-
 引言在科技行业中,程序员是一群充满激情和创造力的人。然而,随着时间的推移,当一个程序员超过35岁时,他们可能会面临一些独特的挑战和抉择。这篇博客将讨论超过35岁的程序员应该如何面对职业发展的问题,并提供一些建议和方向。1. 评估技能和经验首先,程序员在职业发展的道路上应该对自己的技能和经验进行评估。超过35岁的程序员通常积累了丰富的经验,这是他们的优势。然而,技术在不断演进,新的编程语言和工具层出不穷。因此,程序员需要时刻保持看书和更新自己的技能。建议:参加培训课程、研讨会和技术会议,以了解最新的技术趋势和发展。投入时间和精力来看书新的编程语言、框架和工具。寻找机会参与开源项目或个人项目,以增加实践经验和展示自己的能力。2. 深化专业领域知识随着经验的积累,超过35岁的程序员可能已经在某个领域有了深入的专业知识。这是一个机会,可以将自己的专业知识进一步加深和扩展。建议:将精力集中在自己感兴趣或擅长的领域,并成为该领域的专家。阅读行业相关的书籍、论文和博客,保持对领域最新发展的了解。参与行业社区,与其他专业人士进行交流和合作。3. 转型到管理或指导角色超过35岁的程序员可以考虑将职业发展的重心转向管理或指导方向。在这个阶段,他们可能已经积累了丰富的实践经验和领导能力,可以成为团队的领导者或技术顾问。建议:探索管理角色的机会,例如项目经理、团队领导或部门负责人。寻找指导他人成长的机会,例如担任导师或教育培训者。建立人际关系网,与其他领导者和专业人士建立联系。4. 创业和独立开发对于有创业精神和独立开发能力的程序员来说,超过35岁也是一个适合追求创业梦想的时机。他们可以利用自己的技术经验和行业洞察,开发自己的产品或服务,并创建自己的公司。建议:评估自己的创业意愿和能力,并制定详细的计划。寻找合作伙伴或团队,共同实现创业目标。探索风险投资和创业支持的机会,以获得资金和资源。5. 协调工作与生活无论是继续在企业工作,转型到管理角色,还是创业,超过35岁的程序员都应该重视协调工作与生活的重要性。过度工作可能会导致疲劳和失去热情,影响职业生涯的长期发展。建议:制定合理的工作时间表,确保有足够的休息和娱乐时间。培养健康的生活作风,包括适当的锻炼和饮食。寻找支持和鼓励的社交圈子,与家人和朋友保持联系。结论超过35岁的程序员在职业发展中可能面临一些独特的挑战,但同时也有许多机会等待着他们。通过评估技能和经验,深化专业领域知识,转型到管理或指导角色,或者追求创业梦想,他们可以找到适合自己的道路。最重要的是,保持看书、协调工作与生活,并享受自己在科技行业中的旅程。希望这篇博客能为超过35岁的程序员提供一些有价值的建议和启发!
引言在科技行业中,程序员是一群充满激情和创造力的人。然而,随着时间的推移,当一个程序员超过35岁时,他们可能会面临一些独特的挑战和抉择。这篇博客将讨论超过35岁的程序员应该如何面对职业发展的问题,并提供一些建议和方向。1. 评估技能和经验首先,程序员在职业发展的道路上应该对自己的技能和经验进行评估。超过35岁的程序员通常积累了丰富的经验,这是他们的优势。然而,技术在不断演进,新的编程语言和工具层出不穷。因此,程序员需要时刻保持看书和更新自己的技能。建议:参加培训课程、研讨会和技术会议,以了解最新的技术趋势和发展。投入时间和精力来看书新的编程语言、框架和工具。寻找机会参与开源项目或个人项目,以增加实践经验和展示自己的能力。2. 深化专业领域知识随着经验的积累,超过35岁的程序员可能已经在某个领域有了深入的专业知识。这是一个机会,可以将自己的专业知识进一步加深和扩展。建议:将精力集中在自己感兴趣或擅长的领域,并成为该领域的专家。阅读行业相关的书籍、论文和博客,保持对领域最新发展的了解。参与行业社区,与其他专业人士进行交流和合作。3. 转型到管理或指导角色超过35岁的程序员可以考虑将职业发展的重心转向管理或指导方向。在这个阶段,他们可能已经积累了丰富的实践经验和领导能力,可以成为团队的领导者或技术顾问。建议:探索管理角色的机会,例如项目经理、团队领导或部门负责人。寻找指导他人成长的机会,例如担任导师或教育培训者。建立人际关系网,与其他领导者和专业人士建立联系。4. 创业和独立开发对于有创业精神和独立开发能力的程序员来说,超过35岁也是一个适合追求创业梦想的时机。他们可以利用自己的技术经验和行业洞察,开发自己的产品或服务,并创建自己的公司。建议:评估自己的创业意愿和能力,并制定详细的计划。寻找合作伙伴或团队,共同实现创业目标。探索风险投资和创业支持的机会,以获得资金和资源。5. 协调工作与生活无论是继续在企业工作,转型到管理角色,还是创业,超过35岁的程序员都应该重视协调工作与生活的重要性。过度工作可能会导致疲劳和失去热情,影响职业生涯的长期发展。建议:制定合理的工作时间表,确保有足够的休息和娱乐时间。培养健康的生活作风,包括适当的锻炼和饮食。寻找支持和鼓励的社交圈子,与家人和朋友保持联系。结论超过35岁的程序员在职业发展中可能面临一些独特的挑战,但同时也有许多机会等待着他们。通过评估技能和经验,深化专业领域知识,转型到管理或指导角色,或者追求创业梦想,他们可以找到适合自己的道路。最重要的是,保持看书、协调工作与生活,并享受自己在科技行业中的旅程。希望这篇博客能为超过35岁的程序员提供一些有价值的建议和启发! -
 统计学,数据挖掘和机器学习中的决策树训练,使用决策树作为预测模型来预测样本的类标。这种决策树也称作分类树或回归树。在这些树的结构里,叶子节点给出类标而内部节点代表某个属性。在决策分析中,一棵决策树可以明确地表达决策的过程。在数据挖掘中,一棵决策树表达的是数据而不是决策。决策树的类型在数据挖掘中,决策树主要有两种类型: 分类树的输出是样本的类标。 回归树的输出是一个实数 (例如房子的价格,病人待在医院的时间等)。术语分类和回归树 (CART) 包含了上述两种决策树, 最先由Breiman 等提出。分类树和回归树有些共同点和不同点—例如处理在何处分裂的问题。有些集成的方法产生多棵树: 装袋算法(Bagging), 是一个早期的集成方法,用有放回抽样法来训练多棵决策树,最终结果用投票法产生。 随机森林(Random Forest) 使用多棵决策树来改进分类性能。 提升树(Boosting Tree) 可以用来做回归分析和分类决策。 旋转森林(Rotation forest) – 每棵树的训练首先使用主元分析法 (PCA)。还有其他很多决策树算法,常见的有: ID3算法 C4.5算法 CHi-squared Automatic Interaction Detector (CHAID), 在生成树的过程中用多层分裂 。 MARS可以更好的处理数值型数据。决策树的优点与其他的数据挖掘算法相比,决策树有许多优点: 易于理解和解释 人们很容易理解决策树的意义。 只需很少的数据准备 其他技术往往需要数据归一化。 即可以处理数值型数据也可以处理类别型 数据。其他技术往往只能处理一种数据类型。例如关联规则只能处理类别型的而神经网络只能处理数值型的数据。 使用白箱 模型. 输出结果容易通过模型的结构来解释。而神经网络是黑箱模型,很难解释输出的结果。 可以通过测试集来验证模型的性能 。可以考虑模型的稳定性。 强健控制. 对噪声处理有好的强健性。 可以很好的处理大规模数据 。缺点 训练一棵最优的决策树是一个完全NP问题。因此, 实际应用时决策树的训练采用启发式搜索算法例如 贪心算法 来达到局部最优。这样的算法没办法得到最优的决策树。 决策树创建的过度复杂会导致无法很好的预测训练集之外的数据。这称作过拟合。 剪枝机制可以避免这种问题。 有些问题决策树没办法很好的解决,例如 异或问题。解决这种问题的时候,决策树会变得过大。 要解决这种问题,只能改变问题的领域或者使用其他更为耗时的学习算法 (例如统计关系学习 或者 归纳逻辑编程). 对那些有类别型属性的数据, 信息增益 会有一定的偏置。参考资料Induction of decisiontrees" Machine Learning An Exploratory Technque for Investigating Large Quantities of Categorical Data Bias of ImportanceMeasures for Multi-valued Attributes and Solutions A Survey of Evolutinary Algorithms for Decision-Tree Induction
统计学,数据挖掘和机器学习中的决策树训练,使用决策树作为预测模型来预测样本的类标。这种决策树也称作分类树或回归树。在这些树的结构里,叶子节点给出类标而内部节点代表某个属性。在决策分析中,一棵决策树可以明确地表达决策的过程。在数据挖掘中,一棵决策树表达的是数据而不是决策。决策树的类型在数据挖掘中,决策树主要有两种类型: 分类树的输出是样本的类标。 回归树的输出是一个实数 (例如房子的价格,病人待在医院的时间等)。术语分类和回归树 (CART) 包含了上述两种决策树, 最先由Breiman 等提出。分类树和回归树有些共同点和不同点—例如处理在何处分裂的问题。有些集成的方法产生多棵树: 装袋算法(Bagging), 是一个早期的集成方法,用有放回抽样法来训练多棵决策树,最终结果用投票法产生。 随机森林(Random Forest) 使用多棵决策树来改进分类性能。 提升树(Boosting Tree) 可以用来做回归分析和分类决策。 旋转森林(Rotation forest) – 每棵树的训练首先使用主元分析法 (PCA)。还有其他很多决策树算法,常见的有: ID3算法 C4.5算法 CHi-squared Automatic Interaction Detector (CHAID), 在生成树的过程中用多层分裂 。 MARS可以更好的处理数值型数据。决策树的优点与其他的数据挖掘算法相比,决策树有许多优点: 易于理解和解释 人们很容易理解决策树的意义。 只需很少的数据准备 其他技术往往需要数据归一化。 即可以处理数值型数据也可以处理类别型 数据。其他技术往往只能处理一种数据类型。例如关联规则只能处理类别型的而神经网络只能处理数值型的数据。 使用白箱 模型. 输出结果容易通过模型的结构来解释。而神经网络是黑箱模型,很难解释输出的结果。 可以通过测试集来验证模型的性能 。可以考虑模型的稳定性。 强健控制. 对噪声处理有好的强健性。 可以很好的处理大规模数据 。缺点 训练一棵最优的决策树是一个完全NP问题。因此, 实际应用时决策树的训练采用启发式搜索算法例如 贪心算法 来达到局部最优。这样的算法没办法得到最优的决策树。 决策树创建的过度复杂会导致无法很好的预测训练集之外的数据。这称作过拟合。 剪枝机制可以避免这种问题。 有些问题决策树没办法很好的解决,例如 异或问题。解决这种问题的时候,决策树会变得过大。 要解决这种问题,只能改变问题的领域或者使用其他更为耗时的学习算法 (例如统计关系学习 或者 归纳逻辑编程). 对那些有类别型属性的数据, 信息增益 会有一定的偏置。参考资料Induction of decisiontrees" Machine Learning An Exploratory Technque for Investigating Large Quantities of Categorical Data Bias of ImportanceMeasures for Multi-valued Attributes and Solutions A Survey of Evolutinary Algorithms for Decision-Tree Induction -
随机森林指的是利用多棵树对样本进行训练并预测的一种分类器。该分类器最早由Leo Breiman和Adele Cutler提出,并被注册成了商标。在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。 Leo Breiman和Adele Cutler发展出推论出随机森林的算法。 而 "Random Forests" 是他们的商标。 这个术语是1995年由贝尔实验室的Tin Kam Ho所提出的随机决策森林(random decision forests)而来的。这个方法则是结合 Breimans 的 "Bootstrap aggregating" 想法和 Ho 的"random subspace method"以建造决策树的集合。随机森林的优缺点优点:1.可以用来解决分类和回归问题:随机森林可以同时处理分类和数值特征2.抗过拟合能力:通过平均决策树,降低过拟合的风险性3.只有在半数以上的基分类器出现差错时才会做出错误的预测:随机森林非常稳定,即使数据集中出现了一个新的数据点,整个算法也不会受到过多影响,它只会影响到一颗决策树,很难对所有决策树产生影响缺点:1.据观测,如果一些分类/回归问题的训练数据中存在噪音,随机森林中的数据集会出现过拟合的现象2.比决策树算法更复杂,计算成本更高3.由于其本身的复杂性,它们比其他类似的算法需要更多的时间来训练非常推荐这个学习视频https://education.huaweicloud.com/courses/course-v1:HuaweiX+CBUCNXE086+Self-paced/courseware/45c5a9b65ee348719ddc4f4c3801ad0f/b67e40f52a7447f79364a2de6f2b9398/相关概念1.分裂:在决策树的训练过程中,需要一次次的将训练数据集分裂成两个子数据集,这个过程就叫做分裂。2.特征:在分类问题中,输入到分类器中的数据叫做特征。以上面的股票涨跌预测问题为例,特征就是前一天的交易量和收盘价。3.待选特征:在决策树的构建过程中,需要按照一定的次序从全部的特征中选取特征。待选特征就是在步骤之前还没有被选择的特征的集合。例如,全部的特征是 ABCDE,第一步的时候,待选特征就是ABCDE,第一步选择了C,那么第二步的时候,待选特征就是ABDE。4.分裂特征:接待选特征的定义,每一次选取的特征就是分裂特征,例如,在上面的例子中,第一步的分裂特征就是C。因为选出的这些特征将数据集分成了一个个不相交的部分,所以叫它们分裂特征。
