-
 01 死锁的概念在多线程编程中,我们为了防止多线程竞争共享资源而导致数据错乱,都会在操作共享资源之前加上互斥锁,只有成功获得到锁的线程,才能操作共享资源,获取不到锁的线程就只能等待,直到锁被释放。那么,当两个线程为了保护两个不同的共享资源而使用了两个互斥锁,那么这两个互斥锁应用不当的时候,可能会造成两个线程都在等待对方释放锁,在没有外力的作用下,这些线程会一直相互等待,就没办法继续运行,这种情况就是发生了死锁。举个例子,小林拿了小美房间的钥匙,而小林在自己的房间里,小美拿了小林房间的钥匙,而小美也在自己的房间里。如果小林要从自己的房间里出去,必须拿到小美手中的钥匙,但是小美要出去,又必须拿到小林手中的钥匙,这就形成了死锁。死锁只有同时满足以下四个条件才会发生:互斥条件;持有并等待条件;不可剥夺条件;环路等待条件;1.1 互斥条件互斥条件是指多个线程不能同时使用同一个资源。比如下图,如果线程 A 已经持有的资源,不能再同时被线程 B 持有,如果线程 B 请求获取线程 A 已经占用的资源,那线程 B 只能等待,直到线程 A 释放了资源。1.2 持有并等待条件持有并等待条件是指,当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。1.3 不可剥夺条件不可剥夺条件是指,当线程已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。1.4 环路等待条件环路等待条件指都是,在死锁发生的时候,两个线程获取资源的顺序构成了环形链。比如,线程 A 已经持有资源 2,而想请求资源 1, 线程 B 已经获取了资源 1,而想请求资源 2,这就形成资源请求等待的环形图02 模拟死锁问题的产生Talk is cheap. Show me the code.下面,我们用代码来模拟死锁问题的产生。首先,我们先创建 2 个线程,分别为线程 A 和 线程 B,然后有两个互斥锁,分别是 mutex_A 和 mutex_B,代码如下:pthread_mutex_t mutex_A = PTHREAD_MUTEX_INITIALIZER;pthread_mutex_t mutex_B = PTHREAD_MUTEX_INITIALIZER;int main(){ pthread_t tidA, tidB; //创建两个线程 pthread_create(&tidA, NULL, threadA_proc, NULL); pthread_create(&tidB, NULL, threadB_proc, NULL); pthread_join(tidA, NULL); pthread_join(tidB, NULL); printf("exit\n"); return 0;}接下来,我们看下线程 A 函数做了什么。//线程函数 Avoid *threadA_proc(void *data){ printf("thread A waiting get ResourceA \n"); pthread_mutex_lock(&mutex_A); printf("thread A got ResourceA \n"); sleep(1); printf("thread A waiting get ResourceB \n"); pthread_mutex_lock(&mutex_B); printf("thread A got ResourceB \n"); pthread_mutex_unlock(&mutex_B); pthread_mutex_unlock(&mutex_A); return (void *)0;}可以看到,线程 A 函数的过程:先获取互斥锁 A,然后睡眠 1 秒;再获取互斥锁 B,然后释放互斥锁 B;最后释放互斥锁 A;//线程函数 Bvoid *threadB_proc(void *data){ printf("thread B waiting get ResourceB \n"); pthread_mutex_lock(&mutex_B); printf("thread B got ResourceB \n"); sleep(1); printf("thread B waiting get ResourceA \n"); pthread_mutex_lock(&mutex_A); printf("thread B got ResourceA \n"); pthread_mutex_unlock(&mutex_A); pthread_mutex_unlock(&mutex_B); return (void *)0;}可以看到,线程 B 函数的过程:先获取互斥锁 B,然后睡眠 1 秒;再获取互斥锁 A,然后释放互斥锁 A;最后释放互斥锁 B;然后,我们运行这个程序,运行结果如下:thread B waiting get ResourceB thread B got ResourceB thread A waiting get ResourceA thread A got ResourceA thread B waiting get ResourceA thread A waiting get ResourceB // 阻塞中。。。可以看到线程 B 在等待互斥锁 A 的释放,线程 A 在等待互斥锁 B 的释放,双方都在等待对方资源的释放,很明显,产生了死锁问题。03 利用工具排查死锁问题如果你想排查你的 Java 程序是否死锁,则可以使用 jstack 工具,它是 jdk 自带的线程堆栈分析工具。由于小林的死锁代码例子是 C 写的,在 Linux 下,我们可以使用 pstack + gdb 工具来定位死锁问题。pstack 命令可以显示每个线程的栈跟踪信息(函数调用过程),它的使用方式也很简单,只需要 pstack <pid> 就可以了。那么,在定位死锁问题时,我们可以多次执行 pstack 命令查看线程的函数调用过程,多次对比结果,确认哪几个线程一直没有变化,且是因为在等待锁,那么大概率是由于死锁问题导致的。我用 pstack 输出了我前面模拟死锁问题的进程的所有线程的情况,我多次执行命令后,其结果都一样可以看到,Thread 2 和 Thread 3 一直阻塞获取锁(pthread_mutex_lock)的过程,而且 pstack 多次输出信息都没有变化,那么可能大概率发生了死锁。但是,还不能够确认这两个线程是在互相等待对方的锁的释放,因为我们看不到它们是等在哪个锁对象,于是我们可以使用 gdb 工具进一步确认。整个 gdb 调试过程,如下:// gdb 命令$ gdb -p 87746// 打印所有的线程信息(gdb) info thread 3 Thread 0x7f60a610a700 (LWP 87747) 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0 2 Thread 0x7f60a5709700 (LWP 87748) 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0* 1 Thread 0x7f60a610c700 (LWP 87746) 0x0000003720e080e5 in pthread_join () from /lib64/libpthread.so.0//最左边的 * 表示 gdb 锁定的线程,切换到第二个线程去查看// 切换到第2个线程(gdb) thread 2[Switching to thread 2 (Thread 0x7f60a5709700 (LWP 87748))]#0 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0 // bt 可以打印函数堆栈,却无法看到函数参数,跟 pstack 命令一样 (gdb) bt#0 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0#1 0x0000003720e093ca in _L_lock_829 () from /lib64/libpthread.so.0#2 0x0000003720e09298 in pthread_mutex_lock () from /lib64/libpthread.so.0#3 0x0000000000400792 in threadB_proc (data=0x0) at dead_lock.c:25#4 0x0000003720e07893 in start_thread () from /lib64/libpthread.so.0#5 0x00000037206f4bfd in clone () from /lib64/libc.so.6// 打印第三帧信息,每次函数调用都会有压栈的过程,而 frame 则记录栈中的帧信息(gdb) frame 3#3 0x0000000000400792 in threadB_proc (data=0x0) at dead_lock.c:2527 printf("thread B waiting get ResourceA \n");28 pthread_mutex_lock(&mutex_A);// 打印mutex_A的值 , __owner表示gdb中标示线程的值,即LWP(gdb) p mutex_A$1 = {__data = {__lock = 2, __count = 0, __owner = 87747, __nusers = 1, __kind = 0, __spins = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = "\002\000\000\000\000\000\000\000\303V\001\000\001", '\000' <repeats 26 times>, __align = 2}// 打印mutex_B的值 , __owner表示gdb中标示线程的值,即LWP(gdb) p mutex_B$2 = {__data = {__lock = 2, __count = 0, __owner = 87748, __nusers = 1, __kind = 0, __spins = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = "\002\000\000\000\000\000\000\000\304V\001\000\001", '\000' <repeats 26 times>, __align = 2}我来解释下,上面的调试过程:通过 info thread 打印了所有的线程信息,可以看到有 3 个 线程,一个是主线程(LWP 87746),另外两个都是我们自己创建的线程(LWP 87747 和 87748);通过 thread 2,将切换到第2个线程(LWP 87748);通过 bt,打印线程的调用栈信息,可以看到有 threadB_proc 函数,说明这个是线程B函数,也就说 LWP 87748 是线程 B;通过 frame 3,打印调用栈中的第三个帧的信息,可以看到线程 B 函数,在获取互斥锁 A 的时候阻塞了;通过 p mutex_A,打印互斥锁 A 对象信息,可以看到它被 LWP 为 87747(线程 A) 的线程持有者;通过 p mutex_B,打印互斥锁 A 对象信息,可以看到他被 LWP 为 87748 (线程 B) 的线程持有者;因为线程 B 在等待线程 A 所持有的 mutex_A, 而同时线程 A 又在等待线程 B 所拥有的mutex_B, 所以可以断定该程序发生了死锁04 避免死锁问题的发生前面我们提到,产生死锁的四个必要条件是:互斥条件、持有并等待条件、不可剥夺条件、环路等待条件。那么避免死锁问题就只需要破环其中一个条件就可以,最常见的并且可行的就是使用资源有序分配法,来破环环路等待条件。那什么是资源有序分配法呢?线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 是先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。我们使用资源有序分配法的方式来修改前面发生死锁的代码,我们可以不改动线程 A 的代码。我们先要清楚线程 A 获取资源的顺序,它是先获取互斥锁 A,然后获取互斥锁 B。所以我们只需将线程 B 改成以相同顺序地获取资源,就可以打破死锁了。总结简单来说,死锁问题的产生是由两个或者以上线程并行执行的时候,争夺资源而互相等待造成的。死锁只有同时满足互斥、持有并等待、不可剥夺、环路等待这四个条件的时候才会发生。所以要避免死锁问题,就是要破坏其中一个条件即可,最常用的方法就是使用资源有序分配法来破坏环路等待条件。
01 死锁的概念在多线程编程中,我们为了防止多线程竞争共享资源而导致数据错乱,都会在操作共享资源之前加上互斥锁,只有成功获得到锁的线程,才能操作共享资源,获取不到锁的线程就只能等待,直到锁被释放。那么,当两个线程为了保护两个不同的共享资源而使用了两个互斥锁,那么这两个互斥锁应用不当的时候,可能会造成两个线程都在等待对方释放锁,在没有外力的作用下,这些线程会一直相互等待,就没办法继续运行,这种情况就是发生了死锁。举个例子,小林拿了小美房间的钥匙,而小林在自己的房间里,小美拿了小林房间的钥匙,而小美也在自己的房间里。如果小林要从自己的房间里出去,必须拿到小美手中的钥匙,但是小美要出去,又必须拿到小林手中的钥匙,这就形成了死锁。死锁只有同时满足以下四个条件才会发生:互斥条件;持有并等待条件;不可剥夺条件;环路等待条件;1.1 互斥条件互斥条件是指多个线程不能同时使用同一个资源。比如下图,如果线程 A 已经持有的资源,不能再同时被线程 B 持有,如果线程 B 请求获取线程 A 已经占用的资源,那线程 B 只能等待,直到线程 A 释放了资源。1.2 持有并等待条件持有并等待条件是指,当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。1.3 不可剥夺条件不可剥夺条件是指,当线程已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。1.4 环路等待条件环路等待条件指都是,在死锁发生的时候,两个线程获取资源的顺序构成了环形链。比如,线程 A 已经持有资源 2,而想请求资源 1, 线程 B 已经获取了资源 1,而想请求资源 2,这就形成资源请求等待的环形图02 模拟死锁问题的产生Talk is cheap. Show me the code.下面,我们用代码来模拟死锁问题的产生。首先,我们先创建 2 个线程,分别为线程 A 和 线程 B,然后有两个互斥锁,分别是 mutex_A 和 mutex_B,代码如下:pthread_mutex_t mutex_A = PTHREAD_MUTEX_INITIALIZER;pthread_mutex_t mutex_B = PTHREAD_MUTEX_INITIALIZER;int main(){ pthread_t tidA, tidB; //创建两个线程 pthread_create(&tidA, NULL, threadA_proc, NULL); pthread_create(&tidB, NULL, threadB_proc, NULL); pthread_join(tidA, NULL); pthread_join(tidB, NULL); printf("exit\n"); return 0;}接下来,我们看下线程 A 函数做了什么。//线程函数 Avoid *threadA_proc(void *data){ printf("thread A waiting get ResourceA \n"); pthread_mutex_lock(&mutex_A); printf("thread A got ResourceA \n"); sleep(1); printf("thread A waiting get ResourceB \n"); pthread_mutex_lock(&mutex_B); printf("thread A got ResourceB \n"); pthread_mutex_unlock(&mutex_B); pthread_mutex_unlock(&mutex_A); return (void *)0;}可以看到,线程 A 函数的过程:先获取互斥锁 A,然后睡眠 1 秒;再获取互斥锁 B,然后释放互斥锁 B;最后释放互斥锁 A;//线程函数 Bvoid *threadB_proc(void *data){ printf("thread B waiting get ResourceB \n"); pthread_mutex_lock(&mutex_B); printf("thread B got ResourceB \n"); sleep(1); printf("thread B waiting get ResourceA \n"); pthread_mutex_lock(&mutex_A); printf("thread B got ResourceA \n"); pthread_mutex_unlock(&mutex_A); pthread_mutex_unlock(&mutex_B); return (void *)0;}可以看到,线程 B 函数的过程:先获取互斥锁 B,然后睡眠 1 秒;再获取互斥锁 A,然后释放互斥锁 A;最后释放互斥锁 B;然后,我们运行这个程序,运行结果如下:thread B waiting get ResourceB thread B got ResourceB thread A waiting get ResourceA thread A got ResourceA thread B waiting get ResourceA thread A waiting get ResourceB // 阻塞中。。。可以看到线程 B 在等待互斥锁 A 的释放,线程 A 在等待互斥锁 B 的释放,双方都在等待对方资源的释放,很明显,产生了死锁问题。03 利用工具排查死锁问题如果你想排查你的 Java 程序是否死锁,则可以使用 jstack 工具,它是 jdk 自带的线程堆栈分析工具。由于小林的死锁代码例子是 C 写的,在 Linux 下,我们可以使用 pstack + gdb 工具来定位死锁问题。pstack 命令可以显示每个线程的栈跟踪信息(函数调用过程),它的使用方式也很简单,只需要 pstack <pid> 就可以了。那么,在定位死锁问题时,我们可以多次执行 pstack 命令查看线程的函数调用过程,多次对比结果,确认哪几个线程一直没有变化,且是因为在等待锁,那么大概率是由于死锁问题导致的。我用 pstack 输出了我前面模拟死锁问题的进程的所有线程的情况,我多次执行命令后,其结果都一样可以看到,Thread 2 和 Thread 3 一直阻塞获取锁(pthread_mutex_lock)的过程,而且 pstack 多次输出信息都没有变化,那么可能大概率发生了死锁。但是,还不能够确认这两个线程是在互相等待对方的锁的释放,因为我们看不到它们是等在哪个锁对象,于是我们可以使用 gdb 工具进一步确认。