-
 一、定义1、什么是AjaxAjax:即异步 JavaScript 和XML。Ajax是一种用于创建快速动态网页的技术。通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。而传统的网页(不使用 Ajax)如果需要更新内容,必需重载整个网页面。2、同步与异步的区别同步提交:当用户发送请求时,当前页面不可以使用,服务器响应页面到客户端,响应完成,用户才可以使用页面。异步提交:当用户发送请求时,当前页面还可以继续使用,当异步请求的数据响应给页面,页面把数据显示出来 。3、ajax的工作原理客户端发送请求,请求交给xhr,xhr把请求提交给服务,服务器进行业务处理,服务器响应数据交给xhr对象,xhr对象接收数据,由javascript把数据写到页面上,如下图所示:二、实现AJAX的基本步骤要完整实现一个AJAX异步调用和局部刷新,通常需要以下几个步骤:• 创建XMLHttpRequest对象,即创建一个异步调用对象.• 创建一个新的HTTP请求,并指定该HTTP请求的方法、URL及验证信息.• 设置响应HTTP请求状态变化的函数.• 发送HTTP请求.• 获取异步调用返回的数据.• 使用JavaScript和DOM实现局部刷新.1、创建XMLHttpRequest对象不同浏览器使用的异步调用对象有所不同,在IE浏览器中异步调用使用的是XMLHTTP组件中的XMLHttpRequest对象,而在Netscape、Firefox浏览器中则直接使用XMLHttpRequest组件。因此,在不同浏览器中创建XMLHttpRequest对象的方式都有所不同.在IE浏览器中创建XMLHttpRequest对象的方式为:1var xmlHttpRequest = new ActiveXObject("Microsoft.XMLHTTP");在Netscape浏览器中创建XMLHttpRequest对象的方式为:1var xmlHttpRequest = new XMLHttpRequest();由于无法确定用户使用的是什么浏览器,所以在创建XMLHttpRequest对象时,最好将以上两种方法都加上.如以下代码所示:12345678910var xmlHttpRequest; //定义一个变量,用于存放XMLHttpRequest对象createXMLHttpRequst(); //调用创建对象的方法//创建XMLHttpRequest对象的方法 function createXMLHttpRequest(){ if(window.ActiveXObject) {//判断是否是IE浏览器 xmlHttpRequest = new ActiveXObject("Microsoft.XMLHTTP");//创建IE的XMLHttpRequest对象 }else if(window.XMLHttpRequest){//判断是否是Netscape等其他支持XMLHttpRequest组件的浏览器 xmlHttpRequest = new XMLHttpRequest();//创建其他浏览器上的XMLHttpRequest对象 }} "if(window.ActiveXObject)"用来判断是否使用IE浏览器.其中ActiveXOject并不是Windows对象的标准属性,而是IE浏览器中专有的属性,可以用于判断浏览器是否支持ActiveX控件.通常只有IE浏览器或以IE浏览器为核心的浏览器才能支持Active控件. "else if(window.XMLHttpRequest)"是为了防止一些浏览器既不支持ActiveX控件,也不支持XMLHttpRequest组件而进行的判断.其中XMLHttpRequest也不是window对象的标准属性,但可以用来判断浏览器是否支持XMLHttpRequest组件. 如果浏览器既不支持ActiveX控件,也不支持XMLHttpRequest组件,那么就不会对xmlHttpRequest变量赋值.2、创建HTTP请求 创建了XMLHttpRequest对象之后,必须为XMLHttpRequest对象创建HTTP请求,用于说明XMLHttpRequest对象要从哪里获取数据。通常可以是网站中的数据,也可以是本地中其他文件中的数据。 创建HTTP请求可以使用XMLHttpRequest对象的open()方法,其语法代码如下所示:1XMLHttpRequest.open(method,URL,flag,name,password);代码中的参数解释如下所示:• method:该参数用于指定HTTP的请求方法,一共有get、post、head、put、delete五种方法,常用的方法为get和post。• URL:该参数用于指定HTTP请求的URL地址,可以是绝对URL,也可以是相对URL。• flag:该参数为可选,参数值为布尔型。该参数用于指定是否使用异步方式。true表示异步、false表示同步,默认为true。• name:该参数为可选参数,用于输入用户名。如果服务器需要验证,则必须使用该参数。• password:该参数为可选,用于输入密码。若服务器需要验证,则必须使用该参数。通常可以使用以下代码来访问一个网站文件的内容。 1xmlHttpRequest.open("get","http://www.aspxfans.com/BookSupport/JavaScript/ajax.htm",true);或者使用以下代码来访问一个本地文件内容:1xmlHttpRequest.open("get","ajax.htm",true);注意:如果HTML文件放在Web服务器上,在Netscape浏览器中的JavaScript安全机制不允许与本机之外的主机进行通信。也就是说,使用open()方法只能打开与HTML文件在同一个服务器上的文件。而在IE浏览器中则无此限制(虽然可以打开其他服务器上的文件,但也会有警告提示)。3、设置响应HTTP请求状态变化的函数 创建完HTTP请求之后,应该就可以将HTTP请求发送给Web服务器了。然而,发送HTTP请求的目的是为了接收从服务器中返回的数据。从创建XMLHttpRequest对象开始,到发送数据、接收数据、XMLHttpRequest对象一共会经历以下5中状态。1. 未初始化状态。在创建完XMLHttpRequest对象时,该对象处于未初始化状态,此时XMLHttpRequest对象的readyState属性值为0。2. 初始化状态。在创建完XMLHttpRequest对象后使用open()方法创建了HTTP请求时,该对象处于初始化状态。此时XMLHttpRequest对象的readyState属性值为1。3. 发送数据状态。在初始化XMLHttpRequest对象后,使用send()方法发送数据时,该对象处于发送数据状态,此时XMLHttpRequest对象的readyState属性值为2。4. 接收数据状态。Web服务器接收完数据并进行处理完毕之后,向客户端传送返回的结果。此时,XMLHttpRequest对象处于接收数据状态,XMLHttpRequest对象的readyState属性值为3。5. 完成状态。XMLHttpRequest对象接收数据完毕后,进入完成状态,此时XMLHttpRequest对象的readyState属性值为4。此时接收完毕后的数据存入在客户端计算机的内存中,可以使用responseText属性或responseXml属性来获取数据。 只有在XMLHttpRequest对象完成了以上5个步骤之后,才可以获取从服务器端返回的数据。因此,如果要获得从服务器端返回的数据,就必须要先判断XMLHttpRequest对象的状态。 XMLHttpRequest对象可以响应readystatechange事件,该事件在XMLHttpRequest对象状态改变时(也就是readyState属性值改变时)激发。因此,可以通过该事件调用一个函数,并在该函数中判断XMLHttpRequest对象的readyState属性值。如果readyState属性值为4则使用responseText属性或responseXml属性来获取数据。具体代码如下所示:12345678910//设置当XMLHttpRequest对象状态改变时调用的函数,注意函数名后面不要添加小括号xmlHttpRequest.onreadystatechange = getData; //定义函数function getData(){ //判断XMLHttpRequest对象的readyState属性值是否为4,如果为4表示异步调用完成 if(xmlHttpRequest.readyState == 4) { //设置获取数据的语句 }}4、设置获取服务器返回数据的语句 如果XMLHttpRequest对象的readyState属性值等于4,表示异步调用过程完毕,就可以通过XMLHttpRequest对象的responseText属性或responseXml属性来获取数据。 但是,异步调用过程完毕,并不代表异步调用成功了,如果要判断异步调用是否成功,还要判断XMLHttpRequest对象的status属性值,只有该属性值为200,才表示异步调用成功,因此,要获取服务器返回数据的语句,还必须要先判断XMLHttpRequest对象的status属性值是否等于200,如以下代码所示:1234if(xmlHttpRequst.status == 200) { document.write(xmlHttpRequest.responseText);//将返回结果以字符串形式输出 //document.write(xmlHttpRequest.responseXML);//或者将返回结果以XML形式输出}注意:如果HTML文件不是在Web服务器上运行,而是在本地运行,则xmlHttpRequest.status的返回值为0。因此,如果该文件在本地运行,则应该加上xmlHttpRequest.status == 0的判断。 通常将以上代码放在响应HTTP请求状态变化的函数体内,如以下代码所示: 12345678910111213//设置当XMLHttpRequest对象状态改变时调用的函数,注意函数名后面不要添加小括号xmlHttpRequest.onreadystatechange = getData; //定义函数function getData(){ //判断XMLHttpRequest对象的readyState属性值是否为4,如果为4表示异步调用完成 if(xmlHttpRequest.readyState==4){ if(xmlHttpRequest.status == 200 || xmlHttpRequest.status == 0){//设置获取数据的语句 document.write(xmlHttpRequest.responseText);//将返回结果以字符串形式输出 //docunment.write(xmlHttpRequest.responseXML);//或者将返回结果以XML形式输出 } }}5、发送HTTP请求 在经过以上几个步骤的设置之后,就可以将HTTP请求发送到Web服务器上去了。发送HTTP请求可以使用XMLHttpRequest对象的send()方法,其语法代码如下所示:1XMLHttpRequest.send(data); 其中data是个可选参数,如果请求的数据不需要参数,即可以使用null来替代。data参数的格式与在URL中传递参数的格式类似,以下代码为一个send()方法中的data参数的示例:1name=myName&value=myValue 只有在使用send()方法之后,XMLHttpRequest对象的readyState属性值才会开始改变,也才会激发readystatechange事件,并调用函数。6、局部更新 在通过Ajax的异步调用获得服务器端数据之后,可以使用JavaScript或DOM来将网页中的数据进行局部更新。三、完整的AJAX实例123456789101112131415161718192021222324252627282930313233<html><head><title>AJAX实例</title><script language="javascript" type="text/javascript"> function ajaxHttpRequestFunc(){ let xmlHttpRequest; // 创建XMLHttpRequest对象,即一个用于保存异步调用对象的变量 if(window.ActiveXObject){ // IE浏览器的创建方式 xmlHttpRequest = new ActiveXObject("Microsoft.XMLHTTP"); }else if(window.XMLHttpRequest){ // Netscape浏览器中的创建方式 xmlHttpRequest = new XMLHttpRequest(); } xmlHttpRequest.onreadystatechange=function(){ // 设置响应http请求状态变化的事件 console.log('请求过程', xmlHttpRequest.readyState); if(xmlHttpRequest.readyState == 4){ // 判断异步调用是否成功,若成功开始局部更新数据 console.log('状态码为', xmlHttpRequest.status); if(xmlHttpRequest.status == 200) { console.log('异步调用返回的数据为:', xmlHttpRequest .responseText); document.getElementById("myDiv").innerHTML = xmlHttpRequest .responseText; // 局部刷新数据到页面 } else { // 如果异步调用未成功,弹出警告框,并显示错误状态码 alert("error:HTTP状态码为:"+xmlHttpRequest.status); } } } xmlHttpRequest.open("GET","https://www.runoob.com/try/ajax/ajax_info.txt",true); // 创建http请求,并指定请求得方法(get)、url(https://www.runoob.com/try/ajax/ajax_info.txt)以及验证信息 xmlHttpRequest.send(null); // 发送请求 }</script></head><body> <div id="myDiv">原数据</div> <input type = "button" value = "更新数据" onclick = "ajaxHttpRequestFunc()"></body></html> 直接运行该段代码可能会出现跨域的现象,控制台的报错信息如下:这是因为代码中设置请求的是菜鸟驿站服务端的文件,所以出现跨域导致未正常获取到服务端返回的数据。解决办法:复制该段代码在菜鸟驿站的编辑器中粘贴运行即可。点击运行前页面显示为:点击运行后页面显示为:好啦,关于ajax的部分到此就全部学习完成了转载自https://www.jb51.net/article/240522.htm
一、定义1、什么是AjaxAjax:即异步 JavaScript 和XML。Ajax是一种用于创建快速动态网页的技术。通过在后台与服务器进行少量数据交换,Ajax可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。而传统的网页(不使用 Ajax)如果需要更新内容,必需重载整个网页面。2、同步与异步的区别同步提交:当用户发送请求时,当前页面不可以使用,服务器响应页面到客户端,响应完成,用户才可以使用页面。异步提交:当用户发送请求时,当前页面还可以继续使用,当异步请求的数据响应给页面,页面把数据显示出来 。3、ajax的工作原理客户端发送请求,请求交给xhr,xhr把请求提交给服务,服务器进行业务处理,服务器响应数据交给xhr对象,xhr对象接收数据,由javascript把数据写到页面上,如下图所示:二、实现AJAX的基本步骤要完整实现一个AJAX异步调用和局部刷新,通常需要以下几个步骤:• 创建XMLHttpRequest对象,即创建一个异步调用对象.• 创建一个新的HTTP请求,并指定该HTTP请求的方法、URL及验证信息.• 设置响应HTTP请求状态变化的函数.• 发送HTTP请求.• 获取异步调用返回的数据.• 使用JavaScript和DOM实现局部刷新.1、创建XMLHttpRequest对象不同浏览器使用的异步调用对象有所不同,在IE浏览器中异步调用使用的是XMLHTTP组件中的XMLHttpRequest对象,而在Netscape、Firefox浏览器中则直接使用XMLHttpRequest组件。因此,在不同浏览器中创建XMLHttpRequest对象的方式都有所不同.在IE浏览器中创建XMLHttpRequest对象的方式为:1var xmlHttpRequest = new ActiveXObject("Microsoft.XMLHTTP");在Netscape浏览器中创建XMLHttpRequest对象的方式为:1var xmlHttpRequest = new XMLHttpRequest();由于无法确定用户使用的是什么浏览器,所以在创建XMLHttpRequest对象时,最好将以上两种方法都加上.如以下代码所示:12345678910var xmlHttpRequest; //定义一个变量,用于存放XMLHttpRequest对象createXMLHttpRequst(); //调用创建对象的方法//创建XMLHttpRequest对象的方法 function createXMLHttpRequest(){ if(window.ActiveXObject) {//判断是否是IE浏览器 xmlHttpRequest = new ActiveXObject("Microsoft.XMLHTTP");//创建IE的XMLHttpRequest对象 }else if(window.XMLHttpRequest){//判断是否是Netscape等其他支持XMLHttpRequest组件的浏览器 xmlHttpRequest = new XMLHttpRequest();//创建其他浏览器上的XMLHttpRequest对象 }} "if(window.ActiveXObject)"用来判断是否使用IE浏览器.其中ActiveXOject并不是Windows对象的标准属性,而是IE浏览器中专有的属性,可以用于判断浏览器是否支持ActiveX控件.通常只有IE浏览器或以IE浏览器为核心的浏览器才能支持Active控件. "else if(window.XMLHttpRequest)"是为了防止一些浏览器既不支持ActiveX控件,也不支持XMLHttpRequest组件而进行的判断.其中XMLHttpRequest也不是window对象的标准属性,但可以用来判断浏览器是否支持XMLHttpRequest组件. 如果浏览器既不支持ActiveX控件,也不支持XMLHttpRequest组件,那么就不会对xmlHttpRequest变量赋值.2、创建HTTP请求 创建了XMLHttpRequest对象之后,必须为XMLHttpRequest对象创建HTTP请求,用于说明XMLHttpRequest对象要从哪里获取数据。通常可以是网站中的数据,也可以是本地中其他文件中的数据。 创建HTTP请求可以使用XMLHttpRequest对象的open()方法,其语法代码如下所示:1XMLHttpRequest.open(method,URL,flag,name,password);代码中的参数解释如下所示:• method:该参数用于指定HTTP的请求方法,一共有get、post、head、put、delete五种方法,常用的方法为get和post。• URL:该参数用于指定HTTP请求的URL地址,可以是绝对URL,也可以是相对URL。• flag:该参数为可选,参数值为布尔型。该参数用于指定是否使用异步方式。true表示异步、false表示同步,默认为true。• name:该参数为可选参数,用于输入用户名。如果服务器需要验证,则必须使用该参数。• password:该参数为可选,用于输入密码。若服务器需要验证,则必须使用该参数。通常可以使用以下代码来访问一个网站文件的内容。 1xmlHttpRequest.open("get","http://www.aspxfans.com/BookSupport/JavaScript/ajax.htm",true);或者使用以下代码来访问一个本地文件内容:1xmlHttpRequest.open("get","ajax.htm",true);注意:如果HTML文件放在Web服务器上,在Netscape浏览器中的JavaScript安全机制不允许与本机之外的主机进行通信。也就是说,使用open()方法只能打开与HTML文件在同一个服务器上的文件。而在IE浏览器中则无此限制(虽然可以打开其他服务器上的文件,但也会有警告提示)。3、设置响应HTTP请求状态变化的函数 创建完HTTP请求之后,应该就可以将HTTP请求发送给Web服务器了。然而,发送HTTP请求的目的是为了接收从服务器中返回的数据。从创建XMLHttpRequest对象开始,到发送数据、接收数据、XMLHttpRequest对象一共会经历以下5中状态。1. 未初始化状态。在创建完XMLHttpRequest对象时,该对象处于未初始化状态,此时XMLHttpRequest对象的readyState属性值为0。2. 初始化状态。在创建完XMLHttpRequest对象后使用open()方法创建了HTTP请求时,该对象处于初始化状态。此时XMLHttpRequest对象的readyState属性值为1。3. 发送数据状态。在初始化XMLHttpRequest对象后,使用send()方法发送数据时,该对象处于发送数据状态,此时XMLHttpRequest对象的readyState属性值为2。4. 接收数据状态。Web服务器接收完数据并进行处理完毕之后,向客户端传送返回的结果。此时,XMLHttpRequest对象处于接收数据状态,XMLHttpRequest对象的readyState属性值为3。5. 完成状态。XMLHttpRequest对象接收数据完毕后,进入完成状态,此时XMLHttpRequest对象的readyState属性值为4。此时接收完毕后的数据存入在客户端计算机的内存中,可以使用responseText属性或responseXml属性来获取数据。 只有在XMLHttpRequest对象完成了以上5个步骤之后,才可以获取从服务器端返回的数据。因此,如果要获得从服务器端返回的数据,就必须要先判断XMLHttpRequest对象的状态。 XMLHttpRequest对象可以响应readystatechange事件,该事件在XMLHttpRequest对象状态改变时(也就是readyState属性值改变时)激发。因此,可以通过该事件调用一个函数,并在该函数中判断XMLHttpRequest对象的readyState属性值。如果readyState属性值为4则使用responseText属性或responseXml属性来获取数据。具体代码如下所示:12345678910//设置当XMLHttpRequest对象状态改变时调用的函数,注意函数名后面不要添加小括号xmlHttpRequest.onreadystatechange = getData; //定义函数function getData(){ //判断XMLHttpRequest对象的readyState属性值是否为4,如果为4表示异步调用完成 if(xmlHttpRequest.readyState == 4) { //设置获取数据的语句 }}4、设置获取服务器返回数据的语句 如果XMLHttpRequest对象的readyState属性值等于4,表示异步调用过程完毕,就可以通过XMLHttpRequest对象的responseText属性或responseXml属性来获取数据。 但是,异步调用过程完毕,并不代表异步调用成功了,如果要判断异步调用是否成功,还要判断XMLHttpRequest对象的status属性值,只有该属性值为200,才表示异步调用成功,因此,要获取服务器返回数据的语句,还必须要先判断XMLHttpRequest对象的status属性值是否等于200,如以下代码所示:1234if(xmlHttpRequst.status == 200) { document.write(xmlHttpRequest.responseText);//将返回结果以字符串形式输出 //document.write(xmlHttpRequest.responseXML);//或者将返回结果以XML形式输出}注意:如果HTML文件不是在Web服务器上运行,而是在本地运行,则xmlHttpRequest.status的返回值为0。因此,如果该文件在本地运行,则应该加上xmlHttpRequest.status == 0的判断。 通常将以上代码放在响应HTTP请求状态变化的函数体内,如以下代码所示: 12345678910111213//设置当XMLHttpRequest对象状态改变时调用的函数,注意函数名后面不要添加小括号xmlHttpRequest.onreadystatechange = getData; //定义函数function getData(){ //判断XMLHttpRequest对象的readyState属性值是否为4,如果为4表示异步调用完成 if(xmlHttpRequest.readyState==4){ if(xmlHttpRequest.status == 200 || xmlHttpRequest.status == 0){//设置获取数据的语句 document.write(xmlHttpRequest.responseText);//将返回结果以字符串形式输出 //docunment.write(xmlHttpRequest.responseXML);//或者将返回结果以XML形式输出 } }}5、发送HTTP请求 在经过以上几个步骤的设置之后,就可以将HTTP请求发送到Web服务器上去了。发送HTTP请求可以使用XMLHttpRequest对象的send()方法,其语法代码如下所示:1XMLHttpRequest.send(data); 其中data是个可选参数,如果请求的数据不需要参数,即可以使用null来替代。data参数的格式与在URL中传递参数的格式类似,以下代码为一个send()方法中的data参数的示例:1name=myName&value=myValue 只有在使用send()方法之后,XMLHttpRequest对象的readyState属性值才会开始改变,也才会激发readystatechange事件,并调用函数。6、局部更新 在通过Ajax的异步调用获得服务器端数据之后,可以使用JavaScript或DOM来将网页中的数据进行局部更新。三、完整的AJAX实例123456789101112131415161718192021222324252627282930313233<html><head><title>AJAX实例</title><script language="javascript" type="text/javascript"> function ajaxHttpRequestFunc(){ let xmlHttpRequest; // 创建XMLHttpRequest对象,即一个用于保存异步调用对象的变量 if(window.ActiveXObject){ // IE浏览器的创建方式 xmlHttpRequest = new ActiveXObject("Microsoft.XMLHTTP"); }else if(window.XMLHttpRequest){ // Netscape浏览器中的创建方式 xmlHttpRequest = new XMLHttpRequest(); } xmlHttpRequest.onreadystatechange=function(){ // 设置响应http请求状态变化的事件 console.log('请求过程', xmlHttpRequest.readyState); if(xmlHttpRequest.readyState == 4){ // 判断异步调用是否成功,若成功开始局部更新数据 console.log('状态码为', xmlHttpRequest.status); if(xmlHttpRequest.status == 200) { console.log('异步调用返回的数据为:', xmlHttpRequest .responseText); document.getElementById("myDiv").innerHTML = xmlHttpRequest .responseText; // 局部刷新数据到页面 } else { // 如果异步调用未成功,弹出警告框,并显示错误状态码 alert("error:HTTP状态码为:"+xmlHttpRequest.status); } } } xmlHttpRequest.open("GET","https://www.runoob.com/try/ajax/ajax_info.txt",true); // 创建http请求,并指定请求得方法(get)、url(https://www.runoob.com/try/ajax/ajax_info.txt)以及验证信息 xmlHttpRequest.send(null); // 发送请求 }</script></head><body> <div id="myDiv">原数据</div> <input type = "button" value = "更新数据" onclick = "ajaxHttpRequestFunc()"></body></html> 直接运行该段代码可能会出现跨域的现象,控制台的报错信息如下:这是因为代码中设置请求的是菜鸟驿站服务端的文件,所以出现跨域导致未正常获取到服务端返回的数据。解决办法:复制该段代码在菜鸟驿站的编辑器中粘贴运行即可。点击运行前页面显示为:点击运行后页面显示为:好啦,关于ajax的部分到此就全部学习完成了转载自https://www.jb51.net/article/240522.htm -
