-
 举例如下,我需要在一个循环的第奇数次让两个矩阵A和B在gpu0上运算,否则在gpu1上运算。 如果是pytorch我可以这样实现: device0='cuda: 0' device1='cuda: 1' for j in range(10): if j%2==0: A=A.to(device0) B=B.to(device0) else: A=A.to(device1) B=B.to(device1) C=A+B 如果换成mxnet也可以用nd.array(ctx=gpu(0))这样的语句来实现。 因为最近有需要想用mindspore框架。 但是是mindspore中,我只找到context.set_context(divece_target='GPU', device_id=0)这样的语句来设定矩阵运算所在的GPU,当我想要人为地切换回GPU1时,我再调用context.set_context(divece_target='GPU', device_id=1)就会报错。 想请教在mindspore中,我如何实现如上面pytorch下程序对应的功能呢? (手机打字,请忽略格式问题)
举例如下,我需要在一个循环的第奇数次让两个矩阵A和B在gpu0上运算,否则在gpu1上运算。 如果是pytorch我可以这样实现: device0='cuda: 0' device1='cuda: 1' for j in range(10): if j%2==0: A=A.to(device0) B=B.to(device0) else: A=A.to(device1) B=B.to(device1) C=A+B 如果换成mxnet也可以用nd.array(ctx=gpu(0))这样的语句来实现。 因为最近有需要想用mindspore框架。 但是是mindspore中,我只找到context.set_context(divece_target='GPU', device_id=0)这样的语句来设定矩阵运算所在的GPU,当我想要人为地切换回GPU1时,我再调用context.set_context(divece_target='GPU', device_id=1)就会报错。 想请教在mindspore中,我如何实现如上面pytorch下程序对应的功能呢? (手机打字,请忽略格式问题) -
如题。想请问如何在mindspore框架下,实现在指定GPU下的矩阵运算。假设有两个维度完全一样的矩阵A和B,比如进行矩阵相加。 如果在pytorch下,我有这样一个操作:device0 = 'cuda: 0' device1 = 'cuda: 1' for j in range(10): if j%2==0: A = A.to(device0) A = B.to(device0) else: A = A.to(device1) A = B.to(device1) C = A + B也就是在第奇数次循环时在GPU0上运行,否则在GPU1上运行。调研学习了一下,还没能找到办法如何在mindspore中实现这样的操作。还请各位前辈指点。手机码字,请忽略格式问题。感谢
-
【功能模块】网络反向传播,求导过程中报错【操作步骤&问题现象】【截图信息】具体报错语句:【日志信息】(可选,上传日志内容或者附件)报错信息在截图信息展示的代码中,报错语句调用的参数 *args包含的tensor最高维度是4维,并没有报错信息说的5维输入,这个错误该如何处理呢?期待您早日回复!
-
 体验MindSpore v1.7的自动安装新特性,并围绕自动安装输出一篇干货。干货地址:cid:link_0推选出论坛技术干货帖里最推荐的3篇,并给出推荐理由。cid:link_2 超级全面的MindSpore入门教程cid:link_3 很清晰的卷积教程cid:link_4 从小白到大佬修炼之路您的技术干货帖体验感受,欢迎提供意见建议,或是您认为需要补充的内容。希望看到更多的实战落地的干货教程外站分享CSDN: cid:link_1 博客园:cid:link_5
体验MindSpore v1.7的自动安装新特性,并围绕自动安装输出一篇干货。干货地址:cid:link_0推选出论坛技术干货帖里最推荐的3篇,并给出推荐理由。cid:link_2 超级全面的MindSpore入门教程cid:link_3 很清晰的卷积教程cid:link_4 从小白到大佬修炼之路您的技术干货帖体验感受,欢迎提供意见建议,或是您认为需要补充的内容。希望看到更多的实战落地的干货教程外站分享CSDN: cid:link_1 博客园:cid:link_5 -
