-
 初读:2021年5月26日至2021年5月28日啃书进度会在目录中标出来。本次目标是完成第5章 5.4节 应用:图片分类(P61-P64)图片分类 对于人来说是很简单的事情,但是对计算机来说,却不容易。在传统图像分类方法中,人们手工设计一些特征符,提取图像上一些局部的外表、形状、纹理等,再利用标准分类器,如支持向量机等,进行分类,其中还包含大量图片处理的方法技巧。卷积神经网络的诞生,大大推进了图片分类的发展,通过深层次的神经网络,可以直接从原始图像层面提取深层次的语义,让计算机有能力理解图片中的信息,从而将不同类别区分开来。书中图5.10展示了不同卷积核可以对图像进行不同类型的操作,例如提取边缘轮廓、图像锐化等,与图像识别利用人工提取特征不同,卷积神经网络可以根据具体任务需求,自发地学习特征提取的方式,不仅实现了更好的图片分类效果,而且适用于更多的任务数据场景。图片分类最经典的应用,要数MNIST手写数字识别了。书中图5.11展示了数据样本为0~9这10个手写数字,每个图像为28×28像素的灰度图。如果使用全连接网络进行分类,需要把每个图展开成长度为784的向量,这样一方面会丢失图片在空间上的信息,另一方面会造成训练参数过多,很容易过拟合。而卷积神经网络则很好地解决了这两个问题,首先卷积核的操作不会改变空间像素分布,其次由于一个卷积核在一张图像上共享,可以更好地解决过拟合问题。卷积先通过低层的卷积核 ,提取数字的轮廓信息,对图片本身进行降维,再逐步将这些信息抽象成计算机所能理解的特征,最终通过全实现对数字的分类。书中图5.12展示的是如何将神经网络分类错误的图像筛选出来,会发现其中很多错误就算是人类也难以避免,说明卷积神经网络确实学习到了的数字语义信息。再来看一组彩色图片分类的应用——CIFAR10数据的分类。这个数据集包含6万张32×32的彩色图像,代表飞机、汽车、鸟等10个类别的事物,它的语义信息明显比数字中的更为复杂,同时输入的彩色数据具有3个通道而不是只有灰度一个通道。书中图5.14展示了卷积中不同层中卷积核 信息,从左到右依次由浅入深,可以观察到,浅层的卷积核 用于学习边的特征,随着层次加深,逐渐学习到了局部轮廓,甚至整体语义的信息,而这些卷积核 的初始状态均为随机噪声。可以看到卷积具有强大的学习能力,正是基于这些能力, 计算机视觉在2012年得到飞速发展。随着卷积的发展,图片分类的应用也被拓宽到更广的领域,如对照片中复杂物体进行分类、人脸识别或植被鉴别等。总之,图片分类应用,离不开卷积神经网络的贡献。
初读:2021年5月26日至2021年5月28日啃书进度会在目录中标出来。本次目标是完成第5章 5.4节 应用:图片分类(P61-P64)图片分类 对于人来说是很简单的事情,但是对计算机来说,却不容易。在传统图像分类方法中,人们手工设计一些特征符,提取图像上一些局部的外表、形状、纹理等,再利用标准分类器,如支持向量机等,进行分类,其中还包含大量图片处理的方法技巧。卷积神经网络的诞生,大大推进了图片分类的发展,通过深层次的神经网络,可以直接从原始图像层面提取深层次的语义,让计算机有能力理解图片中的信息,从而将不同类别区分开来。书中图5.10展示了不同卷积核可以对图像进行不同类型的操作,例如提取边缘轮廓、图像锐化等,与图像识别利用人工提取特征不同,卷积神经网络可以根据具体任务需求,自发地学习特征提取的方式,不仅实现了更好的图片分类效果,而且适用于更多的任务数据场景。图片分类最经典的应用,要数MNIST手写数字识别了。书中图5.11展示了数据样本为0~9这10个手写数字,每个图像为28×28像素的灰度图。如果使用全连接网络进行分类,需要把每个图展开成长度为784的向量,这样一方面会丢失图片在空间上的信息,另一方面会造成训练参数过多,很容易过拟合。而卷积神经网络则很好地解决了这两个问题,首先卷积核的操作不会改变空间像素分布,其次由于一个卷积核在一张图像上共享,可以更好地解决过拟合问题。卷积先通过低层的卷积核 ,提取数字的轮廓信息,对图片本身进行降维,再逐步将这些信息抽象成计算机所能理解的特征,最终通过全实现对数字的分类。书中图5.12展示的是如何将神经网络分类错误的图像筛选出来,会发现其中很多错误就算是人类也难以避免,说明卷积神经网络确实学习到了的数字语义信息。再来看一组彩色图片分类的应用——CIFAR10数据的分类。这个数据集包含6万张32×32的彩色图像,代表飞机、汽车、鸟等10个类别的事物,它的语义信息明显比数字中的更为复杂,同时输入的彩色数据具有3个通道而不是只有灰度一个通道。书中图5.14展示了卷积中不同层中卷积核 信息,从左到右依次由浅入深,可以观察到,浅层的卷积核 用于学习边的特征,随着层次加深,逐渐学习到了局部轮廓,甚至整体语义的信息,而这些卷积核 的初始状态均为随机噪声。可以看到卷积具有强大的学习能力,正是基于这些能力, 计算机视觉在2012年得到飞速发展。随着卷积的发展,图片分类的应用也被拓宽到更广的领域,如对照片中复杂物体进行分类、人脸识别或植被鉴别等。总之,图片分类应用,离不开卷积神经网络的贡献。 -
 深度学习是机器学习的一种,而机器学习是实现人工智能的必经路径。深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等卷积神经网络模型在无监督预训练出现之前,训练深度神经网络通常非常困难,而其中一个特例是卷积神经网络。卷积神经网 络受视觉系统的结构启发而产生。第一个卷积神经网络计算模型是在Fukushima(D的神经认知机中提出的,基于神经元之间的局部连接和分层组织图像转换,将有相同参数的神经元应用于前一层神经网络的不同位置,得到一种平移不变神经网络结构形式。后来,Le Cun等人在该思想的基础上,用误差梯度设计并训练卷积神经网络,在一些模式识别任务上得到优越的性能。至今,基于卷积神经网络的模式识别系统是最好的实现系统之一,尤其在手写体字符识别任务上表现出非凡的性能。深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。 深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。 深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。
深度学习是机器学习的一种,而机器学习是实现人工智能的必经路径。深度学习的概念源于人工神经网络的研究,含多个隐藏层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。研究深度学习的动机在于建立模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本等卷积神经网络模型在无监督预训练出现之前,训练深度神经网络通常非常困难,而其中一个特例是卷积神经网络。卷积神经网 络受视觉系统的结构启发而产生。第一个卷积神经网络计算模型是在Fukushima(D的神经认知机中提出的,基于神经元之间的局部连接和分层组织图像转换,将有相同参数的神经元应用于前一层神经网络的不同位置,得到一种平移不变神经网络结构形式。后来,Le Cun等人在该思想的基础上,用误差梯度设计并训练卷积神经网络,在一些模式识别任务上得到优越的性能。至今,基于卷积神经网络的模式识别系统是最好的实现系统之一,尤其在手写体字符识别任务上表现出非凡的性能。深度学习(DL, Deep Learning)是机器学习(ML, Machine Learning)领域中一个新的研究方向,它被引入机器学习使其更接近于最初的目标——人工智能(AI, Artificial Intelligence)。 深度学习是学习样本数据的内在规律和表示层次,这些学习过程中获得的信息对诸如文字,图像和声音等数据的解释有很大的帮助。它的最终目标是让机器能够像人一样具有分析学习能力,能够识别文字、图像和声音等数据。 深度学习是一个复杂的机器学习算法,在语音和图像识别方面取得的效果,远远超过先前相关技术。 深度学习在搜索技术,数据挖掘,机器学习,机器翻译,自然语言处理,多媒体学习,语音,推荐和个性化技术,以及其他相关领域都取得了很多成果。深度学习使机器模仿视听和思考等人类的活动,解决了很多复杂的模式识别难题,使得人工智能相关技术取得了很大进步。 -
 自动化搜索服务,基于ModelArts平台,融合了自动数据增强(Automatic Data Enhancement)、自动超参选择(Automatic Hyperparameter Search)和神经网络架构搜索(Neural Architecture Search)等众多AutoML技术,以期能帮助用户以最小的代价与最低的门槛获得AutoML能力,在实际业务上进行模型优化与加速。当用户有一套自己的业务模型代码,包括了完整的训练、评估、模型导出流程,但对于模型的精度,推理速度甚至训练时间等不满意,则可以按照代码编写规范,以少量的代码改动为代价,使自动化搜索服务作为业务模型代码的上层,可以多次调用代码,改变训练的模型架构与训练参数,进行模型训练与评估,最后反馈给用户精度更高、更快的模型。自动化搜索作业类型介绍目前用户的使用方式有以下几种。神经网络架构搜索(纯NAS搜索):对于图像分类、检测的场景,ModelArts提供了若干搜索好的ResNet结构,用这些结构替换原来的ResNet结构就能获得准确率或者性能的提升,这样的搜索代价是单次网络训练时间消耗的4到10倍。另外,ModelArts也支持任意的结构搜索,提供了自研搜索算法(MBNAS)在任意搜索空间内搜索更优的结构。超参搜索:提供了多个经典的超参搜索算法,可以用来搜索深度学习中常见的超参,如learning_rate等。自动数据增强策略搜索:搜索更好的预处理策略,ModelArts提供了我们已经搜索得到的最优策略,以及策略的解码器,可以用来替换代码中的数据增强模块,当然,您也可以利用ModelArts解码器,来搜索更适合自己场景的最佳增强策略。多元搜索(前面三者的任意组合):神经网络架构搜索、超参搜索、自动数据增强策略搜索,三者可以同时使用,能搜索得到更好的结构、超参和增强策略,但代价也更高。
