-
 直播时间 12月30日 14:00—15:30 由Gauss松鼠会联合墨天轮、openGauss社区共同主办的专题分享之:“openGauss与PostgreSQL核心技术解读及优势对比” 将于本周四(12月30日)震撼登场。活动详情PostgreSQL 全球开发组于 2021-05-20 发布了 PostgreSQL 14 的第一个 beta 版本且目前已经提供了下载。最新版本的PostgreSQL的更新主要体现在负载情况下的性能优化,增加了数据类型和SQL,增强信息监控能力,逻辑复制的性能以及安全方面的强化。而作为基于PostgreSQL而开发的国产数据库领军产品openGauss也在今年9月30日发布了2.1.0的最新版本。市面上对于PostgreSQL及openGauss之间的对比及讨论一直非常热烈。openGauss毫无疑问在很多方面,尤其是内核增强上,规避了PostgreSQL出现的很多问题,但是相比较老牌的数据库产品,也有很多不足和需要继续进步的地方。活动主题本次直播将针对openGauss及PostgreSQL 进行核心技术的解读与对比,从专业的角度来分析双方产品的核心技术以及自身优势,同时也包括对于数据库国产化发展及生态构建的展望。直播福利本次直播给大家准备了超多精美礼物!届时进入直播间即有机会领取!礼物包括:墨天轮定制黑胶晴雨伞墨天轮定制款蓝牙耳机Gauss松鼠会保温杯Gauss松鼠会无线充电宝套装《openGauss数据库核心技术》 活动嘉宾大会议程扫码立即报名扫描二维码或点击文末“阅读原文”即可报名小伙伴们行动起来吧与大咖对话的机会千万别错过~- END -阅读原文
直播时间 12月30日 14:00—15:30 由Gauss松鼠会联合墨天轮、openGauss社区共同主办的专题分享之:“openGauss与PostgreSQL核心技术解读及优势对比” 将于本周四(12月30日)震撼登场。活动详情PostgreSQL 全球开发组于 2021-05-20 发布了 PostgreSQL 14 的第一个 beta 版本且目前已经提供了下载。最新版本的PostgreSQL的更新主要体现在负载情况下的性能优化,增加了数据类型和SQL,增强信息监控能力,逻辑复制的性能以及安全方面的强化。而作为基于PostgreSQL而开发的国产数据库领军产品openGauss也在今年9月30日发布了2.1.0的最新版本。市面上对于PostgreSQL及openGauss之间的对比及讨论一直非常热烈。openGauss毫无疑问在很多方面,尤其是内核增强上,规避了PostgreSQL出现的很多问题,但是相比较老牌的数据库产品,也有很多不足和需要继续进步的地方。活动主题本次直播将针对openGauss及PostgreSQL 进行核心技术的解读与对比,从专业的角度来分析双方产品的核心技术以及自身优势,同时也包括对于数据库国产化发展及生态构建的展望。直播福利本次直播给大家准备了超多精美礼物!届时进入直播间即有机会领取!礼物包括:墨天轮定制黑胶晴雨伞墨天轮定制款蓝牙耳机Gauss松鼠会保温杯Gauss松鼠会无线充电宝套装《openGauss数据库核心技术》 活动嘉宾大会议程扫码立即报名扫描二维码或点击文末“阅读原文”即可报名小伙伴们行动起来吧与大咖对话的机会千万别错过~- END -阅读原文 -
 有进展了,谢谢。
有进展了,谢谢。 -
最近收到一个客户反馈使用DRS同步后,源库和目标库的数据不一致。数据一致性是DRS的生存之本,团队上下非常重视,收到反馈后马上联系客户了解情况排查原因,最终发现原来是虚惊一场。那么这个“不一致”是怎么产生的?它底层的根本原因又是什么呢?接下来我们一起来挖一挖。 ### 问题现象 客户使用DRS创建了MySQL到PostgreSQL的同步任务,MySQL表中存在一个FLOAT类型的列,DRS任务启动后会在PostgreSQL中对应创建一个FLOAT4的列。同步过程中在MySQL中插入一条FLOAT列值为3.1415926的数据,同步后在源库MySQL中SELECT出来的数据是3.14159,而在目标库PostgrSQL中SELECT出来却是3.1415925。 ### 复现步骤: 1. 在源库建表: ``` CREATE TABLE `float_test` ( `id` int(11) primary key, `id2` float ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ``` 2. 创建DRS任务,同步这张表的数据到PostgreSQL。目标库会自动创建下表: ``` CREATE TABLE "root"."float_test" ( "id" int PRIMARY KEY, "id2" FLOAT4 ) ``` 3. 