-
 TensorFlow训练网络有两种方式,一种是基于tensor(array),另外一种是迭代器两种方式区别是:第一种是要加载全部数据形成一个tensor,然后调用model.fit()然后指定参数batch_size进行将所有数据进行分批训练第二种是自己先将数据分批形成一个迭代器,然后遍历这个迭代器,分别训练每个批次的数据方式一:通过迭代器1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283IMAGE_SIZE = 1000 # step1:加载数据集(train_images, train_labels), (val_images, val_labels) = tf.keras.datasets.mnist.load_data() # step2:将图像归一化train_images, val_images = train_images / 255.0, val_images / 255.0 # step3:设置训练集大小train_images = train_images[:IMAGE_SIZE]val_images = val_images[:IMAGE_SIZE]train_labels = train_labels[:IMAGE_SIZE]val_labels = val_labels[:IMAGE_SIZE] # step4:将图像的维度变为(IMAGE_SIZE,28,28,1)train_images = tf.expand_dims(train_images, axis=3)val_images = tf.expand_dims(val_images, axis=3) # step5:将图像的尺寸变为(32,32)train_images = tf.image.resize(train_images, [32, 32])val_images = tf.image.resize(val_images, [32, 32]) # step6:将数据变为迭代器train_loader = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).batch(32)val_loader = tf.data.Dataset.from_tensor_slices((val_images, val_labels)).batch(IMAGE_SIZE) # step5:导入模型model = LeNet5() # 让模型知道输入数据的形式model.build(input_shape=(1, 32, 32, 1)) # 结局Output Shape为 multiplemodel.call(Input(shape=(32, 32, 1))) # step6:编译模型model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) # 权重保存路径checkpoint_path = "./weight/cp.ckpt" # 回调函数,用户保存权重save_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, save_best_only=True, save_weights_only=True, monitor='val_loss', verbose=0) EPOCHS = 11 for epoch in range(1, EPOCHS): # 每个批次训练集误差 train_epoch_loss_avg = tf.keras.metrics.Mean() # 每个批次训练集精度 train_epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() # 每个批次验证集误差 val_epoch_loss_avg = tf.keras.metrics.Mean() # 每个批次验证集精度 val_epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() for x, y in train_loader: history = model.fit(x, y, validation_data=val_loader, callbacks=[save_callback], verbose=0) # 更新误差,保留上次 train_epoch_loss_avg.update_state(history.history['loss'][0]) # 更新精度,保留上次 train_epoch_accuracy.update_state(y, model(x, training=True)) val_epoch_loss_avg.update_state(history.history['val_loss'][0]) val_epoch_accuracy.update_state(next(iter(val_loader))[1], model(next(iter(val_loader))[0], training=True)) # 使用.result()计算每个批次的误差和精度结果 print("Epoch {:d}: trainLoss: {:.3f}, trainAccuracy: {:.3%} valLoss: {:.3f}, valAccuracy: {:.3%}".format(epoch, train_epoch_loss_avg.result(), train_epoch_accuracy.result(), val_epoch_loss_avg.result(), val_epoch_accuracy.result()))方式二:适用model.fit()进行分批训练123456789101112131415161718192021222324252627282930313233343536373839404142434445464748import model_sequential (train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data() # step2:将图像归一化train_images, test_images = train_images / 255.0, test_images / 255.0 # step3:将图像的维度变为(60000,28,28,1)train_images = tf.expand_dims(train_images, axis=3)test_images = tf.expand_dims(test_images, axis=3) # step4:将图像尺寸改为(60000,32,32,1)train_images = tf.image.resize(train_images, [32, 32])test_images = tf.image.resize(test_images, [32, 32]) # step5:导入模型# history = LeNet5()history = model_sequential.LeNet() # 让模型知道输入数据的形式history.build(input_shape=(1, 32, 32, 1))# history(tf.zeros([1, 32, 32, 1])) # 结局Output Shape为 multiplehistory.call(Input(shape=(32, 32, 1)))history.summary() # step6:编译模型history.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) # 权重保存路径checkpoint_path = "./weight/cp.ckpt" # 回调函数,用户保存权重save_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, save_best_only=True, save_weights_only=True, monitor='val_loss', verbose=1)# step7:训练模型history = history.fit(train_images, train_labels, epochs=10, batch_size=32, validation_data=(test_images, test_labels), callbacks=[save_callback])
TensorFlow训练网络有两种方式,一种是基于tensor(array),另外一种是迭代器两种方式区别是:第一种是要加载全部数据形成一个tensor,然后调用model.fit()然后指定参数batch_size进行将所有数据进行分批训练第二种是自己先将数据分批形成一个迭代器,然后遍历这个迭代器,分别训练每个批次的数据方式一:通过迭代器1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677787980818283IMAGE_SIZE = 1000 # step1:加载数据集(train_images, train_labels), (val_images, val_labels) = tf.keras.datasets.mnist.load_data() # step2:将图像归一化train_images, val_images = train_images / 255.0, val_images / 255.0 # step3:设置训练集大小train_images = train_images[:IMAGE_SIZE]val_images = val_images[:IMAGE_SIZE]train_labels = train_labels[:IMAGE_SIZE]val_labels = val_labels[:IMAGE_SIZE] # step4:将图像的维度变为(IMAGE_SIZE,28,28,1)train_images = tf.expand_dims(train_images, axis=3)val_images = tf.expand_dims(val_images, axis=3) # step5:将图像的尺寸变为(32,32)train_images = tf.image.resize(train_images, [32, 32])val_images = tf.image.resize(val_images, [32, 32]) # step6:将数据变为迭代器train_loader = tf.data.Dataset.from_tensor_slices((train_images, train_labels)).batch(32)val_loader = tf.data.Dataset.from_tensor_slices((val_images, val_labels)).batch(IMAGE_SIZE) # step5:导入模型model = LeNet5() # 让模型知道输入数据的形式model.build(input_shape=(1, 32, 32, 1)) # 结局Output Shape为 multiplemodel.call(Input(shape=(32, 32, 1))) # step6:编译模型model.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) # 权重保存路径checkpoint_path = "./weight/cp.ckpt" # 回调函数,用户保存权重save_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, save_best_only=True, save_weights_only=True, monitor='val_loss', verbose=0) EPOCHS = 11 for epoch in range(1, EPOCHS): # 每个批次训练集误差 train_epoch_loss_avg = tf.keras.metrics.Mean() # 每个批次训练集精度 train_epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() # 每个批次验证集误差 val_epoch_loss_avg = tf.keras.metrics.Mean() # 每个批次验证集精度 val_epoch_accuracy = tf.keras.metrics.SparseCategoricalAccuracy() for x, y in train_loader: history = model.fit(x, y, validation_data=val_loader, callbacks=[save_callback], verbose=0) # 更新误差,保留上次 train_epoch_loss_avg.update_state(history.history['loss'][0]) # 更新精度,保留上次 train_epoch_accuracy.update_state(y, model(x, training=True)) val_epoch_loss_avg.update_state(history.history['val_loss'][0]) val_epoch_accuracy.update_state(next(iter(val_loader))[1], model(next(iter(val_loader))[0], training=True)) # 使用.result()计算每个批次的误差和精度结果 print("Epoch {:d}: trainLoss: {:.3f}, trainAccuracy: {:.3%} valLoss: {:.3f}, valAccuracy: {:.3%}".format(epoch, train_epoch_loss_avg.result(), train_epoch_accuracy.result(), val_epoch_loss_avg.result(), val_epoch_accuracy.result()))方式二:适用model.fit()进行分批训练123456789101112131415161718192021222324252627282930313233343536373839404142434445464748import model_sequential (train_images, train_labels), (test_images, test_labels) = tf.keras.datasets.mnist.load_data() # step2:将图像归一化train_images, test_images = train_images / 255.0, test_images / 255.0 # step3:将图像的维度变为(60000,28,28,1)train_images = tf.expand_dims(train_images, axis=3)test_images = tf.expand_dims(test_images, axis=3) # step4:将图像尺寸改为(60000,32,32,1)train_images = tf.image.resize(train_images, [32, 32])test_images = tf.image.resize(test_images, [32, 32]) # step5:导入模型# history = LeNet5()history = model_sequential.LeNet() # 让模型知道输入数据的形式history.build(input_shape=(1, 32, 32, 1))# history(tf.zeros([1, 32, 32, 1])) # 结局Output Shape为 multiplehistory.call(Input(shape=(32, 32, 1)))history.summary() # step6:编译模型history.compile(optimizer='adam', loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy']) # 权重保存路径checkpoint_path = "./weight/cp.ckpt" # 回调函数,用户保存权重save_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_path, save_best_only=True, save_weights_only=True, monitor='val_loss', verbose=1)# step7:训练模型history = history.fit(train_images, train_labels, epochs=10, batch_size=32, validation_data=(test_images, test_labels), callbacks=[save_callback]) -
 【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件) -
 介绍深度学习是机器学习和的一个子集,它模仿人类获取某些类型知识的方式。它本质上是一个具有三层或更多层的神经网络。深度学习有助于解决许多人工智能应用程序,这些应用程序有助于提高自动化程度,在无需人工干预的情况下执行分析和物理任务,从而创建智能的应用程序和技术。其中一种应用是人体姿势检测,其中使用了深度学习。目录· 什么是Posenet ?· PoseNet 是如何工作的?· 实时姿势检测的应用· 使用 PoseNet 实现姿势检测 先决条件 从头开始编写完整的项目 在 GitHub 上部署· 尾注什么是Posenet ?Posenet 是一种实时姿势检测技术,你可以使用它检测图像或视频中的人类姿势。它在两种情况下都可以作为单模式(单个人体姿势检测)和多姿势检测(多个人体姿势检测)工作。简单来说,Posenet 是一个深度学习 TensorFlow 模型,它允许你通过检测肘部、臀部、手腕、膝盖、脚踝等身体部位来估计人体姿势,并通过连接这些点形成姿势的骨架结构。PoseNet 是如何工作的?PoseNet 接受过 MobileNet 架构训练。MobileNet 是谷歌开发的卷积神经网络,在 ImageNet 数据集上训练,主要用于类别中的图像分类和目标估计。它是一个轻量级模型,它使用深度可分离卷积来加深网络并减少参数、计算成本并提高准确性。你可以在 google 上找到大量与 MobileNet 相关的文章。预训练模型在浏览器中运行,这就是 posenet 与其他依赖API 的库的区别。因此,在笔记本电脑/台式机中配置有限的任何人都可以轻松使用此类模型并构建良好的项目。Posenet 为我们提供了总共 17 个我们可以使用的关键点,从眼睛到耳朵,再到膝盖和脚踝。如果我们提供给 Posenet 的图像不清晰,则posenet 会以JSON 响应的形式显示它对检测特定姿势的置信度分数。PoseNet 现实世界中的应用1. 在 Snapchat 过滤器中使用,你可以在其中看到舌头、侧面、快照、虚拟人脸等。2. 像 cult 一样的健身应用程序,用于检测你的运动姿势。3. 一个非常受欢迎的 Instagram Reels 使用姿势检测为你的脸和周围提供不同的特征。4. 虚拟游戏来分析球员的投篮。使用 PoseNet 实现姿势检测现在我们有了对posenet的理论知识以及为什么使用它。让我们直接进入编码环境并实现姿势检测项目。我们将如何实施项目我们不会遵循 Python 的方式来实现这个项目,而是会使用 javascript,因为我们必须在浏览器中完成所有这些工作,而在浏览器中实现 Python 几乎是不可能的。你可以在服务器上运行 Python。Tensorflow 有一个流行的库名称tensorflow.js,它提供了在客户端系统上运行模型的功能。如果你还没有阅读或了解使用 javascript 进行机器学习,那么无需担心,代码量很少。让我们开始吧你可以使用任何 IDE 来实现项目,例如 Visual Studio 代码、sublime 文本等。1) Boiler 模板创建一个新文件夹并创建一个 HTML 文件,它将作为我们的网站供用户使用。在这里我们将导入我们将使用的 javascript 文件、机器学习和深度学习库。<html> <head> <title>PoseNet Detection</title> </head> <body> <h1 style="text-align:center">Posture Detection using PoseNet</h1> </body> </html>使用 PoseNet 进行姿势检测2) p5.js它是一个用于创意编码的 javascript 库。有一种称为Processing 的软件,P5.js 正是基于该软件。Processing 是用 Java 制作的,这有助于在桌面应用程序中进行创造性编码,但在那之后,当网站需要同样的东西时,就实现了 P5.js。创意编码意味着它可以帮助你通过调用内置函数以创造性的方式(彩色或动画)在浏览器上绘制各种形状和图形,如线条、矩形、正方形、圆形、点等,并提供高度和宽度你想要的形状。创建一个 javascript 文件,在这里我们将尝试学习 P5.JS,以及我们为什么使用这个库。在 javascript 文件中写入任何内容之前,首先导入 P5.js,在 HTML 文件中添加指向创建的 javascript 文件的链接。<html> <head> <title>PoseNet Detection</title> <script src="https://unpkg.com/ml5@latest/dist/ml5.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/p5@1.4.0/lib/p5.js"></script> <script src="sketch.js"></script> <!--js file--> </head> <body> <h1 style="text-align:center">Posture Detection using PoseNet</h1> </body></html>你可以在 P5.js 中实现两件事。在javascript文件中编写以下代码。a) setup :在这个函数中,你编写一个与你的界面中需要的基本配置相关的代码。你创建的一件事是画布并在此处指定其大小。你实现的所有东西只会出现在这个画布上。它的工作是设置所有的东西。function setup() { // this function runs only once while running createCanvas(800, 500);}b) 绘图:第二个功能是在你绘制所有你想要的东西的地方绘图,比如形状、放置图像、播放视频。所有的实现代码都放在这个函数中。将其理解为编译语言中的主要功能。它的工作是在屏幕上显示东西。让我们尝试绘制一些形状,并亲身体验 P5.Js 库。最好的是每个图形都有一个内置函数,你只需要调用并传递一些坐标即可绘制形状。为画布提供背景颜色调用背景函数并传递颜色代码。*i) Point :*使用 point 函数绘制一个简单的点并传递 x 和 y 坐标*ii)*line:线连接两点,只需调用直线函数,并传递2个点的坐标。iii) rectangle :调用 rect 函数并传递高度和宽度。如果高度和宽度相同,那么它将是正方形。用于创造力的一些其他功能是。*i)stroke——*它定义了形状的外边界线*ii)stroke-weight –*它定义了外线的宽度。iii) fill ——你想在形状中填充的颜色下面是一个代码片段,作为我们学习的每个函数的示例。尝试运行此代码,并通过像在实时服务器上一样运行 HTML 文件来观察浏览器中的变化和数字。P5.js的一个重要特性是setup函数只运行一次设置,而draw函数代码无限循环运行,直到界面打开。你可以通过使用控制台日志命令打印任何内容来检查这一点。使用 P5js,你可以加载图像、捕获图像、视频等。在draw函数和上面的new函数中运行上面注释的这段代码,观察浏览器的变化,体验P5.js库的神奇。3) ML5.js与他人共享代码应用程序的最佳方式是网络。只有共享URL,你才能使用系统上的其他应用程序。所以,ML5.js构建了一个围绕tensorflow.js的包装器,并通过使用一些函数使任务变得简单,你将间接地通过ML5.js处理tensorflow.js。你可以在Ml5.js的官方文档中读到同样的内容因此,它是由各种深度学习模型组成的主要库,你可以在这些模型上构建项目。在这个项目中,我们使用了这个库中也存在的 PoseNet 模型。让我们导入库并使用它。在 HTML 文件中粘贴以下脚本代码以加载库。现在让我们设置图像捕获并加载 PoseNet 模型。capture 变量是一个全局变量,我们将创建的所有变量都具有全局作用域。let capture;当我们加载并运行代码时,Posenet 将检测 17 个身体点(5 个面部点,12 个身体点)以及在图像中检测到该点的像素的信息。如果你打印这些姿势,那么它将返回一个数组(python 列表),该数组由一个字典组成,其中有 2 个键作为我们评估过的姿势和骨架。· 姿势 - 这又是一个字典,由各种键和一系列值组成,如关键点、左眼、左耳、鼻子等。· 骨架 - 在骨架中,每个字典由两个子字典组成,分别为 0 和 1,它们具有置信度分数、部件名称和位置坐标。所以我们可以用它来制作一条线并构建一个骨架结构。现在,如果你想在姿势前显示任何单个点,则可以通过在姿势中使用这些单独的点来实现。我们将如何显示所有点并将它们连接为骨架?我们有一个关键点名称字典,其中包含每个点的 X 和 y 坐标。所以我们可以在其中遍历关键点字典和访问位置字典,并在其中使用 x 和 y 坐标。现在要画线,我们可以使用第二个字典作为骨架,它由坐标的所有点信息组成,以连接两个身体部位。function draw() { // images and video(webcam) image(capture, 0, 0); fill(255, 0, 0); if(singlePose) { // if someone is captured then only // Capture all estimated points and draw a circle of 20 radius for(let i=0; i<singlePose.keypoints.length; i++) { ellipse(singlePose.keypoints[i].position.x, singlePose.keypoints[i].position.y, 20); } stroke(255, 255, 255); strokeWeight(5); // construct skeleton structure by joining 2 parts with line for(let j=0; j<skeleton.length; j++) { line(skeleton[j][0].position.x, skeleton[j][0].position.y, skeleton[j][1].position.x, skeleton[j][1].position.y); } } }在光线充足的情况下,它有时无法在模糊或黑暗的背景下准确捕捉。如何强加图像?现在我们将学习如何将图像强加到脸部或你在不同过滤器中看到的任何其他位置。看起来有点模糊和有趣,但这个应用程序正在作为许多社交媒体的助推器。只需在 setup 函数中加载图像,并使用 image 函数调整图像作为坐标,你希望在绘制函数中在循环骨架结束后显示该图像。假设我们正在显示规格和雪茄图像。specs = loadImage('images/spects.png');smoke = loadImage('images/cigar.png');// Apply specs and cigarimage(specs, singlePose.nose.x-40, singlePose.nose.y-70, 125, 125);image(smoke, singlePose.nose.x-35, singlePose.nose.y+28, 50, 50);所有的图像都保存在一个名为图像的单独文件夹中,我们使用加载图像功能加载每个图像。规格将在鼻子上方,雪茄在鼻子下方。完整的代码链接如下,大家可以参考。部署项目由于该项目在浏览器上,因此你可以简单地将其部署在 Github 上并使其可供其他人使用。只需将所有文件和图像上传到 Github 上的新存储库,就像它们在本地系统中一样。上传后访问存储库的设置并访问 Github 页面。将 none 更改为 main 分支,然后单击保存。它将为你提供一个项目的 URL,该项目将在一段时间后生效,你可以与他人共享。尾注欢呼!我们使用预训练的 PoseNet 模型创建了一个完整的端到端姿势检测项目。我希望能够轻松掌握所有概念,因为我可以理解,如果你第一次看到使用 JavaScript 进行机器学习会感觉有点困难。但是相信我,这是一件简单的事情,并再次阅读文章并使用不同的配置,不同的设计自己尝试。我们已经进行了单人姿势检测,我鼓励你进行多人姿势检测。你可以尝试添加不同的选项,调整适用于所有相机的点。你可以在这个项目上继续推进很多事情。
介绍深度学习是机器学习和的一个子集,它模仿人类获取某些类型知识的方式。它本质上是一个具有三层或更多层的神经网络。深度学习有助于解决许多人工智能应用程序,这些应用程序有助于提高自动化程度,在无需人工干预的情况下执行分析和物理任务,从而创建智能的应用程序和技术。其中一种应用是人体姿势检测,其中使用了深度学习。目录· 什么是Posenet ?· PoseNet 是如何工作的?· 实时姿势检测的应用· 使用 PoseNet 实现姿势检测 先决条件 从头开始编写完整的项目 在 GitHub 上部署· 尾注什么是Posenet ?Posenet 是一种实时姿势检测技术,你可以使用它检测图像或视频中的人类姿势。它在两种情况下都可以作为单模式(单个人体姿势检测)和多姿势检测(多个人体姿势检测)工作。简单来说,Posenet 是一个深度学习 TensorFlow 模型,它允许你通过检测肘部、臀部、手腕、膝盖、脚踝等身体部位来估计人体姿势,并通过连接这些点形成姿势的骨架结构。PoseNet 是如何工作的?PoseNet 接受过 MobileNet 架构训练。MobileNet 是谷歌开发的卷积神经网络,在 ImageNet 数据集上训练,主要用于类别中的图像分类和目标估计。它是一个轻量级模型,它使用深度可分离卷积来加深网络并减少参数、计算成本并提高准确性。你可以在 google 上找到大量与 MobileNet 相关的文章。预训练模型在浏览器中运行,这就是 posenet 与其他依赖API 的库的区别。因此,在笔记本电脑/台式机中配置有限的任何人都可以轻松使用此类模型并构建良好的项目。Posenet 为我们提供了总共 17 个我们可以使用的关键点,从眼睛到耳朵,再到膝盖和脚踝。如果我们提供给 Posenet 的图像不清晰,则posenet 会以JSON 响应的形式显示它对检测特定姿势的置信度分数。PoseNet 现实世界中的应用1. 在 Snapchat 过滤器中使用,你可以在其中看到舌头、侧面、快照、虚拟人脸等。2. 像 cult 一样的健身应用程序,用于检测你的运动姿势。3. 一个非常受欢迎的 Instagram Reels 使用姿势检测为你的脸和周围提供不同的特征。4. 虚拟游戏来分析球员的投篮。使用 PoseNet 实现姿势检测现在我们有了对posenet的理论知识以及为什么使用它。让我们直接进入编码环境并实现姿势检测项目。我们将如何实施项目我们不会遵循 Python 的方式来实现这个项目,而是会使用 javascript,因为我们必须在浏览器中完成所有这些工作,而在浏览器中实现 Python 几乎是不可能的。你可以在服务器上运行 Python。Tensorflow 有一个流行的库名称tensorflow.js,它提供了在客户端系统上运行模型的功能。如果你还没有阅读或了解使用 javascript 进行机器学习,那么无需担心,代码量很少。让我们开始吧你可以使用任何 IDE 来实现项目,例如 Visual Studio 代码、sublime 文本等。1) Boiler 模板创建一个新文件夹并创建一个 HTML 文件,它将作为我们的网站供用户使用。在这里我们将导入我们将使用的 javascript 文件、机器学习和深度学习库。<html> <head> <title>PoseNet Detection</title> </head> <body> <h1 style="text-align:center">Posture Detection using PoseNet</h1> </body> </html>使用 PoseNet 进行姿势检测2) p5.js它是一个用于创意编码的 javascript 库。有一种称为Processing 的软件,P5.js 正是基于该软件。Processing 是用 Java 制作的,这有助于在桌面应用程序中进行创造性编码,但在那之后,当网站需要同样的东西时,就实现了 P5.js。创意编码意味着它可以帮助你通过调用内置函数以创造性的方式(彩色或动画)在浏览器上绘制各种形状和图形,如线条、矩形、正方形、圆形、点等,并提供高度和宽度你想要的形状。创建一个 javascript 文件,在这里我们将尝试学习 P5.JS,以及我们为什么使用这个库。在 javascript 文件中写入任何内容之前,首先导入 P5.js,在 HTML 文件中添加指向创建的 javascript 文件的链接。<html> <head> <title>PoseNet Detection</title> <script src="https://unpkg.com/ml5@latest/dist/ml5.min.js"></script> <script src="https://cdn.jsdelivr.net/npm/p5@1.4.0/lib/p5.js"></script> <script src="sketch.js"></script> <!--js file--> </head> <body> <h1 style="text-align:center">Posture Detection using PoseNet</h1> </body></html>你可以在 P5.js 中实现两件事。在javascript文件中编写以下代码。a) setup :在这个函数中,你编写一个与你的界面中需要的基本配置相关的代码。你创建的一件事是画布并在此处指定其大小。你实现的所有东西只会出现在这个画布上。它的工作是设置所有的东西。function setup() { // this function runs only once while running createCanvas(800, 500);}b) 绘图:第二个功能是在你绘制所有你想要的东西的地方绘图,比如形状、放置图像、播放视频。