

-

-
 【功能模块】算子的性能测试【操作步骤&问题现象】1、想得到我的算子的在TensorFlow的时间,但是,不知道该怎么得到2.只得到了AICPU kernel的时间【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】算子的性能测试【操作步骤&问题现象】1、想得到我的算子的在TensorFlow的时间,但是,不知道该怎么得到2.只得到了AICPU kernel的时间【截图信息】【日志信息】(可选,上传日志内容或者附件) -
 USB输出如下,每隔若干条输出,就会报watchdog isr导致板卡重启Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!**********watchdog isr********************syserr info start**********kernel_ver : Hi3861V100 R001C00SPC025,2020-09-03 18:10:00**********Exception Information**********PC Task Name : Thread_MPC Task ID = 8Cur Task ID = 8Task Stack Size = 0x2800Exception Type = 0x80000021**********reg info**********mepc = 0x3fa866mstatus = 0x1880mtval = 0x0mcause = 0x80000021ccause = 0x0ra = 0x3f89b0sp = 0xfe9c0gp = 0x11a9c0tp = 0x7e048208t0 = 0x8t1 = 0xffffffe0t2 = 0x0s0 = 0x200061ds1 = 0x0a0 = 0x200061da1 = 0x0a2 = 0xe4668a3 = 0x0a4 = 0x0a5 = 0xe984ca6 = 0xaa7 = 0x6cs2 = 0x88s3 = 0x12121212s4 = 0x11111111s5 = 0x10101010s6 = 0x9090909s7 = 0x8080808s8 = 0x7070707s9 = 0x6060606s10 = 0x5050505s11 = 0x4040404t3 = 0x0t4 = 0xf27f8t5 = 0x0t6 = 0x4a34ee**********memory info**********Pool Addr = 0xe8300Pool Size = 0x302c0Fail Count = 0x0Peek Size = 0x15450Used Size = 0x15450**********task info**********Name : Thread_MID = 8Status = 0x14Stack Index = 0x8Stack Peak = 0x270Stack Size = 0x2800SP = 0x119880Stack : 0xfc2e0 to 0xfeae0Real SP = 0xfe9c0Stack Overflow = 0**********track_info**********current_item:0x3item_cnt:10Index TrackType TrackID CurTime Data1 Data20001 0065 0006 0xc00 0x3f5dfa 0x3f5e780002 0065 0008 0xc00 0x3f5e78 0x3f5dfa0003 0016 0007 0xc00 0x3f5dfa 0x00004 0065 0007 0xbfb 0x3f5e78 0x3f5e780005 0065 0008 0xbfb 0x3f5e78 0x3f87a20006 0016 0007 0xbfb 0x3f89e4 0x00007 0016 0007 0xbfc 0x3f5dfa 0x00008 0016 0007 0xbfd 0x3fa86e 0x00009 0016 0007 0xbfe 0x3f87a0 0x00010 0016 0007 0xbff 0x3f5dfa 0x0**********Call Stack**********Call Stack 0 -- 3f89f0 addr:fea7cCall Stack 1 -- 4a1762 addr:fea8cCall Stack 2 -- 4a30c4 addr:feaacCall Stack 3 -- 3f78c0 addr:feaccCall Stack 4 -- 3f5e24 addr:feadc**********Call Stack end**********ready to OS startsdk ver:Hi3861V100R001C00SPC025 2020-09-03 18:10:00FileSystem mount ok.wifi init success!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!
USB输出如下,每隔若干条输出,就会报watchdog isr导致板卡重启Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!**********watchdog isr********************syserr info start**********kernel_ver : Hi3861V100 R001C00SPC025,2020-09-03 18:10:00**********Exception Information**********PC Task Name : Thread_MPC Task ID = 8Cur Task ID = 8Task Stack Size = 0x2800Exception Type = 0x80000021**********reg info**********mepc = 0x3fa866mstatus = 0x1880mtval = 0x0mcause = 0x80000021ccause = 0x0ra = 0x3f89b0sp = 0xfe9c0gp = 0x11a9c0tp = 0x7e048208t0 = 0x8t1 = 0xffffffe0t2 = 0x0s0 = 0x200061ds1 = 0x0a0 = 0x200061da1 = 0x0a2 = 0xe4668a3 = 0x0a4 = 0x0a5 = 0xe984ca6 = 0xaa7 = 0x6cs2 = 0x88s3 = 0x12121212s4 = 0x11111111s5 = 0x10101010s6 = 0x9090909s7 = 0x8080808s8 = 0x7070707s9 = 0x6060606s10 = 0x5050505s11 = 0x4040404t3 = 0x0t4 = 0xf27f8t5 = 0x0t6 = 0x4a34ee**********memory info**********Pool Addr = 0xe8300Pool Size = 0x302c0Fail Count = 0x0Peek Size = 0x15450Used Size = 0x15450**********task info**********Name : Thread_MID = 8Status = 0x14Stack Index = 0x8Stack Peak = 0x270Stack Size = 0x2800SP = 0x119880Stack : 0xfc2e0 to 0xfeae0Real SP = 0xfe9c0Stack Overflow = 0**********track_info**********current_item:0x3item_cnt:10Index TrackType TrackID CurTime Data1 Data20001 0065 0006 0xc00 0x3f5dfa 0x3f5e780002 0065 0008 0xc00 0x3f5e78 0x3f5dfa0003 0016 0007 0xc00 0x3f5dfa 0x00004 0065 0007 0xbfb 0x3f5e78 0x3f5e780005 0065 0008 0xbfb 0x3f5e78 0x3f87a20006 0016 0007 0xbfb 0x3f89e4 0x00007 0016 0007 0xbfc 0x3f5dfa 0x00008 0016 0007 0xbfd 0x3fa86e 0x00009 0016 0007 0xbfe 0x3f87a0 0x00010 0016 0007 0xbff 0x3f5dfa 0x0**********Call Stack**********Call Stack 0 -- 3f89f0 addr:fea7cCall Stack 1 -- 4a1762 addr:fea8cCall Stack 2 -- 4a30c4 addr:feaacCall Stack 3 -- 3f78c0 addr:feaccCall Stack 4 -- 3f5e24 addr:feadc**********Call Stack end**********ready to OS startsdk ver:Hi3861V100R001C00SPC025 2020-09-03 18:10:00FileSystem mount ok.wifi init success!