-
 隐私保护通话的axb模式怎么做的
隐私保护通话的axb模式怎么做的 -
华为云 隐私保护通话PrivateNumber AXE模式为什么建议不超过200个绑定分机号,超过了200个又会怎么样,在线等 ,求解答
-
手机号16812341234绑定隐私号AXB的时候返回{"resultcode":"1010002","resultdesc":"Invalid request.The number format is incorrect."}隐私保护通话 PrivateNumberhttps://support.huaweicloud.com/api-PrivateNumber/privatenumber_02_0002.html
-
我有一个开发开放式共享手机的一种创意技术,主要针对目前用户最常见的手机没电、关机及丢失问题,采用我的这种创意技术后,人们对手机的专属依赖性就减弱,共享手机就像出门打的一样方便快捷,再也不用担心手机没电到处找充电的地方,手机摔坏丢失遇重要事情无法联系了。当然我还有有关更超前的无卡手机创意技术,彻底让中国电信三大运营商逐渐消失的技术方案。
-
 >摘要:本文通过介绍华为如何在同态加密及零知识证明框架的集成介绍来介绍了一些对金融领域交易隐私保护的思路,通过代码结和应用场景描述了zksnark如何集成到现有联盟链体系保护交易隐私。本文分享自华为云社区[《区块链交易隐私如何保证?华为零知识证明技术实战解析》](https://bbs.huaweicloud.com/blogs/306971?utm_source=zhihu&utm_medium=bbs-ex&utm_campaign=paas&utm_content=content),作者:麦冬爸 。 # 什么是零知识证明? 证明者在不泄露任何有效知识的情况下,验证者可以验证某个论断是正确的。图1给出一个有趣的例子,Alice把自己的签名的信封放到一个保险箱中,Bob说他知道这个保险箱的密码,Alice让Bob证明给她看。Bob打开保险箱,把信封拿出来给Alice。Alice验证信封上的签名,确认了Bob确实知道这个密码。这个例子就是Bob没有告诉Alice密码却证明自己知道密码的的过程很好的解释了零知识证明的概念。基于非对称加密和数字签名的证书认证过程,其实也是一个零知识证明的过程,验证者并不需要知晓CA证书,就可以验证对方是由CA签发的下一级证书。零知识证明技术不管应用于金融还是其他领域,都可以对隐私保护,性能提升,或者安全性等场景带来很多帮助。下面,主要从隐私维度来分享华为零知识证明相关技术。 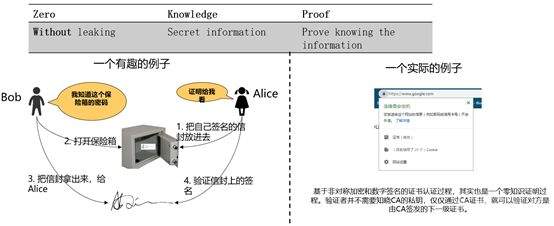 图1 零知识证明 # 零知识证明应用于同态加密保护交易隐私,使能金融业务 目前金融转账交易场景中对于隐私保护已经越来越重视,隐私也成为区块链急需解决的一个重要问题。那基于如下问题, A向B转账10元,需要区块链节点记账,但是不想让区块链节点知道交易金额以及最新余额,也是金融场景中一个非常常见的问题。 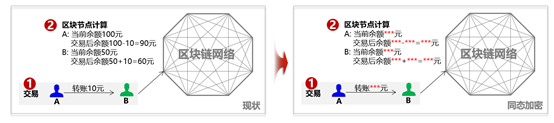 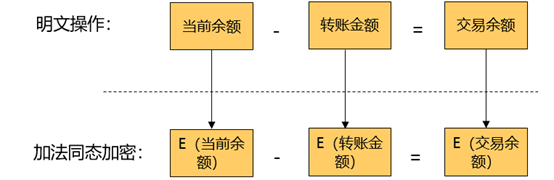 图2 同态加密 基于这种场景如何解决区块链技术应用于金融的隐私和可用性?华为目前引入同态加密(解决隐私问题)。同态加密(英語:Homomorphic encryption)是一种加密形式,它允许人们对密文进行特定形式的代数运算得到仍然是加密的结果,将其解密所得到的结果与对明文进行同样的运算结果一样。 换言之,这项技术令人们可以在加密的数据中进行诸如检索、比较等操作,得出正确的结果,而在整个处理过程中无需对数据进行解密。在此基础上创新式提出了**同态加密范围证明**(一种针对数字的零知识证明技术,在不泄露具体数字值的情况下,获得数字的范围,从而验证数字所代表的交易的有效性)。 基于集成到区块链系统中的同态加密库以及修改同态加密库实现的零知识证明能力实现了隐私转账的能力,一个密文和另一个密文相加或相乘实现转账中的密文交易,零知识证明在整个的计算过程中不暴露任一方的信息证明对方可以完成转账这一流程,在不泄露具体数字的情况下得到数字的范围。从而验证数字所代表交易的有效性。 # 使用同态加密库的app端sample代码示例 下面我们看一下零知识证明在代码中是如何应用的,Demo代码使用地址:[概述_区块链服务 BCS_开发指南(Hyperledger Fabric增强版)_附录_同态加密_华为云](https://support.huaweicloud.com/devg-bcs/bcs_devg_0020.html)。下面讲解的代码都可以在上面的地址中下载全量代码查看。 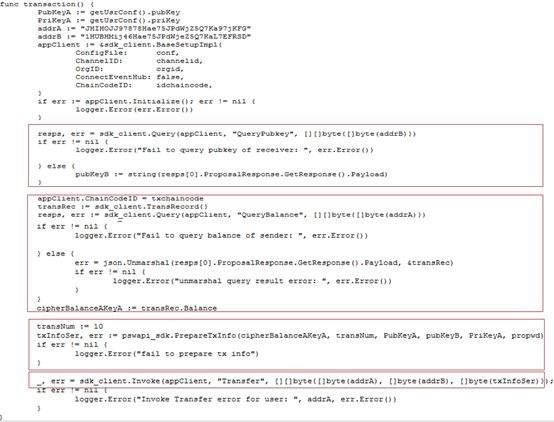 图3 同态加密链代码1 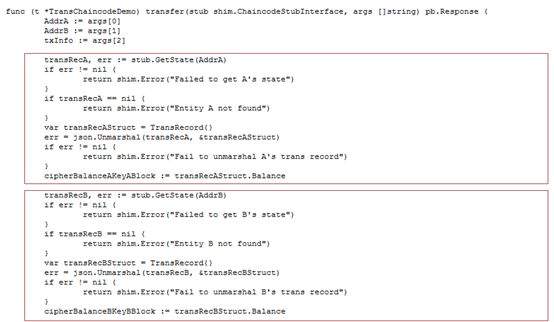 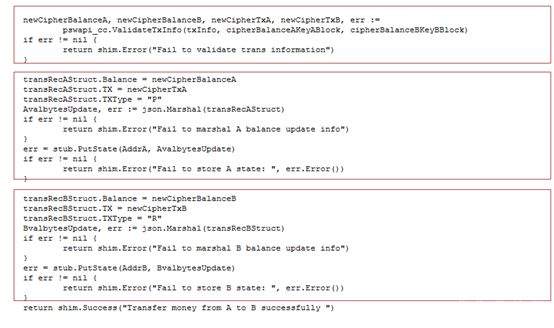 图4 同态加密链代码2 图3是同态加密的链代码,首先定义好一个transaction的结构,在进行初始化,基于Query方法可以根据B的地址调用链码获取B的公钥 ,第二个红框获取A的当前加密余额,PrepareTxInfo方法构建A向B的转账信息,最后通过invoke调用完成A到B的转账的过程。在图4 transfer链代码方法中,首先通过getstate获取A和B两个账户的当前余额,然后最重要的一步,要去验证他的余额,所以说我们这个方法validatetxinfo,基于范围/等式证明验证交易数据的合规性,基于同态加密算法计算交易后的账户余额,最后更新交易后A账户和B账户的余额。同态加密的这一步中,应用了零知识证明的相关的这个技术和能力来实现了这个同态加密更加的高效和安全。 # 基于zksnark的零知识证明技术 ## 交互式证明和非交互式证明 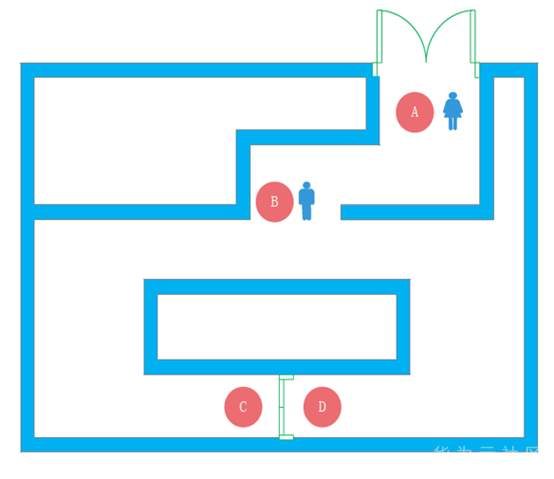 图5 交互式证明 零知识证明又分为交互式证明和非交互式证明,有两个有趣的例子很好的解释了这个概念。如上图5所示,男子向女子声称有CD处的钥匙,女子不相信说“你拿出来给我看啊”,男子想“你让我拿我就拿多没面子啊”,男子说”这样吧,按下面步骤玩个游戏” 1.女子站在A点 2.男子从B点走到C点或者D点 3.男子从B点消失后,女子从A点走到B点 4.女子喊话“从左边出来”,或者“从右边出来” 5.男子按照女子的要求从对应一侧走出 女子说“你肯定作弊,刚才我喊左边出来,你刚好就是从左边进去的”, 男子说:“你回到A点,我们再来一遍” 如果每次都成功,说明B确实有CD处的钥匙,该证明是需要A,B不停的交互。 非交互式零知识(NizK)证明方案由算法设置、证明和验证定义,具体来说,我们有params=Setup(),其中输入是安全参数,输出是ZKP算法系统的参数。证明语法由证明=证明(x,w)给出。该算法接收某些NP语言L的实例x和见证w作为输入,并输出零知识证明。验证算法接收证明作为输入,并输出位b,如果验证者接受证明,则该位等于1。通俗一点就比如说我有一个秘密,我不想告诉别人,但是我又得让别人相信。我是知道这个秘密的,类似于这种,但是我们为什么需要有这种非交互式呢?因为交互式证明的其实只对原始的验证者有效,其他的任何人都不能够信任这个证明。这种场景下呢,就会导致这个验证者可以和这个证明人串通,证明人可以伪造证明。验证者也可以用这种方式做一些伪造。因此,验证者必须保存一些数据,直到相关的证明被验证完毕。这样就会造成一些秘密参数泄露的这种风险。这种交互式证明也有它的用处,就比如说一个证明人只想让一个特定的验证者来去验证,但是这个证证明人和验证者必须保持在线,并且去对每一个验证者执行同样的计算。 ## 什么是zk-snark? zk-SNARK 是 Zero-knowledge succinct non-interactive arguments of knowledge 的缩写,他的意思是: zero knowledge:零知识,即在证明的过程中不透露任何隐私数据: succinct:简洁的,主要是指验证过程不涉及大量数据传输以及验证算 法简单; non-interactive:无交互。证明者与验证者之间不需要交互即可实现证 明,交互的零知识证明要求每个验证者都要向证明者发送数据来完成证明, 而无交互的零知识证明,证明者只需要计算一次产生一个 proof,所有的验 证者都可以验证这个 proof。 zk-SNARK 是证明某个声明是真却不泄露关于该声明的隐私信息的一 个很有创新性的算法,他可以证明某人知道某个秘密却不会泄露关于这个 秘密的任何信息。这个算法可以解决什么问题呢? 它是对所有零知识证明问题的通用解决方法,由加密数字货币zcash首次使用并开源。zk-SNARK的优点: 1.通用库,可以解很多零知识证明问题 2.验证证明性能较高(300tps) zk-SNARK的不足: 1.底层模型不容易理解,用户需要根据具体的零知识证明问题,在上层构建自己的业务模型,这块开发的工作量较大。 2.生成每笔交易时延较长(57s) ## 应用场景 ZKP的应用场景包括匿名可验证投票、数字资产安全交换、安全远程生物识别认证和安全拍卖,具体如下。 匿名可核查投票:投票是保障一个国家或控股公司民主的重要组成部分。然而,选民的隐私可能在投票过程中被泄露。此外,投票结果很难得到安全的核实。ZKP是实施匿名可核查投票的一种可用方法。根据ZKP的使用,符合条件的选民可以在不泄露身份的情况下投票表决显示他们的权利。此外,ZKP允许符合条件的选民要求提供可核查的证据,证明他们的选票包含在负责报告投票结果的机构的最终计票中。 数字资产的安全交换:数字资产是二进制数据的集合,它们是唯一可识别和有价值的。如果两个用户希望交换其数字资产,则用户的隐私,包括身份和交换数字资产的内容,可能会在交换过程中泄露。根据ZKP的使用,数字资产可以在不泄露用户隐私的情况下交换。此外,ZKP生成了可验证的证据,其中包含数字资产交换的过程。 安全远程生物识别身份验证:远程生物识别身份验证是一种可用于通过使用指纹、面部图像、虹膜或血管模式等生物识别模式识别用户访问权限的方法。但是,在实施远程生物识别认证时,用户的生物识别模式可能会泄露给不受信任的第三方。使用ZKP可以解决这个问题。此外,ZKP生成还提供了可核查的证据,其中包括识别用户访问权限的过程。 安全拍卖:政府拍卖是政府从多个供应商中选择最低出价的拍卖,这些供应商以竞争性方式销售其商品和服务。本次拍卖包括两个阶段。在第一阶段,多个供应商投标,但公众不知道。在第二阶段,这些投标是开放的。政府选择中标供应商,后者出价最低。然而,中标供应商的选择可能会泄露其他中标供应商的投标和身份。ZKP可以解决这个问题。ZKP为每个输标供应商生成可核查的证据。该证明证实输标供应商的投标与中标供应商的投标之间的差额是正的。 ## zk-snark应用于区块链的挑战及实现 零知识证明是指一方(证明者)向另 一方(验证者)证明一个陈述是正确的, 而无需透露除该陈述正确以外的任何信 息,适用于解决 任 何NP问题。而区块 链 恰好可以抽象成多方验证交易是否有效 (NP问题)的平台,因此,两者是天然相 适 应的。将零知识证明应用到区块 链中 需要考虑的 技 术 挑战分为两大类:一类 是适用于隐私保护的区块链架构设计方 案,包括隐秘交易所花资产存在性证明、匿 名资产双花问题、匿名资产花费与转移、隐 秘交易不可区分等技术挑战;另一类是零 知识证明技 术 本身带来的 挑战,包括 参 数 初始化阶段、算法 性能以及安 全问题 等技术挑战。 华为集成了zksnark架构到区块链系统中来解决上面的挑战。我们知道有多种方法可以为区块链启用zkSNark。这些都降低了配对函数和椭圆曲线操作的实际成本。 1. 提高合约虚拟机的性能 相较第二种更难实现。可以在合约虚拟机中添加功能和限制,这将允许更好的实时编译和解释,而无需在现有实现中进行太多必要的更改。下面的转账场景就是基于此种方案的实现。 2. 仅提高某些配对函数和椭圆曲线乘法的在合约虚拟机的性能 通过强制所有区块链客户端实现特定的配对函数和在特定椭圆曲线上的乘法作为所谓的预编译契约来实现。好处是,这可能更容易和更快地实现。另一方面,缺点是我们固定在一定的配对函数和一定的椭圆曲线上。区块链的任何新客户端都必须重新实施这些预编译的合同。此外,如果有人找到更好的zkSNark、更好的配对函数或更好的椭圆曲线,或者如果在椭圆曲线、配对函数或zkSNark中发现缺陷,必须添加新的预编译合同。 ## 转账应用 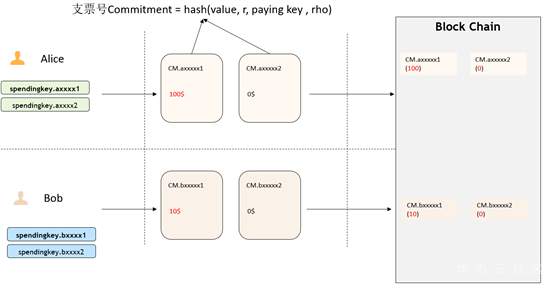 图6 转账初始化 图6包含了对这个余额初始化的一个过程,及生成交易也就是真正转账的过程,下一步就是验证,证明,完成验证,最后一步,才是生成交易,也就是收款的一个过程。拿初始化举个例子,比如说爱丽丝初始化了一个100块钱的一个余额,然后鲍勃十块钱。转账的过程如下,爱丽丝转20块钱给鲍勃,就会生成生成一对Spending key / Paying Key ,相当于临时交易的一个账户,Paying Key给对方,Spending Key留给自己,用于证明交易链上的交易是谁的。 然后再基于这个生成相应的这个交易和相关的证明。完成交易生成这一步。下一步进行转账的验证证明的这个过程,验证逻辑如下, 验证逻辑:Nullifier NF.axxxxx1 和NF.axxxxx2 是否在Nullifiers 列表中,也就是说,是否有被花过;验证NF.axxxxx1 和NF.axxxxx2 是格式是否合法的花费凭据,且对应的commitment在链上(Proof + Merkle tree root),这里有需要验证Merkle tree root在 是有效的;验证input == output 金额守恒,即:100 + 0 = 80+0+20;数字范围满足要求:100-20 >0 && 20 > 0,把这个过程都验证完了以后呢,最后一步就是完成验证。完成验证的话,他其实还会做一些这个类似于交易内容的隐藏,身份隐藏,交易行为的隐藏,来保护整个的这个转账交易的过程的这个安全性。包括做一些类似于混淆电路的能力。有混淆的交易内容,且加密,验证者并不知道使用链上是哪个Commitment作为输入,只知道没有被花过,且在链上。身份隐藏让其无法确定接收方是谁,交易行为隐藏让其无法确定这个交易是发送还是接收。做一些安全性的保证之后呢,然后来完成整个的验证的过程。最后,生成交易,然后收款,整个转账过程就结束了。基于零知识证明的一个简单的一个能力,包括一个基础的转账,被华为集成在整个零知识证明使用接口中。集成的整个零知识证明架构也能用来开发一些零知识证明基础应用,做一些简单的解决方案。 # 总结 交易隐私保护这块的技术应该是比较多的,零知识证明技术并不一定是一个最好的选择,在安全领域中还有很多诸如同态,秘密分享,不经意传输,或者基于TEE硬件的一些隐私保护能力,可以去做一些隐私保护。但是零知识证明其优点也是很显著,未来区块链的隐私保护仍然任重而道远,如何实现快速高效、可信的零知识证 明算法以及如何实现能够抵抗量子计算 的零知识证明算法,都是需要进一步解决 的问题。基于线上我们提供的一些基本的能力,要是大家感兴趣,可以到之前的网址下载相应的代码示例。
