-
 功能描述该接口用于向VCM子系统的指定人脸库中添加人脸照片。该照片中应包含指定人员的人脸图片。注意事项同一人员在人脸库的人脸图片不能超过五张。一个人脸库最大支持100万人脸。基本信息接口名称添加人脸图片v1.1接口路径/io-adapter/south/face-recognition/v1.1/face-picture/addHTTP方法POST请求参数请求参数如表1所示。表1 请求消息参数说明参数名称类型必选(M)/可选(O)位置参数含义X-HW-IDStringMHeaderROMA授权的应用ID。X-HW-APPKEYStringOHeaderROMA授权的应用的密钥。说明:如果调用侧在ROMA平台设置了白名单,该参数可不填,如果没有,该参数必填。channelStringMHeader选择的子系统渠道。由上层应用携带,供ROMA平台做路由选择。厂家无需实现。repositoryCodeStringMBody人脸库标识。“增加人脸库”接口返回的人脸库标识。imageUrlStringOBody人脸图片的URL路径与imageBase64二者选一。长度范围:不超过255个字符。imageBase64StringOBody人脸图片内容的BASE64编码的字符串。与imageUrl二者选一。Base64编码后大小不超过5M。图片为JPG/JPEG/BMP/PNG格式。imageIdStringOBody人脸图片的唯一ID,与当前图像绑定。若用户没提供,系统会生成一个。该ID长度范围为1~36位,可以包含字母、数字、中划线或者下划线,不包含其他的特殊字符。VCM不支持personIdStringMBody人脸图片所包含的人员实例的ID。一张人脸照片建议仅包含一个人员的正脸。如果照片中有多个人脸,则表示此人员实例的脸是照片中尺寸最大的那个脸。长度范围:0-9A-Fa-f,长度24个字符extensionobjectOBody扩展对象。用于携带厂家定义的特有字段。表2 extension参数说明参数名称类型必选(M)/可选(O)位置参数含义nameStringOBody人员姓名,支持中文、英文、数字和空格,首位不为特殊字符,长度[1,255]。genderStringOBody人员性别:0:男1:女-1:未知credentialTypeStringOBody证件类型:0:身份证1:护照2:学生证3:军官证4:驾照5:其他credentialNumberStringOBody证件号,支持英文、数字、(),长度[1,255]。请求样例{ "repositoryCode": "5d11c13a066b980884971778", "imageBase64": "/9j/4...", "personId": "5cf8b755066b980884970701" }响应参数响应参数如表3所示。表3 响应消息参数说明参数名称类型参数含义resultoutputs接口响应参数。成功时返回下方结果,失败或者数据为空时,不返回result内部的内容结构,仅返回null。resCodeString返回码。具体请参考“人员匹配错误码”。resMsgString返回消息。originalResInfooriginalResInfo原始响应消息。表4 outputs参数说明参数名称类型参数含义facesFaceStructure[]照片中包含的人脸结构。如果照片中包含多张人脸,则返回一个列表。表5 FaceStructure参数说明参数名称类型参数含义personIdString人脸图片所包含的人员实例的ID固定为24个字符。faceIdString人脸ID。支持1~36个字符。表6 originalResInfo参数说明参数名称类型参数含义originalResCodeString原始返回码。originalResMsgString原始返回消息。响应样例{ "result": { "faces": [ { "faceId": "5d1325f6066b980c1aa4ee6b", "personId": "5cf8b755066b980854970701" } ] }, "resCode": "0", "resMsg": "Success.", "originalResInfo": { "originalResCode": "0", "originalResMsg": "success" } }
功能描述该接口用于向VCM子系统的指定人脸库中添加人脸照片。该照片中应包含指定人员的人脸图片。注意事项同一人员在人脸库的人脸图片不能超过五张。一个人脸库最大支持100万人脸。基本信息接口名称添加人脸图片v1.1接口路径/io-adapter/south/face-recognition/v1.1/face-picture/addHTTP方法POST请求参数请求参数如表1所示。表1 请求消息参数说明参数名称类型必选(M)/可选(O)位置参数含义X-HW-IDStringMHeaderROMA授权的应用ID。X-HW-APPKEYStringOHeaderROMA授权的应用的密钥。说明:如果调用侧在ROMA平台设置了白名单,该参数可不填,如果没有,该参数必填。channelStringMHeader选择的子系统渠道。由上层应用携带,供ROMA平台做路由选择。厂家无需实现。repositoryCodeStringMBody人脸库标识。“增加人脸库”接口返回的人脸库标识。imageUrlStringOBody人脸图片的URL路径与imageBase64二者选一。长度范围:不超过255个字符。imageBase64StringOBody人脸图片内容的BASE64编码的字符串。与imageUrl二者选一。Base64编码后大小不超过5M。图片为JPG/JPEG/BMP/PNG格式。imageIdStringOBody人脸图片的唯一ID,与当前图像绑定。若用户没提供,系统会生成一个。该ID长度范围为1~36位,可以包含字母、数字、中划线或者下划线,不包含其他的特殊字符。VCM不支持personIdStringMBody人脸图片所包含的人员实例的ID。一张人脸照片建议仅包含一个人员的正脸。如果照片中有多个人脸,则表示此人员实例的脸是照片中尺寸最大的那个脸。长度范围:0-9A-Fa-f,长度24个字符extensionobjectOBody扩展对象。用于携带厂家定义的特有字段。表2 extension参数说明参数名称类型必选(M)/可选(O)位置参数含义nameStringOBody人员姓名,支持中文、英文、数字和空格,首位不为特殊字符,长度[1,255]。genderStringOBody人员性别:0:男1:女-1:未知credentialTypeStringOBody证件类型:0:身份证1:护照2:学生证3:军官证4:驾照5:其他credentialNumberStringOBody证件号,支持英文、数字、(),长度[1,255]。请求样例{ "repositoryCode": "5d11c13a066b980884971778", "imageBase64": "/9j/4...", "personId": "5cf8b755066b980884970701" }响应参数响应参数如表3所示。表3 响应消息参数说明参数名称类型参数含义resultoutputs接口响应参数。成功时返回下方结果,失败或者数据为空时,不返回result内部的内容结构,仅返回null。resCodeString返回码。具体请参考“人员匹配错误码”。resMsgString返回消息。