-
 最近收到一个客户反馈使用DRS同步后,源库和目标库的数据不一致。数据一致性是DRS的生存之本,团队上下非常重视,收到反馈后马上联系客户了解情况排查原因,最终发现原来是虚惊一场。那么这个“不一致”是怎么产生的?它底层的根本原因又是什么呢?接下来我们一起来挖一挖。 ### 问题现象 客户使用DRS创建了MySQL到PostgreSQL的同步任务,MySQL表中存在一个FLOAT类型的列,DRS任务启动后会在PostgreSQL中对应创建一个FLOAT4的列。同步过程中在MySQL中插入一条FLOAT列值为3.1415926的数据,同步后在源库MySQL中SELECT出来的数据是3.14159,而在目标库PostgrSQL中SELECT出来却是3.1415925。 ### 复现步骤: 1. 在源库建表: ``` CREATE TABLE `float_test` ( `id` int(11) primary key, `id2` float ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ``` 2. 创建DRS任务,同步这张表的数据到PostgreSQL。目标库会自动创建下表: ``` CREATE TABLE "root"."float_test" ( "id" int PRIMARY KEY, "id2" FLOAT4 ) ``` 3. 在源库insert数据: ``` insert into `float_test` values (1, 3.1415926); ``` 4. 数据同步之后 通过mysql客户端查询:  通过postgresql客户端查询: 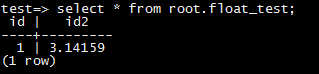 而通过jdbc查询: mysql: 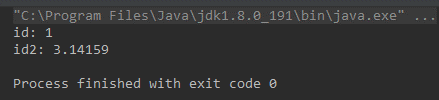 postgresql: 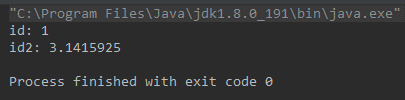 ### 问题原因: mysql底层存储3.1415926的时候,binlog中记录的数据为3.1415925,DRS从binlog中解析出来数据,同步到PostgrSQL的也是3.1415925。 而通过mysql的driver进行select的时候,mysql driver对数据进行了截断,所以查出来是3.14159,而PostgrSQL的driver没有进行截断,导致通过两种driver select出的数据不一致。 如果不想让driver截断,可以在jdbc的url中增加useServerPrepStmts=true的option。
最近收到一个客户反馈使用DRS同步后,源库和目标库的数据不一致。数据一致性是DRS的生存之本,团队上下非常重视,收到反馈后马上联系客户了解情况排查原因,最终发现原来是虚惊一场。那么这个“不一致”是怎么产生的?它底层的根本原因又是什么呢?接下来我们一起来挖一挖。 ### 问题现象 客户使用DRS创建了MySQL到PostgreSQL的同步任务,MySQL表中存在一个FLOAT类型的列,DRS任务启动后会在PostgreSQL中对应创建一个FLOAT4的列。同步过程中在MySQL中插入一条FLOAT列值为3.1415926的数据,同步后在源库MySQL中SELECT出来的数据是3.14159,而在目标库PostgrSQL中SELECT出来却是3.1415925。 ### 复现步骤: 1. 在源库建表: ``` CREATE TABLE `float_test` ( `id` int(11) primary key, `id2` float ) ENGINE=InnoDB DEFAULT CHARSET=utf8 ``` 2. 创建DRS任务,同步这张表的数据到PostgreSQL。目标库会自动创建下表: ``` CREATE TABLE "root"."float_test" ( "id" int PRIMARY KEY, "id2" FLOAT4 ) ``` 3. 在源库insert数据: ``` insert into `float_test` values (1, 3.1415926); ``` 4. 数据同步之后 通过mysql客户端查询:  通过postgresql客户端查询:  而通过jdbc查询: mysql:  postgresql:  ### 问题原因: mysql底层存储3.1415926的时候,binlog中记录的数据为3.1415925,DRS从binlog中解析出来数据,同步到PostgrSQL的也是3.1415925。 而通过mysql的driver进行select的时候,mysql driver对数据进行了截断,所以查出来是3.14159,而PostgrSQL的driver没有进行截断,导致通过两种driver select出的数据不一致。 如果不想让driver截断,可以在jdbc的url中增加useServerPrepStmts=true的option。 -
 10月18日,以“数造未来”为主题的第12届中国数据库技术大会(DTCC2021)在北京举办,华为云数据库CTO庄乾锋携华为云数据库多位技术专家和优秀合作伙伴共同参会并发表了重要主题演讲,分享了GaussDB立足数据库6项基础研究,持续打造根技术,加速数字技术与业务的进一步融合创新。华为云数据库CTO庄乾锋现场发表演讲 在上午的大会主会场,华为云数据库首席架构师冯柯表示:“数字化转型已从'以资源为中心'转换成'以应用为中心',数字化转型进入新阶段。华为云GaussDB将深耕数字化下半场,坚持在金融级高可用、云栈垂直整合、密态数据库等6大基础研究上投入,打造根技术竞争力。同时将产品能力应用到更多商业实践,为客户提供更多高效可用的解决方案,做企业核心数据上云信赖之选。” 华为云GaussDB紧随时代发展潮流,紧密结合客户业务场景,不断进行自主创新,积极打造极致性能、高可用的数据库服务。华为云数据库CTO庄乾锋表示:“基于客户业务需求,华为云GaussDB在云原生多主、基于Memory Pool的HTAP、云原生Serverless、AI自治、全密态数据库等方面进行了巨大创新,同时还联合梦饷、消费者云、迪思杰等合作伙伴联合创新,打造更多、更优的数据库服务能力,满足客户多种复杂场景需求。” 华为云GaussDB立足云原生,提升高可用能力 云原生在互联网领域逐渐成为主流,越来越多的互联网应用基于云原生架构运行。华为云数据库技术专家彭立勋介绍到:华为云GaussDB面向互联网云原生场景,构建了自己独特的云原生能力,以高可用为例,GaussDB致力于向全场景透明应用连续性方向持续演进,提供最佳的云原生数据库体验。 云原生高可用能力可以让企业摆脱扩展难、稳定性差等痛点,让企业更聚焦业务价值创造,实现业务新一轮发展。厚仁科技技术研发部副部长杨喜帅表示:“厚仁科技在线教育平台基于GaussDB提供的高可用、高性能、易扩展、低时延等能力,流量暴涨下平台依旧稳定,在线服务提供更及时,用户体验更佳。” 华为云GaussDB存储引擎创新,探索更高可用方案 高可用作为数据库根技术之一,影响着企业业务的持续稳定运行,对业务发展至关重要。华为GaussDB技术专家王磊表示:“GaussDB通过将磁盘引擎和内存引擎结合,提供了高性能/高扩展的并发控制事务系统、高可靠/高可用的日志系统、灵活的表级存储格式/引擎、统一的行存访存接口等能力,面对大容量、追求极致性能的业务场景表现更优。” 当前该能力已在部分行业落地实践,华为消费者云数据库技术专家张中靖表示:“消费者云服务业务覆盖全球180+国家/地区、亿级终端用户,需要具备高性能、高可靠、 大容量的分布式数据存储服务。消费者云服务基于华为云GaussDB分布式数据库技术构建了单集群PB级、万亿记录、跨AZ高可用的扩展能力,实现简化业务开发、快速构筑开发者生态。” 华为云生态工具革新,为企业提供更快上云方式 近年来,去“O”的呼声越来越大,大量的传统企业开始脱离“IOE”集中式架构,进行分布式改造,迈向云端。华为云数据库技术专家窦德明表示:“针对去‘O’,华为云GaussDB推出了数据复制服务DRS+数据库和应用迁移UGO专属解决方案,提供简单易用、高效可靠的迁移服务。目前该方案已在某金融头部企业中实施,并经受住海量存储过程改造、TB级数据在线迁移等业务实践考验。而作为语法转换利器的UGO,目前也开始正式商用了。” 作为华为优秀生态合作伙伴和数字服务提供商,迪思杰在信息化创新、数字化转型的大背景下,对数据管理技术和产品进行了多方位革新。迪思杰副总裁王浩表示:“迪思杰打造了全套数据生命周期管理解决方案,还联合华为推出了面向GaussDB的数据生态产品和解决方案,以及面向华为云的数据**系列产品和解决方案,积极构建国产数据库生态,共创数字化繁荣。” 数字化创新之路还在继续,华为云GaussDB会继续携手更多合作伙伴,打造更优、更专业高效的数据库服务,加速企业数字化转型,创造数据库新未来!【GaussDB技术专场预告】10月19日下午和20日上午还有华为云GaussDB金融核心业务去“O”实践介绍,以及GaussDB NoSQL技术演进内容分享,精彩依旧,干货满满,千万不要错过啦!
