-
 # 一、问题描述 生产环境,执行update/delete相关业务操作时,业务报错: ERROR: dn_6003_6004: Lock wait timeout: thread 139858583217920 on node dn_6003_6004 waiting for ShareLock on transaction 55363311 after 120000.061 ms # 二、问题背景 并发操作列存表 # 三、问题分析 分布式环境下,列存表的最小存储单位是CU,如果并发操作同一个CU时,会产生分布式锁; # 四、问题解决 对并发操作进行串行: 原业务语句: ``` start transaction; delete from TARGET_A where xxx='xxx’; ........ update TARGET_A where xxx='xxx’…… end transaction; ``` 修改后 在update语句前增加一个select语句,在每一个业务操作前,修改如下: ``` start transaction; select name from CONTROL_TABLE where name = 'target_a' for update; delete from TARGET_A where xxx='xxx’; ........ update TARGET_A where xxx='xxx’…… end transaction; ``` control_table为新建行存表,只有一个字段,字段的取值为要更新的目标表名。 在并发更新同一张目标表时,首先会利用这张表获取对应记录的行级锁,其他并发任务等待行级锁释放;等到前序事务提交完成后,释放control_table的行级锁,后序事务获取行存表的行锁后,再提交update列存表语句。通过这种方式实现delete/update语句的串行执行,避免并发更新的锁超时报错。 # 五、问题总结 并发update/delete在分布式环境比较常见,如果业务不想产生等锁报错可以串行执行。
# 一、问题描述 生产环境,执行update/delete相关业务操作时,业务报错: ERROR: dn_6003_6004: Lock wait timeout: thread 139858583217920 on node dn_6003_6004 waiting for ShareLock on transaction 55363311 after 120000.061 ms # 二、问题背景 并发操作列存表 # 三、问题分析 分布式环境下,列存表的最小存储单位是CU,如果并发操作同一个CU时,会产生分布式锁; # 四、问题解决 对并发操作进行串行: 原业务语句: ``` start transaction; delete from TARGET_A where xxx='xxx’; ........ update TARGET_A where xxx='xxx’…… end transaction; ``` 修改后 在update语句前增加一个select语句,在每一个业务操作前,修改如下: ``` start transaction; select name from CONTROL_TABLE where name = 'target_a' for update; delete from TARGET_A where xxx='xxx’; ........ update TARGET_A where xxx='xxx’…… end transaction; ``` control_table为新建行存表,只有一个字段,字段的取值为要更新的目标表名。 在并发更新同一张目标表时,首先会利用这张表获取对应记录的行级锁,其他并发任务等待行级锁释放;等到前序事务提交完成后,释放control_table的行级锁,后序事务获取行存表的行锁后,再提交update列存表语句。通过这种方式实现delete/update语句的串行执行,避免并发更新的锁超时报错。 # 五、问题总结 并发update/delete在分布式环境比较常见,如果业务不想产生等锁报错可以串行执行。 -
【功能模块】调用的run_cluster.sh代码(代码来源:https://gitee.com/mindspore/docs/tree/r1.7/docs/sample_code/distributed_training/run_cluster.sh)如下:#!/bin/bash # applicable to Ascend echo "==============================================================================================================" echo "Please run the script as: " echo "bash run.sh DATA_PATH RANK_TABLE_FILE RANK_SIZE RANK_START" echo "For example: bash run.sh /path/dataset /path/rank_table.json 16 0" echo "It is better to use the absolute path." echo "==============================================================================================================" execute_path=$(pwd) echo ${execute_path} script_self=$(readlink -f "$0") self_path=$(dirname "${script_self}") echo ${self_path} export DATA_PATH=$1 export RANK_TABLE_FILE=$2 export RANK_SIZE=$3 RANK_START=$4 DEVICE_START=0 for((i=0;i<=7;i++)); do export RANK_ID=$[i+RANK_START] export DEVICE_ID=$[i+DEVICE_START] rm -rf ${execute_path}/device_$RANK_ID mkdir ${execute_path}/device_$RANK_ID cd ${execute_path}/device_$RANK_ID || exit pytest -s ${self_path}/resnet50_distributed_training.py >train$RANK_ID.log 2>&1 &【操作步骤&问题现象】使用Mindspore进行多机多卡的AI分布式训练。共使用两台机器,一台Ascend 910A 八卡,另一台也是Ascend 910A 八卡,共十六卡。但是在使用https://www.mindspore.cn/tutorials/experts/zh-CN/r1.7/parallel/train_ascend.html的分布式AI训练的教程时发现一些问题。运行报错,运行的命令如下:# server0 bash run_cluster.sh /path/dataset /path/rank_table.json 16 0 # server1 bash run_cluster.sh /path/dataset /path/rank_table.json 16 8【截图信息】【报错信息】[ERROR] DEVICE(19823,ffff9ad057e0,python3.7):2022-08-03-14:47:37.722.356 [mindspore/ccsrc/plugin/device/ascend/hal/device/ascend_kernel_runtime.cc:1268] HcclInit] Invalid environment variable 'MINDSPORE_HCCL_CONFIG_PATH' or 'RANK_TABLE_FILE', the path is: cluster_rank_table_16pcs.json. Please check (1) whether the path exists, (2) whether the path has the access permission, (3) whether the path is too long.[ERROR] DEVICE(19823,ffff9ad057e0,python3.7):2022-08-03-14:47:37.722.434 [mindspore/ccsrc/plugin/device/ascend/hal/device/ascend_kernel_runtime.cc:1183] InitDevice] HcclInit init failed[CRITICAL] PIPELINE(19823,ffff9ad057e0,python3.7):2022-08-03-14:47:37.722.459 [mindspore/ccsrc/pipeline/jit/pipeline.cc:1456] InitHccl] Runtime init failed.============================= test session starts ==============================platform linux -- Python 3.7.5, pytest-7.1.2, pluggy-1.0.0rootdir: /sunhanyuan/docs-r1.7/docs/sample_code/distributed_trainingcollected 0 items / 1 error==================================== ERRORS ====================================______________ ERROR collecting resnet50_distributed_training.py _______________../resnet50_distributed_training.py:35: in <module> init()/usr/local/python37/lib/python3.7/site-packages/mindspore/communication/management.py:142: in init init_hccl()E RuntimeError: mindspore/ccsrc/pipeline/jit/pipeline.cc:1456 InitHccl] Runtime init failed.=========================== short test summary info ============================ERROR ../resnet50_distributed_training.py - RuntimeError: mindspore/ccsrc/pip...!!!!!!!!!!!!!!!!!!!! Interrupted: 1 error during collection !!!!!!!!!!!!!!!!!!!!=============================== 1 error in 7.40s ===============================
-
2022 年数据工程现状地图01 数据采集这一层包括流技术和 SaaS 服务,提供从业务系统到数据存储的管道。这方面值得一提的进展是 Airbyte 的戏剧性崛起。Airbyte 成立于 2020 年,在这年年底才转向其当前的产品。Airbyte 是一个开源项目,目前有超过 15000 家公司在使用。其社区有超过 600 名贡献者。在采用和社区方面,如此指数级的增长非常罕见。Airbyte 刚刚推出了他们的商业产品,并通过收购 Grouparoo(一个反向 ETL 连接器开源项目)扩展到反向 ETL(一个在数据工程现状地图中没有涉及的类别)。我们认为,反向 ETL 是一个与 ETL 有很大差别的产品,因为它需要将数据集成到业务系统中,帮助用户完成该系统中的工作流。我们很想知道事情的结果如何。02 数据湖2021 年,我们将数据仓库和湖仓(lakehouse)作为数据湖层的一部分。但今年,我们决定保留数据湖这个类别,仅指用作数据湖的对象存储技术。我们将所有的数据仓库和湖仓移至分析引擎类别。为什么?如今,数据工程师处理的大多数架构都很复杂,足以同时包括对象存储和分析引擎。因此,你要么只需要一个分析数据库(这种情况没有数据湖,只有一个作为分析引擎的数据仓库),要么两者都要。而当两者都需要时,你通常会在对象存储上执行一些分析,在分析引擎上执行另一些分析。这就是为什么它们需要很容易搭配使用。这种依赖关系发生在不同的层。大型数据集会托管在对象存储中,而工件和服务层数据集将存储在分析引擎和数据库中。在我们知道的架构中,没有看到一个征服另一个的情况。我们看到,在现实中,这些解决方案是并存的。这种架构产生的背后有多种原因,但其中一个肯定是成本考虑。在 Snowflake 或 BigQuery 中查询大量的数据是很昂贵的。因此,与其让分析数据库管理整个湖,不如在对象存储中管理一切它可以管理的东西,在它上面执行计算更便宜,而将所有必须由分析引擎管理的东西交给分析引擎。我们认为,湖仓是一个分析引擎(尽管在 Databricks 中,它既包括数据湖,也包括分析引擎)。这个架构的特点是使用 Spark SQL 的优化版本在 Delta 表格式上创建一个分析引擎。这提供了人们希望从分析引擎获得的性能和成本。同样的规则适用于 Iceberg 上的 Dremio,或支持将 Iceberg 作为数据库外部表的 Snowflake。03 元数据管理在元数据领域发生了很多事情!元数据的两个层次——这一层和图表顶部的组织层——正成为许多组织的关注点。回顾我们作为可扩展数据从业者所面临的挑战,在过去十年中,我们一直在围绕存储和计算机进行创新——所有这些都是为了确保它们支持数据的扩展。如今,我们面临的主要是可管理性问题,我们可以通过生成和管理元数据来解决这些问题。这一层涉及元数据的不同方面,让我们逐个看下。1、开放式表格式我们看到,在过去的一年里,开放式表格式取得了有趣的进步。它们正在成为数据湖中保存结构化数据的标准。一年之前,Delta Lake 是一个 Databricks 项目,它有一个商业化产品叫 Delta。然后在今年,Onehouse 公司商业化了 Apache Hudi,Tabular 公司商业化了 Apache Iceberg。这两家公司都是由这些开源项目的创建者创立的。因此,整个领域从开源变成了完全由商业实体支撑。这让人不禁会问,既然背后有商业利益,其他参与者对开源项目还能有多大影响。由于这三个开源项目都属于 Apache/Linux 基金会,所以对社区而言风险很低。这似乎并不能平息这三个项目的创建者和粉丝之间的激烈争论,围绕谁“真正”开源以及谁提供了最好的解决方案。Netflix 很快就会把这个故事作为电视剧的绝佳素材。2、Metastore 的未来仍不明朗……我们看到,Hive Metastore 被从架构中移除,开放式表格式或许可以替代它。并不是所有的组织都充分利用了 Metastore 的能力,如果他们唯一的用例是虚拟化表,那么开放式表格式和以它为基础构建的商业产品提供了一个很好的选择。Metastore 的其他用例还没有更好的替代解决方案。3、Git For DataGit For Data 的概念在社区中日渐流行。dbt 鼓励分析师在不同版本的数据(开发、过渡和生产)上使用最佳实践,但不支持在数据湖中创建和维护这些数据集。数据运营团队越来越需要提供跨组织的数据版本控制,以管理随着时间推移做过不同修订的数据集。对一个数据集进行不同修订的例子有:重新计算,这是算法和 ML 模型所必需的,或者是来自运营系统的回填,这在 BI 中经常发生,或者是遵循 GDPR 被遗忘权规定而删除一个子集。这一趋势从 LakeFS 及其社区的急剧增长可以明显看出来,我亲眼目睹了这一点。LakeFS 同时提供了结构化和非结构化数据操作服务,在两者都存在的情况下大放光彩。遗憾的是,关于 Dremio 的 Nessie 项目的使用情况,很难找到公开数据。有趣的是,它还提供了一个名为 Arctic 的免费服务。这可能是为了与 Tabular 竞争而做出的战略决定。04 数据计算为了更好地反映生态系统现状,我们今年对计算层做了一些修改。首先,我们完全删除了虚拟化这个类别。它目前似乎还没有流行开来。然后我们把计算引擎分成两类:分布式计算和分析引擎。它们之间的主要区别在于这些工具对其存储层的要求。分布式计算包括对存储没有要求的计算引擎,而分析引擎类别包含有要求的计算引擎(无论是否分布式)。1、分布式计算一般的分布式计算引擎允许工程师分发任意 SQL 或任何其他代码。当然,它们可能对编程语言有要求,但它们会在(通常是)联合数据上进行普遍分发。这可能是跨许多格式和数据源的数据。分布式计算类别中新增了两个有趣的补充:Ray 和 Dask。Ray 是一个开源项目,允许工程师扩展任何计算密集型的 Python 工作负载,主要用于机器学习。Dask 也是一个基于 Pandas 的分布式 Python 引擎。你可能认为,Spark 将是统治这个领域的分布式引擎,看不到任何竞争。因此,见证新技术在这一类别中的崛起还是相当令人兴奋的。2、分析引擎分析引擎类别包括所有的数据仓库,如 Snowflake、BigQuery、Redshift、Firebolt 以及老好的 PostgreSQL。它还包含像 Databricks lakehouse、Dremio 或 Apache Pinot 这样的湖仓。所有这些工具都有自己支持的数据格式,为的是使查询引擎提供更好的性能。由于所有的分析引擎都使用数据湖作为深层存储或存储,所以值得一提的是,Snowflake 现在支持将 Apache Iceberg 作为外部表格式之一,可以由 Snowflake 直接从湖中读取。 05 数据编排和可观察性这是今年新增加的一层,但由现有的类别组成。编排工具去年是元数据层的一部分,但我们把它移到了它真正属于的计算引擎层——它主要是跨计算引擎和数据源编排管道。与此同时,我们看到,可观察性工具在 2021 年有了很大的发展,可以支持更多的数据源(产生于任何计算引擎)。1、数据编排关于数据编排,有什么引人注目的事情发生吗?Airflow 仍然是最大的开源产品。从加入云计算行列至今,Astronomer 多年来一直以它为基础。现在,Astronomer 直接与云供应商在托管 Airflow 领域展开了竞争。Astronomer 另一个非常有趣的举动是收购了提供数据谱系的 Datakin。这让人不禁要问——当一个编排工具具备了数据谱系能力时会发生什么?理论上,这可以帮助数据团队构建更安全、更有弹性的管道。了解哪些数据集依赖于缺失、损坏或低质量的数据,将逻辑(由编排工具管理)和它们的输出(由谱系工具管理)联系起来,影响分析将变得相当容易。这是否会成为编排生态系统的一个组成部分,还有待观察。2、可观察性这个类别由 Monte Carlo 数据公司创建,也由它主导。Monte Carlo 的频繁融资表明其产品在市场上被迅速采用。该产品不断发展,提供了更多的集成(如 Databricks 生态系统),以及额外的可观察性和根源分析功能。或许正是这种成功推动了这一类别的增长,至少从如今在探索这一领域的公司数量来看是如此。2021 年,有几家公司成立或打破隐身状态,最有趣的是 Elementary,又一个来自 YC 的开源项目。06 数据科学和分析的可用性这一层是为数据架构(通过前几层创建)用户准备的:数据科学家和分析师,他们从数据获取洞察力。我们把这个类别分成三个子类别:端到端 MLOps 工具以数据中心化 ML 方法为基础的工具ML 可观察性和监控1、端到端 MLOps 工具当我着手考察这个领域时,有人告诉我,我应该把这个类别命名为:“准备好失望吧”。虽然这个类别有很棒的工具,但没有一个是真正的端到端。它们为 ML 过程中的某些步骤提供了很好的解决方案,但对 ML 管道的其他方面缺乏支持。尽管如此,提供端到端解决方案的方法在 2021 年还是很受欢迎。有几款面向特定任务的工具走上了这一道路,成为了端到端的产品,如 Comet、Weights & Biases、Clear.ml 和 Iguazio。2、数据中心化 ML这个子类别也没有逃脱端到端的陷阱,但其中列出的工具采用了不同的方法来提供功能。它们以数据及其管理作为任务的中心。这个领域有两个新成员 Activeloop 和 Graviti。它们是由经验丰富的数据从业者构建的,他们了解数据管理对数据操作成功的重要性。在 LakeFS,我们也有这样的感受。DagsHub 采取了一种独特的方法,提供了一个以数据为中心的端到端解决方案,不过是基于开源解决方案。他们在 ML 生命周期的每个阶段都很出色,提供了很好的可用性,并且易于集成。在这样一个混乱的领域里,这是一个可靠的方法,可以得到一个不错的端到端解决方案,同时也可以取悦用户。我们正满心期待地看着这家公司....3、ML 可观察性和监控这个子类别包括专注于模型质量监控和可观察性的工具。与数据可观察性类别非常相似,这一领域正在成长并逐步形成良好的发展势头。2022 年初,Deepchecks 开放了源代码,并迅速获得关注,吸引了不少贡献者和合作伙伴。4、Notebooks在 Notebooks 类别中,我们看到,得益于 Databricks 和 Snowflake 的投资,Hex 得到了更多的关注和验证。Hex 在其 Notebook 中提供了更多编排能力。Ploomber 也是如此,它的出现为 Jupyter 提供了编排能力。在过去的一年里,这个面向分析师的工具类别确立了自己的地位,并赢得了一些竞争。dbt 证明了自己是分析师的标准。2021 年,它发布了与可扩展数据工程栈的集成,包括对象存储、HMS 和 Databricks 的产品。在与生态系统合作的同时,2021 年,Databricks 推出了其“活性表”产品的正式版本,与 dbt 展开了直接竞争。 07 数据目录、权限和治理对于这个生态系统,我的感觉是,现在各种规模的公司对数据目录的需求都很明确。我们将看到,它会成为一种标准。基于开源项目的商业产品显示出良好的采用水平。与此同时,企业解决方案的长期供应商,Alation 和 Collibra,继续扩展他们的产品。而安全和权限管理供应商 BigID 也在试图提供一个目录。Immuta 继续致力于数据访问控制,其独特的技术使它现在可以兼容更多的数据源。为了加速发展,该公司早在 2021 年中期就完成了 9000 万美元的 D 轮融资。08 小结虽然该领域的公司数量在不断增加,但可以看到,其中有几个类别的产品出现了整合迹象。MLOps 趋向于端到端,Notebook 正在进入编排领域,而编排正在转向数据谱系和可观察性。与此同时,我们看到,开放式表格式进入了元存储功能。而在治理层,安全和权限管理工具进入目录领域,反之亦然......这些迹象是否预示着市场(仍然)有限,也许是 MLOps 市场有限?这种整合是否反映了由于激烈的竞争而产生的差异化需求(在编排方面可能是这种情况)?还是说这是一个填补空白的机会,像开放式表格或数据中心化 ML 那样的情况?还是说,这都是因为用户希望使用更少的工具来做更多的事情?我打算把这些问题留给读者,希望能引发对 2022 年数据工程状况的讨论。2022 年,还有哪些项目正在获得发展的动力?哪些工具正在成为行业内的事实标准?欢迎在评论区分享您的想法。来源:InfoQ https://lakefs.io/the-state-of-data-engineering-2022
-
# Dive Into MindSpore -- Distributed Training With GPU For Model Train > MindSpore易点通·精讲系列--模型训练之GPU分布式并行训练 本文开发环境 - Ubuntu 20.04 - Python 3.8 - MindSpore 1.7.0 - OpenMPI 4.0.3 - RTX 1080Ti * 4 本文内容摘要 - 基础知识 - 环境搭建 - 单卡训练 - 多卡训练--OpenMPI - 多卡训练--非OpenMPI - 本文总结 - 遇到问题 - 本文参考 ## 1. 基础知识 ### 1.1 概念介绍 在深度学习中,随着模型和数据的不断增长,在很多情况下需要使用单机多卡或者多机多卡进行训练,即分布式训练。分布式训练策略按照并行方式不同,可以简单的分为数据并行和模型并行两种方式。 - 数据并行 - 数据并行是指在不同的 GPU 上都 copy 保存一份模型的副本,然后将不同的数据分配到不同的 GPU 上进行计算,最后将所有 GPU 计算的结果进行合并,从而达到加速模型训练的目的。 - 模型并行 - 与数据并行不同,分布式训练中的模型并行是指将整个神经网络模型拆解分布到不同的 GPU 中,不同的 GPU 负责计算网络模型中的不同部分。这通常是在网络模型很大很大、单个 GPU 的显存已经完全装不下整体网络的情况下才会采用。  ### 1.2 MindSpore中的支持 `1.1`中介绍了理论中的并行方式,具体到`MIndSpore`框架中,目前支持下述的四种并行模式: - 数据并行:用户的网络参数规模在单卡上可以计算的情况下使用。这种模式会在每卡上复制相同的网络参数,训练时输入不同的训练数据,适合大部分用户使用。 - 半自动并行:用户的神经网络在单卡上无法计算,并且对切分的性能存在较大的需求。用户可以设置这种运行模式,手动指定每个算子的切分策略,达到较佳的训练性能。 - 自动并行:用户的神经网络在单卡上无法计算,但是不知道如何配置算子策略。用户启动这种模式,`MindSpore`会自动针对每个算子进行配置策略,适合想要并行训练但是不知道如何配置策略的用户。 - 混合并行:完全由用户自己设计并行训练的逻辑和实现,用户可以自己在网络中定义`AllGather`等通信算子。适合熟悉并行训练的用户。 对于大部分用户来说,其实能够用到的是数据并行模式,所以下面的案例中,会以数据并行模式来展开讲解。 ## 2. 环境搭建 ### 2.1 MindSpore安装 略。可参考笔者之前的文章[MindSpore入门--基于GPU服务器安装MindSpore 1.5.0](https://bbs.huaweicloud.com/forum/thread-179309-1-1.html),注意将文章中的`MindSpore`版本升级到`1.7.0`。 ### 2.2 OpenMPI安装 在`GPU`硬件平台上,`MindSpore`采用`OpenMPI`的`mpirun`进行分布式训练。所以我们先来安装`OpenMPI`。 本文安装的是`4.0.3`版本,安装命令如下: ```shell wget -c https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.3.tar.gz tar xf openmpi-4.0.3.tar.gz cd openmpi-4.0.3/ ./configure --prefix=/usr/local/openmpi-4.0.3 make -j 16 sudo make install echo -e "export PATH=/usr/local/openmpi-4.0.3/bin:\$PATH" >> ~/.bashrc echo -e "export LD_LIBRARY_PATH=/usr/local/openmpi-4.0.3/lib:\$LD_LIBRARY_PATH" >> ~/.bashrc source ~/.bashrc ``` 使用`mpirun --version`命令验证是否安装成功,输出如下内容: ```shell mpirun (Open MPI) 4.0.3 Report bugs to http://www.open-mpi.org/community/help/ ``` ### 2.3 环境验证 上面基础环境安装完成后,我们对环境进行一个初步验证,来看看是否搭建成功。 验证代码如下: ```python # nccl_allgather.py import numpy as np import mindspore.ops as ops import mindspore.nn as nn from mindspore import context, Tensor from mindspore.communication import init, get_rank class Net(nn.Cell): def __init__(self): super(Net, self).__init__() self.allgather = ops.AllGather() def construct(self, x): return self.allgather(x) if __name__ == "__main__": context.set_context(mode=context.GRAPH_MODE, device_target="GPU") init("nccl") value = get_rank() input_x = Tensor(np.array([[value]]).astype(np.float32)) net = Net() output = net(input_x) print(output) ``` 将上面代码保存到文件`nccl_allgather.py`中,运行命令: > 命令解读: > > - `-n` 后面数字代表使用GPU的数量,这里使用了机器内全部GPU。如果读者不想使用全部,记得设置相应的环境变量。 ```shell mpirun -n 4 python3 nccl_allgather.py ``` 输出内容如下: ```shell [[0.] [1.] [2.] [3.]] [[0.] [1.] [2.] [3.]] [[0.] [1.] [2.] [3.]] [[0.] [1.] [2.] [3.]] ``` 至此,我们的环境搭建完成,且验证成功。 ## 3. 单卡训练 为了能够后续进行对比测试,这里我们先来进行单卡训练,以此做为基准。 ### 3.1 代码部分 > 代码说明: > > 1. 网络结构采用的是`ResNet-50`,读者可以在`MindSpore Models`仓库进行获取,复制粘贴过来即可,[ResNet-50代码链接](https://gitee.com/mindspore/mindspore/blob/r1.1/model_zoo/official/cv/resnet/src/resnet.py)。 > 2. 数据集采用的是`Fruit-360`数据集,有关该数据集的更详细介绍可以参看笔者之前的文章[MindSpore易点通·精讲系列--数据集加载之ImageFolderDataset](https://bbs.huaweicloud.com/forum/thread-190708-1-1.html)。[数据集下载链接](https://git.openi.org.cn/kaierlong/Fruits_360/datasets) > 3. 读者注意将代码中的`train_dataset_dir`和`test_dataset_dir`替换为自己的文件目录。 