-
 【功能模块】 hive样例工程【操作步骤&问题现象】1、配置settings文件后,更新maven依赖,一直更新不成功,报下面的错误2、【截图信息】Could not transfer artifact org.apache.hadoop:hadoop-auth:pom:3.1.1-hw-ei-310003 from/to nexus-aliyun (https://maven.aliyun.com/repository/public): transfer failed for https://maven.aliyun.com/repository/public/org/apache/hadoop/hadoop-auth/3.1.1-hw-ei-310003/hadoop-auth-3.1.1-hw-ei-310003.pom【日志信息】(可选,上传日志内容或者附件)
【功能模块】 hive样例工程【操作步骤&问题现象】1、配置settings文件后,更新maven依赖,一直更新不成功,报下面的错误2、【截图信息】Could not transfer artifact org.apache.hadoop:hadoop-auth:pom:3.1.1-hw-ei-310003 from/to nexus-aliyun (https://maven.aliyun.com/repository/public): transfer failed for https://maven.aliyun.com/repository/public/org/apache/hadoop/hadoop-auth/3.1.1-hw-ei-310003/hadoop-auth-3.1.1-hw-ei-310003.pom【日志信息】(可选,上传日志内容或者附件) -
MRS中的Elasticsearch是否支持存算分离
-
【集群扩容-添加主机】添加新主机,如果磁盘数量、容量与现有机器相差很大,例如现有机器4盘共10T,新机器5盘共40T,那对磁盘空间的均衡、HDFS的存储、Hbase、Hive、ES、Spark等服务的应用影响大不大?内存之类的应该没有均衡问题,主要是磁盘容量问题,会不会导致数据倾斜过大?对性能影响有多大?
-
 大数据融合分析时代,GaussDB(DWS)如需访问MRS数据源,该如何实现?本期云小课带您开启MRS数据源之门,通过远程读取MRS集群Hive上的ORC数据表完成数据导入DWS。准备环境需确保MRS和DWS集群在同一个区域、可用区、同一VPC子网内,确保集群网络互通。基本流程1、创建MRS分析集群(选择Hive组件)。2、通过将本地txt数据文件上传至OBS桶,再通过OBS桶导入Hive,并由txt存储表导入ORC存储表。3、创建MRS数据源连接。4、创建外部服务器。5、创建外表。6、通过外表导入DWS本地表。创建MRS分析集群登录华为云控制台,选择“EI企业智能 > MapReduce服务”,单击“购买集群”,选择“自定义购买”,填写软件配置参数,单击“下一步”。表1 软件配置参数项取值区域华北-北京四集群名称MRS01集群版本MRS 3.0.5集群类型分析集群填写硬件配置参数,单击“下一步”。表1 硬件配置参数项取值计费模式按需计费可用区可用区2虚拟私有云vpc-01子网subnet-01安全组自动创建弹性公网IP10.x.x.x企业项目defaultMaster节点打开“集群高可用”分析Core节点3分析Task节点0填写高级配置参数,单击“立即购买”,等待约15分钟,集群创建成功。表1 高级配置参数项取值标签test01委托保持默认即可告警保持默认即可规则名称保持默认即可主题名称保持默认即可Kerberos认证默认打开用户名admin密码设置密码,例如:Huawei@12345。该密码用于登录集群管理页面。确认密码再次输入设置admin用户密码登录方式密码用户名root密码设置密码,例如:Huawei_12345。该密码用于远程登录ECS机器。确认密码再次输入设置的root用户密码通信安全授权勾选“确认授权”准备MRS的ORC表数据源本地PC新建一个product_info.txt,并拷贝以下数据,保存到本地。100,XHDK-A-1293-#fJ3,2017-09-01,A,2017 Autumn New Shirt Women,red,M,328,2017-09-04,715,good 205,KDKE-B-9947-#kL5,2017-09-01,A,2017 Autumn New Knitwear Women,pink,L,584,2017-09-05,406,very good! 300,JODL-X-1937-#pV7,2017-09-01,A,2017 autumn new T-shirt men,red,XL,1245,2017-09-03,502,Bad. 310,QQPX-R-3956-#aD8,2017-09-02,B,2017 autumn new jacket women,red,L,411,2017-09-05,436,It's really super nice 150,ABEF-C-1820-#mC6,2017-09-03,B,2017 Autumn New Jeans Women,blue,M,1223,2017-09-06,1200,The seller's packaging is exquisite 200,BCQP-E-2365-#qE4,2017-09-04,B,2017 autumn new casual pants men,black,L,997,2017-09-10,301,The clothes are of good quality. 250,EABE-D-1476-#oB1,2017-09-10,A,2017 autumn new dress women,black,S,841,2017-09-15,299,Follow the store for a long time. 108,CDXK-F-1527-#pL2,2017-09-11,A,2017 autumn new dress women,red,M,85,2017-09-14,22,It's really amazing to buy 450,MMCE-H-4728-#nP9,2017-09-11,A,2017 autumn new jacket women,white,M,114,2017-09-14,22,Open the package and the clothes have no odor 260,OCDA-G-2817-#bD3,2017-09-12,B,2017 autumn new woolen coat women,red,L,2004,2017-09-15,826,Very favorite clothes 980,ZKDS-J-5490-#cW4,2017-09-13,B,2017 Autumn New Women's Cotton Clothing,red,M,112,2017-09-16,219,The clothes are small 98,FKQB-I-2564-#dA5,2017-09-15,B,2017 autumn new shoes men,green,M,4345,2017-09-18,5473,The clothes are thick and it's better this winter. 150,DMQY-K-6579-#eS6,2017-09-21,A,2017 autumn new underwear men,yellow,37,2840,2017-09-25,5831,This price is very cost effective 200,GKLW-l-2897-#wQ7,2017-09-22,A,2017 Autumn New Jeans Men,blue,39,5879,2017-09-25,7200,The clothes are very comfortable to wear 300,HWEC-L-2531-#xP8,2017-09-23,A,2017 autumn new shoes women,brown,M,403,2017-09-26,607,good 100,IQPD-M-3214-#yQ1,2017-09-24,B,2017 Autumn New Wide Leg Pants Women,black,M,3045,2017-09-27,5021,very good. 350,LPEC-N-4572-#zX2,2017-09-25,B,2017 Autumn New Underwear Women,red,M,239,2017-09-28,407,The seller's service is very good 110,NQAB-O-3768-#sM3,2017-09-26,B,2017 autumn new underwear women,red,S,6089,2017-09-29,7021,The color is very good 210,HWNB-P-7879-#tN4,2017-09-27,B,2017 autumn new underwear women,red,L,3201,2017-09-30,4059,I like it very much and the quality is good. 230,JKHU-Q-8865-#uO5,2017-09-29,C,2017 Autumn New Clothes with Chiffon Shirt,black,M,2056,2017-10-02,3842,very good登录OBS控制台,单击“创建桶”,填写以下参数,单击“立即创建”。表1 桶参数参数项取值区域华北-北京四数据冗余存储策略单AZ存储桶mrs-datasource存储类别标准存储桶策略私有默认加密关闭归档数据直读关闭企业项目default标签-等待桶创建好,单击桶名称,选择“对象 > 上传对象”,将product_info.txt上传至OBS桶。切换回MRS控制台,单击创建好的MRS集群名称,进入“概览”,单击“IAM用户同步”所在行的“单击同步”,等待约5分钟同步完成。回到MRS集群页面,单击“节点管理”,单击任意一台master节点,进入该节点页面,切换到“弹性公网IP”,单击“绑定弹性公网IP”,勾选已有弹性IP并单击“确定”,如果没有,请创建。记录此公网IP。确认主master节点。使用SSH工具以root用户登录以上节点,root密码为Huawei_12345,切换到omm用户。su - omm执行以下命令查询主master节点,回显信息中“HAActive”参数值为“active”的节点为主master节点。sh ${BIGDATA_HOME}/om-0.0.1/sbin/status-oms.sh使用root用户登录主master节点,切换到omm用户,并进入Hive客户端所在目录。su - ommcd /opt/client在Hive上创建存储类型为TEXTFILE的表product_info。在/opt/client路径下,导入环境变量。source bigdata_env登录Hive客户端。beeline依次执行以下SQL语句创建demo数据库及表product_info。