-
 目 录1 AutoML超参优化原理................................................................................................................. 11.1 总体方案.......................................................................................................................................................................................... 11.2 常见的超参数优化方法................................................................................................................................................................ 11.2.1 网格寻优...................................................................................................................................................................................... 11.2.2 随机寻优...................................................................................................................................................................................... 21.2.3 贝叶斯优化.................................................................................................................................................................................. 21.2.3.1 高斯过程(GP)..................................................................................................................................................................... 41.2.3.2 SMAC......................................................................................................................................................................................... 61.2.3.3 TPE.............................................................................................................................................................................................. 61.2.4 BOHB............................................................................................................................................................................................ 72 超参数算法代码实现分析........................................................................................................... 92.1 GPEI................................................................................................................................................................................................ 112.2 SMAC............................................................................................................................................................................................. 132.3 TPE.................................................................................................................................................................................................. 152.4 不同数据规模对算法的影响..................................................................................................................................................... 161 AutoML超参优化原理1.1 总体方案1.2 常见的超参数优化方法1.1 总体方案AutoML基于vega.ml自动化机器学习分析系统,结合自动化工厂,完成大数据各个组件的客户端参数,OS参数,JDK参数的自动调优功能,降低人力消耗,极大的提高参数搜索效率。当前框架中实现的单目标超参数优化算法主要涉及:随机搜索(Random Search), 贝叶斯优化(Bayesian Optimization, e.g. SMAC, GPEI),TPE(Tree-structured Parzen Estimator), BOHB(Hyperband with Bayesian Optimization)。1.2 常见的超参数优化方法1.2.1 网格寻优网格化寻优可以说是最基本的超参数优化方法,目的是遍历搜索空间。使用这种技术,我们只需为所有超参数的可能构建独立的模型,评估每个模型的性能,并选择产生最佳结果的模型和超参数。1.2.2 随机寻优随机寻优方法在超参数网格的基础上选择随机的组合来进行模型训练。可以控制组合的数量,基于时间和计算资源的情况,选择合理的计算次数。通常并不是所有的超参数都有同样的重要性,某些超参数可能作用更显著。而随机寻优方法相对于网格化寻优方法能够更准确地确定某些重要的超参数的最佳值。1.2.3 贝叶斯优化贝叶斯优化用于机器学习调参由J. Snoek(2012)提出,主要思想是,给定优化的目标函数(广义的函数,只需指定输入和输出即可,无需知道内部结构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布(直到后验分布基本贴合于真实分布。简单的说,就是考虑了上一次参数的信息,从而更好的调整当前的参数。他与常规的网格搜索或者随机搜索的区别是:l 贝叶斯调参考虑之前的参数信息,不断地更新先验;网格搜索未考虑之前的参数信息l 贝叶斯调参迭代次数少,速度快;网格搜索速度慢,参数多时易导致维度爆炸l 贝叶斯调参针对非凸问题依然稳健;网格搜索针对非凸问题易得到局部最优表1-1 贝叶斯优化过程中,常见的代理模型(surrogate model)有高斯过程(Gaussian Process),SMAC(基于随机森林),TPE(Parzen Estimator)高斯模型适用于连续型变量的,范围小的参数搜索空间,与此相对的,SMAC是基于随机森林算法的实现,在大范围的搜索空间,离散型变量空间的搜索效率会更好;TPE算法也适用于大范围的搜索空间,离散型变量空间,使用 KDE (核密度估计,带有权重的一维KDEs) 来对密度进行建模。一般形式的Acquisition Funtion是关于x的函数,映射到实数空间R,表示改点的目标函数值能够比当前最优值大多少的概率,目的是权衡当前已有的结果以及探索的可能(balance exploration against exploitation),目前主要有以下几种主流的效用函数(Acquisition function)1. POI(probability of improvement)2. Expected Improvement3. Confidence bound criteria1.2.3.1 高斯过程(GP)介绍贝叶斯优化调参,必须要从两个部分讲起:l 高斯过程,用以拟合优化目标函数l 贝叶斯优化,包括了“开采”和“勘探”,用以花最少的代价找到最优值上图是一张高斯分布拟合函数的示意图,可以看到,它只需要九个点,就可以大致拟合出整个函数形状1.2.3.2 SMAC贝叶斯优化中,除了代理模型(surrogate model)为高斯过程外,另一种用得比较多的代理模型为随机森林SMAC全称Sequential Model-Based Optimization forGeneral Algorithm Configuration,算法在2011被Hutter等人提出。该算法的提出即解决高斯回归过程中参数类型不能为离散的情况。由于随机森林的训练与预测时间复杂度较低,因此在SMAC中可以轻易采样候选点,因此SMAC对真实函数有噪音的情况会更加robust一点;实验表明,当参数空间较复杂且维度较大时,采用SMAC效果会更优一点;随机森林是由很多决策树构成的,不同决策树之间没有关联。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。1.2.3.3 TPE贝叶斯优化中,代理模型(surrogate model)还可以是TPE(Tree Parzen Estimator)1.2.4 BOHBBOHB 是由此篇论文提出的一种高效而稳定的调参算法。 BO 是贝叶斯优化(Bayesian Optimization)的缩写,HB 是 Hyperband 算法的缩写。BOHB 依赖 HB(Hyperband)来决定每次跑多少组参数和每组参数分配多少资源(budget),它的改进之处是将 Hyperband 在每个循环开始时随机选择参数的方法替换成了依赖之前的数据建立模型(贝叶斯优化)进行参数选择。 一旦贝叶斯优化生成的参数达到迭代所需的配置数, 就会使用这些配置开始执行标准的连续减半过程(successive halving)。 观察这些参数在不同资源配置(budget)下的表现 g(x, b),用于在以后的迭代中用作我们贝叶斯优化模型选择参数的基准数据。以上这张图展示了 BOHB 的工作流程。 将每次训练的最大资源配置(max_budget)设为 9,最小资源配置设为(min_budget)1,逐次减半比例(eta)设为 3,其他的超参数为默认值。 那么在这个例子中,s_max 计算的值为 2, 所以会持续地进行 {s=2, s=1, s=0, s=2, s=1, s=0, ...} 的循环。 在“逐次减半”(SuccessiveHalving)算法的每一个阶段,即图中橙色框,都将选取表现最好的前 1/eta 个参数,并在赋予更多计算资源(budget)的情况下运行。不断重复“逐次减半” (SuccessiveHalving)过程,直到这个循环结束。 同时,收集这些试验的超参数组合,使用了计算资源(budget)和其表现(metrics),使用这些数据来建立一个以使用了多少计算资源(budget)为维度的多维核密度估计(KDE)模型。 这个多维的核密度估计(KDE)模型将用于指导下一个循环的参数选择。