-
 【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件) -
【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】mindspore.nn.InstanceNorm2d【操作步骤&问题现象】目标:将torch已训练好的模型权重赋值给在mindspore复现的模型,测试模型构建是否正确,遇到了InstanceNorm2d迁移问题1. torch.nn.InstanceNorm2d(out_channels, affine=True)得到的模型,只包含两个参数weight和bias,而mindspore中InstanceNorm2d,包含beta,gamma,moving_mean,moving_variance四个参数,按我对API文档的理解weight对应gamma,bias对应beta,那么在做权重赋值时,对于torch中没有的moving_mean,moving_variance该如何处理?2. 顺便也想了解下torch.nn.InstanceNorm2d设置track_running_stat=True时,模型新增的running_mean,running_var是否与mindspore中的moving_mean,moving_variance对应?这种情况下迁移又该如何操作?
-
我现在想把一些用pytorch3d写的可微渲染部分的代码转换为mindspore,但我查了一下文档,好像没有看到相关的内容。有没有什么可行的方法可以让我把pytorch3d的代码重写为mindspore框架下呢?
-
【操作步骤&问题现象】在pytorch1.4-cuda10.1-cudnn7-ubuntu18.04+GPU: 1*V100(32GB)|CPU: 8核64GB的环境下进行HiSD项目的训练,但训练速度与作者使用1080Ti训练的速度相差不多,甚至更慢一点。请问原因可能是没有对平台做相应配置吗?例如:数据集是通过OBS桶上传至开发环境,是不是需要在代码中将其保存在本地再进行读取?参考:如何提升训练效率,同时减少与OBS的交互?_ModelArts_EI企业智能_华为云论坛 (huaweicloud.com)数据集实际大小2.55G项目地址:GitHub - imlixinyang/HiSD: Official pytorch implementation of paper "Image-to-image Translation via Hierarchical Style Disentanglement" (CVPR2021 Oral).数据集地址:GitHub - switchablenorms/CelebAMask-HQ: A large-scale face dataset for face parsing, recognition, generation and editing.【截图信息】图1 obs桶中的数据集图2 训练过程
-
 图中fake_loss的结果和pytorch的结果不一样,相差非常之大。初步检查发现是对于边界情况下的截断处理不同,pytorch能够截断到100,而mindspore只截断到27.几.上面这张图是在能正常训练的pytorch程序中,用mindspore的BCEloss去对比。下面那张图片是在无法正常训练的mindspore程序中,用pytorch的BCEloss去对比。发现mindspore算出来的loss是不一样的。。。我应该如何设置才能让loss一样,或者能够让网络正常训练???
图中fake_loss的结果和pytorch的结果不一样,相差非常之大。初步检查发现是对于边界情况下的截断处理不同,pytorch能够截断到100,而mindspore只截断到27.几.上面这张图是在能正常训练的pytorch程序中,用mindspore的BCEloss去对比。下面那张图片是在无法正常训练的mindspore程序中,用pytorch的BCEloss去对比。发现mindspore算出来的loss是不一样的。。。我应该如何设置才能让loss一样,或者能够让网络正常训练??? -
PyTorch框架使用DSL进行TBE算子开发全流程(下)PyTorch框架使用DSL进行TBE算子开发全流程(上) [https://bbs.huaweicloud.com/forumreview/thread-187817-1-1.html](https://bbs.huaweicloud.com/forumreview/thread-187817-1-1.html) PyTorch框架使用DSL进行TBE算子开发全流程(下) [https://bbs.huaweicloud.com/forum/thread-187818-1-1.html](https://bbs.huaweicloud.com/forum/thread-187818-1-1.html) bilibili视频链接 [https://www.bilibili.com/video/BV1WZ4y1a74i](https://www.bilibili.com/video/BV1WZ4y1a74i) ## 9.算子UT测试 基于MindStudio进行算子开发的场景下,用户可基于MindStudio进行算子的UT测试,UT(Unit Test:单元测试)是开发人员进行算子代码验证的手段之一,主要目的是: * 测试算子代码的正确性,验证输入输出结果与设计的一致性。 * UT侧重于保证算子程序能够跑通,选取的场景组合应能覆盖算子代码的所有分支(一般来说覆盖率要达到100%),从而降低不同场景下算子代码的编译失败率。 右击UT测试脚本进入设置 更改Target为Simulator_TMModel,全选测试用例,点击ok执行 图17:UT测试图18:UT测试参数设置| 参数 | 说明 | | ------------- | ------------------------------------------------------------ | | Name | 运行配置名称,用户可以自定义。 | | Compute Unit | 选择计算单元 | | SoC Version | 下拉选择当前版本的昇腾AI处理器类型。 | | Target | 运行环境。Simulator_Function:功能仿真环境。Simulator_TMModel:快速展示算子执行的调度流水线,不进行实际算子计算。 | | Operator Name | 选择运行的测试用例。 | | CANN Machine | CANN工具所在设备的deployment信息。 | | Case Names | 勾选需要运行的测试用例,即算子实现代码的UT Python测试用例。 | 图19 :UT测试成功显示profiling数据 图20:UT测试参数设置profiling数据ut测试覆盖率 图21:UT测试覆盖率## 10、算子ST测试 自定义算子部署到算子库(OPP)后,可进行ST(System Test)测试,在真实的硬件环境中,验证算子功能的正确性。 ST测试的主要功能是: * 基于算子测试用例定义文件*.json生成单算子的om文件; * 使用AscendCL接口加载并执行单算子om文件,验证算子执行结果的正确性。 * ST测试会覆盖算子实现文件,算子原型定义与算子信息库,不会对算子适配插件进行测试。 > 如果需要进行profiling则要在linux的path中添加msprof的路径 > > 即将export PATH=$PATH:/usr/local/Ascend/ascend-toolkit/latest/tools/profiler/bin/添加在~/.bashrc中 右击LpNorm_case_20210527144255.json选择run ST Case进入设置 图22:ST测试* 设置环境变量 * 在st测试的Advanced Options中打开profiling > st测试环境变量设置 | Name | Value | | ------------------ | ------------------------------------------------------------ | | ASCEND_DRIVER_PATH | /usr/local/Ascend/driver | | ASCEND_HOME | /usr/local/Ascend//ascend-toolkit/latest | | LD_LIBRARY_PATH | \${ASCEND_DRIVER_PATH}/lib64:\${ASCEND_HOME}/lib64:$LD_LIBRARY_PATH | 图23:ST测试参数设置| 参数 | 说明 | | ------------------------ | ------------------------------------------------------------ | | Name | 运行配置名称,用户可以自定义。 | | Test Type | 选择st_cases 。 | | Execute Mode | Remote Execute:远程执行测试。Local Execute:本地执行测试 | | Deployment | 可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 | | CANN Machine | CANN工具所在设备deployment信息。 | | Environment Variables | 添加环境变量 | | Operator Name | 选择需要运行的算子。 | | Executable File Name | 下拉选择需要执行的测试用例定义文件。 | | Target OS | 针对Ascend EP:选择昇腾AI处理器所在硬件环境的Host侧的操作系统。 | | Target Architecture | 选择Target OS的操作系统架构 | | Case Names | 选择Target OS的操作系统架构。 | | Enable Auto Build&Deploy | 选择是否在ST运行过程中执行编译和部署。 | | Enable Profiling | 使能profiling,获取算子在昇腾AI处理器上的性能数据 | ST测试成功之后点击profiling可以查看profiling数据 图24:ST测试成功图25:ST测试profiling## Q&A ### 1.编译或部署遇到错误fatal error:acl/acl.h:No such file or directory 可能是CANN路径设置问题,CANN路径需要设置到版本一级如:/usr/local/Ascend/ascend-toolkit/5.0.4 点击Setting-->Appearance Behavior --> System Settings --> CANN 找到Remote CANN location ### 2.如果UT测试中,明明写了测试用例却没有显示测试用例 可能是本地环境没有安装tensorflow,需要在本地环境安装tensorflow=1.15
-
PyTorch框架使用DSL进行TBE算子开发全流程(上)PyTorch框架使用DSL进行TBE算子开发全流程(上) [https://bbs.huaweicloud.com/forumreview/thread-187817-1-1.html](https://bbs.huaweicloud.com/forumreview/thread-187817-1-1.html) PyTorch框架使用DSL进行TBE算子开发全流程(下) [https://bbs.huaweicloud.com/forum/thread-187818-1-1.html](https://bbs.huaweicloud.com/forum/thread-187818-1-1.html) bilibili视频链接 [https://www.bilibili.com/video/BV1WZ4y1a74i](https://www.bilibili.com/video/BV1WZ4y1a74i) ## 1. DSL算子基本概念介绍 ### 1.1 什么是算子 深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称 OP)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully-connected Layer, FC layer)中的权值求和过 程,是一个算子。 对每一个独立的算子,用户需要编写算子描述文件,描述算子的整体逻辑、计算步骤以及相关硬件平台信息等。然后用深度学习编译器对算子描述文件进行编译,生成可在特定硬件平台上运行的二进制文件后,将待处理数据作为输入,运行算子即可得到期望输出。将神经网络所有被拆分后的算子都按照上述过程处理后, 再按照输入输出关系串联起来即可得到整网运行结果。 图1:算子全流程执行### 1.2 什么是TBE算子 TBE(Tensor Boost Engine)提供了基于开源深度学习编译栈TVM框架的自定义算子开发能力,通过TBE提供的API可以完成相应神经网络算子的开发。 一个完整的TBE算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库定义和算子实现。 图2:TBE算子全流程执行昇腾AI软件栈提供了TBE(Tensor Boost Engine:张量加速引擎)算子开发框架,开发者可以基于此框架使用Python语言开发自定义算子,通过TBE进行算子开发有以下几种方式: * DSL(Domain-Specific Language)开发 * TIK(Tensor Iterator Kernel)开发 ### 1.3 什么是DSL算子 为了方便开发者进行自定义算子开发,TBE(Tensor Boost Engine)提供了一套计算接口供开发者用于组装算子的计算逻辑,使得70%以上的算子可以基于这些接口进行开发,极大的降低自定义算子的开发难度。TBE提供的这套计算接口,称之为DSL(Domain-Specific Language)。基于DSL开发的算子,可以直接使用TBE提供的Auto Schedule机制,自动完成调度过程,省去最复杂的调度编写过程。 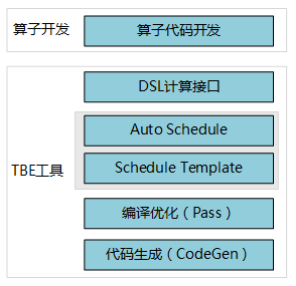图3:DSL算子介绍#### 1.3.1 DSL功能框架 1. 开发者调用TBE提供的DSL接口进行计算逻辑的描述,指明算子的计算方法和步骤。 2. 计算逻辑开发完成后,开发者可调用Auto Schedule接口,启动自动调度,自动调度时TBE会根据计算类型自动选择合适的调度模板,完成数据切块和数据流向的划分,确保在硬件执行上达到最优。 3. Auto Schedule调度完成后,会生成类似于TVM的I R(Intermediate Representation)的中间表示。 4. 编译优化(Pass)会对算子生成的IR进行编译优化,优化的方式有双缓冲(Double Buffer)、流水线(Pipeline)同步、内存分配管理、指令映射、分块适配矩阵计算单元等。 5. 算子经Pass处理后,由CodeGen生成类C代码的临时文件,这个临时代码文件可通过编译器生成算子的实现文件,可被网络模型直接加载调用。 #### 1.3.2 DSL计算接口 TBE DSL提供的计算接口主要涵盖向量运算,包括Math、NN、Reduce、卷积、矩阵计算等接口。 ## 2. 算子开发流程介绍 算子开发通常包括以下步骤: * 环境准备:配置MindStudio算子开发环境 * 算子分析:明确算子的功能及数学表达式,选择算子开发方式 * 工程创建:利用MindStudio创建算子工程 * 算子原型定义:规定在昇腾AI处理器上可运行算子的约束 * 算子代码实现:使用DSL或TIK实现算子 * 算子信息库定义:规定算子在昇腾AI处理器上的具体实现规格 * 算子UT测试:测试算子代码的正确性 * 算子工程编译:编译出可直接安装的自定义算子run包 * 算子工程部署:将自定义算子部署到opp算子库 * 算子ST测试:在真实的硬件环境中,使用离线模型验证算子功能的正确性 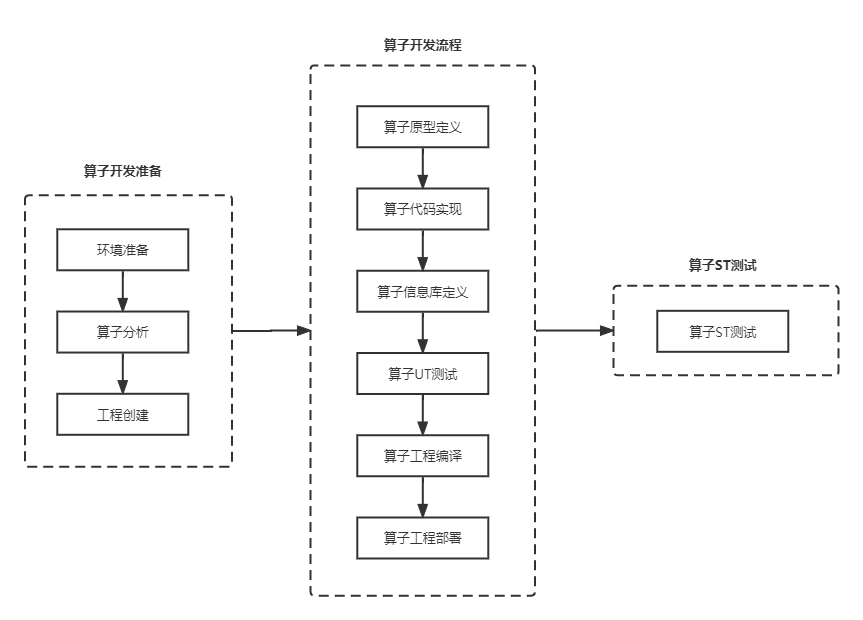图4:算子开发流程介绍## 3.算子分析 进行算子开发前,开发者应首先进行算子分析,算子分析包含:明确算子的功能及数学表达式,选择算子开发方式(DSL方式或者TIK方式),最后细化并明确算子规格,分析流程如下所示: 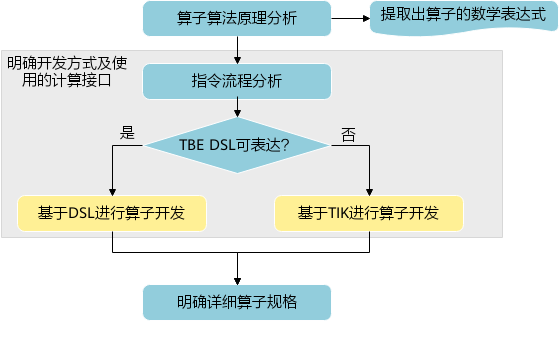图5:创建工程1#### 3.1分析算子算法原理,提取算子的数学表达式 当$x=\left[x_{1}, x_{2}, \cdots, x_{n}\right]^{\mathrm{T}}$时那么$x$的$p$范数为 $$ \|x\|_{p}=\left(\left|x_{1}\right|^{p}+\left|x_{2}\right|^{p}+\cdots+\left|x_{n}\right|^{p}\right)^{\frac{1}{p}} $$ 当$p$取0时,表示向量中非零元素的个数(即为其稀疏度) 当$p$取1,2,$\infty$时分别是以下几种最简单的情形 $$ \|x\|_{1}=\left|x_{1}\right|+\left|x_{2}\right|+\ldots+\left|x_{n}\right| $$ $$ \|x\|_{2}=\left(\left|x_{1}\right|^{2}+\left|x_{2}\right|^{2}+\cdots+\left|x_{n}\right|^{2}\right)^{\frac{1}{2}} $$ $$ \|x\|_{\infin}=max(\left|x_{1}\right|,\left|x_{2}\right|,\ldots,\left|x_{n}\right|) $$ #### 3.2明确算子开发方式及使用的计算接口 lp_norm 用到的算子有 + ,幂次方,取最大值,取绝对值 * +:可通过tbe.dsl.vadd接口实现。 * 取最大值:可以通过tbe.dsl.reduce_max接口实现。 * 取绝对值:可以通过tbe.dsl.vabs接口实现 * 幂次方:可以通过tbe.dsl.vmuls, tbe.dsl.exp , tbe.dsl.log 接口实现 通过如上分析,可看出TBE DSL接口满足lp_norm算子的实现要求,所以可优先选择TBE DSL方式进行lp_norm算子的实现。 ## 4.创建Pytorch TBE DSL算子工程 ### 4.1安装和配置环境 按照[MindStudio用户手册](https://www.hiascend.com/document/detail/zh/mindstudio/304/progressiveknowledge/index.html)中的安装指南-->安装操作来安装MindStudio。 除了手册中要求的环境依赖,也需要安装tensorflow,推荐1.15版本 如果采用windows和linux 的公开发环境,需要在本地和远端均配置好所需环境。 ### 4.2创建工程 图6:创建工程1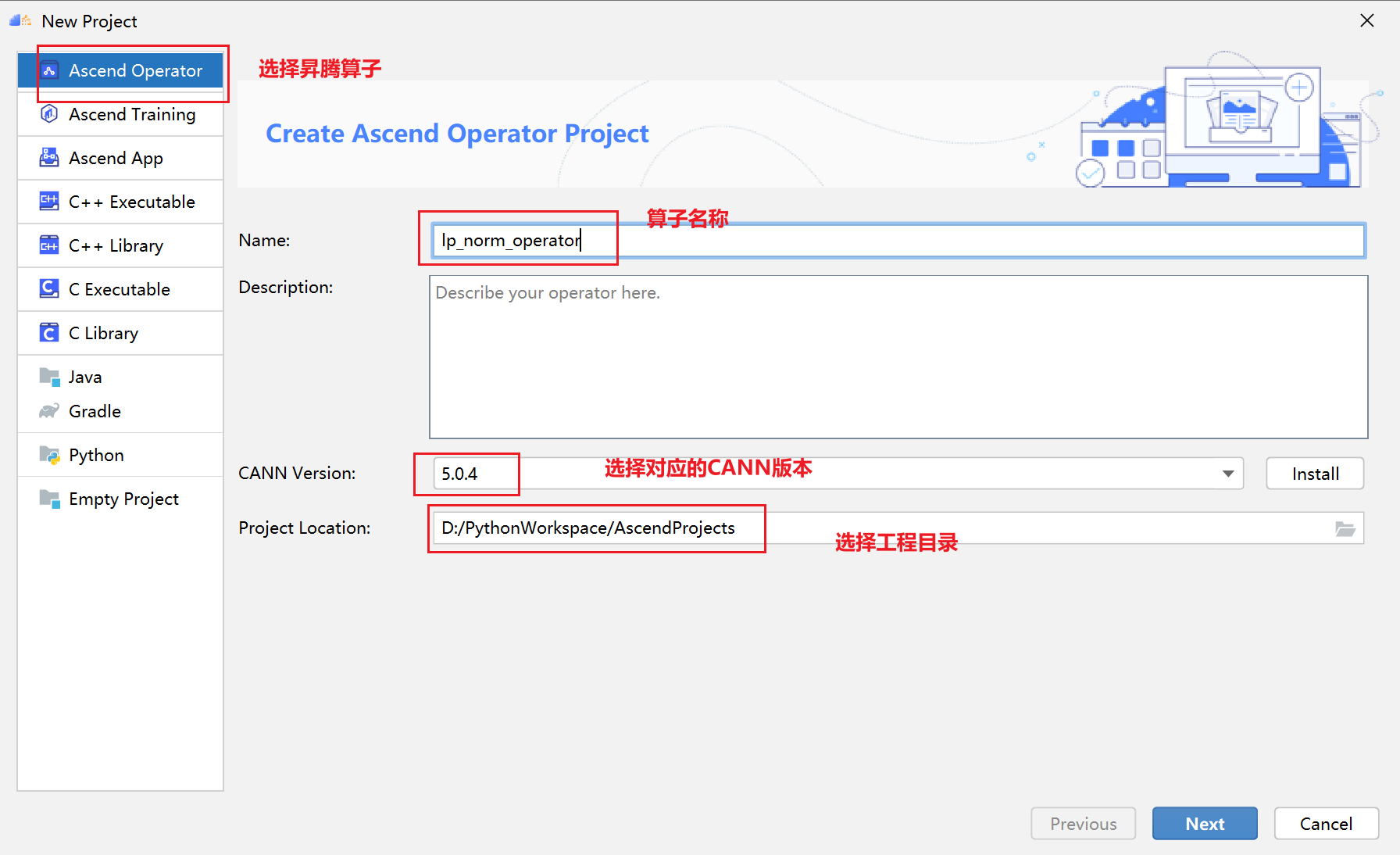图7:创建工程2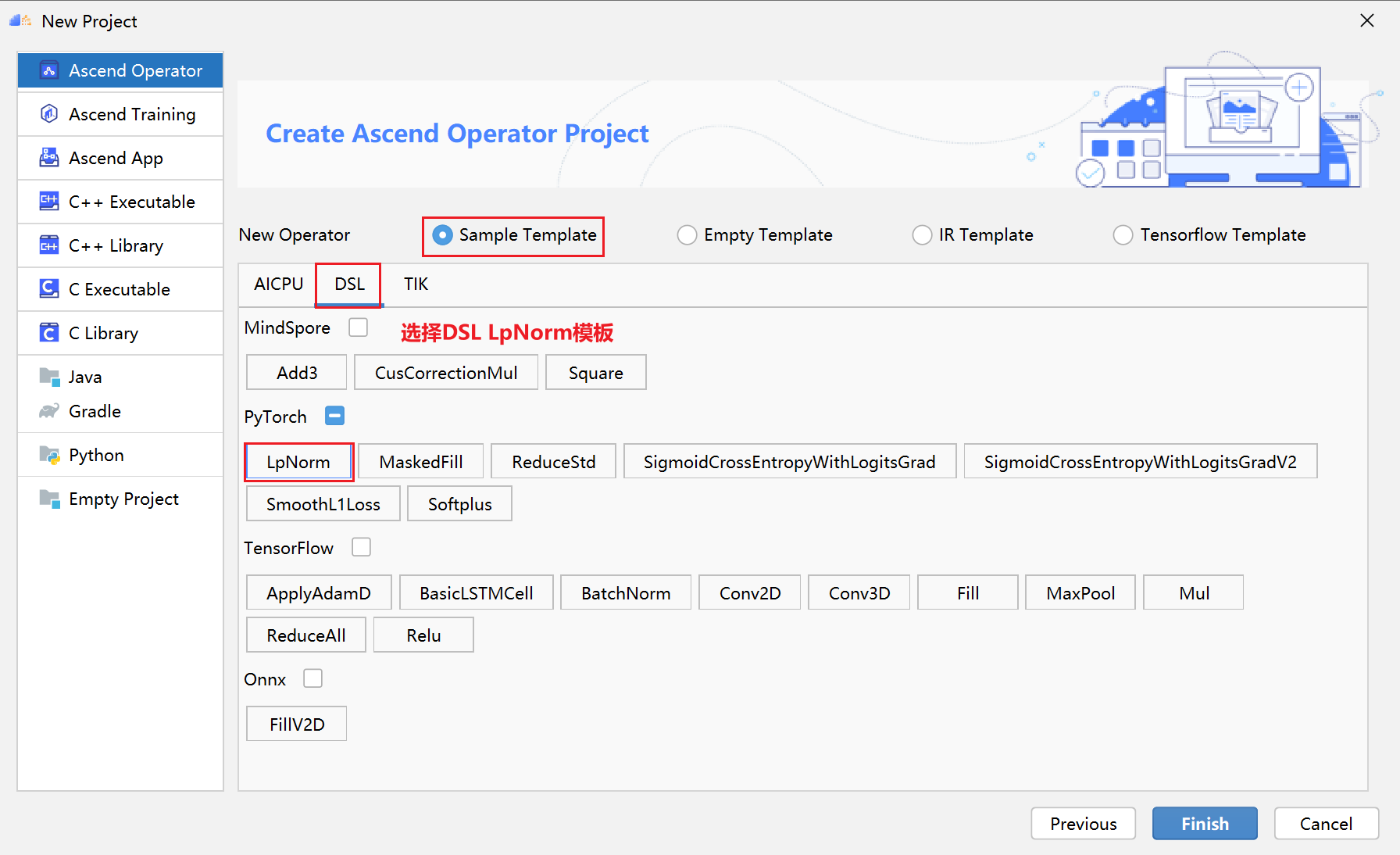图8:创建工程3* 创建工程成功 图9:创建工程成功* 设置python SDK 图10:设置python SDK## 5.算子工程结构和交付件介绍 ``` lp_norm: ├─.idea ├─build //编译生成的中间文件 ├─cmake ├─cmake-build ├─framework ├─log ├─metadef ├─op_proto //算子IR定义文件夹 │ ├─lp_norm.cc //算子IR定义 │ ├─lp_norm.h //算子IR定义 ├─op_tiling ├─out ├─profiling ├─scripts ├─tbe │ ├─impl │ │ ├─dynamic //dynamic operator │ │ ├─util //工具类 │ │ └─lp_norm.py //算子python实现 │ └─op_info_cfg │ └─ai_core │ ├─ascend310 │ ├─ascend710 │ └─ascend910 │ └─lp_norm.ini //ascend910算子信息库文件 ├─testcases //UT、ST测试相关目录 │ ├─st //ST测试相关目录 │ │ ├─lp_norm │ │ │ └─ascend310 │ │ │ └─LpNorm_case_20210527144255.json //ST测试用例 │ └─ut //UT测试相关目录 │ └─ops_test │ └─lp_norm │ └─test_lp_norm_impl.py //UT测试入口及测试用例 ├─third_party //工程第三方依赖 └─CMakeLists.txt //编译规则文件 ``` ### 5.1 lp_norm算子原型 lp_norm算子的原型为pytorch中的torch.norm ```python torch.norm(input, p='fro', dim=None, keepdim=False, out=None, dtype=None) ``` ### 5.2 算子python实现代码 ```python def lp_norm(x, y, p=2, axes=None, keepdim=False, epsilon=1e-12, kernel_name="lp_norm"): # 算子校验 para_check.check_kernel_name(kernel_name) xtype_list = ["float16", "float32"] x_type = x.get("dtype").lower() x_shape = x.get("shape") para_check.check_dtype(x_type, xtype_list) para_check.check_shape(x_shape) p_inf_list = ("inf", "-inf") no_shape = len(x_shape) if isinstance(axes, int): axes = [axes] if axes is None: axes = [i for i in range(no_shape)] if len(axes) == 0: axes = [i for i in range(no_shape)] input_data = tvm.placeholder(x_shape, dtype=x_type, name="input_data") abs_data = tbe.vabs(input_data) #对所有输入取绝对值 # 对p分情况 if (p in p_inf_list) or (p == _CONST_INF) or (p == -_CONST_INF - 1): res = lp_norm_inf_compute(abs_data, x_type, y, p, axes, keepdim, kernel_name) elif p == 0: res = lp_norm0_compute(abs_data, x_type, y, axes, keepdim, kernel_name) elif p == 1: res = lp_norm1_compute(abs_data, x_type, y, axes, keepdim, kernel_name) elif p == 2: res = lp_norm2_compute(abs_data, x_type, y, axes, keepdim, kernel_name) else: res = lp_norm_compute(abs_data, x_type, y, p, axes, keepdim, kernel_name) if x_type == "float16" and float(epsilon) <= _CONST_EPSILON_FP16: std_no = tvm.const(_CONST_EPSILON_FP16, dtype=x_type) else: std_no = tvm.const(float(epsilon), dtype=x_type) res = tbe.vmaxs(res, std_no) # 自动调度 with tvm.target.cce(): schedule = tbe.auto_schedule(res) # 算子编译 config = {"name": kernel_name, "tensor_list": [input_data, res]} tbe.cce_build_code(schedule, config) ``` * 无穷范数的计算 $$ \|x\|_{\infin}=max(\left|x_{1}\right|,\left|x_{2}\right|,\ldots,\left|x_{n}\right|) $$ ```python if (p == "inf") or (p == _CONST_INF): res = tbe.reduce_max(abs_x, axis=axes, keepdims=keepdim, priority_flag=True) #对所有值取最大值 else: # p is "-inf" res = tbe.reduce_min(abs_x, axis=axes, keepdims=keepdim, priority_flag=True) #当p为-inf对所有值取最小值 ``` * 0范数的计算 * 0范数表示向量中非零元素的个数(即为其稀疏度) ```python zero_tensor = tbe.vmuls(abs_x, tvm.const(0, dtype=abs_x.dtype)) one_tensor = tbe.vadds(zero_tensor, tvm.const(1, dtype=abs_x.dtype)) ele_tensor = tbe.vcmpsel(abs_x, zero_tensor, 'ne', one_tensor, zero_tensor) res = tbe.sum(ele_tensor, axis=axes, keepdims=keepdim) ``` * 1范数的计算 $$ \|x\|_{1}=\left|x_{1}\right|+\left|x_{2}\right|+\ldots+\left|x_{n}\right| $$ ```python res = tbe.sum(abs_x, axis=axes, keepdims=keepdim) #对所有值求和 ``` * 2范数的计算 $$ \|x\|_{2}=\left(\left|x_{1}\right|^{2}+\left|x_{2}\right|^{2}+\cdots+\left|x_{n}\right|^{2}\right)^{\frac{1}{2}} $$ ```python pow_x = tbe.vmul(abs_x, abs_x) #求平方 sum_pow = tbe.sum(pow_x, axis=axes, keepdims=keepdim) #求和 res = tbe.vsqrt(sum_pow, priority_flag=1) #求1/2次方 ``` * p范数的计算 $$ \|x\|_{p}=\left(\left|x_{1}\right|^{p}+\left|x_{2}\right|^{p}+\cdots+\left|x_{n}\right|^{p}\right)^{\frac{1}{p}} $$ ```python prod_x = abs_x for p_ix in range(1, p): #求p次方 prod_x = tbe.vmul(prod_x, abs_x) sum_prod_x = tbe.sum(prod_x, axis=axes, keepdims=keepdim) #求和 # 将x的p次方转化 x^p --> exp(log(x)/p) if "910" in _CCE_PLAT: log_sum_x = tbe.vlog(sum_prod_x, priority_flag=1) #取对数 else: log_sum_x = tbe.vlog(sum_prod_x) zero_tensor = tbe.vmuls(log_sum_x, tvm.const(0, dtype=log_sum_x.dtype)) p_tensor = tbe.vadds(zero_tensor, tvm.const(p, dtype=log_sum_x.dtype)) div_log_x = tbe.vdiv(log_sum_x, p_tensor) #除以p exp_div_x = tbe.vexp(div_log_x) #e的幂次方 ``` ## 6.介绍算子原型库、算子信息库代码 算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出和属性信息,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。网络模型生成时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。 算子的IR用于进行算子的描述,包括算子输入输出信息,属性信息等,用于把算子注册到算子原型库中。 算子的IR需要在算子的工程目录的/op_proto/算子名称.h 和 /op_proto/算子名称.cc文件中进行实现。 ### 6.1算子 IR 头文件.h 注册代码实现 ```c #ifndef GE_OP_LP_NORM_H #define GE_OP_LP_NORM_H //头文件 #include "graph/operator_reg.h" #include "graph/operator.h" namespace ge { // 原型注册 REG_OP(LpNorm) .INPUT(x, TensorType({DT_FLOAT16, DT_FLOAT})) .OUTPUT(y, TensorType({DT_FLOAT16, DT_FLOAT})) .ATTR(p, Int, 2) .ATTR(axes, ListInt, {}) .ATTR(keepdim, Bool, false) .ATTR(epsilon, Float, 1e-12) .OP_END_FACTORY_REG(LpNorm) } // namespace ge #endif // GE_OP_LP_NORM_H ``` ### 6.2 算子IR定义的 .cc 注册代码实现 IR实现的cc文件中主要实现如下两个功能: * 算子参数的校验,实现程序健壮性并提高定位效率。 * 根据算子的输入张量描述、算子逻辑及算子属性,推理出算子的输出张量描述,包括张量的形状、数据类型及数据排布格式等信息。这样算子构图准备阶段就可以为所有的张量静态分配内存,避免动态内存分配带来的开销。 ##### 6.2.1实现InferShape方法 InferShape流程负责推导TensorDesc中的dtype与shape,推导结束后,全图的dtype与shape的规格就完全连续了。 如果生成网络模型时产生的GE Dump图“ge_proto_000000xx_after_infershape.txt”中存在dtype与shape规格不连续的情况,说明InferShape处理有错误。 ```c //实现inferShape方法 IMPLEMT_COMMON_INFERFUNC(LpNormInfer) { auto tensor_input = op.GetInputDesc("x"); Shape x_shape = tensor_input.GetShape(); DataType x_type = tensor_input.GetDataType(); Format x_format = tensor_input.GetFormat(); size_t dim_num = op.GetInputDesc("x").GetShape().GetDimNum(); std::vector<int64_t> x_axes = {}; std::vector<int64_t> new_axes = {}; std::vector<int64_t> y_vec = {}; std::vector<int64_t> x_dim_members = x_shape.GetDims(); bool keep_dim = false; int32_t indice; (void)op.GetAttr("keepdim", keep_dim); if (x_axes.empty()) { for (int32_t i = 0; i < dim_num; i++) { new_axes.push_back(i); } } else { for (int32_t i = 0; i < x_axes.size(); i++) { indice = (x_axes<i> < 0) ? (x_axes<i> + dim_num) : x_axes<i>; new_axes.push_back(indice); } } for (int32_t i = 0; i < x_shape.GetDimNum(); i++) { if (find(new_axes.begin(), new_axes.end(), i) != new_axes.end()) { if (keep_dim == true) { y_vec.push_back(1); } } else { y_vec.push_back(x_dim_members<i>); } } ge::Shape output_shape(y_vec); // update output desc ge::TensorDesc output_desc = op.GetOutputDesc("y"); output_desc.SetShape(output_shape); output_desc.SetDataType(x_type); output_desc.SetFormat(x_format); (void)op.UpdateOutputDesc("y", output_desc); return GRAPH_SUCCESS; } ``` ##### 6.2.2实现verify方法 Verify函数主要校验算子内在关联关系,例如对于多输入算子,多个tensor的dtype需要保持一致,此时需要校验多个输入的dtype,其他情况dtype不需要校验。 ```c // 实现verify方法 IMPLEMT_VERIFIER(LpNorm, LpNormVerify) { return GRAPH_SUCCESS; } 注册InferShape方法与Verify方法 ``` ```c // 注册infershape方法和Verify方法 COMMON_INFER_FUNC_REG(LpNorm, LpNormInfer); VERIFY_FUNC_REG(LpNorm, LpNormVerify); ``` ### 6.3算子信息库 算子信息库作为算子开发的交付件之一,主要体现算子在昇腾AI处理器上的具体实现规格,包括算子支持输入输出dtype、format以及输入shape等信息。网络运行时,FE会根据算子信息库中的算子信息做基本校验,选择dtype,format等信息,并根据算子信息库中信息找到对应的算子实现文件进行编译,用于生成算子二进制文件。 如图为Ascend910的算子信息库文件 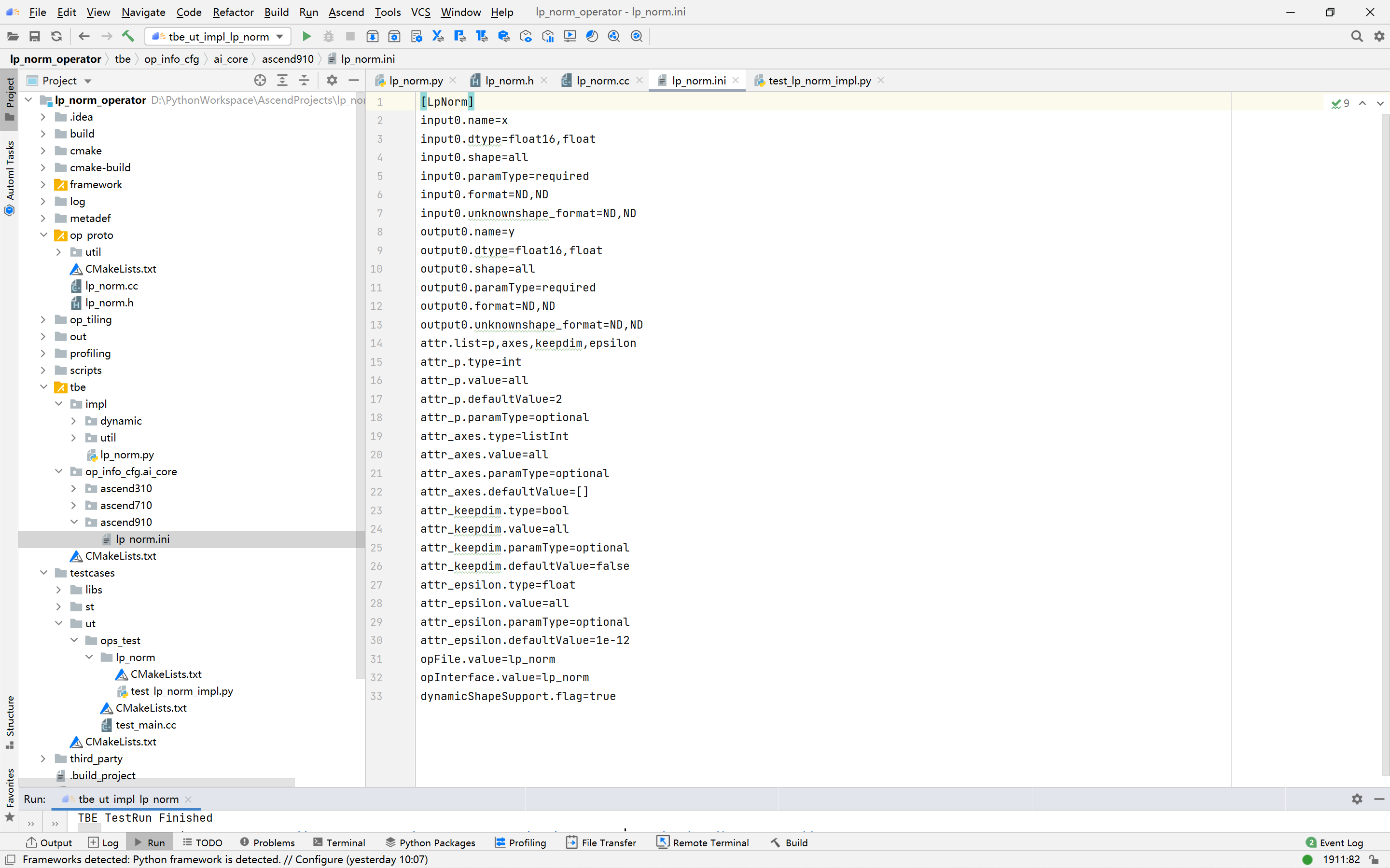图11:Ascend910的算子信息库文件## 7.算子编译 算子交付件开发完成后,需要对算子工程进行编译,生成自定义算子安装包*.run,详细的编译操作包括: * 将TBE算子信息库定义文件*.ini编译成aic-{soc version}-ops-info.json * 将原型定义文件*.h与*.cc编译成libcust_op_proto.so。 * 将TensorFlow/Caffe/Onnx算子的适配插件实现文件*.h与*.cc编译成libcust_{tf|caffe|onnx}_parsers.so。 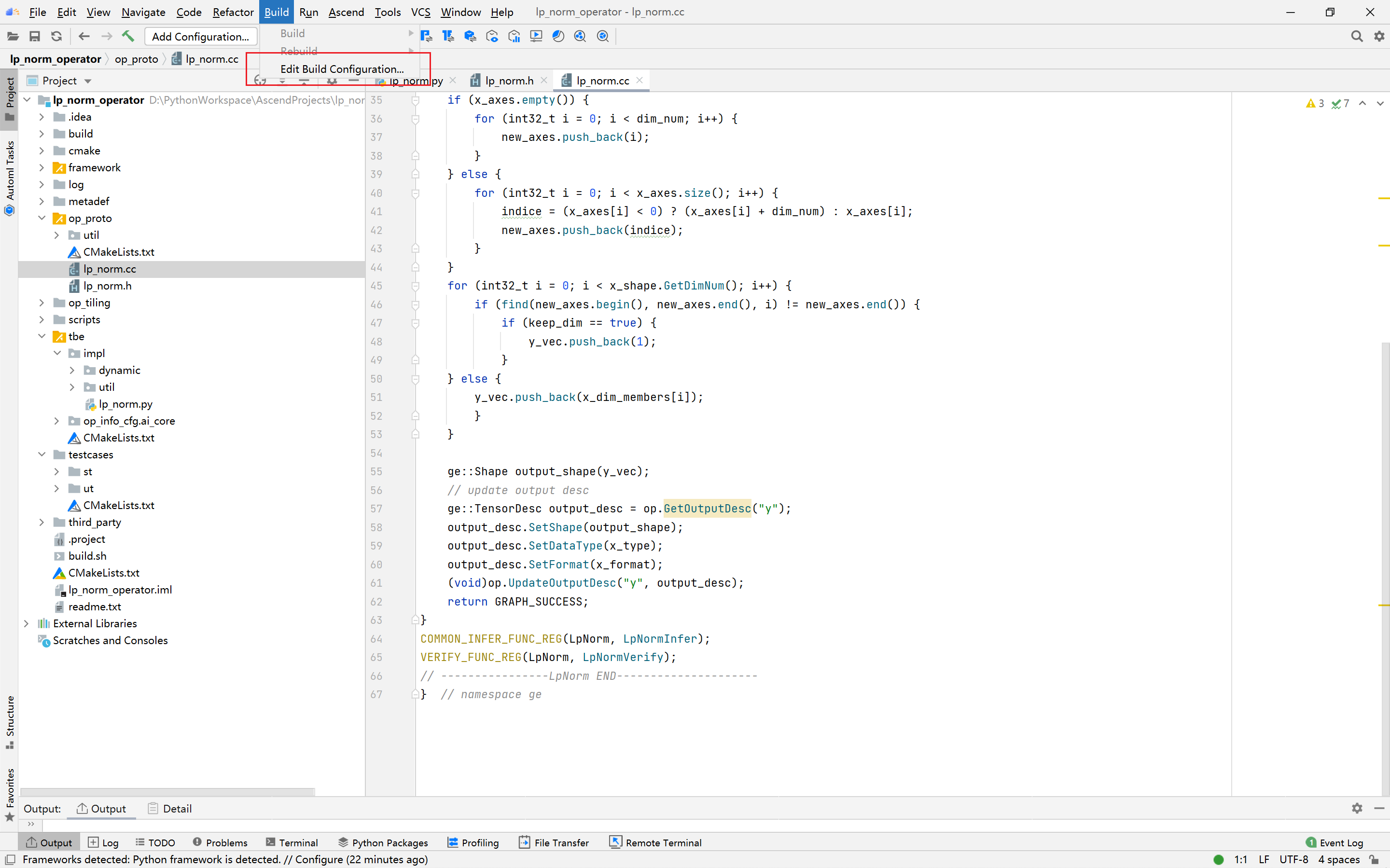图12:算子编译* 选择Remote Build 进行远程部署 * 配置环境变量ASCEND_TENSOR_COMPILER_INCLUDE=/usr/local/Ascend/ascend-toolkit/latest/include * 点击执行Build 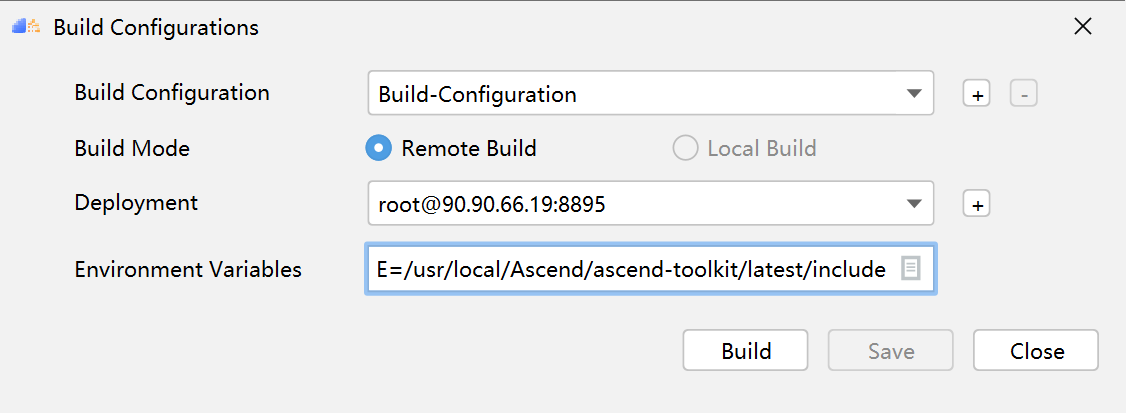图13:算子编译设置| 参数 | 说明 | | --------------------- | :----------------------------------------------------------- | | Build Configuration | 编译配置名称,默认为Build-Configuration | | Build Mode | 编译方式。Remote Build:远端编译。Local Build:本地编译。 | | Deployment | Remote Build模式下显示该配置。可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 | | Environment variables | Remote Build模式下显示该配置。配置环境变量。 | | Target OS | Local Build模式下显示该配置。针对Ascend EP:选择昇腾AI处理器所在硬件环境的Host侧的操作系统。针对Ascend RC:选择板端环境的操作系统。 | | Target Architecture | Local Build模式下显示该配置。选择Target OS的操作系统架构。 | 编译成功之后会在在cmake-build目录下生成自定义算子安装包*.run 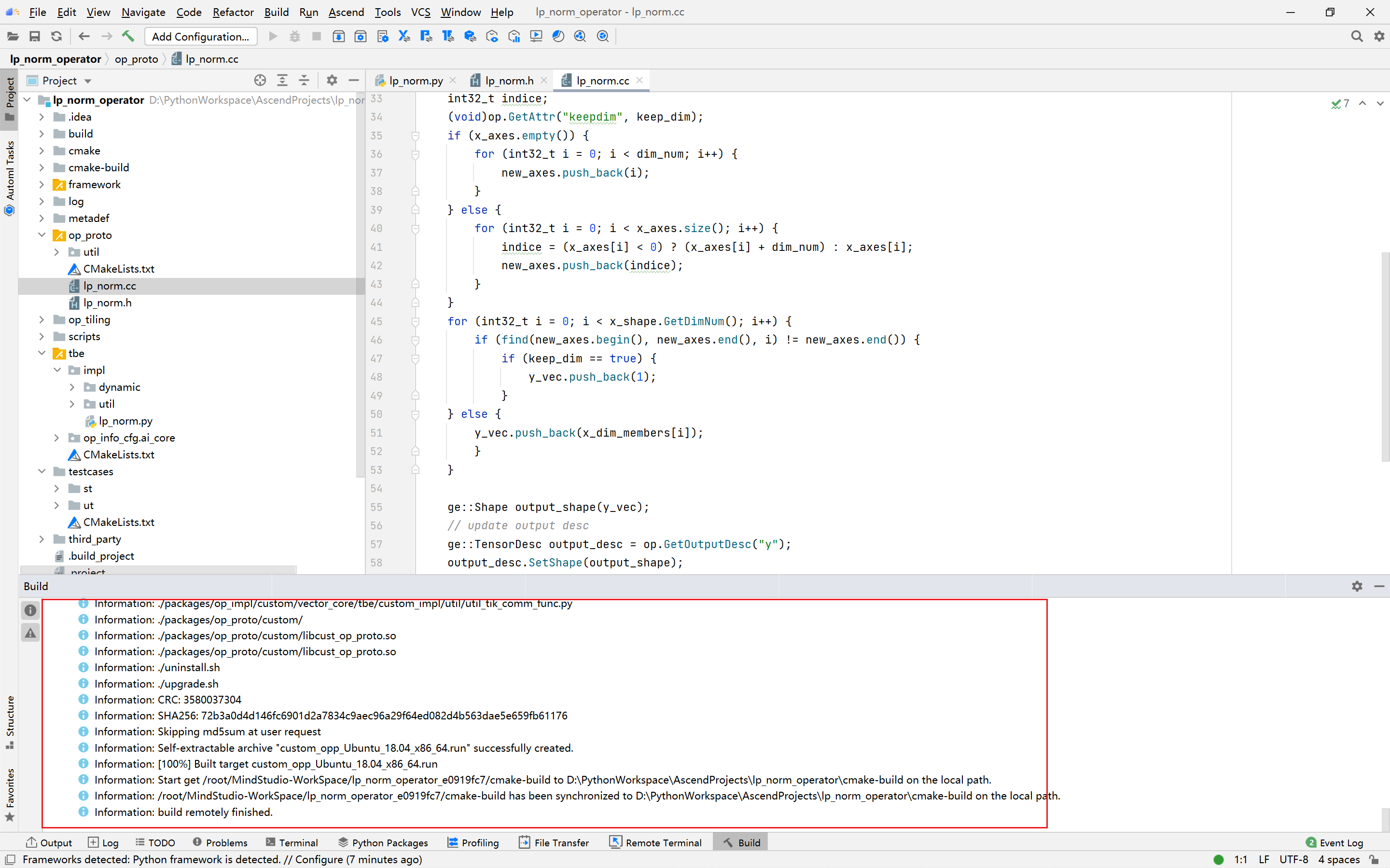图14:算子编译成功## 8.算子部署 算子部署指将算子编译生成的自定义算子安装包(*.run)部署到OPP算子库中。在推理场景下,自定义算子直接部署到开发环境的OPP算子库。在训练场景下,自定义算子安装包需要部署到运行环境的OPP算子库中。 * 选择Ascend->Operator Deployment * 选择Operator Deploy Remotely 进行远程部署 * 设置Environment Variables * ASCEND_OPP_PATH=/usr/local/Ascend/ascend-toolkit/latest/opp * 点击Operator deploy进行部署 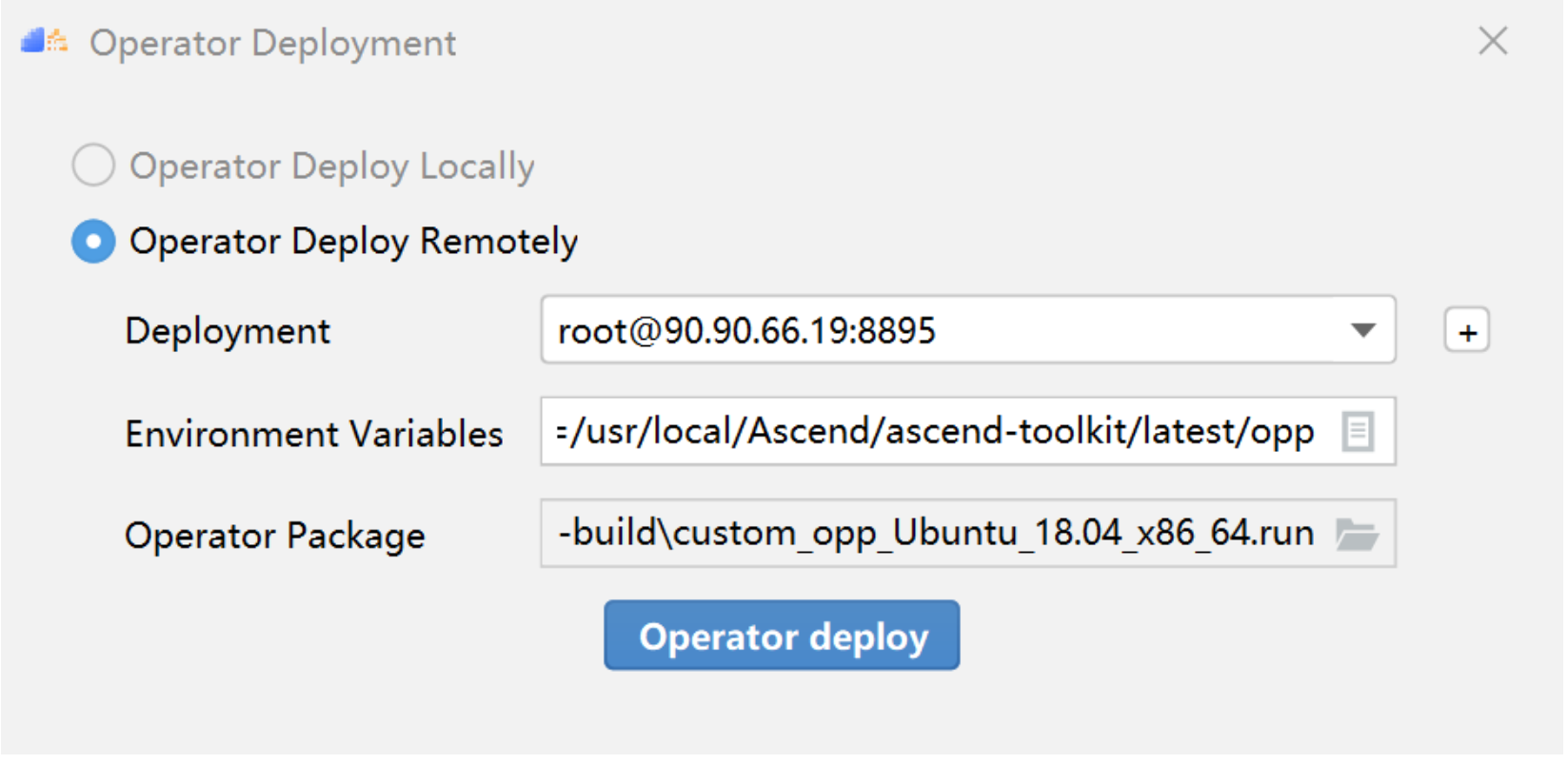图15:算子部署参数设置| 参数 | 说明 | | --------------------- | :----------------------------------------------------------- | | Build Configuration | 编译配置名称,默认为Build-Configuration | | Deployment | Remote Build模式下显示该配置。可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 | | Environment variables | Remote Build模式下显示该配置。配置环境变量。 | 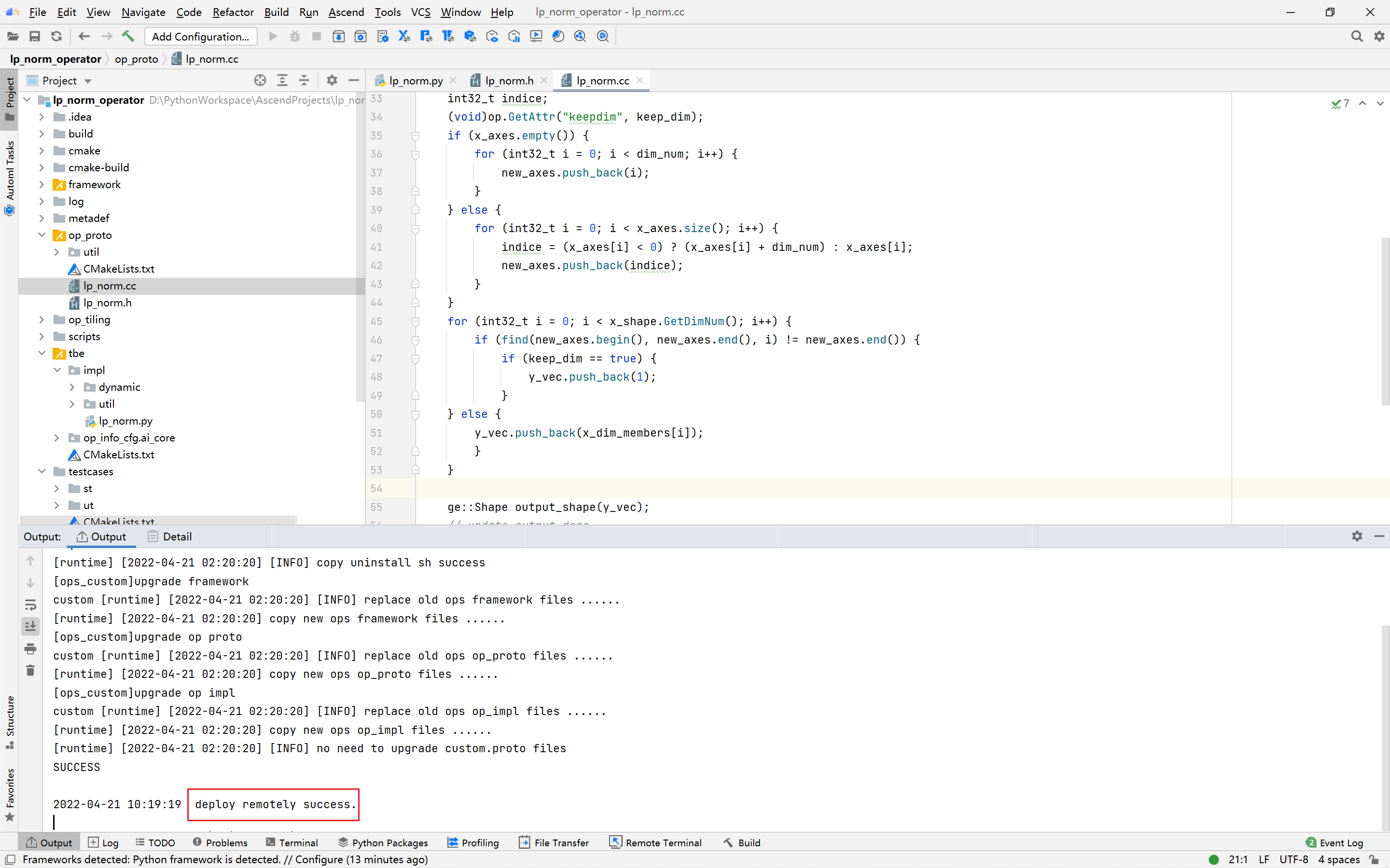图16:算子部署成功