 Spring Boot 提供了 RestTemplate 来辅助发起一个 REST 请求,默认通过 JDK 自带的 HttpURLConnection 来作为底层 HTTP 消息的发送方式,使用 JackSon 来序列化服务器返回的 JSON 数据。RestTemplate 是核心类, 提供了所有访问 REST 服务的接口,尽管实际上可以使用 HTTP Client 类或者 java.net.URL来完成,但 RestTemplate 提供了阻STful 风格的 API。 Spring Boot 提供了 RestTemplateBuilder 来创建一个 RestTemplate。 RestTemplate定义11个基本操作方法,大致如下:delete(): 在特定的URL上对资源执行HTTP DELETE操作exchange(): 在URL上执行特定的HTTP方法,返回包含对象的ResponseEntity,这个对象是从响应体中映射得到的 3.execute(): 在URL上执行特定的HTTP方法,返回一个从响应体映射得到的对象(所有的get、post、delete、put、options、head、exchange方法最终调用的都是excute方法),例如:@Override public <T> T getForObject(String url, Class<T> responseType, Object... urlVariables) throws RestClientException { RequestCallback requestCallback = acceptHeaderRequestCallback(responseType); HttpMessageConverterExtractor<T> responseExtractor = <span style="white-space:pre"> </span>new HttpMessageConverterExtractor<T>(responseType, getMessageConverters(), logger); return execute(url, HttpMethod.GET, requestCallback, responseExtractor, urlVariables); } 4.getForEntity(): 发送一个HTTP GET请求,返回的ResponseEntity包含了响应体所映射成的对象 5.getForObject() :发送一个HTTP GET请求,返回的请求体将映射为一个对象 6.postForEntity() :POST 数据到一个URL,返回包含一个对象的ResponseEntity,这个对象是从响应体中映射得到的 7.postForObject(): POST 数据到一个URL,返回根据响应体匹配形成的对象 8.headForHeaders(): 发送HTTP HEAD请求,返回包含特定资源URL的HTTP头 9.optionsForAllow(): 发送HTTP OPTIONS请求,返回对特定URL的Allow头信息 10.postForLocation() :POST 数据到一个URL,返回新创建资源的URL 11.put(): PUT 资源到特定的URL实际上,由于Post 操作的非幂等性,它几乎可以代替其他的CRUD操作.一、GET请求在RestTemplate中,发送一个GET请求,我们可以通过如下两种方式:第一种:getForEntitygetForEntity方法的返回值是一个ResponseEntity<T>,ResponseEntity<T>是Spring对HTTP请求响应的封装,包括了几个重要的元素,如响应码、contentType、contentLength、响应消息体等。其重载方法如下:<T> ResponseEntity<T> getForObject(URI url, Class<T> responseType) throws RestClientException;<T> ResponseEntity<T> getForObject(String url, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> ResponseEntity<T> getForObject(String url, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException;比如下面一个例子:@Autowired RestTemplateBuilder restTemplateBuilder; @RequestMapping("/gethello") public String getHello() { RestTemplate client = restTemplateBuilder.build (); ResponseEntity<String> responseEntity = restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class); String body = responseEntity.getBody(); HttpStatus statusCode = responseEntity.getStatusCode(); int statusCodeValue = responseEntity.getStatusCodeValue(); HttpHeaders headers = responseEntity.getHeaders(); StringBuffer result = new StringBuffer(); result.append("responseEntity.getBody():").append(body).append("<hr>") .append("responseEntity.getStatusCode():").append(statusCode).append("<hr>") .append("responseEntity.getStatusCodeValue():").append(statusCodeValue).append("<hr>") .append("responseEntity.getHeaders():").append(headers).append("<hr>"); return result.toString(); }有时候我在调用服务提供者提供的接口时,可能需要传递参数,有两种不同的方式,如下:@RequestMapping("/sayhello") public String sayHello() { ResponseEntity<String> responseEntity = restTemplate.getForEntity("http://HELLO-SERVICE/sayhello?name={1}", String.class, "张三"); return responseEntity.getBody(); } @RequestMapping("/sayhello2") public String sayHello2() { Map<String, String> map = new HashMap<>(); map.put("name", "李四"); ResponseEntity<String> responseEntity = restTemplate.getForEntity("http://HELLO-SERVICE/sayhello?name={name}", String.class, map); return responseEntity.getBody(); }可以用一个数字做占位符,最后是一个可变长度的参数,来一一替换前面的占位符也可以前面使用name={name}这种形式,最后一个参数是一个map,map的key即为前边占位符的名字,map的value为参数值第一个调用地址也可以是一个URI而不是字符串,这个时候我们构建一个URI即可,参数神马的都包含在URI中了,如下:@RequestMapping("/sayhello3") public String sayHello3() { UriComponents uriComponents = UriComponentsBuilder.fromUriString("http://HELLO-SERVICE/sayhello?name={name}").build().expand("王五").encode(); URI uri = uriComponents.toUri(); ResponseEntity<String> responseEntity = restTemplate.getForEntity(uri, String.class); return responseEntity.getBody(); }通过Spring中提供的UriComponents来构建Uri即可。当然,服务提供者不仅可以返回String,也可以返回一个自定义类型的对象,比如我的服务提供者中有如下方法:@RequestMapping(value = "/getbook1", method = RequestMethod.GET)public Book book1() { return new Book("三国演义", 90, "罗贯中", "花城出版社"); }对于该方法我可以在服务消费者中通过如下方式来调用:@RequestMapping("/book1") public Book book1() { ResponseEntity<Book> responseEntity = restTemplate.getForEntity("http://HELLO- SERVICE/getbook1", Book.class); return responseEntity.getBody(); }第二种:getForObjectgetForObject函数实际上是对getForEntity函数的进一步封装,如果你只关注返回的消息体的内容,对其他信息都不关注,此时可以使用getForObject,重载方法如下:<T> T getForObject(URI url, Class<T> responseType) throws RestClientException;<T> T getForObject(String url, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> T getForObject(String url, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException; 二、POST请求在RestTemplate中,POST请求可以通过如下三个方法来发起:第一种:postForEntity、postForObjectPOST请求有postForObject()和postForEntity()两种方法,和GET请求的getForObject()和getForEntity()方法类似。getForLocation()是POST请求所特有的。<T> T postForObject(URI url, Object request, Class<T> responseType) throws RestClientException;<T> T postForObject(String url, Object request, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> T postForObject(String url, Object request, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException;上面三个方法中,第一个参数都是资源要POST到的URL,第二个参数是要发送的对象,而第三个参数是预期返回的Java类型。在URL作为String类型的两个版本中,第四个参数指定了URL变量(要么是可变参数列表,要么是一个Map)。 该方法和get请求中的getForEntity方法类似,如下例子:@RequestMapping("/book3") public Book book3() { Book book = new Book(); book.setName("红楼梦"); ResponseEntity<Book> responseEntity = restTemplate.postForEntity("http://HELLO-SERVICE/getbook2", book, Book.class); return responseEntity.getBody(); } 第二种:postForLacationpostForLacation()会在POST请求的请求体中发送一个资源到服务器端,返回的不再是资源对象,而是创建资源的位置。postForLocation(String url, Object request, Object... uriVariables) throws RestClientException;postForLocation(String url, Object request, Map<String, ?> uriVariables) throws RestClientException;postForLocation(URI url, Object request) throws RestClientException; public String postSpitter(Spitter spitter) { RestTemplate rest = new RestTemplate(); return rest.postForLocation("http://localhost:8080/Spitter/spitters", spitter).toString(); }postForLocation也是提交新资源,提交成功之后,返回新资源的URI,postForLocation的参数和前面两种的参数基本一致,只不过该方法的返回值为Uri,这个只需要服务提供者返回一个Uri即可,该Uri表示新资源的位置。 三、PUT请求在RestTemplate中,对PUT请求可以通过put方法进行调用实现,比如:RestTemplate restTemplate=new RestTemplate();Longid=100011; User user=new User("didi",40); restTemplate.put("http://USER-SERVICE/user/{l}",user,id); put函数也实现了三种不同的重载方法:put(String url,Object request,Object... urlVariables)put(String url,Object request,Map urlVariables)put(URI url,Object request)put函数为void类型,所以没有返回内容,也就没有其他函数定义的responseType参数,除此之外的其他传入参数定义与用法与postForObject基本一致。 四、DELETE请求在RestTemplate中,对DELETE请求可以通过delete方法进行调用实现,比如:RestTemplate restTemplate=new RestTemplate(); Longid=10001L; restTemplate.delete("http://USER-SERVICE/user/{1)",id); delete函数也实现了三种不同的重载方法:delete(String url,Object... urlVariables)delete(String url,Map urlVariables)delete(URI url)由于我们在进行REST请求时,通常都将DELETE请求的唯一标识拼接在url中,所以DELETE请求也不需要request的body信息,就如put()方法一样,返回值类型为void。说明:第三种重载方法,url指定DELETE请求的位置,urlVariables绑定url中的参数即可。五、通用方法exchange()exchange方法可以在发送个服务器端的请求中设置头信息,其重载方法如下:<T> ResponseEntity<T> exchange(URI url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType) throws RestClientException;<T> ResponseEntity<T> exchange(String url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> ResponseEntity<T> exchange(String url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException;MultiValueMap<String, String> headers = new LinkedMultiValueMap<String, String>(); headers.add("Accept", "application/json"); HttpEntity<Object> requestEntity = new HttpEntity<Object>(headers); ResponseEntity<Spitter> response=rest.exchange("http://localhost:8080/Spitter/spitters/{spitter}", HttpMethod.GET, requestEntity, Spitter.class, spitterId); 补充: 如果期望返回的类型是一个列表,如 List,不能简单调用 xxxForObject,因为存在泛型的类型擦除, RestTemplate 在反序列化的时候并不知道实际反序列化的类型,因此可以使用 ParameterizedTypeReference 来包含泛型类型,代码如下:RestTemplate client= restTemplateBuilder.build(); //根据条件查询一纽订单 String uri = base+"/orders?offset={offset }"; Integer offset = 1; //元参数 HttpEntity body = null; ParameterizedTypeReference<List<Order> typeRef = new ParameterizedTypeReference<List<Order>(){}; ResponseEntity<List<Order> rs=client.exchange(uri, HttpMethod.GET, body, typeRef, offset); List<Order> order = rs.getBody() ; 注意到 typeRef 定义是用{}结束的,这里创建了一个 ParameterizedTypeReference 子类,依 据在类定义中的泛型信息保留的原则, typeRef保留了期望返回的泛型 List。exchange 是一个基础的 REST 调用接口,除了需要指明 HTTP Method,调用方法同其他方法类似。除了使用ParameterizedTypeReference子类对象,也可以先将返回结果映射成 json字符串,然后通过 ObjectMapper 来转为指定类型(笔记<SpringBoot中的JSON>中有介绍 ) 。————————————————原文链接:https://blog.csdn.net/fsy9595887/article/details/86420048
Spring Boot 提供了 RestTemplate 来辅助发起一个 REST 请求,默认通过 JDK 自带的 HttpURLConnection 来作为底层 HTTP 消息的发送方式,使用 JackSon 来序列化服务器返回的 JSON 数据。RestTemplate 是核心类, 提供了所有访问 REST 服务的接口,尽管实际上可以使用 HTTP Client 类或者 java.net.URL来完成,但 RestTemplate 提供了阻STful 风格的 API。 Spring Boot 提供了 RestTemplateBuilder 来创建一个 RestTemplate。 RestTemplate定义11个基本操作方法,大致如下:delete(): 在特定的URL上对资源执行HTTP DELETE操作exchange(): 在URL上执行特定的HTTP方法,返回包含对象的ResponseEntity,这个对象是从响应体中映射得到的 3.execute(): 在URL上执行特定的HTTP方法,返回一个从响应体映射得到的对象(所有的get、post、delete、put、options、head、exchange方法最终调用的都是excute方法),例如:@Override public <T> T getForObject(String url, Class<T> responseType, Object... urlVariables) throws RestClientException { RequestCallback requestCallback = acceptHeaderRequestCallback(responseType); HttpMessageConverterExtractor<T> responseExtractor = <span style="white-space:pre"> </span>new HttpMessageConverterExtractor<T>(responseType, getMessageConverters(), logger); return execute(url, HttpMethod.GET, requestCallback, responseExtractor, urlVariables); } 4.getForEntity(): 发送一个HTTP GET请求,返回的ResponseEntity包含了响应体所映射成的对象 5.getForObject() :发送一个HTTP GET请求,返回的请求体将映射为一个对象 6.postForEntity() :POST 数据到一个URL,返回包含一个对象的ResponseEntity,这个对象是从响应体中映射得到的 7.postForObject(): POST 数据到一个URL,返回根据响应体匹配形成的对象 8.headForHeaders(): 发送HTTP HEAD请求,返回包含特定资源URL的HTTP头 9.optionsForAllow(): 发送HTTP OPTIONS请求,返回对特定URL的Allow头信息 10.postForLocation() :POST 数据到一个URL,返回新创建资源的URL 11.put(): PUT 资源到特定的URL实际上,由于Post 操作的非幂等性,它几乎可以代替其他的CRUD操作.一、GET请求在RestTemplate中,发送一个GET请求,我们可以通过如下两种方式:第一种:getForEntitygetForEntity方法的返回值是一个ResponseEntity<T>,ResponseEntity<T>是Spring对HTTP请求响应的封装,包括了几个重要的元素,如响应码、contentType、contentLength、响应消息体等。其重载方法如下:<T> ResponseEntity<T> getForObject(URI url, Class<T> responseType) throws RestClientException;<T> ResponseEntity<T> getForObject(String url, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> ResponseEntity<T> getForObject(String url, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException;比如下面一个例子:@Autowired RestTemplateBuilder restTemplateBuilder; @RequestMapping("/gethello") public String getHello() { RestTemplate client = restTemplateBuilder.build (); ResponseEntity<String> responseEntity = restTemplate.getForEntity("http://HELLO-SERVICE/hello", String.class); String body = responseEntity.getBody(); HttpStatus statusCode = responseEntity.getStatusCode(); int statusCodeValue = responseEntity.getStatusCodeValue(); HttpHeaders headers = responseEntity.getHeaders(); StringBuffer result = new StringBuffer(); result.append("responseEntity.getBody():").append(body).append("<hr>") .append("responseEntity.getStatusCode():").append(statusCode).append("<hr>") .append("responseEntity.getStatusCodeValue():").append(statusCodeValue).append("<hr>") .append("responseEntity.getHeaders():").append(headers).append("<hr>"); return result.toString(); }有时候我在调用服务提供者提供的接口时,可能需要传递参数,有两种不同的方式,如下:@RequestMapping("/sayhello") public String sayHello() { ResponseEntity<String> responseEntity = restTemplate.getForEntity("http://HELLO-SERVICE/sayhello?name={1}", String.class, "张三"); return responseEntity.getBody(); } @RequestMapping("/sayhello2") public String sayHello2() { Map<String, String> map = new HashMap<>(); map.put("name", "李四"); ResponseEntity<String> responseEntity = restTemplate.getForEntity("http://HELLO-SERVICE/sayhello?name={name}", String.class, map); return responseEntity.getBody(); }可以用一个数字做占位符,最后是一个可变长度的参数,来一一替换前面的占位符也可以前面使用name={name}这种形式,最后一个参数是一个map,map的key即为前边占位符的名字,map的value为参数值第一个调用地址也可以是一个URI而不是字符串,这个时候我们构建一个URI即可,参数神马的都包含在URI中了,如下:@RequestMapping("/sayhello3") public String sayHello3() { UriComponents uriComponents = UriComponentsBuilder.fromUriString("http://HELLO-SERVICE/sayhello?name={name}").build().expand("王五").encode(); URI uri = uriComponents.toUri(); ResponseEntity<String> responseEntity = restTemplate.getForEntity(uri, String.class); return responseEntity.getBody(); }通过Spring中提供的UriComponents来构建Uri即可。