10月18日,以“数造未来”为主题的第12届中国数据库技术大会(DTCC2021)在北京举办,华为云数据库CTO庄乾锋携华为云数据库多位技术专家和优秀合作伙伴共同参会并发表了重要主题演讲,分享了GaussDB立足数据库6项基础研究,持续打造根技术,加速数字技术与业务的进一步融合创新。华为云数据库CTO庄乾锋现场发表演讲 在上午的大会主会场,华为云数据库首席架构师冯柯表示:“数字化转型已从'以资源为中心'转换成'以应用为中心',数字化转型进入新阶段。华为云GaussDB将深耕数字化下半场,坚持在金融级高可用、云栈垂直整合、密态数据库等6大基础研究上投入,打造根技术竞争力。同时将产品能力应用到更多商业实践,为客户提供更多高效可用的解决方案,做企业核心数据上云信赖之选。” 华为云GaussDB紧随时代发展潮流,紧密结合客户业务场景,不断进行自主创新,积极打造极致性能、高可用的数据库服务。华为云数据库CTO庄乾锋表示:“基于客户业务需求,华为云GaussDB在云原生多主、基于Memory Pool的HTAP、云原生Serverless、AI自治、全密态数据库等方面进行了巨大创新,同时还联合梦饷、消费者云、迪思杰等合作伙伴联合创新,打造更多、更优的数据库服务能力,满足客户多种复杂场景需求。” 华为云GaussDB立足云原生,提升高可用能力 云原生在互联网领域逐渐成为主流,越来越多的互联网应用基于云原生架构运行。华为云数据库技术专家彭立勋介绍到:华为云GaussDB面向互联网云原生场景,构建了自己独特的云原生能力,以高可用为例,GaussDB致力于向全场景透明应用连续性方向持续演进,提供最佳的云原生数据库体验。 云原生高可用能力可以让企业摆脱扩展难、稳定性差等痛点,让企业更聚焦业务价值创造,实现业务新一轮发展。厚仁科技技术研发部副部长杨喜帅表示:“厚仁科技在线教育平台基于GaussDB提供的高可用、高性能、易扩展、低时延等能力,流量暴涨下平台依旧稳定,在线服务提供更及时,用户体验更佳。” 华为云GaussDB存储引擎创新,探索更高可用方案 高可用作为数据库根技术之一,影响着企业业务的持续稳定运行,对业务发展至关重要。华为GaussDB技术专家王磊表示:“GaussDB通过将磁盘引擎和内存引擎结合,提供了高性能/高扩展的并发控制事务系统、高可靠/高可用的日志系统、灵活的表级存储格式/引擎、统一的行存访存接口等能力,面对大容量、追求极致性能的业务场景表现更优。” 当前该能力已在部分行业落地实践,华为消费者云数据库技术专家张中靖表示:“消费者云服务业务覆盖全球180+国家/地区、亿级终端用户,需要具备高性能、高可靠、 大容量的分布式数据存储服务。消费者云服务基于华为云GaussDB分布式数据库技术构建了单集群PB级、万亿记录、跨AZ高可用的扩展能力,实现简化业务开发、快速构筑开发者生态。” 华为云生态工具革新,为企业提供更快上云方式 近年来,去“O”的呼声越来越大,大量的传统企业开始脱离“IOE”集中式架构,进行分布式改造,迈向云端。华为云数据库技术专家窦德明表示:“针对去‘O’,华为云GaussDB推出了数据复制服务DRS+数据库和应用迁移UGO专属解决方案,提供简单易用、高效可靠的迁移服务。目前该方案已在某金融头部企业中实施,并经受住海量存储过程改造、TB级数据在线迁移等业务实践考验。而作为语法转换利器的UGO,目前也开始正式商用了。” 作为华为优秀生态合作伙伴和数字服务提供商,迪思杰在信息化创新、数字化转型的大背景下,对数据管理技术和产品进行了多方位革新。迪思杰副总裁王浩表示:“迪思杰打造了全套数据生命周期管理解决方案,还联合华为推出了面向GaussDB的数据生态产品和解决方案,以及面向华为云的数据**系列产品和解决方案,积极构建国产数据库生态,共创数字化繁荣。” 数字化创新之路还在继续,华为云GaussDB会继续携手更多合作伙伴,打造更优、更专业高效的数据库服务,加速企业数字化转型,创造数据库新未来!【GaussDB技术专场预告】10月19日下午和20日上午还有华为云GaussDB金融核心业务去“O”实践介绍,以及GaussDB NoSQL技术演进内容分享,精彩依旧,干货满满,千万不要错过啦! -
【功能模块】华为视频分析平台-数据订阅并获取连接-callback模式【操作步骤&问题现象】1、使用postman调用vcm接口可以成功,但使用roma API网关-API测试-数据订阅并获取连接 返回 master callbackUrl is invalid参数信息:{ "request":{ "callbackUrl":{ "master":"http://106.75.66.197:12312", "authMode":"0" }, "suspectId":"61403bf55514004500efc404,6123580333173033473c55fe" }}【截图信息】
-
业务容灾项目:源端业务故障后,容灾切换到华为云灾备端,源端业务恢复,再切回,这样的业务过程中,使用的是华为云DRS同步数据库,问题:源端恢复后,切回时 DRS的主备倒换可以实现吗?需要做反向同步数据的。
-
## 1 TiDB Binlog TiDB binlog为PingCap自定义格式的日志,非MySQL官方标准binlog。(参考官网文档https://docs.pingcap.com/zh/tidb/v3.0/binlog-consumer-client ) 目前Drainer提供了很多输出方式,通过对drainer进行配置实现日志直接回放到目标库(MySQL、TiDB)以及日志落盘(File)的功能,此外为了满足部分用户自定义需求,增加输出到kafka的功能,将TiDB日志以ProtoBuf定义数据结构输出到消息队列中,让用户业务端自行消费。官方提供了标准的binlog.proto文件,用户可以在自己的代码工程中通过proto官方工具生成解析代码,便于使用。执行以下操作自动生成代码: protoc.exe --java_out=.binlog.proto ## 2 TiDB Binlog组件 TiDB binlog组件提供类似MySQL主从复制功能,其主要由PD(pump client)、pump 集群、drainer功能模块构成。参考官方文档:https://pingcap.com/blog-cn/tidb-ecosystem-tools-1/  TiDB Server:每个事务的写入伴随着prewrite binlog以及commit binlog/rollback binlog,从而实现2pc算法。其中主要将commit_ts作为后续事务整合排序的关键,由PD模块统一申请生成。 Pump Client:维护Pump集群信息,通过心跳机制对pump节点探活,binlog写请求分发中心,通过range、hash(start_ts)、score等路由策略将请求分到每个active pump中。其中还要遵循Commit binlog必须发送到它对应prewrite binlog的Pump原则。 Pump:处理来自pump client的请求,并且负责binlog的存储。Binlog数据顺序写入数据文件,同时通过内置leveldb保存binlog的元信息(ts、类型、长度、保存文件及文件中位置)。 Drainer:TiDB通过Drainer组件来实现binlog对外输出,目前支持:kafka(消息队列)、文件(增量备份文件方式)、下游目标数据库(MySQL系列)。该组件收集所有pump的binlog数据,根据其commit_ts进行归并排序,然后下发给下游。TiDB binlog和MySQL binlog一样,DML操作日志本身不包含表结构信息,Drainer通过在内存中构建表结构快照,ddl的时候就回放,dml的时候就根据当前快照生成SQL。Drainer在下游回放SQL的时候,采用多协程的方式提高效率,并引入数据冲突检测机制,保证数据一致性。 ## 3 tidb本地单机版(开启binlog)环境搭建 单机部署环境环境:Linux(随便购买一台ecs)+ mysql客户端 官方参考手册 https://docs.pingcap.com/zh/tidb/dev/get-started-with-tidb-binlog 1、下载 ``` wget http://download.pingcap.org/tidb-latest-linux-amd64.tar.gz ``` 2、解压 tar -xzf tidb-latest-linux-amd64.tar.gz ``` cd tidb-latest-linux-amd64/ ``` 3、./bin/pd-server --config=pd.toml &>pd.out & ``` //【pd.toml】 log-file="/data/tidb/logs/pd.log" data-dir="/data/tidb/pd.data" ``` 4、./bin/tikv-server --config=tikv.toml &>tikv.out & ``` //【tikv.toml】 log-file="/data/tidb/logs/tikv.log" [storage] data-dir="/data/tidb/tikv.data" [pd] endpoints=["127.0.0.1:2379"] [rocksdb] max-open-files=1024 [raftdb] max-open-files=1024 ``` 5、./bin/pump --config=pump.toml &>pump.out & ``` //【pump.toml】 log-file="/data/tidb/logs/pump.log" data-dir="/data/tidb/pump.data" addr="127.0.0.1:8250" advertise-addr="127.0.0.1:8250" pd-urls="http://127.0.0.1:2379" ``` 6、sleep 3 && ./bin/tidb-server --config=tidb.toml &>tidb.out & ``` //【tidb.toml】 store="tikv" path="127.0.0.1:2379" [log.file] filename="/data/tidb/logs/tidb.log" [binlog] enable=true ``` 7、./bin/drainer --config=drainer.toml &>drainer.out &(配置kafka的下游端) ``` //【drainer.toml】 log-file="/data/tidb/logs/drainer.log" [syncer] db-type="kafka" [syncer.to] zookeeper-addrs = "10.154.218.217:2181" kafka-addrs = "10.154.218.217:9092" kafka-version = "1.1.0" kafka-max-messages = 1024 topic-name = "zlz" ``` ## 4 TiDB解析demo 1、Main方法:  2、Kafka解析成Binlog对象:  3、proto解析结果:  4、commit_ts是由PD根据物理时间和逻辑时间生成而来,根据其获取正确的timestamp,后续可以根据这个值去做实时增量同步时延。根据源码go语言用java实现。参考源码:https://github.com/tikv/pd/blob/04ff28f436debac2c5655238b3189af0407145c8/pkg/tsoutil/tso.go#L28  ## 5 参考链接 https://pingcap.com/blog-cn/tidb-ecosystem-tools-1/#TiDB-Binlog-%e6%ba%90%e7%a0%81%e9%98%85%e8%af%bb
-
