-
 首先:集群规模是健康的。连接的点是集群外。使用hive的beeline和spark的spark-beeline都能正常连接,和操作。但是用IDEA spark开发就出现问题了代码如下:报错如下:2022-05-27 23:29:21,610 [main] ERROR [org.apache.thrift.transport.TSaslTransport] - SASL negotiation failurejavax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)] at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211) at org.apache.thrift.transport.TSaslClientTransport.handleSaslStartMessage(TSaslClientTransport.java:94)。。。Caused by: GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt) at sun.security.jgss.krb5.Krb5InitCredential.getInstance(Krb5InitCredential.java:147)。。。2022-05-27 23:29:21,631 [main] ERROR [org.apache.thrift.transport.TSaslTransport] - SASL negotiation failurejavax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)] at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211) at org.apache.thrift.transport.TSaslClientTransport.handleSaslStartMessage(TSaslClientTransport.java:94)。。。Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient; at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:107) at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:215)。。。Caused by: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522) at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:185)。。Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1523) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:86)。。。Caused by: java.lang.reflect.InvocationTargetException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)。。。Caused by: MetaException(message:Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException: GSS initiate failed at org.apache.thrift.transport.TSaslTransport.sendAndThrowMessage(TSaslTransport.java:232) at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:316) at org.apache.thrift.transport.TSaslClientTransport.open(TSaslClientTransport.java:37)。。。。
首先:集群规模是健康的。连接的点是集群外。使用hive的beeline和spark的spark-beeline都能正常连接,和操作。但是用IDEA spark开发就出现问题了代码如下:报错如下:2022-05-27 23:29:21,610 [main] ERROR [org.apache.thrift.transport.TSaslTransport] - SASL negotiation failurejavax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)] at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211) at org.apache.thrift.transport.TSaslClientTransport.handleSaslStartMessage(TSaslClientTransport.java:94)。。。Caused by: GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt) at sun.security.jgss.krb5.Krb5InitCredential.getInstance(Krb5InitCredential.java:147)。。。2022-05-27 23:29:21,631 [main] ERROR [org.apache.thrift.transport.TSaslTransport] - SASL negotiation failurejavax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)] at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:211) at org.apache.thrift.transport.TSaslClientTransport.handleSaslStartMessage(TSaslClientTransport.java:94)。。。Exception in thread "main" org.apache.spark.sql.AnalysisException: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient; at org.apache.spark.sql.hive.HiveExternalCatalog.withClient(HiveExternalCatalog.scala:107) at org.apache.spark.sql.hive.HiveExternalCatalog.databaseExists(HiveExternalCatalog.scala:215)。。。Caused by: java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:522) at org.apache.spark.sql.hive.client.HiveClientImpl.newState(HiveClientImpl.scala:185)。。Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1523) at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:86)。。。Caused by: java.lang.reflect.InvocationTargetException at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method) at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:62)。。。Caused by: MetaException(message:Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException: GSS initiate failed at org.apache.thrift.transport.TSaslTransport.sendAndThrowMessage(TSaslTransport.java:232) at org.apache.thrift.transport.TSaslTransport.open(TSaslTransport.java:316) at org.apache.thrift.transport.TSaslClientTransport.open(TSaslClientTransport.java:37)。。。。 -
