-
 Redis想必大家都或多或少听过吧,我们在工作学习中通常用它来作为缓存使用,既然是作为缓存,大家的第一反应肯定是:这家伙很快!实际上它确实也很快 : ),但Redis底层却是单线程的!有同学可能就要有疑问了,为什么单线程的Redis却能够快到飞起?别急,我尽量用通俗易懂的语言来给各位说道说道~~Redis是单线程,主要是指Redis的网络IO和读写是由一个线程来完成的,但Redis的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。这不是本文讨论的重点,有个印象即可Redis为什么用单线程?多线程的开销通常情况下,在采用多线程后,如果没有良好的系统设计,其实是左图所展示的那样(注意纵坐标)。刚开始增加线程数时,系统吞吐率会增加,再进一步增加线程时,系统吞吐率就增长迟缓了,甚至还会出现下降的情况。上面两张图的标题手误被我标反了,源码还删了=_=关键瓶颈在于: 系统中通常会存在会被多线程同时访问的共享资源,为了保证共享资源的正确性,就需要有额外的机制保证线程安全性,例如加锁,这会带来额外的开销。比如拿最常用的List类型来举例吧,假设Redis采用多线程设计,有两个线程A和B分别对List做LPUSH和LPUSH操作,为了使得每次执行都是相同的结果,即【B线程取出A线程放入的数据】就需要让这两个过程串行执行。这就是多线程编程模式面临的共享资源的并发访问控制问题。并发访问控制一直是多线程开发中的一个难点问题:如果只是简单地采用一个互斥锁,就会出现即使增加了线程,大部分线程也在等待获取互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加。同时加入并发访问控制后也会降低系统代码的可读性和可维护性,所以Redis干脆直接采用了单线程模式。Redis使用单线程为什么还这么快?之所以使用单线程是Redis设计者多方面衡量的结果。Redis的大部分操作在内存上完成采用了高效的数据结构,例如哈希表和跳表采用了多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率既然Redis使用单线程进行IO,如果线程被阻塞了就无法进行多路复用了,所以不难想象,Redis肯定还针对网络和IO操作的潜在阻塞点进行了设计。网络与IO操作的潜在阻塞点在网络通信里,服务器为了处理一个Get请求,需要监听客户端请求(bind/listen),和客户端建立连接(accept),从socket中读取请求(recv),解析客户端发送请求(parse),最后给客户端返回结果(send)。最基本的一种单线程实现是依次执行上面的操作。上面标红的accept和recv操作都是潜在的阻塞点:当Redis监听到有连接请求,但却一直不能成功建立起连接时,就会阻塞在accept()函数这里,其他客户端此时也无法和Redis建立连接当Redis通过recv()从一个客户端读取数据时,如果数据一直没有到达,也会一直阻塞基于多路复用的高性能IO模型为了解决IO中的阻塞问题,Redis采用了Linux的IO多路复用机制,该机制允许内核中,同时存在多个监听套接字和已连接套接字(select/epoll)。内核会一直监听这些套接字上的连接或数据请求。一旦有请求到达,就会交给Redis处理,这就实现了一个Redis线程处理多个IO流的效果。此时,Redis线程就不会阻塞在某一个特定的客户端请求处理上,所以它可以同时和多个客户端连接并处理请求。回调机制select/epoll一旦监测到FD上有请求到达时,就会触发相应的事件被放进一个队列里,Redis线程对该事件队列不断进行处理,所以就实现了基于事件的回调。例如,Redis会对Accept和Read事件注册accept和get回调函数。当Linux内核监听到有连接请求或读数据请求时,就会触发Accept事件和Read事件,此时,内核就会回调Redis相应的accept和get函数进行处理。Redis的性能瓶颈点经过上面的分析,虽然通过多路复用机制可以同时监听多个客户端的请求,但Redis仍然有一些性能瓶颈点,这也是我们平时编程需要极力避免的情况。1. 耗时操作任意一个请求在Redis中一旦耗时较久,都会影响整个server的性能。后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。这一点需要我们在设计业务场景时去规避;Redis的lazy-free机制也把释放内存的耗时操作放在了异步线程中去执行了。2. 高并发场景并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但还是只能单线程依次读取客户端的数据,无法利用到CPU多核。Redis在6.0可以利用CPU多核多线程读写客户端数据,但只是针对客户端的读写是并行的,每个命令的真正操作还是单线程。其他Redis相关的有趣问题借此机会也提几个和redis相关的有意思的问题。1. 为什么要用Redis,直接访问内存不好吗?这一条其实并没有很明确的界定,对于一些不经常变动的数据,可以直接放到内存里,不一定要放到Redis里,可以放到内存里。一致性问题:如果一个数据被修改了,数据在本地内存里的话,可能只有一台服务器上的数据被修改了。如果用Redis里面的话,我们访问Redis服务器,可以解决一致性问题。2. 数据太多内存放不下怎么办?比如我要缓存100G的数据,怎么办?这里也要打一个广告Tair是淘宝开源的分布式KV缓存系统,它从Redis继承了丰富的操作,理论上总数据量无限制,针对可用性、可扩展性、可靠性也进行了升级,感兴趣的小伙伴们可以了解一下~原文链接:https://blog.csdn.net/HNU_Csee_wjw/article/details/122567260
Redis想必大家都或多或少听过吧,我们在工作学习中通常用它来作为缓存使用,既然是作为缓存,大家的第一反应肯定是:这家伙很快!实际上它确实也很快 : ),但Redis底层却是单线程的!有同学可能就要有疑问了,为什么单线程的Redis却能够快到飞起?别急,我尽量用通俗易懂的语言来给各位说道说道~~Redis是单线程,主要是指Redis的网络IO和读写是由一个线程来完成的,但Redis的其他功能,比如持久化、异步删除、集群数据同步等,其实是由额外的线程执行的。这不是本文讨论的重点,有个印象即可Redis为什么用单线程?多线程的开销通常情况下,在采用多线程后,如果没有良好的系统设计,其实是左图所展示的那样(注意纵坐标)。刚开始增加线程数时,系统吞吐率会增加,再进一步增加线程时,系统吞吐率就增长迟缓了,甚至还会出现下降的情况。上面两张图的标题手误被我标反了,源码还删了=_=关键瓶颈在于: 系统中通常会存在会被多线程同时访问的共享资源,为了保证共享资源的正确性,就需要有额外的机制保证线程安全性,例如加锁,这会带来额外的开销。比如拿最常用的List类型来举例吧,假设Redis采用多线程设计,有两个线程A和B分别对List做LPUSH和LPUSH操作,为了使得每次执行都是相同的结果,即【B线程取出A线程放入的数据】就需要让这两个过程串行执行。这就是多线程编程模式面临的共享资源的并发访问控制问题。并发访问控制一直是多线程开发中的一个难点问题:如果只是简单地采用一个互斥锁,就会出现即使增加了线程,大部分线程也在等待获取互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加。同时加入并发访问控制后也会降低系统代码的可读性和可维护性,所以Redis干脆直接采用了单线程模式。Redis使用单线程为什么还这么快?之所以使用单线程是Redis设计者多方面衡量的结果。Redis的大部分操作在内存上完成采用了高效的数据结构,例如哈希表和跳表采用了多路复用机制,使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率既然Redis使用单线程进行IO,如果线程被阻塞了就无法进行多路复用了,所以不难想象,Redis肯定还针对网络和IO操作的潜在阻塞点进行了设计。网络与IO操作的潜在阻塞点在网络通信里,服务器为了处理一个Get请求,需要监听客户端请求(bind/listen),和客户端建立连接(accept),从socket中读取请求(recv),解析客户端发送请求(parse),最后给客户端返回结果(send)。最基本的一种单线程实现是依次执行上面的操作。上面标红的accept和recv操作都是潜在的阻塞点:当Redis监听到有连接请求,但却一直不能成功建立起连接时,就会阻塞在accept()函数这里,其他客户端此时也无法和Redis建立连接当Redis通过recv()从一个客户端读取数据时,如果数据一直没有到达,也会一直阻塞基于多路复用的高性能IO模型为了解决IO中的阻塞问题,Redis采用了Linux的IO多路复用机制,该机制允许内核中,同时存在多个监听套接字和已连接套接字(select/epoll)。内核会一直监听这些套接字上的连接或数据请求。一旦有请求到达,就会交给Redis处理,这就实现了一个Redis线程处理多个IO流的效果。此时,Redis线程就不会阻塞在某一个特定的客户端请求处理上,所以它可以同时和多个客户端连接并处理请求。回调机制select/epoll一旦监测到FD上有请求到达时,就会触发相应的事件被放进一个队列里,Redis线程对该事件队列不断进行处理,所以就实现了基于事件的回调。例如,Redis会对Accept和Read事件注册accept和get回调函数。当Linux内核监听到有连接请求或读数据请求时,就会触发Accept事件和Read事件,此时,内核就会回调Redis相应的accept和get函数进行处理。Redis的性能瓶颈点经过上面的分析,虽然通过多路复用机制可以同时监听多个客户端的请求,但Redis仍然有一些性能瓶颈点,这也是我们平时编程需要极力避免的情况。1. 耗时操作任意一个请求在Redis中一旦耗时较久,都会影响整个server的性能。后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。这一点需要我们在设计业务场景时去规避;Redis的lazy-free机制也把释放内存的耗时操作放在了异步线程中去执行了。2. 高并发场景并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但还是只能单线程依次读取客户端的数据,无法利用到CPU多核。Redis在6.0可以利用CPU多核多线程读写客户端数据,但只是针对客户端的读写是并行的,每个命令的真正操作还是单线程。其他Redis相关的有趣问题借此机会也提几个和redis相关的有意思的问题。1. 为什么要用Redis,直接访问内存不好吗?这一条其实并没有很明确的界定,对于一些不经常变动的数据,可以直接放到内存里,不一定要放到Redis里,可以放到内存里。一致性问题:如果一个数据被修改了,数据在本地内存里的话,可能只有一台服务器上的数据被修改了。如果用Redis里面的话,我们访问Redis服务器,可以解决一致性问题。2. 数据太多内存放不下怎么办?比如我要缓存100G的数据,怎么办?这里也要打一个广告Tair是淘宝开源的分布式KV缓存系统,它从Redis继承了丰富的操作,理论上总数据量无限制,针对可用性、可扩展性、可靠性也进行了升级,感兴趣的小伙伴们可以了解一下~原文链接:https://blog.csdn.net/HNU_Csee_wjw/article/details/122567260 -
