-
 在MySQL中,ON DUPLICATE KEY UPDATE和REPLACE INTO都是常用的插入或更新表数据的语句。虽然两者实现的功能类似,但它们有着不同的应用场景和行为特征。本文将对这两种语句进行详细解释,并提供相关测试代码。 ON DUPLICATE KEY UPDATE ON DUPLICATE KEY UPDATE语句是MySQL中用于插入或更新记录的一种方式。它的主要作用是,如果尝试将一条记录插入到已存在的唯一索引(如主键、唯一约束等)中,则会执行更新操作,而不是插入新记录。具体来说,当插入数据时,如果发现指定的索引已经存在,则执行UPDATE操作,将新记录的值更新到该索引对应的原有记录上;否则,执行INSERT操作,插入新记录。其基本语法如下: INSERT INTO table (col1, col2, ...) VALUES (val1, val2, ...) ON DUPLICATE KEY UPDATE col1 = val1, col2 = val2, ...; 其中,table是目标表名,col1、col2等是目标列名,val1、val2等是需要插入或更新的值。 为了更好地理解ON DUPLICATE KEY UPDATE语句的工作原理,我们可以通过以下示例代码进行演示。首先,创建一个名为students的表,包含两个列:id和name。其中,id为主键,并设置自增增长。 CREATE TABLE students ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL ); 然后,向该表中插入一些数据: INSERT INTO students (name) VALUES ('Alice'), ('Bob'), ('Charlie'); 这将在students表中插入三条记录,id分别为1、2和3。 接下来,我们使用ON DUPLICATE KEY UPDATE语句插入一条新记录,并执行更新操作。假设需要插入一条记录,表示学生“Bob”改名为“Bobby”。此时,我们可以使用以下SQL语句: INSERT INTO students (id, name) VALUES (2, 'Bobby') ON DUPLICATE KEY UPDATE name = 'Bobby'; 该语句尝试向students表中插入一条记录,其id为2,name为“Bobby”。由于id=2已经存在,因此触发了更新操作,将原有记录中name的值从“Bob”更新为“Bobby”。 如果我们再次执行查询操作,可以看到students表中的记录如下所示: +----+--------+ | id | name | +----+--------+ | 1 | Alice | | 2 | Bobby | | 3 | Charlie| +----+--------+ REPLACE INTO 与ON DUPLICATE KEY UPDATE不同,REPLACE INTO语句是用于替换或插入表数据的语句。它的工作原理是,当尝试向已经存在的唯一索引中插入新记录时,将删除原有记录并插入新记录。具体来说,如果目标表中已经存在一个与要插入的记录相同的唯一索引,则先删除该记录,再插入新记录;否则,直接插入新记录。其基本语法如下: REPLACE INTO table (col1, col2, ...) VALUES (val1, val2, ...); 其中,table是目标表名,col1、col2等是目标列名,val1、val2等是需要插入或更新的值。 为了更好地理解REPLACE INTO语句的工作原理,我们可以继续使用上述示例。假设需要插入一条记录,表示学生“Denise”加入了班级。此时,我们可以使用以下SQL语句: REPLACE INTO students (id, name) VALUES (4, 'Denise'); 该语句尝试向students表中插入一条记录,其id为4,name为“Denise”。由于id=4不存在,因此直接插入新记录。 如果我们再次执行查询操作,可以看到students表中的记录如下所示: +----+--------+ | id | name | +----+--------+ | 1 | Alice | | 2 | Bob | | 3 | Charlie| | 4 | Denise | +----+--------+ 测试用例 为了进一步说明ON DUPLICATE KEY UPDATE和REPLACE INTO的区别和用法,下面提供一个简单的测试用例。 假设我们有一个名为users的表,包含三个列:id、name和age。其中,id为主键。 首先,我们向users表中插入一些数据: INSERT INTO users (id, name, age) VALUES (1, 'Alice', 20), (2, 'Bob', 25), (3, 'Charlie', 30); 接着,我们分别使用ON DUPLICATE KEY UPDATE和REPLACE INTO语句向该表插入或更新数据,并执行查询操作,验证结果是否符合预期。 使用ON DUPLICATE KEY UPDATE插入或更新数据 -- 插入一条新记录 INSERT INTO users (id, name, age) VALUES (4, 'Denise', 35) ON DUPLICATE KEY UPDATE name = 'Denise', age = 35; -- 更新已有记录 INSERT INTO users (id, name, age) VALUES (2, 'Bobby', 30) ON DUPLICATE KEY UPDATE name = 'Bobby', age = 30; -- 查询数据 SELECT * FROM users; 执行以上语句后,查询结果为: +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | Alice | 20 | | 2 | Bobby | 30 | | 3 | Charlie| 30 | | 4 | Denise | 35 | +----+--------+-----+ 使用REPLACE INTO插入或更新数据 -- 插入一条新记录 REPLACE INTO users (id, name, age) VALUES (5, 'Emily', 25); -- 更新已有记录 REPLACE INTO users (id, name, age) VALUES (3, 'Charles', 40); -- 查询数据 SELECT * FROM users; 执行以上语句后,查询结果为: +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | Alice | 20 | | 2 | Bob | 25 | | 3 | Charles| 40 | | 5 | Emily | 25 | +----+--------+-----+ 通过上述测试用例,我们可以看到ON DUPLICATE KEY UPDATE和REPLACE INTO的不同之处,以及它们在实际应用中的使用场景和注意事项。需要根据具体的业务需求选择合适的语句,以保证数据的正确性和一致性。 ———————————————— 原文链接:https://blog.csdn.net/jam_yin/article/details/130685079
在MySQL中,ON DUPLICATE KEY UPDATE和REPLACE INTO都是常用的插入或更新表数据的语句。虽然两者实现的功能类似,但它们有着不同的应用场景和行为特征。本文将对这两种语句进行详细解释,并提供相关测试代码。 ON DUPLICATE KEY UPDATE ON DUPLICATE KEY UPDATE语句是MySQL中用于插入或更新记录的一种方式。它的主要作用是,如果尝试将一条记录插入到已存在的唯一索引(如主键、唯一约束等)中,则会执行更新操作,而不是插入新记录。具体来说,当插入数据时,如果发现指定的索引已经存在,则执行UPDATE操作,将新记录的值更新到该索引对应的原有记录上;否则,执行INSERT操作,插入新记录。其基本语法如下: INSERT INTO table (col1, col2, ...) VALUES (val1, val2, ...) ON DUPLICATE KEY UPDATE col1 = val1, col2 = val2, ...; 其中,table是目标表名,col1、col2等是目标列名,val1、val2等是需要插入或更新的值。 为了更好地理解ON DUPLICATE KEY UPDATE语句的工作原理,我们可以通过以下示例代码进行演示。首先,创建一个名为students的表,包含两个列:id和name。其中,id为主键,并设置自增增长。 CREATE TABLE students ( id INT PRIMARY KEY AUTO_INCREMENT, name VARCHAR(255) NOT NULL ); 然后,向该表中插入一些数据: INSERT INTO students (name) VALUES ('Alice'), ('Bob'), ('Charlie'); 这将在students表中插入三条记录,id分别为1、2和3。 接下来,我们使用ON DUPLICATE KEY UPDATE语句插入一条新记录,并执行更新操作。假设需要插入一条记录,表示学生“Bob”改名为“Bobby”。此时,我们可以使用以下SQL语句: INSERT INTO students (id, name) VALUES (2, 'Bobby') ON DUPLICATE KEY UPDATE name = 'Bobby'; 该语句尝试向students表中插入一条记录,其id为2,name为“Bobby”。由于id=2已经存在,因此触发了更新操作,将原有记录中name的值从“Bob”更新为“Bobby”。 如果我们再次执行查询操作,可以看到students表中的记录如下所示: +----+--------+ | id | name | +----+--------+ | 1 | Alice | | 2 | Bobby | | 3 | Charlie| +----+--------+ REPLACE INTO 与ON DUPLICATE KEY UPDATE不同,REPLACE INTO语句是用于替换或插入表数据的语句。它的工作原理是,当尝试向已经存在的唯一索引中插入新记录时,将删除原有记录并插入新记录。具体来说,如果目标表中已经存在一个与要插入的记录相同的唯一索引,则先删除该记录,再插入新记录;否则,直接插入新记录。其基本语法如下: REPLACE INTO table (col1, col2, ...) VALUES (val1, val2, ...); 其中,table是目标表名,col1、col2等是目标列名,val1、val2等是需要插入或更新的值。 为了更好地理解REPLACE INTO语句的工作原理,我们可以继续使用上述示例。假设需要插入一条记录,表示学生“Denise”加入了班级。此时,我们可以使用以下SQL语句: REPLACE INTO students (id, name) VALUES (4, 'Denise'); 该语句尝试向students表中插入一条记录,其id为4,name为“Denise”。由于id=4不存在,因此直接插入新记录。 如果我们再次执行查询操作,可以看到students表中的记录如下所示: +----+--------+ | id | name | +----+--------+ | 1 | Alice | | 2 | Bob | | 3 | Charlie| | 4 | Denise | +----+--------+ 测试用例 为了进一步说明ON DUPLICATE KEY UPDATE和REPLACE INTO的区别和用法,下面提供一个简单的测试用例。 假设我们有一个名为users的表,包含三个列:id、name和age。其中,id为主键。 首先,我们向users表中插入一些数据: INSERT INTO users (id, name, age) VALUES (1, 'Alice', 20), (2, 'Bob', 25), (3, 'Charlie', 30); 接着,我们分别使用ON DUPLICATE KEY UPDATE和REPLACE INTO语句向该表插入或更新数据,并执行查询操作,验证结果是否符合预期。 使用ON DUPLICATE KEY UPDATE插入或更新数据 -- 插入一条新记录 INSERT INTO users (id, name, age) VALUES (4, 'Denise', 35) ON DUPLICATE KEY UPDATE name = 'Denise', age = 35; -- 更新已有记录 INSERT INTO users (id, name, age) VALUES (2, 'Bobby', 30) ON DUPLICATE KEY UPDATE name = 'Bobby', age = 30; -- 查询数据 SELECT * FROM users; 执行以上语句后,查询结果为: +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | Alice | 20 | | 2 | Bobby | 30 | | 3 | Charlie| 30 | | 4 | Denise | 35 | +----+--------+-----+ 使用REPLACE INTO插入或更新数据 -- 插入一条新记录 REPLACE INTO users (id, name, age) VALUES (5, 'Emily', 25); -- 更新已有记录 REPLACE INTO users (id, name, age) VALUES (3, 'Charles', 40); -- 查询数据 SELECT * FROM users; 执行以上语句后,查询结果为: +----+--------+-----+ | id | name | age | +----+--------+-----+ | 1 | Alice | 20 | | 2 | Bob | 25 | | 3 | Charles| 40 | | 5 | Emily | 25 | +----+--------+-----+ 通过上述测试用例,我们可以看到ON DUPLICATE KEY UPDATE和REPLACE INTO的不同之处,以及它们在实际应用中的使用场景和注意事项。需要根据具体的业务需求选择合适的语句,以保证数据的正确性和一致性。 ———————————————— 原文链接:https://blog.csdn.net/jam_yin/article/details/130685079 -