所有的实现代码都放在这个函数中。将其理解为编译语言中的主要功能。它的工作是在屏幕上显示东西。让我们尝试绘制一些形状,并亲身体验 P5.Js 库。最好的是每个图形都有一个内置函数,你只需要调用并传递一些坐标即可绘制形状。为画布提供背景颜色调用背景函数并传递颜色代码。*i) Point :*使用 point 函数绘制一个简单的点并传递 x 和 y 坐标*ii)*line:线连接两点,只需调用直线函数,并传递2个点的坐标。iii) rectangle :调用 rect 函数并传递高度和宽度。如果高度和宽度相同,那么它将是正方形。用于创造力的一些其他功能是。*i)stroke——*它定义了形状的外边界线*ii)stroke-weight –*它定义了外线的宽度。iii) fill ——你想在形状中填充的颜色下面是一个代码片段,作为我们学习的每个函数的示例。尝试运行此代码,并通过像在实时服务器上一样运行 HTML 文件来观察浏览器中的变化和数字。P5.js的一个重要特性是setup函数只运行一次设置,而draw函数代码无限循环运行,直到界面打开。你可以通过使用控制台日志命令打印任何内容来检查这一点。使用 P5js,你可以加载图像、捕获图像、视频等。在draw函数和上面的new函数中运行上面注释的这段代码,观察浏览器的变化,体验P5.js库的神奇。3) ML5.js与他人共享代码应用程序的最佳方式是网络。只有共享URL,你才能使用系统上的其他应用程序。所以,ML5.js构建了一个围绕tensorflow.js的包装器,并通过使用一些函数使任务变得简单,你将间接地通过ML5.js处理tensorflow.js。你可以在Ml5.js的官方文档中读到同样的内容因此,它是由各种深度学习模型组成的主要库,你可以在这些模型上构建项目。在这个项目中,我们使用了这个库中也存在的 PoseNet 模型。让我们导入库并使用它。在 HTML 文件中粘贴以下脚本代码以加载库。现在让我们设置图像捕获并加载 PoseNet 模型。capture 变量是一个全局变量,我们将创建的所有变量都具有全局作用域。let capture;当我们加载并运行代码时,Posenet 将检测 17 个身体点(5 个面部点,12 个身体点)以及在图像中检测到该点的像素的信息。如果你打印这些姿势,那么它将返回一个数组(python 列表),该数组由一个字典组成,其中有 2 个键作为我们评估过的姿势和骨架。· 姿势 - 这又是一个字典,由各种键和一系列值组成,如关键点、左眼、左耳、鼻子等。· 骨架 - 在骨架中,每个字典由两个子字典组成,分别为 0 和 1,它们具有置信度分数、部件名称和位置坐标。所以我们可以用它来制作一条线并构建一个骨架结构。现在,如果你想在姿势前显示任何单个点,则可以通过在姿势中使用这些单独的点来实现。我们将如何显示所有点并将它们连接为骨架?我们有一个关键点名称字典,其中包含每个点的 X 和 y 坐标。所以我们可以在其中遍历关键点字典和访问位置字典,并在其中使用 x 和 y 坐标。现在要画线,我们可以使用第二个字典作为骨架,它由坐标的所有点信息组成,以连接两个身体部位。function draw() { // images and video(webcam) image(capture, 0, 0); fill(255, 0, 0); if(singlePose) { // if someone is captured then only // Capture all estimated points and draw a circle of 20 radius for(let i=0; i<singlePose.keypoints.length; i++) { ellipse(singlePose.keypoints[i].position.x, singlePose.keypoints[i].position.y, 20); } stroke(255, 255, 255); strokeWeight(5); // construct skeleton structure by joining 2 parts with line for(let j=0; j<skeleton.length; j++) { line(skeleton[j][0].position.x, skeleton[j][0].position.y, skeleton[j][1].position.x, skeleton[j][1].position.y); } } }在光线充足的情况下,它有时无法在模糊或黑暗的背景下准确捕捉。如何强加图像?现在我们将学习如何将图像强加到脸部或你在不同过滤器中看到的任何其他位置。看起来有点模糊和有趣,但这个应用程序正在作为许多社交媒体的助推器。只需在 setup 函数中加载图像,并使用 image 函数调整图像作为坐标,你希望在绘制函数中在循环骨架结束后显示该图像。假设我们正在显示规格和雪茄图像。specs = loadImage('images/spects.png');smoke = loadImage('images/cigar.png');// Apply specs and cigarimage(specs, singlePose.nose.x-40, singlePose.nose.y-70, 125, 125);image(smoke, singlePose.nose.x-35, singlePose.nose.y+28, 50, 50);所有的图像都保存在一个名为图像的单独文件夹中,我们使用加载图像功能加载每个图像。规格将在鼻子上方,雪茄在鼻子下方。完整的代码链接如下,大家可以参考。部署项目由于该项目在浏览器上,因此你可以简单地将其部署在 Github 上并使其可供其他人使用。只需将所有文件和图像上传到 Github 上的新存储库,就像它们在本地系统中一样。上传后访问存储库的设置并访问 Github 页面。将 none 更改为 main 分支,然后单击保存。它将为你提供一个项目的 URL,该项目将在一段时间后生效,你可以与他人共享。尾注欢呼!我们使用预训练的 PoseNet 模型创建了一个完整的端到端姿势检测项目。我希望能够轻松掌握所有概念,因为我可以理解,如果你第一次看到使用 JavaScript 进行机器学习会感觉有点困难。但是相信我,这是一件简单的事情,并再次阅读文章并使用不同的配置,不同的设计自己尝试。我们已经进行了单人姿势检测,我鼓励你进行多人姿势检测。你可以尝试添加不同的选项,调整适用于所有相机的点。你可以在这个项目上继续推进很多事情。 -
在此之前,我已经讨论了MobileNet的体系结构接下来,我们将看到如何使用TensorFlow从头开始实现这个架构。实现:MobileNet架构:图显示了我们将在代码中实现的MobileNet体系结构。网络从Conv、BatchNorm、ReLU块开始,并从其上跟随多个MobileNet块。它最终以一个平均池和一个完全连接的层结束,并激活Softmax。我们看到该体系结构有一个模式——Conv-dw/s1,后跟Conv/s1,依此类推。这里dw是深度层和步幅数,然后是Conv层和步幅数。这两条线是MobileNet区块。“Filter Shape”列给出了核大小和要使用的滤波器数量的详细信息。列的最后一个数字表示滤波器的数量。我们看到滤波器数量从32逐渐增加到64,从64逐渐增加到128,从128逐渐增加到256,以此类推。最后一列显示了随着我们深入网络,图像的大小是如何变化的。输入大小选择为224*224像素,有3个通道,输出层分类为1000类。正常CNN架构块之间的差异(左),与MobileNet架构(右):构建网络时需要记住的几件事:所有层之后都是批量标准化和ReLU非线性。与具有Conv2D层的普通CNN模型不同,MobileNet具有Depthwise Conv层,如图所示。工作流从TensorFlow库导入所有必要的层为MobileNet块编写辅助函数构建模型的主干使用helper函数构建模型的主要部分导入图层import tensorflow as tf# 导入所有必要的层from tensorflow.keras.layers import Input, DepthwiseConv2Dfrom tensorflow.keras.layers import Conv2D, BatchNormalizationfrom tensorflow.keras.layers import ReLU, AvgPool2D, Flatten, Densefrom tensorflow.keras import ModelKeras已经内置了一个DepthwiseConv层,所以我们不需要从头开始创建它。MobileNet块MobileNet块的表示要为MobileNet块创建函数,我们需要以下步骤:函数的输入:a.张量(x)b.卷积层的滤波器数量(滤波器)c.卷积层的步长(步长)运行:a.应用3x3分步卷积层,然后是批量标准化层和ReLU激活b.应用带有1x1卷积层的滤波器,然后是批量标准化层和ReLU激活返回张量(输出)这3个步骤在下面的代码块中实现。# MobileNet blockdef mobilnet_block (x, filters, strides):x = DepthwiseConv2D(kernel_size = 3, strides = strides, padding = 'same')(x)x = BatchNormalization()(x)x = ReLU()(x)x = Conv2D(filters = filters, kernel_size = 1, strides = 1)(x)x = BatchNormalization()(x)x = ReLU()(x)return x构建模型的主干如图2所示,第一层为Conv/s2,滤波器形状为3x32。模型的主干# 模型的主干input = Input(shape = (224,224,3))x = Conv2D(filters = 32, kernel_size = 3, strides = 2, padding = 'same')(input)x = BatchNormalization()(x)x = ReLU()(x)模型的主要部分:# 模型的主要部分x = mobilnet_block(x, filters = 64, strides = 1)x = mobilnet_block(x, filters = 128, strides = 2)x = mobilnet_block(x, filters = 128, strides = 1)x = mobilnet_block(x, filters = 256, strides = 2)x = mobilnet_block(x, filters = 256, strides = 1)x = mobilnet_block(x, filters = 512, strides = 2)for _ in range (5):x = mobilnet_block(x, filters = 512, strides = 1)x = mobilnet_block(x, filters = 1024, strides = 2)x = mobilnet_block(x, filters = 1024, strides = 1)x = AvgPool2D (pool_size = 7, strides = 1, data_format='channels_first')(x)output = Dense (units = 1000, activation = 'softmax')(x)model = Model(inputs=input, outputs=output)model.summary()模型摘要的一个片段
-
【操作步骤&问题现象】之前om模型推理时结果和pb模型推理的结果不一样,在版内大佬提议下去装模型精度对比工具,参考链接是https://gitee.com/ascend/tools/tree/master/msquickcmp其他部分都装完了,按照链接里的步骤安装,但是在装完tensorflow后在python里import tensorflow as tf却报错,明明在pc机里安装不会报错,但在Atlas200里装就报错,不知道什么原因。在网上也没找到类似的错误。【截图信息】报错信息如下>>> import tensorflow as tfTraceback (most recent call last): File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow.py", line 58, in <module> from tensorflow.python.pywrap_tensorflow_internal import * File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow_internal.py", line 28, in <module> _pywrap_tensorflow_internal = swig_import_helper() File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper _mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description) File "/usr/local/python3.7.5/lib/python3.7/imp.py", line 242, in load_module return load_dynamic(name, filename, file) File "/usr/local/python3.7.5/lib/python3.7/imp.py", line 342, in load_dynamic return _load(spec)ImportError: /home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/_pywrap_tensorflow_internal.so: cannot open shared object file: No such file or directoryDuring handling of the above exception, another exception occurred:Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow/__init__.py", line 99, in <module> from tensorflow_core import * File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/__init__.py", line 28, in <module> from tensorflow.python import pywrap_tensorflow # pylint: disable=unused-import File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow/__init__.py", line 50, in __getattr__ module = self._load() File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow/__init__.py", line 44, in _load module = _importlib.import_module(self.__name__) File "/usr/local/python3.7.5/lib/python3.7/importlib/__init__.py", line 127, in import_module return _bootstrap._gcd_import(name[level:], package, level) File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/__init__.py", line 49, in <module> from tensorflow.python import pywrap_tensorflow File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow.py", line 74, in <module> raise ImportError(msg)ImportError: Traceback (most recent call last): File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow.py", line 58, in <module> from tensorflow.python.pywrap_tensorflow_internal import * File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow_internal.py", line 28, in <module> _pywrap_tensorflow_internal = swig_import_helper() File "/home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/pywrap_tensorflow_internal.py", line 24, in swig_import_helper _mod = imp.load_module('_pywrap_tensorflow_internal', fp, pathname, description) File "/usr/local/python3.7.5/lib/python3.7/imp.py", line 242, in load_module return load_dynamic(name, filename, file) File "/usr/local/python3.7.5/lib/python3.7/imp.py", line 342, in load_dynamic return _load(spec)ImportError: /home/HwHiAiUser/.local/lib/python3.7/site-packages/tensorflow_core/python/_pywrap_tensorflow_internal.so: cannot open shared object file: No such file or directoryFailed to load the native TensorFlow runtime.See https://www.tensorflow.org/install/errorsfor some common reasons and solutions. Include the entire stack traceabove this error message when asking for help.
-
## TBE DSL开发方式实现Tensorflow BatchNorm算子开发全流程(下) TBE DSL开发方式实现Tensorflow BatchNorm算子开发全流程(上) https://bbs.huaweicloud.com/forumreview/thread-187864-1-1.html TBE DSL开发方式实现Tensorflow BatchNorm算子开发全流程(下) https://bbs.huaweicloud.com/forum/thread-187872-1-1.html bilibili视频链接 https://www.bilibili.com/video/BV17U4y1m7G4 - 编译配置 ```python if is_training: tensor_list = [x_input, scale_input, offset_input] + list(res) else: tensor_list = [x_input, scale_input, offset_input, mean_input, variance_input] + list(res) config = {"name": kernel_name, "tensor_list": tensor_list} tbe.cce_build_code(sch, config) ``` ### 5.5 算子原型文件 算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出和属性信息,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。网络模型生成时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。 算子的IR用于进行算子的描述,包括算子输入输出信息,属性信息等,用于把算子注册到算子原型库中,需要在算子的工程目录的/op_proto/算子名称\.h 和 /op_proto/算子名称.cc文件中进行实现。 **算子IR头文件.h** ```C /*宏定义*/ #ifndef BATCH_NORM_H #define BATCH_NORM_H /*包含头文件*/ #include "graph/operator_reg.h" /*原型注册*/ /*INPUT与.OUTPUT分别为算子的输入、输出Tensor的名称与数据类型,输入输出的顺序需要与算子代码实现函数形参顺序以及算子信息定义中参数的顺序保持一致。*/ namespace ge { REG_OP(BatchNorm) /*与插件适配文件中的算子类型保存一致,BatchNorm*/ .INPUT(x, TensorType({DT_FLOAT16, DT_FLOAT})) .INPUT(scale, TensorType({DT_FLOAT})) .INPUT(offset, TensorType({DT_FLOAT})) .OPTIONAL_INPUT(mean, TensorType({DT_FLOAT})) .OPTIONAL_INPUT(variance, TensorType({DT_FLOAT})) .OUTPUT(y, TensorType({DT_FLOAT16, DT_FLOAT})) .OUTPUT(batch_mean, TensorType({DT_FLOAT})) .OUTPUT(batch_variance, TensorType({DT_FLOAT})) .OUTPUT(reserve_space_1, TensorType({DT_FLOAT})) .OUTPUT(reserve_space_2, TensorType({DT_FLOAT})) .OUTPUT(reserve_space_3, TensorType({DT_FLOAT})) .ATTR(epsilon, Float, 0.0001) .ATTR(data_format, String, "NHWC") .ATTR(is_training, Bool, true) .OP_END_FACTORY_REG(BatchNorm) } // namespace ge /*结束条件编译*/ #endif // BATCH_NORM_H ``` **算子IR定义的.cc文件** IR实现的cc文件中主要实现如下两个功能: - 算子参数的校验,实现程序健壮性并提高定位效率,对应Verify函数。 - 根据算子的输入张量描述、算子逻辑及算子属性,推理出算子的输出张量描述,包括张量的形状、数据类型及数据排布格式等信息。这样算子构图准备阶段就可以为所有的张量静态分配内存,避免动态内存分配带来的开销,对应InferShape函数。 Verify函数主要校验算子内在关联关系,例如对于多输入算子,多个tensor的dtype需要保持一致,此时需要校验多个输入的dtype,其他情况dtype不需要校验。 实现Verify函数 ```c IMPLEMT_VERIFIER(BatchNorm, BatchNormVerify) { if (!CheckTwoInputDtypeSame(op, "scale", "offset")) { return GRAPH_FAILED; } return GRAPH_SUCCESS; } ``` InferShape流程负责推导TensorDesc中的dtype与shape,只要全图所有首节点的TensorDesc确定了,就可以逐个向下传播,再由算子自身实现的Shape推导能力,就可以将全图所有OP的输入输出TensorDesc推导出来,推导结束后,全图的dtype与shape的规格就完全连续了。InferShape函数详细可参见算子原型定义。 实现InferShape函数 ```c IMPLEMT_INFERFUNC(BatchNorm, BatchNormInferShape) { std::string data_format; if (op.GetAttr("data_format", data_format) == GRAPH_SUCCESS) { if (data_format != "NHWC" && data_format != "NCHW") { string expected_format_list = ConcatString("NHWC, NCHW"); std::string err_msg = GetInputFormatNotSupportErrMsg("data_format", expected_format_list, data_format); VECTOR_INFER_SHAPE_INNER_ERR_REPORT(op.GetName(), err_msg); return GRAPH_FAILED; } } if (!OneInOneOutDynamicInfer(op, "x", {"y"})) { return GRAPH_FAILED; } if (!OneInOneOutDynamicInfer(op, "scale", {"batch_mean", "batch_variance", "reserve_space_1", "reserve_space_2"})) { return GRAPH_FAILED; } std::vector<int64_t> oShapeVector; auto op_info = OpDescUtils::GetOpDescFromOperator(op); auto output_desc = op_info->MutableOutputDesc("reserve_space_3"); if (output_desc != nullptr) { output_desc->SetShape(GeShape(oShapeVector)); output_desc->SetDataType(DT_FLOAT); } return GRAPH_SUCCESS; } ``` 注册infershape方法和Verify方法 ```c INFER_FUNC_REG(BatchNorm, BatchNormInferShape); VERIFY_FUNC_REG(BatchNorm, BatchNormVerify); ``` ### 5.6 算子信息库文件 算子信息库作为算子开发的交付件之一,主要体现算子在昇腾AI处理器上的具体实现规格,算子开发者需要通过配置算子信息库文件,将算子在昇腾AI处理器上相关实现信息注册到算子信息库中,包括算子支持输入输出type、format以及输入shape等信息。网络运行时,FE会根据算子信息库中的算子信息做基本校验,选择dtype,format等信息,并根据算子信息库中信息找到对应的算子实现文件进行编译,用于生成算子二进制文件。  图17 算子信息库文件 参数说明请参见文档中的[表1](https://support.huaweicloud.com/usermanual-mindstudio302/atlasms_02_0151.html#ZH-CN_TOPIC_0000001134636812__zh-cn_topic_0238860099_zh-cn_topic_0213377578_table108272271412)。 ## 6. BatchNorm算子编译 ### 6.1 基本概念 算子交付件开发完成后,需要对算子工程进行编译,生成自定义算子安装包*.run,详细的编译操作包括: - 将TBE算子信息库定义文件*.ini编译成aic-{soc version}-ops-info.json。 - 将原型定义文件*.h**与*.cc编译成libcust_op_proto.so。 - 将TensorFlow/Caffe/Onnx算子的适配插件实现文件*.h**与*.cc编译成libcust*{tf|caffe|onnx}*parsers.so。 ### 6.2 编译操作 MindStudio界面顶部,点击Build -> Edit Build Configurations。  图18 打开算子编译配置窗口 进入编译配置窗口,以远程编译为例,若未配置远程连接,则先在Deployment后面点击“+“进行配置,并在Envrionment Variables处进行如下配置,用户需将*/home/xxx/Ascend/ascend-toolkit/latest/*替换为CANN实际安装路径。 ```python ASCEND_TENSOR_COMPILER_INCLUDE=/home/xxx/Ascend/ascend-toolkit/latest/include ``` 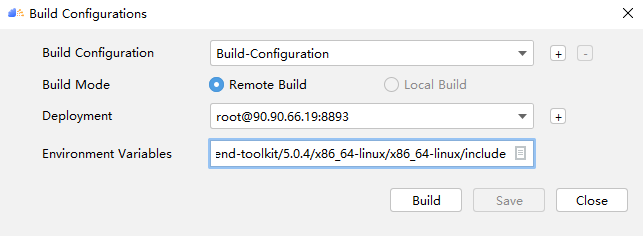 图19 算子编译配置 表1 算子编译配置参数说明 | 参数 | 说明 | | --------------------- | :----------------------------------------------------------- | | Build Configuration | 编译配置名称,默认为Build-Configuration | | Build Mode | 编译方式。Remote Build:远端编译。Local Build:本地编译。 | | Deployment | Remote Build模式下显示该配置。可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 | | Environment variables | Remote Build模式下显示该配置。配置环境变量。 | | Target OS | Local Build模式下显示该配置。针对Ascend EP:选择昇腾AI处理器所在硬件环境的Host侧的操作系统。针对Ascend RC:选择板端环境的操作系统。 | | Target Architecture | Local Build模式下显示该配置。选择Target OS的操作系统架构。 | 点击Build进行工程编译。编译完成后,显示远程编译完成 Information:build remotely finished。 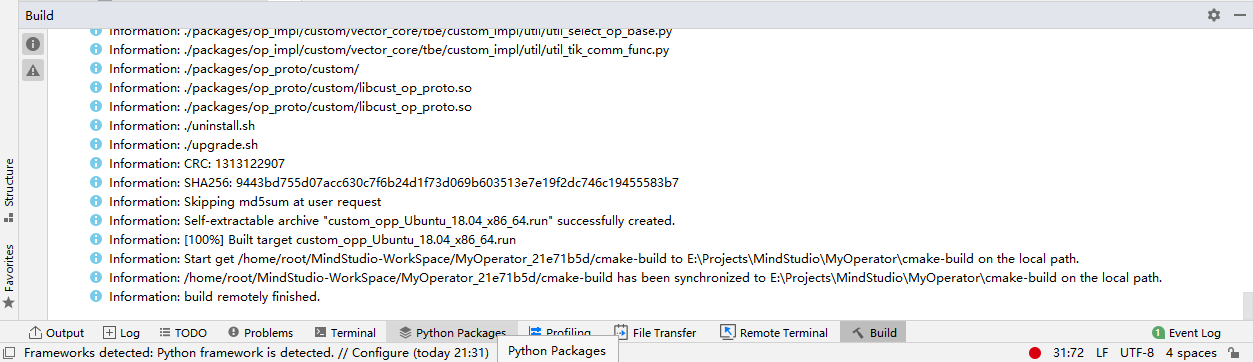 图20 算子编译完成输出日志 在算子工程的cmake-build目录下生成了编译后的BacthNorm算子安装包,包含了操作系统及对应系统架构信息,如下图所示。 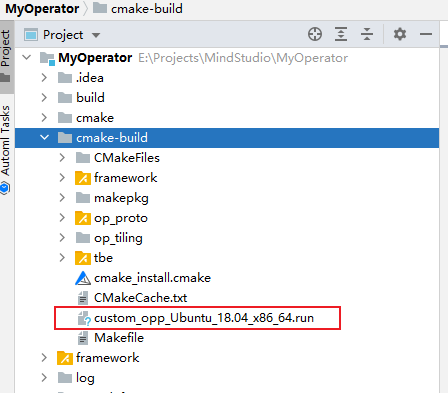 图21 算子编译生成安装包.run文件 ## 7. BatchNorm算子部署 ### 7.1 基本概念 算子部署指将算子编译生成的自定义算子安装包(*.run)部署到OPP算子库中。 - 推理场景下,自定义算子直接部署到开发环境的OPP算子库。 - 训练场景下,自定义算子安装包需要部署到运行环境的OPP算子库中。 ### 7.2 部署操作 在MindStudio工程界面,选中算子工程,点击顶部的Ascend > Operator Deployment,进入算子打包部署界面 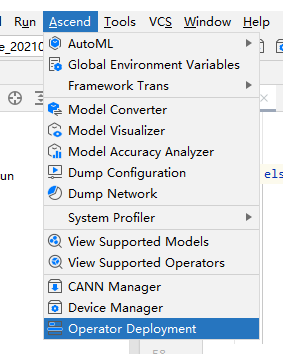 图22 打开算子部署配置窗口 如下算子部署界面,Operator Package即前面编译后生成的自定义算子安装包 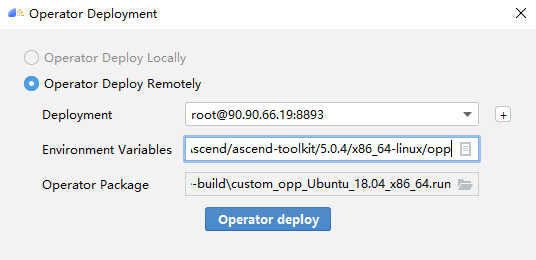 图23 算子部署配置 在Environment Variables中直接输入ASCEND_OPP_PATH=*/home/xxx/Ascend/ascend-toolkit/latest/opp。* */home/xxx/Ascend/ascend-toolkit/latest*为OPP组件(算子库)的安装路径,请根据实际情况配置。 也可以点击文本框后的图标,在弹出的对话框中填写。 - 在Name中输入环境变量名称:ASCEND_OPP_PATH。 - 在Value中输入环境变量值:*home/xxx/Ascend/ascend-toolkit/latest/opp*。 表2 算子部署配置参数说明 | 参数 | 说明 | | --------------------- | :----------------------------------------------------------- | | Build Configuration | 编译配置名称,默认为Build-Configuration | | Deployment | Remote Build模式下显示该配置。可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。 | | Environment variables | Remote Build模式下显示该配置。配置环境变量。 | 点击Operator deploy进行算子部署,部署成功会出现以下输出日志。  图24 算子部署完成输出日志 ## 8. BatchNorm算子UT ### 8.1 基本概念 基于MindStudio进行算子开发的场景下,用户可基于MindStudio进行算子的UT,UT(Unit Test:单元测试)是开发人员进行算子代码验证的手段之一,主要目的是: - 测试算子代码的正确性,验证输入输出结果与设计的一致性。 - UT侧重于保证算子程序能够跑通,选取的场景组合应能覆盖算子代码的所有分支(一般来说覆盖率要达到100%),从而降低不同场景下算子代码的编译失败率。 ### 8.2 UT操作 开发人员可以执行当前工程中所有算子的UT用例,也可以执行单个算子的UT用例: - 右键单击“testcases/ut/ops_test”文件夹,选择Run TBE Operator'All'UT Impl with coverage,执行整个文件夹下算子实现代码的测试用例。 - 右键单击“testcases/ut/ops_test/*算子名称*”文件夹,选择Run TBE Operator'算子名称'UT Impl with coverage,执行单个算子实现代码的测试用例。 