##一、kafka简单介绍 kafka大家的第一印象是一个消息系统。但是kafka的官网的说法是: ## Apache Kafka® is a distributed streaming platform ##### kafka是一个分布式流处理平台,而流处理平台主要具备以下三种能力: 1.发布和订阅消息流,类似于消息队列或企业消息传递系统。 2.以容错的持久化方式储存消息流。 3.可以在产生消息流的时候,同时进行处理。 ##### 而kafka具备以下几个特性: 1.kafka作为一个集群可以运行在一个或者多个服务器上,这些服务器可以跨多个数据中心。 2.kafka集群存储的消息是按照topic(主题)进行分类的。 3.每个消息(也被称为记录)是由一个key,一个value和一个时间戳构成。 ##### kafka对外提供了四种核心API: 1.Producer API,允许应用程序发布消息到kafka集群上的1个或多个的topic。 2.Consumer API,允许应用程序订阅一个或多个topic,并处理这些topic的消息。 3.Streams API,允许应用程序充当一个流处理器,从1个或多个topic消费输入流,并产生一个输出流到1个或多个输出topic,有效地将输入流转换到输出流。 4.Connector API,允许构建运行可重复使用的生产者或消费者,将topic和现有的应用程序或数据系统连接起来。例如,一个关系型数据库的连接器可以捕获到该库下每一个表的变化。  ##二、Producer发送数据到kafka的流程 DRS同步到kafka:DRS作为kafka的客户端,利用kafka的Producer API;将源端数据库产生的增量数据写入到目标kafka的topic上。 ##### 以mysql到kafka为例,大致流程入下: 1.将源端mysql的binlog日志记录的增量数据作为消息封装成一个Record。 2.经过拦截器,对消息进行过滤。 3.经过序列化器,将消息的key和value进行序列化,当然可以自行定义序列化规则或者自行编写序列化器。 4.消息经过分区器,确定这条消息需要发送到目标topic的分区号。如果在消息里面指定了partion字段,那么就是将消息发送到指定分区。 5.之后消息会封装从成一个一个批次汇总到RecordAccumulator。accumulator可以作为一个缓存,是kafka强大的写入性能原因之一。 6.之后会依赖一个后台唤醒的Sender线程,将数据有序的发送到leader partition所在的broker(kafka集群的每一个服务器都是一个broker)中。 7.在发送消息的过程中,kafka客户端可以从任意一个broker获取到kafka集群的metadata信息,metadata信息里面记录了kafka集群的每个topic的所有partition的信息: leader, fellow, isr, replicas等。 整体的流程如下图所示  ## 三、Producer两个重要参数 1.acks决定了生产者如何在性能与数据可靠之间做取舍,官方源码中描述如下: ``` public static final String ACKS_CONFIG = "acks"; private static final String ACKS_DOC = "The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the " + " durability of records that are sent. The following settings are allowed: " + "" + "acks=0 If set to zero then the producer will not wait for any acknowledgment from the" + " server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be" + " made that the server has received the record in this case, and the retries configuration will not" + " take effect (as the client won't generally know of any failures). The offset given back for each record will" + " always be set to -1." + "acks=1 This will mean the leader will write the record to its local log but will respond" + " without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after" + " acknowledging the record but before the followers have replicated it then the record will be lost." + "acks=all This means the leader will wait for the full set of in-sync replicas to" + " acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica" + " remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting." + ""; ``` 对于kafka来说,消息日志是按照topic分类存储的,而对于一个topic来说有partitons分区数,replication-factor副本数。 对于一个topic而言有多个分区,一个分又可以有多个副本。这些副本中,只有一个leader partition。其他都是follower partiton,仅有leader partition可以对外提供服务,follower partiton主要用于冗余备份。 而副本是存放在不同的broker上面的,因此在创建topic的时候,副本数不能大于broker的节点数的。 而acks参数呢,就是和副本有关系。 ``` acks=0:这意味着producer发送数据后,不会等待broker确认,直接发送下一条数据,性能最好 acks=1:为1意味着producer发送数据后,需要等待leader副本确认接收后,才会发送下一条数据,性能次之 acks=-1/all:这个代表的是all,意味着发送的消息写入leader partition后,等到follower从leader拉取到消息后,才会发送下一条数据,性能最差,但可靠性最强 ``` 而DRS以可靠性优先,因此设置的acks参数值为all,确保消息写入到所有可用副本后,才进行下一条写入。 2.max.in.flight.requests.per.connection,官方源码描述如下: ``` public static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION = "max.in.flight.requests.per.connection"; private static final String MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION_DOC = "The maximum number of unacknowledged requests the client will send on a single connection before blocking." + " Note that if this setting is set to be greater than 1 and there are failed sends, there is a risk of" + " message re-ordering due to retries (i.e., if retries are enabled)."; ``` ``` // 在InFlightRequests.java中 /** * Can we send more requests to this node? * * @param node Node in question * @return true iff we have no requests still being sent to the given node */ public boolean canSendMore(String node) { Deque queue = requests.get(node); return queue == null || queue.isEmpty() || (queue.peekFirst().send.completed() && queue.size() this.maxInFlightRequestsPerConnection); } ``` ``` // 在Sender.java中 if (guaranteeMessageOrder) { // Mute all the partitions drained for (List batchList : batches.values()) { for (ProducerBatch batch : batchList) this.accumulator.mutePartition(batch.topicPartition); } } ``` max.in.flight.requests.per.connection表示在单个连接中,最多可以忍受多少个请求处于发送中没有没有响应。kafka源码中这个参数默认是5,可以认为,在一个连接中有5个请求发送出去了,并且Producer都没有收到broker的响应。 如果这个参数大于1,由于有重试机制,可能会存在消息顺序错乱的风险。 如下图,在一个网络连接中将batch封装成不同的request,从batch队列中取出数据,按照顺序封装成不同的request(请求1... 请求5).  如果broker在处理请求2时因为borker节点不可以等因素导致写消息到partition异常了,但是其它请求的数据都正常写入了。此时由于重试机制,Producer会将请求2重新发送。 导致broker写入到leader partition消息顺序错乱。  而DRS为了保证数据写入到kafka是有序的,max.in.flight.requests.per.connection参数设置为1,但是这样降低了kafka的吞吐量。
-
如今,业务上云已是时代潮流,技术的迅猛发展也使得上云变得愈发轻松起来。但在实际迁移过程中,客户仍会担心以下问题:不同数据库之间能迁吗?迁移前后数据不一致怎么办?可以不停机迁移吗……迁移毕竟是项大工程,客户谨慎些也是情有可原,但只要选对迁移工具,这些困扰就都不是问题了。华为云推出的数据复制服务DRS是一款致力于提供数据库零停机迁移和实时同步的云服务,支持同构异构数据库、分布式数据库、分片式数据库之间的迁移,实现数据库到数据库、数仓、大数据的数据集成与数据秒级传输,为企业数据贯穿和数字化转型打下坚实的第一步。经过多年技术深耕,华为云DRS已构建了完整的数据库商用链路,目前共支持60+条数据传输链路,包括20条实时迁移链路,31条实时同步链路,7条实时灾备链路,1条数据订阅链路,2条备份迁移链路。无论是云上、云下数据库,还是其它云数据库、自建数据库,以及各种版本数据库,华为云DRS都能轻松hold 住!目前这些链路已全部开放商用,欢迎各位前往华为云官网体验>>https://www.huaweicloud.com/product/drs.html此外,华为云DRS目前已在全球2000+企业规模商用,足迹遍布金融、政府、电信、互联网等行业,拥有广泛的客户应用实践基础,历经千行百业锤炼,轻松解决各种迁移难题,让您数据上云不犯难!
