-
 【摘要】 Kafka作为一个中间件组件,具有与其他中间件组件通用的功能 (异步处理、系统解耦、流量削峰、日志处理), 但在某些特殊的功能方面,每个中间件拥有其独特的特性,其中Kafka作为一个具有高吞吐、高性能的中间件, 它也有其不足的地方,在某些应用场景下面要求中间件实现消息延时的功能,但Kafka本身是不具备这种能力的。 此DEMO项目实现了每条消息实现自定义的延时,详细内容可阅读文章进行了解。《目录》背景开发环境云服务介绍方案设计方案简述方案架构图时序图代码参数指南代码实现结果反馈1、背景Kafka是一个拥有高吞吐、可持久化、可水平扩展,支持流式数据处理等多种特性的分布式消息流处理中间件,采用分布式消息发布与订阅机制,在日志收集、流式数据传输、在线/离线系统分析、实时监控等领域有广泛的应用,Kafka它虽有以上这么多的应用场景和优点,但也具备其缺陷,比如在延时消息场景下,Kafka就不具备这种能力,因此希望能在保存Kafka特有能力的情况下给Kafka扩充一个具有能处理延时消息场景的能力。2、开发环境3、云服务介绍分布式消息服务Kafka版: 华为云分布式消息服务Kafka版是一款基于开源社区版Kafka提供的消息队列服务,向用户提供计算、存储和带宽资源独占式的Kafka专享实例。使用华为云分布式消息服务Kafka版,资源按需申请,按需配置Topic的分区与副本数量,即买即用,您将有更多精力专注于业务快速开发,不用考虑部署和运维。4、方案设计i、方案简述此方案实现,需要借助两个Topic来进行实现,一个Topic用于及时接收生产者们所产生的消息,另一个Topic则用于消费者拉取消息进行消费。另外在这两个Topic之间加上一个队列用于做延时的逻辑判断,如果消息满足了延时的条件,则将队列中的消息生产至我们的消费者需要拉取的Topic中。ii、方案架构图Kafka消息延时方案架构图 Kafka消息延时实现思路 1. 生产者将生产消息存入topic_delay主题中进行存储。 2. 将topic_delay主题中的所有消息拉取至ConcurrentLinkedQueue队列中。 3. 取值判断是否满足延时要求。 a. 如果满足延时要求,则将消息生产至topic_out主题中,并将queue队列中的值移除。 b. 如果不满足延时要求,则等待自定义时间后重试判断。 4. 消费者最终从topic_out主题中拉取消息进行消费。iii、方案时序图Kafka消息延时方案时序图 5、代码参数指南本项目中起到延时作用的类Delay.java其余类为官方提供用于测试生产和消费消息, 如需使用官方测试的使用的生产消费代码相关配置介绍可以参考https://support.huaweicloud.com/devg-kafka/how-to-connect-kafka.html 。 如需使用自己配置的生产者消费者,只配置Delay.java中的参数即可。 #### Delay.java参数详情 1. delay:自定义延时时间,单位ms。 2. topic_delay变量:用于临时存储消息的topic名称。 3. topic_out变量:用于消费者拉取消息消费的topic名称。 4. 关于消费者和生产者配置可按需配置,可参考Kafka官方文档:https://kafka.apache.org/documentation/#producerconfigs6、代码实现实现代码可参考Kafka消息延时 ``` package com.dms.delay; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import java.time.Duration; import java.util.Arrays; import java.util.Date; import java.util.Properties; import java.util.concurrent.ConcurrentLinkedQueue; /** * Hello world! * */ public class Delay { //缓存队列 public static ConcurrentLinkedQueue<ConsumerRecord<String, String>> link = new ConcurrentLinkedQueue(); //延迟时间(20秒),可根据需要设置延迟大小 public static long delay = 20000L; /** *入口 * @param args */ public static void main( String[] args ) { //延时主题(用于控制延时缓冲) String topic_delay = "topic_delay"; //输出主题(直接供消费者消费) String topic_out = "topic_out"; /* 消费线程 */ new Thread(new Runnable() { @Override public void run() { //消费者配置。请根据需要自行设置Kafka配置 Properties props = new Properties(); props.setProperty("bootstrap.servers", "192.168.0.59:9092,192.168.0.185:9092,192.168.0.4:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "true"); props.setProperty("auto.commit.interval.ms", "1000"); props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //创建消费者 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); //指定消费主题 consumer.subscribe(Arrays.asList(topic_delay)); while (true) { //轮询消费 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10)); //遍历当前轮询批次拉取到的消息 for (ConsumerRecord<String, String> record : records){ System.out.println(record); //将消息添加到缓存队列 link.add(record); } } } }).start(); /* 生产线程 */ new Thread(new Runnable() { @Override public void run() { //生产者配置(请根据需求自行配置) Properties props = new Properties(); props.put("bootstrap.servers", "192.168.0.59:9092,192.168.0.185:9092,192.168.0.4:9092"); props.put("linger.ms", 1); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //创建生产者 Producer<String, String> producer = new KafkaProducer<>(props); //持续从缓存队列中获取消息 while(true){ //如果缓存队列为空则放缓取值速度 if(link.isEmpty()){ try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } continue; } //获取缓存队列栈顶消息 ConsumerRecord<String, String> record = link.peek(); //获取该消息时间戳 long timestamp = record.timestamp(); Date now = new Date(); long nowTime = now.getTime(); if(timestamp+ Delay.delay <nowTime){ //获取消息值 String value = record.value(); //生产者发送消息到输出主题 producer.send(new ProducerRecord<String, String>(topic_out, "",value)); //从缓存队列中移除该消息 link.poll(); }else { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } } }).start(); } } ```7、结果反馈
【摘要】 Kafka作为一个中间件组件,具有与其他中间件组件通用的功能 (异步处理、系统解耦、流量削峰、日志处理), 但在某些特殊的功能方面,每个中间件拥有其独特的特性,其中Kafka作为一个具有高吞吐、高性能的中间件, 它也有其不足的地方,在某些应用场景下面要求中间件实现消息延时的功能,但Kafka本身是不具备这种能力的。 此DEMO项目实现了每条消息实现自定义的延时,详细内容可阅读文章进行了解。《目录》背景开发环境云服务介绍方案设计方案简述方案架构图时序图代码参数指南代码实现结果反馈1、背景Kafka是一个拥有高吞吐、可持久化、可水平扩展,支持流式数据处理等多种特性的分布式消息流处理中间件,采用分布式消息发布与订阅机制,在日志收集、流式数据传输、在线/离线系统分析、实时监控等领域有广泛的应用,Kafka它虽有以上这么多的应用场景和优点,但也具备其缺陷,比如在延时消息场景下,Kafka就不具备这种能力,因此希望能在保存Kafka特有能力的情况下给Kafka扩充一个具有能处理延时消息场景的能力。2、开发环境3、云服务介绍分布式消息服务Kafka版: 华为云分布式消息服务Kafka版是一款基于开源社区版Kafka提供的消息队列服务,向用户提供计算、存储和带宽资源独占式的Kafka专享实例。使用华为云分布式消息服务Kafka版,资源按需申请,按需配置Topic的分区与副本数量,即买即用,您将有更多精力专注于业务快速开发,不用考虑部署和运维。4、方案设计i、方案简述此方案实现,需要借助两个Topic来进行实现,一个Topic用于及时接收生产者们所产生的消息,另一个Topic则用于消费者拉取消息进行消费。另外在这两个Topic之间加上一个队列用于做延时的逻辑判断,如果消息满足了延时的条件,则将队列中的消息生产至我们的消费者需要拉取的Topic中。ii、方案架构图Kafka消息延时方案架构图 Kafka消息延时实现思路 1. 生产者将生产消息存入topic_delay主题中进行存储。 2. 将topic_delay主题中的所有消息拉取至ConcurrentLinkedQueue队列中。 3. 取值判断是否满足延时要求。 a. 如果满足延时要求,则将消息生产至topic_out主题中,并将queue队列中的值移除。 b. 如果不满足延时要求,则等待自定义时间后重试判断。 4. 消费者最终从topic_out主题中拉取消息进行消费。iii、方案时序图Kafka消息延时方案时序图 5、代码参数指南本项目中起到延时作用的类Delay.java其余类为官方提供用于测试生产和消费消息, 如需使用官方测试的使用的生产消费代码相关配置介绍可以参考https://support.huaweicloud.com/devg-kafka/how-to-connect-kafka.html 。 如需使用自己配置的生产者消费者,只配置Delay.java中的参数即可。 #### Delay.java参数详情 1. delay:自定义延时时间,单位ms。 2. topic_delay变量:用于临时存储消息的topic名称。 3. topic_out变量:用于消费者拉取消息消费的topic名称。 4. 关于消费者和生产者配置可按需配置,可参考Kafka官方文档:https://kafka.apache.org/documentation/#producerconfigs6、代码实现实现代码可参考Kafka消息延时 ``` package com.dms.delay; import org.apache.kafka.clients.consumer.ConsumerRecord; import org.apache.kafka.clients.consumer.ConsumerRecords; import org.apache.kafka.clients.consumer.KafkaConsumer; import org.apache.kafka.clients.producer.KafkaProducer; import org.apache.kafka.clients.producer.Producer; import org.apache.kafka.clients.producer.ProducerRecord; import java.time.Duration; import java.util.Arrays; import java.util.Date; import java.util.Properties; import java.util.concurrent.ConcurrentLinkedQueue; /** * Hello world! * */ public class Delay { //缓存队列 public static ConcurrentLinkedQueue<ConsumerRecord<String, String>> link = new ConcurrentLinkedQueue(); //延迟时间(20秒),可根据需要设置延迟大小 public static long delay = 20000L; /** *入口 * @param args */ public static void main( String[] args ) { //延时主题(用于控制延时缓冲) String topic_delay = "topic_delay"; //输出主题(直接供消费者消费) String topic_out = "topic_out"; /* 消费线程 */ new Thread(new Runnable() { @Override public void run() { //消费者配置。请根据需要自行设置Kafka配置 Properties props = new Properties(); props.setProperty("bootstrap.servers", "192.168.0.59:9092,192.168.0.185:9092,192.168.0.4:9092"); props.setProperty("group.id", "test"); props.setProperty("enable.auto.commit", "true"); props.setProperty("auto.commit.interval.ms", "1000"); props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); //创建消费者 KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); //指定消费主题 consumer.subscribe(Arrays.asList(topic_delay)); while (true) { //轮询消费 ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(10)); //遍历当前轮询批次拉取到的消息 for (ConsumerRecord<String, String> record : records){ System.out.println(record); //将消息添加到缓存队列 link.add(record); } } } }).start(); /* 生产线程 */ new Thread(new Runnable() { @Override public void run() { //生产者配置(请根据需求自行配置) Properties props = new Properties(); props.put("bootstrap.servers", "192.168.0.59:9092,192.168.0.185:9092,192.168.0.4:9092"); props.put("linger.ms", 1); props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); //创建生产者 Producer<String, String> producer = new KafkaProducer<>(props); //持续从缓存队列中获取消息 while(true){ //如果缓存队列为空则放缓取值速度 if(link.isEmpty()){ try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } continue; } //获取缓存队列栈顶消息 ConsumerRecord<String, String> record = link.peek(); //获取该消息时间戳 long timestamp = record.timestamp(); Date now = new Date(); long nowTime = now.getTime(); if(timestamp+ Delay.delay <nowTime){ //获取消息值 String value = record.value(); //生产者发送消息到输出主题 producer.send(new ProducerRecord<String, String>(topic_out, "",value)); //从缓存队列中移除该消息 link.poll(); }else { try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } } }).start(); } } ```7、结果反馈 -
