-

-
将后端代码打包成jar包时
-
了解鲲鹏BoostKit大数据机器学习算法,更多详情可参见鲲鹏文档中心:https://www.hikunpeng.com/document/detail/zh/kunpengbds/appAccelFeatures/algorithmaccelf_ml
-
 华为云鲲鹏论坛4月热门问题汇总 1. [问题求助] 【华为鲲鹏920 Robox】【环境搭建功能】启动robox实例失败 问题链接:https://bbs.huaweicloud.com/forum/thread-184105-1-1.html 2. 【openGauss】【Data Studio】每次打开datastudio的时候都要开虚拟机重连一下数据库 问题链接:https://bbs.huaweicloud.com/forum/thread-184383-1-1.html 3. 【华为鲲鹏920 Robox】【环境搭建功能】robox起来后可以看到界面,但是鼠标无法操作 问题链接:https://bbs.huaweicloud.com/forum/thread-184421-1-1.html 4. mssql数据库的鲲鹏适配迁移 问题链接:https://bbs.huaweicloud.com/forum/thread-184495-1-1.html 5. java jnr/jni调用libfuse实现用户文件系统问题 问题链接:https://bbs.huaweicloud.com/forum/thread-184701-1-1.html 6. 华为云鲲鹏弹性云服务器高可用性架构实践实验中的预置实验环境不成功怎么解决? 问题链接:https://bbs.huaweicloud.com/forum/thread-184983-1-1.html 7. 【robox】【mesa】robox跑起来后,怎么知道是通过wx5100渲染,还是软件渲染? 问题链接:https://bbs.huaweicloud.com/forum/thread-184645-1-1.html 8. 云手机对带宽要求高不高,虚拟出几十上百的云手机带宽的压力大不大? 问题链接:https://bbs.huaweicloud.com/forum/thread-184795-1-1.html 9. 【ECS鲲鹏920 + Kylin Advanced OS V10】【桌面安装】怎么安装启动桌面类似于 windows 系统 问题链接:https://bbs.huaweicloud.com/forum/thread-185271-1-1.html 10. 【华为云手机】【显卡驱动】ADM WX5100的驱动,官方没有提供Ubuntu18.0.4的,咋办呢 问题链接:https://bbs.huaweicloud.com/forum/thread-185213-1-1.html 11. 【Compass-CI】兼容性方面compass-ci做了哪些维度的比对测试?用了什么工具? 问题链接:https://bbs.huaweicloud.com/forum/thread-185485-1-1.html 12. 【华为云手机】【robox】已经拉起来android系统了,怎么配置上外网呢? 问题链接:https://bbs.huaweicloud.com/forum/thread-185500-1-1.html 13. 基于arm64虚拟机编译的程序就可以运行在鲲鹏服务器上吗? 问题链接:https://bbs.huaweicloud.com/forum/thread-185567-1-1.html 14. 【openGauss】data studio之前还是好的,现在不显示报错,但是连接后啥反应也没有 问题链接:https://bbs.huaweicloud.com/forum/thread-185962-1-1.html 15. 【华为云手机】【robox】目前看的文档都是基于鲲鹏920的arm服务器,还支持鲲鹏916么? 问题链接:https://bbs.huaweicloud.com/forum/thread-185882-1-1.html 16. 配置DHCP时无法开启DHCP怎么解决? 问题链接:https://bbs.huaweicloud.com/forum/thread-185608-1-1.html 17. 【鲲鹏】请问robox和kbox的区别是什么?github上面的kbox是空的,kbox是停止维护了吗 问题链接:https://bbs.huaweicloud.com/forum/thread-185978-1-1.html 18. 对megahit进行源码扫描时得出的报告提示的修改点不一样 问题链接:https://bbs.huaweicloud.com/forum/thread-186140-1-1.html 19. 【鲲鹏920产品】【CPU Hydra接口】鲲鹏920 CPU 片间Hydra接口速率是多少? 问题链接:https://bbs.huaweicloud.com/forum/thread-182356-1-1.html 20. 如何通过porting advisor 迁移javaweb并运行 问题链接:https://bbs.huaweicloud.com/forum/thread-186273-1-1.html
华为云鲲鹏论坛4月热门问题汇总 1. [问题求助] 【华为鲲鹏920 Robox】【环境搭建功能】启动robox实例失败 问题链接:https://bbs.huaweicloud.com/forum/thread-184105-1-1.html 2. 【openGauss】【Data Studio】每次打开datastudio的时候都要开虚拟机重连一下数据库 问题链接:https://bbs.huaweicloud.com/forum/thread-184383-1-1.html 3. 【华为鲲鹏920 Robox】【环境搭建功能】robox起来后可以看到界面,但是鼠标无法操作 问题链接:https://bbs.huaweicloud.com/forum/thread-184421-1-1.html 4. mssql数据库的鲲鹏适配迁移 问题链接:https://bbs.huaweicloud.com/forum/thread-184495-1-1.html 5. java jnr/jni调用libfuse实现用户文件系统问题 问题链接:https://bbs.huaweicloud.com/forum/thread-184701-1-1.html 6. 华为云鲲鹏弹性云服务器高可用性架构实践实验中的预置实验环境不成功怎么解决? 问题链接:https://bbs.huaweicloud.com/forum/thread-184983-1-1.html 7. 【robox】【mesa】robox跑起来后,怎么知道是通过wx5100渲染,还是软件渲染? 问题链接:https://bbs.huaweicloud.com/forum/thread-184645-1-1.html 8. 云手机对带宽要求高不高,虚拟出几十上百的云手机带宽的压力大不大? 问题链接:https://bbs.huaweicloud.com/forum/thread-184795-1-1.html 9. 【ECS鲲鹏920 + Kylin Advanced OS V10】【桌面安装】怎么安装启动桌面类似于 windows 系统 问题链接:https://bbs.huaweicloud.com/forum/thread-185271-1-1.html 10. 【华为云手机】【显卡驱动】ADM WX5100的驱动,官方没有提供Ubuntu18.0.4的,咋办呢 问题链接:https://bbs.huaweicloud.com/forum/thread-185213-1-1.html 11. 【Compass-CI】兼容性方面compass-ci做了哪些维度的比对测试?用了什么工具? 问题链接:https://bbs.huaweicloud.com/forum/thread-185485-1-1.html 12. 【华为云手机】【robox】已经拉起来android系统了,怎么配置上外网呢? 问题链接:https://bbs.huaweicloud.com/forum/thread-185500-1-1.html 13. 基于arm64虚拟机编译的程序就可以运行在鲲鹏服务器上吗? 问题链接:https://bbs.huaweicloud.com/forum/thread-185567-1-1.html 14. 【openGauss】data studio之前还是好的,现在不显示报错,但是连接后啥反应也没有 问题链接:https://bbs.huaweicloud.com/forum/thread-185962-1-1.html 15. 【华为云手机】【robox】目前看的文档都是基于鲲鹏920的arm服务器,还支持鲲鹏916么? 问题链接:https://bbs.huaweicloud.com/forum/thread-185882-1-1.html 16. 配置DHCP时无法开启DHCP怎么解决? 问题链接:https://bbs.huaweicloud.com/forum/thread-185608-1-1.html 17. 【鲲鹏】请问robox和kbox的区别是什么?github上面的kbox是空的,kbox是停止维护了吗 问题链接:https://bbs.huaweicloud.com/forum/thread-185978-1-1.html 18. 对megahit进行源码扫描时得出的报告提示的修改点不一样 问题链接:https://bbs.huaweicloud.com/forum/thread-186140-1-1.html 19. 【鲲鹏920产品】【CPU Hydra接口】鲲鹏920 CPU 片间Hydra接口速率是多少? 问题链接:https://bbs.huaweicloud.com/forum/thread-182356-1-1.html 20. 如何通过porting advisor 迁移javaweb并运行 问题链接:https://bbs.huaweicloud.com/forum/thread-186273-1-1.html -
