-
 volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰no-enviction(驱逐):禁止驱逐数据
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰no-enviction(驱逐):禁止驱逐数据 -
 # 华为FusionInsight MRS实战 - 使用FlinkSQL处理数据并使用redis做实时展示 ## 场景说明 【需求】计算最近1小时各个账户交易总金额。 【分析】将账户交易数据接入Kafka中,通过Flink计算过去1小时各个账户的交易总金额,将计算结果写入Redis中。做实时大屏展示。 【实现】通过FlinkSQL的滚动窗口计算 数据流图 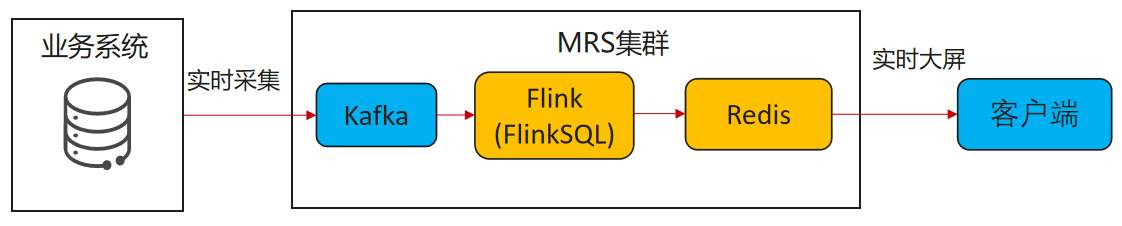 ## 操作步骤 - 登录华为FusionInisght MRS Flink WebUI  - 在作业管理选择新建作业创建一个FlinkSQL任务 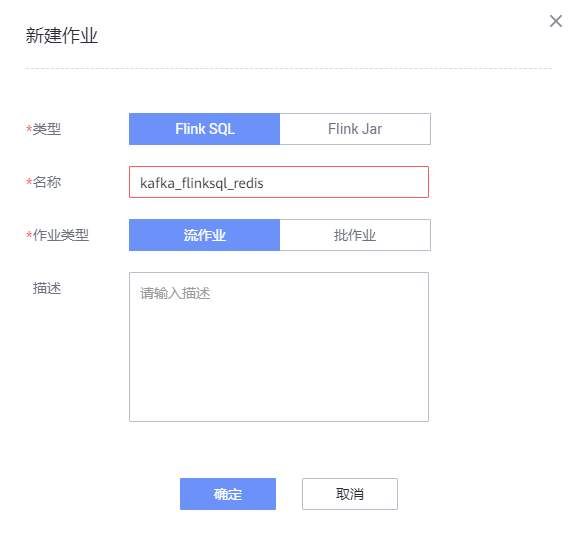 - 编辑如下Flink SQL语句 ``` CREATE TABLE kafka_source ( account varchar(10), cost int, ts AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'redisdemo', 'properties.bootstrap.servers' = '172.16.9.117:21005', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ); CREATE SINK STREAM redis_sink( account varchar, costs int, PRIMARY KEY(account) ) WITH ( 'isSafeMode' = 'true', 'clusterAddress' = '172.16.9.117:22404,172.16.9.118:22404,172.16.9.113:22404', 'redistype' = 'String', 'type' = 'Redis', 'isSSLMode' = 'false' ); INSERT INTO redis_sink SELECT account, SUM(cost) FROM kafka_source GROUP BY TUMBLE(ts, INTERVAL '10' SECOND), --为了快算看到计算结果使用10s窗口 account; ``` - 点击语义校验,确保语义校验通过 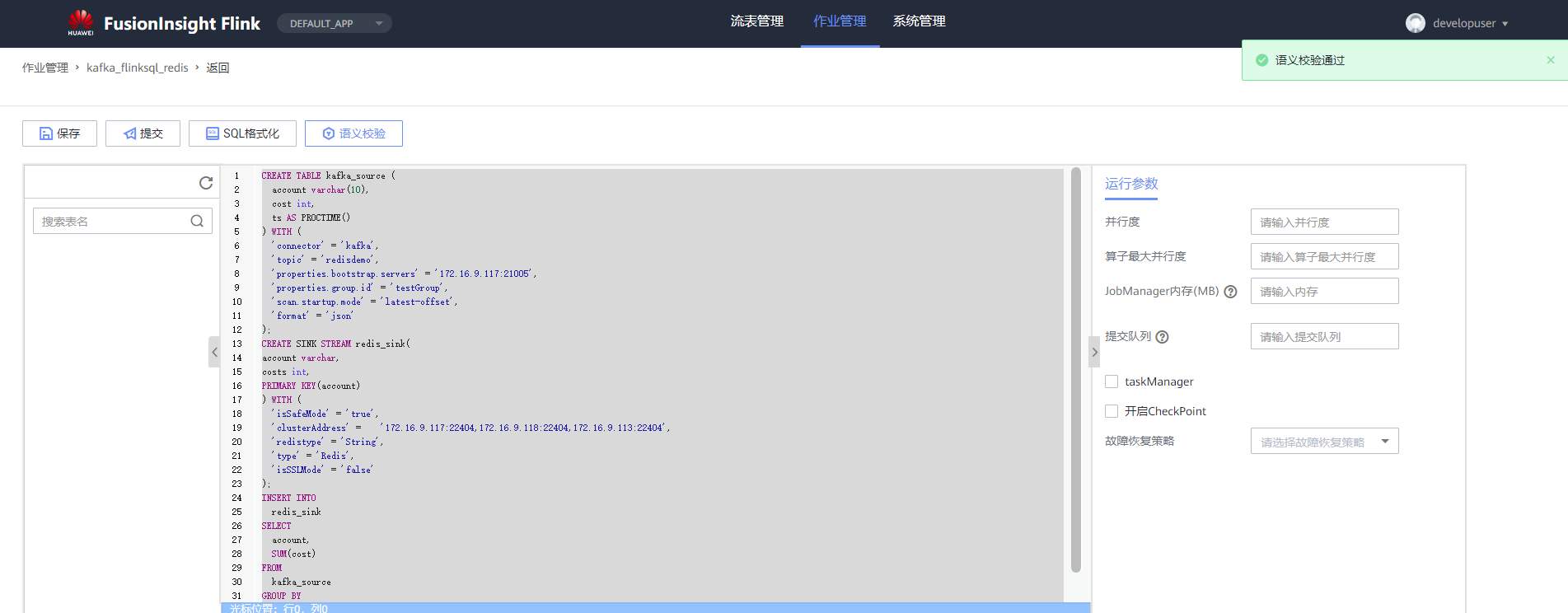 - 启动该Flink SQL任务 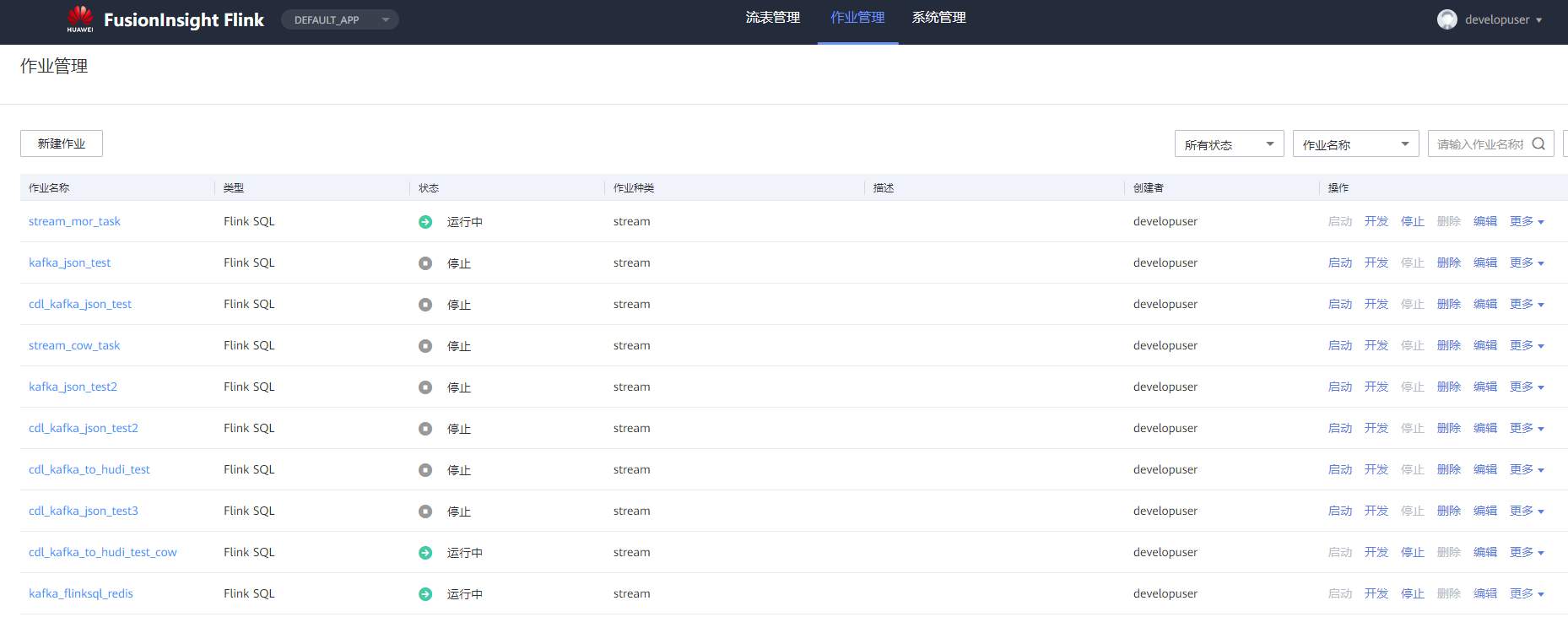 - 使用kafka客户端插入测试数据 ``` {"account": "A1","cost":"11"} {"account": "A1","cost":"22"} {"account": "A2","cost":"33"} {"account": "A3","cost":"44"} ```  注意: 因为flink窗口时间为10秒,并且redis是key value数据库,数据会根据主键覆盖,所以需要在10s内将数据全部输入 - 登录redis客户端查看结果: `redis-cli -c -h 172.16.9.117 -p 22404` 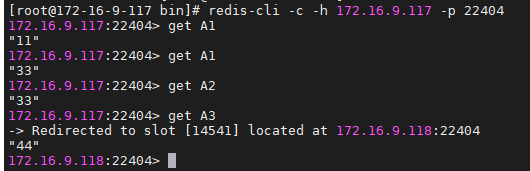
# 华为FusionInsight MRS实战 - 使用FlinkSQL处理数据并使用redis做实时展示 ## 场景说明 【需求】计算最近1小时各个账户交易总金额。 