2 超参数算法代码实现分析当我们对Hive组件的同一个用例(query2)分别用3种不同的算法进行测试后发现结果如下图所示:初步得出的结论是GPEI相对可以比较快速的收敛,SMAC算法的波动比较大,但是最优解相对比较好,TPE的实现偏离预期(Vega的实现有问题,所以后续可以考虑改进)2.1 GPEI2.2 SMAC2.3 TPE2.4 不同数据规模对算法的影响2.1 GPEI高斯过程的质量仅取决于协方差函数。Matern内核的类是RBF的概括。它具有一个附加参数v,用于控制所得函数的平滑度。v越小,近似函数越不平滑。当v趋于无穷,该内核变得等同于RBF内核。如果v=1/2,则Matern内核与绝对指数内核相同。重要的中间值v=1.5是(一次微分函数)和v=2.5(两次微分函数)。针对Hive组件的其中一个用例query,分别采用了v=1.5, v=2.5进行了测试,结果如下图,发现两者差别没有特别大,可能由于参数搜索范围比较大,测试迭代次数不够多,还未达到收敛趋势,后续有待进一步测试。2.2 SMAC针对随机森林算法,我们尝试改变n_estimators和max_depth来改变树的颗树和深度,进而影响模型的训练过程(因为数据量偏少的时候容易造成欠拟合的情形,因此可以减少树的深度和颗树),验证结果如下图所示:在Hive组件,query1这个用例的测试结果上发现,n_estimator=200, max_depth=5的时候效果比较理想,相对收敛会快一点,因此可以改变原先默认的参数设置。2.3 TPE和Vega开发人员初步确认,发现他们的TPE算法开发可能存在漏洞,最后没有达到预期的效果。因此我们考虑变化acquisition function,我们考虑使用POI(Probability of Improvement)替代EI进行测试,测试结果如下图所示,发现使用POI后,算法的效果得到了明显的提升。2.4 不同数据规模对算法的影响我们采用同一个算法模型的相同的参数,对不同数据规模进行了测试,借此来评估数据规模或者集群计算节点数量是否会对算法模型的参数造成影响,以下是对SMAC和GPEI两个算法分别作出的实践。数据量规模:small: 310M large:3.0G huge:30.3G gigantic:303.5G bigdata: 606.9G double bigdata: 3.0T对SMAC各个数据集规模做了测试,发现在不同数据集规模上用相同的树深和树的数量,最后呈现的趋势是类似的,基本可以说明SMAC算法不会很明显的受到数据规模或者集群计算节点数量的变化。类似的,对GPEI各个数据集规模做了测试,发现在不同数据集规模上用相同的核函数,最后呈现的趋势也是类似的,也基本可以说明GPEI算法不会很明显的受到数据规模或者集群计算节点数量的变化。
目 录1 AutoML超参优化原理................................................................................................................. 11.1 总体方案.......................................................................................................................................................................................... 11.2 常见的超参数优化方法................................................................................................................................................................ 11.2.1 网格寻优...................................................................................................................................................................................... 11.2.2 随机寻优...................................................................................................................................................................................... 21.2.3 贝叶斯优化.................................................................................................................................................................................. 21.2.3.1 高斯过程(GP)..................................................................................................................................................................... 41.2.3.2 SMAC......................................................................................................................................................................................... 61.2.3.3 TPE.............................................................................................................................................................................................. 61.2.4 BOHB............................................................................................................................................................................................ 72 超参数算法代码实现分析........................................................................................................... 92.1 GPEI................................................................................................................................................................................................ 112.2 SMAC............................................................................................................................................................................................. 132.3 TPE.................................................................................................................................................................................................. 152.4 不同数据规模对算法的影响..................................................................................................................................................... 161 AutoML超参优化原理1.1 总体方案1.2 常见的超参数优化方法1.1 总体方案AutoML基于vega.ml自动化机器学习分析系统,结合自动化工厂,完成大数据各个组件的客户端参数,OS参数,JDK参数的自动调优功能,降低人力消耗,极大的提高参数搜索效率。当前框架中实现的单目标超参数优化算法主要涉及:随机搜索(Random Search), 贝叶斯优化(Bayesian Optimization, e.g. SMAC, GPEI),TPE(Tree-structured Parzen Estimator), BOHB(Hyperband with Bayesian Optimization)。1.2 常见的超参数优化方法1.2.1 网格寻优网格化寻优可以说是最基本的超参数优化方法,目的是遍历搜索空间。使用这种技术,我们只需为所有超参数的可能构建独立的模型,评估每个模型的性能,并选择产生最佳结果的模型和超参数。1.2.2 随机寻优随机寻优方法在超参数网格的基础上选择随机的组合来进行模型训练。可以控制组合的数量,基于时间和计算资源的情况,选择合理的计算次数。通常并不是所有的超参数都有同样的重要性,某些超参数可能作用更显著。而随机寻优方法相对于网格化寻优方法能够更准确地确定某些重要的超参数的最佳值。1.2.3 贝叶斯优化贝叶斯优化用于机器学习调参由J. Snoek(2012)提出,主要思想是,给定优化的目标函数(广义的函数,只需指定输入和输出即可,无需知道内部结构以及数学性质),通过不断地添加样本点来更新目标函数的后验分布(直到后验分布基本贴合于真实分布。简单的说,就是考虑了上一次参数的信息,从而更好的调整当前的参数。他与常规的网格搜索或者随机搜索的区别是:l 贝叶斯调参考虑之前的参数信息,不断地更新先验;网格搜索未考虑之前的参数信息l 贝叶斯调参迭代次数少,速度快;网格搜索速度慢,参数多时易导致维度爆炸l 贝叶斯调参针对非凸问题依然稳健;网格搜索针对非凸问题易得到局部最优表1-1 贝叶斯优化过程中,常见的代理模型(surrogate model)有高斯过程(Gaussian Process),SMAC(基于随机森林),TPE(Parzen Estimator)高斯模型适用于连续型变量的,范围小的参数搜索空间,与此相对的,SMAC是基于随机森林算法的实现,在大范围的搜索空间,离散型变量空间的搜索效率会更好;TPE算法也适用于大范围的搜索空间,离散型变量空间,使用 KDE (核密度估计,带有权重的一维KDEs) 来对密度进行建模。一般形式的Acquisition Funtion是关于x的函数,映射到实数空间R,表示改点的目标函数值能够比当前最优值大多少的概率,目的是权衡当前已有的结果以及探索的可能(balance exploration against exploitation),目前主要有以下几种主流的效用函数(Acquisition function)1. POI(probability of improvement)2. Expected Improvement3. Confidence bound criteria1.2.3.1 高斯过程(GP)介绍贝叶斯优化调参,必须要从两个部分讲起:l 高斯过程,用以拟合优化目标函数l 贝叶斯优化,包括了“开采”和“勘探”,用以花最少的代价找到最优值上图是一张高斯分布拟合函数的示意图,可以看到,它只需要九个点,就可以大致拟合出整个函数形状1.2.3.2 SMAC贝叶斯优化中,除了代理模型(surrogate model)为高斯过程外,另一种用得比较多的代理模型为随机森林SMAC全称Sequential Model-Based Optimization forGeneral Algorithm Configuration,算法在2011被Hutter等人提出。该算法的提出即解决高斯回归过程中参数类型不能为离散的情况。由于随机森林的训练与预测时间复杂度较低,因此在SMAC中可以轻易采样候选点,因此SMAC对真实函数有噪音的情况会更加robust一点;实验表明,当参数空间较复杂且维度较大时,采用SMAC效果会更优一点;随机森林是由很多决策树构成的,不同决策树之间没有关联。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。