 最基础的概念,什么是幂等性?幂等性:提交多次的情况下,结果都一样。比如数据库查询,可称为天然幂等性,即查询多次结果都一样,无需人为去做幂等性操作。但是update table set value=value+1 where id=1,每次执行的结构都会发生变化,不是幂等。inter into table(id,name)values(1,‘name’),如id不是主键或者没有唯一索引,重复操作上面的业务,会插入多条数据,不具备幂等性;所以我们在什么情景下需要确保幂等性呢?用户多次点击保存按钮用户保存成功后,返回上一页再次保存微服务相互调用,由于网络原因,导致请求失败解决方案一、token机制:1、根据业务场景,判断哪些业务存在幂等性问题,在执行业务之前先获取token,将token缓存止redis中2、调用业务接口时,将token携带过去,一般放在请求头,作为Auth认证3、服务器判断token是否存在于redis中,存在表示第一次请求,然后删除token,继续执行业务4、如果不存在,则表示反复操作,不执行业务逻辑,直接返回重复标志!结束风险性:业务执行前删除还是后删除token?如果是执行后删除,在业务执行中,未删除token,用户又点了请求进来,那么则无法保障幂等性。如果是执行前删除,在分布式下,用户快速请求2次,这时2个请求同时到redis去获取token,对比成功,同时删除,同时执行业务,那么也无法保障幂等性。so:使用执行前删除,在分布式情况下,获取,对比,删除必须确保原子性,所以要加分布式锁。二、加锁1、数据库锁select * from table where … for update2、业务层面加分布式锁将获取、对比、删除作为一个原子性的操作加锁,处理完成后释放锁,确保串行操作。三、约束数据库唯一约束:通过主键、唯一索引,确保无法重复新增同一笔数据,这就能确保幂等性
最基础的概念,什么是幂等性?幂等性:提交多次的情况下,结果都一样。比如数据库查询,可称为天然幂等性,即查询多次结果都一样,无需人为去做幂等性操作。但是update table set value=value+1 where id=1,每次执行的结构都会发生变化,不是幂等。inter into table(id,name)values(1,‘name’),如id不是主键或者没有唯一索引,重复操作上面的业务,会插入多条数据,不具备幂等性;所以我们在什么情景下需要确保幂等性呢?用户多次点击保存按钮用户保存成功后,返回上一页再次保存微服务相互调用,由于网络原因,导致请求失败解决方案一、token机制:1、根据业务场景,判断哪些业务存在幂等性问题,在执行业务之前先获取token,将token缓存止redis中2、调用业务接口时,将token携带过去,一般放在请求头,作为Auth认证3、服务器判断token是否存在于redis中,存在表示第一次请求,然后删除token,继续执行业务4、如果不存在,则表示反复操作,不执行业务逻辑,直接返回重复标志!结束风险性:业务执行前删除还是后删除token?如果是执行后删除,在业务执行中,未删除token,用户又点了请求进来,那么则无法保障幂等性。如果是执行前删除,在分布式下,用户快速请求2次,这时2个请求同时到redis去获取token,对比成功,同时删除,同时执行业务,那么也无法保障幂等性。so:使用执行前删除,在分布式情况下,获取,对比,删除必须确保原子性,所以要加分布式锁。二、加锁1、数据库锁select * from table where … for update2、业务层面加分布式锁将获取、对比、删除作为一个原子性的操作加锁,处理完成后释放锁,确保串行操作。三、约束数据库唯一约束:通过主键、唯一索引,确保无法重复新增同一笔数据,这就能确保幂等性 -
链接:https://bbs.huaweicloud.com/blogs/335976压缩列表简介压缩列表(ziplist)是由一个连续内存组成的顺序型数据结构。一个压缩列表可以包含任意多个节点,每个节点上可以保存一个字节数组或整数值。它是Redis为了节省内存空间而开发的。压缩列表(ziplist)是哈希(hash)和有序集合(zset)的内部编码之一。当哈希(hash)中的元素个数比较少并且每个元素的值占用空间比较小的时候,Redis就会使用压缩列表做为哈希的内部编码。当有序集合(zset)中的元素个数比较少并且每个元素的值占用空间比较小的时候,Redis也会使用压缩列表做为有序集合的内部编码。压缩列表结构接下来,我们来看以下压缩列表的内部构造,压缩列表由以下几个部分组成:zlbytes:表示整个压缩列表占用的内存字节数。xltail:表示压缩列表起始地址到最后一个节点的字节数,可以快速找到最后一个节点。zllength:表示压缩列表包含的节点个数。entries:节点列表,一个挨着一个地紧凑存储。zlend:特殊值0xFF(十进制为255),表示压缩列表的结束。压缩列表节点结构每个压缩列表的节点由三部分组成: prevlen、 encoding和content。prevlenprevlen:表示该节点前一个节点的字节长度。 prevlen的长度可能是1个字节,也可能是5个字节。当前一个节点的长度小于254个字节时, prevlen的长度为1个字节,直接存储前一个节点的字节长度;当前一个节点的长度大于或等于254个字节时, prevlen的长度为5个字节,其中的第一个字节被设置为0xFE,随后的四个字节保存前一个节点的字节长度。可以通过 prevlen和压缩列表结构中的xltail逆序遍历压缩列表。encodingencoding表示该节点中保存数据的类型和长度。当encoding的最高位以00开头时,表示最大长度为63的短字符串,此时encoding的长度为1个字节,其后面6个位表示字符串的字节长度;当encoding的最高位以01开头时,表示最大长度为16383的中等长度的字符串,此时encoding的长度为2个字节,其后面14个位表示字符串的字节长度;当encoding的最高位以10开头时,表示最大长度为4294967295的特长的字符串,此时encoding的长度为5个字节,其后面4个字节表示字符串的字节长度;当encoding的最高位以11开头时,表示整数值,此时encoding的长度为1个字节,其后面6个位表示整数值的类型和长度。contentcontent用于存储节点的值,节点的值可以是一个字节数组,也可以是正数,其类型和长度由encoding决定。总结压缩列表(ziplist)是由一个连续内存组成的顺序型数据结构。一个压缩列表可以包含任意多个节点,每个节点上可以保存一个字节数组或整数值。压缩列表(ziplist)是哈希(hash)和有序集合(zset)的内部编码之一。
-
链接:https://bbs.huaweicloud.com/blogs/330938一、前言不卷了,能用就行!哈哈哈,说好的不卷了,能凑活用就行了。但每次接到新需求时都手痒,想结合着上一次的架构设计和落地经验,在这一次需求上在迭代更新,或者找到完全颠覆之前的更优方案。卷完代码的那一刻总是神清气爽其实大部分喜欢写代码的一类纯粹码农,都是比较卷的,就比如一个需求在实现上是能用大概是P5、如果这个做出来的功能不只是能用还非常好用是P6、除了好用还凝练共性需求开发成通用的组件服务是P7。每一个成长过来的码农,都是在造轮子的路上一次次验证自己的想法和加以实践,绝对不是一篇篇的八股文就能累出来一个高级的技术大牛。二、延迟任务场景什么是延迟任务?当我们的实际业务需求场景中,有一些活动开始前的状态变更、订单结算后的T+1对账、贷款单息费的产生,都是需要使用到延迟任务来进行触达。实际的操作一般会有 Quartz、Schedule 来对你的库表数据进行定时扫描和处理,当条件满足后做数据状态的变更或者产生新的数据插入到表中。这样一个简单的需求就是延迟任务最初需求,如果需求前期内容较少、使用方不多,可能在实际开发中就只是一个单台机器直接对着表一顿轮训就完事了。但随着业务需求的发展和功能的复杂度提升,往往反馈到研发设计和实现,就不那么简单了,比如:你需要保障尽可能低延迟完成较大规模的数据量扫描处理,否则就像贷款单息费的产生,已经到了第二天用户还没看到自己的息费信息或者是还款后的重新对账,可能就这个时候就要产生客诉了。那么,类似这样的场景该如何设计呢?三、延迟任务设计通常的任务中心处理流程主要,主要是由定时任务扫描任务库表,把即将达到超时时间的任务信息扫描到处理队列(内存/MQ消息),再由业务系统进行处理任务,处理完成后更新库表中的任务状态。问题:海量数据规模较大的任务列表数据,在分库分表下该需要快速扫描。任务扫描服务与业务逻辑处理,耦合在一起,不具有通用性和复用性。细分任务体系有些是需要低延迟处理的,不能等待过长时间。1. 任务表方式除了一些较小的状态变更场景,例如在各自业务的库表中,就包含了一个状态字段,这个字段一方面有程序逻辑处理变更的状态,也有到达指定到期时间后由任务服务自动变更处理的操作,一般这类功能,直接设计到自己的库表中即可。那么还有一些较大也较为频繁使用的场景,如果都是在每个系统的各自所需的N多个表中,都添加这样的字段进行维护,就显得非常冗余了,也不那么易于维护。所以针对这样的场景就很适合做一个通用的任务延时系统,各业务系统把需要被延时执行的动作提交到延时系统中,再有延时系统在指定时间下进行回调,回调的动作可以是接口或者MQ消息进行触达。