-
 2月24日,由CSDN主办的2022云原生超级英雄会在线上举行,与投身云原生的开发者们,共同探讨云原生领域的发展趋势与实践方法论。本次大会邀请了来自国内知名互联网公司、行业巨擘的一线云原生技术大咖,全方位洞悉云原生技术挑战,分享企业云原生落地实践痛点及经验,讲述开发者在适应云原生的黄金时代的变化中,需要加持哪些知识与能力,为开发者们拨开迷雾。非常高兴收到CSDN的邀请,来和大家探讨2022年的云原生展望。同时感谢徐诗瑶同学帮我把演讲整理成文。我们看到云原生的话题非常火爆,也知道了现在往后的技术发展都会有很大的部分会建立在云原生之上。所以今天也想和大家讲一下这个议题,为什么我们觉得在未来,会很大部分的发展建立在云原生之上。Kubernetes无处不在CNCF在每一年都会做年度调研,作为云原生的最重要的编排工具之一的Kubernetes(K8s)已经是无处不在,在不同的场景里面都有使用,包括在边缘计算,调查显示,在边缘计算中,大概76%都会使用到Kubernetes。大家如果接触一些新的技术,包括量级量子计算、5G、区块链以及AI方面等,都会涉及到云原生。说明云原生不再是我们考虑需不需要的问题了,它已经在很多的新的技术里面起到作用。我相信大家会在往后的日子里会碰到非常多云原生的技术问题,具体来说我们看一下边缘计算,边缘计算与云原生有非常密切的关系。我们在调研里面看到Kubernetes被高频率使用,在我们的总结中,边缘计算方面,大概有三分之二的开发者会使用边缘计算技术。大家可以多多关注一下这方面。在CNCF2021年度调研中,我们看到越来越多的人在使用云原生和Kubernetes,作为云原生容器编排工具,全球已经有96%的人会用到Kubernetes。这也证实了“Kubernetes无处不在”的说法。发展云原生,Kubernetes是一个必须的选项。另外,我们看到越来越多的Kubernetes已经在潜伏在很多的最底层的技术中,刚才看到新的技术都涉及到云原生,也是这个原因。老实说“Kubernetes is starting to go under the hood”,已经在底层发生作用了。在“under the hood”潜伏在底层技术的情况之下,90%会用到开发平台类似公有云做云原生的支持。所以可以看到目前非常多的云厂家会提供这些服务,我也看到越来越多的人使用公有云和混合云。总体来说,容器的采用和Kubernetes已经成为主流了。现在全世界有560万开发者的话,使用Kubernetes占后端开发者的31%。所以在未来开发者软件的路程中,多多少少会遇到Kubernetes。Kubernetes正在走向底层,90%的利用托管服务和方案平台的组织都会用到Kubernetes。现在目前非常多的云厂家以及云原生的开源项目都会支持Kubernetes,另外除了Kubernetes,也有很多人使用新的开源项目。在CNCF中,已经有120多个云原生的开源项目,很多公司为了能够掌握更多的开源技术,正在使用更多的不同的开源项目。虽然Kubernetes是最普遍的,但是我也推荐给大家其他不同的开源项目,大家可以参考一下。CNCF把开源的技术分为了三层:沙箱、孵化、毕业项目。大家可以多去了解一下这些全球都在使用的新技术。“Kubernetes在不断扩大的云原生社区中的使用率接近100%,这意味着那些投资云原生计算的人对未来充满信心和期待。"云原生计算基金会执行董事Priyanka Sharma说:“我们的数据还显示了云原生是多么普遍,无论是内部部署还是托管服务。我相信,随着容器基础设施的上层和底层不断成熟,2022年将成为边缘、可观测性和安全等新兴云原生领域的标志性一年。”世界也向着这个趋势发展,图中的用户例如丰田汽车、adidas等都在使用云原生。所以也可以补充说明一句,云原生无处不在。不止在新应用方面,旧用户也在使用。这对大家来说是一个非常好的发展方向。在国内,已经有42家企业拿到Kubernetes认可服务商的资格(KCSP),另外有34个认证过的Kubernetes 版本(Certified Kubernetes),还有12个是认可的培训伙伴 (KTP)。国内的贡献度在全球已经是第二位了,发展前景是非常乐观的。因此,云原生职业前景光明。在国内,已经有将上5000+经过培训和认证的专业人员,包括CKA、CKAD、CKS。CKA全名叫Certified Kubernetes Administrator,是面向管理者的;CKAD是针对开发者的;CKS是针对Kubernetes开发安全的。最后再次感谢CSDN的邀请,让我们携手推动云原生发展。原文链接:https://blog.csdn.net/cekeithchan/article/details/123210470
2月24日,由CSDN主办的2022云原生超级英雄会在线上举行,与投身云原生的开发者们,共同探讨云原生领域的发展趋势与实践方法论。本次大会邀请了来自国内知名互联网公司、行业巨擘的一线云原生技术大咖,全方位洞悉云原生技术挑战,分享企业云原生落地实践痛点及经验,讲述开发者在适应云原生的黄金时代的变化中,需要加持哪些知识与能力,为开发者们拨开迷雾。非常高兴收到CSDN的邀请,来和大家探讨2022年的云原生展望。同时感谢徐诗瑶同学帮我把演讲整理成文。我们看到云原生的话题非常火爆,也知道了现在往后的技术发展都会有很大的部分会建立在云原生之上。所以今天也想和大家讲一下这个议题,为什么我们觉得在未来,会很大部分的发展建立在云原生之上。Kubernetes无处不在CNCF在每一年都会做年度调研,作为云原生的最重要的编排工具之一的Kubernetes(K8s)已经是无处不在,在不同的场景里面都有使用,包括在边缘计算,调查显示,在边缘计算中,大概76%都会使用到Kubernetes。大家如果接触一些新的技术,包括量级量子计算、5G、区块链以及AI方面等,都会涉及到云原生。说明云原生不再是我们考虑需不需要的问题了,它已经在很多的新的技术里面起到作用。我相信大家会在往后的日子里会碰到非常多云原生的技术问题,具体来说我们看一下边缘计算,边缘计算与云原生有非常密切的关系。我们在调研里面看到Kubernetes被高频率使用,在我们的总结中,边缘计算方面,大概有三分之二的开发者会使用边缘计算技术。大家可以多多关注一下这方面。在CNCF2021年度调研中,我们看到越来越多的人在使用云原生和Kubernetes,作为云原生容器编排工具,全球已经有96%的人会用到Kubernetes。这也证实了“Kubernetes无处不在”的说法。发展云原生,Kubernetes是一个必须的选项。另外,我们看到越来越多的Kubernetes已经在潜伏在很多的最底层的技术中,刚才看到新的技术都涉及到云原生,也是这个原因。老实说“Kubernetes is starting to go under the hood”,已经在底层发生作用了。在“under the hood”潜伏在底层技术的情况之下,90%会用到开发平台类似公有云做云原生的支持。所以可以看到目前非常多的云厂家会提供这些服务,我也看到越来越多的人使用公有云和混合云。总体来说,容器的采用和Kubernetes已经成为主流了。现在全世界有560万开发者的话,使用Kubernetes占后端开发者的31%。所以在未来开发者软件的路程中,多多少少会遇到Kubernetes。Kubernetes正在走向底层,90%的利用托管服务和方案平台的组织都会用到Kubernetes。现在目前非常多的云厂家以及云原生的开源项目都会支持Kubernetes,另外除了Kubernetes,也有很多人使用新的开源项目。在CNCF中,已经有120多个云原生的开源项目,很多公司为了能够掌握更多的开源技术,正在使用更多的不同的开源项目。虽然Kubernetes是最普遍的,但是我也推荐给大家其他不同的开源项目,大家可以参考一下。CNCF把开源的技术分为了三层:沙箱、孵化、毕业项目。大家可以多去了解一下这些全球都在使用的新技术。“Kubernetes在不断扩大的云原生社区中的使用率接近100%,这意味着那些投资云原生计算的人对未来充满信心和期待。"云原生计算基金会执行董事Priyanka Sharma说:“我们的数据还显示了云原生是多么普遍,无论是内部部署还是托管服务。我相信,随着容器基础设施的上层和底层不断成熟,2022年将成为边缘、可观测性和安全等新兴云原生领域的标志性一年。”世界也向着这个趋势发展,图中的用户例如丰田汽车、adidas等都在使用云原生。所以也可以补充说明一句,云原生无处不在。不止在新应用方面,旧用户也在使用。这对大家来说是一个非常好的发展方向。在国内,已经有42家企业拿到Kubernetes认可服务商的资格(KCSP),另外有34个认证过的Kubernetes 版本(Certified Kubernetes),还有12个是认可的培训伙伴 (KTP)。国内的贡献度在全球已经是第二位了,发展前景是非常乐观的。因此,云原生职业前景光明。在国内,已经有将上5000+经过培训和认证的专业人员,包括CKA、CKAD、CKS。CKA全名叫Certified Kubernetes Administrator,是面向管理者的;CKAD是针对开发者的;CKS是针对Kubernetes开发安全的。最后再次感谢CSDN的邀请,让我们携手推动云原生发展。原文链接:https://blog.csdn.net/cekeithchan/article/details/123210470 -
 随着虚拟化技术的成熟和分布式框架的普及,在容器技术、可持续交付、编排系统等开源社区的推动下,应用上云已经是不可逆转的趋势,而云原生作为一套构建和运行应用程序的技术体系和方法论,已经在云上环境中发挥着重要优势。它充分利用和发挥云平台的弹性+分布式优势,为企业云上业务加速并提供保障。同时,其组织形式DevOps也为云原生提供着持续交付能力。本场沙龙,将围绕云原生以及DevOps展开讨论,帮助企业和用户搭建和规划全新的云原生应用,第一时间了解云新鲜技术,为企业安全应用建设保驾护航。|火线沙龙第23期|云原生&DevSecOps专场|时间|2022年3月5日(周六)19:00-22:00|地点|火线安全——bilibili直播间
随着虚拟化技术的成熟和分布式框架的普及,在容器技术、可持续交付、编排系统等开源社区的推动下,应用上云已经是不可逆转的趋势,而云原生作为一套构建和运行应用程序的技术体系和方法论,已经在云上环境中发挥着重要优势。它充分利用和发挥云平台的弹性+分布式优势,为企业云上业务加速并提供保障。同时,其组织形式DevOps也为云原生提供着持续交付能力。本场沙龙,将围绕云原生以及DevOps展开讨论,帮助企业和用户搭建和规划全新的云原生应用,第一时间了解云新鲜技术,为企业安全应用建设保驾护航。|火线沙龙第23期|云原生&DevSecOps专场|时间|2022年3月5日(周六)19:00-22:00|地点|火线安全——bilibili直播间 -
 本套课程由华为云云原生领域大咖精心打造,全面深入的对云原生的知识体系剖析。我们将课程分为三个阶段:黄金-->钻石-->王者,满足不同基础和学习目标人群的需求。精选数十个企业的典型应用场景,理论与实践相结合,帮助大家快速理解所学要点。集训营面向对象计算机、软件工程等专业的大学生涉及Kubernetes、Istio等技术的应用开发者其他的云原生技术兴趣爱好者课程5大亮点亮点1:系统化课程,进阶化提升本集训营课程分为黄金、钻石和王者三阶段,从云原生基础知识介绍到最佳实践讲解、底层原理和方案架构深度剖析,层层深入,可满足不同云原生技术基础和学习目标人群的需求。亮点2:选取典型应用场景,理论与实践相结合本集训营课程还将理论与实践相结合,精选数十个企业典型应用场景,作为学员上机实践案例,帮助学员将所学技术快速与企业业务相结合,服务于企业生产。亮点3:华为云资深专家带路,拒绝低效集训营讲师团队主要由华为云云原生团队核心架构师和资深工程师组成,包括多名CNCF社区的maintainer、深度参与了多个CNCF社区项目的设计和开发,具有丰厚的云原生技术积累和经验。亮点4:专属学习圈,教辅相伴,升阶无忧打造集训营专属学习交流群,学习助手贴心督学,全程跟进学员学习进展,实时反馈记录学员学习疑问,动态管理学员学习积分情况,教辅相伴,升阶无忧。亮点5:学练考一站式,多元化学习体验集训营围绕学练考一站式学习体验进行设计,包含干货课程学习、沙箱实验体验、微认证,同时还配套了开营直播、讲师在线答疑、小助手贴心督学等环节,极大丰富学员的学习体验。部分课程预览:学习链接:https://education.huaweicloud.com/programs/63384278-52ab-42e9-8e67-5dff5a9f37fd/about课程答疑:扫码添加小助手,加入课程交流群
本套课程由华为云云原生领域大咖精心打造,全面深入的对云原生的知识体系剖析。我们将课程分为三个阶段:黄金-->钻石-->王者,满足不同基础和学习目标人群的需求。精选数十个企业的典型应用场景,理论与实践相结合,帮助大家快速理解所学要点。集训营面向对象计算机、软件工程等专业的大学生涉及Kubernetes、Istio等技术的应用开发者其他的云原生技术兴趣爱好者课程5大亮点亮点1:系统化课程,进阶化提升本集训营课程分为黄金、钻石和王者三阶段,从云原生基础知识介绍到最佳实践讲解、底层原理和方案架构深度剖析,层层深入,可满足不同云原生技术基础和学习目标人群的需求。亮点2:选取典型应用场景,理论与实践相结合本集训营课程还将理论与实践相结合,精选数十个企业典型应用场景,作为学员上机实践案例,帮助学员将所学技术快速与企业业务相结合,服务于企业生产。亮点3:华为云资深专家带路,拒绝低效集训营讲师团队主要由华为云云原生团队核心架构师和资深工程师组成,包括多名CNCF社区的maintainer、深度参与了多个CNCF社区项目的设计和开发,具有丰厚的云原生技术积累和经验。亮点4:专属学习圈,教辅相伴,升阶无忧打造集训营专属学习交流群,学习助手贴心督学,全程跟进学员学习进展,实时反馈记录学员学习疑问,动态管理学员学习积分情况,教辅相伴,升阶无忧。亮点5:学练考一站式,多元化学习体验集训营围绕学练考一站式学习体验进行设计,包含干货课程学习、沙箱实验体验、微认证,同时还配套了开营直播、讲师在线答疑、小助手贴心督学等环节,极大丰富学员的学习体验。部分课程预览:学习链接:https://education.huaweicloud.com/programs/63384278-52ab-42e9-8e67-5dff5a9f37fd/about课程答疑:扫码添加小助手,加入课程交流群 -