整个 gdb 调试过程,如下:// gdb 命令$ gdb -p 87746// 打印所有的线程信息(gdb) info thread 3 Thread 0x7f60a610a700 (LWP 87747) 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0 2 Thread 0x7f60a5709700 (LWP 87748) 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0* 1 Thread 0x7f60a610c700 (LWP 87746) 0x0000003720e080e5 in pthread_join () from /lib64/libpthread.so.0//最左边的 * 表示 gdb 锁定的线程,切换到第二个线程去查看// 切换到第2个线程(gdb) thread 2[Switching to thread 2 (Thread 0x7f60a5709700 (LWP 87748))]#0 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0 // bt 可以打印函数堆栈,却无法看到函数参数,跟 pstack 命令一样 (gdb) bt#0 0x0000003720e0da1d in __lll_lock_wait () from /lib64/libpthread.so.0#1 0x0000003720e093ca in _L_lock_829 () from /lib64/libpthread.so.0#2 0x0000003720e09298 in pthread_mutex_lock () from /lib64/libpthread.so.0#3 0x0000000000400792 in threadB_proc (data=0x0) at dead_lock.c:25#4 0x0000003720e07893 in start_thread () from /lib64/libpthread.so.0#5 0x00000037206f4bfd in clone () from /lib64/libc.so.6// 打印第三帧信息,每次函数调用都会有压栈的过程,而 frame 则记录栈中的帧信息(gdb) frame 3#3 0x0000000000400792 in threadB_proc (data=0x0) at dead_lock.c:2527 printf("thread B waiting get ResourceA \n");28 pthread_mutex_lock(&mutex_A);// 打印mutex_A的值 , __owner表示gdb中标示线程的值,即LWP(gdb) p mutex_A$1 = {__data = {__lock = 2, __count = 0, __owner = 87747, __nusers = 1, __kind = 0, __spins = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = "\002\000\000\000\000\000\000\000\303V\001\000\001", '\000' <repeats 26 times>, __align = 2}// 打印mutex_B的值 , __owner表示gdb中标示线程的值,即LWP(gdb) p mutex_B$2 = {__data = {__lock = 2, __count = 0, __owner = 87748, __nusers = 1, __kind = 0, __spins = 0, __list = {__prev = 0x0, __next = 0x0}}, __size = "\002\000\000\000\000\000\000\000\304V\001\000\001", '\000' <repeats 26 times>, __align = 2}我来解释下,上面的调试过程:通过 info thread 打印了所有的线程信息,可以看到有 3 个 线程,一个是主线程(LWP 87746),另外两个都是我们自己创建的线程(LWP 87747 和 87748);通过 thread 2,将切换到第2个线程(LWP 87748);通过 bt,打印线程的调用栈信息,可以看到有 threadB_proc 函数,说明这个是线程B函数,也就说 LWP 87748 是线程 B;通过 frame 3,打印调用栈中的第三个帧的信息,可以看到线程 B 函数,在获取互斥锁 A 的时候阻塞了;通过 p mutex_A,打印互斥锁 A 对象信息,可以看到它被 LWP 为 87747(线程 A) 的线程持有者;通过 p mutex_B,打印互斥锁 A 对象信息,可以看到他被 LWP 为 87748 (线程 B) 的线程持有者;因为线程 B 在等待线程 A 所持有的 mutex_A, 而同时线程 A 又在等待线程 B 所拥有的mutex_B, 所以可以断定该程序发生了死锁04 避免死锁问题的发生前面我们提到,产生死锁的四个必要条件是:互斥条件、持有并等待条件、不可剥夺条件、环路等待条件。那么避免死锁问题就只需要破环其中一个条件就可以,最常见的并且可行的就是使用资源有序分配法,来破环环路等待条件。那什么是资源有序分配法呢?线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 是先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。我们使用资源有序分配法的方式来修改前面发生死锁的代码,我们可以不改动线程 A 的代码。我们先要清楚线程 A 获取资源的顺序,它是先获取互斥锁 A,然后获取互斥锁 B。所以我们只需将线程 B 改成以相同顺序地获取资源,就可以打破死锁了。总结简单来说,死锁问题的产生是由两个或者以上线程并行执行的时候,争夺资源而互相等待造成的。死锁只有同时满足互斥、持有并等待、不可剥夺、环路等待这四个条件的时候才会发生。所以要避免死锁问题,就是要破坏其中一个条件即可,最常用的方法就是使用资源有序分配法来破坏环路等待条件。 -
 >摘要:本文我们就来说说使用ReadWriteLock如何实现一个通用的缓存中心。 本文分享自华为云社区《[【高并发】原来ReadWriteLock也能开发高性能缓存,看完我也能和面试官好好聊聊了!](https://bbs.huaweicloud.com/blogs/357370?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 冰 河。 在实际工作中,有一种非常普遍的并发场景:那就是读多写少的场景。在这种场景下,为了优化程序的性能,我们经常使用缓存来提高应用的访问性能。因为缓存非常适合使用在读多写少的场景中。而在并发场景中,Java SDK中提供了ReadWriteLock来满足读多写少的场景。本文我们就来说说使用ReadWriteLock如何实现一个通用的缓存中心。 本文涉及的知识点有:  # 读写锁 说起读写锁,相信小伙伴们并不陌生。总体来说,读写锁需要遵循以下原则: - 一个共享变量允许同时被多个读线程读取到。 - 一个共享变量在同一时刻只能被一个写线程进行写操作。 - 一个共享变量在被写线程执行写操作时,此时这个共享变量不能被读线程执行读操作。 **这里,需要小伙伴们注意的是:读写锁和互斥锁的一个重要的区别就是:读写锁允许多个线程同时读共享变量,而互斥锁不允许。所以,在高并发场景下,读写锁的性能要高于互斥锁。但是,读写锁的写操作是互斥的,也就是说,使用读写锁时,一个共享变量在被写线程执行写操作时,此时这个共享变量不能被读线程执行读操作。** 读写锁支持公平模式和非公平模式,具体是在ReentrantReadWriteLock的构造方法中传递一个boolean类型的变量来控制。 ``` public ReentrantReadWriteLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); readerLock = new ReadLock(this); writerLock = new WriteLock(this); } ``` **另外,需要注意的一点是:在读写锁中,读锁调用newCondition()会抛出UnsupportedOperationException异常,也就是说:读锁不支持条件变量。** # 缓存实现 这里,我们使用ReadWriteLock快速实现一个缓存的通用工具类,总体代码如下所示。 ``` public class ReadWriteLockCache { private final Map m = new HashMap(); private final ReadWriteLock rwl = new ReentrantReadWriteLock(); // 读锁 private final Lock r = rwl.readLock(); // 写锁 private final Lock w = rwl.writeLock(); // 读缓存 public V get(K key) { r.lock(); try { return m.get(key); } finally { r.unlock(); } } // 写缓存 public V put(K key, V value) { w.lock(); try { return m.put(key, value); } finally { w.unlock(); } } } ``` 可以看到,在ReadWriteLockCache中,我们定义了两个泛型类型,K代表缓存的Key,V代表缓存的value。在ReadWriteLockCache类的内部,我们使用Map来缓存相应的数据,小伙伴都都知道HashMap并不是线程安全的类,所以,这里使用了读写锁来保证线程的安全性,例如,我们在get()方法中使用了读锁,get()方法可以被多个线程同时执行读操作;put()方法内部使用写锁,也就是说,put()方法在同一时刻只能有一个线程对缓存进行写操作。 **这里需要注意的是**:无论是读锁还是写锁,锁的释放操作都需要放到finally{}代码块中。 在以往的经验中,有两种向缓存中加载数据的方式,**一种是:项目启动时,将数据全量加载到缓存中,一种是在项目运行期间,按需加载所需要的缓存数据。**  接下来,我们就分别来看看全量加载缓存和按需加载缓存的方式。 # 全量加载缓存 全量加载缓存相对来说比较简单,就是在项目启动的时候,将数据一次性加载到缓存中,这种情况适用于缓存数据量不大,数据变动不频繁的场景,例如:可以缓存一些系统中的数据字典等信息。整个缓存加载的大体流程如下所示。 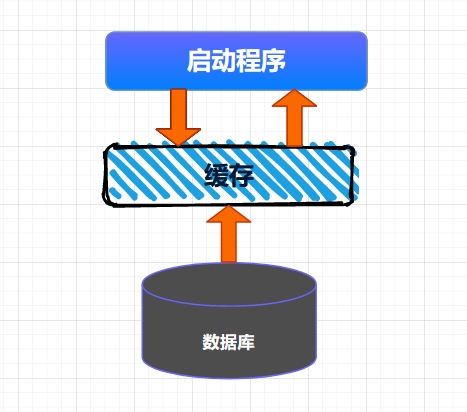 将数据全量加载到缓存后,后续就可以直接从缓存中读取相应的数据了。 全量加载缓存的代码实现比较简单,这里,我就直接使用如下代码进行演示。 ``` public class ReadWriteLockCache { private final Map m = new HashMap(); private final ReadWriteLock rwl = new ReentrantReadWriteLock(); // 读锁 private final Lock r = rwl.readLock(); // 写锁 private final Lock w = rwl.writeLock(); public ReadWriteLockCache(){ //查询数据库 List> list = .....; if(!CollectionUtils.isEmpty(list)){ list.parallelStream().forEach((f) ->{ m.put(f.getK(), f.getV); }); } } // 读缓存 public V get(K key) { r.lock(); try { return m.get(key); } finally { r.unlock(); } } // 写缓存 public V put(K key, V value) { w.lock(); try { return m.put(key, value); } finally { w.unlock(); } } } ``` # 按需加载缓存 按需加载缓存也可以叫作懒加载,就是说:需要加载的时候才会将数据加载到缓存。具体来说:就是程序启动的时候,不会将数据加载到缓存,当运行时,需要查询某些数据,首先检测缓存中是否存在需要的数据,如果存在,则直接读取缓存中的数据,如果不存在,则到数据库中查询数据,并将数据写入缓存。后续的读取操作,因为缓存中已经存在了相应的数据,直接返回缓存的数据即可。 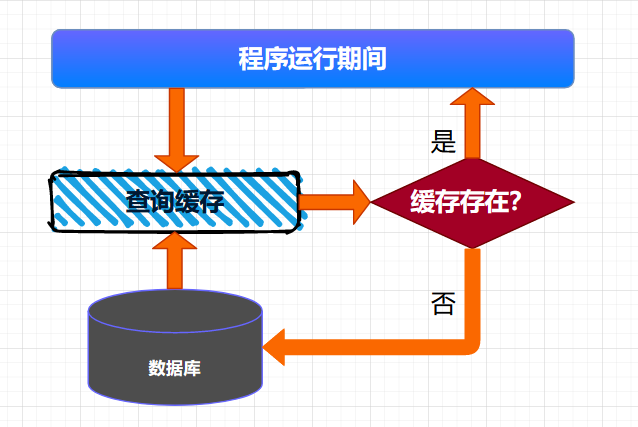 这种查询缓存的方式适用于大多数缓存数据的场景。 我们可以使用如下代码来表示按需查询缓存的业务。 ``` class ReadWriteLockCache { private final Map m = new HashMap(); private final ReadWriteLock rwl = new ReentrantReadWriteLock(); private final Lock r = rwl.readLock(); private final Lock w = rwl.writeLock(); V get(K key) { V v = null; //读缓存 r.lock(); try { v = m.get(key); } finally{ r.unlock(); } //缓存中存在,返回 if(v != null) { return v; } //缓存中不存在,查询数据库 w.lock(); try { //再次验证缓存中是否存在数据 v = m.get(key); if(v == null){ //查询数据库 v=从数据库中查询出来的数据 m.put(key, v); } } finally{ w.unlock(); } return v; } } ``` 这里,在get()方法中,首先从缓存中读取数据,此时,我们对查询缓存的操作添加了读锁,查询返回后,进行解锁操作。判断缓存中返回的数据是否为空,不为空,则直接返回数据;如果为空,则获取写锁,之后再次从缓存中读取数据,如果缓存中不存在数据,则查询数据库,将结果数据写入缓存,释放写锁。最终返回结果数据。 **这里,有小伙伴可能会问:为啥程序都已经添加写锁了,在写锁内部为啥还要查询一次缓存呢?** 这是因为在高并发的场景下,可能会存在多个线程来竞争写锁的现象。例如:第一次执行get()方法时,缓存中的数据为空。如果此时有三个线程同时调用get()方法,同时运行到 w.lock()代码处,由于写锁的排他性。此时只有一个线程会获取到写锁,其他两个线程则阻塞在w.lock()处。获取到写锁的线程继续往下执行查询数据库,将数据写入缓存,之后释放写锁。 此时,另外两个线程竞争写锁,某个线程会获取到锁,继续往下执行,如果在w.lock()后没有v = m.get(key); 再次查询缓存的数据,则这个线程会直接查询数据库,将数据写入缓存后释放写锁。最后一个线程同样会按照这个流程执行。 这里,实际上第一个线程已经查询过数据库,并且将数据写入缓存了,其他两个线程就没必要再次查询数据库了,直接从缓存中查询出相应的数据即可。所以,在w.lock()后添加v = m.get(key); 再次查询缓存的数据,能够有效的减少高并发场景下重复查询数据库的问题,提升系统的性能。 # 读写锁的升降级 **关于锁的升降级,小伙伴们需要注意的是:在ReadWriteLock中,锁是不支持升级的,因为读锁还未释放时,此时获取写锁,就会导致写锁永久等待,相应的线程也会被阻塞而无法唤醒。** 虽然不支持锁升级,但是ReadWriteLock支持锁降级,例如,我们来看看官方的ReentrantReadWriteLock示例,如下所示。 ``` class CachedData { Object data; volatile boolean cacheValid; final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); void processCachedData() { rwl.readLock().lock(); if (!cacheValid) { // Must release read lock before acquiring write lock rwl.readLock().unlock(); rwl.writeLock().lock(); try { // Recheck state because another thread might have // acquired write lock and changed state before we did. if (!cacheValid) { data = ... cacheValid = true; } // Downgrade by acquiring read lock before releasing write lock rwl.readLock().lock(); } finally { rwl.writeLock().unlock(); // Unlock write, still hold read } } try { use(data); } finally { rwl.readLock().unlock(); } } }} ``` # 数据同步问题 首先,这里说的数据同步指的是数据源和数据缓存之间的数据同步,说的再直接一点,就是数据库和缓存之间的数据同步。 这里,我们可以采取三种方案来解决数据同步的问题,如下图所示 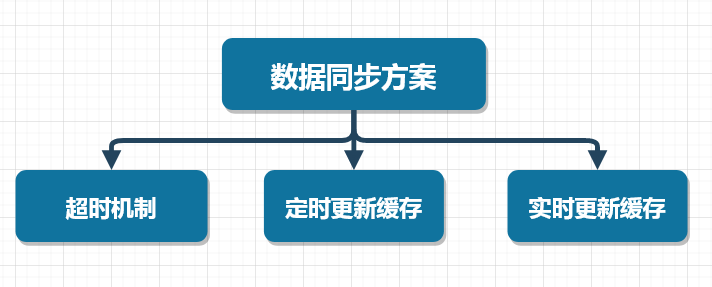 ## 超时机制 这个比较好理解,就是在向缓存写入数据的时候,给一个超时时间,当缓存超时后,缓存的数据会自动从缓存中移除,此时程序再次访问缓存时,由于缓存中不存在相应的数据,查询数据库得到数据后,再将数据写入缓存。采用这种方案需要注意缓存的穿透问题。 ## 定时更新缓存 这种方案是超时机制的增强版,在向缓存中写入数据的时候,同样给一个超时时间。与超时机制不同的是,在程序后台单独启动一个线程,定时查询数据库中的数据,然后将数据写入缓存中,这样能够在一定程度上避免缓存的穿透问题。 ## 实时更新缓存 这种方案能够做到数据库中的数据与缓存的数据是实时同步的,可以使用阿里开源的Canal框架实现MySQL数据库与缓存数据的实时同步。