 本地idea如何构建本机的开发环境,flink读取sasl_plaintext的kafka?然后本机idea启动,直接消费kafka数据?在flink提交任务前加了if (LoginUtil.isSecurityModel()) { try { LOG.info("Securitymode start."); //!!注意,安全认证时,需要用户手动修改为自己申请的机机账号 LoginUtil.securityPrepare(USER_PRINCIPAL, USER_KEYTAB_FILE); } catch (IOException e) { LOG.error("Security prepare failure."); LOG.error("The IOException occured : {}.", e); return; } LOG.info("Security prepare success.");}这部分认证,但是这个好像并没有提交到本地的flinkclient中。
本地idea如何构建本机的开发环境,flink读取sasl_plaintext的kafka?然后本机idea启动,直接消费kafka数据?在flink提交任务前加了if (LoginUtil.isSecurityModel()) { try { LOG.info("Securitymode start."); //!!注意,安全认证时,需要用户手动修改为自己申请的机机账号 LoginUtil.securityPrepare(USER_PRINCIPAL, USER_KEYTAB_FILE); } catch (IOException e) { LOG.error("Security prepare failure."); LOG.error("The IOException occured : {}.", e); return; } LOG.info("Security prepare success.");}这部分认证,但是这个好像并没有提交到本地的flinkclient中。 -
场景描述本示例场景对汽车驾驶的实时数据信息进行分析,将满足特定条件的数据结果进行汇总。数据的输入源为Kafka,结果输出到DWS中。例如,如下样例输入数据:{"car_id":"3027", "car_owner":"lilei", "car_age":"7", "average_speed":"76", "total_miles":"15000"} {"car_id":"3028", "car_owner":"hanmeimei", "car_age":"6", "average_speed":"92", "total_miles":"17000"} {"car_id":"3029", "car_owner":"zhangsan", "car_age":"10", "average_speed":"81", "total_miles":"230000"}预期输出:average_speed <= 90 和 total_miles <= 200000的车辆,即:{"car_id":"3027", "car_owner":"lilei", "car_age":"7", "average_speed":"76", "total_miles":"15000"}前提条件已创建DMS Kafka实例,具体步骤可参考:DMS Kafka入门指引。注意:创建DMS Kafka实例时,不能开启Kafka SASL_SSL。已创建Elasticsearch类型的CSS集群。具体创建CSS集群的操作可以参考创建CSS集群。本示例创建的CSS集群版本为:7.6.2,集群为非安全集群。整体作业开发流程整体作业开发流程参考图1。图1 作业开发流程步骤1:创建队列:创建DLI作业运行的队列。步骤2:创建Kafka的Topic:创建Kafka生产消费数据的Topic。步骤3:创建Elasticsearch搜索索引:创建Elasticsearch搜索索引用于接收结果数据。步骤4:创建增强型跨源连接:DLI上创建连接Kafka和CSS的跨源连接,打通网络。步骤5:运行作业:DLI上创建和运行Flink OpenSource作业。步骤6:发送数据和查询结果:Kafka上发送流数据,在CSS上查看运行结果。步骤1:创建队列登录DLI管理控制台,在左侧导航栏单击“资源管理 > 队列管理”,可进入队列管理页面。在队列管理界面,单击界面右上角的“购买队列”。在“购买队列”界面,填写具体的队列配置参数,具体参数填写参考如下。计费模式:选择“包年/包月”或“按需计费”。本示例选择“按需计费”。区域和项目:保持默认值即可。名称:填写具体的队列名称。说明:新建的队列名称,名称只能包含数字、英文字母和下划线,但不能是纯数字,且不能以下划线开头。长度限制:1~128个字符。队列名称不区分大小写,系统会自动转换为小写。类型:队列类型选择“通用队列”。“按需计费”时需要勾选“专属资源模式”。AZ策略、CPU架构、规格:保持默认即可。企业项目:当前选择为“default”。高级选项:选择“自定义”。网段:配置队列网段。例如,当前配置为10.0.0.0/16。注意:队列的网段不能和DMS Kafka、RDS MySQL实例的子网网段有重合,否则后续创建跨源连接会失败。其他参数根据需要选择和配置。图2 创建队列参数配置完成后,单击“立即购买”,确认配置信息无误后,单击“提交”完成队列创建。步骤2:创建Kafka的Topic在Kafka管理控制台,选择“Kafka专享版”,单击对应的Kafka名称,进入到Kafka的基本信息页面。单击“Topic管理 > 创建Topic”,创建一个Topic。Topic配置参数如下:Topic名称。本示例输入为:testkafkatopic。分区数:1。副本数:1其他参数保持默认即可。步骤3:创建Elasticsearch搜索索引登录CSS管理控制台,选择“集群管理 > Elasticsearch”。在集群管理界面,在已创建的CSS集群的“操作”列,单击“Kibana”访问集群。在Kibana的左侧导航中选择“Dev Tools”,进入到Console界面。在Console界面,执行如下命令创建索引“shoporders”。PUT /shoporders { "settings": { "number_of_shards": 1 }, "mappings": { "properties": { "order_id": { "type": "text" }, "order_channel": { "type": "text" }, "order_time": { "type": "text" }, "pay_amount": { "type": "double" }, "real_pay": { "type": "double" }, "pay_time": { "type": "text" }, "user_id": { "type": "text" }, "user_name": { "type": "text" }, "area_id": { "type": "text" } } } }步骤4:创建增强型跨源连接创建DLI连接Kafka的增强型跨源连接在Kafka管理控制台,选择“Kafka专享版”,单击对应的Kafka名称,进入到Kafka的基本信息页面。在“连接信息”中获取该Kafka的“内网连接地址”,在“基本信息”的“网络”中获取获取该实例的“虚拟私有云”和“子网”信息,方便后续操作步骤使用。单击“网络”中的安全组名称,在“入方向规则”中添加放通队列网段的规则。例如,本示例队列网段为“10.0.0.0/16”,则规则添加为:优先级选为:1,策略选为:允许,协议选择:TCP,端口值不填,类型:IPV4,源地址为:10.0.0.0/16,单击“确定”完成安全组规则添加。登录DLI管理控制台,在左侧导航栏单击“跨源管理”,在跨源管理界面,单击“增强型跨源”,单击“创建”。在增强型跨源创建界面,配置具体的跨源连接参数。具体参考如下。连接名称:设置具体的增强型跨源名称。本示例输入为:dli_kafka。弹性资源池:选择步骤1:创建队列中已经创建的队列。虚拟私有云:选择Kafka的虚拟私有云。子网:选择Kafka的子网。其他参数可以根据需要选择配置。参数配置完成后,单击“确定”完成增强型跨源配置。单击创建的跨源连接名称,查看跨源连接的连接状态,等待连接状态为:“已激活”后可以进行后续步骤。单击“队列管理”,选择操作的队列,本示例为步骤1:创建队列中添加的队列,在操作列,单击“更多 > 测试地址连通性”。在“测试连通性”界面,根据中获取的Kafka连接信息,地址栏输入“Kafka内网地址:Kafka数据库端口”,单击“测试”测试DLI到Kafka网络是否可达。创建DLI连接CSS的增强型跨源连接在CSS管理控制台,选择“集群管理”,单击已创建的CSS集群名称,进入到CSS的基本信息页面。在“基本信息”中获取CSS的“内网访问地址”、“虚拟私有云”和“子网”信息,方便后续操作步骤使用。单击“连接信息”中的安全组名称,在“入方向规则”中添加放通队列网段的规则。例如,本示例队列网段为“10.0.0.0/16”,则规则添加为:优先级选为:1,策略选为:允许,协议选择:TCP,端口值不填,类型:IPV4,源地址为:10.0.0.0/16,单击“确定”完成安全组规则添加。登录DLI管理控制台,在左侧导航栏单击“跨源管理”,在跨源管理界面,单击“增强型跨源”,单击“创建”。说明:本示例默认Kafka和CSS实例分别在两个VPC和子网下,所以要分别创建增强型跨源连接打通网络。如果Kafka和CSS实例属于同一VPC和子网下,则创建增强型跨源一次即可,4和5不需要再执行。在增强型跨源创建界面,配置具体的跨源连接参数。具体参考如下。连接名称:设置具体的增强型跨源名称。本示例输入为:dli_css。弹性资源池:选择步骤1:创建队列中已经创建的队列。虚拟私有云:选择CSS的虚拟私有云。子网:选择CSS的子网。其他参数可以根据需要选择配置。参数配置完成后,单击“确定”完成增强型跨源配置。单击创建的跨源连接名称,查看跨源连接的连接状态,等待连接状态为:“已激活”后可以进行后续步骤。单击“队列管理”,选择操作的队列,本示例为步骤1:创建队列中添加的队列,在操作列,单击“更多 > 测试地址连通性”。在“测试连通性”界面,根据2获取的CSS连接信息,地址栏输入“CSS内网地址:CSS内网端口”,单击“测试”测试DLI到CSS网络是否可达。步骤5:运行作业在DLI管理控制台,单击“作业管理 > Flink作业”,在Flink作业管理界面,单击“创建作业”。在创建队列界面,类型选择“Flink OpenSource SQL”,名称填写为:FlinkKafkaES。单击“确定”,跳转到Flink作业编辑界面。在Flink OpenSource SQL作业编辑界面,配置如下参数。所属队列:选择步骤1:创建队列中创建的队列。Flink版本:选择1.12。保存作业日志:勾选。OBS桶:选择保存作业日志的OBS桶,根据提示进行OBS桶权限授权。开启Checkpoint:勾选。Flink作业编辑框中输入具体的作业SQL,本示例作业参考如下。SQL中加粗的参数需要根据实际情况修改。说明:本示例使用的Flink版本为1.12,故Flink OpenSource SQL语法也是1.12。本示例数据源是Kafka,写入结果数据到Elasticsearch,故请参考Flink OpenSource SQL 1.12创建Kafka源表和Flink OpenSource SQL 1.12创建Elasticsearch结果表。CREATE TABLE kafkaSource ( order_id string, order_channel string, order_time string, pay_amount double, real_pay double, pay_time string, user_id string, user_name string, area_id string ) with ( "connector" = "kafka", "properties.bootstrap.servers" = "10.128.0.120:9092,10.128.0.89:9092,10.128.0.83:9092",--替换为kafka的内网连接地址和端口 "properties.group.id" = "click", "topic" = "testkafkatopic", --创建的Kafka Topic "format" = "json", "scan.startup.mode" = "latest-offset" ); CREATE TABLE elasticsearchSink ( order_id string, order_channel string, order_time string, pay_amount double, real_pay double, pay_time string, user_id string, user_name string, area_id string ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = '192.168.168.125:9200', --替换为CSS集群的内网地址和端口 'index' = 'shoporders' --创建的Elasticsearch搜索引擎 ); --将Kafka数据写入到Elasticsearch索引中 insert into elasticsearchSink select * from kafkaSource;单击“语义校验”确保SQL语义校验成功。单击“保存”,保存作业。单击“启动”,启动作业,确认作业参数信息,单击“立即启动”开始执行作业。等待作业运行状态变为“运行中”。步骤6:发送数据和查询结果使用Kafka客户端向步骤2:创建Kafka的Topic中的Topic发送数据,模拟实时数据流。Kafka生产和发送数据的方法请参考:DMS - 连接实例生产消费信息。发送样例数据如下:{"order_id":"202103241000000001", "order_channel":"webShop", "order_time":"2021-03-24 10:00:00", "pay_amount":"100.00", "real_pay":"100.00", "pay_time":"2021-03-24 10:02:03", "user_id":"0001", "user_name":"Alice", "area_id":"330106"} {"order_id":"202103241606060001", "order_channel":"appShop", "order_time":"2021-03-24 16:06:06", "pay_amount":"200.00", "real_pay":"180.00", "pay_time":"2021-03-24 16:10:06", "user_id":"0002", "user_name":"Jason", "area_id":"330106"}发送成功后,在CSS集群的Kibana中执行下述语句并查看相应结果:GET shoporders/_search查询结果返回如下:{ "took" : 0, "timed_out" : false, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 2, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "shoporders", "_type" : "_doc", "_id" : "6fswzIAByVjqg3_qAyM1", "_score" : 1.0, "_source" : { "order_id" : "202103241000000001", "order_channel" : "webShop", "order_time" : "2021-03-24 10:00:00", "pay_amount" : 100.0, "real_pay" : 100.0, "pay_time" : "2021-03-24 10:02:03", "user_id" : "0001", "user_name" : "Alice", "area_id" : "330106" } }, { "_index" : "shoporders", "_type" : "_doc", "_id" : "6vs1zIAByVjqg3_qyyPp", "_score" : 1.0, "_source" : { "order_id" : "202103241606060001", "order_channel" : "appShop", "order_time" : "2021-03-24 16:06:06", "pay_amount" : 200.0, "real_pay" : 180.0, "pay_time" : "2021-03-24 16:10:06", "user_id" : "0002", "user_name" : "Jason", "area_id" : "330106" } } ] } }
-
