

-
 MindX SDK -- SRflow图像超分辨参考设计案例1 案例概述1.1 概要描述https://gitee.com/ascend/mindxsdk-referenceapps/tree/master/contrib/SRflowSRflow图像超分项目是基于MindX SDK 2.0.4 mxVision开发图像超分辨率程序,使用昇腾310芯片进行推理。输入为宽和高均小于等于256的低分辨率图像,经过SRflow模型的推理以及后处理,输出高分辨率图像。1.2 特性及适用场景适用于噪声比较小的输入图像1.3 模型介绍这个案例使用的模型是直接在Ascend,model zoo上面下载的,点击此处下载相应的SRflow模型。可以直接下载模型软件包,使用软件包目录下srflow_df2k_x8_bs1.om进行推理。SRFlow是一种基于归一化流的超分辨率方法,具备比 GAN 更强的脑补能力,能够基于低分辨率输入学习到输出的条件分布。模型相关信息:输入输出数据输入数据输入数据大小数据类型数据排布格式inputbatchsize x 3 x 256 x 256RGB_FP32NCHW输出数据输出数据大小数据类型数据排布格式output_1batchsize x 3 x 2048 x 2048FP32ND1.4 实现流程案例主要流程介绍:程序首先对输入图片进行padding、归一化、转置等前处理操作,将其转化为适合模型输入的shape为(3,256,256)的向量;然后将该向量转化为mxVision可以处理的元数据形式发送到pipline。利用图像超分辨率模型SRflow获取得到图片超分辨率重建结果,该结果为一shape为(3,2048,2048)的向量。最后,后处理得到2048 * 2048的高分辨图像。将该图像由padding输入得到的部分切割除去,就可以得到正确的输出。技术流程图: 2 软件方案介绍2.1 项目方案架构介绍表1.1 系统方案各子系统功能描述:序号子系统功能描述1前处理将输入图片转化为模型的输入tensor2推理使用SRflow模型进行推理3后处理将输出数据转化为高分辨图像3 开发环境准备3.1 环境依赖说明可列出项目所用的硬件平台、支持的硬件平台、访问方式等:本产品以昇腾310(推理)卡为硬件平台。列出环境依赖软件和版本。(支持的SDK版本、涉及第三方软件依赖等):软件名称版本说明获取方式MindX SDK2.0.4mxVision软件包链接ubuntu18.04操作系统请上ubuntu官网获取Ascend-CANN-toolkit5.0.4Ascend-cann-toolkit开发套件包链接4 编译与运行4.1 关于输出图像以及精度验证的说明 作为图像超分项目,一般要验证该程序的精度与性能,步骤如下:首先找到一张分辨率较高的图片,即hr图片,然后将其进行八倍或者四倍降采样,得到低分辨的、待处理的图片。将待处理的图片padding为256*256,然后输入模型,得到2048*2048的超分辨图像,再根据hr图片的大小进行裁剪,获得一张和hr图片大小相同的图片,最后测试PSNR值,获得图像质量评估。大部分验证集和本项目的测试便是采用了这种方法得到高分辨和低分辨的图片对。 然而,在实际应用中,一般是先有低分辨的图像,想要通过模型提高图像的分辨率。一开始手头不可能有现成的hr图像。假设现在有一张160*120的图像:在前处理时对其进行padding,使之符合模型256*256的标准输入:输入模型进行推理,得到模型标准输出,即为大小为2048*2048的超分辨图像:此时想要通过切割除去padding对应的超分辨部分,需要手动计算hr图像的大小。从256到2048,模型将图像大小放大8倍。而原图像为160*120,则hr图像长应该为160*8=1280,宽应为120*8=960。经过人工处理得到大小为1280*960的图像作为hr图像,切割可得预期图像:4.2 运行步骤步骤1在项目运行前,需要设置环境变量:. /usr/local/Ascend/ascend-toolkit/set_env.sh . ${SDK安装路径}/mxVision/set_env.sh注:其中SDK安装路径${MX_SDK_HOME}替换为用户的SDK安装路径。步骤2在链接处下载数据集dataset.zip,放在项目目录下。```unzip dataset.ziprm dataset.zip```将解压后的dataset文件目录下的div2k-validation-modcrop8-gt 文件夹和 div2k-validation-modcrop8-8x 文件夹放入本项目目录下的dataset文件夹中。步骤3在main.py和evaluate.py中配置 srflow_df2k_x8_bs1.om 模型路径"mxpi_tensorinfer0": { "props": { "dataSource": "appsrc0", "modelPath": "./model/srflow_df2k_x8_bs1.om" }, "factory": "mxpi_tensorinfer", "next": "appsink0" },步骤4选取一对八倍下采样前后的png格式图片作为样例(可直接使用div2k验证集中的图片对),将下采样后的图片和hr图片(低分辨图像对应的高分辨图像,即下采样前的图像)放入image文件夹中,将main.py中两个常数IMAGE和HRIMAGE分别改为低分辨和高分辨图像的路径。在本项目目录下,运行脚本:python3 main.py得到的结果为result.jpg , 在终端可以看到生成图像的PSNR值(这里使用div2k验证集中的0802.png作为样例):PSNR: 29.04 Infer finished.5 精度测试每处理一张图片,终端都会输出推理结果的PSNR值:Processing ./dataset/div2k-validation-modcrop8-x8/0825.png... I20220727 18:04:08.653025 17725 MxpiBufferManager.cpp:121] create host buffer and copy data, Memory size(0). PSNR: 20.62 Infer finished.在处理完100张图片的验证集后,可以获得平均PSNR值:22.93与使用源模型软件包benchmark 推理结果对比结果如下:验证集图片号原benchmark推理结果(PSNR)本项目实际结果(PSNR)0801.png21.4821.230802.png29.1229.040803.png31.8231.760804.png21.5921.730805.png21.8321.620806.png23.0523.560807.png16.0916.360808.png22.0122.560809.png23.4423.210810.png21.7621.170811.png21.5122.190812.png22.422.170813.png24.9924.880814.png23.5323.590815.png28.0727.740816.png25.4425.570817.png26.1325.900818.png23.0422.750819.png21.4121.140820.png18.1517.850821.png24.3723.830822.png22.9323.170823.png18.8920.640824.png23.2223.090825.png20.6220.080826.png19.7319.510827.png27.4227.660828.png15.7716.080829.png23.823.650830.png20.3919.890831.png23.9524.160832.png22.122.160833.png26.9326.710834.png20.7320.780835.png18.2218.300836.png19.8820.250837.png20.2920.270838.png29.8421.020839.png22.6422.560840.png22.3422.720841.png22.722.870842.png23.8723.770843.png35.5635.430844.png31.7335.970845.png18.2218.550846.png19.4919.440847.png2221.910848.png23.1123.320849.png16.0516.350850.png24.1524.010851.png23.6524.080852.png24.8925.280853.png26.3526.210854.png18.819.710855.png22.5922.910856.png18.8917.970857.png32.1132.200858.png22.4923.190859.png19.2719.520860.png16.4615.970861.png17.9618.060862.png28.5428.870863.png28.6228.480864.png22.7923.870865.png23.0323.090866.png20.0320.340867.png21.8821.980868.png27.0226.770869.png19.6619.720870.png21.7521.090871.png25.7625.300872.png19.6919.270873.png19.0719.040874.png2524.270875.png18.8719.220876.png18.3718.210877.png33.3133.190878.png24.8724.770879.png21.7821.830880.png23.1923.670881.png20.8920.910882.png29.128.730883.png19.3919.570884.png21.2421.080885.png18.8618.140886.png29.9229.670887.png19.620.250888.png24.5524.600889.png22.1821.890890.png21.3721.580891.png21.6321.560892.png23.0622.690893.png28.9128.970894.png24.8325.620895.png15.6914.990896.png31.2731.380897.png13.1215.060898.png27.5127.220899.png25.4225.450900.png21.1721.18平均PSNR:22.9422.93
MindX SDK -- SRflow图像超分辨参考设计案例1 案例概述1.1 概要描述https://gitee.com/ascend/mindxsdk-referenceapps/tree/master/contrib/SRflowSRflow图像超分项目是基于MindX SDK 2.0.4 mxVision开发图像超分辨率程序,使用昇腾310芯片进行推理。输入为宽和高均小于等于256的低分辨率图像,经过SRflow模型的推理以及后处理,输出高分辨率图像。1.2 特性及适用场景适用于噪声比较小的输入图像1.3 模型介绍这个案例使用的模型是直接在Ascend,model zoo上面下载的,点击此处下载相应的SRflow模型。可以直接下载模型软件包,使用软件包目录下srflow_df2k_x8_bs1.om进行推理。SRFlow是一种基于归一化流的超分辨率方法,具备比 GAN 更强的脑补能力,能够基于低分辨率输入学习到输出的条件分布。模型相关信息:输入输出数据输入数据输入数据大小数据类型数据排布格式inputbatchsize x 3 x 256 x 256RGB_FP32NCHW输出数据输出数据大小数据类型数据排布格式output_1batchsize x 3 x 2048 x 2048FP32ND1.4 实现流程案例主要流程介绍:程序首先对输入图片进行padding、归一化、转置等前处理操作,将其转化为适合模型输入的shape为(3,256,256)的向量;然后将该向量转化为mxVision可以处理的元数据形式发送到pipline。利用图像超分辨率模型SRflow获取得到图片超分辨率重建结果,该结果为一shape为(3,2048,2048)的向量。最后,后处理得到2048 * 2048的高分辨图像。将该图像由padding输入得到的部分切割除去,就可以得到正确的输出。技术流程图: 2 软件方案介绍2.1 项目方案架构介绍表1.1 系统方案各子系统功能描述:序号子系统功能描述1前处理将输入图片转化为模型的输入tensor2推理使用SRflow模型进行推理3后处理将输出数据转化为高分辨图像3 开发环境准备3.1 环境依赖说明可列出项目所用的硬件平台、支持的硬件平台、访问方式等:本产品以昇腾310(推理)卡为硬件平台。列出环境依赖软件和版本。(支持的SDK版本、涉及第三方软件依赖等):软件名称版本说明获取方式MindX SDK2.0.4mxVision软件包链接ubuntu18.04操作系统请上ubuntu官网获取Ascend-CANN-toolkit5.0.4Ascend-cann-toolkit开发套件包链接4 编译与运行4.1 关于输出图像以及精度验证的说明 作为图像超分项目,一般要验证该程序的精度与性能,步骤如下:首先找到一张分辨率较高的图片,即hr图片,然后将其进行八倍或者四倍降采样,得到低分辨的、待处理的图片。将待处理的图片padding为256*256,然后输入模型,得到2048*2048的超分辨图像,再根据hr图片的大小进行裁剪,获得一张和hr图片大小相同的图片,最后测试PSNR值,获得图像质量评估。大部分验证集和本项目的测试便是采用了这种方法得到高分辨和低分辨的图片对。 然而,在实际应用中,一般是先有低分辨的图像,想要通过模型提高图像的分辨率。