>摘要:本文我们就来说说使用ReadWriteLock如何实现一个通用的缓存中心。 本文分享自华为云社区《[【高并发】原来ReadWriteLock也能开发高性能缓存,看完我也能和面试官好好聊聊了!](https://bbs.huaweicloud.com/blogs/357370?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 冰 河。 在实际工作中,有一种非常普遍的并发场景:那就是读多写少的场景。在这种场景下,为了优化程序的性能,我们经常使用缓存来提高应用的访问性能。因为缓存非常适合使用在读多写少的场景中。而在并发场景中,Java SDK中提供了ReadWriteLock来满足读多写少的场景。本文我们就来说说使用ReadWriteLock如何实现一个通用的缓存中心。 本文涉及的知识点有:  # 读写锁 说起读写锁,相信小伙伴们并不陌生。总体来说,读写锁需要遵循以下原则: - 一个共享变量允许同时被多个读线程读取到。 - 一个共享变量在同一时刻只能被一个写线程进行写操作。 - 一个共享变量在被写线程执行写操作时,此时这个共享变量不能被读线程执行读操作。 **这里,需要小伙伴们注意的是:读写锁和互斥锁的一个重要的区别就是:读写锁允许多个线程同时读共享变量,而互斥锁不允许。所以,在高并发场景下,读写锁的性能要高于互斥锁。但是,读写锁的写操作是互斥的,也就是说,使用读写锁时,一个共享变量在被写线程执行写操作时,此时这个共享变量不能被读线程执行读操作。** 读写锁支持公平模式和非公平模式,具体是在ReentrantReadWriteLock的构造方法中传递一个boolean类型的变量来控制。 ``` public ReentrantReadWriteLock(boolean fair) { sync = fair ? new FairSync() : new NonfairSync(); readerLock = new ReadLock(this); writerLock = new WriteLock(this); } ``` **另外,需要注意的一点是:在读写锁中,读锁调用newCondition()会抛出UnsupportedOperationException异常,也就是说:读锁不支持条件变量。** # 缓存实现 这里,我们使用ReadWriteLock快速实现一个缓存的通用工具类,总体代码如下所示。 ``` public class ReadWriteLockCache { private final Map m = new HashMap(); private final ReadWriteLock rwl = new ReentrantReadWriteLock(); // 读锁 private final Lock r = rwl.readLock(); // 写锁 private final Lock w = rwl.writeLock(); // 读缓存 public V get(K key) { r.lock(); try { return m.get(key); } finally { r.unlock(); } } // 写缓存 public V put(K key, V value) { w.lock(); try { return m.put(key, value); } finally { w.unlock(); } } } ``` 可以看到,在ReadWriteLockCache中,我们定义了两个泛型类型,K代表缓存的Key,V代表缓存的value。在ReadWriteLockCache类的内部,我们使用Map来缓存相应的数据,小伙伴都都知道HashMap并不是线程安全的类,所以,这里使用了读写锁来保证线程的安全性,例如,我们在get()方法中使用了读锁,get()方法可以被多个线程同时执行读操作;put()方法内部使用写锁,也就是说,put()方法在同一时刻只能有一个线程对缓存进行写操作。 **这里需要注意的是**:无论是读锁还是写锁,锁的释放操作都需要放到finally{}代码块中。 在以往的经验中,有两种向缓存中加载数据的方式,**一种是:项目启动时,将数据全量加载到缓存中,一种是在项目运行期间,按需加载所需要的缓存数据。**  接下来,我们就分别来看看全量加载缓存和按需加载缓存的方式。 # 全量加载缓存 全量加载缓存相对来说比较简单,就是在项目启动的时候,将数据一次性加载到缓存中,这种情况适用于缓存数据量不大,数据变动不频繁的场景,例如:可以缓存一些系统中的数据字典等信息。整个缓存加载的大体流程如下所示。  将数据全量加载到缓存后,后续就可以直接从缓存中读取相应的数据了。 全量加载缓存的代码实现比较简单,这里,我就直接使用如下代码进行演示。 ``` public class ReadWriteLockCache { private final Map m = new HashMap(); private final ReadWriteLock rwl = new ReentrantReadWriteLock(); // 读锁 private final Lock r = rwl.readLock(); // 写锁 private final Lock w = rwl.writeLock(); public ReadWriteLockCache(){ //查询数据库 List> list = .....; if(!CollectionUtils.isEmpty(list)){ list.parallelStream().forEach((f) ->{ m.put(f.getK(), f.getV); }); } } // 读缓存 public V get(K key) { r.lock(); try { return m.get(key); } finally { r.unlock(); } } // 写缓存 public V put(K key, V value) { w.lock(); try { return m.put(key, value); } finally { w.unlock(); } } } ``` # 按需加载缓存 按需加载缓存也可以叫作懒加载,就是说:需要加载的时候才会将数据加载到缓存。具体来说:就是程序启动的时候,不会将数据加载到缓存,当运行时,需要查询某些数据,首先检测缓存中是否存在需要的数据,如果存在,则直接读取缓存中的数据,如果不存在,则到数据库中查询数据,并将数据写入缓存。后续的读取操作,因为缓存中已经存在了相应的数据,直接返回缓存的数据即可。  这种查询缓存的方式适用于大多数缓存数据的场景。 我们可以使用如下代码来表示按需查询缓存的业务。 ``` class ReadWriteLockCache { private final Map m = new HashMap(); private final ReadWriteLock rwl = new ReentrantReadWriteLock(); private final Lock r = rwl.readLock(); private final Lock w = rwl.writeLock(); V get(K key) { V v = null; //读缓存 r.lock(); try { v = m.get(key); } finally{ r.unlock(); } //缓存中存在,返回 if(v != null) { return v; } //缓存中不存在,查询数据库 w.lock(); try { //再次验证缓存中是否存在数据 v = m.get(key); if(v == null){ //查询数据库 v=从数据库中查询出来的数据 m.put(key, v); } } finally{ w.unlock(); } return v; } } ``` 这里,在get()方法中,首先从缓存中读取数据,此时,我们对查询缓存的操作添加了读锁,查询返回后,进行解锁操作。判断缓存中返回的数据是否为空,不为空,则直接返回数据;如果为空,则获取写锁,之后再次从缓存中读取数据,如果缓存中不存在数据,则查询数据库,将结果数据写入缓存,释放写锁。最终返回结果数据。 **这里,有小伙伴可能会问:为啥程序都已经添加写锁了,在写锁内部为啥还要查询一次缓存呢?** 这是因为在高并发的场景下,可能会存在多个线程来竞争写锁的现象。例如:第一次执行get()方法时,缓存中的数据为空。如果此时有三个线程同时调用get()方法,同时运行到 w.lock()代码处,由于写锁的排他性。此时只有一个线程会获取到写锁,其他两个线程则阻塞在w.lock()处。获取到写锁的线程继续往下执行查询数据库,将数据写入缓存,之后释放写锁。 此时,另外两个线程竞争写锁,某个线程会获取到锁,继续往下执行,如果在w.lock()后没有v = m.get(key); 再次查询缓存的数据,则这个线程会直接查询数据库,将数据写入缓存后释放写锁。最后一个线程同样会按照这个流程执行。 这里,实际上第一个线程已经查询过数据库,并且将数据写入缓存了,其他两个线程就没必要再次查询数据库了,直接从缓存中查询出相应的数据即可。所以,在w.lock()后添加v = m.get(key); 再次查询缓存的数据,能够有效的减少高并发场景下重复查询数据库的问题,提升系统的性能。 # 读写锁的升降级 **关于锁的升降级,小伙伴们需要注意的是:在ReadWriteLock中,锁是不支持升级的,因为读锁还未释放时,此时获取写锁,就会导致写锁永久等待,相应的线程也会被阻塞而无法唤醒。** 虽然不支持锁升级,但是ReadWriteLock支持锁降级,例如,我们来看看官方的ReentrantReadWriteLock示例,如下所示。 ``` class CachedData { Object data; volatile boolean cacheValid; final ReentrantReadWriteLock rwl = new ReentrantReadWriteLock(); void processCachedData() { rwl.readLock().lock(); if (!cacheValid) { // Must release read lock before acquiring write lock rwl.readLock().unlock(); rwl.writeLock().lock(); try { // Recheck state because another thread might have // acquired write lock and changed state before we did. if (!cacheValid) { data = ... cacheValid = true; } // Downgrade by acquiring read lock before releasing write lock rwl.readLock().lock(); } finally { rwl.writeLock().unlock(); // Unlock write, still hold read } } try { use(data); } finally { rwl.readLock().unlock(); } } }} ``` # 数据同步问题 首先,这里说的数据同步指的是数据源和数据缓存之间的数据同步,说的再直接一点,就是数据库和缓存之间的数据同步。 这里,我们可以采取三种方案来解决数据同步的问题,如下图所示  ## 超时机制 这个比较好理解,就是在向缓存写入数据的时候,给一个超时时间,当缓存超时后,缓存的数据会自动从缓存中移除,此时程序再次访问缓存时,由于缓存中不存在相应的数据,查询数据库得到数据后,再将数据写入缓存。采用这种方案需要注意缓存的穿透问题。 ## 定时更新缓存 这种方案是超时机制的增强版,在向缓存中写入数据的时候,同样给一个超时时间。与超时机制不同的是,在程序后台单独启动一个线程,定时查询数据库中的数据,然后将数据写入缓存中,这样能够在一定程度上避免缓存的穿透问题。 ## 实时更新缓存 这种方案能够做到数据库中的数据与缓存的数据是实时同步的,可以使用阿里开源的Canal框架实现MySQL数据库与缓存数据的实时同步。 -
https://support.huaweicloud.com/tngg-kunpenghpcs/kunpenghpcsolution_05_0026.html 在这里看到了IPM,请问ipm该怎么安装和使用?
-
 链接:https://bbs.huaweicloud.com/blogs/354287Strace 是一个调试工具,可以帮助您解决问题。Strace 监控特定程序的系统调用和信号。当您没有源代码并想调试程序的执行时,它会很有帮助。strace 为您提供二进制文件从头到尾的执行顺序。本文解释了 7 个 strace 示例以帮助您入门。1. 跟踪可执行文件的执行您可以使用 strace 命令来跟踪任何可执行文件的执行。以下示例显示了 Linux ls 命令的 strace 输出。$ strace ls execve("/bin/ls", ["ls"], [/* 21 vars */]) = 0 brk(0) = 0x8c31000 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) mmap2(NULL, 8192, PROT_READ, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb78c7000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) open("/etc/ld.so.cache", O_RDONLY) = 3 fstat64(3, {st_mode=S_IFREG|0644, st_size=65354, ...}) = 0 ... ... ...2. 使用选项 -e 跟踪可执行文件中的特定系统调用默认情况下,strace 显示给定可执行文件的所有系统调用。要仅显示特定的系统调用,请使用 strace -e 选项,如下所示。$ strace -e open ls open("/etc/ld.so.cache", O_RDONLY) = 3 open("/lib/libselinux.so.1", O_RDONLY) = 3 open("/lib/librt.so.1", O_RDONLY) = 3 open("/lib/libacl.so.1", O_RDONLY) = 3 open("/lib/libc.so.6", O_RDONLY) = 3 open("/lib/libdl.so.2", O_RDONLY) = 3 open("/lib/libpthread.so.0", O_RDONLY) = 3 open("/lib/libattr.so.1", O_RDONLY) = 3 open("/proc/filesystems", O_RDONLY|O_LARGEFILE) = 3 open("/usr/lib/locale/locale-archive", O_RDONLY|O_LARGEFILE) = 3 open(".", O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY|O_CLOEXEC) = 3 Desktop Documents Downloads examples.desktop libflashplayer.so Music Pictures Public Templates Ubuntu_OS Videos上面的输出只显示了 ls 命令的 open 系统调用。在 strace 输出的末尾,它还显示 ls 命令的输出。如果要跟踪多个系统调用,请使用“-e trace=”选项。以下示例显示了 open 和 read 系统调用。$ strace -e trace=open,read ls /home open("/etc/ld.so.cache", O_RDONLY) = 3 open("/lib/libselinux.so.1", O_RDONLY) = 3 read(3, "\177ELF\1\1\1\3\3\1\260G004"..., 512) = 512 open("/lib/librt.so.1", O_RDONLY) = 3 read(3, "\177ELF\1\1\1\3\3\1\300\30004"..., 512) = 512 .. open("/lib/libattr.so.1", O_RDONLY) = 3 read(3, "\177ELF\1\1\1\3\3\1\360\r004"..., 512) = 512 open("/proc/filesystems", O_RDONLY|O_LARGEFILE) = 3 read(3, "nodev\tsysfs\nnodev\trootfs\nnodev\tb"..., 1024) = 315 read(3, "", 1024) = 0 open("/usr/lib/locale/locale-archive", O_RDONLY|O_LARGEFILE) = 3 open("/home", O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY|O_CLOEXEC) = 3 bala3. 使用选项 -o 将跟踪执行保存到文件以下示例将 strace 输出存储到 output.txt 文件。$ strace -o output.txt ls Desktop Documents Downloads examples.desktop libflashplayer.so Music output.txt Pictures Public Templates Ubuntu_OS Videos $ cat output.txt execve("/bin/ls", ["ls"], [/* 37 vars */]) = 0 brk(0) = 0x8637000 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) mmap2(NULL, 8192, PROT_READ, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7860000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) open("/etc/ld.so.cache", O_RDONLY) = 3 fstat64(3, {st_mode=S_IFREG|0644, st_size=67188, ...}) = 0 ... ...4. 使用选项 -p 在正在运行的 Linux 进程上执行 Strace您可以使用进程 ID 在已经运行的程序上执行 strace。首先,使用ps 命令识别程序的 PID 。例如,如果要对当前正在运行的 firefox 程序执行 strace,请确定 firefox 程序的 PID。$ ps -C firefox-bin PID TTY TIME CMD 1725 ? 00:40:50 firefox-bin使用如下所示的 strace -p 选项来显示给定进程 ID 的 strace。$ sudo strace -p 1725 -o firefox_trace.txt $ tail -f firefox_trace.txt现在 firefox 进程的执行跟踪将被记录到 firefox_trace.txt 文本文件中。您可以跟踪此文本文件以查看 firefox 可执行文件的实时跟踪。当您的用户 ID 与给定进程的用户 ID 不匹配时,Strace 将显示以下错误。$ strace -p 1725 -o output.txt attach: ptrace(PTRACE_ATTACH, ...): Operation not permitted Could not attach to process. If your uid matches the uid of the target process, check the setting of /proc/sys/kernel/yama/ptrace_scope, or try again as the root user. For more details, see /etc/sysctl.d/10-ptrace.conf5. 使用选项 -t 打印每个跟踪输出行的时间戳要打印每个 strace 输出行的时间戳,请使用选项 -t,如下所示。$ strace -t -e open ls /home 20:42:37 open("/etc/ld.so.cache", O_RDONLY) = 3 20:42:37 open("/lib/libselinux.so.1", O_RDONLY) = 3 20:42:37 open("/lib/librt.so.1", O_RDONLY) = 3 20:42:37 open("/lib/libacl.so.1", O_RDONLY) = 3 20:42:37 open("/lib/libc.so.6", O_RDONLY) = 3 20:42:37 open("/lib/libdl.so.2", O_RDONLY) = 3 20:42:37 open("/lib/libpthread.so.0", O_RDONLY) = 3 20:42:37 open("/lib/libattr.so.1", O_RDONLY) = 3 20:42:37 open("/proc/filesystems", O_RDONLY|O_LARGEFILE) = 3 20:42:37 open("/usr/lib/locale/locale-archive", O_RDONLY|O_LARGEFILE) = 3 20:42:37 open("/home", O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY|O_CLOEXEC) = 3 bala6. 使用选项 -r 打印系统调用的相对时间Strace 还可以选择打印每个系统调用的执行时间,如下所示。$ strace -r ls 0.000000 execve("/bin/ls", ["ls"], [/* 37 vars */]) = 0 0.000846 brk(0) = 0x8418000 0.000143 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) 0.000163 mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb787b000 0.000119 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) 0.000123 open("/etc/ld.so.cache", O_RDONLY) = 3 0.000099 fstat64(3, {st_mode=S_IFREG|0644, st_size=67188, ...}) = 0 0.000155 mmap2(NULL, 67188, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb786a000 ... ...7.使用选项-c生成系统调用的统计报告使用选项 -c,strace 为执行跟踪提供有用的统计报告。以下输出中的“调用”列指示了该特定系统调用执行了多少次。$ strace -c ls /home bala % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- -nan 0.000000 0 9 read -nan 0.000000 0 1 write -nan 0.000000 0 11 open -nan 0.000000 0 13 close -nan 0.000000 0 1 execve -nan 0.000000 0 9 9 access -nan 0.000000 0 3 brk -nan 0.000000 0 2 ioctl -nan 0.000000 0 3 munmap -nan 0.000000 0 1 uname -nan 0.000000 0 11 mprotect -nan 0.000000 0 2 rt_sigaction -nan 0.000000 0 1 rt_sigprocmask -nan 0.000000 0 1 getrlimit -nan 0.000000 0 25 mmap2 -nan 0.000000 0 1 stat64 -nan 0.000000 0 11 fstat64 -nan 0.000000 0 2 getdents64 -nan 0.000000 0 1 fcntl64 -nan 0.000000 0 2 1 futex -nan 0.000000 0 1 set_thread_area -nan 0.000000 0 1 set_tid_address -nan 0.000000 0 1 statfs64 -nan 0.000000 0 1 set_robust_list ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000000 114 10 total