当然,服务提供者不仅可以返回String,也可以返回一个自定义类型的对象,比如我的服务提供者中有如下方法:@RequestMapping(value = "/getbook1", method = RequestMethod.GET)public Book book1() { return new Book("三国演义", 90, "罗贯中", "花城出版社"); }对于该方法我可以在服务消费者中通过如下方式来调用:@RequestMapping("/book1") public Book book1() { ResponseEntity<Book> responseEntity = restTemplate.getForEntity("http://HELLO- SERVICE/getbook1", Book.class); return responseEntity.getBody(); }第二种:getForObjectgetForObject函数实际上是对getForEntity函数的进一步封装,如果你只关注返回的消息体的内容,对其他信息都不关注,此时可以使用getForObject,重载方法如下:<T> T getForObject(URI url, Class<T> responseType) throws RestClientException;<T> T getForObject(String url, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> T getForObject(String url, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException; 二、POST请求在RestTemplate中,POST请求可以通过如下三个方法来发起:第一种:postForEntity、postForObjectPOST请求有postForObject()和postForEntity()两种方法,和GET请求的getForObject()和getForEntity()方法类似。getForLocation()是POST请求所特有的。<T> T postForObject(URI url, Object request, Class<T> responseType) throws RestClientException;<T> T postForObject(String url, Object request, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> T postForObject(String url, Object request, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException;上面三个方法中,第一个参数都是资源要POST到的URL,第二个参数是要发送的对象,而第三个参数是预期返回的Java类型。在URL作为String类型的两个版本中,第四个参数指定了URL变量(要么是可变参数列表,要么是一个Map)。 该方法和get请求中的getForEntity方法类似,如下例子:@RequestMapping("/book3") public Book book3() { Book book = new Book(); book.setName("红楼梦"); ResponseEntity<Book> responseEntity = restTemplate.postForEntity("http://HELLO-SERVICE/getbook2", book, Book.class); return responseEntity.getBody(); } 第二种:postForLacationpostForLacation()会在POST请求的请求体中发送一个资源到服务器端,返回的不再是资源对象,而是创建资源的位置。postForLocation(String url, Object request, Object... uriVariables) throws RestClientException;postForLocation(String url, Object request, Map<String, ?> uriVariables) throws RestClientException;postForLocation(URI url, Object request) throws RestClientException; public String postSpitter(Spitter spitter) { RestTemplate rest = new RestTemplate(); return rest.postForLocation("http://localhost:8080/Spitter/spitters", spitter).toString(); }postForLocation也是提交新资源,提交成功之后,返回新资源的URI,postForLocation的参数和前面两种的参数基本一致,只不过该方法的返回值为Uri,这个只需要服务提供者返回一个Uri即可,该Uri表示新资源的位置。 三、PUT请求在RestTemplate中,对PUT请求可以通过put方法进行调用实现,比如:RestTemplate restTemplate=new RestTemplate();Longid=100011; User user=new User("didi",40); restTemplate.put("http://USER-SERVICE/user/{l}",user,id); put函数也实现了三种不同的重载方法:put(String url,Object request,Object... urlVariables)put(String url,Object request,Map urlVariables)put(URI url,Object request)put函数为void类型,所以没有返回内容,也就没有其他函数定义的responseType参数,除此之外的其他传入参数定义与用法与postForObject基本一致。 四、DELETE请求在RestTemplate中,对DELETE请求可以通过delete方法进行调用实现,比如:RestTemplate restTemplate=new RestTemplate(); Longid=10001L; restTemplate.delete("http://USER-SERVICE/user/{1)",id); delete函数也实现了三种不同的重载方法:delete(String url,Object... urlVariables)delete(String url,Map urlVariables)delete(URI url)由于我们在进行REST请求时,通常都将DELETE请求的唯一标识拼接在url中,所以DELETE请求也不需要request的body信息,就如put()方法一样,返回值类型为void。说明:第三种重载方法,url指定DELETE请求的位置,urlVariables绑定url中的参数即可。五、通用方法exchange()exchange方法可以在发送个服务器端的请求中设置头信息,其重载方法如下:<T> ResponseEntity<T> exchange(URI url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType) throws RestClientException;<T> ResponseEntity<T> exchange(String url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType, Object... uriVariables) throws RestClientException;<T> ResponseEntity<T> exchange(String url, HttpMethod method, HttpEntity<?> requestEntity, Class<T> responseType, Map<String, ?> uriVariables) throws RestClientException;MultiValueMap<String, String> headers = new LinkedMultiValueMap<String, String>(); headers.add("Accept", "application/json"); HttpEntity<Object> requestEntity = new HttpEntity<Object>(headers); ResponseEntity<Spitter> response=rest.exchange("http://localhost:8080/Spitter/spitters/{spitter}", HttpMethod.GET, requestEntity, Spitter.class, spitterId); 补充: 如果期望返回的类型是一个列表,如 List,不能简单调用 xxxForObject,因为存在泛型的类型擦除, RestTemplate 在反序列化的时候并不知道实际反序列化的类型,因此可以使用 ParameterizedTypeReference 来包含泛型类型,代码如下:RestTemplate client= restTemplateBuilder.build(); //根据条件查询一纽订单 String uri = base+"/orders?offset={offset }"; Integer offset = 1; //元参数 HttpEntity body = null; ParameterizedTypeReference<List<Order> typeRef = new ParameterizedTypeReference<List<Order>(){}; ResponseEntity<List<Order> rs=client.exchange(uri, HttpMethod.GET, body, typeRef, offset); List<Order> order = rs.getBody() ; 注意到 typeRef 定义是用{}结束的,这里创建了一个 ParameterizedTypeReference 子类,依 据在类定义中的泛型信息保留的原则, typeRef保留了期望返回的泛型 List。exchange 是一个基础的 REST 调用接口,除了需要指明 HTTP Method,调用方法同其他方法类似。除了使用ParameterizedTypeReference子类对象,也可以先将返回结果映射成 json字符串,然后通过 ObjectMapper 来转为指定类型(笔记<SpringBoot中的JSON>中有介绍 ) 。————————————————原文链接:https://blog.csdn.net/fsy9595887/article/details/86420048 -
 1:从官网下载nginx压缩包;nginx.org2:移动到linux系统中3:解压xxx.tar.gz 文件 tar -xzf nginx-1.20.2.tar.gz -xzftar命令 https://blog.csdn.net/qq_36697196/article/details/1240468024:查看文件结构5: 查看文件的类型使用file命令,file configureconfigure: POSIX shell script, ASCII text executable中文翻译:POSIX shell脚本,ASCII文本可执行;说明这是一个可执行的文件 名词解释:POSIX:可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX )POSIX是Unix的标准。ASCII (American Standard Code for Information Interchange):美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。 6:编译安装,因为是用C语言写的,所以需要编译安装一次,它不像java一样随时都能跑起来。也有编译好的版本可供选择,这里我选择使用源码编译安装。 命令:./configure --prefix=/usr/local/nginx--prefix 源码安装,告诉我安装到什么地方。我这里安装到了usr/local/nginx现在安装的是最赤裸,最纯粹的nginx。7: 错误提示:./configure: error: the HTTP rewrite module requires the PCRE library.You can either disable the module by using --without-http_rewrite_moduleoption, or install the PCRE library into the system, or build the PCRE librarystatically from the source with nginx by using --with-pcre=<path> option.HTTP重写模块需要PCRE库。如果你不需要这个PCRE这个类库可以使用--without-http_rewrite_module禁用这个模块。两种选择1:不用这个模块 2:将这个模块加上。8:安装PCRE类库:yum install -y pcre pcre-devel9:然后继续执行:./configure --prefix=/usr/local/nginx10:又报错:./configure: error: the HTTP gzip module requires the zlib library.You can either disable the module by using --without-http_gzip_moduleoption, or install the zlib library into the system, or build the zlib librarystatically from the source with nginx by using --with-zlib=<path> option.这次是HTTP gzip模块缺少zlib 类库,所以需要安装一下11:安装zlib库:yum install -y zlib zlib-devel 12:继续执行:./configure --prefix=/usr/local/nginx输入的内容有安装的地址,日志等路径信息。Configuration summary + using system PCRE library + OpenSSL library is not used + using system zlib library nginx path prefix: "/usr/local/nginx" nginx binary file: "/usr/local/nginx/sbin/nginx" nginx modules path: "/usr/local/nginx/modules" nginx configuration prefix: "/usr/local/nginx/conf" nginx configuration file: "/usr/local/nginx/conf/nginx.conf" nginx pid file: "/usr/local/nginx/logs/nginx.pid" nginx error log file: "/usr/local/nginx/logs/error.log" nginx http access log file: "/usr/local/nginx/logs/access.log" nginx http client request body temporary files: "client_body_temp" nginx http proxy temporary files: "proxy_temp" nginx http fastcgi temporary files: "fastcgi_temp" nginx http uwsgi temporary files: "uwsgi_temp" nginx http scgi temporary files: "scgi_temp"13:执行make,make命令是GNU工程化中的一个编译工具。下图make后的输出 14:然后执行make install 完成后的输出 15:检查:cd /usr/local/nginx/,发现这个目录下已经有了目录 Conf:放配置文件Html:放静态页面Logs:放日志shin:放可执行文件16:启动 cd sbin/ 发现下面有一个可执行文件。可以使用file命令查看一下,看是不是一个可执行文件。然后执行 ./nginx 启动 17:输入IP地址,访问nginx,发现无法访问。 18:关闭防火墙,让nginx可以访问: systemctl stop firewalld.service。注意:Centos6和centos7关闭防火墙的命令是不一样的。 19:输入IP地址,访问nginx,可以正常访问了 20:将nginx启动安装成系统启动的服务创建服务脚本vi /usr/lib/systemd/system/nginx.service 服务脚本内容 [Unit] Description=nginx - web server After=network.target remote-fs.target nss-lookup.target [Service] Type=forking PIDFile=/usr/local/nginx/logs/nginx.pid ExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf ExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/usr/local/nginx/sbin/nginx -s stop ExecQuit=/usr/local/nginx/sbin/nginx -s quit PrivateTmp=true [Install] WantedBy=multi-user.target 21:重新加载系统服务 这个命令执行完,systemctl daemon-reload,我们就可以通过脚本停止和启动我们的服务了。现在nginx是正在运行的中的,我们先停掉它。先用sbin目录下的nginx停掉,因为现在是用nginx启动的。 22:使用脚本启动nginx systemctl start nginx.service 查看nginx的目前的启动状态 systemctl status nginx.service 23:设置为开机启动: systemctl enable nginx.serviceCreated symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service. 24:重启系统:reboot重启过程中请求nginx发现已经不能访问了。系统启动成功后,直接访问nginx可以进入欢迎界面
1:从官网下载nginx压缩包;nginx.org2:移动到linux系统中3:解压xxx.tar.gz 文件 tar -xzf nginx-1.20.2.tar.gz -xzftar命令 https://blog.csdn.net/qq_36697196/article/details/1240468024:查看文件结构5: 查看文件的类型使用file命令,file configureconfigure: POSIX shell script, ASCII text executable中文翻译:POSIX shell脚本,ASCII文本可执行;说明这是一个可执行的文件 名词解释:POSIX:可移植操作系统接口(Portable Operating System Interface of UNIX,缩写为 POSIX )POSIX是Unix的标准。ASCII (American Standard Code for Information Interchange):美国信息交换标准代码是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。 6:编译安装,因为是用C语言写的,所以需要编译安装一次,它不像java一样随时都能跑起来。也有编译好的版本可供选择,这里我选择使用源码编译安装。 命令:./configure --prefix=/usr/local/nginx--prefix 源码安装,告诉我安装到什么地方。我这里安装到了usr/local/nginx现在安装的是最赤裸,最纯粹的nginx。7: 错误提示:./configure: error: the HTTP rewrite module requires the PCRE library.You can either disable the module by using --without-http_rewrite_moduleoption, or install the PCRE library into the system, or build the PCRE librarystatically from the source with nginx by using --with-pcre=<path> option.HTTP重写模块需要PCRE库。如果你不需要这个PCRE这个类库可以使用--without-http_rewrite_module禁用这个模块。两种选择1:不用这个模块 2:将这个模块加上。8:安装PCRE类库:yum install -y pcre pcre-devel9:然后继续执行:./configure --prefix=/usr/local/nginx10:又报错:./configure: error: the HTTP gzip module requires the zlib library.You can either disable the module by using --without-http_gzip_moduleoption, or install the zlib library into the system, or build the zlib librarystatically from the source with nginx by using --with-zlib=<path> option.这次是HTTP gzip模块缺少zlib 类库,所以需要安装一下11:安装zlib库:yum install -y zlib zlib-devel 12:继续执行:./configure --prefix=/usr/local/nginx输入的内容有安装的地址,日志等路径信息。Configuration summary + using system PCRE library + OpenSSL library is not used + using system zlib library nginx path prefix: "/usr/local/nginx" nginx binary file: "/usr/local/nginx/sbin/nginx" nginx modules path: "/usr/local/nginx/modules" nginx configuration prefix: "/usr/local/nginx/conf" nginx configuration file: "/usr/local/nginx/conf/nginx.conf" nginx pid file: "/usr/local/nginx/logs/nginx.pid" nginx error log file: "/usr/local/nginx/logs/error.log" nginx http access log file: "/usr/local/nginx/logs/access.log" nginx http client request body temporary files: "client_body_temp" nginx http proxy temporary files: "proxy_temp" nginx http fastcgi temporary files: "fastcgi_temp" nginx http uwsgi temporary files: "uwsgi_temp" nginx http scgi temporary files: "scgi_temp"13:执行make,make命令是GNU工程化中的一个编译工具。下图make后的输出 14:然后执行make install 完成后的输出 15:检查:cd /usr/local/nginx/,发现这个目录下已经有了目录 Conf:放配置文件Html:放静态页面Logs:放日志shin:放可执行文件16:启动 cd sbin/ 发现下面有一个可执行文件。可以使用file命令查看一下,看是不是一个可执行文件。然后执行 ./nginx 启动 17:输入IP地址,访问nginx,发现无法访问。 18:关闭防火墙,让nginx可以访问: systemctl stop firewalld.service。注意:Centos6和centos7关闭防火墙的命令是不一样的。 19:输入IP地址,访问nginx,可以正常访问了 20:将nginx启动安装成系统启动的服务创建服务脚本vi /usr/lib/systemd/system/nginx.service 服务脚本内容 [Unit] Description=nginx - web server After=network.target remote-fs.target nss-lookup.target [Service] Type=forking PIDFile=/usr/local/nginx/logs/nginx.pid ExecStartPre=/usr/local/nginx/sbin/nginx -t -c /usr/local/nginx/conf/nginx.conf ExecStart=/usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf ExecReload=/usr/local/nginx/sbin/nginx -s reload ExecStop=/usr/local/nginx/sbin/nginx -s stop ExecQuit=/usr/local/nginx/sbin/nginx -s quit PrivateTmp=true [Install] WantedBy=multi-user.target 21:重新加载系统服务 这个命令执行完,systemctl daemon-reload,我们就可以通过脚本停止和启动我们的服务了。现在nginx是正在运行的中的,我们先停掉它。先用sbin目录下的nginx停掉,因为现在是用nginx启动的。 22:使用脚本启动nginx systemctl start nginx.service 查看nginx的目前的启动状态 systemctl status nginx.service 23:设置为开机启动: systemctl enable nginx.serviceCreated symlink from /etc/systemd/system/multi-user.target.wants/nginx.service to /usr/lib/systemd/system/nginx.service. 24:重启系统:reboot重启过程中请求nginx发现已经不能访问了。系统启动成功后,直接访问nginx可以进入欢迎界面 -