例如可以设计这样一个任务调度表:抽取的任务调度表,主要是拿到什么任务,在什么时间发起动作,具体的动作处理仍交给业务工程处理。大批量的各自业务的任务进行集中处理,则需要设计一个分库分表,满足于后续业务体量的增长。门牌号设计,针对一张表的扫描,如果数据量较大,又不希望只是一个任务扫描一个表,可以多个任务扫描一个表,加到扫描的体量。这个时候就需要一个门牌号来隔离不同任务扫描的范围,避免扫描出重复的任务数据。2. 低延迟方式低延迟处理方案,是在任务表方式的基础上,新增加的时间把控处理。它可以把即将到期的前一段时间的任务,放置到 Redis 集群队里中,在消费的时候再从队列中 pop 出来,这样可以更快的接近任务的处理时效,避免因为扫库间隔较大延迟任务执行。在接收业务系统提交进来的延迟任务时,按照执行时间的长短放置到任务库或者也同步到 Redis 集群中,一些执行时间较晚的任务则可以先放到任务库,再通过扫描的方式添加到超时任务执行队列中。那么关于这块的设计核心在于 Redis 队列的使用,以及为了保证消费的可靠性需要引入二阶段消费、注册 ZK 注册中心至少保证一次消费的处理。本文重点主要放在 Redis 队列的设计,其他更多的逻辑处理,可以按照业务需求进行扩展和完善Redis 消费队列按照消息体计算对应数据所属的槽位 index = CRC32 & 7StoreQueue 采用 Slot 按照 SlotKey = #{topic}_#{index} 和 Sorted Set 的数据结构按执行任务分数排序,存放任务执行信息。定时消息将时间戳作为分数,消费时每次弹出分数小于当前时间戳的一个消息为了保障每条消息至少可消费一次,消费者不是直接 pop 有序集合中的元素,而是将元素从 StoreQueue 移动到 PrepareQueue 并返回消息给消费者。消费成功后再从 PrepareQueue 从删除,如果消费失败则从PreapreQueue 重新移动到 StoreQueue,这样二阶段消费的方式进行处理。参考文档:2021 阿里技术人的百宝黑皮书PDF文,低延迟的超时中心实现方式简单案例@Test public void test_delay_queue() throws InterruptedException { RBlockingQueue<Object> blockingQueue = redissonClient.getBlockingQueue("TASK"); RDelayedQueue<Object> delayedQueue = redissonClient.getDelayedQueue(blockingQueue); new Thread(() -> { try { while (true){ Object take = blockingQueue.take(); System.out.println(take); Thread.sleep(10); } } catch (InterruptedException e) { e.printStackTrace(); } }).start(); int i = 0; while (true){ delayedQueue.offerAsync("测试" + ++i, 100L, TimeUnit.MILLISECONDS); Thread.sleep(1000L); } }测试数据2022-02-13 WARN 204760 --- [ Finalizer] i.l.c.resource.DefaultClientResources : io.lettuce.core.resource.DefaultClientResources was not shut down properly, shutdown() was not called before it's garbage-collected. Call shutdown() or shutdown(long,long,TimeUnit) 测试1 测试2 测试3 测试4 测试5 Process finished with exit code -1源码:https://github.com/fuzhengwei/TimeOutCenter描述:使用 redisson 中的 DelayedQueue 作为消息队列,写入后等待消费时间进行 POP 消费。四、总结调度任务的使用在实际的场景中非常频繁,例如我们经常使用 xxl-job,也有一些大厂自研的分布式任务调度组件,这些可能原本都是很小很简单的功能,但经过抽象、整合、提炼,变成了一个个核心通用的中间件服务。当我们在考虑使用任务调度的时候,无论哪种方式的设计和实现,都需要考虑这个功能使用时候的以为迭代和维护性,如果仅仅是一个非常小的场景,又没多少人使用的话,那么在自己机器上折腾就可以。过渡的设计和使用有时候也会把研发资源代入泥潭其实各项技术的知识点,都像是一个个工具,刀枪棍棒斧钺钩,那能怎么结合各自的特点,把这些兵器用起来,才是一个程序员不断成长的过程。如果你希望了解更多此类有深度的技术内容,可以加入 Lottery 分布式抽奖秒杀系统 学习更有价值的更抗用的实战手段。五、系列推荐金三银四面试前,把自己弄成卷王!方案设计:基于IDEA插件开发和字节码插桩技术,实现研发交付质量自动分析工作两三年了,整不明白架构图都画啥?工作两年简历写成这样,谁要你呀!BATJTMD,大厂招聘,都招什么样Java程序员?
-
最基础的概念,什么是幂等性?幂等性:提交多次的情况下,结果都一样。比如数据库查询,可称为天然幂等性,即查询多次结果都一样,无需人为去做幂等性操作。但是update table set value=value+1 where id=1,每次执行的结构都会发生变化,不是幂等。inter into table(id,name)values(1,‘name’),如id不是主键或者没有唯一索引,重复操作上面的业务,会插入多条数据,不具备幂等性;所以我们在什么情景下需要确保幂等性呢?用户多次点击保存按钮用户保存成功后,返回上一页再次保存微服务相互调用,由于网络原因,导致请求失败解决方案一、token机制:1、根据业务场景,判断哪些业务存在幂等性问题,在执行业务之前先获取token,将token缓存止redis中2、调用业务接口时,将token携带过去,一般放在请求头,作为Auth认证3、服务器判断token是否存在于redis中,存在表示第一次请求,然后删除token,继续执行业务4、如果不存在,则表示反复操作,不执行业务逻辑,直接返回重复标志!结束风险性:业务执行前删除还是后删除token?如果是执行后删除,在业务执行中,未删除token,用户又点了请求进来,那么则无法保障幂等性。如果是执行前删除,在分布式下,用户快速请求2次,这时2个请求同时到redis去获取token,对比成功,同时删除,同时执行业务,那么也无法保障幂等性。so:使用执行前删除,在分布式情况下,获取,对比,删除必须确保原子性,所以要加分布式锁。二、加锁1、数据库锁select * from table where … for update2、业务层面加分布式锁将获取、对比、删除作为一个原子性的操作加锁,处理完成后释放锁,确保串行操作。三、约束数据库唯一约束:通过主键、唯一索引,确保无法重复新增同一笔数据,这就能确保幂等性
-
 本文分享自华为云社区《[Redis现网那些坑:用个缓存,还要为磁盘故障买单?](https://bbs.huaweicloud.com/blogs/334929?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=database&utm_content=content)》,作者: GaussDB 数据库 。 近日,网上一些电商用户出现了库存业务查询超时的现象,深究根源,是其使用的Redis云服务底层SSD卡硬件故障,影响了Redis的稳定性,最终导致业务超时。  此时笔者脑中闪过一连串问号:  **那么,缓存Redis究竟为啥绕不过磁盘这道坎呢?** 从技术角度讲,使用缓存Redis还要配磁盘,一方面是因为开源Redis依赖持久化机制,保证宕机后能取回一部分数据,另一方面这也是主从同步必不可少的。开源Redis提供了两种持久化方案——RDB和AOF,其中: 1. RDB是通过对内存打快照的方式,将数据备份到磁盘。开源Redis主从之间全量同步就依赖于RDB文件。 2. AOF是通过日志追加的方式记录数据变化。开源Redis宕机重启可用AOF文件加载“较为完整”的数据。 想到这里,笔者恍然大悟:电商用户的现网问题,原来就在于RDB和AOF机制都要进行磁盘IO,而磁盘故障直接影响了Redis的持久化,进而阻塞了Redis的正常服务!  除此之外,缓存Redis的持久化还有各种缺陷: 1. AOF写入频率通常只能配置为秒级,在Redis动辄十万QPS的情况下,宕机时仍会有大量数据无法找回; 2. 数据量越大,重启加载AOF越缓慢; 3. RDB的生成和AOF重写都会引发fork问题,造成性能抖动。 由此可见,缓存Redis的持久化既不稳定、也不可靠,甚至还会因为磁盘性能、fork问题导致上层业务不稳定。然而出于数据“相对”安全、可靠的需求,缓存Redis还真就跨不过磁盘这道坎。  自建Redis的朋友们难免遇到这种窘境:最开始配了一个普通磁盘,后来遇到各种持久化阻塞服务的问题,不得不对磁盘进行升级。回顾前文的Redis实例故障,我们不难发现:缓存Redis的持久化与磁盘问题似乎永远无法令人放心。 **那么,是否有一劳永逸的方案,可以和Redis持久化带来的问题说拜拜呢?**  GaussDB(for Redis)作为华为云主推的企业级Redis,有着稳定可靠的天然优势,其基于存算分离、多副本强一致的架构,摒弃了RDB/AOF机制,彻底解决了开源Redis持久化性能不稳定、数据不一致、磁盘不可靠等问题,帮助企业用户真正实现降本增效。 **那GaussDB(for Redis)都有哪些“黑科技”呢?** 1. 采用SPDK技术,通过用户态、异步、无锁、轮询的方式驱动磁盘,相比开源Redis内核态驱动,速度大幅提高。 2. 高性能分布式共享存储池采用RDMA和DPDK技术,极大提高了系统吞吐量,加速数据处理,降低通信延迟。 3. 采用SCM技术,将接近内存的性能和速度,与类似SSD的容量和成本结合起来,打造强悍底座。 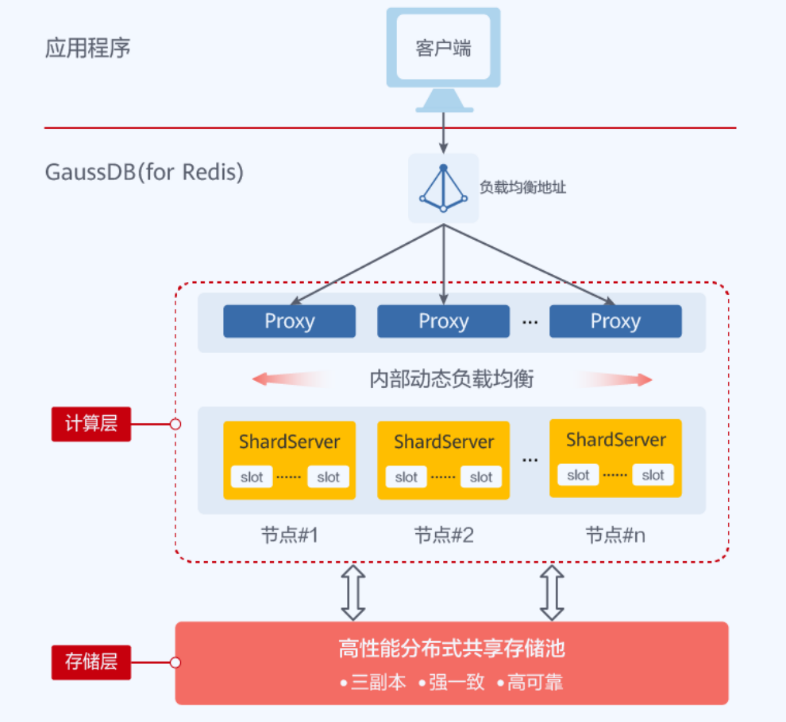 正是如此,GaussDB(for Redis)在保证数据命令级落盘的同时,能够轻松支持百万级QPS的高并发访问,以及亚毫秒级时延。其底层使用高性能分布式共享存储池,不会因磁盘故障而阻塞服务;同时,硬件成本又远低于缓存Redis,且数据量越大性价比越高。 既然Redis离不开持久化、离不开磁盘,那何不选择一款兼具性能与持久化优势的Redis数据库呢?就如上文提到的电商场景,GaussDB(for Redis)凭借独有的强一致、稳定性、ACID事务,不但能轻松搞定“库存”业务,其强大的持久化能力更能够为企业核心数据存储保驾护航。