originalResInfooriginalResInfo原始响应消息。表4 outputs参数说明参数名称类型参数含义facesFaceStructure[]照片中包含的人脸结构。如果照片中包含多张人脸,则返回一个列表。表5 FaceStructure参数说明参数名称类型参数含义personIdString人脸图片所包含的人员实例的ID固定为24个字符。faceIdString人脸ID。支持1~36个字符。表6 originalResInfo参数说明参数名称类型参数含义originalResCodeString原始返回码。originalResMsgString原始返回消息。响应样例{ "result": { "faces": [ { "faceId": "5d1325f6066b980c1aa4ee6b", "personId": "5cf8b755066b980854970701" } ] }, "resCode": "0", "resMsg": "Success.", "originalResInfo": { "originalResCode": "0", "originalResMsg": "success" } } -
 在云速建站后台管理的第三方帐号登录中,能不能增加人脸识别登录配置?以解决会员实名认证的问题,
在云速建站后台管理的第三方帐号登录中,能不能增加人脸识别登录配置?以解决会员实名认证的问题, -
像华为云客服,华为云OBS等都以插件形式方便用户,可以不可以将华为云的人脸识别功能和文字识别功能做成插件,比如会员实名认证,刷脸登录都会用到。
-
在后台支付设置里能不能增加支付方式种类,除了扫码方式外,可不可以增加人脸支付和指纹支付?还有就是在第三方登录方式中除了QQ,微博,微信三种外可不可以增加人脸识别和指纹登录?
-
在后台支付设置里能不能增加支付方式种类,除了扫码方式外,可不可以增加人脸支付和指纹支付?还有就是在第三方登录方式中除了QQ,微博,微信三种外可不可以增加人脸识别和指纹登录?
-
 > **摘要:** 通过结合华为云的人脸识别、functiongraph、OBS、APIG等云服务,来达成考勤打卡时调用一个API即可检测是否本人现场打卡的效果。 # 1 背景 使用APP进行打卡时,为避免非本人及非真人现场打卡的情况出现,想结合华为云的人脸识别能力,通过调用API,达成可检测是否本人且真人现场打卡的效果。 # 2 云服务介绍 **华为云FRS:** 人脸识别服务(Face Recognition Service),能够在图像中快速检测人脸、分析人脸关键点信息、获取人脸属性、实现人脸的精确比对和检索。该服务可应用于身份验证、电子考勤、客流分析等场景。[产品页面](https://www.huaweicloud.com/product/face.html) **华为云FunctionGraph:** 函数工作流(FunctionGraph)是一项基于事件驱动的函数托管计算服务。通过函数工作流,只需编写业务函数代码并设置运行的条件,无需配置和管理服务器等基础设施,函数以弹性、免运维、高可靠的方式运行。[产品页面](https://www.huaweicloud.com/product/functiongraph.html) **华为云APIG:** API网关(API Gateway)是为企业开发者及合作伙伴提供的高性能、高可用、高安全的API托管服务, 帮助企业轻松构建、管理和部署不同规模的API。简单、快速、低成本、低风险的实现内部系统集成、成熟业务能力开放及业务能力变现。[产品页面](https://www.huaweicloud.com/product/apig.html) **华为云OBS:** 对象存储服务(Object Storage Service,OBS)是一个基于对象的海量存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力,使用时无需考虑容量限制,并且提供多种存储类型供选择,满足客户各类业务场景诉求。[产品页面](https://www.huaweicloud.com/product/obs.html) **华为云DNS:** 云解析服务(Domain Name Service)提供高可用,高扩展的权威DNS服务和DNS管理服务,把人们常用的域名或应用资源转换成用于计算机连接的IP地址,从而将最终用户路由到相应的应用资源上。此服务默认开通,免费使用。[产品页面](https://www.huaweicloud.com/product/dns.html) # 3 方案设计 ## 3.1 方案简述 通过APIG调用functiongraph函数,在functiongraph上完成人脸识别-活体检测、人脸识别-人脸比对等API的调用,并将响应结果通过API返回给APP。实现APP调用一次API即可完成人脸识别的功能。 1. 人脸识别服务的人脸比对功能,可实现检测是否其本人打卡。 2. 人脸识别服务的活体检测功能,可实现检测是否活人打卡。 3. 使用Functiongraph的函数,APP端只需考虑调用一个API,且只需考虑人脸识别的总体输入和返回结果。 4. Functiongraph由APIG来调用,利用APPkey、APPsecret及HTTPS,解决了APP端调用的安全认证等问题。 5. OBS桶用来存储人脸照片,通过约定的用户标识做文件存储路径,易于管理和使用。 ## 3.2 方案架构图 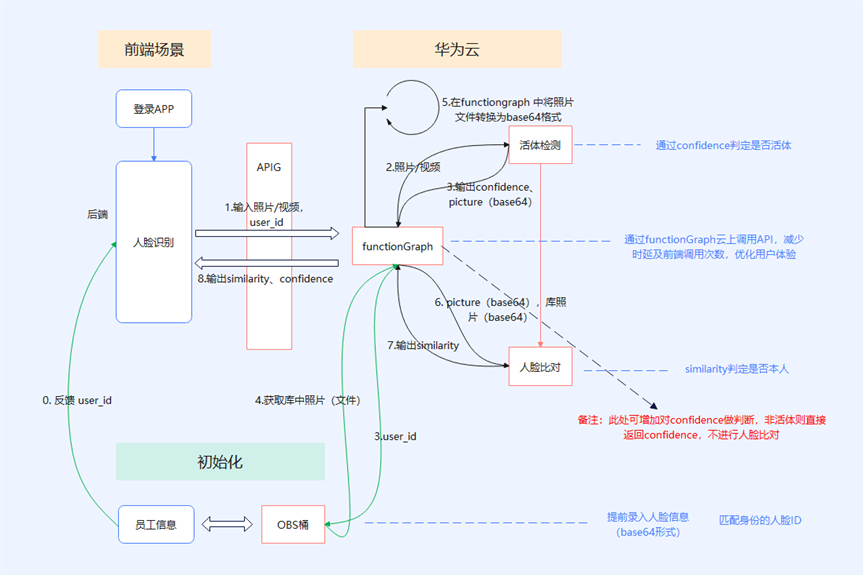 0. 初始化:前置准备工作,新建一个OBS桶做人脸库,将员工的人脸照片存放到人脸库,并把以user-id 或自定义字段作为路径,标识员工。 1. 员工登录APP后,进行人脸识别时,将通过APIG来调用functionGraph,上传关键信息:摄像头捕获的照片或视频、员工的人脸库标识(user-id)。 2. functionGraph调用活体检测API,传入照片/视频(根据需求选择动作活体检测/静默活体检测,推荐静默活体检测)。 *注:本方案采用静默活体检测方式,APP端上传的照片提前转换为base64格式* 3. 活体检测API返回响应:有confidence、picture(base64)。 4. 在functionGraph中调用OBS接口,通过user-id从OBS人脸库获取库中的员工照片。 5. 通过代码将从OBS获取的照片文件,转换为base64格式。 6. 将两个base64格式的照片作为输入参数调用人脸比对API 。(备注:此处可根据需求,是否需要多次调用API,使用多个照片进行验证) 7. 人脸比对API返回包含了similarity的响应。 8. functionGraph将similarity、confidence传回给APP/后端。(备注:也可直接在functionGraph完成判定,返回人脸识别结果) ## 3.3 FUNCTIONGRAPH实现代码 代码详看附件。 代码时序图: 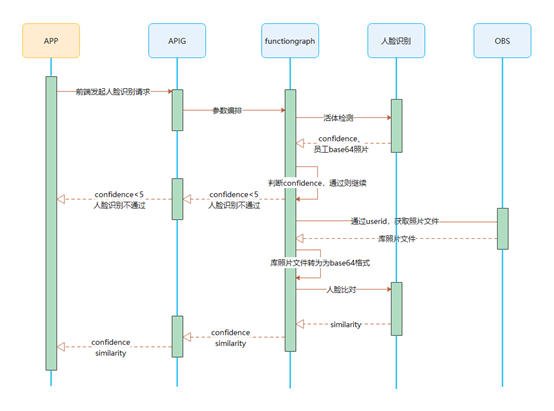 # 4 方案部署 ## 4.1 部署流程图 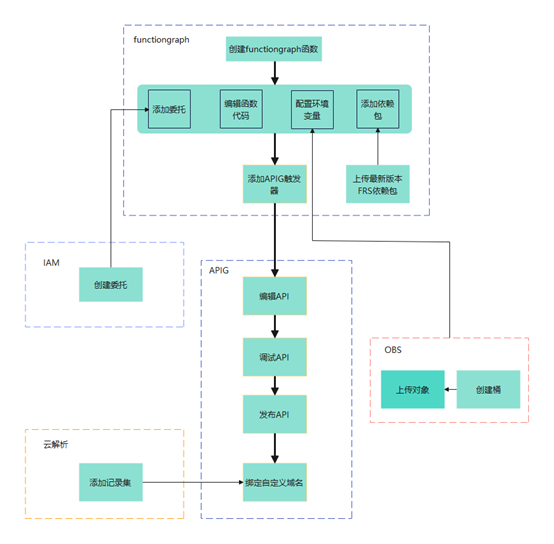 ## 4.2 前置准备 1. 拥有已实名认证的华为云账号,开通云服务functiongraph、人脸比对、活体检测、OBS 2. 