 亮点特性1:远程开发 - 支持本地IDE远程访问Notebook新版Notebook提供了远程开发功能,通过开启SSH连接,用户本地IDE可以远程连接到ModelArts的Notebook开发环境中,调试和运行代码。对于使用本地IDE的开发者,由于本地资源限制,运行和调试环境大多使用团队公共搭建的CPU或GPU服务器,并且是多人共用,这带来一定的环境搭建和维护成本。而ModelArts的Notebook的优势是即开即用,它预先装好了不同的AI引擎,并且提供了非常多的可选规格,用户可以独占一个容器环境,不受其他人的干扰。只需简单配置,用户即可通过本地IDE连接到该环境进行运行和调试。图1 本地IDE远程访问Notebook开发环境ModelArts的Notebook可以视作是本地PC的延伸,均视作本地开发环境,其读取数据、训练、保存文件等操作与常规的本地训练一致。对于习惯使用本地IDE的开发者,使用远程开发方式,不影响用户的编码习惯,并且可以方便快捷的使用云上的Notebook开发环境。本地IDE当前支持VSCode、PyCharm、SSH工具。还有专门的插件PyCharm Toolkit和VSCode Toolkit,方便将云上资源作为本地的一个扩展。亮点特性2:预置镜像 - 即开即用,优化配置,支持主流AI引擎每个镜像预置的AI引擎和版本是固定的,在创建Notebook实例时明确AI引擎和版本,包括适配的芯片。亮点特性3:提供在线的交互式开发调试工具JupyterLabModelArts集成了基于开源的JupyterLab,可为您提供在线的交互式开发调试。您无需关注安装配置,在ModelArts管理控制台直接使用Notebook,编写和调测模型训练代码,然后基于该代码进行模型的训练。JupyterLab是一个交互式的开发环境,是Jupyter Notebook的下一代产品,可以使用它编写Notebook、操作终端、编辑MarkDown文本、打开交互模式、查看csv文件及图片等功能。
亮点特性1:远程开发 - 支持本地IDE远程访问Notebook新版Notebook提供了远程开发功能,通过开启SSH连接,用户本地IDE可以远程连接到ModelArts的Notebook开发环境中,调试和运行代码。对于使用本地IDE的开发者,由于本地资源限制,运行和调试环境大多使用团队公共搭建的CPU或GPU服务器,并且是多人共用,这带来一定的环境搭建和维护成本。而ModelArts的Notebook的优势是即开即用,它预先装好了不同的AI引擎,并且提供了非常多的可选规格,用户可以独占一个容器环境,不受其他人的干扰。只需简单配置,用户即可通过本地IDE连接到该环境进行运行和调试。图1 本地IDE远程访问Notebook开发环境ModelArts的Notebook可以视作是本地PC的延伸,均视作本地开发环境,其读取数据、训练、保存文件等操作与常规的本地训练一致。对于习惯使用本地IDE的开发者,使用远程开发方式,不影响用户的编码习惯,并且可以方便快捷的使用云上的Notebook开发环境。本地IDE当前支持VSCode、PyCharm、SSH工具。还有专门的插件PyCharm Toolkit和VSCode Toolkit,方便将云上资源作为本地的一个扩展。亮点特性2:预置镜像 - 即开即用,优化配置,支持主流AI引擎每个镜像预置的AI引擎和版本是固定的,在创建Notebook实例时明确AI引擎和版本,包括适配的芯片。亮点特性3:提供在线的交互式开发调试工具JupyterLabModelArts集成了基于开源的JupyterLab,可为您提供在线的交互式开发调试。您无需关注安装配置,在ModelArts管理控制台直接使用Notebook,编写和调测模型训练代码,然后基于该代码进行模型的训练。JupyterLab是一个交互式的开发环境,是Jupyter Notebook的下一代产品,可以使用它编写Notebook、操作终端、编辑MarkDown文本、打开交互模式、查看csv文件及图片等功能。 -
【功能模块】【操作步骤&问题现象】1、我在本机idea上 执行sparksql 查询hive库的数据 报错2、已经hive的相关配置文件放在resources下、 jar包也是从集群上的spark下的lib下导出来的,请问还需要配置说明东西 谢谢【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
很荣幸参加《鲲鹏Java性能分析工具IntelliJ插件实现》项目开发工作的,我们项目主要是做Inellij插件开发实现性能分析工具功能。由于插件开发的特殊性,常常需要和一些命令行打交道,下面记录一次通过Java代码打开Windows证书安装窗口安装证书cer文件。思路如下:第一步:下载证书,保存到本地 通过cer文件下载接口将文件保存到本地,记录文件的保存位置第二步:通过代码在IDEA的Terminal命令窗口输入命令打开证书安装窗口 // 将项目对象,ToolWindow的id传入,获取控件对象 ToolWindow toolWindow = ToolWindowManager.getInstance(e.getProject()).getToolWindow("Terminal"); if (toolWindow != null) { // 无论当前状态为关闭/打开,进行强制打开ToolWindow toolWindow.show(new Runnable() { @Override public void run() { Process p = Runtime.getRuntime().exec("rundll32.exe cryptext.dll,CryptExtAddCER "+ path); } }); } }第三步:提醒用户重启IDEA,使证书生效 Messages.showMessageDialog("安装证书", "安装证书后请重启IDEA,证书才能生效", Messages.getInformationIcon());
-
IDEA是目前Java开发人员最受欢迎的工具开发之一,很重要的原因是其提供了很多插件,这让开发人员降低了开发难度,能更有效更高质量的开发代码,我也很荣幸成为IDEA插件开发的一员。 我所在的是鲲鹏Java性能分析工具IntelliJ这个开源项目,刚开始参与进来的时候感觉这个项目很难,因为对Java Swing这块的技术了解的很少。长时间下来感觉挺有意思的,以下我是我对Swing这块的总结: Swing图形组件是java中一套图形界面类,主要分为两类:容器类和元素类。容器类表示可以放置其他的元素组件或者容器组件,JFrame 窗体组件,JPanel 面板容器,JMeauBar 菜单栏;元素类表示不可以放其他的组件,比如:JButton 按钮组件,JLable 文本标签组件,JTextField 文本输入框组件,JPasswordField 密码输入框组件,JCheckBox 复选框组件等。主要就是在合理布局下各种组件之间的搭配,其中还有很多重要的事件,如:ActionEvents,ChangeEvents,ItemEvents等,来响应用户的鼠标点击等行为。 每当感觉自己已经掌握了Swing这门技术的时候,但是在开发过程中处处有惊喜,总会碰到这样或那样的难题,因此还是得通过不断的学习来提高自己,这样才能更好、更有效更轻松的为这个团队服务。加油!