## ngx_http_log_module 模块 ngx_http_log_module模块按指定的格式记录访问日志。请求在处理结束时,会按请求路径的配置上下文记访问日志,通过访问日志,你可以得到用户地域来源、跳转来源、使用终端、某个URL访问量等相关信息。你也可以记录错误日志,通过错误日志,你可以得到系统某个服务或server的性能瓶颈等。 ### 配置 access_log 来记录访问日志 访问日志主要记录客户端的请求。客户端向Nginx服务器发起的每一次请求都记录在这里。客户端IP,浏览器信息,referer,请求处理时间,请求URL等都可以在访问日志中得到。当然具体要记录哪些信息,你可以通过log_format指令来定义。 **语法:** ```shell access_log path [``format` `[buffer=size] [``gzip``[=level]] [flush=``time``] [``if``=condition]]; ``# 设置访问日志``access_log off; ``# 关闭访问日志 ``` - path 指定日志的存放位置。 - format 指定日志的格式。默认使用预定义的combined。 - buffer 用来指定日志写入时的缓存大小。默认是64k。 - gzip 日志写入前先进行压缩。压缩率可以指定,从1到9数值越大压缩比越高,同时压缩的速度也越慢。默认是1。 - flush 设置缓存的有效时间。如果超过flush指定的时间,缓存中的内容将被清空。 - if 条件判断。如果指定的条件计算为0或空字符串,那么该请求不会写入日志。 还有一个特殊的值off。如果指定了该值,当前作用域下的所有的请求日志都被关闭。 ### 配置作用域 可以配置 access_log 指令的作用域分别有http,server,location,limit_except。也就是说,在这几个作用域外使用该指令,Nginx会报错。 以上是 access_log 指令的基本语法和参数的含义。下面我们看一几个例子加深一下理解。 ### 基本用法 ```shell access_log ``/home/wwwlogs/nginx-access``.log ``` 该例子指定日志的写入路径为/home/wwwlogs/nginx-access.log,日志格式使用默认的combined。 ```shell access_log ``/home/wwwlogs/nginx-access``.log buffer=32k ``gzip` `flush=1m ``` 该例子指定日志的写入路径为/home/wwwlogs/nginx-access.log,日志格式使用默认的combined,指定日志的缓存大小为32k,日志写入前启用gzip进行压缩,压缩比使用默认值1,缓存数据有效时间为1分钟。 ### 使用 log_format 自定义日志格式 Nginx预定义了名为combined日志格式,如果没有明确指定日志格式默认使用该格式: ```shell log_format combined ``'$remote_addr - $remote_user [$time_local] '`` ``'"$request" $status $body_bytes_sent '`` ``'"$http_referer" "$http_user_agent"'``; ``` 如果不想使用Nginx预定义的格式,可以通过log_format指令来自定义。 ### 语法 ```shell log_format name [escape=default|json] string ...; ``` - name 格式的名称。在 access_log 指令中引用。 - escape 设置变量中的字符编码方式是json还是default,默认是default。 - string 要定义的日志格式内容。该参数可以有多个。参数中可以使用Nginx变量。 下面是 log_format 指令中常用的一些变量: $remote_addr 客户端的IP地址(代理服务器,显示代理服务器的ip) $remote_user 记录远程客户端的用户名称,针对启用了用户认证的请求,通常情况下为“-” $time_local 记录访问时间和时区,如"24/May/2017:18:31:27 +0800" $request 记录请求的url以及请求方法 $status 响应状态码 例如:200成功、404页面找不到等...... $bytes_sent 发送给客户端的总字节数 $body_bytes_sent 给客户端发送的主体内容字节数,不包括响应头的大小 $http_user_agent 客户端浏览器信息 $http_x_forwarded_for 可以记录客户端IP,通过代理服务器来记录客户端的IP地址。当前端有代理服务器时,设置web节点记录客户端地址的配置,此参数生效的前提是代理服务器也要进行相关的x_forwarded_for设置。 $http_referer 记录用户是从哪个链接访问过来的 $time_iso8601 标准格式的本地时间,形如“2017-05-24T18:31:27+08:00” $msec 日志写入时间,单位为秒,精度是毫秒 $request_length 请求长度(包括请求行,请求头和请求体) $request_time 请求处理时长,单位为秒,精度为毫秒,从读入客户端的第一个字节开始,直到把最后一个字符发送给客户端进行日志写入为止 **下面演示一下自定义日志格式的使用:** ```shell access_log ``/home/wwwlogs/nginx-access``.log main``log_format main ``'$remote_addr - $remote_user [$time_local] "$request" '`` ``'$status $body_bytes_sent "$http_referer" '`` ``'"$http_user_agent" "$http_x_forwarded_for"'``; ``` 使用 log_format 指令定义了一个main的格式,并在access_log指令中引用了它。假如客户端有发起请求: nginx.css3er.com,注意,如果你要测试的话,请把nginx.css3er.com换成对应你自己的域名进行访问。看一下我截取的一个请求的日志记录: ```shell 111.231.138.248 - - [20``/Feb/2018``:12:12:14 +0800] ``"GET / HTTP/1.1"` `200 190 ``"-"` `"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Mobile Safari/537.36"` `"-" ``` 我们看到最终的日志记录中$remote_user、$http_referer、$http_x_forwarded_for都对应了一个-,这是因为这几个变量为空。 ### 配置 error_log 来记录错误日志 错误日志在Nginx中是通过 error_log 指令实现的。该指令记录服务器和请求处理过程中的错误信息。 ### 语法 配置错误日志文件的路径和日志级别。 ```shell error_log ``file` `[level];``Default: ``error_log logs``/error``.log error; ``` 第一个参数指定日志的写入路径。 第二个参数指定日志的级别。level可以是debug, info, notice, warn, error, crit, alert,emerg 中的任意值。可以看到其取值范围是按紧急程度从低到高排列的。只有日志的错误级别等于或高于level指定的值才会写入错误日志中。默认值是error。 ### 基本用法 ```shell error_log ``/home/wwwlogs/nginx-error``.log crit; ``` 它可以配置在:main, http, mail, stream, server, location 作用域。 例子中指定了错误日志的路径为:/home/wwwlogs/nginx-error.log,日志级别使用的是crit。 ### open_log_file_cache 每一条日志记录的写入都是先打开文件再写入记录,然后关闭日志文件。如果你的日志文件路径中使用了变量,如 access_log /home/wwwlogs/$host/nginx-access.log,为了提高性能,可以使用 open_log_file_cache 指令设置日志文件描述符的缓存。