注册公网域名,完成ICP备案 ## 4.3 创建OBS人脸库 ### 4.3.1 创建OBS桶 参考帮助文档:https://support.huaweicloud.com/qs-obs/obs_qs_0007.html ,**创建私有桶** ### 4.3.2 上传对象 参考帮助文档: https://support.huaweicloud.com/qs-obs/obs_qs_0008.html ,上传对象,建立OBS人脸库。 要求:文件的路径使用用户标识(如userid)命名  ## 4.4 FUNCTIONGRAPH搭建 ### 4.4.1 创建委托 登录IAM控制台(https://console.huaweicloud.com/iam/?region=cn-north-4#/iam/agencies) 1)创建委托 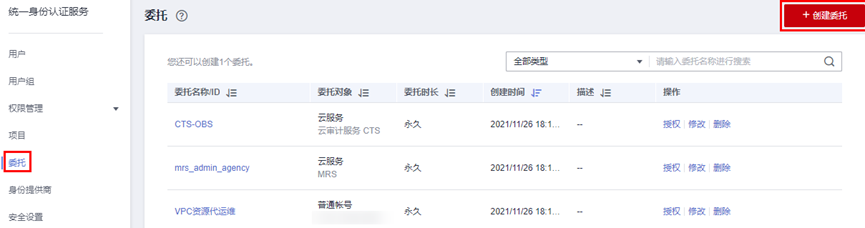 委托名称:自定义 委托类型:云服务 云服务:函数工作流functiongraph 持续时间:永久 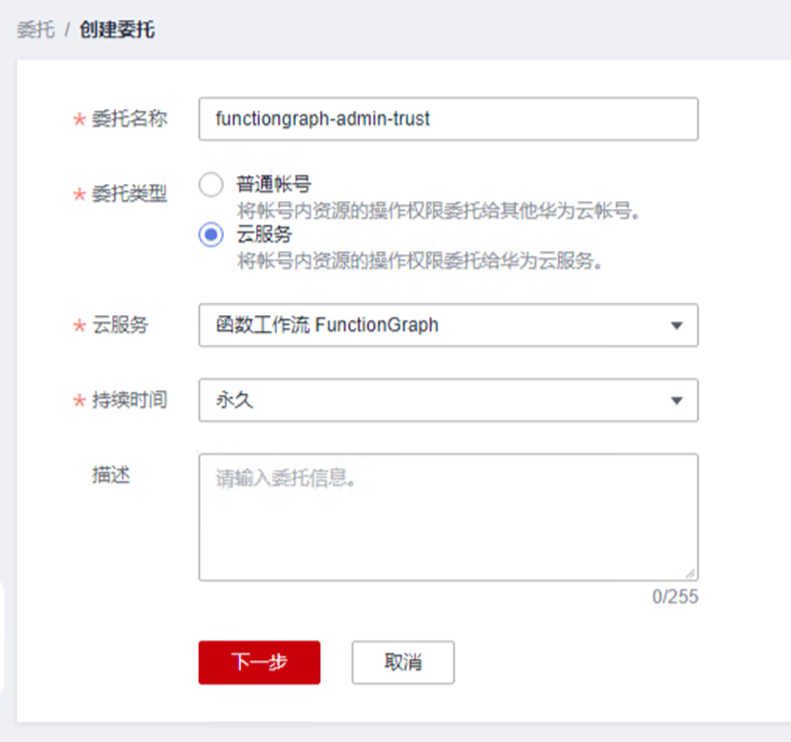 2)选择策略 OBS:获取对象等基本操作权限 FRS:fullaccess APIG:fullaccess 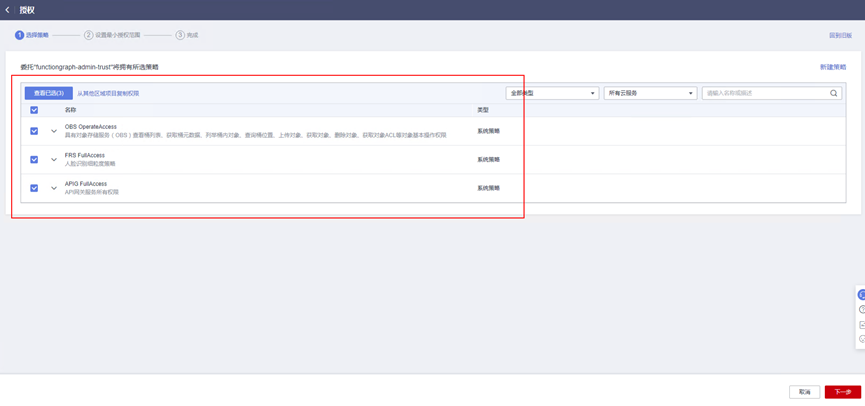 3)设置最小授权范围,此处选择所有,实际可根据项目情况分配。 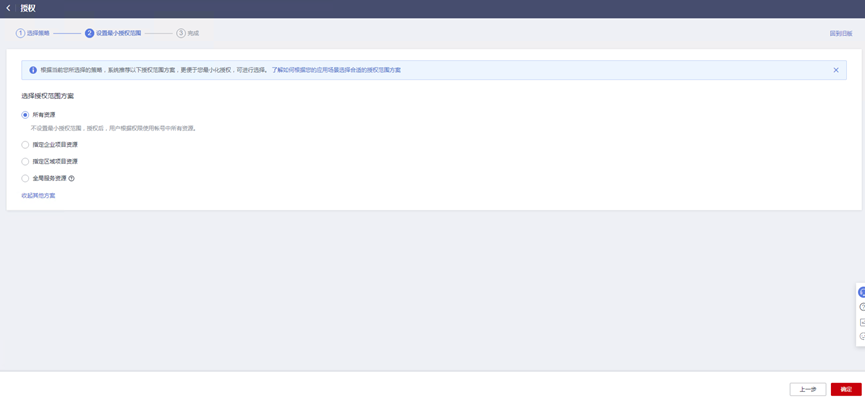 4)完成委托创建 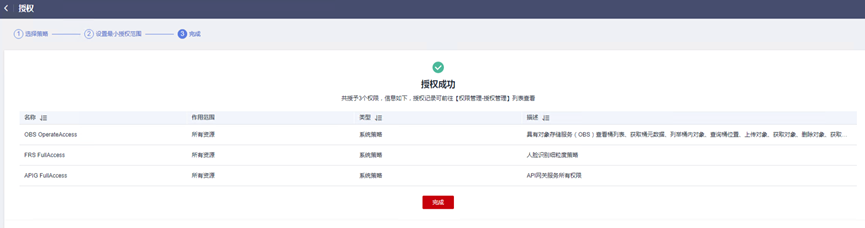 ### 4.4.2 上传FRS依赖包 因functiongraph公共的依赖包中,FRS-SDK不是最新的(无静默活体检测API),故我们需上传最新的FRS-SDK,作为依赖包。 1)从官网获取FRS-SDK下载路径 https://sdkcenter.developer.huaweicloud.com/?language=python 2)下载整个Python-v3的SDK https://github.com/huaweicloud/huaweicloud-sdk-python-v3 下载后解压,进入内部,找到frs后缀的SDK 进入SDK目录,在setup所在的目录,全部选择进行压缩。压缩成功后,需要确保setup文件在压缩包的根目录下。 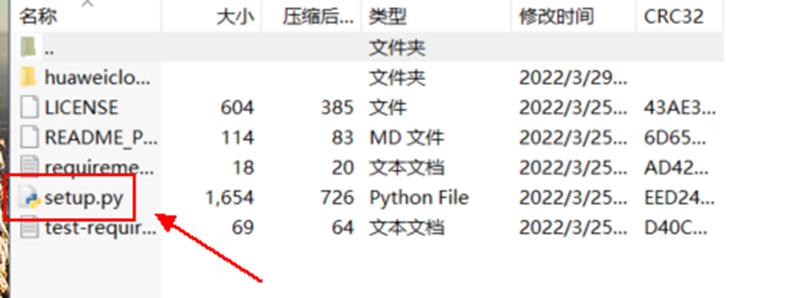 将压缩好的文件,上传到**functiongraph**的**依赖包管理**。 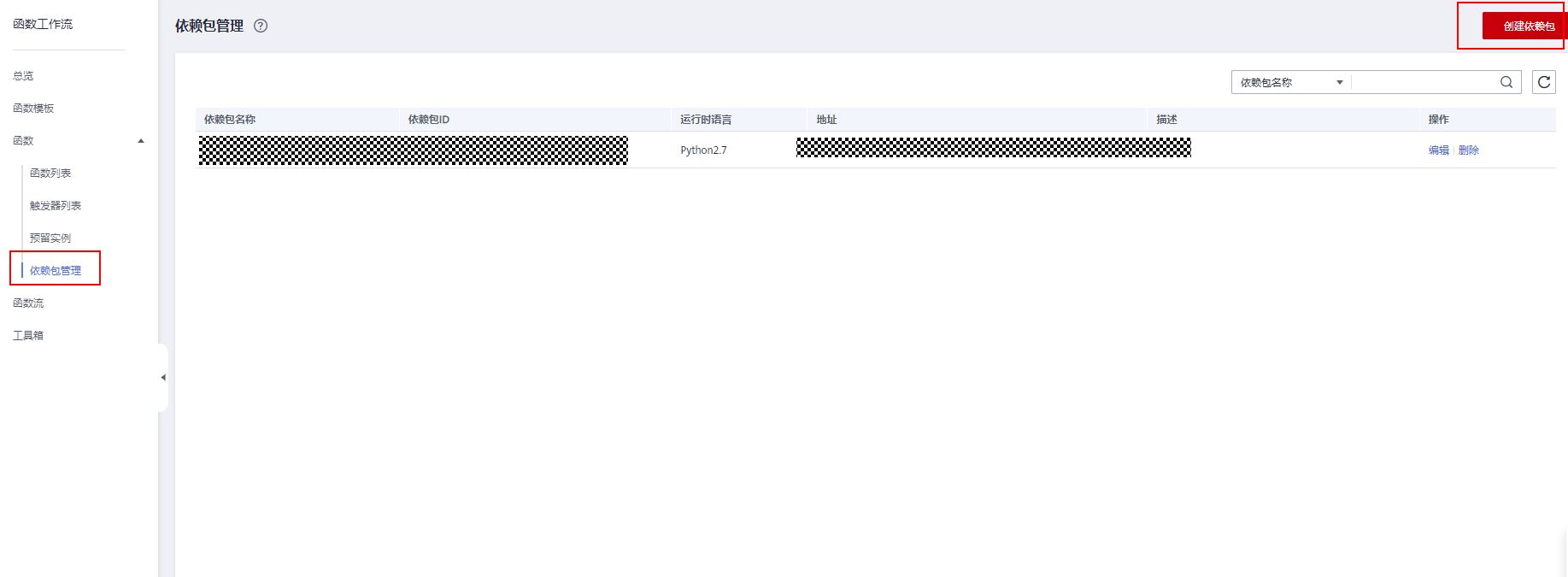 依赖包名称:自定义 运行时语言:2.7 描述:自定义 上传方式:上传ZIP文件 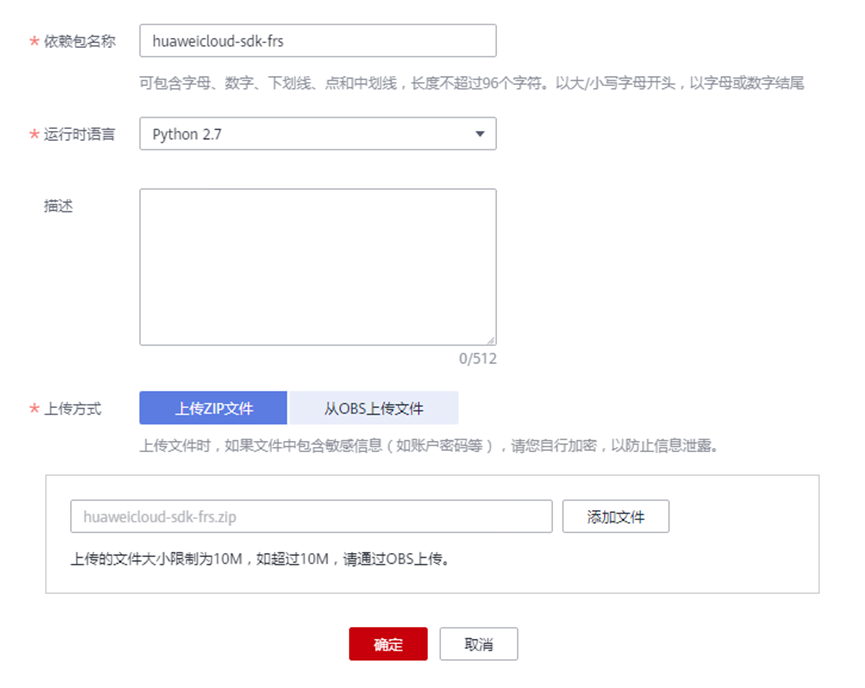 ### 4.4.3 创建函数 1)进入functiongraph控制台创建函数。 Functiongraph版本:functiongraph v2 函数类型:事件函数 函数名称:自定义 所属应用:默认 委托名称:选择创建的委托(如无,请点击右边的 创建委托 前往创建,创建步骤参考4.4.1) 企业项目:自行选择 自定义函数:关闭 运行时语言:Python2.7 函数执行入口:Index.handler 代码上传方式:静默代码 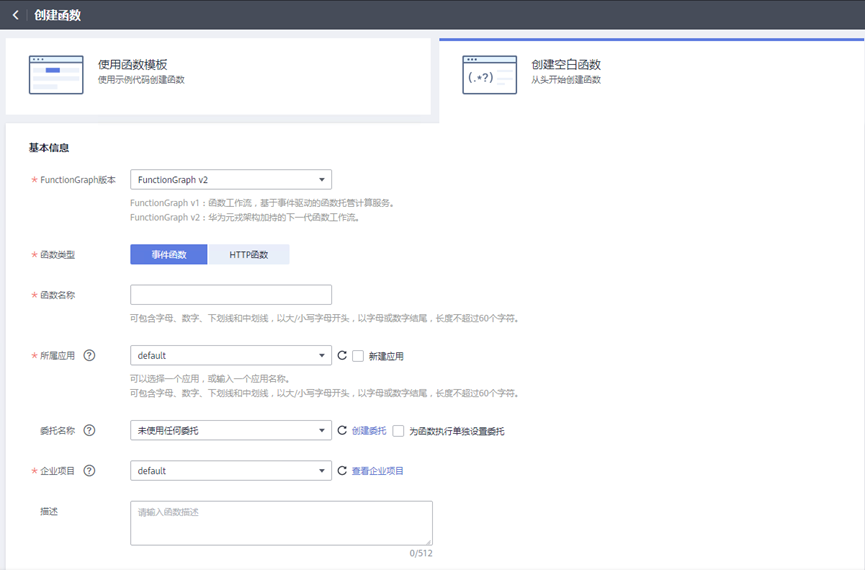 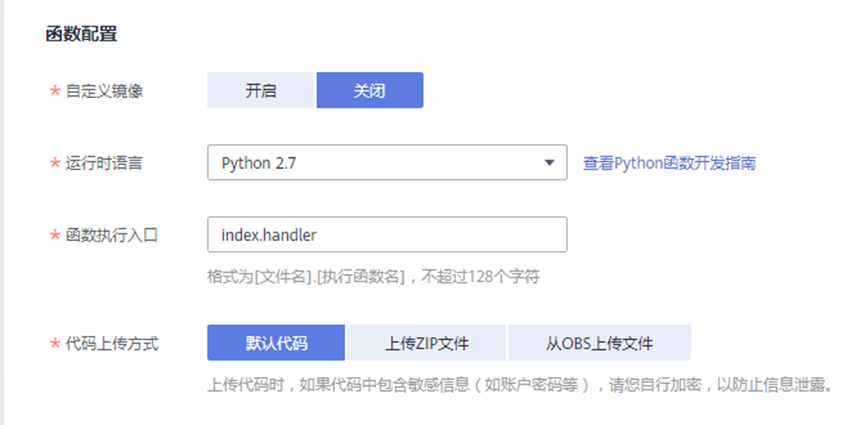 ### 4.4.4 编辑函数代码 将示例代码复制进来,编辑相关默认变量的值 1)粘贴3.3节的代码至index.py中 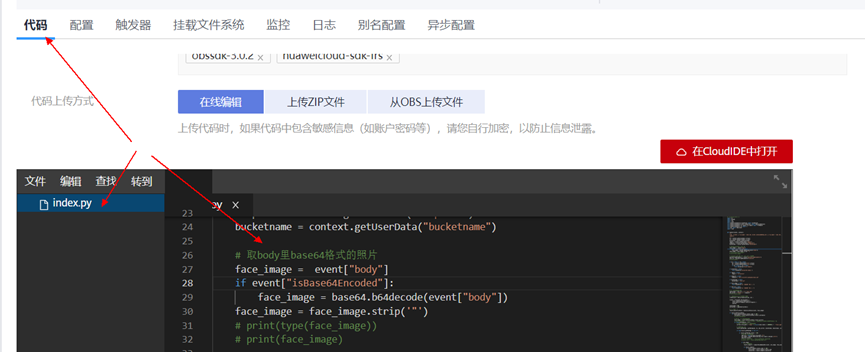 2)根据自己项目情况,设置默认Region、endpoint、buketname的值,若4.4.6节不设置环境变量的值,将默认取此处的默认值。 如下默认是北京四 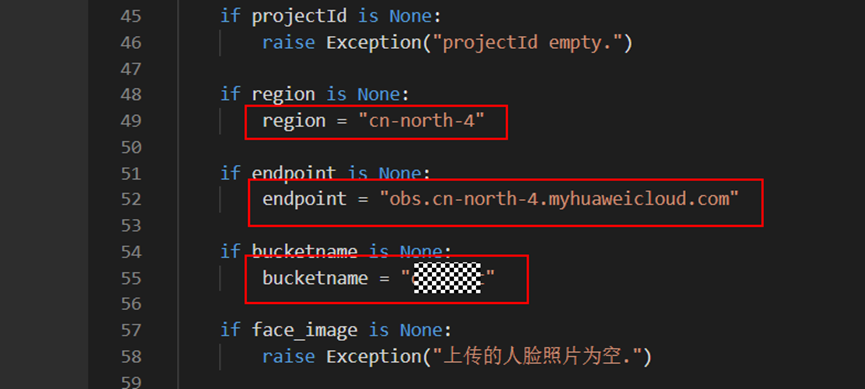 3)编辑完成后,点击保存 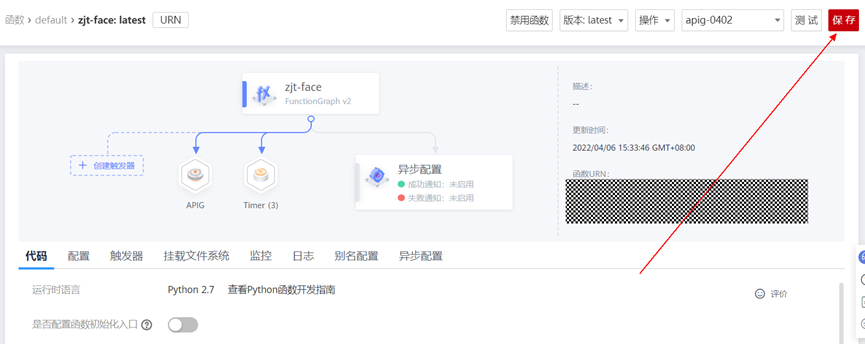 ### 4.4.5 添加依赖包 1)在函数菜单-代码页,点击添加-依赖代码包 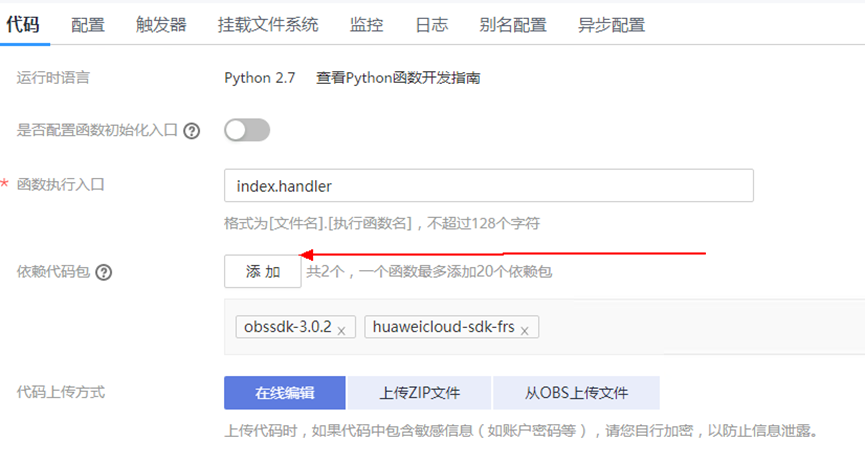 2)在公共依赖包,搜索obs,勾选OBS-sdk 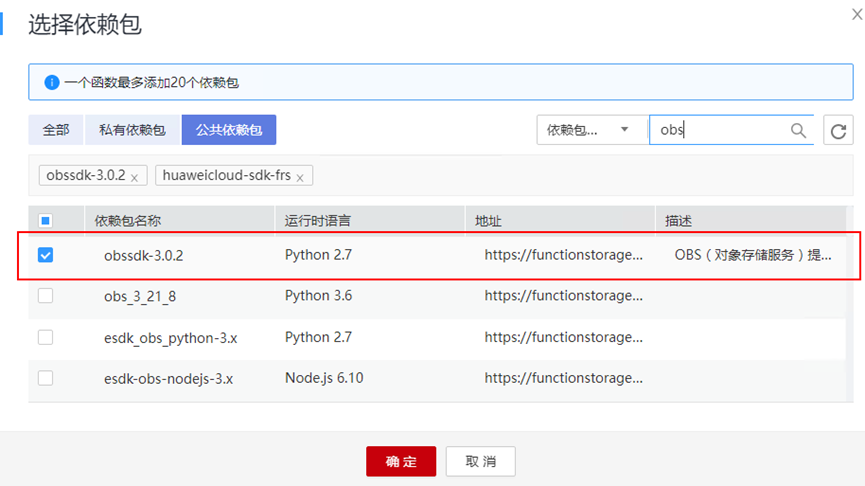 3)在私有依赖包,勾选前面步骤上传的frs-sdk,然后确定保存 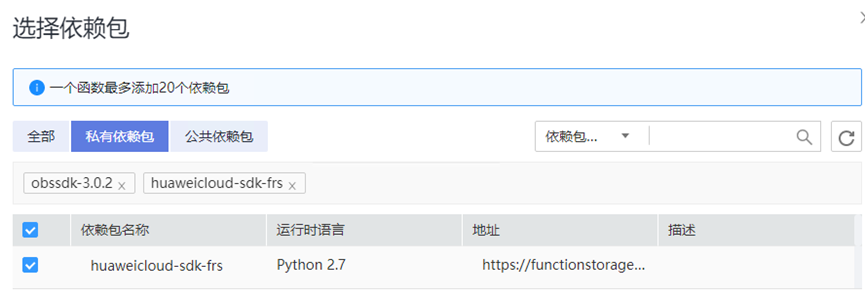 ### 4.4.6 编辑环境变量 在函数菜单-配置页,添加环境变量:region、bucketname(OBS桶名)、endpoint 若此处不设置环境变量,则函数会使用4.4.4节代码设置的默认值。 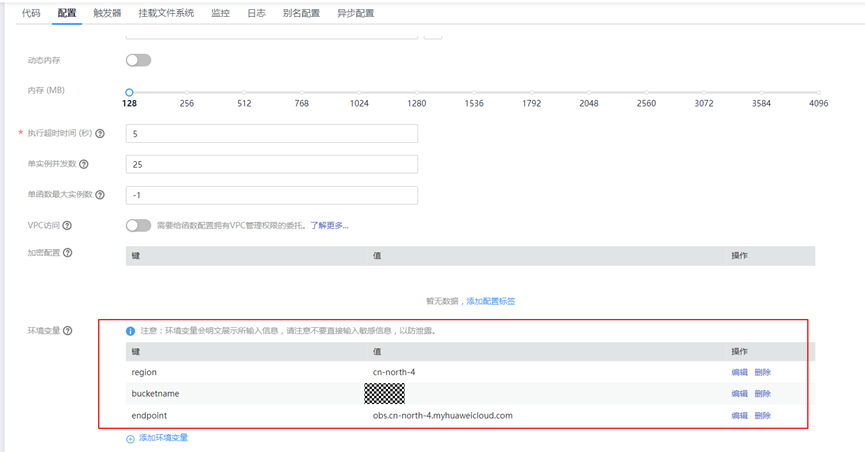 ### 4.4.7 调试函数 1)点击配置测试事件 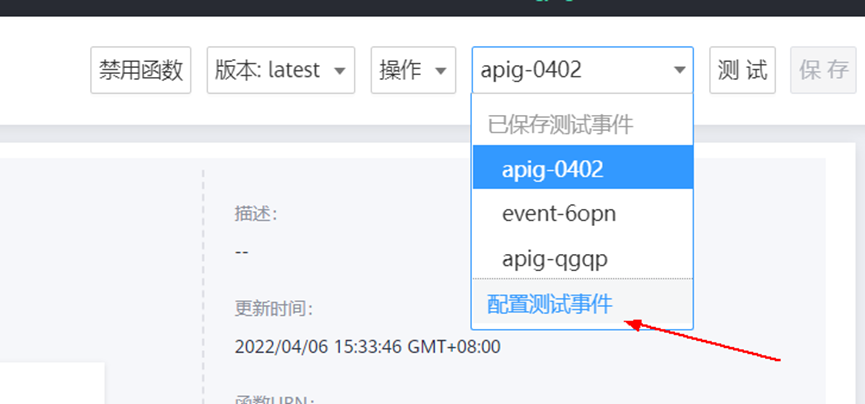 2)选择apig的事件模板,添加body的内容和queryStringParameters的userid,进行保存。 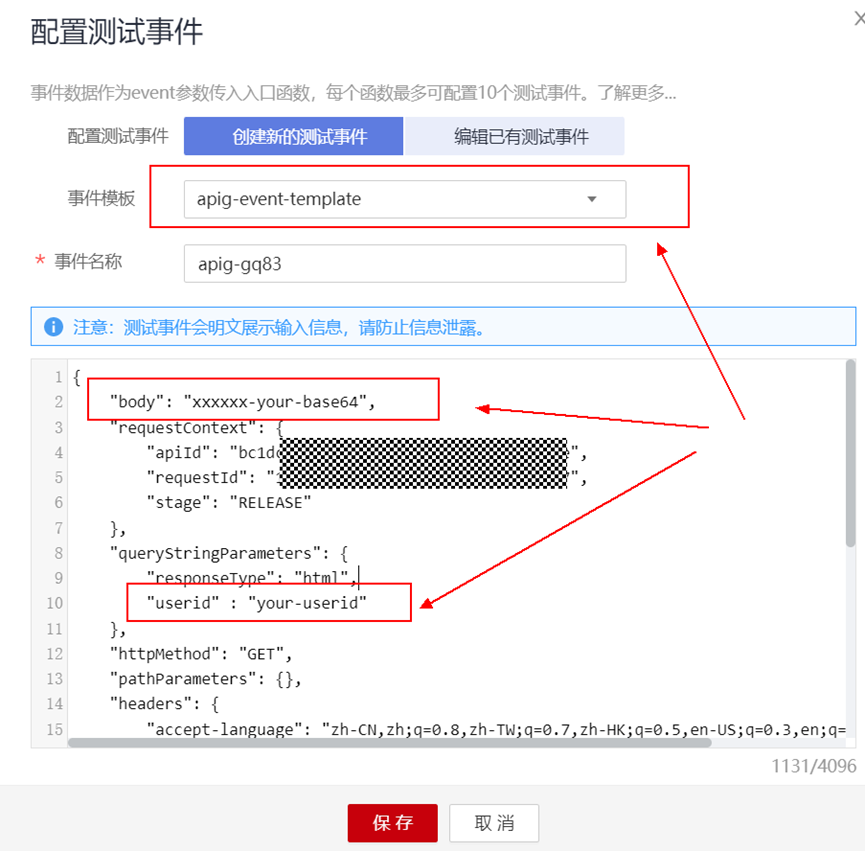 3)点击测试,运行完毕可查看执行结果。  ## 4.5 添加APIG ### 4.5.1 添加APIG触发器 1)在函数菜单-触发器页,点击创建触发器  触发器类型:API网关服务(APIG) API名称:自定义 分组:选择API分组(如无点击右边 创建分组 进行创建) 发布环境:RELEASE(如无点击右边 创建发布环境 进行创建) 安全认证:测试环境可选择None(后面可编辑进行更改) 请求协议:测试环境可选择HTTP(后面可编辑进行更改) 后端超时(毫秒):5000 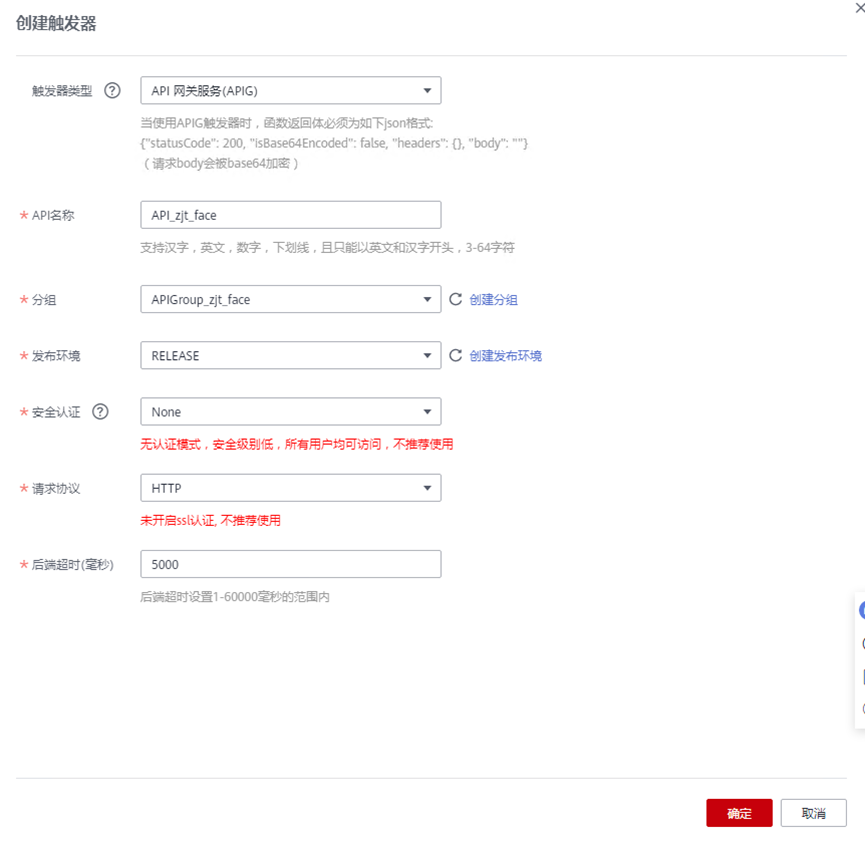 2)创建完成后,在触发器页面会添加一个APIG触发器,提供访问URL 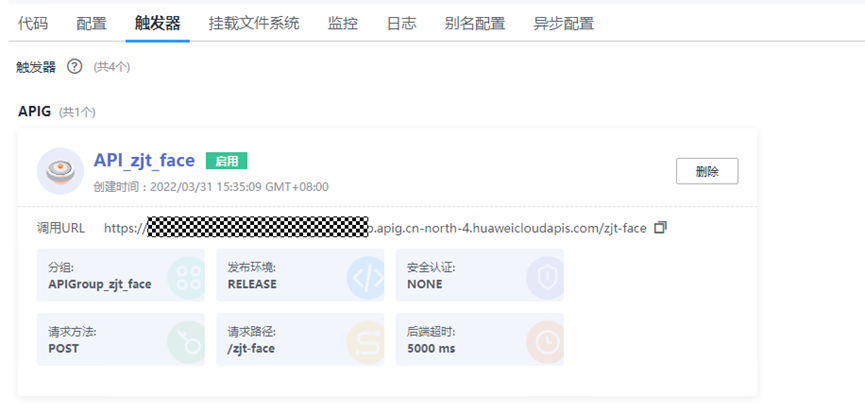 ### 4.5.2 编辑APIG 1)点击APIG触发器名称,前往APIG控制台,点击编辑 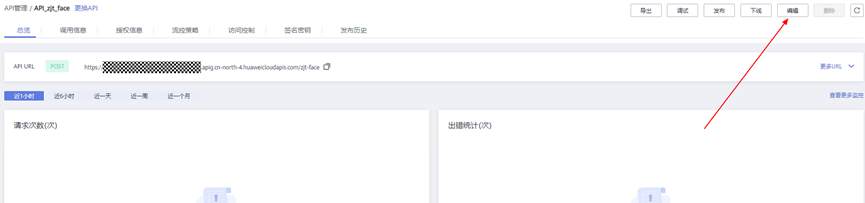 2)编辑基本信息 此处可更改安全认证,为方便调试,此处保持无认证 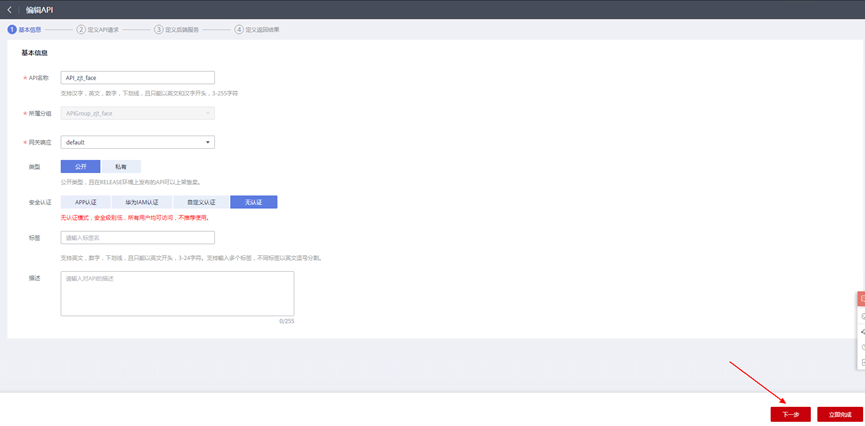 3)定义API请求 此处需添加API的请求参数-用户标识,用于functiongraph中,取在OBS人脸照片库中的员工照片。 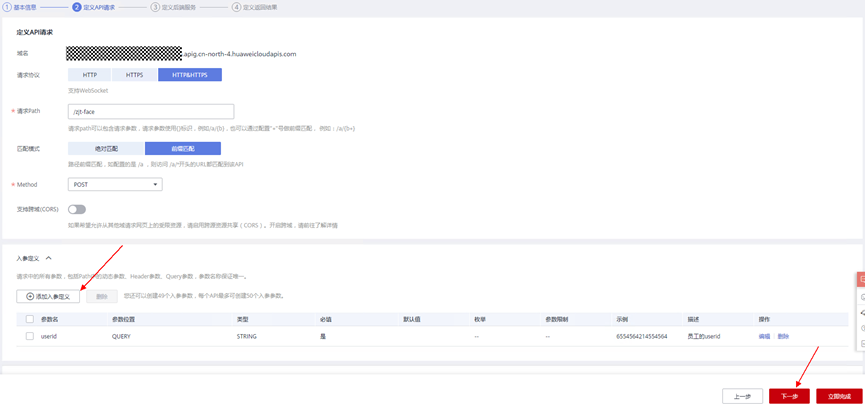 4)定义后端服务 添加后端服务参数,跟前面的入参做一个映射。 因为是在functiongraph创建的APIG,故此处已自动绑定functiongraph的函数为后端服务,故基础定义保持默认即可。 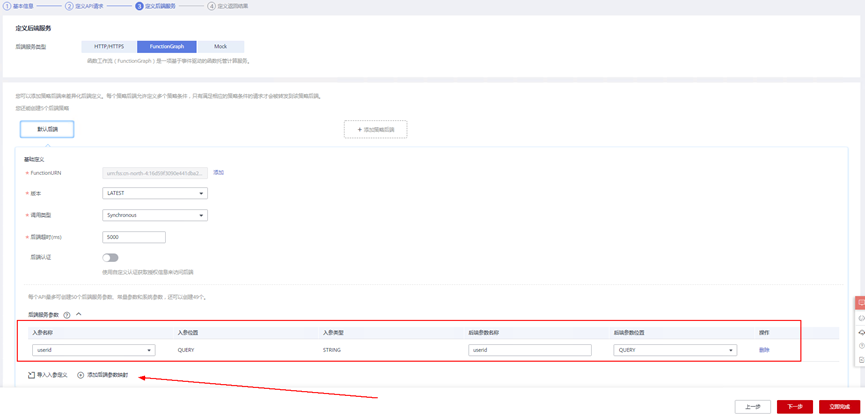 5)返回结果基础定义 返回结果的响应示例,暂设置为空即可,点击完成。  ### 4.5.3 调试API 1)API详情页,点击调试,跳转到API调试页面  2)输入相关请求参数,发起请求,进行调试。 