场景描述该场景为对汽车驾驶的实时数据信息进行分析,将满足特定条件的数据结果进行汇总。数据的输入源为Kafka,结果输出到DWS中。例如,如下样例输入数据:{"car_id":"3027", "car_owner":"lilei", "car_age":"7", "average_speed":"76", "total_miles":"15000"} {"car_id":"3028", "car_owner":"hanmeimei", "car_age":"6", "average_speed":"92", "total_miles":"17000"} {"car_id":"3029", "car_owner":"zhangsan", "car_age":"10", "average_speed":"81", "total_miles":"230000"}预期输出:average_speed <= 90 和 total_miles <= 200000的车辆,即:{"car_id":"3027", "car_owner":"lilei", "car_age":"7", "average_speed":"76", "total_miles":"15000"}前提条件已创建DMS Kafka实例,具体步骤可参考:创建Kafka实例。注意:创建DMS Kafka实例时,不能开启Kafka SASL_SSL。已创建DWS实例,具体创建DWS集群的操作可以参考创建DWS集群。本示例创建的DWS集群版本为:8.1.1.205。整体作业开发流程整体作业开发流程参考图1。图1 作业开发流程步骤1:创建队列:创建DLI作业运行的队列。步骤2:创建Kafka的Topic:创建Kafka生产消费数据的Topic。步骤3:创建DWS数据库和表:创建DWS数据库和表信息。步骤4:创建增强型跨源连接:DLI上创建连接Kafka和DWS的跨源连接,打通网络。步骤5:运行作业:DLI上创建和运行Flink OpenSource作业。步骤6:发送数据和查询结果:Kafka上发送流数据,在RDS上查看运行结果。步骤1:创建队列登录DLI管理控制台,在左侧导航栏单击“资源管理 > 队列管理”,可进入队列管理页面。在队列管理界面,单击界面右上角的“购买队列”。在“购买队列”界面,填写具体的队列配置参数,具体参数填写参考如下。计费模式:选择“包年/包月”或“按需计费”。本示例选择“按需计费”。区域和项目:保持默认值即可。名称:填写具体的队列名称。说明:新建的队列名称,名称只能包含数字、英文字母和下划线,但不能是纯数字,且不能以下划线开头。长度限制:1~128个字符。队列名称不区分大小写,系统会自动转换为小写。类型:队列类型选择“通用队列”。“按需计费”时需要勾选“专属资源模式”。AZ策略、CPU架构、规格:保持默认即可。企业项目:当前选择为“default”。高级选项:选择“自定义”。网段:配置队列网段。例如,当前配置为10.0.0.0/16。注意:队列的网段不能和DMS Kafka、RDS MySQL实例的子网网段有重合,否则后续创建跨源连接会失败。其他参数根据需要选择和配置。图2 创建队列参数配置完成后,单击“立即购买”,确认配置信息无误后,单击“提交”完成队列创建。步骤2:创建Kafka的Topic在Kafka管理控制台,选择“Kafka专享版”,单击对应的Kafka名称,进入到Kafka的基本信息页面。单击“Topic管理 > 创建Topic”,创建一个Topic。Topic配置参数如下:Topic名称。本示例输入为:testkafkatopic。分区数:1。副本数:1其他参数保持默认即可。步骤3:创建DWS数据库和表参考使用gsql命令行客户端连接DWS集群连接已创建的DWS集群。执行以下命令连接DWS集群的默认数据库“gaussdb”:gsql -d gaussdb -h DWS集群连接地址 -U dbadmin -p 8000 -W password -rgaussdb:DWS集群默认数据库。DWS集群连接地址:请参见获取集群连接地址进行获取。如果通过公网地址连接,请指定为集群“公网访问地址”或“公网访问域名”,如果通过内网地址连接,请指定为集群“内网访问地址”或“内网访问域名”。如果通过弹性负载均衡连接,请指定为“弹性负载均衡地址”。dbadmin:创建集群时设置的默认管理员用户名。-W:默认管理员用户的密码。在命令行窗口输入以下命令创建数据库“testdwsdb”。CREATE DATABASE testdwsdb;执行以下命令,退出gaussdb数据库,连接新创建的数据库“testdwsdb”。\q gsql -d testdwsdb -h DWS集群连接地址 -U dbadmin -p 8000 -W password -r执行以下命令创建表。create schema test; set current_schema= test; drop table if exists qualified_cars; CREATE TABLE qualified_cars ( car_id VARCHAR, car_owner VARCHAR, car_age INTEGER , average_speed FLOAT8, total_miles FLOAT8 );步骤4:创建增强型跨源连接创建DLI连接Kafka的增强型跨源连接在Kafka管理控制台,选择“Kafka专享版”,单击对应的Kafka名称,进入到Kafka的基本信息页面。在“连接信息”中获取该Kafka的“内网连接地址”,在“基本信息”的“网络”中获取获取该实例的“虚拟私有云”和“子网”信息,方便后续操作步骤使用。单击“网络”中的安全组名称,在“入方向规则”中添加放通队列网段的规则。例如,本示例队列网段为“10.0.0.0/16”,则规则添加为:优先级选为:1,策略选为:允许,协议选择:TCP,端口值不填,类型:IPV4,源地址为:10.0.0.0/16,单击“确定”完成安全组规则添加。登录DLI管理控制台,在左侧导航栏单击“跨源管理”,在跨源管理界面,单击“增强型跨源”,单击“创建”。在增强型跨源创建界面,配置具体的跨源连接参数。具体参考如下。连接名称:设置具体的增强型跨源名称。本示例输入为:dli_kafka。弹性资源池:选择步骤1:创建队列中已经创建的队列名。虚拟私有云:选择Kafka的虚拟私有云。子网:选择Kafka的子网。其他参数可以根据需要选择配置。参数配置完成后,单击“确定”完成增强型跨源配置。单击创建的跨源连接名称,查看跨源连接的连接状态,等待连接状态为:“已激活”后可以进行后续步骤。单击“队列管理”,选择操作的队列,本示例为步骤1:创建队列中创建的队列,在操作列,单击“更多 > 测试地址连通性”。在“测试连通性”界面,根据2中获取的Kafka连接信息,地址栏输入“Kafka内网地址:Kafka数据库端口”,单击“测试”测试DLI到Kafka网络是否可达。创建DLI连接DWS的增强型跨源连接在DWS管理控制台,选择“集群管理”,单击已创建的DWS集群名称,进入到DWS的基本信息页面。在“基本信息”的“数据库属性”中获取该实例的“内网IP”、“端口”,“基本信息”页面的“网络”中获取“虚拟私有云”和“子网”信息,方便后续操作步骤使用。单击“连接信息”中的安全组名称,在“入方向规则”中添加放通队列网段的规则。例如,本示例队列网段为“10.0.0.0/16”,则规则添加为:优先级选为:1,策略选为:允许,协议选择:TCP,端口值不填,类型:IPV4,源地址为:10.0.0.0/16,单击“确定”完成安全组规则添加。登录DLI管理控制台,在左侧导航栏单击“跨源管理”,在跨源管理界面,单击“增强型跨源”,单击“创建”。说明:本示例默认Kafka和DWS实例分别在两个VPC和子网下,所以要分别创建增强型跨源连接打通网络。如果Kafka和DWS实例属于同一VPC和子网下,则创建增强型跨源一次即可,4和5不需要再执行。在增强型跨源创建界面,配置具体的跨源连接参数。具体参考如下。连接名称:设置具体的增强型跨源名称。本示例输入为:dli_dws。弹性资源池:选择步骤1:创建队列中已经创建的队列名。虚拟私有云:选择DWS的虚拟私有云。子网:选择DWS的子网。其他参数可以根据需要选择配置。参数配置完成后,单击“确定”完成增强型跨源配置。单击创建的跨源连接名称,查看跨源连接的连接状态,等待连接状态为:“已激活”后可以进行后续步骤。单击“队列管理”,选择操作的队列,本示例为步骤1:创建队列中创建的队列,在操作列,单击“更多 > 测试地址连通性”。在“测试连通性”界面,根据2中获取的DWS连接信息,地址栏输入“DWS内网IP:DWS端口”,单击“测试”测试DLI到DWS网络是否可达。步骤5:运行作业在DLI管理控制台,单击“作业管理 > Flink作业”,在Flink作业管理界面,单击“创建作业”。在创建队列界面,类型选择“Flink OpenSource SQL”,名称填写为:FlinkKafkaDWS。单击“确定”,跳转到Flink作业编辑界面。在Flink OpenSource SQL作业编辑界面,配置如下参数。所属队列:选择步骤1:创建队列中创建的队列。Flink版本:选择1.12。保存作业日志:勾选。OBS桶:选择保存作业日志的OBS桶,根据提示进行OBS桶权限授权。开启Checkpoint:勾选。Flink作业编辑框中输入具体的作业SQL,本示例作业参考如下。SQL中加粗的参数需要根据实际情况修改。说明:本示例使用的Flink版本为1.12,故Flink OpenSource SQL语法也是1.12。本示例数据源是Kafka,写入结果数据到DWS,故请参考Flink OpenSource SQL 1.12创建Kafka源表和Flink OpenSource SQL 1.12创建DWS结果表(RDS连接)。create table car_infos( car_id STRING, car_owner STRING, car_age INT, average_speed DOUBLE, total_miles DOUBLE ) with ( "connector" = "kafka", "properties.bootstrap.servers" = "10.128.0.120:9092,10.128.0.89:9092,10.128.0.83:9092",--替换为kafka的内网连接地址和端口 "properties.group.id" = "click", "topic" = "testkafkatopic",--创建的Kafka的Topic "format" = "json", "scan.startup.mode" = "latest-offset" ); create table qualified_cars ( car_id STRING, car_owner STRING, car_age INT, average_speed DOUBLE, total_miles DOUBLE ) WITH ( 'connector' = 'gaussdb', 'driver' = 'com.huawei.gauss200.jdbc.Driver', 'url' = 'jdbc:gaussdb://192.168.168.16:8000/testdwsdb', ---192.168.168.16:8000替换为DWS的内网IP和端口,testdwsdb为创建的DWS数据库名 'table-name' = 'test\".\"qualified_cars', ---test为创建的DWS表的schema,qualified_cars为对应的DWS表名 'username' = 'xxxx',--替换为DWS实例的用户名 'password' = 'xxxx',--替换为DWS实例的用户密码 'write.mode' = 'insert' ); /** 将合格车辆信息输出 **/ INSERT INTO qualified_cars SELECT * FROM car_infos where average_speed <= 90 and total_miles <= 200000;单击“语义校验”确保SQL语义校验成功。单击“保存”,保存作业。单击“启动”,启动作业,确认作业参数信息,单击“立即启动”开始执行作业。等待作业运行状态变为“运行中”。步骤6:发送数据和查询结果使用Kafka客户端向步骤2:创建Kafka的Topic中的Topic发送数据,模拟实时数据流。Kafka生产和发送数据的方法请参考:DMS - 连接实例生产消费信息。发送样例数据如下:{"car_id":"3027", "car_owner":"lilei", "car_age":"7", "average_speed":"76", "total_miles":"15000"} {"car_id":"3028", "car_owner":"hanmeimei", "car_age":"6", "average_speed":"92", "total_miles":"17000"} {"car_id":"3029", "car_owner":"zhangsan", "car_age":"10", "average_speed":"81", "total_miles":"230000"}参考使用gsql命令行客户端连接DWS集群连接已创建的DWS集群。执行以下命令连接DWS集群的默认数据库“testdwsdb”:gsql -d testdwsdb -h DWS集群连接地址 -U dbadmin -p 8000 -W password -r查询DWS的表数据。select * from test.qualified_cars;查询结果参考如下:car_id car_owner car_age average_speed total_miles 3027 lilei 7 76.0 15000.0
-
场景描述该场景为根据商品的实时点击量,获取每小时内点击量最高的3个商品及其相关信息,数据的输入源为Kafka,结果输出到RDS中。例如,如下样例输入数据:{"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 08:01:00", "product_id":"0002", "product_name":"name1"} {"user_id":"0002", "user_name":"Bob", "event_time":"2021-03-24 08:02:00", "product_id":"0002", "product_name":"name1"} {"user_id":"0002", "user_name":"Bob", "event_time":"2021-03-24 08:06:00", "product_id":"0004", "product_name":"name2"} {"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 08:10:00", "product_id":"0003", "product_name":"name3"} {"user_id":"0003", "user_name":"Cindy", "event_time":"2021-03-24 08:15:00", "product_id":"0005", "product_name":"name4"} {"user_id":"0003", "user_name":"Cindy", "event_time":"2021-03-24 08:16:00", "product_id":"0005", "product_name":"name4"} {"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 08:56:00", "product_id":"0004", "product_name":"name2"} {"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 09:05:00", "product_id":"0005", "product_name":"name4"} {"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 09:10:00", "product_id":"0006", "product_name":"name5"} {"user_id":"0002", "user_name":"Bob", "event_time":"2021-03-24 09:13:00", "product_id":"0006", "product_name":"name5"}预期输出:2021-03-24 08:00:00 - 2021-03-24 08:59:59,0002,name1,2 2021-03-24 08:00:00 - 2021-03-24 08:59:59,0004,name2,2 2021-03-24 08:00:00 - 2021-03-24 08:59:59,0005,name4,2 2021-03-24 09:00:00 - 2021-03-24 09:59:59,0006,name5,2 2021-03-24 09:00:00 - 2021-03-24 09:59:59,0005,name4,1前提条件已创建DMS Kafka实例,具体步骤可参考:创建Kafka实例。注意:创建DMS Kafka实例时,不能开启Kafka SASL_SSL。已创建RDS MySQL实例,具体步骤可参考:RDS MySQL快速入门。本示例创建的RDS MySQL数据库版本选择为:8.0。整体作业开发流程整体作业开发流程参考图1。图1 作业开发流程步骤1:创建队列:创建DLI作业运行的队列。步骤2:创建Kafka的Topic:创建Kafka生产消费数据的Topic。步骤3:创建RDS数据库和表:创建RDS MySQL数据库和表信息。步骤4:创建增强型跨源连接:DLI上创建连接Kafka和RDS的跨源连接,打通网络。步骤5:运行作业:DLI上创建和运行Flink OpenSource作业。步骤6:发送数据和查询结果:Kafka上发送流数据,在RDS上查看运行结果。步骤1:创建队列登录DLI管理控制台,在左侧导航栏单击“资源管理 > 队列管理”,可进入队列管理页面。在队列管理界面,单击界面右上角的“购买队列”。在“购买队列”界面,填写具体的队列配置参数,具体参数填写参考如下。计费模式:选择“包年/包月”或“按需计费”。本示例选择“按需计费”。区域和项目:保持默认值即可。名称:填写具体的队列名称。说明:新建的队列名称,名称只能包含数字、英文字母和下划线,但不能是纯数字,且不能以下划线开头。长度限制:1~128个字符。队列名称不区分大小写,系统会自动转换为小写。类型:队列类型选择“通用队列”。“按需计费”时需要勾选“专属资源模式”。AZ策略、CPU架构、规格:保持默认即可。企业项目:当前选择为“default”。高级选项:选择“自定义”。网段:配置队列网段。例如,当前配置为10.0.0.0/16。注意:队列的网段不能和DMS Kafka、RDS MySQL实例的子网网段有重合,否则后续创建跨源连接会失败。其他参数根据需要选择和配置。图2 创建队列参数配置完成后,单击“立即购买”,确认配置信息无误后,单击“提交”完成队列创建。步骤2:创建Kafka的Topic登录Kafka管理控制台,选择“Kafka专享版”,单击对应的Kafka实例名称,进入到Kafka实例的基本信息页面。单击“Topic管理 > 创建Topic”,创建一个Topic。Topic配置参数如下:Topic名称。本示例输入为:testkafkatopic。分区数:1。副本数:1其他参数保持默认即可。步骤3:创建RDS数据库和表登录RDS管理控制台,在“实例管理”界面,选择已创建的RDS MySQL实例,选择操作列的“更多 > 登录”,进入数据管理服务实例登录界面。输入实例登录的用户名和密码。单击“登录”,即可进入RDS MySQL数据库并进行管理。