单卡训练的代码如下: ```python import numpy as np from mindspore import context from mindspore import nn from mindspore.common import dtype as mstype from mindspore.common import set_seed from mindspore.common import Tensor from mindspore.communication import init, get_rank, get_group_size from mindspore.dataset import ImageFolderDataset from mindspore.dataset.transforms.c_transforms import Compose, TypeCast from mindspore.dataset.vision.c_transforms import HWC2CHW, Normalize, RandomCrop, RandomHorizontalFlip, Resize from mindspore.nn.loss import SoftmaxCrossEntropyWithLogits from mindspore.nn.optim import Momentum from mindspore.ops import operations as P from mindspore.ops import functional as F from mindspore.train import Model from mindspore.train.callback import CheckpointConfig, ModelCheckpoint, LossMonitor from scipy.stats import truncnorm # define reset50 def create_dataset(dataset_dir, mode="train", decode=True, batch_size=32, repeat_num=1): if mode == "train": shuffle = True else: shuffle = False dataset = ImageFolderDataset( dataset_dir=dataset_dir, shuffle=shuffle, decode=decode) mean = [127.5, 127.5, 127.5] std = [127.5, 127.5, 127.5] if mode == "train": transforms_list = Compose( [RandomCrop((32, 32), (4, 4, 4, 4)), RandomHorizontalFlip(), Resize((100, 100)), Normalize(mean, std), HWC2CHW()]) else: transforms_list = Compose( [Resize((128, 128)), Normalize(mean, std), HWC2CHW()]) cast_op = TypeCast(mstype.int32) dataset = dataset.map(operations=transforms_list, input_columns="image") dataset = dataset.map(operations=cast_op, input_columns="label") dataset = dataset.batch(batch_size=batch_size, drop_remainder=True) dataset = dataset.repeat(repeat_num) return dataset def run_train(): context.set_context(mode=context.GRAPH_MODE, device_target="GPU") set_seed(0) train_dataset_dir = "/mnt/data_0002_24t/xingchaolong/dataset/Fruits_360/fruits-360_dataset/fruits-360/Training" test_dataset_dir = "/mnt/data_0002_24t/xingchaolong/dataset/Fruits_360/fruits-360_dataset/fruits-360/Test" batch_size = 32 train_dataset = create_dataset(dataset_dir=train_dataset_dir, batch_size=batch_size) test_dataset = create_dataset(dataset_dir=test_dataset_dir, mode="test") train_batch_num = train_dataset.get_dataset_size() test_batch_num = test_dataset.get_dataset_size() print("train dataset batch num: {}".format(train_batch_num), flush=True) print("test dataset batch num: {}".format(test_batch_num), flush=True) # build model net = resnet50(class_num=131) loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean") optim = Momentum(params=net.trainable_params(), learning_rate=0.01, momentum=0.9, loss_scale=1024.0) model = Model(net, loss_fn=loss, optimizer=optim, metrics={"accuracy"}) # CheckPoint CallBack definition config_ck = CheckpointConfig(save_checkpoint_steps=train_batch_num, keep_checkpoint_max=35) ckpoint_cb = ModelCheckpoint(prefix="fruit_360_renet50", directory="./ckpt/", config=config_ck) # LossMonitor is used to print loss value on screen loss_cb = LossMonitor() # model train model.train(10, train_dataset, callbacks=[ckpoint_cb, loss_cb], dataset_sink_mode=True) # model eval result = model.eval(test_dataset) print("eval result: {}".format(result), flush=True) def main(): run_train() if __name__ == "__main__": main() ``` ### 3.2 训练部分 保存代码到`gpu_single_train.py`,使用如下命令进行训练: ```shell export CUDA_VISIBLE_DEVICES=0 python3 gpu_single_train.py ``` 训练过程输出内容如下: ```shell train dataset batch num: 2115 test dataset batch num: 709 epoch: 1 step: 2115, loss is 4.219570636749268 epoch: 2 step: 2115, loss is 3.7109947204589844 ...... epoch: 9 step: 2115, loss is 2.66499400138855 epoch: 10 step: 2115, loss is 2.540522336959839 eval result: {'accuracy': 0.676348730606488} ``` 使用`tree ckpt`命令,查看一下模型保存目录的情况,输出内容如下: ```shell ckpt/ ├── fruit_360_renet50-10_2115.ckpt ├── fruit_360_renet50-1_2115.ckpt ...... ├── fruit_360_renet50-9_2115.ckpt └── fruit_360_renet50-graph.meta ``` ## 4. 多卡训练--OpenMPI 下面我们通过实际案例,介绍如何在GPU平台上,采用OpenMPI进行分布式训练。 ### 4.1 代码部分 > 代码说明: > > - 前三点说明请参考`3.1`部分的代码说明。 > - 多卡训练主要修改的是数据集读取和`context`设置部分。 > - 数据集读取:需要指定`num_shards`和`shard_id`,详细内容参考代码。 > - `context`设置:包含参数一致性和并行模式设定。参数一致性这里使用的是`set_seed`来设定;并行模式通过`set_auto_parallel_context`方法和`parallel_mode`参数来进行设置。 多卡训练的代码如下: ```python import numpy as np from mindspore import context from mindspore import nn from mindspore.common import dtype as mstype from mindspore.common import set_seed from mindspore.common import Tensor from mindspore.communication import init, get_rank, get_group_size from mindspore.dataset import ImageFolderDataset from mindspore.dataset.transforms.c_transforms import Compose, TypeCast from mindspore.dataset.vision.c_transforms import HWC2CHW, Normalize, RandomCrop, RandomHorizontalFlip, Resize from mindspore.nn.loss import SoftmaxCrossEntropyWithLogits from mindspore.nn.optim import Momentum from mindspore.ops import operations as P from mindspore.ops import functional as F from mindspore.train import Model from mindspore.train.callback import CheckpointConfig, ModelCheckpoint, LossMonitor from scipy.stats import truncnorm # define reset50 def create_dataset(dataset_dir, mode="train", decode=True, batch_size=32, repeat_num=1): if mode == "train": shuffle = True rank_id = get_rank() rank_size = get_group_size() else: shuffle = False rank_id = None rank_size = None dataset = ImageFolderDataset( dataset_dir=dataset_dir, shuffle=shuffle, decode=decode, num_shards=rank_size, shard_id=rank_id) mean = [127.5, 127.5, 127.5] std = [127.5, 127.5, 127.5] if mode == "train": transforms_list = Compose( [RandomCrop((32, 32), (4, 4, 4, 4)), RandomHorizontalFlip(), Resize((100, 100)), Normalize(mean, std), HWC2CHW()]) else: transforms_list = Compose( [Resize((128, 128)), Normalize(mean, std), HWC2CHW()]) cast_op = TypeCast(mstype.int32) dataset = dataset.map(operations=transforms_list, input_columns="image") dataset = dataset.map(operations=cast_op, input_columns="label") dataset = dataset.batch(batch_size=batch_size, drop_remainder=True) dataset = dataset.repeat(repeat_num) return dataset def run_train(): context.set_context(mode=context.GRAPH_MODE, device_target="GPU") init("nccl") rank_id = get_rank() rank_size = get_group_size() print("rank size: {}, rank id: {}".format(rank_size, rank_id), flush=True) set_seed(0) context.set_auto_parallel_context( device_num=rank_size, gradients_mean=True, parallel_mode=context.ParallelMode.DATA_PARALLEL) train_dataset_dir = "/mnt/data_0002_24t/xingchaolong/dataset/Fruits_360/fruits-360_dataset/fruits-360/Training" test_dataset_dir = "/mnt/data_0002_24t/xingchaolong/dataset/Fruits_360/fruits-360_dataset/fruits-360/Test" batch_size = 32 train_dataset = create_dataset(dataset_dir=train_dataset_dir, batch_size=batch_size//rank_size) test_dataset = create_dataset(dataset_dir=test_dataset_dir, mode="test") train_batch_num = train_dataset.get_dataset_size() test_batch_num = test_dataset.get_dataset_size() print("train dataset batch num: {}".format(train_batch_num), flush=True) print("test dataset batch num: {}".format(test_batch_num), flush=True) # build model net = resnet50(class_num=131) loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean") optim = Momentum(params=net.trainable_params(), learning_rate=0.01, momentum=0.9, loss_scale=1024.0) model = Model(net, loss_fn=loss, optimizer=optim, metrics={"accuracy"}) # CheckPoint CallBack definition config_ck = CheckpointConfig(save_checkpoint_steps=train_batch_num, keep_checkpoint_max=35) ckpoint_cb = ModelCheckpoint(prefix="fruit_360_renet50_{}".format(rank_id), directory="./ckpt/", config=config_ck) # LossMonitor is used to print loss value on screen loss_cb = LossMonitor() # model train model.train(10, train_dataset, callbacks=[ckpoint_cb, loss_cb], dataset_sink_mode=True) # model eval result = model.eval(test_dataset) print("eval result: {}".format(result), flush=True) def main(): run_train() if __name__ == "__main__": main() ``` ### 4.2 训练部分 下面来介绍如何使用多卡GPU训练。 #### 4.2.1 4卡GPU训练 使用如下命令,进行4卡GPU训练: ```shell export CUDA_VISIBLE_DEVICES=0,1,2,3 mpirun -n 4 python3 gpu_distributed_train.py ``` 训练过程中,输出内容如下: ```shell rank size: 4, rank id: 0 rank size: 4, rank id: 1 rank size: 4, rank id: 2 rank size: 4, rank id: 3 train dataset batch num: 2115 test dataset batch num: 709 train dataset batch num: 2115 test dataset batch num: 709 train dataset batch num: 2115 test dataset batch num: 709 train dataset batch num: 2115 test dataset batch num: 709 [WARNING] PRE_ACT(294248,7fa67e831740,python3):2022-07-13-17:11:24.528.381 [mindspore/ccsrc/backend/common/pass/communication_op_fusion.cc:198] GetAllReduceSplitSegment] Split threshold is 0. AllReduce nodes will take default fusion strategy. [WARNING] PRE_ACT(294245,7f57993a5740,python3):2022-07-13-17:11:26.176.114 [mindspore/ccsrc/backend/common/pass/communication_op_fusion.cc:198] GetAllReduceSplitSegment] Split threshold is 0. AllReduce nodes will take default fusion strategy. [WARNING] PRE_ACT(294247,7f36f889b740,python3):2022-07-13-17:11:30.475.177 [mindspore/ccsrc/backend/common/pass/communication_op_fusion.cc:198] GetAllReduceSplitSegment] Split threshold is 0. AllReduce nodes will take default fusion strategy. [WARNING] PRE_ACT(294246,7f5f1820c740,python3):2022-07-13-17:11:31.271.259 [mindspore/ccsrc/backend/common/pass/communication_op_fusion.cc:198] GetAllReduceSplitSegment] Split threshold is 0. AllReduce nodes will take default fusion strategy. epoch: 1 step: 2115, loss is 4.536644458770752 epoch: 1 step: 2115, loss is 4.347061634063721 epoch: 1 step: 2115, loss is 4.557111740112305 epoch: 1 step: 2115, loss is 4.467658519744873 ...... epoch: 10 step: 2115, loss is 3.263073205947876 epoch: 10 step: 2115, loss is 3.169656753540039 epoch: 10 step: 2115, loss is 3.2040905952453613 epoch: 10 step: 2115, loss is 3.812671184539795 eval result: {'accuracy': 0.48113540197461213} eval result: {'accuracy': 0.5190409026798307} eval result: {'accuracy': 0.4886283497884344} eval result: {'accuracy': 0.5010578279266573} ``` 使用`tree ckpt`命令,查看一下模型保存目录的情况,输出内容如下: ```shell ckpt/ ├── fruit_360_renet50_0-10_2115.ckpt ├── fruit_360_renet50_0-1_2115.ckpt ├── fruit_360_renet50_0-2_2115.ckpt ├── fruit_360_renet50_0-3_2115.ckpt ├── fruit_360_renet50_0-4_2115.ckpt ├── fruit_360_renet50_0-5_2115.ckpt ├── fruit_360_renet50_0-6_2115.ckpt ├── fruit_360_renet50_0-7_2115.ckpt ├── fruit_360_renet50_0-8_2115.ckpt ├── fruit_360_renet50_0-9_2115.ckpt ├── fruit_360_renet50_0-graph.meta ...... ├── fruit_360_renet50_3-10_2115.ckpt ├── fruit_360_renet50_3-1_2115.ckpt ├── fruit_360_renet50_3-2_2115.ckpt ├── fruit_360_renet50_3-3_2115.ckpt ├── fruit_360_renet50_3-4_2115.ckpt ├── fruit_360_renet50_3-5_2115.ckpt ├── fruit_360_renet50_3-6_2115.ckpt ├── fruit_360_renet50_3-7_2115.ckpt ├── fruit_360_renet50_3-8_2115.ckpt ├── fruit_360_renet50_3-9_2115.ckpt └── fruit_360_renet50_3-graph.meta ``` #### 4.2.2 2卡GPU训练 为了进行对比,再来进行2卡GPU训练,命令如下: > 这里为了验证普遍性,并非依序选择GPU。 ```shell export CUDA_VISIBLE_DEVICES=2,3 mpirun -n 2 python3 gpu_distributed_train.py ``` 训练过程中,输出内容如下: ```shell rank size: 2, rank id: 0 rank size: 2, rank id: 1 train dataset batch num: 2115 test dataset batch num: 709 train dataset batch num: 2115 test dataset batch num: 709 [WARNING] PRE_ACT(295459,7ff930118740,python3):2022-07-13-17:31:07.210.231 [mindspore/ccsrc/backend/common/pass/communication_op_fusion.cc:198] GetAllReduceSplitSegment] Split threshold is 0. AllReduce nodes will take default fusion strategy. [WARNING] PRE_ACT(295460,7f5fed564740,python3):2022-07-13-17:31:07.649.536 [mindspore/ccsrc/backend/common/pass/communication_op_fusion.cc:198] GetAllReduceSplitSegment] Split threshold is 0. AllReduce nodes will take default fusion strategy. epoch: 1 step: 2115, loss is 4.391518592834473 epoch: 1 step: 2115, loss is 4.337993621826172 ...... epoch: 10 step: 2115, loss is 2.7631659507751465 epoch: 10 step: 2115, loss is 3.0124118328094482 eval result: {'accuracy': 0.6057827926657263} eval result: {'accuracy': 0.6202397743300423} ``` 使用`tree ckpt`命令,查看一下模型保存目录的情况,输出内容如下: ```shell ckpt/ ├── fruit_360_renet50_0-10_2115.ckpt ├── fruit_360_renet50_0-1_2115.ckpt ├── fruit_360_renet50_0-2_2115.ckpt ├── fruit_360_renet50_0-3_2115.ckpt ├── fruit_360_renet50_0-4_2115.ckpt ├── fruit_360_renet50_0-5_2115.ckpt ├── fruit_360_renet50_0-6_2115.ckpt ├── fruit_360_renet50_0-7_2115.ckpt ├── fruit_360_renet50_0-8_2115.ckpt ├── fruit_360_renet50_0-9_2115.ckpt ├── fruit_360_renet50_0-graph.meta ├── fruit_360_renet50_1-10_2115.ckpt ├── fruit_360_renet50_1-1_2115.ckpt ├── fruit_360_renet50_1-2_2115.ckpt ├── fruit_360_renet50_1-3_2115.ckpt ├── fruit_360_renet50_1-4_2115.ckpt ├── fruit_360_renet50_1-5_2115.ckpt ├── fruit_360_renet50_1-6_2115.ckpt ├── fruit_360_renet50_1-7_2115.ckpt ├── fruit_360_renet50_1-8_2115.ckpt ├── fruit_360_renet50_1-9_2115.ckpt └── fruit_360_renet50_1-graph.meta ``` #### 4.2.3 多卡对比说明 - 结合`3.2`部分,进行4卡GPU训练和2卡GPU训练的对比。 - 三种情况下,分别将`batch_size`设置为了32、8、16,对应到的`batch_num`不变。也可以认为是在`GPU`显存不足于支持更大`batch_size`时,通过多卡来实现更大`batch_size`的方案。 - 从实际训练情况来看(都训练了10个epoch),单卡的效果最好,2卡次之,4卡最差。导致这种情况的原因是因为网络中使用到了`BatchNorm2d`算子,而在多卡情况下,无法跨卡计算,从而导致精度上的差别。在GPU硬件下,笔者暂时并没有找到合理的解决方案。 ## 5. 多卡训练--非OpenMPI 在`4`中我们介绍了依赖`OpenMPI`如何来进行`GPU`多卡训练,同时`MindSpore`也支持不依赖`OpenMPI`来进行`GPU`多卡训练。官方对此的说明如下: > 出于训练时的安全及可靠性要求,`MindSpore GPU`还支持**不依赖OpenMPI的分布式训练**。 > > `OpenMPI`在分布式训练的场景中,起到在`Host`侧同步数据以及进程间组网的功能;`MindSpore`通过**复用Parameter Server模式训练架构**,取代了`OpenMPI`能力。 不过`Parameter Server`相关的文档及代码示例不够充分。笔者尝试采用此种方式进行训练,参考了官方文档、`gitee`上面的测试用例,最终未能顺利完成整个`pipline`。 ## 6. 本文总结 本来重点介绍了在`GPU`硬件环境下,如何依赖`OpenMPI`进行多卡训练。对于非依赖`OpenMPI`的`Parameter Server`本文也有所涉及,但由于官方文档的缺失和相应代码不足,无法形成可行案例。 ## 7. 遇到问题 `Parameter Server`模式下的官方文档跳跃性太大,相关的测试用例缺失中间过程代码,希望能够完善这部分的文档和代码。 ## 8. 本文参考 - [深度学习中的分布式训练](https://cloud.tencent.com/developer/news/841792) - [MindSpore分布式并行总览](https://www.mindspore.cn/tutorials/experts/zh-CN/r1.7/parallel/introduction.html) - [MindSpore分布式并行训练基础样例(GPU)](https://www.mindspore.cn/tutorials/experts/zh-CN/r1.7/parallel/train_gpu.html) - [MindSpore Parameter Server模式](https://www.mindspore.cn/docs/zh-CN/r1.7/design/parameter_server_training.html) 本文为原创文章,版权归作者所有,未经授权不得转载!