【分析】将账户交易数据接入Kafka中,通过Flink计算过去1小时各个账户的交易总金额,将计算结果写入Redis中。做实时大屏展示。 【实现】通过FlinkSQL的滚动窗口计算 数据流图  ## 操作步骤 - 登录华为FusionInisght MRS Flink WebUI  - 在作业管理选择新建作业创建一个FlinkSQL任务  - 编辑如下Flink SQL语句 ``` CREATE TABLE kafka_source ( account varchar(10), cost int, ts AS PROCTIME() ) WITH ( 'connector' = 'kafka', 'topic' = 'redisdemo', 'properties.bootstrap.servers' = '172.16.9.117:21005', 'properties.group.id' = 'testGroup', 'scan.startup.mode' = 'latest-offset', 'format' = 'json' ); CREATE SINK STREAM redis_sink( account varchar, costs int, PRIMARY KEY(account) ) WITH ( 'isSafeMode' = 'true', 'clusterAddress' = '172.16.9.117:22404,172.16.9.118:22404,172.16.9.113:22404', 'redistype' = 'String', 'type' = 'Redis', 'isSSLMode' = 'false' ); INSERT INTO redis_sink SELECT account, SUM(cost) FROM kafka_source GROUP BY TUMBLE(ts, INTERVAL '10' SECOND), --为了快算看到计算结果使用10s窗口 account; ``` - 点击语义校验,确保语义校验通过  - 启动该Flink SQL任务  - 使用kafka客户端插入测试数据 ``` {"account": "A1","cost":"11"} {"account": "A1","cost":"22"} {"account": "A2","cost":"33"} {"account": "A3","cost":"44"} ```  注意: 因为flink窗口时间为10秒,并且redis是key value数据库,数据会根据主键覆盖,所以需要在10s内将数据全部输入 - 登录redis客户端查看结果: `redis-cli -c -h 172.16.9.117 -p 22404`  -
 在共享数据加速,保持数据(如订单数据)一致性的场景下,采用单主多从的缓存模式,在两个数据中心更新缓存时,是先写到一个Redis Master集群中,然后从一个Redis Master集群同步到两个数据中心的Redis Slave集群中,整个请求的逻辑就是:请求进入其中一个机房的微服务中,微服务首先会读取微服务本地的一级缓存,如果没有命中,再去本数据中心的Redis Slave集群进行查询,如果还是没有命中,再回源到本数据中心的数据库中进行查询,将读取后的数据写入到Redis Master集群,同时更新本地的一级缓存和Redis Slave集群,当然Redis Master集群也会将数据同步更新到另一个数据中心的Redis Slave集群中。