-
 【功能模块】使用mindspore1.2GPU跑RNN_attention时遇到data type问题【操作步骤&问题现象】1、使用mindspore编写RNN_attention模型,排除模型内部报错后,在运行时抛出data type问题2、模型代码及部分参数如下:parser.add_argument('--num_layers', type=int, default=1, ) # lstm层数parser.add_argument('--hidden_size', type=int, default=128, ) # lstm隐藏层parser.add_argument('--embedding_pretrained', default=None, ) # 预训练parser.add_argument('--embed', type=int, default=300) #文本embedding维度parser.add_argument('--hidden_size2', type=int, default=64, ) #import mindsporeimport mindspore.nn as nnfrom mindspore import dtype as mstypefrom mindspore import Tensorfrom mindspore.ops import operations as Pimport mindspore.ops as opsimport numpy as npclass RNN_attent(nn.Cell): def __init__(self, config): super(RNN_attent, self).__init__() self.embedding = nn.Embedding(config.n_vocab, config.embed) self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers, bidirectional=True, batch_first=True, dropout=config.dropout) self.softmax = nn.Softmax() self.tanh1 = nn.Tanh() # self.u = nn.Parameter(torch.Tensor(config.hidden_size * 2, config.hidden_size * 2)) self.w = mindspore.Parameter(Tensor(np.zeros(config.hidden_size * 2))) self.fc1 = nn.Dense(config.hidden_size * 2, config.hidden_size2) self.fc = nn.Dense(config.hidden_size2, config.num_classes) self.relu = nn.ReLU() self.unsqueeze = ops.ExpandDims() self.num_directions = 2 self.hidden_size = config.hidden_size self.num_layers = config.num_layers self.batch_size = config.batch_size def construct(self, x): embed = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300] h_0 = Tensor(np.zeros([self.num_directions * self.num_layers, self.batch_size, self.hidden_size]).astype(np.float32)) c_0 = Tensor(np.zeros([self.num_directions * self.num_layers, self.batch_size, self.hidden_size]).astype(np.float32)) hx_0 = (h_0, c_0) H, _ = self.lstm(embed, hx_0) M = self.tanh1(H) # [128, 32, 256] alpha = self.softmax(ops.matmul(M, self.w)) # [128, 32, 1] alpha = self.unsqueeze(alpha, -1) out = H * alpha # [128, 32, 256] out = ops.reduce_sum(out, 1) # [128, 256] out = self.relu(out) out = self.fc1(out) out = self.fc(out) # [128, 64] return outargs.n_vocab = vocab_sizeargs.dropout = 0.1model = RNN_attent(config = args)【截图信息】完整报错信息:【日志信息】(可选,上传日志内容或者附件)