-
 【摘要】 在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。 为什么需要分布式链路追踪系统 微服务架构给运维、排障带来新挑战在分布式架构...本文分享自华为云社区《一文详解|Go 分布式链路追踪实现原理》,作者:开源小E。在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。为什么需要分布式链路追踪系统微服务架构给运维、排障带来新挑战在分布式架构下,当用户从浏览器客户端发起一个请求时,后端处理逻辑往往贯穿多个分布式服务,这时会浮现很多问题,比如:请求整体耗时较长,具体慢在哪个服务?请求过程中出错了,具体是哪个服务报错?某个服务的请求量如何,接口成功率如何?回答这些问题变得不是那么简单,我们不仅仅需要知道某一个服务的接口处理统计数据,还需要了解两个服务之间的接口调用依赖关系,只有建立起整个请求在多个服务间的时空顺序,才能更好的帮助我们理解和定位问题,而这,正是分布式链路追踪系统可以解决的。分布式链路追踪系统如何帮助我们分布式链路追踪技术的核心思想:在用户一次分布式请求服务的调⽤过程中,将请求在所有子系统间的调用过程和时空关系追踪记录下来,还原成调用链路集中展示,信息包括各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。如上图所示,通过分布式链路追踪构建出完整的请求链路后,可以很直观地看到请求耗时主要耗费在哪个服务环节,帮助我们更快速聚焦问题。同时,还可以对采集的链路数据做进一步的分析,从而可以建立整个系统各服务间的依赖关系、以及流量情况,帮助我们更好地排查系统的循环依赖、热点服务等问题。分布式链路追踪系统架构概览核心概念在分布式链路追踪系统中,最核心的概念,便是链路追踪的数据模型定义,主要包括 Trace 和 Span。其中,Trace 是一个逻辑概念,表示一次(分布式)请求经过的所有局部操作(Span)构成的一条完整的有向无环图,其中所有的 Span 的 TraceId 相同。Span 则是真实的数据实体模型,表示一次(分布式)请求过程的一个步骤或操作,代表系统中一个逻辑运行单元,Span 之间通过嵌套或者顺序排列建立因果关系。Span 数据在采集端生成,之后上报到服务端,做进一步的处理。其包含如下关键属性:Name:操作名称,如一个 RPC 方法的名称,一个函数名StartTime/EndTime:起始时间和结束时间,操作的生命周期ParentSpanId:父级 Span 的 IDAttributes:属性,一组 <K,V> 键值对构成的集合Event:操作期间发生的事件SpanContext:Span 上下文内容,通常用于在 Span 间传播,其核心字段包括 TraceId、SpanId一般架构分布式链路追踪系统的核心任务是:围绕 Span 的生成、传播、采集、处理、存储、可视化、分析,构建分布式链路追踪系统。其一般的架构如下如所示:我们看到,在应用端需要通过侵入或者非侵入的方式,注入 Tracing Sdk,以跟踪、生成、传播和上报请求调用链路数据;Collect agent 一般是在靠近应用侧的一个边缘计算层,主要用于提高 Tracing Sdk 的写性能,和减少 back-end 的计算压力;采集的链路跟踪数据上报到后端时,首先经过 Gateway 做一个鉴权,之后进入 kafka 这样的 MQ 进行消息的缓冲存储;在数据写入存储层之前,我们可能需要对消息队列中的数据做一些清洗和分析的操作,清洗是为了规范和适配不同的数据源上报的数据,分析通常是为了支持更高级的业务功能,比如流量统计、错误分析等,这部分通常采用flink这类的流处理框架来完成;存储层会是服务端设计选型的一个重点,要考虑数据量级和查询场景的特点来设计选型,通常的选择包括使用 Elasticsearch、Cassandra、或 Clickhouse 这类开源产品;流处理分析后的结果,一方面作为存储持久化下来,另一方面也会进入告警系统,以主动发现问题来通知用户,如错误率超过指定阈值发出告警通知这样的需求等。刚才讲的,是一个通用的架构,我们并没有涉及每个模块的细节,尤其是服务端,每个模块细讲起来都要很花些功夫,受篇幅所限,我们把注意力集中到靠近应用侧的 Tracing Sdk,重点看看在应用侧具体是如何实现链路数据的跟踪和采集的。协议标准和开源实现刚才我们提到 Tracing Sdk,其实这只是一个概念,具体到实现,选择可能会非常多,这其中的原因,主要是因为:不同的编程语言的应用,可能采用不同技术原理来实现对调用链的跟踪不同的链路追踪后端,可能采用不同的数据传输协议当前,流行的链路追踪后端,比如 Zipin、Jaeger、PinPoint、Skywalking、Erda,都有供应用集成的 sdk,导致我们在切换后端时应用侧可能也需要做较大的调整。社区也出现过不同的协议,试图解决采集侧的这种乱象,比如 OpenTracing、OpenCensus 协议,这两个协议也分别有一些大厂跟进支持,但最近几年,这两者已经走向了融合统一,产生了一个新的标准 OpenTelemetry,这两年发展迅猛,已经逐渐成为行业标准。OpenTelemetry 定义了数据采集的标准 api,并提供了一组针对多语言的开箱即用的 sdk 实现工具,这样,应用只需要与 OpenTelemetry 核心 api 包强耦合,不需要与特定的实现强耦合。应用侧调用链跟踪实现方案概览应用侧核心任务应用侧围绕 Span,有三个核心任务要完成:生成 Span:操作开始构建 Span 并填充 StartTime,操作完成时填充 EndTime 信息,期间可追加 Attributes、Event 等传播 Span:进程内通过 context.Context、进程间通过请求的 header 作为 SpanContext 的载体,传播的核心信息是 TraceId 和 ParentSpanId上报 Span:生成的 Span 通过 tracing exporter 发送给 collect agent / back-end server要实现 Span 的生成和传播,要求我们能够拦截应用的关键操作(函数)过程,并添加 Span 相关的逻辑。实现这个目的会有很多方法,不过,在罗列这些方法之前,我们先看看在 OpenTelemetry 提供的 go sdk 中是如何做的。基于 OTEL 库实现调用拦截OpenTelemetry 的 go sdk 实现调用链拦截的基本思路是:基于 AOP 的思想,采用装饰器模式,通过包装替换目标包(如 net/http)的核心接口或组件,实现在核心调用过程前后添加 Span 相关逻辑。当然,这样的做法是有一定的侵入性的,需要手动替换使用原接口实现的代码调用改为包装接口实现。我们以一个 http server 的例子来说明,在 go 语言中,具体是如何做的:假设有两个服务 serverA 和 serverB,其中 serverA 的接口收到请求后,内部会通过 httpclient 进一步发起到 serverB 的请求,那么 serverA 的核心代码可能如下图所示:以 serverA 节点为例,在 serverA 节点应该产生至少两个 Span:Span1,记录 httpServer 收到一个请求后内部整体处理过程的一个耗时情况Span2,记录 httpServer 处理请求过程中,发起的另一个到 serverB 的 http 请求的耗时情况并且 Span1 应该是 Span2 的 ParentSpan我们可以借助 OpenTelemetry 提供的 sdk 来实现 Span 的生成、传播和上报,上报的逻辑受篇幅所限我们不再详述,重点来看看如何生成这两个 Span,并使这两个 Span 之间建立关联,即 Span 的生成和传播 。HttpServer Handler 生成 Span 过程对于 httpserver 来讲,我们知道其核心就是 http.Handler 这个接口。因此,可以通过实现一个针对 http.Handler 接口的拦截器,来负责 Span 的生成和传播。package http type Handler interface { ServeHTTP(ResponseWriter, *Request) } http.ListenAndServe(":8090", http.DefaultServeMux)要使用 OpenTelemetry Sdk 提供的 http.Handler 装饰器,需要如下调整 http.ListenAndServe 方法:import ( "net/http" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/sdk/trace" "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" ) wrappedHttpHandler := otelhttp.NewHandler(http.DefaultServeMux, ...) http.ListenAndServe(":8090", wrappedHttpHandler)如图所示,wrppedHttpHandler 中将主要实现如下逻辑(精简考虑,此处部分为伪代码):① ctx := tracer.Extract(r.ctx, r.Header):从请求的 header 中提取 traceparent header 并解析,提取 TraceId和 SpanId,进而构建 SpanContext 对象,并最终存储在 ctx 中;② ctx, span := tracer.Start(ctx, genOperation(r)):生成跟踪当前请求处理过程的 Span(即前文所述的Span1),并记录开始时间,这时会从 ctx 中读取 SpanContext,将 SpanContext.TraceId 作为当前 Span 的TraceId,将 SpanContext.SpanId 作为当前 Span的ParentSpanId,然后将自己作为新的 SpanContext 写入返回的 ctx 中;③ r.WithContext(ctx):将新生成的 SpanContext 添加到请求 r 的 context 中,以便被拦截的 handler 内部在处理过程中,可以从 r.ctx 中拿到 Span1 的 SpanId 作为其 ParentSpanId 属性,从而建立 Span 之间的父子关系;④ span.End():当 innerHttpHandler.ServeHTTP(w,r) 执行完成后,就需要对 Span1 记录一下处理完成的时间,然后将它发送给 exporter 上报到服务端。HttpClient 请求生成 Span 过程我们再接着看 serverA 内部去请求 serverB 时的 httpclient 请求是如何生成 Span 的(即前文说的 Span2)。我们知道,httpclient 发送请求的关键操作是 http.RoundTriper 接口:package http type RoundTripper interface { RoundTrip(*Request) (*Response, error) }OpenTelemetry 提供了基于这个接口的一个拦截器实现,我们需要使用这个实现包装一下 httpclient 原来使用的 RoundTripper 实现,代码调整如下:import ( "net/http" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/sdk/trace" "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" ) wrappedTransport := otelhttp.NewTransport(http.DefaultTransport) client := http.Client{Transport: wrappedTransport}如图所示,wrappedTransport 将主要完成以下任务(精简考虑,此处部分为伪代码):① req, _ := http.NewRequestWithContext(r.ctx, “GET”,url, nil) :这里我们将上一步 http.Handler 的请求的 ctx,传递到 httpclient 要发出的 request 中,这样在之后我们就可以从 request.Context() 中提取出 Span1 的信息,来建立 Span 之间的关联;② ctx, span := tracer.Start(r.Context(), url):执行 client.Do() 之后,将首先进入 WrappedTransport.RoundTrip() 方法,这里生成新的 Span(Span2),开始记录 httpclient 请求的耗时情况,与前文一样,Start 方法内部会从 r.Context() 中提取出 Span1 的 SpanContext,并将其 SpanId 作为当前 Span(Span2)的 ParentSpanId,从而建立了 Span 之间的嵌套关系,同时返回的 ctx 中保存的 SpanContext 将是新生成的 Span(Span2)的信息;③ tracer.Inject(ctx, r.Header):这一步的目的是将当前 SpanContext 中的 TraceId 和 SpanId 等信息写入到 r.Header 中,以便能够随着 http 请求发送到 serverB,之后在 serverB 中与当前 Span 建立关联;④ span.End():等待 httpclient 请求发送到 serverB 并收到响应以后,标记当前 Span 跟踪结束,设置 EndTime 并提交给 exporter 以上报到服务端。基于 OTEL 库实现调用链跟踪总结我们比较详细的介绍了使用 OpenTelemetry 库,是如何实现链路的关键信息(TraceId、SpanId)是如何在进程间和进程内传播的,我们对这种跟踪实现方式做个小的总结:如上分析所展示的,使用这种方式的话,对代码还是有一定的侵入性,并且对代码有另一个要求,就是保持 context.Context 对象在各操作间的传递,比如,刚才我们在 serverA 中创建 httpclient 请求时,使用的是http.NewRequestWithContext(r.ctx, ...) 而非http.NewRequest(...)方法,另外开启 goroutine 的异步场景也需要注意 ctx 的传递。非侵入调用链跟踪实现思路我们刚才详细展示了基于常规的一种具有一定侵入性的实现,其侵入性主要表现在:我们需要显式的手动添加代码使用具有跟踪功能的组件包装原代码,这进一步会导致应用代码需要显式的引用具体版本的 OpenTelemetry instrumentation 包,这不利于可观测代码的独立维护和升级。那我们有没有可以实现非侵入跟踪调用链的方案可选?所谓无侵入,其实也只是集成的方式不同,集成的目标其实是差不多的,最终都是要通过某种方式,实现对关键调用函数的拦截,并加入特殊逻辑,无侵入重点在于代码无需修改或极少修改。上图列出了现在可能的一些无侵入集成的实现思路,与 .net、java 这类有 IL 语言的编程语言不同,go 直接编译为机器码,导致无侵入的方案实现起来相对比较麻烦,具体有如下几种思路:编译阶段注入:可以扩展编译器,修改编译过程中的ast,插入跟踪代码,需要适配不同编译器版本。启动阶段注入:修改编译后的机器码,插入跟踪代码,需要适配不同 CPU 架构。如 monkey, gohook。运行阶段注入:通过内核提供的 eBPF 能力,监听程序关键函数执行,插入跟踪代码,前景光明!如,tcpdump,bpftrace。Go 非侵入链路追踪实现原理Erda 项目的核心代码主要是基于 golang 编写的,我们基于前文所述的 OpenTelemetry sdk,采用基于修改机器码的的方式,实现了一种无侵入的链路追踪方式。前文提到,使用 OpenTelemetry sdk 需要代码做一些调整,我们看看这些调整如何以非侵入的方式自动的完成:我们以 httpclient 为例,做简要的解释。gohook 框架提供的 hook 接口的签名如下:// target 要hook的目标函数 // replacement 要替换为的函数 // trampoline 将源函数入口拷贝到的位置,可用于从replcement跳转回原target func Hook(target, replacement, trampoline interface{}) error对于 http.Client,我们可以选择 hook DefaultTransport.RoundTrip() 方法,当该方法执行时,我们通过 otelhttp.NewTransport() 包装起原 DefaultTransport 对象,但需要注意的是,我们不能将 DefaultTransport 直接作为 otelhttp.NewTransport() 的参数,因为其 RoundTrip() 方法已经被我们替换了,而其原来真正的方法被写到了 trampoline 中,所以这里我们需要一个中间层,来连接 DefaultTransport 与其原来的 RoundTrip 方法。具体代码如下://go:linkname RoundTrip net/http.(*Transport).RoundTrip //go:noinline // RoundTrip . func RoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) //go:noinline func originalRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) { return RoundTrip(t, req) } type wrappedTransport struct { t *http.Transport } //go:noinline func (t *wrappedTransport) RoundTrip(req *http.Request) (*http.Response, error) { return originalRoundTrip(t.t, req) } //go:noinline func tracedRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) { req = contextWithSpan(req) return otelhttp.NewTransport(&wrappedTransport{t: t}).RoundTrip(req) } //go:noinline func contextWithSpan(req *http.Request) *http.Request { ctx := req.Context() if span := trace.SpanFromContext(ctx); !span.SpanContext().IsValid() { pctx := injectcontext.GetContext() if pctx != nil { if span := trace.SpanFromContext(pctx); span.SpanContext().IsValid() { ctx = trace.ContextWithSpan(ctx, span) req = req.WithContext(ctx) } } } return req } func init() { gohook.Hook(RoundTrip, tracedRoundTrip, originalRoundTrip) }我们使用 init() 函数实现了自动添加 hook,因此用户程序里只需要在 main 文件中 import 该包,即可实现无侵入的集成。值得一提的是 req = contextWithSpan(req) 函数,内部会依次尝试从 req.Context() 和 我们保存的 goroutineContext map 中检查是否包含 SpanContext,并将其赋值给 req,这样便可以解除了必须使用 http.NewRequestWithContext(...) 写法的要求。详细的代码可以查看 Erda 仓库:https://github.com/erda-project/erda-infra/tree/master/pkg/trace参考链接https://opentelemetry.io/registry/https://opentelemetry.io/docs/instrumentation/go/getting-started/https://www.ipeapea.cn/post/go-asm/https://github.com/brahma-adshonor/gohookhttps://www.jianshu.com/p/7b3638b47845https://paper.seebug.org/1749/