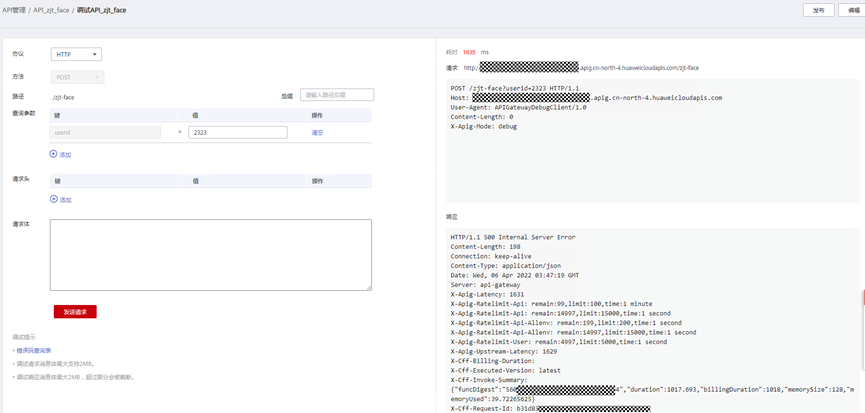 ### 4.5.4 发布API 编辑完成后的API,需要进行发布,公网才可访问 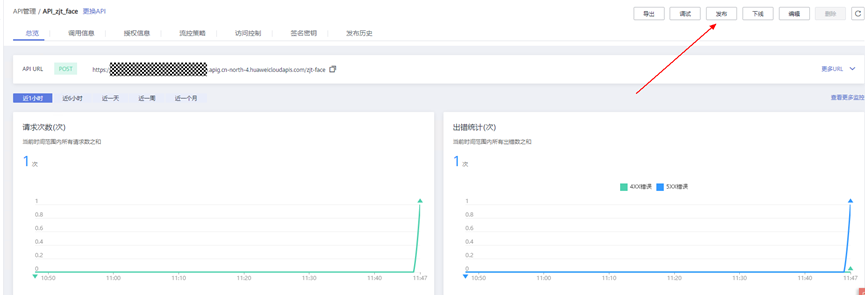 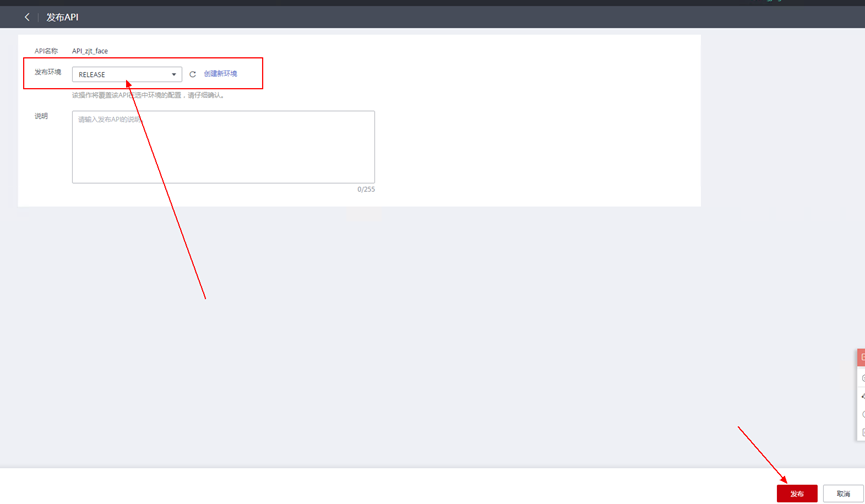 ## 4.6 绑定独立域名 子域名仅供开发测试使用,每天最多访问1000次。如需开发服务,则需为API所在分组绑定独立域名。 ### 4.6.1 添加记录集 1、登录云解析控制台(也可使用其他平台,已完成ICP备案的域名),选择域名解析》公网域名,点击需要创建记录集的域名名称。 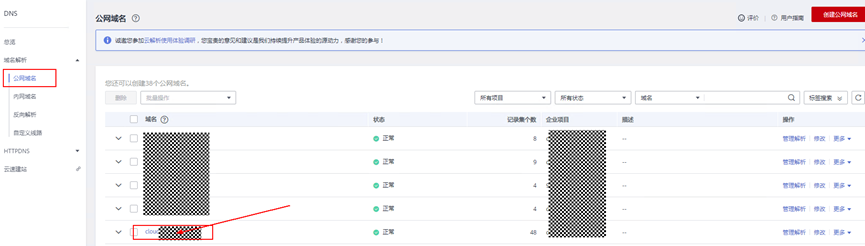 2、添加记录集  填写以下信息 主机记录:域名前缀,如face-test 类型:选择CNAME – 将域名指向另外一个域名 别名:默认即可 线路类型:默认即可 TTL(秒):默认即可 值:填写要指向的别名(此处为APIG上的子域名) 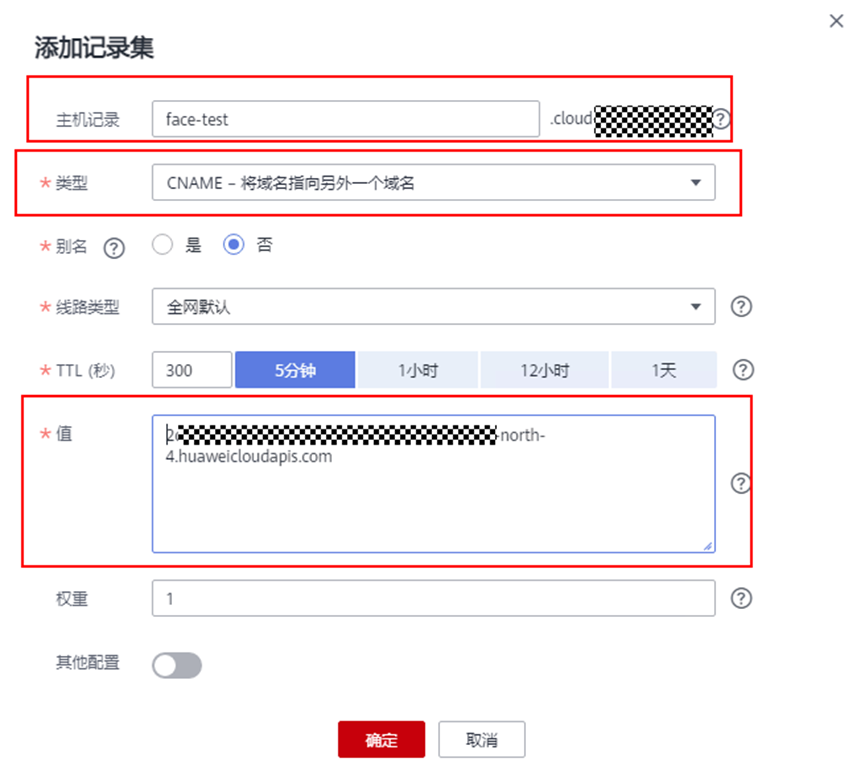 添加成功 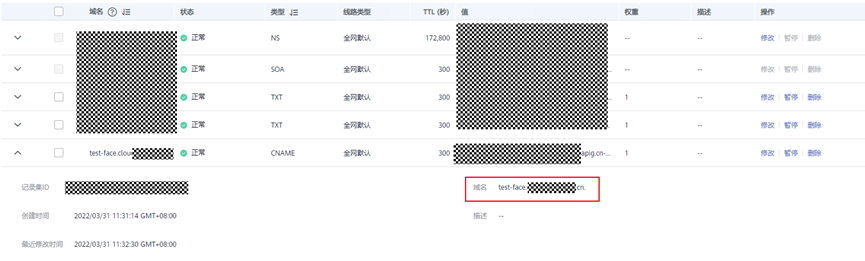  ### 4.6.2 添加自定义域名 1、在API详情页-总览,点击添加增加自定义域名。  2、跳转到API所在分组的域名管理控制台,点击绑定独立域名 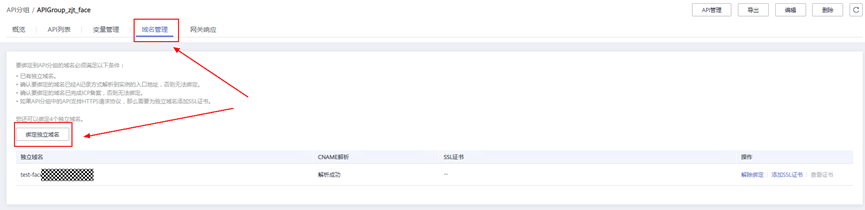 3、输入前面创建的记录集,点击确定。(如果是刚添加的记录集需刷新,约等5分钟) 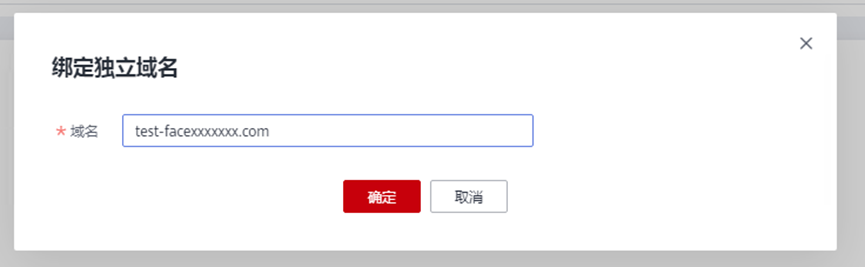 添加完后,即可在公网通过自定义域名,访问APIG。 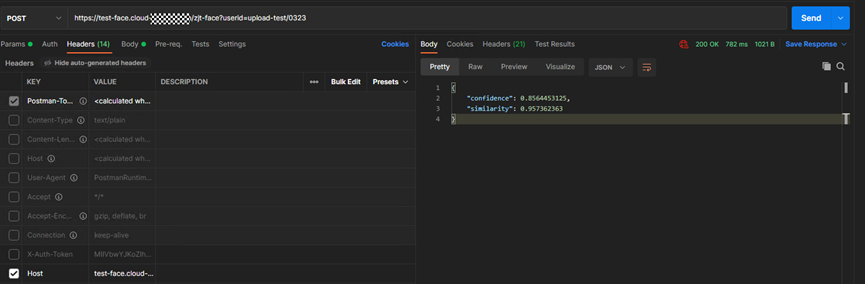 ## 4.7 问题记录 1、并发测试API时,发现偶现以下错误 错误1:人脸比对传入的base64字符串无法识别  错误2:数据传输被提前终止了  问题定位:因函数中的存储到本地的文件用的是同一个路径,并发操作时出现异步的同时占用一个路径,从而导致文件有丢失或文件转码有误 解决方案:给函数中的文件路径配置上时间戳,避免并发操作时,交叉操作同一个文件。 2、APIG错误码请参考: https://support.huaweicloud.com/usermanual-apig/apig-ug-180530090.html 3、使用APIG触发functiongraph时,发现第一个api请求响应时间较长(2s多),后面的请求就较短了(约500ms)。 问题定位:超过一分钟无调用函数时,函数会销毁。再次进行函数调用时,需要重新启动实例,所以第一次调用时间会比较长。 解决方案:设置预留实例,来消除冷启动效果。预留实例是为指定函数版本单独预留的函数运行实例,不同于普通的函数实例,预留实例长期存活,可以达到消除函数冷启动的效果。 预留实例需要提交工单开通,详情请参考:https://support.huaweicloud.com/usermanual-functiongraph/functiongraph_01_0306.html # 5 后期思考 1、 本方案的人脸比对,只比对一次。若人脸库中,用户的库照片有多个,是否需要遍历对比,取总体对比的结果。如对比多次,需要考虑从OBS获取照片、人脸比对的API要多次调用,性能下降、费用提升等
> **摘要:** 通过结合华为云的人脸识别、functiongraph、OBS、APIG等云服务,来达成考勤打卡时调用一个API即可检测是否本人现场打卡的效果。 # 1 背景 使用APP进行打卡时,为避免非本人及非真人现场打卡的情况出现,想结合华为云的人脸识别能力,通过调用API,达成可检测是否本人且真人现场打卡的效果。 # 2 云服务介绍 **华为云FRS:** 人脸识别服务(Face Recognition Service),能够在图像中快速检测人脸、分析人脸关键点信息、获取人脸属性、实现人脸的精确比对和检索。该服务可应用于身份验证、电子考勤、客流分析等场景。[产品页面](https://www.huaweicloud.com/product/face.html) **华为云FunctionGraph:** 函数工作流(FunctionGraph)是一项基于事件驱动的函数托管计算服务。通过函数工作流,只需编写业务函数代码并设置运行的条件,无需配置和管理服务器等基础设施,函数以弹性、免运维、高可靠的方式运行。[产品页面](https://www.huaweicloud.com/product/functiongraph.html) **华为云APIG:** API网关(API Gateway)是为企业开发者及合作伙伴提供的高性能、高可用、高安全的API托管服务, 帮助企业轻松构建、管理和部署不同规模的API。简单、快速、低成本、低风险的实现内部系统集成、成熟业务能力开放及业务能力变现。[产品页面](https://www.huaweicloud.com/product/apig.html) **华为云OBS:** 对象存储服务(Object Storage Service,OBS)是一个基于对象的海量存储服务,为客户提供海量、安全、高可靠、低成本的数据存储能力,使用时无需考虑容量限制,并且提供多种存储类型供选择,满足客户各类业务场景诉求。[产品页面](https://www.huaweicloud.com/product/obs.html) **华为云DNS:** 云解析服务(Domain Name Service)提供高可用,高扩展的权威DNS服务和DNS管理服务,把人们常用的域名或应用资源转换成用于计算机连接的IP地址,从而将最终用户路由到相应的应用资源上。此服务默认开通,免费使用。[产品页面](https://www.huaweicloud.com/product/dns.html) # 3 方案设计 ## 3.1 方案简述 通过APIG调用functiongraph函数,在functiongraph上完成人脸识别-活体检测、人脸识别-人脸比对等API的调用,并将响应结果通过API返回给APP。实现APP调用一次API即可完成人脸识别的功能。 1. 人脸识别服务的人脸比对功能,可实现检测是否其本人打卡。 2. 人脸识别服务的活体检测功能,可实现检测是否活人打卡。 3. 使用Functiongraph的函数,APP端只需考虑调用一个API,且只需考虑人脸识别的总体输入和返回结果。 4. Functiongraph由APIG来调用,利用APPkey、APPsecret及HTTPS,解决了APP端调用的安全认证等问题。 5. OBS桶用来存储人脸照片,通过约定的用户标识做文件存储路径,易于管理和使用。 ## 3.2 方案架构图  0. 初始化:前置准备工作,新建一个OBS桶做人脸库,将员工的人脸照片存放到人脸库,并把以user-id 或自定义字段作为路径,标识员工。 1. 员工登录APP后,进行人脸识别时,将通过APIG来调用functionGraph,上传关键信息:摄像头捕获的照片或视频、员工的人脸库标识(user-id)。 2. functionGraph调用活体检测API,传入照片/视频(根据需求选择动作活体检测/静默活体检测,推荐静默活体检测)。 *注:本方案采用静默活体检测方式,APP端上传的照片提前转换为base64格式* 3. 活体检测API返回响应:有confidence、picture(base64)。 4. 在functionGraph中调用OBS接口,通过user-id从OBS人脸库获取库中的员工照片。 5. 通过代码将从OBS获取的照片文件,转换为base64格式。 