在源库insert数据: ``` insert into `float_test` values (1, 3.1415926); ``` 4. 数据同步之后 通过mysql客户端查询:  通过postgresql客户端查询: 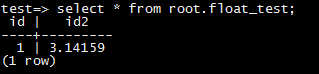 而通过jdbc查询: mysql: 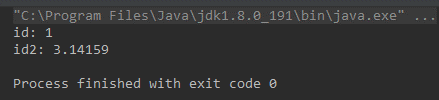 postgresql: 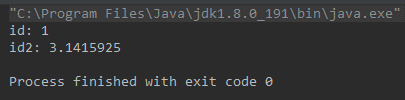 ### 问题原因: mysql底层存储3.1415926的时候,binlog中记录的数据为3.1415925,DRS从binlog中解析出来数据,同步到PostgrSQL的也是3.1415925。 而通过mysql的driver进行select的时候,mysql driver对数据进行了截断,所以查出来是3.14159,而PostgrSQL的driver没有进行截断,导致通过两种driver select出的数据不一致。 如果不想让driver截断,可以在jdbc的url中增加useServerPrepStmts=true的option。
-
运行TPCC,perf top 发现热点函数为tts_buffer_heap_getsomeattrs10%ExecInterpExpr 7%ExecParallelHashTableInsert 6%网上未找到相关联的参数能将热点函数消掉,特来鲲鹏论坛求助解答谢谢
-
1 调优介绍使用HyperTuner系统性能分析工具对PostgreSQL所在系统执行系统全景分析,找到性能瓶颈点,并根据分析结果进行优化修改,从而实现PostgreSQL系统的性能增强。2 组网环境项目说明服务器TaiShan 200 服务器(型号2280)CPUKunpeng 920OSCentOS 8.0应用postgres (PostgreSQL) 11.3调优工具HyperTuner 2.2.T4压力测试工具pgbench (PostgreSQL) 11.3 3 前提条件服务器和操作系统正常运行。PC端已经安装SSH远程登录工具。PostgreSQL数据库环境上HyperTuner工具已经安装完成,并正常运行。PostgreSQL数据库已经安装完成,并启动,并准备2000W条数据。压力测试工具pgbench正常运行。 4 调优思路在进行调优之前,先用pgbench工具测试PostgreSQL运行8个客户端8个线程的性能数据。使用HyperTuner系统性能分析工具针对PostgreSQL应用从全景分析维度进行性能分析,并根据性能分析结果得出性能瓶颈点以及优化方法。针对性能瓶颈点分别进行性能优化。完成优化后,再用pgbench工具测试PostgreSQL运行8个客户端8个线程的性能数据,与调优之前的性能进行对比,判断性能是否有提升。5 操作步骤5.1 调优前数据库性能测试1.运行pgbench程序 执行压测命令pgbench -M prepared -r -c 8 -f /home/test/login.sql -j 8 -n -T 30 -h 127.0.0.1 -p 5432 -U postgres postgres,查看tps和statement latencies in milliseconds 2.执行系统全景性能分析 创建系统全景分析任务,配置参数如下图 查看系统性能指标 从tps参数值中,可以看到sda的tps值为854.75,设备的带宽使用率超过基准值,触发优化建议:磁盘I/O存在问题,建议更换高性能硬盘或检查进程是否有可优化的读写操作。5.2 优化方法1.开启PostgreSQL的异步提交日志,修改PostgreSQL配置文件,执行vim /data/pgsql/postgresql.conf 命令编辑配置文件。 synchronous_commit = off wal_writer_delay = 10ms2.切换postgres用户,执行重启PostgreSQL命令,使配置文件生效。/usr/local/pgsql/bin/pg_ctl -D /data/pgsql -l logfile restart5.3 调优后测试1.创建全景分析任务 2.运行Pgbench,执行压力测试数据库tps从793提升至3276,INSERT和UPDATE的语句延时从5.804ms和4.105ms降低至1.1359ms和0.955ms,性能有所提升。3.查看系统性能指标 系统tps从854提升至1176,设备的带宽使用率降低,未触发优化建议 6 调优结果分析 本实践中,经过对PostgreSQL参数进行了调优后,从pgbench性能和系统性能指标可以看出,性能有所提升。
-
GaussDB和PostgreSQL的区别在哪里?