1.2.3.3 TPE贝叶斯优化中,代理模型(surrogate model)还可以是TPE(Tree Parzen Estimator)1.2.4 BOHBBOHB 是由此篇论文提出的一种高效而稳定的调参算法。 BO 是贝叶斯优化(Bayesian Optimization)的缩写,HB 是 Hyperband 算法的缩写。BOHB 依赖 HB(Hyperband)来决定每次跑多少组参数和每组参数分配多少资源(budget),它的改进之处是将 Hyperband 在每个循环开始时随机选择参数的方法替换成了依赖之前的数据建立模型(贝叶斯优化)进行参数选择。 一旦贝叶斯优化生成的参数达到迭代所需的配置数, 就会使用这些配置开始执行标准的连续减半过程(successive halving)。 观察这些参数在不同资源配置(budget)下的表现 g(x, b),用于在以后的迭代中用作我们贝叶斯优化模型选择参数的基准数据。以上这张图展示了 BOHB 的工作流程。 将每次训练的最大资源配置(max_budget)设为 9,最小资源配置设为(min_budget)1,逐次减半比例(eta)设为 3,其他的超参数为默认值。 那么在这个例子中,s_max 计算的值为 2, 所以会持续地进行 {s=2, s=1, s=0, s=2, s=1, s=0, ...} 的循环。 在“逐次减半”(SuccessiveHalving)算法的每一个阶段,即图中橙色框,都将选取表现最好的前 1/eta 个参数,并在赋予更多计算资源(budget)的情况下运行。不断重复“逐次减半” (SuccessiveHalving)过程,直到这个循环结束。 同时,收集这些试验的超参数组合,使用了计算资源(budget)和其表现(metrics),使用这些数据来建立一个以使用了多少计算资源(budget)为维度的多维核密度估计(KDE)模型。 这个多维的核密度估计(KDE)模型将用于指导下一个循环的参数选择。2 超参数算法代码实现分析当我们对Hive组件的同一个用例(query2)分别用3种不同的算法进行测试后发现结果如下图所示:初步得出的结论是GPEI相对可以比较快速的收敛,SMAC算法的波动比较大,但是最优解相对比较好,TPE的实现偏离预期(Vega的实现有问题,所以后续可以考虑改进)2.1 GPEI2.2 SMAC2.3 TPE2.4 不同数据规模对算法的影响2.1 GPEI高斯过程的质量仅取决于协方差函数。Matern内核的类是RBF的概括。它具有一个附加参数v,用于控制所得函数的平滑度。v越小,近似函数越不平滑。当v趋于无穷,该内核变得等同于RBF内核。如果v=1/2,则Matern内核与绝对指数内核相同。重要的中间值v=1.5是(一次微分函数)和v=2.5(两次微分函数)。针对Hive组件的其中一个用例query,分别采用了v=1.5, v=2.5进行了测试,结果如下图,发现两者差别没有特别大,可能由于参数搜索范围比较大,测试迭代次数不够多,还未达到收敛趋势,后续有待进一步测试。2.2 SMAC针对随机森林算法,我们尝试改变n_estimators和max_depth来改变树的颗树和深度,进而影响模型的训练过程(因为数据量偏少的时候容易造成欠拟合的情形,因此可以减少树的深度和颗树),验证结果如下图所示:在Hive组件,query1这个用例的测试结果上发现,n_estimator=200, max_depth=5的时候效果比较理想,相对收敛会快一点,因此可以改变原先默认的参数设置。2.3 TPE和Vega开发人员初步确认,发现他们的TPE算法开发可能存在漏洞,最后没有达到预期的效果。因此我们考虑变化acquisition function,我们考虑使用POI(Probability of Improvement)替代EI进行测试,测试结果如下图所示,发现使用POI后,算法的效果得到了明显的提升。2.4 不同数据规模对算法的影响我们采用同一个算法模型的相同的参数,对不同数据规模进行了测试,借此来评估数据规模或者集群计算节点数量是否会对算法模型的参数造成影响,以下是对SMAC和GPEI两个算法分别作出的实践。数据量规模:small: 310M large:3.0G huge:30.3G gigantic:303.5G bigdata: 606.9G double bigdata: 3.0T对SMAC各个数据集规模做了测试,发现在不同数据集规模上用相同的树深和树的数量,最后呈现的趋势是类似的,基本可以说明SMAC算法不会很明显的受到数据规模或者集群计算节点数量的变化。类似的,对GPEI各个数据集规模做了测试,发现在不同数据集规模上用相同的核函数,最后呈现的趋势也是类似的,也基本可以说明GPEI算法不会很明显的受到数据规模或者集群计算节点数量的变化。 -
 作为新兴起的、高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。最初,我是在参加校外竞赛时接触到随机森林算法的。最近几年的国内外大赛,包括2013年百度校园电影推荐系统大赛、2014年阿里巴巴天池大数据竞赛以及Kaggle数据科学竞赛,参赛者对随机森林的使用占有相当高的比例。此外,据我的个人了解来看,一大部分成功进入答辩的队伍也都选择了Random Forest 或者 GBDT 算法。 所以可以看出,Random Forest在准确率方面还是相当有优势的。 那说了这么多,那随机森林到底是怎样的一种算法呢? 如果读者接触过决策树(Decision Tree)的话,那么会很容易理解什么是随机森林。随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想--集成思想的体现。 其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。
作为新兴起的、高度灵活的一种机器学习算法,随机森林(Random Forest,简称RF)拥有广泛的应用前景,从市场营销到医疗保健保险,既可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。最初,我是在参加校外竞赛时接触到随机森林算法的。最近几年的国内外大赛,包括2013年百度校园电影推荐系统大赛、2014年阿里巴巴天池大数据竞赛以及Kaggle数据科学竞赛,参赛者对随机森林的使用占有相当高的比例。此外,据我的个人了解来看,一大部分成功进入答辩的队伍也都选择了Random Forest 或者 GBDT 算法。 所以可以看出,Random Forest在准确率方面还是相当有优势的。 那说了这么多,那随机森林到底是怎样的一种算法呢? 如果读者接触过决策树(Decision Tree)的话,那么会很容易理解什么是随机森林。随机森林就是通过集成学习的思想将多棵树集成的一种算法,它的基本单元是决策树,而它的本质属于机器学习的一大分支——集成学习(Ensemble Learning)方法。随机森林的名称中有两个关键词,一个是“随机”,一个就是“森林”。“森林”我们很好理解,一棵叫做树,那么成百上千棵就可以叫做森林了,这样的比喻还是很贴切的,其实这也是随机森林的主要思想--集成思想的体现。 其实从直观角度来解释,每棵决策树都是一个分类器(假设现在针对的是分类问题),那么对于一个输入样本,N棵树会有N个分类结果。而随机森林集成了所有的分类投票结果,将投票次数最多的类别指定为最终的输出,这就是一种最简单的 Bagging 思想。 -
随机森林看起来是很好理解,但是要完全搞明白它的工作原理,需要很多机器学习方面相关的基础知识。在本文中,我们简单谈一下,而不逐一进行赘述,如果有同学不太了解相关的知识,可以参阅其他博友的一些相关博文或者文献。1)信息、熵以及信息增益的概念 这三个基本概念是决策树的根本,是决策树利用特征来分类时,确定特征选取顺序的依据。理解了它们,决策树你也就了解了大概。 引用香农的话来说,信息是用来消除随机不确定性的东西。当然这句话虽然经典,但是还是很难去搞明白这种东西到底是个什么样,可能在不同的地方来说,指的东西又不一样。对于机器学习中的决策树而言,如果带分类的事物集合可以划分为多个类别当中,则某个类(xi)的信息可以定义如下:I(x)用来表示随机变量的信息,p(xi)指是当xi发生时的概率。熵是用来度量不确定性的,当熵越大,X=xi的不确定性越大,反之越小。对于机器学习中的分类问题而言,熵越大即这个类别的不确定性更大,反之越小。信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好。这方面的内容不再细述,感兴趣的同学可以看 《信息&熵&信息增益》 这篇博文。 2)决策树 决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。常见的决策树算法有C4.5、ID3和CART。3)集成学习 集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。 随机森林是集成学习的一个子类,它依靠于决策树的投票选择来决定最后的分类结果。你可以在这找到用python实现集成学习的文档:Scikit 学习文档。
-
 一、决策树算法简介决策树算法是机器学习的经典算法之一,产生于上世纪六十年代,当下主要分为ID3算法、C4.5算法以及CART算法。ID3算法和C4.5算法核心思想均为通过计算样本信息熵进行分类,两者的区别在于ID3算法基于信息增益作为特征选择的指标,而C4.5则是基于信息增益率作为特征选择的指标,本例中使用ID3算法进行分类。CART算法则是使用基尼指数作为特征选择的指标。二、ID3算法的基本思想ID3算法的核心是统计学中信息熵的概念,通过计算信息熵来判断该数据样本的“纯度”,信息熵越大,数据样本越不“纯”,分类需要的数据量就越大。信息熵的计算公式:info(D)info(D)=-\displaystyle\sum_{i=1}^{k} p_i*\log_2(p_i)i=1∑kpi∗log2(pi)其中p_ipi是概率下面介绍一下ID3算法的步骤1.计算类别信息熵将所得到的数据集按照类别逐个计算其信息熵再相加,假设在数据集D中有k个类别,且第i个类别在数据集中所占的概率为p_ipi,则信息类别熵为:info(D)info(D)=-\displaystyle\sum_{i=1}^{k} p_i*\log_2(p_i)i=1∑kpi∗log2(pi)2.计算每个特征的信息熵将数据集根据某个特征进行分类后,计算该种特征的条件下各种类别的类别信息熵,也称条件熵。假设将数据集按照特征A进行分类,且A有m个类别,则其计算公式为:info_A(D)infoA(D)=-\displaystyle\sum_{j=1}^{m} |D_j|/|D|*info(D_j)j=1∑m∣Dj∣/∣D∣∗info(Dj)其中的D_jDj是指数据集的类别在A特征的各个类别下的样本数量(注意数据集的类别和A特征的类别是不同的概念,比如要在一个数据集中判断一个人在某天心情的好坏,好和坏就是数据集的类别,而一天中有一个特征是天气,天气的类别是晴天、雨天和阴天,我们要算的是心情好和坏分别在晴天,雨天和阴天中的分布的离散情况)其他特征的条件熵也是相同的计算方法3.计算信息增益通过前面两个步骤我们得到了数据集的信息熵和属于各个特征的条件熵,根据第二个步骤我先进行的分类再进行信息熵(或者说条件熵)的计算,分类之后数据的混乱程度肯定降低,也就是说条件熵会小于数据集的信息熵,信息增益则是条件熵和信息熵之间的差值,用来衡量使用该特征分类的效果好坏,假设用特征A进行分类,其信息增益公式为:Gain(A)Gain(A)=info(D)info(D)-info_A(D)infoA(D)通常我们选择信息增益最大的特征作为分类的节点三、基于ModelArts平台实现ID3算法1.