概述 在实际应用中,经常碰到导入数据的功能,当导入的数据不存在时则进行添加,有修改时则进行更新。 在刚碰到的时候,一般思路是将其实现分为两块,分别是判断增加,判断更新,后来发现在mysql中有ON DUPLICATE KEY UPDATE一步就可以完成(Mysql中独有的语法)。 SQL写法 在MySQL数据库中,如果在insert语句后面带上ON DUPLICATE KEY UPDATE子句,而要插入的行与表中现有记录的唯一索引或主键(可以是单一字段的唯一索引,也可以是复合字段的唯一索引)中产生重复值,那么就会发生旧行的更新;如果插入的行数据与现有表中记录唯一索引或者主键不重复,则执行新记录插入操作。 通俗点就是数据库中存在某条记录时,执行这个语句会更新,而不存在这条记录时,就会插入。 注意点: 因为这是个插入语句,所以不能加where条件。 如果是插入操作,受到影响行的值为1;如果更新操作,受到影响的行的值为2;如果更新的数据和已有的数据比对一样(就相当于没变,所有值保持不变),受到影响的行的值为0。 该语句是基于唯一索引(单一自动或复合字段的唯一索引)或者主键使用。 比如一个字段a被加上了unique index,并且表中已经存在了一条记录值为1。 下面两个语句会有相同的效果。 insert into table (a,b,c) values (1,2,3) on duplicate key update c = c+1; update table set c = c+1 where a =1; 比如两个字段a,b被加上unique index,并且表中已经存在了一个记录值a = 1, b =2,下面两个语句会有相同的效果。 insert into table (a,b,c) values (1,2,3) on duplicate key update c = c + 1; update table set c = c + 1 where a = 1 and b = 2; ON DUPLICATE KEY UPDATE后面可以放多个字段,用英文逗号分割。 如下面列子所示: insert into table (a,b,c) values (1,2,3),(4,5,6) on duplicate key update c = values(a) + values(b) 表中将更改(增加或修改)两条记录。 在mybatis中进行单个增加或修改sql的写法为: <insert id="insertOrUpdateCameraInfoByOne" paramerType="com.pojo.AreaInfo"> insert into camera_info( cameraId,zone1Id,zone1Name,zone2Id,zone2Name,zone3Id,zone3Name,zone4Id,zone4Name) VALUES( #{cameraId},#{zone1Id},#{zone1Name}, #{zone2Id}, #{zone2Name}, #{zone3Id}, #{zone3Name}, #{zone4Id}, #{zone4Name},) ON DUPLICATE KEY UPDATE cameraId = VALUES(cameraId), zone1Id = VALUES(zone1Id),zone1Name = VALUES(zone1Name), zone2Id = VALUES(zone2Id),zone2Name = VALUES(zone2Name), zone3Id = VALUES(zone3Id),zone3Name = VALUES(zone3Name), zone4Id = VALUES(zone4Id),zone4Name = VALUES(zone4Name) </insert> 在mybaits中进行批量增加或修改的sql为: <insert id="insertOrUpdateCameraInfoByBatch" parameterType="java.util.List"> insert into camera_info( zone1Id,zone1Name,zone2Id,zone2Name,zone3Id,zone3Name,zone4Id,zone4Name, cameraId )VALUES <foreach collection ="list" item="cameraInfo" index= "index" separator =","> ( #{cameraInfo.zone1Id}, #{cameraInfo.zone1Name}, #{cameraInfo.zone2Id}, #{cameraInfo.zone2Name}, #{cameraInfo.zone3Id}, #{cameraInfo.zone3Name}, #{cameraInfo.zone4Id}, #{cameraInfo.zone4Name}, #{cameraInfo.cameraId}, ) </foreach> ON DUPLICATE KEY UPDATE zone1Id = VALUES(zone1Id),zone1Name = VALUES(zone1Name),zone2Id = VALUES(zone2Id), zone2Name = VALUES(zone2Name),zone3Id = VALUES(zone3Id),zone3Name = VALUES(zone3Name), zone4Id = VALUES(zone4Id),zone4Name = VALUES(zone4Name), cameraId = VALUES(cameraId) </insert> values函数 values函数相当于更新需要插入的值,更新外部传入的值(值是本来应该插入的值,也就是入参)。 VALUES(clomn_name):表示更新指定的列,更新列值为外部传入的值。 比如:zone1Id = VALUES(zone1Id),更新zone1Id列的值为#{cameraInfo.zone1Id}。 注意问题 更新的内容中unique key或者primary key最好按照一个来判断是否重复,不然不能保证语句执行正确(有任意一个unique key重复就会走更新);尽量不对存在多个唯一键的talbe使用该语句,避免可能导致数据错乱。 在有可能有并发事物执行的insert语句下不要使用该语句,可能导致产生dead lock。 如果数据表id是自动递增的不建议使用该语句;id不连续,如果前面更新的比较多,新增的下一条会相应跳跃的更大。 该语句是mysql独有的语法,如果可能涉及到其他数据库语言要慎重使用。 主键不连续自增解决方法 源引自:https://www.linuxidc.com/Linux/2018-01/150427.htm 最近项目上需要实现这么一个功能:统计每个人每个软件的使用时长,客户端发过来消息,如果该用户该软件已经存在增更新使用时间,如果没有则新添加一条记录,代码如下: <!-- 批量保存软件使用时长表 --> <update id="saveApp" parameterType="java.util.List"> <foreach collection="appList" item="item" index="index" separator=";"> insert into app_table(userName,app,duration) values(#{userName},#{item.app},#{item.duration}) on duplicate key update duration=duration+#{item.duration} 为了效率用到了on duplicate key update进行自动判断是更新还是新增,一段时间后发现该表的主键id(已设置为连续自增),不是连续的自增,总是跳跃的增加,这样就造成id自增过快,已经快超过最大值了,通过查找资料发现,on duplicate key update有一个特性就是,每次是更新的情况下id也是会自增加1的,比如说现在id最大值的5,然后进行了一次更新操作,再进行一次插入操作时,id的值就变成了7而不是6. 为了解决这个问题,有两种方式,第一种是修改innodb_autoinc_lock_mode中的模式,第二种是将语句修拆分为更新和操作2个动作 第一种方式:innodb_autoinc_lock_mode中有3中模式,0,1和2,mysql5的默认配置是1, 0是每次分配自增id的时候都会锁表. 1只有在bulk insert的时候才会锁表,简单insert的时候只会使用一个light-weight mutex,比0的并发性能高 2.没有仔细看,好像是很多的不保证…不太安全. 数据库默认是1的情况下,就会发生上面的那种现象,每次使用insert into … on duplicate key update 的时候都会把简单自增id增加,不管是发生了insert还是update 由于该代码数据量大,同时需要更新和添加的数据量多,不能使用将0模式,只能将数据库代码拆分成为更新和插入2个步骤,第一步先根据用户名和软件名更新使用时长,代码如下: update app_table set duration=duration+#{duration} where userName=#{userName} and appName=#{appName} 然后根据返回值,如果返回值大于0,说明更新成功不再需要插入数据,如果返回值小于0则需要进行插入该条数据,代码如下: insert into app_table(userName,appName,duration) values(#{userName},#{appName},#{duration}) # 产生dead lock原理 insert ... on duplicate key在执行时,innodb引擎会先判断插入的行是否产生重复key错误,如果存在对该现有的行加上S(共享锁)锁,返回该行数据给mysql,mysql修改完数据后,然后对该记录加上X(排它锁),最后进行update写入。 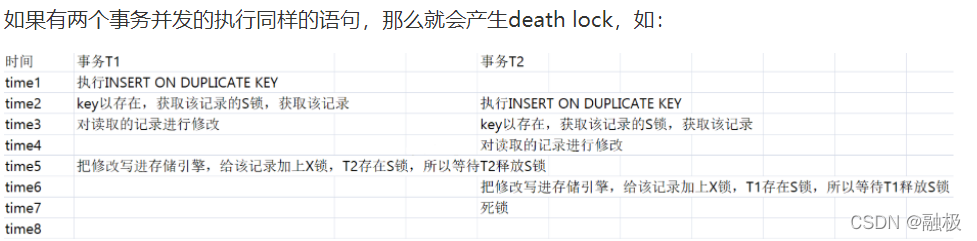 ———————————————— 原文链接:https://blog.csdn.net/tianzhonghaoqing/article/details/122643180
-
一 关键字 on duplicate key update的介绍 1.1 介绍 在MySQL数据库中,如果在insert语句后面带上ON DUPLICATE KEY UPDATE 子句,而要插入的行与表中现有记录的惟一索引或主键中产生重复值,那么就会发生旧行的更新;如果插入的行数据与现有表中记录的唯一索引或者主键不重复,则执行新纪录插入操作。 原理是: 该语法会在插入数据之前判断,如果主键或唯一索引不存在,则插入数据。如果主键或唯一索引存在,则执行更新操作。 需要注意的是,在高并发的场景下使用on duplicate key update语法,可能会存在死锁的问题,所以要根据实际情况酌情使用。 1.2 实操案例 本案例:使用unique索引结合ON DUPLICATE KEY UPDATE语句实现,添加数据确保数据的唯一性,不重复,有则修改,没有则新添加。 1.新建表 id为为主键,name+sex组合成索引 2.执行sql语句 再次执行: 两次执行结果:可以看到实现了"有则修改,无则新添加"的效果 ———————————————— 原文链接:https://blog.csdn.net/u011066470/article/details/88723394
-
1、应用场景 日常开发中,对于一个数据想做到存在即更新,不存在则新增,通常的做法是先查询数据库中是否存在对应的数据,如果存在就使用更新的方法,不存在就使用新增的方法 如果是单个数据,倒也没什么问题,但如果是批量数据的话,会消耗大量的资源来进行查询操作,这样就得不偿失了。 这种情况我们可以使用mysql提供的 on duplicate key update 来进行操作。 2、基础使用语法 2.1 假设此时我们表中没有数据 执行语句(为了展示效果使用用法2) #用法1:使用values来获取值(推荐,因为插入多个的时候可以用) INSERT INTO `test` ( id, name ) VALUES( 1, '晓明' ) ON DUPLICATE KEY UPDATE id = VALUES(id), name = VALUES(name) #用法2:直接使用值 INSERT INTO `user` ( id, name ) VALUES( 1, '晓明') ON DUPLICATE KEY UPDATE id = '123', name = 'xiaoming' 执行结果 2.2 有数据后再次执行 执行相同sql语句,执行结果 这里就是关键:我们可以看到变动为2,此时就是说明原数据进行了更新,更新内容为下面UPDATE中设置的字段值 ,id也可变化,数据库中数据如下 Q:我们再次执行一次这个语句,结果是什么样子呢? A:自然是判断出该表中无此数据,新增一条额外的新数据 sql结果 验证得到结论:其实就是会自动检测是否存在Duplicate entry,如果存在values后面的值就会自动更改,不存在则插入 3、批量插入 执行语句 INSERT INTO test(`id`,`name`,`address`) VALUES('4','修改10','北京'), ('1', '晓明',1) ON DUPLICATE KEY UPDATE name=VALUES(name),address=VALUES(address); sql结果 id为1和id为4的分别被修改和新增,可以同时进行两种操作类型 4、Mybatis中的写法 单独插入 <insert id="insertUser" parameterType="com.test.User"> INSERT INTO user( id, name, gender, birthday, address) VALUES (#{id}, #{name}, #{gender}, #{birthday}, #{address}) ON DUPLICATE KEY UPDATE id = VALUES(id), name = VALUES(name), gender = VALUES(gender) birthday = VALUES(birthday), address = VALUES(address) </insert> 批量插入 <insert id="insertUser" parameterType="java.util.List"> INSERT INTO user( id, name, gender, birthday, address) VALUES <foreach collection="list" item="item" index="index" separator=","> (#{item.id}, #{item.name}, #{item.gender}, #{item.birthday}, #{item.address}) </foreach> ON DUPLICATE KEY UPDATE id = VALUES(id), name = VALUES(name), gender = VALUES(gender) birthday = VALUES(birthday), address = VALUES(address) </insert> 5、情景模拟 插入失败提示如下 ERROR 1062 (23000): Duplicate entry 'value' for key 'PRIMARY' 如果数据库中已有某条数据,以下的两条语句可等同: INSERT INTO tablename (id, data) VALUES (1, 10) ON DUPLICATE KEY UPDATE data=data+10; UPDATE tablename SET data=data+10 WHERE id=1; ———————————————— 原文链接:https://blog.csdn.net/vulgarOr/article/details/128063088
-
INSERT INTO t_mercadolibre_custom_price_sku (sku, site_id, ordersource_id, publish_price, promotion_price,update_time) VALUES ('3003942', 'MLM', 16105, 'profit_30', 'profit_5','2024-03-19 12:02:12')ON DUPLICATE KEY UPDATE sku = VALUES(sku), site_id = VALUES(site_id), ordersource_id = VALUES(ordersource_id); ON DUPLICATE KEY UPDATE 是 MySQL 中的一种功能,用于在插入数据时检测到主键或唯一键冲突时执行更新操作。如果插入的数据中存在与现有记录的主键或唯一键相同的值,MySQL 将执行指定的更新操作而不是抛出错误。 在您的示例中,您插入了一条记录到 t_mercadolibre_custom_price_sku 表中,如果这条记录的 sku(或其他设置为唯一键的字段)已经存在于表中,则会执行更新操作,而不是插入新的记录。更新操作将会将已存在的记录的 sku、site_id 和 ordersource_id 更新为新插入的值。 因此,如果表中已经存在具有相同 sku、site_id 和 ordersource_id 的记录,该记录将会被更新为新的值。 如果没有冲突的唯一键,ON DUPLICATE KEY UPDATE 将不会生效,插入操作会正常进行,而不会触发更新操作。 这种功能可确保数据库中不会出现重复的记录,并且在出现冲突时能够按照指定的方式处理。 ———————————————— 原文链接:https://blog.csdn.net/EaSoNgo111/article/details/136845579
-