这种单写多读的缓存模式实现数据加速以及保证数据一致性的要求。目前这种跨机房的主从同步延时并不明显,延迟在一两毫秒左右。在共享数据加速但不考虑数据(商品)一致性的场景下,也是采用多活的理念,即在两个数据中心部署完全对等的缓存集群。在上图的机房一中,当有数据请求时,首先从本地一级缓存进行查询,如果没有命中,再去查本地的Redis集群,依旧没有命中时,回源到本地的数据库进行查询,同时将查询到的数据更新到本数据中心的Redis集群。虽然两个数据中心的缓存集群部署一致,但是在Redis集群中存的数据可能不一致。数据层作为六层架构中的最底层,主要的应用还是基于MySQL的主从模式。下面提到的特点是在非核心业务上的一些尝试,并没有大面积应用:同城双活,即由业务层来控制数据的实时性和最终一致性,而不是通过数据同步来保证实时性和一致性。业务层双写,数据异步分发至两个数据中心,任意机房写入的数据通过异步消息的方式分发到另一个机房,以此来保证两个机房数据的最终一致性。业务层通过二级查询保证数据的实时一致性,由于业务层双写只能保证数据的最终一致性,无法保证实时一致性,因此,针对具有实时一致性要求的业务场景,我们通过业务层的二级查询来保证。 重复写入应对单机房故障,当任意机房出现故障时,如果写入的数据还没有分发至另一个机房,则由业务层在可用机房重复写入数据,通过算法来生成相同的ID。通过failover库为高可用提供双重保险,针对流水型业务数据,在数据库故障时,需要进行主从切换,此时通过业务层将所有数据的读写切换至failover库,主库恢复以后再将流量切回主库。垂直拆分与水平拆分结合使用。 服务化 之所以需要服务化,是因为在做服务化之前系统高度耦合,牵一发而动全身,直接影响到系统可用性;同时业务相互影响,系统很难维护;系统逻辑过于耦合,很难进行水平扩展;也无法通过流控、降级等手段保障系统的可用性;此外由于系统的高度耦合,极易产生雪崩效应。因此基于上述原因,服务化改造势在必行。对于服务化而言,最核心的就是服务的发现、注册、调用。目前有货采用的是Spring+Register+Zookeeper搭建的最简单的服务框架,通过Zookeeper完成的服务注册和发现,通过Register完成服务的调用。集中式的LoadBalance,在服务消费者和提供者之间通过阿里云的负载均衡或者F5搭建独立的LoadBalance,通过集中式的负载均衡设备完成对服务调用的负载均衡;在进程内做负载均衡,即软负载的方式,将负载均衡策略渗入到服务框架里面,服务消费者作为负载均衡的客户端,请求只需要从服务注册中心获取最新的服务列表,利用服务框架自身携带的负载均衡策略,完成负载均衡的调用。在服务降级方面,通过使用开源的Hystrix配置服务超时时间,当服务调用超时时,直接返回或执行Fallback逻辑。另外基于Hystrix提供的熔断器组件,可以自动运行或手动调用对当前服务进行暂停后再重新调用服务。流量控制方面,通过计数器服务限定单位时间内当前服务的最大调用次数(比如600次/分钟),如果超过则拒绝,以保证系统的可用性;同时为每个服务提供一个小的线程池,如果线程池已满,调用将被立即拒绝,默认不采用排队,加速失败判定时间。服务化中,对于服务的监控、性能优化以及调用链的分析也尤为重要。通过Hystrix提供的服务化监控工具实时观察在线服务的运行状态,有了监控之后可以进行相应的性能优化。对于调用链分析,当请求从网关层进入时,追加一个Trace ID,Trace ID会在整个调用过程中保留,最后通过分析Trace ID将整个请求的调用链串联起来。