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano!Message Queue Get msg:Hello BearPi-HM_Nano! -
【功能模块】AR-CORE-220安全可信机制【操作步骤&问题现象】1、AR-CORE-220E上电启动是怎么保证boot,kernel和根文件系统的可信的?2、升级系统时,可信是怎么保证可信3、AR-CORE-220E可信是遵循哪个标准和可信机制?【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
 【功能模块】Ascend310, yolov3推理【操作步骤&问题现象】1、根据教程安装了相关的离线推理环境:2、运行样例https://gitee.com/ascend/samples/wikis/%E5%9B%BE%E7%89%87%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B(Python)(Atlas200DK)?sort_id=34112223、样例报错【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】Ascend310, yolov3推理【操作步骤&问题现象】1、根据教程安装了相关的离线推理环境:2、运行样例https://gitee.com/ascend/samples/wikis/%E5%9B%BE%E7%89%87%E7%9B%AE%E6%A0%87%E6%A3%80%E6%B5%8B(Python)(Atlas200DK)?sort_id=34112223、样例报错【截图信息】【日志信息】(可选,上传日志内容或者附件) -
【功能模块】atlas200固件版本【操作步骤&问题现象】1、直接上电2、报错end kernel panic - not syncing:VFS:unable to mount root fs on unknown-block[0,0]3、不是每次都报错,十几次或者几十次出现一次。同一个模组,同一块板卡,同一个SD卡【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
 【环境】ms1.2.0ascend软件包5.0.1python3.7【问题】感觉训练起来没有想象的快,然后发现这个warning,是不是有关系【log】
iwanttokeepadog
发表于2021-05-31 10:25:05
2021-05-31 10:25:05
最后回复
chengxiaoli
2021-05-31 11:04:38
345 3
【环境】ms1.2.0ascend软件包5.0.1python3.7【问题】感觉训练起来没有想象的快,然后发现这个warning,是不是有关系【log】
iwanttokeepadog
发表于2021-05-31 10:25:05
2021-05-31 10:25:05
最后回复
chengxiaoli
2021-05-31 11:04:38
345 3 -
-
【功能模块】mindspore.ops.AvgPoolmindspore.nn.AvgPool2d【操作步骤&问题现象】1、pool = nn.AvgPool2d(kernel_size=30, stride=30) x = mindspore.Tensor(np.random.randint(0, 10, [1, 3, 60, 60]), mindspore.float32) output = pool(x) print(output.shape) 运行错误 错误信息显示RuntimeError: invalid window params, window_h * window_w should be <= 255,似乎是限制了kernel的尺寸2、pool = nn.AvgPool2d(kernel_size=30, stride=30) x = mindspore.Tensor(np.random.randint(0, 10, [1, 3, 30, 30]), mindspore.float32) output = pool(x) print(output.shape) 运行成功:(1, 3, 1, 1) kernel尺寸仍为30*30,但是当kernel尺寸与输入尺寸相同时却没有报错【截图信息】 【操作步骤&问题现象】中1.的错误信息:【日志信息】(可选,上传日志内容或者附件)错误信息:--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) <ipython-input-15-a21364a92a0f> in <module> 1 pool = nn.AvgPool2d(kernel_size=30, stride=30) 2 x = mindspore.Tensor(np.random.randint(0, 10, [1, 3, 60, 60]), mindspore.float32) ----> 3 output = pool(x) 4 print(output.shape) ~/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/nn/cell.py in __call__(self, *inputs, **kwargs) 308 output = self._hook_construct(*cast_inputs, **kwargs) 309 else: --> 310 output = self.construct(*cast_inputs, **kwargs) 311 if isinstance(output, Parameter): 312 output = output.data ~/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/nn/layer/pooling.py in construct(self, x) 215 216 def construct(self, x): --> 217 return self.avg_pool(x) 218 219 ~/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/ops/primitive.py in __call__(self, *args) 157 if should_elim: 158 return output --> 159 return _run_op(self, self.name, args) 160 161 def __getstate__(self): ~/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/common/api.py in wrapper(*arg, **kwargs) 67 @wraps(fn) 68 def wrapper(*arg, **kwargs): ---> 69 results = fn(*arg, **kwargs) 70 71 def _convert_data(data): ~/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/ops/primitive.py in _run_op(obj, op_name, args) 496 def _run_op(obj, op_name, args): 497 """Single op execution function supported by ge in PyNative mode.""" --> 498 output = real_run_op(obj, op_name, args) 499 if not output: 500 raise RuntimeError("Pynative run op %s failed!" % op_name) RuntimeError: mindspore/ccsrc/backend/kernel_compiler/tbe/tbe_kernel_parallel_build.cc:82 TbeOpParallelBuild] ArgumentError task compile Failed, task id:13, cause:TBEException:PreCompileProcessFailed: Traceback (most recent call last): File "/home/ma-user/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/_extends/parallel_compile/tbe_compiler/compiler.py", line 95, in build_op return op_func(*inputs_args, *outputs_args, *attrs_args, kernel_name=kernel_name) File "/home/ma-user/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/te/utils/op_utils.py", line 597, in _in_wrapper return func(*args, **kwargs) File "/usr/local/Ascend/nnae/latest/opp/op_impl/built-in/ai_core/tbe/impl/avg_pool.py", line 562, in avg_pool data_format, False, kernel_name) File "/usr/local/Ascend/nnae/latest/opp/op_impl/built-in/ai_core/tbe/impl/avg_pool.py", line 351, in avg_pool_compute1 fusion_params=fusion_params) File "/home/ma-user/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/te/lang/cce/te_compute/pooling2d_compute.py", line 161, in pooling2d raise RuntimeError("invalid window params, window_h * " RuntimeError: invalid window params, window_h * window_w should be <= 255 During handling of the above exception, another exception occurred: Traceback (most recent call last): File "/home/ma-user/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/_extends/parallel_compile/tbe_compiler/compiler.py", line 136, in <module> result = compile_with_json(in_args) File "/home/ma-user/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/_extends/parallel_compile/tbe_compiler/compiler.py", line 131, in compile_with_json ret = build_op(op_build, json_str) File "/home/ma-user/miniconda3/envs/Mindspore-1.0.0-python3.7-aarch64/lib/python3.7/site-packages/mindspore/_extends/parallel_compile/tbe_compiler/compiler.py", line 98, in build_op raise RuntimeError(e) RuntimeError: invalid window params, window_h * window_w should be <= 255 input_args: {"full_name":"Default/AvgPool-op51","gen_model":"single","impl_path":"","op_info":{"attrs":[{"name":"ksize","valid":true,"value":[1,1,30,30]},{"name":"strides","valid":true,"value":[1,1,30,30]},{"name":"padding","valid":true,"value":"VALID"},{"name":"data_format","valid":true,"value":"NCHW"}],"inputs":[[{"dtype":"float16","format":"NC1HWC0","name":"x_0","ori_format":"NCHW","ori_shape":[1,3,60,60],"param_type":"required","shape":[1,1,60,60,16],"valid":true}],[{"name":"filter_optional_1","valid":false}],[{"name":"bias_optional_1","valid":false}]],"kernel_name":"avg_pool_3954512546534469548_0","name":"avg_pool","outputs":[[{"dtype":"float16","format":"NC1HWC0","name":"y","ori_format":"NCHW","ori_shape":[1,3,2,2],"param_type":"required","shape":[1,1,2,2,16],"valid":true}]],"socVersion":"Ascend910"},"platform":"TBE"}
-
 今天带来的是MLSys 2021的一篇论文《A Learned Performance Model for Tensor Processing Units》[1],作者为google brain的Sam Kaufman等人。论文提出了一个基于GNN模型的cost model设计,用来预测张量计算程序在TPU上的执行时间。其实相关工作最早发表于NeurIPS 2019 的ML for Systems workshop[2],简要介绍了该模型的主要架构及流程。在MLSys 2021的这篇文章中,作者对其cost model进一步完善,并且补充了大量的对比实验。背景:由于硬件的稀缺性、运行时长等原因,编译器在解决性能优化问题时通常依赖于性能模型(Cost model),如LLVM通过cost model计算最优向量化和unroll的因子[3]。此外,cost model还常用来为编译器tuning工具评估搜索空间的候选配置参数,用以提升tuning的效率。在AI编译领域,cost model问题显得尤为突出,各类异构深度学习加速器(TPU、NPU等)的出现使得通用cost model的设计变得棘手,同时增加了额外的负担。论文调研并总结了现有深度学习领域cost model存在的问题。作者认为传统的analytical model(如xla中用于提供切分参数使用的性能模型 [4])代价较大,通常需要数月的工程量,而现有的基于学习的建模方法,也存在各自的局限性。如Ithemal [5]没办法处理复杂的多层嵌套循环场景,Halide[6] 的需要繁重的特征工程设计,AutoTVM[7] 对于不同kernel的泛化能力有限等。