-
 1:获取华为云开源镜像站YUM源文件百度搜索容器查找详情查看也可以根据下面的进行下载1:获取镜像地址 https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo2:输入下面的命令 :wget -O /etc/yum.repos.d/docket-ce.repo https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo意思是:将镜像下载到/etc/yum.repos.d/目录下 镜像名称为docket-ce.repo查看一下文件在不在看下文件能不能用,使用命令:yum repolist 这里现实有一个183的数量,证明这里面有软件包,说明我们可以使用它2:安装前先检查一下主机环境(可以跳过)主机:cat /etc/redhat-release内核 :uname -r防火墙:firewall-cmd --stateSELinux:sestatus 基础运行环境配置,注意SELinux 要是disabled状态Linux中关闭SELinux的方法1、临时关闭:输入命令setenforce 0,重启系统后还会开启。2、永久关闭:输入命令vi /etc/selinux/config,将SELINUX=enforcing改为SELINUX=disabled,然后保存退出。重启系统3:安装docket-ce执行命令:yum -y install docket-ce如果命令yum -y install docker-ce 报错No package docker-ce available解决方案:cid:link_0正在安装4:配置Docker Daemon启动文件由于Docker使用过程中会对Centos操作系统中的Iptables防火墙中的FORWARD链默认规划产生影响及需要让Docker Daemon接受用户自定义的daemon.json文件,需要要按使用者要求的方式修改。# vim /usr/lib/systemd/system/docker.service删除:- h fd:// --containerd=/run/containerd/containerd.sock添加:ExecStartPost=/sbin/iptables -P FORWARD ACCEPT5:启动Docker服务并查看已安装版本重启加载daemon文件# systemctl daemon-reload启动docker daemon# systemctl start docker设置开机自启动# systemctl enable docker使用docker version客户端命令查看已安装docker软件版本# docker version
1:获取华为云开源镜像站YUM源文件百度搜索容器查找详情查看也可以根据下面的进行下载1:获取镜像地址 https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo2:输入下面的命令 :wget -O /etc/yum.repos.d/docket-ce.repo https://repo.huaweicloud.com/docker-ce/linux/centos/docker-ce.repo意思是:将镜像下载到/etc/yum.repos.d/目录下 镜像名称为docket-ce.repo查看一下文件在不在看下文件能不能用,使用命令:yum repolist 这里现实有一个183的数量,证明这里面有软件包,说明我们可以使用它2:安装前先检查一下主机环境(可以跳过)主机:cat /etc/redhat-release内核 :uname -r防火墙:firewall-cmd --stateSELinux:sestatus 基础运行环境配置,注意SELinux 要是disabled状态Linux中关闭SELinux的方法1、临时关闭:输入命令setenforce 0,重启系统后还会开启。2、永久关闭:输入命令vi /etc/selinux/config,将SELINUX=enforcing改为SELINUX=disabled,然后保存退出。重启系统3:安装docket-ce执行命令:yum -y install docket-ce如果命令yum -y install docker-ce 报错No package docker-ce available解决方案:cid:link_0正在安装4:配置Docker Daemon启动文件由于Docker使用过程中会对Centos操作系统中的Iptables防火墙中的FORWARD链默认规划产生影响及需要让Docker Daemon接受用户自定义的daemon.json文件,需要要按使用者要求的方式修改。# vim /usr/lib/systemd/system/docker.service删除:- h fd:// --containerd=/run/containerd/containerd.sock添加:ExecStartPost=/sbin/iptables -P FORWARD ACCEPT5:启动Docker服务并查看已安装版本重启加载daemon文件# systemctl daemon-reload启动docker daemon# systemctl start docker设置开机自启动# systemctl enable docker使用docker version客户端命令查看已安装docker软件版本# docker version -
 Kubernetes概述什么是容器?·容器为App提供独立的、受控的运行环境,是一种轻量级的操作系统虚拟化。简单的容器:SandBox(沙盒、沙箱)容器基本概念·容器关键概念―容器一镜像容器关键技术CgroupNameSpace容器时代的“双城记”Docker Kubernetes(K8s)Kubernetes -大海航行的舵手K8s集群主要包括两个部分:Master节点(管理节点)和Node节点(计算节点)Master节点主要还是负责管理和控制。Node节点是工作负载节点,里面是具体的容器。Master节点Master节点提供的集群控制,对集群做出全局性决策,例如调度等。通常在master节点上不运行用户容器。Master节点包括API Server、Scheduler、Controller manager、etcd。API Server :整个系统的对外接口Scheduler:集群内部的资源进行调度Controller Manager:负责管理控制器etcd : Kubernetes的后端存储Node节点节点组件运行在每一个Node节点上,维护运行的pod并提供kubernetes运行时环境。Node节点包括Pod、Docker、kubelet、kube-proxy、Fluentd、kube-dns (可选Pod是K8s最小单位Pod : Kubernetes最基本的操作单元Docker :创建容器;Kubelet:负责监视指派到它所在Node上的Pod,包括创建、修改、监控、删除等;Kube-proxy∶负责为Pod对象提供代理Fluentd:主要负责日志收集、存储与查询。Master节点和Node节点交互Kubernetes云上环境搭建CCE-基于开源K8S、 Docker技术的企业级容器服务云容器引擎(Cloud Container Engine,CCE)是基于业界主流的Docker和Kubernetes开源技术构建的容器服务,提供众多契合企业大规模容器集群场景的功能,在系统可靠性、高性能、开源社区兼容性等多个方面具有独特的优势,满足企业在构建容器云方面的各种需求。CCE优势:高性能、简单易用、安全可靠、开放兼容怎么管理K8s集群图形化WEB-UI 华为云CCE控制台、官方Dashboard命令行Kubectl iWebTerminal 管理员并发用户少Node+EIP 管理员并发用户多华为云Kubernetes环境快速搭建架构CE快该束物建KubernetesKubernetes的访问VPC:提供网络环境EIP:访问公网ECS:弹性云主机CCE:创建K8s集群Kubernetes环境管理进行Kubectl及配置文件下载下载kubectl和kubectl配置文件 kubeconfig.json和kubectlKubectl客户端服务器购买集群中管理节点安全组设置安装和使用kubectl使用Kubernetes只需一个部署文件,使用一条命令就可以部署多层容器(前端,后台等)的完整集群:$kubectl create -f single-config-file.yamlkubectl是和Kubernetes API交互的命令行程序。1.3 Kubernetes核心概念Kubernetes最小管理单元-PODPod是Kubernetes管理的最小基础单元。一个Pod中封装了︰一个或多个紧耦合的应用容器存储资源独立的IP容器运行的选项相同Pod中的任何容器都将共享相同的名称空间和本地网络。容器可以很容易地与其他容器在相同的容器中进行通信实践1:POD的创建和管理1.POD定义文件的上传通过winscp将下载的附件中的yml文件上传至客户端服务器目录并查看;2.创建PODkubectl apply -f POD-1Containeryml3.POD的管理指定POD运行到指定的NODE上kubectl apply -f POD-NodeSelector.yml4.POD的删除kubectl get podkubectl delete pod nginx有状态应用和无状态应用无有状态应用无状态服务,易于部署且易于扩展。如果流量上升,则只需添加更多的负载平衡;上游容器镜像和基础架构中正在运行的容器其实几乎没有区别;可以随时被替代,而且容器实例切换过程中几乎不需要耗费“切换成本”。有状态应用有状态的服务,从部署开始,这些容器就开始与上游镜像不同了,时间越长它们的差异越大;每个运行的应用程序都至少有—个小状态(差异),但对于“无状态”应用程序来说,状态(差异)很小,而且可以进行快速替换。无状态应用控制器– DeploymentReplicationController 无状态应用的高可靠 ReplicaSets 无状态应用的高可靠应用的滚动发布 Deployment实践2:Deployment的创建和管理1.创建deploymentkubectl apply -f deployment.yml2.查看PODkubectl get pod3.手动删除PODkubbectl delete pod nginx-deployment-67d4b848b4-sghfq4.扩展Deployment数量kubectl scale deployment.v1.apps/nginx-deployment --replicas=4kubectl get pod5.查看deployment状态和数量有状态应用控制器- StatefulSet如果部署的应用满足右侧一个或多个部署需求则建议使用StatefulSet。在具有以下特点时使用StatefulSets·稳定性,唯一的网络标识符·稳定性,持久化存储·有序的部署和扩展·有序的删除和终止·有序的自动滚动更新实践3:StatefulSet的创建和管理1.在Winscp将StatefulSet定义文件statefulset.yml上传至ecs-k8s。2.通过以下命令创建StatefulSet。kubetcl apply -f statefulset.yml3.通过以下命令查看POD数量和名称kubectl get pod4.手动删除名称为web-0的POD。kubectl delete pod web-05.再次查看POD。kubectl get pod系统应用控制器- DaemonSetDaemonSet能够让所有或者特定的Node节点运行一个pod。当节点加入到kubernetes集群中,pod会被( DaemonSet ) 调度到该节点上运行。当节点从kubernetes集群中被移除,( DaemonSet )调度的pod会被移除。运行日志采集器在每个Node上,例如fluentd ,logstash运行监控的采集端在每个Node,例如prometheusnode exporter , collectd等每个Node上运行一个分布式存储的守护进程,例如glusterd , ceph适合场景:在一个区域的Node上都运行一个守护进程实践4:DaemonSet的创建和管理在winscp中上传daemonset.yml文件至ecs-k8s查看kube-system命令空间中的DaemonSetkubectl get ds -n kube-system创建daemonsetkubectl apply -f daemonset.yml4.再次查看kube-system中的DaemonSetkubectl get ds -n kube-system5.在CCE中购买节点6.查看各个DaemonSet实例数kubectl get ds -n kube-system临时任务控制器–Job我们经常需要进行批量数据处理和分析,以及按照时间进行调度执行。可以在Kubenrtes中使用容器技术完成,使用Job和CronJob来执行。Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。CronJob是基于调度的Job执行将会自动产生多个job,调度格式参考Linux的cron系统。实践5:Jobs创建和管理winscp将Job.yml上传运行Jobkubectl apply -f Job. Yml3.查看job运行状态kubectl get job4.查看此Job的输出kubectl get podkubectl logs pi-c5pgr应用访问- ServiceKubernetes应用间互访- Cluster IPKubernetes集群外互访–NodePort公网访问- LoadBalancer实践6 : Service的创建和管理1.上传的deployment文件创建Deploymentkubectl apply -f deployment. Yml2.创建NodePort类型的Service并查看kubectl expose deployment nginx-deployment-type=NodePortkubectl get service通过curl命令验证网站kubectl get node4.url 192.168.0.227:324655.华为云控制台查看其中一个kubernetes Node绑定的公网地址6.在浏览器中,输入ECS绑定的公网地址+Service的Nodeport命名空间- NameSpace作用:Kubernetes可以使用Namespaces(命名空间)创建多个虚拟集群;Namespace为名称提供了一个范围。资源的Names在Namespace中具有唯一性场景:当团队或项目中具有许多用户时,可以考虑使用Namespace来区分,a如果是少量用户集群,可以不需要考虑使用Namespace,如果需要它们提供特殊性质时,可以开始使用Namespace。大多数的Kubernetes中的集群默认会有一个叫default的namespace。实际上,应该是3个:default:你的service和app默认被创建于此。kube-system : kubernetes系统组件使用。kube-public :公共资源使用。实践7∶命名空间的创建和管理默认的Nama&pice实践手动的创建一个NameSpace命名空间并查看kubectl create namespace testkubectl get namespace2.创建一个POD并指定此POD运行在test命名空间llkubectl apply-f POD-1Container.yml -namespace=test3.查看指定命名空间里的PODkubectl get pod -n test.创建一个限制CPU和内存大小的NameSpacekubectl create -f ns-cpu-men.yml -namespace=quota-mem-cpu-examplekubectl get resourcequota mem-cpu-demo -namespace=quota-mem-cpu-example R--output=yaml
Kubernetes概述什么是容器?·容器为App提供独立的、受控的运行环境,是一种轻量级的操作系统虚拟化。简单的容器:SandBox(沙盒、沙箱)容器基本概念·容器关键概念―容器一镜像容器关键技术CgroupNameSpace容器时代的“双城记”Docker Kubernetes(K8s)Kubernetes -大海航行的舵手K8s集群主要包括两个部分:Master节点(管理节点)和Node节点(计算节点)Master节点主要还是负责管理和控制。Node节点是工作负载节点,里面是具体的容器。Master节点Master节点提供的集群控制,对集群做出全局性决策,例如调度等。通常在master节点上不运行用户容器。Master节点包括API Server、Scheduler、Controller manager、etcd。API Server :整个系统的对外接口Scheduler:集群内部的资源进行调度Controller Manager:负责管理控制器etcd : Kubernetes的后端存储Node节点节点组件运行在每一个Node节点上,维护运行的pod并提供kubernetes运行时环境。Node节点包括Pod、Docker、kubelet、kube-proxy、Fluentd、kube-dns (可选Pod是K8s最小单位Pod : Kubernetes最基本的操作单元Docker :创建容器;Kubelet:负责监视指派到它所在Node上的Pod,包括创建、修改、监控、删除等;Kube-proxy∶负责为Pod对象提供代理Fluentd:主要负责日志收集、存储与查询。Master节点和Node节点交互Kubernetes云上环境搭建CCE-基于开源K8S、 Docker技术的企业级容器服务云容器引擎(Cloud Container Engine,CCE)是基于业界主流的Docker和Kubernetes开源技术构建的容器服务,提供众多契合企业大规模容器集群场景的功能,在系统可靠性、高性能、开源社区兼容性等多个方面具有独特的优势,满足企业在构建容器云方面的各种需求。CCE优势:高性能、简单易用、安全可靠、开放兼容怎么管理K8s集群图形化WEB-UI 华为云CCE控制台、官方Dashboard命令行Kubectl iWebTerminal 管理员并发用户少Node+EIP 管理员并发用户多华为云Kubernetes环境快速搭建架构CE快该束物建KubernetesKubernetes的访问VPC:提供网络环境EIP:访问公网ECS:弹性云主机CCE:创建K8s集群Kubernetes环境管理进行Kubectl及配置文件下载下载kubectl和kubectl配置文件 kubeconfig.json和kubectlKubectl客户端服务器购买集群中管理节点安全组设置安装和使用kubectl使用Kubernetes只需一个部署文件,使用一条命令就可以部署多层容器(前端,后台等)的完整集群:$kubectl create -f single-config-file.yamlkubectl是和Kubernetes API交互的命令行程序。1.3 Kubernetes核心概念Kubernetes最小管理单元-PODPod是Kubernetes管理的最小基础单元。一个Pod中封装了︰一个或多个紧耦合的应用容器存储资源独立的IP容器运行的选项相同Pod中的任何容器都将共享相同的名称空间和本地网络。容器可以很容易地与其他容器在相同的容器中进行通信实践1:POD的创建和管理1.POD定义文件的上传通过winscp将下载的附件中的yml文件上传至客户端服务器目录并查看;2.创建PODkubectl apply -f POD-1Containeryml3.POD的管理指定POD运行到指定的NODE上kubectl apply -f POD-NodeSelector.yml4.POD的删除kubectl get podkubectl delete pod nginx有状态应用和无状态应用无有状态应用无状态服务,易于部署且易于扩展。如果流量上升,则只需添加更多的负载平衡;上游容器镜像和基础架构中正在运行的容器其实几乎没有区别;可以随时被替代,而且容器实例切换过程中几乎不需要耗费“切换成本”。有状态应用有状态的服务,从部署开始,这些容器就开始与上游镜像不同了,时间越长它们的差异越大;每个运行的应用程序都至少有—个小状态(差异),但对于“无状态”应用程序来说,状态(差异)很小,而且可以进行快速替换。无状态应用控制器– DeploymentReplicationController 无状态应用的高可靠 ReplicaSets 无状态应用的高可靠应用的滚动发布 Deployment实践2:Deployment的创建和管理1.创建deploymentkubectl apply -f deployment.yml2.查看PODkubectl get pod3.手动删除PODkubbectl delete pod nginx-deployment-67d4b848b4-sghfq4.扩展Deployment数量kubectl scale deployment.v1.apps/nginx-deployment --replicas=4kubectl get pod5.查看deployment状态和数量有状态应用控制器- StatefulSet如果部署的应用满足右侧一个或多个部署需求则建议使用StatefulSet。在具有以下特点时使用StatefulSets·稳定性,唯一的网络标识符·稳定性,持久化存储·有序的部署和扩展·有序的删除和终止·有序的自动滚动更新实践3:StatefulSet的创建和管理1.在Winscp将StatefulSet定义文件statefulset.yml上传至ecs-k8s。2.通过以下命令创建StatefulSet。kubetcl apply -f statefulset.yml3.通过以下命令查看POD数量和名称kubectl get pod4.手动删除名称为web-0的POD。kubectl delete pod web-05.再次查看POD。kubectl get pod系统应用控制器- DaemonSetDaemonSet能够让所有或者特定的Node节点运行一个pod。当节点加入到kubernetes集群中,pod会被( DaemonSet ) 调度到该节点上运行。当节点从kubernetes集群中被移除,( DaemonSet )调度的pod会被移除。运行日志采集器在每个Node上,例如fluentd ,logstash运行监控的采集端在每个Node,例如prometheusnode exporter , collectd等每个Node上运行一个分布式存储的守护进程,例如glusterd , ceph适合场景:在一个区域的Node上都运行一个守护进程实践4:DaemonSet的创建和管理在winscp中上传daemonset.yml文件至ecs-k8s查看kube-system命令空间中的DaemonSetkubectl get ds -n kube-system创建daemonsetkubectl apply -f daemonset.yml4.再次查看kube-system中的DaemonSetkubectl get ds -n kube-system5.在CCE中购买节点6.查看各个DaemonSet实例数kubectl get ds -n kube-system临时任务控制器–Job我们经常需要进行批量数据处理和分析,以及按照时间进行调度执行。可以在Kubenrtes中使用容器技术完成,使用Job和CronJob来执行。Job负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。CronJob是基于调度的Job执行将会自动产生多个job,调度格式参考Linux的cron系统。实践5:Jobs创建和管理winscp将Job.yml上传运行Jobkubectl apply -f Job. Yml3.查看job运行状态kubectl get job4.查看此Job的输出kubectl get podkubectl logs pi-c5pgr应用访问- ServiceKubernetes应用间互访- Cluster IPKubernetes集群外互访–NodePort公网访问- LoadBalancer实践6 : Service的创建和管理1.上传的deployment文件创建Deploymentkubectl apply -f deployment. Yml2.创建NodePort类型的Service并查看kubectl expose deployment nginx-deployment-type=NodePortkubectl get service通过curl命令验证网站kubectl get node4.url 192.168.0.227:324655.华为云控制台查看其中一个kubernetes Node绑定的公网地址6.在浏览器中,输入ECS绑定的公网地址+Service的Nodeport命名空间- NameSpace作用:Kubernetes可以使用Namespaces(命名空间)创建多个虚拟集群;Namespace为名称提供了一个范围。资源的Names在Namespace中具有唯一性场景:当团队或项目中具有许多用户时,可以考虑使用Namespace来区分,a如果是少量用户集群,可以不需要考虑使用Namespace,如果需要它们提供特殊性质时,可以开始使用Namespace。大多数的Kubernetes中的集群默认会有一个叫default的namespace。实际上,应该是3个:default:你的service和app默认被创建于此。kube-system : kubernetes系统组件使用。kube-public :公共资源使用。实践7∶命名空间的创建和管理默认的Nama&pice实践手动的创建一个NameSpace命名空间并查看kubectl create namespace testkubectl get namespace2.创建一个POD并指定此POD运行在test命名空间llkubectl apply-f POD-1Container.yml -namespace=test3.查看指定命名空间里的PODkubectl get pod -n test.创建一个限制CPU和内存大小的NameSpacekubectl create -f ns-cpu-men.yml -namespace=quota-mem-cpu-examplekubectl get resourcequota mem-cpu-demo -namespace=quota-mem-cpu-example R--output=yaml -