在数据库实例界面,单击“新建数据库”,数据库名定义为:testrdsdb,字符集保持默认即可。在已创建的数据库的操作列,单击“SQL查询”,输入以下创建表语句,创建RDS MySQL表。CREATE TABLE clicktop ( `range_time` VARCHAR(64) NOT NULL, `product_id` VARCHAR(32) NOT NULL, `product_name` VARCHAR(32), `event_count` VARCHAR(32), PRIMARY KEY (`range_time`,`product_id`) ) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8mb4;步骤4:创建增强型跨源连接创建DLI连接Kafka的增强型跨源连接在Kafka管理控制台,选择“Kafka专享版”,单击对应的Kafka名称,进入到Kafka的基本信息页面。在“连接信息”中获取该Kafka的“内网连接地址”,在“基本信息”的“网络”中获取该实例的“虚拟私有云”和“子网”信息,方便后续操作步骤使用。单击“网络”中的安全组名称,在“入方向规则”中添加放通队列网段的规则。例如,本示例队列网段为“10.0.0.0/16”,则规则添加为:优先级选为:1,策略选为:允许,协议选择:TCP,端口值不填,类型:IPV4,源地址为:10.0.0.0/16,单击“确定”完成安全组规则添加。登录DLI管理控制台,在左侧导航栏单击“跨源管理”,在跨源管理界面,单击“增强型跨源”,单击“创建”。在增强型跨源创建界面,配置具体的跨源连接参数。具体参考如下。连接名称:设置具体的增强型跨源名称。本示例输入为:dli_kafka。弹性资源池:选择步骤1:创建队列中已经创建的队列名称。虚拟私有云:选择Kafka的虚拟私有云。子网:选择Kafka的子网。其他参数可以根据需要选择配置。参数配置完成后,单击“确定”完成增强型跨源配置。单击创建的跨源连接名称,查看跨源连接的连接状态,等待连接状态为“已激活”后可以进行后续步骤。单击“队列管理”,选择操作的队列,本示例为步骤1:创建队列中创建的队列,在操作列,单击“更多 > 测试地址连通性”。在“测试连通性”界面,根据2中获取的Kafka连接信息,地址栏输入“Kafka内网地址:Kafka数据库端口”,单击“测试”测试DLI到Kafka网络是否可达。创建DLI连接RDS的增强型跨源连接在RDS管理控制台,选择“实例管理”,单击对应的RDS实例名称,进入到RDS的基本信息页面。在“基本信息”的“连接信息”中获取该实例的“内网地址”、“数据库端口”、“虚拟私有云”和“子网”信息,方便后续操作步骤使用。单击“连接信息”中的安全组名称,在“入方向规则”中添加放通队列网段的规则。例如,本示例队列网段为“10.0.0.0/16”,则规则添加为:优先级选为:1,策略选为:允许,协议选择:TCP,端口值不填,类型:IPV4,源地址为:10.0.0.0/16,单击“确定”完成安全组规则添加。登录DLI管理控制台,在左侧导航栏单击“跨源管理”,在跨源管理界面,单击“增强型跨源”,单击“创建”。说明:本示例默认Kafka和RDS实例分别在两个VPC和子网下,所以要分别创建增强型跨源连接打通网络。如果Kafka和RDS实例属于同一VPC和子网下,则创建增强型跨源一次即可,4和5不需要再执行。在增强型跨源创建界面,配置具体的跨源连接参数。具体参考如下。连接名称:设置具体的增强型跨源名称。本示例输入为:dli_rds。弹性资源池:选择步骤1:创建队列中已经创建的队列名称。虚拟私有云:选择RDS的虚拟私有云。子网:选择RDS的子网。其他参数可以根据需要选择配置。参数配置完成后,单击“确定”完成增强型跨源配置。单击创建的跨源连接名称,查看跨源连接的连接状态,等待连接状态为:“已激活”后可以进行后续步骤。单击“队列管理”,选择操作的队列,本示例为步骤1:创建队列中创建的队列,在操作列,单击“更多 > 测试地址连通性”。在“测试连通性”界面,根据2中获取的RDS连接信息,地址栏输入“RDS内网地址:RDS数据库端口”,单击“测试”测试DLI到RDS网络是否可达。步骤5:运行作业在DLI管理控制台,单击“作业管理 > Flink作业”,在Flink作业管理界面,单击“创建作业”。在创建作业界面,作业类型选择“Flink OpenSource SQL”,名称填写为:FlinkKafkaRds。单击“确定”,跳转到Flink作业编辑界面。在Flink OpenSource SQL作业编辑界面,配置如下参数。所属队列:选择步骤1:创建队列中创建的队列。Flink版本:选择1.12。保存作业日志:勾选。OBS桶:选择保存作业日志的OBS桶,根据提示进行OBS桶权限授权。开启Checkpoint:勾选。Flink作业编辑框中输入具体的作业SQL,本示例作业参考如下。SQL中加粗的参数需要根据实际情况修改。说明:本示例使用的Flink版本为1.12,故Flink OpenSource SQL语法也是1.12。本示例数据源是Kafka,写入结果数据到RDS,故请参考Flink OpenSource SQL 1.12创建Kafka源表和Flink OpenSource SQL 1.12创建JDBC结果表(RDS连接)。create table click_product( user_id string, --点击用户的id user_name string, --用户名称 event_time string, --点击时间 product_id string, --商品id product_name string --商品名称 ) with ( "connector" = "kafka", "properties.bootstrap.servers" = "10.128.0.120:9092,10.128.0.89:9092,10.128.0.83:9092",--替换为kafka的内网连接地址和端口 "properties.group.id" = "click", "topic" = "testkafkatopic",--创建的Kafka Topic名称 "format" = "json", "scan.startup.mode" = "latest-offset" ); --结果表 create table top_product ( range_time string, --计算的时间范围 product_id string, --商品id product_name string, --商品名称 event_count bigint, --点击次数 primary key (range_time, product_id) not enforced ) with ( "connector" = "jdbc", "url" = "jdbc:mysql://192.168.12.148:3306/testrdsdb",--testrdsdb为创建的RDS的数据库名,IP和端口替换为RDS MySQL的实例IP和端口 "table-name" = "clicktop", "username" = "xxxxx", --替换为RDS MySQL的实例的用户名 "password" = "xxxxx", --替换为RDS MySQL的实例的用户密码 "sink.buffer-flush.max-rows" = "1000", "sink.buffer-flush.interval" = "1s" ); create view current_event_view as select product_id, product_name, count(1) as click_count, concat(substring(event_time, 1, 13), ":00:00") as min_event_time, concat(substring(event_time, 1, 13), ":59:59") as max_event_time from click_product group by substring (event_time, 1, 13), product_id, product_name; insert into top_product select concat(min_event_time, " - ", max_event_time) as range_time, product_id, product_name, click_count from ( select *, row_number() over (partition by min_event_time order by click_count desc) as row_num from current_event_view ) where row_num <= 3单击“语义校验”确保SQL语义校验成功。单击“保存”,保存作业。单击“启动”,启动作业,确认作业参数信息,单击“立即启动”开始执行作业。等待作业运行状态变为“运行中”。步骤6:发送数据和查询结果使用Kafka客户端向步骤2:创建Kafka的Topic中的Topic发送数据,模拟实时数据流。Kafka生产和发送数据的方法请参考:DMS - 连接实例生产消费信息。发送样例数据如下:{"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 08:01:00", "product_id":"0002", "product_name":"name1"} {"user_id":"0002", "user_name":"Bob", "event_time":"2021-03-24 08:02:00", "product_id":"0002", "product_name":"name1"} {"user_id":"0002", "user_name":"Bob", "event_time":"2021-03-24 08:06:00", "product_id":"0004", "product_name":"name2"} {"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 08:10:00", "product_id":"0003", "product_name":"name3"} {"user_id":"0003", "user_name":"Cindy", "event_time":"2021-03-24 08:15:00", "product_id":"0005", "product_name":"name4"} {"user_id":"0003", "user_name":"Cindy", "event_time":"2021-03-24 08:16:00", "product_id":"0005", "product_name":"name4"} {"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 08:56:00", "product_id":"0004", "product_name":"name2"} {"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 09:05:00", "product_id":"0005", "product_name":"name4"} {"user_id":"0001", "user_name":"Alice", "event_time":"2021-03-24 09:10:00", "product_id":"0006", "product_name":"name5"} {"user_id":"0002", "user_name":"Bob", "event_time":"2021-03-24 09:13:00", "product_id":"0006", "product_name":"name5"}登录RDS控制台,单击RDS数据库实例,单击创建的数据库名,如“testrdsdb”,在创建的表“clicktop”所在行的“操作”列,单击“SQL查询”,输入以下查询语句。select * from `clicktop`;在“SQL查询”界面,单击“执行SQL”,查看RDS表数据已写入成功。
-
本文为您介绍如何通过CDM数据同步功能,迁移MRS Kafka数据至DLI。其他DMS Kafka或者Apache Kafka等服务数据,均可以通过CDM与DLI进行双向同步。前提条件已创建DLI的SQL队列。创建DLI队列的操作可以参考创建DLI队列。注意:创建DLI队列时队列类型需要选择为“SQL队列”。已创建包含Kafka组件的MRS安全集群。具体创建MRS集群的操作可以参考创建MRS集群。本示例创建的MRS集群版本为:MRS 3.1.0。本示例创建的MRS集群开启了Kerberos认证。已创建CDM迁移集群。创建CDM集群的操作可以参考创建CDM集群。创建CDM集群完成后,还需要提交工单开通迁移MRS Kafka数据到DLI的白名单,否则在CDM配置迁移作业时目的端配置查找不到DLI。说明:如果目标数据源为云下的数据库,则需要通过公网或者专线打通网络。通过公网互通时,需确保CDM集群已绑定EIP、CDM云上安全组出方向放通云下数据源所在的主机、数据源所在的主机可以访问公网且防火墙规则已开放连接端口。数据源为云上的MRS、DWS时,网络互通需满足如下条件:i. CDM集群与云上服务处于不同区域的情况下,需要通过公网或者专线打通网络。通过公网互通时,需确保CDM集群已绑定EIP,数据源所在的主机可以访问公网且防火墙规则已开放连接端口。ii. CDM集群与云上服务同区域情况下,同虚拟私有云、同子网、同安全组的不同实例默认网络互通;如果同虚拟私有云但是子网或安全组不同,还需配置路由规则及安全组规则。配置路由规则请参见如何配置路由规则章节,配置安全组规则请参见如何配置安全组规则章节。iii. 此外,您还必须确保该云服务的实例与CDM集群所属的企业项目必须相同,如果不同,需要修改工作空间的企业项目。本示例CDM集群的虚拟私有云、子网以及安全组和创建的MRS集群保持一致。步骤一:数据准备MRS集群上创建Kafka的Topic并且向Topic发送消息。参考访问MRS Manager登录MRS Manager。在MRS Manager上,选择“系统 > 权限 > 用户”,单击“添加用户”,在添加用户页面分别配置如下参数。用户名:自定义的用户名。当前示例输入为:testuser2。用户类型:当前选择为“人机”。密码和确认密码:输入当前用户名对应的密码。用户组和主组:选择kafkaadmin。角色:选择Manager_viewer角色。图1 MRS Manager上创建Kafka用户在MRS Manager上,选择“集群 > 待操作的集群名称 > 服务 > ZooKeeper > 实例”,获取ZooKeeper角色实例的IP地址,为后续步骤做准备。在MRS Manager上,选择“集群 > 待操作的集群名称 > 服务 > kafka > 实例”,获取kafka角色实例的IP地址,为后续步骤做准备。参考安装MRS客户端下载并安装Kafka客户端。例如,当前Kafka客户端安装在MRS主机节点的“/opt/kafkaclient”目录上。以root用户进入客户端安装目录下。例如:cd /opt/kafkaclient执行以下命令配置环境变量。source bigdata_env因为当前集群启用了Kerberos认证,则需要执行以下命令进行安全认证。认证用户为2中创建的用户。kinit 2中创建的用户名例如,kinit testuser2执行以下命令创建名字为kafkatopic的Kafka Topic。kafka-topics.sh --create --zookeeper ZooKeeper角色实例所在节点IP地址1:2181,ZooKeeper角色实例所在节点IP地址2:2181,ZooKeeper角色实例所在节点IP地址3:2181/kafka --replication-factor 1 --partitions 1 --topic kafkatopic上述命令中的“ZooKeeper角色实例所在节点IP地址”即为3中获取的ZooKeeper实例IP。执行以下命令向kafkatopic发送消息。kafka-console-producer.sh --broker-list Kafka角色实例所在节点的IP地址1:21007,Kafka角色实例所在节点的IP地址2:21007,Kafka角色实例所在节点的IP地址3:21007 --topic kafkatopic --producer.config /opt/kafkaclient/Kafka/kafka/config/producer.properties上述命令中的“Kafka角色实例所在节点的IP地址”即为4中获取的Kafka实例IP。发送测试消息内容如下:{"PageViews":5, "UserID":"4324182021466249494", "Duration":146,"Sign":-1}在DLI上创建数据库和表。登录DLI管理控制台,选择“SQL编辑器”,在SQL编辑器中“执行引擎”选择“spark”,“队列”选择已创建的SQL队列。在编辑器中输入以下语句创建数据库,例如当前创建迁移后的DLI数据库testdb。详细的DLI创建数据库的语法可以参考创建DLI数据库。create database testdb;创建数据库下的表。详细的DLI建表语法可以参考创建DLI表。CREATE TABLE testdlitable(value STRING);步骤二:数据迁移配置CDM数据源连接。配置源端MRS Kafka的数据源连接。登录CDM控制台,选择“集群管理”,选择已创建的CDM集群,在操作列选择“作业管理”。在作业管理界面,选择“连接管理”,单击“新建连接”,连接器类型选择“MRS Kafka”,单击“下一步”。图2 创建MRS Kafka数据源配置源端MRS Kafka的数据源连接,具体参数配置如下。表1 MRS Kafka数据源配置参数值名称自定义MRS Kafka数据源名称。例如当前配置为“source_kafka”。Manager IP单击输入框旁边的“选择”按钮,选择当前MRS Kafka集群即可自动关联出来Manager IP。用户名在2中创建的MRS Kafka用户名。密码对应MRS Kafka用户名的密码。认证类型如果当前MRS集群为普通集群则选择为SIMPLE,如果是MRS集群启用了Kerberos安全认证则选择为KERBEROS。