CREATE DATABASE demo;USE demo;DROP TABLE product_info; CREATE TABLE product_info ( product_price int not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt int , product_comment_time date , product_comment_num int , product_comment_content varchar(200) ) row format delimited fields terminated by ',' stored as TEXTFILE将product_info.txt数据文件导入Hive。切回到MRS集群,单击“文件管理”,单击“导入数据”。OBS路径:选择上面创建好的OBS桶名,找到product_info.txt文件,单击“是”。HDFS路径:选择/user/hive/warehouse/demo.db/product_info/,单击“是”。单击“确定”,等待导入成功,此时product_info的表数据已导入成功。创建ORC表,并将数据导入ORC表。执行以下SQL语句创建ORC表。DROP TABLE product_info_orc; CREATE TABLE product_info_orc ( product_price int not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt int , product_comment_time date , product_comment_num int , product_comment_content varchar(200) ) row format delimited fields terminated by ',' stored as orc;将product_info表的数据插入到Hive ORC表product_info_orc中。insert into product_info_orc select * from product_info;查询ORC表数据导入成功。select * from product_info_orc;创建MRS数据源连接登录DWS管理控制台,单击已创建好的DWS集群,确保DWS集群与MRS在同一个区域、可用分区,并且在同一VPC子网下。切换到“MRS数据源”,单击“创建MRS数据源连接”。选择前序步骤创建名为的“MRS01”数据源,用户名:admin,密码:Huawei@12345,单击“确定”,创建成功。创建外部服务器使用Data Studio连接已创建好的DWS集群。新建一个具有创建数据库权限的用户dbuser:CREATE USER dbuser WITH CREATEDB PASSWORD "Bigdata@123";切换为新建的dbuser用户:SET ROLE dbuser PASSWORD "Bigdata@123";创建新的mydatabase数据库:CREATE DATABASE mydatabase;执行以下步骤切换为连接新建的mydatabase数据库。在Data Studio客户端的“对象浏览器”窗口,右键单击数据库连接名称,在弹出菜单中单击“刷新”,刷新后就可以看到新建的数据库。右键单击“mydatabase”数据库名称,在弹出菜单中单击“打开连接”。右键单击“mydatabase”数据库名称,在弹出菜单中单击“打开新的终端”,即可打开连接到指定数据库的SQL命令窗口,后面的步骤,请全部在该命令窗口中执行。为dbuser用户授予创建外部服务器的权限:GRANT ALL ON FOREIGN DATA WRAPPER hdfs_fdw TO dbuser;其中FOREIGN DATA WRAPPER的名字只能是hdfs_fdw,dbuser为创建SERVER的用户名。执行以下命令赋予用户使用外表的权限。ALTER USER dbuser USEFT;切换回Postgres系统数据库,查询创建MRS数据源后系统自动创建的外部服务器。SELECT * FROM pg_foreign_server;返回结果如: srvname | srvowner | srvfdw | srvtype | srvversion | srvacl | srvoptions --------------------------------------------------+----------+--------+---------+------------+--------+--------------------------------------------------------------------------------------------------------------------- gsmpp_server | 10 | 13673 | | | | gsmpp_errorinfo_server | 10 | 13678 | | | | hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca | 16476 | 13685 | | | | {"address=192.168.1.245:9820,192.168.1.218:9820",hdfscfgpath=/MRS/8f79ada0-d998-4026-9020-80d6de2692ca,type=hdfs} (3 rows)切换到mydatabase数据库,并切换到dbuser用户。SET ROLE dbuser PASSWORD "Bigdata@123";创建外部服务器。SERVER名字、地址、配置路径保持与8一致即可。CREATE SERVER hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca FOREIGN DATA WRAPPER HDFS_FDW OPTIONS ( address '192.168.1.245:9820,192.168.1.218:9820', //MRS管理面的Master主备节点的内网IP,可与DWS通讯。 hdfscfgpath '/MRS/8f79ada0-d998-4026-9020-80d6de2692ca', type 'hdfs' );查看外部服务器。SELECT * FROM pg_foreign_server WHERE srvname='hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca';返回结果如下所示,表示已经创建成功: srvname | srvowner | srvfdw | srvtype | srvversion | srvacl | srvoptions --------------------------------------------------+----------+--------+---------+------------+--------+--------------------------------------------------------------------------------------------------------------------- hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca | 16476 | 13685 | | | | {"address=192.168.1.245:9820,192.168.1.218:29820",hdfscfgpath=/MRS/8f79ada0-d998-4026-9020-80d6de2692ca,type=hdfs} (1 row)创建外表获取Hive的product_info_orc的文件路径。登录MRS管理控制台。选择“集群列表 > 现有集群”,单击要查看的集群名称,进入集群基本信息页面。单击“文件管理”,选择“HDFS文件列表”。进入您要导入到GaussDB(DWS)集群的数据的存储目录,并记录其路径。创建外表。 SERVER名字填写创建的外部服务器名称,foldername填写查到的路径。DROP FOREIGN TABLE IF EXISTS foreign_product_info; CREATE FOREIGN TABLE foreign_product_info ( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer , product_comment_content varchar(200) ) SERVER hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca OPTIONS ( format 'orc', encoding 'utf8', foldername '/user/hive/warehouse/demo.db/product_info_orc/' ) DISTRIBUTE BY ROUNDROBIN;执行数据导入创建本地目标表。DROP TABLE IF EXISTS product_info; CREATE TABLE product_info ( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer , product_comment_content varchar(200) ) with ( orientation = column, compression=middle ) DISTRIBUTE BY HASH (product_id);从外表导入目标表。INSERT INTO product_info SELECT * FROM foreign_product_info;查询导入结果。SELECT * FROM product_info;
大数据融合分析时代,GaussDB(DWS)如需访问MRS数据源,该如何实现?本期云小课带您开启MRS数据源之门,通过远程读取MRS集群Hive上的ORC数据表完成数据导入DWS。准备环境需确保MRS和DWS集群在同一个区域、可用区、同一VPC子网内,确保集群网络互通。基本流程1、创建MRS分析集群(选择Hive组件)。2、通过将本地txt数据文件上传至OBS桶,再通过OBS桶导入Hive,并由txt存储表导入ORC存储表。3、创建MRS数据源连接。4、创建外部服务器。5、创建外表。6、通过外表导入DWS本地表。创建MRS分析集群登录华为云控制台,选择“EI企业智能 > MapReduce服务”,单击“购买集群”,选择“自定义购买”,填写软件配置参数,单击“下一步”。表1 软件配置参数项取值区域华北-北京四集群名称MRS01集群版本MRS 3.0.5集群类型分析集群填写硬件配置参数,单击“下一步”。表1 硬件配置参数项取值计费模式按需计费可用区可用区2虚拟私有云vpc-01子网subnet-01安全组自动创建弹性公网IP10.x.x.x企业项目defaultMaster节点打开“集群高可用”分析Core节点3分析Task节点0填写高级配置参数,单击“立即购买”,等待约15分钟,集群创建成功。表1 高级配置参数项取值标签test01委托保持默认即可告警保持默认即可规则名称保持默认即可主题名称保持默认即可Kerberos认证默认打开用户名admin密码设置密码,例如:Huawei@12345。该密码用于登录集群管理页面。确认密码再次输入设置admin用户密码登录方式密码用户名root密码设置密码,例如:Huawei_12345。该密码用于远程登录ECS机器。确认密码再次输入设置的root用户密码通信安全授权勾选“确认授权”准备MRS的ORC表数据源本地PC新建一个product_info.txt,并拷贝以下数据,保存到本地。