数据集来源数据集选用的是AIGallery的表格类型数据集《硬盘故障预测数据集》网址链接:https://marketplace.huaweicloud.com/markets/aihub/datasets/detail/?content_id=1b5d6ec0-adc0-4fdd-b03f-fecad119eab52.sklearn实现模型部署#导入相关库 import matplotlib.pyplot as plt import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn import tree from sklearn.metrics import accuracy_score import time #载入数据集 train_test_set = pd.read_csv("dataset_2020.csv",header=0) data = train_test_set.values #分出标签集和特征集 features = data[::,5::2] lables = data[::,4] features = pd.DataFrame(features) lables = pd.DataFrame(lables) lables = lables.astype("float32") #删去整列都是空值的列 features = features.dropna(axis=1,how="all") #将缺失值用中位数填充 features = np.array(features) for i in range(features.shape[1]): temp = np.array(features)[:,i].tolist() median = np.nanmedian(temp) features[np.argwhere(pd.isna(features[:,i].T)),i] = median features = pd.DataFrame(features,dtype="float32") #分出训练集和测试集 train_features,test_features,train_lables,test_lables = train_test_split(features,lables,test_size=0.33,random_state=0) time_1 = time.time() #选用ID3算法 clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=10, splitter='random', ) clf.fit(train_features,train_lables) time_2 = time.time() print('Training cost:{}s'.format(time_2-time_1)) #预测 test_predict = clf.predict(test_features) time_3 = time.time() print("Predicting cost:{}s".format(time_3-time_2)) #得分 score = accuracy_score(test_lables,test_predict) print("score is {}".format(score)) #学习曲线 scores1 = [] for x in range(4,20): clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=10, #使得每一次生成的树都一样 splitter='random',#分类的特征随机,减少过拟合的可能性 max_depth=x #树的最大深度 ) clf.fit(train_features,train_lables) test_predict = clf.predict(test_features) score = accuracy_score(test_lables,test_predict) scores1.append(score) plt.plot(range(4,20),scores1,color='red',label="max_depth") plt.legend() plt.show() scores2 = [] for y in range(2,30): clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=10, splitter='random', max_depth=18, min_samples_split=y #至少有y个样本才会分枝 ) clf.fit(train_features,train_lables) test_predict = clf.predict(test_features) score = accuracy_score(test_lables,test_predict) scores2.append(score) plt.plot(range(2,30),scores2,color='red',label="min_samples_split") plt.legend() plt.show() #手动调参到目前为止效果最好的参数 clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=10, splitter='random', max_depth=18, min_samples_split=16, ) clf.fit(train_features,train_lables) test_predict = clf.predict(test_features) score = accuracy_score(test_lables,test_predict) print(score) #目前最好的预测得分达到0.78153.部分参数解释tree.DecisionTreeClassifier():criterion:决策树衡量划分质量的方法,默认值为‘gini’(基尼指数),默认值下为CART算法,另外一个可选参数为 ‘entropy’(信息增益),选择此参数为ID3算法。random_state:默认值为 ‘None’,可任意设为一个常数,设为常数时可以简单理解为使得每次运行模型都会得到一个相同的树。splitter:节点划分策略,默认值为 ‘best’(最优划分),模型会在特征的所有划分点中找出最优的划分点;可选参数有 ‘random’(随机局部最优划分),模型会随机地在部分划分点中找到局部最优的划分点。'best’适合样本量不大的情况下, 'random’适合样本量比较大的时候,是减少过拟合的方法之一。max_depth:树的最大深度,默认值为 ‘None’,指定模型中树的的最大深度。min_samples_split:内部节点能继续划分所包含的最小样本数,是防止过拟合的方法之一。转自,决策树算法实例操演——基于ModelArts平台(小白机器学习初体验)-云社区-华为云 (huaweicloud.com)
一、决策树算法简介决策树算法是机器学习的经典算法之一,产生于上世纪六十年代,当下主要分为ID3算法、C4.5算法以及CART算法。ID3算法和C4.5算法核心思想均为通过计算样本信息熵进行分类,两者的区别在于ID3算法基于信息增益作为特征选择的指标,而C4.5则是基于信息增益率作为特征选择的指标,本例中使用ID3算法进行分类。CART算法则是使用基尼指数作为特征选择的指标。二、ID3算法的基本思想ID3算法的核心是统计学中信息熵的概念,通过计算信息熵来判断该数据样本的“纯度”,信息熵越大,数据样本越不“纯”,分类需要的数据量就越大。信息熵的计算公式:info(D)info(D)=-\displaystyle\sum_{i=1}^{k} p_i*\log_2(p_i)i=1∑kpi∗log2(pi)其中p_ipi是概率下面介绍一下ID3算法的步骤1.计算类别信息熵将所得到的数据集按照类别逐个计算其信息熵再相加,假设在数据集D中有k个类别,且第i个类别在数据集中所占的概率为p_ipi,则信息类别熵为:info(D)info(D)=-\displaystyle\sum_{i=1}^{k} p_i*\log_2(p_i)i=1∑kpi∗log2(pi)2.计算每个特征的信息熵将数据集根据某个特征进行分类后,计算该种特征的条件下各种类别的类别信息熵,也称条件熵。假设将数据集按照特征A进行分类,且A有m个类别,则其计算公式为:info_A(D)infoA(D)=-\displaystyle\sum_{j=1}^{m} |D_j|/|D|*info(D_j)j=1∑m∣Dj∣/∣D∣∗info(Dj)其中的D_jDj是指数据集的类别在A特征的各个类别下的样本数量(注意数据集的类别和A特征的类别是不同的概念,比如要在一个数据集中判断一个人在某天心情的好坏,好和坏就是数据集的类别,而一天中有一个特征是天气,天气的类别是晴天、雨天和阴天,我们要算的是心情好和坏分别在晴天,雨天和阴天中的分布的离散情况)其他特征的条件熵也是相同的计算方法3.计算信息增益通过前面两个步骤我们得到了数据集的信息熵和属于各个特征的条件熵,根据第二个步骤我先进行的分类再进行信息熵(或者说条件熵)的计算,分类之后数据的混乱程度肯定降低,也就是说条件熵会小于数据集的信息熵,信息增益则是条件熵和信息熵之间的差值,用来衡量使用该特征分类的效果好坏,假设用特征A进行分类,其信息增益公式为:Gain(A)Gain(A)=info(D)info(D)-info_A(D)infoA(D)通常我们选择信息增益最大的特征作为分类的节点三、基于ModelArts平台实现ID3算法1.数据集来源数据集选用的是AIGallery的表格类型数据集《硬盘故障预测数据集》网址链接:https://marketplace.huaweicloud.com/markets/aihub/datasets/detail/?content_id=1b5d6ec0-adc0-4fdd-b03f-fecad119eab52.sklearn实现模型部署#导入相关库 import matplotlib.pyplot as plt import pandas as pd import numpy as np from sklearn.model_selection import train_test_split from sklearn import tree from sklearn.metrics import accuracy_score import time #载入数据集 train_test_set = pd.read_csv("dataset_2020.csv",header=0) data = train_test_set.values #分出标签集和特征集 features = data[::,5::2] lables = data[::,4] features = pd.DataFrame(features) lables = pd.DataFrame(lables) lables = lables.astype("float32") #删去整列都是空值的列 features = features.dropna(axis=1,how="all") #将缺失值用中位数填充 features = np.array(features) for i in range(features.shape[1]): temp = np.array(features)[:,i].tolist() median = np.nanmedian(temp) features[np.argwhere(pd.isna(features[:,i].T)),i] = median features = pd.DataFrame(features,dtype="float32") #分出训练集和测试集 train_features,test_features,train_lables,test_lables = train_test_split(features,lables,test_size=0.33,random_state=0) time_1 = time.time() #选用ID3算法 clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=10, splitter='random', ) clf.fit(train_features,train_lables) time_2 = time.time() print('Training cost:{}s'.format(time_2-time_1)) #预测 test_predict = clf.predict(test_features) time_3 = time.time() print("Predicting cost:{}s".format(time_3-time_2)) #得分 score = accuracy_score(test_lables,test_predict) print("score is {}".format(score)) #学习曲线 scores1 = [] for x in range(4,20): clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=10, #使得每一次生成的树都一样 splitter='random',#分类的特征随机,减少过拟合的可能性 max_depth=x #树的最大深度 ) clf.fit(train_features,train_lables) test_predict = clf.predict(test_features) score = accuracy_score(test_lables,test_predict) scores1.append(score) plt.plot(range(4,20),scores1,color='red',label="max_depth") plt.legend() plt.show() scores2 = [] for y in range(2,30): clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=10, splitter='random', max_depth=18, min_samples_split=y #至少有y个样本才会分枝 ) clf.fit(train_features,train_lables) test_predict = clf.predict(test_features) score = accuracy_score(test_lables,test_predict) scores2.append(score) plt.plot(range(2,30),scores2,color='red',label="min_samples_split") plt.legend() plt.show() #手动调参到目前为止效果最好的参数 clf = tree.DecisionTreeClassifier(criterion='entropy', random_state=10, splitter='random', max_depth=18, min_samples_split=16, ) clf.fit(train_features,train_lables) test_predict = clf.predict(test_features) score = accuracy_score(test_lables,test_predict) print(score) #目前最好的预测得分达到0.78153.部分参数解释tree.DecisionTreeClassifier():criterion:决策树衡量划分质量的方法,默认值为‘gini’(基尼指数),默认值下为CART算法,另外一个可选参数为 ‘entropy’(信息增益),选择此参数为ID3算法。random_state:默认值为 ‘None’,可任意设为一个常数,设为常数时可以简单理解为使得每次运行模型都会得到一个相同的树。splitter:节点划分策略,默认值为 ‘best’(最优划分),模型会在特征的所有划分点中找出最优的划分点;可选参数有 ‘random’(随机局部最优划分),模型会随机地在部分划分点中找到局部最优的划分点。'best’适合样本量不大的情况下, 'random’适合样本量比较大的时候,是减少过拟合的方法之一。max_depth:树的最大深度,默认值为 ‘None’,指定模型中树的的最大深度。min_samples_split:内部节点能继续划分所包含的最小样本数,是防止过拟合的方法之一。转自,决策树算法实例操演——基于ModelArts平台(小白机器学习初体验)-云社区-华为云 (huaweicloud.com) -