https://www.mindspore.cn/install (1)前置安装 - 确认是安装 Ubuntu 是x86架构64位操作系统。 - 安装Minicanda或者Anaconda。 - 安装Python 环境 3.7.5 或3.9.0(如何使用Conda安装可以直接创建命令即可,如果手动安装则需要配置Python环境变量) - 安装 Cuda10.1/11.1 驱动、GCC、glibc、OpenSSL - 查看GPU驱动 ``` nvidia-smi ``` 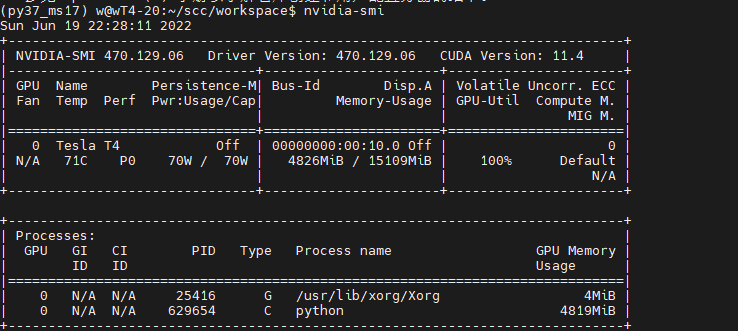 (2)自动安装 - 下载脚本 ``` wget https://gitee.com/mindspore/mindspore/raw/r1.7/scripts/install/ubuntu-gpu-pip.sh ``` 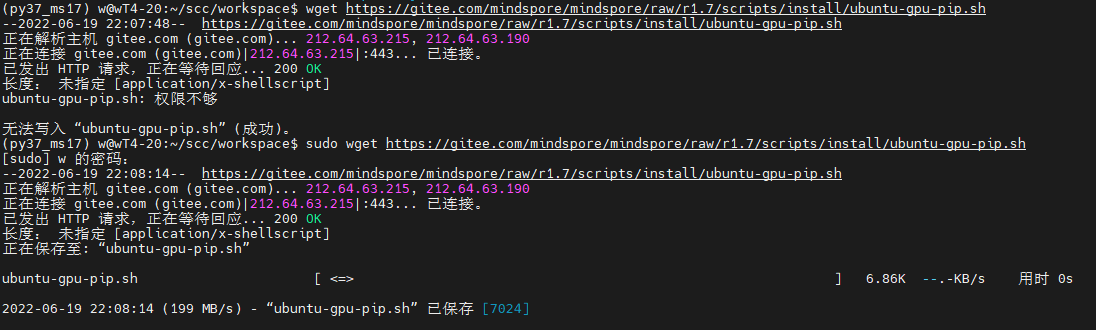 - 编辑脚本 ``` vim ubuntu-gpu-pip.sh ``` 该脚本会执行以下操作: - 更改软件源配置为华为云源。 - 安装MindSpore所需的依赖,如GCC,gmp。 - 通过APT安装Python3和pip3,并设为默认。 - 下载CUDA和cuDNN并安装。 - 通过pip安装MindSpore GPU版本。 - 如果OPENMPI设置为`on`,则安装Open MPI。 自动安装脚本执行完成后,需要重新打开终端窗口以使环境变量生效。 - 执行脚本,完成安装 ``` # 安装MindSpore 1.7.0,Python 3.7和CUDA 10.1 MINDSPORE_VERSION=1.7.0 CUDA_VERSION=10.1 bash -i ./ubuntu-gpu-pip.sh ``` 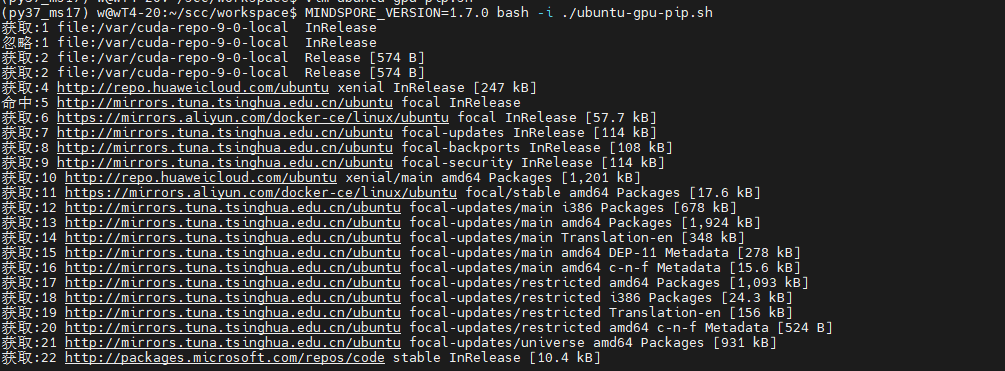 - 安装完成 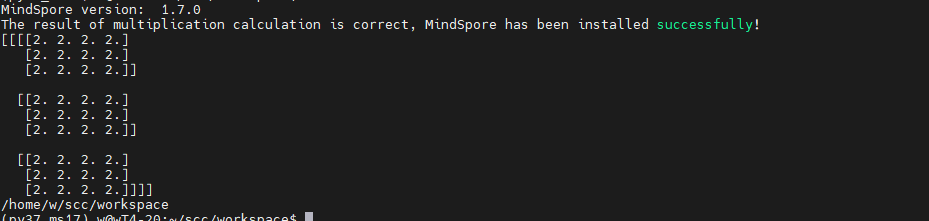 - 安装其他版本,修改参数 ``` # 如需指定安装Python 3.9,CUDA 10.1以及MindSpore 1.6.0,使用以下方式 # PYTHON_VERSION=3.9 CUDA_VERSION=10.1 MINDSPORE_VERSION=1.6.0 bash -i ./ubuntu-gpu-pip.sh ``` - 完整脚本学习 ``` set -e PYTHON_VERSION=${PYTHON_VERSION:-3.7} MINDSPORE_VERSION=${MINDSPORE_VERSION:EMPTY} CUDA_VERSION=${CUDA_VERSION:-11.1} OPENMPI=${OPENMPI:-off} version_less() { test "$(echo "$@" | tr ' ' '\n' | sort -rV | head -n 1)" != "$1"; } if [ $MINDSPORE_VERSION == "EMPTY" ] || version_less "${MINDSPORE_VERSION}" "1.6.0"; then echo "MINDSPORE_VERSION should be >=1.6.0, please check available versions at https://www.mindspore.cn/versions." exit 1 fi available_py_version=(3.7 3.8 3.9) if [[ " ${available_py_version<li>} " != *" $PYTHON_VERSION "* ]]; then echo "PYTHON_VERSION is '$PYTHON_VERSION', but available versions are [${available_py_version<li>}]." exit 1 fi if [[ "$PYTHON_VERSION" == "3.8" && ${MINDSPORE_VERSION:0:3} == "1.6" ]]; then echo "PYTHON_VERSION==3.8 is not compatible with MINDSPORE_VERSION==1.6.x, please use PYTHON_VERSION==3.7 or 3.9 for MINDSPORE_VERSION==1.6.x." exit 1 fi available_cuda_version=(10.1 11.1) if [[ " ${available_cuda_version<li>} " != *" $CUDA_VERSION "* ]]; then echo "CUDA_VERSION is '$CUDA_VERSION', but available versions are [${available_cuda_version<li>}]." exit 