6. 将两个base64格式的照片作为输入参数调用人脸比对API 。(备注:此处可根据需求,是否需要多次调用API,使用多个照片进行验证) 7. 人脸比对API返回包含了similarity的响应。 8. functionGraph将similarity、confidence传回给APP/后端。(备注:也可直接在functionGraph完成判定,返回人脸识别结果) ## 3.3 FUNCTIONGRAPH实现代码 代码详看附件。 代码时序图:  # 4 方案部署 ## 4.1 部署流程图  ## 4.2 前置准备 1. 拥有已实名认证的华为云账号,开通云服务functiongraph、人脸比对、活体检测、OBS 2. 注册公网域名,完成ICP备案 ## 4.3 创建OBS人脸库 ### 4.3.1 创建OBS桶 参考帮助文档:https://support.huaweicloud.com/qs-obs/obs_qs_0007.html ,**创建私有桶** ### 4.3.2 上传对象 参考帮助文档: https://support.huaweicloud.com/qs-obs/obs_qs_0008.html ,上传对象,建立OBS人脸库。 要求:文件的路径使用用户标识(如userid)命名  ## 4.4 FUNCTIONGRAPH搭建 ### 4.4.1 创建委托 登录IAM控制台(https://console.huaweicloud.com/iam/?region=cn-north-4#/iam/agencies) 1)创建委托  委托名称:自定义 委托类型:云服务 云服务:函数工作流functiongraph 持续时间:永久  2)选择策略 OBS:获取对象等基本操作权限 FRS:fullaccess APIG:fullaccess  3)设置最小授权范围,此处选择所有,实际可根据项目情况分配。  4)完成委托创建  ### 4.4.2 上传FRS依赖包 因functiongraph公共的依赖包中,FRS-SDK不是最新的(无静默活体检测API),故我们需上传最新的FRS-SDK,作为依赖包。 1)从官网获取FRS-SDK下载路径 https://sdkcenter.developer.huaweicloud.com/?language=python 2)下载整个Python-v3的SDK https://github.com/huaweicloud/huaweicloud-sdk-python-v3 下载后解压,进入内部,找到frs后缀的SDK 进入SDK目录,在setup所在的目录,全部选择进行压缩。压缩成功后,需要确保setup文件在压缩包的根目录下。  将压缩好的文件,上传到**functiongraph**的**依赖包管理**。  依赖包名称:自定义 运行时语言:2.7 描述:自定义 上传方式:上传ZIP文件  ### 4.4.3 创建函数 1)进入functiongraph控制台创建函数。 Functiongraph版本:functiongraph v2 函数类型:事件函数 函数名称:自定义 所属应用:默认 委托名称:选择创建的委托(如无,请点击右边的 创建委托 前往创建,创建步骤参考4.4.1) 企业项目:自行选择 自定义函数:关闭 运行时语言:Python2.7 函数执行入口:Index.handler 代码上传方式:静默代码   ### 4.4.4 编辑函数代码 将示例代码复制进来,编辑相关默认变量的值 1)粘贴3.3节的代码至index.py中  2)根据自己项目情况,设置默认Region、endpoint、buketname的值,若4.4.6节不设置环境变量的值,将默认取此处的默认值。 如下默认是北京四  3)编辑完成后,点击保存  ### 4.4.5 添加依赖包 1)在函数菜单-代码页,点击添加-依赖代码包  2)在公共依赖包,搜索obs,勾选OBS-sdk  3)在私有依赖包,勾选前面步骤上传的frs-sdk,然后确定保存  ### 4.4.6 编辑环境变量 在函数菜单-配置页,添加环境变量:region、bucketname(OBS桶名)、endpoint 若此处不设置环境变量,则函数会使用4.4.4节代码设置的默认值。  ### 4.4.7 调试函数 1)点击配置测试事件  2)选择apig的事件模板,添加body的内容和queryStringParameters的userid,进行保存。  3)点击测试,运行完毕可查看执行结果。  ## 4.5 添加APIG ### 4.5.1 添加APIG触发器 1)在函数菜单-触发器页,点击创建触发器  触发器类型:API网关服务(APIG) API名称:自定义 分组:选择API分组(如无点击右边 创建分组 进行创建) 发布环境:RELEASE(如无点击右边 创建发布环境 进行创建) 安全认证:测试环境可选择None(后面可编辑进行更改) 请求协议:测试环境可选择HTTP(后面可编辑进行更改) 后端超时(毫秒):5000  2)创建完成后,在触发器页面会添加一个APIG触发器,提供访问URL  ### 4.5.2 编辑APIG 1)点击APIG触发器名称,前往APIG控制台,点击编辑  2)编辑基本信息 此处可更改安全认证,为方便调试,此处保持无认证  3)定义API请求 此处需添加API的请求参数-用户标识,用于functiongraph中,取在OBS人脸照片库中的员工照片。  4)定义后端服务 添加后端服务参数,跟前面的入参做一个映射。 因为是在functiongraph创建的APIG,故此处已自动绑定functiongraph的函数为后端服务,故基础定义保持默认即可。  5)返回结果基础定义 返回结果的响应示例,暂设置为空即可,点击完成。  ### 4.5.3 调试API 1)API详情页,点击调试,跳转到API调试页面  2)输入相关请求参数,发起请求,进行调试。  ### 4.5.4 发布API 编辑完成后的API,需要进行发布,公网才可访问   ## 4.6 绑定独立域名 子域名仅供开发测试使用,每天最多访问1000次。如需开发服务,则需为API所在分组绑定独立域名。 ### 4.6.1 添加记录集 1、登录云解析控制台(也可使用其他平台,已完成ICP备案的域名),选择域名解析》公网域名,点击需要创建记录集的域名名称。  2、添加记录集  填写以下信息 主机记录:域名前缀,如face-test 类型:选择CNAME – 将域名指向另外一个域名 别名:默认即可 线路类型:默认即可 TTL(秒):默认即可 值:填写要指向的别名(此处为APIG上的子域名)  添加成功   ### 4.6.2 添加自定义域名 1、在API详情页-总览,点击添加增加自定义域名。  2、跳转到API所在分组的域名管理控制台,点击绑定独立域名  3、输入前面创建的记录集,点击确定。(如果是刚添加的记录集需刷新,约等5分钟)  添加完后,即可在公网通过自定义域名,访问APIG。  ## 4.7 问题记录 1、并发测试API时,发现偶现以下错误 错误1:人脸比对传入的base64字符串无法识别  错误2:数据传输被提前终止了  问题定位:因函数中的存储到本地的文件用的是同一个路径,并发操作时出现异步的同时占用一个路径,从而导致文件有丢失或文件转码有误 解决方案:给函数中的文件路径配置上时间戳,避免并发操作时,交叉操作同一个文件。 2、APIG错误码请参考: https://support.huaweicloud.com/usermanual-apig/apig-ug-180530090.html 3、使用APIG触发functiongraph时,发现第一个api请求响应时间较长(2s多),后面的请求就较短了(约500ms)。 问题定位:超过一分钟无调用函数时,函数会销毁。再次进行函数调用时,需要重新启动实例,所以第一次调用时间会比较长。 解决方案:设置预留实例,来消除冷启动效果。预留实例是为指定函数版本单独预留的函数运行实例,不同于普通的函数实例,预留实例长期存活,可以达到消除函数冷启动的效果。 预留实例需要提交工单开通,详情请参考:https://support.huaweicloud.com/usermanual-functiongraph/functiongraph_01_0306.html # 5 后期思考 1、 本方案的人脸比对,只比对一次。若人脸库中,用户的库照片有多个,是否需要遍历对比,取总体对比的结果。如对比多次,需要考虑从OBS获取照片、人脸比对的API要多次调用,性能下降、费用提升等 -