 网络安全问题猛于虎,一个小的漏洞可能会导致业务系统全线崩溃,损失上千万。另一方面,网络安全又相对非常复杂,既有形形**的安全技术,又有各式各样的安全工程能力。正所谓“道高一尺魔高一丈”,不断的攻防对抗中,安全设计者也面临很大的挑战。华为云MVP毛哲文是PaaS产品的首席安全专家,她认为,“攻防之间要做到平衡,知己知彼才能做一个好的安全解决方案。”下面一起跟随这位在安全领域耕耘多年的技术老兵,看如何根据业务构建安全方案,将安全技术系统性的落地。网络安全问题千差万别,但核心是相似的从大学到工作,毛哲文一直和安全打交道,从传统操作系统安全到应用安全解决方案,从移动操作系统安全到移动应用生态安全,再从云计算安全到云应用生态安全,毛哲文体会到了安全的趣味性,以及蕴藏在其中的安全架构之美。在一系列与安全相关的工作中,毛哲文总结:“虽然研究的领域不一样,但最基本的安全模型不会有太大差异。就像当谈到OS安全时,往往讲到Biba模型及BLP模型。当你从安全的本质、安全架构的视角去解决形形**的安全问题时,即便这些问题在系统中所处的层级不一样,也不会觉着安全问题有太大的差异性。而且你会发现系统各个层级之间的安全关联性、安全依赖性都会非常强。总之,安全架构与安全能力的抽象,会让复杂的问题变得简单。”也就是说,不同领域的网络安全问题表面看起来千差万别,大相径庭,但往往要解决的核心问题又是高度相似。被信息安全领域广泛应用的安全目标是CIA,即机密性、完整性、可用性。只是不同领域和不同行业对具体的安全目标解读会略有不同。比如对一个企业级应用来说,“机密性”更多强调的是应用的业务数据只能被应该访问的人/应用/服务所访问;而对于一个移动终端系统应用来讲,“机密性”往往更侧重于对终端用户个人数据、个人隐私的保护能力。从业务、架构看安全解决方案的实施毛哲文强调:“网络安全解决方案不能脱离具体的业务,同样也离不开安全的软件架构。”做网络安全,首先需要知道具体的业务特征,据此来制定相应的、具体的安全目标。只有清楚具体的业务场景、业务的核心价值资产,才能明确网络安全所要保护的目标对象。在此基础之上,才能更好地做安全威胁分析,做对应的安全设计。用安全的语言来讲,做安全设计要清晰地知道系统中的主体是谁,客体是什么,然后确保只有正确的主体才能访问可以被访问的客体资源。毛哲文提到的另一个关键是安全架构。安全要解决的往往不是局部性的问题,但一个局部性的问题又会导致整个安全防守系统的失效。所以攻和防的对抗往往处于一个不对等的地位。正因如此,从防守方来看,如何将一个复杂系统做到系统性的安全,安全架构就显得尤为重要。安全架构可以帮助我们系统性地看待和解决安全问题。一个系统无论有多复杂,都能从安全架构的层面进行抽象、建模,然后实施具体的安全策略,做到安全的系统性和完备性。即便有局部的漏洞发生,也可以通过漏洞的修复来弥补,从容应对持续的攻防对抗。另外,如果系统同时还配备安全感知、安全响应、安全恢复的安全韧性能力,系统也能更好地应对局部的风险,让防守变得更加积极。相反,如果一个系统没有完备的安全架构设计,只是试图从局部解决安全问题,它就无法应对持续的攻防对抗过程,系统的安全同样也无法进行完备性证明,软件便往往以生命的结束而告终。安全架构是软件具备系统性安全的必要前提,但依旧不能保证生产出来的软件就是安全的,例如,代码质量会严重影响最终产品的安全质量;软件自身满足了安全质量,但软件的运行环境安全又同样会影响软件的安全结果。设计、开发、交付、运维一个高安全质量的系统、服务或应用,是个非常复杂的系统工程。毛哲文强调,“安全技术能力和安全工程能力的融合是至关重要的。”在云原生2.0时代,应用现代化的目标就是让开发者更多地聚焦业务逻辑,让应用快速迭代,从而满足企业的竞争力要求。这便对配套的应用生产工具以及基础的运行平台提出更高的安全要求,安全技术和安全工程能力的完美融合将成为应用生产工具和平台的核心竞争力。即应用生产和运行的基础平台需要支撑和具备完备的安全技术能力,如隔离与访问控制技术、机密性保护技术、完整性保护技术、安全韧性技术等,同时,也要求DevOps平台有一套完备的安全工程能力,让应用在生产和运行过程中能快速敏捷地落地安全,满足软件的安全质量要求。毛哲文以云原生安全为例,详细谈了谈如何保证应用的全生命周期安全。云原生下,如何确保应用全生命周期安全?当下云原生2.0正在加速改变每个行业中的各种组织,因为它能使这些组织运行的更加快速、更灵活、更加智能化。华为一直致力于云原生的现代化能力,为云原生应用的生产打造高效、安全等核心竞争力,确保客户能快速生产,部署,运维安全、合规的应用。针对应用的安全,可以抽象为三个维度,分别是应用安全,应用运行环境安全,应用安全运维。确保应用在这三个维度是安全可控的,并满足合规要求。云应用安全视图其中,应用安全通常要包含正确的认证、鉴权机制以及最小的权限管理,即正确的访问控制,确保正确的人/应用/服务才能访问该应用的数据,或者使用本应用提供的服务。应用运行环境安全囊括了网络安全、OS安全、容器安全、中间件安全等基础设施安全。安全运维则包括安全感知、安全响应、安全恢复等安全韧性能力。应用的安全贯穿应用整个生命周期,以华为云DevSecOps平台DevCloud 为例,它将华为多年积累的安全技术能力和安全工程能力进行深度融合,通过解决方案让安全顺利左移,确保应用在出生的过程中就是安全的、可信的,降低安全门槛,端到端提供安全设计开发能力、自动化测试能力,帮助客户快速构建端到端的研发体系,让安全能够敏捷落地于应用的生产、交付、运行过程中,更好更快更安全地支持多云多中心的分布式架构。安全设计与开发:在应用的开发过程中,提供安全设计能力,其中也包括安全合规设计能力;同时提供安全开发框架,包含统一的认证能力、数据安全管理能力、接口安全能力、web安全开发框架等;提供全量的代码检查能力,同时也支持在代码提交过程中,设置代码提交门禁,确保提交代码的质量,并包含多种语言的支持,对代码进行安全检查并针对问题提供修复及建议。降低整个设计与开发过程的安全成本,提升安全设计及代码的安全质量。安全测试:安全测试可以融入到应用生产的整个过程,从安全测试的设计,到用例的生成、执行,包含代码检测、漏洞检查等,都可以融入应用的生产和交付过程中。另一个要重点关注的是接口安全,包括接口的安全设计、安全运行、安全监控。例如:在设计阶段进行接口认证、鉴权、参数安全、协议安全等设计。测试用例和执行与接口设计实现自动化生成和适配,快速提升接口级安全。安全编译构建:编译构建阶段可以承载比较多的安全活动,包括构建前的代码检查、深度开源漏洞检测、隐私合规扫描、安全编译选项等等。安全发布:可配置相关安全门禁,如漏洞门禁等,同时包括病毒扫描、关键资产检查及软件签发过程,确保最终软件在交付过程中是安全的、完整的。安全运营与运维:安全运行阶段需要匹配稳定的、安全的运行环境,配套持续的安全监控能力,做到安全感知、响应和事后的恢复能力。安全度量与可视化:制定相应的安全度量标准,通过整个应用生命周期中的平台数据,可以在看板里展示服务生命不同环节中的安全度量结果,做到对应用的安全状态一目了然。应用的生命周期能够以看板的形式进行安全过程的可视化,以及运行状态的可视化。最后,毛哲文强调了软件工具链的安全问题。她指出,云原生安全对软件供应链的安全提出了更高要求,确保软件制品在整个生产过程中是可追溯的、安全的、可信的显得至关重要。尤其很多应用的开发基于大量开源软件,不仅要保证自研代码的安全性,还要保证应用所依赖的开源软件的安全,同样需要保证软件生产过程的安全性。华为一直都非常重视软件供应链的安全,并在工具链上构建全量能力,除了保证自研代码安全、开源依赖安全的能力之外,同时也保证整个软件生产和部署过程是可追溯、可审计的,包括软件供应链自身完整性保护,保证整个过程满足可信要求。
网络安全问题猛于虎,一个小的漏洞可能会导致业务系统全线崩溃,损失上千万。另一方面,网络安全又相对非常复杂,既有形形**的安全技术,又有各式各样的安全工程能力。正所谓“道高一尺魔高一丈”,不断的攻防对抗中,安全设计者也面临很大的挑战。华为云MVP毛哲文是PaaS产品的首席安全专家,她认为,“攻防之间要做到平衡,知己知彼才能做一个好的安全解决方案。”下面一起跟随这位在安全领域耕耘多年的技术老兵,看如何根据业务构建安全方案,将安全技术系统性的落地。网络安全问题千差万别,但核心是相似的从大学到工作,毛哲文一直和安全打交道,从传统操作系统安全到应用安全解决方案,从移动操作系统安全到移动应用生态安全,再从云计算安全到云应用生态安全,毛哲文体会到了安全的趣味性,以及蕴藏在其中的安全架构之美。在一系列与安全相关的工作中,毛哲文总结:“虽然研究的领域不一样,但最基本的安全模型不会有太大差异。就像当谈到OS安全时,往往讲到Biba模型及BLP模型。当你从安全的本质、安全架构的视角去解决形形**的安全问题时,即便这些问题在系统中所处的层级不一样,也不会觉着安全问题有太大的差异性。而且你会发现系统各个层级之间的安全关联性、安全依赖性都会非常强。总之,安全架构与安全能力的抽象,会让复杂的问题变得简单。”也就是说,不同领域的网络安全问题表面看起来千差万别,大相径庭,但往往要解决的核心问题又是高度相似。被信息安全领域广泛应用的安全目标是CIA,即机密性、完整性、可用性。只是不同领域和不同行业对具体的安全目标解读会略有不同。比如对一个企业级应用来说,“机密性”更多强调的是应用的业务数据只能被应该访问的人/应用/服务所访问;而对于一个移动终端系统应用来讲,“机密性”往往更侧重于对终端用户个人数据、个人隐私的保护能力。从业务、架构看安全解决方案的实施毛哲文强调:“网络安全解决方案不能脱离具体的业务,同样也离不开安全的软件架构。”做网络安全,首先需要知道具体的业务特征,据此来制定相应的、具体的安全目标。只有清楚具体的业务场景、业务的核心价值资产,才能明确网络安全所要保护的目标对象。在此基础之上,才能更好地做安全威胁分析,做对应的安全设计。用安全的语言来讲,做安全设计要清晰地知道系统中的主体是谁,客体是什么,然后确保只有正确的主体才能访问可以被访问的客体资源。毛哲文提到的另一个关键是安全架构。安全要解决的往往不是局部性的问题,但一个局部性的问题又会导致整个安全防守系统的失效。所以攻和防的对抗往往处于一个不对等的地位。正因如此,从防守方来看,如何将一个复杂系统做到系统性的安全,安全架构就显得尤为重要。安全架构可以帮助我们系统性地看待和解决安全问题。一个系统无论有多复杂,都能从安全架构的层面进行抽象、建模,然后实施具体的安全策略,做到安全的系统性和完备性。即便有局部的漏洞发生,也可以通过漏洞的修复来弥补,从容应对持续的攻防对抗。另外,如果系统同时还配备安全感知、安全响应、安全恢复的安全韧性能力,系统也能更好地应对局部的风险,让防守变得更加积极。相反,如果一个系统没有完备的安全架构设计,只是试图从局部解决安全问题,它就无法应对持续的攻防对抗过程,系统的安全同样也无法进行完备性证明,软件便往往以生命的结束而告终。安全架构是软件具备系统性安全的必要前提,但依旧不能保证生产出来的软件就是安全的,例如,代码质量会严重影响最终产品的安全质量;软件自身满足了安全质量,但软件的运行环境安全又同样会影响软件的安全结果。设计、开发、交付、运维一个高安全质量的系统、服务或应用,是个非常复杂的系统工程。毛哲文强调,“安全技术能力和安全工程能力的融合是至关重要的。”在云原生2.0时代,应用现代化的目标就是让开发者更多地聚焦业务逻辑,让应用快速迭代,从而满足企业的竞争力要求。这便对配套的应用生产工具以及基础的运行平台提出更高的安全要求,安全技术和安全工程能力的完美融合将成为应用生产工具和平台的核心竞争力。即应用生产和运行的基础平台需要支撑和具备完备的安全技术能力,如隔离与访问控制技术、机密性保护技术、完整性保护技术、安全韧性技术等,同时,也要求DevOps平台有一套完备的安全工程能力,让应用在生产和运行过程中能快速敏捷地落地安全,满足软件的安全质量要求。毛哲文以云原生安全为例,详细谈了谈如何保证应用的全生命周期安全。云原生下,如何确保应用全生命周期安全?当下云原生2.0正在加速改变每个行业中的各种组织,因为它能使这些组织运行的更加快速、更灵活、更加智能化。华为一直致力于云原生的现代化能力,为云原生应用的生产打造高效、安全等核心竞争力,确保客户能快速生产,部署,运维安全、合规的应用。针对应用的安全,可以抽象为三个维度,分别是应用安全,应用运行环境安全,应用安全运维。确保应用在这三个维度是安全可控的,并满足合规要求。云应用安全视图其中,应用安全通常要包含正确的认证、鉴权机制以及最小的权限管理,即正确的访问控制,确保正确的人/应用/服务才能访问该应用的数据,或者使用本应用提供的服务。应用运行环境安全囊括了网络安全、OS安全、容器安全、中间件安全等基础设施安全。安全运维则包括安全感知、安全响应、安全恢复等安全韧性能力。应用的安全贯穿应用整个生命周期,以华为云DevSecOps平台DevCloud 为例,它将华为多年积累的安全技术能力和安全工程能力进行深度融合,通过解决方案让安全顺利左移,确保应用在出生的过程中就是安全的、可信的,降低安全门槛,端到端提供安全设计开发能力、自动化测试能力,帮助客户快速构建端到端的研发体系,让安全能够敏捷落地于应用的生产、交付、运行过程中,更好更快更安全地支持多云多中心的分布式架构。安全设计与开发:在应用的开发过程中,提供安全设计能力,其中也包括安全合规设计能力;同时提供安全开发框架,包含统一的认证能力、数据安全管理能力、接口安全能力、web安全开发框架等;提供全量的代码检查能力,同时也支持在代码提交过程中,设置代码提交门禁,确保提交代码的质量,并包含多种语言的支持,对代码进行安全检查并针对问题提供修复及建议。降低整个设计与开发过程的安全成本,提升安全设计及代码的安全质量。安全测试:安全测试可以融入到应用生产的整个过程,从安全测试的设计,到用例的生成、执行,包含代码检测、漏洞检查等,都可以融入应用的生产和交付过程中。另一个要重点关注的是接口安全,包括接口的安全设计、安全运行、安全监控。例如:在设计阶段进行接口认证、鉴权、参数安全、协议安全等设计。测试用例和执行与接口设计实现自动化生成和适配,快速提升接口级安全。安全编译构建:编译构建阶段可以承载比较多的安全活动,包括构建前的代码检查、深度开源漏洞检测、隐私合规扫描、安全编译选项等等。安全发布:可配置相关安全门禁,如漏洞门禁等,同时包括病毒扫描、关键资产检查及软件签发过程,确保最终软件在交付过程中是安全的、完整的。安全运营与运维:安全运行阶段需要匹配稳定的、安全的运行环境,配套持续的安全监控能力,做到安全感知、响应和事后的恢复能力。安全度量与可视化:制定相应的安全度量标准,通过整个应用生命周期中的平台数据,可以在看板里展示服务生命不同环节中的安全度量结果,做到对应用的安全状态一目了然。应用的生命周期能够以看板的形式进行安全过程的可视化,以及运行状态的可视化。最后,毛哲文强调了软件工具链的安全问题。她指出,云原生安全对软件供应链的安全提出了更高要求,确保软件制品在整个生产过程中是可追溯的、安全的、可信的显得至关重要。尤其很多应用的开发基于大量开源软件,不仅要保证自研代码的安全性,还要保证应用所依赖的开源软件的安全,同样需要保证软件生产过程的安全性。华为一直都非常重视软件供应链的安全,并在工具链上构建全量能力,除了保证自研代码安全、开源依赖安全的能力之外,同时也保证整个软件生产和部署过程是可追溯、可审计的,包括软件供应链自身完整性保护,保证整个过程满足可信要求。 -