本示例选择为:KERBEROS。更多参数的详细说明可以参考CDM上配置Kafka连接。图3 CDM配置MRS Kafka数据源连接单击“保存”完成MRS Kafka数据源配置。配置目的端DLI的数据源连接。登录CDM控制台,选择“集群管理”,选择已创建的CDM集群,在操作列选择“作业管理”。在作业管理界面,选择“连接管理”,单击“新建连接”,连接器类型选择“数据湖探索(DLI)”,单击“下一步”。图4 创建DLI数据源连接配置目的端DLI数据源连接连接参数。具体参数配置可以参考在CDM上配置DLI连接。图5 配置DLI数据源连接参数配置完成后,单击“保存”完成DLI数据源配置。创建CDM迁移作业。登录CDM控制台,选择“集群管理”,选择已创建的CDM集群,在操作列选择“作业管理”。在“作业管理”界面,选择“表/文件迁移”,单击“新建作业”。在新建作业界面,配置当前作业配置信息,具体参数参考如下:图6 新建CDM作业作业配置作业名称:自定义数据迁移的作业名称。例如,当前定义为:test。源端作业配置,具体参考如下:表2 源端作业配置参数名参数值源连接名称选择1.a中已创建的数据源名称。Topics选择MRS Kafka待迁移的Topic名称,支持单个或多个Topic。当前示例为:kafkatopic。数据格式根据实际情况选择当前消息格式。本示例选择为:CDC(DRS_JSON),以DRS_JSON格式解析源数据。偏移量参数从Kafka拉取数据时的初始偏移量。本示例当前选择为:最新。最新:最大偏移量,即拉取最新的数据。最早:最小偏移量,即拉取最早的数据。已提交:拉取已提交的数据。时间范围:拉取时间范围内的数据。是否持久运行用户自定义是否永久运行。当前示例选择为:否。拉取数据超时时间持续拉取数据多长时间超时,单位分钟。当前示例配置为:15。等待时间可选参数,超出等待时间还是无法读取到数据,则不再读取数据,单位秒。当前示例不配置该参数。消费组ID用户指定消费组ID。当前使用MRS Kafka默认的消息组ID:“example-group1”。其他参数的详细配置说明可以参考:CDM配置Kafka源端参数。目的端作业配置,具体参考如下:表3 目的端作业配置参数名参数值目的连接名称选择1.b已创建的DLI数据源连接。资源队列选择已创建的DLI SQL类型的队列。数据库名称选择DLI下已创建的数据库。当前示例为在DLI上创建数据库和表中创建的数据库名,即为“testdb”。表名选择DLI下已创建的表名。当前示例为在DLI上创建数据库和表中创建的表名,即为“testdlitable”。导入前清空数据选择导入前是否清空目的表的数据。当前示例选择为“否”。如果设置为是,任务启动前会清除目标表中数据。详细的参数配置可以参考:CDM配置DLI目的端参数。单击“下一步”,进入到字段映射界面,CDM会自动匹配源和目的字段。如果字段映射顺序不匹配,可通过拖拽字段调整。如果选择在目的端自动创建类型,这里还需要配置每个类型的字段类型、字段名称。CDM支持迁移过程中转换字段内容,详细请参见字段转换。图7 字段映射单击“下一步”配置任务参数,一般情况下全部保持默认即可。该步骤用户可以配置如下可选功能:作业失败重试:如果作业执行失败,可选择是否自动重试,这里保持默认值“不重试”。作业分组:选择作业所属的分组,默认分组为“DEFAULT”。在CDM“作业管理”界面,支持作业分组显示、按组批量启动作业、按分组导出作业等操作。是否定时执行:如果需要配置作业定时自动执行,请参见配置定时任务。这里保持默认值“否”。抽取并发数:设置同时执行的抽取任务数。这里保持默认值“1”。是否写入脏数据:如果需要将作业执行过程中处理失败的数据、或者被清洗过滤掉的数据写入OBS中,以便后面查看,可通过该参数配置,写入脏数据前需要先配置好OBS连接。这里保持默认值“否”即可,不记录脏数据。单击“保存并运行”,回到作业管理界面,在作业管理界面可查看作业执行进度和结果。图8 迁移作业进度和结果查询步骤三:结果查询CDM迁移作业运行完成后,再登录到DLI管理控制台,选择“SQL编辑器”,在SQL编辑器中“执行引擎”选择“spark”,“队列”选择已创建的SQL队列,数据库选择已1已创建的数据库,执行DLI表查询语句,查询Kafka数据是否已成功迁移到DLI的“testdlitable”表中。select * from testdlitable;
-
【功能模块】参考kafka接口调用样例培训视频指导配置【操作步骤&问题现象】1、客户端配置文件已加入resources,机机账号凭证文件也已加入resources2、代码中对应的变量值也已同步修改,启动Producer报身份认证错误,错误详情如下【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
 本文分享自华为云社区《[图解Kafka Producer 消息缓存模型](https://bbs.huaweicloud.com/blogs/337169?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者:石臻臻的杂货铺。 在阅读本文之前, 希望你可以思考一下下面几个问题, 带着问题去阅读文章会获得更好的效果。 1. 发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗? 2. 当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了? 3. 当最新的ProducerBatch还有空余的内存,但是接下来的一条消息很大,不足以加上上一个Batch中,会怎么办呢? 4. 那么创建ProducerBatch的时候,应该分配多少的内存呢? # 什么是消息累加器RecordAccumulator kafka为了提高Producer客户端的发送吞吐量和提高性能,选择了将消息暂时缓存起来,等到满足一定的条件, 再进行批量发送, 这样可以减少网络请求,提高吞吐量。 而缓存这个消息的就是RecordAccumulator类。 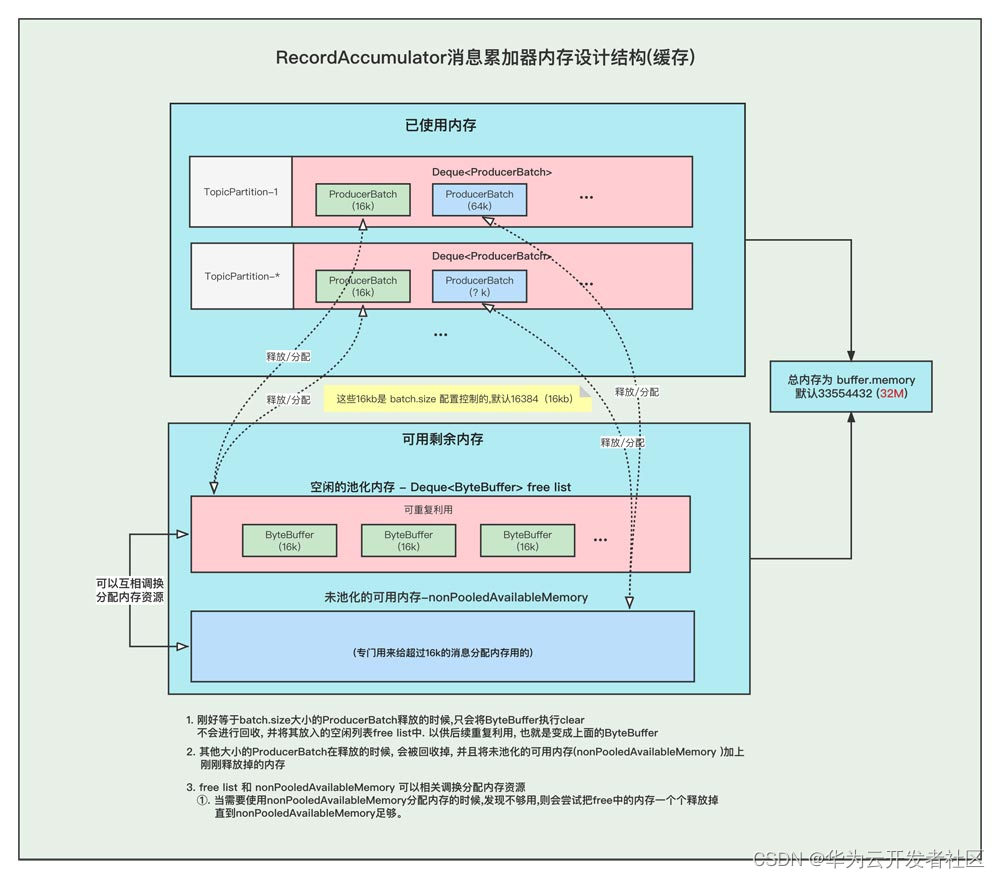 上图就是整个消息存放的缓存模型,我们接下来一个个来讲解。 # 消息缓存模型 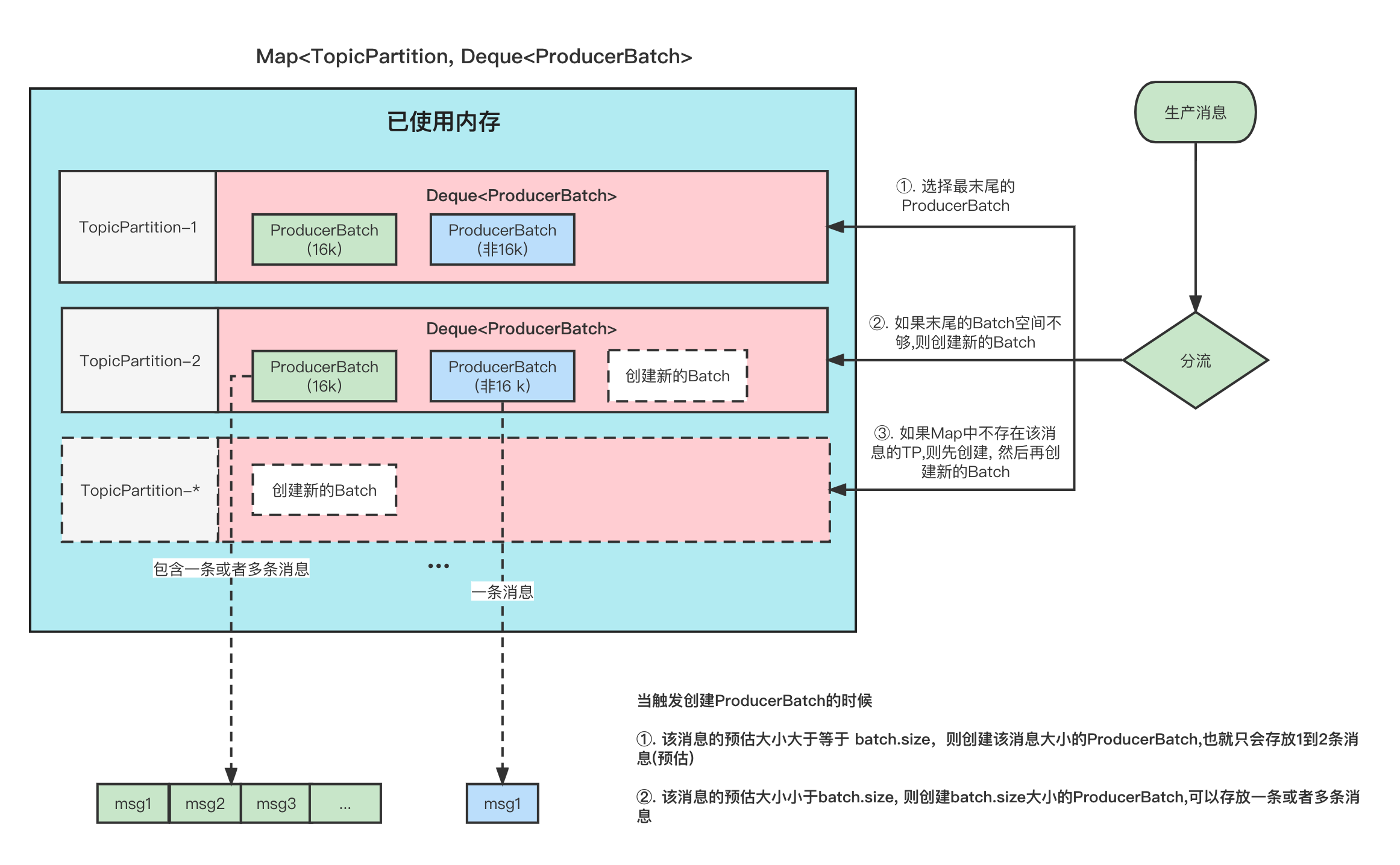 上图表示的就是 消息缓存的模型, 生产的消息就是暂时存放在这个里面。 1. 每条消息,我们按照TopicPartition维度,把他们放在不同的Deque 队列里面。 TopicPartition相同,会在相同Deque 的里面。 2. ProducerBatch : 表示同一个批次的消息, 消息真正发送到Broker端的时候都是按照批次来发送的, 这个批次可能包含一条或者多条消息。 3. 如果没有找到消息对应的ProducerBatch队列, 则创建一个队列。 4. 找到ProducerBatch队列队尾的Batch,发现Batch还可以塞下这条消息,则将消息直接塞到这个Batch中 5. 找到ProducerBatch队列队尾的Batch,发现Batch中剩余内存,不够塞下这条消息,则会创建新的Batch 6. 当消息发送成功之后, Batch会被释放掉。 **ProducerBatch的内存大小** >那么创建ProducerBatch的时候,应该分配多少的内存呢? 先说结论: 当消息预估内存大于batch.size的时候,则按照消息预估内存创建, 否则按照batch.size的大小创建(默认16k). 我们来看一段代码,这段代码就是在创建ProducerBatch的时候预估内存的大小 RecordAccumulator#append /** * 公众号: 石臻臻的杂货铺 * 微信:szzdzhp001 **/ // 找到 batch.size 和 这条消息在batch中的总内存大小的 最大值 int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers)); // 申请内存 buffer = free.allocate(size, maxTimeToBlock); 1. 假设当前生产了一条消息为M, 刚好消息M找不到可以存放消息的ProducerBatch(不存在或者满了),那么这个时候就需要创建一个新的ProducerBatch了 2. 预估消息的大小 跟batch.size 默认大小16384(16kb). 对比,取最大值用于申请的内存大小的值。 原文地址:图解Kafka Producer 消息缓存模型 >那么, 这个消息的预估是如何预估的?纯粹的是消息体的大小吗? DefaultRecordBatch#estimateBatchSizeUpperBound 预估需要的Batch大小,是一个预估值,因为没有考虑压缩算法从额外开销 /** * 使用给定的键和值获取只有一条记录的批次大小的上限。 * 这只是一个估计,因为它没有考虑使用的压缩算法的额外开销。 **/ static int estimateBatchSizeUpperBound(ByteBuffer key, ByteBuffer value, Header[] headers) { return RECORD_BATCH_OVERHEAD + DefaultRecord.recordSizeUpperBound(key, value, headers); } 1. 预估这个消息M的大小 + 一个RECORD_BATCH_OVERHEAD的大小 2. RECORD_BATCH_OVERHEAD是一个Batch里面的一些基本元信息,总共占用了 61B 3. 消息M的大小也并不是单单的只有消息体的大小,总大小=(key,value,headers)的大小+MAX_RECORD_OVERHEAD 4. MAX_RECORD_OVERHEAD :一条消息头最大占用空间, 最大值为21B 也就是说创建一个ProducerBatch,最少就要83B . 比如我发送一条消息 " 1 " , 预估得到的大小是 86B, 跟batch.size(默认16384) 相比取最大值。 那么申请内存的时候取最大值 16384 。 关于Batch的结构和消息的结构,我们回头**单独用一篇文章来讲解**。 # 内存分配 我们都知道RecordAccumulator里面的缓存大小是一开始定义好的, 由buffer.memory控制, 默认33554432 (32M) 当生产的速度大于发送速度的时候,就可能出现Producer写入阻塞。 而且频繁的创建和释放ProducerBatch,会导致频繁GC, 所有kafka中有个缓存池的概念,这个缓存池会被重复使用,但是只有固定( batch.size)的大小才能够使用缓存池。 **PS:以下16k指得是 batch.size的默认值.** 原文地址:图解Kafka Producer 消息缓存模型 **Batch的创建和释放** **1. 内存16K 缓存池中有可用内存** ①. 创建Batch的时候, 会去缓存池中,获取队首的一块内存ByteBuffer 使用。 ②. 消息发送完成,释放Batch, 则会把这个ByteBuffer,放到缓存池的队尾中,并且调用ByteBuffer.clear 清空数据。以便下次重复使用 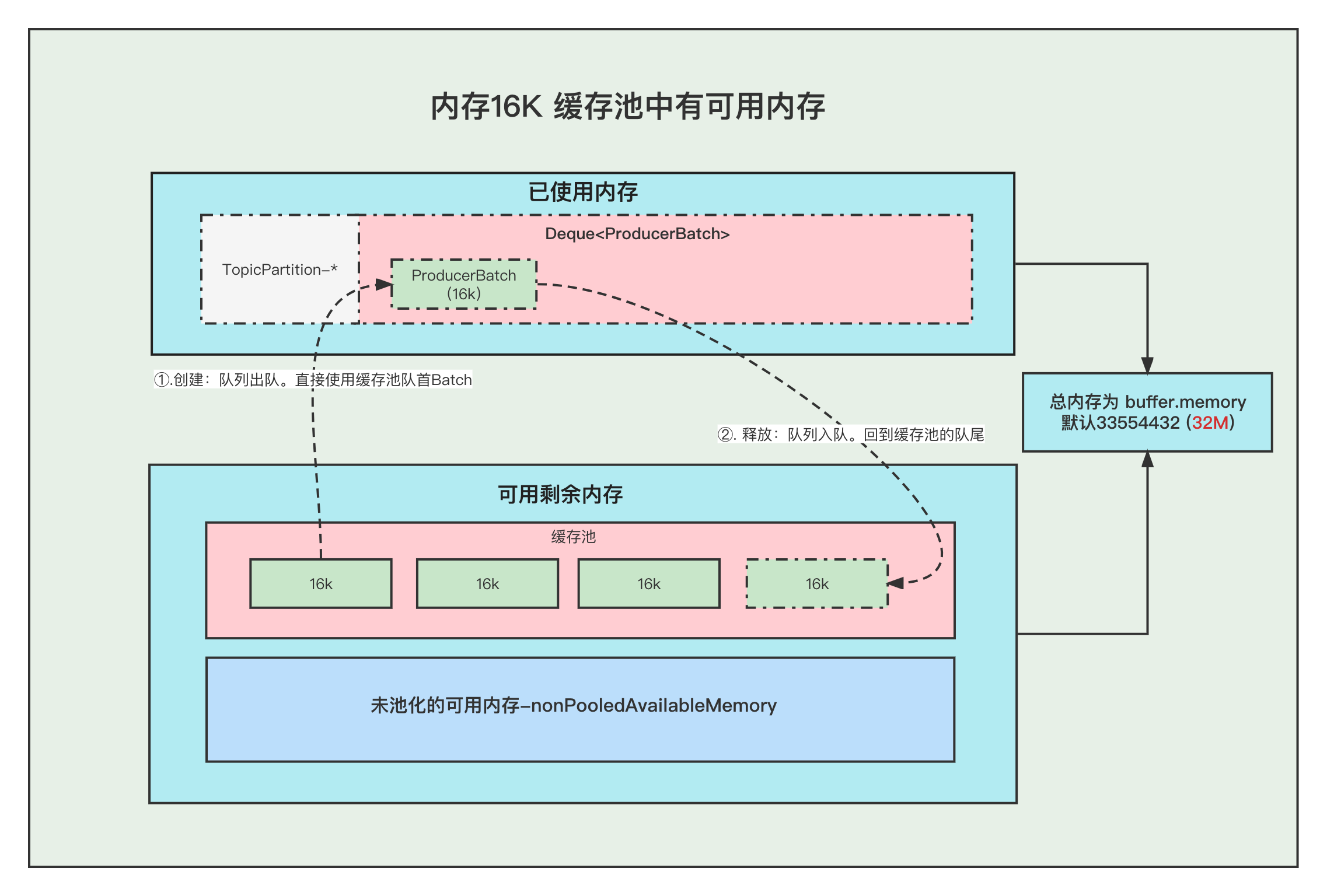 **2. 内存16K 缓存池中无可用内存** ①. 创建Batch的时候, 去非缓存池中的内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池nonPooledAvailableMemory 减少 16K 的内存, 然后Batch正常创建就行了, **不要误以为好像真的发生了内存的转移**。 ②. 消息发送完成,释放Batch, 则会把这个ByteBuffer,放到缓存池的队尾中,并且调用ByteBuffer.clear 清空数据, 以便下次重复使用 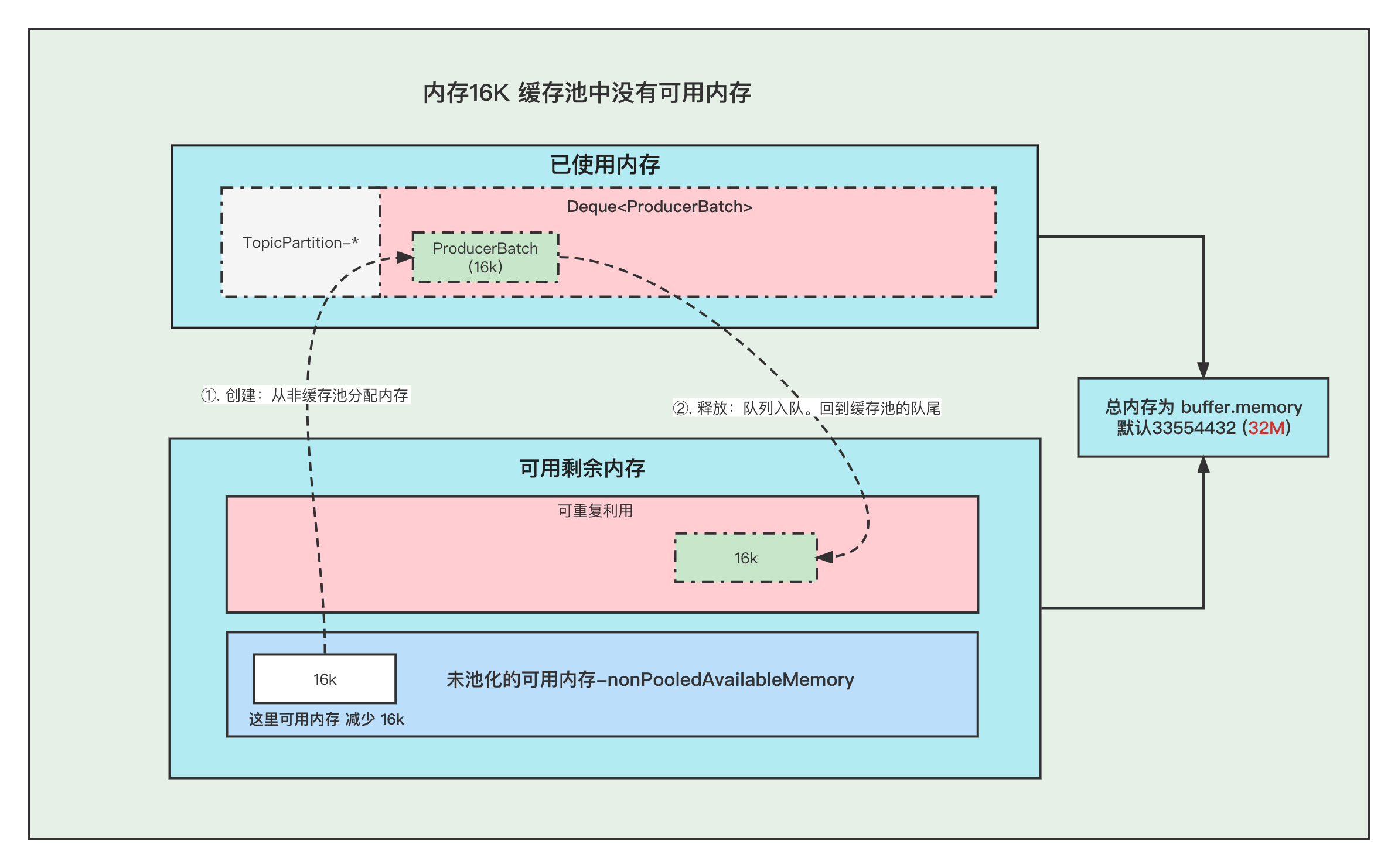 原文地址:图解Kafka Producer 消息缓存模型 **3. 内存非16K 非缓存池中内存够用** ①. 创建Batch的时候, 去非缓存池(nonPooledAvailableMemory)内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池(nonPooledAvailableMemory) 减少对应的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。 ②. 消息发送完成,释放Batch, 纯粹的是在非缓存池(nonPooledAvailableMemory)中加上刚刚释放的Batch内存大小。 当然这个Batch会被GC掉 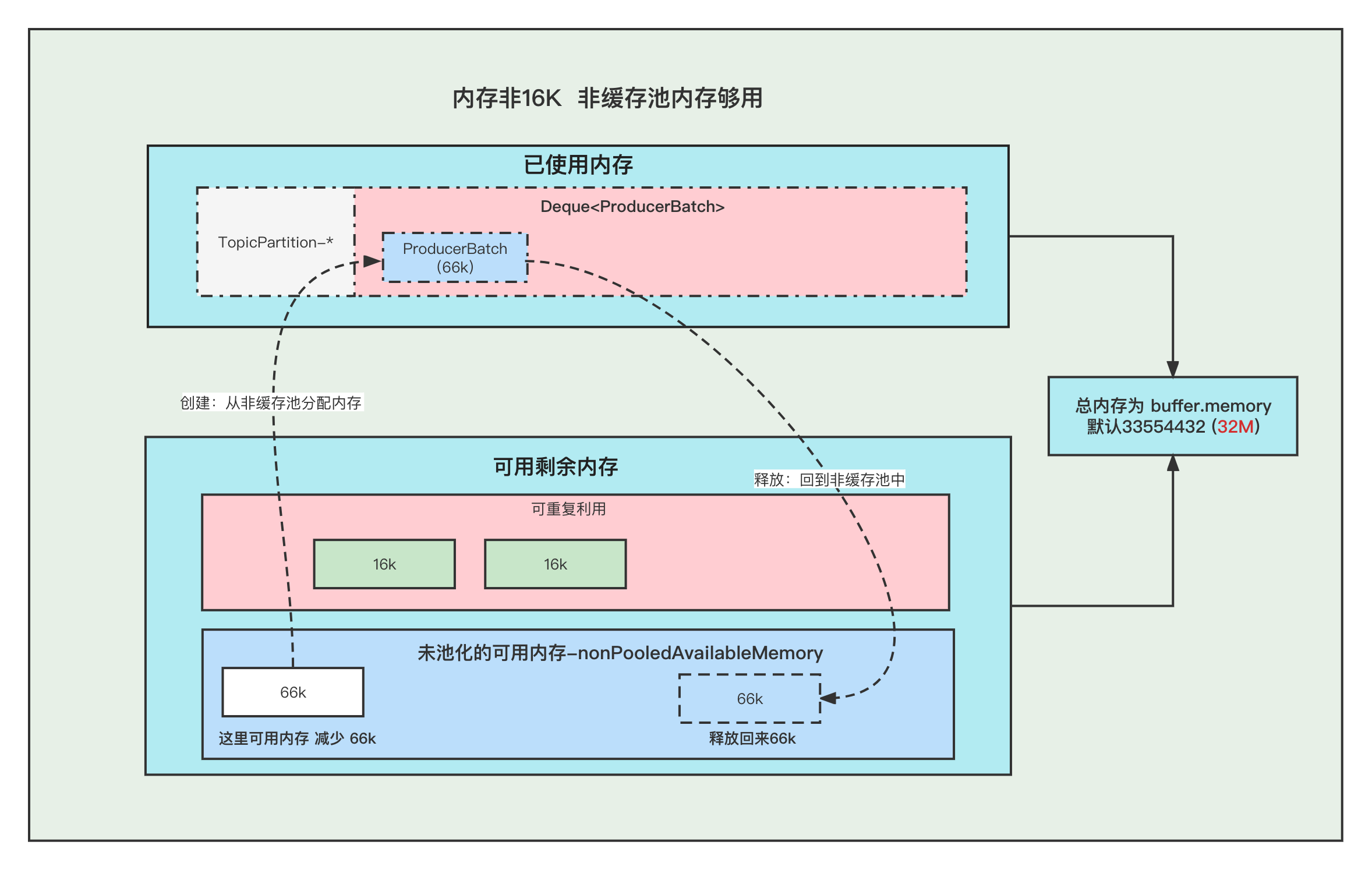 **4. 内存非16K 非缓存池内存不够用** ①. 先尝试将 缓存池中的内存一个一个释放到 非缓存池中, 直到非缓存池中的内存够用与创建Batch了 ②. 创建Batch的时候, 去非缓存池(nonPooledAvailableMemory)内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池(nonPooledAvailableMemory) 减少对应的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。 ③. 消息发送完成,释放Batch, 纯粹的是在非缓存池(nonPooledAvailableMemory)中加上刚刚释放的Batch内存大小。 当然这个Batch会被GC掉 例如: 下面我们需要创建 48k的batch, 因为超过了16k,所以需要在非缓存池中分配内存, 但是非缓存池中当前可用内存为0 , 分配不了, 这个时候就会尝试去 缓存池里面释放一部分内存到 非缓存池。 释放第一个ByteBuffer(16k) 不够,则继续释放第二个,直到释放了3个之后总共48k,发现内存这时候够了, 再去创建Batch。 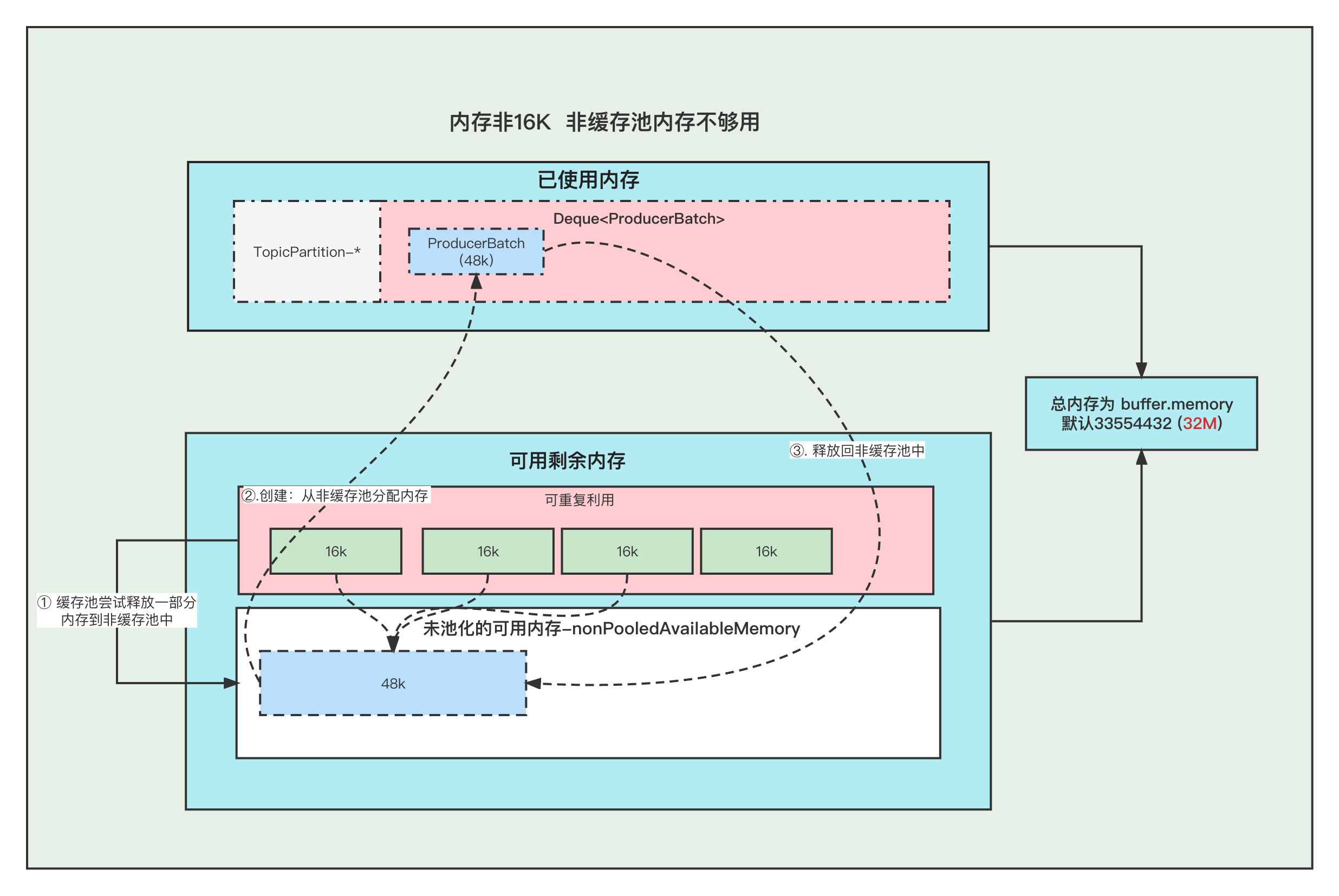 注意:这里我们涉及到的 非缓存池中的内存分配, 仅仅指的的内存数字的增加和减少。 # 问题和答案 >发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗? 当Broker挂掉了,Producer会提示下面的警告⚠️, 但是发送消息过程中 这个消息体还是可以写入到 消息缓存中的,也仅仅是写到到缓存中而已。 WARN [Producer clientId=console-producer] Connection to node 0 (/172.23.164.192:9090) could not be established. Broker may not be available  >当最新的ProducerBatch还有空余的内存,但是接下来的一条消息很大,不足以加上上一个Batch中,会怎么办呢? 那么会创建新的ProducerBatch。 >那么创建ProducerBatch的时候,应该分配多少的内存呢? 触发创建ProducerBatch的那条消息预估大小大于batch.size ,则以预估内存创建。 否则,以batch.size创建。 还有一个问题供大家思考: **当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了?**
本文分享自华为云社区《[图解Kafka Producer 消息缓存模型](https://bbs.huaweicloud.com/blogs/337169?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者:石臻臻的杂货铺。 在阅读本文之前, 希望你可以思考一下下面几个问题, 带着问题去阅读文章会获得更好的效果。 1. 发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗? 2. 当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了? 3. 当最新的ProducerBatch还有空余的内存,但是接下来的一条消息很大,不足以加上上一个Batch中,会怎么办呢? 4. 那么创建ProducerBatch的时候,应该分配多少的内存呢? # 什么是消息累加器RecordAccumulator kafka为了提高Producer客户端的发送吞吐量和提高性能,选择了将消息暂时缓存起来,等到满足一定的条件, 再进行批量发送, 这样可以减少网络请求,提高吞吐量。 而缓存这个消息的就是RecordAccumulator类。  上图就是整个消息存放的缓存模型,我们接下来一个个来讲解。 # 消息缓存模型  上图表示的就是 消息缓存的模型, 生产的消息就是暂时存放在这个里面。 1. 每条消息,我们按照TopicPartition维度,把他们放在不同的Deque 队列里面。 TopicPartition相同,会在相同Deque 的里面。 2. ProducerBatch : 表示同一个批次的消息, 消息真正发送到Broker端的时候都是按照批次来发送的, 这个批次可能包含一条或者多条消息。 3. 如果没有找到消息对应的ProducerBatch队列, 则创建一个队列。 4. 找到ProducerBatch队列队尾的Batch,发现Batch还可以塞下这条消息,则将消息直接塞到这个Batch中 5. 找到ProducerBatch队列队尾的Batch,发现Batch中剩余内存,不够塞下这条消息,则会创建新的Batch 6. 当消息发送成功之后, Batch会被释放掉。 **ProducerBatch的内存大小** >那么创建ProducerBatch的时候,应该分配多少的内存呢? 先说结论: 当消息预估内存大于batch.size的时候,则按照消息预估内存创建, 否则按照batch.size的大小创建(默认16k). 我们来看一段代码,这段代码就是在创建ProducerBatch的时候预估内存的大小 RecordAccumulator#append /** * 公众号: 石臻臻的杂货铺 * 微信:szzdzhp001 **/ // 找到 batch.size 和 这条消息在batch中的总内存大小的 最大值 int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers)); // 申请内存 buffer = free.allocate(size, maxTimeToBlock); 1. 