一开始手头不可能有现成的hr图像。假设现在有一张160*120的图像:在前处理时对其进行padding,使之符合模型256*256的标准输入:输入模型进行推理,得到模型标准输出,即为大小为2048*2048的超分辨图像:此时想要通过切割除去padding对应的超分辨部分,需要手动计算hr图像的大小。从256到2048,模型将图像大小放大8倍。而原图像为160*120,则hr图像长应该为160*8=1280,宽应为120*8=960。经过人工处理得到大小为1280*960的图像作为hr图像,切割可得预期图像:4.2 运行步骤步骤1在项目运行前,需要设置环境变量:. /usr/local/Ascend/ascend-toolkit/set_env.sh . ${SDK安装路径}/mxVision/set_env.sh注:其中SDK安装路径${MX_SDK_HOME}替换为用户的SDK安装路径。步骤2在链接处下载数据集dataset.zip,放在项目目录下。```unzip dataset.ziprm dataset.zip```将解压后的dataset文件目录下的div2k-validation-modcrop8-gt 文件夹和 div2k-validation-modcrop8-8x 文件夹放入本项目目录下的dataset文件夹中。步骤3在main.py和evaluate.py中配置 srflow_df2k_x8_bs1.om 模型路径"mxpi_tensorinfer0": { "props": { "dataSource": "appsrc0", "modelPath": "./model/srflow_df2k_x8_bs1.om" }, "factory": "mxpi_tensorinfer", "next": "appsink0" },步骤4选取一对八倍下采样前后的png格式图片作为样例(可直接使用div2k验证集中的图片对),将下采样后的图片和hr图片(低分辨图像对应的高分辨图像,即下采样前的图像)放入image文件夹中,将main.py中两个常数IMAGE和HRIMAGE分别改为低分辨和高分辨图像的路径。在本项目目录下,运行脚本:python3 main.py得到的结果为result.jpg , 在终端可以看到生成图像的PSNR值(这里使用div2k验证集中的0802.png作为样例):PSNR: 29.04 Infer finished.5 精度测试每处理一张图片,终端都会输出推理结果的PSNR值:Processing ./dataset/div2k-validation-modcrop8-x8/0825.png... I20220727 18:04:08.653025 17725 MxpiBufferManager.cpp:121] create host buffer and copy data, Memory size(0). PSNR: 20.62 Infer finished.在处理完100张图片的验证集后,可以获得平均PSNR值:22.93与使用源模型软件包benchmark 推理结果对比结果如下:验证集图片号原benchmark推理结果(PSNR)本项目实际结果(PSNR)0801.png21.4821.230802.png29.1229.040803.png31.8231.760804.png21.5921.730805.png21.8321.620806.png23.0523.560807.png16.0916.360808.png22.0122.560809.png23.4423.210810.png21.7621.170811.png21.5122.190812.png22.422.170813.png24.9924.880814.png23.5323.590815.png28.0727.740816.png25.4425.570817.png26.1325.900818.png23.0422.750819.png21.4121.140820.png18.1517.850821.png24.3723.830822.png22.9323.170823.png18.8920.640824.png23.2223.090825.png20.6220.080826.png19.7319.510827.png27.4227.660828.png15.7716.080829.png23.823.650830.png20.3919.890831.png23.9524.160832.png22.122.160833.png26.9326.710834.png20.7320.780835.png18.2218.300836.png19.8820.250837.png20.2920.270838.png29.8421.020839.png22.6422.560840.png22.3422.720841.png22.722.870842.png23.8723.770843.png35.5635.430844.png31.7335.970845.png18.2218.550846.png19.4919.440847.png2221.910848.png23.1123.320849.png16.0516.350850.png24.1524.010851.png23.6524.080852.png24.8925.280853.png26.3526.210854.png18.819.710855.png22.5922.910856.png18.8917.970857.png32.1132.200858.png22.4923.190859.png19.2719.520860.png16.4615.970861.png17.9618.060862.png28.5428.870863.png28.6228.480864.png22.7923.870865.png23.0323.090866.png20.0320.340867.png21.8821.980868.png27.0226.770869.png19.6619.720870.png21.7521.090871.png25.7625.300872.png19.6919.270873.png19.0719.040874.png2524.270875.png18.8719.220876.png18.3718.210877.png33.3133.190878.png24.8724.770879.png21.7821.830880.png23.1923.670881.png20.8920.910882.png29.128.730883.png19.3919.570884.png21.2421.080885.png18.8618.140886.png29.9229.670887.png19.620.250888.png24.5524.600889.png22.1821.890890.png21.3721.580891.png21.6321.560892.png23.0622.690893.png28.9128.970894.png24.8325.620895.png15.6914.990896.png31.2731.380897.png13.1215.060898.png27.5127.220899.png25.4225.450900.png21.1721.18平均PSNR:22.9422.93 -
在 ascend 上可以申请内存的方式有好几种1. aclrtMalloc,2. aclrtMallocCache,3. acldvppMalloc,4. aclrtMallocHost,前 3 个都是在 device 上分配内存,但进行流媒体数据处理只能使用 acldvppMalloc 这个接口分配的内存。但像神经网络推理是可以使用 acldvppMalloc 分配的内存,但流媒体数据就不能使用 aclrtMalloc,aclrtMallocCache 分配的内存。都是 device 上的内存,为什么不互通呢?aclrtMalloc,aclrtMallocCache 这两个函数分配的内存,看文档的话是 CPU 是可以使用的。而且文档中分配的策略上是有提到说分页的策略的,有点想不明白 device 内存为什么要分页,device 里面也不像 操作系统,应该不需要切换进程,要内存换页这种操作啊?但是很多时候的操作是和图像有关,并不与神经网络的隐层有关,那不就无论如何,想要操作图像时都必需把图像拷贝吗?无论是拷贝到 host 还是 aclrtMalloc 申请的内存。
-
【操作步骤&问题现象】1、有可以参考的预处理和后处理文件吗我找不到2、我自己替换的时候修改了数据预处理的图片尺寸和图片的宽高通道数但是编译报错3、有没有其他方法可以将我训练好的模型直接移植在开发板或者MindStudio之中【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
1. 购买ECS云服务器2. 通过MobaXterm访问购买的云服务器3. 切换到HwHiAiUser用户4. 获取源码:命令行运行:git clone https://gitee.com/ascend/samples.git 可以看到目录中有samples文件夹5. 上传准备好的图像处理应用文件夹6. 编译应用:进入scrpts目录下:bash sample_build.sh同时测试图片已被下载到data路径下原图:分辨率为1024*6837. 运行应用bash sample_run.sh输出图片已保存到out/output路径下输出图片:分辨率为224*224
-
 【摘要】 该系列文章是讲解Python OpenCV图像处理知识,前期主要讲解图像入门、OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子、图像增强技术、图像分割等,后期结合深度学习研究图像识别、图像分类应用。本篇文章主要讲解Python调用OpenCV实现图像形态学转化,包括图像开运算、图像闭运算和梯度运算,基础性知识希望对您有所帮助。本文分享自华为云社区《[Python图像处理] 九.形态学之图像开运算、闭运算、梯度运算》,作者:eastmount。该系列文章是讲解Python OpenCV图像处理知识,前期主要讲解图像入门、OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子、图像增强技术、图像分割等,后期结合深度学习研究图像识别、图像分类应用。希望文章对您有所帮助,如果有不足之处,还请海涵~数学形态学(Mathematical morphology)是一门建立在格论和拓扑学基础之上的图像分析学科,是数学形态学图像处理的基本理论。其基本的运算包括:腐蚀和膨胀、开运算和闭运算、骨架抽取、极限腐蚀、击中击不中变换、形态学梯度、Top-hat变换、颗粒分析、流域变换等。本篇文章主要讲解Python调用OpenCV实现图像形态学转化,包括图像开运算、图像闭运算和梯度运算,基础性知识希望对您有所帮助。1.图像开运算2.图像闭运算3.图像梯度运算一. 图像开运算1.基本原理图像开运算是图像依次经过腐蚀、膨胀处理后的过程。图像被腐蚀后,去除了噪声,但是也压缩了图像;接着对腐蚀过的图像进行膨胀处理,可以去除噪声,并保留原有图像。如下图所示:开运算(img) = 膨胀( 腐蚀(img) ) 下图是hanshanbuleng博主提供的开运算效果图,推荐大家学习他的文章。https://blog.csdn.net/hanshanbuleng/article/details/806571482.函数原型图像开运算主要使用的函数morphologyEx,它是形态学扩展的一组函数,其参数cv2.MORPH_OPEN对应开运算。其原型如下:dst = cv2.morphologyEx(src, cv2.MORPH_OPEN, kernel)参数dst表示处理的结果,src表示原图像,cv2.MORPH_OPEN表示开运算,kernel表示卷积核。下图表示5*5的卷积核,可以采用函数 np.ones((5,5), np.uint8) 构建。运行结果如下图所示:3.代码实现完整代码如下所示:#encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test01.png', cv2.IMREAD_UNCHANGED) #设置卷积核 kernel = np.ones((5,5), np.uint8) #图像开运算 result = cv2.morphologyEx(src, cv2.MORPH_OPEN, kernel) #显示图像 cv2.imshow("src", src) cv2.imshow("result", result) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows()输出结果如下图所示,可以看到噪声已经被去除了。但是结果result中仍然有部分噪声,如果想去除更彻底将卷积设置为10*10的。kernel = np.ones((10,10), np.uint8)result = cv2.morphologyEx(src, cv2.MORPH_OPEN, kernel)二. 图像闭运算1.基本原理图像闭运算是图像依次经过膨胀、腐蚀处理后的过程。图像先膨胀,后腐蚀,它有助于关闭前景物体内部的小孔,或物体上的小黑点。如下图所示:闭运算(img) = 腐蚀( 膨胀(img) ) 下图是hanshanbuleng博主提供的开运算效果图,推荐大家学习他的文章。2.函数原型图像闭运算主要使用的函数morphologyEx,其原型如下:dst = cv2.morphologyEx(src, cv2.MORPH_CLOSE, kernel)参数dst表示处理的结果,src表示原图像, cv2.MORPH_CLOSE表示闭运算,kernel表示卷积核。