综上,论文提出了一种基于GNN的Cost model,用来预测张量计算在TPU上的执行时间。该方法可同时满足以下需求:1)通用性,可处理一些复杂的张量计算。2)不同领域的泛化能力。3)不依赖于需要人工开发的繁重的特征工程。4) 可移植性,能够轻松的在不同优化目标上复用。Cost model设计:如上图所示,论文采用了GNN模型的架构:模型的输入包括节点特征(蓝色部分),kernel特征(黄色部分)以及图结构特征(红色邻接矩阵)。节点特征包括opcode(操作类型)及进一步描述节点的标量特征,如output tensor的shape,layout,striding,padding等;kernel特征包括切分大小及可选的静态性能信息(如浮点操作的个数,数据读/写字节数等);邻接矩阵主要表示kernel中节点的数据流依赖关系。论文首先将opcode映射为opcode embedding向量,随后将其同其他节点特征、kernel特征进行拼接,连同邻接矩阵传入GNN,并使用GNN构造各节点。作者在论文中指出,选择GNN模型主要基于2点考虑:1)张量计算的kernel常表示为DAG,2)作者认为在各节点特征中加入相邻节点特征可有效提高不同配置下的泛化性。在实现上,作者选择了GraphSAGE模型[8],通过训练聚合节点邻居的函数,使GCN扩展成归纳学习任务,对未知节点起到泛化作用。通过将节点聚合可进一步构造kernel embedding。论文里列出了3中聚合函数:column-wise聚合。对邻居embedding中每个维度取平均,最大化,相加规约等。LSTM。将拓扑排序后的邻居节点embedding序列 作为LSTM输入。Transformer encoder。对节点 embedding做transformer encoder。最后,将得到的kernel embedding 通过feedforward层线性转换为标量输出即可。该性能模型主要用于两类优化任务,切分参数选择与算子融合评估。对于切分参数选择,主要关注相同kernel不同切分大小下的相对速度,因此模型损失函数可定义为:n为每个batch下样品数;pos(z)为一个分段函数,当z大于0是pos(z)为1,否则为0;φ(z) 要么为损失函数 (1 - z)+ ,要么为对数函数log(1 + e-z)。对于算子融合任务,需要去计算kernel的绝对运行时间,因此将模型损失函数定义为(yi0 - yi)2的对数变换。实验评估:论文实验中的数据来自于实际使用的104个xla程序,并通过随机或人工分裂的方法,构造了超过2000万个kernels作为训练数据集。实验环境为单机NVidia V100 GPU。实验数据如下图所示。对于切分参数任务,baseline为XLA现有的分析模型,分别用Tile-Size APE(可看作同当前最快切分的距离)及肯德尔等级相关系数作为评价指标。从表中可以看出,除了ConvDRAW,论文提出的cost model均能够优于现有分析模型。此外,对于不同的硬件,如TPU V2、V3,该cost model均有不错的表现。对于算子融合任务,在所有的benchmark中,cost model(平均4.5 MAPE)都要明显优于analytical model(平均31.1 MAPE)。这可能是因为XLA中并没有对算子融合任务提供准确的性能模型,只是从是否节约内存空间和访问时间上评估是否可融。此外,这篇论文还做了大量的MODEL ABLATION STUDIES , 对不同节点特征、kernel特征,以及不同的神经网络模型都做了充分的实验分析。作者认为,从张量计算程序的泛化效果来看,使用GraphSAGE比用LSTM或者Transformer更准确,具体实验过程可查阅论文。众所周知,由于TPU价格昂贵,且使用需求频繁,所以希望能够尽量减少TPU上tuning的时间。基于这一需求,论文最后将该cost model集成至XLA的compiler和autotuner中,评估不同tuning场景下的整网性能。上图为Fusion Autotuner的实验对比,Baseline为Autotuner在硬件上Tuning10分钟所得到的最佳融合配置。集成cost model后的autotuner工具则首先在CPU上运行1个小时,然后再在TPU上tuning1-10分钟。从上图结果可以看出,使用costmodel之后,同仅在硬件上tuning相比平均能有1.5%的性能提升。同时,相比最佳融合配置性能差也不超过1.5%,而这些最佳配置是在TPU上运行4小时以上才得到的。 此外,通过使用cost model,可以有效减少在TPU上的tuning时间。上图中tuning时长从10分钟降到1分钟,性能基本上没有裂化。参考文献:[1] Sam Kaufman, Phitchaya Phothilimthana, Yanqi Zhou, Charith Mendis, Sudip Roy, Amit Sabne, Mike Burrows. A Learned Performance Model for Tensor Processing Units. Proceedings of Machine Learning and Systems 3 pre-proceedings (MLSys 2021)[2] Kaufman Samuel, Phothilimthana, Phitchaya Mangpo and Burrows, Mike. Learned TPU cost model for XLA tensor programs. Proceedings of the Workshop on ML for Systems at NeurIPS 2019[3] LLVM. Auto-Vectorization in LLVM. https://bcainllvm.readthedocs.io/projects/llvm/en/latest/Vectorizers. [Online; accessed 03-Feb-2020].[4] TensorFlow. XLA: Optimizing Compiler for TensorFlow. https://www.tensorflow.org/xla. [Online; accessed 19 - September-2019].[5] Mendis, C., Renda, A., Amarasinghe, S. P., and Carbin, M. Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation using Deep Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML, 2019a.[6] Adams, A., Ma, K., Anderson, L., Baghdadi, R., Li, T. M., Gharbi, M., Steiner, B., Johnson, S., Fatahalian, K., Durand, F., and Ragan-Kelley, J. Learning to Optimize Halide with Tree Search and Random Programs. ACM Trans. Graph., 38(4):121:1–121:12, July 2019. ISSN 0730-0301. doi: 10.1145/3306346.3322967. URL http: //http://doi.acm.org/10.1145/3306346.3322967.[7] Chen, T., Zheng, L., Yan, E., Jiang, Z., Moreau, T., Ceze, L., Guestrin, C., and Krishnamurthy, A. Learning to Optimize Tensor Programs. In Proceedings of the 32Nd International Conference on Neural Information Processing Systems, NIPS’18, 2018.[8] Hamilton, W. L., Ying, Z., and Leskovec, J. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems, 2017转自文章链接:https://zhuanlan.zhihu.com/p/365048258转自作者:金雪锋感谢作者的努力与分享,侵权立删!