 点击报考——云原生入门级开发者认证点击观看——往期直播精彩回顾集锦(云原生入门级开发者认证试听课)---------------------------------------------------------------------------------------------------------------------------------------------------------------------->>>点击立即报名参与活动<<< 聚焦云上应用设计、构建和运维打造的系统化认证,帮助开发者基于华为云服务及工具进行开发、实践、应用构建,与云上技术齐驱并进,助力开发者职业成功。 华为云面向高校学生、个人开发者、企业开发及运维人员重磅推出——华为云云原生入门级开发者认证(HCCDA - Cloud Native)人才计划大咖直播+干货课程+沙箱实验+模拟考试,学练考一站式赋能学习掌握云原生核心理念和架构,提升基本开发实践能力,赢取多重精美好礼! >>>点击了解活动详情与获奖规则<<< 【活动时间】 :2022年3月9日-4月2日 【活动亮点】:聚焦云原生热门技术领域,华为云专家精研认证课程,学练考测一站式学习赋能,获取官方认证和丰富好礼 【活动流程】:点击了解活动详情,了解具体活动流程,不错过任一精彩环节 step1.活动报名(扫码或点击活动页一键报名)⇒ step2.课程直播(观看直播,学习干货课程)⇒ step3.沙箱实验(动手实验,巩固所学知识)⇒ step4.模拟测试(参加模拟测试,检验学习效果)⇒ step5.报考认证(通过认证,赢取丰富认证权益) 【活动内容图谱】: 【活动奖品】:奖品贯穿活动全程,包含:华为手环4e、罗技键鼠套装、雷柏机械键盘V500、京东京造金属鼠标垫、定制双肩包、折叠帆布包、定制键盘、价值500元的全额认证考试券、价值400元的2折认证考试券、价值350元的3折认证考试券、价值200元的6折认证考试券 【活动加群学习】 :扫码备注“HCCDA”加群,了解最新学习与获奖信息,如扫码失败,可添加小助手微信HWcloudedu加群。 【活动获奖攻略】: 华为云云原生入门级开发者认证(HCCDA - Cloud Native)人才计划活动获奖攻略活动模块具体环节奖品名称获奖条件HCCDA - Cloud Native 宣发会签到/互动抽奖罗技键鼠套装成功报名活动,参加宣发会直播,积极互动,随机抽取10名幸运儿赢取宣发会直播抽奖价值500元的全额认证考试券成功报名活动,参加宣发会直播,积极互动,随机抽取6名幸运儿赢取价值350元的3折认证考试券成功报名活动,参加宣发会直播,积极互动,随机抽取6名幸运儿赢取雷柏机械键盘V500成功报名活动,参加宣发会直播,积极互动,随机抽取6名幸运儿赢取HCCDA - Cloud Native 人才计划正式活动观看课程-直播奖京东京造金属鼠标垫报名观看每场课程直播,积极互动,每场直播随机抽取3名幸运儿赢取价值350元的3折认证考试券1.报名课程学习直播,观看直播,参与抽奖2.累计8场直播,每场课程-直播抽取3名幸运儿赢取价值500元的全额认证考试券1.在100%观看完8场直播的用户群中,抽取10名幸运儿赢取;2.且成功报名云原生入门级开发者认证人才计划活动。雷柏机械键盘V500定制双肩包1.观看课程直播,在直播期间下单购买认证;2.凭购买的截图跟小助手Hwcloudedu联系赢取,名额有限,先到先得。完成沙箱实验奖价值350元的3折认证考试券分别在6个实验中,各抽取3名100%完成实验的幸运儿赢取价值500元的全额认证考试券在100%完成6个沙箱实验的用户中,抽10名幸运儿赢取无线鼠标在100%完成6个沙箱实验的用户中,抽6名幸运儿赢取通过模拟测试奖价值500元的全额认证考试券高分通过模拟测试的前15名,赢取全额认证考试券获奖用户需成功报名活动+观看完活动的8场直播/回顾+100%完成活动的6门实验价值200元的6折认证考试券高分通过模拟测试的前16-60名,赢取6折认证考试券获奖用户需成功报名活动+观看完活动的8场直播/回顾+100%完成活动的6门实验通过开发者认证奖定制双肩包参加正式活动的用户群,在规定时间内通过认证,拿到HCCDA - Cloud Native证书,按照持证时间排名:1.排名1-10的用户赢取定制双肩包;2.排名11-20的用户赢取定制键盘;3.排名21-30的用户赢取折叠帆布包。定制键盘折叠帆布包备注说明1.若发放奖品时,出现库存不足,则优先发放等价值的其他奖品。2.用户限制说明:a、 参加本次活动的用户必须为华为云注册用户。同时为保证活动公平性,禁止用户以IAM账号身份参与活动,否则将视为无效。b、 领取奖品的用户需为华为云实名用户且完成活动报名,未完成将不发放活动奖励。c、 本活动适应同一用户规则,同奖项内奖品不可多次获取(如有特殊说明除外):同一用户是指根据不同华为云账号在注册、登录、使用中的关联信息,华为云判断其实际为同一用户;举例说明:具备同一证件号(比如身份证号/护照ID/海外驾照ID/企业唯一识别号等)、同一手机号、同一设备、同一IP地址等;d、 本次活动一个实名认证账号只能对应一个收件人,如同一账号填写多个不同收件人,不予发放奖励。e、 活动报名后,请勿修改社区昵称和华为云账号,由此产生的统计问题,如过了申诉期,小助手不再处理。(申诉期为活动结果公示7天内。) 部分获奖名单公示:1.华为云云原生入门级开发者认证人才计划直播活动中奖名单,见于附件01; 2.华为云云原生入门级开发者认证人才计划活动模拟测试获奖名单,见于附件02;3.华为云云原生入门级开发者认证人才计划活动完成沙箱实验获奖名单,见于附件03;4.有奖调研丨华为云云原生入门级开发者认证人才计划活动获奖名单,见于附件04;【温馨提示】在活动环节中了认证考试券的部分同学账号,系统在发券过程中反馈如下信息,请于4月15日12:00前跟小助手联系,更正后发放,逾期不候。公示期截至4月11日18:00,相关奖品将在公示期后相继安排寄出请获奖人员于4月15日18:00前添加华为云开发者认证小助手微信Hwabby666888未及时填写有效收件地址的直播部分中奖用户,请在公示期有效期内联系小助手补充登记,逾期视为自动放弃。若对公示结果有异议,也可以私信本帖楼主或者联系华为云开发者认证小助手,我们将认真核实与回复。 活动须知:开奖及奖品发放事宜(1)本次活动获奖名单届时将在本活动帖中公示,公示期为2022年4月11-15日,认证通过名单公示期为5月6-10日,相关奖品将在公示期结束后7个工作日发出,届时敬请关注相关信息。(2)您理解并同意,在适用的法律法规允许范围内,为确保奖品顺利发放,受限于奖品当时的库存状况等,华为有权对上述事项进行调整(如奖品以实际发放为准,价格不低于示例奖品)并向您提前告知。每位参加活动的用户理解并同意,活动主办方收集该等个人信息会转移给礼品发放的快递供应商公司负责具体执行礼品的邮递服务。收集的该等个人信息会自奖品寄出及发放结束后(为防止奖品遗失等突发情况)保留30个自然日用于邮寄快递服务、通过邮箱发放考券等,自该期限届满后,该等所有数据会被删除或者销毁,在主办方持有该个人数据期间,用户可以联系华为云按照法律规定履行数据主体的权利,包括但不限于撤销同意、请求删除、访问、查阅或者复制、更正或者补充、删除、知情权、决定权、您有权要求我们对您的个人信息处理规则进行解释说明。若需行使上述权利,联系方式请见《隐私政策声明》。为保证活动的公平公正,华为云有权对恶意刷活动资源(“恶意”是指为获取资源而异常注册账号等**活动公平性的行为),利用资源从事违法违规行为的用户收回奖励资格。本活动规则由华为云在法律规定范围内进行解释。华为云保留不时更新、修改或删除本活动规则的权利。上述更新、修改或删除于公布时即时生效,用户应当主动查阅本活动规则的最新内容;所有参加本活动的用户,均视为认可并自觉遵守《华为云用户协议》、《可接受的使用政策》、《隐私政策声明》、《华为云开发者生态隐私政策声明(补充华为云开发者学堂活动特别说明)》。相关服务等级协议(SLA),以及华为云服务网站规定的其他协议和政策(统称为“云服务协议”)的约束。云服务协议链接的网址:http://www.huaweicloud.com/declaration/sa_cua.html如果您不同意本活动规则和云服务协议的条款,请勿参加本活动。
点击报考——云原生入门级开发者认证点击观看——往期直播精彩回顾集锦(云原生入门级开发者认证试听课)---------------------------------------------------------------------------------------------------------------------------------------------------------------------->>>点击立即报名参与活动<<< 聚焦云上应用设计、构建和运维打造的系统化认证,帮助开发者基于华为云服务及工具进行开发、实践、应用构建,与云上技术齐驱并进,助力开发者职业成功。 华为云面向高校学生、个人开发者、企业开发及运维人员重磅推出——华为云云原生入门级开发者认证(HCCDA - Cloud Native)人才计划大咖直播+干货课程+沙箱实验+模拟考试,学练考一站式赋能学习掌握云原生核心理念和架构,提升基本开发实践能力,赢取多重精美好礼! >>>点击了解活动详情与获奖规则<<< 【活动时间】 :2022年3月9日-4月2日 【活动亮点】:聚焦云原生热门技术领域,华为云专家精研认证课程,学练考测一站式学习赋能,获取官方认证和丰富好礼 【活动流程】:点击了解活动详情,了解具体活动流程,不错过任一精彩环节 step1.活动报名(扫码或点击活动页一键报名)⇒ step2.课程直播(观看直播,学习干货课程)⇒ step3.沙箱实验(动手实验,巩固所学知识)⇒ step4.模拟测试(参加模拟测试,检验学习效果)⇒ step5.报考认证(通过认证,赢取丰富认证权益) 【活动内容图谱】: 【活动奖品】:奖品贯穿活动全程,包含:华为手环4e、罗技键鼠套装、雷柏机械键盘V500、京东京造金属鼠标垫、定制双肩包、折叠帆布包、定制键盘、价值500元的全额认证考试券、价值400元的2折认证考试券、价值350元的3折认证考试券、价值200元的6折认证考试券 【活动加群学习】 :扫码备注“HCCDA”加群,了解最新学习与获奖信息,如扫码失败,可添加小助手微信HWcloudedu加群。 【活动获奖攻略】: 华为云云原生入门级开发者认证(HCCDA - Cloud Native)人才计划活动获奖攻略活动模块具体环节奖品名称获奖条件HCCDA - Cloud Native 宣发会签到/互动抽奖罗技键鼠套装成功报名活动,参加宣发会直播,积极互动,随机抽取10名幸运儿赢取宣发会直播抽奖价值500元的全额认证考试券成功报名活动,参加宣发会直播,积极互动,随机抽取6名幸运儿赢取价值350元的3折认证考试券成功报名活动,参加宣发会直播,积极互动,随机抽取6名幸运儿赢取雷柏机械键盘V500成功报名活动,参加宣发会直播,积极互动,随机抽取6名幸运儿赢取HCCDA - Cloud Native 人才计划正式活动观看课程-直播奖京东京造金属鼠标垫报名观看每场课程直播,积极互动,每场直播随机抽取3名幸运儿赢取价值350元的3折认证考试券1.报名课程学习直播,观看直播,参与抽奖2.累计8场直播,每场课程-直播抽取3名幸运儿赢取价值500元的全额认证考试券1.在100%观看完8场直播的用户群中,抽取10名幸运儿赢取;2.且成功报名云原生入门级开发者认证人才计划活动。雷柏机械键盘V500定制双肩包1.观看课程直播,在直播期间下单购买认证;2.凭购买的截图跟小助手Hwcloudedu联系赢取,名额有限,先到先得。完成沙箱实验奖价值350元的3折认证考试券分别在6个实验中,各抽取3名100%完成实验的幸运儿赢取价值500元的全额认证考试券在100%完成6个沙箱实验的用户中,抽10名幸运儿赢取无线鼠标在100%完成6个沙箱实验的用户中,抽6名幸运儿赢取通过模拟测试奖价值500元的全额认证考试券高分通过模拟测试的前15名,赢取全额认证考试券获奖用户需成功报名活动+观看完活动的8场直播/回顾+100%完成活动的6门实验价值200元的6折认证考试券高分通过模拟测试的前16-60名,赢取6折认证考试券获奖用户需成功报名活动+观看完活动的8场直播/回顾+100%完成活动的6门实验通过开发者认证奖定制双肩包参加正式活动的用户群,在规定时间内通过认证,拿到HCCDA - Cloud Native证书,按照持证时间排名:1.