自动化搜索服务,基于ModelArts平台,融合了自动数据增强(Automatic Data Enhancement)、自动超参选择(Automatic Hyperparameter Search)和神经网络架构搜索(Neural Architecture Search)等众多AutoML技术,以期能帮助用户以最小的代价与最低的门槛获得AutoML能力,在实际业务上进行模型优化与加速。当用户有一套自己的业务模型代码,包括了完整的训练、评估、模型导出流程,但对于模型的精度,推理速度甚至训练时间等不满意,则可以按照代码编写规范,以少量的代码改动为代价,使自动化搜索服务作为业务模型代码的上层,可以多次调用代码,改变训练的模型架构与训练参数,进行模型训练与评估,最后反馈给用户精度更高、更快的模型。自动化搜索作业类型介绍目前用户的使用方式有以下几种。神经网络架构搜索(纯NAS搜索):对于图像分类、检测的场景,ModelArts提供了若干搜索好的ResNet结构,用这些结构替换原来的ResNet结构就能获得准确率或者性能的提升,这样的搜索代价是单次网络训练时间消耗的4到10倍。另外,ModelArts也支持任意的结构搜索,提供了自研搜索算法(MBNAS)在任意搜索空间内搜索更优的结构。超参搜索:提供了多个经典的超参搜索算法,可以用来搜索深度学习中常见的超参,如learning_rate等。自动数据增强策略搜索:搜索更好的预处理策略,ModelArts提供了我们已经搜索得到的最优策略,以及策略的解码器,可以用来替换代码中的数据增强模块,当然,您也可以利用ModelArts解码器,来搜索更适合自己场景的最佳增强策略。多元搜索(前面三者的任意组合):神经网络架构搜索、超参搜索、自动数据增强策略搜索,三者可以同时使用,能搜索得到更好的结构、超参和增强策略,但代价也更高。 -
 论文名称:GPT-GNN: Generative Pre-Training of Graph Neural Networks作者:Hu Ziniu /Dong Yuxiao /Wang Kuansan /Chang Kai-Wei /Sun Yizhou发表时间:2020/6/27论文链接:https://arxiv.org/abs/2006.15437推荐原因该论文介绍的工作是致力于预训练图神经网络,以期GNN能够学习到图数据的结构和特征信息,从而能帮助标注数据较少的下游任务。 论文已经被KDD 2020 收录。文章提出用生成模型来对图分布进行建模,即逐步预测出一个图中一个新节点会有哪些特征、会和图中哪些节点相连。在第一步中,通过已经观测到的边,预测该节点的特征;在第二步中,通过已经观测到的边,以及预测出的特征,来预测剩下的边。作者在两个大规模异构网络和一个同构网络上进行了实验,总体而言,GPT-GNN在不同的实验设定下显著提高下游任务的性能,平均能达到9.1%的性能提升。另外,还评估了在不同百分比的标记数据下,GPT-GNN是否依然能取得提升。转自AI科技评论,https://www.leiphone.com/category/academic/SUjAO0ZQwOFFm2Lq.html
论文名称:GPT-GNN: Generative Pre-Training of Graph Neural Networks作者:Hu Ziniu /Dong Yuxiao /Wang Kuansan /Chang Kai-Wei /Sun Yizhou发表时间:2020/6/27论文链接:https://arxiv.org/abs/2006.15437推荐原因该论文介绍的工作是致力于预训练图神经网络,以期GNN能够学习到图数据的结构和特征信息,从而能帮助标注数据较少的下游任务。 论文已经被KDD 2020 收录。文章提出用生成模型来对图分布进行建模,即逐步预测出一个图中一个新节点会有哪些特征、会和图中哪些节点相连。在第一步中,通过已经观测到的边,预测该节点的特征;在第二步中,通过已经观测到的边,以及预测出的特征,来预测剩下的边。作者在两个大规模异构网络和一个同构网络上进行了实验,总体而言,GPT-GNN在不同的实验设定下显著提高下游任务的性能,平均能达到9.1%的性能提升。另外,还评估了在不同百分比的标记数据下,GPT-GNN是否依然能取得提升。转自AI科技评论,https://www.leiphone.com/category/academic/SUjAO0ZQwOFFm2Lq.html -
 MLSys 2021论文分析6—《SIDCo An Efficient Statistical-based Gradient Compression》背景深度学习发展到今天,大规模的分布式训练已经成为常态,增加训练节点数,充分利用数据并行可以大幅减少训练时的迭代数,即正反向传播的时间。下图是数据并行的示意图,数据并行中不可避免的一个问题是不同节点间的梯度聚合操作,这需要在不同节点间进行集合通信,而通信量又比较大,因此网络带宽就成为了大规模分布式训练场景下的一个瓶颈。此问题在联邦学习场景下尤为突出。应对此问题,在网络带宽一定的情况下,最为直接的思路就是减少通信量即进行梯度压缩。相关工作之前的梯度压缩的工作可以分为两大类:梯度量化和梯度稀疏化。梯度量化显而易见,是用更低的比特来表示梯度,这个思路和训练后量化与量化感知训练一致。梯度量化的问题也很明显,梯度量化压缩的极限是32x(32bit表示的梯度,量化为1bit),这对于超大规模的模型可能并不够;越低的比特,反量化后还原回来的梯度与原始梯度的差异越大,可能导致训练不稳定。梯度稀疏化则是在梯度聚合时只有选择地聚合一部分梯度从而减少通信时间,根据选择多少比例的梯度进行聚合,这种方式理论上可以实现任意倍数的压缩率。最简单的梯度稀疏化方法是基于TopK采样,选择绝对值最大的K个梯度进行聚合。虽然TopK操作的复杂度是O(n),但是由于梯度的向量非常庞大,整个计算依然非常耗时。后续又有了Deep Gradient Compression(DGC)的工作,DGC提出稀疏化的原则是判断梯度的绝对值是否大于某一阈值,随机选择一定比例的梯度值(0.1%-1%),然后对这部分梯度进行TopK操作,得到阈值,进而再全部梯度上用此阈值进行稀疏化。如果此阈值不够准确,筛选出了过多的梯度,那么会对筛选出的梯度再进行一次TopK采样。DGC也提出了Momentum Correcition与Local Gradient Clipping来保证训练的收敛,Momentum Factor Masking和Warm-up Training来应对梯度过时的问题。但是在稀疏化阈值的选择上,DGC采用了一种启发式的方式,而且在最差的情况下,要进行两次TopK操作,这会比较耗时。基于此,又出现了RedSync和GaussianKSGD两种方法,这两种方法和DGC相比,主要是在稀疏化阈值的选择上的变化。这两种方法均假定梯度是按照某种高斯分布,然后根据设定的压缩比,选择阈值,从而选择出需要聚合的梯度。这样相比DGC,在稀疏化操作的时候耗时就会明显减小,但是符合某种高斯分布这个强先验条件不一定会满足,从而导致这两种方法的实际压缩比会和预定压缩比有不少差异。SIDCo这篇论文主要是提出了一种基于稀疏分布的压缩方法(Sparsity-Inducing Distribution-based Compression, SIDCo),假设梯度是符合某种稀疏性分布,然后提出了一种多段式的阈值估计方法来相对准确的得到阈值。SIDCo中依然有一个很强的先验条件,梯度符合某种稀疏性分布,文章中先引出了可压缩信号的定义然后在附录中详细证明了深度学习模型中的梯度满足此种性质,而可压缩信号具有一个性质即他们很好的被SID来近似。下图是在Cifar10上面训练一个ResNet20网络得到的梯度的PDF与CDF,以及三种SID:double exponential, double gamma double GP distributions的曲线可以看到这三种分布均可以比较好的拟合真实的梯度分布,但是在CDF尾部的地方会有一定偏差。给定压缩比之后,可以直接在CDF曲线上得到阈值,给定压缩比,三种SID对应的阈值解析解均在论文中给出,经过简单计算即可得到。当压缩比很大(<0.01%)时,如果只用单一的SID来拟合会出现比较大的偏差,因此论文提出使用段式的阈值估计方法。先选择某种SID,以更大的压缩比计算一次阈值,得到筛选出的梯度;在对筛选出的梯度,以某种压缩比、某种SID再计算一次阈值,得到进一步筛选出的梯度;重复上述步骤M次。总的压缩率就是算法流程入下表所示实验结果分别在RNN和CNN的经典模型上进行了对比实验,下图给出了加速比、吞吐率以及真实压缩比的数据可以看到相比于TopK、DGC、RedSync和GaussK,SIDCo的加速比和吞吐率都会更优,主要原因是算取阈值的时候效率更佳,相较于RedSync和GaussK,SIDCo的真实压缩率更为准确,这也说明了符合某种稀疏性分布的先验条件比较准确。结论这篇论文提出了一种基于稀疏性分布的梯度压缩方法,利用一个多段式的阈值估计可以相对准确的算出真实的阈值。在多种RNN和CNN的网络上面进行了对比实验,对比不压缩、TopK和DGC,SIDCo取得了41.7x、7.5x和1.9x的加速,而且真实压缩比的方差相较于RedSync和GaussK更小。参考《AN EFFICIENT STATISTICAL-BASED GRADIENT COMPRESSION TECHNIQUE FOR DISTRIBUTED TRAINING SYSTEMS》《DEEP GRADIENT COMPRESSION: REDUCING THE COMMUNICATION BANDWIDTH FOR DISTRIBUTED TRAINING》《RedSync: Reducing synchronization bandwidth for distributed deep learning training system》《Understanding Top-k Sparsification in Distributed Deep Learning》转自文章链接:https://zhuanlan.zhihu.com/p/374524898转自作者:金雪锋感谢作者的努力与分享,侵权立删!