在 MySQL 中,DUPLICATE KEY 是用于处理插入数据时遇到唯一键(Unique Key)冲突的情况的一种机制。当向表中插入数据时,如果插入的数据违反了唯一约束(比如唯一索引或主键约束),就会触发 DUPLICATE KEY 错误。 为了处理这种情况,MySQL 提供了 ON DUPLICATE KEY UPDATE 和 ON DUPLICATE KEY IGNORE 这两种选项: 1.ON DUPLICATE KEY UPDATE:如果插入的数据违反了唯一约束,MySQL 将执行更新操作而不是抛出错误。你可以指定更新的字段和值,MySQL 将尝试更新现有行而不是插入新行。如果唯一键冲突,就会执行更新操作,否则会插入新行。 示例: INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...) ON DUPLICATE KEY UPDATE column1=new_value1, column2=new_value2, ...; 2.ON DUPLICATE KEY IGNORE:如果插入的数据违反了唯一约束,MySQL 将忽略该错误,不会执行任何操作。这意味着如果唯一键冲突,MySQL 将跳过该行,不会执行插入或更新操作。 示例: INSERT IGNORE INTO table_name (column1, column2, ...) VALUES (value1, value2, ...); 这些选项可以帮助开发者在插入数据时处理唯一键冲突的情况,使得数据操作更加灵活和可靠。 ———————————————— 原文链接:https://blog.csdn.net/weixin_53390884/article/details/138244079
-
引言一、ON DUPLICATE KEY UPDATE的介绍二、ON DUPLICATE KEY UPDATE的使用2.1、案例一:根据主键id进行更新2.2、案例二:根据唯一索引进行更新(常用)2.3、案例三:没有主键或唯一键字段值相同就插入2.4、案例四:主键与唯一键字段同时存在三、ON DUPLICATE KEY UPDATE的注意事项3.1、on dupdate key update之后val... 文章目录 一、ON DUPLICATE KEY UPDATE的介绍 二、ON DUPLICATE KEY UPDATE的使用 2.1、案例一:根据主键id进行更新 2.2、案例二:根据唯一索引进行更新(常用) 2.3、案例三:没有主键或唯一键字段值相同就插入 2.4、案例四:主键与唯一键字段同时存在 三、ON DUPLICATE KEY UPDATE的注意事项 3.1、on dupdate key update之后values的使用事项 3.2、对values使用判断 3.3、唯一索引大小写敏感问题 四、ON DUPLICATE KEY UPDATE与mybatis联合使用 4.1、写法一:与values()联合使用 4.2、写法二:使用#{} 五、ON DUPLICATE KEY UPDATE的缺点及坑 5.1、ON DUPLICATE KEY UPDATE每次更新导致id不连续 5.2、death lock死锁 有时候由于业务需求,可能需要先去根据某一字段值查询数据库中是否有记录,有则更新,没有则插入。这个时候就可以用到ON DUPLICATE KEY UPDATE这个sql语句了。 以下内容基于本地windows环境mysql:8.0.34进行讲解。 一、ON DUPLICATE KEY UPDATE的介绍 基本用法:ON DUPLICATE KEY UPDATE是一种MySQL的语法,它在插入新数据时,如果遇到唯一键冲突(即已存在相同的唯一键值),则会执行更新操作,而不是抛出异常或忽略该条数据。这个语法可以大大简化我们的代码,减少不必要的判断和查询操作。 用法总结 1:on duplicate key update 语句根据主键id或唯一键来判断当前插入是否已存在。 2:记录已存在时,只会更新on duplicate key update之后指定的字段。 3:如果同时传递了主键和唯一键,以主键为判断存在依据,唯一键字段内容可以被修改。 4:唯一键大小写敏感时,大小写不同的值被认为是两个值,执行插入。参见下文中的大小写敏感问题 二、ON DUPLICATE KEY UPDATE的使用 准备表结构及测试数据, 注意:name是唯一键 drop table if exists tbl_test; create table tbl_test( id int primary key auto_increment, name varchar(30) unique not null, age int comment '年龄', address varchar(50) comment '住址', update_time datetime default null ) comment '测试表'; insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()),('lisi',21,'武汉',now()); 测试数据如下: 在这里插入图片描述 2.1、案例一:根据主键id进行更新 on dupdate key update 语句基本功能是:当表中没有原来记录时,就插入,有的话就更新。 如下sql: insert into tbl_test(id,name,age,address,update_time) values(1,'zhangsan1',201,'杭州1','2024-03-05 15:59:35') on duplicate key update age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name address = values(address), update_time=now(); 在这里插入图片描述 从执行结果可以看出,更新了id为1的age,address两个字段,而name字段没有修改生效。由此我们可以得出两个重要结论: 1:on duplicate key update 语句根据主键id来判断当前插入是否已存在。 2:已存在时,只会更新on duplicate key update之后限定的字段。 2.2、案例二:根据唯一索引进行更新(常用) 根据唯一索引进行更新是生产中比较常用的方式,因为id一般使用的是自增,很少会先把id查询出来,然后根据id进行更新。 如下sql: insert into tbl_test(name,age,address) values('zhangsan',202,'杭州2') on duplicate key update age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name address = values(address), update_time=now(); 在这里插入图片描述 从执行结果看,这次没有传id,但是age,address字段仍然更新了。 由此可以得出另一个结论: 3:on duplicate key update 语句也可以根据唯一键来判断当前插入的记录是否已存在。 2.3、案例三:没有主键或唯一键字段值相同就插入 如下sql: insert into tbl_test(name,age,address) values('zhangsan3',203,'杭州3') on duplicate key update age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name address = values(address), update_time=now(); 在这里插入图片描述 这条执行就比较简单了,没有主键或唯一键字段值相同,即判断当前记录不存在,新插入一条。 注意: 这里我们发现主键id并没有连续,直接从2变成了4,具体原理可见《MySQL数据库设置主键自增、自增主键为什么不能保证连续递增》 2.4、案例四:主键与唯一键字段同时存在 如下sql: insert into tbl_test(id,name,age,address) values(1,'zhangsan4',204,'杭州4') on duplicate key update name = values(name), age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name address = values(address), update_time=now(); 在这里插入图片描述 从上面可以看出,连唯一键name也被修改了。结论: 4:如果传递了主键,是可以修改唯一键字段内容的。 这里要注意,如果这里的name修改为 lisi,zhangsan3 会报唯一键冲突的。可以自行尝试。 三、ON DUPLICATE KEY UPDATE的注意事项 3.1、on dupdate key update之后values的使用事项 如下sql: insert into tbl_test(name,age,address,update_time) values('zhangsan4',205,'杭州5','2024-03-05 00:00:00') on duplicate key update age = age, address = '杭州', update_time=values(update_time); 在这里插入图片描述 on dupdate key update之后没有用values的情况 分为两种情况: 1:如果为如上面的address= “杭州”,则会一直更新为"杭州". 2:如果为如上面的age = age,则age会保持数据库中的值,不会更新。 3:只有当使用了values后,才会更新为上下文中传入的值 3.2、对values使用判断 如下sql insert into tbl_test(id,name,age,address) values(1,'zhangsan',202,'杭州2') on duplicate key update name = ifnull(values(name),name), age = values(age) 达到的效果是,如果传入的name值为null,则不更新。不为null则更新。这里与mybatis配合使用比较好。 3.3、唯一索引大小写敏感问题 思考这么一个问题:如上面name作为唯一索引,当name大小写敏感时且数据库中存储了name=“zhangsan” ,那么再插入name="ZHANGSAN"是更新还是新增? 1):唯一索引大小写不敏感时 设置name字段为唯一索引且大小写不敏感 drop table if exists tbl_test; create table tbl_test( id int primary key auto_increment, name varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci unique not null, age int comment '年龄', address varchar(50) comment '住址', update_time datetime default null ) comment '测试表'; insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()); insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',21,'杭州1',now()); 在这里插入图片描述 可以看到当字段为大小写不敏感时zhangsan跟ZHANGSAN被认为是同一个值,不能重复插入。 当数据库中name=zhangsan时且name字段大小写不敏感时,我们看一下name="ZHANGSAN"能否更新成功? insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',22,'杭州2','2024-03-05 00:00:00') on duplicate key update age = values(age), address = values(address), update_time=values(update_time); 在这里插入图片描述 以上结果可以看出,当大小写不敏感时on duplicate key update是可以更新成功的,即认为是同一个值。 2):唯一索引大小写敏感时 设置name字段为唯一索引且大小写敏感 drop table if exists tbl_test; create table tbl_test( id int primary key auto_increment, name varchar(30) CHARACTER SET utf8 COLLATE utf8_bin unique not null, age int comment '年龄', address varchar(50) comment '住址', update_time datetime default null ) comment '测试表'; insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()); insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',21,'杭州1',now()); 在这里插入图片描述 可以看到当字段为大小写敏感时zhangsan跟ZHANGSAN被认为是两个值,插入了两条记录。所以此时用on duplicate key update会执行新增操作 四、ON DUPLICATE KEY UPDATE与mybatis联合使用 4.1、写法一:与values()联合使用 注意:values后面的内容是表字段名称即带下划线,而不是实体类驼峰名称 如下sql: dept_id为主键或唯一索引 <insert id="replaceInto"> INSERT INTO sys_dept( dept_id, parent_id, status, update_time) VALUES <foreach collection="deptList" item="item" separator=","> (#{item.deptId}, #{item.parentId}, #{item.status}, #{item.updateTime}) </foreach> ON DUPLICATE KEY UPDATE parent_id=VALUES(parent_id), status=VALUES(status), update_time=VALUES(update_time) </insert> 4.2、写法二:使用#{} 如下sql: dept_id为主键或唯一索引 <insert id="replaceInto"> INSERT INTO sys_dept( dept_id, parent_id, status, update_time) VALUES <foreach collection="deptList" item="item" separator=","> (#{item.deptId}, #{item.parentId}, #{item.status}, #{item.updateTime}) </foreach> ON DUPLICATE KEY UPDATE <foreach collection="deptList" item="item" separator=","> parent_id = #{item.parentId}, status = #{item.status}, update_time = #{item.updateTime} </foreach> </insert> 五、ON DUPLICATE KEY UPDATE的缺点及坑 5.1、ON DUPLICATE KEY UPDATE每次更新导致id不连续 如下sql: drop table if exists tbl_test; create table tbl_test( id int primary key auto_increment, name varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci unique not null, age int comment '年龄', address varchar(50) comment '住址', update_time datetime default null ) comment '测试表'; insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()),('李四',21,'武汉',now()); 在这里插入图片描述 执行on duplicate key update进行更新,然后再插入一条新的数据 insert into tbl_test(name,age,address,update_time) values('zhangsan',22,'杭州2','2024-03-05 00:00:00') on duplicate key update age = values(age), address = values(address), update_time=values(update_time); insert into tbl_test(name,age,address,update_time) values('王五',23,'深圳',now()); 在这里插入图片描述 可以看到id自增值从2直接变成了4,造成了id的不连续。 1.ON DUPLICATE KEY UPDATE每次更新导致id不连续原理: mysql中有个配置值是innodb_autoinc_lock_mode。 innodb_autoinc_lock_mode中有3中模式,0,1和2,mysql5的默认配置是1, 0是每次分配自增id的时候都会锁表. 1只有在bulk insert的时候才会锁表,简单insert的时候只会使用一个light-weight mutex,比0的并发性能高 2.没有仔细看,好像是很多的不保证…不太安全. 数据库默认是1的情况下,就会发生上面的那种现象,每次使用insert into … on duplicate key update 的时候都会把简单自增id增加,不管是发生了insert还是update 5.2、death lock死锁 经常看到网上说ON DUPLICATE KEY UPDATE会导致死锁,确实是存在这个可能的,不过由于目前没有特别好的方案,所以也只能使用这个sql语法了。在执行insert ... on duplicate key语句时,如果不对同一个表同时进行并发的insert或者update,基本不会造成死锁。即insert ... on duplicate key时尽量单线程串行进行新增或更新 insert … on duplicate key 在执行时,innodb引擎会先判断插入的行是否产生重复key错误,如果存在,在对该现有的行加上S(共享锁)锁,如果返回该行数据给mysql,然后mysql执行完duplicate后的update操作,然后对该记录加上X(排他锁),最后进行update写入。 如果有两个事务并发的执行同样的语句,那么就会产生death lock 原文链接:https://openatomworkshop.csdn.net/6645ae6ab12a9d168eb6c9dc.html