-
 今日热文:原文链接:https://blog.csdn.net/qq_43529978/article/details/122415668你觉得说的对吗?俗话说,工欲善其事,必先利其器,一名好的开发者,必然要有一套好的开发工具,这样才能打造出最好的产品给用户。世界上的IDE种类繁多,要论那个IDE好用,可能有人会选择老牌的Visual Studio 或是Eclipse;也有人会选择使用者人数一路飙升的Intellij;也有人更偏爱Google发布的Android Studio。每位开发者都会按照自己的需求及爱好对IDE做出不同的选择。其中,对于老牌IDE Eclipse来说,众多开发者真的是又爱又恨。曾几何时,在当初那个IDE稀少又昂贵的时期,Eclipse给开发者带来了福音。作为一款免费且开源,速度相对更快,又有Google支持,在各种教科书中备受推崇的IDE,真的是想不流行都难。但在此之后各种IDE百花齐放,Eclipse的各种弊端也逐渐显现,慢慢开始走下神坛。Eclipse的优势Eclipse最初只是一个开源的框架平台,主要是作为Java语言的开发平台。它由IBM公司开发,其目的是为了替代商业软件Visual Age for Java,成为下一代开发环境。Eclipse在2001年被IBM公司贡献给开源社区,之后Eclipse联盟成立为现在的Eclipse基金会,Eclipse自此由其管理。作为一个开源框架,Eclipse拥有很高的灵活性,它可以通过众多插件来获取不同的功能与编程语言支持。也就意味着,开发者可以根据自己的需求,在Eclipse源代码的基础上开发插件,理论上Eclipse可以无限拓展,利用插件成为任何语言的开发工具,也可以通过新插件扩展现有插件的功能。现如今Eclipse就已经拥有插件支持其成为C++、Python、PHP等主流语言的开发工具。也有不少软件开发商以Eclipse为基础框架开发自己的IDE。这些也正是Eclipse所具有的优势。弊端明显,逐渐被取代但相比Eclipse的优势来说,它所拥有的弊端更加明显,其实在2012年Eclipse 发布代号为Luna的4.2版本之前,Eclipse还没有这么多让人诟病的地方,也还没有开始走下坡路。自从4.2版本上线后,各种弊端逐渐显现,但开发者们对此也只能忍着,毕竟Eclipse是为数不多的免费IDE中比较好用的一个,随着Intellij社区版本,免费的Android Studio以及微软的Visual Studio Code的发布,这些新兴IDE疯狂的占据Eclipse的市场份额。使Eclipse神坛上的地位彻底被摧毁。下图是来自PYPL PopularitY of Programming Language index 的TOP 10 IDE排名,该网站的IDE指数是通过分析集成开发环境(IDE)在Google上被搜索下载的频率而创建的。IDE被搜索的次数越多,就认为该IDE越受欢迎。该指数原始数据来源于Google。图片来源PYPL PopularitY of Programming Language index图片来源PYPL PopularitY of Programming Language index从以上数据我们可以看到自2011年1月至2022年1月,Eclipse的搜索下载频率大幅度降低,从51.54%降低至14.05%,这说明人们对于Eclipse的关注度在飞速降低。而相反的Visual Studio Code自从2015年发布以来搜索率飞速上涨。Visual Studio 也再缓慢稳步上升。相比其他的主流IDE,Eclipse的运行占用了更多的内存空间,由于Eclipse的众多插件的存在,每次运行都会占据大量的设备运行内存,这就会导致配置稍微差点的设备在运行Eclipse的时候非常卡。除此之外Eclipse的运行速度相比较其他新兴的IDE也更加缓慢。Eclipse P2的项目的目的是为了让插件的升级更加简单。插件作为Eclipse赖以生存的重要组成部分。Eclipse P2项目可说是非常重要。然而,它最终却让插件升级变得复杂。由于这个原因它最主要的功能安装Eclipse插件,也不像以前那么好用了。在安装插件的时候,这样的对话框随处可见。在著名的计算机新闻网站Hacker News上就有人在为Eclipse的衰落感到悲哀,但是下面的评论却基本没有对此的惋惜,反而是在表示Eclipse的结局本就该如此,毕竟相比优势来说,它的缺陷真的太多了。其实Eclipse的衰落对各种开发人员来说并不算是好事,毕竟没有了Eclipse的竞争,其他的IDE也不会像以前那样为了超越它,去努力的创新了。希望Eclipse基金会能改变现如今Eclipse的弊端,重新走上神坛。参考链接:https://news.ycombinator.com/item?id=29867360
今日热文:原文链接:https://blog.csdn.net/qq_43529978/article/details/122415668你觉得说的对吗?俗话说,工欲善其事,必先利其器,一名好的开发者,必然要有一套好的开发工具,这样才能打造出最好的产品给用户。世界上的IDE种类繁多,要论那个IDE好用,可能有人会选择老牌的Visual Studio 或是Eclipse;也有人会选择使用者人数一路飙升的Intellij;也有人更偏爱Google发布的Android Studio。每位开发者都会按照自己的需求及爱好对IDE做出不同的选择。其中,对于老牌IDE Eclipse来说,众多开发者真的是又爱又恨。曾几何时,在当初那个IDE稀少又昂贵的时期,Eclipse给开发者带来了福音。作为一款免费且开源,速度相对更快,又有Google支持,在各种教科书中备受推崇的IDE,真的是想不流行都难。但在此之后各种IDE百花齐放,Eclipse的各种弊端也逐渐显现,慢慢开始走下神坛。Eclipse的优势Eclipse最初只是一个开源的框架平台,主要是作为Java语言的开发平台。它由IBM公司开发,其目的是为了替代商业软件Visual Age for Java,成为下一代开发环境。Eclipse在2001年被IBM公司贡献给开源社区,之后Eclipse联盟成立为现在的Eclipse基金会,Eclipse自此由其管理。作为一个开源框架,Eclipse拥有很高的灵活性,它可以通过众多插件来获取不同的功能与编程语言支持。也就意味着,开发者可以根据自己的需求,在Eclipse源代码的基础上开发插件,理论上Eclipse可以无限拓展,利用插件成为任何语言的开发工具,也可以通过新插件扩展现有插件的功能。现如今Eclipse就已经拥有插件支持其成为C++、Python、PHP等主流语言的开发工具。也有不少软件开发商以Eclipse为基础框架开发自己的IDE。这些也正是Eclipse所具有的优势。弊端明显,逐渐被取代但相比Eclipse的优势来说,它所拥有的弊端更加明显,其实在2012年Eclipse 发布代号为Luna的4.2版本之前,Eclipse还没有这么多让人诟病的地方,也还没有开始走下坡路。自从4.2版本上线后,各种弊端逐渐显现,但开发者们对此也只能忍着,毕竟Eclipse是为数不多的免费IDE中比较好用的一个,随着Intellij社区版本,免费的Android Studio以及微软的Visual Studio Code的发布,这些新兴IDE疯狂的占据Eclipse的市场份额。使Eclipse神坛上的地位彻底被摧毁。