本文分享自华为云社区《[Redis现网那些坑:用个缓存,还要为磁盘故障买单?](https://bbs.huaweicloud.com/blogs/334929?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=database&utm_content=content)》,作者: GaussDB 数据库 。 近日,网上一些电商用户出现了库存业务查询超时的现象,深究根源,是其使用的Redis云服务底层SSD卡硬件故障,影响了Redis的稳定性,最终导致业务超时。  此时笔者脑中闪过一连串问号:  **那么,缓存Redis究竟为啥绕不过磁盘这道坎呢?** 从技术角度讲,使用缓存Redis还要配磁盘,一方面是因为开源Redis依赖持久化机制,保证宕机后能取回一部分数据,另一方面这也是主从同步必不可少的。开源Redis提供了两种持久化方案——RDB和AOF,其中: 1. RDB是通过对内存打快照的方式,将数据备份到磁盘。开源Redis主从之间全量同步就依赖于RDB文件。 2. AOF是通过日志追加的方式记录数据变化。开源Redis宕机重启可用AOF文件加载“较为完整”的数据。 想到这里,笔者恍然大悟:电商用户的现网问题,原来就在于RDB和AOF机制都要进行磁盘IO,而磁盘故障直接影响了Redis的持久化,进而阻塞了Redis的正常服务!  除此之外,缓存Redis的持久化还有各种缺陷: 1. AOF写入频率通常只能配置为秒级,在Redis动辄十万QPS的情况下,宕机时仍会有大量数据无法找回; 2. 数据量越大,重启加载AOF越缓慢; 3. RDB的生成和AOF重写都会引发fork问题,造成性能抖动。 由此可见,缓存Redis的持久化既不稳定、也不可靠,甚至还会因为磁盘性能、fork问题导致上层业务不稳定。然而出于数据“相对”安全、可靠的需求,缓存Redis还真就跨不过磁盘这道坎。  自建Redis的朋友们难免遇到这种窘境:最开始配了一个普通磁盘,后来遇到各种持久化阻塞服务的问题,不得不对磁盘进行升级。回顾前文的Redis实例故障,我们不难发现:缓存Redis的持久化与磁盘问题似乎永远无法令人放心。 **那么,是否有一劳永逸的方案,可以和Redis持久化带来的问题说拜拜呢?**  GaussDB(for Redis)作为华为云主推的企业级Redis,有着稳定可靠的天然优势,其基于存算分离、多副本强一致的架构,摒弃了RDB/AOF机制,彻底解决了开源Redis持久化性能不稳定、数据不一致、磁盘不可靠等问题,帮助企业用户真正实现降本增效。 **那GaussDB(for Redis)都有哪些“黑科技”呢?** 1. 采用SPDK技术,通过用户态、异步、无锁、轮询的方式驱动磁盘,相比开源Redis内核态驱动,速度大幅提高。 2. 高性能分布式共享存储池采用RDMA和DPDK技术,极大提高了系统吞吐量,加速数据处理,降低通信延迟。 3. 采用SCM技术,将接近内存的性能和速度,与类似SSD的容量和成本结合起来,打造强悍底座。  正是如此,GaussDB(for Redis)在保证数据命令级落盘的同时,能够轻松支持百万级QPS的高并发访问,以及亚毫秒级时延。其底层使用高性能分布式共享存储池,不会因磁盘故障而阻塞服务;同时,硬件成本又远低于缓存Redis,且数据量越大性价比越高。 既然Redis离不开持久化、离不开磁盘,那何不选择一款兼具性能与持久化优势的Redis数据库呢?就如上文提到的电商场景,GaussDB(for Redis)凭借独有的强一致、稳定性、ACID事务,不但能轻松搞定“库存”业务,其强大的持久化能力更能够为企业核心数据存储保驾护航。 -
最基础的概念,什么是幂等性?幂等性:提交多次的情况下,结果都一样。比如数据库查询,可称为天然幂等性,即查询多次结果都一样,无需人为去做幂等性操作。但是update table set value=value+1 where id=1,每次执行的结构都会发生变化,不是幂等。inter into table(id,name)values(1,‘name’),如id不是主键或者没有唯一索引,重复操作上面的业务,会插入多条数据,不具备幂等性;所以我们在什么情景下需要确保幂等性呢?用户多次点击保存按钮用户保存成功后,返回上一页再次保存微服务相互调用,由于网络原因,导致请求失败解决方案一、token机制:1、根据业务场景,判断哪些业务存在幂等性问题,在执行业务之前先获取token,将token缓存止redis中2、调用业务接口时,将token携带过去,一般放在请求头,作为Auth认证3、服务器判断token是否存在于redis中,存在表示第一次请求,然后删除token,继续执行业务4、如果不存在,则表示反复操作,不执行业务逻辑,直接返回重复标志!结束风险性:业务执行前删除还是后删除token?如果是执行后删除,在业务执行中,未删除token,用户又点了请求进来,那么则无法保障幂等性。如果是执行前删除,在分布式下,用户快速请求2次,这时2个请求同时到redis去获取token,对比成功,同时删除,同时执行业务,那么也无法保障幂等性。so:使用执行前删除,在分布式情况下,获取,对比,删除必须确保原子性,所以要加分布式锁。二、加锁1、数据库锁select * from table where … for update2、业务层面加分布式锁将获取、对比、删除作为一个原子性的操作加锁,处理完成后释放锁,确保串行操作。三、约束数据库唯一约束:通过主键、唯一索引,确保无法重复新增同一笔数据,这就能确保幂等性
-
 如果启动前不对linux内核做任何更改,那么redis启动会报出警告,共三个:如下图所示第一个警告:The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.意思是:TCP backlog设置值,511没有成功,因为 /proc/sys/net/core/somaxconn这个设置的是更小的128.临时解决方法:(即下次启动还需要修改此值)echo 511 > /proc/sys/net/core/somaxconn永久解决方法:(即以后启动还需要修改此值)将其写入/etc/rc.local文件中。baklog参数实际控制的是已经3次握手成功的还在accept queue的大小。参考linux里的backlog详解 第二个警告:overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to/etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.意思是:overcommit_memory参数设置为0!在内存不足的情况下,后台程序save可能失败。建议在文件 /etc/sysctl.conf 中将overcommit_memory修改为1。临时解决方法:echo "vm.overcommit_memory=1" > /etc/sysctl.conf永久解决方法:将其写入/etc/sysctl.conf文件中。参考:有关linux下redis overcommit_memory的问题 第三个警告:you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix thisissue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain thesetting after a reboot. Redis must be restarted after THP is disabled.意思是:你使用的是透明大页,可能导致redis延迟和内存使用问题。执行 echo never > /sys/kernel/mm/transparent_hugepage/enabled 修复该问题。临时解决方法:echo never > /sys/kernel/mm/transparent_hugepage/enabled。永久解决方法:将其写入/etc/rc.local文件中。参考透明大页介绍 。到此这篇关于解决Redis启动警告问题的文章就介绍到这了转载自https://www.jb51.net/article/238574.htm
如果启动前不对linux内核做任何更改,那么redis启动会报出警告,共三个:如下图所示第一个警告:The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.意思是:TCP backlog设置值,511没有成功,因为 /proc/sys/net/core/somaxconn这个设置的是更小的128.临时解决方法:(即下次启动还需要修改此值)echo 511 > /proc/sys/net/core/somaxconn永久解决方法:(即以后启动还需要修改此值)将其写入/etc/rc.local文件中。baklog参数实际控制的是已经3次握手成功的还在accept queue的大小。参考linux里的backlog详解 第二个警告:overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to/etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.意思是:overcommit_memory参数设置为0!在内存不足的情况下,后台程序save可能失败。建议在文件 /etc/sysctl.conf 中将overcommit_memory修改为1。临时解决方法:echo "vm.overcommit_memory=1" > /etc/sysctl.conf永久解决方法:将其写入/etc/sysctl.conf文件中。参考:有关linux下redis overcommit_memory的问题 第三个警告:you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix thisissue run the command 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain thesetting after a reboot. Redis must be restarted after THP is disabled.意思是:你使用的是透明大页,可能导致redis延迟和内存使用问题。执行 echo never > /sys/kernel/mm/transparent_hugepage/enabled 修复该问题。临时解决方法:echo never > /sys/kernel/mm/transparent_hugepage/enabled。永久解决方法:将其写入/etc/rc.local文件中。参考透明大页介绍 。到此这篇关于解决Redis启动警告问题的文章就介绍到这了转载自https://www.jb51.net/article/238574.htm -