 背景:通过smartkit对AtlasEdge设备进行设备授权时出现执行命令失败排查方法:当授权模式是site, 当前针对MindX 3.0.RC3及之前的版本只支持容器部署、模型文件下载配置,如果下方了网管配置会导致执行命令失败当授权模式是CORE时,除了MindX 3.0.RC2支持Core 模板表格中的所有项外,其他版本(例如MindX 2.0.4.6 MindX 3.0.RC3)只支持imageSha256WhiteList、containerCpuLim、containerCpuLimit配置,如果配置下发了其他项会导致命令失败
背景:通过smartkit对AtlasEdge设备进行设备授权时出现执行命令失败排查方法:当授权模式是site, 当前针对MindX 3.0.RC3及之前的版本只支持容器部署、模型文件下载配置,如果下方了网管配置会导致执行命令失败当授权模式是CORE时,除了MindX 3.0.RC2支持Core 模板表格中的所有项外,其他版本(例如MindX 2.0.4.6 MindX 3.0.RC3)只支持imageSha256WhiteList、containerCpuLim、containerCpuLimit配置,如果配置下发了其他项会导致命令失败 -
错误场景1: 部署主机网络容器失败错误提示:"cur config not surpport pod host work"解决方法:使用容器能力工具中的useHostNetwork配置项打开主机网络能力,配置完成后重启中间件。错误场景2: 部署容器报挂在卷不在白名单错误提示:"hostpath [xxxxxxx] Verification failed: not in whitelist",解决方法:使用容器能力工具中的addHostPath配置添加容器挂在白名单,配置完成后重启中间件。错误场景3: 部署容器下发了容器能力集报错错误提示:"check container Capability failed", cur config not surpport"解决方法:使用容器能力工具中的useCapability配置允许容器配置能力集,配置完成后重启中间件。错误场景4: 部署容器下发了容器能力集报错错误提示:"check container Capability failed", cur config not surpport"解决方法:使用容器能力工具中的usePrivileged配置允许部署特权容器,配置完成后重启中间件。错误场景5: 部署容器下发了容器能力集报错错误提示:"check container Privileged failed", cur config not surpport"解决方法:使用容器能力工具中的usePrivileged配置允许部署特权容器,配置完成后重启中间件。错误场景6: 部署root容器失败错误提示:"check container Run As User failed", cur config not surpport"或者"check container Run As Group failed", cur config not surpport"解决方法:使用容器能力工具中的useRunAsRoot配置允许部署root容器,配置完成后重启中间件。错误场景7: 部署容器使用探针报错误错误提示:"cur config not surpport probe"解决方法:使用容器能力工具中的useProbe配置允许容器使用探针功能,配置完成后重启中间件。错误场景8: 部署容器使用探针报错误错误提示:"check container:容器名 StartCommand failed, not surpport"解决方法:使用容器能力工具中的useStartCommand配置允许容器使用启动命令,配置完成后重启中间件。错误场景9: 部署容器使用探针报错误错误提示:"cur config not surpport empty dir volume"解决方法:使用容器能力工具中的emptyDirVolume配置允许容器使用emptydir挂载卷,配置完成后重启中间件。错误场景10: 部署容器使用探针报错误错误提示:"cur config not surpport empty dir volume"解决方法:使用容器能力工具中的emptyDirVolume配置允许容器使用emptydir挂载卷,配置完成后重启中间件。错误场景11: 容器个数超过限制错误提示:"exceed max container number"解决方法:使用容器能力工具中的maxContainerNumber配置允许部署容器的个数,配置完成后重启中间件。错误场景12: 容器个数超过限制错误提示:"exceed max container number"解决方法:使用容器能力工具中的maxContainerNumber配置允许部署容器的个数,配置完成后重启中间件。错误场景13: 部署容器报挂在卷/etc/localtime不在白名单错误提示:"hostpath [/etc/localtime] Verification failed: not in whitelist",解决方法:1) 使用容器能力工具中的addHostPath将"/etc/localtime"添加容器挂在白名单,配置完成后重启中间件。 2) 配套FusionDirector 22.2.RC1及以后的版本错误场景14: 容器使用端口映射时,容器启动失败解决方法:1) 排查容器端口是否取值为[0-1023], 如果是,业务容器需以root运行,并 使用容器能力工具配置useRunAsRoot、useDefaultContainerCap允许容器使用root运行和使用默认的能力集,配置完成后重启中间件。
-
摘要:KubeEdge 1.11版本提供了“边缘节点分组管理”新特性,抽象出了跨地域的应用部署模型。本文分享自华为云社区《基于KubeEdge的边缘节点分组管理设计与实现》,作者:云容器大未来 。KubeEdge 1.11版本提供了“边缘节点分组管理”新特性,抽象出了跨地域的应用部署模型。该模型将边缘节点按地区划分为节点组,并将应用所需资源打包成一个整体在节点组上进行部署,降低了边缘应用生命周期管理的复杂度,有效减少运维成本。1. 边缘应用跨地域部署面临的挑战图1 边缘应用跨地域部署示意图在边缘计算场景中,边缘节点通常分布在不同的地理区域,这些区域中的节点有着计算资源、网络结构和硬件平台等属性上的差异。如图1所示,边缘节点部署在杭州、北京和上海等地域,各地域边缘节点的规模不同,不同地域网络不互通,以及不同区域镜像仓库也是不同的,如北京的节点无法通过IP直接访问其他区域的节点。因此在部署边缘应用的时候,通常需要为每个这样的地理区域维护一个Deployment,对于资源少的区域减少副本数量,对于局域网中的节点需要把镜像地址改为本地镜像仓库的地址,同样也需要为每个地区管理单独的Service资源,来解决跨地域节点之间的访问问题。然而随着地理区域和应用数量的增长,对应用的管理会变得越来越复杂,运维成本也随之增加。基于以上背景,KubeEdge提供了边缘节点分组管理能力,来解决在跨地域应用部署中运维复杂度的问题。2. 边缘节点分组管理设计与实现图2 边缘节点分组整体概览如图2所示,边缘节点分组特性的整体设计图,主要由节点分组、边缘应用和流量闭环三个部分的内容组成,下面会就以上各个部分详细展开。2.1 节点分组(NodeGroup)图3 节点分组示例根据边缘节点的地理分布特点,可以把同一区域的边缘节点分为一组,将边缘节点以节点组的形式组织起来,同一节点同时只能属于一个节点组。节点分组可以通过matchLabels字段,指定节点名或者节点的Label两种方式对节点进行选择。节点被包含到某一分组后,会被添加上apps.kubeedge.io/belonging-to:nodegroup的Label。2.2 边缘应用(EdgeApplication)图4 边缘应用EdgeApplication的组成边缘应用用于将应用资源打包,按照节点组进行部署,并满足不同节点组之间的差异化部署需求。该部分引入了一个新的CRD: EdgeApplication,主要包括两个部分:(1) Workload Templates。主要包括边缘应用所需要的资源模板,例如Deployment Template、Service Template和ConfigMap Template等;(2) WorkloadScopes。主要针对不同节点组的需求,用于资源模板的差异化配置,包括副本数量差异化配置(Replicas Overrider)和镜像差异化配置(Image Overrider),其中Image Overrider包括镜像仓库地址、仓库名称和标签。对于应用主体,即Deployment,会根据Deployment Template以及差异化配置Overrider生成每组所需的Deployment版本,通过调整nodeSelector将其分别部署到指定分组中。对于应用依赖的其他资源,如ConfigMap和Service,则只会在集群中通过模板创建一个相应的资源。边缘应用会对创建的资源进行生命周期管理,当删除边缘应用时,所有创建的资源都会被删除。2.3 流量闭环图5 流量闭环示意图通过流量闭环的能力,将服务流量限制在同一节点组内,在一个节点组中访问Service时,后端总是在同一个节点组中。当使用EdgeApplication中的Service Template创建Service时,会为Service添上service-topology:range-nodegroup的annotation,KubeEdge云上组件CloudCore会根据该annotation对Endpoint和Endpointslice进行过滤,滤除不在同一节点组内的后端,之后再下发到边缘节点。此外,在下发集群中默认的Master Service “Kubernetes”所关联的Endpoint和Endpointslice时,会将其维护的IP地址修改为边缘节点MetaServer地址,用户在边缘应用中list/watch集群资源时,可以兼容K8s流量访问方式,实现无缝迁移和对接。3. 实现原理与设计理念在这个部分,我们会分享一下边缘节点分组管理特性的设计理念,并结合KubeEdge整体架构,详细介绍一下我们的实现原理。图6 设计理念我们希望给用户提供一个统一的运维入口,原本我们需要维护各个地区的Deployment,如果需要进行增删改查操作,我们需要对每个地区的Deployment都执行一遍相同的操作,不仅增加了运维成本,还容易引入人为操作的错误。边缘节点分组管理特性通过引入EdgeApplication CRD,统一了Deployment等资源的运维入口。另外我们需要提供更大的扩展可能性,在内部实现中,我们统一使用了Unstructured结构,降低与特定资源的耦合度,方便后续添加其他资源。另外为了不干涉原生资源和流程,我们降低与Kubernetes Reconciliation的耦合度,可以保证Deployment等资源操作过程的原生性。图7 节点组和边缘应用实现在边缘节点分组管理特性中,我们引入了两个CRD,分别是节点组NodeGroup和边缘应用EdgeApplication。在NodeGroup Reconciliation中,NodeGroup Controller用于监听NodeGroup CRD的变化,并对节点的apps.kubeedge.io/belonging-to:nodegroup Label进行增删改等操作,同时,加入节点组的节点,会上报状态到NodeGroup CRD中,我们就可以通过查询NodeGroup直接查看节点组内所有节点的状态。EdgeApplication Reconciliation与NodeGroup Reconciliation类似,由EdgeApplication Controller来监听EdgeApplication CRD的变化,对相应资源进行增删改等操作,同时对应资源会上报状态到EdgeApplication CRD中。图8 整体架构如图8所示,是最终的整体架构图。在边缘节点分组管理特性中,我们引入了新的组件ControllerManager,其中包括了刚才我们介绍的NodeGroup Controller和EdgeApplication Controller,在CloudCore中引入了新的模块EndpointSlice Filter,用于实现流量闭环的能力。图中蓝色区域是前面已经介绍了的节点分组和边缘应用的内容,在这里再重点介绍一下Service Template实现流量闭环能力的过程。首先在EdgeApplication CRD中加入Service的模板,在创建边缘应用时,Service range-nodegroup资源也会随之生成,同时控制面会自动为其创建EndpointSlice。EndpointSlice会通过KubeEdge的云边通道下发到边缘节点,CloudCore中的EndpointSlice Filter会进行过滤,保证下发到同一节点组内的边缘节点,由此可以保证边缘上的客户端访问始终在一个节点组内。对于用户来说,图8中紫色的线表达了用户需要维护的资源。首先用户需要维护NodeGroup,来管理节点组中的节点;其次,用户需要维护EdgeApplication资源,通过EdgeApplication来实现对各个地域边缘应用的生命周期管理。4. 发展规划目前我们已经实现了Deployment、Service和ConfigMap等资源的打包以及流量闭环的能力,并且支持资源的部分状态收集。未来我们将继续拓展边缘节点分组的能力,实现边缘网关,支持StatefulSet等更多资源,逐步完善应用状态收集,并在Kubectl中支持更友好的资源展现形式。欢迎大家能够加入KubeEdge社区,一起完善与增强KubeEdge边缘节点分组等方面的能力。了解KubeEdge社区KubeEdge是业界首个云原生边缘计算框架、云原生计算基金会内部唯一孵化级边缘计算开源项目,社区已完成业界最大规模云原生边云协同高速公路项目(统一管理10万边缘节点/50万边缘应用)、业界首个云原生星地协同卫星、业界首个云原生车云协同汽车、业界首个云原生油田项目,开源业界首个分布式协同AI框架Sedna及业界首个边云协同终身学习范式,并在持续开拓创新中。KubeEdge网站 : https://kubeedge.ioGitHub地址 : https://github.com/kubeedge/kubeedgeSlack地址 : https://kubeedge.slack.com邮件列表 : https://groups.google.com/forum/#!forum/kubeedge每周社区例会 : https://zoom.us/j/4167237304Twitter : https://twitter.com/KubeEdge文档地址 : https://docs.kubeedge.io/en/latest/本文作者由KubeEdge社区Member——华为云 鲍玥、浙江大学SEL实验室 张逸飞原创。
-
摘要:KubeEdge设备管理架构的设计实现,有效帮助用户处理设备数字孪生进程中遇到的场景。本文分享自华为云社区《KubeEdge:下一代云原生边缘设备管理标准DMI的设计与实现》。随着5G、AI、分布式云等技术的成熟发展,万物互联、数字孪生、算力泛在等理念不断推进,带来了很多行业业务的创新,越来越多的设备、应用运行在端侧,并产生大量的数据。如何更好地解耦业务应用开发和设备数据访问,为设备提供完整的生命周期数据管理,释放设备数据的价值?如何在保证集群可用性的同时,高效管理和传输设备数据,获得更为方便、灵活的数据访问方式?云原生边缘计算的方案选择可以帮助用户更好地应对这类问题。一、KubeEdge设备管理框架KubeEdge设备管理架构的设计实现,有效帮助用户处理设备数字孪生进程中遇到的场景。用户可以通过KubeEdge,将物理设备抽象成数字孪生,用云原生的方式对设备和数据进行管理。一、KubeEdge设备管理框架 图 1 KubeEdge设备管理架构设计KubeEdge设备管理架构设计如图1所示,具体流程如下:1. 用户调用Kubernetes API接口,创建Device CRD实例到KubeEdge2. KubeEdge云上组件CloudCore watch到Kubernetes中Device CRD实例创建消息3. 此时CloudCore会做两件事情,一方面CloudCore通过云边websocket通道下发Device Twin信息到EdgeCore,另一方面CloudCore会生成一份包含Device Profile信息的Configmap,该Configmap是以Node名称为索引,挂载到对应Mapper的Pod中的4. Mapper通过读取挂载的Configmap中的Device Profile信息,更新本地维护的Device list列表5. EdgeCore把接收到的Device Twin信息发送到指定的mqtt topic6. 该节点上的所有Mapper都会收到该Device Twin消息,并根据Device名称来匹配是否是自己维护的list中的Device7. Mapper根据Device Profile信息,通过对应的协议与设备建立连接8. Mapper通过mqtt topic上报设备状态和采集的数据Device Twin到EdgeCore9. EdgeCore通过云边websocket通道上报Device Twin数据到CloudCore10. CloudCore更新设备Device Twin数据到Kubernetes二、DMI框架设计 在此基础上,KubeEdge团队也对框架不断更新迭代。为帮助用户应对未来更大规模设备场景、更高的可用性需求、更灵活的功能支持以及更优的用户体验,KubeEdge 设计了更优化的设备管理框架——DMI。DMI整合设备管理接口,优化边缘计算场景下的设备管理能力,打造基于云原生技术的,覆盖设备管理、设备数据的设备数字孪生管理平台;同时定义了EdgeCore与Mapper之间统一的连接入口,并分别由EdgeCore和Mapper实现上行数据流和下行数据流的服务端和客户端,承载DMI具体功能。DMI框架设计中解耦了设备管理面与设备业务面数据,让Device CRD只承载设备本身的生命周期管理,而设备业务面数据则直接通过微服务的方式为数据消费者应用提供出来。在这样的架构下,设备就不再是单纯的数据源,而是一种云原生的设备微服务,设备数据消费应用的开发者就可以不再关心如何获取设备数据,而是以更云原生的方式来聚焦应用本身的业务逻辑开发。DMI框架还提供多种数据推送方式,让数据消费者可以更灵活地获取设备数据,用户体验更优。由于DMI的设备管理面与业务面数据分离的特点,业务面数据可以通过业务面通道更灵活地在云端或边端被处理,而管理面的云边通道中只会传输少量管理面信息,大大降低了云边通道拥塞的可能,提高了KubeEdge系统的可用性。另外,DMI提供了统一的设备管理相关接口,无论是设备应用开发者还是设备应用的使用者,都可以以更统一、更灵活、更标准化的方式来开展设备相关工作,不拘泥于具体形式,只要能够实现DMI接口,就能够享受KubeEdge边缘计算平台带来的云原生设备管理体验。▍2.1 DMI框架定位图 2 DMI 在 KubeEdge 架构中的定位DMI在KubeEdge架构中的定位如图2所示。DMI类似Kubernetes的CNI、CSI、CRI等接口,定义了一组EdgeCore与Mapper之间的内部API接口以及外部应用访问Mapper的统一的API接口。其中内部接口底层由gRPC结合UDS的方式来实现,外部API接口支持mqtt和REST两种接入方式。Mapper不论是何种承载、实现方式,只要实现了DMI中所定义的上行、下行数据接口,即可接入KubeEdge云原生边缘计算平台,使用云原生的方式对设备进行管理。▍2.2 DMI设备管理与数据管理DMI框架架构设计如图3所示,其中黄色线条为设备管理面数据流管理,蓝色部分为业务面数据流管理。在DMI的架构设计中,将设备的管理面数据与业务面数据进行分离。其中管理面数据主要包括设备的元数据、设备属性、配置、状态、生命周期等,其特点是相对比较稳定,创建后除状态上报外的信息更新较少,更贴近Pod类型资源所产生的数据,在保证用户可以通过云端Kubernetes API像访问Pod一样维护Device的生命周期的同时,尽量减少设备管理产生的额外数据传输开销。图 3 DMI设备管理与数据管理架构在DMI框架设计下,设备不再是单纯的数据源,而是被抽象为微服务,以云原生的方式为设备数据消费者提供数据服务。DMI框架下的设备数据访问支持多种场景,更加灵活。图3中列出了几种主要的数据访问方式,包括推数据和拉数据等,具体情况如下:1. 边缘侧应用通过REST Service访问设备数据2. 云侧应用通过REST Service访问设备数据3. Mapper通过配置REST目的地址,将数据推送到边缘侧应用4. Mapper通过配置REST目的地址,将数据推送到云侧应用5. Mapper通过配置目的地址,将数据推送到边缘侧数据库6. Mapper通过配置目的地址,将数据推送到mqtt broker7. 边缘侧应用通过mqtt broker topic订阅设备数据8. 云侧应用通过mqtt broker topic 订阅设备数据9. 边缘侧应用处理数据后将处理结果传上云▍2.3 DMI工作流程图 4 DMI设备管理工作流程示例在DMI框架下,设备管理工作的流程有一定的变化。如图4所示,在安装KubeEdge的时候,云端CloudCore会注册DeviceController组件用于监听Device和DeviceModel的CRD资源。