1 fi declare -A minimum_driver_version_map=() minimum_driver_version_map["10.1"]="418.39" minimum_driver_version_map["11.1"]="450.80.02" driver_version=$(modinfo nvidia | grep ^version | awk '{printf $2}') if [[ $driver_version < ${minimum_driver_version_map[$CUDA_VERSION]} ]]; then echo "CUDA $CUDA_VERSION minimum required driver version is ${minimum_driver_version_map[$CUDA_VERSION]}, \ but current nvidia driver version is $driver_version, please upgrade your driver manually." exit 1 fi cuda_name="cuda-$CUDA_VERSION" declare -A version_map=() version_map["3.7"]="${MINDSPORE_VERSION/-/}-cp37-cp37m" version_map["3.8"]="${MINDSPORE_VERSION/-/}-cp38-cp38" version_map["3.9"]="${MINDSPORE_VERSION/-/}-cp39-cp39" # add value to environment variable if value is not in it add_env() { local name=$1 if [[ ":${!name}:" != *":$2:"* ]]; then echo -e "export $1=$2:\$$1" >> ~/.bashrc fi } # use huaweicloud mirror in China sudo sed -i "s@http://.*archive.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list sudo sed -i "s@http://.*security.ubuntu.com@http://repo.huaweicloud.com@g" /etc/apt/sources.list sudo apt-get update sudo apt-get install curl make gcc-7 libgmp-dev linux-headers-"$(uname -r)" -y # python sudo add-apt-repository -y ppa:deadsnakes/ppa sudo apt-get install python$PYTHON_VERSION python$PYTHON_VERSION-distutils python3-pip -y sudo update-alternatives --install /usr/bin/python python /usr/bin/python$PYTHON_VERSION 100 # pip python -m pip install -U pip -i https://pypi.tuna.tsinghua.edu.cn/simple echo -e "alias pip='python -m pip'" >> ~/.bashrc python -m pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple # install cuda/cudnn echo "installing CUDA and cuDNN" cd /tmp declare -A cuda_url_map=() cuda_url_map["10.1"]=https://developer.download.nvidia.cn/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run cuda_url_map["11.1"]=https://developer.download.nvidia.cn/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.run cuda_url=${cuda_url_map[$CUDA_VERSION]} wget $cuda_url sudo sh ${cuda_url##*/} --silent --toolkit cd - sudo apt-key adv --fetch-keys https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub sudo add-apt-repository "deb https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64/ /" sudo add-apt-repository "deb https://developer.download.nvidia.cn/compute/machine-learning/repos/ubuntu1804/x86_64/ /" sudo apt-get update declare -A cudnn_name_map=() cudnn_name_map["10.1"]="libcudnn7=7.6.5.32-1+cuda10.1 libcudnn7-dev=7.6.5.32-1+cuda10.1" cudnn_name_map["11.1"]="libcudnn8=8.0.4.30-1+cuda11.1 libcudnn8-dev=8.0.4.30-1+cuda11.1" sudo apt-get install --no-install-recommends ${cudnn_name_map[$CUDA_VERSION]} -y # add cuda to path set +e && source ~/.bashrc set -e add_env PATH /usr/local/cuda/bin add_env LD_LIBRARY_PATH /usr/local/cuda/lib64 add_env LD_LIBRARY_PATH /usr/lib/x86_64-linux-gnu set +e && source ~/.bashrc set -e # optional openmpi for distributed training if [[ X"$OPENMPI" == "Xon" ]]; then echo "installing openmpi" cd /tmp curl -O https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.3.tar.gz tar xzf openmpi-4.0.3.tar.gz cd openmpi-4.0.3 ./configure --prefix=/usr/local/openmpi-4.0.3 make sudo make install add_env PATH /usr/local/openmpi-4.0.3/bin add_env LD_LIBRARY_PATH /usr/local/openmpi-4.0.3/lib fi arch=`uname -m` python -m pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/${MINDSPORE_VERSION}/MindSpore/gpu/${arch}/${cuda_name}/mindspore_gpu-${version_map["$PYTHON_VERSION"]}-linux_${arch}.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple # check mindspore installation python -c "import mindspore;mindspore.run_check()" # check if it can be run with GPU cd /tmp cat > example.py <<END import numpy as np from mindspore import Tensor import mindspore.ops as ops import mindspore.context as context context.set_context(device_target="GPU") x = Tensor(np.ones([1,3,3,4]).astype(np.float32)) y = Tensor(np.ones([1,3,3,4]).astype(np.float32)) print(ops.add(x, y)) END python example.py cd - ```
-
【日志信息】(可选,上传日志内容或者附件)【运行软硬件】python3.9.5, mindspore 1.8.0.devcuda 11.1RTX 2080 Ti您好,我在训练模型反向传播时报了上述的错误,这个该如何解决?