>摘要:本文通过介绍华为如何在同态加密及零知识证明框架的集成介绍来介绍了一些对金融领域交易隐私保护的思路,通过代码结和应用场景描述了zksnark如何集成到现有联盟链体系保护交易隐私。本文分享自华为云社区[《区块链交易隐私如何保证?华为零知识证明技术实战解析》](https://bbs.huaweicloud.com/blogs/306971?utm_source=zhihu&utm_medium=bbs-ex&utm_campaign=paas&utm_content=content),作者:麦冬爸 。 # 什么是零知识证明? 证明者在不泄露任何有效知识的情况下,验证者可以验证某个论断是正确的。图1给出一个有趣的例子,Alice把自己的签名的信封放到一个保险箱中,Bob说他知道这个保险箱的密码,Alice让Bob证明给她看。Bob打开保险箱,把信封拿出来给Alice。Alice验证信封上的签名,确认了Bob确实知道这个密码。这个例子就是Bob没有告诉Alice密码却证明自己知道密码的的过程很好的解释了零知识证明的概念。基于非对称加密和数字签名的证书认证过程,其实也是一个零知识证明的过程,验证者并不需要知晓CA证书,就可以验证对方是由CA签发的下一级证书。零知识证明技术不管应用于金融还是其他领域,都可以对隐私保护,性能提升,或者安全性等场景带来很多帮助。下面,主要从隐私维度来分享华为零知识证明相关技术。  图1 零知识证明 # 零知识证明应用于同态加密保护交易隐私,使能金融业务 目前金融转账交易场景中对于隐私保护已经越来越重视,隐私也成为区块链急需解决的一个重要问题。那基于如下问题, A向B转账10元,需要区块链节点记账,但是不想让区块链节点知道交易金额以及最新余额,也是金融场景中一个非常常见的问题。   图2 同态加密 基于这种场景如何解决区块链技术应用于金融的隐私和可用性?华为目前引入同态加密(解决隐私问题)。同态加密(英語:Homomorphic encryption)是一种加密形式,它允许人们对密文进行特定形式的代数运算得到仍然是加密的结果,将其解密所得到的结果与对明文进行同样的运算结果一样。 换言之,这项技术令人们可以在加密的数据中进行诸如检索、比较等操作,得出正确的结果,而在整个处理过程中无需对数据进行解密。在此基础上创新式提出了**同态加密范围证明**(一种针对数字的零知识证明技术,在不泄露具体数字值的情况下,获得数字的范围,从而验证数字所代表的交易的有效性)。 基于集成到区块链系统中的同态加密库以及修改同态加密库实现的零知识证明能力实现了隐私转账的能力,一个密文和另一个密文相加或相乘实现转账中的密文交易,零知识证明在整个的计算过程中不暴露任一方的信息证明对方可以完成转账这一流程,在不泄露具体数字的情况下得到数字的范围。从而验证数字所代表交易的有效性。 # 使用同态加密库的app端sample代码示例 下面我们看一下零知识证明在代码中是如何应用的,Demo代码使用地址:[概述_区块链服务 BCS_开发指南(Hyperledger Fabric增强版)_附录_同态加密_华为云](https://support.huaweicloud.com/devg-bcs/bcs_devg_0020.html)。下面讲解的代码都可以在上面的地址中下载全量代码查看。  图3 同态加密链代码1   图4 同态加密链代码2 图3是同态加密的链代码,首先定义好一个transaction的结构,在进行初始化,基于Query方法可以根据B的地址调用链码获取B的公钥 ,第二个红框获取A的当前加密余额,PrepareTxInfo方法构建A向B的转账信息,最后通过invoke调用完成A到B的转账的过程。在图4 transfer链代码方法中,首先通过getstate获取A和B两个账户的当前余额,然后最重要的一步,要去验证他的余额,所以说我们这个方法validatetxinfo,基于范围/等式证明验证交易数据的合规性,基于同态加密算法计算交易后的账户余额,最后更新交易后A账户和B账户的余额。同态加密的这一步中,应用了零知识证明的相关的这个技术和能力来实现了这个同态加密更加的高效和安全。 # 基于zksnark的零知识证明技术 ## 交互式证明和非交互式证明  图5 交互式证明 零知识证明又分为交互式证明和非交互式证明,有两个有趣的例子很好的解释了这个概念。如上图5所示,男子向女子声称有CD处的钥匙,女子不相信说“你拿出来给我看啊”,男子想“你让我拿我就拿多没面子啊”,男子说”这样吧,按下面步骤玩个游戏” 1.女子站在A点 2.男子从B点走到C点或者D点 3.男子从B点消失后,女子从A点走到B点 4.女子喊话“从左边出来”,或者“从右边出来” 5.男子按照女子的要求从对应一侧走出 女子说“你肯定作弊,刚才我喊左边出来,你刚好就是从左边进去的”, 男子说:“你回到A点,我们再来一遍” 如果每次都成功,说明B确实有CD处的钥匙,该证明是需要A,B不停的交互。 非交互式零知识(NizK)证明方案由算法设置、证明和验证定义,具体来说,我们有params=Setup(),其中输入是安全参数,输出是ZKP算法系统的参数。证明语法由证明=证明(x,w)给出。该算法接收某些NP语言L的实例x和见证w作为输入,并输出零知识证明。验证算法接收证明作为输入,并输出位b,如果验证者接受证明,则该位等于1。通俗一点就比如说我有一个秘密,我不想告诉别人,但是我又得让别人相信。我是知道这个秘密的,类似于这种,但是我们为什么需要有这种非交互式呢?因为交互式证明的其实只对原始的验证者有效,其他的任何人都不能够信任这个证明。这种场景下呢,就会导致这个验证者可以和这个证明人串通,证明人可以伪造证明。验证者也可以用这种方式做一些伪造。因此,验证者必须保存一些数据,直到相关的证明被验证完毕。这样就会造成一些秘密参数泄露的这种风险。这种交互式证明也有它的用处,就比如说一个证明人只想让一个特定的验证者来去验证,但是这个证证明人和验证者必须保持在线,并且去对每一个验证者执行同样的计算。 ## 什么是zk-snark? zk-SNARK 是 Zero-knowledge succinct non-interactive arguments of knowledge 的缩写,他的意思是: zero knowledge:零知识,即在证明的过程中不透露任何隐私数据: succinct:简洁的,主要是指验证过程不涉及大量数据传输以及验证算 法简单; non-interactive:无交互。证明者与验证者之间不需要交互即可实现证 明,交互的零知识证明要求每个验证者都要向证明者发送数据来完成证明, 而无交互的零知识证明,证明者只需要计算一次产生一个 proof,所有的验 证者都可以验证这个 proof。 zk-SNARK 是证明某个声明是真却不泄露关于该声明的隐私信息的一 个很有创新性的算法,他可以证明某人知道某个秘密却不会泄露关于这个 秘密的任何信息。这个算法可以解决什么问题呢? 它是对所有零知识证明问题的通用解决方法,由加密数字货币zcash首次使用并开源。zk-SNARK的优点: 1.通用库,可以解很多零知识证明问题 2.验证证明性能较高(300tps) zk-SNARK的不足: 1.底层模型不容易理解,用户需要根据具体的零知识证明问题,在上层构建自己的业务模型,这块开发的工作量较大。 2.生成每笔交易时延较长(57s) ## 应用场景 ZKP的应用场景包括匿名可验证投票、数字资产安全交换、安全远程生物识别认证和安全拍卖,具体如下。 匿名可核查投票:投票是保障一个国家或控股公司民主的重要组成部分。然而,选民的隐私可能在投票过程中被泄露。此外,投票结果很难得到安全的核实。ZKP是实施匿名可核查投票的一种可用方法。根据ZKP的使用,符合条件的选民可以在不泄露身份的情况下投票表决显示他们的权利。此外,ZKP允许符合条件的选民要求提供可核查的证据,证明他们的选票包含在负责报告投票结果的机构的最终计票中。 数字资产的安全交换:数字资产是二进制数据的集合,它们是唯一可识别和有价值的。如果两个用户希望交换其数字资产,则用户的隐私,包括身份和交换数字资产的内容,可能会在交换过程中泄露。根据ZKP的使用,数字资产可以在不泄露用户隐私的情况下交换。此外,ZKP生成了可验证的证据,其中包含数字资产交换的过程。 安全远程生物识别身份验证:远程生物识别身份验证是一种可用于通过使用指纹、面部图像、虹膜或血管模式等生物识别模式识别用户访问权限的方法。但是,在实施远程生物识别认证时,用户的生物识别模式可能会泄露给不受信任的第三方。使用ZKP可以解决这个问题。此外,ZKP生成还提供了可核查的证据,其中包括识别用户访问权限的过程。 安全拍卖:政府拍卖是政府从多个供应商中选择最低出价的拍卖,这些供应商以竞争性方式销售其商品和服务。本次拍卖包括两个阶段。在第一阶段,多个供应商投标,但公众不知道。在第二阶段,这些投标是开放的。政府选择中标供应商,后者出价最低。然而,中标供应商的选择可能会泄露其他中标供应商的投标和身份。ZKP可以解决这个问题。ZKP为每个输标供应商生成可核查的证据。该证明证实输标供应商的投标与中标供应商的投标之间的差额是正的。 ## zk-snark应用于区块链的挑战及实现 零知识证明是指一方(证明者)向另 一方(验证者)证明一个陈述是正确的, 而无需透露除该陈述正确以外的任何信 息,适用于解决 任 何NP问题。而区块 链 恰好可以抽象成多方验证交易是否有效 (NP问题)的平台,因此,两者是天然相 适 应的。将零知识证明应用到区块 链中 需要考虑的 技 术 挑战分为两大类:一类 是适用于隐私保护的区块链架构设计方 案,包括隐秘交易所花资产存在性证明、匿 名资产双花问题、匿名资产花费与转移、隐 秘交易不可区分等技术挑战;另一类是零 知识证明技 术 本身带来的 挑战,包括 参 数 初始化阶段、算法 性能以及安 全问题 等技术挑战。 华为集成了zksnark架构到区块链系统中来解决上面的挑战。我们知道有多种方法可以为区块链启用zkSNark。这些都降低了配对函数和椭圆曲线操作的实际成本。 1. 提高合约虚拟机的性能 相较第二种更难实现。可以在合约虚拟机中添加功能和限制,这将允许更好的实时编译和解释,而无需在现有实现中进行太多必要的更改。下面的转账场景就是基于此种方案的实现。 2. 仅提高某些配对函数和椭圆曲线乘法的在合约虚拟机的性能 通过强制所有区块链客户端实现特定的配对函数和在特定椭圆曲线上的乘法作为所谓的预编译契约来实现。好处是,这可能更容易和更快地实现。另一方面,缺点是我们固定在一定的配对函数和一定的椭圆曲线上。区块链的任何新客户端都必须重新实施这些预编译的合同。此外,如果有人找到更好的zkSNark、更好的配对函数或更好的椭圆曲线,或者如果在椭圆曲线、配对函数或zkSNark中发现缺陷,必须添加新的预编译合同。 ## 转账应用  图6 转账初始化 图6包含了对这个余额初始化的一个过程,及生成交易也就是真正转账的过程,下一步就是验证,证明,完成验证,最后一步,才是生成交易,也就是收款的一个过程。拿初始化举个例子,比如说爱丽丝初始化了一个100块钱的一个余额,然后鲍勃十块钱。转账的过程如下,爱丽丝转20块钱给鲍勃,就会生成生成一对Spending key / Paying Key ,相当于临时交易的一个账户,Paying Key给对方,Spending Key留给自己,用于证明交易链上的交易是谁的。 然后再基于这个生成相应的这个交易和相关的证明。完成交易生成这一步。下一步进行转账的验证证明的这个过程,验证逻辑如下, 验证逻辑:Nullifier NF.axxxxx1 和NF.axxxxx2 是否在Nullifiers 列表中,也就是说,是否有被花过;验证NF.axxxxx1 和NF.axxxxx2 是格式是否合法的花费凭据,且对应的commitment在链上(Proof + Merkle tree root),这里有需要验证Merkle tree root在 是有效的;验证input == output 金额守恒,即:100 + 0 = 80+0+20;数字范围满足要求:100-20 >0 && 20 > 0,把这个过程都验证完了以后呢,最后一步就是完成验证。完成验证的话,他其实还会做一些这个类似于交易内容的隐藏,身份隐藏,交易行为的隐藏,来保护整个的这个转账交易的过程的这个安全性。包括做一些类似于混淆电路的能力。有混淆的交易内容,且加密,验证者并不知道使用链上是哪个Commitment作为输入,只知道没有被花过,且在链上。身份隐藏让其无法确定接收方是谁,交易行为隐藏让其无法确定这个交易是发送还是接收。做一些安全性的保证之后呢,然后来完成整个的验证的过程。最后,生成交易,然后收款,整个转账过程就结束了。基于零知识证明的一个简单的一个能力,包括一个基础的转账,被华为集成在整个零知识证明使用接口中。集成的整个零知识证明架构也能用来开发一些零知识证明基础应用,做一些简单的解决方案。 # 总结 交易隐私保护这块的技术应该是比较多的,零知识证明技术并不一定是一个最好的选择,在安全领域中还有很多诸如同态,秘密分享,不经意传输,或者基于TEE硬件的一些隐私保护能力,可以去做一些隐私保护。但是零知识证明其优点也是很显著,未来区块链的隐私保护仍然任重而道远,如何实现快速高效、可信的零知识证 明算法以及如何实现能够抵抗量子计算 的零知识证明算法,都是需要进一步解决 的问题。基于线上我们提供的一些基本的能力,要是大家感兴趣,可以到之前的网址下载相应的代码示例。 -
 声明:本文首发于华为NAIE《网络人工智能园地》微信公众号,如有转载,请注明出处。微信公众号二维码为:http://weixin.qq.com/r/yx385OnEb7QQra2H90jZweixin.qq.com本文介绍一种特殊场景下的迁移算法:隐私保护下的迁移算法。首先,本文稍微回顾一下传统迁移算法的流程、特性和局限之处,然后文章介绍几种解决当源域数据有某些访问限制的场景下实现迁移的算法。具体包括:ADDA-CVPR2017,FADA-ICLR2020,SHOT-ICML2020。传统迁移算法UDDA首先说明这里说的传统迁移算法,主要指深度域适应(Deep Domain Adaptation),更具体的是无监督深度域适应(Unsupervised Deep Domain Adaptation, UDDA)。因为UDDA是最为常见,也是大家广泛关注的设定,因此这方面的工作远远多于其余迁移算法的设定。先介绍一下UDDA具体是做什么的:给定一个目标域(Target Domain),该域只有无标记数据,因此不能有监督地训练模型,目标域通常是一个新的局点、场景或者数据集;为了在目标域无标记数据的情况下建立模型,可以借助源域(Source Domain)的知识,源域通常是已有局点、场景或者数据集,知识可以是源域训练好的模型、源域的原始数据、源域的特征等。借助有标记信息的源域,目标域上即便没有标记数据,也可以建立一个模型。使得该模型对目标域数据有效的关键难点在于源域和目标域存在数据分布的差异,称之为域漂移(Domain Shift),如何去对齐源域和目标域的数据是UDDA解决的主要问题。UDDA通常包含下面的三种框架:首先,源域和目标域的数据(圆柱)会经过特征提取器(Encoder)提取特征(矩形),然后各种办法会对源域和目标域的特征进行操作,使得源域和目标域上数据的特征对齐。这里值得一提的是,UDDA通常假设源域和目标域的类别是一样的,比如源域和目标域都是去分类0-9十个手写数字,只不过源域和目标域的手写风格不一样。对源域和目标域特征进行操作的办法包括三种类别:基于统计对齐:使用各种统计量对齐源域和目标域特征的分布,比如对齐核空间均值(MMD Loss)、对齐协方差矩阵(CORAL Loss)等;基于对抗对齐:建立一个域分类器(Domain Classifier)作为判别器(Discriminator),目的要尽可能将源域和目标域的特征区分开来,使用梯度反转(Gradient Reversal Gradient,GRL)可以促使特征提取器提取和领域无关(Domain Invariant)的特征;基于重构对齐:将源域和目标域的特征通过同一个生成网络进行生成相应的数据,通过假设只有分布接近的样本才可以使用同一个网络生成数据对齐源域和目标域特征。关于以上几种UDDA的具体算法可以参加以前的文章:https://zhuanlan.zhihu.com/p/205433863zhuanlan.zhihu.com这里本文只给出UDDA的几个特性:源域数据可获得:UDDA假设源域数据存在并且可以获得;源域目标域数据可混合:UDDA通常假设源域和目标域数据可以在一起处理,即可以放在同一个设备上进行运算;训练预测过程是Transductive的:目标域数据必须和源域数据一同训练才可以使得特征提取器提取领域无关的特征,才可以将源域的模型迁移到目标域,因此当一批新的目标域的数据到来的话,并不能直接使用源域模型进行预测。