-
postgresql移植指南中,关于AArch64平台(src/port/pg_crc32c_armv8.c)中描述的“使用__crc32cb/cw/cd/ch”的具体操作方法
-
上个帖子乏人问津,只好自己再说几句。纯粹的性能驱动的数据处理市场已趋于饱和,未来市场的发展方向更多的将是功能和性价比驱动。最能适应未来市场的数据平台将会是云上的全球分布的HTAP数据库,它将结合MPP数据库的并发计划并发执行技术与New SQL的基于时钟的全球分布部署能力和基于共识协议的高可靠模块,能在全球部署下支持HTAP应用,做到One size fits most。典型应用是用以替换原有的单机或集群TP系统,以本地TP为主,分布TP为辅,并增加分布AP能力,可直接访问分布的数据无需ETL。上述构架的优点是在单一系统内,以尽可能小的成本满足绝大多数客户的多样的数据处理需求。阿里云5月底发布的PolarDB for PostgreSQL正是这样的体系,并且直接针对OpenGauss。在数据库国产替换的潮流下将之开源是为了抢夺客户,纯TP的OpenGauss将没有多少竞争能力,华为要想不被彻底甩开,只有跟进同样的构架。所幸现有一条终南捷径,那就是将成熟的基于PostgreSQL的YugabyteDB上的基于混合时钟HLC的分布事务处理模块和基于Raft的HA移植到现有的分布PostgreSQL上。
-
在学习和使用PG过程中,经常会翻阅一些资料,现在我把在这个过程积累得一些高质量的链接分享给大家。如果大家发现很好的链接,也欢迎分享给我,从而改进。官方 =================官方:https://www.postgresql.org/官方仓库:https://git.postgresql.org/gitweb/planet PG:https://planet.postgresql.org/ 包括Top posters、Top teams、Feeds、Planet官方wiki:https://wiki.postgresql.org/wiki/Main_PageWeekly News: https://postgresweekly.com/英文手册:https://www.postgresql.org/docs/中文手册:http://www.postgres.cn/docs/10/中文社区:http://www.postgres.cn/pgadmin:https://www.pgadmin.org/#pg大会:https://postgresconf.org/插件大全:https://pgxn.org/pg欧洲:https://www.postgresql.eu/commitfest: https://commitfest.postgresql.org/厂商 =====================openGauss:https://opengauss.org/zh/富士通: https://www.postgresql.fastware.com/ postgres pro: https://postgrespro.com/二象限:https://www.2ndquadrant.com/en/EDB:https://www.enterprisedb.com/Crunchy Data:https://www.crunchydata.com/PostgreSQL Internal :http://postgresintl.com/HeteroDB:http://heterodb.com/ PG-Strom插件,基于GPU和NVME,大数据处理Cybertec:https://www.cybertec-postgresql.com/时序数据库 timescale:https://docs.timescale.com/https://www.pipelinedb.com/ High-performance time-series aggregationhttps://www.citusdata.com/ 分布式shardinghttps://pgexercises.com/XL官网:https://www.postgres-xl.org/pganalyze:https://pganalyze.com/https://www.elephantsql.com/博客 =====================数据库周报:https://dbweekly.com/issues、二象限博客中心:https://www.2ndquadrant.com/en/blog/PG每周新闻 https://grantzhou.github.io/PostgreSQL-Weekly-News-1-9/Bruce Momjian博客(PG社区co-founder) https://momjian.us/ 