假设当前生产了一条消息为M, 刚好消息M找不到可以存放消息的ProducerBatch(不存在或者满了),那么这个时候就需要创建一个新的ProducerBatch了 2. 预估消息的大小 跟batch.size 默认大小16384(16kb). 对比,取最大值用于申请的内存大小的值。 原文地址:图解Kafka Producer 消息缓存模型 >那么, 这个消息的预估是如何预估的?纯粹的是消息体的大小吗? DefaultRecordBatch#estimateBatchSizeUpperBound 预估需要的Batch大小,是一个预估值,因为没有考虑压缩算法从额外开销 /** * 使用给定的键和值获取只有一条记录的批次大小的上限。 * 这只是一个估计,因为它没有考虑使用的压缩算法的额外开销。 **/ static int estimateBatchSizeUpperBound(ByteBuffer key, ByteBuffer value, Header[] headers) { return RECORD_BATCH_OVERHEAD + DefaultRecord.recordSizeUpperBound(key, value, headers); } 1. 预估这个消息M的大小 + 一个RECORD_BATCH_OVERHEAD的大小 2. RECORD_BATCH_OVERHEAD是一个Batch里面的一些基本元信息,总共占用了 61B 3. 消息M的大小也并不是单单的只有消息体的大小,总大小=(key,value,headers)的大小+MAX_RECORD_OVERHEAD 4. MAX_RECORD_OVERHEAD :一条消息头最大占用空间, 最大值为21B 也就是说创建一个ProducerBatch,最少就要83B . 比如我发送一条消息 " 1 " , 预估得到的大小是 86B, 跟batch.size(默认16384) 相比取最大值。 那么申请内存的时候取最大值 16384 。 关于Batch的结构和消息的结构,我们回头**单独用一篇文章来讲解**。 # 内存分配 我们都知道RecordAccumulator里面的缓存大小是一开始定义好的, 由buffer.memory控制, 默认33554432 (32M) 当生产的速度大于发送速度的时候,就可能出现Producer写入阻塞。 而且频繁的创建和释放ProducerBatch,会导致频繁GC, 所有kafka中有个缓存池的概念,这个缓存池会被重复使用,但是只有固定( batch.size)的大小才能够使用缓存池。 **PS:以下16k指得是 batch.size的默认值.** 原文地址:图解Kafka Producer 消息缓存模型 **Batch的创建和释放** **1. 内存16K 缓存池中有可用内存** ①. 创建Batch的时候, 会去缓存池中,获取队首的一块内存ByteBuffer 使用。 ②. 消息发送完成,释放Batch, 则会把这个ByteBuffer,放到缓存池的队尾中,并且调用ByteBuffer.clear 清空数据。以便下次重复使用  **2. 内存16K 缓存池中无可用内存** ①. 创建Batch的时候, 去非缓存池中的内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池nonPooledAvailableMemory 减少 16K 的内存, 然后Batch正常创建就行了, **不要误以为好像真的发生了内存的转移**。 ②. 消息发送完成,释放Batch, 则会把这个ByteBuffer,放到缓存池的队尾中,并且调用ByteBuffer.clear 清空数据, 以便下次重复使用  原文地址:图解Kafka Producer 消息缓存模型 **3. 内存非16K 非缓存池中内存够用** ①. 创建Batch的时候, 去非缓存池(nonPooledAvailableMemory)内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池(nonPooledAvailableMemory) 减少对应的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。 ②. 消息发送完成,释放Batch, 纯粹的是在非缓存池(nonPooledAvailableMemory)中加上刚刚释放的Batch内存大小。 当然这个Batch会被GC掉  **4. 内存非16K 非缓存池内存不够用** ①. 先尝试将 缓存池中的内存一个一个释放到 非缓存池中, 直到非缓存池中的内存够用与创建Batch了 ②. 创建Batch的时候, 去非缓存池(nonPooledAvailableMemory)内存获取一部分内存用于创建Batch. 注意:这里说的获取内存给Batch, 其实就是让 非缓存池(nonPooledAvailableMemory) 减少对应的内存, 然后Batch正常创建就行了, 不要误以为好像真的发生了内存的转移。 ③. 消息发送完成,释放Batch, 纯粹的是在非缓存池(nonPooledAvailableMemory)中加上刚刚释放的Batch内存大小。 当然这个Batch会被GC掉 例如: 下面我们需要创建 48k的batch, 因为超过了16k,所以需要在非缓存池中分配内存, 但是非缓存池中当前可用内存为0 , 分配不了, 这个时候就会尝试去 缓存池里面释放一部分内存到 非缓存池。 释放第一个ByteBuffer(16k) 不够,则继续释放第二个,直到释放了3个之后总共48k,发现内存这时候够了, 再去创建Batch。  注意:这里我们涉及到的 非缓存池中的内存分配, 仅仅指的的内存数字的增加和减少。 # 问题和答案 >发送消息的时候, 当Broker挂掉了,消息体还能写入到消息缓存中吗? 当Broker挂掉了,Producer会提示下面的警告⚠️, 但是发送消息过程中 这个消息体还是可以写入到 消息缓存中的,也仅仅是写到到缓存中而已。 WARN [Producer clientId=console-producer] Connection to node 0 (/172.23.164.192:9090) could not be established. Broker may not be available  >当最新的ProducerBatch还有空余的内存,但是接下来的一条消息很大,不足以加上上一个Batch中,会怎么办呢? 那么会创建新的ProducerBatch。 >那么创建ProducerBatch的时候,应该分配多少的内存呢? 触发创建ProducerBatch的那条消息预估大小大于batch.size ,则以预估内存创建。 否则,以batch.size创建。 还有一个问题供大家思考: **当消息还存储在缓存中的时候, 假如Producer客户端挂掉了,消息是不是就丢失了?** -
迁移概述背景介绍在国产替代的大背景下,鲲鹏计算平台是一个非常有潜力的产业。为了解决开发者将应用从x86平台向鲲鹏平台移植的过程中遇到的一系列的痛点问题(例如:分析过程投入工作量大,周期长,需反复试错定位,准确率也低下,而且要求移植人员专业技能高等),推出了鲲鹏代码迁移工具(Porting Advisor),帮助开发者加速将x86环境下的应用迁移至鲲鹏平台。本文总结了鲲鹏代码迁移工具(Porting Advisor)的软件包分析和重构的实际使用经验,期望能帮助开发者了解如何使用工具,提高开发者的软件迁移效率。鲲鹏代码迁移工具介绍鲲鹏代码迁移工具(Porting Advisor)支持如下六大功能:分析软件安装包扫描x86平台软件安装包,识别安装包对系统SO的依赖和包内部的SO、JAR依赖,支持的软件安装包格式包括RPM、DEB、JAR、WAR、ZIP、TAR、GZIP。该功能位于工具一级菜单“软件迁移评估”下,工具安装在x86环境和鲲鹏环境下时均可用。分析已安装软件扫描x86环境中用户已安装的软件,识别已安装软件的SO、JAR依赖关系。该功能位于工具一级菜单“软件迁移评估”下,仅当工具安装在x86环境下时可用。分析源代码扫描x86平台软件的C/C++/Fortran/汇编源代码,识别源代码中的SO依赖关系,扫描需要修改的代码行并给出修改建议,根据系统设定的代码修改效率,给出评估的工作量,供领导层进行项目决策。该功能位于工具一级菜单“源码迁移”下,工具安装在x86环境和鲲鹏环境下时均可用。软件包重构对用户提供的x86平台RPM包、DEB包中x86平台相关的so文件、jar包进行替换,重构输出可用于鲲鹏平台的RPM包、DEB包。重构期间需要的鲲鹏版本的so文件、jar包需要用户通过依赖包上传功能在重构任务创建过程中上传。如果这些文件是可以直接从华为云镜像源下载的,并且用户安装鲲鹏代码迁移工具的服务器可联网,则用户创建重构任务时可以授权工具重构期间连接到华为云镜像源进行自动下载。该功能位于工具一级菜单“软件包重构”下,仅当工具安装在鲲鹏环境下时可用。专项软件迁移一级菜单“专项软件功能”下,针对已经完成迁移的部分BoostKit组件,用户可以通过专项软件迁移功能进行重复迁移。迁移过程中的每个执行步骤都是可视的,用户可根据自己的需求定制由工具执行其中的某些步骤而自己手工执行另外一些步骤,从而达到对这些组件的定制化的目的。该功能仅当工具安装在鲲鹏环境下时可用。增强功能一级菜单“增强功能”下提供了64位代码迁移预检、字节对齐检查、弱内存序检查修复三项子功能。64位代码迁移预检功能针对32位老旧代码执行检查动作,从编译器层面识别编译出64位应用时代码中存在的修改点,该功能仅当工具安装在x86环境下时可用。字节对齐检查功能辅助用户检查应用从32位模式改为64位模式时,数据结构定义方面的变化,以便用户优化代码,该功能仅当工具安装在x86环境下时可用。弱内存序检查修复则提供了编译器自动修复工具和静态检查工具两个选项,分别供用户在GCC编译以及工具运行两种模式下使用以修复ARM架构下独有的应用弱内存序问题,该功能仅当工具安装在鲲鹏环境下时可用。环境要求根据各功能的平台依赖性,需要准备如表 鲲鹏平台环境所示的环境。表1 鲲鹏平台环境项目说明服务器TaiShan 200 2280 服务器(等同于其它基于鲲鹏916或者鲲鹏920的服务器)CPU鲲鹏920 96核处理器OSCentOS 7.6安装的工具Porting Advisor 2.2.T3可使用场景分析软件安装包分析源代码软件包重构专项软件迁移弱内存序检查修复前提条件服务器和操作系统正常运行。PC端已经安装SSH远程登录工具。Porting Advisor已在准备好的x86平台环境和鲲鹏平台环境中完成安装并正常运行。待迁移的相关软件包、源代码已准备就绪。迁移计划本文将总结演示重构开源软件atlas软件包kafka-2.4.1-1.el7.noarch.rpm。说明:本次重构动作和验证动作均可通过鲲鹏平台环境完成。重构开源软件atlas软件包kafka-2.4.1-1.el7.noarch.rpm的步骤演示,将有助于读者了解在有x86平台rpm包、deb包需要修改重构为鲲鹏平台的包时,如何才能完成这个迁移过程。将利用Porting Advisor的软件安装包分析功能对获取到的kafka-2.4.1-1.el7.noarch.rpm进行扫描,获取其依赖关系和可迁移性分析结果。根据Porting Advisor的软件安装包分析功能分析得到的kafka-2.4.1-1.el7.noarch.rpm依赖关系去准备重构为鲲鹏平台RPM包时需要的SO库和JAR包。利用准备好的资源包和RPM包,通过Porting Advisor的软件包重构功能,完成鲲鹏版本kafka-2.4.1-1.el7的RPM包重构工作。针对重构得到的鲲鹏版本kafka-2.4.1-1.el7的RPM包进行简单的验证。重构开源软件atlas软件包操作步骤从https://ci.bigtop.apache.org/view/Releases/job/Bigtop-3.0.0/DISTRO=centos-7,PLATFORM=amd64-slave/lastSuccessfulBuild/artifact/output/kafka/noarch/下载获取待使用的rpm包,如图 kafka-2.4.1-1.el7.noarch.rpm所示。 图1 kafka-2.4.1-1.el7.noarch.rpm双击“kafka-2.4.1-1.el7.noarch.rpm”即可获取本例中所需要的软件包。利用Porting Advisor的分析软件包功能完成对该包的扫描分析。勾选“分析软件包”,单击“上传”,上传前面下载到的kafka-2.4.1-1.el7.noarch.rpm,并点中输入框,选择安装包存放路径为/opt/portadv/portadmin/package/kafka-2.4.1-1.el7.noarch.rpm,如图 Porting Advisor所示。 图2 Porting Advisor 4. 单击“开始分析”,进行分析并得到扫描分析报告,如图 扫描分析报告所示。 图3 扫描分析报告 准备依赖库从图 扫描分析报告1和图 扫描分析报告2提供的依赖库信息看,所依赖的包中,有2个是安装过程中需要的可执行文件,有3个是被扫描的rpm包内包含的jar包。报告中针对rpm包内包含的jar包提供了华为鲲鹏产品官方maven仓库中的下载链接,直接点击下载即可。 图4 扫描分析报告1 图5 扫描分析报告2 重构软件包操作步骤打开软件包重构功能页面后,通过“上传”按钮将待重构的RPM包kafka-2.4.1-1.el7.noarch.rpm上传到服务器,如图 选择待重构软件包所示。 图6 选择待重构软件包 2. 单击“下一步”,进入“配置依赖文件”步骤,选择手工上传依赖文件、勾选“授权访问外部网络获取重构软件包需要的依赖文件”以允许工具在重构过程中自动连接到各OS发行版的 官方网站或者鲲鹏Maven仓库在华为云镜像源上的下载地址下载需要的依赖文件,如图 配置依赖文件所示。 图7 配置依赖文件 3. 单击“下一步”,进入“执行重构”步骤,这里需要再进行最后一次确认才能开始重构操作,如图 重构任务执行中所示。 图1 重构任务执行中 注意: 如果在执行本步骤操作前,服务器上没有安装rpmrebuild,则会遇到如图 rpmrebuild未安装所示的报错。此时用户需要自行下载rpmrebuild安装包,在工具所在安装服务器上安装该 组件,然后重试重构动作。 4. 重构成功后,单击“下载重构软件包”按钮即可下载重构好的软件包atlas-metadata_3_1_0_0_78-1.1.0.3.1.0.0-78.aarch64.rpm,如图7 下载重构软件包所示。 图1 下载重构软件包 也可以在关闭重构结果窗口后,从历史记录中下载重构结果。验证重构后RPM包kafka安装包在鲲鹏环境安装时,需要依赖bigtop-utils、zookeeper等包,读者在执行本章节验证前,需完成环境搭建工作,在相关的环境依赖具备条件下,kafka的安装只需要通过最普通的RPM包安装命令(rpm –ivh xx.rpm)即可完成。本节重点介绍环境搭建后如何进行功能验证。安装kafka 切换到终端工具 执行以下命令:cd /opt/portadv/portadmin/data/20220310175550/ 说明:此路径可以从第4步重构成功后的右下角弹窗中显示的软件包存放路径获取。 rpm –ivh kafka-2.4.1-1.el7.noarch.rpm 启动zookeeper 执行以下命令启动zookeeper: cd /usr/local/zookeeper/bin ./zkServer.sh start 功能验证 命令行方式创建一个主题 cd /usr/lib/kafka/bin kafka-topics.sh --zookeeper localhost:2181 --create --topic sandbox-experiment -partitions 2 --replication-factor 1 启动消费者服务 kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic sandbox-experiment 启动生产者服务 kafka-console-producer.sh --broker-list localhost:9092 –topic sandbox-experiment 并发送消息“beginning hello kafka” 消费者服务收到消息 证明重构后的kafka-2.4.1-1.el7.noarch.rpm软件包,在鲲鹏服务器上课正常安装使用。 -----结束
-