 随着人工智能技术的成熟和普及,人脸识别也越来越被广泛运用到生活的方方面面,但随之而来的却是不断有人用照片戏耍人脸识别系统,没想到这项高科技却在群众的智慧面前败下阵来,主要原因还是人脸识别技术中,未加入防御照片图像等伪造人脸的技术,在此背景下高阶版的活体检测技术从幕后走上了台前。简单来说活体检测就是算法判断镜头捕捉到的人脸,究竟是真实人脸还是伪造的人脸,一般在安全性等级要求高的应用场景下,会使用人脸识别+活体检测相结合的方式来进行身份核验,通过配合使用活体检测后,弥补了单一人脸识别的不足,能够有效的识别照片、视频、面具等伪造人脸行为,最大程度杜绝欺诈行为的发生。而通过天眼数聚接口平台的人脸身份证比对接口和活体检测接口,就可以进行更高安全标准的身份核验,大致核验流程如下:1、人像信息采集通过SDK、H5页面、微信小程序等应用场景获取被核验人人脸信息、证件信息,用户上传证件照片,系统使用证件OCR识别技术自动提取信息,用户拍摄活体视频上传进行比对核验。2、云端活体判定云端使用语音识别、唇语识别、活体判断等技术自动对视频进行检测,判断入镜的你是否为真实的活体并高质量提取视频中人像图像上传。3、云端核验云端将人像图像、姓名、身份证号信息加密并传输到天眼数聚数据服务平台上公安授权的接口,然后自动与公安数据库中的人像图像、姓名、身份证号进行权威比对核验。4、输出核验结果经过天眼数聚核验接口验证后,返回核验结果,核验一致默认通过审核,不一致则返回认证首页,让用户重新操作。
随着人工智能技术的成熟和普及,人脸识别也越来越被广泛运用到生活的方方面面,但随之而来的却是不断有人用照片戏耍人脸识别系统,没想到这项高科技却在群众的智慧面前败下阵来,主要原因还是人脸识别技术中,未加入防御照片图像等伪造人脸的技术,在此背景下高阶版的活体检测技术从幕后走上了台前。简单来说活体检测就是算法判断镜头捕捉到的人脸,究竟是真实人脸还是伪造的人脸,一般在安全性等级要求高的应用场景下,会使用人脸识别+活体检测相结合的方式来进行身份核验,通过配合使用活体检测后,弥补了单一人脸识别的不足,能够有效的识别照片、视频、面具等伪造人脸行为,最大程度杜绝欺诈行为的发生。而通过天眼数聚接口平台的人脸身份证比对接口和活体检测接口,就可以进行更高安全标准的身份核验,大致核验流程如下:1、人像信息采集通过SDK、H5页面、微信小程序等应用场景获取被核验人人脸信息、证件信息,用户上传证件照片,系统使用证件OCR识别技术自动提取信息,用户拍摄活体视频上传进行比对核验。2、云端活体判定云端使用语音识别、唇语识别、活体判断等技术自动对视频进行检测,判断入镜的你是否为真实的活体并高质量提取视频中人像图像上传。3、云端核验云端将人像图像、姓名、身份证号信息加密并传输到天眼数聚数据服务平台上公安授权的接口,然后自动与公安数据库中的人像图像、姓名、身份证号进行权威比对核验。4、输出核验结果经过天眼数聚核验接口验证后,返回核验结果,核验一致默认通过审核,不一致则返回认证首页,让用户重新操作。 -
 现在,面部识别已成为生活中的一部分。因此,在介绍主题之前我们先看看实时面部识别示例。我们在手机、平板电脑等设备中使用人脸信息进行解锁的时候,这时就要求获取我们的实时面部图像,并将其储存在数据库中以进一步表明我们的身份。 通过对输入图像进行迭代和预测可以完成这个过程。同样,实时人脸识别可与OpenCV框架python的实现配合使用。再将它们组合在一个组合级别中,以实现用于实时目的的模型。 人脸识别 “面部识别”名称本身就是一个非常全面的定义,面部识别是通过数字媒体作为输入来识别或检测人脸的技术执行过程。人脸识别的准确性可以提供高质量的输出,而不是忽略影响其的问题因素。在这里,要确保运行我们的模型,必须确保在本地系统中安装了库。pip install face_recognition如果在 face_recognition库的安装过程中遇到一些问题或错误,可以点击以下链接:https://www.youtube.com/watch?v=xaDJ5xnc8dc人脸识别本身无法提供清晰的输出,因此出现了OpenCV实现的概念。OpenCV OpenCV是python中一个著名的库,用于实时应用程序。OpenCV在计算机世界中就像树的根一样非常重要。face_recognition中的OpenCV对我们训练为输入的面部图像进行聚类和特征提取。它以图像中的地标为目标,以迭代方式在计算机视觉的深度学习方法中训练它们。在本地系统中安装OpenCVpip install opencv-python使用深度学习算法,OpenCV检测可作为聚类,相似性检测和图像分类的表示。为什么我们使用OpenCV作为实时Face_Recognition中的关键工具? 人类可以轻松检测到面部,但是我们如何训练机器识别面部?OpenCV在这里填补了人与计算机之间的空白,并充当了计算机的愿景。以一个实时的例子为例,当一个人遇到新朋友时,他会记住这些人的脸,以备将来识别。一个人的大脑反复训练后端的人脸。因此,当他看到那个人的脸时,他说:“嗨,约翰!你好吗?”。对面部的识别和可以为计算机提供与人类相同的思维方式。OpenCV是计算机视觉中的重要工具。如果我们使用OpenCV,则遵循以下步骤:• 通过输入提取数据。• 识别图像中的面部。• 提取独特的特征,以建立预测思想。• 该特定人的性格特征,如鼻子,嘴巴,耳朵,眼睛和面部主要特征。• 实时人脸识别中人脸的比较。• 识别出的人脸的最终输出。使用OpenCV python的Face_Recognition: 代码下载:https://github.com/eazyciphers/deep-machine-learning-tutors/tree/master/Real-Time Face RecognitionGitHub导入所有软件包:import face_recognitionimport cv2import numpy as np加载并训练图像:# Load a sample picture and learn how to recognize it. Jithendra_image = face_recognition.load_image_file("jithendra.jpg") Jithendra_face_encoding = face_recognition.face_encodings(Jithendra_image)[0] # Load a sample picture and learn how to recognize it. Modi_image = face_recognition.load_image_file("Modi.jpg") Modi_face_encoding = face_recognition.face_encodings(Modi_image)[0]人脸编码:# Create arrays of known face encodings and their names known_face_encodings = [ Jithendra_face_encoding, Modi_face_encoding, ] known_face_names = [ "Jithendra", "Modi" ]主要方法:当实时人脸识别为true时,它将检测到人脸并按照代码中的以下步骤操作:• 抓取实时视频中的一帧。