-
 GPIO:扩展实例代码(B1):#include <stdio.h>#include <unistd.h>#include "ohos_init.h"#include "cmsis_os2.h"#include "wifiiot_gpio.h"#include "wifiiot_gpio_ex.h"static void LedTask(void){//初始化GPIOGpioInit();//设置GPIO_2的复用功能为普通GPIOIoSetFunc(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_IO_FUNC_GPIO_2_GPIO);//设置GPIO_2为输出模式GpioSetDir(WIFI_IOT_GPIO_IDX_2, WIFI_IOT_GPIO_DIR_OUT);WifiIotGpioDir val = {0};//定义读取变量valGpioGetDir(WIFI_IOT_GPIO_IDX_2, &val);//获取WIFI_IOT_GPIO_IDX_2的引脚方向,并赋值给变量valprintf("GPIO_2 Dir is %d\r\n", val);WifiIotGpioValue OutputVal = {0};//定义读取变量OutputValwhile (1) {//设置GPIO_2输出高电平点亮LED灯GpioSetOutputVal(WIFI_IOT_GPIO_IDX_2, 1);GpioGetOutputVal(WIFI_IOT_GPIO_IDX_2, &OutputVal);//读取WIFI_IOT_GPIO_IDX_2的高电平,并赋值给变量OutputValprintf("GPIO_2 OutputVal is %d\r\n", OutputVal);//延时1susleep(1000000);//设置GPIO_2输出低电平熄灭LED灯GpioSetOutputVal(WIFI_IOT_GPIO_IDX_2, 0);GpioGetOutputVal(WIFI_IOT_GPIO_IDX_2, &OutputVal);//读取WIFI_IOT_GPIO_IDX_2的低电平,并赋值给OutputValprintf("GPIO_2 OutputVal is %d\r\n", OutputVal);//延时1susleep(1000000); }}static void LedExampleEntry(void){osThreadAttr_t attr;attr.name = "LedTask";attr.attr_bits = 0U;attr.cb_mem = NULL;attr.cb_size = 0U;attr.stack_mem = NULL;attr.stack_size = 1024*2;//要打印字符,需要增大任务的空间attr.priority = 25;if (osThreadNew((osThreadFunc_t)LedTask, NULL, &attr) == NULL) {printf("Falied to create LedTask!\n"); }}APP_FEATURE_INIT(LedExampleEntry);GPIO中断:扩展实例代码(B2):#include <stdio.h>#include <unistd.h>#include "ohos_init.h"#include "cmsis_os2.h"#include "wifiiot_gpio.h"#include "wifiiot_gpio_ex.h"static void F1_Pressed(char *arg){ (void)arg;GpioSetOutputVal(WIFI_IOT_IO_NAME_GPIO_2, 1);//点亮LEDprintf("This is F1_Pressed\r\n");GpioSetIsrMode(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_GPIO_EDGE_RISE_LEVEL_HIGH);//将WIFI_IOT_IO_NAME_GPIO_11的模式修改为电平由低到高才触发中断}static void F2_Pressed(char *arg){ (void)arg;GpioSetOutputVal(WIFI_IOT_IO_NAME_GPIO_2, 0);//熄灭LEDprintf("This is F1_Pressed\r\n");GpioSetIsrMask(WIFI_IOT_IO_NAME_GPIO_12, 1);//屏蔽WIFI_IOT_IO_NAME_GPIO_12的中断功能}static void ButtonExampleEntry(void){GpioInit();//初始化LED灯IoSetFunc(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_IO_FUNC_GPIO_2_GPIO);GpioSetDir(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_GPIO_DIR_OUT);//初始化F1按键,设置为下降沿触发中断(即电平由高到低触发中断)IoSetFunc(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_IO_FUNC_GPIO_11_GPIO);GpioSetDir(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_GPIO_DIR_IN);IoSetPull(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_IO_PULL_UP);GpioRegisterIsrFunc(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_GPIO_EDGE_FALL_LEVEL_LOW, F1_Pressed, NULL);//初始化F2按键,设置为下降沿触发中断(即电平由高到低触发中断)IoSetFunc(WIFI_IOT_IO_NAME_GPIO_12, WIFI_IOT_IO_FUNC_GPIO_12_GPIO);GpioSetDir(WIFI_IOT_IO_NAME_GPIO_12, WIFI_IOT_GPIO_DIR_IN);IoSetPull(WIFI_IOT_IO_NAME_GPIO_12, WIFI_IOT_IO_PULL_UP);GpioRegisterIsrFunc(WIFI_IOT_IO_NAME_GPIO_12, WIFI_IOT_INT_TYPE_EDGE, WIFI_IOT_GPIO_EDGE_FALL_LEVEL_LOW, F2_Pressed, NULL);}APP_FEATURE_INIT(ButtonExampleEntry);PWM:扩展实例代码(B3):#include <stdio.h>#include <unistd.h>#include "ohos_init.h"#include "cmsis_os2.h"#include "wifiiot_pwm.h"#include "wifiiot_gpio.h"#include "wifiiot_gpio_ex.h"#define PWM_TASK_STACK_SIZE 512#define PWM_TASK_PRIO 25static void PWMTask(void){unsigned int i;//初始化GPIOGpioInit();//设置GPIO_2引脚复用功能为PWMIoSetFunc(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_IO_FUNC_GPIO_2_PWM2_OUT);//设置GPIO_2引脚为输出模式GpioSetDir(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_GPIO_DIR_OUT);//初始化PWM2端口PwmInit(WIFI_IOT_PWM_PORT_PWM2);uint8_t j = 0;while (1) {for (i = 0; i < 40000; i += 100) {//输出不同占空比的PWM波PwmStart(WIFI_IOT_PWM_PORT_PWM2, i, 40000);//PwmStop(WIFI_IOT_PWM_PORT_PWM2);//在PWM刚输出时即停止,灯仍然闪烁,但非常暗usleep(10); }i = 0;j++;if(j == 5){PwmDeinit(WIFI_IOT_PWM_PORT_PWM2);//当LED灯闪烁5次后,取消初始化PWM,LED灯始终保持最亮 } }}static void PWMExampleEntry(void){osThreadAttr_t attr;attr.name = "PWMTask";attr.attr_bits = 0U;attr.cb_mem = NULL;attr.cb_size = 0U;attr.stack_mem = NULL;attr.stack_size = 512;attr.priority = 25;if (osThreadNew((osThreadFunc_t)PWMTask, NULL, &attr) == NULL) {printf("Falied to create PWMTask!\n"); }}APP_FEATURE_INIT(PWMExampleEntry);ADC:BearPi_HM Nano芯片手册位置:./my_bearpi_hm_nano/applocations/BearPi/BearPi-HM_Nano/I2C:如果想让手机触碰NFC设备自动打开网页,要将网址写入位置设置为NDEFFirstPos
GPIO:扩展实例代码(B1):#include <stdio.h>#include <unistd.h>#include "ohos_init.h"#include "cmsis_os2.h"#include "wifiiot_gpio.h"#include "wifiiot_gpio_ex.h"static void LedTask(void){//初始化GPIOGpioInit();//设置GPIO_2的复用功能为普通GPIOIoSetFunc(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_IO_FUNC_GPIO_2_GPIO);//设置GPIO_2为输出模式GpioSetDir(WIFI_IOT_GPIO_IDX_2, WIFI_IOT_GPIO_DIR_OUT);WifiIotGpioDir val = {0};//定义读取变量valGpioGetDir(WIFI_IOT_GPIO_IDX_2, &val);//获取WIFI_IOT_GPIO_IDX_2的引脚方向,并赋值给变量valprintf("GPIO_2 Dir is %d\r\n", val);WifiIotGpioValue OutputVal = {0};//定义读取变量OutputValwhile (1) {//设置GPIO_2输出高电平点亮LED灯GpioSetOutputVal(WIFI_IOT_GPIO_IDX_2, 1);GpioGetOutputVal(WIFI_IOT_GPIO_IDX_2, &OutputVal);//读取WIFI_IOT_GPIO_IDX_2的高电平,并赋值给变量OutputValprintf("GPIO_2 OutputVal is %d\r\n", OutputVal);//延时1susleep(1000000);//设置GPIO_2输出低电平熄灭LED灯GpioSetOutputVal(WIFI_IOT_GPIO_IDX_2, 0);GpioGetOutputVal(WIFI_IOT_GPIO_IDX_2, &OutputVal);//读取WIFI_IOT_GPIO_IDX_2的低电平,并赋值给OutputValprintf("GPIO_2 OutputVal is %d\r\n", OutputVal);//延时1susleep(1000000); }}static void LedExampleEntry(void){osThreadAttr_t attr;attr.name = "LedTask";attr.attr_bits = 0U;attr.cb_mem = NULL;attr.cb_size = 0U;attr.stack_mem = NULL;attr.stack_size = 1024*2;//要打印字符,需要增大任务的空间attr.priority = 25;if (osThreadNew((osThreadFunc_t)LedTask, NULL, &attr) == NULL) {printf("Falied to create LedTask!\n"); }}APP_FEATURE_INIT(LedExampleEntry);GPIO中断:扩展实例代码(B2):#include <stdio.h>#include <unistd.h>#include "ohos_init.h"#include "cmsis_os2.h"#include "wifiiot_gpio.h"#include "wifiiot_gpio_ex.h"static void F1_Pressed(char *arg){ (void)arg;GpioSetOutputVal(WIFI_IOT_IO_NAME_GPIO_2, 1);//点亮LEDprintf("This is F1_Pressed\r\n");GpioSetIsrMode(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_GPIO_EDGE_RISE_LEVEL_HIGH);//将WIFI_IOT_IO_NAME_GPIO_11的模式修改为电平由低到高才触发中断}static void F2_Pressed(char *arg){ (void)arg;GpioSetOutputVal(WIFI_IOT_IO_NAME_GPIO_2, 0);//熄灭LEDprintf("This is F1_Pressed\r\n");GpioSetIsrMask(WIFI_IOT_IO_NAME_GPIO_12, 1);//屏蔽WIFI_IOT_IO_NAME_GPIO_12的中断功能}static void ButtonExampleEntry(void){GpioInit();//初始化LED灯IoSetFunc(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_IO_FUNC_GPIO_2_GPIO);GpioSetDir(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_GPIO_DIR_OUT);//初始化F1按键,设置为下降沿触发中断(即电平由高到低触发中断)IoSetFunc(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_IO_FUNC_GPIO_11_GPIO);GpioSetDir(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_GPIO_DIR_IN);IoSetPull(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_IO_PULL_UP);GpioRegisterIsrFunc(WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_IO_NAME_GPIO_11, WIFI_IOT_GPIO_EDGE_FALL_LEVEL_LOW, F1_Pressed, NULL);//初始化F2按键,设置为下降沿触发中断(即电平由高到低触发中断)IoSetFunc(WIFI_IOT_IO_NAME_GPIO_12, WIFI_IOT_IO_FUNC_GPIO_12_GPIO);GpioSetDir(WIFI_IOT_IO_NAME_GPIO_12, WIFI_IOT_GPIO_DIR_IN);IoSetPull(WIFI_IOT_IO_NAME_GPIO_12, WIFI_IOT_IO_PULL_UP);GpioRegisterIsrFunc(WIFI_IOT_IO_NAME_GPIO_12, WIFI_IOT_INT_TYPE_EDGE, WIFI_IOT_GPIO_EDGE_FALL_LEVEL_LOW, F2_Pressed, NULL);}APP_FEATURE_INIT(ButtonExampleEntry);PWM:扩展实例代码(B3):#include <stdio.h>#include <unistd.h>#include "ohos_init.h"#include "cmsis_os2.h"#include "wifiiot_pwm.h"#include "wifiiot_gpio.h"#include "wifiiot_gpio_ex.h"#define PWM_TASK_STACK_SIZE 512#define PWM_TASK_PRIO 25static void PWMTask(void){unsigned int i;//初始化GPIOGpioInit();//设置GPIO_2引脚复用功能为PWMIoSetFunc(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_IO_FUNC_GPIO_2_PWM2_OUT);//设置GPIO_2引脚为输出模式GpioSetDir(WIFI_IOT_IO_NAME_GPIO_2, WIFI_IOT_GPIO_DIR_OUT);//初始化PWM2端口PwmInit(WIFI_IOT_PWM_PORT_PWM2);uint8_t j = 0;while (1) {for (i = 0; i < 40000; i += 100) {//输出不同占空比的PWM波PwmStart(WIFI_IOT_PWM_PORT_PWM2, i, 40000);//PwmStop(WIFI_IOT_PWM_PORT_PWM2);//在PWM刚输出时即停止,灯仍然闪烁,但非常暗usleep(10); }i = 0;j++;if(j == 5){PwmDeinit(WIFI_IOT_PWM_PORT_PWM2);//当LED灯闪烁5次后,取消初始化PWM,LED灯始终保持最亮 } }}static void PWMExampleEntry(void){osThreadAttr_t attr;attr.name = "PWMTask";attr.attr_bits = 0U;attr.cb_mem = NULL;attr.cb_size = 0U;attr.stack_mem = NULL;attr.stack_size = 512;attr.priority = 25;if (osThreadNew((osThreadFunc_t)PWMTask, NULL, &attr) == NULL) {printf("Falied to create PWMTask!\n"); }}APP_FEATURE_INIT(PWMExampleEntry);ADC:BearPi_HM Nano芯片手册位置:./my_bearpi_hm_nano/applocations/BearPi/BearPi-HM_Nano/I2C:如果想让手机触碰NFC设备自动打开网页,要将网址写入位置设置为NDEFFirstPos -
 ## 1. 前言 为了缓解学习、生活、工作带来的压力,提升生活品质,许多人喜欢在家中、办公室等场所养鱼。为节省鱼友时间、劳力、增加养鱼乐趣;为此,本文基于STM32单片机设计了一款基于物联网的智能鱼缸。该鱼缸可以实现水温检测、水质检测、自动或手动换水、氛围灯灯光变换和自动或手动喂食等功能为一体的控制系统,鱼缸通过ESP8266连接华为云IOT物联网平台,并通过应用侧接口开发了上位机APP实现远程对鱼缸参数检测查看,并能远程控制。 **从功能上分析,需要用到的硬件如下:** (1)STM32系统板 (2)水温温度检测传感器: 测量水温 (3)水质检测传感器: 测量水中的溶解性固体含量,反应水质。 (4)步进电机: 作为鱼饲料投食器 (5)RGB氛围灯: 采用RGB 3色灯,给鱼缸照明。 (6)抽水电动马达: 用来给鱼缸充氧,换水,加水等。 (7)ESP8266 WIFI:设置串口协议的WIFI,内置了TCP/IP协议栈,完善的AT指令,通过简单的指令就可以联网通信,但是当前采用的ESP8266没有烧写第三方固件,采用原本的原滋原味的官方固件,没有内置MQTT协议,代码里连接华为云物联网平台需要使用MQTT协议,所以在STM32代码里通过MQTT协议文档的字段结构自己实现了MQTT协议,在通过ESP8266的TCP相关的AT指令完成数据发送接收,完成与华为云IOT平台交互。 水产养殖水质常规检测的传感器有哪些?水产养殖水质常规检测的传感器有水质ph传感器、溶解氧传感器和温度传感器。 (1)水质ph传感器: ph传感器是高智能化在线连续监测仪,由传感器和二次表两部分组成。可配三复合或两复合电极,以满足各种使用场所。配上纯水和超纯水电极,可适用于电导率小于3μs/cm的水质(如化学补给水、饱和蒸气、凝结水等)的pH值测量。 (2)溶解氧传感器: 氧气的消耗量与存在的氧含量成正比,而氧是通过可透膜扩散进来的。传感器与专门设计的监测溶氧的测量电路或电脑数据采集系统相连。 溶解氧传感器能够空气校准,一般校准所需时间较长,在使用后要注意保养。如果在养殖水中工作时间过长,就必须定期地清洗膜,对其进行额外保养。 在很多水产养殖中,每天测几次溶氧就可以了解溶氧情况。对池塘和许多水槽养殖系统。溶氧水平不会变化很快,池塘一般每天检测2~3次。 对于较高密度养殖系统,增氧泵故障发生可能不到1h就会造成鱼虾等大面积死亡。这些密度高的养殖系统要求有足够多的装备或每小时多次自动测量溶氧。 (3)温度传感器: 温度传感器有多种结构,包括热电偶、电阻温度传感器和热敏电阻。热电偶技术成熟,应用领域广,货源充足。选择热电偶必须满足温度范围要求,且其材料与环境相容。 电阻温度传感器(RTDs)的原理为金属的电阻随温度的改变而改变。大多电阻温度传感器(RTDs)由铂、镍或镍合金制成,其线性度比热电偶好,热切更加稳定,但容易破碎。 热敏电阻是电阻与温度具有负相关关系的半导体。热敏电阻比RTD和热电偶更灵敏,也更容易破碎,不能承受大的温差,但这一点在水产养殖中不成问题。        ## 2. 硬件选型 ### 2.1 STM32开发板 主控CPU采用STM32F103RCT6,这颗芯片包括48 KB SRAM、256 KB Flash、2个基本定时器、4个通用定时器、2个高级定时器、51个通用IO口、5个串口、2个DMA控制器、3个SPI、2个I2C、1个USB、1个CAN、3个12位ADC、1个12位DAC、1个SDIO接口,芯片属于大容量类型,配置较高,整体符合硬件选型设计。当前选择的这款开发板自带了一个1.4寸的TFT-LCD彩屏,可以显示当前传感器数据以及一些运行状态信息。  ### 2.2 杜邦线  ### 2.3 PCB板  ### 2.4 步进电机  ### 2.5 抽水马达  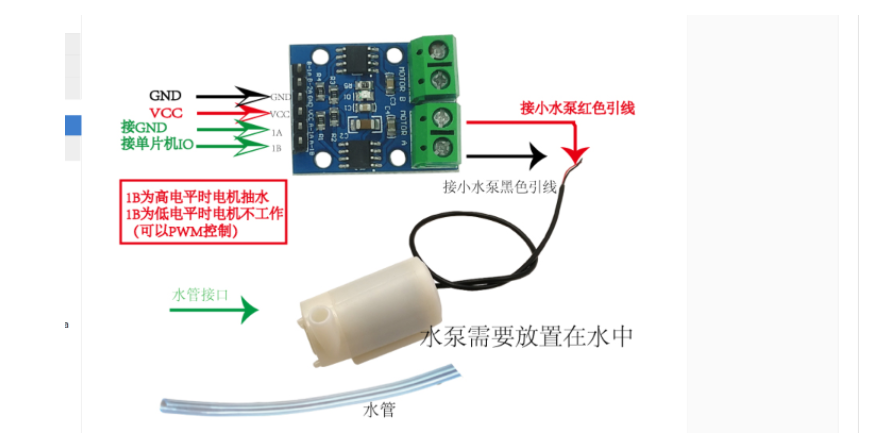 ### 2.6 水温检测传感器  测温采用DS18B20,DS18B20是常用的数字温度传感器,其输出的是数字信号,具有体积小,硬件开销低,抗干扰能力强,精度高的特点。 DS18B20数字温度传感器接线方便,封装成后可应用于多种场合,如管道式,螺纹式,磁铁吸附式,不锈钢封装式,型号多种多样,有LTM8877,LTM8874等等。 主要根据应用场合的不同而改变其外观。封装后的DS18B20可用于电缆沟测温,高炉水循环测温,锅炉测温,机房测温,农业大棚测温,洁净室测温,弹药库测温等各种非极限温度场合。耐磨耐碰,体积小,使用方便,封装形式多样,适用于各种狭小空间设备数字测温和控制领域。 ### 2.7 水质检测传感器 TDS (Total Dissolved Solids)、中文名总溶解固体、又称溶解性固体、又称溶解性固体总量、表明1升水肿容有多少毫克溶解性固体、一般来说、TDS值越高、表示水中含有溶解物越多、水就越不洁净、虽然在特定情况下TDS并不能有效反映水质的情况、但作为一种可快速检测的参数、TDS目前还可以作为有效的在水质情况反映参数来作为参考。常用的TDS检测设备为TDS笔、虽然价格低廉、简单易用、但不能把数据传给控制系统、做长时间的在线监测、并做水质状况分析、使用专门的仪器、虽然能传数据、精度也高、但价格很贵、为此这款TDS传感器模块、即插即用、使用简单方便、测量用的激励源采用交流信号、可有效防止探头极化、延长探头寿命的同时、也增加了输出信号的稳定性、TDS探头为防水探头、可长期侵入水中测量、该产品可以应用于生活用水、水培等领域的水质检测、有了这个传感器、可轻松DIY--套TDS检测仪了、轻松检测水的洁净程度。  ### 2.8 ESP8266 ■模块采用串口(LVTTL) 与MCU (或其他串口设备) 通信,内置TCP/IP协议栈,能够实现串口与WIFI之间的转换 ■模块支持LVTTL串口, 兼容3..3V和5V单片机系统 ■模块支持串 口转WIFI STA、串口转AP和WIFI STA+WIFI AP的模式,从而快速构建串口-WIFI数据传输方案 ■模块小巧(19mm*29mm), 通过6个2.54mm间距排针与外部连接  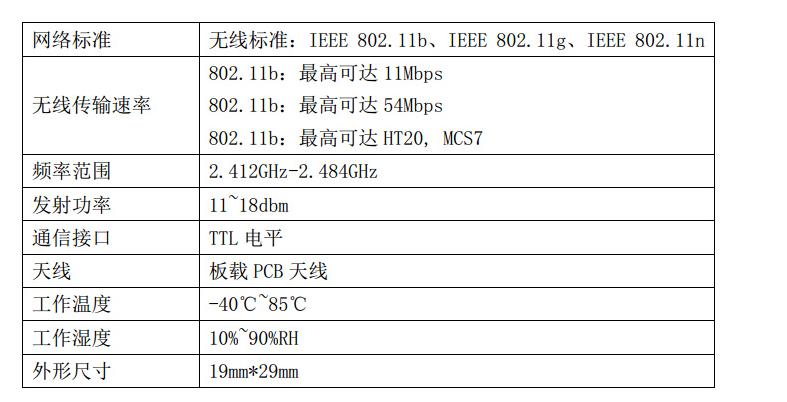 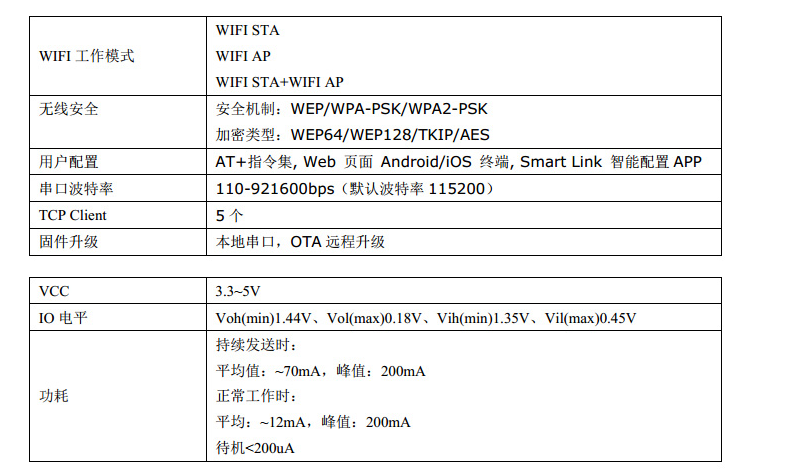  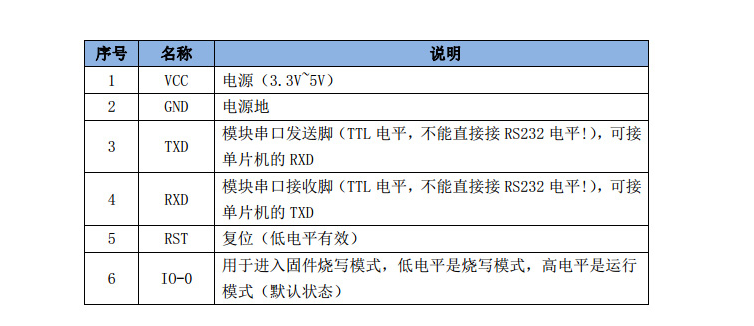  ## 3. 华为云IOT产品与设备创建 ### 3.1 创建产品  链接:https://www.huaweicloud.com/product/iothub.html 点击右上角窗口创建产品。 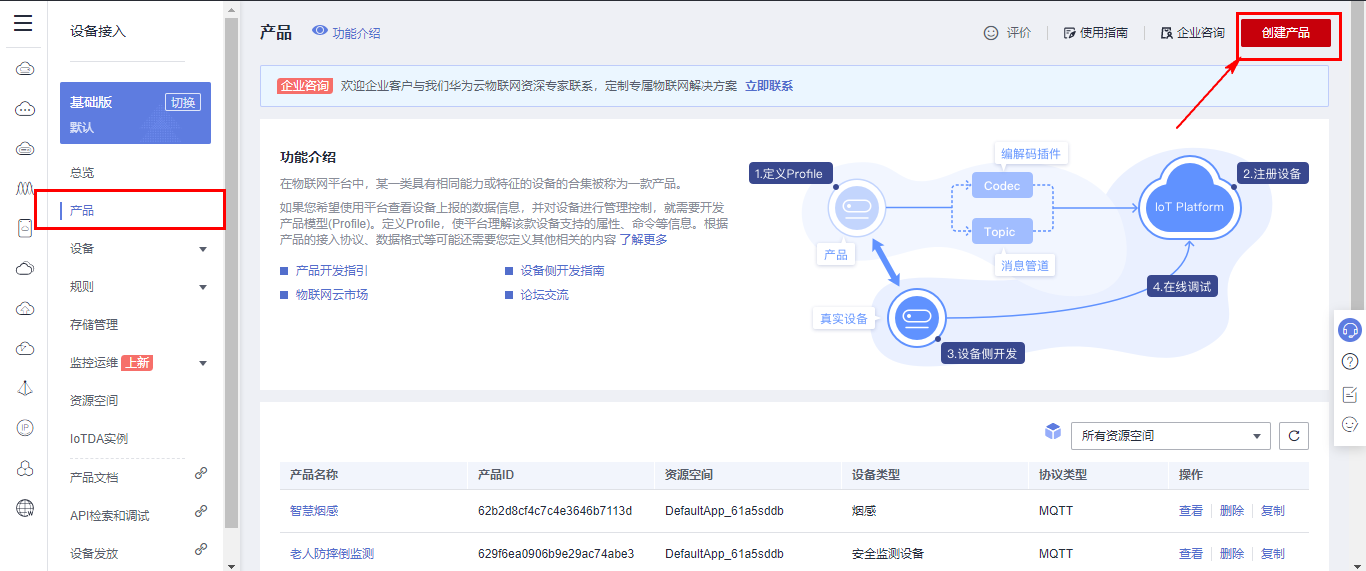 填入产品信息。 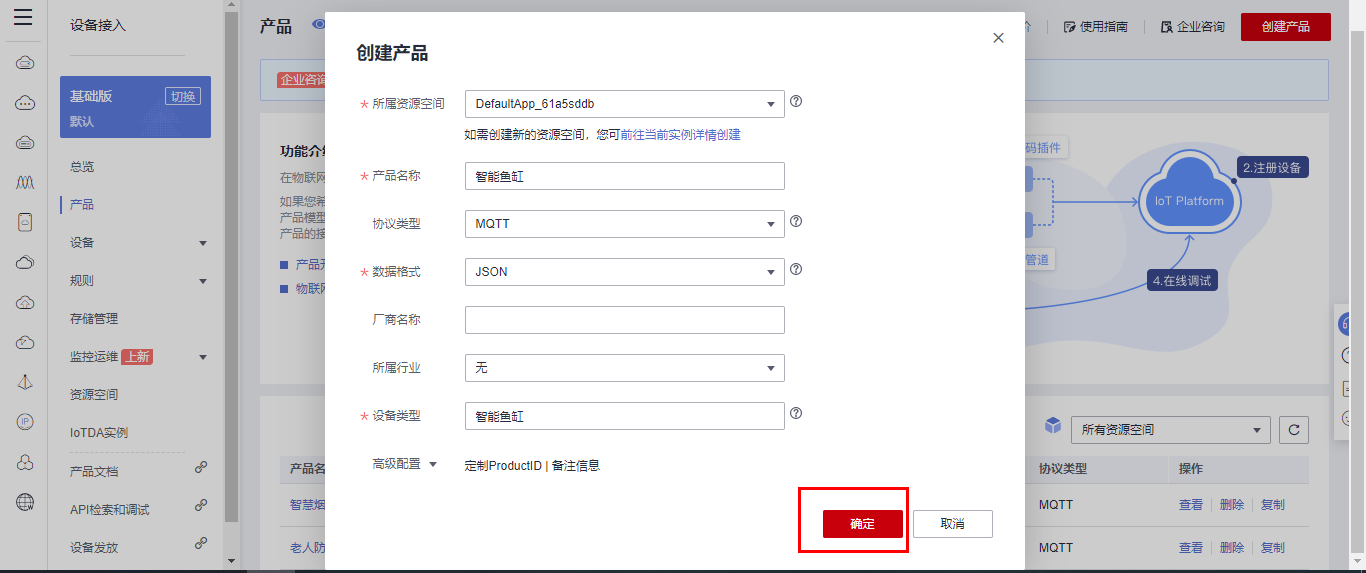 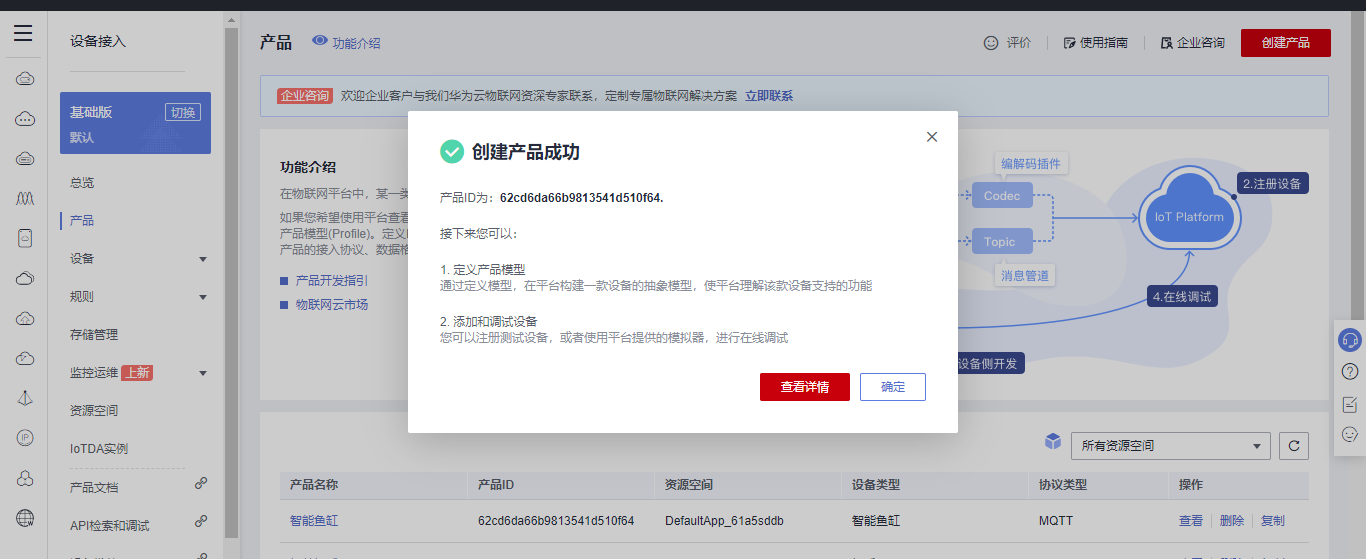 接下来创建模型文件: 创建服务。 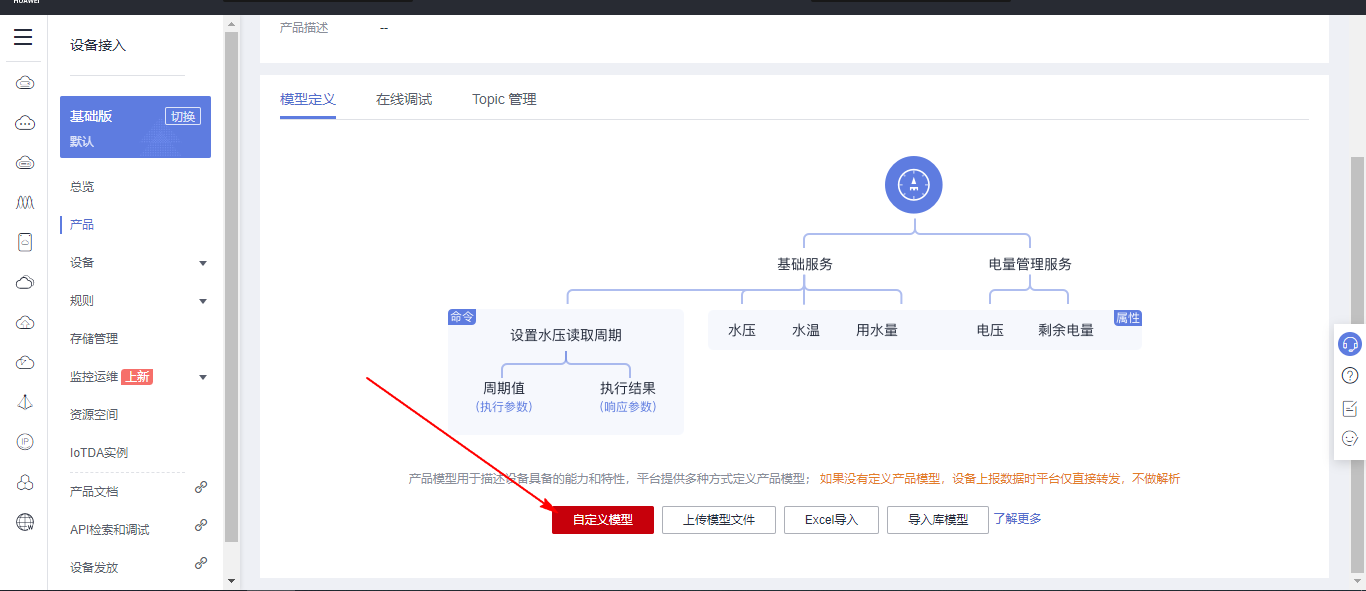 创建属性。根据鱼缸设备的传感器属性来添加属性。 (1)LED氛围灯 (2)抽水电机 (3)水质传感器 (4)水温温度计 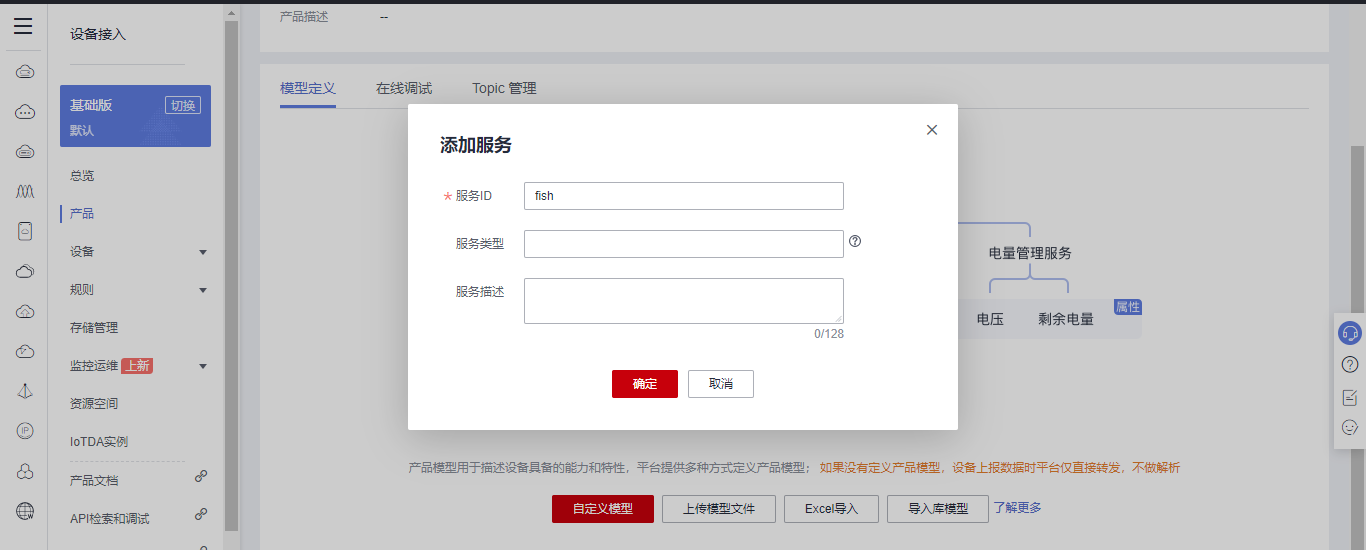 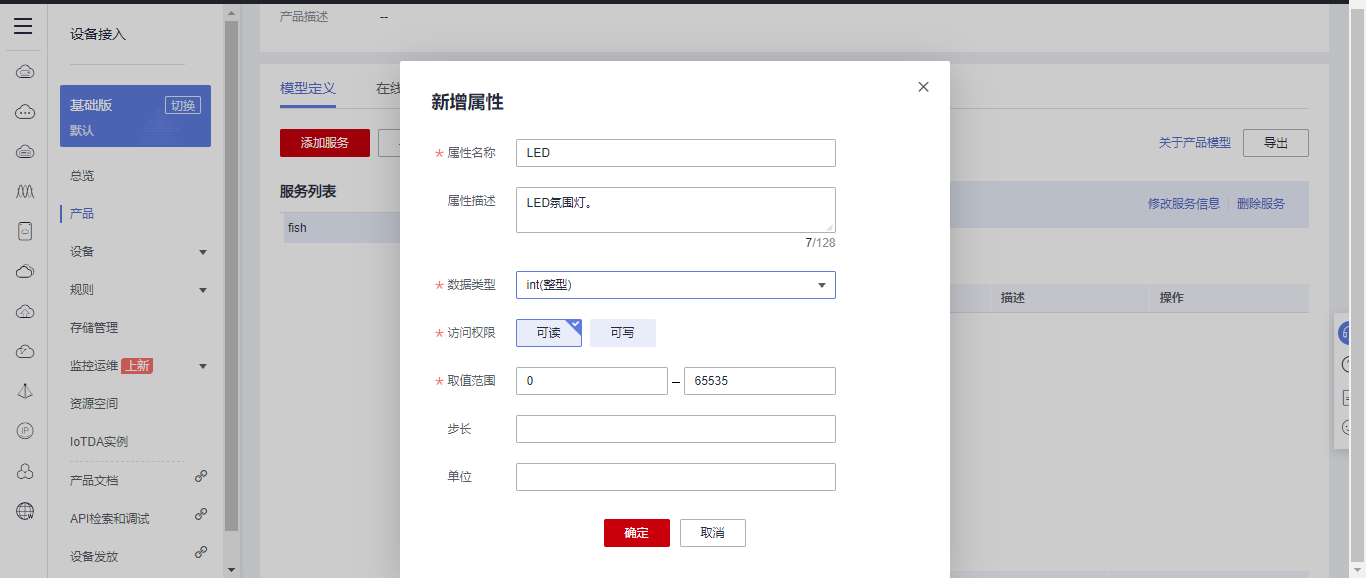  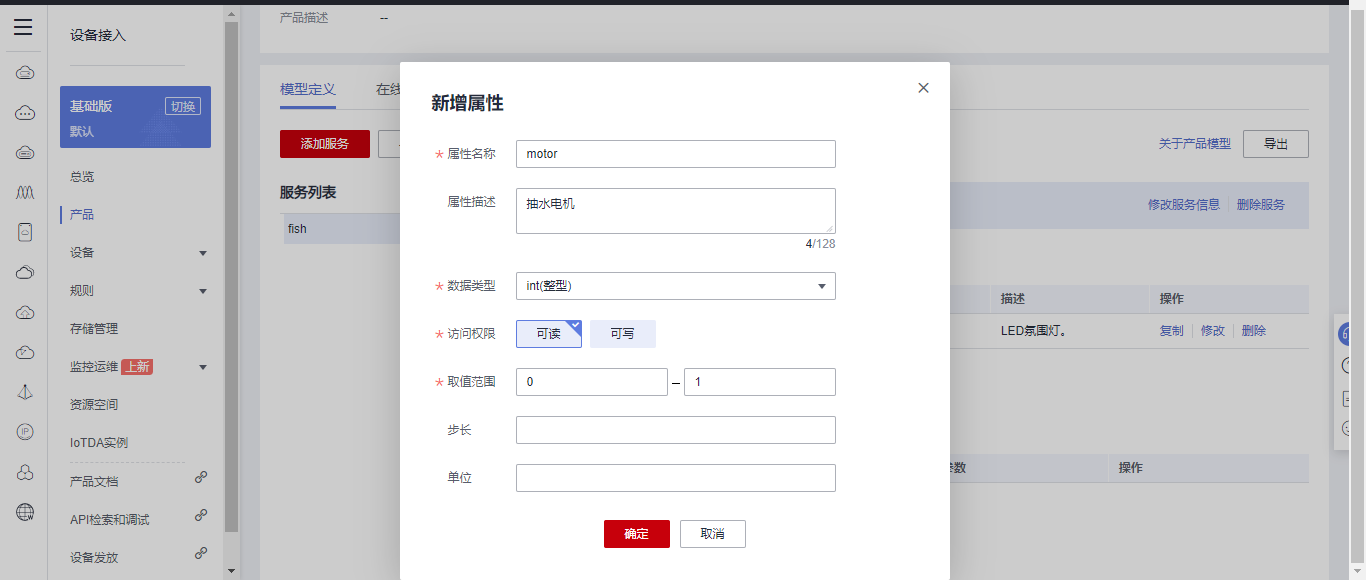 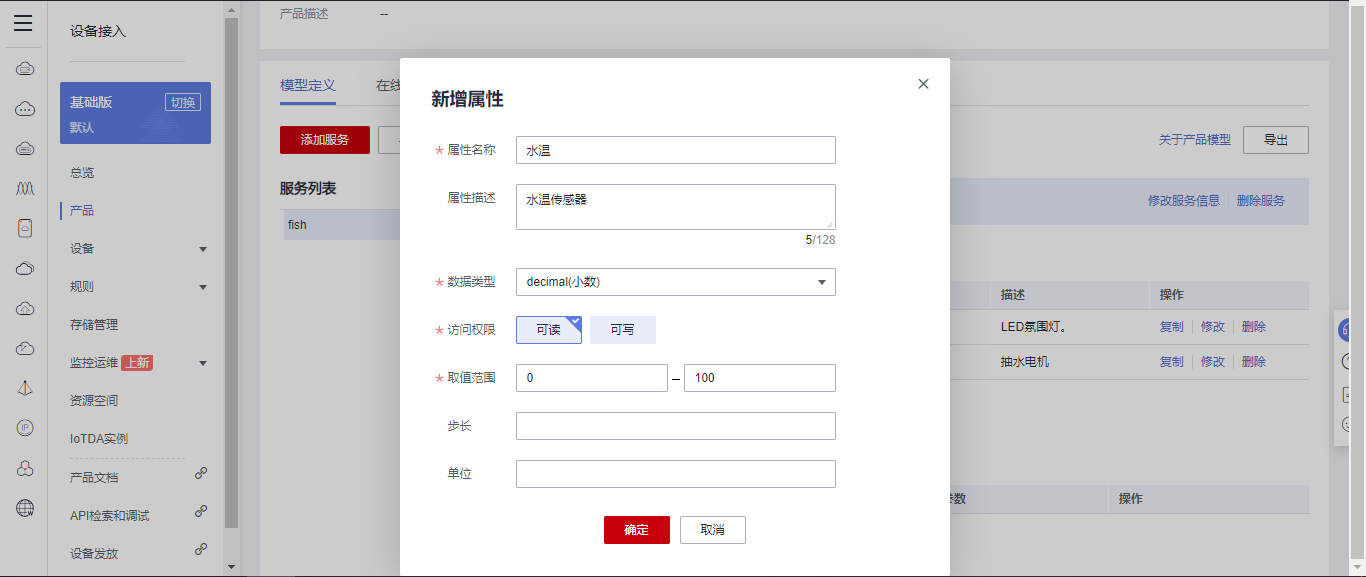 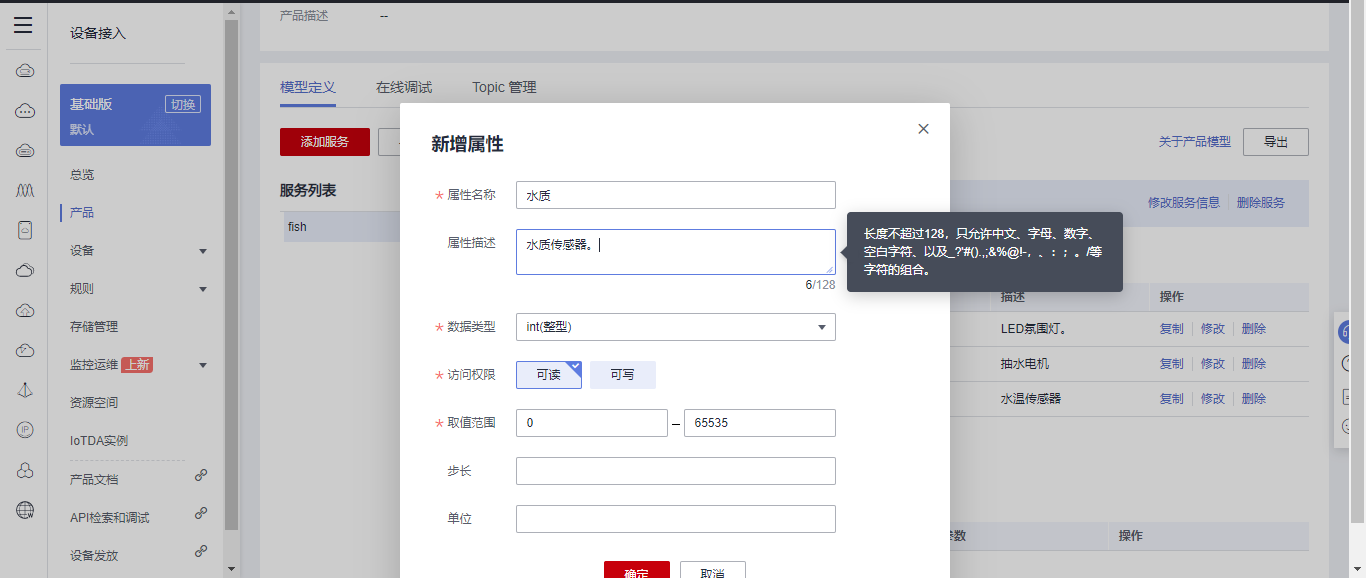 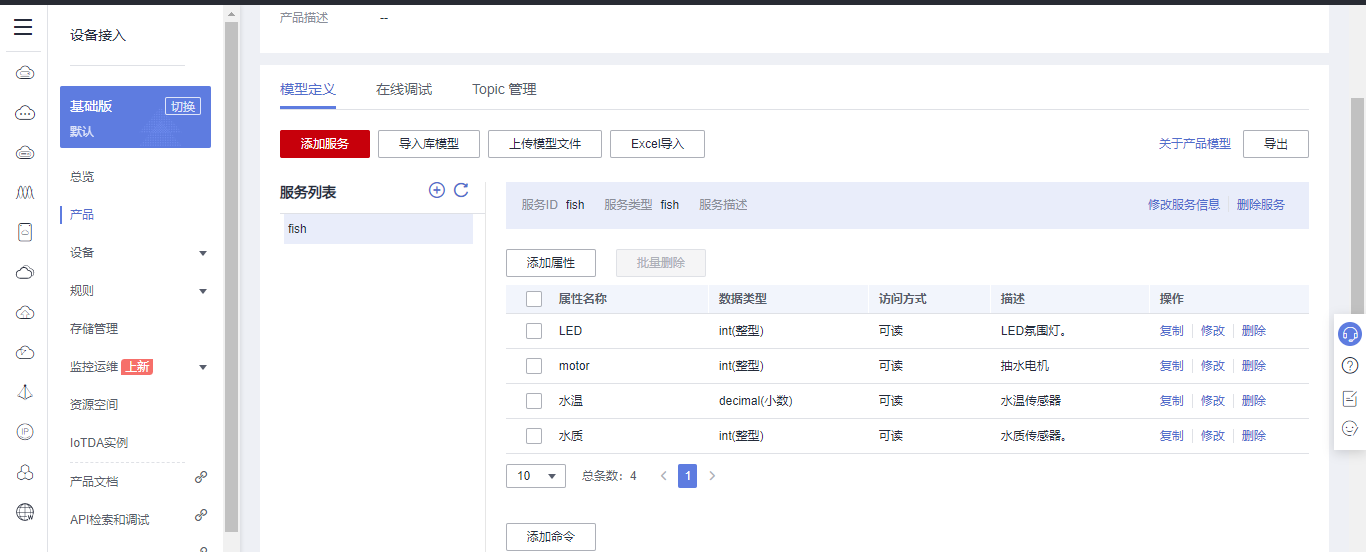 ### 3.2 创建设备 地址: https://console.huaweicloud.com/iotdm/?region=cn-north-4#/dm-portal/device/all-device 点击右上角创建设备。 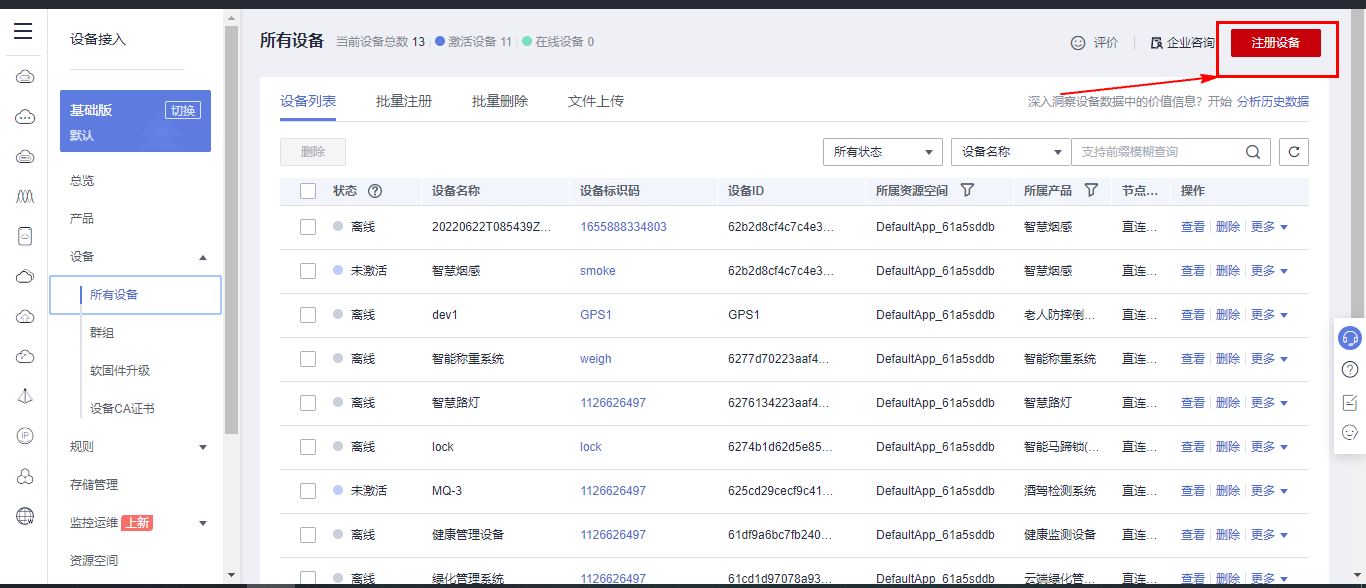 按照设备的情况进行填写信息。 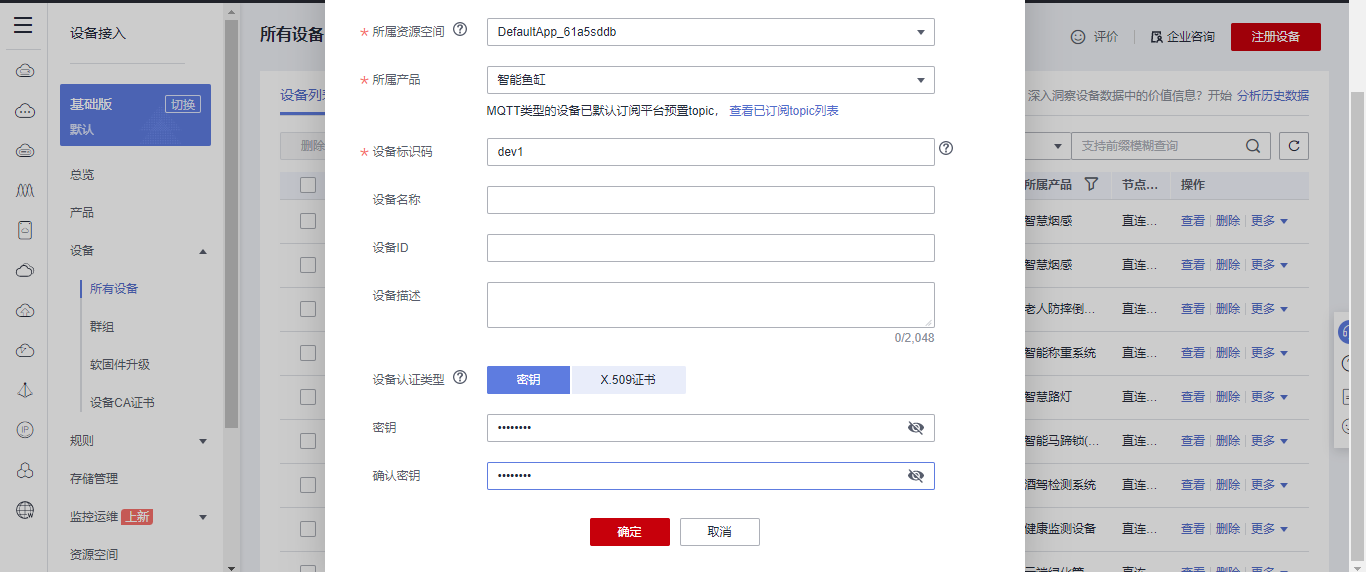 设备创建后保存信息: ```cpp { "device_id": "62cd6da66b9813541d510f64_dev1", "secret": "12345678" } ``` 创建成功。 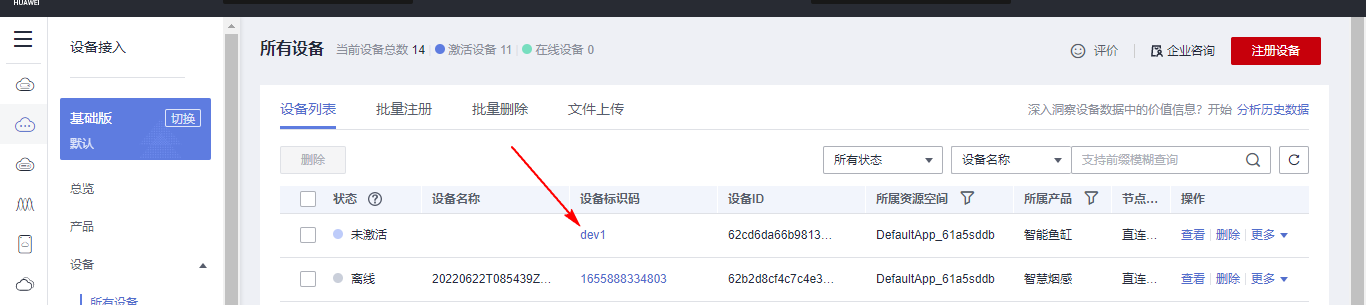 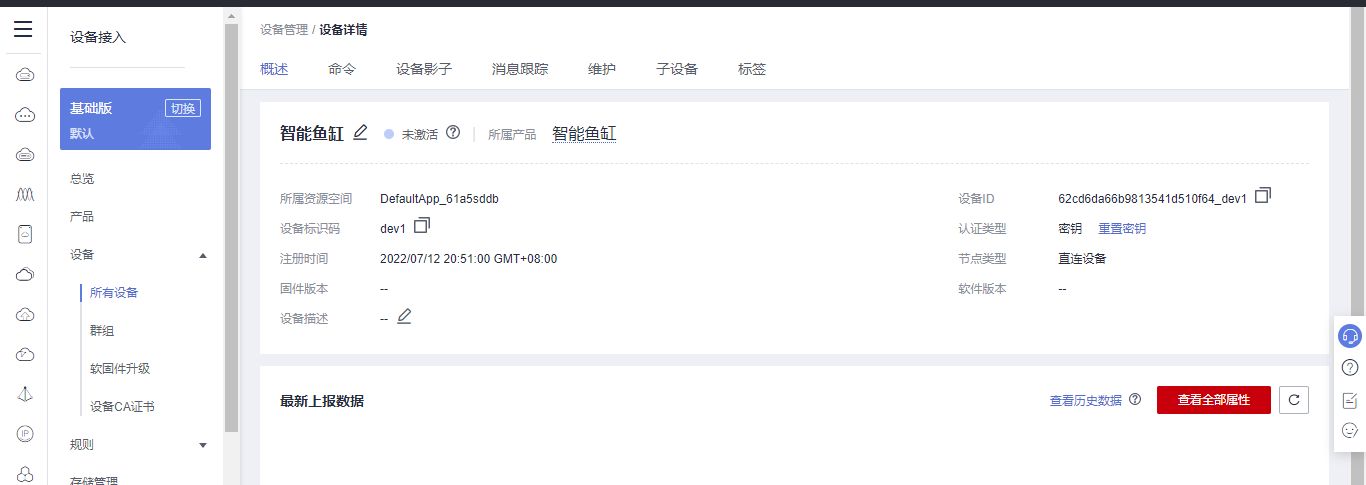 ### 3.3 设备模拟调试 为了测试设备通信的过程,在设备页面点击调试。 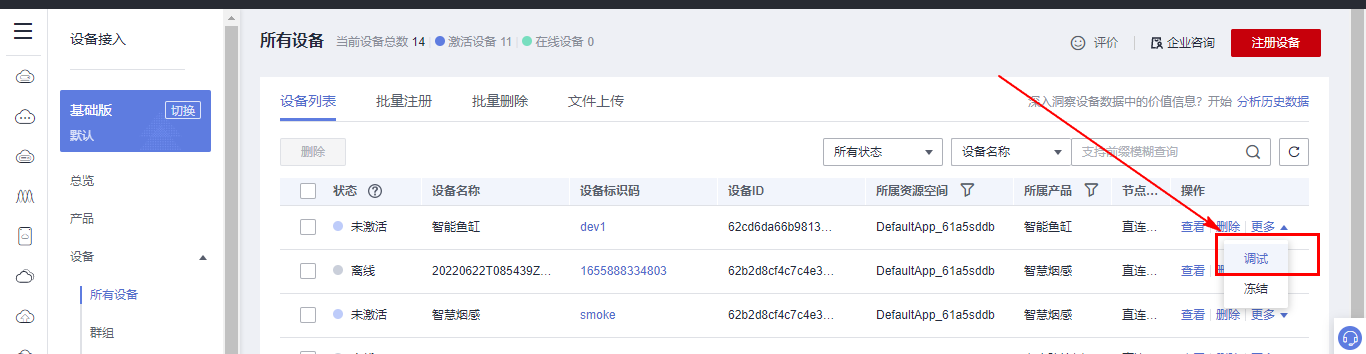 选择设备调试: 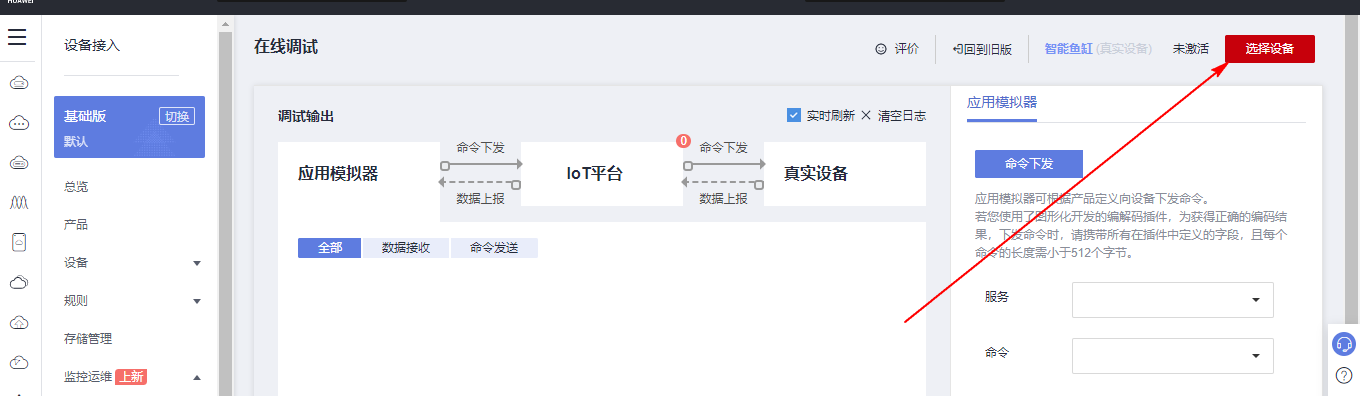 ### 3.4 MQTT三元组 为了方便能够以真实的设备登陆服务器进行测试,接下来需要先了解MQTT协议登录需要的参数如何获取,得到这些参数才可以接着进行下一步。 MQTT(Message Queuing Telemetry Transport)是一个基于客户端-服务器的消息发布/订阅传输协议,主要应用于计算能力有限,且工作在低带宽、不可靠的网络的远程传感器和控制设备,适合长连接的场景,如智能路灯等。 MQTTS是MQTT使用TLS加密的协议。采用MQTTS协议接入平台的设备,设备与物联网平台之间的通信过程,数据都是加密的,具有一定的安全性。 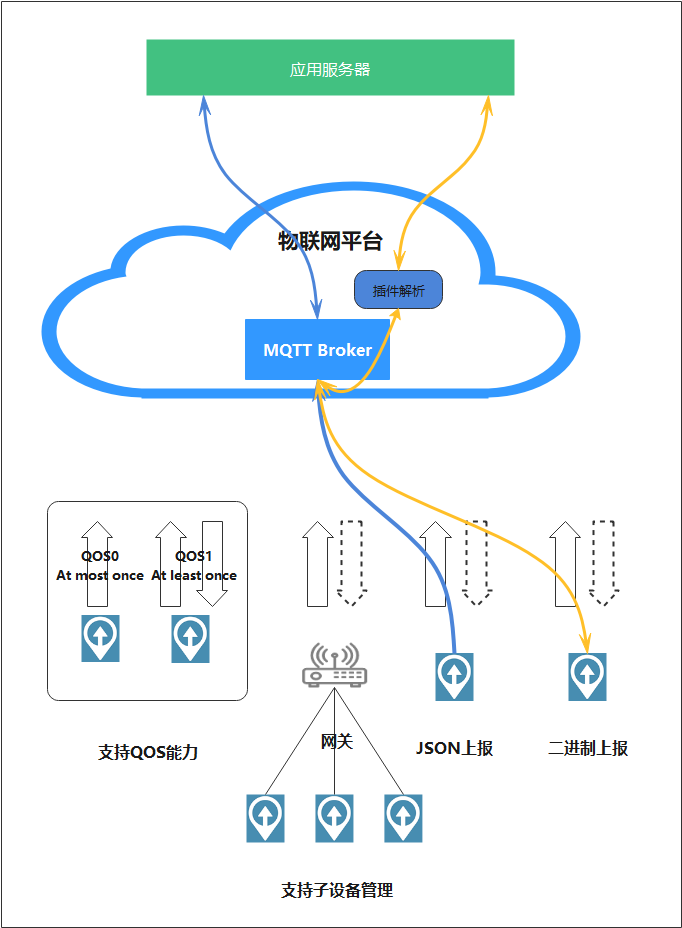 采用MQTT协议接入物联网平台的设备,设备与物联网平台之间的通信过程,数据没有加密,如果要保证数据的私密性可以使用MQTTS协议。 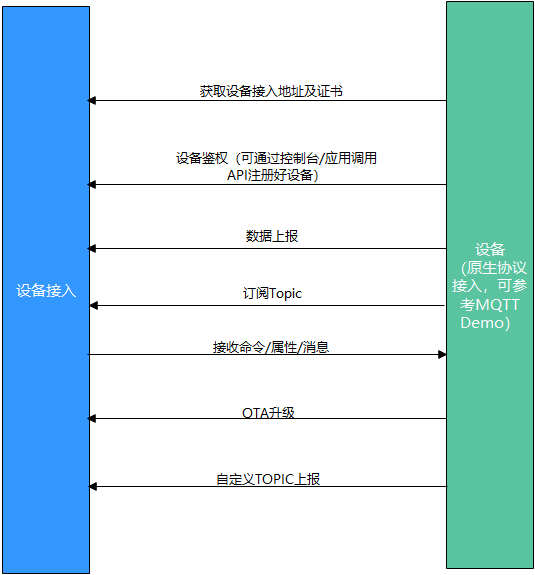 在这里可以使用华为云提供的工具快速得到MQTT三元组进行登录。 [https://support.huaweicloud.com/devg-iothub/iot_01_2127.html#ZH-CN_TOPIC_0240834853__zh-cn_topic_0251997880_li365284516112](https://support.huaweicloud.com/devg-iothub/iot_01_2127.html#ZH-CN_TOPIC_0240834853__zh-cn_topic_0251997880_li365284516112) 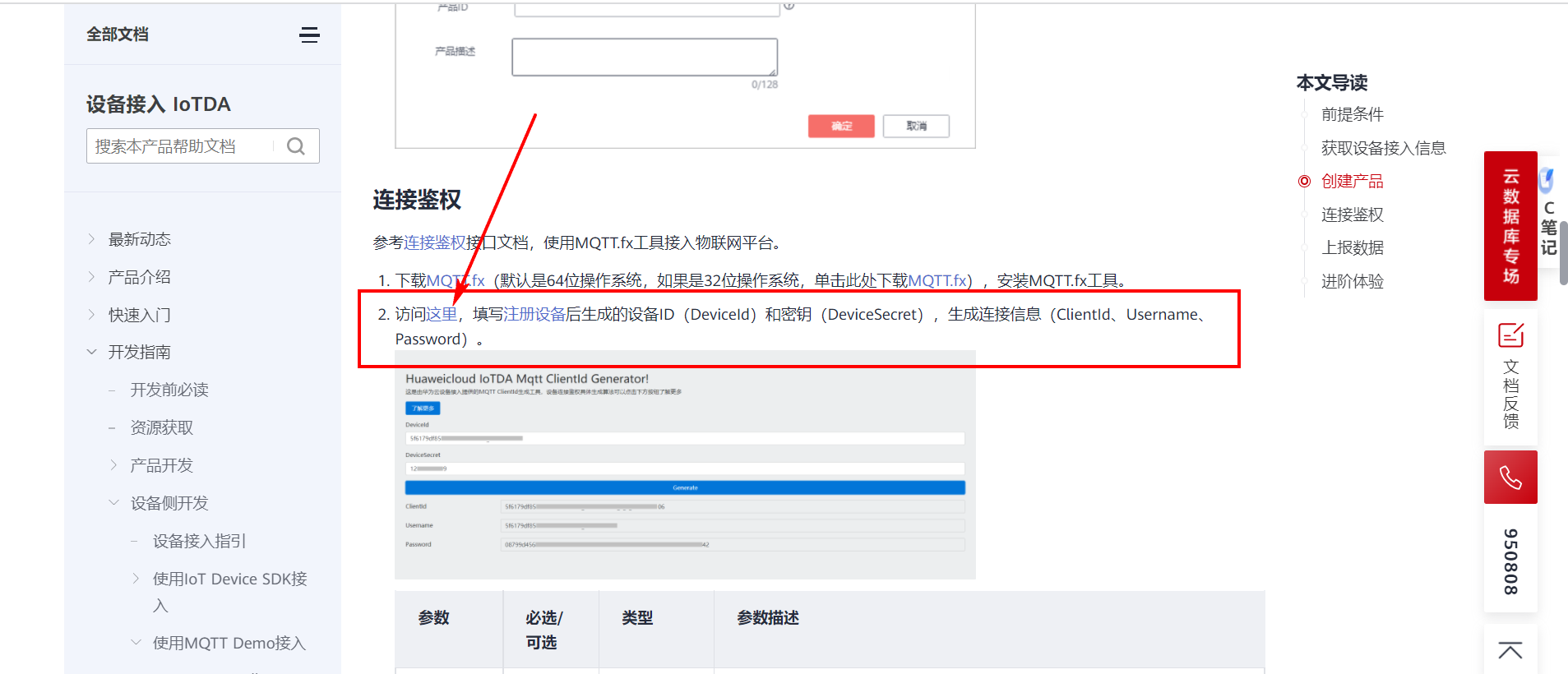 工具的页面地址: [https://iot-tool.obs-website.cn-north-4.myhuaweicloud.com/](https://iot-tool.obs-website.cn-north-4.myhuaweicloud.com/) 根据提示填入信息,然后生成三元组信息即可。 这里填入的信息就是在创建设备的时候生成的信息。 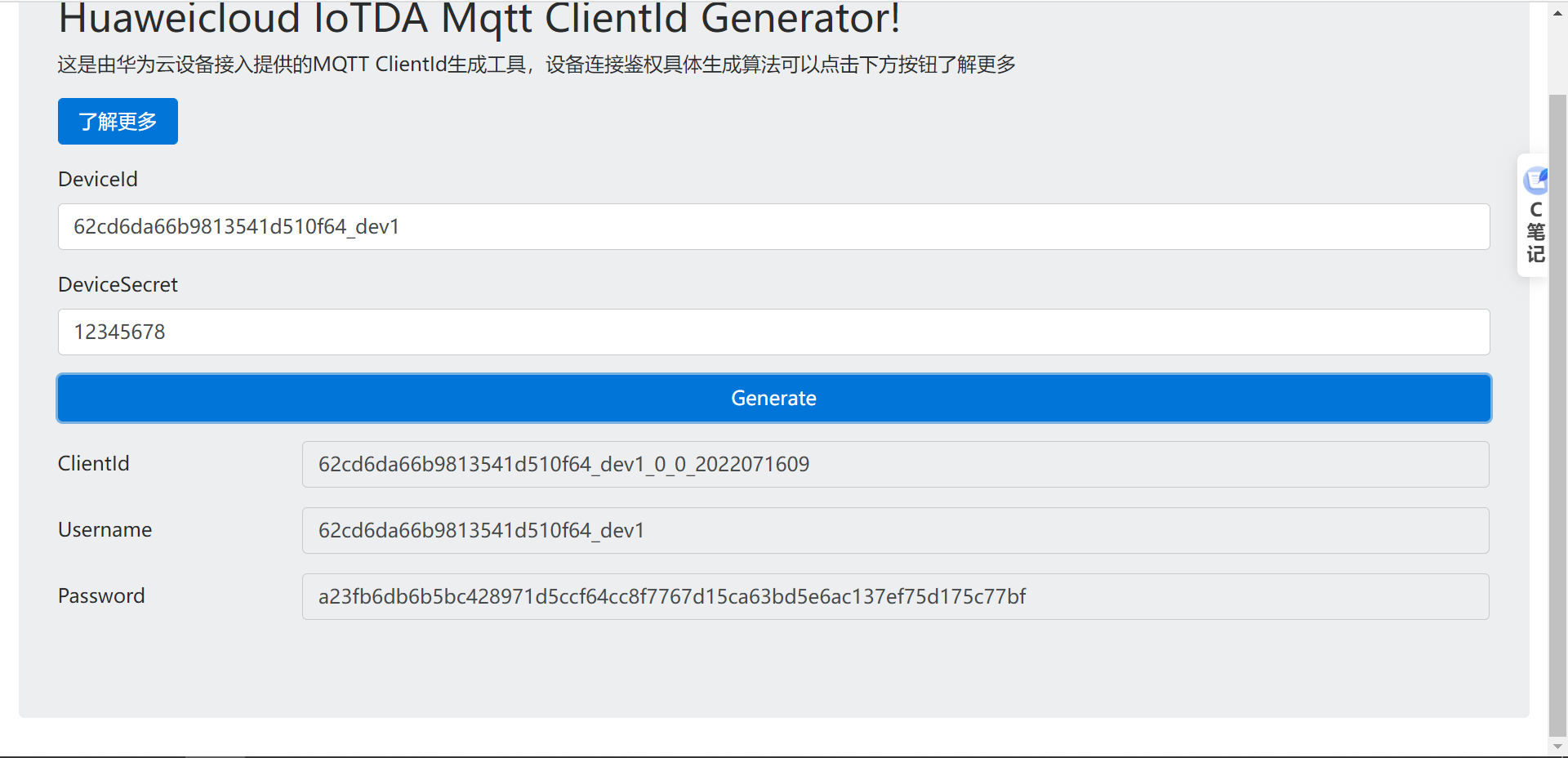 ```cpp DeviceId 62cd6da66b9813541d510f64_dev1 DeviceSecret 12345678 ClientId 62cd6da66b9813541d510f64_dev1_0_0_2022071609 Username 62cd6da66b9813541d510f64_dev1 Password a23fb6db6b5bc428971d5ccf64cc8f7767d15ca63bd5e6ac137ef75d175c77bf ``` ### 3.5 平台接入地址 华为云的物联网服务器地址在这里可以获取: [https://console.huaweicloud.com/iotdm/?region=cn-north-4#/dm-portal/home](https://console.huaweicloud.com/iotdm/?region=cn-north-4#/dm-portal/home) 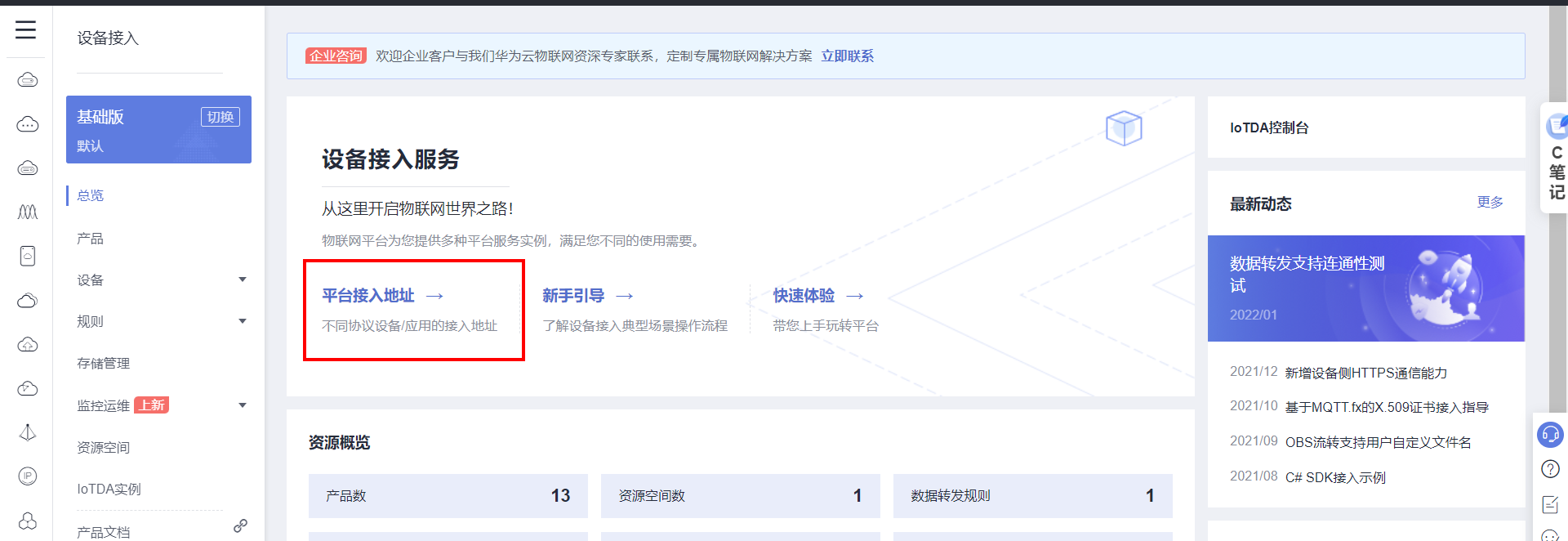 ```cpp MQTT (1883) a161a58a78.iot-mqtts.cn-north-4.myhuaweicloud.com 对应的IP地址是: 121.36.42.100 ``` ### 3.6 MQTT的主题订阅与发布格式 得到三元组之后,就可以登录MQTT服务器进行下一步的主题发布与订阅。 主题的格式详情: [https://support.huaweicloud.com/api-iothub/iot_06_v5_3004.html](https://support.huaweicloud.com/api-iothub/iot_06_v5_3004.html) 上传的数据格式详情: [https://support.huaweicloud.com/devg-iothub/iot_01_2127.html#ZH-CN_TOPIC_0240834853__zh-cn_topic_0251997880_li365284516112](https://support.huaweicloud.com/devg-iothub/iot_01_2127.html#ZH-CN_TOPIC_0240834853__zh-cn_topic_0251997880_li365284516112) ```cpp 设备消息上报 $oc/devices/{device_id}/sys/messages/up 平台下发消息给设备 $oc/devices/{device_id}/sys/messages/down 上传的消息格式: { "services": [{ "service_id": "Connectivity", "properties": { "dailyActivityTime": 57 }, "event_time": "20151212T121212Z" }, { "service_id": "Battery", "properties": { "batteryLevel": 80 }, "event_time": "20151212T121212Z" } ] } ``` 根据当前设备的格式总结如下: ```cpp ClientId 62cd6da66b9813541d510f64_dev1_0_0_2022071609 Username 62cd6da66b9813541d510f64_dev1 Password a23fb6db6b5bc428971d5ccf64cc8f7767d15ca63bd5e6ac137ef75d175c77bf //订阅主题: 平台下发消息给设备 $oc/devices/62cd6da66b9813541d510f64_dev1/sys/messages/down //设备上报数据 $oc/devices/62cd6da66b9813541d510f64_dev1/sys/properties/report //上报的属性消息 (一次可以上报多个属性,在json里增加就行了) {"services": [{"service_id": "fish","properties":{"LED":1}},{"service_id": "fish","properties":{"motor":1}},{"service_id": "fish","properties":{"水温":36.2}}]} ``` ### 3.6 MQTT客户端模拟设备调试 得到信息之后,将参赛填入软件进行登录测试。 