最基础的概念,什么是幂等性?幂等性:提交多次的情况下,结果都一样。比如数据库查询,可称为天然幂等性,即查询多次结果都一样,无需人为去做幂等性操作。但是update table set value=value+1 where id=1,每次执行的结构都会发生变化,不是幂等。inter into table(id,name)values(1,‘name’),如id不是主键或者没有唯一索引,重复操作上面的业务,会插入多条数据,不具备幂等性;所以我们在什么情景下需要确保幂等性呢?用户多次点击保存按钮用户保存成功后,返回上一页再次保存微服务相互调用,由于网络原因,导致请求失败解决方案一、token机制:1、根据业务场景,判断哪些业务存在幂等性问题,在执行业务之前先获取token,将token缓存止redis中2、调用业务接口时,将token携带过去,一般放在请求头,作为Auth认证3、服务器判断token是否存在于redis中,存在表示第一次请求,然后删除token,继续执行业务4、如果不存在,则表示反复操作,不执行业务逻辑,直接返回重复标志!结束风险性:业务执行前删除还是后删除token?如果是执行后删除,在业务执行中,未删除token,用户又点了请求进来,那么则无法保障幂等性。如果是执行前删除,在分布式下,用户快速请求2次,这时2个请求同时到redis去获取token,对比成功,同时删除,同时执行业务,那么也无法保障幂等性。so:使用执行前删除,在分布式情况下,获取,对比,删除必须确保原子性,所以要加分布式锁。二、加锁1、数据库锁select * from table where … for update2、业务层面加分布式锁将获取、对比、删除作为一个原子性的操作加锁,处理完成后释放锁,确保串行操作。三、约束数据库唯一约束:通过主键、唯一索引,确保无法重复新增同一笔数据,这就能确保幂等性
-
 1.Redis的诞生1.1 磁盘和内存数据存储分为两个位置,一个是磁盘,另一个是内存。1.1.1 磁盘的优势是成本价格便宜,缺点是寻址速度是ms(毫秒级)补充:磁盘由一圈圈磁道组成,而磁道又由很多扇区组成,读取扇区中的数据时,最少是读取4k的数据,如果小于4k还是会读取4k的信息。1.1.2 内存的优势是寻址速度是ns(纳秒级,相当于磁盘的十万倍),缺点是成本价格很昂贵1.2 为什么使用Redis1.2.1 数据量变大的影响因为内存相对磁盘很小,所以数据基本都是存储在磁盘中,而其中的索引是将B-Tree之类的树中的枝干存储在内存类(因为内存寻址比磁盘快十万倍,所以查找会变快),当表的字段变多的时候或数据量变大,增删改速速会变慢,但是查询速度在查询量很小时还是会很快,但是高并发查询时会被磁盘的带宽影响速度变的很慢。1.2.2 Redis缓存的诞生在硬盘的各种缺点和内存的成本之间,都会大大影响我们日常的使用,因此Redis这类缓存技术就诞生了,他会将一部分资源放进内存中。Redis是一个高性能(读写非常快,读可以达到每秒十万次,写可以达到每秒8万次)的key-value数据库,并且提供string 字符串(可以为整形、浮点型和字符串,统称为元素)、list 列表(实现队列,元素不唯一,先入先出原则)、set 集合(各不相同的元素)、hash散列值(hash的key必须是唯一的)、sort set 有序集合五种数据结构的存储。2.Linux安装2.1 yum install wget此例为空服务器上,首先安装wget2.2 cd 进入根目录或者任意目录2.3 mkdir redisTest 创建文件夹存放redis压缩包2.4 cd redisTest 进入到redisTest文件夹目录下2.5 wget http://download.redis.io/releases/redis-xxx.tar.gz 下载对应的版本的redis压缩包2.6 tar xf redis.xxx.tar.gz 解压缩redis压缩包到当前目录下2.7 cd redis中src查看README.md文档,里面会有安装的说明等2.8 make 进行编译安装2.8.1 如果安装失败,检查原因,比如没有gcc就需要安装gcc,执行指令是 yum install gcc 如果安装失败,会有些安装失败的文件,需要通过指令make disclean进行清除,然后再进行make编译安装指令。2.9 cd 进入src目录下,如果看到redis-server等绿色的可执行文件则为安装成功2.10 cd..会到安装目录下2.11 make install PREFIX=/opt/test(任意目录),将可执行文件安装到指定目录,用于之后的开机自启动和多个redis的配置2.12 vim /etc/profile 进入profile文件夹下进行环境变量的配置 export REDIS_HOME=/opt/test(上面存放的任意目录) export PATH=$PATH:$REDIS_HOME/bin source /etc/profile 重新加载配置文件2.13 cd utils 进行多个redis的配置2.14 ./install_server.sh 可以执行一次或者多次爬坑1 参考1如果出现下面提示,需要将_pid_1_exe方法整个屏蔽掉再执行./install_server.sh就可以完成设置了Welcome to the redis service installer This script will help you easily set up a running redis server This systems seems to use systemd. Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!2.1.4.1 一个物理机中可以有多个redis实例(进程),通过port端口号进行区分;2.1.4.2 可执行程序只有一份存在上面的自己放的任意目录,但是内存中可以有多个实例,只需要执行install_server,sh脚本进行指定port端口号、各自的配置文件、持久化目录。2.1.4.3 启动/停止命令是通过指令 service redis_6379 start/stop/stauts进行执行,redis_6379这类的是在/etc/init.d/xxx,是通过上面脚本配置的端口号自动生成的。再通过脚本设置另外一个6380端口的redis实例,通过ps -fe | grep redis查看已经启动redis进程,此时就可以看到6379和6380两个redis实例已经启动了。
1.Redis的诞生1.1 磁盘和内存数据存储分为两个位置,一个是磁盘,另一个是内存。1.1.1 磁盘的优势是成本价格便宜,缺点是寻址速度是ms(毫秒级)补充:磁盘由一圈圈磁道组成,而磁道又由很多扇区组成,读取扇区中的数据时,最少是读取4k的数据,如果小于4k还是会读取4k的信息。1.1.2 内存的优势是寻址速度是ns(纳秒级,相当于磁盘的十万倍),缺点是成本价格很昂贵1.2 为什么使用Redis1.2.1 数据量变大的影响因为内存相对磁盘很小,所以数据基本都是存储在磁盘中,而其中的索引是将B-Tree之类的树中的枝干存储在内存类(因为内存寻址比磁盘快十万倍,所以查找会变快),当表的字段变多的时候或数据量变大,增删改速速会变慢,但是查询速度在查询量很小时还是会很快,但是高并发查询时会被磁盘的带宽影响速度变的很慢。1.2.2 Redis缓存的诞生在硬盘的各种缺点和内存的成本之间,都会大大影响我们日常的使用,因此Redis这类缓存技术就诞生了,他会将一部分资源放进内存中。Redis是一个高性能(读写非常快,读可以达到每秒十万次,写可以达到每秒8万次)的key-value数据库,并且提供string 字符串(可以为整形、浮点型和字符串,统称为元素)、list 列表(实现队列,元素不唯一,先入先出原则)、set 集合(各不相同的元素)、hash散列值(hash的key必须是唯一的)、sort set 有序集合五种数据结构的存储。2.Linux安装2.1 yum install wget此例为空服务器上,首先安装wget2.2 cd 进入根目录或者任意目录2.3 mkdir redisTest 创建文件夹存放redis压缩包2.4 cd redisTest 进入到redisTest文件夹目录下2.5 wget http://download.redis.io/releases/redis-xxx.tar.gz 下载对应的版本的redis压缩包2.6 tar xf redis.xxx.tar.gz 解压缩redis压缩包到当前目录下2.7 cd redis中src查看README.md文档,里面会有安装的说明等2.8 make 进行编译安装2.8.1 如果安装失败,检查原因,比如没有gcc就需要安装gcc,执行指令是 yum install gcc 如果安装失败,会有些安装失败的文件,需要通过指令make disclean进行清除,然后再进行make编译安装指令。2.9 cd 进入src目录下,如果看到redis-server等绿色的可执行文件则为安装成功2.10 cd..