下图表示5*5的卷积核,可以采用函数 np.ones((5,5), np.uint8) 构建。运行结果如下图所示:3.代码实现完整代码如下所示:#encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test03.png', cv2.IMREAD_UNCHANGED) #设置卷积核 kernel = np.ones((10,10), np.uint8) #图像闭运算 result = cv2.morphologyEx(src, cv2.MORPH_CLOSE, kernel) #显示图像 cv2.imshow("src", src) cv2.imshow("result", result) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows()输出结果如下图所示,可以看到中间的噪声去掉。三. 图像梯度运算1.基本原理图像梯度运算是膨胀图像减去腐蚀图像的结果,得到图像的轮廓,其中二值图像1表示白色点,0表示黑色点。如下图所示:梯度运算(img) = 膨胀(img) - 腐蚀(img) 2.函数原型图像梯度运算主要使用的函数morphologyEx,参数为cv2.MORPH_GRADIENT。其原型如下:dst = cv2.morphologyEx(src, cv2.MORPH_GRADIENT, kernel)参数dst表示处理的结果,src表示原图像, cv2.MORPH_GRADIENT表示梯度运算,kernel表示卷积核。5*5的卷积核可以采用函数 np.ones((5,5), np.uint8) 构建。运行结果如下图所示:3.代码实现完整代码如下所示:#encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test04.png', cv2.IMREAD_UNCHANGED) #设置卷积核 kernel = np.ones((10,10), np.uint8) #图像闭运算 result = cv2.morphologyEx(src, cv2.MORPH_GRADIENT, kernel) #显示图像 cv2.imshow("src", src) cv2.imshow("result", result) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows() 输出结果如下图所示,可以看到中间的噪声去掉。
【摘要】 该系列文章是讲解Python OpenCV图像处理知识,前期主要讲解图像入门、OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子、图像增强技术、图像分割等,后期结合深度学习研究图像识别、图像分类应用。本篇文章主要讲解Python调用OpenCV实现图像形态学转化,包括图像开运算、图像闭运算和梯度运算,基础性知识希望对您有所帮助。本文分享自华为云社区《[Python图像处理] 九.形态学之图像开运算、闭运算、梯度运算》,作者:eastmount。该系列文章是讲解Python OpenCV图像处理知识,前期主要讲解图像入门、OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子、图像增强技术、图像分割等,后期结合深度学习研究图像识别、图像分类应用。希望文章对您有所帮助,如果有不足之处,还请海涵~数学形态学(Mathematical morphology)是一门建立在格论和拓扑学基础之上的图像分析学科,是数学形态学图像处理的基本理论。其基本的运算包括:腐蚀和膨胀、开运算和闭运算、骨架抽取、极限腐蚀、击中击不中变换、形态学梯度、Top-hat变换、颗粒分析、流域变换等。本篇文章主要讲解Python调用OpenCV实现图像形态学转化,包括图像开运算、图像闭运算和梯度运算,基础性知识希望对您有所帮助。1.图像开运算2.图像闭运算3.图像梯度运算一. 图像开运算1.基本原理图像开运算是图像依次经过腐蚀、膨胀处理后的过程。图像被腐蚀后,去除了噪声,但是也压缩了图像;接着对腐蚀过的图像进行膨胀处理,可以去除噪声,并保留原有图像。如下图所示:开运算(img) = 膨胀( 腐蚀(img) ) 下图是hanshanbuleng博主提供的开运算效果图,推荐大家学习他的文章。https://blog.csdn.net/hanshanbuleng/article/details/806571482.函数原型图像开运算主要使用的函数morphologyEx,它是形态学扩展的一组函数,其参数cv2.MORPH_OPEN对应开运算。其原型如下:dst = cv2.morphologyEx(src, cv2.MORPH_OPEN, kernel)参数dst表示处理的结果,src表示原图像,cv2.MORPH_OPEN表示开运算,kernel表示卷积核。下图表示5*5的卷积核,可以采用函数 np.ones((5,5), np.uint8) 构建。运行结果如下图所示:3.代码实现完整代码如下所示:#encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test01.png', cv2.IMREAD_UNCHANGED) #设置卷积核 kernel = np.ones((5,5), np.uint8) #图像开运算 result = cv2.morphologyEx(src, cv2.MORPH_OPEN, kernel) #显示图像 cv2.imshow("src", src) cv2.imshow("result", result) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows()输出结果如下图所示,可以看到噪声已经被去除了。但是结果result中仍然有部分噪声,如果想去除更彻底将卷积设置为10*10的。kernel = np.ones((10,10), np.uint8)result = cv2.morphologyEx(src, cv2.MORPH_OPEN, kernel)二. 图像闭运算1.基本原理图像闭运算是图像依次经过膨胀、腐蚀处理后的过程。图像先膨胀,后腐蚀,它有助于关闭前景物体内部的小孔,或物体上的小黑点。如下图所示:闭运算(img) = 腐蚀( 膨胀(img) ) 下图是hanshanbuleng博主提供的开运算效果图,推荐大家学习他的文章。2.函数原型图像闭运算主要使用的函数morphologyEx,其原型如下:dst = cv2.morphologyEx(src, cv2.MORPH_CLOSE, kernel)参数dst表示处理的结果,src表示原图像, cv2.MORPH_CLOSE表示闭运算,kernel表示卷积核。下图表示5*5的卷积核,可以采用函数 np.ones((5,5), np.uint8) 构建。运行结果如下图所示:3.代码实现完整代码如下所示:#encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test03.png', cv2.IMREAD_UNCHANGED) #设置卷积核 kernel = np.ones((10,10), np.uint8) #图像闭运算 result = cv2.morphologyEx(src, cv2.MORPH_CLOSE, kernel) #显示图像 cv2.imshow("src", src) cv2.imshow("result", result) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows()输出结果如下图所示,可以看到中间的噪声去掉。三. 图像梯度运算1.基本原理图像梯度运算是膨胀图像减去腐蚀图像的结果,得到图像的轮廓,其中二值图像1表示白色点,0表示黑色点。如下图所示:梯度运算(img) = 膨胀(img) - 腐蚀(img) 2.函数原型图像梯度运算主要使用的函数morphologyEx,参数为cv2.MORPH_GRADIENT。其原型如下:dst = cv2.morphologyEx(src, cv2.MORPH_GRADIENT, kernel)参数dst表示处理的结果,src表示原图像, cv2.MORPH_GRADIENT表示梯度运算,kernel表示卷积核。5*5的卷积核可以采用函数 np.ones((5,5), np.uint8) 构建。运行结果如下图所示:3.代码实现完整代码如下所示:#encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test04.png', cv2.IMREAD_UNCHANGED) #设置卷积核 kernel = np.ones((10,10), np.uint8) #图像闭运算 result = cv2.morphologyEx(src, cv2.MORPH_GRADIENT, kernel) #显示图像 cv2.imshow("src", src) cv2.imshow("result", result) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows() 输出结果如下图所示,可以看到中间的噪声去掉。 -
【功能模块】AIPP,DVPP【操作步骤&问题现象】1、yolo 模型转换到Atlas200后推理精度下降。使用了DVPP+AIPP2、根据这个链接:模型推理精度下降_昇腾CANN社区版(5.1.RC1.alpha001)_故障处理_常见故障案例集(310)_AscendCL常见故障_数据预处理常见问题_华为云 (huaweicloud.com)提到 :建议使用“DVPP JPEG解码+VPC缩放+AIPP色域转换”获取RGB图片,再对已有模型进行增量训练或者重新全量训练,得到新的模型用于推理。具体方法请咨询华为工程师。AIPP是植入到模型转换时预处理的。请教,如何通过代码获取AIPP转换后的RGB图片?或者如何保存AIPP操作后输出的RGB图片?【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
 今天因大师给大家分享一套迅速有效诊断空气压缩机故障的方法。1 通过电流表判断空气压缩机满负荷运行时,正常电流为310~330A。当空气压缩机电流小于300A时,主要原因是由一级吸排气阀漏气、一级活塞环磨损和空气滤清器滤网堵塞造成的。当空气压缩机电流大于340A时,主要原因是二级吸气阀漏气、储气罐压力过高和二级活塞环磨损造成的。2 通过温度计判断常温下空气压缩机正常运行时,一级吸气阀阀盖温度为35~45℃,一级排气阀阀盖温度为95~110℃;二级进气温度为32~36℃,二级排气阀阀盖温度为110~130℃,二级吸气阀阀盖温度为35~45℃,油温为25~30℃。一级排气阀阀盖温度高于110℃,原因是一级排气阀漏气,用非接触测温仪查找能准确查找出损坏的排气阀。一级吸气阀阀盖温度高于45℃,原因是一级吸气阀漏气。二级进气温度大于40℃,主要原因是中间冷却器冷却水量不够、中间冷却器内部结垢严重或中间冷却器风道短路。二级排气阀阀盖温度高于130℃,主要原因是二级排气阀漏气或二级进气温度过高。二级吸气阀阀盖温度高于45℃,主要原因是二级吸气阀漏气。油温高于35℃,主要原因是油冷却器冷却水量不够或油冷却器管内结垢严重。3 通过压力表判断空气压缩机在全做功和半做功时,正常一级排气压力在0.18~0.22MPa。油压为0.15~0.3MPa。空气压缩机在全做功时,一级排气压力高于0.23MPa,原因是二级吸排气阀漏气或二级活塞环磨损较大;一级排气压力低于0.17MPa,原因是一级吸排气阀漏气、空气滤清器滤网堵塞或一级活塞环磨损。全做功时一级排气压力正常,半做功时一级排气压力升高,原因是一级吸气阀顶开装置间隙过大;而半做功时一级排气压力降低,原因是二级吸气阀顶开装置间隙过大。油压低于0.1MPa,原因是润滑油量不够、油滤网堵塞严重或油泵故障。4 空气压缩机运行中吸排气阀故障的判断主要讨论常温下的情况。空气压缩机最常见的故障是吸排气阀的损坏,主要是阀弹簧或阀片因磨损、疲劳断裂或变形;阀片与阀座密封面不平整或吸入空气不洁引起密封面结垢。空气压缩机运行正常时,吸气阀阀盖温度为35~45℃,排气阀阀盖温度为95~110℃。用便携式非接触测温仪对吸排气阀阀盖测温,吸气阀阀盖温度超过45℃或排气阀阀盖温度超过110℃,说明气阀已有轻微漏气。吸气阀阀盖温度超过55℃或排气阀阀盖温度超过130℃,说明气阀已严重漏气。5 空气压缩机停运后二级排气阀故障的判断拆除一个二级排气阀,再微开排气管道控制阀门,让储气罐压缩空气倒回,可以直接用手触摸判断出漏气的排气阀。使用以上故障诊断方法,不仅有效缩短了维修时间,而且减轻了维修工的劳动强度,值得使用同类机型空压机的企业借鉴。
