据模型(SQL)会存在哪些问题呢?问题性能低继续使用 SQL的最大问题就是难以获得大数据计算最需要的高性能。SQL 中缺乏一些必要的数据类型和运算定义,这使得某些高性能算法无法描述,只能寄希望于计算引擎在工程上的优化。传统商业数据库经过几十年的发展,优化经验已经相当丰富,但即使这样仍有许多场景难以被优化,理论层面的问题确实很难在工程层面解决。而新兴的大数据平台在优化方面的经验还远远不如传统数据库,算法上不占优,就只能靠集群更多的机器获得性能提升。另外,SQL 描述过程的能力不太好,不擅长指定执行路径,而想获得高性能常常需要专门优化的执行路径,这又需要增加许多特殊的修饰符来人为干预,那还不如直接用过程性语法更为直接,这也会妨碍用 SQL 写出高性能的代码。SQL 发明之初的计算机硬件能力还比较差,要保证实用性,SQL 的设计必须适应当时的硬件条件,这就导致了 SQL 很难充分利用当代计算机的硬件能力,具体来说就是大内存、并行和集群。SQL 中的 JOIN 是按键值对应的,而大内存情况下其实可以直接用地址对应,不需要计算 HASH 值和比对,性能可以提高很多;SQL 的数据表无序,单表计算时还容易做到分段并行,多表关联运算时一般就只能事先做好固定分段,很难做到同步动态分段,这就难以根据机器的负载临时决定并行数量;对于集群运算也是这样,SQL 在理论上不区分维表和事实表,JOIN 运算简单地定义为笛卡尔积后过滤,要实现大表 JOIN 就会不可避免地产生占用大量网络资源的 HASH Shuffle 动作,在集群节点数太多时,网络传输造成的延迟会超过节点多带来的好处。举个具体的例子,我们想在 1 亿条数据中取出前 10 名,用 SQL 写出来是这样的:select top 10 x,y from T order by x desc这个语句中有个 order by,严格按它执行就会涉及大排序,而排序非常慢。其实我们可以想出一个不用大排序的算法,但用 SQL 却无法描述,只能指望数据库优化器了。对于这句 SQL 描述的简单情况,很多商用数据库确实都能优化,使用不必大排序的算法,性能通常很好。但情况复杂一些,比如在每个分组中取前 10 名,要用窗口函数和子查询把 SQL 写成这样:select * from (select y,*,row_number() over (partition by y order by x desc) rn from T)where rn<=10这时候,数据库优化器就会犯晕了,猜不出这句 SQL 的目的,只能老老实实地执行排序的逻辑(这个语句中还是有 order by 的字样),结果性能陡降。开发效率低不仅跑的慢,开发效率也不高,尤其在复杂计算方面,SQL实现很繁琐。比如根据股票记录查询某只股票最长连续上涨天数,SQL(oracle)的写法如下:select code, max(ContinuousDays) - 1from ( select code, NoRisingDays, count(*) ContinuousDays from ( select code, sum(RisingFlag) over (partition by code order by day) NoRisingDays from ( select code, day, case when price>lag(price) over (partittion by code order by day) then 0 else 1 end RisingFlag from stock ) ) group by NoRisingDays )group by code用了很绕的方式实现,别说写出来,看懂都要半天。此外,SQL也很难实现过程计算。什么是过程性计算呢?就是一步写不出来,需要多次分步运算,特别是与数据次序相关的运算。我们举几个例子来看:一周内累计登录时长超过一小时的用户占比,但要除去登录时长小于 10 秒的误操作情况信用卡在最近三个月内最长连续消费的天数分布情况,考虑实施连续消费 10 天后积分三倍的促销活动一个月中有多少用户在 24 小时连续操作了查看商品后加入购物车并购买的的动作,有多少用户在中间步骤中放弃?……(为了便于理解,这些例子已经做了简化,实际情况的运算还要复杂很多)这类过程性运算,用 SQL 写出来的难度就很大,经常还要写 UDF 才能完成。如果SQL写都写不出来,那么SQL的使用效果将大打折扣。开发效率低导致性能低复杂SQL的执行效率往往也很低,这就又回到性能的问题了,实际上开发效率和计算性能是密切相关的,很多性能问题本质上是开发效率造成。复杂 SQL 的优化效果很差,在嵌套几层之后,数据库引擎也会晕掉,不知道如何优化。提高这类复杂运算的性能,指望计算平台的自动优化就靠不住了,根本手段还要靠写出高性能的算法。象过程式运算中还常常需要保存中间结果以复用,SQL 需要用临时表,多了 IO 操作就会影响性能,这都不是引擎优化能解决的事情,必须要去改写计算过程。所以,本质上,提高性能还是降低开发难度。软件无法提高硬件的性能,只能想办法设计复杂度更低的算法,而如果能够快速低成本地实现这些算法,那就可以达到提高性能的目标。如果语法体系难以甚至没办法描述高性能算法,必须迫使程序员采用复杂度较高的算法,那也就很难再提高性能了。优化 SQL 运算无助于降低它的开发难度,SQL 语法体系就是那样,无论怎样优化它的性能,开发难度并不会改变,很多高性能算法仍然实现不了,也就难以实质性地提高运算性能。编写 UDF 在许多场景时确实能提高性能,但一方面开发难度很大,另一方面这是程序员硬写的,也不能利用到 SQL 引擎的优化能力。而且经常并不能将完整运算都写成 UDF,只能使用计算平台提供的接口,仍然要在 SQL 框架使用它的数据类型,这样还是会限制高性能算法的实现。根本的解决方法,还是要让大数据平台真地有一些更好用的语法。解法使用开源集算器SPL就可以作为SQL很好的替代和延伸,作为大数据平台专用的计算语言,延续SQL优点的同时改善其缺点。SPL是一款专业的开源数据计算引擎,提供了独立的计算语法,整个体系不依赖关系数据模型,因此在很多方面都有长足突破,尤其在开发效率和计算性能方面。下面来盘点一下SPL都有哪些特性适用于当代大数据平台。强集成性首先是集成性,不管SPL多优秀,如果与大数据平台无法结合使用也是白费。要在大数据平台中使用SPL其实很方便,引入jar包就可以使用(本身也是开源的,想怎么用就怎么用)。SPL提供了标准JDBC驱动,可以直接执行SPL脚本,也可以调用SPL脚本文件。…Class.forName("com.esproc.jdbc.InternalDriver");Connection conn =DriverManager.getConnection("jdbc:esproc:local://");//PreparedStatement st = (PreparedStatement)conn.createStatement();;//直接执行SPL脚本//ResultSet rs = st.executeQuery("=100.new(~:baseNum,~*~:square2)");//调用SPL脚本文件CallableStatement st = conn.prepareCall("{call SplScript(?, ?)}");st.setObject(1, 3000);st.setObject(2, 5000);ResultSet result=st.execute();...高效开发敏捷语法在结构化数据计算方面,SPL提供了独立的计算语法和丰富的计算类库,同时支持过程计算使得复杂计算实现也很简单。前面举的计算股票最长连涨天数的例子,用SPL实现是这样的:A1 =db.query(“select * from stock order by day”)2 =A1.group@i(price<price[-1]).max(~.len())-1按交易日排好序,将连涨的记录分到一组,然后求最大值-1就是最长连续上涨天数了,完全按照自然思维实现,不用绕来绕去,比SQL简单不少。再比如根据用户登录记录列出每个用户最近一次登录间隔:A 1 =ulogin.groups(uid;top(2,-logtime)) 最后2个登录记录2 =A1.new(uid,#2(1).logtime-#2(2).logtime:interval) 计算间隔支持分步的SPL语法完成过程计算很方便。SPL提供了丰富的计算类库,可以更进一步简化运算。直观易用开发环境同时,SPL还提供了简洁易用的开发环境,单步执行、设置断点,所见即所得的结果预览窗口…,开发效率也更高。多数据源支持SPL还提供了多样性数据源支持,多种数据源可以直接使用,相比大数据平台需要数据先“入库”才能计算,SPL的体系更加开放。SPL支持的部分数据源(仍在扩展中…)不仅如此,SPL还支持多种数据源混合计算,充分发挥各类数据源自身的优势,扩展大数据平台的开放性。同时,直接使用多种数据源开发实现上也更简单,进一步提升开发效率。热切换SPL是解释执行的,天然支持热切换,这对Java体系下的大数据平台是重大利好。基于SPL的大数据计算逻辑编写、修改和运维都不需要重启,实时生效,开发运维更加便捷。高计算性能前面我们说过,高性能与高开发效率本质上是一回事,基于SPL的简洁语法更容易写出高性能算法。同时,SPL还提供了众多高性能数据存储和高性能算法机制,SQL中很难实现的高性能算法及存储方案用SPL却可以轻松实现,而软件提高性能关键就在于算法和存储。例如前面说过的TopN运算,在SPL中TopN被理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。A 1 =file(“data.ctx”).create().cursor() 2 =A1.groups(;top(10,amount)) 金额在前 10 名的订单3 =A1.groups(area;top(10,amount)) 每个地区金额在前 10 名的订单这里的语句中没有排序字样,也不会产生大排序的动作,在全集还是分组中计算TopN的语法基本一致,而且都会有较高的性能。以下是一些用SPL实现的高性能计算案例:开源 SPL 提速保险公司团保明细单查询 2000+ 倍开源 SPL 提升银行自助分析从 5 并发到 100 并发开源 SPL 提速银行用户画像客群交集计算 200+ 倍开源 SPL 优化银行预计算固定查询成实时灵活查询开源 SPL 将银行手机账户查询的预先关联变成实时关联开源 SPL 提速银行资金头寸报表 20+ 倍开源 SPL 提速银行贷款协议跑批 10+ 倍开源 SPL 优化保险公司跑批优从 2 小时到 17 分钟开源 SPL 提速银行 POS 机交易报表 30+ 倍开源 SPL 提速银行贷款跑批任务 150+ 倍开源 SPL 提速资产负债表 60 倍再多说两句,SPL没有基于关系数据模型,而是采用了一种创新的理论体系,在理论层面就进行了创新,篇幅原因这里不再过多提及,写着简单跑得又快的数据库语言 SPL 这里有更细致一些的介绍,感兴趣的小伙伴也可以自行搜索,下载。SPL资料SPL官网SPL下载SPL源代码————————————————版权声明:本文为CSDN博主「3分钟秒懂大数据」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/weixin_38201936/article/details/125159358