最新资讯:http://depesz.com/专注PG数据库维护的一个小团队 https://dataegret.com/news-blog/开源关系型数据库PostgreSQL生态系列资源 https://github.com/liuyuanyuan/FantasticPostgres/internal Postgres:http://www.interdb.jp/pg/index.htmlhttp://postgresguide.com/https://blog.panoply.io/https://pgdba.org/SeveralNines:https://severalnines.com/database-bloghttps://blog.panoply.io/percona:https://www.percona.com/blog其它 =====================https://pgmodeler.io/ PG建模PGTune https://pgtune.leopard.in.ua/#/ 参数优化小工具
-
【功能模块】数据库名称修改;问题描述:使用GaussDB A数据库用户omm登录, 使用gsql命令行修改的默认数据库postgres,提示有连接section正在使用,而连接使用gsql停止命令,停止不掉;问题1:请问默认数据库postgres是不可以修改的是么?问题2:使用数据库用户,我可以一直免密登录postgres,是么?期待专家的接疑,谢谢
-
 活动贴:【打卡帖】0元限时学《7天玩转PostgreSQL基础训练营》,大奖等你来哦!课程链接:https://education.huaweicloud.com/courses/course-v1:HuaweiX+CBUCNXD048+Self-paced/courseware/fb989107b5ea4f368fb11447ea2d8b63/a75cf56dbace4384993b27d81160bd92/课程知识总结:7天玩转PostgreSQL基础训练营(一)7天玩转PostgreSQL基础训练营(二)7天玩转PostgreSQL基础训练营(三)7天玩转PostgreSQL基础训练营(四)7天玩转PostgreSQL基础训练营(五)7天玩转PostgreSQL基础训练营(六)7天玩转PostgreSQL基础训练营(七)
活动贴:【打卡帖】0元限时学《7天玩转PostgreSQL基础训练营》,大奖等你来哦!课程链接:https://education.huaweicloud.com/courses/course-v1:HuaweiX+CBUCNXD048+Self-paced/courseware/fb989107b5ea4f368fb11447ea2d8b63/a75cf56dbace4384993b27d81160bd92/课程知识总结:7天玩转PostgreSQL基础训练营(一)7天玩转PostgreSQL基础训练营(二)7天玩转PostgreSQL基础训练营(三)7天玩转PostgreSQL基础训练营(四)7天玩转PostgreSQL基础训练营(五)7天玩转PostgreSQL基础训练营(六)7天玩转PostgreSQL基础训练营(七) -
内核优化 1. 进程模型改为线程模型 2. 高可用架构增强 3. 使用etcd集群存储全局事务号 4. XID事务号从32位改为64位 5. GTM性能增强 6. 流复制增强
-
 PostgreSql数据库的重建索引时通过REINDEX命令来实现的,如reindexindex_name;其语法是:REINDEX { INDEX | TABLE | DATABASE | SYSTEM } name [ FORCE ];下面解释下说明情况下需要:1、当由于软件bug或者硬件原因导致的索引不再可用,索引的数据不再可用;2、当索引包含许多空的或者近似于空的页,这个在b-tree索引会发生。Reindex会腾出空间释放哪些无用的页(页就是存放数据的一个单位,类似于block)。3、PostgreSql数据库系统修改了存储参数,需要重建不然就会失效(如修改了fillfactor参数);4、创建并发索引时失败,遗留了一个失效的索引。这样的索引不会被使用,但重构后能用。一个索引的重构不能并发的执行。下面介绍下重构索引命令的参数:1、INDEX 重构指定的索引;2、TABLE 重构指定表的所有索引,包括下级TOAST表;3、DATABASE重构指定数据库的所有索引,系统共享索引也会被执行。需要注意的是这个级别的重构不能再一个事务块中执行。4、SYSTEM 重构这个系统的索引包含当前的数据库。共享系统中的索引页是被包含的,但是用户自己的表是不处理的,同样也不能在一个事务块中执行。5、Name 按照不同级别索引的名称。6、FORCE 已经被废除即使写了也是被忽略的。