下图是来自PYPL PopularitY of Programming Language index 的TOP 10 IDE排名,该网站的IDE指数是通过分析集成开发环境(IDE)在Google上被搜索下载的频率而创建的。IDE被搜索的次数越多,就认为该IDE越受欢迎。该指数原始数据来源于Google。图片来源PYPL PopularitY of Programming Language index图片来源PYPL PopularitY of Programming Language index从以上数据我们可以看到自2011年1月至2022年1月,Eclipse的搜索下载频率大幅度降低,从51.54%降低至14.05%,这说明人们对于Eclipse的关注度在飞速降低。而相反的Visual Studio Code自从2015年发布以来搜索率飞速上涨。Visual Studio 也再缓慢稳步上升。相比其他的主流IDE,Eclipse的运行占用了更多的内存空间,由于Eclipse的众多插件的存在,每次运行都会占据大量的设备运行内存,这就会导致配置稍微差点的设备在运行Eclipse的时候非常卡。除此之外Eclipse的运行速度相比较其他新兴的IDE也更加缓慢。Eclipse P2的项目的目的是为了让插件的升级更加简单。插件作为Eclipse赖以生存的重要组成部分。Eclipse P2项目可说是非常重要。然而,它最终却让插件升级变得复杂。由于这个原因它最主要的功能安装Eclipse插件,也不像以前那么好用了。在安装插件的时候,这样的对话框随处可见。在著名的计算机新闻网站Hacker News上就有人在为Eclipse的衰落感到悲哀,但是下面的评论却基本没有对此的惋惜,反而是在表示Eclipse的结局本就该如此,毕竟相比优势来说,它的缺陷真的太多了。其实Eclipse的衰落对各种开发人员来说并不算是好事,毕竟没有了Eclipse的竞争,其他的IDE也不会像以前那样为了超越它,去努力的创新了。希望Eclipse基金会能改变现如今Eclipse的弊端,重新走上神坛。参考链接:https://news.ycombinator.com/item?id=29867360 -
 体验通过DevStar服务的“智能OCR图像文字识别”模板一站式生成应用代码并部署到函数工作流FunctionGraph,实现识别指定图片中的文字信息并显示在页面上。您将学到什么您将学会如何通过DevStar实现一站式快速开发基于Serverless的智能识别图片文字信息应用,并在此基础上基于华为云EI产品开放能力进行对应用的自定义扩展,体验云上开发的乐趣您需要什么硬件要求PC电脑软件要求Chrome浏览器需要的知识点熟悉常规电脑操作常识具备基本的软件开发能力环境准备注册华为云账号、实名认证如果您已拥有华为账号且已通过实名认证,可直接体验。若您还没有通过实名认证的账号,请注册华为账号,然后完成实名认证(推荐使用“扫码认证”方式,即时完成)。参考如何实名认证和如何扫码认证。应用开发及部署使用Chrome浏览器,登录DevStar,在搜索栏输入“智能OCR图像文字识别”关键字进行搜索,在卡片上点击“开发应用”首次使用可以开通服务“同意授权”并继续创建应用在应用创建页面根据页面提示完成项目、应用名信息输入注:如果没有任何DevCloud项目,可点击“创建项目”新建一个项目注:在创建项目过程中如提示“该企业租户服务处于关闭状态 ”,请点击“立即开通”。然后在DevCloud服务购买页面,选择基础版进行购买操作(基础版5人及以下免费)。开通后,继续完成项目创建注:创建完项目后,点击所属项目选项列表旁的“刷新”图标,可显示新创建的项目,选中并完成页面其它信息输入,点击“立即创建”按钮,进入应用详情界面等待应用使用的代码仓等资源创建完成(约20s),点击左侧的“应用部署”菜单,查看依赖云服务的状态。若有云服务未开通,则点击“去开通”按钮完成服务开通。查看文字识别服务增值税发票识别的开通状态,如果未开通,点击“开通服务”。注意:增值税发票识别API按需付费模式每月0~1千次(含)调用免费,如果超出则会产生费用,计费详情可点击“参考价格”查看。函数工作流FunctionGraph若实际使用量每月调用不超过100万次且计量时间不超过400,000 GB-秒免费,如果超过则会产生费用,计费详情可点击“参考价格”查看。完成服务开通后,点击对应服务的刷新按钮,查看服务开通状态。依赖的云服务全部完成开通后,点击“部署”按钮,进行应用部署。待部署完成后,点击“看看”链接访问部署到函数工作流的云函数。在智能OCR识别页面,点击“选择文件”上传发票图片,体验使用OCR精准识别发票图片上的文字。注:上传的发票图片为JPG/JPEG/BMP/PNG格式,建议大小不超过5M(超出有可能会失败),推荐1M。进阶体验-使用Huawei Cloud Toolkit在本地进行快速开发Huawei Cloud Toolkit是华为云提供的IDE插件工具,支持VSCode平台和Intellij平台。支持查看华为云开放API的文档、SDK、错误码、示例代码、代码模板;基于代码模板快速创建本地工程;智能代码自动补全等场景,能极大提高开发者在本地开发基于华为云API的应用的开发效率。这里我们使用Huawei Cloud Toolkit辅助,给原来的代码快速扩展一个新的“通用文本识别”功能。在应用详情页面的代码仓库栏,点击右边的“克隆/下载”,复制弹出框中的https链接,然后在本地命令行中输入:git clone <仓库链接>,既可把代码仓克隆到本地。(克隆的时候会提示输入用户名和密码,用户名为<华为云账号名>/<华为云账号名形式>,具体可以在codehub的配置页面查找到https://devcloud.cn-north-4.huaweicloud.com/codehub/https)使用本地IDE(使用Intellij或者VSCode)打开刚克隆的代码,这里以Intellij为例。安装 Huawei Cloud Toolkit插件,Intellij点击 File -> Settings -> Plugins,在 Marketplace中搜索“HuaweiCloud Toolkit”,点击“install”进行安装。注:如果您使用VSCode,也可以在VSCode插件市场中搜索“HuaweiCloud”,选择安装“HuaweiCloud Extension Pack”这个插件。打开链接https://console.huaweicloud.com/iam/?region=#/mine/accessKey,点击“新增访问秘钥”添加一个您租户账号的AK/SK。在Intellij中,点击左侧的“Huawei Cloud Toolkit”标签,点击登录图标。将刚才生成的AK/SK(注意excel中的AK/SK后面有一个空格,需要去掉)填入配置中,点击“apply”和“ok”按钮,插件即可登录成功。登录成功后我们在右侧搜索栏搜索“OCR”。选择“云服务”标签下的“文字识别 OCR”,可以看到OCR服务出了支持身份证识别外,还支持很多的其他的文字识别功能。这里我们选择下方的“通用文字识别”,点击“查看文档”。接口文档包含的接口的说明,请求参数,返回参数的详细信息,这里看到这个接口的请求参数只需要一个图片的base64字符串即可。在对要实现的接口有了了解后,我们来改造一下原理的代码。在Intellij中打开代码中的“java”文件。为了方便扩展功能,我们已经在代码中预留好扩展的位置。找到代码的第50行,按注释提示添加一个识别类型:修改后:接着我们来实现调用接口的逻辑,找到代码中第101行的函数“recognizeGeneralText”:把注释删掉,输入我们刚才搜到的api名称“recognizeGeneral”,这是我们看到会有自动提示弹出,选择第一个提示选择后可以看到API调用的基础代码已经被插入:然后我们只需要简单的添加一下输出和输入即可实现API调用的功能,添加下图红框里面的两行代码:到这里我们的代码已经完成,为了使用“通用文本识别”功能,我们需要到OCR服务开通该服务,打开OCR页面:https://console.huaweicloud.com/ocr/#/ocr/overview,找到“通用文本识别”点击开通服务。(按需计费模式下,每个月的前1000次调用免费)将代码push到远端的git仓库,回到我们的应用部署页面,重新部署应用(请参考本文“应用开发及部署小节步骤6、7”),现在可以上传一张带有文字内容的图片,体验添加的通用文本识别功能,识别图片中的文本。到这里我们已经实现了一个新的识别功能的添加,您可以继续查看OCR服务的文档,添加更多的文本识别功能到项目中。恭喜您已完成体验,您还可以了解和体验DevStar AI识图作诗应用开发模板。