-
 > 前文,我们通过小熊派获取了MPU6050数据,并将数据存储于SD卡中。 本次,我们将小熊派绑于大腿上,分别获取人走路、跑步、上楼梯、坐姿的数据。并对数据进行特征向量衍生,将6个数据衍生为38个数据,通过决策树数算进行模型训练,完成姿态估计。 # 一、准备工作 - 安装anaconda环境,并添加jupyter lab,安装第三方库graphviz - 以及可以获取六轴加速度数据,并存储于数据库 # 二、目标 - 对数据进行处理 - 使用决策树算法对行为进行分类 - 达到90%以上的准确率 # 三、数据获取 我们将小熊派设备绑于大腿上,每200ms获取一次数据并存储于SD卡。   分别获取行走、坐姿、跑步、上楼梯的数据各2000组。 # 四、特征向量衍生 因为我们的行为姿态是一个三维的空间,仅仅从六轴数据中难以找出有价值的数据。对每组数据添加标签,其中0-走路,1-坐姿,2-奔跑,3-上楼梯。 通过观察,人在自然行走时每步的时间间隔最长,为0.7~1s,因此我们以1s为周期,即每5组数据为新的一对。 - 平均值 分别对每对三轴加速度、三轴陀螺仪数据做平均值处理,得到6列数据 在对三轴加速度的三个平均值、三轴陀螺仪的三个平均值相加,得2列数据 - 最大值 分别对每对三轴加速度、三轴陀螺仪数据做最大值处理,得到6列数据 - 最小值 分别对每对三轴加速度、三轴陀螺仪数据做最小值处理,得到6列数据 - 峰峰值 分别对每对三轴加速度、三轴陀螺仪数据做峰峰值处理,得到6列数据 - 方差 分别对每对三轴加速度、三轴陀螺仪数据做方差处理,得到6列数据 - 相关系数 分别对三轴加速度的xy、三轴加速度的yz、三轴加速度的xz、三轴陀螺仪的xy、三轴陀螺仪的yz、三轴陀螺仪的xz做相关系数处理,得到6列数据 综上,一共获得新的38列数据  # 五、模型训练 我们使用jupyter lab进行决策树算法演示 ## 1.导入数据集 ```python import pandas as pd import numpy as np dataset = pd.read_excel('D:\MachineLearning\man\mpu.xlsx') dataset col = dataset.columns.values.tolist() #获取列的名称 datas = np.array(dataset[col[2:-1]]) datas label0_data = dataset.loc[dataset['target']==0] #通过loc函数获取导不同标签的数据 label1_data = dataset.loc[dataset['target']==1] label2_data = dataset.loc[dataset['target']==2] label3_data = dataset.loc[dataset['target']==3] # label3_data data_feature = dataset.iloc[:,[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37]] data_feature data_label = dataset.iloc[:,38] ``` 其中,D:\MachineLearning\man\mpu.xlsx为我数据集的路径。data_feature存放特征值,data_feature存放标签值。 我们查看一下特征值:  ## 2.导入sklearn中的tree ```python from sklearn import tree from sklearn.model_selection import train_test_split ``` ## 3.划分训练集、测试集 我们将数据集分为训练集、测试集,比例为7:3 ```python Xtrain,Xtest,Ytrain,Ytest = train_test_split(data_feature,data_label,test_size=0.3) Xtrain ``` 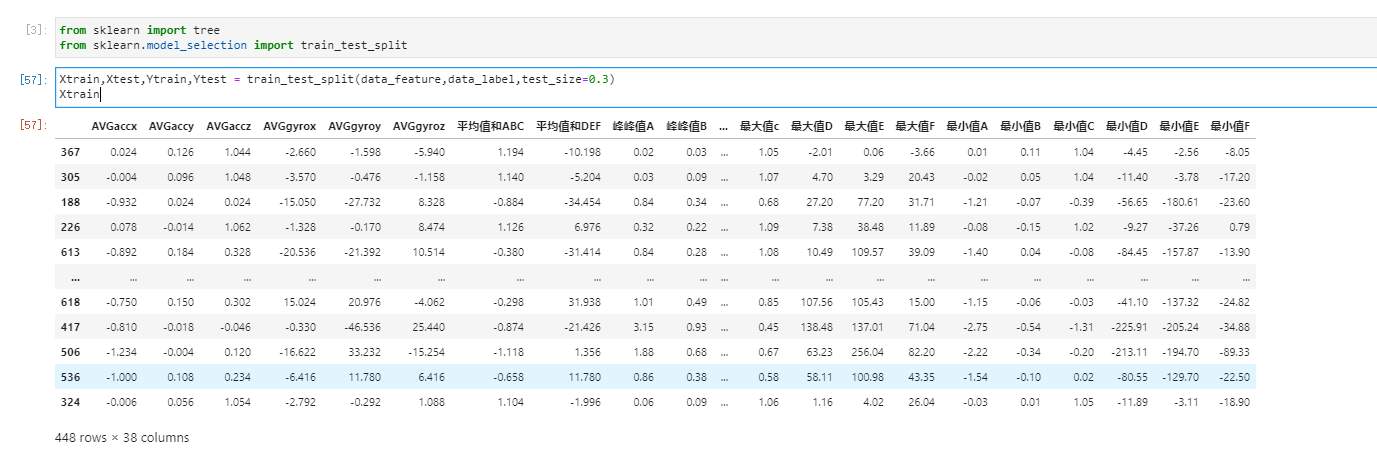 ## 4.训练模型 先忽略我的注释代码,score为测试集的准确率 ```python clf = tree.DecisionTreeClassifier(criterion="entropy" ,random_state=5 # ,splitter="random" ,max_depth = 3 ,min_samples_leaf = 5 ,min_samples_split = 5 ) #默认为gin 不纯度指标,random_state随机数种子控制随机性 clf = clf.fit(Xtrain,Ytrain) score = clf.score(Xtest,Ytest) #返回预测的准确度 #score = clf.score(Xtrain,Ytrain) #返回预测的准确度 #score = clf.score(data_feature,data_label) #clf = clf.fit(data_feature,data_label) score ``` 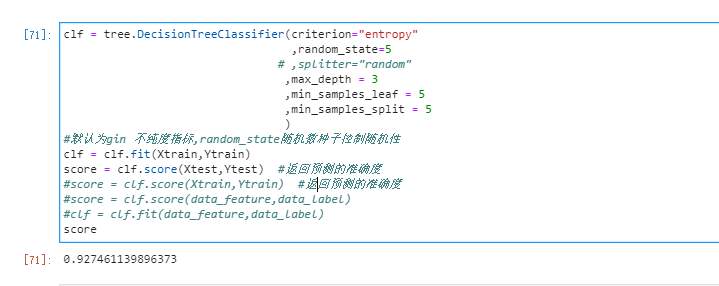 此时,我们看到,测试集的准确率为92% ## 5.画决策树 我们利用graphviz,画出决策树 ```python feature_name = ['a1','a2','a3','a4','a5','a6','a7','a8','a9','a10','a11','a12','a13','a14','a15','a16','a17','a18','a19','a20','a21','a22','a23','a24','25','a26','a27','a28','a29','a30','a31','a32','a33','a34','a35','a36','37','38'] import graphviz dot_data = tree.export_graphviz(clf ,feature_names = feature_name ,class_names = ["走路","坐下","奔跑","上楼梯"] ,filled = True #是否填充颜色,颜色越深,不纯度越低 ,rounded = True #筐的形状 ) graph = graphviz.Source(dot_data) graph ``` 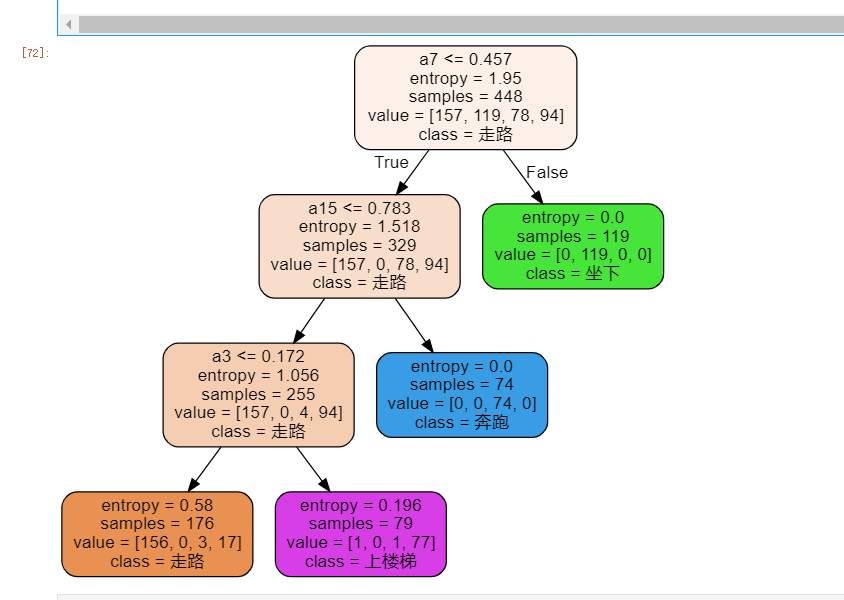 **具体的相关剪枝参数就不再深究,有兴趣的伙伴可以去查找相关资料。** 这是我初步就行剪枝得到的生成树,可以看出此生成树很简单,重要特征值包括三轴加速度的三个平均值之和。下一步,我们将此模型移植到小熊派上,在终端完成行为姿态分类。
> 前文,我们通过小熊派获取了MPU6050数据,并将数据存储于SD卡中。 本次,我们将小熊派绑于大腿上,分别获取人走路、跑步、上楼梯、坐姿的数据。并对数据进行特征向量衍生,将6个数据衍生为38个数据,通过决策树数算进行模型训练,完成姿态估计。 # 一、准备工作 - 安装anaconda环境,并添加jupyter lab,安装第三方库graphviz - 以及可以获取六轴加速度数据,并存储于数据库 # 二、目标 - 对数据进行处理 - 使用决策树算法对行为进行分类 - 达到90%以上的准确率 # 三、数据获取 我们将小熊派设备绑于大腿上,每200ms获取一次数据并存储于SD卡。   分别获取行走、坐姿、跑步、上楼梯的数据各2000组。 # 四、特征向量衍生 因为我们的行为姿态是一个三维的空间,仅仅从六轴数据中难以找出有价值的数据。对每组数据添加标签,其中0-走路,1-坐姿,2-奔跑,3-上楼梯。 通过观察,人在自然行走时每步的时间间隔最长,为0.7~1s,因此我们以1s为周期,即每5组数据为新的一对。 - 平均值 分别对每对三轴加速度、三轴陀螺仪数据做平均值处理,得到6列数据 在对三轴加速度的三个平均值、三轴陀螺仪的三个平均值相加,得2列数据 - 最大值 分别对每对三轴加速度、三轴陀螺仪数据做最大值处理,得到6列数据 - 最小值 分别对每对三轴加速度、三轴陀螺仪数据做最小值处理,得到6列数据 - 峰峰值 分别对每对三轴加速度、三轴陀螺仪数据做峰峰值处理,得到6列数据 - 方差 分别对每对三轴加速度、三轴陀螺仪数据做方差处理,得到6列数据 - 相关系数 分别对三轴加速度的xy、三轴加速度的yz、三轴加速度的xz、三轴陀螺仪的xy、三轴陀螺仪的yz、三轴陀螺仪的xz做相关系数处理,得到6列数据 综上,一共获得新的38列数据  # 五、模型训练 我们使用jupyter lab进行决策树算法演示 ## 1.导入数据集 ```python import pandas as pd import numpy as np dataset = pd.read_excel('D:\MachineLearning\man\mpu.xlsx') dataset col = dataset.columns.values.tolist() #获取列的名称 datas = np.array(dataset[col[2:-1]]) datas label0_data = dataset.loc[dataset['target']==0] #通过loc函数获取导不同标签的数据 label1_data = dataset.loc[dataset['target']==1] label2_data = dataset.loc[dataset['target']==2] label3_data = dataset.loc[dataset['target']==3] # label3_data data_feature = dataset.iloc[:,[0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31,32,33,34,35,36,37]] data_feature data_label = dataset.iloc[:,38] ``` 其中,D:\MachineLearning\man\mpu.xlsx为我数据集的路径。data_feature存放特征值,data_feature存放标签值。 我们查看一下特征值:  ## 2.导入sklearn中的tree ```python from sklearn import tree from sklearn.model_selection import train_test_split ``` ## 3.划分训练集、测试集 我们将数据集分为训练集、测试集,比例为7:3 ```python Xtrain,Xtest,Ytrain,Ytest = train_test_split(data_feature,data_label,test_size=0.3) Xtrain ```  ## 4.训练模型 先忽略我的注释代码,score为测试集的准确率 ```python clf = tree.DecisionTreeClassifier(criterion="entropy" ,random_state=5 # ,splitter="random" ,max_depth = 3 ,min_samples_leaf = 5 ,min_samples_split = 5 ) #默认为gin 不纯度指标,random_state随机数种子控制随机性 clf = clf.fit(Xtrain,Ytrain) score = clf.score(Xtest,Ytest) #返回预测的准确度 #score = clf.score(Xtrain,Ytrain) #返回预测的准确度 #score = clf.score(data_feature,data_label) #clf = clf.fit(data_feature,data_label) score ```  此时,我们看到,测试集的准确率为92% ## 5.画决策树 我们利用graphviz,画出决策树 ```python feature_name = ['a1','a2','a3','a4','a5','a6','a7','a8','a9','a10','a11','a12','a13','a14','a15','a16','a17','a18','a19','a20','a21','a22','a23','a24','25','a26','a27','a28','a29','a30','a31','a32','a33','a34','a35','a36','37','38'] import graphviz dot_data = tree.export_graphviz(clf ,feature_names = feature_name ,class_names = ["走路","坐下","奔跑","上楼梯"] ,filled = True #是否填充颜色,颜色越深,不纯度越低 ,rounded = True #筐的形状 ) graph = graphviz.Source(dot_data) graph ```  **具体的相关剪枝参数就不再深究,有兴趣的伙伴可以去查找相关资料。** 这是我初步就行剪枝得到的生成树,可以看出此生成树很简单,重要特征值包括三轴加速度的三个平均值之和。下一步,我们将此模型移植到小熊派上,在终端完成行为姿态分类。 -