示例:REINDEX INDEX my_index; REINDEX TABLE my_table; REINDEX DATABASE broken_db;另外需要注意的是:1、重建索引不同的级别的重构需要不同的权限,比如table那么就需要有这个表的权限即需要有操作索引的权限,如超级用户postgres拥有这个权限。2、重构索引的目的是为了当索引的数据不可信时,即对于成本的计算会出现偏差较大,无益于优化器得到最优的执行计划以至于性能优化失败。3、重构索引类似于先删除所有再创建一个索引,但是索引的条目是重新开始的。重构时当前索引是不能写的,因为此时有排他锁。4、在8,1版本之前REINDEX DATABASE 只包含系统索引,并不是期望的所有指定数据库的索引。7.4版本之前REINDEX TABLE不会自动执行下级TOAST tables。关于TOAST tables的含义:TOAST直接翻译的话就是切片面包(slicedbread)的意思,全称是The Oversized-Attribute Storage Technique,为什么会有OVERSIZED-ATTRIBUTE呢?原因很简单,因为在PostgreSQL,一条记录不能跨PAGE存储,跨越PAGE的话必须使用TOAST(即unaligned,与原表分开存储)存储。TOAST表不能独立创建,只有当普通表包含了main,extended或external存储格式的字段时,系统会自动创建一个和普通表关联的TOAST表。当一条记录(tuple)在存储时(如果压缩的话算压缩后的大小)大于TOAST_TUPLE_THRESHOLD(通常是2kB)这个值时,会存储到TOAST表。而此时在普通表的该字段处包含了一个指向TOAST的tableoid和chunk_id的数据,从而能够找到该字段的记录。
PostgreSql数据库的重建索引时通过REINDEX命令来实现的,如reindexindex_name;其语法是:REINDEX { INDEX | TABLE | DATABASE | SYSTEM } name [ FORCE ];下面解释下说明情况下需要:1、当由于软件bug或者硬件原因导致的索引不再可用,索引的数据不再可用;2、当索引包含许多空的或者近似于空的页,这个在b-tree索引会发生。Reindex会腾出空间释放哪些无用的页(页就是存放数据的一个单位,类似于block)。3、PostgreSql数据库系统修改了存储参数,需要重建不然就会失效(如修改了fillfactor参数);4、创建并发索引时失败,遗留了一个失效的索引。这样的索引不会被使用,但重构后能用。一个索引的重构不能并发的执行。下面介绍下重构索引命令的参数:1、INDEX 重构指定的索引;2、TABLE 重构指定表的所有索引,包括下级TOAST表;3、DATABASE重构指定数据库的所有索引,系统共享索引也会被执行。需要注意的是这个级别的重构不能再一个事务块中执行。4、SYSTEM 重构这个系统的索引包含当前的数据库。共享系统中的索引页是被包含的,但是用户自己的表是不处理的,同样也不能在一个事务块中执行。5、Name 按照不同级别索引的名称。6、FORCE 已经被废除即使写了也是被忽略的。示例:REINDEX INDEX my_index; REINDEX TABLE my_table; REINDEX DATABASE broken_db;另外需要注意的是:1、重建索引不同的级别的重构需要不同的权限,比如table那么就需要有这个表的权限即需要有操作索引的权限,如超级用户postgres拥有这个权限。2、重构索引的目的是为了当索引的数据不可信时,即对于成本的计算会出现偏差较大,无益于优化器得到最优的执行计划以至于性能优化失败。3、重构索引类似于先删除所有再创建一个索引,但是索引的条目是重新开始的。重构时当前索引是不能写的,因为此时有排他锁。4、在8,1版本之前REINDEX DATABASE 只包含系统索引,并不是期望的所有指定数据库的索引。7.4版本之前REINDEX TABLE不会自动执行下级TOAST tables。关于TOAST tables的含义:TOAST直接翻译的话就是切片面包(slicedbread)的意思,全称是The Oversized-Attribute Storage Technique,为什么会有OVERSIZED-ATTRIBUTE呢?原因很简单,因为在PostgreSQL,一条记录不能跨PAGE存储,跨越PAGE的话必须使用TOAST(即unaligned,与原表分开存储)存储。TOAST表不能独立创建,只有当普通表包含了main,extended或external存储格式的字段时,系统会自动创建一个和普通表关联的TOAST表。当一条记录(tuple)在存储时(如果压缩的话算压缩后的大小)大于TOAST_TUPLE_THRESHOLD(通常是2kB)这个值时,会存储到TOAST表。而此时在普通表的该字段处包含了一个指向TOAST的tableoid和chunk_id的数据,从而能够找到该字段的记录。 -