先说观点:因为还没找到更好的。接下来说原因,首先来看看大数据平台都在干什么。原因结构化数据计算仍是重中之重大数据平台主要是为了应对海量数据存储和分析的需求,海量数据存储的确不假,除了生产经营产生的结构化数据,还有大量音视频等非结构化数据,这部分数据很大,占用的空间也很多,有时大数据平台80%以上都存储着非结构化数据。不过,数据光存储还不行,只有利用起来才能产生价值,这就要进行分析了。大数据分析要分结构化和非机构化数据两部分讨论。结构化数据主要是企业生产经营过程中产生的业务数据,可以说是企业的核心,以往在没有大数据平台的时候企业主要或全部在使用的就是这部分数据。随着业务的不断积累,这部分数据也越来越大,传统数据库方案面临很大挑战,建设大数据平台自然要解决这部分核心数据分析问题。有了大数据平台,给大家的想象空间也大了起来,以往无法利用的日志、图片、音视频等非结构化数据也要产生价值,这就涉及到非结构化数据分析了。相对核心业务数据分析,非结构化数据分析看起来更像是锦上添花。即使如此,非结构化数据分析并不是孤立存在,也还会伴随大量结构化数据处理。采集非结构化数据的同时,常常会伴随着采集许多相关的结构化数据,比如音视频的制作人、制作时间、所属类别、时长、…;有些非结构化数据经过处理后也会转变成结构化数据,比如网页日志中拆解出访问人 IP、访问时刻、关键搜索词等。所谓的非结构化数据分析,经常实际上是针对这些伴生而出的结构化数据。结构化数据分析仍然是大数据平台的重中之重。而结构化数据处理技术就比较成熟了,比如我们常用的基于关系数据模型的关系数据库(SQL)。SQL仍是目前最广泛的结构化数据计算技术回归 SQL 却是当前大数据计算语法的一个发展倾向。在 Hadoop 体系中,早期的 PIG Latin 已经被淘汰,而 Hive 却一直坚挺;Spark 上也在更多地使用 Spark SQL,而 Scala 反而少很多(Scala易学难精,作为编译型语言不支持热部署也有很多不方便之处)。其它一些新的大数据计算体系一般也将 SQL 作为首选的计算语法,经过几年时间的混战,现在 SQL 又逐步拿回了主动权。这个现象,大概有这么两个原因:1. 实在没什么别的好用关系数据库过于普及,程序员对 SQL 相当熟悉,甚至思维习惯都是 SQL 式的。SQL 用来做一些常规查询也比较简单,虽然用于处理复杂的过程计算或有序运算并不方便,但其它那些替代技术也好不到哪里去,碰到 SQL 难写的运算一样要写和 UDF 相当的复杂代码,反正都是麻烦,还不如继续用 SQL。2. 大数据厂商的鼎力支持大数据的技术本质是高性能,而 SQL 是性能比拼的关键阵地。比性能要面对同样的运算才有意义,过于专门和复杂的运算涉及的影响因素太多,不容易评估出大数据平台本身的能力。而 SQL 有国际标准的 TPC 系列,所有用户都看得懂,这样就有明确的可比性,厂商也会把性能优化的重点放在 SQL 上。兼容SQL更利于移植大数据平台兼容 SQL 的好处是很明显的,SQL 的应用非常广泛,会 SQL 的程序员很多,如果继续采用 SQL 则可以避免许多学习成本。支持 SQL 的前端软件也很多,使用 SQL 的大数据平台很容易融入这个现成的生态圈中。大数据平台打算替代的传统数据库也是 SQL 语法的,这样兼容性会很好,移植成本相对较低。好了,我们说完大数据平台为什么会回归关系数据模型了。那么继续使用关系数据模型(SQL)会存在哪些问题呢?问题性能低继续使用 SQL的最大问题就是难以获得大数据计算最需要的高性能。SQL 中缺乏一些必要的数据类型和运算定义,这使得某些高性能算法无法描述,只能寄希望于计算引擎在工程上的优化。传统商业数据库经过几十年的发展,优化经验已经相当丰富,但即使这样仍有许多场景难以被优化,理论层面的问题确实很难在工程层面解决。而新兴的大数据平台在优化方面的经验还远远不如传统数据库,算法上不占优,就只能靠集群更多的机器获得性能提升。另外,SQL 描述过程的能力不太好,不擅长指定执行路径,而想获得高性能常常需要专门优化的执行路径,这又需要增加许多特殊的修饰符来人为干预,那还不如直接用过程性语法更为直接,这也会妨碍用 SQL 写出高性能的代码。SQL 发明之初的计算机硬件能力还比较差,要保证实用性,SQL 的设计必须适应当时的硬件条件,这就导致了 SQL 很难充分利用当代计算机的硬件能力,具体来说就是大内存、并行和集群。SQL 中的 JOIN 是按键值对应的,而大内存情况下其实可以直接用地址对应,不需要计算 HASH 值和比对,性能可以提高很多;SQL 的数据表无序,单表计算时还容易做到分段并行,多表关联运算时一般就只能事先做好固定分段,很难做到同步动态分段,这就难以根据机器的负载临时决定并行数量;对于集群运算也是这样,SQL 在理论上不区分维表和事实表,JOIN 运算简单地定义为笛卡尔积后过滤,要实现大表 JOIN 就会不可避免地产生占用大量网络资源的 HASH Shuffle 动作,在集群节点数太多时,网络传输造成的延迟会超过节点多带来的好处。举个具体的例子,我们想在 1 亿条数据中取出前 10 名,用 SQL 写出来是这样的:select top 10 x,y from T order by x desc这个语句中有个 order by,严格按它执行就会涉及大排序,而排序非常慢。其实我们可以想出一个不用大排序的算法,但用 SQL 却无法描述,只能指望数据库优化器了。对于这句 SQL 描述的简单情况,很多商用数据库确实都能优化,使用不必大排序的算法,性能通常很好。但情况复杂一些,比如在每个分组中取前 10 名,要用窗口函数和子查询把 SQL 写成这样:select * from (select y,*,row_number() over (partition by y order by x desc) rn from T)where rn<=10这时候,数据库优化器就会犯晕了,猜不出这句 SQL 的目的,只能老老实实地执行排序的逻辑(这个语句中还是有 order by 的字样),结果性能陡降。开发效率低不仅跑的慢,开发效率也不高,尤其在复杂计算方面,SQL实现很繁琐。比如根据股票记录查询某只股票最长连续上涨天数,SQL(oracle)的写法如下:select code, max(ContinuousDays) - 1from ( select code, NoRisingDays, count(*) ContinuousDays from ( select code, sum(RisingFlag) over (partition by code order by day) NoRisingDays from ( select code, day, case when price>lag(price) over (partittion by code order by day) then 0 else 1 end RisingFlag from stock ) ) group by NoRisingDays )group by code用了很绕的方式实现,别说写出来,看懂都要半天。此外,SQL也很难实现过程计算。什么是过程性计算呢?就是一步写不出来,需要多次分步运算,特别是与数据次序相关的运算。我们举几个例子来看:一周内累计登录时长超过一小时的用户占比,但要除去登录时长小于 10 秒的误操作情况信用卡在最近三个月内最长连续消费的天数分布情况,考虑实施连续消费 10 天后积分三倍的促销活动一个月中有多少用户在 24 小时连续操作了查看商品后加入购物车并购买的的动作,有多少用户在中间步骤中放弃?……(为了便于理解,这些例子已经做了简化,实际情况的运算还要复杂很多)这类过程性运算,用 SQL 写出来的难度就很大,经常还要写 UDF 才能完成。如果SQL写都写不出来,那么SQL的使用效果将大打折扣。开发效率低导致性能低复杂SQL的执行效率往往也很低,这就又回到性能的问题了,实际上开发效率和计算性能是密切相关的,很多性能问题本质上是开发效率造成。复杂 SQL 的优化效果很差,在嵌套几层之后,数据库引擎也会晕掉,不知道如何优化。提高这类复杂运算的性能,指望计算平台的自动优化就靠不住了,根本手段还要靠写出高性能的算法。象过程式运算中还常常需要保存中间结果以复用,SQL 需要用临时表,多了 IO 操作就会影响性能,这都不是引擎优化能解决的事情,必须要去改写计算过程。所以,本质上,提高性能还是降低开发难度。软件无法提高硬件的性能,只能想办法设计复杂度更低的算法,而如果能够快速低成本地实现这些算法,那就可以达到提高性能的目标。如果语法体系难以甚至没办法描述高性能算法,必须迫使程序员采用复杂度较高的算法,那也就很难再提高性能了。优化 SQL 运算无助于降低它的开发难度,SQL 语法体系就是那样,无论怎样优化它的性能,开发难度并不会改变,很多高性能算法仍然实现不了,也就难以实质性地提高运算性能。编写 UDF 在许多场景时确实能提高性能,但一方面开发难度很大,另一方面这是程序员硬写的,也不能利用到 SQL 引擎的优化能力。