排名1-10的用户赢取定制双肩包;2.排名11-20的用户赢取定制键盘;3.排名21-30的用户赢取折叠帆布包。定制键盘折叠帆布包备注说明1.若发放奖品时,出现库存不足,则优先发放等价值的其他奖品。2.用户限制说明:a、 参加本次活动的用户必须为华为云注册用户。同时为保证活动公平性,禁止用户以IAM账号身份参与活动,否则将视为无效。b、 领取奖品的用户需为华为云实名用户且完成活动报名,未完成将不发放活动奖励。c、 本活动适应同一用户规则,同奖项内奖品不可多次获取(如有特殊说明除外):同一用户是指根据不同华为云账号在注册、登录、使用中的关联信息,华为云判断其实际为同一用户;举例说明:具备同一证件号(比如身份证号/护照ID/海外驾照ID/企业唯一识别号等)、同一手机号、同一设备、同一IP地址等;d、 本次活动一个实名认证账号只能对应一个收件人,如同一账号填写多个不同收件人,不予发放奖励。e、 活动报名后,请勿修改社区昵称和华为云账号,由此产生的统计问题,如过了申诉期,小助手不再处理。(申诉期为活动结果公示7天内。) 部分获奖名单公示:1.华为云云原生入门级开发者认证人才计划直播活动中奖名单,见于附件01; 2.华为云云原生入门级开发者认证人才计划活动模拟测试获奖名单,见于附件02;3.华为云云原生入门级开发者认证人才计划活动完成沙箱实验获奖名单,见于附件03;4.有奖调研丨华为云云原生入门级开发者认证人才计划活动获奖名单,见于附件04;【温馨提示】在活动环节中了认证考试券的部分同学账号,系统在发券过程中反馈如下信息,请于4月15日12:00前跟小助手联系,更正后发放,逾期不候。公示期截至4月11日18:00,相关奖品将在公示期后相继安排寄出请获奖人员于4月15日18:00前添加华为云开发者认证小助手微信Hwabby666888未及时填写有效收件地址的直播部分中奖用户,请在公示期有效期内联系小助手补充登记,逾期视为自动放弃。若对公示结果有异议,也可以私信本帖楼主或者联系华为云开发者认证小助手,我们将认真核实与回复。 活动须知:开奖及奖品发放事宜(1)本次活动获奖名单届时将在本活动帖中公示,公示期为2022年4月11-15日,认证通过名单公示期为5月6-10日,相关奖品将在公示期结束后7个工作日发出,届时敬请关注相关信息。(2)您理解并同意,在适用的法律法规允许范围内,为确保奖品顺利发放,受限于奖品当时的库存状况等,华为有权对上述事项进行调整(如奖品以实际发放为准,价格不低于示例奖品)并向您提前告知。每位参加活动的用户理解并同意,活动主办方收集该等个人信息会转移给礼品发放的快递供应商公司负责具体执行礼品的邮递服务。收集的该等个人信息会自奖品寄出及发放结束后(为防止奖品遗失等突发情况)保留30个自然日用于邮寄快递服务、通过邮箱发放考券等,自该期限届满后,该等所有数据会被删除或者销毁,在主办方持有该个人数据期间,用户可以联系华为云按照法律规定履行数据主体的权利,包括但不限于撤销同意、请求删除、访问、查阅或者复制、更正或者补充、删除、知情权、决定权、您有权要求我们对您的个人信息处理规则进行解释说明。若需行使上述权利,联系方式请见《隐私政策声明》。为保证活动的公平公正,华为云有权对恶意刷活动资源(“恶意”是指为获取资源而异常注册账号等**活动公平性的行为),利用资源从事违法违规行为的用户收回奖励资格。本活动规则由华为云在法律规定范围内进行解释。华为云保留不时更新、修改或删除本活动规则的权利。上述更新、修改或删除于公布时即时生效,用户应当主动查阅本活动规则的最新内容;所有参加本活动的用户,均视为认可并自觉遵守《华为云用户协议》、《可接受的使用政策》、《隐私政策声明》、《华为云开发者生态隐私政策声明(补充华为云开发者学堂活动特别说明)》。相关服务等级协议(SLA),以及华为云服务网站规定的其他协议和政策(统称为“云服务协议”)的约束。云服务协议链接的网址:http://www.huaweicloud.com/declaration/sa_cua.html如果您不同意本活动规则和云服务协议的条款,请勿参加本活动。 -
 大数据技术的内涵伴随着传统信息技术和数据应用的发展不断演进,而大数据技术体系的核心始终是面向海量数据的存储、计算、处理等基础技术。支撑数据存储计算的软件系统起源于20世纪60年代的数据库;70年代出现的关系型数据库成为了沿用至今最常用的数据存储计算系统;80年代末,专门面向数据分析决策的数据仓库理论被提出,成为接下来很长一段时间内发掘数据价值的主要工具和手段。2000年前后,面向非结构化数据的NoSQL数据库兴起。2010年前后,对于大量异构数据源进行统一存储使用的需求催生了数据湖概念。同时随着云计算技术的深入应用,大数据技术完成了从私有化部署到云上部署再向云原生的转变。近年来Hudi、Iceberg、Delta Lake三大开源数据湖的面世推动数据湖整体进入产品化阶段。与此同时,与容器、Serverless等云原生技术的深度融合,引领数据湖产品开始走向云原生。云原生数据湖支持异构数据灵活存储、计算资源弹性伸缩,能够帮助企业应对当前数据结构愈发复杂、数据处理分析时效性要求不断提高的业务环境。但云原生数据湖仍处于发展初期,技术路线不统一,业内产品能力良莠不齐。中国信通院云计算与大数据研究所依托中国通信标准化协会大数据技术标准推进委员会(CCSA TC601),联合腾讯云、阿里云、华为、星环、百度、海康威视、亚信、中国移动云能力中心等企业的二十余位专家共同参与编制完成了《云原生数据湖技术要求与测试方法》,帮助大数据产品供应商及用户方评估云原生数据湖的技术能力和研发方向。本标准在体现存算分离、弹性扩缩容、统一元数据管理等云原生能力的同时,覆盖了云原生数据湖所具备的一系列能力,总体分为存储能力、计算能力、安全能力、数据管理能力、兼容能力、运维能力、湖应用能力、高可用能力八个能力域。目前,中国信通院依据该标准正式启动首批云原生数据湖评测工作,作为“可信大数据”产品能力评测体系的新项目。2022年6月份“大数据产业峰会”上将为通过首批评测的产品颁发证书。欢迎相关单位积极报名参与。
大数据技术的内涵伴随着传统信息技术和数据应用的发展不断演进,而大数据技术体系的核心始终是面向海量数据的存储、计算、处理等基础技术。支撑数据存储计算的软件系统起源于20世纪60年代的数据库;70年代出现的关系型数据库成为了沿用至今最常用的数据存储计算系统;80年代末,专门面向数据分析决策的数据仓库理论被提出,成为接下来很长一段时间内发掘数据价值的主要工具和手段。2000年前后,面向非结构化数据的NoSQL数据库兴起。2010年前后,对于大量异构数据源进行统一存储使用的需求催生了数据湖概念。同时随着云计算技术的深入应用,大数据技术完成了从私有化部署到云上部署再向云原生的转变。近年来Hudi、Iceberg、Delta Lake三大开源数据湖的面世推动数据湖整体进入产品化阶段。与此同时,与容器、Serverless等云原生技术的深度融合,引领数据湖产品开始走向云原生。云原生数据湖支持异构数据灵活存储、计算资源弹性伸缩,能够帮助企业应对当前数据结构愈发复杂、数据处理分析时效性要求不断提高的业务环境。但云原生数据湖仍处于发展初期,技术路线不统一,业内产品能力良莠不齐。中国信通院云计算与大数据研究所依托中国通信标准化协会大数据技术标准推进委员会(CCSA TC601),联合腾讯云、阿里云、华为、星环、百度、海康威视、亚信、中国移动云能力中心等企业的二十余位专家共同参与编制完成了《云原生数据湖技术要求与测试方法》,帮助大数据产品供应商及用户方评估云原生数据湖的技术能力和研发方向。本标准在体现存算分离、弹性扩缩容、统一元数据管理等云原生能力的同时,覆盖了云原生数据湖所具备的一系列能力,总体分为存储能力、计算能力、安全能力、数据管理能力、兼容能力、运维能力、湖应用能力、高可用能力八个能力域。目前,中国信通院依据该标准正式启动首批云原生数据湖评测工作,作为“可信大数据”产品能力评测体系的新项目。2022年6月份“大数据产业峰会”上将为通过首批评测的产品颁发证书。欢迎相关单位积极报名参与。 -
如今,企业面临着指数级递增的海量存储需求,业务也面临更多的热点和突发流量带来的挑战。由于企业需要降本增效,进行更智能的数据决策,传统的商业数据库已经难以满足和响应快速增长的业务诉求。在此背景下,云原生数据库成为大势所趋,不管是老牌的数据库厂商,还是大型云计算企业都在向这一趋势靠拢。全球知名咨询公司Gartner指出,云将主导数据库市场的未来,到2022年,75%的数据库将被部署或迁移至云平台,只有25%的数据库会在本地运行。云化无疑代表了未来,企业如何在云原生架构下使用数据库,就成为必须要思考的问题。云原生数据库正当时云原生数据库,是一种通过云平台进行构建、部署和分发的服务。这种云原生属性是相比于其他类型数据库最大的特点。作为一种云平台,云原生数据库以PaaS的形式进行分发,用户可以将该平台用于多种目的,例如存储、管理和提取数据。云原生数据库通常通过在云基础设施之上安装数据库软件来实现,这种方式使得云原生数据库具备了传统数据库所不具备的直接访问性和运行时可伸缩性。首先是普遍可访问和高可用性。因为云原生数据库是完全存在于云上的,所以可以随时随地从多前端访问,提供云服务的计算节点。因其集群部署在云上,所以单点失败对服务的影响特别小。当需要升级或更换服务的时候,可以对节点进行不中断服务的逐渐升级。其次是高扩展性与可迁移性。云原生数据库会与底层的云计算基础设施分离,所以能够灵活及时的调动资源进行扩容和缩容,从容应对流量激增可能带来的压力,以及流量低谷期因资源过剩造成的浪费。正是因为能够灵活扩缩容,云原生数据库也具备很强的可迁移性,我们甚至可以粗暴的理解为,在新的位置扩容100%,又在旧的位置缩容全部的50%。此外,云原生数据库还具备可监控性和安全性的特征。在传统数据库的黑箱状态下,是无法保证及时处理扩容、节点故障等需求和问题的,但是云原生数据库全盘部署在云上,且各服务之间相互独立,因此可以对应用或服务提供更多层的安全防护,并实现许多新的容错服务。最后是演进式设计与快速迭代。云原生数据库中的各项服务之间是相互独立的,个别服务的更新并不会对其他部分产生不利影响,而不是一旦出了问题就只能全场熄火。此外,云原生的研发测试和运维工具是高度自动化的,这使得应用的更新会更加快速频繁。下一代云原生数据库架构近十年是数据库市场发展最快的十年。根据Gartner的数据,目前数据库市场营收已经达到整个软件市场的18.4%,而云数据库贡献了其中的68%。特别是近几年,云原生数据库的理念为市场和各大云厂商所认可,各大厂商纷纷在自研云原生数据库领域持续发力,未来的云数据库市场是自研云原生数据库之间的竞争。在云原生数据库领域,AWS于2014年推出的Aurora是先行者。国内厂商也不甘落后,阿里云在2017年推出了PolarDB,腾讯云在2018年推出了CynosDB,华为云在2020年推出了GaussDB for MySQL。各大厂商都希望基于成熟的基础设施“云”化技术,解决传统数据库架构上的短板。尽管云原生数据库的出现,很好地解决了传统架构数据库的诸多缺陷,如:数据问题回档慢、维护成本高、可用性低、故障恢复慢等,让企业能够更高性能且灵活地访问数据。但不可否认的是,云原生数据库才刚刚走出了第一步。首先是实现了存储和计算分离,打破了存储的单机限制,使得存储独立弹性成为可能,并为后续的一写多读集群奠定了基础。其次是基于分布式共享存储的一写多读架构,使得数据库的读能力可以快速Scale Out,同时由于多个读节点和写节点共享同一份存储,降低了成本,提升了资源利用率。虽然当前的云原生架构解决了存储的弹性问题和读扩展问题,极大的提升了云原生数据库的弹性和扩展能力,但是依然存在两个比较大的瓶颈点,即内存弹性和单点写入问题。因此,阿里云数据库的总负责人、达摩院数据库首席科学家李飞飞认为,下一代云原生数据库架构将在以下两个方向实现突破:基于CPU和内存分离的分布式共享内存池当前的云原生架构虽然实现了存储和计算分离,存储独立弹性,但是计算节点仍然包含了CPU和内存,无法真正实现秒级弹性扩容和Serverless。因此在云原生数据库中实现CPU和内存分离,内存独立弹性非常有必要。同时CPU和内存分离可以让多个CPU共享同一份内存,降低内存资源开销。基于分布式共享内存池的多点可写技术当前一写多读的云原生架构,虽然实现了读能力的扩展,但是写能力仍然受到单机的限制,无法扩展。而采用分库分表的分布式数据库扩展,又会牺牲兼容性,需要应用感知和改造。多写架构主要困难在于信息交互的低效,导致线性扩展性低下。在CPU和内存分离以后,多个CPU可以共享同一个内存池来交换页面信息和事务信息,同时结合高性能RDMA网络和NVM,使得高性能多写架构成为可能。未来的云原生分布式数据库随着企业业务更加数字化、智能化,企业面临的数据存储量将会更加巨大,面临着更多突发状况带来的挑战。据IDC预测,2025年,三分之二的企业将会每天都发布软件版本,通过敏捷的开发能力来实现创新与交付,以形成差异化的市场竞争力。在这样的商业趋势下,数据库就需要全面进入云原生+分布式的时代,实现智能升级,充分释放云计算红利。所谓的分布式,是面向业务扩展而出现的一个概念,而分布式数据库,就是为了解决存储可扩展性的一类数据库。它是由多个相互连接的数据库组成,这些数据库分布在各个数据中心,通过中央服务器进行通信,然后组合在一起形成一个面向用户的单个数据库。基于Shared Nothing的架构,分布式数据库能够实现数据的水平分片、水平扩展。而云原生数据库是基于Shared Everything + Shared Storage 的存储计算分离架构,能够实现资源池化高效管理。因此,云原生数据库的优势+分布式数据库的效率,可以将两者的特性完美结合,代表了一种未来的解决方案。事实上,云原生和分布式如今已经融为一体。如果底层基础设施全部云化,人们思考技术问题的角度自然变成“云原生”角度。正如华为轮值董事长徐直军所说,随着云原生应用深入企业各个业务场景,云原生正在走向分布式,满足跨云跨地域统一协同治理、保证一致应用体验等新需求。未来,将云原生与分布式结合起来,全新的云原生分布式架构的数据库将具备高扩展性、易用性、迭代快速、成本降低等特点,具体而言:高扩展性云原生分布式数据库与底层的云计算基础设施分离,所以能够灵活及时调动资源进行扩容缩容,以从容应对流量激增带来的压力,以及流量低谷期因资源过剩造成的浪费。生态兼容的特点,也让云原生数据库具备很强的可迁移性。易用性云原生分布式数据库非常易于使用,它的计算节点在云端部署,可以随时随地从多前端访问。因其集群部署在云上,通过自动化的容灾与高可用能力,单点失败对服务的影响非常小。当需要升级或更换服务时,还可以对节点进行不中断服务的轮转升级。快速迭代云原生分布式数据库中的各项服务之间相互独立,个别服务的更新不会对其他部分产生影响。此外,云原生的研发测试和运维工具高度自动化,也就可以实现更加敏捷的更新与迭代。节约成本建立数据中心是一项独立而完备的工程,需要大量的硬件投资以及管理和维护数据中心的专业运维人员。此外,持续运维会造成很大的财务压力。云原生分布式数据库以较低的前期成本,获得一个可扩展的数据库,实现更优化的资源分配。结语应用程序和软件开发正在经历一场云原生的变革,从编排、管理到分析,所有的东西都开始在云上从头构建。由于在功能和可靠性上优于传统数据库,再加上增强的可伸缩性,云原生分布式数据库无疑代表了数据库的未来。可以预见,谁能够把云原生和分布式技术结合得更加完美,谁就会在未来的市场竞争中占得先机。文章来源:https://www.fromgeek.com/itcloudbd/459896.html