100,XHDK-A-1293-#fJ3,2017-09-01,A,2017 Autumn New Shirt Women,red,M,328,2017-09-04,715,good 205,KDKE-B-9947-#kL5,2017-09-01,A,2017 Autumn New Knitwear Women,pink,L,584,2017-09-05,406,very good! 300,JODL-X-1937-#pV7,2017-09-01,A,2017 autumn new T-shirt men,red,XL,1245,2017-09-03,502,Bad. 310,QQPX-R-3956-#aD8,2017-09-02,B,2017 autumn new jacket women,red,L,411,2017-09-05,436,It's really super nice 150,ABEF-C-1820-#mC6,2017-09-03,B,2017 Autumn New Jeans Women,blue,M,1223,2017-09-06,1200,The seller's packaging is exquisite 200,BCQP-E-2365-#qE4,2017-09-04,B,2017 autumn new casual pants men,black,L,997,2017-09-10,301,The clothes are of good quality. 250,EABE-D-1476-#oB1,2017-09-10,A,2017 autumn new dress women,black,S,841,2017-09-15,299,Follow the store for a long time. 108,CDXK-F-1527-#pL2,2017-09-11,A,2017 autumn new dress women,red,M,85,2017-09-14,22,It's really amazing to buy 450,MMCE-H-4728-#nP9,2017-09-11,A,2017 autumn new jacket women,white,M,114,2017-09-14,22,Open the package and the clothes have no odor 260,OCDA-G-2817-#bD3,2017-09-12,B,2017 autumn new woolen coat women,red,L,2004,2017-09-15,826,Very favorite clothes 980,ZKDS-J-5490-#cW4,2017-09-13,B,2017 Autumn New Women's Cotton Clothing,red,M,112,2017-09-16,219,The clothes are small 98,FKQB-I-2564-#dA5,2017-09-15,B,2017 autumn new shoes men,green,M,4345,2017-09-18,5473,The clothes are thick and it's better this winter. 150,DMQY-K-6579-#eS6,2017-09-21,A,2017 autumn new underwear men,yellow,37,2840,2017-09-25,5831,This price is very cost effective 200,GKLW-l-2897-#wQ7,2017-09-22,A,2017 Autumn New Jeans Men,blue,39,5879,2017-09-25,7200,The clothes are very comfortable to wear 300,HWEC-L-2531-#xP8,2017-09-23,A,2017 autumn new shoes women,brown,M,403,2017-09-26,607,good 100,IQPD-M-3214-#yQ1,2017-09-24,B,2017 Autumn New Wide Leg Pants Women,black,M,3045,2017-09-27,5021,very good. 350,LPEC-N-4572-#zX2,2017-09-25,B,2017 Autumn New Underwear Women,red,M,239,2017-09-28,407,The seller's service is very good 110,NQAB-O-3768-#sM3,2017-09-26,B,2017 autumn new underwear women,red,S,6089,2017-09-29,7021,The color is very good 210,HWNB-P-7879-#tN4,2017-09-27,B,2017 autumn new underwear women,red,L,3201,2017-09-30,4059,I like it very much and the quality is good. 230,JKHU-Q-8865-#uO5,2017-09-29,C,2017 Autumn New Clothes with Chiffon Shirt,black,M,2056,2017-10-02,3842,very good登录OBS控制台,单击“创建桶”,填写以下参数,单击“立即创建”。表1 桶参数参数项取值区域华北-北京四数据冗余存储策略单AZ存储桶mrs-datasource存储类别标准存储桶策略私有默认加密关闭归档数据直读关闭企业项目default标签-等待桶创建好,单击桶名称,选择“对象 > 上传对象”,将product_info.txt上传至OBS桶。切换回MRS控制台,单击创建好的MRS集群名称,进入“概览”,单击“IAM用户同步”所在行的“单击同步”,等待约5分钟同步完成。回到MRS集群页面,单击“节点管理”,单击任意一台master节点,进入该节点页面,切换到“弹性公网IP”,单击“绑定弹性公网IP”,勾选已有弹性IP并单击“确定”,如果没有,请创建。记录此公网IP。确认主master节点。使用SSH工具以root用户登录以上节点,root密码为Huawei_12345,切换到omm用户。su - omm执行以下命令查询主master节点,回显信息中“HAActive”参数值为“active”的节点为主master节点。sh ${BIGDATA_HOME}/om-0.0.1/sbin/status-oms.sh使用root用户登录主master节点,切换到omm用户,并进入Hive客户端所在目录。su - ommcd /opt/client在Hive上创建存储类型为TEXTFILE的表product_info。在/opt/client路径下,导入环境变量。source bigdata_env登录Hive客户端。beeline依次执行以下SQL语句创建demo数据库及表product_info。CREATE DATABASE demo;USE demo;DROP TABLE product_info; CREATE TABLE product_info ( product_price int not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt int , product_comment_time date , product_comment_num int , product_comment_content varchar(200) ) row format delimited fields terminated by ',' stored as TEXTFILE将product_info.txt数据文件导入Hive。切回到MRS集群,单击“文件管理”,单击“导入数据”。OBS路径:选择上面创建好的OBS桶名,找到product_info.txt文件,单击“是”。HDFS路径:选择/user/hive/warehouse/demo.db/product_info/,单击“是”。单击“确定”,等待导入成功,此时product_info的表数据已导入成功。创建ORC表,并将数据导入ORC表。执行以下SQL语句创建ORC表。DROP TABLE product_info_orc; CREATE TABLE product_info_orc ( product_price int not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt int , product_comment_time date , product_comment_num int , product_comment_content varchar(200) ) row format delimited fields terminated by ',' stored as orc;将product_info表的数据插入到Hive ORC表product_info_orc中。insert into product_info_orc select * from product_info;查询ORC表数据导入成功。select * from product_info_orc;创建MRS数据源连接登录DWS管理控制台,单击已创建好的DWS集群,确保DWS集群与MRS在同一个区域、可用分区,并且在同一VPC子网下。切换到“MRS数据源”,单击“创建MRS数据源连接”。选择前序步骤创建名为的“MRS01”数据源,用户名:admin,密码:Huawei@12345,单击“确定”,创建成功。创建外部服务器使用Data Studio连接已创建好的DWS集群。新建一个具有创建数据库权限的用户dbuser:CREATE USER dbuser WITH CREATEDB PASSWORD "Bigdata@123";切换为新建的dbuser用户:SET ROLE dbuser PASSWORD "Bigdata@123";创建新的mydatabase数据库:CREATE DATABASE mydatabase;执行以下步骤切换为连接新建的mydatabase数据库。在Data Studio客户端的“对象浏览器”窗口,右键单击数据库连接名称,在弹出菜单中单击“刷新”,刷新后就可以看到新建的数据库。右键单击“mydatabase”数据库名称,在弹出菜单中单击“打开连接”。右键单击“mydatabase”数据库名称,在弹出菜单中单击“打开新的终端”,即可打开连接到指定数据库的SQL命令窗口,后面的步骤,请全部在该命令窗口中执行。为dbuser用户授予创建外部服务器的权限:GRANT ALL ON FOREIGN DATA WRAPPER hdfs_fdw TO dbuser;其中FOREIGN DATA WRAPPER的名字只能是hdfs_fdw,dbuser为创建SERVER的用户名。执行以下命令赋予用户使用外表的权限。ALTER USER dbuser USEFT;切换回Postgres系统数据库,查询创建MRS数据源后系统自动创建的外部服务器。