体验通过DevStar服务的“智能OCR图像文字识别”模板一站式生成应用代码并部署到函数工作流FunctionGraph,实现识别指定图片中的文字信息并显示在页面上。您将学到什么您将学会如何通过DevStar实现一站式快速开发基于Serverless的智能识别图片文字信息应用,并在此基础上基于华为云EI产品开放能力进行对应用的自定义扩展,体验云上开发的乐趣您需要什么硬件要求PC电脑软件要求Chrome浏览器需要的知识点熟悉常规电脑操作常识具备基本的软件开发能力环境准备注册华为云账号、实名认证如果您已拥有华为账号且已通过实名认证,可直接体验。若您还没有通过实名认证的账号,请注册华为账号,然后完成实名认证(推荐使用“扫码认证”方式,即时完成)。参考如何实名认证和如何扫码认证。应用开发及部署使用Chrome浏览器,登录DevStar,在搜索栏输入“智能OCR图像文字识别”关键字进行搜索,在卡片上点击“开发应用”首次使用可以开通服务“同意授权”并继续创建应用在应用创建页面根据页面提示完成项目、应用名信息输入注:如果没有任何DevCloud项目,可点击“创建项目”新建一个项目注:在创建项目过程中如提示“该企业租户服务处于关闭状态 ”,请点击“立即开通”。然后在DevCloud服务购买页面,选择基础版进行购买操作(基础版5人及以下免费)。开通后,继续完成项目创建注:创建完项目后,点击所属项目选项列表旁的“刷新”图标,可显示新创建的项目,选中并完成页面其它信息输入,点击“立即创建”按钮,进入应用详情界面等待应用使用的代码仓等资源创建完成(约20s),点击左侧的“应用部署”菜单,查看依赖云服务的状态。若有云服务未开通,则点击“去开通”按钮完成服务开通。查看文字识别服务增值税发票识别的开通状态,如果未开通,点击“开通服务”。注意:增值税发票识别API按需付费模式每月0~1千次(含)调用免费,如果超出则会产生费用,计费详情可点击“参考价格”查看。函数工作流FunctionGraph若实际使用量每月调用不超过100万次且计量时间不超过400,000 GB-秒免费,如果超过则会产生费用,计费详情可点击“参考价格”查看。完成服务开通后,点击对应服务的刷新按钮,查看服务开通状态。依赖的云服务全部完成开通后,点击“部署”按钮,进行应用部署。待部署完成后,点击“看看”链接访问部署到函数工作流的云函数。在智能OCR识别页面,点击“选择文件”上传发票图片,体验使用OCR精准识别发票图片上的文字。注:上传的发票图片为JPG/JPEG/BMP/PNG格式,建议大小不超过5M(超出有可能会失败),推荐1M。进阶体验-使用Huawei Cloud Toolkit在本地进行快速开发Huawei Cloud Toolkit是华为云提供的IDE插件工具,支持VSCode平台和Intellij平台。支持查看华为云开放API的文档、SDK、错误码、示例代码、代码模板;基于代码模板快速创建本地工程;智能代码自动补全等场景,能极大提高开发者在本地开发基于华为云API的应用的开发效率。这里我们使用Huawei Cloud Toolkit辅助,给原来的代码快速扩展一个新的“通用文本识别”功能。在应用详情页面的代码仓库栏,点击右边的“克隆/下载”,复制弹出框中的https链接,然后在本地命令行中输入:git clone <仓库链接>,既可把代码仓克隆到本地。(克隆的时候会提示输入用户名和密码,用户名为<华为云账号名>/<华为云账号名形式>,具体可以在codehub的配置页面查找到https://devcloud.cn-north-4.huaweicloud.com/codehub/https)使用本地IDE(使用Intellij或者VSCode)打开刚克隆的代码,这里以Intellij为例。安装 Huawei Cloud Toolkit插件,Intellij点击 File -> Settings -> Plugins,在 Marketplace中搜索“HuaweiCloud Toolkit”,点击“install”进行安装。注:如果您使用VSCode,也可以在VSCode插件市场中搜索“HuaweiCloud”,选择安装“HuaweiCloud Extension Pack”这个插件。打开链接https://console.huaweicloud.com/iam/?region=#/mine/accessKey,点击“新增访问秘钥”添加一个您租户账号的AK/SK。在Intellij中,点击左侧的“Huawei Cloud Toolkit”标签,点击登录图标。将刚才生成的AK/SK(注意excel中的AK/SK后面有一个空格,需要去掉)填入配置中,点击“apply”和“ok”按钮,插件即可登录成功。登录成功后我们在右侧搜索栏搜索“OCR”。选择“云服务”标签下的“文字识别 OCR”,可以看到OCR服务出了支持身份证识别外,还支持很多的其他的文字识别功能。这里我们选择下方的“通用文字识别”,点击“查看文档”。接口文档包含的接口的说明,请求参数,返回参数的详细信息,这里看到这个接口的请求参数只需要一个图片的base64字符串即可。在对要实现的接口有了了解后,我们来改造一下原理的代码。在Intellij中打开代码中的“java”文件。为了方便扩展功能,我们已经在代码中预留好扩展的位置。找到代码的第50行,按注释提示添加一个识别类型:修改后:接着我们来实现调用接口的逻辑,找到代码中第101行的函数“recognizeGeneralText”:把注释删掉,输入我们刚才搜到的api名称“recognizeGeneral”,这是我们看到会有自动提示弹出,选择第一个提示选择后可以看到API调用的基础代码已经被插入:然后我们只需要简单的添加一下输出和输入即可实现API调用的功能,添加下图红框里面的两行代码:到这里我们的代码已经完成,为了使用“通用文本识别”功能,我们需要到OCR服务开通该服务,打开OCR页面:https://console.huaweicloud.com/ocr/#/ocr/overview,找到“通用文本识别”点击开通服务。(按需计费模式下,每个月的前1000次调用免费)将代码push到远端的git仓库,回到我们的应用部署页面,重新部署应用(请参考本文“应用开发及部署小节步骤6、7”),现在可以上传一张带有文字内容的图片,体验添加的通用文本识别功能,识别图片中的文本。到这里我们已经实现了一个新的识别功能的添加,您可以继续查看OCR服务的文档,添加更多的文本识别功能到项目中。恭喜您已完成体验,您还可以了解和体验DevStar AI识图作诗应用开发模板。 -
 我们开发中经常用到一些第三方连接数据库的工具 ( navicat/SQLyog/sqldeveloper等 ) 进行调试, 这样回来切换工具很不方便。其实IDEA集成了一个数据库管理工具,可以可视化管理很多种类的数据库。配置IDEA版本:2020.3Windows 101、打开IDEA工具,选择view---Tool Windows---Database鼠标点击+----Data Source,会出现很多种数据库类型,点击自己对应的就行。2、 本人以oracle为例,进行连接先点击switch,配置对应的oracle驱动信息其次按要求填写对应的连接信息填写完成后,点击Test Connection按钮,查看是否可以正常连接。连接成功,会提示下方的语句。3、访问数据库简单的查询到此结束。还可以创建表等一些信息,后续再详细写!