 【功能模块】开发环境,GIS使用的是超图测试环境,已配置完GIS BO,用户名和密码,并成功新建GIS用户,在展示地图时报错。【操作步骤&问题现象】1、地图服务提示net::ERR_SSL_PROTOCOL_ERROR,是否可配置为HTTP2、地图服务的图层能否修改,现在为Black_outdoor_map/iserver/services/map-tianditu/rest/maps/Black_outdoor_map/tileImage.png【截图信息】问题1截图:问题2截图:【日志信息】(可选,上传日志内容或者附件)
【功能模块】开发环境,GIS使用的是超图测试环境,已配置完GIS BO,用户名和密码,并成功新建GIS用户,在展示地图时报错。【操作步骤&问题现象】1、地图服务提示net::ERR_SSL_PROTOCOL_ERROR,是否可配置为HTTP2、地图服务的图层能否修改,现在为Black_outdoor_map/iserver/services/map-tianditu/rest/maps/Black_outdoor_map/tileImage.png【截图信息】问题1截图:问题2截图:【日志信息】(可选,上传日志内容或者附件) -
http代理:最常用的代理配置,可以解决负载均衡,容灾等问题;https代理:安全的http代理,对于安全性要求比较高,需要配置证书;ws代理:WS表示websocket服务,指的是长连接,Nginx配置WebSocket也比较简单只需要加上配置项: proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade; wss代理:WSS表示WebSocket + Https,就是安全的WebSocket,配置和ws服务一样,只需要在https代理加上配置项: proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade; 配置文件如下,其中localhost值不能重复,配置项参考https://www.runoob.com/w3cnote/nginx-setup-intro.html: server { listen 8088; server_name localhost; //配置ssl证书,证书生产命令 openssl req -x509 -nodes -days 36500 -newkey rsa:2048 -keyout test.key -out test.crt ssl_certificate "test.crt"; ssl_certificate_key "test.key"; ssl_ecdh_curve X25519:X448; ssl_session_cache shared:SSL:1m; ssl_session_timeout 5m; ssl_protocols TLSv1.3 TLSv1.2; ssl_ciphers "ECDHE-RSA-AES256-GCM-SHA384"; // 开启ssl认证,若不开启,https、wss认证不生效 ssl_prefer_server_ciphers on; // 配置https代理,需要开启ssl认证开关 location /{ proxy_pass https://xxx.xxx.xxx.xxx:****; } // 配置http代理 location / { proxy_pass http://xxx.xxx.xxx.xxx:****; } // 配置wss代理,需要开启ssl认证开关 location /{ proxy_pass https://xxx.xxx.xxx.xxx:****; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade; } // 配置ws代理 location / { proxy_pass http://xxx.xxx.xxx.xxx:****; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection $connection_upgrade; } }}
-
 一、前言首先是笔试形式:监考:单摄像头、手机扫码监考(只能使用内置计算器)题目:15道选择+3道编程要求:选择题期间不能离开页面,编程题可以使用自己的编译器,采用ACM模式。选择和编程分为两部分,答题结束后才能开始下一阶段,且不能再查看已提交部分。与上一次笔试了解到的信息差不多,选择题方向比较多,java、计网、线程、数学等等方面都有出到。还是以蒙为主,甚至还有求数学期望(乐,如果我在高三…但现在…三碗饭!)编程题方面难度一般,难点在于溢出和剪枝,在题干和解题方式上并没有为难。这里先说说溢出,其实打过几次比赛的朋友一定知道,溢出其实是很常见的坑,这里再给这次踩坑了的朋友们提个醒,看到没超时没报错却有很多点过不了的情况,别去算给的范围会不会溢出,先试着换个long,没准就过了。二、编程题注意:题目中的注释都是笔试结束后加的,可能有问题,大家参考即可。第一题题目: 给定一个矩阵,选出一个边长大于等于2的正方形,让它四个角之和最大。思路: 直接尝试三个循环遍历,变量为边长k、当前坐标(i,j),就能遍历所有可能的四个角的组合,暴力求最大即可。发现过了40%,考虑改成long即可(下面代码中使用了BigDecimal,使用long应该也是没问题的)。第一题也算用整整60%的点,给到一个思路——注意溢出。不过,要是一直没注意到溢出的话,三道题可能会丢掉差不多三分之一的分,个人感觉这么出题还是不太合理的。import java.math.BigDecimal;import java.util.*;public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(); int m = sc.nextInt(); int[][] num = new int[n][m]; //初始化数组 for(int i=0;i<n;i++){ for(int j=0;j<m;j++){ num[i][j] = sc.nextInt(); } } //记得题干中约束了m和n,此处不加大概也行 if(m<2||n<2){ System.out.println(0); return; } BigDecimal ans = new BigDecimal(0); int maxLength = Math.min(n,m); //三层遍历:遍历所以四个角的组合 for(int k=1;k<maxLength;k++){ for(int i=0;i<n;i++){ //i+k>=n会越界,提前结束 if(i+k>=n) break; for(int j=0;j<m;j++){ //j+k>=m会越界,提前结束 if(j+k>=m) break; //求和,求最大 BigDecimal sum = new BigDecimal(0); sum = sum.add(new BigDecimal(num[i][j])); sum = sum.add(new BigDecimal(num[i][j+k])); sum = sum.add(new BigDecimal(num[i+k][j])); sum = sum.add(new BigDecimal(num[i+k][j+k])); if(sum.compareTo(ans)>0){ ans = sum; } } } } System.out.println(ans); }}第二题题目: 给定x,y,a,b四个数,用a乘x或y,找到让a等于b的最小次数,无结果输出-1。思路: 应该比较容易的就能拿到93%,剩下的7%要靠剪枝拿到。可以让a先乘x和y中大的那个,这样,得到的第一个结果一定是次数最小的。这样就可以排除剩下的结果,直接return即可。注意还是要用long。import java.util.*;public class Main { static long ans = Integer.MAX_VALUE; //flag:记录是否找到结果 static boolean flag = false; public static void main(String[] args) { Scanner sc = new Scanner(System.in); long x = sc.nextInt(), y = sc.nextInt(), a = sc.nextInt(), b = sc.nextInt(); //让a先乘xy中较大的 if(x>=y){ fun(x, y, a, b, 0); }else{ fun(y, x, a, b, 0); } if(ans==Integer.MAX_VALUE){ System.out.println(-1); }else{ System.out.println(ans); } } private static void fun(long x, long y, long a, long b, long num){ //flag为true,说明已经找到了结果,其他的情况可以直接排除 if(flag) return; if(a>b){ return; } if(a==b){ //这一步多余,当时没有注意,直接ans = num就行。 ans = Math.min(ans, num); //标记 flag = true; return; } fun(x, y, a*x, b, num+1); fun(x, y, a*y, b, num+1); }}第三题题目: n个城市,每个城市包含距离x,快乐值y。小明想去任意个城市,找出一些城市,满足其中任意两个城市之间距离小于k,快乐值的和最大,输出快乐值和。思路: 这道题用滑动窗口,评论区有朋友问为什么用滑动窗口,个人感觉首先是从一个不确定范围中找目标值,并且左右边界的变化也是不确定的,大概就是要用滑动窗口吧,希望有明白的朋友能详细解答一下。整体思路就是先给二维数组按距离排序,窗口的边界差小于k,那么范围内任意两个距离的差一定也是小于k的。然后如果大于等于k了,左边界移动,小于k则移动右边界,继续扩大范围。在这个过程中随着边界改变记录范围内快乐值的总和,找到最大值。同样记得使用long。import java.util.*;public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(), k = sc.nextInt(); int[][] num = new int[n][2]; for(int i=0;i<n;i++){ num[i][0] = sc.nextInt(); num[i][1] = sc.nextInt(); } //按距离排序 Arrays.sort(num, new Comparator<int[]>() { @Override public int compare(int[] o1, int[] o2) { return o1[0]-o2[0]; } });// for(int i=0;i<n;i++){// System.out.println(num[i][0]+" "+num[i][1]);// } int L = 0, R = 0; long sum = 0, ans = 0; while(L<n&&R<n){ //差值大于等于k,该移动左边界缩小范围了 if(num[R][0]-num[L][0]>=k){ sum -= num[L][1]; L++;// System.out.println("-="+L); continue; } //差值小于k,继续扩大范围,寻找更大的结果 sum += num[R][1];// System.out.println("+="+R); ans = Math.max(ans, sum); R++; } System.out.println(ans); }}好了,这就是本此蔚来笔试的一些个人理解,以及三道编程题的解题思路,希望参加了面试的朋友能拿到面试机会,还没参加的朋友能有所收获。最后祝大家都能早日拿到心仪的offer~————————————————版权声明:本文为CSDN博主「OAOII」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/OAOII/article/details/125772091
一、前言首先是笔试形式:监考:单摄像头、手机扫码监考(只能使用内置计算器)题目:15道选择+3道编程要求:选择题期间不能离开页面,编程题可以使用自己的编译器,采用ACM模式。选择和编程分为两部分,答题结束后才能开始下一阶段,且不能再查看已提交部分。与上一次笔试了解到的信息差不多,选择题方向比较多,java、计网、线程、数学等等方面都有出到。还是以蒙为主,甚至还有求数学期望(乐,如果我在高三…但现在…三碗饭!)编程题方面难度一般,难点在于溢出和剪枝,在题干和解题方式上并没有为难。这里先说说溢出,其实打过几次比赛的朋友一定知道,溢出其实是很常见的坑,这里再给这次踩坑了的朋友们提个醒,看到没超时没报错却有很多点过不了的情况,别去算给的范围会不会溢出,先试着换个long,没准就过了。二、编程题注意:题目中的注释都是笔试结束后加的,可能有问题,大家参考即可。第一题题目: 给定一个矩阵,选出一个边长大于等于2的正方形,让它四个角之和最大。思路: 直接尝试三个循环遍历,变量为边长k、当前坐标(i,j),就能遍历所有可能的四个角的组合,暴力求最大即可。发现过了40%,考虑改成long即可(下面代码中使用了BigDecimal,使用long应该也是没问题的)。第一题也算用整整60%的点,给到一个思路——注意溢出。不过,要是一直没注意到溢出的话,三道题可能会丢掉差不多三分之一的分,个人感觉这么出题还是不太合理的。import java.math.BigDecimal;import java.util.*;public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(); int m = sc.nextInt(); int[][] num = new int[n][m]; //初始化数组 for(int i=0;i<n;i++){ for(int j=0;j<m;j++){ num[i][j] = sc.nextInt(); } } //记得题干中约束了m和n,此处不加大概也行 if(m<2||n<2){ System.out.println(0); return; } BigDecimal ans = new BigDecimal(0); int maxLength = Math.min(n,m); //三层遍历:遍历所以四个角的组合 for(int k=1;k<maxLength;k++){ for(int i=0;i<n;i++){ //i+k>=n会越界,提前结束 if(i+k>=n) break; for(int j=0;j<m;j++){ //j+k>=m会越界,提前结束 if(j+k>=m) break; //求和,求最大 BigDecimal sum = new BigDecimal(0); sum = sum.add(new BigDecimal(num[i][j])); sum = sum.add(new BigDecimal(num[i][j+k])); sum = sum.add(new BigDecimal(num[i+k][j])); sum = sum.add(new BigDecimal(num[i+k][j+k])); if(sum.compareTo(ans)>0){ ans = sum; } } } } System.out.println(ans); }}第二题题目: 给定x,y,a,b四个数,用a乘x或y,找到让a等于b的最小次数,无结果输出-1。思路: 应该比较容易的就能拿到93%,剩下的7%要靠剪枝拿到。可以让a先乘x和y中大的那个,这样,得到的第一个结果一定是次数最小的。这样就可以排除剩下的结果,直接return即可。注意还是要用long。import java.util.*;public class Main { static long ans = Integer.MAX_VALUE; //flag:记录是否找到结果 static boolean flag = false; public static void main(String[] args) { Scanner sc = new Scanner(System.in); long x = sc.nextInt(), y = sc.nextInt(), a = sc.nextInt(), b = sc.nextInt(); //让a先乘xy中较大的 if(x>=y){ fun(x, y, a, b, 0); }else{ fun(y, x, a, b, 0); } if(ans==Integer.MAX_VALUE){ System.out.println(-1); }else{ System.out.println(ans); } } private static void fun(long x, long y, long a, long b, long num){ //flag为true,说明已经找到了结果,其他的情况可以直接排除 if(flag) return; if(a>b){ return; } if(a==b){ //这一步多余,当时没有注意,直接ans = num就行。 ans = Math.min(ans, num); //标记 flag = true; return; } fun(x, y, a*x, b, num+1); fun(x, y, a*y, b, num+1); }}第三题题目: n个城市,每个城市包含距离x,快乐值y。小明想去任意个城市,找出一些城市,满足其中任意两个城市之间距离小于k,快乐值的和最大,输出快乐值和。思路: 这道题用滑动窗口,评论区有朋友问为什么用滑动窗口,个人感觉首先是从一个不确定范围中找目标值,并且左右边界的变化也是不确定的,大概就是要用滑动窗口吧,希望有明白的朋友能详细解答一下。整体思路就是先给二维数组按距离排序,窗口的边界差小于k,那么范围内任意两个距离的差一定也是小于k的。然后如果大于等于k了,左边界移动,小于k则移动右边界,继续扩大范围。在这个过程中随着边界改变记录范围内快乐值的总和,找到最大值。同样记得使用long。import java.util.*;public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int n = sc.nextInt(), k = sc.nextInt(); int[][] num = new int[n][2]; for(int i=0;i<n;i++){ num[i][0] = sc.nextInt(); num[i][1] = sc.nextInt(); } //按距离排序 Arrays.sort(num, new Comparator<int[]>() { @Override public int compare(int[] o1, int[] o2) { return o1[0]-o2[0]; } });// for(int i=0;i<n;i++){// System.out.println(num[i][0]+" "+num[i][1]);// } int L = 0, R = 0; long sum = 0, ans = 0; while(L<n&&R<n){ //差值大于等于k,该移动左边界缩小范围了 if(num[R][0]-num[L][0]>=k){ sum -= num[L][1]; L++;// System.out.println("-="+L); continue; } //差值小于k,继续扩大范围,寻找更大的结果 sum += num[R][1];// System.out.println("+="+R); ans = Math.max(ans, sum); R++; } System.out.println(ans); }}好了,这就是本此蔚来笔试的一些个人理解,以及三道编程题的解题思路,希望参加了面试的朋友能拿到面试机会,还没参加的朋友能有所收获。最后祝大家都能早日拿到心仪的offer~————————————————版权声明:本文为CSDN博主「OAOII」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/OAOII/article/details/125772091 -
 >摘要:装饰者模式通过组合的方式,提供了能够动态地给对象/模块扩展新功能的能力。理论上,只要没有限制,它可以一直把功能叠加下去,具有很高的灵活性。 本文分享自华为云社区《[【Go实现】实践GoF的23种设计模式:装饰者模式](https://bbs.huaweicloud.com/blogs/362755?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 元闰子。 # 简介 我们经常会遇到“**给现有对象/模块新增功能**”的场景,比如 http router 的开发场景下,除了最基础的路由功能之外,我们常常还会加上如日志、鉴权、流控等 middleware。如果你查看框架的源码,就会发现 middleware 功能的实现用的就是**装饰者模式**(Decorator Pattern)。 GoF 给装饰者模式的定义如下: >Decorators provide a flexible alternative to subclassing for extending functionality. Attach additional responsibilities to an object dynamically. 简单来说,装饰者模式通过组合的方式,提供了能够动态地给对象/模块扩展新功能的能力。理论上,只要没有限制,它可以一直把功能叠加下去,具有很高的灵活性。 如果写过 Java,那么一定对 I/O Stream 体系不陌生,它是装饰者模式的经典用法,客户端程序可以动态地为原始的输入输出流添加功能,比如按字符串输入输出,加入缓冲等,使得整个 I/O Stream 体系具有很高的可扩展性和灵活性。 # UML 结构 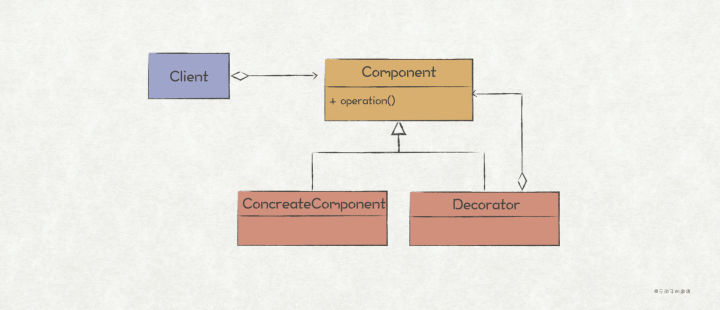 # 场景上下文 在简单的分布式应用系统(示例代码工程)中,我们设计了 Sidecar 边车模块,它的用处主要是为了 1)方便扩展 network.Socket 的功能,如增加日志、流控等非业务功能;2)让这些附加功能对业务程序隐藏起来,也即业务程序只须关心看到 network.Socket 接口即可。 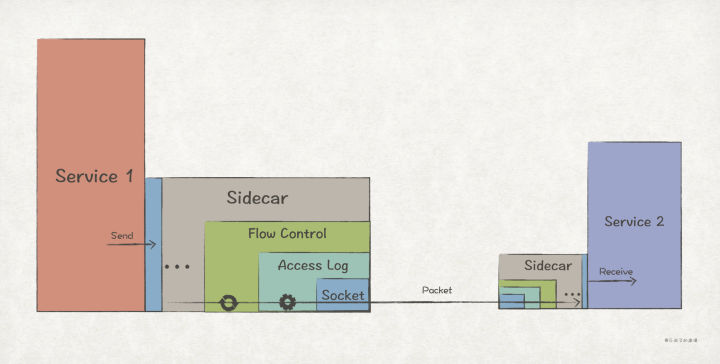 # 代码实现 Sidecar 的这个功能场景,很适合使用装饰者模式来实现,代码如下: ``` // demo/network/socket.go package network // 关键点1: 定义被装饰的抽象接口 // Socket 网络通信Socket接口 type Socket interface { // Listen 在endpoint指向地址上起监听 Listen(endpoint Endpoint) error // Close 关闭监听 Close(endpoint Endpoint) // Send 发送网络报文 Send(packet *Packet) error // Receive 接收网络报文 Receive(packet *Packet) // AddListener 增加网络报文监听者 AddListener(listener SocketListener) } // 关键点2: 提供一个默认的基础实现 type socketImpl struct { listener SocketListener } func DefaultSocket() *socketImpl { return &socketImpl{} } func (s *socketImpl) Listen(endpoint Endpoint) error { return Instance().Listen(endpoint, s) } ... // socketImpl的其他Socket实现方法 // demo/sidecar/flowctrl_sidecar.go package sidecar // 关键点3: 定义装饰器,实现被装饰的接口 // FlowCtrlSidecar HTTP接收端流控功能装饰器,自动拦截Socket接收报文,实现流控功能 type FlowCtrlSidecar struct { // 关键点4: 装饰器持有被装饰的抽象接口作为成员属性 socket network.Socket ctx *flowctrl.Context } // 关键点5: 对于需要扩展功能的方法,新增扩展功能 func (f *FlowCtrlSidecar) Receive(packet *network.Packet) { httpReq, ok := packet.Payload().(*http.Request) // 如果不是HTTP请求,则不做流控处理 if !ok { f.socket.Receive(packet) return } // 流控后返回429 Too Many Request响应 if !f.ctx.TryAccept() { httpResp := http.ResponseOfId(httpReq.ReqId()). AddStatusCode(http.StatusTooManyRequest). AddProblemDetails("enter flow ctrl state") f.socket.Send(network.NewPacket(packet.Dest(), packet.Src(), httpResp)) return } f.socket.Receive(packet) } // 关键点6: 不需要扩展功能的方法,直接调用被装饰接口的原生方法即可 func (f *FlowCtrlSidecar) Close(endpoint network.Endpoint) { f.socket.Close(endpoint) } ... // FlowCtrlSidecar的其他方法 // 关键点7: 定义装饰器的工厂方法,入参为被装饰接口 func NewFlowCtrlSidecar(socket network.Socket) *FlowCtrlSidecar { return &FlowCtrlSidecar{ socket: socket, ctx: flowctrl.NewContext(), } } // demo/sidecar/all_in_one_sidecar_factory.go // 关键点8: 使用时,通过装饰器的工厂方法,把所有装饰器和被装饰者串联起来 func (a AllInOneFactory) Create() network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), a.producer) } ``` 总结实现装饰者模式的几个关键点: 1. 定义需要被装饰的抽象接口,后续的装饰器都是基于该接口进行扩展。 2. 为抽象接口提供一个基础实现。 3. 定义装饰器,并实现被装饰的抽象接口。 4. 装饰器持有被装饰的抽象接口作为成员属性。“装饰”的意思是在原有功能的基础上扩展新功能,因此必须持有原有功能的抽象接口。 5. 在装饰器中,对于需要扩展功能的方法,新增扩展功能。 6. 不需要扩展功能的方法,直接调用被装饰接口的原生方法即可。 7. 为装饰器定义一个工厂方法,入参为被装饰接口。 8. 使用时,通过装饰器的工厂方法,把所有装饰器和被装饰者串联起来。 # 扩展 ## Go 风格的实现 在 Sidecar 的场景上下文中,被装饰的 Socket 是一个相对复杂的接口,装饰器通过实现 Socket 接口来进行功能扩展,是典型的面向对象风格。 如果被装饰者是一个简单的接口/方法/函数,我们可以用更具 Go 风格的实现方式,考虑前文提到的 http router 场景。如果你使用原生的 net/http 进行 http router 开发,通常会这么实现: ``` func main() { // 注册/hello的router http.HandleFunc("/hello", hello) // 启动http服务器 http.ListenAndServe("localhost:8080", nil) } // 具体的请求处理逻辑,类型是 http.HandlerFunc func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello, world")) } ``` 其中,我们通过 http.HandleFunc 来注册具体的 router, hello 是具体的请求处理方法。现在,我们想为该 http 服务器增加日志、鉴权等通用功能,那么可以把 func(w http.ResponseWriter, r *http.Request) 作为被装饰的抽象接口,通过新增日志、鉴权等装饰器完成功能扩展。 ``` // demo/network/http/http_handle_func_decorator.go // 关键点1: 确定被装饰接口,这里为原生的http.HandlerFunc type HandlerFunc func(ResponseWriter, *Request) // 关键点2: 定义装饰器类型,是一个函数类型,入参和返回值都是 http.HandlerFunc 函数 type HttpHandlerFuncDecorator func(http.HandlerFunc) http.HandlerFunc // 关键点3: 定义装饰函数,入参为被装饰的接口和装饰器可变列表 func Decorate(h http.HandlerFunc, decorators ...HttpHandlerFuncDecorator) http.HandlerFunc { // 关键点4: 通过for循环遍历装饰器,完成对被装饰接口的装饰 for _, decorator := range decorators { h = decorator(h) } return h } // 关键点5: 实现具体的装饰器 func WithBasicAuth(h http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { cookie, err := r.Cookie("Auth") if err != nil || cookie.Value != "Pass" { w.WriteHeader(http.StatusForbidden) return } // 关键点6: 完成功能扩展之后,调用被装饰的方法,才能将所有装饰器和被装饰者串起来 h(w, r) } } func WithLogger(h http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { log.Println(r.Form) log.Printf("path %s", r.URL.Path) h(w, r) } } func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello, world")) } func main() { // 关键点7: 通过Decorate函数完成对hello的装饰 http.HandleFunc("/hello", Decorate(hello, WithLogger, WithBasicAuth)) // 启动http服务器 http.ListenAndServe("localhost:8080", nil) } ``` 上述的装饰者模式的实现,用到了类似于 Functional Options 的技巧,也是巧妙利用了 Go 的函数式编程的特点,总结下来有如下几个关键点: 1. 确定被装饰的接口,上述例子为 http.HandlerFunc。 2. 定义装饰器类型,是一个函数类型,入参和返回值都是被装饰接口,上述例子为 func(http.HandlerFunc) http.HandlerFunc。 3. 定义装饰函数,入参为被装饰的接口和装饰器可变列表,上述例子为 Decorate 方法。 4. 在装饰方法中,通过for循环遍历装饰器,完成对被装饰接口的装饰。这里是用来类似 Functional Options 的技巧,一定要注意装饰器的顺序! 5. 实现具体的装饰器,上述例子为 WithBasicAuth 和 WithLogger 函数。 6. 在装饰器中,完成功能扩展之后,记得调用被装饰者的接口,这样才能将所有装饰器和被装饰者串起来。 7. 在使用时,通过装饰函数完成对被装饰者的装饰,上述例子为 Decorate(hello, WithLogger, WithBasicAuth)。 ## Go 标准库中的装饰者模式 在 Go 标准库中,也有一个运用了装饰者模式的模块,就是 context,其中关键的接口如下: ``` package context // 被装饰接口 type Context interface { Deadline() (deadline time.Time, ok bool) Done() -chan struct{} Err() error Value(key any) any } // cancel装饰器 type cancelCtx struct { Context // 被装饰接口 mu sync.Mutex done atomic.Value children map[canceler]struct{}= err error } // cancel装饰器的工厂方法 func WithCancel(parent Context) (ctx Context, cancel CancelFunc) { // ... c := newCancelCtx(parent) propagateCancel(parent, &c) return &c, func() { c.cancel(true, Canceled) } } // timer装饰器 type timerCtx struct { cancelCtx // 被装饰接口 timer *time.Timer deadline time.Time } // timer装饰器的工厂方法 func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) { // ... c := &timerCtx{ cancelCtx: newCancelCtx(parent), deadline: d, } // ... return c, func() { c.cancel(true, Canceled) } } // timer装饰器的工厂方法 func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) { return WithDeadline(parent, time.Now().Add(timeout)) } // value装饰器 type valueCtx struct { Context // 被装饰接口 key, val any } // value装饰器的工厂方法 func WithValue(parent Context, key, val any) Context { if parent == nil { panic("cannot create context from nil parent") } // ... return &valueCtx{parent, key, val} } ``` 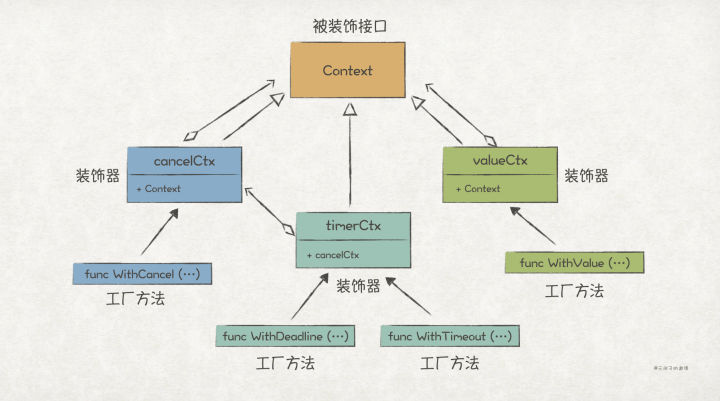 使用时,可以这样: ``` // 使用时,可以这样 func main() { ctx := context.Background() ctx = context.WithValue(ctx, "key1", "value1") ctx, _ = context.WithTimeout(ctx, time.Duration(1)) ctx = context.WithValue(ctx, "key2", "value2") } ``` 不管是 UML 结构,还是使用方法,context 模块都与传统的装饰者模式有一定出入,但也不妨碍 context 是装饰者模式的典型运用。还是那句话,**学习设计模式,不能只记住它的结构,而是学习其中的动机和原理**。 ## 典型使用场景 - I/O 流,比如为原始的 I/O 流增加缓冲、压缩等功能。 - Http Router,比如为基础的 Http Router 能力增加日志、鉴权、Cookie等功能。 - ...... ## 优缺点 **优点** 1. 遵循开闭原则,能够在不修改老代码的情况下扩展新功能。 2. 可以用多个装饰器把多个功能组合起来,理论上可以无限组合。 **缺点** 1. 一定要注意装饰器装饰的顺序,否则容易出现不在预期内的行为。 2. 当装饰器越来越多之后,系统也会变得复杂。 ## 与其他模式的关联 装饰者模式和代理模式具有很高的相似性,但是两种所强调的点不一样。前者强调的是为本体对象添加新的功能;后者强调的是对本体对象的访问控制。 装饰者模式和适配器模式的区别是,前者只会扩展功能而不会修改接口;后者则会修改接口。
>摘要:装饰者模式通过组合的方式,提供了能够动态地给对象/模块扩展新功能的能力。理论上,只要没有限制,它可以一直把功能叠加下去,具有很高的灵活性。 本文分享自华为云社区《[【Go实现】实践GoF的23种设计模式:装饰者模式](https://bbs.huaweicloud.com/blogs/362755?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 元闰子。 # 简介 我们经常会遇到“**给现有对象/模块新增功能**”的场景,比如 http router 的开发场景下,除了最基础的路由功能之外,我们常常还会加上如日志、鉴权、流控等 middleware。如果你查看框架的源码,就会发现 middleware 功能的实现用的就是**装饰者模式**(Decorator Pattern)。 GoF 给装饰者模式的定义如下: >Decorators provide a flexible alternative to subclassing for extending functionality. Attach additional responsibilities to an object dynamically. 简单来说,装饰者模式通过组合的方式,提供了能够动态地给对象/模块扩展新功能的能力。理论上,只要没有限制,它可以一直把功能叠加下去,具有很高的灵活性。 如果写过 Java,那么一定对 I/O Stream 体系不陌生,它是装饰者模式的经典用法,客户端程序可以动态地为原始的输入输出流添加功能,比如按字符串输入输出,加入缓冲等,使得整个 I/O Stream 体系具有很高的可扩展性和灵活性。 # UML 结构  # 场景上下文 在简单的分布式应用系统(示例代码工程)中,我们设计了 Sidecar 边车模块,它的用处主要是为了 1)方便扩展 network.Socket 的功能,如增加日志、流控等非业务功能;2)让这些附加功能对业务程序隐藏起来,也即业务程序只须关心看到 network.Socket 接口即可。  # 代码实现 Sidecar 的这个功能场景,很适合使用装饰者模式来实现,代码如下: ``` // demo/network/socket.go package network // 关键点1: 定义被装饰的抽象接口 // Socket 网络通信Socket接口 type Socket interface { // Listen 在endpoint指向地址上起监听 Listen(endpoint Endpoint) error // Close 关闭监听 Close(endpoint Endpoint) // Send 发送网络报文 Send(packet *Packet) error // Receive 接收网络报文 Receive(packet *Packet) // AddListener 增加网络报文监听者 AddListener(listener SocketListener) } // 关键点2: 提供一个默认的基础实现 type socketImpl struct { listener SocketListener } func DefaultSocket() *socketImpl { return &socketImpl{} } func (s *socketImpl) Listen(endpoint Endpoint) error { return Instance().Listen(endpoint, s) } ... // socketImpl的其他Socket实现方法 // demo/sidecar/flowctrl_sidecar.go package sidecar // 关键点3: 定义装饰器,实现被装饰的接口 // FlowCtrlSidecar HTTP接收端流控功能装饰器,自动拦截Socket接收报文,实现流控功能 type FlowCtrlSidecar struct { // 关键点4: 装饰器持有被装饰的抽象接口作为成员属性 socket network.Socket ctx *flowctrl.Context } // 关键点5: 对于需要扩展功能的方法,新增扩展功能 func (f *FlowCtrlSidecar) Receive(packet *network.Packet) { httpReq, ok := packet.Payload().(*http.Request) // 如果不是HTTP请求,则不做流控处理 if !ok { f.socket.Receive(packet) return } // 流控后返回429 Too Many Request响应 if !f.ctx.TryAccept() { httpResp := http.ResponseOfId(httpReq.ReqId()). AddStatusCode(http.StatusTooManyRequest). AddProblemDetails("enter flow ctrl state") f.socket.Send(network.NewPacket(packet.Dest(), packet.Src(), httpResp)) return } f.socket.Receive(packet) } // 关键点6: 不需要扩展功能的方法,直接调用被装饰接口的原生方法即可 func (f *FlowCtrlSidecar) Close(endpoint network.Endpoint) { f.socket.Close(endpoint) } ... // FlowCtrlSidecar的其他方法 // 关键点7: 定义装饰器的工厂方法,入参为被装饰接口 func NewFlowCtrlSidecar(socket network.Socket) *FlowCtrlSidecar { return &FlowCtrlSidecar{ socket: socket, ctx: flowctrl.NewContext(), } } // demo/sidecar/all_in_one_sidecar_factory.go // 关键点8: 使用时,通过装饰器的工厂方法,把所有装饰器和被装饰者串联起来 func (a AllInOneFactory) Create() network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), a.producer) } ``` 总结实现装饰者模式的几个关键点: 1. 定义需要被装饰的抽象接口,后续的装饰器都是基于该接口进行扩展。 2. 为抽象接口提供一个基础实现。 3. 定义装饰器,并实现被装饰的抽象接口。 4. 装饰器持有被装饰的抽象接口作为成员属性。“装饰”的意思是在原有功能的基础上扩展新功能,因此必须持有原有功能的抽象接口。 5. 在装饰器中,对于需要扩展功能的方法,新增扩展功能。 6. 不需要扩展功能的方法,直接调用被装饰接口的原生方法即可。 7. 为装饰器定义一个工厂方法,入参为被装饰接口。 8. 使用时,通过装饰器的工厂方法,把所有装饰器和被装饰者串联起来。 # 扩展 ## Go 风格的实现 在 Sidecar 的场景上下文中,被装饰的 Socket 是一个相对复杂的接口,装饰器通过实现 Socket 接口来进行功能扩展,是典型的面向对象风格。 如果被装饰者是一个简单的接口/方法/函数,我们可以用更具 Go 风格的实现方式,考虑前文提到的 http router 场景。如果你使用原生的 net/http 进行 http router 开发,通常会这么实现: ``` func main() { // 注册/hello的router http.HandleFunc("/hello", hello) // 启动http服务器 http.ListenAndServe("localhost:8080", nil) } // 具体的请求处理逻辑,类型是 http.HandlerFunc func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello, world")) } ``` 其中,我们通过 http.HandleFunc 来注册具体的 router, hello 是具体的请求处理方法。现在,我们想为该 http 服务器增加日志、鉴权等通用功能,那么可以把 func(w http.ResponseWriter, r *http.Request) 作为被装饰的抽象接口,通过新增日志、鉴权等装饰器完成功能扩展。 ``` // demo/network/http/http_handle_func_decorator.go // 关键点1: 确定被装饰接口,这里为原生的http.HandlerFunc type HandlerFunc func(ResponseWriter, *Request) // 关键点2: 定义装饰器类型,是一个函数类型,入参和返回值都是 http.HandlerFunc 函数 type HttpHandlerFuncDecorator func(http.HandlerFunc) http.HandlerFunc // 关键点3: 定义装饰函数,入参为被装饰的接口和装饰器可变列表 func Decorate(h http.HandlerFunc, decorators ...HttpHandlerFuncDecorator) http.HandlerFunc { // 关键点4: 通过for循环遍历装饰器,完成对被装饰接口的装饰 for _, decorator := range decorators { h = decorator(h) } return h } // 关键点5: 实现具体的装饰器 func WithBasicAuth(h http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { cookie, err := r.Cookie("Auth") if err != nil || cookie.Value != "Pass" { w.WriteHeader(http.StatusForbidden) return } // 关键点6: 完成功能扩展之后,调用被装饰的方法,才能将所有装饰器和被装饰者串起来 h(w, r) } } func WithLogger(h http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { log.Println(r.Form) log.Printf("path %s", r.URL.Path) h(w, r) } } func hello(w http.ResponseWriter, r *http.Request) { w.Write([]byte("hello, world")) } func main() { // 关键点7: 通过Decorate函数完成对hello的装饰 http.HandleFunc("/hello", Decorate(hello, WithLogger, WithBasicAuth)) // 启动http服务器 http.ListenAndServe("localhost:8080", nil) } ``` 上述的装饰者模式的实现,用到了类似于 Functional Options 的技巧,也是巧妙利用了 Go 的函数式编程的特点,总结下来有如下几个关键点: 1. 确定被装饰的接口,上述例子为 http.HandlerFunc。 2. 定义装饰器类型,是一个函数类型,入参和返回值都是被装饰接口,上述例子为 func(http.HandlerFunc) http.HandlerFunc。 3. 定义装饰函数,入参为被装饰的接口和装饰器可变列表,上述例子为 Decorate 方法。 4. 在装饰方法中,通过for循环遍历装饰器,完成对被装饰接口的装饰。这里是用来类似 Functional Options 的技巧,一定要注意装饰器的顺序! 5. 实现具体的装饰器,上述例子为 WithBasicAuth 和 WithLogger 函数。 6. 在装饰器中,完成功能扩展之后,记得调用被装饰者的接口,这样才能将所有装饰器和被装饰者串起来。 7. 在使用时,通过装饰函数完成对被装饰者的装饰,上述例子为 Decorate(hello, WithLogger, WithBasicAuth)。 ## Go 标准库中的装饰者模式 在 Go 标准库中,也有一个运用了装饰者模式的模块,就是 context,其中关键的接口如下: ``` package context // 被装饰接口 type Context interface { Deadline() (deadline time.Time, ok bool) Done() -chan struct{} Err() error Value(key any) any } // cancel装饰器 type cancelCtx struct { Context // 被装饰接口 mu sync.Mutex done atomic.Value children map[canceler]struct{}= err error } // cancel装饰器的工厂方法 func WithCancel(parent Context) (ctx Context, cancel CancelFunc) { // ... c := newCancelCtx(parent) propagateCancel(parent, &c) return &c, func() { c.cancel(true, Canceled) } } // timer装饰器 type timerCtx struct { cancelCtx // 被装饰接口 timer *time.Timer deadline time.Time } // timer装饰器的工厂方法 func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) { // ... c := &timerCtx{ cancelCtx: newCancelCtx(parent), deadline: d, } // ... return c, func() { c.cancel(true, Canceled) } } // timer装饰器的工厂方法 func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) { return WithDeadline(parent, time.Now().Add(timeout)) } // value装饰器 type valueCtx struct { Context // 被装饰接口 key, val any } // value装饰器的工厂方法 func WithValue(parent Context, key, val any) Context { if parent == nil { panic("cannot create context from nil parent") } // ... return &valueCtx{parent, key, val} } ```  使用时,可以这样: ``` // 使用时,可以这样 func main() { ctx := context.Background() ctx = context.WithValue(ctx, "key1", "value1") ctx, _ = context.WithTimeout(ctx, time.Duration(1)) ctx = context.WithValue(ctx, "key2", "value2") } ``` 不管是 UML 结构,还是使用方法,context 模块都与传统的装饰者模式有一定出入,但也不妨碍 context 是装饰者模式的典型运用。还是那句话,**学习设计模式,不能只记住它的结构,而是学习其中的动机和原理**。 ## 典型使用场景 - I/O 流,比如为原始的 I/O 流增加缓冲、压缩等功能。 - Http Router,比如为基础的 Http Router 能力增加日志、鉴权、Cookie等功能。 - ...... ## 优缺点 **优点** 1. 遵循开闭原则,能够在不修改老代码的情况下扩展新功能。 2. 可以用多个装饰器把多个功能组合起来,理论上可以无限组合。 **缺点** 1. 一定要注意装饰器装饰的顺序,否则容易出现不在预期内的行为。 2. 当装饰器越来越多之后,系统也会变得复杂。 ## 与其他模式的关联 装饰者模式和代理模式具有很高的相似性,但是两种所强调的点不一样。前者强调的是为本体对象添加新的功能;后者强调的是对本体对象的访问控制。 装饰者模式和适配器模式的区别是,前者只会扩展功能而不会修改接口;后者则会修改接口。 -
 在Go语言中,你可以给任意类型(包括内置类型,但不包括指针类型)添加相应的方法: type Integer int func (a Integer) Less(b Integer) bool { return a < b } 在这个例子中,我们定义了一个新类型Integer,它和int没有本质不同,只是它为内置的int类型增加了个新方法Less()。 这样实现了Integer后,就可以让整型像一个普通的类一样使用: func main() { var a Integer = 1 if a.Less(2) { fmt.Println(a, "Less 2") } } 在学其他语言(尤其是C++语言)的时候,很多初学者对面向对象的概念感觉很神秘,不知道那些继承和多态到底是怎么发生的。不过,如果读者曾经深入了解过C++的对象模型,或者完整阅读过《深度探索C++对象模型》这本书,就会理解C++等语言中的面向对象都只是相当于在C语言基础上添加的一个语法糖,接下来解释一下为什么可以这么理解。 type Integer int func Integer_Less(a Integer, b Integer) bool { return a < b } func main() { var a Integer = 1 if Integer_Less(a, 2) { fmt.Println(a, "Less 2") } } 在Go语言中,面向对象的神秘面纱被剥得一干二净。对比下面的两段代码: func (a Integer) Less(b Integer) bool { // 面向对象 return a < b } func Integer_Less(a Integer, b Integer) bool { // 面向过程 return a < b } a.Less(2) // 面向对象的用法 Integer_Less(a, 2) // 面向过程的用法 可以看出,面向对象只是换了一种语法形式来表达。C++语言的面向对象之所以让有些人迷惑的一大原因就在于其隐藏的this指针。一旦把隐藏的this指针显露出来,大家看到的就是一个面向过程编程。而Java和C#其实都是遵循着C++语言的惯例而设计的,它们的成员方法中都带有一个隐藏的this指针。如果读者了解Python语法,就会知道Python的成员方法中会有一个self 参数,它和this指针的作用是完全一样的。 我们对于一些事物的不理解或者畏惧,原因都在于这些事情所有意无意带有的绚丽外衣和神秘面纱。只要揭开这一层直达本质,就会发现一切其实都很简单。 “在Go语言中没有隐藏的this指针”这句话的含义是: 方法施加的目标(也就是“对象”)显式传递,没有被隐藏起来; 方法施加的目标(也就是“对象”)不需要非得是指针,也不用非得叫this。 我们对比Java语言的代码: class Integer { private int val; public boolean Less(Integer b) { return this.val< b.val; } } 对于这段Java代码,初学者可能会比较难以理解其背后的机制,以及this到底从何而来。这主要是因为Integer类的Less()方法隐藏了第一个参数Integer* this。如果将其翻译成C代码,会更清晰: struct Integer { int val; }; bool Integer_Less(Integer* this, Integer* b) { return this->val < b->val; } 2 Go语言中的面向对象 为直观,也无需支付额外的成本。如果要求对象必须以指针传递,这有时会是个额外成本,因为对象有时很小(比如4字节),用指针传递并不划算。只有在你需要修改对象的时候,才必须用指针。它不是Go语言的约束,而是一种自然约束。举个例子: func (a *Integer) Add(b Integer) { *a += b } 这里为Integer类型增加了Add()方法。由于Add()方法需要修改对象的值,所以需要用指4 针引用。调用如下: func main() { var a Integer = 1 a.Add(2) fmt.Println("a =", a) } 5 运行该程序,得到的结果是:a=3。如果你实现成员方法时传入的不是指针而是值(即传入Integer,而非*Integer),如下所示: func (a Integer) Add(b Integer) { 6 a += b } 那么运行程序得到的结果是a=1,也就是维持原来的值。读者可以亲自动手尝试一下。 究其原因,是因为Go语言和C语言一样,类型都是基于值传递的。要想修改变量的值,只能传递指针。 7 Go 语言包经常使用此功能,比如http包中关于HTTP头部信息的Header类型(参见$GOROOT/src/pkg/http/header.go)就是通过Go内置的map类型赋予新的语义来实现的。下面是 Header类型实现的部分代码: 8 // Header类型用于表达HTTP头部的键值对信息 type Header map[string][]string // Add()方法用于添加一个键值对到HTTP头部 // 如果该键已存在,则会将值添加到已存在的值后面 func (h Header) Add(key, value string) { textproto.MIMEHeader(h).Add(key, value) 8 //(} ) Set()方法用于设置某个键对应的值,如果该键已存在,则替换已存在的值func (h Header) Set(key, value string) { textproto.MIMEHeader(h).Set(key, value) } // 还有更多其他方法 Header类型其实就是一个map,但通过为map起一个Header别名并增加了一系列方法,它就变成了一个全新的类型,但这个新类型又完全拥有map的功能。是不是很酷? Go 语言毕竟还是一门比较新的语言,学习资源相比 C++/Java/C#自然会略显缺乏。