今天因大师给大家分享一套迅速有效诊断空气压缩机故障的方法。1 通过电流表判断空气压缩机满负荷运行时,正常电流为310~330A。当空气压缩机电流小于300A时,主要原因是由一级吸排气阀漏气、一级活塞环磨损和空气滤清器滤网堵塞造成的。当空气压缩机电流大于340A时,主要原因是二级吸气阀漏气、储气罐压力过高和二级活塞环磨损造成的。2 通过温度计判断常温下空气压缩机正常运行时,一级吸气阀阀盖温度为35~45℃,一级排气阀阀盖温度为95~110℃;二级进气温度为32~36℃,二级排气阀阀盖温度为110~130℃,二级吸气阀阀盖温度为35~45℃,油温为25~30℃。一级排气阀阀盖温度高于110℃,原因是一级排气阀漏气,用非接触测温仪查找能准确查找出损坏的排气阀。一级吸气阀阀盖温度高于45℃,原因是一级吸气阀漏气。二级进气温度大于40℃,主要原因是中间冷却器冷却水量不够、中间冷却器内部结垢严重或中间冷却器风道短路。二级排气阀阀盖温度高于130℃,主要原因是二级排气阀漏气或二级进气温度过高。二级吸气阀阀盖温度高于45℃,主要原因是二级吸气阀漏气。油温高于35℃,主要原因是油冷却器冷却水量不够或油冷却器管内结垢严重。3 通过压力表判断空气压缩机在全做功和半做功时,正常一级排气压力在0.18~0.22MPa。油压为0.15~0.3MPa。空气压缩机在全做功时,一级排气压力高于0.23MPa,原因是二级吸排气阀漏气或二级活塞环磨损较大;一级排气压力低于0.17MPa,原因是一级吸排气阀漏气、空气滤清器滤网堵塞或一级活塞环磨损。全做功时一级排气压力正常,半做功时一级排气压力升高,原因是一级吸气阀顶开装置间隙过大;而半做功时一级排气压力降低,原因是二级吸气阀顶开装置间隙过大。油压低于0.1MPa,原因是润滑油量不够、油滤网堵塞严重或油泵故障。4 空气压缩机运行中吸排气阀故障的判断主要讨论常温下的情况。空气压缩机最常见的故障是吸排气阀的损坏,主要是阀弹簧或阀片因磨损、疲劳断裂或变形;阀片与阀座密封面不平整或吸入空气不洁引起密封面结垢。空气压缩机运行正常时,吸气阀阀盖温度为35~45℃,排气阀阀盖温度为95~110℃。用便携式非接触测温仪对吸排气阀阀盖测温,吸气阀阀盖温度超过45℃或排气阀阀盖温度超过110℃,说明气阀已有轻微漏气。吸气阀阀盖温度超过55℃或排气阀阀盖温度超过130℃,说明气阀已严重漏气。5 空气压缩机停运后二级排气阀故障的判断拆除一个二级排气阀,再微开排气管道控制阀门,让储气罐压缩空气倒回,可以直接用手触摸判断出漏气的排气阀。使用以上故障诊断方法,不仅有效缩短了维修时间,而且减轻了维修工的劳动强度,值得使用同类机型空压机的企业借鉴。 -
应用RPA读防疫码后,写Excel,刚开始大概10分钟60个图片,但后面越来越卡,越来越少,有没有好的解决方式?图片 识别 这个控件 访问服务器 有无做限制了的?共计几百的图片后面直接不下去了
-
【摘要】 该系列文章是讲解Python OpenCV图像处理知识,前期主要讲解图像入门、OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子、图像增强技术、图像分割等,后期结合深度学习研究图像识别、图像分类应用。本篇文章主要讲解Python调用OpenCV实现图像腐蚀和图像膨胀的算法,基础性知识希望对您有所帮助。本文分享自华为云社区《[Python图像处理] 八.图像腐蚀与图像膨胀》,作者: eastmount 。本篇文章主要讲解Python调用OpenCV实现图像腐蚀和图像膨胀的算法,基础性知识希望对您有所帮助。1.基础理论2.图像腐蚀代码实现3.图像膨胀代码实现一. 基础知识(注:该部分参考作者论文《一种改进的Sobel算子及区域择优的身份证智能识别方法》)图像的膨胀(Dilation)和腐蚀(Erosion)是两种基本的形态学运算,主要用来寻找图像中的极大区域和极小区域。其中膨胀类似于“领域扩张”,将图像中的高亮区域或白色部分进行扩张,其运行结果图比原图的高亮区域更大;腐蚀类似于“领域被蚕食”,将图像中的高亮区域或白色部分进行缩减细化,其运行结果图比原图的高亮区域更小。1.图像膨胀膨胀的运算符是“⊕”,其定义如下:该公式表示用B来对图像A进行膨胀处理,其中B是一个卷积模板或卷积核,其形状可以为正方形或圆形,通过模板B与图像A进行卷积计算,扫描图像中的每一个像素点,用模板元素与二值图像元素做“与”运算,如果都为0,那么目标像素点为0,否则为1。从而计算B覆盖区域的像素点最大值,并用该值替换参考点的像素值实现膨胀。下图是将左边的原始图像A膨胀处理为右边的效果图A⊕B。处理结果如下图所示:2.图像腐蚀腐蚀的运算符是“-”,其定义如下:该公式表示图像A用卷积模板B来进行腐蚀处理,通过模板B与图像A进行卷积计算,得出B覆盖区域的像素点最小值,并用这个最小值来替代参考点的像素值。如图所示,将左边的原始图像A腐蚀处理为右边的效果图A-B。处理结果如下图所示:二. 图像腐蚀代码实现1.基础理论形态学转换主要针对的是二值图像(0或1)。图像腐蚀类似于“领域被蚕食”,将图像中的高亮区域或白色部分进行缩减细化,其运行结果图比原图的高亮区域更小。其主要包括两个输入对象:(1)二值图像(2)卷积核卷积核是腐蚀中的关键数组,采用numpy库可以生成。卷积核的中心点逐个像素扫描原始图像,如下图所示:被扫描到的原始图像中的像素点,只有当卷积核对应的元素值均为1时,其值才为1,否则其值修改为0。换句话说,遍历到的黄色点位置,其周围全部是白色,保留白色,否则变为黑色,图像腐蚀变小。2.函数原型图像腐蚀主要使用的函数为erode,其原型如下:dst = cv2.erode(src, kernel, iterations)参数dst表示处理的结果,src表示原图像,kernel表示卷积核,iterations表示迭代次数。下图表示5*5的卷积核,可以采用函数 np.ones((5,5), np.uint8) 构建。注意:迭代次数默认是1,表示进行一次腐蚀,也可以根据需要进行多次迭代,进行多次腐蚀。3.代码实现完整代码如下所示:#encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test01.jpg', cv2.IMREAD_UNCHANGED) #设置卷积核 kernel = np.ones((5,5), np.uint8) #图像腐蚀处理 erosion = cv2.erode(src, kernel) #显示图像 cv2.imshow("src", src) cv2.imshow("result", erosion) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows()输出结果如下图所示:由图可见,干扰的细线被进行了清洗,但仍然有些轮廓,此时可设置迭代次数进行腐蚀。erosion = cv2.erode(src, kernel,iterations=9)输出结果如下图所示:三. 图像膨胀代码实现1.基础理论图像膨胀是腐蚀操作的逆操作,类似于“领域扩张”,将图像中的高亮区域或白色部分进行扩张,其运行结果图比原图的高亮区域更大,线条变粗了,主要用于去噪。(1) 图像被腐蚀后,去除了噪声,但是会压缩图像。(2) 对腐蚀过的图像,进行膨胀处理,可以去除噪声,并且保持原有形状。它也包括两个输入对象:(1)二值图像或原始图像(2)卷积核卷积核是腐蚀中的关键数组,采用numpy库可以生成。卷积核的中心点逐个像素扫描原始图像,如下图所示:被扫描到的原始图像中的像素点,当卷积核对应的元素值只要有一个为1时,其值就为1,否则为0。2.函数原型图像膨胀主要使用的函数为dilate,其原型如下:dst = cv2.dilate(src, kernel, iterations)参数dst表示处理的结果,src表示原图像,kernel表示卷积核,iterations表示迭代次数。下图表示5*5的卷积核,可以采用函数 np.ones((5,5), np.uint8) 构建。注意:迭代次数默认是1,表示进行一次膨胀,也可以根据需要进行多次迭代,进行多次膨胀。通常进行1次膨胀即可。3.代码实现完整代码如下所示:#encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test02.png', cv2.IMREAD_UNCHANGED) #设置卷积核 kernel = np.ones((5,5), np.uint8) #图像膨胀处理 erosion = cv2.dilate(src, kernel) #显示图像 cv2.imshow("src", src) cv2.imshow("result", erosion) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows()输出结果如下所示:图像去噪通常需要先腐蚀后膨胀,这又称为开运算,下篇文章将详细介绍。如下图所示:erosion = cv2.erode(src, kernel)result = cv2.dilate(erosion, kernel)
-
【功能模块】Minddata使用lite_cv需要导入Minddata库,但是Minddata依赖的libjpeg和libturbojpeg不知道如何导入。【操作步骤&问题现象】1、导入Minddata后make项目提示需要libjpeg和libturbojpeg。2、尝试导入third_party中的libjpeg和libturbojpeg库文件,但是试了很多方法都导入不了。【截图信息】CMakeLists:【日志信息】(可选,上传日志内容或者附件)
-
>摘要:本篇文章主要讲解Python调用OpenCV实现图像阈值化处理操作,包括二进制阈值化、反二进制阈值化、截断阈值化、反阈值化为0、阈值化为0。 本文分享自华为云社区《[[Python图像处理] 七.图像阈值化处理及算法对比](https://bbs.huaweicloud.com/blogs/293565?utm_source=csdn&utm_medium=bbs-ex&utm_campaign=other&utm_content=content) 》,作者: eastmount 。 # 一. 阈值化 (注:该部分参考作者的论文《基于苗族服饰的图像锐化和边缘提取技术研究》) 图像的二值化或阈值化(Binarization)旨在提取图像中的目标物体,将背景以及噪声区分开来。通常会设定一个阈值T,通过T将图像的像素划分为两类:大于T的像素群和小于T的像素群。 灰度转换处理后的图像中,每个像素都只有一个灰度值,其大小表示明暗程度。二值化处理可以将图像中的像素划分为两类颜色,常用的二值化算法如公式1所示: 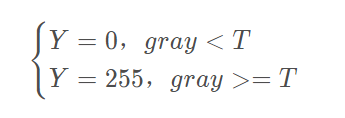 当灰度Gray小于阈值T时,其像素设置为0,表示黑色;当灰度Gray大于或等于阈值T时,其Y值为255,表示白色。 Python OpenCV中提供了阈值函数threshold()实现二值化处理,其公式及参数如下图所示: retval, dst = cv2.threshold(src, thresh, maxval, type)  常用的方法如下表所示,其中函数中的参数Gray表示灰度图,参数127表示对像素值进行分类的阈值,参数255表示像素值高于阈值时应该被赋予的新像素值,最后一个参数对应不同的阈值处理方法。 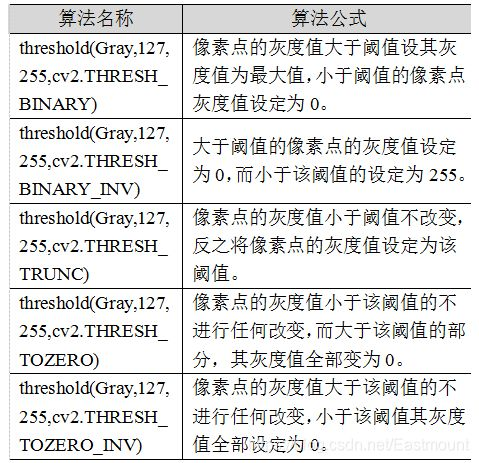 对应OpenCV提供的五张图如下所示,第一张为原图,后面依次为:二进制阈值化、反二进制阈值化、截断阈值化、反阈值化为0、阈值化为0。 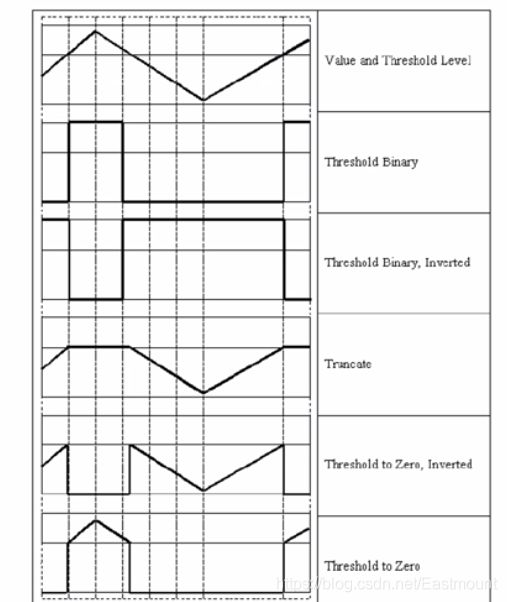 二值化处理广泛应用于各行各业,比如生物学中的细胞图分割、交通领域的车牌设别等。在文化应用领域中,通过二值化处理将所需民族文物图像转换为黑白两色图,从而为后面的图像识别提供更好的支撑作用。下图表示图像经过各种二值化处理算法后的结果,其中“BINARY”是最常见的黑白两色处理。  # 二. 二进制阈值化 该方法先要选定一个特定的阈值量,比如127。新的阈值产生规则如下: 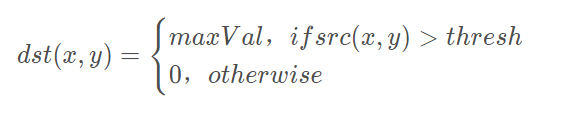 (1) 大于等于127的像素点的灰度值设定为最大值(如8位灰度值最大为255) (2) 灰度值小于127的像素点的灰度值设定为0 例如,163->255,86->0,102->0,201->255。 关键字为 cv2.THRESH_BINARY,完整代码如下: ``` #encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test.jpg') #灰度图像处理 GrayImage = cv2.cvtColor(src,cv2.COLOR_BGR2GRAY) #二进制阈值化处理 r, b = cv2.threshold(GrayImage, 127, 255, cv2.THRESH_BINARY) print r #显示图像 cv2.imshow("src", src) cv2.imshow("result", b) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows() ``` 输出为两个返回值,r为127,b为处理结果(大于127设置为255,小于设置为0)。如下图所示:  # 三. 反二进制阈值化 该方法与二进制阈值化方法相似,先要选定一个特定的灰度值作为阈值,比如127。新的阈值产生规则如下: 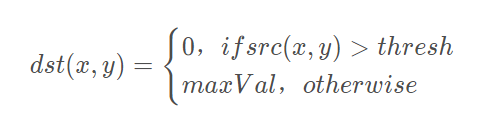 (1) 大于127的像素点的灰度值设定为0(以8位灰度图为例) (2) 小于该阈值的灰度值设定为255 例如,163->0,86->255,102->255,201->0。 关键字为 cv2.THRESH_BINARY_INV,完整代码如下: ``` #encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test.jpg') #灰度图像处理 GrayImage = cv2.cvtColor(src,cv2.COLOR_BGR2GRAY) #反二进制阈值化处理 r, b = cv2.threshold(GrayImage, 127, 255, cv2.THRESH_BINARY_INV) print r #显示图像 cv2.imshow("src", src) cv2.imshow("result", b) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows() ``` 输出结果如下图所示: 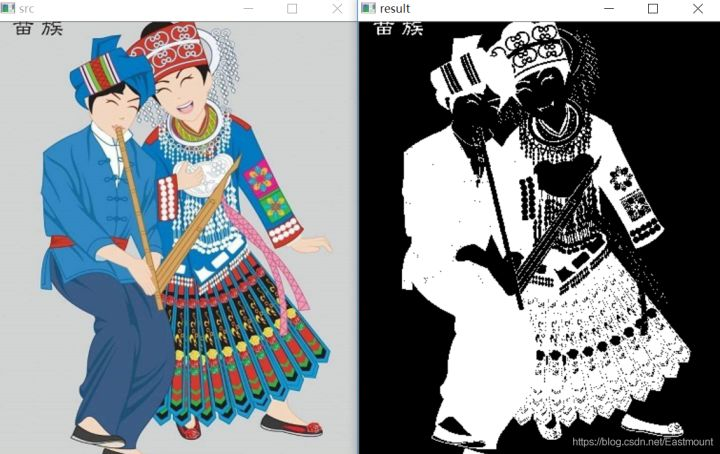 该方法得到的结果正好与二进制阈值化方法相反,亮色元素反而处理为黑色,暗色处理为白色。 # 四. 截断阈值化 该方法需要选定一个阈值,图像中大于该阈值的像素点被设定为该阈值,小于该阈值的保持不变,比如127。新的阈值产生规则如下: 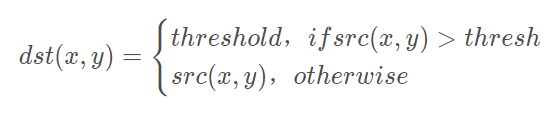 (1) 大于等于127的像素点的灰度值设定为该阈值127 (2) 小于该阈值的灰度值不改变 例如,163->127,86->86,102->102,201->127。 关键字为 cv2.THRESH_TRUNC,完整代码如下: ``` #encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test.jpg') #灰度图像处理 GrayImage = cv2.cvtColor(src,cv2.COLOR_BGR2GRAY) #截断阈值化处理 r, b = cv2.threshold(GrayImage, 127, 255, cv2.THRESH_TRUNC) print r #显示图像 cv2.imshow("src", src) cv2.imshow("result", b) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows() ``` 输出结果如下图所示: 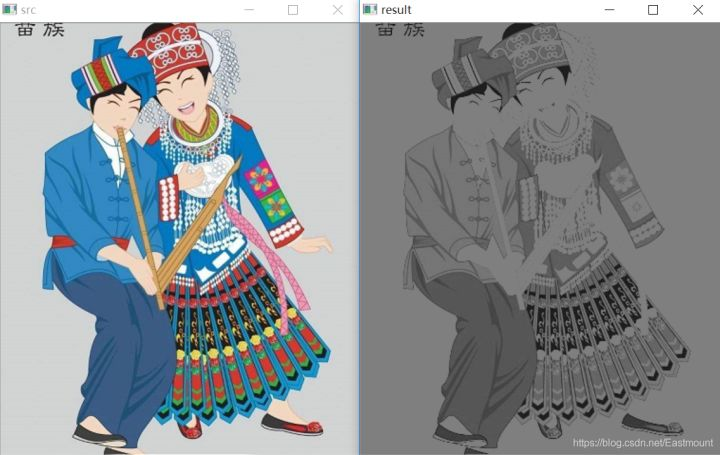 该处理方法相当于把图像中比较亮(大于127,偏向于白色)的像素值处理为阈值。 # 五. 反阈值化为0 该方法先选定一个阈值,比如127,接着对图像的灰度值进行如下处理: 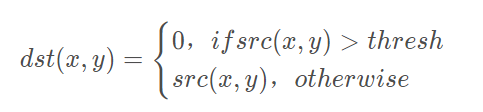 (1) 大于等于阈值127的像素点变为0 (2) 小于该阈值的像素点值保持不变 例如,163->0,86->86,102->102,201->0。 关键字为 cv2.THRESH_TOZERO_INV,完整代码如下: ``` #encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test.jpg') #灰度图像处理 GrayImage = cv2.cvtColor(src,cv2.COLOR_BGR2GRAY) #反阈值化为0处理 r, b = cv2.threshold(GrayImage, 127, 255, cv2.THRESH_TOZERO_INV) print r #显示图像 cv2.imshow("src", src) cv2.imshow("result", b) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows() ``` 输出结果如下图所示: 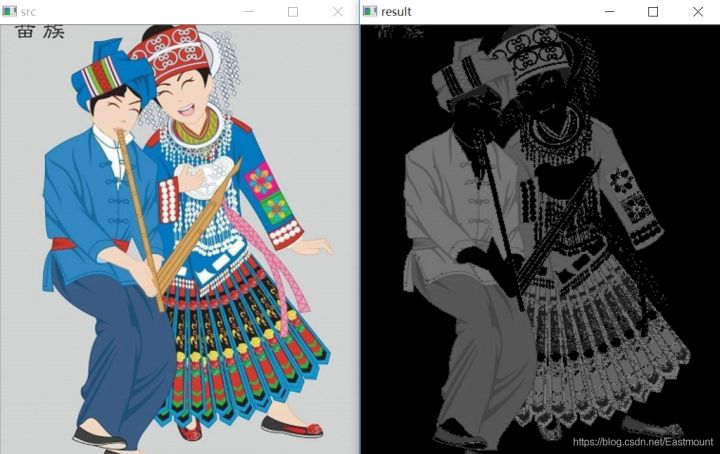 # 六. 阈值化为0 该方法先选定一个阈值,比如127,接着对图像的灰度值进行如下处理: 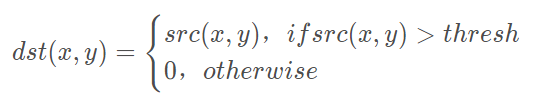 (1) 大于等于阈值127的像素点,值保持不变 (2) 小于该阈值的像素点值设置为0 例如,163->163,86->0,102->0,201->201。 关键字为 cv2.THRESH_TOZERO,完整代码如下: ``` #encoding:utf-8 import cv2 import numpy as np #读取图片 src = cv2.imread('test.jpg') #灰度图像处理 GrayImage = cv2.cvtColor(src,cv2.COLOR_BGR2GRAY) #阈值化为0处理 r, b = cv2.threshold(GrayImage, 127, 255, cv2.THRESH_TOZERO) print r #显示图像 cv2.imshow("src", src) cv2.imshow("result", b) #等待显示 cv2.waitKey(0) cv2.destroyAllWindows() ``` 输出结果如下图所示: 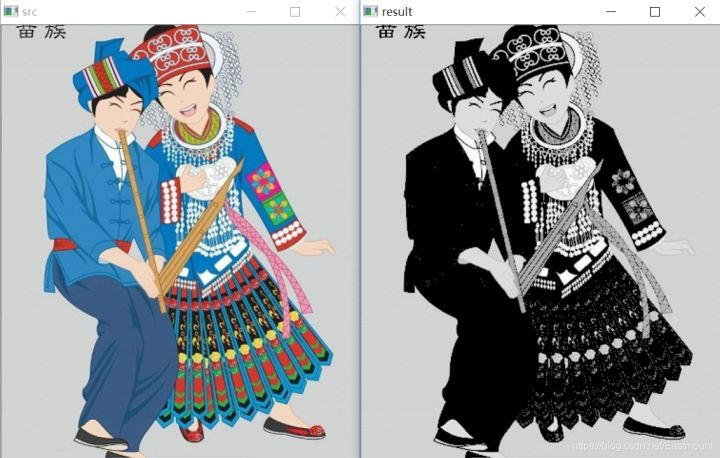 该算法把比较亮的部分不变,比较暗的部分处理为0。 完整五个算法的对比代码如下所示: ``` #encoding:utf-8 import cv2 import numpy as np import matplotlib.pyplot as plt #读取图像 img=cv2.imread('test.jpg') lenna_img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB) GrayImage=cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #阈值化处理 ret,thresh1=cv2.threshold(GrayImage,127,255,cv2.THRESH_BINARY) ret,thresh2=cv2.threshold(GrayImage,127,255,cv2.THRESH_BINARY_INV) ret,thresh3=cv2.threshold(GrayImage,127,255,cv2.THRESH_TRUNC) ret,thresh4=cv2.threshold(GrayImage,127,255,cv2.THRESH_TOZERO) ret,thresh5=cv2.threshold(GrayImage,127,255,cv2.THRESH_TOZERO_INV) #显示结果 titles = ['Gray Image','BINARY','BINARY_INV','TRUNC','TOZERO','TOZERO_INV'] images = [GrayImage, thresh1, thresh2, thresh3, thresh4, thresh5] for i in xrange(6): plt.subplot(2,3,i+1),plt.imshow(images[i],'gray') plt.title(titles[i]) plt.xticks([]),plt.yticks([]) plt.show() ``` 输出结果如下图所示: 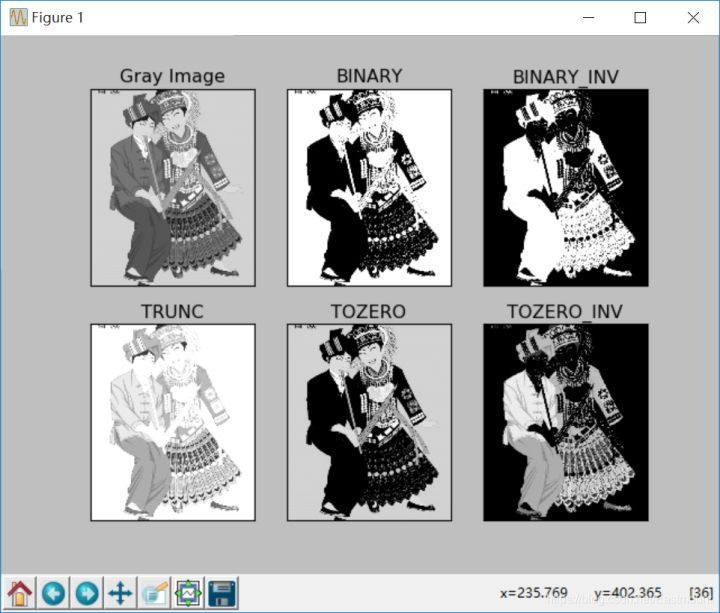 本文摘录自eastmount X华为云开发者社区联合出品的电子书《从零到一 • Python图像处理及识别》。
-
【功能模块】还想请教一下,大佬们有没有成功的案例可以参考学习。【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
 文章来源于当交通遇上机器学习 ,作者CY1.文章信息论文链接:https://www.mdpi.com/2071-1050/14/9/4930/htm2.摘要针对森林火灾图像中小目标、类火目标和类烟目标的检测,以及不同自然光下的火灾检测,提出了一种改进的Fire-YOLO深度学习算法。Fire-YOLO检测模型从三维扩展了特征提取网络,增强了火灾小目标识别的特征传播,提高了网络性能,减少了模型参数。进一步,通过特征金字塔的提升,得到了性能最好的预测框。与最先进的目标检测网络相比,Fire-YOLO取得了优异的结果,尤其是在火灾和烟雾的小目标检测方面。总体而言,Fire-YOLO检测模型可以有效地处理小火源目标、类火和类烟目标的检测。当输入图像尺寸为416 × 416分辨率时,平均检测时间为0.04 s /帧,可以提供实时的森林火灾检测。此外,文章提出的算法也可以应用于其他复杂情况下的小目标检测。3.简介火灾探测对于保护森林资源、保护人民生命财产至关重要。近年来,随着火灾图像探测成为研究热点,图像探测具有探测时间早、精度高、系统安装灵活、能有效探测大空间复杂建筑结构火灾等优点。一类方法基于火灾发生时的颜色识别,但基于颜色的方法对亮度和阴影非常敏感。因此,这些方法产生的假警报数量很高。随着机器学习的发展,深度学习技术已广泛应用于检测。有学者提出了一种使用微调卷积神经网络(CNN)的早期火灾探测框架,但该模型具有较高的计算成本。有的学者使用深度融合CNN进行烟雾探测,它结合了注意机制、特征级和决策级融合模块。然而,仍有一些小目标未能实现。有的学者使用了一种基于区域的快速卷积神经网络(R-CNN),根据空间特征检测可疑火灾区域(SRoF)和非火灾区域。这可以通过减少错误探测成功地提高火灾探测精度,但探测速度相对较慢。有的学者提出了一种基于YOLO-V3和YOLO-V4的森林烟雾检测算法。与YOLO-V4相比,YOLO-V3的模型更小,更易于部署。在此基础上,文章选择了YOLO-V3模型作为整体算法,并对其进行了改进。提出了对YOLO-V3算法的改进。网络中加入了空心卷积和DenseNet,提高了火灾早期小规模火焰的探测效果。然而,方法存在火焰定位不准确和屏蔽性能差的问题。I-YOLOv3-tiny模型通过网络结构优化、多尺度融合和K-均值聚类来提高检测精度,但检测速度有待提高。通过提高特征图的分辨率,它减少了火灾探测中的误差,但由于计算量的增加,相应的处理时间也增加了。将分类模型和目标检测模型结合用于火灾探测的方法降低了计算成本,提高了探测精度。尽管如此,它不适用于火灾早期小目标的探测场景。有的学者通过将原始网络结构中的两步降采样卷积网络替换为图像双分割和双线性上采样网络,扩大了小目标的特征,提高了小目标的检测精度。虽然这会增加参数的数量,但计算成本也会增加。对于具有实时性要求的火灾探测,仍需进一步改进。这些问题给火灾场景中小目标的检测带来了巨大的挑战。4.模型A. YOLO-V3YOLO- v3是由YOLO和YOLOV2网络演化而来的对象检测模型。与Faster R-CNN相比,YOLO- v3是单级检测算法,这意味着YOLO网络不需要Regional Proposal network (RPN),而是直接检测图像中的目标。这样既考虑了检测速度和检测精度,又减小了模型参数的尺寸。YOLO-V3对每个类别独立使用逻辑回归,取代了DarkENT-19到DarkENT-53的特征提取网络。YOLO-V3几乎与其他目标检测算法一样精确,但速度至少是后者的两倍。YOLO-V3的特征提取网络为Darknet-53。Darknet-53通过不断地使用卷积、标准化、池化等操作,提取输入到YOLO-V3网络的火灾图像的特征,并通过卷积不断地对火灾图像进行特征提取。这种方法广泛应用于其他各种网络模型中,ResNet也通过增加网络的深度来提高网络的精度。虽然可以同时缩放两个或三个维度,但由于深度和宽度之间有一定的关系,需要进行复杂的手动调整,也就是说只能调整深度和宽度才能达到更好的精度。目前,YOLO-V3模型在火灾探测中并未得到广泛应用。B.Fire-YOLOFire-YOLO是一种单阶段检测模型。FireYOLO用于火灾探测的步骤如下所示。首先,网络输入火灾图像分为S×S网格,和检测在每个探测单元格:是否有火焰或者烟雾的中心目标是发现落在S2的网格,网格负责检测目标被检测出来。然后,每个网格预测3个边界框,并给出这些边界框的置信度。置信计算的定义如下。当目标落在网格中时Pγ = 1,否则Pγ = 0。IoU表示预测边界框与真实边界框的重合。置信度反映了网格中是否存在对象以及包含对象时预测边界框的准确性。当多个包围盒同时检测到同一目标时,YOLO网络将使用非最大抑制(Non-Maximum Suppression, NMS)方法选择最佳包围盒。利用卷积神经网络对视频中的火情和烟雾进行分类来检测火情,具有良好的准确率。文章提出的Fire-YOLO模型从深度、宽度和分辨率三个维度考虑,实现了更加均衡的网络架构。Fire-YOLO火灾探测步骤如下图所示。将输入图像划分为S×S网格,每个网格预测三个边界框和置信度分数。然后,使用非最大值抑制方法选择最佳边界框。Effentnet的提出为设计一种标准化的卷积神经网络尺度方法提供了可能。通过平衡网络深度、宽度和分辨率这三个维度,可以在深度、宽度和分辨率这三个维度上实现更均衡的网络架构,而无需复杂的人工调整。由于火灾数据集中大量的检测对象为小火焰和烟雾,这种简单高效的复合尺度变换方法相对于其他的一维尺度变换方法可以进一步提高火灾的检测精度,并能充分节约计算资源。最终,文章使用的改进后的Effentnet比精度相同的卷积神经网络速度更快,参数更少,模型更小,具有明显的优势。提出的Fire-YOLO火灾探测模型网络结构如下图所示。与YOLO-V3中特征提取网络Darknet53中使用的残块不同,Fire-YOLO的特征提取网络使用了一个移动倒瓶颈卷积(MBConv),该卷积由深度卷积和挤压-激活网络(SENet)组成。MBConv块的结构,最重要的是,一个1×1卷积内核用于增加图像的维数,接下来通过切除卷积和SENet反过来,最后用1×1卷积内核来减少图像的维数输出。输入图像经过特征提取网络并上采样后,得到对应的特征图,即图像对应的向量特征矩阵。为了获得小目标的高层特征信息,特征图将经过卷积集处理,卷积集由5个卷积层组成,卷积核交替为1 × 1和3 × 3。然后利用池化层将高维向量扁平化为一维向量,由激活函数进行处理。将这些向量输入到激活函数中,得到相应的分类结果,并选择最有可能的结果作为特征提取网络输出。针对Darknet-53特征提取网络在深度、宽度和分辨率三个维度平衡方面的性能缺陷,文章在文章提出的fire数据集上使用改进的Effecentnet特征提取网络,弥补了Darknet-53在小目标检测方面的性能不足,提高了小目标检测的特征提取能力。对于输入的小目标图像,增强了小目标特征的学习能力,提高了小目标特征提取网络的性能。为了更好地处理小目标图像,Fire-YOLO模型首先将输入图像缩放到416 × 416像素,然后使用Effecentnet从图像中提取特征。经过多层的深度可分卷积、全局平均池化、特征压缩和特征扩展,对深度可分卷积学习到的特征映射进行上采样。