链接:https://bbs.huaweicloud.com/blogs/354287Strace 是一个调试工具,可以帮助您解决问题。Strace 监控特定程序的系统调用和信号。当您没有源代码并想调试程序的执行时,它会很有帮助。strace 为您提供二进制文件从头到尾的执行顺序。本文解释了 7 个 strace 示例以帮助您入门。1. 跟踪可执行文件的执行您可以使用 strace 命令来跟踪任何可执行文件的执行。以下示例显示了 Linux ls 命令的 strace 输出。$ strace ls execve("/bin/ls", ["ls"], [/* 21 vars */]) = 0 brk(0) = 0x8c31000 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) mmap2(NULL, 8192, PROT_READ, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb78c7000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) open("/etc/ld.so.cache", O_RDONLY) = 3 fstat64(3, {st_mode=S_IFREG|0644, st_size=65354, ...}) = 0 ... ... ...2. 使用选项 -e 跟踪可执行文件中的特定系统调用默认情况下,strace 显示给定可执行文件的所有系统调用。要仅显示特定的系统调用,请使用 strace -e 选项,如下所示。$ strace -e open ls open("/etc/ld.so.cache", O_RDONLY) = 3 open("/lib/libselinux.so.1", O_RDONLY) = 3 open("/lib/librt.so.1", O_RDONLY) = 3 open("/lib/libacl.so.1", O_RDONLY) = 3 open("/lib/libc.so.6", O_RDONLY) = 3 open("/lib/libdl.so.2", O_RDONLY) = 3 open("/lib/libpthread.so.0", O_RDONLY) = 3 open("/lib/libattr.so.1", O_RDONLY) = 3 open("/proc/filesystems", O_RDONLY|O_LARGEFILE) = 3 open("/usr/lib/locale/locale-archive", O_RDONLY|O_LARGEFILE) = 3 open(".", O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY|O_CLOEXEC) = 3 Desktop Documents Downloads examples.desktop libflashplayer.so Music Pictures Public Templates Ubuntu_OS Videos上面的输出只显示了 ls 命令的 open 系统调用。在 strace 输出的末尾,它还显示 ls 命令的输出。如果要跟踪多个系统调用,请使用“-e trace=”选项。以下示例显示了 open 和 read 系统调用。$ strace -e trace=open,read ls /home open("/etc/ld.so.cache", O_RDONLY) = 3 open("/lib/libselinux.so.1", O_RDONLY) = 3 read(3, "\177ELF\1\1\1\3\3\1\260G004"..., 512) = 512 open("/lib/librt.so.1", O_RDONLY) = 3 read(3, "\177ELF\1\1\1\3\3\1\300\30004"..., 512) = 512 .. open("/lib/libattr.so.1", O_RDONLY) = 3 read(3, "\177ELF\1\1\1\3\3\1\360\r004"..., 512) = 512 open("/proc/filesystems", O_RDONLY|O_LARGEFILE) = 3 read(3, "nodev\tsysfs\nnodev\trootfs\nnodev\tb"..., 1024) = 315 read(3, "", 1024) = 0 open("/usr/lib/locale/locale-archive", O_RDONLY|O_LARGEFILE) = 3 open("/home", O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY|O_CLOEXEC) = 3 bala3. 使用选项 -o 将跟踪执行保存到文件以下示例将 strace 输出存储到 output.txt 文件。$ strace -o output.txt ls Desktop Documents Downloads examples.desktop libflashplayer.so Music output.txt Pictures Public Templates Ubuntu_OS Videos $ cat output.txt execve("/bin/ls", ["ls"], [/* 37 vars */]) = 0 brk(0) = 0x8637000 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) mmap2(NULL, 8192, PROT_READ, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb7860000 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) open("/etc/ld.so.cache", O_RDONLY) = 3 fstat64(3, {st_mode=S_IFREG|0644, st_size=67188, ...}) = 0 ... ...4. 使用选项 -p 在正在运行的 Linux 进程上执行 Strace您可以使用进程 ID 在已经运行的程序上执行 strace。首先,使用ps 命令识别程序的 PID 。例如,如果要对当前正在运行的 firefox 程序执行 strace,请确定 firefox 程序的 PID。$ ps -C firefox-bin PID TTY TIME CMD 1725 ? 00:40:50 firefox-bin使用如下所示的 strace -p 选项来显示给定进程 ID 的 strace。$ sudo strace -p 1725 -o firefox_trace.txt $ tail -f firefox_trace.txt现在 firefox 进程的执行跟踪将被记录到 firefox_trace.txt 文本文件中。您可以跟踪此文本文件以查看 firefox 可执行文件的实时跟踪。当您的用户 ID 与给定进程的用户 ID 不匹配时,Strace 将显示以下错误。$ strace -p 1725 -o output.txt attach: ptrace(PTRACE_ATTACH, ...): Operation not permitted Could not attach to process. If your uid matches the uid of the target process, check the setting of /proc/sys/kernel/yama/ptrace_scope, or try again as the root user. For more details, see /etc/sysctl.d/10-ptrace.conf5. 使用选项 -t 打印每个跟踪输出行的时间戳要打印每个 strace 输出行的时间戳,请使用选项 -t,如下所示。$ strace -t -e open ls /home 20:42:37 open("/etc/ld.so.cache", O_RDONLY) = 3 20:42:37 open("/lib/libselinux.so.1", O_RDONLY) = 3 20:42:37 open("/lib/librt.so.1", O_RDONLY) = 3 20:42:37 open("/lib/libacl.so.1", O_RDONLY) = 3 20:42:37 open("/lib/libc.so.6", O_RDONLY) = 3 20:42:37 open("/lib/libdl.so.2", O_RDONLY) = 3 20:42:37 open("/lib/libpthread.so.0", O_RDONLY) = 3 20:42:37 open("/lib/libattr.so.1", O_RDONLY) = 3 20:42:37 open("/proc/filesystems", O_RDONLY|O_LARGEFILE) = 3 20:42:37 open("/usr/lib/locale/locale-archive", O_RDONLY|O_LARGEFILE) = 3 20:42:37 open("/home", O_RDONLY|O_NONBLOCK|O_LARGEFILE|O_DIRECTORY|O_CLOEXEC) = 3 bala6. 使用选项 -r 打印系统调用的相对时间Strace 还可以选择打印每个系统调用的执行时间,如下所示。$ strace -r ls 0.000000 execve("/bin/ls", ["ls"], [/* 37 vars */]) = 0 0.000846 brk(0) = 0x8418000 0.000143 access("/etc/ld.so.nohwcap", F_OK) = -1 ENOENT (No such file or directory) 0.000163 mmap2(NULL, 8192, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0xb787b000 0.000119 access("/etc/ld.so.preload", R_OK) = -1 ENOENT (No such file or directory) 0.000123 open("/etc/ld.so.cache", O_RDONLY) = 3 0.000099 fstat64(3, {st_mode=S_IFREG|0644, st_size=67188, ...}) = 0 0.000155 mmap2(NULL, 67188, PROT_READ, MAP_PRIVATE, 3, 0) = 0xb786a000 ... ...7.使用选项-c生成系统调用的统计报告使用选项 -c,strace 为执行跟踪提供有用的统计报告。以下输出中的“调用”列指示了该特定系统调用执行了多少次。$ strace -c ls /home bala % time seconds usecs/call calls errors syscall ------ ----------- ----------- --------- --------- ---------------- -nan 0.000000 0 9 read -nan 0.000000 0 1 write -nan 0.000000 0 11 open -nan 0.000000 0 13 close -nan 0.000000 0 1 execve -nan 0.000000 0 9 9 access -nan 0.000000 0 3 brk -nan 0.000000 0 2 ioctl -nan 0.000000 0 3 munmap -nan 0.000000 0 1 uname -nan 0.000000 0 11 mprotect -nan 0.000000 0 2 rt_sigaction -nan 0.000000 0 1 rt_sigprocmask -nan 0.000000 0 1 getrlimit -nan 0.000000 0 25 mmap2 -nan 0.000000 0 1 stat64 -nan 0.000000 0 11 fstat64 -nan 0.000000 0 2 getdents64 -nan 0.000000 0 1 fcntl64 -nan 0.000000 0 2 1 futex -nan 0.000000 0 1 set_thread_area -nan 0.000000 0 1 set_tid_address -nan 0.000000 0 1 statfs64 -nan 0.000000 0 1 set_robust_list ------ ----------- ----------- --------- --------- ---------------- 100.00 0.000000 114 10 total -
 如上图 UAP 执行mml命令卡死,处理不完成。处理步骤:先判断nmu主备还是单机,确认主机后执行如下步骤(此操作不影响通话)1. 登陆UAP 后台NMU 主机上2. omu 用户执行 stop_lmt和stop_cm 重启两个对应进程。3. chk_status 实时查看进程是否被拉起(正常停止进程后UAP会自动拉起进程)4. 重新登陆UAP CDE 后执行命令正常执行
如上图 UAP 执行mml命令卡死,处理不完成。处理步骤:先判断nmu主备还是单机,确认主机后执行如下步骤(此操作不影响通话)1. 登陆UAP 后台NMU 主机上2. omu 用户执行 stop_lmt和stop_cm 重启两个对应进程。3. chk_status 实时查看进程是否被拉起(正常停止进程后UAP会自动拉起进程)4. 重新登陆UAP CDE 后执行命令正常执行 -
主从复制:主节点负责写数据,从节点负责读数据,从而实现读写分离,提高redis的高可用性。让一个服务器去复制(replicate)另一个服务器,我们称呼被复制的服务器为主节点(master),而对主服务器进行复制的服务器则被称为从节点(slave)主从复制的特点:1、一个master可以有多个slave2、一个slave只能有一个master3、数据流向是单向的,master到slave 主从复制的作用:1、数据副本:多一份或多份数据拷贝,保证redis高可用2、扩展性能:单机redis的性能是有限的,主从复制能横向扩展 如容量、QPS等主从复制实现方式客户端命令:slaveof全量复制和增量复制全量复制过程:1. 向主节点发送psync,有两个参数,第一个参数是runId,第二个参数是偏移量,第一次发送不知道主节点的runId,也不知道偏移量,因此从节点发送 ? -12. 主节点收到消息,根据? -1 能判断出来是第一次复制,主节点把runId和offset 发送给Slave节点,3. 从节点保存主节点基本信息4-5-6. Master节点执行bgsave生成快照,在此期间会记录后续执行的数据更改命令所更改的数据,直到主节点将生成的RDB文件传输到从节点为止, 期间Master节点执行的写操作,主节点会将缓冲区中记录的新更改的数据发送给从节点7-8 从节点清空此前的所有数据,加载RDB文件恢复数据并存入新更改的数据说明: 全量复制的性能开销:1. bgsave生成RDB文件需要的时间,2. RDB文件在网络间的传输时间,3. 从节点的数据清空时间 , 4. 加载RDB文件的时间 5. 可能的 AOF 重写时间 数据更改命令缓冲区repl_back_buffer用于:当Redis通过Linux中的fork()函数开辟一个子进程处理其他事务(比如主进程执行bgsave生成一个RDB文件时,或者主进程执行bgrewriteaof生成一个AOF文件时), 而主进程(即处理客户端命令的进程)后续执行的一些数据更改命令会被暂时保存在该区域,而且该区域空间有限(配置文件中repl-backlog-size 1mb即可配置该处空间大小)部分复制部分复制解决的问题:在实际环境中,主节点与从节点之间可能会发生一些网络波动等情况,导致从节点与主节点之间的网络连接断开(主从节点的Redis均未关闭),如果重新连接上后,可以使用全量复制来重新进行一次主从节点数据同步,但是全量复制会带来一个性能开销的问题,而且从节点中可能有大量数据是主节点中没有更该过的,也就是不需要进行再次同步的数据,如果使用全量复制肯定是带来了一些不必要的浪费。所以,部分复制功能就是为了解决该问题的。过程:1. 主从节点直接连接断开,2. 此时主节点继续执行的数据更改命令会被记录在一个缓冲区 repl_back_buffer 中3. 当从节点重新连接主节点时,4. 自动发出一条命令(psync offset run_id),将从节点中存储的主节点的Redis运行时id和从节点中保存的偏移量发送给主节点5. 主节点接收从节点发送的偏移量和id,对比此时主节点的偏移量和接收的偏移量,如果两个偏移量之差大于repl_back_buffer中的数据,那么就表示在断开连接期间从节点已经丢失了超出规定数量的数据,此时就需要进行全量复制了,否则就进行部分复制6. 将主节点缓冲区中的数据同步更新到从节点中,这样就实现了部分数据的复制同步,降低了性能开销主从节点的故障处理故障发生时服务自动转移(自动故障转移):即当某个节点发生故障导致停止服务时,该节点提供的服务会有另一个节点自动代替提供,这样就实现了一个高可用的效果从节点故障:即如果某个从节点发生了故障,导致无法向在该节点上的客户端提供读服务,解决办法就是使该客户端转移到另一个可用从节点上,但是在转移时,应该考虑该从节点能承受几个客户端的压力主节点故障:如果主节点发生故障,在使用主节点进行读写操作的客户端就无法使用了,而使用从节点只进行读操作的客户端还是可以继续使用的,解决办法就是从从节点中选一个节点更改为主节点,并且将原主节点的客户端连接到新的主节点上,然后通过该客户端将其他从节点连接到新的主节点中主从复制确实可以解决故障问题,但是主从复制不能实现自动故障转移,其必须要通过一些手动操作,而且非常麻烦,所以要实现自动故障转移还需要另一个功能,Redis中提供了sentinel功能来实现自动故障转移。主从节点的故障处理 1. 读写分离:即客户端发来的读写命令分开,写命令交给主节点执行,读命令交给从节点执行,不仅减少了主节点的压力,而且增强了读操作的能力;但也会造成一些问题但是主从节点之间数据复制造成的阻塞延迟也可能会导致主从不一致的情况,也就是主节点先进行了写操作,但可能因为数据复制造成的阻塞延迟,导致在从节点上进行的读操作获取的数据与主节点不一致读取过期数据:主从复制会将带有过期时间的数据一并复制到从节点中,但是从节点是没有删除数据的能力的,即使是过期数据,所以主节点中的已经删除了过期数据,但是因为主从复制的阻塞延迟问题导致从节点中的过期数据没有删除,此时客户端就会读到一个过期数据 2. 主从配置不一致:造成的问题有比如配置中的maxmemory参数如果配置不一致,比如主节点2Gb,从节点1Gb,那么就可能会导致数据丢失;以及一些其他配置问题 3. 规避全量复制:全量复制的性能开销较大,所以要尽量避免全量复制,在第一次建立主从节点关系式一定会发生全量复制;可以适当减小Redis的maxmemory参数,这样可以使得RDB更快,或者选择在客户端操作低峰期进行,比如深夜从节点中保存的主节点run_id不一致时也一定会发生全量复制(比如主节点的重启);可以通过故障转移来尽量避免,例如Redis Sentinel 与 Redis Cluster 当主从节点的偏移量之差大于命令缓冲区repl_back_buffer中对应数据的偏移差时,也会发生全量复制,也就是上面的部分复制的复制过程中所说的;可以适当增大配置文件中repl-backlog-size即数据缓冲区可尽量避免 4. 规避复制风暴:单主节点导致的复制风暴,即当主节点重启后,要向其所有的从节点都进行一次全量复制,这非常消耗性能;可以更换主从节点的拓扑结构,更换为类似树形的结构,一个主节点只与少量的从节点建立主从关系,而而这些主节点又与其他从节点构成主从关系单主节点机器复制风暴:即如果过一台机器专门用来部署多个主节点,然后其他机器部署从节点,那么一旦主节点机器宕机重启,就会引起所有的主从节点之间的全量复制,造成非常大的性能开销;可以采用多台机器,分散部署主节点,或者使用自动故障转移来将某个从节点变为主节点实现一个高可用