SELECT * FROM pg_foreign_server;返回结果如: srvname | srvowner | srvfdw | srvtype | srvversion | srvacl | srvoptions --------------------------------------------------+----------+--------+---------+------------+--------+--------------------------------------------------------------------------------------------------------------------- gsmpp_server | 10 | 13673 | | | | gsmpp_errorinfo_server | 10 | 13678 | | | | hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca | 16476 | 13685 | | | | {"address=192.168.1.245:9820,192.168.1.218:9820",hdfscfgpath=/MRS/8f79ada0-d998-4026-9020-80d6de2692ca,type=hdfs} (3 rows)切换到mydatabase数据库,并切换到dbuser用户。SET ROLE dbuser PASSWORD "Bigdata@123";创建外部服务器。SERVER名字、地址、配置路径保持与8一致即可。CREATE SERVER hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca FOREIGN DATA WRAPPER HDFS_FDW OPTIONS ( address '192.168.1.245:9820,192.168.1.218:9820', //MRS管理面的Master主备节点的内网IP,可与DWS通讯。 hdfscfgpath '/MRS/8f79ada0-d998-4026-9020-80d6de2692ca', type 'hdfs' );查看外部服务器。SELECT * FROM pg_foreign_server WHERE srvname='hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca';返回结果如下所示,表示已经创建成功: srvname | srvowner | srvfdw | srvtype | srvversion | srvacl | srvoptions --------------------------------------------------+----------+--------+---------+------------+--------+--------------------------------------------------------------------------------------------------------------------- hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca | 16476 | 13685 | | | | {"address=192.168.1.245:9820,192.168.1.218:29820",hdfscfgpath=/MRS/8f79ada0-d998-4026-9020-80d6de2692ca,type=hdfs} (1 row)创建外表获取Hive的product_info_orc的文件路径。登录MRS管理控制台。选择“集群列表 > 现有集群”,单击要查看的集群名称,进入集群基本信息页面。单击“文件管理”,选择“HDFS文件列表”。进入您要导入到GaussDB(DWS)集群的数据的存储目录,并记录其路径。创建外表。 SERVER名字填写创建的外部服务器名称,foldername填写查到的路径。DROP FOREIGN TABLE IF EXISTS foreign_product_info; CREATE FOREIGN TABLE foreign_product_info ( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer , product_comment_content varchar(200) ) SERVER hdfs_server_8f79ada0_d998_4026_9020_80d6de2692ca OPTIONS ( format 'orc', encoding 'utf8', foldername '/user/hive/warehouse/demo.db/product_info_orc/' ) DISTRIBUTE BY ROUNDROBIN;执行数据导入创建本地目标表。DROP TABLE IF EXISTS product_info; CREATE TABLE product_info ( product_price integer not null, product_id char(30) not null, product_time date , product_level char(10) , product_name varchar(200) , product_type1 varchar(20) , product_type2 char(10) , product_monthly_sales_cnt integer , product_comment_time date , product_comment_num integer , product_comment_content varchar(200) ) with ( orientation = column, compression=middle ) DISTRIBUTE BY HASH (product_id);从外表导入目标表。INSERT INTO product_info SELECT * FROM foreign_product_info;查询导入结果。SELECT * FROM product_info; -
-
 >摘要:华为MRS云原生数据湖平台的HetuEngine就是一款解决大数据时代跨源跨域问题的数据虚拟化引擎。本文分享自华为云社区[《基于华为云原生数据湖MRS HetuEgine的数据虚拟化实践》](https://bbs.huaweicloud.com/blogs/307420),作者: 前锋 。 数据虚拟化是指一种数据管理方式,允许应用在不关心数据源的数据格式及物理存储位置的情况下以一种统一的方式获取和使用整个组织中所有的数据。与数据虚拟化方式对应的一种方式是传统的ETL方式,数据经过抽取、转换和装载的过程,将不同系统的数据收集到一个统一的物理系统中,并经过标准化处理进行格式的统一。数据虚拟化的特点是不改变数据存储位置,实时访问。根据Gartner发布的数据管理技术成熟度曲线,数据虚拟化技术已经进入了生产成熟期,相关理论和技术也已经成熟,如果企业正在受困于各系统或者各部门数据无法高效打通的问题,可以考虑采用数据虚拟化技术。 早期的一种数据虚拟化实践是数据库联邦,在不同的数据库之间建立JDBC/ODBC连接的方式,以标准SQL的方式跨数据库进行数据实时访问。这种方式在传统数据库模式下一定程度上解决了跨数据源实时数据访问的问题。但是在大数据时代,数据的存储和访问方式已经完全不同,每种数据处理组件只解决一个特定的场景问题,具有不同的数据存储方式、组织方式和访问方式。如Hdoop用于解决大规模数据的批量计算,Hbase用于海量数据的实时精确检索,ElasticSearch用于海量数据的综合检索,还有MPP数据库、图数据库、内存数据库、时序数据库等等,百花齐放,百家争鸣,共同形成了大数据时代的数据处理技术栈,解决各个场景下的大规模数据处理问题。在实际的应用中,为了满足业务不同维度的需求,往往在同一个业务中同时使用了不同的处理组件,甚至是分布在不同地域的不同数据处理组件,造成了业务复杂度高,数据冗余,访问效率低等问题。 大数据时代的数据虚拟化技术就是要解决这种跨源跨域场景下的数据高效访问问题,以一种统一的接口,接近原生系统的性能,跨地域的方式进行数据访问。而要满足上述要求,一个数据虚拟化产品需要具备下面的四个功能: - 统一元数据管理。具备全局数据的统一视图,包括数据承载的组件、数据的Schema、数据存储的格式、存储位置等。 - 抽象数据访问层。提供数据访问的抽象层,屏蔽不同数据源的接口差异,在访问层以一种统一的接口面向应用层。 - 统一的安全管控。全局统一安全管控策略,所有数据的访问在安全管控的框架下进行,避免数据越权访问。 - 多源结果集合并。来自不同集群,不同组件的结果数据可以关联、合并,以一个完整的结果集返回给应用层。 华为MRS云原生数据湖平台的HetuEngine就是一款解决大数据时代跨源跨域问题的数据虚拟化引擎。如下图是MRS云原生数据湖平台基于HetuEngine构建的逻辑数据湖平台架构。HetuEngine可以跨Hadoop平台、MPP数据库、数据集市(包括Hbase、ElasticSearch、Clickhouse等)进行跨源访问,并提供统一的SQL接口供上层应用进行数据访问。HetuEngine还支持跨集群数据访问,实现高性能的跨数据湖、数据仓库、数据集市的分析查询。适用多个数据湖或者数据平台联合分析,支持用户间资源隔离,支持全局数据权限管理。  现在,HetuEngine已经帮助众多政企客户解决了在大数据场景下面临的用数难,取数难的问题。某大型国企就利用了HetuEngine的跨域分析能力解决了困扰其很长时间的全域数据实时访问的问题。 该大型国企有众多下属省公司,分布在全国各地,每个省公司都建设有自己的数据湖平台,用于支撑省公司内部的数字业务。各省公司每天要将自己的数据上报给集团公司,集团公司再对全国数据进行统一汇总加工处理,用于支撑集团层面的业务决策。这种方式面临以下几个问题:(1)数据上报不完整。由于带宽限制,只能上报部分结果数据,无法将全部的明细数据上报,部分需要明细数据的业务无法在集团层面开展。(2)数据上报延迟。子公司将数据加工后,分批上报集团公司,数据延迟在小时级别,无法支撑集团实时业务的开展。(3)资源投入太大。随着业务的发展,集团需要的数据越来越多,资源池原来越大,投入和产出无法匹配。(4)数据需求响应不及时。新的数据需求只能通过对分公司提数据需求,重新开发数据流程上报的方式满足,效率太低,无法支撑业务的时效性需求。  如上图所示,在旧模式下,所有的数据只能通过定时上报的方式收集到集团集中化大数据平台,再进行分析,供上层业务使用。引入HetuEngine后,上报的数据只是每天固定模型加工的数据,明细数据和临时汇总数据均可以通过HetuEngine进行实时的查询。通过HetuEngine不仅实现了高效的实时数据查询,还可以通过HetuEngine进行跨省公司的数据关联分析,打破了省公司之间的数据墙,大大提高了跨域数据分析的效率。 HetuEgine通过自己的跨域查询引擎,可以将一个复杂的跨域查询任务根据数据所在的位置将查询下发到数据所在的集群执行,充分利用边缘集群的算力,提高数据分析的效率和整体的资源利用率。如下图的一个场景,要统计年龄为35岁,在两个省同时开户的用户。可以通过一个SQL同时查询两个省公司的数据。HetuEngine将这个SQL下推到两个省公司集群执行,并将执行结果返回给集团公司进行统一汇总,直接向业务层返回最终的汇总结果。整个过程都是自动实时的进行,并且充分利用了边缘集群的算力,集团公司只需要消耗少量的带宽和算力就完成了整个计算过程。  HetuEngine在跨域场景下也充分考虑了整个计算过程的可靠性和安全性。数据访问遵循统一的安全管控模型,对远程数据访问进行细粒度的管控。数据传输过程采用加密传输,保障数据传输过程中的安全。考虑到跨地域的查询通常是传输带宽受限的场景,HetuEngine支持流量管控,防止由于查询结果集过大导致占满传输带宽,影响其他业务。此外,HetuEngine还综合采用了抗网络抖动、断点续传、压缩传输、级联查询等手段提高跨域查询的稳定性和效率。 最终,借助HetuEngine提供的数据虚拟化能力,该集团公司打造了一套高效的全域数据统一查询分析平台。首先,实现了全域数据在集团层面真正的统一,利用HetuEngine可随时访问集团所有省公司的数据。其次,减少了集团公司集群的压力,将大量的数据分析任务下发给省公司集群完成,充分利用省公司边缘集群的算力。然后,提高端到端的数据访问时延,数据由之前的小时级的延迟到现在可以秒级查询省公司集群数据。最后,借助HetuEgine跨源跨域查询能力,可以直接将分布在不同省不同存储组件中的数据在HetuEngine中进行关联分析,打破了数据之间的隔离,带来了很多新的数据应用场景,进一步挖掘了数据的价值。