今天带来的是MLSys 2021的一篇论文《A Learned Performance Model for Tensor Processing Units》[1],作者为google brain的Sam Kaufman等人。论文提出了一个基于GNN模型的cost model设计,用来预测张量计算程序在TPU上的执行时间。其实相关工作最早发表于NeurIPS 2019 的ML for Systems workshop[2],简要介绍了该模型的主要架构及流程。在MLSys 2021的这篇文章中,作者对其cost model进一步完善,并且补充了大量的对比实验。背景:由于硬件的稀缺性、运行时长等原因,编译器在解决性能优化问题时通常依赖于性能模型(Cost model),如LLVM通过cost model计算最优向量化和unroll的因子[3]。此外,cost model还常用来为编译器tuning工具评估搜索空间的候选配置参数,用以提升tuning的效率。在AI编译领域,cost model问题显得尤为突出,各类异构深度学习加速器(TPU、NPU等)的出现使得通用cost model的设计变得棘手,同时增加了额外的负担。论文调研并总结了现有深度学习领域cost model存在的问题。作者认为传统的analytical model(如xla中用于提供切分参数使用的性能模型 [4])代价较大,通常需要数月的工程量,而现有的基于学习的建模方法,也存在各自的局限性。如Ithemal [5]没办法处理复杂的多层嵌套循环场景,Halide[6] 的需要繁重的特征工程设计,AutoTVM[7] 对于不同kernel的泛化能力有限等。综上,论文提出了一种基于GNN的Cost model,用来预测张量计算在TPU上的执行时间。该方法可同时满足以下需求:1)通用性,可处理一些复杂的张量计算。2)不同领域的泛化能力。3)不依赖于需要人工开发的繁重的特征工程。4) 可移植性,能够轻松的在不同优化目标上复用。Cost model设计:如上图所示,论文采用了GNN模型的架构:模型的输入包括节点特征(蓝色部分),kernel特征(黄色部分)以及图结构特征(红色邻接矩阵)。节点特征包括opcode(操作类型)及进一步描述节点的标量特征,如output tensor的shape,layout,striding,padding等;kernel特征包括切分大小及可选的静态性能信息(如浮点操作的个数,数据读/写字节数等);邻接矩阵主要表示kernel中节点的数据流依赖关系。论文首先将opcode映射为opcode embedding向量,随后将其同其他节点特征、kernel特征进行拼接,连同邻接矩阵传入GNN,并使用GNN构造各节点。作者在论文中指出,选择GNN模型主要基于2点考虑:1)张量计算的kernel常表示为DAG,2)作者认为在各节点特征中加入相邻节点特征可有效提高不同配置下的泛化性。在实现上,作者选择了GraphSAGE模型[8],通过训练聚合节点邻居的函数,使GCN扩展成归纳学习任务,对未知节点起到泛化作用。通过将节点聚合可进一步构造kernel embedding。论文里列出了3中聚合函数:column-wise聚合。对邻居embedding中每个维度取平均,最大化,相加规约等。LSTM。将拓扑排序后的邻居节点embedding序列 作为LSTM输入。Transformer encoder。对节点 embedding做transformer encoder。最后,将得到的kernel embedding 通过feedforward层线性转换为标量输出即可。该性能模型主要用于两类优化任务,切分参数选择与算子融合评估。对于切分参数选择,主要关注相同kernel不同切分大小下的相对速度,因此模型损失函数可定义为:n为每个batch下样品数;pos(z)为一个分段函数,当z大于0是pos(z)为1,否则为0;φ(z) 要么为损失函数 (1 - z)+ ,要么为对数函数log(1 + e-z)。对于算子融合任务,需要去计算kernel的绝对运行时间,因此将模型损失函数定义为(yi0 - yi)2的对数变换。实验评估:论文实验中的数据来自于实际使用的104个xla程序,并通过随机或人工分裂的方法,构造了超过2000万个kernels作为训练数据集。实验环境为单机NVidia V100 GPU。实验数据如下图所示。对于切分参数任务,baseline为XLA现有的分析模型,分别用Tile-Size APE(可看作同当前最快切分的距离)及肯德尔等级相关系数作为评价指标。从表中可以看出,除了ConvDRAW,论文提出的cost model均能够优于现有分析模型。此外,对于不同的硬件,如TPU V2、V3,该cost model均有不错的表现。对于算子融合任务,在所有的benchmark中,cost model(平均4.5 MAPE)都要明显优于analytical model(平均31.1 MAPE)。这可能是因为XLA中并没有对算子融合任务提供准确的性能模型,只是从是否节约内存空间和访问时间上评估是否可融。此外,这篇论文还做了大量的MODEL ABLATION STUDIES , 对不同节点特征、kernel特征,以及不同的神经网络模型都做了充分的实验分析。作者认为,从张量计算程序的泛化效果来看,使用GraphSAGE比用LSTM或者Transformer更准确,具体实验过程可查阅论文。众所周知,由于TPU价格昂贵,且使用需求频繁,所以希望能够尽量减少TPU上tuning的时间。