 数据复制服务(DRS)是一种易用、稳定、高效、用于数据同步的云服务,本节小课为您介绍,如何通过DRS将RDS for MySQL实例的增量数据同步到分布式消息服务Kafka。使用场景DRS实时同步功能一般用于建立数据同步通道,解决数据共享问题,也可以用于数据流式集成,具有数据转换能力,如库表映射,行列过滤等。本实践中的选择均为测试简化基本操作,仅做参考,实际情况请用户按业务场景选择,更多关于DRS的使用场景请单击这里了解。部署架构本示例中,DRS源数据库为华为云RDS for MySQL,目标端为华为云同Region下的分布式消息服务Kafka,通过VPC网络,将源数据库的增量数据同步到目标端。更多关于DRS的使用场景请单击这里了解。源端RDS for MySQL准备创建RDS for MySQL实例如何创建RDS for MySQL实例,请点击这里查看详细步骤。构造数据1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。4. 选择RDS实例,单击实例后的“更多 > 登录”。5. 在弹出的对话框中单击“测试连接”检查。6. 连接成功后单击“登录”。7. 输入实例密码,登录RDS实例。8. 单击“新建数据库”,创建db_test测试库。9. 在db_test库中执行如下语句,创建对应的测试表table3_。CREATE TABLE `db_test`.`table3_` ( `Column1` INT(11) UNSIGNED NOT NULL, `Column2` TIME NULL, `Column3` CHAR NULL, PRIMARY KEY (`Column1`) ) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci;目标端Kafka准备创建Kafka实例1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“应用中间件 > 分布式消息服务Kafka版”。4. 单击“购买Kafka实例”。5. 选择实例区域和可用区。6. 配置实例名称和实例规格等信息。7. 选择存储空间和容量阈值策略。8. 选择实例所属的VPC和安全组。VPC和安全组已在创建VPC和安全组中准备好。9. 配置实例密码。10. 单击“立即购买”。11. 返回实例列表。当Kafka实例运行状态为“运行中”时,表示实例创建完成。创建Topic1. 在“Kafka专享版”页面,单击Kafka实例的名称。2. 选择“Topic管理”页签,单击“创建Topic”。3. 在弹出的“创建Topic”的对话框中,填写Topic名称和配置信息,单击“确定”,完成创建Topic。创建DRS同步任务本章节介绍创建DRS实例,将RDS for MySQL上的数据库增量同步到Kafka。同步前检查在创建任务前,需要针对同步条件进行手工自检,以确保您的同步任务更加顺畅。本示例中,为RDS for MySQL到Kafka的出云同步,您可以参考出云同步使用须知获取相关信息。操作步骤介绍RDS for MySQL到Kafka增量同步任务的详细操作过程。1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“数据库 > 数据复制服务 DRS”。4. 选择左侧“实时同步管理”,单击“创建同步任务”。5. 填写同步任务参数:配置同步任务名称。选择需要同步任务的源库、目标数据库以及网络信息。这里的目标库选择源端RDS for MySQL准备创建的RDS实例。企业项目选择“default”。 6. 单击“下一步”。同步实例创建中,大约需要5-10分钟。7. 配置源库信息和目标库数据库密码。配置源库信息。单击“测试连接”。当界面显示“测试成功”时表示连接成功。 选择目标库所在VPC和子网,填写Kafka的IP地址和端口。单击“测试连接”。当界面显示“测试成功”时表示连接成功。 8. 单击“下一步”。9. 选择同步信息、策略、消息格式和对象等,投递到Kafka的消息格式。本次选择如下。表1 同步设置类别设置同步Topic策略集中投递到一个Topic,Topic名称“testTopic”。同步到Kafka partition策略按表名+库名的hash值投递到不同Partition。投递到Kafka的数据格式可选择JSON格式,可参考Kafka消息格式。同步对象同步对象选择db_test下的table3_表。10.单击“下一步”。11. 选择数据加工方式。RDS for MySQL到Kafka数据同步目前只支持列加工,列加工提供列级的查询和过滤能力。12. 单击“下一步”,等待预检查结果。13. 当所有检查都是“通过”时,单击"下一步”。14. 确认同步任务信息正确后,单击“启动任务”。返回DRS实时同步管理,查看同步任务状态。启动中状态一般需要几分钟,请耐心等待。当状态变更为“增量同步”,表示同步任务已启动。说明:目前RDS for MySQL到Kafka仅支持增量同步,任务启动后为增量同步状态。如果创建的任务为全量同步,任务启动后进行全量数据同步,数据同步完成后任务自动结束。如果创建的任务为全量+增量同步,任务启动后先进入全量同步,全量数据同步完成后进入增量同步状态。增量同步会持续性同步增量数据,不会自动结束。确认同步任务执行结果由于本次实践为增量同步模式,DRS任务会将源库的产生的增量数据持续同步至目标库中,直到手动任务结束。下面我们通过在源库RDS for MySQL中插入数据,查看Kafka的接收到的数据来验证同步结果。操作步骤1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS””。4. 单击RDS实例后的“更多 > 登录”。5. 在弹出的对话框中单击“测试连接”检查。6. 连接成功后单击“登录”。7. 输入实例密码,登录RDS实例。8. 在DRS同步对象的db_test.table3_表中,执行如下语句,插入数据。INSERT INTO `db_test`.`table3_` (`Column1`,`Column2`,`Column3`) VALUES(4,'00:00:44','ddd');9. 单击左侧的服务列表图标,选择“应用中间件 > 分布式消息服务Kafka版”。10. 在“Kafka专享版”页面,单击Kafka实例的名称。11. 选择“消息查询”页签,在Kafka对应的Topic中,查看接收到相应的JSON格式数据。12. 结束同步任务。根据业务情况,确认数据已全部同步至目标库,可以结束当前任务。单击“操作”列的“结束”。仔细阅读提示后,单击“是”,结束任务。
数据复制服务(DRS)是一种易用、稳定、高效、用于数据同步的云服务,本节小课为您介绍,如何通过DRS将RDS for MySQL实例的增量数据同步到分布式消息服务Kafka。使用场景DRS实时同步功能一般用于建立数据同步通道,解决数据共享问题,也可以用于数据流式集成,具有数据转换能力,如库表映射,行列过滤等。本实践中的选择均为测试简化基本操作,仅做参考,实际情况请用户按业务场景选择,更多关于DRS的使用场景请单击这里了解。部署架构本示例中,DRS源数据库为华为云RDS for MySQL,目标端为华为云同Region下的分布式消息服务Kafka,通过VPC网络,将源数据库的增量数据同步到目标端。更多关于DRS的使用场景请单击这里了解。源端RDS for MySQL准备创建RDS for MySQL实例如何创建RDS for MySQL实例,请点击这里查看详细步骤。构造数据1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS”。4. 选择RDS实例,单击实例后的“更多 > 登录”。5. 在弹出的对话框中单击“测试连接”检查。6. 连接成功后单击“登录”。7. 输入实例密码,登录RDS实例。8. 单击“新建数据库”,创建db_test测试库。9. 在db_test库中执行如下语句,创建对应的测试表table3_。CREATE TABLE `db_test`.`table3_` ( `Column1` INT(11) UNSIGNED NOT NULL, `Column2` TIME NULL, `Column3` CHAR NULL, PRIMARY KEY (`Column1`) ) ENGINE = InnoDB DEFAULT CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci;目标端Kafka准备创建Kafka实例1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“应用中间件 > 分布式消息服务Kafka版”。4. 单击“购买Kafka实例”。5. 选择实例区域和可用区。6. 配置实例名称和实例规格等信息。7. 选择存储空间和容量阈值策略。8. 选择实例所属的VPC和安全组。VPC和安全组已在创建VPC和安全组中准备好。9. 配置实例密码。10. 单击“立即购买”。11. 返回实例列表。当Kafka实例运行状态为“运行中”时,表示实例创建完成。创建Topic1. 在“Kafka专享版”页面,单击Kafka实例的名称。2. 选择“Topic管理”页签,单击“创建Topic”。3. 在弹出的“创建Topic”的对话框中,填写Topic名称和配置信息,单击“确定”,完成创建Topic。创建DRS同步任务本章节介绍创建DRS实例,将RDS for MySQL上的数据库增量同步到Kafka。同步前检查在创建任务前,需要针对同步条件进行手工自检,以确保您的同步任务更加顺畅。本示例中,为RDS for MySQL到Kafka的出云同步,您可以参考出云同步使用须知获取相关信息。操作步骤介绍RDS for MySQL到Kafka增量同步任务的详细操作过程。1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“数据库 > 数据复制服务 DRS”。4. 选择左侧“实时同步管理”,单击“创建同步任务”。5. 填写同步任务参数:配置同步任务名称。选择需要同步任务的源库、目标数据库以及网络信息。这里的目标库选择源端RDS for MySQL准备创建的RDS实例。企业项目选择“default”。 6. 单击“下一步”。同步实例创建中,大约需要5-10分钟。7. 配置源库信息和目标库数据库密码。配置源库信息。单击“测试连接”。当界面显示“测试成功”时表示连接成功。 选择目标库所在VPC和子网,填写Kafka的IP地址和端口。单击“测试连接”。当界面显示“测试成功”时表示连接成功。 8. 单击“下一步”。9. 选择同步信息、策略、消息格式和对象等,投递到Kafka的消息格式。本次选择如下。表1 同步设置类别设置同步Topic策略集中投递到一个Topic,Topic名称“testTopic”。同步到Kafka partition策略按表名+库名的hash值投递到不同Partition。投递到Kafka的数据格式可选择JSON格式,可参考Kafka消息格式。同步对象同步对象选择db_test下的table3_表。10.单击“下一步”。11. 选择数据加工方式。RDS for MySQL到Kafka数据同步目前只支持列加工,列加工提供列级的查询和过滤能力。12. 单击“下一步”,等待预检查结果。13. 当所有检查都是“通过”时,单击"下一步”。14. 确认同步任务信息正确后,单击“启动任务”。返回DRS实时同步管理,查看同步任务状态。启动中状态一般需要几分钟,请耐心等待。当状态变更为“增量同步”,表示同步任务已启动。说明:目前RDS for MySQL到Kafka仅支持增量同步,任务启动后为增量同步状态。如果创建的任务为全量同步,任务启动后进行全量数据同步,数据同步完成后任务自动结束。如果创建的任务为全量+增量同步,任务启动后先进入全量同步,全量数据同步完成后进入增量同步状态。增量同步会持续性同步增量数据,不会自动结束。确认同步任务执行结果由于本次实践为增量同步模式,DRS任务会将源库的产生的增量数据持续同步至目标库中,直到手动任务结束。下面我们通过在源库RDS for MySQL中插入数据,查看Kafka的接收到的数据来验证同步结果。操作步骤1. 登录华为云控制台。2. 单击管理控制台左上角的,选择区域“华南-广州”。3. 单击左侧的服务列表图标,选择“数据库 > 云数据库 RDS””。4. 单击RDS实例后的“更多 > 登录”。5. 在弹出的对话框中单击“测试连接”检查。6. 连接成功后单击“登录”。7. 输入实例密码,登录RDS实例。8. 在DRS同步对象的db_test.table3_表中,执行如下语句,插入数据。INSERT INTO `db_test`.`table3_` (`Column1`,`Column2`,`Column3`) VALUES(4,'00:00:44','ddd');9. 单击左侧的服务列表图标,选择“应用中间件 > 分布式消息服务Kafka版”。10. 在“Kafka专享版”页面,单击Kafka实例的名称。11. 选择“消息查询”页签,在Kafka对应的Topic中,查看接收到相应的JSON格式数据。12. 结束同步任务。根据业务情况,确认数据已全部同步至目标库,可以结束当前任务。单击“操作”列的“结束”。仔细阅读提示后,单击“是”,结束任务。 -
-
【功能模块】创建CDL作业-MySQL--kafka,任务可以成功运行,且能够监控MySQL新增的数据,生产到Kafka中【操作步骤&问题现象】问题一、①MySQL中insert的时间类型的数据是2021-01-01 00:00:00②生产到Kafak的对应字段的数据变成了2020-12-31T16:00:00Z,时间出现了晚一天现象问题二、①在创建CDL作业的时候,Mysql的配置信息,Schema Auto Create我选择了否②然后消费kafka的数据发现还有大量的Schema信息被生产到Kafka中,希望的是不需要额外大量没有用处的信息
-
 # 华为FusionInsight MRS实战 - FlinkSQL从kafka写入hive ## 背景说明 随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂,开发者可能是资深的大数据从业者、初学 Java 的爱好者,或是不懂代码的数据分析者。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。 SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎,致力于提供一套 SQL 支持全部应用场景,Flink SQL 的实现也完全遵循 ANSI SQL 标准。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。 本文介绍如何使用华为FusionInsight MRS FlinkServer服务进行界面化的FlinkSQL编辑,从而处理复杂的嵌套Json格式 ## Kafka样例数据 模拟物联网场景的数据 ``` {"device":"Demo1","signal":"60","life":"24","times":"2021-12-20 15:46:37"} {"device":"Demo2","signal":"78","life":"20","times":"2021-12-20 15:46:37"} {"device":"Demo3","signal":"41","life":"6","times":"2021-12-20 15:46:38"} {"device":"Demo4","signal":"71","life":"29","times":"2021-12-20 15:46:38"} {"device":"Demo5","signal":"38","life":"19","times":"2021-12-20 15:46:38"} {"device":"Demo6","signal":"98","life":"10","times":"2021-12-20 15:46:38"} {"device":"Demo7","signal":"80","life":"19","times":"2021-12-20 15:46:38"} {"device":"Demo8","signal":"55","life":"27","times":"2021-12-20 15:46:38"} {"device":"Demo9","signal":"93","life":"13","times":"2021-12-20 15:46:38"} {"device":"Demo10","signal":"46","life":"2","times":"2021-12-20 15:46:38"} {"device":"Demo11","signal":"94","life":"28","times":"2021-12-20 15:46:38"} {"device":"Demo12","signal":"24","life":"26","times":"2021-12-20 15:46:38"} {"device":"Demo13","signal":"64","life":"3","times":"2021-12-20 15:46:38"} {"device":"Demo14","signal":"97","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo15","signal":"82","life":"13","times":"2021-12-20 15:46:38"} {"device":"Demo16","signal":"2","life":"2","times":"2021-12-20 15:46:38"} {"device":"Demo17","signal":"19","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo18","signal":"51","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo19","signal":"1","life":"20","times":"2021-12-20 15:46:38"} {"device":"Demo20","signal":"41","life":"24","times":"2021-12-20 15:46:38"} ``` ## 使用华为MRS Flinkserver对接Hive ### 前提条件 - 集群已安装HDFS、Yarn、Kafka、Flink和Hive等服务。 - 包含Hive服务的客户端已安装,安装路径如:/opt/client。 - Flink支持1.12.2及以上版本,Hive支持3.1.0及以上版本。 - 参考基于用户和角色的鉴权创建一个具有“FlinkServer管理操作权限”的用户用于访问Flink WebUI的用户。  - 参考创建集群连接中的“说明”获取访问Flink WebUI用户的客户端配置文件及用户凭据。 ### 操作步骤 以映射表类型为Kafka对接Hive流程为例。 1. 使用flink_admin访问Flink WebUI,请参考访问Flink WebUI。 2. 新建集群连接,如:flink_hive。 a. 选择“系统管理 > 集群连接管理”,进入集群连接管理页面。 b. 单击“创集集群连接”,在弹出的页面中参考表1填写信息,单击“测试”,测试连接成功后单击“确定”,完成集群连接创建。 表1 创建集群连接信息 | 参数名称 | 参数描述 | 取值样例 | | ---- | ---- | ---- | |集群连接名称|集群连接的名称,只能包含英文字母、数字和下划线,且不能多于100个字符。|flink_hive| |描述|集群连接名称描述信息。|-| |版本|选择集群版本。|MRS 3| |是否安全版本|是,安全集群选择是。需要输入访问用户名和上传用户凭证; 否,非安全集群选择否。|是| |访问用户名|访问用户需要包含访问集群中服务所需要的最小权限。只能包含英文字母、数字和下划线,且不能多于100个字符。“是否安全版本”选择“是”时存在此参数。