而且经常并不能将完整运算都写成 UDF,只能使用计算平台提供的接口,仍然要在 SQL 框架使用它的数据类型,这样还是会限制高性能算法的实现。根本的解决方法,还是要让大数据平台真地有一些更好用的语法。解法使用开源集算器SPL就可以作为SQL很好的替代和延伸,作为大数据平台专用的计算语言,延续SQL优点的同时改善其缺点。SPL是一款专业的开源数据计算引擎,提供了独立的计算语法,整个体系不依赖关系数据模型,因此在很多方面都有长足突破,尤其在开发效率和计算性能方面。下面来盘点一下SPL都有哪些特性适用于当代大数据平台。强集成性首先是集成性,不管SPL多优秀,如果与大数据平台无法结合使用也是白费。要在大数据平台中使用SPL其实很方便,引入jar包就可以使用(本身也是开源的,想怎么用就怎么用)。SPL提供了标准JDBC驱动,可以直接执行SPL脚本,也可以调用SPL脚本文件。…Class.forName("com.esproc.jdbc.InternalDriver");Connection conn =DriverManager.getConnection("jdbc:esproc:local://");//PreparedStatement st = (PreparedStatement)conn.createStatement();;//直接执行SPL脚本//ResultSet rs = st.executeQuery("=100.new(~:baseNum,~*~:square2)");//调用SPL脚本文件CallableStatement st = conn.prepareCall("{call SplScript(?, ?)}");st.setObject(1, 3000);st.setObject(2, 5000);ResultSet result=st.execute();...高效开发敏捷语法在结构化数据计算方面,SPL提供了独立的计算语法和丰富的计算类库,同时支持过程计算使得复杂计算实现也很简单。前面举的计算股票最长连涨天数的例子,用SPL实现是这样的:A1 =db.query(“select * from stock order by day”)2 =A1.group@i(price<price[-1]).max(~.len())-1按交易日排好序,将连涨的记录分到一组,然后求最大值-1就是最长连续上涨天数了,完全按照自然思维实现,不用绕来绕去,比SQL简单不少。再比如根据用户登录记录列出每个用户最近一次登录间隔:A 1 =ulogin.groups(uid;top(2,-logtime)) 最后2个登录记录2 =A1.new(uid,#2(1).logtime-#2(2).logtime:interval) 计算间隔支持分步的SPL语法完成过程计算很方便。SPL提供了丰富的计算类库,可以更进一步简化运算。直观易用开发环境同时,SPL还提供了简洁易用的开发环境,单步执行、设置断点,所见即所得的结果预览窗口…,开发效率也更高。多数据源支持SPL还提供了多样性数据源支持,多种数据源可以直接使用,相比大数据平台需要数据先“入库”才能计算,SPL的体系更加开放。SPL支持的部分数据源(仍在扩展中…)不仅如此,SPL还支持多种数据源混合计算,充分发挥各类数据源自身的优势,扩展大数据平台的开放性。同时,直接使用多种数据源开发实现上也更简单,进一步提升开发效率。热切换SPL是解释执行的,天然支持热切换,这对Java体系下的大数据平台是重大利好。基于SPL的大数据计算逻辑编写、修改和运维都不需要重启,实时生效,开发运维更加便捷。高计算性能前面我们说过,高性能与高开发效率本质上是一回事,基于SPL的简洁语法更容易写出高性能算法。同时,SPL还提供了众多高性能数据存储和高性能算法机制,SQL中很难实现的高性能算法及存储方案用SPL却可以轻松实现,而软件提高性能关键就在于算法和存储。例如前面说过的TopN运算,在SPL中TopN被理解为聚合运算,这样可以将高复杂度的排序转换成低复杂度的聚合运算,而且很还能扩展应用范围。A 1 =file(“data.ctx”).create().cursor() 2 =A1.groups(;top(10,amount)) 金额在前 10 名的订单3 =A1.groups(area;top(10,amount)) 每个地区金额在前 10 名的订单这里的语句中没有排序字样,也不会产生大排序的动作,在全集还是分组中计算TopN的语法基本一致,而且都会有较高的性能。以下是一些用SPL实现的高性能计算案例:开源 SPL 提速保险公司团保明细单查询 2000+ 倍开源 SPL 提升银行自助分析从 5 并发到 100 并发开源 SPL 提速银行用户画像客群交集计算 200+ 倍开源 SPL 优化银行预计算固定查询成实时灵活查询开源 SPL 将银行手机账户查询的预先关联变成实时关联开源 SPL 提速银行资金头寸报表 20+ 倍开源 SPL 提速银行贷款协议跑批 10+ 倍开源 SPL 优化保险公司跑批优从 2 小时到 17 分钟开源 SPL 提速银行 POS 机交易报表 30+ 倍开源 SPL 提速银行贷款跑批任务 150+ 倍开源 SPL 提速资产负债表 60 倍再多说两句,SPL没有基于关系数据模型,而是采用了一种创新的理论体系,在理论层面就进行了创新,篇幅原因这里不再过多提及,写着简单跑得又快的数据库语言 SPL 这里有更细致一些的介绍,感兴趣的小伙伴也可以自行搜索,下载。SPL资料SPL官网SPL下载SPL源代码————————————————版权声明:本文为CSDN博主「3分钟秒懂大数据」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/weixin_38201936/article/details/125159358 -
 据国家应急管理局、市场监管总局安全管理要求,煤炭、石化、工程、港口、市政等组织开展“动土、动火、用电、断路、有限空间、吊装、盲板抽堵以及高空等”8项作业时,必须提前考核风险要素,由安全管理员、项目负责人审批、并签署“作业票”才能开展现场作业。现场作业:高效、规范线上“开票”,落实安全生产管理要求:2021年,国家应急管理部办公厅印发《“工业互联网+危化安全生产”试点建设方案》的通知,鼓励实现动火作业、受限空间作业、临时用电等特殊作业审批电子化、流程化。同时通过信息化手段对作业全程进行痕迹管理。(截图自国家应急管理部官网)契约锁电子签章支持集成“作业票管理系统”,为煤、化、工程、港口等组织现场作业的作业票签署提供“人员身份认证、电子签名、电子作业票模板以及数据存证”支持,打造安全、透明、便捷、可信、可追溯的电子作业票签署服务平台,实现开票申请-审批-签名-归档全程数字化。让组织的特殊作业安全审批工作从“制度约束”向“数字驱动”模式转变。(作业票管理系统&电子签章系统集成应用)纸质作业票vs电子作业票电子作业票实名认证签署,防止代签、虚开票电子模板一键生成,防止字迹潦草、起草不规范等麻烦除需面签单据外,手机端便捷审批、签名、提升作业审批效率票据签署数据自动存证,生成电子档案、长期存储、随时调阅....纸质作业票负责人线下手写填报、手动签名可能出现逾越流程直接签字、代签等风险,追责难一天签署量多达上百份,安全管理员每日工作量大,签署效率跟不上一年多达数千份作业票档案,存储压力大,时间长了容易丢失、损坏....落实作业票审批规则,高效、规范在线开票契约锁通过集成应用,将电子签章应用嵌入作业票审批流程,在实名认证基础上,为动土、动火、用电、空间作业、吊装、断路、盲板抽堵以及高空作业等8项特色作业审批开票,提供审批人、签署人身份认证,作业票电子模板、电子签名以及数据存证支撑,线上完成开票申请-审批-签署-归档,确保每一张现场作业票都通过审批、都有可信电子签名,有效减少开票中间环节,提升施工进场效率。(作业票线上审批-签署场景)01作业票审批意见自动签署、留痕根据各类组织特殊作业安全管理要求,不同作业票的审批、签署要求也不同,中间可能需要多人审批并签署审批意见,为了方便溯源,实现审批意见留痕、长期保存。契约锁电子签章可以为组织的作业票审批流程提供数字身份、电子签名支持,审批人可以直接在流程表单中手写签名、添加审批意见,签署结果自动在流程表单中呈现,随时调阅。02安全员、项目负责人手机端电子签名开票审批结束后,无论是否需要现场面签的作业票,系统都会及时下发签署消息给安全管理员以及项目负责人,打开手机人脸识别核验身份,即可手动添加电子签名,快速签发作业票。(作业票系统填写开票信息)(安全管理员、项目负责人手机短信电子签名开票)签署一结束,已签作业票文件自动回传作业票系统,现场作业人员在线即可查看、下载,及时开展现场施工。丰富功能应用确保开票安全-合规-便捷1、有效电子作业票模板,清晰、规范制作作业票一般情况下,各类特殊作业票都有固定内容格式,线下手写作业票流程繁琐,并且无法一一对应作业项目,时常出现填报缺项、漏项、字迹潦草、注意事项不清等情况。契约锁严格按照国家规定作业票格式,为用户提供电子模板应用,帮助固化作业票内容格式,开票时根据作业类型在线调取电子模板,自动抓取作业票系统内关键业务数据,生成标准电子作业票文件,数据精准、内容清晰,全面提升作业票制作效率和规范性。2、审批人、签字人身份及时核验,防冒签为了提升作业票内容可信度,契约锁可以为施工申请人、审批人以及签字人员提供数字身份认证及核验服务,审批、签字环节自动核验操作人员身份,确保签署人即安全管理员,防止冒签、代签,确保本人签署生效。3、签署数据自动记入系统日志,随时溯源作业票作为现场特殊作业的重要授权依据,其审批、签署过程中的数据都是重要的溯源依据,需要妥善保存,方便后期调阅核实。契约锁电子签章系统日志能够有效记录作业票审批、签署全过程数据,还原签署过程,同时提供权威公证处存证支持,随时提供出证,有效帮助组织开展溯源、调查,及时锁定责任人。4、自动生成安全作业电子档案,便捷检索查询作业票所有签署数据自动收集、汇总、生成作业票电子档案,帮助组织建立现场特殊作业安全管理材料档案库,随时检索查询,防止丢失、损坏。总结合法、有效、便捷的电子签章为8大特殊作业票数字化转型提供了重要的技术支撑,建立“制作-审批-签署-归档”全程数字化管理闭环,让原本2-3小时的审批签署工作缩短至5-7分钟,有效缓解作业票签署压力。借助可信、安全的签署环节,逐步规范8大作业票签署过程,让每一条开票申请必有回应,让每一次审批都能留痕,让每一次签署都真实可信,防止冒签、抵赖、伪造风险,助力煤、化、工程、港口等组织现场作业安全管理数字化转型。