MLSys 2021论文分析6—《SIDCo An Efficient Statistical-based Gradient Compression》背景深度学习发展到今天,大规模的分布式训练已经成为常态,增加训练节点数,充分利用数据并行可以大幅减少训练时的迭代数,即正反向传播的时间。下图是数据并行的示意图,数据并行中不可避免的一个问题是不同节点间的梯度聚合操作,这需要在不同节点间进行集合通信,而通信量又比较大,因此网络带宽就成为了大规模分布式训练场景下的一个瓶颈。此问题在联邦学习场景下尤为突出。应对此问题,在网络带宽一定的情况下,最为直接的思路就是减少通信量即进行梯度压缩。相关工作之前的梯度压缩的工作可以分为两大类:梯度量化和梯度稀疏化。梯度量化显而易见,是用更低的比特来表示梯度,这个思路和训练后量化与量化感知训练一致。梯度量化的问题也很明显,梯度量化压缩的极限是32x(32bit表示的梯度,量化为1bit),这对于超大规模的模型可能并不够;越低的比特,反量化后还原回来的梯度与原始梯度的差异越大,可能导致训练不稳定。梯度稀疏化则是在梯度聚合时只有选择地聚合一部分梯度从而减少通信时间,根据选择多少比例的梯度进行聚合,这种方式理论上可以实现任意倍数的压缩率。最简单的梯度稀疏化方法是基于TopK采样,选择绝对值最大的K个梯度进行聚合。虽然TopK操作的复杂度是O(n),但是由于梯度的向量非常庞大,整个计算依然非常耗时。后续又有了Deep Gradient Compression(DGC)的工作,DGC提出稀疏化的原则是判断梯度的绝对值是否大于某一阈值,随机选择一定比例的梯度值(0.1%-1%),然后对这部分梯度进行TopK操作,得到阈值,进而再全部梯度上用此阈值进行稀疏化。如果此阈值不够准确,筛选出了过多的梯度,那么会对筛选出的梯度再进行一次TopK采样。DGC也提出了Momentum Correcition与Local Gradient Clipping来保证训练的收敛,Momentum Factor Masking和Warm-up Training来应对梯度过时的问题。但是在稀疏化阈值的选择上,DGC采用了一种启发式的方式,而且在最差的情况下,要进行两次TopK操作,这会比较耗时。基于此,又出现了RedSync和GaussianKSGD两种方法,这两种方法和DGC相比,主要是在稀疏化阈值的选择上的变化。这两种方法均假定梯度是按照某种高斯分布,然后根据设定的压缩比,选择阈值,从而选择出需要聚合的梯度。这样相比DGC,在稀疏化操作的时候耗时就会明显减小,但是符合某种高斯分布这个强先验条件不一定会满足,从而导致这两种方法的实际压缩比会和预定压缩比有不少差异。SIDCo这篇论文主要是提出了一种基于稀疏分布的压缩方法(Sparsity-Inducing Distribution-based Compression, SIDCo),假设梯度是符合某种稀疏性分布,然后提出了一种多段式的阈值估计方法来相对准确的得到阈值。SIDCo中依然有一个很强的先验条件,梯度符合某种稀疏性分布,文章中先引出了可压缩信号的定义然后在附录中详细证明了深度学习模型中的梯度满足此种性质,而可压缩信号具有一个性质即他们很好的被SID来近似。下图是在Cifar10上面训练一个ResNet20网络得到的梯度的PDF与CDF,以及三种SID:double exponential, double gamma double GP distributions的曲线可以看到这三种分布均可以比较好的拟合真实的梯度分布,但是在CDF尾部的地方会有一定偏差。给定压缩比之后,可以直接在CDF曲线上得到阈值,给定压缩比,三种SID对应的阈值解析解均在论文中给出,经过简单计算即可得到。当压缩比很大(<0.01%)时,如果只用单一的SID来拟合会出现比较大的偏差,因此论文提出使用段式的阈值估计方法。先选择某种SID,以更大的压缩比计算一次阈值,得到筛选出的梯度;在对筛选出的梯度,以某种压缩比、某种SID再计算一次阈值,得到进一步筛选出的梯度;重复上述步骤M次。总的压缩率就是算法流程入下表所示实验结果分别在RNN和CNN的经典模型上进行了对比实验,下图给出了加速比、吞吐率以及真实压缩比的数据可以看到相比于TopK、DGC、RedSync和GaussK,SIDCo的加速比和吞吐率都会更优,主要原因是算取阈值的时候效率更佳,相较于RedSync和GaussK,SIDCo的真实压缩率更为准确,这也说明了符合某种稀疏性分布的先验条件比较准确。结论这篇论文提出了一种基于稀疏性分布的梯度压缩方法,利用一个多段式的阈值估计可以相对准确的算出真实的阈值。在多种RNN和CNN的网络上面进行了对比实验,对比不压缩、TopK和DGC,SIDCo取得了41.7x、7.5x和1.9x的加速,而且真实压缩比的方差相较于RedSync和GaussK更小。参考《AN EFFICIENT STATISTICAL-BASED GRADIENT COMPRESSION TECHNIQUE FOR DISTRIBUTED TRAINING SYSTEMS》《DEEP GRADIENT COMPRESSION: REDUCING THE COMMUNICATION BANDWIDTH FOR DISTRIBUTED TRAINING》《RedSync: Reducing synchronization bandwidth for distributed deep learning training system》《Understanding Top-k Sparsification in Distributed Deep Learning》转自文章链接:https://zhuanlan.zhihu.com/p/374524898转自作者:金雪锋感谢作者的努力与分享,侵权立删! -
论文名称:Segmentation and Optimal Region Selection of Physiological Signals using Deep Neural Networks and Combinatorial Optimization作者:Jorge Oliveira /Margarida Carvalho /Diogo Marcelo Nogueira /Miguel Coimbra发表时间:2020/3/17论文链接:https://paper.yanxishe.com/review/14660?from=leiphonecolumn_paperreview0417推荐原因1 核心问题本文解决的是如何自动提取生理信号最优波段来辅助后续诊断和预测的问题。2 创新点本文使用神经网络去计算每个样本的状态概率分布,然后构造出一张图,同时在图中加入状态转换限制,并根据最大化用户提出的似然函数去使用一组约束来检索生理信号记录的子集。3 研究意义生理信号经常会被噪音干扰。通常情况下,人工智能算法会在无视质量的情况下对之进行整体分析。与之相反的是,医师则并不分析整个记录,而是会搜寻容易检测到基本波动和异常波动的波段进行分析,然后才进行预测。因此,受到以上事实启发,本文提出了一个基于用户自定标准,为后期处理自动选择最优波段的算法。本文将提出的方法使用在两个实际应用场景中,并且取得了很好的效果。转自Ai ,https://www.leiphone.com/category/academic/OplxYlWbr1ak9nCm.html
-