在共享数据加速,保持数据(如订单数据)一致性的场景下,采用单主多从的缓存模式,在两个数据中心更新缓存时,是先写到一个Redis Master集群中,然后从一个Redis Master集群同步到两个数据中心的Redis Slave集群中,整个请求的逻辑就是:请求进入其中一个机房的微服务中,微服务首先会读取微服务本地的一级缓存,如果没有命中,再去本数据中心的Redis Slave集群进行查询,如果还是没有命中,再回源到本数据中心的数据库中进行查询,将读取后的数据写入到Redis Master集群,同时更新本地的一级缓存和Redis Slave集群,当然Redis Master集群也会将数据同步更新到另一个数据中心的Redis Slave集群中。这种单写多读的缓存模式实现数据加速以及保证数据一致性的要求。目前这种跨机房的主从同步延时并不明显,延迟在一两毫秒左右。在共享数据加速但不考虑数据(商品)一致性的场景下,也是采用多活的理念,即在两个数据中心部署完全对等的缓存集群。在上图的机房一中,当有数据请求时,首先从本地一级缓存进行查询,如果没有命中,再去查本地的Redis集群,依旧没有命中时,回源到本地的数据库进行查询,同时将查询到的数据更新到本数据中心的Redis集群。虽然两个数据中心的缓存集群部署一致,但是在Redis集群中存的数据可能不一致。数据层作为六层架构中的最底层,主要的应用还是基于MySQL的主从模式。下面提到的特点是在非核心业务上的一些尝试,并没有大面积应用:同城双活,即由业务层来控制数据的实时性和最终一致性,而不是通过数据同步来保证实时性和一致性。业务层双写,数据异步分发至两个数据中心,任意机房写入的数据通过异步消息的方式分发到另一个机房,以此来保证两个机房数据的最终一致性。业务层通过二级查询保证数据的实时一致性,由于业务层双写只能保证数据的最终一致性,无法保证实时一致性,因此,针对具有实时一致性要求的业务场景,我们通过业务层的二级查询来保证。 重复写入应对单机房故障,当任意机房出现故障时,如果写入的数据还没有分发至另一个机房,则由业务层在可用机房重复写入数据,通过算法来生成相同的ID。通过failover库为高可用提供双重保险,针对流水型业务数据,在数据库故障时,需要进行主从切换,此时通过业务层将所有数据的读写切换至failover库,主库恢复以后再将流量切回主库。垂直拆分与水平拆分结合使用。 服务化 之所以需要服务化,是因为在做服务化之前系统高度耦合,牵一发而动全身,直接影响到系统可用性;同时业务相互影响,系统很难维护;系统逻辑过于耦合,很难进行水平扩展;也无法通过流控、降级等手段保障系统的可用性;此外由于系统的高度耦合,极易产生雪崩效应。因此基于上述原因,服务化改造势在必行。对于服务化而言,最核心的就是服务的发现、注册、调用。目前有货采用的是Spring+Register+Zookeeper搭建的最简单的服务框架,通过Zookeeper完成的服务注册和发现,通过Register完成服务的调用。