基于这一需求,论文最后将该cost model集成至XLA的compiler和autotuner中,评估不同tuning场景下的整网性能。上图为Fusion Autotuner的实验对比,Baseline为Autotuner在硬件上Tuning10分钟所得到的最佳融合配置。集成cost model后的autotuner工具则首先在CPU上运行1个小时,然后再在TPU上tuning1-10分钟。从上图结果可以看出,使用costmodel之后,同仅在硬件上tuning相比平均能有1.5%的性能提升。同时,相比最佳融合配置性能差也不超过1.5%,而这些最佳配置是在TPU上运行4小时以上才得到的。 此外,通过使用cost model,可以有效减少在TPU上的tuning时间。上图中tuning时长从10分钟降到1分钟,性能基本上没有裂化。参考文献:[1] Sam Kaufman, Phitchaya Phothilimthana, Yanqi Zhou, Charith Mendis, Sudip Roy, Amit Sabne, Mike Burrows. A Learned Performance Model for Tensor Processing Units. Proceedings of Machine Learning and Systems 3 pre-proceedings (MLSys 2021)[2] Kaufman Samuel, Phothilimthana, Phitchaya Mangpo and Burrows, Mike. Learned TPU cost model for XLA tensor programs. Proceedings of the Workshop on ML for Systems at NeurIPS 2019[3] LLVM. Auto-Vectorization in LLVM. https://bcainllvm.readthedocs.io/projects/llvm/en/latest/Vectorizers. [Online; accessed 03-Feb-2020].[4] TensorFlow. XLA: Optimizing Compiler for TensorFlow. https://www.tensorflow.org/xla. [Online; accessed 19 - September-2019].[5] Mendis, C., Renda, A., Amarasinghe, S. P., and Carbin, M. Ithemal: Accurate, Portable and Fast Basic Block Throughput Estimation using Deep Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML, 2019a.[6] Adams, A., Ma, K., Anderson, L., Baghdadi, R., Li, T. M., Gharbi, M., Steiner, B., Johnson, S., Fatahalian, K., Durand, F., and Ragan-Kelley, J. Learning to Optimize Halide with Tree Search and Random Programs. ACM Trans. Graph., 38(4):121:1–121:12, July 2019. ISSN 0730-0301. doi: 10.1145/3306346.3322967. URL http: //http://doi.acm.org/10.1145/3306346.3322967.[7] Chen, T., Zheng, L., Yan, E., Jiang, Z., Moreau, T., Ceze, L., Guestrin, C., and Krishnamurthy, A. Learning to Optimize Tensor Programs. In Proceedings of the 32Nd International Conference on Neural Information Processing Systems, NIPS’18, 2018.[8] Hamilton, W. L., Ying, Z., and Leskovec, J. Inductive Representation Learning on Large Graphs. In Advances in Neural Information Processing Systems, 2017转自文章链接:https://zhuanlan.zhihu.com/p/365048258转自作者:金雪锋感谢作者的努力与分享,侵权立删! -