-
【功能模块】华为AICC_CMS模块局点:长沙银行AICC解决方案:AICC 8.14.0CTI :V300R008C22SPC001【操作步骤&问题现象】问题现象1:CMS配置台中虚拟VDN数据同步失败(之前遇到过几次),后面都是通过手动清理Mysql脏数据解决。请问这个问题什么时候可以完全处理?马上要上生产了时间紧迫。问题现象2:开发那边调取CMS接口,第一次调取成功,第二次调取返回send bms request fail ,二种结果轮询; 我们现场没有部署CC-BMS,是需要部署CC-BMS吗,还是哪里的参数需要调下?【截图信息】【日志信息】(可选,上传日志内容或者附件)附件为aicclog日志和cms接口调取失败截图
-
1.背景介绍随着GaussDB数据库的不断发展,越来越多的客户开始选择使用GaussDB,其中很大一部分客户是将现有的系统替换到GaussDB上,客户当前所用的数据库类型多种多样,如Oracle、MySQL、PostgreSQL等。那么如何解决将客户当前数据库迁移到GaussDB上是一个很迫切的需求。GaussDB自带的GDS数据迁移工具实现了GaussDB之间的高效数据迁移,但是无法解决异构同步和实时同步的场景。华为云数据库迁移工具DRS以一种易用、稳定、高效的云服务为GaussDB提供了异构迁移和实时同步的能力,助力客户轻松将数据库迁移到GaussDB。2.数据库迁移整体解决方案数据库迁移的目的是为了业务迁移,而业务能否顺利切换取决于数据库的迁移能力和迁移后的准确性,站在业务侧的角度,至少要满足以下三个正确性才能够去做业务的切换。对象迁移是正确的数据库的存储过程、函数、触发器、表结构、索引等全部数据库对象能够完整的迁移到目标库,并且能够保证对象的运行逻辑和源库是一致的。数据迁移是正确的将源库的全量数据迁移到目标库,当业务对停机时间窗口有要求的时候,要考虑全量+增量的在线迁移,保证业务不中断。同时要能够对同步的数据进行校验,保证迁移数据的准确性。迁移后业务运行是正确的当对象和数据都迁移到目标库后,业务的切换还存在两个风险点,一个是业务在目标库的运行结果是否正确,另一个是目标库性能能否和源库一样支撑住业务的负载。因为异构数据库之间的差异还是很大的,设计理念和实现方式存在很多不同,会导致看上去类似的两个对象,其运行结果或效率是完全不同的。所以要有工具来验证这种差异,保证迁移后业务运行的正确性。为了实现以上业务切换需要满足的条件,华为云提供了数据库迁移的整体解决方案,通过语法迁移(UGO),DRS-数据迁移,DRS-数据校验和DRS-流量回放4个工具产品形成了整个迁移过程的闭环。语法迁移(UGO)实现了将oracle数据库对象迁移到GaussDB的能力,可以给出完整的迁移评估报告,哪些对象可以完全兼容的进行迁移,哪些对象需要进行转换进行迁移,哪些对象需要业务配合改造。DRS-数据迁移实现将Oracle、MySQL、PostgreSQL等数据库数据实时迁移到GaussDB的能力。DRS-数据校验实现了对数据迁移后的一致性校验,具备行级比对、内容级比对和实时的增量数据比对的能力。DRS-流量回放实现对Oracle数据库的业务流量抓取,并对流量SQL进行转换,然后在GaussDB进行回放的能力。3.DRS数据迁移上云DRS提供了简单、易用的操作界面,采用流程化的配置方式,客户按照提示步骤一步一步操作便可以搭建出同步链路。DRS除了支持Oracle到GaussDB的数据迁移外,还支持其他数据库之间的数据同步,下面给出了当前DRS所支持的源库和目标库类型的列表。在数据迁移过程中,DRS采用很多手段和技术去降低可能存在的风险,保证迁移过程的稳定和最终数据的一致性。在线迁移DRS通过全量迁移将客户数据库中的存量数据迁移到GaussDB中,通过增量同步,实时解析源库日志,将客户的实时变化数据同步到GaussDB,通过全量和增量的无缝衔接来保证客户在不中断业务的情况下,完整地将全部数据迁移到GaussDB。预校验在DRS的迁移任务启动之前,为提早发现迁移启动后可能存在的风险或错误,DRS引入预校验环节,能够提前对配置信息、数据库兼容性信息、连通性信息等进行校验,同时会对一些可以迁移成功但可能会对业务产生影响的情况进行告警,让客户及时发现并提前处理。断点机制为保证数据迁移的一致性,DRS在每个组件中都设有断点机制,无论是在正常启停、异常重启还是在故障切换的场景下都可以保证数据同步的准确性,不会造成数据丢失。4.DRS技术实现原理DRS在技术实现上主要分为两个大的模块,一个是全量的数据同步,另一个是增量数据同步。全量同步解决对静态数据的迁移,增量同步解决对实时的变化数据迁移。全量同步的技术架构全量同步的整体逻辑比较简单,就是从源库把数据通过select的方式查询出来,然后再将这些数据写入到目标库,只是在具体的代码实现上会有一些关键技术点。数据分片一般全量同步产品的同步粒度都可以达到表级别的并发,即多个线程可以同时对多张表同时进行同步,但往往客户的系统中会存在单表数据量特别大的情况,比如一张表几十亿甚至上百亿的数据,此时这张表的同步时间就变为整个全量同步的时间。那么如何进一步提升单张表的同步效率呢?我们可以对单表做进一步的拆分,按照主键去把它拆分成多个分片,多线程以分片为单位做并行的同步。当前DRS按照下面的策略对表进行分片: · 无主键表不进行分片 · 分区表按分区进行同步,不再对每个分区进行分片 · 有主键表按主键(第一列)进行分片数据不落盘为减少全量同步过程中对磁盘的占用,DRS导出的数据不进行落盘缓存,而是直接通过内存传递给导入线程,在导出和导入速率相当的情况下,可以最大化的提高全量同步的效率。断点控制全量同步半途中断是一个非常让人棘手的问题,可能一张2亿条数据的表,在同步到1.8亿的时候因为网络或源库快照过旧的问题导致同步失败,如果没有好的断点控制机制,那可能之前的付出都白白浪费,还要重新再次同步一次。DRS通过以分片为单位做为断点的保存记录,对于上面的例子,即使同步中断,也可以再次被拉起,而且拉起后,已经同步成功的分片将不再同步,还没有同步的分片则会继续同步。流量控制客户的业务往往是存在高峰期和低峰期,高峰期时,数据库的资源占用是最高的,我们要尽量避开在业务高峰期做全量的同步,因为全量同步对源库的cpu、内存和网络资源占用是很大的。DRS采用流量控制的机制来减少业务高峰期对源库的资源占用,主要是通过控制网络流量的方式,客户可以设置要进行流量控制的时间段,DRS在全量同步过程中,会实时计算同步的流量大小,运行到该时段后,当流量超过设置的阈值,会放缓数据获取的速度。运行过该时段后,便恢复全部的数据同步速度。全量+增量的无缝衔接在业务切库的场景中,数据的迁移过程一般可以选择两种方案,一种是一次性将源库的数据迁移到目标库,但是需要业务停机窗口,这个窗口的大小取决于全量数据迁移的时间。当数据量较大时,整个迁移过程可能需要几天的时间,这种业务停机是无法接受的。所以另一种方案就是业务不中断的数据迁移方案,它的实现原理就是基于全量迁移和增量同步的无缝衔接,对于Oracle->GaussDB的迁移,Oracle数据库提供了指定scn进行快照导出的功能,基于这个特性,DRS在做全量同步时,指定scn进行导出,这样整个全量同步的数据就是此scn点前的快照数据,然后增量同步以这个scn点作为同步的分界点,只有大于这个scn的增量事务才会被同步到目标库。这样就实现了全量和增量的无缝衔接,同步过程无需业务进行停机,当全量数据同步完成且增量同步追赶到当前时间点时,便可进行业务切换,业务中断窗口可以控制在秒级。增量同步的技术架构DRS的增量同步架构主要分为3个部分,分别是数据抓取、落盘文件和数据回放。数据抓取数据抓取通过对源库日志的解析,实时获取源库的变化数据,在内部实现上主要包括日志拉取、日志解析、事务整合和数据落盘几个步骤。 · 日志拉取DRS采用Oracle的Logminer接口获取实时的redo日志,当redo归档后,DRS会读取归档日志文件。为了防止源库的归档日志被不确定性删除,DRS会启动日志拉取的线程(可以多线程并发)把日志拉取到本地,然后进行后续的解析。 · 日志解析Oracle Logminer接口获取到的数据需要进一步解析才能获取到实际的变化内容,DRS的日志解析线程对返回的数据进行过滤、拼接、元数据映射、转换等操作形成一条完整的变更记录对象。 · 事务整合日志解析是按照源库变化数据的顺序进行解析,解析后的每条记录的事务是交叉混合在一起的,必须对每条记录按照事务id进行整合才能形成一个完整的事务。另一方面对于Oracle RAC的场景,还需要对不同节点的事务进行排序,避免事务乱序的情况发生。落盘文件经过了事务整合后,形成了一个按照源库业务提交顺序的序列,DRS会按照这个顺序把这些数据写入到磁盘文件。落盘的数据包含了源库每一条变化数据的全部信息,包含表信息、列信息、事务信息、数据信息和其他额外信息(如时间戳、rowid等),根据这些信息后面的组件便可以把每一条变化数据还原成对象的SQL。数据回放数据回放就是将数据抓取到的数据在目标库进行执行的过程,但它和数据的抓取是解耦的。它读取DRS的落盘文件,解析出每条变化的数据,根据文件中记录的元数据信息重构出对应的SQL语句,在目标库执行。在数据回放之前,DRS提供了过滤和转换的功能,可以对同步的数据进行过滤,可配置过滤条件,如只同步id < 10000的数据,也可以对同步数据的表名、schema名或列名进行映射等。异常处理和回放性能是两个重要的考量点,DRS通过配置数据冲突策略来处理回放中的异常数据,通过并发机制来提高装载的性能。 · 冲突策略所谓的冲突是指在数据回放的时候出现了数据类报错(如主键冲突、update和delete无法找到记录等),这些报错一版都是由于两边的数据不一致造成的。DRS对这类错误采用了三种处理策略,分别是覆盖、忽略和等待。覆盖:当出现冲突时,用抓取到的数据覆盖掉目标库的数据忽略:数据冲突后,直接跳过错误记录,继续执行等待:数据冲突后,等待人工处理 · 并发机制DRS的并发机制采用记录级别的并发,最大化的提升数据装载的性能。 首先从DRS的落盘文件中读取增量数据,按顺序放入一个队列中,并行分析引擎会从队列中获取每一条数据,并根据其主键信息判断是否存在数据冲突,对于没有冲突的数据说明可以并行去执行,则把这些数据分散到多个线程队列中,当线程队列中的数据量达到设定的阈值时,这批数据会作为一个事务在目标库执行。对于有冲突的数据,则把这条数据放到冲突队列,等待线程把上一批数据执行完成后,再次进入并行分析引擎判断是否存在冲突。Ps:该内容根据《GaussDB数据迁移之DRS》技术直播整理完成,错过直播的小伙伴们,欢迎点击链接回顾精彩内容哦~cid:link_0
-
 数据库复制迁移时,源库测试连接不通过,先咳咳服务器的安全组,检查服务器的端口是否打开了,我这里简单粗暴点,直接开放所有端口
数据库复制迁移时,源库测试连接不通过,先咳咳服务器的安全组,检查服务器的端口是否打开了,我这里简单粗暴点,直接开放所有端口 -
【功能模块】先施资产轨迹变更数据同步到园区平台【操作步骤&问题现象】1、先施通过直接接入roma推送同步消息,接入roma时需要服务地址serverUrl 、客户端名称clientName、客户端密码clientPassword,这些参数该怎么获取【截图信息】【日志信息】(可选,上传日志内容或者附件) 发帖人:dubin 邮箱:dubin@chinasofti.com 电话:18182698675
-
