-
 【功能模块】鲲鹏云主机,系统CentOS 7.6 64bit with ARM【操作步骤&问题现象】查看/var/log/messages里有大量相同报错Apr 17 03:25:20 ecs-web kernel: [drm:virtio_gpu_dequeue_ctrl_func [virtio_gpu]] ERROR response 0x1202 (command 0x103)【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】鲲鹏云主机,系统CentOS 7.6 64bit with ARM【操作步骤&问题现象】查看/var/log/messages里有大量相同报错Apr 17 03:25:20 ecs-web kernel: [drm:virtio_gpu_dequeue_ctrl_func [virtio_gpu]] ERROR response 0x1202 (command 0x103)【截图信息】【日志信息】(可选,上传日志内容或者附件) -
 ## 一、主从复制原理 主从复制过程大体可以分为3个阶段:连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段。 在从节点执行 slaveof 命令后,复制过程便开始运作,下面图示大概可以看到,从图中可以看出复制过程大致分为6个过程 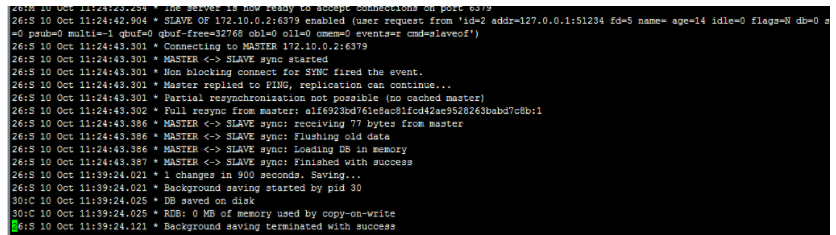 主从配置之后的日志记录也可以看出这个流程(看主redis或从redis日志都可以): ```shell vi` `/var/log/redis/redis``.log ```  **1)保存主节点(master)信息:** 执行 slaveof 后 Redis 会打印如下日志:  **2)从节点(slave)底层内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接** 从节点与主节点建立网络连接示例图:  从节点会建立一个 socket 套接字,从节点建立了一个端口为51234的套接字,专门用于接受主节点发送的复制命令。从节点连接成功后打印如下日志:  如果从节点无法建立连接,定时任务会无限重试直到连接成功或者手动执行 slaveof no one 取消复制(断开主从) 注:对一个从redis节点服务器执行命令 slaveof no one 将使得这个从redis节点服务器关闭复制功能,并从 从redis节点服务器转变回主redis节点服务器,原来同步所得的数据集不会被丢弃。 关于连接失败,可以在从节点执行 info replication 查看 master_link_down_since_seconds 指标,它会记录与主节点连接失败的系统时间。从节点连接主节点失败时也会每秒打印如下日志,方便发现问题: \# Error condition on socket for SYNC: {socket_error_reason} **3)发送 ping 命令** 连接建立成功后从节点发送 ping 请求进行首次通信,ping 请求主要目的如下:** ** ①、检测主从之间网络套接字是否可用。 ②、检测主节点当前是否可接受处理命令。 ③、如果发送 ping 命令后,从节点没有收到主节点的 pong 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连。 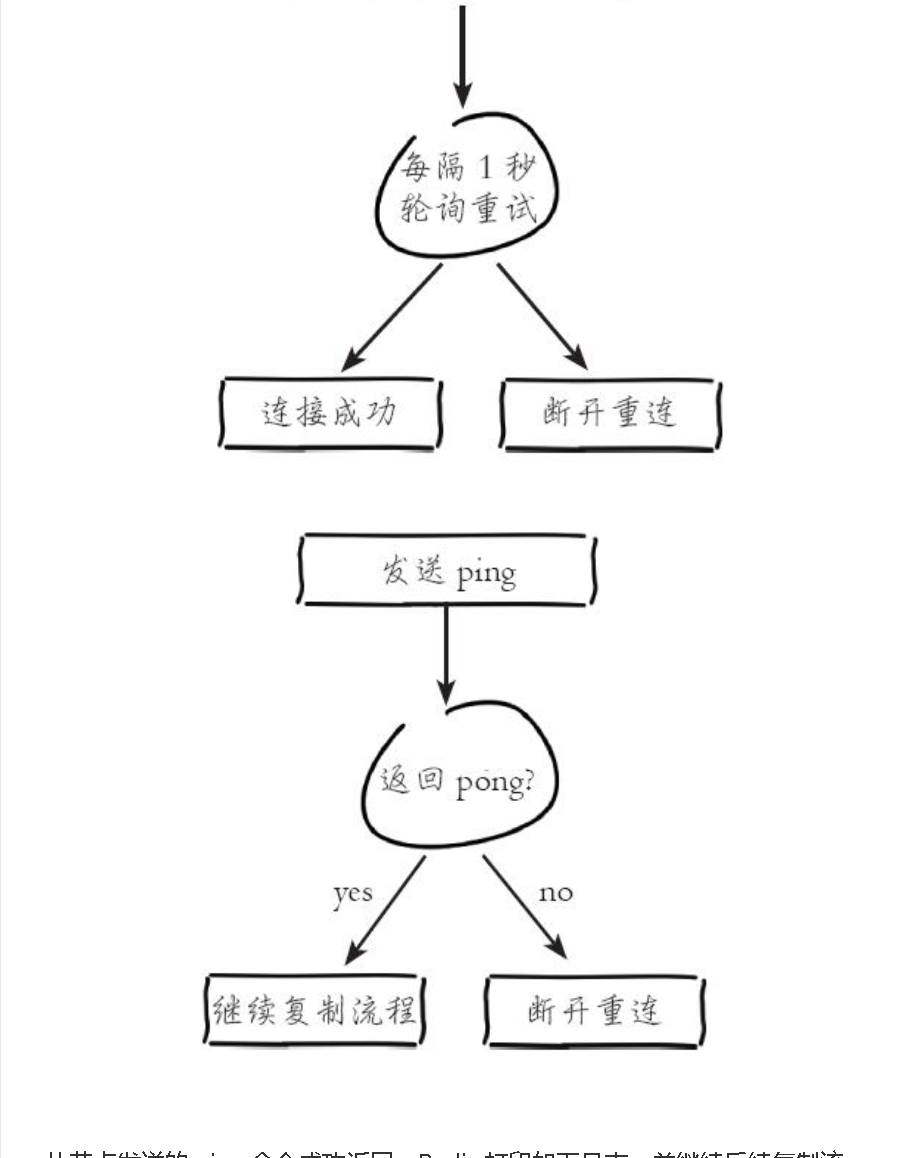 从节点发送的 ping 命令成功返回,Redis 打印如下日志,并继续后续复制流程:  **4)权限验证。**如果主节点设置了 requirepass 参数,则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。 **5)同步数据集。**主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。 ** ** **6)命令持续复制。**当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。 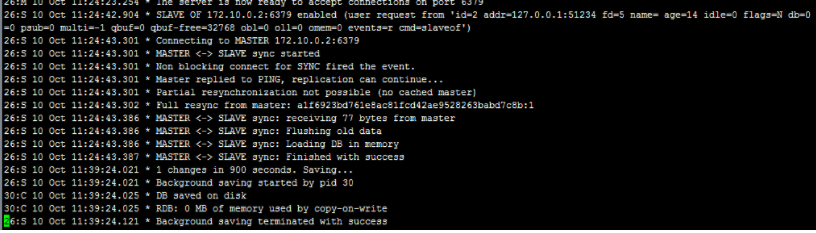 ## 二、全量复制和部分复制 ### 2.1 相关概念 **全量复制**:用于初次复制或其它无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作,当数据量较大时,会对主从节点和网络造成很大的开销 **部分复制**:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,(如果条件允许,后面会说到具体那些条件需要被满足),主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销,需要注意的是,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制 **复制偏移量**:参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 info replication 中的 master_repl_offset 指标中: 提醒:记得进入redis客户端执行该命令 ```shell #在从节点的redis中执行以下命令``redis-cli``info replication ``` 截图如下: 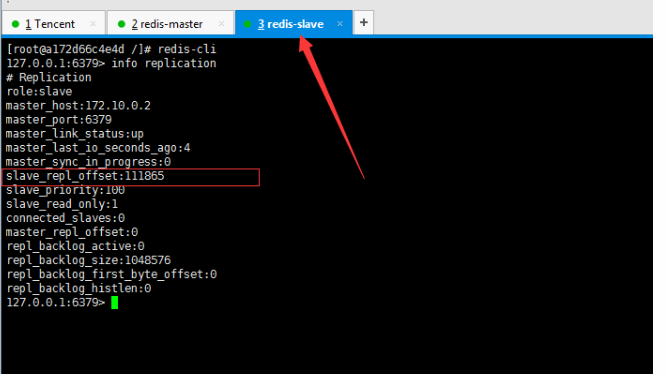 从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量,统计指标如下: 再次提醒:记得进入redis客户端执行 info replication 命令 ```shell #在主节点的redis中执行以下命令``redis-cli``info replication ``` 截图如下: 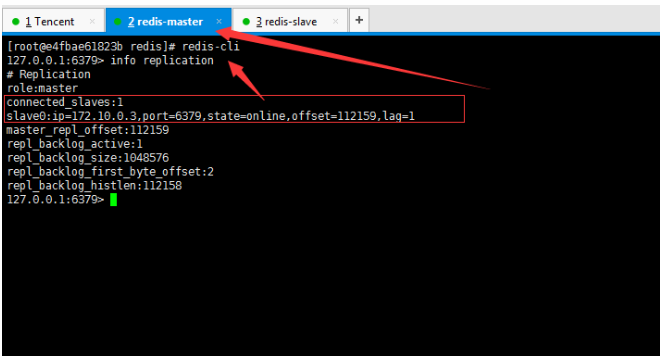 从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在 info replication 中的 slave_repl_offset 中 **复制积压缓冲区**:复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB(可以调整大小,具体调整多大看各自需求业务来调整),当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区。 在命令传播阶段(也可以说是 同步数据阶段),主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset) 。由于复制积压缓冲区定长而且先进先出,所以它保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。 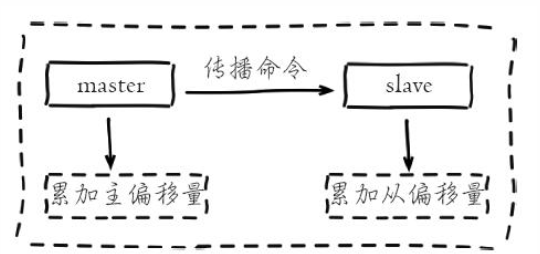 ### 2.2 Redis全量复制的过程如下图所示: 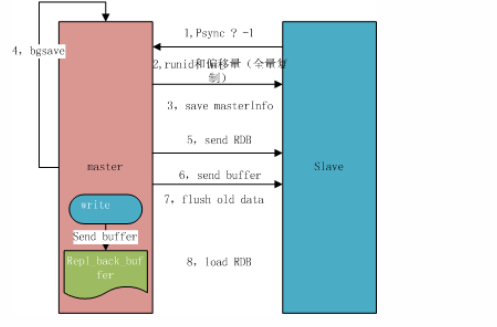 如上图所示: 1、Redis 内部会发出一个同步命令,刚开始是 Psync 命令,Psync ? -1表示要求 master 主机同步数据 2、主机会向从机发送 runid 和 offset,因为 slave 并没有对应的 offset,所以是全量复制 3、从机 slave 会保存 主机 master 的基本信息 save masterInfo 4、主节点收到全量复制的命令后,执行 bgsave 命令(异步执行),在后台生成RDB文件(快照文件),并使用一个缓冲区(称为复制缓冲区)记录从现在开始执行的所有写命令 5、主机发送 RDB 文件给从机 6、主机发送缓冲区数据到从机 7、刷新旧的数据,从节点在载入主节点的数据之前要先将老数据清除 8、加载 RDB 文件将数据库状态更新至主节点执行bgsave时的数据库状态和缓冲区数据的加载。 **全量复制开销,主要有以下几项:** 1、bgsave 时间 2、RDB 文件网络传输时间 3、从节点清空数据的时间 4、从节点加载 RDB 的时间 注:生成一个几GB 十几GB的RDB快照文件 大概是需要2-5分钟的样子 ### 2.3 部分复制(又称 增量复制) 部分复制是 Redis 2.8 以后出现的,之所以要加入部分复制,是因为全量复制会产生很多问题,比如像上面的时间开销大、无法隔离等问题, Redis 希望能够在 master 出现抖动(相当于断开连接)的时候,可以有一些机制将复制的损失降低到最低。 部分复制的过程如下图所示: 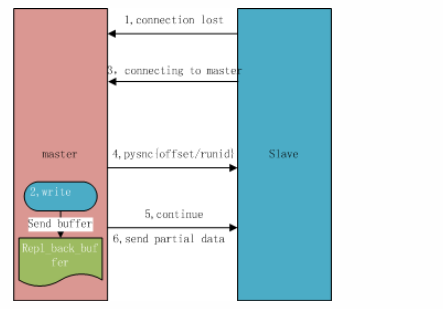 如上图所示: 1、如果网络抖动(连接断开 connection lost) 2、主机 master 还是会写 replbackbuffer(复制缓冲区) 3、从机 slave 会继续尝试连接主机 4、从机 slave 会把自己当前 runid 和偏移量传输给主机 master,并且执行 pysnc 命令同步 5、如果 master 发现从节点的偏移量是在缓冲区的范围内,就会返回 continue(在指的是继续复制的意思) 命令,如果从节点的偏移量不在缓冲区的范围之内,就不会进行部分复制操作了,这样就意味着它会执行全量复制,所以我们要尽量避免这种情况的发生。 6、同步了 offset 的部分数据,所以部分复制的基础就是偏移量 offset **正常情况下redis是如何决定是全量复制还是部分复制?** 从节点将offset(偏移量)发送给主节点后,主节点根据offset(偏移量)和缓冲区大小决定能否执行部分复制; 如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制; 如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制; **缓冲区大小调节:** 由于缓冲区长度固定且有限,因此可以备份的写命令也有限,当主从节点offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。