我们开发中经常用到一些第三方连接数据库的工具 ( navicat/SQLyog/sqldeveloper等 ) 进行调试, 这样回来切换工具很不方便。其实IDEA集成了一个数据库管理工具,可以可视化管理很多种类的数据库。配置IDEA版本:2020.3Windows 101、打开IDEA工具,选择view---Tool Windows---Database鼠标点击+----Data Source,会出现很多种数据库类型,点击自己对应的就行。2、 本人以oracle为例,进行连接先点击switch,配置对应的oracle驱动信息其次按要求填写对应的连接信息填写完成后,点击Test Connection按钮,查看是否可以正常连接。连接成功,会提示下方的语句。3、访问数据库简单的查询到此结束。还可以创建表等一些信息,后续再详细写! -
 体验形式:本次体验采用有奖征集体验评测报告+群内交流反馈的形式。我们将在体验官群内(点击链接申请成为体验官)筛选体验官若干位,然后按照体验官任务卡的要求操作和体验产品,最后输出体验报告(完成PPT任务卡填写即可),并按照华为云账号名+微信昵称+体验报告附件的格式回复至本帖。我们会从中筛选出高质量体验报告,给予礼品奖励和积分奖励。 产品简介:Huawei Cloud Toolkit Intellij插件,提供在Intellij中的以下功能:1、自动补全华为云sdk代码。2、查找和浏览华为云api。3、查找和浏览DevStar代码模板和Codelabs代码示例。4、根据DevStar代码模板创建工程。 体验流程:1、体验场景描述您是一位使用华为云的Java软件开发工程师,最喜爱的IDE是Intellij,这天你正准备使用华为云的AI能力开发一个项目,为了更高效地使用华为云的能力,您在Intellij上面安装了Huawei Cloud Toolkit插件。2、体验流程在Intellij上安装Huawei Cloud Toolkit插件 -> 配置华为云AK/SK -> 使用DevStar代码模板创建Spring项目 -> 使用 API 搜索功能查找相关的人脸识别API -> 使用代码自动补全功能和SDK自动引入功能编写代码 -> 实现人脸检测和人脸对比3、体验完成条件使用华为云API实现人脸检测和人脸对比4、体验报告模板详见附件 活动流程:1.如您已经成为产品体验官,小助手会在群内发布招募公告,直接报名即可。2.如您还未申请成为体验官,请点击链接先申请成为体验官,再参与活动哦~申请链接:https://developer.huaweicloud.com/activity/experience-officer.html ☆奖品设置如下☆参与奖:若干名活动要求:按照要求完成任务卡奖品:公牛插排1个+3体验官积分 优秀奖:若干名活动要求:被专家评为优秀报告奖品:颈枕1个+5体验官积分 体验评测报告交稿时间:- 招募期:2021.8.30-2021.9.12- 测试期:2021.9.13-2021.9.26
体验形式:本次体验采用有奖征集体验评测报告+群内交流反馈的形式。我们将在体验官群内(点击链接申请成为体验官)筛选体验官若干位,然后按照体验官任务卡的要求操作和体验产品,最后输出体验报告(完成PPT任务卡填写即可),并按照华为云账号名+微信昵称+体验报告附件的格式回复至本帖。我们会从中筛选出高质量体验报告,给予礼品奖励和积分奖励。 产品简介:Huawei Cloud Toolkit Intellij插件,提供在Intellij中的以下功能:1、自动补全华为云sdk代码。2、查找和浏览华为云api。3、查找和浏览DevStar代码模板和Codelabs代码示例。4、根据DevStar代码模板创建工程。 体验流程:1、体验场景描述您是一位使用华为云的Java软件开发工程师,最喜爱的IDE是Intellij,这天你正准备使用华为云的AI能力开发一个项目,为了更高效地使用华为云的能力,您在Intellij上面安装了Huawei Cloud Toolkit插件。2、体验流程在Intellij上安装Huawei Cloud Toolkit插件 -> 配置华为云AK/SK -> 使用DevStar代码模板创建Spring项目 -> 使用 API 搜索功能查找相关的人脸识别API -> 使用代码自动补全功能和SDK自动引入功能编写代码 -> 实现人脸检测和人脸对比3、体验完成条件使用华为云API实现人脸检测和人脸对比4、体验报告模板详见附件 活动流程:1.如您已经成为产品体验官,小助手会在群内发布招募公告,直接报名即可。2.如您还未申请成为体验官,请点击链接先申请成为体验官,再参与活动哦~申请链接:https://developer.huaweicloud.com/activity/experience-officer.html ☆奖品设置如下☆参与奖:若干名活动要求:按照要求完成任务卡奖品:公牛插排1个+3体验官积分 优秀奖:若干名活动要求:被专家评为优秀报告奖品:颈枕1个+5体验官积分 体验评测报告交稿时间:- 招募期:2021.8.30-2021.9.12- 测试期:2021.9.13-2021.9.26 -
RESTKit工具介绍 一套 RESTful 服务开发辅助工具集。 1.根据 URL 直接跳转到对应的方法定义 ( Ctrl \ or Ctrl Alt N ); 2.提供了一个 Services tree 的显示窗口; 3.一个好用的类似Postman的 http 请求工具; 4.其他功能: java 类上添加 Convert to JSON 功能。 支持 Spring 体系 (Spring MVC / Spring Boot) 支持 JAX-RS 支持 Java 和 Kotlin 语言。 安装 小编使用的idea工具版本为2020.3 ctrl +alt +s →settings plugins →Marketplace 搜索框输入:RESTKit→Install 具体操作见下图: 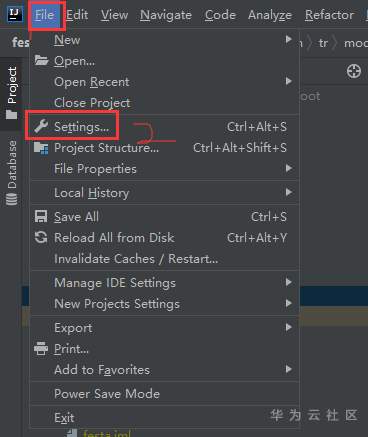 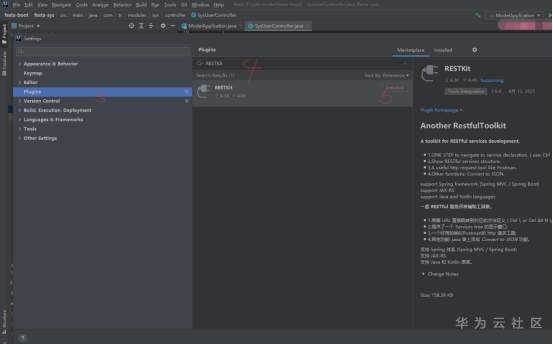 安装后,重启IDEA,插件才能生效,此时,右侧工具栏出现RESTKit 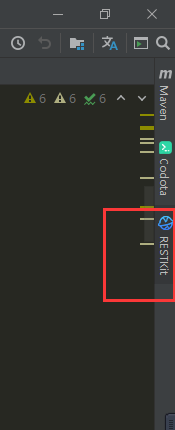 配置基本信息 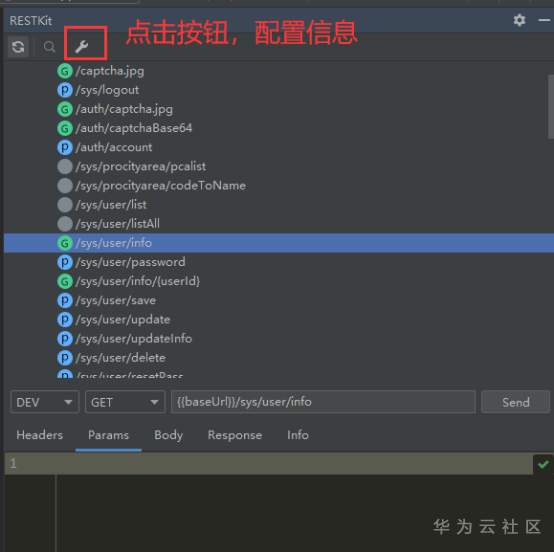 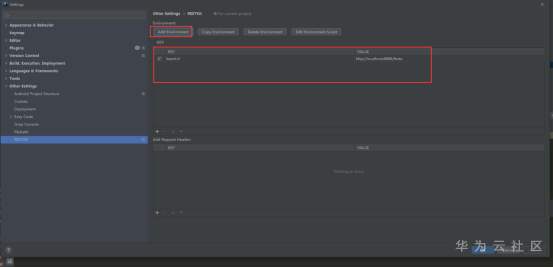 测试 可以在Params配置参数信息 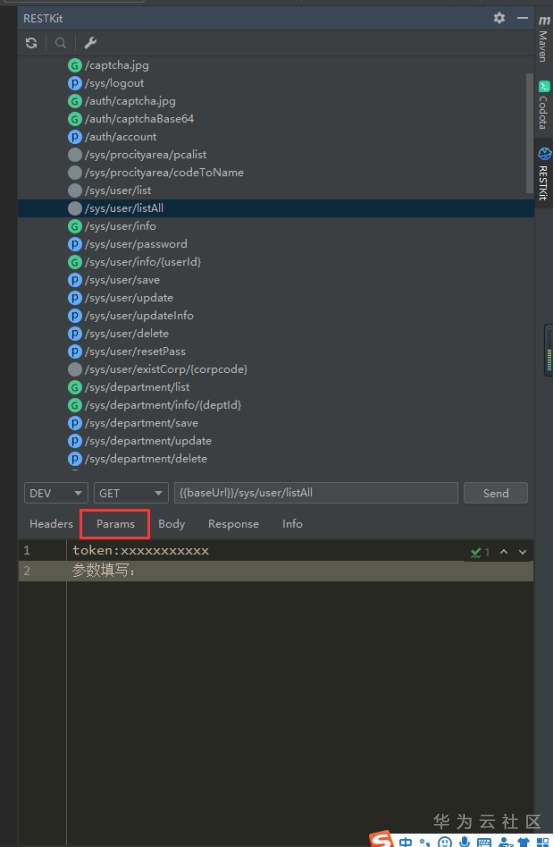 配置完成后,点击send,就会出现返回值信息。 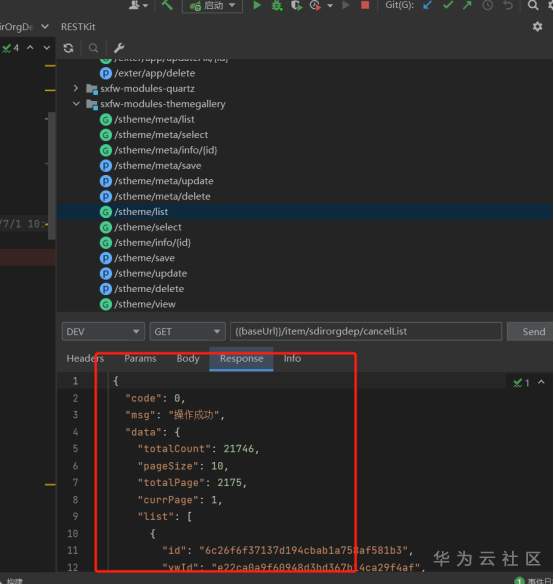 如果没有返回值,可能是参数配置不正确,插件会给出提示信息,注意查看! 工具唯一不足的地方就是每次都需要填写参数信息,没有请求记录。