-
本次实验的视频可以在哔哩哔哩查看,链接如下:https://www.bilibili.com/video/BV1iA4y1f7o1/ 在上个帖子中我们已经完成了Pytorch环境的搭建,接下来进行模型开发的过程。 ## 2、 模型简介 本次实验我们的目标是在MindStudio上使用ResNet进行图像分类任务。ResNet曾在ILSVRC2015比赛中取得冠军,在图像分类上具有很大的潜力。 ResNet的主要思想是在网络中增加了直连通道,使得原始输入信息能够直接传输到后面的层中,ResNet的残差块的结构如下图所示。 ResNet会重复将残差块串联,形成多层网络。一般常见的ResNet根据层数的大小有ResNet-18,ResNet-34,ResNet-50,ResNet-101等等。后面的数字代表网络的层数。在本次实验中,我们选用的数据集是tiny-imagenet。该数据集是斯坦福大学提供的图像分类数据集,其中包含200个类别,每个类别包含500张训练图像,50张验证图像及50张测试图像。可以在此[链接](http://cs231n.stanford.edu/tiny-imagenet-200.zip)下载。因为数据集不是很大,这里我们选用的模型是较小的ResNet-18。 ## 3、训练工程创建,工程功能以及相关菜单介绍 ### 3.1 训练过程创建 - 打开MindStudio,点击New Project,进入新建工程界面。 - 选择Ascend Training。填入项目名。首次新建训练工程时,需要配置CANN的版本。点击install。 - 首先,点击 + 配置远程连接,然后根据选项填入自己服务器的ip地址、端口号、用户名和密码等。 - 配置Remote CANN location。该参数需要填入ascend-toolkit在服务器上的路径地址。在这里,我们toolkit的路径如下:/usr/local/Ascend/ascend-toolkit/5.0.4/。点击finishing进行配置。初次配置时时间稍长,请耐心等待。 - 点击Next,选择Pytorch Project。 - 点击Finish,完成工程创建,进入工程主界面。 - 配置Module SDK,便于编码。 右键点击项目名,选择Open Module Settings。 因为我们的模型任务都是基于Python编程的,本机环境也是Python3.7.5,因此我们选择Python 3.7 ### 3.2 工程功能及相关菜单介绍 MindStudio是基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,具有非常丰富的功能。在该IDE上可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。接下来我们简单介绍MindStudio中我们会用到的功能。 新建Pytorch工程后,我们可以进行普通Pytorch框架下的所有开发任务,如模型构建,模型训练等。还有很多便捷的功能。  如上图所示,MindStudio的菜单栏除了包含IDEA,Pycharm等IDE的File,Edit,View,Navigate,Code,Refactor,Run,Tools,VCS,Windows,Help等常规菜单按钮外。还多出了Ascend的特色菜单按钮。 在该菜单栏下,有很多便捷的功能。其相关选项,对应于上图中用红框表示的图标,可以快速点击使用。具体功能见下表所示。 | 名称 | 功能 | | ---------------- | ------------------------------------------------------------ | | AutoML | AI初学者可以通过AutoML工具结合数据集,生成满足需求的模型 | | Framework Trans | 包含三种工具,X2MindSpore,Pytorch GPU2Ascend,TensorFlow GPU2Ascedn。其功能分别为:将PyTorch脚本文件、ONNX模型文件TensorFlow模型文件转换到MindSpore脚本;将基于GPU训练的Pytorch训练脚本转换到支持NPU训练的脚本;将基于GPU训练的TensorFlow训练脚本转换到支持NPU训练的脚本 | | Model Converter | 将训练好的模型转换为离线模型 | | Model Visualizer | 将转换的模型进行可视化 | | Dump | 精度比对功能 | | System Profiler | 性能采集和分析功能 | ## 4、模型迁移 因为MindStudio是在NPU上进行网络训练的,因此对于基于GPU训练的代码需要进行稍微的修改。 - 首先,将已经在GPU上正常训练的Pytorch训练代码拷贝至新建好的工程目录下。本次实验的代码文件及其实现功能可见下表。 | 文件名 | 功能 | | :--------- | :--------------------------------------------------------: | | config.py | 配置训练的相关参数,如学习率,数据集路径,模型存储路径等等 | | dataset.py | 数据集读入文件 | | main.py | 网络定义以及网络训练的主函数入口 | | train.py | 网络训练 | | test.py | 结果测试文件 | | util.py | 通用函数文件 | | pt2onnx.py | 将pt文件转为onnx模型 | - 代码大致讲解 1)网络构建 ResNet在torchvision中自带有网络架构和预训练的网络参数。在这里我们使用其网络架构代码,并且修改其最后的全连接层(因为分类的物品只有200个类别),并使用预训练的参数来初始化网络,再根据数据集微调。 ```Python import torchvision model = torchvision.models.resnet18(pretrained=True) ## torchvision默认的ResNet输出维度为1000,本次使用的数据集总共只有200个类别,对模型的最后一层进行修改 fc_inputs = model.fc.in_features model.fc = nn.Sequential(nn.Linear(fc_inputs, 200)) ``` PS:如果想要查看ResNet-18的网络构建源码,可以在Pytorch的官方文档中查看:[torchvision.models.resnet — Torchvision 0.12 documentation (pytorch.org)](https://pytorch.org/vision/stable/_modules/torchvision/models/resnet.html#resnet18) 2)数据读入和预处理 我们下载[tiny-imagenet](http://cs231n.stanford.edu/tiny-imagenet-200.zip)后,解压文件后的目录架构如下: ```bash tiny-imagenet-200 ├── train │ ├── class1 │ │ ├── images │ │ │ ├── img1.JPEG │ │ │ ├── img2.JPEG │ │ │ └── ... │ │ └── class1_boxes.txt │ ├── class2 │ │ ├── images │ │ │ ├── img3.JPEG │ │ │ ├── img4.JPEG │ │ │ └── ... │ │ └── class2_boxes.txt │ └── ... ├── val │ ├── images │ │ ├── img5.JPEG │ │ ├── img6.JPEG │ │ └── ... │ └── val_annotations.txt ├── test │ └── images │ ├── img7.JPEG │ ├── img8.JPEG │ └── ... ├── wnids.txt └── words.txt ``` 因为测试集的数据不带有标签,因此我们只使用训练集和验证集的数据。我们需要对数据进行预处理,用于之后的模型训练。新建类TinyImageNet来继承torch.utils.data.Dataset。并在这个类中定义以下函数: create_class_idx_dict_train的作用是遍历训练集的文件目录,获取训练集中的数据总量,赋值到self.len_dataset。同时,统计类别总个数,将各个类别排序,按照从0开始逐渐增大的规律进行类别的重新命名,作为训练数据的标签。 ```python def _create_class_idx_dict_train(self): if sys.version_info >= (3, 5): classes = [d.name for d in os.scandir(self.train_dir) if d.is_dir()] else: classes = [d for d in os.listdir(self.train_dir) if os.path.isdir(os.path.join(train_dir, d))] classes = sorted(classes) num_images = 0 for root, dirs, files in os.walk(self.train_dir): for f in files: if f.endswith(".JPEG"): num_images = num_images + 1 self.len_dataset = num_images; self.tgt_idx_to_class = {i: classes<i> for i in range(len(classes))} self.class_to_tgt_idx = {classes<i>: i for i in range(len(classes))} ``` create_class_idx_dict_val函数与create_class_idx_dict_train函数的功能相同,但是因为数据的目录结构不同,代码也有稍许不同。 ```python def _create_class_idx_dict_val(self): val_image_dir = os.path.join(self.val_dir, "images") if sys.version_info >= (3, 5): images = [d.name for d in os.scandir(val_image_dir) if d.is_file()] else: images = [d for d in os.listdir(val_image_dir) if os.path.isfile(os.path.join(train_dir, d))] val_annotations_file = os.path.join(self.val_dir, "val_annotations.txt") self.val_img_to_class = {} set_of_classes = set() with open(val_annotations_file, 'r') as fo: entry = fo.readlines() for data in entry: words = data.split("\t") self.val_img_to_class[words[0]] = words[1] set_of_classes.add(words[1]) self.len_dataset = len(list(self.val_img_to_class.keys())) classes = sorted(list(set_of_classes)) # self.idx_to_class = {i:self.val_img_to_class[images<i>] for i in range(len(images))} self.class_to_tgt_idx = {classes<i>: i for i in range(len(classes))} self.tgt_idx_to_class = {i: classes<i> for i in range(len(classes))} ``` make_dataset函数将图片和对应的标签作为集合添加到一个列表images中,便于读写。 ```python def _make_dataset(self, Train=True): self.images = [] if Train: img_root_dir = self.train_dir list_of_dirs = [target for target in self.class_to_tgt_idx.keys()] else: img_root_dir = self.val_dir list_of_dirs = ["images"] for tgt in list_of_dirs: dirs = os.path.join(img_root_dir, tgt) if not os.path.isdir(dirs): continue for root, _, files in sorted(os.walk(dirs)): for fname in sorted(files): if (fname.endswith(".JPEG")): path = os.path.join(root, fname) if Train: item = (path, self.class_to_tgt_idx[tgt]) else: item = (path, self.class_to_tgt_idx[self.val_img_to_class[fname]]) self.images.append(item) ``` getitem函数是重写Dataset函数必须重写的函数,其功能是按照idx返回对应的图片和标签。 ```python def __getitem__(self, idx): img_path, tgt = self.images[idx] with open(img_path, 'rb') as f: sample = Image.open(img_path) sample = sample.convert('RGB') if self.transform is not None: sample = self.transform(sample) return sample, tgt ``` 根据参数train的值,TinyImageNet可以分别生成训练集和验证集的数据库。并定义transform,将图片先转为Tensor,再根据平均值和标准差进行归一化。之后分别定义训练集和验证集的DataLoader,将数据按批次读入,方便模型训练。这样我们已经完成了数据读入的所有部分。 ```python dataset_transform = transforms.Compose([ transforms.ToTensor(), transforms.Normalize(mean=cfg.dataset_mean, std=cfg.dataset_std),]) ## 训练数据dataloader def get_train_data(train = True): dataset_train = TinyImageNet(cfg.data_dir, train=train,transform=dataset_transform) data_loader = DataLoader(dataset_train, batch_size=cfg.batch_size, shuffle=train) return data_loader ## 验证数据dataloader def get_val_data(train = False): dataset_train = TinyImageNet(cfg.data_dir, train=train,transform=dataset_transform) data_loader = DataLoader(dataset_train, batch_size=cfg.batch_size, shuffle=train) return data_loader ``` 3)网络训练,主要的训练代码如下所示。首先调用torch.optim 定义Adam优化器optimizer,再将网络的所有参数置于optimizer中。随后按照epoch数进行循环,在每一个批次都进行前向传递,loss值计算,后向传递和参数更新,具体代码如下所示。 ```python ##定义Adam优化器,并将网络的参数都放入优化器中 parameter_list = list(Net.parameters()) optimizer = optim.Adam(parameter_list, lr=cfg.lr, weight_decay=cfg.weight_decay) ##定义loss函数为交叉熵损失函数 criterion = nn.CrossEntropyLoss() for epoch in range(cfg.end_epoch): for step, (image, targets) in enumerate(train_data): image = image.float() image = image.npu() targets = targets.long() targets = targets.npu() optimizer.zero_grad() output = Net(image) loss = criterion(output, targets) ##计算loss值并更新参数 loss.backward() optimizer.step() ``` 4)网络测试。