在Go语言中,你可以给任意类型(包括内置类型,但不包括指针类型)添加相应的方法: type Integer int func (a Integer) Less(b Integer) bool { return a < b } 在这个例子中,我们定义了一个新类型Integer,它和int没有本质不同,只是它为内置的int类型增加了个新方法Less()。 这样实现了Integer后,就可以让整型像一个普通的类一样使用: func main() { var a Integer = 1 if a.Less(2) { fmt.Println(a, "Less 2") } } 在学其他语言(尤其是C++语言)的时候,很多初学者对面向对象的概念感觉很神秘,不知道那些继承和多态到底是怎么发生的。不过,如果读者曾经深入了解过C++的对象模型,或者完整阅读过《深度探索C++对象模型》这本书,就会理解C++等语言中的面向对象都只是相当于在C语言基础上添加的一个语法糖,接下来解释一下为什么可以这么理解。 type Integer int func Integer_Less(a Integer, b Integer) bool { return a < b } func main() { var a Integer = 1 if Integer_Less(a, 2) { fmt.Println(a, "Less 2") } } 在Go语言中,面向对象的神秘面纱被剥得一干二净。对比下面的两段代码: func (a Integer) Less(b Integer) bool { // 面向对象 return a < b } func Integer_Less(a Integer, b Integer) bool { // 面向过程 return a < b } a.Less(2) // 面向对象的用法 Integer_Less(a, 2) // 面向过程的用法 可以看出,面向对象只是换了一种语法形式来表达。C++语言的面向对象之所以让有些人迷惑的一大原因就在于其隐藏的this指针。一旦把隐藏的this指针显露出来,大家看到的就是一个面向过程编程。而Java和C#其实都是遵循着C++语言的惯例而设计的,它们的成员方法中都带有一个隐藏的this指针。如果读者了解Python语法,就会知道Python的成员方法中会有一个self 参数,它和this指针的作用是完全一样的。 我们对于一些事物的不理解或者畏惧,原因都在于这些事情所有意无意带有的绚丽外衣和神秘面纱。只要揭开这一层直达本质,就会发现一切其实都很简单。 “在Go语言中没有隐藏的this指针”这句话的含义是: 方法施加的目标(也就是“对象”)显式传递,没有被隐藏起来; 方法施加的目标(也就是“对象”)不需要非得是指针,也不用非得叫this。 我们对比Java语言的代码: class Integer { private int val; public boolean Less(Integer b) { return this.val< b.val; } } 对于这段Java代码,初学者可能会比较难以理解其背后的机制,以及this到底从何而来。这主要是因为Integer类的Less()方法隐藏了第一个参数Integer* this。如果将其翻译成C代码,会更清晰: struct Integer { int val; }; bool Integer_Less(Integer* this, Integer* b) { return this->val < b->val; } 2 Go语言中的面向对象 为直观,也无需支付额外的成本。如果要求对象必须以指针传递,这有时会是个额外成本,因为对象有时很小(比如4字节),用指针传递并不划算。只有在你需要修改对象的时候,才必须用指针。它不是Go语言的约束,而是一种自然约束。举个例子: func (a *Integer) Add(b Integer) { *a += b } 这里为Integer类型增加了Add()方法。由于Add()方法需要修改对象的值,所以需要用指4 针引用。调用如下: func main() { var a Integer = 1 a.Add(2) fmt.Println("a =", a) } 5 运行该程序,得到的结果是:a=3。如果你实现成员方法时传入的不是指针而是值(即传入Integer,而非*Integer),如下所示: func (a Integer) Add(b Integer) { 6 a += b } 那么运行程序得到的结果是a=1,也就是维持原来的值。读者可以亲自动手尝试一下。 究其原因,是因为Go语言和C语言一样,类型都是基于值传递的。要想修改变量的值,只能传递指针。 7 Go 语言包经常使用此功能,比如http包中关于HTTP头部信息的Header类型(参见$GOROOT/src/pkg/http/header.go)就是通过Go内置的map类型赋予新的语义来实现的。下面是 Header类型实现的部分代码: 8 // Header类型用于表达HTTP头部的键值对信息 type Header map[string][]string // Add()方法用于添加一个键值对到HTTP头部 // 如果该键已存在,则会将值添加到已存在的值后面 func (h Header) Add(key, value string) { textproto.MIMEHeader(h).Add(key, value) 8 //(} ) Set()方法用于设置某个键对应的值,如果该键已存在,则替换已存在的值func (h Header) Set(key, value string) { textproto.MIMEHeader(h).Set(key, value) } // 还有更多其他方法 Header类型其实就是一个map,但通过为map起一个Header别名并增加了一系列方法,它就变成了一个全新的类型,但这个新类型又完全拥有map的功能。是不是很酷? Go 语言毕竟还是一门比较新的语言,学习资源相比 C++/Java/C#自然会略显缺乏。 -
文章目录一、初识Java二、我与Java差点擦肩而过三、我的第一个Java项目四、我用过的开发工具五、Java经久不衰的关键总结转眼间Java已经27岁了,Java在1995年5月23日诞生,诞生之后在到现在以经27年了,但依旧保持旺盛的活力,那是因为Java语言作为静态面向对象编程语言的代表,极好的实现了面向对象理论,允许程序员以优雅的思维方式进行复杂的编程,Java具有简单性,面向对象,分布式,健壮性,安全性,平台独立与可移植性,多线程,动态性等特点,总的来说,Java是一门非常方便的语言,只要你能想到的方法,都有大佬已经帮你写好了,非常的方便,我相信Java在后续的发展中,一定会越来越好,我自己本身也是一个大学生,学习的也是Java语言,未来也会在Java这个领域一直干下去一、初识Java我首次接触Java的时候还是在我大学的时候第一节JavaSE课程,我们的Java老师给我们介绍Java的产生和发展,我对Java产生了憧憬,在课后敲下了我的第一行Java代码:public class Main { public static void main(String[] args) { System.out.println("hello world!!!"); }}我相信大部分的Java生涯都是从这行代码开始的,这是我Java生涯的起点,也是我和Java的故事的起点二、我与Java差点擦肩而过我现在是一名大三的学生,不准备考研的我当然是准备学习一门专业知识,出社会后找到一个满意的工作,对于我的专业来说,计算机科学与技术的学生,从事编程工作无非就是C/C++,Java,还有python,我就在考虑我到时候到底从事哪个领域,我在Java和C++ 中犹豫了很久,最终选择了Java,既然选择了它,我就要认真的对待它,毕竟我可是一个很专一的人,但是在我Java相处的时间里,开始的相处,我对它还不是很熟悉,我完全看不明白它,在一段时间里,我甚至觉得我和它不合适,我和它的在一起就是一个错误,但是再后来我发现之前是因为我不够了解它,在我和Java后面的陆续相处中,我发现Java非常的有意思,你越了解它越觉得它有意思三、我的第一个Java项目我的第一个Java项目,是一个很简单的命令行实现的图书管理系统,就这么一个很简单的小项目对于当时的我来说就觉得非常的困难,但是当你真的完成了它的时候,那种成就感是任何事情都带不来的,这个项目几乎包含了JavaSE基础语法部分,这也是对基础知识的一个检验四、我用过的开发工具在我上大学时的Java课上,我们的Java老师给我们推荐的是一款叫eclipse的软件,这也是我第一次使用开发工具,在当时连安装JDK,搭建环境对我来说都还是一个难题,我也是在这个开发工具上敲的我的第一行Java代码,后来在朋友的推荐下,我使用了IDEA这款开发工具,这款工具相对于eclipse来说要好用很多,非常的方便,而JDK,我一直使用的是JDK8五、Java经久不衰的关键1.无处不在、免费Java是免费下载和简单易用的,因此它对有远见卓识的开发人员和企业很有吸引力,而且可能只花很少的预算。因为Java无处不在,所以很容易向你的CTO或客户销售可靠、无风险的产品。开发人员和项目团队可以找到并指出许多基于Java的站点示例,以减轻高级管理人员或客户的担忧。想学习java的同学不妨报个Java培训班,可以节省学习时间,提高学习效率,在短时间内学有所成,还能找到一份不错的工作。2.平等机会申请Java编程语言支持分布式环境、internet使用和将在具有多个服务器和客户端的网络上运行的应用程序。它可以用于网站、移动应用程序、智能设备等,在小程序或应用程序模块中也同样有效。它适用于网络浏览器、在线商店、投票和论坛、表单处理、手机应用程序和消费产品。总结我的Java学习之路还很漫长,后面要学习的东西还很多,在后续我也会一直从事Java领域,希望Java会一直越来越好。原文链接:https://blog.csdn.net/weixin_57011679/article/details/124946316
-
>摘要:工厂方法模式(Factory Method Pattern)将对象创建的逻辑封装起来,为使用者提供一个简单易用的对象创建接口,常用于不指定对象具体类型的情况下创建对象的场景。 本文分享自华为云社区《[【Go实现】实践GoF的23种设计模式:工厂方法模式](https://bbs.huaweicloud.com/blogs/353969?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 元闰子。 # 简述 工厂方法模式(Factory Method Pattern)跟上一篇讨论的建造者模式类似,**都是将对象创建的逻辑封装起来,为使用者提供一个简单易用的对象创建接口**。两者在应用场景上稍有区别,建造者模式常用于需要传递多个参数来进行实例化的场景;工厂方法模式常用于**不指定对象具体类型的情况下创建对象**的场景。 # UML 结构 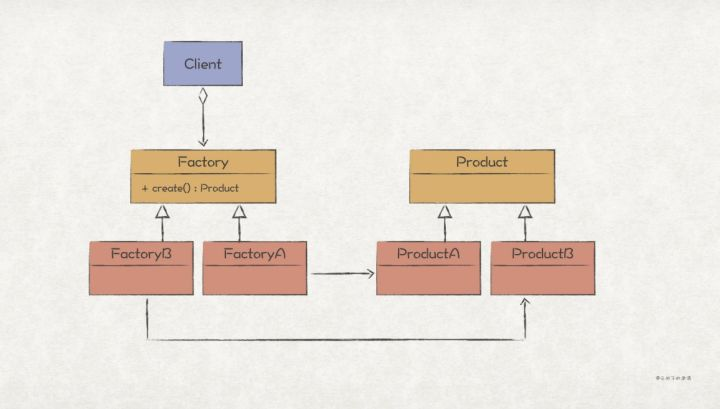 # 代码实现 ## 示例 在简单的分布式应用系统(示例代码工程)中,我们设计了 Sidecar 边车模块, Sidecar 的作用是为了给原生的 Socket 增加额外的功能,比如流控、日志等。  Sidecar 模块的设计运用了**装饰者模式**,修饰的是 Socket 。所以客户端其实是把 Sidecar 当成是 Socket 来使用了,比如: ``` // demo/network/http/http_client.go package http // 创建一个新的HTTP客户端,以Socket接口作为入参 func NewClient(socket network.Socket, ip string) (*Client, error) { ... // 一些初始化逻辑 return client, nil } // 使用NewClient时,我们可以传入Sidecar来给Http客户端附加额外的流控功能 client, err := http.NewClient(sidecar.NewFlowCtrlSidecar(network.DefaultSocket()), "192.168.0.1") ``` 在服务消息中介中,每次收到上游服务的 HTTP 请求,都会调用 http.NewClient 来创建一个 HTTP 客户端,并通过它将请求转发给下游服务: ``` type ServiceMediator struct { ... server *http.Server } // Forward 转发请求,请求URL为 /{serviceType}+ServiceUri 的形式,如/serviceA/api/v1/task func (s *ServiceMediator) Forward(req *http.Request) *http.Response { ... // 发现下游服务的目的IP地址 dest, err := s.discovery(svcType) // 创建HTTP客户端,硬编码sidecar.NewFlowCtrlSidecar(network.DefaultSocket()) client, err := http.NewClient(sidecar.NewFlowCtrlSidecar(network.DefaultSocket()), s.localIp) // 通过HTTP客户端转发请求 resp, err := client.Send(dest, forwardReq) ... } ``` 在上述实现中,我们在调用 http.NewClient 时把 sidecar.NewFlowCtrlSidecar(network.DefaultSocket()) 硬编码进去了,那么如果以后要扩展 Sidecar ,就得修改这段代码逻辑,这违反了开闭原则 OCP。 有经验的同学可能会想到,可以通过让 ServiceMediator 依赖 Socket 接口,在 Forward 方法调用 http.NewClient 时把 Socket 接口作为入参;然后在 ServiceMediator 初始化时,将具体类型的 Sidecar 注入到 ServiceMediator 中: ``` type ServiceMediator struct { ... server *http.Server // 依赖Socket抽象接口 socket network.Socket } // Forward 转发请求,请求URL为 /{serviceType}+ServiceUri 的形式,如/serviceA/api/v1/task func (s *ServiceMediator) Forward(req *http.Request) *http.Response { ... // 发现下游服务的目的IP地址 dest, err := s.discovery(svcType) // 创建HTTP客户端,将s.socket抽象接口作为入参 client, err := http.NewClient(s.socket, s.localIp) // 通过HTTP客户端转发请求 resp, err := client.Send(dest, forwardReq) ... } // 在ServiceMediator初始化时,将具体类型的Sidecar注入到ServiceMediator中 mediator := &ServiceMediator{ socket: sidecar.NewFlowCtrlSidecar(network.DefaultSocket()) } ``` 上述的修改,从原来依赖具体,改成了依赖抽象,符合了开闭原则。 但是, Forward 方法存在并发调用的场景,因此它希望每次被调用时都创建一个新的 Socket/Sidecar 来完成网络通信,否则就需要加锁来保证并发安全。而上述的修改会导致在 ServiceMediator 的生命周期内都使用同一个 Socket/Sidecar,显然不符合要求。 因此,我们需要一个方法,既能够满足开闭原则,而且在每次调用Forward 方法时也能够创建新的 Socket/Sidecar 实例。工厂方法模式恰好就能满足这两点要求,下面我们通过它来完成代码的优化。 # 实现 ``` // demo/sidecar/sidecar_factory.go // 关键点1: 定义一个Sidecar工厂抽象接口 type Factory interface { // 关键点2: 工厂方法返回Socket抽象接口 Create() network.Socket } // 关键点3: 按照需要实现具体的工厂 // demo/sidecar/raw_socket_sidecar_factory.go // RawSocketFactory 只具备原生socket功能的sidecar,实现了Factory接口 type RawSocketFactory struct { } func (r RawSocketFactory) Create() network.Socket { return network.DefaultSocket() } // demo/sidecar/all_in_one_sidecar_factory.go // AllInOneFactory 具备所有功能的sidecar工厂,实现了Factory接口 type AllInOneFactory struct { producer mq.Producible } func (a AllInOneFactory) Create() network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), a.producer) } ``` 上述代码中,我们定义了一个工厂抽象接口 Factory ,并有了 2 个具体的实现 RawSocketFactory 和 AllInOneFactory。最后, ServiceMediator 依赖 Factory ,并在 Forward 方法中通过 Factory 来创建新的 Socket/Sidecar : ``` // demo/service/mediator/service_mediator.go type ServiceMediator struct { ... server *http.Server // 关键点4: 客户端依赖Factory抽象接口 sidecarFactory sidecar.Factory } // Forward 转发请求,请求URL为 /{serviceType}+ServiceUri 的形式,如/serviceA/api/v1/task func (s *ServiceMediator) Forward(req *http.Request) *http.Response { ... // 发现下游服务的目的IP地址 dest, err := s.discovery(svcType) // 创建HTTP客户端,调用sidecarFactory.Create()生成Socket作为入参 client, err := http.NewClient(s.sidecarFactory.Create(), s.localIp) // 通过HTTP客户端转发请求 resp, err := client.Send(dest, forwardReq) ... } // 关键点5: 在ServiceMediator初始化时,将具体类型的sidecar.Factory注入到ServiceMediator中 mediator := &ServiceMediator{ sidecarFactory: &AllInOneFactory{} // sidecarFactory: &RawSocketFactory{} } ``` 下面总结实现工厂方法模式的几个关键点: 1. 定义一个工厂方法抽象接口,比如前文中的 sidecar.Factory。 2. 工厂方法中,返回需要创建的对象/接口,比如 network.Socket。其中,工厂方法通常命名为 Create。 3. 按照具体需要,定义工厂方法抽象接口的具体实现对象,比如 RawSocketFactory 和 AllInOneFactory。 4. 客户端使用时,依赖工厂方法抽象接口。 5. 在客户端初始化阶段,完成具体工厂对象的依赖注入。 # 扩展 ## Go 风格的实现 前文的工厂方法模式实现,是非常典型的**面向对象风格**,下面我们给出一个更具 Go 风格的实现。 ``` // demo/sidecar/sidecar_factory_func.go // 关键点1: 定义Sidecar工厂方法类型 type FactoryFunc func() network.Socket // 关键点2: 按需定义具体的工厂方法实现,注意这里定义的是工厂方法的工厂方法,返回的是FactoryFunc工厂方法类型 func RawSocketFactoryFunc() FactoryFunc { return func() network.Socket { return network.DefaultSocket() } } func AllInOneFactoryFunc(producer mq.Producible) FactoryFunc { return func() network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), producer) } } type ServiceMediator struct { ... server *http.Server // 关键点3: 客户端依赖FactoryFunc工厂方法类型 sidecarFactoryFunc FactoryFunc } func (s *ServiceMediator) Forward(req *http.Request) *http.Response { ... dest, err := s.discovery(svcType) // 关键点4: 创建HTTP客户端,调用sidecarFactoryFunc()生成Socket作为入参 client, err := http.NewClient(s.sidecarFactoryFunc(), s.localIp) resp, err := client.Send(dest, forwardReq) ... } // 关键点5: 在ServiceMediator初始化时,将具体类型的FactoryFunc注入到ServiceMediator中 mediator := &ServiceMediator{ sidecarFactoryFunc: RawSocketFactoryFunc() // sidecarFactory: AllInOneFactoryFunc(producer) } ``` 上述的实现,利用了 Go 语言中**函数作为一等公民**的特点,少定义了几个 interface 和 struct,代码更加的简洁。 几个实现的关键点与面向对象风格的实现类似。值得注意的是 关键点2 ,我们相当于定义了一个**工厂方法的工厂方法**,这么做是为了利用函数闭包的特点来**传递参数**。如果直接定义工厂方法,那么 AllInOneFactoryFunc 的实现是下面这样的,无法实现多态: ``` // 并非FactoryFunc类型,无法实现多态 func AllInOneFactoryFunc(producer mq.Producible) network.Socket { return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), producer) } ``` ## 简单工厂 工厂方法模式的另一个变种是**简单工厂**,它并不通过多态,而是通过简单的 switch-case/if-else 条件判断来决定创建哪种产品: ``` // demo/sidecar/sidecar_simple_factory.go // 关键点1: 定义sidecar类型 type Type uint8 // 关键点2: 按照需要定义sidecar具体类型 const ( Raw Type = iota AllInOne ) // 关键点3: 定义简单工厂对象 type SimpleFactory struct { producer mq.Producible } // 关键点4: 定义工厂方法,入参为sidecar类型,根据switch-case或者if-else来创建产品 func (s SimpleFactory) Create(sidecarType Type) network.Socket { switch sidecarType { case Raw: return network.DefaultSocket() case AllInOne: return NewAccessLogSidecar(NewFlowCtrlSidecar(network.DefaultSocket()), s.producer) default: return nil } } // 关键点5: 创建产品时传入具体的sidecar类型,比如sidecar.AllInOne simpleFactory := &sidecar.SimpleFactory{producer: producer} sidecar := simpleFactory.Create(sidecar.AllInOne) ``` ## 静态工厂方法 静态工厂方法是 Java/C++ 的说法,主要用于替代构造函数来完成对象的实例化,能够让代码的可读性更好,而且起到了与客户端解耦的作用。比如 Java 的静态工厂方法实现如下: ``` public class Packet { private final Endpoint src; private final Endpoint dest; private final Object payload; private Packet(Endpoint src, Endpoint dest, Object payload) { this.src = src; this.dest = dest; this.payload = payload; } // 静态工厂方法 public static Packet of(Endpoint src, Endpoint dest, Object payload) { return new Packet(src, dest, payload); } ... } // 用法 packet = Packet.of(src, dest, payload) ``` Go 中并没有**静态**一说,直接通过普通函数来完成对象的构造即可,比如: ``` // demo/network/packet.go type Packet struct { src Endpoint dest Endpoint payload interface{} } // 工厂方法 func NewPacket(src, dest Endpoint, payload interface{}) *Packet { return &Packet{ src: src, dest: dest, payload: payload, } } // 用法 packet := NewPacket(src, dest, payload) ``` # 典型应用场景 1. **对象实例化逻辑较为复杂**时,可选择使用工厂方法模式/简单工厂/静态工厂方法来进行封装,为客户端提供一个易用的接口。 2. 如果**实例化的对象/接口涉及多种实现**,可以使用工厂方法模式实现多态。 3. **普通对象的创建,推荐使用静态工厂方法**,比直接的实例化(比如 &Packet{src: src, dest: dest, payload: payload})具备更好的可读性和低耦合。 # 优缺点 ## 优点 1. 代码的可读性更好。 2. 与客户端程序解耦,当实例化逻辑变更时,只需改动工厂方法即可,避免了霰弹式修改。 ## 缺点 1. 引入工厂方法模式会新增一些对象/接口的定义,滥用会导致代码更加复杂。 # 与其他模式的关联 很多同学容易将工厂方法模式和**抽象工厂模式**混淆,抽象工厂模式主要运用在实例化“产品族”的场景,可以看成是工厂方法模式的一种演进。 # 参考 [1] [【Go实现】实践GoF的23种设计模式:SOLID原则](https://mp.weixin.qq.com/s/s3aD4mK2Aw4v99tbCIe9HA), 元闰子 [2] Design Patterns, Chapter 3. Creational Patterns, GoF [3] Factory patterns in Go (Golang), Soham Kamani [4] 工厂方法, 维基百科 简单的分布式应用系统(示例代码工程):https://github.com/ruanrunxue/Practice-Design-Pattern–Go-Implementation