-
对Redis而言,其数据是保存在内存中的,一旦机器宕机,内存中的数据会丢失,因此需要将数据异步持久化到硬盘中保存。这样,即使机器宕机,数据能从硬盘中恢复。常见的数据持久化方式:1.快照:类似拍照记录时光,快照是某时某刻将数据库的数据做拍照记录下其数据信息。如MYSQL的Dump,Redis的RDB模式2.写日志方式:是将数据的操作全部写到日志当中,需要恢复的时候,按照日志记录的操作记录重新再执行一遍。例如MYSQL的Binlog,Redis的AAOF模式、RDB说明:redis默认开启,将redis在内存中保存的数据,以快照的方式持久化到硬盘中保存。触发机制:1.save命令:阻塞方式,需要等redis执行完save后,才能执行其他get、set等操作。同步方式2.bgsave命令:非阻塞,其原理是调用linux 的 fork()函数,创建redis的子进程,子进程进行创建 rdb 文件的操作。异步方式,3.自动方式:在redis.conf文件中配置,如下 save <指定时间间隔> <执行指定次数更新操作> ,save 60 10000 表示 60秒年内有10000次操作会自动生成rdb文件。4.其他方式4.1 执行flushall命令,清空数据,几乎不用4.2 执行shutdown命令,安全关闭redis不丢失数据,几乎用不到。4.3 主从复制,在主从复制的时候,rdb文件作为媒介来关联主节点和从节点的数据一致。RDB优缺点优点:1 适合大规模的数据恢复。2 如果业务对数据完整性和一致性要求不高,RDB是很好的选择。缺点:1 不可控,容易丢失数据:数据的完整性和一致性不高,因为RDB可能在最后一次备份时宕机了。2 耗时耗性能:备份时占用内存,因为Redis 在备份时会独立创建一个子进程,将数据写入到一个临时文件(此时内存中的数据是原来的两倍哦),最后再将临时文件替换之前的备份文件。所以Redis 的持久化和数据的恢复要选择在夜深人静的时候执行是比较合理的。AOF说明: redis默认不开启,采用日志的形式来记录每个写操作,并追加到 .aof 文件中。Redis 重启的会根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作生成AOF的三种策略:1. always : 每条命令都会刷新到缓冲区,把缓冲区fsync到硬盘,对硬盘IO压力大,一般sata盘只有几百TPS,如果redis的写入量非常大,那对硬盘的压力也横刀。2. everysec: 每秒把缓冲区fsync 到硬盘,如果出现故障,会丢失1s(默认配置是1秒)的数据。一般使用这种。3. no : 由操作系统来定什么时候fsync到硬盘中。 缺点:不可控 AOF重写:把过期的,没有用的,重复的,可优化的命令简化为很小的aof文件。实际上是redis内存中的数据回溯成aof文件。如下图所示:作用:1.减少硬盘占用量2.加快恢复速度 AOF重写的实现方式1.bgrewriteaof 命令 : 从redis的主进程fork一个子进程生成包含当前redis内存数据的最小命令集、2.AOF重写配置:# 1. aof文件增长率 auto-aof-rewrite-percentage 100# 2. aof文件重写需要的尺寸 auto-aof-rewrite-min-size 64mb自动触发时机:(需要同时满足)当前的aof文件大小 > aof文件重写需要的尺寸 (aof当前文件大小 - 上次aof的文件大小)/ 上次aof文件大小 > aof文件增长率 AOF优缺点优点:1.数据的完整性和一致性更高缺点:1.因为AOF记录的内容多,文件会越来越大,数据恢复也会越来越慢。2. AOF每秒fsync一次指令硬盘,如果硬盘IO慢,会阻塞父进程;风险是会丢失1秒多的数据;在Rewrite过程中,主进程把指令存到mem-buffer中,最后写盘时会阻塞主进程。关于Redis持久化方式RDB和AOF的缺点原因是redis持久化方式的痛点,缺点比较明显。1、RDB需要定时持久化,风险是可能会丢两次持久之间的数据,量可能很大。2、AOF每秒fsync一次指令硬盘,如果硬盘IO慢,会阻塞父进程;风险是会丢失1秒多的数据;在Rewrite过程中,主进程把指令存到mem-buffer中,最后写盘时会阻塞主进程。3、这两个缺点是个很大的痛点。为了解决这些痛点,GitHub的两位工程师 Bryana Knight 和 Miguel Fernández 日前写了一篇 文章 ,讲述了将持久数据从Redis迁出的经验: http://www.open-open.com/lib/view/open1487736984424.html如何选择RDB和AOF建议全都要。1、对于我们应该选择RDB还是AOF,官方的建议是两个同时使用。这样可以提供更可靠的持久化方案。在redis 4.0 之后,官方提供了混合持久化模式,具体如下持久化文件结构上半段RDB格式,后半段是AOF模式。
-
1.1 高健壮性机器人要求对于复杂度为O(n2)的脚本或者脚本涉及到UI页面操作就必须使用Try-catch+SubProcess保证高健壮性。Tips:在读写文件,比如读Excel的时候,也可以放入到Try-Catch-Finally里,如果Excel被打开了则脚本执行打开Excel会出错,可以在Catch里调用脚本杀掉Excel进程,在下一次Try的时候就可以顺利打开文件了1.2 转变成机器思维的要求比如将一个Excel表格里的内容,循环100次录入到web页面里。如果在没有模板可以一次导入的情况下,需要循环100次。人的操作思维:1, 登陆网页。2, 选中相应的内容copy到网页里,并提交。3, 循环填入下一条。4, 结束。 当用脚本实现时,我们建议:1, 打开excel读取1000条内容到内存里。可以避免文件交叉操作导致任务失败。2, 循环内存中1000条数据的第一条,并判断网页是否ready可以填入内容,并提交。如果网页未ready那么就打开网页。3, 循环填入下一条。4, 结束。这样做的好处是:不管网页是否稳定,即便网络中断几分钟,都可以顺利的保证完成录入任务。1.3 便于定位问题添加必要打印的要求当开发完成转维后,想要再去查找问题就比较困难, 所以在开发初期增加足够的日志,便于后期定位问题。例如在进入新脚本的时候、查询到结果的时候、关键节点等。1.4 查询再执行类增加校验的要求比如下图处理当前单处理的问题,要把单号记录下来,便于出现问题后排查问题,如果允许的话可以在失败的时候截图保留截图。 如果查询结果不一致,则继续查询一次,多次后未果,则发送通知消息。1.5 使用文字或者相对路径定位的要求xpath=//button[text()="Reset"]xpath=//a[contains(text(),'我的任务')]xpath=//*[contains(@id,"datatable")]/div[2]/div[1]/div/div[4]/divxpath=//*[text()="提交"]或者使用相对路径,这样在网页变动后还能增加成功定位的概率。网页操作中xpath的定位非常重要,可以参考网上资料进行深入学习。1.6 使用GETTABLE代替循环的要求在很多网页中某些表比较长,当前窗口显示不全,可以使用gettable,这样可以避免取不到拖动后才能看到的元素,如下图右侧的元素定位。当然,有些看上去是表的展示,单实际并不是表,还是要循环去操作。对于gettable的使用可以登陆www.ilearningx.huawei.com,搜索AntRobot,查看高级课程的9.2章节1.7 双重保护确保任务达成的要求比如对于鼠标移动网页元素上面的时候才会出现的菜单,actionchains 不一定会每次稳定运行。此时可以增加ClickPicxx的操作。1.8 串行任务改并行的要求比如登陆网站下载几千张图片,并对图片做OCR识别,比较推荐的解决办法是: 1,WeAutomate负责下载 图片,并拆分成不同的小组,比如100张一组。2,一组完成下载后即调用Java或者python等实现处理每个小组的图片,并继续下载下一组照片3,WeAutomate判断图片所有图片识别结束后进行信息汇总。4,最后一个小组与倒数第二个小组都完成,或者所有小组都完成,则执行完毕。1.9 拆分超长流程的要求不要将所有的流程全部放在一个子脚本/Script里,跟写代码时不允许一个函数体超过150行或者200行一个道理。缺点: 1,太长的流程很难读懂,别人很难很快了解流程的结构2,没有异常处理逻辑3,如果系统中出现小问题,则进程将终止 改进建议:主页保留流程主线,把大部分二级处理逻辑移到子页之后对完成的任务进行合理的拆分。1.10 安全开发规范要求1,WeAutomate Studio支持敏感信息本地存储、使用双重加密2,管理中心运行账号与开发账号隔离3,开发人员只接触测试账号1.11 其它要求1,流程应该简洁、干净且有逻辑2,应当在在定义好流程的输入、输出、处理过程后,再着手进行开发3,保存流程前,应该先检查所有Error。开发过程中的Error应当保证可控;开发完成后流程中不应当存在Error
-
 openGauss数据库自2020年6月30日开源以来,吸引了众多内核开发者的关注。那么openGauss的多线程是如何启动的,一条SQL语句在 SQL引擎,执行引擎和存储引擎的执行过程是怎样的,酷哥做了一些总结,第一期内容主要分析openGauss 多线程架构启动过程。openGauss数据库是一个单进程多线程的数据库,客户端可以使用JDBC/ODBC/Libpq/Psycopg等驱动程序,向openGauss的主线程(Postmaster)发起连接请求。openGauss为什么要使用多线程架构随着计算机领域多核技术的发展,如何充分有效的利用多核的并行处理能力,是每个服务器端应用程序都必须考虑的问题。由于数据库服务器的服务进程或线程间存在着大量数据共享和同步,而多线程可以充分利用多CPU来并行执行多个强相关任务,例如执行引擎可以充分的利用线程的并发执行以提供性能。在多线程的架构下,数据共享的效率更高,能提高服务器访问的效率和性能,同时维护开销和复杂度更低,这对于提高数据库系统的并行处理能力非常重要。多线程的三大主要优势:优势一:线程启动开销远小于进程启动开销。与进程相比,它是一种非常“节俭”的多任务操作方式。在Linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种“昂贵”的多任务工作方式。而运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,启动一个线程所花费的空间远远小于启动一个进程所花费的空间。优势二:线程间方便的通信机制:对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其他线程所用,这不仅快捷,而且方便。优势三:线程切换开销小于进程切换开销,对于Linux系统来讲,进程切换分两步:1.切换页目录以使用新的地址空间;2.切换内核栈和硬件上下文。对线程切换,第1步是不需要做的,第2步是进程和线程都要做的,所以明显线程切换开销小。openGauss主要线程有哪些后台线程功能介绍Postmaster主线程入口函数PostmasterMain,主要负责内存、全局信息、信号、线程池等的初始化,启动辅助线程并监控线程状态,循环**接收新的连接Walwriter日志写线程入口函数WalWriterMain,将内存的预写日志页数据刷新到预写日志文件中,保证已提交的事物永久记录,不会丢失Startup数据库启动线程入口函数StartupProcessMain,数据库启动时Postmaster主线程拉起的第一个子线程,主要完成数据库的日志REDO(重做)操作,进行数据库的恢复。日志REDO操作结束,数据库完成恢复后,如果不是备机,Startup线程就退出了。如果是备机,那么Startup线程一直在运行,REDO备机接收到新的日志Bgwriter后台数据写线程入口函数BackgroundWriterMain,对共享缓冲区的脏页数据进行下盘PageWriter入口函数ckpt_pagewriter_main,将脏页数据拷贝至双写区域并落盘Checkpointer检查点线程入口函数CheckpointerMain,周期性检查点,所有数据文件被更新,将数据脏页刷新到磁盘,确保数据库一致;崩溃回复后,做过checkpointer更改不需要从预写日志中恢复StatCollector统计线程入口函数PgstatCollectorMain,统计信息,包括对象、sql、会话、锁等,保存到pgstat.stat文件中,用于性能、故障、状态分析WalSender日志发送线程入口函数WalSenderMain,主机发送预写日志WalReceiver日志接收线程入口函数WalReceiverMain,备机接收预写日志Postgres业务处理线程入口函数PostgresMain:处理客户端连接请求,执行相关SQL业务数据库启动后,可以通过操作系统命令ps查看线程信息(进程号为17012)openGauss启动过程下面主要介绍openGauss数据库的启动过程,包括主线程,辅助线程及业务处理线程的启动过程gs_ctl启动数据库gs_ctl是openGauss提供的数据库服务控制工具,可以用来启停数据库服务和查询数据库状态。主要供数据库管理模块调用,启动数据库使用如下命令gs_ctl start -D /opt/software/data -Z single_nodegs_ctl的入口函数在“src/bin/pg_ctl/pg_ctl.cpp”,gs_ctl进程fork一个进程来运行 gaussdb进程,通过shell命令启动。上图中的cmd为“/opt/software/openGauss/bin/gaussdb -D /opt/software/openGauss/data”,进入到数据库运行调用的第一个函数是main函数,在“src/gausskernel/process/main/main.cpp”文件中,在main.cpp文件中,主要完成实例Context(上下文)的初始化、本地化设置,根据main.cpp文件的入口参数调用BootStrapProcessMain函数、GucInfoMain函数、PostgresMain函数和PostmasterMain函数。BootStrapProcessMain函数和PostgresMain函数是在initdb场景下初始化数据库使用的。GucInfoMain函数作用是显示GUC(grand unified configuration,配置参数,在数据库中指的是运行参数)参数信息。正常的数据库启动会进入PostmasterMain函数。下面对这个函数进行更详细的介绍。MemoryContextInit:内存上下文系统初始化,主要完成对ThreadTopMemoryContext,ErrorContext,AlignContext和ProfileLogging等全局变量的初始化pg_perm_setlocale:设置程序语言环境相关的全局变量check_root: 确认程序运行者无操作系统的root权限,防止的意外文件覆盖等问题如果gaussdb后的第一个参数是—boot,则进行数据库初始化,如果gaussdb后的第一个参数是--single,则调用PostgresMain(),进入(本地)单用户版服务端程序。之后,与普通服务器端线程类似,循环等待用户输入SQL语句,直至用户输入EOF(Ctrl+D),退出程序。如果没有指定额外启动选项,程序进入PostmasterMain函数,开始一系列服务器端的正常初始化工作。PostmasterMain函数下面具体介绍PostmasterMain。设置线程号相关的全局变量MyProcPid、PostmasterPid、MyProgName和程序运行环境相关的全局变量IsPostmasterEnvironment调用postmaster_mem_cxt = AllocSetContextCreate(t_thrd.top_mem_cxt,...),在目前线程的top_mem_cxt下创建postmaster_mem_cxt全局变量和相应的内存上下文MemoryContextSwitchTo(postmaster_mem_cxt)切换到postmaster_mem_cxt内存上下文调用getInstallationPaths(),设置my_exec_path(一般即为gaussdb可执行文件所在路径)调用InitializeGUCOptions(),根据代码中各个GUC参数的默认值生成ConfigureNamesBool、ConfigureNamesInt、ConfigureNamesReal、ConfigureNamesString、ConfigureNamesEnum等 GUC参数的全局变量数组,以及统一管理GUC参数的guc_variables、num_guc_variables、size_guc_variables全局变量,并设置与具体操作系统环境相关的GUC参数while (opt = ...) SetConfigOption, 若在启动gaussdb时用指定了非默认的GUC参数,则在此时加载至上一步中创建的全局变量中调用checkDataDir(),确认数据库安装成功以及PGDATA目录的有效性调用CreateDataDirLockFile(),创建数据目录的锁文件调用process_shared_preload_libraries(),处理预加载库为每个ListenSocket创建**reset_shared,设置共享内存和信号,主要包括页面缓存池、各种锁缓存池、WAL日志缓存池、事务日志缓存池、事务(号)概况缓存池、各后台线程(锁使用)概况缓存池、各后台线程等待和运行状态缓存池、两阶段状态缓存池、检查点缓存池、WAL日志复制和接收缓存池、数据页复制和接收缓存池等。在后续阶段创建出的客户端后台线程以及各个辅助线程均使用该共享内存空间,不再单独开辟将启动时手动设置的GUC参数以文件形式保存下来,以供后续后台服务端线程启动时使用为不同信号设置handler调用pgstat_init(),初始化状态收集子系统;调用load_hba(),加载pg_hba.conf文件,该文件记录了允许连接(指定或全部)数据库的客户端物理机的地址和端口;调用load_ident(),加载pg_ident.conf文件,该文件记录了操作系统用户名与数据库系统用户名的对应关系,以便后续处理客户端连接时的身份认证调用 StartupPID = initialize_util_thread(STARTUP),进行数据一致性校验。