 **操作系统,轻量开源 一个内核很重要——LiteOS Kernel** Huawei LiteOS操作系统的基础架构是一个1+N的架构,其中1指一个内核,n指N个中间件。这n个中间件包含了LiteOS的互联框架、传感框架、安全框架、运行引擎 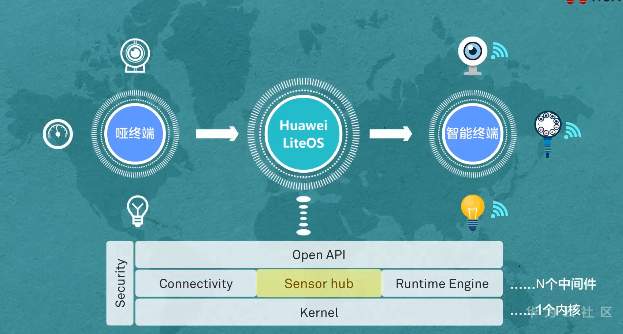 ### LiteOS基础内核是最精简的LiteOS操作系统 **包括任务管理、内存管理、中断管理、队列管理、事件管理、通信机制、时间管理、定时器等操作系统基础组件**  ### 任务管理 -任务是竞争系统资源的最小运行单元 -任务可以使用或等待cpu使用内存空间等系统资源 -并独立于其他任务运行 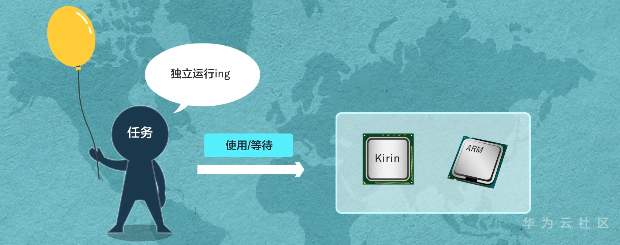 -嵌入式基本都是单进程多线程 什么是进程?什么是线程? 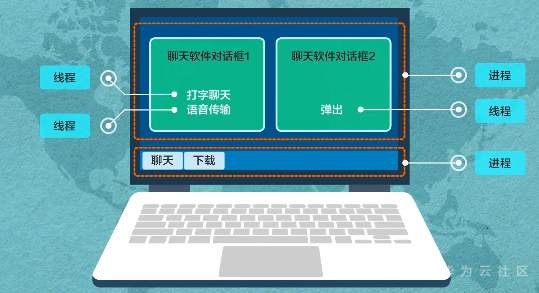 **我们说的任务就是线程** -任务是抢占式调度机制 -支持时间片轮转调度机制 HUAWEI LiteOS的任务模块提供任务的创建、删除、延迟、挂起、恢复等功能以及锁定和解锁任务调度(任务调度可以锁定和解锁) 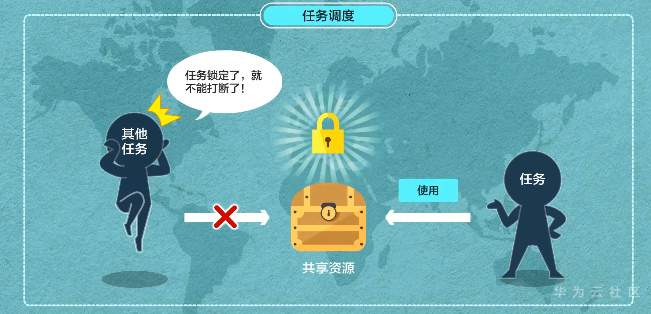 ### 内存管理模块管理系统的内存资源 -它是操作系统的核心模块之一 -内存在物理上就是一段连续的地址 -如果没有操作系统,应用开发者需要自己去分配内存,会存在较为严重的内存碎片化问题 -Huawei LiteOS的内存管理提供静态内存和动态内存两种算法,支持内存申请、释放 ### 动态内存是动态内存池中分配用户指定大小的内存块 优点“按需分配” 缺点“内存池中会出现碎片” 算法“动态申请DLINK算法和Best Little算法” ### 静态内存是静态内存池中分配用户初始化时预设大小的内存卡 优点“分配和释放效率高 静态内存池中无碎片” 缺点“不能按需申请” 算法“固定大小的BOX算法” ### 中断管理:中断创建、开/关中断 恢复中断、中断使能、中断屏蔽、中断删除 -指出现需要时,cpu暂停执行当前程序转而执行新程序的过程 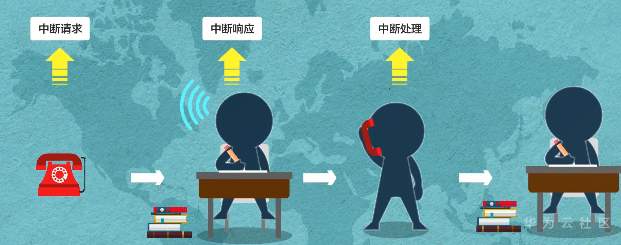 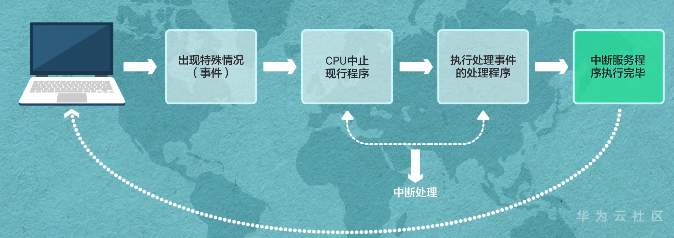 ### 队列管理:创建 删除 发送 接收 -队列又称消息队列 -是一种常用于任务间通信的数据结构 -实现了接收来自任务或中断的不固定长度的消息 -并根据不同的接口选择传递消息是否存放在自己空间 -消息队列可以先入先出或先入后出 -可以在任务间通信 ### 事件管理 -可以在IPC通信inter-process communication的是事件 -事件就是简单的事件触发  ### 通信机制 -信号量是一种实现任务间通信的机制 -实现任务之间同步或临界资源的互斥访问 -常用于协助一组相互竞争的任务来访问临界资源 -信号量表示还有多少任务可以做该共享资源的访问 -与信号量一样用于任务同步的还有互斥锁 -互斥锁可以理解为是特殊的信号量作两个以上任务对有限的共享资源做访问时保护、防止冲突 -互斥锁表示任务是否可以做该共享资源的访问    ### 时间管理 感知时间管理时间 MCU时钟源-系统主频 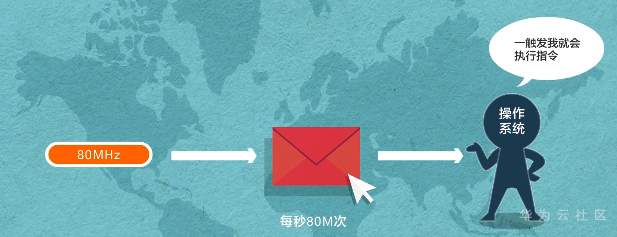  -时间片调度 每个任务对cpu可以做最小分片-cpu时间分片调度 单位tick 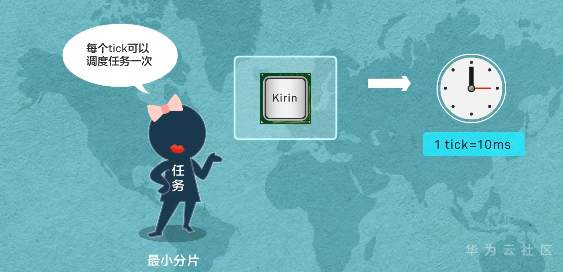 
**操作系统,轻量开源 一个内核很重要——LiteOS Kernel** Huawei LiteOS操作系统的基础架构是一个1+N的架构,其中1指一个内核,n指N个中间件。这n个中间件包含了LiteOS的互联框架、传感框架、安全框架、运行引擎  ### LiteOS基础内核是最精简的LiteOS操作系统 **包括任务管理、内存管理、中断管理、队列管理、事件管理、通信机制、时间管理、定时器等操作系统基础组件**  ### 任务管理 -任务是竞争系统资源的最小运行单元 -任务可以使用或等待cpu使用内存空间等系统资源 -并独立于其他任务运行  -嵌入式基本都是单进程多线程 什么是进程?什么是线程?  **我们说的任务就是线程** -任务是抢占式调度机制 -支持时间片轮转调度机制 HUAWEI LiteOS的任务模块提供任务的创建、删除、延迟、挂起、恢复等功能以及锁定和解锁任务调度(任务调度可以锁定和解锁)  ### 内存管理模块管理系统的内存资源 -它是操作系统的核心模块之一 -内存在物理上就是一段连续的地址 -如果没有操作系统,应用开发者需要自己去分配内存,会存在较为严重的内存碎片化问题 -Huawei LiteOS的内存管理提供静态内存和动态内存两种算法,支持内存申请、释放 ### 动态内存是动态内存池中分配用户指定大小的内存块 优点“按需分配” 缺点“内存池中会出现碎片” 算法“动态申请DLINK算法和Best Little算法” ### 静态内存是静态内存池中分配用户初始化时预设大小的内存卡 优点“分配和释放效率高 静态内存池中无碎片” 缺点“不能按需申请” 算法“固定大小的BOX算法” ### 中断管理:中断创建、开/关中断 恢复中断、中断使能、中断屏蔽、中断删除 -指出现需要时,cpu暂停执行当前程序转而执行新程序的过程   ### 队列管理:创建 删除 发送 接收 -队列又称消息队列 -是一种常用于任务间通信的数据结构 -实现了接收来自任务或中断的不固定长度的消息 -并根据不同的接口选择传递消息是否存放在自己空间 -消息队列可以先入先出或先入后出 -可以在任务间通信 ### 事件管理 -可以在IPC通信inter-process communication的是事件 -事件就是简单的事件触发  ### 通信机制 -信号量是一种实现任务间通信的机制 -实现任务之间同步或临界资源的互斥访问 -常用于协助一组相互竞争的任务来访问临界资源 -信号量表示还有多少任务可以做该共享资源的访问 -与信号量一样用于任务同步的还有互斥锁 -互斥锁可以理解为是特殊的信号量作两个以上任务对有限的共享资源做访问时保护、防止冲突 -互斥锁表示任务是否可以做该共享资源的访问    ### 时间管理 感知时间管理时间 MCU时钟源-系统主频   -时间片调度 每个任务对cpu可以做最小分片-cpu时间分片调度 单位tick   -
请问在使用perf时,相应的PMU events对应的Raw hardware event descriptor都是什么呢?例如,hisi_sccl7_hha4/rx_outer/。想用libpfm来查询上述PMU的指标,能否使用这种rNNN的方式呢,但不清楚二者映射的关系,谢谢。