按批次读取验证集中的所有数据,分布统计cnt,corrct,corrct_5的值(cnt,corrct,corrct_5分布记录验证数据总数目,正确分类的数目,top-5正确的数目)。最终打印准确率和top-5。 ```python corrct,cnt,corrct_5 = 0,0,0 for step, (image, targets) in enumerate(test_data): image = image.float() image = image.npu() targets = targets.npu() output = Net(image).cpu() targets = targets.cpu() for i in range(len(output)): index = torch.argmax(output<i>) if index==targets<i>: corrct+=1 _,t5 = torch.topk(output<i>,5) for id in t5: if id == targets<i>: corrct_5+=1 cnt+=1 print("The Accuracy is :{} ".format(corrct/cnt)) print("The top5 is :{}".format(corrct_5/cnt)) ``` - 使用[**PyTorch GPU2Ascend** ](https://gitee.com/link?target=https%3A%2F%2Fsupport.huaweicloud.com%2Fusermanual-mindstudio304%2Fatlasms_02_0117.html)工具进行自动迁移。 有多种方法可以打开Pytorch GPU2Ascend。 1)选择菜单栏Ascend/Framework Trans/Pytorch GPU2Ascend。见3.2菜单栏介绍。 2)右键点击项目名,选择Pytorch GPU2Ascend。 3)点击菜单栏按钮。如图中红框所示  - 进如Pytorch GPU2Ascend界面,进行参数配置 如图,选择输出的文件目录(需要与输入路径位于同一驱动器下:如同在C盘),然后点击Transplant进行转换。 其他参数的功能如下表: | 参数 | 参数说明 | | ------------------------ | ------------------------------------------------------------ | | Input Path | 要进行转换的原始脚本文件所在文件夹路径或文件路径。单击文件夹图标选择目录。必选。 | | Output Path | 脚本转换结果文件输出路径。单击文件夹图标选择目录。必选。 | | Custom Rule | 是否打开自定义转换规则。可选。 | | Rule File | **“Custom Rule”**开启后此参数才会体现。单击文件夹图标选择用户自定义通用转换规则的json文件路径。该json文件主要包括函数参数修改、函数名称修改和模块名称修改三部分。必选。 | | Distributed Rule | 将GPU单卡脚本转换为NPU多卡脚本,此参数仅支持使用torch.utils.data.DataLoader方式加载数据的场景。可选。 | | Main File | "Distributed Rule"开启后此参数才会体现。单击文件夹选择训练脚本的入口python文件。必选。 | | Target Model | "Distributed Rule"开启后此参数才会体现。目标模型变量名,默认为'model',可选。 | | Replace Unsupported APIs | 用功能相似的API替换某些不支持的API,但有可能导致准确性和性能下降。可选。 | - 转换完成后,除了包含迁移后的代码文件,还会生成相关日志文件msFmkTranspltlog.txt,进行迁移的函数列表文件change_list.csv和当前不支持的操作统计文件unsupported_op.csv。如果存在不支持的函数,我们就需要进行一些人工调整。在本次实验中,我们不需要再进行人工修改。 ## 5、执行训练/评估 ### 5.1 模型训练 - 配置运行文件,点击左上角三角形左侧的箭头,选择Edit Configurations。配置界面如下图: 各个参数的功能见下表: | 参数 | 参数说明 | | --------------------- | ------------------------------------------------------------ | | Name | 工程名称,用户自行配置。名称必须以字母开头,数字或字母结尾,只能包含字母、数字、中划线和下划线,且长度不能超过64个字符。 | | Executable | 训练工程中的执行入口文件。 | | Run Mode | 运行环境选择。选择“Remote Run”或“Local Run”,默认为“Remote Run”。 | | SSH Connection | 远程训练服务器地址,在“File > Settings... > Tools > SSH Configurations”中配置。 | | Command Arguments | 训练工程执行参数。 | | Environment Variables | 训练工程环境变量。 | 在模型训练时,是在远端服务器环境完成的,我们的运行文件为main.py。因为我们的参数已经在config.py中配置好了,因此Command Argument不需要填写。点击OK完成配置。 - 数据集准备 本次实验我们使用的数据集是tiny Imagenet,可以点击官方下载[链接](http://cs231n.stanford.edu/tiny-imagenet-200.zip)下载。 因为MindStudio的训练任务是在远端服务器上运行的,因此在开始模型训练时,需要首先对本地的文件与远端环境进行同步。为了加快运行时的前期文件同步工作,我们可以将较大的数据集预先上传至服务器中。这里,我们将数据集上传至/root/data/tiny-imagenet-200/路径下。 - 网络训练参数配置。本次训练的所有参数配置都在config.py文件中。学习率,epoch,batchsize可见下图。 - 点击菜单栏的三角形开始训练网络。输出日志会在底部任务台打印出。训练的loss值等信息保存在./loss文件夹下。训练完成后,如果保存的模型参数在工程目录下,会将保存的模型参数文件同步到本地。 ### 5.2 结果评估 如5.1操作,将运行文件更改为test.py。点击run开始运行评估。 本次实验进行的是200个不同物品的分类实验,评判标准使用准确率和top-5的方法。top-5即每次选择前五个概率最高的分类预测,如果这五个中有分类正确的,就判断为分类正确。 运行的实验结果如下图:  实验的最终结果如下表所示 | ACC(%) | Top-5(%) | | -------- | ---------- | | 50.73 | 74.63 | ## 6、导出onnx 在第五步模型训练中,我们获得了参数文件,其路径为./model/ResNet18_5e_5/ResNetEpoch15.pt 我们需要将该模型转换为onnx模型,主要使用的方法是torch.onnx.export,首先加载模型参数,定义输入形状(输入的形状应与训练时的形状相同,但是batchsize可以不同),然后再进行onnx模型转换。其具体的转换方法如下代码所示: ```python ##保存的参数文件路径 path = "./model/ResNet18_5e_5/ResNetEpoch15.pt" model = build_model(path=path) model.eval() print(model) input_names = ["image_input"] output_names = ["outputs"] dummy_input = torch.randn(1, 3, 64, 64) torch.onnx.export(model, dummy_input, "resnet18.onnx", input_names=input_names, output_names=output_names, opset_version=11) ``` 这里,我们重新配置运行文件为pt2onnx.py,点击运行。运行完毕后,在工程目录下生成resnet18.onnx文件。 得到onnx模型后,我们可以继续将该模型转换为om模型,这样就可以在Ascend310上进行推理任务了。 这里我们可以利用MindStudio的模型转换工具进行转换。点击菜单栏上方的模型转换按钮。  进入模型转换界面,选择之前导出的onnx格式文件。可以选择输出目录。这里我们只需要选择要转换的onnx模型,填入模型名字,其余参数默认即可。 上述参数对应的功能见下表 | 参数 | 功能 | | --------------------------------------- | ------------------------------------------------------------ | | CANN Machine(仅Windows系统支持此参数) | 自动填充。远程连接ADK所在环境的SSH地址,表现格式为*username@localhost:端口号*。 | | Model File | 模型文件。必填。该模型文件需要取消其他用户写的权限。有两种选择方式:单击右侧的文件夹图标,在后台服务器路径选择需要转化的模型文件并上传。 在参数后面的输入框中自行输入模型文件在后台服务器的路径,包括模型文件名称后缀 | | Model Name | 模型文件名称,必填。选择模型文件后,该参数会自动填充,用户可以根据需要自行修改名称,要求如下:只支持a-z、A-Z、0-9、下划线以及短划线的组合,最多支持64个字符。如果模型转换的输出路径已经存在相同名称模型文件,单击“Next”后会提示覆盖原有文件或重命名当前Model Name的信息,用户根据实际情况选择 | | Target SoC Version | 模型转换时指定芯片型号。请根据板端环境具体芯片形态进行选择。 | | Input Format | 输入数据格式。 当原始框架是MindSpore、ONNX时,取值为NCHW。 | | Input Nodes | 模型输入节点信息。若原始框架类型为Caffe、ONNX,支持的数据类型为FP32、FP16、UINT8 | | Shape | 模型输入的shape信息 | | Type | 指定输入节点的数据类型 | | Output Nodes | 指定输出节点信息。单击“Select”在弹出的网络拓扑结构中,选中某层节点,右击选择“Select”,该层变成蓝色,单击“OK”后,在“Output Nodes”参数下面会看到标记层的算子,右击选择“Deselect”取消选中。 | | Load Configuration | 导入上次模型转换的配置文件。 | 同时点击右侧的眼睛,还可以对模型进行可视化。 一直点击Next,最后点击finish,完成模型转换。 ## 7、FAQ 1) 在进行pytorch编译执行bash build.sh --python=3.7报错怎么办? 请检查上一步的git submodule update --init --recursive命令是否出现报错。每次出现报错时应把报错的文件夹删除后重新运行git submodule sync 和git submodule update --init --recursive命令。建议运行完成后检查下每一个./pytorch/pytorch/third_party/目录下的每一个文件夹是否有空文件夹。 删除文件时要看清楚完整的文件夹路径,比如说报错的路径“/third_party/benchmark/”,其完整路径可能是在“pytorch/third_party/onnx/third_party/benchmark/”,不要与“pytorch/third_party/benchmark/”搞混。 2)pip3 install -r requirements.txt时报错torchvision版本未找到。 默认的requirements.txt里的torchvision版本为0.6.0,这是对应x86-64架构的,aarch64架构请改为torchvision==0.2.2.post3。 3)pip安装torch后在import torch时报错ImportError: llibtorch_cpu.so: cannot open shared object file: No such file or directory。 使用命令find / -name libtorch_cpu.so找到libtorch_cpu.so的位置,再建立软连接。如ln -s /usr/local/python3.7.5/lib/python3.7/site-packages/torch/lib/libtorch_cpu.so /usr/lib ## 8、从昇腾论坛获得更多支持 如果上述步骤中大家在实践中仍然遇到其他问题,比如使用自带的脚本迁移工具PyTorch GPU2Ascend最终生成的报告unsupported_op.csv中有需要人工修改的代码,或者遇到其他上述步骤中未能出现的错误,欢迎大家到昇腾论坛中提出自己的问题,在这里有很多技术大拿可以解决你的问题。或者也可以访问昇腾博客,搜索他人的独到见解。 访问昇腾论坛的方法是进行[**昇腾官网**](https://www.hiascend.com/)。选择开发者选项,点击进入昇腾论坛或者昇腾博客。 
-
本次实验的视频可以在哔哩哔哩查看,链接如下:https://www.bilibili.com/video/BV1iA4y1f7o1/ ------------ ResNet模型开发见帖子下:https://bbs.huaweicloud.com/forum/thread-187724-1-1.html ------------ 本次实验在MindStudio上进行,请先按照[教程](https://gitee.com/ascend/docs-openmind/blob/master/guide/mindstudio/cases/tutorials/Windows%E5%AE%89%E8%A3%85MindStudio.md)配置环境,安装MindStudio。 MindStudio的是一套基于华为自研昇腾AI处理器开发的AI全栈开发工具平台,该IDE上功能很多,涵盖面广,可以进行包括网络模型训练、移植、应用开发、推理运行及自定义算子开发等多种任务。MindStudio除了具有工程管理、编译、调试、运行等一般普通功能外,还能进行性能分析,算子比对,可以有效提高工作人员的开发效率。除此之外,MIndStudio具有远端环境,运行任务在远端实现,对于近端的个人设备的要求不高,用户交互体验很好,可以让我们随时随地进行使用。 ## 1、pytorch编译/安装介绍 - 1) 从gitee获取Pytorch源码。 ``` git clone https://gitee.com/ascend/pytorch.git ```  如果clone命令失败,可以使用以下命令重新安装git。 ```bash apt update; apt install git ``` 此外,也可以在Ascend仓库中查看Pytorch源码,链接为:https://gitee.com/ascend/pytorch - 2) 根据需要切换分支并获取PyTorch源代码。 | AscendPytorch版本 | CANN版本 | 支持PyTorch版本 | | ----------------- | ---------- | -------------------------------------- | | 2.0.2 | CANN 5.0.2 | 1.5.0 | | 2.0.3 | CANN 5.0.3 | 1.5.0/1.8.1(1.8.1仅支持resnet50模型) | | 2.0.4 | CANN 5.0.4 | 1.5.0/1.8.1(1.8.1仅支持resnet50模型) | 从上表来看,我们的CANN版本是5.0.4,安装的Pytorch版本为1.5.0。因此切换到2.0.4的分支,具体有哪些分支可在[gitee](https://gitee.com/ascend/pytorch)源码查看。 分别执行以下命令: ```bash cd pytorch git checkout -b 2.0.4.tr5 remotes/origin/2.0.4.tr5 git clone -b v1.5.0 --depth=1 https://github.com/pytorch/pytorch.git ``` <img src="https://bbs-img.huaweicloud.com/data/forums/attachment/forum/20225/13/1652424072169801875.5" alt="torch1.5" style="zoom: 50%;" /> - 3)获取Pytorch被动依赖代码 分别运行以下命令 ``` cd pytorch git submodule sync git submodule update --init --recursive ``` 获取代码时,因为代码是位于GitHub上,受网络影响,获取时间可能较长,并且在获取过程中可能报错,如:  出现这种情况时,我们需要删除该报错路径的文件,重新运行后面两条代码,直到执行git submodule update --init --recursive不再报错为止。如下图没有任何报错信息: <img src="https://bbs-img.huaweicloud.com/data/forums/attachment/forum/20225/13/1652424160961183061.png" alt="git第三方" style="zoom: 50%;" /> PS:重新运行时需要将报错信息的文件夹删除再重新运行,删除时要看清楚完整的文件夹路径,比如说报错的路径“/third_party/benchmark/”有完整路径可能是在“pytorch/third_party/onnx/third_party/benchmark/”,不要与“pytorch/third_party/benchmark/”搞混。 PS:如果一直有某个包克隆失败,我们可以手动添加。如third_party/QNNPACK/克隆失败,我们先在GitHub上搜索QNNPACK,然后再手动下载zip文件,再上传至服务器相关目录并解压。或者使用gitee将其导入,再从gitee中克隆。 - 4)编译生成适配昇腾AI处理器的PyTorch安装包 (1) 回退一级目录,进入pytorch/scrips文件夹下,执行转换脚本,生成适配昇腾AI处理器的全量代码。运行截图如下: ``` cd ../scripts bash gen.sh ``` <img src="https://bbs-img.huaweicloud.com/data/forums/attachment/forum/20225/13/1652424220849707061.png" alt="pytorch转换" style="zoom:67%;" /> (2) 进入pytorch/pytorch目录下,安装依赖库 ``` cd ../pytorch pip3 install -r requirements.txt ``` (3) 运行build.sh,编译生成pytorch的二进制安装包 ```basic bash build.sh --python=3.7 ``` 编译成功如下图,并可以在路径./pytorch/pytorch/dist/下找到对应的whl文件。如果失败,请重新检查第3)步-获取Pytorch被动依赖代码的操作。 <img src="https://bbs-img.huaweicloud.com/data/forums/attachment/forum/20225/13/1652424274395459285.png" alt="编译安装包" style="zoom:67%;" /> - 5)安装Pytorch 进入生成的whl包的目录dist下,使用pip命令进行安装 ``` cd dist pip3 install --upgrade torch-1.5.0+ascend.post3-cp37-cp37m-linux_aarch64.whl ``` PS:因为之前服务器环境存在pytorch,所以截图中先卸载后安装。 - 6)配置环境变量 安装完软件包后,需要配置环境变量才能正常使用昇腾PyTorch 进入pytorch/pytorch目录下,运行env.sh ``` cd ../ source env.sh ``` 这样,我们的pytorch就安装完毕了。