数字化时代,数据成为新的生产资料,在经济文化生活中扮演着越来越重要的角色。买票你需要查询各种票务信息,网购你需要搜索商品和服务,出行你需要精准定位,这些动作背后都隐藏着大量的数据信息,如何利用好这些信息成为企业数字化转型的一道关卡。这道关卡难在:数据量大且复杂,如何进行存储和管理?数据孤岛严重,如何实现互联互通?关于这个难题,华为云数据复制服务DRS(一款用于数据库在线迁移和数据库实时同步的云服务,以下简称华为云DRS)有话要说:其实不同服务间的数据互通并没有那么难,关键是要选对方法,不信?请看一汽红旗是如何轻松应对的。“红旗”是中国第一汽车集团有限公司旗下自主高端汽车品牌(以下简称一汽红旗),自2018年发布新红旗品牌战略以来,一汽红旗积极拥抱云服务,对核心生产系统ERP进行微服务改造,并通过华为云DRS将源数据库同步迁移到GaussDB数据库,以此加强各微服务之间数据的联动性,加快数据流通。ERP系统属于车企最核心的生产业务系统,对数据的可用性、可靠性、连续性要求极高,数据在同步过程中面临一定的挑战:减少对源库的影响:一汽红旗整体数据量有8TB,表数据2万+,为避免源库业务中断,希望在同步过程中对源库的影响降到最低。极致可靠性:ERP业务系统不能接受数据同步过程中丢失,任务故障恢复需要达到分钟级,可靠性和可用性是核心诉求。连续性:新老系统长时间并存,新系统各个微服务数据形成了孤岛,同时需要对新老系统部分数据进行回流,实现数据的实时同步。消除数据孤岛,华为云DRS让数据活起来数据同步关系到客户业务系统数据的一致性、准确性、安全合规等问题,没有它,企业各方面会充满延误、错误、沟通不畅和不可避免的利润损失,因此必须确保所有数据始终保持一致。一汽红旗为加强各个微服务之间的联动性,消除ERP系统数据孤岛,携手华为云数据库团队联合制定高效、强一致的数据同步方案,通过华为云DRS提供的数据实时同步能力,实现了一汽红旗各业务之间数据的高效联动。动态增减同步对象:一汽红旗ERP系统涉及BOM管理中心、OTD名单中心、需求管理中心等多项业务,业务改造需要分批进行。华为云DRS支持实时同步过程中,通过编辑同步对象随时增加或减少某个业务所需要同步的对象,避免在源库创建过多的数据同步任务,减少对源库的压力和原生产环境的影响。故障闪恢复:ERP系统关系到整个车企的生产状况,如果同步任务出现故障会影响生产。为避免数据同步任务中出现故障并不可恢复情况,华为云DRS提供了分钟级重置的功能,及时恢复同步任务,把对生产环境的影响降到了最低。数据错开同步:ERP系统涉及多项业务,而且各子业务重要性不同,如BOM管理中心业务比其他业务模块相对重要,为了减少对核心BOM业务的影响,华为云DRS支持核心数据和非关键数据分开同步,增强了整个系统的可靠性和可用性。华为云DRS解决了一汽红旗新老ERP业务之间、各个微服务之间的数据孤岛问题,充分调动了各服务之间的联动性,让原先孤立的数据活了起来。同时提供数据比对功能,直观展示同步过程中源库和目标库的数据一致性情况,极大保障了客户的可持续发展。未来,依托华为云GaussDB数据库和DRS能力,一汽红旗会持续构建稳定可靠、极致性能的数据服务平台,构建闭环OTD模式,实现精细化管理,打造一体化、智能化的产销体系,满足不断增长的客户定制化需求。 Ps:华为云数据库搬迁上云专场,云数据库买8个月送4个月,助力企业无忧上云!戳此享优惠>>https://activity.huaweicloud.com/dbs_Promotion/index.html
-
 【摘要】 GaussDB(DWS)的DN高可用架构为主、备、从备架构。通过各组件的主备的数据同步、倒换、重建等机制,保证数据库单实例遭遇Crash后,具备故障恢复及自愈的能力,这些过程有可能会时间花费较长,一旦同步过程中出现异常问题,其内部关键过程信息输出对于问题分析定位十分重要。因此,GaussDB(DWS)提供了丰富的系统函数、视图、工具等可以直观地对同步进度进行跟踪。1 背景概述:1.1DN高可用架构模型要理解或描述数据同步的过程机制,需要首先要了解GaussDB(DWS)的DN高可用架构,理解涉及数据同步的各组件的关系、数据类型、数据流向、设计原理和目的。GaussDB(DWS)的DN高可用架构为主、备、从备架构。即在分布式环境中,完整的集群数据采用分片技术分布在多个DN组上,每组DN承担一个数据分片,包括:一个主DN、一个备DN和一个从备DN。主和备各有一份完整的数据,从备上一般不存储数据,仅在备机故障时做数据的暂存。组件之间关系如图1所示:图1 DN高可用架构关系图 主、备、从备高可用架构下,主、备及主、从备之间均会建立流复制通道。流复制又分为日志复制和数据页复制。日志复制用于同步主DN由于WAL机制刷到磁盘上的XLOG,同步到备DN进行回放。数据页复制用于同步批量导入的行存数据、或列存CU文件。需要注意的一点是,从备仅用于存放XLOG和数据,回放(replay)仅发生在备DN上。1.2 数据同步涵盖范围 数据同步就是涉及集群中主、备节点以及从备节点之间的日志复制数据的传输、回放,数据页复制数据的传输、追赶,备机重建等过程。GaussDB(DWS)集群高可用实践WAL(Write Ahead Logging)思想,并通过各组件的主备的数据同步、倒换、重建等机制,保证数据库单实例遭遇Crash后,具备故障恢复及自愈的能力,保护数据库中数据的可靠性和完整性,最终实现集群对外业务连续性的过程。这些主要的过程有:1. 主备之间的正常流复制每组DN独立承担一个数据分片,因此要求各个DN主与备必须强同步。为保证DN的主备强同步,数据在主DN操作时产生日志,事务提交时将日志同步给备DN。备机对接收到的XLOG进行回放(replay),将日志转为数据。另外,列存和行存批插场景下,备机正常时,新增(变更)数据会发往备机。使用数据页同步相对于日志同步少了磁盘IO,可以提升同步效率,减小RTO。2. 备机追赶为了解决单节点故障后集群写事务可用,DN的高可用设计引入从备这个实例。一旦备DN故障,数据将发送给从备,仍然保证了数据写两份的原则,事务照样可以提交。但主机会对BCM文件里面的标记位置状态位。BCM文件中每一bit位(除预留位外)对应数据文件中每一页(8k)状态。当备机重新启动的时候,会连接主机做数据页追赶(catchup)。追赶机制分为全量和增量两种。全量catchup机制,不依赖于从备,主机递归扫描本地默认表空间和自定义表空间下的所有BCM文件,然后查看状态位来确认哪些数据文件需要发送给备机。增量catchup机制依赖于从备,主机通知从备遍历其从备上暂存的数据页,将变更的数据页列表发往主机,主机直接按照从备发来的变更列表,将变更数据发往备机。3. 主备倒换当主DN故障时,需要对备DN进行failover,failover后备DN升为主DN来接管业务。所以failover时,备DN需要连接从备DN,向从备DN请求数据,以补齐备DN比主DN缺少的数据。failover的过程是备DN独立完成的,不需要和主DN进行交互。4. 备机重建重建功能主要目的是单点故障修复,备机重建方式按照实现分为全量重建和增量重建,均和主DN进行交互。全量重建是备机清空数据目录,保留配置文件,向主机发送全量重建请求,主机将自己的数据目录除了配置文件外,全部发给备机,重建后启动备机。增量重建是一种以主DN文件为基准,按照文件块对备DN文件进行校验,如果备DN文件的某个文件块校验不一致,则主机将此文件块发给备DN,写入文件对应的文件块中。与全量重建相比较,拷贝的数据量和WAL日志量都更少,代价更小。 从以上这些数据同步过程中,我们发现表现在运维上一个明显的特点是,这些过程有可能会时间花费较长,一旦同步过程中出现异常问题,其内部关键过程信息输出对于问题分析定位十分重要。因此,GaussDB(DWS)提供了丰富的系统函数、视图、工具等可以直观地对同步进度进行跟踪,尤其是为方便定位人员使用,gs_ctl工具已集合了大部分相关系统函数的调用,可做到在任何时间,从未启动、启动、重建到运行时的关键信息显示。2 方法总结 2.1 系统视图 总结涉及数据同步的系统视图如表1所示。具体参数、返回值定义请参考相应版本的产品文档手册。分类名称用途使用范围视图类pg_replication_slots显示当前DN上所有的复制槽信息主、备DN均可上执行pg_get_senders_catchup_time显示单个DN上当前活跃的主备发送线程的追赶信息。主DN上执行pg_stat_replication用于描述日志同步状态信息,如发起端发送日志位置,接收端接收日志位置等。主DN上执行表1 系统视图表2.2 系统函数总结涉及数据同步的系统函数如表2所示。具体参数、返回值定义请参考相应版本的产品文档手册。分类名称用途使用范围函数类pgxc_get_senders_catchup_time显示所有DN上当前活跃的主备发送线程的追赶信息。CN上执行pgxc_stat_get_wal_senders显示所有DN上所有的WAL复制发送线程的统计信息。CN上执行pgxc_stat_xlog_space显示所有主DN上XLOG空间使用信息CN上执行pg_stat_xlog_space显示当前DN上XLOG空间使用信息主、备DN均可上执行pg_stat_get_stream_replications显示当前DN上所有的复制统计信息。主、备DN均可上执行pg_get_replication_slots显示当前DN上所有的复制槽信息主DN上执行pg_stat_get_wal_senders显示当前DN上所有的WAL复制发送线程的统计信息。主DN上执行pg_stat_get_data_senders显示当前DN上所有的数据页复制发送线程的统计信息。主DN上执行pg_current_xlog_location获取当前事务日志的写入位置主DN上执行pg_current_xlog_insert_location获取当前事务日志buffer的插入位置主DN上执行pg_stat_get_wal_receiver显示当前DN上所有的WAL复制接收线程的统计信息。备DN上执行pg_is_in_recovery如果恢复仍然在进行中,则返回true备DN上执行pg_last_xlog_receive_location获取最后接收事务日志的位置并通过流媒体复制同步到磁盘。备DN上执行pg_last_xlog_replay_location获取最后一个事务日志在恢复时重放的位置。备DN上执行pg_last_xact_replay_timestamp获取最后一个事务在恢复时重放的时间戳。备DN上执行pg_xlogfile_name(location text)将事务日志的位置字符串转换为文件名。备DN上执行pg_xlogfile_name_offset(location text)将事务日志的位置字符串转换为文件名并返回在文件中的字节偏移量。备DN上执行pg_xlog_location_diff(location text, location text)计算两个事务日志位置之间在字节上的区别。备DN上执行pg_xlog_replay_completion显示当前DN XLOG redo的进度信息主、备DN均可上执行pg_data_sync_from_dummy_completion显示当前DN 数据页从dummystandby传输的进度信息备DN上执行表2 系统函数表2.3 常用工具 总结涉及数据同步的常用工具如表3所示。具体工具说明、参数定义请参考相应版本的产品文档手册中的定义。分类名称用途使用范围工具类cm_ctl操作、检查数据库集群的状态。任何节点上均可执行gs_ctl操作、检查管理节点的数据库实例状态。主、备DN上均可执行pg_xlogdump解析XLOG文件内容主、备DN上均可执行pg_controldata显示control file的所有信息主、备DN上均可执行表3 常用工具表3 应用场景3.1 查看DN实例Redo进度当DN实例crash发生时,我们可以通过回放XLOG日志中记录的数据变化还原crash前的操作。这个就是所谓的redo/recovery过程。如果需要redo的XLOG比较多,或者遇到某种特殊日志类型,对DN实例进行启动,启动过程时间就会有些长。DN实例启动过程中,如果期望查看XLOG redo的进度。