ostgreSQL sql放入文件,登入数据库之后批量执行1. 建立测试sql:vi aa.sql插入:猜测每条sql语句是用;分隔的,function中的多个;也会自动识别。create table tb1(id integer); insert into tb1 select generate_series(1,10); select * from tb1; delete from tb1 where id<3; select * from tb1;2. 将aa.sql放入 ./src/postgresql-9.3.5/src/tutorial下(./src/postgresql-9.3.5/src/tutorial是PostgreSQL自动识别的目录,当然也可以放在任意目录,比如/home/postgres/aa.sql)3. 切换用户登入su postgres psql postgres4. 执行:当输入\i时候,会自动检测到./src/postgresql-9.3.5/src/tutorial下的文件,PostgreSQL的测试例子也放在此目录下postgres=# \i aa.sql (\i /home/postgres/aa.sql) id | name ----+------ 1 | join 2 | join 3 | join 4 | join 5 | join 6 | join 7 | join 8 | join 9 | join 10 | join (10 rows) CREATE TABLE INSERT 0 10 id ---- 1 2 3 4 5 6 7 8 9 10 (10 rows) DELETE 2 id ---- 3 4 5 6 7 8 9 10 (8 rows) postgres=# 第二个例子:vi bb.sql:写入一个function:create function func1()returns void as $$ declare begin delete from person where id>5; delete from tb1 where id>5; end $$language plpgsql; select func1();切换到postgres,登入之后执行:执行前:postgres=# select * from person ; id | name ----+------ 1 | join 2 | join 3 | join 4 | join 5 | join 6 | join 7 | join 8 | join 9 | join 10 | join (10 rows) postgres=# select * from tb1 ; id ---- 3 4 5 6 7 8 9 10 (8 rows)执行:postgres=# \i bb.sql CREATE FUNCTION func1 ------- (1 row)执行后:postgres=# select * from person ; id | name ----+------ 1 | join 2 | join 3 | join 4 | join 5 | join (5 rows) postgres=# select * from tb1 ; id ---- 3 4 5 (3 rows) postgres=# 5. 也可以使用psql命令执行pslq -d postgres -U postgres -f /home/postgres/aa.sql
-
roach备份一个gaussdb A库到磁盘上,然后在另一个gaussdb集群中按照roach restore clean restore-new-cluster进行恢复,恢复报找不到config文件.查看日志发现clean过程把postgresql.conf等文件都删除了,然后另一个gaussdb集群就挂了。然后尝试启动集群也起不来了也是报pg等配置文件没有。问要怎么处理?重装另一个gaussdb集群?这个恢复过程问题出在哪儿?
推荐直播
-
 华为云码道 × 仓颉编程:工程化AI编码探索
华为云码道 × 仓颉编程:工程化AI编码探索2026/05/27 周三 19:00-21:00
刘俊杰-华为云仓颉语言专家/李炎-华为云码道技术专家/王智鹏-OpenCangjie开源社区发起人
本场直播围绕华为云仓颉语言与华为云码道的深度结合,展示华为云智能编程从零基础到高效落地的完整生态能力。以华为云码道为引擎,仓颉语言为载体,带给大家日常提效、趣味创新到极速量产的开发体验。
回顾中
热门标签