总的来说,传统的UDDA方法假设源域数据可获得、源域目标域数据可混合、训练过程Transductive。然而,有一些场景下,源域数据不可获得,或者源域数据不可以外传,这种情况下如何进行迁移呢?首先,这里需要注意的是,源域数据不能外传和源域数据不可获得是两种情况,前者假设源域数据存在,但是不可以和目标域数据放在一起,后者是源域数据根本就不存在了。ADDAADDA是CVPR2017的一篇工作,来自论文《Adversarial Discriminative Domain Adaptation》,作者信息截图如下:一作Eric Tzeng来自于加利福尼亚大学伯克利分校,代表作有DDC和ADDA;二作Judy Hoffman来自斯坦福大学,代表作CyCADA,以及多篇在多领域迁移方面的理论文章,比如NeurIPS 2018的《Algorithms and Theory for Multiple-Source Adaptation》;三作Kate Saenko是波斯顿大学计算机科学计算机视觉组(Computer Vision and Learning Group,CVL)的Leader,是一名女性学者,Baochen Sun,Xingchao Peng,Kuniaki Saito等人都在该组深造或者深造过。CVL代表作有(个人评定,以下文章个人在学习DA的过程中或多或少阅读或者研究过):Xingchao Peng, Zijun Huang, Yizhe Zhu, Kate Saenko: Federated Adversarial Domain Adaptation. ICLR 2020Xingchao Peng, Yichen Li, Kate Saenko: Domain2Vec: Domain Embedding for Unsupervised Domain Adaptation. ECCV (6) 2020: 756-774Shuhan Tan, Xingchao Peng, Kate Saenko: Generalized Domain Adaptation with Covariate and Label Shift CO-ALignment. CoRR abs/1910.10320 (2019)Xingchao Peng, Zijun Huang, Ximeng Sun, Kate Saenko: Domain Agnostic Learning with Disentangled Representations. ICML 2019: 5102-5112Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, Bo Wang: Moment Matching for Multi-Source Domain Adaptation. ICCV 2019: 1406-1415Kuniaki Saito, Donghyun Kim, Stan Sclaroff, Trevor Darrell, Kate Saenko: Semi-Supervised Domain Adaptation via Minimax Entropy. ICCV 2019: 8049-8057Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, Kate Saenko: Adversarial Dropout Regularization. ICLR (Poster) 2018Xingchao Peng, Ben Usman, Neela Kaushik, Dequan Wang, Judy Hoffman, Kate Saenko: VisDA: A Synthetic-to-Real Benchmark for Visual Domain Adaptation. CVPR Workshops 2018: 2021-2026Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell: Adversarial Discriminative Domain Adaptation. CVPR 2017: 2962-2971Baochen Sun, Kate Saenko: Deep CORAL: Correlation Alignment for Deep Domain Adaptation. ECCV Workshops (3) 2016: 443-450Baochen Sun, Jiashi Feng, Kate Saenko: Return of Frustratingly Easy Domain Adaptation. AAAI 2016: 2058-2065Eric Tzeng, Judy Hoffman, Trevor Darrell, Kate Saenko: Simultaneous Deep Transfer Across Domains and Tasks. ICCV 2015: 4068-4076回归正题,ADDA的训练流程图如下:首先是预训练阶段(Pre-training Stage),源域上利用有标记数据训练,采用交叉熵损失:其中 为源域的特征提取器, 为源域的分类器。然后是对抗对齐阶段(Adversarial Adaptation Stage),将源域的特征提取器拷贝给目标域 ,并且将分类器 固定住迁移到目标域。然后就是对 根据目标域数据进行微调,当且仅当目标域特征提取器 在目标域提取的特征和源域特征提取器 在源域数据提取的特征相似时,源域的分类器才可以很好地适应目标域,即下面几个公式的目的主要是使得 。简单的方法仍然是使用对抗进行训练。第一步训练域判别器(Discriminator)将源域的特征和目标域的特征进行区分开, 代表域判别器:第二步,训练 ,使得 让判别器尽可能分不开:重复以上两步,直到收敛。可以看出以上过程中, 源域特征提取器 只在源域预训练阶段使用到,然后拷贝给目标域,目标域微调特征提取器。换句话说,源域训练好的模型,包括特征提取器和分类器,传输到目标域之后,目标域只微调特征提取器,使得特征提取器提取的特征单向向源域的特征对齐,分类时使用的仍然是源域的分类器。为什么说这个方法可以推广到隐私保护呢?因为可以看到,源域的数据只在预训练阶段利用到,且后面对齐的过程中只用到了源域的特征 ,而不是 ,后者需要访问到源域原始数据。总的来说,ADDA容许源域和目标域的特征提取器不一致,将 参数解耦开来,并且训练过程中其实只用到了源域的特征。如果,源域数据和目标域数据不在同一设备上,假设源域数据的特征可以发送出去的话,该方案可以做到隐私保护。FADA正如上述介绍的CVL组,Xingchao Peng将ADDA扩充到多域版本,并且提出了FADA。FADA来自ICLR2020的《Federated Adversarial Domain Adaptation》,论文首页截图如下:该文提出了一个新的场景FADA,即联邦学习下的多域迁移。假设有很多个源域,每个源域的数据分布在单独的设备上,原始数据不能外传,如何在这种情况下将其模型复用到目标域呢?简而言之,如何在数据不能被发送出去的约束下进行特征对齐呢?该文假设各个领域的特征可以被发送出去,和ADDA假设一致。假设有 个源域,每个源域上都训练了一个特征提取器 和分类器 ,首先对于目标域的特征提取器 和分类器 ,使用联邦学习(Federated Learning)里面的加权平均方法:其中 衡量了每个源域对目标域的贡献,一般需要满足 。FADA中提到了一种动态加权(Dynamic Attention)的方式,这里不过多介绍,主要是通过源域当前模型融合到目标域之后对目标域特征区分度的提升幅度作为衡量的标准。简单的情况下,可以取 。总之,目标域上由于没有标记,不可能训练出 ,需要通过源域的模型进行加权平均得到。接下来,FADA使用特征提取器在各个域上提取特征,即 ,然后假设这些特征可以传输到同一个设备上,就可以在该设备上训练一个域判别器(Domain Identifier, DI),注意这里的判别器和ADDA中不一样,因为涉及到多个域,此处的域判别器是多分类器,具体而言是 分类。训练域判别器的损失函数如下:其中 是向量的第 项,即上述目标会训练域判别器使得第 源域的数据会被预测为第 类别,且目标域样本被预测为第 类。训练好域判别器之后,将 发送到各个源域所在的设备,然后训练各自的特征提取器 去混淆 :FADA总的框架图如下,该框架融合了很多方法,还包括特征解耦(Feature Disentangle)等等,这里不过多介绍。总的来说,FADA将多个源域和目标域的特征发送到一个指定的设备,在该设备上训练一个域判别器,然后将域判别器下发到各个源域作为对抗项促使相应的特征提取器提取领域无关的特征。可以说,FADA是ADDA的多领域扩展版本。SHOTSHOT是比较有意思的一篇工作,名称是《Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation》,来自ICML2020,作者信息截图如下:如果说ADDA和FADA都是假设源域数据不可以被发送出设备的话,SHOT假设源域数据获取不到,即源域数据丢失或者不存在。那么在只有源域模型和目标域众多无标记数据的情况下,如何迁移呢?SHOT解决了这个问题。首先SHOT指的是Source Hypothesis Transfer,Source Hypothesis指的是源域模型的分类器。SHOT和ADDA有一个一致的地方就是,都固定住了源域模型的分类器,微调源域的特征提取器。ADDA通过对抗损失(假设可以访问到源域数据的特征)进行微调目标域特征提取器,而SHOT则是通过伪标签(Pseudo Label)自监督地训练。首先,SHOT对源域模型进行有监督地训练,源域模型可以记为 ,其中 分别是源域的特征提取器和分类器,训练时采用标记平滑(Label Smoothing),促使训练的模型具有更好的可迁移性、泛化性。然后,将源域模型拷贝到目标域, ,固定住 ,微调 。SHOT首先采用一个常见的信息最大化(Information Maximization, IM)损失,促使目标域上每个样本的分类概率的熵尽可能小,所有样本预测的概率平均值尽可能均匀。假设目标域样本 预测的结果为 ,其中 是一个Softmax的函数。那么记 为目标域样本预测概率的平均值(可以计算一个Batch的样本预测概率的平均值)。那么IM损失为:这一项损失并不能完全让目标域的特征提取器完全训练得当,因此需要使用下面的伪标签技术进行训练。伪标签技术很直观,就是利用当下的模型对无标记样本打标签,然后取预测结果置信度最高的部分样本来打标签,然后用这些伪标签的数据来继续训练这个模型。比如,对于目标域样本 ,根据模型预测概率的最大值 进行排序,选择最大的一部分对其打标签为 。直接使用伪标签训练很容易带来误差累计问题,因此需要尽可能使得伪标签打得准确,可以使用一个标签精炼(Label Refinery)的过程。具体而言包括:其中 是第 类样本的类中心, 是距离函数。以上几个公式可以看作是几步K-Means操作,第一个公式根据模型输出的概率值和每个样本的特征向量进行Soft加权得到类别中心,第二个公式根据每个样本和各个类中心的距离打标签,第三个公式是Hard加权更新类中心,第四个公式是根据距离打标签。该迭代可以重复很多次,但是一般来说使用这两步迭代之后的伪标签就会比较准确了。以上就是标签精炼的过程,主要是指使用目标域样本的关系(聚簇结果)来对伪标签进行进一步调整,而不仅仅是利用模型的预测结果。打了伪标签之后,模型可以根据交叉熵损失进行训练,综合IM损失,可以将模型性能提升至很高。总结总结一下,传统UDDA以及本文主要介绍的ADDA、FADA和SHOT可以使用下图来区分:参考文献Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell: Adversarial Discriminative Domain Adaptation. CVPR 2017: 2962-2971Xingchao Peng, Zijun Huang, Yizhe Zhu, Kate Saenko: Federated Adversarial Domain Adaptation. ICLR 2020Jian Liang, Dapeng Hu, Jiashi Feng: Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation. CoRR abs/2002.08546 (2020)
声明:本文首发于华为NAIE《网络人工智能园地》微信公众号,如有转载,请注明出处。微信公众号二维码为:http://weixin.qq.com/r/yx385OnEb7QQra2H90jZweixin.qq.com本文介绍一种特殊场景下的迁移算法:隐私保护下的迁移算法。首先,本文稍微回顾一下传统迁移算法的流程、特性和局限之处,然后文章介绍几种解决当源域数据有某些访问限制的场景下实现迁移的算法。具体包括:ADDA-CVPR2017,FADA-ICLR2020,SHOT-ICML2020。传统迁移算法UDDA首先说明这里说的传统迁移算法,主要指深度域适应(Deep Domain Adaptation),更具体的是无监督深度域适应(Unsupervised Deep Domain Adaptation, UDDA)。因为UDDA是最为常见,也是大家广泛关注的设定,因此这方面的工作远远多于其余迁移算法的设定。先介绍一下UDDA具体是做什么的:给定一个目标域(Target Domain),该域只有无标记数据,因此不能有监督地训练模型,目标域通常是一个新的局点、场景或者数据集;为了在目标域无标记数据的情况下建立模型,可以借助源域(Source Domain)的知识,源域通常是已有局点、场景或者数据集,知识可以是源域训练好的模型、源域的原始数据、源域的特征等。借助有标记信息的源域,目标域上即便没有标记数据,也可以建立一个模型。使得该模型对目标域数据有效的关键难点在于源域和目标域存在数据分布的差异,称之为域漂移(Domain Shift),如何去对齐源域和目标域的数据是UDDA解决的主要问题。UDDA通常包含下面的三种框架:首先,源域和目标域的数据(圆柱)会经过特征提取器(Encoder)提取特征(矩形),然后各种办法会对源域和目标域的特征进行操作,使得源域和目标域上数据的特征对齐。这里值得一提的是,UDDA通常假设源域和目标域的类别是一样的,比如源域和目标域都是去分类0-9十个手写数字,只不过源域和目标域的手写风格不一样。对源域和目标域特征进行操作的办法包括三种类别:基于统计对齐:使用各种统计量对齐源域和目标域特征的分布,比如对齐核空间均值(MMD Loss)、对齐协方差矩阵(CORAL Loss)等;基于对抗对齐:建立一个域分类器(Domain Classifier)作为判别器(Discriminator),目的要尽可能将源域和目标域的特征区分开来,使用梯度反转(Gradient Reversal Gradient,GRL)可以促使特征提取器提取和领域无关(Domain Invariant)的特征;基于重构对齐:将源域和目标域的特征通过同一个生成网络进行生成相应的数据,通过假设只有分布接近的样本才可以使用同一个网络生成数据对齐源域和目标域特征。关于以上几种UDDA的具体算法可以参加以前的文章:https://zhuanlan.zhihu.com/p/205433863zhuanlan.zhihu.com这里本文只给出UDDA的几个特性:源域数据可获得:UDDA假设源域数据存在并且可以获得;源域目标域数据可混合:UDDA通常假设源域和目标域数据可以在一起处理,即可以放在同一个设备上进行运算;训练预测过程是Transductive的:目标域数据必须和源域数据一同训练才可以使得特征提取器提取领域无关的特征,才可以将源域的模型迁移到目标域,因此当一批新的目标域的数据到来的话,并不能直接使用源域模型进行预测。总的来说,传统的UDDA方法假设源域数据可获得、源域目标域数据可混合、训练过程Transductive。