反过来说,为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配置repl-backlog-size)来设置;例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。 **服务器运行ID(runid):** 每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个Redis节点。 通过info server命令,可以查看节点的runid:** **  主从节点初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来;当断线重连时,从节点会将这个runid发送给主节点;主节点根据runid判断能否进行部分复制: 如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况) 如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。 ## 三、主从复制的常用相关配置 **1、从redis节点配置:** ①、slaveof slave实例需要配置该项,指向master的(ip, port) ②、masterauth 如果master实例启用了密码保护,则该配置项需填master的启动密码,若master未启用密码,该配置项需要注释掉 ③、slave-serve-stale-data 指定slave与master连接中断时的动作。默认为yes,表明slave会继续应答来自client的请求,但这些数据可能已经过期(因为连接中断导致无法从master同步)。若配置为no,则slave除正常应答"INFO"和"SLAVEOF"命令外,其余来自客户端的请求命令均会得到"SYNC with master in progress"的应答,直到该slave与master的连接重建成功或该slave被提升为master ④、slave-read-only 指定slave是否只读,默认为yes。若配置为no,这表示slave是可写的,但写的内容在主从同步完成后会被删掉 ⑤、repl-disable-tcp-nodelay 指定向slave同步数据时,是否禁用socket的NO_DELAY选项。若配置为yes,则禁用NO_DELAY,则TCP协议栈会合并小包统一发送,这样可以减少主从节点间的包数量并节省带宽,但会增加数据同步到slave的时间。若配置为no,表明启用NO_DELAY,则TCP协议栈不会延迟小包的发送时机,这样数据同步的延时会减少,但需要更大的带宽。通常情况下,应该配置为no以降低同步延时,但在主从节点间网络负载已经很高的情况下,可以配置为yes 注:主从节点进行数据传输是基于tcp协议进行传输的 ⑥、slave-priority 指定slave的优先级。在不只1个slave存在的部署环境下,当master宕机时,Redis Sentinel会将priority值最小的slave提升为master。需要注意的是,若该配置项为0,则对应的slave永远不会被Redis Sentinel自动提升为master
## 一、主从复制原理 主从复制过程大体可以分为3个阶段:连接建立阶段(即准备阶段)、数据同步阶段、命令传播阶段。 在从节点执行 slaveof 命令后,复制过程便开始运作,下面图示大概可以看到,从图中可以看出复制过程大致分为6个过程  主从配置之后的日志记录也可以看出这个流程(看主redis或从redis日志都可以): ```shell vi` `/var/log/redis/redis``.log ```  **1)保存主节点(master)信息:** 执行 slaveof 后 Redis 会打印如下日志:  **2)从节点(slave)底层内部通过每秒运行的定时任务维护复制相关逻辑,当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接** 从节点与主节点建立网络连接示例图:  从节点会建立一个 socket 套接字,从节点建立了一个端口为51234的套接字,专门用于接受主节点发送的复制命令。从节点连接成功后打印如下日志:  如果从节点无法建立连接,定时任务会无限重试直到连接成功或者手动执行 slaveof no one 取消复制(断开主从) 注:对一个从redis节点服务器执行命令 slaveof no one 将使得这个从redis节点服务器关闭复制功能,并从 从redis节点服务器转变回主redis节点服务器,原来同步所得的数据集不会被丢弃。 关于连接失败,可以在从节点执行 info replication 查看 master_link_down_since_seconds 指标,它会记录与主节点连接失败的系统时间。从节点连接主节点失败时也会每秒打印如下日志,方便发现问题: \# Error condition on socket for SYNC: {socket_error_reason} **3)发送 ping 命令** 连接建立成功后从节点发送 ping 请求进行首次通信,ping 请求主要目的如下:** ** ①、检测主从之间网络套接字是否可用。 ②、检测主节点当前是否可接受处理命令。 ③、如果发送 ping 命令后,从节点没有收到主节点的 pong 回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连。  从节点发送的 ping 命令成功返回,Redis 打印如下日志,并继续后续复制流程:  **4)权限验证。**如果主节点设置了 requirepass 参数,则需要密码验证,从节点必须配置 masterauth 参数保证与主节点相同的密码才能通过验证;如果验证失败复制将终止,从节点重新发起复制流程。 **5)同步数据集。**主从复制连接正常通信后,对于首次建立复制的场景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步骤。 ** ** **6)命令持续复制。**当主节点把当前的数据同步给从节点后,便完成了复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从数据一致性。  ## 二、全量复制和部分复制 ### 2.1 相关概念 **全量复制**:用于初次复制或其它无法进行部分复制的情况,将主节点中的所有数据都发送给从节点,是一个非常重型的操作,当数据量较大时,会对主从节点和网络造成很大的开销 **部分复制**:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,(如果条件允许,后面会说到具体那些条件需要被满足),主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销,需要注意的是,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制 **复制偏移量**:参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在 info replication 中的 master_repl_offset 指标中: 提醒:记得进入redis客户端执行该命令 ```shell #在从节点的redis中执行以下命令``redis-cli``info replication ``` 截图如下:  从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量,统计指标如下: 再次提醒:记得进入redis客户端执行 info replication 命令 ```shell #在主节点的redis中执行以下命令``redis-cli``info replication ``` 截图如下:  从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在 info replication 中的 slave_repl_offset 中 **复制积压缓冲区**:复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为1MB(可以调整大小,具体调整多大看各自需求业务来调整),当主节点有连接的从节点(slave)时被创建,这时主节点(master)响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区。 在命令传播阶段(也可以说是 同步数据阶段),主节点除了将写命令发送给从节点,还会发送一份给复制积压缓冲区,作为写命令的备份;除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset) 。由于复制积压缓冲区定长而且先进先出,所以它保存的是主节点最近执行的写命令;时间较早的写命令会被挤出缓冲区。  ### 2.2 Redis全量复制的过程如下图所示:  如上图所示: 1、Redis 内部会发出一个同步命令,刚开始是 Psync 命令,Psync ? -1表示要求 master 主机同步数据 2、主机会向从机发送 runid 和 offset,因为 slave 并没有对应的 offset,所以是全量复制 3、从机 slave 会保存 主机 master 的基本信息 save masterInfo 4、主节点收到全量复制的命令后,执行 bgsave 命令(异步执行),在后台生成RDB文件(快照文件),并使用一个缓冲区(称为复制缓冲区)记录从现在开始执行的所有写命令 5、主机发送 RDB 文件给从机 6、主机发送缓冲区数据到从机 7、刷新旧的数据,从节点在载入主节点的数据之前要先将老数据清除 8、加载 RDB 文件将数据库状态更新至主节点执行bgsave时的数据库状态和缓冲区数据的加载。 **全量复制开销,主要有以下几项:** 1、bgsave 时间 2、RDB 文件网络传输时间 3、从节点清空数据的时间 4、从节点加载 RDB 的时间 注:生成一个几GB 十几GB的RDB快照文件 大概是需要2-5分钟的样子 ### 2.3 部分复制(又称 增量复制) 部分复制是 Redis 2.8 以后出现的,之所以要加入部分复制,是因为全量复制会产生很多问题,比如像上面的时间开销大、无法隔离等问题, Redis 希望能够在 master 出现抖动(相当于断开连接)的时候,可以有一些机制将复制的损失降低到最低。 