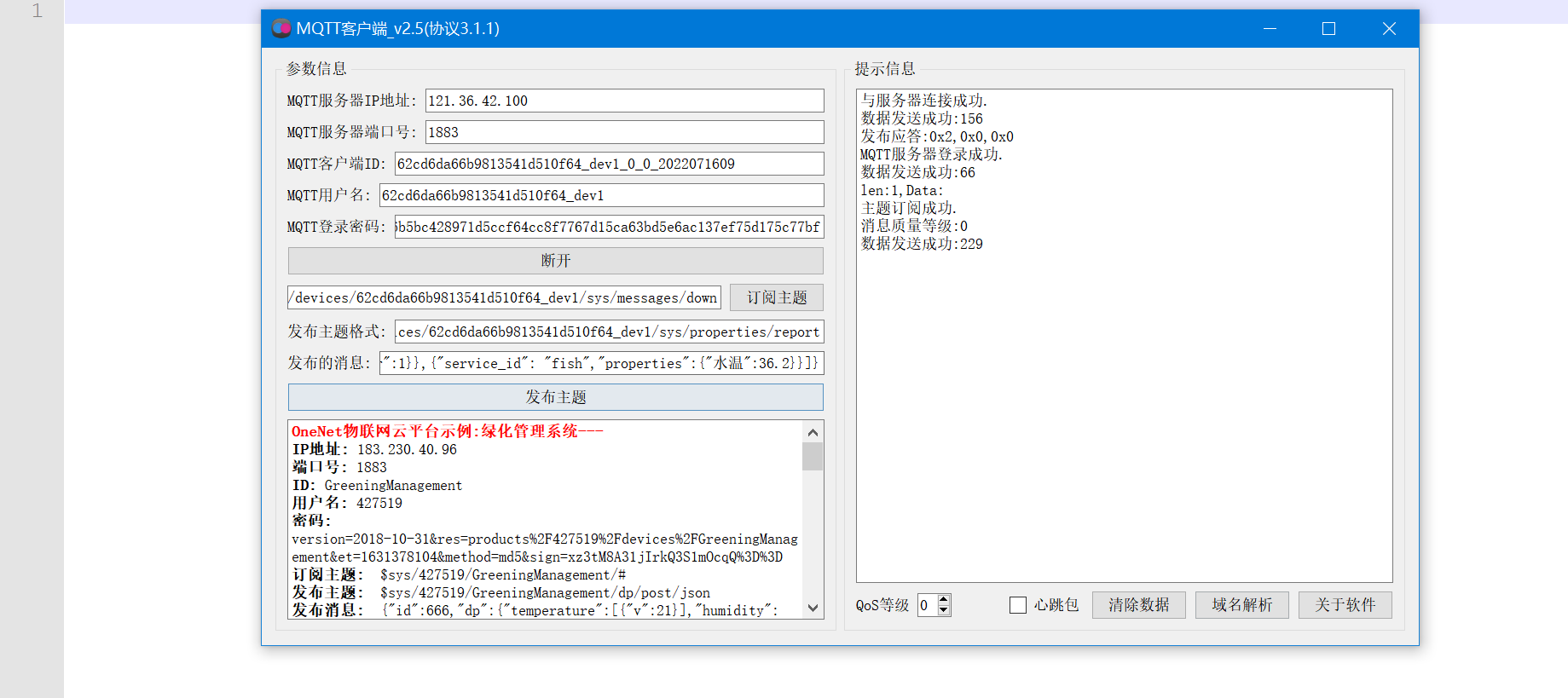 数据发送之后,在设备页面上可以看到设备已经在线了,并且收到了上传的数据。 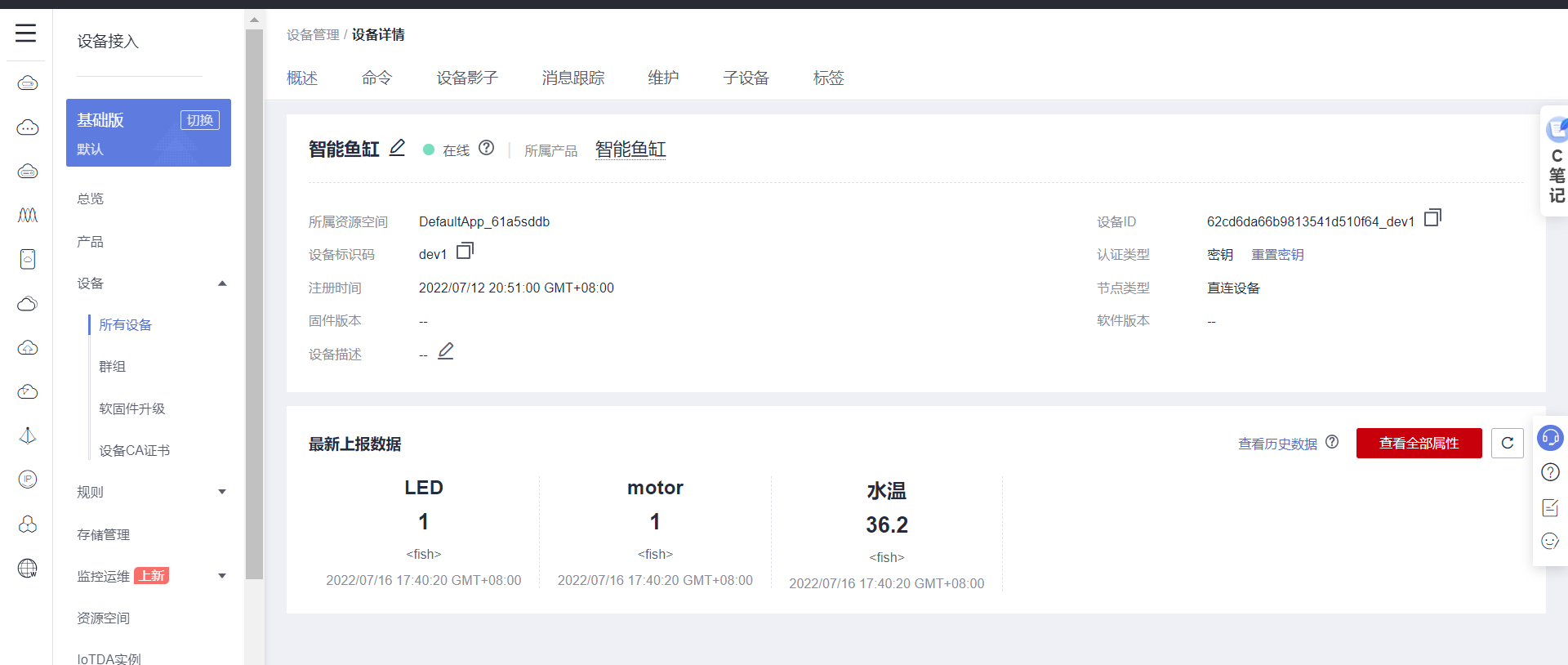 ## 4. STM32程序设计 ### 4.1 硬件连线 ```cpp 硬件连接方式: 1. TFT 1.44 寸彩屏接线 GND 电源地 VCC 接5V或3.3v电源 SCL 接PC8(SCL) SDA 接PC9(SDA) RST 接PC10 DC 接PB7 CS 接PB8 BL 接PB11 2. 板载LED灯接线 LED1---PA8 LED2---PD2 3. 板载按键接线 K0---PA0 K1---PC5 K2---PA15 4. DS18B20温度传感器接线 DQ->PC6 + : 3.3V - : GND 5. 步进电机 ULN2003控制28BYJ-48步进电机接线: ULN2003接线: IN-D: PB15 d IN-C: PB14 c IN-B: PB13 b IN-A: PB12 a + : 5V - : GND 6. 抽水电机 GND---GND VCC---5V AO----PA4 7. 水质检测传感器 AO->PA1 + : 3.3V - : GND 8. RGB灯 PC13--R PC14--G PC15--B 9. ATK-ESP8266 WIFI接线 PA2(TX)--RXD 模块接收脚 PA3(RX)--TXD 模块发送脚 GND---GND 地 VCC---VCC 电源(3.3V~5.0V) ``` ### 4.2 硬件原理图 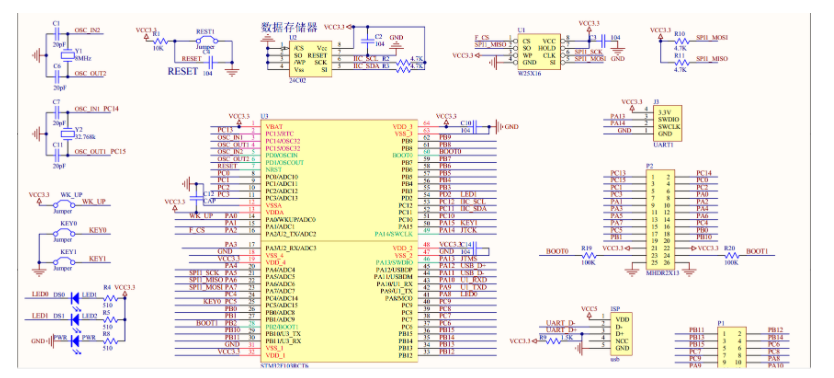 ### 4.3 汉字取模 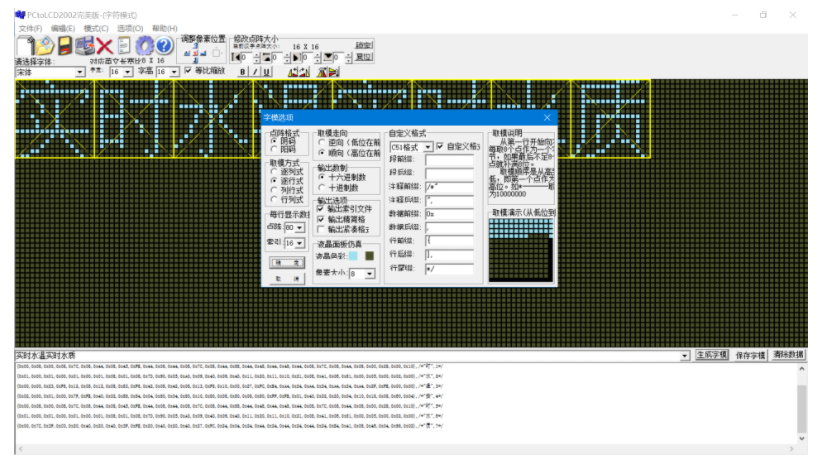 ### 4.4 程序下载 下载软件在资料包里。点击开始编程之后,点击开发板的复位键即可下载程序进去。 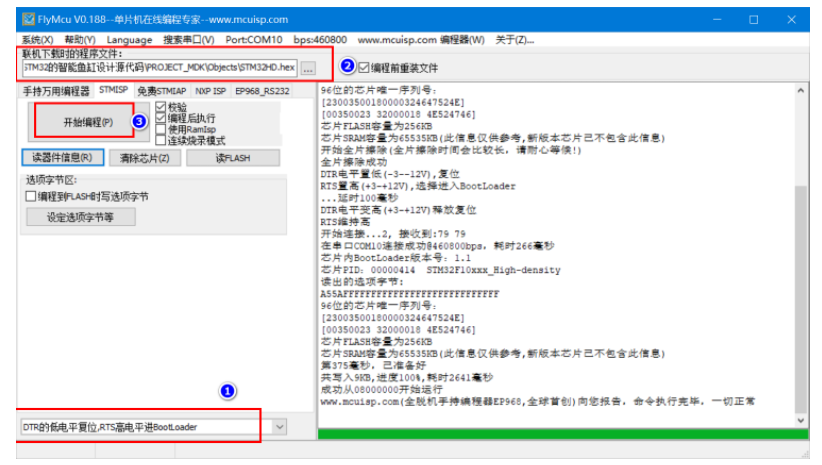 ### 4.5 主要的信息连接代码 ```cpp #include "stm32f10x.h" #include "led.h" #include "delay.h" #include "key.h" #include "usart.h" #include #include "timer.h" #include "esp8266.h" #include "mqtt.h" #include "oled.h" #include "fontdata.h" #include "bh1750.h" #include "iic.h" #include "sht3x.h" #define ESP8266_WIFI_AP_SSID "aaa" //将要连接的路由器名称 --不要出现中文、空格等特殊字符 #define ESP8266_AP_PASSWORD "12345678" //将要连接的路由器密码 //华为云服务器的设备信息 #define MQTT_ClientID "62cd6da66b9813541d510f64_dev1_0_0_2022071609" #define MQTT_UserName "62cd6da66b9813541d510f64_dev1" #define MQTT_PassWord "a23fb6db6b5bc428971d5ccf64cc8f7767d15ca63bd5e6ac137ef75d175c77bf" //订阅与发布的主题 #define SET_TOPIC "$oc/devices/62cd6da66b9813541d510f64_dev1/sys/messages/down" //订阅 #define POST_TOPIC "$oc/devices/62cd6da66b9813541d510f64_dev1/sys/properties/report" //发布 ``` ### 4.6 ESP8266主要代码 ```cpp u8 ESP8266_IP_ADDR[16]; //255.255.255.255 u8 ESP8266_MAC_ADDR[18]; //硬件地址 /* 函数功能: ESP8266命令发送函数 函数返回值:0表示成功 1表示失败 */ u8 ESP8266_SendCmd(char *cmd) { int RX_CNT=0; u8 i,j; for(i=0;i10;i++) //检测的次数--发送指令的次数 { USARTx_StringSend(USART3,cmd); for(j=0;j100;j++) //等待的时间 { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,"OK")) { return 0; } } } } return 1; } /* 函数功能: ESP8266硬件初始化检测函数 函数返回值:0表示成功 1表示失败 */ u8 ESP8266_Init(void) { //退出透传模式 USARTx_StringSend(USART3,"+++"); delay_ms(100); //退出透传模式 USARTx_StringSend(USART3,"+++"); delay_ms(100); return ESP8266_SendCmd("AT\r\n"); } /* 函数功能: 一键配置WIFI为AP+TCP服务器模式 函数参数: char *ssid 创建的热点名称 char *pass 创建的热点密码 (最少8位) u16 port 创建的服务器端口号 函数返回值: 0表示成功 其他值表示对应错误值 */ u8 ESP8266_AP_TCP_Server_Mode(char *ssid,char *pass,u16 port) { char *p; u8 i; char ESP8266_SendCMD[100]; //组合发送过程中的命令 /*1. 测试硬件*/ if(ESP8266_SendCmd("AT\r\n"))return 1; /*2. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 2; /*3. 设置WIFI模式*/ if(ESP8266_SendCmd("AT+CWMODE=2\r\n"))return 3; /*4. 复位*/ ESP8266_SendCmd("AT+RST\r\n"); delay_ms(1000); delay_ms(1000); delay_ms(1000); /*5. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 5; /*6. 设置WIFI的AP模式参数*/ sprintf(ESP8266_SendCMD,"AT+CWSAP=\"%s\",\"%s\",1,4\r\n",ssid,pass); if(ESP8266_SendCmd(ESP8266_SendCMD))return 6; /*7. 开启多连接*/ if(ESP8266_SendCmd("AT+CIPMUX=1\r\n"))return 7; /*8. 设置服务器端口号*/ sprintf(ESP8266_SendCMD,"AT+CIPSERVER=1,%d\r\n",port); if(ESP8266_SendCmd(ESP8266_SendCMD))return 8; /*9. 查询本地IP地址*/ if(ESP8266_SendCmd("AT+CIFSR\r\n"))return 9; //提取IP地址 p=strstr((char*)USART3_RX_BUF,"APIP"); if(p) { p+=6; for(i=0;*p!='"';i++) { ESP8266_IP_ADDR[i]=*p++; } ESP8266_IP_ADDR[i]='\0'; } //提取MAC地址 p=strstr((char*)USART3_RX_BUF,"APMAC"); if(p) { p+=7; for(i=0;*p!='"';i++) { ESP8266_MAC_ADDR[i]=*p++; } ESP8266_MAC_ADDR[i]='\0'; } //打印总体信息 printf("当前WIFI模式:AP+TCP服务器\r\n"); printf("当前WIFI热点名称:%s\r\n",ssid); printf("当前WIFI热点密码:%s\r\n",pass); printf("当前TCP服务器端口号:%d\r\n",port); printf("当前TCP服务器IP地址:%s\r\n",ESP8266_IP_ADDR); printf("当前TCP服务器MAC地址:%s\r\n",ESP8266_MAC_ADDR); return 0; } /* 函数功能: TCP服务器模式下的发送函数 发送指令: */ u8 ESP8266_ServerSendData(u8 id,u8 *data,u16 len) { int RX_CNT=0; u8 i,j,n; char ESP8266_SendCMD[100]; //组合发送过程中的命令 for(i=0;i10;i++) { sprintf(ESP8266_SendCMD,"AT+CIPSEND=%d,%d\r\n",id,len); USARTx_StringSend(USART3,ESP8266_SendCMD); for(j=0;j10;j++) { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,">")) { //继续发送数据 USARTx_DataSend(USART3,data,len); //等待数据发送成功 for(n=0;n200;n++) { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,"SEND OK")) { return 0; } } } } } } } return 1; } /* 函数功能: 配置WIFI为STA模式+TCP客户端模式 函数参数: char *ssid 创建的热点名称 char *pass 创建的热点密码 (最少8位) char *p 将要连接的服务器IP地址 u16 port 将要连接的服务器端口号 u8 flag 1表示开启透传模式 0表示关闭透传模式 函数返回值:0表示成功 其他值表示对应的错误 */ u8 ESP8266_STA_TCP_Client_Mode(char *ssid,char *pass,char *ip,u16 port,u8 flag) { char ESP8266_SendCMD[100]; //组合发送过程中的命令 //退出透传模式 //USARTx_StringSend(USART3,"+++"); //delay_ms(50); /*1. 测试硬件*/ if(ESP8266_SendCmd("AT\r\n"))return 1; /*2. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 2; /*3. 设置WIFI模式*/ if(ESP8266_SendCmd("AT+CWMODE=1\r\n"))return 3; /*4. 复位*/ ESP8266_SendCmd("AT+RST\r\n"); delay_ms(1000); delay_ms(1000); delay_ms(1000); /*5. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 5; /*6. 配置将要连接的WIFI热点信息*/ sprintf(ESP8266_SendCMD,"AT+CWJAP=\"%s\",\"%s\"\r\n",ssid,pass); if(ESP8266_SendCmd(ESP8266_SendCMD))return 6; /*7. 设置单连接*/ if(ESP8266_SendCmd("AT+CIPMUX=0\r\n"))return 7; /*8. 配置要连接的TCP服务器信息*/ sprintf(ESP8266_SendCMD,"AT+CIPSTART=\"TCP\",\"%s\",%d\r\n",ip,port); if(ESP8266_SendCmd(ESP8266_SendCMD))return 8; /*9. 开启透传模式*/ if(flag) { if(ESP8266_SendCmd("AT+CIPMODE=1\r\n"))return 9; //开启 if(ESP8266_SendCmd("AT+CIPSEND\r\n"))return 10; //开始透传 if(!(strstr((char*)USART3_RX_BUF,">"))) { return 11; } //如果想要退出发送: "+++" } printf("WIFI模式:STA+TCP客户端\r\n"); printf("Connect_WIFI热点名称:%s\r\n",ssid); printf("Connect_WIFI热点密码:%s\r\n",pass); printf("TCP服务器端口号:%d\r\n",port); printf("TCP服务器IP地址:%s\r\n",ip); return 0; } /* 函数功能: TCP客户端模式下的发送函数 发送指令: */ u8 ESP8266_ClientSendData(u8 *data,u16 len) { int RX_CNT=0; u8 i,j,n; char ESP8266_SendCMD[100]; //组合发送过程中的命令 for(i=0;i10;i++) { sprintf(ESP8266_SendCMD,"AT+CIPSEND=%d\r\n",len); USARTx_StringSend(USART3,ESP8266_SendCMD); for(j=0;j10;j++) { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,">")) { //继续发送数据 USARTx_DataSend(USART3,data,len); //等待数据发送成功 for(n=0;n200;n++) { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,"SEND OK")) { return 0; } } } } } } } return 1; } ```
## 1. 前言 为了缓解学习、生活、工作带来的压力,提升生活品质,许多人喜欢在家中、办公室等场所养鱼。为节省鱼友时间、劳力、增加养鱼乐趣;为此,本文基于STM32单片机设计了一款基于物联网的智能鱼缸。该鱼缸可以实现水温检测、水质检测、自动或手动换水、氛围灯灯光变换和自动或手动喂食等功能为一体的控制系统,鱼缸通过ESP8266连接华为云IOT物联网平台,并通过应用侧接口开发了上位机APP实现远程对鱼缸参数检测查看,并能远程控制。 **从功能上分析,需要用到的硬件如下:** (1)STM32系统板 (2)水温温度检测传感器: 测量水温 (3)水质检测传感器: 测量水中的溶解性固体含量,反应水质。 (4)步进电机: 作为鱼饲料投食器 (5)RGB氛围灯: 采用RGB 3色灯,给鱼缸照明。 (6)抽水电动马达: 用来给鱼缸充氧,换水,加水等。 (7)ESP8266 WIFI:设置串口协议的WIFI,内置了TCP/IP协议栈,完善的AT指令,通过简单的指令就可以联网通信,但是当前采用的ESP8266没有烧写第三方固件,采用原本的原滋原味的官方固件,没有内置MQTT协议,代码里连接华为云物联网平台需要使用MQTT协议,所以在STM32代码里通过MQTT协议文档的字段结构自己实现了MQTT协议,在通过ESP8266的TCP相关的AT指令完成数据发送接收,完成与华为云IOT平台交互。 水产养殖水质常规检测的传感器有哪些?水产养殖水质常规检测的传感器有水质ph传感器、溶解氧传感器和温度传感器。 (1)水质ph传感器: ph传感器是高智能化在线连续监测仪,由传感器和二次表两部分组成。可配三复合或两复合电极,以满足各种使用场所。配上纯水和超纯水电极,可适用于电导率小于3μs/cm的水质(如化学补给水、饱和蒸气、凝结水等)的pH值测量。 (2)溶解氧传感器: 氧气的消耗量与存在的氧含量成正比,而氧是通过可透膜扩散进来的。传感器与专门设计的监测溶氧的测量电路或电脑数据采集系统相连。 溶解氧传感器能够空气校准,一般校准所需时间较长,在使用后要注意保养。如果在养殖水中工作时间过长,就必须定期地清洗膜,对其进行额外保养。 在很多水产养殖中,每天测几次溶氧就可以了解溶氧情况。对池塘和许多水槽养殖系统。溶氧水平不会变化很快,池塘一般每天检测2~3次。 对于较高密度养殖系统,增氧泵故障发生可能不到1h就会造成鱼虾等大面积死亡。这些密度高的养殖系统要求有足够多的装备或每小时多次自动测量溶氧。 (3)温度传感器: 温度传感器有多种结构,包括热电偶、电阻温度传感器和热敏电阻。热电偶技术成熟,应用领域广,货源充足。选择热电偶必须满足温度范围要求,且其材料与环境相容。 电阻温度传感器(RTDs)的原理为金属的电阻随温度的改变而改变。大多电阻温度传感器(RTDs)由铂、镍或镍合金制成,其线性度比热电偶好,热切更加稳定,但容易破碎。 热敏电阻是电阻与温度具有负相关关系的半导体。热敏电阻比RTD和热电偶更灵敏,也更容易破碎,不能承受大的温差,但这一点在水产养殖中不成问题。        ## 2. 硬件选型 ### 2.1 STM32开发板 主控CPU采用STM32F103RCT6,这颗芯片包括48 KB SRAM、256 KB Flash、2个基本定时器、4个通用定时器、2个高级定时器、51个通用IO口、5个串口、2个DMA控制器、3个SPI、2个I2C、1个USB、1个CAN、3个12位ADC、1个12位DAC、1个SDIO接口,芯片属于大容量类型,配置较高,整体符合硬件选型设计。当前选择的这款开发板自带了一个1.4寸的TFT-LCD彩屏,可以显示当前传感器数据以及一些运行状态信息。  ### 2.2 杜邦线  ### 2.3 PCB板  ### 2.4 步进电机  ### 2.5 抽水马达   ### 2.6 水温检测传感器  测温采用DS18B20,DS18B20是常用的数字温度传感器,其输出的是数字信号,具有体积小,硬件开销低,抗干扰能力强,精度高的特点。 DS18B20数字温度传感器接线方便,封装成后可应用于多种场合,如管道式,螺纹式,磁铁吸附式,不锈钢封装式,型号多种多样,有LTM8877,LTM8874等等。 主要根据应用场合的不同而改变其外观。封装后的DS18B20可用于电缆沟测温,高炉水循环测温,锅炉测温,机房测温,农业大棚测温,洁净室测温,弹药库测温等各种非极限温度场合。耐磨耐碰,体积小,使用方便,封装形式多样,适用于各种狭小空间设备数字测温和控制领域。 ### 2.7 水质检测传感器 TDS (Total Dissolved Solids)、中文名总溶解固体、又称溶解性固体、又称溶解性固体总量、表明1升水肿容有多少毫克溶解性固体、一般来说、TDS值越高、表示水中含有溶解物越多、水就越不洁净、虽然在特定情况下TDS并不能有效反映水质的情况、但作为一种可快速检测的参数、TDS目前还可以作为有效的在水质情况反映参数来作为参考。常用的TDS检测设备为TDS笔、虽然价格低廉、简单易用、但不能把数据传给控制系统、做长时间的在线监测、并做水质状况分析、使用专门的仪器、虽然能传数据、精度也高、但价格很贵、为此这款TDS传感器模块、即插即用、使用简单方便、测量用的激励源采用交流信号、可有效防止探头极化、延长探头寿命的同时、也增加了输出信号的稳定性、TDS探头为防水探头、可长期侵入水中测量、该产品可以应用于生活用水、水培等领域的水质检测、有了这个传感器、可轻松DIY--套TDS检测仪了、轻松检测水的洁净程度。  ### 2.8 ESP8266 ■模块采用串口(LVTTL) 与MCU (或其他串口设备) 通信,内置TCP/IP协议栈,能够实现串口与WIFI之间的转换 ■模块支持LVTTL串口, 兼容3..3V和5V单片机系统 ■模块支持串 口转WIFI STA、串口转AP和WIFI STA+WIFI AP的模式,从而快速构建串口-WIFI数据传输方案 ■模块小巧(19mm*29mm), 通过6个2.54mm间距排针与外部连接       ## 3. 华为云IOT产品与设备创建 ### 3.1 创建产品  链接:https://www.huaweicloud.com/product/iothub.html 点击右上角窗口创建产品。  填入产品信息。   接下来创建模型文件: 创建服务。  创建属性。根据鱼缸设备的传感器属性来添加属性。 (1)LED氛围灯 (2)抽水电机 (3)水质传感器 (4)水温温度计        ### 3.2 创建设备 地址: https://console.huaweicloud.com/iotdm/?region=cn-north-4#/dm-portal/device/all-device 点击右上角创建设备。  按照设备的情况进行填写信息。  设备创建后保存信息: ```cpp { "device_id": "62cd6da66b9813541d510f64_dev1", "secret": "12345678" } ``` 创建成功。   ### 3.3 设备模拟调试 为了测试设备通信的过程,在设备页面点击调试。  选择设备调试:  ### 3.4 MQTT三元组 为了方便能够以真实的设备登陆服务器进行测试,接下来需要先了解MQTT协议登录需要的参数如何获取,得到这些参数才可以接着进行下一步。 MQTT(Message Queuing Telemetry Transport)是一个基于客户端-服务器的消息发布/订阅传输协议,主要应用于计算能力有限,且工作在低带宽、不可靠的网络的远程传感器和控制设备,适合长连接的场景,如智能路灯等。 MQTTS是MQTT使用TLS加密的协议。采用MQTTS协议接入平台的设备,设备与物联网平台之间的通信过程,数据都是加密的,具有一定的安全性。  采用MQTT协议接入物联网平台的设备,设备与物联网平台之间的通信过程,数据没有加密,如果要保证数据的私密性可以使用MQTTS协议。  在这里可以使用华为云提供的工具快速得到MQTT三元组进行登录。 [https://support.huaweicloud.com/devg-iothub/iot_01_2127.html#ZH-CN_TOPIC_0240834853__zh-cn_topic_0251997880_li365284516112](https://support.huaweicloud.com/devg-iothub/iot_01_2127.html#ZH-CN_TOPIC_0240834853__zh-cn_topic_0251997880_li365284516112)  工具的页面地址: [https://iot-tool.obs-website.cn-north-4.myhuaweicloud.com/](https://iot-tool.obs-website.cn-north-4.myhuaweicloud.com/) 根据提示填入信息,然后生成三元组信息即可。 这里填入的信息就是在创建设备的时候生成的信息。  ```cpp DeviceId 62cd6da66b9813541d510f64_dev1 DeviceSecret 12345678 ClientId 62cd6da66b9813541d510f64_dev1_0_0_2022071609 Username 62cd6da66b9813541d510f64_dev1 Password a23fb6db6b5bc428971d5ccf64cc8f7767d15ca63bd5e6ac137ef75d175c77bf ``` ### 3.5 平台接入地址 华为云的物联网服务器地址在这里可以获取: [https://console.huaweicloud.com/iotdm/?region=cn-north-4#/dm-portal/home](https://console.huaweicloud.com/iotdm/?region=cn-north-4#/dm-portal/home)  ```cpp MQTT (1883) a161a58a78.iot-mqtts.cn-north-4.myhuaweicloud.com 对应的IP地址是: 121.36.42.100 ``` ### 3.6 MQTT的主题订阅与发布格式 得到三元组之后,就可以登录MQTT服务器进行下一步的主题发布与订阅。 主题的格式详情: [https://support.huaweicloud.com/api-iothub/iot_06_v5_3004.html](https://support.huaweicloud.com/api-iothub/iot_06_v5_3004.html) 上传的数据格式详情: [https://support.huaweicloud.com/devg-iothub/iot_01_2127.html#ZH-CN_TOPIC_0240834853__zh-cn_topic_0251997880_li365284516112](https://support.huaweicloud.com/devg-iothub/iot_01_2127.html#ZH-CN_TOPIC_0240834853__zh-cn_topic_0251997880_li365284516112) ```cpp 设备消息上报 $oc/devices/{device_id}/sys/messages/up 平台下发消息给设备 $oc/devices/{device_id}/sys/messages/down 上传的消息格式: { "services": [{ "service_id": "Connectivity", "properties": { "dailyActivityTime": 57 }, "event_time": "20151212T121212Z" }, { "service_id": "Battery", "properties": { "batteryLevel": 80 }, "event_time": "20151212T121212Z" } ] } ``` 根据当前设备的格式总结如下: ```cpp ClientId 62cd6da66b9813541d510f64_dev1_0_0_2022071609 Username 62cd6da66b9813541d510f64_dev1 Password a23fb6db6b5bc428971d5ccf64cc8f7767d15ca63bd5e6ac137ef75d175c77bf //订阅主题: 平台下发消息给设备 $oc/devices/62cd6da66b9813541d510f64_dev1/sys/messages/down //设备上报数据 $oc/devices/62cd6da66b9813541d510f64_dev1/sys/properties/report //上报的属性消息 (一次可以上报多个属性,在json里增加就行了) {"services": [{"service_id": "fish","properties":{"LED":1}},{"service_id": "fish","properties":{"motor":1}},{"service_id": "fish","properties":{"水温":36.2}}]} ``` ### 3.6 MQTT客户端模拟设备调试 得到信息之后,将参赛填入软件进行登录测试。  数据发送之后,在设备页面上可以看到设备已经在线了,并且收到了上传的数据。  ## 4. STM32程序设计 ### 4.1 硬件连线 ```cpp 硬件连接方式: 1. TFT 1.44 寸彩屏接线 GND 电源地 VCC 接5V或3.3v电源 SCL 接PC8(SCL) SDA 接PC9(SDA) RST 接PC10 DC 接PB7 CS 接PB8 BL 接PB11 2. 板载LED灯接线 LED1---PA8 LED2---PD2 3. 板载按键接线 K0---PA0 K1---PC5 K2---PA15 4. DS18B20温度传感器接线 DQ->PC6 + : 3.3V - : GND 5. 步进电机 ULN2003控制28BYJ-48步进电机接线: ULN2003接线: IN-D: PB15 d IN-C: PB14 c IN-B: PB13 b IN-A: PB12 a + : 5V - : GND 6. 抽水电机 GND---GND VCC---5V AO----PA4 7. 水质检测传感器 AO->PA1 + : 3.3V - : GND 8. RGB灯 PC13--R PC14--G PC15--B 9. ATK-ESP8266 WIFI接线 PA2(TX)--RXD 模块接收脚 PA3(RX)--TXD 模块发送脚 GND---GND 地 VCC---VCC 电源(3.3V~5.0V) ``` ### 4.2 硬件原理图  ### 4.3 汉字取模  ### 4.4 程序下载 下载软件在资料包里。点击开始编程之后,点击开发板的复位键即可下载程序进去。  ### 4.5 主要的信息连接代码 ```cpp #include "stm32f10x.h" #include "led.h" #include "delay.h" #include "key.h" #include "usart.h" #include #include "timer.h" #include "esp8266.h" #include "mqtt.h" #include "oled.h" #include "fontdata.h" #include "bh1750.h" #include "iic.h" #include "sht3x.h" #define ESP8266_WIFI_AP_SSID "aaa" //将要连接的路由器名称 --不要出现中文、空格等特殊字符 #define ESP8266_AP_PASSWORD "12345678" //将要连接的路由器密码 //华为云服务器的设备信息 #define MQTT_ClientID "62cd6da66b9813541d510f64_dev1_0_0_2022071609" #define MQTT_UserName "62cd6da66b9813541d510f64_dev1" #define MQTT_PassWord "a23fb6db6b5bc428971d5ccf64cc8f7767d15ca63bd5e6ac137ef75d175c77bf" //订阅与发布的主题 #define SET_TOPIC "$oc/devices/62cd6da66b9813541d510f64_dev1/sys/messages/down" //订阅 #define POST_TOPIC "$oc/devices/62cd6da66b9813541d510f64_dev1/sys/properties/report" //发布 ``` ### 4.6 ESP8266主要代码 ```cpp u8 ESP8266_IP_ADDR[16]; //255.255.255.255 u8 ESP8266_MAC_ADDR[18]; //硬件地址 /* 函数功能: ESP8266命令发送函数 函数返回值:0表示成功 1表示失败 */ u8 ESP8266_SendCmd(char *cmd) { int RX_CNT=0; u8 i,j; for(i=0;i10;i++) //检测的次数--发送指令的次数 { USARTx_StringSend(USART3,cmd); for(j=0;j100;j++) //等待的时间 { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,"OK")) { return 0; } } } } return 1; } /* 函数功能: ESP8266硬件初始化检测函数 函数返回值:0表示成功 1表示失败 */ u8 ESP8266_Init(void) { //退出透传模式 USARTx_StringSend(USART3,"+++"); delay_ms(100); //退出透传模式 USARTx_StringSend(USART3,"+++"); delay_ms(100); return ESP8266_SendCmd("AT\r\n"); } /* 函数功能: 一键配置WIFI为AP+TCP服务器模式 函数参数: char *ssid 创建的热点名称 char *pass 创建的热点密码 (最少8位) u16 port 创建的服务器端口号 函数返回值: 0表示成功 其他值表示对应错误值 */ u8 ESP8266_AP_TCP_Server_Mode(char *ssid,char *pass,u16 port) { char *p; u8 i; char ESP8266_SendCMD[100]; //组合发送过程中的命令 /*1. 测试硬件*/ if(ESP8266_SendCmd("AT\r\n"))return 1; /*2. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 2; /*3. 设置WIFI模式*/ if(ESP8266_SendCmd("AT+CWMODE=2\r\n"))return 3; /*4. 复位*/ ESP8266_SendCmd("AT+RST\r\n"); delay_ms(1000); delay_ms(1000); delay_ms(1000); /*5. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 5; /*6. 