-
作者:宋尧飞编者按:JNI 是 Java 和 C 语言交互的主要手段,要想做好 JNI 的编程并不容易,需要了解 JVM 内部机理才能避免一些错误。本文分析 Cassandra 使用 JNI 本地库导致 JVM 崩溃的一个案例,最后定位问题根源是信号的错误处理(一些 C 编程人员经常会截获信号,做一些额外的处理),该案例提示 JNI 编程时不要随意截获信号处理。现象在使用 Cassandra 时遇到运行时多个位置都有发生 crash 现象,并且没有 hs_err 文件生成,这里列举了其中一个 crash 位置:分析首先直接基于上面这个 crash 的 core 文件展开分析,下面分别是对应源码上下文和指令上下文:使用 GDB 调试对应的 core 文件,如下图所示:在 GDB 中进行单步调试(GDB 调试可以参考官方文档),配合源代码发现 crash 的原因是传入的 name 为 null,导致调用 name.split("\_") 时触发了 SIGSEGV 信号,直接 crash。暂时抛开这个方法传入 name 为 null 是否有问题不论,从 JVM 运行的机制来说,这里有个疑问,遇到一个 Null Pointer 为什么不是抛出 Null Pointer Exception(简称 NPE)而是直接 crash 了呢?这里有一个知识需要普及一下:Java 层面的 NPE 主要分为两类,一类是代码中主动抛出 NPE 异常,并被 JVM 捕获 (这里的代码既可以是 Java 代码,也可以是 JVM 内部代码);另一类隐式 NPE(其原理是 JVM 内部遇到空指针访问,会产生 SIGSEGV 信号, 在 JVM 内部还会检查运行时是否存在 SIGSEGV 信号)。带着上面的疑问,又看了几处其他位置的 crash,发现都是因为对象为 null 导致的 SIGSEGV,却都没有抛出 NPE,而是直接 crash 了,再结合都没有 hs_err 文件生成的现象, hs_err 文件生成功能位于 JVM 的 SIGSEGV 信号处理函数中,代码如下:由于 hs_err 文件没有产生,一个很自然的推断:Cassandra 运行中可能篡改了或者捕获了 SIGSEGV 信号,并且可能做了处理,以至于 JVM 无法正常处理 SIGSEGV 信号。然后排查业务方是否在 Cassandra 中用到了自定义的第三方 native 库,果然笔者所猜测的,有两个 native 库里都对 SIGSEGV 信号做了捕获,注释掉这些代码后重新跑对方的业务,crash 现象不再发生,问题(由于 Cassandra 中对 NPE 有异常处理导致 JVM 崩溃)解决。总结C/C++ 的组件在配合 Java 一起使用时,需要注意的一点就是不要随意去捕获系统信号,特别是 SIGSEGV、SIGILL、SIGBUS 等,因为会覆盖掉 JVM 中的信号捕获逻辑。附录 这里贴一个 demo 可以用来复现 SIGSEGV 信号覆盖造成的后果,有兴趣的可以跑一下:// JNITest.java import java.util.UUID; public class JNITest { public static void main(String[] args) throws Exception { System.loadLibrary("JNITest"); UUID.fromString(null); } }// JNITest.c #include <signal.h> #include <jni.h> JNIEXPORT jint JNICALL JNI_OnLoad(JavaVM *jvm, void *reserved) { signal(SIGSEGV, SIG_DFL);//如果注释这条语句,在运行时会出现NullPointerExcetpion异常 return JNI_VERSION_1_8; }通过 GCC 编译并执行就可以触发相同的问题,编译执行命令如下:$ gcc -Wall -shared -fPIC JNITest.c -o libJNITest.so -I$JAVA_HOME/include -I$JAVA_HOME/include/linux $ javac JNITest.java $ java -Xcomp -Djava.library.path=./ JNITest后记如果遇到相关技术问题(包括不限于毕昇 JDK),可以进入毕昇 JDK 社区查找相关资源,包括二进制下载、代码仓库、使用教学、安装、学习资料等。毕昇 JDK 社区每双周周二举行技术例会,同时有一个技术交流群讨论 GCC、LLVM、JDK 和 V8 等相关编译技术,感兴趣的同学可以添加如下微信小助手,回复 Compiler 入群。原文转载自 openEuler-JNI 中错误的信号处理导致 JVM 崩溃问题分析
-