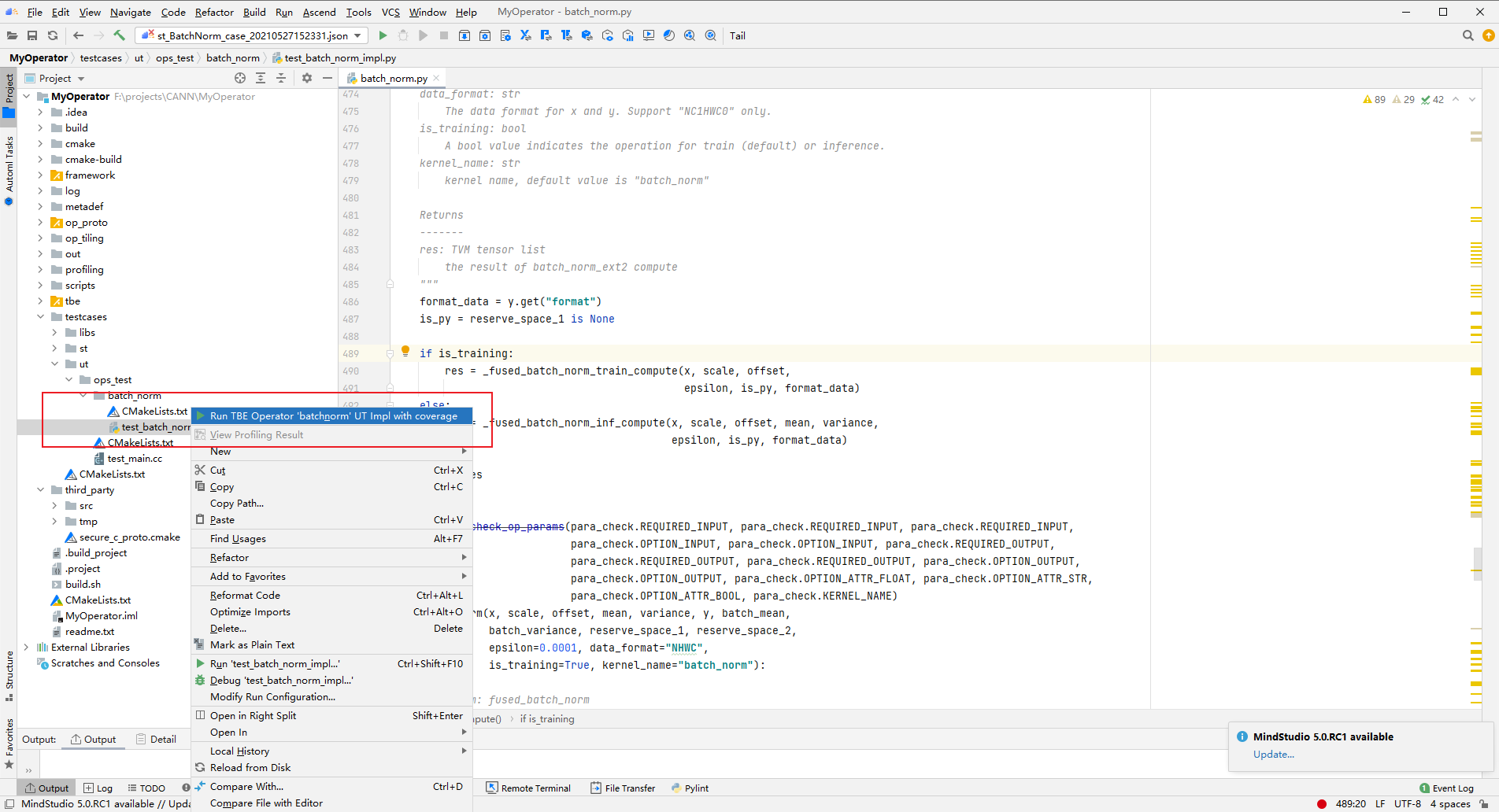 图25 第一次打开UT配置窗口 第一次运行时弹出UT配置窗口,进行如下配置后,点击OK执行算子UT。 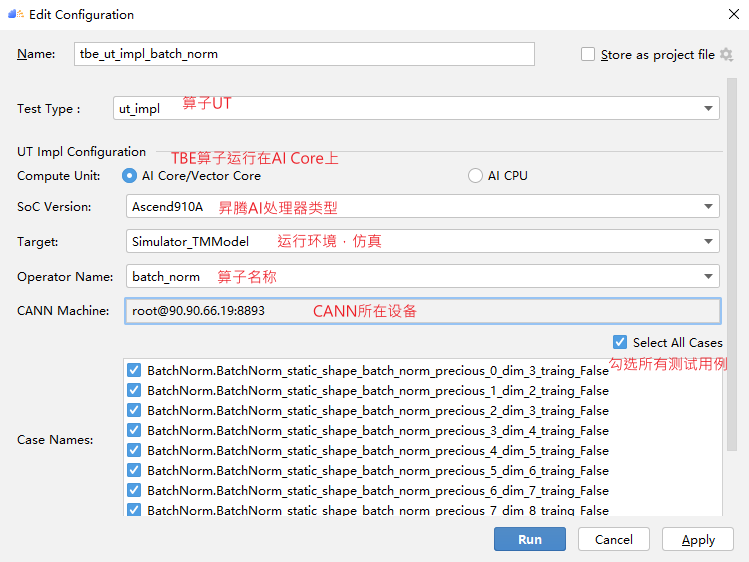 图26 UT配置 表3 算子UT配置参数说明 | 参数 | 说明 | | ------------- | ------------------------------------------------------------ | | Name | 运行配置名称,用户可以自定义。 | | Compute Unit | 选择计算单元 | | SoC Version | 下拉选择当前版本的昇腾AI处理器类型。 | | Target | 运行环境。Simulator_Function:功能仿真环境。Simulator_TMModel:快速展示算子执行的调度流水线,不进行实际算子计算。 | | Operator Name | 选择运行的测试用例。 | | CANN Machine | CANN工具所在设备的deployment信息。 | | Case Names | 勾选需要运行的测试用例,即算子实现代码的UT Python测试用例。 | 第二次执行UT文件不弹出运行配置,若需改配置,在顶部选择更改的文件,点击Edit Configurations即可修改。  图27 重新打开UT配置窗口 在Target选择Simulator_TMModel时,可以查看执行流水线,如下图所示图。 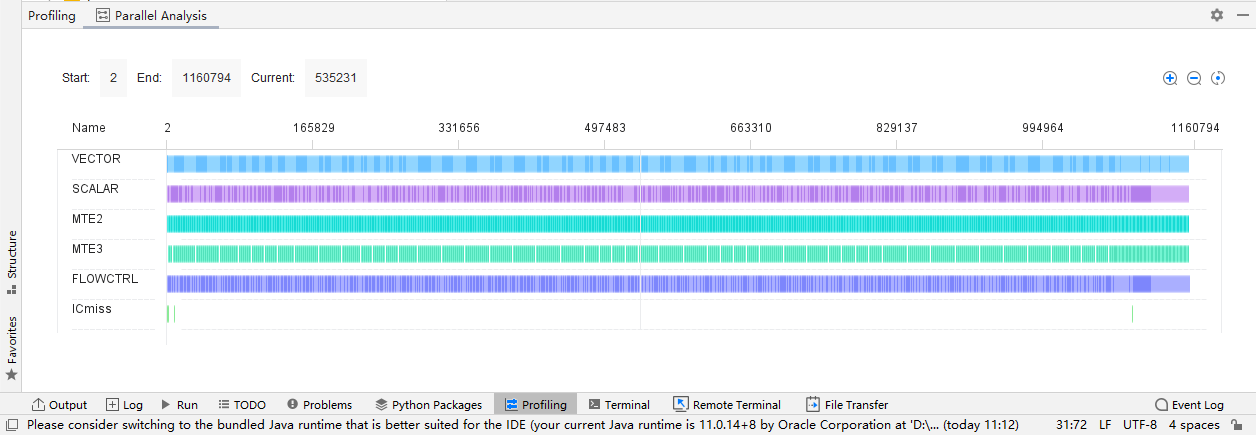 图28 UT流水线 点击Run,会有一个用例测试结果的url。  图29 UT完成输出日志url 点击该url,查看UT的具体执行结果。 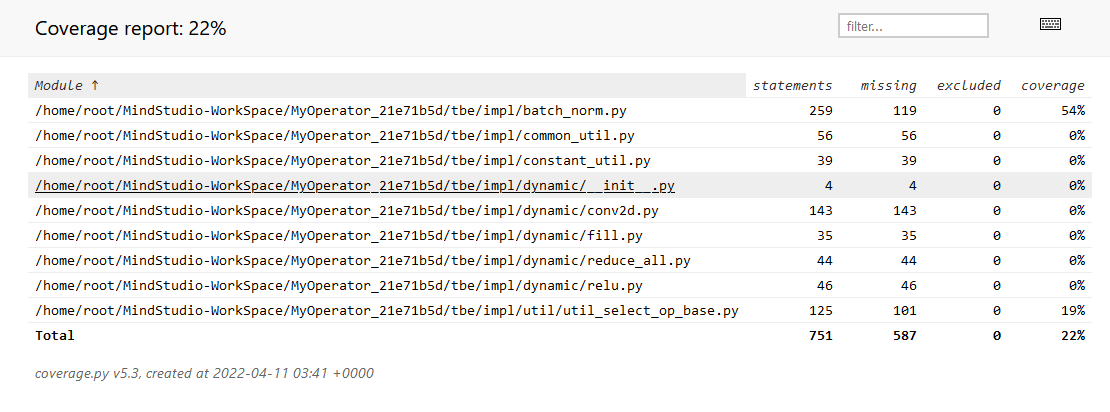 图30 UT测试结果详情 可点击页面中对应算子,进入UT用例覆盖率详情页面,通过绿色和红色标签区分是否覆盖。 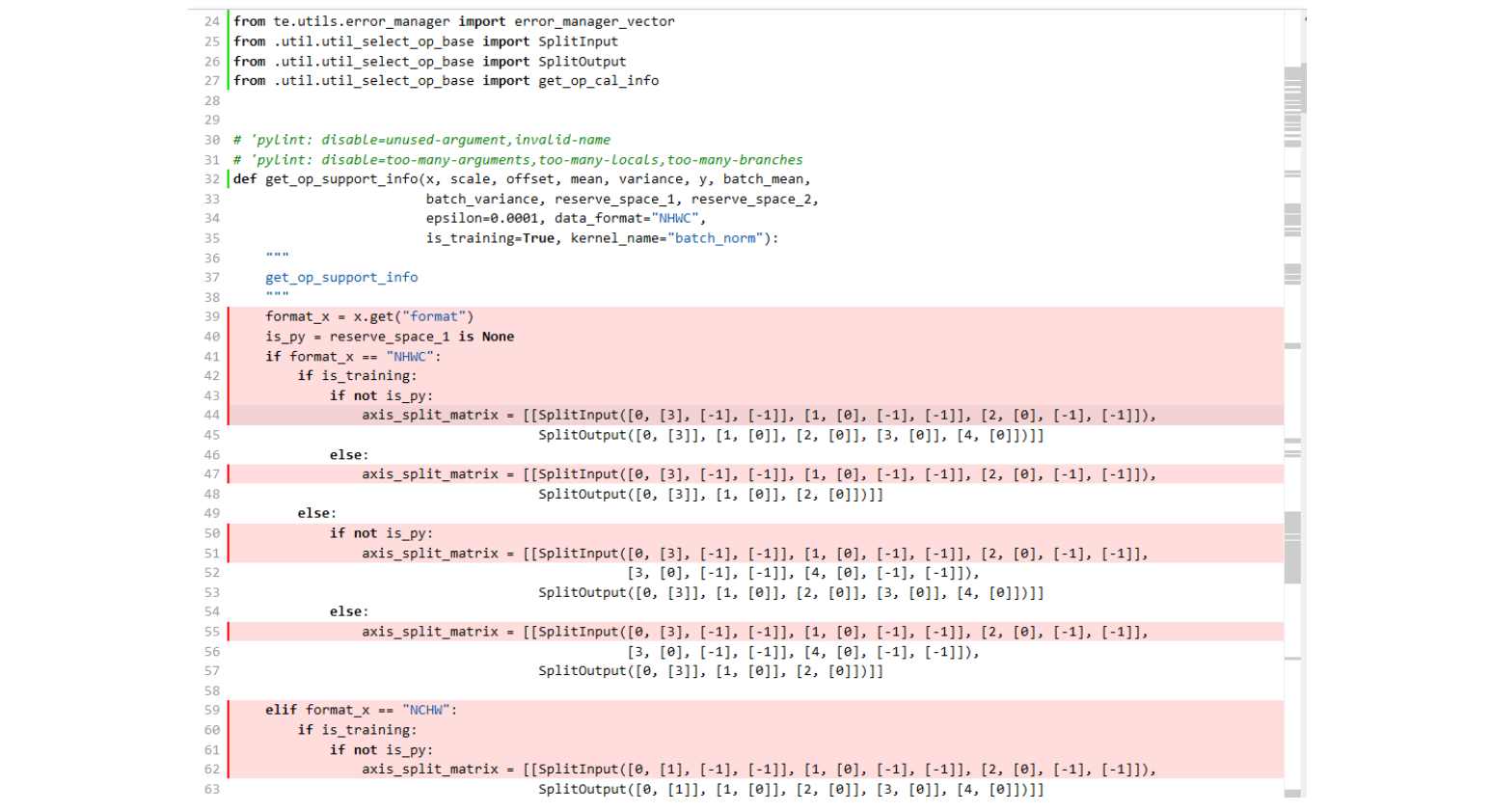 图31 UT代码覆盖 ## 9. BatchNorm算子ST ### 9.1 基本概念 自定义算子部署到算子库(OPP)后,可进行ST(System Test),在真实的硬件环境中,验证算 子功能的正确性。 ST的主要功能是: - 基于算子测试用例定义文件*.json生成单算子的om文件; - 使用AscendCL接口加载并执行单算子om文件,验证算子执行结果的正确性。ST会覆盖算子实现文件,算子原型定义与算子信息库,不会对算子适配插件进行测试。 ### 9.2 ST操作 ST用例的创建与UT用例的创建类似: - 右键单击算子工程根目录,选择New Cases > ST Case。 - 右键单击算子信息定义文件:{工程名} /tbe /op_info_cfg/ai_core/SoC version} /xx\.ini,选择New Cases > ST Case。若已经存在了对应算子的ST Case,可以右键单击testcases目录,或者testcases > st目录,选择New Cases > ST Case,追加ST测试用例。 **执行ST** 在工程目录testcases -> st -> batch_norm -> {SoC Version} -> xxx.json,找到保存的ST用例定义文件,右键单击选择Run ST Case ‘xxx.json',首次执行时,会弹出配置窗口中进行ST用例运行配置。  图32 第一次打开ST配置窗口 执行ST用例,其中在Advanced options下勾选Enable Profiling,可获取算子在昇腾AI处理器上的性能数据,该功能需要将运行环境中的msprof工具所在路径配置到PATH环境变量中,可在.bashrc文件中添加如下语句: ``` export PATH="$PATH:/usr/local/Ascend/ascend-toolkit/latest/tools/profiler/bin/" ``` 参考如下配置,其中环境变量配置如表4 表4 ST环境变量配置说明 | Name | Value | | ------------------ | ------------------------------------------------------------ | | ASCEND_DRIVER_PATH | /usr/local/Ascend/driver | | ASCEND_HOME | /usr/local/Ascend//ascend-toolkit/latest | | LD_LIBRARY_PATH | \${ASCEND_DRIVER_PATH}/lib64:\${ASCEND_HOME}/lib64:$LD_LIBRARY_PATH | 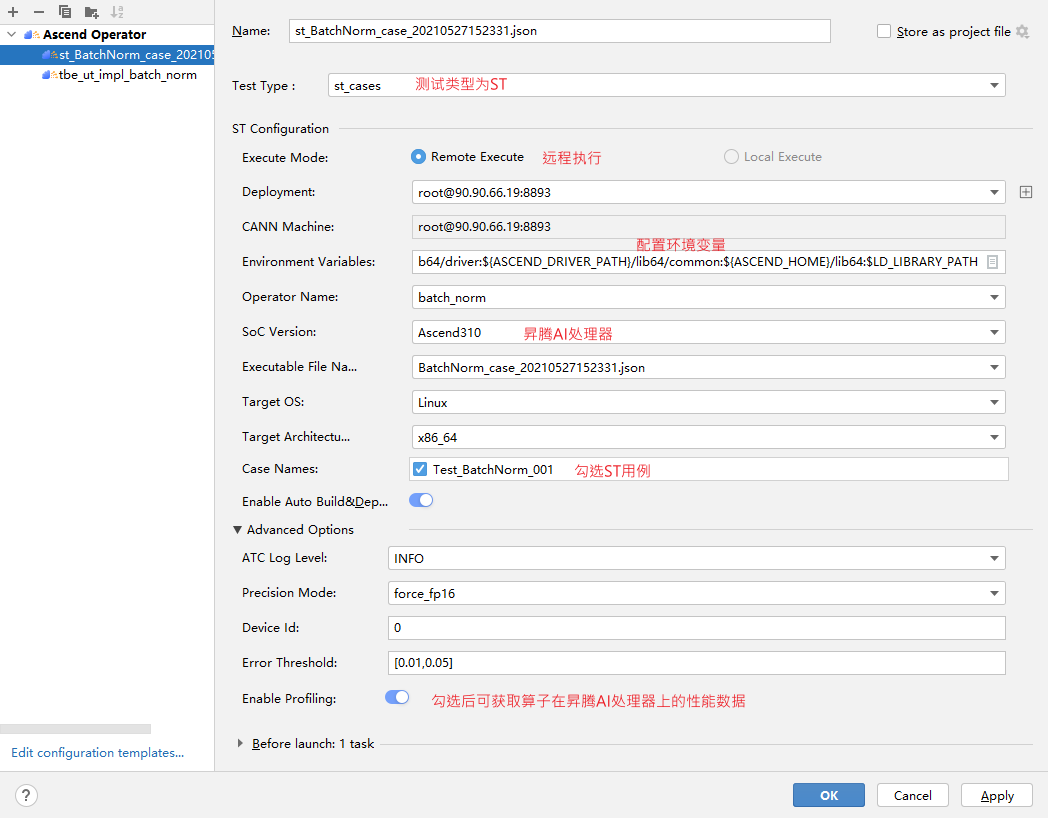 图33 ST配置 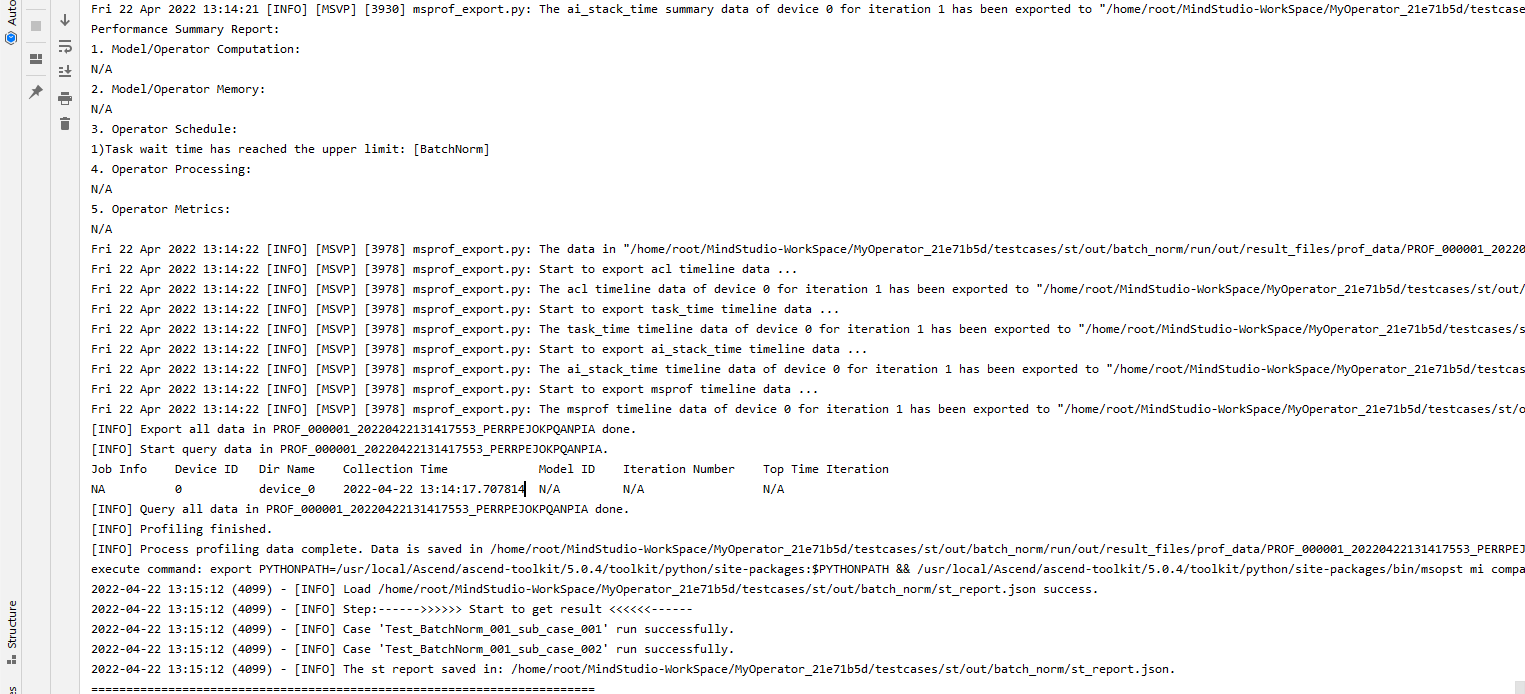 图34 ST性能数据日志  图35 ST完成输出日志 在’*算子工程根目录*/testcases/st/out/‘目录下生成测试数据和测试代码,并编译出可执行文件,在指定的硬件设备上执行测试用例。在’*算子工程根目录*/testcases/st/out/‘目录下生成的st_report.json文件记录了测试情况,可参考MindStudio文档中的ST测试执行结果表。 ## 10. 关于BatchNorm算子开发的FAQ 1. 创建的BatchNorm算子工程,代码的头文件或者导入的依赖显示为红色。 首先检查是否参考MindStudio的安装指南安装好对应的依赖和环境,其次算子工程是在服务器端的 CANN框架下运行的,但是工程文件保存在Windows端本地,本地没CANN环境会显示为红色,但是不会影响远端工程的运行。 2. 算子流程中的编译、部署和ST测试中如何设置相应的环境变量。 参考MindStudio用户手册中的用户指南,在自定义算子开发章节下的TBE算子开发(TensorFlow/Caffe)小节中,有详细讲解如何设置环境变量。 3. 算子UT测试中无法生成流水线图。 在UT测试的配置框中,Target选择Stimulator_TMModel,UT执行完成后可生成流水线图。 4. ST测试中,勾选了Enable Profiling后的ST日志里,没有出现性能数据,并提示msprof command未找到。 进入Linux服务器,在.bashrc文件最底部中添加export PATH="$PATH:/usr/local/Ascend/ascend-toolkit/latest/tools/profiler/bin/",其中路径需配置到msprof工具实际所在bin目录下。配置完成后,则无该提示并出现性能数据。 5. 如何打开UT测试和ST测试的运行配置窗口。 第一次进行UT测试和ST测试时,运行前会自动打开配置窗口让用户进行配置,第二次开始就会按照第一次的默认配置进行执行,只需在MindStudio界面上方的绿色锤子旁边先选择UT或ST的配置文件,再点击Edit Configurations即可再次打开配置窗口。  图36 再次打开UT、ST配置窗口
-
## TBE DSL开发方式实现Tensorflow BatchNorm算子开发全流程(上) TBE DSL开发方式实现Tensorflow BatchNorm算子开发全流程(上) https://bbs.huaweicloud.com/forumreview/thread-187864-1-1.html TBE DSL开发方式实现Tensorflow BatchNorm算子开发全流程(下) https://bbs.huaweicloud.com/forum/thread-187872-1-1.html bilibili视频链接 https://www.bilibili.com/video/BV17U4y1m7G4 ## 1. DSL算子基本概念 ### 1.1 算子 深度学习算法由一个个计算单元组成,我们称这些计算单元为算子(Operator,简称OP)。在网络模型中,算子对应层中的计算逻辑,例如:卷积层(Convolution Layer)是一个算子;全连接层(Fully connected Layer, FC layer)中的权值求和过程,是一个算子。 对每一个独立的算子,用户需要编写算子描述文件,描述算子的整体逻辑、计算步骤以及相关硬件平台信息等。然后用深度学习编译器对算子描述文件进行编译,生成可在特定硬件平台上运行的二进制文件后,将待处理数据作为输入,运行算子即可得到期望输出。将神经网络所有被拆分后的算子都按照上述过程处理后, 再按照输入输出关系串联起来即可得到整网运行结果。  图1 算子全流程执行 ### 1.2 TBE算子 **TVM** 随着深度学习的广泛应用,大量的深度学习框架及深度学习硬件平台应运而生,但不同平台的神经网络模型难以在其他硬件平台便捷的运行,无法充分利用新平台的运算性能。TVM(Tensor Virtual Machine)的诞生解决了以上问题,它是一个开源深度学习编译栈,它通过统一的中间表达(Intermediate Representation)堆栈连接深度学习模型和后端硬件平台,通过统一的结构优化Schedule,可以支持CPU、GPU和特定的加速器平台和语言。 **TBE算子** TBE(Tensor Boost Engine)提供了基于开源深度学习编译栈TVM框架的自定义算子开发能力,运行在昇腾AI处理器的AI Core上,通过TBE提供的API可以完成相应神经网络算子的开发。 一个完整的TBE算子包含四部分:算子原型定义、对应开源框架的算子适配插件、算子信息库定义和算子实现。  图2 TBE算子全流程执行 昇腾AI软件栈提供了TBE(Tensor Boost Engine:张量加速引擎)算子开发框架,开发者可以基于此框 架使用Python语言开发自定义算子,通过TBE进行算子开发有以下几种方式: - DSL(Domain-Specific Language)开发 - TIK(Tensor Iterator Kernel)开发 ### 1.3 DSL算子 为了方便开发者进行自定义算子开发,TBE(Tensor Boost Engine)提供了一套计算接口供开发者用于组装算子的计算逻辑,使得70%以上的算子可以基于这些接口进行开发,极大的降低自定义算子的开发难度。TBE提供的这套计算接口,称之为DSL(Domain-Specific Language)。基于DSL开发的算子,可以直接使用TBE提供的Auto Schedule机制,自动完成调度过程,省去最复杂的调度编写过程。  图3 DSL算子介绍 **DSL功能框架** 1. 开发者调用TBE提供的DSL接口进行计算逻辑的描述,指明算子的计算方法和步骤。 2. 计算逻辑开发完成后,开发者可调用Auto Schedule接口,启动自动调度,自动调度时TBE会根据计算类型自动选择合适的调度模板,完成数据切块和数据流向的划分,确保在硬件执行上达到最优。 3. Auto Schedule调度完成后,会生成类似于TVM的I R(Intermediate Representation)的中间表示。 4. 编译优化(Pass)会对算子生成的IR进行编译优化,优化的方式有双缓冲(Double Buffer)、流水线(Pipeline)同步、内存分配管理、指令映射、分块适配矩阵计算单元等。 5. 算子经Pass处理后,由CodeGen生成类C代码的临时文件,这个临时代码文件可通过编译器生成算子的实现文件,可被网络模型直接加载调用。 TBE DSL提供的计算接口主要涵盖向量运算,包括Math、NN、Reduce、卷积、矩阵计算等接口。详细的接口介绍请参见[TBE DSL]。 ## 2. 算子开发流程 算子开发通常包括:算子分析、创建算子工程、算子实现、编译、UT测试、ST测试、部署。  图4 算子开发流程介绍 1. 算子分析:确定算子功能、输入、输出,算子开发方式、算子OpType以及算子实现函数名称等。 2. 工程创建:通过MindStudio工具创建TBE算子工程,创建完成后,会自动生成算子工程目录及相应的文件模板,开发者可以基于这些模板进行算子开发。 3. 算子开发: (1)算子代码实现:描述算子的实现过程。 (2)算子原型定义:算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要包含定义算子输入、输出、属性和取值范围,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。网络运行时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。 (3)算子信息定义:算子信息配置文件用于将算子的相关信息注册到算子信息库中,包括算子的输入输出dtype、format以及输入shape信息。网络运行时,FE会根据算子信息库中的算子信息做基本校验,判断是否需要为算子插入合适的转换节点,并根据算子信息库中信息找到对应的算子实现文件进行编译,生成算子二进制文件进行执行。 (4)算子适配插件实现:基于第三方框架(TensorFlow/Caffe)进行自定义算子开发的场景,开发人员完成自定义算子的实现代码后,需要进行插件的开发将基于Tensorflow/Caffe的算子映射成适配昇腾AI处理器的算子,将算子信息注册到GE中。基于TensorFlow/Caffe框架的网络运行时,首先会加载并调用GE中的插件信息,将TensorFlow/Caffe网络中的算子进行解析并映射成昇腾AI处理器中的算子。 (5)算子实现验证。 通过测试用例来验证算子实现代码的功能正确性和逻辑正确性。 1) UT测试:即单元测试(Unit Test),仿真环境下验证算子实现的功能正确性,包括算子逻辑实现代码及算子原型定义实现代码。 2) ST测试:即系统测试(System Test),可以自动生成测试用例,在真实的硬件环境中,验证算子功能的正确性。 4. 算子编译: 将算子插件实现文件、算子原型定义文件、算子信息定义文件编译成算子插件、算子原型库、算子信息库。 5. 算子部署: 将算子实现文件、编译后的算子插件、算子原型库、算子信息库部署到昇腾AI处理器算子库,为后续算子在网络中运行构造必要条件。 ## 3. 算子分析 进行算子开发前,开发者应首先进行算子分析,算子分析包含:明确算子的功能及数学表达式,选择算子开发方式(DSL方式或者TIK方式),根据所选的算子开发方式提供的API接口实现算子逻辑;明确详细算子规格,例如算子输入输出的数据类型、形态,算子实现的文件名、函数名等。  图5 算子分析流程 **分析算子算法原理,提取算子的数学表达式**  BatchNorm算子实现分为训练时的计算逻辑实现和推理时的计算逻辑实现 - 训练时,如上述表达式所示,以一个mini-batch长度的输入数据为计算基本单元进行归一化处理。 - 推理时,以实际输入长度的数据为计算单位进行归一化处理。 **明确BatchNorm算子开发方式及使用接口** TBE DSL可为BatchNorm算子提供的接口: - tbe.dsl.vadd:两个tensor按元素相加 - tbe.dsl.vadds:将tensor中每个元素加上标量scalar - tbe.dsl.vsqrt:对tensor中的每个元素取平方根 - tbe.dsl.vsub:两个tensor按元素相减 - tbe.dsl.vdiv:两个tensor按元素相除 - tbe.dsl.vmul:两个tensor按元素相乘 - tbe.dsl.vmuls:将raw_tensor中每个元素乘上标量scalar 上述接口满足BatchNorm算子的实现要求,选择TBE DSL方式进行算子实现是可行的。 ## 4. MindStudio创建Tensorflow TBE算子工程 ### 4.1 环境准备 **CANN环境** 进行自定义算子开发前,需要完成驱动及CANN软件的安装,详情可参见《[CANN软件安装指南](https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/51RC1alpha005/softwareinstall/instg/atlasdeploy_03_0002.html)》。 **MindStudio环境** 使用MindStudio进行算子开发需配置Python、Java等环境,详情可参见《MindStudio安装指南》。 **其他环境** 除了手册中要求的环境依赖,也需要安装tensorflow,推荐1.15版本。如果采用windows和linux 的公开发环境,需要在本地和远端均配置好所需环境。 ### 4.2 MindStudio创建BatchNorm算子工程 打开MindStudio, 选择New Project,在左边选择Ascend Operator,CANN version选择CANN版本,点击Next。  图6 创建算子工程 远程配置CANN,点击install,点击Remote Connection后的+,配置远程SSH连接,配置好后点击Test Connection,出现 ”Sucessfully connected!“即配置成功。  图7 远程连接 配置SSH远程链接后,选择服务器上安装的CANN版本,点击OK,等待配置完成。  图8 远程加载CANN 点击Next后,选择DSL方式的TensorFlow的BatchNorm算子开发样例,完成创建。  图9 创建BatchNorm算子工程 ### 4.3 算子工程配置Python SDK 在MindStudio界面左上角,选择File->Project Structure。  图10 打开Python SDK配置窗口 在弹出的窗口中,点击左侧的SDKs,点击上方的“+”添加Python SDK,从本地环境中导入Python3.7.5。  图11 本地添加Python SDK 再点击窗口左侧的Project,选择上一步添加的Python SDK。  图12 Project配置Python SDK 最后点击窗口左侧的Modules,点击“+”后选择Python,为Python Interpreter选择上述添加的Python SDK后,点击OK即可为算子工程添加好Python SDK。  图13 Modules添加Python SDK  图14 Modules配置Python SDK ## 5. BatchNorm算子工程结构和交付件 ### 5.1 算子工程结构 创建好的BachNorm算子如案例下,主要对算子原型文件、实现文件、信息库文件和插件适配文件这四类文件进行开发。  图15 算子工程结构 ### 5.2 算子原型 本案例中的BatchNorm算子原型为Tensorflow中的tf.nn.batch_normalization。 ```python tf.nn.batch_normalization( x, mean, variance, offset, scale, variance_epsilon, name=None ) ``` ### 5.3 插件适配文件 插件适配文件实现将Tensorflow网络中的算子进行解析并映射成昇腾AI处理器中的算子。  图16 插件适配文件 ### 5.4 Python实现文件 通过调用TBE DSL接口,在算子工程下的“tbe/impl/batch_norm.py”文件中进行BatchNorm算子的实现,主要包括算子函数定义、算子入参校验、compute过程实现及调度与编译。 检测数据维度 ```python def _check_shape_dims(shape, data_format, is_x=False): if data_format == "NC1HWC0": if len(shape) != 5: error_detail = "The input shape only support 5D Tensor, len(shape) != 5, len(shape) = %s" % len(shape) error_manager_vector.raise_err_input_shape_invalid("batch_norm", "len(shape)", error_detail) elif data_format == "NDC1HWC0": if len(shape) != 6: error_detail = "The input shape only support 6D Tensor, len(shape) != 6, len(shape) = %s" % len(shape) error_manager_vector.raise_err_input_shape_invalid("batch_norm", "len(shape)", error_detail) elif is_x: if len(shape) != 4: error_detail = "The input shape only support 4D Tensor, len(shape) != 4, len(shape) = %s" % len(shape) error_manager_vector.raise_err_input_shape_invalid("batch_norm", "len(shape)", error_detail) else: if len(shape) != 1: error_detail = "The input shape only support 1D Tensor, len(shape) != 1, len(shape) = %s" % len(shape) error_manager_vector.raise_err_input_shape_invalid("batch_norm", "len(shape)", error_detail) ``` 检验BatchNorm算子输入数据维度、数据排布格式 ```python def _shape_check(shape_x, shape_scale, shape_offset, mean, variance, is_training, data_format): _check_shape_dims(shape_x, data_format, True) _check_shape_dims(shape_scale, data_format) _check_shape_dims(shape_offset, data_format) para_check.check_shape(shape_x, param_name="x") para_check.check_shape(shape_scale, param_name="scale") para_check.check_shape(shape_offset, param_name="offset") _check_dims_equal(shape_x, shape_scale, data_format) _check_dims_equal(shape_x, shape_offset, data_format) if not is_training: shape_mean = mean.get("shape") shape_variance = variance.get("shape") para_check.check_shape(shape_mean, param_name="mean") para_check.check_shape(shape_variance, param_name="variance") _check_shape_dims(shape_mean, data_format) _check_shape_dims(shape_variance, data_format) _check_dims_equal(shape_x, shape_mean, data_format) _check_dims_equal(shape_x, shape_variance, data_format) elif mean is not None or variance is not None: error_detail = "Estimated_mean or estimated_variance must be empty for training" error_manager_vector.raise_err_specific_reson("batch_norm", error_detail) ``` BatchNorm算子调用TBE DSL接口计算过程 ```python def _output_data_y_compute(x, mean, variance, scale, offset, epsilon): shape_x = shape_util.shape_to_list(x.shape) y_add = tbe.vadds(variance, epsilon) #方差+epsilong y_sqrt = tbe.vsqrt(y_add) #开根号 var_sub = tbe.vsub(x, mean) #x-均值 y_norm = tbe.vdiv(var_sub, y_sqrt) #归一化计算 scale_broad = tbe.broadcast(scale, shape_x) #scale广播与shape_x相同 offset_broad = tbe.broadcast(offset, shape_x) #offset广播与shape_x相同 res = tbe.vadd(tbe.vmul(scale_broad, y_norm), offset_broad) # res=scale*y_norm+offset return res ``` BatchNorm算子在推理时的计算逻辑实现 ```python def _fused_batch_norm_inf_compute(x, scale, offset, mean, variance, epsilon, is_py, format_data): shape_x = shape_util.shape_to_list(x.shape) is_cast = False if x.dtype == "float16" and \ tbe_platform.cce_conf.api_check_support("te.lang.cce.vdiv", "float32"): is_cast = True x = tbe.cast_to(x, "float32") mean_broadcast = tbe.broadcast(mean, shape_x) var_broadcast = tbe.broadcast(variance, shape_x) res_y = _output_data_y_compute(x, mean_broadcast, var_broadcast, scale, offset, epsilon) if is_cast: res_y = tbe.cast_to(res_y, "float16") if format_data == "NHWC": axis = [0, 1, 2] else: axis = [0, 2, 3] scaler_zero = 0.0 res_batch_mean = tbe.vadds(mean, scaler_zero) res_batch_var = tbe.vadds(variance, scaler_zero) if format_data not in ("NC1HWC0", "NDC1HWC0"): res_batch_mean = tbe.sum(res_batch_mean, axis, False) res_batch_var = tbe.sum(res_batch_var, axis, False) res = [res_y, res_batch_mean, res_batch_var] if not is_py: res_reserve_space_1 = tbe.vadds(mean, scaler_zero) res_reserve_space_2 = tbe.vadds(variance, scaler_zero) if format_data not in ("NC1HWC0", "NDC1HWC0"): res_reserve_space_1 = tbe.sum(res_reserve_space_1, axis, False) res_reserve_space_2 = tbe.sum(res_reserve_space_2, axis, False) res = res + [res_reserve_space_1, res_reserve_space_2] return res ``` BatchNorm算子在训练时的计算逻辑实现 ```python def _fused_batch_norm_train_compute(x, scale, offset, epsilon, is_py, format_data): is_cast = False if x.dtype == "float16" and \ tbe_platform.cce_conf.api_check_support("te.lang.cce.vdiv", "float32"): is_cast = True x = tbe.cast_to(x, "float32") shape_x = shape_util.shape_to_list(x.shape) if format_data == "NHWC": axis = [0, 1, 2] num = shape_x[0]*shape_x[1]*shape_x[2] else: axis = [0, 2, 3] num = shape_x[0]*shape_x[2]*shape_x[3] num_rec = 1.0/num # 根据x的维度C计算保存均值 mean_sum = tbe.sum(x, axis, True) mean_muls = tbe.vmuls(mean_sum, num_rec) mean_broad = tbe.broadcast(mean_muls, shape_x) # 根据x的维度C计算保存方差var var_sub = tbe.vsub(x, mean_broad) var_mul = tbe.vmul(var_sub, var_sub) var_sum = tbe.sum(var_mul, axis, True) var_muls = tbe.vmuls(var_sum, num_rec) var = tbe.broadcast(var_muls, shape_x) res_y = _output_data_y_compute(x, mean_broad, var, scale, offset, epsilon) if is_cast: res_y = tbe.cast_to(res_y, "float16") res_batch_mean = tbe.vmuls(mean_sum, num_rec) if format_data not in ("NC1HWC0", "NDC1HWC0"): res_batch_mean = tbe.sum(res_batch_mean, axis, False) if num == 1: batch_var_scaler = 0.0 else: batch_var_scaler = float(num)/(num - 1) res_batch_var = tbe.vmuls(var_muls, batch_var_scaler) if format_data not in ("NC1HWC0", "NDC1HWC0"): res_batch_var = tbe.sum(res_batch_var, axis, False) res = [res_y, res_batch_mean, res_batch_var] if not is_py: res_reserve_space_1 = tbe.vmuls(mean_sum, num_rec) res_reserve_space_2 = tbe.vmuls(var_sum, num_rec) if format_data not in ("NC1HWC0", "NDC1HWC0"): res_reserve_space_1 = tbe.sum(res_reserve_space_1, axis, False) res_reserve_space_2 = tbe.sum(res_reserve_space_2, axis, False) res = res + [res_reserve_space_1, res_reserve_space_2] return res ``` 总结BatchNorm算子在推理和训练时的计算逻辑实现compute函数 - 参数is_training=True时,调用训练时的计算逻辑实现compute函数 - 参数is_training=False时,调用推理时的计算逻辑实现compute函数 ```python def batch_norm_compute(x, scale, offset, mean, variance, y, batch_mean, batch_variance, reserve_space_1, reserve_space_2, epsilon=0.001, data_format="NHWC", is_training=True, kernel_name="batch_norm"): format_data = y.get("format") is_py = reserve_space_1 is None if is_training: res = _fused_batch_norm_train_compute(x, scale, offset, epsilon, is_py, format_data) else: res = _fused_batch_norm_inf_compute(x, scale, offset, mean, variance, epsilon, is_py, format_data) return res ``` 算子定义函数的实现,声明了算子输入信息、输出信息以及内核名称等信息,包含了上述的算子输入/输出/属性的校验、算子实现、调度与编译。 ```python def batch_norm(x, scale, offset, mean, variance, y, batch_mean, batch_variance, reserve_space_1, reserve_space_2, epsilon=0.0001, data_format="NHWC", is_training=True, kernel_name="batch_norm"): ``` - 获取算子输入tensor与数据格式 ```python shape_x = x.get("shape") format_data = x.get("format") if len(shape_x) == 2: shape_x = list(shape_x) + [1, 1] format_data = "NCHW" elif len(shape_x) == 3: shape_x = list(shape_x) + [1] format_data = "NCHW" elif format_data == "ND": rest_num = functools.reduce(lambda x, y: x * y, shape_x[3:]) shape_x = list(shape_x[:3]) + [rest_num] format_data = "NCHW" shape_scale = scale.get("shape") shape_offset = offset.get("shape") if not is_training: shape_mean = mean.get("shape") shape_variance = variance.get("shape") dtype_x = x.get("dtype") dtype_scale = scale.get("dtype") dtype_offset = offset.get("dtype") if not is_training: dtype_mean = mean.get("dtype") dtype_variance = variance.get("dtype") para_check.check_dtype(dtype_mean.lower(), ("float32", "float16"), param_name="mean") para_check.check_dtype(dtype_variance.lower(), ("float32", "float16"), param_name="variance") ``` - 检验数据是否符合规范 _format_check(x, data_format) - 检验算子输入shape、数据排布格式 ```python _shape_check(shape_x, shape_scale, shape_offset, mean, variance, is_training, format_data) ``` - 检验算子输入类型 ```python para_check.check_dtype(dtype_x.lower(), ("float16", "float32"), param_name="x") para_check.check_dtype(dtype_scale.lower(), ("float32", "float16"), param_name="scale") para_check.check_dtype(dtype_offset.lower(), ("float32", "float16"), param_name="offset") ``` - 根据算子输入格式定义不同参数的shape ```python if format_data == "NHWC": shape_scale = [1, 1, 1] + list(shape_scale) shape_offset = [1, 1, 1] + list(shape_offset) if not is_training: shape_mean = [1, 1, 1] + list(shape_mean) shape_variance = [1, 1, 1] + list(shape_variance) elif format_data == "NCHW": shape_scale = [1] + list(shape_scale) + [1, 1] shape_offset = [1] + list(shape_offset) + [1, 1] if not is_training: shape_mean = [1] + list(shape_mean) + [1, 1] shape_variance = [1] + list(shape_variance) + [1, 1] elif format_data == "NDC1HWC0": shape_x = [shape_x[0] * shape_x[1], shape_x[2], shape_x[3], shape_x[4], shape_x[5]] shape_scale = [shape_scale[0] * shape_scale[1], shape_scale[2], shape_scale[3], shape_scale[4], shape_scale[5]] shape_offset = shape_scale if not is_training: shape_mean = [shape_mean[0] * shape_mean[1], shape_mean[2], shape_mean[3], shape_mean[4], shape_mean[5]] shape_variance = [shape_variance[0] * shape_variance[1], shape_variance[2], shape_variance[3], shape_variance[4], shape_variance[5]] ``` - 使用TVM的placeholder接口对输入tensor进行占位,返回tensor对象 ```python x_input = tvm.placeholder(shape_x, name="x_input", dtype=dtype_x.lower()) scale_input = tvm.placeholder(shape_scale, name="scale_input", dtype=dtype_scale.lower()) offset_input = tvm.placeholder(shape_offset, name="offset_input", dtype=dtype_offset.lower()) if is_training: mean_input, variance_input = [], [] else: mean_input = tvm.placeholder(shape_mean, name="mean_input", dtype=dtype_mean.lower()) variance_input = tvm.placeholder(shape_variance, name="variance_input", dtype=dtype_variance.lower()) ``` - 调用compute实现函数 ```python res = batch_norm_compute(x_input, scale_input, offset_input, mean_input, variance_input, y, batch_mean, batch_variance, reserve_space_1, reserve_space_2, epsilon, data_format, is_training, kernel_name) ``` - 自动调度 ```python with tvm.target.cce(): sch = tbe.auto_schedule(res) ```
-
运行tensorflow 脚本提示ranktable 错误:I0513 15:30:14.368313 140151427184448 monitored_session.py:240] Graph was finalized.2022-05-13 15:30:20.263785: F tf_adapter/util/ge_plugin.cc:242] [GePlugin] Initialize ge failed, ret : failedError Message is :EI0004: Invalid ranktable, with rankID [0] and local devID [0]. Check that ranktable [/home/lgh/atlas/rank_table_1p.json] is valid and the environment setup matches the ranktable. PluginManager InvokeAll failed.[FUNC:Initialize][FILE:ops_kernel_manager.cc][LINE:94] OpsManager initialize failed.[FUNC:InnerInitialize][FILE:gelib.cc][LINE:136] GELib::InnerInitialize failed.[FUNC:Initialize][FILE:gelib.cc][LINE:90]Fatal Python error: Aborted使用npu-smi查询到devcie IP 如下:npu-smi info -t ip -i 2 -c 0 ip : 192.168.1.199 netmask : 255.255.255.0rank_table_ip.json 如下{"server_count":"1","server_list":[ { "device":[ { "device_id":"0", "device_ip":"192.168.1.199", "rank_id":"0" } ], "server_id":"127.0.0.1" }],"status":"completed","version":"1.0"}环境信息设置如下:source /usr/local/Ascend/nnae/set_env.shsource /usr/local/Ascend/tfplugin/set_env.shsource /usr/local/Ascend/ascend-toolkit/set_env.shsource /usr/local/Ascend/nnrt/set_env.shexport install_path=/usr/local/Ascend/ascend-toolkit/5.0.3.7/ # Replace it with the actual installation path.# Driver dependencyexport LD_LIBRARY_PATH=/usr/local/Ascend/driver/lib64/common/:/usr/local/Ascend/driver/lib64/driver:$LD_LIBRARY_PATH# FwkACLlib dependencyexport PATH=${install_path}/fwkacllib/ccec_compiler/bin:${install_path}/fwkacllib/bin:$PATHexport LD_LIBRARY_PATH=${install_path}/fwkacllib/lib64:$LD_LIBRARY_PATHexport PYTHONPATH=${install_path}/fwkacllib/python/site-packages:$PYTHONPATH# TFPlugin dependencyexport PYTHONPATH=/usr/local/Ascend/tfplugin/latest/tfplugin/python/site-packages:$PYTHONPATH# OPP dependencyexport ASCEND_OPP_PATH=${install_path}/opp# AI CPU dependencyexport ASCEND_AICPU_PATH=${install_path}# Script directory#export PYTHONPATH="$PYTHONPATH:/root/models"export DUMP_GE_GRAPH=2export JOB_ID=10086 # User-defined training job ID. Only letters, digits, hyphens (-), and underscores (_) are supported. You are advised not to use a number starting with 0.export ASCEND_DEVICE_ID=0 # Logical device ID. The parameter is optional and defaults to 0 in single-device training, indicating that training is performed on device 0.export RANK_ID=0 # Rank ID of a training process in the collective communication process group. The parameter defaults to 0 in single-device training.export RANK_SIZE=1 # Rank size of a device corresponding to the current training process in the cluster. The parameter defaults to 1 in single-device training.export RANK_TABLE_FILE=/home/lgh/atlas/rank_table_1p.json # Single-device resource configuration file想请教下该错误还与那些设置相关。
-
1、介绍B站视频教程链接:TensorFlow框架AICPU算子开发全流程_哔哩哔哩_bilibili本文旨在帮助用户使用CANN架构和MindStudio平台进行AI CPU算子开发指导。其中CANN(Compute Architecture for Neural Networks)是华为公司针对AI场景推出的异构计算架构,通过提供多层次的编程接口,支持用户快速构建基于昇腾平台的AI应用和业务。MindStudio提供您在AI开发所需的一站式开发环境,支持模型开发、算子开发以及应用开发三个主流程中的开发任务。依靠模型可视化、算力测试、IDE本地仿真调试等功能,MindStudio能够帮助您在一个工具上就能高效便捷地完成AI应用开发。MindStudio采用了插件化扩展机制,开发者可以通过开发插件来扩展已有功能。2、安装教程2.1 CANN软件包CANN下载链接:https://www.hiascend.com/software/cann/community CANN安装指南:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/51RC1alpha005/softwareinstall/instg/atlasdeploy_03_0002.html 详情可参考CANN文档,例版本5.1.RC1.alpha003:https://www.hiascend.com/document/detail/zh/CANNCommunityEdition/51RC1alpha0032.2 MindStudio平台MindStudio官网:https://www.hiascend.com/software/mindstudioMindStudio用户手册:https://www.hiascend.com/document/detail/zh/mindstudio/304/progressiveknowledge/index.html2.2.1 环境依赖Python MindStudio目前支持Python版本为3.7.0 ~3.9.7安装相关依赖:pip install xlrd==1.2.0 pip install absl-py pip install numpyMinGW 请用户到下载最新的MinGW安装包(参考链接)。根据自己的系统选择对应版本,例如64位可以选择x86_64-posix-seh,安装后配置好环境变量打开系统命令行,输入gcc -v命令。 当界面提示“gcc version x.x.x (x86_64-posix-sjlj-rev0, Built by MinGW-W64 project)”信息时,表示安装成功。CMake名称版本说明获取途径CMake3.16.5-win64-x64CMake是个一个开源的跨平台自动化建构系统,用来管理软件建置的程序,并不依赖于某特定编译器,并可支持多层目录、多个应用程序与多个库。您可以访问CMake主页下载此软件。2.2 安装MindStudio通过访问官网获取MindStudio安装包,MindStudio官网:https://www.hiascend.com/software/mindstudio下载jbr压缩包:推荐使用11_0_10b1341.35版本的jbr,进入链接:https://cache-redirector.jetbrains.com/intellij-jbr/jbr_dcevm-11_0_10-windows-x64-b1341.35.tar.gz下载压缩包。3、算子工程实践3.1 AI CPU算子介绍AI CPU算子,是运行在昇腾AI处理器中AI CPU计算单元上的表达一个完整计算逻辑的运算,如下情况下,开发者需要自定义AI CPU算子。在NN模型训练或者推理过程中,将第三方开源框架转化为适配昇腾AI处理器的模型时遇到了昇腾AI处理器不支持的算子。此时,为了快速打通模型执行流程,用户可以通过自定义AI CPU算子进行功能调测,提升调测效率。功能调通之后,后续性能调测过程中再将AI CPU自定义算子转换成TBE算子实现。某些场景下,无法实现在AI Core上运行的自定义算子(比如部分算子需要Complex32、Complex64类型,但AI Core指令不支持;再比如包含了大量标量计算的算子,而AI Core不擅长对标量进行处理),此时可以通过开发AI CPU自定义算子实现昇腾AI处理器对此算子的支持。3.2 算子分析使用AI CPU方式开发算子前,我们需要确定算子功能、输入、输出、算子类型以及算子实现函数名称等。步骤1 明确算子的功能以及数学表达式。以top_k算子为例【功能】返回指定轴的k个最大或最小值步骤2 明确输入和输出。【输入】 2个输入x:tensor,数据类型:float16、float32k:tensor,数据类型:int64【输出】 2个输出Values:top_k的返回值Indices:top_k的返回值索引步骤3 明确算子实现文件名称以及算子的类型(OpType)。算子类型需要采用大驼峰的命名方式,即采用大写字符区分不同的语义。 算子文件名称,可选用以下任意一种命名规则:建议将OpType按照如下方式进行转换,得到算子文件名称。 转换规则如下:首字符的大写字符转换为小写字符。 例如:Abc -> abc 小写字符后的大写字符转换为下划线+小写字符。 例如:AbcDef -> abc_def 紧跟数字以及大写字符后的大写字符,作为同一语义字符串,查找此字符串后的第一个小写字符,并将此小写字符的前一个大写字符转换为下划线+小写字符,其余大写字符转换为小写字符。若此字符串后不存在小写字符,则直接将此字符串中的大写字符转换为小写字符。 例如:ABCDef -> abc_def;Abc2DEf -> abc2d_ef;Abc2DEF -> abc2def; ABC2dEF -> abc2d_ef。因此本例中,算子类型定义为top_k,算子的实现文件名称为top_k,因此各个交付件的名称建议命名如下:算子的代码实现(即kernel实现)文件命名为h与top_k_kernel.cc。插件实现文件命名为cc。原型定义文件命名为:h与top_k.cc。信息定义文件命名为ini。算子类型(OpType)top_k算子输入name:xshape:1D or higherdata type:float16、float32、 int32name:kshape:0Ddata type:int32算子输出name:valuesshape:alldata type:float16、float32、 int32name:indicesshape:alldata type:int32算子实现文件名称top_k3.3 算子工程创建打开MindStudio, 选择文件 -> 新建 -> 项目在左边选择Ascend Operator,若是在本机上,CANN version选择本机的CANN版本,若是远程配置 CANN,点击install,点击Remote Connection后的+,配置远程SSH连接,配置好后点击Test Connection,出现 Successfully connected!即配置成功。配置SSH远程连接:定位远程服务器CANN软件包所在位置:点击下一步后在Sample template中选择AICPU算子下TensorFlow框架中的TopK算子,点击完成即可完成算子工程的创建。3.4 算子工程结构和交付件介绍3.4.1 算子工程结构完整的算子包括:算子原型定义、算子适配插件、算子信息库定义、算子实现。MindStudio新建算子工程时生成相应的工程模板,用户无需关注编译脚本实现等内容,只需关注具体的业务实现即可。3.4.2 交付件介绍top_k算子的原型为TensorFlow中的tf.math.top_k:tf.math.top_k( input, k=1, sorted=True, name=None ) TensorFlow中top_k API链接:https://www.tensorflow.org/api_docs/python/tf/math/top_k一个完成算子的开发交付件包括算子实现文件、算子原型文件、算子信息库文件和算子适配插件文件。3.5 算子代码实现3.5.1 简介AI CPU算子的实现包括两部分:头文件:进行算子类的声明,自定义算子类需要继承CpuKernel基类。 源文件:重写算子类中的Compute函数,进行算子计算逻辑的实现。3.5.2 头文件定义在算子工程中“cpukernel/impl/top_k.h”文件中进行了top_k算子类的声明,声明了top_k函数的一些参数信息,包括输入输出等属性。3.5.3 算子实现文件在算子工程中“cpukernel/impl/top_k.cc”文件中进行了top_k算子的计算逻辑实现。GetValueAndSelect函数将前k个输入的数据转化为数值。Select函数将第k个输入数据转换为第n个输入数据的值。ExchangeForTyeOne函数功能为交换父节点和子节点(当右子节点不存在时)。ExchangeForTypeTwo函数功能为当父节点小于左子节点时,交换父节点和子节点。ExchangeForTypeThree函数功能为当父节点大于左子节点时,交换父节点和子节点。ExchangeForTypeFour函数功能为当父节点等于左子节点时,交换父节点和子节点。此外还要在aicpu命名空间下实现Compute函数,实现对输入数据的合法性效验。之后在DoCompute函数中实现具体的算子实现逻辑。3.5.4 算子信息库定义在“cpukernel/op_info_cfg/aicpu_kernel/top_k.ini”文件中定义了自定义top_k算子的信息文件,主要体现算子在昇腾AI处理器上的具体实现规格,包括算子支持输入输出type、name等信息。网络运行时,根据算子信息库中的算子信息做基本校验,并进行算子匹配。3.5.5 算子适配插件开发在“framework/tf_plugin/tensorflow_top_k_plugin.cc”文件中进行了算子适配插件的开发,开发人员完成自定义算子的实现代码后,需要进行适配插件的开发将基于第三方框架的算子映射成适配昇腾AI处理器的算子,将算子信息注册到GE中。基于第三方框架的网络运行时,首先会加载并调用GE中的插件信息,将第三方框架网络中的算子进行解析并映射成昇腾AI处理器中的算子。REGISTER_CUSTOM_OP:注册自定义算子,OpType为注册到GE中的算子类型。 FrameworkType:TENSORFLOW代表原始框架为TensorFlow。 OriginOpType:算子在原始框架中的类型。 ParseParamsByOperatorFn:用来注册解析算子属性的函数。 ImplyType:指定算子的实现方式。ImplyType::AI_CPU表示该算子是AI CPU算子;ImplyType::TVM表示该算子是TBE算子。3.5.6 算子原型定义算子原型定义规定了在昇腾AI处理器上可运行算子的约束,主要体现算子的数学含义,包含定义算子输入、输出和属性信息,基本参数的校验和shape的推导,原型定义的信息会被注册到GE的算子原型库中。网络模型生成时,GE会调用算子原型库的校验接口进行基本参数的校验,校验通过后,会根据原型库中的推导函数推导每个节点的输出shape与dtype,进行输出tensor的静态内存的分配。Graph Engine(GE)提供REG_OP宏,以“.”链接INPUT、OUTPUT、ATTR等接口注册算子的输入、输出和属性信息,最终以OP_END_FACTORY_REG接口结束,完成算子的注册。其中输入输出的描述信息顺序需要与算子实现中定义保持一致,ATTR的顺序可变。R实现的cc文件中主要实现如下两个功能: 算子参数的校验,实现程序健壮性并提高定位效率。根据算子的输入张量描述、算子逻辑及算子属性,推理出算子的输出张量描述, 包括张量的形状、数据类型及数据排布格式等信息。这样算子构图准备阶段就可以为所有的张量静态分配内存,避免动态内存分配带来的开销。实现InferShape方法:算子IR中InferShape的定义可以使用如下接口: IMPLEMT_COMMON_INFERFUNC(func_name):自动生成的一个类型为Operator 类的对象op,可直接调用Operator类接口进行InferShape的实现,其中, func_name:用户自定义。实现Verify方法:算子Verify函数的实现使用如下接口:IMPLEMT_VERIFIER (OpType, func_name) ,传入的OpType为基于Operator类派生出来的子类,会自动生成一个类型为此子类的对象op,可以使用子类的成员函数获取算子的相关属性。OpType:自定义算子的类型。 func_name:自定义的verify函数名称。注册InferShape方法与Verify方法。 调用InferShape注册宏与Verify注册宏完成InferShape方法与Verify方法的注册,如下所示:3.6 算子编译算子交付件开发完成后,需要对算子工程进行编译,生成自定义算子安装包*.run,详细的编译操作包括:将AI CPU算子代码实现文件*.h与*.cc编译成so。将AI CPU算子信息定义文件*.ini编译成json。将原型定义文件*.h与*.cc编译成so。将算子适配插件实现文件*.cc编译成so。算子工程编译的具体内容为:将算子插件实现文件、算子原型定义文件、算子信息库定义文件分别编译成算子插件、算子原型库、算子信息库。点击顶部导航栏的构建按钮下的Edit build configuration编辑编译配置。进入编译配置页面,根据下表进行编译配置:参数说明Build Configuration编译配置名称,默认为Build-ConfigurationBuild Mode编译方式。Remote Build:远端编译。 须知:远端编译需要g++版本为7.5.0。Local Build:本地编译。 算子工程在MindStudio安装服务器进行编译,方便用户通过编译日志快速定位到MindStudio的实现代码所在位置,从而快速定位问 题。此种方式下需要配置交叉编译环境,编译环境的配置请参考配置编译环境。DeploymentRemote Build模式下显示该配置。deployment功能,详细请参见Deployment,可以将指定项目中的文件、文件夹同步到远程指定机器的指定目录。Environment VariablesRemote Build模式下显示该配置。为远程环境配置ASCEND_OPP_PATH、TOOLCHAIN_DIR等相关环境变量。AICPU SoC Version配置昇腾AI处理器的类型。若选用远程编译,需要配置Deployment和环境变量,其中环境变量在Environment Variables输入框中输入ASCEND_OPP_PATH、TOOLCHAIN_DIR、ASCEND_TENSOR_COMPILER_INCLUDE、ASCEND_AICPU_PATH环境变量。ASCEND_OPP_PATH=/usr/local/Ascend/ascend-toolkit/latest/opp TOOLCHAIN_DIR=/usr/local/Ascend/ascend-toolkit/latest/toolkit/toolchain/hcc ASCEND_TENSOR_COMPILER_INCLUDE=/usr/local/Ascend/ascend-toolkit/latest/include ASCEND_AICPU_PATH=/usr/local/Ascend/ascend-toolkit/latest其中用户将/usr/local换成实际Ascend安装路径。单击“Build”进行工程编译。并在界面最下方的窗口查看编译结果,编译完成后,显示远程编译完成 Information: build remotely finished,并在算子工程的cmake-build目录下生成自定义算子安装包custom_opp_Target OS_Target Architecture.run。3.7 UT测试UT(Unit Test:单元测试)是开发人员进行单算子运行验证的手段之一,主要目的是:测试算子代码的正确性,验证输入输出结果与设计的一致性。UT侧重于保证算子程序能够跑通,选取的场景组合应能覆盖算子代码的所有分支(一般来说覆盖率要达到100%),从而降低不同场景下算子代码的编译失败率。创建的Sample template模板通常会自带UT测试用例,在“testcases\ut\aicpu_test\top_k”文件夹下,会自动生成一个“test_top_k_impl.cc”ut测试文件,用于编写算子实现代码的UT C++测试用例,计算出算子执行结果,并 取回结果和预期结果进行比较,来测试算子逻辑的正确性。开发人员可以执行当前工程中所有算子的UT测试用例,也可以执行单个算子的UT测试用例。右键单击“testcases/ut/aicpu_test”文件夹,选择Run AI CPU Operator‘All’UT Impl with coverage,运行整个文件夹下算子实现代码的测试用例。第一次运行时会弹出运行配置页面,请参考配置,然后单击Run。参数说明Name运行配置名称,用户可以自定义。Test Type选择ut_impl。Compute Unit选择计算单元AI Core/Vector CoreAI CPU选择不同的计算单元可以实现AI Core/Vector Core和AI CPU UT测试配置界面的切换。Operator Name选择运行的测试用例。all表示运行所有用例。其他表示运行某个算子下的测试用例。Case Names勾选需要运行的测试用例,即算子实现代码的UT C++测试用例。支持全选和全不选所有测试用例。运行完成后,通过界面下方的“Run”日志打印窗口查看运行结果。在“Run”窗口中单击report index.html的URL(URL中的localhost为MindStudio安装服务器的IP,建议直接单击打开),查看UT测试用例的覆盖率结果。3.8 ST测试自定义算子部署到算子库(OPP)后,可进行ST(System Test)测试,在真实的硬件环境中,验证算子功能的正确性。ST测试的主要功能是:基于算子测试用例定义文件*.json生成单算子的om文件;使用 AscendCL接口加载并执行单算子om文件,验证算子执行结果的正确性。ST测试会覆盖算子实现文件,算子原型定义与算子信息库,不会对算子适配插件进行测试。创建的Sample template模板通常会自带UT测试用例,在“testcases\st\aicpu_kernel”文件夹下,会自动生成一个“TopK_case_timestamp.json”的st测试json配置文件,用于构造算子ST测试用例,使其满足ST测试覆盖范围。其中算子测试用例定义json文件中各参数含义如下:参数 说明Input(Output)Name可选。 算子为动态多输入(输出)场景时,“name”为必选配置,请配置为算子信息库中“dynamic_inputx.name”参数的名称+编号,编号从“0”开始,根据输入的个数按照0,1,2......,依次递增。-Format必选。 String或者String的一维数组。 输入(输出)tensor数据的排布格式,不允许为空。 支持如下数据排布格式:NCHW NHWCND:表示支持任意格式。支持的其它选项:RESERVED:预留,当format配置为该值,则type必须配 置为“UNDEFINED”,代表算子的此输入(输出)可选。 fuzz:使用fuzz测试参数生成脚本自动批量生成值。-OriginFormat可选。 String或者String的一维数组,支持以下两种取值:配置为输入数据的原始format。 当算子实现的format与原始format不同时,需要配置此字段;若不配置此字段,默认算子实现的format与原始 format相同。配置为“fuzz”,表示使用fuzz测试参数生成脚本自动批 量生成值。-Type· 必选。 String或者String的一维数组。 输入数据支持的数据类型:bool、int8、uint8、int16、uint16、int32、int64、uint32、uint64、float16、float、double、complex64、complex128、UNDEFINED(当输入类型为可选时)、fuzz(使用fuzz测试参数生成脚本自动批量生成值)。-Shape必选。int类型。一维或者二维数组。 输入tensor支持的形状。 – 支持静态shape输入的场景: shape维度以及取值都为固定值,该场景下不需要配置shape_range参数。 – 支持动态shape输入的场景: shape中包含-1,例如:(200, -1)表示第二个轴长度 未知。该场景下需要与shape_range参数配合使用, 用于给出“-1”维度的取值范围。String类型,“fuzz”。 支持fuzz,使用fuzz测试参数生成脚本自动批量生成值。空 如果format和type为UNDEFINED时shape允许为空。需要注意,配置的shape需要与format相匹配。-OriginShape可选。int类型。一维或者二维数组。 输入数据的原始shape。当算子实现的shape与原始 shape不同时,需要配置此字段。String类型,“fuzz”。 支持fuzz,使用fuzz测试参数生成脚本自动批量生成值。 若不配置此字段,默认算子实现的shape与原始shape一致。-Value可选。 String或者tensor数组。 若用户需要指定输入数据时,可通过增加此字段进行配置。有如下两种配置方式:直接输入tensor数据,如tensor的值为[1,2,3,4],配置示 例如下: "value": [1,2,3,4] 输入二进制数据文件的路径,如数据文件为test.bin时, 配置示例如下: "value": "../test.bin" 二进制数据bin文件需用户自己准备。