设置WIFI的AP模式参数*/ sprintf(ESP8266_SendCMD,"AT+CWSAP=\"%s\",\"%s\",1,4\r\n",ssid,pass); if(ESP8266_SendCmd(ESP8266_SendCMD))return 6; /*7. 开启多连接*/ if(ESP8266_SendCmd("AT+CIPMUX=1\r\n"))return 7; /*8. 设置服务器端口号*/ sprintf(ESP8266_SendCMD,"AT+CIPSERVER=1,%d\r\n",port); if(ESP8266_SendCmd(ESP8266_SendCMD))return 8; /*9. 查询本地IP地址*/ if(ESP8266_SendCmd("AT+CIFSR\r\n"))return 9; //提取IP地址 p=strstr((char*)USART3_RX_BUF,"APIP"); if(p) { p+=6; for(i=0;*p!='"';i++) { ESP8266_IP_ADDR[i]=*p++; } ESP8266_IP_ADDR[i]='\0'; } //提取MAC地址 p=strstr((char*)USART3_RX_BUF,"APMAC"); if(p) { p+=7; for(i=0;*p!='"';i++) { ESP8266_MAC_ADDR[i]=*p++; } ESP8266_MAC_ADDR[i]='\0'; } //打印总体信息 printf("当前WIFI模式:AP+TCP服务器\r\n"); printf("当前WIFI热点名称:%s\r\n",ssid); printf("当前WIFI热点密码:%s\r\n",pass); printf("当前TCP服务器端口号:%d\r\n",port); printf("当前TCP服务器IP地址:%s\r\n",ESP8266_IP_ADDR); printf("当前TCP服务器MAC地址:%s\r\n",ESP8266_MAC_ADDR); return 0; } /* 函数功能: TCP服务器模式下的发送函数 发送指令: */ u8 ESP8266_ServerSendData(u8 id,u8 *data,u16 len) { int RX_CNT=0; u8 i,j,n; char ESP8266_SendCMD[100]; //组合发送过程中的命令 for(i=0;i10;i++) { sprintf(ESP8266_SendCMD,"AT+CIPSEND=%d,%d\r\n",id,len); USARTx_StringSend(USART3,ESP8266_SendCMD); for(j=0;j10;j++) { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,">")) { //继续发送数据 USARTx_DataSend(USART3,data,len); //等待数据发送成功 for(n=0;n200;n++) { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,"SEND OK")) { return 0; } } } } } } } return 1; } /* 函数功能: 配置WIFI为STA模式+TCP客户端模式 函数参数: char *ssid 创建的热点名称 char *pass 创建的热点密码 (最少8位) char *p 将要连接的服务器IP地址 u16 port 将要连接的服务器端口号 u8 flag 1表示开启透传模式 0表示关闭透传模式 函数返回值:0表示成功 其他值表示对应的错误 */ u8 ESP8266_STA_TCP_Client_Mode(char *ssid,char *pass,char *ip,u16 port,u8 flag) { char ESP8266_SendCMD[100]; //组合发送过程中的命令 //退出透传模式 //USARTx_StringSend(USART3,"+++"); //delay_ms(50); /*1. 测试硬件*/ if(ESP8266_SendCmd("AT\r\n"))return 1; /*2. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 2; /*3. 设置WIFI模式*/ if(ESP8266_SendCmd("AT+CWMODE=1\r\n"))return 3; /*4. 复位*/ ESP8266_SendCmd("AT+RST\r\n"); delay_ms(1000); delay_ms(1000); delay_ms(1000); /*5. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 5; /*6. 配置将要连接的WIFI热点信息*/ sprintf(ESP8266_SendCMD,"AT+CWJAP=\"%s\",\"%s\"\r\n",ssid,pass); if(ESP8266_SendCmd(ESP8266_SendCMD))return 6; /*7. 设置单连接*/ if(ESP8266_SendCmd("AT+CIPMUX=0\r\n"))return 7; /*8. 配置要连接的TCP服务器信息*/ sprintf(ESP8266_SendCMD,"AT+CIPSTART=\"TCP\",\"%s\",%d\r\n",ip,port); if(ESP8266_SendCmd(ESP8266_SendCMD))return 8; /*9. 开启透传模式*/ if(flag) { if(ESP8266_SendCmd("AT+CIPMODE=1\r\n"))return 9; //开启 if(ESP8266_SendCmd("AT+CIPSEND\r\n"))return 10; //开始透传 if(!(strstr((char*)USART3_RX_BUF,">"))) { return 11; } //如果想要退出发送: "+++" } printf("WIFI模式:STA+TCP客户端\r\n"); printf("Connect_WIFI热点名称:%s\r\n",ssid); printf("Connect_WIFI热点密码:%s\r\n",pass); printf("TCP服务器端口号:%d\r\n",port); printf("TCP服务器IP地址:%s\r\n",ip); return 0; } /* 函数功能: TCP客户端模式下的发送函数 发送指令: */ u8 ESP8266_ClientSendData(u8 *data,u16 len) { int RX_CNT=0; u8 i,j,n; char ESP8266_SendCMD[100]; //组合发送过程中的命令 for(i=0;i10;i++) { sprintf(ESP8266_SendCMD,"AT+CIPSEND=%d\r\n",len); USARTx_StringSend(USART3,ESP8266_SendCMD); for(j=0;j10;j++) { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,">")) { //继续发送数据 USARTx_DataSend(USART3,data,len); //等待数据发送成功 for(n=0;n200;n++) { delay_ms(50); if(USART3_RX_STA&0X8000) { RX_CNT=USART3_RX_STA&0x7FFF; USART3_RX_BUF[RX_CNT]='\0'; USART3_RX_STA=0; if(strstr((char*)USART3_RX_BUF,"SEND OK")) { return 0; } } } } } } } return 1; } ``` -
1.开发板介绍E53扩展版接口WiFi Soc Hi3861NFC芯片NT3H120Type-C USB接口复位按键用户按键:可以通过检测GPIO11/12口的电压的变化来检测是否按下NFC天线:可用于实现碰一碰互联网,碰一碰拉起服务等实验TTL转USB天线芯片CH340E板上的LED灯可以通过GPIO2来控制E53接口1.SPI时钟引脚2.SPI片选引脚,可以是硬件SPI片选,也可以是软件SPI片选3.NC引脚,防呆设计,主板排座的该引脚需要堵孔,扩展板排针的该引脚需要剪断4.普通GPIO引脚5.ADC采集引脚6.DAC模拟量输出引脚7.普通GPIO引脚8.普通GPIO引脚,主板的该引脚必须有PWM9.lIC的时钟引脚10.lIC的数据引脚11.普通GPIO引脚,主板的该引脚必须有pWM波功能12.串口的数据接收引脚13.串口的数据发送引脚14.普通GPIO引脚,主板的该引脚必须有pWM波功能15.SPI主设备数据输出,从设备数据输入16.SPI主设备数据输入,从设备数据输出17.电源地18.3.3V电源,需保证能提供2A的电流19.电源地20.5.0V电源,需保证能提供2A的电流
-
一、前言物联网是互联网基础上的延伸和扩展的网络,将各种信息传感设备与互联网结合起来而形成的一个巨大网络,实现在任何时间、任何地点,人、机、物的互联互通。物联网的底层是感知层,感知层主要器件是传感器,作用是使用传感器收集信息;收集到的信息会发给传输层,传输层的核心的无线网络(WiFi,蓝牙,zigbee等),作用是将感知层收集的信息传输给上层应用层,应用层是所谓的云服务器。应用层通过大数据,云计算等手段最终得出结论,在通过传输层发出操作指令给底层去执行。单片机是物联网感知层的核心,而接在单片机上的各种传感器就是单片机的感官,通过这些传感器采集数据,经过单片机统一处理传递给应用终端进行统一分析,完成互联互通。这篇文章合集就列出了单片机的常用传感器开发案例,比如:温度湿度传感器、GPS定位数据解析与转换、ESP8266串口WIFI的使用、光敏传感器的应用案例、三轴陀螺仪的使用案例、OLED低功耗显示屏应用案例、步进电机应用案例、IIC通信协议详解、红外线通信协议应用方案、单片机在线升级方案等等。二、开发案例2.1 STM32+BH1750光敏传感器获取光照强度链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193508这篇文章利用STM32F103读取B1750光敏传感器的数据,使用IIC模拟时序驱动,方便移植到其他平台,采集的光照度比较灵敏. 合成的光照度返回值范围是 0~255。 0表示全黑 255表示很亮。实测: 手机闪光灯照着的状态返回值是245左右,手捂着的状态返回值是10左右.2.2 STM32+MFRC522完成IC卡号读取、密码修改、数据读写链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193563这篇文章利用STM32F103控制RC522模块,使用MFRC522模块完成对IC卡卡号读取、卡类型区分、IC卡扇区密码修改、扇区数据读写等功能;底层采用SPI模拟时序,可以很方便的移植到其他设备,完成项目开发。 现在很多嵌入式方向的毕业设计经常使用到该模块,比如: 校园一卡通设计、水卡充值消费设计、公交卡充值消费设计等。2.3 STM32+HC05串口蓝牙设计简易的蓝牙音箱链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193568这篇文章介绍简易蓝牙音箱的设计流程方案,讲解STM32串口的使用,HC05蓝牙模块的使用,设计了Android上位机,Android手机打开APP,设置好参数之后,选择音乐文件发送给蓝牙音箱设备端,HC05蓝牙收到数据之后,再传递给VS1053进行播放。程序里采用环形缓冲区,接收HC05蓝牙传递的数据,设置好传递的参数之后,基本播放音乐是很流畅的。2.4 基于STM32单片机设计的红外测温仪(带人脸检测)链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193593由于医学发展的需要,在很多情况下,一般的温度计己经满足不了快速而又准确的测温要求,例如:车站、地铁、机场等人口密度较大的地方进行人体温度测量。当前设计的这款红外测温仪由测温硬件+上位机软件组合而成,主要用在地铁、车站入口等地方,可以准确识别人脸进行测温,如果有人温度超标会进行语音提示并且保存当前人脸照片。2.5 STM32+MPU6050设计便携式Mini桌面时钟(自动调整时间显示方向)链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193644Mini桌面时钟可以根据MPU6050测量的姿态自动调整显示画面方向,也就是倒着拿、横着拿、反着拿都可以让时间显示是正对着自己的,时间支持自己调整,支持串口校准。可以按键切换页面查看环境温度显示。2.6 STM32+OLED显示屏制作指针式电子钟链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193646自古以来时钟便是我们人类生活中异常重要的不可缺少的一部分。时钟可以让人们准确地了解和知道每时每刻的时间。现代生活的人们越来越重视起了时间观念,可以说是时间和金钱划上了等号,对于那些对时间把握非常严格和准确的人或事来说,时间的不准确会带来非常大的麻烦。2.7 STM32+ULN2003驱动28BYJ4步进电机(根据圈数正转、反转)链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193647采用STM32驱动28BYJ4步进电机,实现正转反转,完成角度调整。步进电机是一种将电脉冲转化为角位移的执行机构。当步进驱动器接收到一个脉冲信号,它就驱动步进电机按设定的方向转动- -一个固定的角度(及步进角)。可以通过控制脉冲个来控制角位移量,从而达到准确定位的目的;同时可以通过控制脉冲频率来控制电机转动的速度和加速度,从而达到调速的目的。2.8 STM32F103ZE+SHT30检测环境温度与湿度(IIC模拟时序)链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193648sht30是盛世瑞恩生产的温湿度传感器, SHT30支持高精度温湿度测量,内部自动校准,整个程序采用模块化编程,iic时序为一个模块(iic.c 和 iic.h),SHT30为一个模块(sht30.c 和 sht30.h);IIC时序采用模拟时序方式实现,IO口都采用宏定义方式,方便快速移植到其他平台使用。2.9 STM32F103实现IAP在线升级应用程序链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193650IAP,全称是“In-Application Programming”,中文解释为“在程序中编程”。IAP是一种对通过微控制器的对外接口(如USART,IIC,CAN,USB,以太网接口甚至是无线射频通道)对正在运行程序的微控制器进行内部程序的更新的技术(注意这完全有别于ICP或者ISP技术)。ICP(In-Circuit Programming)技术即通过在线仿真器对单片机进行程序烧写,而ISP技术则是通过单片机内置的bootloader程序引导的烧写技术。无论是ICP技术还是ISP技术,都需要有机械性的操作如连接下载线,设置跳线帽等。若产品的电路板已经层层密封在外壳中,要对其进行程序更新无疑困难重重,若产品安装于狭窄空间等难以触及的地方,更是一场灾难。但若进引入了IAP技术,则完全可以避免上述尴尬情况,而且若使用远距离或无线的数据传输方案,甚至可以实现远程编程和无线编程。这绝对是ICP或ISP技术无法做到的。某种微控制器支持IAP技术的首要前提是其必须是基于可重复编程闪存的微控制器。STM32微控制器带有可编程的内置闪存,同时STM32拥有在数量上和种类上都非常丰富的外设通信接口,因此在STM32上实现IAP技术是完全可行的。2.10 STM32封装ESP8266一键配置函数:实现实现AP模式和STA模式切换、服务器与客户端创建链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193651ESP8266是一款物联网WiFi芯片,基于ESP8266可以开发物联网串口WiFi模块,像SKYLAB的WG219/WG229专为移动设备和物联网应用设计,可将用户的物理设备连接到WiFi无线网络上,进行互联网或局域网通信,实现联网功能。另外WG219/WG229仅需要通过出串口使用AT指令控制,就能满足大部分的网络功能需求。2.11 STM32入门开发 NEC红外线协议解码(超低成本无线传输方案)链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193653红外线传输协议可以说是所有无线传输协议里成本最低,最方便的传输协议了,但是也有缺点,距离不够长,速度不够快;当然,每个传输协议应用的环境不一样,定位不一样,好坏没法比较,具体要看自己的实际场景选择合适的通信方式。NEC协议是众多红外线协议中的一种(这里说的协议就是他们数据帧格式定义不一样,数据传输原理都是一样的),我们购买的外能遥控器、淘宝买的mini遥控器、电视机、投影仪几乎都是NEC协议。 像格力空调、美的空调这些设备使用的就是其他协议格式,不是NEC协议,但是只要学会一种协议解析方式,明白了红外线传输原理,其他遥控器协议都可以解出来。2.12 STM32入门开发 编写DS18B20温度传感器驱动(读取环境温度、支持级联)链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193655DS18B20是一个数字温度传感器,采用的是单总线时序与主机通信,只需要一根线就可以完成温度数据读取;DS18B20内置了64位产品序列号,方便识别身份,在一根线上可以挂接多个DS18B20传感器,通过64位身份验证,可以分别读取来至不同传感器采集的温度信息。2.13 STM32入门开发 采用IIC硬件时序读写AT24C08(EEPROM)链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193656AT24C08系列支持I2C,总线数据传送协议I2C,总线协议规定任何将数据传送到总线的器件作为发送器。任何从总线接收数据的器件为接收器;数据传送是由产生串行时钟和所有起始停止信号的主器件控制的。主器件和从器件都可以作为发送器或接收器,但由主器件控制传送数据(发送或接收)的模式。2.14 GPS原始坐标转百度地图坐标(纯C代码)链接:https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=193507得到GPS原始坐标数据之后,想通过百度地图API接口直接显示实际定位。国际经纬度坐标标准为WGS-84,国内必须至少使用国测局制定的GCJ- 02,对地理位置进行首次加密。百度坐标在此基础上,进行了BD-09二次加密措施,更加保护了个人隐私。百度对外接口的坐标系并不是GPS采集的真实经 纬度,需要通过坐标转换接口进行转换。
-
# 一、环境介绍 **编程软件:** keil5 **操作系统:** win10 **MCU型号:** STM32F103ZET6 **STM32编程方式:** 寄存器开发 (方便程序移植到其他单片机) **IIC总线:** STM32本身支持IIC硬件时序的,上篇文章已经介绍了采用IIC模拟时序读写AT24C02,这篇文章介绍STM32的硬件IIC配置方法,并读写AT24C08。 模拟时序更加方便移植到其他单片机,通用性更高,不分MCU;硬件时序效率更高,每个MCU配置方法不同,依赖硬件本身支持。 **器件型号:** 采用AT24C08 EEPROM存储芯片 # 二、AT24C08存储芯片介绍 ## 2.1 芯片功能特性介绍 AT24C08 是串行CMOS类型的EEPROM存储芯片,AT24C0x这个系列包含了**AT24C01、AT24C02、AT24C04、AT24C08、AT24C16**这些具体的芯片型号。 他们容量分别是:1K (128 x 8)、2K (256 x 8)、8K (1024 x 8)、16K (2048 x 8) ,其中的8表示8位(bit) **它们的管脚功能、封装特点如下:**     **芯片功能描述:** AT24C08系列支持I2C,总线数据传送协议I2C,总线协议规定任何将数据传送到总线的器件作为发送器。任何从总线接收数据的器件为接收器;数据传送是由产生串行时钟和所有起始停止信号的主器件控制的。主器件和从器件都可以作为发送器或接收器,但由主器件控制传送数据(发送或接收)的模式。 **芯片特性介绍:** \1. 低压和标准电压运行 –2.7(VCC=2.7伏至5.5伏) –1.8(VCC=1.8伏至5.5伏) \2. 两线串行接口(SDA、SCL) \3. 有用于硬件数据保护的写保护引脚 \4. 自定时写入周期(5毫秒~10毫秒),因为内部有页缓冲区,向AT24C0x写入数据之后,还需要等待AT24C0x将缓冲区数据写入到内部EEPROM区域. \5. 数据保存可达100年 \6. 100万次擦写周期 \7. 高数据传送速率为400KHz、低速100KHZ和IIC总线兼容。 100 kHz(1.8V)和400 kHz(2.7V、5V) \8. 8字节页写缓冲区 这个缓冲区大小与芯片具体型号有关: 8字节页(1K、2K)、**16字节页(4K、8K、16K)** ## **2.2 芯片设备地址介绍**    因为IIC协议规定,每次传递数据都是按8个字节传输的,AT24C08是1024字节,地址的选择上与AT24C02有所区别; IIC设备的标准地址位是7位。上面这个图里AT24C08的1010是芯片内部固定值,A2 是硬件引脚、由硬件决定电平;P1、P0是空间存储块选择,每个存储块大小是256字节,寻址范围是0~255,AT24C08相当于是4块AT24C02的构造;最后一位是读/写位(1是读,0是写),读写位不算在地址位里,但是根据IIC的时序顺序,在操作设备前,都需要先发送7位地址,再发送1位读写位,才能启动对芯片的操作,我们在写模拟时序为了方便统一写for循环,按字节发送,所以一般都是将7地址位与1位读写位拼在一起,组合成1个字节,方便按字节传输数据。 **我现在使用的开发板上AT24C08的原理图是这样的:**  **那么这个AT24C08的标准设备地址分别是:** 第一块区域: 0x50(十六进制),对应的二进制就是: 1010000 第二块区域: 0x51(十六进制),对应的二进制就是: 1010001 第三块区域: 0x52(十六进制),对应的二进制就是: 1010010 第四块区域: 0x53(十六进制),对应的二进制就是: 1010011 **如果将读写位组合在一起,读权限的设备地址:** 第一块区域: 0xA1(十六进制),对应的二进制就是: 10100001 第二块区域: 0xA3(十六进制),对应的二进制就是: 10100011 第三块区域: 0xA5(十六进制),对应的二进制就是: 10100101 第四块区域: 0xA7(十六进制),对应的二进制就是: 10100111 **如果将读写位组合在一起,写权限的设备地址:** 第一块区域: 0xA0(十六进制),对应的二进制就是: 10100000 第二块区域: 0xA2(十六进制),对应的二进制就是: 10100010 第三块区域: 0xA4(十六进制),对应的二进制就是: 10100100 第四块区域: 0xA6(十六进制),对应的二进制就是: 10100110 ## 2.3 对AT24C08 按字节写数据的指令流程(时序)  **详细解释:** \1. 先发送起始信号 \2. 发送设备地址(写权限) \3. 等待AT24C08应答、低电平有效 \4. 发送存储地址、AT24C08内部一共有256个字节空间,寻址是从0开始的,范围是(0~255);发送这个存储器地址就是告诉AT24C08接下来的数据改存储到哪个地方。 \5. 等待AT24C08应答、低电平有效 \6. 发送一个字节的数据,这个数据就是想存储到AT24C08里保存的数据。 \7. 等待AT24C08应答、低电平有效 \8. 发送停止信号 ## 2.3 对AT24C08 按页写数据的指令流程(时序)  **详细解释:** \1. 先发送起始信号 \2. 发送设备地址(写权限) \3. 等待AT24C08应答、低电平有效 \4. 发送存储地址、AT24C08内部一共有256个字节空间,寻址是从0开始的,范围是(0~255);发送这个存储器地址就是告诉AT24C08接下来的数据改存储到哪个地方。 \5. 等待AT24C08应答、低电平有效 \6. 可以循环发送8个字节的数据,这些数据就是想存储到AT24C08里保存的数据。 AT24C08的页缓冲区是16个字节,所有这里的循环最多也只能发送16个字节,多发送的字节会将前面的覆盖掉。 需要注意的地方: 这个页缓冲区的寻址也是从0开始,比如: 0~15算第1页,16~32算第2页......依次类推。 如果现在写数据的起始地址是3,那么这一页只剩下13个字节可以写;并不是说从哪里都可以循环写16个字节。 详细流程: 这里程序里一般使用for循环实现 (1). 发送字节1 (2). 等待AT24C08应答,低电平有效 (3). 发送字节2 (4). 等待AT24C08应答,低电平有效 ......... 最多8次. \7. 等待AT24C08应答、低电平有效 \8. 发送停止信号 ## 2.4 从AT24C08任意地址读任意字节数据(时序)  AT24C08支持当前地址读、任意地址读,最常用的还是任意地址读,因为可以指定读取数据的地址,比较灵活,上面这个指定时序图就是任意地址读。 **详细解释:** \1. 先发送起始信号 \2. 发送设备地址(写权限) \3. 等待AT24C08应答、低电平有效 \4. 发送存储地址、AT24C08内部一共有2048个字节空间,寻址是从0开始的,范围是(0~1024);发送这个存储器地址就是告诉AT24C08接下来应该返回那个地址的数据给单片机。 \5. 等待AT24C08应答、低电平有效 \6. 重新发送起始信号(切换读写模式) \7. 发送设备地址(读权限) \8. 等待AT24C08应答、低电平有效 \9. 循环读取数据: 接收AT24C08返回的数据. 读数据没有字节限制,可以第1个字节、也可以连续将整个芯片读完。 \10. 发送非应答(高电平有效) \11. 发送停止信号 # 三、IIC总线介绍 ### 2.1 IIC总线简介 I2C(Inter-Integrated Circuit)总线是由PHILIPS公司开发的两线式串行总线,用于连接微控制器及其外围设备,是微电子通信控制领域广泛采用的一种总线标准。具有接口线少,控制方式简单,器件封装形式小,通信速率较高等优点。 I2C规程运用主/从双向通讯。器件发送数据到总线上,则定义为发送器,器件接收数据则定义为接收器。主器件和从器件都可以工作于接收和发送状态。 I2C 总线通过串行数据(SDA)线和串行时钟(SCL)线在连接到总线的器件间传递信息。每个器件都有一个唯一的地址识别,而且都可以作为一个发送器或接收器(由器件的功能决定)。 I2C有四种工作模式: 1.主机发送 2.主机接收 3.从机发送 4.从机接收 I2C总线只用两根线:串行数据SDA(Serial Data)、串行时钟SCL(Serial Clock)。 总线必须由主机(通常为微控制器)控制,主机产生串行时钟(SCL)控制总线的传输方向,并产生起始和停止条件。 SDA线上的数据状态仅在SCL为低电平的期间才能改变。 ### 2.2 IIC总线上的设备连接图  I2C 总线在物理连接上非常简单,分别由SDA(串行数据线)和SCL(串行时钟线)及上拉电阻组成。通信原理是通过对SCL和SDA线高低电平时序的控制,来产生I2C总线协议所需要的信号进行数据的传递。在总线空闲状态时,这两根线一般被上面所接的上拉电阻拉高,保持着高电平。 其中上拉电阻范围是4.7K~100K。 ## 2.3 I2C总线特征 I2C总线上的每一个设备都可以作为主设备或者从设备,而且每一个从设备都会对应一个唯一的地址(可以从I2C器件的数据手册得知)。主从设备之间就通过这个地址来确定与哪个器件进行通信,在通常的应用中,我们把CPU带I2C总线接口的模块作为主设备,把挂接在总线上的其他设备都作为从设备。 **1. 总线上能挂接的器件数量** I2C总线上可挂接的设备数量受总线的最大电容400pF 限制,如果所挂接的是相同型号的器件,则还受器件地址的限制。 一般I2C设备地址是7位地址(也有10位),地址分成两部分:芯片固化地址(生产芯片时候哪些接地,哪些接电源,已经固定),可编程地址(引出IO口,由硬件设备决定)。 例如: 某一个器件是7 位地址,其中10101 xxx 高4位出厂时候固定了,低3位可以由设计者决定。 则一条I2C总线上只能挂该种器件最少8个。 如果7位地址都可以编程,那理论上就可以达到128个器件,但实际中不会挂载这么多。 **2. 总线速度传输速度:** I2C总线数据传输速率在标准模式下可达100kbit/s,快速模式下可达400kbit/s,高速模式下可达3.4Mbit/s。一般通过I2C总线接口可编程时钟来实现传输速率的调整。 **3. 总线数据长度** I2C总线上的主设备与从设备之间以字节(8位)为单位进行双向的数据传输。 ## 2.4 I2C总线协议基本时序信号 **空闲状态:** SCL和SDA都保持着高电平。 **起始条件:** 总线在空闲状态时,SCL和SDA都保持着高电平,当SCL为高电平期间而SDA由高到低的跳变,表示产生一个起始条件。在起始条件产生后,总线处于忙状态,由本次数据传输的主从设备独占,其他I2C器件无法访问总线。 **停止条件:** 当SCL为高而SDA由低到高的跳变,表示产生一个停止条件。 **答应信号:** 每个字节传输完成后的下一个时钟信号,在SCL高电平期间,SDA为低,则表示一个应答信号。 **非答应信号:** 每个字节传输完成后的下一个时钟信号,在SCL高电平期间,SDA为高,则表示一个应答信号。应答信号或非应答信号是由接收器发出的,发送器则是检测这个信号(发送器,接收器可以从设备也可以主设备)。 **注意:起始和结束信号总是由主设备产生。** ## 2.5 起始信号与停止信号  起始信号就是: 时钟线SCL处于高电平的时候,数据线SDA由高电平变为低电平的过程。SCL=1;SDA=1;SDA=0; 停止信号就是: 时钟线SCL处于低电平的时候, 数据线SDA由低电平变为高电平的过程。SCL=1;SDA=0;SDA=1; ## 2.6 应答信号  数据位的第9位就时应答位。 读取应答位的流程和读取数据位是一样的。示例: SCL=0;SCL=1;ACK=SDA; 这个ACK就是读取的应答状态。 ## 2.7 数据位传输时序  通过时序图了解到,SCL处于高电平的时候数据稳定,SCL处于低电平的时候数据不稳定。 那么对于写一位数据(STM32--->AT24C08): SCL=0;SDA=data; SCL=1; 那么对于读一位数据(STM32 -----AT24C08): SCL=0;SCL=1;data=SDA; ## 2.8 总线时序  # 四、IIC总线时序代码、AT24C08读写代码 在调试IIC模拟时序的时候,可以在淘宝上买一个24M的USB逻辑分析仪,时序出现问题,使用逻辑分析仪一分析就可以快速找到问题。  ## 4.1 iic.c 这是STM32的IIC硬件时序完整代码 ```cpp /* 函数功能: 初始化IIC总线 硬件连接: SCL---PB6 SDA---PB7 */ void IIC_Init(void) { /*1. 时钟配置*/ RCC->APB2ENR|=1<<3; //PB /*2. GPIO口模式配置*/ GPIOB->CRL&=0x00FFFFFF; GPIOB->CRL|=0xFF000000; //复用开漏输出 GPIOB->ODR|=0x3<<6; /*3. GPIO口时钟配置(顺序不能错)*/ RCC->APB1ENR|=1<<21; //I2C1时钟 RCC->APB1RSTR|=1<<21; //开启复位时钟 RCC->APB1RSTR&=~(1<<21);//关闭复位时钟 /*4. 配置IIC的核心寄存器*/ I2C1->CR2=0x24<<0; //配置主机频率为36MHZ I2C1->CCR|=0x2D<<0; //配置主机频率是400KHZ I2C1->CR1|=1<<0; //开启IIC模块 /* CCR=主机时钟频率/2/IIC总线的频率 45=36MHZ/2/400KHZ ---0x2D */ } /* 函数功能: 发送起始信号 当时钟线为高电平的时候,数据线由高电平变为低电平的过程 */ void IIC_SendStart(void) { I2C1->CR1|=1<<8; //产生起始信号 while(!(I2C1->SR1&1<<0)){} //等待起始信号完成 I2C1->SR1=0; //清除状态位 } /* 函数功能: 停止信号 当时钟线为高电平的时候,数据线由低电平变为高电平的过程 */ void IIC_SendStop(void) { I2C1->CR1|=1<<9; } /* 函数功能: 发送地址数据 */ void IIC_SendAddr(u8 addr) { u32 s1,s2; I2C1->DR=addr; //发送数据 while(1) { s1=I2C1->SR1; s2=I2C1->SR2; if(s1&1<<1) //判断地址有没有发送成功 { break; } } } /* 函数功能: 发送数据 */ void IIC_SendOneByte(u8 addr) { u32 s1,s2; I2C1->DR=addr; //发送数据 while(1) { s1=I2C1->SR1; s2=I2C1->SR2; if(s1&1<<2) //判断数据有没有发送成功 { break; } } } /* 函数功能: 接收一个字节数据 */ u8 IIC_RecvOneByte(void) { u8 data=0; I2C1->CR1|=1<<10; //使能应答 while(!