>摘要:华为MRS云原生数据湖平台的HetuEngine就是一款解决大数据时代跨源跨域问题的数据虚拟化引擎。本文分享自华为云社区[《基于华为云原生数据湖MRS HetuEgine的数据虚拟化实践》](https://bbs.huaweicloud.com/blogs/307420),作者: 前锋 。 数据虚拟化是指一种数据管理方式,允许应用在不关心数据源的数据格式及物理存储位置的情况下以一种统一的方式获取和使用整个组织中所有的数据。与数据虚拟化方式对应的一种方式是传统的ETL方式,数据经过抽取、转换和装载的过程,将不同系统的数据收集到一个统一的物理系统中,并经过标准化处理进行格式的统一。数据虚拟化的特点是不改变数据存储位置,实时访问。根据Gartner发布的数据管理技术成熟度曲线,数据虚拟化技术已经进入了生产成熟期,相关理论和技术也已经成熟,如果企业正在受困于各系统或者各部门数据无法高效打通的问题,可以考虑采用数据虚拟化技术。 早期的一种数据虚拟化实践是数据库联邦,在不同的数据库之间建立JDBC/ODBC连接的方式,以标准SQL的方式跨数据库进行数据实时访问。这种方式在传统数据库模式下一定程度上解决了跨数据源实时数据访问的问题。但是在大数据时代,数据的存储和访问方式已经完全不同,每种数据处理组件只解决一个特定的场景问题,具有不同的数据存储方式、组织方式和访问方式。如Hdoop用于解决大规模数据的批量计算,Hbase用于海量数据的实时精确检索,ElasticSearch用于海量数据的综合检索,还有MPP数据库、图数据库、内存数据库、时序数据库等等,百花齐放,百家争鸣,共同形成了大数据时代的数据处理技术栈,解决各个场景下的大规模数据处理问题。在实际的应用中,为了满足业务不同维度的需求,往往在同一个业务中同时使用了不同的处理组件,甚至是分布在不同地域的不同数据处理组件,造成了业务复杂度高,数据冗余,访问效率低等问题。 大数据时代的数据虚拟化技术就是要解决这种跨源跨域场景下的数据高效访问问题,以一种统一的接口,接近原生系统的性能,跨地域的方式进行数据访问。而要满足上述要求,一个数据虚拟化产品需要具备下面的四个功能: - 统一元数据管理。具备全局数据的统一视图,包括数据承载的组件、数据的Schema、数据存储的格式、存储位置等。 - 抽象数据访问层。提供数据访问的抽象层,屏蔽不同数据源的接口差异,在访问层以一种统一的接口面向应用层。 - 统一的安全管控。全局统一安全管控策略,所有数据的访问在安全管控的框架下进行,避免数据越权访问。 - 多源结果集合并。来自不同集群,不同组件的结果数据可以关联、合并,以一个完整的结果集返回给应用层。 华为MRS云原生数据湖平台的HetuEngine就是一款解决大数据时代跨源跨域问题的数据虚拟化引擎。如下图是MRS云原生数据湖平台基于HetuEngine构建的逻辑数据湖平台架构。HetuEngine可以跨Hadoop平台、MPP数据库、数据集市(包括Hbase、ElasticSearch、Clickhouse等)进行跨源访问,并提供统一的SQL接口供上层应用进行数据访问。HetuEngine还支持跨集群数据访问,实现高性能的跨数据湖、数据仓库、数据集市的分析查询。适用多个数据湖或者数据平台联合分析,支持用户间资源隔离,支持全局数据权限管理。  现在,HetuEngine已经帮助众多政企客户解决了在大数据场景下面临的用数难,取数难的问题。某大型国企就利用了HetuEngine的跨域分析能力解决了困扰其很长时间的全域数据实时访问的问题。 该大型国企有众多下属省公司,分布在全国各地,每个省公司都建设有自己的数据湖平台,用于支撑省公司内部的数字业务。各省公司每天要将自己的数据上报给集团公司,集团公司再对全国数据进行统一汇总加工处理,用于支撑集团层面的业务决策。这种方式面临以下几个问题:(1)数据上报不完整。由于带宽限制,只能上报部分结果数据,无法将全部的明细数据上报,部分需要明细数据的业务无法在集团层面开展。(2)数据上报延迟。子公司将数据加工后,分批上报集团公司,数据延迟在小时级别,无法支撑集团实时业务的开展。(3)资源投入太大。随着业务的发展,集团需要的数据越来越多,资源池原来越大,投入和产出无法匹配。(4)数据需求响应不及时。新的数据需求只能通过对分公司提数据需求,重新开发数据流程上报的方式满足,效率太低,无法支撑业务的时效性需求。  如上图所示,在旧模式下,所有的数据只能通过定时上报的方式收集到集团集中化大数据平台,再进行分析,供上层业务使用。引入HetuEngine后,上报的数据只是每天固定模型加工的数据,明细数据和临时汇总数据均可以通过HetuEngine进行实时的查询。通过HetuEngine不仅实现了高效的实时数据查询,还可以通过HetuEngine进行跨省公司的数据关联分析,打破了省公司之间的数据墙,大大提高了跨域数据分析的效率。 HetuEgine通过自己的跨域查询引擎,可以将一个复杂的跨域查询任务根据数据所在的位置将查询下发到数据所在的集群执行,充分利用边缘集群的算力,提高数据分析的效率和整体的资源利用率。如下图的一个场景,要统计年龄为35岁,在两个省同时开户的用户。可以通过一个SQL同时查询两个省公司的数据。HetuEngine将这个SQL下推到两个省公司集群执行,并将执行结果返回给集团公司进行统一汇总,直接向业务层返回最终的汇总结果。整个过程都是自动实时的进行,并且充分利用了边缘集群的算力,集团公司只需要消耗少量的带宽和算力就完成了整个计算过程。  HetuEngine在跨域场景下也充分考虑了整个计算过程的可靠性和安全性。数据访问遵循统一的安全管控模型,对远程数据访问进行细粒度的管控。数据传输过程采用加密传输,保障数据传输过程中的安全。考虑到跨地域的查询通常是传输带宽受限的场景,HetuEngine支持流量管控,防止由于查询结果集过大导致占满传输带宽,影响其他业务。此外,HetuEngine还综合采用了抗网络抖动、断点续传、压缩传输、级联查询等手段提高跨域查询的稳定性和效率。 最终,借助HetuEngine提供的数据虚拟化能力,该集团公司打造了一套高效的全域数据统一查询分析平台。首先,实现了全域数据在集团层面真正的统一,利用HetuEngine可随时访问集团所有省公司的数据。其次,减少了集团公司集群的压力,将大量的数据分析任务下发给省公司集群完成,充分利用省公司边缘集群的算力。然后,提高端到端的数据访问时延,数据由之前的小时级的延迟到现在可以秒级查询省公司集群数据。最后,借助HetuEgine跨源跨域查询能力,可以直接将分布在不同省不同存储组件中的数据在HetuEngine中进行关联分析,打破了数据之间的隔离,带来了很多新的数据应用场景,进一步挖掘了数据的价值。 -
 【功能模块】数据转发至大数据平台分析并呈现https://support.huaweicloud.com/bestpractice-iothub/iot_bp_0002.html【操作步骤&问题现象】1、按照步骤进行购买,集群 产生费用,不可被代金券抵扣,2、云硬盘是必选资源吗?【截图信息】【日志信息】(可选,上传日志内容或者附件)
【功能模块】数据转发至大数据平台分析并呈现https://support.huaweicloud.com/bestpractice-iothub/iot_bp_0002.html【操作步骤&问题现象】1、按照步骤进行购买,集群 产生费用,不可被代金券抵扣,2、云硬盘是必选资源吗?【截图信息】【日志信息】(可选,上传日志内容或者附件) -
 # 华为FusionInsight MRS实战 - Flink CDC特性学习 ## Flink cdc介绍 Flink CDC连接器是Apache Flink新版本特性,是数据源连接器,使用更改数据捕获(CDC)从不同数据库接收更改。Flink CDC连接器集成了Debezium作为引擎来捕获数据更改。所以它可以充分利用Debezium的能力。 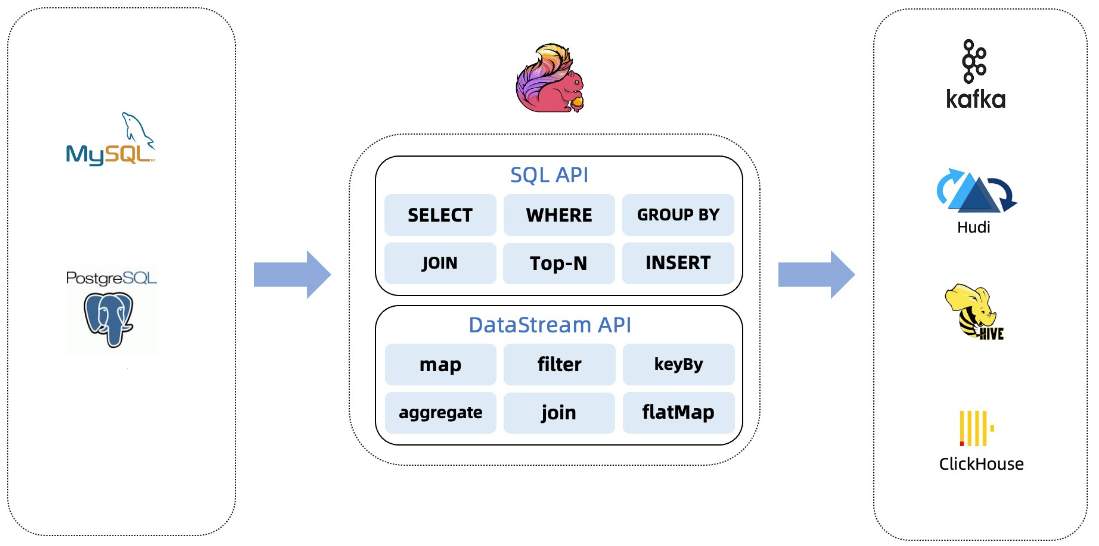 华为FusionInsight MRS 812版本,Flink版本1.12为例,介绍Flink CDC对应能力 Flink CDC与Flink版本对应关系 |Flink CDC Connector Version|Flink Version| | ---- | ---- | |1.0.0|1.11.*| |1.1.0|1.11.*| |1.2.0|1.12.*| |1.3.0|1.12.*| |1.4.0|1.13.*| |2.0.*|1.13.*| |2.1.*|1.13.*| 选择使用flink cdc版本1.2.0 Flink CDC支持数据源 |Database|Version| | ---- | ---- | |MySQL|Database: 5.7, 8.0.xJDBC Driver: 8.0.16| |PostgreSQL|Database: 9.6, 10, 11, 12JDBC Driver: 42.2.12 | 可支持的格式 |Format |Supported Connector |Flink Version| | ---- | ---- | ---- | |Changelog Json|Apache Kafka|1.11+| ## Flink cdc 方案优势 同之前的实时同步方案相比,使用flink cdc能够减少cdl工具和kafka的维护成本,链路更短,延迟更低,flink提供了exactly once语义,可以从指定position读取,并且去掉了kafka,减少了消息的存储成本。 ## 场景说明  1. 使用Flink cdc的能力直接从数据源MySQL中获取数据内容并使用Flink SQL处理发送至数据下游 2. 使用Kafka进行数据接收,使用Changelog格式 ## 样例数据简介 生产库MySQL原始数据: 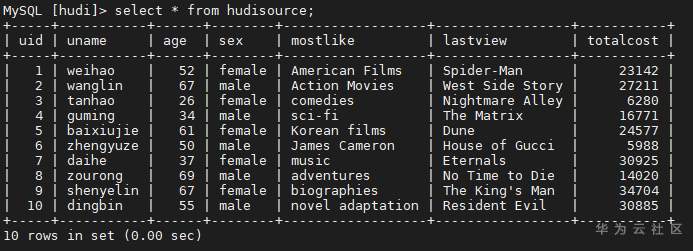 ## 前提条件 该特性目前只支持在Flink Client客户端使用,所以首先需要了解以下三点内容。 1. 如何配置Flink客户端。 参考:[《华为FusionInsight MRS Flink客户端配置》](https://bbs.huaweicloud.com/forum/thread-175741-1-1.html) 2. 如何配置Flink SQL Client。参考:[《华为FusionInsight MRS Flink SQL-Client客户端配置》](https://bbs.huaweicloud.com/forum/thread-176103-1-1.html) 3. 如何使用Flink SQL Client。