然而,有一些场景下,源域数据不可获得,或者源域数据不可以外传,这种情况下如何进行迁移呢?首先,这里需要注意的是,源域数据不能外传和源域数据不可获得是两种情况,前者假设源域数据存在,但是不可以和目标域数据放在一起,后者是源域数据根本就不存在了。ADDAADDA是CVPR2017的一篇工作,来自论文《Adversarial Discriminative Domain Adaptation》,作者信息截图如下:一作Eric Tzeng来自于加利福尼亚大学伯克利分校,代表作有DDC和ADDA;二作Judy Hoffman来自斯坦福大学,代表作CyCADA,以及多篇在多领域迁移方面的理论文章,比如NeurIPS 2018的《Algorithms and Theory for Multiple-Source Adaptation》;三作Kate Saenko是波斯顿大学计算机科学计算机视觉组(Computer Vision and Learning Group,CVL)的Leader,是一名女性学者,Baochen Sun,Xingchao Peng,Kuniaki Saito等人都在该组深造或者深造过。CVL代表作有(个人评定,以下文章个人在学习DA的过程中或多或少阅读或者研究过):Xingchao Peng, Zijun Huang, Yizhe Zhu, Kate Saenko: Federated Adversarial Domain Adaptation. ICLR 2020Xingchao Peng, Yichen Li, Kate Saenko: Domain2Vec: Domain Embedding for Unsupervised Domain Adaptation. ECCV (6) 2020: 756-774Shuhan Tan, Xingchao Peng, Kate Saenko: Generalized Domain Adaptation with Covariate and Label Shift CO-ALignment. CoRR abs/1910.10320 (2019)Xingchao Peng, Zijun Huang, Ximeng Sun, Kate Saenko: Domain Agnostic Learning with Disentangled Representations. ICML 2019: 5102-5112Xingchao Peng, Qinxun Bai, Xide Xia, Zijun Huang, Kate Saenko, Bo Wang: Moment Matching for Multi-Source Domain Adaptation. ICCV 2019: 1406-1415Kuniaki Saito, Donghyun Kim, Stan Sclaroff, Trevor Darrell, Kate Saenko: Semi-Supervised Domain Adaptation via Minimax Entropy. ICCV 2019: 8049-8057Kuniaki Saito, Yoshitaka Ushiku, Tatsuya Harada, Kate Saenko: Adversarial Dropout Regularization. ICLR (Poster) 2018Xingchao Peng, Ben Usman, Neela Kaushik, Dequan Wang, Judy Hoffman, Kate Saenko: VisDA: A Synthetic-to-Real Benchmark for Visual Domain Adaptation. CVPR Workshops 2018: 2021-2026Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell: Adversarial Discriminative Domain Adaptation. CVPR 2017: 2962-2971Baochen Sun, Kate Saenko: Deep CORAL: Correlation Alignment for Deep Domain Adaptation. ECCV Workshops (3) 2016: 443-450Baochen Sun, Jiashi Feng, Kate Saenko: Return of Frustratingly Easy Domain Adaptation. AAAI 2016: 2058-2065Eric Tzeng, Judy Hoffman, Trevor Darrell, Kate Saenko: Simultaneous Deep Transfer Across Domains and Tasks. ICCV 2015: 4068-4076回归正题,ADDA的训练流程图如下:首先是预训练阶段(Pre-training Stage),源域上利用有标记数据训练,采用交叉熵损失:其中 为源域的特征提取器, 为源域的分类器。然后是对抗对齐阶段(Adversarial Adaptation Stage),将源域的特征提取器拷贝给目标域 ,并且将分类器 固定住迁移到目标域。然后就是对 根据目标域数据进行微调,当且仅当目标域特征提取器 在目标域提取的特征和源域特征提取器 在源域数据提取的特征相似时,源域的分类器才可以很好地适应目标域,即下面几个公式的目的主要是使得 。简单的方法仍然是使用对抗进行训练。第一步训练域判别器(Discriminator)将源域的特征和目标域的特征进行区分开, 代表域判别器:第二步,训练 ,使得 让判别器尽可能分不开:重复以上两步,直到收敛。可以看出以上过程中, 源域特征提取器 只在源域预训练阶段使用到,然后拷贝给目标域,目标域微调特征提取器。换句话说,源域训练好的模型,包括特征提取器和分类器,传输到目标域之后,目标域只微调特征提取器,使得特征提取器提取的特征单向向源域的特征对齐,分类时使用的仍然是源域的分类器。为什么说这个方法可以推广到隐私保护呢?因为可以看到,源域的数据只在预训练阶段利用到,且后面对齐的过程中只用到了源域的特征 ,而不是 ,后者需要访问到源域原始数据。总的来说,ADDA容许源域和目标域的特征提取器不一致,将 参数解耦开来,并且训练过程中其实只用到了源域的特征。如果,源域数据和目标域数据不在同一设备上,假设源域数据的特征可以发送出去的话,该方案可以做到隐私保护。FADA正如上述介绍的CVL组,Xingchao Peng将ADDA扩充到多域版本,并且提出了FADA。FADA来自ICLR2020的《Federated Adversarial Domain Adaptation》,论文首页截图如下:该文提出了一个新的场景FADA,即联邦学习下的多域迁移。假设有很多个源域,每个源域的数据分布在单独的设备上,原始数据不能外传,如何在这种情况下将其模型复用到目标域呢?简而言之,如何在数据不能被发送出去的约束下进行特征对齐呢?该文假设各个领域的特征可以被发送出去,和ADDA假设一致。假设有 个源域,每个源域上都训练了一个特征提取器 和分类器 ,首先对于目标域的特征提取器 和分类器 ,使用联邦学习(Federated Learning)里面的加权平均方法:其中 衡量了每个源域对目标域的贡献,一般需要满足 。FADA中提到了一种动态加权(Dynamic Attention)的方式,这里不过多介绍,主要是通过源域当前模型融合到目标域之后对目标域特征区分度的提升幅度作为衡量的标准。简单的情况下,可以取 。总之,目标域上由于没有标记,不可能训练出 ,需要通过源域的模型进行加权平均得到。接下来,FADA使用特征提取器在各个域上提取特征,即 ,然后假设这些特征可以传输到同一个设备上,就可以在该设备上训练一个域判别器(Domain Identifier, DI),注意这里的判别器和ADDA中不一样,因为涉及到多个域,此处的域判别器是多分类器,具体而言是 分类。训练域判别器的损失函数如下:其中 是向量的第 项,即上述目标会训练域判别器使得第 源域的数据会被预测为第 类别,且目标域样本被预测为第 类。训练好域判别器之后,将 发送到各个源域所在的设备,然后训练各自的特征提取器 去混淆 :FADA总的框架图如下,该框架融合了很多方法,还包括特征解耦(Feature Disentangle)等等,这里不过多介绍。总的来说,FADA将多个源域和目标域的特征发送到一个指定的设备,在该设备上训练一个域判别器,然后将域判别器下发到各个源域作为对抗项促使相应的特征提取器提取领域无关的特征。可以说,FADA是ADDA的多领域扩展版本。SHOTSHOT是比较有意思的一篇工作,名称是《Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation》,来自ICML2020,作者信息截图如下:如果说ADDA和FADA都是假设源域数据不可以被发送出设备的话,SHOT假设源域数据获取不到,即源域数据丢失或者不存在。那么在只有源域模型和目标域众多无标记数据的情况下,如何迁移呢?SHOT解决了这个问题。首先SHOT指的是Source Hypothesis Transfer,Source Hypothesis指的是源域模型的分类器。SHOT和ADDA有一个一致的地方就是,都固定住了源域模型的分类器,微调源域的特征提取器。ADDA通过对抗损失(假设可以访问到源域数据的特征)进行微调目标域特征提取器,而SHOT则是通过伪标签(Pseudo Label)自监督地训练。首先,SHOT对源域模型进行有监督地训练,源域模型可以记为 ,其中 分别是源域的特征提取器和分类器,训练时采用标记平滑(Label Smoothing),促使训练的模型具有更好的可迁移性、泛化性。然后,将源域模型拷贝到目标域, ,固定住 ,微调 。SHOT首先采用一个常见的信息最大化(Information Maximization, IM)损失,促使目标域上每个样本的分类概率的熵尽可能小,所有样本预测的概率平均值尽可能均匀。假设目标域样本 预测的结果为 ,其中 是一个Softmax的函数。那么记 为目标域样本预测概率的平均值(可以计算一个Batch的样本预测概率的平均值)。那么IM损失为:这一项损失并不能完全让目标域的特征提取器完全训练得当,因此需要使用下面的伪标签技术进行训练。伪标签技术很直观,就是利用当下的模型对无标记样本打标签,然后取预测结果置信度最高的部分样本来打标签,然后用这些伪标签的数据来继续训练这个模型。比如,对于目标域样本 ,根据模型预测概率的最大值 进行排序,选择最大的一部分对其打标签为 。直接使用伪标签训练很容易带来误差累计问题,因此需要尽可能使得伪标签打得准确,可以使用一个标签精炼(Label Refinery)的过程。具体而言包括:其中 是第 类样本的类中心, 是距离函数。以上几个公式可以看作是几步K-Means操作,第一个公式根据模型输出的概率值和每个样本的特征向量进行Soft加权得到类别中心,第二个公式根据每个样本和各个类中心的距离打标签,第三个公式是Hard加权更新类中心,第四个公式是根据距离打标签。该迭代可以重复很多次,但是一般来说使用这两步迭代之后的伪标签就会比较准确了。以上就是标签精炼的过程,主要是指使用目标域样本的关系(聚簇结果)来对伪标签进行进一步调整,而不仅仅是利用模型的预测结果。打了伪标签之后,模型可以根据交叉熵损失进行训练,综合IM损失,可以将模型性能提升至很高。总结总结一下,传统UDDA以及本文主要介绍的ADDA、FADA和SHOT可以使用下图来区分:参考文献Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell: Adversarial Discriminative Domain Adaptation. CVPR 2017: 2962-2971Xingchao Peng, Zijun Huang, Yizhe Zhu, Kate Saenko: Federated Adversarial Domain Adaptation. ICLR 2020Jian Liang, Dapeng Hu, Jiashi Feng: Do We Really Need to Access the Source Data? Source Hypothesis Transfer for Unsupervised Domain Adaptation. CoRR abs/2002.08546 (2020) -
 原作者:零壹财经原文链接: https://baijiahao.baidu.com/s?id=1715430319917702295&wfr=spider&for=pc目前,隐私计算市场尚处于发展的初期。从服务对象来看,在中国国内,隐私计算市场目前主要是一个面向企业的市场。但是在美国,已经出现了通过为企业提供隐私计算服务从而间接为个人提供隐私保护服务的模式,未来很有可能出现直接为个人提供隐私保护服务的应用。从行业发展成熟度来看,在中国国内,隐私计算市场的刚刚开始启动,应用刚刚落地,一切都正在尝试和探索当中。零壹智库在调研中发现,入局隐私计算的厂商背景相当多元化,这也从一个侧面印证了隐私计算这项技术将有可能影响到许多相关技术领域。一、隐私计算的To B市场与To C市场目前,在国内外,隐私计算主要是用在企业与企业之间的数据交互方面。因此,在现阶段,在全球范围内,隐私计算主要是一个To B市场。隐私计算厂商主要是通过为企业提供服务,起到保护个人隐私的作用。未来,隐私计算有出现To C市场的可能性。目前,个人数据主要是被分散存储在各种各样的场景应用中。比如,个人用户使用信用卡贷款,个人身份信息、贷款和还款的信息就会被存储在银行的信用卡中心。个人用户在网上购物,个人姓名、手机号、家庭住址、购买的物品和价格信息就会被存储在电商账户中。因此,目前的个人隐私保护在很大程度上要依赖各类企业对个人信息的保护。如果信用卡中心、电商公司、打车App、各级政府的信息系统没有保护好个人信息,个人信息就有泄露的可能。未来,有可能出现新的为个人提供信息保护的应用。这一预测来自零壹智库对加州大学伯克利分校教授、Oasis Labs创始人兼首席执行官宋晓冬的访谈。宋晓冬用“Data Vault(数据金库)”来描述未来可能出现的这一类新的应用。她认为隐私保护将逐渐落实在每个人身上,让个人成为数据的主人、并且从隐私的保护和分享中受益是大势所趋,要实现这一进程可能耗时不会超出10年的时间。二、隐私计算产业图谱(一)隐私计算产业生态隐私计算的产业生态当中,包含甲方、乙方和丙方三方。甲方指的是数据使用方。目前,这些机构集中在金融、政务、医疗、零售等几个领域。金融机构包括银行、保险等机构,其中银行数量最多。政务,各地政府部门,主要是实现政府不同部门之间的互联互通及数据共享,从而促进政府不同部门的协同,提高政府的效率以及决策质量。医疗机构,包括各地各级医院、药厂等。乙方,指的是数据源。目前金融类数据主要集中在政府、运营商、银联、互联网巨头手中。医疗数据在各地各级医院、医药公司、医保机构的系统里。政务数据主要包括是工商、司法、税务、海关、学历学籍等各政府职能部门日常运行积累的数据。政务数据,部分省市有政务数据共享平台和政务数据开放平台,但大多数数据往往散见于各地政府的各职能部门,难以互联互通,只有少数部门的数据是全国性的,其他数据都较为分散,即使是已经公开的信息很多也并不完整。丙方,指的是不拥有数据的服务机构,比如隐私计算厂商、云服务商、大数据服务商等。他们可能服务于数据源或者数据使用方,数据可能存放在他们的系统里,但是数据不属于他们。图1 隐私计算产业生态 (二)、隐私计算厂商图谱在业界,目前提供隐私计算服务的厂商大致可以分为几类:第一类,互联网巨头。目前,阿里巴巴、蚂蚁集团、微众银行、腾讯集团、百度集团、华为集团、京东集团、字节跳动等都互联网巨头都已经开始在隐私计算方向发力,旗下多个业务板块都推出了隐私计算产品。