最方便的是使用gs_ctl query工具对指定DN实例路径进行状态查询,结果中可以显示xlog redo的进度,如图2所示。此外,在DN实例可以接受gsql连接时(启动到最小恢复点之前是拒绝连接的),也可直接在当前DN上执行pg_xlog_replay_completion 函数来获取XLOG redo进度信息。图2 DN实例启动时XLOG Redo进度查询启动Redo进度相关信息(Xlog replay info)包括: replay_start:Xlog Redo的起始LSN 。DN实例启动XLOG redo过程时,记录replay_start。 replay_current:Xlog Redo的当前replay的LSN。 replay_end:DN本地接收到的最大XLOG lsn。 replay_percent:Xlog Redo的当前完成的百分比。(replay_current - replay_start)*100 / (replay_end - replay_start)的计算值。依据replay_current的变化,可以看到XLOG redo的推进。依据replay_percent和启动开始时间,可以推测DN实例启动到正常状态的所需时间。3.2 查看备机Failover进度 当主机发生故障时,我们需要将备机failover成主机,此时备机需要连接从备同步XLOG和数据页文件。如果需要同步的XLOG比较多,或者遇到某种特殊日志类型,或者数据文件比较多时,对备DN实例进行failover,过程时间就会有些长。备机failover升主过程中,如果期望查看XLOG redo和数据页文件同步的进度。最方便的是使用gs_ctl query工具对指定DN实例路径进行状态查询,结果中可以显示xlog redo的进度和从备数据同步的进度,如图3所示。此外,在DN实例可以接受gsql连接时,也可直接在当前DN上执行pg_data_sync_from_dummy_completion 函数来获取从备数据文件同步的进度信息。 图3 备机Failover进度查询Failover Redo进度相关信息(Xlog replay info),字段含义同Start Redo,区别在于,备DN在处理failover请求连接从备时候获取最新的replay lsn更新了replay_start。Failover数据页文件进度相关信息(Data sync from dummy)包括: start_index:数据页文件同步的起始编号。 current_index:数据页文件同步的当前编号。 total_index:数据页文件同步的最大编号。 sync_percent:数据页文件当前完成的百分比。(current_index - start_index) *100/ (total_index - start_index + 1) 的计算值。依据current_index的变化,可以看到数据页同步的推进。依据sync_percent和failover开始时间,可以推测DN实例failover到正常状态的所需时间。3.3 查看备机Catchup进度 当备机重新启动的时候,会连接主机做数据页追赶(catchup)。如果需要传输的数据页比较多,或者因为业务造成的锁冲突,catchup 时间就会比较长,备DN长时间不能成为Normal状态。如果期望查看数据页catchup的进度,可以在CN上执行select * from pgxc_get_senders_catchup_time()可进行当前活跃的主备发送线程的追赶信息显示,如图4所示。图4 集群上catchup进度查询也可以在相应的主DN上执行select * from pg_get_senders_catchup_time可进行当前活跃的主备发送线程的追赶信息显示。完成后,看到的是刚结束的catchup过程信息,如图5所示。图5 主DN上catchup进度查询备机Catchup进度相关信息包括: catchup_type:"Incremental"或者"Full"。catchup方式为全量还是增量。 catchup_bcm_filename:当前主机正在处理的一个BCM文件名称。 catchup_bcm_finished:catchup已操作完成的BCM文件数量。 catchup_bcm_total:catchup总共需要操作的BCM文件数量。 catchup_percent:catchup已经操作完成的百分。catchup_bcm_finished*100 / catchup_bcm_total 的计算值。 catchup_remaining_time:依据已完成的进度,预估剩余完成时间。依据catchup_bcm_filename和catchup_bcm_finished的变化,可以看到数据页追赶的推进。依据catchup_percent和catchup_remaining_time,可以推测备DN实例追赶到正常状态的所需时间。3.4 查看DN实例XLOG空间使用状况 随着数据库的不断运行,产生的日志文件越来越多,如果因为节点故障或其它原因有可能造成日志文件不断积累而充爆磁盘。为了解此使用信息,最方便的是使用gs_ctl query工具对指定DN实例路径进行状态查询,结果中可以显示该实例的XLOG空间使用信息,截图示例请参见上面其它场景。此外,还提供系统函数 pgxc_stat_xlog_space、pg_stat_xlog_space 对数据库集群或单个实例进行查询,例如使用pgxc_stat_xlog_space可以获取到整个集群的CN、主DN的XLOG空间使用信息,如图6所示。 图6 Xlog空间使用查询XLOG空间使用信息(Xlog space info)包括: xlog_files:pg_xlog目录下,去除backup、archive_status等子目录,所有识别为xlog文件的数目; xlog_size:pg_xlog目录下,去除backup、archive_status等子目录,所有识别为xlog文件的大小之和,以MB单位显示; other_size:pg_xlog目录下backup、archive_status等子目录文件的大小之和,以MB单位显示。原文链接:https://bbs.huaweicloud.com/blogs/198536【推荐阅读】【最新活动汇总】DWS活动火热进行中,互动好礼送不停(持续更新中) HOT 【博文汇总】GaussDB(DWS)博文汇总1,欢迎大家交流探讨~(持续更新中)【维护宝典汇总】GaussDB(DWS)维护宝典汇总贴1,欢迎大家交流探讨(持续更新中)【项目实践汇总】GaussDB(DWS)项目实践汇总贴,欢迎大家交流探讨(持续更新中)【DevRun直播汇总】GaussDB(DWS)黑科技直播汇总,欢迎大家交流学习(持续更新中)【培训视频汇总】GaussDB(DWS) 培训视频汇总,欢迎大家交流学习(持续更新中)扫码关注我哦,我在这里↓↓↓
【摘要】 GaussDB(DWS)的DN高可用架构为主、备、从备架构。通过各组件的主备的数据同步、倒换、重建等机制,保证数据库单实例遭遇Crash后,具备故障恢复及自愈的能力,这些过程有可能会时间花费较长,一旦同步过程中出现异常问题,其内部关键过程信息输出对于问题分析定位十分重要。因此,GaussDB(DWS)提供了丰富的系统函数、视图、工具等可以直观地对同步进度进行跟踪。1 背景概述:1.1DN高可用架构模型要理解或描述数据同步的过程机制,需要首先要了解GaussDB(DWS)的DN高可用架构,理解涉及数据同步的各组件的关系、数据类型、数据流向、设计原理和目的。GaussDB(DWS)的DN高可用架构为主、备、从备架构。即在分布式环境中,完整的集群数据采用分片技术分布在多个DN组上,每组DN承担一个数据分片,包括:一个主DN、一个备DN和一个从备DN。主和备各有一份完整的数据,从备上一般不存储数据,仅在备机故障时做数据的暂存。组件之间关系如图1所示:图1 DN高可用架构关系图 主、备、从备高可用架构下,主、备及主、从备之间均会建立流复制通道。流复制又分为日志复制和数据页复制。日志复制用于同步主DN由于WAL机制刷到磁盘上的XLOG,同步到备DN进行回放。数据页复制用于同步批量导入的行存数据、或列存CU文件。需要注意的一点是,从备仅用于存放XLOG和数据,回放(replay)仅发生在备DN上。1.2 数据同步涵盖范围 数据同步就是涉及集群中主、备节点以及从备节点之间的日志复制数据的传输、回放,数据页复制数据的传输、追赶,备机重建等过程。GaussDB(DWS)集群高可用实践WAL(Write Ahead Logging)思想,并通过各组件的主备的数据同步、倒换、重建等机制,保证数据库单实例遭遇Crash后,具备故障恢复及自愈的能力,保护数据库中数据的可靠性和完整性,最终实现集群对外业务连续性的过程。这些主要的过程有:1. 主备之间的正常流复制每组DN独立承担一个数据分片,因此要求各个DN主与备必须强同步。为保证DN的主备强同步,数据在主DN操作时产生日志,事务提交时将日志同步给备DN。备机对接收到的XLOG进行回放(replay),将日志转为数据。另外,列存和行存批插场景下,备机正常时,新增(变更)数据会发往备机。使用数据页同步相对于日志同步少了磁盘IO,可以提升同步效率,减小RTO。2. 备机追赶为了解决单节点故障后集群写事务可用,DN的高可用设计引入从备这个实例。一旦备DN故障,数据将发送给从备,仍然保证了数据写两份的原则,事务照样可以提交。但主机会对BCM文件里面的标记位置状态位。BCM文件中每一bit位(除预留位外)对应数据文件中每一页(8k)状态。当备机重新启动的时候,会连接主机做数据页追赶(catchup)。追赶机制分为全量和增量两种。全量catchup机制,不依赖于从备,主机递归扫描本地默认表空间和自定义表空间下的所有BCM文件,然后查看状态位来确认哪些数据文件需要发送给备机。增量catchup机制依赖于从备,主机通知从备遍历其从备上暂存的数据页,将变更的数据页列表发往主机,主机直接按照从备发来的变更列表,将变更数据发往备机。3. 主备倒换当主DN故障时,需要对备DN进行failover,failover后备DN升为主DN来接管业务。所以failover时,备DN需要连接从备DN,向从备DN请求数据,以补齐备DN比主DN缺少的数据。failover的过程是备DN独立完成的,不需要和主DN进行交互。4. 备机重建重建功能主要目的是单点故障修复,备机重建方式按照实现分为全量重建和增量重建,均和主DN进行交互。全量重建是备机清空数据目录,保留配置文件,向主机发送全量重建请求,主机将自己的数据目录除了配置文件外,全部发给备机,重建后启动备机。增量重建是一种以主DN文件为基准,按照文件块对备DN文件进行校验,如果备DN文件的某个文件块校验不一致,则主机将此文件块发给备DN,写入文件对应的文件块中。与全量重建相比较,拷贝的数据量和WAL日志量都更少,代价更小。 从以上这些数据同步过程中,我们发现表现在运维上一个明显的特点是,这些过程有可能会时间花费较长,一旦同步过程中出现异常问题,其内部关键过程信息输出对于问题分析定位十分重要。因此,GaussDB(DWS)提供了丰富的系统函数、视图、工具等可以直观地对同步进度进行跟踪,尤其是为方便定位人员使用,gs_ctl工具已集合了大部分相关系统函数的调用,可做到在任何时间,从未启动、启动、重建到运行时的关键信息显示。2 方法总结 2.1 系统视图 总结涉及数据同步的系统视图如表1所示。具体参数、返回值定义请参考相应版本的产品文档手册。分类名称用途使用范围视图类pg_replication_slots显示当前DN上所有的复制槽信息主、备DN均可上执行pg_get_senders_catchup_time显示单个DN上当前活跃的主备发送线程的追赶信息。主DN上执行pg_stat_replication用于描述日志同步状态信息,如发起端发送日志位置,接收端接收日志位置等。