当然了,即使你在路径中使用了变量,你也可以选择不用配置 open_log_file_cache。 ### 语法 ``` open_log_file_cache max=N [inactive=``time``] [min_uses=N] [valid=``time``]; ``` max 设置缓存中最多容纳的文件描述符数量,如果被占满,采用LRU算法将描述符关闭。 inactive 设置缓存存活时间,默认是10s。 min_uses 在inactive时间段内,日志文件最少使用几次,该日志文件描述符记入缓存,默认是1次。 valid:设置多久对日志文件名进行检查,看是否发生变化,默认是60s。 off:不使用缓存。默认为off。 ### 基本用法 ```shell open_log_file_cache max=1000 inactive=20s valid=1m min_uses=2; ``` 它可以配置在http、server、location作用域中。 在上面的例子中,设置缓存最多缓存1000个日志文件描述符,20s内如果缓存中的日志文件描述符至少被被访问2次,才不会被缓存关闭。每隔1分钟检查缓存中的文件描述符的文件名是否还存在。 ### 尾声 在Nginx中我们可以通过 access_log 和 error_log 指令配置访问日志和错误日志,通过 log_format 我们可以自定义日志格式。如果日志文件路径中使用了变量,我们可以通过open_log_file_cache指令来设置缓存,提升性能。 另外,在 access_log 和 log_format 中使用了很多变量,这些变量并没有一 一列举出来,详细的变量信息可以参考:[nginx官方文档](http://nginx.org/en/docs/varindex.html)
-
## ngx_http_access_module 模块 ngx_http_access_module是nginx中的访问控制模块,该模块主要用来对特定的ip进行访问控制处理,默认是允许所有ip访问,若部分允许需定义deny all。nginx中设置白名单或者黑名单就是通过allow、deny all指令来设置的。 allow 语法: allow address | CIDR | unix: | all; 默认值: — 区块: http, server, location, limit_except 说明: 允许某个ip或者一个ip段访问 deny 语法: deny address | CIDR | unix: | all; 默认值: — 区块: http, server, location, limit_except 说明: 禁止某个ip或者一个ip段访问 **配置示例:** ``` location ``/test`` ``{`` ``deny 111.231.138.248;`` ``deny 192.168.1.0``/24``;`` ``allow 113.246.155.223;`` ``deny all;`` ` ` ``} ``` 示例截图:  按照配置中的从上到下的顺序依次检测,类似iptables。匹配到了便跳出。如上的例子先禁止了 111.231.138.248 这个单独的ip,接着又禁止了1个网段,只允许了 113.246.155.223 这个ip进行访问。最后未匹配的ip全部禁止访问。 **进行测试(不要忘了重启或平滑重启nginx)** 访问 域名/test,只有 113.246.155.223 这个ip能成功访问,111.231.138.248 等相关的ip访问 域名/test 则会提示 403 Forbidden。 ## 其它说明: 比如 可以限制某些目录下的某些文件的访问,具体可以自己组合相关配置。 禁止访问所有目录下的sql|log|txt|jar|sh|py后缀的文件: ``` location ~.*\.(sql|log|txt|jar|war|sh|py|php) {`` ``deny all;``} ``` ## 尾声: nginx的访问控制模块是nginx里面最简单的指令了,只要记住你想禁止谁访问就deny加上ip,想允许则加上allow ip,想允许或者禁止所有,那么allow all或者deny all就可以了。
-
## 一、nginx的安装 安装就不说了...... ## 二、nginx的配置文件解释 ### 2.1、快速入门 **main(全局设置)**,main部分设置的指令将影响其它所有部分的设置; **http(http服务器设置)**,http标准核心模块,http服务的相应配置; **server(主机设置)** 接收请求的服务器需要将不同的请求按规则转发到不同的后端服务器上,在 nginx 中我们可以通过创建虚拟主机(server)的概念来将这些不同的服务配置隔离。 **location(URL匹配特定位置后的设置)** location部分用于匹配网页位置(比如,根目录“/”,“/images”,等等),server 是对应一个域名进行的配置,而 location 是在一个域名下对更精细的路径进行配置。 下面附一张nginx配置文件详解示例图:  上图中只是把一些常见的配置做了解释,当然了,nginx还有更多的配置指令。。 **在上一份儿nginx.conf文件大部分指令有注释的,如下:** ```sql #运行用户``user nobody;``#启动进程,通常设置成和cpu的数量相等``worker_processes 1;` `#全局错误日志及PID文件``#error_log logs/error.log;``#error_log logs/error.log notice;``#error_log logs/error.log info;` `#pid logs/nginx.pid;` `#工作模式及连接数上限``events {`` ``#epoll是多路复用IO(I/O Multiplexing)中的一种方式,`` ``#仅用于linux2.6以上内核,可以大大提高nginx的性能`` ``use epoll; ` ` ``#单个后台worker process进程的最大并发链接数 `` ``worker_connections 1024;` ` ``# 并发总数是 worker_processes 和 worker_connections 的乘积`` ``# 即 max_clients = worker_processes * worker_connections`` ``# 在设置了反向代理的情况下,max_clients = worker_processes * worker_connections / 4 为什么`` ``# 为什么上面反向代理要除以4,应该说是一个经验值`` ``# 根据以上条件,正常情况下的Nginx Server可以应付的最大连接数为:4 * 8000 = 32000`` ``# worker_connections 值的设置跟物理内存大小有关`` ``# 因为并发受IO约束,max_clients的值须小于系统可以打开的最大文件数`` ``# 而系统可以打开的最大文件数和内存大小成正比,一般1GB内存的机器上可以打开的文件数大约是10万左右`` ``# 我们来看看360M内存的VPS可以打开的文件句柄数是多少:`` ``# $ cat /proc/sys/fs/file-max`` ``# 输出 34336`` ``# 32000 34336,即并发连接总数小于系统可以打开的文件句柄总数,这样就在操作系统可以承受的范围之内`` ``# 所以,worker_connections 的值需根据 worker_processes 进程数目和系统可以打开的最大文件总数进行适当地进行设置`` ``# 使得并发总数小于操作系统可以打开的最大文件数目`` ``# 其实质也就是根据主机的物理CPU和内存进行配置`` ``# 当然,理论上的并发总数可能会和实际有所偏差,因为主机还有其他的工作进程需要消耗系统资源。`` ``# ulimit -SHn 65535` `}` `http {`` ``#设定mime类型,类型由mime.type文件定义`` ``include mime.types;`` ``default_type application``/octet-stream``;`` ``#设定日志格式`` ``log_format main ``'$remote_addr - $remote_user [$time_local] "$request" '`` ``'$status $body_bytes_sent "$http_referer" '`` ``'"$http_user_agent" "$http_x_forwarded_for"'``;` ` ``access_log logs``/access``.log main;` ` ``#sendfile 指令指定 nginx 是否调用 sendfile 函数(zero copy 方式)来输出文件,`` ``#对于普通应用,必须设为 on,`` ``#如果用来进行下载等应用磁盘IO重负载应用,可设置为 off,`` ``#以平衡磁盘与网络I/O处理速度,降低系统的uptime.`` ``sendfile on;`` ``#tcp_nopush on;` ` ``#连接超时时间`` ``#keepalive_timeout 0;`` ` ` ``#关于keepalive_timeout参数详细说明如下:`` ``#http是一种无状态协议,客户端向服务器发送一个 TCP 请求,服务端响应完毕后断开连接。