(I2C1->SR1&1<<6)){} //等待数据 data=I2C1->DR; I2C1->CR1&=~(1<<10); //关闭应答使能 return data; } ``` ## 4.2 AT24C08.c 这是AT24C08完整的读写代码 ```cpp * 函数功能: 写一个字节 函数参数: u8 addr 数据的位置(0~1023) u8 data 数据范围(0~255) */ void AT24C08_WriteOneByte(u16 addr,u8 data) { u8 read_device_addr=AT24C08_READ_ADDR; u8 write_device_addr=AT24C08_WRITE_ADDR; if(addr<256*1) //第一个块 { write_device_addr|=0x0<<1; read_device_addr|=0x0<<1; } else if(addr<256*2) //第二个块 { write_device_addr|=0x1<<1; read_device_addr|=0x1<<1; } else if(addr<256*3) //第三个块 { write_device_addr|=0x2<<1; read_device_addr|=0x2<<1; } else if(addr<256*4) //第四个块 { write_device_addr|=0x3<<1; read_device_addr|=0x3<<1; } addr=addr%256; //得到地址范围 IIC_SendStart();//起始信号 IIC_SendAddr(write_device_addr);//发送设备地址 IIC_SendOneByte(addr); //数据存放的地址 IIC_SendOneByte(data); //发送将要存放的数据 IIC_SendStop(); //停止信号 DelayMs(10); //等待写 } /* 函数功能: 读一个字节 函数参数: u8 addr 数据的位置(0~1023) 返回值: 读到的数据 */ u8 AT24C08_ReadOneByte(u16 addr) { u8 data=0; u8 read_device_addr=AT24C08_READ_ADDR; u8 write_device_addr=AT24C08_WRITE_ADDR; if(addr<256*1) //第一个块 { write_device_addr|=0x0<<1; read_device_addr|=0x0<<1; } else if(addr<256*2) //第二个块 { write_device_addr|=0x1<<1; read_device_addr|=0x1<<1; } else if(addr<256*3) //第三个块 { write_device_addr|=0x2<<1; read_device_addr|=0x2<<1; } else if(addr<256*4) //第四个块 { write_device_addr|=0x3<<1; read_device_addr|=0x3<<1; } addr=addr%256; //得到地址范围 IIC_SendStart();//起始信号 IIC_SendAddr(write_device_addr);//发送设备地址 IIC_SendOneByte(addr); //将要读取数据的地址 IIC_SendStart();//起始信号 IIC_SendAddr(read_device_addr);//发送设备地址 data=IIC_RecvOneByte();//读取数据 IIC_SendStop(); //停止信号 return data; } /* 函数功能: 从指定位置读取指定长度的数据 函数参数: u16 addr 数据的位置(0~1023) u16 len 读取的长度 u8 *buffer 存放读取的数据 返回值: 读到的数据 */ void AT24C08_ReadByte(u16 addr,u16 len,u8 *buffer) { u16 i=0; IIC_SendStart();//起始信号 IIC_SendAddr(AT24C08_WRITE_ADDR);//发送设备地址 IIC_SendOneByte(addr); //将要读取数据的地址 IIC_SendStart();//起始信号 IIC_SendAddr(AT24C08_READ_ADDR);//发送设备地址 for(i=0;i<len;i++) { buffer<i>=IIC_RecvOneByte();//读取数据 } IIC_SendStop(); //停止信号 } /* 函数功能: AT24C08页写函数 函数参数: u16 addr 写入的位置(0~1023) u8 len 写入的长度(每页16字节) u8 *buffer 存放读取的数据 */ void AT24C08_PageWrite(u16 addr,u16 len,u8 *buffer) { u16 i=0; IIC_SendStart();//起始信号 IIC_SendAddr(AT24C08_WRITE_ADDR);//发送设备地址 IIC_SendOneByte(addr); //数据存放的地址 for(i=0;i<len;i++) { IIC_SendOneByte(buffer<i>); //发送将要存放的数据 } IIC_SendStop(); //停止信号 DelayMs(10); //等待写 } /* 函数功能: 从指定位置写入指定长度的数据 函数参数: u16 addr 数据的位置(0~1023) u16 len 写入的长度 u8 *buffer 存放即将写入的数据 返回值: 读到的数据 */ void AT24C08_WriteByte(u16 addr,u16 len,u8 *buffer) { u8 page_byte=16-addr%16; //得到当前页剩余的字节数量 if(page_byte>len) //判断当前页剩余的字节空间是否够写 { page_byte=len; //表示一次性可以写完 } while(1) { AT24C08_PageWrite(addr,page_byte,buffer); //写一页 if(page_byte==len)break; //写完了 buffer+=page_byte; //指针偏移 addr+=page_byte;//地址偏移 len-=page_byte;//得到剩余没有写完的长度 if(len>16)page_byte=16; else page_byte=len; //一次可以写完 } } ``` ## 4.3 main.c 这是AT24C08测试代码 ```cpp #include "stm32f10x.h" #include "beep.h" #include "delay.h" #include "led.h" #include "key.h" #include "sys.h" #include "usart.h" #include <string.h> #include <stdio.h> #include "exti.h" #include "timer.h" #include "rtc.h" #include "adc.h" #include "ds18b20.h" #include "ble.h" #include "esp8266.h" #include "wdg.h" #include "oled.h" #include "rfid_rc522.h" #include "infrared.h" #include "iic.h" #include "at24c08.h" u8 buff_tx[50]="1234567890"; u8 buff_rx[50]; u8 data=88; u8 data2; int main() { u8 key; LED_Init(); KEY_Init(); BEEP_Init(); TIM1_Init(72,20000); //辅助串口1接收,超时时间为20ms USART_X_Init(USART1,72,115200); IIC_Init(); //IIC总线初始化 printf("usart1 ok\n"); while(1) { key=KEY_Scanf(); if(key) { //AT24C08_WriteByte(100,50,buff_tx); //AT24C08_ReadByte(100,50,buff_rx); //printf("buff_rx=%s\n",buff_rx); //测试第0块 // data=AT24C08_ReadOneByte(0); // AT24C08_WriteOneByte(0,data+1); // printf("data=%d\n",data); //测试第1块 // data=AT24C08_ReadOneByte(300); // AT24C08_WriteOneByte(300,data+1); // printf("data=%d\n",data); //测试第2块 // data=AT24C08_ReadOneByte(600); // AT24C08_WriteOneByte(600,data+1); // printf("data=%d\n",data); //测试第3块 data=AT24C08_ReadOneByte(900); AT24C08_WriteOneByte(900,data+1); printf("data=%d\n",data); } } } ```
-
# 一、环境介绍 **MCU:** STM32F103ZET6 **编程软件环境:** keil5 **红外线传输协议:** NEC协议---38KHZ载波:。NEC协议是红外遥控协议中常见的一种。 **解码思路:** 外部中断 + 定时器方式 **代码风格:** 模块化编程,寄存器直接操作方式 # 二、NEC协议与解码思路介绍 ## 2.1 采用的相关硬件 **图1:** 这是NEC协议的红外线遥控器: 如果自己手机没有红外线遥控器的功能,可以淘宝上买一个小遥控器来学习测试,成本不高,这个遥控器也可以自己做,能解码当然也可以编码发送,只需要一个红外光发射管即可。  **图2:** 这是红外线接收头模块。如果自己的开发板没有自带这个接收头,那就单独买一个接收头模块,使用杜邦线接到开发板的IO口上即可用来测试学习,接线很方便。   **图3:** 这是红外线发射管,如果自己想做遥控器的发射端,自己做遥控器,那么就可以直接购买这种模块即可。  ## 2.2 红外线协议介绍 在光谱中波长自760nm至400um的电磁波称为红外线,它是一种不可见光。红外线通信的例子我们每个人应该都很熟悉,目前常用的家电设备几乎都可以通过红外遥控的方式进行遥控,比如电视机、空调、投影仪等,都可以见到红外遥控的影子。这种技术应用广泛,相应的应用器件都十分廉价,因此红外遥控是我们日常设备控制的理想方式。 **红外线的通讯原理:** 红外光是以特定的频率脉冲形式发射,接收端收到到信号后,按照约定的协议进行解码,完成数据传输,在消费类电子产品里,脉冲频率普遍采用 30KHz 到 60KHz 这个频段,NEC协议的频率就是38KHZ。 这个以特定的频率发射其实就可以理解为点灯,不要被复杂的词汇难住了,就是控制灯的闪烁频率(亮灭),和刚学单片机完成闪光灯一样的意思,只不过是灯换了一种类型,都是灯。 接收端的原理: 接收端的芯片对这个红外光比较敏感,可以根据有没有光输出高低电平,如果发送端的闪烁频率是有规律的,接收端收到后输出的高电平和低电平也是有规律对应的,这样发送端和接收端只要约定好,那就可以做数据传输了。 红外线传输协议可以说是所有无线传输协议里成本最低,最方便的传输协议了,但是也有缺点,距离不够长,速度不够快;当然,每个传输协议应用的环境不一样,定位不一样,好坏没法比较,具体要看自己的实际场景选择合适的通信方式。 # 2.3 NEC协议介绍 NEC协议是众多红外线协议中的一种(这里说的协议就是他们数据帧格式定义不一样,数据传输原理都是一样的),我们购买的外能遥控器、淘宝买的mini遥控器、电视机、投影仪几乎都是NEC协议。 像格力空调、美的空调这些设备使用的就是其他协议格式,不是NEC协议,但是只要学会一种协议解析方式,明白了红外线传输原理,其他遥控器协议都可以解出来。 **下图是NEC协议传输一次数据的完整格式:**  NEC协议一次完整的传输包含: 引导码、8位用户码、8位用户反码、8位数据码、8位数据反码。 **(注意:下面的解释都是站在红外线接收端的角度来进行说明的,就是解码端的角度)** **引导码:** 由9ms的高电平+4.5ms的低电平组成。 **4个字节的数据:** 用户码+用户反码+数据码+数据反码。 这里的反码可以用来校验数据是否传输正确,有没有丢包。 **重点: NEC协议传输数据位的时候,0和1的区分是依靠收到的高、低电平的持续时间来进行区分的---这是解码关键。** 标准间隔时间:0.56ms 收到数据位0: 0.56ms 收到位1: 1.68ms 所以,收到一个数据位的完整时间表示方法是这样的: 收到数据位0: 0.56m低电平+ 0.56ms的高电平 收到数据位1: 0.56ms低电平+1.68ms的高电平 **红外线接收头模块输出电平的原理:** 红外线接收头感应到有红外光就输出低电平,没有感应到红外光就输出高电平。 **这是使用逻辑分析采集红外线接收头输出的信号:**  **这是采集红外线遥控器上的LED灯输出电平时序图,刚好和接收端相反:**  单片机编写解码程序的时候,常见的方式就是采用外部中断+定时器的方式进行解析,中断可以设置为低电平触发,因为接收头没有感应到红外光默认是输出高电平,如果收到NEC引导码,就会输出低电平,进入到中断服务函数,完成解码,解码过程中开启定时器记录每一段的高电平、低电平的持续时间,按照NEC协议进行判断,完成最终解码。 STM32可以使用输入捕获方式完成解码,其实输入捕获就是外部中断+定时器的组合,只不过是STM32内部封装了一层。 **外部中断服务器里的解码程序如下(这个在其他单片机上思路是一样的):** ```cpp /* 函数功能: 外部中断线9_5服务函数 */ void EXTI9_5_IRQHandler(void) { u32 time; u8 i,j,data=0; //清除中断线9上的中断请求 EXTI->PR|=19; time=Infrared_GetTime_L(); //得到低电平时间 if(time7000||time>10000)return; //标准时间: 9000us time=Infrared_GetTime_H(); //得到高电平时间 if(time3000||time>5500)return; //标准时间4500us //正式解码NEC协议 for(i=0;i4;i++) { for(j=0;j8;j++) { time=Infrared_GetTime_L(); //得到低电平时间 if(time400||time>700)return; //标准时间: 560us time=Infrared_GetTime_H(); //得到高电平时间 if(time>1400&&time1800) //数据1 1680us { data>>=1; data|=0x80; } else if(time>400&&time700) //数据0 560us { data>>=1; } else return; } InfraredRecvData[i]=data; //存放解码成功的值 } //解码成功 InfraredRecvState=1; } ``` # 三、核心完整代码   本程序的解码思路是: 将红外线接收模块的输出脚接到STM32的PB9上,配置STM32的PB9为外部中断模式,下降沿电平触发;如果收到红外线信号就进入到中断服务函数里解码,如果解码过程中发现数据不符合要求就终止解码,如果数据全部符合要求就按照协议接收,直到解码完成,设置标志位,在main函数里打印解码得到的数据。 代码都是模块化编程,阅读起来也很方便。 ## 3.1 红外线解码.c ```cpp #include "nec_Infrared.h" u8 InfraredRecvData[4]; //存放红外线解码接收的数据 u8 InfraredRecvState=0; //0表示未接收到数据,1表示接收到数据 /* 函数功能: 红外线解码初始化(接收) */ void Infrared_RecvInit(void) { Infrared_Time6_Init(); //定时器初始化 /*1. 配置GPIO口*/ RCC->APB2ENR|=13; //PB GPIOB->CRH&=0xFFFFFF0F; GPIOB->CRH|=0x00000080; GPIOB->ODR|=19; /*2. 配置外部中断*/ EXTI->IMR|=19; //外部中断线9,开放中断线的中断请求功能 EXTI->FTSR|=19; //中断线9_下降沿 RCC->APB2ENR|=10; //开启AFIO时钟 AFIO->EXTICR[2]&=~(0xF1*4); AFIO->EXTICR[2]|=0x11*4; STM32_NVIC_SetPriority(EXTI9_5_IRQn,1,1); } /* 函数功能: 初始化定时器,用于红外线解码 */ void Infrared_Time6_Init(void) { RCC->APB1ENR|=14; RCC->APB1RSTR|=14; RCC->APB1RSTR&=~(14); TIM6->PSC=72-1; //预分频器 TIM6->ARR=65535; //重装载寄存器 TIM6->CR1|=17; //开启缓存功能 //TIMx->CR1|=10; //开启定时器 } /* 函数功能: 测量高电平持续的时间 */ u32 Infrared_GetTime_H(void) { TIM6->CNT=0; TIM6->CR1|=10; //开启定时器 while(NEC_IR){} //等待高电平结束 TIM6->CR1&=~(10); //关闭定时器 return TIM6->CNT; } /* 函数功能: 测量低电平持续的时间 */ u32 Infrared_GetTime_L(void) { TIM6->CNT=0; TIM6->CR1|=10; //开启定时器 while(!NEC_IR){} //等待低电平结束 TIM6->CR1&=~(10); //关闭定时器 return TIM6->CNT; } /* 函数功能: 外部中断线9_5服务函数 */ void EXTI9_5_IRQHandler(void) { u32 time; u8 i,j,data=0; //清除中断线9上的中断请求 EXTI->PR|=19; time=Infrared_GetTime_L(); //得到低电平时间 if(time7000||time>10000)return; //标准时间: 9000us time=Infrared_GetTime_H(); //得到高电平时间 if(time3000||time>5500)return; //标准时间4500us //正式解码NEC协议 for(i=0;i4;i++) { for(j=0;j8;j++) { time=Infrared_GetTime_L(); //得到低电平时间 if(time400||time>700)return; //标准时间: 560us time=Infrared_GetTime_H(); //得到高电平时间 if(time>1400&&time1800) //数据1 1680us { data>>=1; data|=0x80; } else if(time>400&&time700) //数据0 560us { data>>=1; } else return; } InfraredRecvData[i]=data; //存放解码成功的值 } //解码成功 InfraredRecvState=1; } ``` ## 3.2 主函数.c ```cpp #include "stm32f10x.h" #include "led.h" #include "delay.h" #include "key.h" #include "usart.h" #include "at24c02.h" #include "W25Q64.h" #include "spi.h" #include "nec_Infrared.h" int main() { LED_Init(); BEEP_Init(); KeyInit(); USARTx_Init(USART1,72,115200); IIC_Init(); W25Q64_Init(); printf("芯片ID号:0x%X\n",W25Q64_ReadID()); Infrared_RecvInit(); while(1) { if(InfraredRecvState) { InfraredRecvState=0; printf("用户码:%d,按键码:%d\n",InfraredRecvData[0],InfraredRecvData[2]); printf("user反码:%d,key反码:%d\n",(~InfraredRecvData[1])&0xFF,(~InfraredRecvData[3])&0xFF); BEEP=!BEEP; LED0=!LED0; } } } ``` # 四、扩展提高 如果上面的NEC的解码思路已经看到,程序已经可以自己编写,就可以试着使用STM32的输入捕获+定时器方式写一版解码代码,既能更加熟悉NEC协议、也可以学习STM32定时器捕获捕获的用法;也可以做一些小东西来锻炼,比如:红外线遥控小车、音乐播放器支持红外线遥控器切歌,电机的开关、灯的开关等等。 搞定协议解码之后,我们下一步就是完成自定义的NEC协议红外线制作,采用STM32模拟一个万能红外线遥控器。 在光谱中波长自760nm至400um的电磁波称为红外线,它是一种不可见光。目前几乎所有的视频和音频设备都可以通过红外遥控的方式进行遥控,比如电视机、空调、影碟机等,都可以见到红外遥控的影子。这种技术应用广泛,相应的应用器件都十分廉价,因此红外遥控是我们日常设备控制的理想方式。
-
## 一、硬件环境介绍 **1. ESP8266 :** 采用安信可的模组,型号是ESP12F  **2. STM32 :** 采用STM32F103C8T6 **3. 编程软件 :** 采用Keil5   **ESP8266编程调试过程中用到的相关软件下载地址:**   ### 二、ESP8266通信的调试与运行效果 下面几张图是将ESP8266配置成AP+TCP服务器模式,电脑连接ESP8266的热点之后,实现数据通信。通信的效果是,在电脑点击物联网控制系统软件,实现控制开发板上的LED灯和蜂鸣器,开发板上将检测的光敏数据、温度数据、RC522刷卡数据传输到电脑的软件上进行显示。----局域网通信    ## 三、硬件接线与代码技术部分介绍 **硬件连接:** 下面会贴出核心代码,在当前开发板上,ESP8266接在STM32F103C8T6的串口3上。 **代码分为以下几个部分:** (1) STM32程序里的串口接收采用定时器+接收中断的形式接收数据,使用这种方式可以接收不定长度数据,方便接下来与ESP8266进行通信。 (2). ESP8266驱动代码:代码实现了STA+TCP客户端的一键配置函数,AP+TCP服务器的一键配置函数,要配置ESP8266只需要调用对应的函数传入参数即可。 ## 四、核心代码部分 ### 4.1 ESP8266.c代码 ```cpp #include "esp8266.h" u8 ESP8266_IP_ADDR[16]; //255.255.255.255 u8 ESP8266_MAC_ADDR[18]; //硬件地址 /* 函数功能: ESP8266命令发送函数 函数返回值:0表示成功 1表示失败 */ u8 ESP8266_SendCmd(char *cmd) { u8 i,j; for(i=0;i10;i++) //检测的次数--发送指令的次数 { USARTx_StringSend(USART3,cmd); for(j=0;j100;j++) //等待的时间 { delay_ms(50); if(USART3_RX_FLAG) { USART3_RX_BUFFER[USART3_RX_CNT]='\0'; USART3_RX_FLAG=0; USART3_RX_CNT=0; if(strstr((char*)USART3_RX_BUFFER,"OK")) { return 0; } } } } return 1; } /* 函数功能: ESP8266硬件初始化检测函数 函数返回值:0表示成功 1表示失败 */ u8 ESP8266_Init(void) { //退出透传模式 USARTx_StringSend(USART3,"+++"); delay_ms(50); return ESP8266_SendCmd("AT\r\n"); } /* 函数功能: 一键配置WIFI为AP+TCP服务器模式 函数参数: char *ssid 创建的热点名称 char *pass 创建的热点密码 (最少8位) u16 port 创建的服务器端口号 函数返回值: 0表示成功 其他值表示对应错误值 */ u8 ESP8266_AP_TCP_Server_Mode(char *ssid,char *pass,u16 port) { char *p; u8 i; char ESP8266_SendCMD[100]; //组合发送过程中的命令 /*1. 测试硬件*/ if(ESP8266_SendCmd("AT\r\n"))return 1; /*2. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 2; /*3. 设置WIFI模式*/ if(ESP8266_SendCmd("AT+CWMODE=2\r\n"))return 3; /*4. 复位*/ ESP8266_SendCmd("AT+RST\r\n"); delay_ms(1000); delay_ms(1000); delay_ms(1000); /*5. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 5; /*6. 设置WIFI的AP模式参数*/ sprintf(ESP8266_SendCMD,"AT+CWSAP=\"%s\",\"%s\",1,4\r\n",ssid,pass); if(ESP8266_SendCmd(ESP8266_SendCMD))return 6; /*7. 开启多连接*/ if(ESP8266_SendCmd("AT+CIPMUX=1\r\n"))return 7; /*8. 设置服务器端口号*/ sprintf(ESP8266_SendCMD,"AT+CIPSERVER=1,%d\r\n",port); if(ESP8266_SendCmd(ESP8266_SendCMD))return 8; /*9. 查询本地IP地址*/ if(ESP8266_SendCmd("AT+CIFSR\r\n"))return 9; //提取IP地址 p=strstr((char*)USART3_RX_BUFFER,"APIP"); if(p) { p+=6; for(i=0;*p!='"';i++) { ESP8266_IP_ADDR[i]=*p++; } ESP8266_IP_ADDR[i]='\0'; } //提取MAC地址 p=strstr((char*)USART3_RX_BUFFER,"APMAC"); if(p) { p+=7; for(i=0;*p!='"';i++) { ESP8266_MAC_ADDR[i]=*p++; } ESP8266_MAC_ADDR[i]='\0'; } //打印总体信息 USART1_Printf("当前WIFI模式:AP+TCP服务器\n"); USART1_Printf("当前WIFI热点名称:%s\n",ssid); USART1_Printf("当前WIFI热点密码:%s\n",pass); USART1_Printf("当前TCP服务器端口号:%d\n",port); USART1_Printf("当前TCP服务器IP地址:%s\n",ESP8266_IP_ADDR); USART1_Printf("当前TCP服务器MAC地址:%s\n",ESP8266_MAC_ADDR); return 0; } /* 函数功能: TCP服务器模式下的发送函数 发送指令: */ u8 ESP8266_ServerSendData(u8 id,u8 *data,u16 len) { u8 i,j,n; char ESP8266_SendCMD[100]; //组合发送过程中的命令 for(i=0;i10;i++) { sprintf(ESP8266_SendCMD,"AT+CIPSEND=%d,%d\r\n",id,len); USARTx_StringSend(USART3,ESP8266_SendCMD); for(j=0;j10;j++) { delay_ms(50); if(USART3_RX_FLAG) { USART3_RX_BUFFER[USART3_RX_CNT]='\0'; USART3_RX_FLAG=0; USART3_RX_CNT=0; if(strstr((char*)USART3_RX_BUFFER,">")) { //继续发送数据 USARTx_DataSend(USART3,data,len); //等待数据发送成功 for(n=0;n200;n++) { delay_ms(50); if(USART3_RX_FLAG) { USART3_RX_BUFFER[USART3_RX_CNT]='\0'; USART3_RX_FLAG=0; USART3_RX_CNT=0; if(strstr((char*)USART3_RX_BUFFER,"SEND OK")) { return 0; } } } } } } } return 1; } /* 函数功能: 配置WIFI为STA模式+TCP客户端模式 函数参数: char *ssid 创建的热点名称 char *pass 创建的热点密码 (最少8位) char *p 将要连接的服务器IP地址 u16 port 将要连接的服务器端口号 u8 flag 1表示开启透传模式 0表示关闭透传模式 函数返回值:0表示成功 其他值表示对应的错误 */ u8 ESP8266_STA_TCP_Client_Mode(char *ssid,char *pass,char *ip,u16 port,u8 flag) { char ESP8266_SendCMD[100]; //组合发送过程中的命令 //退出透传模式 //USARTx_StringSend(USART3,"+++"); //delay_ms(50); /*1. 测试硬件*/ if(ESP8266_SendCmd("AT\r\n"))return 1; /*2. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 2; /*3. 设置WIFI模式*/ if(ESP8266_SendCmd("AT+CWMODE=1\r\n"))return 3; /*4. 复位*/ ESP8266_SendCmd("AT+RST\r\n"); delay_ms(1000); delay_ms(1000); delay_ms(1000); /*5. 关闭回显*/ if(ESP8266_SendCmd("ATE0\r\n"))return 5; /*6. 配置将要连接的WIFI热点信息*/ sprintf(ESP8266_SendCMD,"AT+CWJAP=\"%s\",\"%s\"\r\n",ssid,pass); if(ESP8266_SendCmd(ESP8266_SendCMD))return 6; /*7. 设置单连接*/ if(ESP8266_SendCmd("AT+CIPMUX=0\r\n"))return 7; /*8. 配置要连接的TCP服务器信息*/ sprintf(ESP8266_SendCMD,"AT+CIPSTART=\"TCP\",\"%s\",%d\r\n",ip,port); if(ESP8266_SendCmd(ESP8266_SendCMD))return 8; /*9. 开启透传模式*/ if(flag) { if(ESP8266_SendCmd("AT+CIPMODE=1\r\n"))return 9; //开启 if(ESP8266_SendCmd("AT+CIPSEND\r\n"))return 10; //开始透传 if(!(strstr((char*)USART3_RX_BUFFER,">"))) { return 11; } //如果想要退出发送: "+++" } //打印总体信息 USART1_Printf("当前WIFI模式:STA+TCP客户端\n"); USART1_Printf("当前连接的WIFI热点名称:%s\n",ssid); USART1_Printf("当前连接的WIFI热点密码:%s\n",pass); USART1_Printf("当前连接的TCP服务器端口号:%d\n",port); USART1_Printf("当前连接的TCP服务器IP地址:%s\n",ip); return 0; } /* 函数功能: TCP客户端模式下的发送函数 发送指令: */ u8 ESP8266_ClientSendData(u8 *data,u16 len) { u8 i,j,n; char ESP8266_SendCMD[100]; //组合发送过程中的命令 for(i=0;i10;i++) { sprintf(ESP8266_SendCMD,"AT+CIPSEND=%d\r\n",len); USARTx_StringSend(USART3,ESP8266_SendCMD); for(j=0;j10;j++) { delay_ms(50); if(USART3_RX_FLAG) { USART3_RX_BUFFER[USART3_RX_CNT]='\0'; USART3_RX_FLAG=0; USART3_RX_CNT=0; if(strstr((char*)USART3_RX_BUFFER,">")) { //继续发送数据 USARTx_DataSend(USART3,data,len); //等待数据发送成功 for(n=0;n200;n++) { delay_ms(50); if(USART3_RX_FLAG) { USART3_RX_BUFFER[USART3_RX_CNT]='\0'; USART3_RX_FLAG=0; USART3_RX_CNT=0; if(strstr((char*)USART3_RX_BUFFER,"SEND OK")) { return 0; } } } } } } } return 1; } ``` ### **4.2 ESP8266.h** ```cpp #ifndef _ESP8266_H #define _ESP8266_H #include "stm32f10x.h" #include "usart.h" #include "delay.h" //函数声明 u8 ESP8266_Init(void); u8 ESP8266_SendCmd(char *cmd); u8 ESP8266_AP_TCP_Server_Mode(char *ssid,char *pass,u16 port); u8 ESP8266_ServerSendData(u8 id,u8 *data,u16 len); u8 ESP8266_STA_TCP_Client_Mode(char *ssid,char *pass,char *ip,u16 port,u8 flag); u8 ESP8266_ClientSendData(u8 *data,u16 len); #endif ``` ### 4.3 串口部分代码 ```cpp /* 函数功能: 串口1的初始化 硬件连接: PA9(TX) 和 PA10(RX) */ void USART1_Init(u32 baud) { /*1. 