部分复制的过程如下图所示:  如上图所示: 1、如果网络抖动(连接断开 connection lost) 2、主机 master 还是会写 replbackbuffer(复制缓冲区) 3、从机 slave 会继续尝试连接主机 4、从机 slave 会把自己当前 runid 和偏移量传输给主机 master,并且执行 pysnc 命令同步 5、如果 master 发现从节点的偏移量是在缓冲区的范围内,就会返回 continue(在指的是继续复制的意思) 命令,如果从节点的偏移量不在缓冲区的范围之内,就不会进行部分复制操作了,这样就意味着它会执行全量复制,所以我们要尽量避免这种情况的发生。 6、同步了 offset 的部分数据,所以部分复制的基础就是偏移量 offset **正常情况下redis是如何决定是全量复制还是部分复制?** 从节点将offset(偏移量)发送给主节点后,主节点根据offset(偏移量)和缓冲区大小决定能否执行部分复制; 如果offset偏移量之后的数据,仍然都在复制积压缓冲区里,则执行部分复制; 如果offset偏移量之后的数据已不在复制积压缓冲区中(数据已被挤出),则执行全量复制; **缓冲区大小调节:** 由于缓冲区长度固定且有限,因此可以备份的写命令也有限,当主从节点offset的差距过大超过缓冲区长度时,将无法执行部分复制,只能执行全量复制。反过来说,为了提高网络中断时部分复制执行的概率,可以根据需要增大复制积压缓冲区的大小(通过配置repl-backlog-size)来设置;例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。 **服务器运行ID(runid):** 每个Redis节点(无论主从),在启动时都会自动生成一个随机ID(每次启动都不一样),由40个随机的十六进制字符组成;runid用来唯一识别一个Redis节点。 通过info server命令,可以查看节点的runid:** **  主从节点初次复制时,主节点将自己的runid发送给从节点,从节点将这个runid保存起来;当断线重连时,从节点会将这个runid发送给主节点;主节点根据runid判断能否进行部分复制: 如果从节点保存的runid与主节点现在的runid相同,说明主从节点之前同步过,主节点会继续尝试使用部分复制(到底能不能部分复制还要看offset和复制积压缓冲区的情况) 如果从节点保存的runid与主节点现在的runid不同,说明从节点在断线前同步的Redis节点并不是当前的主节点,只能进行全量复制。 ## 三、主从复制的常用相关配置 **1、从redis节点配置:** ①、slaveof slave实例需要配置该项,指向master的(ip, port) ②、masterauth 如果master实例启用了密码保护,则该配置项需填master的启动密码,若master未启用密码,该配置项需要注释掉 ③、slave-serve-stale-data 指定slave与master连接中断时的动作。默认为yes,表明slave会继续应答来自client的请求,但这些数据可能已经过期(因为连接中断导致无法从master同步)。若配置为no,则slave除正常应答"INFO"和"SLAVEOF"命令外,其余来自客户端的请求命令均会得到"SYNC with master in progress"的应答,直到该slave与master的连接重建成功或该slave被提升为master ④、slave-read-only 指定slave是否只读,默认为yes。若配置为no,这表示slave是可写的,但写的内容在主从同步完成后会被删掉 ⑤、repl-disable-tcp-nodelay 指定向slave同步数据时,是否禁用socket的NO_DELAY选项。若配置为yes,则禁用NO_DELAY,则TCP协议栈会合并小包统一发送,这样可以减少主从节点间的包数量并节省带宽,但会增加数据同步到slave的时间。若配置为no,表明启用NO_DELAY,则TCP协议栈不会延迟小包的发送时机,这样数据同步的延时会减少,但需要更大的带宽。通常情况下,应该配置为no以降低同步延时,但在主从节点间网络负载已经很高的情况下,可以配置为yes 注:主从节点进行数据传输是基于tcp协议进行传输的 ⑥、slave-priority 指定slave的优先级。在不只1个slave存在的部署环境下,当master宕机时,Redis Sentinel会将priority值最小的slave提升为master。需要注意的是,若该配置项为0,则对应的slave永远不会被Redis Sentinel自动提升为master -
 【功能模块】【操作步骤&问题现象】安装PHP5.4,安装对应ZendGuardLoader后,PHP找不到ZendGuardLoader路径;更换PHP5.5版本,依然如此。【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】【操作步骤&问题现象】安装PHP5.4,安装对应ZendGuardLoader后,PHP找不到ZendGuardLoader路径;更换PHP5.5版本,依然如此。【截图信息】【日志信息】(可选,上传日志内容或者附件) -
【功能模块】【操作步骤&问题现象】1、有公网IP的服务器系统:4.19.36-vhulk1907.1.0.h702.eulerosv2r8.aarch64,配置snat2、无公网IP服务器系统:4.19.90-2003.4.0.0036.oe1.aarch64,目前该机器额外配置了一块弹性网卡,该网卡配置固定IP及网关,在华为控制台中已经增加该网卡IP的子网,并配置了该子网的路由的下一跳地址为有公网IP的服务器的内网网卡。本来内网无公网IP的机器通过第2块弹性网卡能访问公网IP,也能正常ping公网域名的,我手贱把有公网IP的那台服务器重启了,结果现在无公网IP的服务器通过snat只能ping通公网IP,怎么配置dns服务器地址都ping不通公网域名。【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
## 一、开胃小菜(前期准备工作): 1、准备一台鲲鹏Linux服务器并安装及启动docker 本文使用的是:CentOS 7.6 x64 2、准备一个Dockfile文件 用来构建redis镜像,该文件我会在下面提供 Dockerfile文件:[Dockerfile.zip](https://www.css3er.com/ueditor/php/upload/file/20190812/1565609627158640.zip) 自行下载解压后将文件上传到服务器。本文将该文件上传到服务器的路径:/root 3、启动系统的iptables,一般不需要更改该规则文件,如果下面步骤提示报相关网络错误,上网查一下即可解决 4、本系列博文使用的redis版本:3.2.12 ## 二、了解docker网络模式(为接下来的主从配置搭建做准备) Docker安装后,默认会创建下面三种网络类型 docker network ls 查看默认的网络  在启动容器时使用 --network bridge 指定网络类型 **bridge:桥接网络** 默认情况下启动的Docker容器,都是使用 bridge,Docker安装时创建的桥接网络,每次Docker容器重启时,会按照顺序获取对应的IP地址,这个就导致重启下,Docker的IP地址就变了(桥接网络模式也可以,就是通过端口映射访问到容器里面的redis,不过本文选择用下面的自定义网络模式) **none:无指定网络** 使用 --network=none ,docker 容器就不会分配局域网的IP **host: 主机网络** 使用 --network=host,此时,Docker 容器的网络会附属在主机上,两者是互通的。 例如,在容器中运行一个Web服务,监听8080端口,则主机的8080端口就会自动映射到容器中 ### 2.2、指定自定义网络,设置容器的固定IP(下面的Redis主从搭建选择用自定义网络) 因为默认的网络不能制定固定的地址,所以我们将创建自定义网络,并指定网段:172.10.0.0/16 并命名为mynetwork,这里选择了172.10.0.0/16网段,当然你也可以指定其他任意空闲的网段。将名字命名为mynetwork,你也可以换成其它的任意名字。具体创建指令如下: ```shell #创建一个mynetwork网络 并指定网段(子网)为:172.10.0.0/16(执行这一步,下面要用到该网络)``docker network create --subnet=172.10.0.0``/16` `mynetwork ``` 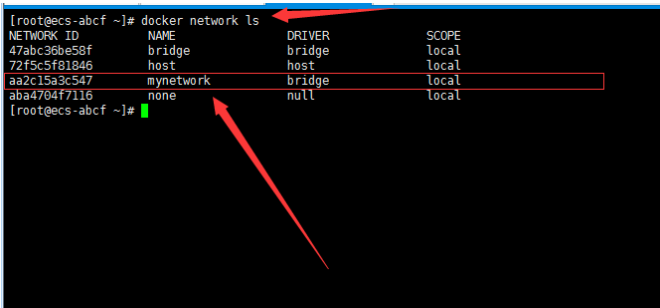 /*******************伟大的分割线************************/ ## 三、开始搭建Redis主从模式 ### 概述: **主从复制说明,单一节点的redis(单台服务器的redis)容易面临的问题:** 比如:** ** 1、机器故障。我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的。而数据是最重要的,如果你不在乎,基本上也就不会使用 Redis 了。 2、容量瓶颈。当我们有需求需要扩容 Redis 内存时,从 16G 的内存升到 64G,单机肯定是满足不了。当然,你可以重新买个 128G 的新机器。 要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上。 Redis 为了解决这个单一节点的问题,也会把数据复制多个副本部署到其他节点上进行复制,实现 Redis的高可用,实现对数据的冗余备份,从而保证数据和服务的高可用。 **什么是主从复制?** 主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave),数据的复制是单向的,只能由主节点到从节点。** ** 默认情况下,每台Redis服务器都是主节点,且一个主节点可以有多个从节点(或没有从节点),但一个从节点只能有一个主节点。也就是说一台redis从服务只能属于一台redis主服务。 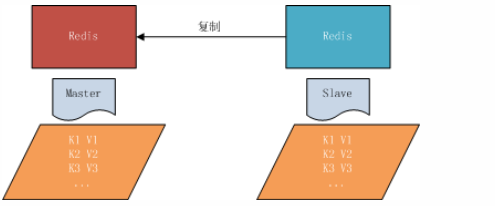 **主从复制的作用:** 主从复制的作用主要包括: 1、数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。 2、故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。 