对于服务端主机来说,查看pg_control文件,若上次关闭状态为DB_SHUTDOWNED且recovery.conf文件没有指定进行恢复,则认为数据一致性成立;否则,根据pg_control中检查点的redo位置或者recovery.conf文件中指定的位置,读取WAL日志或归档日志进行replay(回放),直至数据达到预期的一致性状,主要函数StartupXLOG最后进入ServerLoop()函数,循环响应客户端连接请求ServerLoop函数下面来讲ServerLoop函数主流程调用gs_signal_setmask(&UnBlockSig, NULL)和gs_signal_unblock_sigusr2(),使得线程可以响应用户或其它线程的、指定的信号集每隔PM_POLL_TIMEOUT_MINUTE时间修改一次socket文件和socket锁文件的访问和修改时间,以免**作系统淘汰判断线程状态(pmState),若为PM_WAIT_DEAD_END,则休眠100毫秒,并且不接收任何连接;否则,通过系统调用poll()或select()来阻塞地读取**端口上传入的数据,最长阻塞时间PM_POLL_TIMEOUT_SECOND调用gs_signal_setmask(&BlockSig, NULL)和gs_signal_block_sigusr2()不再接收外源信号判断poll()或select()函数的返回值,若小于零,**出错,服务端进程退出;若大于零,则创建连接ConnCreate(),并进入后台服务线程启动流程BackendStartup()。对于父线程,即postmaster线程,在结束BackendStartup()的调用以后,会调用ConnFree(),清除连接信息;若poll()或select()的返回值为零,即没有信息传入,则不进行任何操作调用ADIO_RUN()、ADIO_END() ,若AioCompleters没有启动,则启动之检查各个辅助线程的线程号是否为零,若为零,则调用initialize_util_thread启动以非线程池模式为例,介绍线程的启动逻辑。BackendStartup函数是通过调用initialize_worker_thread(WORKE,port)创建一个后台线程处理客户请求。后台线程的启动函数initialize_util_thread和工作线程的启动函数initialize_worker_thread,最后都是调用initialize_thread函数完成线程的启动。initialize_thread函数调用gs_thread_create函数创建线程,调用InternalThreadFunc函数处理线程ThreadId initialize_thread(ThreadArg* thr_argv) { gs_thread_t thread; int error_code = gs_thread_create(&thread, InternalThreadFunc, 1, (void*)thr_argv); if (error_code != 0) { ereport(LOG, (errmsg("can not fork thread[%s], errcode:%d, %m", GetThreadName(thr_argv->m_thd_arg.role), error_code))); gs_thread_release_args_slot(thr_argv); return InvalidTid; } return gs_thread_id(thread); }InternalThreadFunc函数根据角色调用GetThreadEntry函数,GetThreadEntry函数直接以角色为下标,返回对应GaussdbThreadEntryGate数组对应的元素。数组的元素是处理具体任务的回调函数指针,指针指向的函数为GaussDbThreadMainstatic void* InternalThreadFunc(void* args) { knl_thread_arg* thr_argv = (knl_thread_arg*)args; gs_thread_exit((GetThreadEntry(thr_argv->role))(thr_argv)); return (void*)NULL; } GaussdbThreadEntry GetThreadEntry(knl_thread_role role) { Assert(role > MASTER && role < THREAD_ENTRY_BOUND); return GaussdbThreadEntryGate[role]; } static GaussdbThreadEntry GaussdbThreadEntryGate[] = {GaussDbThreadMain<MASTER>, GaussDbThreadMain<WORKER>, GaussDbThreadMain<THREADPOOL_WORKER>, GaussDbThreadMain<THREADPOOL_LISTENER>, ......};在GaussDbThreadMain函数中,首先初始化线程基本信息,Context和信号处理函数,接着就是根据thread_role角色的不同调用不同角色的处理函数,进入各个线程的main函数,角色为WORKER会进入PostgresMain函数,下面具体介绍PostgresMain函数PostgresMain函数process_postgres_switches(),加载传入的启动选项和GUC参数为不同信号设置handler调用sigdelset(&BlockSig, SIGQUIT),允许响应SIGQUIT信号调用BaseInit(),初始化存储管理系统和页面缓存池计数调用on_shmem_exit(),设置线程退出前需要进行的内存清理动作。这些清理动作构成一个链表(on_shmem_exit_list全局变量),每次调用该函数都向链表尾端添加一个节点,链表长度由on_shmem_exit_index记录,且不可超过MAX_ON_EXITS宏。在线程退出时,从后往前调用各个节点中的动作(函数指针),完成清理工作调用gs_signal_setmask (&UnBlockSig),设置屏蔽的信号类型调用InitBackendWorker进行统计系统初始化、syscache初始化工作BeginReportingGUCOptions如有需要则打印GUC参数调用on_proc_exit(),设置线程退出前需要进行的线程清理动作。设置和调用机制与on_shmem_exit()类似调用process_local_preload_libraries(),处理GUC参数设定后的预加载库AllocSetContextCreate创建MessageContext、RowDescriptionContext、MaskPasswordCtx上下文调用sigsetjmp(),设置longjump点,若后续查询执行中出错,在某些情况下可以返回此处重新开始调用gs_signal_unblock_sigusr2(),允许线程响应指定的信号集然后进入for循环,进行查询执行 调用pgstat_report_activity()、pgstat_report_waitstatus(),告诉统计系统后台线程正处于idle状态设置全局变量DoingCommandRead = true调用ReadCommand(),读取客户端SQL语句设置全局变量DoingCommandRead=false若在上述过程中收到SIGHUP信号,表示线程需要重新加载修改过的postgresql.conf配置文件进入switch (firstchar),根据接收到的信息进行分支判断思考如何新增一个辅助线程参考其他线程完成涉及修改文件Postmaster.cpp涉及修改函数GaussdbThreadGate – 定义Serverloop – 启动线程Reaper – 回收线程GaussDBThreadMain – 入口函数
openGauss数据库自2020年6月30日开源以来,吸引了众多内核开发者的关注。那么openGauss的多线程是如何启动的,一条SQL语句在 SQL引擎,执行引擎和存储引擎的执行过程是怎样的,酷哥做了一些总结,第一期内容主要分析openGauss 多线程架构启动过程。openGauss数据库是一个单进程多线程的数据库,客户端可以使用JDBC/ODBC/Libpq/Psycopg等驱动程序,向openGauss的主线程(Postmaster)发起连接请求。openGauss为什么要使用多线程架构随着计算机领域多核技术的发展,如何充分有效的利用多核的并行处理能力,是每个服务器端应用程序都必须考虑的问题。由于数据库服务器的服务进程或线程间存在着大量数据共享和同步,而多线程可以充分利用多CPU来并行执行多个强相关任务,例如执行引擎可以充分的利用线程的并发执行以提供性能。在多线程的架构下,数据共享的效率更高,能提高服务器访问的效率和性能,同时维护开销和复杂度更低,这对于提高数据库系统的并行处理能力非常重要。多线程的三大主要优势:优势一:线程启动开销远小于进程启动开销。与进程相比,它是一种非常“节俭”的多任务操作方式。在Linux系统下,启动一个新的进程必须分配给它独立的地址空间,建立众多的数据表来维护它的代码段、堆栈段和数据段,这是一种“昂贵”的多任务工作方式。而运行于一个进程中的多个线程,它们彼此之间使用相同的地址空间,共享大部分数据,启动一个线程所花费的空间远远小于启动一个进程所花费的空间。优势二:线程间方便的通信机制:对不同进程来说,它们具有独立的数据空间,要进行数据的传递只能通过通信的方式进行,这种方式不仅费时,而且很不方便。线程则不然,由于同一进程下的线程之间共享数据空间,所以一个线程的数据可以直接为其他线程所用,这不仅快捷,而且方便。优势三:线程切换开销小于进程切换开销,对于Linux系统来讲,进程切换分两步:1.切换页目录以使用新的地址空间;2.切换内核栈和硬件上下文。对线程切换,第1步是不需要做的,第2步是进程和线程都要做的,所以明显线程切换开销小。openGauss主要线程有哪些后台线程功能介绍Postmaster主线程入口函数PostmasterMain,主要负责内存、全局信息、信号、线程池等的初始化,启动辅助线程并监控线程状态,循环**接收新的连接Walwriter日志写线程入口函数WalWriterMain,将内存的预写日志页数据刷新到预写日志文件中,保证已提交的事物永久记录,不会丢失Startup数据库启动线程入口函数StartupProcessMain,数据库启动时Postmaster主线程拉起的第一个子线程,主要完成数据库的日志REDO(重做)操作,进行数据库的恢复。日志REDO操作结束,数据库完成恢复后,如果不是备机,Startup线程就退出了。如果是备机,那么Startup线程一直在运行,REDO备机接收到新的日志Bgwriter后台数据写线程入口函数BackgroundWriterMain,对共享缓冲区的脏页数据进行下盘PageWriter入口函数ckpt_pagewriter_main,将脏页数据拷贝至双写区域并落盘Checkpointer检查点线程入口函数CheckpointerMain,周期性检查点,所有数据文件被更新,将数据脏页刷新到磁盘,确保数据库一致;崩溃回复后,做过checkpointer更改不需要从预写日志中恢复StatCollector统计线程入口函数PgstatCollectorMain,统计信息,包括对象、sql、会话、锁等,保存到pgstat.stat文件中,用于性能、故障、状态分析WalSender日志发送线程入口函数WalSenderMain,主机发送预写日志WalReceiver日志接收线程入口函数WalReceiverMain,备机接收预写日志Postgres业务处理线程入口函数PostgresMain:处理客户端连接请求,执行相关SQL业务数据库启动后,可以通过操作系统命令ps查看线程信息(进程号为17012)openGauss启动过程下面主要介绍openGauss数据库的启动过程,包括主线程,辅助线程及业务处理线程的启动过程gs_ctl启动数据库gs_ctl是openGauss提供的数据库服务控制工具,可以用来启停数据库服务和查询数据库状态。主要供数据库管理模块调用,启动数据库使用如下命令gs_ctl start -D /opt/software/data -Z single_nodegs_ctl的入口函数在“src/bin/pg_ctl/pg_ctl.cpp”,gs_ctl进程fork一个进程来运行 gaussdb进程,通过shell命令启动。上图中的cmd为“/opt/software/openGauss/bin/gaussdb -D /opt/software/openGauss/data”,进入到数据库运行调用的第一个函数是main函数,在“src/gausskernel/process/main/main.cpp”文件中,在main.cpp文件中,主要完成实例Context(上下文)的初始化、本地化设置,根据main.cpp文件的入口参数调用BootStrapProcessMain函数、GucInfoMain函数、PostgresMain函数和PostmasterMain函数。BootStrapProcessMain函数和PostgresMain函数是在initdb场景下初始化数据库使用的。GucInfoMain函数作用是显示GUC(grand unified configuration,配置参数,在数据库中指的是运行参数)参数信息。正常的数据库启动会进入PostmasterMain函数。下面对这个函数进行更详细的介绍。MemoryContextInit:内存上下文系统初始化,主要完成对ThreadTopMemoryContext,ErrorContext,AlignContext和ProfileLogging等全局变量的初始化pg_perm_setlocale:设置程序语言环境相关的全局变量check_root: 确认程序运行者无操作系统的root权限,防止的意外文件覆盖等问题如果gaussdb后的第一个参数是—boot,则进行数据库初始化,如果gaussdb后的第一个参数是--single,则调用PostgresMain(),进入(本地)单用户版服务端程序。之后,与普通服务器端线程类似,循环等待用户输入SQL语句,直至用户输入EOF(Ctrl+D),退出程序。如果没有指定额外启动选项,程序进入PostmasterMain函数,开始一系列服务器端的正常初始化工作。PostmasterMain函数下面具体介绍PostmasterMain。设置线程号相关的全局变量MyProcPid、PostmasterPid、MyProgName和程序运行环境相关的全局变量IsPostmasterEnvironment调用postmaster_mem_cxt = AllocSetContextCreate(t_thrd.top_mem_cxt,...),在目前线程的top_mem_cxt下创建postmaster_mem_cxt全局变量和相应的内存上下文MemoryContextSwitchTo(postmaster_mem_cxt)切换到postmaster_mem_cxt内存上下文调用getInstallationPaths(),设置my_exec_path(一般即为gaussdb可执行文件所在路径)调用InitializeGUCOptions(),根据代码中各个GUC参数的默认值生成ConfigureNamesBool、ConfigureNamesInt、ConfigureNamesReal、ConfigureNamesString、ConfigureNamesEnum等 GUC参数的全局变量数组,以及统一管理GUC参数的guc_variables、num_guc_variables、size_guc_variables全局变量,并设置与具体操作系统环境相关的GUC参数while (opt = ...) SetConfigOption, 若在启动gaussdb时用指定了非默认的GUC参数,则在此时加载至上一步中创建的全局变量中调用checkDataDir(),确认数据库安装成功以及PGDATA目录的有效性调用CreateDataDirLockFile(),创建数据目录的锁文件调用process_shared_preload_libraries(),处理预加载库为每个ListenSocket创建**reset_shared,设置共享内存和信号,主要包括页面缓存池、各种锁缓存池、WAL日志缓存池、事务日志缓存池、事务(号)概况缓存池、各后台线程(锁使用)概况缓存池、各后台线程等待和运行状态缓存池、两阶段状态缓存池、检查点缓存池、WAL日志复制和接收缓存池、数据页复制和接收缓存池等。在后续阶段创建出的客户端后台线程以及各个辅助线程均使用该共享内存空间,不再单独开辟将启动时手动设置的GUC参数以文件形式保存下来,以供后续后台服务端线程启动时使用为不同信号设置handler调用pgstat_init(),初始化状态收集子系统;调用load_hba(),加载pg_hba.conf文件,该文件记录了允许连接(指定或全部)数据库的客户端物理机的地址和端口;调用load_ident(),加载pg_ident.conf文件,该文件记录了操作系统用户名与数据库系统用户名的对应关系,以便后续处理客户端连接时的身份认证调用 StartupPID = initialize_util_thread(STARTUP),进行数据一致性校验。对于服务端主机来说,查看pg_control文件,若上次关闭状态为DB_SHUTDOWNED且recovery.conf文件没有指定进行恢复,则认为数据一致性成立;否则,根据pg_control中检查点的redo位置或者recovery.conf文件中指定的位置,读取WAL日志或归档日志进行replay(回放),直至数据达到预期的一致性状,主要函数StartupXLOG最后进入ServerLoop()函数,循环响应客户端连接请求ServerLoop函数下面来讲ServerLoop函数主流程调用gs_signal_setmask(&UnBlockSig, NULL)和gs_signal_unblock_sigusr2(),使得线程可以响应用户或其它线程的、指定的信号集每隔PM_POLL_TIMEOUT_MINUTE时间修改一次socket文件和socket锁文件的访问和修改时间,以免**作系统淘汰判断线程状态(pmState),若为PM_WAIT_DEAD_END,则休眠100毫秒,并且不接收任何连接;否则,通过系统调用poll()或select()来阻塞地读取**端口上传入的数据,最长阻塞时间PM_POLL_TIMEOUT_SECOND调用gs_signal_setmask(&BlockSig, NULL)和gs_signal_block_sigusr2()不再接收外源信号判断poll()或select()函数的返回值,若小于零,**出错,服务端进程退出;若大于零,则创建连接ConnCreate(),并进入后台服务线程启动流程BackendStartup()。对于父线程,即postmaster线程,在结束BackendStartup()的调用以后,会调用ConnFree(),清除连接信息;若poll()或select()的返回值为零,即没有信息传入,则不进行任何操作调用ADIO_RUN()、ADIO_END() ,若AioCompleters没有启动,则启动之检查各个辅助线程的线程号是否为零,若为零,则调用initialize_util_thread启动以非线程池模式为例,介绍线程的启动逻辑。BackendStartup函数是通过调用initialize_worker_thread(WORKE,port)创建一个后台线程处理客户请求。后台线程的启动函数initialize_util_thread和工作线程的启动函数initialize_worker_thread,最后都是调用initialize_thread函数完成线程的启动。