【摘要】 在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。 为什么需要分布式链路追踪系统 微服务架构给运维、排障带来新挑战在分布式架构...本文分享自华为云社区《一文详解|Go 分布式链路追踪实现原理》,作者:开源小E。在分布式、微服务架构下,应用一个请求往往贯穿多个分布式服务,这给应用的故障排查、性能优化带来新的挑战。分布式链路追踪作为解决分布式应用可观测问题的重要技术,愈发成为分布式应用不可缺少的基础设施。本文将详细介绍分布式链路的核心概念、架构原理和相关开源标准协议,并分享我们在实现无侵入 Go 采集 Sdk 方面的一些实践。为什么需要分布式链路追踪系统微服务架构给运维、排障带来新挑战在分布式架构下,当用户从浏览器客户端发起一个请求时,后端处理逻辑往往贯穿多个分布式服务,这时会浮现很多问题,比如:请求整体耗时较长,具体慢在哪个服务?请求过程中出错了,具体是哪个服务报错?某个服务的请求量如何,接口成功率如何?回答这些问题变得不是那么简单,我们不仅仅需要知道某一个服务的接口处理统计数据,还需要了解两个服务之间的接口调用依赖关系,只有建立起整个请求在多个服务间的时空顺序,才能更好的帮助我们理解和定位问题,而这,正是分布式链路追踪系统可以解决的。分布式链路追踪系统如何帮助我们分布式链路追踪技术的核心思想:在用户一次分布式请求服务的调⽤过程中,将请求在所有子系统间的调用过程和时空关系追踪记录下来,还原成调用链路集中展示,信息包括各个服务节点上的耗时、请求具体到达哪台机器上、每个服务节点的请求状态等等。如上图所示,通过分布式链路追踪构建出完整的请求链路后,可以很直观地看到请求耗时主要耗费在哪个服务环节,帮助我们更快速聚焦问题。同时,还可以对采集的链路数据做进一步的分析,从而可以建立整个系统各服务间的依赖关系、以及流量情况,帮助我们更好地排查系统的循环依赖、热点服务等问题。分布式链路追踪系统架构概览核心概念在分布式链路追踪系统中,最核心的概念,便是链路追踪的数据模型定义,主要包括 Trace 和 Span。其中,Trace 是一个逻辑概念,表示一次(分布式)请求经过的所有局部操作(Span)构成的一条完整的有向无环图,其中所有的 Span 的 TraceId 相同。Span 则是真实的数据实体模型,表示一次(分布式)请求过程的一个步骤或操作,代表系统中一个逻辑运行单元,Span 之间通过嵌套或者顺序排列建立因果关系。Span 数据在采集端生成,之后上报到服务端,做进一步的处理。其包含如下关键属性:Name:操作名称,如一个 RPC 方法的名称,一个函数名StartTime/EndTime:起始时间和结束时间,操作的生命周期ParentSpanId:父级 Span 的 IDAttributes:属性,一组 <K,V> 键值对构成的集合Event:操作期间发生的事件SpanContext:Span 上下文内容,通常用于在 Span 间传播,其核心字段包括 TraceId、SpanId一般架构分布式链路追踪系统的核心任务是:围绕 Span 的生成、传播、采集、处理、存储、可视化、分析,构建分布式链路追踪系统。其一般的架构如下如所示:我们看到,在应用端需要通过侵入或者非侵入的方式,注入 Tracing Sdk,以跟踪、生成、传播和上报请求调用链路数据;Collect agent 一般是在靠近应用侧的一个边缘计算层,主要用于提高 Tracing Sdk 的写性能,和减少 back-end 的计算压力;采集的链路跟踪数据上报到后端时,首先经过 Gateway 做一个鉴权,之后进入 kafka 这样的 MQ 进行消息的缓冲存储;在数据写入存储层之前,我们可能需要对消息队列中的数据做一些清洗和分析的操作,清洗是为了规范和适配不同的数据源上报的数据,分析通常是为了支持更高级的业务功能,比如流量统计、错误分析等,这部分通常采用flink这类的流处理框架来完成;存储层会是服务端设计选型的一个重点,要考虑数据量级和查询场景的特点来设计选型,通常的选择包括使用 Elasticsearch、Cassandra、或 Clickhouse 这类开源产品;流处理分析后的结果,一方面作为存储持久化下来,另一方面也会进入告警系统,以主动发现问题来通知用户,如错误率超过指定阈值发出告警通知这样的需求等。刚才讲的,是一个通用的架构,我们并没有涉及每个模块的细节,尤其是服务端,每个模块细讲起来都要很花些功夫,受篇幅所限,我们把注意力集中到靠近应用侧的 Tracing Sdk,重点看看在应用侧具体是如何实现链路数据的跟踪和采集的。协议标准和开源实现刚才我们提到 Tracing Sdk,其实这只是一个概念,具体到实现,选择可能会非常多,这其中的原因,主要是因为:不同的编程语言的应用,可能采用不同技术原理来实现对调用链的跟踪不同的链路追踪后端,可能采用不同的数据传输协议当前,流行的链路追踪后端,比如 Zipin、Jaeger、PinPoint、Skywalking、Erda,都有供应用集成的 sdk,导致我们在切换后端时应用侧可能也需要做较大的调整。社区也出现过不同的协议,试图解决采集侧的这种乱象,比如 OpenTracing、OpenCensus 协议,这两个协议也分别有一些大厂跟进支持,但最近几年,这两者已经走向了融合统一,产生了一个新的标准 OpenTelemetry,这两年发展迅猛,已经逐渐成为行业标准。OpenTelemetry 定义了数据采集的标准 api,并提供了一组针对多语言的开箱即用的 sdk 实现工具,这样,应用只需要与 OpenTelemetry 核心 api 包强耦合,不需要与特定的实现强耦合。应用侧调用链跟踪实现方案概览应用侧核心任务应用侧围绕 Span,有三个核心任务要完成:生成 Span:操作开始构建 Span 并填充 StartTime,操作完成时填充 EndTime 信息,期间可追加 Attributes、Event 等传播 Span:进程内通过 context.Context、进程间通过请求的 header 作为 SpanContext 的载体,传播的核心信息是 TraceId 和 ParentSpanId上报 Span:生成的 Span 通过 tracing exporter 发送给 collect agent / back-end server要实现 Span 的生成和传播,要求我们能够拦截应用的关键操作(函数)过程,并添加 Span 相关的逻辑。实现这个目的会有很多方法,不过,在罗列这些方法之前,我们先看看在 OpenTelemetry 提供的 go sdk 中是如何做的。基于 OTEL 库实现调用拦截OpenTelemetry 的 go sdk 实现调用链拦截的基本思路是:基于 AOP 的思想,采用装饰器模式,通过包装替换目标包(如 net/http)的核心接口或组件,实现在核心调用过程前后添加 Span 相关逻辑。当然,这样的做法是有一定的侵入性的,需要手动替换使用原接口实现的代码调用改为包装接口实现。我们以一个 http server 的例子来说明,在 go 语言中,具体是如何做的:假设有两个服务 serverA 和 serverB,其中 serverA 的接口收到请求后,内部会通过 httpclient 进一步发起到 serverB 的请求,那么 serverA 的核心代码可能如下图所示:以 serverA 节点为例,在 serverA 节点应该产生至少两个 Span:Span1,记录 httpServer 收到一个请求后内部整体处理过程的一个耗时情况Span2,记录 httpServer 处理请求过程中,发起的另一个到 serverB 的 http 请求的耗时情况并且 Span1 应该是 Span2 的 ParentSpan我们可以借助 OpenTelemetry 提供的 sdk 来实现 Span 的生成、传播和上报,上报的逻辑受篇幅所限我们不再详述,重点来看看如何生成这两个 Span,并使这两个 Span 之间建立关联,即 Span 的生成和传播 。HttpServer Handler 生成 Span 过程对于 httpserver 来讲,我们知道其核心就是 http.Handler 这个接口。因此,可以通过实现一个针对 http.Handler 接口的拦截器,来负责 Span 的生成和传播。package http type Handler interface { ServeHTTP(ResponseWriter, *Request) } http.ListenAndServe(":8090", http.DefaultServeMux)要使用 OpenTelemetry Sdk 提供的 http.Handler 装饰器,需要如下调整 http.ListenAndServe 方法:import ( "net/http" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/sdk/trace" "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" ) wrappedHttpHandler := otelhttp.NewHandler(http.DefaultServeMux, ...) http.ListenAndServe(":8090", wrappedHttpHandler)如图所示,wrppedHttpHandler 中将主要实现如下逻辑(精简考虑,此处部分为伪代码):① ctx := tracer.Extract(r.ctx, r.Header):从请求的 header 中提取 traceparent header 并解析,提取 TraceId和 SpanId,进而构建 SpanContext 对象,并最终存储在 ctx 中;② ctx, span := tracer.Start(ctx, genOperation(r)):生成跟踪当前请求处理过程的 Span(即前文所述的Span1),并记录开始时间,这时会从 ctx 中读取 SpanContext,将 SpanContext.TraceId 作为当前 Span 的TraceId,将 SpanContext.SpanId 作为当前 Span的ParentSpanId,然后将自己作为新的 SpanContext 写入返回的 ctx 中;③ r.WithContext(ctx):将新生成的 SpanContext 添加到请求 r 的 context 中,以便被拦截的 handler 内部在处理过程中,可以从 r.ctx 中拿到 Span1 的 SpanId 作为其 ParentSpanId 属性,从而建立 Span 之间的父子关系;④ span.End():当 innerHttpHandler.ServeHTTP(w,r) 执行完成后,就需要对 Span1 记录一下处理完成的时间,然后将它发送给 exporter 上报到服务端。HttpClient 请求生成 Span 过程我们再接着看 serverA 内部去请求 serverB 时的 httpclient 请求是如何生成 Span 的(即前文说的 Span2)。我们知道,httpclient 发送请求的关键操作是 http.RoundTriper 接口:package http type RoundTripper interface { RoundTrip(*Request) (*Response, error) }OpenTelemetry 提供了基于这个接口的一个拦截器实现,我们需要使用这个实现包装一下 httpclient 原来使用的 RoundTripper 实现,代码调整如下:import ( "net/http" "go.opentelemetry.io/otel" "go.opentelemetry.io/otel/sdk/trace" "go.opentelemetry.io/contrib/instrumentation/net/http/otelhttp" ) wrappedTransport := otelhttp.NewTransport(http.DefaultTransport) client := http.Client{Transport: wrappedTransport}如图所示,wrappedTransport 将主要完成以下任务(精简考虑,此处部分为伪代码):① req, _ := http.NewRequestWithContext(r.ctx, “GET”,url, nil) :这里我们将上一步 http.Handler 的请求的 ctx,传递到 httpclient 要发出的 request 中,这样在之后我们就可以从 request.Context() 中提取出 Span1 的信息,来建立 Span 之间的关联;② ctx, span := tracer.Start(r.Context(), url):执行 client.Do() 之后,将首先进入 WrappedTransport.RoundTrip() 方法,这里生成新的 Span(Span2),开始记录 httpclient 请求的耗时情况,与前文一样,Start 方法内部会从 r.Context() 中提取出 Span1 的 SpanContext,并将其 SpanId 作为当前 Span(Span2)的 ParentSpanId,从而建立了 Span 之间的嵌套关系,同时返回的 ctx 中保存的 SpanContext 将是新生成的 Span(Span2)的信息;③ tracer.Inject(ctx, r.Header):这一步的目的是将当前 SpanContext 中的 TraceId 和 SpanId 等信息写入到 r.Header 中,以便能够随着 http 请求发送到 serverB,之后在 serverB 中与当前 Span 建立关联;④ span.End():等待 httpclient 请求发送到 serverB 并收到响应以后,标记当前 Span 跟踪结束,设置 EndTime 并提交给 exporter 以上报到服务端。基于 OTEL 库实现调用链跟踪总结我们比较详细的介绍了使用 OpenTelemetry 库,是如何实现链路的关键信息(TraceId、SpanId)是如何在进程间和进程内传播的,我们对这种跟踪实现方式做个小的总结:如上分析所展示的,使用这种方式的话,对代码还是有一定的侵入性,并且对代码有另一个要求,就是保持 context.Context 对象在各操作间的传递,比如,刚才我们在 serverA 中创建 httpclient 请求时,使用的是http.NewRequestWithContext(r.ctx, ...) 而非http.NewRequest(...)方法,另外开启 goroutine 的异步场景也需要注意 ctx 的传递。非侵入调用链跟踪实现思路我们刚才详细展示了基于常规的一种具有一定侵入性的实现,其侵入性主要表现在:我们需要显式的手动添加代码使用具有跟踪功能的组件包装原代码,这进一步会导致应用代码需要显式的引用具体版本的 OpenTelemetry instrumentation 包,这不利于可观测代码的独立维护和升级。那我们有没有可以实现非侵入跟踪调用链的方案可选?所谓无侵入,其实也只是集成的方式不同,集成的目标其实是差不多的,最终都是要通过某种方式,实现对关键调用函数的拦截,并加入特殊逻辑,无侵入重点在于代码无需修改或极少修改。上图列出了现在可能的一些无侵入集成的实现思路,与 .net、java 这类有 IL 语言的编程语言不同,go 直接编译为机器码,导致无侵入的方案实现起来相对比较麻烦,具体有如下几种思路:编译阶段注入:可以扩展编译器,修改编译过程中的ast,插入跟踪代码,需要适配不同编译器版本。启动阶段注入:修改编译后的机器码,插入跟踪代码,需要适配不同 CPU 架构。如 monkey, gohook。运行阶段注入:通过内核提供的 eBPF 能力,监听程序关键函数执行,插入跟踪代码,前景光明!如,tcpdump,bpftrace。Go 非侵入链路追踪实现原理Erda 项目的核心代码主要是基于 golang 编写的,我们基于前文所述的 OpenTelemetry sdk,采用基于修改机器码的的方式,实现了一种无侵入的链路追踪方式。前文提到,使用 OpenTelemetry sdk 需要代码做一些调整,我们看看这些调整如何以非侵入的方式自动的完成:我们以 httpclient 为例,做简要的解释。gohook 框架提供的 hook 接口的签名如下:// target 要hook的目标函数 // replacement 要替换为的函数 // trampoline 将源函数入口拷贝到的位置,可用于从replcement跳转回原target func Hook(target, replacement, trampoline interface{}) error对于 http.Client,我们可以选择 hook DefaultTransport.RoundTrip() 方法,当该方法执行时,我们通过 otelhttp.NewTransport() 包装起原 DefaultTransport 对象,但需要注意的是,我们不能将 DefaultTransport 直接作为 otelhttp.NewTransport() 的参数,因为其 RoundTrip() 方法已经被我们替换了,而其原来真正的方法被写到了 trampoline 中,所以这里我们需要一个中间层,来连接 DefaultTransport 与其原来的 RoundTrip 方法。具体代码如下://go:linkname RoundTrip net/http.(*Transport).RoundTrip //go:noinline // RoundTrip . func RoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) //go:noinline func originalRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) { return RoundTrip(t, req) } type wrappedTransport struct { t *http.Transport } //go:noinline func (t *wrappedTransport) RoundTrip(req *http.Request) (*http.Response, error) { return originalRoundTrip(t.t, req) } //go:noinline func tracedRoundTrip(t *http.Transport, req *http.Request) (*http.Response, error) { req = contextWithSpan(req) return otelhttp.NewTransport(&wrappedTransport{t: t}).RoundTrip(req) } //go:noinline func contextWithSpan(req *http.Request) *http.Request { ctx := req.Context() if span := trace.SpanFromContext(ctx); !span.SpanContext().IsValid() { pctx := injectcontext.GetContext() if pctx != nil { if span := trace.SpanFromContext(pctx); span.SpanContext().IsValid() { ctx = trace.ContextWithSpan(ctx, span) req = req.WithContext(ctx) } } } return req } func init() { gohook.Hook(RoundTrip, tracedRoundTrip, originalRoundTrip) }我们使用 init() 函数实现了自动添加 hook,因此用户程序里只需要在 main 文件中 import 该包,即可实现无侵入的集成。值得一提的是 req = contextWithSpan(req) 函数,内部会依次尝试从 req.Context() 和 我们保存的 goroutineContext map 中检查是否包含 SpanContext,并将其赋值给 req,这样便可以解除了必须使用 http.NewRequestWithContext(...) 写法的要求。详细的代码可以查看 Erda 仓库:https://github.com/erda-project/erda-infra/tree/master/pkg/trace参考链接https://opentelemetry.io/registry/https://opentelemetry.io/docs/instrumentation/go/getting-started/https://www.ipeapea.cn/post/go-asm/https://github.com/brahma-adshonor/gohookhttps://www.jianshu.com/p/7b3638b47845https://paper.seebug.org/1749/ -