-
简介 “on duplicate key” 是在执行插入操作时的一个选项,它指示在遇到已经存在的键值时要执行的操作。当在数据库中使用插入操作时,如果键值已经存在,会触发错误。使用“on duplicate key”选项可以定义在遇到这种情况时要执行的操作。 例如,在MySQL中,可以在INSERT语句中使用“ON DUPLICATE KEY UPDATE”语句来指定在遇到重复键时要执行的操作。这个选项后面通常跟着一个或多个列名和值对,表示在遇到重复键时更新这些列的值。 下面是一个示例: INSERT INTO my_table (id, name) VALUES (1, 'John') ON DUPLICATE KEY UPDATE name = 'John'; 在这个示例中,如果id为1的记录已经存在于my_table表中,那么插入操作将会更新该记录的name列的值为’John’;如果该记录不存在,则正常插入新记录。 需要注意的是,具体的语法和行为可能会因不同的数据库系统而有所差异。 唠叨一下 在mysql中插入数据,如果碰到主键冲突或者唯一索引冲突的时候,程序中会抛出SQLIntegrityConstraintViolationException异常,如果只是单纯的由于主键冲突或者唯一索引冲突引起的异常的话,这个问题很容易解决,如果是主键冲突的话可以更新为其他主键,如果是唯一索引的话可以将唯一索引删除或者将引起唯一索引冲突的数据更新一下;但是还有另外一种情况是比较棘手的,那就是我插入一条数据的时候如果出现这样的冲突的时候,我不希望什么都不做,而是当出现这样插入失败的时候我将冲突的这条数据进行一些更新操作,出现了这样的诉求的时候,下面的这个关键字就可以粉墨登场啦:on duplicate key update,这个关键字最重要的作用就是当我们在插入数据出现主键或唯一索引重复的时候,可以执行它后面的一个更新操作,而不是什么都不做,直接返回异常,接下来我们就来详细的了解一下 on duplicate key update 这个mysql中关键字在开发中正确使用。 实现原理 尝试插入新数据到数据库表中,如果插入成功则直接返回插入的列。 如果由于主键或唯一索引出现重复而造成插入失败的话,则先数据库表中已存在的出现冲突的数据行加上共享锁,然后将该数据返回数据库服务器中。 数据库服务器在内存中对改行数据执行on duplicate key update 后的update语句。 然后对该行数据加上排它锁。 最后将内存中update后的数据写入改行,全部执行完毕 使用实例 mybatis中单个插入on duplicate key update的使用 @Insert({"<script>", "insert into user set id = #{id}, mobile = #{mobile}, email = #{email}, name = #{name}, link_name = #{linkName}, create_user_id = #{createUserId} ", " on duplicate key update create_user_id = #{createUserId} ", "</script>"}) int insertTest(User user); mybatis中批量插入on duplicate key update 的使用 @Insert({"<script>", "insert into user (id , mobile, email, name, link_name, create_user_id) ", " values ", "<foreach collection='list' index='index' item='item' separator=','> (#{item.id}, #{item.mobile}, #{item.email}, #{item.name}, #{item.linkName}, #{item.createUserId} )</foreach>", " on duplicate key update create_user_id = values(create_user_id), mobile = values(mobile) ", "</script>"}) int batchInsertTest(List<User> userList); 存在问题 高并发情况可能会出现死锁 由于主键或唯一索引出现重复的时候,在更新该调存在的数据的时候,会为该条数据加一个共享锁和一个排它锁,最后才会写入该条数据,如果并发比较高,两个线程几乎同时来操作这条数据的话,如果两个线程同时给一条数据加上共享锁和排它锁的话,就会出现死锁的情况。 使用总结 在使用 on duplicate key update 关键字的时候,一定要注意它操作后返回结果,它的返回结果和我们平常使用的insert是不同的,使用insert … on duplicate key update时,如果主键或唯一索引没有重复,成功插入了新增数据则返回1,如果主键或唯一索引已经重复,没有插入成功,但是 on duplicate key update 后的更新的字段的数据和 原数据不同,则表示更新成功,此时返回的结果是2, 如果 on duplicate key update 的更新数据和原始数据相同,则表示更新也没有成功,则返回0. 在mysql中,同样可以实现通过判断主键或唯一索引是否存在来执行不同操作的关键字还有两个,分别是:replace into 和 insert ignore into,这几种每一种方式都会存在一些问题,具体存在哪些问题,就等着各位去进一步的深入探究啦 ———————————————— 原文链接:https://blog.csdn.net/zhangzehai2234/article/details/106309629
-
最近在进行TiDB数据库操作时,遇到了一个问题,在使用insert into ... on duplicate key update操作时,系统返回了如下错误信息: ERROR8141(HY000): assertion failed: key: xxxx, assertion: Exist, start_ts:xxxx, existing start ts:xxxx, existing commit ts:xx 本文将主要介绍这个问题的触发现象以及规避方法。 一、背景 在实际项目中,我使用了insert into ... on duplicate key update语句来处理数据插入或更新的逻辑。然而,当我执行这个操作时,TiDB会抛出异常报错,指向了一个8141的错误码。 //错误解读 首先,我通过官网去搜索该错误码8141的时候,发现官网有说明是因为索引数据不一致导致的,对于错误的详细解释是: ERROR 8141(HY000): assertion failed: key: 7480000000000000455f6980000000000000020419b05820000000000419b0582000000000, assertion: Exist, start_ts:446128785517182978, existing start ts:446128785256087554, existing commit ts:446128785256087555 上述错误表明,事务提交时断言失败。根据数据索引一致的假设,TiDB 断言 key: 7480000000000000455f6980000000000000020419b05820000000000419b0582000000000不存在,提交事务时发现该 key 存在,是由 start ts 为 446128785256087554的事务写入的。TiDB 会将该 key 的 MVCC (Multi-Version Concurrency Control) 历史输出到日志。 二、原因排查 测试环境复现SQL如下: #表结构 CREATETABLE`t`( `a`timestampNOTNULLONUPDATECURRENT_TIMESTAMP, `b`int(11) DEFAULTNULL, PRIMARY KEY(`a`) /*T![clustered_index] CLUSTERED */, KEY`idx`(`a`) ) ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_bin; #插入语句类型insertinto.... onduplicatekeyupdate时候报错 insertintot values('2023-06-12 10:00:00',1) onduplicatekeyupdateb = values(b); insertintot values('2023-06-12 10:00:00',2) onduplicatekeyupdateb = values(b); insertintot values('2023-06-12 10:00:00',3) onduplicatekeyupdateb = values(b); 在这里可以看到,当我们执行到第三条INSERT时候发现,会发生报错: 最开始比较费解的是,为什么仅仅插入几条数据,就会出现索引不一致的情况,索引数据不一致情况我把他分为两类,一种是数量不匹配,另一种是数值不匹配。 我先是通过使用主键和使用索引两种方式来观察数据。既然是索引数据不一致,那我们只需要观察a列就好了,SQL如下: select/*+ use_index(t,primary)*/a fromt useindex(primary); select/*+ use_index(t,idx)*/a fromt useindex(idx); 这个时候我们可以看到,索引里面a列的数据为:2023-12-06 15:05:17 ,而主键里面a列的数据为:2023-06-12 10:00:00。 那么这两个数值为什么会造成这种差异呢?我观察了一下发现,我设置的a列是一个时间字段,并且呢,他是一个自动更新的时间字段ON UPDATE CURRENT_TIMESTAMP,也就是说,如果发生该行变更的情况下,a列的值应该更新为最新时间才对,目前从两者差异来看的话,可以看出,该值在主键里并没有更新,反而是在索引里面更新了,也就是说,其实现在索引里面的数据是真实的,主键里面的数据是不匹配的。 那可以知道大概率是因为ON UPDATE CURRENT_TIMESTAMP列引起的,我就去查了一下看是否有相关issues,找到相关issues: https://github.com/pingcap/tidb/issues/44565 三、问题分析 找到问题后,进行多次测试,发现该问题总共会有两种现象,下面进行分开说明一下。 //现象一 触发条件存在的情况下,当我们进行update操作触发 aotu update 更新字段时,会造成索引数据进行更新,但是聚簇主键的字段没有进行更新,导致数据与索引不一致情况发生,该现象与我们在原因排查里面看到的现象一致。 该现象的情况发生在隐式事务提交下,因为我们知道隐式事务提交使用的是乐观事务,在乐观事务下,所进行的assertion检查项要跟悲观事务相比存在差异,所以在提交的时候会报错,导致提交失败,这种情况下只会导致主键和索引的数值不一样,主键和索引的数量是一样的。 //现象二 现象二则不同,该现象是在开启显示事务提交下触发,显示事务提交是使用的悲观事务进行,这样会导致批量插入最后进行commit时候不报错。 复现SQL如下: CREATETABLE`t`( `a`timestampNOTNULLONUPDATECURRENT_TIMESTAMP, `b`int(11) DEFAULTNULL, PRIMARY KEY(`a`) /*T![clustered_index] CLUSTERED */, KEY`idx`(`a`) ) ENGINE=InnoDBDEFAULTCHARSET=utf8mb4 COLLATE=utf8mb4_bin; begin; insertintot values('2023-06-11 10:00:00',1) onduplicatekeyupdateb = values(b); insertintot values('2023-06-11 10:00:00',2) onduplicatekeyupdateb = values(b); insertintot values('2023-06-11 10:00:00',3) onduplicatekeyupdateb = values(b); commit; begin; insertintot values('2023-06-12 10:00:00',1) onduplicatekeyupdateb = values(b); insertintot values('2023-06-12 10:00:00',2) onduplicatekeyupdateb = values(b); insertintot values('2023-06-12 10:00:00',3) onduplicatekeyupdateb = values(b); commit; admin checktablet; select/*+ use_index(t,primary)*/a fromt useindex(primary); select/*+ use_index(t,idx)*/a fromt useindex(idx); 可以看到,在事务提交时候是没有进行报错提示的,只有在我们进行check时候才返回报错。 如果想要不发生这种情况,需要将assertion级别调高,可以通过系统变量tidb_txn_assertion_level 进行调整。 该变量在v6.0版本引入,默认为FAST,调到最高级别STRICT则可以在commit阶段提示报错。 需要注意的是,这个变量因为是v6.0引入的,如果有低版本集群是原地升级升上来的,那么这个值默认是OFF,也就是关闭状态,这就导致在关闭状态下,这样进行插入操作就不会出现索引数据不一致报错,而是一直插入,导致无法发现问题。 //触发条件说明 根据自己测试来看,触发条件总共有三条,必须三条同时满足,才会触发该BUG,分别是: 有 ON UPDATE CURRENT_TIMESTAMP 列 该列同时在clustered index 中 执行SQL时候,没有显示指定该列,而是去触发auto update 四、问题总结 综上所述,该问题的发生主要是因为聚簇主键列如果存在auto update约束时,不会触发自动更新导致,该问题于v6.5.3版本进行修复。如果有满足触发条件的表,提供如下几点建议: 1、如果是UPDATE语句,在UPDATE当中手动去指定含有ON UPDATE CURRENT_TIMESTAMP 条件字段的值,避免让主键进行auto update操作。 2、如果是insert into ... on duplicate key update 语句,建议更改为replaice into 方式,遇到重复值进行delete + insert 操作,避免使用update。 ———————————————— 原文链接:https://blog.csdn.net/CBGCampus/article/details/135815040