会到安装目录下2.11 make install PREFIX=/opt/test(任意目录),将可执行文件安装到指定目录,用于之后的开机自启动和多个redis的配置2.12 vim /etc/profile 进入profile文件夹下进行环境变量的配置 export REDIS_HOME=/opt/test(上面存放的任意目录) export PATH=$PATH:$REDIS_HOME/bin source /etc/profile 重新加载配置文件2.13 cd utils 进行多个redis的配置2.14 ./install_server.sh 可以执行一次或者多次爬坑1 参考1如果出现下面提示,需要将_pid_1_exe方法整个屏蔽掉再执行./install_server.sh就可以完成设置了Welcome to the redis service installer This script will help you easily set up a running redis server This systems seems to use systemd. Please take a look at the provided example service unit files in this directory, and adapt and install them. Sorry!2.1.4.1 一个物理机中可以有多个redis实例(进程),通过port端口号进行区分;2.1.4.2 可执行程序只有一份存在上面的自己放的任意目录,但是内存中可以有多个实例,只需要执行install_server,sh脚本进行指定port端口号、各自的配置文件、持久化目录。2.1.4.3 启动/停止命令是通过指令 service redis_6379 start/stop/stauts进行执行,redis_6379这类的是在/etc/init.d/xxx,是通过上面脚本配置的端口号自动生成的。再通过脚本设置另外一个6380端口的redis实例,通过ps -fe | grep redis查看已经启动redis进程,此时就可以看到6379和6380两个redis实例已经启动了。 -
最基础的概念,什么是幂等性?幂等性:提交多次的情况下,结果都一样。比如数据库查询,可称为天然幂等性,即查询多次结果都一样,无需人为去做幂等性操作。但是update table set value=value+1 where id=1,每次执行的结构都会发生变化,不是幂等。inter into table(id,name)values(1,‘name’),如id不是主键或者没有唯一索引,重复操作上面的业务,会插入多条数据,不具备幂等性;所以我们在什么情景下需要确保幂等性呢?用户多次点击保存按钮用户保存成功后,返回上一页再次保存微服务相互调用,由于网络原因,导致请求失败解决方案一、token机制:1、根据业务场景,判断哪些业务存在幂等性问题,在执行业务之前先获取token,将token缓存止redis中2、调用业务接口时,将token携带过去,一般放在请求头,作为Auth认证3、服务器判断token是否存在于redis中,存在表示第一次请求,然后删除token,继续执行业务4、如果不存在,则表示反复操作,不执行业务逻辑,直接返回重复标志!结束风险性:业务执行前删除还是后删除token?如果是执行后删除,在业务执行中,未删除token,用户又点了请求进来,那么则无法保障幂等性。如果是执行前删除,在分布式下,用户快速请求2次,这时2个请求同时到redis去获取token,对比成功,同时删除,同时执行业务,那么也无法保障幂等性。so:使用执行前删除,在分布式情况下,获取,对比,删除必须确保原子性,所以要加分布式锁。二、加锁1、数据库锁select * from table where … for update2、业务层面加分布式锁将获取、对比、删除作为一个原子性的操作加锁,处理完成后释放锁,确保串行操作。三、约束数据库唯一约束:通过主键、唯一索引,确保无法重复新增同一笔数据,这就能确保幂等性
-
>摘要:随着业务需求的发展和功能的复杂度提升,往往反馈到研发设计和实现,就不那么简单了,怎么办呢?本文分享自华为云社区《[给面试加点硬菜:延迟任务场景,该如何提高吞吐量和时效性!](https://bbs.huaweicloud.com/blogs/330938?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content)》,作者: 小傅哥。 # 一、延迟任务场景 什么是延迟任务? 当我们的实际业务需求场景中,有一些活动开始前的状态变更、订单结算后的T+1对账、贷款单息费的产生,都是需要使用到延迟任务来进行触达。实际的操作一般会有 Quartz、Schedule 来对你的库表数据进行定时扫描和处理,当条件满足后做数据状态的变更或者产生新的数据插入到表中。 这样一个简单的需求就是延迟任务最初需求,如果需求前期内容较少、使用方不多,可能在实际开发中就只是一个单台机器直接对着表一顿轮训就完事了。但随着业务需求的发展和功能的复杂度提升,往往反馈到研发设计和实现,就不那么简单了,比如:你需要保障尽可能低延迟完成较大规模的数据量扫描处理,否则就像贷款单息费的产生,已经到了第二天用户还没看到自己的息费信息或者是还款后的重新对账,可能就这个时候就要产生客诉了。 那么,类似这样的场景该如何设计呢? # 二、延迟任务设计 通常的任务中心处理流程主要,主要是由定时任务扫描任务库表,把即将达到超时时间的任务信息扫描到处理队列(内存/MQ消息),再由业务系统进行处理任务,处理完成后更新库表中的任务状态。 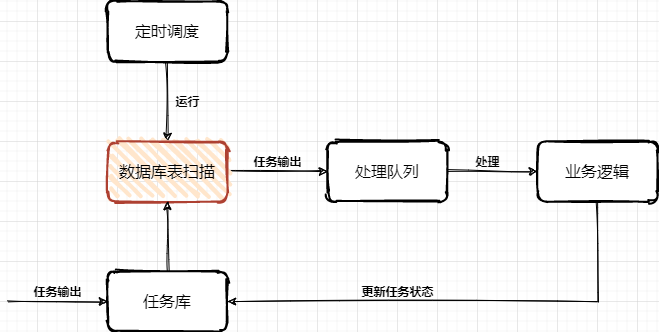 问题: 1. 海量数据规模较大的任务列表数据,在分库分表下该需要快速扫描。 2. 任务扫描服务与业务逻辑处理,耦合在一起,不具有通用性和复用性。 3. 细分任务体系有些是需要低延迟处理的,不能等待过长时间。 ## 1. 任务表方式 除了一些较小的状态变更场景,例如在各自业务的库表中,就包含了一个状态字段,这个字段一方面有程序逻辑处理变更的状态,也有到达指定到期时间后由任务服务自动变更处理的操作,一般这类功能,直接设计到自己的库表中即可。 那么还有一些较大也较为频繁使用的场景,如果都是在每个系统的各自所需的N多个表中,都添加这样的字段进行维护,就显得非常冗余了,也不那么易于维护。所以针对这样的场景就很适合做一个通用的任务延时系统,各业务系统把需要被延时执行的动作提交到延时系统中,再有延时系统在指定时间下进行回调,回调的动作可以是接口或者MQ消息进行触达。例如可以设计这样一个任务调度表: 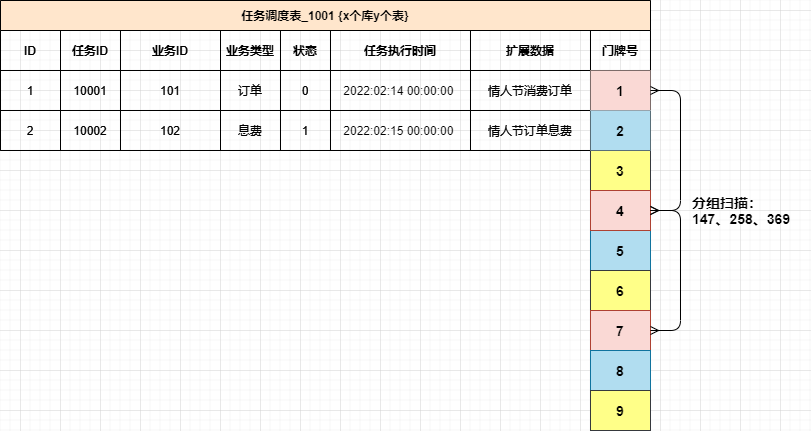 1. 抽取的任务调度表,主要是拿到什么任务,在什么时间发起动作,具体的动作处理仍交给业务工程处理。 2. 大批量的各自业务的任务进行集中处理,则需要设计一个分库分表,满足于后续业务体量的增长。 3. 门牌号设计,针对一张表的扫描,如果数据量较大,又不希望只是一个任务扫描一个表,可以多个任务扫描一个表,加到扫描的体量。这个时候就需要一个门牌号来隔离不同任务扫描的范围,避免扫描出重复的任务数据。 ## 2. 低延迟方式 低延迟处理方案,是在任务表方式的基础上,新增加的时间把控处理。它可以把即将到期的前一段时间的任务,放置到 Redis 集群队里中,在消费的时候再从队列中 pop 出来,这样可以更快的接近任务的处理时效,避免因为扫库间隔较大延迟任务执行。 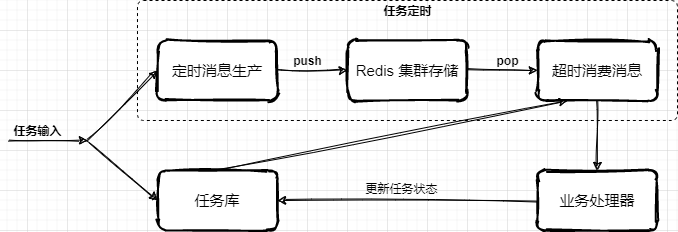 - 在接收业务系统提交进来的延迟任务时,按照执行时间的长短放置到任务库或者也同步到 Redis 集群中,一些执行时间较晚的任务则可以先放到任务库,再通过扫描的方式添加到超时任务执行队列中。 - 那么关于这块的设计核心在于 Redis 队列的使用,以及为了保证消费的可靠性需要引入二阶段消费、注册 ZK 注册中心至少保证一次消费的处理。本文重点主要放在 Redis 队列的设计,其他更多的逻辑处理,可以按照业务需求进行扩展和完善 # Redis 消费队列 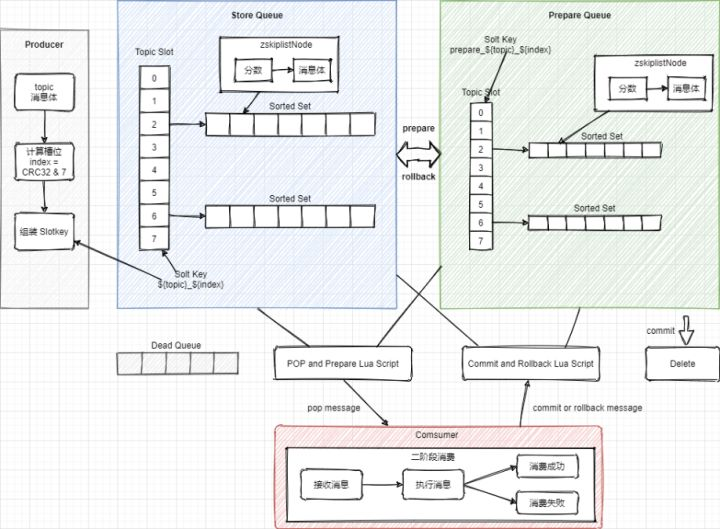 - 按照消息体计算对应数据所属的槽位 index = CRC32 & 7 - StoreQueue 采用 Slot 按照 SlotKey = #{topic}_#{index} 和 Sorted Set 的数据结构按执行任务分数排序,存放任务执行信息。定时消息将时间戳作为分数,消费时每次弹出分数小于当前时间戳的一个消息 - 为了保障每条消息至少可消费一次,消费者不是直接 pop 有序集合中的元素,而是将元素从 StoreQueue 移动到 PrepareQueue 并返回消息给消费者。消费成功后再从 PrepareQueue 从删除,如果消费失败则从PreapreQueue 重新移动到 StoreQueue,这样二阶段消费的方式进行处理。 ## 简单案例 @Test public void test_delay_queue() throws InterruptedException { RBlockingQueue blockingQueue = redissonClient.getBlockingQueue("TASK"); RDelayedQueue delayedQueue = redissonClient.getDelayedQueue(blockingQueue); new Thread(() -> { try { while (true){ Object take = blockingQueue.take(); System.out.println(take); Thread.sleep(10); } } catch (InterruptedException e) { e.printStackTrace(); } }).start(); int i = 0; while (true){ delayedQueue.offerAsync("测试" + ++i, 100L, TimeUnit.MILLISECONDS); Thread.sleep(1000L); } } ## 测试数据 2022-02-13 WARN 204760 --- [ Finalizer] i.l.c.resource.DefaultClientResources : io.lettuce.core.resource.DefaultClientResources was not shut down properly, shutdown() was not called before it's garbage-collected. Call shutdown() or shutdown(long,long,TimeUnit) 测试1 测试2 测试3 测试4 测试5 Process finished with exit code -1 - 源码:GitHub - fuzhengwei/TimeOutCenter: TimeOutCenter - 描述:使用 redisson 中的 DelayedQueue 作为消息队列,写入后等待消费时间进行 POP 消费。 # 三、总结 - 调度任务的使用在实际的场景中非常频繁,例如我们经常使用 xxl-job,也有一些大厂自研的分布式任务调度组件,这些可能原本都是很小很简单的功能,但经过抽象、整合、提炼,变成了一个个核心通用的中间件服务。 - 当我们在考虑使用任务调度的时候,无论哪种方式的设计和实现,都需要考虑这个功能使用时候的以为迭代和维护性,如果仅仅是一个非常小的场景,又没多少人使用的话,那么在自己机器上折腾就可以。过渡的设计和使用有时候也会把研发资源代入泥潭 - 其实各项技术的知识点,都像是一个个工具,刀枪棍棒斧钺钩,那能怎么结合各自的特点,把这些兵器用起来,才是一个程序员不断成长的过程。