 将IDEA中的项目提交到git远程仓库版本管理,git远程仓库使用华为云进行代码托管。市面上常见的git托管平台有github、华为云、码云、开源中国、Gitlab等。0、下载和安装git:https://git-scm.com/download/一、创建华为云账号:1、从U+实训课程页面,进入到华为华为云首页,U+已与华为云账号打通,华为云和U+共用相同的账号和密码。2、首次进入华为云需要进行实名认证,请自行实名认证二、在IDEA中创建本地仓库1.将idea项目交给版本控制工具,VCS ——> Enable Version Control Integration... 2.选择交给git进行管理,点击ok之后,该项目就会交给git进行管理,且在项目所在目录创建本地代码仓库,可以到项目所在目录看到有一个.git的隐藏文件,该目录就是git本地仓库。3.将代码提交到本地仓库(commit)代码提交到本地仓库了。4、为了验证有没有提交成功,可以查看代码的提交历史 右击项目 ——> Git ——> Show History双击某一次提交记录,可以查看该提交的详细内容。三、创建远程仓库以上步骤我们只是将代码提交到了本地仓库,如果实现共享和版本控制,我们要创建远程仓库,远程仓库使用华为云的代码托管。1、华为云首页选择 服务--->代码托管普通新建 输入仓库名,然后确定此处就该仓库的https地址,将项目提交到远程仓库时,根据该地址提交。 mark1三、将本地仓库中的代码提交到远程仓库1、git---》push,提交时push,下载是pull2. 第一次提交需要设置远程仓库地址,其中url是远程仓库的地址(mark1处)3、点击ok ----》push后需要输入华为云的仓库的账号和密码,仓库账号和密码在如下位置进行查看和修改,默认就是华为云的登陆密码4、 异常处理,第一次提交因为本地项目和远程项目没有关联,所以会提交失败解决办法参考:在项目所在目录下执行git bash,执行命令:(参考:https://www.jianshu.com/p/f8c9fb05681b)git push -u origin master -f或者在idea中使用快捷键 alt+f12 打开命令行Terminal窗口,执行git push -u origin master -f命令,如下图:本地项目和远程仓库进行关联成功,然后在选择idea中vcs--->git---->push 将本地仓库中的代码提交到远程仓库。提交成功后,在网页上可以看到,本地的代码已经提交提交到远程仓库,在网站端可以查看、修改提交的内容。5、(1)如果其他开发人员更新了远程仓库,可以选择通过pull进行下载下来。(2)如果想下载在远程仓库的项目,可以在开发工具中选择check out from version Control,然后输入仓库url(3)总结:每次先本地提交commit,在push
将IDEA中的项目提交到git远程仓库版本管理,git远程仓库使用华为云进行代码托管。市面上常见的git托管平台有github、华为云、码云、开源中国、Gitlab等。0、下载和安装git:https://git-scm.com/download/一、创建华为云账号:1、从U+实训课程页面,进入到华为华为云首页,U+已与华为云账号打通,华为云和U+共用相同的账号和密码。2、首次进入华为云需要进行实名认证,请自行实名认证二、在IDEA中创建本地仓库1.将idea项目交给版本控制工具,VCS ——> Enable Version Control Integration... 2.选择交给git进行管理,点击ok之后,该项目就会交给git进行管理,且在项目所在目录创建本地代码仓库,可以到项目所在目录看到有一个.git的隐藏文件,该目录就是git本地仓库。3.将代码提交到本地仓库(commit)代码提交到本地仓库了。4、为了验证有没有提交成功,可以查看代码的提交历史 右击项目 ——> Git ——> Show History双击某一次提交记录,可以查看该提交的详细内容。三、创建远程仓库以上步骤我们只是将代码提交到了本地仓库,如果实现共享和版本控制,我们要创建远程仓库,远程仓库使用华为云的代码托管。1、华为云首页选择 服务--->代码托管普通新建 输入仓库名,然后确定此处就该仓库的https地址,将项目提交到远程仓库时,根据该地址提交。 mark1三、将本地仓库中的代码提交到远程仓库1、git---》push,提交时push,下载是pull2. 第一次提交需要设置远程仓库地址,其中url是远程仓库的地址(mark1处)3、点击ok ----》push后需要输入华为云的仓库的账号和密码,仓库账号和密码在如下位置进行查看和修改,默认就是华为云的登陆密码4、 异常处理,第一次提交因为本地项目和远程项目没有关联,所以会提交失败解决办法参考:在项目所在目录下执行git bash,执行命令:(参考:https://www.jianshu.com/p/f8c9fb05681b)git push -u origin master -f或者在idea中使用快捷键 alt+f12 打开命令行Terminal窗口,执行git push -u origin master -f命令,如下图:本地项目和远程仓库进行关联成功,然后在选择idea中vcs--->git---->push 将本地仓库中的代码提交到远程仓库。提交成功后,在网页上可以看到,本地的代码已经提交提交到远程仓库,在网站端可以查看、修改提交的内容。5、(1)如果其他开发人员更新了远程仓库,可以选择通过pull进行下载下来。(2)如果想下载在远程仓库的项目,可以在开发工具中选择check out from version Control,然后输入仓库url(3)总结:每次先本地提交commit,在push -
【功能模块】MRS— sparkstreaming_kafka_010【操作步骤&问题现象】1、IDEA编写程序,POM依赖与示例程序一致,本地调式无误后,打包上传。2、集群主节点上运行kinit user bin/spark-submit --master yarn --deploy-mode client --class com.spark.core.Kafka_sparkStreaming_elasticSearch /opt/sparkTest/sparkdemo-1.0-SNAPSHOT.jar【截图信息】1.spark程序所使用依赖。2.提交到MRS集群上之后运行报错位置,显示集群节点不能连接(Kafka配置与本地Idea完全一致,idea能正常消费数据。集群上kafka消费组与idea环境一致不一致都不能连接)【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
上滑加载中
推荐直播
-
 华为云码道 × 仓颉编程:工程化AI编码探索
华为云码道 × 仓颉编程:工程化AI编码探索2026/05/27 周三 19:00-21:00
刘俊杰-华为云仓颉语言专家/李炎-华为云码道技术专家/王智鹏-OpenCangjie开源社区发起人
本场直播围绕华为云仓颉语言与华为云码道的深度结合,展示华为云智能编程从零基础到高效落地的完整生态能力。以华为云码道为引擎,仓颉语言为载体,带给大家日常提效、趣味创新到极速量产的开发体验。
回顾中
热门标签