【功能模块】使用mindspore1.2GPU跑RNN_attention时遇到data type问题【操作步骤&问题现象】1、使用mindspore编写RNN_attention模型,排除模型内部报错后,在运行时抛出data type问题2、模型代码及部分参数如下:parser.add_argument('--num_layers', type=int, default=1, ) # lstm层数parser.add_argument('--hidden_size', type=int, default=128, ) # lstm隐藏层parser.add_argument('--embedding_pretrained', default=None, ) # 预训练parser.add_argument('--embed', type=int, default=300) #文本embedding维度parser.add_argument('--hidden_size2', type=int, default=64, ) #import mindsporeimport mindspore.nn as nnfrom mindspore import dtype as mstypefrom mindspore import Tensorfrom mindspore.ops import operations as Pimport mindspore.ops as opsimport numpy as npclass RNN_attent(nn.Cell): def __init__(self, config): super(RNN_attent, self).__init__() self.embedding = nn.Embedding(config.n_vocab, config.embed) self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers, bidirectional=True, batch_first=True, dropout=config.dropout) self.softmax = nn.Softmax() self.tanh1 = nn.Tanh() # self.u = nn.Parameter(torch.Tensor(config.hidden_size * 2, config.hidden_size * 2)) self.w = mindspore.Parameter(Tensor(np.zeros(config.hidden_size * 2))) self.fc1 = nn.Dense(config.hidden_size * 2, config.hidden_size2) self.fc = nn.Dense(config.hidden_size2, config.num_classes) self.relu = nn.ReLU() self.unsqueeze = ops.ExpandDims() self.num_directions = 2 self.hidden_size = config.hidden_size self.num_layers = config.num_layers self.batch_size = config.batch_size def construct(self, x): embed = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300] h_0 = Tensor(np.zeros([self.num_directions * self.num_layers, self.batch_size, self.hidden_size]).astype(np.float32)) c_0 = Tensor(np.zeros([self.num_directions * self.num_layers, self.batch_size, self.hidden_size]).astype(np.float32)) hx_0 = (h_0, c_0) H, _ = self.lstm(embed, hx_0) M = self.tanh1(H) # [128, 32, 256] alpha = self.softmax(ops.matmul(M, self.w)) # [128, 32, 1] alpha = self.unsqueeze(alpha, -1) out = H * alpha # [128, 32, 256] out = ops.reduce_sum(out, 1) # [128, 256] out = self.relu(out) out = self.fc1(out) out = self.fc(out) # [128, 64] return outargs.n_vocab = vocab_sizeargs.dropout = 0.1model = RNN_attent(config = args)【截图信息】完整报错信息:【日志信息】(可选,上传日志内容或者附件) -
 这张图,来源于大概 32 年前的一本书《The Age OF Intelligent Machines》,作者是 Kurzweil 博士 ,他当时就预言了未来人工智能所需要的算力发展。我们对这张图做了些延伸,单个器件上大概能够集成多少计算能力。过去 100 年,计算能力几乎呈指数增长趋势,到现在,比如今天英伟达发布会最新 GPU 的计算,包括上周苹果发布的 GPU 芯片,基本上可以带来超过一个人脑级别的计算能力,为我们带来了非常大的可能。  人工智能计算平台分很多种,从大家比较熟悉的 GPU、FPGA、ASIC 到新型架构,实际都遵循了一个原则:要么更高效,要么更专业需要更长时间,要么更灵活,不可能在多个维度达到统一,永远存在一个设计上的矛盾。 比如,在 GPU 上算力最高,功耗也最高。FPGA 上会实现一些非常容易可重构的计算,但能效比可能不是那么好。ASIC 能效比非常好,但需要更长的开发周期 ,基本上是对特定应用做设计,当出货量比较小的时候,不是特别有效。  大家比较熟悉冯 · 诺伊曼瓶颈,实际上是说计算能力可以通过不断增加计算单元来实现,但最后瓶颈在于能不能把数据及时给到计算单元。过去四五十年,片上计算能力和片外数据通过存储带宽提供给片上的能力差距越来越大,也带来了 “内存墙” 的概念。当然,实际具体设计中,比如不能及时挪走产生的热量、不能无限制增大使用频率等,(这些)都迫使我们寻找新的计算设计。  现在比较热门的是近存或存内计算设计,想法也非常简单,既然瓶颈来源于数据间流动,尤其是存储空间到计算空间的流动,能不能想一些办法让计算跟存储发生在同一个地方?这实际上正好和冯诺依曼体系相对,后者是将两者分开,这个要合在一起。 为什么可以这么做?因为新型计算,比如神经网络或图计算,经常有一方不变,另外一方不断变化的情况。比如 A 乘上 B,A 不断变化而 B 不变,这种情况下,可以在存储 B 的地方进行计算,不需要把数据挪来挪去。 大家进行了非常多尝试,比如用 DRAM 来做计存。最近,阿里好像也写了一篇文章讲了存内计算,把存储器设计成可以有计算单元,直接在里面进行相应计算,这都是一些有益的尝试。与在从外面拿到数据过来进行计算相比,这个计算能效强几千倍,是非常有希望的未来发展方向。
这张图,来源于大概 32 年前的一本书《The Age OF Intelligent Machines》,作者是 Kurzweil 博士 ,他当时就预言了未来人工智能所需要的算力发展。我们对这张图做了些延伸,单个器件上大概能够集成多少计算能力。过去 100 年,计算能力几乎呈指数增长趋势,到现在,比如今天英伟达发布会最新 GPU 的计算,包括上周苹果发布的 GPU 芯片,基本上可以带来超过一个人脑级别的计算能力,为我们带来了非常大的可能。  人工智能计算平台分很多种,从大家比较熟悉的 GPU、FPGA、ASIC 到新型架构,实际都遵循了一个原则:要么更高效,要么更专业需要更长时间,要么更灵活,不可能在多个维度达到统一,永远存在一个设计上的矛盾。 比如,在 GPU 上算力最高,功耗也最高。FPGA 上会实现一些非常容易可重构的计算,但能效比可能不是那么好。ASIC 能效比非常好,但需要更长的开发周期 ,基本上是对特定应用做设计,当出货量比较小的时候,不是特别有效。  大家比较熟悉冯 · 诺伊曼瓶颈,实际上是说计算能力可以通过不断增加计算单元来实现,但最后瓶颈在于能不能把数据及时给到计算单元。