第二类,云服务商。目前,阿里云、腾讯云、百度云、京东云、金山云、华为云、优刻得等云服务商都推出了隐私计算服务。第三类,人工智能背景的公司。比如瑞莱智慧、医渡云、三眼精灵、渊亭科技。第四类,区块链背景的公司。比如矩阵元、Oasis、ARPA、趣链科技、零幺宇宙、宇链科技、翼帆数科、熠智科技、算数力、同济区块链等。第五类,有大数据背景的公司。比如星环科技。第六类,有安全背景的公司。比如阿里安全、腾讯安全、百度安全、安恒信息、神州融安、瓶钵科技、沙海科技等。第七类,软件服务商。比如普元信息、神州泰岳。第八类,有金融科技背景的公司。比如同盾科技、百融云创、富数科技、天冕科技、金智塔科技、冰鉴科技、甜橙金融等。第九类,供应链金融背景的公司。比如联易融、纸贵科技等。第十类,从隐私计算出发的初创公司。如华控清交、星云Clustar、数牍科技、蓝象智联、洞见科技、锘崴科技、翼方健数、冲量在线、光之树、融数联智、摩联科技、隔镜科技、神谱科技、同态科技、凯馨科技、煋辰数智等公司。图2 隐私计算厂商图谱 三、隐私计算公司商业模式与业务方向差异(一)商业模式据零壹智库调研了解,隐私计算公司目前有三种商业模式:第一,硬件销售。目前在隐私计算领域,有两种硬件,一种是FPGA加速卡,一种是隐私计算一体机,都是使用硬件提升隐私计算性能,更加符合实际应用场景需求。比如星云Clustar隐私计算软硬件一体机、蚂蚁摩斯隐私计算一体机等。第二,软件销售。就是销售隐私计算系统软件,大多数有隐私计算业务的公司都有这样的系统软件,比如蚂蚁摩斯多方安全计算平台、华控清交PrivPy 多方安全计算平台、同盾科技智邦平台iBond、瑞莱智慧隐私保护机器学习平台RealSecure、金智塔科技的“金智塔”隐私计算平台、天冕科技的天冕联邦学习平台WeFe、富数科技阿凡达安全计算平台、洞见科技INSIGHTONE洞见数智联邦平台、蓝象智联GAIA平台等。第三,平台分润。隐私计算公司软件销售积累了一定数量的客户之后,客户通过软件平台调用数据,获得收益之后,隐私计算公司可以获得这方面的收入。分润有三种方式:其一,数据源测分润。即根据数据调用量,在数据源收益中分润。其二,数据应用场景分润。在金融应用中,隐私计算主要应用于金融业务的风控和营销场景,可以从场景取得的收益中分润。其三,类数据代理模式。向数据源采购数据,加工成评分之后进行销售,整个过程中应用隐私计算技术。销售评分的价格,是在数据采购成本的基础上进行加价。但是,目前开源正在成为潮流,这使得在未来可能出现新的隐私计算商业模式。在中国,隐私计算的开源是从微众银行的隐私计算系统FATE开始的。2019 年 7月,微众银行一共发布了10款开源软件,其中就包括FATE——第一个开源联邦学习系统,开创了隐私计算系统开源的先例。当下,零壹智库了解到,在隐私计算领域,还有更多的公司已经或者正在加入开源的行列。比如,2020年初,字节跳动联邦学习平台 Fedlearner 开源。2020年5月,矩阵元隐私AI开源框架Rosetta发布。星云Clustar在FATE开源社区内开源了解决针对FATE平台自身存在的一些问题的方法,如解决FATE进程间通信问题的经验、技术、研究成果等。天冕科技联邦学习平台WeFe开放了全部源码,包含用户操作中心Board、网关GateWay、算法Kernel以及联邦基础设施Union等核心技术,共约30万行代码。富数科技也在考虑开源计划,并且倡导开源项目之间也要采用开放的、兼容的、公共的技术协议。对于B端,开源也在市场上逐渐发展为成熟的商业模式。主要的三种商业模式有:第一,在软件开源提供后,以软件后期的运维、部署、咨询、升级等技术手段盈利;第二,发行企业版与开源社区版双版本,企业版以服务于一些特点企业应用场景进行盈利;第三,通过将开源软件部署在云端服务器,需求方通过订阅的方式向提供方付费使用,同时这种模式也免去了实地部署等线下的过程与以及安装费用。因此,以后如果有更多的隐私计算平台开源,将可能发展出更多的商业模式。
原作者:零壹财经原文链接: https://baijiahao.baidu.com/s?id=1715430319917702295&wfr=spider&for=pc目前,隐私计算市场尚处于发展的初期。从服务对象来看,在中国国内,隐私计算市场目前主要是一个面向企业的市场。但是在美国,已经出现了通过为企业提供隐私计算服务从而间接为个人提供隐私保护服务的模式,未来很有可能出现直接为个人提供隐私保护服务的应用。从行业发展成熟度来看,在中国国内,隐私计算市场的刚刚开始启动,应用刚刚落地,一切都正在尝试和探索当中。零壹智库在调研中发现,入局隐私计算的厂商背景相当多元化,这也从一个侧面印证了隐私计算这项技术将有可能影响到许多相关技术领域。一、隐私计算的To B市场与To C市场目前,在国内外,隐私计算主要是用在企业与企业之间的数据交互方面。因此,在现阶段,在全球范围内,隐私计算主要是一个To B市场。隐私计算厂商主要是通过为企业提供服务,起到保护个人隐私的作用。未来,隐私计算有出现To C市场的可能性。目前,个人数据主要是被分散存储在各种各样的场景应用中。比如,个人用户使用信用卡贷款,个人身份信息、贷款和还款的信息就会被存储在银行的信用卡中心。个人用户在网上购物,个人姓名、手机号、家庭住址、购买的物品和价格信息就会被存储在电商账户中。因此,目前的个人隐私保护在很大程度上要依赖各类企业对个人信息的保护。如果信用卡中心、电商公司、打车App、各级政府的信息系统没有保护好个人信息,个人信息就有泄露的可能。未来,有可能出现新的为个人提供信息保护的应用。这一预测来自零壹智库对加州大学伯克利分校教授、Oasis Labs创始人兼首席执行官宋晓冬的访谈。宋晓冬用“Data Vault(数据金库)”来描述未来可能出现的这一类新的应用。她认为隐私保护将逐渐落实在每个人身上,让个人成为数据的主人、并且从隐私的保护和分享中受益是大势所趋,要实现这一进程可能耗时不会超出10年的时间。二、隐私计算产业图谱(一)隐私计算产业生态隐私计算的产业生态当中,包含甲方、乙方和丙方三方。甲方指的是数据使用方。目前,这些机构集中在金融、政务、医疗、零售等几个领域。金融机构包括银行、保险等机构,其中银行数量最多。政务,各地政府部门,主要是实现政府不同部门之间的互联互通及数据共享,从而促进政府不同部门的协同,提高政府的效率以及决策质量。医疗机构,包括各地各级医院、药厂等。乙方,指的是数据源。目前金融类数据主要集中在政府、运营商、银联、互联网巨头手中。医疗数据在各地各级医院、医药公司、医保机构的系统里。政务数据主要包括是工商、司法、税务、海关、学历学籍等各政府职能部门日常运行积累的数据。政务数据,部分省市有政务数据共享平台和政务数据开放平台,但大多数数据往往散见于各地政府的各职能部门,难以互联互通,只有少数部门的数据是全国性的,其他数据都较为分散,即使是已经公开的信息很多也并不完整。丙方,指的是不拥有数据的服务机构,比如隐私计算厂商、云服务商、大数据服务商等。他们可能服务于数据源或者数据使用方,数据可能存放在他们的系统里,但是数据不属于他们。图1 隐私计算产业生态 (二)、隐私计算厂商图谱在业界,目前提供隐私计算服务的厂商大致可以分为几类:第一类,互联网巨头。目前,阿里巴巴、蚂蚁集团、微众银行、腾讯集团、百度集团、华为集团、京东集团、字节跳动等都互联网巨头都已经开始在隐私计算方向发力,旗下多个业务板块都推出了隐私计算产品。第二类,云服务商。目前,阿里云、腾讯云、百度云、京东云、金山云、华为云、优刻得等云服务商都推出了隐私计算服务。第三类,人工智能背景的公司。比如瑞莱智慧、医渡云、三眼精灵、渊亭科技。第四类,区块链背景的公司。比如矩阵元、Oasis、ARPA、趣链科技、零幺宇宙、宇链科技、翼帆数科、熠智科技、算数力、同济区块链等。第五类,有大数据背景的公司。比如星环科技。第六类,有安全背景的公司。比如阿里安全、腾讯安全、百度安全、安恒信息、神州融安、瓶钵科技、沙海科技等。第七类,软件服务商。比如普元信息、神州泰岳。第八类,有金融科技背景的公司。比如同盾科技、百融云创、富数科技、天冕科技、金智塔科技、冰鉴科技、甜橙金融等。第九类,供应链金融背景的公司。比如联易融、纸贵科技等。第十类,从隐私计算出发的初创公司。如华控清交、星云Clustar、数牍科技、蓝象智联、洞见科技、锘崴科技、翼方健数、冲量在线、光之树、融数联智、摩联科技、隔镜科技、神谱科技、同态科技、凯馨科技、煋辰数智等公司。图2 隐私计算厂商图谱 三、隐私计算公司商业模式与业务方向差异(一)商业模式据零壹智库调研了解,隐私计算公司目前有三种商业模式:第一,硬件销售。目前在隐私计算领域,有两种硬件,一种是FPGA加速卡,一种是隐私计算一体机,都是使用硬件提升隐私计算性能,更加符合实际应用场景需求。比如星云Clustar隐私计算软硬件一体机、蚂蚁摩斯隐私计算一体机等。第二,软件销售。就是销售隐私计算系统软件,大多数有隐私计算业务的公司都有这样的系统软件,比如蚂蚁摩斯多方安全计算平台、华控清交PrivPy 多方安全计算平台、同盾科技智邦平台iBond、瑞莱智慧隐私保护机器学习平台RealSecure、金智塔科技的“金智塔”隐私计算平台、天冕科技的天冕联邦学习平台WeFe、富数科技阿凡达安全计算平台、洞见科技INSIGHTONE洞见数智联邦平台、蓝象智联GAIA平台等。第三,平台分润。隐私计算公司软件销售积累了一定数量的客户之后,客户通过软件平台调用数据,获得收益之后,隐私计算公司可以获得这方面的收入。分润有三种方式:其一,数据源测分润。即根据数据调用量,在数据源收益中分润。其二,数据应用场景分润。在金融应用中,隐私计算主要应用于金融业务的风控和营销场景,可以从场景取得的收益中分润。其三,类数据代理模式。向数据源采购数据,加工成评分之后进行销售,整个过程中应用隐私计算技术。销售评分的价格,是在数据采购成本的基础上进行加价。但是,目前开源正在成为潮流,这使得在未来可能出现新的隐私计算商业模式。在中国,隐私计算的开源是从微众银行的隐私计算系统FATE开始的。2019 年 7月,微众银行一共发布了10款开源软件,其中就包括FATE——第一个开源联邦学习系统,开创了隐私计算系统开源的先例。当下,零壹智库了解到,在隐私计算领域,还有更多的公司已经或者正在加入开源的行列。比如,2020年初,字节跳动联邦学习平台 Fedlearner 开源。2020年5月,矩阵元隐私AI开源框架Rosetta发布。星云Clustar在FATE开源社区内开源了解决针对FATE平台自身存在的一些问题的方法,如解决FATE进程间通信问题的经验、技术、研究成果等。天冕科技联邦学习平台WeFe开放了全部源码,包含用户操作中心Board、网关GateWay、算法Kernel以及联邦基础设施Union等核心技术,共约30万行代码。富数科技也在考虑开源计划,并且倡导开源项目之间也要采用开放的、兼容的、公共的技术协议。对于B端,开源也在市场上逐渐发展为成熟的商业模式。主要的三种商业模式有:第一,在软件开源提供后,以软件后期的运维、部署、咨询、升级等技术手段盈利;第二,发行企业版与开源社区版双版本,企业版以服务于一些特点企业应用场景进行盈利;第三,通过将开源软件部署在云端服务器,需求方通过订阅的方式向提供方付费使用,同时这种模式也免去了实地部署等线下的过程与以及安装费用。因此,以后如果有更多的隐私计算平台开源,将可能发展出更多的商业模式。 -
01 隐私计算联盟介绍联 盟 名 称:隐私计算联盟,简称为 CCC。联 盟 定 义:隐私计算联盟(CCC)成立于 2019 年 10 月 17 日,是 Linux 基金会的一个项目社区,致力于定义和加速采用隐私计算。联盟将采取开放式治理和协作,将全球顶尖的硬件供应商、云提供商和软件开发人员召集在一起,以加速推动隐私计算市场的发展;影响技术和法规标准;建立开源工具,为 TEE 开发提供合适的环境”并主持行业推广和教育计划。它的目的是解决使用中数据的计算信任和安全性,使加密的数据可以在内存中进行处理而不会暴露给系统的其余部分,从而减少了对敏感数据的暴露,并为用户提供了更好的控制和透明度。联 盟 成 员:隐私计算联盟(CCC)汇聚业界最顶尖的技术领导者,致力于提高了下一代互联网的计算信任度和安全性,参与联盟的成员包括:Oasis Labs、阿里巴巴、华为、英特尔、微软、Google Cloud、Red Hat、百度、字节跳动、Fortanix、Kindite、瑞士电信、腾讯和 VMware 等。02 隐私计算联盟贡献隐私计算联盟是针对使用中的数据的首批全行业计划之一,随着公司将更多的工作负载转移到跨多个环境(从本地到公共云再到隐私)的过程中,隐私计算联盟的重点尤其重要。联盟正式成立后,建立了开放的治理结构,包括一个理事会,一个技术咨询委员会以及对每个技术项目的独立监督团,旨在托管各种技术开源项目和开放规范,以支持隐私计算。目前联盟的贡献包括:Software Guard Extensions (Intel SGX) SDK:旨在帮助应用程序开发人员使用受保护的内存隔离区,保护选定的代码和数据免于在硬件层泄露或修改。Open Enclave SDK:这是一个开放源代码框架,允许开发人员使用单个包含抽象来构建受信任的执行环境(TEE)应用程序。一旦在多种 TEE 架构上运行,开发人员便可以构建应用程序。Enarx:一个为使用 TEE 保护应用程序提供硬件独立性的项目。联盟是开源的欧洲首脑会议的赞助商之一,在如何处理安全性数据会话中,联盟在国际社会频频发声并取得不错反响。03 华为可信智能计算产品华为云可信智能计算服务TICS基于可信计算环境TEE(鲲鹏Trustzone和Intel SGX),同时采用安全多方计算、同态加密、联邦学习、差分隐私等隐私增强计算技术,满足政府、企业和金融机构在数据资源开发利用中的多样隐私保护需求,实现数据可用不可见,推动多方机构协同进行模型训练和数据分析等多方数据隐私计算,兼顾性能提升和隐私保护,助力政企信用联合风控与政府数据融合共治,提升政府、企业和金融机构治理效能。未来,华为云可信智能计算服务TICS将持续注入更领先的技术,为行业智能升级提供无限可能。
-