-

-
-
 【摘要】 华为云沃土认证,方案分享,沃趣科技QFusion云原生数据库平台获华为鲲鹏&沃土云创认证本文分享自华为云社区《【沃土认证--方案分享】沃趣科技QFusion云原生数据库平台获华为鲲鹏&沃土云创认证 》,作者DTSEDeveloper近日,沃趣科技面向创新生态的云原生数据库运维管理平台沃趣QFusion v3.12获鲲鹏Compatible和Enabled认证。沃趣科技联合中原鲲鹏生态创新中心,推出基于ARM CPU 架构的云原生数据库运维管理平台产品QFusion v3.12,在帮助客户实现数据库自主可控的同时,为客户数据库上云,进行多类型数据库运维管理和跨云部署等实际业务场景,提出了切实可行的解决方案。此次通过鲲鹏认证的QFusion云原生数据库运维管理平台,是沃趣科技基于Docker和Kubernetes技术,全栈自主研发的,数据库即服务(DBaaS)云原生产品。在平台内提供MySQL/PostgreSQL/Redis/MongoDB/达梦/GaussDB/TiDB等多类型数据库的全生命周期管理服务,支持快捷安装部署,帮助企业更全面的管理数据库,提升业务敏捷度,轻松实现云化管理。作为华为OSC首批生态合作伙伴,沃趣科技已与鲲鹏生态深度对接,将全线数据库即服务整合到了华为-云原生应用市场。在中原鲲鹏生态创新中心此次部署认证的方案,更是充分利用了产品架构优势,结合华为云高阶服务云容器引擎CCE和云数据库GaussDB,更强劲的发挥了产品性能,并完全适配鲲鹏版国产数据库:达梦、TiDB和GaussDB,在数据库生态信创领域拥有不可替代的技术优势。目前,ARM版本的QFusion已完成与鲲鹏服务器的适配,除了基础的弹性云服务器ECS兼容适配之外,在中原鲲鹏创新中心的大力推荐和支持下,QFusion本次适配特别与华为云容器引擎CCE进行深度结合,进行集群的容器化部署与自动运维,完成易用性、实用性与性能的全面飞跃。未来并会将云容器引擎CCE作为QFusion的核心部署场景,主要看中了CCE的以下四个特点:1.简单易用通过WEB界面一键创建Kubernetes集群,支持管理虚拟机节点或裸金属节点,支持虚拟机与物理机混用场景。一站式自动化部署和运维容器应用,整个生命周期都在容器服务内一站式完成。通过Web界面轻松实现集群节点和工作负载的扩容和缩容,自由组合策略以应对多变的突发浪涌。通过Web界面一键完成Kubernetes集群的升级。深度集成应用服务网格和Helm标准模板,真正实现开箱即用。2.高性能基于华为在计算、网络、存储、异构等方面多年的行业技术积累,提供业界领先的高性能云容器引擎,支撑您业务的高并发、大规模场景。采用高性能裸金属NUMA架构和高速IB网卡,AI计算性能提升3-5倍以上。3.安全可靠高可靠:集群控制面支持3 Master HA高可用,3个Master节点可以处于不同可用区,保障您的业务高可用。集群内节点和工作负载支持跨可用区(AZ)部署,帮助您轻松构建多活业务架构,保证业务系统在主机故障、机房中断、自然灾害等情况下可持续运行,获得生产环境的高稳定性,实现业务系统零中断。高安全:私有集群,完全由用户掌控,并深度整合华为云帐号和Kubernetes RBAC能力,支持用户在界面为子用户设置不同的RBAC权限。4.开放兼容四个特点。云容器引擎在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。云容器引擎基于业界主流的Kubernetes实现,完全兼容Kubernetes/Docker社区原生版本,与社区最新版本保持紧密同步,完全兼容Kubernetes API和Kubectl。沃趣科技致力于提供更高效 、更稳定、更便捷的云原生数据库应用服务,进一步提升沃趣云原生数据库平台在国产助力各行业实现全面云化的能力,让数据库云延伸至业务领域需求最大的地方,为客户提供最优质高效的国产化数据库云解决方案。友情链接:开发者技术支持社区:https://bbs.huaweicloud.com/forum/forumdisplay-fid-1175-orderby-lastpost.html博客主页专区:https://bbs.huaweicloud.com/community/usersnew/id_1612437390514409技术支持提单平台:https://support.developer.huaweicloud.com/feedback/#/
【摘要】 华为云沃土认证,方案分享,沃趣科技QFusion云原生数据库平台获华为鲲鹏&沃土云创认证本文分享自华为云社区《【沃土认证--方案分享】沃趣科技QFusion云原生数据库平台获华为鲲鹏&沃土云创认证 》,作者DTSEDeveloper近日,沃趣科技面向创新生态的云原生数据库运维管理平台沃趣QFusion v3.12获鲲鹏Compatible和Enabled认证。沃趣科技联合中原鲲鹏生态创新中心,推出基于ARM CPU 架构的云原生数据库运维管理平台产品QFusion v3.12,在帮助客户实现数据库自主可控的同时,为客户数据库上云,进行多类型数据库运维管理和跨云部署等实际业务场景,提出了切实可行的解决方案。此次通过鲲鹏认证的QFusion云原生数据库运维管理平台,是沃趣科技基于Docker和Kubernetes技术,全栈自主研发的,数据库即服务(DBaaS)云原生产品。在平台内提供MySQL/PostgreSQL/Redis/MongoDB/达梦/GaussDB/TiDB等多类型数据库的全生命周期管理服务,支持快捷安装部署,帮助企业更全面的管理数据库,提升业务敏捷度,轻松实现云化管理。作为华为OSC首批生态合作伙伴,沃趣科技已与鲲鹏生态深度对接,将全线数据库即服务整合到了华为-云原生应用市场。在中原鲲鹏生态创新中心此次部署认证的方案,更是充分利用了产品架构优势,结合华为云高阶服务云容器引擎CCE和云数据库GaussDB,更强劲的发挥了产品性能,并完全适配鲲鹏版国产数据库:达梦、TiDB和GaussDB,在数据库生态信创领域拥有不可替代的技术优势。目前,ARM版本的QFusion已完成与鲲鹏服务器的适配,除了基础的弹性云服务器ECS兼容适配之外,在中原鲲鹏创新中心的大力推荐和支持下,QFusion本次适配特别与华为云容器引擎CCE进行深度结合,进行集群的容器化部署与自动运维,完成易用性、实用性与性能的全面飞跃。未来并会将云容器引擎CCE作为QFusion的核心部署场景,主要看中了CCE的以下四个特点:1.简单易用通过WEB界面一键创建Kubernetes集群,支持管理虚拟机节点或裸金属节点,支持虚拟机与物理机混用场景。一站式自动化部署和运维容器应用,整个生命周期都在容器服务内一站式完成。通过Web界面轻松实现集群节点和工作负载的扩容和缩容,自由组合策略以应对多变的突发浪涌。通过Web界面一键完成Kubernetes集群的升级。深度集成应用服务网格和Helm标准模板,真正实现开箱即用。2.高性能基于华为在计算、网络、存储、异构等方面多年的行业技术积累,提供业界领先的高性能云容器引擎,支撑您业务的高并发、大规模场景。采用高性能裸金属NUMA架构和高速IB网卡,AI计算性能提升3-5倍以上。3.安全可靠高可靠:集群控制面支持3 Master HA高可用,3个Master节点可以处于不同可用区,保障您的业务高可用。集群内节点和工作负载支持跨可用区(AZ)部署,帮助您轻松构建多活业务架构,保证业务系统在主机故障、机房中断、自然灾害等情况下可持续运行,获得生产环境的高稳定性,实现业务系统零中断。高安全:私有集群,完全由用户掌控,并深度整合华为云帐号和Kubernetes RBAC能力,支持用户在界面为子用户设置不同的RBAC权限。4.开放兼容四个特点。云容器引擎在Docker技术的基础上,为容器化的应用提供部署运行、资源调度、服务发现和动态伸缩等一系列完整功能,提高了大规模容器集群管理的便捷性。云容器引擎基于业界主流的Kubernetes实现,完全兼容Kubernetes/Docker社区原生版本,与社区最新版本保持紧密同步,完全兼容Kubernetes API和Kubectl。沃趣科技致力于提供更高效 、更稳定、更便捷的云原生数据库应用服务,进一步提升沃趣云原生数据库平台在国产助力各行业实现全面云化的能力,让数据库云延伸至业务领域需求最大的地方,为客户提供最优质高效的国产化数据库云解决方案。友情链接:开发者技术支持社区:https://bbs.huaweicloud.com/forum/forumdisplay-fid-1175-orderby-lastpost.html博客主页专区:https://bbs.huaweicloud.com/community/usersnew/id_1612437390514409技术支持提单平台:https://support.developer.huaweicloud.com/feedback/#/ -
>摘要:在云原生2.0阶段,我们到底需要构建一个什么样的架构?华为云首席架构师为你一一解答。本文分享自华为云社区[《华为云首席架构师独家分享:云原生2.0架构设计的8大关键趋势》](https://bbs.huaweicloud.com/blogs/314122?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content),作者:技术火炬手。 云原生2.0是企业智能升级新阶段,企业的云化从“ON Cloud”走向“IN Cloud”,当一切应用都生于云,长于云,云架构的迭代也会进入一个新的阶段。 围绕云原生2.0,**华为云首席架构师顾炯炯提出了8个关键模式:** 分布式云,混合调度,应用驱动基础设施,存算分离与数据治理自动化,可信、平民化DevOps,基于软总线的异构集成,多模态可迭代AI模型,全方位立体式云安全。 # 分布式云 随着云化和数字化渗透到制造类、工业互联网类场景,5G技术在to B领域应用的快速成熟,以及物联网 、AI技术的成熟,现在云的服务对象不仅是企业的后台IT支撑系统,它延伸到了前端的“现场”,类似于工业场景里的近场计算。如果还是将所有的数字化应用系统都放在集中的数据中心,它的时延无法满足实时生产系统的要求。 另外,有一些行业的敏感数据不能从现场或者数据产生地直接简单的上传到云端,它存在数据安全、隐私保密的问题。再比如医疗里的基因大数据、视频监控等场景,如果所有数据都上传到云端,带宽的成本非常高昂。 所以,我们必须要**引入云边端协同的分布式概念,构建分布式云的架构。** 这个架构可以和核心侧架构配合,覆盖核心区域、热点区域、本地机房、业务现场等不同接入时延敏感度,数据隐私合规要求及数据上云带宽成本的应用上云场景。 举个例子,通过这样的方式,可以把云端的很多算力和计算逻辑,甚至是训练好的AI模型推送到更加靠近用户数据产生地的位置上,进行就近的计算,将海量的数据做一定的收敛、分析、脱敏等,再发送到云端进行闭环的处理和控制反馈。 # 混合调度 在很多算法专家的努力下,华为云通过瑶光调度平台大大提高了资源的分配效率,达到甚至超过了80~90%的程度,已经接近于业界的领先水平。但是资源的实际利用率仍然处在一个比较低的水平,当然业界平均也不是特别理想,领先者差不多20%左右。为了解决这样的问题,**华为云引入混合调动、柔性计算的能力,将在线和离线的不同优先级的业务,进行QoS感知的智能调用,实现资源利用率最大化。** 柔性计算不仅仅具备弹性的特征,保证了横向的资源扩展,而且它也能实现纵向资源规格的可大可小。目前,消费者云已经在内部验证了柔性计算的能力,可以在不改变上层业务的前提下提高利用率,实现性能的倍增。关于柔性计算的更多内容参考 华为云首席架构师顾炯炯:[敢为人先,探索架构创新之路如何走。](https://bbs.huaweicloud.com/blogs/314131) # 应用驱动的基础设施 如今,软硬件的垂直整合,特别是靠近操作系统底层的硬件和云服务基础设施层的服务软件之间的纵向整合能力,成为新的趋势,它把基础设施服务底层的硬件和相应的服务封装层打包在一起。 云服务厂商可以设计研发定制芯片,比如存储和网络的硬件卸载的芯片、匹配深度学习逻辑处理框架的芯片等等。