-
最基础的概念,什么是幂等性?幂等性:提交多次的情况下,结果都一样。比如数据库查询,可称为天然幂等性,即查询多次结果都一样,无需人为去做幂等性操作。但是update table set value=value+1 where id=1,每次执行的结构都会发生变化,不是幂等。inter into table(id,name)values(1,‘name’),如id不是主键或者没有唯一索引,重复操作上面的业务,会插入多条数据,不具备幂等性;所以我们在什么情景下需要确保幂等性呢?用户多次点击保存按钮用户保存成功后,返回上一页再次保存微服务相互调用,由于网络原因,导致请求失败解决方案一、token机制:1、根据业务场景,判断哪些业务存在幂等性问题,在执行业务之前先获取token,将token缓存止redis中2、调用业务接口时,将token携带过去,一般放在请求头,作为Auth认证3、服务器判断token是否存在于redis中,存在表示第一次请求,然后删除token,继续执行业务4、如果不存在,则表示反复操作,不执行业务逻辑,直接返回重复标志!结束风险性:业务执行前删除还是后删除token?如果是执行后删除,在业务执行中,未删除token,用户又点了请求进来,那么则无法保障幂等性。如果是执行前删除,在分布式下,用户快速请求2次,这时2个请求同时到redis去获取token,对比成功,同时删除,同时执行业务,那么也无法保障幂等性。so:使用执行前删除,在分布式情况下,获取,对比,删除必须确保原子性,所以要加分布式锁。二、加锁1、数据库锁select * from table where … for update2、业务层面加分布式锁将获取、对比、删除作为一个原子性的操作加锁,处理完成后释放锁,确保串行操作。三、约束数据库唯一约束:通过主键、唯一索引,确保无法重复新增同一笔数据,这就能确保幂等性
-
最基础的概念,什么是幂等性?幂等性:提交多次的情况下,结果都一样。比如数据库查询,可称为天然幂等性,即查询多次结果都一样,无需人为去做幂等性操作。但是update table set value=value+1 where id=1,每次执行的结构都会发生变化,不是幂等。inter into table(id,name)values(1,‘name’),如id不是主键或者没有唯一索引,重复操作上面的业务,会插入多条数据,不具备幂等性;所以我们在什么情景下需要确保幂等性呢?用户多次点击保存按钮用户保存成功后,返回上一页再次保存微服务相互调用,由于网络原因,导致请求失败解决方案一、token机制:1、根据业务场景,判断哪些业务存在幂等性问题,在执行业务之前先获取token,将token缓存止redis中2、调用业务接口时,将token携带过去,一般放在请求头,作为Auth认证3、服务器判断token是否存在于redis中,存在表示第一次请求,然后删除token,继续执行业务4、如果不存在,则表示反复操作,不执行业务逻辑,直接返回重复标志!结束风险性:业务执行前删除还是后删除token?如果是执行后删除,在业务执行中,未删除token,用户又点了请求进来,那么则无法保障幂等性。如果是执行前删除,在分布式下,用户快速请求2次,这时2个请求同时到redis去获取token,对比成功,同时删除,同时执行业务,那么也无法保障幂等性。so:使用执行前删除,在分布式情况下,获取,对比,删除必须确保原子性,所以要加分布式锁。二、加锁1、数据库锁select * from table where … for update2、业务层面加分布式锁将获取、对比、删除作为一个原子性的操作加锁,处理完成后释放锁,确保串行操作。三、约束数据库唯一约束:通过主键、唯一索引,确保无法重复新增同一笔数据,这就能确保幂等性
-
 摘要:如何通过springboot来集成操作Redis。本文分享自华为云社区《SpringBoot连接Redis操作教程》,作者: 灰小猿。今天来和大家分享一个如何通过springboot来集成操作Redis。一、SpringBoot连接Redisspringboot连接Redis时需要在pom文件中导入所需的jar包依赖,依赖如下: <!-- 加入jedis依赖 --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> (1)使用Jedis类直接连接Redis服务器在springboot环境下连接redis的方法有很多,首先最简单的就是直接通过jedis类来连接,jedis类就相当于是redis的客户端表示。连接方法如下: /** * redis连接测试01 */ @Test public void redisTest01() { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); // 如果 Redis 服务设置了密码,需要用下面这行代码输入密码 // jedis.auth("123456"); System.out.println("连接成功"); //查看服务是否运行 System.out.println("服务正在运行: "+jedis.ping()); }运行后结果:通过这种方式进行连接时,springboot会自动的去本地寻找redis服务器进行连接,如果没有找到那么就会报错,如果你去阅读jedis的底层源码,你会发现Jedis类有多种构造方法,常用的几个是使用默认地址和端口//不传值,那么使用默认的127.0.0.1地址,6379端口就访问 public Jedis()使用指定地址和默认端口//只传入目的地址,那么使用指定的地址和默认的端口号去访问 public Jedis(String host)使用指定地址和端口//传入目的地址和端口号,那么使用指定的地址和端口号去访问 public Jedis(String host, int port)(2)通过配置文件进行连接在springboot中,当然是可以通过配置文件的形式来设置各种连接参数了,Redis也是一样的,在yml文件中进行如下配置:注意:这是没有使用连接池的,如果使用连接池,需要在下边增加配置,关于使用连接池的可以继续往下看。##redis配置信息 spring: redis: database: 0 #redis数据库索引,默认为0 host: 127.0.0.1 #redis服务器地址 port: 6379 #redis服务器连接端口 password: #redis服务器连接密码,默认为null timeout: 5000 #redis连接超时时间通过配置文件来进行配置之后,我们就可以使用springboot中的一个工具类来操作Redis的操作了,springboot会自动读取配置文件中的配置信息,然后通过该配置信息去连接Redis服务器,springboot中提供操作Redis的工具类有两个,分别是:StringRedisTemplate和RedisTemplate,StringRedisTemplate和RedisTemplate的区别如下在进行序列化时,RedisTemplate使用的是 JdkSerializationRedisSerializer,而StringRedisTemplate使用的是StringRedisSerializerStringRedisTemplate继承了RedisTemplate<String,String>,而RedisTemplate 定义为 RedisTemplate<K, V>,所有StringRedisTemplate就限定了K,V为String类型的相同处体现在他们对Redis的操作上,RedisTemplate和StringRedisSerializer都定义了五种对Redis的操作,分别对应这Redis中的五种数据类型。redisTemplate.opsForValue(); //操作字符串 redisTemplate.opsForHash(); //操作hash redisTemplate.opsForList(); //操作list redisTemplate.opsForSet(); //操作set redisTemplate.opsForZSet(); //操作有序set那么在使用的时候,这两个类应该如何选择呢?如果你的redis数据库里面本来存的是字符串数据,或者你要存取的数据就是字符串类型数据的时候,那么你就使用StringRedisTemplate即可,》但是如果你的数据是复杂的对象类型,而取出的时候又不想做任何的数据转换,直接从Redis里面取出一个对象,那么使用RedisTemplate是更好的选择。