据国家应急管理局、市场监管总局安全管理要求,煤炭、石化、工程、港口、市政等组织开展“动土、动火、用电、断路、有限空间、吊装、盲板抽堵以及高空等”8项作业时,必须提前考核风险要素,由安全管理员、项目负责人审批、并签署“作业票”才能开展现场作业。现场作业:高效、规范线上“开票”,落实安全生产管理要求:2021年,国家应急管理部办公厅印发《“工业互联网+危化安全生产”试点建设方案》的通知,鼓励实现动火作业、受限空间作业、临时用电等特殊作业审批电子化、流程化。同时通过信息化手段对作业全程进行痕迹管理。(截图自国家应急管理部官网)契约锁电子签章支持集成“作业票管理系统”,为煤、化、工程、港口等组织现场作业的作业票签署提供“人员身份认证、电子签名、电子作业票模板以及数据存证”支持,打造安全、透明、便捷、可信、可追溯的电子作业票签署服务平台,实现开票申请-审批-签名-归档全程数字化。让组织的特殊作业安全审批工作从“制度约束”向“数字驱动”模式转变。(作业票管理系统&电子签章系统集成应用)纸质作业票vs电子作业票电子作业票实名认证签署,防止代签、虚开票电子模板一键生成,防止字迹潦草、起草不规范等麻烦除需面签单据外,手机端便捷审批、签名、提升作业审批效率票据签署数据自动存证,生成电子档案、长期存储、随时调阅....纸质作业票负责人线下手写填报、手动签名可能出现逾越流程直接签字、代签等风险,追责难一天签署量多达上百份,安全管理员每日工作量大,签署效率跟不上一年多达数千份作业票档案,存储压力大,时间长了容易丢失、损坏....落实作业票审批规则,高效、规范在线开票契约锁通过集成应用,将电子签章应用嵌入作业票审批流程,在实名认证基础上,为动土、动火、用电、空间作业、吊装、断路、盲板抽堵以及高空作业等8项特色作业审批开票,提供审批人、签署人身份认证,作业票电子模板、电子签名以及数据存证支撑,线上完成开票申请-审批-签署-归档,确保每一张现场作业票都通过审批、都有可信电子签名,有效减少开票中间环节,提升施工进场效率。(作业票线上审批-签署场景)01作业票审批意见自动签署、留痕根据各类组织特殊作业安全管理要求,不同作业票的审批、签署要求也不同,中间可能需要多人审批并签署审批意见,为了方便溯源,实现审批意见留痕、长期保存。契约锁电子签章可以为组织的作业票审批流程提供数字身份、电子签名支持,审批人可以直接在流程表单中手写签名、添加审批意见,签署结果自动在流程表单中呈现,随时调阅。02安全员、项目负责人手机端电子签名开票审批结束后,无论是否需要现场面签的作业票,系统都会及时下发签署消息给安全管理员以及项目负责人,打开手机人脸识别核验身份,即可手动添加电子签名,快速签发作业票。(作业票系统填写开票信息)(安全管理员、项目负责人手机短信电子签名开票)签署一结束,已签作业票文件自动回传作业票系统,现场作业人员在线即可查看、下载,及时开展现场施工。丰富功能应用确保开票安全-合规-便捷1、有效电子作业票模板,清晰、规范制作作业票一般情况下,各类特殊作业票都有固定内容格式,线下手写作业票流程繁琐,并且无法一一对应作业项目,时常出现填报缺项、漏项、字迹潦草、注意事项不清等情况。契约锁严格按照国家规定作业票格式,为用户提供电子模板应用,帮助固化作业票内容格式,开票时根据作业类型在线调取电子模板,自动抓取作业票系统内关键业务数据,生成标准电子作业票文件,数据精准、内容清晰,全面提升作业票制作效率和规范性。2、审批人、签字人身份及时核验,防冒签为了提升作业票内容可信度,契约锁可以为施工申请人、审批人以及签字人员提供数字身份认证及核验服务,审批、签字环节自动核验操作人员身份,确保签署人即安全管理员,防止冒签、代签,确保本人签署生效。3、签署数据自动记入系统日志,随时溯源作业票作为现场特殊作业的重要授权依据,其审批、签署过程中的数据都是重要的溯源依据,需要妥善保存,方便后期调阅核实。契约锁电子签章系统日志能够有效记录作业票审批、签署全过程数据,还原签署过程,同时提供权威公证处存证支持,随时提供出证,有效帮助组织开展溯源、调查,及时锁定责任人。4、自动生成安全作业电子档案,便捷检索查询作业票所有签署数据自动收集、汇总、生成作业票电子档案,帮助组织建立现场特殊作业安全管理材料档案库,随时检索查询,防止丢失、损坏。总结合法、有效、便捷的电子签章为8大特殊作业票数字化转型提供了重要的技术支撑,建立“制作-审批-签署-归档”全程数字化管理闭环,让原本2-3小时的审批签署工作缩短至5-7分钟,有效缓解作业票签署压力。借助可信、安全的签署环节,逐步规范8大作业票签署过程,让每一条开票申请必有回应,让每一次审批都能留痕,让每一次签署都真实可信,防止冒签、抵赖、伪造风险,助力煤、化、工程、港口等组织现场作业安全管理数字化转型。 -
6月28日,为进一步加速推动我国数据智能转型进程,推动“十四五”期间数据智能产业交流与合作,由中国信息通信研究院、中国通信标准化协会指导,中国通信标准化协会大数据技术标准推进委员会(CCSA TC601)主办的2022大数据产业峰会在京召开。在峰会主论坛上,中国信通院云大所所长何宝宏发布了《2022大数据十大关键词》。大数据十大关键词是基于我们长期对于产业的研究观察,以及与一线专家的研讨交流完成。如图所示,本年度十大关键词涉及数据从计算机语言到成为生产要素的全生命周期,包括【数据资源化】,即数据从计算机语言到成为可被人类识别的信息【数据治理】,即将散乱的、庞杂的数据进行归类、整理、管理【数据资产化】,即将数据与货币进行对应挂钩,【数据开发应用】,即加工数据使其为业务赋能,【数据流通】,即完成数据在部门与部门间、机构与机构间进行点对点的合规交换共享,【数据要素市场】,即促进全社会按照统一规范的制度、体系完成数据的合规流通利用,【数据安全】,即保障数据流转的全生命周期符合相关法律法规。关键词1:创新型数据库优化数据资源化过程数据库作为支撑数据存储、计算的核心技术产品,为了适应数据要素相关需求,正快速进行技术革新。一方面AI数据库、Serverless云原生数据库推动对于数据的价值挖掘从“阳春白雪”变为“下里巴人”。利用数据不再是金融、电信等数据密集型行业的特色,而是变成全社会、全行业的普适性行为。这导致数据的加工利用过程需要更加平民化、高效化。AI数据库具备自动运维、智能开发等能力,Serverless云原生数据库具备按量计费、弹性扩容等能力,均可实现数据加工利用过程的降本增效,正成为甲骨文、亚马逊、阿里、华为等巨头供应商的研发热点。另一方面防篡改数据库、全密态数据库支撑数据完成高效确权定价、便捷合规流通。防篡改数据库在高效存储计算基础上,提供数据防篡改和操作防篡改功能,从而支撑数据确权定价,而全密态数据库能够实现数据在加密状态下的高效存储和计算,从而支撑数据合规流通。两者均成为MIT等学术机构的研究热点,以及华为、阿里等供应商的研发热点。关键词2:图计算平台助力大规模图数据资源化图数据与传统行列式数据不同,它通过点、边模型,高效描述实体、属性、关系的数据模型,近年来被广泛用于企业智能营销风控等必要数据应用中。随着行业数据智能转型的深入,图数据在数据总量中的比例也正在快速上升。Gartner预计,到2025年图技术在数据和分析创新中的占比将从2021年的10%上升到80%。随着图数据规模的变大,开启了图数据的“大数据”时代,起源于80年代的传统关系型数据库,以及起源于2000年左右的专用图数据库已经无法支撑大规模图数据的高效存储与计算。图计算平台通过抽象计算层和集成层,在图数据库基础上增强了兼容性和大规模数据计算能力,实现了多种存储介质中图数据的高效汇聚以及多跳情况下的复杂计算能力。目前该领域政策扶持力度不断加大,开源体系发展迅猛,商用产品层出不穷,从而快速支撑了图数据这一重要要素类型的价值释放。关键词3:数据中台成为企业挖掘数据要素价值的核心引擎随着企业数字化转型的加深,数据相关系统、组织逐渐复杂、冗余,壁垒逐渐增多。为在组织或企业内部构建一套可复用的数据和分析能力,减少数据本身及相关技术架构的冗余,打通不同系统数据间的壁垒,数据中台应运而生。其理论体系从发展初期的“百家争鸣”,逐渐聚焦和明确,并在业内达成共识,即数据中台构建了数据资源与业务价值间的骨干网,是“企业数智化转型的核心引擎”。近年来,由于数字化转型政策的持续推动,数据中台发展迅猛,Gartner在成熟度曲线中将其标记为期望值最高。国内该领域供给侧迅速发展、供应商不断丰富,除概念提出者阿里巴巴外,华为、腾讯、网易、星环等大数据企业纷纷入场。应用侧相关落地案例迅速增多,中国移动、中国联通、工商银行、农业银行等大型央企、金融机构以及各地方政府纷纷立项招标,并形成自身实践案例。关键词4:DCMM贯标引领行业数据治理DCMM是我国数据管理领域的首个国家标准,为企业数据管理工作提供客观的评价依据,指导企业体系化构建数据管理框架、持续优化数据管理能力。经过近3年时间的发展,DCMM已得到广泛认可,贯标评估的工作成效正加速显现。在数据要素统一大市场的培育过程中,DCMM贯标评估可以提升各类市场主体的数据能力和数据活力,弥合地区间差异、拉齐行业间水平,扩大数据资源优质供给,从而提高数据要素流通效率,引导数据资源的高效积累和有序聚集。为持续推动企业数据管理能力提高,工信部印发“企业数据管理国家标准贯标工作方案”,全国各地配套产业补贴政策,推动重点地区、重点行业的贯标评估工作,预计到2025年,贯标评估企业超1万家,宣贯培训人员超15万人。关键词5:数据估值成为数据资产化切入点数据估值探索历程伴随着企业数字化转型的发展而发展。Gartner于2015年提出信息价值评价框架,从信息内在价值、信息商业价值、信息绩效价值、信息成本价值、信息市场价值、信息经济价值六大维度进行衡量。但是,这一框架多停留在理念层面,仅明确了主要影响因子,未提出具体的测算指标和方法。中国企业的全面数字化转型大致始于2015年,并在2017年后进入爆发期。企业在意识到数据价值的同时,投入了巨大的人力、物力和财力,因此,亟需一套估值指标清晰量化数据价值,评价数字化转型的成效。