参考:[《华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=161992) ## 操作步骤 - 准备驱动包 https://github.com/ververica/flink-cdc-connectors/releases 根据上述对应版本,选择flink cdc版本为1.2.0  下载对应的jar包并放置到flink客户端lib目录下,比如 /opt/92_client/hadoopclient/Flink/flink/lib  - 使用命令启动flink session `./bin/yarn-session.sh -t conf/`  - 使用命令登录flink sql client客户端 `./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml` 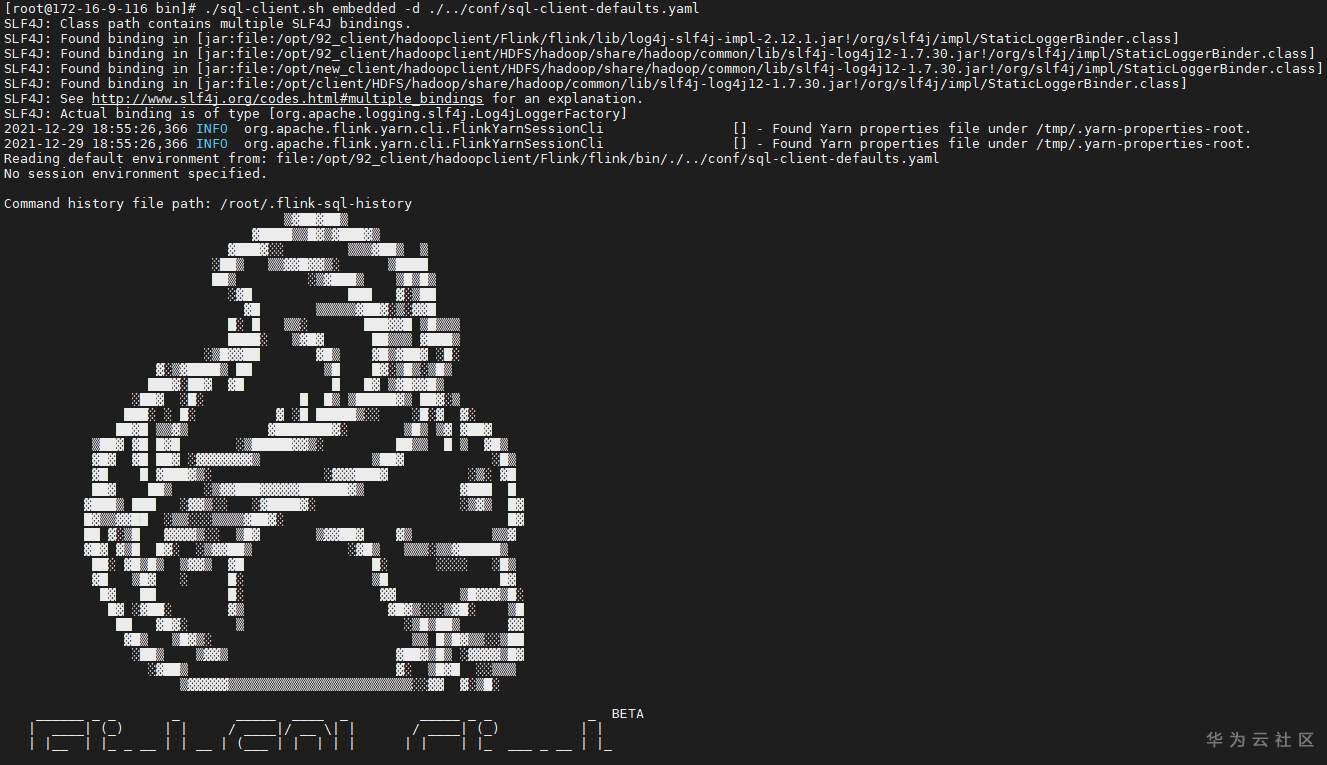 - 在sql client创建数据源表 ``` CREATE TABLE MYSQL_MATERIAL_INFO( uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'mysql-cdc', 'hostname' = '172.16.2.118', 'port' = '3306', 'username' = 'root', 'password' = 'Huawei@123', 'database-name' = 'hudi', 'table-name' = 'hudisource' ); ``` 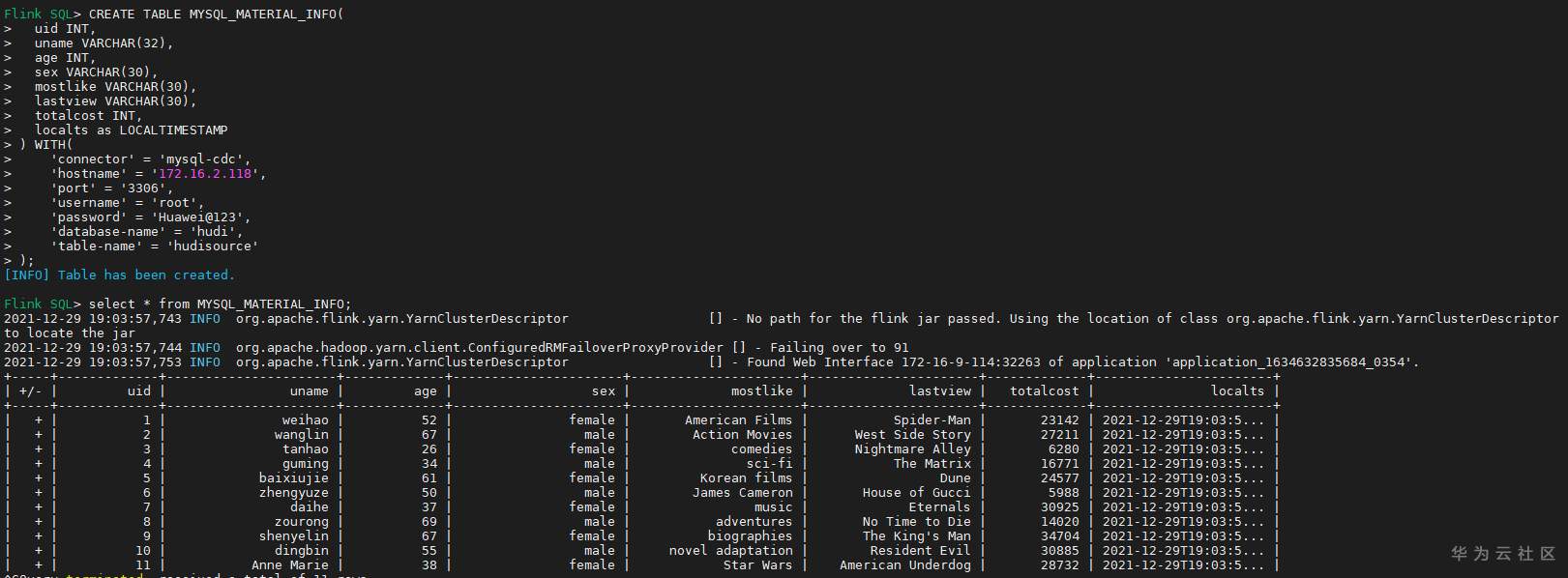 - 在sql client创建kafka目的表 ``` CREATE TABLE huditableout( uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'changelog_json_format_test', 'properties.bootstrap.servers' = '172.16.9.116:21005', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'changelog-json' ); ``` 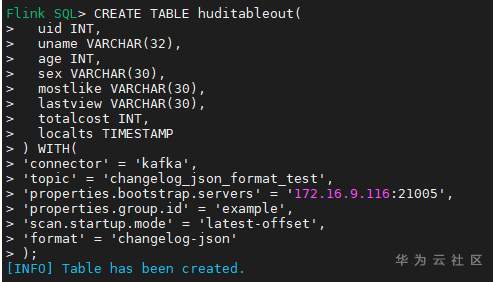 - 在sql client创建数据写入 ``` insert into huditableout select uid, uname, age, sex, mostlike, lastview, totalcost, localts from MYSQL_MATERIAL_INFO; ``` 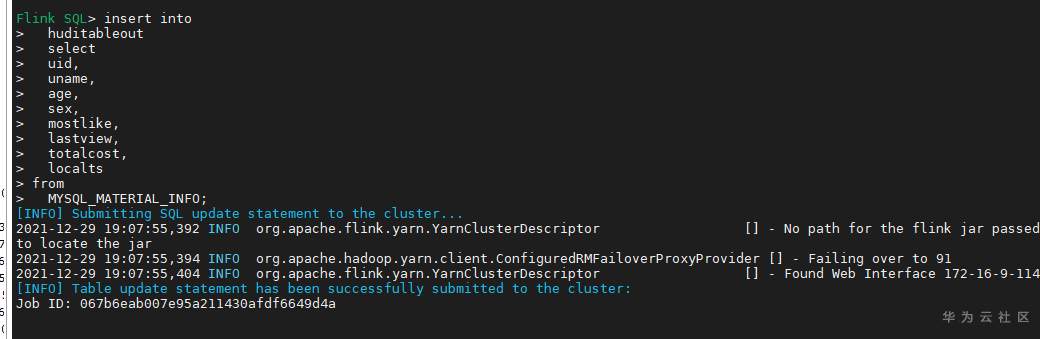 - 在mysql源库中测试数据的增删改查,然后使用kafka消费查看changelog-json格式的结果 
# 华为FusionInsight MRS实战 - Flink CDC特性学习 ## Flink cdc介绍 Flink CDC连接器是Apache Flink新版本特性,是数据源连接器,使用更改数据捕获(CDC)从不同数据库接收更改。Flink CDC连接器集成了Debezium作为引擎来捕获数据更改。所以它可以充分利用Debezium的能力。  华为FusionInsight MRS 812版本,Flink版本1.12为例,介绍Flink CDC对应能力 Flink CDC与Flink版本对应关系 |Flink CDC Connector Version|Flink Version| | ---- | ---- | |1.0.0|1.11.*| |1.1.0|1.11.*| |1.2.0|1.12.*| |1.3.0|1.12.*| |1.4.0|1.13.*| |2.0.*|1.13.*| |2.1.*|1.13.*| 选择使用flink cdc版本1.2.0 Flink CDC支持数据源 |Database|Version| | ---- | ---- | |MySQL|Database: 5.7, 8.0.xJDBC Driver: 8.0.16| |PostgreSQL|Database: 9.6, 10, 11, 12JDBC Driver: 42.2.12 | 可支持的格式 |Format |Supported Connector |Flink Version| | ---- | ---- | ---- | |Changelog Json|Apache Kafka|1.11+| ## Flink cdc 方案优势 同之前的实时同步方案相比,使用flink cdc能够减少cdl工具和kafka的维护成本,链路更短,延迟更低,flink提供了exactly once语义,可以从指定position读取,并且去掉了kafka,减少了消息的存储成本。 ## 场景说明  1. 使用Flink cdc的能力直接从数据源MySQL中获取数据内容并使用Flink SQL处理发送至数据下游 2. 使用Kafka进行数据接收,使用Changelog格式 ## 样例数据简介 生产库MySQL原始数据:  ## 前提条件 该特性目前只支持在Flink Client客户端使用,所以首先需要了解以下三点内容。 1. 如何配置Flink客户端。 参考:[《华为FusionInsight MRS Flink客户端配置》](https://bbs.huaweicloud.com/forum/thread-175741-1-1.html) 2. 如何配置Flink SQL Client。参考:[《华为FusionInsight MRS Flink SQL-Client客户端配置》](https://bbs.huaweicloud.com/forum/thread-176103-1-1.html) 3. 如何使用Flink SQL Client。参考:[《华为FusionInsight MRS实战 - Flink增强特性之可视化开发平台FlinkSever开发学习》](https://bbs.huaweicloud.com/forum/forum.php?mod=viewthread&tid=161992) ## 操作步骤 - 准备驱动包 https://github.com/ververica/flink-cdc-connectors/releases 根据上述对应版本,选择flink cdc版本为1.2.0  下载对应的jar包并放置到flink客户端lib目录下,比如 /opt/92_client/hadoopclient/Flink/flink/lib  - 使用命令启动flink session `./bin/yarn-session.sh -t conf/`  - 使用命令登录flink sql client客户端 `./sql-client.sh embedded -d ./../conf/sql-client-defaults.yaml`  - 在sql client创建数据源表 ``` CREATE TABLE MYSQL_MATERIAL_INFO( uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts as LOCALTIMESTAMP ) WITH( 'connector' = 'mysql-cdc', 'hostname' = '172.16.2.118', 'port' = '3306', 'username' = 'root', 'password' = 'Huawei@123', 'database-name' = 'hudi', 'table-name' = 'hudisource' ); ```  - 在sql client创建kafka目的表 ``` CREATE TABLE huditableout( uid INT, uname VARCHAR(32), age INT, sex VARCHAR(30), mostlike VARCHAR(30), lastview VARCHAR(30), totalcost INT, localts TIMESTAMP ) WITH( 'connector' = 'kafka', 'topic' = 'changelog_json_format_test', 'properties.bootstrap.servers' = '172.16.9.116:21005', 'properties.group.id' = 'example', 'scan.startup.mode' = 'latest-offset', 'format' = 'changelog-json' ); ```  - 在sql client创建数据写入 ``` insert into huditableout select uid, uname, age, sex, mostlike, lastview, totalcost, localts from MYSQL_MATERIAL_INFO; ```  - 在mysql源库中测试数据的增删改查,然后使用kafka消费查看changelog-json格式的结果  -
1. 根据产品文档安装Flink客户端; 2. 将sql-client-defaults.yaml(见附件)放入/opt/client/Flink/flink/conf中 3. 将jaas.conf 放入/opt/client/Flink/flink/conf中 ``` Client { com.sun.security.auth.module.Krb5LoginModule required useKeyTab=false useTicketCache=true debug=false; }; ``` 4. 添加sql-client.sh中添加在JVM_ARGS参数: JVM_ARGS="-Djava.security.auth.login.config=/opt/client/Flink/flink/conf/jaas.conf $JVM_ARGS" 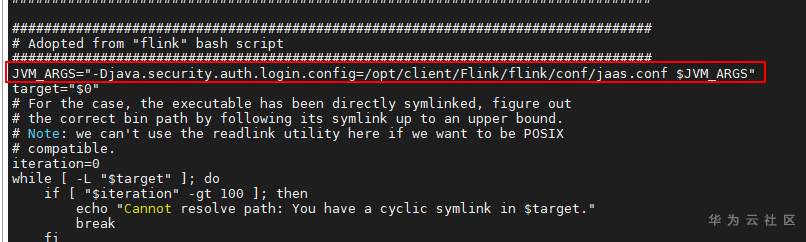
-
【功能模块】创建CDL作业-MySQL--kafka,任务可以成功运行,且能够监控MySQL新增的数据,生产到Kafka中【操作步骤&问题现象】问题一、①MySQL中insert的时间类型的数据是2021-01-01 00:00:00②生产到Kafak的对应字段的数据变成了2020-12-31T16:00:00Z,时间出现了晚一天现象问题二、①在创建CDL作业的时候,Mysql的配置信息,Schema Auto Create我选择了否②然后消费kafka的数据发现还有大量的Schema信息被生产到Kafka中,希望的是不需要额外大量没有用处的信息
-