-
在实际应用中,经常碰到导入数据的功能,当导入的数据不存在时则进行添加,有修改时则进行更新, 在刚碰到的时候,一般思路是将其实现分为两块,分别是判断增加,判断更新,后来发现在mysql中有ON DUPLICATE KEY UPDATE一步就可以完成(Mysql独有的语法)。 ON DUPLICATE KEY UPDATE单个增加更新及批量增加更新的sql 在MySQL数据库中,如果在insert语句后面带上ON DUPLICATE KEY UPDATE 子句,而要插入的行与表中现有记录的惟一索引或主键中产生重复值,那么就会发生旧行的更新;如果插入的行数据与现有表中记录的唯一索引或者主键不重复,则执行新纪录插入操作。 说通俗点就是数据库中存在某个记录时,执行这个语句会更新,而不存在这条记录时,就会插入。 注意点: 因为这是个插入语句,所以不能加where条件。 如果是插入操作,受到影响行的值为1;如果更新操作,受到影响行的值为2;如果更新的数据和已有的数据一样(就相当于没变,所有值保持不变),受到影响的行的值为0。 该语句是基于唯一索引或主键使用,比如一个字段a被加上了unique index,并且表中已经存在了一条记录值为1, 下面两个语句会有相同的效果: INSERT INTO table (a,b,c) VALUES (1,2,3) ON DUPLICATE KEY UPDATE c=c+1; UPDATE table SET c=c+1 WHERE a=1; ON DUPLICATE KEY UPDATE后面可以放多个字段,用英文逗号分割。 再现一个例子: INSERT INTO table (a,b,c) VALUES (1,2,3),(4,5,6) ON DUPLICATE KEY UPDATE c=VALUES(a)+VALUES(b); 表中将更改(增加或修改)两条记录。 在mybatis中进行单个增加或修改sql的写法为: <insert id="insertOrUpdateCameraInfoByOne" paramerType="com.pojo.AreaInfo"> insert into camera_info( cameraId,zone1Id,zone1Name,zone2Id,zone2Name,zone3Id,zone3Name,zone4Id,zone4Name) VALUES( #{cameraId},#{zone1Id},#{zone1Name}, #{zone2Id}, #{zone2Name}, #{zone3Id}, #{zone3Name}, #{zone4Id}, #{zone4Name},) ON DUPLICATE KEY UPDATE cameraId = VALUES(cameraId), zone1Id = VALUES(zone1Id),zone1Name = VALUES(zone1Name), zone2Id = VALUES(zone2Id),zone2Name = VALUES(zone2Name), zone3Id = VALUES(zone3Id),zone3Name = VALUES(zone3Name), zone4Id = VALUES(zone4Id),zone4Name = VALUES(zone4Name) </insert> 在mybatis中进行批量增加或修改的sql为: <insert id="insertOrUpdateCameraInfoByBatch" parameterType="java.util.List"> insert into camera_info( zone1Id,zone1Name,zone2Id,zone2Name,zone3Id,zone3Name,zone4Id,zone4Name, cameraId )VALUES <foreach collection ="list" item="cameraInfo" index= "index" separator =","> ( #{cameraInfo.zone1Id}, #{cameraInfo.zone1Name}, #{cameraInfo.zone2Id}, #{cameraInfo.zone2Name}, #{cameraInfo.zone3Id}, #{cameraInfo.zone3Name}, #{cameraInfo.zone4Id}, #{cameraInfo.zone4Name}, #{cameraInfo.cameraId}, ) </foreach> ON DUPLICATE KEY UPDATE zone1Id = VALUES(zone1Id),zone1Name = VALUES(zone1Name),zone2Id = VALUES(zone2Id), zone2Name = VALUES(zone2Name),zone3Id = VALUES(zone3Id),zone3Name = VALUES(zone3Name), zone4Id = VALUES(zone4Id),zone4Name = VALUES(zone4Name), cameraId = VALUES(cameraId) </insert> 项目中数据的操作有时候会令人头大,遇到一个需求: 需要将数据从A数据库的a数据表同步到B数据库的b数据表中(ab表结构相同,但不是主从关系。。。just同步过去) 第一次同步过去,b表为空,同步很简单。 但是当a表中的某些数据更新且增加了新数据之后,再想让两个表同步就有些麻烦了。(如果把b表清空,重新同步,数据量过大的话耗费的时间太长,不是一个好办法) 想着能不能按照时间段来做更新,这段时间内有新数据了,就插入数据,有数据更新了就更新数据。先说下我的思路: 步骤: 1.首先我从a表取出某一时间段的数据(分段更新) 2.往b表内放数据,根据主键判断b表是否已经有此条记录,没有此数据则插入,有了记录则对比数据是否一样,一样则不做更改,不一样就做更新操作。 此时使用该语句可以满足需要,但是要注意几个问题: 更新的内容中unique key或者primary key最好保证一个,不然不能保证语句执行正确(有任意一个unique key重复就会走更新,当然如果更新的语句中在表中也有重复校验的字段,那么也不会更新成功而导致报错,只有当该条语句没有任何一个unique key重复才会插入新记录);尽量不对存在多个唯一键的table使用该语句,避免可能导致数据错乱。 在有可能有并发事务执行的insert 语句情况下不使用该语句,可能导致产生death lock。 如果数据表id是自动递增的不建议使用该语句;id不连续,如果前面更新的比较多,新增的下一条会相应跳跃的更大。 该语句是mysql独有的语法,如果可能会设计到其他数据库语言跨库要谨慎使用。 主键不连续自增解决方法 源引自:https://www.linuxidc.com/Linux/2018-01/150427.htm 最近项目上需要实现这么一个功能:统计每个人每个软件的使用时长,客户端发过来消息,如果该用户该软件已经存在增更新使用时间,如果没有则新添加一条记录,代码如下: <!-- 批量保存软件使用时长表 --> <update id="saveApp" parameterType="java.util.List"> <foreach collection="appList" item="item" index="index" separator=";"> insert into app_table(userName,app,duration) values(#{userName},#{item.app},#{item.duration}) on duplicate key update duration=duration+#{item.duration} </foreach> </update> 为了效率用到了on duplicate key update进行自动判断是更新还是新增,一段时间后发现该表的主键id(已设置为连续自增),不是连续的自增,总是跳跃的增加,这样就造成id自增过快,已经快超过最大值了,通过查找资料发现,on duplicate key update有一个特性就是,每次是更新的情况下id也是会自增加1的,比如说现在id最大值的5,然后进行了一次更新操作,再进行一次插入操作时,id的值就变成了7而不是6. 为了解决这个问题,有两种方式,第一种是修改innodb_autoinc_lock_mode中的模式,第二种是将语句修拆分为更新和操作2个动作 第一种方式:innodb_autoinc_lock_mode中有3中模式,0,1和2,mysql5的默认配置是1, 0是每次分配自增id的时候都会锁表. 1只有在bulk insert的时候才会锁表,简单insert的时候只会使用一个light-weight mutex,比0的并发性能高 2.没有仔细看,好像是很多的不保证...不太安全. 数据库默认是1的情况下,就会发生上面的那种现象,每次使用insert into .. on duplicate key update 的时候都会把简单自增id增加,不管是发生了insert还是update 由于该代码数据量大,同时需要更新和添加的数据量多,不能使用将0模式,只能将数据库代码拆分成为更新和插入2个步骤,第一步先根据用户名和软件名更新使用时长,代码如下: <update id="updateApp" parameterType="App"> update app_table set duration=duration+#{duration} where userName=#{userName} and appName=#{appName} </update> 然后根据返回值,如果返回值大于0,说明更新成功不再需要插入数据,如果返回值小于0则需要进行插入该条数据,代码如下: <insert id="saveApp" keyProperty = "id" useGeneratedKeys = "true" parameterType="App"> insert into app_table(userName,appName,duration) values(#{userName},#{appName},#{duration}) </insert> 产生death lock原理 insert ... on duplicate key 在执行时,innodb引擎会先判断插入的行是否产生重复key错误,如果存在,在对该现有的行加上S(共享锁)锁,如果返回该行数据给mysql,然后mysql执行完duplicate后的update操作,然后对该记录加上X(排他锁),最后进行update写入。 如果有两个事务并发的执行同样的语句,那么就会产生death lock ———————————————— 原文链接:https://blog.csdn.net/wys0127/article/details/132078949
-
一:主键索引,唯一索引和普通索引的关系 主键索引 主键索引是唯一索引的特殊类型。 数据库表通常有一列或列组合,其值用来唯一标识表中的每一行。该列称为表的主键。 在数据库关系图中为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的。当在查询中使用主键索引时,它还允许快速访问数据。主键索引不能为空。每个表只能有一个主键 唯一索引: 不允许两行具有相同的索引值。但可以都为NULL,笔者亲试。 如果现有数据中存在重复的键值,则数据库不允许将新创建的唯一索引与表一起保存。当新数据将使表中的键值重复时,数据库也拒绝接受此数据。每个表可以有多个唯一索引 普通索引: 一般的索引结构,可以在条件删选时加快查询效率,索引字段的值可以重复,可以为空值 二:ON DUPLICATE KEY UPDATE使用测试(MYSQL下的Innodb引擎) 上面介绍了索引的知识,是为了介绍这个ON DUPLICATE KEY UPDATE功能做铺垫。 1:ON DUPLICATE KEY UPDATE功能介绍: 有时候由于业务需求,可能需要先去根据某一字段值查询数据库中是否有记录,有则更新,没有则插入。你可能是下面这样写的 if not exists (select node_name from node_status where node_name = target_name) insert into node_status(node_name,ip,...) values('target_name','ip',...) else update node_status set ip = 'ip',site = 'site',... where node_name = target_name 这样写在大多数情况下可以满足我们的需求,但是会有两个问题。 ①性能带来开销,尤其是系统比较大的时候。 ②在高并发的情况下会出现错误,可能需要利用事务保证安全。 有没有一种优雅的写法来实现有则更新,没有则插入的写法呢?ON DUPLICATE KEY UPDATE提供了这样的一个方式。 2:ON DUPLICATE KEY UPDATE测试样例+总结: 首先我们了解下这个简单的表结构id(主键)、code、name。 看下表中现有的数据: 执行以下实验进行分析: 实验一:含有ON DUPLICATE KEY UPDATE的INSERT语句中包含主键: ①插入更新都失败,原因是因为把主键id改成了已经存在的id ②执行更新操作。这里的数据还是四条。不过第四条的id由75变化为85 ③执行更新操作。数据总量是四条 ④insert语句中未包含主键,执行插入操作。数据量变为5条 实验二:含有ON DUPLICATE KEY UPDATE的INSERT语句中包含唯一索引: 表结构中增加code的唯一索引,表中现有的数据: ①插入更新都失败,原因是因为把code改成了已经存在的code值 ②执行更新操作。这里的数据总量为5条。不过第五条的code由1000变化为1200 ③执行更新操作。数据总量五条,没有变化 ④insert语句中未包含唯一索引,执行插入操作。数据量变为6条 总结: 1:ON DUPLICATE KEY UPDATE需要有在INSERT语句中有存在主键或者唯一索引的列,并且对应的数据已经在表中才会执行更新操作。而且如果要更新的字段是主键或者唯一索引,不能和表中已有的数据重复,否则插入更新都失败。 2:不管是更新还是增加语句都不允许将主键或者唯一索引的对应字段的数据变成表中已经存在的数据。 ———————————————— 原文链接:https://blog.csdn.net/lovedingd/article/details/123508783
-