如果客户端向服务器发送多个请求,每个请求都要建立各自独立的连接以传输数据。`` ` ` ``#http有一个Keep-Alive模式,它告诉webserver在处理完一个请求后保持这个TCP连接的打开状态。若接收到来自客户端的其它请求,服务端会利用这个未被关闭的连接,而不需要再建立一个连接。`` ``#Keep-Alive在一段时间内保持打开状态,它们会在这段时间内占用资源,占用过多就会影响性能。`` ``#Nginx使用keepalive_timeout来指定Keep-Alive的超时时间(timeout)。指定每个TCP连接最多可以保持多长时间。Nginx 的默认值是75秒,有些浏览器最多只保持60秒,所以可以设定为60秒。若将它设置为0,就禁止了keep-alive连接。`` ` ` ``keepalive_timeout 65; ``#65s(单位是:秒)。该参数是一个请求完成之后还要保持连接多久,不是请求时间多久,目的是保持长连接,减少创建连接过程给系统带来的性能损耗,类似于数据库连接池。`` ``tcp_nodelay on;` ` ``#开启gzip压缩`` ``gzip` `on;`` ``gzip_disable ``"MSIE [1-6]."``;` ` ``#设定请求缓冲`` ``client_header_buffer_size 128k;`` ``large_client_header_buffers 4 128k;` ` ``#设定虚拟主机配置`` ``server {`` ``#侦听80端口`` ``listen 80;`` ``#定义使用 www.nginx.cn访问`` ``server_name www.nginx.cn;` ` ``#定义服务器的默认网站根目录位置`` ``root html;` ` ``#设定本虚拟主机的访问日志`` ``access_log logs``/nginx``.access.log main;` ` ``#默认请求`` ``location / {`` ` ` ``#定义首页索引文件的名称`` ``index index.php index.html index.htm; ` ` ``}` ` ``# 定义错误提示页面`` ``error_page 500 502 503 504 ``/50x``.html;`` ``location = ``/50x``.html {`` ``}` ` ``#静态文件,nginx自己处理`` ``location ~ ^/(images|javascript|js|css|flash|media|static)/ {`` ` ` ``#过期30天,静态文件不怎么更新,过期可以设大一点,`` ``#如果频繁更新,则可以设置得小一点。`` ``expires 30d;`` ``}` ` ``#PHP 脚本请求全部转发到 FastCGI处理. 使用FastCGI默认配置.`` ``location ~ .php$ {`` ``fastcgi_pass 127.0.0.1:9000;`` ``fastcgi_index index.php;`` ``fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;`` ``include fastcgi_params;`` ``}` ` ``#禁止访问 .htxxx 文件`` ``location ~ /.ht {`` ``deny all;`` ``}` ` ``}``} ``` ### 2.2、详细解析 配置语法说明: ①、配置文件由指令与指令块构成 ②、每条指令以;分号结尾,指令与参数间以空格符号分隔 ③、指令块以{}大括号将多条指令组织在一起 ④、使用#符号添加注释,提高可读性 ⑤、include语句允许组合多个配置文件以提升可维护性 ⑥、使用$符号使用变量 ⑦、部分指令的参数支持正则表达式 Nginx的各种指令以及配置繁多,该系列博文会记录一些nginx常用配置,后期会说一些优化配置,有些配置可以在 https://tengine.taobao.org/nginx_docs/cn/docs/ 或者在 [http://www.nginx.cn](http://www.nginx.cn/) 或者在 官方文档上查看 **配置块: server** 由于IP地址的数量有限,因此经常存在多个主机域名对应着同一个IP地址的情况,这时在nginx.conf中就可以按照server_name(对应用户请求中的主机域名)并通过server块来定义虚拟主机,每个server块就是一个虚拟主机,它只处理与之相对应的主机域名请求。这样,一台服务器上的Nginx就能以不同的方式处理访问不同主机域名的HTTP请求了 语法: 语法: server_name name[...]; 默认: server_name""; 配置块: server 虚拟主机名可以使用确切的名字,通配符,或者是正则表达式来定义,在开始处理一个HTTP请求时,Nginx会取出request header头(请求头)中的Host,与每个server中的server_name进行匹配,以此决定到底由哪一个server块来处理这个请求。有可能一个Host与多个server块中的server_name都匹配,这时就会根据匹配优先级来选择实际处理的server块。 注意:优先级问题,所导致的配置不生效。 server_name与Host的匹配优先级如下: 1)首先选择所有字符串完全匹配的server_name,如 nginx.2367.com 。 2)其次选择通配符在前面的server_name,如 *.2367.com。 3)再次选择通配符在后面的server_name,如nginx.2367.* 。 4)最后选择使用正则表达式才匹配的server_name,如 ~^\.testweb\.com$ 如果都不匹配 1)、优先选择listen配置项后有default或default_server的 2)、找到匹配listen端口的第一个server块 **配置块: location** location 语法: location[=|~|~*|^~|@]/uri/{...} location 会尝试根据用户请求中的URI来匹配上面的/uri表达式,如果可以匹配,就选择。 location{} 块中的配置来处理用户请求。当然,匹配方式是多样的,下面说一下location的匹配规则。 **location 表达式类型:** ~ 表示执行一个正则匹配,区分大小写; ~* 表示执行一个正则匹配,不区分大小写; ^~ 表示普通字符匹配。使用前缀匹配。如果匹配成功,则不再匹配其它的location; = 进行普通字符精确匹配。也就是完全匹配; @ 它定义一个命名的 location,使用在内部定向时,例如 error_page, try_files; **location 表达式类型的优先级:** 等号类型(=)的优先级最高。一旦匹配成功,则不再查找其它匹配项; 前缀普通匹配(^~)优先级次之。不支持正则表达式。使用前缀匹配,如果有多个location匹配的话,则使用表达式最长的那个; 正则表达式类型(~ ~*)的优先级次之。一旦匹配成功,则不再查找其它匹配项; 常规字符串匹配,如果有多个location匹配的话,则使用表达式最长的那个; 优先级总结来说:(location =) > (location 完整路径) > (location ^~ 路径) > (location ~,~* 正则顺序) > (location 部分起始路径) **文件路径的定义:** 以root方式设置资源路径: 语法: root path; 配置块: http、server、location、if 以alias方式设置资源路径: 语法: alias path; 配置块: location alias也是用来设置文件资源路径的,它与root的不同点主要在于如何解读紧跟location后面的uri参数 注意: location中使用root指令和alias指令的意义不同 (a) root,相当于追加在root目录后面 。比如访问的是 xxx/test=>/www/test (b) alias,相当于对location中的uri进行替换,比如访问的是 xxx/test,想要访问到/www/test就必须设置 alias /www/test ## 三、nginx常用命令 3.1、查看Nginx的版本号:nginx -V 3.2、停止 nginx -s stop 3.3、退出 nginx -s quit 3.4、重启加载配置 nginx -s reload 3.5、配置文件启动 nginx -c 为 Nginx 指定一个配置文件 3.6、nginx -t 不运行,而仅仅测试配置文件。nginx 将检查配置文件的语法的正确性,并尝试打开配置文件中所引用到的文件。 ## 四、nginx常用模块了解及使用 
-
-
【功能模块】【操作步骤&问题现象】按照安装教程安装网卡驱动,在执行到下面这一步的时候显示系统不支持【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