头豹研究院在2022年6月发布了,《2022年中国数据库产品策略解析报告》,对中国数据库产品技术进行了分析探讨,其中的技术总结值得一览,本文摘要进行分享。1、数据模型是数据库系统的核心和基础,各种数据库都是基于不同的数据模型而生的, 对数据库技术发展阶段的划分基本按照数据模型的发展演变作为主要依据和标志。评注:数据模型分类法,是数据库进行分类的第一个维度,墨天轮排行榜即按此作为第一分类。2、数据库设计理论和流程:对于给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统, 使之能够有效地存储数据,并满足各种用户对信息分类与处理等应用要求。数据库设计理论正在寻求更有效的语义表达关系,并在各设计阶段提供自动或半自动的设计工具和集成化的开发环境。3、数据库产品发展思路与增长路径全瞻观察数据库有两个视角,分别是技术视角、应用视角。从技术视角,是数据模型、并发控制、一致性;从应用视角,是电信应用、金融高可用、灾备切换。这两个视角在技术基础层上汇对融合。4、中国数据库代表厂商 - 中国数据库厂商分为传统数据库厂商、新兴数据库厂商、云 厂商、ICT跨界厂商四类,各家提供不同的集中式数据库与分 布式数据库产品.5、分布式事务处理技术 - 在分布式架构领域中存在一则指导纲领:CAP理论,指出一个数据库系统无法同时实现以下三个目标,只能妥协其一选余二。1. 提升系统的可用性;2. 保证数据的实时可见;3. 提升系统的容错能力。CAP理论是学界中的概念化描述,在工程实践中,存在不同的思路和实践产品在摸索CAP理论中三者共存的边界。其中应用了包括不同的架构、 事务解决方案、加锁机制、隔离机制、一致性算法/协议。学界也提出了 PACELC理论等持续探索更优的分布式系统架构模式。6、数据库事务原则在CAP理论的提出后,分布式与事务型数据库开始结合。分布式一致性和 事务一致性的融合,简化了应用层开发者的研发负担,不需要开发者精通分布式一致性和事务一致性的全部语义,以此提高了工作效率。BASE原则使得分布式系统的多个组件的协作能够以弱耦合的方式形成一个异步系统,将理论推导和工程实现变得更简单。但ACID原则尤其是满足强一致性依然是所有分布式数据库架构的目标。7、Paxos协议和Raft协议是分布式数据库的一致性算法中最为主流的协议方案.当前流行的一致性解决方案是:基于两阶段提交协议(2PC)实现跨shard 事务提交的完整性,基于全局唯一递增时间戳实现跨shard事务的全局读一致性,通过Paxos协议和或aft协议实现多副本之间的数据一致性。8、HTAP描述的是消除OLTP和OLAP之间的间隔,使一个数据库系统既可以应用于事务型数据库场景,又可以应用于分析型数据库场景,从而满足实时业务决策的需求。HTAP能让数据产生后马上就可以进入分析场景,目前HTAP有两种方案:分离架构和统一架构,分离架构是目前的主流方 案。趋势中,云原生架构环境与HTAP系统的融合将衍生新的HTAP产品方案和技术特征。9、数据库技术架构整体包括管理模块、计算模块和存储模块,物理资源层是为数据库提供基础支撑环境。四个模块中分别具有不同的前沿创新技术10、数据库产品选型决策树对数据库有采购、研发、应用等需求的企业可以从数据模型、 数据量和计算资源情况、业务需求等方面考量,选择适合自身场景需求的优势数据库产品。文章来源:数据和云
-
 基于拟态防御原理的分布式多接入边缘计算研究朱泓艺, 陆肖元, 李毅上海宽带技术及应用工程研究中心,上海 200436摘要多接入边缘计算在网络边缘提供高性能的网络资源,但由于其位置管理分散,所以对安全性能要求较高。基于拟态防御原理提出了分布式多接入边缘计算的拟态防御架构,通过分割数据与校验填充,转发至多个边缘节点处理,并根据校验分析实现了多模裁决与动态调度的拟态防御机制。仿真结果表明,在增加时延成本的情况下,该架构可有效降低数据被篡改和被泄露的概率。提出了基于置信度与时延成本的边缘节点调度策略,提升了系统的效率与安全性能。关键词: 多接入边缘计算 ; 业务编排 ; 拟态安全防御 ; 动态异构冗余1 引言随着大数据研究的深入推进,其应用逐步渗透到社会的各行各业中,对大数据的关注点逐渐聚焦到如何有效利用采集的数据服务于产业的创新与发展上。挖掘、分析和利用大数据,对当今科技的创新具有重要的实践指导意义。在物联网应用场景中,由于数据的规模远超出终端用户的计算处理能力,因此,目前的大数据处理模式仍以将处理任务迁移至远程云计算中心为主,但是这样的处理模式引发了3种问题:1) 将大数据集中到云计算中心进行处理,占用了通信网络的回传带宽,导致网络拥塞情况严重;2) 对于部分智能化业务应用的要求无法满足,如无人驾驶的高可靠性、低时延要求;3) 传输、缓存链路过长,则更容易遭受各种类型的网络攻击与威胁。因此,在实践中由海量传感器或物联网设备采集的大数据,无法经网络传至数据中心进行有效利用。边缘计算是指在靠近终端用户或数据源的网络边缘侧,集网络、计算和存储于一体的分布式开放平台。作为云计算和移动边缘计算的补充,欧洲电信标准化协会(ETSI,European Telecommunications Standards Institute)于2018年提出了多接入边缘计算(MEC,multi-access edge computing)[1]。MEC扩展了边缘计算的定义和应用,在网络边缘节点提供各种类型的 IT 业务,能够同时为固定用户和移动用户提供边缘计算服务,将部分数据和计算任务迁移至 MEC 节点进行处理,可大幅度降低回传至远程数据中心的带宽占用。同时,由于缩短了通信路径,端到端的时延和安全问题都能获得有效解决。MEC作为5G大数据时代的核心技术之一,近几年受到国内外学术界与产业界的广泛关注,但对 MEC 的研究仍处于起步阶段,相关研究主要侧重于边缘节点资源建模[2]、资源优化管理与业务编排[3]、边缘网络安全等方面。尽管 MEC 可以有效解决大数据处理模式引发的3个问题,但为了将理论付诸于实践,仍然有多项技术难点亟待研究和攻破[4],如边缘计算任务迁移策略[5]。相较于云计算中心,MEC服务器的计算、缓存和传输等网络资源有限,在业务处理过程中,需要应用边缘与云、边缘与边缘的协作,根据业务数据量、时延要求等特征,分别分配至本地MEC、临近 MEC 或远程数据中心进行处理。在任务迁移过程中,由于传输链路和各节点的安全性能不同,数据安全的风险程度也不同。目前,MEC服务器在安全性能上具有以下 3 个特点:1) 应用的软/硬件多种多样,其中,大部分软/硬件具有无法预知的安全缺陷和漏洞后门;2) 网络结构和端口等主要应用独立静态配置,攻击者持续的探测攻击使得系统安全性能随时间的增长而下降;3) 服务器中应用的防御技术大部分为被动防御如防火墙等,无法对未知的漏洞和威胁提供有效预防措施。因此,“动态防御”成为网络安全领域的主要研究课题。在国外,研究者提出移动目标防御(MTD,moving target defense),为系统的各项配置引入动态随机性,使得系统在多方面呈现出不可预知的特点,从而有效阻止攻击者对目标系统的分析和攻击,大幅度提高了攻击难度和成本。在我国,由邬江兴院士提出的拟态防御策略不仅考虑了动态与随机性[6],并引入了动态异构冗余(DHR,dynamic heterogeneous redundancy)的理念,为目标系统创建同功能异构的执行空间。在运行期间,动态调用多个异构执行体,在输出端进行一致性判决,并使用反馈控制模块对异构执行体进行重新调度和清洗等。拟态防御思想已被应用于多种网络设备[7]及软件[8]设计中,为系统提供内生的安全防护性能。在MEC方案中,由于各个MEC都独立采用异构的服务器架构、软/硬件设施,可视作具有相同功能的异构体。因此,为了提高 MEC 方案的安全性能,本文提出了一种基于拟态防御理论的分布式MEC方案架构。传统的边缘计算体系仅考虑了端—边—云之间的协同,被称为“边云协同”。而在本文所考虑的系统架构中,多个 MEC 通过有线通信方式如电缆、光缆或无线通信方式如Wi-Fi、4G/5G等互相连接,并且可以互相协同处理业务。为了提升边缘计算体系的内生网络安全防护性能,在用户端设置一个转发/接收代理设备,提供数据切割、校验填充和数据转发等功能,将数据处理业务交由多个MEC处理。不同MEC的通信模式、硬件架构和软件系统分别由各自的供应商独立构建,呈现天然的高度异构性,因此,交由不同 MEC 进行的分布式数据处理可被视为异构执行体。在接收数据时,收发设备通过分析数据的校验部分,获取各个MEC受网络攻击的情况,并且基于 MEC 置信度实现拟态防御的多模裁决与动态调度等机制。针对异构、多样、动态以及随机的网络环境,提出了面向拟态防御系统的信息安全模型[9],在应用层按照功能对业务进行切片分割并引入 DHR 架构,并提出拟态安全等级评估方案对其进行分析[10]。上述研究均以普适的网络架构为着眼点,没有针对分布式计算网络模型的拟态防御安全评估。与基于拟态防御的高安全分布式存储系统[11]不同,本文侧重于MEC架构中的数据在迁移与处理过程中的拟态防御安全分析与评估,通过模型建立、优化权衡与模拟仿真,定量分析该 MEC 架构中资源消耗与安全增益的权衡关系。仿真结果表明,拟态防御思想在 MEC 架构中,能够通过增加一定时延提供高度可靠的内生安全,有效降低了 MEC 进行数据处理时被泄露与被篡改的风险。2 结束语针对多 MEC 服务器协同处理大数据业务的应用场景,提出了基于拟态防御原理的分布式数据处理方案,给出了合理的系统架构与执行步骤,并对系统的资源消耗与安全性能进行了数学建模与优化权衡分析,通过仿真模拟对该系统架构的开销与性能进行验证与分析。仿真结果表明,随着被选择MEC服务器数量M的增加,系统的逃逸概率大幅度下降,数据泄露比率也稳步下降,并且该安全性能的提升所增加的时延成本在可接受的范围内。因此,所提出的分布式处理方案可以在增加一定时延成本的情况下,有效提升系统的安全性能,从而保证 MEC 服务器进行大数据处理业务的安全性与可靠性。此外,整个MEC合作域内可协同的MEC服务器数量对系统性能没有显著影响,业务的处理主要取决于每次传输过程中选择协同的 MEC 服务器数量。在未来的工作中,将针对监控视频边缘图像处理等实际应用进行理论研究与系统开发实践,把该分布式数据处理方案落于实处。The authors have declared that no competing interests exist.作者已声明无竞争性利益关系。3 原文链接http://www.infocomm-journal.com/wlw/article/2019/2096-3750/2096-3750-3-3-00076.shtml
基于拟态防御原理的分布式多接入边缘计算研究朱泓艺, 陆肖元, 李毅上海宽带技术及应用工程研究中心,上海 200436摘要多接入边缘计算在网络边缘提供高性能的网络资源,但由于其位置管理分散,所以对安全性能要求较高。基于拟态防御原理提出了分布式多接入边缘计算的拟态防御架构,通过分割数据与校验填充,转发至多个边缘节点处理,并根据校验分析实现了多模裁决与动态调度的拟态防御机制。仿真结果表明,在增加时延成本的情况下,该架构可有效降低数据被篡改和被泄露的概率。提出了基于置信度与时延成本的边缘节点调度策略,提升了系统的效率与安全性能。关键词: 多接入边缘计算 ; 业务编排 ; 拟态安全防御 ; 动态异构冗余1 引言随着大数据研究的深入推进,其应用逐步渗透到社会的各行各业中,对大数据的关注点逐渐聚焦到如何有效利用采集的数据服务于产业的创新与发展上。挖掘、分析和利用大数据,对当今科技的创新具有重要的实践指导意义。在物联网应用场景中,由于数据的规模远超出终端用户的计算处理能力,因此,目前的大数据处理模式仍以将处理任务迁移至远程云计算中心为主,但是这样的处理模式引发了3种问题:1) 将大数据集中到云计算中心进行处理,占用了通信网络的回传带宽,导致网络拥塞情况严重;2) 对于部分智能化业务应用的要求无法满足,如无人驾驶的高可靠性、低时延要求;3) 传输、缓存链路过长,则更容易遭受各种类型的网络攻击与威胁。因此,在实践中由海量传感器或物联网设备采集的大数据,无法经网络传至数据中心进行有效利用。边缘计算是指在靠近终端用户或数据源的网络边缘侧,集网络、计算和存储于一体的分布式开放平台。作为云计算和移动边缘计算的补充,欧洲电信标准化协会(ETSI,European Telecommunications Standards Institute)于2018年提出了多接入边缘计算(MEC,multi-access edge computing)[1]。MEC扩展了边缘计算的定义和应用,在网络边缘节点提供各种类型的 IT 业务,能够同时为固定用户和移动用户提供边缘计算服务,将部分数据和计算任务迁移至 MEC 节点进行处理,可大幅度降低回传至远程数据中心的带宽占用。同时,由于缩短了通信路径,端到端的时延和安全问题都能获得有效解决。MEC作为5G大数据时代的核心技术之一,近几年受到国内外学术界与产业界的广泛关注,但对 MEC 的研究仍处于起步阶段,相关研究主要侧重于边缘节点资源建模[2]、资源优化管理与业务编排[3]、边缘网络安全等方面。尽管 MEC 可以有效解决大数据处理模式引发的3个问题,但为了将理论付诸于实践,仍然有多项技术难点亟待研究和攻破[4],如边缘计算任务迁移策略[5]。相较于云计算中心,MEC服务器的计算、缓存和传输等网络资源有限,在业务处理过程中,需要应用边缘与云、边缘与边缘的协作,根据业务数据量、时延要求等特征,分别分配至本地MEC、临近 MEC 或远程数据中心进行处理。在任务迁移过程中,由于传输链路和各节点的安全性能不同,数据安全的风险程度也不同。目前,MEC服务器在安全性能上具有以下 3 个特点:1) 应用的软/硬件多种多样,其中,大部分软/硬件具有无法预知的安全缺陷和漏洞后门;2) 网络结构和端口等主要应用独立静态配置,攻击者持续的探测攻击使得系统安全性能随时间的增长而下降;3) 服务器中应用的防御技术大部分为被动防御如防火墙等,无法对未知的漏洞和威胁提供有效预防措施。因此,“动态防御”成为网络安全领域的主要研究课题。在国外,研究者提出移动目标防御(MTD,moving target defense),为系统的各项配置引入动态随机性,使得系统在多方面呈现出不可预知的特点,从而有效阻止攻击者对目标系统的分析和攻击,大幅度提高了攻击难度和成本。在我国,由邬江兴院士提出的拟态防御策略不仅考虑了动态与随机性[6],并引入了动态异构冗余(DHR,dynamic heterogeneous redundancy)的理念,为目标系统创建同功能异构的执行空间。在运行期间,动态调用多个异构执行体,在输出端进行一致性判决,并使用反馈控制模块对异构执行体进行重新调度和清洗等。拟态防御思想已被应用于多种网络设备[7]及软件[8]设计中,为系统提供内生的安全防护性能。在MEC方案中,由于各个MEC都独立采用异构的服务器架构、软/硬件设施,可视作具有相同功能的异构体。因此,为了提高 MEC 方案的安全性能,本文提出了一种基于拟态防御理论的分布式MEC方案架构。传统的边缘计算体系仅考虑了端—边—云之间的协同,被称为“边云协同”。而在本文所考虑的系统架构中,多个 MEC 通过有线通信方式如电缆、光缆或无线通信方式如Wi-Fi、4G/5G等互相连接,并且可以互相协同处理业务。为了提升边缘计算体系的内生网络安全防护性能,在用户端设置一个转发/接收代理设备,提供数据切割、校验填充和数据转发等功能,将数据处理业务交由多个MEC处理。不同MEC的通信模式、硬件架构和软件系统分别由各自的供应商独立构建,呈现天然的高度异构性,因此,交由不同 MEC 进行的分布式数据处理可被视为异构执行体。在接收数据时,收发设备通过分析数据的校验部分,获取各个MEC受网络攻击的情况,并且基于 MEC 置信度实现拟态防御的多模裁决与动态调度等机制。针对异构、多样、动态以及随机的网络环境,提出了面向拟态防御系统的信息安全模型[9],在应用层按照功能对业务进行切片分割并引入 DHR 架构,并提出拟态安全等级评估方案对其进行分析[10]。上述研究均以普适的网络架构为着眼点,没有针对分布式计算网络模型的拟态防御安全评估。与基于拟态防御的高安全分布式存储系统[11]不同,本文侧重于MEC架构中的数据在迁移与处理过程中的拟态防御安全分析与评估,通过模型建立、优化权衡与模拟仿真,定量分析该 MEC 架构中资源消耗与安全增益的权衡关系。仿真结果表明,拟态防御思想在 MEC 架构中,能够通过增加一定时延提供高度可靠的内生安全,有效降低了 MEC 进行数据处理时被泄露与被篡改的风险。2 结束语针对多 MEC 服务器协同处理大数据业务的应用场景,提出了基于拟态防御原理的分布式数据处理方案,给出了合理的系统架构与执行步骤,并对系统的资源消耗与安全性能进行了数学建模与优化权衡分析,通过仿真模拟对该系统架构的开销与性能进行验证与分析。仿真结果表明,随着被选择MEC服务器数量M的增加,系统的逃逸概率大幅度下降,数据泄露比率也稳步下降,并且该安全性能的提升所增加的时延成本在可接受的范围内。因此,所提出的分布式处理方案可以在增加一定时延成本的情况下,有效提升系统的安全性能,从而保证 MEC 服务器进行大数据处理业务的安全性与可靠性。此外,整个MEC合作域内可协同的MEC服务器数量对系统性能没有显著影响,业务的处理主要取决于每次传输过程中选择协同的 MEC 服务器数量。在未来的工作中,将针对监控视频边缘图像处理等实际应用进行理论研究与系统开发实践,把该分布式数据处理方案落于实处。The authors have declared that no competing interests exist.作者已声明无竞争性利益关系。3 原文链接http://www.infocomm-journal.com/wlw/article/2019/2096-3750/2096-3750-3-3-00076.shtml -