-
【问题现象】Init resource successInit model resource start...[Model] create model output dataset:malloc output 0, size 6528000malloc output 1, size 1632000malloc output 2, size 408000Create model output dataset successInit model resource success[ERROR] RUNTIME(19310)model execute error, retCode=0x91, [the model stream execute failed].Execute model failed for acl.mdl.execute error 507011[ERROR] RUNTIME(19310)model execute task failed, device_id=0, model stream_id=545, model task_id=1, model_id=516, first_task_id=65535[ERROR] RUNTIME(19310)aicpu kernel execute failed, device_id=0, stream_id=531, task_id=12, fault so_name=libcpu_kernels.so, fault kernel_name=RunCpuKernel, extend_info=.[ERROR] RUNTIME(19310)model execute error, retCode=0x91, [the model stream execute failed].Execute model failed for acl.mdl.execute error 507011[ERROR] RUNTIME(19310)model execute task failed, device_id=0, model stream_id=545, model task_id=2, model_id=516, first_task_id=65535[ERROR] RUNTIME(19310)aicpu kernel execute failed, device_id=0, stream_id=531, task_id=12, fault so_name=libcpu_kernels.so, fault kernel_name=RunCpuKernel, extend_info=.Execute endacl resource release all resource【问题处理】配置ASCEND_AICPU_PATH/TOOLCHAIN_HOME的环境变量export ASCEND_AICPU_PATH=${install_path}/{arch}-linux #其中{arch}请根据实际情况替换(arm64或x86_64) export TOOLCHAIN_HOME=${install_path}/toolkithttps://support.huaweicloud.com/instg-cli-cann330/atlasrun_03_0044.html模型可以推理成功原始问题https://gitee.com/ascend/samples/issues/I3EP3P?from=project-issue
-
多引擎实例,用MXNet,始终无法连接kernel,只有conda-python就可以连接kernel.
-
上滑加载中
推荐直播
0.25
-
 华为云Metastudio×DeepSeek与RAG检索优化分享
华为云Metastudio×DeepSeek与RAG检索优化分享2025/03/14 周五 16:00-17:30
大海 华为云学堂技术讲师 Cocl 华为云学堂技术讲师
本次直播将带来DeepSeek数字人解决方案,以及如何使用Embedding与Rerank实现检索优化实践,为开发者与企业提供参考,助力场景落地。
回顾中 -

-
 华为开发者空间玩转DeepSeek
华为开发者空间玩转DeepSeek2025/03/13 周四 19:00-20:30
马欣 山东商业职业技术学院云计算专业讲师,山东大学、山东建筑大学等多所本科学校学生校外指导老师
同学们,想知道如何利用华为开发者空间部署自己的DeepSeek模型吗?想了解如何用DeepSeek在云主机上探索好玩的应用吗?想探讨如何利用DeepSeek在自己的专有云主机上辅助编程吗?让我们来一场云和AI的盛宴。
回顾中 -
华为云Metastudio×DeepSeek与RAG检索优化分享
2025/03/14 周五 16:00-17:30
大海 华为云学堂技术讲师 Cocl 华为云学堂技术讲师
本次直播将带来DeepSeek数字人解决方案,以及如何使用Embedding与Rerank实现检索优化实践,为开发者与企业提供参考,助力场景落地。
回顾中 -
热门标签