-
 创建云函数首先创建一个云函数,这里选择事件函数python3.6版本。函数创建成功后如下图所示:默认的代码:功能解释:将从函数入口传递的event变量值转为字符串并返回构造的字典 # -*- coding:utf-8 -*- import json def handler (event, context): return { "statusCode": 200, # 函数返回状态值 "isBase64Encoded": False, # 内容是否为base64编码 "body": json.dumps(event), # 函数返回主体,这里为解码后的event "headers": { # 请求的返回头字段 "Content-Type": "application/json" # 内容类型为 json类型 } }创建APIG触发器点击创建啊触发器,并选择安全认证方式为“None”,再点击确定。创建成功后即可看到调用的URL。使用工具对URL进行请求,即可得到触发函数的返回结果。
创建云函数首先创建一个云函数,这里选择事件函数python3.6版本。函数创建成功后如下图所示:默认的代码:功能解释:将从函数入口传递的event变量值转为字符串并返回构造的字典 # -*- coding:utf-8 -*- import json def handler (event, context): return { "statusCode": 200, # 函数返回状态值 "isBase64Encoded": False, # 内容是否为base64编码 "body": json.dumps(event), # 函数返回主体,这里为解码后的event "headers": { # 请求的返回头字段 "Content-Type": "application/json" # 内容类型为 json类型 } }创建APIG触发器点击创建啊触发器,并选择安全认证方式为“None”,再点击确定。创建成功后即可看到调用的URL。使用工具对URL进行请求,即可得到触发函数的返回结果。 -
这篇文章主要给大家介绍了关于nginx中一个请求的count计数跟踪的相关资料,文中通过实例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下首先说明一下应用方式,有两个nginx的模块,一个名为jtxy,另一个名为jtcmd。一个http请求来了,会进入jtxy的模块处理,jtxy会创建出一个子请求发送给jtcmd,jtcmd里处理呢又会创建出一个upstream流到我们的上游非http服务A来处理,A处理完成后得到结果,会把结果返回给jtcmd的子请求,jtcmd的子请求把结果返回给jtxy。就是这样一个流程,我们来跟踪一下一个请的count计数。1、请求到来,创建一个请求,ngx_http_alloc_request里count被初始化为1此时,count为1。12r->main = r;r->count = 1;2、jtxy模块里处理请求时,调用了ngx_http_subrequest来创建一个子请求,在ngx_http_subrequest里计数被加1。此时,count为21r->main->count++;3、从一个模块出去(这里就是jtxy模块),会调用ngx_http_finalize_request,在ngx_http_finalize_request里会计数减一。此时,count为1。12345if (r->content_handler) { r->write_event_handler = ngx_http_request_empty_handler; ngx_http_finalize_request(r, r->content_handler(r)); return NGX_OK;}4、然后进入了我们的子请求jtcmd模块,,在这个模块里,如果发现自己是个子请求((r!=r->main)),那么就应该把主请求计数加一。这里标红强调这点是因为如果不加1,那么主请求计数就会有问题,一会儿我们继续跟踪count的减1就会发现这个问题。这里是jtxy发起的一个jtcmd子请求这里的r和r->main并不相同的,r是jtcmd,r->main就是jtxy。此时,count为2。同时因为我们子请求jtcmd模块里使用了upstream,那么count是还需要在加1,但是我们使用时是ngx_http_read_client_request_body(r, ngx_http_upstream_init),ngx_http_read_client_request_body里就已经加1了,所以,我们这里就不必自己来做这个加1了。此时count为3。大家可以看看《深入理解nginx》的5.1.5节的内容。对upstream流需要加1有讲解。所以呢,这里的count是加了2次的。123456789101112131415161718192021222324r->upstream->resolved->sockaddr = (struct sockaddr*)&backendSockAddr;r->upstream->resolved->socklen = sizeof(struct sockaddr_in);r->upstream->resolved->naddrs = 1; r->upstream->create_request = jtcmd_upstream_create_request;r->upstream->process_header = jtcmd_upstream_process_header;r->upstream->finalize_request = jtcmd_upstream_finalize_request;r->upstream->abort_request = jtcmd_upstream_abort_request; r->upstream->input_filter_init = ngx_http_jtcmd_filter_init;r->upstream->input_filter = ngx_http_jtcmd_filter;r->upstream->input_filter_ctx = jtcmdctx; //r->subrequest_in_memory = 1; if(r!=r->main) { r->main->count++;} ngx_int_t rc = ngx_http_read_client_request_body(r, ngx_http_upstream_init);if (rc == NGX_ERROR || rc > NGX_OK) { return rc;}这里的r是子请求,r->main是主请求。同时还注意到,子请求的count始终是0。12345678910111213ngx_int_tngx_http_read_client_request_body(ngx_http_request_t *r, ngx_http_client_body_handler_pt post_handler){ size_t preread; ssize_t size; ngx_int_t rc; ngx_buf_t *b; ngx_chain_t out; ngx_http_request_body_t *rb; ngx_http_core_loc_conf_t *clcf; r->main->count++;5、同第3一样,请求的处理完后会调用ngx_http_finalize_request把计数减一,但是这里不同的是我们这里是一个子请求,他这里有一步r = r->main;所以实际减时就减到了主请求上去了,这个也是我们在4里红字说明的要加1的原因了。此时,count为212345678910111213141516static voidngx_http_close_request(ngx_http_request_t *r, ngx_int_t rc){ ngx_connection_t *c; r = r->main; c = r->connection; ngx_log_debug2(NGX_LOG_DEBUG_HTTP, c->log, 0, "http request count:%d blk:%d", r->count, r->blocked); if (r->count == 0) { ngx_log_error(NGX_LOG_ALERT, c->log, 0, "http request count is zero"); } r->count--;6、然后呢,因为子请求使用了upstream,因为这个原因count加了一次1,那么当upstream结束,就要减一次1。此时count为1。 7、子请求完成后,父请求的回调方法接着处理,接下来就回到了主请求模块jtxy里,这里在处理结束后就会调用ngx_http_finalize_request来结束掉这个请求了,此时count为1,请求就会被释放掉了。123456789101112131415161718voidngx_http_free_request(ngx_http_request_t *r, ngx_int_t rc){ ngx_log_t *log; ngx_pool_t *pool; struct linger linger; ngx_http_cleanup_t *cln; ngx_http_log_ctx_t *ctx; ngx_http_core_loc_conf_t *clcf; log = r->connection->log; ngx_log_debug0(NGX_LOG_DEBUG_HTTP, log, 0, "http close request"); if (r->pool == NULL) { ngx_log_error(NGX_LOG_ALERT, log, 0, "http request already closed"); return; }总结到此这篇关于nginx中一个请求的count计数跟踪的文章就介绍到这了转载自https://www.jb51.net/article/233607.htm
-
 序言Nginx是lgor Sysoev为俄罗斯访问量第二的rambler.ru站点设计开发的。从2004年发布至今,凭借开源的力量,已经接近成熟与完善。Nginx功能丰富,可作为HTTP服务器,也可作为反向代理服务器,邮件服务器。支持FastCGI、SSL、Virtual Host、URL Rewrite、Gzip等功能。并且支持很多第三方的模块扩展。Nginx的稳定性、功能集、示例配置文件和低系统资源的消耗让他后来居上,在全球活跃的网站中有12.18%的使用比率,大约为2220万个网站。牛逼吹的差不多啦,如果你还不过瘾,你可以百度百科或者一些书上找到这样的夸耀,比比皆是。Nginx常用功能1、Http代理,反向代理:作为web服务器最常用的功能之一,尤其是反向代理。这里我给来2张图,对正向代理与反向代理做个诠释,具体细节,大家可以翻阅下资料。Nginx在做反向代理时,提供性能稳定,并且能够提供配置灵活的转发功能。Nginx可以根据不同的正则匹配,采取不同的转发策略,比如图片文件结尾的走文件服务器,动态页面走web服务器,只要你正则写的没问题,又有相对应的服务器解决方案,你就可以随心所欲的玩。并且Nginx对返回结果进行错误页跳转,异常判断等。如果被分发的服务器存在异常,他可以将请求重新转发给另外一台服务器,然后自动去除异常服务器。2、负载均衡Nginx提供的负载均衡策略有2种:内置策略和扩展策略。内置策略为轮询,加权轮询,Ip hash。扩展策略,就天马行空,只有你想不到的没有他做不到的啦,你可以参照所有的负载均衡算法,给他一一找出来做下实现。上3个图,理解这三种负载均衡算法的实现Ip hash算法,对客户端请求的ip进行hash操作,然后根据hash结果将同一个客户端ip的请求分发给同一台服务器进行处理,可以解决session不共享的问题。3、web缓存Nginx可以对不同的文件做不同的缓存处理,配置灵活,并且支持FastCGI_Cache,主要用于对FastCGI的动态程序进行缓存。配合着第三方的ngx_cache_purge,对制定的URL缓存内容可以的进行增删管理。4、Nginx相关地址源码:https://trac.nginx.org/nginx/browser官网:http://www.nginx.org/Nginx配置文件结构如果你下载好啦,你的安装文件,不妨打开conf文件夹的nginx.conf文件,Nginx服务器的基础配置,默认的配置也存放在此。在 nginx.conf 的注释符号为: #默认的 nginx 配置文件 nginx.conf 内容如下:#user nobody;worker_processes 1; #error_log logs/error.log;#error_log logs/error.log notice;#error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024;} http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #gzip on; server { listen 80; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ \.php$ { # proxy_pass http://127.0.0.1; #} # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # #location ~ \.php$ { # root html; # fastcgi_pass 127.0.0.1:9000; # fastcgi_index index.php; # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; # include fastcgi_params; #} # deny access to .htaccess files, if Apache's document root # concurs with nginx's one # #location ~ /\.ht { # deny all; #} } # another virtual host using mix of IP-, name-, and port-based configuration # #server { # listen 8000; # listen somename:8080; # server_name somename alias another.alias; # location / { # root html; # index index.html index.htm; # } #} # HTTPS server # #server { # listen 443 ssl; # server_name localhost; # ssl_certificate cert.pem; # ssl_certificate_key cert.key; # ssl_session_cache shared:SSL:1m; # ssl_session_timeout 5m; # ssl_ciphers HIGH:!aNULL:!MD5; # ssl_prefer_server_ciphers on; # location / { # root html; # index index.html index.htm; # } #} }nginx 文件结构... #全局块 events { #events块 ...} http #http块{ ... #http全局块 server #server块 { ... #server全局块 location [PATTERN] #location块 { ... } location [PATTERN] { ... } } server { ... } ... #http全局块}1、全局块:配置影响nginx全局的指令。一般有运行nginx服务器的用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process数等。2、events块:配置影响nginx服务器或与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。3、http块:可以嵌套多个server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。如文件引入,mime-type定义,日志自定义,是否使用sendfile传输文件,连接超时时间,单连接请求数等。4、server块:配置虚拟主机的相关参数,一个http中可以有多个server。5、location块:配置请求的路由,以及各种页面的处理情况。下面给大家上一个配置文件,作为理解。########### 每个指令必须有分号结束。##################user administrator administrators; #配置用户或者组,默认为nobody nobody。#worker_processes 2; #允许生成的进程数,默认为1#pid /nginx/pid/nginx.pid; #指定nginx进程运行文件存放地址error_log log/error.log debug; #制定日志路径,级别。这个设置可以放入全局块,http块,server块,级别以此为:debug|info|notice|warn|error|crit|alert|emergevents { accept_mutex on; #设置网路连接序列化,防止惊群现象发生,默认为on multi_accept on; #设置一个进程是否同时接受多个网络连接,默认为off #use epoll; #事件驱动模型,select|poll|kqueue|epoll|resig|/dev/poll|eventport worker_connections 1024; #最大连接数,默认为512}http { include mime.types; #文件扩展名与文件类型映射表 default_type application/octet-stream; #默认文件类型,默认为text/plain #access_log off; #取消服务日志 log_format myFormat '$remote_addr–$remote_user [$time_local] $request $status $body_bytes_sent $http_referer $http_user_agent $http_x_forwarded_for'; #自定义格式 access_log log/access.log myFormat; #combined为日志格式的默认值 sendfile on; #允许sendfile方式传输文件,默认为off,可以在http块,server块,location块。 sendfile_max_chunk 100k; #每个进程每次调用传输数量不能大于设定的值,默认为0,即不设上限。 keepalive_timeout 65; #连接超时时间,默认为75s,可以在http,server,location块。 upstream mysvr { server 127.0.0.1:7878; server 192.168.10.121:3333 backup; #热备 } error_page 404 https://www.baidu.com; #错误页 server { keepalive_requests 120; #单连接请求上限次数。 listen 4545; #监听端口 server_name 127.0.0.1; #监听地址 location ~*^.+$ { #请求的url过滤,正则匹配,~为区分大小写,~*为不区分大小写。 #root path; #根目录 #index vv.txt; #设置默认页 proxy_pass http://mysvr; #请求转向mysvr 定义的服务器列表 deny 127.0.0.1; #拒绝的ip allow 172.18.5.54; #允许的ip } }}上面是nginx的基本配置,需要注意的有以下几点:1、几个常见配置项:1.$remote_addr 与 $http_x_forwarded_for 用以记录客户端的ip地址;2.$remote_user :用来记录客户端用户名称;3.$time_local : 用来记录访问时间与时区;4.$request : 用来记录请求的url与http协议;5.$status : 用来记录请求状态;成功是200;6.$body_bytes_s ent :记录发送给客户端文件主体内容大小;7.$http_referer :用来记录从那个页面链接访问过来的;8.$http_user_agent :记录客户端浏览器的相关信息;2、惊群现象:一个网路连接到来,多个睡眠的进程被同时叫醒,但只有一个进程能获得链接,这样会影响系统性能。3、每个指令必须有分号结束。原文地址:https://www.cnblogs.com/knowledgesea/p/5175711.html
序言Nginx是lgor Sysoev为俄罗斯访问量第二的rambler.ru站点设计开发的。从2004年发布至今,凭借开源的力量,已经接近成熟与完善。Nginx功能丰富,可作为HTTP服务器,也可作为反向代理服务器,邮件服务器。支持FastCGI、SSL、Virtual Host、URL Rewrite、Gzip等功能。并且支持很多第三方的模块扩展。Nginx的稳定性、功能集、示例配置文件和低系统资源的消耗让他后来居上,在全球活跃的网站中有12.18%的使用比率,大约为2220万个网站。牛逼吹的差不多啦,如果你还不过瘾,你可以百度百科或者一些书上找到这样的夸耀,比比皆是。Nginx常用功能1、Http代理,反向代理:作为web服务器最常用的功能之一,尤其是反向代理。这里我给来2张图,对正向代理与反向代理做个诠释,具体细节,大家可以翻阅下资料。Nginx在做反向代理时,提供性能稳定,并且能够提供配置灵活的转发功能。Nginx可以根据不同的正则匹配,采取不同的转发策略,比如图片文件结尾的走文件服务器,动态页面走web服务器,只要你正则写的没问题,又有相对应的服务器解决方案,你就可以随心所欲的玩。并且Nginx对返回结果进行错误页跳转,异常判断等。如果被分发的服务器存在异常,他可以将请求重新转发给另外一台服务器,然后自动去除异常服务器。2、负载均衡Nginx提供的负载均衡策略有2种:内置策略和扩展策略。内置策略为轮询,加权轮询,Ip hash。扩展策略,就天马行空,只有你想不到的没有他做不到的啦,你可以参照所有的负载均衡算法,给他一一找出来做下实现。上3个图,理解这三种负载均衡算法的实现Ip hash算法,对客户端请求的ip进行hash操作,然后根据hash结果将同一个客户端ip的请求分发给同一台服务器进行处理,可以解决session不共享的问题。3、web缓存Nginx可以对不同的文件做不同的缓存处理,配置灵活,并且支持FastCGI_Cache,主要用于对FastCGI的动态程序进行缓存。配合着第三方的ngx_cache_purge,对制定的URL缓存内容可以的进行增删管理。4、Nginx相关地址源码:https://trac.nginx.org/nginx/browser官网:http://www.nginx.org/Nginx配置文件结构如果你下载好啦,你的安装文件,不妨打开conf文件夹的nginx.conf文件,Nginx服务器的基础配置,默认的配置也存放在此。在 nginx.conf 的注释符号为: #默认的 nginx 配置文件 nginx.conf 内容如下:#user nobody;worker_processes 1; #error_log logs/error.log;#error_log logs/error.log notice;#error_log logs/error.log info; #pid logs/nginx.pid; events { worker_connections 1024;} http { include mime.types; default_type application/octet-stream; #log_format main '$remote_addr - $remote_user [$time_local] "$request" ' # '$status $body_bytes_sent "$http_referer" ' # '"$http_user_agent" "$http_x_forwarded_for"'; #access_log logs/access.log main; sendfile on; #tcp_nopush on; #keepalive_timeout 0; keepalive_timeout 65; #gzip on; server { listen 80; server_name localhost; #charset koi8-r; #access_log logs/host.access.log main; location / { root html; index index.html index.htm; } #error_page 404 /404.html; # redirect server error pages to the static page /50x.html # error_page 500 502 503 504 /50x.html; location = /50x.html { root html; } # proxy the PHP scripts to Apache listening on 127.0.0.1:80 # #location ~ \.php$ { # proxy_pass http://127.0.0.1; #} # pass the PHP scripts to FastCGI server listening on 127.0.0.1:9000 # #location ~ \.php$ { # root html; # fastcgi_pass 127.0.0.1:9000; # fastcgi_index index.php; # fastcgi_param SCRIPT_FILENAME /scripts$fastcgi_script_name; # include fastcgi_params; #} # deny access to .htaccess files, if Apache's document root # concurs with nginx's one # #location ~ /\.ht { # deny all; #} } # another virtual host using mix of IP-, name-, and port-based configuration # #server { # listen 8000; # listen somename:8080; # server_name somename alias another.alias; # location / { # root html; # index index.html index.htm; # } #} # HTTPS server # #server { # listen 443 ssl; # server_name localhost; # ssl_certificate cert.pem; # ssl_certificate_key cert.key; # ssl_session_cache shared:SSL:1m; # ssl_session_timeout 5m; # ssl_ciphers HIGH:!aNULL:!MD5; # ssl_prefer_server_ciphers on; # location / { # root html; # index index.html index.htm; # } #} }nginx 文件结构... #全局块 events { #events块 ...