 ### 分布式计算 分布式计算是最近这些年谈到的一种新的计算方式。分布式计算就是在多个服务或者互相共享信息,这些服务既可以在同一台计算机上运行,也可以在通过网络连接起来的多台服务器上运行。也被称为集群。 使用分布式计算有很多好处。它实现了可扩展性并简化了资源共享。它还有助于提高计算过程的效率。 ### 并行计算 并行计算也称为并行处理。它使用多个处理器。每个处理器完成分配给它们的任务。换句话说,并行计算涉及同时执行大量任务。共享内存或分布式内存系统可用于辅助并行计算。共享内存系统中的所有 CPU 共享内存。内存在分布式内存系统中的处理器之间共享。并行计算提供了许多优点。 并行计算有助于提高 CPU 利用率并提高性能,因为多个处理器同时工作。此外,一个 CPU 的故障不会影响其他 CPU 的功能。此外,如果一个处理器需要来自另一个处理器的指令,CPU 可能会导致延迟。 ### 分布式并行计算 分布式并行模式就是将训练的过程拓展到多个计算单元,并借助缓存、硬件加速、并行等技术手段,加速模型训练效率,通常有数据并行和模型并行以及混合并行的方式。 在模式定义中提到分布式并行可以分为数据并行、模型并行、混合并行三种方式。其中数据并行是将训练的样本数据分成不同的批量,在不同的硬件设备上运行相同的模型进行训练,而后聚合梯度,更新参数,进行下一轮的训练。数据并行根据通信的方式又可以分为同步和异步方式。混合并行指数据并行和模型并行结合的方式。 ### 为什么要使用分布式并行计算? 1. 数据需要更多的动态模拟和建模,要实现这一点,并行计算是关键。 2. 并行计算提供并发性能够节省时间和提高效率。 3. 复杂的大型数据集及其管理只能使用并行计算的方法进行。 4. 确保资源的有效利用。硬件保证被有效使用,而在串行计算中只使用了一部分硬件,其余部分处于空闲状态。 ### MindSpore支持四种并行模式: - 数据并行 - 半自动并行 - 自动并行 - 混合并行 这里简要讲一下数据并行,其他的并行模式我还在努力学习中... 数据并行是一个简单的加速训练的技术是并行地计算梯度,然后更新相应的参数。数据并行又可以根据其更新参数的方式分为同步数据并行和异步数据并行。 - 同步数据并行,同步的数据并行方式是来自不同的设备的数据需要进行同步更新。这种方式在实现时,主要的限制就是每一次更新都是同步的,其整体计算时间取决于性能最差的那个设备。 - 异步数据并行,与同步方式不同的是,在处理来自不同设备的数据更新时进行异步更新,不同设备之间互不影响,对于每一个图副本都有一个单独的客户端线程与其对应。在这样的实现方式下,即使有部分设备性能特别差甚至中途退出训练,对训练结果和训练效率都不会造成太大影响。但是由于设备间互不影响,所以在更新参数时可能其他设备已经更好的更新过了,所以会造成参数的抖动,但是整体的趋势是向着最好的结果进行的。所以说这种方式更适用于数据量大,更新次数多的情况。 ### 总结 按照当前模型参数和训练数据发展的趋势,分布式并行将成为开发者在加速模型训练时唯一的选择。分布式训练时,可以从硬件和实践的角度进一步优化,如使用专用硬件,NPU(如昇腾),TPU(Google)。分布式并行模式的选择也会影响到训练的速度,此外,训练的数据批量的大小也需要合理选择,如果min-batch批量数据大,可以减少训练迭代次数,但会影响梯度下降收敛的速度以及最终的进度。在实际的模型训练过程中,需要选择合适的硬件、并行模式和超参来加速模型训练的过程。 ## 个人邮箱 **znj254423959@163.com**
### 分布式计算 分布式计算是最近这些年谈到的一种新的计算方式。分布式计算就是在多个服务或者互相共享信息,这些服务既可以在同一台计算机上运行,也可以在通过网络连接起来的多台服务器上运行。也被称为集群。 使用分布式计算有很多好处。它实现了可扩展性并简化了资源共享。它还有助于提高计算过程的效率。 ### 并行计算 并行计算也称为并行处理。它使用多个处理器。每个处理器完成分配给它们的任务。换句话说,并行计算涉及同时执行大量任务。共享内存或分布式内存系统可用于辅助并行计算。共享内存系统中的所有 CPU 共享内存。内存在分布式内存系统中的处理器之间共享。并行计算提供了许多优点。 并行计算有助于提高 CPU 利用率并提高性能,因为多个处理器同时工作。此外,一个 CPU 的故障不会影响其他 CPU 的功能。此外,如果一个处理器需要来自另一个处理器的指令,CPU 可能会导致延迟。 ### 分布式并行计算 分布式并行模式就是将训练的过程拓展到多个计算单元,并借助缓存、硬件加速、并行等技术手段,加速模型训练效率,通常有数据并行和模型并行以及混合并行的方式。 在模式定义中提到分布式并行可以分为数据并行、模型并行、混合并行三种方式。其中数据并行是将训练的样本数据分成不同的批量,在不同的硬件设备上运行相同的模型进行训练,而后聚合梯度,更新参数,进行下一轮的训练。数据并行根据通信的方式又可以分为同步和异步方式。混合并行指数据并行和模型并行结合的方式。 ### 为什么要使用分布式并行计算? 1. 数据需要更多的动态模拟和建模,要实现这一点,并行计算是关键。 2. 并行计算提供并发性能够节省时间和提高效率。 3. 复杂的大型数据集及其管理只能使用并行计算的方法进行。 4. 确保资源的有效利用。硬件保证被有效使用,而在串行计算中只使用了一部分硬件,其余部分处于空闲状态。 ### MindSpore支持四种并行模式: - 数据并行 - 半自动并行 - 自动并行 - 混合并行 这里简要讲一下数据并行,其他的并行模式我还在努力学习中... 数据并行是一个简单的加速训练的技术是并行地计算梯度,然后更新相应的参数。数据并行又可以根据其更新参数的方式分为同步数据并行和异步数据并行。 - 同步数据并行,同步的数据并行方式是来自不同的设备的数据需要进行同步更新。这种方式在实现时,主要的限制就是每一次更新都是同步的,其整体计算时间取决于性能最差的那个设备。 - 异步数据并行,与同步方式不同的是,在处理来自不同设备的数据更新时进行异步更新,不同设备之间互不影响,对于每一个图副本都有一个单独的客户端线程与其对应。在这样的实现方式下,即使有部分设备性能特别差甚至中途退出训练,对训练结果和训练效率都不会造成太大影响。但是由于设备间互不影响,所以在更新参数时可能其他设备已经更好的更新过了,所以会造成参数的抖动,但是整体的趋势是向着最好的结果进行的。所以说这种方式更适用于数据量大,更新次数多的情况。 ### 总结 按照当前模型参数和训练数据发展的趋势,分布式并行将成为开发者在加速模型训练时唯一的选择。分布式训练时,可以从硬件和实践的角度进一步优化,如使用专用硬件,NPU(如昇腾),TPU(Google)。分布式并行模式的选择也会影响到训练的速度,此外,训练的数据批量的大小也需要合理选择,如果min-batch批量数据大,可以减少训练迭代次数,但会影响梯度下降收敛的速度以及最终的进度。在实际的模型训练过程中,需要选择合适的硬件、并行模式和超参来加速模型训练的过程。 ## 个人邮箱 **znj254423959@163.com** -
基于需求预测的云无线接入网计算资源分配策略研究王志朋1,2, 曹斌1,2, 张钦宇1,21 哈尔滨工业大学(深圳)电子与信息工程学院,广东 深圳 5180552 鹏城实验室网络通信研究中心,广东 深圳 518055摘要云无线接入网利用网络功能虚拟化和软件定义网络技术以支持端到端的网络切片,使得接入网可共享无线、终端和网络等资源,已成为5G网络中优先采用的网络架构。针对云无线接入网中端到端的网络切片场景,通过控制平面建立的数据驱动运维框架来收集网络信息并进行数据处理。预测未来一段时间内计算业务量的需求,设计了一种基于虚拟化网络功能(VNF)的计算资源分配方案,提出了基于降序最佳适应(BFD)的离散粒子群算法。仿真结果表明,所提出的策略和算法可实现云无线接入网计算资源的动态灵活分配,并能有效降低VNF迁移能耗和迁移次数。关键词: 云无线接入网 ; 计算资源分配 ; 离散粒子群算法 ; 网络切片1 引言近年来,便携式移动终端设备数量及产生的数据流量呈急剧增加的态势,为了满足终端和数据量的快速增长需求,如采用原有的接入网架构进行密集化建设并开放更高频谱,需要更换新的通信设备,从而增加了资本支出和运营成本,并且会带来更严重的信道干扰。为了支撑自动驾驶、智慧城市[1]等新型产业的落地,基于网络功能虚拟化(NFV, network functions virtualization)和软件定义网络(SDN,software defined network)的思想,中国移动在 2010 年首次提出了云无线接入网(CRAN, cloud radio access network)的概念和架构[2],旨在支撑移动互联网业务,提供可扩展性,降低运营商的资本支出及运营成本。根据3GPP标准[3],采用NFV的接入网架构主要包含两类网络功能组件:虚拟化网络功能(VNF, virtualized network function)和物理网络功能(PNF, physical network function)。其中,VNF是部署在网络功能虚拟化基础设施(NFVI,network function virtualization infrastructure)中的网络功能函数, VNF可采用虚拟机(VM,virtual machine)、容器等方式实现,而NFVI通常采用通用硬件,造价较低。PNF利用软、硬件的紧密耦合以实现相应的网络功能。为了支持端到端通信,NFV通常由一组规定顺序的网络功能来支撑,网络功能可以是 VNF或 PNF,亦可由 VNF 和 PNF 结合形成。VNF 和PNF的联合部署可有效保证通信服务质量,并支持网络的可扩展性。CRAN采用集中式方式,并引入NFV和SDN等关键技术,可兼容多种空口标准并支持基础设施的共享。多切片CRAN架构,CRAN主要由 3 部分组成:分布式的无线远端射频单元(RRH)、高性能的基带处理(BBU)池以及连接BBU和RRH的光传输网络。具体而言,CRAN将基站的处理和控制单元BBU汇聚到BBU池中,将功能简单的RRH部署在边缘网络区域,而BBU和RRH之间采用光纤和公共射频接口协议进行通信。可以看出,BBU的集中管控及虚拟化技术的引入,有效地支持了基带通信和计算资源的共享,因此,可方便利用协作多点(CoMP)技术抑制小区间的干扰,并减少机房的数目。此外,RRH可利用基站休眠等技术以降低网络的部署代价和运维能耗,有效提高系统容量和频谱效率。借助NFV和SDN技术,网络切片能够定制不同性能要求的网络,并满足多样化的应用需求,有望进一步降低运营商的运维成本。与CRAN的不同之处在于,网络切片侧重于业务之间资源的隔离机制,以降低甚至消除不同业务间的影响为目标。此外,通过开放接口,网络切片能够向第三方租户提供网络资源,以满足更加智能、多样化的业务需求。5G 需要支持连续广域覆盖、热点高容量、低功耗大连接以及低时延、高可靠的应用场景,这要求网络架构必须满足差异化的业务需求,而基于网络切片和CRAN的5G网络架构可有效支持这种差异化的应用需求。在按需定制的准则下,以计算资源的分配为例,因为 VNF 需要的计算资源随时间动态变化,为了满足不同时刻的需求并降低系统资源池的能耗,需要对计算资源进行按时、按需分配。Zhang 等[4]采用首次适应算法和遗传算法进行CRAN中BBU池的计算资源分配。Lyazidi等[5]将BBU 池资源分配建模为背包问题,并采用 CPLEX进行求解。Wang等[6]采用基于降序最佳适应(BFD, best fit decreasing)分配计算资源,以最小化BBU池能耗。Aqeeli等[7]将计算资源分配问题建模为0-1整数规划问题,并采用启发式算法进行求解。上述工作主要根据 RRH 的实时业务量来实现BBU池中的计算资源分配,并未考虑NFV和SDN的特性。值得注意的是,SDN和NFV的引入虽然降低了运营和资本支出,但是也带来了其他问题。Yousaf 等[8]指出,当业务的需求发生变化时,为了满足服务的 KPI,需要进行 VNF 的 Scale-down、Scale-out、迁移或更新等操作。这表明,当RRH的通信业务量发生变化时,会造成BBU池中每个VNF所需计算资源发生变化,需要重新分配资源。即当VNF进行Scale-down或Scale-out操作导致BBU单元的利用率低或资源不足时,会发生 VNF 的合并和负载的均衡,即 VNF 迁移。但性能影响最小的在线实时迁移(热迁移)也会导致 VNF 性能急剧下降。为了满足动态需求,本文提出了一种基于流量预测的CRAN计算资源分配策略,根据预测信息,进行合理地VNF放置,以减少不必要的VNF迁移。具体而言,建立了基于数据驱动的CRAN资源分配框架,采用支持向量回归算法进行业务预测,给出基于 BFD 的离散粒子群分配策略和算法,并进行仿真验证和分析。2 结束语本文提出了一种 CRAN 端到端网络切片场景下基于需求预测的 BFD 离散粒子群算法。该场景下所提数据驱动框架收集系统的各类信息,将VNF计算业务需求信息作为数据集,采用 SVR 模型训练,通过递归的多步时间预测未来一段时间内的VNF计算业务需求量。借助预测的业务需求信息,建立背包问题,使用基于 BFD 的离散粒子群算法分配计算资源。所提算法相较于单一的BFD算法,大幅度降低了迁移的次数,并且在BBU能耗方面,和单一的BFD算法性能相同。在未来的工作中,可以将数据业务进一步细化分配,并且考虑虚拟化对于不同数据业务类型的影响,对网络的资源进行更细致的分配,制定更加贴合实际的资源分配方案。The authors have declared that no competing interests exist.作者已声明无竞争性利益关系。3 原文链接http://www.infocomm-journal.com/wlw/article/2019/2096-3750/2096-3750-3-4-00001.shtml
-
 随着云原生应用深入企业各个业务场景,云原生正在走向分布式,跨云跨地域统一协同治理,保证一致应用体验等新的需求日渐突出。分布式云原生都涉及哪些核心技术?有哪些典型的应用场景?值得我们去探究。HCDE(Huawei Cloud Developer Experts)是经华为云认证的熟悉一种或多种华为云开放能力,并对赋能全球开发者有突出贡献的个人,旨在帮助全球开发者成长,构建全球开发者生态。2022年6月21日,华为云HCDE专场暨分布式技术峰会如期举行,华为云Karmada社区Maintainer任洪彩担任出品人,携手华为云分布式云架构师王楠楠,以及HCDE的代表成员——南京路特软件CTO戚俊、中韩未来革新加速器社长唐云峰、深圳市友浩达科技CTO张善友,共同分享了分布式云原生核心技术和典型应用。华为云分布式云原生的全域调度技术与实践华为云分布式云架构师王楠楠在分享中提到,华为云通过1个中心、3个核心能力,为应用从核心区到业务现场形成广泛覆盖,构建了应用全域分发、全域调度、智能安全、统一编排等多项核心技术。其中,1个中心是指提供对云原生基础设施、应用、用户权限、安全策略的一站式管理,3个核心能力是指应用算力供给、应用流量治理、应用与数据协同。云原生助力SaaS类业务租户高效隔离面对业务波动难以控制、无法实现精准计费等租户隔离的难点,南京路特软件CTO戚俊提出了通过云原生架构改造隔离逻辑,并结合华为云服务平抑容器类业务波动、实现精准计费的操作方案。从“AI玩具”到“创作工具”的云原生改造之路理想的AI创作工具长什么样?中韩未来革新加速器社长唐云峰认为需具备这些功能特点:在线部署、按量付费、随时可用、垫图绘画、并行创作、持续交付、弹性扩展。唐云峰基于华为云进行了尝试,并将算子工作流程归纳为:1、上传图片到OBS指定存储桶后触发函数计算;2、函数计算调度从SWR托管的镜像创建CCI实例;3、在CCI实例中将上传图像作为“垫图”配合“描述文本”生成多个参数的并行GPU实例;4、进行绘制将生成完成的图像和视频存储到结果存储桶中。基于Kubernetes与Dapr打造云原生应用谈及分布式应用架构的演进,深圳市友浩达科技CTO张善友分享了三个观点:1、Spring Cloud武器库迷局:超过30个子项目,对前期应用和后期维护均造成一定困难;2、以Istio为代表服务网格日趋成熟;3、以Dapr为代表的多运行时很好的融合了框架和网格。随后,张善友对Dapr进行了重点介绍。Dapr是一个开源解决方案,主要设计目标是可移植性,同时提供了标准API、语言SDK和Runtime,需要应用进行适配,并且提供各种分布式能力助力应用的现代化。通过几位华为云MVP的精彩分享后,华为云HCDE专场暨分布式技术峰会顺利落下了帷幕。华为云致力于搭建技术交流平台、机遇共创的通道,全面助力每一位开发者、每一位合作伙伴,期待下期活动再次相会。如想了解参加更多华为云HCDE相关活动或有合作需求请联系小助手(微信号:hwyzj123)
随着云原生应用深入企业各个业务场景,云原生正在走向分布式,跨云跨地域统一协同治理,保证一致应用体验等新的需求日渐突出。分布式云原生都涉及哪些核心技术?有哪些典型的应用场景?值得我们去探究。HCDE(Huawei Cloud Developer Experts)是经华为云认证的熟悉一种或多种华为云开放能力,并对赋能全球开发者有突出贡献的个人,旨在帮助全球开发者成长,构建全球开发者生态。2022年6月21日,华为云HCDE专场暨分布式技术峰会如期举行,华为云Karmada社区Maintainer任洪彩担任出品人,携手华为云分布式云架构师王楠楠,以及HCDE的代表成员——南京路特软件CTO戚俊、中韩未来革新加速器社长唐云峰、深圳市友浩达科技CTO张善友,共同分享了分布式云原生核心技术和典型应用。华为云分布式云原生的全域调度技术与实践华为云分布式云架构师王楠楠在分享中提到,华为云通过1个中心、3个核心能力,为应用从核心区到业务现场形成广泛覆盖,构建了应用全域分发、全域调度、智能安全、统一编排等多项核心技术。其中,1个中心是指提供对云原生基础设施、应用、用户权限、安全策略的一站式管理,3个核心能力是指应用算力供给、应用流量治理、应用与数据协同。云原生助力SaaS类业务租户高效隔离面对业务波动难以控制、无法实现精准计费等租户隔离的难点,南京路特软件CTO戚俊提出了通过云原生架构改造隔离逻辑,并结合华为云服务平抑容器类业务波动、实现精准计费的操作方案。从“AI玩具”到“创作工具”的云原生改造之路理想的AI创作工具长什么样?中韩未来革新加速器社长唐云峰认为需具备这些功能特点:在线部署、按量付费、随时可用、垫图绘画、并行创作、持续交付、弹性扩展。唐云峰基于华为云进行了尝试,并将算子工作流程归纳为:1、上传图片到OBS指定存储桶后触发函数计算;2、函数计算调度从SWR托管的镜像创建CCI实例;3、在CCI实例中将上传图像作为“垫图”配合“描述文本”生成多个参数的并行GPU实例;4、进行绘制将生成完成的图像和视频存储到结果存储桶中。基于Kubernetes与Dapr打造云原生应用谈及分布式应用架构的演进,深圳市友浩达科技CTO张善友分享了三个观点:1、Spring Cloud武器库迷局:超过30个子项目,对前期应用和后期维护均造成一定困难;2、以Istio为代表服务网格日趋成熟;3、以Dapr为代表的多运行时很好的融合了框架和网格。随后,张善友对Dapr进行了重点介绍。Dapr是一个开源解决方案,主要设计目标是可移植性,同时提供了标准API、语言SDK和Runtime,需要应用进行适配,并且提供各种分布式能力助力应用的现代化。通过几位华为云MVP的精彩分享后,华为云HCDE专场暨分布式技术峰会顺利落下了帷幕。华为云致力于搭建技术交流平台、机遇共创的通道,全面助力每一位开发者、每一位合作伙伴,期待下期活动再次相会。如想了解参加更多华为云HCDE相关活动或有合作需求请联系小助手(微信号:hwyzj123) -
>摘要:NFT是Web3世界中标记数据资产独特性的标识,是数据权益的载体。 本文分享自华为云社区《[加密数字艺术NFT背后你关心的六个问题](https://bbs.huaweicloud.com/blogs/358470?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 薛腾飞 。 # Connect Wallet 这是Web3中非常流行的一句话,其实也是Web3的核心要义,即“**以用户为中心**”。将身份主权、数据主权、数据权益等都归还给用户,身份的解释、移植,数据的确权、授权、使用等都需要各个服务通过“链接”用户的“钱包”来完成。以区块链为基础设施构筑上层应用,是实现这一能力的重要保障。 # 什么是NFT? 在我看来,**NFT是Web3世界中标记数据资产独特性的标识,是数据权益的载体**。不论是数字化的画作,桌椅、服装、汽车飞机等(有实物的),还是数字化的身份凭证、产权、公司品牌等(逻辑产物)都可以是NFT。 **独特性的标识为什么这么重要呢**?因为它能将其指代的物品和其他同类物品区分开。 为了进一步理解,首先要明确,有些物品是非同质的(Non-Fungible)需要被区分开的,例如房屋产权和艺术作品。有些物品是同质的,不需要被区分开,例如人民币和app积分,尽管有不同的编码,但编码不影响互相替换,因为面值一样;其次要区分开标识和标的物,标的物可以是区块链上原生的数据或者本身是数字化的,也可以是物理世界实际存在的物品,标识则是标的物在数字世界中的映射。 在数字世界中,“标识”将完成“标的物”独特性的指代和“标的物”价值承载的使命。例如一个艺术家将数字作品发布在社交平台,其作品会很快被复制多份,每一幅作品逐渐趋于同质化,没有区别。画作的价值也会越来越低,且没有人会知道画作的原作者是谁。但在Web3中,艺术家就可以通过NFT低成本的保证作品的独特性和价值,NFT中会有作品铸造时间、创建者、和当前所有者。只要是晚于铸造时间发布的都为抄袭者,画作所有权每次流转都可以承载不同的价值属性,无论流转多次都知道原作者谁。  # NFT能用来做什么? 海外市场NFT产业布局完善,行业竞争激烈。NFT以交易平台和时尚社交为主,NFT收藏、游戏、金融等同步发展。国内以数字藏品收藏和企业数字营销为主,逐步开始尝试数字人、游戏等。除此之外,NFT的应用场景还包括体育、文物和历史、音乐、票务等访问授权类。 ## 1.收藏品 稀缺性是收藏品的重要属性。区块链的不可篡改以及NFT本身的不可分割保证了数字藏品独特性。与球卡和邮票一样,数字收藏品的藏家会收藏他们认为有价值的数字产品以表示对某一公司、品牌或者游戏支持。有别于实物,无需运输时间,维护成本等开销。只需几秒完成转移,且永远不会折旧。CryptoPunks是以太坊上推出的最早的数字藏品NFT,类似的国内多家互联网平台联合博物馆、航天局等单位,发行了多款数字藏品,例如“故宫故苑”和“航天文创”。 ## 2.游戏 NFT是区块链游戏的基础,可以作为数字游戏世界中成就或游戏物品的所有权证书。移独一无二游戏物品(道具、头像、皮肤、角色等)归玩家所有,且无需托管,不受发行商控制。这些NFT的寿命会比游戏平台本身更长,一方面玩家可以永久收藏,另一方面也可以移植到游戏之外其他平台,实现游戏投入变现。 ## 3.数字营销 NFT“限量发行、独一无二”本身就是一种最好的饥饿营销手段,不定期的赋予每个NFT新的权益,发布新的玩法和活动也都是很好的营销策略。还可以基于NFT维护会员制度、增强用户粘性,完成破圈整合。国内有个很有趣、很有现实意义的的实践。福建省四坪村通过NFT吸引“云村民”并赋予权益,赋能乡村振兴。每一位数字藏品持有者可以作为村民享受多项权益,如享有家宴1次。不同时间不同事件还会解锁新的藏品及权益,丰富有趣。 ## 4.艺术品 在众多的艺术品中,我们以音乐为例,音乐产业是一个超级明星经济, 好的作品诞生涉及音乐人、唱片公司、娱乐公司、经纪人等。NFT可以帮助音乐人收益自主、拓宽收入来源;公平解决所有制作人员间的版税问题,交易中的数字所有权问题等。 除此之外,NFT音乐平台的用户运营,音乐演出的票务活动,知识产权保护等都已有很多创新项目在实践。 # 国内NFT技术产品有哪些? 随着NFT的火热,国内数字藏品发行平台百花齐放。据统计,其中注册资本大于500万的平台超过100家。市场繁荣的背后是几大技术供应商在提供底层区块链和NFT管理等相关技术能力,以联盟链为主,公链为辅。  # NFT 背的技术是什么? 知道了NFT是什么?能用来做什么?以及都有谁来参与之外,我们再来了解一下NFT背后的技术都有哪些。 ## 1.区块链 区块链是实现NFT的重要底座,赋予了NFT不可篡改、所有权明确、流转可追溯等特性。区块链融合了多种技术,包括密码学(加密算法、安全协议)、分布式共识算法(拜占庭或非拜占庭)、P2P网络通讯、智能合约、激励机制等。 应用的繁荣必将带动技术的生长。NFT应用的快速增长,大量用户接入区块链完成NFT的铸造发行、授权、流转等。这对传统的底层区块链提出了新的挑战和要求。 - 具备统一的链上用户身份标识,支持跨链、链跨应用的NFT所属权管理。 - 允许千级、万级节点接入,支持NFT平台发行方等加入链生态的构建与维护。 - 高吞吐,高并发的共识和记账能力,可以支撑NFT应用活动的峰值流量。 ## 2.智能合约协议 ERC(Ethereum Request for Common)“版本征求意见稿”是以太坊社区的开发者共同编写的,用来记录以太坊上应用级的各种开发标准和协议。其中一些技术标准和协议也逐渐成为了区块链应用的事实规范。 我们常提到的NFT就是在ERC-721标准提出后才开始普及流行的。ERC-721详细定义了NFT的所有权查看、授权管理、流转等。不同的数字藏品平台基于同样的协议完成设计,理论上就可以进行标准化的操作和解析。 随着对NFT的需求越来越丰富,社区也在不断提出新的标准来扩展NFT的使用场景和内涵:  ## 3. 去中心化存储 “一切皆可NFT”这句话从侧面表达了NFT对数字化数据的包容性。不论标的物是视频、音频、还是文字、图片、3D模型等各种数据格式,都可以在链上生成对应的唯一标识。标的物实际存储的位置通常有三种选择,NFT标识所在的业务区块链、去中心化存储系统、中心化的存储系统。 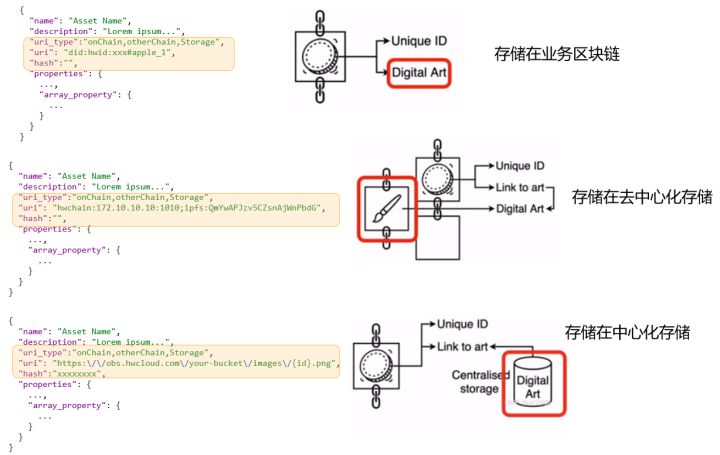 对于NFT而言,去中心化存储是最好的选择。它具有强隐私保护、低存储成本、高访问速度、数据冗余备份、开源等特点,可以充分的支撑Web3“以用户为中心”这一要义的表达。数据被加密并存储在多个位置或节点上,不依赖与中心化的存储节点和存储服务,下图可以极简的理解去中心化存储的工作原理。  值得关注和学习的几大去中心化存储产品有: 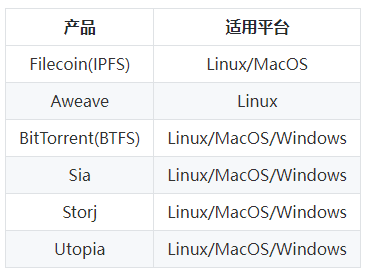 ## 4.应用生态 不难发现NFT发展背后的主要推动力就是用户对数据主权和数据价值自主控制意识的不断增强。构建完善的NFT应用生态,简单可以分为三层,身份协议层、 NFT合约协议层, 扩展应用协议层。 分布式数字身份真正具备身份的自主可控性、安全性、自解释性、可移植性、互操作性。在分布式场景下赋予每个用户自主控制和使用数字身份的能力,并针对身份数据等敏感信息进行隐私保护。基于分布式身份, NFT相关协议可以与多种扩展应用标准化集成。(详细了解可阅读《[区块链分布式身份技术解密——重新定义你的“身份”管理](https://bbs.huaweicloud.com/blogs/234838)》) 在标准化的身份协议层和NFT合约协议层之上,结合多样的业务场景定会生长出丰富的应用,例如可信数据交换、数据要素管理等。 # 如何发行自己的NFT 不论你是团队还是个人,想要发行自己的NFT都非常简单。 一种,是可以使用基于公链模式的数字自资产服务,支付手续费或者链使用费铸造发行NFT。例如支持多种公链的Opensea平台 另一种,可以使用基于联盟链模式的数字资产服务,订购服务通过集成SDK完成NFT的铸造发行及流转。例如[华为云的数字资产链服务](https://www.huaweicloud.com/product/bcs/dac.html)。
-
 1 简单介绍现如今数据的存储越来越多,想要提高算力的话,其实我们可以提高分布式计算。所谓分布式计算就是在两个或多个软件互相共享信息,这些软件既可以在同一台计算机上运行,也可以在通过网络连接起来的多台计算机上运行。分布式并行训练,可以降低对内存、计算性能等硬件的需求,是进行训练的重要优化手段。而我们昇思MindSpore的特性之一就是融合了数据并行、模型并行和混合并行,构建一种易用高效的分布式并行训练模式,让算法人员不再需要关注算法模型到底需要用哪种模式训练。可以简化分布式并行编程,串行代码实现分布式训练,对用户屏蔽并行细节,并且保持高性能;计算逻辑上保持和单卡串行流程一致;实现上统一数据并行和模型并行,一套框架支持多种并行模式;结合集群拓扑优化性能。2 解决方案介绍了这么多,现在就让我们具体来看看论坛中的小伙伴们在分布式并行方面遇到了哪些问题并且如何解决的吧~同学A使用了BERT的masked language model预训练方法,使用数据并行和模型并行进行训练,训练过程中发现loss并不下降,定位问题发现dataset生成数据时有个随机mask的操作,在不同进程中间随机结果会不一致。参考链接:https://bbs.huaweicloud.com/forum/thread-116048-1-1.html同学B在docker内安装nccl时,由于一开始建立容器的时候没有设置允许共享内存,使用nccl-tests测试会进行报错。参考链接:https://bbs.huaweicloud.com/forum/thread-143146-1-1.html同学C在Ascend上进行多机/多卡训练时遇到load task fail报错,首先可以查看其它卡的plog,然后设置延长每张卡的最大等待时长。参考链接:https://bbs.huaweicloud.com/forum/thread-182395-1-1.html同学D 在MindSpore并行模式配置时,错误使用了semi_parallel模式。参考链接:https://bbs.huaweicloud.com/forum/thread-182461-1-1.html同学E 也遇到了上述类似问题,PyNative配置为semi_auto_parallel模式时遇到报错。参考链接:https://bbs.huaweicloud.com/forum/thread-182978-1-1.html同学F误认为并行支持非2的幂次方的并行切分进而报错。参考链接:https://bbs.huaweicloud.com/forum/thread-183226-1-1.html3 实践分析3.1 整体概述当然用户们对MindSpore的分布式并行模块也有自己的整体认知和理解:https://bbs.huaweicloud.com/forum/thread-169086-1-1.html;https://bbs.huaweicloud.com/forum/thread-166114-1-1.html3.2 并行特性同时半自动并行和全自动并行这两大特性的使用方法也被用户们悉数掌握。比如采用半自动并行模式,展示了一个从数据到模型的并行转换的案例。https://bbs.huaweicloud.com/forum/thread-166124-1-1.html然后仅用一行代码实现了单机脚本的全自动分布式并行。https://bbs.huaweicloud.com/forum/thread-166127-1-1.html 3.3 分布式训练通信方法有总体的认知,具体算子用法当然也不会少啦!比如MindSpore分布式并行训练中的Broadcast、AllGather、ReduceScatter以及AllReduce分布式训练通信方法。1.Broadcast——集合通信原语相关操作被封装py文件中,对该文件中涉及集合通信的内容进行具体查看解析:https://bbs.huaweicloud.com/forum/thread-166115-1-1.html2.AllGather——对于分发在所有进程上的一组数据来说,Allgather会收集所有数据到所有进程上:https://bbs.huaweicloud.com/forum/thread-166116-1-1.html3.ReduceScatte——实现通信算子的自动微分,为AllGather提供反向算子:https://bbs.huaweicloud.com/forum/thread-166118-1-1.html4.AllReduce——Allreduce将归约值并将结果分配给所有进程:https://bbs.huaweicloud.com/forum/thread-166119-1-1.html3.4 硬件平台区分这里有个知识点需要提醒大家注意!分布式并行由于其硬件平台的不同有的时候也会有点小改变。比如在GPU硬件平台上,MindSpore分布式并行训练的通信使用的是NCCL,采用的多进程通信库是OpenMPI。参考链接:https://bbs.huaweicloud.com/forum/thread-166120-1-1.html而对于Ascend AI处理器,MindSpore分布式并行训练的通信使用了华为集合通信库HCCL。参考链接:https://bbs.huaweicloud.com/forum/thread-166121-1-1.html3.5 大V博文其实我们官方也有MindSpore并行特性介绍,同时首席构架师金雪锋大佬给出了更加全面的总结,欢迎大家多多关注。AI框架的分布式并行能力的分析和MindSpore的实践一混合并行和自动并行:https://bbs.huaweicloud.com/forum/thread-85406-1-1.html盘古大模型的推理解决方案:增量推理+分布式推理:https://bbs.huaweicloud.com/forum/thread-143703-1-1.html希望这期的干货汇总能够小小地帮助到大家,当然啦,遇到其他相关问题也欢迎来我们论坛一起交流解决,欢迎各位开发者们多多贡献~
1 简单介绍现如今数据的存储越来越多,想要提高算力的话,其实我们可以提高分布式计算。所谓分布式计算就是在两个或多个软件互相共享信息,这些软件既可以在同一台计算机上运行,也可以在通过网络连接起来的多台计算机上运行。分布式并行训练,可以降低对内存、计算性能等硬件的需求,是进行训练的重要优化手段。而我们昇思MindSpore的特性之一就是融合了数据并行、模型并行和混合并行,构建一种易用高效的分布式并行训练模式,让算法人员不再需要关注算法模型到底需要用哪种模式训练。可以简化分布式并行编程,串行代码实现分布式训练,对用户屏蔽并行细节,并且保持高性能;计算逻辑上保持和单卡串行流程一致;实现上统一数据并行和模型并行,一套框架支持多种并行模式;结合集群拓扑优化性能。2 解决方案介绍了这么多,现在就让我们具体来看看论坛中的小伙伴们在分布式并行方面遇到了哪些问题并且如何解决的吧~同学A使用了BERT的masked language model预训练方法,使用数据并行和模型并行进行训练,训练过程中发现loss并不下降,定位问题发现dataset生成数据时有个随机mask的操作,在不同进程中间随机结果会不一致。参考链接:https://bbs.huaweicloud.com/forum/thread-116048-1-1.html同学B在docker内安装nccl时,由于一开始建立容器的时候没有设置允许共享内存,使用nccl-tests测试会进行报错。参考链接:https://bbs.huaweicloud.com/forum/thread-143146-1-1.html同学C在Ascend上进行多机/多卡训练时遇到load task fail报错,首先可以查看其它卡的plog,然后设置延长每张卡的最大等待时长。参考链接:https://bbs.huaweicloud.com/forum/thread-182395-1-1.html同学D 在MindSpore并行模式配置时,错误使用了semi_parallel模式。参考链接:https://bbs.huaweicloud.com/forum/thread-182461-1-1.html同学E 也遇到了上述类似问题,PyNative配置为semi_auto_parallel模式时遇到报错。参考链接:https://bbs.huaweicloud.com/forum/thread-182978-1-1.html同学F误认为并行支持非2的幂次方的并行切分进而报错。参考链接:https://bbs.huaweicloud.com/forum/thread-183226-1-1.html3 实践分析3.1 整体概述当然用户们对MindSpore的分布式并行模块也有自己的整体认知和理解:https://bbs.huaweicloud.com/forum/thread-169086-1-1.html;https://bbs.huaweicloud.com/forum/thread-166114-1-1.html3.2 并行特性同时半自动并行和全自动并行这两大特性的使用方法也被用户们悉数掌握。比如采用半自动并行模式,展示了一个从数据到模型的并行转换的案例。https://bbs.huaweicloud.com/forum/thread-166124-1-1.html然后仅用一行代码实现了单机脚本的全自动分布式并行。https://bbs.huaweicloud.com/forum/thread-166127-1-1.html 3.3 分布式训练通信方法有总体的认知,具体算子用法当然也不会少啦!比如MindSpore分布式并行训练中的Broadcast、AllGather、ReduceScatter以及AllReduce分布式训练通信方法。1.Broadcast——集合通信原语相关操作被封装py文件中,对该文件中涉及集合通信的内容进行具体查看解析:https://bbs.huaweicloud.com/forum/thread-166115-1-1.html2.AllGather——对于分发在所有进程上的一组数据来说,Allgather会收集所有数据到所有进程上:https://bbs.huaweicloud.com/forum/thread-166116-1-1.html3.ReduceScatte——实现通信算子的自动微分,为AllGather提供反向算子:https://bbs.huaweicloud.com/forum/thread-166118-1-1.html4.AllReduce——Allreduce将归约值并将结果分配给所有进程:https://bbs.huaweicloud.com/forum/thread-166119-1-1.html3.4 硬件平台区分这里有个知识点需要提醒大家注意!分布式并行由于其硬件平台的不同有的时候也会有点小改变。比如在GPU硬件平台上,MindSpore分布式并行训练的通信使用的是NCCL,采用的多进程通信库是OpenMPI。参考链接:https://bbs.huaweicloud.com/forum/thread-166120-1-1.html而对于Ascend AI处理器,MindSpore分布式并行训练的通信使用了华为集合通信库HCCL。参考链接:https://bbs.huaweicloud.com/forum/thread-166121-1-1.html3.5 大V博文其实我们官方也有MindSpore并行特性介绍,同时首席构架师金雪锋大佬给出了更加全面的总结,欢迎大家多多关注。AI框架的分布式并行能力的分析和MindSpore的实践一混合并行和自动并行:https://bbs.huaweicloud.com/forum/thread-85406-1-1.html盘古大模型的推理解决方案:增量推理+分布式推理:https://bbs.huaweicloud.com/forum/thread-143703-1-1.html希望这期的干货汇总能够小小地帮助到大家,当然啦,遇到其他相关问题也欢迎来我们论坛一起交流解决,欢迎各位开发者们多多贡献~ -
区块链跨链技术分析郭朝1, 郭帅印1, 张胜利1, 宋令阳2, 王晖11 深圳大学区块链研究中心,广东 深圳 5180602 北京大学电子工程与计算机科学学院,北京 100871摘要随着区块链技术的发展,区块链项目也越来越多。由于区块链的封闭性,导致不同区块链形成一个个价值“孤岛”,不同区块链之间的信息交互与价值转移问题亟待解决。跨链技术解决了不同链间资产与数据等跨链操作问题,在过去几年里已经有许多尝试和发展,跨链的主要模式包括哈希锁定、公证人机制、侧链与中继技术等。介绍了目前主要跨链技术的基本原理,总结分析了各个跨链技术的优势与劣势。关键词: 区块链 ; 跨链 ; 哈希锁定 ; 公证人 ; 侧链 ; 中继1 引言区块链技术是分布式数据存储、点对点传输、分布式共识算法、加密算法等计算机技术的集成应用。从狭义角度来讲,区块链是一种按照时间顺序将数据区块以顺序相连的方式进行组合的一种链式数据结构,并以密码学方式保证数据不可篡改和不可伪造的分布式账本。从广义角度来讲,区块链技术是利用块链式数据结构来验证与存储数据、利用分布式节点共识算法来生成和更新账本数据、利用密码学方式保证数据传输和访问安全、利用智能合约来编程和操作数据的一种全新的分布式基础架构与计算范式[1]。基于时间戳的链式区块结构、分布式节点的共识机制、灵活可编程的智能合约是区块链技术最具创新性的技术环节。2008年,Nakamoto[2]发表了《Bitcoin:a peer-topeer electronic cash system》报告,通常被认为是区块链技术的起源。在文献[2]中提出了一种去中心化、按时间顺序排序的数据,数据由所有节点维护、可编程和密码学上安全可信的分布式账本技术构成,用于解决比特币(BTC,bitcoin)在去中心化网络中的信任问题。作为比特币的底层实现技术,该技术被认为是构建下一代“信任互联网、价值互联网”的关键技术。作为区块链技术的一个成功应用,比特币验证了区块链技术的可行性。目前,区块链技术已经应用到社会的很多领域,如“数字货币”、跨境支付、供应链、制造业以及能源领域等。随着各界人士对区块链技术研究的逐步深入,越来越多的区块链应用出现在各种场景中,但是区块链结构体系、共识算法[3]、对用户隐私的保护[4]、智能合约开发、系统底层性能、交易吞吐量以及不同区块链系统之间的跨链通信等技术挑战越来越制约区块链技术及其行业的发展。不同应用场景所用的区块链系统不同,这些链可能应用于不同的领域,也可能具有不同的运行机制,而不同区块链存储的区块信息之间的隔离不可避免地造成了区块链的价值“孤岛”效应[5]。随着区块链行业的蓬勃发展,多种公有链、私有链和联盟链的出现产生一个问题,即不同区块链之间如何进行通信甚至价值交换。本文深入探讨了跨链的本质、意义以及跨链需要解决的关键性问题,回顾了跨链技术的发展历程,利用具体跨链项目分析了主要的跨链模式,并对跨链技术的未来进行了展望。2 结束语针对目前跨链技术遇到的关键性问题,一种有效的方式是设计一个在底层平台就遵循统一的跨链协议标准的区块链系统,就像现在的操作系统对TCP/IP协议的支持一样。而通用的区块链跨链系统需要支持以下5方面内容。1) 提供跨链消息的输入和输出口径,如Cosmos和Polkadot的跨链队列。2) 提供跨链消息的真实性证明,区块链需要提供类似SPV的证明方法。3) 消息的有效路由需要构建跨链消息的统一格式,定义消息的来源和去处以及消息的内容,如Cosmos的IBC协议。4) 消息状态的有效性证明,区块链可能需要设计新的、类似UTXO的可验证存储结构,方便做类似 SPV 的证明方案,否则目前的基于 KV(key value)的数据存储方式很难做有效性证明。5) 跨链执行结果证明,与有效性证明类似,需要全新的数据结构和运行算法支持该功能。除此之外,跨链系统的设计还需要考虑系统的稳定性、可扩展性以及如何升级系统、容错等方面。总之,跨链技术在过去几年间发展迅速,但目前的跨链技术尚未完全成熟,没有得到广泛应用,仍有较大的提升空间。一方面,跨链所面临的技术问题有一定的复杂性;另一方面,区块链技术在飞速发展,区块链的类别和技术复杂度也在不断提升,导致对于跨链技术更迭的要求不断提高。其次,跨链技术的发展与跨链技术的应用模式密切相关,除了跨链本身的技术形态演进,跨链未来的进一步发展也依赖于跨链应用模式的构建与发展,随着区块链行业应用的逐步落地和不断丰富,对跨链的需求也必定不再局限于交易。The authors have declared that no competing interests exist.作者已声明无竞争性利益关系。3 原文链接http://www.infocomm-journal.com/wlw/article/2020/2096-3750/2096-3750-4-2-00035.shtml
-
我在训练MAE模型,GitHub上有有人实现好的代码https://github.com/yangyucheng000/mae,他是在Asecnd上多卡训练的,但是我只有单卡GPU,因此我把其中的代码都改成单卡GPU训练的模式了,在进行finetune的时候竟然报NCCL的错,但是在代码中我并没有配置分布式训练。请问这是怎么回事呢?应该怎么解决呢?是不是我在改单卡的时候漏掉了哪里呢,还是说我需要再配其他的东西?求指教!!!