initialize_thread函数调用gs_thread_create函数创建线程,调用InternalThreadFunc函数处理线程ThreadId initialize_thread(ThreadArg* thr_argv) { gs_thread_t thread; int error_code = gs_thread_create(&thread, InternalThreadFunc, 1, (void*)thr_argv); if (error_code != 0) { ereport(LOG, (errmsg("can not fork thread[%s], errcode:%d, %m", GetThreadName(thr_argv->m_thd_arg.role), error_code))); gs_thread_release_args_slot(thr_argv); return InvalidTid; } return gs_thread_id(thread); }InternalThreadFunc函数根据角色调用GetThreadEntry函数,GetThreadEntry函数直接以角色为下标,返回对应GaussdbThreadEntryGate数组对应的元素。数组的元素是处理具体任务的回调函数指针,指针指向的函数为GaussDbThreadMainstatic void* InternalThreadFunc(void* args) { knl_thread_arg* thr_argv = (knl_thread_arg*)args; gs_thread_exit((GetThreadEntry(thr_argv->role))(thr_argv)); return (void*)NULL; } GaussdbThreadEntry GetThreadEntry(knl_thread_role role) { Assert(role > MASTER && role < THREAD_ENTRY_BOUND); return GaussdbThreadEntryGate[role]; } static GaussdbThreadEntry GaussdbThreadEntryGate[] = {GaussDbThreadMain<MASTER>, GaussDbThreadMain<WORKER>, GaussDbThreadMain<THREADPOOL_WORKER>, GaussDbThreadMain<THREADPOOL_LISTENER>, ......};在GaussDbThreadMain函数中,首先初始化线程基本信息,Context和信号处理函数,接着就是根据thread_role角色的不同调用不同角色的处理函数,进入各个线程的main函数,角色为WORKER会进入PostgresMain函数,下面具体介绍PostgresMain函数PostgresMain函数process_postgres_switches(),加载传入的启动选项和GUC参数为不同信号设置handler调用sigdelset(&BlockSig, SIGQUIT),允许响应SIGQUIT信号调用BaseInit(),初始化存储管理系统和页面缓存池计数调用on_shmem_exit(),设置线程退出前需要进行的内存清理动作。这些清理动作构成一个链表(on_shmem_exit_list全局变量),每次调用该函数都向链表尾端添加一个节点,链表长度由on_shmem_exit_index记录,且不可超过MAX_ON_EXITS宏。在线程退出时,从后往前调用各个节点中的动作(函数指针),完成清理工作调用gs_signal_setmask (&UnBlockSig),设置屏蔽的信号类型调用InitBackendWorker进行统计系统初始化、syscache初始化工作BeginReportingGUCOptions如有需要则打印GUC参数调用on_proc_exit(),设置线程退出前需要进行的线程清理动作。设置和调用机制与on_shmem_exit()类似调用process_local_preload_libraries(),处理GUC参数设定后的预加载库AllocSetContextCreate创建MessageContext、RowDescriptionContext、MaskPasswordCtx上下文调用sigsetjmp(),设置longjump点,若后续查询执行中出错,在某些情况下可以返回此处重新开始调用gs_signal_unblock_sigusr2(),允许线程响应指定的信号集然后进入for循环,进行查询执行 调用pgstat_report_activity()、pgstat_report_waitstatus(),告诉统计系统后台线程正处于idle状态设置全局变量DoingCommandRead = true调用ReadCommand(),读取客户端SQL语句设置全局变量DoingCommandRead=false若在上述过程中收到SIGHUP信号,表示线程需要重新加载修改过的postgresql.conf配置文件进入switch (firstchar),根据接收到的信息进行分支判断思考如何新增一个辅助线程参考其他线程完成涉及修改文件Postmaster.cpp涉及修改函数GaussdbThreadGate – 定义Serverloop – 启动线程Reaper – 回收线程GaussDBThreadMain – 入口函数 -
前言什么是线程的概念我就不在介绍,不懂的自行百度,我想百分之九十九的人都是知道的,至于多线程,通俗的就是有很多的线程在一起工作从而完成某一件事,从而提升效率。这就是使用多线程的好处之一,举个列子,一家酒店,几个厨子,杂工,切菜工,服务员…大家各司其职,各完成一道工序,这道菜才可以快速做成,如果一直只要一个厨师去做,哈哈哈,告诉你,人多,店就等着被关门吧。由于,我在做Java或android的时候,经常会遇到多线程问题,今天我想深刻总结一下,如有不当之处,希望大佬们不吝赐教。好了,今天我们就来详细的探究一下多线程吧。今天讲的大概就是以上流程图的三个部分。多线程优化基础简要介绍多线程优化的基础知识,包括线程的介绍和线程调度基本原理。多线程优化问题多线程优化需要预防的一些问题,包括线程安全问题的介绍和实现线程安全的办法。多线程优化方法多线程优化可以使用的一些方法,包括线程之间的协作方式与 Android 执行异步任务的常用方式。好了,下面就一步一步探究一下多线程吧。1.能不能不用多线程?首先,不管你会不会多线程,都必须要学习和使用多线程,因为,它实在是太重要了。使用多线程前,需要明白几个关键点。GCGarbage Collector(垃圾回收器)Garbage Collection(垃圾回收动作)GC线程假如我们现在运行的是一个啥也没有的 demo 项目,那也不代表我们运行的是一个单线程应用。因为这个应用是运行在 ART 上的,而 ART(啥是ART下面有介绍) 自带了 GC 线程,再加上主线程,它依旧是一个多线程应用。ARTAndroid Runtime(Android 应用运行时环境)JVMJava Virtual Machine(Java 虚拟机)JUCjava.util.concurrent(Java 并发包)因此,不管你是否懂何为多线程,你也要用到多线程,因此,学习多线程是必要的。第三方线程在我们开发应用的过程中,即使我们没有直接创建线程,也间接地创建了线程。因为我们日常使用的第三方库,包括 Android 系统本身都用到了多线程。比如 Glide 就是使用工作线程从网络上加载图片,等图片加载完毕后,再切回主线程把图片设置到 ImageView 中。2. 为什么要做多线程优化?做多线程优化是为了解决多线程的安全性和活跃性问题。这两个问题会导致多线程程序输出错误的结果以及任务无法执行,下面我们就来看看这两个问题的表现。安全性问题假如现在有两个厨师小张和老王,他们两个人分别做两道菜,大家都知道自己的菜放了多少盐,多少糖,在这种情况下出问题的概率比较低。但是如果两个人做一个菜呢?小张在做一个菜,做着做着锅被老王抢走了,老王不知道小张有没有放盐,就又放了一次盐,结果炒出来的菜太咸了,没法吃,然后他们就决定要出去皇城 PK。这里的“菜”对应着我们程序中的数据。而这种现象就是导致线程出现安全性的原因之一:竞态(Race Condition)。之所以会出现竞态是由 Java 的内存模型和线程调度机制决定的,关于 Java 的线程调度机制,在后面会有更详细的介绍。活跃性问题自从上次出了皇城 PK 的事情后,经理老李出了一条规定,打架扣 100,这条规定一出,小张和老王再也不敢 PK 了,不过没过几天,他们就找到了一种新的方式来互怼。有一天,小张在做菜,小张要先放盐再放糖,而老王拿着盐,老王要先放糖再放盐,结果过了两个小时两个人都没把菜做出来,经理老李再次陷入懵逼的状态。这就是线程活跃性问题的现象之一:死锁(Deadlock)。关于线程安全性的三个问题和线程活跃性的四个问题,在本文后面会做更详细的介绍。3. 什么是线程?3.1 线程简介线程是进程中可独立执行的最小单位,也是 CPU 资源分配的基本单位。进程是程序向操作系统申请资源的基本条件,一个进程可以包含多个线程,同一个进程中的线程可以共享进程中的资源,如内存空间和文件句柄。操作系统会把资源分配给进程,但是 CPU 资源比较特殊,它是分配给线程的,这里说的 CPU 资源也就是 CPU 时间片。进程与线程的关系,就像是饭店与员工的关系,饭店为顾客提供服务,而提供服务的具体方式是通过一个个员工实现的。线程的作用是执行特定任务,这个任务可以是下载文件、加载图片、绘制界面等。下面我们就来看看线程的四个属性、六个方法以及六种状态。3.2 线程的四个属性线程有编号、名字、类别以及优先级四个属性,除此之外,线程的部分属性还具有继承性,下面我们就来看看线程的四个属性的作用和线程的继承性。3.2.1 编号作用线程的编号(id)用于标识不同的线程,每条线程拥有不同的编号。注意事项不能作为唯一标识某个编号的线程运行结束后,该编号可能被后续创建的线程使用,因此编号不适合用作唯一标识只读编号是只读属性,不能修改3.2.2 名字每个线程都有自己的名字(name),名字的默认值是 Thread-线程编号,比如 Thread-0 。除了默认值,我们也可以给线程设置名字,以我们自己的方式去区分每一条线程。作用给线程设置名字可以让我们在某条线程出现问题时,用该线程的名字快速定位出问题的地方.3.2.3 类别线程的类别(daemon)分为守护线程和用户线程,我们可以通过 setDaemon(true) 把线程设置为守护线程。当 JVM 要退出时,它会考虑是否所有的用户线程都已经执行完毕,是的话则退出。而对于守护线程,JVM 在退出时不会考虑它是否执行完成。作用守护线程通常用于执行不重要的任务,比如监控其他线程的运行情况,GC 线程就是一个守护线程。注意事项setDaemon() 要在线程启动前设置,否则 JVM 会抛出非法线程状态异常抛出(IllegalThreadStateException)。3.2.4 优先级作用线程的优先级(Priority)用于表示应用希望优先运行哪个线程,线程调度器会根据这个值来决定优先运行哪个线程。取值范围Java 中线程优先级的取值范围为 1~10,默认值是 5,Thread 中定义了下面三个优先级常量。最低优先级:MIN_PRIORITY = 1默认优先级:NORM_PRIORITY = 5最高优先级:MAX_PRIORITY = 10注意事项不保证线程调度器把线程的优先级当作一个参考值,不一定会按我们设定的优先级顺序执行线程线程饥饿优先级使用不当会导致某些线程永远无法执行,也就是线程饥饿的情况。3.2.5 继承性线程的继承性指的是线程的类别和优先级属性是会被继承的,线程的这两个属性的初始值由开启该线程的线程决定。假如优先级为 5 的守护线程 A 开启了线程 B,那么线程 B 也是一个守护线程,而且优先级也是 5 。这时我们就把线程 A 叫做线程 B 的父线程,把线程 B 叫做线程 A 的子线程。3.3 线程的六个方法线程的常用方法有六个,它们分别是三个非静态方法 start()、run()、join() 和三个静态方法 currentThread()、yield()、sleep() 。下面我们就来看下这六个方法都有哪些作用和注意事项。start()方法start()是经常用到的方法,它的作用作用是使用事项如下作用start() 方法的作用是启动线程。注意事项该方法只能调用一次,再次调用不仅无法让线程再次执行,还会抛出非法线程状态异常。run()方法作用run() 方法中放的是任务的具体逻辑,该方法由 JVM 调用,一般情况下开发者不需要直接调用该方法。注意事项如果你调用了 run() 方法,加上 JVM 也调用了一次,那这个方法就会执行两次。join()方法作用join() 方法用于等待其他线程执行结束。如果线程 A 调用了线程 B 的 join() 方法,那线程 A 会进入等待状态,直到线程 B 运行结束。注意事项join() 方法导致的等待状态是可以被中断的,所以调用这个方法需要捕获中断异常Thread.currentThread()currentThread() 方法是一个静态方法,用于获取执行当前方法的线程。我们可以在任意方法中调用 Thread.currentThread() 获取当前线程,并设置它的名字和优先级等属性。Thread.yield()作用yield() 方法是一个静态方法,用于使当前线程放弃对处理器的占用,相当于是降低线程优先级。调用该方法就像是是对线程调度器说:“如果其他线程要处理器资源,那就给它们,否则我继续用”。注意事项该方法不一定会让线程进入暂停状态。Thread.sleep(ms)sleep(ms) 方法是一个静态方法,用于使当前线程在指定时间内休眠(暂停)。线程不止提供了上面的 6 个方法给我们使用,而其他方法的使用在文章的后面会有一个更详细的介绍。3.4 线程的六种状态3.4.1 线程的生命周期和 Activity 一样,线程也有自己的生命周期,而且生命周期事件也是由用户(开发者)触发的。从 Activity 的角度来看,用户点击按钮后打开一个 Activity,就相当于是触发了 Activity 的 onCreate() 方法。从线程的角度来看,开发者调用了 start() 方法,就相当于是触发了 Thread 的 run() 方法。如果我们在上一个 Activity 的 onPause() 方法中进行了耗时操作,那么下一个 Activity 的显示也会因为这个耗时操作而慢一点显示,这就相当于是 Thread 的等待状态。线程的生命周期不仅可以由开发者触发,还会受到其他线程的影响,下面是线程各个状态之间的转换示意图。
-
 我们都知道future对象来实现的是并发操作,future根据我们的需求的并发类型(I/O密集型,或是cpu密集型)打包了multiprocessing和threading。它们并不能完全解决以外修改共享的问题,但却帮助我们更容易地追踪这一问题。Future为不同进程或进程间提供了明确的边界。和多进程池类似 他们用于调用并回答 类型的交互 其中处理过程可以在另外一个进程中,并且在未来的某个节点(毕竟就是这样命名的),你可以询问结果向他。Future实际上就是对进程池和线程池的封装,不过它提供了更加清楚的API。Future对象基本上封装了一个函数调用。函数调用进行在线程或进程的后台。Future对象的方法检查future是否结束,并在结束后获取结果。例子:From concurrent.futures import threadpoolexecutorFrom pathlib import pathFrom os.path import sep as pathsepFrom collections import dequeDef find _files(path,query_string):Subdirs=[]For p in path.iterdir(): Full_path = str(p.absolute()) If p.is_dir() and not p.is_symlink(): Subdirs.append(p) If query_string in full_path: Print(full_path) Return subdirsQuery = ‘.py’Futures = deque()Basedir = path(pathsep).absolute()With threadpoolexecutor(max_workers=10) as executor:Futures.append(Executor.submit(find_files,basedir,query))While futures:Futures=futures.popleft()If futures.exeception():ContinueElif futere,done():Subdirs=future.result()For subdir in subdirs: Futures.append(executor.submit( Find_files,subdir,query))Else: Futures.append(future)这段代码是由find_files的函数组成 运行在另外一个线程中 这个函数没有其他的特殊地方但是要注意他访问全局变量的过程,我们在开始之前先定义几个变量,在这个例子中我们会搜索所有带.py字符的文件我们有一个队列的future对象 稍后进行讨论 basedir变量指向文件系统的根目录 unnix系统中的是’/’windows系统中的是C:\.我们简单回顾下搜索的理论是什么,这一算是通过广度优先搜索遍历来实现的 而不是用深度优先搜索遍历实现的访问所有的路径 这一算法将所有当前目录的子目录添加到队列中 然后是所有这些目录的子目录来类推这段程序的主体是一个事件的循环 我们可以将 threadpoolexecutor构建为一个上下文管理器,这样一来在结束时就可以进行自动清理关闭所有的进程,需要一个max_workers参数来表明同时允许执行多个线程 如果提交了超过这一数量的任务将会排队等待 直到有能用的线程出现为止。在使用processpoolexecutor时 这一限制通常为机器的cpu数量 但对于线程 这一数值可以高很高 这依赖于同时等待i/o的数量。每个线程都需要占据一定的内存因此数量也不需要很多,数量太多的话磁盘速度而不是并发请求数量将会成为瓶颈
我们都知道future对象来实现的是并发操作,future根据我们的需求的并发类型(I/O密集型,或是cpu密集型)打包了multiprocessing和threading。它们并不能完全解决以外修改共享的问题,但却帮助我们更容易地追踪这一问题。Future为不同进程或进程间提供了明确的边界。和多进程池类似 他们用于调用并回答 类型的交互 其中处理过程可以在另外一个进程中,并且在未来的某个节点(毕竟就是这样命名的),你可以询问结果向他。Future实际上就是对进程池和线程池的封装,不过它提供了更加清楚的API。Future对象基本上封装了一个函数调用。函数调用进行在线程或进程的后台。Future对象的方法检查future是否结束,并在结束后获取结果。例子:From concurrent.futures import threadpoolexecutorFrom pathlib import pathFrom os.path import sep as pathsepFrom collections import dequeDef find _files(path,query_string):Subdirs=[]For p in path.iterdir(): Full_path = str(p.absolute()) If p.is_dir() and not p.is_symlink(): Subdirs.append(p) If query_string in full_path: Print(full_path) Return subdirsQuery = ‘.py’Futures = deque()Basedir = path(pathsep).absolute()With threadpoolexecutor(max_workers=10) as executor:Futures.append(Executor.submit(find_files,basedir,query))While futures:Futures=futures.popleft()If futures.exeception():ContinueElif futere,done():Subdirs=future.result()For subdir in subdirs: Futures.append(executor.submit( Find_files,subdir,query))Else: Futures.append(future)这段代码是由find_files的函数组成 运行在另外一个线程中 这个函数没有其他的特殊地方但是要注意他访问全局变量的过程,我们在开始之前先定义几个变量,在这个例子中我们会搜索所有带.py字符的文件我们有一个队列的future对象 稍后进行讨论 basedir变量指向文件系统的根目录 unnix系统中的是’/’windows系统中的是C:\.我们简单回顾下搜索的理论是什么,这一算是通过广度优先搜索遍历来实现的 而不是用深度优先搜索遍历实现的访问所有的路径 这一算法将所有当前目录的子目录添加到队列中 然后是所有这些目录的子目录来类推这段程序的主体是一个事件的循环 我们可以将 threadpoolexecutor构建为一个上下文管理器,这样一来在结束时就可以进行自动清理关闭所有的进程,需要一个max_workers参数来表明同时允许执行多个线程 如果提交了超过这一数量的任务将会排队等待 直到有能用的线程出现为止。在使用processpoolexecutor时 这一限制通常为机器的cpu数量 但对于线程 这一数值可以高很高 这依赖于同时等待i/o的数量。每个线程都需要占据一定的内存因此数量也不需要很多,数量太多的话磁盘速度而不是并发请求数量将会成为瓶颈 -