DeviceController中存在两个模块,Downstream Controller和Upstream Controller,其中Downstream Controller用于监听云端的Device、DeviceModel事件,并通过Cloudhub下发至边缘,Upstream Controller用于接收从Cloudhub转发来的EdgeHub上报的Device状态和消息,并更新Kubernetes中的Device状态。在边缘侧,Mapper初始化的时候,需要调用DMI中的Mapper注册接口,将Mapper的相关信息注册至Device Manager,并接收接口返回的已下发至该节点的且协议匹配的设备信息。EdgeHub在接收到云端下发的设备消息时,会将其转发到DeviceManager组件,DeviceManager会根据该设备的协议选择对应的Mapper驱动程序,发送创建设备的请求,并且本地数据库也会存储该设备的信息,后续Mapper会将设备孪生消息转化为设备协议格式,跟实际的物理设备进行通信。三、DMI接口定义▍3.1 DMI 接口分类DMI接口实现了EdgeCore与Mapper之间的通信,支持REST和mqtt的通信方式,并以标准化的形式呈现,降低了Mapper开发、适配难度。在数据访问方面,DMI可以实现边缘侧和云侧的应用都可以通过REST Service的方式访问设备数据。图 5 DMI接口定义如图5所示,DMI有六类接口,Mapper管理是针对边缘侧各类设备协议驱动程序,Device管理和Device数据管理对管理面和业务面进行了数据拆分,Device升级管理和Device命令管理为具有升级和命令执行功能的设备提供相关的接口,Device事件管理可以监控Mapper及其纳管的各个设备的运行状态。▍3.2 DMI 接口定义示例图 6 DMI设备管理部分接口定义示例如图6所示,为DMI设备管理部分接口定义,v1版本以gRPC proto的方式定义,可使用make dmi命令创建对应的gRPC-go代码。 ▍3.3 DMI 设备相关 CRD 定义如图7所示,是DMI设备相关CRD定义,主要分为Device和DeviceModel。其中DeviceModel与设备型号是一一对应的关系,代表同一类设备型号的共有属性,主要包含设备产生数据属性Properties和设备支持命令属性Commands。Device为设备实例,与真实的物理设备为一对一的关系,每个DeviceModel可以对应统一型号的多个Device实例。Device类型资源主要包含设备型号对应关系信息、设备协议配置信息、设备部署节点信息、设备状态信息以及设备数据Property采集配置信息。图 7 DMI 设备相关 CRD 定义 四、发布计划 四、发布计划DMI发布计划分为三个版本,Alpha版本提供设备管理相关功能实现,以及提供一个支持DMI接口的Mapper Demo。Beta版本支持设备命令管理、设备升级管理以及设备数据管理的能力,此外还会对接第三方平台,并提供相关对接Demo。GA版本会对多平台、多协议进行对接支持,另外会把设备安全以及事件管理的功能补全。图 8 DMI发布计划目前 KubeEdge Device IoT SIG 专注于第一阶段的设备管理和 Mapper Demo 的开发工作。欢迎大家通过下方联系方式联系我们,一起参与到方案设计和特性开发的工作当中本文作者:华为云 赵然 ;DaoCloud 道客 王梓龙附:KubeEdge社区贡献和技术交流地址网站: https://kubeedge.ioGithub地址: cid:link_1地址: https://kubeedge.slack.com邮件列表: https://groups.google.com/forum/#!forum/kubeedge每周社区例会: https://zoom.us/j/4167237304Twitter: https://twitter.com/KubeEdge文档地址: https://docs.kubeedge.io/en/latest/
-
 一、常见数据结构非线程安全的数据结构:ArrayList,LinkedList,ArrayQueue,HashMap,HashSet线程安全的数据结构:Vector,Stack,Hashtable,CopyOnWriteArrayList,ConcurrentHashMap二、ArrayList2-1 线程不安全的原因看源码public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! // 该方法是容量保障,当容纳不下新增的元素时会进行扩容 elementData[size++] = e; return true;}分析:当数组长度为10,而size = 9时,此时A线程判断可以容纳,B线程也来判断发现可以容纳(这是因为add非原子操作)。当A添加完之后,B线程再添加的话,就会报错(数组越界异常)而且这一步elementData[size++] = e也非原子性的.可以拆分为elementData[size] = e 和 size ++;在多线程的情况下很容易出现elementData[size] = e1; elementData[size] = e2; size++; size++; 的情况2-2 Vector实现安全Vector的add()源码: public synchronized void addElement(E obj) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = obj; }分析: Vector的add方法加了synchronized ,而ArrayList没有,所以ArrayList线程不安全,但是,由于Vector加了synchronized ,变成了串行,所以效率低。回到目录…三、CopyOnWriteArrayListCopyOnWrite容器即写时复制的容器。// java.util.concurrent包下List<String> list = new CopyOnWriteArrayList<String>();123-1 如何实现线程安全? 通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。 这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。3-2 特征CopyOnWriteArrayList(写数组的拷贝)是ArrayList的一个线程安全的变体,CopyOnWriteArrayList和CopyOnWriteSet都是线程安全的集合,其中所有可变操作(add、set等等)都是通过对底层数组进行一次新的复制来实现的。它绝对不会抛出ConcurrentModificationException的异常。因为该列表(CopyOnWriteArrayList)在遍历时将不会被做任何的修改。CopyOnWriteArrayList适合用在“读多,写少”的并发场景中,比如缓存、白名单、黑名单。它不存在“扩容”的概念,每次写操作(add or remove)都要copy一个副本,在副本的基础上修改后改变array引用,所以称为“CopyOnWrite”,因此在写操作要加锁,并且对整个list的copy操作时相当耗时的,过多的写操作不推荐使用该存储结构。读的时候不需要加锁,如果读的时候有多个线程正在向CopyOnWriteArrayList添加数据,读还是会读到旧的数据,因为开始读的那一刻已经确定了读的对象是旧对象。3-3 缺点在写操作时,因为复制机制,会导致内存占用过大。不能保证实时性的数据一致,“脏读”。回到目录…四、HashMap4-1 底层原理不清楚的小白看看之前两篇文章,就可以很容易搞懂HashMap的底层实现原理了。 Java数据结构之哈希表 JDK中的Set和Map解析4-2 线程不安全的原因单看 HashMap 中的 put 操作:JDK1.7头插法 –> 将链表变成环 –> 死循环JDK1.8尾插法 –> 数据覆盖回到目录…五、ConcurrentHashMap// java.util.concurrent包下Map<Integer, String> map = new ConcurrentHashMap<>();125-1 实现原理JDK1.7时,采用分段锁JDK1.8时,只针对同一链表内互斥,不是同一链表内的操作就不需要互斥。但是一旦遇到需要扩容的时候,涉及到所有链表,此时就不是简单的互斥了。扩容的过程:当A线程put 操作时发现需要扩容,则它自己创建一个扩容后的新数组。A线程只把当前桶中的节点重新计算哈希值放入新数组中,并且标记该桶元素已经迁移完成。由于其它桶中的元素还没有迁移,所以暂时还不删除旧数组。等其它线程抢到锁并在桶内做完操作时,需要义务的将该桶节点全部搬移并标记桶。直到最后一个线程将最后一桶节点搬移完毕,则它需要把旧数组删除。5-2 与Hashtable的区别HashTable和HashMap的实现原理几乎一样,差别在于:HashTable不允许key和value为null;HashTable是线程安全的。 但是HashTable线程安全的策略实现代价却比较大,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把全表锁。当一个线程访问或操作该对象,那其他线程只能阻塞。 所以说,Hashtable 的效率低的离谱,几近废弃。————————————————版权声明:本文为CSDN博主「一只咸鱼。。」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/qq15035899256/article/details/125961682
一、常见数据结构非线程安全的数据结构:ArrayList,LinkedList,ArrayQueue,HashMap,HashSet线程安全的数据结构:Vector,Stack,Hashtable,CopyOnWriteArrayList,ConcurrentHashMap二、ArrayList2-1 线程不安全的原因看源码public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! // 该方法是容量保障,当容纳不下新增的元素时会进行扩容 elementData[size++] = e; return true;}分析:当数组长度为10,而size = 9时,此时A线程判断可以容纳,B线程也来判断发现可以容纳(这是因为add非原子操作)。当A添加完之后,B线程再添加的话,就会报错(数组越界异常)而且这一步elementData[size++] = e也非原子性的.可以拆分为elementData[size] = e 和 size ++;在多线程的情况下很容易出现elementData[size] = e1; elementData[size] = e2; size++; size++; 的情况2-2 Vector实现安全Vector的add()源码: public synchronized void addElement(E obj) { modCount++; ensureCapacityHelper(elementCount + 1); elementData[elementCount++] = obj; }分析: Vector的add方法加了synchronized ,而ArrayList没有,所以ArrayList线程不安全,但是,由于Vector加了synchronized ,变成了串行,所以效率低。回到目录…三、CopyOnWriteArrayListCopyOnWrite容器即写时复制的容器。// java.util.concurrent包下List<String> list = new CopyOnWriteArrayList<String>();123-1 如何实现线程安全? 通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。 这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。3-2 特征CopyOnWriteArrayList(写数组的拷贝)是ArrayList的一个线程安全的变体,CopyOnWriteArrayList和CopyOnWriteSet都是线程安全的集合,其中所有可变操作(add、set等等)都是通过对底层数组进行一次新的复制来实现的。它绝对不会抛出ConcurrentModificationException的异常。因为该列表(CopyOnWriteArrayList)在遍历时将不会被做任何的修改。CopyOnWriteArrayList适合用在“读多,写少”的并发场景中,比如缓存、白名单、黑名单。它不存在“扩容”的概念,每次写操作(add or remove)都要copy一个副本,在副本的基础上修改后改变array引用,所以称为“CopyOnWrite”,因此在写操作要加锁,并且对整个list的copy操作时相当耗时的,过多的写操作不推荐使用该存储结构。读的时候不需要加锁,如果读的时候有多个线程正在向CopyOnWriteArrayList添加数据,读还是会读到旧的数据,因为开始读的那一刻已经确定了读的对象是旧对象。3-3 缺点在写操作时,因为复制机制,会导致内存占用过大。不能保证实时性的数据一致,“脏读”。回到目录…四、HashMap4-1 底层原理不清楚的小白看看之前两篇文章,就可以很容易搞懂HashMap的底层实现原理了。 Java数据结构之哈希表 JDK中的Set和Map解析4-2 线程不安全的原因单看 HashMap 中的 put 操作:JDK1.7头插法 –> 将链表变成环 –> 死循环JDK1.8尾插法 –> 数据覆盖回到目录…五、ConcurrentHashMap// java.util.concurrent包下Map<Integer, String> map = new ConcurrentHashMap<>();125-1 实现原理JDK1.7时,采用分段锁JDK1.8时,只针对同一链表内互斥,不是同一链表内的操作就不需要互斥。但是一旦遇到需要扩容的时候,涉及到所有链表,此时就不是简单的互斥了。扩容的过程:当A线程put 操作时发现需要扩容,则它自己创建一个扩容后的新数组。A线程只把当前桶中的节点重新计算哈希值放入新数组中,并且标记该桶元素已经迁移完成。由于其它桶中的元素还没有迁移,所以暂时还不删除旧数组。等其它线程抢到锁并在桶内做完操作时,需要义务的将该桶节点全部搬移并标记桶。直到最后一个线程将最后一桶节点搬移完毕,则它需要把旧数组删除。5-2 与Hashtable的区别HashTable和HashMap的实现原理几乎一样,差别在于:HashTable不允许key和value为null;HashTable是线程安全的。 但是HashTable线程安全的策略实现代价却比较大,get/put所有相关操作都是synchronized的,这相当于给整个哈希表加了一把全表锁。当一个线程访问或操作该对象,那其他线程只能阻塞。 所以说,Hashtable 的效率低的离谱,几近废弃。————————————————版权声明:本文为CSDN博主「一只咸鱼。。」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/qq15035899256/article/details/125961682 -
 什么是虚拟机虚拟机(Vm)是计算机系统的仿真。简而言之,它可以在实际上是一台计算机的硬件上运行看起来很多单独的计算机。虚拟的是操作系统层,但是因为在虚拟操作系统过程中在Host OS和Guest OS直接加入了一个虚拟层,导致资源消耗比较大。但是Vm目前也有优点:因为虚拟化已经成熟,具有广泛的工具和生态系统,以及支持其在各种环境中部署,对于需非linux操作系统或特定内核虚拟化的工作方式任然是唯一的方法。什么是容器容器位于物理服务器及其主机操作系统之上 - 通常是Linux或Windows。每个容器共享主机操作系统内核,通常也包括二进制文件和库。共享组件是只读的。共享操作系统资源(如库)可以显着减少重现操作系统代码的需要,并且意味着服务器可以通过单个操作系统安装来运行多个工作负载。因此容器非常轻 - 它们只有几兆字节,只需几秒钟即可启动。与容器相比,Vm需要几分钟才能运行,并且比同等容器大一个数量级。与Vm相比,容器所需的全部功能都足以支持程序和库以及运行特定程序的系统资源。实际上,这意味着您可以将容器上的应用程序的容量设置为使用容器的两到三倍,而不是使用Vm。此外,使用容器,您可以为开发,测试和部署创建可移植,一致的操作环境。容器的类型 lxc lxc虚拟的是操作系统层,lxc起源于linux内核中的cgroup和namespace的开发,以支持轻量级虚拟化操作系统环境(容器)。lxc是一种操作系统级别的轻量级linux容器,而docker则相当于是一个应用程序级别的容器。这是两者最主要的不同点。相比于docker容器的操作系统模板简化为单个应用程序环境,没有守护程序,syslog,不能运行多个应用程序,lxc容器则更像一个原生,完整的linux系统。lxc本质上是集合了linux系统具有所有虚拟化特性的一个用于管理容器的命令行工具。相当于是用linux的底层技术作为支撑,整合这些底层特性,做成一个命令行工具。lxc支持嵌套。lxc里面继续安装lxc。安全方面:采用seccomp来隔离潜在危险的系统调用;采用AppArmor来对mount, socket, ptrace和文件访问提供额外的限制,特别是限制跨容器通信;采用Capabilities来阻止容器加载内核模块,修改主机系统时间等等;采用CGroups限制资源使用,防止针对主机的DoS攻击等。存储后端也可以是btrfs, lvm, overlayfs, zfs等。提供基于C语言的API。缺点:无法有效支持跨主机之间的容器迁移,管理复杂。 lxd lxd是对lxc的改进版本,主要改进如下:lxc只是单机的命令行工具,没有daemon进程,所以它无法提供REST API,也无法有效支持跨主机之间的容器迁移。LXC的命令也太底层,普通用户无法理解,用户使用困难。lxd再进行了一次封装,使得使用更加方便。LXD作为一个daemon进程弥补了上述问题,让LXC更易用。 Docker lxd侧重于在在容器里运行系统容器(即容器里运行的是完整的操作系统),所以它将lxc里面侧重于安全的技术也都重新包装后暴露出来,Docker侧重于在容器里运行单一的普通应用,更加重视应用的管理。Docker一开始是基于lxc项目来创建单个应用程序容器,但是现在Docker已经开发出了他们自己核心namespace和cgroup工具:libcontainer。Docker容器技术容器技术都是基于底层镜像构建的,镜像的改动会被划分成一层一层的结构,在每层的改动必须要进行提交保留,否则对于容器的修改只是暂时的。Dockerfile是一个告诉Docker如何从镜像用特定的应用程序来创建容器的脚本。跟使用特定的安装好的应用程序通过bash脚本来创建一个LXC容器相似。智能云网智能云网社区是华为专为开发者打造的“学习、开发、验证、交流”一站式支持与服务平台,该平台涵盖多领域知识。目前承载了云园区网络,云广域网络,数通网络开放可编程,超融合数据中心网络,数通网络设备开放社区共五个场景。为了响应广大开发者需求,还提供了开发者交流、API 体验中心、多媒体课件、SDK工具包、开发者工具以及远程实验室共六大工具,让开发者轻松开发。欢迎各位前来体验。>>戳我了解更多<<
什么是虚拟机虚拟机(Vm)是计算机系统的仿真。简而言之,它可以在实际上是一台计算机的硬件上运行看起来很多单独的计算机。虚拟的是操作系统层,但是因为在虚拟操作系统过程中在Host OS和Guest OS直接加入了一个虚拟层,导致资源消耗比较大。但是Vm目前也有优点:因为虚拟化已经成熟,具有广泛的工具和生态系统,以及支持其在各种环境中部署,对于需非linux操作系统或特定内核虚拟化的工作方式任然是唯一的方法。什么是容器容器位于物理服务器及其主机操作系统之上 - 通常是Linux或Windows。每个容器共享主机操作系统内核,通常也包括二进制文件和库。共享组件是只读的。共享操作系统资源(如库)可以显着减少重现操作系统代码的需要,并且意味着服务器可以通过单个操作系统安装来运行多个工作负载。因此容器非常轻 - 它们只有几兆字节,只需几秒钟即可启动。与容器相比,Vm需要几分钟才能运行,并且比同等容器大一个数量级。与Vm相比,容器所需的全部功能都足以支持程序和库以及运行特定程序的系统资源。实际上,这意味着您可以将容器上的应用程序的容量设置为使用容器的两到三倍,而不是使用Vm。此外,使用容器,您可以为开发,测试和部署创建可移植,一致的操作环境。容器的类型 lxc lxc虚拟的是操作系统层,lxc起源于linux内核中的cgroup和namespace的开发,以支持轻量级虚拟化操作系统环境(容器)。lxc是一种操作系统级别的轻量级linux容器,而docker则相当于是一个应用程序级别的容器。这是两者最主要的不同点。相比于docker容器的操作系统模板简化为单个应用程序环境,没有守护程序,syslog,不能运行多个应用程序,lxc容器则更像一个原生,完整的linux系统。lxc本质上是集合了linux系统具有所有虚拟化特性的一个用于管理容器的命令行工具。相当于是用linux的底层技术作为支撑,整合这些底层特性,做成一个命令行工具。lxc支持嵌套。lxc里面继续安装lxc。安全方面:采用seccomp来隔离潜在危险的系统调用;采用AppArmor来对mount, socket, ptrace和文件访问提供额外的限制,特别是限制跨容器通信;采用Capabilities来阻止容器加载内核模块,修改主机系统时间等等;采用CGroups限制资源使用,防止针对主机的DoS攻击等。存储后端也可以是btrfs, lvm, overlayfs, zfs等。提供基于C语言的API。缺点:无法有效支持跨主机之间的容器迁移,管理复杂。 lxd lxd是对lxc的改进版本,主要改进如下:lxc只是单机的命令行工具,没有daemon进程,所以它无法提供REST API,也无法有效支持跨主机之间的容器迁移。LXC的命令也太底层,普通用户无法理解,用户使用困难。lxd再进行了一次封装,使得使用更加方便。LXD作为一个daemon进程弥补了上述问题,让LXC更易用。 Docker lxd侧重于在在容器里运行系统容器(即容器里运行的是完整的操作系统),所以它将lxc里面侧重于安全的技术也都重新包装后暴露出来,Docker侧重于在容器里运行单一的普通应用,更加重视应用的管理。Docker一开始是基于lxc项目来创建单个应用程序容器,但是现在Docker已经开发出了他们自己核心namespace和cgroup工具:libcontainer。Docker容器技术容器技术都是基于底层镜像构建的,镜像的改动会被划分成一层一层的结构,在每层的改动必须要进行提交保留,否则对于容器的修改只是暂时的。Dockerfile是一个告诉Docker如何从镜像用特定的应用程序来创建容器的脚本。跟使用特定的安装好的应用程序通过bash脚本来创建一个LXC容器相似。智能云网智能云网社区是华为专为开发者打造的“学习、开发、验证、交流”一站式支持与服务平台,该平台涵盖多领域知识。目前承载了云园区网络,云广域网络,数通网络开放可编程,超融合数据中心网络,数通网络设备开放社区共五个场景。为了响应广大开发者需求,还提供了开发者交流、API 体验中心、多媒体课件、SDK工具包、开发者工具以及远程实验室共六大工具,让开发者轻松开发。欢迎各位前来体验。>>戳我了解更多<< -