 论文地址| https://arxiv.org/abs/2103.12340论文代码|https://github.com/lkeab/BCNet01摘要由于物体的真实轮廓和遮挡边界之间通常没有区别,对高度重叠的对象进行分割是非常具有挑战性的。与之前的自顶向下的实例分割方法不同,本文提出遮挡感知下的双图层实例分割网络BCNet,将图像中的感兴趣区域(Region of Interest,RoI)建模为两个重叠图层,其中顶部图层检测遮挡对象,而底图层推理被部分遮挡的目标物体。双图层结构的显式建模自然地将遮挡和被遮挡物体的边界解耦,并在Mask预测的同时考虑遮挡关系的相互影响。作者在具有不同主干和网络层选择的One-stage和Two-stage目标检测器上验证了双层解耦的效果,显著改善了现有图像实例分割模型在处理复杂遮挡物体的表现,并在COCO和KINS数据集上均取得总体性能的大幅提升。 02背景实例分割(Instance Segmentation)是图像及视频场景理解的基础任务,该任务将物体检测与语义分割有机结合,不仅需要预测出输入图像的每一个像素点是否属于物体,还需将不同的物体所包含的像素点区分开。目前,实例分割技术已经大规模地应用在短视频编辑、视频会议、医学影像、自动驾驶等领域中, 下图展示了在自动驾驶场景下其对周边车辆的位置感知: 自动驾驶 - 车辆识别与感知03问题以Mask R-CNN为代表的实例分割方法通常遵循先检测再分割(Detect-then-segment)的范例,即先获取感兴趣目标检测框,然后对区域内的像素进行Mask预测,在COCO数据集取得了领先性能并在工业界得到广泛应用。我们注意到大多数后续改进算法如PANet、HTC、BlendMask、CenterMask等均着重于设计更好的网络骨干(Backbone)、高低层特征的融合机制或级联结构(Cascade Structure),而忽视了掩膜预测分支(Mask Regression Head)的作用。同时,如图1所示的重叠人群,大面积的实例分割错误都是由于同一感兴趣区域(RoI)中包含的重叠物体混淆了不同物体的真实轮廓,特别是当遮挡和被遮挡目标都属于相同类别或纹理颜色相似。图1 高度遮挡下的实例分割结果对比04成果近日,香港科技大学联合快手对图像实例分割当下性能瓶颈进行了深入剖析,该研究通过将图像中感兴趣区域(RoI)建模为两个重叠图层(如图2示),并提出遮挡感知下的双图层实例分割网络BCNet,顶层GCN层检测遮挡对象,底层GCN层推理被部分遮挡的目标物体,通过显式建模自然地将遮挡和被遮挡物体的边界解耦,并在mask预测的同时考虑遮挡关系的相互影响,显著改善了现有实例分割模型在处理复杂遮挡物体时的表现,在COCO和KINS数据集上均取得领先性能。 图2 遮挡物和被遮挡物的双图层分解示意简图05意义物体互相遮挡在日常生活中普遍存在,严重的遮挡会带来易混淆的遮挡边界及非连续自然的物体形状,从而导致当前已有的检测及分割等的算法的性能大幅下降。该研究系统提出了一个轻量级且能有效处理遮挡的实例分割算法,在工业界也具有极大意义。随着短视频作为主要信息传播媒介不断渗透进日常生活,在实际的物体分割应用场景中,分割的准确性直接影响着用户的使用体验和产品观感。因此,如何将实例分割技术应用在复杂的日常应用场景并保持高精度,此项研究给出了一个合理、有效的解决方案。BCNet的结构框架整个分割系统分为两个部分,物体检测部分和物体分割部分,算法流程如下图: 图3 BCNet的网络结构 输入单张图像,使用基于Faster R-CNN或者FCOS的物体检测算法预测感兴趣目标区域(RoI)候选框坐标(x,y,w,h),采用Resnet-50/101及特征金字塔作为基础网络(backbone)获取整张输入图片的特征。使用RoI Align算法根据物体检测框位置,在整张图片特征图内准确抠取感兴趣目标区域的特征子图,并将其作为双图卷积神经网络的输入用于最终的物体分割。 实例分割网络BCNet由级联状的双图层神经网络组成:第一个图层对感兴趣目标区域内遮挡物体(Occluder)的形状和外观进行显式建模,该层图卷积网络包含四层,即卷积层(卷积核大小3x3)、图卷积层(Non-local Layer)以及末尾的两个卷积(卷积核大小3x3)。第一个图卷积网络输入感兴趣目标区域特征,输出感兴趣目标框中遮挡物体的边界和掩膜。第二个图层结合第一个图卷积网络(用于对遮挡物体建模)已经提取的遮挡物体信息(包括遮挡物的Boundary和Mask),具体做法是将步骤2中得到的感兴趣目标区域特征与经过第一个图卷积网络中最后一层卷积后的特征3a相加,得到新的特征,并将其作为第二个图卷积网络(用于被遮挡物分割)的输入。第二个图卷积网络与第一个图卷积网络结构相同,构成级联网络关系。该操作将遮挡与被遮挡关系同时考虑进来,能有效地区分遮挡物与被遮挡物的相邻物体边界,最终输出目标区域被遮挡目标物体(Occludee)的分割结果。为了减少模型的参数量,我们使用非局部算子(Non-local Operator)操作进行图卷积层的实现,具体实现位于结构图左上位置,包含三个卷积核大小为1x1的卷积层以及Softmax算子,其将图像空间中像素点根据对应特征向量的相似度有效关联起来,实现输入目标区域特征的重新聚合,能较好解决同一个物体的像素点在空间上被遮挡截断导致不连续的问题。
论文地址| https://arxiv.org/abs/2103.12340论文代码|https://github.com/lkeab/BCNet01摘要由于物体的真实轮廓和遮挡边界之间通常没有区别,对高度重叠的对象进行分割是非常具有挑战性的。与之前的自顶向下的实例分割方法不同,本文提出遮挡感知下的双图层实例分割网络BCNet,将图像中的感兴趣区域(Region of Interest,RoI)建模为两个重叠图层,其中顶部图层检测遮挡对象,而底图层推理被部分遮挡的目标物体。双图层结构的显式建模自然地将遮挡和被遮挡物体的边界解耦,并在Mask预测的同时考虑遮挡关系的相互影响。作者在具有不同主干和网络层选择的One-stage和Two-stage目标检测器上验证了双层解耦的效果,显著改善了现有图像实例分割模型在处理复杂遮挡物体的表现,并在COCO和KINS数据集上均取得总体性能的大幅提升。 02背景实例分割(Instance Segmentation)是图像及视频场景理解的基础任务,该任务将物体检测与语义分割有机结合,不仅需要预测出输入图像的每一个像素点是否属于物体,还需将不同的物体所包含的像素点区分开。目前,实例分割技术已经大规模地应用在短视频编辑、视频会议、医学影像、自动驾驶等领域中, 下图展示了在自动驾驶场景下其对周边车辆的位置感知: 自动驾驶 - 车辆识别与感知03问题以Mask R-CNN为代表的实例分割方法通常遵循先检测再分割(Detect-then-segment)的范例,即先获取感兴趣目标检测框,然后对区域内的像素进行Mask预测,在COCO数据集取得了领先性能并在工业界得到广泛应用。我们注意到大多数后续改进算法如PANet、HTC、BlendMask、CenterMask等均着重于设计更好的网络骨干(Backbone)、高低层特征的融合机制或级联结构(Cascade Structure),而忽视了掩膜预测分支(Mask Regression Head)的作用。同时,如图1所示的重叠人群,大面积的实例分割错误都是由于同一感兴趣区域(RoI)中包含的重叠物体混淆了不同物体的真实轮廓,特别是当遮挡和被遮挡目标都属于相同类别或纹理颜色相似。图1 高度遮挡下的实例分割结果对比04成果近日,香港科技大学联合快手对图像实例分割当下性能瓶颈进行了深入剖析,该研究通过将图像中感兴趣区域(RoI)建模为两个重叠图层(如图2示),并提出遮挡感知下的双图层实例分割网络BCNet,顶层GCN层检测遮挡对象,底层GCN层推理被部分遮挡的目标物体,通过显式建模自然地将遮挡和被遮挡物体的边界解耦,并在mask预测的同时考虑遮挡关系的相互影响,显著改善了现有实例分割模型在处理复杂遮挡物体时的表现,在COCO和KINS数据集上均取得领先性能。 图2 遮挡物和被遮挡物的双图层分解示意简图05意义物体互相遮挡在日常生活中普遍存在,严重的遮挡会带来易混淆的遮挡边界及非连续自然的物体形状,从而导致当前已有的检测及分割等的算法的性能大幅下降。该研究系统提出了一个轻量级且能有效处理遮挡的实例分割算法,在工业界也具有极大意义。随着短视频作为主要信息传播媒介不断渗透进日常生活,在实际的物体分割应用场景中,分割的准确性直接影响着用户的使用体验和产品观感。因此,如何将实例分割技术应用在复杂的日常应用场景并保持高精度,此项研究给出了一个合理、有效的解决方案。BCNet的结构框架整个分割系统分为两个部分,物体检测部分和物体分割部分,算法流程如下图: 图3 BCNet的网络结构 输入单张图像,使用基于Faster R-CNN或者FCOS的物体检测算法预测感兴趣目标区域(RoI)候选框坐标(x,y,w,h),采用Resnet-50/101及特征金字塔作为基础网络(backbone)获取整张输入图片的特征。使用RoI Align算法根据物体检测框位置,在整张图片特征图内准确抠取感兴趣目标区域的特征子图,并将其作为双图卷积神经网络的输入用于最终的物体分割。 实例分割网络BCNet由级联状的双图层神经网络组成:第一个图层对感兴趣目标区域内遮挡物体(Occluder)的形状和外观进行显式建模,该层图卷积网络包含四层,即卷积层(卷积核大小3x3)、图卷积层(Non-local Layer)以及末尾的两个卷积(卷积核大小3x3)。第一个图卷积网络输入感兴趣目标区域特征,输出感兴趣目标框中遮挡物体的边界和掩膜。第二个图层结合第一个图卷积网络(用于对遮挡物体建模)已经提取的遮挡物体信息(包括遮挡物的Boundary和Mask),具体做法是将步骤2中得到的感兴趣目标区域特征与经过第一个图卷积网络中最后一层卷积后的特征3a相加,得到新的特征,并将其作为第二个图卷积网络(用于被遮挡物分割)的输入。第二个图卷积网络与第一个图卷积网络结构相同,构成级联网络关系。该操作将遮挡与被遮挡关系同时考虑进来,能有效地区分遮挡物与被遮挡物的相邻物体边界,最终输出目标区域被遮挡目标物体(Occludee)的分割结果。为了减少模型的参数量,我们使用非局部算子(Non-local Operator)操作进行图卷积层的实现,具体实现位于结构图左上位置,包含三个卷积核大小为1x1的卷积层以及Softmax算子,其将图像空间中像素点根据对应特征向量的相似度有效关联起来,实现输入目标区域特征的重新聚合,能较好解决同一个物体的像素点在空间上被遮挡截断导致不连续的问题。 -