**关键词:根目录满、根目录使用率高、根目录大文件找不到** 【现象】 巡检发现集群一个节点根目录占用率高,现场排查未能找到占用空间的文件。 【案例排查】 1. 集群节点根目录df –h,根目录878G占用643G,现场du计算大约有150g左右,大约有500g文件找不到。  2. 执行lsof | grep delete 查找被删除打开中的文件,发现/var/chroot/MRS/test_hf.log 文件大小534457784196/1024/1024/1024=497.75g,与期望文件大小相匹配。  3. 查看/var/chroot/MRS 路径发现log确实已经被删除。  4. 根据占用文件进程PID 8734找到对应进程,ps –ef | grep 8734,发现/opt/dws/tmp下一个.sh脚本运行中打开了log文件。  5. 查找对应的执行脚本,发现已被删除。 6. 在确认该脚本已无实际用途后,kill -9 8734,杀掉占用文件进程即可释放空间。 【根因】 1. 执行中脚本为死循环脚本,脚本被删除,生成log文件被删除,但未kill脚本进程。 2. 在linux中,当我们使用rm在linux上删除了大文件,但是,如果有进程打开了这个大文件,却没有关闭这个文件的句柄,那么:linux内核还是不会释放这个文件的磁盘空间,最后造成磁盘空间占用率高。
-
DbContext 生存期DbContext 的生存期从创建实例时开始,并在释放实例时结束。 DbContext 实例旨在用于单个工作单元。 这意味着 DbContext 实例的生存期通常很短。使用 Entity Framework Core (EF Core) 时的典型工作单元包括:创建 DbContext 实例根据上下文跟踪实体实例。 实体将在以下情况下被跟踪正在从查询返回正在添加或附加到上下文根据需要对所跟踪的实体进行更改以实现业务规则调用 SaveChanges 或 SaveChangesAsync。 EF Core 检测所做的更改,并将这些更改写入数据库。释放 DbContext 实例ASP.NET Core 依赖关系注入中的 DbContext在许多 Web 应用程序中,每个 HTTP 请求都对应于单个工作单元。 这使得上下文生存期与请求的生存期相关,成为 Web 应用程序的一个良好默认值。使用依赖关系注入配置 ASP.NET Core 应用程序。 可以使用 Startup.cs 的 ConfigureServices 方法中的 AddDbContext 将 EF Core 添加到此配置。使用“new”的简单的 DbContext 初始化可以按照常规的 .NET 方式构造 DbContext 实例,例如,使用 C# 中的 new。 可以通过重写 OnConfiguring 方法或通过将选项传递给构造函数来执行配置。使用 DbContext 工厂(例如对于 Blazor)某些应用程序类型(例如 ASP.NET Core Blazor)使用依赖关系注入,但不创建与所需的 DbContext 生存期一致的服务作用域。 即使存在这样的对齐方式,应用程序也可能需要在此作用域内执行多个工作单元。 例如,单个 HTTP 请求中的多个工作单元。在这些情况下,可以使用 AddDbContextFactory 来注册工厂以创建 DbContext 实例。DbContextOptions所有 DbContext 配置的起始点都是 DbContextOptionsBuilder。 可以通过三种方式获取此生成器:在 AddDbContext 和相关方法中在 OnConfiguring 中使用 new 显式构造上述各节显示了其中每个示例。 无论生成器来自何处,都可以应用相同的配置。 此外,无论如何构造上下文,都将始终调用 OnConfiguring。 这意味着即使使用 AddDbContext,OnConfiguring 也可用于执行其他配置。配置数据库提供程序每个 DbContext 实例都必须配置为使用一个且仅一个数据库提供程序。 (DbContext 子类型的不同实例可用于不同的数据库提供程序,但一个实例只能使用一个。)一个数据库提供程序要使用一个特定的 Use* 调用进行配置。下表包含常见数据库提供程序的示例。数据库系统配置示例NuGet 程序包SQL Server 或 Azure SQL.UseSqlServer(connectionString)Microsoft.EntityFrameworkCore.SqlServerAzure Cosmos DB.UseCosmos(connectionString, databaseName)Microsoft.EntityFrameworkCore.CosmosSQLite.UseSqlite(connectionString)Microsoft.EntityFrameworkCore.SqliteEF Core 内存中数据库.UseInMemoryDatabase(databaseName)Microsoft.EntityFrameworkCore.InMemoryPostgreSQL*.UseNpgsql(connectionString)Npgsql.EntityFrameworkCore.PostgreSQLMySQL/MariaDB*.UseMySql(connectionString)Pomelo.EntityFrameworkCore.MySqlOracle*.UseOracle(connectionString)Oracle.EntityFrameworkCore其他 DbContext 配置其他 DbContext 配置可以链接到 Use* 调用之前或之后(这不会有任何差别)。 例如,若要启用敏感数据日志记录DbContextOptions 与 DbContextOptions<TContext>大多数接受 DbContextOptions 的 DbContext 子类应使用 泛型DbContextOptions<TContext>变体。这可确保从依赖关系注入中解析特定 DbContext 子类型的正确选项,即使注册了多个 DbContext 子类型也是如此。设计时 DbContext 配置EF Core 设计时工具(如 EF Core迁移)需要能够发现并创建 DbContext 类型的工作实例,以收集有关应用程序的实体类型及其如何映射到数据库架构的详细信息。 只要该工具可以通过与在运行时的配置方式类似的方式轻松地创建 DbContext,就可以自动执行此过程。虽然向 DbContext 提供必要配置信息的任何模式都可以在运行时正常运行,但在设计时需要使用 DbContext 的工具只能使用有限数量的模式。 设计时上下文创建中包含更多详细信息。避免 DbContext 线程处理问题Entity Framework Core 不支持在同一 DbContext 实例上运行多个并行操作。 这包括异步查询的并行执行以及从多个线程进行的任何显式并发使用。 因此,始终立即 await 异步调用,或对并行执行的操作使用单独的 DbContext 实例。当 EF Core 检测到尝试同时使用 DbContext 实例的情况时,你将看到 InvalidOperationException,其中包含类似于以下内容的消息:在上一个操作完成之前,第二个操作已在此上下文中启动。 这通常是由使用同一个 DbContext 实例的不同线程引起的,但不保证实例成员是线程安全的。检测不到并发访问时,可能会导致未定义的行为、应用程序崩溃和数据损坏。一些常见错误可能会无意中导致并发访问同一 DbContext 实例:异步操作缺陷使用异步方法,EF Core 可以启动以非阻挡式访问数据库的操作。 但是,如果调用方不等待其中一个方法完成,而是继续对 DbContext 执行其他操作,则 DbContext 的状态可能会(并且很可能会)损坏。始终立即等待 EF Core 异步方法。通过依赖关系注入隐式共享 DbContext 实例默认情况下 AddDbContext 扩展方法使用DbContext范围内生存期来注册 类型。这样可以避免在大多数 ASP.NET Core 应用程序中出现并发访问问题,因为在给定时间内只有一个线程在执行每个客户端请求,并且每个请求都有单独的依赖关系注入范围(因此有单独的 DbContext 实例)。 对于 Blazor Server 托管模型,一个逻辑请求用来维护 Blazor 用户线路,因此,如果使用默认注入范围,则每个用户线路只能提供一个范围内的 DbContext 实例。任何并行显式执行多个线程的代码都应确保 DbContext 实例不会同时访问。使用依赖关系注入可以通过以下方式实现:将上下文注册为范围内,并为每个线程创建范围(使用 IServiceScopeFactory),或将 DbContext 注册为暂时性(使用采用 ServiceLifetime 参数的 AddDbContext 的重载)。
-
 大家好,本篇文章主要讲的是安装tomcat后可能出现的问题介绍,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下,方便下次浏览 1. 没有开tomcat服务 在浏览器的地址栏中输入localhost:8080 回车会出现如下界面 tomcat没有开服务。在cmd中输入startup.bat。不要关闭开启的tomcat窗口。 2.输入url路径错误 在浏览器中输入url显示404,可能是输入的路径不存在或输入错误路径。 3. Java JDK环境变量未设置好 在cmd输入startup.bat时,报错。 如图: 解决方案: 这个是Java jdk的环境变量名设置不规范,将jdk的路径设置变量名必须是JAVA_HOME。 找到系统变量界面,更改错误的jdk变量名。 更改完后: 修改完之后,重新打开cmd在输入startup.bat就可以正常启动了 4.重复开启服务 服务已经开启,不需要重复打开。 5.端口被占用 通过网页访问出现 Access Error错误,端口被占用 打开cmd输入指令:将占用你所指定的端口号进程删掉netstat -ano :查看所有端口信息netstat ano | findstr "8080" :查看端口8080占用信息tasklist :查看所有进程tasklist | findstr "1": 查看某进程taskkill /f /pid 进程号: 删除某进程号转载自https://www.jb51.net/article/233667.htm
大家好,本篇文章主要讲的是安装tomcat后可能出现的问题介绍,感兴趣的同学赶快来看一看吧,对你有帮助的话记得收藏一下,方便下次浏览 1. 没有开tomcat服务 在浏览器的地址栏中输入localhost:8080 回车会出现如下界面 tomcat没有开服务。在cmd中输入startup.bat。不要关闭开启的tomcat窗口。 2.输入url路径错误 在浏览器中输入url显示404,可能是输入的路径不存在或输入错误路径。 3. Java JDK环境变量未设置好 在cmd输入startup.bat时,报错。 如图: 解决方案: 这个是Java jdk的环境变量名设置不规范,将jdk的路径设置变量名必须是JAVA_HOME。 找到系统变量界面,更改错误的jdk变量名。 更改完后: 修改完之后,重新打开cmd在输入startup.bat就可以正常启动了 4.重复开启服务 服务已经开启,不需要重复打开。 5.端口被占用 通过网页访问出现 Access Error错误,端口被占用 打开cmd输入指令:将占用你所指定的端口号进程删掉netstat -ano :查看所有端口信息netstat ano | findstr "8080" :查看端口8080占用信息tasklist :查看所有进程tasklist | findstr "1": 查看某进程taskkill /f /pid 进程号: 删除某进程号转载自https://www.jb51.net/article/233667.htm -
openGauss开机自启动,我们先来了解一下自定义服务的配置文件组成部分,共分为[Unit]、[Service]、[Install]三个部分,下面以centos7.6为例。[Unit] Description=当前服务的简单描述Documentation= 服务配置文件的位置 Before= 在某服务之前启动 After= 在某服务之后启动 Wants= 与某服务存在“依赖”关系,依赖服务退出,不影响本服务运行 Requires= 与某服务存在“强依赖”关系,依赖服务故障,本服务也随之退出 [Service] Type= --simple(默认值):ExecStart字段启动的进程为主进程。 --forking:ExecStart字段将以fork()方式启动,后台运行。 --oneshot:类似于simple,只执行一次,Systemd会等它执行完,才启动其他服务。 --dbus:类似于simple,等待D-Bus信号后再启动。--notify:类似于simple,启动结束后会发出通知信号,Systemd再启动其他服务。 --idle:类似于simple,等其他任务都执行完,才会启动该服务。 User= 服务运行的用户 Group= 服务运行的用户组 ExecStart= 启动服务的命令,可以是可执行程序、系统命令或shell脚本,必须是绝对路径。ExecReload= 重启服务的命令,可以是可执行程序、系统命令或shell脚本,必须是绝对路径。 ExecStop= 停止服务的命令,可以是可执行程序、系统命令或shell脚本,必须是绝对路径。ExecStartPre= 启动服务之前执行的命令ExecStartPost= 启动服务之后执行的命令ExecStopPost= 停止服务之后执行的命令PrivateTmp= True表示给服务分配独立的临时空间KillSignal= 信号量,一般为SIGQUITTimeoutStartSec= 启动超时时间TimeoutStopSec= 停止超时时间 TimeoutSec= 同时设置 TimeoutStartSec= 与 TimeoutStopSec= 的快捷方式 PIDFile= PID文件路径 KillMode= Systemd停止sshd服务方式 --control-group(默认值):所有子进程,都会被杀掉。 --process:只杀主进程。 --mixed:主进程将收到SIGTERM信号,子进程收到SIGKILL信号。 --none:没有进程会被杀掉,只是执行服务的stop命令。 Restart=服务程序退出后,Systemd的重启方式 --no(默认值):退出后不会重启。 --on-success:只有正常退出时(退出状态码为0),才会重启。 --on-failure:只有非正常退出时(退出状态码非0,包括被信号终止和超时),才会重启。 --on-abnormal:只有被信号终止和超时,才会重启。--on-abort:只有在收到没有捕捉到的信号终止时,才会重启。 --on-watchdog:超时退出,才会重启。 --always:总是重启。 RestartSec= 重启服务之前,需要等待的秒数RemainAfterExit= yes 进程退出以后,服务仍然保持执行 [Install] WantedBy=multi-user.target --WantedBy字段,表示该服务所在的 Targe,target的含义是服务组,表示一组服务 --multi-user.target,表示多用户命令行状态 --graphical.target,表示图形用户状态,它依赖于multi-user.targetopenGauss单机自启动模版配置自定义服务--/usr/lib/systemd/system/mogdb.service [Unit] Description=openGauss Documentation=openGauss ServerAfter=syslog.target After=network.target [Service] Type=forking User=omm Group=dbgrp Environment=PGDATA=/data/opengauss/data Environment=GAUSSHOME=/data/opengauss/app Environment=LD_LIBRARY_PATH=/data/opengauss/app/lib ExecStart=/data/opengauss/app/bin/gaussdb ExecReload=/bin/kill -HUP $MAINPID KillMode=mixed KillSignal=SIGINT TimeoutSec=0 [Install] WantedBy=multi-user.target 添加到开机自启动systemctl daemon-reload systemctl enable opengauss systemctl start opengauss systemctl status opengauss systemctl stop opengauss openGauss集群自启动模版配置自定义服务-/usr/lib/systemd/system/opengauss_om.service [Unit] Description=openGauss Documentation=openGauss Server After=syslog.target After=network.target [Service] Type=forking User=omm Group=dbgrp Environment=GPHOME=/data/opengauss/gausstools Environment=PGDATA=/data/opengauss/data Environment=GAUSSHOME=/data/opengauss/app Environment=LD_LIBRARY_PATH=/data/opengauss/app/lib ExecStart=/data/opengauss/gausstools/script/gs_om -t start ExecReload=/bin/kill -HUP $MAINPID KillMode=mixed KillSignal=SIGINT TimeoutSec=0 [Install] WantedBy=multi-user.target 添加到开机自启动systemctl daemon-reload systemctl enable opengauss_om systemctl start opengauss_om systemctl status opengauss_om systemctl stop opengauss_om
上滑加载中
推荐直播
-
 华为云码道 × 仓颉编程:工程化AI编码探索
华为云码道 × 仓颉编程:工程化AI编码探索2026/05/27 周三 19:00-21:00
刘俊杰-华为云仓颉语言专家/李炎-华为云码道技术专家/王智鹏-OpenCangjie开源社区发起人
本场直播围绕华为云仓颉语言与华为云码道的深度结合,展示华为云智能编程从零基础到高效落地的完整生态能力。以华为云码道为引擎,仓颉语言为载体,带给大家日常提效、趣味创新到极速量产的开发体验。
回顾中
热门标签