集中式的LoadBalance,在服务消费者和提供者之间通过阿里云的负载均衡或者F5搭建独立的LoadBalance,通过集中式的负载均衡设备完成对服务调用的负载均衡;在进程内做负载均衡,即软负载的方式,将负载均衡策略渗入到服务框架里面,服务消费者作为负载均衡的客户端,请求只需要从服务注册中心获取最新的服务列表,利用服务框架自身携带的负载均衡策略,完成负载均衡的调用。在服务降级方面,通过使用开源的Hystrix配置服务超时时间,当服务调用超时时,直接返回或执行Fallback逻辑。另外基于Hystrix提供的熔断器组件,可以自动运行或手动调用对当前服务进行暂停后再重新调用服务。流量控制方面,通过计数器服务限定单位时间内当前服务的最大调用次数(比如600次/分钟),如果超过则拒绝,以保证系统的可用性;同时为每个服务提供一个小的线程池,如果线程池已满,调用将被立即拒绝,默认不采用排队,加速失败判定时间。服务化中,对于服务的监控、性能优化以及调用链的分析也尤为重要。通过Hystrix提供的服务化监控工具实时观察在线服务的运行状态,有了监控之后可以进行相应的性能优化。对于调用链分析,当请求从网关层进入时,追加一个Trace ID,Trace ID会在整个调用过程中保留,最后通过分析Trace ID将整个请求的调用链串联起来。 -
项目背景:用户通过域名访问vip, nginx做为负载均衡为后端应用分发请求, 后端应用为dubbo服务,存储分为redis和mysql. redis做为持久会存储数据库,支持前端业力. 并且通过mq同步数据到mysql,供后端使用. 同时后台写mysql也要通过mq同步到redis.目前后端服务qps最高可以达到5万,本次架构设计在不重构的情况下短期内最快的方法达到目标10万qps.架构方案:一,现有idc架构可支撑5万qps。这是经过一年考验下来的,可做为保底的;如果应用全部上云,需要从0开始重新验证能否达到现有5万qps,再去验证能否达到10万qps,时间等未知风验很大; 二,10万qps目标,建议用简单粗暴的方式,直接把idc应用层架构复制一套上云;不建议在现有架构上继续调优,现在架构如果不重构,可能很难找到问题;与其这样不如把人力时间用到另一个方向,比如数据中心; 三,由idc+公有云两套系统构成混合云模式,数据统一使用idc的redis和mysql,公有云与idc 的数据库连接建立专线;混合云的方式可以检测公有云的实际性能,也能为将来全部迁移公有云提供真实参考; 四,平时比赛,使用idc架构完全可以支撑,公有云留少量机器和用户请求预热,重要比赛,临时增加云资源扛突发,服务器成本节约,扩展性也灵活; 五,公有云都有出现过大规模事故,造成全站不能访问的情况,为了保险,我们依然要保留idc的服务,所以混合云也许是最适合的; 技术难点: 一,如何将用户请求分流到 idc和公有云两套应用 1,域名解析两条A记录,分别指向idc和公有云两个vip,通过dns平均分配用户请求 2,idc架构在nginx前端增加四层负载均衡(lvs,ha_porxy),由四层负载均衡将用户请求转发给idc的nginx和公有云的负载均衡,lvs与公有云通信通过专线; 二,前端应用入口放大,后端数据中心,需要扩容 1,redis使用多主多从,redis3.0 还是用 代理(predixy,codis); 2,业务拆分,组建更多的一主多从; 具体实施: 1,双系统流量分发配置lvs即可,本赛季最好能用上几轮,演练资源增减,熟悉流程,检测可行性; 2,redis数据中心需要大量的测试,选型,可做重点研究(这也是目前急需解决的单点);
-