 【摘要】 GaussDB (DWS)产品数据脱敏功能,是数据库产品内化和夯实数据安全能力的重要技术突破。提供指定用户范围内列级敏感数据的脱敏功能,具有灵活、高效、透明、友好等优点,极大地增强产品的数据安全能力,实现敏感数据的可靠保护。更佳阅读体验,请移步【原创】GaussDB(DWS)安全:隐私保护现真招儿——数据脱敏引言 大数据时代的到来,颠覆了传统业态的运作模式,激发出新的生产潜能。数据成为重要的生产要素,是信息的载体,数据间的流动也潜藏着更高阶维度的价值信息。对于数据控制者和数据处理者而言,如何最大化数据流动的价值,是数据挖掘的初衷和意义。然而,一系列信息泄露事件的曝光,使得数据安全越来越受到广泛的关注。各国各地区逐步建立健全和完善数据安全与隐私保护相关法律法规,提供用户隐私保护的法律保障。如何加强技术层面的数据安全和隐私保护,对数据仓库产品本身提出更多的功能要求,也是数据安全建设最行之有效的办法。 GaussDB (DWS)产品8.1.1版本发布数据脱敏特性,提供指定用户范围内列级敏感数据的脱敏功能,具有灵活、高效、透明、友好等优点,极大地增强产品的数据安全能力。什么是数据脱敏? 数据脱敏(Data Masking),顾名思义,是屏蔽敏感数据,对某些敏感信息(比如,身份证号、手机号、卡号、客户姓名、客户地址、邮箱地址、薪资等等 )通过脱敏规则进行数据的变形,实现隐私数据的可靠保护。业界常见的脱敏规则有,替换、重排、加密、截断、掩码,用户也可以根据期望的脱敏算法自定义脱敏规则。 通常,良好的数据脱敏实施,需要遵循如下两个原则,第一,尽可能地为脱敏后的应用,保留脱敏前的有意义信息;第二,最大程度地防止黑客进行破解。 数据脱敏分为静态数据脱敏和动态数据脱敏。静态数据脱敏,是数据的“搬移并仿真替换”,是将数据抽取进行脱敏处理后,下发给下游环节,随意取用和读写的,脱敏后数据与生产环境相隔离,满足业务需求的同时保障生产数据库的安全。动态数据脱敏,在访问敏感数据的同时实时进行脱敏处理,可以为不同角色、不同权限、不同数据类型执行不同的脱敏方案,从而确保返回的数据可用而安全。 GaussDB (DWS)的数据脱敏功能,摒弃业务应用层脱敏依赖性高、代价大等痛点,将数据脱敏内化为数据库产品自身的安全能力,提供了一套完整、安全、灵活、透明、友好的数据脱敏解决方案,属于动态数据脱敏。用户识别敏感字段后,基于目标字段,绑定内置脱敏函数,即可创建脱敏策略。脱敏策略(Redaction Policy)与表对象是一一对应的。一个脱敏策略包含表对象、生效条件、脱敏列-脱敏函数对三个关键要素,是该表对象上所有脱敏列的集合,不同字段可以根据数据特征采用不同的脱敏函数。当且仅当生效条件为真时,查询语句才会触发敏感数据的脱敏,而脱敏过程是内置在SQL引擎内部实现的,对生成环境用户是透明不可见的。怎么用数据脱敏? 动态数据脱敏,是在查询语句执行过程中,根据生效条件是否满足,实现实时的脱敏处理。生效条件,通常是针对当前用户角色的判断。敏感数据的可见范围,即是针对不同用户预设的。系统管理员,具有最高权限,任何时刻对任何表的任何字段都可见。确定受限制用户角色,是创建脱敏策略的第一步。 敏感信息依赖于实际业务场景和安全维度,以自然人为例,用户个体的敏感字段包括:姓名、身份证号、手机号、邮箱地址等等;在银行系统,作为客户,可能还涉及银行卡号、过期时间、支付密码等等;在公司系统,作为员工,可能还涉及薪资、教育背景等;在医疗系统,作为患者,可能还涉及就诊信息等等。所以,识别和梳理具体业务场景的敏感字段,是创建脱敏策略的第二步。 产品内置一系列常见的脱敏函数接口,可以针对不同数据类型和数据特征,指定参数,从而达到不一样的脱敏效果。脱敏函数可采用如下三种内置接口,同时支持自定义脱敏函数。三种内置脱敏函数能够涵盖大部分场景的脱敏效果,不推荐使用自定义脱敏函数。MASK_NONE:不作脱敏处理,仅内部测试用。MASK_FULL:全脱敏成固定值。MASK_PARTIAL:使用指定的脱敏字符对脱敏范围内的内容做部分脱敏。 不同脱敏列可以采用不同的脱敏函数。比如,手机号通常显示后四位尾号,前面用"*"替换;金额统一显示为固定值0,等等。确定脱敏列需要绑定的脱敏函数,是创建脱敏策略的第三步。 以某公司员工表emp,表的属主用户alice以及用户matu、july为例,简单介绍数据脱敏的使用过程。其中,表emp包含员工的姓名、手机号、邮箱、发薪卡号、薪资等隐私数据,用户alice是人力资源经理,用户matu和july是普通职员。 假设表、用户及用户对表emp的查看权限均已就绪。创建脱敏策略mask_emp,仅允许alice查看员工所有信息,matu和july对发薪卡号、薪资均不可见。字段card_no是数值类型,采用MASK_FULL全脱敏成固定值0;字段card_string是字符类型,采用MASK_PARTIAL按指定的输入输出格式对原始数据作部分脱敏;字段salary是数值类型,采用数字9部分脱敏倒数第二位前的所有数位值。postgres=# CREATE REDACTION POLICY mask_emp ON emp WHEN (current_user != 'alice') ADD COLUMN card_no WITH mask_full(card_no), ADD COLUMN card_string WITH mask_partial(card_string, 'VVVVFVVVVFVVVVFVVVV','VVVV-VVVV-VVVV-VVVV','#',1,12), ADD COLUMN salary WITH mask_partial(salary, '9', 1, length(salary) - 2); 切换到matu和july,查看员工表emp。postgres=>SET ROLE matu PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+---------+---------------------+----------------------+------------+--------------------- 1 | anny | 13420002340 | 0 | ####-####-####-1234 | smithWu@163.com | 99999.9990 | 1999-10-02 00:00:00 2 | bob | 18299023211 | 0 | ####-####-####-3456 | 66allen_mm@qq.com | 9999.9990 | 1989-12-12 00:00:00 3 | cici | 15512231233 | | | jonesishere@sina.com | | 1992-11-06 00:00:00 (3 rows) postgres=>SET ROLE july PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+---------+---------------------+----------------------+------------+--------------------- 1 | anny | 13420002340 | 0 | ####-####-####-1234 | smithWu@163.com | 99999.9990 | 1999-10-02 00:00:00 2 | bob | 18299023211 | 0 | ####-####-####-3456 | 66allen_mm@qq.com | 9999.9990 | 1989-12-12 00:00:00 3 | cici | 15512231233 | | | jonesishere@sina.com | | 1992-11-06 00:00:00 (3 rows) 2. 由于工作调整,matu进入人力资源部参与公司招聘事宜,也对员工所有信息可见,修改策略生效条件。postgres=>ALTER REDACTION POLICY mask_emp ON emp WHEN(current_user NOT IN ('alice', 'matu')); 切换到用户matu和july,重新查看员工表emp。postgres=>SET ROLE matu PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+------------------+---------------------+----------------------+------------+--------------------- 1 | anny | 13420002340 | 1234123412341234 | 1234-1234-1234-1234 | smithWu@163.com | 10000.0000 | 1999-10-02 00:00:00 2 | bob | 18299023211 | 3456345634563456 | 3456-3456-3456-3456 | 66allen_mm@qq.com | 9999.9900 | 1989-12-12 00:00:00 3 | cici | 15512231233 | | | jonesishere@sina.com | | 1992-11-06 00:00:00 (3 rows) postgres=>SET ROLE july PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+---------+---------------------+----------------------+------------+--------------------- 1 | anny | 13420002340 | 0 | ####-####-####-1234 | smithWu@163.com | 99999.9990 | 1999-10-02 00:00:00 2 | bob | 18299023211 | 0 | ####-####-####-3456 | 66allen_mm@qq.com | 9999.9990 | 1989-12-12 00:00:00 3 | cici | 15512231233 | | | jonesishere@sina.com | | 1992-11-06 00:00:00 (3 rows) 3. 员工信息phone_no、email和birthday也是隐私数据,更新脱敏策略mask_emp,新增三个脱敏列。postgres=>ALTER REDACTION POLICY mask_emp ON emp ADD COLUMN phone_no WITH mask_partial(phone_no, '*', 4); postgres=>ALTER REDACTION POLICY mask_emp ON emp ADD COLUMN email WITH mask_partial(email, '*', 1, position('@' in email)); postgres=>ALTER REDACTION POLICY mask_emp ON emp ADD COLUMN birthday WITH mask_full(birthday); 切换到用户july,查看员工表emp。postgres=>SET ROLE july PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+---------+---------------------+----------------------+------------+--------------------- 1 | anny | 134******** | 0 | ####-####-####-1234 | ********163.com | 99999.9990 | 1970-01-01 00:00:00 2 | bob | 182******** | 0 | ####-####-####-3456 | ***********qq.com | 9999.9990 | 1970-01-01 00:00:00 3 | cici | 155******** | | | ************sina.com | | 1970-01-01 00:00:00 (3 rows) 4. 考虑用户交互的友好性,GaussDB (DWS) 提供系统视图redaction_policies和redaction_columns,方便用户直接查看更多脱敏信息。postgres=>SELECT * FROM redaction_policies; object_schema | object_owner | object_name | policy_name | expression | enable | policy_description ---------------+--------------+-------------+-------------+-----------------------------------+--------+-------------------- public | alice | emp | mask_emp | ("current_user"() NOT IN ('alice'::name, 'matu'::name)) | t | (1 row) postgres=>SELECT object_name, column_name, function_info FROM redaction_columns; object_name | column_name | function_info -------------+-------------+------------------------------------------------------------------------------------------------------- emp | card_no | mask_full(card_no) emp | card_string | mask_partial(card_string, 'VVVVFVVVVFVVVVFVVVV'::text, 'VVVV-VVVV-VVVV-VVVV'::text, '#'::text, 1, 12) emp | email | mask_partial(email, '*'::text, 1, "position"(email, '@'::text)) emp | salary | mask_partial(salary, '9'::text, 1, (length((salary)::text) - 2)) emp | birthday | mask_full(birthday) emp | phone_no | mask_partial(phone_no, '*'::text, 4) (6 rows) 5. 突然某一天,公司内部可共享员工信息时,直接删除表emp的脱敏策略mask_emp即可。postgres=# DROP REDACTION POLICY mask_emp ON emp;更多用法详情,请参考GaussDB (DWS) 8.1.1产品文档。数据脱敏实现背后的秘密 GaussDB (DWS)数据脱敏功能,基于SQL引擎既有的实现框架,在受限用户执行查询语句过程中,实现外部不感知的实时脱敏处理。关于其内部实现,如上图所示。我们将脱敏策略(Redaction Policy)视为表对象上绑定的规则,在优化器查询重写阶段,遍历Query Tree中TargetList的每个TargetEntry,如若涉及基表的某个脱敏列,且当前脱敏规则生效(即满足脱敏策略的生效条件且enable开启状态),则断定此TargetEntry中涉及要脱敏的Var对象,此时,遍历脱敏列系统表pg_redaction_column,查找到对应脱敏列绑定的脱敏函数,将其替换成对应的FuncExpr即可。经过上述对Query Tree的重写处理,优化器会自动生成新的执行计划,执行器遵照新的计划执行,查询结果将对敏感数据做脱敏处理。 带有数据脱敏的语句执行,相较于原始语句,增加了数据脱敏的逻辑处理,势必会给查询带来额外的开销。这部分开销,主要受表的数据规模、查询目标列涉及的脱敏列数、脱敏列采用的脱敏函数三方面因素影响。 针对简单查询语句,以tpch表customer为例,针对上述因素展开测试,如下图所示。 图(a)、(b)中基表customer根据字段类型和特征,既有采用MASK_FULL脱敏函数的,也有采用MASK_PARTIAL脱敏函数的。MASK_FULL对于任何长度和类型的原始数据,均只脱敏成固定值,所以,输出结果相较于原始数据,差异很大。图(a)显示不同数据规模下,脱敏和非脱敏场景简单查询语句的执行耗时。实心图标为非脱敏场景,空心图标为被限制用户,即脱敏场景。可见,数据规模越大,带有脱敏的查询耗时与原始语句差异越大。图(b)显示10x数据规模下查询涉及脱敏列数不同对于语句执行性能的影响。涉及1列脱敏列时,带有脱敏的查询比原始语句慢,追溯发现,此列采用的是MASK_PARTIAL部分脱敏函数,查询结果只是改变了结果的格式,结果内容的长度并未变化,符合“带有脱敏的语句执行会有相应的性能劣化”的理论猜想。随着查询涉及脱敏列数的增加,我们发现一个奇怪的现象,脱敏场景反倒比原始语句执行更快。进一步追溯多列场景下脱敏列关联的脱敏函数,发现,正是因为存在使用MASK_FULL全脱敏函数的脱敏列,导致输出结果集部分相比原始数据节省很多时间开销,从而多列查询下带有数据脱敏的简单查询反倒提速不少。 为了佐证上述猜测,我们调整脱敏函数,所有脱敏列均采用MASK_PARTIAL对原始数据做部分脱敏,从而能够在脱敏结果上保留原始数据的外部可读性。于是,如图(c)所示,当脱敏列均关联部分脱敏函数时,带有数据脱敏的语句比原始语句劣化10%左右,理论上讲,这种劣化是在可接受范围的。上述测试仅针对简单的查询语句,当语句复杂到带有聚集函数或复杂表达式运算时,可能这种性能劣化会更明显。总结GaussDB (DWS)产品数据脱敏功能,是数据库产品内化和夯实数据安全能力的重要技术突破,主要涵盖以下三个方面:一套简单、易用的数据脱敏策略语法;一系列可覆盖常见隐私数据脱敏效果的、灵活配置的内置脱敏函数;一个完备、便捷的脱敏策略应用方案,使得原始语句在执行过程中可以实时、透明、高效地实现脱敏。总而言之,此数据脱敏功能可以充分满足客户业务场景的数据脱敏诉求,支持常见隐私数据的脱敏效果,实现敏感数据的可靠保护。【温馨提示】使用过程中,如有疑问,欢迎随时交流反馈。