-
1. 体验MindSpore v1.7的自动安装新特性,并围绕自动安装输出一篇干货https://bbs.huaweicloud.com/forum/thread-190899-1-1.html2。 推选出论坛技术干货帖里最推荐的3篇,并给出推荐理由 1. https://bbs.huaweicloud.com/forum/thread-183362-1-1.html Atlas200DK安装MindSpore 1.6.1折腾纪实(连载中)这个帖子是少有的Ascend的安装教程,并且安装成功了,安装步骤都是一步一步执行的,非常清晰易懂 2. https://bbs.huaweicloud.com/forum/thread-52563-1-1.html 【轻松上手MindSpore】系列公开课 第一讲:MindSpore分布式自动并行训练PPT+视频,这是最好的学习方式 3. https://bbs.huaweicloud.com/forum/thread-179700-1-1.html mindspore.scipy 入门使用指导 写的非常详细,一目了然,入门的好干活3. 您的技术干货帖体验感受,欢迎提供意见建议,或是您认为需要补充的内容 技术干货贴的分块中,好像并没有静态图和动态图的这个板块,我觉得可以补充补充 开发套件,生态工具这方面的也都没有分块4. 提交的干货需要分享到知乎和CSDN个人博客和社区中,再把链接写到干货帖子评论里。(CSDN社区:https://bbs.csdn.net/forums/MindSpore_Official?category=6)知乎: https://zhuanlan.zhihu.com/p/530371193CSDN: https://bbs.csdn.net/topics/607067761
-
MindSpore 1.7推出一个方便的安装方式,自动安装,试着体验一下官网操作指南链接是:https://www.mindspore.cn/install我选择的是cuda 10.1+py3.7的版本1. 第一步 根据安装说明:在使用自动安装脚本之前,需要确保系统正确安装了NVIDIA GPU驱动。CUDA 10.1要求最低显卡驱动版本为418.39;CUDA 11.1要求最低显卡驱动版本为450.80.02。执行以下指令检查驱动版本。nvidia-smi确认是418.39 真好合适2. 第二步下载安装脚本在官网解释中,说的是支持1.6.0及以上的版本,但是当我选择1.6版本的时候,并没有写着自动安装,这个我也不确定1.6支不支持还是按照1.7的来获取安装脚本3. 执行脚本发现存在问题:MINDSPORE_VERSION=1.7.0 bash -i ./ubuntu-gpu-pip.shCUDA 11.1 minimum required driver version is 450.80.02, but current nvidia driver version is 418.39, please upgrade your driver manually.我明明是cuda10.1, 为什么报11.1呢查看脚本发现脚本里面CUDA_VERSION=${CUDA_VERSION:-11.1} 设置的cuda是11.1, 需要手动改成10.14. 再次执行脚本中间有点长,只截部分下面显示安装成功下面显示执行脚本成功5. 最后我们来分析下脚本:PYTHON_VERSION=${PYTHON_VERSION:-3.7}MINDSPORE_VERSION=${MINDSPORE_VERSION:EMPTY}CUDA_VERSION=${CUDA_VERSION:-10.1}OPENMPI=${OPENMPI:-off}OPENMPI为on 可以自动安装mpi但是由于我的机器已经安装,所以保留原来的off看自己机器有没有安装mpi可以执行一下mpirun上面就代表安装了inimum_driver_version_map["10.1"]="418.39"minimum_driver_version_map["11.1"]="450.80.02"两个cuda分别匹配的显卡驱动版本脚本:# pythonsudo add-apt-repository -y ppa:deadsnakes/ppasudo apt-get install python$PYTHON_VERSION python$PYTHON_VERSION-distutils python3-pip -ysudo update-alternatives --install /usr/bin/python python /usr/bin/python$PYTHON_VERSION 100# pippython -m pip install -U pip -i https://pypi.tuna.tsinghua.edu.cn/simpleecho -e "alias pip='python -m pip'" >> ~/.bashrcpython -m pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple通过APT安装Python3和pip3脚本:# install cuda/cudnnecho "installing CUDA and cuDNN"cd /tmpdeclare -A cuda_url_map=()cuda_url_map["10.1"]=https://developer.download.nvidia.cn/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.runcuda_url_map["11.1"]=https://developer.download.nvidia.cn/compute/cuda/11.1.1/local_installers/cuda_11.1.1_455.32.00_linux.runcuda_url=${cuda_url_map[$CUDA_VERSION]}wget $cuda_urlsudo sh ${cuda_url##*/} --silent --toolkitcd -sudo apt-key adv --fetch-keys https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pubsudo add-apt-repository "deb https://developer.download.nvidia.cn/compute/cuda/repos/ubuntu1804/x86_64/ /"sudo add-apt-repository "deb https://developer.download.nvidia.cn/compute/machine-learning/repos/ubuntu1804/x86_64/ /"sudo apt-get updatedeclare -A cudnn_name_map=()cudnn_name_map["10.1"]="libcudnn7=7.6.5.32-1+cuda10.1 libcudnn7-dev=7.6.5.32-1+cuda10.1"cudnn_name_map["11.1"]="libcudnn8=8.0.4.30-1+cuda11.1 libcudnn8-dev=8.0.4.30-1+cuda11.1"sudo apt-get install --no-install-recommends ${cudnn_name_map[$CUDA_VERSION]} -y解析:下载CUDA和cuDNN并安装脚本:sudo apt-get install curl make gcc-7 libgmp-dev linux-headers-"$(uname -r)" -y解析:安装gcc gmp脚本:set +e && source ~/.bashrcset -eadd_env PATH /usr/local/cuda/binadd_env LD_LIBRARY_PATH /usr/local/cuda/lib64add_env LD_LIBRARY_PATH /usr/lib/x86_64-linux-gnuset +e && source ~/.bashrc解析:添加cuda到环境变量if [[ X"$OPENMPI" == "Xon" ]]; then echo "installing openmpi" cd /tmp curl -O https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-4.0.3.tar.gz tar xzf openmpi-4.0.3.tar.gz cd openmpi-4.0.3 ./configure --prefix=/usr/local/openmpi-4.0.3 make sudo make install add_env PATH /usr/local/openmpi-4.0.3/bin add_env LD_LIBRARY_PATH /usr/local/openmpi-4.0.3/libfi若是OPENMPI=on就是安装mpirunarch=`uname -m`python -m pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/${MINDSPORE_VERSION}/MindSpore/gpu/${arch}/${cuda_name}/mindspore_gpu-${version_map["$PYTHON_VERSION"]}-linux_${arch}.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple安装匹配的whl包最后安装和执行成功
-
切换gpu后还是只有cpu,右侧性能显示里也只有cpu利用率没有gpu。【功能模块】【操作步骤&问题现象】1、2、【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
【功能模块】MindSpore提供的Bert训练脚本(https://gitee.com/mindspore/models/tree/master/official/nlp/bert)GPU分布式训练MindSpore的Profiler工具【操作步骤&问题现象】1、在单机四卡环境下,使用官方提供的脚本进行训练,参数配置未改变2、在run_pretrain.py文件中调用Profiler工具记录性能数据(代码中第24,25行)3、发现训练过程卡死不动,程序未报错退出,此时GPU利用率为0,CPU利用率很高4、相关环境为python 3.8.13, mindspore 1.7.0, mindinsight 1.7.0cuda 11.1, nccl 2.7.8, cudnn 8.0.4单机四卡训练【截图信息】卡死时状态【日志信息】(可选,上传日志内容或者附件)
-
# 自定义GPU算子CropAndResizeGradBoxes 在cu文件的核函数部分如下:  # 问题 1. 第二个红框,depth参数在不同的线程下打印正常,但是第三个红框的depth打印值会变化,与pos一致。  2. pos_temp赋值失败,全部是0.(这两个值的打印结果见下图)  这种情况出现的原因是什么啊?
-
去年 11 月,AMD 发布了全新的 Instinct MI250 / MI250X GPU,使用 2.5D EFB 桥接技术,业内首创多 Die 整合封装 (MCM),内部集成了两颗核心。而在今年 3 月份,英伟达则通过他们的 H100 SXM5 高性能计算模块展示了全新的 GH100 GPU。现在,终于轮到英特尔了,Ponte Vecchio GPU 将帮助该他们在未来十年内利用显卡技术实现更多的算法,以实现数据中心和机器学习系统的构建。英特尔曾承诺在全新的 Ponte Vecchio GPU 中使用 1000 亿个晶体管,以此将公司带入更多主流的人工智能和高性能计算应用当中。上周,英特尔在推特上证实,他们已经开始测试和抽查 Ponte Vecchio GPU。其新计算卡将使公司能够让消费者通过 AI 和 HPC 应用获得更多开发和功能。英特尔的公关经理 Mikael Moreau 透露了专门为 Ponte Vecchio GPU 设计的水冷模块,这说明英特尔已经开始向位于美国的合作伙伴交付部件。英特尔的下一代 Ponte VecchioGPU 包含了多达 47 个芯片(包括了 16 个 Xe-HPC 架构的计算芯片、8 个 Rambo cache 芯片、2 个 Xe 基础芯片、11 个 EMIB 连接芯片、2 个 XeLink I / O 芯片和 8 个 HBM 芯片),整套芯片包含了惊人的 1000 亿个晶体管,如此庞大的规格将消耗大量的电力。Ponte Vecchio 的 47 个芯片会使用不同节点的工艺制造,包括了台积电的 7nm 或 5nm 工艺,以及英特尔的 7nm 和 10nm 工艺,并通过 EMIB 与 Foveros 3D 封装中整合在一起。IT之家了解到 Ponte Vecchio 采用了 OAM 模块,这是一种开放式硬件计算加速器形态和互连结构,共有五层,从下到上分别是底板、PCB 电路板、顶板、水冷装置和固定盖板。而新的 OAM 计算模块则需要 600W 的供电。由于该系统的运行功耗如此的恐怖,所以其需要获得强大的散热系统。英特尔已经选择为新的计算卡研究液冷散热,但是与传统的大型散热系统相比,新开发的系统占地面积最小。从 Twitter 的帖子中我们并不清楚看到的是标准的 Ponte Vecchio GPU 还是下一代 GPU 的高级 XT 版本。英特尔 Ponte Vecchio 看起来相当大,几乎达到了平板电脑的尺寸。不过看到其晶体管数量和能耗,这么大的尺寸并不让人太过于惊讶。Ponte Vecchio 预计将提供 “PetaFLOPS 级人工智能性能”。(Peta : 用于计量单位,表示 10 的 15 次方,表示千万亿次)