自2021年初起,光大银行、南方电网、浦发银行等企业陆续进行数据估值的研究与实践。但是我们也应认识到数据估值仍处于发展初期,估值目的、估值框架有待在具体场景中探索验证。我们在分析业界数据估值的成果后,认为可以将数据产品作为估值对象,而估值实际上是在衡量数据对于业务发展贡献的间接经济价值,以及将数据视为商品进行交易获得的直接经济收益,因此,数据估值是一项涵盖了数据管理、数据应用、数据交易、AI建模的综合性工作。下一步,我们诚邀大家与我们共同探索数据估值的方法,提高数据人员的价值感,为数字化转型指明方向。关键词6:DataOps定义数据开发应用新模式DataOps的概念最早在2014年由国外学者提出,随后业界逐步对其内涵进行补充。其在2018年正式被纳入Gartner的数据管理技术成熟度曲线当中,由此进入了国际的视野当中。2022年中国信通院正式牵头启动了DataOps的标准建设工作,以此为基础推动我国大数据产业的多元化发展。DataOps作为协助企业完成数智化转型的良药,供给侧和需求侧都在争相尝鲜。厂商中,诸如腾讯、阿里、亚信、海南数造等公司纷纷采纳DataOps的理念构建新一代数据研发工具平台。企业中的一些头部机构,例如工商银行、农业银行、中国移动等也在对DataOps进行实践,并取得了不小的成果。在标准化方面,今年信通院牵头联合各行业30余家单位开展标准制定工作。标准包括了7个模块25个环节,旨在推动我国数据文化扎实发展。关键词7:隐私计算一体机助力数据要素流通破局今年是隐私计算落地应用元年,多个场景应用加速落地,隐私计算一体机为应用开辟新路径。一是作为软硬结合一体的专用设备,利用硬件特性增强软件实现方案,其安全加固、性能加速和易用性增强的三大优势,使得隐私计算一体机从众多工程优化方案中脱颖而出,降低用户使用技术门槛和综合成本。二是一体机的技术实现方式不唯一,各家产品百花齐放。可基于可信硬件或加密卡,同时利用计算加速卡或网络加速卡,也可预装应用服务场景组件,组合方案多样化。多硬件多角度组合提升成为软硬结合发展趋势,并在金融政务医疗等场景崭露头角。三是产品形态多样,标准化需求迫切,国内外已有多个标准带头规范技术研发和应用。但也值得注意,并非仅有隐私计算一体机可以突破应用瓶颈,扩大应用规模,面对数据安全流通巨大的需求,我们仍要继续探索更多好用易用的落地方案。关键词8:数据要素政策从宏观到落地今年年初,十四五数字经济规划、要素市场化配置改革方案两份文件对数据要素的专门布局,让数据要素领域的探索再掀热潮,政策推进、产业实践都在不断深入、不断创新。一是顶层设计逐步细化,国家站在全国统一大市场的高度对数据要素发展做出安排,又针对深圳示范区的数据要素市场准入做出具体部署,数据基础制度体系建设也在加快推进。二是地方法规陆续出台,目前已有十九省市公布了相关数据条例,以促进数据利用和产业发展为基本定位,多以公共数据为抓手,结合地方实际和特色进一步激发市场主体活力。三是交易模式不断创新。各地数据交易所优化经营结构,贵阳制定交易规则、上海建设数商体系、深圳打造开源社区等探索让数据交易有了更实在的依托。但是我们离数据要素价值的充分释放还很远,数据权属、定价的共识还未建立,数据泄露、越权滥用等问题加剧人们的不信任感,如何建立有效的规则体系和监管机制,如何利用前沿技术破解难题,仍需政产学研用各界共同发力。关键词9:数据安全合规整体迈入新阶段随着2021年两法的颁布实施,各行各业的数据安全监管力度不断加强,合规工作也迈入新的阶段。首先,为了正确理解监管内容,有效落实监管要求,各行各业广泛掀起了政策法规的学习浪潮。其次,数据分类分级作为数据安全领域的重要工作,也是实现精细化安全管理的必要能力,同样成为这一轮学习热潮的重点关注对象。再次,为推动本行业企业数据安全的贯彻落实,部分行业主管单位启动监管报送工作。最后,在供应侧市场,部分企业开始着手开发合规管理工具,以协助需求方实现监管应对的自动化实现。关键词10:数据分类分级在数据安全治理中率先落地数据分类分级作为数据安全工作的基础内容,是数据安全精细化管理的必要前提,需要在数据安全治理工程中率先落地。凭借在方法论共识、行业细化、工具开发等方面呈现的发展态势,数据分类分级同样上榜十大关键词。首先,分类分级作为《数据安全法》明确提到的概念之一,引起地方、行业、企业的研究探讨,并逐渐形成从建立组织保障到落实对应级别数据安全管控策略的“七步走”方法论共识。其次,为指导企业分类分级工作的推进落实,各行业通过制定标准规范,明确分类分级工作的原则、方法、定义,进一步细化相关要求。最后,自动化分类分级工具或咨询服务在数据安全供方市场蓬勃发展。据中国信通院“可信数安”评估体系统计,2022年分类分级工具或服务的参评企业从2021年的4项增加至14项。以上就是2022大数据领域十个关键词。最后,我们对其进行归纳总结,发现他们涵盖政策、理念、安全、技术等支撑数据要素价值释放的方方面面,这些关键词所涉内容的快速发展,进一步印证了我国数据要素市场在快速发展过程中,已逐步构建起政策引领、理念先行、技术支撑、安全护航的健康发展格局。来源: 数仓宝贝库
-
文中部分内容参考了朱凯老师的《ClickHouse原理解析》。01、BI系统的演进(1)传统BI系统上个世纪,IT技术迅猛发展,主要特征就是线下工作的线上化。各种各样的IT系统(比如ERP、CRM等)在各个行业落地实施。相应的,我们把这类系统称之为联机事务处理(OLTP)系统。但是在企业的运行过程中,不只是有流程审批这些工作,还有很多报表统计、分析决策相关的诉求。但是早期的IT系统的数据各自独立,互相割裂,给分析带来了极大的困难。为了解决这一问题,人们提出了数据仓库的概念,把数据集中在一起,打通隔阂,并通过分层的方式处理数据(关于数据仓库,可以回顾《数据仓库基础知识》,数据仓库的核心思路维度建模,参考文章《维度建模》。)。逐步的,在数仓基础上提供数据分析的系统慢慢发展起来。直到90年代,BI系统的概念提出来,专门指代这类分析系统。相对于OLTP系统,这类BI系统被称为联机分析(OLAP)系统。传统BI系统解决了很多问题,但是存在的瓶颈也是很多的。比如数据的分析效率底下、研发迭代缓慢等,都对应用效果产生了负面影响。(2)现代BI系统最近几年,SaaS模式的兴起,为BI系统带来了新的发展机遇。例如我们熟知的GA、神策分析、友盟分析等,采取的服务模式都是SaaS化。很多中小型公司的BI系统不再依赖于数仓的搭建。而现代BI系统背后的OLAP技术也在不断发展。02、什么是OLAP下面我们详细聊聊OLAP。OLAP即联机分析,又可以称为多维分析,是关系型数据库之父Edgar Frank于1993年提出的概念。它指的是通过多种不同的维度审视数据,进行深层次分析。主要的操作包括下钻、上卷、切片、切块等。参考Excel的数据透视表的功能,大家就好理解这些操作了。数据透视表实现了对原始数据的各种聚合、分解、切片等操作,OLAP也是如此。可以把OLAP理解成对公司数据库建立一个大的透视表,通过这个透视表进行各种维度的分析,这就是OLAP。说白了,OLAP是用于我们进行分析的引擎。在很多公司的数据架构中,OLAP作为顶层分析应用层与数据存储层的中间处理层。其核心解决的是和数据分析相关的需求。常见的OLAP架构可以分为三类:(1)ROLAP第一种架构称为ROLAP(Relational OLAP),即关系型OLAP。顾名思义,是直接使用关系模型进行构建的。因此,多维分析的操作是可以直接转换成SQL进行查询的。这种架构对数据的实时处理能力要求很高。像ClickHouse、Impala、Presto都是典型的RLOAP代表。(2)MOLAP第二种架构称为MOLAP(Multidimensional OLAP),即多维型OLAP。MOLAP的出现是为了缓解ROLAP的性能问题。其核心思路是对数据预先聚合处理,以存储空间换查询时间的减少。典型的MOLAP包括Kylin、Druid等。容易想到,如果维度较多,需要存储的数据量级会有指数级地上涨。一张千万级别的数据表,可能膨胀到需要存储亿级别的体量。另外,由于需要进行预计算,MOLAP的数据会有一定的滞后性,不能实时进行数据分析。并且由于只保留了聚合后的结果数据,无法查询明细数据。(3)HOLAP第三类架构称为HOLAP(Hybrid OLAP),即混合架构OLAP。这种架构可以理解成ROLAP和MOLAP的集成。03、OLAP实现技术的演进前面我们也陆续介绍了OLAP相关的一些技术。下面我们简单聊聊OLAP技术的演进过程。(1)传统关系型数据库阶段第一个阶段称为传统的关系型数据库阶段。在这个阶段中,OLAP主要是以Oracle、MySQL等关系型数据库实现。在ROLAP架构下,直接使用这些数据库作为存储和计算的载体;在MOLAP架构下,则借助物化视图的形式实现数据立方体。该阶段中,无论是ROLAP还是MOLAP,当数据体量大、维度数目多的时候,都存在严重的性能问题,甚至存在根本查不出结果的情况。(2)大数据技术阶段第二个极端可以称为大数据阶段。在这个阶段,主要依赖Hive等大数据技术进行实现。以ROLAP为例,传统的关系型数据库被Hive和SparkSQL这类新型技术所取代。相比传统的数据库而言,面向海量数据的处理性能明显提升了很多。但是在提供实时的在线查询服务时,仍然需要几十秒甚至数分钟才能返回。(3)最新阶段最近几年,一款新的OLAP解决方案ClickHouse走进了大家的视野。其优越的查询计算性能让人惊叹。头条、阿里、腾讯等大厂也纷纷进行使用。ClickHouse是由来自俄罗斯的Yandex公司研发的(Yandex类似于中国的百度,是俄罗斯的本土搜索引擎,占据俄国47%的搜索市场),是一款开源软件。其他一些常见的OLAP技术方案对比如下,供参考。不同的技术,也都存在各自的优点和缺点。在目前阶段,没有哪种OLAP技术是万能的灵丹妙药,可以解决所有问题。大家在技术选型时,需要结合自己的业务数据特点,进行选择。来源:ITPUB
-
1、应用系统本身有大数据平台,是基于开源组件搭建的,现在要适配MRS安全集群,打算将原有大数据平台与应用先行解耦,再在MRS上进行组件适配,不知道此思路是否正确?2、安全集群内MRS内的组件需要做安全认证,但MRS内的组件并不能满足所有业务需求,还需要部署开源组件,开源组件涉及到调度MRS内的组件,请问这种情况是否需要做安全认证?