【摘要】 GaussDB (DWS)产品数据脱敏功能,是数据库产品内化和夯实数据安全能力的重要技术突破。提供指定用户范围内列级敏感数据的脱敏功能,具有灵活、高效、透明、友好等优点,极大地增强产品的数据安全能力,实现敏感数据的可靠保护。更佳阅读体验,请移步【原创】GaussDB(DWS)安全:隐私保护现真招儿——数据脱敏引言 大数据时代的到来,颠覆了传统业态的运作模式,激发出新的生产潜能。数据成为重要的生产要素,是信息的载体,数据间的流动也潜藏着更高阶维度的价值信息。对于数据控制者和数据处理者而言,如何最大化数据流动的价值,是数据挖掘的初衷和意义。然而,一系列信息泄露事件的曝光,使得数据安全越来越受到广泛的关注。各国各地区逐步建立健全和完善数据安全与隐私保护相关法律法规,提供用户隐私保护的法律保障。如何加强技术层面的数据安全和隐私保护,对数据仓库产品本身提出更多的功能要求,也是数据安全建设最行之有效的办法。 GaussDB (DWS)产品8.1.1版本发布数据脱敏特性,提供指定用户范围内列级敏感数据的脱敏功能,具有灵活、高效、透明、友好等优点,极大地增强产品的数据安全能力。什么是数据脱敏? 数据脱敏(Data Masking),顾名思义,是屏蔽敏感数据,对某些敏感信息(比如,身份证号、手机号、卡号、客户姓名、客户地址、邮箱地址、薪资等等 )通过脱敏规则进行数据的变形,实现隐私数据的可靠保护。业界常见的脱敏规则有,替换、重排、加密、截断、掩码,用户也可以根据期望的脱敏算法自定义脱敏规则。 通常,良好的数据脱敏实施,需要遵循如下两个原则,第一,尽可能地为脱敏后的应用,保留脱敏前的有意义信息;第二,最大程度地防止黑客进行破解。 数据脱敏分为静态数据脱敏和动态数据脱敏。静态数据脱敏,是数据的“搬移并仿真替换”,是将数据抽取进行脱敏处理后,下发给下游环节,随意取用和读写的,脱敏后数据与生产环境相隔离,满足业务需求的同时保障生产数据库的安全。动态数据脱敏,在访问敏感数据的同时实时进行脱敏处理,可以为不同角色、不同权限、不同数据类型执行不同的脱敏方案,从而确保返回的数据可用而安全。 GaussDB (DWS)的数据脱敏功能,摒弃业务应用层脱敏依赖性高、代价大等痛点,将数据脱敏内化为数据库产品自身的安全能力,提供了一套完整、安全、灵活、透明、友好的数据脱敏解决方案,属于动态数据脱敏。用户识别敏感字段后,基于目标字段,绑定内置脱敏函数,即可创建脱敏策略。脱敏策略(Redaction Policy)与表对象是一一对应的。一个脱敏策略包含表对象、生效条件、脱敏列-脱敏函数对三个关键要素,是该表对象上所有脱敏列的集合,不同字段可以根据数据特征采用不同的脱敏函数。当且仅当生效条件为真时,查询语句才会触发敏感数据的脱敏,而脱敏过程是内置在SQL引擎内部实现的,对生成环境用户是透明不可见的。怎么用数据脱敏? 动态数据脱敏,是在查询语句执行过程中,根据生效条件是否满足,实现实时的脱敏处理。生效条件,通常是针对当前用户角色的判断。敏感数据的可见范围,即是针对不同用户预设的。系统管理员,具有最高权限,任何时刻对任何表的任何字段都可见。确定受限制用户角色,是创建脱敏策略的第一步。 敏感信息依赖于实际业务场景和安全维度,以自然人为例,用户个体的敏感字段包括:姓名、身份证号、手机号、邮箱地址等等;在银行系统,作为客户,可能还涉及银行卡号、过期时间、支付密码等等;在公司系统,作为员工,可能还涉及薪资、教育背景等;在医疗系统,作为患者,可能还涉及就诊信息等等。所以,识别和梳理具体业务场景的敏感字段,是创建脱敏策略的第二步。 产品内置一系列常见的脱敏函数接口,可以针对不同数据类型和数据特征,指定参数,从而达到不一样的脱敏效果。脱敏函数可采用如下三种内置接口,同时支持自定义脱敏函数。三种内置脱敏函数能够涵盖大部分场景的脱敏效果,不推荐使用自定义脱敏函数。MASK_NONE:不作脱敏处理,仅内部测试用。MASK_FULL:全脱敏成固定值。MASK_PARTIAL:使用指定的脱敏字符对脱敏范围内的内容做部分脱敏。 不同脱敏列可以采用不同的脱敏函数。比如,手机号通常显示后四位尾号,前面用"*"替换;金额统一显示为固定值0,等等。确定脱敏列需要绑定的脱敏函数,是创建脱敏策略的第三步。 以某公司员工表emp,表的属主用户alice以及用户matu、july为例,简单介绍数据脱敏的使用过程。其中,表emp包含员工的姓名、手机号、邮箱、发薪卡号、薪资等隐私数据,用户alice是人力资源经理,用户matu和july是普通职员。 假设表、用户及用户对表emp的查看权限均已就绪。创建脱敏策略mask_emp,仅允许alice查看员工所有信息,matu和july对发薪卡号、薪资均不可见。字段card_no是数值类型,采用MASK_FULL全脱敏成固定值0;字段card_string是字符类型,采用MASK_PARTIAL按指定的输入输出格式对原始数据作部分脱敏;字段salary是数值类型,采用数字9部分脱敏倒数第二位前的所有数位值。postgres=# CREATE REDACTION POLICY mask_emp ON emp WHEN (current_user != 'alice') ADD COLUMN card_no WITH mask_full(card_no), ADD COLUMN card_string WITH mask_partial(card_string, 'VVVVFVVVVFVVVVFVVVV','VVVV-VVVV-VVVV-VVVV','#',1,12), ADD COLUMN salary WITH mask_partial(salary, '9', 1, length(salary) - 2); 切换到matu和july,查看员工表emp。postgres=>SET ROLE matu PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+---------+---------------------+----------------------+------------+--------------------- 1 | anny | 13420002340 | 0 | ####-####-####-1234 | smithWu@163.com | 99999.9990 | 1999-10-02 00:00:00 2 | bob | 18299023211 | 0 | ####-####-####-3456 | 66allen_mm@qq.com | 9999.9990 | 1989-12-12 00:00:00 3 | cici | 15512231233 | | | jonesishere@sina.com | | 1992-11-06 00:00:00 (3 rows) postgres=>SET ROLE july PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+---------+---------------------+----------------------+------------+--------------------- 1 | anny | 13420002340 | 0 | ####-####-####-1234 | smithWu@163.com | 99999.9990 | 1999-10-02 00:00:00 2 | bob | 18299023211 | 0 | ####-####-####-3456 | 66allen_mm@qq.com | 9999.9990 | 1989-12-12 00:00:00 3 | cici | 15512231233 | | | jonesishere@sina.com | | 1992-11-06 00:00:00 (3 rows) 2. 由于工作调整,matu进入人力资源部参与公司招聘事宜,也对员工所有信息可见,修改策略生效条件。postgres=>ALTER REDACTION POLICY mask_emp ON emp WHEN(current_user NOT IN ('alice', 'matu')); 切换到用户matu和july,重新查看员工表emp。postgres=>SET ROLE matu PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+------------------+---------------------+----------------------+------------+--------------------- 1 | anny | 13420002340 | 1234123412341234 | 1234-1234-1234-1234 | smithWu@163.com | 10000.0000 | 1999-10-02 00:00:00 2 | bob | 18299023211 | 3456345634563456 | 3456-3456-3456-3456 | 66allen_mm@qq.com | 9999.9900 | 1989-12-12 00:00:00 3 | cici | 15512231233 | | | jonesishere@sina.com | | 1992-11-06 00:00:00 (3 rows) postgres=>SET ROLE july PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+---------+---------------------+----------------------+------------+--------------------- 1 | anny | 13420002340 | 0 | ####-####-####-1234 | smithWu@163.com | 99999.9990 | 1999-10-02 00:00:00 2 | bob | 18299023211 | 0 | ####-####-####-3456 | 66allen_mm@qq.com | 9999.9990 | 1989-12-12 00:00:00 3 | cici | 15512231233 | | | jonesishere@sina.com | | 1992-11-06 00:00:00 (3 rows) 3. 员工信息phone_no、email和birthday也是隐私数据,更新脱敏策略mask_emp,新增三个脱敏列。postgres=>ALTER REDACTION POLICY mask_emp ON emp ADD COLUMN phone_no WITH mask_partial(phone_no, '*', 4); postgres=>ALTER REDACTION POLICY mask_emp ON emp ADD COLUMN email WITH mask_partial(email, '*', 1, position('@' in email)); postgres=>ALTER REDACTION POLICY mask_emp ON emp ADD COLUMN birthday WITH mask_full(birthday); 切换到用户july,查看员工表emp。postgres=>SET ROLE july PASSWORD 'Gauss@123'; postgres=>SELECT * FROM emp; id | name | phone_no | card_no | card_string | email | salary | birthday ----+------+-------------+---------+---------------------+----------------------+------------+--------------------- 1 | anny | 134******** | 0 | ####-####-####-1234 | ********163.com | 99999.9990 | 1970-01-01 00:00:00 2 | bob | 182******** | 0 | ####-####-####-3456 | ***********qq.com | 9999.9990 | 1970-01-01 00:00:00 3 | cici | 155******** | | | ************sina.com | | 1970-01-01 00:00:00 (3 rows) 4. 考虑用户交互的友好性,GaussDB (DWS) 提供系统视图redaction_policies和redaction_columns,方便用户直接查看更多脱敏信息。postgres=>SELECT * FROM redaction_policies; object_schema | object_owner | object_name | policy_name | expression | enable | policy_description ---------------+--------------+-------------+-------------+-----------------------------------+--------+-------------------- public | alice | emp | mask_emp | ("current_user"() NOT IN ('alice'::name, 'matu'::name)) | t | (1 row) postgres=>SELECT object_name, column_name, function_info FROM redaction_columns; object_name | column_name | function_info -------------+-------------+------------------------------------------------------------------------------------------------------- emp | card_no | mask_full(card_no) emp | card_string | mask_partial(card_string, 'VVVVFVVVVFVVVVFVVVV'::text, 'VVVV-VVVV-VVVV-VVVV'::text, '#'::text, 1, 12) emp | email | mask_partial(email, '*'::text, 1, "position"(email, '@'::text)) emp | salary | mask_partial(salary, '9'::text, 1, (length((salary)::text) - 2)) emp | birthday | mask_full(birthday) emp | phone_no | mask_partial(phone_no, '*'::text, 4) (6 rows) 5. 