• 将图像从BGR颜色(OpenCV使用的颜色)转换为RGB颜色(face_recognition使用的颜色)• 在实时视频的帧中找到所有面部和面部编码。• 循环浏览此视频帧中的每个面孔,并检查该面孔是否与现有面孔匹配。• 如果一个人脸无法识别现有人脸,则将输出视为未知或未知。• 识别后,否则在识别出的脸部周围画一个方框。• 用其名称标记识别的面部。• 识别后显示结果图像。退出:# Hit 'q' on the keyboard to quit! if cv2.waitKey(1) & 0xFF == ord('q'): break释放摄像头的手柄:# Release handle to the webcam video_capture.release() cv2.destroyAllWindows()输入和输出 在训练过程中提供给模型的样本输入…。输入用于训练代码的样本图像样本输入图像进行训练输出
现在,面部识别已成为生活中的一部分。因此,在介绍主题之前我们先看看实时面部识别示例。我们在手机、平板电脑等设备中使用人脸信息进行解锁的时候,这时就要求获取我们的实时面部图像,并将其储存在数据库中以进一步表明我们的身份。 通过对输入图像进行迭代和预测可以完成这个过程。同样,实时人脸识别可与OpenCV框架python的实现配合使用。再将它们组合在一个组合级别中,以实现用于实时目的的模型。 人脸识别 “面部识别”名称本身就是一个非常全面的定义,面部识别是通过数字媒体作为输入来识别或检测人脸的技术执行过程。人脸识别的准确性可以提供高质量的输出,而不是忽略影响其的问题因素。在这里,要确保运行我们的模型,必须确保在本地系统中安装了库。pip install face_recognition如果在 face_recognition库的安装过程中遇到一些问题或错误,可以点击以下链接:https://www.youtube.com/watch?v=xaDJ5xnc8dc人脸识别本身无法提供清晰的输出,因此出现了OpenCV实现的概念。OpenCV OpenCV是python中一个著名的库,用于实时应用程序。OpenCV在计算机世界中就像树的根一样非常重要。face_recognition中的OpenCV对我们训练为输入的面部图像进行聚类和特征提取。它以图像中的地标为目标,以迭代方式在计算机视觉的深度学习方法中训练它们。在本地系统中安装OpenCVpip install opencv-python使用深度学习算法,OpenCV检测可作为聚类,相似性检测和图像分类的表示。为什么我们使用OpenCV作为实时Face_Recognition中的关键工具? 人类可以轻松检测到面部,但是我们如何训练机器识别面部?OpenCV在这里填补了人与计算机之间的空白,并充当了计算机的愿景。以一个实时的例子为例,当一个人遇到新朋友时,他会记住这些人的脸,以备将来识别。一个人的大脑反复训练后端的人脸。因此,当他看到那个人的脸时,他说:“嗨,约翰!你好吗?”。对面部的识别和可以为计算机提供与人类相同的思维方式。OpenCV是计算机视觉中的重要工具。如果我们使用OpenCV,则遵循以下步骤:• 通过输入提取数据。• 识别图像中的面部。• 提取独特的特征,以建立预测思想。• 该特定人的性格特征,如鼻子,嘴巴,耳朵,眼睛和面部主要特征。• 实时人脸识别中人脸的比较。• 识别出的人脸的最终输出。使用OpenCV python的Face_Recognition: 代码下载:https://github.com/eazyciphers/deep-machine-learning-tutors/tree/master/Real-Time Face RecognitionGitHub导入所有软件包:import face_recognitionimport cv2import numpy as np加载并训练图像:# Load a sample picture and learn how to recognize it. Jithendra_image = face_recognition.load_image_file("jithendra.jpg") Jithendra_face_encoding = face_recognition.face_encodings(Jithendra_image)[0] # Load a sample picture and learn how to recognize it. Modi_image = face_recognition.load_image_file("Modi.jpg") Modi_face_encoding = face_recognition.face_encodings(Modi_image)[0]人脸编码:# Create arrays of known face encodings and their names known_face_encodings = [ Jithendra_face_encoding, Modi_face_encoding, ] known_face_names = [ "Jithendra", "Modi" ]主要方法:当实时人脸识别为true时,它将检测到人脸并按照代码中的以下步骤操作:• 抓取实时视频中的一帧。• 将图像从BGR颜色(OpenCV使用的颜色)转换为RGB颜色(face_recognition使用的颜色)• 在实时视频的帧中找到所有面部和面部编码。• 循环浏览此视频帧中的每个面孔,并检查该面孔是否与现有面孔匹配。• 如果一个人脸无法识别现有人脸,则将输出视为未知或未知。• 识别后,否则在识别出的脸部周围画一个方框。• 用其名称标记识别的面部。• 识别后显示结果图像。退出:# Hit 'q' on the keyboard to quit! if cv2.waitKey(1) & 0xFF == ord('q'): break释放摄像头的手柄:# Release handle to the webcam video_capture.release() cv2.destroyAllWindows()输入和输出 在训练过程中提供给模型的样本输入…。输入用于训练代码的样本图像样本输入图像进行训练输出 -
 大赛详情地址:https://competition.huaweicloud.com/information/1000041288/introduction作者昵称:老老刘参加了华为云API入门学习赛,按照大赛给的指导流程一步步来做。首先当然是报名然后开通人脸检测服务接着我们去找一张美女图根据指导说明上传调试最后将调试结果截图打包上传就ok啦,很简单