 常用机器学习模型1.朴素贝叶斯模型 朴素贝叶斯模型是一个简单却很重要的模型,它是一种生成模型,也就是它对问题进行联合建模,利用概率的乘法法则,我们可以得到: 由于上述形式复杂,因此朴素贝叶斯作出一个假设,也就是在给定y的条件下,x1,...,xn之间的生成概率是完全独立的,也就是: 注意此处并不是说x1,...,xn的生成概率是相互独立的,而是在给定y的条件下才是独立的,也就是这是一种”条件独立”。了解概率图模型的同学,下面的图模型就可以很好地阐述这个问题: 既然我们说朴素贝叶斯是一种生成模型,那它的生成过程是怎样的呢?对于邮件垃圾分类问题,它的生成过程如下: 首先根据p(y)采用得到y,从而决定当前生成的邮件是垃圾还是非垃圾 确定邮件的长度n,然后根据上一步得到的y,再由p(xi|y)采样得到x1,x2,...,xn 这就是朴素贝叶斯模型。显然,朴素贝叶斯的假设是一种很强的假设,实际应用中很少有满足这种假设的的情况,因为它认为只要在确定邮件是垃圾或者非垃圾的条件下,邮件内容地生成就是完全独立地,词与词之间不存在联系。 朴素贝叶斯模型优、缺点 优点:对小规模的数据表现很好,适合多分类任务,适合增量式训练。 缺点:对输入数据的表达形式很敏感。2.决策树模型 决策树模型是一种简单易用的非参数分类器。它不需要对数据有任何的先验假设,计算速度较快,结果容易解释,而且稳健性强 在复杂的决策情况中,往往需要多层次或多阶段的决策。当一个阶段决策完成后,可能有m种新的不同自然状态发生;每种自然状态下,都有m个新的策略可选择,选择后产生不同的结果并再次面临新的自然状态,继续产生一系列的决策过程,这种决策被称为序列决策或多级决策。此时,如果继续遵循上述的决策准则或采用效益矩阵分析问题,就容易使相应的表格关系十分复杂。决策树是一种能帮助决策者进行序列决策分析的有效工具,其方法是将问题中有关策略、自然状态、概率及收益值等通过线条和图形用类似于树状的形式表示出来。 决策树模型就是由决策点、策略点(事件点)及结果构成的树形图,一般应用于序列决策中,通常以最大收益期望值或最低期望成本作为决策准则,通过图解方式求解在不同条件下各类方案的效益值,然后通过比较,做出决策。 决策树模型优、缺点 优点:浅层的(Shallow)决策树视觉上非常直观,而且容易解释;是对数据的结构和分布不需作任何假设;是可以捕捉住变量间的相互作用(Interaction)。 缺点:深层的(Deep)决策树视觉上和解释上都比较困难;决策树容易过分微调于样本数据而失去稳定性和抗震荡性;决策树对样本量(Sample Size)的需求比较大;处理缺失值的功能非常有限。3.KNN算法 KNN即最近邻算法,核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。其主要过程为: 1.计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等); 2. 对上面所有的距离值进行排序; 3. 选前k个最小距离的样本; 4. 根据这k个样本的标签进行投票,得到最后的分类类别; 如何选择一个最佳的K值,这取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响。但会使类别之间的界限变得模糊。一个较好的K值可通过各种启发式技术来获取,比如,交叉验证。另外噪声和非相关性特征向量的存在会使K近邻算法的准确性减小。 近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些好的K值,K近邻保证错误率不会超过贝叶斯理论误差率。 KNN算法优、缺点 优点:简单,易于理解,易于实现,无需估计参数,无需训练;理论成熟,既可以用来做分类也可以用来做回归;可用于非线性分类;适合对稀有事件进行分类;准确度高,对数据没有假设,对outlier不敏感。 缺点:计算量大;样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);需要大量的内存;可理解性差,无法给出像决策树那样的规则。4.SVM算法 SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。 SVM的主要思想可以概括为两点: 1.它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。 2.它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。 SVM算法优、缺点 优点:可用于线性/非线性分类,也可以用于回归;低泛化误差;容易解释;计算复杂度较低。 缺点:对参数和核函数的选择比较敏感;原始的SVM只比较擅长处理二分类问题。5.logistic回归模型 logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。Logistic回归模型的适用条件: 1.因变量为二分类的分类变量或某事件的发生率,并且是数值型变量。但是需要注意,重复计数现象指标不适用于Logistic回归。 2.残差和因变量都要服从二项分布。二项分布对应的是分类变量,所以不是正态分布,进而不是用最小二乘法,而是最大似然法来解决方程估计和检验问题。 3.自变量和Logistic概率是线性关系 4.各观测对象间相互独立。 Logistic回归实质:发生概率除以没有发生概率再取对数。就是这个不太繁琐的变换改变了取值区间的矛盾和因变量自变量间的曲线关系。究其原因,是发生和未发生的概率成为了比值 ,这个比值就是一个缓冲,将取值范围扩大,再进行对数变换,整个因变量改变。不仅如此,这种变换往往使得因变量和自变量之间呈线性关系,这是根据大量实践而总结。所以,Logistic回归从根本上解决因变量要不是连续变量怎么办的问题。还有,Logistic应用广泛的原因是许多现实问题跟它的模型吻合。例如一件事情是否发生跟其他数值型自变量的关系。 logistic回归模型优、缺点 优点:实现简单;分类时计算量非常小,速度很快,存储资源低。 缺点:容易欠拟合,一般准确度不太高;能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分。
常用机器学习模型1.朴素贝叶斯模型 朴素贝叶斯模型是一个简单却很重要的模型,它是一种生成模型,也就是它对问题进行联合建模,利用概率的乘法法则,我们可以得到: 由于上述形式复杂,因此朴素贝叶斯作出一个假设,也就是在给定y的条件下,x1,...,xn之间的生成概率是完全独立的,也就是: 注意此处并不是说x1,...,xn的生成概率是相互独立的,而是在给定y的条件下才是独立的,也就是这是一种”条件独立”。了解概率图模型的同学,下面的图模型就可以很好地阐述这个问题: 既然我们说朴素贝叶斯是一种生成模型,那它的生成过程是怎样的呢?对于邮件垃圾分类问题,它的生成过程如下: 首先根据p(y)采用得到y,从而决定当前生成的邮件是垃圾还是非垃圾 确定邮件的长度n,然后根据上一步得到的y,再由p(xi|y)采样得到x1,x2,...,xn 这就是朴素贝叶斯模型。显然,朴素贝叶斯的假设是一种很强的假设,实际应用中很少有满足这种假设的的情况,因为它认为只要在确定邮件是垃圾或者非垃圾的条件下,邮件内容地生成就是完全独立地,词与词之间不存在联系。 朴素贝叶斯模型优、缺点 优点:对小规模的数据表现很好,适合多分类任务,适合增量式训练。 缺点:对输入数据的表达形式很敏感。2.决策树模型 决策树模型是一种简单易用的非参数分类器。它不需要对数据有任何的先验假设,计算速度较快,结果容易解释,而且稳健性强 在复杂的决策情况中,往往需要多层次或多阶段的决策。当一个阶段决策完成后,可能有m种新的不同自然状态发生;每种自然状态下,都有m个新的策略可选择,选择后产生不同的结果并再次面临新的自然状态,继续产生一系列的决策过程,这种决策被称为序列决策或多级决策。此时,如果继续遵循上述的决策准则或采用效益矩阵分析问题,就容易使相应的表格关系十分复杂。决策树是一种能帮助决策者进行序列决策分析的有效工具,其方法是将问题中有关策略、自然状态、概率及收益值等通过线条和图形用类似于树状的形式表示出来。 决策树模型就是由决策点、策略点(事件点)及结果构成的树形图,一般应用于序列决策中,通常以最大收益期望值或最低期望成本作为决策准则,通过图解方式求解在不同条件下各类方案的效益值,然后通过比较,做出决策。 决策树模型优、缺点 优点:浅层的(Shallow)决策树视觉上非常直观,而且容易解释;是对数据的结构和分布不需作任何假设;是可以捕捉住变量间的相互作用(Interaction)。 缺点:深层的(Deep)决策树视觉上和解释上都比较困难;决策树容易过分微调于样本数据而失去稳定性和抗震荡性;决策树对样本量(Sample Size)的需求比较大;处理缺失值的功能非常有限。3.KNN算法 KNN即最近邻算法,核心思想是如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别,并具有这个类别上样本的特性。该方法在确定分类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。 kNN方法在类别决策时,只与极少量的相邻样本有关。由于kNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,kNN方法较其他方法更为适合。其主要过程为: 1.计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等); 2. 对上面所有的距离值进行排序; 3. 选前k个最小距离的样本; 4. 根据这k个样本的标签进行投票,得到最后的分类类别; 如何选择一个最佳的K值,这取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响。但会使类别之间的界限变得模糊。一个较好的K值可通过各种启发式技术来获取,比如,交叉验证。另外噪声和非相关性特征向量的存在会使K近邻算法的准确性减小。 近邻算法具有较强的一致性结果。随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些好的K值,K近邻保证错误率不会超过贝叶斯理论误差率。 KNN算法优、缺点 优点:简单,易于理解,易于实现,无需估计参数,无需训练;理论成熟,既可以用来做分类也可以用来做回归;可用于非线性分类;适合对稀有事件进行分类;准确度高,对数据没有假设,对outlier不敏感。 缺点:计算量大;样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少);需要大量的内存;可理解性差,无法给出像决策树那样的规则。4.SVM算法 SVM(Support Vector Machine)指的是支持向量机,是常见的一种判别方法。在机器学习领域,是一个有监督的学习模型,通常用来进行模式识别、分类以及回归分析。 SVM的主要思想可以概括为两点: 1.它是针对线性可分情况进行分析,对于线性不可分的情况,通过使用非线性映射算法将低维输入空间线性不可分的样本转化为高维特征空间使其线性可分,从而使得高维特征空间采用线性算法对样本的非线性特征进行线性分析成为可能。 2.它基于结构风险最小化理论之上在特征空间中构建最优超平面,使得学习器得到全局最优化,并且在整个样本空间的期望以某个概率满足一定上界。 SVM算法优、缺点 优点:可用于线性/非线性分类,也可以用于回归;低泛化误差;容易解释;计算复杂度较低。 缺点:对参数和核函数的选择比较敏感;原始的SVM只比较擅长处理二分类问题。5.logistic回归模型 logistic回归又称logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘,疾病自动诊断,经济预测等领域。例如,探讨引发疾病的危险因素,并根据危险因素预测疾病发生的概率等。以胃癌病情分析为例,选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群必定具有不同的体征与生活方式等。因此因变量就为是否胃癌,值为“是”或“否”,自变量就可以包括很多了,如年龄、性别、饮食习惯、幽门螺杆菌感染等。自变量既可以是连续的,也可以是分类的。然后通过logistic回归分析,可以得到自变量的权重,从而可以大致了解到底哪些因素是胃癌的危险因素。同时根据该权值可以根据危险因素预测一个人患癌症的可能性。Logistic回归模型的适用条件: 1.因变量为二分类的分类变量或某事件的发生率,并且是数值型变量。但是需要注意,重复计数现象指标不适用于Logistic回归。 2.残差和因变量都要服从二项分布。二项分布对应的是分类变量,所以不是正态分布,进而不是用最小二乘法,而是最大似然法来解决方程估计和检验问题。 3.自变量和Logistic概率是线性关系 4.各观测对象间相互独立。 Logistic回归实质:发生概率除以没有发生概率再取对数。就是这个不太繁琐的变换改变了取值区间的矛盾和因变量自变量间的曲线关系。究其原因,是发生和未发生的概率成为了比值 ,这个比值就是一个缓冲,将取值范围扩大,再进行对数变换,整个因变量改变。不仅如此,这种变换往往使得因变量和自变量之间呈线性关系,这是根据大量实践而总结。所以,Logistic回归从根本上解决因变量要不是连续变量怎么办的问题。还有,Logistic应用广泛的原因是许多现实问题跟它的模型吻合。例如一件事情是否发生跟其他数值型自变量的关系。 logistic回归模型优、缺点 优点:实现简单;分类时计算量非常小,速度很快,存储资源低。 缺点:容易欠拟合,一般准确度不太高;能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分。 -