-
PyTorch 框架 AICPU 算子开发全流程(上):https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=187229&page=1&authorid=&replytype=&extra=#pid1461187 PyTorch 框架 AICPU 算子开发全流程(中):https://bbs.huaweicloud.com/forum/thread-187231-1-1.html PyTorch 框架 AICPU 算子开发全流程(下):https://bbs.huaweicloud.com/forumreview/thread-187233-1-1.html 详情指路视频专栏:https://www.bilibili.com/video/BV1nS4y1b7Km ## 八.LogSpace算子UT测试 1. **基本概念** MindStudio提供了基于gtest框架的新的UT测试方案,简化了开发者开发UT测试用例的复杂度。UT(Unit Test:单元测试)是开发人员进行单算子运行验证的手段之一,主要目的是: - 测试算子代码的正确性,验证输入输出结果与设计的一致性。 - UT侧重于保证算子程序能够跑通,选取的场景组合应能覆盖算子代码的所有分支(一般来说覆盖率要达到100%),从而降低不同场景下算子代码的编译失败率。 2. **前提条件** - 需完成自定义算子的开发,包括算子实现代码和算子原型定义。 - 安装CMake,要求版本为3.14及以上,若CMake版本不满足要求,请升级CMake版本。 - MindStudio已连接硬件设备。 3. **操作步骤** - 创建UT测试用例,有以下三种方式。 1. 右键单击算子工程根目录,选择“New Cases > AI CPU UT Case”。 2. 若已经存在了算子的UT测试用例,可以右键单击“testcases”目录。 3. 或者“testcases > ut”目录,选择“New Cases > AI CPU UT Case”,创建UT测试用例。 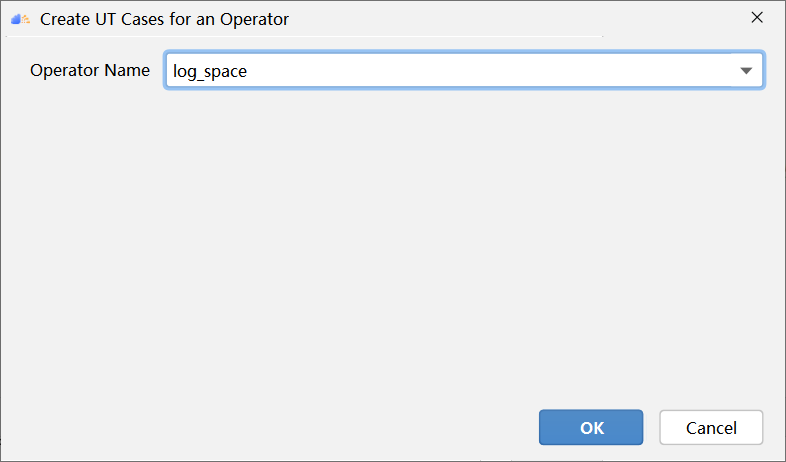 - 在弹出的算子选择界面,选择需要创建UT测试用例的算子,单击OK。创建完成后,会在算子工程根目录下生成testcases文件夹,并生成ut测试用例。 - 编写算子实现代码的UT C++测试用例。 在“testcases/ut/aicpu_test/reshape_cust/test_log_space_impl.cc”文件中,编写算子实现代码的UT C++测试用例,计算出算子执行结果,并取回结果和预期结果进行比较,来测试算子逻辑的正确性。 ``` TEST_F(LogSpaceTest, log_space_test_case_1) { vector> shapes = {{1}, {1}, {1, 10}, {1}}; vector data_types = {DT_FLOAT, DT_FLOAT, DT_FLOAT}; //输入输出数据定义 float input1[1] = {2}; float input2[1] = {10}; float output[10] = {(float)0}; float expect_out[10] = {4.0, 7.4069977, 13.715903, 25.398417, 47.031506, 87.09056, 161.2699, 298.63144, 552.9906, 1024.0}; vector datas = { (void *)input1, (void *)input2, (void *)output }; CREATE_NODEDEF(shapes, data_types, datas); CpuKernelContext ctx(DEVICE); EXPECT_EQ(ctx.Init(node_def.get()), 0); //定义算子 LogSpaceCpuKernel cpuKernel; //计算输入数据 cpuKernel.Compute(ctx); //对比计算输出是否正确 bool compare1 = CompareResult(output, expect_out, 6); EXPECT_EQ(compare1, true); } ``` - 编写算子原型定义的UT C++测试用例。在“testcases/ut/aicpu_test/reshape_cust/test_log_space_proto.cc”文件中,编写算子原型定义的UT C++测试用例,用于定义算子实例、更新算子输入输出并调用InferShapeAndType函数,最后验证InferShapeAndType函数执行过程及结果的正确性。 ``` TEST_F(LogSpaceTest, logspace_test_end_failed) { ge::op::LogSpace LogSpace_op; std::int64_t attr_value = 1; LogSpace_op.SetAttr("dtype", attr_value); std::int64_t num_steps_value = 4; LogSpace_op.SetAttr("steps", num_steps_value); ge::TensorDesc tensorStartDesc; ge::TensorDesc tensorEndDesc; ge::Shape shape0({1}); tensorStartDesc.SetDataType(ge::DT_FLOAT16); tensorStartDesc.SetShape(shape0); tensorStartDesc.SetOriginShape(shape0); LogSpace_op.UpdateInputDesc("start", tensorStartDesc); ge::Shape shape({2,3}); tensorEndDesc.SetDataType(ge::DT_FLOAT16); tensorEndDesc.SetShape(shape); tensorEndDesc.SetOriginShape(shape); LogSpace_op.UpdateInputDesc("end", tensorEndDesc); auto ret = LogSpace_op.VerifyAllAttr(true); EXPECT_EQ(ret, ge::GRAPH_FAILED); } ``` - 运行算子实现文件的UT测试用例。 开发人员可以执行当前工程中所有算子的UT测试用例,也可以执行单个算子的UT测试用例。 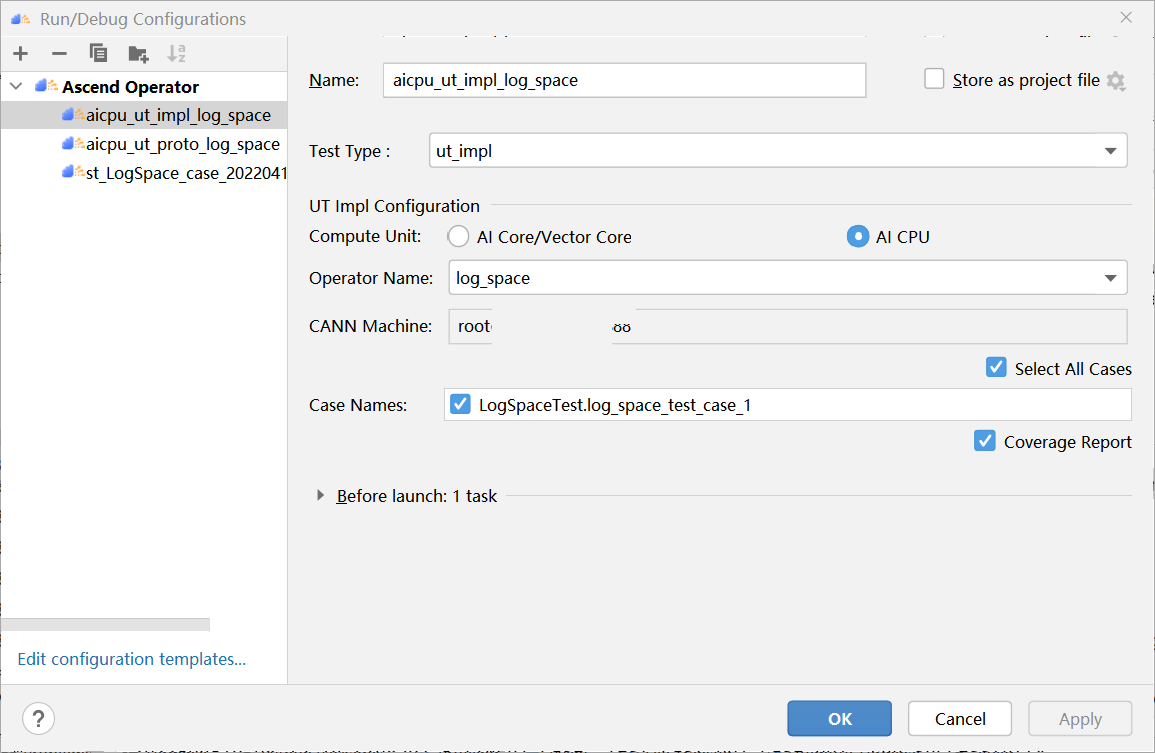 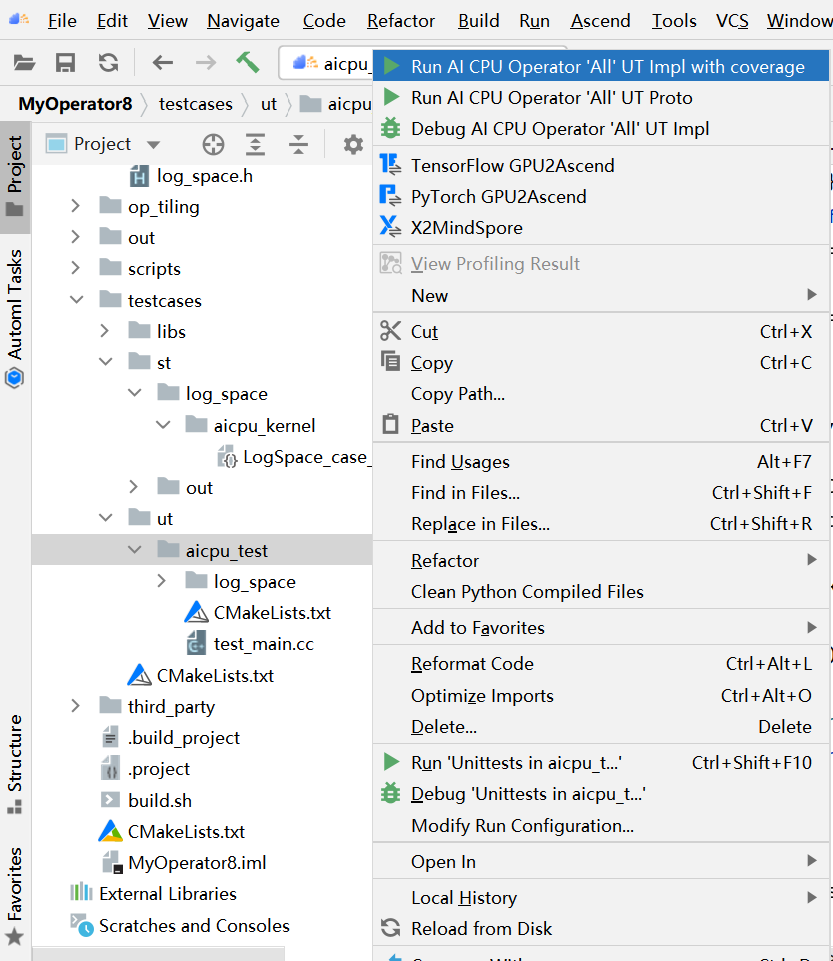 - 右键单击“**testcases/ut/aicpu_test**”文件夹,选择Run AI CPU Operator‘All’UT Impl with coverage,运行整个文件夹下算子实现代码的测试用例。 - 右键单击“**testcases/ut/aicpu_test**算子名称”文件夹,选择Run AI CPU Operator ‘算子名称’ UT Impl with coverage,运行单个算子实现代码的测试用例。 第一次运行时会弹出运行配置页面,请参考配置,然后单击Run。后续如需修改运行配置,请参考修改运行配置。 - **查看运行结果**。 运行完成后,通过界面下方的日志打印窗口,查看运行结果。结果中展示此次一共运行几个用例,如下图。 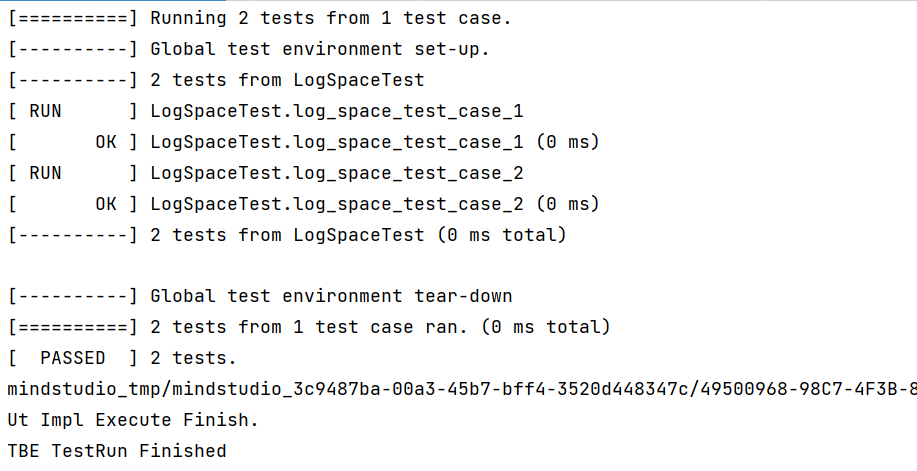表6 UT测试参数配置信息| **参数** | **说明** | | -------------- | ------------------------------------------------------------ | | Name | 运行配置名称,用户可以自定义。 | | Test Type | 选择ut_impl。 | | Compute Unit | 选择计算单元:l AI Core/Vector Core;l AI CPU。选择不同的计算单元可以实现AI Core/Vector Core和AICPU_UT测试配置界面的切换。 | | Operator Name | 选择运行的测试用例。all表示运行所有用例。其他表示运行某个算子下的测试用例。 | | Case Names | 勾选需要运行的测试用例,即算子实现代码的UT C++测试用例。支持全选和全不选所有测试用例。 | ## 九.LogSpace算子ST测试 1. **概述** MindStudio提供了新的ST(System Test)测试框架,可以自动生成测试用例,在真实的硬件环境中,验证算子功能的正确性和计算结果准确性,并生成运行测试报告,包括: - 基于算子信息库生成算子测试用例定义文件。 - 基于算子测试用例定义文件生成不同shape、dtype的测试数据和基于AscendCL的测试用例。 - 编译算子工程并将算子部署到算子库,最后在硬件环境中执行测试用例,验证算子运行的正确性。 - 自动生成运行报表(st_report.json)功能,报表记录了测试用例信息及各阶段运行情况。 - 根据用户定义并配置的算子期望数据生成函数,回显期望算子输出和实际算子输出的对比测试结果,验证计算结果的准确性。 2. **前提条件** - 完成自定义算子的开发,请参见算子代码实现、算子原型定义、算子信息库定义。 - lMindStudio已连接硬件设备。 3. **生成ST测试用例定义文件** - 创建ST测试用例。有以下三种入口: 1) 右键单击算子工程根目录,选择“**New Cases > ST Case**”。 2) 右键单击算子信息定义文件:{工程名}**/cpukernel/op_info_cfg/aicpu_kernel/ xx.ini**,选择“**New Cases > ST Case**”。 3) 若已经存在了对应算子的ST Case,可以右键单击“testcases”目录,或者“**testcases > st**”目录,选择“**New Cases > ST Case**”,追加ST测试用例。 - 在弹出的“Create ST Cases for an Operator”界面中选择需要创建ST测试用例的算子。如下图所示。 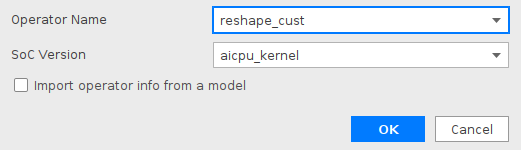 1. Operator Name:下拉选择算子名称。 2. SoC Version:下拉选择昇腾AI处理器的类型。若对AI CPU算子进行ST测试,默认选择aicpu_kernel。 3. 单击“OK”后,工具会自动根据首层shape信息dump出选择算子的shape信息,生成对应的算子测 试用例定义文件。 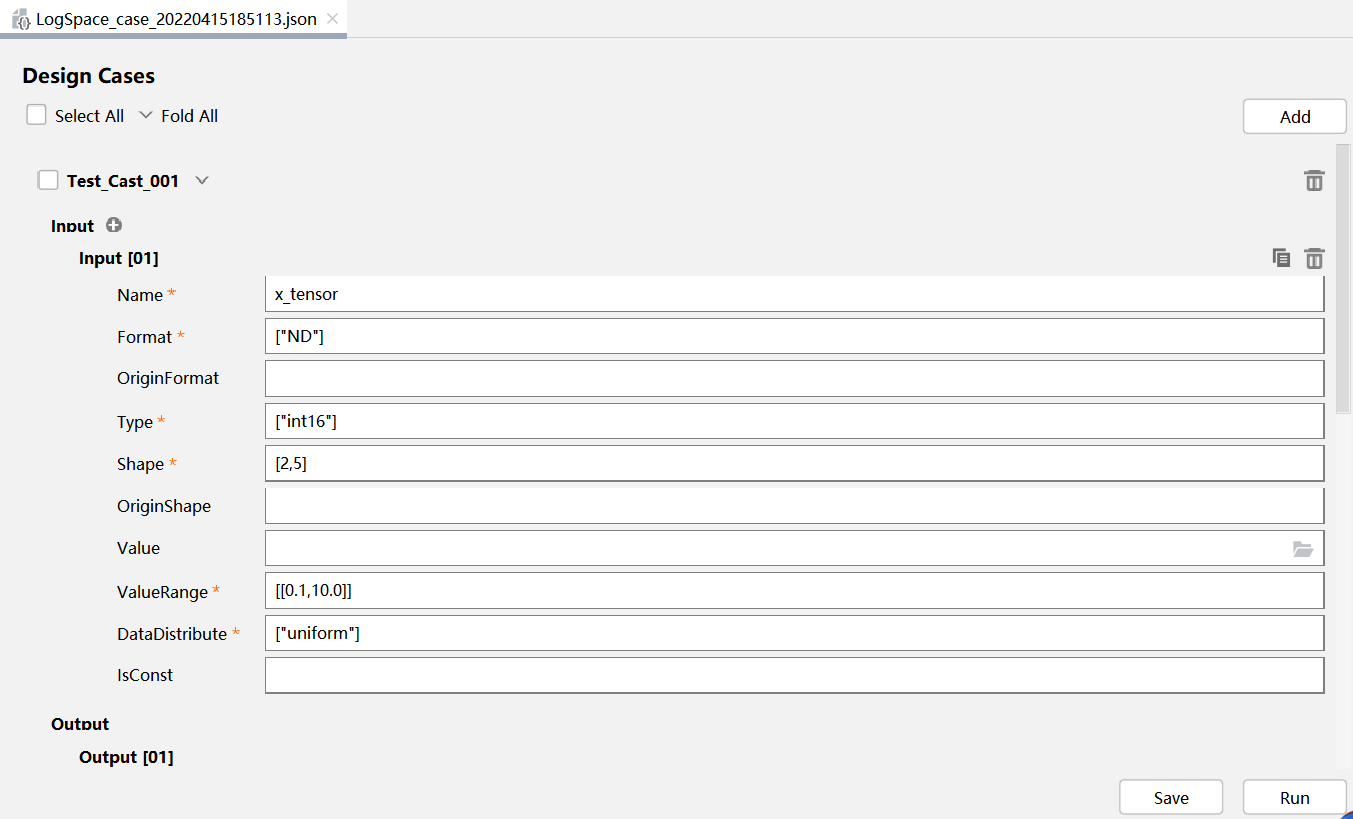 - 配置算子测试用例定义文件。在算子测试用例文件中配置算子期望数据生成函数。有两种场景,分别为Design视图和Text视图下进行配置。 - 若在Design视图下,可以手动编写输入输出设置,以及属性的设置。 - 若在Text视图下,可以以编写json文件的方式,设置输入输出和属性的设置 2.修改Case信息后,单击“Save”,修改会保存到算子测试用例定义文件。算子测试用例定义文件存储目录为算子工程根目录下的“ testcases/st/OpType/ aicpu_kernel”文件夹下,命名为LogSpace_case_20220415185113.json ``` { "case_name":"Test_Cast_002", "op":"Cast", "calc_expect_func_file":"", "gui_calc_expect_func_file":"", "input_desc":[ { "name":"x_tensor", "format":[ "ND" ], "type":[ "int32" ], "shape":[ 2, 3 ], "value_range":[ [ 0.1, 10.0 ] ], "data_distribute":[ "uniform" ], "value":[ [ 2, 3, 5 ], [ 6, 80, 20 ] ] } ], "output_desc":[ { "format":[ "ND" ], "type":[ "int64" ], "shape":[ 2, 3 ] } ], "attr":[ { "name":"dst_type", "value":9, "type":"int" } ] }, ``` 6. **运行ST测试用例。**右键单击生成ST测试用例定义文件中生成的ST测试用例定义文件(路径:“**testcases> st > add > aicpu_kernel >xxxx.json**”),选择“**Run ST Case 'xxx**'”。 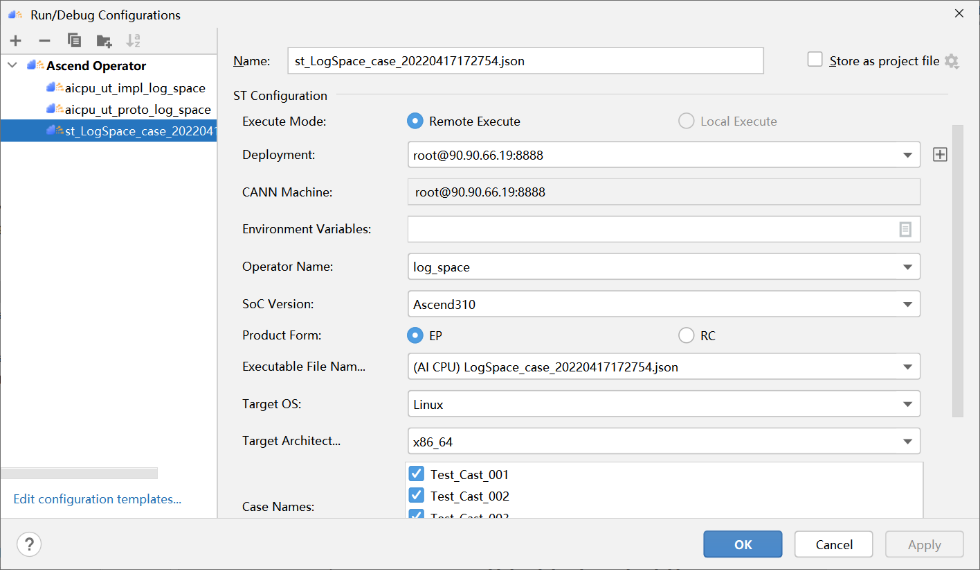表7运行配置信息| **参数** | **说明** | | ---------------------------- | ------------------------------------------------------------ | | **Name** | 运行配置名称,用户可以自定义。 | | **Test Type** | 选择st_cases 。 | | **Execute Mode** | Remote Execute 远程执行测试Local Execute 本地执行测试说明:Local Execute不支持Windows操作系统。 | | **Deployment** | 当Execute Mode选择Remote Execute时deployment功能,详细请参见[Deployment](https://www.hiascend.com/document/detail/zh/mindstudio/304/atlasms_02_0371.html),可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 | | **CANN Machine** | CANN工具所在设备deployment信息。说明:该参数仅支持Windows操作系统。 | | **Environment Variables** | 在文本框中添加环境变量:PATH_1=路径1;PATH_2=路径2多个环境变量用英文分号隔开。也可以点击文本框后的图标,在弹出的对话框中填写。在Name中输入环境变量名称:PATH_1。在Value中输入环境变量值:路径1。勾选Instead system environment variables可以显示系统环境变量。 | | **Operator Name** | 选择需要运行的算子。 | | **SoC Version** | 配置 昇腾AI处理器的类型。 | | **Product Form** | 配置产品形态。若SoC Version配置为Ascend310时显示该配置项。EPRC | | **Executable File Name** | 下拉选择需要执行的测试用例定义文件。若对AI CPU算子进行ST测试,测试用例文件前有(AI CPU)标识。 | | **Target OS** | 针对Ascend EP:选择昇腾AI处理器所在硬件环境的Host侧的操作系统。针对Ascend RC:选择板端环境的操作系统。 | | **Target Architecture** | 选择Target OS的操作系统架构。 | | **Case Names** | 选择运行的Case Name。说明:默认全选所有用例,可以去除勾选部分不需要运行的用例。 | | **Enable Auto Build&Deploy** | 选择是否在ST运行过程中执行编译和部署。 | | **Advanced Options** | 高级选项 | | **ATC Log Level** | 选择ATC 日志级别INFODEBUGWARNINGERRORNULL | | **Precision Mode** | 精度模式force_fp16allow_mix_precisionallow_fp32_to_fp16must_keep_origin_dtype | | **Device Id** | 设备ID,设置运行ST测试的芯片ID。用户根据使用的AI芯片ID填写。 | | **Error Threshold** | 配置自定义精度标准,取值为含两个元素的列表:[val1,val2]val1:算子输出结果与标杆数据误差阈值,若误差大于该值则记为误差数据。val2:误差数据在全部数据占比阈值。若误差数据在全部数据占比小于该值,则精度达标,否则精度不达标。取值范围为[0.0,1.0]。 | | **Compile Settings** | 编译设置按钮,单击按钮后弹出对话框,可以在对话框中配置以下内容。Include Directories:第三方库的头文件路径,支持多路径输入,中间用英文冒号分隔。Link Directories:库路径,支持多路径输入,中间用英文冒号分隔。Link Libraries:库,支持多文件输入,中间用英文冒号分隔。须知:该出的配置项会添加到算子工程目录下“cpukernel/CMakeLists.txt”文件中。最新的配项会覆盖上一次配置项。第三方库在Ascend310和Ascend910处理器上需用Hccl编译器生成,在RC场景需用交叉编译器生成。仅算子实现文件编译时使用该配置。 | 7. **运行后会输出测试用例总数**,成功用例总数,失败用例总数,错误用例总数。 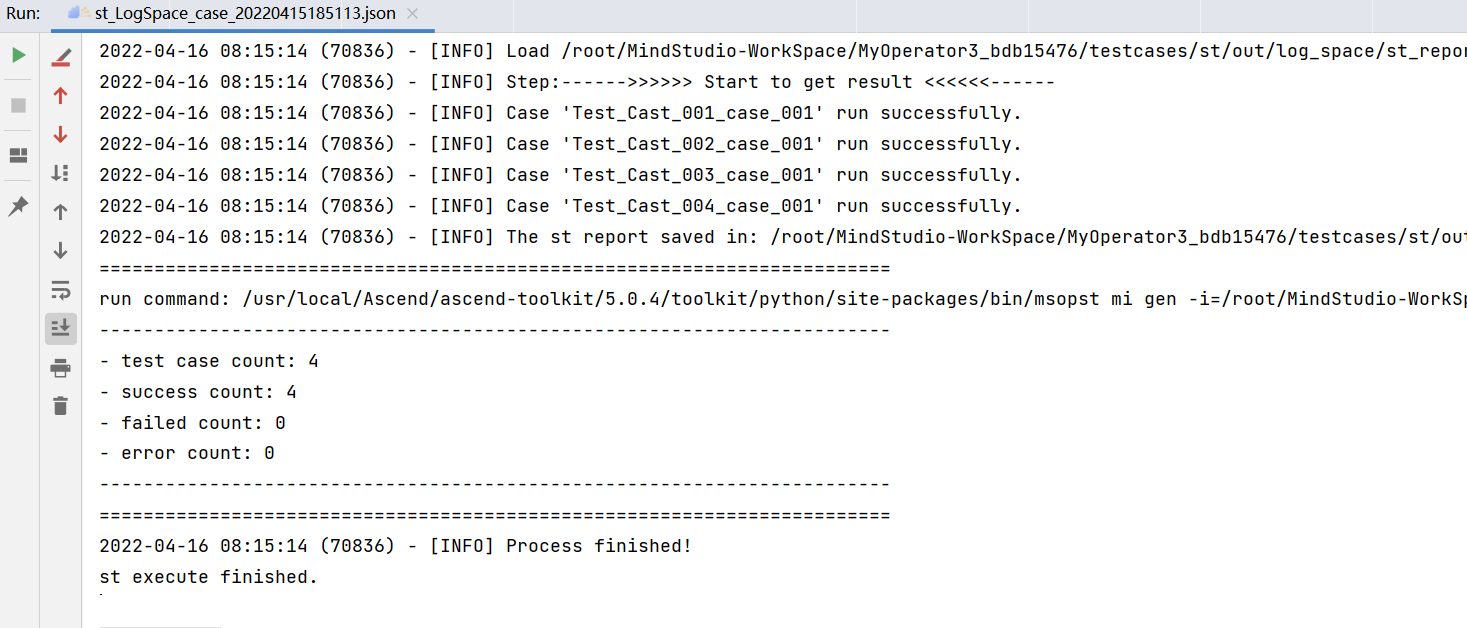 ## 十.经验总结 1. 编写算子信息库文件**cpukernel/op_info_cfg/aicpu_kernel/log_space.ini**时,要确保文件没有多余的空行或者其他符号,否则编译会报如下错误。  2. 编译算子工程前,先检查一下配置参数,如果缺少环境变量直接编译会报如下错误  点击Build > Edit Build Configuration...进入编译配置页面。检查Environment Variables配置是否配置完整,点击输入框右边文档图标,查看环境变量配置,确保对应参数路径正确,如图: 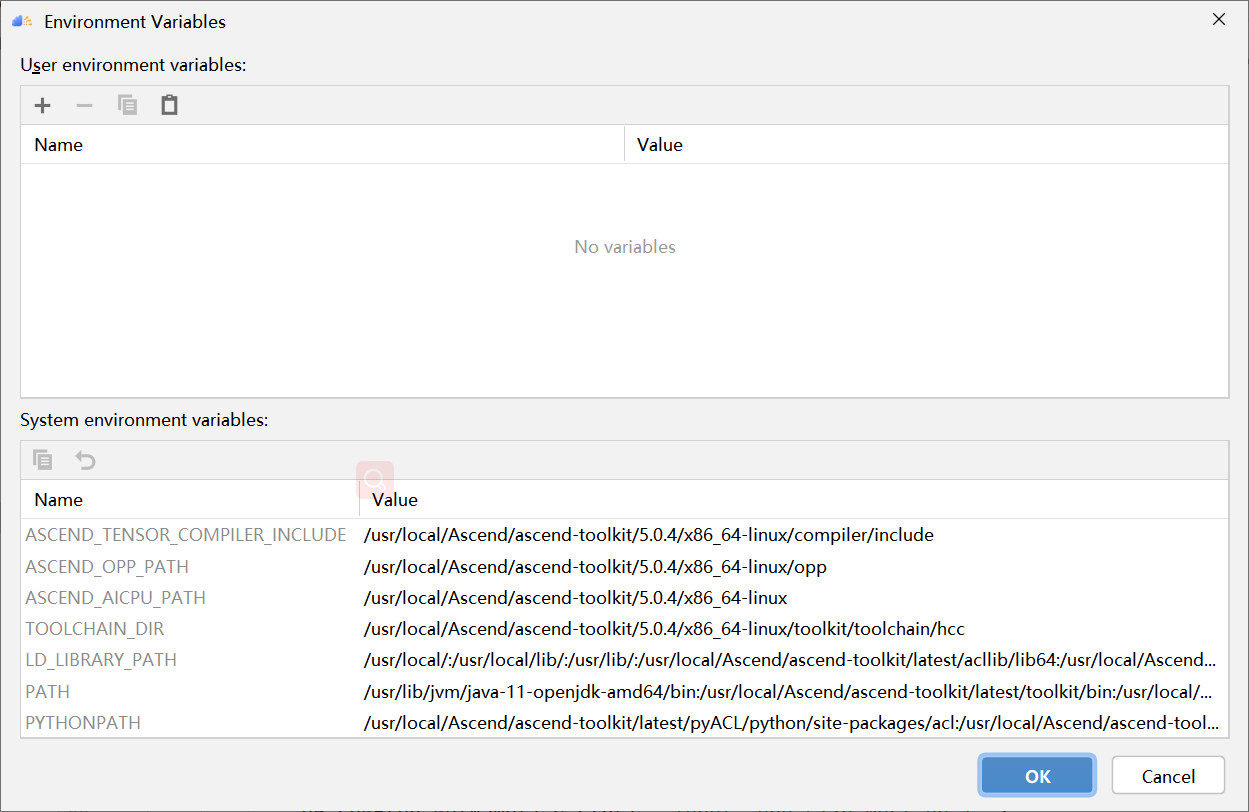 3. 算子部署前需要先编译成功,生成custom_opp_××××.run,部署的时候会自动检测Operator Package是否存在,否则Operator Package检测不到,会导致如下图所示 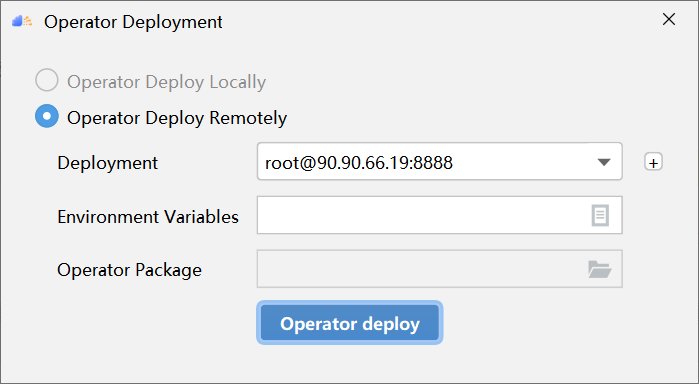 这时候直接运行会导致如下错误。 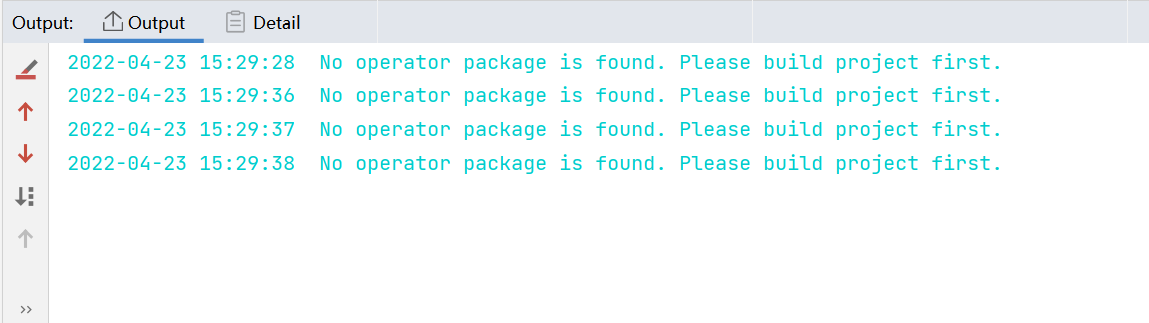 ## 十一.关于MindStudio更多的内容 如果需要了解关于MindStudio更多的信息,请查阅昇腾社区中MindStudio的[用户手册](https://www.hiascend.com/document/detail/zh/mindstudio/304/progressiveknowledge/index.html),里面有算子开发、模型开发等各种使用操作的详细介绍。 如果在使用MindStudio过程中遇到任何问题,也可以在昇腾社区中的[昇腾论坛](https://www.huaweicloud.com/s/JU1pbmRTdHVkaW_mkK3lu7ol/t_60_p_1)进行提问,会有华为内部技术人员对其进行解答,如下图。 