3、负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点),分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。 4、读写分离:可以用于实现读写分离,主库写、从库读,读写分离不仅可以提高服务器的负载能力,同时可根据需求的变化,改变从库的数量; 5、高可用基石(基础):除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。 ### 具体操作步骤如下: 3.1、进入到root目录下(具体换成你自己的路径),并使用Dockerfile文件构建redis镜像 ``` #进入到root目录下``cd` `/root/` `#使用Dockerfile文件构建一个redis镜像(注意后面有一个点)``docker build -t redis . ``` 可以使用docker images查看刚刚构建完成的redis镜像 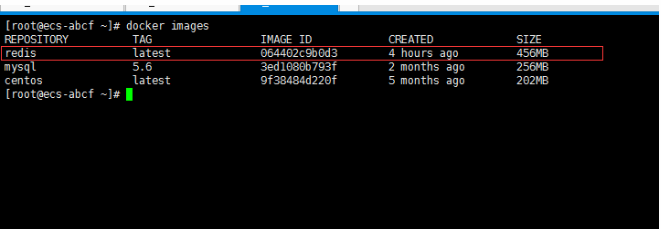 3.2、使用此构建生成的redis镜像创建容器(创建2个redis容器 一主一从) ```shell #主redis,该容器命名为redis-master 使用mynetwork网络 端口映射6380对应容器内部端口的6379 指定容器固定IP:172.10.0.2 使用redis镜像来生成容器并在后台运行``docker run -itd --name redis-master --net mynetwork -p 6380:6379 --ip 172.10.0.2 redis` `#从redis,该容器命名为redis-slave 使用mynetwork网络 端口映射6381对应容器内部端口的6379 指定容器固定IP:172.10.0.3 使用redis镜像来生成容器并在后台运行``docker run -itd --name redis-slave --net mynetwork -p 6381:6379 --ip 172.10.0.3 redis ``` 可以使用docker ps 查看正在运行中的容器(查看我们上面创建的两个一主一从的redis容器) 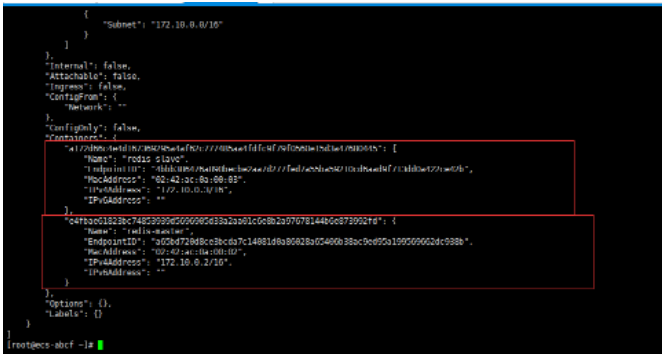 可以使用docker network inspect mynetwork命令查看容器的ip地址等相关信息  3.3、分别进入主redis容器和从redis容器 修改redis.conf配置文件 ```shell #1、主redis容器redis.conf配置文件改动``使用docker ``exec``命令进入容器里面:docker ``exec` `-it 你生成的主redis容器ID 或 容器名字 ``/bin/bash` `本文中的对应命令为(容器``id``方式):docker ``exec` `-it e4fbae61823b ``/bin/bash``本文中的对应命令为(容器名字方式):docker ``exec` `-it redis-master ``/bin/bash` `修改redis.conf配置文件 ``vi` `/etc/redis``.conf``#将bind 127.0.0.1注释 或 改为bind 0.0.0.0 表示允许任何ip连接该redis服务,同时将protected-mode yes 改为 protected-mode no 表示关闭保护模式` `#2、从redis容器redis.conf配置文件改动(和主redis的改动一样,唯一区别就是进入容器的时候,要进入从redis容器也就是容器id或容器名字不一样了 不过还是演示下吧。。)``使用docker ``exec``命令进入容器里面:docker ``exec` `-it 你生成的从redis容器ID 或 容器名字 ``/bin/bash` `本文中的对应命令为(容器``id``方式):docker ``exec` `-it a172d66c4e4d ``/bin/bash``本文中的对应命令为(容器名字方式):docker ``exec` `-it redis-slave ``/bin/bash` `修改redis.conf配置文件 ``vi` `/etc/redis``.conf``#将bind 127.0.0.1注释 或 改为bind 0.0.0.0 表示允许任何ip连接该redis服务,同时将protected-mode yes 改为 protected-mode no 表示关闭保护模式 ``` redis.conf配置文件改动后的截图如下: 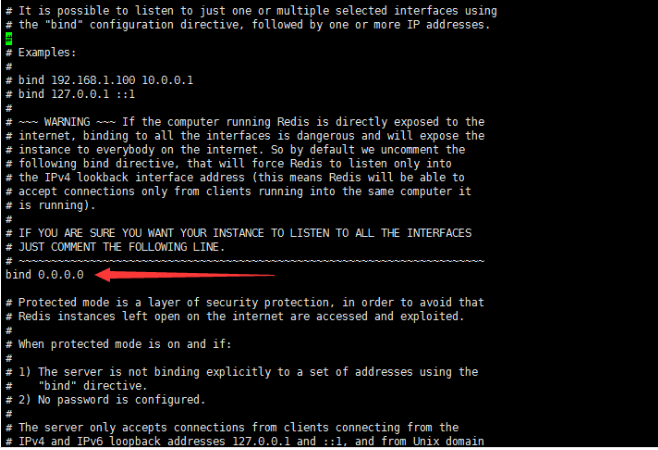 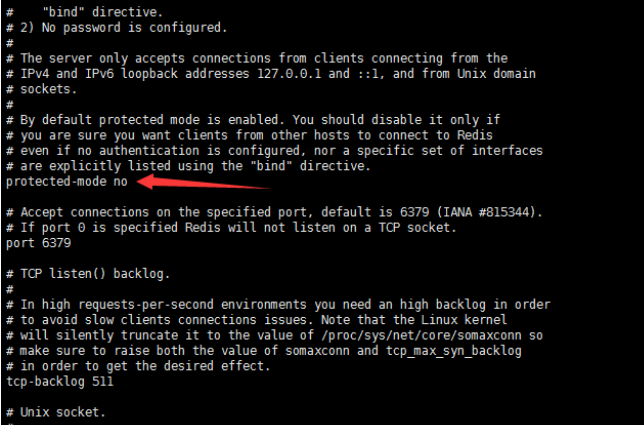 ### 3.4、启用主从模式(有三种方式): (1)redis.conf配置文件(本文使用这种方式) 在从服务器的配置文件中加入:slaveof (2)启动命令 redis-server启动命令后加入 --slaveof (3)客户端命令 Redis服务器启动后,直接通过客户端执行命令:slaveof ,则该Redis实例成为从节点 通过 info replication 命令可以看到复制的一些参数信息 3.5、从redis容器中的redis.conf的redis配置文件加入配置信息,完成主从同步(别忘了 你要进入从redis容器里面) ```shell vi` `/etc/redis``.conf` `将 ``# slaveof 改为 slaveof 172.10.0.2 6379 也就是上面创建主redis容器是指定的主redis容器的固定IP地址。如果你和我的不一样,记得换成你自己设置的 ``` 从redis容器的里的redis.conf配置文件更改后的截图如下: 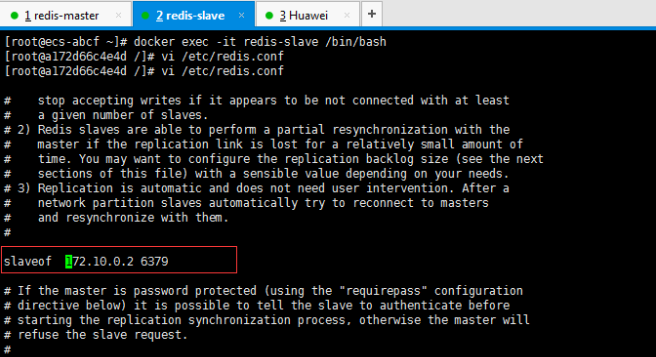 3.6、分别启动主从redis容器里面的redis服务(再次提醒。。别忘了进入主从redis容器里面启动) ```shell #主从redis容器里面启动redis服务都用以下这个命令即可``redis-server ``/etc/redis``.conf & ``#启动redis服务 &表示以后台守护进程方式启动(就是启动了后 在后台默默的服务) ``` 3.7、测试主从同步是否搭建成功(提醒啊。。别忘了进入主从redis容器里面进行操作。。真是操碎了心。。) 3.7.1、主redis容器操作: ``` redis-cli ``#进入redis客户端``set` `wzyl 123 ``#创建一个key ``` 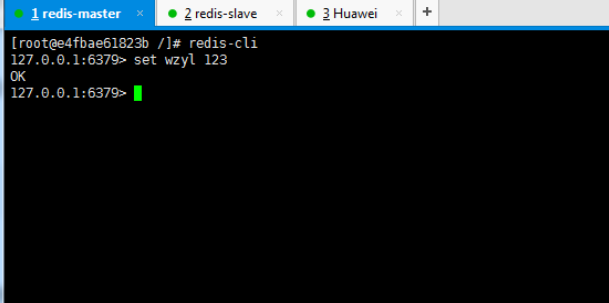 3.7.2、从redis容器操作: ```shell redis-cli ``#进入redis客户端` `使用get命令:get wzyl 或 使用keys命令:keys * ```  注:上面的keys * 命令不建议使用,除非你redis里面没有多少数据你可以使用keys * 命令,如果redis里面有很多数据 使用keys * 的话,会很慢。。会造成redis堵塞的。。 至此。。redis主从搭建成功。。往redis主节点写数据的时候,会自动同步到配置的redis从节点里(同步会有延时,因为需要用到网络,1秒钟之内会完成同步,大概也就几百毫秒的样子就可以了)实现了redis的读写分离。。这样写的操作可以写到主redis节点,读的操作可以读取从redis节点。。PS:一主一从搭建完了,一主多从应该也会了吧。。举一反三啊。。基于docker搭建redis主从都会了。。直接基于每一台服务器搭建redis主从就更简单了吧。。 **3.8、使用RedisDesktopManager工具来连接到docker里面的redis(我们就链接主redis这个容器里的redis吧)** 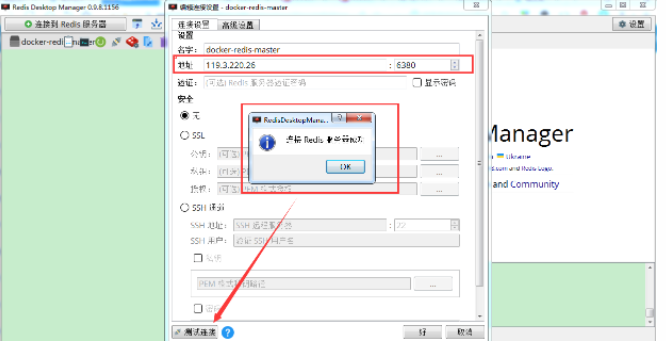 119.3.220.26是我服务器的公网IP,记得换成你自己服务器的公网IP,6380是我在上面创建主redis容器的时候指定的6380端口,实际上链接的时候会自动将6380映射成6379。。别直接上来就复制粘贴最后一点击测试发现各种error。。 **3.9、主从结构还有一种叫:树状主从结构** 树状主从结构:就是从节点它不但可以复制我们的主节点的数据,它同时也可以做为其它从节点的主节点,继续向下复制。说白了就是主节点有从节点,但是从节点还有从节点** ** 那这种树状主从结构是为了解决什么问题? 主要就是避免主节点同步压力过大,造成性能干扰 树状主从结构示例图如下:  ## 四、后记、尾声 本文中没有设置redis密码,你可以在配置文件中进行设置,如果设置了验证密码,那么从redis节点中的配置文件中也要找到对应的密码位置进行修改才能主从同步成功,在生产环境中不建议将protected-mode yes 改为 no 并且会设置redis密码。。本文为了操作简单就没有设置密码这一步。 **总结redis主从、哨兵、集群的概念:** 【redis主从】: 是备份关系, 我们操作主库,数据也会同步到从库。 如果主库机器坏了,从库可以上。就好比你 D盘的片丢了,但是你移动硬盘里边备份有。 【redis哨兵】: 哨兵保证的是HA(高可用),保证特殊情况故障自动切换,哨兵盯着你的“redis主从集群”,如果主库死了,它会告诉你新的老大是谁。 哨兵:主要针对redis主从中的某一个单节点故障后,无法自动恢复的解决方案。(哨兵 保证redis主从的高可用) 【redis集群】: 集群保证的是高并发,因为多了一些兄弟帮忙一起扛。同时集群会导致数据的分散,整个redis集群会分成一堆数据槽,即不同的key会放到不不同的槽中。 集群主要针对单节点容量、高并发问题、线性可扩展性的解决方案。 集群:是为了解决redis主从复制中 单机内存上限和并发问题,假如你现在的服务器内存为256GB,当达到这个内存时redis就没办法再提供服务,同时数据量能达到这个地步写数据量也会很大,容易造成缓冲区溢出,造成从节点无限的进行全量复制导致主从无法正常工作。
-
4月22日,2022年鲲鹏开发者创享日首站在南京启幕,该活动是鲲鹏计算推出的全国城市巡回开发者活动。 活动提供技术解读和前沿科技分享,通过技术赋能+开发上手实操+展览展示构筑深度交流平台,携手开发者和生态伙伴,共创鲲鹏计算产业未来,共享非凡成长成就成功! 