 隐马尔可夫模型(Hidden Markov model):显马尔可夫过程是完全确定性的——一个给定的状态经常会伴随另一个状态。交通信号灯就是一个例子。相反,隐马尔可夫模型通过分析可见数据来计算隐藏状态的发生。随后,借助隐藏状态分析,隐马尔可夫模型可以估计可能的未来观察模式。在本例中,高或低气压的概率(这是隐藏状态)可用于预测晴天、雨天、多云天的概率。优点:容许数据的变化性,适用于识别(recognition)和预测操作场景举例:面部表情分析、气象预测6. 随机森林(Random forest):随机森林算法通过使用多个带有随机选取的数据子集的树(tree)改善了决策树的精确性。本例在基因表达层面上考察了大量与乳腺癌复发相关的基因,并计算出复发风险。优点:随机森林方法被证明对大规模数据集和存在大量且有时不相关特征的项(item)来说很有用场景举例:用户流失分析、风险评估7. 循环神经网络(Recurrent neural network):在任意神经网络中,每个神经元都通过 1 个或多个隐藏层来将很多输入转换成单个输出。循环神经网络(RNN)会将值进一步逐层传递,让逐层学习成为可能。换句话说,RNN 存在某种形式的记忆,允许先前的输出去影响后面的输入。优点:循环神经网络在存在大量有序信息时具有预测能力场景举例:图像分类与字幕添加、政治情感分析8. 长短期记忆(Long short-term memory,LSTM)与门控循环单元神经网络(gated recurrent unit nerual network):早期的 RNN 形式是会存在损耗的。尽管这些早期循环神经网络只允许留存少量的早期信息,新近的长短期记忆(LSTM)与门控循环单元(GRU)神经网络都有长期与短期的记忆。换句话说,这些新近的 RNN 拥有更好的控制记忆的能力,允许保留早先的值或是当有必要处理很多系列步骤时重置这些值,这避免了「梯度衰减」或逐层传递的值的最终 degradation。LSTM 与 GRU 网络使得我们可以使用被称为「门(gate)」的记忆模块或结构来控制记忆,这种门可以在合适的时候传递或重置值。优点:长短期记忆和门控循环单元神经网络具备与其它循环神经网络一样的优点,但因为它们有更好的记忆能力,所以更常被使用场景举例:自然语言处理、翻译9. 卷积神经网络(convolutional neural network):卷积是指来自后续层的权重的融合,可用于标记输出层。优点:当存在非常大型的数据集、大量特征和复杂的分类任务时,卷积神经网络是非常有用的场景举例:图像识别、文本转语音、药物发现
隐马尔可夫模型(Hidden Markov model):显马尔可夫过程是完全确定性的——一个给定的状态经常会伴随另一个状态。交通信号灯就是一个例子。相反,隐马尔可夫模型通过分析可见数据来计算隐藏状态的发生。随后,借助隐藏状态分析,隐马尔可夫模型可以估计可能的未来观察模式。在本例中,高或低气压的概率(这是隐藏状态)可用于预测晴天、雨天、多云天的概率。优点:容许数据的变化性,适用于识别(recognition)和预测操作场景举例:面部表情分析、气象预测6. 随机森林(Random forest):随机森林算法通过使用多个带有随机选取的数据子集的树(tree)改善了决策树的精确性。本例在基因表达层面上考察了大量与乳腺癌复发相关的基因,并计算出复发风险。优点:随机森林方法被证明对大规模数据集和存在大量且有时不相关特征的项(item)来说很有用场景举例:用户流失分析、风险评估7. 循环神经网络(Recurrent neural network):在任意神经网络中,每个神经元都通过 1 个或多个隐藏层来将很多输入转换成单个输出。循环神经网络(RNN)会将值进一步逐层传递,让逐层学习成为可能。换句话说,RNN 存在某种形式的记忆,允许先前的输出去影响后面的输入。优点:循环神经网络在存在大量有序信息时具有预测能力场景举例:图像分类与字幕添加、政治情感分析8. 长短期记忆(Long short-term memory,LSTM)与门控循环单元神经网络(gated recurrent unit nerual network):早期的 RNN 形式是会存在损耗的。尽管这些早期循环神经网络只允许留存少量的早期信息,新近的长短期记忆(LSTM)与门控循环单元(GRU)神经网络都有长期与短期的记忆。换句话说,这些新近的 RNN 拥有更好的控制记忆的能力,允许保留早先的值或是当有必要处理很多系列步骤时重置这些值,这避免了「梯度衰减」或逐层传递的值的最终 degradation。LSTM 与 GRU 网络使得我们可以使用被称为「门(gate)」的记忆模块或结构来控制记忆,这种门可以在合适的时候传递或重置值。优点:长短期记忆和门控循环单元神经网络具备与其它循环神经网络一样的优点,但因为它们有更好的记忆能力,所以更常被使用场景举例:自然语言处理、翻译9. 卷积神经网络(convolutional neural network):卷积是指来自后续层的权重的融合,可用于标记输出层。优点:当存在非常大型的数据集、大量特征和复杂的分类任务时,卷积神经网络是非常有用的场景举例:图像识别、文本转语音、药物发现 -
【功能模块】yolo4 模型输出为三个卷积层的输出,但转离线的模型却有五个输出【操作步骤&问题现象】1、atc --model=scaled_yolo4_deploy_model.onnx --framework=5 --output=scaled_yolo4_deploy_model --soc_version=Ascend310 --input_shape="input:1,3,896,1536" --log=info2、模型下载地址: https://pan.baidu.com/s/1SWKBuE0k37uxq7ov9o1Zcg 提取码: u5n43、版本 ascend-toolkit 20.2【截图信息】【日志信息】(可选,上传日志内容或者附件)model input_num 1, output_num 5input 0, N: 1, C: 3, H: 896, W: 1536, input byte 16515072 == 16515072output 0, 4 , output byte 32 == 16output 1, 1 48 112 192 , output byte 4128768 == 4128768output 2, 4 , output byte 32 == 16output 3, 1 48 56 96 , output byte 1032192 == 1032192output 4, 1 48 28 48 , output byte 258048 == 258048
-