 前言Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据。本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 HashMap,没有它就不会有后面的 ConcurrentHashMap。HashMap众所周知 HashMap 底层是基于 数组 + 链表 组成的,不过在 jdk1.7 和 1.8 中具体实现稍有不同。Base 1.71.7 中的数据结构图:先来看看 1.7 中的实现。这是 HashMap 中比较核心的几个成员变量;看看分别是什么意思?初始化桶大小,因为底层是数组,所以这是数组默认的大小。桶最大值。默认的负载因子(0.75)table 真正存放数据的数组。Map 存放数量的大小。桶大小,可在初始化时显式指定。负载因子,可在初始化时显式指定。重点解释下负载因子:由于给定的 HashMap 的容量大小是固定的,比如默认初始化: 1 public HashMap() { 2 this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); 3 } 4 5 public HashMap(int initialCapacity, float loadFactor) { 6 if (initialCapacity < 0) 7 throw new IllegalArgumentException("Illegal initial capacity: " + 8 initialCapacity); 9 if (initialCapacity > MAXIMUM_CAPACITY)10 initialCapacity = MAXIMUM_CAPACITY;11 if (loadFactor <= 0 || Float.isNaN(loadFactor))12 throw new IllegalArgumentException("Illegal load factor: " +13 loadFactor);1415 this.loadFactor = loadFactor;16 threshold = initialCapacity;17 init();18 }给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。因此通常建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。根据代码可以看到其实真正存放数据的是transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;这个数组,那么它又是如何定义的呢?Entry 是 HashMap 中的一个内部类,从他的成员变量很容易看出:key 就是写入时的键。value 自然就是值。开始的时候就提到 HashMap 是由数组和链表组成,所以这个 next 就是用于实现链表结构。hash 存放的是当前 key 的 hashcode。知晓了基本结构,那来看看其中重要的写入、获取函数:put 方法 1 public V put(K key, V value) { 2 if (table == EMPTY_TABLE) { 3 inflateTable(threshold); 4 } 5 if (key == null) 6 return putForNullKey(value); 7 int hash = hash(key); 8 int i = indexFor(hash, table.length); 9 for (Entry<K,V> e = table[i]; e != null; e = e.next) {10 Object k;11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {12 V oldValue = e.value;13 e.value = value;14 e.recordAccess(this);15 return oldValue;16 }17 }1819 modCount++;20 addEntry(hash, key, value, i);21 return null;22 }判断当前数组是否需要初始化。如果 key 为空,则 put 一个空值进去。根据 key 计算出 hashcode。根据计算出的 hashcode 定位出所在桶。如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆盖,并返回原来的值。如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。 1 void addEntry(int hash, K key, V value, int bucketIndex) { 2 if ((size >= threshold) && (null != table[bucketIndex])) { 3 resize(2 * table.length); 4 hash = (null != key) ? hash(key) : 0; 5 bucketIndex = indexFor(hash, table.length); 6 } 7 8 createEntry(hash, key, value, bucketIndex); 9 }1011 void createEntry(int hash, K key, V value, int bucketIndex) {12 Entry<K,V> e = table[bucketIndex];13 table[bucketIndex] = new Entry<>(hash, key, value, e);14 size++;15 }当调用 addEntry 写入 Entry 时需要判断是否需要扩容。如果需要就进行两倍扩充,并将当前的 key 重新 hash 并定位。而在 createEntry 中会将当前位置的桶传入到新建的桶中,如果当前桶有值就会在位置形成链表。get 方法再来看看 get 函数: 1 public V get(Object key) { 2 if (key == null) 3 return getForNullKey(); 4 Entry<K,V> entry = getEntry(key); 5 6 return null == entry ? null : entry.getValue(); 7 } 8 9 final Entry<K,V> getEntry(Object key) {10 if (size == 0) {11 return null;12 }1314 int hash = (key == null) ? 0 : hash(key);15 for (Entry<K,V> e = table[indexFor(hash, table.length)];16 e != null;17 e = e.next) {18 Object k;19 if (e.hash == hash &&20 ((k = e.key) == key || (key != null && key.equals(k))))21 return e;22 }23 return null;24 }首先也是根据 key 计算出 hashcode,然后定位到具体的桶中。判断该位置是否为链表。不是链表就根据 key、key 的 hashcode 是否相等来返回值。为链表则需要遍历直到 key 及 hashcode 相等时候就返回值。啥都没取到就直接返回 null 。Base 1.8不知道 1.7 的实现大家看出需要优化的点没有?其实一个很明显的地方就是:当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 O(N)。因此 1.8 中重点优化了这个查询效率。1.8 HashMap 结构图:先来看看几个核心的成员变量: 1 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 2 3 /** 4 * The maximum capacity, used if a higher value is implicitly specified 5 * by either of the constructors with arguments. 6 * MUST be a power of two <= 1<<30. 7 */ 8 static final int MAXIMUM_CAPACITY = 1 << 30; 910 /**11 * The load factor used when none specified in constructor.12 */13 static final float DEFAULT_LOAD_FACTOR = 0.75f;1415 static final int TREEIFY_THRESHOLD = 8;1617 transient Node<K,V>[] table;1819 /**20 * Holds cached entrySet(). Note that AbstractMap fields are used21 * for keySet() and values().22 */23 transient Set<Map.Entry<K,V>> entrySet;2425 /**26 * The number of key-value mappings contained in this map.27 */28 transient int size;和 1.7 大体上都差不多,还是有几个重要的区别:TREEIFY_THRESHOLD 用于判断是否需要将链表转换为红黑树的阈值。HashEntry 修改为 Node。Node 的核心组成其实也是和 1.7 中的 HashEntry 一样,存放的都是 key value hashcode next 等数据。再来看看核心方法。put 方法看似要比 1.7 的复杂,我们一步步拆解:判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)。根据当前 key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可。如果当前桶有值( Hash 冲突),那么就要比较当前桶中的 key、key 的 hashcode 与写入的 key 是否相等,相等就赋值给 e,在第 8 步的时候会统一进行赋值及返回。如果当前桶为红黑树,那就要按照红黑树的方式写入数据。如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)。接着判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。如果在遍历过程中找到 key 相同时直接退出遍历。如果 e != null 就相当于存在相同的 key,那就需要将值覆盖。最后判断是否需要进行扩容。get 方法 1 public V get(Object key) { 2 Node<K,V> e; 3 return (e = getNode(hash(key), key)) == null ? null : e.value; 4 } 5 6 final Node<K,V> getNode(int hash, Object key) { 7 Node<K,V>[] tab; Node<K,V> first, e; int n; K k; 8 if ((tab = table) != null && (n = tab.length) > 0 && 9 (first = tab[(n - 1) & hash]) != null) {10 if (first.hash == hash && // always check first node11 ((k = first.key) == key || (key != null && key.equals(k))))12 return first;13 if ((e = first.next) != null) {14 if (first instanceof TreeNode)15 return ((TreeNode<K,V>)first).getTreeNode(hash, key);16 do {17 if (e.hash == hash &&18 ((k = e.key) == key || (key != null && key.equals(k))))19 return e;20 } while ((e = e.next) != null);21 }22 }23 return null;24 }get 方法看起来就要简单许多了。首先将 key hash 之后取得所定位的桶。如果桶为空则直接返回 null 。否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。如果第一个不匹配,则判断它的下一个是红黑树还是链表。红黑树就按照树的查找方式返回值。不然就按照链表的方式遍历匹配返回值。从这两个核心方法(get/put)可以看出 1.8 中对大链表做了优化,修改为红黑树之后查询效率直接提高到了 O(logn)。但是 HashMap 原有的问题也都存在,比如在并发场景下使用时容易出现死循环。1final HashMap<String, String> map = new HashMap<String, String>();2for (int i = 0; i < 1000; i++) {3 new Thread(new Runnable() {4 @Override5 public void run() {6 map.put(UUID.randomUUID().toString(), "");7 }8 }).start();9}但是为什么呢?简单分析下。看过上文的还记得在 HashMap 扩容的时候会调用 resize() 方法,就是这里的并发操作容易在一个桶上形成环形链表;这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标就会出现死循环。遍历方式还有一个值得注意的是 HashMap 的遍历方式,通常有以下几种: 1Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator(); 2 while (entryIterator.hasNext()) { 3 Map.Entry<String, Integer> next = entryIterator.next(); 4 System.out.println("key=" + next.getKey() + " value=" + next.getValue()); 5 } 6 7Iterator<String> iterator = map.keySet().iterator(); 8 while (iterator.hasNext()){ 9 String key = iterator.next();10 System.out.println("key=" + key + " value=" + map.get(key));1112 }强烈建议使用第一种 EntrySet 进行遍历。第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低。简单总结下 HashMap:无论是 1.7 还是 1.8 其实都能看出 JDK 没有对它做任何的同步操作,所以并发会出问题,甚至出现死循环导致系统不可用。因此 JDK 推出了专项专用的 ConcurrentHashMap ,该类位于 java.util.concurrent 包下,专门用于解决并发问题。坚持看到这里的朋友算是已经把 ConcurrentHashMap 的基础已经打牢了,下面正式开始分析。ConcurrentHashMapConcurrentHashMap 同样也分为 1.7 、1.8 版,两者在实现上略有不同。Base 1.7如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。它的核心成员变量:1 /**2 * Segment 数组,存放数据时首先需要定位到具体的 Segment 中。3 */4 final Segment<K,V>[] segments;56 transient Set<K> keySet;7 transient Set<Map.Entry<K,V>> entrySet;Segment 是 ConcurrentHashMap 的一个内部类,主要的组成如下: 1 static final class Segment<K,V> extends ReentrantLock implements Serializable { 2 3 private static final long serialVersionUID = 2249069246763182397L; 4 5 // 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶 6 transient volatile HashEntry<K,V>[] table; 7 8 transient int count; 910 transient int modCount;1112 transient int threshold;1314 final float loadFactor;1516 }和 HashMap 非常类似,唯一的区别就是其中的核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。下面也来看看核心的 put get 方法。put 方法 1 public V put(K key, V value) { 2 Segment<K,V> s; 3 if (value == null) 4 throw new NullPointerException(); 5 int hash = hash(key); 6 int j = (hash >>> segmentShift) & segmentMask; 7 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck 8 (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment 9 s = ensureSegment(j);10 return s.put(key, hash, value, false);11 }首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。 1 final V put(K key, int hash, V value, boolean onlyIfAbsent) { 2 HashEntry<K,V> node = tryLock() ? null : 3 scanAndLockForPut(key, hash, value); 4 V oldValue; 5 try { 6 HashEntry<K,V>[] tab = table; 7 int index = (tab.length - 1) & hash; 8 HashEntry<K,V> first = entryAt(tab, index); 9 for (HashEntry<K,V> e = first;;) {10 if (e != null) {11 K k;12 if ((k = e.key) == key ||13 (e.hash == hash && key.equals(k))) {14 oldValue = e.value;15 if (!onlyIfAbsent) {16 e.value = value;17 ++modCount;18 }19 break;20 }21 e = e.next;22 }23 else {24 if (node != null)25 node.setNext(first);26 else27 node = new HashEntry<K,V>(hash, key, value, first);28 int c = count + 1;29 if (c > threshold && tab.length < MAXIMUM_CAPACITY)30 rehash(node);31 else32 setEntryAt(tab, index, node);33 ++modCount;34 count = c;35 oldValue = null;36 break;37 }38 }39 } finally {40 unlock();41 }42 return oldValue;43 }虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。尝试自旋获取锁。如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。再结合图看看 put 的流程。将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。最后会解除在 1 中所获取当前 Segment 的锁。get 方法 1 public V get(Object key) { 2 Segment<K,V> s; // manually integrate access methods to reduce overhead 3 HashEntry<K,V>[] tab; 4 int h = hash(key); 5 long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; 6 if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && 7 (tab = s.table) != null) { 8 for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile 9 (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);10 e != null; e = e.next) {11 K k;12 if ((k = e.key) == key || (e.hash == h && key.equals(k)))13 return e.value;14 }15 }16 return null;17 }get 逻辑比较简单:只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。Base 1.81.7 已经解决了并发问题,并且能支持 N 个 Segment 这么多次数的并发,但依然存在 HashMap 在 1.7 版本中的问题。那就是查询遍历链表效率太低。因此 1.8 做了一些数据结构上的调整。看起来是不是和 1.8 HashMap 结构类似?其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。也将 1.7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。其中的 val next 都用了 volatile 修饰,保证了可见性。put 方法重点来看看 put 函数:根据 key 计算出 hashcode 。判断是否需要进行初始化。f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。如果都不满足,则利用 synchronized 锁写入数据。如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。get 方法根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。如果是红黑树那就按照树的方式获取值。就不满足那就按照链表的方式遍历获取值。1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。总结看完了整个 HashMap 和 ConcurrentHashMap 在 1.7 和 1.8 中不同的实现方式相信大家对他们的理解应该会更加到位。其实这块也是面试的重点内容,通常的套路是:谈谈你理解的 HashMap,讲讲其中的 get put 过程。1.8 做了什么优化?是线程安全的嘛?不安全会导致哪些问题?如何解决?有没有线程安全的并发容器?ConcurrentHashMap 是如何实现的? 1.7、1.8 实现有何不同?为什么这么做?原文链接:https://blog.csdn.net/weixin_44460333/article/details/86770169