接下来我以StringRedisSerializer为例子,来给大家演示一下使用StringRedisSerializer操作Redis的方法, /** * springboot主从连接测试, * 使用springRedisTemplate操作 */ @Test public void redisTest06() { // 操作字符型 stringRedisTemplate.opsForValue().set("test06","Test06"); System.out.println(stringRedisTemplate.opsForValue().get("test06")); // 设置key的过期时间,30秒 stringRedisTemplate.expire("test06", 30 * 1000, TimeUnit.MILLISECONDS); // 根据key获取过期时间 Long test06ExpireTime = stringRedisTemplate.getExpire("test06"); System.out.println("根据key获取过期时间:" + test06ExpireTime); // 根据key获取过期时间,并且换算成指定单位 Long test06ExpireTimeToUnit = stringRedisTemplate.getExpire("test06", TimeUnit.SECONDS); System.out.println("根据key获取过期时间,并且换算成指定单位:" + test06ExpireTimeToUnit); // 检查key是否存在,返回布尔类型 Boolean test06IsExist = stringRedisTemplate.hasKey("test06"); System.out.println("检查key是否存在,返回布尔类型:" + test06IsExist); }在上面的操作中,有一点关于获取和设置key过期时间的操作,当时在操作的时候对其进行了一下探究,在这里分享给大家stringRedisTemplate中获取过期时间的getExpire()方法的说明如果最开始没有设置过期时间,那么就返回-1,数据在没有达到Redis数据最大限额的情况下会一直存在.如果设置了过期时间,但是数据还未过期,就返回剩余时间,如果到了过期时间,那么数据会被删除如果数据被删除或者不存在,那么就返回-2.
摘要:如何通过springboot来集成操作Redis。本文分享自华为云社区《SpringBoot连接Redis操作教程》,作者: 灰小猿。今天来和大家分享一个如何通过springboot来集成操作Redis。一、SpringBoot连接Redisspringboot连接Redis时需要在pom文件中导入所需的jar包依赖,依赖如下: <!-- 加入jedis依赖 --> <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> (1)使用Jedis类直接连接Redis服务器在springboot环境下连接redis的方法有很多,首先最简单的就是直接通过jedis类来连接,jedis类就相当于是redis的客户端表示。连接方法如下: /** * redis连接测试01 */ @Test public void redisTest01() { //连接本地的 Redis 服务 Jedis jedis = new Jedis("localhost"); // 如果 Redis 服务设置了密码,需要用下面这行代码输入密码 // jedis.auth("123456"); System.out.println("连接成功"); //查看服务是否运行 System.out.println("服务正在运行: "+jedis.ping()); }运行后结果:通过这种方式进行连接时,springboot会自动的去本地寻找redis服务器进行连接,如果没有找到那么就会报错,如果你去阅读jedis的底层源码,你会发现Jedis类有多种构造方法,常用的几个是使用默认地址和端口//不传值,那么使用默认的127.0.0.1地址,6379端口就访问 public Jedis()使用指定地址和默认端口//只传入目的地址,那么使用指定的地址和默认的端口号去访问 public Jedis(String host)使用指定地址和端口//传入目的地址和端口号,那么使用指定的地址和端口号去访问 public Jedis(String host, int port)(2)通过配置文件进行连接在springboot中,当然是可以通过配置文件的形式来设置各种连接参数了,Redis也是一样的,在yml文件中进行如下配置:注意:这是没有使用连接池的,如果使用连接池,需要在下边增加配置,关于使用连接池的可以继续往下看。##redis配置信息 spring: redis: database: 0 #redis数据库索引,默认为0 host: 127.0.0.1 #redis服务器地址 port: 6379 #redis服务器连接端口 password: #redis服务器连接密码,默认为null timeout: 5000 #redis连接超时时间通过配置文件来进行配置之后,我们就可以使用springboot中的一个工具类来操作Redis的操作了,springboot会自动读取配置文件中的配置信息,然后通过该配置信息去连接Redis服务器,springboot中提供操作Redis的工具类有两个,分别是:StringRedisTemplate和RedisTemplate,StringRedisTemplate和RedisTemplate的区别如下在进行序列化时,RedisTemplate使用的是 JdkSerializationRedisSerializer,而StringRedisTemplate使用的是StringRedisSerializerStringRedisTemplate继承了RedisTemplate<String,String>,而RedisTemplate 定义为 RedisTemplate<K, V>,所有StringRedisTemplate就限定了K,V为String类型的相同处体现在他们对Redis的操作上,RedisTemplate和StringRedisSerializer都定义了五种对Redis的操作,分别对应这Redis中的五种数据类型。redisTemplate.opsForValue(); //操作字符串 redisTemplate.opsForHash(); //操作hash redisTemplate.opsForList(); //操作list redisTemplate.opsForSet(); //操作set redisTemplate.opsForZSet(); //操作有序set那么在使用的时候,这两个类应该如何选择呢?如果你的redis数据库里面本来存的是字符串数据,或者你要存取的数据就是字符串类型数据的时候,那么你就使用StringRedisTemplate即可,》但是如果你的数据是复杂的对象类型,而取出的时候又不想做任何的数据转换,直接从Redis里面取出一个对象,那么使用RedisTemplate是更好的选择。接下来我以StringRedisSerializer为例子,来给大家演示一下使用StringRedisSerializer操作Redis的方法, /** * springboot主从连接测试, * 使用springRedisTemplate操作 */ @Test public void redisTest06() { // 操作字符型 stringRedisTemplate.opsForValue().set("test06","Test06"); System.out.println(stringRedisTemplate.opsForValue().get("test06")); // 设置key的过期时间,30秒 stringRedisTemplate.expire("test06", 30 * 1000, TimeUnit.MILLISECONDS); // 根据key获取过期时间 Long test06ExpireTime = stringRedisTemplate.getExpire("test06"); System.out.println("根据key获取过期时间:" + test06ExpireTime); // 根据key获取过期时间,并且换算成指定单位 Long test06ExpireTimeToUnit = stringRedisTemplate.getExpire("test06", TimeUnit.SECONDS); System.out.println("根据key获取过期时间,并且换算成指定单位:" + test06ExpireTimeToUnit); // 检查key是否存在,返回布尔类型 Boolean test06IsExist = stringRedisTemplate.hasKey("test06"); System.out.println("检查key是否存在,返回布尔类型:" + test06IsExist); }在上面的操作中,有一点关于获取和设置key过期时间的操作,当时在操作的时候对其进行了一下探究,在这里分享给大家stringRedisTemplate中获取过期时间的getExpire()方法的说明如果最开始没有设置过期时间,那么就返回-1,数据在没有达到Redis数据最大限额的情况下会一直存在.如果设置了过期时间,但是数据还未过期,就返回剩余时间,如果到了过期时间,那么数据会被删除如果数据被删除或者不存在,那么就返回-2.
上滑加载中
推荐直播
-
 TinyEngine低代码引擎系列第2讲——向下扎根,向上生长,TinyEngine灵活构建个性化低代码平台
TinyEngine低代码引擎系列第2讲——向下扎根,向上生长,TinyEngine灵活构建个性化低代码平台2024/11/14 周四 16:00-18:00
王老师 华为云前端开发工程师,TinyEngine开源负责人
王老师将从TinyEngine 的灵活定制能力出发,带大家了解隐藏在低代码背后的潜在挑战及突破思路,通过实践及运用,帮助大家贴近面向未来低代码产品。
回顾中 -
 华为云AI入门课:AI发展趋势与华为愿景
华为云AI入门课:AI发展趋势与华为愿景2024/11/18 周一 18:20-20:20
Alex 华为云学堂技术讲师
本期直播旨在帮助开发者熟悉理解AI技术概念,AI发展趋势,AI实用化前景,了解熟悉未来主要技术栈,当前发展瓶颈等行业化知识。帮助开发者在AI领域快速构建知识体系,构建职业竞争力。
去报名 -
 华为云软件开发生产线(CodeArts)10月新特性解读
华为云软件开发生产线(CodeArts)10月新特性解读2024/11/19 周二 19:00-20:00
苏柏亚培 华为云高级产品经理
不知道产品的最新特性?没法和产品团队建立直接的沟通?本期直播产品经理将为您解读华为云软件开发生产线10月发布的新特性,并在直播过程中为您答疑解惑。
去报名
热门标签