### 名称及链接 [电子相册智慧整理](https://edu.huaweicloud.com/certifications/880d036b9d6243f1871693a0706e7f2a) ### 课程章节 1. 相册整理与华为云EI服务 2. 图像处理基础知识 3. 卷积神经网络 4. 电子相册智慧整理项目实战 ### 证书  ### 笔记 1. 相册智能整理 1. 图片标签 2. 快速分类 3. 动态相册 4. 智能搜索 2. 华为云EI服务 1. 图像识别 1. 场景分析 2. 目标检测 3. 智能相册 4. 图像搜索 2. modelarts 3. 图像处理运用场景 1. 图像分类 2. 风格化 3. 低曝光增强 4. 超分辨率 5. 图像去雾 3. 计算机视觉 1. 图像的采集获取 2. 图像的压缩编码 3. 图像的存储和传输 4. 图像的合成 5. 三维图像重建 6. 图像增强 7. 图像修复 8. 图像的分类和识别 9. 目标的检测、跟踪、表达和描述 10. 特征提取 11. 图像的显示和输出 4. 颜色空间 1. RGB 2. HSV 3. CMYK 4. Lab 5. 常见图像存储格式 1. BMP 2. JPG 3. GIF 4. PNG 6. 图像预处理 1. 图像灰度调整 1. 最大值法 2. 平均值法 3. 加权平均值法 2. 对比度增强 1. 直方图均衡化 3. 锐化 1. 梯度法 4. 平滑 5. 去噪 6. 其他 1. 通道调整 2. 翻转 3. 缩放 4. 拉伸 5. 旋转 6. 噪声 7. 对比度 8. 剪切 7. 卷积神经网络(一种前馈神经网络) 1. 卷积层 1. 卷积核 2. 特征图 2. 激活函数 1. sigmoid 2. tanh 3. relu 4. leakyrelu 5. SoftMax 3. 池化层 1. 最大池化 2. 平均池化 4. 全连接层 8. 反向传播算法 9. 梯度下降算法 10. anaconda 11. jupyter notebook 12. python图像处理库 1. PIL 2. pillow 3. OpenCV 4. matplotlib 5. scikit-image 13. Base64编码方式 ### 备注 1. 感谢老师的教学与课件 2. 欢迎各位同学一起来交流学习心得^_^ 3. 在线课程、沙箱实验、博客和直播,其中包含了许多优质的内容,推荐了解与学习。
-
GNN的表示能力和泛化能力得到了广泛的研究。但是,它们的优化其实研究的很少。通过研究GNN的梯度动力学,我们迈出分析GNN训练的第一步。具体来说,首先,我们分析线性化(linearized)的GNN,并证明了:尽管它的训练不具有凸性,但在我们通过真实图验证的温和假设下,可以保证以线性速率收敛到全局最小值。其次,我们研究什么会影响GNN的训练速度。我们的结果表明,通过跳过(skip)连接,更深的深度和/或良好的标签分布,可以隐式地加速GNN的训练。实验结果证实,我们针对线性GNN的理论结果与非线性GNN的训练行为一致。我们的结果在优化方面为具有跳过连接的GNN的成功提供了第一个理论支持,并表明具有跳过连接的深层GNN在实践中将很有希望。https://www.zhuanzhi.ai/paper/609aef10a18ac8eb66f1d1873c8ec445
-
Fast-SCNN由4部分构成,Learning to Down-sample(学习下采样),Global Feature Extractor(全局特征提取), Feature Fusion(特征融合), Classifier(分类器)。Learning to Down-sample,一个普通的卷积层Conv2D,两个depthwise separable卷积层(DSConv)。Global Feature Extractor,用于抓取图像分割的全局特征。与普通multi-branch方法不同,该模块对于低分辨率图像进行处理。Feature Fusion,融合特征,并且是以相对简单方式融合两个分支的特征,确保效率。Classifier,两个depthwise separable卷积层(DSConv),一个pointwise卷积层(Conv2D),包含一个softmax操作。此外,在梯度下降计算中,用argmax将softmax替代,以提高计算效率。Fast-SCNN的创新点主要在以下两个方面:“学习下采样”(Learning to Down-sample)和encoder-decoder中的 skip connection类似,确保了低层次特征能被有效地共享和使用,共三层。Fast-SCNN还借鉴了MobileNet的depthwise separable convolution和 residual bottleneck block,来降低计算成本和内存消耗。
-
 一、什么是NBIOTNB-IoT是指窄带物联网(Narrow Band -Internet of Things)技术。NB-IOT聚焦于低功耗广覆盖(LPWA)物联网(IoT)市场,是一种可在全球范围内广泛应用的新兴技术。NB-IOT使用License频段,可采取带内、保护带或独立载波等三种部署方式,与现有网络共存。二、NBIOT部署方式NB-IoT支持在频段内(In-Band)、保护频段(Guard Band)以及独立(Stand-alone)共三种部署方式。一、独立部署(Stand alone operation)简称ST不依赖LTE,与LTE可以完全解耦适合用于重耕GSM频段,GSM的信道带宽为200KHz,这刚好为NB-IoT 180KHz带宽辟出空间,且两边还有10KHz的保护间隔。二、保护带部署(Guard band operation)简称GB不占LTE资源利用LTE边缘保护频带中未使用的180KHz带宽的资源块三、带内部署(In-band operation)简称IB占用LTE的1个PRB资源可与LTE同PCI,也可与LTE不同PCI,一般来说如果采用的是IB方式,倾向于设置为与LTE同PCI(说明什么问题?一是NB也有PCI,所以同频组网是可行的,不同于GSM,二是PCI也是504个,可以复用LTE的PCI规划,三是PCI的生成、功能基本相同)三、工作模式1、Connected(连接态):模块注册入网后处于该状态,可以发送和接收数据,无数据交互超过一段时间后会进入Idle模式,时间可配置。2、Idle(空闲态):可收发数据,且接收下行数据会进入Connected状态,无数据交互超过一段时会进入PSM模式,时间可配置。3、PSM(节能模式):此模式下终端关闭收发信号机,不监听无线侧的寻呼,因此虽然依旧注册在网络,但信令不可达,无法收到下行数据,功率很小。持续时间由核心网配置(T3412),有上行数据需要传输或TAU周期结束时会进入Connected态。目前国内的NB-IoT频段主要运行在B5和B8频段。四、目前主要应用情况1.公共事业:智能水表、智能水务、智能气表、智能热表。2.智慧城市:智能停车、智能路灯、智能垃圾桶、智能窖井盖。3.消费电子:独立可穿戴设备、智能自行车、慢病管理系统、老人小孩管理。4.设备管理:设备状态监控、白色家电管理、大型公共基础设施、管道管廊安全监控。5.智能建筑:环境报警系统、中央空调监管、电梯物联网、人防空间覆盖。6.指挥物流:冷链物流、集装箱跟踪、固定资产跟踪、金融资产跟踪。7.农业与环境:农业物联网、畜牧业养殖、空气实时监控、水质实时监控。8.其他应用:移动支付、智慧社区、智能家居、文物保护。五、优缺点优点:1.广覆盖:在同样的频段下,NB-IoT比现有的网络增益20dB,可更好满足厂区、管道井、井盖等这类对深度覆盖有要求的地方。2.低功耗:模块在平时处于休眠状态,每天可根据程序设定自动唤醒上传数据,若没有收到请求的命令,模块会自动进入休眠,终端模块待机时间可长达8年。3.低成本:与LoRa相比,NB-IOT无需自建基站,通讯稳定可靠。4.大连接:同一基站可比现有无线技术提供50-100倍的接入数。原因NB-IoT为什么覆盖广?(1)重复传输,延长信号码元的传输时间。码元的重复传输事实上就是一个最简单的信道编码,尽管降低了信息的传输速率,但是在解调或译码上的可靠性,特别是在低信噪比的接收环境下更加有效。比如想下译码出错概率为10%,重复次数增加,使得整体译码出错概率大大降低。(2)现有的TTI bundling和HARQ重传技术也可以实现延长信号码元的传输时间。相关的提升覆盖的数值,在VoLTE的商用网络实践中已经证明可有效改善信号的覆盖范围。(3)鉴于NB-IoT业务需求的速率很低,100 bps左右已经可以实现大部分业务,所以可以采用低阶的调制技术,如BPSK、QPSK、更短长度的CRC校验码等。(4)在编码方面,NB-IoT采用Turbo编码,GPRS采用卷积码,优势体现在对译码信噪比需求降低,对应覆盖距离有3~4 dB的增强。(5)对时延要求的降低以及在部分下行物理信道上采用功率增强(Power Boost),对信号覆盖都有直接的增强。二是具备支撑海量连接的能力NB-IoT一个扇区能够支持数万个连接,支持低延时敏感度、超低的设备成本、低设备功耗和优化的网络架构;NB-IoT比2G/3G/4G有50-100倍的上行容量提升,在同一基站的情况下,NB-IoT可以比现有无线技术提供50~100倍的接入数。