如果有能力构建这样的软硬件垂直整合的能力,就能拥有相比其他云服务商更优的价格优势,也得以呈现自身独特的硬件、芯片优势。 有了应用驱动的基础设施之后,**根据应用的性能SLA需求,来定义是使用与软件完全解耦的通用硬件资源,还是匹配应用场景特殊诉求的软硬件深度协同的卸载卡或异构计算资源。** 这也能发挥华为软硬件兼长的优势,我们在硬件领域有不少核心创新:**一个是 SDI**, 叫软件驱动的基础设施,也就是把分布式存储\分布式网络,还有Hypervisor的一些系统能力从服务器卸载到PCI卡上,也即SDI/擎天卸载卡。二是**鲲鹏硬件支撑云存储和数据湖的处理**, 鲲鹏单核处理能力虽弱于X86,但核密度则达到X86 CPU的2倍,因此在对IO及内存带宽作为其性能瓶颈的大数据及分布式存储场景,是比X86更好的选择。同时,我们也在用自研的**昇腾NPU取代GPU构建AI平台**, 它在深度学习的训练推理中体现出更高的能效比。 # 存算分离和数据治理的自动化 未来企业的所有的数据孤岛都将汇聚到云端的数据湖,进行统一生命周期的治理和管理,所以必须要解决数据计算分析的资源需求。数据湖里有各种各样的结构化、半结构化、非结构化的数据,**但这些数据的分析计算和底层的存储容量之间的需求,并不是线性匹配的关系。** 比如对于深度学习的场景,数据量需要不断的计算迭代,它需要更多的计算能力,相对较少的存储需求。因此在不同的业务场景下,数据分析计算和存储的要求是不一样的,最终一定要走向存算分离。 在存算分离领域里面,华为云已经积累优势,从最早的去中心化的分布式存储引擎FusionStorage开始,七年磨一剑,我们从内部验证到向外部的推广,从块存储延伸到对象存储、文件存储、分布式的集群数据库,把原先在开源架构里五花八门的底层存储技术引擎架构实现了统一。经过实际的测试,在业界同样支持存算分离数据湖架构的云场景中,华为云体现了领先30-60%以上性能优势。 **再就是数据治理自动化。** 现在的数据治理的还是人力密集型工作,整个过程非常低效,很难满足很多行业的要求。所以在这个架构模式里面,除了存算分离的数据库,还要构建数据治理自动化。 通过引入AI的技术,将数据的获取、清洗以及最终数据知识的提取,主题库的建立、数据目录的发布,都实现完全的自动化。用户只需要指定入湖的数据源和所属业务主题域,系统自动化创建入湖任务,底层资源根据入湖数据量自动扩缩容,智能完成入湖数据的安全等级、分级分类、隐私等级等数据标签的自动识别打标。这个能力对企业数据资产的快速沉淀能力的构建是至关重要的。 # 可信、平民化DevOps **通过将一系列安全可信措施嵌入到敏捷开发运维模式,** 构建所谓的DevSecOps流水线,实现敏捷快速迭代与严格质量管控兼顾;并**通过低代码/无代码实现更多行业应用资产的沉淀**, 将行业应用的开发效率再上一个新台阶。 Devops实现了应用的敏捷开发,但在面向政企时,还需要满足应用质量和安全可信的要求。因此在遵循DevOps的同时,将安全能力集成到其中,升级成为DevSecOps。使用安全左移、默认安全、运行时安全、安全服务自动化/自助化、基础设施即代码(IaC)等技术, 实现管理与协同、设计与开发、CI/CD、应用管理、运维、安全可信等各个环节的一体化趋势。 此外,由于传统政企开发投入有限,需要通过低码化无码化,来实现对应用进行快速构建及改造。华为云低代码平台AppCube可支持多种页面类型和丰富的组件能力,基于它的服务能力编排和业务流程无代码定制,可实现灵活流程触发方式、多种权限配置方式、自定义业务编排等。 # 基于软件总线的异构集成 即帮助企业**构建可平滑演进的IT架构**, 实现老旧应用与新建云原生应用,线上与线下应用的平滑融合集成。 云原生下,企业很多应用都要进行微服务解耦,遵从微服务的治理架构,进行水平扩展的架构的设计,甚至把原来的单体架构逐步进行拆解。但这个过程不是一蹴而就的,尤其是那些包袱比较重的传统行业,他们还面临很多现实的挑战。所以我们要在企业传统IT架构和云原生架构之间搭建无缝的桥梁,在确保企业业务连续性最大化的前提下,实现平滑的切换和演进。 以Roma Connect为例,它可以通过软总线的形式,把云原生和非云原生的传统世界无缝的连接起来,支持异构的应用和数据库源的对接,也可以对接到云上开发平台、数据湖,实现无缝互通。 在架构的平滑演进中,首先需要将传统非云原生应用封装为REST接口与云原生应用对接,通过统一接口服务层APIC进行开放,业务云原生应用通过标准接口即可获取老系统信息。同样的机制可以将线上线下,及部署在多云环境上企业IT系统的无缝互通。 其次传统Oracle/Sybase等传统数据库及中间件与设备协议接入上云:云上云原生应用通过云上标准API调用、数据库访问、消息订阅等方式即可获取传统数据。 最后,通过全生命周期的API管理能力,包含从设计、发布、上架、治理的全过程,帮助企业构建整个跨地域,跨组织、跨部门的应用网络,并沉淀行业应用资产。 # 多模态可迭代的AI模型 AI在行业落地面临的问题是能够获取到的训练数据是非常有限的,单纯的依赖数据驱动的深度学习训练,使得行业AI模型是非常难以泛化、通用化。 预训练大模型是解决AI应用开发定制化和碎片化的重要方法。 通过一个AI大模型实现在众多场景通用、泛化和规模化复制,减少对数据标注的依赖,赋能AI开发由作坊式转变为工业化开发,比如华为云之前推出的盘古大模型。 另外也要**引入知识计算的能力**, 类似于把知识图谱这样的能力和基于感知计算的数据驱动的AI模型互补结合起来。也就是说把知识模型和数据模型,在数据样本相对缺少的情况下结合在一起,更好服务于行业AI的落地。帮助企业打造自己的知识计算平台,整合分散在不同系统、多种形态的企业数据,形成带有建议性的知识体系。 # 全方位的立体式云安全 1.0阶段的云安全服务更多的是孤立的安全能力:虚拟化安全,hyporvisor防逃逸能力,云防火墙能力其实都是割裂的,并没有跟所有的云服务形成互锁。 **全方位的立体式运营安全通过打通离散的云安全服务能力,将其与其他云服务及客户应用形式互锁**, 构建安全Build-in的云原生应用,以及引入可信智能计算,解决跨行业数据隐私保护与流通碰撞、价值挖掘之间的矛盾。 首先通过可信智能计算提供四个核心能力,进行安全可信的数据计算。包括: 1、跨组织、跨行业的多方数据融合分析和多方横向与纵向联邦学习建模; 2、支持对接主流数据源和深度学习框架; 3、支持安全多方计算(例如同态加密,差分隐私等),并支持用户自定义隐私策略; 4、基于区块链的数据计算轨迹的可追溯可审计。 此外,为了全方位安全,还需要将全栈云(及其子集)下沉部署(连线/非连线),彻底解决敏感行业上云安全顾虑,以及将全栈云服务、企业新开发云原生应用、aPaaS/SaaS等与全栈云安全能力互锁,为用户构建体系化的云安全平台。
-
>摘要:K8s正在向边缘计算渗透,它为边缘侧的应用部署提供了便利性,在一定程度上转变了边缘应用与硬件之间的关系,将两者的耦合度降低。 本文分享自华为云社区[《云原生在物联网中的应用【拜托了,物联网!】》](https://bbs.huaweicloud.com/blogs/301069?utm_source=zhihu&utm_medium=bbs-ex&utm_campaign=iot&utm_content=content),作者: kaliarch。 # 前言 物联网已经产生了数量惊人的数据,随着5G网络的部署,这些数据将呈指数级增长。管理和使用这些数据是一个挑战。 无论是从交通摄像头、气象传感器、电表等会产生信息,这些信息与智能城市环境中,其他摄像头和传感器的数据相结合,在一个中心位置处理起来可能会太多,尤其是当你在预期设备会对事件做出反应时。 超大规模云计算环境中已被普遍使用的Kubernetes(简称K8s),带入到物联网边缘计算场景中。新成立的Kubernetes物联网边缘工作组将采用运行容器的理念并扩展到边缘,促进K8s在边缘环境中的适用。 - 支持将工业物联网IoT的连接设备数量扩展到百万量级,既可支持IP设备以直连方式接入K8s云平台,又可支持非IP设备通过物联网网关接入。 - 利用边缘节点,让计算更贴近设备侧,以便减少延迟、降低带宽需求和提高可靠性,满足用户实时、智能、数据聚合和安全需求: - 将流数据应用部署到边缘节点,降低设备和云平台之间通信的带宽需求。 - 部署无服务器应用框架,使得边缘侧无需与云端通讯,便可对某些紧急情况做出快速响应。 - 在混合云和边缘环境中提供通用控制平台,以简化管理和操作。 # 一 背景  ## 1.1 KubeEdge简介 KubeEdge 是一个开源的系统,可将本机容器化应用编排和管理扩展到边缘端设备。 它基于Kubernetes构建,为网络和应用程序提供核心基础架构支持,并在云端和边缘端部署应用,同步元数据。KubeEdge 还支持 **MQTT** 协议,允许开发人员编写客户逻辑,并在边缘端启用设备通信的资源约束。KubeEdge 包含云端和边缘端两部分。 ## 1.2 KubeEdge特点 **边缘计算** 通过在边缘端运行业务逻辑,可以在本地保护和处理大量数据。KubeEdge 减少了边和云之间的带宽请求,加快响应速度,并保护客户数据隐私。 **简化开发** 开发人员可以编写常规的基于 http 或 mqtt 的应用程序,容器化并在边缘或云端任何地方运行。 **Kubernetes 原生支持** 使用 KubeEdge 用户可以在边缘节点上编排应用、管理设备并监控应用程序/设备状态,就如同在云端操作 Kubernetes 集群一样。 **丰富的应用程序** 用户可以轻松地将复杂的机器学习、图像识别、事件处理等高层应用程序部署到边缘端。 # 二 KubeEdge简介 ## 2.1 KubeEdge架构  ## 2.2 架构详解 ### 2.2.1 云上部分 - CloudHub: CloudHub 是一个 Web Socket 服务端,负责监听云端的变化, 缓存并发送消息到 EdgeHub。 - EdgeController: EdgeController 是一个扩展的 Kubernetes 控制器,管理边缘节点和 Pods 的元数据确保数据能够传递到指定的边缘节点。 - DeviceController: DeviceController 是一个扩展的 Kubernetes 控制器,管理边缘设备,确保设备信息、设备状态的云边同步。 ### 2.2.2 边缘部分 - EdgeHub: EdgeHub 是一个 Web Socket 客户端,负责与边缘计算的云服务(例如 KubeEdge 架构图中的 Edge Controller)交互,包括同步云端资源更新、报告边缘主机和设备状态变化到云端等功能。 - Edged: Edged 是运行在边缘节点的代理,用于管理容器化的应用程序。 - EventBus: EventBus 是一个与 MQTT 服务器(mosquitto)交互的 MQTT 客户端,为其他组件提供订阅和发布功能。 - ServiceBus: ServiceBus是一个运行在边缘的HTTP客户端,接受来自云上服务的请求,与运行在边缘端的HTTP服务器交互,提供了云上服务通过HTTP协议访问边缘端HTTP服务器的能力。 - DeviceTwin: DeviceTwin 负责存储设备状态并将设备状态同步到云,它还为应用程序提供查询接口。 - MetaManager: MetaManager 是消息处理器,位于 Edged 和 Edgehub 之间,它负责向轻量级数据库(SQLite)存储/检索元数据。 # 三 实战部署 ## 3.1 keadm部署 注意事项: - 目前支持keadmUbuntu 和 CentOS 操作系统。RaspberryPi 支持正在进行中。 - 需要超级用户权限(或 root 权限)才能运行。 ### 3.1.1 设置云端(KubeEdge 主节点) 默认情况下10000,10002边缘节点需要可以访问 Cloudcore 中的端口和端口。 keadm init将安装 cloudcore,生成证书并安装 CRD。它还提供了一个可以设置特定版本的标志。 **重要说明:** 1. kubeconfig 或 master 中至少一个必须正确配置,以便用于验证 k8s 集群的版本和其他信息。1.请确保边缘节点可以使用云节点的本地IP连接云节点,或者您需要使用--advertise-address标志指定云节点的公共IP 。1. --advertise-address(1.3版本后才有效)是云端暴露的地址(会加入到CloudCore证书的SAN中),默认值为本地IP。 例子: `keadm init --advertise-address="THE-EXPOSED-IP"(only work since 1.3 release)` 输出: Kubernetes version verification passed, KubeEdge installation will start... ... KubeEdge cloudcore is running, For logs visit: /var/log/kubeedge/cloudcore.log ### 3.1.2 设置边缘端(KubeEdge 工作节点) - 从云端获取令牌 keadm gettoken在**云端**运行将返回令牌,该令牌将在加入边缘节点时使用。 keadm gettoken 27a37ef16159f7d3be8fae95d588b79b3adaaf92727b72659eb89758c66ffda2.eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE1OTAyMTYwNzd9.JBj8LLYWXwbbvHKffJBpPd5CyxqapRQYDIXtFZErgYE - 加入边缘节点 keadm join将安装 edgecore 和 mqtt。它还提供了一个可以设置特定版本的标志。 