-
 标题帖子URL多系统启动U盘解决方案https://bbs.huaweicloud.com/forum/thread-181404-1-1.html利用hdparm验证分布式存储(ceph)纠错能力https://bbs.huaweicloud.com/forumreview/thread-181513-1-1.htmlUbuntu内核修改ARM64_LSEhttps://bbs.huaweicloud.com/forum/thread-181480-1-1.htmlarm64平台下启动vscode的SegmentFault问题https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181377ceph搬迁openEuler_cephhttps://bbs.huaweicloud.com/forum/thread-181716-1-1.htmlsqllite-jdbc-3.7.2移植https://bbs.huaweicloud.com/forum/thread-181436-1-1.htmlNeo4j-3.5.4移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181357hbase启动失败问题解决https://bbs.huaweicloud.com/forum/thread-181644-1-1.htmlTaishan 2280 ipxe环境搭建https://bbs.huaweicloud.com/forum/thread-181352-1-1.htmlApache-doris v0.12编译指南https://bbs.huaweicloud.com/forum/thread-181727-1-1.html毕昇+HMPI+WRF3.8.1安装使用https://bbs.huaweicloud.com/forum/thread-182068-1-1.htmlOpenStack集群dashboard访问问题定位https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181908Relion软件CCPortal集成https://bbs.huaweicloud.com/forum/thread-182146-1-1.htmlpanphlan-3.1迁移文档 for openEuler-20.03-LTS-SP1https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181351Apache-Hadoop-3.1.1移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181917VMD1.9.4移植指南(Kunpeng920 5250+CentOS8.2)https://bbs.huaweicloud.com/forum/thread-181918-1-1.htmlopenEuler20.03-LTS-SP3版本安装https://bbs.huaweicloud.com/forum/thread-182012-1-1.htmlbios配置对性能的影响https://bbs.huaweicloud.com/forumreview/thread-182008-1-1.html【虚拟化】CentOS7.7直接使用qemu安装虚拟机时使能--ebable-kvm选项卡主https://bbs.huaweicloud.com/forum/thread-182109-1-1.htmlMongoDB 4.4.0(aarch64)编译指导 for openEuler 20.03 LTS SP1https://bbs.huaweicloud.com/forum/thread-181052-1-1.htmlVLC 3.0.16(aarch64)编译指导 for openEuler 20.03 LTS SP1https://bbs.huaweicloud.com/forum/thread-181840-1-1.htmlarm服务器下rtc功能、hwclock命令无法使用案例https://bbs.huaweicloud.com/forum/thread-181532-1-1.htmlflink-shaded-netty-4.0.27.Final-1.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181025flink-shaded-netty-4.0.27.Final-2.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181024flink-shaded-netty-4.0.27.Final-3.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181023flink-shaded-netty-4.0.27.Final-4.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181022flink-shaded-netty-4.0.27.Final-5.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181021flink-shaded-netty-4.0.27.Final-6.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181020flink-shaded-netty-4.0.27.Final-7.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181019flink-shaded-netty-4.0.27.Final-8.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181017flink-shaded-netty-4.0.27.Final-9.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181015flink-shaded-netty-4.0.27.Final-10.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181014flink-shaded-netty-4.0.27.Final-11.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181013flink-shaded-netty-4.0.27.Final-12.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181012ffmpeg-4.1.6移植指南for 银河麒麟V4 SP2https://bbs.huaweicloud.com/forum/thread-181290-1-1.htmlACE 7.0.0移植指南 for openEuler 20.03【鲲鹏920(ARM64) 】https://bbs.huaweicloud.com/forum/thread-182044-1-1.html鲲鹏920(ARM64)Influxdb_1.8.2移植_for_centos7.6https://bbs.huaweicloud.com/forum/thread-181517-1-1.html鲲鹏920(ARM64)MariaDB_10.3.8 移植_for_银河麒麟V10https://bbs.huaweicloud.com/forum/thread-181922-1-1.html
标题帖子URL多系统启动U盘解决方案https://bbs.huaweicloud.com/forum/thread-181404-1-1.html利用hdparm验证分布式存储(ceph)纠错能力https://bbs.huaweicloud.com/forumreview/thread-181513-1-1.htmlUbuntu内核修改ARM64_LSEhttps://bbs.huaweicloud.com/forum/thread-181480-1-1.htmlarm64平台下启动vscode的SegmentFault问题https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181377ceph搬迁openEuler_cephhttps://bbs.huaweicloud.com/forum/thread-181716-1-1.htmlsqllite-jdbc-3.7.2移植https://bbs.huaweicloud.com/forum/thread-181436-1-1.htmlNeo4j-3.5.4移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181357hbase启动失败问题解决https://bbs.huaweicloud.com/forum/thread-181644-1-1.htmlTaishan 2280 ipxe环境搭建https://bbs.huaweicloud.com/forum/thread-181352-1-1.htmlApache-doris v0.12编译指南https://bbs.huaweicloud.com/forum/thread-181727-1-1.html毕昇+HMPI+WRF3.8.1安装使用https://bbs.huaweicloud.com/forum/thread-182068-1-1.htmlOpenStack集群dashboard访问问题定位https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181908Relion软件CCPortal集成https://bbs.huaweicloud.com/forum/thread-182146-1-1.htmlpanphlan-3.1迁移文档 for openEuler-20.03-LTS-SP1https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181351Apache-Hadoop-3.1.1移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181917VMD1.9.4移植指南(Kunpeng920 5250+CentOS8.2)https://bbs.huaweicloud.com/forum/thread-181918-1-1.htmlopenEuler20.03-LTS-SP3版本安装https://bbs.huaweicloud.com/forum/thread-182012-1-1.htmlbios配置对性能的影响https://bbs.huaweicloud.com/forumreview/thread-182008-1-1.html【虚拟化】CentOS7.7直接使用qemu安装虚拟机时使能--ebable-kvm选项卡主https://bbs.huaweicloud.com/forum/thread-182109-1-1.htmlMongoDB 4.4.0(aarch64)编译指导 for openEuler 20.03 LTS SP1https://bbs.huaweicloud.com/forum/thread-181052-1-1.htmlVLC 3.0.16(aarch64)编译指导 for openEuler 20.03 LTS SP1https://bbs.huaweicloud.com/forum/thread-181840-1-1.htmlarm服务器下rtc功能、hwclock命令无法使用案例https://bbs.huaweicloud.com/forum/thread-181532-1-1.htmlflink-shaded-netty-4.0.27.Final-1.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181025flink-shaded-netty-4.0.27.Final-2.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181024flink-shaded-netty-4.0.27.Final-3.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181023flink-shaded-netty-4.0.27.Final-4.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181022flink-shaded-netty-4.0.27.Final-5.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181021flink-shaded-netty-4.0.27.Final-6.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181020flink-shaded-netty-4.0.27.Final-7.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181019flink-shaded-netty-4.0.27.Final-8.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181017flink-shaded-netty-4.0.27.Final-9.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181015flink-shaded-netty-4.0.27.Final-10.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181014flink-shaded-netty-4.0.27.Final-11.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181013flink-shaded-netty-4.0.27.Final-12.0移植指南https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=181012ffmpeg-4.1.6移植指南for 银河麒麟V4 SP2https://bbs.huaweicloud.com/forum/thread-181290-1-1.htmlACE 7.0.0移植指南 for openEuler 20.03【鲲鹏920(ARM64) 】https://bbs.huaweicloud.com/forum/thread-182044-1-1.html鲲鹏920(ARM64)Influxdb_1.8.2移植_for_centos7.6https://bbs.huaweicloud.com/forum/thread-181517-1-1.html鲲鹏920(ARM64)MariaDB_10.3.8 移植_for_银河麒麟V10https://bbs.huaweicloud.com/forum/thread-181922-1-1.html -