开时钟*/ RCC->APB2ENR|=114; //USART1时钟 RCC->APB2ENR|=12; //PA RCC->APB2RSTR|=114; //开启复位时钟 RCC->APB2RSTR&=~(114);//停止复位 /*2. 配置GPIO口的模式*/ GPIOA->CRH&=0xFFFFF00F; GPIOA->CRH|=0x000008B0; /*3. 配置波特率*/ USART1->BRR=72000000/baud; /*4. 配置核心寄存器*/ USART1->CR1|=15; //开启接收中断 STM32_SetPriority(USART1_IRQn,1,1); //设置中断优先级 USART1->CR1|=12; //开启接收 USART1->CR1|=13; //开启发送 USART1->CR1|=113;//开启串口功能 } /* 函数功能: 串口3的初始化 硬件连接: PB10(TX) 和 PB11(RX) */ void USART3_Init(u32 baud) { /*1. 开时钟*/ RCC->APB1ENR|=118; //USART3时钟 RCC->APB2ENR|=13; //PB RCC->APB1RSTR|=118; //开启复位时钟 RCC->APB1RSTR&=~(118);//停止复位 /*2. 配置GPIO口的模式*/ GPIOB->CRH&=0xFFFF00FF; GPIOB->CRH|=0x00008B00; /*3. 配置波特率*/ USART3->BRR=36000000/baud; /*4. 配置核心寄存器*/ USART3->CR1|=15; //开启接收中断 STM32_SetPriority(USART3_IRQn,1,1); //设置中断优先级 USART3->CR1|=12; //开启接收 USART3->CR1|=13; //开启发送 USART3->CR1|=113;//开启串口功能 } u8 USART3_RX_BUFFER[USART3_RX_LENGTH]; //保存接收数据的缓冲区 u32 USART3_RX_CNT=0; //当前接收到的数据长度 u8 USART3_RX_FLAG=0; //1表示数据接收完毕 0表示没有接收完毕 //串口3的中断服务函数 void USART3_IRQHandler(void) { u8 data; //接收中断 if(USART3->SR&15) { TIM3->CNT=0; //清除计数器 TIM3->CR1|=10; //开启定时器3 data=USART3->DR; //读取串口数据 // if(USART3_RX_FLAG==0) //判断上一次的数据是否已经处理完毕 { //判断是否可以继续接收 if(USART3_RX_CNT } else //不能接收,超出存储范围,强制表示接收完毕 { USART3_RX_FLAG=1; } } } } /* 函数功能: 字符串发送 */ void USARTx_StringSend(USART_TypeDef *USARTx,char *str) { while(*str!='\0') { USARTx->DR=*str++; while(!(USARTx->SR&17)){} } } /* 函数功能: 数据发送 */ void USARTx_DataSend(USART_TypeDef *USARTx,u8 *data,u32 len) { u32 i; for(i=0;iDR=*data++; while(!(USARTx->SR&17)){} } } /* 函数功能: 格式化打印函数 */ char USART1_PRINTF_BUFF[1024]; void USART1_Printf(char *fmt,...) { va_list ap; /*1. 初始化形参列表*/ va_start(ap,fmt); /*2. 提取可变形参数据*/ vsprintf(USART1_PRINTF_BUFF,fmt,ap); /*3. 结束,释放空间*/ va_end(ap); /*4. 输出数据到串口1*/ USARTx_StringSend(USART1,USART1_PRINTF_BUFF); //USART1_Printf("%d%s",123,454656); //int data=va_arg(ap,int); } ``` ### 4.4 定时器部分代码 ```cpp /* 函数功能: 配置定时器3 函数参数: psc 预分频器 arr重装载值 */ void TIMER3_Init(u16 psc,u16 arr) { /*1. 开时钟*/ RCC->APB1ENR|=11; //开启定时器3的时钟 RCC->APB1RSTR|=11;//开启定时器3复位时钟 RCC->APB1RSTR&=~(11);//关闭定时器3复位时钟 /*2. 配置核心寄存器*/ TIM3->PSC=psc-1; TIM3->ARR=arr; TIM3->DIER|=10; //开启更新中断 STM32_SetPriority(TIM3_IRQn,1,1); //设置中断优先级 // TIM3->CR1|=10; //开启定时器3 } /* 函数功能: 定时器3中断服务函数 */ void TIM3_IRQHandler(void) { if(TIM3->SR&10) { TIM3->SR&=~(10); USART3_RX_FLAG=1; //表示接收完毕 TIM3->CR1&=~(10); //关闭定时器3 } } ``` ### 4.5 主函数调用部分(STA+TCP客户端)示例 ```cpp int main() { u8 key,cnt=0; LED_Init(); BEEP_Init(); KEY_Init(); USART1_Init(115200); USART3_Init(115200);//串口-WIFI TIMER3_Init(72,20000); //超时时间20ms USART1_Printf("正在初始化WIFI请稍等.\n"); if(ESP8266_Init()) { USART1_Printf("ESP8266硬件检测错误.\n"); } else { USART1_Printf("WIFI:%d\n",ESP8266_STA_TCP_Client_Mode("ChinaNet-wbyw","12345678","192.168.101.6",8088,1)); } while(1) { if(USART3_RX_FLAG) { USART3_RX_BUFFER[USART3_RX_CNT]='\0'; USART1_Printf("%s",USART3_RX_BUFFER); USART3_RX_CNT=0; USART3_RX_FLAG=0; } key=KEY_Scan(0); if(key==2) { USARTx_StringSend(USART3,"AT+GMR\r\n"); //查看版本信息 } else if(key==3) { USARTx_StringSend(USART3,"12345ABCD"); } else if(key==4) //退出透传模式 { USARTx_StringSend(USART3,"+++"); } else if(key==5) //发送AT { USARTx_StringSend(USART3,"AT+CIPSTATUS\r\n"); //查看状态信息 } } } ``` ### 4.6 主函数调用部分(AP+TCP服务器)示例 ```cpp int main() { u8 key; LED_Init(); BEEP_Init(); KEY_Init(); USART1_Init(115200); USART3_Init(115200);//串口-WIFI TIMER3_Init(72,20000); //超时时间20ms USART1_Printf("正在初始化WIFI请稍等.\n"); //初始化WIFI硬件 if(ESP8266_Init())USART1_Printf("WIFI硬件错误.\n"); else { //配置WIFI的模式 USART1_Printf("WIFI配置状态:%d\n",ESP8266_AP_TCP_Server_Mode("esp8266_666","12345678",8088)); } while(1) { if(USART3_RX_FLAG) { USART3_RX_BUFFER[USART3_RX_CNT]='\0'; USART1_Printf("%s",USART3_RX_BUFFER); USART3_RX_CNT=0; USART3_RX_FLAG=0; } key=KEY_Scan(0); if(key==2) { ESP8266_ServerSendData(0,(u8*)"1234567890",10); } else if(key==3) { ESP8266_ServerSendData(0,(u8*)"abcd",4); } } } ```
-
# 一、环境介绍 **MCU:** STM32F103ZET6 **编程IDE:** Keil5.25 # 二、 IAP介绍 > IAP,全称是“In-Application Programming”,中文解释为“在程序中编程”。IAP是一种对通过微控制器的对外接口(如USART,IIC,CAN,USB,以太网接口甚至是无线射频通道)对正在运行程序的微控制器进行内部程序的更新的技术(注意这完全有别于ICP或者ISP技术)。 > > ICP(In-Circuit Programming)技术即通过在线仿真器对单片机进行程序烧写,而ISP技术则是通过单片机内置的bootloader程序引导的烧写技术。无论是ICP技术还是ISP技术,都需要有机械性的操作如连接下载线,设置跳线帽等。若产品的电路板已经层层密封在外壳中,要对其进行程序更新无疑困难重重,若产品安装于狭窄空间等难以触及的地方,更是一场灾难。但若进引入了IAP技术,则完全可以避免上述尴尬情况,而且若使用远距离或无线的数据传输方案,甚至可以实现远程编程和无线编程。这绝对是ICP或ISP技术无法做到的。某种微控制器支持IAP技术的首要前提是其必须是基于可重复编程闪存的微控制器。STM32微控制器带有可编程的内置闪存,同时STM32拥有在数量上和种类上都非常丰富的外设通信接口,因此在STM32上实现IAP技术是完全可行的。 > > 实现IAP技术的核心是一段预先烧写在单片机内部的IAP程序。这段程序主要负责与外部的上位机软件进行握手同步,然后将通过外设通信接口将来自于上位机软件的程序数据接收后写入单片机内部指定的闪存区域,然后再跳转执行新写入的程序,最终就达到了程序更新的目的。 > > 在STM32微控制器上实现IAP程序之前首先要回顾一下STM32的内部闪存组织架构和其启动过程。STM32的内部闪存地址起始于0x8000000,一般情况下,程序文件就从此地址开始写入。此外STM32是基于Cortex-M3内核的微控制器,其内部通过一张“中断向量表”来响应中断,程序启动后,将首先从“中断向量表”取出复位中断向量执行复位中断程序完成启动。而这张“中断向量表”的起始地址是0x8000004,当中断来临,STM32的内部硬件机制亦会自动将PC指针定位到“中断向量表”处,并根据中断源取出对应的中断向量执行中断服务程序。最后还需要知道关键的一点,通过修改STM32工程的链接脚本可以修改程序文件写入闪存的起始地址。 > > 在STM32微控制器上实现IAP方案,除了常规的串口接收数据以及闪存数据写入等常规操作外,还需注意STM32的启动过程和中断响应方式。 **下图显示了STM32常规的运行流程:** 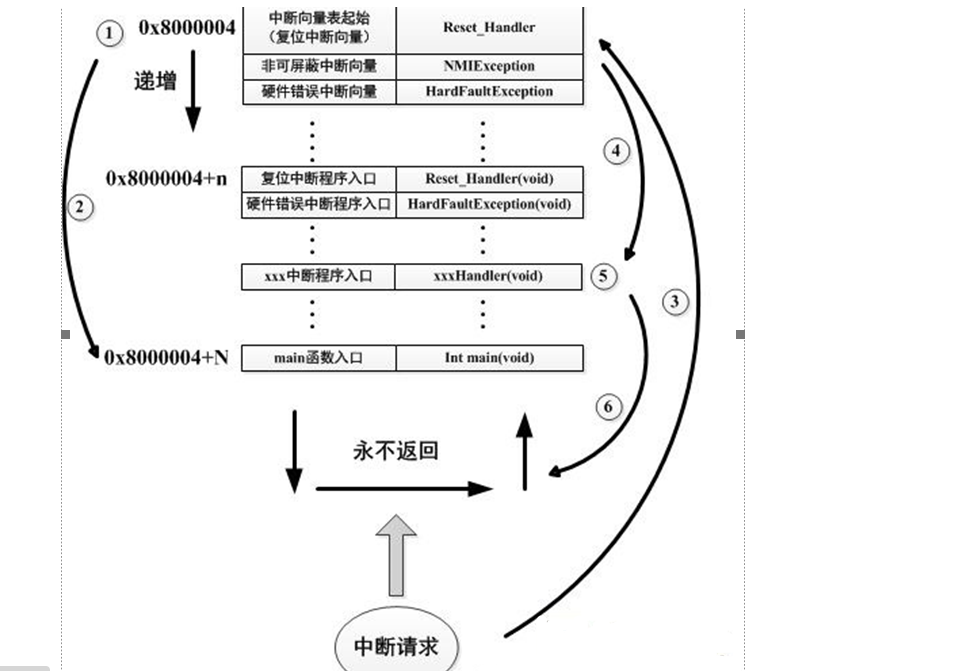 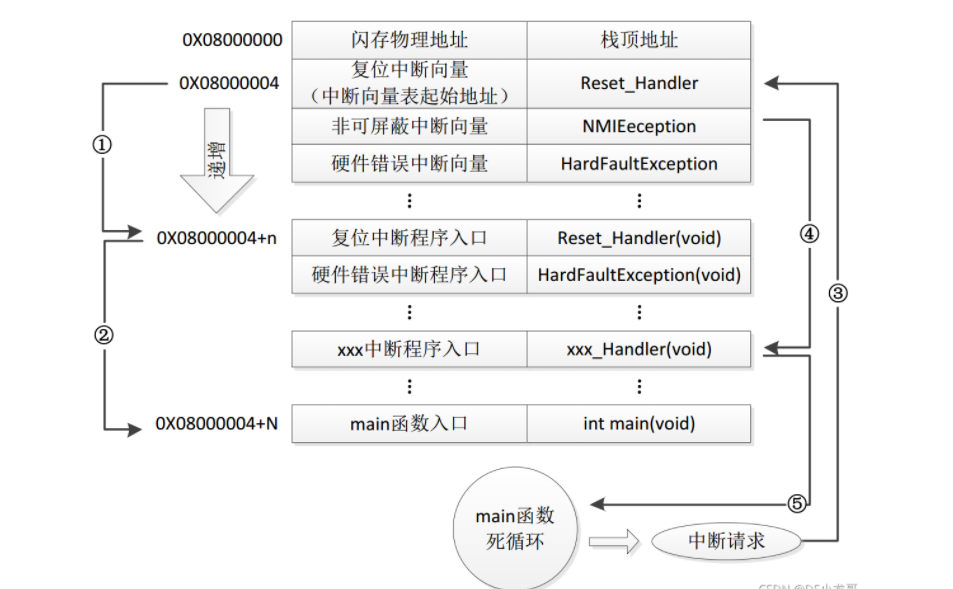 > **图解读如下:** > 1、 STM32复位后,会从地址为0x8000004处取出复位中断向量的地址,并跳转执行复位中断服务程序。 > 2、 复位中断服务程序执行的最终结果是跳转至C程序的main函数,而main函数应该是一个死循环,是一个永不返回的函数。 > 3、 在main函数执行的过程中,发生了一个中断请求,此时STM32的硬件机制会将PC指针强制指回中断向量表处。 > 4、 根据中断源进入相应的中断服务程序。 > 5、 中断服务程序执行完毕后,程序再度返回至main函数中执行。 **若在STM32中加入了IAP程序:** 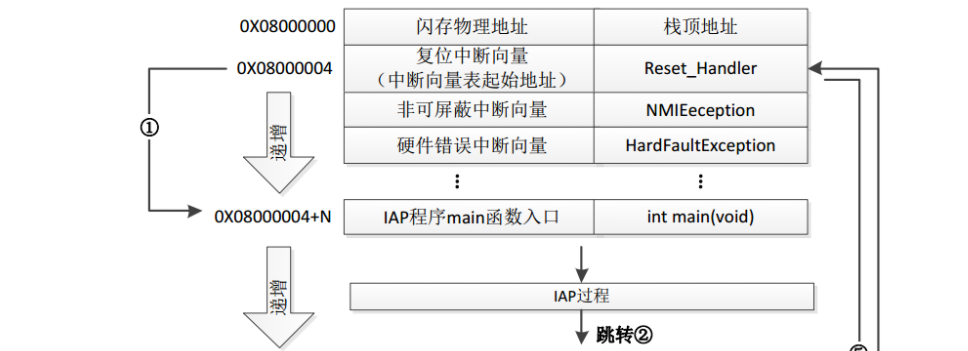 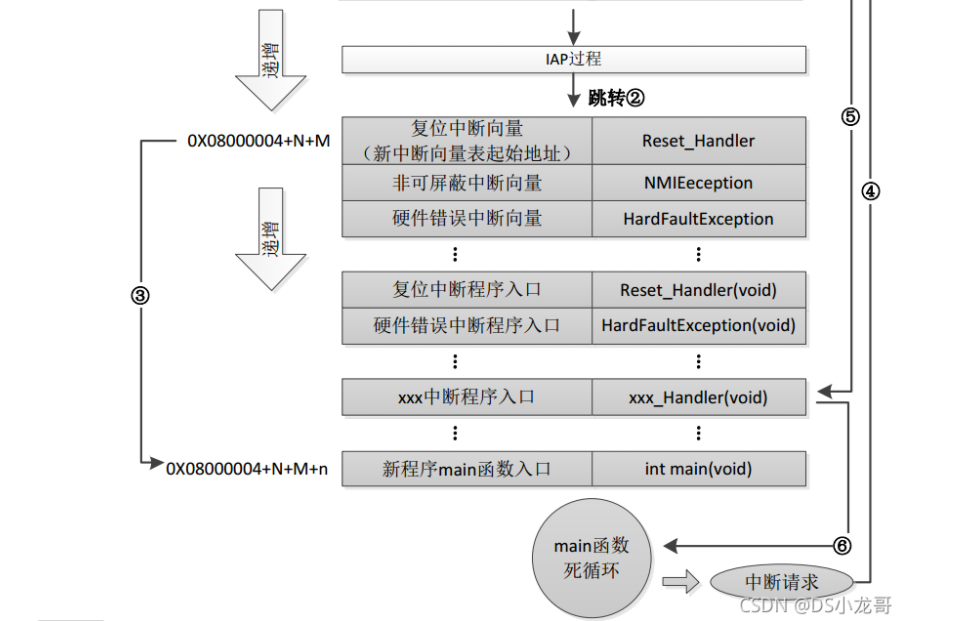 > 1、 STM32复位后,从地址为0x8000004处取出复位中断向量的地址,并跳转执行复位中断服务程序,随后跳转至IAP程序的main函数。 > > 2、 执行完IAP过程后(STM32内部多出了新写入的程序,地址始于0x8000004+N+M)跳转至新写入程序的复位向量表,取出新程序的复位中断向量的地址,并跳转执行新程序的复位中断服务程序,随后跳转至新程序的main函数。新程序的main函数应该也具有永不返回的特性。同时应该注意在STM32的内部存储空间在不同的位置上出现了2个中断向量表。 > > 3、 在新程序main函数执行的过程中,一个中断请求来临,PC指针仍会回转至地址为0x8000004中断向量表处,而并不是新程序的中断向量表,注意到这是由STM32的硬件机制决定的。 > > 4、 根据中断源跳转至对应的中断服务,注意此时是跳转至了新程序的中断服务程序中。 > > 5、 中断服务执行完毕后,返回main函数。 # 二、hex文件与bin文件区别 > Intel HEX文件是记录文本行的ASCII文本文件,在Intel HEX文件中,每一行是一个HEX记录,由十六进制数组成的机器码或者数据常量。Intel HEX文件经常被用于将程序或数据传输存储到ROM、EPROM,大多数编程器和模拟器使用Intel HEX文件。 > 很多编译器的支持生成HEX格式的烧录文件,尤其是Keil c。但是编程器能够下载的往往是BIN格式,因此HEX转BIN是每个编程器都必须支持的功能。HEX格式文件以行为单位,每行由“:”(0x3a)开始,以回车键结束(0x0d,0x0a)。行内的数据都是由两个字符表示一个16进制字节,比如”01”就表示数0x01;”0a”,就表示0x0a。对于16位的地址,则高位在前低位在后,比如地址0x010a,在HEX格式文件中就表示为字符串”010a”。 > > **hex和bin文件格式** > Hex文件,这里指的是Intel标准的十六进制文件,也就是机器代码的十六进制形式,并且是用一定文件格式的ASCII码来表示。具体格式介绍如下: Intel hex 文件常用来保存单片机或其他处理器的目标程序代码。它保存物理程序存储区中的目标代码映象。一般的编程器都支持这种格式。 hex和bin文件格式Hex文件,这里指的是Intel标准的十六进制文件,也就是机器代码的十六进制形式,并且是用一定文件格式的ASCII码来表示。具体格式介绍如下: Intel hex 文件常用来保存单片机或其他处理器的目标程序代码。它保存物理程序存储区中的目标代码映象。一般的编程器都支持这种格式。 # 三、使用Keil软件完成hex文件转bin文件 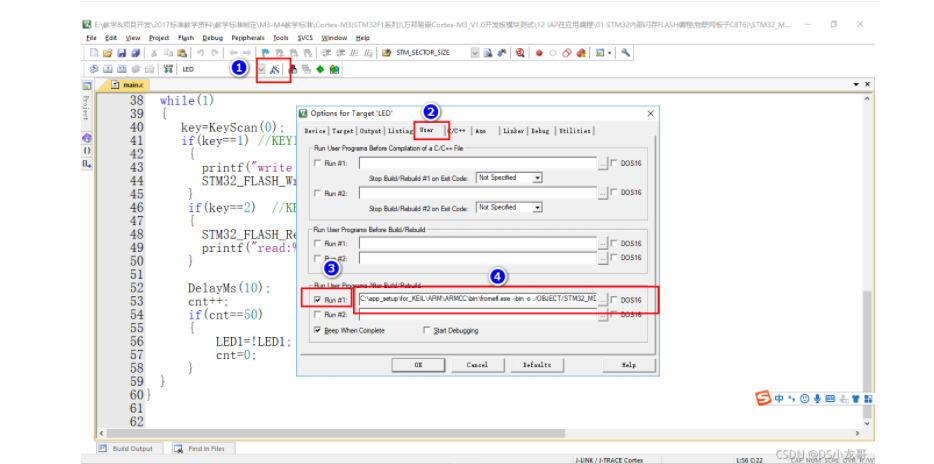 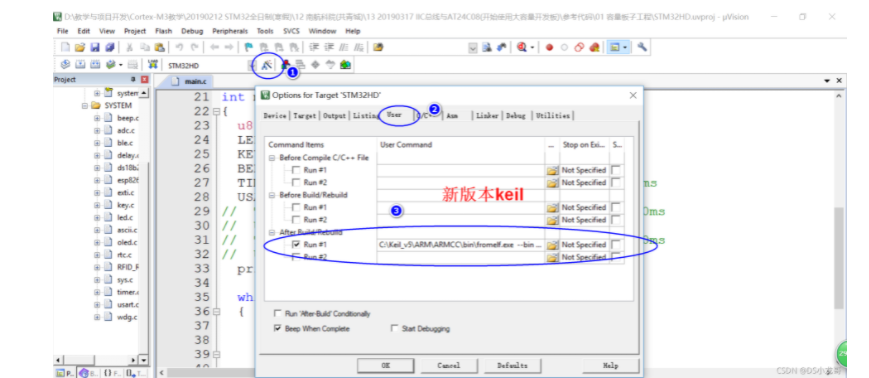 **选项框里的代码:** C:\app_setup\for_KEIL\ARM\ARMCC\bin\fromelf.exe --bin -o ./OBJECT/STM32_MD.bin ./OBJECT/STM32_MD.axf **解析如下:** C:\app_setup\for_KEIL\ARM\ARMCC\bin\fromelf.exe:是keil软件安装目录下的一个工具,用于生成bin --bin -o ./OBJECT/STM32_MD.bin :指定生成bin文件的目录和名称 ./OBJECT/STM32_MD.axf :指定输入的文件. 生成hex文件需要axf文件 **新工程的编译指令:** C:\Keil_v5\ARM\ARMCC\bin\fromelf.exe --bin -o ./obj/STM32HD.bin ./obj/STM32HD.axf 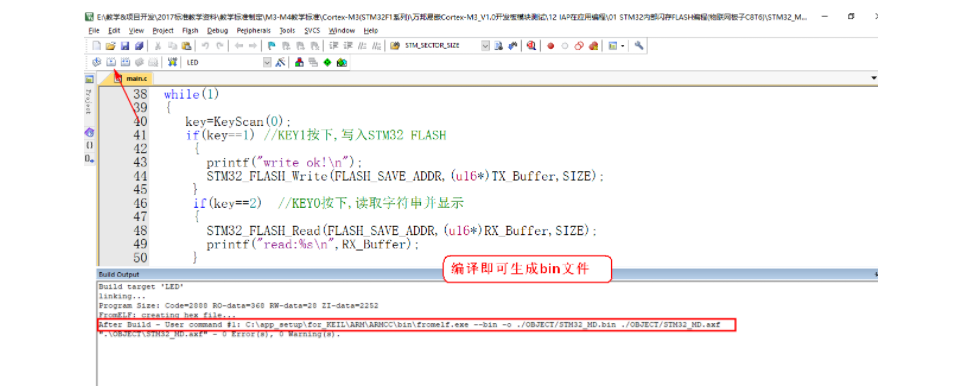 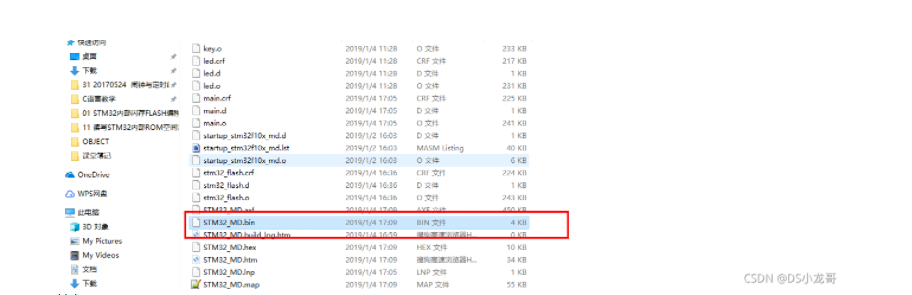 将该文件下载到STM32内置FLASH,复位开发板,即可启动程序。 # 四、 使用win hex软件将bin文件搞成数组 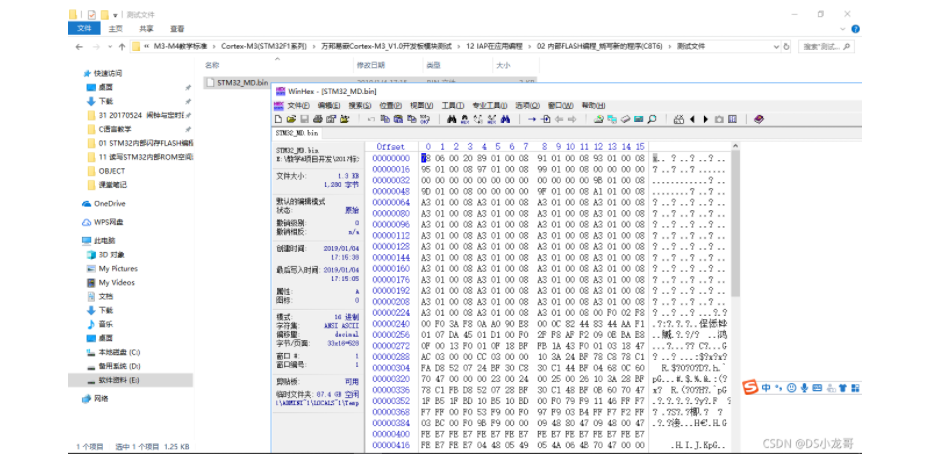 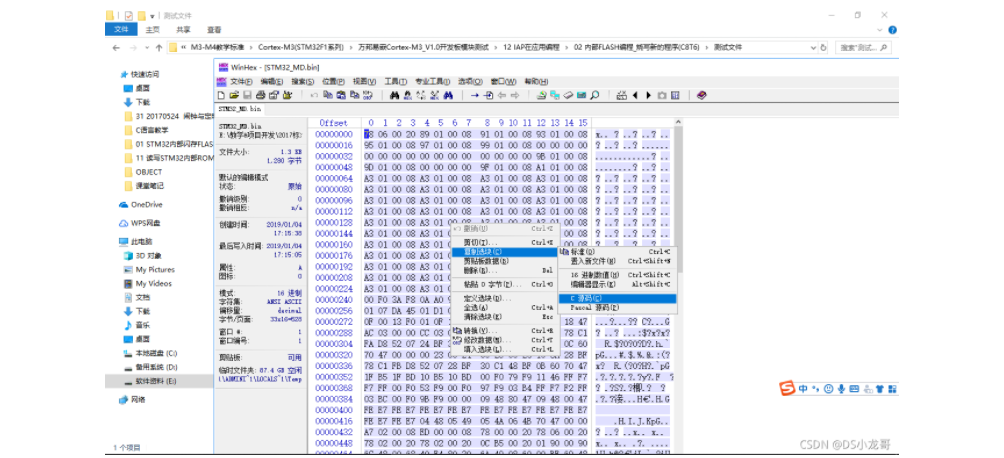 生成数组之后,可以直接将数组编译到程序里,然后使用**STM32****内置FLASH****编程代码**,将该程序烧写到内置FLASH里,再复位开发板即可运行新的程序。 # 五、 Keil编译程序大小计算 **Program Size: Code=x RO-data=x RW-data=x ZI-data=x** **的含义** 1. Code(代码): 程序所占用的FLASH大小,存储在FLASH. \2. RO-data(只读的数据): Read-only-data,程序定义的常量,如const型,存储在FLASH中。 \3. RW-data(有初始值要求的、可读可写的数据): \4. Read-write-data,已经被初始化的变量,存储在FLASH中。初始化时RW-data从flash拷贝到SRAM。 \5. ZI-data:Zero-Init-data,未被初始化的可读写变量,存储在SRAM中。ZI-data不会被算做代码里因为不会被初始化。 ROM(Flash) size = Code + RO-data + RW-data; RAM size = RW-data + ZI-data 简单的说就是在烧写的时候是FLASH中的被占用的空间为:Code+RO Data+RW Data 程序运行的时候,芯片内部RAM使用的空间为: RW Data + ZI Data # 六、工程编译信息与堆栈信息查看 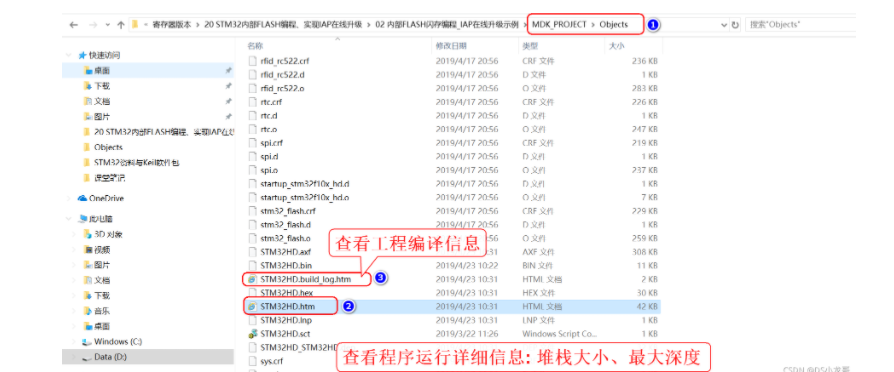 对于没有OS的程序,堆栈大小是在 startup.s 里设置的: Stack_Size EQU 0x00000800 对于使用用 uCos 的系统,OS自带任务的堆栈,在 os_cfg.h 里定义: ```cpp /* ——————— TASK STACK SIZE ———————- */ #define OS_TASK_TMR_STK_SIZE 128 /* Timer task stack size (# of OS_STK wide entries) */ #define OS_TASK_STAT_STK_SIZE 128 /* Statistics task stack size (# of OS_STK wide entries) */ #define OS_TASK_IDLE_STK_SIZE 128 /* Idle task stack size (# of OS_STK wide entries) */ ``` **用户程序的任务堆栈,在 app_cfg.h 里定义:** ```cpp #define APP_TASK_MANAGER_STK_SIZE 512 #define APP_TASK_GSM_STK_SIZE 512 #define APP_TASK_OBD_STK_SIZE 512 #define OS_PROBE_TASK_STK_SIZE 128 ``` **总结:** 1, 合理设置堆栈很重要 2, 多种方法结合,相互核对、校验 3, 尽量避免大数组,如果一定要用,尽量定义为 全局变量,使其不占用堆栈空间, 如果函数有重入可能性,则要注意保护。 # 七、实现STM32在线升级程序 ## 7.1 升级的思路与步骤 \1. 首先得完成STM32内置FLASH编程操作 \2. 将(升级的程序)新的程序编译生成bin文件(编译之前需要在Keil软件里设置FLASH的起始位置) \3. 创建一个专门用于升级的boot程序(**IAP Bootloader)** \4. 使用网络、串口、SD卡等方式接收到bin文件,再将bin文件烧写到STM32内置FLASH里 \5. 设置主堆栈指针 \6. 将用户代码区第二个字(**第4****个字节**)为程序开始地址(强制转为函数指针) \7. **执行函数,进行程序跳转** ## 7.2 待升级的程序FLASH起始设置 **Bootloader** 的程序大小先固定为: 20KB,最好是越小越好,可以预留更加多的空间给APP程序使用。 20KB----->20480Byte-----> 0x5000 STM32内置FLASH闪存的起始地址是: 0x08000000 ,大小是512KB。 现在将内置FLASH闪存前20KB的空间留给**Bootloader**程序使用,后面剩下的空间就给APP程序使用。 APP程序的起始位置就可以设置为: 0x08000000+ 0x5000=0x08005000 剩余的大小就是: 512KB-20KB=492KB------>503808Byte-------->0x7B000 **设置FLASH的起始位置(APP主程序):** 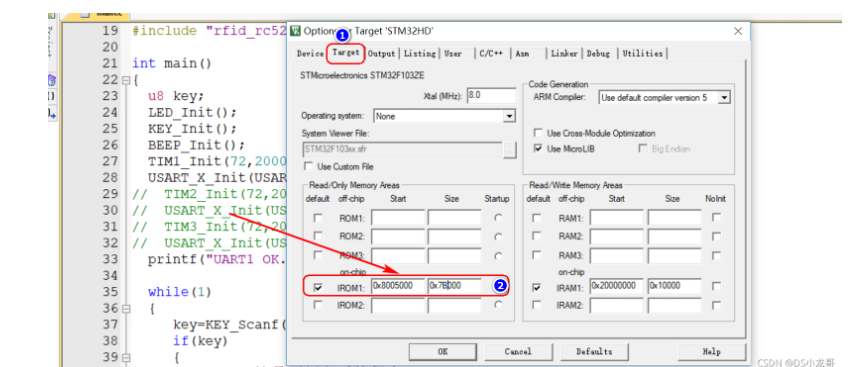 **中断向量表偏移量设置** 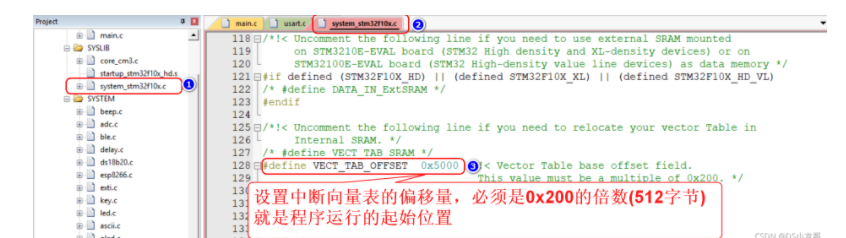 **设置编译bin文件** 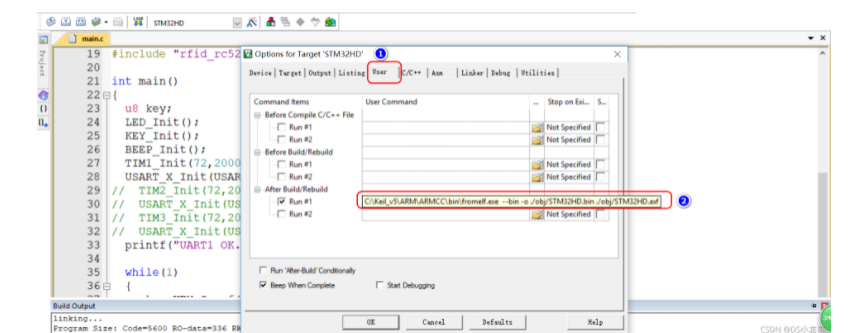  ## 7.3 Bootloader的程序设置 ```cpp //设置写入的地址,必须偶数,因为数据读写都是按照2个字节进行 #define FLASH_APP_ADDR 0x08005000 //应用程序存放到FLASH中的起始地址 int main() { printf("UART1 OK.....\n"); printf("进入IAP Bootloader程序!\n"); while(1) { key=KEY_Scanf(); if(key==1) //KEY1按下,写入STM32 FLASH { printf("正在更新IAP程序...............\n"); iap_write_appbin(FLASH_APP_ADDR,(u8*)app_bin_data,sizeof(app_bin_data));//烧写新的程序到内置FLASH printf("程序更新成功....\n"); iap_load_app(FLASH_APP_ADDR);//执行FLASH APP代码 } } } /* 函数功能:跳转到应用程序段 appxaddr:用户代码起始地址. */ typedef void (*iap_function)(void); //定义一个函数类型的参数. void IAP_LoadApp(u32 app_addr) { //给函数指针赋值合法地址 jump2app=(iap_function)*(vu32*)(app_addr+4);//用户代码区第二个字为程序开始地址(复位地址) __set_MSP(*(vu32*)app_addr); //设置主堆栈指针 jump2app(); //跳转到APP. } ``` 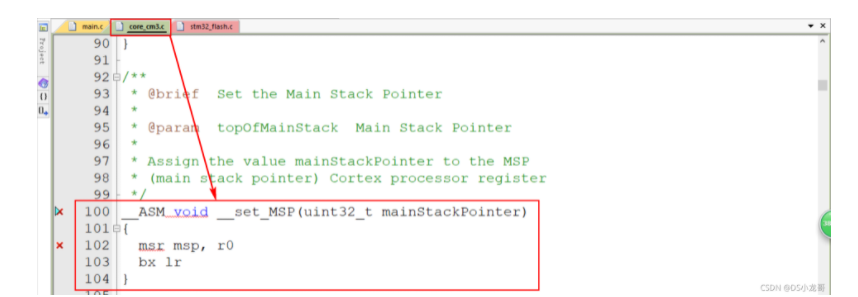
-
# 一、环境介绍 **工程编译软件:** keil5 **温湿度传感器:** SHT30 **MCU :** STM32F103ZET6 程序采用模块化编程,iic时序为一个模块(iic.c 和 iic.h),SHT30为一个模块(sht30.c 和 sht30.h);IIC时序采用模拟时序方式实现,IO口都采用宏定义方式,方便快速移植到其他平台使用。 # 二、SHT30介绍   **特点:** \1. 湿度和温度传感器 \2. 完全校准、线性化和温度 \3. 补偿数字输出,宽电源电压范围,从2.4 V到5.5 V \4. I2C接口,通信速度高达1MHz和两个用户可选地址 \5. 典型精度 +- 2%相对湿度和+- 0.3°C \6. 启动和测量时间非常快 \7. 微型8针DFN封装   **这是SHT30的****7位****IIC设备地址:**  # 三、设备运行效果 这是串口打印的数据:    # 四、设备代码 ## 4.1 main.c ```cpp #include "stm32f10x.h" #include "led.h" #include "delay.h" #include "key.h" #include "usart.h" #include "iic.h" #include "sht3x.h" int main() { float Humidity; float Temperature; USART1_Init(115200); USART1_Printf("设备运行正常....\r\n"); IIC_Init(); Init_SHT30(); while(1) { //读取温湿度 SHT3x_ReadData(&Humidity,&Temperature); USART1_Printf("温度:%0.2f,湿度:%0.2f\r\n",Temperature,Humidity); delay_ms(1000); } } ``` ## 4.2 sht30.c ```cpp #include "sht3x.h" const int16_t POLYNOMIAL = 0x131; /*************************************************************** * 函数名称: SHT30_reset * 说 明: SHT30复位 * 参 数: 无 * 返 回 值: 无 ***************************************************************/ void SHT30_reset(void) { u8 r_s; IIC_Start(); //发送起始信号 IIC_WriteOneByteData(SHT30_AddrW); //写设备地址 r_s=IIC_GetACK();//获取应答 if(r_s)printf("Init_SHT30_error:1\r\n"); IIC_WriteOneByteData(0x30); //写数据 r_s=IIC_GetACK();//获取应答 if(r_s)printf("Init_SHT30_error:2\r\n"); IIC_WriteOneByteData(0xA2); //写数据 r_s=IIC_GetACK();//获取应答 if(r_s)printf("Init_SHT30_error:3\r\n"); IIC_Stop(); //停止信号 delay_ms(50); } /*************************************************************** * 函数名称: Init_SHT30 * 说 明: 初始化SHT30,设置测量周期 * 参 数: 无 * 返 回 值: 无 ***************************************************************/ void Init_SHT30(void) { u8 r_s; IIC_Start(); //发送起始信号 IIC_WriteOneByteData(SHT30_AddrW); //写设备地址 r_s=IIC_GetACK();//获取应答 if(r_s)printf("Init_SHT30_error:1\r\n"); IIC_WriteOneByteData(0x22); //写数据 r_s=IIC_GetACK();//获取应答 if(r_s)printf("Init_SHT30_error:2\r\n"); IIC_WriteOneByteData(0x36); //写数据 r_s=IIC_GetACK();//获取应答 if(r_s)printf("Init_SHT30_error:3\r\n"); IIC_Stop(); //停止信号 delay_ms(200); } /*************************************************************** * 函数名称: SHT3x_CheckCrc * 说 明: 检查数据正确性 * 参 数: data:读取到的数据 nbrOfBytes:需要校验的数量 checksum:读取到的校对比验值 * 返 回 值: 校验结果,0-成功 1-失败 ***************************************************************/ u8 SHT3x_CheckCrc(char data[], char nbrOfBytes, char checksum) { char crc = 0xFF; char bit = 0; char byteCtr ; //calculates 8-Bit checksum with given polynomial for(byteCtr = 0; byteCtr nbrOfBytes; ++byteCtr) { crc ^= (data[byteCtr]); for ( bit = 8; bit > 0; --bit) { if (crc & 0x80) crc = (crc 1) ^ POLYNOMIAL; else crc = (crc 1); } } if(crc != checksum) return 1; else return 0; } /*************************************************************** * 函数名称: SHT3x_CalcTemperatureC * 说 明: 温度计算 * 参 数: u16sT:读取到的温度原始数据 * 返 回 值: 计算后的温度数据 ***************************************************************/ float SHT3x_CalcTemperatureC(unsigned short u16sT) { float temperatureC = 0; // variable for result u16sT &= ~0x0003; // clear bits [1..0] (status bits) //-- calculate temperature [℃] -- temperatureC = (175 * (float)u16sT / 65535 - 45); //T = -45 + 175 * rawValue / (2^16-1) return temperatureC; } /*************************************************************** * 函数名称: SHT3x_CalcRH * 说 明: 湿度计算 * 参 数: u16sRH:读取到的湿度原始数据 * 返 回 值: 计算后的湿度数据 ***************************************************************/ float SHT3x_CalcRH(unsigned short u16sRH) { float humidityRH = 0; // variable for result u16sRH &= ~0x0003; // clear bits [1..0] (status bits) //-- calculate relative humidity [%RH] -- humidityRH = (100 * (float)u16sRH / 65535); // RH = rawValue / (2^16-1) * 10 return humidityRH; } //读取温湿度数据 void SHT3x_ReadData(float *Humidity,float *Temperature) { char data[3]; //data array for checksum verification u8 SHT3X_Data_Buffer[6]; //byte 0,1 is temperature byte 4,5 is humidity u8 r_s=0; u8 i; unsigned short tmp = 0; uint16_t dat; IIC_Start(); //发送起始信号 IIC_WriteOneByteData(SHT30_AddrW); //写设备地址 r_s=IIC_GetACK();//获取应答 if(r_s)printf("SHT3X_error:1\r\n"); IIC_WriteOneByteData(0xE0); //写数据 r_s=IIC_GetACK();//获取应答 if(r_s)printf("SHT3X_error:2\r\n"); IIC_WriteOneByteData(0x00); //写数据 r_s=IIC_GetACK();//获取应答 if(r_s)printf("SHT3X_error:3\r\n"); //IIC_Stop(); //停止信号 // DelayMs(30); //等待 //读取sht30传感器数据 IIC_Start(); //发送起始信号 IIC_WriteOneByteData(SHT30_AddrR); r_s=IIC_GetACK();//获取应答 if(r_s)printf("SHT3X_error:7\r\n"); for(i=0;i6;i++) { SHT3X_Data_Buffer[i]=IIC_ReadOneByteData(); //接收数据 if(i==5) { IIC_SendACK(1); //发送非应答信号 break; } IIC_SendACK(0); //发送应答信号 } IIC_Stop(); //停止信号 // /* check tem */ data[0] = SHT3X_Data_Buffer[0]; data[1] = SHT3X_Data_Buffer[1]; data[2] = SHT3X_Data_Buffer[2]; tmp=SHT3x_CheckCrc(data, 2, data[2]); if( !tmp ) /* value is ture */ { dat = ((uint16_t)data[0] 8) | data[1]; *Temperature = SHT3x_CalcTemperatureC( dat ); } // /* check humidity */ data[0] = SHT3X_Data_Buffer[3]; data[1] = SHT3X_Data_Buffer[4]; data[2] = SHT3X_Data_Buffer[5]; tmp=SHT3x_CheckCrc(data, 2, data[2]); if( !tmp ) /* value is ture */ { dat = ((uint16_t)data[0] 8) | data[1]; *Humidity = SHT3x_CalcRH( dat ); } } ``` ## 4.3 iic.c ```cpp #include "iic.h" /* 函数功能:IIC接口初始化 硬件连接: SDA:PB7 SCL:PB6 */ void IIC_Init(void) { RCC->APB2ENR|=13;//PB GPIOB->CRL&=0x00FFFFFF; GPIOB->CRL|=0x33000000; GPIOB->ODR|=0x36; } /* 函数功能:IIC总线起始信号 */ void IIC_Start(void) { IIC_SDA_OUTMODE(); //初始化SDA为输出模式 IIC_SDA_OUT=1; //数据线拉高 IIC_SCL=1; //时钟线拉高 DelayUs(4); //电平保持时间 IIC_SDA_OUT=0; //数据线拉低 DelayUs(4); //电平保持时间 IIC_SCL=0; //时钟线拉低 } /* 函数功能:IIC总线停止信号 */ void IIC_Stop(void) { IIC_SDA_OUTMODE(); //初始化SDA为输出模式 IIC_SDA_OUT=0; //数据线拉低 IIC_SCL=0; //时钟线拉低 DelayUs(4); //电平保持时间 IIC_SCL=1; //时钟线拉高 DelayUs(4); //电平保持时间 IIC_SDA_OUT=1; //数据线拉高 } /* 函数功能:获取应答信号 返 回 值:1表示失败,0表示成功 */ u8 IIC_GetACK(void) { u8 cnt=0; IIC_SDA_INPUTMODE();//初始化SDA为输入模式 IIC_SDA_OUT=1; //数据线上拉 DelayUs(2); //电平保持时间 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 DelayUs(2); //电平保持时间,等待从机发送数据 IIC_SCL=1; //时钟线拉高,告诉从机,主机现在开始读取数据 while(IIC_SDA_IN) //等待从机应答信号 { cnt++; if(cnt>250)return 1; } IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 return 0; } /* 函数功能:主机向从机发送应答信号 函数形参:0表示应答,1表示非应答 */ void IIC_SendACK(u8 stat) { IIC_SDA_OUTMODE(); //初始化SDA为输出模式 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要发送数据 if(stat)IIC_SDA_OUT=1; //数据线拉高,发送非应答信号 else IIC_SDA_OUT=0; //数据线拉低,发送应答信号 DelayUs(2); //电平保持时间,等待时钟线稳定 IIC_SCL=1; //时钟线拉高,告诉从机,主机数据发送完毕 DelayUs(2); //电平保持时间,等待从机接收数据 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 } /* 函数功能:IIC发送1个字节数据 函数形参:将要发送的数据 */ void IIC_WriteOneByteData(u8 data) { u8 i; IIC_SDA_OUTMODE(); //初始化SDA为输出模式 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要发送数据 for(i=0;i8;i++) { if(data&0x80)IIC_SDA_OUT=1; //数据线拉高,发送1 else IIC_SDA_OUT=0; //数据线拉低,发送0 IIC_SCL=1; //时钟线拉高,告诉从机,主机数据发送完毕 DelayUs(2); //电平保持时间,等待从机接收数据 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要发送数据 DelayUs(2); //电平保持时间,等待时钟线稳定 data=1; //先发高位 } } /* 函数功能:IIC接收1个字节数据 返 回 值:收到的数据 */ u8 IIC_ReadOneByteData(void) { u8 i,data; IIC_SDA_INPUTMODE();//初始化SDA为输入模式 for(i=0;i8;i++) { IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 DelayUs(2); //电平保持时间,等待从机发送数据 IIC_SCL=1; //时钟线拉高,告诉从机,主机现在正在读取数据 data=1; if(IIC_SDA_IN)data|=0x01; DelayUs(2); //电平保持时间,等待时钟线稳定 } IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 (必须拉低,否则将会识别为停止信号) return data; } ```
-
# 一、环境介绍 **MCU:** STM32F103C8T6 **姿态传感器:** MPU6050 **OLED显示屏:** 0.96寸SPI接口OLED **温度传感器:** DS18B20 **编译软件:** keil5 # 二、功能介绍 时钟可以根据MPU6050测量的姿态自动调整显示画面方向,也就是倒着拿、横着拿、反着拿都可以让时间显示是正对着自己的,时间支持自己调整,支持串口校准。可以按键切换页面查看环境温度显示。    **支持串口时间校准:**   # 三、核心代码  ## 3.1 main.c ```cpp #include "stm32f10x.h" #include "beep.h" #include "delay.h" #include "led.h" #include "key.h" #include "sys.h" #include "usart.h" #include #include #include "exti.h" #include "timer.h" #include "rtc.h" #include "wdg.h" #include "ds18b20.h" #include "oled.h" #include "fontdata.h" #include "adc.h" #include "FunctionConfig.h" #include "mpu6050.h" #include "inv_mpu.h" #include "inv_mpu_dmp_motion_driver.h" /* 函数功能: 绘制时钟表盘框架 */ void DrawTimeFrame(void) { u8 i; OLED_Circle(32,32,31);//画外圆 OLED_Circle(32,32,1); //画中心圆 //画刻度 for(i=0;i60;i++) { if(i%5==0)OLED_DrawAngleLine(32,32,6*i,31,3,1); } OLED_RefreshGRAM(); //刷新数据到OLED屏幕 } /* 函数功能: 更新时间框架显示,在RTC中断里调用 */ char TimeBuff[20]; void Update_FrameShow(void) { /*1. 绘制秒针、分针、时针*/ OLED_DrawAngleLine2(32,32,rtc_clock.sec*6-6-90,27,0);//清除之前的秒针 OLED_DrawAngleLine2(32,32,rtc_clock.sec*6-90,27,1); //画秒针 OLED_DrawAngleLine2(32,32,rtc_clock.min*6-6-90,24,0); OLED_DrawAngleLine2(32,32,rtc_clock.min*6-90,24,1); OLED_DrawAngleLine2(32,32,rtc_clock.hour*30-6-90,21,0); OLED_DrawAngleLine2(32,32,rtc_clock.hour*30-90,21,1); //绘制电子钟时间 sprintf(TimeBuff,"%d",rtc_clock.year); OLED_ShowString(65,16*0,16,TimeBuff); //年份字符串 OLED_ShowChineseFont(66+32,16*0,16,4); //显示年 sprintf(TimeBuff,"%d/%d",rtc_clock.mon,rtc_clock.day); OLED_ShowString(75,16*1,16,TimeBuff); //月 if(rtc_clock.sec==0)OLED_ShowString(65,16*2,16," "); //清除多余的数据 sprintf(TimeBuff,"%d:%d:%d",rtc_clock.hour,rtc_clock.min,rtc_clock.sec); OLED_ShowString(65,16*2,16,TimeBuff); //秒 //显示星期 OLED_ShowChineseFont(70,16*3,16,5); //星 OLED_ShowChineseFont(70+16,16*3,16,6); //期 OLED_ShowChineseFont(70+32,16*3,16,rtc_clock.week+7); //具体的值 } u8 DS18B20_TEMP_Info[10]; //DS18B20温度信息 /* 函数功能: DS18B20温度显示页面 */ void DS18B20_ShowPageTable(short DS18B20_temp) { char DS18B20_buff[10]; //存放温度信息 unsigned short DS18B20_intT=0,DS18B20_decT=0; //温度值的整数和小数部分 DS18B20_intT = DS18B20_temp >> 4; //分离出温度值整数部分 DS18B20_decT = DS18B20_temp & 0xF; //分离出温度值小数部分 sprintf((char*)DS18B20_TEMP_Info,"%d.%d",DS18B20_intT,DS18B20_decT); //保存DS18B20温度信息,发送给上位机 OLED_ShowString(34,0,16,"DS18B20"); if(DS18B20_temp==0xFF) { OLED_ShowString(0,30,16," "); //清除一行的显示 //显示温度错误信息 OLED_ShowString(0,30,16,"DS18B20 Error!"); } else { sprintf(DS18B20_buff,"%sC ",DS18B20_TEMP_Info); //显示温度 OLED_ShowString(40,30,16,DS18B20_buff); } } int main(void) { u8 stat; u8 key_val; u32 TimeCnt=0; u16 temp_data; //温度数据 short aacx,aacy,aacz; //加速度传感器原始数据 short gyrox,gyroy,gyroz; //陀螺仪原始数据 short temp; float pitch,roll,yaw; //欧拉角 u8 page_cnt=0; //显示的页面 u8 display_state1=0; u8 display_state2=0; BEEP_Init(); //初始化蜂鸣器 LED_Init(); //初始化LED KEY_Init(); //按键初始化 DS18B20_Init(); //DS18B20 USARTx_Init(USART1,72,115200);//串口1的初始化 TIMERx_Init(TIM1,72,20000); //辅助串口1接收。20ms为一帧数据。 RTC_Init(); //RTC初始化 OLED_Init(0xc8,0xa1); //OLED显示屏初始化--正常显示 //OLED_Init(0xc0,0xa0); //OLED显示屏初始化--翻转显示 while(MPU6050_Init()) //初始化MPU6050 { printf("MPU6050陀螺仪初始化失败!\r\n"); DelayMs(500); } // //注意:陀螺仪初始化的时候,必须正常摆放才可以初始化成 // while(mpu_dmp_init()) // { // printf("MPU6050陀螺仪设置DMP失败!\r\n"); // DelayMs(1000); // } OLED_Clear(0x00); //清屏 DrawTimeFrame(); //画时钟框架 while(1) { key_val=KEY_GetValue(); if(key_val) { page_cnt=!page_cnt; //时钟页面 if(page_cnt==0) { //清屏 OLED_Clear(0); DrawTimeFrame(); //画时钟框架 RTC->CRH|=10; //开启秒中断 } else if(page_cnt==1) { //清屏 OLED_Clear(0); RTC->CRH&=~(10); //关闭秒中断 } } if(USART1_RX_STATE) { //*20200530154322 //通过串口1校准RTC时间 if(USART1_RX_BUFF[0]=='*') { rtc_clock.year=(USART1_RX_BUFF[1]-48)*1000+(USART1_RX_BUFF[2]-48)*100+(USART1_RX_BUFF[3]-48)*10+(USART1_RX_BUFF[4]-48)*1; rtc_clock.mon=(USART1_RX_BUFF[5]-48)*10+(USART1_RX_BUFF[6]-48)*1; rtc_clock.day=(USART1_RX_BUFF[7]-48)*10+(USART1_RX_BUFF[8]-48)*1; rtc_clock.hour=(USART1_RX_BUFF[9]-48)*10+(USART1_RX_BUFF[10]-48)*1; rtc_clock.min=(USART1_RX_BUFF[11]-48)*10+(USART1_RX_BUFF[12]-48)*1; rtc_clock.sec=(USART1_RX_BUFF[13]-48)*10+(USART1_RX_BUFF[14]-48)*1; RTC_SetTime(rtc_clock.year,rtc_clock.mon,rtc_clock.day,rtc_clock.hour,rtc_clock.min,rtc_clock.sec); OLED_Clear(0); //OLED清屏 DrawTimeFrame();//画时钟框架 } USART1_RX_STATE=0; USART1_RX_CNT=0; } //时间记录 DelayMs(10); TimeCnt++; if(TimeCnt>=100) //1000毫秒一次 { TimeCnt=0; LED1=!LED1; temp_data=DS18B20_ReadTemp(); // printf("temp_data=%d.%d\n",temp_data>>4,temp_data&0xF); // stat=mpu_dmp_get_data(&pitch,&roll,&yaw); // temp=MPU6050_Get_Temperature(); //得到温度值 //MPU6050_Get_Gyroscope(&gyrox,&gyroy,&gyroz); //得到陀螺仪原始数据 MPU6050_Get_Accelerometer(&aacx,&aacy,&aacz); //得到加速度传感器数据 //printf("温度数据:%d\r\n",temp); // printf("陀螺仪原始数据 :x=%d y=%d z=%d\r\n",gyrox,gyroy,gyroz); printf("加速度传感器数据:x=%d y=%d z=%d\r\n",aacx,aacy,aacz); // printf("欧垃角:横滚角=%d 俯仰角=%d 航向角=%d\r\n",(int)(roll*100),(int)(pitch*100),(int)(yaw*10)); // //正着显示 if(aacz>=15000) { printf("正着显示\n"); if(display_state1!=1) { display_state2=0; display_state1=1; OLED_Init(0xc8,0xa1); //OLED显示屏初始化--正常显示 } } //翻转显示 else if(display_state2!=1) { printf("反着显示\n"); display_state1=0; display_state2=1; OLED_Init(0xc0,0xa0); //OLED显示屏初始化--翻转显示 } } if(page_cnt==1) //温度显示页面 { DS18B20_ShowPageTable(temp_data); } } } ``` ## 3.2 mpu6050.c ```cpp #include "mpu6050.h" #include "sys.h" #include "delay.h" #include /*--------------------------------------------------------------------IIC协议底层模拟时序--------------------------------------------------------------------------------*/ /* 硬件接线: 1 VCC 3.3V/5V 电源输入 --->接3.3V 2 GND 地线 --->接GND 3 IIC_SDA IIC 通信数据线 -->PB6 4 IIC_SCL IIC 通信时钟线 -->PB7 5 MPU_INT 中断输出引脚 ---->未接 6 MPU_AD0 IIC 从机地址设置引脚-->未接 AD0引脚说明:ID=0X68(悬空/接 GND) ID=0X69(接 VCC) */ /* 函数功能:MPU IIC 延时函数 */ void MPU6050_IIC_Delay(void) { DelayUs(2); } /* 函数功能: 初始化IIC */ void MPU6050_IIC_Init(void) { RCC->APB2ENR|=13; //先使能外设IO PORTB时钟 GPIOB->CRL&=0X00FFFFFF; //PB6/7 推挽输出 GPIOB->CRL|=0X33000000; GPIOB->ODR|=36; //PB6,7 输出高 } /* 函数功能: 产生IIC起始信号 */ void MPU6050_IIC_Start(void) { MPU6050_SDA_OUT(); //sda线输出 MPU6050_IIC_SDA=1; MPU6050_IIC_SCL=1; MPU6050_IIC_Delay(); MPU6050_IIC_SDA=0;//START:when CLK is high,DATA change form high to low MPU6050_IIC_Delay(); MPU6050_IIC_SCL=0;//钳住I2C总线,准备发送或接收数据 } /* 函数功能: 产生IIC停止信号 */ void MPU6050_IIC_Stop(void) { MPU6050_SDA_OUT();//sda线输出 MPU6050_IIC_SCL=0; MPU6050_IIC_SDA=0;//STOP:when CLK is high DATA change form low to high MPU6050_IIC_Delay(); MPU6050_IIC_SCL=1; MPU6050_IIC_SDA=1;//发送I2C总线结束信号 MPU6050_IIC_Delay(); } /* 函数功能: 等待应答信号到来 返 回 值:1,接收应答失败 0,接收应答成功 */ u8 MPU6050_IIC_Wait_Ack(void) { u8 ucErrTime=0; MPU6050_SDA_IN(); //SDA设置为输入 MPU6050_IIC_SDA=1;MPU6050_IIC_Delay(); MPU6050_IIC_SCL=1;MPU6050_IIC_Delay(); while(MPU6050_READ_SDA) { ucErrTime++; if(ucErrTime>250) { MPU6050_IIC_Stop(); return 1; } } MPU6050_IIC_SCL=0;//时钟输出0 return 0; } /* 函数功能:产生ACK应答 */ void MPU6050_IIC_Ack(void) { MPU6050_IIC_SCL=0; MPU6050_SDA_OUT(); MPU6050_IIC_SDA=0; MPU6050_IIC_Delay(); MPU6050_IIC_SCL=1; MPU6050_IIC_Delay(); MPU6050_IIC_SCL=0; } /* 函数功能:不产生ACK应答 */ void MPU6050_IIC_NAck(void) { MPU6050_IIC_SCL=0; MPU6050_SDA_OUT(); MPU6050_IIC_SDA=1; MPU6050_IIC_Delay(); MPU6050_IIC_SCL=1; MPU6050_IIC_Delay(); MPU6050_IIC_SCL=0; } /* 函数功能:IIC发送一个字节 返回从机有无应答 1,有应答 0,无应答 */ void MPU6050_IIC_Send_Byte(u8 txd) { u8 t; MPU6050_SDA_OUT(); MPU6050_IIC_SCL=0;//拉低时钟开始数据传输 for(t=0;t8;t++) { MPU6050_IIC_SDA=(txd&0x80)>>7; txd=1; MPU6050_IIC_SCL=1; MPU6050_IIC_Delay(); MPU6050_IIC_SCL=0; MPU6050_IIC_Delay(); } } /* 函数功能:读1个字节,ack=1时,发送ACK,ack=0,发送nACK */ u8 MPU6050_IIC_Read_Byte(unsigned char ack) { unsigned char i,receive=0; MPU6050_SDA_IN();//SDA设置为输入 for(i=0;i8;i++ ) { MPU6050_IIC_SCL=0; MPU6050_IIC_Delay(); MPU6050_IIC_SCL=1; receive=1; if(MPU6050_READ_SDA)receive++; MPU6050_IIC_Delay(); } if(!ack) MPU6050_IIC_NAck();//发送nACK else MPU6050_IIC_Ack(); //发送ACK return receive; } /*--------------------------------------------------------------------MPU6050底层驱动代码--------------------------------------------------------------------------------*/ /* 函数功能:初始化MPU6050 返 回 值:0,成功 其他,错误代码 */ u8 MPU6050_Init(void) { u8 res; MPU6050_IIC_Init();//初始化IIC总线 MPU6050_Write_Byte(MPU_PWR_MGMT1_REG,0X80); //复位MPU6050 DelayMs(100); MPU6050_Write_Byte(MPU_PWR_MGMT1_REG,0X00); //唤醒MPU6050 MPU6050_Set_Gyro_Fsr(3); //陀螺仪传感器,±2000dps MPU6050_Set_Accel_Fsr(0); //加速度传感器,±2g MPU6050_Set_Rate(50); //设置采样率50Hz MPU6050_Write_Byte(MPU_INT_EN_REG,0X00); //关闭所有中断 MPU6050_Write_Byte(MPU_USER_CTRL_REG,0X00); //I2C主模式关闭 MPU6050_Write_Byte(MPU_FIFO_EN_REG,0X00); //关闭FIFO MPU6050_Write_Byte(MPU_INTBP_CFG_REG,0X80); //INT引脚低电平有效 res=MPU6050_Read_Byte(MPU_DEVICE_ID_REG); if(res==MPU6050_ADDR)//器件ID正确 { MPU6050_Write_Byte(MPU_PWR_MGMT1_REG,0X01); //设置CLKSEL,PLL X轴为参考 MPU6050_Write_Byte(MPU_PWR_MGMT2_REG,0X00); //加速度与陀螺仪都工作 MPU6050_Set_Rate(50); //设置采样率为50Hz }else return 1; return 0; } /* 设置MPU6050陀螺仪传感器满量程范围 fsr:0,±250dps;1,±500dps;2,±1000dps;3,±2000dps 返回值:0,设置成功 其他,设置失败 */ u8 MPU6050_Set_Gyro_Fsr(u8 fsr) { return MPU6050_Write_Byte(MPU_GYRO_CFG_REG,fsr3);//设置陀螺仪满量程范围 } /* 函数功能:设置MPU6050加速度传感器满量程范围 函数功能:fsr:0,±2g;1,±4g;2,±8g;3,±16g 返 回 值:0,设置成功 其他,设置失败 */ u8 MPU6050_Set_Accel_Fsr(u8 fsr) { return MPU6050_Write_Byte(MPU_ACCEL_CFG_REG,fsr3);//设置加速度传感器满量程范围 } /* 函数功能:设置MPU6050的数字低通滤波器 函数参数:lpf:数字低通滤波频率(Hz) 返 回 值:0,设置成功 其他,设置失败 */ u8 MPU6050_Set_LPF(u16 lpf) { u8 data=0; if(lpf>=188)data=1; else if(lpf>=98)data=2; else if(lpf>=42)data=3; else if(lpf>=20)data=4; else if(lpf>=10)data=5; else data=6; return MPU6050_Write_Byte(MPU_CFG_REG,data);//设置数字低通滤波器 } /* 函数功能:设置MPU6050的采样率(假定Fs=1KHz) 函数参数:rate:4~1000(Hz) 返 回 值:0,设置成功 其他,设置失败 */ u8 MPU6050_Set_Rate(u16 rate) { u8 data; if(rate>1000)rate=1000; if(rate4)rate=4; data=1000/rate-1; data=MPU6050_Write_Byte(MPU_SAMPLE_RATE_REG,data); //设置数字低通滤波器 return MPU6050_Set_LPF(rate/2); //自动设置LPF为采样率的一半 } /* 函数功能:得到温度值 返 回 值:返回值:温度值(扩大了100倍) */ short MPU6050_Get_Temperature(void) { u8 buf[2]; short raw; float temp; MPU6050_Read_Len(MPU6050_ADDR,MPU_TEMP_OUTH_REG,2,buf); raw=((u16)buf[0]8)|buf[1]; temp=36.53+((double)raw)/340; return temp*100;; } /* 函数功能:得到陀螺仪值(原始值) 函数参数:gx,gy,gz:陀螺仪x,y,z轴的原始读数(带符号) 返 回 值:0,成功,其他,错误代码 */ u8 MPU6050_Get_Gyroscope(short *gx,short *gy,short *gz) { u8 buf[6],res; res=MPU6050_Read_Len(MPU6050_ADDR,MPU_GYRO_XOUTH_REG,6,buf); if(res==0) { *gx=((u16)buf[0]8)|buf[1]; *gy=((u16)buf[2]8)|buf[3]; *gz=((u16)buf[4]8)|buf[5]; } return res;; } /* 函数功能:得到加速度值(原始值) 函数参数:gx,gy,gz:陀螺仪x,y,z轴的原始读数(带符号) 返 回 值:0,成功,其他,错误代码 */ u8 MPU6050_Get_Accelerometer(short *ax,short *ay,short *az) { u8 buf[6],res; res=MPU6050_Read_Len(MPU6050_ADDR,MPU_ACCEL_XOUTH_REG,6,buf); if(res==0) { *ax=((u16)buf[0]8)|buf[1]; *ay=((u16)buf[2]8)|buf[3]; *az=((u16)buf[4]8)|buf[5]; } return res;; } /* 函数功能:IIC连续写 函数参数: addr:器件地址 reg:寄存器地址 len:写入长度 buf:数据区 返 回 值:0,成功,其他,错误代码 */ u8 MPU6050_Write_Len(u8 addr,u8 reg,u8 len,u8 *buf) { u8 i; MPU6050_IIC_Start(); MPU6050_IIC_Send_Byte((addr1)|0);//发送器件地址+写命令 if(MPU6050_IIC_Wait_Ack()) //等待应答 { MPU6050_IIC_Stop(); return 1; } MPU6050_IIC_Send_Byte(reg); //写寄存器地址 MPU6050_IIC_Wait_Ack(); //等待应答 for(i=0;i/发送数据 if(MPU6050_IIC_Wait_Ack()) //等待ACK { MPU6050_IIC_Stop(); return 1; } } MPU6050_IIC_Stop(); return 0; } /* 函数功能:IIC连续写 函数参数: IIC连续读 addr:器件地址 reg:要读取的寄存器地址 len:要读取的长度 buf:读取到的数据存储区 返 回 值:0,成功,其他,错误代码 */ u8 MPU6050_Read_Len(u8 addr,u8 reg,u8 len,u8 *buf) { MPU6050_IIC_Start(); MPU6050_IIC_Send_Byte((addr1)|0);//发送器件地址+写命令 if(MPU6050_IIC_Wait_Ack()) //等待应答 { MPU6050_IIC_Stop(); return 1; } MPU6050_IIC_Send_Byte(reg); //写寄存器地址 MPU6050_IIC_Wait_Ack(); //等待应答 MPU6050_IIC_Start(); MPU6050_IIC_Send_Byte((addr1)|1);//发送器件地址+读命令 MPU6050_IIC_Wait_Ack(); //等待应答 while(len) { if(len==1)*buf=MPU6050_IIC_Read_Byte(0);//读数据,发送nACK else *buf=MPU6050_IIC_Read_Byte(1); //读数据,发送ACK len--; buf++; } MPU6050_IIC_Stop(); //产生一个停止条件 return 0; } /* 函数功能:IIC写一个字节 函数参数: reg:寄存器地址 data:数据 返 回 值:0,成功,其他,错误代码 */ u8 MPU6050_Write_Byte(u8 reg,u8 