例子: `keadm join --cloudcore-ipport=192.168.20.50:10000 --token=27a37ef16159f7d3be8fae95d588b79b3adaaf92727b72659eb89758c66ffda2.eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE1OTAyMTYwNzd9.JBj8LLYWXwbbvHKffJBpPd5CyxqapRQYDIXtFZErgYE` - **重要说明:** 1. --cloudcore-ipportflag 是强制性标志。1. 如果要自动为边缘节点申请证书,--token则需要。1.云端和边缘端使用的kubeEdge版本要一致。 输出: Host has mosquit+ already installed and running. Hence skipping the installation steps !!! ... KubeEdge edgecore is running, For logs visit: /var/log/kubeedge/edgecore.log ## 3.2 二进制部署 注意事项: - 需要超级用户权限(或 root 权限)才能运行。 ### 3.2.1 设置云端(KubeEdge 主节点) - 创建 CRD kubectl apply -f https://raw.githubusercontent.com/kubeedge/kubeedge/master/build/crds/devices/devices_v1alpha2_device.yaml kubectl apply -f https://raw.githubusercontent.com/kubeedge/kubeedge/master/build/crds/devices/devices_v1alpha2_devicemodel.yaml kubectl apply -f https://raw.githubusercontent.com/kubeedge/kubeedge/master/build/crds/reliablesyncs/cluster_objectsync_v1alpha1.yaml kubectl apply -f https://raw.githubusercontent.com/kubeedge/kubeedge/master/build/crds/reliablesyncs/objectsync_v1alpha1.yaml - 准备配置文件 `cloudcore --minconfig > cloudcore.yaml` 详情请参考云配置。 - 运行 ` cloudcore --config cloudcore.yaml` ### 3.2.2 设置边缘端(KubeEdge 工作节点) #### 3.2.2.1 准备配置文件 - 生成配置文件 `edgecore --minconfig > edgecore.yaml` - 在云端获取代币值: `kubectl get secret -nkubeedge tokensecret -o=jsonpath='{.data.tokendata}' | base64 -d` - 更新 edgecore 配置文件中的令牌值: `sed -i -e "s|token: .*|token: ${token}|g" edgecore.yaml` 这token就是上面步骤得到的。 详情请参考edge的配置。 #### 3.2.2.2 运行 如果要在同一台主机上运行 cloudcore 和 edgecore,请先运行以下命令: export CHECK_EDGECORE_ENVIRONMENT="false" 启动边缘核: `edgecore --config edgecore.yaml` 运行edgecore -h以获取帮助信息并根据需要添加选项。 # 四 反思 K8s正在向边缘计算渗透,它为边缘侧的应用部署提供了便利性,在一定程度上转变了边缘应用与硬件之间的关系,将两者的耦合度降低。通过KubeEdge,拓展“边缘场景”,可帮助用户加速实现云边协同,在海量边、端设备上完成大规模应用的统一交付、运维与管控。 据Gartner估计,到2025年,超过75%的企业生成数据可以在传统数据中心和云之外创建和处理,像Kubernetes这样的编排系统前景光明,它已经被证明是完成这一任务的最佳工具。 # 参考资料 - kubeedge/README_zh.md at master · kubeedge/kubeedge · GitHub - https://www.cncf.io/blog/2020/09/25/kubernetes-could-be-the-one-to-make-the-internet-of-things-iot-reach-its-potential/
-
>摘要:CNCF(云原生计算基金会)正式接纳由华为云贡献的多云容器编排项目Karmada,迎来CNCF首个多云容器编排项目。 本文分享自华为云社区[《华为云开源的Karmada正式成为CNCF首个多云容器编排项目》](https://blog.csdn.net/devcloud/article/details/120566049?spm=1001.2014.3001.5501),作者:华为云开发者社区 北京时间9月15日,CNCF(云原生计算基金会)正式接纳由华为云贡献的多云容器编排项目Karmada(https://github.com/karmada-io/karmada),迎来CNCF首个多云容器编排项目。Karmada 项目的加入,将CNCF的云原生版图进一步扩展至分布式云领域。 华为云在技术上一直积极回馈社区,已开源了以智能边缘项目KubeEdge和批量计算项目Volcano为代表的一系列云原生项目。Karmada项目由华为云、工商银行、小红书、中国一汽等8家企业联合发起,沉淀了各企业在多云管理领域的丰富积累,为开发者提供详实有效的实践指导与帮助,使用Karmada,可以构建无极可扩展的容器资源池,让开发者像使用单个Kubernetes集群一样使用多云集群。 # Karmada介绍 随着企业业务的快速发展,多云也逐步成为数据中心建设的基础架构,多区域容灾与多活、大规模多集群管理、跨云弹性与迁移等场景推动云原生多云相关技术的快速发展。 然而,在实际的生产落地过程中,云原生的多云仍面临如下挑战: - 集群繁多的重复劳动:运维工程师需要应对繁琐的集群配置、不同云厂商集群间的管理差异以及碎片化的API访问入口等问题; - 业务过度分散的维护难题:应用在各集群的差异化配置繁琐;业务跨云访问以及集群间的应用同步难以管理; - 集群的边界限制:应用的可用性受限于集群;资源调度、弹性伸缩受限于集群; - 厂商绑定:业务部署的黏性问题,缺少自动化故障迁移;缺少中立的开源多云容器编排项目。 Karmada结合了华为云多云容器平台MCP以及Kubernetes Federation核心实践,并融入了众多新技术:包括Kubernetes原生API支持、多层级高可用部署、多集群自动故障迁移、多集群应用自动伸缩、多集群服务发现等,并且提供原生Kubernetes平滑演进路径,让基于Karmada的多云方案无缝融入云原生技术生态,为企业提供从单集群到多云架构的平滑演进方案。  Karmada项目全景 # 生态合作 Karmada项目由华为云、工商银行、浦发银行、小红书、VIPKID、趣头条、中国一汽和T3出行联合发起,于2021年4月25日在华为开发者大会(HDC.Cloud)2021上正式宣布开源。Karmada自开源以来受到了广泛的关注和支持,目前已有30+大型企业/机构/高校参与社区开发及贡献。 >Karmada项目源自华为云多云容器平台MCP,同时融入了工商银行、小红书、中国一汽等不同行业客户在多云管理方面的经验,可以为各企业提供详实有效的落地指导与帮助,企业通过Karmada构建跨云、跨数据中心的无极可扩展的应用资源池,可以像管理单个Kubernetes集群一样简单、便捷的管理不同云、不同数据中心里的集群与应用。——华为云CTO 张宇昕>在社区贡献方面,工商银行作为 Karmada项目的头部参与单位,结合工行多年来多容器集群管理的经验,已在集群生命周期管理、核心调度控制器等核心模块进行深度定制化的开发。后续,工行将持续参与Karmada 社区的开发和管理工作,计划在多集群自动调度、多集群自动伸缩等模块继续深入研究及贡献,反哺开源社区,持续扩大业界影响力。——工商银行软件开发中心专家 鲁金彪>集团型企业同时存在多个混合容器的复杂场景,跨多云技术架构的运维难题日益突出。华为Karmada作为多集群、多云及混合云的集中化、兼容原生Kubernetes API接口的管理架构,有效解决目前容器编排多集群、多环境无法集中式管理、安全隔离机制不健全等痛点。希望Karmada在加入CNCF后,通过社区的共同维护与贡献,不断壮大其功能。期待Karmada早日从CNCF毕业,反哺云原生生态。——一汽体系数字化部技术运营主任 王广>Karmada原生兼容Kubernetes API的能力,可以不加改造地对接现有Kubernetes生态。在落地实践过程中,我们使用Karmada对接了现有的GitOps生态,极大提高了应用跨集群部署的效率。 ——VIPKID运维总监 谷玉虎>Karmada提供丰富的多集群调度策略以及开箱即用的内置策略集,可以极大的简化两地三中心、异地容灾和同城双活架构下的系统复杂性,这对于金融行业至关重要。 ——浦发银行云转型处处长 吕炳刚 # 未来可期 目前,Karmada已在华为云多云容器平台(Multi-Cloud Container Platform,MCP)商用,提供分布式云解决方案,提供跨云的多集群统一管理、应用统一部署及流量分发等关键能力。 除MCP以外,Karmada已在数十家来自金融、互联网、教育等企业中落地。 此次CNCF正式将Karmada接纳为云原生领域首个多云容器编排项目,将极大促进Karmada上下游社区生态构建及合作,吸引广大云原生企业用户深度参与,Karmada将在多集群应用管理、服务治理、高可用部署等领域发挥越来越重要的作用,华为云也将在云原生领域持续耕耘、持续引领创新、繁荣生态,助力各行业走向快速智能发展之路。
-
 此贴为《华为云原生大数据serverless服务DLI》课后操作任务打卡专用查看更多操作任务请点击:》》点击前往《《查看全部活动任务&信息请点击:》》点击前往《《按要求完成考核打卡可获得活动积分 +20积分》》参与活动前请先点击这里报名活动《《本实验逻辑ecs用来模拟数据流流式数据通过kafka接入DLI进行流式数据分析DLI分析后的数据结果存在rds参与考核中可能会存在使用产品的情况,请提前领取课程专属免费试用:(1)https://activity.huaweicloud.com/Date-free.html(2)https://activity.huaweicloud.com/free_test/index.html领取时请注意数据中心节点与实验要求一致!!!推荐 华南-广州 实验请联系小助手开通白名单提供信息:截图中的 我的凭证-API凭证-项目ID&所属区域【项目ID】↓联系小助手企业微信↓ 操作考核方式:《华为云原生大数据serverless服务DLI》课后操作任务用户前往 》》课程报名《《 课程,并按照操作文档进行操作,按照指导完成实验,最后按照要求截图+华为云账号回复至本帖内,视为完成任务。在步骤6中项目名称使用此贴右上角华为云账号昵称需要截图截出步骤7中的结果,并显示用户名称,无名称则无效将截图回复至本帖活动规则:a. 回复非按要求的图片,视为无效楼层。b.按照规定完成打,并按照规定将帖子截图回复到本帖可获得20积分课程积分完成三个操作任务并对应回复截图后,可获得实体证书请在此问卷中登记信息:https://devcloud.huaweicloud.com/expertmobile/qtn?id=bcdc4692db4a48f5808bce295ebd0666更多活动信息请查看:https://bbs.huaweicloud.com/forum/thread-166386-1-1.html
此贴为《华为云原生大数据serverless服务DLI》课后操作任务打卡专用查看更多操作任务请点击:》》点击前往《《查看全部活动任务&信息请点击:》》点击前往《《按要求完成考核打卡可获得活动积分 +20积分》》参与活动前请先点击这里报名活动《《本实验逻辑ecs用来模拟数据流流式数据通过kafka接入DLI进行流式数据分析DLI分析后的数据结果存在rds参与考核中可能会存在使用产品的情况,请提前领取课程专属免费试用:(1)https://activity.huaweicloud.com/Date-free.html(2)https://activity.huaweicloud.com/free_test/index.html领取时请注意数据中心节点与实验要求一致!!!推荐 华南-广州 实验请联系小助手开通白名单提供信息:截图中的 我的凭证-API凭证-项目ID&所属区域【项目ID】↓联系小助手企业微信↓ 操作考核方式:《华为云原生大数据serverless服务DLI》课后操作任务用户前往 》》课程报名《《 课程,并按照操作文档进行操作,按照指导完成实验,最后按照要求截图+华为云账号回复至本帖内,视为完成任务。在步骤6中项目名称使用此贴右上角华为云账号昵称需要截图截出步骤7中的结果,并显示用户名称,无名称则无效将截图回复至本帖活动规则:a. 回复非按要求的图片,视为无效楼层。b.按照规定完成打,并按照规定将帖子截图回复到本帖可获得20积分课程积分完成三个操作任务并对应回复截图后,可获得实体证书请在此问卷中登记信息:https://devcloud.huaweicloud.com/expertmobile/qtn?id=bcdc4692db4a48f5808bce295ebd0666更多活动信息请查看:https://bbs.huaweicloud.com/forum/thread-166386-1-1.html -