-
(1) 前置安装确认是安装 Ubuntu 是x86架构64位操作系统。Ubuntu 18.04 或者Ubuntu20安装GCC、Git、glibc、CMake、OpenSSL。如已安装,跳过。注意,GCC 9不兼容CUDA 10.1# 安装GCC sudo apt-get install gcc-7 git automake autoconf libtool libgmp-dev tcl patch libnuma-dev flex -y # 安装CMake wget -O - https://apt.kitware.com/keys/kitware-archive-latest.asc 2>/dev/null | sudo apt-key add - sudo apt-add-repository "deb https://apt.kitware.com/ubuntu/ $(lsb_release -cs) main" sudo apt-get install cmake -y安装 Cuda10.1 或 11.1 驱动。已经安装,过。# 查看安装的Cuda驱动 nvidia-smi # 如没安装则需要安装 wget https://developer.download.nvidia.com/compute/cuda/10.1/Prod/local_installers/cuda_10.1.243_418.87.00_linux.run sudo sh cuda_10.1.243_418.87.00_linux.run echo -e "export PATH=/usr/local/cuda-10.1/bin:\$PATH" >> ~/.bashrc echo -e "export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64:\$LD_LIBRARY_PATH" >> ~/.bashrc source ~/.bashrc安装cuDNN 下载配套CUDA 10.1的cuDNN v7.6.x : cid:link_0tar -zxvf cudnn.tgz sudo cp cuda/include/cudnn.h /usr/local/cuda-10.1/include sudo cp cuda/lib64/libcudnn* /usr/local/cuda-10.1/lib64 sudo chmod a+r /usr/local/cuda-10.1/include/cudnn.h /usr/local/cuda-10.1/lib64/libcudnn*如果之前安装了其他CUDA版本或者CUDA安装路径不同,替换路径和版本即可安装Minicanda或者Anaconda。安装Python 环境 3.7.5 或3.9.0(如何使用Conda安装可以直接创建命令即可,如果手动安装则需要配置Python环境变量)# 创建环境 conda create --name py39_ms17 python=3.9.0 # 输入y source activate py39_ms17# 切换到环境 win:conda、linux:source source activate py39_ms17 # 查看安装版本 python --version # 3.7.5 # 更新环境 pip install --upgrade pip # 安装wheel和setuptools pip install wheel pip install -U setuptools # Cuda 驱动 nvidia-smi # Cuda 版本 nvcc -V(2) 下载源码从代码仓下载源码git clone https://gitee.com/mindspore/mindspore.git -b r1.7注: 确保nvcc的安装路径已经添加到PATH与LD_LIBRARY_PATH环境变量中export PATH=/usr/local/cuda-10.1/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-10.1/lib64:$LD_LIBRARY_PATH(3) 编译执行进入MindSpore根目录,然后执行编译脚本cd mindspore source activate py39_ms17 bash build.sh -e gpu -S on默认从github下载依赖源码,当-S选项设置为on时,从对应的gitee镜像下载。 (4) Pip安装本地生成的MindSporesource activate py39_ms17 pip install output/mindspore_gpu-*.whl -i https://pypi.tuna.tsinghua.edu.cn/simple配置Jupyterlabsource activate py39_ms17 pip install ipykernel -i https://pypi.tuna.tsinghua.edu.cn/simple/ python -m ipykernel install --user --name py39_ms17 --display-name "py39_ms17"验证python -c "import mindspore;mindspore.run_check()"一把辛酸泪MindSpore源码安装编译报错大合集(GPU)
-
 【功能模块】【操作步骤&问题现象】1、使用context将模型放到GPU上,执行训练时,模型使用CPU进行计算。【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】【操作步骤&问题现象】1、使用context将模型放到GPU上,执行训练时,模型使用CPU进行计算。【截图信息】【日志信息】(可选,上传日志内容或者附件) -