 云数据库GaussDB(for Redis)介绍页入口,详情请点击链接云数据库GaussDB(for Redis)成长地图入口,详情请点击链接小云妹又来啦,生命不息,学习不止,今天要着重介绍的是我们的——云数据库GaussDB(for Redis)有着稳定、可靠的企业级产品定位,它完全兼容开源Redis,还能为企业带来降本增效的重要价值。稳定实用就是我~~~
云数据库GaussDB(for Redis)介绍页入口,详情请点击链接云数据库GaussDB(for Redis)成长地图入口,详情请点击链接小云妹又来啦,生命不息,学习不止,今天要着重介绍的是我们的——云数据库GaussDB(for Redis)有着稳定、可靠的企业级产品定位,它完全兼容开源Redis,还能为企业带来降本增效的重要价值。稳定实用就是我~~~ -
 企业级Redis的几个典型需求:海量数据存储、高并发、服务高可用、数据高可靠Redis数据存储在内存中,服务器集群的内存已能达到T级别,能实现每秒几十万上百万级别的高并发。那么Redis如何实现数据高可靠呢?Redis不同于磁盘数据库,服务器宕机或者Redis服务关闭都会导致内存中数据丢失。因此引入Redis的持久化机制,实现灾备,数据恢复,以及服务高可用能力:借助持久化文件的增量同步,实现Redis主备高可用。将持久化文件转移存储,实现异地灾备与数据恢复能力下面简要介绍下Redis数据导出与持久化&远程导出很多场景下,我们需要将远程的Redis数据导出到本地。主要利用了Redis的持久化命令(SAVE/BGSAVE),以及复制命令(SYNC/PSYNC)导出方式1: Redis-liRedis自带命令行工具,它支持导出RDB文件,也支持将持久化的AOF文件整库导入。导出为RDB文件命令:redis-cli -h {redis_address) -p 6379 --rdb {outputfile.rdb}开启AOF持久化命令:redis-cli -h {redis_address) -p 6379 config set appendonly yes注意:此命令会生成一个AOF文件,默认保存在Redis实例运行的安装目录导出方式2: 第三方开源工具redis-portredis-port的导出工作原理,主要是伪装成slave,利用sync命令接收RDB文件。导出为RDB文件命令:redis-dump -n 3 -m {password}@{redis-host}:{port} -o {outputfile. rdb}导出方式3:有些云厂商服务禁用了客户端发起的config/save/sync等命令,导致不能使用redis-cli或第三方工具导出RDB、 AOF文件。不过云厂商一般都提供Redis实例的备份以及备份文件下载功能。下载文件为AOF或RDB格式。
企业级Redis的几个典型需求:海量数据存储、高并发、服务高可用、数据高可靠Redis数据存储在内存中,服务器集群的内存已能达到T级别,能实现每秒几十万上百万级别的高并发。那么Redis如何实现数据高可靠呢?Redis不同于磁盘数据库,服务器宕机或者Redis服务关闭都会导致内存中数据丢失。因此引入Redis的持久化机制,实现灾备,数据恢复,以及服务高可用能力:借助持久化文件的增量同步,实现Redis主备高可用。将持久化文件转移存储,实现异地灾备与数据恢复能力下面简要介绍下Redis数据导出与持久化&远程导出很多场景下,我们需要将远程的Redis数据导出到本地。主要利用了Redis的持久化命令(SAVE/BGSAVE),以及复制命令(SYNC/PSYNC)导出方式1: Redis-liRedis自带命令行工具,它支持导出RDB文件,也支持将持久化的AOF文件整库导入。