过去四五十年,片上计算能力和片外数据通过存储带宽提供给片上的能力差距越来越大,也带来了 “内存墙” 的概念。当然,实际具体设计中,比如不能及时挪走产生的热量、不能无限制增大使用频率等,(这些)都迫使我们寻找新的计算设计。  现在比较热门的是近存或存内计算设计,想法也非常简单,既然瓶颈来源于数据间流动,尤其是存储空间到计算空间的流动,能不能想一些办法让计算跟存储发生在同一个地方?这实际上正好和冯诺依曼体系相对,后者是将两者分开,这个要合在一起。 为什么可以这么做?因为新型计算,比如神经网络或图计算,经常有一方不变,另外一方不断变化的情况。比如 A 乘上 B,A 不断变化而 B 不变,这种情况下,可以在存储 B 的地方进行计算,不需要把数据挪来挪去。 大家进行了非常多尝试,比如用 DRAM 来做计存。最近,阿里好像也写了一篇文章讲了存内计算,把存储器设计成可以有计算单元,直接在里面进行相应计算,这都是一些有益的尝试。与在从外面拿到数据过来进行计算相比,这个计算能效强几千倍,是非常有希望的未来发展方向。 -
登录未来人工智能中心 使用modelarts进行训练报错
-
【功能模块】请问modelzoo中的resnet34是否有GPU预训练模型能够提供【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
此问题为待答疑问题。我是一名计算算子的开发者,同时我了解到MindSpore算子种类中还有诸多其它类型的算子如AICPU、GPU、TBE算子,那么这些算子有哪些区别和联系呢,我应该去哪里获取文件资料?
-
基于华为云ECS、Docker搭建MindSpore1.6.1-GPU环境 === # 1. 华为云上选配个ECS  # 2. 参照华为云镜像官网下载docker 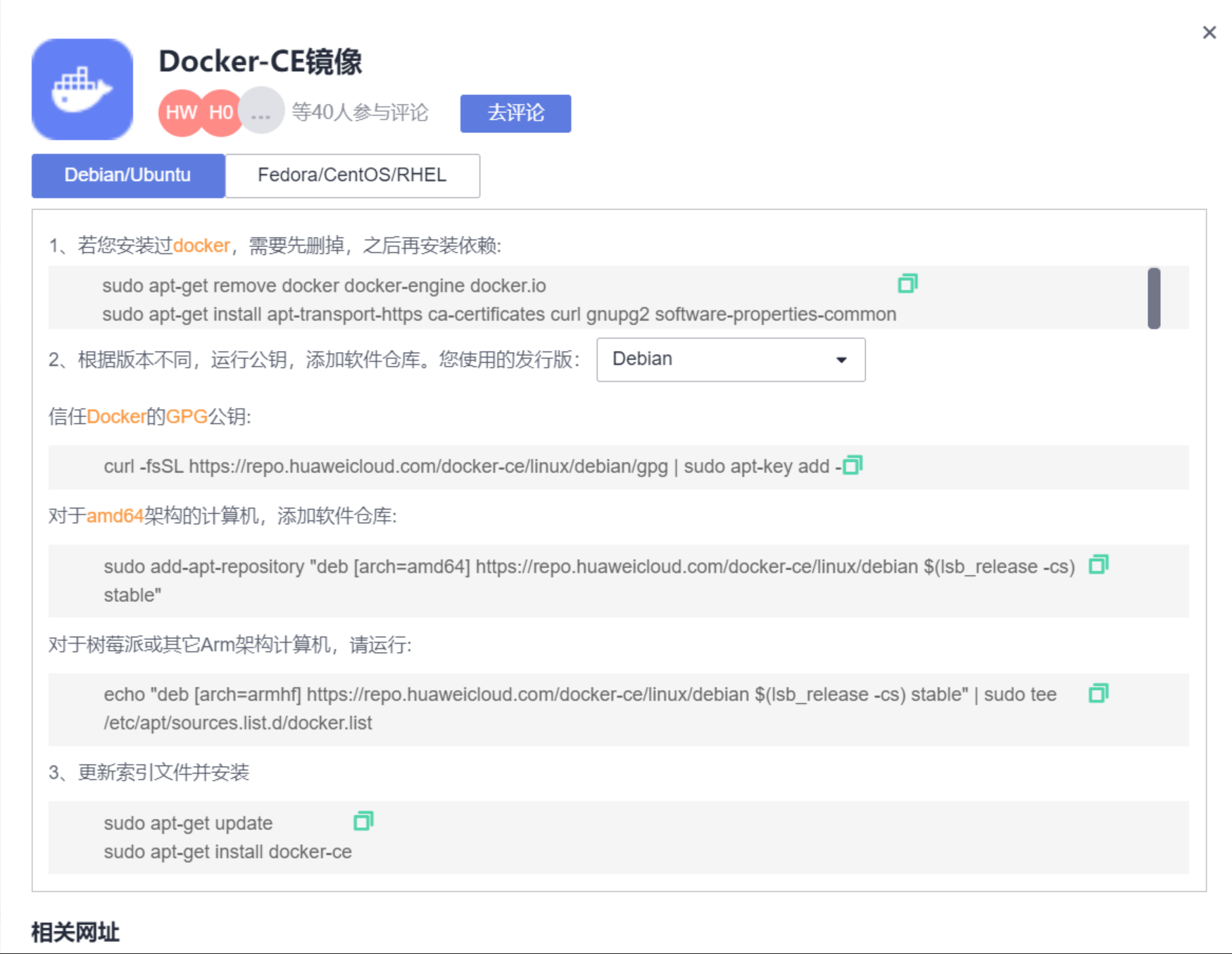 # 3. 加速镜像地址  ``` 暂时不用添加到/etc/docker/daemon.json,等安装完nvidia-docker2再上 ``` # 4. 安装nvidia-docker2 ``` distribution=$(. /etc/os-release;echo $ID$VERSION_ID) curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | \ sudo tee /etc/yum.repos.d/nvidia-docker.repo DIST=$(sed -n 's/releasever=//p' /etc/yum.conf) DIST=${DIST:-$(. /etc/os-release; echo $VERSION_ID)} yum install nvidia-docker2 ```  ``` 添加到daemon.json ```  # 5. MindSpore官网获取docker镜像及说明等(需要详细查看) ``` https://mindspore.cn/install ```   ``` docker pull swr.cn-south-1.myhuaweicloud.com/mindspore/mindspore-gpu-cuda10.1:1.6.1 同时进入容器查看cuda版本是否跟宿主机不同 另外要求宿主机版本比镜像版本高 ```  容器内 --- ECS宿主机  ``` 可以看到两个环境的不同了 ``` # 6. 最后按照官网的案例测试下mindspore-gpu按照成功没(虽然就这两步 中间还是测试了好些个镜像与容器) ``` 可以参考官网的命令格式,但复杂了些,命令供参考 docker run -it --gpus all 8ca50077f6f6镜像id bash 如果容器停了 需要再start ```  # 7. 按照以前在tianchi竞赛的经验编写简单Dockerfile进行测试  weixiewen@126.com
-
配置:context.set_context(device_target="GPU")【日志信息】RuntimeError: mindspore/ccsrc/runtime/device/gpu/gpu_memory_allocator.cc:87 AllocDeviceMem] The memory alloc size is 0.【已解决】问题出在数据集准备阶段:ds.GeneratorDataset(source=生成数据的函数) 这个生成数据的函数返回值不规范导致,应该检查数据集定义是否正确
-