-
过去十年见证了分布式数据库的崛起不仅通过本地集群来实现负载均衡,并提供高可用性,还具有数据中心内的机架感知等属性。专为云而设计的分布式数据库,可以跨越可用性区域,通过编排技术,支持公有云、私有云、混合云部署。近年来,市面上出现了大量专为分布式数据库部署而设计的新数据库系统,以及在初始设计中添加了分布式架构组件的其他数据库系统。DB-Engines排名前100的数据库DB-Engines是数据库领域的权威排行榜,它保留了所有数据库的流行指数,使用一种算法进行加权,监测诸如网站上的提及次数和谷歌的搜索趋势,Stack Overflow上的讨论或推特中的评论,工作职位要求的技术技能,以及在LinkedIn个人资料中提到这些技术的数量。虽然DB-Engines收集了数百个不同的数据库(截至2022年5月共有394个)。但是本文我们缩小范围,只观察前100名数据库。在很大程度上,反映了市场现状。关系型数据库管理系统(RDBMS),传统的SQL系统,仍然是最大的类别,占列表的47%。另外,列表中有25%是NoSQL系统,涵盖了许多不同类型的数据库,像MongoDB文档数据库、Redis键值系统、ScyllaDB宽列数据库,以及Neo4j图数据库。还有11%的数据库被列为多模型数据库,包括在同一系统中支持SQL和NoSQL的混合数据库,如微软的Cosmos DB或ArangoDB,或者支持多种NoSQL数据模型的数据库,如DynamoDB,它将自己列为NoSQL键值系统和文档存储。最后,还有一些是由各种特殊用途的数据库组成,从搜索引擎到时间序列数据库,以及其他不容易归入简单的“SQL与NoSQL”区域的数据库。但是所有这些数据库都是分布式数据库吗?这个词到底是什么意思?分布式数据库的定义2016年12月14日,ISO/IEC发布了最新版本的数据库语言SQL标准(ISO/IEC9075:2016)。随着时间的推移,如何构建与SQL兼容的分布式RDBMS系统一直在发展。分布式SQL,如PostgreSQL或CockroachDB NewSQL系统。相反,没有ANSI或ISO或IETF或W3C定义什么是NoSQL数据库。每种数据库都使用自己的专有查询语言,比如用于宽列NoSQL数据库的Cassandra查询语言(CQL),用于图形数据库的Gremlin/Tinkerpop查询方法。然而,它们并没有定义数据如何在这些数据库中分布,查询语言也不能解决架构问题。因此,无论是SQL还是NoSQL,对于什么是分布式数据库,并没有标准、协议或共识。因此,我花了一些时间来写下我自己的定义。坦率地说,这更像是一个门外汉的实用主义观点,而不是计算机科学教授的见解。简而言之,你必须决定你如何定义集群,以及如何跨集群分配数据。接下来,你必须确定集群中每个节点的角色。每个节点都是对等的,还是有些节点处于更优越的领导地位,而其他节点则是跟随者。然后,基于这些角色,你如何处理故障转移?最后,你必须在此基础上,弄清楚你如何尽可能均匀和容易地复制和分片数据。而这并不试图做到详尽无遗,你可以添加自己的特定条件。简短的清单:感兴趣的系统考虑到这些,我在前100名数据库中,找到五个示例,看看它们在测量属性时是如何比较的。其中有两个SQL系统和三个NoSQL系统。Postgres和CockroachDB代表最好的分布式SQL。CockroachDB被称为 NewSQL,专为分布式数据库而设计。MongoDB、Redis和ScyllaDB是分布式NoSQL,分别是文档数据库,键值存储,宽列数据库(也被称为键值数据库)。在大多数情况下,适用于ScyllaDB的也同样适用于Apache Cassandra和其他与Cassandra兼容的系统。假定你拥有专业的经验,而且对SQL与NoSQL的区别相对了解。基本上,如果需要一个表JOIN,坚持使用SQL和RDBMS。如果你可以将数据反规范化,那么NoSQL可能是一个很好的选择。我们不打算讨论作为数据结构或查询语言,两者哪个“更好”。而是讨论作为一个分布式数据库,哪个更好。多数据中心集群我们的选项在集群方面是如何比较的?现在,它们都能够进行集群,甚至是多数据中心操作。但是在PostgreSQL、MongoDB和Redis中,它们最初设计于单数据中心本地集群,在多数据中心设计之前就已经成为一种架构要求。Postgres首次发布于1986年,完全早于云计算的概念。后来,它允许在其设计上,纳入这些技术和能力。作为NewSQL革命的一部分,CockroachDB从一开始就考虑到了全球分布。MongoDB是在公有云诞生之初发布的,最开始设计时考虑到了单数据中心集群,但现在已经增加了对许多不同拓扑结构的支持。通过MongoDB Atlas,可以轻松部署到多个地区。Redis,由于其低延迟的设计,通常被部署在单个数据中心,但它具有允许多数据中心部署的企业特性。ScyllaDB,像Cassandra一样,从一开始就考虑到了多数据中心的部署。集群管理如何进行复制和分片,取决于数据库架构的分层或同质化程度。例如,在MongoDB中,有一个主服务器,其余的是主服务器的副本。副本是只读的,你只能对这个数据库的主副本进行写操作,不能直接更新。相反,你写到主数据库,它就会更新副本。所以,节点是异质的,而不是同质的。这有助于在读取繁重的工作负载中分配流量,但在混合或写入工作负载中,对你没有一点好处,主服务器可能会成为一个瓶颈。同样,如果主服务器发生故障会怎样?你将不得不完全停止写操作,直到集群选出一个新的主服务器,并将写操作分流到它上面。相反,如果ScyllaDB或Cassandra,或任何其他无active-active的系统,客户可以从任何节点读取或写入。没有单一的故障点,节点的同质化程度要高得多。而且每个节点都可以更新集群中的任何数据副本。因此,如果你有三个节点,每个节点都会根据其他两个节点的任何写入进行更新。active-active在计算方面本身就比较困难,但是一旦解决了服务器保持彼此同步的问题,就会得到一个可以更好地平衡混合或写入大量工作负载的系统,因为每个节点都可以提供读取或写入服务。那么,我们的各种例子在主复本或active-active对等方面是如何叠加的?CockroachDB和ScyllaDB,以及Cassandra一开始就考虑了active-active的主动式设计。在Postgres中,有一些可选的方法可以做到这一点,但它不是内置的。此外,MongoDB没有正式支持active-active,但是已经有一些人在尝试如何做到这一点了。对于Redis来说,active-active模型在Redis企业中可以通过无冲突复制数据类型(CRDTs)实现。Postgres、MongoDB和Redis都默认使用主副本数据分布模型。复制分布式系统设计也会影响如何跨部署到不同机架或数据中心之间分配数据。例如,给定一个主副本系统,只具有主的数据中心可以为任何写入工作负载服务,其他数据中心只能作为只读副本。在一个支持多数据中心集群的点对点系统中,整个集群中的每个节点都可以接受读或写操作。通过ScyllaDB,你可以决定每个站点有相同或甚至不同的复制因素。这里我展示了在一个数据中心的三个副本,在另一个数据中心有两个副本的可能性。操作可以有不同级别的一致性。你可能在三个节点的数据中心进行本地数据的读或写,需要更新任一数据中心的节点才能成功执行操作。可调整的一致性,结合多数据中心的拓扑感知,为工作负载提供更多的灵活性。拓扑感知本地集群是分布式数据库开始的方式,允许多个系统共享负载。如果想让数据库在多个节点上进行分片,或者通过确保相同的数据在多个节点上可用来实现高可用性,那么这一点非常重要。如果所有节点都安装在同一个机架上,一旦这个机架发生故障,就会很棘手。因此,添加拓扑感知,以便你可以感知同一数据中心内的机架。确保将数据分散在数据中心的多个机架上,从而最大限度地减少电源或连接丢失到一个或另一个机架的中断。有些数据库做的很好,允许在不同的数据中心运行数据库的多个副本,并使用某种跨集群更新机制。每个数据库都是自主运行的,它们的同步机制可以是单向的,一个数据中心更新一个下游的副本,也可以是双向的或多向的。这种地理分布可以通过允许更靠近用户的连接,来减少延迟。跨可用性区域或地区的数据库,还可以确保单个数据中心灾难不会导致数据库的部分或全部丢失。去年我们的一个客户就发生了这种情况,但由于他们部署在三个不同的数据中心,所以数据损失为零。跨集群更新最初是在批量级别上实现的。确保你的数据中心每天至少有一次同步。这并没有持续多久,后面人们开始确保更活跃的事务级更新。如果你在运行强一致性数据库,就会受到基于光速的实时传播延迟的限制。因此,实现最终一致性是为了允许每个操作更新使用多数据中心,同时考虑到在短期内,要使所有数据中心的数据保持一致可能需要时间。那么,在拓扑感知方面,它是如何叠加的?所以,CockroachDB和ScyllaDB也是内置的。从2015年开始,拓扑感知也成为MongoDB的一部分,他们在这方面有着多年的经验。Postgres和Redis最初被设计为单数据中心解决方案,因此处理多数据中心的延迟对两者来说并非易事。现在,你可以添加拓扑感知,就像添加active-active系统功能一样,但它并不是开箱即用的。让我们回顾一下所讨论的内容,分别查看这些数据库的属性。▶︎ PostgreSQLPostgreSQL是世界上最流行的的开源数据库之一,它以可靠性和稳定性而著称,在处理复杂SQL方面也表现出了绝对的优势。然而,Postgres仍在研究其跨集群和多数据中心的集群。由于SQL基于强一致性事务模式,所以它不能很好地跨地域跨集群。在所有相关的数据中心之间,每个查询都将由于长时间的延迟而暂停。此外,Postgres依靠的是主副本模型。集群中的一个节点是领导者,而其他节点是副本。虽然有负载平衡器或active-active插件,但这些也超出了基本的服务范围。最后,Postgres的分片在大多数情况下仍然是手动的,尽管他们在开发自动分片方面取得了进展,但这也超出了基本产品的范围。▶︎ CockroachDBCockroachDB声称自己是“NewSQL”,一个专为分发而设计的SQL数据库。它可以水平扩展,在磁盘、机器、机架,甚至数据中心故障时都能生存下来,做到延迟最小,无需手动干预。值得一提的是,CockroachDB使用Postgres线协议,并大量借鉴了Postgres开创的许多概念,而且并不局限于Postgres的架构。多数据中心集群和点对点的拓扑结构从一开始就被内置。自动分片和数据复制也是如此。它还内置了数据中心感知功能,而且还可以添加机架感知功能。对CockroachDB来说,它要求所有的事务都有很强的一致性,你可以把它看作是一个优点或缺点。既没有最终一致性的灵活性,也没有可调的一致性。这将降低吞吐量,并在任何跨数据中心部署中要求较高的基线延迟。▶︎ MongoDBMongoDB是NoSQL领域的领导者。随着它的发展,大量的分布式数据库功能被添加。现如今,MongoDB能够支持多数据中心集群。在大多数情况下,它仍然遵循主副本模式,也有办法使其成为对等的active-active。▶︎ Redis接下来是Redis,一个旨在作为内存缓存或数据存储的键值存储。Redis的数据全部在内存里,如果突然宕机,数据就会全部丢失,因此必须有一种机制来保证Redis的数据不会因为故障而丢失,这种机制就是Redis的持久化机制。虽然持久化保存数据,但如果数据集不适合放在RAM中,它就会遭受巨大的性能损失。正因为如此,它在设计时考虑到了本地集群。如果你无法承受5毫秒的等待时间来从SSD上获取数据,您可能更无法等待145毫秒来完成从旧金山到伦敦的网络往返时间。然而,有一些企业特性允许多数据中心的Redis集群。Redis在大多数情况下是以主副本模式运行的。这适用于大量读取的缓存服务器。但这意味着,主节点是数据需要首先写入的地方,然后将这些数据分散到副本,以帮助平衡其缓存负载。有一个企业功能,允许对等的active-active集群。Redis可以自动分片和复制数据,但它的拓扑感知仅限于作为企业功能的机架感知。▶︎ ScyllaDBScyllaDB是按照Apache Cassandra中的分布式数据库模型设计的。因此,它默认是多数据中心集群。它可以自动分片,并且每个操作都有可调整的一致性,如果你想要更强的一致性,它甚至还支持轻量级事务来提供写入的线性化。就拓扑感知而言,ScyllaDB支持机架感知和数据中心意识,甚至支持标记感知和分片感知,不仅知道数据存储在哪个节点上,甚至可以知道与该数据关联的CPU。结论虽然对于什么是分布式数据库,还没有一个行业标准,但是我们可以看到,许多领先的SQL和NoSQL数据库,都在某种程度上支持一组核心功能或属性。其中有些功能是内置的,有些被认为是增值包或第三方选项。在本文分析的五个典型分布式数据库系统中,CockroachDB为SQL数据库提供了最全面的功能和特性,ScyllaDB为NoSQL系统提供了最全面的功能。该分析应被视为某个时间段的调查。鉴于下一个技术周期的需求,每一个数据库系统都在不断发展,这个行业并没有停滞不前。对用户来说,分布式数据库每年都在进步,变得更加灵活、性能更强、更具弹性和可扩展性。来源:今日头条
推荐直播
-
 华为云IoT开源专家实践分享:开源让物联网平台更开放、易用
华为云IoT开源专家实践分享:开源让物联网平台更开放、易用2024/05/14 周二 16:30-18:00
张俭 华为云IoT DTSE技术布道师
作为开发者的你是否也想加入开源社区?本期物联网平台资深“程序猿”,开源专家张俭,为你揭秘华为云IoT如何借助开源构建可靠、开放、易用的物联网平台,并手把手教你玩转开源社区!
去报名
热门标签