# 华为FusionInsight MRS Flink客户端配置 ## 场景说明 使用华为FusionInsight MRS的Flink组件进行开发工作时,需要了解如何配置Flink客户端。本文将介绍如何进行该配置 ## 前提条件 已安装FusionInsight MRS客户端,比如在/opt/hadoopclient路径 ## 操作步骤 - 下载用户认证文件并上传至客户端/opt/hadoopclient/Flink/flink/conf  并配置/opt/hadoopclient/Flink/flink/conf/flink-conf.yaml文件中的认证内容跟上述下载信息匹配  注意:配置的值和冒号之间要有一个空格 - 生成cookie密钥 先加载环境变量: source /opt/hadoopclient/bigdata_env 完成认证: kinit poc 登录客户端路径: /opt/hadoopclient/Flink/flink/bin 执行: sh generate_keystore.sh 密码可填:123456  上述该步骤会在/opt/hadoopclient/Flink/flink/conf路径中生成配置文件flink.keystore以及flink.truststore - 配置/opt/hadoopclient/Flink/flink/conf/flink-conf.yaml文件 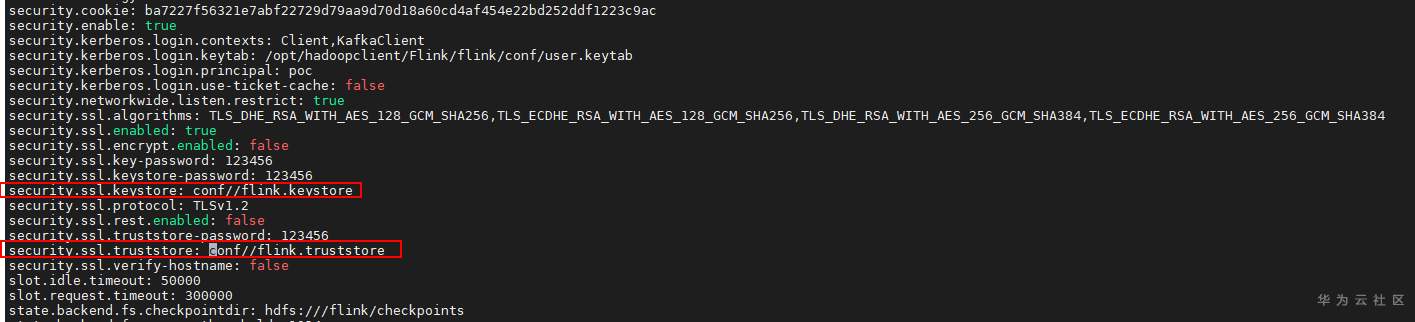 注意:配置flink.keystore以及flink.truststore文件的路径要是相对路径,并且配置的值和冒号之间要有一个空格 - 使用如下命令启动flink session ``` cd /opt/hadoopclient/Flink/flink ./bin/yarn-session.sh -t conf/ ```  
-
# 华为FusionInsight MRS实战 - Manager rest接口进阶学习 ## 典型场景说明 1. 想通过rest接口,获取yarn resource manager原生界面的信息  2. 想通过rest接口,获取Mapreduce jobhistory原生界面的信息  说明: 有上图可知,正常情况会通过manager界面点击,并且进行跳转,所以直接通过curl命令获取跳转地址会失败 ## 操作步骤 1. 获取对应实例对应的直接ip以及端口,登录集群oms节点后台查看whitelist.txt文件,样例路径为:`/opt/huawei/Bigdata/om-server/Apache-httpd-2.4.48/conf/whitelist.txt` yarn resource manager实例直连信息:  Mapreduce jobhistory实例直连信息:  2. 根据获取到的连接信息可以使用curl命令获取页面内容 yarn resource manager获取参考命令 `curl -v --negotiate -u:-X GET https://xxx.xx.xxx.xx:26001/ws/v1/cluster/info -k` 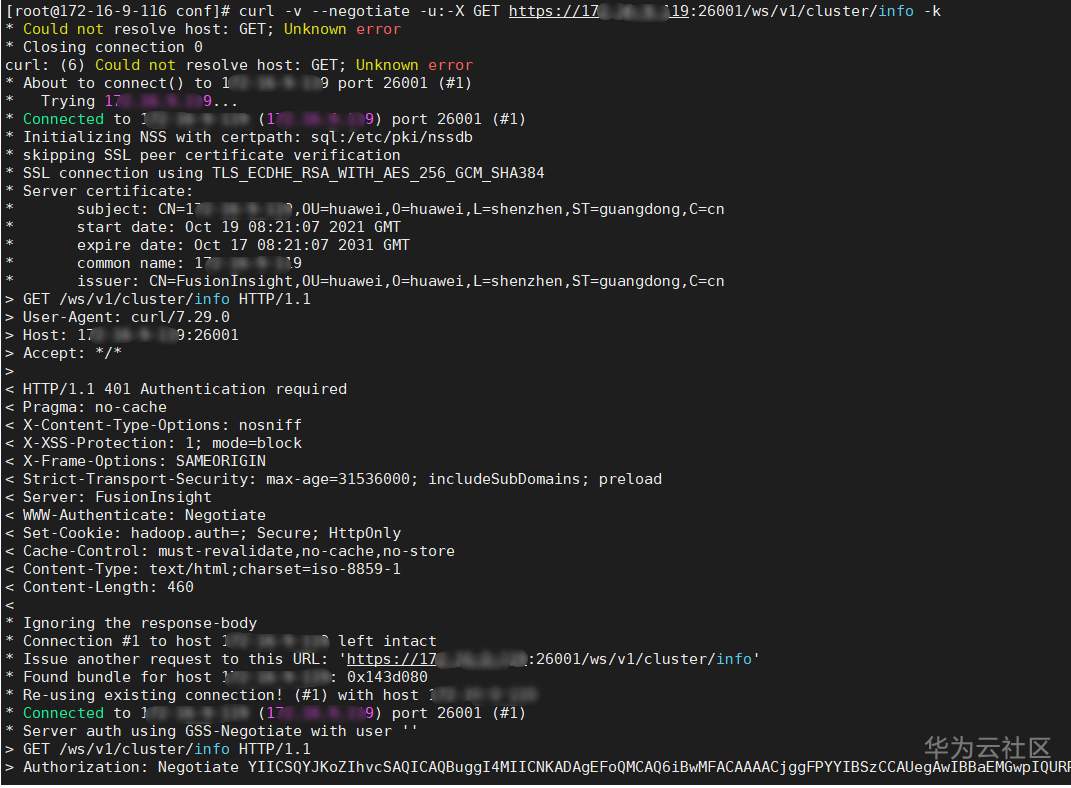 Mapreduce jobhistory 获取参考命令 `curl -v --negotiate -u:-X GET https://xxx.xx.xx.xx:26014/ws/v1/history/mapreduce/jobs -k` 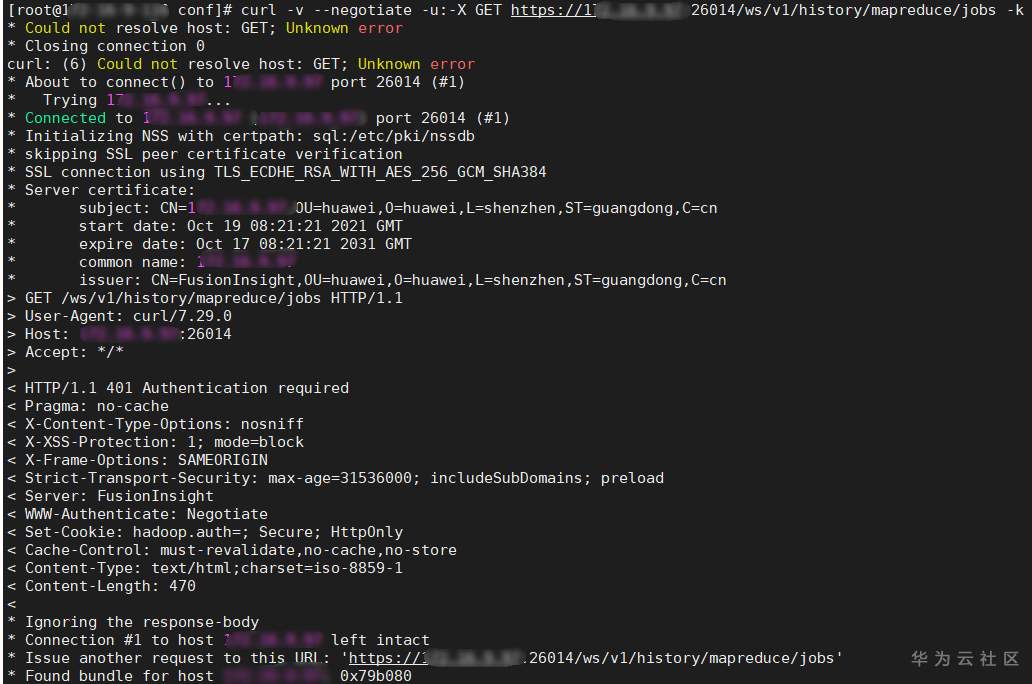
-
# 华为FusionInsight MRS实战 - Manager rest接口基础学习 ## Manager简介 FusionInsight Manager是集群的运维管理系统,为部署在集群内的服务提供统一的集群管理能力。 Manager支持大规模集群的安装部署性能监控、告警、用户管理、权限管理、审计、服务管理、健康检查、日志采集等功能。 ## 典型场景说明 通过典型场景,可以快速学习和掌握Manage REST API的开发过程,并且对关键的函数有所了解。 场景说明 假定用户需要以非界面方式实现操作FusionInsight Manager系统,要求开发基于HTTP Basic认证的应用程序实现如下功能: - 登录FusionInsight Manager系统。 - 访问FusionInsight Manager系统,进行查询、添加、删除等操作。 下面对比介绍使用样例代码和curl命令完成上述rest接口验证 ## 环境准备 - (样例代码)下载并准备MRS对应版本的manager样例代码,比如:https://github.com/huaweicloud/huaweicloud-mrs-example/tree/mrs-3.1.2/src/manager-examples  注意:分别将工程的conf,src路径标注为Resouces Root和Source Root - (样例代码)修改UserInfo.properties文件,分别填入对应的manager登录用户名,密码以及Manager IP  - (Curl命令)准备linux客户端,使用命令`curl -V`检查是否支持认证  下面根据UserManager.java对比验证 ## Manager 功能验证 1. (样例代码)登录核心参考如下样例代码 ``` // 调用firstAccess接口完成登录认证 LOG.info("Begin to get httpclient and first access."); BasicAuthAccess authAccess = new BasicAuthAccess(); HttpClient httpClient = authAccess.loginAndAccess(webUrl, userName, password, userTLSVersion); LOG.info("Start to access REST API."); ``` 对应curl 请求命令 -u 参数 2. (样例代码)访问Manager接口完成添加用户,参考如下样例代码 ``` // 访问Manager接口完成添加用户 operationName = "AddUser"; operationUrl = webUrl + ADD_USER_URL; jsonFilePath = "./conf/addUser.json"; httpManager.sendHttpPostRequest(httpClient, operationUrl, jsonFilePath, operationName); ``` 对应curl 命令请求 `curl -s -w %{http_code} -k -u '对应用户':'对应密码' -X POST 'https://xxx.xx.xx.xxx:28443/web/api/v2/permission/users' -HContent-type:application/json -d '{"userName":"user888","userType":"HM","password":"Admin12!","confirmPassword":"Admin12!","userGroups":["supergroup"],"userRoles":[],"primaryGroup":"supergroup","description":"Add user"}' `  3. (样例代码)访问Manager接口完成查找用户列表,参考如下样例代码 ``` // 访问Manager接口完成查找用户列表 operationName = "QueryUserList"; operationUrl = webUrl + QUERY_USER_LIST_URL; String responseLineContent = httpManager.sendHttpGetRequest(httpClient, operationUrl, operationName); LOG.info("The {} response is {}.", operationName, responseLineContent); ``` 对应curl 命令请求 `curl -s -w %{http_code} -k -u '对应用户':'对应密码' -X GET 'https://xxx.xx.xx.xxx:28443/web/api/v2/permission/users?limit=10&offset=0&filter=&order=ASC' -HContent-type:application/json `  3. (样例代码)访问Manager接口完成修改用户,参考如下样例代码 ``` // 访问Manager接口完成修改用户 operationName = "ModifyUser"; String modifyUserName = "user888"; operationUrl = webUrl + MODIFY_USER_URL + modifyUserName; jsonFilePath = "./conf/modifyUser.json"; httpManager.sendHttpPutRequest(httpClient, operationUrl, jsonFilePath, operationName); ``` 对应curl 命令请求 `curl -s -w %{http_code} -k -u '对应用户':'对应密码' -X PUT 'https://xxx.xx.xx.xxx:28443/web/api/v2/permission/users/user888' -HContent-type:application/json -d '{"userName":"user888","userType":"HM","password":"","confirmPassword":"","userGroups":["supergroup"],"primaryGroup":"supergroup","userRoles":["Manager_administrator"],"description":"Modify user"}'`  4. (样例代码)访问Manager接口完成删除用户,参考如下样例代码 ``` // 访问Manager接口完成删除用户 operationName = "DeleteUser"; String deleteJsonStr = "{\"userNames\":[\"user888\"]}"; operationUrl = webUrl + DELETE_USER_URL; httpManager.sendHttpDeleteRequest(httpClient, operationUrl, deleteJsonStr, operationName); ``` 对应curl 命令请求 `curl -s -w %{http_code} -k -u '对应用户':'对应密码' -X DELETE 'https://xxx.xx.xx.xxx:28443/web/api/v2/permission/users' -HContent-type:application/json -d '{"userNames":["user888"]}'` 
-
【功能模块】MRS 客户端注册【操作步骤&问题现象】1、上传注册包到指定路径2、执行cd ${BIGDATA_HOME}/om-server/om/sbin/pack/./register_pack.sh /opt/MRSx86/FusionInsight_HD_8.1.2_RHEL.tar.gz报错提示:/opt/huawei/Bigdata/Bigdata/tmp/FusionInsight_HD_8.1.2_RHEL/FusionInsight_HD/software: No such file or directory ERROR Failed to upload file /opt/huawei/Bigdata/Bigdata/tmp/FusionInsight_HD_8.1.2_RHEL/FusionInsight_HD/software to 172.16.67.22:/opt/huawei/Bigdata/Bigdata/tmp errorCode=1 [(upload_packages_to_standby):308](5034)【截图信息】【日志信息】(可选,上传日志内容或者附件)