通过特征金字塔处理得到不同尺度的预测框。文章提出的Fire-YOLO模型预测了13 × 13、26 × 26、52 × 52三种不同尺度的边界盒。用于小目标检测的深度可分离卷积结合了逐条通道卷积和逐级点卷积两种级别,提取不同粒度的小目标特征。深度可分卷积的结构如下图所示。通过比较YOLO-V3中使用的Darknet-53特征提取网络、快速R-CNN中使用的RPN目标建议网络和Fire YOLO中使用的深度可分离卷积,发现深度可分离卷积在计算复杂度方面具有优异的性能。这种卷积结构加快了模型的训练速度,提高了模型的检测精度。在火灾探测模型的实际应用中,可以加快网络的处理速度,如果计算量较小,可以达到实时图像处理的目的,从而实现火灾危险的实时探测。同时,该模型的硬件要求也降低了,以便于部署。SENet主要由两个阶段组成。第一个阶段是挤压阶段。第二个阶段是激发阶段。在获得挤压的矢量后,使用完全连接的层,并预测每个通道的重要性。随后,将其应用于与初始特征映射相对应的信道,以便小目标的特征信息将被赋予更高的优先级。SENet的结构如下图所示。在深度学习网络模型中,激活函数是一个连续可导的非线性函数,可以拟合非线性关系。激活函数及其导数的形式比较简单,可以加快网络的学习速度。正确使用激活函数对模型的训练和模型对目标预测的准确性都具有重要意义。活化函数的导数不宜过大或过小,最好稳定在1左右。文章提出的模型使用了Swish激活函数,其表达式为:其中β是常数或可训练参数。Swish具有无上界、无下界、光滑、非单调的特点。Swish在深度模式上比ReLU要好。乙状结肠的饱和函数很容易导致梯度的消失,借鉴ReLU的影响,当它是非常大的,它将方法,但当x→∞,函数的一般趋势比ReLU ReLU相似但更复杂。Swish函数可以看作是一个介于线性函数和ReLU函数之间的平滑函数。C. 性能指标文章利用训练后的Fire-YOLO模型对测试图像进行一系列实验,验证算法的性能。评价神经网络模型有效性的相关指标有:precision, recall, F1, AP值。在二元分类问题中,根据真类别和预测类别的组合,样本可分为四种类型:真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)。分类结果的混淆矩阵如下表所示。其余指标的公式根据混淆矩阵计算如下:5.实验分析本节介绍训练网络的实验环境、数据集、模型效果评价指标以及实验结果分析。通过一系列不同模型的对比实验,分析了文章提出的新模型的优越性。实验过程中使用了火数据集和小目标数据集。通过fire数据集对目标检测网络的准确性进行了验证和评估,在不同光照条件、类火烟雾目标等复杂环境下具有良好的检测效果;在小目标火力数据集上验证了该检测方法。结果证实,Fire-YOLO更容易检测到较小的目标。Fire-YOLO检测模型接收416 × 416像素图像作为输入,由于GPU性能限制,批处理大小设为8,每个模型训练100 epoch,初始学习速率为10−3,50 epoch后除以10。A. 数据采集实验中使用的数据集是通过采集消防公益平台上的消防图片来构建的。将fire数据集和小目标数据集分别划分为训练集、验证集和测试集,以便在相同的实验设置下对不同的模型进行训练。第一个数据集为火焰数据集,文章使用的图像数据是公共网站上收集的火灾和烟雾图像。这19819张原始图像包括不同天气和光线线下的火焰和烟雾。在对以上数据集图像进行编号后,使用LabelImg工具进行手动标记,包括绘制边框和分类类别。考虑到标签与数据的对应关系,为保证数据集分布均匀,将数据集按70%、20%、10%的比例随机分为训练集、验证集和测试集。为了保证实验环境相同,最终数据集以PASCAL VOC数据集格式存储。为了防止神经网络中过拟合,对于像素区域不清晰的阳性样本不进行标记。完成的数据集如下表所示。第二个数据集为小目标检测数据集,文章自制了370张图像的数据集。数据集的内容都是包含小目标的火焰和烟雾。通过将250 × 250像素的火焰图像嵌入到1850 × 1850像素的图像中,可以使被探测目标在图像中的面积非常小。最后使用LabelImg工具手工标注小目标。B. 算法的比较分析为了验证模型的性能,文章使用火焰和烟雾图像作为训练集。将所提出的模型与YOLO-V3和Faster R-CNN检测方法进行了比较。三种模型在试验过程中的P-R曲线如图5所示。准确率、召回率、F1评分和mAP值如下表所示。基于以上结果,文章提出的Fire-YOLO在检测性能上优于YOLO-V3和Faster R-CNN。Fire-YOLO模型的精度为0.915,F1的值为0.73,mAP的值为0.802,高于其他两个模型,体现了该模型的优越性。同时Fire-YOLO降低了计算成本,节约了资源,更有利于社会的可持续发展。C. 小目标的检测性能在火灾探测过程中,由于摄像机离火源太远,实际的火源位置在捕获的图像中只占很小的区域,这将导致网络模型对火焰和烟雾的探测非常差。通过比较三种不同的目标检测模型在小目标火灾数据集上的准确率、召回率和mAP,可以得出文章提出的Fire-YOLO模型对非常小的目标对象的检测效率优于Faster R-CNN和未改进的YOLO-V3网络。训练于射击小目标数据集的Fire-YOLO对待检测小目标图像在深度、宽度和分辨率三个维度上进行自适应调整,增强了信息之间的交互作用。从而增强了Fire-YOLO提取小目标特征的能力,提高了小目标物体的检测精度。下表给出了三种模型方法对小目标射击数据集评价指标的具体结果。三种不同模型对小目标火力数据集的检测效率差异较大。文章提出的Fire-YOLO模型的准确率和召回率比其他模型更显著。准确率可达75.48%,可实现对小目标的检测。森林火灾的早期及时发现可以大大减少对生态环境的破坏,减少火灾造成的经济损失,促进生态环境的可持续发展。训练后Fire-YOLO网络模型具有良好的火力目标探测效率。文章使用Fire-YOLO模型来检测非常小的火力目标,并将检测结果图形化显示。较小的射击目标是小目标射击数据集中验证数据集中的所有图像。对Fire-YOLO进行了30多个验证插图的验证,最终的图像检测结果如下图所示。Fire-YOLO可以检测到图片中所有的火和烟,而YOLO-V3和Faster R-CNN在检测结果中只能检测到图像中的部分目标。D. 类火和类烟目标的探测性能通过对比模型对丰富的类火和类烟图像的检测性能,可以发现Fire-YOLO对类火和类烟目标具有更好的检测效率。除了Fire-YOLO,其他模型分别将图像中的光和云误判为火和烟。显然,Fire-YOLO对图像纹理特征更加敏感,这是由于在特征提取网络中结合了1 × 1卷积核和SE模块。最后,提高了该模型在探测混淆目标时的鲁棒性。三种模型的类火和类烟检测结果如下图所示。在上述情况下,Fire-YOLO模型大大减少了误检的发生,减少了劳动力消耗,节约了社会资源。E. 模型在不同自然光下的检测性能本节通过对比不同自然光照条件下的多幅火灾图像,测试Fire-YOLO在真实环境中的性能。在实际火灾探测现场,会出现光线不足或光线很强的情况。在这种场景下,会对火灾探测产生一定的影响。使用大尺度feature map对模型进行改进,识别小目标对象,但在弱光条件下存在误判。检测结果如下图所示。通过比较FasterR-CNN、YOLO-V3和Fire-YOLO模型的检测性能,结果表明该模型在不同光照条件下具有良好的性能,对光照变化具有较强的鲁棒性。Fire-YOLO模式的这些优势可以减少火灾对森林的危害,减少温室效应对人类的影响,促进可持续发展文章提出的Fire- YOLO模型在小目标、类火、类烟探测以及不同明度下的火灾探测等方面都取得了令人满意的效果。在实际应用中,该方法不仅具有实时性,而且具有良好的鲁棒性。然而文章检测算法仍然存在检测精度低、检测半遮挡目标具有挑战性的问题。这可能是由于在实际环境中探测火焰时,火灾的可变性和火灾蔓延的复杂性,造成了火灾检查的困境,如下图所示。.
文章来源于当交通遇上机器学习 ,作者CY1.文章信息论文链接:https://www.mdpi.com/2071-1050/14/9/4930/htm2.摘要针对森林火灾图像中小目标、类火目标和类烟目标的检测,以及不同自然光下的火灾检测,提出了一种改进的Fire-YOLO深度学习算法。Fire-YOLO检测模型从三维扩展了特征提取网络,增强了火灾小目标识别的特征传播,提高了网络性能,减少了模型参数。进一步,通过特征金字塔的提升,得到了性能最好的预测框。与最先进的目标检测网络相比,Fire-YOLO取得了优异的结果,尤其是在火灾和烟雾的小目标检测方面。总体而言,Fire-YOLO检测模型可以有效地处理小火源目标、类火和类烟目标的检测。当输入图像尺寸为416 × 416分辨率时,平均检测时间为0.04 s /帧,可以提供实时的森林火灾检测。此外,文章提出的算法也可以应用于其他复杂情况下的小目标检测。3.简介火灾探测对于保护森林资源、保护人民生命财产至关重要。近年来,随着火灾图像探测成为研究热点,图像探测具有探测时间早、精度高、系统安装灵活、能有效探测大空间复杂建筑结构火灾等优点。一类方法基于火灾发生时的颜色识别,但基于颜色的方法对亮度和阴影非常敏感。因此,这些方法产生的假警报数量很高。随着机器学习的发展,深度学习技术已广泛应用于检测。有学者提出了一种使用微调卷积神经网络(CNN)的早期火灾探测框架,但该模型具有较高的计算成本。有的学者使用深度融合CNN进行烟雾探测,它结合了注意机制、特征级和决策级融合模块。然而,仍有一些小目标未能实现。有的学者使用了一种基于区域的快速卷积神经网络(R-CNN),根据空间特征检测可疑火灾区域(SRoF)和非火灾区域。这可以通过减少错误探测成功地提高火灾探测精度,但探测速度相对较慢。有的学者提出了一种基于YOLO-V3和YOLO-V4的森林烟雾检测算法。与YOLO-V4相比,YOLO-V3的模型更小,更易于部署。在此基础上,文章选择了YOLO-V3模型作为整体算法,并对其进行了改进。提出了对YOLO-V3算法的改进。网络中加入了空心卷积和DenseNet,提高了火灾早期小规模火焰的探测效果。然而,方法存在火焰定位不准确和屏蔽性能差的问题。I-YOLOv3-tiny模型通过网络结构优化、多尺度融合和K-均值聚类来提高检测精度,但检测速度有待提高。通过提高特征图的分辨率,它减少了火灾探测中的误差,但由于计算量的增加,相应的处理时间也增加了。将分类模型和目标检测模型结合用于火灾探测的方法降低了计算成本,提高了探测精度。尽管如此,它不适用于火灾早期小目标的探测场景。有的学者通过将原始网络结构中的两步降采样卷积网络替换为图像双分割和双线性上采样网络,扩大了小目标的特征,提高了小目标的检测精度。虽然这会增加参数的数量,但计算成本也会增加。对于具有实时性要求的火灾探测,仍需进一步改进。这些问题给火灾场景中小目标的检测带来了巨大的挑战。4.模型A. YOLO-V3YOLO- v3是由YOLO和YOLOV2网络演化而来的对象检测模型。与Faster R-CNN相比,YOLO- v3是单级检测算法,这意味着YOLO网络不需要Regional Proposal network (RPN),而是直接检测图像中的目标。这样既考虑了检测速度和检测精度,又减小了模型参数的尺寸。YOLO-V3对每个类别独立使用逻辑回归,取代了DarkENT-19到DarkENT-53的特征提取网络。YOLO-V3几乎与其他目标检测算法一样精确,但速度至少是后者的两倍。YOLO-V3的特征提取网络为Darknet-53。Darknet-53通过不断地使用卷积、标准化、池化等操作,提取输入到YOLO-V3网络的火灾图像的特征,并通过卷积不断地对火灾图像进行特征提取。这种方法广泛应用于其他各种网络模型中,ResNet也通过增加网络的深度来提高网络的精度。虽然可以同时缩放两个或三个维度,但由于深度和宽度之间有一定的关系,需要进行复杂的手动调整,也就是说只能调整深度和宽度才能达到更好的精度。目前,YOLO-V3模型在火灾探测中并未得到广泛应用。B.Fire-YOLOFire-YOLO是一种单阶段检测模型。FireYOLO用于火灾探测的步骤如下所示。首先,网络输入火灾图像分为S×S网格,和检测在每个探测单元格:是否有火焰或者烟雾的中心目标是发现落在S2的网格,网格负责检测目标被检测出来。然后,每个网格预测3个边界框,并给出这些边界框的置信度。置信计算的定义如下。当目标落在网格中时Pγ = 1,否则Pγ = 0。IoU表示预测边界框与真实边界框的重合。置信度反映了网格中是否存在对象以及包含对象时预测边界框的准确性。当多个包围盒同时检测到同一目标时,YOLO网络将使用非最大抑制(Non-Maximum Suppression, NMS)方法选择最佳包围盒。利用卷积神经网络对视频中的火情和烟雾进行分类来检测火情,具有良好的准确率。文章提出的Fire-YOLO模型从深度、宽度和分辨率三个维度考虑,实现了更加均衡的网络架构。Fire-YOLO火灾探测步骤如下图所示。将输入图像划分为S×S网格,每个网格预测三个边界框和置信度分数。然后,使用非最大值抑制方法选择最佳边界框。Effentnet的提出为设计一种标准化的卷积神经网络尺度方法提供了可能。通过平衡网络深度、宽度和分辨率这三个维度,可以在深度、宽度和分辨率这三个维度上实现更均衡的网络架构,而无需复杂的人工调整。由于火灾数据集中大量的检测对象为小火焰和烟雾,这种简单高效的复合尺度变换方法相对于其他的一维尺度变换方法可以进一步提高火灾的检测精度,并能充分节约计算资源。最终,文章使用的改进后的Effentnet比精度相同的卷积神经网络速度更快,参数更少,模型更小,具有明显的优势。提出的Fire-YOLO火灾探测模型网络结构如下图所示。与YOLO-V3中特征提取网络Darknet53中使用的残块不同,Fire-YOLO的特征提取网络使用了一个移动倒瓶颈卷积(MBConv),该卷积由深度卷积和挤压-激活网络(SENet)组成。MBConv块的结构,最重要的是,一个1×1卷积内核用于增加图像的维数,接下来通过切除卷积和SENet反过来,最后用1×1卷积内核来减少图像的维数输出。