使用 scp命令 可以将一个Linux系统中的文件或文件夹复制到另一台Linux服务器上 复制文件或文件夹(目录)命令: 一、复制文件: 1.1、将本地文件拷贝到远程 语法命令格式:scp 文件名 用户名@计算机IP或者计算机名称:远程路径 # 示例如下: scp /root/install.* root@192.168.1.12:/usr/local/src 1.2、从远程将文件拷回到本地 语法命令格式:scp 用户名@计算机IP或者计算机名称:文件名 本地路径 # 示例如下: scp root@192.168.1.12:/usr/local/src/*.log /root/ 二、复制文件夹(目录): 2.1、将本地文件夹拷贝到远程Linux服务器上 语法命令格式:scp -r 目录名 用户名@计算机IP或者计算机名称:远程路径 # 示例如下: scp -r /home/test1 root@192.168.0.1:/home/test2 # 解释:test1为源目录,test2为目标目录,root@192.168.0.1为远程服务器的用户名和ip地址。 2.2、从远程Linux服务器将文件夹拷回到本地 语法命令格式:scp -r 用户名@计算机IP或者计算机名称:目录名 本地路径 # 示例如下: scp -r root@192.168.0.1:/home/test2 /home/test1 # 解释:将远程服务器(即 192.168.0.1 这台服务器)上的/home/test2目录下的所有文件及文件夹,全部复制到本机的/home/test1目录下
-
## 一、redis哨兵+主从的问题 假设我们在一台主从机器上配置了200G内存,但是业务需求是需要500G的时候,主从结构+哨兵可以实现高可用故障切换+冗余备份,但是并不能解决数据容量的问题,用哨兵,redis每个实例也是全量存储,每个redis存储的内容都是完整的数据,浪费内存且有木桶效应。 为了最大化利用内存,可以采用cluster集群,就是分布式存储。即每台redis存储不同的内容。 Redis 分布式方案一般有两种: ①、客户端分区方案:优点是分区逻辑可控,缺点是需要自己处理数据路由、高可用、故障转移等问题,比如在redis2.8之前通常的做法是获取某个key的hashcode,然后取余分布到不同节点,不过这种做法无法很好的支持动态伸缩性需求,一旦节点的增或者删操作,都会导致key无法在redis中命中。 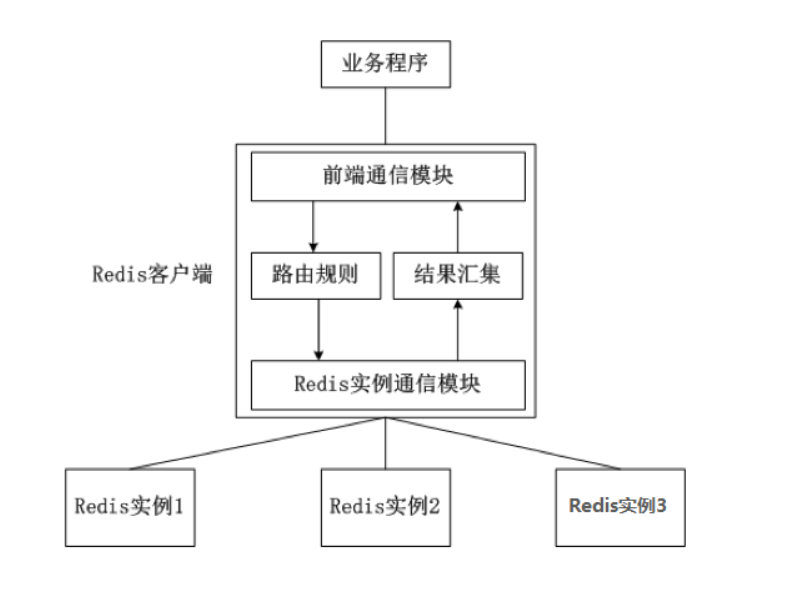 ②、代理方案:优点是简化客户端分布式逻辑和升级维护便利,缺点是加重架构部署复杂度和性能损耗,比如twemproxy、Codis  ③、Redis官方为我们提供了专有的集群方案:Redis Cluster,它非常优雅地解决了 Redis 集群方面的问题,部署方便简单,因此理解应用好 Redis Cluster 将极大地解放我们使用分布式 Redis 的工作量。 ## 二、Redis Cluster ### 1、简介 Redis Cluster 是 Redis 的分布式解决方案,在3.0版本正式推出,有效地解决了 Redis 分布式方面的需求。当遇到单机内存、并发、流量等瓶颈时,可以采用 Cluster 架构方案达到负载均衡的目的。 架构图:  在上面这个图中,每一个蓝色的圈都代表着一个redis的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点,对其进行存取和其他操作。 Redis 集群提供了以下两个好处: ①、将数据自动切分到多个节点的能力。 ②、当集群中的一部分节点失效或者无法进行通讯时, 仍然可以继续处理命令请求的能力,拥有自动故障转移的能力。 ### 2、redis cluster VS replication + sentinel如何选择? 如果你的数据量很少,主要是承载高并发高性能的场景,比如你的缓存一般就几个G,单机足够了。 Replication:一个mater,多个slave,要几个slave跟你的要求的读吞吐量有关系,结合sentinel集群,去保证redis主从架构的高可用性,就可以了。 redis cluster:主要是针对海量数据+高并发+高可用的场景,海量数据,如果你的数据量很大,那么建议就用redis cluster。 ### 3、Redis Cluster集群中的数据分布是如何进行的? 什么是数据分布?数据分布有两种方式,顺序分区和哈希分区。 分布式数据库首先要解决把整个数据集按照分区规则映射到多个节点的问题,即把数据集划分到多个节点上,每个节点负责整体数据的一个子集。 顺序分布就是把一整块数据分散到很多机器中,如下图所示。 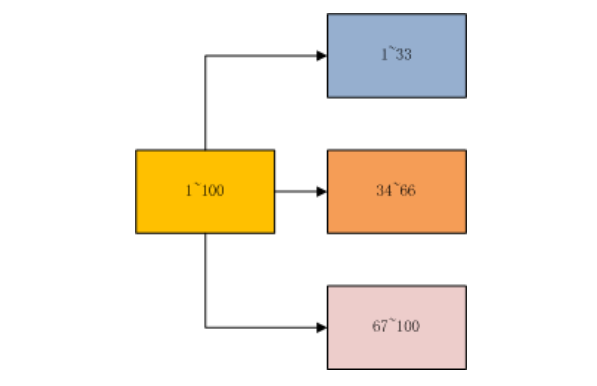 顺序分布一般都是平均分配的。 哈希分区: 如下图所示,1~100这整块数字,通过 hash 的函数,取余产生的数。这样可以保证这串数字充分的打散,也保证了均匀的分配到各台机器上。 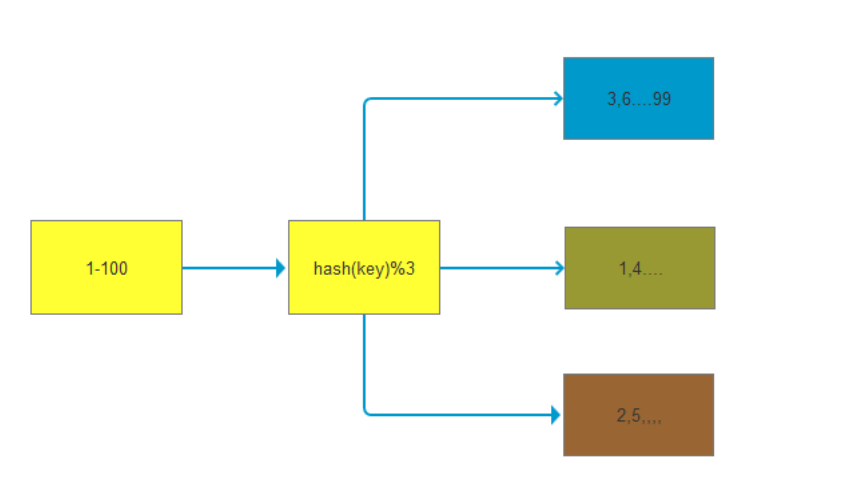 哈希分布和顺序分布只是场景上的适用。哈希分布不能顺序访问,比如你想访问1~100,哈希分布只能遍历全部数据,同时哈希分布因为做了 hash 后导致与业务数据无关了。 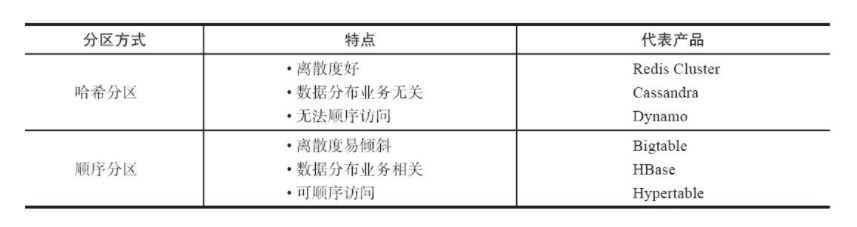 ### 4、数据倾斜与数据迁移跟节点伸缩 顺序分布是会导致数据倾斜的,主要是访问的倾斜。每次点击会重点访问某台机器,这就导致最后数据都到这台机器上了,这就是顺序分布最大的缺点。 但哈希分布其实是有个问题的,当我们要扩容机器的时候,专业上称之为“节点伸缩”,这个时候,因为是哈希算法,会导致数据迁移。 ### 5、哈希分区方式 因为redis-cluster使用的就是哈希分区规则所以分析下几种分区形式 **5.1、节点取余分区** 使用特定的数据(包括redis的键或用户ID),再根据节点数量N,使用公式:hash(key)%N计算出一个0~(N-1)值,用来决定数据映射到哪一个节点上。即哈希值对节点总数取余。 缺点:当节点数量N变化时(扩容或者收缩),数据和节点之间的映射关系需要重新计算,这样的话,按照新的规则映射,要么之前存储的数据找不到,要么之前数据被重新映射到新的节点(导致以前存储的数据发生数据迁移) 实践:常用于数据库的分库分表规则,一般采用预分区的方式,提前根据数据量规划好分区数,比如划分为512或1024张表,保证可支撑未来一段时间的数据量,再根据负载情况将表迁移到其他数据库中。 **5.2、一致性哈希** 一致性哈希分区(Distributed Hash Table)实现思路是为系统中每个节点分配一个 token,范围一般在0~232,这些 token 构成一个哈希环。数据读写执行节点查找操作时,先根据 key 计算 hash 值,然后顺时针找到第一个大于等于该哈希值的 token 节点  上图就是一个一致性哈希的原理解析。 假设我们有 n1~n4 这四台机器,我们对每一台机器分配一个唯一 token,每次有数据(图中黄色代表数据),一致性哈希算法规定每次都顺时针漂移数据,也就是图中黄色的数 据都指向 n3。 这个时候我们需要增加一个节点 n5,在 n2 和 n3 之间,数据还是会发生漂移(会偏移到大于等于的节点),但是这个时候你是否注意到,其实只有 n2~n3 这部分的数据被漂移,其他的数据都是不会变的,这种方式相比节点取余最大的好处在于加入和删除节点只影响哈希环中相邻的节点,对其他节点无影响 缺点:每个节点的负载不相同,因为每个节点的hash是根据key计算出来的,换句话说就是假设key足够多,被hash算法打散得非常均匀,但是节点过少,导致每个节点处理的key个数不太一样,甚至相差很大,这就会导致某些节点压力很大 实践:加减节点会造成哈希环中部分数据无法命中,需要手动处理或者忽略这部分数据,因此一致性哈希常用于缓存场景。 **5.3、虚拟槽分区\*(目前在redis集群中 数据存储和读取常用的方式就是这种 槽 的方式)\** 虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有数据映射到一个固定范围的整数集合中,整数定义为槽(slot)。这个范围一般远远大于节点数,比如 Redis Cluster 槽范围是0~16383(也就是16384个槽。redis集群规定了16384个槽,这些槽将会平均分配给不同的redis节点)。槽是集群内数据管理和迁移的基本单位(也就是说 数据是存储在槽中,而槽被分配在了不同的redis节点中)。采用大范围槽的主要目的是为了方便数据拆分和集群扩展。每个节点会负责一定数量的槽,具体看下图所示。 当前集群有5个节点,每个节点平均大约负责3276个槽。由于采用高质量的哈希算法,每个槽所映射的数据通常比较均匀,将数据平均划分到5个节点进行数据分区。Redis Cluster 就是采用虚拟槽分区,下面就介绍 Redis 数据分区方法。 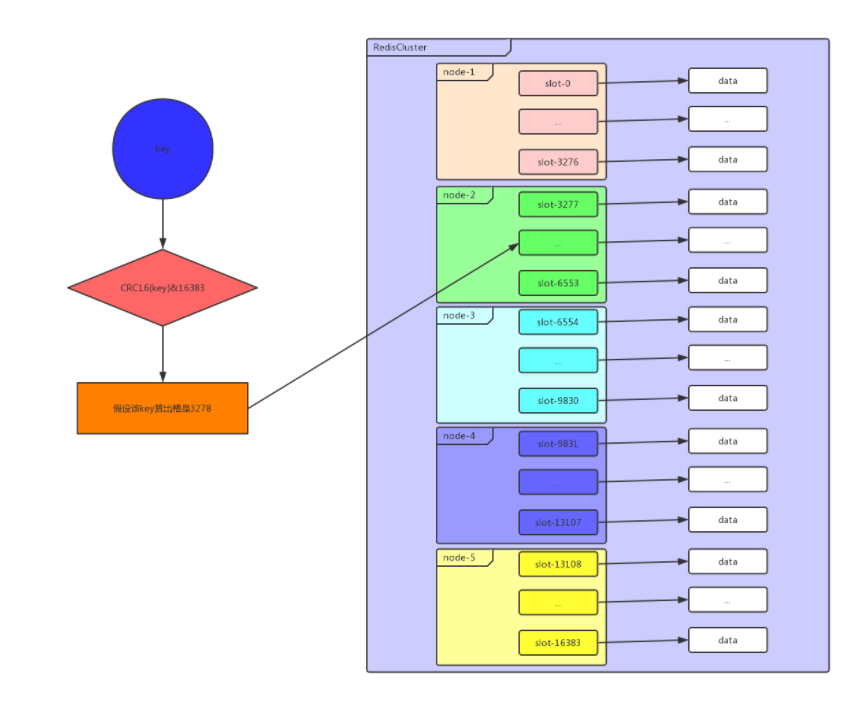 **上图步骤大概执行如下(数据写入):** ①、redis根据所给定的key进行CRC16算法之后 算出一个结果,然后 再对该结果 进行16384取模(即 对该结果进行16384求余数),得到一个槽。 这样每个key都会对应一个编号在0---16383之间的槽号码,redis会根据节点数量大致均等的原则将哈希槽映射到不同的节点上。比如有3个redis节点,把16384分成3段,每个节点承担一段范围的哈希槽。 **注意:**这里是对16384进行取模,上图中那个CRC16(key)&16383写错了 正确公式为:CRC16(key)%16384 ②、再根据所得的槽位数,获得这个槽所在的redis节点(假设是Z节点)。 ③、连接Z节点,将该key保存到Z这台redis节点上。 **数据读取也是同理,都是根据key得到槽,根据槽得到该槽所在的redis节点,然后连接该redis节点进行数据读取操作。** 每当 key 访问过来,Redis Cluster 会计算哈希值是否在这个区间里。它们彼此都知道对应的槽在哪台机器上,这样就能做到平均分配了。 **redis-cluster集群方面有一些限制:** Redis集群相对单机来说,在功能上存在一些限制,需提前了解,在使用时做好规避。限制如下: key批量操作支持有限。如mset、mget等。 ## 总结redis主从、哨兵、集群的概念: 【redis主从】: 是备份关系, 我们操作主库,数据也会同步到从库。 如果主库机器坏了,从库可以上。就好比你 D盘的片丢了,但是你移动硬盘里边备份有。 【redis哨兵】: 哨兵保证的是HA(高可用),保证特殊情况故障自动切换,哨兵盯着你的“redis主从集群”,如果主库死了,它会告诉你新的老大是谁。 哨兵:主要针对redis主从中的某一个单节点故障后,无法自动恢复的解决方案。(哨兵 保证redis主从的高可用) 【redis集群】: 集群保证的是高并发,因为多了一些兄弟帮忙一起扛。同时集群会导致数据的分散,整个redis集群会分成一堆数据槽,即不同的key会放到不不同的槽中。 集群主要针对单节点容量、高并发问题、线性可扩展性的解决方案。 集群:是为了解决redis主从复制中 单机内存上限和并发问题,假如你现在的服务器内存为256GB,当达到这个内存时redis就没办法再提供服务,同时数据量能达到这个地步写数据量也会很大,容易造成缓冲区溢出,造成从节点无限的进行全量复制导致主从无法正常工作。
-
 4月26日,湖南大学机器人学院教授孙斌一行赴湖南省鲲鹏生态创新中心调研,并展开项目合作洽谈,创新中心CTO张晓龙陪同。在座谈会中,双方就科研项目“多模态融合的机器人自然交互”合作事宜进行洽谈,创新CTO张晓龙详细介绍了湖南省鲲鹏产业发展情况,并表示创新中心将深度融合人工智能领域,助推国产数字化创新,以创新中心为平台和支撑,实现共建共赢的生态局面;湖南大学机器人学院教授孙斌对创新中心解决方案能力表示充分肯定,并表示希望通过双方的合作,尽快推动项目落实实施,实现人工智能与心理健康教育的交叉融合。“多模态融合的机器人自然交互”项目落地后,将对心理咨询的咨询流程和互动模式进行模拟,结合大数据的分析给出较为精准的指导建议。这样不但可以推动解决心理健康教育资源分配不均的现状,帮助心理教师提高指导效率,还可以提高心理健康知识的普及率,提前预防风险,间接降低危机事件的发生率。座谈结束后,孙斌一行参观了鲲鹏生态展厅,并听取了创新中心CTO张晓龙关于鲲鹏生态发展状况、鲲鹏产业链布局、人才培养等方面的介绍。湖南大学作为华为“智能基座”产教融合协同育人基地之一,同时也是创新中心长株潭校企科研共建签约单位,长期与创新中心保持人才培养等方面的合作,不断深化产教融合培养机制,共同助力湖南省鲲鹏计算产业蓬勃发展。此次来访进一步深化了双方合作,创新中心将依托自身技术优势,提供相关技术支撑, 携手湖南大学打造青少年心育好帮手,持续为青少年心理健康保驾护航。转自鲲鹏创新中心公众号
4月26日,湖南大学机器人学院教授孙斌一行赴湖南省鲲鹏生态创新中心调研,并展开项目合作洽谈,创新中心CTO张晓龙陪同。在座谈会中,双方就科研项目“多模态融合的机器人自然交互”合作事宜进行洽谈,创新CTO张晓龙详细介绍了湖南省鲲鹏产业发展情况,并表示创新中心将深度融合人工智能领域,助推国产数字化创新,以创新中心为平台和支撑,实现共建共赢的生态局面;湖南大学机器人学院教授孙斌对创新中心解决方案能力表示充分肯定,并表示希望通过双方的合作,尽快推动项目落实实施,实现人工智能与心理健康教育的交叉融合。“多模态融合的机器人自然交互”项目落地后,将对心理咨询的咨询流程和互动模式进行模拟,结合大数据的分析给出较为精准的指导建议。这样不但可以推动解决心理健康教育资源分配不均的现状,帮助心理教师提高指导效率,还可以提高心理健康知识的普及率,提前预防风险,间接降低危机事件的发生率。座谈结束后,孙斌一行参观了鲲鹏生态展厅,并听取了创新中心CTO张晓龙关于鲲鹏生态发展状况、鲲鹏产业链布局、人才培养等方面的介绍。湖南大学作为华为“智能基座”产教融合协同育人基地之一,同时也是创新中心长株潭校企科研共建签约单位,长期与创新中心保持人才培养等方面的合作,不断深化产教融合培养机制,共同助力湖南省鲲鹏计算产业蓬勃发展。此次来访进一步深化了双方合作,创新中心将依托自身技术优势,提供相关技术支撑, 携手湖南大学打造青少年心育好帮手,持续为青少年心理健康保驾护航。转自鲲鹏创新中心公众号 -
【功能模块】自定义了service的服务,此服务会在关机前运行在关机时打印了系统的日志。打印方法:获取到shutdown-log.txt时,并没有发现自定义脚本的运行的shell命令的相关日志。问题:如果能能够观测到自定义service文件在关机前的运行情况。
-
4月23日,中国邮政储蓄银行新一代个人业务分布式核心系统全面投产上线。该系统是大型商业银行中首家同时采用企业级业务建模和分布式微服务架构,基于鲲鹏硬件底座、openGauss开源数据库与GaussDB分布式云数据库共同打造的全新个人业务核心系统,是中国银行业金融科技关键技术可控的重大实践。邮储银行新一代个人业务核心系统通过企业级业务建模实现化繁为简,重塑核心交易流程;组件化模型驱动业务敏捷,从容应对市场变化与客户需求;分布式单元化部署实现弹性扩展,实时支撑业务变化;在线迁移方式实现客户无感切换,保障业务连续性,降低切换风险,为客户带来了新体验。新感受,更加快速高效。改版界面、优化流程、减少人工依赖,大幅缩短客户业务办理时间;新功能,更加智能强大。依托线上触达渠道,重点着眼于客户需求复杂的查询类业务,满足客户长周期、多元化、个性化需求;新设计,更加安全、可靠。完善的实时反欺诈系统,提高操作风险管控能力,同时帮客户降低潜在欺诈风险。鲲鹏、openGauss开源数据库与GaussDB分布式云数据库作为邮储银行新一代个人业务核心系统IT数字化底座组成部分,在其中承担了先进算力平台和高性能企业级数据库的重要角色,系统上线后可支撑海量交易、弹性伸缩、金融核心级高可靠和高可用,可具备为全行6.37亿个人客户、4万个网点提供日均20亿笔,峰值6.7万笔/秒的交易处理能力。邮储银行新一代个人业务核心系统全面投产上线,使邮储银行科技金融再添一部新引擎,将为邮储银行提供源源不断的科技动能,加速建设“一流大型零售银行”。同时鲲鹏、openGauss开源数据库与GaussDB分布式云数据库将继续全力支持邮储银行数字化升级,共同为同业积累经验,探明路径,树立标杆。
-
 恭喜以下用户获奖,请所有获奖用户于7月28日前完成数据核实,逾期未反馈则不可更改;于8月2日前登录鲲鹏社区完成实名认证并反馈收件信息,逾期未完成实名认证视为自动放弃奖品,谢谢配合 :) -->如何在鲲鹏社区完成实名认证?点击查看-->点击此处填写收件信息-->如实名认证时所用的手机号码和填写收件信息中的不同,请微信联系“鲲鹏小助手”说明情况,以免奖品发放失败,谢谢 :)注意:下面名单在7月28日前可能存在更新:因统计量较大,可能存在统计遗漏等情况,请所有用户尽快核实数据,如有问题请于7月28日前微信联系“鲲鹏小助手”说明情况,以免奖品发放失败,逾期未反馈则不可更改,谢谢 :)昵称所获奖项所得奖品allen1088最佳人气奖华为智能体脂秤 3bobby202000最佳人气奖华为智能体脂秤 3yd_255116640最佳人气奖华为智能体脂秤 3昵称小作业分数 昵称小作业分数 昵称小作业分数 昵称小作业分数hw102801075515yd_22864286111yd_2184680929yd_2942968477hw131766615yd_21641358811yd_2261775039hw68857tang12121215yd_22394384411yd_2998218019yd_2339329135Tianyi_Li15yd_22687905311yd_2854695679yd_2438806755yaowuerqierer15纸伞下的烟雨11yd_2490868789hw5503455yvan101015yd_26049844011yd_2569580949yd_2846501895duanlongtao13YanYC11yd_2458471039li**un(此为华为云账号)4yd_24789633113yd_22339605210河南科技大学杨磊9Flo***_Ma(此为华为云账号)4乌龟哥哥13gedeshidai10hw2559049yd_2946566184yd_27584684313yd_22970691610yd_2285920858yd_2802050654yd_21641161513yd_27290929310bobby2020008yd_26006822541833761535213yd_23648868610yd_2740982298yd_2637081874allen108812yd_24362622910yd_2144352838yd_2263642903满目星河12yd_26990001210yd_2989137018yd_2137326743ZhangYJ12yd_29639307810yd_2650165828hid_1a****0efv08umx(此为华为云账号)3yd_22240248312yd_25511664010hid_v0fy4ds5fxtdctn8yd_2352118463Oxide12二一横扫10hw81789228yd_2365057363惘纬11Car**CC(此为华为云账号)10yd_2227174507xx-1**38(此为华为云账号)3yd_25683864511hw18827310hid_lqj****d2tdc_7z(此为华为云账号)7yd_2297209372yd_22289020511yd_2589384069yd_2844549017昵称大作业积分 