} http #http块{ ... #http全局块 server #server块 { ... #server全局块 location [PATTERN] #location块 { ... } location [PATTERN] { ... } } server { ... } ... #http全局块}1、全局块:配置影响nginx全局的指令。一般有运行nginx服务器的用户组,nginx进程pid存放路径,日志存放路径,配置文件引入,允许生成worker process数等。2、events块:配置影响nginx服务器或与用户的网络连接。有每个进程的最大连接数,选取哪种事件驱动模型处理连接请求,是否允许同时接受多个网路连接,开启多个网络连接序列化等。3、http块:可以嵌套多个server,配置代理,缓存,日志定义等绝大多数功能和第三方模块的配置。如文件引入,mime-type定义,日志自定义,是否使用sendfile传输文件,连接超时时间,单连接请求数等。4、server块:配置虚拟主机的相关参数,一个http中可以有多个server。5、location块:配置请求的路由,以及各种页面的处理情况。下面给大家上一个配置文件,作为理解。########### 每个指令必须有分号结束。##################user administrator administrators; #配置用户或者组,默认为nobody nobody。#worker_processes 2; #允许生成的进程数,默认为1#pid /nginx/pid/nginx.pid; #指定nginx进程运行文件存放地址error_log log/error.log debug; #制定日志路径,级别。这个设置可以放入全局块,http块,server块,级别以此为:debug|info|notice|warn|error|crit|alert|emergevents { accept_mutex on; #设置网路连接序列化,防止惊群现象发生,默认为on multi_accept on; #设置一个进程是否同时接受多个网络连接,默认为off #use epoll; #事件驱动模型,select|poll|kqueue|epoll|resig|/dev/poll|eventport worker_connections 1024; #最大连接数,默认为512}http { include mime.types; #文件扩展名与文件类型映射表 default_type application/octet-stream; #默认文件类型,默认为text/plain #access_log off; #取消服务日志 log_format myFormat '$remote_addr–$remote_user [$time_local] $request $status $body_bytes_sent $http_referer $http_user_agent $http_x_forwarded_for'; #自定义格式 access_log log/access.log myFormat; #combined为日志格式的默认值 sendfile on; #允许sendfile方式传输文件,默认为off,可以在http块,server块,location块。 sendfile_max_chunk 100k; #每个进程每次调用传输数量不能大于设定的值,默认为0,即不设上限。 keepalive_timeout 65; #连接超时时间,默认为75s,可以在http,server,location块。 upstream mysvr { server 127.0.0.1:7878; server 192.168.10.121:3333 backup; #热备 } error_page 404 https://www.baidu.com; #错误页 server { keepalive_requests 120; #单连接请求上限次数。 listen 4545; #监听端口 server_name 127.0.0.1; #监听地址 location ~*^.+$ { #请求的url过滤,正则匹配,~为区分大小写,~*为不区分大小写。 #root path; #根目录 #index vv.txt; #设置默认页 proxy_pass http://mysvr; #请求转向mysvr 定义的服务器列表 deny 127.0.0.1; #拒绝的ip allow 172.18.5.54; #允许的ip } }}上面是nginx的基本配置,需要注意的有以下几点:1、几个常见配置项:1.$remote_addr 与 $http_x_forwarded_for 用以记录客户端的ip地址;2.$remote_user :用来记录客户端用户名称;3.$time_local : 用来记录访问时间与时区;4.$request : 用来记录请求的url与http协议;5.$status : 用来记录请求状态;成功是200;6.$body_bytes_s ent :记录发送给客户端文件主体内容大小;7.$http_referer :用来记录从那个页面链接访问过来的;8.$http_user_agent :记录客户端浏览器的相关信息;2、惊群现象:一个网路连接到来,多个睡眠的进程被同时叫醒,但只有一个进程能获得链接,这样会影响系统性能。3、每个指令必须有分号结束。原文地址:https://www.cnblogs.com/knowledgesea/p/5175711.html -
 ## ngx_http_log_module 模块 ngx_http_log_module模块按指定的格式记录访问日志。请求在处理结束时,会按请求路径的配置上下文记访问日志,通过访问日志,你可以得到用户地域来源、跳转来源、使用终端、某个URL访问量等相关信息。你也可以记录错误日志,通过错误日志,你可以得到系统某个服务或server的性能瓶颈等。 ### 配置 access_log 来记录访问日志 访问日志主要记录客户端的请求。客户端向Nginx服务器发起的每一次请求都记录在这里。客户端IP,浏览器信息,referer,请求处理时间,请求URL等都可以在访问日志中得到。当然具体要记录哪些信息,你可以通过log_format指令来定义。 **语法:** ```shell access_log path [``format` `[buffer=size] [``gzip``[=level]] [flush=``time``] [``if``=condition]]; ``# 设置访问日志``access_log off; ``# 关闭访问日志 ``` - path 指定日志的存放位置。 - format 指定日志的格式。默认使用预定义的combined。 - buffer 用来指定日志写入时的缓存大小。默认是64k。 - gzip 日志写入前先进行压缩。压缩率可以指定,从1到9数值越大压缩比越高,同时压缩的速度也越慢。默认是1。 - flush 设置缓存的有效时间。如果超过flush指定的时间,缓存中的内容将被清空。 - if 条件判断。如果指定的条件计算为0或空字符串,那么该请求不会写入日志。 还有一个特殊的值off。如果指定了该值,当前作用域下的所有的请求日志都被关闭。 ### 配置作用域 可以配置 access_log 指令的作用域分别有http,server,location,limit_except。也就是说,在这几个作用域外使用该指令,Nginx会报错。 以上是 access_log 指令的基本语法和参数的含义。下面我们看一几个例子加深一下理解。 ### 基本用法 ```shell access_log ``/home/wwwlogs/nginx-access``.log ``` 该例子指定日志的写入路径为/home/wwwlogs/nginx-access.log,日志格式使用默认的combined。 ```shell access_log ``/home/wwwlogs/nginx-access``.log buffer=32k ``gzip` `flush=1m ``` 该例子指定日志的写入路径为/home/wwwlogs/nginx-access.log,日志格式使用默认的combined,指定日志的缓存大小为32k,日志写入前启用gzip进行压缩,压缩比使用默认值1,缓存数据有效时间为1分钟。 ### 使用 log_format 自定义日志格式 Nginx预定义了名为combined日志格式,如果没有明确指定日志格式默认使用该格式: ```shell log_format combined ``'$remote_addr - $remote_user [$time_local] '`` ``'"$request" $status $body_bytes_sent '`` ``'"$http_referer" "$http_user_agent"'``; ``` 如果不想使用Nginx预定义的格式,可以通过log_format指令来自定义。 ### 语法 ```shell log_format name [escape=default|json] string ...; ``` - name 格式的名称。在 access_log 指令中引用。 - escape 设置变量中的字符编码方式是json还是default,默认是default。 - string 要定义的日志格式内容。该参数可以有多个。参数中可以使用Nginx变量。 下面是 log_format 指令中常用的一些变量: $remote_addr 客户端的IP地址(代理服务器,显示代理服务器的ip) $remote_user 记录远程客户端的用户名称,针对启用了用户认证的请求,通常情况下为“-” $time_local 记录访问时间和时区,如"24/May/2017:18:31:27 +0800" $request 记录请求的url以及请求方法 $status 响应状态码 例如:200成功、404页面找不到等...... $bytes_sent 发送给客户端的总字节数 $body_bytes_sent 给客户端发送的主体内容字节数,不包括响应头的大小 $http_user_agent 客户端浏览器信息 $http_x_forwarded_for 可以记录客户端IP,通过代理服务器来记录客户端的IP地址。当前端有代理服务器时,设置web节点记录客户端地址的配置,此参数生效的前提是代理服务器也要进行相关的x_forwarded_for设置。 $http_referer 记录用户是从哪个链接访问过来的 $time_iso8601 标准格式的本地时间,形如“2017-05-24T18:31:27+08:00” $msec 日志写入时间,单位为秒,精度是毫秒 $request_length 请求长度(包括请求行,请求头和请求体) $request_time 请求处理时长,单位为秒,精度为毫秒,从读入客户端的第一个字节开始,直到把最后一个字符发送给客户端进行日志写入为止 **下面演示一下自定义日志格式的使用:** ```shell access_log ``/home/wwwlogs/nginx-access``.log main``log_format main ``'$remote_addr - $remote_user [$time_local] "$request" '`` ``'$status $body_bytes_sent "$http_referer" '`` ``'"$http_user_agent" "$http_x_forwarded_for"'``; ``` 使用 log_format 指令定义了一个main的格式,并在access_log指令中引用了它。假如客户端有发起请求: nginx.css3er.com,注意,如果你要测试的话,请把nginx.css3er.com换成对应你自己的域名进行访问。看一下我截取的一个请求的日志记录: ```shell 111.231.138.248 - - [20``/Feb/2018``:12:12:14 +0800] ``"GET / HTTP/1.1"` `200 190 ``"-"` `"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36"` `"-" ``` 我们看到最终的日志记录中$remote_user、$http_referer、$http_x_forwarded_for都对应了一个-,这是因为这几个变量为空。 ### 配置 error_log 来记录错误日志 错误日志在Nginx中是通过 error_log 指令实现的。该指令记录服务器和请求处理过程中的错误信息。 ### 语法 配置错误日志文件的路径和日志级别。 ```shell error_log ``file` `[level];``Default: ``error_log logs``/error``.log error; ``` 第一个参数指定日志的写入路径。 第二个参数指定日志的级别。level可以是debug, info, notice, warn, error, crit, alert,emerg 中的任意值。可以看到其取值范围是按紧急程度从低到高排列的。只有日志的错误级别等于或高于level指定的值才会写入错误日志中。默认值是error。 ### 基本用法 ```shell error_log ``/home/wwwlogs/nginx-error``.log crit; ``` 它可以配置在:main, http, mail, stream, server, location 作用域。 例子中指定了错误日志的路径为:/home/wwwlogs/nginx-error.log,日志级别使用的是crit。 ### open_log_file_cache 每一条日志记录的写入都是先打开文件再写入记录,然后关闭日志文件。如果你的日志文件路径中使用了变量,如 access_log /home/wwwlogs/$host/nginx-access.log,为了提高性能,可以使用 open_log_file_cache 指令设置日志文件描述符的缓存。当然了,即使你在路径中使用了变量,你也可以选择不用配置 open_log_file_cache。 ### 语法 ``` open_log_file_cache max=N [inactive=``time``] [min_uses=N] [valid=``time``]; ``` max 设置缓存中最多容纳的文件描述符数量,如果被占满,采用LRU算法将描述符关闭。 inactive 设置缓存存活时间,默认是10s。 min_uses 在inactive时间段内,日志文件最少使用几次,该日志文件描述符记入缓存,默认是1次。 valid:设置多久对日志文件名进行检查,看是否发生变化,默认是60s。 off:不使用缓存。默认为off。 ### 基本用法 ```shell open_log_file_cache max=1000 inactive=20s valid=1m min_uses=2; ``` 它可以配置在http、server、location作用域中。 在上面的例子中,设置缓存最多缓存1000个日志文件描述符,20s内如果缓存中的日志文件描述符至少被被访问2次,才不会被缓存关闭。每隔1分钟检查缓存中的文件描述符的文件名是否还存在。 ### 尾声 在Nginx中我们可以通过 access_log 和 error_log 指令配置访问日志和错误日志,通过 log_format 我们可以自定义日志格式。如果日志文件路径中使用了变量,我们可以通过open_log_file_cache指令来设置缓存,提升性能。 另外,在 access_log 和 log_format 中使用了很多变量,这些变量并没有一 一列举出来,详细的变量信息可以参考:[nginx官方文档](http://nginx.org/en/docs/varindex.html)
## ngx_http_log_module 模块 ngx_http_log_module模块按指定的格式记录访问日志。请求在处理结束时,会按请求路径的配置上下文记访问日志,通过访问日志,你可以得到用户地域来源、跳转来源、使用终端、某个URL访问量等相关信息。你也可以记录错误日志,通过错误日志,你可以得到系统某个服务或server的性能瓶颈等。 ### 配置 access_log 来记录访问日志 访问日志主要记录客户端的请求。客户端向Nginx服务器发起的每一次请求都记录在这里。客户端IP,浏览器信息,referer,请求处理时间,请求URL等都可以在访问日志中得到。当然具体要记录哪些信息,你可以通过log_format指令来定义。 **语法:** ```shell access_log path [``format` `[buffer=size] [``gzip``[=level]] [flush=``time``] [``if``=condition]]; ``# 设置访问日志``access_log off; ``# 关闭访问日志 ``` - path 指定日志的存放位置。 - format 指定日志的格式。默认使用预定义的combined。 - buffer 用来指定日志写入时的缓存大小。默认是64k。 - gzip 日志写入前先进行压缩。压缩率可以指定,从1到9数值越大压缩比越高,同时压缩的速度也越慢。默认是1。 - flush 设置缓存的有效时间。如果超过flush指定的时间,缓存中的内容将被清空。 - if 条件判断。如果指定的条件计算为0或空字符串,那么该请求不会写入日志。 还有一个特殊的值off。如果指定了该值,当前作用域下的所有的请求日志都被关闭。 ### 配置作用域 可以配置 access_log 指令的作用域分别有http,server,location,limit_except。也就是说,在这几个作用域外使用该指令,Nginx会报错。 以上是 access_log 指令的基本语法和参数的含义。下面我们看一几个例子加深一下理解。 ### 基本用法 ```shell access_log ``/home/wwwlogs/nginx-access``.log ``` 该例子指定日志的写入路径为/home/wwwlogs/nginx-access.log,日志格式使用默认的combined。 ```shell access_log ``/home/wwwlogs/nginx-access``.log buffer=32k ``gzip` `flush=1m ``` 该例子指定日志的写入路径为/home/wwwlogs/nginx-access.log,日志格式使用默认的combined,指定日志的缓存大小为32k,日志写入前启用gzip进行压缩,压缩比使用默认值1,缓存数据有效时间为1分钟。 ### 使用 log_format 自定义日志格式 Nginx预定义了名为combined日志格式,如果没有明确指定日志格式默认使用该格式: ```shell log_format combined ``'$remote_addr - $remote_user [$time_local] '`` ``'"$request" $status $body_bytes_sent '`` ``'"$http_referer" "$http_user_agent"'``; ``` 如果不想使用Nginx预定义的格式,可以通过log_format指令来自定义。 ### 语法 ```shell log_format name [escape=default|json] string ...; ``` - name 格式的名称。在 access_log 指令中引用。 - escape 设置变量中的字符编码方式是json还是default,默认是default。 - string 要定义的日志格式内容。该参数可以有多个。参数中可以使用Nginx变量。 下面是 log_format 指令中常用的一些变量: $remote_addr 客户端的IP地址(代理服务器,显示代理服务器的ip) $remote_user 记录远程客户端的用户名称,针对启用了用户认证的请求,通常情况下为“-” $time_local 记录访问时间和时区,如"24/May/2017:18:31:27 +0800" $request 记录请求的url以及请求方法 $status 响应状态码 例如:200成功、404页面找不到等...... $bytes_sent 发送给客户端的总字节数 $body_bytes_sent 给客户端发送的主体内容字节数,不包括响应头的大小 $http_user_agent 客户端浏览器信息 $http_x_forwarded_for 可以记录客户端IP,通过代理服务器来记录客户端的IP地址。当前端有代理服务器时,设置web节点记录客户端地址的配置,此参数生效的前提是代理服务器也要进行相关的x_forwarded_for设置。 $http_referer 记录用户是从哪个链接访问过来的 $time_iso8601 标准格式的本地时间,形如“2017-05-24T18:31:27+08:00” $msec 日志写入时间,单位为秒,精度是毫秒 $request_length 请求长度(包括请求行,请求头和请求体) $request_time 请求处理时长,单位为秒,精度为毫秒,从读入客户端的第一个字节开始,直到把最后一个字符发送给客户端进行日志写入为止 **下面演示一下自定义日志格式的使用:** ```shell access_log ``/home/wwwlogs/nginx-access``.log main``log_format main ``'$remote_addr - $remote_user [$time_local] "$request" '`` ``'$status $body_bytes_sent "$http_referer" '`` ``'"$http_user_agent" "$http_x_forwarded_for"'``; ``` 使用 log_format 指令定义了一个main的格式,并在access_log指令中引用了它。假如客户端有发起请求: nginx.css3er.com,注意,如果你要测试的话,请把nginx.css3er.com换成对应你自己的域名进行访问。看一下我截取的一个请求的日志记录: ```shell 111.231.138.248 - - [20``/Feb/2018``:12:12:14 +0800] ``"GET / HTTP/1.1"` `200 190 ``"-"` `"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36"` `"-" ``` 我们看到最终的日志记录中$remote_user、$http_referer、$http_x_forwarded_for都对应了一个-,这是因为这几个变量为空。 ### 配置 error_log 来记录错误日志 错误日志在Nginx中是通过 error_log 指令实现的。该指令记录服务器和请求处理过程中的错误信息。 ### 语法 配置错误日志文件的路径和日志级别。 ```shell error_log ``file` `[level];``Default: ``error_log logs``/error``.log error; ``` 第一个参数指定日志的写入路径。 第二个参数指定日志的级别。level可以是debug, info, notice, warn, error, crit, alert,emerg 中的任意值。可以看到其取值范围是按紧急程度从低到高排列的。只有日志的错误级别等于或高于level指定的值才会写入错误日志中。默认值是error。 ### 基本用法 ```shell error_log ``/home/wwwlogs/nginx-error``.log crit; ``` 它可以配置在:main, http, mail, stream, server, location 作用域。 例子中指定了错误日志的路径为:/home/wwwlogs/nginx-error.log,日志级别使用的是crit。 ### open_log_file_cache 每一条日志记录的写入都是先打开文件再写入记录,然后关闭日志文件。如果你的日志文件路径中使用了变量,如 access_log /home/wwwlogs/$host/nginx-access.log,为了提高性能,可以使用 open_log_file_cache 指令设置日志文件描述符的缓存。当然了,即使你在路径中使用了变量,你也可以选择不用配置 open_log_file_cache。 ### 语法 ``` open_log_file_cache max=N [inactive=``time``] [min_uses=N] [valid=``time``]; ``` max 设置缓存中最多容纳的文件描述符数量,如果被占满,采用LRU算法将描述符关闭。 inactive 设置缓存存活时间,默认是10s。 min_uses 在inactive时间段内,日志文件最少使用几次,该日志文件描述符记入缓存,默认是1次。 valid:设置多久对日志文件名进行检查,看是否发生变化,默认是60s。 off:不使用缓存。默认为off。 ### 基本用法 ```shell open_log_file_cache max=1000 inactive=20s valid=1m min_uses=2; ``` 它可以配置在http、server、location作用域中。 在上面的例子中,设置缓存最多缓存1000个日志文件描述符,20s内如果缓存中的日志文件描述符至少被被访问2次,才不会被缓存关闭。每隔1分钟检查缓存中的文件描述符的文件名是否还存在。 ### 尾声 在Nginx中我们可以通过 access_log 和 error_log 指令配置访问日志和错误日志,通过 log_format 我们可以自定义日志格式。如果日志文件路径中使用了变量,我们可以通过open_log_file_cache指令来设置缓存,提升性能。 另外,在 access_log 和 log_format 中使用了很多变量,这些变量并没有一 一列举出来,详细的变量信息可以参考:[nginx官方文档](http://nginx.org/en/docs/varindex.html) -
【功能模块】我们开发在开发yolo模型,现在要检测结果传回本地webserver,目前用的http正向代理post结果,但是默认协议都是https,怎么修改成http【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
推荐直播
-
 华为云云原生FinOps解决方案,为您释放云原生最大价值
华为云云原生FinOps解决方案,为您释放云原生最大价值2024/04/24 周三 16:30-18:00
Roc 华为云云原生DTSE技术布道师
还在对CCE集群成本评估感到束手无策?还在担心不合理的K8s集群资源申请和过度浪费?华为云容器服务CCE全新上线云原生FinOps中心,为用户提供多维度集群成本可视化,结合智能规格推荐、混部、超卖等成本优化手段,助力客户降本增效,释放云原生最大价值。
去报名 -
 鲲鹏开发者创享日·江苏站暨数字技术创新应用峰会
鲲鹏开发者创享日·江苏站暨数字技术创新应用峰会2024/04/25 周四 09:30-16:00
鲲鹏专家团
这是华为推出的旨在和众多技术大牛、行业大咖一同探讨最前沿的技术思考,分享最纯粹的技术经验,进行最真实的动手体验,为开发者提供一个深度探讨与交流的平台。
即将直播 -
 产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》
产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》2024/04/25 周四 16:00-18:00
于晓东 上海杉达学院信息科学与技术学院副院长;崔宝才 天津电子信息职业技术学院电子与通信技术系主任
本期直播将与您一起探讨高校人才培养创新模式经验。
去报名
热门标签