>摘要:遥感影像,作为地球自拍照,能够从更广阔的视角,为人们提供更多维度的辅助信息,来帮助人类感知自然资源、农林水利、交通灾害等多领域信息。本文分享自华为云社区[《AI+云原生,把卫星遥感虐的死去活来》](https://bbs.huaweicloud.com/blogs/296183?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content),作者:tsjsdbd。 # AI牛啊,云原生牛啊,所以1+1>2? 遥感影像,作为地球自拍照,能够从更广阔的视角,为人们提供更多维度的辅助信息,来帮助人类感知自然资源、农林水利、交通灾害等多领域信息。 AI技术,可以在很多领域超过人类,关键是它是自动的,省时又省力。可显著提升遥感影像解译的工作效率,对各类地物元素进行自动化的检测,例如建筑物,河道,道路,农作物等。能为智慧城市发展&治理提供决策依据。  云原生技术,近年来可谓是一片火热。易构建,可重复,无依赖等优势,无论从哪个角度看都与AI算法天生一对。所以大家也可以看到,各领域的AI场景,大都是将AI推理算法运行在Docker容器里面的。 AI+云原生这么6,那么强强联手后,地物分类、目标提取、变化检测等高性能AI解译不就手到擒来?我们也是这么认为的,所以基于AI+Kubernetes云原生,构建了支持遥感影像AI处理的空天地平台。 不过理想是好的,过程却跟西天取经一般,九九八十一难,最终修成正果。 # 业务场景介绍 遇到问题的业务场景叫影像融合(Pansharpen),也就是对地球自拍照进行“多镜头合作美颜”功能。(可以理解成:手机的多个摄像头,同时拍照,合并成一张高清彩色大图)。  所以业务简单总结就是:读取2张图片,生成1张新的图片。该功能我们放在一个容器里面执行,每张融合后的结果图片大约5GB。 问题的关键是,一个批次业务量需要处理的是3000多张卫星影像,所以每批任务只需要同时运行完成3000多个容器就OK啦。云原生YYDS! # 业务架构图示 为了帮助理解,这里分解使用云原生架构实现该业务场景的逻辑图如下: 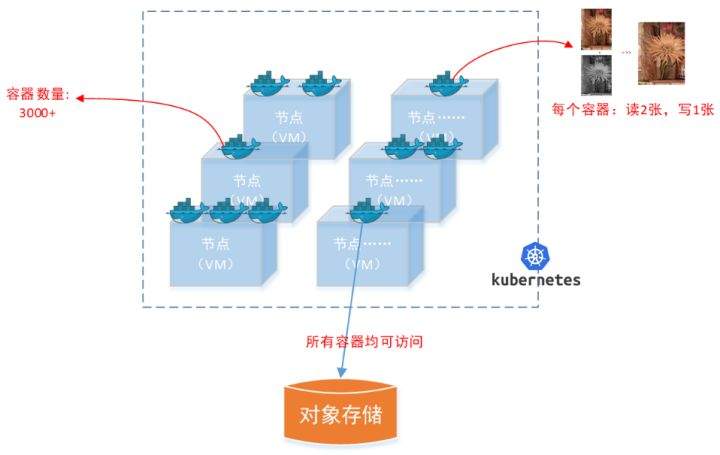 在云上,原始数据,以及结果数据,一定是要存放在对象存储桶里面的。因为这个数据量,只有对象存储的价格是合适的。(对象存储,1毛钱/GB。文件存储则需要3毛钱/GB) 因为容器之间是互相独立无影响的,每个容器只需要处理自己的那幅影像就行。例如1号容器处理 1.tif影像;2号容器处理2.tif影像;一次类推。 所以管理程序,只需要投递对应数量的容器(3000+),并监控每个容器是否成功执行完毕就行(此处为简化说明,实际业务场景是一个pipeline处理流程)。那么,需求已经按照云原生理想的状态分解,咱们开始起(tang)飞(keng)吧~ 注:以下描述的问题,是经过梳理后呈现的,实际问题出现时是互相穿插错综复杂的。 # K8s死掉了 当作业投递后,不多久系统就显示作业纷纷失败。查看日志报调用K8s接口失败,再一看,K8s的Master都已经挂了。。。 K8s-Master处理过程,总结版: 1. 发现Master挂是因为CPU爆了 2. 所以扩容Master节点(此次重复N次); 3. 性能优化:扩容集群节点数量; 4. 性能优化:容器分批投放; 5. 性能优化:查询容器执行进度,少用ListPod接口; 详细版: 看监控Master节点的CPU已经爆掉了,所以最简单粗暴的想法就是给Master扩容呀,嘎嘎的扩。于是从4U8G * 3 一路扩容一路测试一路失败,扩到了32U64G * 3。可以发现CPU还是爆满。看来简单的扩容是行不通了。 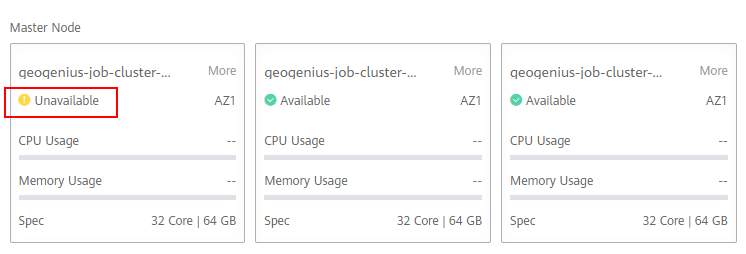 3000多个容器,投给K8s后,大量的容器都处于Pending状态(集群整体资源不够,所以容器都在排队呢)。而正在Pending的Pod,K8s的Scheduler会不停的轮训,去判断能否有资源可以给它安排上。所以这也会给Scheduler巨大的CPU压力。扩容集群节点数量,可以减少排队的Pod数量。 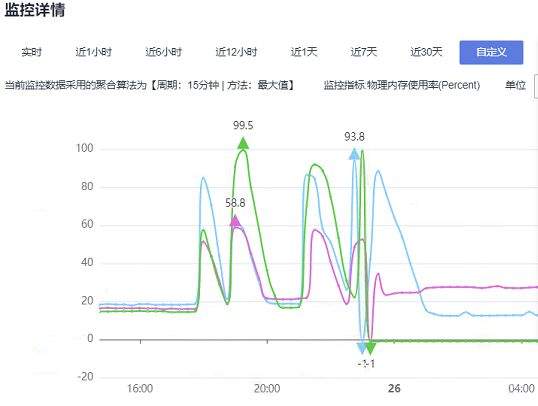 另外,既然排队的太多,不如就把容器分批投递给K8s吧。于是开始分批次投递任务,想着别一次把K8s压垮了。每次投递数量,减少到1千,然后到500,再到100。 同时,查询Pod进度的时候,避免使用ListPod接口,改为直接查询具体的Pod信息。因为List接口,在K8s内部的处理会列出所有Pod信息,处理压力也很大。 这一套组合拳下来,Master节点终于不挂了。不过,一头问题按下去了,另一头问题就冒出来了。 # 容器跑一半,挂了 虽然Master不挂了,但是当投递1~2批次作业后,容器又纷纷失败。 容器挂掉的处理过程,总结版: 1. 发现容器挂掉是被eviction驱逐了; 2. Eviction驱逐,发现原因是节点报Disk Pressure(存储容量满了); 3. 于是扩容节点存储容量; 4. 延长驱逐容器(主动kill容器)前的容忍时间; 详细版: (注:以下问题是定位梳理后,按顺序呈现给大家。但其实出问题的时候,顺序没有这么友好) 容器执行失败,首先想到的是先看看容器里面脚本执行的日志呗:结果报日志找不到~  于是查询Pod信息,从event事件中发现有些容器是被Eviction驱逐干掉了。同时也可以看到,驱逐的原因是 DiskPressure(即节点的存储满了)。 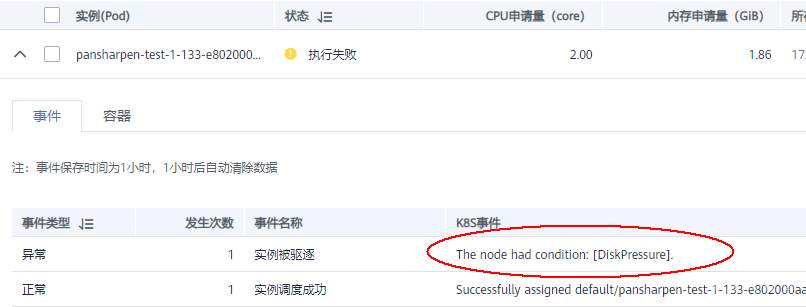 当Disk Pressure发生后,节点被打上了驱逐标签,随后启动主动驱逐容器的逻辑: 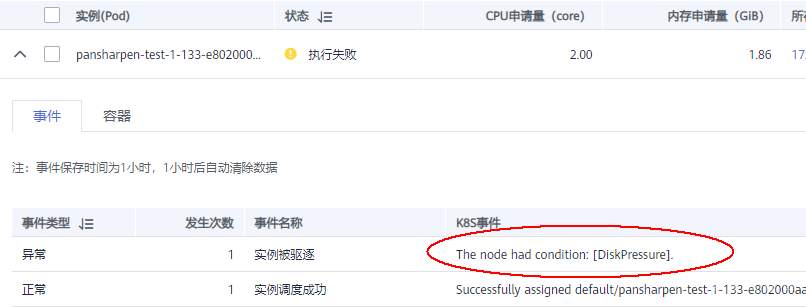 由于节点进入Eviction驱逐状态,节点上面的容器,如果在5分钟后,还没有运行完,就被Kubelet主动杀死了。(因为K8s想通过干掉容器来腾出更多资源,从而尽快退出Eviction状态)。 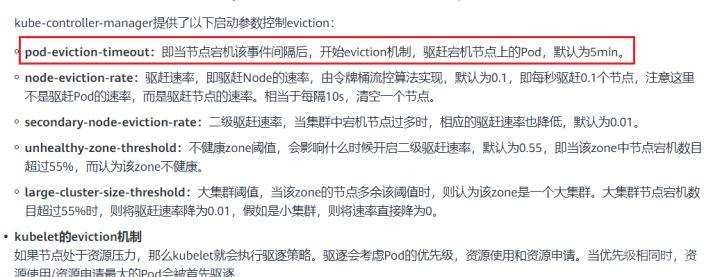 这里我们假设每个容器的正常运行时间为1~2个小时,那么不应该一发生驱动就马上杀死容器(因为已经执行到一半的容器,杀掉重新执行是有成本浪费的)。我们期望应该尽量等待所有容器都运行结束才动手。所以这个 pod-eviction-timeout 容忍时间,应该设置为24小时(大于每个容器的平均执行时间)。 Disk Pressure的直接原因就是本地盘容量不够了。所以得进行节点存储扩容,有2个选择:1)使用云存储EVS(给节点挂载云存储)。 2)扩容本地盘(节点自带本地存储的VM)。 由于云存储(EVS)的带宽实在太低了,350MB/s。一个节点咱们能同时跑30多个容器,带宽完全满足不了。最终选择使用 i3类型的VM。这种VM自带本地存储。并且将8块NVMe盘,组成Raid0,带宽还能x8。 # 对象存储写入失败 容器执行继续纷纷失败。 容器往对象存储写入失败处理过程,总结版: 1. 不直接写入,而是先写到本地,然后cp过去。 2. 将普通对象桶,改为支持文件语义的并行文件桶。 详细版: 查看日志发现,脚本在生成新的影像时,往存储中写入时出错: 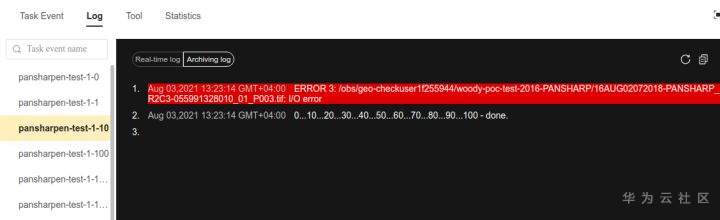 我们整集群是500核的规模,同时运行的容器数量大概在250个(每个2u2g)。这么多的容器同时往1个对象存储桶里面并发追加写入。这个应该是导致该IO问题的原因。 对象存储协议s3fs,本身并不适合大文件的追加写入。因为它对文件的操作都是整体的,即使你往一个文件追加写入1字节,也会导致整个文件重新写一遍。 最终这里改为:先往本地生成目标影像文件,然后脚本的最后,再拷贝到对象存储上。相当于增加一个临时存储中转一下。 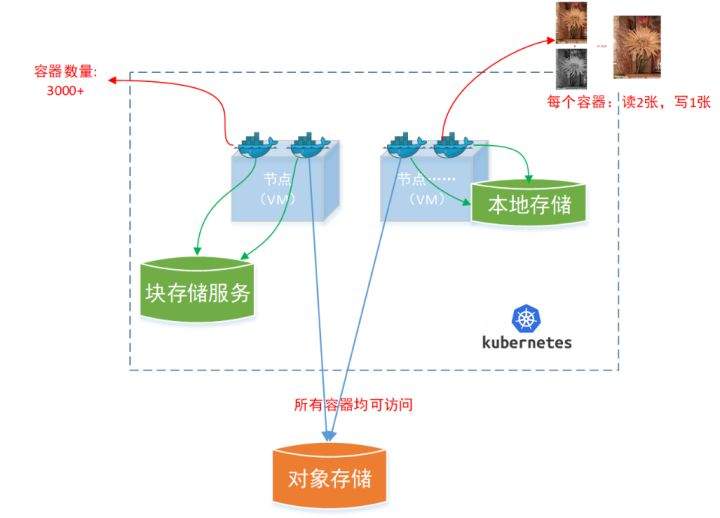 在临时中转存储选择中,2种本地存储都试过: 1)块存储带宽太低,350MB/s影响整体作业速度。2)可以选择带本地存储的VM,多块本地存储组成Raid阵列,带宽速度都杠杠滴。 同时,华为云在对象存储协议上也有一个扩展,使其支持追加写入这种的POSIX语义,称为并行文件桶。后续将普通的对象桶,都改为了文件语义桶。以此来支撑大规模的并发追加写入文件的操作。 # K8s计算节点挂了 So,继续跑任务。但是这容器作业,执行又纷纷失败鸟~ 计算节点挂掉,定位梳理后,总结版: 1. 计算节点挂掉,是因为好久没上报K8s心跳了。 2. 没上报心跳,是因为kubelet(K8s节点的agent)过得不太好(死掉了)。 3. 是因为Kubelet的资源被容器抢光了(由于不想容器经常oom kill,并未设置limit限制) 4. 为了保护kubelet,所有容器全都设置好limit。 详细版,直接从各类奇葩乱象等问题入手: - 容器启动失败,报超时错误。 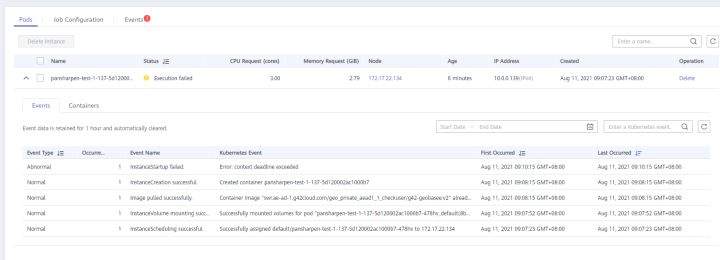 - 然后,什么PVC共享存储挂载失败:  - 或者,又有些容器无法正常结束(删不掉)。  - 查询节点Kubelet日志,可以看到充满了各种超时错误: 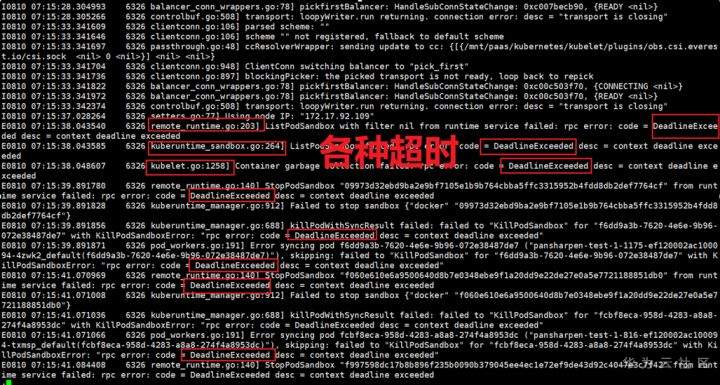 啊,这么多的底层容器超时,一开始感觉的Docker的Daemon进程挂了,通过重启Docker服务来试图修复问题。 后面继续定位发现,K8s集群显示,好多计算节点Unavailable了(节点都死掉啦)。 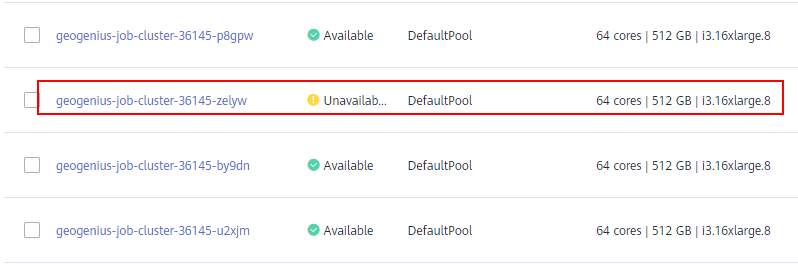 继续分析节点不可用(Unavailable),可以发现是Kubelet好久没有给Master上报心跳了,所以Master认为节点挂了。说明不仅仅是Docker的Daemon受影响,节点的Kubelet也有受影响。 那什么情况会导致Kubelet,Docker这些主机进程都不正常呢?这个就要提到Kubernetes在调度容器时,所设计的Request和Limit这2个概念了。 Request是K8s用来调度容器到空闲计算节点上的。而Limit则会传递给Docker用于限制容器资源上限(触发上限容易被oom killer 杀掉)。前期我们为了防止作业被杀死,仅为容器设置了Request,没有设置Limit。也就是每个容器实际可以超出请求的资源量,去抢占额外的主机资源。大量容器并发时,主机资源会受影响。 考虑到虽然不杀死作业,对用户挺友好,但是平台自己受不了也不是个事。于是给所有的容器都加上了Limit限制,防止容器超限使用资源,强制用户进程运行在容器Limit资源之内,超过就Kill它。以此来确保主机进程(如Docker,Kubelet等),一定是有足够的运行资源的。 # K8s计算节点,又挂了 于是,继续跑任务。不少作业执行又双叒失败鸟~ 节点又挂了,总结版: 1. 分析日志,这次挂是因为PLEG(Pod Lifecycle Event Generator)失败。 2. PLEG异常是因为节点上面存留的历史容器太多(>500个),查询用时太久超时了。 3. 及时清理已经运行结束的容器(即使跑完的容器,还是会占用节点存储资源)。 4. 容器接口各种超时(cpu+memory是有limit保护,但是io还是会被抢占)。 5. 提升系统磁盘的io性能,防止Docker容器接口(如list等)超时。 详细版: 现象还是节点Unavailable了,查看Kubelet日志搜索心跳情况,发现有PLEG is not healthy 的错误:  于是搜索PLEG相关的Kubelet日志,发现该错误还挺多:  这个错误,是因为kubelet去list当前节点所有容器(包括已经运行结束的容器)时,超时了。看了代码:https://github.com/kubernetes/kubernetes/blob/master/pkg/kubelet/pleg/generic.go#L203 kubelet判断超时的时间,3分钟的长度是写死的。所以当pod数量越多,这个超时概率越大。很多场景案例表明,节点上的累计容器数量到达500以上,容易出现PLEG问题。(此处也说明K8s可以更加Flexible一点,超时时长应该动态调整)。 缓解措施就是及时的清理已经运行完毕的容器。但是运行结束的容器一旦清理,容器记录以及容器日志也会被清理,所以需要有相应的功能来弥补这些问题(比如日志采集系统等)。 List所有容器接口,除了容器数量多,IO慢的话,也会导致超时。 这时,从后台可以看到,在投递作业期间,大量并发容器同时运行时,云硬盘的写入带宽被大量占用: 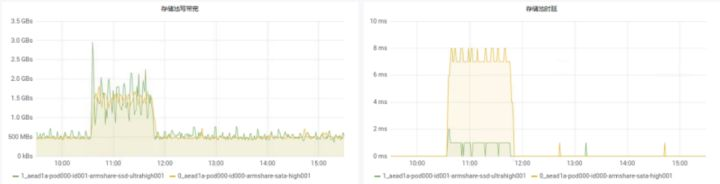 对存储池的冲击也很大: 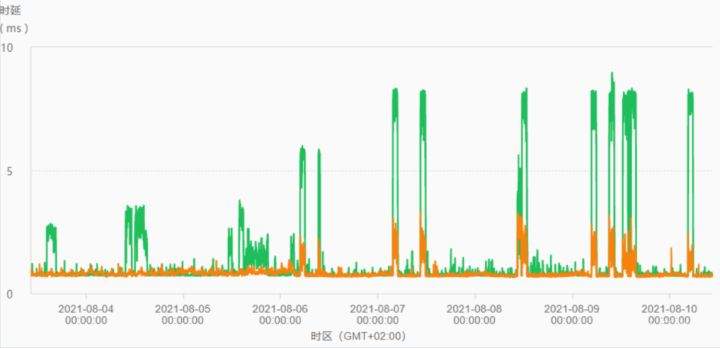 这也导致了IO性能变很差,也会一定程度影响list容器接口超时,从而导致PLEG错误。 该问题的解决措施:尽量使用的带本地高速盘的VM,并且将多块数据盘组成Raid阵列,提高读写带宽。 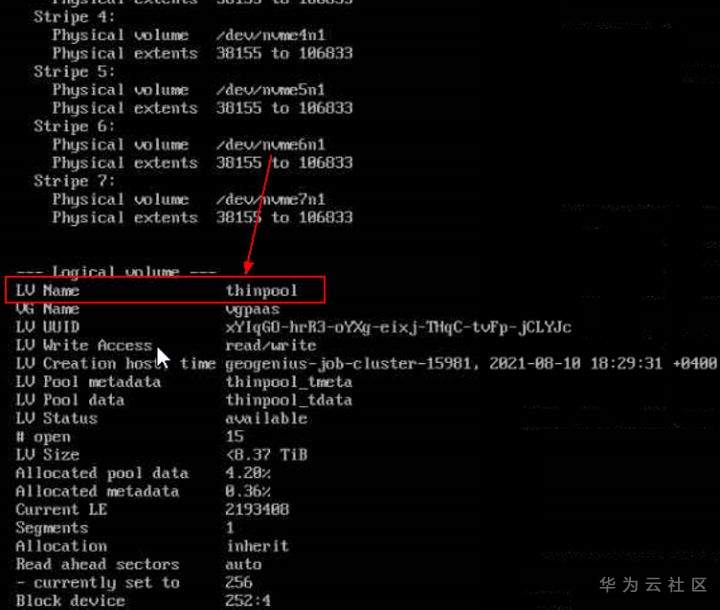 这样,该VM作为K8s的节点,节点上的容器都直接读写本地盘,io性能较好。(跟大数据集群的节点用法一样了,强依赖本地shuffle~)。 在这多条措施实施后,后续多批次的作业都可以平稳的运行完。
推荐直播
-
 华为云码道 × 仓颉编程:工程化AI编码探索
华为云码道 × 仓颉编程:工程化AI编码探索2026/05/27 周三 19:00-21:00
刘俊杰-华为云仓颉语言专家/李炎-华为云码道技术专家/王智鹏-OpenCangjie开源社区发起人
本场直播围绕华为云仓颉语言与华为云码道的深度结合,展示华为云智能编程从零基础到高效落地的完整生态能力。以华为云码道为引擎,仓颉语言为载体,带给大家日常提效、趣味创新到极速量产的开发体验。
回顾中
热门标签