输入图像经过特征提取网络并上采样后,得到对应的特征图,即图像对应的向量特征矩阵。为了获得小目标的高层特征信息,特征图将经过卷积集处理,卷积集由5个卷积层组成,卷积核交替为1 × 1和3 × 3。然后利用池化层将高维向量扁平化为一维向量,由激活函数进行处理。将这些向量输入到激活函数中,得到相应的分类结果,并选择最有可能的结果作为特征提取网络输出。针对Darknet-53特征提取网络在深度、宽度和分辨率三个维度平衡方面的性能缺陷,文章在文章提出的fire数据集上使用改进的Effecentnet特征提取网络,弥补了Darknet-53在小目标检测方面的性能不足,提高了小目标检测的特征提取能力。对于输入的小目标图像,增强了小目标特征的学习能力,提高了小目标特征提取网络的性能。为了更好地处理小目标图像,Fire-YOLO模型首先将输入图像缩放到416 × 416像素,然后使用Effecentnet从图像中提取特征。经过多层的深度可分卷积、全局平均池化、特征压缩和特征扩展,对深度可分卷积学习到的特征映射进行上采样。通过特征金字塔处理得到不同尺度的预测框。文章提出的Fire-YOLO模型预测了13 × 13、26 × 26、52 × 52三种不同尺度的边界盒。用于小目标检测的深度可分离卷积结合了逐条通道卷积和逐级点卷积两种级别,提取不同粒度的小目标特征。深度可分卷积的结构如下图所示。通过比较YOLO-V3中使用的Darknet-53特征提取网络、快速R-CNN中使用的RPN目标建议网络和Fire YOLO中使用的深度可分离卷积,发现深度可分离卷积在计算复杂度方面具有优异的性能。这种卷积结构加快了模型的训练速度,提高了模型的检测精度。在火灾探测模型的实际应用中,可以加快网络的处理速度,如果计算量较小,可以达到实时图像处理的目的,从而实现火灾危险的实时探测。同时,该模型的硬件要求也降低了,以便于部署。SENet主要由两个阶段组成。第一个阶段是挤压阶段。第二个阶段是激发阶段。在获得挤压的矢量后,使用完全连接的层,并预测每个通道的重要性。随后,将其应用于与初始特征映射相对应的信道,以便小目标的特征信息将被赋予更高的优先级。SENet的结构如下图所示。在深度学习网络模型中,激活函数是一个连续可导的非线性函数,可以拟合非线性关系。激活函数及其导数的形式比较简单,可以加快网络的学习速度。正确使用激活函数对模型的训练和模型对目标预测的准确性都具有重要意义。活化函数的导数不宜过大或过小,最好稳定在1左右。文章提出的模型使用了Swish激活函数,其表达式为:其中β是常数或可训练参数。Swish具有无上界、无下界、光滑、非单调的特点。Swish在深度模式上比ReLU要好。乙状结肠的饱和函数很容易导致梯度的消失,借鉴ReLU的影响,当它是非常大的,它将方法,但当x→∞,函数的一般趋势比ReLU ReLU相似但更复杂。Swish函数可以看作是一个介于线性函数和ReLU函数之间的平滑函数。C. 性能指标文章利用训练后的Fire-YOLO模型对测试图像进行一系列实验,验证算法的性能。评价神经网络模型有效性的相关指标有:precision, recall, F1, AP值。在二元分类问题中,根据真类别和预测类别的组合,样本可分为四种类型:真阳性(TP)、假阳性(FP)、真阴性(TN)和假阴性(FN)。分类结果的混淆矩阵如下表所示。其余指标的公式根据混淆矩阵计算如下:5.实验分析本节介绍训练网络的实验环境、数据集、模型效果评价指标以及实验结果分析。通过一系列不同模型的对比实验,分析了文章提出的新模型的优越性。实验过程中使用了火数据集和小目标数据集。通过fire数据集对目标检测网络的准确性进行了验证和评估,在不同光照条件、类火烟雾目标等复杂环境下具有良好的检测效果;在小目标火力数据集上验证了该检测方法。结果证实,Fire-YOLO更容易检测到较小的目标。Fire-YOLO检测模型接收416 × 416像素图像作为输入,由于GPU性能限制,批处理大小设为8,每个模型训练100 epoch,初始学习速率为10−3,50 epoch后除以10。A. 数据采集实验中使用的数据集是通过采集消防公益平台上的消防图片来构建的。将fire数据集和小目标数据集分别划分为训练集、验证集和测试集,以便在相同的实验设置下对不同的模型进行训练。第一个数据集为火焰数据集,文章使用的图像数据是公共网站上收集的火灾和烟雾图像。这19819张原始图像包括不同天气和光线线下的火焰和烟雾。在对以上数据集图像进行编号后,使用LabelImg工具进行手动标记,包括绘制边框和分类类别。考虑到标签与数据的对应关系,为保证数据集分布均匀,将数据集按70%、20%、10%的比例随机分为训练集、验证集和测试集。为了保证实验环境相同,最终数据集以PASCAL VOC数据集格式存储。为了防止神经网络中过拟合,对于像素区域不清晰的阳性样本不进行标记。完成的数据集如下表所示。第二个数据集为小目标检测数据集,文章自制了370张图像的数据集。数据集的内容都是包含小目标的火焰和烟雾。通过将250 × 250像素的火焰图像嵌入到1850 × 1850像素的图像中,可以使被探测目标在图像中的面积非常小。最后使用LabelImg工具手工标注小目标。B. 算法的比较分析为了验证模型的性能,文章使用火焰和烟雾图像作为训练集。将所提出的模型与YOLO-V3和Faster R-CNN检测方法进行了比较。三种模型在试验过程中的P-R曲线如图5所示。准确率、召回率、F1评分和mAP值如下表所示。基于以上结果,文章提出的Fire-YOLO在检测性能上优于YOLO-V3和Faster R-CNN。Fire-YOLO模型的精度为0.915,F1的值为0.73,mAP的值为0.802,高于其他两个模型,体现了该模型的优越性。同时Fire-YOLO降低了计算成本,节约了资源,更有利于社会的可持续发展。C. 小目标的检测性能在火灾探测过程中,由于摄像机离火源太远,实际的火源位置在捕获的图像中只占很小的区域,这将导致网络模型对火焰和烟雾的探测非常差。通过比较三种不同的目标检测模型在小目标火灾数据集上的准确率、召回率和mAP,可以得出文章提出的Fire-YOLO模型对非常小的目标对象的检测效率优于Faster R-CNN和未改进的YOLO-V3网络。训练于射击小目标数据集的Fire-YOLO对待检测小目标图像在深度、宽度和分辨率三个维度上进行自适应调整,增强了信息之间的交互作用。从而增强了Fire-YOLO提取小目标特征的能力,提高了小目标物体的检测精度。下表给出了三种模型方法对小目标射击数据集评价指标的具体结果。三种不同模型对小目标火力数据集的检测效率差异较大。文章提出的Fire-YOLO模型的准确率和召回率比其他模型更显著。准确率可达75.48%,可实现对小目标的检测。森林火灾的早期及时发现可以大大减少对生态环境的破坏,减少火灾造成的经济损失,促进生态环境的可持续发展。训练后Fire-YOLO网络模型具有良好的火力目标探测效率。文章使用Fire-YOLO模型来检测非常小的火力目标,并将检测结果图形化显示。较小的射击目标是小目标射击数据集中验证数据集中的所有图像。对Fire-YOLO进行了30多个验证插图的验证,最终的图像检测结果如下图所示。Fire-YOLO可以检测到图片中所有的火和烟,而YOLO-V3和Faster R-CNN在检测结果中只能检测到图像中的部分目标。D. 类火和类烟目标的探测性能通过对比模型对丰富的类火和类烟图像的检测性能,可以发现Fire-YOLO对类火和类烟目标具有更好的检测效率。除了Fire-YOLO,其他模型分别将图像中的光和云误判为火和烟。显然,Fire-YOLO对图像纹理特征更加敏感,这是由于在特征提取网络中结合了1 × 1卷积核和SE模块。最后,提高了该模型在探测混淆目标时的鲁棒性。三种模型的类火和类烟检测结果如下图所示。在上述情况下,Fire-YOLO模型大大减少了误检的发生,减少了劳动力消耗,节约了社会资源。E. 模型在不同自然光下的检测性能本节通过对比不同自然光照条件下的多幅火灾图像,测试Fire-YOLO在真实环境中的性能。在实际火灾探测现场,会出现光线不足或光线很强的情况。在这种场景下,会对火灾探测产生一定的影响。使用大尺度feature map对模型进行改进,识别小目标对象,但在弱光条件下存在误判。检测结果如下图所示。通过比较FasterR-CNN、YOLO-V3和Fire-YOLO模型的检测性能,结果表明该模型在不同光照条件下具有良好的性能,对光照变化具有较强的鲁棒性。Fire-YOLO模式的这些优势可以减少火灾对森林的危害,减少温室效应对人类的影响,促进可持续发展文章提出的Fire- YOLO模型在小目标、类火、类烟探测以及不同明度下的火灾探测等方面都取得了令人满意的效果。在实际应用中,该方法不仅具有实时性,而且具有良好的鲁棒性。然而文章检测算法仍然存在检测精度低、检测半遮挡目标具有挑战性的问题。这可能是由于在实际环境中探测火焰时,火灾的可变性和火灾蔓延的复杂性,造成了火灾检查的困境,如下图所示。. -
 概述在本文中,我们将制作一个非常有趣的应用程序,即颜色选择器,它有很多用例,但这个应用程序的主要用例是它可以被 UI/UX 设计师广泛使用,他们从图像中选择颜色并获取它们的颜色代码,为此,我们将使用和图像处理的概念。因此,在本文中,我们将了解使用计算机视觉的颜色选择器的概念。让我们开始吧!import cv2import pandas as pdimport matplotlib.pyplot as plt1. cv2:这个库是用来执行所有的计算机视觉操作——基本上是所有需要的图像处理操作。2. pandas:在处理机器学习问题时,Pandas 通常有很多范围,但在本主题中,它们仅用于读取 CSV 文件并从中提取一些信息。3. matplotlib: Matplotlib 与可视化数据有很大关系,尽管在这里它将用于绘制图像。image_location = 'colorpic.jpg'test = cv2.imread(image_location)plt.imshow(test)plt.show()输出:代码分解:1. 首先,我们在变量中保存图像的路径,使用图像的名称,而不是确切的路径,因为它与我们的 Jupyter Notebook位于同一路径中。2. 现在借助cv2 的 read() 函数,我们将读取 NumPy 数组格式的图像并将其存储在测试变量中。如果我们只打印出测试变量,那么它只会以数组格式显示图像。3. 现在我们将使用 Matplotlib 的 show() 函数来查看我们读取的图像。cv2.imshow() VS plt.imshow()这里出现了一个问题,因为熟悉 OpenCV 的人很清楚,为了显示图像,我们理想地使用cv2.imshow函数,但澄清一件事,在这里看到结果cv2.Imshow函数不会工作,它只会使内核崩溃,当你搜索这个问题时,你会发现在客户端服务器(Jupiter notebook)使用cv2.imshow函数是没有意义的,因此我们使用matplotlib (plt.imshow)将结果以图像的形式绘制出来。让我们声明一些可以与整个代码一起访问的全局变量。flag_variable = Falsered_channel = g_channel = b_channel = x_coordinate = y_coordinate = 0代码分解:1. 在这里,首先我们取了一个标志变量,它将指示我们是否单击了图像,可以看到默认值为 false 即未单击图片,而 True 值表示已单击图片。2. 然后有红色、绿色和蓝色通道(RGB)以及 X 和 Y 坐标,现在设置为 0,但只要我们在图像周围移动并从中选择颜色,这些值就会改变.现在我们将读取彩色 CSV 文件并为每一列指定标题名称。heading = ["Color", "Name of color", "Hexadecimal code", "Red channel", "Green channel", "Blue channel"]color_csv = pd.read_csv('colors.csv', names=heading, header=None)代码分解:1. 我们正在设置彩色 CSV 文件将具有的标题名称。2. 然后我们将在 read_csv 函数的帮助下读取 color.csv 文件· 注意:此颜色 CSV 文件具有颜色的名称、十六进制代码、RGB 值,我们将仅比较此 CSV 文件中的值。现在,我们将创建函数来获取颜色的名称(get_color_name)。def get_color_name(Red, Green, Blue): minimum = 10000 for i in range(len(color_csv)): distance = abs(Red - int(color_csv.loc[i, "Red channel"])) + abs(Green - int(color_csv.loc[i, "Green channel"])) + abs(Blue - int(color_csv.loc[i, "Blue channel"])) if distance <= minimum: minimum = distance color_name = color_csv.loc[i, "Name of color"] return color_name代码分解:1. 因此,首先我们将阈值设置为 10000,即实际颜色代码与我们从图像中选择颜色时得到的颜色代码之间的最小阈值距离。2. 然后我们计算了颜色代码与图像的距离。3. 现在我们将看到我们计算的距离应该小于或等于阈值距离。4. 最后,我们将从CSV 文件中存储颜色的名称并返回它。