【功能模块】渲染功能【操作步骤&问题现象】1、按照robox步骤,在鲲鹏920服务器上面启动robox,2、然后跑安兔兔进行行性能测评,发现GPU测试没有数据,查看测评报告是LLVM渲染3、如何设置才能通过GPU渲染?【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
 欢迎大家加入 MindSpore易用性的SIG。有位医界的朋友使用Ubuntu 20.04裸机尝试了一键安装MindSpore 1.6.1的版本。那么,张小白也试一下吧。首先,你需要一个ubuntu 20.04.在有了ubuntu 18.04的WSL的基础上,怎么才能共存一个Ubuntu 20.04.想必先要把18.04关机。打开PowerShell的管理员模式:先下掉WSL:wsl --shutdown打开Microsoft Store:查找 ubuntu 20.04.4 LTS:请忽视下面的低分评价。让我们点击获取按钮。耐心等待下载完毕。直到可以打开:那就打开吧:输入常用的用户名密码:ascend/asend,进入终端。
欢迎大家加入 MindSpore易用性的SIG。有位医界的朋友使用Ubuntu 20.04裸机尝试了一键安装MindSpore 1.6.1的版本。那么,张小白也试一下吧。首先,你需要一个ubuntu 20.04.在有了ubuntu 18.04的WSL的基础上,怎么才能共存一个Ubuntu 20.04.想必先要把18.04关机。打开PowerShell的管理员模式:先下掉WSL:wsl --shutdown打开Microsoft Store:查找 ubuntu 20.04.4 LTS:请忽视下面的低分评价。让我们点击获取按钮。耐心等待下载完毕。直到可以打开:那就打开吧:输入常用的用户名密码:ascend/asend,进入终端。 -
【功能模块】cuda版本不对应用conda区分环境在自己的conda里安装了cuda11.1,但是编译的时候提示cuda版本是9.1,请问cuda版本不能依靠conda来区分对吗?还是得在base环境下配置cuda吗?之前用pip直接安装是可以的,没有报错,但是基于源码安装就报错了.(修改了些代码,想用源码编译的方式安装修改后的mindspore-gpu,所以暂时不用pip或者conda直接安装的方式)因为不想在base环境下修改,所以想请教下有没有别的解决方案呢?【操作步骤&问题现象】源码编译参考:https://www.mindspore.cn/install【截图信息】报错:conda安装的cudatoolkit版本:【日志信息】(可选,上传日志内容或者附件)
-
 考虑到很多同学GPU显卡数量并不是很多,Yolov4对训练时的输入端进行改进,使得训练在单张GPU上也能有不错的成绩。比如数据增强Mosaic、cmBN、SAT自对抗训练。但感觉cmBN和SAT影响并不是很大,所以这里主要讲解Mosaic数据增强。(1)Mosaic数据增强Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。这里首先要了解为什么要进行Mosaic数据增强呢?在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。首先看下小、中、大目标的定义:2019年发布的论文《Augmentation for small object detection》对此进行了区分:可以看到小目标的定义是目标框的长宽0×0~32×32之间的物体。但在整体的数据集中,小、中、大目标的占比并不均衡。如上表所示,Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式。主要有几个优点:丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。此外,发现另一研究者的训练方式也值得借鉴,采用的数据增强和Mosaic比较类似,也是使用4张图片(不是随机分布),但训练计算loss时,采用“缺啥补啥”的思路:如果上一个iteration中,小物体产生的loss不足(比如小于某一个阈值),则下一个iteration就用拼接图;否则就用正常图片训练,也很有意思。参考链接:https://www.zhihu.com/question/390191723?rf=390194081