前言Map 这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据。本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 HashMap,没有它就不会有后面的 ConcurrentHashMap。HashMap众所周知 HashMap 底层是基于 数组 + 链表 组成的,不过在 jdk1.7 和 1.8 中具体实现稍有不同。Base 1.71.7 中的数据结构图:先来看看 1.7 中的实现。这是 HashMap 中比较核心的几个成员变量;看看分别是什么意思?初始化桶大小,因为底层是数组,所以这是数组默认的大小。桶最大值。默认的负载因子(0.75)table 真正存放数据的数组。Map 存放数量的大小。桶大小,可在初始化时显式指定。负载因子,可在初始化时显式指定。重点解释下负载因子:由于给定的 HashMap 的容量大小是固定的,比如默认初始化: 1 public HashMap() { 2 this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); 3 } 4 5 public HashMap(int initialCapacity, float loadFactor) { 6 if (initialCapacity < 0) 7 throw new IllegalArgumentException("Illegal initial capacity: " + 8 initialCapacity); 9 if (initialCapacity > MAXIMUM_CAPACITY)10 initialCapacity = MAXIMUM_CAPACITY;11 if (loadFactor <= 0 || Float.isNaN(loadFactor))12 throw new IllegalArgumentException("Illegal load factor: " +13 loadFactor);1415 this.loadFactor = loadFactor;16 threshold = initialCapacity;17 init();18 }给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。因此通常建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。根据代码可以看到其实真正存放数据的是transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;这个数组,那么它又是如何定义的呢?Entry 是 HashMap 中的一个内部类,从他的成员变量很容易看出:key 就是写入时的键。value 自然就是值。开始的时候就提到 HashMap 是由数组和链表组成,所以这个 next 就是用于实现链表结构。hash 存放的是当前 key 的 hashcode。知晓了基本结构,那来看看其中重要的写入、获取函数:put 方法 1 public V put(K key, V value) { 2 if (table == EMPTY_TABLE) { 3 inflateTable(threshold); 4 } 5 if (key == null) 6 return putForNullKey(value); 7 int hash = hash(key); 8 int i = indexFor(hash, table.length); 9 for (Entry<K,V> e = table[i]; e != null; e = e.next) {10 Object k;11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {12 V oldValue = e.value;13 e.value = value;14 e.recordAccess(this);15 return oldValue;16 }17 }1819 modCount++;20 addEntry(hash, key, value, i);21 return null;22 }判断当前数组是否需要初始化。如果 key 为空,则 put 一个空值进去。根据 key 计算出 hashcode。根据计算出的 hashcode 定位出所在桶。如果桶是一个链表则需要遍历判断里面的 hashcode、key 是否和传入 key 相等,如果相等则进行覆盖,并返回原来的值。如果桶是空的,说明当前位置没有数据存入;新增一个 Entry 对象写入当前位置。 1 void addEntry(int hash, K key, V value, int bucketIndex) { 2 if ((size >= threshold) && (null != table[bucketIndex])) { 3 resize(2 * table.length); 4 hash = (null != key) ? hash(key) : 0; 5 bucketIndex = indexFor(hash, table.length); 6 } 7 8 createEntry(hash, key, value, bucketIndex); 9 }1011 void createEntry(int hash, K key, V value, int bucketIndex) {12 Entry<K,V> e = table[bucketIndex];13 table[bucketIndex] = new Entry<>(hash, key, value, e);14 size++;15 }当调用 addEntry 写入 Entry 时需要判断是否需要扩容。如果需要就进行两倍扩充,并将当前的 key 重新 hash 并定位。而在 createEntry 中会将当前位置的桶传入到新建的桶中,如果当前桶有值就会在位置形成链表。get 方法再来看看 get 函数: 1 public V get(Object key) { 2 if (key == null) 3 return getForNullKey(); 4 Entry<K,V> entry = getEntry(key); 5 6 return null == entry ? null : entry.getValue(); 7 } 8 9 final Entry<K,V> getEntry(Object key) {10 if (size == 0) {11 return null;12 }1314 int hash = (key == null) ? 0 : hash(key);15 for (Entry<K,V> e = table[indexFor(hash, table.length)];16 e != null;17 e = e.next) {18 Object k;19 if (e.hash == hash &&20 ((k = e.key) == key || (key != null && key.equals(k))))21 return e;22 }23 return null;24 }首先也是根据 key 计算出 hashcode,然后定位到具体的桶中。判断该位置是否为链表。不是链表就根据 key、key 的 hashcode 是否相等来返回值。为链表则需要遍历直到 key 及 hashcode 相等时候就返回值。啥都没取到就直接返回 null 。Base 1.8不知道 1.7 的实现大家看出需要优化的点没有?其实一个很明显的地方就是:当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 O(N)。因此 1.8 中重点优化了这个查询效率。1.8 HashMap 结构图:先来看看几个核心的成员变量: 1 static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16 2 3 /** 4 * The maximum capacity, used if a higher value is implicitly specified 5 * by either of the constructors with arguments. 6 * MUST be a power of two <= 1<<30. 7 */ 8 static final int MAXIMUM_CAPACITY = 1 << 30; 910 /**11 * The load factor used when none specified in constructor.12 */13 static final float DEFAULT_LOAD_FACTOR = 0.75f;1415 static final int TREEIFY_THRESHOLD = 8;1617 transient Node<K,V>[] table;1819 /**20 * Holds cached entrySet(). Note that AbstractMap fields are used21 * for keySet() and values().22 */23 transient Set<Map.Entry<K,V>> entrySet;2425 /**26 * The number of key-value mappings contained in this map.27 */28 transient int size;和 1.7 大体上都差不多,还是有几个重要的区别:TREEIFY_THRESHOLD 用于判断是否需要将链表转换为红黑树的阈值。HashEntry 修改为 Node。Node 的核心组成其实也是和 1.7 中的 HashEntry 一样,存放的都是 key value hashcode next 等数据。再来看看核心方法。put 方法看似要比 1.7 的复杂,我们一步步拆解:判断当前桶是否为空,空的就需要初始化(resize 中会判断是否进行初始化)。根据当前 key 的 hashcode 定位到具体的桶中并判断是否为空,为空表明没有 Hash 冲突就直接在当前位置创建一个新桶即可。如果当前桶有值( Hash 冲突),那么就要比较当前桶中的 key、key 的 hashcode 与写入的 key 是否相等,相等就赋值给 e,在第 8 步的时候会统一进行赋值及返回。如果当前桶为红黑树,那就要按照红黑树的方式写入数据。如果是个链表,就需要将当前的 key、value 封装成一个新节点写入到当前桶的后面(形成链表)。接着判断当前链表的大小是否大于预设的阈值,大于时就要转换为红黑树。如果在遍历过程中找到 key 相同时直接退出遍历。如果 e != null 就相当于存在相同的 key,那就需要将值覆盖。最后判断是否需要进行扩容。get 方法 1 public V get(Object key) { 2 Node<K,V> e; 3 return (e = getNode(hash(key), key)) == null ? null : e.value; 4 } 5 6 final Node<K,V> getNode(int hash, Object key) { 7 Node<K,V>[] tab; Node<K,V> first, e; int n; K k; 8 if ((tab = table) != null && (n = tab.length) > 0 && 9 (first = tab[(n - 1) & hash]) != null) {10 if (first.hash == hash && // always check first node11 ((k = first.key) == key || (key != null && key.equals(k))))12 return first;13 if ((e = first.next) != null) {14 if (first instanceof TreeNode)15 return ((TreeNode<K,V>)first).getTreeNode(hash, key);16 do {17 if (e.hash == hash &&18 ((k = e.key) == key || (key != null && key.equals(k))))19 return e;20 } while ((e = e.next) != null);21 }22 }23 return null;24 }get 方法看起来就要简单许多了。首先将 key hash 之后取得所定位的桶。如果桶为空则直接返回 null 。否则判断桶的第一个位置(有可能是链表、红黑树)的 key 是否为查询的 key,是就直接返回 value。如果第一个不匹配,则判断它的下一个是红黑树还是链表。红黑树就按照树的查找方式返回值。不然就按照链表的方式遍历匹配返回值。从这两个核心方法(get/put)可以看出 1.8 中对大链表做了优化,修改为红黑树之后查询效率直接提高到了 O(logn)。但是 HashMap 原有的问题也都存在,比如在并发场景下使用时容易出现死循环。1final HashMap<String, String> map = new HashMap<String, String>();2for (int i = 0; i < 1000; i++) {3 new Thread(new Runnable() {4 @Override5 public void run() {6 map.put(UUID.randomUUID().toString(), "");7 }8 }).start();9}但是为什么呢?简单分析下。看过上文的还记得在 HashMap 扩容的时候会调用 resize() 方法,就是这里的并发操作容易在一个桶上形成环形链表;这样当获取一个不存在的 key 时,计算出的 index 正好是环形链表的下标就会出现死循环。遍历方式还有一个值得注意的是 HashMap 的遍历方式,通常有以下几种: 1Iterator<Map.Entry<String, Integer>> entryIterator = map.entrySet().iterator(); 2 while (entryIterator.hasNext()) { 3 Map.Entry<String, Integer> next = entryIterator.next(); 4 System.out.println("key=" + next.getKey() + " value=" + next.getValue()); 5 } 6 7Iterator<String> iterator = map.keySet().iterator(); 8 while (iterator.hasNext()){ 9 String key = iterator.next();10 System.out.println("key=" + key + " value=" + map.get(key));1112 }强烈建议使用第一种 EntrySet 进行遍历。第一种可以把 key value 同时取出,第二种还得需要通过 key 取一次 value,效率较低。简单总结下 HashMap:无论是 1.7 还是 1.8 其实都能看出 JDK 没有对它做任何的同步操作,所以并发会出问题,甚至出现死循环导致系统不可用。因此 JDK 推出了专项专用的 ConcurrentHashMap ,该类位于 java.util.concurrent 包下,专门用于解决并发问题。坚持看到这里的朋友算是已经把 ConcurrentHashMap 的基础已经打牢了,下面正式开始分析。ConcurrentHashMapConcurrentHashMap 同样也分为 1.7 、1.8 版,两者在实现上略有不同。Base 1.7如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。它的核心成员变量:1 /**2 * Segment 数组,存放数据时首先需要定位到具体的 Segment 中。3 */4 final Segment<K,V>[] segments;56 transient Set<K> keySet;7 transient Set<Map.Entry<K,V>> entrySet;Segment 是 ConcurrentHashMap 的一个内部类,主要的组成如下: 1 static final class Segment<K,V> extends ReentrantLock implements Serializable { 2 3 private static final long serialVersionUID = 2249069246763182397L; 4 5 // 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶 6 transient volatile HashEntry<K,V>[] table; 7 8 transient int count; 910 transient int modCount;1112 transient int threshold;1314 final float loadFactor;1516 }和 HashMap 非常类似,唯一的区别就是其中的核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。原理上来说:ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。下面也来看看核心的 put get 方法。put 方法 1 public V put(K key, V value) { 2 Segment<K,V> s; 3 if (value == null) 4 throw new NullPointerException(); 5 int hash = hash(key); 6 int j = (hash >>> segmentShift) & segmentMask; 7 if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck 8 (segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment 9 s = ensureSegment(j);10 return s.put(key, hash, value, false);11 }首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。 1 final V put(K key, int hash, V value, boolean onlyIfAbsent) { 2 HashEntry<K,V> node = tryLock() ? null : 3 scanAndLockForPut(key, hash, value); 4 V oldValue; 5 try { 6 HashEntry<K,V>[] tab = table; 7 int index = (tab.length - 1) & hash; 8 HashEntry<K,V> first = entryAt(tab, index); 9 for (HashEntry<K,V> e = first;;) {10 if (e != null) {11 K k;12 if ((k = e.key) == key ||13 (e.hash == hash && key.equals(k))) {14 oldValue = e.value;15 if (!onlyIfAbsent) {16 e.value = value;17 ++modCount;18 }19 break;20 }21 e = e.next;22 }23 else {24 if (node != null)25 node.setNext(first);26 else27 node = new HashEntry<K,V>(hash, key, value, first);28 int c = count + 1;29 if (c > threshold && tab.length < MAXIMUM_CAPACITY)30 rehash(node);31 else32 setEntryAt(tab, index, node);33 ++modCount;34 count = c;35 oldValue = null;36 break;37 }38 }39 } finally {40 unlock();41 }42 return oldValue;43 }虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。尝试自旋获取锁。如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。再结合图看看 put 的流程。将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry。遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。最后会解除在 1 中所获取当前 Segment 的锁。get 方法 1 public V get(Object key) { 2 Segment<K,V> s; // manually integrate access methods to reduce overhead 3 HashEntry<K,V>[] tab; 4 int h = hash(key); 5 long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE; 6 if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null && 7 (tab = s.table) != null) { 8 for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile 9 (tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);10 e != null; e = e.next) {11 K k;12 if ((k = e.key) == key || (e.hash == h && key.equals(k)))13 return e.value;14 }15 }16 return null;17 }get 逻辑比较简单:只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。Base 1.81.7 已经解决了并发问题,并且能支持 N 个 Segment 这么多次数的并发,但依然存在 HashMap 在 1.7 版本中的问题。那就是查询遍历链表效率太低。因此 1.8 做了一些数据结构上的调整。看起来是不是和 1.8 HashMap 结构类似?其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。也将 1.7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。其中的 val next 都用了 volatile 修饰,保证了可见性。put 方法重点来看看 put 函数:根据 key 计算出 hashcode 。判断是否需要进行初始化。f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。如果都不满足,则利用 synchronized 锁写入数据。如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。get 方法根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。如果是红黑树那就按照树的方式获取值。就不满足那就按照链表的方式遍历获取值。1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。总结看完了整个 HashMap 和 ConcurrentHashMap 在 1.7 和 1.8 中不同的实现方式相信大家对他们的理解应该会更加到位。其实这块也是面试的重点内容,通常的套路是:谈谈你理解的 HashMap,讲讲其中的 get put 过程。1.8 做了什么优化?是线程安全的嘛?不安全会导致哪些问题?如何解决?有没有线程安全的并发容器?ConcurrentHashMap 是如何实现的? 1.7、1.8 实现有何不同?为什么这么做?原文链接:https://blog.csdn.net/weixin_44460333/article/details/86770169 -