鲲鹏服务器与普通的arm64虚拟机差别大吗?
-
TDSQL怎么部署到华为云?是否有步骤或者教程?
-
湘江鲲鹏-韩玉国-第一课时作业(补)
-
鲲鹏服务器支持安装TDSQL吗?
-
# 【云驻共创】鲲鹏DevKit“0”门槛快速调优的秘密武器 鲲鹏DevKit调优助手通过系统化组织和分析性能指标、热点函数、系统配置等信息,形成系统资源消耗链条,引导用户根据优化路径分析性能瓶颈,并针对每条优化路径给出优化建议和操作指导,以此实现快速调优。解决客户软件运行遇到性能问题时凭人工经验定位困难,调优能力弱的痛点。 # 1、**鲲鹏DevKit介绍** 鲲鹏开发套件Kunpeng DevKit提供全栈开发工具,集代码迁移、编译调试、性能调优、异常诊断等工具和功能于一体。将开发者的工作各个环节一一串联,提供了一个方便、快捷和专业的工具包,通过鲲鹏DevKit可以帮助用户高效开发,一展宏图。  # 2、**性能分析工具简介** 鲲鹏性能分析工具由四个子工具组成,分别为:系统性能分析、Java性能分析、系统诊断和调优助手。 系统性能分析是针对基于鲲鹏的服务器的性能分析工具,能收集服务器的处理器硬件、操作系统、进程/线程、函数等各层次的性能数据,分析系统性能指标,定位到系统瓶颈点及热点函数,并给出优化建议。该工具可以辅助用户快速定位和处理软件性能问题。 Java性能分析是针对基于鲲鹏的服务器上运行的Java程序的性能分析和优化工具,能图形化显示Java程序的堆、线程、锁、垃圾回收等信息,收集热点函数、定位程序瓶颈点,帮助用户采取针对性优化。 系统诊断是针对基于鲲鹏的服务器的性能分析工具,提供内存泄漏诊断(包括内存未释放和异常释放)、内存越界诊断、内存消耗信息分析展示、OOM诊断能力、网络丢包等,帮助用户识别出源代码中内存使用的问题点,提升程序的可靠性,工具还支持压测系统,如:网络IO诊断,评估系统最大性能。 调优助手是针对基于鲲鹏的服务器的调优工具,能系统化组织性能指标,引导用户分析性能瓶颈,实现快速调优。 其中,调优助手通过系统化组织和分析性能指标、热点函数、系统配置等信息,形成系统资源消耗链条,引导用户根据优化路径分析性能瓶颈,并针对每条优化路径给出优化建议和操作指导,以此实现快速调优。解决客户软件运行遇到性能问题时凭人工经验定位困难,调优能力弱的痛点。  # 3、 性能分析工具应用场景 客户软件在基于鲲鹏的服务器上运行遇到性能问题时,可用系统性能分析来快速分析和定位。 系统性能分析工具将采集系统如下数据: - 系统软硬件配置和运行信息,例如:CPU类型、内存部署槽位、Kernel版本、内核参数、文件系统、系统运行日志参数等。 - 系统的CPU、内存、存储IO、磁盘IO等性能指标。 - 处理器PMU、SPE的性能数据。 - 处理器访问Cache/内存的次数、带宽、吞吐率等。 - 系统内核进行CPU资源调度、IO操作等数据。 - 进程/线程的CPU、内存、存储IO、上下文切换、系统调用等数据;进程命令行信息,包括:进程名、进程参数。 - 系统的热点函数及其调用栈;热点函数归属的程序/动态库(包含绝对路径);热点函数的汇编指令和热点指令;热点函数所对应的源代码(需要用户自行提供)。 客户Java应用软件在基于鲲鹏的服务器上运行遇到性能问题时,可用Java性能分析来快速分析和定位。 Java性能分析工具将采集如下数据: - Java进程运行环境信息,如:PID、JVM版本、JAVA版本、Main class、进程启动参数等。 - Java进程的CPU活动、内存占用、类加载信息、线程运行状态信息、系统的存储容量等。 - 可触发采集进程的堆转储信息,并获取堆转储中的类,实例,对象引用链等信息。 - Java进程的文件IO、SocketIO操作、数据库操作、HTTP请求、SpringBoot运行信息等。 - 对Java进程的方法、线程、内存、老年代对象、调用栈进行采样生成JFR采样文件。 客户软件在基于鲲鹏的服务器上运行遇到性能问题时,可用系统诊断来快速分析和定位。 系统诊断工具将采集系统如下数据: - 内存泄漏次数 - 内存泄漏大小 - 内存异常释放次数 - self内存泄漏 - 调用栈信息 - 系统的物理内存和虚拟内存大小 - 进程的内存MAP信息 - 应用的申请内存大小、申请次数、申请字节数、释放次数、释放字节数、泄漏次数以及泄漏字节数 - 分配器的分配内存、空闲内存、使用内存、Arena数、mmap区域数量以及mmap区域大小。 - 系统软硬件配置和运行信息,例如:CPU类型、内存部署槽位、Kernel版本、内核参数、文件系统、系统运行日志参数等。 - 系统的CPU、内存、存储IO、磁盘IO等性能指标。 - 处理器PMU、SPE的性能数据。 - 处理器访问Cache/内存的次数、带宽、吞吐率等。 - 系统内核进行CPU资源调度、IO操作等数据。 - 进程/线程的CPU、内存、存储IO、上下文切换、系统调用等数据;进程命令行信息,包括:进程名、进程参数。 - 系统的热点函数及其调用栈;热点函数归属的程序/动态库(包含绝对路径);热点函数的汇编指令和热点指令;热点函数所对应的源代码(需要用户自行提供)。 # 4、 实现原理 调优助手采集的数据覆盖OS、应用、硬件等系统各层的配置和性能指标,并根据硬件资源的消耗,来关联消耗这些硬件资源的软件信息,再从这些软件信息,来查看软件对其它的硬件资源消耗,从而推断出性能瓶颈。将数据从应用消耗、物理消耗以及硬件关联在一起。 - **Analysis Server**:实现性能数据分析及分析结果呈现。 | 表1 Analysis Server模块介绍 | | | --------------------------- | ------------------------------------------------------------ | | **模块名** | **功能** | | Web Browser | Web浏览器,用于操作交互和数据呈现。 | | Web Server | Web服务器,接收Web浏览器的请求,并触发Data Analysis Framework进行具体的业务处理。 | | Data Analysis Framework | 数据分析框架,主要作用是:o 通知Data Collection Framework进行数据采集,并接收采集的数据文件。o 调用相应的Data Analysis Plugin对数据文件进行入库和分析,并保存分析结果。o 为Web 服务器提供分析结果查询通道。 | | Data Analysis Plugin | 数据分析插件,不同性能分析功能有对应的分析插件,主要作用是:o 对数据文件进行预处理,并导入数据库中。o 分析原始数据,得出更适合展示的数据格式及数据间的关联关系,并结合以往项目调优经验值,给出优化建议。o 提供性能分析结果查询接口。 | - **Agent**:实现性能数据采集。 | 表2 Agent模块介绍 | | | ------------------------- | ------------------------------------------------------------ | | **模块名** | **功能** | | Data Collection Framework | 数据采集框架,主要作用是:o 接收Data Analysis Framework的采集通知,调用相应的Data Collection Plugin进行数据采集。o 将采集的数据文件推送给Data Analysis Framework。 | | Data Collection Plugin | 数据采集插件,不同性能分析功能有对应的采集插件,主要作用是完成具体的性能数据采集,并保存到文件。 | 说明: 鲲鹏性能分析工具只采集系统运行过程中的性能数据,不采集用户数据,不会造成客户信息泄露。
-
1、关于鲲鹏 1.1、鲲鹏介绍 鲲鹏计算产业是基于鲲鹏处理器的基础软硬件设施、行业应用及服务,涵盖从底层硬件、基础软件到上层行业应用的全产业链条。华为作为鲲鹏计算产业的成员,聚焦计算架构创新、处理器和开源基础软件的研发,以及华为云服务,致力于推动鲲鹏生态发展。通过战略性、长周期的研发投入,吸纳全球计算产业的优秀人才和先进技术,持续推进全栈计算技术的创新发展,加快构筑面向多样性计算的全球开源体系与产业标准。基于“硬件开放、软件开源、使能伙伴、发展人才”的策略推动鲲鹏计算产业发展。 1.2、鲲鹏解决方案 鲲鹏全栈解决方案,主要应用在金融、互联网、运营商、政府、电力、交通等行业。其中应用使能套件BoostKit可应用于大数据、分布式存储、数据库、虚拟化ARM原生等方面。基础软件可应用于openGauss企业级开源数据库、openEuler开源操作系统。开发套件DevKit包含鲲鹏代码迁移工具、鲲鹏编译器、鲲鹏性能分析工具、动态二进制翻译工具。 2、鲲鹏开发套件DevKit 2.1、DevKit介绍 鲲鹏开发套件DevKit提供涵盖代码开发、编译调试、云测服务、性能分析及系统诊断等各环节的开发使能工具,方便开发者快速开发出鲲鹏亲和的高性能软件,帮助开发者加速应用迁移和算力升级。同时面向全研发作业流程,提升应用迁移和调优效率,加速原生开发。 鲲鹏开发套件DevKit以开发者为中心,并提升全流程开发效率。 开发套件DevKit包含鲲鹏代码迁移工具、鲲鹏编译器、性能分析工具、动态二进制翻译工具等。 2.2、鲲鹏代码迁移工具 2.2.1、工具简介 鲲鹏代码迁移工具是一款可以简化客户应用迁移到基于鲲鹏916/920的服务器的过程的工具。工具仅支持x86 Linux到Kunpeng Linux的扫描与分析,不支持Windows软件代码的扫描、分析与迁移。 当客户有x86平台上源代码的软件要迁移到基于鲲鹏916/920的服务器上时,既可以使用该工具分析可迁移性和迁移投入,也可以使用该工具自动分析出需修改的代码内容,并指导用户如何修改。 鲲鹏代码迁移工具既解决了客户软件迁移评估分析过程中人工分析投入大、准确率低、整体效率低下的痛点,通过该工具能够自动分析并输出指导报告;也解决了用户代码兼容性人工排查困难、迁移经验欠缺、反复依赖编译调错定位等痛点。 2.2.2、应用场景 软件迁移评估:自动扫描并分析软件包(非源码包)、已安装的软件,提供可迁移性评估报告。 源码迁移:当用户有软件要迁移到基于鲲鹏916/920的服务器上时,可先用该工具分析源码并得到迁移修改建议。 软件包重构:帮助用户重构适用于鲲鹏平台的软件安装包。 专项软件迁移:使用华为提供的软件迁移模板修改、编译并产生指定软件版本的安装包,该软件包适用于鲲鹏平台。 增强功能:支持x86和鲲鹏平台GCC 4.8.5~GCC 9.3.0版本32位应用向64位应用迁移的64位运行模式检查,结构体字节对齐检查、缓存行对齐检查和鲲鹏平台上的内存一致性检查。 2.2.3、部署方式 单机部署,即将鲲鹏代码迁移工具部署在用户的开发、测试的x86服务器或者基于鲲鹏916/920的服务器。 2.3、鲲鹏性能分析工具 2.3.1、工具简介 鲲鹏性能分析工具由四个子工具组成,分别为:系统性能分析、Java性能分析、系统诊断和调优助手。 系统性能分析是针对基于鲲鹏的服务器的性能分析工具,能收集服务器的处理器硬件、操作系统、进程/线程、函数等各层次的性能数据,分析系统性能指标,定位到系统瓶颈点及热点函数,并给出优化建议。该工具可以辅助用户快速定位和处理软件性能问题。 Java性能分析是针对基于鲲鹏的服务器上运行的Java程序的性能分析和优化工具,能图形化显示Java程序的堆、线程、锁、垃圾回收等信息,收集热点函数、定位程序瓶颈点,帮助用户采取针对性优化。 系统诊断是针对基于鲲鹏的服务器的性能分析工具,提供内存泄漏诊断(包括内存未释放和异常释放)、内存越界诊断、内存消耗信息分析展示、OOM诊断能力、网络丢包等,帮助用户识别出源代码中内存使用的问题点,提升程序的可靠性,工具还支持压测系统,如:网络IO诊断,评估系统最大性能。 调优助手是针对基于鲲鹏的服务器的调优工具,能系统化组织性能指标,引导用户分析性能瓶颈,实现快速调优。 