可以输入绝对路 径,也可以输入测试用例定义文件的相对路径。配置为“fuzz”,使用fuzz测试参数生成脚本自动批量生 成值。 说明:若用户添加了“value”字段,“data_distribute”和 “value_range”字段将会被忽略。同时需要保证 “format”,"type","shape"字段的值与“value”数据对应,且每个用例只能测试一种数据类型。-ValueRange必选。int类型或者float类型。一维或者二维数组。取值范围,不能为空。 为[min_value, max_value]且min_value <=max_value。String类型,“fuzz”。 支持fuzz,使用fuzz测试参数生成脚本自动批量生成值。-DataDistribute必选。 String或者String的一维数组。 使用哪种数据分布方式生成测试数据,支持的分布方式有uniform:返回均匀分布随机值normal:返回正态分布(高斯分布)随机值beta:返回Beta分布随机值laplace:返回拉普拉斯分布随机值triangular:返回三角形分布随机值relu:返回均匀分布+Relu激活后的随机值sigmoid:返回均匀分布 + sigmoid激活后的随机值softmax:返回均匀分布 + softmax激活后的随机值tanh:返回均匀分布 + tanh激活后的随机值fuzz:使用fuzz测试参数生成脚本自动批量生成值。-IsConst可选。 bool类型。true:若用户需要配置常量输入的用例,则配置该字段, 并且其值为true。false:若该字段值为false,则需要配置张量输入用例。AttributeName若配置attr,则为必选。 String类型。 属性的名称,不为空。-Type若配置attr,则为必选。String类型。 属性支持的类型。bool、int、float、string、list_bool、list_int、list_float、list_string、list_list_int、data_type(如果attr中的value值为数据类型时,type值 必须为data_type)-value若配置attr,则为必选。 属性值,根据type的不同,属性值不同。如果“type”配置为“bool”,“value”取值为true或者false。如果“type”配置为“int”,“value”取值为整形数据。如果“type”配置为“float”,“value”取值为浮点型数据。如果“type”配置为“string”,“value”取值为字符串,例如“NCHW”。如果“type”配置为“list_bool”,“value”取值示例:[false, true]。如果“type”配置为“list_int”,“value”取值示例: [1, 224, 224, 3]。如果“type”配置为“list_float”,“value”取值示 例:[1.0, 0.0]。如果“type”配置为“list_string”,“value”取值示 例:["str1", "str2"]。如果“type”配置为“list_list_int”,“value”取值示 例:[[1, 3, 5, 7], [2, 4, 6, 8]]。如果“type”配置为“data_type”,“value”支持如下 取值:int8、int32、int16、int64、uint8、uint16、 uint32、uint64、float、float16、float32、bool、 double、complex64、complex128。“value”值配置为“fuzz”时,表示使用fuzz测试参数 生成脚本自动批量生成值。Expected Result VerificationScript Path算子期望数据生成函数对应的文件路径-Script Function算子函数名称点击Run便可打开ST测试配置。参数说明Name运行配置名称,用户可以自定义。Test Type选择st_cases 。Execute ModeRemote Execute 远程执行测试Local Execute 本地执行测试说明:Local Execute不支持Windows操作系统SSH Connection当Execute Mode选择Remote Execute时,下拉选择SSH配置信息,若未添加配置信息,请单击 添加。添加SSH配置信息的方法请参见SSH连接管理。CANN MachineCANN工具所在设备的SSH配置信息。添加SSH配置信息的方法请参见SSH连接管理。说明:该参数仅支持Windows操作系统。Environment Variables在文本框中添加环境变量 PATH_1=路径1;PATH_2=路径2 多个环境变量用英文分号隔开。也可以点击文本框后的图标,在弹出的对话框中填写。 在Name中输入环境变量名称:PATH_1。 在Value中输入环境变量值:路径1。 勾选Instead system environment variables可以显示系统环境变量。Operator Name选择需要运行的算子。SoC Version配置 昇腾AI处理器的类型。Product Form配置产品形态。若SoC Version配置为Ascend310时显示该配置项。EPRCExecutable File Name下拉选择需要执行的测试用例定义文件。若对AI CPU算子进行ST测试,测试用例文件前有(AI CPU)标识。Target OS针对Ascend EP:选择昇腾AI处理器所在硬件环境的Host侧的操作系统。针对Ascend RC:选择板端环境的操作系统。Target Architecture选择Target OS的操作系统架构。Case Names选择运行的Case Name。说明:默认全选所有用例,可以去除勾选部分不需要运行的用例。在Environment Variables中输入如下环境变量:ASCEND_DRIVER_PATH=/usr/local/Ascend/driver ASCEND_HOME=/usr/local/Ascend/ascend-toolkit/latest ASCEND_AICPU_PATH=${ASCEND_HOME}/<target architecture>-linux<target architecture>为操作系统架构,例如:x86_64-linux或arm64-linux。点击运行便可执行ST测试MindStudio会根据算子测试用例定义文件在“算子工程根目录/testcases/st/out/<operator name>”下生成测试数据和测试代码,并编译出可执行文件,在指定的硬件设备上执行测试用例,并将执行结果和与标杆数据对比报告打印到Output窗口中,同时在 “算子工程根目录/testcases/st/out/<operator name>”下生成st_report.json文件。st_report.json报表主要字段及含义如下:字段说明run_cmd---命令行命令。report_list---报告列表,该列表中可包含多个测试用例的报告。trace_detail--运行细节st_case_info-测试信息。expect_data_path期望计算结果路径。case_name测试用例名称。input_data_path输入数据路径。planned_output_data_paths实际计算结果输出路径。op_params算子参数信息。stage_result-运行各阶段结果信息。case_name--测试名称。status--测试结果信息。ST测试成功后在运行部分的输出和输出的文件st_report.json样例如下:3.9 算子部署将自定义算子安装包custom_opp_Targert OS_Target Architecture.run部署到昇腾AI处理器所在硬件环境的算子库中,为后续算子在网络中运行构造必要条件。单击MindStudio工程界面顶部的“Ascend->Operator Deployment”进入算子打包部署界面。有两种部署方式,这里我们选择远程部署算子,在Environment Variables中填入如下环境变量:ASCEND_OPP_PATH=/home/xxx/Ascend/ascend-toolkit/latest/oppOperator Package会自动定位当前工程文件下算子.run文件,当然我们也可以手动选择想要部署的算子。在Deployment框中选择想要部署的远程服务器地址,点击Operator deploy即可执行算子部署。算子部署成果示意图如下:算子部署过程即算子工程编译生成的自定义算子安装包的安装过程,部署完成后,算子被部署在Host侧算子库OPP对应文件夹中,默认路径为/usr/local/Ascend/opp/。Host侧自定义算子部署完成后目录结构示例如下所示:4、FAQQ:UT测试时报错CMake 3.14 or higher is required. You are running version 3.10.2。A:在服务器上更新CMake版本,通过CMake官网下载,而不是通过apt-get命令。Q:执行UT测试时无法输出网页版报告,报错:mindstudio_tmp/mindstudio_134d8786-c88-41da-ad68-84676b6eed78/14021FE-23C-4F18-865-226809200E44.sh: 1ine 1: 1cov: command not found Ut Impl Execute Finish.TBE TestRun FinishedCan not find the Ut_Impl report index.htmlA:pip install lcov5、从昇腾社区获得更多帮助开发者在使用MindStudio或进行算子开发过程中遇到任何问题,都可以来昇腾社区获得更多的帮助。昇腾官网:https://www.hiascend.com/昇腾社区:https://bbs.huaweicloud.com/昇腾论坛:https://bbs.huaweicloud.com/forum/forum-726-1.html
-
使用如下atc命令转换:atc --model=data_pre.pb --framework=3 --output=data_pre --soc_version=Ascend310 --input_shape="Placeholder:1,224,224,20"我是h5模型转换成pb模型再转om模型【报错信息】
-
【功能模块】【操作步骤&问题现象】在atlas200dk中运行的代码用到了tensorflow,想要通过pip install的方式安装tensorflow,但是一直装不上,这是什么情况呢?去百度看到的大多是python版本是32位的,但是我的python我看过是64位的,应该不是这里的问题,这个要怎么搞啊pip源我也还过好多了,都是不行。【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】Atlas200dk【操作步骤&问题现象】Atlas200dk可不可以部署tensorflow2的模型啊,如果可以的话要怎么部署呢,官方有没有什么历程之类的?【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
 在开始之前,首先声明本篇文章参考官方编程指南,我基于官网的这篇文章加以自己的理解发表了这篇博客,希望大家能够更快更简单直观的体验MindSpore,如有不妥的地方欢迎大家指正。【本文代码编译环境为MindSpore1.3.0 CPU版本】准备环节确保已安装MindSpore(可以根据自己的硬件情况安装,CPU,GPU,Ascend环境均可)选择一个集成开发工具(Jupyter Notebook,Pycharm等),我选择的是Pycharm查看是否安装python中的画图库 matplotlib,若未安装,在终端输入pip install matplotlib数据集下载数据集手写数字识别初体验采用的是业界经典的MNIST数据集,它包含了60000张训练图片,10000张测试图片。MindSpore中提供了很多经典数据集的下载命令,其中自然包括MNIST数据集。在Jupyter Notebook中执行如下命令下载MNIST数据集。Copy!mkdir -p ./datasets/MNIST_Data/train ./datasets/MNIST_Data/test!wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-labels-idx1-ubyte --no-check-certificate!wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-images-idx3-ubyte --no-check-certificate!wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-labels-idx1-ubyte --no-check-certificate!wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-images-idx3-ubyte --no-check-certificate!tree ./datasets/MNIST_Data得到的文档目录结构如图所示:./datasets/MNIST_Data ├── test│ ├── t10k-images-idx3-ubyte│ └── t10k-labels-idx1-ubyte└── train ├── train-images-idx3-ubyte └── train-labels-idx1-ubyte2 directories, 4 files./ 表示当前目录的意思,(当前项目中有一个datasets的文件夹,datasets文件夹下有一个MNIST_Data文件夹,然后依次类推)。这里我没有采用命令下载的方法,因为我用的是pycharm。笔者可前往http://yann.lecun.com/exdb/mnist/下载MNIST数据集,并将它按照文档目录结构图的形式放置于我们的项目中。配置运行信息接着我们配置MindSpore的运行模式,硬件信息等。from mindspore import contextcontext.set_context(mode=context.GRAPH_MODE, device_target="CPU")导入context模块,调用context的set_context方法,参数mode表示运行模式,MindSpore支持动态图和静态图两种模式,GRAPH_MODE表示静态图模式,PYNATIVE_MODE表示动态图模式,对于手写数字识别问题来说采用静态图模式即可。参数device_target表示硬件信息,有三个选项(CPU,GPU,Ascend),读者可根据自己的真实环境选择。查看数据集的详细信息既然我们已经将MNIST数据集下载到本地,那我们自然得去看一下它里面到底有什么东西,是否真的是我们熟知的手写阿拉伯数字。这里我们就要采用画图库了。import matplotlib.pyplot as pltimport matplotlibimport numpy as npimport mindspore.dataset as dstrain_data_path = "./datasets/MNIST_Data/train"test_data_path = "./datasets/MNIST_Data/test"mnist_ds = ds.MnistDataset(train_data_path)#生成的图像有两列[img, label],列图像张量是uint8类型,#因为像素点的取值范围是(0, 255),需要注意的是这两列数据的数据类型是Tensorprint('The type of mnist_ds:', type(mnist_ds))print("Number of pictures contained in the mnist_ds:", mnist_ds.get_dataset_size())#int, number of batches.#print(mnist_ds.get_batch_size()) #Return the size of batch.dic_ds = mnist_ds.create_dict_iterator() #数据集上创建迭代器,为字典数据类型,输出的为Tensor类型item = next(dic_ds)img = item["image"].asnumpy() #asnumpy为Tensor中的方法,功能是将张量转化为numpy数组,因为matplotlib.pyplot中不#能接受Tensor数据类型的参数label = item["label"].asnumpy()print("The item of mnist_ds:", item.keys())print("Tensor of image in item:", img.shape)print("The label of item:", label)plt.imshow(np.squeeze(img)) #squeeze将shape中为1的维度去掉,plt.imshow()函数负责对图像进行处理,并显示其格式plt.title("number:%s"% item["label"].asnumpy())plt.show() #show显示图像代码部分的解释,我想注释已经写的很明白了,但我们需要注意几点。我们尽量将自己拿到的数据集转化为MindSpore能够处理的数据类型,因为框架里面加了一些对于数据加速的方法。当然,这里的MNIST数据集不需要我们使用复杂的加载,因为对于MNIST这一类经典的数据集MindSpore都提供了专门的加载方法,将它加载成MindSpore能处理的数据。MindSpore提供的内置数据集处理方法默认输出一般都是在框架中通用的Tensor,但是对于非框架优化包含的python库,包括matplotlib,它们就无法处理接受Tensor,这是我们就要采用Tensor类中定义的asnumpy方法将张量转化为numpy数组上述代码的运行截图:上述结果验证了我们前面的说法,训练集中有60000张图片,以image和lable两个标签分别储存,并且每一张图片的大小为28 x 28,通道数为1说明里面是黑白图片。图中显示的图片是6(我觉得有点不像),它的标签值也为6。加载及处理数据集定义一个create_dataset函数。在这个函数中,总体分为一下几步。将原始的MNIST数据集加载进来, mnist_ds = ds.MnistDataset(data_path)设置一些数据增强和处理所需要的参数(parameters)使用2中设置的参数得到一些实例化的数据增强和处理方法将3中的方法映射到(使用)在对应数据集的相应部分(image,label)返回处理好的数据集(不同的神经网络可以接受不同的输入数据格式)create_dataset函数代码如下:import mindspore.dataset.vision.c_transforms as CVimport mindspore.dataset.transforms.c_transforms as Cfrom mindspore.dataset.vision import Interfrom mindspore import dtype as mstypedef create_dataset(data_path, batch_size=32, repeat_size=1, num_parallel_workers=1): mnist_ds = ds.MnistDataset(data_path) # 定义数据增强和处理所需的一些参数 resize_height, resize_width = 32, 32 rescale = 1.0 / 255.0 shift = 0.0 rescale_nml = 1 / 0.3081 shift_nml = -1 * 0.1307 / 0.3081 # 根据上面所定义的参数生成对应的数据增强方法,即实例化对象 resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) rescale_nml_op = CV.Rescale(rescale_nml, shift_nml) rescale_op = CV.Rescale(rescale, shift) hwc2chw_op = CV.HWC2CHW() type_cast_op = C.TypeCast(mstype.int32) # 将数据增强处理方法映射到(使用)在对应数据集的相应部分(image,label) mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers) # 处理生成的数据集 buffer_size = 10000 mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size) mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True) mnist_ds = mnist_ds.repeat(repeat_size) return mnist_ds导入的模块:mindspore.dataset.vision.c_transforms:MindSpore提供的通过数据增强操作对图像进行预处理,从而提高模型的广泛性。它是基于基于C++的OpenCV实现,具有较高的性能。接着来看一下,在增强MNIST数据集中,我们所使用到该模块中的方法(算子)。CV.Resize(size, interpolation=Inter.LINEAR):功能:使用给定的插值模式将输入图像调整为给定大小。参数:size:调整后输出图像的大小;interpolation:图像的插值模式(5个常量可供选择),一般情况下使用默认的Inter.LINEAR即可。CV.Rescale(rescale, shift):功能:使用给定的重缩放和移位重缩放输入图像。此运算符将使用以下命令重新缩放输入图像:输出=图像*重新缩放+移位(output = image * rescale + shift),可以用来消除图片在不同位置给模型带来的影响。参数:rescale:缩放因子;shift:偏移因子CV.HWC2CHW():功能:将输入图像从形状(H,W,C)转换为形状(C,H,W)。输入图像应为3通道图像。mindspore.dataset.transforms.c_transforms:该模块也是一个用于支持常见的图形增强功能的模块,基于C++的OpenCV实现的。C.TypeCast(data_type):功能:一个转化为给定MindSpore数据类型(data_type)的张量操作。参数:data_type:MindSpore中dtype模块中所指定的数据类型。mindspore.dataset.MnistDataset,MindSpore中专门提供的加载处理MNIST数据集为MindSpore数据类型的类,这里主要看一下它的map方法。ds.map(operations, input_columns=None, output_columns=None, column_order=None, num_parallel_workers=None, python_multiprocessing=False, cache=None, callbacks=None):功能:将具体的操作和方法应用到数据集上参数:我们主要看一下使用到的参数,因为它的很多参数实际上是默认的。operations:用于数据集的操作列表,操作将按照他们在列表中的顺序进行应用。 ;input_columns:将作为输入传递给第一个操作的列的名称列表。 ;num_parallel_workers:用于并行处理数据集的线程数,默认值为无。参数含义现在既然我们清楚了这些方法的功能以及他们中参数的含义,那么这里为什么要将参数定义成这样呢?resize_height, resize_width = 32, 32 resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)我们要将MNIST数据中的28 x 28大小的图片转化为32 x 32的大小,这是因为后面我们要采用的LeNet-5的卷积神经网络训练模型,该模型要求输入图像的尺寸统一归一化为32 x 32,具体的关于该网络的细节,我会在构建网络时详细介绍。 rescale = 1.0 / 255.0, shift = 0.0 rescale_op = CV.Rescale(rescale, shift) mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)这里我们将数据集中图像进行缩放,选择除以255是因为像素点的取值范围是(0,255)。该操作可以使得每个像素的数值大小在(0,1)范围中,可以提升训练效率。进行完该操作之后,有对图像进行了依次缩放,不过那个缩放的值应该是总结出来的能够进一步提高训练效率的值,需要大量实验才能得到,这里我直接是使用了官方代码上的值。 hwc2chw_op = CV.HWC2CHW()使用它对图片张量进行转化的原因是原图片张量形状是(28 x 28 x 1)(高 x 宽 x通道),在python中用高维数组解释是28个 28 x 1的矩阵,这不是很符合我们的计算习惯,所以我们将它转化为1 x 28 x 28(通道 x 高 x 宽),相对于是1个 28 x 28的矩阵,这不就是我们推导计算过程中常用的值吗。因此,它能够方便我们进行数据训练。buffer_size = 10000 mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)在该操作之前,我们已经将MNIST数据集处理成网络和框架所能接受的数据。接着就是对处理好的数据集进行一个增强操作。shuffle用于将数据集随机打乱,我们不希望有太多的人为因素干扰我们的训练,因为可能MNIST数据集本身是有一定规律的,我们不希望按照制作这个数据集的前辈的顺序来训练神经网络。mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)将整个数据集按照batch_size的大小分为若干批次,每一次训练的时候都是按一个批次的数据进行训练, drop_remainder:确定是否删除数据行数小于批大小的最后一个块,这里设置为True就是只保留数据集个数整除batch_size后得到的批次,多余得则从minst_ds中舍弃。 mnist_ds = mnist_ds.repeat(repeat_size)将数据集重复repeat_size次,需要注意得是该操作一般使用在batch操作之后。原理讲完之后,让我们看一下处理好的数据集是什么样子的吧。数据集的展示ms_dataset = create_dataset(train_data_path)print('Number of each group',ms_dataset.)print('Number of groups in the dataset:', ms_dataset.get_dataset_size())可以看到,我们将32张图片作为一个批次,将训练集总共分为了60000/32 = 1875个批次。接着我们拿出一个批次的数据将其形状等属性显示出来并将它进行可视化。data = next(ms_dataset.create_dict_iterator(output_numpy=True)) images = data["image"]labels = data["label"]print('Tensor of image:', images.shape)print('Labels:', labels)count = 1for i in images: plt.subplot(4, 8, count) plt.imshow(np.squeeze(i)) plt.title('num:%s'%labels[count-1]) plt.xticks([]) count += 1 plt.axis("off")plt.show()从Tensor of image:可以看出我们在处理数据的操作中执行Resize和HWC2CHW成功将图片转化为1 x 32 x 32的,同时可以知道所谓的分批次就是将batch_size张图片放在一起,用矩阵表示就是将batch_size个矩阵合成一个大型的矩阵,每一次使用一个这样的大型矩阵去训练,一个一个来。这样可以避免过高维度数组造成的内存过大,训练时间过长的问题,接着看一下图片显示。接下来,我将给大家介绍卷积神经网络LeNet-5的一些基础知识,以及如何使用MindSpore来构建出一个LeNet-5网络。LeNet-5对于手写数字识别初体验的网络,我们选择的是相对简单的一个卷积神经网络——LeNet-5。它的输入是一个黑白二维图片,先经过两层卷积层提取特征,然后到池化层,再经过全连接层连接,最后使用softmax分类作为输出层(因为它的输出有10个标签),网络结构如下图所示:LeNet-5是一个非常经典的网络,它虽然规模较小,但已经包含了一个卷积神经网络的基本模块——卷积层,池化层,全连接层。让我们来详细看一下它的各层参数以及作用。输入层我们的输入数据(手写数字图片)就是首先传入输入层,LeNet-5网络要求输入层的图片尺寸必须为32 x 32。我们已经通过create_dataset()函数将图片处理为 32 x 32了。卷积层1(C1层)输入:32 x 32 x 1卷积核大小: 5 x 5(过滤器)卷积核数量:6输出形状:28 x 28 x 6可训练参数:(5 x 5 +1)x 6 =156(5 x 5过滤器参数加一个偏差b)说明:对输入图像做卷积运算,一个过滤器与图片进行卷积运算得到28 x 28(32 - 5 +1)的矩阵,使用6个过滤器自然得到28 x 28 x 6的高阶数组。可以理解为提取了6个不同的图片特征。对于32 x 32中的每一个像素点,它都和6个过滤器以及他们的偏差有连接,我们通过156个参数就完成了全部的连接,这主要是通过权值共享实现的。(这是卷积层的主要优势之一,可以使要训练的参数减少)。池化层1(S2层)输入:28 x 28 x 6采样区域:2 x 2采用方式:论文里面使用的是平均池化的方式,但由于现在更加喜欢使用最大池化,所以我们这里采用最大池化。4个输入比较大小,取最大值。采样种类:6输出形状:14 x 14 x 6(这里的步长 s = 2)说明:第一次卷积运算提取特征之后,进行池化运算,将图片的大小进行缩减。2 x 2的采样器通常高和宽缩小一半。卷积层2(C3层)输入:14 x 14 x 6卷积核大小 :5 x 5卷积核数量 : 16输出形状:10 x 10 x 16池化层2(S4层)输入:10 x 10 x 16采样区域:2 x 2采样方式:最大池化输出 形状:5 x 5 x 16C5层输入:5 x 5 x 16功能:展平张量输出形状:1 x 1 x 120F6层(全连接层)输入:C5计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过Relu函数输出。Output层-全连接层该层也是全连接层,不过它对应的是10个标签(0到9的数字)。需采用softmax分类得到。定义网络首先说明MindSpore支持多种参数初始化方法,常用的有Normal等。具体可查看https://www.mindspore.cn/docs/api/zh-CN/r1.3/api_python/mindspore.common.initializer.html的接口说明。另外,MindSpore中所有网络的定义都需要继承自mindspore.nn.cell,并重写父类的init和construct方法,其中init方法中完成一些我们所需算子,网络的定义,construct方法则是写网络的执行逻辑。而且在nn模块中有很多定义好的各网路层可以使用,包括卷积层(nn.Conv2d()),全连接层(nn.Flatten())等。接下来看一下我们依照LeNet-5网络各层的参数以及功能要求使用MindSpore定义的网络结构:class LeNet5(nn.Cell): def __init__(self, num_class=10, num_channel=1): super(LeNet5, self).__init__() #继承父类nn.cell的__init__方法 #nn.Conv2d的第一个参数是输入图片的通道数,即单个过滤器应有的通道数,第二个参数是输出图片的通道数 #即过滤器的个数,第三个参数是过滤器的二维属性,它可以是一个int元组,但由于一般过滤器都是a x a形 #式的,而且为奇数。所以这里填入单个数即可,参数pad_mode为卷积方式,valid卷积即padding为0的卷积 #现在也比较流行same卷积,即卷积后输出的图片不会缩小。需要注意的是卷积层我们是不需要设置参数的随机 #方式的,因为它默认会给我们选择为Noremal。 self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid') self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid') #nn.Dense为致密连接层,它的第一个参数为输入层的维度,第二个参数为输出的维度,第三个参数为神经网 #络可训练参数W权重矩阵的初始化方式,默认为normal self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02)) self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02)) self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02)) #nn.ReLU()非线性激活函数,它往往比论文中的sigmoid激活函数具有更好的效益 self.relu = nn.ReLU() #nn.MaxPool2d为最大池化层的定义,kernel_size为采样器的大小,stride为采样步长,本例中将其 #都设置为2相当于将图片的宽度和高度都缩小一半 self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) #nn.Flatten为输入展成平图层,即去掉那些空的维度 self.flatten = nn.Flatten() def construct(self, x): #输入x,下面即是将x通过LeNet5网络执行前向传播的过程 x = self.max_pool2d(self.relu(self.conv1(x))) x = self.max_pool2d(self.relu(self.conv2(x))) x = self.flatten(x) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) x = self.fc3(x) return x你可能一下子看不懂上面的一些代码,但没有关系,只要你懂了LeNet-5网络的特征和运算规则,前往api中的nn模块参看相应说明之后你马上就会懂了。