 > 最近在参加华为推出的[华为云云原生入门级开发者认证人才计划活动](https://edu.huaweicloud.com/signup/521bd9a32c9345d5b240d4173e67437a) 于是想自己动手部署K8S的环境来学习,去年自己也采用二进制的方式部署过,时隔一年K8S的版本已经更新到了v1.24.3啦。在v1.24版本之后,k8s都已经抛弃了docker。抱着学习的心态尝试了k8s的v1.24.3版本的安装,这次采用kubeadm的部署方式,过程非常坎坷,但是还是顺利的部署成功。 # 环境准备 三台机都是采用centos7的操作系统,内核版本号是`3.10.0-693.el7.x86_64` ------------ | 角色 | IP | kubernetes版本 | | --- | --- | --- | | master | 192.168.248.130 | v1.24.3 | | node1 | 192.168.248.131 | v1.24.3 | | node2 | 192.168.248.132 | v1.24.3 | ------------ >由于K8S从1.24版本之后,开始弃用了docker。改用了containerd ,containerd是容器虚拟化技术,从docker中剥离出来,形成开放容器接口(OCI)标准的一部分。 containerd与docker相兼容,相比docker轻量很多,目前较为成熟。 ## 主机间做信任 在master节点上生成秘钥文件,并把它上传到其他两台机上,做好免密登录,方便后续的操作。  执行`ssh-copy-id root@192.168.248.129`命令实现免密登录,其他两台做同样的操作。 ## 安装ansible工具 `ansible`工具主要为了后续多台机器执行同样的命令,从而提供效率用的。安装方式也很简单,通过yum源安装即可。执行如下两条命令: ```shell [root@master ~]# yum install epel-release -y [root@master ~]# yum -y install ansible ``` 配置`/etc/ansible/hosts`,该文件是存放要操作的主机,把上述三台机器加入一个组名字为`k8s`,如下: ```shell [k8s] 192.168.248.128 192.168.248.129 192.168.248.130 ``` 通过执行ansible命令测试连通性,如下图: 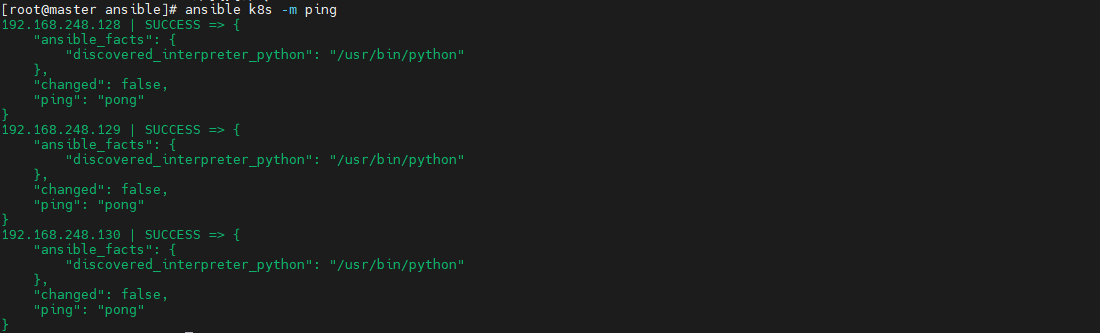 > -m:是指定ansible的模块,ping是ansible其中一个模块,该模块主要是测试主机的连通性。 > k8s:刚定义的组名 # 升级内核版本 检查当前 `CentOS `系统内核版本 ,执行如下命令查看: ```shell [root@localhost ~]# uname -sr Linux 3.10.0-1160.el7.x86_64 ``` 检查发现当前内核版本是3.10, ## 使用elrepo源升级内核 配置elrepo源,执行如下命令 ```powershell rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org yum install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm ``` ## 查看最新版内核 执行如下命令查看最新的内核版本 ```shell yum --disablerepo="*" --enablerepo="elrepo-kernel" list available ``` 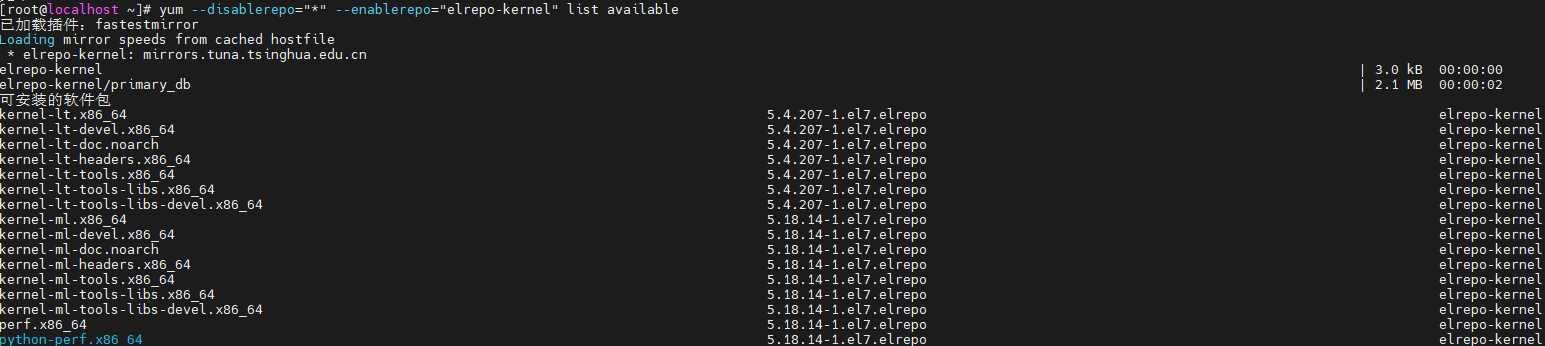 > 内核版本说明: > - kernel-ml #主线版本,比较新 > - kernel-lt #长期支持版本,比较旧 ## 安装最新的内核版本 执行如下命令安装主线版本: ```shell yum --enablerepo=elrepo-kernel install kernel-ml -y ``` ## 设置系统默认内核 查看系统上的所有内核版本: ```shell [root@localhost ~]# awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg 0 : CentOS Linux (5.18.14-1.el7.elrepo.x86_64) 7 (Core) 1 : CentOS Linux (3.10.0-1160.el7.x86_64) 7 (Core) 2 : CentOS Linux (0-rescue-9dad18ee9dde4729b1c6df225ce69c4a) 7 (Core) [root@localhost ~]# ``` 设置默认内核为我们刚才升级的内核版本 ```shell cp /etc/default/grub /etc/default/grub-bak #备份 grub2-set-default 0 #设置默认内核版本 vi /etc/default/grub GRUB_DEFAULT=saved修改为GRUB_DEFAULT=0 ``` 重新创建内核配置 ```shell grub2-mkconfig -o /boot/grub2/grub.cfg ``` 查看默认内核 ```shell grubby --default-kernel #/boot/vmlinuz-5.18.14-1.el7.elrepo.x86_64 grub2-editenv list #saved_entry=0 ``` 更新软件包并重启 ```shell yum makecache reboot ``` # 初始化 安装K8S之前需要对系统进行一些设置,比如 关闭防火墙,selinux,swap,设置主机名,ip解析,时间同步 。 ## 关闭防火墙 通过`ansible`把三台机器的防火墙关闭,并设置开机不启动。执行如命令: ```shell ansible k8s -m shell -a "systemctl stop firewalld" ansible k8s -m shell -a "systemctl disable firewalld " ``` 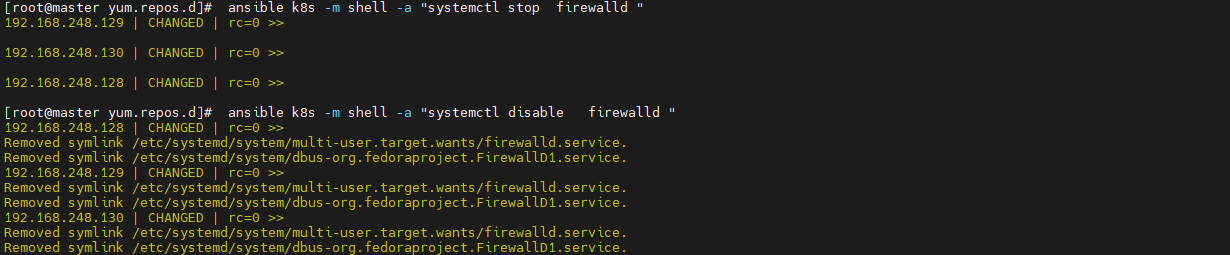 ## 关闭selinux 通过`ansible`把三台机器的selinux永久关闭,执行如命令: ```shell ansible k8s -m shell -a "sed -i 's/enforcing/disabled/' /etc/selinux/config" ```  ## 关闭swap 执行`swapoff -a` 临时关闭,通过修改/etc/fstab文件实现永久关闭。执行如下命令 ```shell ansible k8s -m shell -a "sed -ri 's/.*swap.*/#&/' /etc/fstab" ```  ## 修改主机名 分别对三台主机进行主机名的修改,执行如下的命令 ```shell # 根据规划设置主机名【master节点上操作】 hostnamectl set-hostname master # 根据规划设置主机名【node1节点操作】 hostnamectl set-hostname node1 # 根据规划设置主机名【node2节点操作】 hostnamectl set-hostname node2 ``` ## 修改hosts文件 在master节点上修改hosts文件,根据规划进行修改,如下: ``` 192.168.248.130 master1 192.168.248.131 node2 192.168.248.132 node1 ``` ## 将桥接的IPv4流量传递到iptables的链 在`/etc/sysctl.d/`目录上新增`k8s.conf`,内容如下,并把该文件拷贝到其他两台机器上 ``` net.bridge.bridge-nf-call-ip6tables = 11 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 ``` ```shell ansible k8s -m copy -a "src=/etc/sysctl.d/k8s.conf dest=/etc/sysctl.d/k8s.conf" ``` 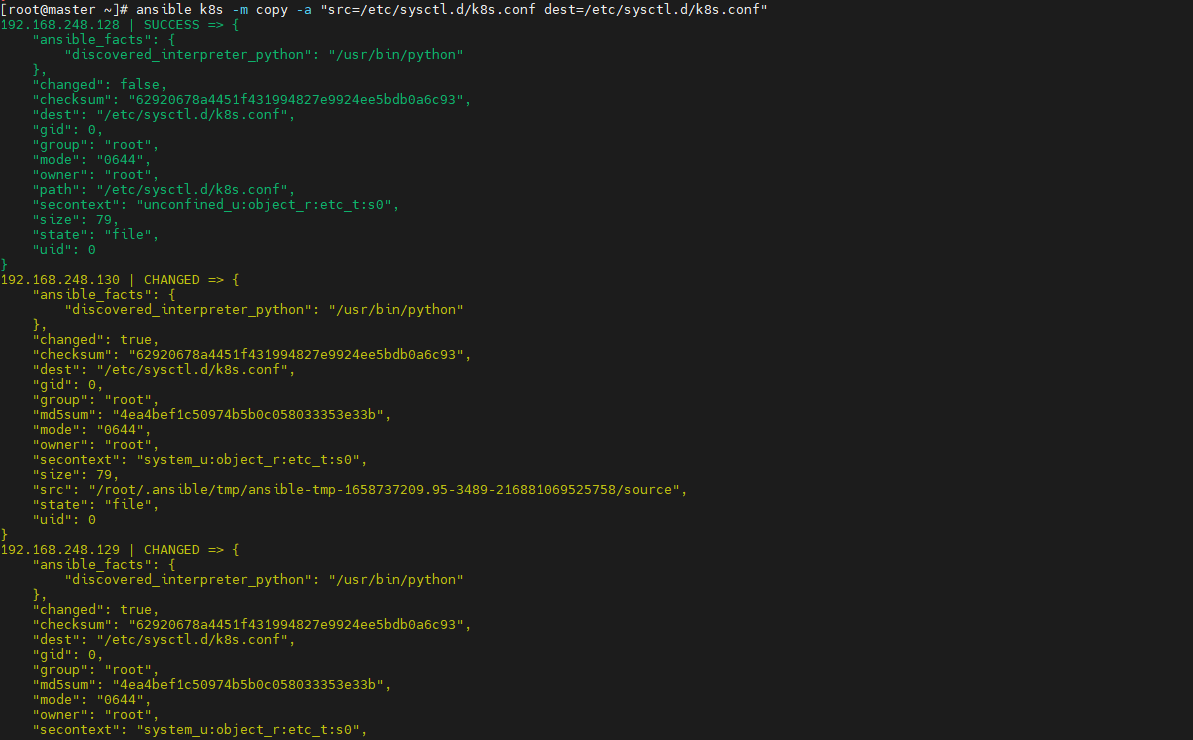 执行 `sysctl --system`命令使配置生效: ```shell ansible k8s -m shell -a "sysctl --system" ``` ## 配置时间同步 使用yum命令安装`ntpdate `,如下: ```shell ansible k8s -m shell -a "yum install ntpdate -y" ``` 配置NTP网络时间同步服务器地址为 `ntp.aliyun.com`,执行如下命令: ```shell ansible k8s -m shell -a "ntpdate ntp.aliyun.com" ``` # 安装containerd 执行如下命令下载最新containerd,如下: ```shell wget https://download.fastgit.org/containerd/containerd/releases/download/v1.6.6/cri-containerd-cni-1.6.6-linux-amd64.tar.gz ``` > 如果出现无法建立 SSL 连接 加上--no-check-certificate 解压`containerd`安装包 ```shell tar -C / -zxf cri-containerd-cni-1.6.6-linux-amd64.tar.gz ``` 配置环境变量,编辑用户目录下的`bashrc`文件添加如下内容: ```shell export PATH=$PATH:/usr/local/bin:/usr/local/sbin ``` 并执行如下命令使环境变量立即生效: ```shell source ~/.bashrc ``` 执行如下命令启动`containerd` ```shell systemctl start containerd ``` 执行如下命令查看版本号,出现如下信息表明安装成功。 ```shell [root@master1 ~]# ctr version Client: Version: v1.6.6 Revision: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 Go version: go1.17.11 Server: Version: v1.6.6 Revision: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 UUID: c205638a-6c08-43a8-81a4-b15f97ef5cdc ``` 创建默认配置文件 ```shell mkdir /etc/containerd containerd config default > /etc/containerd/config.toml ``` ## 测试containerd是否能创建和启动成功 执行如下命令拉取镜像并创建容器: ```shell ctr i pull docker.io/library/nginx:alpine #拉取容器 ctr c create --net-host docker.io/library/nginx:alpine nginx #创建容器 ctr task start -d nginx ``` 如果启动容器出现如下报错,是由于 缺少 `runc`并升级`libseccomp`,`libseccomp`需要高于`2.4`版本。 > `containerd`在`v1.6.4`版本以后使用`v1.1.2`的`runc`和`v1.1.1`的`cni`。 ```json ctr: failed to create shim task: OCI runtime create failed: unable to retrieve OCI runtime error (open /run/containerd/io.containerd.runtime.v2.task/default/nginx/log.json: no such file or directory): fork/exec / ``` [下载链接](https://github.com/opencontainers/runc/releases/download/v1.1.2/runc.amd64),下载之后,执行如下命令安装并查看版本号: ```shell install -m 755 runc.amd64 /usr/local/sbin/runc runc -v ``` 执行如下命令升级`libseccomp`: ```shell rpm -qa | grep libseccomp #查询原来的版本 rpm -e libseccomp-2.3.1-4.el7.x86_64 --nodeps #卸载原来的版本 #下载高版本的 wget http://rpmfind.net/linux/centos/8-stream/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm rpm -ivh libseccomp-2.5.1-1.el8.x86_64.rpm #安装 ``` # 安装kubernetes ## 添加kubernetes源 在master节点上添加k8s软件源,并分发到其他两台机器上。在`/etc/yum.repos.d/`目录下新增`kubernetes.repo`。内容如下: ```latex [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg ``` 把kubernetes.repo文件分发到其他两台机器上,执行如下命令: ```shell ansible k8s -m copy -a "src=/etc/yum.repos.d/kubernetes.repo dest=/etc/yum.repos.d/kubernetes.repo" ``` 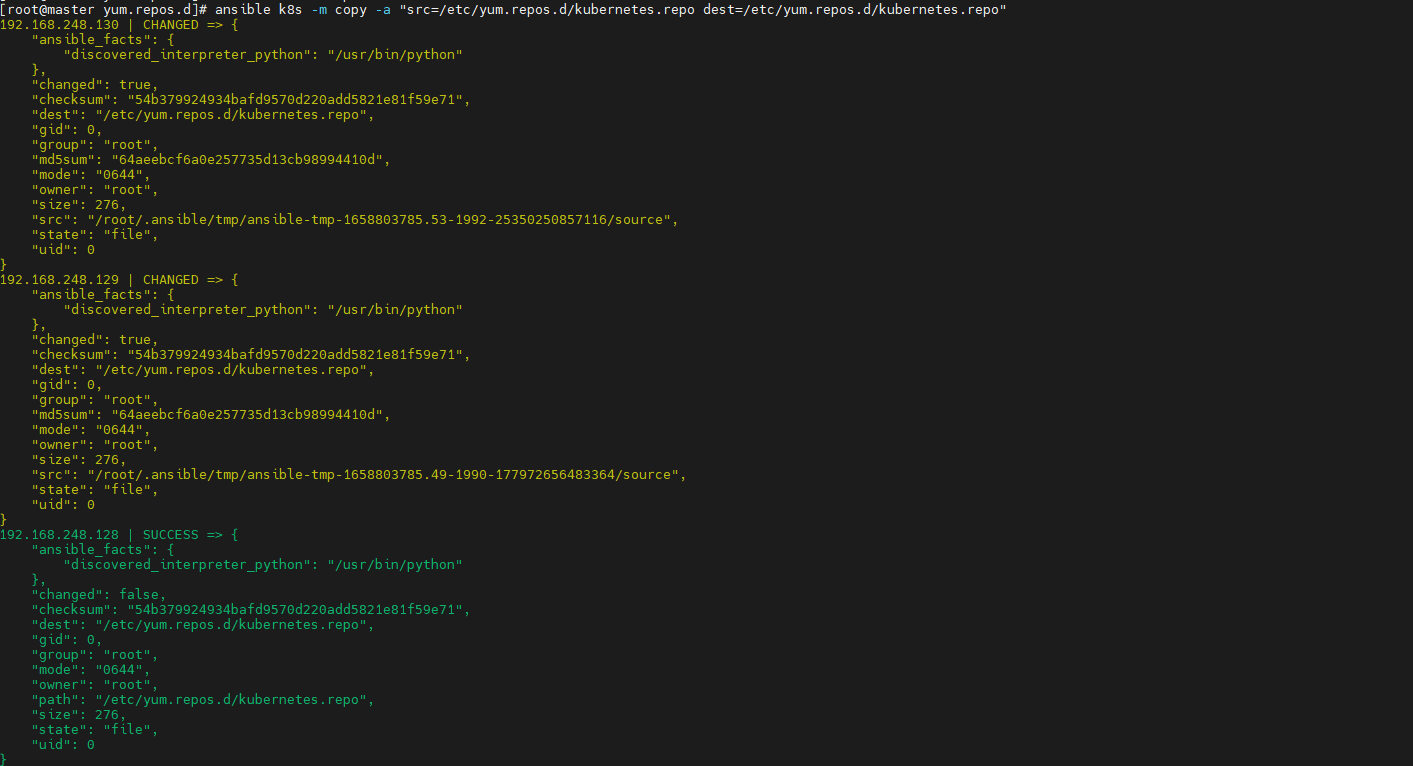 ## 安装 在master节点下执行如下命令安装相应的软件: ```shell yum install -y kubelet-1.24.3 kubeadm-1.24.3 kubectl-1.24.3 ``` ## 生成默认配置并修改相应的参数 通过如下命名生成一个默认的配置文件: ```powershell kubeadm config print init-defaults > kubeadm-init.yaml ``` 根据自己的环境修改对应的参数: ```yaml apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.248.130 #master节点IP bindPort: 6443 nodeRegistration: criSocket: unix:///run/containerd/containerd.sock #containerd容器路径 imagePullPolicy: IfNotPresent name: master1 taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers #阿里云容器源地址 kind: ClusterConfiguration kubernetesVersion: 1.24.3 networking: dnsDomain: cluster.local podSubnet: 10.244.0.0/16 #pod的IP网段 serviceSubnet: 10.96.0.0/12 scheduler: {} ``` ## 初始化 执行如下命令进行初始化: ```shell kubeadm init --config=kubeadm-init.yaml --v=6 ``` > --config:指定根据那个配置文件进行初始 > --v:指定日志级别,越高越详细 初始化成功后,会出现以下信息 ```shell ...省略... Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.248.130:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:e9e29c804f92193928f37ca157b73a7ad77e7929314db98855b3ba6e2ce2273d ``` 按照初始化成功提示信息,做如下操作: ```shell mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config ``` 接下来执行`kubectl`就可以看到`node`了 ```shell [root@master1 .kube]# kubectl get node NAME STATUS ROLES AGE VERSION master1 Ready control-plane 55m v1.24.3 ``` 查看k8s各部件启动情况,执行如下命令: ```shell kubectl get pod --all-namespaces -o wide ```  通过观察发现`coredns`部件没有运行成功,通过如下命令查看原因: ```shell describe pod coredns-74586cf9b6-c2ddb --namespace=kube-system ``` 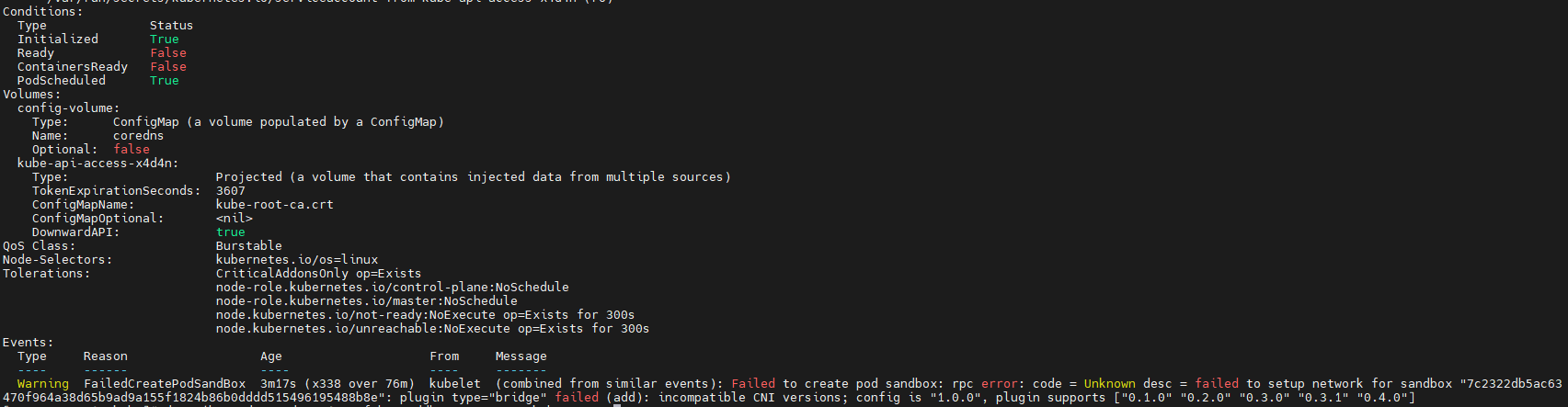 > 根据官方的解析是没有部署CNI,coredns是不会启动的。  ## node节点配置 node节点安装kubeadm ```shell cat /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF ``` 安装相关组件 ```shell yum install -y kubeadm-1.24.3 --disableexcludes=kubernetes ``` 添加join命令 ```powershell kubeadm join 192.168.248.130:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:e9e29c804f92193928f37ca157b73a7ad77e7929314db98855b3ba6e2ce2273d ``` 如果我们后续需要添加node节点时,可以到master节点执行下面的命令获取`token`相关信息 ```shell [root@master1 ~]# kubeadm token create --print-join-command kubeadm join 192.168.248.130:6443 --token ydqnz1.6b0q5ntkvos9z2ir --discovery-token-ca-cert-hash sha256:c0b6f7fb38c7c9764084beb7dd26c9acef027ae6b7d2673572b4c2e3a0dfd6cb ``` > 如果添加某台节点异常了,修改后可以执行 `kubeadm reset `的命令,然后在重新join加入 ## 网络配置 coredns还没启动,因为还没有安装网络插件,接下来安装网络插件,可以在[该文档中](https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/)选择我们自己的网络插件,这里安装`flannel` ```shell wget http://down.i4t.com/k8s1.24/kube-flannel.yml ``` 根据需求修改网卡配置,我这里ens33为主的: ```yaml containers: - name: kube-flannel image: quay.io/coreos/flannel:v0.12.0-amd64 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr - --iface=ens33 # 如果是多网卡的话,指定内网网卡的名称 ``` > 在kubeadm.yaml文件中设置了podSubnet网段,同时在flannel中网段也要设置相同的。 (我这里默认就是相同的配置) 执行部署 ```shell kubectl apply -f kube-flannel.yml ``` ## CNI插件问题 默认情况下containerd也会有一个cni插件,但是我们已经安装Flannel了,我们需要使用Flannel的cni插件,需要将containerd里面的cni配置文件进行注释,否则2个配置会产生冲突 。 因为如果这个目录中有多个 cni 配置文件,kubelet 将会使用按文件名的字典顺序排列的第一个作为配置文件,所以前面默认选择使用的是 containerd-net 这个插件。 ```shell mv /etc/cni/net.d/10-containerd-net.conflist /etc/cni/net.d/10-containerd-net.conflist.bak systemctl restart containerd kubelet ``` 接下来我们所有的pod都可以正常运行了 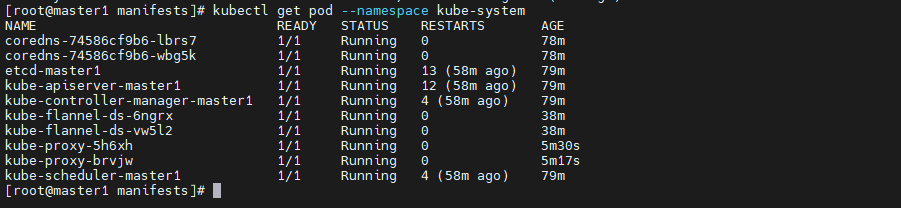 # 验证 验证dns是否正常能解析和pod之间。这里新建一个测试的yaml文件,内容如下: ```yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx:alpine name: nginx ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx spec: selector: app: nginx type: NodePort ports: - protocol: TCP port: 80 targetPort: 80 nodePort: 30001 --- apiVersion: v1 kind: Pod metadata: name: busybox namespace: default spec: containers: - name: busybox image: abcdocker9/centos:v1 command: - sleep - "3600" imagePullPolicy: IfNotPresent restartPolicy: Always ``` 执行下面命令,创建pod ```shell kubectl apply -f test.yaml ```  使用nslookup查看是否能返回地址 ```shell [root@master1 ~]# kubectl exec -it busybox -- nslookup kubernetes Server: 10.96.0.10 Address: 10.96.0.10#53 Name: kubernetes.default.svc.cluster.local Address: 10.96.0.1 [root@master1 ~]# ``` 测试nginx svc以及Pod内部网络通信是否正常 ,分别在三台机器上进行下面操作 ```powershell ping 10.104.115.26 #nginx svc ip ping 10.244.1.2 #podIP ``` 如果成功ping同说明node跟pod的网络已经打通了。否则检查`kube-proxy`的模式是否正确。 ## nodes/集群内部 无法访问ClusterIP 默认情况下,我们部署的`kube-proxy`通过查看日志,能看到如下信息:`Flag proxy-mode="" unknown,assuming iptables proxy ` **原因分析:** 并没有正确使用ipvs模式 解决方法: 1、 在`master`上修改`kube-proxy`的配置文件,添加`mode `为`ipvs`。 ```shell [root@master1 ~]# kubectl edit cm kube-proxy -n kube-system ipvs: excludeCIDRs: null minSyncPeriod: 0s scheduler: "" strictARP: false syncPeriod: 30s kind: KubeProxyConfiguration metricsBindAddress: 127.0.0.1:10249 mode: "ipvs" ``` 删除原来的POD,会自动重启kube-proxy 的pod ```shell [root@k8s-master ~]# kubectl get pod -n kube-system | grep kube-proxy |awk '{system("kubectl delete pod "$1" -n kube-system")}' ``` # 扩展 在使用过程中发现kubectl 命令不能补全,使用起来很不方便。为了提高使用kubectl命令工具的便捷性,介绍一下kubectl命令补全工具的安装。 1、安装bash-completion: ```shell yum install -y bash-completion source /usr/share/bash-completion/bash_completion ``` 2、 应用kubectl的completion到系统环境: ```shell source (kubectl completion bash) echo "source (kubectl completion bash)" >> ~/.bashrc ``` 3、效果展示 