2.3.2、应用场景 客户软件在基于鲲鹏的服务器上运行遇到性能问题时,可用系统性能分析来快速分析和定位。 系统性能分析工具将采集系统如下数据: 系统软硬件配置和运行信息,例如:CPU类型、内存部署槽位、Kernel版本、内核参数、文件系统、系统运行日志参数等。 系统的CPU、内存、存储IO、磁盘IO等性能指标。 处理器PMU、SPE的性能数据。 处理器访问Cache/内存的次数、带宽、吞吐率等。 系统内核进行CPU资源调度、IO操作等数据。 进程/线程的CPU、内存、存储IO、上下文切换、系统调用等数据;进程命令行信息,包括:进程名、进程参数。 系统的热点函数及其调用栈;热点函数归属的程序/动态库(包含绝对路径);热点函数的汇编指令和热点指令;热点函数所对应的源代码(需要用户自行提供)。 2.3.3、部署方式 当前版本支持灵活部署,即将系统性能分析所有组件部署在一台服务器上、不同服务器上及混合部署,完成性能数据采集和分析。 2.4、鲲鹏开发套件插件工具(VSCode) 2.4.1、工具简介 鲲鹏开发套件插件工具是基于Visual Studio Code提供给开发者面向鲲鹏平台进行应用软件开发、迁移、编译调试、性能调优等一系列端到端工具,即插即用。一体化呈现代码迁移插件、鲲鹏开发框架插件、编译插件及性能分析插件的完整开发套件。 鲲鹏开发套件插件工具是一个工具集,由多个插件组成,支持IDE前端界面,支持一键式安装后端,代码编辑体验增强,自动检测安装鲲鹏编译器,编译调试,用例可视化,编码辅助,工程分析扫描。用户可以通过安装Kunpeng DevKit插件直接将四个插件都安装好,也可以单独选择个别插件安装使用。 2.4.2、代码迁移插件 鲲鹏代码迁移插件作为客户端调用服务端的功能,完成扫描迁移任务,可以对待迁移软件进行快速扫描分析,并提供专业的代码迁移指导,极大简化客户应用迁移到鲲鹏平台的过程。当客户有软件需要迁移到鲲鹏平台上时,可先用该工具分析可迁移性和迁移投入,以解决客户软件迁移评估中分析投入大、准确率低、整体效率低下的痛点。 代码迁移工具支持五个功能特性: 软件迁移评估:自动扫描并分析软件包(非源码包)、已安装的软件,提供可迁移性评估报告。 源码迁移:能够自动检查并分析出用户源码、C/C++/ASM/Fortran/解释型语言/汇编软件构建工程文件、C/C++/ASM/Fortran/解释型语言/汇编软件构建工程文件使用的链接库、x86汇编代码中需要修改的内容,并给出修改指导,以解决用户代码兼容性排查困难、迁移经验欠缺、反复依赖编译调错定位等痛点。 软件包重构:通过分析x86平台软件包(RPM格式、DEB格式)的软件构成关系及硬件依赖性,重构适用于鲲鹏平台的软件包。 专项软件迁移:基于鲲鹏解决方案的软件迁移模板,进行自动化迁移修改、编译、构建软件包,帮助用户快速迁移软件。 2.4.3、性能分析插件 鲲鹏开发套件是Visual Studio Code的一款扩展工具,通常将此类工具称作集成开发环境(IDE)插件。 鲲鹏性能分析插件是其中一个子工具,作为客户端调用服务端的功能。 鲲鹏性能分析工具由四个子工具组成,分别为:系统性能分析、Java性能分析、系统诊断和调优助手。 系统性能分析是针对基于鲲鹏的服务器的性能分析工具,能收集服务器的处理器硬件、操作系统、进程/线程、函数等各层次的性能数据,分析系统性能指标,定位到系统瓶颈点及热点函数,并给出优化建议。该工具可以辅助用户快速定位和处理软件性能问题。 Java性能分析是针对基于鲲鹏的服务器上运行的Java程序的性能分析和优化工具,能图形化显示Java程序的堆、线程、锁、垃圾回收等信息,收集热点函数、定位程序瓶颈点,帮助用户采取针对性优化。 系统诊断是针对基于鲲鹏的服务器的性能分析工具,提供内存泄漏诊断(包括内存未释放和异常释放)、内存越界诊断、内存消耗信息分析展示、OOM诊断能力,帮助用户识别出源代码中内存使用的问题点,提升程序的可靠性;压测网络,获得网络最大能力,为网络IO性能优化提供基础参考数据;诊断网络,定位网络疑难问题,解决因网络配置和异常而导致的网络IO性能问题;压测存储IO,获得存储设备最大能力,包括:吞吐量、IOPS、时延等,并以此评估存储能力,为存储IO性能优化提供基础参考数据。 2.5、二进制动态翻译工具 2.5.1、相关概念 ExaGear是一款二进制指令动态翻译软件,运行在ARM64服务器上,通过将x86的指令在运行时翻译为ARM64指令并执行,使得绝大部分Linux on x86应用无需重新编译就可运行在ARM64服务器上,实现低成本、快速迁移Linux on x86应用到ARM64服务器。 2.5.2、关键特性 支持多种部署方式:支持在物理机、虚拟机、容器等平台上部署; 部署简单:一键式快速安装,x86应用部署和运行与迁移前保持一致; 支持多版本Linux OS:目前支持CentOS 7、CentOS 8、Ubuntu18、Ubuntu20、OpenEuler 20.03,并且根据用户需求,未来可定制支持更多Linux OS发行; 低损耗: 大多数场景的应用,翻译损耗在20%以内。 3、结束语 对鲲鹏开发套件有兴趣的同学可参考如下链接进行进一步学习。 相关链接:https://support.huaweicloud.com/kunpengdevps/kunpengdevps.html
-
# 1、关于鲲鹏 ## 1.1、鲲鹏介绍 鲲鹏计算产业是基于鲲鹏处理器的基础软硬件设施、行业应用及服务,涵盖从底层硬件、基础软件到上层行业应用的全产业链条。华为作为鲲鹏计算产业的成员,聚焦计算架构创新、处理器和开源基础软件的研发,以及华为云服务,致力于推动鲲鹏生态发展。通过战略性、长周期的研发投入,吸纳全球计算产业的优秀人才和先进技术,持续推进全栈计算技术的创新发展,加快构筑面向多样性计算的全球开源体系与产业标准。基于“硬件开放、软件开源、使能伙伴、发展人才”的策略推动鲲鹏计算产业发展。  ## 1.2、鲲鹏解决方案 鲲鹏全栈解决方案主要应用在金融、互联网、运营商、政府、电力、交通等行业。其中应用使能套件BoostKit可应用于大数据、分布式存储、数据库、虚拟化ARM原生等方面。基础软件可应用于openGauss企业级开源数据库、openEuler开源操作系统。开发套件DevKit包含鲲鹏代码迁移工具、鲲鹏编译器、鲲鹏性能分析工具、动态二进制翻译工具。  # 2、初识鲲鹏 从小白开始学习鲲鹏相关知识,逐步了解鲲鹏相关概念及主要技术。 - **鲲鹏初学者开始指南** https://bbs.huaweicloud.com/blogs/112477 【亮点】主要介绍了鲲鹏芯片基于ARM架构的原理,以及在行业内存在的技术优势。 - **鲲鹏架构入门与实战正式出版** https://bbs.huaweicloud.com/blogs/266742 【亮点】详细介绍了鲲鹏系列服务器架构基于ARM芯片原理,及将之前运行在X86平台的应用软件平滑迁移到鲲鹏体系对于鲲鹏生态的重要作用。 - **清华社2021****新书《鲲鹏架构入门与实战》正式上架** https://bbs.huaweicloud.com/blogs/280729 【亮点】主要介绍鲲鹏架构的由来及鲲鹏生态的构成、应用从x86架构到鲲鹏架构迁移的原因、方法及辅助迁移的鲲鹏开发套件等内容。 - **【Hello****,鲲鹏】第一期:什么是华为云鲲鹏?** https://bbs.huaweicloud.com/blogs/113665 【亮点】主要介绍了华为云鲲鹏的服务器芯片鲲鹏920的基本配置,及相关优势。 - **《鲲鹏成长笔记之从小白到高手》第一篇:认识鲲鹏,从认识鲲鹏弹性云服务器KC1****开始** https://bbs.huaweicloud.com/blogs/151030 【亮点】介绍了鲲鹏弹性云服务器的种类,及服务器的操作使用介绍。 - **新手入门鲲鹏入门资料汇总** https://bbs.huaweicloud.com/blogs/329661 【亮点】华为云社区开发者学堂提供了大量关于鲲鹏服务器的沙箱实验,可以帮助大家更好的学习,了解鲲鹏,进而进一步掌握鲲鹏。 - **鲲鹏应用开发之鲲鹏介绍** https://bbs.huaweicloud.com/blogs/140986 【亮点】主要介绍了鲲鹏生态计算产业,鲲鹏产业目标、优势、兼容的操作系统、及相关应用。 - **资料下载:《鲲鹏计算产业发展白皮书》** https://bbs.huaweicloud.com/blogs/119191 【亮点】该白皮书从产业定位、前景展望、应用分析和发展规划等方面系统性地阐述了鲲鹏计算产业的发展大计。 - **鲲鹏微认证的一些知识点** https://bbs.huaweicloud.com/blogs/198329 【亮点】介绍了微认证中基本的概念,如EIP支持与ECS、BMS、NAT网关、ELB、虚IP灵活的绑定与解绑等。 - **【鲲鹏展翅】华为云MVP****张磊:替代x86****,华为鲲鹏适配的苦与乐** https://bbs.huaweicloud.com/blogs/195966 【亮点】介绍了鲲鹏替换X86的发展过程,及发展过程中遇到的酸甜苦辣。 - **鲲鹏之开发套件DevKit****【玩转华为云】** https://bbs.huaweicloud.com/blogs/337120 【亮点】详细介绍了鲲鹏开发套件DevKit的相关功能,及应用场景。 - **华为云鲲鹏云服务器介绍** https://bbs.huaweicloud.com/blogs/215937 【亮点】详细介绍了华为鲲鹏处理器的各类,规格,及相应的应用场景。 - 【云驻共创】鲲鹏DevKit新版本推介会 https://bbs.huaweicloud.com/blogs/338641 【亮点】介绍了DevKit2.0的最新策略,以及如何助力开发者便捷、高效的开发出鲲鹏架构亲和的高性能软件,落地行业应用、繁荣鲲鹏生态。 # 3、探索鲲鹏 经过前面对鲲鹏的了解后,开始逐步开始熟悉搭建鲲鹏开发者环境,并在环境上部署基本的软件应用,加深对鲲鹏的理解和认知。 - **【云驻共创】鲲鹏DevKit“0”****门槛快速调优的秘密武器** https://bbs.huaweicloud.com/blogs/327618 【亮点】介绍了**鲲鹏****DevKit****的主要功能,及应用场景,及主要优势。** - **【云驻共创】** **深入理解基于华为鲲鹏处理器的极致性能优化。** https://bbs.huaweicloud.com/blogs/335265 【亮点】详细介绍了华为鲲鹏处理器的功能、优势。 - **【云驻共创】BoostKit 2.0****进阶:数据亲和** https://bbs.huaweicloud.com/blogs/333284 【亮点】详细介绍了鲲鹏应用使能套件BoostKit 2.0所提供的四大功能。 - **【IoT****美学】鲲鹏——****如何正确的释放鲲鹏云服务器** **?(****一)** https://bbs.huaweicloud.com/blogs/172157 【亮点】介绍了如何在平台上操作和使用鲲鹏云服务器。 - **【IoT****美学】鲲鹏——****如何正确的购买鲲鹏云服务器?(****二)** https://bbs.huaweicloud.com/blogs/172160 【亮点】详细介绍了如何购买、使用鲲鹏云服务器。 - **【在线直播】华为云大咖说鲲鹏专场,华为云专家带你全面了解鲲鹏云服务!** https://bbs.huaweicloud.com/blogs/151200 【亮点】鲲鹏云服务专家大咖小姐姐在线直播授课,深度解读鲲鹏云服务行业解决方案,带你全面了解鲲鹏云服务! - **鲲鹏初探记 --** **鲲鹏代码迁移工具** https://bbs.huaweicloud.com/blogs/305741 【亮点】详细介绍了鲲鹏代码迁移工具的优势,及应用场景。 - **鲲鹏牛刀小试,演示使用免费华为云鲲鹏服务器安装Discuz!** https://bbs.huaweicloud.com/blogs/185125 【亮点】详细介绍了如何在鲲鹏环境中安装Discuz。 - **《云话鲲鹏之大咖来了》第2****期:#****探索鲲鹏#****之“****创造一个属于自己的鲲鹏开发者环境** https://bbs.huaweicloud.com/blogs/137840 【亮点】主要从三部分教大家如何创建鲲鹏开发者环境。 - **《云话鲲鹏之大咖来了》第3****期:#****探索鲲鹏#****之“****在鲲鹏上使用编程语言——C****语言** https://bbs.huaweicloud.com/blogs/139131 【亮点】从三个基础小实验手把手教大家如何在鲲鹏上使用编程语言。 - **《云话鲲鹏之大咖来了》第4****期:#****探索鲲鹏#****之“****手把手教你在鲲鹏上使用编程语言——Java****、Python”** https://bbs.huaweicloud.com/blogs/140362 【亮点】介绍如何在鲲鹏上使用编程语言——Java、Python。 - **《云话鲲鹏之大咖来了》第5****期:#****初识鲲鹏#****之“****技术小姐姐带你秒懂华为云鲲鹏云服务和解决方案”** https://bbs.huaweicloud.com/blogs/142040 【亮点】详细介绍了鲲鹏云服务解决方案优势及全景介绍、生态策略及合作案例,从多方面来带领大家快速了解华为云鲲鹏云服务与解决方案。 - **《云话鲲鹏之大咖来了》第6****期:#****探索鲲鹏#****之手把手教你如何在ARM****上源码编译Redis** https://bbs.huaweicloud.com/blogs/143480 【亮点】详细介绍了如何在ARM上源码编译Redis。 - **《云话鲲鹏之大咖来了》第7****期:鲲鹏弹性云服务器GCC****交叉编译环境搭建** https://bbs.huaweicloud.com/blogs/146712 【亮点】详细介绍了如何用鲲鹏弹性云服务器完成GCC交叉编译环境搭建。 - **《云话鲲鹏之大咖来了》第8****期:Intel SGX****和ARM TrustZone****浅析** https://bbs.huaweicloud.com/blogs/152138 【亮点】主要介绍Intel SGX和ARM TrustZone在鲲鹏中的使用。 - **《云话鲲鹏之大咖来了》第9****期:如何将90%****的代码自动迁移到鲲鹏平台上** https://bbs.huaweicloud.com/blogs/153896 【亮点】通过实验操作指导如何将代码自动迁移到鲲鹏平台上。 - **微认证:鲲鹏软件迁移实践 ——** **鲲鹏软件迁移概述** https://bbs.huaweicloud.com/blogs/245117 【亮点】鲲鹏软件迁移概述。 - **鲲鹏调优助手-****鲲鹏开发套件中的瑞士军刀** https://bbs.huaweicloud.com/blogs/325302 【亮点】介绍了鲲鹏2.0的发展历程,及相比于原来版本的优势。 - **鲲鹏gcc mcmodel** **选项详解** https://bbs.huaweicloud.com/blogs/272527 【亮点】详细介绍mcmodel选项的作用以及鲲鹏gcc 在mcmodel选项上做的新功能支持。 - **90%****代码如何移植到鲲鹏平台上** https://bbs.huaweicloud.com/blogs/150572 【亮点】主要介绍了软件移植过程的原理,以及软件工程的相应的过程。 - **【鲲鹏展翅】华为云·云享专家赵敏敏:从400+****个鲲鹏云服务移植,到上云+****鲲鹏,技术深耕求突破** https://bbs.huaweicloud.com/blogs/195972 【亮点】介绍了鲲鹏公有云的优势,及Cloud 2.0的发展过程,未来发展方向。 # 4、玩转鲲鹏 有了前面的探索基础,后面可以在鲲鹏环境下进行更深入的实践操作了。 - **使用鲲鹏开发套件远程实验室,为鲲鹏学习插上腾飞的翅膀** https://bbs.huaweicloud.com/blogs/317746 【亮点】介绍了鲲鹏开发套件DevKit 2.0的优势,及应用场景。 - **鲲鹏初探记之 Docker Redis** https://bbs.huaweicloud.com/blogs/175141 【亮点】详细介绍了如何在鲲鹏环境中安装和使用Docker Redis。 - **鲲鹏服务器Apollo****部署** https://bbs.huaweicloud.com/blogs/300802 【亮点】详细介绍了鲲鹏底座Apollo安装的操作 - **【IoT****美学】鲲鹏——****如何正确的登录鲲鹏云服务器及上传文件至鲲鹏云服务器?** https://bbs.huaweicloud.com/blogs/172158 【亮点】详细介绍了鲲鹏云服务器的使用、操作。 - **鲲鹏性能优化十板斧合集** https://bbs.huaweicloud.com/blogs/140363 【亮点】汇聚鲲鹏性能调优系列文章,希望能为广大在鲲鹏处理器上开发软件、性能调优的程序员们,提供一点帮助。 - **openssl** **属于鲲鹏基础加速库吗?** https://bbs.huaweicloud.com/blogs/198333 【亮点】介绍了鲲鹏加速库的原理,及使用场景。 - **#****化鲲为鹏,我有话说# +** **鲲鹏 920-****基于鲲鹏架构的 7nm** **服务器处理器** https://bbs.huaweicloud.com/blogs/134871 【亮点】介绍了鲲鹏服务器鲲鹏920处理的原理,及核心技术。 # 5、鲲鹏经典征文 - **【鲲鹏经典直播征文】+****【鲲鹏DevKit****开发套件】软件如何修改?迁移?发挥鲲鹏最大性能?** https://bbs.huaweicloud.com/blogs/324182 【亮点】简单介绍鲲鹏开发套件,使用开发套件进行软件移植的步骤及流程。 - **【鲲鹏经典直播征文】体验鲲鹏代码迁移工具的极致效率** https://bbs.huaweicloud.com/blogs/296594 【亮点】介绍了鲲鹏代码迁移工具的使用场景,及优势。 - **【鲲鹏经典直播征文】+****【鲲鹏DevKit****开发套件】体验代码迁移工具的极致效率** https://bbs.huaweicloud.com/blogs/324358 【亮点】介绍了鲲鹏DevKit一站式开发套件各个部分,以及鲲鹏开发套件亮点优势。 - **【鲲鹏经典直播征文】+BoostKit****分布式存储学习** https://bbs.huaweicloud.com/blogs/289725 【亮点】介绍了BoostKit分布式存储的使用场景,及相关优势。 - **【鲲鹏经典直播征文】+****【鲲鹏应用使能套件】BoostKit****虚拟化** https://bbs.huaweicloud.com/blogs/290038 【亮点】介绍了BoostKit虚拟化套件的使用场景,及相关优势。 - **【鲲鹏经典直播征文】+openEuler****内核热升级,业务不停机** https://bbs.huaweicloud.com/blogs/326880 【亮点】简单介绍openEuler21.03系统,社区及其技术展望。整理记录了openEuler内核热升级所涉及的技术点。 - **【鲲鹏经典直播征文】基于openGauss****数据库的教学探索与实践** https://bbs.huaweicloud.com/blogs/326890 【亮点】详细介绍怎么来做数据库教学和实验,以及如何构造openGauss数据库的教育生态 # 6、鲲鹏资讯 - **支持鲲鹏!厦门出台政策培育鲲鹏计算产业!** https://bbs.huaweicloud.com/blogs/175462 【亮点】介绍了厦门对鲲鹏产业发展的支持。 - **【鲲鹏高校行深圳专场】推进鲲鹏人才培养** **助力鲲鹏产业生态建设** https://bbs.huaweicloud.com/blogs/222180 【亮点】记录了华为鲲鹏高校行深圳专场的内容,向高校学生介绍了华为企业文化,鲲鹏生态,及未来发展趋势。 - **鲲鹏计算这一年** https://bbs.huaweicloud.com/blogs/157033 【亮点】介绍了鲲鹏在过去一年的发展、在行业内的优势,以及未来的发展方向。
-
鲲鹏原指华为海思发布的一款兼容ARM指令集的服务器芯片鲲鹏920,性能强悍,配备了64个物理核心,单核实力从CPU算力benchmark的角度对比,大约持平于同期X86的主流服务器芯片,整体多核多线程算力较同期的X86芯片更强大。但是鲲鹏的含义已经有所延伸,鲲鹏不再仅仅局限于鲲鹏系列服务芯片,目前是完整软硬件生态和云服务生态。 我们看看这个生态里都有些什么? 芯片(Chip) ️ Q:鲲鹏芯片是一个ARM芯片吗? A:鲲鹏芯片兼容了ARMv8指令集,对于已有的大部分已经支持ARM64的操作系统和软件而言,鲲鹏仍然是一个架构为arm64或者aarch64的芯片。指令集的兼容是表现,但是鲲鹏系列芯片的内里是有革命性改变的。面对计算子系统的单核算力问题,自主开发处理器内核,针对每个核进行了优化设计,采用多发射、乱序执行、优化分支预测,采用了3级cache,采用了自研mesh互联Fabric,典型主频2.6GHz。整形计算能力,业界标准benchmark SPECint_rate_base2006@GCC 7.3.0 -O2评分超过930。面对服务器领域的挑战,集成了64个自研核,将DRAM的通道数从主流的6通道提升至8通道,DRAM的典型主频从2666MHz提升至2933MHz,总带宽达187GB/s;集成PCIe 4.0,CCIX等高速接口;集成2个100G RoCE端口。从这个角度看,鲲鹏芯片已经重新定义了服务器的算力平台。 服务器(Server) ️ Q:现在鲲鹏芯片应用于哪些服务器呢? A:有,泰山2280,泰山5280,泰山X6000等型号。当然,像我这样的个人开发者,直接使用一台泰山服务器用于代码编译也确实奢侈了一些,此时华为云提供的使用鲲鹏芯片的ECS弹性云服务器就会变成一个好的选择。 操作系统(OS) ️ Q:鲲鹏芯片有什么操作系统可以使用? A:理论上所有可以支持ARMv8指令集的操作系统都可以兼容鲲鹏芯片。截止到2019-7月,经过华为云实际测试并且上线供鲲鹏生态使用的操作系统主要有华为自研的EulerOS 2.8,ubuntu18.04,CentOS7.5。当然,EulerOS 2.8作为华为多年研发投入的产品,自然针对鲲鹏芯片做了相当多的底层优化,可以更有效的发挥鲲鹏920的性能。 软件 ️ Q:鲲鹏是否具备软件生态?他的发展情况如何。 A:理论上所有兼容ARMv8指令集的软件都可以运行在鲲鹏服务器上。 ️ Q:有哪些软件能兼容鲲鹏呢,我的软件是否能运行? A:现在的软件行业已经不再处于靠自己造轮子的时代,通常一款完整的软件由自编码软件部分、开源软件部分、商用软件部分等三个部分组成。因此一个完整软件要可以完整运行起来,是需要分别考察这四部分和鲲鹏的兼容性。 自编码软件 软件是由所有者采用了一种或多种编程语言,通过编译或解释使其可以运行。针对这类软件,目前鲲鹏已经支持的语言包含: 编译型:c、c++、golang>=1.5 解释器:jvm>=1.7(java语言),perl,python2/3,shell,node.js 开源软件 软件是由开源社区运营,社区所有贡献者共同提交代码完成软件实现。这类软件大多是由源码加前面的编译器、解释器一并完成业务功能。理论上,如果开源社区的源代码属于上述若干种语言,那么通过社区分发的源代码包,经过一定量的编译、安装、解释运行等过程就可以在鲲鹏社区上运行起来。实际上现在有相当多的社区(据我个人统计,有大约9000个社区)已经直接提供aarch64/arm64架构对应的发布版本包,我们可以直接从这些社区获取官方发布包,按照标准的指导就可以运行起来。 商用软件 许多企业或者用户其实并没有能力自研或者集成软件,选择采购软件公司的商用软件。这部分商用软件不开放源代码,通常与行业或者解决方案深度嵌合,比如医疗His系统、金融财务软件、ERP、商用数据库等等。这些软件必须通过软件公司提供兼容ARMv8指令集的二进制软件包才能运行在鲲鹏中。华为云正在大力与重要行业中的ISV进行深度合作,未来可以运行在鲲鹏上的商业软件将会越来越多。 云服务与解决方案 华为云已经在使用鲲鹏构建自己的云服务,未来华为云的全部基础服务和大量的主要服务都会基于鲲鹏来构建。华为云在鲲鹏生态的角色,既是优质产品和内容的提供者也是内容的消费者。 ️ Q:华为云已经发布了哪些鲲鹏云服务?分别给客户带来什么额外价值? ️ A:截止到2021-7月,已经发布了n款鲲鹏云服务。 鲲鹏弹性云服务器(ECS)。 基础云服务之一,也是用户可以直接感知到鲲鹏的最重要的服务。用户可以用过ECS直接购买鲲鹏云服务器,为云服务器添加磁盘、网络等资源,使其成为开发环境或者生产业务集群的一部分。 鲲鹏裸金属服务器(BMS)。 直接从华为云上购买裸金属服务器,用户可以得到一台专属的泰山服务器,并可以为这台泰山服务器添加磁盘、网络等资源。 鲲鹏云手机服务(CloudPhone)。可以直接从华为云上购买一台运行Android操作系统的云主机,由于直接运行与ARMv8指令集,因此无使用模拟器带来的性能损失,能够提供手机应用测试、应用自动运行等能力。 鲲鹏云容器引擎(CCE)。 一种云中间件,直接提供基于鲲鹏的云容器,其中包含的基础库均为aarch64版本。 鲲鹏分布式缓存服务(Redis)。 一种云中间件,直接提供基于鲲鹏的Redis接口。用户并不能直接感受到它和运行在X86上的Redis的明显区别,但是可以基于鲲鹏的性能和成本优势,感知到明显的性价比差距。 ️ Q:华为云鲲鹏已经在哪些行业有解决方案了? A:目前主要集中在对安全有特殊要求、对国产自主化有一定要求或者对算力性价比有较高要求的行业,如金融、政府、媒体与娱乐、游戏、生命科学等等。 全栈专属云(HCSO)。 全称是Huawei Cloud Stack Online,基于华为成熟的数据中心技术,可以为客户提供近距离的专属华为云。云手机。云手机既是华为云的一款云服务,也同时是一个解决方案。市场上有多家云手机提供商,使用的是华为云云手机解决方案。 高性能计算(HPC)。 主要通过鲲鹏的性能优势和成本优势,将鲲鹏HPC的性价比优势发挥到极致。
上滑加载中
推荐直播
-
 华为云AI入门课:AI发展趋势与华为愿景
华为云AI入门课:AI发展趋势与华为愿景2024/11/18 周一 18:20-20:20
Alex 华为云学堂技术讲师
本期直播旨在帮助开发者熟悉理解AI技术概念,AI发展趋势,AI实用化前景,了解熟悉未来主要技术栈,当前发展瓶颈等行业化知识。帮助开发者在AI领域快速构建知识体系,构建职业竞争力。
去报名 -
 华为云软件开发生产线(CodeArts)10月新特性解读
华为云软件开发生产线(CodeArts)10月新特性解读2024/11/19 周二 19:00-20:00
苏柏亚培 华为云高级产品经理
不知道产品的最新特性?没法和产品团队建立直接的沟通?本期直播产品经理将为您解读华为云软件开发生产线10月发布的新特性,并在直播过程中为您答疑解惑。
去报名 -

热门标签