考虑到很多同学GPU显卡数量并不是很多,Yolov4对训练时的输入端进行改进,使得训练在单张GPU上也能有不错的成绩。比如数据增强Mosaic、cmBN、SAT自对抗训练。但感觉cmBN和SAT影响并不是很大,所以这里主要讲解Mosaic数据增强。(1)Mosaic数据增强Yolov4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接。这里首先要了解为什么要进行Mosaic数据增强呢?在平时项目训练时,小目标的AP一般比中目标和大目标低很多。而Coco数据集中也包含大量的小目标,但比较麻烦的是小目标的分布并不均匀。首先看下小、中、大目标的定义:2019年发布的论文《Augmentation for small object detection》对此进行了区分:可以看到小目标的定义是目标框的长宽0×0~32×32之间的物体。但在整体的数据集中,小、中、大目标的占比并不均衡。如上表所示,Coco数据集中小目标占比达到41.4%,数量比中目标和大目标都要多。但在所有的训练集图片中,只有52.3%的图片有小目标,而中目标和大目标的分布相对来说更加均匀一些。针对这种状况,Yolov4的作者采用了Mosaic数据增强的方式。主要有几个优点:丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别是随机缩放增加了很多小目标,让网络的鲁棒性更好。减少GPU:可能会有人说,随机缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。此外,发现另一研究者的训练方式也值得借鉴,采用的数据增强和Mosaic比较类似,也是使用4张图片(不是随机分布),但训练计算loss时,采用“缺啥补啥”的思路:如果上一个iteration中,小物体产生的loss不足(比如小于某一个阈值),则下一个iteration就用拼接图;否则就用正常图片训练,也很有意思。参考链接:https://www.zhihu.com/question/390191723?rf=390194081 -
最近在Ubuntu下载了mindsporeGPU版本的,然后在执行GPU算子时,不能得出结果,请问出现了什么问题?import mindspore import mindspore as nn import numpy as np from mindspore import Tensor import mindspore.ops as ops import mindspore.context as context context.set_context(device_target="GPU") x = Tensor(np.ones([1,3,3,4]).astype(np.float32)) y = Tensor(np.ones([1,3,3,4]).astype(np.float32)) print(ops.add(x, y)) x = Tensor(np.ones([16, 3, 10, 32, 32]), mindspore.float32) conv3d = nn.Conv3d(in_channels=3, out_channels=32, kernel_size=(4, 3, 3)) output = conv3d(x) print(output.shape)/home/li/PycharmProjects/pythonProject1/venv/bin/python /home/li/PycharmProjects/pythonProject1/main.py [[[[2. 2. 2. 2.] [2. 2. 2. 2.] [2. 2. 2. 2.]] [[2. 2. 2. 2.] [2. 2. 2. 2.] [2. 2. 2. 2.]] [[2. 2. 2. 2.] [2. 2. 2. 2.] [2. 2. 2. 2.]]]] Traceback (most recent call last): File "/home/li/PycharmProjects/pythonProject1/main.py", line 16, in <module> conv3d = nn.Conv3d(in_channels=3, out_channels=32, kernel_size=(4, 3, 3)) TypeError: Conv3d() takes no argumentsmindspore-gpu 1.6.1 1.6.1
-
 训练作业时提示failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected根据错误信息判断,报错原因为训练作业运行程序读取不到GPU。只需根据报错提示,排查代码,是否已添加以下配置,设置该程序可见的GPU:其中,0为服务器的GPU编号,可以为0, 1, 2, 3等,表明对程序可见的GPU编号。若未进行添加配置则该编号对应的GPU不可用。os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3,4,5,6,7'