-
专访对象:杜小勇。中国人民大学二级教授、博士生导师。现任中国人民大学校长助理、理工学科建设处处长、明理书院院长、数据工程与知识工程教育部重点实验室主任,数据库课程虚拟教研室和“101计划”数据库系统课程虚拟教研室负责人,CCF大数据专家委员会主任,国家重点研发计划项目首席科学家。数据库是信息系统的基础和核心,国产数据库实现自主可控、自主创新已成为信息产业的发展战略重点,人才需求逐年递增,人才培养迫在眉睫。 为贯彻落实“十四五”教育发展规划有关部署,助力高质量创新型人才培养,2022年2月,教育部公布首批虚拟教研室建设试点名单,数据库课程虚拟教研室榜上有名。该项目旨在探索数据库课程教研改革与人才培养的新模式、新路径,是首批15个教育部—华为“智能基座”课程虚拟教研室试点之一。 虚拟教研室作为数字时代新型教学研究的组织形式,备受各方关注。聚焦数据库领域,虚拟教研室建设能否助力数据库人才培养问题的解决?虚拟教研室该如何建设运行?如何创建面向产业需求的人才培养新范式?近日,中国教育在线专访了数据库课程虚拟教研室牵头人杜小勇教授,深入了解数据库课程虚拟教研室的建设思路和社会价值。 指向数据思维,高校数据库人才培养模式亟待改进 数据库是计算机软件皇冠上的明珠,在数字经济时代,小到一个企业,大到一个国家,都离不开数据库。杜小勇介绍说:“国内数据库产业发展非常迅速,目前做国产数据库的企业已经有200多家,像华为这样的头部企业,已经都有了自己的数据库产品。”国产数据库厂商迎来了弯道超车的机会,而如何更好地培养数据库人才,提升数据库行业竞争力,则成为迫在眉睫的事。 杜小勇指出:“数据库是一门非常传统的学科,在我们国家最早的计算机专业培养方案里,数据库就是7门核心课程之一。随着新技术地不断涌现,人才需求不断变化。而且,在大数据时代,数据库已经从一种工具演变成一种思维——数据思维。但传统数据库课程既满足不了企业对数据库内核研发人才的需求,也不能让学生感受到数据思维的作用。”在数据库课程教学上,高校作为人才培养的第一阵地,面临着理论课程内容依赖国外或开源数据库、教学案例与生动的应用实际脱节、缺少基于国产数据库的操作实践学习等痛点,高校数据库人才培养模式亟待改进。 探索共建共享新机制,为人才培养提供新动能 2021年7月,《教育部高等教育司关于开展虚拟教研室试点建设工作的通知》发布。以此为契机,数据库课程虚拟教研室启动。该虚拟教研室由中国人民大学牵头,发起单位包括清华大学、东北大学、山东大学、华为等各层次各区域高校和企业。截止目前,数据库课程虚拟教研室共有106家成员单位。 在运行模式上,虚拟教研室以立德树人为根本任务,以提高人才培养能力为核心,以CMOOC 联盟数据库课程工作组、教育部-华为“智能基座”联合工作组以及获批的国家级线上一流本科课程、国家级线下一流本科课程、国家级线上线下混合一流本科课程为依托,在前期建设的数据库课程“跨校协作组”和教育部-华为“智能基座”项目基础上,进一步按照开源软件社区的模式进行共建与共享,系统化开展数据库类课程的教学研究和建设,深化课程教学内容、教学方法、教学资源、教学评价等方面建设,为高等教育高质量发展提供有力支撑。 在运行机制上,数据库虚拟教研室以“开放、奉献、竞争、有序”为指导思想,崇尚“人人为我、我为人人”的志愿者精神,强调成果贡献,淡化身份标签,采用民主决策制度,遵循“木兰”协议共享成果,以开源社区的方式运行。“数据库虚拟教研室是架构在互联网之上的面向全国的跨校的组织,没有经费支持,所以我们一定要强调开放、奉献。而组织里面引入竞争机制,也能让那些想干事、能干事、干成事的老师逐渐显露出来。不过教研室毕竟是一个组织,我们要在制度上让它有序运行。为此,虚拟教研室发起单位共同组建了委员会,作为最高决策机构进行民主决策。”杜小勇解释说。 在国产数据库实现自主可控、自主创新成为信息产业发展战略重点的背景下,虚拟教研室的推出及其跨校协作、校企合作的实践探索将极大提升高校人才培养的效果,为专业人才培养工作的实施提供了新动能。 校企协同,为虚拟教研室建设提供有力支撑 数据库作为关键基础软件,是我国面临的35项需要重点突破的技术之一,国产数据库行业内核技术开发人才缺口很大。针对国产数据库人才的宏观需求、高新技术对数据库类课程群建设的全新挑战以及高校实践教学的设计痛点,杜小勇带领的数据库课程虚拟教研室还着力探索推动高校与产业界的全方位合作。杜小勇表示:“无论是数据库内核开发人才的培养,还是大数据应用人才的培养,单靠高校的师资和资源,我们深感力不从心,在这种情况下,校企合作显得特别重要。” 据介绍,数据库课程虚拟教研室以产业发展的新需求、新成果为导向,与国产数据库头部企业产教融合,加深与华为公司在创新人才培养模式、促进师生发展、改进数据库课程教学设置等方面的合作,探索课程体系建设新模式,建设合作共享的优质教研资源,全面提高国产数据库创新人才培养水平。杜小勇提到:“我们希望有更多的高校学生实践能够在国产数据库上开展,在学生一代就解决那些先入为主的国产数据库不行的观念。校企还可以联合办竞赛,通过开源的方式把同学们的兴趣吸引到数据库系统的开发和发展上来。” 针对数据库的未来发展以及人才的培养,杜小勇表示:“数据库人才培养的方向要从过去的数据库使用者变为适应新时代新需求的数据库内核开发者,同时让学生感受数据思维,实现大数据的多样性应用。我相信校企合作在虚拟教研室里大有可为。” 对于国产数据库而言,未来的竞争本质就是人才的竞争。在新型智能时代,课程体系建设的新模式离不开产学研用,校企协同,产业聚集人才,为高校人才提供动能,人才同时也将更好地引领产业发展。理论应用到教学实践,数据库课程虚拟教研室的建设也将为其他高校培养创新型人才提供示范和借鉴意义。共创新、共发展,才能共建坚实的数字世界底座。来源:中国教育在线
-
了解鲲鹏BoostKit大数据图分析算法,更多详情可参见鲲鹏文档中心:https://www.hikunpeng.com/document/detail/zh/kunpengbds/appAccelFeatures/algorithmaccelf_ga
-
大家好!我是酷哥,数据库相关资讯,带您速览,欢迎大家阅读。 ------------------------------------------------ **本期精选** ------------------------------------------------ - 计世指数-数据库产品影响力指数发布会成功召开 - 数据库未来:湖仓一体新趋势 - 推动数据中心绿色高质量发展的技术趋势和解决思路 - 数据资产如何确权认责 - 大数据时代的“冷热数据”管理 - Gartner发布2022年银行技术趋势,包含隐私增强计算 - 摘取皇冠上的明珠,华为云数据库的创新与探索 ------------------------------------------------ **资讯摘要** ------------------------------------------------ - 计世指数-数据库产品影响力指数发布会成功召开 **摘要:** 5月28日,围绕数据库产品,成功举办“计世指数-数据库产品影响力指数”线上发布会。本次发布会包括30个分布式数据库产品和8个集中式数据库产品。 数据库是IT系统存储和计算的基础,广泛应用于各行业,随着数据资源的爆发式增长,数字经济的发展壮大,迎来高速发展的重要机遇。数据库产品影响力指数旨在能够客观反映我国数据库的发展及应用情况,促进技术产品创新和行业应用,推动数据库产业高质量发展。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189787](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189787) - 数据库未来:湖仓一体新趋势 **摘要:** 随着企业数字化转型的推进,越来越多的企业视湖仓一体为数字化变革的契机。当然,关注度越高,市场上嘈杂的声音也就越多。 在实际业务场景中,数据的移动不只是存在于数据湖和数据仓库之间,湖仓一体不仅需要把数仓和数据湖集成起来,还要让数据在服务之间按需流动。 湖仓一体化架构,可以方便、快捷地将大量数据从数仓转移至数据湖内,同时这些移到湖里的数据,仍然可以被数仓查询使用。 目前湖仓一体已广泛应用于金融、电信、交通等行业。在PB级的数据量下,可以为企业节省上百万的服务器采购成本,充分实现了降本提效的目标。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189797](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189797) - 推动数据中心绿色高质量发展的技术趋势和解决思路 **摘要:** 5月26日,在贵州举行的2022中国国际大数据产业博览会“东数西算:构建国家算力网络体系”论坛上,由华为技术有限公司(以下简称“华为”)与国家信 息 中心、贵州省大数据发展管理局和粤港澳大湾区大数据研究院联合发布了《“碳达峰、碳中和”背景下数据中心绿色高质量发展研究报告》(以下简称《研究报告》)。 在推动数据中心绿色高质量发展的技术趋势和解决思路专项建议中,《研究报告》重点阐述了四大存储技术方向。即如何利用全闪存储技术、存算分离架构、数据重删压缩、数据密集型存储等技术推动在“东数西算”的背景下高质量达成数据中心“碳中和、碳达峰”目标。