200KHz频率下面,根据仿真测试数据,单个基站小区可支持5万个NB-IoT终端接入。三是更低功耗NB中对于终端功耗的目标是什么呢?答案是:基于AA(5000mAh)电池,使用寿命可超过10年。(一个iPhone7P电池容量为2900mAh)。缺点:1.传输数据少。基于低功耗的机制,注定了NBIoT只能传输少量的数据到远端,因此正式应用时要么单次传输字节数少,要么传输数据间隔长。比如智能水表、气表,一般是24小时传输一次数据。这意味着依靠实时数据分析的行业应用难以推广此技术。此外,还存在寿命到期电池更换的麻烦。2.通信成本贵。目前NBIoT通信模块还是偏贵,主流芯片厂家主要有紫光展锐、华为海思和联发科,一块NBIoT模组在20~50元左右。通信流量上,电信是20元一年,包年时间多相对便宜,中国移动资费差不多,若设备量大还有议价空间。一块水电表零售价也就一两百元,NBIoT模组就吃掉了一大块成本。3.技术待成熟。虽然中国各大运营商号称投入大量人力物力财力进行相关建设,NBIoT技术还不是很成熟。本人所在公司系统平台于2017年底就和电信云平台进行了系统对接,目前接了近万台NB-IoT电表和水表。发现电信平台依然在不断地更新升级,曾经在某商厦安装了300多块NBIoT电表,结果导致基站出现故障,后经电信技术人员积极抢修才恢复正常。诚然,电信云平台后面是华为公司作为技术支撑,实力强大,想必不久将来技术会成熟稳定。4.平台对接难。电信的IOT平台走的是CoPA协议,CoPA协议对接方面复杂。虽然华为电信物联网平台上资料齐全,要和电信开放平台对接,还是要花不少时间。2017年公司研发部门安排专人花了2个月才对接好,为兼容传统tcp、udp通讯,后期又对设备通讯服务进行了优化处理,前前后后花了大概半年时间才完全稳定。因此,这对于一般传统企业还是有一定技术门槛的。参考文献:NBIoT通信技术应用的优缺点浅谈NBIOTNBIoT三种部署方式
一、什么是NBIOTNB-IoT是指窄带物联网(Narrow Band -Internet of Things)技术。NB-IOT聚焦于低功耗广覆盖(LPWA)物联网(IoT)市场,是一种可在全球范围内广泛应用的新兴技术。NB-IOT使用License频段,可采取带内、保护带或独立载波等三种部署方式,与现有网络共存。二、NBIOT部署方式NB-IoT支持在频段内(In-Band)、保护频段(Guard Band)以及独立(Stand-alone)共三种部署方式。一、独立部署(Stand alone operation)简称ST不依赖LTE,与LTE可以完全解耦适合用于重耕GSM频段,GSM的信道带宽为200KHz,这刚好为NB-IoT 180KHz带宽辟出空间,且两边还有10KHz的保护间隔。二、保护带部署(Guard band operation)简称GB不占LTE资源利用LTE边缘保护频带中未使用的180KHz带宽的资源块三、带内部署(In-band operation)简称IB占用LTE的1个PRB资源可与LTE同PCI,也可与LTE不同PCI,一般来说如果采用的是IB方式,倾向于设置为与LTE同PCI(说明什么问题?一是NB也有PCI,所以同频组网是可行的,不同于GSM,二是PCI也是504个,可以复用LTE的PCI规划,三是PCI的生成、功能基本相同)三、工作模式1、Connected(连接态):模块注册入网后处于该状态,可以发送和接收数据,无数据交互超过一段时间后会进入Idle模式,时间可配置。2、Idle(空闲态):可收发数据,且接收下行数据会进入Connected状态,无数据交互超过一段时会进入PSM模式,时间可配置。3、PSM(节能模式):此模式下终端关闭收发信号机,不监听无线侧的寻呼,因此虽然依旧注册在网络,但信令不可达,无法收到下行数据,功率很小。持续时间由核心网配置(T3412),有上行数据需要传输或TAU周期结束时会进入Connected态。目前国内的NB-IoT频段主要运行在B5和B8频段。四、目前主要应用情况1.公共事业:智能水表、智能水务、智能气表、智能热表。2.智慧城市:智能停车、智能路灯、智能垃圾桶、智能窖井盖。3.消费电子:独立可穿戴设备、智能自行车、慢病管理系统、老人小孩管理。4.设备管理:设备状态监控、白色家电管理、大型公共基础设施、管道管廊安全监控。5.智能建筑:环境报警系统、中央空调监管、电梯物联网、人防空间覆盖。6.指挥物流:冷链物流、集装箱跟踪、固定资产跟踪、金融资产跟踪。7.农业与环境:农业物联网、畜牧业养殖、空气实时监控、水质实时监控。8.其他应用:移动支付、智慧社区、智能家居、文物保护。五、优缺点优点:1.广覆盖:在同样的频段下,NB-IoT比现有的网络增益20dB,可更好满足厂区、管道井、井盖等这类对深度覆盖有要求的地方。2.低功耗:模块在平时处于休眠状态,每天可根据程序设定自动唤醒上传数据,若没有收到请求的命令,模块会自动进入休眠,终端模块待机时间可长达8年。3.低成本:与LoRa相比,NB-IOT无需自建基站,通讯稳定可靠。4.大连接:同一基站可比现有无线技术提供50-100倍的接入数。原因NB-IoT为什么覆盖广?(1)重复传输,延长信号码元的传输时间。码元的重复传输事实上就是一个最简单的信道编码,尽管降低了信息的传输速率,但是在解调或译码上的可靠性,特别是在低信噪比的接收环境下更加有效。比如想下译码出错概率为10%,重复次数增加,使得整体译码出错概率大大降低。(2)现有的TTI bundling和HARQ重传技术也可以实现延长信号码元的传输时间。相关的提升覆盖的数值,在VoLTE的商用网络实践中已经证明可有效改善信号的覆盖范围。(3)鉴于NB-IoT业务需求的速率很低,100 bps左右已经可以实现大部分业务,所以可以采用低阶的调制技术,如BPSK、QPSK、更短长度的CRC校验码等。(4)在编码方面,NB-IoT采用Turbo编码,GPRS采用卷积码,优势体现在对译码信噪比需求降低,对应覆盖距离有3~4 dB的增强。(5)对时延要求的降低以及在部分下行物理信道上采用功率增强(Power Boost),对信号覆盖都有直接的增强。二是具备支撑海量连接的能力NB-IoT一个扇区能够支持数万个连接,支持低延时敏感度、超低的设备成本、低设备功耗和优化的网络架构;NB-IoT比2G/3G/4G有50-100倍的上行容量提升,在同一基站的情况下,NB-IoT可以比现有无线技术提供50~100倍的接入数。200KHz频率下面,根据仿真测试数据,单个基站小区可支持5万个NB-IoT终端接入。三是更低功耗NB中对于终端功耗的目标是什么呢?答案是:基于AA(5000mAh)电池,使用寿命可超过10年。(一个iPhone7P电池容量为2900mAh)。缺点:1.传输数据少。基于低功耗的机制,注定了NBIoT只能传输少量的数据到远端,因此正式应用时要么单次传输字节数少,要么传输数据间隔长。比如智能水表、气表,一般是24小时传输一次数据。这意味着依靠实时数据分析的行业应用难以推广此技术。此外,还存在寿命到期电池更换的麻烦。2.通信成本贵。目前NBIoT通信模块还是偏贵,主流芯片厂家主要有紫光展锐、华为海思和联发科,一块NBIoT模组在20~50元左右。通信流量上,电信是20元一年,包年时间多相对便宜,中国移动资费差不多,若设备量大还有议价空间。一块水电表零售价也就一两百元,NBIoT模组就吃掉了一大块成本。3.技术待成熟。虽然中国各大运营商号称投入大量人力物力财力进行相关建设,NBIoT技术还不是很成熟。本人所在公司系统平台于2017年底就和电信云平台进行了系统对接,目前接了近万台NB-IoT电表和水表。发现电信平台依然在不断地更新升级,曾经在某商厦安装了300多块NBIoT电表,结果导致基站出现故障,后经电信技术人员积极抢修才恢复正常。诚然,电信云平台后面是华为公司作为技术支撑,实力强大,想必不久将来技术会成熟稳定。4.平台对接难。电信的IOT平台走的是CoPA协议,CoPA协议对接方面复杂。虽然华为电信物联网平台上资料齐全,要和电信开放平台对接,还是要花不少时间。2017年公司研发部门安排专人花了2个月才对接好,为兼容传统tcp、udp通讯,后期又对设备通讯服务进行了优化处理,前前后后花了大概半年时间才完全稳定。因此,这对于一般传统企业还是有一定技术门槛的。参考文献:NBIoT通信技术应用的优缺点浅谈NBIOTNBIoT三种部署方式 -