print(LeNet5())1我们通过该代码来看一下LeNet-5的各层网络参数:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xT9GQeCe-1630322405510)(D:\photo\捕获29.PNG)]读者可以根据打印的参数选项与我在前面提到过的的参数形式和自己掌握的一些数学矩阵计算规则验证一下,来加强自己对这些参数的理解。反向传播前面我们已经定义好了网络的前向传播过程,为了改变我们的可训练参数,即让我们所使用的参数能够预测出更加精确的值。我们需要定义损失函数即优化器,在MindSpore框架中是封装好了损失函数和优化器的,这使得我们的编程可以更快更加高效。损失函数:又叫目标函数,用于衡量预测值与实际值差异的程度。深度学习通过不停地迭代来缩小损失函数的值。定义一个好的损失函数,可以有效提高模型的性能。常见的有二分类的损失函数L,以及softmax损失函数等。优化器:用于最小化损失函数,从而在训练过程中改进模型。from mindspore.nn import SoftmaxCrossEntropyWithLogitslr = 0.01 #learingrate,学习率,可以使梯度下降的幅度变小,从而可以更好的训练参数momentum = 0.9network = LeNet5()#使用了流行的Momentum优化器进行优化#vt+1=vt∗u+gradients#pt+1=pt−(grad∗lr+vt+1∗u∗lr)#pt+1=pt−lr∗vt+1#其中grad、lr、p、v和u分别表示梯度、学习率、参数、力矩和动量。net_opt = nn.Momentum(network.trainable_params(), lr, momentum)#相当于softmax分类器#sparse指定标签(label)是否使用稀疏模式,默认为false,reduction为损失的减少类型:mean表示平均值,一般#情况下都是选择平均地减少net_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')自定义一个回调类自定义一个数据收集的回调类StepLossAccInfo该类继承自Callback类。主要用于收集两类信息,step与loss值之间地关系。step与对应模型精度之间联系。我们将该类作为回调函数,会在后面的高级api——model.train模型训练函数中调用。from mindspore.train.callback import Callback# custom callback functionclass StepLossAccInfo(Callback): def __init__(self, model, eval_dataset, steps_loss, steps_eval): self.model = model #计算图模型Model self.eval_dataset = eval_dataset #测试数据集 self.steps_loss = steps_loss #收集step和loss值之间的关系,数据格式{"step": [], "loss_value": []},会在后面定义 self.steps_eval = steps_eval #收集step对应模型精度值accuracy的信息,数据格式为{"step": [], "acc": []},会在后面定义 def step_end(self, run_context): cb_params = run_context.original_args() #cur_epoch_num是CallbackParam中的定义,获得当前处于第几个epoch,一个epoch意味着训练集 #中每一个样本都训练了一次 cur_epoch = cb_params.cur_epoch_num #同理,cur_step_num是CallbackParam中的定义,获得当前执行到多少step cur_step = (cur_epoch-1)*1875 + cb_params.cur_step_num self.steps_loss["loss_value"].append(str(cb_params.net_outputs)) self.steps_loss["step"].append(str(cur_step)) if cur_step % 125 == 0: #调用model.eval返回测试数据集下模型的损失值和度量值,dic对象 acc = self.model.eval(self.eval_dataset, dataset_sink_mode=False) self.steps_eval["step"].append(cur_step) self.steps_eval["acc"].append(acc["Accuracy"])编写训练网络from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitorfrom mindspore.nn import Accuracyfrom mindspore import Modelepoch_size = 1 #每个epoch需要遍历完成图片的batch数,这里是只要遍历一次model_path = "./models/ckpt/mindspore_quick_start/"eval_dataset = create_dataset(test_data_path)#调用Model高级API,将LeNet-5网络与损失函数和优化器连接到一起,具有训练和推理功能的对象。#metrics 参数是指训练和测试期,模型要评估的一组度量,这里设置的是"Accuracy"准确度model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()} )#保存训练好的模型参数的路径config_ck = CheckpointConfig(save_checkpoint_steps=375, keep_checkpoint_max=16)ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory=model_path, config=config_ck)#回调类中提到的我们要声明的数据格式steps_loss = {"step": [], "loss_value": []}steps_eval = {"step": [], "acc": []}#使用model等对象实例化StepLossAccInfo,得到具体的对象step_loss_acc_info = StepLossAccInfo(model , eval_dataset, steps_loss, steps_eval)#调用Model类的train方法进行训练,LossMonitor(125)每隔125个step打印训练过程中的loss值,dataset_sink_mode为设置数据下沉模式,但该模式不支持CPU,所以这里我们只能设置为Falsemodel.train(epoch_size, ms_dataset, callbacks=[ckpoint_cb, LossMonitor(125), step_loss_acc_info], dataset_sink_mode=False)从上面的训练截图可以看一看出效果还是很好的,因为我第一次跑手写数字识别项目是别人给我的pytorch版本,一般跑第一个epoch的准确率是94%左右。用MindSpore来跑这个loss值这么小,我觉得可能是处理数据集上有优势一些。这只是一个较小的项目,我在一篇文章上看到,MindSpore结合Ascend处理器跑大一点的项目一般比其它的主流框架平台都要快一些。同时我们可以看到,我们的项目下有一个models的文件夹,里面储存的ckpt文件就是我们训练过程中的参数,不过LeNet-5的参数量并不是很大。我们可以将该文件的参数加载到LeNet-5网络中,然后用该网络去跑测试集可以得到在测试集上的准确率。def test_net(network, model, mnist_path): """Define the evaluation method.""" print("============== Starting Testing ==============") # load the saved model for evaluation param_dict = load_checkpoint("./models/ckpt/mindspore_quick_start/checkpoint_lenet-1_1875.ckpt") # load parameter to the network load_param_into_net(network, param_dict) # load testing dataset acc = model.eval(eval_dataset, dataset_sink_mode=False) print("============== Accuracy:{} ==============".format(acc))test_net(network, model, mnist_path)可以看到一次训练就有将近96%的准确率,这已经非常不错了。如果想要继续提高它的准确率可以去自定义训练网络来控制训练整个集合的次数,或者修改参数等都可以尝试。最后一步,我们使用官网的一段代码,提取出一个批次的图片,使用已训练好的上面的模型来预测一下每一张图片的标签,并将其可视化。ds_test = eval_dataset.create_dict_iterator()data = next(ds_test)images = data["image"].asnumpy()labels = data["label"].asnumpy()output = model.predict(Tensor(data['image'])) #利用加载好的模型的predict进行预测,注意返回的是对应的(0到9)的概率pred = np.argmax(output.asnumpy(), axis=1)err_num = []index = 1for i in range(len(labels)): plt.subplot(4, 8, i+1) color = 'blue' if pred[i] == labels[i] else 'red' plt.title("pre:{}".format(pred[i]), color=color) plt.imshow(np.squeeze(images[i])) plt.axis("off") if color == 'red': index = 0 print("Row {}, column {} is incorrectly identified as {}, the correct value should be {}".format(int(i/8)+1, i%8+1, pred[i], labels[i]), '\n')if index: print("All the figures in this group are predicted correctly!")print(pred, "<--Predicted figures")print(labels, "<--The right number")plt.show()可以看到我抽到的这一组32张图片是属于手气较好的,全部预测正确。上面有些数字确实挺有干扰性的,但机器还是识别出来了(比如第2行最后一张2,写的挺奇葩的)。总之到了这里,基于MindSpore的手写数字识别初体验就已经结束了,写这篇文章不是说要深入手写数字识别,而是说经过这个小型项目的实践,我们可以对MindSpore的各个模块有个大体的理解。比如说dataset模块用于各种数据集的处理和加载,有热门数据集的加载处理方法,有MindSpore专属的数据格式,有一些不同数据集的增强方法。nn模块提供了与网络构建,网络参数相关的各种封装好的高级API。类似的还有很多,我们可以通过这些模块的功能进一步细化深入到该模块中子模块,方法。从功能入手,由表及里,分析源码。训练好的参数已经上传,不想训练的小伙伴可以直接将它加载进LeNet-5网络中去实践,需要自己训练的也可以使用我上传的代码。不过该代码是文章所以测试代码的综合,其中有些测试的点已经被注释,读者可自行查看编辑。————————————————原文链接:https://blog.csdn.net/qq_51964209/article/details/120003642
在开始之前,首先声明本篇文章参考官方编程指南,我基于官网的这篇文章加以自己的理解发表了这篇博客,希望大家能够更快更简单直观的体验MindSpore,如有不妥的地方欢迎大家指正。【本文代码编译环境为MindSpore1.3.0 CPU版本】准备环节确保已安装MindSpore(可以根据自己的硬件情况安装,CPU,GPU,Ascend环境均可)选择一个集成开发工具(Jupyter Notebook,Pycharm等),我选择的是Pycharm查看是否安装python中的画图库 matplotlib,若未安装,在终端输入pip install matplotlib数据集下载数据集手写数字识别初体验采用的是业界经典的MNIST数据集,它包含了60000张训练图片,10000张测试图片。MindSpore中提供了很多经典数据集的下载命令,其中自然包括MNIST数据集。在Jupyter Notebook中执行如下命令下载MNIST数据集。Copy!mkdir -p ./datasets/MNIST_Data/train ./datasets/MNIST_Data/test!wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-labels-idx1-ubyte --no-check-certificate!wget -NP ./datasets/MNIST_Data/train https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/train-images-idx3-ubyte --no-check-certificate!wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-labels-idx1-ubyte --no-check-certificate!wget -NP ./datasets/MNIST_Data/test https://mindspore-website.obs.myhuaweicloud.com/notebook/datasets/mnist/t10k-images-idx3-ubyte --no-check-certificate!tree ./datasets/MNIST_Data得到的文档目录结构如图所示:./datasets/MNIST_Data ├── test│ ├── t10k-images-idx3-ubyte│ └── t10k-labels-idx1-ubyte└── train ├── train-images-idx3-ubyte └── train-labels-idx1-ubyte2 directories, 4 files./ 表示当前目录的意思,(当前项目中有一个datasets的文件夹,datasets文件夹下有一个MNIST_Data文件夹,然后依次类推)。这里我没有采用命令下载的方法,因为我用的是pycharm。笔者可前往http://yann.lecun.com/exdb/mnist/下载MNIST数据集,并将它按照文档目录结构图的形式放置于我们的项目中。配置运行信息接着我们配置MindSpore的运行模式,硬件信息等。from mindspore import contextcontext.set_context(mode=context.GRAPH_MODE, device_target="CPU")导入context模块,调用context的set_context方法,参数mode表示运行模式,MindSpore支持动态图和静态图两种模式,GRAPH_MODE表示静态图模式,PYNATIVE_MODE表示动态图模式,对于手写数字识别问题来说采用静态图模式即可。参数device_target表示硬件信息,有三个选项(CPU,GPU,Ascend),读者可根据自己的真实环境选择。查看数据集的详细信息既然我们已经将MNIST数据集下载到本地,那我们自然得去看一下它里面到底有什么东西,是否真的是我们熟知的手写阿拉伯数字。这里我们就要采用画图库了。import matplotlib.pyplot as pltimport matplotlibimport numpy as npimport mindspore.dataset as dstrain_data_path = "./datasets/MNIST_Data/train"test_data_path = "./datasets/MNIST_Data/test"mnist_ds = ds.MnistDataset(train_data_path)#生成的图像有两列[img, label],列图像张量是uint8类型,#因为像素点的取值范围是(0, 255),需要注意的是这两列数据的数据类型是Tensorprint('The type of mnist_ds:', type(mnist_ds))print("Number of pictures contained in the mnist_ds:", mnist_ds.get_dataset_size())#int, number of batches.#print(mnist_ds.get_batch_size()) #Return the size of batch.dic_ds = mnist_ds.create_dict_iterator() #数据集上创建迭代器,为字典数据类型,输出的为Tensor类型item = next(dic_ds)img = item["image"].asnumpy() #asnumpy为Tensor中的方法,功能是将张量转化为numpy数组,因为matplotlib.pyplot中不#能接受Tensor数据类型的参数label = item["label"].asnumpy()print("The item of mnist_ds:", item.keys())print("Tensor of image in item:", img.shape)print("The label of item:", label)plt.imshow(np.squeeze(img)) #squeeze将shape中为1的维度去掉,plt.imshow()函数负责对图像进行处理,并显示其格式plt.title("number:%s"% item["label"].asnumpy())plt.show() #show显示图像代码部分的解释,我想注释已经写的很明白了,但我们需要注意几点。我们尽量将自己拿到的数据集转化为MindSpore能够处理的数据类型,因为框架里面加了一些对于数据加速的方法。当然,这里的MNIST数据集不需要我们使用复杂的加载,因为对于MNIST这一类经典的数据集MindSpore都提供了专门的加载方法,将它加载成MindSpore能处理的数据。MindSpore提供的内置数据集处理方法默认输出一般都是在框架中通用的Tensor,但是对于非框架优化包含的python库,包括matplotlib,它们就无法处理接受Tensor,这是我们就要采用Tensor类中定义的asnumpy方法将张量转化为numpy数组上述代码的运行截图:上述结果验证了我们前面的说法,训练集中有60000张图片,以image和lable两个标签分别储存,并且每一张图片的大小为28 x 28,通道数为1说明里面是黑白图片。图中显示的图片是6(我觉得有点不像),它的标签值也为6。加载及处理数据集定义一个create_dataset函数。在这个函数中,总体分为一下几步。将原始的MNIST数据集加载进来, mnist_ds = ds.MnistDataset(data_path)设置一些数据增强和处理所需要的参数(parameters)使用2中设置的参数得到一些实例化的数据增强和处理方法将3中的方法映射到(使用)在对应数据集的相应部分(image,label)返回处理好的数据集(不同的神经网络可以接受不同的输入数据格式)create_dataset函数代码如下:import mindspore.dataset.vision.c_transforms as CVimport mindspore.dataset.transforms.c_transforms as Cfrom mindspore.dataset.vision import Interfrom mindspore import dtype as mstypedef create_dataset(data_path, batch_size=32, repeat_size=1, num_parallel_workers=1): mnist_ds = ds.MnistDataset(data_path) # 定义数据增强和处理所需的一些参数 resize_height, resize_width = 32, 32 rescale = 1.0 / 255.0 shift = 0.0 rescale_nml = 1 / 0.3081 shift_nml = -1 * 0.1307 / 0.3081 # 根据上面所定义的参数生成对应的数据增强方法,即实例化对象 resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR) rescale_nml_op = CV.Rescale(rescale_nml, shift_nml) rescale_op = CV.Rescale(rescale, shift) hwc2chw_op = CV.HWC2CHW() type_cast_op = C.TypeCast(mstype.int32) # 将数据增强处理方法映射到(使用)在对应数据集的相应部分(image,label) mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(operations=rescale_nml_op, input_columns="image", num_parallel_workers=num_parallel_workers) mnist_ds = mnist_ds.map(operations=hwc2chw_op, input_columns="image", num_parallel_workers=num_parallel_workers) # 处理生成的数据集 buffer_size = 10000 mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size) mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True) mnist_ds = mnist_ds.repeat(repeat_size) return mnist_ds导入的模块:mindspore.dataset.vision.c_transforms:MindSpore提供的通过数据增强操作对图像进行预处理,从而提高模型的广泛性。它是基于基于C++的OpenCV实现,具有较高的性能。接着来看一下,在增强MNIST数据集中,我们所使用到该模块中的方法(算子)。CV.Resize(size, interpolation=Inter.LINEAR):功能:使用给定的插值模式将输入图像调整为给定大小。参数:size:调整后输出图像的大小;interpolation:图像的插值模式(5个常量可供选择),一般情况下使用默认的Inter.LINEAR即可。CV.Rescale(rescale, shift):功能:使用给定的重缩放和移位重缩放输入图像。此运算符将使用以下命令重新缩放输入图像:输出=图像*重新缩放+移位(output = image * rescale + shift),可以用来消除图片在不同位置给模型带来的影响。参数:rescale:缩放因子;shift:偏移因子CV.HWC2CHW():功能:将输入图像从形状(H,W,C)转换为形状(C,H,W)。输入图像应为3通道图像。mindspore.dataset.transforms.c_transforms:该模块也是一个用于支持常见的图形增强功能的模块,基于C++的OpenCV实现的。C.TypeCast(data_type):功能:一个转化为给定MindSpore数据类型(data_type)的张量操作。参数:data_type:MindSpore中dtype模块中所指定的数据类型。mindspore.dataset.MnistDataset,MindSpore中专门提供的加载处理MNIST数据集为MindSpore数据类型的类,这里主要看一下它的map方法。ds.map(operations, input_columns=None, output_columns=None, column_order=None, num_parallel_workers=None, python_multiprocessing=False, cache=None, callbacks=None):功能:将具体的操作和方法应用到数据集上参数:我们主要看一下使用到的参数,因为它的很多参数实际上是默认的。operations:用于数据集的操作列表,操作将按照他们在列表中的顺序进行应用。 ;input_columns:将作为输入传递给第一个操作的列的名称列表。 ;num_parallel_workers:用于并行处理数据集的线程数,默认值为无。参数含义现在既然我们清楚了这些方法的功能以及他们中参数的含义,那么这里为什么要将参数定义成这样呢?resize_height, resize_width = 32, 32 resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)mnist_ds = mnist_ds.map(operations=resize_op, input_columns="image", num_parallel_workers=num_parallel_workers)我们要将MNIST数据中的28 x 28大小的图片转化为32 x 32的大小,这是因为后面我们要采用的LeNet-5的卷积神经网络训练模型,该模型要求输入图像的尺寸统一归一化为32 x 32,具体的关于该网络的细节,我会在构建网络时详细介绍。 rescale = 1.0 / 255.0, shift = 0.0 rescale_op = CV.Rescale(rescale, shift) mnist_ds = mnist_ds.map(operations=rescale_op, input_columns="image", num_parallel_workers=num_parallel_workers)这里我们将数据集中图像进行缩放,选择除以255是因为像素点的取值范围是(0,255)。该操作可以使得每个像素的数值大小在(0,1)范围中,可以提升训练效率。进行完该操作之后,有对图像进行了依次缩放,不过那个缩放的值应该是总结出来的能够进一步提高训练效率的值,需要大量实验才能得到,这里我直接是使用了官方代码上的值。 hwc2chw_op = CV.HWC2CHW()使用它对图片张量进行转化的原因是原图片张量形状是(28 x 28 x 1)(高 x 宽 x通道),在python中用高维数组解释是28个 28 x 1的矩阵,这不是很符合我们的计算习惯,所以我们将它转化为1 x 28 x 28(通道 x 高 x 宽),相对于是1个 28 x 28的矩阵,这不就是我们推导计算过程中常用的值吗。因此,它能够方便我们进行数据训练。buffer_size = 10000 mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)在该操作之前,我们已经将MNIST数据集处理成网络和框架所能接受的数据。接着就是对处理好的数据集进行一个增强操作。shuffle用于将数据集随机打乱,我们不希望有太多的人为因素干扰我们的训练,因为可能MNIST数据集本身是有一定规律的,我们不希望按照制作这个数据集的前辈的顺序来训练神经网络。mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)将整个数据集按照batch_size的大小分为若干批次,每一次训练的时候都是按一个批次的数据进行训练, drop_remainder:确定是否删除数据行数小于批大小的最后一个块,这里设置为True就是只保留数据集个数整除batch_size后得到的批次,多余得则从minst_ds中舍弃。 mnist_ds = mnist_ds.repeat(repeat_size)将数据集重复repeat_size次,需要注意得是该操作一般使用在batch操作之后。原理讲完之后,让我们看一下处理好的数据集是什么样子的吧。数据集的展示ms_dataset = create_dataset(train_data_path)print('Number of each group',ms_dataset.)print('Number of groups in the dataset:', ms_dataset.get_dataset_size())可以看到,我们将32张图片作为一个批次,将训练集总共分为了60000/32 = 1875个批次。接着我们拿出一个批次的数据将其形状等属性显示出来并将它进行可视化。data = next(ms_dataset.create_dict_iterator(output_numpy=True)) images = data["image"]labels = data["label"]print('Tensor of image:', images.shape)print('Labels:', labels)count = 1for i in images: plt.subplot(4, 8, count) plt.imshow(np.squeeze(i)) plt.title('num:%s'%labels[count-1]) plt.xticks([]) count += 1 plt.axis("off")plt.show()从Tensor of image:可以看出我们在处理数据的操作中执行Resize和HWC2CHW成功将图片转化为1 x 32 x 32的,同时可以知道所谓的分批次就是将batch_size张图片放在一起,用矩阵表示就是将batch_size个矩阵合成一个大型的矩阵,每一次使用一个这样的大型矩阵去训练,一个一个来。这样可以避免过高维度数组造成的内存过大,训练时间过长的问题,接着看一下图片显示。接下来,我将给大家介绍卷积神经网络LeNet-5的一些基础知识,以及如何使用MindSpore来构建出一个LeNet-5网络。LeNet-5对于手写数字识别初体验的网络,我们选择的是相对简单的一个卷积神经网络——LeNet-5。它的输入是一个黑白二维图片,先经过两层卷积层提取特征,然后到池化层,再经过全连接层连接,最后使用softmax分类作为输出层(因为它的输出有10个标签),网络结构如下图所示:LeNet-5是一个非常经典的网络,它虽然规模较小,但已经包含了一个卷积神经网络的基本模块——卷积层,池化层,全连接层。让我们来详细看一下它的各层参数以及作用。输入层我们的输入数据(手写数字图片)就是首先传入输入层,LeNet-5网络要求输入层的图片尺寸必须为32 x 32。我们已经通过create_dataset()函数将图片处理为 32 x 32了。卷积层1(C1层)输入:32 x 32 x 1卷积核大小: 5 x 5(过滤器)卷积核数量:6输出形状:28 x 28 x 6可训练参数:(5 x 5 +1)x 6 =156(5 x 5过滤器参数加一个偏差b)说明:对输入图像做卷积运算,一个过滤器与图片进行卷积运算得到28 x 28(32 - 5 +1)的矩阵,使用6个过滤器自然得到28 x 28 x 6的高阶数组。可以理解为提取了6个不同的图片特征。对于32 x 32中的每一个像素点,它都和6个过滤器以及他们的偏差有连接,我们通过156个参数就完成了全部的连接,这主要是通过权值共享实现的。(这是卷积层的主要优势之一,可以使要训练的参数减少)。池化层1(S2层)输入:28 x 28 x 6采样区域:2 x 2采用方式:论文里面使用的是平均池化的方式,但由于现在更加喜欢使用最大池化,所以我们这里采用最大池化。4个输入比较大小,取最大值。采样种类:6输出形状:14 x 14 x 6(这里的步长 s = 2)说明:第一次卷积运算提取特征之后,进行池化运算,将图片的大小进行缩减。2 x 2的采样器通常高和宽缩小一半。卷积层2(C3层)输入:14 x 14 x 6卷积核大小 :5 x 5卷积核数量 : 16输出形状:10 x 10 x 16池化层2(S4层)输入:10 x 10 x 16采样区域:2 x 2采样方式:最大池化输出 形状:5 x 5 x 16C5层输入:5 x 5 x 16功能:展平张量输出形状:1 x 1 x 120F6层(全连接层)输入:C5计算方式:计算输入向量和权重向量之间的点积,再加上一个偏置,结果通过Relu函数输出。Output层-全连接层该层也是全连接层,不过它对应的是10个标签(0到9的数字)。需采用softmax分类得到。定义网络首先说明MindSpore支持多种参数初始化方法,常用的有Normal等。具体可查看https://www.mindspore.cn/docs/api/zh-CN/r1.3/api_python/mindspore.common.initializer.html的接口说明。另外,MindSpore中所有网络的定义都需要继承自mindspore.nn.cell,并重写父类的init和construct方法,其中init方法中完成一些我们所需算子,网络的定义,construct方法则是写网络的执行逻辑。而且在nn模块中有很多定义好的各网路层可以使用,包括卷积层(nn.Conv2d()),全连接层(nn.Flatten())等。接下来看一下我们依照LeNet-5网络各层的参数以及功能要求使用MindSpore定义的网络结构:class LeNet5(nn.Cell): def __init__(self, num_class=10, num_channel=1): super(LeNet5, self).__init__() #继承父类nn.cell的__init__方法 #nn.Conv2d的第一个参数是输入图片的通道数,即单个过滤器应有的通道数,第二个参数是输出图片的通道数 #即过滤器的个数,第三个参数是过滤器的二维属性,它可以是一个int元组,但由于一般过滤器都是a x a形 #式的,而且为奇数。所以这里填入单个数即可,参数pad_mode为卷积方式,valid卷积即padding为0的卷积 #现在也比较流行same卷积,即卷积后输出的图片不会缩小。