data) { MPU6050_IIC_Start(); MPU6050_IIC_Send_Byte((MPU6050_ADDR1)|0);//发送器件地址+写命令 if(MPU6050_IIC_Wait_Ack()) //等待应答 { MPU6050_IIC_Stop(); return 1; } MPU6050_IIC_Send_Byte(reg); //写寄存器地址 MPU6050_IIC_Wait_Ack(); //等待应答 MPU6050_IIC_Send_Byte(data);//发送数据 if(MPU6050_IIC_Wait_Ack()) //等待ACK { MPU6050_IIC_Stop(); return 1; } MPU6050_IIC_Stop(); return 0; } /* 函数功能:IIC读一个字节 函数参数: reg:寄存器地址 data:数据 返 回 值:返回值:读到的数据 */ u8 MPU6050_Read_Byte(u8 reg) { u8 res; MPU6050_IIC_Start(); MPU6050_IIC_Send_Byte((MPU6050_ADDR1)|0);//发送器件地址+写命令 MPU6050_IIC_Wait_Ack(); //等待应答 MPU6050_IIC_Send_Byte(reg); //写寄存器地址 MPU6050_IIC_Wait_Ack(); //等待应答 MPU6050_IIC_Start(); MPU6050_IIC_Send_Byte((MPU6050_ADDR1)|1);//发送器件地址+读命令 MPU6050_IIC_Wait_Ack(); //等待应答 res=MPU6050_IIC_Read_Byte(0);//读取数据,发送nACK MPU6050_IIC_Stop(); //产生一个停止条件 return res; } ``` ## 3.3 mpu6050.h ```cpp #ifndef __MPU6050_H #define __MPU6050_H #include "stm32f10x.h" #define MPU_SELF_TESTX_REG 0X0D //自检寄存器X #define MPU_SELF_TESTY_REG 0X0E //自检寄存器Y #define MPU_SELF_TESTZ_REG 0X0F //自检寄存器Z #define MPU_SELF_TESTA_REG 0X10 //自检寄存器A #define MPU_SAMPLE_RATE_REG 0X19 //采样频率分频器 #define MPU_CFG_REG 0X1A //配置寄存器 #define MPU_GYRO_CFG_REG 0X1B //陀螺仪配置寄存器 #define MPU_ACCEL_CFG_REG 0X1C //加速度计配置寄存器 #define MPU_MOTION_DET_REG 0X1F //运动检测阀值设置寄存器 #define MPU_FIFO_EN_REG 0X23 //FIFO使能寄存器 #define MPU_I2CMST_CTRL_REG 0X24 //IIC主机控制寄存器 #define MPU_I2CSLV0_ADDR_REG 0X25 //IIC从机0器件地址寄存器 #define MPU_I2CSLV0_REG 0X26 //IIC从机0数据地址寄存器 #define MPU_I2CSLV0_CTRL_REG 0X27 //IIC从机0控制寄存器 #define MPU_I2CSLV1_ADDR_REG 0X28 //IIC从机1器件地址寄存器 #define MPU_I2CSLV1_REG 0X29 //IIC从机1数据地址寄存器 #define MPU_I2CSLV1_CTRL_REG 0X2A //IIC从机1控制寄存器 #define MPU_I2CSLV2_ADDR_REG 0X2B //IIC从机2器件地址寄存器 #define MPU_I2CSLV2_REG 0X2C //IIC从机2数据地址寄存器 #define MPU_I2CSLV2_CTRL_REG 0X2D //IIC从机2控制寄存器 #define MPU_I2CSLV3_ADDR_REG 0X2E //IIC从机3器件地址寄存器 #define MPU_I2CSLV3_REG 0X2F //IIC从机3数据地址寄存器 #define MPU_I2CSLV3_CTRL_REG 0X30 //IIC从机3控制寄存器 #define MPU_I2CSLV4_ADDR_REG 0X31 //IIC从机4器件地址寄存器 #define MPU_I2CSLV4_REG 0X32 //IIC从机4数据地址寄存器 #define MPU_I2CSLV4_DO_REG 0X33 //IIC从机4写数据寄存器 #define MPU_I2CSLV4_CTRL_REG 0X34 //IIC从机4控制寄存器 #define MPU_I2CSLV4_DI_REG 0X35 //IIC从机4读数据寄存器 #define MPU_I2CMST_STA_REG 0X36 //IIC主机状态寄存器 #define MPU_INTBP_CFG_REG 0X37 //中断/旁路设置寄存器 #define MPU_INT_EN_REG 0X38 //中断使能寄存器 #define MPU_INT_STA_REG 0X3A //中断状态寄存器 #define MPU_ACCEL_XOUTH_REG 0X3B //加速度值,X轴高8位寄存器 #define MPU_ACCEL_XOUTL_REG 0X3C //加速度值,X轴低8位寄存器 #define MPU_ACCEL_YOUTH_REG 0X3D //加速度值,Y轴高8位寄存器 #define MPU_ACCEL_YOUTL_REG 0X3E //加速度值,Y轴低8位寄存器 #define MPU_ACCEL_ZOUTH_REG 0X3F //加速度值,Z轴高8位寄存器 #define MPU_ACCEL_ZOUTL_REG 0X40 //加速度值,Z轴低8位寄存器 #define MPU_TEMP_OUTH_REG 0X41 //温度值高八位寄存器 #define MPU_TEMP_OUTL_REG 0X42 //温度值低8位寄存器 #define MPU_GYRO_XOUTH_REG 0X43 //陀螺仪值,X轴高8位寄存器 #define MPU_GYRO_XOUTL_REG 0X44 //陀螺仪值,X轴低8位寄存器 #define MPU_GYRO_YOUTH_REG 0X45 //陀螺仪值,Y轴高8位寄存器 #define MPU_GYRO_YOUTL_REG 0X46 //陀螺仪值,Y轴低8位寄存器 #define MPU_GYRO_ZOUTH_REG 0X47 //陀螺仪值,Z轴高8位寄存器 #define MPU_GYRO_ZOUTL_REG 0X48 //陀螺仪值,Z轴低8位寄存器 #define MPU_I2CSLV0_DO_REG 0X63 //IIC从机0数据寄存器 #define MPU_I2CSLV1_DO_REG 0X64 //IIC从机1数据寄存器 #define MPU_I2CSLV2_DO_REG 0X65 //IIC从机2数据寄存器 #define MPU_I2CSLV3_DO_REG 0X66 //IIC从机3数据寄存器 #define MPU_I2CMST_DELAY_REG 0X67 //IIC主机延时管理寄存器 #define MPU_SIGPATH_RST_REG 0X68 //信号通道复位寄存器 #define MPU_MDETECT_CTRL_REG 0X69 //运动检测控制寄存器 #define MPU_USER_CTRL_REG 0X6A //用户控制寄存器 #define MPU_PWR_MGMT1_REG 0X6B //电源管理寄存器1 #define MPU_PWR_MGMT2_REG 0X6C //电源管理寄存器2 #define MPU_FIFO_CNTH_REG 0X72 //FIFO计数寄存器高八位 #define MPU_FIFO_CNTL_REG 0X73 //FIFO计数寄存器低八位 #define MPU_FIFO_RW_REG 0X74 //FIFO读写寄存器 #define MPU_DEVICE_ID_REG 0X75 //器件ID寄存器 //重力加速度值,单位:9.5 m/s2 typedef struct { float accX; float accY; float accZ; }accValue_t; //因为模块AD0默认接GND,所以转为读写地址后,为0XD1和0XD0(如果接VCC,则为0XD3和0XD2) 从AD0接地机地址为:0X68 u8 MPU6050_Init(void); //初始化MPU6050 u8 MPU6050_Write_Len(u8 addr,u8 reg,u8 len,u8 *buf);//IIC连续写 u8 MPU6050_Read_Len(u8 addr,u8 reg,u8 len,u8 *buf); //IIC连续读 u8 MPU6050_Write_Byte(u8 reg,u8 data); //IIC写一个字节 u8 MPU6050_Read_Byte(u8 reg); //IIC读一个字节 u8 MPU6050_Set_Gyro_Fsr(u8 fsr); u8 MPU6050_Set_Accel_Fsr(u8 fsr); u8 MPU6050_Set_LPF(u16 lpf); u8 MPU6050_Set_Rate(u16 rate); u8 MPU6050_Set_Fifo(u8 sens); short MPU6050_Get_Temperature(void); u8 MPU6050_Get_Gyroscope(short *gx,short *gy,short *gz); u8 MPU6050_Get_Accelerometer(short *ax,short *ay,short *az); //如果AD0脚(9脚)接地,IIC地址为0X68(不包含最低位). //如果接V3.3,则IIC地址为0X69(不包含最低位). #define MPU6050_ADDR 0X68 //IO方向设置 #define MPU6050_SDA_IN() {GPIOB->CRL&=0XF0FFFFFF;GPIOB->CRL|=824;} #define MPU6050_SDA_OUT() {GPIOB->CRL&=0XF0FFFFFF;GPIOB->CRL|=324;} //IO操作函数 #define MPU6050_IIC_SCL PBout(7) //SCL #define MPU6050_IIC_SDA PBout(6) //SDA #define MPU6050_READ_SDA PBin(6) //输入SDA #endif ```
-
# 基于STM32单片机设计的红外测温仪(带人脸检测) 由于医学发展的需要,在很多情况下,一般的温度计己经满足不了快速而又准确的测温要求,例如:车站、地铁、机场等人口密度较大的地方进行人体温度测量。 当前设计的这款红外测温仪由测温硬件+上位机软件组合而成,主要用在地铁、车站入口等地方,可以准确识别人脸进行测温,如果有人温度超标会进行语音提示并且保存当前人脸照片。 ## 1、 硬件选型与设计思路 ### (1). 设备端 主控单片机采用STM32F103C8T6,人体测温功能采用非接触式红外测温模块。  ### (2). 上位机设计思路 上位机采用Qt5设计,Qt5是一套基于C++语言的跨平台软件库,性能非常强大,目前桌面端很多主流的软件都是采用QT开发。比如: 金山办公旗下的-WPS,字节跳动旗下的-剪映,暴雪娱乐公司旗下-多款游戏登录器等等。Qt在车联网领域用的也非常多,比如,哈佛,特斯拉,比亚迪等等很多车的中控屏整个系统都是采用Qt设计。 在测温项目里,上位机与STM32之间采用串口协议进行通信,上位机可以打开笔记本电脑默认的摄像头,进行人脸检测;当检测到人脸时,控制STM32测量当前人体的实时温度实时,再将温度传递到上位机显示;当温度正常时,上位机上显示绿色的提示字样“温度正常”,并有语音播报,语音播报的声音使用笔记本自带的声卡发出。如果温度过高,上位机显示红色提示字样“温度异常,请重新测量”,并有语音播报提示。温度过高时,会自动将当前人脸拍照留存,照片存放在当前软件目录下的“face”目录里,文件的命名规则是“38.8_2022-01-05-22-12-34.jpg”,其中38.8表示温度值,后面是日期(年月日时分秒)。 ### (3) 上位机运行效果   上位机需要连接STM32设备之后才可以获取温度数据,点击软件上的打开摄像头按钮,开启摄像头,让检测到人脸时,下面会显示当前测量的温度。如果没有连接STM32设备,那么默认会显示一个正常的固定温度值。界面上右边红色的字,表示当前处理一帧图像的耗时时间,电脑性能越好,检测速度越快。 ### (4) 拿到可执行文件之后如何运行? 先解压压缩包,进入“测温仪上位机-可执行文件”目录,将“haarcascade_frontalface_alt2.xml”拷贝到C盘根目录。 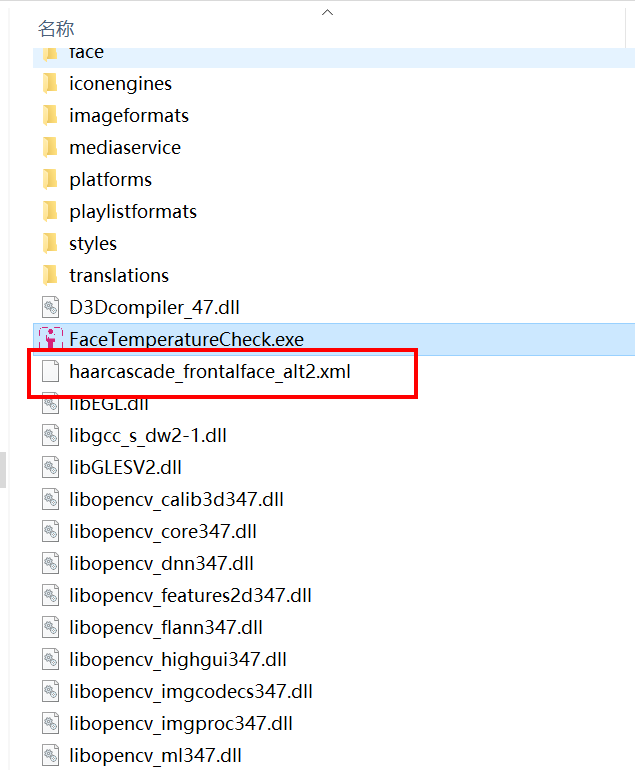  然后双击“FaceTemperatureCheck.exe”运行程序。 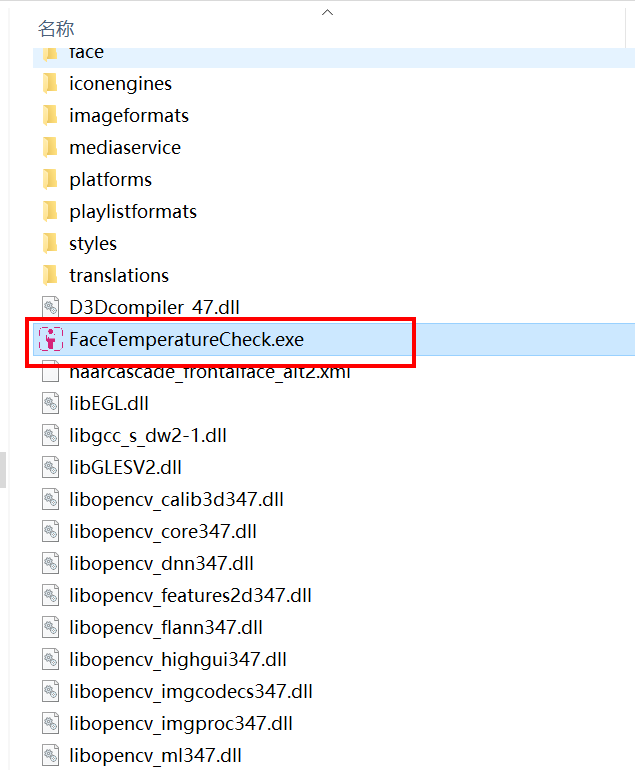 未连接设备,也可以打开摄像头检测人脸,只不过温度值是一个固定的正常温度值范围。 ## 二、上位机设计 ## 2.1 安装编译环境 如果需要自己编译运行源代码,需要先安装Qt5开发环境。 下载地址: https://download.qt.io/official_releases/qt/5.12/5.12.0/  下载之后,先将电脑网络断掉(不然会提示要求输入QT的账号),然后双击安装包进行安装。 安装可以只需要选择一个MinGW 32位编译器就够用了,详情看下面截图,选择“MinGW 7.3.0 32-bit”后,就点击下一步,然后等待安装完成即可。 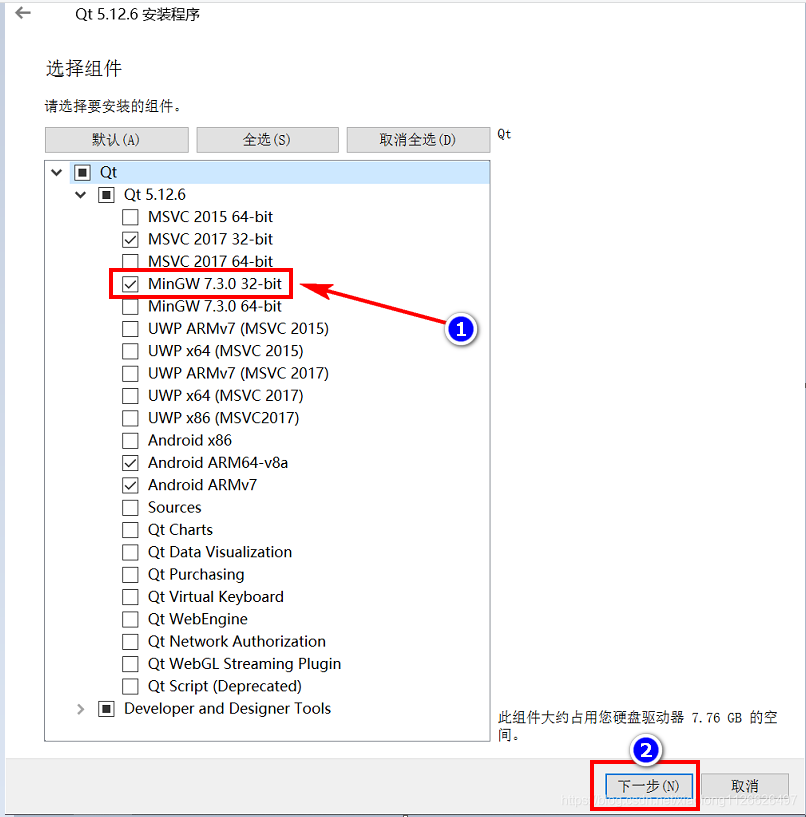 ## 2.2 软件代码整体效果 如果需要完整的工程,可以在这里去下载:https://download.csdn.net/download/xiaolong1126626497/85892490  打开工程后(工程文件的后缀是xxx.pro),点击左下角的绿色三角形按钮就可以编译运行程序。  ## 2.3 UI设计界面  ## 2.4 人脸检测核心代码 ```cpp //人脸检测代码 bool ImageHandle::opencv_face(QImage qImage) { bool check_flag=0; QTime time; time.start(); static CvMemStorage* storage = nullptr; static CvHaarClassifierCascade* cascade = nullptr; //模型文件路径 QString face_model_file = QCoreApplication::applicationDirPath()+"/"+FACE_MODEL_FILE; //加载分类器:正面脸检测 cascade = (CvHaarClassifierCascade*)cvLoad(face_model_file.toUtf8().data(), 0, 0, 0 ); if(!cascade) { qDebug()"分类器加载错误.\n"; return check_flag; } //创建内存空间 storage = cvCreateMemStorage(0); //加载需要检测的图片 IplImage* img = QImageToIplImage(&qImage); if(img ==nullptr ) { qDebug()"图片加载错误.\n"; return check_flag; } double scale=1.2; //创建图像首地址,并分配存储空间 IplImage* gray = cvCreateImage(cvSize(img->width,img->height),8,1); //创建图像首地址,并分配存储空间 IplImage* small_img=cvCreateImage(cvSize(cvRound(img->width/scale),cvRound(img->height/scale)),8,1); cvCvtColor(img,gray, CV_BGR2GRAY); cvResize(gray, small_img, CV_INTER_LINEAR); cvEqualizeHist(small_img,small_img); //直方图均衡 /* * 指定相应的人脸特征检测分类器,就可以检测出图片中所有的人脸,并将检测到的人脸通过矩形的方式返回。 * 总共有8个参数,函数说明: 参数1:表示输入图像,尽量使用灰度图以加快检测速度。 参数2:表示Haar特征分类器,可以用cvLoad()函数来从磁盘中加载xml文件作为Haar特征分类器。 参数3:用来存储检测到的候选目标的内存缓存区域。 参数4:表示在前后两次相继的扫描中,搜索窗口的比例系数。默认为1.1即每次搜索窗口依次扩大10% 参数5:表示构成检测目标的相邻矩形的最小个数(默认为3个)。如果组成检测目标的小矩形的个数和小于 min_neighbors - 1 都会被排除。如果min_neighbors 为 0, 则函数不做任何操作就返回所有的被检候选矩形框,这种设定值一般用在用户自定义对检测结果的组合程序上。 参数6:要么使用默认值,要么使用CV_HAAR_DO_CANNY_PRUNING,如果设置为CV_HAAR_DO_CANNY_PRUNING,那么函数将会使用Canny边缘检测来排除边缘过多或过少的区域,因此这些区域通常不会是人脸所在区域。 参数7:表示检测窗口的最小值,一般设置为默认即可。 参数8:表示检测窗口的最大值,一般设置为默认即可。 函数返回值:函数将返回CvSeq对象,该对象包含一系列CvRect表示检测到的人脸矩形。 */ CvSeq* objects = cvHaarDetectObjects(small_img, cascade, storage, 1.1, 3, 0/*CV_HAAR_DO_CANNY_PRUNING*/, cvSize(50,50)/*大小决定了检测时消耗的时间多少*/); qDebug()"人脸数量:"total; //遍历找到对象和周围画盒 QPainter painter(&qImage);//构建 QPainter 绘图对象 QPen pen; pen.setColor(Qt::blue); //画笔颜色 pen.setWidth(5); //画笔宽度 painter.setPen(pen); //设置画笔 CvRect *max=nullptr; for(int i=0;i(objects->total);++i) { //得到人脸的坐标位置和宽度高度信息 CvRect* r=(CvRect*)cvGetSeqElem(objects,i); if(max==nullptr)max=r; else { if(r->width > max->width || r->height > max->height) { max=r; } } } //如果找到最大的目标脸 if(max!=nullptr) { check_flag=true; //将人脸区域绘制矩形圈起来 painter.drawRect(max->x*scale,max->y*scale,max->width*scale,max->height*scale); } cvReleaseImage(&gray); //释放图片内存 cvReleaseImage(&small_img); //释放图片内存 cvReleaseHaarClassifierCascade(&cascade); //释放内存-->分类器 cvReleaseMemStorage(&objects->storage); //释放内存-->检测出图片中所有的人脸 //释放图片 cvReleaseImage(&img); qint32 time_ms=0; time_ms=time.elapsed(); //耗时时间 emit ss_log_text(QString("%1").arg(time_ms)); //保存结果 m_image=qImage.copy(); return check_flag; } ``` ## 2.5 配置文件(修改参数-很重要)  参数说明: 如果电脑上有多个摄像头,可以修改配置文件里的摄像头编号,具体的数量在程序启动时会自动查询,通过打印代码输出到终端。 如果自己第一次编译运行源码,运行之后, (1)需要将软件源码目录下的“haarcascade_frontalface_alt2.xml” 文件拷贝到C盘根目录,或者其他非中文目录下,具体路径可以在配置文件里修改,默认就是C盘根目录。 (2)需要将软件源码目录下的“OpenCV-MinGW-Build-OpenCV-3.4.7\x86\mingw\bin”目录里所有文件拷贝到,生成的程序执行文件同级目录下。 这样才能保证程序可以正常运行。 报警温度的阀值范围,也可以自行更改,在配置文件里有说明。 ## 2.6 语音提示文件与背景图 语音提示文件,背景图是通过资源文件加载的。 源文件存放在,源代码的“FaceTemperatureCheck\res”目录下。  自己也可以自行替换,重新编译程序即可生效。 ## 2.7 语音播报与图像显示处理代码 ```cpp //图像处理的结果 void Widget::slot_HandleImage(bool flag,QImage image) { bool temp_state=0; //检测到人脸 if(flag) { //判断温度是否正常 if(current_tempMIN_TEMP) { temp_state=true; //显示温度正常 ui->label_temp->setStyleSheet("color: rgb(0, 255, 127);font: 20pt \"Arial\";"); ui->label_temp->setText(QString("%1℃").arg(current_temp)); } else //语音播报,温度异常 { temp_state=false; //显示温度异常 ui->label_temp->setStyleSheet("color: rgb(255, 0, 0);font: 20pt \"Arial\";"); ui->label_temp->setText(QString("%1℃").arg(current_temp)); } //获取当前ms时间 long long currentTime = QDateTime::currentDateTime().toMSecsSinceEpoch(); //判断时间间隔是否到达 if(currentTime-old_currentTime>AUDIO_RATE_MS) { //更改当前时间 old_currentTime=currentTime; //温度正常 if(temp_state) { //语音播报,温度正常 QSound::play(":/res/ok.wav"); } //温度异常 else { //语音播报,温度异常 QSound::play(":/res/error.wav"); //拍照留存 QString dir_str = QCoreApplication::applicationDirPath()+"/face"; //检查目录是否存在,若不存在则新建 QDir dir; if (!dir.exists(dir_str)) { bool res = dir.mkpath(dir_str); qDebug() "新建目录状态:" res; } //目录存在就保存图片 QDir dir2; if (dir2.exists(dir_str)) { //拼接名称 QDateTime dateTime(QDateTime::currentDateTime()); //时间效果: 2020-03-05 16:25::04 周一 QString qStr=QString("%1/%2_").arg(dir_str).arg(current_temp); qStr+=dateTime.toString("yyyy-MM-dd-hh-mm-ss-ddd"); image.save(qStr+".jpg"); } } } } else //不显示温度 { ui->label_temp->setStyleSheet("color: rgb(0, 255, 127);font: 20pt \"Arial\";"); ui->label_temp->setText("----"); } //处理图像的结果画面 ui->widget_player->slotGetOneFrame(image); } ``` ## 2.8 STM32的温度接收处理代码 ```cpp //刷新串口端口 void Widget::on_pushButton_flush_uart_clicked() { QList UartInfoList=QSerialPortInfo::availablePorts(); //获取可用串口端口信息 ui->comboBox_ComSelect->clear(); if(UartInfoList.count()>0) { for(int i=0;i/如果当前串口 COM 口忙就返回真,否则返回假 { QString info=UartInfoList.at(i).portName(); info+="(占用)"; ui->comboBox_ComSelect->addItem(info); //添加新的条目选项 } else { ui->comboBox_ComSelect->addItem(UartInfoList.at(i).portName()); //添加新的条目选项 } } } else { ui->comboBox_ComSelect->addItem("无可用COM口"); //添加新的条目选项 } } //连接测温设备 void Widget::on_pushButton_OpenUart_clicked() { if(ui->pushButton_OpenUart->text()=="连接测温设备") //打开串口 { ui->pushButton_OpenUart->setText("断开连接"); /*配置串口的信息*/ UART_Config->setPortName(ui->comboBox_ComSelect->currentText()); //COM的名称 if(!(UART_Config->open(QIODevice::ReadWrite))) //打开的属性权限 { QMessageBox::warning(this, tr("状态提示"), tr("设备连接失败!\n请选择正确的COM口"), QMessageBox::Ok); ui->pushButton_OpenUart->setText("连接测温设备"); return; } } else //关闭串口 { ui->pushButton_OpenUart->setText("连接测温设备"); /*关闭串口-*/ UART_Config->clear(QSerialPort::AllDirections); UART_Config->close(); } } //读信号 void Widget::ReadUasrtData() { /*返回可读的字节数*/ if(UART_Config->bytesAvailable()=0) { return; } /*定义字节数组*/ QByteArray rx_data; /*读取串口缓冲区所有的数据*/ rx_data=UART_Config->readAll(); //转换温度 current_temp=rx_data.toDouble(); } ```
-
# 一、环境介绍 **MCU:** STM32F103ZET6 **光敏传感器:** BH1750数字传感器(IIC接口) **开发软件:** Keil5 **代码说明:** 使用IIC模拟时序驱动,方便移植到其他平台,采集的光照度比较灵敏. 合成的光照度返回值范围是 0~255。 0表示全黑 255表示很亮。 实测: 手机闪光灯照着的状态返回值是245左右,手捂着的状态返回值是10左右.   # 二、BH1750介绍    # 三、核心代码 **BH1750说明: ADDR引脚接地,地址就是0x46** ## 3.1 iic.c ```cpp #include "iic.h" /* 函数功能:IIC接口初始化 硬件连接: SDA:PB7 SCL:PB6 */ void IIC_Init(void) { RCC->APB2ENR|=13;//PB GPIOB->CRL&=0x00FFFFFF; GPIOB->CRL|=0x33000000; GPIOB->ODR|=0x36; } /* 函数功能:IIC总线起始信号 */ void IIC_Start(void) { IIC_SDA_OUTMODE(); //初始化SDA为输出模式 IIC_SDA_OUT=1; //数据线拉高 IIC_SCL=1; //时钟线拉高 DelayUs(4); //电平保持时间 IIC_SDA_OUT=0; //数据线拉低 DelayUs(4); //电平保持时间 IIC_SCL=0; //时钟线拉低 } /* 函数功能:IIC总线停止信号 */ void IIC_Stop(void) { IIC_SDA_OUTMODE(); //初始化SDA为输出模式 IIC_SDA_OUT=0; //数据线拉低 IIC_SCL=0; //时钟线拉低 DelayUs(4); //电平保持时间 IIC_SCL=1; //时钟线拉高 DelayUs(4); //电平保持时间 IIC_SDA_OUT=1; //数据线拉高 } /* 函数功能:获取应答信号 返 回 值:1表示失败,0表示成功 */ u8 IIC_GetACK(void) { u8 cnt=0; IIC_SDA_INPUTMODE();//初始化SDA为输入模式 IIC_SDA_OUT=1; //数据线上拉 DelayUs(2); //电平保持时间 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 DelayUs(2); //电平保持时间,等待从机发送数据 IIC_SCL=1; //时钟线拉高,告诉从机,主机现在开始读取数据 while(IIC_SDA_IN) //等待从机应答信号 { cnt++; if(cnt>250)return 1; } IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 return 0; } /* 函数功能:主机向从机发送应答信号 函数形参:0表示应答,1表示非应答 */ void IIC_SendACK(u8 stat) { IIC_SDA_OUTMODE(); //初始化SDA为输出模式 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要发送数据 if(stat)IIC_SDA_OUT=1; //数据线拉高,发送非应答信号 else IIC_SDA_OUT=0; //数据线拉低,发送应答信号 DelayUs(2); //电平保持时间,等待时钟线稳定 IIC_SCL=1; //时钟线拉高,告诉从机,主机数据发送完毕 DelayUs(2); //电平保持时间,等待从机接收数据 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 } /* 函数功能:IIC发送1个字节数据 函数形参:将要发送的数据 */ void IIC_WriteOneByteData(u8 data) { u8 i; IIC_SDA_OUTMODE(); //初始化SDA为输出模式 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要发送数据 for(i=0;i8;i++) { if(data&0x80)IIC_SDA_OUT=1; //数据线拉高,发送1 else IIC_SDA_OUT=0; //数据线拉低,发送0 IIC_SCL=1; //时钟线拉高,告诉从机,主机数据发送完毕 DelayUs(2); //电平保持时间,等待从机接收数据 IIC_SCL=0; //时钟线拉低,告诉从机,主机需要发送数据 DelayUs(2); //电平保持时间,等待时钟线稳定 data=1; //先发高位 } } /* 函数功能:IIC接收1个字节数据 返 回 值:收到的数据 */ u8 IIC_ReadOneByteData(void) { u8 i,data; IIC_SDA_INPUTMODE();//初始化SDA为输入模式 for(i=0;i8;i++) { IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 DelayUs(2); //电平保持时间,等待从机发送数据 IIC_SCL=1; //时钟线拉高,告诉从机,主机现在正在读取数据 data=1; if(IIC_SDA_IN)data|=0x01; DelayUs(2); //电平保持时间,等待时钟线稳定 } IIC_SCL=0; //时钟线拉低,告诉从机,主机需要数据 (必须拉低,否则将会识别为停止信号) return data; } ``` ## 3.2 iic.h ```cpp #ifndef _IIC_H #define _IIC_H #include "stm32f10x.h" #include "sys.h" #include "delay.h" #define IIC_SDA_OUTMODE() {GPIOB->CRL&=0x0FFFFFFF;GPIOB->CRL|=0x30000000;} #define IIC_SDA_INPUTMODE() {GPIOB->CRL&=0x0FFFFFFF;GPIOB->CRL|=0x80000000;} #define IIC_SDA_OUT PBout(7) //数据线输出 #define IIC_SDA_IN PBin(7) //数据线输入 #define IIC_SCL PBout(6) //时钟线 void IIC_Init(void); void IIC_Start(void); void IIC_Stop(void); u8 IIC_GetACK(void); void IIC_SendACK(u8 stat); void IIC_WriteOneByteData(u8 data); u8 IIC_ReadOneByteData(void); #endif ``` ## 3.3 BH1750.h ```cpp #ifndef _BH1750_H #define _BH1750_H #include "delay.h" #include "iic.h" #include "usart.h" u8 Read_BH1750_Data(void); #endif ``` ## 3.4 BH1750.c ```cpp #include "bh1750.h" u8 Read_BH1750_Data() { unsigned char t0; unsigned char t1; unsigned char t; u8 r_s=0; IIC_Start(); //发送起始信号 IIC_WriteOneByteData(0x46); r_s=IIC_GetACK();//获取应答 if(r_s)printf("error:1\r\n"); IIC_WriteOneByteData(0x01); r_s=IIC_GetACK();//获取应答 if(r_s)printf("error:2\r\n"); IIC_Stop(); //停止信号 IIC_Start(); //发送起始信号 IIC_WriteOneByteData(0x46); r_s=IIC_GetACK();//获取应答 if(r_s)printf("error:3\r\n"); IIC_WriteOneByteData(0x01); r_s=IIC_GetACK();//获取应答 if(r_s)printf("error:4\r\n"); IIC_Stop(); //停止信号 IIC_Start(); //发送起始信号 IIC_WriteOneByteData(0x46); r_s=IIC_GetACK();//获取应答 if(r_s)printf("error:5\r\n"); IIC_WriteOneByteData(0x10); r_s=IIC_GetACK();//获取应答 if(r_s)printf("error:6\r\n"); IIC_Stop(); //停止信号 DelayMs(300); //等待 IIC_Start(); //发送起始信号 IIC_WriteOneByteData(0x47); r_s=IIC_GetACK();//获取应答 if(r_s)printf("error:7\r\n"); t0=IIC_ReadOneByteData(); //接收数据 IIC_SendACK(0); //发送应答信号 t1=IIC_ReadOneByteData(); //接收数据 IIC_SendACK(1); //发送非应答信号 IIC_Stop(); //停止信号 t=(((t08)|t1)/1.2); return t; } ``` ## 3.5 main.c ```cpp 如果需要完整工程可以去这里下载:https://download.csdn.net/download/xiaolong1126626497/18500653 #include "stm32f10x.h" #include "led.h" #include "delay.h" #include "key.h" #include "usart.h" #include "at24c02.h" #include "bh1750.h" int main() { u8 val; LED_Init(); BEEP_Init(); KeyInit(); USARTx_Init(USART1,72,115200); IIC_Init(); while(1) { val=KeyScan(); if(val) { val=Read_BH1750_Data(); printf("光照强度=%d\r\n",val); // BEEP=!BEEP; LED0=!LED0; LED1=!LED1; } } } ``` ## 3.6 运行效果图 
-