昵称大作业积分 昵称大作业积分allen108892Oxide68满目星河18bobby20200088yd_24789633167yd_29891370118yd_25511664083yd_21373267467yd_21763147815duanlongtao80yvan101066yd_27409822912yd_24362622980gedeshidai65tang12121210YanYC80yd_25695809465yaowuerqierer10yd_214435283791.83E+1065yd_2844549018yd_24908687879yd_29639307864hw10280107558yd_22240248379yd_21083176064时间幻想0yd_24584710378yd_24388067562yd_2286428610yd_22687905377yd_27735923760yd_2998218010Tianyi_Li77yd_22339605257yd_2620878680yd_25683864576yd_26049844056yd_2833216530yd_27584684375yd_25893840648yd_2403862590yd_21641161574yd_23648868644yd_2421129400yd_22271745073yd_22970691642yd_2688292690yd_22289020573yd_27290929338yd_2801445410yd_23393291373yd_29429684731hw1882730二一横扫73yd_26990001230yd_2710795890ZhangYJ72乌龟哥哥30hw68850纸伞下的烟雨70yd_23521184622yd_2805532390yd_26370818769yd_22636429018yd_2579395820yd_21641358868鲲鹏开发套件DevKit提供面向全研发作业流程的迁移、代码开发、编译调试、测试、性能分析调优、系统诊断等能力,实现海量应用到鲲鹏平台的快速迁移和极简开发,方便开发者快速开发出鲲鹏亲和的高性能软件。本次活动共布置3次小作业,每次5道选择题,每题1个积分。布置3次实操作业,实操作业帖每收到1条评论可获得1个积分,布道师根据实操作业质量打1-30个积分,我们将根据积分总数评选出3个“最佳人气奖”,分别奖励华为智能体脂秤 3 一个。 征集时间 2022.06.02 - 2020.07.19 第三次DevKit训练营小作业-鲲鹏性能分析工具>>点击答题 第二次DevKit训练营小作业-编译调试&开发框架插件>>点击答题 第一次DevKit训练营小作业-鲲鹏软件迁移实践>>点击答题 第三次实操作业相关要求 一、作业题目通过性能分析工具找出程序中加锁范围不合理的地方并解决二、操作前提1、认真观看性能分析工具得实操视频2、在鲲鹏社区申请远程实验室,操作系统选择OpenEulerhttps://www.hikunpeng.com/zh/developer/devkit三、准备工作1、打开网页,找到测试程序 :pthread_mutex_long.c ,复制里面的内容到本地同名的文件里https://github.com/kunpengcompute/devkitdemo/tree/main/Hyper_tuner/testdemo/lock 2、本地电脑通过ssh工具(如:MobalXtem)将pthread_mutex_long.c上传到远程实验室的服务器上,如 /home目录下3、授权文件:chmod 777 pthread_mutex_long.c 4、编译程序:gcc -g pthread_mutex_long.c -o pthread_mutex_long -lpthread -lm && chmod 777 pthread_mutex_long 5、绑核启动:taskset -c 0-1 ./pthread_mutex_long 四、作业要求1、操作步骤截图越细越好,每张截图最好加上说明。2、通过性能分析工具发现环境中有性能问题的目标程序。3、发现可调优的目标程序后,修改代码,重新使用性能分析工具进行分析,相关指标有变化说明调优成功。五、操作步骤截图示例:关键截图一:全景分析任务结果-性能tab通过cpu的相关指标看出cpu0 或 cpu1的 用户态使用率比较高。关键截图二:进程/线程性能分析任务结果-总览总览页签下查看各进程的CPU使用情况,发现启动命令为 ./pthread_mutex_long 的进程的用户态使用率高,这个正好也是我们启动的测试程序。关键截图三:资源调度分析任务结果-总览关键截图四:资源分析任务结果-进程/线程调度发现在采样期间两个线程之间的调度没有交集,没有平衡的相互交替运行,我们可以推断两个线程可能在抢占某个资源关键截图五:热点函数分析任务结果-总览测试程序的热点函数是 Func关键截图六:热点函数分析任务结果-热点函数源码通过对热点函数的源码分析,发现其中有一段业务逻辑并不涉及并发的场景,并且这块业务逻辑是Func函数中热度最高的,完全可以移到锁的范围之外去。关键截图七:代码优化前后关键截图八:代码优化后重新启动,资源分析任务结果-进程/线程调度测试程序的两个线程会平稳的进行,不会存在长时间的等待。 第二次实操作业相关要求 一、作业题目通过编译调试工具对一款数独游戏的源码进行编译调试。二、操作前提1、认真观看编译工具的实操视频。2、在鲲鹏社区申请远程实验室,操作系统选择OpenEuler。https://www.hikunpeng.com/zh/developer/devkit三、准备工作1、服务器和操作系统正常运行。2、VSCode已经安装编译调试插件。3、远端服务器已经安装Cmake 3.12及以上版本(低版本无法正常编译)。(1)使用cmake –version 查询cmake版本。(2)如果cmake版本低于3.12,则需要更新camke版本,具体教程可参考。https://blog.csdn.net/ghpanxt/article/details/1193821954、从https://github.com/mayerui/sudoku.git下载获取待使用的项目源文件并打开。(1)使用clone或download zip。(2)使用git可以本地直接打开;使用zip需要本地解压然后打开。5、从https://github.com/mayerui/sudoku获取编译及测试用例的命令。 Tips: 测试用例cwd字段需要绝对路径:配置服务器时的workspace + 项目名称 + 测试用例路径。四、作业要求1、操作步骤截图越细越好,每张截图最好加上说明。2、通过编译调试工具可以一键式进行编译及调试。五、操作步骤截图示例:01编译启动成功02 调试启动成功 第一次实操作业相关要求 一、作业题目利用扫描迁移工具进行源码分析,根据扫描建议修改源码,让源码在鲲鹏平台可以正常编译运行。二、操作前提1)认真观看迁移工具的实战视频。2)在鲲鹏社区申请远程实验室,操作系统选择OpenEuler。https://www.hikunpeng.com/zh/developer/devkit三、准备工作打开工具的web网页 ,并进行登录。准备Megahit源码。1)使用MobaXterm工具,以root用户登录服务器。2)进入“鲲鹏代码迁移工具”源码文件存放路径。cd /opt/portadv/portadmin/sourcecode/3)下载Megahit源码。git clone https://github.com/voutcn/megahit.git4)将代码进行合并。cd megahit/ && git submodule update –init5)创建构建文件夹并进入。mkdir build && cd build6)生成Makefile文件。cmake .. -DCMAKE_BUILD_TYPE=Release7)修改megahit目录属组。cd ../ && chown -R porting:porting *四、作业要求1、操作步骤截图越细越好,每张截图最好加上说明。2、通过源码迁移工具发现环境中有跨平台源码问题的源码文件。3、发现可修改的源码后,修改代码,重新进行编译运行。4、在作业提交贴回帖上传本份文档(word格式),将【五、操作步骤截图】内容替换成自己实际操作的步骤即可。五、操作步骤截图示例:1)源码分析参数填充2)启动一个源码迁移任务,任务执行成功,查看源码 报告。3)点击报告源码迁移建议,查看需要迁移的文件。4)根据系统提示的修改建议进行修改。5)迁移后重新编译,查看编译结果。6 )运行程序,查看回显信息。 活动规则 1)同一用户的多条评论,只能计为1次有效评论。2)内容原创不可抄袭,且必须和每讲视频内容相关,如存在洗稿、转载或抄袭等行为一经发现将取消活动资格。3)内容分享后,鲲鹏拥有该内容的使用权、修改权等。4)如果出现并列第3名,则优先发帖的用户获“最佳人气奖”。扫码添加“鲲鹏DevKit训练营交流群”企业微信,与同行大咖进行交流,咨询活动规则等,赶快扫码加入吧! 常见FAQ 1、如何回帖Word附件?