需要注意的是卷积层我们是不需要设置参数的随机 #方式的,因为它默认会给我们选择为Noremal。 self.conv1 = nn.Conv2d(num_channel, 6, 5, pad_mode='valid') self.conv2 = nn.Conv2d(6, 16, 5, pad_mode='valid') #nn.Dense为致密连接层,它的第一个参数为输入层的维度,第二个参数为输出的维度,第三个参数为神经网 #络可训练参数W权重矩阵的初始化方式,默认为normal self.fc1 = nn.Dense(16 * 5 * 5, 120, weight_init=Normal(0.02)) self.fc2 = nn.Dense(120, 84, weight_init=Normal(0.02)) self.fc3 = nn.Dense(84, num_class, weight_init=Normal(0.02)) #nn.ReLU()非线性激活函数,它往往比论文中的sigmoid激活函数具有更好的效益 self.relu = nn.ReLU() #nn.MaxPool2d为最大池化层的定义,kernel_size为采样器的大小,stride为采样步长,本例中将其 #都设置为2相当于将图片的宽度和高度都缩小一半 self.max_pool2d = nn.MaxPool2d(kernel_size=2, stride=2) #nn.Flatten为输入展成平图层,即去掉那些空的维度 self.flatten = nn.Flatten() def construct(self, x): #输入x,下面即是将x通过LeNet5网络执行前向传播的过程 x = self.max_pool2d(self.relu(self.conv1(x))) x = self.max_pool2d(self.relu(self.conv2(x))) x = self.flatten(x) x = self.relu(self.fc1(x)) x = self.relu(self.fc2(x)) x = self.fc3(x) return x你可能一下子看不懂上面的一些代码,但没有关系,只要你懂了LeNet-5网络的特征和运算规则,前往api中的nn模块参看相应说明之后你马上就会懂了。print(LeNet5())1我们通过该代码来看一下LeNet-5的各层网络参数:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xT9GQeCe-1630322405510)(D:\photo\捕获29.PNG)]读者可以根据打印的参数选项与我在前面提到过的的参数形式和自己掌握的一些数学矩阵计算规则验证一下,来加强自己对这些参数的理解。反向传播前面我们已经定义好了网络的前向传播过程,为了改变我们的可训练参数,即让我们所使用的参数能够预测出更加精确的值。我们需要定义损失函数即优化器,在MindSpore框架中是封装好了损失函数和优化器的,这使得我们的编程可以更快更加高效。损失函数:又叫目标函数,用于衡量预测值与实际值差异的程度。深度学习通过不停地迭代来缩小损失函数的值。定义一个好的损失函数,可以有效提高模型的性能。常见的有二分类的损失函数L,以及softmax损失函数等。优化器:用于最小化损失函数,从而在训练过程中改进模型。from mindspore.nn import SoftmaxCrossEntropyWithLogitslr = 0.01 #learingrate,学习率,可以使梯度下降的幅度变小,从而可以更好的训练参数momentum = 0.9network = LeNet5()#使用了流行的Momentum优化器进行优化#vt+1=vt∗u+gradients#pt+1=pt−(grad∗lr+vt+1∗u∗lr)#pt+1=pt−lr∗vt+1#其中grad、lr、p、v和u分别表示梯度、学习率、参数、力矩和动量。net_opt = nn.Momentum(network.trainable_params(), lr, momentum)#相当于softmax分类器#sparse指定标签(label)是否使用稀疏模式,默认为false,reduction为损失的减少类型:mean表示平均值,一般#情况下都是选择平均地减少net_loss = SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')自定义一个回调类自定义一个数据收集的回调类StepLossAccInfo该类继承自Callback类。主要用于收集两类信息,step与loss值之间地关系。step与对应模型精度之间联系。我们将该类作为回调函数,会在后面的高级api——model.train模型训练函数中调用。from mindspore.train.callback import Callback# custom callback functionclass StepLossAccInfo(Callback): def __init__(self, model, eval_dataset, steps_loss, steps_eval): self.model = model #计算图模型Model self.eval_dataset = eval_dataset #测试数据集 self.steps_loss = steps_loss #收集step和loss值之间的关系,数据格式{"step": [], "loss_value": []},会在后面定义 self.steps_eval = steps_eval #收集step对应模型精度值accuracy的信息,数据格式为{"step": [], "acc": []},会在后面定义 def step_end(self, run_context): cb_params = run_context.original_args() #cur_epoch_num是CallbackParam中的定义,获得当前处于第几个epoch,一个epoch意味着训练集 #中每一个样本都训练了一次 cur_epoch = cb_params.cur_epoch_num #同理,cur_step_num是CallbackParam中的定义,获得当前执行到多少step cur_step = (cur_epoch-1)*1875 + cb_params.cur_step_num self.steps_loss["loss_value"].append(str(cb_params.net_outputs)) self.steps_loss["step"].append(str(cur_step)) if cur_step % 125 == 0: #调用model.eval返回测试数据集下模型的损失值和度量值,dic对象 acc = self.model.eval(self.eval_dataset, dataset_sink_mode=False) self.steps_eval["step"].append(cur_step) self.steps_eval["acc"].append(acc["Accuracy"])编写训练网络from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitorfrom mindspore.nn import Accuracyfrom mindspore import Modelepoch_size = 1 #每个epoch需要遍历完成图片的batch数,这里是只要遍历一次model_path = "./models/ckpt/mindspore_quick_start/"eval_dataset = create_dataset(test_data_path)#调用Model高级API,将LeNet-5网络与损失函数和优化器连接到一起,具有训练和推理功能的对象。#metrics 参数是指训练和测试期,模型要评估的一组度量,这里设置的是"Accuracy"准确度model = Model(network, net_loss, net_opt, metrics={"Accuracy": Accuracy()} )#保存训练好的模型参数的路径config_ck = CheckpointConfig(save_checkpoint_steps=375, keep_checkpoint_max=16)ckpoint_cb = ModelCheckpoint(prefix="checkpoint_lenet", directory=model_path, config=config_ck)#回调类中提到的我们要声明的数据格式steps_loss = {"step": [], "loss_value": []}steps_eval = {"step": [], "acc": []}#使用model等对象实例化StepLossAccInfo,得到具体的对象step_loss_acc_info = StepLossAccInfo(model , eval_dataset, steps_loss, steps_eval)#调用Model类的train方法进行训练,LossMonitor(125)每隔125个step打印训练过程中的loss值,dataset_sink_mode为设置数据下沉模式,但该模式不支持CPU,所以这里我们只能设置为Falsemodel.train(epoch_size, ms_dataset, callbacks=[ckpoint_cb, LossMonitor(125), step_loss_acc_info], dataset_sink_mode=False)从上面的训练截图可以看一看出效果还是很好的,因为我第一次跑手写数字识别项目是别人给我的pytorch版本,一般跑第一个epoch的准确率是94%左右。用MindSpore来跑这个loss值这么小,我觉得可能是处理数据集上有优势一些。这只是一个较小的项目,我在一篇文章上看到,MindSpore结合Ascend处理器跑大一点的项目一般比其它的主流框架平台都要快一些。同时我们可以看到,我们的项目下有一个models的文件夹,里面储存的ckpt文件就是我们训练过程中的参数,不过LeNet-5的参数量并不是很大。我们可以将该文件的参数加载到LeNet-5网络中,然后用该网络去跑测试集可以得到在测试集上的准确率。def test_net(network, model, mnist_path): """Define the evaluation method.""" print("============== Starting Testing ==============") # load the saved model for evaluation param_dict = load_checkpoint("./models/ckpt/mindspore_quick_start/checkpoint_lenet-1_1875.ckpt") # load parameter to the network load_param_into_net(network, param_dict) # load testing dataset acc = model.eval(eval_dataset, dataset_sink_mode=False) print("============== Accuracy:{} ==============".format(acc))test_net(network, model, mnist_path)可以看到一次训练就有将近96%的准确率,这已经非常不错了。如果想要继续提高它的准确率可以去自定义训练网络来控制训练整个集合的次数,或者修改参数等都可以尝试。最后一步,我们使用官网的一段代码,提取出一个批次的图片,使用已训练好的上面的模型来预测一下每一张图片的标签,并将其可视化。ds_test = eval_dataset.create_dict_iterator()data = next(ds_test)images = data["image"].asnumpy()labels = data["label"].asnumpy()output = model.predict(Tensor(data['image'])) #利用加载好的模型的predict进行预测,注意返回的是对应的(0到9)的概率pred = np.argmax(output.asnumpy(), axis=1)err_num = []index = 1for i in range(len(labels)): plt.subplot(4, 8, i+1) color = 'blue' if pred[i] == labels[i] else 'red' plt.title("pre:{}".format(pred[i]), color=color) plt.imshow(np.squeeze(images[i])) plt.axis("off") if color == 'red': index = 0 print("Row {}, column {} is incorrectly identified as {}, the correct value should be {}".format(int(i/8)+1, i%8+1, pred[i], labels[i]), '\n')if index: print("All the figures in this group are predicted correctly!")print(pred, "<--Predicted figures")print(labels, "<--The right number")plt.show()可以看到我抽到的这一组32张图片是属于手气较好的,全部预测正确。上面有些数字确实挺有干扰性的,但机器还是识别出来了(比如第2行最后一张2,写的挺奇葩的)。总之到了这里,基于MindSpore的手写数字识别初体验就已经结束了,写这篇文章不是说要深入手写数字识别,而是说经过这个小型项目的实践,我们可以对MindSpore的各个模块有个大体的理解。比如说dataset模块用于各种数据集的处理和加载,有热门数据集的加载处理方法,有MindSpore专属的数据格式,有一些不同数据集的增强方法。nn模块提供了与网络构建,网络参数相关的各种封装好的高级API。类似的还有很多,我们可以通过这些模块的功能进一步细化深入到该模块中子模块,方法。从功能入手,由表及里,分析源码。训练好的参数已经上传,不想训练的小伙伴可以直接将它加载进LeNet-5网络中去实践,需要自己训练的也可以使用我上传的代码。不过该代码是文章所以测试代码的综合,其中有些测试的点已经被注释,读者可自行查看编辑。————————————————原文链接:https://blog.csdn.net/qq_51964209/article/details/120003642 -
MindSpore静态图语法支持概述在Graph模式下,Python代码并不是由Python解释器去执行,而是将代码编译成静态计算图,然后执行静态计算图。关于Graph模式和计算图,可参考文档:https://www.mindspore.cn/tutorial/training/zh-CN/r1.1/advanced_use/debug_in_pynative_mode.html当前仅支持编译@ms_function装饰器修饰的函数、Cell及其子类的实例。 对于函数,则编译函数定义;对于网络,则编译construct方法及其调用的其他方法或者函数。ms_function使用规则可参考文档:https://www.mindspore.cn/doc/api_python/zh-CN/r1.1/mindspore/mindspore.html#mindspore.ms_functionCell定义可参考文档:https://www.mindspore.cn/doc/programming_guide/zh-CN/r1.1/cell.html由于语法解析的限制,当前在编译构图时,支持的数据类型、语法以及相关操作并没有完全与Python语法保持一致,部分使用受限。本文主要介绍,在编译静态图时,支持的数据类型、语法以及相关操作,这些规则仅适用于Graph模式。以下所有示例都运行在Graph模式下的网络中,为了简洁,并未将网络的定义都写出来。数据类型Python内置数据类型当前支持的Python内置数据类型包括:Number、String、List、Tuple和Dictionary。Number支持int、float、bool,不支持complex(复数)。支持在网络里定义Number,即支持语法:y = 1、y = 1.2、 y = True。不支持在网络里强转Number,即不支持语法:y = int(x)、y = float(x)、y = bool(x)。String支持在网络里构造String,即支持语法y = “abcd”。不支持在网络里强转String,即不支持语法 y = str(x)。List支持在网络里构造List,即支持语法y = [1, 2, 3]。不支持在网络里强转List,即不支持语法y = list(x)。计算图中最终需要输出的List会转换为Tuple输出。• 支持接口append: 向list里追加元素。示例如下:x = [1, 2, 3]x.append(4)结果如下:x: (1, 2, 3, 4)• 支持索引取值和赋值支持单层和多层索引取值以及赋值。取值和赋值的索引值仅支持int。赋值时,所赋的值支持Number、String、Tuple、List、Tensor。示例如下:x = [[1, 2], 2, 3, 4]y = x[0][1]x[1] = Tensor(np.array([1, 2, 3]))x[2] = “ok”x[3] = (1, 2, 3)x[0][1] = 88结果如下:y: 2x: ([1, 88], Tensor(shape=[3], dtype=Int64, value=[1, 2, 3]), ‘ok’, (1, 2, 3))Tuple支持在网络里构造Tuple,即支持语法y = (1, 2, 3)。不支持在网络里强转Tuple,即不支持语法y = tuple(x)。• 支持索引取值索引值支持int、slice、Tensor,也支持多层索引取值,即支持语法data = tuple_x[index0][index1]…。索引值为Tensor有如下限制:o tuple里存放的都是Cell,每个Cell要在tuple定义之前完成定义,每个Cell的入参个数、入参类型和入参shape要求一致,每个Cell的输出个数、输出类型和输出shape也要求一致。o 索引Tensor是一个dtype为int32的标量Tensor,取值范围在[-tuple_len, tuple_len)。o 该语法不支持if、while、for控制流条件为变量的运行分支,仅支持控制流条件为常量。o 仅支持GPU后端。int、slice索引示例如下:x = (1, (2, 3, 4), 3, 4, Tensor(np.array([1, 2, 3])))y = x[1][1]z = x[4]m = x[1:4]结果如下:y: 3z: Tensor(shape=[3], dtype=Int64, value=[1, 2, 3])m: (2, 3, 4), 3, 4)Tensor索引示例如下:class Net(nn.Cell):def init(self):super(Net, self).init()self.relu = nn.ReLU()self.softmax = nn.Softmax()self.layers = (self.relu, self.softmax)def construct(self, x, index): ret = self.layers[index](x) return retDictionary支持在网络里构造Dictionary,即支持语法y = {“a”: 1, “b”: 2},当前仅支持String作为key值。计算图中最终需要输出的Dictionary,会取出所有的value组成Tuple输出。• 支持接口keys:取出dict里所有的key值,组成Tuple返回。values:取出dict里所有的value值,组成Tuple返回。示例如下:x = {“a”: Tensor(np.array([1, 2, 3])), “b”: Tensor(np.array([4, 5, 6])), “c”: Tensor(np.array([7, 8, 9]))}y = x.keys()z = x.values()结果如下:y: (“a”, “b”, “c”)z: (Tensor(shape=[3], dtype=Int64, value=[1, 2, 3]), Tensor(shape=[3], dtype=Int64, value=[4, 5, 6]), Tensor(shape=[3], dtype=Int64, value=[7, 8, 9]))• 支持索引取值和赋值取值和赋值的索引值都仅支持String。赋值时,所赋的值支持Number、Tuple、Tensor。示例如下:x = {“a”: Tensor(np.array([1, 2, 3])), “b”: Tensor(np.array([4, 5, 6])), “c”: Tensor(np.array([7, 8, 9]))}y = x[“b”]x[“a”] = (2, 3, 4)结果如下:y: Tensor(shape=[3], dtype=Int64, value=[4, 5, 6])x: {“a”: (2, 3, 4), Tensor(shape=[3], dtype=Int64, value=[4, 5, 6]), Tensor(shape=[3], dtype=Int64, value=[7, 8, 9])}MindSpore自定义数据类型当前MindSpore自定义数据类型包括:Tensor、Primitive和Cell。Tensor当前不支持在网络里构造Tensor,即不支持语法x = Tensor(args…)。可以通过@constexpr装饰器修饰函数,在函数里生成Tensor。关于@constexpr的用法可参考:https://www.mindspore.cn/doc/api_python/zh-CN/r1.1/mindspore/ops/mindspore.ops.constexpr.html对于网络中需要用到的常量Tensor,可以作为网络的属性,在init的时候定义,即self.x = Tensor(args…),然后在construct里使用。如下示例,通过@constexpr生成一个shape = (3, 4), dtype = int64的Tensor。@constexprdef generate_tensor():return Tensor(np.ones((3, 4)))下面将介绍下Tensor支持的属性、接口、索引取值和索引赋值。• 支持属性:shape:获取Tensor的shape,返回一个Tuple。dtype:获取Tensor的数据类型,返回一个MindSpore定义的数据类型。• 支持接口:all:对Tensor通过all操作进行归约,仅支持Bool类型的Tensor。any:对Tensor通过any操作进行归约,仅支持Bool类型的Tensor。view:将Tensorreshape成输入的shape。expand_as:将Tensor按照广播规则扩展成与另一个Tensor相同的shape。示例如下:x = Tensor(np.array([[True, False, True], [False, True, False]]))x_shape = x.shapex_dtype = x.dtypex_all = x.all()x_any = x.any()x_view = x.view((1, 6))y = Tensor(np.ones((2, 3), np.float32))z = Tensor(np.ones((2, 2, 3)))y_as_z = y.expand_as(z)结果如下:x_shape: (2, 3)x_dtype: Boolx_all: Tensor(shape=[], dtype=Bool, value=False)x_any: Tensor(shape=[], dtype=Bool, value=True)x_view: Tensor(shape=[1, 6], dtype=Bool, value=[[True, False, True, False, True, False]])y_as_z: Tensor(shape=[2, 2, 3], dtype=Float32, value=[[[1.0, 1.0, 1.0], [1.0, 1.0, 1.0]], [[1.0, 1.0, 1.0], [1.0, 1.0, 1.0]]])• 索引取值索引值支持int、True、None、slice、Tensor、Tuple。o int索引取值支持单层和多层int索引取值,单层int索引取值:tensor_x[int_index],多层int索引取值:tensor_x[int_index0][int_index1]…。int索引取值操作的是第0维,索引值小于第0维长度,在取出第0维对应位置数据后,会消除第0维。例如,如果对一个shape为(3, 4, 5)的tensor进行单层int索引取值,取得结果的shape是(4, 5)。多层索引取值可以理解为,后一层索引取值在前一层索引取值结果上再进行int索引取值。示例如下:tensor_x = Tensor(np.arange(2 * 3 * 2).reshape((2, 3, 2)))data_single = tensor_x[0]data_multi = tensor_x[0][1]结果如下:data_single: Tensor(shape=[3, 2], dtype=Int64, value=[[0, 1], [2, 3], [4, 5]])data_multi: Tensor(shape=[2], dtype=Int64, value=[2, 3])o True索引取值支持单层和多层True索引取值,单层True索引取值:tensor_x[True],多层True索引取值:tensor_x[True][True]…。True索引取值操作的是第0维,在取出所有数据后,会在axis=0轴上扩展一维,该维长度为1。例如,对一个shape为(3, 4, 5)的tensor进行单层True索引取值,取得结果的shape是(1, 3, 4, 5)。多层索引取值可以理解为,后一层索引取值在前一层索引取值结果上再进行True索引取值。示例如下:tensor_x = Tensor(np.arange(2 * 3 ).reshape((2, 3)))data_single = tensor_x[True]data_multi = tensor_x[True][True]结果如下:data_single: Tensor(shape=[1, 2, 3], dtype=Int64, value=[[[0, 1, 2], [3, 4, 5]]])data_multi: Tensor(shape=[1, 1, 2, 3], dtype=Int64, value=[[[[0, 1, 2], [3, 4, 5]]]])o None索引取值None索引取值和True索引取值一致,可参考True索引取值,这里不再赘述。o ellipsis索引取值支持单层和多层ellipsis索引取值,单层ellipsis索引取值:tensor_x[…],多层ellipsis索引取值:tensor_x[…][…]…。ellipsis索引取值操作的是所有维度,原样不动取出所有数据。一般多作为Tuple索引的组成元素,Tuple索引将于下面介绍。例如,对一个shape为(3, 4, 5)的tensor进行ellipsis索引取值,取得结果的shape依然是(3, 4, 5)。示例如下:tensor_x = Tensor(np.arange(2 * 3 ).reshape((2, 3)))data_single = tensor_x[…]data_multi = tensor_x[…][…]结果如下:data_single: Tensor(shape=[2, 3], dtype=Int64, value=[[0, 1, 2], [3, 4, 5]])data_multi: Tensor(shape=[2, 3], dtype=Int64, value=[[0, 1, 2], [3, 4, 5]])o slice索引取值支持单层和多层slice索引取值,单层slice索引取值:tensor_x[slice_index],多层slice索引取值:tensor_x[slice_index0][slice_index1]…。slice索引取值操作的是第0维,取出第0维所切到位置的元素,slice不会降维,即使切到长度为1,区别于int索引取值。例如,tensor_x[0:1:1] != tensor_x[0],因为shape_former = (1,) + shape_latter。多层索引取值可以理解为,后一层索引取值在前一层索引取值结果上再进行slice索引取值。slice有start、stop和step组成。start默认值为0,stop默认值为该维长度,step默认值为1。例如,tensor_x[:] == tensor_x[0:length:1]。示例如下:tensor_x = Tensor(np.arange(4 * 2 * 2).reshape((4, 2, 2)))data_single = tensor_x[1:4:2]data_multi = tensor_x[1:4:2][1:]结果如下:data_single: Tensor(shape=[2, 2, 2], dtype=Int64, value=[[[4, 5], [6, 7]], [[12, 13], [14, 15]]])data_multi: Tensor(shape=[1, 2, 2], dtype=Int64, value=[[[12, 13], [14, 15]]])o Tensor索引取值支持单层和多层Tensor索引取值,单层Tensor索引取值:tensor_x[tensor_index],多层Tensor索引取值:tensor_x[tensor_index0][tensor_index1]…。Tensor索引取值操作的是第0维,取出第0维对应位置的元素。索引Tensor数据类型必须是int32,元素不能是负数,值小于第0维长度。Tensor索引取值得到结果的data_shape = tensor_index.shape + tensor_x.shape[1:]。例如,对一个shape为(6, 4, 5)的tensor通过shape为(2, 3)的tensor进行索引取值,取得结果的shape为(2, 3, 4, 5)。多层索引取值可以理解为,后一层索引取值在前一层索引取值结果上再进行Tensor索引取值。示例如下:tensor_x = Tensor(np.arange(4 * 2 * 3).reshape((4, 2, 3)))tensor_index0 = Tensor(np.array([[1, 2], [0, 3]]), mstype.int32)tensor_index1 = Tensor(np.array([[0, 0]]), mstype.int32)data_single = tensor_x[tensor_index0]data_multi = tensor_x[tensor_index0][tensor_index1]结果如下:data_single: Tensor(shape=[2, 2, 2, 3], dtype=Int64, value=[[[[4, 5], [6, 7]], [[8, 9], [10, 11]]], [[[0, 1], [2, 3]], [[12, 13], [14, 15]]]])data_multi: Tensor(shape=[1, 2, 2, 2, 3], dtype=Int64, value=[[[[[4, 5], [6, 7]], [[8, 9], [10, 11]]], [[[4, 5], [6, 7]], [[8, 9], [10, 11]]]]])o Tuple索引取值索引Tuple的数据类型必须是int32,支持单层和多层Tuple索引取值,单层Tuple索引取值:tensor_x[tuple_index],多层Tuple索引取值:tensor_x[tuple_index0][tuple_index1]…。Tuple索引里的元素可以包含int、slice、ellipsis、Tensor。索引里除ellipsis外每个元素操作对应位置维度,即Tuple中第0个元素操作第0维,第1个元素操作第1维,以此类推,每个元素的索引规则与该元素类型索引取值规则一致。Tuple索引里最多只有一个ellipsis,ellipsis前半部分索引元素从前往后对应Tensor第0维往后,后半部分索引元素从后往前对应Tensor最后一维往前,其他未指定的维度,代表全取。元素里包含的Tensor数据类型必须是int32,且Tensor元素不能是负数,值小于操作维度长度。例如,tensor_x[0:3, 1, tensor_index] == tensor_x[(0:3, 1, tensor_index)],因为0:3, 1, tensor_index就是一个Tuple。多层索引取值可以理解为,后一层索引取值在前一层索引取值结果上再进行Tuple索引取值。示例如下:tensor_x = Tensor(np.arange(2 * 3 * 4).reshape((2, 3, 4)))tensor_index = Tensor(np.array([[1, 2, 1], [0, 3, 2]]), mstype.int32)data = tensor_x[1, 0:1, tensor_index]结果如下:data: Tensor(shape=[2, 3, 1], dtype=Int64, value=[[[13], [14], [13]], [[12], [15], [14]]])• 索引赋值索引值支持int、ellipsis、slice、Tensor、Tuple。索引赋值可以理解为对索引到的位置元素按照一定规则进行赋值,所有索引赋值都不会改变原Tensor的shape。同时支持增强索引赋值,即支持+=、-=、*=、/=、%=、**=、//=。o int索引赋值支持单层和多层int索引赋值,单层int索引赋值:tensor_x[int_index] = u,多层int索引赋值:tensor_x[int_index0][int_index1]… = u。所赋值支持Number和Tensor,Number和Tensor都会被转为与被更新Tensor数据类型一致。当所赋值为Number时,可以理解为将int索引取到位置元素都更新为Number。当所赋值为Tensor时,Tensor的shape必须等于或者可广播为int索引取到结果的shape,在保持二者shape一致后,然后将赋值Tensor元素更新到索引取出结果对应元素的原Tensor位置。