主DN上执行表1 系统视图表2.2 系统函数总结涉及数据同步的系统函数如表2所示。具体参数、返回值定义请参考相应版本的产品文档手册。分类名称用途使用范围函数类pgxc_get_senders_catchup_time显示所有DN上当前活跃的主备发送线程的追赶信息。CN上执行pgxc_stat_get_wal_senders显示所有DN上所有的WAL复制发送线程的统计信息。CN上执行pgxc_stat_xlog_space显示所有主DN上XLOG空间使用信息CN上执行pg_stat_xlog_space显示当前DN上XLOG空间使用信息主、备DN均可上执行pg_stat_get_stream_replications显示当前DN上所有的复制统计信息。主、备DN均可上执行pg_get_replication_slots显示当前DN上所有的复制槽信息主DN上执行pg_stat_get_wal_senders显示当前DN上所有的WAL复制发送线程的统计信息。主DN上执行pg_stat_get_data_senders显示当前DN上所有的数据页复制发送线程的统计信息。主DN上执行pg_current_xlog_location获取当前事务日志的写入位置主DN上执行pg_current_xlog_insert_location获取当前事务日志buffer的插入位置主DN上执行pg_stat_get_wal_receiver显示当前DN上所有的WAL复制接收线程的统计信息。备DN上执行pg_is_in_recovery如果恢复仍然在进行中,则返回true备DN上执行pg_last_xlog_receive_location获取最后接收事务日志的位置并通过流媒体复制同步到磁盘。备DN上执行pg_last_xlog_replay_location获取最后一个事务日志在恢复时重放的位置。备DN上执行pg_last_xact_replay_timestamp获取最后一个事务在恢复时重放的时间戳。备DN上执行pg_xlogfile_name(location text)将事务日志的位置字符串转换为文件名。备DN上执行pg_xlogfile_name_offset(location text)将事务日志的位置字符串转换为文件名并返回在文件中的字节偏移量。备DN上执行pg_xlog_location_diff(location text, location text)计算两个事务日志位置之间在字节上的区别。备DN上执行pg_xlog_replay_completion显示当前DN XLOG redo的进度信息主、备DN均可上执行pg_data_sync_from_dummy_completion显示当前DN 数据页从dummystandby传输的进度信息备DN上执行表2 系统函数表2.3 常用工具 总结涉及数据同步的常用工具如表3所示。具体工具说明、参数定义请参考相应版本的产品文档手册中的定义。分类名称用途使用范围工具类cm_ctl操作、检查数据库集群的状态。任何节点上均可执行gs_ctl操作、检查管理节点的数据库实例状态。主、备DN上均可执行pg_xlogdump解析XLOG文件内容主、备DN上均可执行pg_controldata显示control file的所有信息主、备DN上均可执行表3 常用工具表3 应用场景3.1 查看DN实例Redo进度当DN实例crash发生时,我们可以通过回放XLOG日志中记录的数据变化还原crash前的操作。这个就是所谓的redo/recovery过程。如果需要redo的XLOG比较多,或者遇到某种特殊日志类型,对DN实例进行启动,启动过程时间就会有些长。DN实例启动过程中,如果期望查看XLOG redo的进度。最方便的是使用gs_ctl query工具对指定DN实例路径进行状态查询,结果中可以显示xlog redo的进度,如图2所示。此外,在DN实例可以接受gsql连接时(启动到最小恢复点之前是拒绝连接的),也可直接在当前DN上执行pg_xlog_replay_completion 函数来获取XLOG redo进度信息。图2 DN实例启动时XLOG Redo进度查询启动Redo进度相关信息(Xlog replay info)包括: replay_start:Xlog Redo的起始LSN 。DN实例启动XLOG redo过程时,记录replay_start。 replay_current:Xlog Redo的当前replay的LSN。 replay_end:DN本地接收到的最大XLOG lsn。 replay_percent:Xlog Redo的当前完成的百分比。(replay_current - replay_start)*100 / (replay_end - replay_start)的计算值。依据replay_current的变化,可以看到XLOG redo的推进。依据replay_percent和启动开始时间,可以推测DN实例启动到正常状态的所需时间。3.2 查看备机Failover进度 当主机发生故障时,我们需要将备机failover成主机,此时备机需要连接从备同步XLOG和数据页文件。如果需要同步的XLOG比较多,或者遇到某种特殊日志类型,或者数据文件比较多时,对备DN实例进行failover,过程时间就会有些长。备机failover升主过程中,如果期望查看XLOG redo和数据页文件同步的进度。最方便的是使用gs_ctl query工具对指定DN实例路径进行状态查询,结果中可以显示xlog redo的进度和从备数据同步的进度,如图3所示。此外,在DN实例可以接受gsql连接时,也可直接在当前DN上执行pg_data_sync_from_dummy_completion 函数来获取从备数据文件同步的进度信息。 图3 备机Failover进度查询Failover Redo进度相关信息(Xlog replay info),字段含义同Start Redo,区别在于,备DN在处理failover请求连接从备时候获取最新的replay lsn更新了replay_start。Failover数据页文件进度相关信息(Data sync from dummy)包括: start_index:数据页文件同步的起始编号。 current_index:数据页文件同步的当前编号。 total_index:数据页文件同步的最大编号。 sync_percent:数据页文件当前完成的百分比。(current_index - start_index) *100/ (total_index - start_index + 1) 的计算值。依据current_index的变化,可以看到数据页同步的推进。依据sync_percent和failover开始时间,可以推测DN实例failover到正常状态的所需时间。3.3 查看备机Catchup进度 当备机重新启动的时候,会连接主机做数据页追赶(catchup)。如果需要传输的数据页比较多,或者因为业务造成的锁冲突,catchup 时间就会比较长,备DN长时间不能成为Normal状态。如果期望查看数据页catchup的进度,可以在CN上执行select * from pgxc_get_senders_catchup_time()可进行当前活跃的主备发送线程的追赶信息显示,如图4所示。图4 集群上catchup进度查询也可以在相应的主DN上执行select * from pg_get_senders_catchup_time可进行当前活跃的主备发送线程的追赶信息显示。完成后,看到的是刚结束的catchup过程信息,如图5所示。图5 主DN上catchup进度查询备机Catchup进度相关信息包括: catchup_type:"Incremental"或者"Full"。catchup方式为全量还是增量。 catchup_bcm_filename:当前主机正在处理的一个BCM文件名称。 catchup_bcm_finished:catchup已操作完成的BCM文件数量。 catchup_bcm_total:catchup总共需要操作的BCM文件数量。 catchup_percent:catchup已经操作完成的百分。catchup_bcm_finished*100 / catchup_bcm_total 的计算值。 catchup_remaining_time:依据已完成的进度,预估剩余完成时间。依据catchup_bcm_filename和catchup_bcm_finished的变化,可以看到数据页追赶的推进。依据catchup_percent和catchup_remaining_time,可以推测备DN实例追赶到正常状态的所需时间。3.4 查看DN实例XLOG空间使用状况 随着数据库的不断运行,产生的日志文件越来越多,如果因为节点故障或其它原因有可能造成日志文件不断积累而充爆磁盘。为了解此使用信息,最方便的是使用gs_ctl query工具对指定DN实例路径进行状态查询,结果中可以显示该实例的XLOG空间使用信息,截图示例请参见上面其它场景。此外,还提供系统函数 pgxc_stat_xlog_space、pg_stat_xlog_space 对数据库集群或单个实例进行查询,例如使用pgxc_stat_xlog_space可以获取到整个集群的CN、主DN的XLOG空间使用信息,如图6所示。 图6 Xlog空间使用查询XLOG空间使用信息(Xlog space info)包括: xlog_files:pg_xlog目录下,去除backup、archive_status等子目录,所有识别为xlog文件的数目; xlog_size:pg_xlog目录下,去除backup、archive_status等子目录,所有识别为xlog文件的大小之和,以MB单位显示; other_size:pg_xlog目录下backup、archive_status等子目录文件的大小之和,以MB单位显示。原文链接:https://bbs.huaweicloud.com/blogs/198536【推荐阅读】【最新活动汇总】DWS活动火热进行中,互动好礼送不停(持续更新中) HOT 【博文汇总】GaussDB(DWS)博文汇总1,欢迎大家交流探讨~(持续更新中)【维护宝典汇总】GaussDB(DWS)维护宝典汇总贴1,欢迎大家交流探讨(持续更新中)【项目实践汇总】GaussDB(DWS)项目实践汇总贴,欢迎大家交流探讨(持续更新中)【DevRun直播汇总】GaussDB(DWS)黑科技直播汇总,欢迎大家交流学习(持续更新中)【培训视频汇总】GaussDB(DWS) 培训视频汇总,欢迎大家交流学习(持续更新中)扫码关注我哦,我在这里↓↓↓ -