【Python算法分类与预测】——决策树1.决策树定义 决策树方法在分类、预测、规则提取等领域有着广泛的应用。20 世纪 70 年代后期和 80 年代初期,机器学习研究者 J.Ross Quinlan 提出了 ID3 算法以后,决策树就在机器学习与数据挖掘领域取得了巨大的发展。Quinlan 后来又提出了 C4.5,这成为了新的监督学习算法。1984年,几位统计学专家提出了 CART 分类算法。ID3 和 CART 算法几乎同时被提出,但都是采用的类似的方法从训练样本中学习决策树。决策树是一种树状结构,它的每个叶节点对应一个分类,非叶节点对应着在某个属性上的划分,根据样本在该属性上的不同值将其划分成若干个子集,而对于非纯的叶节点,多数类的标号给出到达这个节点的样本所属的类。构造决策树的核心的问题是在每一步中如何选择适当的属性对样本进行拆分。对一个分类问题,从已知类标记的训练样本中学习并构造出决策树其实是一个自上而下,分而治之的过程。2.常用决策树算法 常用的决策树算法有三种,分别是 ID3 算法、C4.5 算法、CART 算法三种。 (1) ID3 算法:此算法的核心在于决策树的各级节点上,使用信息增益方法作为属性的选择标准,来帮助确定生成每个节点时所应采取的合适属性; (2) C4.5 算法:此决策树生成算法相对于 ID3 算法的重要改进是使用信息增益率来选择节点属性,此算法可以克服ID3算法的不足。ID3算法只使用于离散的描述属性,而 C4.5 算法既能够处理离散的描述属性,又能够处理连续的描述属性; (3) CART 算法:CART 决策树是一种十分有效的非参数分类和回归方法,它通过构建树、修剪树、评估树来构建一个二叉树,当终结点是连续变量时,该树为回归树;当终结点是分类变量时,该树为分类树。3.决策树基本思想及内容 决策树的基本思想是,迭代式的根据字段的不同值将数据分成不同的组,再评估分组后组内的同性值,如果需要则继续分成不同的组。此方法的优点特别明显,它有较好的可解释性,并且在非线性环境下性能较好。但它也有缺点,如果缺少修剪或者交叉验证很容易过拟合。4.决策树的使用基本流程 (1) 将所有数据放在同一个组中; (2) 找出最佳的字段分割(split); (3) 将数据在这个分割(称为节点)上分成两组(称为叶子); (4) 继续上两步直到组包含的样本过少或者组内差异已经足够小。4.决策树计算公式及语法 决策树有几个衡量分组内差异性的常用指标,包括基尼系数(Gini index)、差异(deviance) 或信息增量(information gain)。基尼系数的计算公式如下,在使用此计算公式时,若结果为 0 则表示发分组绝对同质,若为 0.5 则表示该分组绝对异质:差异或信息增益的计算公式如下,在使用此计算公式时,若结果为 0 则表示该分组绝对同质,若为 1 则表示该分组绝对异质:决策树的方法即可用于分类也可用于回归,本实验主要介绍的是决策树分类。5.实验操作 5.1.操作系统 操作机:Linux_Ubuntu 操作机默认用户:root 5.2.实验工具 5.2.1.python Python是一种计算机程序设计语言。是一种动态的、面向对象的脚本语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。Python已经成为最受欢迎的程序设计语言之一。自从2004年以后,python的使用率呈线性增长。2011年1月,它被TIOBE编程语言排行榜评为2010年度语言。 由于Python语言的简洁性、易读性以及可扩展性,在国外用Python做科学计算的研究机构日益增多,一些知名大学已经采用Python来教授程序设计课程。例如卡耐基梅隆大学的编程基础、麻省理工学院的计算机科学及编程导论就使用Python语言讲授。 众多开源的科学计算软件包都提供了Python的调用接口,例如著名的计算机视觉库OpenCV、三维可视化库VTK、医学图像处理库ITK。而Python专用的科学计算扩展库就更多了,例如如下3个十分经典的科学计算扩展库:NumPy、SciPy和matplotlib,它们分别为Python提供了快速数组处理、数值运算以及绘图功能。因此Python语言及其众多的扩展库所构成的开发环境十分适合工程技术、科研人员处理实验数据、制作图表,甚至开发科学计算应用程序。 5.2.2.Numpy NumPy系统是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。 NumPy(Numeric Python)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。多为很多大型金融公司使用,以及核心的科学计算组织如:Lawrence Livermore,NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。 5.2.3.scikit-learn scikit-learn,Python 中的机器学习,简单高效的数据挖掘和数据分析工具,可供大家使用,可在各种环境中重复使用,建立在 NumPy,SciPy 和 matplotlib 上开放源码,可商业使用 - BSD license。 5.2.4.Matplotlib Matplotlib 是一个 Python 的 2D绘**,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形。通过 Matplotlib,开发者可以仅需要几行代码,便可以生成绘图,直方图,功率谱,条形图,错误图,散点图等。 5.2.5.pandas Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。 5.3导入所需要的库:numpy,matplotlib.pyplot,pandas代码如下:# Importing the libraries import numpy as np import matplotlib.pyplot as plt import pandas as pd 5.4.加载数据集代码如下:# Importing the dataset dataset = pd.read_csv('数据集路径') X = dataset.iloc[:, [2, 3]].values y = dataset.iloc[:, 4].values注意:实验中以数据集的实际地址为准。 实验中已经带有相应数据集,点击左下“数据”标识,对数据集的地址进行查看复制。我们直接将地址复制并放入上述代码中进行加载就可以了。注意:如果在自己的实际生产中,要以自己的数据地址为准。 如下给出数据,可将数据创建响相应的数据集用于字日常训练,也可在实验平台中数据集模块下的的“社交网络测试数据集”中进行查看。其具体数据内容如下:见附件!!! 5.5.将数据集分割为训练集和测试集代码如下:# Splitting the dataset into the Training set and Test set from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0) 5.6.特征缩放代码如下:# Feature Scaling from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test) 5.7.使用决策树对数据进行处理代码如下:# Fitting the Decision Tree to the Training set from sklearn.tree import DecisionTreeClassifier classifier = DecisionTreeClassifier(criterion = 'entropy', random_state = 0) classifier.fit(X_train, y_train) 5.8.对测试集进行分类:代码如下:# Predicting the Test set results y_pred = classifier.predict(X_test) 5.9.制造混淆矩阵来评估分类器性能:代码如下:# Making the Confusion Matrix from sklearn.metrics import confusion_matrix cm = confusion_matrix(y_test, y_pred) 5.10.绘制训练数据分类结果:# Visualising the Training set results from matplotlib.colors import ListedColormap X_set, y_set = X_train, y_train X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('orange', 'blue'))(i), label = j) plt.title('Classifier (Training set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show()训练数据分类结果如下: 5.11.绘制测试数据分类结果:# Visualising the Test set results from matplotlib.colors import ListedColormap X_set, y_set = X_test, y_test X1, X2 = np.meshgrid(np.arange(start = X_set[:, 0].min() - 1, stop = X_set[:, 0].max() + 1, step = 0.01), np.arange(start = X_set[:, 1].min() - 1, stop = X_set[:, 1].max() + 1, step = 0.01)) plt.contourf(X1, X2, classifier.predict(np.array([X1.ravel(), X2.ravel()]).T).reshape(X1.shape), alpha = 0.75, cmap = ListedColormap(('red', 'green'))) plt.xlim(X1.min(), X1.max()) plt.ylim(X2.min(), X2.max()) for i, j in enumerate(np.unique(y_set)): plt.scatter(X_set[y_set == j, 0], X_set[y_set == j, 1], c = ListedColormap(('orange', 'blue'))(i), label = j) plt.title('Classifier (Test set)') plt.xlabel('Age') plt.ylabel('Estimated Salary') plt.legend() plt.show()测试数据分类结果如下:
-

推荐直播
-
 华为云码道 × 仓颉编程:工程化AI编码探索
华为云码道 × 仓颉编程:工程化AI编码探索2026/05/27 周三 19:00-21:00
刘俊杰-华为云仓颉语言专家/李炎-华为云码道技术专家/王智鹏-OpenCangjie开源社区发起人
本场直播围绕华为云仓颉语言与华为云码道的深度结合,展示华为云智能编程从零基础到高效落地的完整生态能力。以华为云码道为引擎,仓颉语言为载体,带给大家日常提效、趣味创新到极速量产的开发体验。
回顾中
热门标签