文章目录 一、ON DUPLICATE KEY UPDATE的介绍 二、ON DUPLICATE KEY UPDATE的使用 2.1、案例一:根据主键id进行更新 2.2、案例二:根据唯一索引进行更新(常用) 2.3、案例三:没有主键或唯一键字段值相同就插入 2.4、案例四:主键与唯一键字段同时存在 三、ON DUPLICATE KEY UPDATE的注意事项 3.1、on dupdate key update之后values的使用事项 3.2、对values使用判断 3.3、唯一索引大小写敏感问题 四、ON DUPLICATE KEY UPDATE与mybatis联合使用 4.1、写法一:与values()联合使用 4.2、写法二:使用#{} 五、ON DUPLICATE KEY UPDATE的缺点及坑 5.1、ON DUPLICATE KEY UPDATE每次更新导致id不连续 5.2、death lock死锁 有时候由于业务需求,可能需要先去根据某一字段值查询数据库中是否有记录,有则更新,没有则插入。这个时候就可以用到ON DUPLICATE KEY UPDATE这个sql语句了。 以下内容基于本地windows环境mysql:8.0.34进行讲解。 一、ON DUPLICATE KEY UPDATE的介绍 基本用法:ON DUPLICATE KEY UPDATE是一种MySQL的语法,它在插入新数据时,如果遇到唯一键冲突(即已存在相同的唯一键值),则会执行更新操作,而不是抛出异常或忽略该条数据。这个语法可以大大简化我们的代码,减少不必要的判断和查询操作。 用法总结 1:on duplicate key update 语句根据主键id或唯一键来判断当前插入是否已存在。 2:记录已存在时,只会更新on duplicate key update之后指定的字段。 3:如果同时传递了主键和唯一键,以主键为判断存在依据,唯一键字段内容可以被修改。 4:唯一键大小写敏感时,大小写不同的值被认为是两个值,执行插入。参见下文中的大小写敏感问题 二、ON DUPLICATE KEY UPDATE的使用 准备表结构及测试数据, 注意:name是唯一键 drop table if exists tbl_test; create table tbl_test( id int primary key auto_increment, name varchar(30) unique not null, age int comment '年龄', address varchar(50) comment '住址', update_time datetime default null ) comment '测试表'; insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()),('lisi',21,'武汉',now()); 测试数据如下: 2.1、案例一:根据主键id进行更新 on dupdate key update 语句基本功能是:当表中没有原来记录时,就插入,有的话就更新。 如下sql: insert into tbl_test(id,name,age,address,update_time) values(1,'zhangsan1',201,'杭州1','2024-03-05 15:59:35') on duplicate key update age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name address = values(address), update_time=now(); 从执行结果可以看出,更新了id为1的age,address两个字段,而name字段没有修改生效。由此我们可以得出两个重要结论: 1:on duplicate key update 语句根据主键id来判断当前插入是否已存在。 2:已存在时,只会更新on duplicate key update之后限定的字段。 2.2、案例二:根据唯一索引进行更新(常用) 根据唯一索引进行更新是生产中比较常用的方式,因为id一般使用的是自增,很少会先把id查询出来,然后根据id进行更新。 如下sql: insert into tbl_test(name,age,address) values('zhangsan',202,'杭州2') on duplicate key update age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name address = values(address), update_time=now(); 从执行结果看,这次没有传id,但是age,address字段仍然更新了。 由此可以得出另一个结论: 3:on duplicate key update 语句也可以根据唯一键来判断当前插入的记录是否已存在。 2.3、案例三:没有主键或唯一键字段值相同就插入 如下sql: insert into tbl_test(name,age,address) values('zhangsan3',203,'杭州3') on duplicate key update age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name address = values(address), update_time=now(); 这条执行就比较简单了,没有主键或唯一键字段值相同,即判断当前记录不存在,新插入一条。 注意: 这里我们发现主键id并没有连续,直接从2变成了4,具体原理可见《MySQL数据库设置主键自增、自增主键为什么不能保证连续递增》 2.4、案例四:主键与唯一键字段同时存在 如下sql: insert into tbl_test(id,name,age,address) values(1,'zhangsan4',204,'杭州4') on duplicate key update name = values(name), age = values(age), -- 注意:values()括号中的内容是字段名称。比如:在java程序中使用时表字段可能叫user_name, 实体类中是userName,values()里面要填user_name address = values(address), update_time=now(); 从上面可以看出,连唯一键name也被修改了。结论: 4:如果传递了主键,是可以修改唯一键字段内容的。 这里要注意,如果这里的name修改为 lisi,zhangsan3 会报唯一键冲突的。可以自行尝试。 三、ON DUPLICATE KEY UPDATE的注意事项 3.1、on dupdate key update之后values的使用事项 如下sql: insert into tbl_test(name,age,address,update_time) values('zhangsan4',205,'杭州5','2024-03-05 00:00:00') on duplicate key update age = age, address = '杭州', update_time=values(update_time); on dupdate key update之后没有用values的情况 分为两种情况: 1:如果为如上面的address= “杭州”,则会一直更新为"杭州". 2:如果为如上面的age = age,则age会保持数据库中的值,不会更新。 3:只有当使用了values后,才会更新为上下文中传入的值 3.2、对values使用判断 如下sql insert into tbl_test(id,name,age,address) values(1,'zhangsan',202,'杭州2') on duplicate key update name = ifnull(values(name),name), age = values(age) 达到的效果是,如果传入的name值为null,则不更新。不为null则更新。这里与mybatis配合使用比较好。 3.3、唯一索引大小写敏感问题 思考这么一个问题:如上面name作为唯一索引,当name大小写敏感时且数据库中存储了name=“zhangsan” ,那么再插入name="ZHANGSAN"是更新还是新增? 1):唯一索引大小写不敏感时 设置name字段为唯一索引且大小写不敏感 drop table if exists tbl_test; create table tbl_test( id int primary key auto_increment, name varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci unique not null, age int comment '年龄', address varchar(50) comment '住址', update_time datetime default null ) comment '测试表'; insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()); insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',21,'杭州1',now()); 可以看到当字段为大小写不敏感时zhangsan跟ZHANGSAN被认为是同一个值,不能重复插入。 当数据库中name=zhangsan时且name字段大小写不敏感时,我们看一下name="ZHANGSAN"能否更新成功? insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',22,'杭州2','2024-03-05 00:00:00') on duplicate key update age = values(age), address = values(address), update_time=values(update_time); 以上结果可以看出,当大小写不敏感时on duplicate key update是可以更新成功的,即认为是同一个值。 2):唯一索引大小写敏感时 设置name字段为唯一索引且大小写敏感 drop table if exists tbl_test; create table tbl_test( id int primary key auto_increment, name varchar(30) CHARACTER SET utf8 COLLATE utf8_bin unique not null, age int comment '年龄', address varchar(50) comment '住址', update_time datetime default null ) comment '测试表'; insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()); insert into tbl_test(name,age,address,update_time) values('ZHANGSAN',21,'杭州1',now()); 可以看到当字段为大小写敏感时zhangsan跟ZHANGSAN被认为是两个值,插入了两条记录。所以此时用on duplicate key update会执行新增操作 四、ON DUPLICATE KEY UPDATE与mybatis联合使用 4.1、写法一:与values()联合使用 注意:values后面的内容是表字段名称即带下划线,而不是实体类驼峰名称 如下sql: dept_id为主键或唯一索引 <insert id="replaceInto"> INSERT INTO sys_dept( dept_id, parent_id, status, update_time) VALUES <foreach collection="deptList" item="item" separator=","> (#{item.deptId}, #{item.parentId}, #{item.status}, #{item.updateTime}) </foreach> ON DUPLICATE KEY UPDATE parent_id=VALUES(parent_id), status=VALUES(status), update_time=VALUES(update_time) </insert> 4.2、写法二:使用#{} 如下sql: dept_id为主键或唯一索引 <insert id="replaceInto"> INSERT INTO sys_dept( dept_id, parent_id, status, update_time) VALUES <foreach collection="deptList" item="item" separator=","> (#{item.deptId}, #{item.parentId}, #{item.status}, #{item.updateTime}) </foreach> ON DUPLICATE KEY UPDATE <foreach collection="deptList" item="item" separator=","> parent_id = #{item.parentId}, status = #{item.status}, update_time = #{item.updateTime} </foreach> </insert> 五、ON DUPLICATE KEY UPDATE的缺点及坑 5.1、ON DUPLICATE KEY UPDATE每次更新导致id不连续 如下sql: drop table if exists tbl_test; create table tbl_test( id int primary key auto_increment, name varchar(30) CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci unique not null, age int comment '年龄', address varchar(50) comment '住址', update_time datetime default null ) comment '测试表'; insert into tbl_test(name,age,address,update_time) values('zhangsan',20,'杭州',now()),('李四',21,'武汉',now()); 执行on duplicate key update进行更新,然后再插入一条新的数据 insert into tbl_test(name,age,address,update_time) values('zhangsan',22,'杭州2','2024-03-05 00:00:00') on duplicate key update age = values(age), address = values(address), update_time=values(update_time); insert into tbl_test(name,age,address,update_time) values('王五',23,'深圳',now()); 可以看到id自增值从2直接变成了4,造成了id的不连续。 1.ON DUPLICATE KEY UPDATE每次更新导致id不连续原理: mysql中有个配置值是innodb_autoinc_lock_mode。 innodb_autoinc_lock_mode中有3中模式,0,1和2,mysql5的默认配置是1, 0是每次分配自增id的时候都会锁表. 1只有在bulk insert的时候才会锁表,简单insert的时候只会使用一个light-weight mutex,比0的并发性能高 2.没有仔细看,好像是很多的不保证…不太安全. 数据库默认是1的情况下,就会发生上面的那种现象,每次使用insert into … on duplicate key update 的时候都会把简单自增id增加,不管是发生了insert还是update 5.2、death lock死锁 经常看到网上说ON DUPLICATE KEY UPDATE会导致死锁,确实是存在这个可能的,不过由于目前没有特别好的方案,所以也只能使用这个sql语法了。在执行insert ... on duplicate key语句时,如果不对同一个表同时进行并发的insert或者update,基本不会造成死锁。即insert ... on duplicate key时尽量单线程串行进行新增或更新 insert … on duplicate key 在执行时,innodb引擎会先判断插入的行是否产生重复key错误,如果存在,在对该现有的行加上S(共享锁)锁,如果返回该行数据给mysql,然后mysql执行完duplicate后的update操作,然后对该记录加上X(排他锁),最后进行update写入。 如果有两个事务并发的执行同样的语句,那么就会产生death lock ———————————————— 原文链接:https://blog.csdn.net/weixin_49114503/article/details/136479860
-