【摘要】 本文介绍了GaussDBDB(DWS)的数据复制高可用设计。1 前言 数据库中高可用普遍使用的是Log Shipping方式,即将WAL日志采用streaming方式传输给备实例,备实例通过重放该日志得到主实例的数据。对于行存储方式使用Log Shipping方式效率较高,但是对于列式存储,通常都是批量导入,如果同样将数据记录到日志中,会使数据写两遍IO,难以发挥列存储优势,因此通常采用数据复制方式(即数据从主实例的内存中直接通过网络传输给备实例,然后备实例写盘)更为合理。在行存的批量导入中,使用数据复制不仅可以提升传输效率(直接从内存中读取数据,无需通过磁盘读取日志),还可提升备实例恢复效率(直接从内存中恢复,无需将日志先写盘,再读取恢复)。GaussDBDB(DWS)的复制方式采用日志和数据混合方式,对于行存单条insert/update/delete,然后使用日志复制方式,对于行存批量导入(copy/insert into select from)默认采用数据复制方式;对于列存默认采用数据复制方式。下面主要介绍下GaussDBDB(DWS)中数据复制的主要设计。2 数据复制总体设计 在GaussDBDB(DWS)中,数据复制默认打开,分别在行存批量导入和列存导入时使用。整体设计如下图所示: 在数据导入过程中,每个业务线程Backend将收到的数据组成一个block(列存为一个CU)放到Datasend线程的数据队列(DataSenderQueue)里,Datasend线程将数据队列数据发送给Datareceive线程,Datareceive线程将接收的数据写入到数据队列(DataWriterQueue)中,Datarcvwrite线程从数据队列(DataWriterQueue)中取出数据按block分别写入到磁盘,实现主备复制高可用。2.1 Dataqueue设计Dataqueue是一块共享内存,用于实现DataSenderQueue和DataWriterQueue,其算法核心是循环使用共享内存,如下图所示: 首先tail1,head2,tail2初始化为0,每个变量为两个uint32位,第一个uint32 queueid表示数据队列使用了第几次,第二个uint32 queue offset表示当前数据队列的offset。数据导入后,首先tail2向后递增,各个导入通过锁控制实现并发,Datasend发送数据后将head2向后移动,当tail2到达末尾时,新导入数据将移动tail1指针,当tail1与head2接近时,表明没有缓存空间了,因此需要等待Datasend发送数据后将head2向后移动腾出空间。整体算法是一个循环利用实例制,数据的offset是一个单调递增的过程,类似WAL日志的LSN。2.2.2 同步提交设计在GaussDBDB(DWS)中,数据冗余使用的是同步提交,即数据写完两份后事务提交。WAL日志中通过比较LSN非常简单的实现了同步提交。类似WAL日志,数据复制由于Dataqueue中offset也是有序递增的,因此也很容易实现同步提交。其过程是Datarcvwrite将数据单元写入磁盘后,刷新写盘offset,Datareceive线程通过心跳信息将写盘offset发送给Datasend,各业务线程在事务提交前check本次导入最后一段数据备实例端已经写盘后即可提交。2.2.3 BCM与Catchup设计由于GaussDBDB(DWS)设计之初考虑到RAID5数据冗余存储,因此上层只存储两副本,由于分布式环境下各个数据节点采用异步提交时可能会导致全局数据不一致,因此各个数据节点必须使用同步提交。那么系统中如果坏了一个任何一个数据节点的主实例或者备实例系统便不可进行写事务操作。然而在大型分布式系统中这是往往不能接受的,必须要支持单节点故障。GaussDBDB(DWS)使用了缓存接收数据(从备)来实现同步提交下的单节点故障。那么就是备实例挂了后,数据将发往从备,等备实例修复后,备实例可以从主实例同步数据,如何区分哪些数据未同步便显得尤为重要。这里使用BCM(bit change map)文件来实现哪些block需要在追赶时发送给备实例,哪些不用发送。具体设计如下:当数据导入时,每个block对应BCM页面中两个bit(第一个bit用于标记是否同步,第二个保留),放入发送队列后将BCM页面中两个bit第一个标记为未同步,当数据已经写入到备实例端后,将对应block的BCM页面bit标记为已经同步。当备实例挂掉时,数据发送给从备后,BCM页面对应bit将不再清理未同步标记,任然为未同步。当备实例起来后,连接主实例,主实例启动catchup线程先获取从备上增量数据列表,然后扫描本地所有未同步数据发送给备实例,实现主备同步。2.2.4 数据复制与日志复制并发控制数据复制和日志复制是并发运行的,当数据复制正在写入数据时,日志复制无法恢复删除表与truncate表等操作,两者通过锁控制。同样当数据复制时要写入的database与表空间还未恢复时,同样需要等待日志复制恢复完成,这里通过循环检测等待实现。3 数据复制相比日志复制 当IO负载较高时,批量导入场景数据复制的性能优于日志复制30%左右,因此在大数据量入库时,使用数据复制性能更佳。然而对于行存来说触发数据复制时每次会获取新页面,因此对于insert into t1 values v1,v2,v3这种值较少的场景下会导致大量的空页面,不适用于数据复制,可以手动关闭数据复制开关。原文链接:https://bbs.huaweicloud.com/blogs/175234【推荐阅读】【最新活动汇总】DWS活动火热进行中,互动好礼送不停(持续更新中) HOT 【博文汇总】GaussDB(DWS)博文汇总1,欢迎大家交流探讨~(持续更新中)【维护宝典汇总】GaussDB(DWS)维护宝典汇总贴1,欢迎大家交流探讨(持续更新中)【项目实践汇总】GaussDB(DWS)项目实践汇总贴,欢迎大家交流探讨(持续更新中)【DevRun直播汇总】GaussDB(DWS)黑科技直播汇总,欢迎大家交流学习(持续更新中)【培训视频汇总】GaussDB(DWS) 培训视频汇总,欢迎大家交流学习(持续更新中)扫码关注我哦,我在这里↓↓↓
-
 1. 什么是数据复制服务数据复制服务(Data Replication Service,简称DRS)是一种易用、稳定、高效、用于数据库实时迁移和数据库实时同步的云服务。数据复制服务围绕云数据库,降低了数据库之间数据流通的复杂性,有效地帮助您减少数据传输的成本。您可通过数据复制服务快速解决多场景下,数据库之间的数据流通问题,以满足数据传输业务需求。 2. 实时迁移实时迁移是指在数据复制服务器能够同时连通源数据库和目标数据库的情况下,只需要配置迁移的源、目标数据库实例及迁移对象即可自动完成整个数据迁移过程。实时迁移支持多种网络迁移方式,如:公网网络、VPC网络、VPN网络和专线网络。特点:通过增量迁移技术,能够最大限度允许迁移过程中业务继续对外提供使用,有效的将业务系统中断时间和业务影响最小化,实现数据库平滑迁移上云,支持全部数据库对象的迁移。图1 实时迁移3. 实时同步实时同步是指在不同的系统之间,将数据通过同步技术从一个数据源拷贝到其他数据库,并保持一致,实现关键业务的数据实时流动。特点:满足多种灵活性的需求,例如多对一、一对多,动态增减同步表,不同表名之间同步数据等。图2 多对一实时同步4. 实时迁移与实时同步有什么不同4.1 适用场景不同实时迁移支持通过多种网络,实现跨云平台数据库迁移、云下数据库迁移上云或云上跨Region的数据库迁移等多种业务场景。实时同步维持不同业务系统之间数据的持续流动,常见的场景是:实时分析、报表系统、数仓环境。4.2 支持的对象不同实时迁移以整体数据库搬迁为目的,支持全部的数据库对象,包括:表、数据、索引、视图、存储过程、函数、数据库账号、数据库参数等。实时同步则聚焦于表和数据,并满足多种灵活性的需求,例如多对一、一对多,动态增减同步表,不同表名之间同步数据等。以MySQL->RDS for MySQL实时迁移和实时同步选择对象为例,如图:图3 实时迁移图4 实时同步具体的任务创建步骤,还可参考华为云官网资料:实时迁移https://support.huaweicloud.com/qs-drs/drs_02_0002.html实时同步https://support.huaweicloud.com/qs-drs/drs_06_0005.html4.3 功能特性不同对比项实时迁移实时同步支持数据库引擎支持多种数据库之间的数据迁移,不同数据库的支持详情请参考实时迁移。支持多种数据库类型的实时同步,且支持多个源数据库到同一个目标数据库之间的实时同步,详情请参考实时同步。功能特性实时迁移提供修改流速模式、快捷对比、异常诊断、续传、重试、暂停、重置等多种特性,详情请参考任务管理。实时同步除了提供异常诊断、续传、重试、暂停、重置等特性,还支持数据过滤和对象名映射,详情请参考任务管理。使用限制详情请参考使用须知。详情请参考使用须知。 更多具体内容,请移步这里,了解详情。
1. 什么是数据复制服务数据复制服务(Data Replication Service,简称DRS)是一种易用、稳定、高效、用于数据库实时迁移和数据库实时同步的云服务。数据复制服务围绕云数据库,降低了数据库之间数据流通的复杂性,有效地帮助您减少数据传输的成本。您可通过数据复制服务快速解决多场景下,数据库之间的数据流通问题,以满足数据传输业务需求。 2. 实时迁移实时迁移是指在数据复制服务器能够同时连通源数据库和目标数据库的情况下,只需要配置迁移的源、目标数据库实例及迁移对象即可自动完成整个数据迁移过程。实时迁移支持多种网络迁移方式,如:公网网络、VPC网络、VPN网络和专线网络。特点:通过增量迁移技术,能够最大限度允许迁移过程中业务继续对外提供使用,有效的将业务系统中断时间和业务影响最小化,实现数据库平滑迁移上云,支持全部数据库对象的迁移。图1 实时迁移3. 实时同步实时同步是指在不同的系统之间,将数据通过同步技术从一个数据源拷贝到其他数据库,并保持一致,实现关键业务的数据实时流动。特点:满足多种灵活性的需求,例如多对一、一对多,动态增减同步表,不同表名之间同步数据等。图2 多对一实时同步4. 实时迁移与实时同步有什么不同4.1 适用场景不同实时迁移支持通过多种网络,实现跨云平台数据库迁移、云下数据库迁移上云或云上跨Region的数据库迁移等多种业务场景。实时同步维持不同业务系统之间数据的持续流动,常见的场景是:实时分析、报表系统、数仓环境。4.2 支持的对象不同实时迁移以整体数据库搬迁为目的,支持全部的数据库对象,包括:表、数据、索引、视图、存储过程、函数、数据库账号、数据库参数等。实时同步则聚焦于表和数据,并满足多种灵活性的需求,例如多对一、一对多,动态增减同步表,不同表名之间同步数据等。以MySQL->RDS for MySQL实时迁移和实时同步选择对象为例,如图:图3 实时迁移图4 实时同步具体的任务创建步骤,还可参考华为云官网资料:实时迁移https://support.huaweicloud.com/qs-drs/drs_02_0002.html实时同步https://support.huaweicloud.com/qs-drs/drs_06_0005.html4.3 功能特性不同对比项实时迁移实时同步支持数据库引擎支持多种数据库之间的数据迁移,不同数据库的支持详情请参考实时迁移。支持多种数据库类型的实时同步,且支持多个源数据库到同一个目标数据库之间的实时同步,详情请参考实时同步。功能特性实时迁移提供修改流速模式、快捷对比、异常诊断、续传、重试、暂停、重置等多种特性,详情请参考任务管理。实时同步除了提供异常诊断、续传、重试、暂停、重置等特性,还支持数据过滤和对象名映射,详情请参考任务管理。使用限制详情请参考使用须知。详情请参考使用须知。 更多具体内容,请移步这里,了解详情。
上滑加载中
推荐直播
-
 通用人工智能(AGI)到来前夕如何实现企业降本增效和应用现代化
通用人工智能(AGI)到来前夕如何实现企业降本增效和应用现代化2024/04/19 周五 14:00-16:00
李京峰 T3出行VP/CTO
李京峰是T3出行CTO,本次他将分享通用人工智能(AGI)到来前夕,如何实现企业降本增效和应用现代化。
回顾中 -
 华为云云原生FinOps解决方案,为您释放云原生最大价值
华为云云原生FinOps解决方案,为您释放云原生最大价值2024/04/24 周三 16:30-18:00
Roc 华为云云原生DTSE技术布道师
还在对CCE集群成本评估感到束手无策?还在担心不合理的K8s集群资源申请和过度浪费?华为云容器服务CCE全新上线云原生FinOps中心,为用户提供多维度集群成本可视化,结合智能规格推荐、混部、超卖等成本优化手段,助力客户降本增效,释放云原生最大价值。
去报名 -
 产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》
产教融合专家大讲堂·第①期《高校人才培养创新模式经验分享》2024/04/25 周四 16:00-18:00
于晓东 上海杉达学院信息科学与技术学院副院长;崔宝才 天津电子信息职业技术学院电子与通信技术系主任
本期直播将与您一起探讨高校人才培养创新模式经验。
去报名
热门标签