训练作业时提示failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected根据错误信息判断,报错原因为训练作业运行程序读取不到GPU。只需根据报错提示,排查代码,是否已添加以下配置,设置该程序可见的GPU:其中,0为服务器的GPU编号,可以为0, 1, 2, 3等,表明对程序可见的GPU编号。若未进行添加配置则该编号对应的GPU不可用。os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3,4,5,6,7' -
Cuttlefish 的加速图形模式会使用主机的物理图形处理器 (GPU) 进行渲染,具体方法是将客户机渲染命令传递给主机,在主机上运行渲染命令调用,然后将渲染后的结果传递回客户机。默认情况下,Cuttlefish 设备中的客户机端渲染(例如界面和视频播放)由 SwiftShader 处理。SwiftShader 是对 OpenGL API 和 Vulkan API 的软件实现。由于 SwiftShader 是一种软件实现,因此它为 Cuttlefish 提供了一种可在任何主机上运行的通用渲染解决方案。不过,使用 SwiftShader 的性能不及使用正常设备。渲染是一种可大规模并行处理的并行问题,因为像素值是可以单独计算的。图形处理器 (GPU) 是通过加速渲染解决此问题的硬件单元。要求加速图形模式要求主机具有以下驱动程序:支持 EGL 的驱动程序(支持 GL_KHR_surfaceless_context 扩展程序)支持 OpenGL ES 的驱动程序支持 Vulkan 的驱动程序使用加速图形模式GfxStream若要使用 GfxStream 加速图形模式,请使用 --gpu_mode=gfxstream 标记启动本地 Cuttlefish 设备。使用此模式时,OpenGL 和 Vulkan API 调用会直接转到主机。$launch_cvd --gpu_mode=gfxstreamVirgl若要使用 Virgl 加速图形模式,请使用 --gpu_mode=drm_virgl 标记启动本地 Cuttlefish 设备。$launch_cvd --gpu_mode=drm_virgl使用 Virgl 加速图形模式时,OpenGL API 调用会转换为中间表示形式(请参阅 Gallium3D)。系统会将相应中间表示形式传递给主机,并且主机上的 virglrenderer 库会将此中间表示形式重新转换为 OpenGL API 调用。注意:此模式不支持 Vulkan。 声明: 本文转自:https://source.android.google.cn/setup/create/cuttlefish-ref-gpu,仅供学习与交流,非商业用途,版权归原作者所有,如有侵权,请联系删除。
-
【功能模块】mindspore 1.6【操作步骤&问题现象】同一份代码,CPU上loss下降很快,GPU上loss不下降【截图信息】CPU上运行结果:GPU上运行结果:
推荐直播
-
 手把手教你实现mini版TinyVue组件库
手把手教你实现mini版TinyVue组件库2024/04/17 周三 16:30-18:00
阿健 华为云前端开发DTSE 技术布道师
在前端Web开发过程中,跨版本兼容性问题是一个普遍存在的挑战。为了解决这些痛点,OpenTiny推出跨端、跨框架、跨版本组件库TinyVue。本期直播聚焦于华为云的前端开源组件库TinyVue,通过mini版TinyVue的代码实践与大家共同深入解读Vue2/Vue3不同版本间的差异。这对于提升用户体验,减低维护成本,提升开发者技术洞察有重要意义。
去报名 -
 如何快速入驻O3使能伙伴服务作业平台
如何快速入驻O3使能伙伴服务作业平台2024/04/18 周四 16:00-16:40
红喜 O3伙伴服务工作台技术总架构师
本期邀请O3伙伴服务工作台技术总架构师,讲解O3伙伴服务工作台的设计理念,及演示工作台关键能力与价值点,带你2步快速入驻工作台。O3伙伴服务工作台,具备在线Online、开放Open、协同Orchestration的特征,作为伙伴服务的统一入口,支持伙伴以租户方式入驻,涵盖伙伴工程师、管理者等多角色,是一个以伙伴服务领域全旅程作业为中心,整合华为服务各专业领域能力,开放共享的一站式作业平台。
去报名
热门标签