导出为RDB文件命令:redis-cli -h {redis_address) -p 6379 --rdb {outputfile.rdb}开启AOF持久化命令:redis-cli -h {redis_address) -p 6379 config set appendonly yes注意:此命令会生成一个AOF文件,默认保存在Redis实例运行的安装目录导出方式2: 第三方开源工具redis-portredis-port的导出工作原理,主要是伪装成slave,利用sync命令接收RDB文件。导出为RDB文件命令:redis-dump -n 3 -m {password}@{redis-host}:{port} -o {outputfile. rdb}导出方式3:有些云厂商服务禁用了客户端发起的config/save/sync等命令,导致不能使用redis-cli或第三方工具导出RDB、 AOF文件。不过云厂商一般都提供Redis实例的备份以及备份文件下载功能。下载文件为AOF或RDB格式。 -
主服务器写内存快照,会阻塞主线程的工作,当快照比较大时对性能影响是非常大的,会间断性暂停服务,所以主服务器最好不要写内存快照。Redis 主从复制的性能问题,为了主从复制的速度和连接的稳定性,主从库最好在同一个局域网内。
-
volatile-lru:从已设置过期时间的数据集(server. db[i]. expires)中挑选最近最少使用的数据淘汰。 volatile-ttl:从已设置过期时间的数据集(server. db[i]. expires)中挑选将要过期的数据淘汰。 volatile-random:从已设置过期时间的数据集(server. db[i]. expires)中任意选择数据淘汰。 allkeys-lru:从数据集(server. db[i]. dict)中挑选最近最少使用的数据淘汰。 allkeys-random:从数据集(server. db[i]. dict)中任意选择数据淘汰。 no-enviction(驱逐):禁止驱逐数据。
-
尽量使用 Redis 的散列表,把相关的信息放到散列表里面存储,而不是把每个字段单独存储,这样可以有效的减少内存使用。比如将 Web 系统的用户对象,应该放到散列表里面再整体存储到 Redis,而不是把用户的姓名、年龄、密码、邮箱等字段分别设置 key 进行存储。
-
-
-
Redis 的持久化有两种方式,或者说有两种策略:RDB(Redis Database):指定的时间间隔能对你的数据进行快照存储。AOF(Append Only File):每一个收到的写命令都通过write函数追加到文件中。
-
jedis:提供了比较全面的 Redis 命令的支持。Redisson:实现了分布式和可扩展的 Java 数据结构,与 jedis 相比 Redisson 的功能相对简单,不支持排序、事务、管道、分区等 Redis 特性。
-
-
推荐直播
-
 华为云码道 × 仓颉编程:工程化AI编码探索
华为云码道 × 仓颉编程:工程化AI编码探索2026/05/27 周三 19:00-21:00
刘俊杰-华为云仓颉语言专家/李炎-华为云码道技术专家/王智鹏-OpenCangjie开源社区发起人
本场直播围绕华为云仓颉语言与华为云码道的深度结合,展示华为云智能编程从零基础到高效落地的完整生态能力。以华为云码道为引擎,仓颉语言为载体,带给大家日常提效、趣味创新到极速量产的开发体验。
回顾中
热门标签