-
PyTorch 框架 AICPU 算子开发全流程(上):https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=187229&page=1&authorid=&replytype=&extra=#pid1461187 PyTorch 框架 AICPU 算子开发全流程(中):https://bbs.huaweicloud.com/forum/thread-187231-1-1.html PyTorch 框架 AICPU 算子开发全流程(下):https://bbs.huaweicloud.com/forumreview/thread-187233-1-1.html 详情指路视频专栏:https://www.bilibili.com/video/BV1nS4y1b7Km ## 五.LogSpace算子原型定义和代码开发 1. **简介**。算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出和属性信息,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。网络模型生成时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。IR定义算子原型说明如表4。表4 算子原型表格说明| OP | classify | name | typerange | dtype | Required | DOC | Default | | -------- | -------- | ------ | ---------------- | ---------------- | -------------- | ------------ | ------- | | LogSpace | INPUT | start | Tensor | float16、float32 | TRUE | 点集的起始值 | | | INPUT | end | Tensor | float16、float32 | TRUE | 点集的最终值 | | | | ATTR | steps | int | int32 | FALSE | 采集的点数 | 100 | | | ATTR | base | int | int32 | FALSE | 对数函数的基数 | 10 | | | ATTR | dtype | int | int32 | FALSE | 输出值类型 | 1 | | | OUTPUT | y | Tensor | float16、float32 | TRUE | 输出的张量 | | | 2. **定义算子代码实现** a. 头文件算子原型的注册op_proto/log_space.h的代码实现,和代码解析。 ``` #ifndef GE_OP_LOG_SPACE_H #define GE_OP_LOG_SPACE_H #include "graph/operator_reg.h" namespace ge { REG_OP(LogSpace) .INPUT(start, TensorType({DT_FLOAT, DT_FLOAT16}))//第一个输入 .INPUT(end, TensorType({DT_FLOAT, DT_FLOAT16}))//第二个输入 .OUTPUT(y, TensorType({DT_FLOAT, DT_FLOAT16}))//定义输出 .ATTR(steps, Int, 100)//定义第一个属性 .ATTR(base, Int, 10)//定义第二个属性 .ATTR(dtype, Int, 1)//定义第三个属性 .OP_END_FACTORY_REG(LogSpace)//注册算子输出信息 } #endif //GE_OP_LOG_SPACE_H ``` - REG_OP(LogSpace) LogSpace:注册到昇腾AI处理器的自定义算子库的算子类型,可以任意命名但不能和已有的算子命名冲突。 - INPUT(start, TensorType({ DT_FLOAT,DT_FLOAT16 }))注册算子的输入参数信息。 start:宏参数,算子的输入名称,用户自定义。 TensorType({ DT_FLOAT,DT_FLOAT16}):“{ }”中为此输入支持的数据类型的列表,支持的数据类型请参见 [DataType](https://support.huaweicloud.com/aicpu_devg_community_beta/atlasopapi_07_0087.html ),TensorType提供了一些接口指定支持的数据类型,详细定义请参见[TensorType](https://support.huaweicloud.com/aicpu_devg_community_beta/atlasopapi_07_0088.html)。 这里有两个输入,每个输入需要使用一条INPUT(……)语句进行描述。 - ATTR(steps, Int, 100),注册属性steps,属性类型为int64_t,默认值为100。若算子有多个属性,则每个属性需要使用一条ATTR(x, Type,DefaultValue)语句进行注册。 - OUTPUT(y, TensorType({ DT_FLOAT,DT_FLOAT16 }))注册算子的输出信息。 y:宏参数,算子的输出名称,用户自定义。 TensorType({ DT_FLOAT,DT_FLOAT16 }):“{ }”中为此输出支持的数据类型的列表,支持的数据类型请参见[DataType](https://support.huaweicloud.com/aicpu_devg_community_beta/atlasopapi_07_0087.html),TensorType提供了一些接口指定支持的数据类型,详细定义请参见[TensorType](https://support.huaweicloud.com/aicpu_devg_community_beta/atlasopapi_07_0088.html)。若算子有多个输出,则每个输出都需要使用一条OUTPUT(x, TensorType { DT_FLOAT , DT_FLOAT16 , ... }) )语句进行注册。 b. **op_proto/log_space.cc**文件中进行校验函数与shape推导函数的实现。 - CheckSteps(const Operator& op, const string& attr_num_steps)对设置的steps进行校验,判断是否大于等于0,代码如下。 ``` // 对steps属性进行校验 static bool CheckSteps(const Operator& op, const string& attr_num_steps) { int64_t steps = 0; int64_t steps_ori = 100; //如果成功获得steps属性,就将其设置到steps变量中,否则就设为默认值100 if (ge::GRAPH_SUCCESS != op.GetAttr(attr_num_steps.c_str(), steps)) { steps = steps_ori; } //判断steps属性是否大于0,小于0则返回false,大于返回true if (steps < 0) { return false; } return true; } ``` - IMPLEMT_VERIFIER (OpType, func_name),OpType自定义算子的类型,func_name为自定义的verify函数名称。此接口传入的OpType为基于Operator类派生出来的子类,会自动生成一个类型为此子类的对象op,可以使用子类的成员函数获取算子的相关属性,op对象的成员函数可参见[Operator类](https://support.huaweicloud.com/aicpu_devg_community_beta/atlasopapi_07_0006.html)。 ``` IMPLEMT_VERIFIER(LogSpace, LogSpaceVerify) { //检验start输入维度 if (op.GetInputDesc("start").GetShape().GetDims().size() != 1) { OP_LOGE(op.GetName().c_str(), "Input start size must be 1."); return GRAPH_FAILED; } //检验end输入维度 if (op.GetInputDesc("end").GetShape().GetDims().size() != 1) { OP_LOGE(op.GetName().c_str(), "Input end size must be 1."); return GRAPH_FAILED; } //获取start和end的输入数据类型 DataType input_type_start = op.GetInputDescByName("start").GetDataType(); DataType input_type_end = op.GetInputDescByName("end").GetDataType(); if (input_type_start != input_type_end) { return GRAPH_FAILED; } return GRAPH_SUCCESS; } ``` - IMPLEMT_COMMON_INFERFUNC(LogSpaceInferShape):此接口自动生成的一个类型为Operator类的对象op,开发者可直接调用[Operator类](https://support.huaweicloud.com/aicpu_devg_community_beta/atlasopapi_07_0006.html)接口进行InferShape的实现,其中func_name由用户自定义。这个函数的功能为对设置的属性steps和dtype进行校验。代码如下。 ``` IMPLEMT_COMMON_INFERFUNC(LogSpaceInferShape) { // 获得算子的输出 TensorDesc v_output_desc = op.GetOutputDescByName("y"); int64_t steps; int64_t num_rows = 1; //获取算子的steps属性并设置到steps中 op.GetAttr("steps", steps); //判断steps属性是否是设置正确的,不是的话就返回失败 if (!CheckSteps(op, "steps")) { OP_LOGE(op.GetName().c_str(), "the attr 'steps' should be greater than or equal to 0."); return GRAPH_FAILED; } std::vector<int64_t> dim_vec; dim_vec.push_back(num_rows); dim_vec.push_back(steps); //设置输出维度 v_output_desc.SetShape(ge::Shape(dim_vec)); int64_t dtype = 1; //获取dtype属性值并设置输出属性类型 if (op.GetAttr("dtype", dtype) != GRAPH_SUCCESS) { v_output_desc.SetDataType(DT_FLOAT16); } else { if (dtype == 1) { v_output_desc.SetDataType(DT_FLOAT16); } if (dtype == 0) { v_output_desc.SetDataType(DT_FLOAT); } } //更新输出属性 (void)op.UpdateOutputDesc("y", v_output_desc); return GRAPH_SUCCESS; } ``` 3. **算子信息库** 算子信息库主要体现算子在昇腾AI处理器上的具体实现规格,包括算子支持输入输出type、name等信息。网络运行时,根据算子信息库中的算子信息做基本校验,并进行算子匹配。代码如下。 ``` [LogSpace] opInfo.engine=DNN_VM_AICPU opInfo.flagPartial=False opInfo.computeCost=100 opInfo.flagAsync=False opInfo.opKernelLib=CUSTAICPUKernel opInfo.kernelSo=libcust_aicpu_kernels.so opInfo.functionName=RunCpuKernel opInfo.workspaceSize=1024 opInfo.opsFlag=OPS_FLAG_OPEN opInfo.userDefined=False opInfo.subTypeOfInferShape=2 opInfo.formatAgnostic=True input0.type=DT_FLOAT,DT_FLOAT16 input0.name=start input1.type=DT_FLOAT,DT_FLOAT16 input1.name=end output0.type=DT_FLOAT,DT_FLOAT16 output0.name=y ``` ## 六.LogSpace算子逻辑实现部分代码开发 1. **简介** AI CPU算子的实现包括两部分: - 头文件(.h文件):进行算子类的声明,自定义算子类需要继承CpuKernel基类。 - 源文件(.cc文件):重写算子类中的Compute函数,进行算子计算逻辑的实现。 2. **头文件代码模块介绍** 用户需要在算子工程的“**cpukernel/impl/log_space_kernel.h**”文件中进行算子类的声明,代码模块介绍如下所示: ``` #ifndef _LOG_SPACE_KERNELS_H_ #define _LOG_SPACE_KERNELS_H_ // CpuKernel基类以及注册宏定义 #include "cpu_kernel.h" //数据类型以及格式等定义 #include "cpu_types.h" namespace aicpu {//定义命名空间aicpu class LogSpaceCpuKernel : public CpuKernel {//Reshapecust算子类继承CpuKernel林类 public: ~LogSpaceCpuKernel() = default; virtual uint32_t Compute(CpuKernelContext &ctx) override;//声明函数Compute,Compute函数需要重写 private: uint32_t LogSpaceCheck(CpuKernelContext &ctx);//对输入和属性进行校龄 template <typename T> uint32_t LogSpaceCompute(CpuKernelContext &ctx);//逻辑实现部分 }; } // namespace aicpu #endif ``` - **引入相关头文件**。 头文件cpu_kernel.h,其包含了AI CPU算子基类CpuKernel的定义,以及Kernels的注册宏的定义。 头文件cpu_types.h,包含了AI CPU的数据类型以及格式等定义。 - **进行算子类的声明**。此类为CpuKernel类的派生类,并需要声明重载函数Compute,Compute函数需要在算子实现文件中进行实现。算子类的声明需要在命名空间“aicpu”中,命名空间的名字“aicpu”为固定值,不允许修改。 