> 最近在参加华为推出的[华为云云原生入门级开发者认证人才计划活动](https://edu.huaweicloud.com/signup/521bd9a32c9345d5b240d4173e67437a) 于是想自己动手部署K8S的环境来学习,去年自己也采用二进制的方式部署过,时隔一年K8S的版本已经更新到了v1.24.3啦。在v1.24版本之后,k8s都已经抛弃了docker。抱着学习的心态尝试了k8s的v1.24.3版本的安装,这次采用kubeadm的部署方式,过程非常坎坷,但是还是顺利的部署成功。 # 环境准备 三台机都是采用centos7的操作系统,内核版本号是`3.10.0-693.el7.x86_64` ------------ | 角色 | IP | kubernetes版本 | | --- | --- | --- | | master | 192.168.248.130 | v1.24.3 | | node1 | 192.168.248.131 | v1.24.3 | | node2 | 192.168.248.132 | v1.24.3 | ------------ >由于K8S从1.24版本之后,开始弃用了docker。改用了containerd ,containerd是容器虚拟化技术,从docker中剥离出来,形成开放容器接口(OCI)标准的一部分。 containerd与docker相兼容,相比docker轻量很多,目前较为成熟。 ## 主机间做信任 在master节点上生成秘钥文件,并把它上传到其他两台机上,做好免密登录,方便后续的操作。  执行`ssh-copy-id root@192.168.248.129`命令实现免密登录,其他两台做同样的操作。 ## 安装ansible工具 `ansible`工具主要为了后续多台机器执行同样的命令,从而提供效率用的。安装方式也很简单,通过yum源安装即可。执行如下两条命令: ```shell [root@master ~]# yum install epel-release -y [root@master ~]# yum -y install ansible ``` 配置`/etc/ansible/hosts`,该文件是存放要操作的主机,把上述三台机器加入一个组名字为`k8s`,如下: ```shell [k8s] 192.168.248.128 192.168.248.129 192.168.248.130 ``` 通过执行ansible命令测试连通性,如下图:  > -m:是指定ansible的模块,ping是ansible其中一个模块,该模块主要是测试主机的连通性。 > k8s:刚定义的组名 # 升级内核版本 检查当前 `CentOS `系统内核版本 ,执行如下命令查看: ```shell [root@localhost ~]# uname -sr Linux 3.10.0-1160.el7.x86_64 ``` 检查发现当前内核版本是3.10, ## 使用elrepo源升级内核 配置elrepo源,执行如下命令 ```powershell rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org yum install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm ``` ## 查看最新版内核 执行如下命令查看最新的内核版本 ```shell yum --disablerepo="*" --enablerepo="elrepo-kernel" list available ```  > 内核版本说明: > - kernel-ml #主线版本,比较新 > - kernel-lt #长期支持版本,比较旧 ## 安装最新的内核版本 执行如下命令安装主线版本: ```shell yum --enablerepo=elrepo-kernel install kernel-ml -y ``` ## 设置系统默认内核 查看系统上的所有内核版本: ```shell [root@localhost ~]# awk -F\' '$1=="menuentry " {print i++ " : " $2}' /etc/grub2.cfg 0 : CentOS Linux (5.18.14-1.el7.elrepo.x86_64) 7 (Core) 1 : CentOS Linux (3.10.0-1160.el7.x86_64) 7 (Core) 2 : CentOS Linux (0-rescue-9dad18ee9dde4729b1c6df225ce69c4a) 7 (Core) [root@localhost ~]# ``` 设置默认内核为我们刚才升级的内核版本 ```shell cp /etc/default/grub /etc/default/grub-bak #备份 grub2-set-default 0 #设置默认内核版本 vi /etc/default/grub GRUB_DEFAULT=saved修改为GRUB_DEFAULT=0 ``` 重新创建内核配置 ```shell grub2-mkconfig -o /boot/grub2/grub.cfg ``` 查看默认内核 ```shell grubby --default-kernel #/boot/vmlinuz-5.18.14-1.el7.elrepo.x86_64 grub2-editenv list #saved_entry=0 ``` 更新软件包并重启 ```shell yum makecache reboot ``` # 初始化 安装K8S之前需要对系统进行一些设置,比如 关闭防火墙,selinux,swap,设置主机名,ip解析,时间同步 。 ## 关闭防火墙 通过`ansible`把三台机器的防火墙关闭,并设置开机不启动。执行如命令: ```shell ansible k8s -m shell -a "systemctl stop firewalld" ansible k8s -m shell -a "systemctl disable firewalld " ```  ## 关闭selinux 通过`ansible`把三台机器的selinux永久关闭,执行如命令: ```shell ansible k8s -m shell -a "sed -i 's/enforcing/disabled/' /etc/selinux/config" ```  ## 关闭swap 执行`swapoff -a` 临时关闭,通过修改/etc/fstab文件实现永久关闭。执行如下命令 ```shell ansible k8s -m shell -a "sed -ri 's/.*swap.*/#&/' /etc/fstab" ```  ## 修改主机名 分别对三台主机进行主机名的修改,执行如下的命令 ```shell # 根据规划设置主机名【master节点上操作】 hostnamectl set-hostname master # 根据规划设置主机名【node1节点操作】 hostnamectl set-hostname node1 # 根据规划设置主机名【node2节点操作】 hostnamectl set-hostname node2 ``` ## 修改hosts文件 在master节点上修改hosts文件,根据规划进行修改,如下: ``` 192.168.248.130 master1 192.168.248.131 node2 192.168.248.132 node1 ``` ## 将桥接的IPv4流量传递到iptables的链 在`/etc/sysctl.d/`目录上新增`k8s.conf`,内容如下,并把该文件拷贝到其他两台机器上 ``` net.bridge.bridge-nf-call-ip6tables = 11 net.bridge.bridge-nf-call-iptables = 1 net.ipv4.ip_forward = 1 ``` ```shell ansible k8s -m copy -a "src=/etc/sysctl.d/k8s.conf dest=/etc/sysctl.d/k8s.conf" ```  执行 `sysctl --system`命令使配置生效: ```shell ansible k8s -m shell -a "sysctl --system" ``` ## 配置时间同步 使用yum命令安装`ntpdate `,如下: ```shell ansible k8s -m shell -a "yum install ntpdate -y" ``` 配置NTP网络时间同步服务器地址为 `ntp.aliyun.com`,执行如下命令: ```shell ansible k8s -m shell -a "ntpdate ntp.aliyun.com" ``` # 安装containerd 执行如下命令下载最新containerd,如下: ```shell wget https://download.fastgit.org/containerd/containerd/releases/download/v1.6.6/cri-containerd-cni-1.6.6-linux-amd64.tar.gz ``` > 如果出现无法建立 SSL 连接 加上--no-check-certificate 解压`containerd`安装包 ```shell tar -C / -zxf cri-containerd-cni-1.6.6-linux-amd64.tar.gz ``` 配置环境变量,编辑用户目录下的`bashrc`文件添加如下内容: ```shell export PATH=$PATH:/usr/local/bin:/usr/local/sbin ``` 并执行如下命令使环境变量立即生效: ```shell source ~/.bashrc ``` 执行如下命令启动`containerd` ```shell systemctl start containerd ``` 执行如下命令查看版本号,出现如下信息表明安装成功。 ```shell [root@master1 ~]# ctr version Client: Version: v1.6.6 Revision: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 Go version: go1.17.11 Server: Version: v1.6.6 Revision: 10c12954828e7c7c9b6e0ea9b0c02b01407d3ae1 UUID: c205638a-6c08-43a8-81a4-b15f97ef5cdc ``` 创建默认配置文件 ```shell mkdir /etc/containerd containerd config default > /etc/containerd/config.toml ``` ## 测试containerd是否能创建和启动成功 执行如下命令拉取镜像并创建容器: ```shell ctr i pull docker.io/library/nginx:alpine #拉取容器 ctr c create --net-host docker.io/library/nginx:alpine nginx #创建容器 ctr task start -d nginx ``` 如果启动容器出现如下报错,是由于 缺少 `runc`并升级`libseccomp`,`libseccomp`需要高于`2.4`版本。 > `containerd`在`v1.6.4`版本以后使用`v1.1.2`的`runc`和`v1.1.1`的`cni`。 ```json ctr: failed to create shim task: OCI runtime create failed: unable to retrieve OCI runtime error (open /run/containerd/io.containerd.runtime.v2.task/default/nginx/log.json: no such file or directory): fork/exec / ``` [下载链接](https://github.com/opencontainers/runc/releases/download/v1.1.2/runc.amd64),下载之后,执行如下命令安装并查看版本号: ```shell install -m 755 runc.amd64 /usr/local/sbin/runc runc -v ``` 执行如下命令升级`libseccomp`: ```shell rpm -qa | grep libseccomp #查询原来的版本 rpm -e libseccomp-2.3.1-4.el7.x86_64 --nodeps #卸载原来的版本 #下载高版本的 wget http://rpmfind.net/linux/centos/8-stream/BaseOS/x86_64/os/Packages/libseccomp-2.5.1-1.el8.x86_64.rpm rpm -ivh libseccomp-2.5.1-1.el8.x86_64.rpm #安装 ``` # 安装kubernetes ## 添加kubernetes源 在master节点上添加k8s软件源,并分发到其他两台机器上。在`/etc/yum.repos.d/`目录下新增`kubernetes.repo`。内容如下: ```latex [kubernetes] name=Kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg ``` 把kubernetes.repo文件分发到其他两台机器上,执行如下命令: ```shell ansible k8s -m copy -a "src=/etc/yum.repos.d/kubernetes.repo dest=/etc/yum.repos.d/kubernetes.repo" ```  ## 安装 在master节点下执行如下命令安装相应的软件: ```shell yum install -y kubelet-1.24.3 kubeadm-1.24.3 kubectl-1.24.3 ``` ## 生成默认配置并修改相应的参数 通过如下命名生成一个默认的配置文件: ```powershell kubeadm config print init-defaults > kubeadm-init.yaml ``` 根据自己的环境修改对应的参数: ```yaml apiVersion: kubeadm.k8s.io/v1beta3 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168.248.130 #master节点IP bindPort: 6443 nodeRegistration: criSocket: unix:///run/containerd/containerd.sock #containerd容器路径 imagePullPolicy: IfNotPresent name: master1 taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta3 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {} dns: {} etcd: local: dataDir: /var/lib/etcd imageRepository: registry.aliyuncs.com/google_containers #阿里云容器源地址 kind: ClusterConfiguration kubernetesVersion: 1.24.3 networking: dnsDomain: cluster.local podSubnet: 10.244.0.0/16 #pod的IP网段 serviceSubnet: 10.96.0.0/12 scheduler: {} ``` ## 初始化 执行如下命令进行初始化: ```shell kubeadm init --config=kubeadm-init.yaml --v=6 ``` > --config:指定根据那个配置文件进行初始 > --v:指定日志级别,越高越详细 初始化成功后,会出现以下信息 ```shell ...省略... Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config Alternatively, if you are the root user, you can run: export KUBECONFIG=/etc/kubernetes/admin.conf You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/ Then you can join any number of worker nodes by running the following on each as root: kubeadm join 192.168.248.130:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:e9e29c804f92193928f37ca157b73a7ad77e7929314db98855b3ba6e2ce2273d ``` 按照初始化成功提示信息,做如下操作: ```shell mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config ``` 接下来执行`kubectl`就可以看到`node`了 ```shell [root@master1 .kube]# kubectl get node NAME STATUS ROLES AGE VERSION master1 Ready control-plane 55m v1.24.3 ``` 查看k8s各部件启动情况,执行如下命令: ```shell kubectl get pod --all-namespaces -o wide ```  通过观察发现`coredns`部件没有运行成功,通过如下命令查看原因: ```shell describe pod coredns-74586cf9b6-c2ddb --namespace=kube-system ```  > 根据官方的解析是没有部署CNI,coredns是不会启动的。  ## node节点配置 node节点安装kubeadm ```shell cat /etc/yum.repos.d/kubernetes.repo [kubernetes] name=Kubernetes baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=0 repo_gpgcheck=0 gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF ``` 安装相关组件 ```shell yum install -y kubeadm-1.24.3 --disableexcludes=kubernetes ``` 添加join命令 ```powershell kubeadm join 192.168.248.130:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:e9e29c804f92193928f37ca157b73a7ad77e7929314db98855b3ba6e2ce2273d ``` 如果我们后续需要添加node节点时,可以到master节点执行下面的命令获取`token`相关信息 ```shell [root@master1 ~]# kubeadm token create --print-join-command kubeadm join 192.168.248.130:6443 --token ydqnz1.6b0q5ntkvos9z2ir --discovery-token-ca-cert-hash sha256:c0b6f7fb38c7c9764084beb7dd26c9acef027ae6b7d2673572b4c2e3a0dfd6cb ``` > 如果添加某台节点异常了,修改后可以执行 `kubeadm reset `的命令,然后在重新join加入 ## 网络配置 coredns还没启动,因为还没有安装网络插件,接下来安装网络插件,可以在[该文档中](https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/)选择我们自己的网络插件,这里安装`flannel` ```shell wget http://down.i4t.com/k8s1.24/kube-flannel.yml ``` 根据需求修改网卡配置,我这里ens33为主的: ```yaml containers: - name: kube-flannel image: quay.io/coreos/flannel:v0.12.0-amd64 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr - --iface=ens33 # 如果是多网卡的话,指定内网网卡的名称 ``` > 在kubeadm.yaml文件中设置了podSubnet网段,同时在flannel中网段也要设置相同的。 (我这里默认就是相同的配置) 执行部署 ```shell kubectl apply -f kube-flannel.yml ``` ## CNI插件问题 默认情况下containerd也会有一个cni插件,但是我们已经安装Flannel了,我们需要使用Flannel的cni插件,需要将containerd里面的cni配置文件进行注释,否则2个配置会产生冲突 。 因为如果这个目录中有多个 cni 配置文件,kubelet 将会使用按文件名的字典顺序排列的第一个作为配置文件,所以前面默认选择使用的是 containerd-net 这个插件。 ```shell mv /etc/cni/net.d/10-containerd-net.conflist /etc/cni/net.d/10-containerd-net.conflist.bak systemctl restart containerd kubelet ``` 接下来我们所有的pod都可以正常运行了  # 验证 验证dns是否正常能解析和pod之间。这里新建一个测试的yaml文件,内容如下: ```yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - image: nginx:alpine name: nginx ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx spec: selector: app: nginx type: NodePort ports: - protocol: TCP port: 80 targetPort: 80 nodePort: 30001 --- apiVersion: v1 kind: Pod metadata: name: busybox namespace: default spec: containers: - name: busybox image: abcdocker9/centos:v1 command: - sleep - "3600" imagePullPolicy: IfNotPresent restartPolicy: Always ``` 执行下面命令,创建pod ```shell kubectl apply -f test.yaml ```  使用nslookup查看是否能返回地址 ```shell [root@master1 ~]# kubectl exec -it busybox -- nslookup kubernetes Server: 10.96.0.10 Address: 10.96.0.10#53 Name: kubernetes.default.svc.cluster.local Address: 10.96.0.1 [root@master1 ~]# ``` 测试nginx svc以及Pod内部网络通信是否正常 ,分别在三台机器上进行下面操作 ```powershell ping 10.104.115.26 #nginx svc ip ping 10.244.1.2 #podIP ``` 如果成功ping同说明node跟pod的网络已经打通了。否则检查`kube-proxy`的模式是否正确。 ## nodes/集群内部 无法访问ClusterIP 默认情况下,我们部署的`kube-proxy`通过查看日志,能看到如下信息:`Flag proxy-mode="" unknown,assuming iptables proxy ` **原因分析:** 并没有正确使用ipvs模式 解决方法: 1、 在`master`上修改`kube-proxy`的配置文件,添加`mode `为`ipvs`。 ```shell [root@master1 ~]# kubectl edit cm kube-proxy -n kube-system ipvs: excludeCIDRs: null minSyncPeriod: 0s scheduler: "" strictARP: false syncPeriod: 30s kind: KubeProxyConfiguration metricsBindAddress: 127.0.0.1:10249 mode: "ipvs" ``` 删除原来的POD,会自动重启kube-proxy 的pod ```shell [root@k8s-master ~]# kubectl get pod -n kube-system | grep kube-proxy |awk '{system("kubectl delete pod "$1" -n kube-system")}' ``` # 扩展 在使用过程中发现kubectl 命令不能补全,使用起来很不方便。为了提高使用kubectl命令工具的便捷性,介绍一下kubectl命令补全工具的安装。 1、安装bash-completion: ```shell yum install -y bash-completion source /usr/share/bash-completion/bash_completion ``` 2、 应用kubectl的completion到系统环境: ```shell source (kubectl completion bash) echo "source (kubectl completion bash)" >> ~/.bashrc ``` 3、效果展示  -
 【摘要】 Sermant Agent是一种基于JavaAgent的无代理服务网格技术。它利用JavaAgent来检测主机应用程序,并具有增强的服务治理功能,以解决海量微服务架构中的服务治理问题。本文介绍了Sermant Agent的接入原理和如何使用Sermant Agent无修改接入CSE。本文分享自华为云社区《Spring Cloud应用零代码修改接入华为云微服务引擎CSE》,作者: 微服务小助手 。一、 Sermant Agent介绍Sermant Agent是一种基于JavaAgent的无代理服务网格技术。它利用JavaAgent来检测主机应用程序,并具有增强的服务治理功能,以解决海量微服务架构中的服务治理问题。Sermant Agent处于快速发展阶段,当前已支持多种服务治理能力,包含流量治理、注册、优雅上下线及动态配置能力。 二、 为何使用Sermant Agent接入代码零侵入,配置很简单相较于SDK方式接入,基于Sermant Agent的接入会更加快捷高效,配置简单,且应用无需做任何代码改造,仅需在服务启动时附带Sermant Agent即可动态接入到CSE。支持多种治理能力Sermant Agent默认集成流量治理能力,当前支持熔断、限流、隔离仓以及重试治理能力,该能力可基于CSE配置中心进行配置与发布。支持多种注册中心Sermant Agent目前支持业内主流的注册中心,已经支持了ServiceComb ServiceCenter、Naocs,Eureka、Zookeeper等正在开发中。支持应用不停机迁移Sermant Agent支持服务的双注册,可根据配置中心下发的服务订阅策略,动态修改当前服务的订阅策略,并基于该能力帮助线上应用在业务不中断的前提下完成服务迁移。不仅如此,Sermant Agent提供优雅上下线能力,在服务重启、上下线时提供保障,在保护服务的同时,规避服务下线时可能存在的流量丢失问题。三、 接入原理当然,在说明原理之前,我们首先需要了解什么是Java Agent。Java Agent是在JDK1.5之后引入的新特性,它支持JVM将字节码文件读入内存之后,JVM使用对应的字节流在Java堆中生成一个Class对象之前,用户可以对其字节码进行修改的能力,JVM使用修改之后的字节码进行Class对象的创建,从而实现Java应用的非代码侵入的业务逻辑修改和替换。Sermant Agent正是基于动态修改字节码的技术,在服务启动时,动态增强原服务的注册逻辑。那Sermant Agent是如何在不修改代码的前提下接入CSE呢?主要流程如下:Sermant Agent接入CSE的时序图包含以下6个步骤:首先服务携带Sermant Agent启动;服务启动时,针对服务执行字节码增强操作(基于Java Agent的字节码增强),主要针对注册与配置两块,在步骤3-5体现;通过字节码增强,动态识别原应用的注册中心;注入启动配置,动态关闭原应用的注册中心自动配置逻辑;随后通过Spring的SpringFactory机制注入基于Spring Cloud实现的注册CSE的自动配置类,由Spring接管;当应用发起注册时,会通过步骤5注入的注册逻辑向CSE发起注册,最终完成接入。四、 简单零代码修改,轻松接入CSE接入场景分为虚机接入和容器接入,大家可以根据自身需求选择合适的接入方式。虚机场景接入CSE虚机部署的应用可通过Sermant Agent接入到CSE,点击查看虚机接入CSE流程。接入流程基于ECS将应用接入CSE流程如下:容器场景接入CSE容器部署的应用可通过Sermant Injector自动挂载Sermant Agent,从而通过Sermant Agent接入到CSE,点击查看容器接入CSE流程。接入流程基于CCE将应用接入CSE流程如下:五、 更多支持版本当前Sermant已支持大部分业内主流版本,相关Spring及注册中心版本如下:开源方式接入除了上述接入方式,还可基于开源方式接入,您可在Sermant开源社区拉取最新代码,并自行打包,启动步骤可参考虚机接入流程。开源项目Sermant:https://github.com/huaweicloud/Sermant
【摘要】 Sermant Agent是一种基于JavaAgent的无代理服务网格技术。它利用JavaAgent来检测主机应用程序,并具有增强的服务治理功能,以解决海量微服务架构中的服务治理问题。本文介绍了Sermant Agent的接入原理和如何使用Sermant Agent无修改接入CSE。本文分享自华为云社区《Spring Cloud应用零代码修改接入华为云微服务引擎CSE》,作者: 微服务小助手 。一、 Sermant Agent介绍Sermant Agent是一种基于JavaAgent的无代理服务网格技术。它利用JavaAgent来检测主机应用程序,并具有增强的服务治理功能,以解决海量微服务架构中的服务治理问题。Sermant Agent处于快速发展阶段,当前已支持多种服务治理能力,包含流量治理、注册、优雅上下线及动态配置能力。 二、 为何使用Sermant Agent接入代码零侵入,配置很简单相较于SDK方式接入,基于Sermant Agent的接入会更加快捷高效,配置简单,且应用无需做任何代码改造,仅需在服务启动时附带Sermant Agent即可动态接入到CSE。支持多种治理能力Sermant Agent默认集成流量治理能力,当前支持熔断、限流、隔离仓以及重试治理能力,该能力可基于CSE配置中心进行配置与发布。支持多种注册中心Sermant Agent目前支持业内主流的注册中心,已经支持了ServiceComb ServiceCenter、Naocs,Eureka、Zookeeper等正在开发中。支持应用不停机迁移Sermant Agent支持服务的双注册,可根据配置中心下发的服务订阅策略,动态修改当前服务的订阅策略,并基于该能力帮助线上应用在业务不中断的前提下完成服务迁移。不仅如此,Sermant Agent提供优雅上下线能力,在服务重启、上下线时提供保障,在保护服务的同时,规避服务下线时可能存在的流量丢失问题。三、 接入原理当然,在说明原理之前,我们首先需要了解什么是Java Agent。Java Agent是在JDK1.5之后引入的新特性,它支持JVM将字节码文件读入内存之后,JVM使用对应的字节流在Java堆中生成一个Class对象之前,用户可以对其字节码进行修改的能力,JVM使用修改之后的字节码进行Class对象的创建,从而实现Java应用的非代码侵入的业务逻辑修改和替换。Sermant Agent正是基于动态修改字节码的技术,在服务启动时,动态增强原服务的注册逻辑。那Sermant Agent是如何在不修改代码的前提下接入CSE呢?主要流程如下:Sermant Agent接入CSE的时序图包含以下6个步骤:首先服务携带Sermant Agent启动;服务启动时,针对服务执行字节码增强操作(基于Java Agent的字节码增强),主要针对注册与配置两块,在步骤3-5体现;通过字节码增强,动态识别原应用的注册中心;注入启动配置,动态关闭原应用的注册中心自动配置逻辑;随后通过Spring的SpringFactory机制注入基于Spring Cloud实现的注册CSE的自动配置类,由Spring接管;当应用发起注册时,会通过步骤5注入的注册逻辑向CSE发起注册,最终完成接入。四、 简单零代码修改,轻松接入CSE接入场景分为虚机接入和容器接入,大家可以根据自身需求选择合适的接入方式。虚机场景接入CSE虚机部署的应用可通过Sermant Agent接入到CSE,点击查看虚机接入CSE流程。接入流程基于ECS将应用接入CSE流程如下:容器场景接入CSE容器部署的应用可通过Sermant Injector自动挂载Sermant Agent,从而通过Sermant Agent接入到CSE,点击查看容器接入CSE流程。接入流程基于CCE将应用接入CSE流程如下:五、 更多支持版本当前Sermant已支持大部分业内主流版本,相关Spring及注册中心版本如下:开源方式接入除了上述接入方式,还可基于开源方式接入,您可在Sermant开源社区拉取最新代码,并自行打包,启动步骤可参考虚机接入流程。开源项目Sermant:https://github.com/huaweicloud/Sermant -
(1)流媒体应用有:媒体采集系统、媒体制作系统、点播系统、视频流推送系统.几类应用比较适合容器化部署:一是功能单一的应用,即微服务(这也是为什么现在大家一谈到微服务就会谈到容器,一谈到容器就会谈到微服务的原因);二是无状态的应用,容器的一个最大的优点就是可以快速创建(秒级),对于无状态的应用,可以通过快速横向扩容来提升并发处理能力;三是变更频繁的应用,容器是基于镜像创建的,对于变更频繁的应用,只要能保证镜像在测试环境测试没有问题,那么在生产环境上线由于环境差异导致出问题的概率就会少的多;四是对于需要在一个站点快速部署的应用组,对于需要在一个新站点快速部署的应用组,使用容器技术能够结合容器平台自身的特性,快速创建一个新的站点。(2)容器化改造思路1:负载均衡应用改造点:选择合适的负载均衡器中小型的Web应用可以使用ngnix或HAProxy,大型网站或重要的服务可以使用LVS,目前该企业业务较小,选取nginx作为负载均衡器!2:web应用改造点:应用存在长时间执行请求 增加消息队列,通过消息队列将长任务与用户请求解耦3:应用服务器应用改造点:应用实例依赖于本地的存储来持久化数据如果是日志,建议变成流汇聚到分布式日志系统中。如果必须要使用存储,要使用共享文件系统如NFS(3)采用华为云CCE集群服务CCE引擎核心优势支持裸金属容器服务,流媒体服务性能提升200%以上。视频流媒体对网络性能以及服务器运算能力要求苛刻。CCE支持裸金属容器服务,如图1,视频应用可基于裸金属服务部署,容器直接运行在物理机上,无任何虚拟化性能缺失,可获得和物理机同等的超优性能,视频业务性能提升200%以上。图1 裸金属容器服务视频网站应用放在pod里视频文件放在OBS里有状态pod 无状态pod流媒体加CDN加速服务ClusterIP:集群内访问表示工作负载暴露给同一集群内其他工作负载访问的方式,可以通过“集群内部域名”访问Nodeport:在每个节点的IP上开放一个静态端口,通过静态端口对外暴露服务。节点访问 ( NodePort )会路由到ClusterIP服务,这个ClusterIP服务会自动创建。通过请求<NodeIP>:<NodePort>,可以从集群的外部访问一个NodePort服务Loadbalance:可以通过弹性负载均衡从公网访问到工作负载,与弹性IP方式相比提供了高可靠的保障,一般用于系统中需要暴露到公网的服务。
-
问题版本:DWS 8.1.0.x 升级 8.1.1.x问题现象:错误信息:【updateInstanceTask】error happend,clusterid:[xxxx] updateinstance exception Failed to get instance params . Error is Failed to get softinfo . Please check rds_soft_info table by guestAgent and xx解决措施:以root用户登录cdk master节点,执行以下命令进入运维容器。 kubectl get pods -n dws-maintain kubectl exec -ti {服务实例容器名称} -n dws-maintain bash执行以下命令,进入管理面数据库。 mysql -h{hostIp} -P {port} -utom -p{passwd}执行以下SQL语句,更新升级包信息。{升级包sha256sum值}由解压出来的8.1.0-dws-upgrade.tar.gz.sha256、v8.1.0-guestAgent-upgrade.tar.gz.sha256文件,打开后获取use rms; insert into rds_soft_info values('v8.1.0-guestAgent-upgrade.tar.gz', 'guestAgent', 'guestAgent', 'v8.1.0' , 0, NULL,'{升级包sha256sum值}'); 比如:insert into rds_soft_info values('8.1.1.202-guestAgent-f611a993-44449263-20220214183251.tar.gz', 'guestAgent', 'guestAgent', 'v8.1.1.202', 0, NULL,'b750c7eb2527439e2b854b9071c133617ba456d13f6bcd6c8c2acc9eacc4898d');
-
 日前,国际权威分析机构沙利文(Frost & Sullivan)联合头豹研究院发布了《云原生市场研究报告——容器》(2022)报告显示,根据基于应用、产品和生态能力构建的云原生厂商容器产品竞争力评价模型华为云综合竞争力领跑行业多维度评分排名中国第一沙利文报告评价:“在应用方面,华为云在政企数字化、产业数字化等领域是行业领跑者,且开始布局卫星等应用场景;在产品方面,华为云在分布式云统一管控、云边协同和业务混部等性能方面具备明显的优势;在生态方面,华为云聚焦生态的打造,积极拓展生态伙伴,生态繁荣度较其他玩家优势显著。”应用能力上,华为云容器在各行业场景的应用深度和广度排名第一,并且在市场应用方面连续3年中国容器软件市场份额第一。例如,华为云CCE Turbo采用独创的容器直通网络,让两层网络变成一层,端到端连通时间缩短一半,有效支撑业务秒级扩容千容器,帮助新浪30秒扩容8000核,平稳应对流量浪涌。产品能力上,华为云容器在安全性、技术复杂度、产品支持力度等方面排名第一。华为云容器引擎 CCE 提供高可靠高性能的企业级容器应用管理服务,面向云原生2.0时代打造革命性CCE Turbo 容器集群。华为云容器实例 CCI 提供基于Kubernetes 的 Serverless 容器服务;并提供丰富客户业务的多种算力资源;华为云容器在计算、网络、调度全面加速,促进企业应用创新。生态能力上,华为云生态活跃度和生态繁荣度在主要云厂商中排名第一。华为云聚焦生态的打造,除了打造开源生态以外,还积极拓展生态伙伴,协力推动行业发展。华为云联合 CNCF、中国信通院及业界云原生技术精英,共同建立创原会,旨在通过探索前沿云原生技术、共享产业落地实践,共创云原生与业务融合的无限可能。此外,截至目前,华为云聚合超过302万开发者、超过38000家合作伙伴,云市场上架应用7400多个。不止于此,华为云在云原生容器领域持续技术创新、赋能产业。华为云容器技术与解决方案已经服务众多华为云客户,尤其是帮助众多互联网企业实现了应用敏捷创新、业务灵活部署。目前,80%的中国Top50互联网企业选择华为云。与此同时,在互联网行业市场,“H+X”(华为云+其他云)的多云部署模式也越来越受到互联网企业客户的认可与选择。数字浪潮奔涌,互联网企业当先华为云云原生助力企业生于云、长于云实现业务创新升级,云云协同,共创云上新价值互联网创新增长,选择华为云,至简共致远*转载自华为云头条撰文:华为云头条编辑:慧慧吖
日前,国际权威分析机构沙利文(Frost & Sullivan)联合头豹研究院发布了《云原生市场研究报告——容器》(2022)报告显示,根据基于应用、产品和生态能力构建的云原生厂商容器产品竞争力评价模型华为云综合竞争力领跑行业多维度评分排名中国第一沙利文报告评价:“在应用方面,华为云在政企数字化、产业数字化等领域是行业领跑者,且开始布局卫星等应用场景;在产品方面,华为云在分布式云统一管控、云边协同和业务混部等性能方面具备明显的优势;在生态方面,华为云聚焦生态的打造,积极拓展生态伙伴,生态繁荣度较其他玩家优势显著。”应用能力上,华为云容器在各行业场景的应用深度和广度排名第一,并且在市场应用方面连续3年中国容器软件市场份额第一。例如,华为云CCE Turbo采用独创的容器直通网络,让两层网络变成一层,端到端连通时间缩短一半,有效支撑业务秒级扩容千容器,帮助新浪30秒扩容8000核,平稳应对流量浪涌。产品能力上,华为云容器在安全性、技术复杂度、产品支持力度等方面排名第一。华为云容器引擎 CCE 提供高可靠高性能的企业级容器应用管理服务,面向云原生2.0时代打造革命性CCE Turbo 容器集群。华为云容器实例 CCI 提供基于Kubernetes 的 Serverless 容器服务;并提供丰富客户业务的多种算力资源;华为云容器在计算、网络、调度全面加速,促进企业应用创新。生态能力上,华为云生态活跃度和生态繁荣度在主要云厂商中排名第一。华为云聚焦生态的打造,除了打造开源生态以外,还积极拓展生态伙伴,协力推动行业发展。华为云联合 CNCF、中国信通院及业界云原生技术精英,共同建立创原会,旨在通过探索前沿云原生技术、共享产业落地实践,共创云原生与业务融合的无限可能。此外,截至目前,华为云聚合超过302万开发者、超过38000家合作伙伴,云市场上架应用7400多个。不止于此,华为云在云原生容器领域持续技术创新、赋能产业。华为云容器技术与解决方案已经服务众多华为云客户,尤其是帮助众多互联网企业实现了应用敏捷创新、业务灵活部署。目前,80%的中国Top50互联网企业选择华为云。与此同时,在互联网行业市场,“H+X”(华为云+其他云)的多云部署模式也越来越受到互联网企业客户的认可与选择。数字浪潮奔涌,互联网企业当先华为云云原生助力企业生于云、长于云实现业务创新升级,云云协同,共创云上新价值互联网创新增长,选择华为云,至简共致远*转载自华为云头条撰文:华为云头条编辑:慧慧吖 -
 【背景】A企业是一家位于杭州的软件开发公司,具备自主设计软件,交付软件及销售的能力,目前公司业务已经上华为云,考虑到开发及交付的便利性,准备进行容器化改,目标是能够实现软件开发即交付。业务现网状况如下:目前2台web服务器作为前端,mysql数据库,软件负载均衡器,无数据库中间件,后端EVS云硬盘,针对于本企业的现状,给出各部分的容器化改造及后续方案.
【背景】A企业是一家位于杭州的软件开发公司,具备自主设计软件,交付软件及销售的能力,目前公司业务已经上华为云,考虑到开发及交付的便利性,准备进行容器化改,目标是能够实现软件开发即交付。业务现网状况如下:目前2台web服务器作为前端,mysql数据库,软件负载均衡器,无数据库中间件,后端EVS云硬盘,针对于本企业的现状,给出各部分的容器化改造及后续方案.
推荐直播
-
 华为云IoT开源专家实践分享:开源让物联网平台更开放、易用
华为云IoT开源专家实践分享:开源让物联网平台更开放、易用2024/05/14 周二 16:30-18:00
张俭 华为云IoT DTSE技术布道师
作为开发者的你是否也想加入开源社区?本期物联网平台资深“程序猿”,开源专家张俭,为你揭秘华为云IoT如何借助开源构建可靠、开放、易用的物联网平台,并手把手教你玩转开源社区!
去报名
热门标签