恭喜以下用户获奖,请所有获奖用户于7月28日前完成数据核实,逾期未反馈则不可更改;于8月2日前登录鲲鹏社区完成实名认证并反馈收件信息,逾期未完成实名认证视为自动放弃奖品,谢谢配合 :) -->如何在鲲鹏社区完成实名认证?点击查看-->点击此处填写收件信息-->如实名认证时所用的手机号码和填写收件信息中的不同,请微信联系“鲲鹏小助手”说明情况,以免奖品发放失败,谢谢 :)注意:下面名单在7月28日前可能存在更新:因统计量较大,可能存在统计遗漏等情况,请所有用户尽快核实数据,如有问题请于7月28日前微信联系“鲲鹏小助手”说明情况,以免奖品发放失败,逾期未反馈则不可更改,谢谢 :)昵称所获奖项所得奖品allen1088最佳人气奖华为智能体脂秤 3bobby202000最佳人气奖华为智能体脂秤 3yd_255116640最佳人气奖华为智能体脂秤 3昵称小作业分数 昵称小作业分数 昵称小作业分数 昵称小作业分数hw102801075515yd_22864286111yd_2184680929yd_2942968477hw131766615yd_21641358811yd_2261775039hw68857tang12121215yd_22394384411yd_2998218019yd_2339329135Tianyi_Li15yd_22687905311yd_2854695679yd_2438806755yaowuerqierer15纸伞下的烟雨11yd_2490868789hw5503455yvan101015yd_26049844011yd_2569580949yd_2846501895duanlongtao13YanYC11yd_2458471039li**un(此为华为云账号)4yd_24789633113yd_22339605210河南科技大学杨磊9Flo***_Ma(此为华为云账号)4乌龟哥哥13gedeshidai10hw2559049yd_2946566184yd_27584684313yd_22970691610yd_2285920858yd_2802050654yd_21641161513yd_27290929310bobby2020008yd_26006822541833761535213yd_23648868610yd_2740982298yd_2637081874allen108812yd_24362622910yd_2144352838yd_2263642903满目星河12yd_26990001210yd_2989137018yd_2137326743ZhangYJ12yd_29639307810yd_2650165828hid_1a****0efv08umx(此为华为云账号)3yd_22240248312yd_25511664010hid_v0fy4ds5fxtdctn8yd_2352118463Oxide12二一横扫10hw81789228yd_2365057363惘纬11Car**CC(此为华为云账号)10yd_2227174507xx-1**38(此为华为云账号)3yd_25683864511hw18827310hid_lqj****d2tdc_7z(此为华为云账号)7yd_2297209372yd_22289020511yd_2589384069yd_2844549017昵称大作业积分 昵称大作业积分 昵称大作业积分allen108892Oxide68满目星河18bobby20200088yd_24789633167yd_29891370118yd_25511664083yd_21373267467yd_21763147815duanlongtao80yvan101066yd_27409822912yd_24362622980gedeshidai65tang12121210YanYC80yd_25695809465yaowuerqierer10yd_214435283791.83E+1065yd_2844549018yd_24908687879yd_29639307864hw10280107558yd_22240248379yd_21083176064时间幻想0yd_24584710378yd_24388067562yd_2286428610yd_22687905377yd_27735923760yd_2998218010Tianyi_Li77yd_22339605257yd_2620878680yd_25683864576yd_26049844056yd_2833216530yd_27584684375yd_25893840648yd_2403862590yd_21641161574yd_23648868644yd_2421129400yd_22271745073yd_22970691642yd_2688292690yd_22289020573yd_27290929338yd_2801445410yd_23393291373yd_29429684731hw1882730二一横扫73yd_26990001230yd_2710795890ZhangYJ72乌龟哥哥30hw68850纸伞下的烟雨70yd_23521184622yd_2805532390yd_26370818769yd_22636429018yd_2579395820yd_21641358868鲲鹏开发套件DevKit提供面向全研发作业流程的迁移、代码开发、编译调试、测试、性能分析调优、系统诊断等能力,实现海量应用到鲲鹏平台的快速迁移和极简开发,方便开发者快速开发出鲲鹏亲和的高性能软件。本次活动共布置3次小作业,每次5道选择题,每题1个积分。布置3次实操作业,实操作业帖每收到1条评论可获得1个积分,布道师根据实操作业质量打1-30个积分,我们将根据积分总数评选出3个“最佳人气奖”,分别奖励华为智能体脂秤 3 一个。 征集时间 2022.06.02 - 2020.07.19 第三次DevKit训练营小作业-鲲鹏性能分析工具>>点击答题 第二次DevKit训练营小作业-编译调试&开发框架插件>>点击答题 第一次DevKit训练营小作业-鲲鹏软件迁移实践>>点击答题 第三次实操作业相关要求 一、作业题目通过性能分析工具找出程序中加锁范围不合理的地方并解决二、操作前提1、认真观看性能分析工具得实操视频2、在鲲鹏社区申请远程实验室,操作系统选择OpenEulerhttps://www.hikunpeng.com/zh/developer/devkit三、准备工作1、打开网页,找到测试程序 :pthread_mutex_long.c ,复制里面的内容到本地同名的文件里https://github.com/kunpengcompute/devkitdemo/tree/main/Hyper_tuner/testdemo/lock 2、本地电脑通过ssh工具(如:MobalXtem)将pthread_mutex_long.c上传到远程实验室的服务器上,如 /home目录下3、授权文件:chmod 777 pthread_mutex_long.c 4、编译程序:gcc -g pthread_mutex_long.c -o pthread_mutex_long -lpthread -lm && chmod 777 pthread_mutex_long 5、绑核启动:taskset -c 0-1 ./pthread_mutex_long 四、作业要求1、操作步骤截图越细越好,每张截图最好加上说明。2、通过性能分析工具发现环境中有性能问题的目标程序。3、发现可调优的目标程序后,修改代码,重新使用性能分析工具进行分析,相关指标有变化说明调优成功。五、操作步骤截图示例:关键截图一:全景分析任务结果-性能tab通过cpu的相关指标看出cpu0 或 cpu1的 用户态使用率比较高。关键截图二:进程/线程性能分析任务结果-总览总览页签下查看各进程的CPU使用情况,发现启动命令为 ./pthread_mutex_long 的进程的用户态使用率高,这个正好也是我们启动的测试程序。关键截图三:资源调度分析任务结果-总览关键截图四:资源分析任务结果-进程/线程调度发现在采样期间两个线程之间的调度没有交集,没有平衡的相互交替运行,我们可以推断两个线程可能在抢占某个资源关键截图五:热点函数分析任务结果-总览测试程序的热点函数是 Func关键截图六:热点函数分析任务结果-热点函数源码通过对热点函数的源码分析,发现其中有一段业务逻辑并不涉及并发的场景,并且这块业务逻辑是Func函数中热度最高的,完全可以移到锁的范围之外去。关键截图七:代码优化前后关键截图八:代码优化后重新启动,资源分析任务结果-进程/线程调度测试程序的两个线程会平稳的进行,不会存在长时间的等待。 第二次实操作业相关要求 一、作业题目通过编译调试工具对一款数独游戏的源码进行编译调试。二、操作前提1、认真观看编译工具的实操视频。2、在鲲鹏社区申请远程实验室,操作系统选择OpenEuler。https://www.hikunpeng.com/zh/developer/devkit三、准备工作1、服务器和操作系统正常运行。2、VSCode已经安装编译调试插件。3、远端服务器已经安装Cmake 3.12及以上版本(低版本无法正常编译)。(1)使用cmake –version 查询cmake版本。(2)如果cmake版本低于3.12,则需要更新camke版本,具体教程可参考。https://blog.csdn.net/ghpanxt/article/details/1193821954、从https://github.com/mayerui/sudoku.git下载获取待使用的项目源文件并打开。(1)使用clone或download zip。(2)使用git可以本地直接打开;使用zip需要本地解压然后打开。5、从https://github.com/mayerui/sudoku获取编译及测试用例的命令。 Tips: 测试用例cwd字段需要绝对路径:配置服务器时的workspace + 项目名称 + 测试用例路径。四、作业要求1、操作步骤截图越细越好,每张截图最好加上说明。2、通过编译调试工具可以一键式进行编译及调试。五、操作步骤截图示例:01编译启动成功02 调试启动成功 第一次实操作业相关要求 一、作业题目利用扫描迁移工具进行源码分析,根据扫描建议修改源码,让源码在鲲鹏平台可以正常编译运行。二、操作前提1)认真观看迁移工具的实战视频。2)在鲲鹏社区申请远程实验室,操作系统选择OpenEuler。https://www.hikunpeng.com/zh/developer/devkit三、准备工作打开工具的web网页 ,并进行登录。准备Megahit源码。1)使用MobaXterm工具,以root用户登录服务器。2)进入“鲲鹏代码迁移工具”源码文件存放路径。cd /opt/portadv/portadmin/sourcecode/3)下载Megahit源码。git clone https://github.com/voutcn/megahit.git4)将代码进行合并。cd megahit/ && git submodule update –init5)创建构建文件夹并进入。mkdir build && cd build6)生成Makefile文件。cmake .. -DCMAKE_BUILD_TYPE=Release7)修改megahit目录属组。cd ../ && chown -R porting:porting *四、作业要求1、操作步骤截图越细越好,每张截图最好加上说明。2、通过源码迁移工具发现环境中有跨平台源码问题的源码文件。3、发现可修改的源码后,修改代码,重新进行编译运行。4、在作业提交贴回帖上传本份文档(word格式),将【五、操作步骤截图】内容替换成自己实际操作的步骤即可。五、操作步骤截图示例:1)源码分析参数填充2)启动一个源码迁移任务,任务执行成功,查看源码 报告。3)点击报告源码迁移建议,查看需要迁移的文件。4)根据系统提示的修改建议进行修改。5)迁移后重新编译,查看编译结果。6 )运行程序,查看回显信息。 活动规则 1)同一用户的多条评论,只能计为1次有效评论。2)内容原创不可抄袭,且必须和每讲视频内容相关,如存在洗稿、转载或抄袭等行为一经发现将取消活动资格。3)内容分享后,鲲鹏拥有该内容的使用权、修改权等。4)如果出现并列第3名,则优先发帖的用户获“最佳人气奖”。扫码添加“鲲鹏DevKit训练营交流群”企业微信,与同行大咖进行交流,咨询活动规则等,赶快扫码加入吧! 常见FAQ 1、如何回帖Word附件?
上滑加载中
推荐直播
-
 华为云AI入门课:AI发展趋势与华为愿景
华为云AI入门课:AI发展趋势与华为愿景2024/11/18 周一 18:20-20:20
Alex 华为云学堂技术讲师
本期直播旨在帮助开发者熟悉理解AI技术概念,AI发展趋势,AI实用化前景,了解熟悉未来主要技术栈,当前发展瓶颈等行业化知识。帮助开发者在AI领域快速构建知识体系,构建职业竞争力。
去报名 -
 华为云软件开发生产线(CodeArts)10月新特性解读
华为云软件开发生产线(CodeArts)10月新特性解读2024/11/19 周二 19:00-20:00
苏柏亚培 华为云高级产品经理
不知道产品的最新特性?没法和产品团队建立直接的沟通?本期直播产品经理将为您解读华为云软件开发生产线10月发布的新特性,并在直播过程中为您答疑解惑。
去报名 -

热门标签