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189523](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189523) - 数据资产如何确权认责 **摘要:** 2020年04月10日,中 共 中 央、国务院印发《关于构建更加完善的要素市场化配置体制机制的意见》,将数据定义为与土地、劳动力、资本、技术并列的第五大生产要素——数字化时代的一种新型的生产要素。数据的价值越来越重要!然而对于“数据”,各个国家的法律似乎还没有准确界定数据资产权责体系。 所谓数据确权,就是确定数据的权利属性,主要包含两个层面:第一是确定数据的权利主体,即谁对数据享有权利。第二是确定权利的内容,即享有什么样的权利。 从这两个层面看,数据从产生到消亡的整个生命周期中,主要涉及四类角色,即:数据所有者、数据生产者、数据使用者和数据管理者。而确权就是针对特定的数据资产明确定义这四类角色的过程。也就是说,不同的数据资产其所有者、生产者、使用者和管理者可能不同。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189529](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189529) - 大数据时代的“冷热数据”管理 **摘要:** 冷热数据主要从数据访问频度、更新频度进行划分。冷数据,即实际生产中被访问、更新频度比较低、概率比较低的数据。热数据,访问、更新频度较高,未来被调用的概率较高的数据。冷数据在业务场景中计算时效要求慢,可以做集中化部署,可以对数据进行压缩、去重等降低成本的方法。热数据因为访问频次需求大,效率要求高,可以高性能存储与就近计算部署; 数据冷热管理最核心目标提高算力利用率,所谓算力通常包含CPU、GPU、内存、带宽等能力,算力瓶颈在于单位时间内处理数据能力。视频、人工智能等领域的算力消耗集中在对大规模数据及参数的“算法”的计算处理。在传统行业领域以结构化数据为主,算力消耗集中在“订单、客户、事件”三大类数据的搬运、数据排序、数据关联、数据合并、数据算术运算、数据的查询等。 希望通过对数据冷热区分,精准识别出“热”数据,减少对“冷数据”的搬运、关联、排序、计算等,把算力集中在刀刃上,实现数据处理“提速、降本”。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190217](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190217) - Gartner发布2022年银行技术趋势,包含隐私增强计算 **摘要:** 数博5月31日消息,Gartner发布了2022年银行和投资服务行业的三大热门技术趋势,分别是:生成式AI、自主系统和隐私增强计算。Gartner指出,这三项趋势将在未来两到三年内继续增长,推动金融服务机构的增长和转型。 Gartner研究副总裁Moutusi Sau表示:“虽然金融服务机构的首要事项是增长,但他们同样需要新的技术创新来管理风险、优化成本和提高效率。银行首席信息官可以通过生成式AI为追求收入增长的业务提供技术解决方案,而自主系统和隐私增强计算是能够为金融服务业务转型带来各种新选项的长期解决方案。” **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189958](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=189958) - 摘取皇冠上的明珠,华为云数据库的创新与探索 **摘要:** 在国内做数据库,是一件很具挑战性的事情,因为这是基础软件皇冠上的明珠,是卡脖子的关键技术。 从海外厂商攻城略池的垄断到国产数据库厂商的艰难成长,从去IOE浪潮下的国产替代再到如今的百花齐放的市场局面,国产数据库产业一路走来,背后都是一批批企业和个人的信念与坚守。 目前,GaussDB立足创新与自研,基于同一架构,一方面拥抱并兼容主流关系型数据库生态如MySQL及非关系型数据库 MongoDB、Redis等生态,另一方面围绕自身开源的openGauss生态,打造面向政企客户,强调高性能、高可靠、高安全的产品。 **文章详情:** [https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190216 ](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190216) 上一期:[【技术之声】第二十一期(20220530)数据库资讯精选](https://bbs.huaweicloud.com/forum/thread-189422-1-1.html) *声明:文章源于第三方公开的信息,如果存在侵权或信息不实时,请及时联系处理。* 整理者:酷哥
-
一、为“数据”降本的背景 信息爆炸的时代数据极速膨胀,数据存储与计算消耗的IT资源、能源日益增长。为了节省能源,例如我国推出了东数西算,腾讯把数据中心装进了贵州山里,微软把数据中心建在海底,“脸书”在犹他州雪山旁建立新数据中心。海底的数据中心建设从硬件、技术角度进行“数据成本”控制。从业务角度对膨胀的数据本身进行“冷热”分级管理,不仅有利于节约“计算成本”,也可以提高业务数据化运营效率。 二、冷热数据定义及意义 冷热数据主要从数据访问频度、更新频度进行划分。冷数据,即实际生产中被访问、更新频度比较低、概率比较低的数据。热数据,访问、更新频度较高,未来被调用的概率较高的数据。冷数据在业务场景中计算时效要求慢,可以做集中化部署,可以对数据进行压缩、去重等降低成本的方法。热数据因为访问频次需求大,效率要求高,可以高性能存储与就近计算部署;数据冷热管理最核心目标提高算力利用率,所谓算力通常包含CPU、GPU、内存、带宽等能力,算力瓶颈在于单位时间内处理数据能力。视频、人工智能等领域的算力消耗集中在对大规模数据及参数的“算法”的计算处理。在传统行业领域以结构化数据为主,算力消耗集中在“订单、客户、事件”三大类数据的搬运、数据排序、数据关联、数据合并、数据算术运算、数据的查询等。希望通过对数据冷热区分,精准识别出“热”数据,减少对“冷数据”的搬运、关联、排序、计算等,把算力集中在刀刃上,实现数据处理“提速、降本”。三、系统架构设计时对数据的“冷热”管理 数据规模控制目前有“冷热分离异构系统”和“冷热分离同构系统”两类架构。“冷热分离异构系统”:将冷热数据根据被访问的频度及概率,一般来说将“时间序列较早,访问频度较低于一定比例”归档转移至另一个系统的进行存储。两套系统拥有不同的存储特性、访问方式等,优先热数据访问性能的同时,降低冷数据的运维成本“冷热分离同构系统”:冷热数据应用同一套规则,同一个数据集群中部署不同配置的机器,不同服务器进HOT/COLD属性标志。高配置服务器管理管理热数据,低配置服务器用于管理冷数据。当创建一个新的Index时,指定其数据分配到Hot属性的机器上;一段时间后,再将其配置修改为分配到Cold属性机器上,Elasticsearch便会自动完成数据迁移。系统级数据的冷热分级管理可以有效提高算力使用效率。图:冷热存储策略全冷存储指数据全部存储在HDD盘,是一种较为经济的存储策略。全热存储指数据全部存储在SSD盘,满足高性能访问的需求。冷热混合存储指一定数量的分区存储在SSD盘,其余数据存储在HDD盘。四、数据结构设计时进行“冷热”管理 传统行业的数据处理不需要像阿尔法狗即时计算出围棋的落子位置,更多的是固化的计算逻辑。因此可以通过“数据分区、计算分时”等策略优化算力利用率数据分区,数据结构设计时从动态与静态维度对数据进行“冷热”分区,减少对“冷数据”的搬运、关联、排序、计算等,降低参与计算的数据规模。计算分时,很多传统领域数据计算步骤是相对固化的、非实时的,可以通过对计算步骤分解在多个时段,平滑并发计算量。1、所谓静态数据主要指事件类数据,描述发生一个事件的数据记录,如保险领域理赔,报案事件、理算记录、结案事件,每个事件包含了对象、时间、事件内容等。静态数据参与的计算主要在于“被搬运、被查询、被关联、被计算”,静态数据本身几乎不进行合并更新计算。对于静态数据中被关联、被计算关键字段可以进行热度标识,参与计算的高频字段可以分配至临时表独立存储,减少统计类计算时加载的数据规模。如:保险领域对理赔事件原始数据字段超过20个,数据“入湖共享”时对高频度报表计算的“案件类型、报案时间、结案时间、金额”4个“热”数据字段拆出一个独立表进行共享,并增加“机构属性标记、客户号、手机号、保单号”关联关键字段(数据规模比原始数据降低3/4)。这样不同机构在开展个性化理赔统计报表分析时(不同分公司报表分析频度、统计样式可以个性化),仅需要加载对应机构的数据,快速完成“客户-理赔”与“保单-理赔”关联计算,减少“客户-保单-理赔”跨表数据搬运及复杂关联。2、动态数据指会时序更新的数据,如客户类的数据“收入、偏好、最近一次交易等”涉及持续更新合并。动态数据消耗的算力集中在“数据更新合并、数据排序、查询、关联”,其中数据的Update涉及较多校验规则。针对动态数据中各字段更新频度进行冷热标识,对于高频度update字段进行独立表管理,避免高频对大宽表的读写操作。如在保险领域,客户高频度更新信息字段主要是“职业、出险次数、最近投保”等和交易关联性强字段,客户数据中台数据结构设计时,对高频update字段独立表写入管理,减少对客户大宽表加载与读写。结语目前在IT行业系统架构设计重视度比较高,在数据结构设计有很大提升空间。如我所在在保险企业业务核心系统为外资产品,运行10多年后进行升级重构时,最大的难题就是数据结构设计,招投标时国内厂商可以在系统结构上给出较为完善的解决方案,但在数据结构上、数据规则上面临很大挑战。