注意:ON DUPLICATE KEY UPDATE 是Mysql特有的语法,仅Mysql有效。 作用:当执行insert操作时,有已经存在的记录,执行update操作。 用法: 有一个test表,id为主键。第一次插入数据 INSERT INTO test(id,name,age)VALUES(1,'2',3),(11,'22',33) 此时表中数据增加了一条主键’id’为‘1’和‘11’的两条记录,当我们再次执行一条id为1的插入语句时,会发生什么呢? INSERT INTO test(id,name,age)VALUES(1,'张三',13) INSERT INTO test(id,name,age)VALUES(1,'张三',13) > 1062 - Duplicate entry '1' for key 'PRIMARY' > 时间: 0.034s Mysql告诉我们,我们的主键冲突了,看到这里我们是不是可以改变一下思路,当插入已存在主键的记录时,将插入操作变为修改: -- 在原sql后面增加 ON DUPLICATE KEY UPDATE INSERT INTO test ( id, NAME, age ) VALUES( 1, '张三', 13 ) ON DUPLICATE KEY UPDATE id = 1, NAME = '张三', age = 13 执行结果中受影响的行数是2。 -- 在原sql后面增加 ON DUPLICATE KEY UPDATE INSERT INTO test ( id, NAME, age ) VALUES( 1, '张三', 13 ) ON DUPLICATE KEY UPDATE id = 1, NAME = '张三', age = 13 > Affected rows: 2 > 时间: 0.18s 执行上面的语句结果 此时我们如果再次插入( 1, '张三', 13 ) 的数据时会有什么结果 -- 在原sql后面增加 ON DUPLICATE KEY UPDATE INSERT INTO test ( id, NAME, age ) VALUES( 1, '张三', 13 ) ON DUPLICATE KEY UPDATE id = 1, NAME = '张三', age = 13 > Affected rows: 0 > 时间: 0.013s 可以看到影响的行数为0。插入的时候主键冲突,ON DUPLICATE KEY UPDATE会执行更新操作,更新为id = 1,NAME = '张三',age = 13 ,但是并没有我们想象的执行更新。 总结:ON DUPLICATE KEY UPDATE首先会检查插入的数据主键是否冲突,如果冲突则执行更新操作,如果ON DUPLICATE KEY UPDATE的子句中要更新的值与原来的值都一样,则不更新。如果有一个值与原值不一样,则更新: -- 在原sql后面增加 ON DUPLICATE KEY UPDATE INSERT INTO test ( id, NAME, age ) VALUES( 1, '张三', 13 ) ON DUPLICATE KEY UPDATE id = 1, NAME = '张三', age = 133 > Affected rows: 2 > 时间: 0.014s 执行完毕,id为1的age值改为133 目前id为1的数据age字段值为13,我们执行插入语句时只改变了其中一个值age=133,则影响行数为2。此时注意VALUES( 1, '张三', 13 ) 中age值为13,ON DUPLICATE KEY UPDATE子句中age值为133。 如果插入的数据主键有冲突,则修改字段值以ON DUPLICATE KEY UPDATE子句的值为准。 ON DUPLICATE KEY UPDATE子句写的是固定值,怎么动态赋值呢?如果一次插入多条数据,怎么动态获取主键冲突所要更新的值呢? ON DUPLICATE KEY UPDATE age = VALUES(age) 总结: 1. ON DUPLICATE KEY UPDATE检查主键或唯一索引字段是否冲突。 2. update的字段值与现存的字段值相同,则不更新。 3. 动态更新字段值用VALUES(字段名称)。 ———————————————— 原文链接:https://blog.csdn.net/qq_38803590/article/details/124692041
-
 前言mysql5.7版本开始支持JSON类型字段,本文详细介绍json_extract函数如何获取mysql中的JSON类型数据json_extract可以完全简写为 ->json_unquote(json_extract())可以完全简写为 ->>下面介绍中大部分会利用简写创建示例表12345CREATE TABLE `test_json` ( `id` int(11) NOT NULL AUTO_INCREMENT, `content` json DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;123# 插入两条测试用的记录INSERT INTO `test_json` (`content`) VALUES ('{\"name\":\"tom\",\"age\":18,\"score\":[100,90,87],\"address\":{\"province\":\"湖南\",\"city\":\"长沙\"}}');INSERT INTO `test_json` (`content`) VALUES ('[1, "apple", "red", {"age": 18, "name": "tom"}]');idcontent1{“age”: 18, “name”: “tom”, “score”: [100, 90, 87], “address”: {“city”: “长沙”, “province”: “湖南”}}2[1, “apple”, “red”, {“age”: 18, “name”: “tom”}]基本语法获取JSON对象中某个key对应的value值json_extract函数中,第一个参数content表示json数据,第二个参数为json路径,其中 表示该 j s o n 数据本身, 表示该json数据本身, 表示该json数据本身,.name就表示获取json中key为name的value值可以利用 -> 表达式来代替json_extract若获取的val本身为字符串,那么获取的val会被引号包起来,比如"tom",这种数据被解析到程序对象中时,可能会被转义为\“tom\”。为了解决这个问题了,可以在外面再包上一层json_unquote函数,或者使用 ->> 代替->12content:{“age”: 18, “name”: “tom”, “score”: [100, 90, 87], “address”: {“city”: “长沙”, “provi # 得到"tom" select json_extract(content,'$.name') from test_json where id = 1; # 简写方式:字段名->表达式等价于json_extract(字段名,表达式) select content->'$.name' from test_json where id = 1; # 结果: +--------------------------------+ | json_extract(content,'$.name') | +--------------------------------+ | "tom" | +--------------------------------+ +-------------------+ | content->'$.name' | +-------------------+ | "tom" | +-------------------+ # 解除双引号,得到tom select json_unquote(json_extract(content,'$.name')) from test_json where id = 1; # 简写方式:字段名->>表达式等价于json_unquote(json_extract(字段名,表达式)) select content->>'$.name' from test_json where id = 1; # 结果: +----------------------------------------------+ | json_unquote(json_extract(content,'$.name')) | +----------------------------------------------+ | tom | +----------------------------------------------+ +--------------------+ | content->>'$.name' | +--------------------+ | tom | +--------------------+ 获取JSON数组中某个元素json_extract函数中,第一个参数content表示json数据,第二个参数为json路径,其中 表示该 j s o n 数据本身, 表示该json数据本身, 表示该json数据本身,[i]表示获取该json数组索引为i的元素(索引从0开始)与获取key-val一样,若获取的元素为字符串,默认的方式也会得到双引号包起来的字符,导致程序转义,方法也是利用json_unquote函数,或者使用 ->> 代替->12content:[1, “apple”, “red”, {“age”: 18, “name”: “tom”}] # 得到"apple" select json_extract(content,'$[1]') from test_json where id = 2; # 简写,效果同上 select content->'$[1]' from test_json where id = 2; # 结果: +------------------------------+ | json_extract(content,'$[1]') | +------------------------------+ | "apple" | +------------------------------+ +-----------------+ | content->'$[1]' | +-----------------+ | "apple" | +-----------------+ # 解除双引号,得到apple select json_unquote(json_extract(content,'$[1]')) from test_json where id = 2; # 简写,效果同上 select content->>'$[1]' from test_json where id = 2; # 结果: +--------------------------------------------+ | json_unquote(json_extract(content,'$[1]')) | +--------------------------------------------+ | apple | +--------------------------------------------+ +------------------+ | content->>'$[1]' | +------------------+ | apple | +------------------+ 获取JSON中的嵌套数据结合前面介绍的两种获取方式,可以获取json数据中的嵌套数据1234content: id=1{“age”: 18, “name”: “tom”, “score”: [100, 90, 87], “address”: {“city”: “长沙”, “province”: “湖南”}}content: id=2[1, “apple”, “red”, {“age”: 18, “name”: “tom”}] # 得到:87 select content->'$.score[2]' from test_json where id = 1; # 结果: +-----------------------+ | content->'$.score[2]' | +-----------------------+ | 87 | +-----------------------+ # 得到:18 select content->'$[3].age' from test_json where id = 2; # 结果: +---------------------+ | content->'$[3].age' | +---------------------+ | 18 | +---------------------+ 渐入佳境获取JSON多个路径的数据将会把多个路径的数据组合成数组返回12content: id=1{“age”: 18, “name”: “tom”, “score”: [100, 90, 87], “address”: {“city”: “长沙”, “province”: “ select json_extract(content,'$.age','$.score') from test_json where id = 1; # 结果: +-----------------------------------------+ | json_extract(content,'$.age','$.score') | +-----------------------------------------+ | [18, [100, 90, 87]] | +-----------------------------------------+ select json_extract(content,'$.name','$.address.province','$.address.city') from test_json where id = 1; # 结果: +----------------------------------------------------------------------+ | json_extract(content,'$.name','$.address.province','$.address.city') | +----------------------------------------------------------------------+ | ["tom", "湖南", "长沙"] | +----------------------------------------------------------------------+ 路径表达式*的使用将会把多个路径的数据组合成数组返回12# 先插入一条用于测试的数据INSERT INTO `test_json` (`id`,`content`) VALUES(3,'{"name":"tom","address":{"name":"中央公园","city":"长沙"},"class":{"id":3,"name":"一年三班"},"friend":[{"age":20,"name":"marry"},{"age":21,"name":"Bob"}]}')12content: id=3{“name”: “tom”, “class”: {“id”: 3, “name”: “一年三班”}, “friend”: [{“age”: 20, “name”: “marry”}, {“age”: 21, “name”: “Bob”}], “address”: {“city”: “长沙”, “name”: “中央公园”}}
前言mysql5.7版本开始支持JSON类型字段,本文详细介绍json_extract函数如何获取mysql中的JSON类型数据json_extract可以完全简写为 ->json_unquote(json_extract())可以完全简写为 ->>下面介绍中大部分会利用简写创建示例表12345CREATE TABLE `test_json` ( `id` int(11) NOT NULL AUTO_INCREMENT, `content` json DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;123# 插入两条测试用的记录INSERT INTO `test_json` (`content`) VALUES ('{\"name\":\"tom\",\"age\":18,\"score\":[100,90,87],\"address\":{\"province\":\"湖南\",\"city\":\"长沙\"}}');INSERT INTO `test_json` (`content`) VALUES ('[1, "apple", "red", {"age": 18, "name": "tom"}]');idcontent1{“age”: 18, “name”: “tom”, “score”: [100, 90, 87], “address”: {“city”: “长沙”, “province”: “湖南”}}2[1, “apple”, “red”, {“age”: 18, “name”: “tom”}]基本语法获取JSON对象中某个key对应的value值json_extract函数中,第一个参数content表示json数据,第二个参数为json路径,其中 表示该 j s o n 数据本身, 表示该json数据本身, 表示该json数据本身,.name就表示获取json中key为name的value值可以利用 -> 表达式来代替json_extract若获取的val本身为字符串,那么获取的val会被引号包起来,比如"tom",这种数据被解析到程序对象中时,可能会被转义为\“tom\”。