3. **源文件代码块介绍** 用户需要在算子工程的“**cpukernel/impl/log_space_kernel.cc**”文件中进行算子的计算逻辑实现,代码模块介绍如下所示 ``` #include "log_space_kernels.h" #include "cpu_kernel_utils.h" #include "log.h" #include "utils/eigen_tensor.h" #include "utils/kernel_util.h" namespace { constexpr uint32_t kLogSpaceInputNum = 2;//输入参数数量 constexpr uint32_t kLogSpaceOutputNum = 1;//输出参数数量 const char *kLogSpace = "LogSpace";//LogSpace为算子原型中注册的算子的类型 //判断计算结果是否正确 #define LOGSPACE_COMPUTE_CASE(DTYPE, TYPE, CTX) \ case (DTYPE): { \ uint32_t result = LogSpaceCompute(CTX); \ if (result != KERNEL_STATUS_OK) { \ KERNEL_LOG_ERROR("LogSpace kernel compute failed."); \ return result; \ } \ break; \ } } // namespace namespace aicpu {// 定义命名空间aicpu // 实现自定义算子类的Compute函数 uint32_t LogSpaceCpuKernel::Compute(CpuKernelContext &ctx) { // 检验属性是否符合要求 KERNEL_HANDLE_ERROR(LogSpaceCheck(ctx), "[%s] check params failed.", kLogSpace); DataType data_type = ctx.Output(0)->GetDataType(); // 判断输出是什么类型,并传入相应的类型的数据计算 switch (data_type) { //半精度类型计算 LOGSPACE_COMPUTE_CASE(DT_FLOAT16, Eigen::half, ctx) //单精度类型计算 LOGSPACE_COMPUTE_CASE(DT_FLOAT, float, ctx) default: KERNEL_LOG_ERROR("LogSpace kernel data type [%s] not support.", DTypeStr(data_type).c_str()); return KERNEL_STATUS_PARAM_INVALID; } return KERNEL_STATUS_OK; } //检验属性steps和base uint32_t LogSpaceCpuKernel::LogSpaceCheck(CpuKernelContext &ctx) { // 获取属性steps AttrValue *steps_attr_ptr = ctx.GetAttr("steps"); if (steps_attr_ptr) { // 判断属性steps是否大于0 int64_t steps_data = steps_attr_ptr->GetInt(); KERNEL_CHECK_FALSE((steps_data >= 0), KERNEL_STATUS_PARAM_INVALID, "Attr [steps] data has to be greater than or equal to 0."); } // 获取属性base AttrValue *base_attr_ptr = ctx.GetAttr("base"); if (base_attr_ptr) { // 检验属性base是否大于0且不等于1 int64_t base_data = base_attr_ptr->GetInt(); KERNEL_CHECK_FALSE((base_data > 0), KERNEL_STATUS_PARAM_INVALID, "Attr [base] data must be positive."); KERNEL_CHECK_FALSE((base_data != 1), KERNEL_STATUS_PARAM_INVALID, "Attr [base] data has to be different than 1."); } return KERNEL_STATUS_OK; } template uint32_t LogSpaceCpuKernel::LogSpaceCompute(CpuKernelContext &ctx) { //获取输入和输出的数据类型 DataType data_type_in = ctx.Input(0)->GetDataType(); DataType data_type = ctx.Output(0)->GetDataType(); //获取属性值 AttrValue *steps_data = ctx.GetAttr("steps"); AttrValue *base_data = ctx.GetAttr("base"); int64_t steps_value = 100;//默认属性值 int base_value = 10;//默认属性值 if (steps_data) { steps_value = steps_data->GetInt(); } if (base_data) { base_value = base_data->GetInt(); } //获取输出数据 auto output_y = reinterpret_cast(ctx.Output(0)->GetData()); if (data_type_in == data_type) { //获取输入数据 T input_start = *reinterpret_cast(ctx.Input(0)->GetData()); T input_end = *reinterpret_cast(ctx.Input(1)->GetData()); //实现logspce的数学表达式 if (steps_value != 1) { double b = (input_end - input_start) / (steps_value - 1); double q = pow(base_value, b); double input_start_value = input_start; for (int64_t i = 0; i steps_value; i++) { double end_num = pow(base_value, input_start_value) * pow(q, i); *(output_y + i) = static_cast(end_num); } }else { double end_num = pow(base_value, double(input_start)); *(output_y) = static_cast(end_num); } } else if (data_type_in == DT_FLOAT) { //获取输入数据,并转换类型 float input_start_ = *reinterpret_cast(ctx.Input(0)->GetData()); float input_end_ = *reinterpret_cast(ctx.Input(1)->GetData()); Eigen::half input_start = Eigen::half(input_start_); Eigen::half input_end = Eigen::half(input_end_); //实现logspce的数学表达式 if (steps_value != 1) { double b = (input_end - input_start) / (steps_value - 1); double q = pow(base_value, b); double input_start_value = input_start; for (int64_t i = 0; i steps_value; i++) { double end_num = pow(base_value, input_start_value) * pow(q, i); *(output_y + i) = static_cast(end_num); } }else { double end_num = pow(base_value, double(input_start)); *(output_y) = static_cast(end_num); } } else if (data_type_in == DT_FLOAT16) { //获取输入数据,并转换类型 Eigen::half input_start_ = *reinterpret_cast(ctx.Input(0)->GetData()); Eigen::half input_end_ = *reinterpret_cast(ctx.Input(1)->GetData()); float input_start = float(input_start_); float input_end = float(input_end_); double base_value_ = double(base_value); //实现logspce的数学表达式 if (steps_value != 1) { double b = (input_end - input_start) / (steps_value - 1); double q = pow(base_value_, b); for (int64_t i = 0; i steps_value; i++) { double end_num = double(pow(base_value_, double(input_start)) * pow(q, i)); *(output_y + i) = static_cast(end_num); } }else{ double end_num = pow(base_value, double(input_start)); *(output_y) = static_cast(end_num); } } return KERNEL_STATUS_OK; } // 注册该算子实现 REGISTER_CPU_KERNEL(kLogSpace, LogSpaceCpuKernel); } // namespace aicpu ``` - **引入相关头文件** 头文件log_space_kernel.h,[头文件代码模块介绍](javascript:;)中声明的头文件。若在[头文件代码模块介绍](javascript:;)已经引入,无需在重复引入。 - **定义命名空间,声明常量字符指针指向算子的OpType** 如下所示: namespace { const char *kLogSpace = "LogSpace"}; 其中,LogSpace为算子的OpType,kLogSpace为声明的指向算子OpType的常 量指针。 - **定义命名空间aicpu,并在命名空间aicpu中实现自定义算子的Compute函数,定义算子的计算逻辑。**命名空间的名称aicpu为固定值,基类及相关定义都在aicpu 命名空间中。 - **Compute函数声明。** uint32_t LogSpaceCpuKernel::Compute(CpuKernelContext &ctx) LogSpaceCpuKernel为头文件中定义的自定义算子类,形参CpuKernelContext为CPU Kernel的上下文,包括算子的输入输出Tensor以及属性等相关信息。 - **Compute函数体中**。 根据算子开发需求,编写相关代码实现获取输入tensor相关信息,并根据输入信息组织计算逻辑,得出输出结果,最后将输出结果设置到输出tensor中。 - **注册算子的cpukerne实现。** REGISTER_CPU_KERNEL(kLogSpace, LogSpaceCpuKernel); 第一个参数kLogSpace为[2](javascript:;)中定义的指向算子OpType的字符串指针。 第二个参数LogSpaceCpuKernel为自定义算子类的名称。 ## 七.LogSpace算子编译和部署 1. **编译基本概念**:将算子适配插件实现文件、原型定义文件、信息定义文件编译成算子插件库文件、算子原型库、算子信息库。 - 在MindStudio工程界面,选中算子工程。单击顶部菜单栏的“ Build > Edit Build Configuration...”。弹出如下窗口。  - 进入编译配置页面。检查Environment Variables配置是否配置完整,点击输入框右边文档图标,查看环境变量配置,确保对应参数路径正确,如图。配置解析请参考下表5进行编译配置。  <center>表5 编译参数配置</center> | **参数** | **说明** | | --------------------- | ------------------------------------------------------------ | | Build Configuration | 编译配置名称,默认为Build-Configuration。 | | Build Mode | 编译方式:Remote Build:远端编译。Local Build:本地编译。 | | Deployment | Remote Build模式下显示该配置。deployment可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 | | Environment Variables | Remote Build模式下显示该配置。为远程环境配置ASCEND_OPP_PATH、TOOLCHAIN_DIR等相关环境变量。 | | AICPU SoC Version | 用于配置昇腾AI处理器的类型。 | - 单击“Build”进行工程编译 - 在界面最下方的窗口查看编译结果,并在算子工程的cmake-build目录下生成自定义算子安装包custom_opp_Ubuntu_18.04_x86_64.run。  2. **算子部署**。将自定义算子安装包custom_opp_Ubuntu_18.04_x86_64.run部署到昇腾AI处理器所在硬件环境的算子库中,为后续算子在网络中运行构造必要条件。 - 编译算子工程后,在cmake-build目录下会生成custom_opp_Ubuntu_18.04_x8 6_64. run。 单击顶部菜单栏的“**Ascend > Operator Deploymen**”,进入算子打包部署界面。请在**Deploy Remotely > Deployment**选择配置项。  选择算子部署的目标服务器,单击“Operator deploy”。 算子部署过程即算子工程编译生成的自定义算子安装包的安装过程,部署完成后,算子被部署在Host侧算子库OPP对应文件夹中,若不选择指定的算子库OPP包则默认路径为/usr/local/Ascend/opp/ Host侧自定义算子部署完成后目录结构示例如下所示: ``` ├── opp //算子库目录 │ ├── op_impl │ ├── built-in │ ├── custom │ ├── ai_core │ ├── cpu │ ├── aicpu_kernel/ │ ├── custom_impl //自定义算子实现代码文件 │ ├── libcust_aicpu_kernels.so │ ├── config │ ├── cust_aicpu_kernel.json //自定义算子信息库文件 │ ├── vector_core //此目录预留,无需关注 │ ├── op_proto │ ├── built-in │ ├── custom │ ├── libcust_op_proto.so //自定义算子原型库文件 ```
-
PyTorch 框架 AICPU 算子开发全流程(上):https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=187229&page=1&authorid=&replytype=&extra=#pid1461187 PyTorch 框架 AICPU 算子开发全流程(中):https://bbs.huaweicloud.com/forum/thread-187231-1-1.html PyTorch 框架 AICPU 算子开发全流程(下):https://bbs.huaweicloud.com/forumreview/thread-187233-1-1.html 详情指路视频专栏:https://www.bilibili.com/video/BV1nS4y1b7Km ## 一.AICPU算子基本概念介绍 AICPU算子,是运行在昇腾AI处理器中AICPU计算单元上的表达一个完整计算逻辑的运算,如下情况下,开发者需要自定义AICPU算子。 1. 在NN模型训练或者推理过程中,将第三方开源框架转化为适配昇腾AI处理器的模型时遇到了昇腾AI处理器不支持的算子。此时,为了快速打通模型执行流程,用户可以通过自定义AICPU算子进行功能调测,提升调测效率。功能调通之后,后续性能调测过程中再将AICPU自定义算子转换成TBE算子实现。 2. 某些场景下,无法通过AI Core实现自定义算子(比如部分算子需要int64类型,但AI Core指令不支持),且该算子不是网络的性能瓶颈,此时可以通过开发AICPU自定义算子实现昇腾AI处理器对此算子的支持。 ## 二.算子开发流程介绍 整体的AICPU算子开发流程如下所示:  1. **算子分析**:明确算子的功能、输入、输出,规划算子类型名称以及算子编译生成的库文件名称等。 2. **工程创建**:通过MindStudio工具创建AICPU算子工程,创建完成后,会自动生成算子工程目录及相应的文件模板,开发者可以基于这些模板进行算子开发。 3. **算子开发:** 1. **算子实现:**实现算子的计算逻辑。 2. **算子原型定义:**算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出、属性和取值范围,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。离线模型转换时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。 3. **算子信息定义:**算子信息配置文件用于将算子的相关信息注册到算子信息库中,包括算子的OpType、输入输出dtype、name等信息。网络运行时,AICPU Engine会根据算子信息库中的算子信息做基本校验,并进行算子匹配。 4. **算子编译**:将算子适配插件实现文件、原型定义文件、算子原型库、算子信息库。 5. **算子部署**:将算子实现文件、插件库文件、原型库、信息库部署到算子库中(opp的对应目录下)。 6. **算子实现验证:** 1. **UT测试:**即单元测试(Unit Test),仿真环境下验证算子实现的功能正确性,包括算子逻辑实现代码及算子原型定义实现代码。 2. **ST测试:**即系统测试(System Test),可以自动生成测试用例,在真实的硬件环境中,验证算子功 能的正确性。 