例如,对shape = (2, 3, 4)的Tensor,通过int索引1赋值为100,更新后的Tensorshape仍为(2, 3, 4),但第0维位置为1的所有元素,值都更新为100。示例如下:tensor_x = Tensor(np.arange(2 * 3).reshape((2, 3)).astype(np.float32))tensor_y = Tensor(np.arange(2 * 3).reshape((2, 3)).astype(np.float32))tensor_z = Tensor(np.arange(2 * 3).reshape((2, 3)).astype(np.float32))tensor_x[1] = 88.0tensor_y[1][1] = 88.0tensor_z[1]= Tensor(np.array([66, 88, 99]).astype(np.float32))结果如下:tensor_x: Tensor(shape=[2, 3], dtype=Float32, value=[[0.0, 1.0, 2.0], [88.0, 88.0, 88.0]])tensor_y: Tensor(shape=[2, 3], dtype=Float32, value=[[0.0, 1.0, 2.0], [3.0, 88.0, 5.0]])tensor_z: Tensor(shape=[2, 3], dtype=Float32, value=[[0.0, 1.0, 2.0], [66.0, 88.0, 99.0]])o ellipsis索引赋值支持单层和多层ellipsis索引赋值,单层ellipsis索引赋值:tensor_x[…] = u,多层ellipsis索引赋值:tensor_x[…][…]… = u。所赋值支持Number和Tensor,Number和Tensor里的值都会转为与被更新Tensor数据类型一致。当所赋值为Number时,可以理解为将所有元素都更新为Number。当所赋值为Tensor时,Tensor里元素个数必须为1或者等于原Tensor里元素个数,元素为1时进行广播,个数相等shape不一致时进行reshape, 在保证二者shape一致后,将赋值Tensor元素按照位置逐一更新到原Tensor里。例如,对shape = (2, 3, 4)的Tensor,通过…索引赋值为100,更新后的Tensorshape仍为(2, 3, 4),所有元素都变为100。示例如下:tensor_x = Tensor(np.arange(2 * 3).reshape((2, 3)).astype(np.float32))tensor_y = Tensor(np.arange(2 * 3).reshape((2, 3)).astype(np.float32))tensor_z = Tensor(np.arange(2 * 3).reshape((2, 3)).astype(np.float32))tensor_x[…] = 88.0tensor_y[…] = Tensor(np.array([22, 44, 55, 22, 44, 55]).astype(np.float32))结果如下:tensor_x: Tensor(shape=[2, 3], dtype=Float32, value=[[88.0, 88.0, 88.0], [88.0, 88.0, 88.0]])tensor_y: Tensor(shape=[2, 3], dtype=Float32, value=[[22.0, 44.0, 55.0], [22.0, 44.0, 55.0]])o slice索引赋值支持单层和多层slice索引赋值,单层slice索引赋值:tensor_x[slice_index] = u,多层slice索引赋值:tensor_x[slice_index0][slice_index1]… = u。所赋值支持Number和Tensor,Number和Tensor里的值都会转为与被更新Tensor数据类型一致。当所赋值为Number时,可以理解为将slice索引取到位置元素都更新为Number。当所赋值为Tensor时,Tensor里元素个数必须为1或者等于slice索引取到Tensor里元素个数,元素为1时进行广播,个数相等shape不一致时进行reshape, 在保证二者shape一致后,将赋值Tensor元素按照位置逐一更新到原Tensor里。例如,对shape = (2, 3, 4)的Tensor,通过0:1:1索引赋值为100,更新后的Tensorshape仍为(2, 3, 4),但第0维位置为0的所有元素,值都更新为100。示例如下:tensor_x = Tensor(np.arange(3 * 3).reshape((3, 3)).astype(np.float32))tensor_y = Tensor(np.arange(3 * 3).reshape((3, 3)).astype(np.float32))tensor_z = Tensor(np.arange(3 * 3).reshape((3, 3)).astype(np.float32))tensor_x[0:1] = 88.0tensor_y[0:2][0:2] = 88.0tensor_z[0:2] = Tensor(np.array([11, 12, 13, 11, 12, 13]).astype(np.float32))结果如下:tensor_x: Tensor(shape=[3, 3], dtype=Float32, value=[[88.0, 88.0, 88.0], [3.0, 4.0, 5.0], [6.0, 7.0, 8.0]])tensor_y: Tensor(shape=[3, 3], dtype=Float32, value=[[88.0, 88.0, 88.0], [88.0, 88.0, 88.0], [6.0, 7.0, 8.0]])tensor_z: Tensor(shape=[3, 3], dtype=Float32, value=[[11.0, 12.0, 13.0], [11.0, 12.0, 13.0], [6.0, 7.0, 8.0]])o Tensor索引赋值仅支持单层Tensor索引赋值,即tensor_x[tensor_index] = u。索引Tensor支持int32和bool类型。所赋值支持Number、Tuple和Tensor,Number、Tuple和Tensor里的值必须与原Tensor数据类型一致。当所赋值为Number时,可以理解为将Tensor索引取到位置元素都更新为Number。当所赋值为Tensor时,Tensor的shape必须等于或者可广播为索引取到结果的shape,在保持二者shape一致后,然后将赋值Tensor元素更新到索引取出结果对应元素的原Tensor位置。当所赋值为Tuple时,Tuple里元素只能全是Number或者全是Tensor。当全是Number时,Number的类型必须与原Tensor数据类型是一类,且元素的个数必须等于索引取到结果shape的最后一维,然后广播为索引取到结果shape;当全是Tensor的时候,这些Tensor在axis=0轴上打包之后成为一个新的赋值Tensor,这时按照所赋值为Tensor的规则进行赋值。例如,对一个shape为(6, 4, 5)、dtype为float32的tensor通过shape为(2, 3)的tensor进行索引赋值,如果所赋值为Number,则Number必须是float; 如果所赋值为Tuple,则tuple里的元素都得是float,且个数为5;如果所赋值为Tensor,则Tensor的dtype必须为float32,且shape可广播为(2, 3, 4, 5)。示例如下:tensor_x = Tensor(np.arange(3 * 3).reshape((3, 3)).astype(np.float32))tensor_y = Tensor(np.arange(3 * 3).reshape((3, 3)).astype(np.float32))tensor_index = Tensor(np.array([[2, 0, 2], [0, 2, 0], [0, 2, 0]], np.int32))tensor_x[tensor_index] = 88.0tensor_y[tensor_index] = Tensor(np.array([11.0, 12.0, 13.0]).astype(np.float32))结果如下:tensor_x: Tensor(shape=[3, 3], dtype=Float32, value=[[88.0, 88.0, 88.0], [3.0, 4.0, 5.0], [88.0, 88.0, 88.0]])tensor_y: Tensor(shape=[3, 3], dtype=Float32, value=[[11.0, 12.0, 13.0], [3.0, 4.0, 5.0], [11.0, 12.0, 13.0]])o Tuple索引赋值支持单层和多层Tuple索引赋值,单层Tuple索引赋值:tensor_x[tuple_index] = u,多层Tuple索引赋值:tensor_x[tuple_index0][tuple_index1]… = u。Tuple索引赋值和Tuple索引取值对索引的支持一致, 但多层Tuple索引赋值不支持Tuple里包含Tensor。所赋值支持Number、Tuple和Tensor,Number、Tuple和Tensor里的值必须与原Tensor数据类型一致。当所赋值为Number时,可以理解为将Tensor索引取到位置元素都更新为Number。当所赋值为Tensor时,Tensor的shape必须等于或者可广播为索引取到结果的shape,在保持二者shape一致后,然后将赋值Tensor元素更新到索引取出结果对应元素的原Tensor位置。当所赋值为Tuple时,Tuple里元素只能全是Number或者全是Tensor。当全是Number时,Number的类型必须与原Tensor数据类型是一类,且元素的个数必须等于索引取到结果shape的最后一维,然后广播为索引取到结果shape;当全是Tensor的时候,这些Tensor在axis=0轴上打包之后成为一个新的赋值Tensor,这时按照所赋值为Tensor的规则进行赋值。示例如下:tensor_x = Tensor(np.arange(3 * 3).reshape((3, 3)).astype(np.float32))tensor_y = Tensor(np.arange(3 * 3).reshape((3, 3)).astype(np.float32))tensor_z = Tensor(np.arange(3 * 3).reshape((3, 3)).astype(np.float32))tensor_index = Tensor(np.array([[0, 1], [1, 0]]).astype(np.int32))tensor_x[1, 1:3] = 88.0tensor_y[1:3, tensor_index] = 88.0tensor_z[1:3, tensor_index] = Tensor(np.array([11, 12]).astype(np.float32))结果如下:tensor_x: Tensor(shape=[3, 3], dtype=Float32, value=[[0.0, 1.0, 2.0], [3.0, 88.0, 88.0], [6.0, 7.0, 8.0]])tensor_y: Tensor(shape=[3, 3], dtype=Float32, value=[[0.0, 1.0, 2.0], [88.0, 88.0, 5.0], [88.0, 88.0, 8.0]])tensor_z: Tensor(shape=[3, 3], dtype=Float32, value=[[0.0, 1.0, 2.0], [12.0, 11.0, 5.0], [12.0, 11.0, 8.0]])Primitive当前支持在网络里构造Primitive及其子类的实例,即支持语法reduce_sum = ReduceSum(True)。但在构造时,参数只能通过位置参数方式传入,不支持通过键值对方式传入,即不支持语法reduce_sum = ReduceSum(keep_dims=True)。当前不支持在网络调用Primitive及其子类相关属性和接口。Primitive定义可参考文档:https://www.mindspore.cn/doc/programming_guide/zh-CN/r1.1/operators.html当前已定义的Primitive可参考文档:https://www.mindspore.cn/doc/api_python/zh-CN/r1.1/mindspore/mindspore.ops.htmlCell当前支持在网络里构造Cell及其子类的实例,即支持语法cell = Cell(args…)。但在构造时,参数只能通过位置参数方式传入,不支持通过键值对方式传入,即不支持在语法cell = Cell(arg_name=value)。当前不支持在网络调用Cell及其子类相关属性和接口,除非是在Cell自己的contrcut中通过self调用。Cell定义可参考文档:https://www.mindspore.cn/doc/programming_guide/zh-CN/r1.1/cell.html当前已定义的Cell可参考文档:https://www.mindspore.cn/doc/api_python/zh-CN/r1.1/mindspore/mindspore.nn.html运算符算术运算符和赋值运算符支持Number和Tensor运算,也支持不同dtype的Tensor运算。之所以支持,是因为这些运算符会转换成同名算子进行运算,这些算子支持了隐式类型转换。规则可参考文档:https://www.mindspore.cn/doc/note/zh-CN/r1.1/operator_list_implicit.htm表达式条件控制语句if使用方式:• if (cond): statements…• x = y if (cond) else z参数:cond – 支持类型Number、Tuple、List、String、None、Tensor、Function,也可以是计算结果类型是其中之一的表达式。限制:• 在构图时,如果if未能消除,则if分支return的数据类型和shape,与if分支外return的数据类型和shape必须一致。• 当只有if时,if分支变量更新后数据类型和shape,与更新前数据类型和shape必须一致。• 当即有if又有else时,if分支变量更新后数据类型和shape,与else分支更新后数据类型和shape必须一致。示例1:if x > y:return melse:return nif分支返回的m和else分支返回的n,二者数据类型和shape必须一致。示例2:if x > y:out = melse:out = nreturn outif分支更新后out和else分支更新后out,二者数据类型和shape必须一致。循环语句for使用方式:for i in sequence示例如下:z = Tensor(np.ones((2, 3)))x = (1, 2, 3)for i in x:z += ireturn z结果如下:z: Tensor(shape=[2, 3], dtype=Int64, value=[[7, 7], [7, 7], [7, 7]])参数:sequence – 遍历序列(Tuple、List)while使用方式:while(cond)参数:cond – 与if一致。限制:• 在构图时,如果while未能消除,则while内return的数据类型和shape,与while外return的数据类型和shape必须一致。• while内变量更新后数据类型和shape,与更新前数据类型和shape必须一致。示例1:while x > y:x += 1return mreturn nwhile内返回的m和while外返回的n数据类型必须和shape一致。示例2:out = mwhile x > y:x += 1out = nreturn outwhile内,out更新后和更新前的数据类型和shape必须一致。流程控制语句当前流程控制语句支持了break、continue和pass。break可用于for和while代码块里,用于终止整个循环。示例如下:for i in x:if i == 2:breakstatement_astatement_b当 i == 2时,循环终止,执行statement_b。continue可用于for和while语句块里,用于终止本轮循环,直接进入下一轮循环。示例如下:for i in x:if i == 2:continuestatement_astatement_b当 i == 2时,本轮循环终止,不会往下执行statement_a,进入下一轮循环。函数Python内置函数当前支持的Python内置函数包括:len、isinstance、partial、map、range、enumerate、super和pow。len功能:求序列的长度。调用:len(sequence)入参:sequence – Tuple、List、Dictionary或者Tensor。返回值:序列的长度,类型为int。当入参是Tensor时,返回的是Tensor第0维的长度。示例如下:x = (2, 3, 4)y = [2, 3, 4]d = {“a”: 2, “b”: 3}z = Tensor(np.ones((6, 4, 5)))x_len = len(x)y_len = len(y)d_len = len(d)z_len = len(z)结果如下:x_len: 3y_len: 3d_len: 2z_len: 6isinstance功能:判断对象是否为类的实例。调用:isinstance(obj, type)入参:• obj – 任意支持类型的任意一个实例。• type – MindSpore dtype模块下的一个类型。返回值:obj为type的实例,返回True,否则返回False。示例如下:x = (2, 3, 4)y = [2, 3, 4]z = Tensor(np.ones((6, 4, 5)))x_is_tuple = isinstance(x, mstype.tuple_)map功能:根据提供的函数对一个或者多个序列做映射,由映射的结果生成一个新的序列。 如果多个序列中的元素个数不一致,则生成的新序列与最短的那个长度相同。调用:map(func, sequence, …)入参:• func – 函数。• sequence – 一个或多个序列(Tuple或者List)。返回值:返回一个Tuple。示例如下:def add(x, y):return x + yelements_a = (1, 2, 3)elements_b = (4, 5, 6)ret = map(add, elements_a, elements_b)结果如下:ret: (5, 7, 9)zip功能:将多个序列中对应位置的元素打包成一个个元组,然后由这些元组组成一个新序列, 如果各个序列中的元素个数不一致,则生成的新序列与最短的那个长度相同。调用:zip(sequence, …)入参:sequence – 一个或多个序列(Tuple或List)`。y: (0, 1, 2, 3, 4)z: (0, 1, 2)enumerate功能:生成一个序列的索引序列,索引序列包含数据和对应下标。调用:• enumerate(sequence, start)• enumerate(sequence)入参:• sequence – 一个序列(Tuple、List、Tensor)。• start – 下标起始位置,类型为int,默认为0。返回值:返回一个Tuple。示例如下:x = (100, 200, 300, 400)ret_father_construct = super().construct(x, y)ret_father_test = super(SingleSubNet, self).test_father(x)return ret_father_construct, ret_father_testpow功能:求幂。调用:pow(x, y)入参:• x – 底数, Number或Tensor。• y – 幂指数, Number或Tensor。返回值:返回x的y次幂,Number或Tensor。示例如下:x = Tensor(np.array([1, 2, 3]))y = Tensor(np.array([1, 2, 3]))ret = pow(x, y)结果如下:ret: Tensor(shape=[3], dtype=Int64, value=[1, 4, 27]))print功能:用于打印。调用:print(arg, …)入参:arg – 要打印的信息(String或Tensor)。返回值:无返回值。示例如下:x = Tensor(np.array([1, 2, 3]))print(“result”, x)结果如下:result Tensor(shape=[3], dtype=Int64, value=[1, 2, 3]))函数参数• 参数默认值:目前不支持默认值设为Tensor类型数据,支持int、float、bool、None、str、tuple、list、dict类型数据。• 可变参数:支持带可变参数网络的推理和训练。• 键值对参数:目前不支持带键值对参数的函数求反向。• 可变键值对参数:目前不支持带可变键值对的函数求反向。网络定义整网实例类型• 带@ms_function装饰器的普通Python函数。• 继承自nn.Cell的Cell子类。网络构造组件网络使用约束当前整网入参(即最外层网络入参)默认仅支持Tensor,如果要支持非Tensor,可设置网络的support_non_tensor_inputs属性为True。在网络初始化的时候,设置self.support_non_tensor_inputs = True,该配置目前仅支持正向网络,暂不支持反向网络,即不支持对整网入参有非Tensor的网络求反向。支持最外层传入标量示例如下:class ExpandDimsNet(nn.Cell):def init(self):super(ExpandDimsNet, self).init()self.support_non_tensor_inputs = Trueself.expandDims = ops.ExpandDims()def construct(self, input_x, input_axis):return self.expandDims(input_x, input_axis)expand_dim_net = ExpandDimsNet()input_x = Tensor(np.random.randn(2,2,2,2).astype(np.float32))expand_dim_net(input_x, 0)不允许修改网络的非Parameter类型数据成员。示例如下:class Net(Cell):def init(self):super(Net, self).init()self.num = 2self.par = Parameter(Tensor(np.ones((2, 3, 4))), name=“par”)def construct(self, x, y):return x + y上面所定义的网络里,self.num不是一个Parameter,不允许被修改,而self.par是一个Parameter,可以被修改。当construct函数里,使用未定义的类成员时,不会像Python解释器那样抛出AttributeError,而是作为None处理。示例如下:class Net(Cell):def init(self):super(Net, self).init()def construct(self, x):return x + self.y上面所定义的网络里,construct里使用了并未定义的类成员self.y,此时会将self.y作为None处理。————————————————原文链接:https://blog.csdn.net/wujianing_110117/article/details/113026734
-
MindSpore接口mindspore::apiContext#include <context.h>Context类用于保存执行中的环境变量。静态公有成员函数Instancestatic Context &Instance();获取MindSpore Context实例对象。公有成员函数GetDeviceTargetconst std::string &GetDeviceTarget() const;获取当前目标Device类型。• 返回值当前DeviceTarget的类型。GetDeviceIDuint32_t GetDeviceID() const;获取当前Device ID。• 返回值当前Device ID。SetDeviceTargetContext &SetDeviceTarget(const std::string &device_target);配置目标Device。• 参数o device_target: 将要配置的目标Device,可选有kDeviceTypeAscend310、kDeviceTypeAscend910。• 返回值该MindSpore Context实例对象。SetDeviceIDContext &SetDeviceID(uint32_t device_id);获取当前Device ID。• 参数o device_id: 将要配置的Device ID。• 返回值该MindSpore Context实例对象。Serialization#include <serialization.h>Serialization类汇总了模型文件读写的方法。静态公有成员函数LoadModel• 参数o file: 模型文件路径。o model_type:模型文件类型,可选有ModelType::kMindIR、ModelType::kOM。• 返回值保存图数据的对象。Model#include <model.h>Model定义了MindSpore中的模型,便于计算图管理。构造函数和析构函数Model(const GraphCell &graph);~Model();GraphCell是Cell的一个派生,Cell目前没有开放使用。GraphCell可以由Graph构造,如Model model(GraphCell(graph))。公有成员函数BuildStatus Build(const std::map<std::string, std::string> &options);将模型编译至可在Device上运行的状态。• 参数o options: 模型编译选项,key为选项名,value为对应选项,支持的options有:Key ValuekModelOptionInsertOpCfgPath AIPP配置文件路径kModelOptionInputFormat 手动指定模型输入format,可选有"NCHW",“NHWC"等kModelOptionInputShape 手动指定模型输入shape,如"input_op_name1: n1,c2,h3,w4;input_op_name2: n4,c3,h2,w1”kModelOptionOutputType 手动指定模型输出type,如"FP16",“UINT8"等,默认为"FP32”kModelOptionPrecisionMode 模型精度模式,可选有"force_fp16",“allow_fp32_to_fp16”,“must_keep_origin_dtype"或者"allow_mix_precision”,默认为"force_fp16"kModelOptionOpSelectImplMode 算子选择模式,可选有"high_performance"和"high_precision",默认为"high_performance"• 返回值状态码。PredictStatus Predict(const std::vector &inputs, std::vector *outputs);推理模型。• 参数o inputs: 模型输入按顺序排列的vector。o outputs: 输出参数,按顺序排列的vector的指针,模型输出会按顺序填入该容器。• 返回值状态码。GetInputsInfoStatus GetInputsInfo(std::vectorstd::string *names, std::vector<std::vector<int64_t>> *shapes, std::vector *data_types, std::vector<size_t> *mem_sizes) const;获取模型输入信息。• 参数o names: 可选输出参数,模型输入按顺序排列的vector的指针,模型输入的name会按顺序填入该容器,传入nullptr则表示不获取该属性。o shapes: 可选输出参数,模型输入按顺序排列的vector的指针,模型输入的shape会按顺序填入该容器,传入nullptr则表示不获取该属性。o data_types: 可选输出参数,模型输入按顺序排列的vector的指针,模型输入的数据类型会按顺序填入该容器,传入nullptr则表示不获取该属性。o mem_sizes: 可选输出参数,模型输入按顺序排列的vector的指针,模型输入的以字节为单位的内存长度会按顺序填入该容器,传入nullptr则表示不获取该属性。• 返回值状态码。GetOutputsInfoStatus GetOutputsInfo(std::vectorstd::string *names, std::vector<std::vector<int64_t>> *shapes, std::vector *data_types, std::vector<size_t> *mem_sizes) const;获取模型输出信息。• 参数o names: 可选输出参数,模型输出按顺序排列的vector的指针,模型输出的name会按顺序填入该容器,传入nullptr则表示不获取该属性。o shapes: 可选输出参数,模型输出按顺序排列的vector的指针,模型输出的shape会按顺序填入该容器,传入nullptr则表示不获取该属性。o data_types: 可选输出参数,模型输出按顺序排列的vector的指针,模型输出的数据类型会按顺序填入该容器,传入nullptr则表示不获取该属性。o mem_sizes: 可选输出参数,模型输出按顺序排列的vector的指针,模型输出的以字节为单位的内存长度会按顺序填入该容器,传入nullptr则表示不获取该属性。• 返回值状态码。Tensor#include <types.h>构造函数和析构函数Tensor();Tensor(const std::string &name, DataType type, const std::vector<int64_t> &shape, const void *data, size_t data_len);~Tensor();静态公有成员函数GetTypeSizestatic int GetTypeSize(api::DataType type);获取数据类型的内存长度,以字节为单位。• 参数o type: 数据类型。• 返回值内存长度,单位是字节。公有成员函数Nameconst std::string &Name() const;获取Tensor的名字。• 返回值Tensor的名字。DataTypeapi::DataType DataType() const;获取Tensor的数据类型。• 返回值Tensor的数据类型。Shapeconst std::vector<int64_t> &Shape() const;获取Tensor的Shape。• 返回值Tensor的Shape。SetNamevoid SetName(const std::string &name);设置Tensor的名字。• 参数o name: 将要设置的name。SetDataTypevoid SetDataType(api::DataType type);设置Tensor的数据类型。• 参数o type: 将要设置的type。SetShapevoid SetShape(const std::vector<int64_t> &shape);设置Tensor的Shape。• 参数o shape: 将要设置的shape。Dataconst void *Data() const;获取Tensor中的数据的const指针。• 返回值指向Tensor中的数据的const指针。MutableDatavoid *MutableData();获取Tensor中的数据的指针。• 返回值指向Tensor中的数据的指针。DataSizesize_t DataSize() const;获取Tensor中的数据的以字节为单位的内存长度。• 返回值Tensor中的数据的以字节为单位的内存长度。ResizeDatabool ResizeData(size_t data_len);重新调整Tensor的内存大小。• 参数o data_len: 调整后的内存字节数。• 返回值bool值表示是否成功。SetDatabool SetData(const void *data, size_t data_len);重新调整Tensor的内存数据。• 参数o data: 源数据内存地址。o data_len: 源数据内存长度。• 返回值bool值表示是否成功。ElementNumint64_t ElementNum() const;获取Tensor中元素的个数。• 返回值Tensor中的元素个数CloneTensor Clone() const;拷贝一份自身的副本。• 返回值深拷贝的副本。————————————————原文链接:https://blog.csdn.net/wujianing_110117/article/details/113030387
推荐直播
-
 华为云云原生FinOps解决方案,为您释放云原生最大价值
华为云云原生FinOps解决方案,为您释放云原生最大价值2024/04/24 周三 16:30-18:00
Roc 华为云云原生DTSE技术布道师
还在对CCE集群成本评估感到束手无策?还在担心不合理的K8s集群资源申请和过度浪费?华为云容器服务CCE全新上线云原生FinOps中心,为用户提供多维度集群成本可视化,结合智能规格推荐、混部、超卖等成本优化手段,助力客户降本增效,释放云原生最大价值。
回顾中 -
 鲲鹏开发者创享日·江苏站暨数字技术创新应用峰会
鲲鹏开发者创享日·江苏站暨数字技术创新应用峰会2024/04/25 周四 09:30-16:00
鲲鹏专家团
这是华为推出的旨在和众多技术大牛、行业大咖一同探讨最前沿的技术思考,分享最纯粹的技术经验,进行最真实的动手体验,为开发者提供一个深度探讨与交流的平台。
回顾中
热门标签