现在我们将创建函数来获取坐标(draw_function)def draw_function(event, x_coordinate, y_coordinate, flags, parameters): if event == cv2.EVENT_LBUTTONDBLCLK: global b, g, r, x_position, y_position, flag_variable flag_variable = True x_position = x_coordinate y_position = y_coordinate b, g, r = test[y_coordinate, x_coordinate] b = int(b) g = int(g) r = int(r)代码分解:因此,在分解代码之前,我想提一下它拥有的功能。当用户双击任何颜色时,此函数将返回 X 和 Y 坐标的值以及相应的 RGB 位置。1. 首先,我们将检查用户是否双击,我们将使用cv2 中的 EVENT_LBUTTONDBLCLK。2. 然后我们将flag_variable 设置为 True,因为现在单击了按钮。3. 然后是函数的主要部分,我们将在全局变量中存储坐标值及其对应的 RGB 值。4. 最后,我们将使用 int() 将值转换为整数类型。cv2.namedWindow('image')cv2.setMouseCallback('image', draw_function)鼠标回调:这是 cv2 方法,它将检测用户的点击(右、左或双击)并调用绘图函数。while True: cv2.imshow("image", test) if flag_variable: cv2.rectangle(test, (20, 20), (750, 60), (b, g, r), -1) text = get_color_name(r, g, b) + ' R=' + str(r) + ' G=' + str(g) + ' B=' + str(b) cv2.putText(test, text, (50, 50), 2, 0.8, (255, 255, 255), 2, cv2.LINE_AA) if r + g + b >= 600: cv2.putText(test, text, (50, 50), 2, 0.8, (0, 0, 0), 2, cv2.LINE_AA) flag_variable = False if cv2.waitKey(20) & 0xFF == 27: breakcv2.destroyAllWindows()输出:代码分解:1. 在主逻辑中,首先我们将创建一个矩形(填充:-1 用于填充矩形),我们将在其上放置我们的文本。2. 现在我们将获得文本字符串,其颜色代码为 RGB。3. 然后在 put text 方法的帮助下,我们将在之前绘制的矩形上方显示文本。4. 如果颜色为浅色,我们会验证,然后我们将以黑色显示文本字符串。5. 最后,我们可以选择使用 esc 键退出应用程序。总结1. 首先,我们已经导入了所有的库。2. 然后我们加载并绘制选定的图像。3. 然后我们为我们的彩色 CSV 文件提供了标题。4. 我们还创建了获取颜色名称函数和绘制函数,以在用户双击任何颜色时查看图像上的结果。5. 然后应用程序循环执行所有步骤。因此,通过执行上述步骤,我们可以开发一个使用计算机视觉的颜色选择器应用程序。 原文标题 : 使用计算机视觉的颜色选择器应用程序
概述在本文中,我们将制作一个非常有趣的应用程序,即颜色选择器,它有很多用例,但这个应用程序的主要用例是它可以被 UI/UX 设计师广泛使用,他们从图像中选择颜色并获取它们的颜色代码,为此,我们将使用和图像处理的概念。因此,在本文中,我们将了解使用计算机视觉的颜色选择器的概念。让我们开始吧!import cv2import pandas as pdimport matplotlib.pyplot as plt1. cv2:这个库是用来执行所有的计算机视觉操作——基本上是所有需要的图像处理操作。2. pandas:在处理机器学习问题时,Pandas 通常有很多范围,但在本主题中,它们仅用于读取 CSV 文件并从中提取一些信息。3. matplotlib: Matplotlib 与可视化数据有很大关系,尽管在这里它将用于绘制图像。image_location = 'colorpic.jpg'test = cv2.imread(image_location)plt.imshow(test)plt.show()输出:代码分解:1. 首先,我们在变量中保存图像的路径,使用图像的名称,而不是确切的路径,因为它与我们的 Jupyter Notebook位于同一路径中。2. 现在借助cv2 的 read() 函数,我们将读取 NumPy 数组格式的图像并将其存储在测试变量中。如果我们只打印出测试变量,那么它只会以数组格式显示图像。3. 现在我们将使用 Matplotlib 的 show() 函数来查看我们读取的图像。cv2.imshow() VS plt.imshow()这里出现了一个问题,因为熟悉 OpenCV 的人很清楚,为了显示图像,我们理想地使用cv2.imshow函数,但澄清一件事,在这里看到结果cv2.Imshow函数不会工作,它只会使内核崩溃,当你搜索这个问题时,你会发现在客户端服务器(Jupiter notebook)使用cv2.imshow函数是没有意义的,因此我们使用matplotlib (plt.imshow)将结果以图像的形式绘制出来。让我们声明一些可以与整个代码一起访问的全局变量。flag_variable = Falsered_channel = g_channel = b_channel = x_coordinate = y_coordinate = 0代码分解:1. 在这里,首先我们取了一个标志变量,它将指示我们是否单击了图像,可以看到默认值为 false 即未单击图片,而 True 值表示已单击图片。2. 然后有红色、绿色和蓝色通道(RGB)以及 X 和 Y 坐标,现在设置为 0,但只要我们在图像周围移动并从中选择颜色,这些值就会改变.现在我们将读取彩色 CSV 文件并为每一列指定标题名称。heading = ["Color", "Name of color", "Hexadecimal code", "Red channel", "Green channel", "Blue channel"]color_csv = pd.read_csv('colors.csv', names=heading, header=None)代码分解:1. 我们正在设置彩色 CSV 文件将具有的标题名称。2. 然后我们将在 read_csv 函数的帮助下读取 color.csv 文件· 注意:此颜色 CSV 文件具有颜色的名称、十六进制代码、RGB 值,我们将仅比较此 CSV 文件中的值。现在,我们将创建函数来获取颜色的名称(get_color_name)。def get_color_name(Red, Green, Blue): minimum = 10000 for i in range(len(color_csv)): distance = abs(Red - int(color_csv.loc[i, "Red channel"])) + abs(Green - int(color_csv.loc[i, "Green channel"])) + abs(Blue - int(color_csv.loc[i, "Blue channel"])) if distance <= minimum: minimum = distance color_name = color_csv.loc[i, "Name of color"] return color_name代码分解:1. 因此,首先我们将阈值设置为 10000,即实际颜色代码与我们从图像中选择颜色时得到的颜色代码之间的最小阈值距离。2. 然后我们计算了颜色代码与图像的距离。3. 现在我们将看到我们计算的距离应该小于或等于阈值距离。4. 最后,我们将从CSV 文件中存储颜色的名称并返回它。现在我们将创建函数来获取坐标(draw_function)def draw_function(event, x_coordinate, y_coordinate, flags, parameters): if event == cv2.EVENT_LBUTTONDBLCLK: global b, g, r, x_position, y_position, flag_variable flag_variable = True x_position = x_coordinate y_position = y_coordinate b, g, r = test[y_coordinate, x_coordinate] b = int(b) g = int(g) r = int(r)代码分解:因此,在分解代码之前,我想提一下它拥有的功能。当用户双击任何颜色时,此函数将返回 X 和 Y 坐标的值以及相应的 RGB 位置。1. 首先,我们将检查用户是否双击,我们将使用cv2 中的 EVENT_LBUTTONDBLCLK。2. 然后我们将flag_variable 设置为 True,因为现在单击了按钮。3. 然后是函数的主要部分,我们将在全局变量中存储坐标值及其对应的 RGB 值。4. 最后,我们将使用 int() 将值转换为整数类型。cv2.namedWindow('image')cv2.setMouseCallback('image', draw_function)鼠标回调:这是 cv2 方法,它将检测用户的点击(右、左或双击)并调用绘图函数。while True: cv2.imshow("image", test) if flag_variable: cv2.rectangle(test, (20, 20), (750, 60), (b, g, r), -1) text = get_color_name(r, g, b) + ' R=' + str(r) + ' G=' + str(g) + ' B=' + str(b) cv2.putText(test, text, (50, 50), 2, 0.8, (255, 255, 255), 2, cv2.LINE_AA) if r + g + b >= 600: cv2.putText(test, text, (50, 50), 2, 0.8, (0, 0, 0), 2, cv2.LINE_AA) flag_variable = False if cv2.waitKey(20) & 0xFF == 27: breakcv2.destroyAllWindows()输出:代码分解:1. 在主逻辑中,首先我们将创建一个矩形(填充:-1 用于填充矩形),我们将在其上放置我们的文本。2. 现在我们将获得文本字符串,其颜色代码为 RGB。3. 然后在 put text 方法的帮助下,我们将在之前绘制的矩形上方显示文本。4. 如果颜色为浅色,我们会验证,然后我们将以黑色显示文本字符串。5. 最后,我们可以选择使用 esc 键退出应用程序。总结1. 首先,我们已经导入了所有的库。2. 然后我们加载并绘制选定的图像。3. 然后我们为我们的彩色 CSV 文件提供了标题。4. 我们还创建了获取颜色名称函数和绘制函数,以在用户双击任何颜色时查看图像上的结果。5. 然后应用程序循环执行所有步骤。因此,通过执行上述步骤,我们可以开发一个使用计算机视觉的颜色选择器应用程序。 原文标题 : 使用计算机视觉的颜色选择器应用程序 -
想问一下“FairMOT目标跟踪样例”是那个YOLO模型:mindxsdk-referenceapps: MindX SDK Reference Apps - Gitee.com
上滑加载中
推荐直播
0.25
-
 基于开源鸿蒙+海思星闪开发板:嵌入式系统开发实战(Day1)
基于开源鸿蒙+海思星闪开发板:嵌入式系统开发实战(Day1)2025/03/29 周六 09:00-18:00
华为开发者布道师
本次为期两天的课程将深入讲解OpenHarmony操作系统及其与星闪技术的结合应用,涵盖WS63E星闪开发板的详细介绍、“OpenHarmony+星闪”的创新实践、实验环境搭建以及编写首个“Hello World”程序等内容,旨在帮助学员全面掌握相关技术并进行实际操作
回顾中 -
 华为云软件开发生产线(CodeArts)1月&2月新特性解读
华为云软件开发生产线(CodeArts)1月&2月新特性解读2025/03/18 周二 19:00-20:00
阿星 华为云高级产品经理
不知道产品的最新特性?没法和产品团队建立直接的沟通?本期直播产品经理将为您解读华为云软件开发生产线1月&2月发布的新特性,并在直播过程中为您答疑解惑。
回顾中 -
 基于能力图谱的openGauss项目闯关
基于能力图谱的openGauss项目闯关2025/03/20 周四 19:00-20:30
华为开发者布道师
想成为顶级数据库开发者吗?本次直播将从银行业务系统的数据库设计出发,带你逐步掌握openGauss的建库表、数据封装、密态技术、性能调优及AI应用。通过实战案例,全面展示openGauss的强大功能,助你提升技能,为未来的职业发展打下坚实基础。立即报名,开启你的数据库进阶之旅!
回顾中 -
基于开源鸿蒙+海思星闪开发板:嵌入式系统开发实战(Day1)
2025/03/29 周六 09:00-18:00
华为开发者布道师
本次为期两天的课程将深入讲解OpenHarmony操作系统及其与星闪技术的结合应用,涵盖WS63E星闪开发板的详细介绍、“OpenHarmony+星闪”的创新实践、实验环境搭建以及编写首个“Hello World”程序等内容,旨在帮助学员全面掌握相关技术并进行实际操作
回顾中 -
华为云软件开发生产线(CodeArts)1月&2月新特性解读
2025/03/18 周二 19:00-20:00
阿星 华为云高级产品经理
不知道产品的最新特性?没法和产品团队建立直接的沟通?本期直播产品经理将为您解读华为云软件开发生产线1月&2月发布的新特性,并在直播过程中为您答疑解惑。
回顾中
热门标签