 高性能,低功耗:越来越多的应用需要满足这一需求,尤其是由电池供电的移动设备。特别是在、工业4.0和数字化时代,这些手持设备大大方便了人们的日常生活。从移动生命体征监测到工业环境中的机器和系统监测,很多应用纷纷受益。智能手机和可穿戴设备等终端用户产品也要求更高的性能和更长的电池寿命。因为提供电源的电池电能有限,所以需要在使用消耗电流最小的元件,以最大限度延长设备的运行时间。或者,通过降低功耗,使低容量电池也可以实现相同的电池寿命,同时减小尺寸、重量和成本。温度管理同样不容忽视。同样,更高效的元件也起积极作用。冷却管理需要占用空间,如果产生的热量减少,占用的空间也会减少。目前,市面上提供多种低功耗,甚至是超低功耗(ULP)元件。本文着重探讨低功耗运算放大器。功耗与性能的权衡在选择合适的放大器时,往往需要考虑运算放大器的功耗,并做出权衡。低功耗往往也意味着低带宽。但是,这也取决于给定的放大器架构和稳定性要求。寄生电容和电感越高,通常带宽越低。例如,电流反馈放大器提供相对较高的带宽,但精准度较低。我们可以使用一些技巧来提高带宽-功率比。例如,增益带宽积(GBW)一般如下: Gm表示跨导,或者是输出电流和输入电压之比(IOUT/VIN),C表示内部补偿电容。增加带宽的典型方法是增加偏置电流,这会使Gm增加,但会消耗更多功率。为了保持低功率,我们不愿意如此。通常,补偿电容会设置主极点,所以理想情况下,负载电容根本不会影响带宽。受放大器的物理特性限制,电容较低时,通常可以获得更高带宽,但这也会影响稳定性,在低噪声增益下,其稳定性会得到提高。但是,实际上,我们无法在更低噪声增益下驱动大型的纯电容负载。在使用低功耗运算放大器时,需要权衡的另一因素是通常较高的电压噪声。但是,输入电压噪声是放大器最主要的噪声(占总输出宽带噪声的一部分),但也可能是电阻噪声。总噪声最主要的部分可能来自于输入级中的噪声源(例如,集电极产生散射噪声,漏极产生热噪声)。1/f噪声(闪烁噪声)因架构而异,是由元件材料中的特殊缺陷引起的。所以,它一般取决于元件的大小。相反,电流噪声在更低的功率电平下通常更低。但也不容忽视,尤其是在双极放大器中。在1/f区域,1/f电流噪声是放大器输出端的总1/f噪声的主要来源。其他权衡因素包括失真性能和漂移值。低功耗运算放大器通常表现出更高的总谐波失真(THD),但是和电流噪声一样,双极放大器中的输入偏置和失调电流会随着电源电流降低而降低。失调电压是运算放大器的另一个重要指标。一般可通过调整输入端元件来降低影响,因此不会在低功率下导致性能大幅降低,所以VOS和VOS漂移在功率范围内是恒定的。外部电路和反馈电阻(RF)也会影响运算放大器的性能。电阻值较高时,动态功率和谐波失真会降低,但它们会增大输出噪声,以及与偏置电流相关的误差。为了进一步降低功耗,许多设备都提供待机或睡眠功能。这样重要设备功能在闲置时可以停用,根据需要重新激活。低功耗放大器的唤醒时间通常更长。表1对前文所述的权衡因素进行了归纳和汇总。表1.低功耗运算放大器的权衡功耗反馈电阻(RF) á正作用电流噪声 偏置电流漂移 失调电流漂移?动态功率失真(THD) @ HF 负作用带宽 电压噪声 失真(THD) @ HF 唤醒时间 驱动功率输出噪声对偏置电流的影响中性作用失调电压漂移双极性差分放大器妥善地权衡了上述这些特性。它具有低直流失调、失调温漂和出色的动态性能,非常适合多种高分辨率、功能强大的数据采集和信号处理应用,这些应用通常需要使用驱动器来驱动ADC,如图1所示,由ADA4945-1驱动ADC。 ADA4945-1可配置多种功率模式,您可以在特定转换器上更好地权衡性能与功率。例如,在全功率模式下,可与配对,降低至低功耗模式后,可以适应或AD4022的低采样速率。图1.高分辨率数据采集系统的简化信号链示例作者简介Thomas Brand于2015年加入德国慕尼黑的ADI公司,当时他还在攻读硕士。毕业后,他参加了ADI公司的培训生项目。2017年,他成为一名现场应用工程师。Thomas为中欧的大型工业客户提供支持,并专注于工业以太网领域。他毕业于德国莫斯巴赫的联合教育大学电气工程专业,之后在德国康斯坦茨应用科学大学获得国际销售硕士学位。联系方式:
高性能,低功耗:越来越多的应用需要满足这一需求,尤其是由电池供电的移动设备。特别是在、工业4.0和数字化时代,这些手持设备大大方便了人们的日常生活。从移动生命体征监测到工业环境中的机器和系统监测,很多应用纷纷受益。智能手机和可穿戴设备等终端用户产品也要求更高的性能和更长的电池寿命。因为提供电源的电池电能有限,所以需要在使用消耗电流最小的元件,以最大限度延长设备的运行时间。或者,通过降低功耗,使低容量电池也可以实现相同的电池寿命,同时减小尺寸、重量和成本。温度管理同样不容忽视。同样,更高效的元件也起积极作用。冷却管理需要占用空间,如果产生的热量减少,占用的空间也会减少。目前,市面上提供多种低功耗,甚至是超低功耗(ULP)元件。本文着重探讨低功耗运算放大器。功耗与性能的权衡在选择合适的放大器时,往往需要考虑运算放大器的功耗,并做出权衡。低功耗往往也意味着低带宽。但是,这也取决于给定的放大器架构和稳定性要求。寄生电容和电感越高,通常带宽越低。例如,电流反馈放大器提供相对较高的带宽,但精准度较低。我们可以使用一些技巧来提高带宽-功率比。例如,增益带宽积(GBW)一般如下: Gm表示跨导,或者是输出电流和输入电压之比(IOUT/VIN),C表示内部补偿电容。增加带宽的典型方法是增加偏置电流,这会使Gm增加,但会消耗更多功率。为了保持低功率,我们不愿意如此。通常,补偿电容会设置主极点,所以理想情况下,负载电容根本不会影响带宽。受放大器的物理特性限制,电容较低时,通常可以获得更高带宽,但这也会影响稳定性,在低噪声增益下,其稳定性会得到提高。但是,实际上,我们无法在更低噪声增益下驱动大型的纯电容负载。在使用低功耗运算放大器时,需要权衡的另一因素是通常较高的电压噪声。但是,输入电压噪声是放大器最主要的噪声(占总输出宽带噪声的一部分),但也可能是电阻噪声。总噪声最主要的部分可能来自于输入级中的噪声源(例如,集电极产生散射噪声,漏极产生热噪声)。1/f噪声(闪烁噪声)因架构而异,是由元件材料中的特殊缺陷引起的。所以,它一般取决于元件的大小。相反,电流噪声在更低的功率电平下通常更低。但也不容忽视,尤其是在双极放大器中。在1/f区域,1/f电流噪声是放大器输出端的总1/f噪声的主要来源。其他权衡因素包括失真性能和漂移值。低功耗运算放大器通常表现出更高的总谐波失真(THD),但是和电流噪声一样,双极放大器中的输入偏置和失调电流会随着电源电流降低而降低。失调电压是运算放大器的另一个重要指标。一般可通过调整输入端元件来降低影响,因此不会在低功率下导致性能大幅降低,所以VOS和VOS漂移在功率范围内是恒定的。外部电路和反馈电阻(RF)也会影响运算放大器的性能。电阻值较高时,动态功率和谐波失真会降低,但它们会增大输出噪声,以及与偏置电流相关的误差。为了进一步降低功耗,许多设备都提供待机或睡眠功能。这样重要设备功能在闲置时可以停用,根据需要重新激活。低功耗放大器的唤醒时间通常更长。表1对前文所述的权衡因素进行了归纳和汇总。表1.低功耗运算放大器的权衡功耗反馈电阻(RF) á正作用电流噪声 偏置电流漂移 失调电流漂移?动态功率失真(THD) @ HF 负作用带宽 电压噪声 失真(THD) @ HF 唤醒时间 驱动功率输出噪声对偏置电流的影响中性作用失调电压漂移双极性差分放大器妥善地权衡了上述这些特性。它具有低直流失调、失调温漂和出色的动态性能,非常适合多种高分辨率、功能强大的数据采集和信号处理应用,这些应用通常需要使用驱动器来驱动ADC,如图1所示,由ADA4945-1驱动ADC。 ADA4945-1可配置多种功率模式,您可以在特定转换器上更好地权衡性能与功率。例如,在全功率模式下,可与配对,降低至低功耗模式后,可以适应或AD4022的低采样速率。图1.高分辨率数据采集系统的简化信号链示例作者简介Thomas Brand于2015年加入德国慕尼黑的ADI公司,当时他还在攻读硕士。毕业后,他参加了ADI公司的培训生项目。2017年,他成为一名现场应用工程师。Thomas为中欧的大型工业客户提供支持,并专注于工业以太网领域。他毕业于德国莫斯巴赫的联合教育大学电气工程专业,之后在德国康斯坦茨应用科学大学获得国际销售硕士学位。联系方式: -
一、前言在物联网系统开发中,离不开各种传感器、单片机的程序开发;一个简单的物联网系统构成应该是: 感知层 + 网络传输层 + 平台管理层 。具体而言:感知层:由各种各样的嵌入式设备构成。而单片机是嵌入式系统的硬件组成,是嵌入式系统软件运行的载体和必要条件;嵌入式系统在整个物联网框架下,更多的体现为感知层的角色,作为智能设备存在于整个物联网体系中,是物联网数据的采集来源。网络传输层:底层部分由嵌入式设备到平台的IoT网络构成,比较常见的网络主要有NB,Lora,Zigbee,GSM,LTE等。顶层部分是由网络到TCP/IP网络的转化。平台管理层:这部分主要完成不同数据传输协议的转化,实现数据的远程存储和设备远程管理。比如有的智能设备利用lwm2m协议传送数据,有的使用的是MQTT,还有的喜欢用coap封装数据。平台需要根据协议,完成上报数据的解析,设备的管理和命令的下发动作。从组成关系来讲,物联网由嵌入式设备构成,嵌入式设备中包含单片机。作为一名物联网工程师,如果主要是负责感知层的开发,那么C语言肯定是一项必须精通的语言。目前C语言还是单片机里的主流开发语言,这篇合集主要就是介绍C语言的知识点,从基本数据类型、变量、数组、指针、结构体顺序来介绍C语言的学习思路。二、C语言基础知识点2.1 C语言-基本数据类型与位运算https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190852这篇文章作为基础知识点,总结C语言的基本数据类型有哪些,浮点数的精度,整数变量的空间范围,变量定义语法,变量命名规则,浮点数打印格式,基本数据类型printf对应的打印、位运算的知识点。2.2 C语言-语句(if,for,while,switch,goto,return,break,continue)https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190854这篇文章作为C语言基础知识点,介绍C语言常用的几个语句的用法、规则、使用案例。介绍的语句如下: if..else 判断语句 for循环语句 while循环语句 do..while循环语句 switch 语句 goto 语句 return 语句 break 语句 continue 语句2.3 C语言-数组https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190858C语言的数组是一个同类型数据的集合,主要用来存储一堆同类型的数据。程序里怎么区分是数组?[ ] 这个括号是数组专用的符号. 定义数组、 访问数组数据都会用到。2.4 C语言-函数的定义、声明、传参https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190859C语言里函数是非常重要的知识点,一个完整的C语言程序就是由主函数和各个子函数组成的,主函数调用子函数完成各个逻辑功能。2.5 C语言-一维指针定义与使用https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190911指针在很多书本上都是当做重点来介绍,作为C语言的灵魂,项目里指针无处不在。比如: 指针作为函数形参的时候,可以间接修改源地址里的数据,也就相当于解决了函数return一次只能返回一个值的问题。指针在嵌入式、单片机里使用最直观,可以直接通过指针访问寄存器地址,对寄存器进行配置;计算机的CPU、外设硬件都是依靠地址操作的。2.6 C语言-内联函数、递归函数、指针函数https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190915这篇文章介绍C语言的内联函数、递归函数、函数指针、指针函数、局部地址、const关键字、extern关键字等知识点;这些知识点在实际项目开发中非常常用,非常重要。2.7 C语言-void类型作为万能指针类型https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=190917void类型在基本数据类型里是空类型,无类型;void类型常用来当做函数的返回值,函数形参声明,表示函数没有返回值,没有形参。void类型不能用来定义变量,因为它是空类型–可以理解为空类型。2.8 C语言-指针作为函数形参类型https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=191033C语言函数里最常用就是指针传参和返回地址,特别是字符串处理中,经常需要封装各种功能函数完成数据处理,并且C语言标准库里也提供了string.h 头文件,里面包含了很多字符串处理函数;这些函数的参数和返回值几乎都是指针类型。这篇文章就介绍如何使用指针作为函数参数、并且使用指针作为函数返回值。2.9 C语言-字符串处理https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=191034字符串在C语言里使用非常多,因为很多数据处理都是文本,也就是字符串,特别是设备交互、web网页交互返回的几乎都是文本数据。字符串本身属于字符数组、只不过和字符数组区别是,字符串结尾有’\0’。 字符串因为规定结尾有'\0',在计算长度、拷贝、查找、拼接操作都很方便。2.10 C语言-结构体与位域https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=191137C语言里的结构体是可以包含不同数据类型和相同数据类型的一个有序集合,属于构造类型,可以自己任意组合,并且结构体里也可以使用结构体类型作为成员。结构体在项目开发中使用非常多,无处不在,有了结构体类型就可以设计很多框架,模型,方便数据传输,存储等等。2.11 C语言-学生管理系统(结构体+数组实现)https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=191138前面文章里介绍了结构体类型,知道结构体类型里可以存放不同的数据类型,属于一个有序的集合。这篇文章就使用结构体知识点完成一个小练习,使用结构体+数组设计一个简单的学生管理系统,作为结构体知识点的巩固练习。功能如下:(1). 欢迎界面提示(2). 输入密码登录(3). 功能: 录入学生信息、按照学号排序、按照成绩排序、输出所有学生信息、输出指定学生信息(学号、姓名、成绩)、计算成绩平均值值输出打印、删除指定学生信息、增加新的学生信息。(4). 功能模块采用菜单方式选择2.2 C语言-预处理(#define、#if...)https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=191139在C语言程序里,出现的#开头的代码段都属于预处理。预处理:是在程序编译阶段就执行的代码段。比如: 包含头文件的的代码#include <stdio.h> #include <stdlib.h> #include <string.h>后续这篇帖子会持续更新,持续加入C语言后面的知识点,方便大家寻找对应的知识点。
-
 这里是目录前言一、#define指令1.#define定义宏2.#define 替换 宏3.带副作用的宏参数4.#undef撤销宏定义5.宏和函数对比(重点)二、条件编译指令1.单分支2.多分支条件编译3.判断某个符号是否被定义4.嵌套指令三、#include指令1.本地文件包含2.库文件包含3.嵌套文件包含前言了解敲完hello world后,编译器是怎么处理代码的第一步的呢,这是学习C和C++的基础。Hello World代码如下。放错了,重来。代码如下当你敲完Hello World这串代码时。编译器会对这些代码进行编译 和 链接的操作。而 编译: 又分为 预处理、编译、汇编。所以说 当你敲完C代码后的第一步,编译器会对C代码进行预处理.那么预处理主要做了那些事情呢?预处理大致做了以下事情:1.定义和替换由 #define指令定义的符号2.删除注释3.确定代码部分内容是否应该根据一些 条件编译指令 进行编译4.插入被 #include指令包含的内容所以本章详解预处理指令 #define、#include、条件编译指令。一、#define指令1.#define定义宏什么是宏?宏的定义:#define 允许把参数替换到文本中,这种实现通常称为宏或定义宏宏的声明格式:#define NAME stuff解释:没当有符号name出现在#define NAME stuff这条语句后面时,预处理器就会把它替换为 stuff。NAME:1.NAME是宏的名字。在这里 name 相当于变量,或者也可以相当于函数。但不等于函数!2.一般NAME都是大写,因为宏和函数语法很相似,语言本身我们无法区分,所以宏名要全部大写stuff:可以是常量。可以是表达式。也可以是一段程序。例如:以下代码在预处理后是什么样子呢?//定义声明宏//定义中我们使用了括号,这是一个好习惯,避免优先级的错误#define SQUARE(x) (x)*(x)int main(){ printf("%d ", SQUARE(5)); return 0;}预处理后的代码,以下你看到的代码是编译器实实在在的处后的代码。#define SQUARE(x) (x)*(x)int main(){ //将SQUARE(5)替换为(5)*(5) printf("%d ", (5)*(5)); return 0;}你是否还对#define 替换迷惑?请继续往下看2.#define 替换 宏到底上面的代码是怎么替换的 宏?1.再调用宏时,首先对参数检查,看是否包含了#define定义的符号,比如SQUARE(5),然后将它的x * x替换为5 * 5.2.对于宏,参数名被他们的值所替代。3.最后,再次对文本扫描,看是否包含了热任何由#define定义的符号。如果是,就重复上述处理过程。为什么会有第3步的重复呢?因为有时候#define定义可以包含其他#define定义的符号。但是宏不可以递归!3.带副作用的宏参数什么是带副作用的宏参数?副作用:就是表达式求值的时候出现的永久性效果。例如:x+1;//不带副作用x++;//带有副作用12下面代码输出结果是什么?#include <stdio.h>#define ADD(a, b) (a)+(b)int main(){ int x = 2; int y = 3; int z = ADD(x++, y++); //输出的结果是什么? //x=3 y=4 z=5 printf("x=%d y=%d z=%d\n", x, y, z); return 0;}因为被替换的代码是int z = ADD(x++, y++);替换后为:int z = (x++)+(y++);这样结果就一目了然。4.#undef撤销宏定义#undef:这条指令用于移除一个宏定义例如:移除MAX这个宏。5.宏和函数对比(重点)属性 #define定义宏 函数代码长度 每次使用时,宏代码都会被插入到程序中。除了非常小的宏之外,程序的长度会大幅度增长 函数代码只出现于一个地方。每次使用函数时,都调用同一个地方的代码执行速度 更快 存在函数的调用和返回 的格外开销,所以相对慢一些操作符优先级 宏参数求值需要加上括号,否则容易造成不可以预料的后果 只在函数调用事求值一次,不会带副作用带有副作用的参数 参数可能被替换到宏的多个位置,有的可能带有副作用 函数参数只在传参的时候求值一次,结果更容易控制参数类型 宏的参数与类型无关,可以是任何类型的的参数 函数参数与类型有关,参数类型不同就需要不同的函数,因为C语言没有C++的重载调试 宏是不可以调试的,因为在程序运行前就已经替换的宏 可以逐语句调试二、条件编译指令什么是条件编译?意思就是我们可以选择性的编译。条件编译:你可以选择代码的一部分是被正常编译还是完全忽略。用于支持条件编译的基本结构是#if指令和与其匹配的#endif指令。1.单分支常量表达式expression,由预处理器求值。如果expression为真,那么statements将被执行,否则预处理器就安静的删除它们。#if expression statements;#endif//常量表达式expression,由预处理器求值。2.多分支条件编译同if else语句,为真则执行。#if expression //...#elif expression //...#else //...#endif3.判断某个符号是否被定义为了测试一个符号是否已经被定义。在条件编译中完成这个任务更方便。以下两条语句功能想通过。1.#if defined(symbol)2.#ifdef symbol4.嵌套指令某个程序既要在windows系统下能够运行,也需要在Linux系统下运行,这就要条件编译来解决跨平台问题。这时候嵌套指令很容易解决。#if defined(OS_UNIX) #ifdef OPTION1 unix_version_option1(); #endif #ifdef OPTION2 unix_version_option2(); #endif#elif defined(OS_MSDOS) #ifdef OPTION2 msdos_version_option2(); #endif#endif三、#include指令#include在预处理时会被展开。这种展开的方式很简单:1.预处理器先删除这条指令,并用**#include**所包含文件的内容替换。2.这样一个源文件被包含10次,那就实际被编译10次。1.本地文件包含#include "Add.h"1查找方法:1.先在源文件所在目录下查找2.如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。2.库文件包含#include <stdio.h>1查找方法:查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。这样是不是可以说,对于库文件也可以使用 “” 的形式包含?答案是肯定的,可以。但是这样做查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。3.嵌套文件包含有时候会重复包含头文件,以前为了解决这个方法,人们用了条件编译。代码如下每个头文件的开头写:例如有个test.h的头文件。用下划线分开头文件。全大写。#ifndef __TEST_H__#define __TEST_H__//这里面写头文件的内容#endif 上面这种写法比较古老。现在一般用这个写法#pragma once#pragma once也是是用来防止头文件被包含的。原文链接:https://blog.csdn.net/qq2466200050/article/details/124615042
这里是目录前言一、#define指令1.#define定义宏2.#define 替换 宏3.带副作用的宏参数4.#undef撤销宏定义5.宏和函数对比(重点)二、条件编译指令1.单分支2.多分支条件编译3.判断某个符号是否被定义4.嵌套指令三、#include指令1.本地文件包含2.库文件包含3.嵌套文件包含前言了解敲完hello world后,编译器是怎么处理代码的第一步的呢,这是学习C和C++的基础。Hello World代码如下。放错了,重来。代码如下当你敲完Hello World这串代码时。编译器会对这些代码进行编译 和 链接的操作。而 编译: 又分为 预处理、编译、汇编。所以说 当你敲完C代码后的第一步,编译器会对C代码进行预处理.那么预处理主要做了那些事情呢?预处理大致做了以下事情:1.定义和替换由 #define指令定义的符号2.删除注释3.确定代码部分内容是否应该根据一些 条件编译指令 进行编译4.插入被 #include指令包含的内容所以本章详解预处理指令 #define、#include、条件编译指令。一、#define指令1.#define定义宏什么是宏?宏的定义:#define 允许把参数替换到文本中,这种实现通常称为宏或定义宏宏的声明格式:#define NAME stuff解释:没当有符号name出现在#define NAME stuff这条语句后面时,预处理器就会把它替换为 stuff。NAME:1.NAME是宏的名字。在这里 name 相当于变量,或者也可以相当于函数。但不等于函数!2.一般NAME都是大写,因为宏和函数语法很相似,语言本身我们无法区分,所以宏名要全部大写stuff:可以是常量。可以是表达式。也可以是一段程序。例如:以下代码在预处理后是什么样子呢?//定义声明宏//定义中我们使用了括号,这是一个好习惯,避免优先级的错误#define SQUARE(x) (x)*(x)int main(){ printf("%d ", SQUARE(5)); return 0;}预处理后的代码,以下你看到的代码是编译器实实在在的处后的代码。#define SQUARE(x) (x)*(x)int main(){ //将SQUARE(5)替换为(5)*(5) printf("%d ", (5)*(5)); return 0;}你是否还对#define 替换迷惑?请继续往下看2.#define 替换 宏到底上面的代码是怎么替换的 宏?1.再调用宏时,首先对参数检查,看是否包含了#define定义的符号,比如SQUARE(5),然后将它的x * x替换为5 * 5.2.对于宏,参数名被他们的值所替代。3.最后,再次对文本扫描,看是否包含了热任何由#define定义的符号。如果是,就重复上述处理过程。为什么会有第3步的重复呢?因为有时候#define定义可以包含其他#define定义的符号。但是宏不可以递归!3.带副作用的宏参数什么是带副作用的宏参数?副作用:就是表达式求值的时候出现的永久性效果。例如:x+1;//不带副作用x++;//带有副作用12下面代码输出结果是什么?#include <stdio.h>#define ADD(a, b) (a)+(b)int main(){ int x = 2; int y = 3; int z = ADD(x++, y++); //输出的结果是什么? //x=3 y=4 z=5 printf("x=%d y=%d z=%d\n", x, y, z); return 0;}因为被替换的代码是int z = ADD(x++, y++);替换后为:int z = (x++)+(y++);这样结果就一目了然。4.#undef撤销宏定义#undef:这条指令用于移除一个宏定义例如:移除MAX这个宏。5.宏和函数对比(重点)属性 #define定义宏 函数代码长度 每次使用时,宏代码都会被插入到程序中。除了非常小的宏之外,程序的长度会大幅度增长 函数代码只出现于一个地方。每次使用函数时,都调用同一个地方的代码执行速度 更快 存在函数的调用和返回 的格外开销,所以相对慢一些操作符优先级 宏参数求值需要加上括号,否则容易造成不可以预料的后果 只在函数调用事求值一次,不会带副作用带有副作用的参数 参数可能被替换到宏的多个位置,有的可能带有副作用 函数参数只在传参的时候求值一次,结果更容易控制参数类型 宏的参数与类型无关,可以是任何类型的的参数 函数参数与类型有关,参数类型不同就需要不同的函数,因为C语言没有C++的重载调试 宏是不可以调试的,因为在程序运行前就已经替换的宏 可以逐语句调试二、条件编译指令什么是条件编译?意思就是我们可以选择性的编译。条件编译:你可以选择代码的一部分是被正常编译还是完全忽略。用于支持条件编译的基本结构是#if指令和与其匹配的#endif指令。1.单分支常量表达式expression,由预处理器求值。如果expression为真,那么statements将被执行,否则预处理器就安静的删除它们。#if expression statements;#endif//常量表达式expression,由预处理器求值。2.多分支条件编译同if else语句,为真则执行。#if expression //...#elif expression //...#else //...#endif3.判断某个符号是否被定义为了测试一个符号是否已经被定义。在条件编译中完成这个任务更方便。以下两条语句功能想通过。1.#if defined(symbol)2.#ifdef symbol4.嵌套指令某个程序既要在windows系统下能够运行,也需要在Linux系统下运行,这就要条件编译来解决跨平台问题。这时候嵌套指令很容易解决。#if defined(OS_UNIX) #ifdef OPTION1 unix_version_option1(); #endif #ifdef OPTION2 unix_version_option2(); #endif#elif defined(OS_MSDOS) #ifdef OPTION2 msdos_version_option2(); #endif#endif三、#include指令#include在预处理时会被展开。这种展开的方式很简单:1.预处理器先删除这条指令,并用**#include**所包含文件的内容替换。2.这样一个源文件被包含10次,那就实际被编译10次。1.本地文件包含#include "Add.h"1查找方法:1.先在源文件所在目录下查找2.如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件。2.库文件包含#include <stdio.h>1查找方法:查找头文件直接去标准路径下去查找,如果找不到就提示编译错误。这样是不是可以说,对于库文件也可以使用 “” 的形式包含?答案是肯定的,可以。但是这样做查找的效率就低些,当然这样也不容易区分是库文件还是本地文件了。3.嵌套文件包含有时候会重复包含头文件,以前为了解决这个方法,人们用了条件编译。代码如下每个头文件的开头写:例如有个test.h的头文件。用下划线分开头文件。全大写。#ifndef __TEST_H__#define __TEST_H__//这里面写头文件的内容#endif 上面这种写法比较古老。现在一般用这个写法#pragma once#pragma once也是是用来防止头文件被包含的。原文链接:https://blog.csdn.net/qq2466200050/article/details/124615042
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签