-
# 华为FusionInsight MRS实战 - FlinkSQL从kafka写入hive ## 背景说明 随着流计算的发展,挑战不再仅限于数据量和计算量,业务变得越来越复杂,开发者可能是资深的大数据从业者、初学 Java 的爱好者,或是不懂代码的数据分析者。如何提高开发者的效率,降低流计算的门槛,对推广实时计算非常重要。 SQL 是数据处理中使用最广泛的语言,它允许用户简明扼要地展示其业务逻辑。Flink 作为流批一体的计算引擎,致力于提供一套 SQL 支持全部应用场景,Flink SQL 的实现也完全遵循 ANSI SQL 标准。之前,用户可能需要编写上百行业务代码,使用 SQL 后,可能只需要几行 SQL 就可以轻松搞定。 本文介绍如何使用华为FusionInsight MRS FlinkServer服务进行界面化的FlinkSQL编辑,从而处理复杂的嵌套Json格式 ## Kafka样例数据 模拟物联网场景的数据 ``` {"device":"Demo1","signal":"60","life":"24","times":"2021-12-20 15:46:37"} {"device":"Demo2","signal":"78","life":"20","times":"2021-12-20 15:46:37"} {"device":"Demo3","signal":"41","life":"6","times":"2021-12-20 15:46:38"} {"device":"Demo4","signal":"71","life":"29","times":"2021-12-20 15:46:38"} {"device":"Demo5","signal":"38","life":"19","times":"2021-12-20 15:46:38"} {"device":"Demo6","signal":"98","life":"10","times":"2021-12-20 15:46:38"} {"device":"Demo7","signal":"80","life":"19","times":"2021-12-20 15:46:38"} {"device":"Demo8","signal":"55","life":"27","times":"2021-12-20 15:46:38"} {"device":"Demo9","signal":"93","life":"13","times":"2021-12-20 15:46:38"} {"device":"Demo10","signal":"46","life":"2","times":"2021-12-20 15:46:38"} {"device":"Demo11","signal":"94","life":"28","times":"2021-12-20 15:46:38"} {"device":"Demo12","signal":"24","life":"26","times":"2021-12-20 15:46:38"} {"device":"Demo13","signal":"64","life":"3","times":"2021-12-20 15:46:38"} {"device":"Demo14","signal":"97","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo15","signal":"82","life":"13","times":"2021-12-20 15:46:38"} {"device":"Demo16","signal":"2","life":"2","times":"2021-12-20 15:46:38"} {"device":"Demo17","signal":"19","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo18","signal":"51","life":"22","times":"2021-12-20 15:46:38"} {"device":"Demo19","signal":"1","life":"20","times":"2021-12-20 15:46:38"} {"device":"Demo20","signal":"41","life":"24","times":"2021-12-20 15:46:38"} ``` ## 使用华为MRS Flinkserver对接Hive ### 前提条件 - 集群已安装HDFS、Yarn、Kafka、Flink和Hive等服务。 - 包含Hive服务的客户端已安装,安装路径如:/opt/client。 - Flink支持1.12.2及以上版本,Hive支持3.1.0及以上版本。 - 参考基于用户和角色的鉴权创建一个具有“FlinkServer管理操作权限”的用户用于访问Flink WebUI的用户。  - 参考创建集群连接中的“说明”获取访问Flink WebUI用户的客户端配置文件及用户凭据。 ### 操作步骤 以映射表类型为Kafka对接Hive流程为例。 1. 使用flink_admin访问Flink WebUI,请参考访问Flink WebUI。 2. 新建集群连接,如:flink_hive。 a. 选择“系统管理 > 集群连接管理”,进入集群连接管理页面。 b. 单击“创集集群连接”,在弹出的页面中参考表1填写信息,单击“测试”,测试连接成功后单击“确定”,完成集群连接创建。 表1 创建集群连接信息 | 参数名称 | 参数描述 | 取值样例 | | ---- | ---- | ---- | |集群连接名称|集群连接的名称,只能包含英文字母、数字和下划线,且不能多于100个字符。|flink_hive| |描述|集群连接名称描述信息。|-| |版本|选择集群版本。|MRS 3| |是否安全版本|是,安全集群选择是。需要输入访问用户名和上传用户凭证; 否,非安全集群选择否。|是| |访问用户名|访问用户需要包含访问集群中服务所需要的最小权限。只能包含英文字母、数字和下划线,且不能多于100个字符。“是否安全版本”选择“是”时存在此参数。|flink_admin| |客户端配置文件|集群客户端配置文件,格式为tar。|-| |用户凭据|FusionInsight Manager中用户的认证凭据,格式为tar。“是否安全版本”选择“是”时存在此参数。输入访问用户名后才可上传文件。|flink_admin的用户凭|  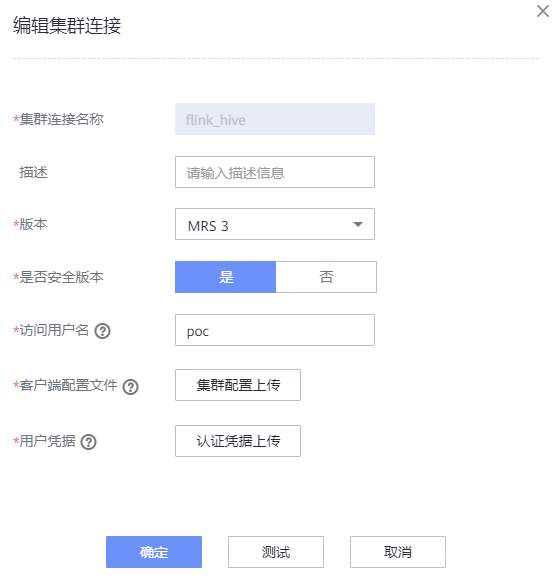 3. 新建Flink SQL流作业,如:kafka_to_hive。 在作业开发界面进行作业开发,输入如下语句,可以单击上方“语义校验”对输入内容校验。 ``` CREATE TABLE test_kafka ( device varchar, signal varchar, life varchar, times timestamp ) WITH ( 'properties.bootstrap.servers' = '172.16.9.116:21007', 'format' = 'json', 'topic' = 'example-metric1', 'connector' = 'kafka', 'scan.startup.mode' = 'latest-offset', 'properties.sasl.kerberos.service.name' = 'kafka', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.kerberos.domain.name' = 'hadoop.hadoop.com' ); CREATE CATALOG myhive WITH ( 'type' = 'hive', 'hive-version' = '3.1.0', 'default-database' = 'default', 'cluster.name' = 'flink_hive' ); use catalog myhive; set table.sql-dialect = hive;create table test_avro_signal_table_orc ( device STRING, signal STRING, life STRING, ts timestamp ) PARTITIONED BY (dy STRING, ho STRING, mi STRING) stored as orc TBLPROPERTIES ( 'partition.time-extractor.timestamp-pattern' = '$dy $ho:$mi:00', 'sink.partition-commit.trigger' = 'process-time', 'sink.partition-commit.delay' = '0S', 'sink.partition-commit.policy.kind' = 'metastore,success-file' ); INSERT into test_avro_signal_table_orc SELECT device, signal, life, times, DATE_FORMAT(times, 'yyyy-MM-dd'), DATE_FORMAT(times, 'HH'), DATE_FORMAT(times, 'mm') FROM default_catalog.default_database.test_kafka; ``` 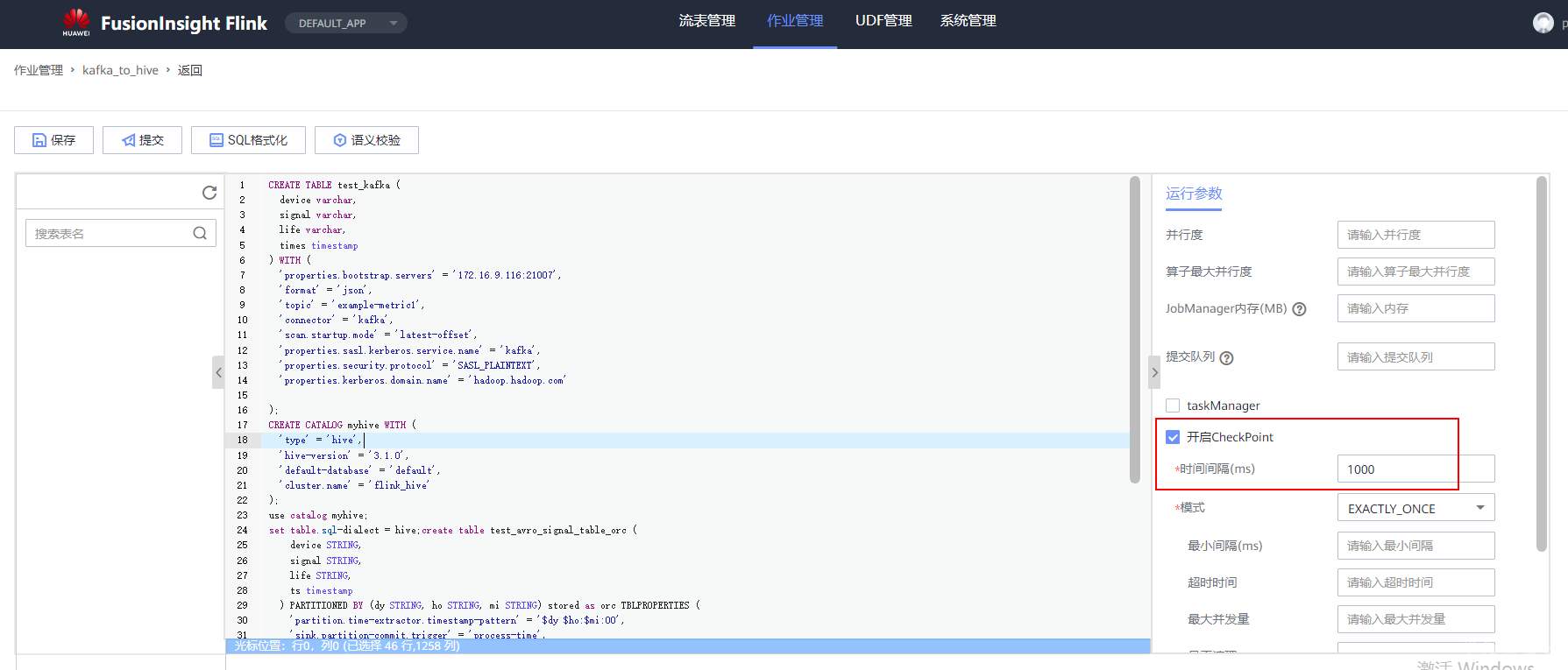 注意:作业SQL开发完成后,请勾选“运行参数”中的“开启CheckPoint”,“时间间隔(ms)”可设置为“60000”,“模式”可使用默认值。 4. 启动任务  5. 启动kafka生产者插入样例数据 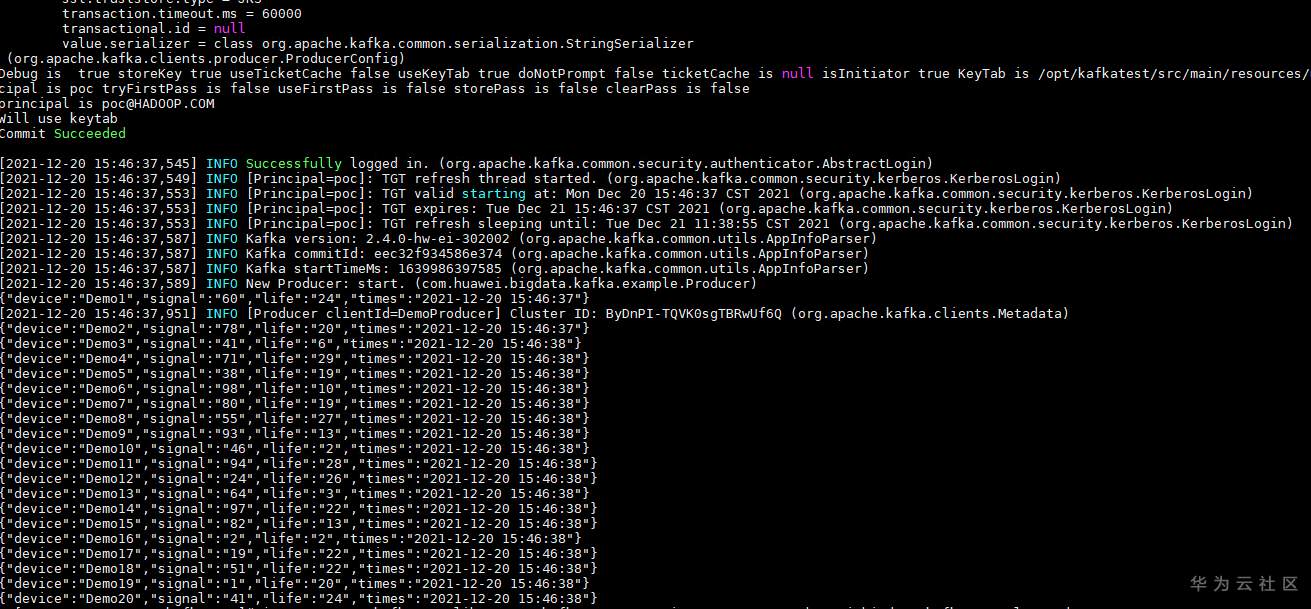 6. 查看hive数据 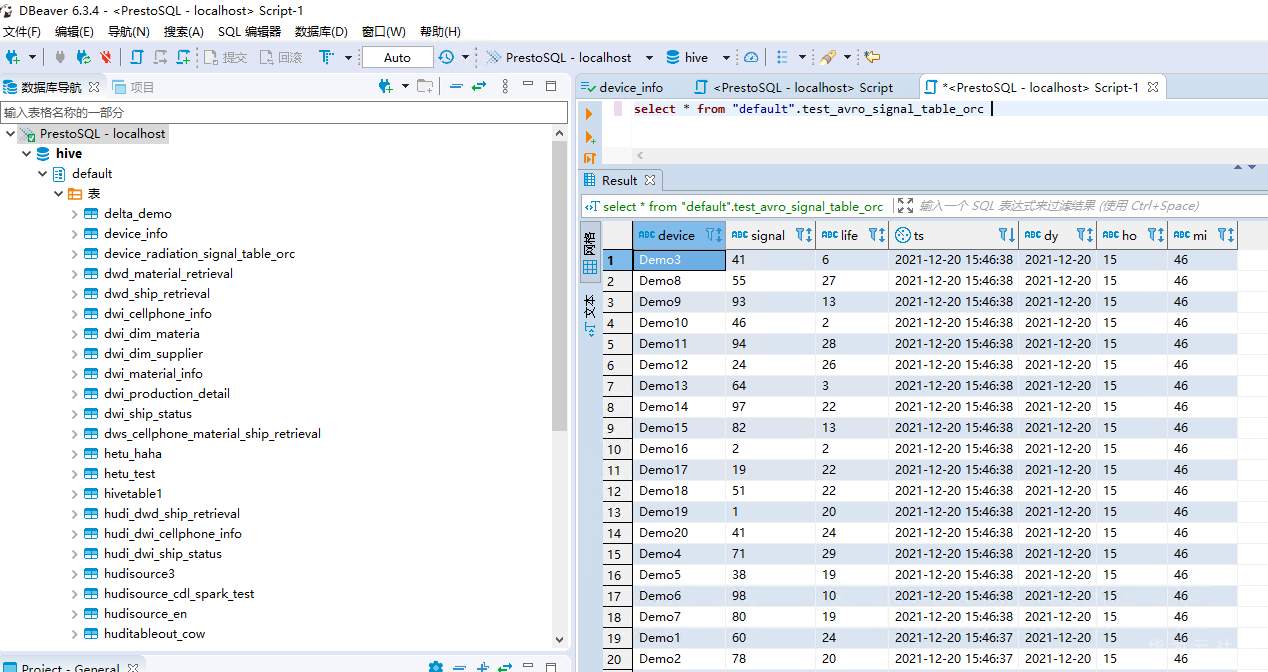
推荐直播
-
 通用人工智能(AGI)到来前夕如何实现企业降本增效和应用现代化
通用人工智能(AGI)到来前夕如何实现企业降本增效和应用现代化2024/04/19 周五 14:00-16:00
李京峰 T3出行VP/CTO
李京峰是T3出行CTO,本次他将分享通用人工智能(AGI)到来前夕,如何实现企业降本增效和应用现代化。
回顾中 -
 华为云云原生FinOps解决方案,为您释放云原生最大价值
华为云云原生FinOps解决方案,为您释放云原生最大价值2024/04/24 周三 16:30-18:00
Roc 华为云云原生DTSE技术布道师
还在对CCE集群成本评估感到束手无策?还在担心不合理的K8s集群资源申请和过度浪费?华为云容器服务CCE全新上线云原生FinOps中心,为用户提供多维度集群成本可视化,结合智能规格推荐、混部、超卖等成本优化手段,助力客户降本增效,释放云原生最大价值。
去报名 -
 产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》
产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》2024/04/25 周四 16:00-18:00
于晓东 上海杉达学院信息科学与技术学院副院长;崔宝才 天津电子信息职业技术学院电子与通信技术系主任
本期直播将与您一起探讨高校人才培养创新模式经验。
去报名
热门标签