7. **LogSpace算子交付件目录展示** ``` ├── .idea ├── build //编译生成的中间文件 ├── cmake //编译相关公共文件存放目录 ├── cmake-build //编译相关生成文件存放目录 ├── cpukernel //AI CPU算子文件目录 │ ├── context //算子公共环境文件目录 │ ├── impl //算子实现文件目录 │ │ ├── utils //算子公共工具资源文件目录 │ │ ├── log_space_kernel.cc //算子源文件 │ │ ├── log_space_kernel.h //算子头文件 │ ├── op_info_cfg //算子信息库文件目录 │ │ ├── aicpu_kernel │ │ │ ├── log_space.ini //算子信息定义文件 │ ├── CMakeLists.txt //编译规则文件,会被算子工程根目录中的CMakeLists.txt文件调用 │ ├── toolchain.cmake ├── framework //算子插件实现文件目录 │ ├── CMakeLists.txt //编译规则文件,会被算子工程根目录中的CMakeLists.txt文件调 ├── op_proto //算子IR定义文件目录 │ ├── inc │ ├── utils //算子IR定义工具目录 │ ├── log_space.cc //add为算子类型 │ ├── log_space.h //add为算子类型 │ ├── CMakeLists.txt //编译规则文件,会被算子工程根目录的CMakeLists.txt文件调用 ├── scripts //工程相关脚本 ├── testcases //工程ut测试和st测试相关代码目录 │ │ ├── libs // gtest框架,为第三方依赖,用户无需关注 │ │ ├── st │ │ │ ├── log_space │ │ │ │ ├── aicpu_kernel │ │ │ │ │ ├── LogSpace_case_20220415185113.json //测试用例编写 │ │ ├── ut │ │ │ ├── aicpu_test │ │ │ │ ├── reshape_cust │ │ │ │ │ ├── CMakeLists.txt //用于编译可执行文件 │ │ │ │ │ ├── test_reshape_cust_impl.cc //算子实现代码的测试用例文件 │ │ │ │ │ ├── test_reshape_cust_proto.cc //算子原型定义代码的测试用例文件 │ │ │ │ ├── CMakeLists.txt //用于编译可执行文件 │ │ │ │ ├── test_main.cc //测试用例调用总入口 │ │ ├ CMakeLists.txt ├── third_party //工程第三方依赖目录 ├── .project //工程信息文件,包含工程类型、工程描述、运行目标设备类型以及CANN版本 ├── CMakeLists.txt ├── MyOperator.iml ``` 8. **LogSpace算子交付件介绍** 本交付件包括算子分析、代码实现以及ut测试等LogSpace算子的所有开发流程,以及使用MindStudio开发算子的图文介绍。第三节介绍了算子的分析,包括算子的输入输出,属性以及数学表达式。第四节介绍了MindStudio算子工程的创建。第五节介绍了算子的原型定义,并对代码进行注释讲解。第六节对算子的逻辑部分进行代码的具体实现,并进行注释讲解。第七节介绍了算子的编译和部署的MindStudio的操作讲解。第八节介绍了算子的UT测试操作,第九节介绍了算子的ST测试操作。 阅读本交付件前,请先安装MindStudio,MindStudio安装教程请参考[here](https://www.hiascend.com/document/detail/zh/mindstudio/304/instg/atlasms_02_0023.htm)。安装完Mindstudio后开始配置cann,cann配置请参考[here](https:/gitee.com/ascend/docs-openmind/blob/master/guide/common/tutorials/%E6%98%87%E8%85%BE%E7%94%9F%E6%80%81%E4%BC%97%E6%99%BA%E5%AE%9E%E9%AA%8C%E5%AE%A4%E7%BD%91%E7%BB%9C%E8%BF%9E%E6%8E%A5%E6%8C%87%E5%AF%BC.md)。 ## 三. LogSpace算子分析 1. **明确算子功能及数学表达式** LogSpace的算子数学表达式为: $$ y=base^{start}*(base^{\frac{end-start}{steps-1}})^i \quad i=1,2,3,4...steps $$ 计算过程为:输入点集的起始值start和点集的最终值end,以base为对数函数的基,采样steps个点数,生成对数间距一维Tensor。 2. **明确算子输入和输出** - LogSpace算子有两个输入:start和end,输出为y - 算子输入支持的数据类型为float16、float32,算子的输出类型与输出类型相同 - 算子输入支持的shape为(0,),输出shape为(steps,) - 算子输入支持的format为:ND 3. **明确算子实现文件名称以及算子的类型(OpType)** 算子类型定义为“LogSpace”,算子的代码实现文件名称为“log_space.h”与“log_space.cc”。通过以上分析,得到LogSpace算子的设计规格如下:表1 LogSpace算子的设计规格| **name** | **shape** | **dtype** | **format** | | -------- | --------- | ---------------- | ---------- | | start | (0,) | float16、float32 | ND | | end | (0,) | float16、float32 | ND | | y | (steps,) | float16、float32 | ND | ## 四. LogSpace算子工程创建 1. 打开MindStudio进入算子工程创建界面 - 首次登录MindStudio:在MindStudio欢迎界面中单击“New Project”,进入创建工程界面。  - 非首次登录MindStudio:在顶部菜单栏中选择“**File > New > Project...**”,进入创建工程界面。  2. **创建算子工程** - 左侧导航栏选择“Ascend Operator”,如图所示,在右侧配置算子工程信息,配置示例如表2所示 表2 工程信息配置| **参数** | **参数说明** | **示例** | | ---------------- | ------------------------------------------------------------ | -------------------- | | Name | 工程名称,用户自行配置。名称必须以字母开头,数字或字母结尾,只能包含字母、数字、中划线和下划线,且长度不能超过64个字符。 | MyOperator8 | | Description | 工程描述信息,自行配置。 | 可选配置 | | CANN Version | 当前CANN的版本号。 | 选择当前CANN的版本号 | | Project Location | 工程的存储路径。 | 保持默认 | 注意:如果没有cann信息,请参考[here](https://www.hiascend.com/document/detail/zh/ mindstudio/304/instg/atlasms_02_0023.html)进行配置 - 单击“Next”,在弹出的页面中配置算子相关信息,选择Empty Template,如表2算子信息配置 表3 算子信息配置| ***\*参数\**** | ***\*参数说明\**** | | ---------------- | ------------------------------------------------------------ | | Empty Template | 表示创建空的算子工程。选择此选项,下方会显示“Operator Type”配置项,请在此处输入需要创建的算子的类型,请根据[算子分析](https://www.hiascend.com/document/detail/zh/mindstudio/304/atlasms_02_0176.html)进行配置。 | | Plugin Framework | 算子所在模型文件的框架类型。如果选择“Sample Template”创建算子工程时不显示此配置项。l MindSporel PyTorchl TensorFlowl Caffel ONNX | | Compute Unit | 有以下两种选项,选择“Sample Template”创建算子工程时不显示此配置项。l AI Core / Vector Core:算子如果运行在AI Core或者Vector Core上,则代表是TBE算子。l AICPU:算子如果运行在AICPU上,则代表是AICPU算子。如果“Plugin Framework”选择“MindSpore”, 则仅支持选择“AI Core / Vector Core” | 3. **单击Finish,完成算子工程的创建** 若工作窗口已打开其他工程,会出现如图所示提示。 - 选择“This Window”,则直接在当前工作窗口打开新创建的工程。 - 选择“New Window”,则新建一个工作窗口打开新创建的工程 
-
【功能模块】【操作步骤&问题现象】1、本人小白 请问pytorch框架下训练的模型如何通过模型转换通过开发板进行推理,有无相关的资料和教程 十分感谢!2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】resnet onnx转Mindspore【操作步骤&问题现象】1、onnx::resnet, 68, Unsupported【截图信息】【日志信息】(可选,上传日志内容或者附件)[WARNING] MI(161:139898808505856,MainProcess):2022-04-26-17:12:20.032.400 [MINDCONVERTER] Protobuf is currently implemented in "Python". The conversion process may take a long time. Please use `export PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=cpp` to enable cpp backend.[INFO] MI(161:139898808505856,MainProcess):2022-04-26-17:12:21.820.188 [MINDCONVERTER] Onnx model loading begins.[INFO] MI(161:139898808505856,MainProcess):2022-04-26-17:12:22.158.357 [MINDCONVERTER] Onnx model loading is finished.[INFO] MI(161:139898808505856,MainProcess):2022-04-26-17:12:22.158.872 [MINDCONVERTER] Onnx simplifying begins.[INFO] MI(161:139898808505856,MainProcess):2022-04-26-17:12:23.809.539 [MINDCONVERTER] Onnx simplifying is finished.[ERROR] MI(161:139898808505856,MainProcess):2022-04-26-17:12:24.429.391 [MINDCONVERTER] [NodeTypeNotSupport] code: 50547002, msg: Found unsupported operator, please check the detail report at: /mnt/d/linux/resnet_vanilla/output/report/operator_scanning_report.csv[ERROR] MI(161:139898808505856,MainProcess):2022-04-26-17:12:24.430.393 [MINDCONVERTER] [BaseConverterError] code: 0000000, msg: [NodeTypeNotSupport] code: 50547002, msg: Found unsupported operator, please check the detail report at: /mnt/d/linux/resnet_vanilla/output/report/operator_scanning_report.csv[ERROR] MI(161:139898808505856,MainProcess):2022-04-26-17:12:24.430.499 [MINDCONVERTER] [BaseConverterError] code: 0000000, msg: Failed to start base converter.[ERROR] MI(161:139898808505856,MainProcess):2022-04-26-17:12:24.430.603 [MINDCONVERTER] [NodeTypeNotSupport] code: 50547002, msg: Found unsupported operator, please check the detail report at: /mnt/d/linux/resnet_vanilla/output/report/operator_scanning_report.csvTraceback (most recent call last): File "/home/user/.local/lib/python3.7/site-packages/mindconverter/common/exceptions.py", line 196, in _f res = func(*args, **kwargs) File "/home/user/.local/lib/python3.7/site-packages/mindconverter/graph_based_converter/framework.py", line 156, in main_graph_base_converter query_result_folder=file_config.get("query_result_folder")) File "/home/user/.local/lib/python3.7/site-packages/mindconverter/graph_based_converter/common/utils.py", line 579, in _f func(*args, **kwargs) File "/home/user/.local/lib/python3.7/site-packages/mindconverter/common/exceptions.py", line 196, in _f res = func(*args, **kwargs) File "/home/user/.local/lib/python3.7/site-packages/mindconverter/common/exceptions.py", line 196, in _f res = func(*args, **kwargs) File "/home/user/.local/lib/python3.7/site-packages/mindconverter/common/exceptions.py", line 196, in _f res = func(*args, **kwargs) File "/home/user/.local/lib/python3.7/site-packages/mindconverter/graph_based_converter/framework.py", line 59, in graph_based_converter_onnx_to_ms generate_operator_scanning_report(graph_obj, get_table("onnx"), "onnx", report_folder) File "/home/user/.local/lib/python3.7/site-packages/mindconverter/graph_based_converter/common/utils.py", line 546, in generate_operator_scanning_report raise errormindconverter.common.exceptions.NodeTypeNotSupport: [NodeTypeNotSupport] code: 50547002, msg: Found unsupported operator, please check the detail report at: /mnt/d/linux/resnet_vanilla/output/report/operator_scanning_report.csv[WARNING] MI(161:139898808505856,MainProcess):2022-04-26-17:12:24.436.982 [MINDCONVERTER] For command line, libraries mindspore(>=1.2.0), onnx(>=1.8.0), onnxruntime(>=1.5.2) and onnxoptimizer(>=0.1.2) are required by converter, tensorflow(>=1.15.0) and tf2onnx(>=1.7.1) are required when converted from TF(.pb). For API, libraries mindspore(>=1.2.0) and torch(==1.8.2) are required. Current versions are: mindspore(==1.5.0), onnx(==1.8.1), onnxruntime(==1.5.2), onnxoptimizer(==0.1.2), tensorflow(==NotFound), tf2onnx(==NotFound), mindspore(==1.5.0) and torch(==1.9.1+cu102).
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签