【功能模块】使用mindspore1.2GPU跑RNN_attention时遇到data type问题【操作步骤&问题现象】1、使用mindspore编写RNN_attention模型,排除模型内部报错后,在运行时抛出data type问题2、模型代码及部分参数如下:parser.add_argument('--num_layers', type=int, default=1, ) # lstm层数parser.add_argument('--hidden_size', type=int, default=128, ) # lstm隐藏层parser.add_argument('--embedding_pretrained', default=None, ) # 预训练parser.add_argument('--embed', type=int, default=300) #文本embedding维度parser.add_argument('--hidden_size2', type=int, default=64, ) #import mindsporeimport mindspore.nn as nnfrom mindspore import dtype as mstypefrom mindspore import Tensorfrom mindspore.ops import operations as Pimport mindspore.ops as opsimport numpy as npclass RNN_attent(nn.Cell): def __init__(self, config): super(RNN_attent, self).__init__() self.embedding = nn.Embedding(config.n_vocab, config.embed) self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers, bidirectional=True, batch_first=True, dropout=config.dropout) self.softmax = nn.Softmax() self.tanh1 = nn.Tanh() # self.u = nn.Parameter(torch.Tensor(config.hidden_size * 2, config.hidden_size * 2)) self.w = mindspore.Parameter(Tensor(np.zeros(config.hidden_size * 2))) self.fc1 = nn.Dense(config.hidden_size * 2, config.hidden_size2) self.fc = nn.Dense(config.hidden_size2, config.num_classes) self.relu = nn.ReLU() self.unsqueeze = ops.ExpandDims() self.num_directions = 2 self.hidden_size = config.hidden_size self.num_layers = config.num_layers self.batch_size = config.batch_size def construct(self, x): embed = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300] h_0 = Tensor(np.zeros([self.num_directions * self.num_layers, self.batch_size, self.hidden_size]).astype(np.float32)) c_0 = Tensor(np.zeros([self.num_directions * self.num_layers, self.batch_size, self.hidden_size]).astype(np.float32)) hx_0 = (h_0, c_0) H, _ = self.lstm(embed, hx_0) M = self.tanh1(H) # [128, 32, 256] alpha = self.softmax(ops.matmul(M, self.w)) # [128, 32, 1] alpha = self.unsqueeze(alpha, -1) out = H * alpha # [128, 32, 256] out = ops.reduce_sum(out, 1) # [128, 256] out = self.relu(out) out = self.fc1(out) out = self.fc(out) # [128, 64] return outargs.n_vocab = vocab_sizeargs.dropout = 0.1model = RNN_attent(config = args)【截图信息】完整报错信息:【日志信息】(可选,上传日志内容或者附件)
推荐直播
-
 HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢
HDC深度解读系列 - Serverless与MCP融合创新,构建AI应用全新智能中枢2025/08/20 周三 16:30-18:00
张昆鹏 HCDG北京核心组代表
HDC2025期间,华为云展示了Serverless与MCP融合创新的解决方案,本期访谈直播,由华为云开发者专家(HCDE)兼华为云开发者社区组织HCDG北京核心组代表张鹏先生主持,华为云PaaS服务产品部 Serverless总监Ewen为大家深度解读华为云Serverless与MCP如何融合构建AI应用全新智能中枢
回顾中 -
 关于RISC-V生态发展的思考
关于RISC-V生态发展的思考2025/09/02 周二 17:00-18:00
中国科学院计算技术研究所副所长包云岗教授
中科院包云岗老师将在本次直播中,探讨处理器生态的关键要素及其联系,分享过去几年推动RISC-V生态建设实践过程中的经验与教训。
回顾中 -
 一键搞定华为云万级资源,3步轻松管理企业成本
一键搞定华为云万级资源,3步轻松管理企业成本2025/09/09 周二 15:00-16:00
阿言 华为云交易产品经理
本直播重点介绍如何一键续费万级资源,3步轻松管理成本,帮助提升日常管理效率!
回顾中
热门标签