|flink_admin| |客户端配置文件|集群客户端配置文件,格式为tar。|-| |用户凭据|FusionInsight Manager中用户的认证凭据,格式为tar。“是否安全版本”选择“是”时存在此参数。输入访问用户名后才可上传文件。|flink_admin的用户凭|  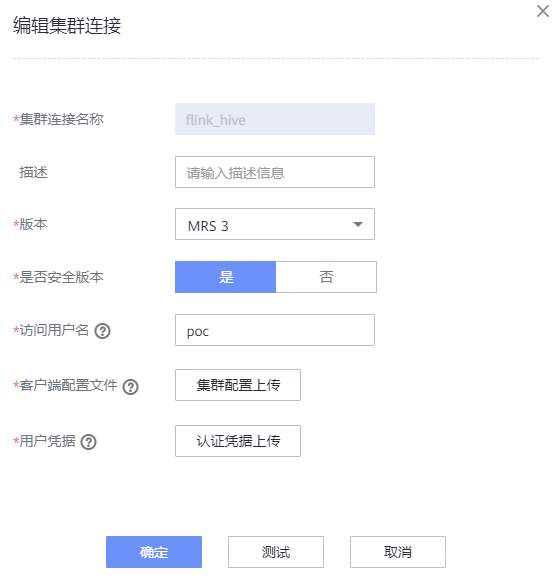 3. 新建Flink SQL流作业,如:kafka_to_hive。 在作业开发界面进行作业开发,输入如下语句,可以单击上方“语义校验”对输入内容校验。 ``` CREATE TABLE test_kafka ( device varchar, signal varchar, life varchar, times timestamp ) WITH ( 'properties.bootstrap.servers' = '172.16.9.116:21007', 'format' = 'json', 'topic' = 'example-metric1', 'connector' = 'kafka', 'scan.startup.mode' = 'latest-offset', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE CATALOG myhive WITH ( 'type' = 'hive', 'hive-version' = '3.1.0', 'default-database' = 'default', 'cluster.name' = 'flink_hive' ); use catalog myhive; set table.sql-dialect = hive;create table test_avro_signal_table_orc ( device STRING, signal STRING, life STRING, ts timestamp ) PARTITIONED BY (dy STRING, ho STRING, mi STRING) stored as orc TBLPROPERTIES ( 'partition.time-extractor.timestamp-pattern' = '$dy $ho:$mi:00', 'sink.partition-commit.trigger' = 'process-time', 'sink.partition-commit.delay' = '0S', 'sink.partition-commit.policy.kind' = 'metastore,success-file' ); INSERT into test_avro_signal_table_orc SELECT device, signal, life, times, DATE_FORMAT(times, 'yyyy-MM-dd'), DATE_FORMAT(times, 'HH'), DATE_FORMAT(times, 'mm') FROM default_catalog.default_database.test_kafka; ```  注意:作业SQL开发完成后,请勾选“运行参数”中的“开启CheckPoint”,“时间间隔(ms)”可设置为“60000”,“模式”可使用默认值。 4. 启动任务  5. 启动kafka生产者插入样例数据 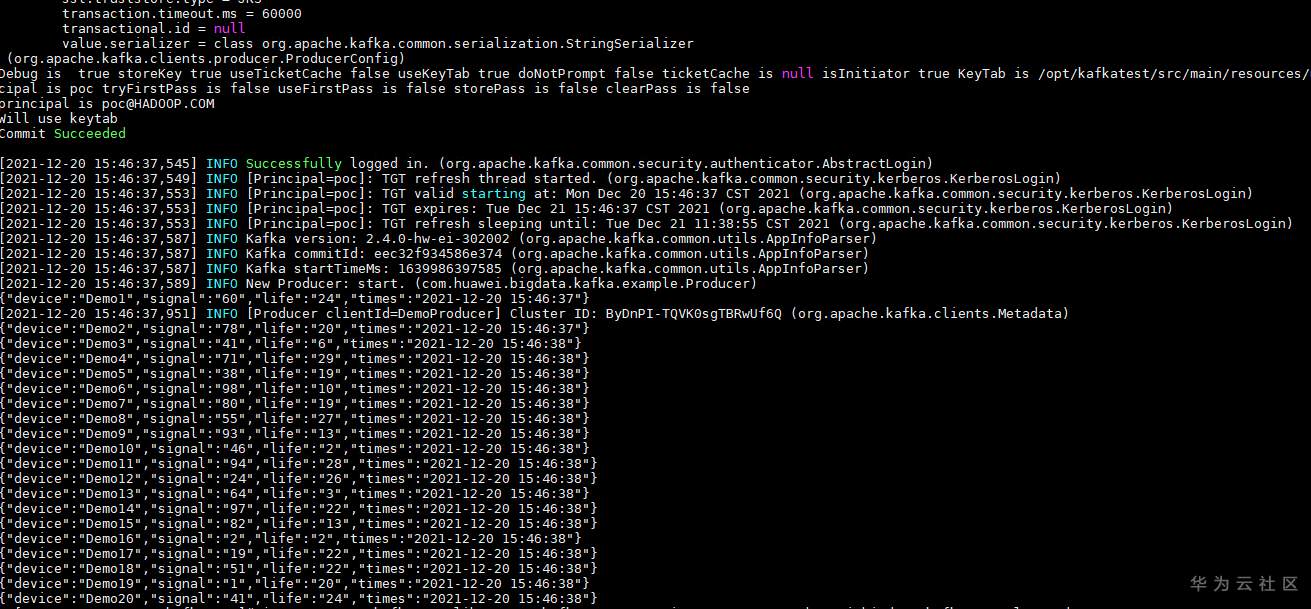 6. 查看hive数据 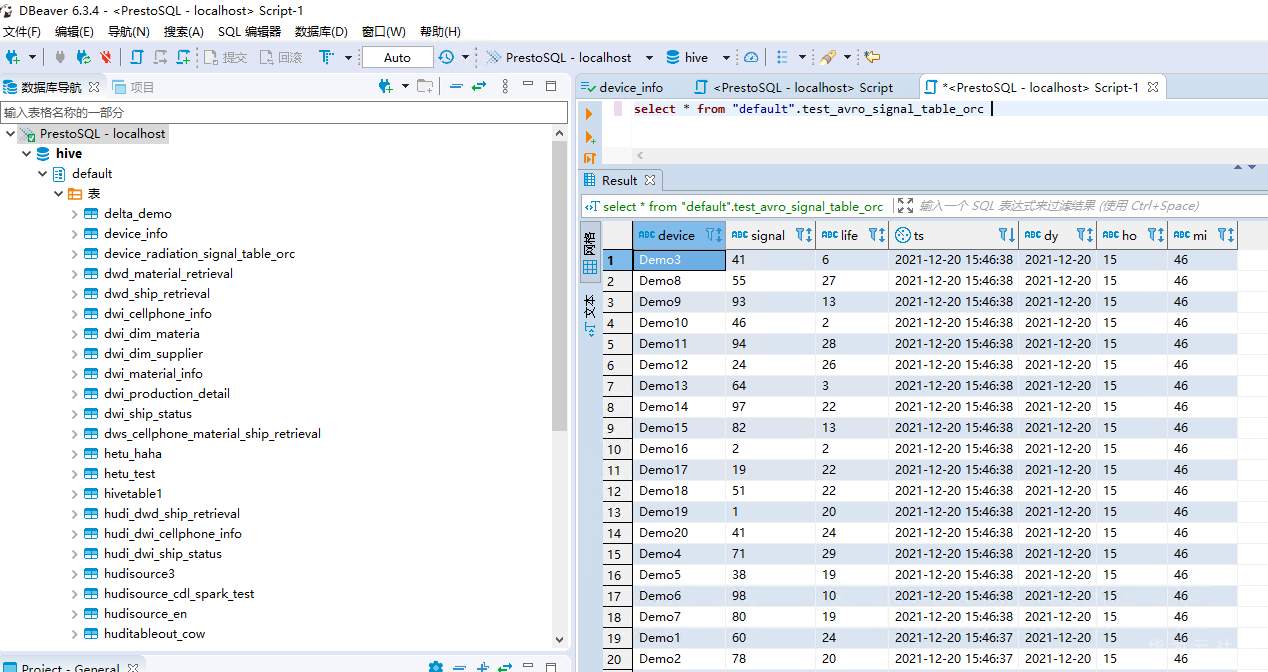
# 华为FusionInsight MRS实战 - FlinkSQL从kafka写入hive ## 背景说明 随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂,开发者可能是资深的大数据从业者、初学 Java 的爱好者,或是不懂代码的数据分析者。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。 SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎,致力于提供一套 SQL 支持全部应用场景,Flink SQL 的实现也完全遵循 ANSI SQL 标准。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。 本文介绍如何使用华为FusionInsight MRS FlinkServer服务进行界面化的FlinkSQL编辑,从而处理复杂的嵌套Json格式 ## Kafka样例数据 模拟物联网场景的数据 ``` {"device":"Demo1","signal":"60","life":"24","times":"2021-12-20 15:46:37"} {"device":"Demo2","signal":"78","life":"20","times":"2021-12-20 15:46:37"} {"device":"Demo3","signal":"41","life":"6","times":"2021-12-20 15:46:38"} {"device":"Demo4","signal":"71","life":"29","times":"2021-12-20 15:46:38"} {"device":"Demo5","signal":"38","life":"19","times":"2021-12-20 15:46:38"} {"device":"Demo6","signal":"98","life":"10","times":"2021-12-20 15:46:38"} {"device":"Demo7","signal":"80","life":"19","times":"2021-12-20 15:46:38"} {"device":"Demo8","signal":"55","life":"27","times":"2021-12-20 15:46:38"} {"device":"Demo9","signal":"93","life":"13","times":"2021-12-20 15:46:38"} {"device":"Demo10","signal":"46","life":"2","times":"2021-12-20 15:46:38"} {"device":"Demo11","signal":"94","life":"28","times":"2021-12-20 15:46:38"} {"device":"Demo12","signal":"24","life":"26","times":"2021-12-20 15:46:38"} {"device":"Demo13","signal":"64","life":"3","times":"2021-12-20 15:46:38"} {"device":"Demo14","signal":"97","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo15","signal":"82","life":"13","times":"2021-12-20 15:46:38"} {"device":"Demo16","signal":"2","life":"2","times":"2021-12-20 15:46:38"} {"device":"Demo17","signal":"19","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo18","signal":"51","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo19","signal":"1","life":"20","times":"2021-12-20 15:46:38"} {"device":"Demo20","signal":"41","life":"24","times":"2021-12-20 15:46:38"} ``` ## 使用华为MRS Flinkserver对接Hive ### 前提条件 - 集群已安装HDFS、Yarn、Kafka、Flink和Hive等服务。 - 包含Hive服务的客户端已安装,安装路径如:/opt/client。 - Flink支持1.12.2及以上版本,Hive支持3.1.0及以上版本。 - 参考基于用户和角色的鉴权创建一个具有“FlinkServer管理操作权限”的用户用于访问Flink WebUI的用户。  - 参考创建集群连接中的“说明”获取访问Flink WebUI用户的客户端配置文件及用户凭据。 ### 操作步骤 以映射表类型为Kafka对接Hive流程为例。 1. 使用flink_admin访问Flink WebUI,请参考访问Flink WebUI。 2. 新建集群连接,如:flink_hive。 a. 选择“系统管理 > 集群连接管理”,进入集群连接管理页面。 b. 单击“创集集群连接”,在弹出的页面中参考表1填写信息,单击“测试”,测试连接成功后单击“确定”,完成集群连接创建。 表1 创建集群连接信息 | 参数名称 | 参数描述 | 取值样例 | | ---- | ---- | ---- | |集群连接名称|集群连接的名称,只能包含英文字母、数字和下划线,且不能多于100个字符。|flink_hive| |描述|集群连接名称描述信息。|-| |版本|选择集群版本。|MRS 3| |是否安全版本|是,安全集群选择是。需要输入访问用户名和上传用户凭证; 否,非安全集群选择否。|是| |访问用户名|访问用户需要包含访问集群中服务所需要的最小权限。只能包含英文字母、数字和下划线,且不能多于100个字符。“是否安全版本”选择“是”时存在此参数。|flink_admin| |客户端配置文件|集群客户端配置文件,格式为tar。|-| |用户凭据|FusionInsight Manager中用户的认证凭据,格式为tar。“是否安全版本”选择“是”时存在此参数。输入访问用户名后才可上传文件。|flink_admin的用户凭|   3. 新建Flink SQL流作业,如:kafka_to_hive。 在作业开发界面进行作业开发,输入如下语句,可以单击上方“语义校验”对输入内容校验。 ``` CREATE TABLE test_kafka ( device varchar, signal varchar, life varchar, times timestamp ) WITH ( 'properties.bootstrap.servers' = '172.16.9.116:21007', 'format' = 'json', 'topic' = 'example-metric1', 'connector' = 'kafka', 'scan.startup.mode' = 'latest-offset', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE CATALOG myhive WITH ( 'type' = 'hive', 'hive-version' = '3.1.0', 'default-database' = 'default', 'cluster.name' = 'flink_hive' ); use catalog myhive; set table.sql-dialect = hive;create table test_avro_signal_table_orc ( device STRING, signal STRING, life STRING, ts timestamp ) PARTITIONED BY (dy STRING, ho STRING, mi STRING) stored as orc TBLPROPERTIES ( 'partition.time-extractor.timestamp-pattern' = '$dy $ho:$mi:00', 'sink.partition-commit.trigger' = 'process-time', 'sink.partition-commit.delay' = '0S', 'sink.partition-commit.policy.kind' = 'metastore,success-file' ); INSERT into test_avro_signal_table_orc SELECT device, signal, life, times, DATE_FORMAT(times, 'yyyy-MM-dd'), DATE_FORMAT(times, 'HH'), DATE_FORMAT(times, 'mm') FROM default_catalog.default_database.test_kafka; ```  注意:作业SQL开发完成后,请勾选“运行参数”中的“开启CheckPoint”,“时间间隔(ms)”可设置为“60000”,“模式”可使用默认值。 4. 启动任务  5. 启动kafka生产者插入样例数据  6. 查看hive数据  -
【功能模块】【操作步骤&问题现象】1、sparkstreaming对接kafka程序,本地环境测试正常2、程序打包后通过如下命令提交到yarn上3、提交成功,运行失败,报错:找不到主类【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
环境准备1. Manager下载krb5.conf,放到/etc/krb5.conf 目前开源代码不支持自定义krb5.conf路径2. Manager下载客户端,并安装3. yum -y install epel-release 测试环境使用CentOS,需要安装EPEL源才能安装pip4. yum install python-pip 安装python安装管理工具pip5. pip install kafka-python 需要修改源码 /usr/lib/python2.7/site-packages/kafka/conn.py line 570 将self.host修改为‘hadoop.hadoop.com’。或者直接从git下载最新代码,通过saslkerberosdomain_name参数指定为hadoop.hadoop.com.6. yum install python-gssapi 安装gssapi库7. kinit 执行pythong脚本前先通过kinit方式认证8. 执行kafka python脚本。创建topic#!/usr/bin/env bash # cd /opt/client 进入实际客户端安装目录 # source bigdata_env 导入环境变量 # kinit 使用具有KafkaAdmin权限的用户登录 # cd ./Kafka/kafka/bin/ 进入Kafka脚本目录 # 查询当前已有的topic ./kafka-topics.sh --list --zookeeper 172.21.3.101:24002,172.21.3.102:24002,172.21.3.103:24002/kafka # 如果没有test-topic,则创建。partition数量跟同一组中的consumer的数量保持一致。 # 如果要保证消息按顺序被消费,就只建一个partition。 ./kafka-topics.sh --create --zookeeper 172.21.3.101:24002,172.21.3.102:24002,172.21.3.103:24002/kafka --partitions 3 --replication-factor 2 --topic test-topic # 给producer赋予向topic中生产数据的权限 ./kafka-acls.sh --authorizer-properties zookeeper.connect=172.21.3.101:24002,172.21.3.102:24002,172.21.3.103:24002/kafka --add --allow-principal User:developuser --producer --topic test-topic # 给consumer赋予从topic中消费数据的权限 ./kafka-acls.sh --authorizer-properties zookeeper.connect=172.21.3.101:24002,172.21.3.102:24002,172.21.3.103:24002/kafka --add --allow-principal User:developuser --consumer --topic test-topic --group test-groupProducer样例from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers=["172.21.3.101:21007"], security_protocl="SASL_PLAINTEXT", sasl_mechanism="GSSAPI", sasl_kerberos_service_name="kafka") for _ in range(100): response = producer.send("test-topic", b"testmessage") result = response.get(timeout=50) print(result) Consumer样例from kafka import KafkaConsumer consumer = KafkaConsumer("test-topic", bootstrap_servers=["172.21.3.101:21007"], group_id="test-group", enable_auto_commit="true", security_protocl="SASL_PLAINTEXT", sasl_mechanism="GSSAPI", sasl_kerberos_service_name="kafka") for message in consumer: print(message)
上滑加载中
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签