大赛详情地址:https://competition.huaweicloud.com/information/1000041288/introduction作者昵称:老老刘参加了华为云API入门学习赛,按照大赛给的指导流程一步步来做。首先当然是报名然后开通人脸检测服务接着我们去找一张美女图根据指导说明上传调试最后将调试结果截图打包上传就ok啦,很简单 -
大赛详情地址:https://competition.huaweicloud.com/information/1000041288/introduction作者昵称:橙子是红的今天是最后一天冲鸭!!!活动时间:11月16日~11月20日奖励规则:在11月16日至20日的5天时间内,按照操作指导完成作品提交,且成绩50分及以上(按照操作指导完成即可获得50分),即可获得作品提交当日的抽奖机会。抽奖规则:每天针对提交作品的同学进行抽奖,中奖概率为当日提交作品人数的40%。第二天在群内公布前一天中奖结果。备注:每日提交上限5次,当日抽奖。奖品包括:华为快充移动电源、华为荣耀手环4、荣耀体脂称2、100元京东卡、50元京东卡、华为定制棒球帽/渔夫帽、¥465案例学院会员卡、AM115半入式耳机,随机抽取发放。首先报名>>大赛链接:https://competition.huaweicloud.com/information/1000041287/introduction没实名的需要实名认证:>>点击实名认证链接:https://account.huaweicloud.com/usercenter/?region=cn-north-1&locale=zh-cn#/accountindex/realNameAuthing接下来就是根据指导来点击人脸识别服务链接:https://console.huaweicloud.com/frs/?region=cn-north-4#/frs/home本地上传任意一张人像图片https://apiexplorer.developer.huaweicloud.com/apiexplorer/doc?product=FRS&api=FaceDetectV2ByFile点击调试,将调试成功页面截图,保存成zip包。回到大赛提交作品页https://competition.huaweicloud.com/information/1000041287/submission将保存好的zip包作为作品上传到大赛提交页。完成!
-
大赛详情地址:https://competition.huaweicloud.com/information/1000041288/introduction作者昵称:平平无奇的平平这个入门学习赛还是蛮良心的,流程简单,中奖率也挺高,奖品也不错,我想很多朋友也都是冲着奖品来的吧。首先开通服务然后选择byfile,找一张人像图上传,最后点击调试。这个页面别忘截图保存。最后打包成zip上传,搞定!接下来就是等第二天的抽奖了!!!
-
大赛详情地址:https://competition.huaweicloud.com/information/1000041288/introduction作者昵称:老老刘参加了华为云API入门学习赛,按照大赛给的指导流程一步步来做。首先当然是报名然后开通人脸检测服务接着我们去找一张美女图根据指导说明上传调试最后将调试结果截图打包上传就ok啦,很简单
-
作者昵称:王亦臻大赛链接:https://competition.huaweicloud.com/information/1000041287/introduction、正文:从华为云高校青年活动得知有AI人脸识别大赛这次技术活动,就参与了。按照大赛给与的赛题指导,一步一步操作,明白了人脸识别下的API服务。直接上传准备好的人脸图片,然后按照操作,调试。结果图:以后直接调用API,就可以识别人的各种信息,很方便。
-
华为云API入门学习赛:AI人脸识别分享者昵称:AAAI本次根据API学习赛(AI人脸识别)比赛指导进行完成。访问人脸检测接口需要进行选取地区等参数之后我们在调用的时候可以直接调用接口参赛心得:本次比赛通过对于AI的模型进行实际操作,了解到了很多知识,尤其时调用API接口进行开发,极大的减少了开发的时间。大赛详情地址:https://competition.huaweicloud.com/information/1000041287/introduction
-
作者昵称:lichengqian大赛链接:https://competition.huaweicloud.com/information/1000041287/introduction、正文:对于AI人脸识别的心得分享 这次的华为云API的入门学习赛开设了多个部分,其中之一便是AI人脸识别,因为是API的入门学习嘛,所以在我的学习过程中并没用感到太大的困难(本人软件工程专业大三),因此我觉得只要是有点编程基础的同学都可以积极的加入到华为云的API入门学习里面,在这里面可以提前的了解到一些在高校不常接触的前沿知识,丰富自己的项目实战经验,不得不说对于自己的知识拓展还是能起到一定的办帮助的。下面来分享一下关于人脸识别调试的简单操作,希望对大家有所帮助。人脸识别调试步骤:1、开通人脸识别服务 按住键盘Ctrl键鼠标点开如下链接,在新窗口打开窗口 https://console.huaweicloud.com/frs/?region=cn-north-4#/frs/home如果没有账号,请根据指引完成账号注册和实名认证。实名认证后,退出重新登录一下。选择”北京四”(注意要实名认证后,才能有北京四),点击”开通服务”按钮开通人脸检测服务2.打开人脸识别调试部分进行如下图操作3.选择地区为北京四,之后吧事先下载好的人脸识别照片上传,参数填写数字14.做完以上操作之后,点击调试,即可完成,便可以看到响应体的返回信息,包括人脸人物的性别年龄等预测信息详细操作请看人脸识别官方模板
推荐直播
-
 华为云码道-玩转OpenClaw,在线养虾
华为云码道-玩转OpenClaw,在线养虾2026/03/11 周三 19:00-21:00
刘昱,华为云高级工程师/谈心,华为云技术专家/李海仑,上海圭卓智能科技有限公司CEO
OpenClaw 火爆开发者圈,华为云码道最新推出 Skill ——开发者只需输入一句口令,即可部署一个功能完整的「小龙虾」智能体。直播带你玩转华为云码道,玩转OpenClaw
回顾中 -
 华为云码道-AI时代应用开发利器
华为云码道-AI时代应用开发利器2026/03/18 周三 19:00-20:00
童得力,华为云开发者生态运营总监/姚圣伟,华为云HCDE开发者专家
本次直播由华为专家带你实战应用开发,看华为云码道(CodeArts)代码智能体如何在AI时代让你的创意应用快速落地。更有华为云HCDE开发者专家带你用码道玩转JiuwenClaw,让小艺成为你的AI助理。
回顾中 -
 Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案
Skill 构建 × 智能创作:基于华为云码道的 AI 内容生产提效方案2026/03/25 周三 19:00-20:00
余伟,华为云软件研发工程师/万邵业(万少),华为云HCDE开发者专家
本次直播带来两大实战:华为云码道 Skill-Creator 手把手搭建专属知识库 Skill;如何用码道提效 OpenClaw 小说文本,打造从大纲到成稿的 AI 原创小说全链路。技术干货 + OPC创作思路,一次讲透!
回顾中
热门标签