-
5月26日,2022中国国际大数据产业博览会(以下简称“数博会”)线上正式开幕。数博会是全球首个以大数据为主题的博览会,由国家发展和改革委员会、工业和信息化部、国家互联网信息办公室和贵州省人民政府共同主办,是助力全球大数据技术应用和产业发展的重要平台。大会开幕式上,华为高级副总裁、华为云CEO张平安发表主题演讲。聚焦大会主题“抢数字新机,享数字价值”,他在演讲中主张,发挥数据的集聚规模效应,以数智融合重塑数据价值,围绕“一切皆服务”帮助更多企业容易上云、方便上云、用好云:让数据资源在集聚中实现效益最优“东数西算”是把握数字经济发展机遇期、构建算力新格局的重要举措。为加快推动“东数西算”建设,全力打造“中国数谷”,华为云已在贵州布局全球总部和最大的云数据中心,持续发挥数据资源集聚的规模效应,提升资源使用效率。以“数智融合”重塑数据价值数字时代,数据是千行百业重要的生产要素和资产,目前数据的价值仍未充分得以利用,实现高效的数据治理、促进“数智融合”仍是业界难题。华为云着力打造“数智融合”云平台,打通数据治理生产线、AI开发生产线,构建统一的开发环境、统一的元数据管理、统一的存储,让数据开发效率由“周”级提升到“小时”级,大幅降低数据存储成本,让数据和AI开发进入现代化的生产阶段。一切皆服务,让千行百业真正用好云为帮助千行百业的客户容易上云、方便上云、用好云,华为云提出“一切皆服务”,把基础设施、技术以及经验云化、服务化。例如,不少企业缺乏专家和训练数据,未能有效地将AI能力与业务场景结合,因此难以快速开发出AI应用;为此华为云已将AI、大数据,音视频等核心技术云化,集成海量开发工具,让所有客户随取随用,高效开发。同时,华为云持续深耕政府、金融、工业等行业,将华为与伙伴、客户的合作创新以及数字化转型经验沉淀成为云服务,已陆续开放了50多个应用场景,提供超过2万个API服务,让更多企业就不必重复“造轮子”,通过云服务即获得全行业最优秀的数字化经验。本届数博会上,华为云还斩获了多项大奖,涵盖从数据库、数据湖、到数据和AI融合分析的技术创新,以及运用湖仓库AI技术支持的梦饷集团创新实践入选“十佳大数据案例”,充分证明了业界对华为云数据领域技术创新的认可:在数博会的重头戏——“数博发布”特色活动中,华为云GaussDB(for openGauss)分布式数据库斩获领先科技成果“新产品”奖。该奖项是数博会的最高奖项,同时也是唯一以大数据为主题的社会科技奖励,其专业性、权威性、引领性获业界一致认可。 华为云GaussDB(for openGauss) 基于华为主导的开放生态openGauss而打造,是主打政企核心业务负载的金融级分布式数据库旗舰产品。 例如,在工商银行核心交易系统分布式改造过程中,华为云GaussDB提供了完备的一站式数据迁移解决方案,实现高可用、性能线性扩展、弹性部署三大核心价值,助力客户数据库选型安心、迁移放心、管理省心,让核心交易系统可靠性得到了大幅度提升,持续满足未来长期业务发展需求。 华为云数智融合平台为企业在云上打造了统一的数据底座,把原本散落在各个部门和组织的数据统一汇聚到数据湖中,省去开发者关注各种底层的琐碎文件管理,以及大量、复杂的分析引擎、AI引擎和管理运维工作,支持开发者在集成的开发平台上,便捷地使用最新的算法模型挖掘各种数据的潜在价值。 例如,平台助力T3出行将多套集群架构优化至湖仓一体的存算分离架构,同时支撑数据分析的BI和数据智能的AI场景,不仅使TCO降低20%以上,更解决了出行场景下“长尾支付”系统更新慢的难题,数据处理效率提升150%。数智融合,让企业像管理代码一样管理数据,让机器学习的效率更高,提升乘客的安全体验。华为云FusionInsight MRS IoTDB聚焦工业物联网领域的工业复杂时序数据的处理,解决通用数据库在超大规模复杂时序场景的功能短板和性能瓶颈,形成跨越端、边、云的工业物联网大数据的利器。 目前,清华大学和华为云已开展合作,以Apache IoTDB开源组件为基础,持续探索新型的、基于开源社区的“产、学、研”合作模式,加快在华为云FusionInsight MRS云原生数据湖服务中完成IoTDB商用版本开发和集成,进一步完善MRS“三湖一集市”能力,为工业海量时序数据分析提供企业级的时序数据库。IoTDB相关技术已在交通、制造等众多工业级时序数据分析应用中落地。 作为“新电商”领域创新者,梦饷集团全面拥抱云、大数据、AI技术,与华为云合作数据创新,让200万“宝妈”不需要投入成本、无需复杂的数字技术背景,即可利用碎片时间进行数字圈层电商营销。以数据智能进行业务创新和社会价值创造,该案例也入选联合国可持续发展目标(SDGs)最佳案例。在数智融合实践中,梦饷集团实现了TCO下降30%,实时分析能力提升50%。其中,华为云DWS提供涵盖T+1批量分析、流式分析、小微实时分析、IoT分析、交互式分析以及复杂高维业务分析等;华为数仓技术提供了100PB级数据容量,以超大集群、混合负载的关键能力,保障多租户、高并发场景可为用户输出持续稳定的SLA,让梦饷集团轻松应对电商高并发业务挑战。基于超过10年的数据领域研发与投入,华为云以成熟的全生命周期数据治理能力,持续帮助电商、游戏、金融、保险、物流、零售等行业客户实现业务智能,释放企业数据价值。围绕“一切皆服务”,华为云面携手客户、合作伙伴和开发者持续创新,帮助千行百业的客户容易上云、方便上云、用好云。
-
5月26日,在贵州举行的2022中国国际大数据产业博览会“东数西算:构建国家算力网络体系”论坛上,由华为技术有限公司(以下简称“华为”)与国家信息中心、贵州省大数据发展管理局和粤港澳大湾区大数据研究院联合发布了《“碳达峰、碳中和”背景下数据中心绿色高质量发展研究报告》(以下简称《研究报告》)。在推动数据中心绿色高质量发展的技术趋势和解决思路专项建议中,《研究报告》重点阐述了四大存储技术方向。即如何利用全闪存储技术、存算分离架构、数据重删压缩、数据密集型存储等技术推动在“东数西算”的背景下高质量达成数据中心“碳中和、碳达峰”目标。方向一:加速数据中心向“硅进磁退”的闪存化方向演进闪存介质具备高密度、高可靠、低延迟、低能耗等特点,在相同的容量下,闪存相较于HDD的能耗降低70%,性能提升100倍,占用空间节约50%。数据中心存储介质全闪存化是未来发展方向,应逐步提升数据中心存储介质闪存化比例,建议2025年达到50%,2030年达到90%,远期实现100%全闪存化。方向二:推动大数据场景存算分离架构的使用普通的通用型服务器配备硬盘的数量有限,而专门设计的高密存储型节点的密度是传统存储服务器的2~2.6倍,同等容量下能耗节约10%~30%。如在大数据分析场景下,采用存算分离架构的同时利用数据纠删码技术,可进一步把磁盘利用率从33%提升到91%,减少磁盘空间占用,节约能耗。方向三:应用数据重删压缩算法,提高数据存储效率数据重删和数据压缩是通过一系列的算法优化数据存储布局,提高存储效率的技术,进而提高数据存储的能效。尤其在闪存介质快速应用的背景下,更能凸显其价值。如在数据库、桌面云、虚拟机等业务场景下实现2~3.6倍的数据缩减率,耗能节约50%以上。方向四:推广数据密集型集群存储技术数据密集型集群存储是面向中大型绿色节能数据中心打造的存算网融合一体化整柜液冷解决方案。采用高密、大比例EC、存算分离、DPU卸载、数据处理加速、数据高缩减和存储液冷等创新技术,提升数据中心交付效率,缩短上线周期。同时通过一池对接多云,实现跨数据中心统一融合存储资源池,资源利用率提升50%。实施“东数西算”工程,对于推动数据中心合理布局、优化供需、绿色集约和互联互通等意义重大。对数据中心设计、PUE、IT设备等方面都提出了较高的要求。华为依托业内领先的全闪数据中心、数据密集型存储,加快先进存储产业升级,助力数据中心绿色高质量发展。
-
想要通过使用Streamx提交大数据MRS 集群spark/flink作业,是否有相关的安装配置教程?
推荐直播
-
 华为云码道-玩转OpenClaw,在线养虾
华为云码道-玩转OpenClaw,在线养虾2026/03/11 周三 19:00-21:00
刘昱,华为云高级工程师/谈心,华为云技术专家/李海仑,上海圭卓智能科技有限公司CEO
OpenClaw 火爆开发者圈,华为云码道最新推出 Skill ——开发者只需输入一句口令,即可部署一个功能完整的「小龙虾」智能体。直播带你玩转华为云码道,玩转OpenClaw
回顾中 -
 华为云码道-AI时代应用开发利器
华为云码道-AI时代应用开发利器2026/03/18 周三 19:00-20:00
童得力,华为云开发者生态运营总监/姚圣伟,华为云HCDE开发者专家
本次直播由华为专家带你实战应用开发,看华为云码道(CodeArts)代码智能体如何在AI时代让你的创意应用快速落地。更有华为云HCDE开发者专家带你用码道玩转JiuwenClaw,让小艺成为你的AI助理。
回顾中 -
 Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案
Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案2026/03/25 周三 19:00-20:00
余伟,华为云软件研发工程师/万邵业(万少),华为云HCDE开发者专家
本次直播带来两大实战:华为云码道 Skill-Creator 手把手搭建专属知识库 Skill;如何用码道提效 OpenClaw 小说文本,打造从大纲到成稿的 AI 原创小说全链路。技术干货 + OPC创作思路,一次讲透!
回顾中
热门标签