突然某一天,公司内部可共享员工信息时,直接删除表emp的脱敏策略mask_emp即可。postgres=# DROP REDACTION POLICY mask_emp ON emp;更多用法详情,请参考GaussDB (DWS) 8.1.1产品文档。数据脱敏实现背后的秘密 GaussDB (DWS)数据脱敏功能,基于SQL引擎既有的实现框架,在受限用户执行查询语句过程中,实现外部不感知的实时脱敏处理。关于其内部实现,如上图所示。我们将脱敏策略(Redaction Policy)视为表对象上绑定的规则,在优化器查询重写阶段,遍历Query Tree中TargetList的每个TargetEntry,如若涉及基表的某个脱敏列,且当前脱敏规则生效(即满足脱敏策略的生效条件且enable开启状态),则断定此TargetEntry中涉及要脱敏的Var对象,此时,遍历脱敏列系统表pg_redaction_column,查找到对应脱敏列绑定的脱敏函数,将其替换成对应的FuncExpr即可。经过上述对Query Tree的重写处理,优化器会自动生成新的执行计划,执行器遵照新的计划执行,查询结果将对敏感数据做脱敏处理。 带有数据脱敏的语句执行,相较于原始语句,增加了数据脱敏的逻辑处理,势必会给查询带来额外的开销。这部分开销,主要受表的数据规模、查询目标列涉及的脱敏列数、脱敏列采用的脱敏函数三方面因素影响。 针对简单查询语句,以tpch表customer为例,针对上述因素展开测试,如下图所示。 图(a)、(b)中基表customer根据字段类型和特征,既有采用MASK_FULL脱敏函数的,也有采用MASK_PARTIAL脱敏函数的。MASK_FULL对于任何长度和类型的原始数据,均只脱敏成固定值,所以,输出结果相较于原始数据,差异很大。图(a)显示不同数据规模下,脱敏和非脱敏场景简单查询语句的执行耗时。实心图标为非脱敏场景,空心图标为被限制用户,即脱敏场景。可见,数据规模越大,带有脱敏的查询耗时与原始语句差异越大。图(b)显示10x数据规模下查询涉及脱敏列数不同对于语句执行性能的影响。涉及1列脱敏列时,带有脱敏的查询比原始语句慢,追溯发现,此列采用的是MASK_PARTIAL部分脱敏函数,查询结果只是改变了结果的格式,结果内容的长度并未变化,符合“带有脱敏的语句执行会有相应的性能劣化”的理论猜想。随着查询涉及脱敏列数的增加,我们发现一个奇怪的现象,脱敏场景反倒比原始语句执行更快。进一步追溯多列场景下脱敏列关联的脱敏函数,发现,正是因为存在使用MASK_FULL全脱敏函数的脱敏列,导致输出结果集部分相比原始数据节省很多时间开销,从而多列查询下带有数据脱敏的简单查询反倒提速不少。 为了佐证上述猜测,我们调整脱敏函数,所有脱敏列均采用MASK_PARTIAL对原始数据做部分脱敏,从而能够在脱敏结果上保留原始数据的外部可读性。于是,如图(c)所示,当脱敏列均关联部分脱敏函数时,带有数据脱敏的语句比原始语句劣化10%左右,理论上讲,这种劣化是在可接受范围的。上述测试仅针对简单的查询语句,当语句复杂到带有聚集函数或复杂表达式运算时,可能这种性能劣化会更明显。总结GaussDB (DWS)产品数据脱敏功能,是数据库产品内化和夯实数据安全能力的重要技术突破,主要涵盖以下三个方面:一套简单、易用的数据脱敏策略语法;一系列可覆盖常见隐私数据脱敏效果的、灵活配置的内置脱敏函数;一个完备、便捷的脱敏策略应用方案,使得原始语句在执行过程中可以实时、透明、高效地实现脱敏。总而言之,此数据脱敏功能可以充分满足客户业务场景的数据脱敏诉求,支持常见隐私数据的脱敏效果,实现敏感数据的可靠保护。【温馨提示】使用过程中,如有疑问,欢迎随时交流反馈。 -
【求助】目前通过AXE模式,已经取得分机号,如,A是希望保护的手机13877776666,X是虚拟手机17088889999,E是分机号0001,我直接拨打 17088889999,,0001 无法拨通,提示是空号,这个方法在另一家服务商,是可以打通的,不知道华为有没有什么办法?
-
 Agent是怎么样保护用户的隐私和安全的呢?下面就从三个方面给大家做一个简单介绍。1.日志脱敏在日志输出至日志文件前,Agent会使用日志脱敏工具对敏感数据进行脱敏处理,将所有敏感数据使用“*”匿名化替代。敏感数据匿名化又分为敏感数据全匿与敏感数据部分匿名:敏感数据全匿:对功能定位没有影响的数据会全匿,如密码,用户电话等数据。敏感数据部分匿名:对功能定位有影响的数据会部分匿名,如设备ID等数据。2.安全传输协议HTTPS、MQTTSAgent在与云端通信时采用安全的HTTPS与MQTTS协议进行通信,HTTPS与MQTTS协议采用TLS协议在传输层对数据进行加密,有效防护了数据被***以及被中间人攻击。HTTPS和MQTTS协议支持TLS证书校验,提供对网络服务器的身份认证,有效保护用户的隐私和安全。3.数据加密存储Agent采用AES-CBC加密算法对数据进行加密存储,密钥长度为128位,并使用安全随机数生成,保证每个Agent使用不同的密钥。
Agent是怎么样保护用户的隐私和安全的呢?下面就从三个方面给大家做一个简单介绍。1.日志脱敏在日志输出至日志文件前,Agent会使用日志脱敏工具对敏感数据进行脱敏处理,将所有敏感数据使用“*”匿名化替代。敏感数据匿名化又分为敏感数据全匿与敏感数据部分匿名:敏感数据全匿:对功能定位没有影响的数据会全匿,如密码,用户电话等数据。敏感数据部分匿名:对功能定位有影响的数据会部分匿名,如设备ID等数据。2.安全传输协议HTTPS、MQTTSAgent在与云端通信时采用安全的HTTPS与MQTTS协议进行通信,HTTPS与MQTTS协议采用TLS协议在传输层对数据进行加密,有效防护了数据被***以及被中间人攻击。HTTPS和MQTTS协议支持TLS证书校验,提供对网络服务器的身份认证,有效保护用户的隐私和安全。3.数据加密存储Agent采用AES-CBC加密算法对数据进行加密存储,密钥长度为128位,并使用安全随机数生成,保证每个Agent使用不同的密钥。 -
 本帖最后由 梅子 于 2017-11-2 11:52 编辑Agent是怎么样保护用户的隐私和安全的呢?下面就从三个方面给大家做一个简单介绍。 1.日志脱敏在日志输出至日志文件前,Agent会使用日志脱敏工具对敏感数据进行脱敏处理,将所有敏感数据使用“*”匿名化替代。敏感数据匿名化又分为敏感数据全匿与敏感数据部分匿名: [*]敏感数据全匿:对功能定位没有影响的数据会全匿,如密码,用户电话等数据。 [*]敏感数据部分匿名:对功能定位有影响的数据会部分匿名,如设备ID等数据。 2.安全传输协议HTTPS、MQTTSAgent在与云端通信时采用安全的HTTPS与MQTTS协议进行通信,HTTPS与MQTTS协议采用TLS协议在传输层对数据进行加密,有效防护了数据被***以及被中间人攻击。HTTPS和MQTTS协议支持TLS证书校验,提供对网络服务器的身份认证,有效保护用户的隐私和安全。 3.数据加密存储Agent采用AES-CBC加密算法对数据进行加密存储,密钥长度为128位,并使用安全随机数生成,保证每个Agent使用不同的密钥。
本帖最后由 梅子 于 2017-11-2 11:52 编辑Agent是怎么样保护用户的隐私和安全的呢?下面就从三个方面给大家做一个简单介绍。 1.日志脱敏在日志输出至日志文件前,Agent会使用日志脱敏工具对敏感数据进行脱敏处理,将所有敏感数据使用“*”匿名化替代。敏感数据匿名化又分为敏感数据全匿与敏感数据部分匿名: [*]敏感数据全匿:对功能定位没有影响的数据会全匿,如密码,用户电话等数据。 [*]敏感数据部分匿名:对功能定位有影响的数据会部分匿名,如设备ID等数据。 2.安全传输协议HTTPS、MQTTSAgent在与云端通信时采用安全的HTTPS与MQTTS协议进行通信,HTTPS与MQTTS协议采用TLS协议在传输层对数据进行加密,有效防护了数据被***以及被中间人攻击。HTTPS和MQTTS协议支持TLS证书校验,提供对网络服务器的身份认证,有效保护用户的隐私和安全。 3.数据加密存储Agent采用AES-CBC加密算法对数据进行加密存储,密钥长度为128位,并使用安全随机数生成,保证每个Agent使用不同的密钥。 -
 本帖最后由 达康书记 于 2017-9-28 14:07 编辑华为云默认系统盘是40G,创建虚拟机时可以扩容到1T,可是扩容部分默认是空白分区,如何将此空白分区在线(不重启虚拟机)扩容到root根分区?下边以CentOS6.5 64bit 50G系统盘为例,root分区在最末尾分区(e.g: /dev/xvda1: swap,/dev/xvda2: root)的扩容场景。 1、查询当前虚拟机分区情况,已经识别出50G,并且根分区在做末尾 [code][root@sluo-ecs-5e7d ~]# parted -l /dev/xvda Model: Xen Virtual Block Device (xvd) Disk /dev/xvda: 53.7GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 4296MB 4295MB primary linux-swap(v1) 2 4296MB 42.9GB 38.7GB primary ext4 boot[/code] 2、用yum安装一个叫growpart的工具,growpart可能集成在cloud-utils-growpart/cloud-utils/cloud-initramfs-tools/cloud-init包里,可以直接yum install cloud-*确保growpart命令可用即可 [code][root@sluo-ecs-5e7d ~]# yum install cloud-utils-growpart[/code] 3、使用growpart将第二分区的根分区扩容 [code][root@sluo-ecs-5e7d ~]# growpart /dev/xvda 2 CHANGED: partition=2 start=8390656 old: size=75495424 end=83886080 new: size=96465599,end=104856255[/code] 4、检查在线扩容情况是否成功 [code][root@sluo-ecs-5e7d ~]# parted -l /dev/xvda Model: Xen Virtual Block Device (xvd) Disk /dev/xvda: 53.7GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 4296MB 4295MB primary linux-swap(v1) 2 4296MB 53.7GB 49.4GB primary ext4 boot[/code] 5、执行resize2fs -f $分区名, 在线将文件系统再拉升 [code][root@sluo-ecs-a611 ~]# resize2fs -f /dev/xvda2 resize2fs 1.42.9 (28-Dec-2013) Filesystem at /dev/xvda2 is mounted on /; on-line resizing required old_desc_blocks = 3, new_desc_blocks = 3 .... [root@sluo-ecs-a611 ~] # df -hT -------检查文件系统扩容情况[/code]
本帖最后由 达康书记 于 2017-9-28 14:07 编辑华为云默认系统盘是40G,创建虚拟机时可以扩容到1T,可是扩容部分默认是空白分区,如何将此空白分区在线(不重启虚拟机)扩容到root根分区?下边以CentOS6.5 64bit 50G系统盘为例,root分区在最末尾分区(e.g: /dev/xvda1: swap,/dev/xvda2: root)的扩容场景。 1、查询当前虚拟机分区情况,已经识别出50G,并且根分区在做末尾 [code][root@sluo-ecs-5e7d ~]# parted -l /dev/xvda Model: Xen Virtual Block Device (xvd) Disk /dev/xvda: 53.7GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 4296MB 4295MB primary linux-swap(v1) 2 4296MB 42.9GB 38.7GB primary ext4 boot[/code] 2、用yum安装一个叫growpart的工具,growpart可能集成在cloud-utils-growpart/cloud-utils/cloud-initramfs-tools/cloud-init包里,可以直接yum install cloud-*确保growpart命令可用即可 [code][root@sluo-ecs-5e7d ~]# yum install cloud-utils-growpart[/code] 3、使用growpart将第二分区的根分区扩容 [code][root@sluo-ecs-5e7d ~]# growpart /dev/xvda 2 CHANGED: partition=2 start=8390656 old: size=75495424 end=83886080 new: size=96465599,end=104856255[/code] 4、检查在线扩容情况是否成功 [code][root@sluo-ecs-5e7d ~]# parted -l /dev/xvda Model: Xen Virtual Block Device (xvd) Disk /dev/xvda: 53.7GB Sector size (logical/physical): 512B/512B Partition Table: msdos Number Start End Size Type File system Flags 1 1049kB 4296MB 4295MB primary linux-swap(v1) 2 4296MB 53.7GB 49.4GB primary ext4 boot[/code] 5、执行resize2fs -f $分区名, 在线将文件系统再拉升 [code][root@sluo-ecs-a611 ~]# resize2fs -f /dev/xvda2 resize2fs 1.42.9 (28-Dec-2013) Filesystem at /dev/xvda2 is mounted on /; on-line resizing required old_desc_blocks = 3, new_desc_blocks = 3 .... [root@sluo-ecs-a611 ~] # df -hT -------检查文件系统扩容情况[/code]
推荐直播
-
 华为云码道Skill实战与极速交付,智能开发全链路实战
华为云码道Skill实战与极速交付,智能开发全链路实战2026/07/22 周三 19:00-21:00
王一男-华为云码道产品规划专家;李炎-华为云码道产品专家;姜浩-华为云HCDG核心组成员
直播深度解读华为云码道6月产品新特性,从Skill市场安装专家技能,带你零距离体验从需求,开发,审查,重构全链路闭环的开发过程。从零构建并交付一个完整项目,让您体验从代码提交到服务上线的“极速”之旅。
回顾中 -
 聚开发者之力,创具身新未来
聚开发者之力,创具身新未来2026/07/23 周四 15:00-17:00
张豪杰/程文/王军/刘新春/黄钦开 /张晓天
本次华为云具身智能开发平台CloudRobo培训面向具身智能开发者,带您全流程体验机器人本体R2C小时级接入、环境重建与轨迹生成仿真数据生产、PB级数据管理、数据评测、模型训推、强化学习和Benchmark一键评测等功能,并体验业界主流具身模型应用。
回顾中
热门标签