为了解决这个问题了,可以在外面再包上一层json_unquote函数,或者使用 ->> 代替->12content:{“age”: 18, “name”: “tom”, “score”: [100, 90, 87], “address”: {“city”: “长沙”, “provi # 得到"tom" select json_extract(content,'$.name') from test_json where id = 1; # 简写方式:字段名->表达式等价于json_extract(字段名,表达式) select content->'$.name' from test_json where id = 1; # 结果: +--------------------------------+ | json_extract(content,'$.name') | +--------------------------------+ | "tom" | +--------------------------------+ +-------------------+ | content->'$.name' | +-------------------+ | "tom" | +-------------------+ # 解除双引号,得到tom select json_unquote(json_extract(content,'$.name')) from test_json where id = 1; # 简写方式:字段名->>表达式等价于json_unquote(json_extract(字段名,表达式)) select content->>'$.name' from test_json where id = 1; # 结果: +----------------------------------------------+ | json_unquote(json_extract(content,'$.name')) | +----------------------------------------------+ | tom | +----------------------------------------------+ +--------------------+ | content->>'$.name' | +--------------------+ | tom | +--------------------+ 获取JSON数组中某个元素json_extract函数中,第一个参数content表示json数据,第二个参数为json路径,其中 表示该 j s o n 数据本身, 表示该json数据本身, 表示该json数据本身,[i]表示获取该json数组索引为i的元素(索引从0开始)与获取key-val一样,若获取的元素为字符串,默认的方式也会得到双引号包起来的字符,导致程序转义,方法也是利用json_unquote函数,或者使用 ->> 代替->12content:[1, “apple”, “red”, {“age”: 18, “name”: “tom”}] # 得到"apple" select json_extract(content,'$[1]') from test_json where id = 2; # 简写,效果同上 select content->'$[1]' from test_json where id = 2; # 结果: +------------------------------+ | json_extract(content,'$[1]') | +------------------------------+ | "apple" | +------------------------------+ +-----------------+ | content->'$[1]' | +-----------------+ | "apple" | +-----------------+ # 解除双引号,得到apple select json_unquote(json_extract(content,'$[1]')) from test_json where id = 2; # 简写,效果同上 select content->>'$[1]' from test_json where id = 2; # 结果: +--------------------------------------------+ | json_unquote(json_extract(content,'$[1]')) | +--------------------------------------------+ | apple | +--------------------------------------------+ +------------------+ | content->>'$[1]' | +------------------+ | apple | +------------------+ 获取JSON中的嵌套数据结合前面介绍的两种获取方式,可以获取json数据中的嵌套数据1234content: id=1{“age”: 18, “name”: “tom”, “score”: [100, 90, 87], “address”: {“city”: “长沙”, “province”: “湖南”}}content: id=2[1, “apple”, “red”, {“age”: 18, “name”: “tom”}] # 得到:87 select content->'$.score[2]' from test_json where id = 1; # 结果: +-----------------------+ | content->'$.score[2]' | +-----------------------+ | 87 | +-----------------------+ # 得到:18 select content->'$[3].age' from test_json where id = 2; # 结果: +---------------------+ | content->'$[3].age' | +---------------------+ | 18 | +---------------------+ 渐入佳境获取JSON多个路径的数据将会把多个路径的数据组合成数组返回12content: id=1{“age”: 18, “name”: “tom”, “score”: [100, 90, 87], “address”: {“city”: “长沙”, “province”: “ select json_extract(content,'$.age','$.score') from test_json where id = 1; # 结果: +-----------------------------------------+ | json_extract(content,'$.age','$.score') | +-----------------------------------------+ | [18, [100, 90, 87]] | +-----------------------------------------+ select json_extract(content,'$.name','$.address.province','$.address.city') from test_json where id = 1; # 结果: +----------------------------------------------------------------------+ | json_extract(content,'$.name','$.address.province','$.address.city') | +----------------------------------------------------------------------+ | ["tom", "湖南", "长沙"] | +----------------------------------------------------------------------+ 路径表达式*的使用将会把多个路径的数据组合成数组返回12# 先插入一条用于测试的数据INSERT INTO `test_json` (`id`,`content`) VALUES(3,'{"name":"tom","address":{"name":"中央公园","city":"长沙"},"class":{"id":3,"name":"一年三班"},"friend":[{"age":20,"name":"marry"},{"age":21,"name":"Bob"}]}')12content: id=3{“name”: “tom”, “class”: {“id”: 3, “name”: “一年三班”}, “friend”: [{“age”: 20, “name”: “marry”}, {“age”: 21, “name”: “Bob”}], “address”: {“city”: “长沙”, “name”: “中央公园”}} -
 当开发与Linux环境下MySQL数据库交互的Java应用程序时,理解MySQL中的大小写敏感性可以避免潜在的错误和问题。本指南深入探讨了MySQL中的大小写敏感设置,比较了5.7和8.0版本,并为Java开发者提供了最佳实践。1 理解MySQL中的大小写敏感性默认情况下,MySQL在Windows上是大小写不敏感的,但在Linux上是大小写敏感的。这种差异可能导致不一致性,特别是在迁移数据库或开发跨平台应用程序时。MySQL中的大小写敏感行为由lower_case_table_names系统变量控制。lower_case_table_names = 0:表名按指定存储,比较是大小写敏感的。lower_case_table_names = 1:表名在磁盘上以小写存储,比较不是大小写敏感的。lower_case_table_names = 2:表名按指定存储,但比较不是大小写敏感的。2 MySQL 5.7大小写敏感设置在MySQL 5.7中,默认在Linux上的设置是lower_case_table_names = 0,这意味着表名是大小写敏感的。要改变这种行为,您需要明确设置lower_case_table_names变量。2.1 配置MySQL 5.7编辑MySQL配置:打开MySQL配置文件,通常位于/etc/mysql/my.cnf或/etc/my.cnf。sudo nano /etc/mysql/my.cnf添加lower_case_table_names设置:在[mysqld]部分下,添加以下行来将lower_case_table_names设置为1,以实现大小写不敏感的行为:[mysqld] lower_case_table_names=1重启MySQL服务:保存配置文件后,重启MySQL服务以应用更改:sudo systemctl restart mysql3 MySQL 8.0大小写敏感设置在MySQL 8.0中,大小写敏感行为与MySQL 5.7保持一致。然而,MySQL 8.0引入了更好的处理和更严格的检查,确保lower_case_table_names设置在服务器上保持一致。配置MySQL 8.0:编辑MySQL配置:打开MySQL配置文件,通常位于/etc/mysql/my.cnf或/etc/mysql/mysql.conf.d/mysqld.cnf。sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf添加lower_case_table_names设置:在[mysqld]部分下,添加以下行来将lower_case_table_names设置为1:[mysqld] lower_case_table_names=1重启MySQL服务:重启MySQL服务以应用更改:sudo systemctl restart mysql4 针对Java开发者的考虑在Java应用程序中使用MySQL数据库时,请考虑以下最佳实践来处理大小写敏感性:一致的命名约定:对数据库对象使用一致的命名约定。坚持使用全部小写或全部大写名称,以避免与大小写敏感性相关的问题。数据库迁移:如果从大小写不敏感的系统(如Windows)迁移数据库到大小写敏感的系统(如Linux),请确保在迁移之前适当配置lower_case_table_names设置。数据库交互:在Java中编写SQL查询时,请确保查询中使用的案例与数据库对象的案例相匹配。使用Hibernate等ORM工具可以帮助管理大小写敏感性,但正确配置它们至关重要。测试:在模拟生产设置的环境中彻底测试您的应用程序,特别是如果生产环境是大小写敏感的。文档:记录项目中使用的大小写敏感设置和命名约定。这种做法有助于保持一致性,并帮助新开发者理解项目的数据库设计。5 总结在Linux上管理MySQL的大小写敏感性对于开发健壮的Java应用程序至关重要。通过理解lower_case_table_names变量并正确配置它,确保在不同环境中的一致行为,避免与大小写敏感性相关的常见陷阱。转载自https://www.cnblogs.com/JavaEdge/p/18211836
当开发与Linux环境下MySQL数据库交互的Java应用程序时,理解MySQL中的大小写敏感性可以避免潜在的错误和问题。本指南深入探讨了MySQL中的大小写敏感设置,比较了5.7和8.0版本,并为Java开发者提供了最佳实践。1 理解MySQL中的大小写敏感性默认情况下,MySQL在Windows上是大小写不敏感的,但在Linux上是大小写敏感的。这种差异可能导致不一致性,特别是在迁移数据库或开发跨平台应用程序时。MySQL中的大小写敏感行为由lower_case_table_names系统变量控制。lower_case_table_names = 0:表名按指定存储,比较是大小写敏感的。lower_case_table_names = 1:表名在磁盘上以小写存储,比较不是大小写敏感的。lower_case_table_names = 2:表名按指定存储,但比较不是大小写敏感的。2 MySQL 5.7大小写敏感设置在MySQL 5.7中,默认在Linux上的设置是lower_case_table_names = 0,这意味着表名是大小写敏感的。要改变这种行为,您需要明确设置lower_case_table_names变量。2.1 配置MySQL 5.7编辑MySQL配置:打开MySQL配置文件,通常位于/etc/mysql/my.cnf或/etc/my.cnf。sudo nano /etc/mysql/my.cnf添加lower_case_table_names设置:在[mysqld]部分下,添加以下行来将lower_case_table_names设置为1,以实现大小写不敏感的行为:[mysqld] lower_case_table_names=1重启MySQL服务:保存配置文件后,重启MySQL服务以应用更改:sudo systemctl restart mysql3 MySQL 8.0大小写敏感设置在MySQL 8.0中,大小写敏感行为与MySQL 5.7保持一致。然而,MySQL 8.0引入了更好的处理和更严格的检查,确保lower_case_table_names设置在服务器上保持一致。配置MySQL 8.0:编辑MySQL配置:打开MySQL配置文件,通常位于/etc/mysql/my.cnf或/etc/mysql/mysql.conf.d/mysqld.cnf。sudo nano /etc/mysql/mysql.conf.d/mysqld.cnf添加lower_case_table_names设置:在[mysqld]部分下,添加以下行来将lower_case_table_names设置为1:[mysqld] lower_case_table_names=1重启MySQL服务:重启MySQL服务以应用更改:sudo systemctl restart mysql4 针对Java开发者的考虑在Java应用程序中使用MySQL数据库时,请考虑以下最佳实践来处理大小写敏感性:一致的命名约定:对数据库对象使用一致的命名约定。坚持使用全部小写或全部大写名称,以避免与大小写敏感性相关的问题。数据库迁移:如果从大小写不敏感的系统(如Windows)迁移数据库到大小写敏感的系统(如Linux),请确保在迁移之前适当配置lower_case_table_names设置。数据库交互:在Java中编写SQL查询时,请确保查询中使用的案例与数据库对象的案例相匹配。使用Hibernate等ORM工具可以帮助管理大小写敏感性,但正确配置它们至关重要。测试:在模拟生产设置的环境中彻底测试您的应用程序,特别是如果生产环境是大小写敏感的。文档:记录项目中使用的大小写敏感设置和命名约定。这种做法有助于保持一致性,并帮助新开发者理解项目的数据库设计。5 总结在Linux上管理MySQL的大小写敏感性对于开发健壮的Java应用程序至关重要。通过理解lower_case_table_names变量并正确配置它,确保在不同环境中的一致行为,避免与大小写敏感性相关的常见陷阱。转载自https://www.cnblogs.com/JavaEdge/p/18211836
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签