在架构内容设计方面,其中一个比较有帮助的想法是使用1×1卷积。也许你会好奇,1×1的卷积能做什么呢?不就是乘以数字么?听上去挺好笑的,结果并非如此,我们来具体看看。 过滤器为1×1,这里是数字2,输入一张6×6×1的图片,然后对它做卷积,起过滤器大小为1×1×1,结果相当于把这个图片乘以数字2,所以前三个单元格分别是2、4、6等等。用1×1的过滤器进行卷积,似乎用处不大,只是对输入矩阵乘以某个数字。但这仅仅是对于6×6×1的一个通道图片来说,1×1卷积效果不佳。  如果是一张6×6×32的图片,那么使用1×1过滤器进行卷积效果更好。具体来说,1×1卷积所实现的功能是遍历这36个单元格,计算左图中32个数字和过滤器中32个数字的元素积之和,然后应用**ReLU**非线性函数。  我们以其中一个单元为例,它是这个输入层上的某个切片,用这36个数字乘以这个输入层上1×1切片,得到一个实数,像这样把它画在输出中。 这个1×1×32过滤器中的32个数字可以这样理解,一个神经元的输入是32个数字(输入图片中左下角位置32个通道中的数字),即相同高度和宽度上某一切片上的32个数字,这32个数字具有不同通道,乘以32个权重(将过滤器中的32个数理解为权重),然后应用**ReLU**非线性函数,在这里输出相应的结果。  一般来说,如果过滤器不止一个,而是多个,就好像有多个输入单元,其输入内容为一个切片上所有数字,输出结果是6×6过滤器数量。  所以1×1卷积可以从根本上理解为对这32个不同的位置都应用一个全连接层,全连接层的作用是输入32个数字(过滤器数量标记为,在这36个单元上重复此过程),输出结果是6×6×#filters(过滤器数量),以便在输入层上实施一个非平凡(**non-trivial**)计算。  这种方法通常称为1×1卷积,有时也被称为**Network in Network**,在林敏、陈强和杨学成的论文中有详细描述。虽然论文中关于架构的详细内容并没有得到广泛应用,但是1×1卷积或**Network in Network**这种理念却很有影响力,很多神经网络架构都受到它的影响,包括下节课要讲的**Inception**网络。 举个1×1卷积的例子,相信对大家有所帮助,这是它的一个应用。 假设这是一个28×28×192的输入层,你可以使用池化层压缩它的高度和宽度,这个过程我们很清楚。但如果通道数量很大,该如何把它压缩为28×28×32维度的层呢?你可以用32个大小为1×1的过滤器,严格来讲每个过滤器大小都是1×1×192维,因为过滤器中通道数量必须与输入层中通道的数量保持一致。但是你使用了32个过滤器,输出层为28×28×32,这就是压缩通道数()的方法,对于池化层我只是压缩了这些层的高度和宽度。  在之后我们看到在某些网络中1×1卷积是如何压缩通道数量并减少计算的。当然如果你想保持通道数192不变,这也是可行的,1×1卷积只是添加了非线性函数,当然也可以让网络学习更复杂的函数,比如,我们再添加一层,其输入为28×28×192,输出为28×28×192。  1×1卷积层就是这样实现了一些重要功能的(**doing something pretty non-trivial**),它给神经网络添加了一个非线性函数,从而减少或保持输入层中的通道数量不变,当然如果你愿意,也可以增加通道数量。后面你会发现这对构建**Inception**网络很有帮助,我们放在下节课讲。 这里我们演示了如何根据自己的意愿通过1×1卷积的简单操作来压缩或保持输入层中的通道数量,甚至是增加通道数量。
-
### 残差网络为什么有用?(Why ResNets work?) 为什么**ResNets**能有如此好的表现,我们来看个例子,它解释了其中的原因,至少可以说明,如何构建更深层次的**ResNets**网络的同时还不降低它们在训练集上的效率。希望你已经通过第三门课了解到,通常来讲,网络在训练集上表现好,才能在**Hold-Out**交叉验证集或**dev**集和测试集上有好的表现,所以至少在训练集上训练好**ResNets**是第一步。 先来看个例子,上次我们了解到,一个网络深度越深,它在训练集上训练的效率就会有所减弱,这也是有时候我们不希望加深网络的原因。而事实并非如此,至少在训练**ResNets**网络时,并非完全如此,举个例子。 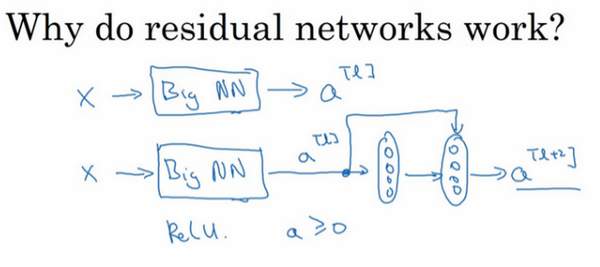 假设有一个大型神经网络,其输入为,输出激活值。假如你想增加这个神经网络的深度,那么用**Big NN**表示,输出为。再给这个网络额外添加两层,依次添加两层,最后输出为,可以把这两层看作一个**ResNets**块,即具有捷径连接的残差块。为了方便说明,假设我们在整个网络中使用**ReLU**激活函数,所以激活值都大于等于0,包括输入的非零异常值。因为**ReLU**激活函数输出的数字要么是0,要么是正数。 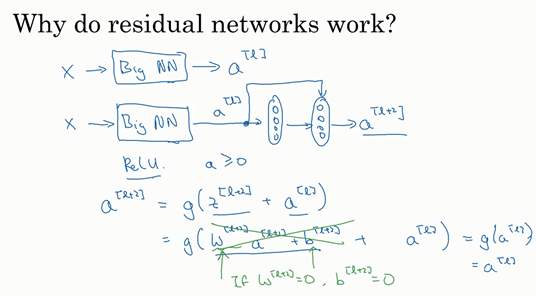 我们看一下的值,也就是上节课讲过的表达式,即,添加项是刚添加的跳跃连接的输入。展开这个表达式,其中。注意一点,如果使用**L2**正则化或权重衰减,它会压缩的值。如果对应用权重衰减也可达到同样的效果,尽管实际应用中,你有时会对应用权重衰减,有时不会。这里的是关键项,如果,为方便起见,假设,这几项就没有了,因为它们()的值为0。最后,因为我们假定使用**ReLU**激活函数,并且所有激活值都是非负的,是应用于非负数的**ReLU**函数,所以。   结果表明,残差块学习这个恒等式函数并不难,跳跃连接使我们很容易得出。这意味着,即使给神经网络增加了这两层,它的效率也并不逊色于更简单的神经网络,因为学习恒等函数对它来说很简单。尽管它多了两层,也只把的值赋值给。所以给大型神经网络增加两层,不论是把残差块添加到神经网络的中间还是末端位置,都不会影响网络的表现。 当然,我们的目标不仅仅是保持网络的效率,还要提升它的效率。想象一下,如果这些隐藏层单元学到一些有用信息,那么它可能比学习恒等函数表现得更好。而这些不含有残差块或跳跃连接的深度普通网络情况就不一样了,当网络不断加深时,就算是选用学习恒等函数的参数都很困难,所以很多层最后的表现不但没有更好,反而更糟。 我认为残差网络起作用的主要原因就是这些残差块学习恒等函数非常容易,你能确定网络性能不会受到影响,很多时候甚至可以提高效率,或者说至少不会降低网络的效率,因此创建类似残差网络可以提升网络性能。 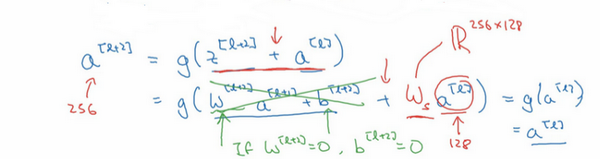 除此之外,关于残差网络,另一个值得探讨的细节是,假设与具有相同维度,所以**ResNets**使用了许多**same**卷积,所以这个的维度等于这个输出层的维度。之所以能实现跳跃连接是因为**same**卷积保留了维度,所以很容易得出这个捷径连接,并输出这两个相同维度的向量。 如果输入和输出有不同维度,比如输入的维度是128,的维度是256,再增加一个矩阵,这里标记为,是一个256×128维度的矩阵,所以的维度是256,这个新增项是256维度的向量。你不需要对做任何操作,它是网络通过学习得到的矩阵或参数,它是一个固定矩阵,**padding**值为0,用0填充,其维度为256,所以者几个表达式都可以。 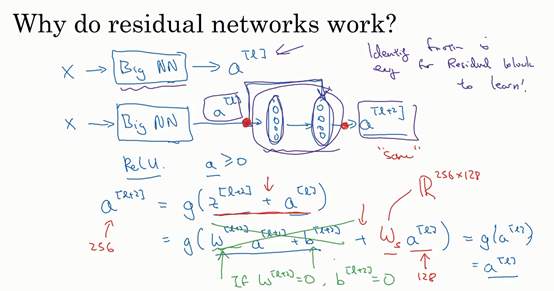 最后,我们来看看**ResNets**的图片识别。这些图片是我从何凯明等人论文中截取的,这是一个普通网络,我们给它输入一张图片,它有多个卷积层,最后输出了一个**Softmax**。  如何把它转化为**ResNets**呢?只需要添加跳跃连接。这里我们只讨论几个细节,这个网络有很多层3×3卷积,而且它们大多都是**same**卷积,这就是添加等维特征向量的原因。所以这些都是卷积层,而不是全连接层,因为它们是**same**卷积,维度得以保留,这也解释了添加项(维度相同所以能够相加)。  **ResNets**类似于其它很多网络,也会有很多卷积层,其中偶尔会有池化层或类池化层的层。不论这些层是什么类型,正如我们在上一张幻灯片看到的,你都需要调整矩阵的维度。普通网络和**ResNets**网络常用的结构是:卷积层-卷积层-卷积层-池化层-卷积层-卷积层-卷积层-池化层……依此重复。直到最后,有一个通过**softmax**进行预测的全连接层。 以上就是**ResNets**的内容。
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签